
Page de présentation d'une ronéo.docx - ampcfusion.com€¦ · Web viewMesure de l’effet du...
24
UE11 – Recherche Clinique - n°3 28/10/2015 Raphaël PORCHER [email protected] RT : Yohan GAGNARD RL : Steve ZHOU Cours 3 : Mesure de l’effet du traitement et multiplicité Données manquantes (1 ère partie) Mesure de l’effet du traitement et multiplicité I. Mesure de l’effet du traitement A- Différence moyenne 1)Définition 2) Calcul de la différence moyenne avec R 3) Calcul de la différence moyenne avec le paquet Epi B- Critères de jugement catégoriels 1) Calcul des valeurs de RD, RR et OR avec R 2) Intervalles de confiance de RD, RR et OR 3) Lien entre RR et OR II. Multiplicité (plus de deux bras de traitement) A- Principe et méthodes d’ajustement B- Application à l’essai ACTG175 Données manquantes (1 ère partie)
-
Upload
nguyenkien -
Category
Documents
-
view
213 -
download
0
Transcript of Page de présentation d'une ronéo.docx - ampcfusion.com€¦ · Web viewMesure de l’effet du...

UE11 – Recherche Clinique - n°3 28/10/2015
Raphaël [email protected]
RT : Yohan GAGNARDRL : Steve ZHOU
Cours 3 : Mesure de l’effet du traitement et multiplicité
Données manquantes (1ère partie)
Mesure de l’effet du traitement et multiplicité
I. Mesure de l’effet du traitement A- Différence moyenne
1) Définition2) Calcul de la différence moyenne avec R3) Calcul de la différence moyenne avec le paquet Epi
B- Critères de jugement catégoriels1) Calcul des valeurs de RD, RR et OR avec R2) Intervalles de confiance de RD, RR et OR3) Lien entre RR et OR
II. Multiplicité (plus de deux bras de traitement) A- Principe et méthodes d’ajustementB- Application à l’essai ACTG175
Données manquantes (1ère partie)
I. Données manquantes A- Introduction
1) Missing data2) Example : ACTG175 trial3) Analysis with missing data
B- Typology of missing data

1) Three types of missing data2) Example3) In practice4) Back to complete case analysis
II. Imputation simple
A- Idée de baseB- Méthode du biais maximumC- Imputation par la moyenne ou la médianeD- LOCF (last observation carried forward)E- Utiliser un modèle de régression
1) Imputation à partir de la prédiction d’un modèle2) Autre solutions
F- Conclusion
III. Imputation multiple (plan non détaillé car traité lors du prochain cours)
Mesure de l’effet du traitement et multiplicité
I. Mesure de l’effet du traitement
On travaille toujours sur le même essai : ACTG175.
Nous allons mesurer l’effet du traitement antirétroviral grâce à la différence moyenne (MD), à la différence de risque (RD), à l’odds-ratio (OR) et au risque relatif (RR).
Ce sont des mesures utilisées dans le cas où les données ne sont pas censurées.
A chaque fois qu’on calcule une de ces valeurs, il faut toujours rapporter l’IC à 95% avec l’estimation ponctuelle.
A- Différence moyenne
1) Définition
La différence moyenne (mean difference = MD) est une mesure de l’effet adaptée à un critère de jugement quantitatif continu.
C’est la différence des moyennes. Dans notre exemple, c’est la différence des moyennes des CD4 entre le groupe 0 (AZT) et le groupe 3 (DDI).

2) Calcul de la différence moyenne avec R
On charge les données de l’essai, comme d’habitude (cf. script R pour les commandes à effectuer au début du cours. Ce script est disponible sur le drive de l’an dernier notamment) :
>library(speff2trial)>data(ACTG175)
Pour déterminer l’efficacité du traitement, on considérera le taux de CD4 à 96 semaines.
On crée alors une variable pour les CD4 à S96 dans les bras 0 (x0) et 3 (x3) :
>x0 <-ACTG175$cd496[ACTG175$arms==0]
Explications : on charge dans x0 les valeurs de CD4 à S96 des patients du bras 0.
On charge de manière similaire les valeurs du bras 3 dans x3 :
>x3 <-ACTG175$cd496[ACTG175$arms==3]On peut alors calculer la différence des moyennes :
>mean(x0, na.rm = TRUE) – mean(x3, na.rm = TRUE)
On obtient le résultat suivant :
[1] -41.1752
Pour calculer l’intervalle de confiance à 95%, on fait réaliser à R un test de Student avec la commande :
>welch <-t.test(x0, x3, alternative=”two.sided”, var.equal=FALSE)
Explications : on crée un objet “welch” dans lequel on stocke les résultats du test. C’est un test bilatéral (« two.sided »). Ici on ne considère pas que les variances sont égales dans chaque groupe (« var.equal=FALSE »).
On souhaite alors obtenir l’intervalle de confiance :
>welch$conf.int
[1] -67.2809 -15.0695
La différence est significative puisque l’intervalle de confiance ne contient pas 0.

