
Les EntréesLes Entrées ENTRÉES FROIDES Salade verte 3,00 € Salade de tomate 3,50 € ENTRÉES CHAUDES
Upload
hoangduongCategory
view
218download
0
AGROCAMPUSOUEST
Année universitaire : 2014-2015
Spécialité : Statistique
Spécialisation (et option éventuelle) :
…………………………………………………
Mémoire de Fin d'Études
Méthodes d'analyse de sensibilité de modèlespour entrées climatiques
Par : Franck BOIZARD
Soutenu à Rennes le 18 septembre 2015
Devant le jury composé de :
Président : David CAUSEUR
Maître de stage : Robert FAIVRE
Enseignant référent : David CAUSEUR
Autres membres du jury :
Sébastien LÊ
Les analyses et les conclusions de ce travail d'étudiant n'engagent que la responsabilité de son auteur et non celle d’AGROCAMPUS OUEST
CFR Angers
CFR Rennes
d’Ingénieur de l’Institut Supérieur des Sciences agronomiques, agroalimentaires, horticoles et du paysage
de Master de l’Institut Supérieur des Sciences agronomiques, agroalimentaires, horticoles et du paysage
d'un autre établissement (étudiant arrivé en M2)


Remerciements
Mes premiers remerciements s'adressent à mes encadrants : Robert Faivre et Ronan Trépos.Leur patience et leur disponibilité ont permis une collaboration enrichissante, autant sur le planprofessionnel que personnel. Je généralise ces remerciements à toute l’unité du MIAT qui m'a faitdécouvrir le milieu de la recherche et m'a donné l'envie de continuer à le faire.
La collaboration avec le CATI IUMA, et en particulier avec Sabastien Roux et Samuel Buis, m'abeaucoup apportée et je tiens à les remercier pour leur confiance.
Je tiens enfin à remercier tous ceux qui m'ont supporté pendant mon stage : les membres dubocal bien sûr ; ainsi que tous ceux qui ne sont pas restés que des collègues à l'INRA ; Sarah pourton soutien dans les moment les moins et les plus rigolo ; et les rennais qui m'ont aidé dans ladernière ligne droite, ma famille et Flo'.


Table des matières
Remerciements..............................................................................................................................3
Liste des annexes...........................................................................................................................6
Liste des figures.............................................................................................................................7
Avant propos..................................................................................................................................9
Introduction.....................................................................................................................................1
Méthodes........................................................................................................................................3
1.Traitement des données climatiques...........................................................................3
2.Classification...............................................................................................................7
Classification Ascendante Hiérarchique :..................................................................7
Choix du nombre de classes.....................................................................................9
K-medoids.................................................................................................................9
3.Analyse de sensibilité................................................................................................11
Principe de l'analyse de sensibilité..........................................................................11
Estimation des indices de sensibilité par la méthode de Sobol'...............................12
Méthodes pour données climatiques.......................................................................14
Matériels.......................................................................................................................................20
Résultats...................................................................................................................................... 23
1.Présentation des données.........................................................................................23
2.Classification.............................................................................................................24
Calcul des distances................................................................................................24
Choix du nombre de classes...................................................................................25
Caractérisation des classes de climat......................................................................25
3.AS indépendantes par climat....................................................................................28
4.Anova sur les indices de sensibilité...........................................................................29
5.Analyse de sensibilité conjointe................................................................................31
Discussion....................................................................................................................................33
Bibliographie.................................................................................................................................34
Annexes....................................................................................................................................... 36
Annexe I : Première méthode de classification.............................................................................36

Liste des annexes
Annexe I : Première méthode de classification :...........................................................................40
Annexe II : AS sur les poids :........................................................................................................41
Annexe III : Algorithme partitionning around medoids...................................................................42
Annexe IV : Stacked plot sur des classes par années..................................................................44
Annexe V : AS avec le modèle sunflo...........................................................................................45

Liste des figures
Figure 1 : Courbes de données climatiques (Dijon, 1975) avec 5 variables: l'ensoleillement, les précipitations, latempérature maximale et minimale et l'évapotranspiration.......................................................................................1
Figure 2 : Appariement DTW de deux séries ETP......................................................................................................4
Figure 3 : Step pattern symetry2 (par défaut) de la fonction dtw..............................................................................6
Figure 4 : Illustration de l'algorithme CAH : étapes de regroupement et dendrogramme correspondant................7
Figure 5 : Dendrogramme de la CAH par la méthodes de Ward sur 190 séries climatiques. La ligne rouge est lapartition choisie par le critère du seuil du R2 à 80 %................................................................................................8
Figure 6 : Regroupement successifs de la l'algorithme des K-medoids (illustration Wikipedia)............................10
Figure 7 : Exemple d'un plan d'expérience...............................................................................................................15
Figure 8 : Simulation pour chaque climat de deux LHS différents..........................................................................16
Figure 9: Plan d'expérience unique, constitué de LHS répétés................................................................................17
Figure 10 : Calcul de la première colonne de XB, noté s , exemple avec K=4 avec i le rang du LHS dans le planet j le rang du sous bloc dans le LHS........................................................................................................................18
Figure 11 : Représentation du modèle sunflo, à gauche les entrées du modèle, à droite les sorties.......................22
Figure 12 : courbe du R2 en fonction du nombre de classes de la CAH, et droite à 80ù du R2..............................24
Figure 13 : Treilli plot des données climatiques avec 5 variable, selon leur centre de classe (6 classes)..............25
Figure 14 : Treilli plot des précipitations selon leurs centres et la courbe moyenne par classe.............................25
Figure 15 : Stacked plot des classes de climats selon les villes de prélèvement......................................................26
Figure 16 : Résultat des l'AS indépendantes par climat par la fonction sobolEff, avec un plan de départ de taille1000, triés par classe.................................................................................................................................................27
Figure 17 : Boxplot des IS par climat et résultat de l'Anova, fonction catdes.........................................................28
Figure 18 : Boxplot des SI par climat et par classe et résultat des tests de moyennes, fonction catdes.................29
Figure 19 : Résultats de l'AS conjointe sur le modèle jouet dans le cas bigbounds, fonction sobol2002, taille deplan de départ 1600 lignes (400 par classe).............................................................................................................30
Figure 20 : AS conjointe sur le modèle jouet dans le cas littelbounds ; fonction sobol2002, taille de plan dedépart 1600 lignes (400 par classe) .........................................................................................................................31
Figure 21 : Matrice de confusion pour une procédure de K-medoids à 4 classes ; répétée 50 fois.......................35
Figure 22 : exemple de planification d'un AS sur les poids,.....................................................................................36
Figure 23 : Stacked plot sur 6 classes par années (1978-2012)...............................................................................39
Figure 24 : Résultats de l'AS conjointe sur le modèle sunflo ; fonction soboljansen 1000 par classe, représentantpar un centre dans la classe......................................................................................................................................40
Figure 25 : Simulation du rendement du modèle sunflo selon le plan XA...............................................................41
Figure 26 : Résultats de l'AS conjointe sur le modèle sunflo, le représentant d'une classe est un climat aléatoirede la classe; fonction soboljansen ; taille du plan de départ 6000 lignes (1000 par classe)..................................41


Avant propos
Ce rapport présente le résultat du travail effectué au cours de mon stage de fin d'études,d'une durée de 6 mois, à l'Institut National de Recherche Agronomique (INRA) de Toulouse. Cetravail finalise ma deuxième année de master « Statistiques pour les sciences agronomiques etagroalimentaires » de l'Agrocampus ouest. J'ai intégré l'équipe de Modélisation des Agro-écosystèmes et Décision (MAD) de l'unité de Mathématiques et Informatique Appliquées deToulouse (MIAT). L'équipe MAD, dont fait partie Robert Faivre, a pour mission l’exploration demodèles par simulation. Le partage et la diffusion de leurs méthodes et travaux s'appuient sur laplateforme RECORD, dont fait partie Ronan Trépos, et sur le réseau scientifique MEXICO(Méthodes pour l'Exploration Informatique de modèles Complexes).
Ma mission a été initiée par le CATI (Centre automatisé de traitement de l’information) IUMA(Informatisation et Utilisation des Modèles dédiés aux Agro-écosystèmes). Le CATI IUMA a été créépour la promotion des outils permettant l'informatisation des modèles. J'ai eu l'occasion pendantmon stage de présenter mon travail et de le faire valider par différents chercheurs dans le cadre dece collectif scientifique. La méthode développée durant mon stage a pour finalité d'être réutiliséepour différents modèles hébergés par des plateformes de modélisation (OpenAlea, Sol Virtuel,Capsis, Paysage Virtuel) partenaires du CATI IUMA.
Introduction
Mon stage a pour sujet les méthodes d'analyse de sensibilité de modèles pour entréesclimatiques. L'objectif est de créer une méthode générique d'analyse de sensibilité pour desmodèles qui utilisent comme l'une de leurs entrées des données climatiques. Ce sujet s’inscrit dansles objectifs d'exploration de modèles par simulation du département MIAT :
« Les modèles de systèmes agro-environnementaux devenant de plus en plus complexes(par la dimension paramétrique de l'espace des entrées ou par le temps de calcul de leursévaluations numériques), l'exploration de tels modèles nécessite la conception de méthodesadaptatives pour l'exploration des modèles numériques coûteux à évaluer, dans un butd'analyse de sensibilité des réponses aux facteurs d'entrées. » (site web MIAT)
La complexité des modèles qui m'intéressent vient du format des entrées du modèle que sontles données climatiques. Il faut donc créer des méthodes spécifiques pour explorer ces modèlesparticuliers. Trois aspects sont donc à prendre en compte dans ce sujet : le modèle, les entréesclimatiques, l'analyse de sensibilité.
Les modèles que j'ai étudiés, sont examinés en tant que boîte noire. En effet les méthodesdéveloppées ne dépendes pas du modèle auquel elles sont appliquées. Ces modèles calculent parexemple le rendement ou la qualité d'une récolte à partir de données phénotypiques, des conditionsde culture... Ils ont en commun l'utilisation des données climatiques comme une de leurs entrées.
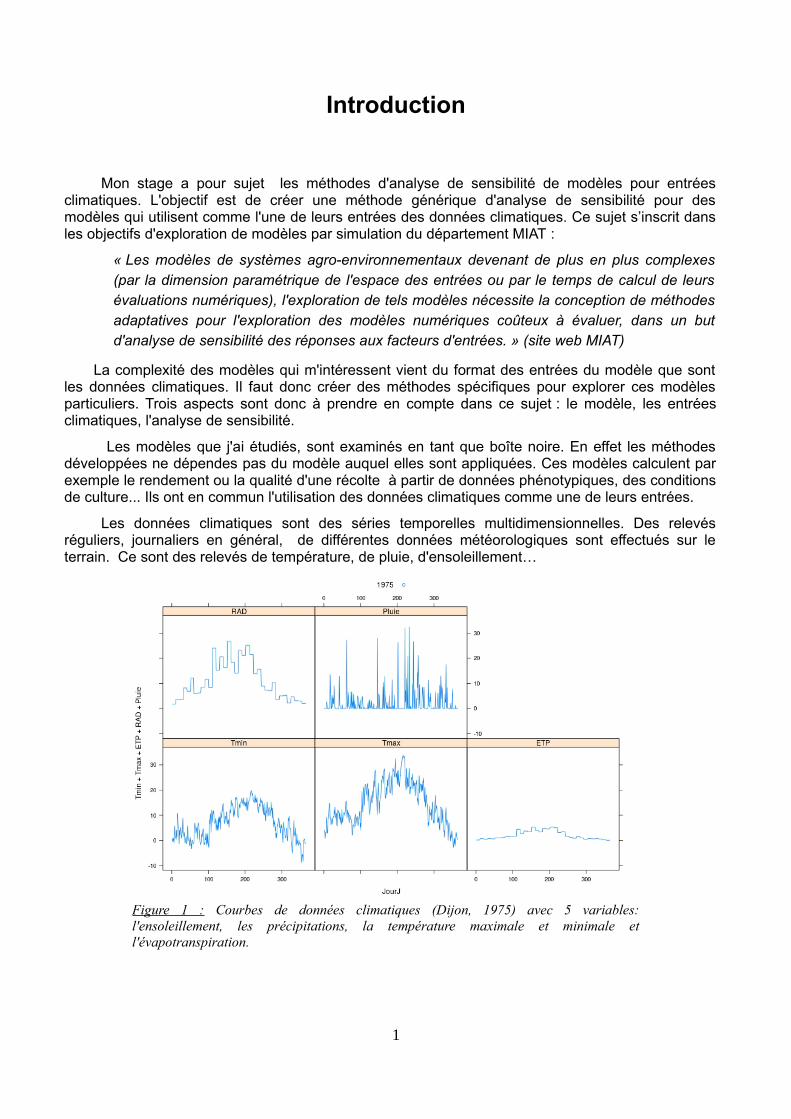
Les données climatiques sont des séries temporelles multidimensionnelles. Des relevésréguliers, journaliers en général, de différentes données météorologiques sont effectués sur leterrain. Ce sont des relevés de température, de pluie, d'ensoleillement…
Figure 1 : Courbes de données climatiques (Dijon, 1975) avec 5 variables:l'ensoleillement, les précipitations, la température maximale et minimale etl'évapotranspiration.
1

