Évaluation Qualitative et Quantitative d'Outils de ...keller/Publications/Theses/msc-bassil.pdf ·...
148
Transcript of Évaluation Qualitative et Quantitative d'Outils de ...keller/Publications/Theses/msc-bassil.pdf ·...


Université de Montréal
Évaluation Qualitative et Quantitative d’Outils de Visualisation Logicielle
par
Sarita Bassil
Département d’Informatique et de Recherche Opérationnelle
Faculté des Arts et des Sciences
Mémoire présenté à la Faculté des Études Supérieuresen vue de l’obtention du grade de
Maître ès Sciences (M.Sc.)en informatique
Décembre, 2000
� Sarita Bassil, 2000

Université de MontréalFaculté des Études Supérieures
Ce mémoire intitulé:
Évaluation Qualitative et Quantitative d’Outils de Visualisation Logicielle
présenté par:
Sarita Bassil
a été évalué par un jury composé des personnes suivantes:
Président-rapporteur: François Lustman
Directeur de recherche: Rudolf K. Keller
Membre du jury: Houari Sahraoui
Mémoire accepté le: ___________________________

Sommaire
De nos jours, plusieurs techniques et outils de visualisation logicielle (VL) sont rendus
disponibles pour aider les développeurs entre autres à bien “comprendre” leurs logiciels.
Il existe suffisamment de preuve anecdotique qu’une présentation claire et visuelle d’un
logiciel peut réduire, de façon significative, l’effort dépensé sur sa compréhension et sa
maintenance. Cependant, à notre connaissance, aucune enquête quantitative au sujet des
outils de VL n’a jamais été conduite.
Dans ce mémoire, nous avons commencé par identifier un ensemble d’outils de VL que
nous avons décrit puis évalué de façon qualitative en se basant sur une taxonomie bien
particulière, celle de Price et al. Ensuite, une évaluation quantitative a été effectuée. En
effet, une enquête sur les outils de VL a été conduite au printemps 2000 avec plus de
100 participants. Un questionnaire a donc été mis on-line; il adressait divers aspects
fonctionnels, pratiques et cognitifs ainsi que des aspects liés à l’analyse de code que les
utilisateurs peuvent rechercher dans des outils de VL. Les participants de l’enquête ont
évalué l’utilité et l’importance de ces aspects. Ils ont aussi proposé de nouveaux aspects.
Ils étaient en général satisfaits de l’outil de VL qu’ils utilisaient. Néanmoins, une
différence entre les aspects souhaités et la présence de ces aspects dans les outils de VL
actuels a été identifiée. En outre, une liste d’améliorations qui devraient être apportées
aux outils a été rassemblée. Bref, des résultats fort intéressants ont été trouvés à partir de
la collecte de données. L’emphase a surtout été mise sur l’analyse et la discussion des
résultats liés aux différentes parties, sections et questions du questionnaire.
Mots clés: génie logiciel, outil de visualisation logicielle, évaluation qualitative,
enquête, questionnaire, compréhension de logiciel, analyse de code source.

Abstract
Recently, many software visualization (SV) techniques and tools have become available
to developers in order to help them understand their software. There is ample anecdotal
evidence that appropriate visualization can significantly reduce the effort spent on
system comprehension and maintenance, yet we are not aware of any quantitative
investigation and survey of SV tools.
In this thesis, firstly, we identified a list of SV tools that we described, and evaluated
qualitatively using the taxonomy of Price et al. Then, a quantitative evaluation was
conducted in spring 2000 with more than 100 participants. Indeed, a questionnaire was
put on-line; it addresses various functional, practical, cognitive as well as code analysis
aspects that users may be looking for in SV tools. The participants of the survey rated
the usefulness and importance of these aspects, and came up with aspects of their own.
The participants were in general quite pleased with the SV tool they were using and
mentioned various benefits. Nevertheless, a big gap between desired aspects and the
features of current SV tools was identified. In addition, a list of improvements that
should be done to current tools was assembled. In brief, the collected data suggest
interesting results. We especially put the emphases on the analysis and the discussion of
the results related to the various parts, sections and questions of the questionnaire.
Keywords: software engineering, software visualization tool, qualitative evaluation,
survey, questionnaire, software comprehension, source code analysis.

Table des matières
SOMMAIRE ----------------------------------------------------------------------------------------------------------III
ABSTRACT----------------------------------------------------------------------------------------------------------- IV
TABLE DES MATIÈRES------------------------------------------------------------------------------------------- V
LISTE DES TABLEAUX-----------------------------------------------------------------------------------------VIII
LISTE DES FIGURES---------------------------------------------------------------------------------------------- IX
REMERCIEMENTS ------------------------------------------------------------------------------------------------XI
CHAPITRE 1. INTRODUCTION----------------------------------------------------------------------------------1
1.1 MOTIVATION ------------------------------------------------------------------------------------------------------11.2 CONTEXTE DE CE TRAVAIL --------------------------------------------------------------------------------------11.3 PROBLÉMATIQUE ET APPROCHE DE RECHERCHE -------------------------------------------------------------21.4 STRUCTURE DU MÉMOIRE ---------------------------------------------------------------------------------------31.5 CONTRIBUTIONS PRINCIPALES ----------------------------------------------------------------------------------4
CHAPITRE 2. ÉTAT DE L’ART-----------------------------------------------------------------------------------7
2.1 INTRODUCTION ----------------------------------------------------------------------------------------------------72.2 DÉFINITION DE LA VL--------------------------------------------------------------------------------------------82.3 POSITION DE LA VL PAR RAPPORT AUX AUTRES DOMAINES --------------------------------------------- 102.4 HISTORIQUE DE LA VL----------------------------------------------------------------------------------------- 122.5 TAXONOMIES LIÉES À LA VL---------------------------------------------------------------------------------- 132.6 VL ET COMPRÉHENSION DE PROGRAMME------------------------------------------------------------------- 152.7 RECHERCHES EN VL-------------------------------------------------------------------------------------------- 162.8 CONCLUSION ---------------------------------------------------------------------------------------------------- 18
CHAPITRE 3. INVENTAIRE D’OUTILS DE VL------------------------------------------------------------ 19
3.1 INTRODUCTION -------------------------------------------------------------------------------------------------- 193.2 IDENTIFICATION D’OUTILS DE VL---------------------------------------------------------------------------- 203.3 OUTILS DE VL RETENUS --------------------------------------------------------------------------------------- 22
3.3.1 Software understanding system (xSuds) ---------------------------------------------------------- 223.3.1.1 Démonstration de xAtac------------------------------------------------------------------------------------- 233.3.1.2 Démonstration de xVue ------------------------------------------------------------------------------------- 26
3.3.2 Tom Sawyer Graph Layout Toolkit & Graph Editor Toolkit----------------------------------- 273.3.3 Discover ---------------------------------------------------------------------------------------------- 293.3.4 Visualizing Graphs with Java (VGJ) -------------------------------------------------------------- 293.3.5 daVinci ------------------------------------------------------------------------------------------------ 303.3.6 Swan--------------------------------------------------------------------------------------------------- 30

vi
3.3.7 Visualization of Compiler Graphs (VCG) & Call Graph Drawing Interface (CGDI)------ 323.3.7.1 Démonstration du CGDI ------------------------------------------------------------------------------------ 32
3.4 CONCLUSION ---------------------------------------------------------------------------------------------------- 33
CHAPITRE 4. ÉVALUATION QUALITATIVE D’OUTILS DE VL------------------------------------- 35
4.1 INTRODUCTION -------------------------------------------------------------------------------------------------- 354.2 DESCRIPTION DE LA TAXONOMIE DE PRICE ET AL. --------------------------------------------------------- 36
4.2.1 Catégorie Scope ------------------------------------------------------------------------------------- 364.2.2 Catégorie Content ----------------------------------------------------------------------------------- 364.2.3 Catégorie Form -------------------------------------------------------------------------------------- 374.2.4 Catégorie Method ----------------------------------------------------------------------------------- 384.2.5 Catégorie Interaction ------------------------------------------------------------------------------- 384.2.6 Catégorie Effectiveness ----------------------------------------------------------------------------- 39
4.3 ÉVALUATION DE SEPT OUTILS DE VL ------------------------------------------------------------------------ 394.3.1 Éléments retenus - Catégorie Scope--------------------------------------------------------------- 404.3.2 Éléments retenus - Catégorie Content ------------------------------------------------------------ 414.3.3 Éléments retenus - Catégorie Form --------------------------------------------------------------- 424.3.4 Éléments retenus - Catégorie Method------------------------------------------------------------- 434.3.5 Éléments retenus - Catégorie Interaction -------------------------------------------------------- 434.3.6 Éléments retenus - Catégorie Effectiveness ------------------------------------------------------ 44
4.4 CONCLUSION ---------------------------------------------------------------------------------------------------- 44
CHAPITRE 5. ENQUÊTE SUR LES OUTILS DE VL ------------------------------------------------------ 46
5.1 INTRODUCTION -------------------------------------------------------------------------------------------------- 465.2 DESCRIPTION DU QUESTIONNAIRE SUR LES OUTILS DE VL ----------------------------------------------- 47
5.2.1 Description de la partie I --------------------------------------------------------------------------- 485.2.1.1 Renseignements concernant le participant ---------------------------------------------------------------- 485.2.1.2 Renseignements sur les systèmes logiciels visualisés --------------------------------------------------- 495.2.1.3 Aspects fonctionnels des outils de VL -------------------------------------------------------------------- 505.2.1.4 Aspects pratiques des outils de VL ------------------------------------------------------------------------ 525.2.1.5 Évaluation cognitive de l’outil de VL en main----------------------------------------------------------- 535.2.1.6 Bénéfices et améliorations de l’outil de VL en main ---------------------------------------------------- 54
5.2.2 Description de la partie II -------------------------------------------------------------------------- 545.2.2.1 Renseignements techniques sur l’outil de VL en main-------------------------------------------------- 545.2.2.2 Support de l’analyse du code par l’outil de VL en main ------------------------------------------------ 55
5.3 CONCLUSION ---------------------------------------------------------------------------------------------------- 57
CHAPITRE 6. CONCEPTION TECHNIQUE DU QUESTIONNAIRE --------------------------------- 59
6.1 INTRODUCTION -------------------------------------------------------------------------------------------------- 596.2 GÉNÉRATION DES FICHIERS HTML -------------------------------------------------------------------------- 596.3 PROGRAMMATION JAVASCRIPT ------------------------------------------------------------------------------ 626.4 PROGRAMMATION CGI ET PRÉPARATION DES DONNÉES-------------------------------------------------- 636.5 CONCLUSION ET DISCUSSION---------------------------------------------------------------------------------- 65
CHAPITRE 7. ANALYSE DE L’ENQUÊTE ------------------------------------------------------------------ 67
7.1 INTRODUCTION -------------------------------------------------------------------------------------------------- 677.2 COLLECTE DE DONNÉES ET ANALYSE ------------------------------------------------------------------------ 687.3 ANALYSE DE LA PARTIE I -------------------------------------------------------------------------------------- 69
7.3.1 Distribution des participants----------------------------------------------------------------------- 697.3.2 Caractéristiques des SLV --------------------------------------------------------------------------- 707.3.3 Aspects fonctionnels d’outil de VL ---------------------------------------------------------------- 71
7.3.3.1 Utilité des aspects fonctionnels----------------------------------------------------------------------------- 727.3.3.2 Facteurs d’influence sur l’utilité d’aspects fonctionnels ------------------------------------------------ 737.3.3.3 Relations entre les aspects fonctionnels------------------------------------------------------------------- 75
7.3.4 Aspects pratiques des outils de VL ---------------------------------------------------------------- 757.3.4.1 Importance des aspects pratiques -------------------------------------------------------------------------- 767.3.4.2 Facteurs d’influence sur l’importance d’aspects pratiques --------------------------------------------- 76