NB : On pourrait également demander la p-val dans le but de savoir si ce test est significatif ou non.
3) Calcul de la différence moyenne avec le paquet Epi
Il est aussi possible d’utiliser des fonctions qui se trouvent dans la librairie Epi.On installe d’abord le package « Epi » en passant par le menu, puis on le charge comme précédemment :
>library(Epi)
En effet, en utilisant directement la fonction effx sur la variable cd496 en fonction de l’exposition (donc du bras de traitement), on obtient des résultats identiques :
Explications :
- « factor » permet de déclarer la variable ‘arms’ comme catégorielle et non pas numérique (en effet, elle est codée de 0 à 3 dans notre cas).- « %in% » signifie « dans ».- « c(0, 3) permet de créer un objet R contenant deux valeurs : 0 et 3.
B- Critères de jugement catégoriels
Nous allons ici étudier successivement la différence de risque (DR), le risque relatif (RR) et l’odds-ratio (OR). Ce sont des mesures de l’effet adaptées à des critères de jugement dits catégoriels (notamment les critères binaires c.-à-d. qui ne prennent que deux modalités, par exemple : succès/échec du traitement).
On peut rapporter une mesure de la différence de proportions (différence de risque absolue), mais également des mesures relatives (RR ou OR).Chaque mesure a son interprétation et ses limites. Il est recommandé dans CONSORT de rapporter une mesure absolue ET une mesure relative de l’effet du traitement.
1) Calcul des valeurs de RD, RR et OR avec R

Exemple pour un critère binaire, entre les bras 3 (DDI) et 0 (AZT) :
Le critère de jugement principal dépend de la censure. Nous allons créer un événement binaire et l’analyser, à titre d’illustration, sans tenir compte de cette censure.
Création de la variable :
On crée alors un critère event=1 si CD4<200 à S96. (fait sur la diapositive à titre d’exemple, mais le prof ne l’a pas fait en cours)
Si les données sont manquantes à S96 mais qu’une donnée indique que le patient est en échec entre S96 et 707 jours (S96 + 5 semaines), on considérera qu’il est en échec à S96.En utilisant le package ‘gmodels’, on peut visualiser le tableau de contingence :