Ces séries temporelles sont très corrélées. La température maximale et minimale évoluent demanière similaire au cours de l'année. De plus les méthodes d'analyse de sensibilité usuellesutilisent des données unidimensionnelles. Il est donc nécessaire de développer une méthodespécifique pour traiter ce type de données.
L'analyse de sensibilité est une méthode d'exploration des entrées d'un modèle. Son objectifpremier est de quantifier l'effet de chaque variable d'entrée sur la sortie d'un modèle. Par uneplanification précise des entrées et des simulations successives du modèle, ces méthodesparviennent à identifier et à quantifier l'effet de la variation de chaque entrée sur la variabilité de lasortie du modèle.
Aujourd'hui l'information climatique n'est pas exploitée de manière satisfaisante car il estdifficile de traiter ces séries. On connaît l'importance de l'effet climatique sur le rendement ou laqualité d'une récolte mais on ne peut le quantifier grâce aux modèles de simulations. Plusieursméthodes sont utilisées mais ne permettent toujours pas d'évaluer un effet précis du climat. Une desméthodes utilisées pour l'analyse de sensibilité est un tirage aléatoire d'une série climatique àchaque évaluation du modèle. Cela permet d'évaluer les effets des autres entrées du modèle maispas l'effet climatique sur la sortie. Des méthodes de classification sont aussi utilisées pour résumerl'information des données climatiques. Les climatologues classent empiriquement les annéescomme pluvieuses ou sèches, chaudes ou froides. C'est donc par expertise que l'on peut constituerdes groupes de climats. Mais suivant la période de récolte de chaque culture, une même année peutêtre considérée comme pluvieuse ou non, si il y a eu beaucoup de pluie pendant une périodeimportante pour la plante ou non. Une analyse de sensibilité par classe pouvait alors être faite grâceà la typologie construite. Ces méthodes ne sont donc pas automatisées. On doit passer par un avisd'expert pour avoir une idée de l'effet du climat.
Le but de mon stage est de construire une méthode générique et automatique en adaptant lesméthodes déjà connues. Une routine pouvant être lancée sur n'importe quel modèle utilisant desdonnées climatiques. Dans ce but, j'ai utilisé le langage R qui permet de partager facilement etefficacement mon travail. Plusieurs solutions ont été envisagées. Diviser les données en semaine ouen mois, en faisant des moyennes sur chaque période. Cela permet de discrétiser l’année etd'obtenir des variables continues. Cette solution fait l'objet d'un autre stage cette année à l'INRA.Une deuxième stratégie est d'utiliser des générateurs climatiques. L'avantage de cette méthode estque les modèles qui génèrent ces séries sont manipulables par des paramètres artificiels de typecontinus (température moyenne, fréquence de retour des précipitations, …), qui sont donc plusadaptés à une analyse de sensibilité. L'effet du climat pourrait alors être évalué par l'intermédiaire deces paramètres. Ces générateurs n'ont pas été assez explorés pour être une solution solide. Il esten effet très difficile de générer des séries cohérentes pour certaines variables climatiques.
La solution envisagée au cours de mon stage est la création d'une typologie de climats, pourrésumer les données climatiques, avant une analyse de sensibilité. Une classification des climatspermet la création d'une variable qualitative mieux adaptée aux méthodes connues d'analyse desensibilité. Une méthode de classification de courbes doit donc être mise en place puis uneplanification particulière des entrées, mélangeant variables quantitatives continues et qualitatives,pour ensuite lancer une analyse de sensibilité. Cette approche sur les données climatiques permetdans un premier temps la caractérisation de profils climatiques grâce à la classification. Elle permetensuite l'exploration efficace de toutes les entrées des modèles.
Je vais dans un premier temps présenter les méthodes et algorithmes utilisés dans leprocessus de traitement des données climatiques et de l'analyse de sensibilité. La partie matérieldécrit précisément le matériel auquel j'ai eux accès durant mon stage et les fonctions ou packagesmis en œuvre sur R. La partie résultat présentera ensuite les graphes et sorties des différentesétapes de la méthodes. En dernier lieu, la partie discussion fera le bilan de mon travail et de l'apportde ce stage dans mon cursus.
2

Méthodes
Dans cette partie je vais m'appliquer à expliquer théoriquement les méthodes et algorithmesutilisés. Les méthodes déjà présentes dans la littérature seront moins détaillées que cellesspécifiques à la problématique de mon stage. Je vais d'abord développer les étapes qui m'amènentà la création d'une typologie de climat. Pour ensuite exposer les méthodes d'analyse de sensibilité.
Notation :
P un entier, nombre de variables climatiques.
N un entier, nombre de séries climatiques.
L un entier, longueur de chaque série climatique (nombre de jours).
X1,…,XM entrée non-climatique du modèle.
K nombre de classes issu de la classification.
1. Traitement des données climatiques
Avant toute étape de classification il est obligatoire de définir une distance entre chaqueindividu. Un climat étant composé de plusieurs séries temporelles, définir une distance entre climatc'est d'abord définir une distance entre ces variables climatiques. De plus cette distance entrecourbes doit admettre certaines contraintes pour correspondre à la problématique des donnéesclimatiques. Elle doit d'abord admettre une certaine déformation temporelle. En effet une fortechaleur (ou une forte précipitation) aura le même effet sur la plante, le rendement de l'année parexemple, si elle est décalée de seulement quelques jours. En pratique, si on considère 3 jourscomme un décalage acceptable, deux courbes de précipitations identiques décalées de 3 joursdoivent être distantes de 0.
La distance Dynamic Time Warping, permet de prendre en compte cette contrainte.
Dynamic Time Warping est une classe d'algorithmes qui comparent des séries entre elles . Cesalgorithmes associent les points des deux courbes de façon non-linéaire en respectant certainscritères. Le but de l'algorithme est de trouver l'association des points qui minimise la distance entreles deux séries temporelles. La distance entre les deux courbes est alors la somme des distancesentre les points nouvellement alignés. Cette déformation de courbe permet d'inclure un certaindécalage temporel qui correspond mieux à la réalité.
3
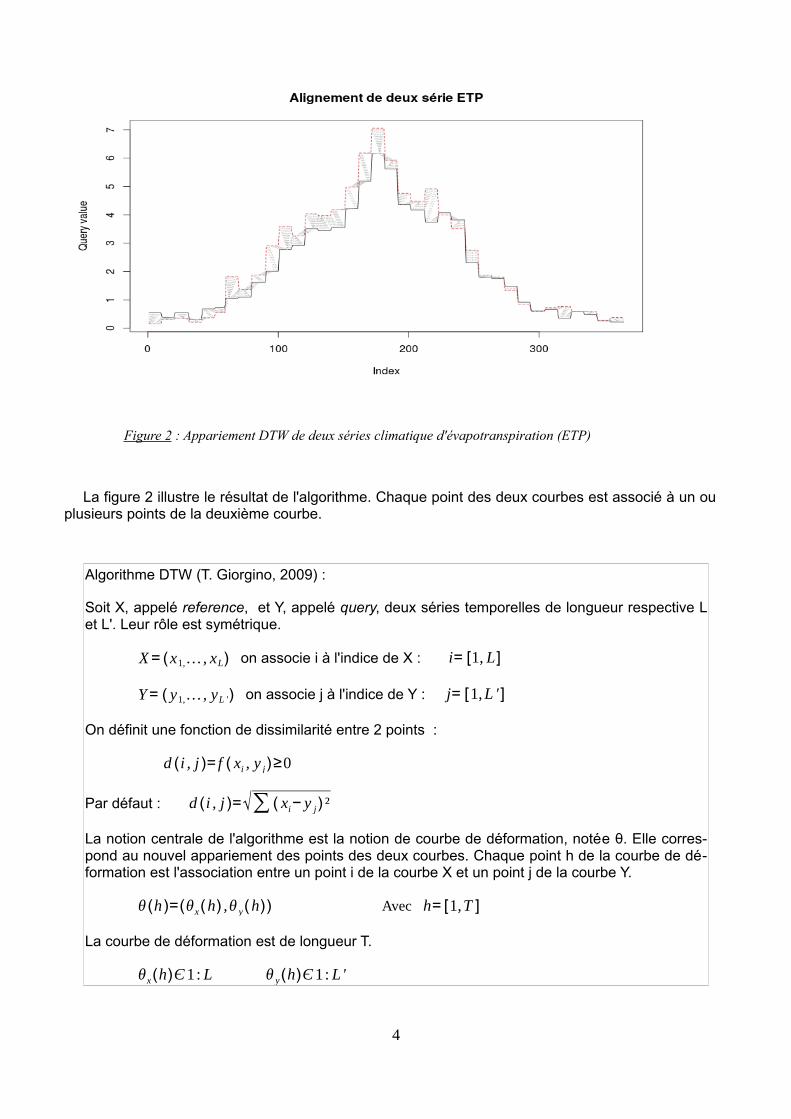
Figure 2 : Appariement DTW de deux séries climatique d'évapotranspiration (ETP)
La figure 2 illustre le résultat de l'algorithme. Chaque point des deux courbes est associé à un ouplusieurs points de la deuxième courbe.
Algorithme DTW (T. Giorgino, 2009) :
Soit X, appelé reference, et Y, appelé query, deux séries temporelles de longueur respective Let L'. Leur rôle est symétrique.
X= (x1, …, xL) on associe i à l'indice de X : i= [1, L]
Y= ( y1, …, yL ') on associe j à l'indice de Y : j= [1,L ' ]
On définit une fonction de dissimilarité entre 2 points :
d (i , j )= f ( xi , y j)≥0
Par défaut : d (i , j )=√∑ ( xi− y j) ²
La notion centrale de l'algorithme est la notion de courbe de déformation, notée θ. Elle corres-pond au nouvel appariement des points des deux courbes. Chaque point h de la courbe de dé-formation est l'association entre un point i de la courbe X et un point j de la courbe Y.
θ (h )=(θx(h) ,θ y(h)) Avec h= [1,T ]
La courbe de déformation est de longueur T.
θx(h)Є 1: L θ y(h)Є 1: L'
4

Étapes :
1. θ(1)= (1,1)
Le premier point de la courbe de déformation est le premier point de chaque courbe.
2. On doit ensuite associer chaque point en minimisant la distance entre les courbes. A chaquepas h l’algorithme à trois choix possibles pour avancer.
θ(k+1)= (θx(i) ,θ y( j+1))
ou θ(k+1)= (θx(i+1),θ y ( j))
ou θ(k+1)= (θx(i+1),θ y ( j+1))
exemple si h=2 : θ(2)= (1,2)ou (2,1)ou (2,2) car θ(1)= (1,1)
Certaines contraintes sont appliquées à la courbe de déformation pour assurer un appariementraisonnable des courbes :
- Le Step pattern contraint les valeurs admissibles au prochain point de la déformation :
Le step pattern est une contrainte locale. La contrainte par défaut, symetry2, multiplie par deuxla distance entre les points (i+1,j+1).
- Monotonie de la transformation :
θ y(h+1)≥ θ y(h)
θx(h+1)≥ θx(h)
L'ordre des indices doit être conservé. L'algorithme ne peut donc pas revenir en arrière enchoisissant un point à l'indice strictement inférieur à i ou j.
-Déformation maximale :
|θx(h)− θ y(h)|≤ T 0
On définit un certain T0 correspondant à la déformation maximale entre les deux courbes.
3. Répétition de la deuxième étape jusqu'à la fin des deux courbes :
θ(T )= (L , L' )
4. Calcul de la distance minimale. La distance entre X et Y est définie comme :
dθ (X ,Y )=∑h= 1
T
d (θx (h) ,θ y(h))×mθ (h)
M θ
avec mθ le poids associé à chaque pas et Mθ une constance de normalisation.
5

Figure 3 : Step pattern symetry2 (par défaut) de la fonction dtw
L'algorithme DTW calcule une distance entre chaque variable climatique de chaque climat. Ladifférence entre deux climats est caractérisée par P distances, avec P le nombre de variablesclimatiques. Nous obtenons donc une matrice de distances pour chaque variable. Les méthodes declassification utilisent en entrée une matrice de distance. Il faut donc « rassembler » les P matricesen une matrice de distances globales. De plus chaque matrice de distances n'est pas comparable,les unités de chaque variable climatique n'étant pas les mêmes. Il est en effet impossible decomparer les distances entre courbes de précipitations, en millimètre, et les courbes detempératures, en degrés Celsius. Il est donc nécessaire de passer par une étape de normalisationdes distances avant le calcul de la matrice de distances globales.
Beaucoup de façons de normaliser une matrice sont présentes dans la littérature. Plusieursméthodes ont été utilisées. Les méthodes utilisées se révèlent équivalentes. Pour cette raison, jelaisse le choix à l'utilisateur de la méthode de normalisation. Après une normalisation quantile lesmatrices de distances sont comparables. Cette normalisation utilise l'ordre des valeurs des deuxmatrices pour leur donner une même valeur. Les plus petites valeurs de chaque matrice aurons ainsila même valeur. Le poids associé à chaque variable aura ainsi le même impact. En effet la matricede distance globale est égale à la somme pondérée des matrices de distances normalisées.
Soit D(c,c') distance entre le climat c et le climat c'.
D(c , c ' )=∑p= 1
P
wp d p(c ,c ')
Avec wp le poids accordé à la variable p et dp (c,c') la distance normalisée de la variable p entre iet j.
L'impact de la pondération sur la classification peut être quantifié pour aider dans le choix dupoids à donner pour chaque variable climatique, grâce à une analyse de sensibilité sur les poids.Cette méthode est présentée en annexe.
2. Classification
Le but d'un algorithme de classification est de trouver une partition des N individus la meilleurepossible au sens d'un critère choisi. Chaque classe formée doit être la plus homogène possible
6

(variance intra-classe la plus basse possible) et les classes doivent être les plus différentespossibles (variance inter-classe la plus grande possible). A partir de la matrice de distance calculéeprécédemment, l'objectif est de procéder à un regroupement des climats en classes cohérentes.Une bonne classification regrouperait des climats qui ont les mêmes caractéristiques et sépareraitles climats différents.
De nombreuses méthodes permettent une classification à partir d'une matrice de distance. J'aid'abord choisi une méthode de K-medoids. Les centres de classe de départs sont tirées au hasard.C'est une méthode de classification stochastique. Il fallait donc évaluer la robustesse de la méthodesur les données (voir méthode en annexe). De plus il faut choisir à priori le nombre de classes. Pourcette raison j'ai complété cette méthode avec une Classification Ascendante Hiérarchique (CAH).En effet, en précédant les K-medoids par une CAH, cela permet d'obtenir une classificationdéterministe et de fournir une méthode de sélection du nombre de classes, qui peut êtreautomatisée tout en s'adaptant aux données.
Classification Ascendante Hiérarchique :
L'objectif de cette méthode est de donner une hiérarchisation de partitions de moins en moinsfine, avec de moins en moins de classes. L'algorithme fonctionne par regroupement successif. Ilconsidère d'abord que chaque individu est un groupe de taille un. A partir de la matrice de distances,il regroupe successivement les 2 groupes les plus proches jusqu’à ce qu'il ne reste plus qu'un seulgroupe.
Figure 4 : Illustration de l'algorithme CAH : étapes de regroupement etdendrogramme correspondant.
7