vii
7.3.5 Évaluation cognitive d’outils de VL--------------------------------------------------------------- 787.3.6 Bénéfices et améliorations des outils de VL------------------------------------------------------ 79
7.4 ANALYSE DE LA PARTIE II ------------------------------------------------------------------------------------- 807.4.1 Aspects techniques des outils de VL--------------------------------------------------------------- 807.4.2 Support de l’analyse du code par l’outil de VL-------------------------------------------------- 82
7.4.2.1 Traitement de réponses multiples -------------------------------------------------------------------------- 827.4.2.2 Résultats pour le support de l’analyse du code----------------------------------------------------------- 83
7.5 DISCUSSION ET PERSPECTIVES -------------------------------------------------------------------------------- 857.5.1 Améliorations du questionnaire ------------------------------------------------------------------- 857.5.2 Résumé et impact des trouvailles ------------------------------------------------------------------ 86
CHAPITRE 8. CONCLUSION ----------------------------------------------------------------------------------- 89
8.1 SYNTHÈSE-------------------------------------------------------------------------------------------------------- 898.1.1 Inventaire d’outils de VL et évaluation qualitative---------------------------------------------- 898.1.2 Évaluation quantitative ----------------------------------------------------------------------------- 90
8.2 TRAVAUX FUTURS ---------------------------------------------------------------------------------------------- 91
BIBLIOGRAPHIE--------------------------------------------------------------------------------------------------- 93
ANNEXE A. DESCRIPTION DE LA TAXONOMIE DE PRICE ET AL. -------------------------------- I
ANNEXE B. ÉVALUATION DE SEPT OUTILS DE VL -------------------------------------------------- IX
ANNEXE C. QUESTIONNAIRE SUR LES OUTILS DE VL ---------------------------------------- XVIII
ANNEXE D. TECHNIQUES STATISTIQUES-------------------------------------------------------- XXXIII

Liste des tableaux
TABLEAU 1. LISTE DES 30 OUTILS DE VL IDENTIFIÉS. --------------------------------------------------- 21
TABLEAU 2. ASPECTS FONCTIONNELS DES OUTILS DE VL. ------------------------------------------- 51
TABLEAU 3. ASPECTS PRATIQUES DES OUTILS DE VL.-------------------------------------------------- 52
TABLEAU 4. RÉPARTITION DES 24 SOUS-ASPECTS DE L’ANALYSE DU CODE PAR ASPECT.
------------------------------------------------------------------------------------------------------------------------ 56
TABLEAU 5. DÉPENDANCES ENTRE LES SOUS-ASPECTS DU SUPPORT DE L’ANALYSE DU
CODE. --------------------------------------------------------------------------------------------------------------- 57

Liste des figures
FIGURE 1. DIAGRAMME DES TERMES LIÉES À LA VL (STRUCTURE PROPOSÉE DANS
[PRICE93]).--------------------------------------------------------------------------------------------------------- 11
FIGURE 2. DIAGRAMME DES TERMES LIÉES À LA VL (STRUCTURE PROPOSÉE DANS
[YOUNG96]). ------------------------------------------------------------------------------------------------------ 12
FIGURE 3. XATAC AFFICHANT LES DEUX FICHIERS MAIN.ATAC ET WC.ATAC.---------------- 24
FIGURE 4. XATAC AFFICHANT MAIN.ATAC ET WC.ATAC APRÈS OUVERTURE DU FICHIER
WORDCOUNT.TRACE.----------------------------------------------------------------------------------------- 24
FIGURE 5. UN RÉSUMÉ PAR FICHIER DE LA COUVERTURE DES BLOCS DANS XATAC.------ 25
FIGURE 6. UN RÉSUMÉ PAR TEST DE LA COUVERTURE DES BLOCS DANS XVUE. ------------ 26
FIGURE 7. SPÉCIFICATION D’UNE CARACTÉRISTIQUE DANS XVUE. ------------------------------- 26
FIGURE 8. PASSAGE DE LA FENÊTRE DES HEURISTIQUES À CELLE DE LA VISUALISATION
DU CODE SOURCE. --------------------------------------------------------------------------------------------- 27
FIGURE 9. UNE SÉANCE DE DÉMONSTRATION DU CGDI. ----------------------------------------------- 33
FIGURE 10. UTILITÉ DES ASPECTS FONCTIONNELS (REPRÉSENTÉE EN %).---------------------- 72
FIGURE 11. UTILITÉ DES ASPECTS FONCTIONNELS (REPRÉSENTÉE PAR UNE MOYENNE, EN
ORDRE DÉCROISSANT). -------------------------------------------------------------------------------------- 72
FIGURE 12. IMPORTANCE DES ASPECTS PRATIQUES, EN CONSIDÉRANT
L’ENVIRONNEMENT DE TRAVAIL (REPRÉSENTÉE PAR UNE MOYENNE, EN ORDRE
DÉCROISSANT PAR RAPPORT À LA COMPAGNIE). ------------------------------------------------- 77

A mes très chers Jean, Colette et Joanna
pour leur amour et soutien…

Remerciements
Mes plus grands remerciements reviennent à Monsieur Rudolf K. Keller, professeur à
l’Université de Montréal, pour m’avoir donné l’occasion de faire partie de l’équipe du
projet SPOOL, ainsi que pour avoir supervisé cette recherche. Sa grande disponibilité, sa
persévérance, son souci du détail ainsi que son encouragement m’ont beaucoup aidée
tout le long de ce travail. Que ce mémoire soit le modeste témoignage de ma
reconnaissance et de mon admiration.
Je remercie vivement chacun des 107 participants d’avoir rempli le questionnaire sur les
outils de visualisation logicielle. Je suis également reconnaissante envers les personnes
qui m’ont aidée à distribuer l’URL du questionnaire partout dans le monde. De plus, je
remercie mes collègues dans le groupe GÉLO (GÉnie LOgiciel) ainsi que dans CSER
(Consortium for Software Engineering Research), en particulier Janice Singer du CNR
(Conseil National de Recherche) Ottawa, qui m’a aidée à améliorer les premières
versions du questionnaire.
Enfin, je tiens à remercier mes parents et ma sœur qui m’ont toujours supportée, surtout
dans les moments les moins faciles. Trouvez ici l’expression de ma profonde gratitude…

Chapitre 1. Introduction
1.1 Motivation
De nos jours, les systèmes logiciels sont de plus en plus grands et complexes, et leur
développement et maintenance demandent la collaboration de plusieurs personnes. Ceci
rend les tâches de programmation, de compréhension et de modification du logiciel de
plus en plus difficiles, surtout lorsque le travail s’effectue sur le code de quelqu’un
d’autre. Par conséquent, des outils qui supportent ces tâches sont devenus essentiels. Un
aspect clé d’un tel support est la Visualisation Logicielle (VL). De nos jours, beaucoup
de techniques et d’outils de VL sont disponibles aux développeurs1 pour les aider entre
autres à bien “comprendre” leurs logiciels. Il peut s’agir d’outils d’analyse, de
conception, de test, de débogage ou encore de maintenance. En génie logiciel, il existe
suffisamment de preuve anecdotique qu’une présentation claire et visuelle d’un logiciel
peut réduire, de façon significative, l’effort de sa compréhension. Harel, par exemple,
déclare que “l’utilisation de formalismes visuels appropriés peut avoir un effet
spectaculaire sur des ingénieurs et des programmeurs.” [Harel92]. Cependant, à notre
connaissance, aucune enquête quantitative au sujet des outils de VL n’a été conduite.
1.2 Contexte de ce travail
Dans le projet SPOOL (Spreading desirable Properties into the design of Object-
Oriented, Large-scale software systems), une collaboration entre l’équipe de l’évaluation
de la qualité logicielle chez Bell Canada et le groupe GÉLO (Génie Logiciel) de
1 Dans le présent mémoire, le masculin désigne aussi le féminin.

2
l’Université de Montréal, nous nous intéressons principalement à identifier des concepts
et des outils pour évaluer et améliorer la conception de systèmes logiciels à grande
échelle. C’est pourquoi, dans le cadre de ce projet, un environnement de rétro-ingénierie
a été développé pour fournir l’infrastructure informatique nécessaire à l’étude des
activités de maintenance, d’évaluation et de compréhension de ces systèmes. Cet
environnement comporte différents outils d’analyse et de visualisation et supporte de
telles activités en ayant recours à des patrons de conception [Keller99, Robitaille00,
Schauer98]. L’étude présentée dans le cadre de ce mémoire a pour but d’inscrire le
projet SPOOL dans une perspective plus large, et de fournir à Bell Canada des
informations qualitatives et quantitatives, via une enquête, sur des techniques et outils de
VL commerciaux et académiques.
1.3 Problématique et approche de recherche
La compagnie de télécommunication Bell Canada dépense chaque année plusieurs
centaines de millions de dollars pour l’achat et la maintenance de systèmes logiciels de
grande taille. Étant donnée la croissance rapide du domaine des télécommunications,
Bell Canada veut être sure que les logiciels en question répondent à certains critères de
qualité en vue de les entretenir et d’y rajouter de nouvelles fonctionnalités facilement.
Par conséquent, l’équipe de l’évaluation de la qualité logicielle chez Bell Canada utilise
plusieurs techniques et outils pour évaluer ces systèmes avant leur achat, mais aussi
pendant toutes les phases de leur évolution. Les membres de cette équipe utilisent
plusieurs sortes d’outils (des outils graphiques, des outils de calculs de métriques, etc.)
pour faire l’étude de ces systèmes. Certains de ces outils sont considérés comme étant
des outils de VL qui facilitent, entre autres, la compréhension de systèmes. Ils utilisent
donc ces outils sans pour autant avoir une vision plus large des autres techniques et
outils de VL existants que ce soit dans le milieu commercial ou même dans le milieu
académique. Ils souhaitent donc avoir une liste exhaustive de ces outils, avec en quelque
sorte, une évaluation qualitative de certains d’entre eux, ainsi qu’une évaluation
quantitative dans laquelle l’opinion des utilisateurs sera surtout recherchée.