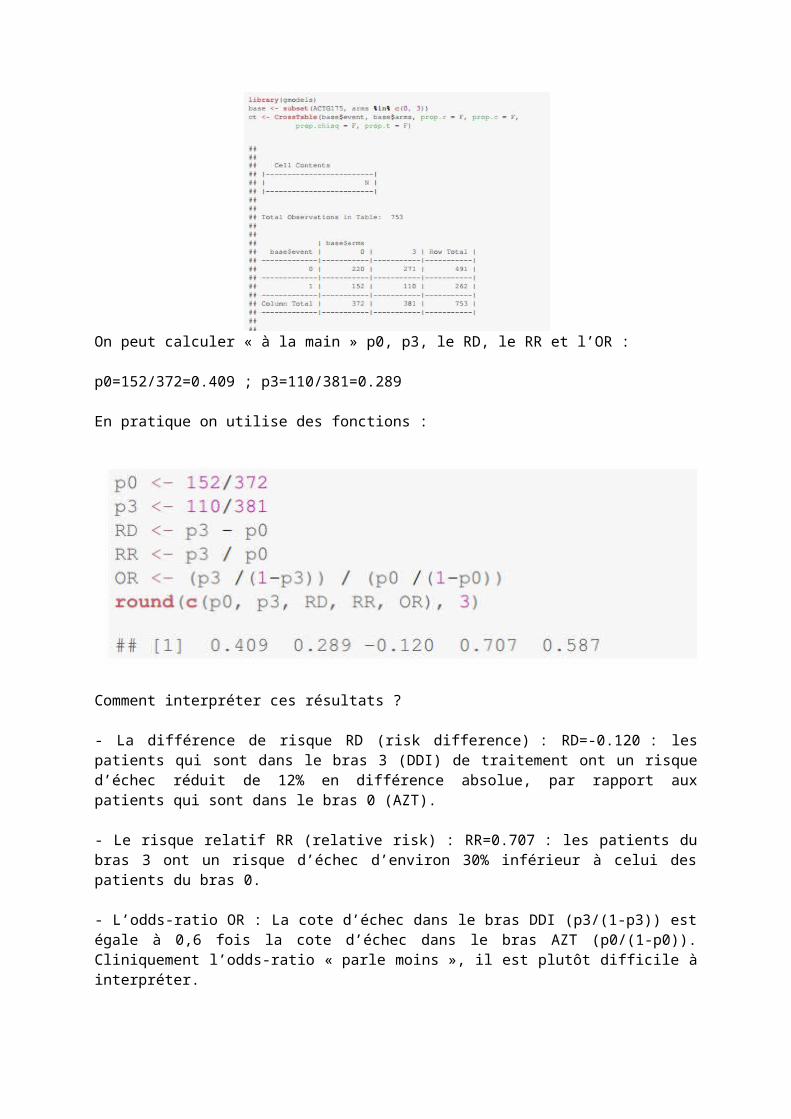
On peut calculer « à la main » p0, p3, le RD, le RR et l’OR :
p0=152/372=0.409 ; p3=110/381=0.289
En pratique on utilise des fonctions :
Comment interpréter ces résultats ?
- La différence de risque RD (risk difference) : RD=-0.120 : les patients qui sont dans le bras 3 (DDI) de traitement ont un risque d’échec réduit de 12% en différence absolue, par rapport aux patients qui sont dans le bras 0 (AZT).
- Le risque relatif RR (relative risk) : RR=0.707 : les patients du bras 3 ont un risque d’échec d’environ 30% inférieur à celui des patients du bras 0.
- L’odds-ratio OR : La cote d’échec dans le bras DDI (p3/(1-p3)) est égale à 0,6 fois la cote d’échec dans le bras AZT (p0/(1-p0)). Cliniquement l’odds-ratio « parle moins », il est plutôt difficile à interpréter.
NB : l'OR est symétrique: l'OR d'échec est égal à l'inverse (1/x) de l'OR de succès contrairement au RR.
Exemple : Si RR = 0.50, le traitement divise par deux le risque d'échec, mais cela ne veut pas dire qu'il double les chances de succès. Par exemple, si le traitement fait passer le risque de succès de 90% à 95% => RR = 1.06 ce qui peut être exprimé par le fait que le traitement fait passer la probabilité d'échec de 10% à 5% => RR=0.5. On voit que 1/0.5 n'est pas égal à 1.06. Par contre, pour l'OR il y a symétrie: OR de succès = 0.53 et OR d'échec = 1.89.
2) Intervalles de confiance de RD, RR et OR
Il nous faut alors un IC pour chacune de ces valeurs.
o Intervalle de confiance de RD :
Le test de comparaison de deux proportions est le test Z dont voici la formule :
Calculs en illustration de cette formule :
NB : n0 et n3 sont les totaux après avoir enlevé les données manquantes. ‘qnorm’ donne les valeurs de Z pour 2.5% et 97.5% (les deux bornes de l'IC). La valeur de 0.5 est là juste pour retrouver l'estimation ponctuelle (qnorm(0.025) = -1.96, qnorm(0.5) = 0 et qnorm(0.975) = 1.96)
On obtient dans l’ordre : la première borne de l’IC (-0.187), le RD (-0.120) et la dernière borne de l’IC (-0.052).
En pratique, on utilise des fonctions et notamment la fonction ‘prop.test’ qui, en plus de réaliser un test du chi-deux, donne aussi l’intervalle de confiance de la différence de proportions:
o Intervalle de confiance du RR :
Pour calculer cet intervalle de confiance, on effectue une transformation logarithmique comme suit :