Algorithme CAH:
On considère chaque individu comme un groupe de taille 1.
1. A partir de la matrice de distances, on regroupe les 2 groupes les plus proches.
2. Calculer les distances entre le groupe nouvellement formé et les autres groupes de la ma-trice de distances et actualiser la matrice de distance. (Plusieurs méthodes existent pour calcu-ler la distance entre 2 groupes.)
3. Répétition de l'étape 1 et 2 jusqu'à ce qu'il ne reste plus qu'un seul groupe qui regroupe tousles individus.
Pour calculer la distance entre 2 groupes j'ai utilisé la méthode de Ward (F. Murtagh, 2011) . Leregroupement sélectionné est celui qui fait le moins baisser l'inertie inter-classe.
Les résultats de cette méthode sont souvent présentés sous la forme d'un dendrogramme.
Figure 5 : Dendrogramme de la CAH par la méthodes de Ward sur 190 sériesclimatiques. La ligne rouge est la partition choisie par le critère du seuil du R2 à 80 %.
Le dendrogramme représente les regroupements successifs. En abscisse, sont représentés lesindividus de la classification, en ordonnée , height, la variance intra-classe de la partition. Lavariance intra-classe est égale à 0 quand il y a autant de groupes que d'iindivius. Il n'y a en effetaucune variance possible avec un seul point. Et elle est égale à la variance totale quand il n'y aqu'une seule classe. La meilleure partition est celle qui minimise la variance intra, et qui maximise lavariance inter. D'après la formule de la décomposition de la variance :
Var tot= Var intra+Var inter
Si l'on minimise la variance intra, on maximise la variance-inter car la variance totale est fixe. Lameilleure partition sera donc celle qui maximise la variance intra ou qui minimise la variance inter.
8

La méthode de Ward minimise la perte de variance inter-classe à chaque regroupement. Cetteméthode regroupe des classes ayant leurs centres de gravité proches.
1. Choix du nombre de classes
Il n'existe pas dans la littérature de critère objectif et automatique sélectionnant le nombre declasses. C'est toujours un choix qui nécessite de faire un compromis entre un critère et le nombrede classes. Plus le nombre de classes sera grand moins il y aura d'erreurs de classement, et plus legroupe sera homogène. En pratique on retient souvent plusieurs classifications avec des nombresde classes différents dans le but de les comparer en termes de qualité ou d'interprétabilité.
Dans le but d'une méthode automatique, le choix du nombre de classes après une CAH estune vraie problématique à laquelle je n'ai pas de réponse optimale. En effet, ce choix se fait demanière visuelle ou avec des critères subjectifs comme la règle du coude, qui consiste à rechercherune cassure dans la courbe de la variance expliquée par la classification, significative d'unchangement structurel dans les données. L'oeil du statisticien prend souvent la dernière décision, etsupplante donc toute règle objective. Je propose 3 critères pour aider le statisticien à faire le choixdu nombre de classes : R2, PseudoF et la thumb rule.
R ²=I inter
I tot
Le R2 représente la variance expliquée par la classification. L'objectif est que la partitionchoisie explique la plus grande partie de la variance possible sans avoir trop de classes. La partitionest sélectionnée après un grand saut du R2. Pour l'utiliser de manière automatique, j'ai choisi unseuil (0,8). Le nombre de classes sélectionné est la partition avec le moins de classes qui explique80 % de la variabilité.
F= R ² /(k− 1)(1− R ²)/(N− k )
Ce critère compare une partition à k classes à une partition a k-1 classes. C'est une statistiquede même nature que la statistique F en analyse de variance (J.-P.Nakache, 2004 ; Reboul L., 2015).Le Pseudo F est un critère à maximiser. Je choisis donc le nombre de classes pour lequel lePseudo F atteint son maximum.
k=E [ √N /2 ] avec E[e] la partie entière du réel e
Une des alternatives à ces critères basés sur la variance est un critère uniquement basé sur lenombre d'individus. Empiriquement la thumb rule (K.Mardia et al.,1979) est proche du nombre declasses sélectionnées par les autres méthodes.
L'objectif de la CAH dans ma méthode est de donner un point de départ pour l'algorithme desK-medoids. L'algorithme de la CAH nous donne une partition des climats. Le centre d'une classe estsélectionné comme l'individu qui a la distance moyenne avec les individus de sa classe la plusbasse . Ces centres de classe sont sélectionnés comme initialisation de l'algorithme des K-medoids.
2. K-medoids
C'est une méthode de partitionnement proche de l'algorithme des K-means. La différence réside
9

dans le fait qu'elle ne calcule pas des moyennes pour définir les centres de classe mais utilise lesindividus de la matrice de dissimilarités. C'est une méthode qui est plus lourde en temps de calculque les K-means, mais qui n'est pas sensible aux données extrêmes (Tiwari M., 2012) et s'adaptebien à notre méthode. L'algorithme PAM est un algorithme de K-medoids.
Figure 6 : Regroupement successifs de la l'algorithme des K-medoids (illustrationWikipedia)
L'algorithme PAM (Partitionning Around Medoids) (M.Maechler, 2014) se décompose en deuxphases : BUILD (initialisation) construit les premiers centres ; SWAP, améliore la sélection descentres et la qualité de la classification (minimise la somme des dissimilarités entre les centres etles autres individus). La première partie de l'algorithme ne concerne pas cette méthode puisque lescentres sont calculés avec le résultat de la CAH. Les détails de l'algorithme sont présentés enannexe.
L'algorithme SWAP est donc lancé avec les centres issus de la CAH. Toutes les permutationsde centres possibles (entre un centre et un autre individu) sont faites et on calcule leurs effets sur lasomme des dissimilarités entre les centres et les autres individus. Elle correspond à une varianceintra-classe qui doit être la plus petite possible pour avoir des classes les plus homogènes possibles.L'échange qui réduit le plus cette somme est effectué. Puis la somme est recalculée avec lesnouveaux centres. L'algorithme s'arrête quand aucun des échanges n'a d'effet négatif sur la somme.
Cette méthode de classification mixte, mélangeant classification hiérarchique et departitionnement a permis d'améliorer le résultat de la CAH et de d'accélérer l'algorithme des K-medoids. En effet en autorisant des réaffectations individuelles autour des centres de classe issusde la CAH on obtient un optimum local. De plus utiliser les résultats de la CAH permet d'accélérerl'algorithme en supprimant l'étape d'initialisation et en assurant une convergence plus rapide.
Après cette étape de classification on obtient une partition des N climats. Chaque climat estcaractérisé par son appartenance à une classe. L'information des données climatiques a étérésumée pour pouvoir les inclure dans une analyse de sensibilité. Le processus de classificationnous permet de regrouper des climats qui se ressemblent en prenant en compte les différentesvariables climatiques. C'est une méthode générique et déterministe. En fournissant des outils decaractérisations des classes on obtient des résultats intéressants sur les données qui peuventcompléter les résultats de l'analyse de sensibilité.
10

3. Analyse de sensibilité
On considère dans cette partie la sortie Y du modèle comme :
Y= f (c , X 1 , ... , XM )
Le modèle utilise une série climatique c, composée de plusieurs séries, et M variables continues.La sortie Y est un réel.
1. Principe de l'analyse de sensibilité
L'analyse de sensibilité détermine l'importance de la classe du climat et des autres entrées dumodèle sur la variable de sortie. Cela permet de hiérarchiser l'influence des entrées ou de groupesd'entrées avec une échelle normalisée. En effet les indices de sensibilité sont compris entre 0 et 1.On pourra donc déterminer quelles entrées ont le plus d'influence sur la sortie et doivent donc êtreconnues avec plus de précision.
On utilise une méthode d'analyse de sensibilité globale. L'analyse de sensibilité globale, àopposer à l'analyse de sensibilité locale, explore l'espace des entrées sur un domaine de définition.L'analyse de sensibilité locale l'explore autour d'une valeur précise. L'approche développée dans cerapport est une méthode basée sur l'analyse de la variance.
Une analyse de sensibilité se décompose en 4 étapes (Faivre et al., 2013):
- Définition des distributions des M entrées (X1… XM), souvent uniformes dans leur domainede définition ou avis expert.
- Génération d'un échantillon, X, des entrées conditionnellement aux distributions. (MonteCarlo, Latine Hypercube Sampling ...)
- Calcul de la sortie Y du modèle sur le plan X.
- Estimation des indices de sensibilité. ( modèle considéré comme trop complexe pour per-mettre un calcul analytique de ces indices).
Indices de sensibilité basés sur l'analyse de la variance.
Soit Y la sortie d'intérêt du modèle et X l'ensemble des paramètres du modèle.
Décomposition de la variance :
Var(Y )= V (X1)+...+V (XM )+V (X1 , X2)+ ...+V (X M− 1 , X M )+...+V (X1, …, X M)
V(X1) désigne la part de variance de Y attribuée au facteur X1. Chaque V représente la part devariance de Y attribuée à un ensemble de facteurs, noté U. La variance de Y est la somme desvariances induites par les facteurs (principaux et interactions).
A partir de ce résultat on définit un indice de sensibilité SI d'un facteur ou d'un groupe de facteurXU comme :
SI Xu=V (XU )Var (Y )
11

L'indice de sensibilité de Xu , notée SIXu, est compris entre 0 et 1 car la variance induite de Xu estinférieure à la variance de Y d'après la formule de décomposition de la variance. La somme desindices est égale à 1. Les facteurs qui ont les indices les plus élevés influencent le plus la réponseY du modèle. Ils sont par conséquent les facteurs les plus importants dans le modèle, ce sont ceuxdont il faudra avoir une connaissance la plus précise.
D'un point de vue probabiliste, la variance induite de chaque ensemble de facteur peut êtredéfinie comme une combinaison linéaire de variances d’espérances conditionnelles. Soit pour XU
fixé :
V Xu=Var (E (Y ∣XU ))
La décomposition de la variance permet de calculer les indices de sensibilité de chaque termedu modèle. En pratique, on ne s'intéresse qu'à certaines combinaisons de facteurs.
L'indice de sensibilité de premier ordre, noté SI, est celui associé à l'effet principal seul.Ces indices sont étudiés en priorité car ils expliquent en général une bonne partie de la variabilitétotale. Ils sont plus facilement interprétables et calculables. L'indice de premier ordre de la variableXU correspond au pourcentage de la variance induite par XU seule. L'ensemble XU désigne alors unseul paramètre d'entrée du modèle. Il est estimé en calculant la variance de Y sachant XU fixée.
L'indice de premier ordre s'obtient par :
SI i=Var (E (Y ∣XU ))
Var (Y )
On a aussi :
SI i=1−E (Var (Y ∣XU ))
Var (Y )
Déduit de l'égalité suivante sur les probabilités conditionnelles :
Var (Y )=Var (E (Y ∣XU ))+E (Var (Y ∣XU ))
Les SI de premier ordre permettent de classer les entrées par ordre de priorité et de déterminerles entrées dont il faut réduire l'incertitude en priorité pour réduire l'incertitude sur Y.
Si les SI de premier ordre jouent un rôle important sur Y, il est parfois important d'estimer desindices de sensibilité plus complexes, notamment quand le nombre de variables est grand car lenombre d’interactions est plus grand.
L'indice de sensibilité totale, noté TSI, correspond à tous les effets associés au facteur Xi.C'est donc la somme des indices associés à Xi. Il est calculé comme la variance de Y induite par Xi
sachant les autres variables fixées. X-i désigne l'ensemble des facteurs à l’exception de Xi.
TSI i= 1−Var (E (Y ∣X−U ))
Var (Y )= E
(Var (Y ∣X−U ))Var (Y )
Les facteurs avec une TSI faible sont des facteurs qui peuvent être fixés sans influencer la sortieY.
TSI i≥ SI i La différence entre les deux indices correspond aux interactions de l'effet Xi avec lesautres facteurs.
2. Estimation des indices de sensibilité par la méthode de Sobol'
Il existe dans la littérature beaucoup de méthodes de calcul des indices de sensibilité globale(FAST ou Morris ). Durant ce stage j'ai utilisé la méthode de Sobol'.
12

Sobol' est une méthode model free, sans contrainte sur le modèle. La seule hypothèse faite estque la variance et l’espérance sont finies. Mon projet étant de créer une méthode génériqued'analyse de sensibilité, c'est une méthode adaptée. Méthode éprouvée dans la littérature, elleexige en contrepartie un grand nombre de simulations, n*(M+2) simulations avec M le nombre deparamètres et n la taille du plan. On choisit n en fonction du temps d'évaluation du modèle, souventsupérieur à 500. Elle peut être appliquée à un méta-modèle, approximation du modèle, si lessimulations sont coûteuses.
Pour estimer les indices de sensibilité, cette méthode utilise des simulations appariéesqui ne sont différentes que par un certain groupe d'entrées. La différence sur Y entre lesdeux n' est alors imputable qu'aux facteurs qui sont différents.
Étape de la méthode de Sobol' (Faivre et al., 2013):
Elle nécessite n(M+2) simulations (M le nombre de paramètres).
1.Tirage aléatoire de XA et XB (matrices n*M) par la méthode de Monte Carlo ou LHS (Latin Hy-percube Sampling) .
X A=|X 1,1A ... X 1, M
A
. .
. .X n ,1
A ... X n , MA | X B=|X 1,1
B ... X 1, MB
. .
. .X n ,1
B ... X n , MB |
2. Construction des Xc,i qui correspondent à XA à l’exception de la mème colonne qui appartient àB. On parle de pick and freeze, car on choisit une colonne du plan XB en fixant les autres en-trées du plan XA.
X iC=|X 1,1
A ... X 1,mB ... X 1,M
A
. . .
. . .X n ,1
A ... X n, mB ... X n, M
A |Il y a donc n lignes dans chaque plan : XA,XB,XC
1,...,XC,m,...,XC
,M.
3. Calcul de Ya, Yb, Yc1, …, Yc
m, …, YcM : vecteurs des n(M+2) réponses obtenues pour le mo-
dèle.
4. Calcul pour chaque entrée Xm des estimateurs des indices SI et TSI.
Cette méthode calcule des estimateurs des indices de sensibilité car il est impossible de lescalculer de façon analytique. La précision des estimateurs des indices de sensibilité dépendent de lataille n des échantillons. Cette précision est évaluée par une procédure boostrap, sans avoir àréévaluer le modèle.
Estimation boostrap (Gilles Pujol, 2015) :
Soit nb la taille de l'échantillon bootstrap (environ une centaine).
13