3
Conduit surtout par le besoin de l’équipe de l’évaluation de la qualité logicielle chez
Bell Canada, l’approche de recherche que nous avons adoptée vise donc à identifier un
certain nombre d’outils de VL et à les évaluer de deux façons différentes. Nous allons
donc commencer cette étude par identifier et évaluer de façon qualitative des techniques
et des outils de VL qui prétendent réduire l’effort de l’évaluation et de la compréhension
de logiciel. Nous allons nous baser sur la taxonomie de Price et al. [Price93] pour ainsi
évaluer qualitativement l’ensemble des outils de VL identifiés. Ensuite, comme
deuxième étape, nous devons créer un catalogue de propriétés, désirables ou non, de
techniques et d’outils de VL en nous inspirant des travaux déjà effectués dans le
domaine de la VL et surtout des taxonomies existantes. A partir de ce catalogue, il va
falloir créer une enquête dans laquelle nous questionnerons les utilisateurs de techniques
et d’outils de VL sur leurs perceptions, sur ce qui a marché et ce qui n’a pas marché lors
de l’application de la technique ou de l’outil en main.
1.4 Structure du mémoire
Le chapitre suivant présente l’état de l’art lié à la VL en général. Il commence par
définir le terme “Visualisation Logicielle”, il discute ensuite la position de la VL par
rapport à d’autres domaines tels que la visualisation d’algorithme, la visualisation de
programme, etc. Un résumé de l’historique de la VL est donné avant de présenter un
survol des différentes taxonomies liées à la VL. Ce chapitre discute aussi le lien qui
existe entre cette dernière et le grand domaine de la compréhension logicielle. Enfin, il
présente les recherches qui existent dans le domaine de la VL.
Le chapitre 3 commence par donner un inventaire des outils de VL que nous avons
identifiés. Il expose ensuite l’ensemble des outils que nous avons retenus tout en les
décrivant de façon brève. Deux démonstrations de deux outils seront aussi fournies.
Les outils retenus aux chapitres 3 seront évalués qualitativement au chapitre 4. Une
description rapide de la taxonomie de Price et al. [Price93] sera fournie au départ (une
description plus complète est donnée à l’annexe A). Ensuite, les points les plus

4
intéressants de l’évaluation des outils utilisant la taxonomie déjà décrite seront exposés
(l’annexe B donne cette évaluation au complet).
Le chapitre 5 décrit les différentes questions des deux parties du questionnaire2 sur les
outils de VL. Une version “papier” du questionnaire est donnée à l’annexe C.
Le chapitre 6 expose la conception technique du questionnaire qui a été mis on-line, en
discutant d’une part, la génération des fichiers HTML, et d’autre part, la programmation
en JavaScript et Perl (CGI) pour le contrôle et la collecte des données.
Le chapitre 7 présente les résultats de notre enquête dont le contenu et la conception
technique ont été décrits aux deux chapitres précédents. Dans ce chapitre, nous mettrons
surtout l’emphase sur l’analyse et la discussion des résultats liés aux différentes parties,
sections et questions du questionnaire. Quelques-unes des améliorations que peuvent
être apportées au questionnaire seront discutées, avant de résumer les résultats
principaux de cette enquête ainsi que leur impact que ce soit sur les constructeurs
d’outils de VL ou bien sur la communauté des chercheurs dans le domaine de la VL.
L’annexe D est liée à ce chapitre. Elle explique de façon brève les différentes techniques
statistiques auxquelles ce chapitre fait référence.
Finalement, le chapitre 8 résume brièvement ce travail, et une discussion des travaux
futurs conclut ce mémoire.
1.5 Contributions principales
Deux contributions majeures sont le fruit de ce travail. Une première contribution
concerne le projet SPOOL en tant que tel et l’équipe de l’évaluation de la qualité
logicielle chez Bell Canada, quant à la deuxième contribution, elle concerne la
2 Le questionnaire est disponible on-line, en anglais ou en français, à l’adresse suivante:
<http://www.iro.umontreal.ca/labs/gelo/sv-survey/questionnaire.html>.

5
communauté des personnes qui s’intéressent au domaine de la VL et surtout aux outils
de VL.
En effet, le travail présenté dans ce mémoire apporte au projet SPOOL une perspective
plus large quant aux outils de VL existants que ce soit sur le marché ou bien en tant que
prototype de recherche. En fait, les membres de l’équipe de l’évaluation de la qualité
logicielle chez Bell Canada se sont rendus compte de quelques nouveaux outils de VL
forts intéressants qu’ils ne connaissaient pas avant cette étude. Se basant sur les résultats
de notre enquête, ils ont aussi pu comparer les caractéristiques qu’offrent – ou non – les
outils de VL d’aujourd’hui et l’intérêt que des utilisateurs réels de ces outils accordent à
de tels caractéristiques. En combinant ces informations, l’enquête permet de retirer de
façon ciblée des informations quant aux versions actuelles des outils de VL ainsi que de
les comparer aux besoins réels des utilisateurs de tels outils. Bref, une approche basée
sur un questionnaire n’a guère été employée auparavant pour recueillir des informations
sur des outils de VL, et voilà qu’elle promet maintenant d’ouvrir de nouvelles
possibilités pour concevoir des questionnaires plus spécifiques, liés à des types bien
particuliers d’outils de VL.
Bien sûr, nous estimons que cette recherche et les résultats obtenus seront aussi utiles
au-delà du projet SPOOL, et ceci au moins de quatre façons différentes. D’abord,
l’évaluation qualitative effectuée peut aider les personnes intéressées en leur donnant un
exemple sur comment utiliser une taxonomie bien particulière pour évaluer les outils de
VL de nos jours. Ensuite, la liste de souhaits et les problèmes exprimés par les
participants à l’enquête donneront à des constructeurs d’outil de VL des informations
valables pour de futures versions de leurs produits. En outre, les acheteurs éventuels et
les utilisateurs d’outils de VL peuvent consulter les deux listes exhaustives d’outils de
VL (tableau 1 de la section 3.2 et liste on-line des outils de VL3) couverts par cette étude
et employer le questionnaire pour effectuer leurs propres évaluations. Enfin, les
3 Une liste complète des noms et références web des outils de VL pour lesquels nous avons reçu une ou
plusieurs réponses au questionnaire peut être trouvée à l’adresse suivante: <http://www.iro.umontreal.ca
/labs/gelo/sv-survey/list-of-tools.html>.

6
imperfections et les limitations de la technologie actuelle de VL comme indiquées par
l’enquête peuvent définir une liste de points pour des recherches plus poussées dans le
domaine.
Différents aspects de ce travail ont déjà donnée lieu à trois rapports techniques
[Bassil00a, Bassil00b, Bassil00c] à l’intérieur du laboratoire GÉLO et de Bell Canada,
ainsi qu’à la publication d’un article au congrès international IWPC’2001 (International
Workshop on Program Comprehension) [Bassil01].

Chapitre 2. État de l’art
2.1 Introduction
La VL se trouve être l’un des domaines de recherche qui tente d’aider à la
compréhension de programme. Elle se base sur le fait que le cerveau humain est en
mesure d’identifier, de manipuler et de traiter des images de façon fructueuse. Lire un
texte est un cas spécial du traitement visuel. Le cerveau abstrait chaque caractère (ou
mot) en une représentation interne. Nous trouverons dans la littérature liée à la
compréhension de programme les mots techniques relatifs aux représentations internes
ainsi que les descriptions qui leur sont associées. À titre d’exemple, les beacons
[Brooks83] et les chunks [Shneiderman80] sont des représentations internes de
structures textuelles de bas niveau.
Cette aide à la compréhension est rendue possible par la VL en présentant à
l’observateur (viewer) une image d’un logiciel comportant des informations complexes.
Ainsi, l’observateur pourra rapidement générer un modèle mental initial du logiciel et
utiliser ceci comme une base pour pousser plus loin son étude de ce logiciel. Bref, la VL
est souvent associée à des domaines de génération et de manipulation d’images. Ces
images ne sont pas nécessairement de nature graphique. C’est ce que nous allons
discuter plus loin dans ce chapitre, à la fin de la section 2.2.
Avant d’aborder l’étude effectuée sur les outils de VL, plusieurs questions se posent, et
nécessitent une revue de la littérature liée à la VL. Plusieurs définitions formelles de la
VL ont été proposées dans la littérature. Un résumé de ces définitions sera exposé à la

8
section suivante. Les sections 2.3 à 2.7 répondront respectivement aux questions liées à
la position de la VL par rapport aux autres domaines, tel que la visualisation de
programme, l’animation d’algorithme, etc. (section 2.3), à son historique (section 2.4),
aux taxonomies qui lui sont associées (section 2.5), à son lien avec la compréhension de
programme (section 2.6), et finalement, à l’état actuel des recherches dans ce domaine
(section 2.7).
2.2 Définition de la VL
Plusieurs chercheurs dans le domaine de la VL ont essayé de définir ce terme. Une
sélection représentative de ces définitions sera présentée dans les paragraphes qui
suivent. Malheureusement, la VL reste un terme vague, englobant presque toutes les
formes de visualisation liées à la représentation de n’importe quel aspect d’un système
logiciel. Un certain nombre de domaines plus spécialisés, comme la visualisation de
programme, l’animation d’algorithmes, la programmation visuelle, et la visualisation de
calcul (computation visualisation) ont évolué sous l’apparence de la VL. Leur position
par rapport à cette dernière sera présentée à la section suivante (2.3). Toutefois, un
aperçu des définitions et des interprétations liées à la visualisation de programme et à la
VL est présenté dans cette section. Cet aperçu regroupe les définitions que nous jugeons
les plus représentatives parmi une grande variété offerte dans la littérature. Tout compte
fait, nous exposons à la fin de cette section, la définition que nous retenons pour ce
travail. Celle-ci sera raffinée au chapitre 3.
Les débuts de la VL étaient axés sur la “Visualisation de Programme” (VP) qui est de
nos jours considérée comme un sous-domaine du grand domaine de la VL. En 1990,
Myers [Myers90] donne une définition de l’expression VP. Il précise que la VP utilise le
graphisme pour illustrer certains aspects du programme ou bien de son exécution; le
programme étant spécifié de façon conventionnelle (textuelle). En 1992, Roman et Cox
[Roman92] re-définissent la VP en mentionnant que, bien qu’elle fasse appel à des
représentations graphiques, la surveillance et l’exploration du programme seront
exprimées sous forme textuelle. Un an plus tard [Roman93], ces deux mêmes personnes
introduisent dans leur définition de la VP le terme “mapping”: “La VP est un mapping,