En illustration de la formule précédente, à partir de notre tableau 2x2 :
En pratique encore, on utilise des fonctions, notamment la fonction effx (cf. paquet ‘Epi’) :

o Intervalle de confiance de l’OR :
Même chose que précédemment, on effectue une transformation logarithmique :
Application numérique pour l’illustration :
Avec la fonction effx du paquet ‘Epi’ :
3) Lien entre RR et OR
L’OR est plus intéressant mathématiquement que le RR, mais le RR est bien plus « parlant ».
On peut convertir l’OR en RR, et cela dépend de p0 :

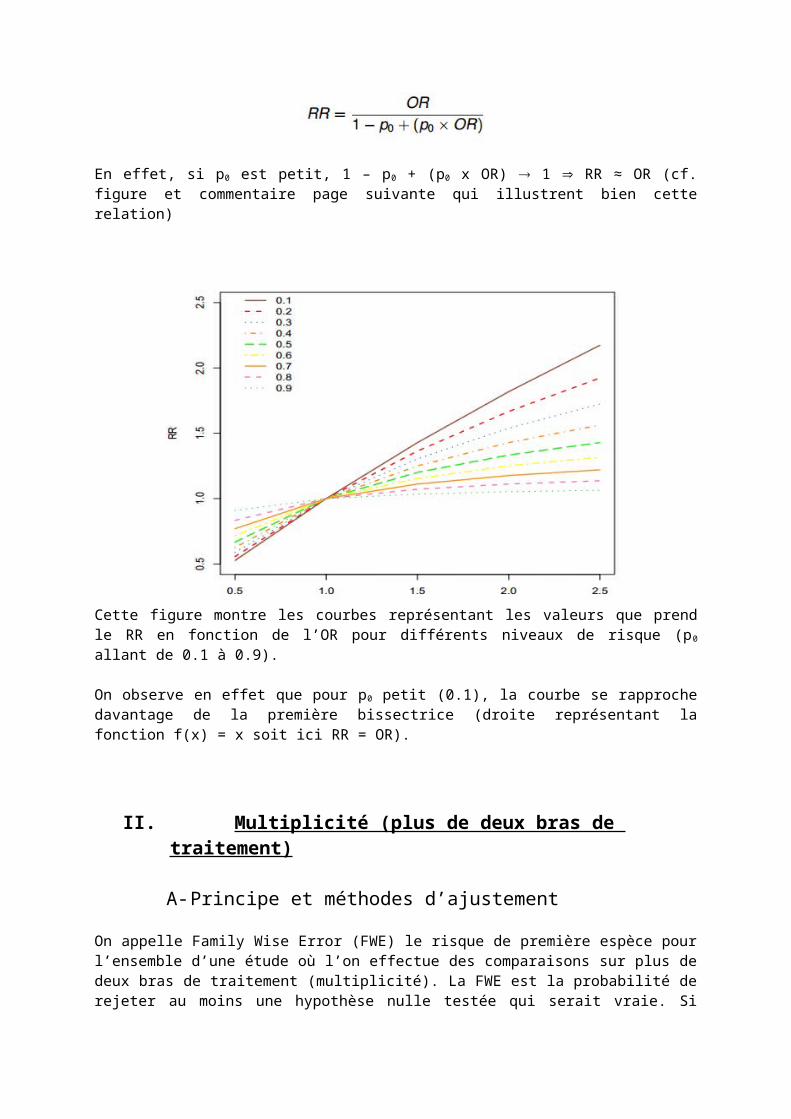
En effet, si p0 est petit, 1 – p0 + (p0 x OR) 1 RR ≈ OR (cf. figure et commentaire page suivante qui illustrent bien cette relation)
Cette figure montre les courbes représentant les valeurs que prend le RR en fonction de l’OR pour différents niveaux de risque (p0 allant de 0.1 à 0.9).
On observe en effet que pour p0 petit (0.1), la courbe se rapproche davantage de la première bissectrice (droite représentant la fonction f(x) = x soit ici RR = OR).
II. Multiplicité (plus de deux bras de traitement)
A- Principe et méthodes d’ajustement
On appelle Family Wise Error (FWE) le risque de première espèce pour l’ensemble d’une étude où l’on effectue des comparaisons sur plus de deux bras de traitement (multiplicité). La FWE est la probabilité de rejeter au moins une hypothèse nulle testée qui serait vraie. Si l’on compare deux à deux plusieurs traitements avec un risque = 0.05 à chaque fois, le FWE sera bienα supérieur à 5%.
Dans le cas d’ACTG175 : on dispose de quatre bras de traitement, on peut donc faire six comparaisons deux à deux (entre 0-1, 0-2, 0-3, 1-2, 1-3, 2-3).
Si les tests sont indépendants, on a :