1. Tirage aléatoire avec remise de taille n dans les indices lignes des matrice A et B.
On obtient : jb=jb1, … , jbi, … , jbn avec jbi entre 1 et n.
2. Arrangement des simulations avec les indices jb : XbA,Xb
B,XbC,1,...,Xb
C,m,...,XbC,M et récupération
des résultats du modèle, associés à chaque ligne par extraction des coordonnées dans les sor-ties précédemment calculées. Yb
a, Ybb, Yb
c1, … , Ybcm, … , Yb
cM.
3.Calcul des estimateurs des indices de sensibilité de la méthode de Sobol'.
4. Calcul des biais et des intervalles de confiance grâce à la distribution des indices Sib et TSIb
calculés.
Cette méthode permet l'évaluation de la précision sans relancer de simulations.
3. Méthodes pour données climatiques
A partir de ces méthodes peuvent être étudiés les effets des variables qui nous intéressent. Laparticularité de nos données demeure dans la dimension des données climatiques. La classificationréduit la complexité de ces données en créant une partition. La variabilité climatique se résume doncà une appartenance à une classe de climat, une variable discrète allant de 1 à K.
En plus des données climatiques, on veut étudier l'effet de M variables continues du modèle. J'aiétudié 2 stratégies :
→ analyses de sensibilité indépendantes.
→ analyse de sensibilité conjointe.
Les analyses de sensibilité indépendantes permettent de quantifier l'effet des variables continueset d'évaluer leurs interactions avec le climat. Une analyse de sensibilité conjointe inclue le climatdans les variables de l'analyse de sensibilité. La première étape de chaque analyse est uneplanification des deux matrices de départ XA et XB de la méthode de Sobol'. Il est en effet importantde bien identifier la problématique pour créer des plans d'expérience adaptés.
Planification
Le plan d'expérience est un ensemble de n vecteurs d'entrées du modèle, de taille M+1 : M entréescontinues plus l'entrée relative au climat. Dans toute analyse de modèle, des plans d'expériencessont utilisés. Les deux simulations XA et XB utilisées comme point de départ de la méthode de Sobol'sont deux réalisations indépendantes de la même méthode de planification. En effet il est difficile defaire toutes les expériences (ou simulations) possibles. Elles doivent donc être le mieux répartiespossibles dans l'espace des entrées pour que les sorties Y soient le plus possible représentativesdes sorties. Dans notre cas nous n'avons pas de connaissance à priori sur les paramètres quiinfluencent le plus le modèle. Il est donc important de choisir des plans qui couvrent bien leursdomaines de définition, ne laissant aucune zone sous ou sur échantillonnée de façon à ne pasgaspiller de calculs. Nous avons donc recourt à des méthodes d'échantillonnage pour explorer ledomaine des entrées continues. La variable climatique est une variable traitée de façon différentepuisque c'est une variable catégorielle. Dans la suite, la première colonne de chaque matrice X estdéfini comme la variable climatique.
14

X=|x1,1 x1, M+1 ... x1,M+1
. . .
. . .
. . .xn ,1 x1, M+1 ... xn, M+1
|Figure 7 : Exemple d'un plan d'expérience
La méthode de Monte Carlo ( ou de quasi Monte Carlo) est beaucoup utilisée dans la littérature si le nombre d'expérimentations est élevé. Chaque élément x de la matrice est tiré dans une loi définie ( ici U(0,1)), puis ajustée selon le domaine de définition de la variable p. Durant le stage, j'ai utilisé une autre méthode d'échantillonnage qu'est le Latine Hypercube Sampling (LHS). La méthodeLHS assure une exploration efficace de tout le domaine de chaque facteur.
Un hypercube latin de n lignes et M colonnes est une matrice n*M dont chaque colonne est unepermutation de l'ensemble {1,2, …, n }. La méthode LHS découpe donc le domaine de définition dechaque variable et sélectionne un nombre dans chaque intervalle. Elle réordonne ensuite ces nvecteurs de taille M pour créer la matrice X. Un plan LHS est facile à générer mais n'est pas unique.La qualité de ce plan n'est donc pas assurée et peut être mauvaise. Il existe donc des critères pouroptimiser ce plan. Certaines méthodes de LHS optimisés minimisent la distance maximale entre lespoint, ou maximise la distance minimum. Mais elles sont coûteuses en temps de calcul. La méthodeque j'ai utilisée respecte une distance optimale entre les points pour éviter l’agglomération de pointsdans une partie de l'espace (R.Stocki, 2005).
Les méthodes de planification et d'analyse de sensibilité, sont adaptées pour des variablescontinues. La planification sera adaptée à chaque méthodes utilisées.
Analyses de Sensibilité indépendantes
Cette méthode permet de contourner la difficulté liée aux données climatiques. On procède à Nanalyses de sensibilité, le climat est fixe à l'intérieur de chaque analyse de sensibilité, seules varientles variables continues. Dans un premier temps, les indices de sensibilité des variables continuessont estimés pour chaque climat. La variance de Y n'étant pas excessivement différente entrechaque analyse, les indices sont normalisés : il n'est pas tenu compte de la différence de variancede Y entre chaque climat. Elle ne permet pas de quantifier l'effet du climat mais donne unehiérarchisation des effets des variables continues. Pour évaluer l'effet du climat sur ces indices il estnécessaire d'utiliser les résultats de la classification. Des analyses de variance et des tests d'égalitéde moyennes, permettent de savoir si les variables continues ont un effet différent selon les classesde climat.
X1A=|1 x1,1
A ... x1, MA
. . .
. . .
. . .1 xn ,1
A ... xn ,MA| X1
B=|1 x1,1B ... x1, M
B
. . .
. . .
. . .1 xn ,1
B ... xn, MB|
[...]
15

X NA=|N x1,1
A ... x1, MA
. . .
. . .
. . .N xn ,1
A ... xn ,MA| X N
B=|N x1,1B ... x1, M
B
. . .
. . .
. . .N xn ,1
B ... xn ,MB|
Figure 8 : Simulation pour chaque climat de deux LHS différents
Pour chaque analyse de sensibilité, sont créés deux LHS optimisés à n lignes et M colonnes(figure 8). Le climat est considéré comme fixé pour chaque analyse.
Cette méthode est une première approche d'analyse du modèle et permet une estimation desentrées continues du modèle. Elle est coûteuse en temps de calcul si le nombre de climats estélevé. Le modèle est lancé N*n*(P+2) fois avec la méthode de Sobol'. Enfin le résultat estdifficilement interprétable, d'autant plus si le nombre de séries climatiques est important. Procéder àune analyse de sensibilité par classe, en choisissant un représentant permet de réduire le nombrede simulations du modèle. K analyses de sensibilité sont alors lancées, soit K*n*(P+2) simulations.
Le résultat de cette méthode est donc composé de M indices de sensibilité par climat. Il est doncimportant de retravailler ces résultats pour pouvoir les interpréter. Les résultats de la classificationpermettent un tri des indices de sensibilité obtenus. Une série d'anova à un facteur permetd'expliquer les indices de sensibilité grâce à la classification. Le but est alors de savoir si les indicesde sensibilité des variables continues sont différents selon les classes de climat. (Rakotomalala R.,2012). On procède donc à M analyses de variance à un facteur.
SI M= μ+α K+r
L'Indice de Sensibilité de la variable M (SIM) est décomposé par la somme de sa moyenne (µ), del'effet de chaque classe K (αK) et d'un résidu (r). On teste ensuite la significativité de cet effet encomparant les moyennes dans K sous-groupes par le test de Ficher. Si un effet est significatif, celaveut dire que la moyenne est significativement différente de la moyenne générale dans au moinsdeux classes. Dans notre cas si l'effet de la classe de climat est significatif, cela veut dire que lavariable continue à un impact différent sur le rendement suivant le climat.
Le tests de Student, qui compare deux moyennes permet de décrire l'effet d'une classe de climatparticulière sur les indices de sensibilité. L'objectif est alors de savoir si les indices de sensibilitésont différents dans cette classe de climat par rapport à l'ensemble des climats.
AS conjointe
Grâce à cette méthode, une seule analyse de sensibilité est nécessaire. Elle permet uneestimation conjointe des indices de sensibilité, de la variable relative au climat et des paramètrescontinus. La difficulté de prendre en compte la variable climatique dans une analyse de sensibilitéréside dans le fait que sont mélangées une variable qualitative (l'appartenance à une classe declimat) et des variables continues. La plan d'expérience doit être adapté aux calculs des indices desensibilité.
16

X A=| 1 x1,1A . . . x1, M
A
. . .
. . .
. . .1 xn ,1
A . . . xn, MA
2 x1,1A . . . x1, M
A
. . .
. . .
. . .2 xn ,1 . . . xn, M
. . .
. . .
. . .K x1,1
A . . . x1, MA
. . .
. . .
. . .K xn ,1
A . . . xn, MA
| X B=|s1 x1,1B . . . x1, M
B
. . .
. . .
. . .
. xn ,1B . . . xn , M
B
. x1,1B . . . x1, M
B
. . .
. . .
. . .
. xn ,1B . . . xn , M
B
. . .
. . .
. . .
. x1,1B . . . x1, M
B
. . .
. . .
. . .sn xn ,1
B . . . xn , MB
|Figure 9: Plan d'expérience unique, constitué de LHS répétés.
Chaque plan est constitué de K plans LHS. Les K classes doivent être représentées de la mêmemanière pour pouvoir évaluer l'indice de sensibilité du climat avec la méthodes de Sobol'.L'appartenance à une classe de climats étant une variable catégorielle les calculs des indices desensibilité sont possibles si tous les niveaux sont présents dans le plan. Le même plan LHS estrépété pour avoir orthogonalité entre les variables continues et le paramètre climatique. C'est doncun plan complet entre le paramètre du climat et le LHS. Cela permet de ne pas confondre les effets.Un seul plan LHS de taille (n,P) est simulé. Il est agrégé K fois puis chaque ligne se voit attribuerune classe de climat. On obtient un plan de dimension (n*K,M+1) (figure 9).
Pour pouvoir croiser le plan XA et XB pendant l'étape du pick and freeze de la méthode de Sobol',l'appartenance à une classe pour chaque ligne ne doit pas être la même. Auquel cas la méthode nepourrait mesurer l'impact de la classe de climat. La première colonne, relative au climat, du plan XA
est la répétition K climats dans l'ordre. Le plan XB doit respecter la contrainte de non égalité de lapremière colonne et une bonne distribution des expériences avec les variables continues. Unepermutation des lignes aléatoire n'est pas possible car la probabilité que le remplacement soit lemême est loin d'être nulle, d'autant plus si le nombre de classes n'est pas grand : une probabilité de1/K d'avoir le même. Dans ce cas la méthode évalue trop de fois la même simulation pour estimerl'effet du climat. Il est donc important de procéder à une permutation déterministe des classes. Cettepermutation doit être corrélée le moins possible à la distribution des classes du premier plan et doitavoir une probabilité nul d'être la même que la colonne de XA.
La solution choisie est une permutation par sous-bloc. Chaque LHS, de rang i, est partagé en K-1sous bloc. Chaque soit bloc se voit attribuer une classe entre 1 et K qui ne soit pas égale à i. De plusle plan doit garder ces propriétés. Chaque classe doit être simulée avec les variables continue defaçon à constituer un LHS.
Pour calculer la première colonne de façon automatique j'ai utilisé cette formule :
17

sh= E [i+ j÷ K+1]+reste (i+ j÷ K+1)
La classe attribuée à chaque sous bloc sh est égale à la somme du quotient et du reste de ladivision euclidienne de (i+j) par (K+1) ; i étant le rang du LSH et j le rang du sous bloc dans le LHS.Chaque attribution de classe est répétée n/(K*2-1). Exemple pour K=4 :
|s i j2 1 13 1 24 1 33 2 14 2 21 2 34 3 11 3 22 3 31 4 12 4 23 4 3
|Figure 10 : Calcul de la première colonne de XB, noté s , exemple avec K=4 avec i lerang du LHS dans le plan et j le rang du sous bloc dans le LHS.
Cette planification permet de calculer toutes les permutations de lignes. En effet le climat 1 estremplacé par toutes les autres climats etc... Il permet aussi de conserver les caractéristiques d'unplan complet entre la classe de climat et les LHS des variables continues. Chaque classe est simulerle même nombre de fois de façon à ce que les variables continues forme un LHS. Chaque plan issudu pick end freeze est un plan avec les mêmes propriétés que le plan XA.
Au delà d'une appartenance à une classe, le modèle a besoin d'une série climatique pourcalculer la sortie. Il faut donc choisir un représentant de classe pour chaque expérience simulée.Deux choix sont possibles pour sélectionner ce climat : de façon aléatoire ou le calcul d'un centre declasse. Un tirage aléatoire du climat permet d'introduire un aspect stochastique qui reflète plus laréalité. Cela introduit une variabilité supplémentaire dans la réponse Y qui ne peut être attribuée auclimat par le biais de l'analyse de sensibilité car l'effet calculé par l'analyse de sensibilité est l'effet dela variable appartenance à une classe. La variabilité ajoutée en plus ne pourra être quantifiée parl'analyse de sensibilité. Le calcul d'un centre de classe, permet une évaluation plus précise des SI,car il y a moins de variabilité dans la réponse de Y. Le climat reste le même entre deux expériencesd'une même classe. L'effet du climat sera donc plus élevé car la variabilité intra-classe a été retirée.
Le plan utilisé a de bonnes propriétés mais l'indépendance des deux plans n'est pas respectée.Les plans XA, XB de départ ne sont pas construits de façon indépendante. En effet on doit respecterun certain nombre de contraintes, expliquées précédemment. Le calcul des variances et desespérances est biaisé. Cela entraîne un biais dans le calcul des estimateurs, qu'il faudra mesurer etcorriger dans l'évaluation des indices de sensibilité.
18

Matériels
L'objectif de cette partie est de présenter de manière succincte le matériel auquel j'ai eu accès etque j'ai été amené à manipuler. Décrire les conditions d'utilisations de mes outils permettra uneréutilisation des méthodes. Je commencerai par décrire les machines sur lesquelles j'ai travaillé.Puis je détaillerai l'utilisation des principaux packages et fonctions utilisés.
Les temps de calcul indiqué pour certaine méthodes sont basés sur les temps écoulé (fonctionproc.time) d'un ordinateur portable avec 8 Go de RAM, d'un processeur à 8 threads d'une fréquencede 2,5Ghz. Certaines méthodes, notamment le calcul des distances et l'analyse de sensibilitédemande un temps de calcul important. Il a donc été nécessaire de recourir à un cluster de calcul.Dans les locaux de l'INRA de Toulouse, est hébergée la Génopole de Toulouse. Les plateformesGenotoul donnent accès à un cluster de calcul performant et disponible facilement. Outre lapossibilité de transférer les calculs sur des machines performantes, cet accès a aussi permis deparalléliser les calculs.
Packages
Cette section liste les principaux packages et fonctions utilisés ainsi que leur mise en œuvre surle logiciel R.
Rvle : Package qui permet la communication avec le simulateur VLE (Quesnel G., 1999) souslequel est présent le modèle sunflo détaillé par la suite. Il permet de lancer des simulations et dechanger les conditions initiales du modèle à partir d'un appel R. Le modèle sunflo met environ uneseconde pour une simulation.
dtw : calcule des distances entre séries climatiques.
library(dtw)
dtw(x = DONNEES[[couples[1] ]], y = DONNEES[[couples[2] ]], window.type="sakoechiba",window.size=wsize,distance.only=T)$distance
Cette ligne de code calcule la distance dtw entre deux courbes contenues dans 'DONNEES'.Avec la contrainte que les indices ne doivent pas être plus espacés que 'wsize' (un entier),équivalent de T0 (voir page 10). L'argument 'distance.only=T' permet d'alléger les calculs en necalculant que les distances.
hclust : implémentation de l'algorithme CAH.
library(fastcluster)library(stats)
d<-dist(distances)CAH<-hclust(d,method="ward.D2")K<-nbclasse(CAH,method="R2",nb=10)C<-cutree(CAH, k = K)centre<-centreclasse(distances,C)
19
Temps écoulé : 7171
Temps écoulé : 3.61