9
ou bien une transformation, d’un programme en une représentation graphique.” Encore
une fois, en 1995, Kings [Kings95] précise dans sa définition que la VP est la
représentation de code source, et d’autres documents, de façon graphique; alors que
Jerding et Stasko [Jerding94] affirment que la VP utilise non simplement le graphisme
mais aussi l’animation pour ainsi décrire et illustrer visuellement les logiciels et leurs
fonctions.
Une chose sur laquelle tous les chercheurs semblent être d’accord est le fait que la VP
forme un sous-ensemble du domaine connu sous le nom de la VL. Selon Stasko
[Stasko93], la VL illustre des processus informatiques et des données en plus des
programmes réguliers, alors que la VP illustre les structures de données, l’état du
programme et le code du programme.
Nous présentons trois autres définitions de la VL. La première provient de Domingue et
al. [Domingue92]: “La VL décrit des systèmes qui utilisent des médias visuels (et
autres), et ceci pour augmenter la compréhension d’un programmeur du travail effectué
par une autre personne (ou bien par lui-même).” La deuxième est celle de Price et al.
[Price93]: “La VL est l’utilisation du métier de la typographie, du design graphique, de
l’animation et de la cinématographie avec la technologie moderne de l’interaction
humain-machine et ceci pour faciliter (1) la compréhension humaine et (2) l’utilisation
pertinente des logiciels informatiques.” Finalement, une définition de
Muthukumarasamy et de Stasko [Muthukumarasamy95] est la suivante: “La VL est
l’utilisation des techniques de la visualisation et de l’animation pour aider les personnes
à comprendre les caractéristiques et les exécutions de programmes informatiques.”
Nous remarquons que la plupart de ces définitions offrent plusieurs niveaux de détail et
d’abstraction. Une évidence commune dans la majorité des définitions c’est l’emphase
sur les représentations visuelles. Les deux termes VL et VP sont généralement définis
comme comportant exclusivement des représentations graphiques. Plusieurs chercheurs
dans le domaine de la VL considèrent ceci comme trop restrictif. Nous sommes d’accord
avec eux sur le fait que la VL devrait permettre des représentations autres que

10
graphiques. Price et al. [Price93] redéfinissent le terme “Visualisation” pour inclure une
telle flexibilité: “Le pouvoir ou le processus de former une image mentale ou bien une
vision de quelque chose qui n’est pas réellement présent à la vue.” De même, en 1995,
Watson et Buchanan [Watson95] donnent une définition de ce terme, en précisant de
façon claire la non-obligation d’avoir des vues graphiques: “La visualisation est le
processus de créer et de manipuler une image visuelle qui fournit une image mentale
[…]. Ces images peuvent être soit statiques soit dynamiques et n’ont pas nécessairement
besoin d’être de nature graphique, ce qui donne la possibilité d’avoir des images
comprenant des constructeurs symboliques.”
Bref, nous venons de présenter un survol de plusieurs définitions rencontrées dans la
littérature concernant la VL. Nous adoptons pour ce travail une définition qui tient
compte de la compréhension de programme. En effet, la VL doit permettre à
l’observateur de former une image mentale du logiciel visualisé, sans recourir
nécessairement à des représentations graphiques. Notre définition est en accord avec les
définitions proposées dans [Domingue92, Price93, Muthukumarasamy95]. Cependant,
elle met plus l’emphase sur la compréhension d’un logiciel (le résultat final de la VL)
que sur les techniques utilisées pour représenter ce logiciel (les étapes de la VL). Un
raffinement de cette définition sera discuté au chapitre suivant.
2.3 Position de la VL par rapport aux autres domaines
Un grand nombre d’auteurs [Price93, Stasko92a, Stasko92b, Myers90] a tenté
d’identifier et de classifier les sous-domaines de la VL, et de positionner cette dernière
par rapport aux autres domaines. Price et al. [Price93] voient la VL comme étant un
domaine qui englobe les deux domaines distincts de la VP et de l’Animation
d’Algorithme (AA). Dans la structure qu’ils proposent (figure 1), la VP inclut le
domaine de la Programmation Visuelle (PV). Cette notion est en contradiction avec
d’autres points de vue qui considèrent la VP et la PV comme étant deux domaines
différents [Roman93, Myers90]. Par contre, dans sa revue de la littérature concernant la
VL [Young96b], Young trouve que l’idée de Price et al. de considérer la PV comme
faisant partie de la VP est valable, puisque pour pouvoir créer un environnement de PV,

11
nous devons avant tout être capable de visualiser des programmes. Cependant, il semble
non raisonnable d’exclure l’AA de la VP et de ne pas le faire pour la PV.
Price et al. décrivent la VP comme étant composée de visualisations de (1) code et de (2)
données statiques et dynamiques, alors que la PV ne touche qu’à la visualisation statique
(code et données). Young trouve que ce point est ouvert à toute discussion [Young96b].
En effet, puisque la PV comprend l’implantation visuelle de programmes, ce processus
ne peut se restreindre seulement aux visualisations statiques. Un argument simple serait
le débogage et le traçage de code. Dans le sens visuel, la seule façon dans laquelle ces
deux activités peuvent être présentées est à travers des visualisations animées. Nous ne
pouvons donc pas limiter le paradigme de la PV aux visualisations purement statiques.
Les arguments exposés ci-dessus offrent une critique constructive à la classification des
différents domaines dans le cadre de la VL. La figure 1 proposée par Price et al. a été
révisée par Young [Young96b], et une nouvelle classification des termes a été proposée
en tenant compte des arguments ci-dessus. En plus du domaine de la VL, le terme
Figure 1. Diagramme des termes liées à la VL (structure proposée dans [Price93]).
SoftwareVisualisation
AlgorithmVisualisation
ProgramVisualisation
Static AlgorithmVisualisation
AlgorithmAnimation
VisualProgramming
CodeAnimation
Static DataVisualisation
DataAnimation
Static CodeVisualisation
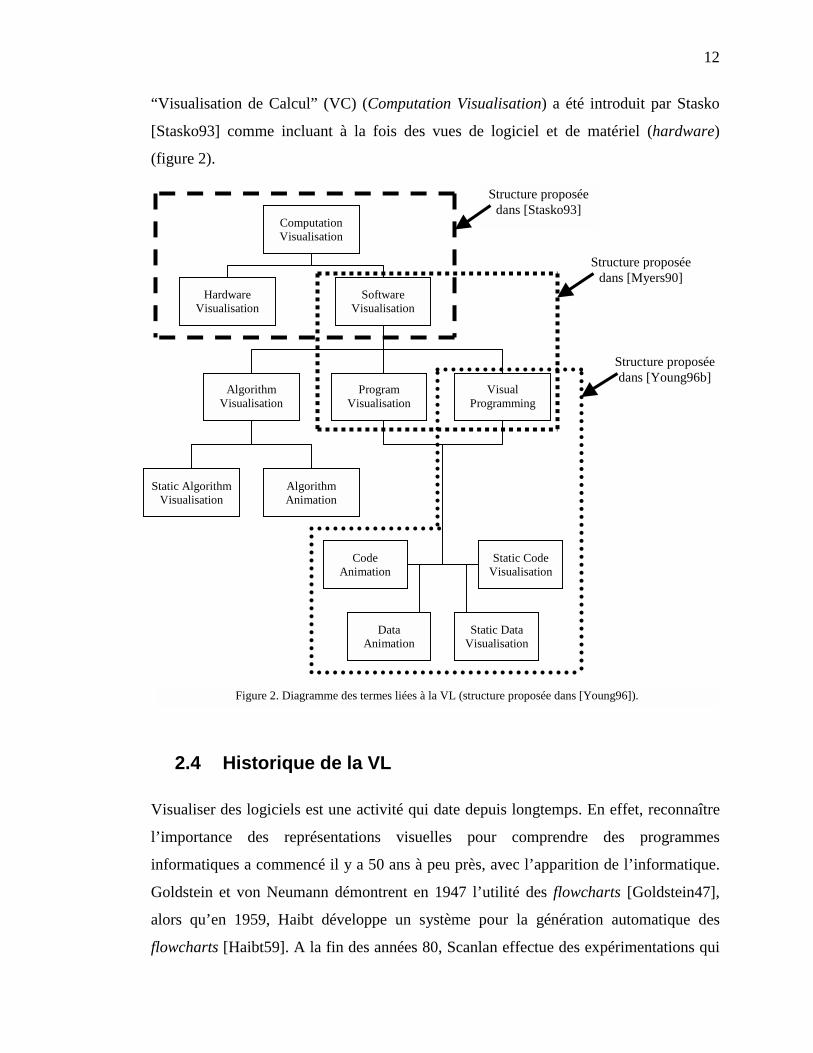
12
“Visualisation de Calcul” (VC) (Computation Visualisation) a été introduit par Stasko
[Stasko93] comme incluant à la fois des vues de logiciel et de matériel (hardware)
(figure 2).
2.4 Historique de la VL
Visualiser des logiciels est une activité qui date depuis longtemps. En effet, reconnaître
l’importance des représentations visuelles pour comprendre des programmes
informatiques a commencé il y a 50 ans à peu près, avec l’apparition de l’informatique.
Goldstein et von Neumann démontrent en 1947 l’utilité des flowcharts [Goldstein47],
alors qu’en 1959, Haibt développe un système pour la génération automatique des
flowcharts [Haibt59]. A la fin des années 80, Scanlan effectue des expérimentations qui
Figure 2. Diagramme des termes liées à la VL (structure proposée dans [Young96]).
Static AlgorithmVisualisation
AlgorithmAnimation
VisualProgramming
CodeAnimation
Static DataVisualisation
DataAnimation
Static CodeVisualisation
HardwareVisualisation
ComputationVisualisation
SoftwareVisualisation
ProgramVisualisation
AlgorithmVisualisation
Structure proposéedans [Stasko93]
Structure proposéedans [Young96b]
Structure proposéedans [Myers90]

13
mettent en évidence la valeur des flowcharts comme étant une aide à la compréhension
[Scanlan89]. Les films de Knowlton, développés en 1966, donnent une approche
différente à la visualisation en montrant une manipulation de listes [Knowlton66a,
Knowlton66b]. Ceci fut le premier travail à utiliser des techniques dynamiques (par
opposition à statique), et à adresser la visualisation des structures de données. A partir de
1975, Baecker donne une direction pédagogique à la VL en travaillant sur des systèmes
pour montrer des abstractions de structures de données dans des programmes en
exécution [Baecker75]. En 1981, il sort le film Sorting Out Sorting (SOS) qui a pour but
de montrer une course de neuf algorithmes de tri différents, s’exécutant sur un grand
ensemble de données [Baecker81]. Aussi, dans les années 70, Ledgard expose la
technique du pretty-printing qui consiste à utiliser des espaces, de l’indentation et
différents layouts pour rendre le code source plus facile à lire dans un langage structuré
[Ledgard75]. Plusieurs systèmes furent développés pour le pretty-printing automatique.
Un exemple serait le système de Hueras et Ledgard pour le langage Pascal [Hueras77].
En 1990, Baecker et Marcus font le passage du pretty-printing, considéré comme une
utilité simple, au système SEE qui prend automatiquement un ensemble de programmes
en C et formate à partir d’eux un “program book” [Baecker90]. Les années 80 sont
consacrées à des recherches en VL moderne. Les chercheurs profitent des nouvelles
technologies graphiques pour construire des systèmes pour visualiser que ce soit des
programmes informatiques ou bien des algorithmes. BALSA est un exemple de système,
créé en 1984, pour l’animation d’algorithme [Brown84]. Une nouvelle version de ce
système (BALSA-II) est mise au point en 1988 [Brown88]. BALSA-II permet aux
étudiants d’interagir avec des visualisations dynamiques de haut niveau de programmes
en Pascal. De nos jours, plusieurs outils de VL sont disponibles utilisant les technologies
modernes d’interface Humain-Machine. La plupart de ces outils viennent des milieux de
recherche, et ne sont pas applicables à des logicielles de grande taille.
2.5 Taxonomies liées à la VL
Plusieurs taxonomies ont été appliquées aux systèmes de VL. Deux taxonomies, basées
sur les aspects concrets des outils de VL, prédominent dans ce domaine: une première
taxonomie de Myers [Myers90] et une taxonomie plus récente de Price et al. [Price93].