Dans le cas d’ACTG175, k=6 FWE = 1-(0.95)6 ≈ 1-0.74≈0.26, soit 26% (attention, les tests ne sont pas indépendants, et donc ce calcul n’est en théorie pas exact)
D’autres stratégies d’analyse que les comparaisons deux à deux sont envisageables.
Il existe par ailleurs des méthodes d’ajustement du risque de première espèce α : elles consistent à prendre une valeur plus réduite de risque afin d’obtenir un risque global égal à 5%. La méthode la plus utilisée est la méthode dite de Bonferroni :
Explications : Plutôt que de présenter les p-values en indiquant qu'elles sont significatives à *,α on présente habituellement des p-val ajustées (pour Bonferroni, on multiplie par k les p-val en mettant une p-val de 1 si le produit est supérieur à1).En effet, si * α 0, FWE = 1- (1- *)α k = 1 - (1-( /k))α k . On a donc bien un risque global (FWE)α égal à 5%.(NB : Pour les puristes, je viens d’essayer de comprendre pourquoi : j’ai raisonné à partir du développement limité de (1+x)α au voisinage de 0 :
En développant au premier ordre on obtient donc (1- *)α k = 1-k * = 1 – k x ( /k) = 1- .α α αD’où FWE = 1 – (1- ) = .)α α
Faut-il ajuster ? Cette question est encore débattue aujourd’hui.
En effet :
o si les comparaisons avaient été faites dans deux essais séparés, il n’y aurait pas eu d’ajustement
o les tests ne sont pas indépendants si on utilise un bras contrôle commun
o cela dépend des hypothèses testées : - Si on veut tester H0 : DDI est supérieure à toutes les alternatives, on peut faire chaque test à 5%, le risque global ne sera pas plus grand que 5%. - Si on veut donner l’AMM à la DDI si une seule comparaison est significative, il faut ajuster
Résumé des cas dans lesquels on doit ajuster :
Dans tous les cas, et c’est le message le plus important à retenir, il faut prévoir à l’avance la stratégie d’analyse et ne pas la modifier en fonction des résultats car sinon il peut y avoir un ‘selective reporting bias’ (biais de notification).
Les auteurs ont souvent tendance à ne pas rapporter à l’avance leur stratégie ou bien à s’en éloigner au cours de l’étude et des premiers résultats.
B- Application à l’essai ACTG175
Le critère de jugement principal est toujours identique : le nombre de CD4 à S96.
On réalise les 6 comparaisons deux à deux, et on stocke à chaque fois les p-values dans un objet nommé « p », puis on affiche ces valeurs :
On obtient alors les p-val dites « normales », avant ajustement.
On utilise alors la fonction ‘p.adjust’ sur R, en utilisant au choix la méthode de Bonferroni ou de Holm :

On obtient alors la valeur de toutes les p-val ajustées.
NB : dans la partie théorique, on disait que dans la méthode de Bonferroni, on multiplie généralement les p-val par k. On retrouve cela ici :
En effet, la p-val non ajustée pour la comparaison entre les bras 0 et 1 donne 6.118 x 10-5 :
R donnait comme p-val ajustée avec Bonferroni 3.671 x 10-4. Or 3.671 x 10-4 = 6 x 6.118 x 10-5 , on retrouve bien le coefficient k = 6 ici.
Données manquantes (1ère partie)
I. Missing data
A- Introduction
1) Données manquantes
Les données manquantes sont très fréquentes en recherche clinique et même au sein d’essais contrôlés randomisés. Il y a de nombreuses raisons justifiant l’absence de données et donc de nombreux types de données manquantes.
Parmi les raisons les plus fréquentes, on retrouve :
- Le mauvais report de données : erreurs de collecte, illisibilité…- Donnée non recueillie (visite non faite, prélèvement non fait, …)- Sortie de l’étude ou arrêt de la prise du traitement (en cas d’effets indésirables ++)- Décès
Légalement, tout individu peut demander à quitter l’étude et à ce qu’on n’utilise pas les données le concernant : il faut alors les supprimer. Toute analyse gère les données manquantes, d’une façon ou d’une autre (parfois mal).
2) Example : ACTG175 trial
Analysons maintenant les CD4 à S96 :
Les données sont manquantes pour 797 des 2139 patients, soit 37%.Il peut y avoir plusieurs explications :
- le patient est décédé ou ses CD4 ont chuté d’au moins 50 avant S96- le patient a quitté l’essai avant S96- le patient est perdu de vue avant S96