La variable 'distance' est une matrice de distances modifiée par la fonction 'dist' du package proxycar la fonction utilise ce format. 'nbclasse' est une fonction qui calcule le nombre de classes, K, defaçon automatique à partir du dendrogramme. La partition est sélectionnée en fonction du K calculé.Le centre de classe est calculé avec la fonction 'centreclasse'. Le centre est l'individu qui minimise lasomme des distances avec les autre individus de sa classe.
pam : implémentation de l'algorithme PAM (Partitionning Around Medoids)
library(cluster)
res.pam<-pam(distances,k = K,diss = T,medoids = centre,cluster.only = T)
À partir des centres et de la matrice de distances, 'pam' lance l'algorithme et rend une nouvellepartition.
improvedlhs : création des plans d'expérience.
library(lhs)
res_lhs <-matrix(0,nrow = n*K,ncol=nrow(bounds)+1) LHS<- improvedLHS(n ,nrow(bounds)) LHS<-t(apply(LHS,MARGIN=1,FUN = function(x) (x*c(bounds[,"max"]-bounds[,"min"])+bounds[,"min"]))) for ( i in 1:K) {res_lhs[((i*n)-(n-1)):(i*n),2:ncol(res_lhs)]<-LHS} res_lhs[,1]<-rep(1:K,each=n) planexp<-res_lhs
La fonction 'improveLHS' créé un LHS qu'il faut recalculer avec les bornes des variablescontinues car la fonction calcule des LHS avec des éléments entre 0 et 1. Ce LHS est agrégé K foisdans la variable 'res_lhs'. La variable d’appartenance de classe est ensuite calculée et définiecomme la première colonne du plan.
Package sensitivity : à partir de la méthode de Sobol', des estimateurs, plus efficaces quel'algorithme de base ont été construits. SobolEff estime les indices de premier ordre avec seulementN*(P+1) simulations. La fonction soboljansen estime les indices totaux et de premier ordre enappelant le modèle N*(P+2) fois.
sobolEff :
library(sensitivity)
indices.ordre1 <- sobolEff(model=mod,X1,X2,nboot=100)
sobol jansen :
library(sensitivity)
indices.totaux <- soboljansen(model=mod,X1,X2,nboot=100)
Les 2 fonctions ont la même utilisation. Les variables 'X1' et 'X2' sont 2 plans d'expériencesindépendants. 'mod' est une fonction qui prend en entrées une ligne de ce plan et rend la sortie
20
Temps écoulé : 0.11
Temps écoulé : 6.39
Temps écoulé : 66000
Temps écoulé : 60000

d'intérêt. 'nboot' est la taille de l'échantillon bootstrap.
Catdes :
library(FactoMineR)
classedes <- catdes(donnee=ISclimat,numvar=1,proba=0.05)
Cette fonction permet la description de la partition de climat par les varaible continue que sont lesindices de sensibilité des variables. 'Isclimat' est un data frame avec dans la première colonne,'numvar=1', la partition de climat, au format facteur. Les autre colonnes sot les indices de sensibilitédes variables continues.
Fonctions graphiques : R possède nombre de librairies de graphes avancés, ggplot et lattice ensont 2 très utilisées. Leur utilisation nécessite une syntaxe particulière.
Stackedplot :
library(ggplot2)
ggplot(tabclimat, aes(Classe, fill = NomStation)) + geom_bar()
'tabclimat' est un dataframe avec toutes les données, dont l'appartenance à une classe et le nomde la station. La fonction sépare d'abord les données d'après la classe, en K barres, puis remplit cesbarres en fonction des stations (voir figure 16).
Trelliplot:
library(lattice)
expr<-paste(paste(VAR.met[4]),"~ jour|factor(classe)")equ<-formula(expr)xyplot(x = equ,data = donclimatIC,type="l",group=type,grid=T,as.table=T,main="Climat moyen par classe", col=c("mediumblue","mediumblue","mediumblue","brown2"),lty=c(2,2,1,1),par.settings = list(superpose.line = list(col=c("mediumblue", "brown2"))), auto.key=list(text=c("moyen","+proche"),space="top",columns=2, lines=TRUE, points=FALSE) )
L'utilisation de graphiques lattice nécessite la déclaration d'une variable équation 'equ' qui décriten fonction de quelles variables le graphique doit être séparé. Ici la variable 'VAR.met[4]' est utilisée(Température maximum) comme courbe séparée par classe (voir Annexe X). Sur chaque fenêtregraphique on obtient des courbes contenues dans 'donclimatIC' séparées par la variable de classe.
21
Temps écoulé : 0.39

Résultats
1. Présentation des données
Dans cette partie je présenterai les différents résultats graphiques qui pourront être proposés àl'utilisateur de la méthode. Je m'appliquerai à les expliquer et à les interpréter au mieux à l'aide d'unexemple. Au delà du résultat, cette partie illustrera de manière plus concrète la mise en œuvre desméthodes présentées.
Le modèle avec lequel j'ai travaillé dans un premier temps est un modèle de simulationdynamique déterministe SUNFLO de Pierre Casadebaig. Je ne me suis pas intéressé aufonctionnement exact de ce modèle que j'ai considéré comme boîte noire. Il estime le résultat d'unerécolte de tournesol à partir des conditions de sa culture et de données phénotypiques de la plante.Ce modèle accepte 3 familles de données en entrée et calcule 2 sorties.
Les entrées du modèle sont des données climatiques, phénotypiques et de contexte de culture.
Avec ces trois groupes de paramètres d’entrée, le modèle de simulation calcule :
– Le rendement sur la parcelle en quintal par hectare,
– La teneur en huile du tournesol en pourcentage.
Figure 11 : Représentation du modèle sunflo, à gauche les entrées du modèle, à droite les sorties
Données climatiques :
Le jeu de données climatiques utilisé a été prélevé sur cinq lieux différents (Avignon, Blagnac,Dijon, Poitiers et Reims) de 1975 à 2012. Ceci a conduit à travailler sur un jeu de données de 190séries temporelles multidimensionnelles.
Chaque climat est composé de 5 séries temporelles. Ce sont des relevés quotidiens sur uneannée de la température minimale (Tmin), la température maximale (Tmax), l’évapotranspiration
22

(ETP), l’ensoleillement (RAD) et les précipitations (Pluie ) (voir figure 1).
Données phénotypiques :
Les 8 traits phénotypiques sont des variables continues. Elles varient de façon uniforme entre unmaximum et un minimum, calculés à partir d'un jeu de données de validation.
- TDF1 є [765, 907] : temps entre la levée et le stade de floraison,
- TDM3 є [1537, 1831] : durée entre la phase de levée et de maturité,
- TLN є [22.2, 36.7] : nombre de feuilles potentielles,
- K є [0.78, 0.95] : coefficient d’extinction du rayonnement lors de la phase végétative,
- LLH є [13.5, 20.6] : rang de la plus grande feuille du profil foliaire à la floraison ,
- LLS є [334, 670] : surface de la plus grande feuille du profil foliaire à la floraison (cm2 ),
- LE є [−15.6, −2.3] : seuil de réponse de l’expansion foliaire à une contrainte hydrique,
-TR є [−14.2, −5.8] : seuil de réponse de la conductance stomatique à une contrainte hydrique.
Contexte de culture :
Ce type de données sont des données de types de sol ( taux de cailloux, vitesse deminéralisation, profondeur du sol...) et de comportements de l'agriculteur ( dates de semis et derécolte, fertilisation, irrigation...). Ces données on été considérées comme constantes pour l'analysede sensibilité du modèle.
Sorties du modèle :
Seul le rendement a été retenue pour illustrer l'analyse. Le rendement par parcelle varie de 15 à35 q/ha.
L'analyse de sensibilité quantifie l'effet du climat et du type de plante sur le rendement.
2. Classification
La classification a deux objectifs : le prétraitement des données climatiques en vue de l'analysede sensibilité, mais c'est aussi un outil d'exploration de l'information climatique. Le développementd'outils graphiques pour caractériser les classes créées est important pour le suivi et lacompréhension de la méthode par l'utilisateur.
23

1. Calcul des distances
Avant l'étape de classification il faut définir les paramètre de calcul des distances entre courbes.Dans l’algorithme dtw il est nécessaire de définir un décalage maximal entre 2 séries. D'après unavis expert un décalage entre 2 séries climatiques peut être de 7 jours tout en ayant, le même effetsur le rendement du tournesol. Les matrices de distances ainsi calculées ont été normalisé par unenormalisation quantile. De plus l'importance de chaque variable climatique à été définie commeidentique. Dans le calcul de la matrice de distances globales, chaque variable est pondéré par 1/5, 5étant le nombre de variables climatiques.
2. Choix du nombre de classes
La CAH est lancéz sur la matrices de distances globales. Il faut donc choisir le nombre declasses à conserver. Pour l'utilisateur ce choix se résume au choix du critère : seuil à 80 % du R2,maximum du Pseudo F ou thumb rule. Dans cet exemple j'ai utilisé le R2. Critère qui se rapproche leplus du choix qui est fait graphiquement. Le critère sélectionne 6 classes car c'est la partition de laCAH avec le moins de classes qui a un R2 supérieur à 80 %. L’inconvénient de ce critère est quetoutes les classifications n'atteignent pas 80 % de variance expliquée avant le dernier saut, avant ledernier regroupement. Il faut donc dans ce cas choisir un autre critère.
Figure 12 : courbe du R2 en fonction du nombre de classes de la CAH, et droite à 80 %
3. Caractérisation des classes de climat
Au delà de résumer l'information climatique, la classification peut avoir un rôle d'explorationdes données. Une caractérisation des classes permet aussi de compléter l'interprétation de l'analysede sensibilité. Le format particulier des séries climatiques ne permet pas d'utiliser les tests designificativité sans résumer l'information. Mais il est parfois insuffisant de résumer une sérietemporelle par un chiffre comme sa moyenne ou son écart type. De plus l'aspect graphique est un
24

enjeu important dans la compréhension et la diffusion de la méthode. Les classes peuvent êtrecaractérisées selon 2 type de variables : les variables climatiques ou des variables discrètes tellesque l'année ou le lieu de prélèvement.
Caractérisation selon les variables climatiques
Graphiquement des treillis plot, courbes caractérisées par des variables catégorielles, peuventpermettre de mieux expliquer les classes de climats.
Figure 13 : Treilli plot des données climatiques avec 5 variable, selon leur centre declasse (6 classes)
Les classes semblent former un gradient de températures. Les classes 6, 5 semblent être lesclasses qui rassemblent les climats plus chauds tout au long de l'année pour la températuremaximale et minimale. De façon opposée, les classes 1, 2, et 3 semblent être des classes de climatplus froid. L'ETP et l'évapotranspiration suivent le même classement. Cela paraît cohérent puisquece sont deux variables calculées en partie grâce aux températures. Il est par contre plus difficiled'avancer une interprétation des classes en fonction des précipitations avec ce graphique.
25

Figure 14 : Treilli plot des précipitations selon leur centre et la courbe moyennepar classe
Un graphe par variable peut apporter des précisions quant au comportement d'une variable danschaque classe. Le treillis plot des précipitations nous permet d'identifier différents profils de climatsannuels. Les classes 5 et 6, caractérisées comme des climats chauds ont un profil de précipitationtrès différents des autres classes. On peut en effet distinguer une période sèche plus ou moinsgrande sur ces deux classes avec des périodes de fortes pluies. Alors que les autres classes declimats, malgré une différence de précipitions moyennes, présentent des pluies plus uniformémentréparties sur l'année.
Caractérisation selon les variables discrètes
Les séries climatiques sont aussi décrites par des variables discrètes ou catégorielles qu'il peutêtre intéressant de mettre en avant pour une meilleure compréhension de l'ensemble du jeu dedonnées.
26
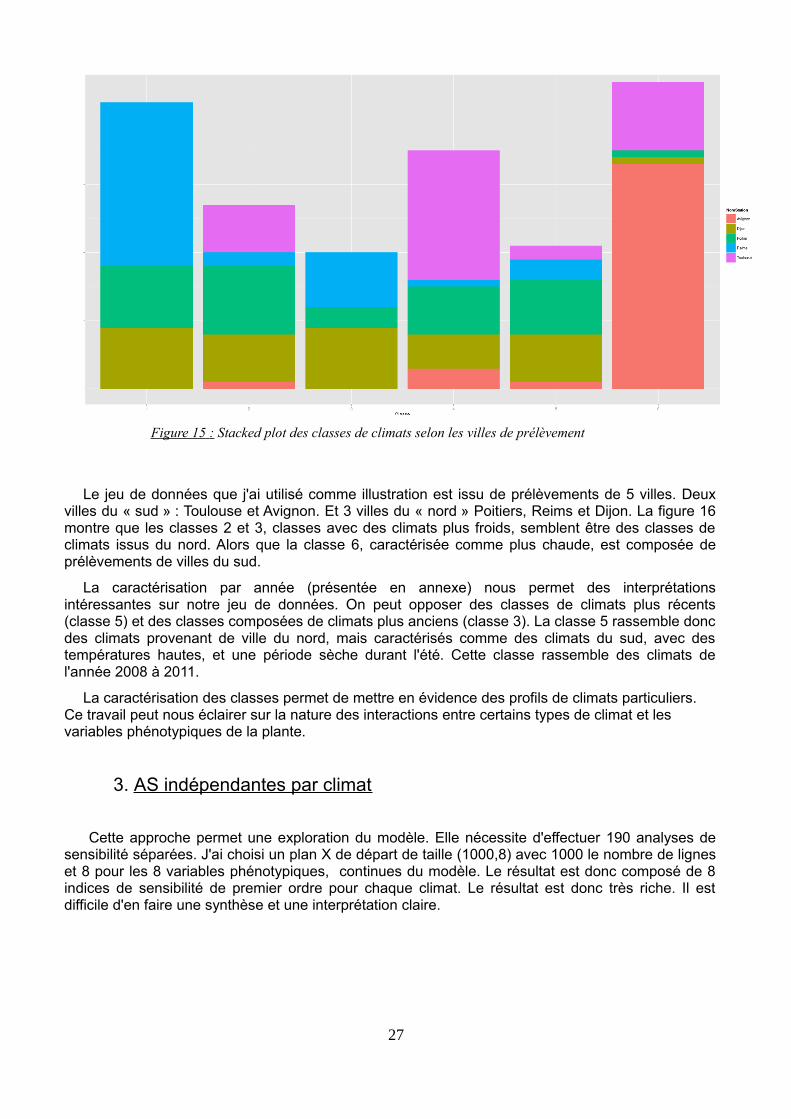
Figure 15 : Stacked plot des classes de climats selon les villes de prélèvement
Le jeu de données que j'ai utilisé comme illustration est issu de prélèvements de 5 villes. Deuxvilles du « sud » : Toulouse et Avignon. Et 3 villes du « nord » Poitiers, Reims et Dijon. La figure 16montre que les classes 2 et 3, classes avec des climats plus froids, semblent être des classes declimats issus du nord. Alors que la classe 6, caractérisée comme plus chaude, est composée deprélèvements de villes du sud.
La caractérisation par année (présentée en annexe) nous permet des interprétationsintéressantes sur notre jeu de données. On peut opposer des classes de climats plus récents(classe 5) et des classes composées de climats plus anciens (classe 3). La classe 5 rassemble doncdes climats provenant de ville du nord, mais caractérisés comme des climats du sud, avec destempératures hautes, et une période sèche durant l'été. Cette classe rassemble des climats del'année 2008 à 2011.
La caractérisation des classes permet de mettre en évidence des profils de climats particuliers. Ce travail peut nous éclairer sur la nature des interactions entre certains types de climat et les variables phénotypiques de la plante.
3. AS indépendantes par climat
Cette approche permet une exploration du modèle. Elle nécessite d'effectuer 190 analyses desensibilité séparées. J'ai choisi un plan X de départ de taille (1000,8) avec 1000 le nombre de ligneset 8 pour les 8 variables phénotypiques, continues du modèle. Le résultat est donc composé de 8indices de sensibilité de premier ordre pour chaque climat. Le résultat est donc très riche. Il estdifficile d'en faire une synthèse et une interprétation claire.
27