14
La taxonomie de Myers a été mise à jour deux fois. Une première version a été créée en
1986. Puis, deux autres versions ont suivi (1988 et 1990). Myers fait l’étude de 19
systèmes de VL, et il les classifie selon deux axes principaux: (1) leur niveau
d’abstraction (code, donnée ou algorithme), et (2) leur niveau d’animation lors de
l’affichage (statique ou dynamique). Une expansion de cette première taxonomie est
celle de Price et al. Ces derniers catégorisent les systèmes de façon plus systématique et
tentent de structurer la taxonomie pour permettre une flexibilité pour une future
expansion et révision. Il est à noter qu’aucune expansion n’a été effectuée de façon
formelle jusqu’à présent. Cette taxonomie se base sur une structure hiérarchique de
classification qui permet un ajout simple de nouvelles catégories. Elle est composée de
six catégories (Scope, Content, Form, Method, Interaction, Effectiveness) et plus de 30
nœuds (niveau feuille) sur quatre niveaux hiérarchiques. Le niveau le plus élevé de cette
hiérarchie dérive d’un modèle très général de logiciel (black-box). Cette taxonomie fut
utilisée pour classifier 12 systèmes de VL. Nous reverrons plus en détail, dans la section
4.2, les six catégories de cette taxonomie.
D’autres taxonomies basées sur les aspects concrets des outils de VL existent. En effet,
Stasko et Patterson [Stasko92] introduisent une taxonomie à quatre catégories: aspect,
abstraction, animation et automatisation. Une autre taxonomie est celle de Roman et Cox
[Roman92] qui identifiait initialement des systèmes utilisant les catégories suivantes:
plage (scope), abstraction, méthode de spécification, et technique. Ensuite, cette
taxonomie de départ fut raffinée [Roman93] en remplaçant la catégorie “technique” par
les deux catégories “interface” et “présentation”. Roman et Cox voient la visualisation
comme étant un mapping des programmes vers des représentations graphiques
[Roman92], avec les catégories de la taxonomie représentant les aspects de ce mapping.
La plage couvre les aspects du programme qui sont visualisés, l’abstraction et la
méthode de spécification couvrent le processus de visualisation, alors que l’interface et
la présentation (correspondant à la catégorie “technique” dans le travail initial) couvrent
la représentation graphique.

15
Une taxonomie alternative à celle de Price et al., basée sur les aspects cognitifs de
l’utilisateur plutôt que les aspects concrets des outils de VL eux-mêmes, est celle de
Storey et al. [Storey99]. Ces derniers croient que les outils de VL doivent (1) supporter
plusieurs stratégies de compréhension, (2) supporter le switching entre ces stratégies, et
(3) réduire l’overhead cognitif. Ils ont donc commencé par examiner des modèles
cognitifs de compréhension de programme. A partir de ces modèles, ils ont dérivé une
hiérarchie de 14 éléments de conception cognitive. Ensuite, ils ont appliqué ces 14
éléments à la conception et l’évaluation d’un outil d’exploration logicielle (SHriMP). La
hiérarchie proposée comporte deux branches: (1) La première branche (améliorer la
compréhension d’un programme) a pour but de capturer les processus essentiels des
différentes stratégies appliquées par les programmeurs lors de leur compréhension d’un
programme. (2) La deuxième branche (réduire l’overhead cognitif du programmeur)
adresse l’overhead cognitif expérimenté par un utilisateur lors du browsing et de la
navigation de la visualisation de structures logicielles.
2.6 VL et compréhension de programme
Le domaine de la VL est avant tout considéré comme un domaine important de
recherche à l’intérieur du domaine général de la compréhension de programme. Il existe,
dans la littérature, une explication cohérente de ceci. En effet, il est connu que la
compréhension de programme joue le plus grand rôle dans n’importe quelle activité de
maintenance. Aussi, les différentes théories de compréhension de programme mettent
l’emphase sur la construction dans l’esprit du développeur de maintenance, d’un modèle
mental du logiciel [Young96a]. La VL tente de fournir par des outils un support pour
générer ce modèle mental ou bien cette compréhension.
Les modèles mentaux proposés par différents chercheurs dans le domaine de la
compréhension de programme [Young96a] sont tous composés de constructeurs
sémantiques. Ces constructeurs sont typiquement des abstractions, à différents niveaux,
de caractéristiques du programme. Le réseau formé de ces constructeurs constitue pour
le développeur de maintenance la compréhension et la représentation du programme.
Selon Young, la VL tente de fournir un mapping du code du programme à une

16
représentation visuelle (et d’autres médias) qui apparie (matches) le modèle mental du
développeur de maintenance de la façon la plus proche possible. Le fait de mettre en
évidence et de créer automatiquement ces constructeurs sémantiques soulagera beaucoup
l’effort effectué par le développeur de maintenance, spécifiquement, ceci exigera moins
de temps pour la lecture du code source.
2.7 Recherches en VL
Les recherches actuelles en VL sont diverses. Initialement, des systèmes de visualisation
d’algorithme étaient développés pour enseigner l’analyse et la conception d’algorithme.
Une autre application de la VL est pour le débogage et le traçage lors de l’exécution,
particulièrement avec des langages impératifs. Plus récemment, des recherches ont été
effectuées sur des visualisations structurelles de code. Ces visualisations se concentrent
sur des vues à grande échelle, et des exemples typiques sont les graphes d’appel de
fonction et de flux de contrôle et les dépendances entre les différentes composantes
(variables, classes, fonctions, méthodes, fichiers, modules) qui forment le système
logiciel. Des exemples de systèmes de VL structurelle comprennent: SNiFF, Rigi
[Storey95], Narcissus [Hendley95], SemNet [Fairchild88], et GraphVisualiser3D
[GV3D95]. De tels systèmes ne sont pas couverts par les taxonomies existantes, mais ils
pourraient facilement être incorporés par les différents critères des taxonomies. En plus,
il y a un intérêt de recherche très actif pour la visualisation de programmes en parallèle,
se concentrant généralement sur leur comportement lors de l’exécution [Koike95,
Kraemer93, Miller93, PVMTrace95].
Les recherches dans le domaine de la visualisation d’algorithme se concentrent sur la
production de visualisations et d’animations significatives et ceci pour aider à la
compréhension des opérations de l’algorithme. Plusieurs systèmes ont été développés
pour ce type de visualisation, et un grand nombre d’entre eux sont décrits dans les
différentes taxonomies [Myers90, Price93, Roman93]. De tels systèmes comprennent:
BALSA, Balsa-II, Zeus, TANGO, Polka3D, et ANIM.

17
Le débogage visuel n’est pas généralement accepté comme étant un sujet bien spécifique
de la VL bien qu’il existe un grand nombre de systèmes (Pascal Genie, UWPI, TPM,
Pavane, LogoMedia, CentreLine ObjectCentre (Saber-C++), et PVMTrace) qui utilisent
la visualisation comme une aide primaire au débogage. Ces systèmes sont aussi décrits
et classifiés dans les différentes taxonomies.
De nos jours, la majorité des systèmes de VL se sont concentrés sur la production de
représentations et d’animations en 2D des différents aspects d’un système logiciel.
Toutefois, l’application de graphiques en 3D et de la technologie de réalité virtuelle à la
VL constitue un domaine de recherche en expansion. Les recherches dans le domaine de
la visualisation en 3D de logiciel tentent d’aborder le problème de deux manières: (1) en
terme des données à représenter et (2) en terme de la capacité des utilisateurs à naviguer
ces données. Stasko et Wehrli discutent trois catégories différentes de la visualisation en
3D [Stasko93]:
• Augmented 2D views, dont le but se restreint juste à la présentation et à l’esthétique.
• Inherent 3D application domain views, où la représentation 3D est une nécessité.
• Adapted 2D views, où la troisième dimension ajoute une nouvelle caractéristique à la
visualisation.
Bien que le potentiel complet de l’utilisation de vues en 3D n’ait pas encore été réalisé,
un certain nombre de systèmes logiciels ont été développés pour examiner leur valeur.
La majorité de ces systèmes étendent et adaptent simplement en 3D les techniques de
visualisation 2D déjà établies [Brown93, Reiss94]. Brown et Najork [Brown93]
décrivent trois utilisations fondamentales du 3D:
• fournir des informations ou attributs additionnels sur les objets initialement en 2D,
• unir plusieurs vues, et
• fournir un historique d’exécution.
Voici quelques systèmes de VL en 3D, variant de la visualisation d’algorithme à la
visualisation structurelle: Zeus, PVMTrace [PVMTrace95], VOGUE, VisuaLinda
[Koike95], SemNet [Fairchild88] et Graph Visualizer3D [GV3D95, Ware93].