- les CD4 du patient n’ont pas été enregistrés entre S96 – 5 semaines et S96 + 5 semaines3) Analyse en presence de données manquantes
Chaque test prend en compte les données manquantes… d’une certaine manière.Supposons que l’on veuille comparer le bras 0 (AZT) avec le bras 1 (AZT+DDI).
Que se passe-t-il si l’on effectue un test ?
Les données manquantes ont été supprimées donc nous avons choisi implicitement une méthode pour les traiter. On parle de ‘complete case analysis’.
Est-ce statistiquement valide comme méthode ?
Ce n’est valide que si les données manquantes sont manquantes aléatoirement, ce qui est impossible à démontrer et difficilement envisageable dans le cadre de cet essai (et de beaucoup d’autres).
B- Typologie des données manquantes
1) Trois types de données manquantesOn distingue généralement trois types de données manquantes.
- Complètement au hasard (ex. : un tube à essai se brise dans le laboratoire d’analyses)

- Au hasard : ne dépend pas de la valeur elle-même manquante (ex. : les filles répondent moins que les garçons à une question sur leur poids – ou le contraire)
- Manquantes non aléatoirement : la donnée manquante dépend de la valeur elle-même manquante (ex. : les CD4 < 60 sont manquants : on éliminerait les individus en moins bonne santé dans une analyse des cas complets. Les résultats seraient alors biaisés)
2) Exemple
Considérons que l’on analyse le poids des patients dans une étude où des données sont manquantes.
MCAR : il n’y a pas de raison particulière pour laquelle certains patients ont rempli leur poids et d’autres non. Dans ce cas, la distribution observée doit correspondre à la distribution réelle.
MAR : les hommes sont moins réticents à remplir leur poids que les femmes, ou le contraire. Dans ce cas, en tenant compte des caractéristiques des sujets (ici leur sexe), on peut obtenir une estimation sans biais de la distribution des poids.
MNAR : les patients avec des poids extrêmes (obèses ou trop maigres) auront tendance à cacher leurs poids. Dans ce cas, il sera difficile d’estimer la vraie distribution des poids.
3) En pratique
Il n’y a pas de test formel pour MAR/MNAR, mais il en existe un pour MCAR.
On peut difficilement assurer que les données sont manquantes complètement au hasard (notamment dans les essais contrôlés randomisés ou les études de cohorte).
Quand les variables observées peuvent présager des données manquantes, alors les méthodes pour les MAR peuvent être raisonnablement utilisées, même si l’on est dans un cas de MNAR.
4) Retour à l’analyse des cas complets
Les analyses de cas complets sont valides si les données manquantes sont MCAR (ce n’est certainement pas le cas pour notre essai ACTG175). Ces études sont biaisées sous MAR ou MNAR.
Dans un essai contrôlé randomisé, les études de types cas-contrôles (comme ici) violent les principes de l’’intention-to-treat’.
Une solution est alors d’imputer des valeurs aux données manquantes.
II. Imputation simple
A- Idée de base
L’idée générale est de remplacer les données manquantes en leur imputant une valeur.
B- Méthode du biais maximum