Figure 16 : Résultat des l'AS indépendantes par climat par la fonction sobolEff, avecun plan de départ de taille 1000, triés par classe
Les climats sont représentés en abscisse. Chaque unité correspond à un climat. En ordonnéesont représentés les indices de sensibilité de premier ordre cumulés pour chaque variablephénotypique.
Première observation : certaines sommes d'indices dépassent 1. Ce qui met en avantl'approximation faite par les estimateurs des indices de sensibilité.
Deuxième observation : certains indices sont inférieurs à 0. En effet les estimateurs des indicessont des différences, il ne sont pas contraints et peuvent donc être inférieurs à 0. Le nombre desimulations, 1000 par climats, est trop faible pour éviter ces approximations.
Une somme élevée des indices de premier ordre veut aussi dire qu'il y a peu d’interaction entreles variables continues. En effet si leur somme est proche de 1, proche d'expliquer toute lavariabilité de Y, cela veut dire que les interactions entre les entrées ne sont pas très importantes. Iln'est donc pas nécessaire de s'y intéresser. L'interprétation des résultats en eux même est trèsdifficile car les indices de sensibilité sont très variables en fonction des climats, même au sein dechaque classe. On peut voir que des variables semblent avoir plus d'effets sur le rendement demanière générale, comme la variable TDM3 en rouge, TDF1 en noir, et TR en gris. Ces observationspeuvent être confirmées en présentant des moyennes de ces indices.
Cette méthode permet une hiérarchie des variables continues mais ne prend pas en comptel'effet du climat. C'est une méthode facile à mettre en œuvre car ne nécessitant pas deméthodologie adaptée, puisque ne sont utilisées uniquement les variables continues. Mais c'est uneméthode lourde en terme de calculs.
28
4. Anova sur les indices de sensibilité
Même trié par classe, il est difficile dégager une tendance grâce la figure 16. Une Anova sur lesindices de sensibilité va nous permettre de caractériser les classes et de compléter l'interprétationdes résultats. Le but de l'anova à un facteur est de savoir si le fait d'appartenir à une classe declimat a un impact sur les indices de sensibilité des variables continues.
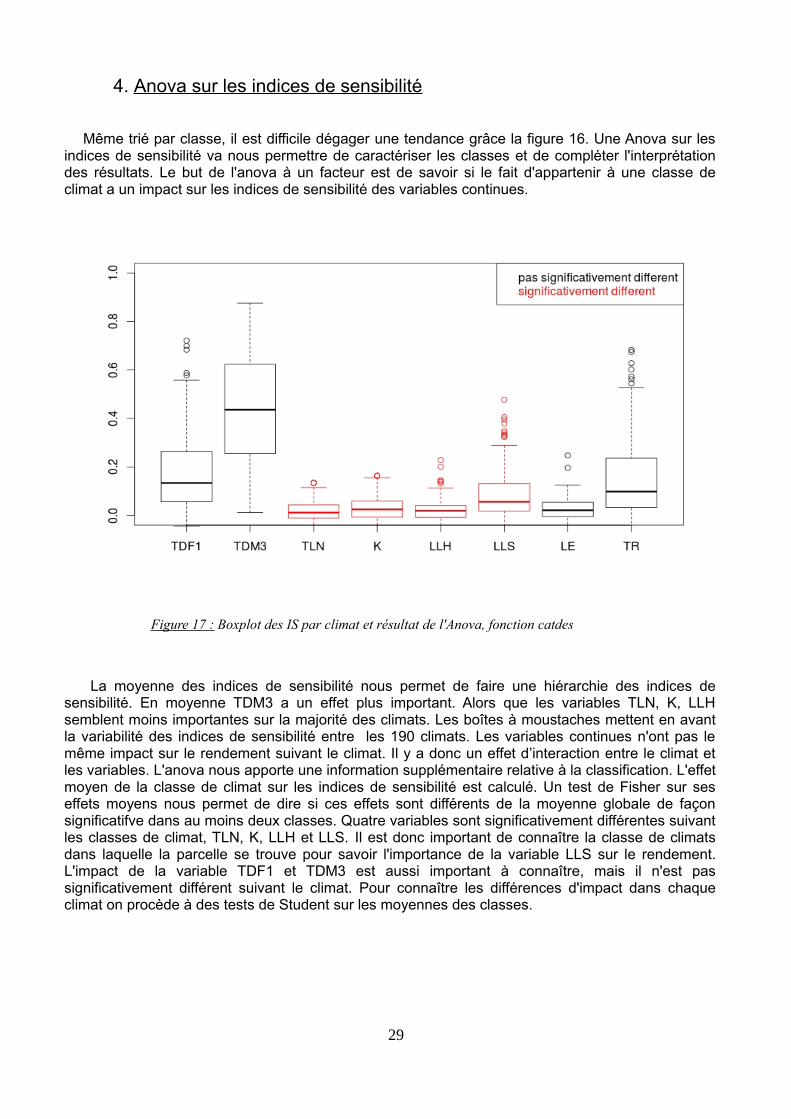
Figure 17 : Boxplot des IS par climat et résultat de l'Anova, fonction catdes
La moyenne des indices de sensibilité nous permet de faire une hiérarchie des indices desensibilité. En moyenne TDM3 a un effet plus important. Alors que les variables TLN, K, LLHsemblent moins importantes sur la majorité des climats. Les boîtes à moustaches mettent en avantla variabilité des indices de sensibilité entre les 190 climats. Les variables continues n'ont pas lemême impact sur le rendement suivant le climat. Il y a donc un effet d’interaction entre le climat etles variables. L'anova nous apporte une information supplémentaire relative à la classification. L'effetmoyen de la classe de climat sur les indices de sensibilité est calculé. Un test de Fisher sur seseffets moyens nous permet de dire si ces effets sont différents de la moyenne globale de façonsignificatifve dans au moins deux classes. Quatre variables sont significativement différentes suivantles classes de climat, TLN, K, LLH et LLS. Il est donc important de connaître la classe de climatsdans laquelle la parcelle se trouve pour savoir l'importance de la variable LLS sur le rendement.L'impact de la variable TDF1 et TDM3 est aussi important à connaître, mais il n'est passignificativement différent suivant le climat. Pour connaître les différences d'impact dans chaqueclimat on procède à des tests de Student sur les moyennes des classes.
29

Figure 18 : Boxpot des SI par climat et par classe et résultat des tests de moyennes,fonction catdes
Ces résultats par classe montrent la distribution des indices de sensibilité des variables continuespar classe. Les résultats des tests indiquent si les différences que l'on peut observer sontsignificativement différentes selon la classe. Les boxplots rouge sont les IS significativement plusgrands dans cette classe. Les boxplots de couleur bleu représentent des variables qui sont moinsimportante dans cette classe que pour les autre climats. Ceux de couleur noir ne sont passignificativement différents dans cette classe. Les classes 1,3 et la classe 6 ont des résultatsopposés. Les variables TLN, K, LLH sont moins importantes sur le rendement dans les climatschauds que dans les climats froids. Et inversement, le TR a plus d'impact sur le rendement dans unclimat du sud de la France. On peut observer que la variable qui en moyenne est la plus importanteest toujours la variable TDM3, et ce quelque soit la classe. Elle est toujours très variable. Le climat5, années chaudes de ville du nord, se détache en ayant un TDM3 qui a plus d'effet sur la sortie lerendement.
Cette méthode nous permet le calcul des effets de toutes les variables continue du modèle. Ellenous permet une hiérarchisation de ses effets ainsi que l'évaluation de l’interaction avec le climat.
5. Analyse de sensibilité conjointe
La présentation des résultats de cette méthode se fera sur un modèle plus simple que le modèle
30
Pas significativement différentSignificativement plus grandSignificativement plus faible

sunflo. Un modèle dont les effets sont connus et peuvent être maîtrisés ; un modèle dit modèlejouet. En effet le modèle sunflo est un modèle complexe et plus lourd en temps de calcul. La miseen évidence des résultats de la méthode est donc plus aisée grâce à ce modèle. Les résultats del'analyse de sensibilité conjointe sur le modèle sunflo sont présentés en annexe et nous permettentdes conclusions intéressantes.
C'est un modèle de test créer par Sébastien Roux, de Monpelier SupAgro. Ce modèle utilise unesérie climatique et 3 variables continues (tau_tmoy, kc, ttsw ).
La méthodologie au préalable est la même. Une classification à été faites sur les 42 sériesclimatiques associées à ce modèle. 4 classes ont été sélectionnées. L'analyse de sensibilitéconjointe à été lancée dans 2 situations : une où les bornes des variables continues sont grandes,big bounds et l'autre on elles sont plus petites littlebound. Le fait de sélectionner les variablescontinues dans un plus petit intervalle permet de moins les faire varier et de leur donnermécaniquement moins d'impact sur la sortie Y. Cela nous permet d'évaluer la cohérence desrésultats de la méthode. Le taille du plan X de départ est 1200 lignes (400 par classe) dans les deuxcas.
Figure 19 : Résultats de l'AS conjointe sur le modèle jouet dans le cas bigbounds, fonctionsobol2002, taille de plan de départ 1600 lignes (400 par classe)
Cette méthode nous permet une quantification de l'effet climatique seul. La figure X nousprésente les effets principaux et les effets totaux de toutes les variables d'entrée du modèle. L'effetdu climat est dans ce modèle peu influent sur la sortie du modèle. L'effet total du climat, effet propreplus tous les effets d'interactions, est aussi peu élevé. Il est surtout intéressant de comparer cesrésultats à la deuxième situation.
31
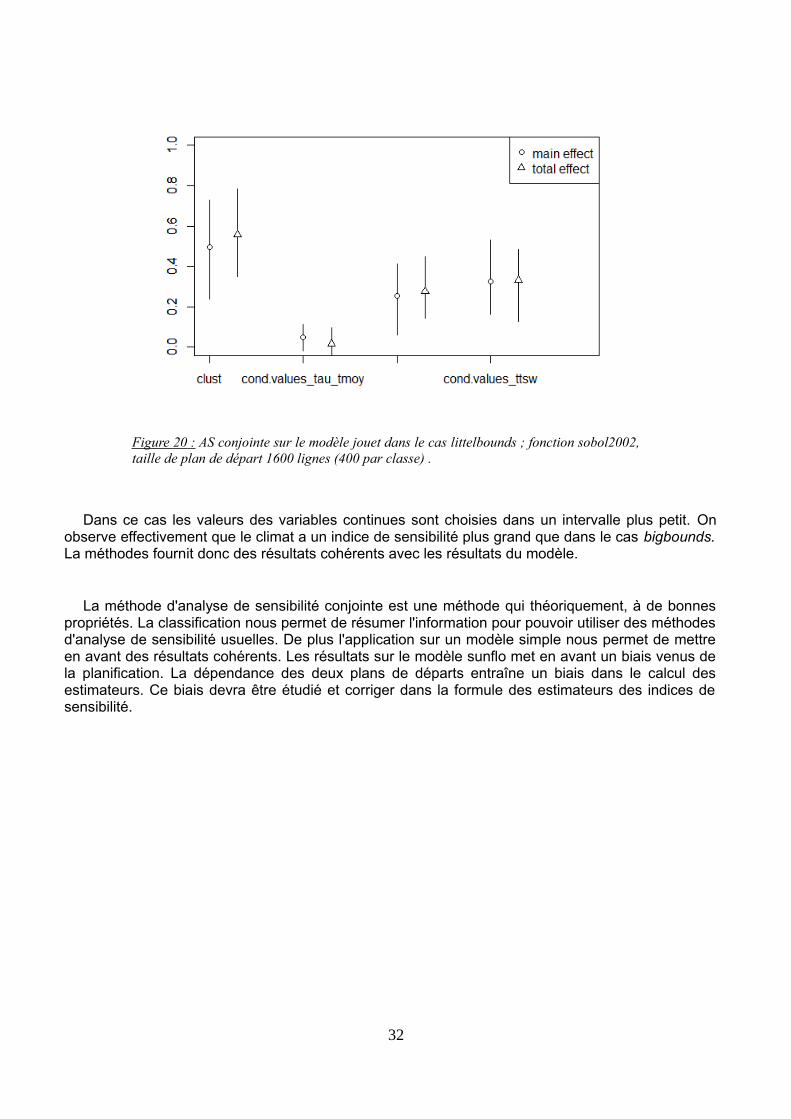
Figure 20 : AS conjointe sur le modèle jouet dans le cas littelbounds ; fonction sobol2002,taille de plan de départ 1600 lignes (400 par classe) .
Dans ce cas les valeurs des variables continues sont choisies dans un intervalle plus petit. Onobserve effectivement que le climat a un indice de sensibilité plus grand que dans le cas bigbounds.La méthodes fournit donc des résultats cohérents avec les résultats du modèle.
La méthode d'analyse de sensibilité conjointe est une méthode qui théoriquement, à de bonnespropriétés. La classification nous permet de résumer l'information pour pouvoir utiliser des méthodesd'analyse de sensibilité usuelles. De plus l'application sur un modèle simple nous permet de mettreen avant des résultats cohérents. Les résultats sur le modèle sunflo met en avant un biais venus dela planification. La dépendance des deux plans de départs entraîne un biais dans le calcul desestimateurs. Ce biais devra être étudié et corriger dans la formule des estimateurs des indices desensibilité.
32