18
2.8 Conclusion
Ce chapitre a décrit l’état de l’art courant en VL. Une attention particulière a été
accordée à la définition de la VL et des domaines reliés à elle, à son historique, à son
application à la compréhension logicielle, ainsi qu’à l’état actuel et à la direction des
efforts de recherche. Il existe un certain nombre de conclusions qui peuvent être
effectuées:
• Jusqu’à présent, il n’existe pas encore un consensus commun sur la définition de la
VL. De même, sa position par rapport aux autres domaines reste ambiguë.
• Après cinquante ans de recherches dans le domaine de la VL il reste encore
beaucoup de travaux à faire pour aboutir à des outils de VL viables lorsque
appliquées sur des grandes applications industrielles.
• Il existe actuellement un manque et un besoin pour des évaluations empiriques de
systèmes de VL. Toutefois, quelques exceptions existent [Bellay97, Linos93,
Mulholland95, Rajlich94, Steckel92, Storey96]. De même, à part les différentes
taxonomies pour classifier les systèmes, il n’existe aucune méthode empirique pour
comparer ces systèmes.
En conclusion, nous sommes presque certains que les recherches et l’intérêt dans le
domaine de la VL continueront à se développer. Puisque la technologie du matériel
s’améliore de plus en plus et que les prix continuent à baisser, les soucis pour créer des
innovations dans le domaine de la VL n’existent plus. Malgré le grand nombre d’outils
de VL peu d’entre eux sont utilisés en pratique. A notre avis, leur acceptation dans le
monde industriel exige que les recherches courantes dans le domaine de développement
de tels outils adressent les besoins réels des utilisateurs. Identifier ces besoins nécessite
avant tout une connaissance assez élaborée ainsi qu’une évaluation de techniques et
d’outils de VL existants. Pour cela, nous commencerons par exposer au chapitre suivant,
un inventaire exhaustif – mais non complet – d’outils de VL. A partir de cet inventaire,
un ensemble d’outils sera retenu et décrit avant de passer, dans le chapitre 4, à
l’évaluation utilisant une taxonomie déjà existante, celle de Price et al. [Price93].

Chapitre 3. Inventaire d’outils de VL
3.1 Introduction
Il est plus facile d’identifier, de comprendre et de comparer les propriétés et
caractéristiques d’outils de VL si nous avons un certain nombre d’exemples de ces outils
à évaluer. Pour cela, ce chapitre a pour but essentiel d’identifier une liste d’outils de VL
et de fournir une description brève de sept outils de VL retenus à partir de cette liste. Ces
sept outils seront par la suite (chapitre 4) évalués utilisant la taxonomie de Price et al.
Un grand nombre des travaux d’évaluation qui ont été effectués jusqu’à présent (par
exemple, le travail d’évaluation de [Myers90] ou bien de [Price93]), et qui se basent sur
une taxonomie bien particulière, s’est contenté d’évaluer juste des systèmes de
recherche, sans pour autant toucher à des systèmes commerciaux. Cependant, évaluer à
la fois des outils académiques (provenant de milieux de recherche) et des outils
commerciaux, permet de comparer ces deux genres d’outils et donne l’opportunité de
tirer des points saillants à partir de cette comparaison. Par conséquent, notre travail
d’identification vise à la fois les outils académiques et commerciaux.
Plusieurs définitions ont été proposées au chapitre précédent. Il serait intelligent
d’utiliser comme critère d’identification des outils de VL les propriétés précisées dans
l’une ou l’autre de ces définitions. Cependant, puisqu’aucun consensus n’existe jusqu’à
présent, nous nous sommes contentés de considérer la propriété suivante comme seul
critère d’identification: Un outil de VL est tout outil qui aide d’une façon ou d’une autre
à la compréhension de logiciel. Il n’est donc pas nécessaire que l’outil en question

20
présente du graphisme comme le suggèrent beaucoup des définitions rencontrées dans la
littérature. Une simple présentation claire du logiciel peut faciliter la compréhension,
sans pour autant recourir à des graphes très sophistiqués.
Dans la section suivante, nous présentons l’inventaire des 30 outils de VL que nous
avons établi. La section 3.3 expose les sept outils retenus à partir de cette longue liste.
Une description brève de chacun de ces sept outils sera donnée. Deux démonstrations de
deux outils bien particuliers (un académique et l’autre commercial) seront aussi
exposées.
3.2 Identification d’outils de VL
Comme il a déjà était précisé dans l’introduction de ce chapitre, nous nous sommes
basés sur un critère bien particulier pour identifier un ensemble d’outils de VL. En effet,
un outil de VL est tout outil qui apporte de l’aide à la compréhension de logiciel. Suite à
cette précision, une première liste de 30 outils de VL a été établie. Cette longue liste
comporte à la fois des outils commerciaux, au nombre de 13, et des outils académiques,
au nombre de 17. Le tableau 1 présente la liste au complet des outils identifiés, avec une
séparation claire entre les outils commerciaux et ceux du milieu de recherche. Nous
avons remarqué qu’il est plus facile d’identifier des outils de VL dans le monde
académique que dans le monde commercial. Bien que plusieurs grandes entreprises se
soient mises à développer de tels outils, intégrés ou non dans des environnements de
développement (IDE), le domaine de la VL et le développement d’outils de VL restent
plus connus dans les milieux de recherche.
Un rapport interne au laboratoire GÉLO (Génie Logiciel) ainsi qu’à Bell Canada,
comportant la description de chacun des 30 outils identifiés a été généré [Bassil00].
Cependant, dans ce présent mémoire, nous ne présenterons que la description des sept
outils retenus. Ces derniers sont marqués par � dans le tableau 1, et seront présentés
dans la section suivante.

21
Outil de VL (Fournisseur) Référence (Adresse web)Visual IDL Programming Environment (Research Systems) http://www.rsinc.com/vip/index.cfm
VisualAge for Java (IBM) http://www-4.ibm.com/software/ad/vajava/
Source Explorer (Intland) http://www.intland.com/
Understand for Ada (Scientific Toolworks, Inc.) http://www.scitools.com/uada.html
xSuds - Software understanding system - (Telcordia
Technologies) �http://xsuds.argreenhouse.com/
GraphViz (AT&T) http://www.research.att.com/~north/graphviz/
InterAct Diagramming Object (ProtoView) http://www.protoview.com/interact/
Tom Sawyer Graph Layout Toolkit & Graph Editor Toolkit � http://www.tomsawyer.com/products.html
Imagix 4D (Imagix) http://www.imagix.com/products/imagix4d.html
Jtest (ParaSoft) http://www.parasoft.com/products/jtest/index.htm
Visual CASE (Rogue Wave Software) http://www.roguewave.com/products/vcase
Algorithms for Graph Drawing (Algorithmic Solutions)http://www.algorithmic-
solutions.com/as_html/products/products.html
Out
ils C
omm
erci
aux
Discover (Upspring Software) � http://www.upspringsoftware.com/products/discover/index.html
Visualizing Graphs with Java (Université d’Auburn) �http://www.eng.auburn.edu/department/cse/research/graph_
drawing/graph_drawing.html
daVinci (Université de Bremen) � http://www.informatik.uni-bremen.de/daVinci/
GraphEd (Université de Passau) http://www.infosun.fmi.uni-passau.de/GraphEd/
GraphLet (Université de Passau) http://www.infosun.fmi.uni-passau.de/Graphlet/
FfGraph (Université de Passau) http://www.fmi.uni-passau.de/~friedric/ffgraph/main.shtml
Edge tool (Université de Karlsruhe) http://www.fmi.uni-passau.de/~himsoft/graphdrawing.html
GraphPlace (Université de Warwick)ftp://ftp.dcs.warwick.ac.uk/people/Martyn.Amos/packages/
graphplace/graphplace.tar.gz
The Lens system (Graphics, Visualization & Usability (GVU)
Center - Georgia Tech)http://www.cc.gatech.edu/gvu/softviz/visdebug/visdebug.html
The GROOVE system (Graphics, Visualization & Usability
(GVU) Center - Georgia Tech)http://www.cc.gatech.edu/gvu/softviz/ooviz/ooviz.html
Swan (Virginia Tech) � http://geosim.cs.vt.edu/Swan/Swan.html
GEM3D (Université de Karlsruhe) http://i44s11.info.uni-karlsruhe.de/~frick/gd/gem3Ddraw/
Data Display Debugger (TU Braunschweig) http://www.gnu.org/software/ddd/
The DOT tool (Université de Californie) http://seclab.cs.ucdavis.edu/~hoagland/Dot.html
VCG (Université des Saarlandes) & CGDI (Université de
Linkoping) �
http://www.cs.uni-sb.de/RW/users/sander/html/gsvcg1.html
http://www.ida.liu.se/~vaden/cgdi/
Interactive Graph Display System DG (Ogeron Graduate
Institute of Science and Technology)http://www.cse.ogi.edu/Sparse/dg.html
SHriMP (Université de Victoria) http://www.csr.uvic.ca/~mstorey/research/shrimp/shrimp.html
Out
ils d
e R
eche
rche
Rigi (Université de Victoria) http://www.rigi.csc.uvic.ca/rigi/rigiframe1.shtml
Tableau 1. Liste des 30 outils de VL identifiés.

22
3.3 Outils de VL retenus
Quatre critères principaux ont été appliqués pour retenir l’ensemble des sept outils de
VL parmi les 30 identifiés. En effet, comme premier critère, nous voulions évaluer à la
fois des outils académiques et commerciaux et non pas juste une seule de ces deux
catégories. Le deuxième critère, quant à lui, exigeait que les outils retenus soient
intéressants pour la rétro-ingénierie; alors que le troisième et le quatrième critère
concernaient respectivement la disponibilité des outils et l’intérêt accordé à ces outils
par l’équipe de l’évaluation de la qualité logicielle chez Bell Canada. En se basant sur
ces critères et en utilisant notre intuition pour tenter de choisir un ensemble d’outils
assez représentatif des 30 identifiés, quatre outils académiques et trois commerciaux ont
été retenus. Une étude de la documentation liée à chacun de ces outils a été effectuée.
Dans les sous-sections ci-dessous, nous décrirons ces outils en exposant un résumé de
cette étude. En plus de l’étude théorique effectuée sur ces outils, nous avons installé les
quatre outils académiques retenus (VGJ, daVinci, Swan et VCG / CGDI)) ainsi qu’une
version de démonstration d’un outil commercial (xSuds). Les deux autres outils
commerciaux retenus (les produits de Tom Sawyer et Discover) étaient trop chers et
n’offraient pas de version de démonstration. Deux démonstrations, la première portant
sur deux outils de xSuds et l’autre sur VCG / CGDI, ont été effectuées devant l’équipe
de Bell Canada durant l’une de nos rencontres régulières. Nous nous sommes limités à
effectuer juste deux démonstrations formelles, à cause des contraintes de temps et de la
disponibilité d’outils commerciaux. Bref, nous présentons les deux démonstrations
effectuées dans les sous-sections se rapportant respectivement à xSuds et à VCG /
CGDI. La préparation de ces démonstrations nous a permis de compléter nos
informations en vue de l’évaluation qualitative qui sera présentée au chapitre 4.
3.3.1 Software understanding system (xSuds)
xSuds [xSuds98] est formé d’un ensemble d’outils qui permettent de comprendre un
logiciel écrit en C ou C++, de le tester et d’analyser son comportement dynamique. Ces
outils ont été développés dans les laboratoires de recherche de Bellcore - Telcordia
Technologies, et ils sont commercialisés chez ce dernier sous le nom de “xSuds”, ainsi
que chez IBM sous le nom de “IBM C & C++ Maintenance & Test Toolsuite”.