Cette méthode est plutôt adaptée aux événements dits binaires (succès/échec), et principalement destinée aux essais contrôlés randomisés. Elle consiste à remplacer les données qui sont manquantes par un succès dans le bras contrôle et par un échec dans le bras expérimental.
C’est donc une méthode biaisée au maximum, mais biaisée dans le sens de l’hypothèse nulle H0. De ce fait, si on rejette H0 avec cette analyse, on aurait également rejeté H0 avec les vraies valeurs des données manquantes.
On peut d’ailleurs utiliser cette méthode comme un test de sensitivité.
D’autres stratégies peuvent être mises en place pour tester la sensibilité des résultats aux choix d’analyse : inverser les échecs et les succès pour les données imputées, considérer toutes les données manquantes comme un échec, considérer toutes les données manquantes comme un échec, etc.
Pour des études où les critères de jugement sont continus, il est plus complexe de définir des stratégies.
On pourrait par exemple attribuer des valeurs extrêmes à un score. Pour l’essai ACTG175 par exemple, cela n’aurait pas réellement de sens. En effet, quel est le maximum du taux de CD4 ? On définirait plutôt un autre type de stratégie pour imputer : ex. : le taux de CD4 des patients à 96S serait considéré comme bas si les patients sont décédés ou ont développé le stade SIDA auparavant.
C- Imputation par la moyenne ou la médiane
Cette méthode est destinée aux critères de jugement continus.
Principe : on impute les données manquantes par la valeur de la moyenne (ou la médiane, ou encore la moyenne géométrique) des données non manquantes.
Non biaisée seulement si les données sont manquantes complètement au hasard (MCAR) (auquel cas les études de type cas-contrôles sont également non biaisées).
Cela réduit artificiellement la variabilité des données.
C’est une très mauvaise idée d’utiliser cette méthode.
D- LOCF (last observation carried forward)
Destinée à des critères de jugement continus avec des mesures répétées (taux de CD4, score pour évaluer la douleur, …)
Principe : on impute les données manquantes par la dernière valeur enregistrée chez ce même patient. Schématiquement, on complète la courbe stoppée par une droite y =cte où cette constante est la dernière valeur observée.
Ceci est sans biais si les données sont manquantes au hasard (MAR) et qu’il n’y a pas d’évolution dans le temps.

Cette méthode peut biaiser la variance dans n’importe quel sens et n’est pas très bonne même si elle est en pratique très utilisée.
E- Utiliser un modèle de régression
1) Imputation à partir de la prediction d’un modèle
Ex. : Y = poids et X = taille d’un enfant.
On a un modèle de régression de la forme Y = f(X) + e où e est l’erreur résiduelle.On choisit le modèle le plus simple : la relation linéaire. On obtient alors une équation de la forme Y = X+ +e. β μ
On impute alors les données manquantes de Y par l’image de la vraie valeur correspondante de X par cette transformation affine.
Cela nécessite un bon modèle de données et des données manquantes au hasard (MAR).
Problème : on ne tient pas compte de l’erreur résiduelle, ce qui diminue la variabilité.
2) Autres solutions
On dénombre trois solutions possibles :
- ajouter une erreur aléatoire (résiduelle) (ex. : à taille égale, tous les enfants n’ont pas le même poids)

- établir aléatoirement les paramètres du modèle de régression pour justifier leur incertitude- effectuer une imputation multiple (objet du prochain cours)
F- Conclusion
L’imputation simple n’est pas une bonne idée, exceptée dans les études « worst cases » (où l’on imagine le pire scénario).
En effet, elle a tendance à réduire la variabilité des données.
Elle est cependant acceptable si l’on ajoute des erreurs aléatoires mais même dans ce dernier cas, on lui préférera l’imputation multiple.
III. Imputation multiple (traité lors du prochain cours)
Abréviations : toutes les abréviations sont explicitées au fur et à mesure du cours.
Mot du RT : le cours 3 a été entièrement traité et une bonne partie du cours 4 a été vue également.
Un groupe a présenté un article traitant des lombalgies.
Le prof n’a pas donné de « homework » pour la semaine prochaine.
FICHE RECAPITULATIVE

Différence des moyennes : >mean(x0, na.rm = TRUE) – mean(x3, na.rm = TRUE)
Test Student (IC 95%) : >welch <-t.test(x0, x3, alternative=”two.sided”, var.equal=FALSE)
Calcul IC RD :
Calcul IC RR :
Calcul IC OR :
P-val ajustées par méthode Bonferroni : p.adjust(p,method= « bonferroni »)
P-val ajustées par méthode Holm : p.adjust(p,method= « holm »)


