Discussion
L'objectif de mon stage était la création d'une méthode générique d'analyse de sensibilité demodèles pour entrées climatiques. Je devais donc étudier les méthodes existantes pour les réutiliserdans un contexte particulier. J'ai su créer une méthode générique. Je me suis appliqué àdévelopper, à coder ma méthode de façon à pouvoir être réutilisable facilement. Les deux méthodesd'analyse de sensibilité présentées permette une évaluation des effets des variables d'entrées dumodèle. L'analyse de sensibilité permet l'évaluation de l'indice de première ordre du climat sur lasortie du modèle. Cet effet est quantifiable et comparable aux effets des entrées continues dumodèle.
Ces méthodes sont aussi adaptées aux données climatiques et permet de résumer l'informationde ces données de manière à les adapter à une analyse de sensibilité mais aussi à explorerl'information qu'elles contiennent. Cette approche permet aussi, avec l'analyse par classe, d'estimerles interactions entre un type de climat, un profil climatique, et les autres variables du modèlecomme le type de plante. La méthode d'analyse de sensibilité par climat donne de bon résultats etdoit être testée sur d'autres modèles. Elle pourrait être complétée par une analyse de la variancemultidimensionnelle. De plus une classification sur les indices de sensibilité, est une piste à explorer.La deuxième piste que j'ai étudiée, malgré des résultats encourageant, amène à une estimationbiaisée. Le biais mis en avant par mon travail doit être corrigé de façon théorique.
A l'heure actuelle, cette méthode n'a pas encore été appliquée sur d'autres modèles complexes.Dans le cadre du CATI IUMA la méthode sera testée en automne 2015 sur des modèles existant surles plateformes faisant partie du projet.
Au-delà des résultats, ce stage m'a permis de mettre en application des méthodes avancées enstatistiques et de me mettre à l'épreuve sur des problématiques où la littérature ne donnait pas deméthodes optimales. Intégrer une équipe de recherche et être encadré par deux spécialistes dedomaines différents m'a permis un apprentissage complet. De plus le contexte de mon stage, ausein du CATI IUMA m'a donné l'occasion de présenter mon travail devant des chercheurs. Cetteexpérience m'a permis de me rendre compte des enjeux de la recherche.
33

Bibliographie
[1] Faivre R., Iooss B., Mahévas S., Makowski D., Monod H. (2013). Analyse de sensibilité etexploration de modèles : application aux sciences de la nature et de l'environnement. éditions Quae, Collection Savoir faire, Versailles, 324p.
[2] Nakache J.-P, Confais J. (2004). Approche pragmatique de la classification. Édition Technip, Paris, 262 p.
[3] Palm R. (1996). La classification numérique : Principes et application. Notes Stat. Inform. (Gembloux), 96/1, 28p.
[4] Bhat A., (2014) K-medoids Clustering Using partitionung around medoids for performing face recocnition, International Journal of Soft Conputing, Mathematics and Control (IJSCMC), Vol. 3, No. 3, août 2014.
[5] Tiwari M., Singh R., (2012), Comparative Investigation of K-means and K-medoid Algorithm on iris Data. International Journal of Engineering Research an Development, Volume 4, Novembre 2012, PP. 69-72.
[6] Tissot J.-Y., Prieur C., (2014). A randomized Orthogonal Array based procedure for estimation of first and second-order Sobol' indices. Journal of Statistical Computation and Simulation, Taylors & Francis : STM, Behavioural Science and Public Health Titles,2014, pp. 1-24.
[7] Murtagh F., Legendre P., (2011), Ward's Hierarchical Clustering Method : Clustering Critrtion and Agglomerative Algorithm, arXiv:1111.6285v2 [stat.ML], 20p.
[8] Quesnel G., Ramat E., Soulié J.-., Duvivier D., Duboz R., (1999). Studia Informatica Universalis., Suger, Saint-Denis, pp. 205 234.
[9] Poublan B., (2014), Optimisation de variétés de tournesol sous incertitude climatique, rapport de stage de fin d'étude, Master MSID, Université de Pau et des Pays de L'adour, 38p.
[10] Coustaroux M., (2013). Analyse de sensibilité et planification d’expériences, rapport de
stage, INSA, Toulouse, 48p.
[11] Giorgino T (2009). Computing and Visualizing Dynamic Time Warping Alignments in R: The dtw Package. Journal of Statistical Software, pp. 1-24.
[12] Maechler, M., Rousseeuw, P., Struyf, A., Hubert, M., Hornik, K.(2014). Cluster Analysis Basics and Extensions. R package version 1.15.3.
[13] Carnell R. (2012). Latin Hypercube Samples. R package version 0.10. http://CRAN.R-project.org/package=lhs (consulté le 08/09/2015)
34

[14] Mardia K.V., Kent J.T., Bibby J.M. (1979). Multivariate Analysis, Academic Press. Extensions. R package version 1.15.3.
[15] Stocki, R. (2005) A method to improve design reliability using optimal Latin hypercube sampling, Computer Assisted Mechanics and Engineering Sciences 12, 87–10.
[16] Pujol G. , Iooss B. , Janon A., Lemaitre P. contrib., Gilquin L. contrib., Le Gratiet L. contrib., Touati T. contrib., Ramos B. contrib., Jana Fruth contrib.and Sebastien Da Veiga contrib. (2014). Sensitivity Analysis. R package version 1.10.1. http://CRAN.R-project.org/package=sensitivity, (consulté le 08/09/2015).
[17] Reboul L., (2015), Institut de mathématique de Marseille. http://iml.univ-mrs.fr/~reboul/ADD4-MAB.pdf ,(consulté le 11/05/2015).
[18] Irène Gannaz I., (2008), Mathématique Lyon 1. http://math.univ-lyon1.fr/~gannaz/2008-11- 20_sensibilite.pdf, (consulté le 18/03/2015).
[19] Unité de Mathématiques et Informatique Appliquées de Toulouse, (2015). https://carlit.toulouse.inra.fr/wikiz/index.php/Accueil, (consulté 08/09/2015)
35
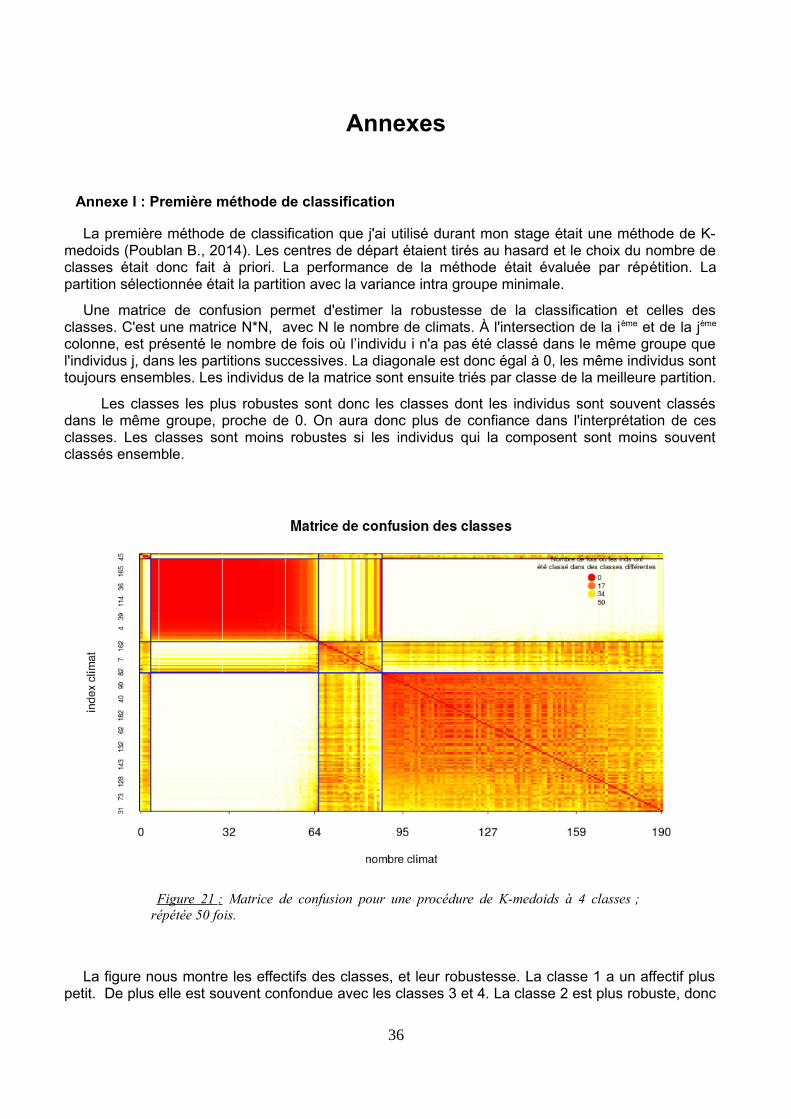
Annexes
Annexe I : Première méthode de classification
La première méthode de classification que j'ai utilisé durant mon stage était une méthode de K-medoids (Poublan B., 2014). Les centres de départ étaient tirés au hasard et le choix du nombre declasses était donc fait à priori. La performance de la méthode était évaluée par répétition. Lapartition sélectionnée était la partition avec la variance intra groupe minimale.
Une matrice de confusion permet d'estimer la robustesse de la classification et celles desclasses. C'est une matrice N*N, avec N le nombre de climats. À l'intersection de la ième et de la jème
colonne, est présenté le nombre de fois où l’individu i n'a pas été classé dans le même groupe quel'individus j, dans les partitions successives. La diagonale est donc égal à 0, les même individus sonttoujours ensembles. Les individus de la matrice sont ensuite triés par classe de la meilleure partition.
Les classes les plus robustes sont donc les classes dont les individus sont souvent classésdans le même groupe, proche de 0. On aura donc plus de confiance dans l'interprétation de cesclasses. Les classes sont moins robustes si les individus qui la composent sont moins souventclassés ensemble.
Figure 21 : Matrice de confusion pour une procédure de K-medoids à 4 classes ;répétée 50 fois.
La figure nous montre les effectifs des classes, et leur robustesse. La classe 1 a un affectif pluspetit. De plus elle est souvent confondue avec les classes 3 et 4. La classe 2 est plus robuste, donc
36

c'est une classe qui regroupe des climats qui se ressemblent. Cette figure permet une évaluationrapide de la robustesse de la méthode de classification.
37

Annexe II : Analyse de Sensibilité sur les poids
Le but de cette analyse de sensibilité est d'analyser l'impact de la pondération de chaquevariable climatique sur la classification. Cette analyse fais face à 2 problématiques : la somme despoids et la sortie sur laquelle évaluer cette sensibilité.
Les poids sont des variables continues, donc adaptés pour les méthodes d'analyses de sensibilitéusuelles. La contrainte de cette analyse est que la somme de ces poids doit être égale à 1. Chaqueligne du plan de départ est tiré dans une distribution Dirichlet. Mais lors du pick and freeze de laméthode de Sobol', la contrainte de la somme doit être respectée. Pendant cette étape, la ou lescolonnes qui sont fixées doivent restées les même que dans le plan de départ. Les autre colonnessont modifié pour respecter la contrainte.
Le modèle de cette analyse de sensibilité est la méthode de classification. Le résultat de laclassification est une partition des climats. C'est une sortie multivariée et catégorielle. Le résultat surlequel on peut évaluer l'impact des poids est la matrice de co-allocation. C'est une matrice quicaractérise la partition. C'est une matrice qui présente 1 croisement de la ième ligne et de la jème
colonne si les individus i et j sont dans la même classe, 0 sinon. C'est donc une matrice symétriqueavec la diagonale toujours égale à 1. Il n'est pas possible de faire une analyse de sensibilité avecune matrice comme sortie. On est donc contraint de résumer cette information. J'ai fait le choix de lerésumer par un pourcentage de ressemblance avec une matrice de co-allocation de référence.Cette matrice est la matrice qui résulte de la classification faite avec une pondération homogène( toutes les variables ont le même poids).
X=|x1,1 ... x1,P
. .
. .
. .xn ,1 ... xn, P
| Y =| y1
.
.
.yn
|Figure 22 : exemple de planification d'un AS sur les poids,
X est le plan d'expérience des poids. Y est la sortie associée. La somme d'une ligne est toujourségale à 1. La sortie y1 est le pourcentage de ressemblance de la matrice de co-allocation de laclassification avec les poids (x1,1,…,x1,P) avec la matrice de référence (avec des poids de 1/P).
On pourra donc déduire de cette analyse de sensibilité l'importance du poids de chaque variablesur la classification.
38

Annexe III : Algorithme partitionning around medoids
Cette algorithme de partitionnement sélectionne k centres, appelés médoïdes, qui minimisent ladissimilarité moyenne entre les individus et le centre qui leur est le plus proche.
Soit : C l'ensemble des centres,
U l'ensemble des autres individus,
Dp la distance de l'individu p à son plus proche centre,
Ep la distance de l'individu p à son deuxième centre.
BUILD : construction des premiers centres.
1. On sélectionne le premier centre comme celui qui minimise la somme des dissimilarités.
2. Soit i appartient a U. i un point candidat.
3. Calcul Dj et de d(i,j), dissimilarité entre i et j, avec j∈U {− i} .
4. Calcul de Cij= max {0, D j− d (i , j)} : gain de distance en sélectionnant i comme centre.Soit i est plus proche de j que tous les autres centres D j>d (i , j) , il apporte donc un gainégal à la différence, soit il est plus éloigné et le gain est donc nul.
5. Calcul du gain totale Gi=∑ C ij .
6. Soit i' maximise le point qui maximise le gain. S= S+{i ' } et U=U− {i ' }
Retour à l'étape 2 jusqu’à Card(S)= k , avec k le nombre de classes voulu.
L'algorithme SWAP tend à améliorer la sélection des centres en calculant l'effet de toutes lespermutations possibles entre un centre i et un autre individu h. Si une permutation améliore lapartition on effectue alors la permutation. Si aucune l'améliore, l’algorithme s'arrête.
Soit : (i ,h)∈CxU ,
j∈U ,
Tih : l'effet sur la somme des dissimilarités, de la permutation de i et de h (i va dans U et hva dans C),
Kijh : la contribution sur Tih de chaque individu j à la permutation (i,h).
SWAP : amélioration de la sélection des centres.
1. Calcul de tous les Kijh, les contributions de chaque j à l'effet de la permutation (i,h). On dis-tingue 2 cas :
a. d (i , j)>D j : i n'est pas le plus proche centre de j
K ijh= min {0, d( j ,h)− D j}
39