23
L’utilisateur de xSuds sera capable de visualiser en couleur, à travers ces différents
outils, le code source d’un logiciel. En bref, xSuds comprend un total de sept outils
exposés ci-dessous. Nous décrivons chacun de ces outils en précisant les tâches qu’il
facilite.
• xAtac: Cet outil améliore le testage (testing) à travers la création d’un ensemble
minimisé de tests cibles, et précise la mesure de la couverture.
• xRegress: Cet outil permet d’effectuer des tests de régression.
• xVue: Cet outil permet à ceux qui effectuent la maintenance de voir où sont
implantées les fonctions, et d’identifier la partie du logiciel qui implante une certaine
caractéristique.
• xSlice: Cet outil localise les erreurs à partir des échecs.
• xProf: Cet outil identifie visuellement les bottlenecks d’un logiciel.
• xFind: Cet outil permet le traçage des dépendances statiques dans un logiciel.
• xDiff: Cet outil affiche de façon efficace les différences qui existent dans deux
versions différentes d’un logiciel.
Suite à cet aperçu rapide des différents outils de xSuds, nous exposerons aux sous-
sections suivantes deux démonstrations effectuées respectivement sur deux de ces outils.
Nous avons donc dû installer une version de démonstration de xSuds (V1.2) sur
Windows NT. Un système de test (Wordcount) est fourni avec cette version. Ce système
est un programme écrit en C et son but est de compter le nombre de lignes, de mots et de
caractères dans un fichier en entrée. Notons que la version de démonstration de xSuds
est faite de telle sorte que seul le programme Wordcount peut être exécuté. Les deux
outils (xAtac et xVue) pour lesquels nous avons effectué une démonstration se
concentrent respectivement sur les deux phases les plus chères du cycle de vie d’un
logiciel, soient test et maintenance, où presque 70% des coûts sont investis.
3.3.1.1 Démonstration de xAtac
Le code source du programme Wordcount est composé de deux fichiers (main.c et wc.c).
La démonstration consiste à effectuer en ordre les étapes suivantes:

24
1. Compiler le programme avec l’utilitaire ATAC. En plus de créer les fichiers
main.obj, wc.obj et un fichier exécutable wordcount.exe, ATAC crée deux fichiers
additionnels: main.atac et wc.atac (à chaque fichier “.c” correspond un fichier
“.atac”). Ces derniers comportent des informations de couverture statique et vont être
utilisés par l’outil xAtac, plus tard durant l’analyse des tests.
2. Ouvrir les fichiers main.atac et wc.atac à partir de l’outil xAtac (figure 3). Chaque
couleur représente un poids donné. xAtac détermine ces poids en effectuant une
analyse détaillée du flux de contrôle du programme. Si, par exemple, un bloc (bout
de code) possède le poids 17, alors n’importe quel cas de test qui couvre ce bloc,
couvre un minimum de 16 autres blocs.
3. Suite aux deux étapes précédentes, l’utilisateur (l’observateur) doit analyser le code
en portant son attention surtout aux blocs avec le plus haut poids. Dans ce cas, les
deux blocs en rouge (avec le plus haut poids) sont exécutés lorsque le programme lit
son entrée à partir d’un fichier. Pour cela, Wordcount doit être exécuté sur un fichier
en entrée (par exemple, input1). L’utilisateur crée alors un test couvrant les deux
blocs mentionnés ci-dessous de même qu’un minimum de 16 autres blocs. En plus
de la sortie ordinaire de cette exécution, il y a création d’un fichier wordcount.trace
qui contient la trace de cette exécution (les informations de la couverture dynamique
effectuée par ce test). Notons que les informations dynamiques additionnelles
Figure 3. xAtac affichant les deux fichiers main.atacet wc.atac.
Figure 4. xAtac affichant main.atac et wc.atac aprèsouverture du fichier wordcount.trace.

25
générées par les tests qui vont suivre, s’ajouteront à ce même fichier
(wordcount.trace).
4. Pour incorporer les informations dynamiques du fichier wordcount.trace à
l’affichage déjà créé par xAtac, ce fichier doit être ouvert dans xAtac. Ce dernier va
alors lire le fichier et faire une mise-à-jour de l’affichage. Un changement de couleur
apparaîtra alors dans la fenêtre de xAtac (figure 4).
5. Pour créer un nouveau test, l’utilisateur doit repérer la prochaine tache rouge (red
spot), analyser le bloc qui lui est rattaché et identifier la situation durant laquelle ce
bloc s’exécute. Les informations de couverture du deuxième test vont être rajoutées
dans le fichier wordcount.trace. Le bouton Update va alors s’allumer, et il suffit de
cliquer sur ce bouton pour effectuer une mise-à-jour des couleurs.
6. Rappelons que le programme comporte deux fichiers (main.c et wc.c). Le bouton
Summary permet d’afficher la couverture des blocs par fichier (figure 5). Un résumé
de la couverture par type et par fonction est aussi possible.
7. L’utilisateur continue à effectuer des tests tant qu’il y a des blocs à couvrir, c’est-à-
dire tant qu’il y a des bouts de code colorées (dont la couleur est différente de blanc).
Suite à cette démonstration, il est important de préciser que xAtac ne construit aucun
test, son rôle est juste de permettre la visualisation de la couverture. Cette visualisation
Figure 5. Un résumé par fichier de la couverture desblocs dans xAtac.

26
est rendue plus facile par le scroll bar à gauche de la fenêtre. En effet, ce dernier affiche
un thumbnail sketch de tout le fichier. Il est très utile pour pouvoir localiser rapidement
les blocs d’une certaine couleur (exemple, en rouge) qui se trouvent dans le fichier. En
cliquant sur n’importe quel spot dans le scroll bar, la région correspondante dans le
fichier sera visualisée dans la fenêtre source.
3.3.1.2 Démonstration de xVue
La démonstration de xVue consiste à effectuer en ordre les étapes suivantes:
1. Compiler le programme avec ATAC, et ouvrir les fichiers main.atac et wc.atac dans
xVue.
2. Exécuter un ensemble de tests (ces tests seront nommés: atac.1, atac.2, atac.3, etc.
par xVue). Ceci va produire le fichier wordcount.trace qui va être utilisé par l’outil
xVue, pour incorporer les informations dynamiques dans l’affichage.
3. Pour vérifier les informations dynamiques rajoutées, il faut cliquer sur le bouton
TestCases. Un résumé de la couverture des blocs par test est alors affiché (figure 6).
4. L’utilisateur peut toujours effectuer d’autres tests. Les nouvelles informations vont
alors se rajouter au fichier wordcount.trace, et le bouton Update s’allumera, offrant
alors la possibilité de faire une mise-à-jour de l’affichage dans xVue.
5. Pour spécifier une certaine caractéristique (par exemple, la caractéristique
Character_counting qui consiste à compter les caractères dans un fichier), il s’agit
Figure 6. Un résumé par test de la couverture desblocs dans xVue.
Figure 7. Spécification d’une caractéristique dansxVue.

27
d’accéder avant tout à l’écran des caractéristiques, en cliquant sur le bouton Features
(figure 7). Le bouton add permet d’ajouter cette caractéristique, et ceci en saisissant
son nom (Feature Name) ainsi qu’une description (Description), et en lui spécifiant
les tests qui l’invoquent (invoking_tests) et les tests qui l’excluent (exluding_tests). Il
est possible de sauvegarder la caractéristique dans un fichier “.features”, pour ne pas
avoir à la spécifier de nouveau lors d’une prochaine session de travail.
6. A partir de ce moment, il est déjà possible de commencer à répondre à la question
suivante: “où est implantée dans les deux fichiers source de Wordcount, la
caractéristique définie (Character_counting)?”
7. Il s’agit maintenant de sélectionner Character_counting de la liste des
caractéristiques définies (ici il n’y en a qu’une), et de cliquer sur heuristics (figure
8). Plusieurs heuristiques sont possibles dont l’union (heuristic A). En cliquant sur le
bouton find_code, le système va colorer (en rouge) le bloc du code qui est exécuté
par le test atac.2 mais non par l’un ou l’autre des deux tests atac.3 et atac.4.
3.3.2 Tom Sawyer Graph Layout Toolkit & Graph Editor Toolkit
Les produits de Tom Sawyer [TomSawyer00a] se composent de deux outils principaux:
1. Graph Layout Toolkit (GLT) qui facilite le layout graphique.
2. Graph Editor Toolkit (GET) qui facilite l’édition graphique.
Figure 8. Passage de la fenêtre des heuristiques à celle de la visualisation du code source.

28
Plusieurs des techniques de visualisation sont rendues possibles par ces outils. Dans la
documentation, on met surtout l’emphase sur la performance optimisée pour les grands
diagrammes (applications industrielles). Une version de démonstration est disponible à
partir du site [TomSawyer00b], c’est sur elle que nous nous sommes basés pour évaluer
ces produits. Dans ce qui suit, nous ne détaillerons que le GLT, puisqu’il est considéré
comme étant l’outil de visualisation dans les produits de Tom Sawyer. Le GET reste un
outil d’édition graphique qui fournit des fonctions d’édition avancées.
Le GLT rend possible la visualisation graphique de relations dans des applications à
grande échelle, facilitant ainsi la compréhension des utilisateurs. Il possède un système
de gestion de graphe capable entre autres de gérer la structure de graphe même si la
taille ou la complexité des données augmente. Il fournit quatre types (ou layout) de
graphes différents (circulaires, hiérarchiques, orthogonaux, et symétriques). Chacun de
ces types possède une librairie pour calculer automatiquement les positions des nœuds et
des arcs en se basant sur des critères spécifiques. Une option de layout incrémental
existe. Cette propriété permet aux utilisateurs de maintenir leur position dans le
diagramme alors qu’un changement de données a lieu et qu’une application de layouts
subséquents est effectuée. Nous faisons appel ici à des aspects cognitifs de l’utilisateur.
Effectivement, en gardant sa position, le risque de confusion est réduit. Un système
automatique de positionnement d’étiquettes, indépendant du système de layout de
graphe, est aussi fourni par le GLT. Une bonne documentation pour le GLT, détaillant
les points mentionnés ci-dessus (le système de gestion de graphe, les librairies de layout
automatique, etc.), existe.
Finalement, des interfaces spécifiques du GLT sont disponibles pour plusieurs langages
de programmation dont C, C++ et Java. Ces interfaces mettent en évidence les
caractéristiques de chacun de ces langages. Le GLT offre aussi beaucoup de flexibilité.
En effet, il peut être utilisé avec n’importe quel système d’affichage (par exemple,
Rational Rose [9]) et peut être lié à n’importe quelle base de données.