→ d ( j ,h)≥ Dj K ijh= 0 , la distance au nouveau centre h est plus grande, lacontribution Kijh est nulle.
→ d ( j ,h)<D j K ijk= d ( j ,h)− D j , h est plus proche de j que i, contribution né-gative à Tih.
b. d (i , j)= D j : i est le centre le plus proche de j.
K jih= min{d ( j ,h), E j}− D j
→ d ( j ,h)<E j K ijh= d( j , h)− D j , la distance au nouveau centre h est plus petiteque la distance avec le second centre. h est un potentiel nouveau centre de classe pour j.Contribution négative ou positive à Kijh.
→ d ( j ,h)≥ E j K ijh= E j− D j
h est plus loin que le deuxième centre contribution est fortement positive.
2. T ih=∑ K ijh j∈U Calcul de l'effet de la permutation sur la somme des dissimilaritésentre les individus, appartenant à U, et de leurs centres le plus proche.
3. Sélection de la permutation qui minimise Tij.
4. min(T ij)<0 On effectue la permutation et on revient à la première étape.
min(T ij)≥ 0 Toutes les permutations augmentent la somme des dissimilarités descentres à leurs individus le plus proche. L'algorithme s'arrête.
40
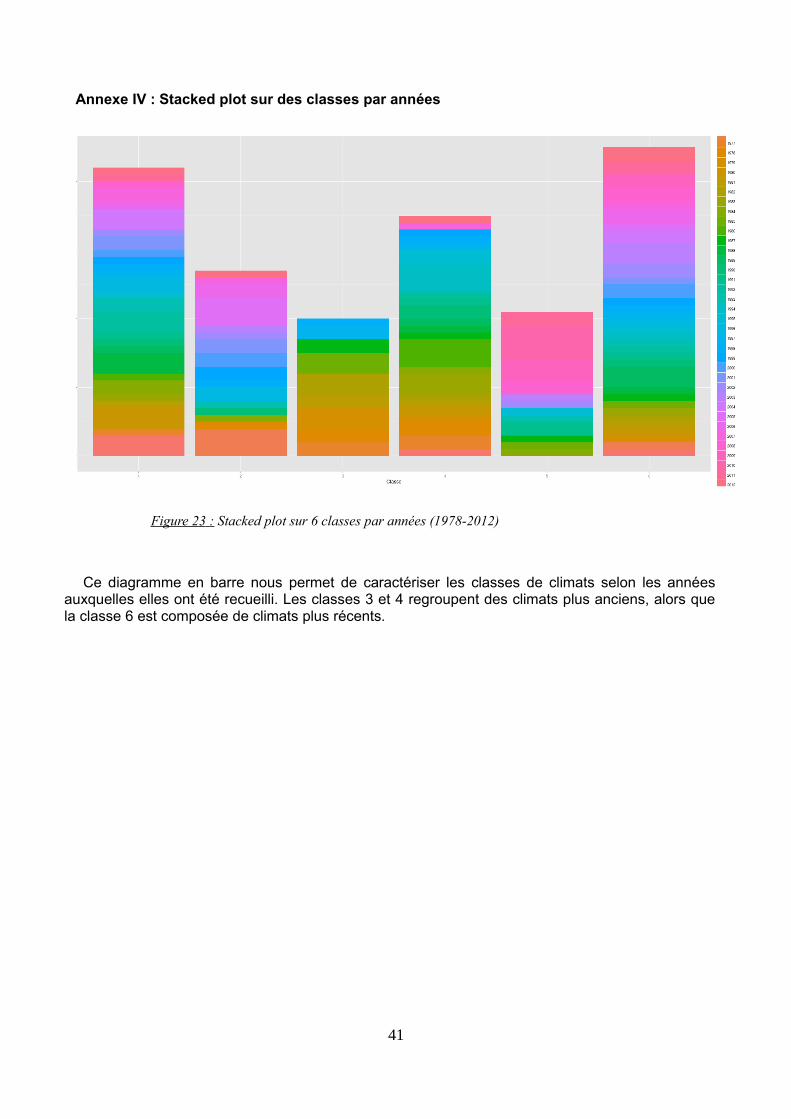
Annexe IV : Stacked plot sur des classes par années
Figure 23 : Stacked plot sur 6 classes par années (1978-2012)
Ce diagramme en barre nous permet de caractériser les classes de climats selon les annéesauxquelles elles ont été recueilli. Les classes 3 et 4 regroupent des climats plus anciens, alors quela classe 6 est composée de climats plus récents.
41

Annexe V : Analyse de Sensibilité avec le modèle sunflo
Le mise en œuvre de la méthode sur le modèle sunflo a été faite dans deux situations : la sériequi représente la classe est un centre (figure 24) ou c'est un climat tirées au hasard dans la classede climat à chaque simulation (figure 26).
Les deux premières figures présentent les résultats dans la situation où le climat représentant laclasse est le centre de classe.
Figure 24 : Résultats de l'AS conjointe sur le modèle sunflo ; fonction soboljansen1000 par classe, représentant par un centre dans la classe.
La première observation que l'on peut faire est que l'effet de climat est très important, on peutaussi l'évaluer avec la deuxième figure représentant la sortie du modèle (figure X). On peut voir queles rendement par classe sont très distinct les uns les autres. Cette effet est surestimer par lareprésentation par un centre. En effet la variabilité intra-classe est effacé car les 6 classes de climatsont résumer en 6 climats. Cette analyse ne permet pas de mettre en avant les effets des variablecontinues. La deuxième observation que l'on fait est la valeur des indices de première ordre de cesvariables continues. Elles sont toutes bien supérieur à 0, -0,18. Cette valeur est théoriquementimpossible. En pratique les indices de sensibilité sont estimé par une différence, dans l'estimateurde la fonction soboljansen, et peuvent donc être une peu en dessous de 0. Mais une valeur si faibleest le résultat d'un biais dans la méthodes. Il provient de la non dépendance des plan XA et XB dedépart.
42

Figure 25 : Simulation du rendement du modèle sunflo selon le plan XA
L'analyse de sensibilité conjointe avec un tirage aléatoire du représentent à chaque simulationajoute une variabilité à la sortie Y que la méthode de Sobol' ne peut imputer à un effet climatique.
Figure 26 : Résultats de l'AS conjointe sur le modèle sunflo, le représentant d'uneclasse est un climat aléatoire de la classe; fonction soboljansen ; taille du plan dedépart 6000 lignes (1000 par classe).
L'analyse de sensibilité conjointe avec sélection des climats de façon aléatoire distingue un effetdu climat plus petit sur le rendement et des effet d'interaction très grand. On a vu que les indices desensibilité des variables continues pouvaient être très variable selon les climats (figure X). Lavariabilité supplémentaire est interpréter comme une interaction et ne nous permet pas dehiérarchiser l'importance des variables continues dans le modèle.
43

Ces résultats mettent en avant un biais dans le calcul des estimateur. et des intéractions que laméthode ne parviens pas a identifier et à caractériser par variables. Ces résultats devront êtreétudiés de façon théorique.
44

Diplôme : Master
Spécialité : Statistique
Spécialisation / option :
Enseignant référent : David CAUSEUR
Auteur(s) : Franck BOIZARD
Date de naissance* :10/01/1992
Organisme d'accueil : Unité de Mathématiques et informatique Appliquées (UR875 MIA T)
Adresse : INRA Chemin de Borde-Rouge
Auzeville CS 52627
F-31326 Castanet-Tolosan cedex,France
Maître de stage : Robert FAIVRE
Nb pages : 44 Annexe(s) : 5
Année de soutenance : 2015
Titre français : Méthodes d'analyse de sensibilité de modèles pour entrées climatiques
Résumé (1600 caractères maximum) :
Ce rapport présente le résultat du travail que j'ai effectué au cours de mon stage de fin d'études, d'unedurée de 6 mois, à l'Institut National de Recherche Agronomique (INRA) de Toulouse. Ce stage a pour sujetles méthodes d'analyses de sensibilité de modèles pour entrées climatiques. L'objectif est la mise au point deméthodes génériques d'analyse de sensibilité basée sur la décomposition de la variance permettant de traiter desentrées de type « séries climatiques ». La complexité des modèles qui m'intéressent vient du format des entréesdu modèle que sont les données climatiques. Il faut donc créer des méthodes spécifiques pour explorer cesmodèles particuliers. Trois aspects sont donc à prendre en compte dans ce sujet : le modèle, les entréesclimatiques et l'analyse de sensibilité.
Les modèles que j'ai étudié, sont examinés en tant que boîte noire. En effet les méthodes développées nedépendent pas du modèle. Ces modèles calculent par exemple le rendement ou la qualité d'une récolte à partirde données phénotypiques, des conditions de culture... Ils ont en commun l'utilisation des données climatiquescomme une de leurs entrées.
Les données climatiques sont des séries temporelles multidimensionnelles. Des relevés réguliers, journaliersen général, de différentes données météorologiques sont effectués sur le terrain. Ce sont des relevés detempérature, de pluie, d'ensoleillement… Ces séries temporelles sont très corrélées. La température maximale etminimale évoluent de manière similaire au cours de l'année. De plus les méthodes d'analyses de sensibilitéusuelles utilisent des données unidimensionnelles. Il est donc nécessaire de développer des méthodesspécifiques pour traiter ce type de données.
L'analyse de sensibilité est une méthode d'exploration des entrées d'un modèle. Son objectif premier est dequantifier l'effet de chaque variable d'entrée sur la sortie d'un modèle grâce au calcul d'indices de sensibilité.Ses indices de sensibilité sont compris entre 0 et 1. Plus grand est cet indice pour une variable donnée, plus fortest sont impact sur la sortie du modèle. Par une planification précise des entrées et des simulations successivesdu modèle, ces méthodes parviennent à identifier et à quantifier l'effet de la variation de chaque entrée sur lavariabilité de la sortie du modèle.

La première contrainte liée à ce sujet est la dimension de ces données climatiques. Les méthodes usuellesd’analyses de sensibilité ne sont en effet pas adaptées à des séries multidimensionnelles. L'approche qui a étéétudiée est de procéder à une étape de classification de séquences climatiques par des méthodes statistiques declassification et ensuite à procéder à une analyse de sensibilité du modèle. La méthode d'analyse de sensibilitéqui a été privilégiée est la méthode de Sobol'. C'est une méthode qui fait très peu d'hypothèse sur le modèle, elleest donc adaptée à une méthode ayant pour objectif d'être applicable à des modèles différents.
La classification à pour objectif de résumer les variables climatiques en une partition de climats. Unepremière étape de cette classification est la définition de distances appropriées entre les climats et donc entreséries temporelles. La distance Dynamic Time Warping permet d'établir une distance entre les séries temporellesadaptée à la problématique des séries climatiques. Elle permet en effet d'accepter une déformation temporelleentre deux séries de telle sorte que deux séries de température identiques mais décalées de quelques jours (cequi n'aura pas d'impact différent sur la plante) seront distante de 0. Cette algorithme nous permet de définir unedistance entre chaque climat et ainsi utiliser les méthodes de classification usuelle. En gardant l'objectif decréer une méthode utilisable par les utilisateurs de modèle, une classification mixte a été utilisée, classificationhiérarchique (CAH) puis une méthode de partitionnement (K-medoids) car cela permet une classification sansconnaissance à priori sur les données. La mise en place de critères pour le choix du nombre de classe autoriseune méthode automatisée.
Deux stratégies d'analyse de sensibilité ont été étudiées : Des analyse de sensibilités indépendante par climat,et une analyse de sensibilité conjointe.
Des analyses de sensibilité par climats, avec un climat fixé pour chaque analyse, permet l'évaluation desindices de sensibilité des variables continues. L'effet du climat est étudié par analyse de variance grâce à latypologie de climats précédemment créée. Cette approche permet une exploration du modèle et l'étude desinteractions du climat avec les variables continues du modèle.
L'analyse de sensibilité conjointe de la classe de climat et des variables continues impose une planificationadaptée : la méthode de Sobol' étant construite pour des variables continues et la variable liée au climat étantune variable catégorielle. Cette méthode évalue les effets de chaque entrée du modèle sur sa sortie.
Cette méthode a été testée sur 2 modèles différents. Le premier est le modèle sunflo calculant le rendementd'une parcelle de tournesols en fonction du climat et de variables continues relatives à la plante. Le jeu dedonnées relatif à ce modèle est composé de 190 climats. Le deuxième est un modèle de test, plus simple et surlequel les effets des variables sont connues et modifiables. L'application de la méthode de classification surplusieurs jeux de données climatiques avance une première validation de la méthode. La caractérisation desclasses met en évidence des profils de climats interprétables. Cette étape peut nous éclairer sur la nature desinteractions entre certaines classes de climat et les variables continues du modèle. Les résultats de la premièreapproche d'analyse de sensibilité donne des résultats intéressants sur le modèle. L'anova sur les indices desensibilité des variables phénotypiques de la plante calcul un effet d'interaction du climat. Les résultats et lesinterprétations de la classification nous permettent d'aller plus loin dans l'interprétation de ces effets en lecatégorisant par classe de climat. La mise en pratique de l'analyse de sensibilité conjointe à été faite à deuxniveaux. Son application au modèle simple nous à permis de mettre en avant des résultats cohérents suivant lesmodifications du modèle. Les effets mesurés du climat et des autres variables du modèle, correspondent à lastructure du modèle. L'utilisation sur le modèle sunflo, plus complexe, met en avant un fort effet du climat surle rendement d'une parcelle et des interactions nombreuses entre les variables continues.
Les méthodes étudiées durant ce stage ont permis de répondre à la problématique de mon stage. C'est eneffet une série de méthode qui permettent l'évaluation des effets de chaque variable d'entrée de modèle avecentrées climatiques. Ce sont des méthodes génériques dans le sens où elles peuvent s'adapter à toutes sériesclimatiques et à tous modèle qui les utilisent avec des entrée continues. Cette méthodologie sera par la suitetestée et réutilisée dans le cadre du CATI (Centre automatisé de traitement de l’information) IUMA(Informatisation et Utilisation des Modèles dédiés aux Agro-écosystèmes).
Mots-clés : Analyse de sensibilité, classification de courbes.
* Elément qui permet d’enregistrer les notices auteurs dans le catalogue des bibliothèques universitaires


