29
3.3.3 Discover
Discover est un système d’information commercialisé par Upspring Software. Il
supporte les deux langages de programmation C et C++. Nous avons tiré une description
de ce logiciel à partir de la documentation disponible [Barr96, Discover00, Tilley97].
Discover se compose d’un ensemble d’outils (Develop/set, CM/set, Reengineer/set,
Doc/set, Admin/set) et d’applications pour la compréhension et le développement de
logiciels de grande taille. Les outils sont destinés surtout aux gestionnaires de projet, à
l’architecte du système et aux développeurs. Discover analyse le code source et crée une
base de données appelée Information Model (IM) relatant les caractéristiques d’un
logiciel. Les différentes applications de Discover permettent de consulter et d’interroger
cette base de données.
L’outil Develop de Discover est celui qui nous intéresse le plus puisque c’est lui qui
adresse le plus la compréhension de logiciel. En effet, il permet aux développeurs
d’accélérer leur capacité à modifier le code. Il fournit notamment une palette d’outils
graphiques permettant différents types de visualisation. Bref, l’outil Develop possède
plusieurs fonctionnalités dont les suivantes:
• Naviguer avec une visibilité globale, macroscopique et microscopique.
• Évaluer l’impact d’un changement sur le reste de l’application.
• Établir des liens avec les spécifications et les tests.
• Vérifier la qualité de développement par rapport à des critères prédéfinis.
• Accéder au IM à partir de chaque ligne du code.
3.3.4 Visualizing Graphs with Java (VGJ)
VGJ est un outil de layout graphique et d’édition de graphes, écrit en Java [VGJ98]. Il a
été développé à l’Université d’Auburn par l’équipe de recherche de Larry Barowski. Il
comprend entre autres une nouvelle technique pour des graphes dirigés hiérarchiques. Il
supporte une entrée et une sortie de fichiers en GML (Graph Modeling Language) qui
est considéré comme un langage de spécification de graphes de plus en plus répandu. De
façon plus précise, l’entrée à VGJ peut s’effectuer de deux façons différentes, soit avec

30
une description textuelle (GML), soit à travers un graphe que l’utilisateur crée utilisant
l’éditeur de texte fourni avec VGJ. L’utilisateur sélectionne ensuite un algorithme pour
afficher le graphe de façon organisée et esthétique.
3.3.5 daVinci
daVinci [daVinci00] est un outil de VL pour des graphes orientés, similaire en quelque
sorte à l’outil VCG décrit à la section 3.3.7. Il a été développé à l’Université de Bremen
en Allemagne et est présentement disponible dans la version V2.0.3. daVinci prend
comme entrée un fichier de format TR (Term Representation). Par conséquent, pour
pouvoir évaluer cet outil, nous avons dû développer un programme de transformation
qui vise à produire un fichier TR à partir d’un fichier TA (Tuple Attribute). En effet,
dans l’environnement SPOOL, les systèmes sont représentés dans le format Datrix-TA
qui est le format de sortie du système d’analyse/traduction DatrixTM [Datrix99]. Le
programme de transformation a été implanté en Java (jdk–1.2) et comporte un total de
240 LOC.
daVinci possède plusieurs caractéristiques dont:
• Le layout graphique automatique et incrémental.
• La spécification des attributs (couleurs, formes, etc.) pour chacune des composantes
(nœuds et arcs) dans l’ancienne version et pour un type (ou classe) de composante
dans la nouvelle version.
• Les abstractions interactives (cacher des sous-graphes, cacher des arcs, etc.).
• Les opérations pour avoir des overviews d’un graphe.
• Les sorties en PostScript.
Plusieurs autres propriétés restent encore non supportés par daVinci, tel que l’étiquetage
des arcs, les nested graphs, etc.
3.3.6 Swan
Swan [Swan95] est un système de visualisation de structure de données développé au
département d’informatique de Virginia Tech comme partie du projet NSF Educational

31
Infrastructure. Swan montre de façon graphique les structures de données d’un
programme en exécution. Ce dernier doit être écrit en C ou C++. Il sera alors annoté par
des appels à une librairie (SAIL - Swan Annotation Interface Library) qui contrôle la
séquence de visualisation. Cette annotation permet de fournir des vues (graphes) des
structures de données implantées dans le programme, qui seront alors affichés via un
viewer (SVI – Swan Viewer Interface). Deux termes sont connus pour les utilisateurs de
Swan:
• Annotator (personne qui annote à l’aide de la librairie SAIL)
• Viewer (personne qui exécute le programme annoté en utilisant le SVI)
Avant de pouvoir concevoir des vues d’une structure de données, l’annotator doit
posséder une connaissance claire de cette dernière. Le viewer quant à lui, a la possibilité
de modifier non seulement les attributs graphiques, mais aussi leur structure logique,
bien sûr si ceci est permis par l’annotator. La compréhension d’une structure de données
d’un programme dépend de la façon dont on annote ce programme. Dans la
documentation, nous retrouvons la phrase suivante: “Swan ne présume aucune
responsabilité pour la compréhension.”
Swan a été au départ spécialement conçu pour supporter la visualisation de programmes
implantant différents algorithmes de layout graphique. Par la suite, il a joué deux autres
rôles:
• Moyen de présentation pour des instructions dans des cours de structures de données
et d’algorithme.
• Aide lors du débogage dans des cours de programmation.
Swan permet un layout manuel et fournit plusieurs algorithmes de layout automatique
(circulaires, hiérarchiques, en étoile) et des méthodes spéciales pour les arbres, les listes
linéaires et les tableaux. Le layout automatique permet à l’annotator de se concentrer sur
les structures logiques des vues sans se soucier de leur affichage graphique. Une
caractéristique importante de SWAN est de permettre à la visualisation d’être un
processus de communication à deux sens, entre la vue et le programme.

32
3.3.7 Visualization of Compiler Graphs (VCG) & Call GraphDrawing Interface (CGDI)
L’outil VCG [VCG95a, VCG95b] lit une spécification textuelle d’un graphe (format
GDL – Graph Description Language) et permet de la visualiser utilisant des algorithmes
de layout avancés, et donnant la possibilité d’avoir une sortie de la visualisation en
PostScript. Il a été développé à l’Université des Saarlandes, et il est distribué par ftp
anonyme, sous les termes de la GNU General Public License. VCG ne fournit aucun
éditeur de graphe. Il est juste destiné à visualiser des graphes qui sont automatiquement
produits par des programmes. Un exemple de tels programmes serait le Call Graph
Drawing Interface (CGDI) [CGDI96] développé par Vadim Engelson, à Linköpings
Universitet en Suède. Le CGDI consiste en un ensemble de petits outils qui permettent
de créer le fichier d’entrée à VCG (format GDL) pour ainsi visualiser des graphes
d’appels dynamiques d’un programme écrit en C ou C++. Il utilise gprof pour détecter la
structure d’appel de fonction du programme et deux programmes filtres (g2v et vco)
écrits en C++ pour créer le fichier GDL. La sous-section suivante expose la
démonstration effectuée pour le CGDI, dans le cadre d’une rencontre avec une équipe de
Bell Canada.
3.3.7.1 Démonstration du CGDI
Nous possédons un petit programme cgtest.c écrit en C (figure 9, fenêtre a). Son seul but
est d’appeler des fonctions qui affichent simplement à l’écran un message qui précise
que cette fonction a été appelée. La démonstration consiste à effectuer en ordre les
étapes suivantes (figure 9, fenêtre b):
1. Compiler le programme cgtest.c.
2. Exécuter le programme, ceci va produire le fichier gmon.out qui contient la trace de
l’exécution.
3. Il y a possibilité d’afficher soit les appels de fonction qui ont été exécutés au moins
une fois, soit tous les appels de fonction qui se trouvent dans le code. Ceci est
distingué par l’ajout d’une simple option lors de l’exécution du gprof. Dans notre
démonstration, nous avons choisi le premier cas.

33
4. Exécuter le filtre g2v pour ainsi créer le fichier cgtest.pair (figu
comporte des informations d’appel de fonction (index, nom de la
5. Choisir les fonctions qu’on ne veut pas voir dans le graphe et é
un fichier .exc. Ce dernier peut être vide. En effet, le fichier cgtes
6. Exécuter le filtre vco pour créer le fichier cgtest.vcg qui servir
VCG (figure 9, fenêtre d).
3.4 Conclusion
Dans les sections précédentes, nous avons commencé par présent
d’outils de VL. A partir de cette liste, un ensemble de sept outil
l’évaluation qualitative qui sera présentée au chapitre suivant. Une de
de ces outils, ainsi que des démonstrations de xSuds et de VC
exposées. Suite à cette étude, nous avons pu tirer quelques conclu
comparant les deux catégories (outils académiques et commerciaux) q
• Les outils commerciaux supportent plus la visualisation de
industrielle que les outils académiques.
• L’interface des outils commerciaux est souvent plus raffinée q
académiques.
Figure 9. Une séance de démonstration du CGDI.
b
c
d
a
re 9, fenêtre c) qui
fonction, etc.).
crire leur nom dans
t.exc l’est.
a d’entrée à l’outil
er une longue liste
s a été retenu pour
scription de chacun
G / CGDI ont été
sions intéressantes
ui existent:
logiciels de taille
ue celle des outils

34
• Il est difficile d’obtenir une licence d’évaluation pour la plupart des outils
commerciaux. En effet, cette licence est souvent chère et les commerçants sont peu
coopératifs. Il existe parfois des versions d’évaluation que nous pouvons installer,
mais elles se restreignent à une simple démonstration du produit avec des fichiers
d’entrée bien définis (par exemple, le programme Wordcount de xSuds). Par contre,
les outils académiques sont plus faciles à obtenir.
Un aspect important sur lequel nous nous sommes attardés lors de l’étude des différents
outils de VL est le format d’entrée à l’outil. En effet, des outils de VL différents
requièrent des entrées différentes. Cet aspect est connu sous le nom de “style de
spécification de la visualisation” dans la catégorie Method de la taxonomie de Price et
al. [Price93] que nous allons décrire au chapitre suivant. Nous y exposerons aussi plus
en détail le format requis à chacun des sept outils de VL retenus.
Bref, un des buts principaux de ce chapitre était de décrire les différents outils de VL
retenus, en vue d’effectuer l’évaluation qualitative au chapitre suivant. En effet, cette
évaluation se base sur l’étude de la documentation ainsi que les manipulations que nous
avons effectuées sur quelques uns de ces outils.

Chapitre 4. Évaluation qualitative d’outils de VL
4.1 Introduction
Le présent chapitre est la suite logique du chapitre précédent. En effet, après avoir
identifié et décrit un ensemble de sept outils de VL, il semble évident de vouloir les
évaluer pour ainsi illustrer leurs caractéristiques. Nous utilisons une taxonomie
existante, celle de Price et al. [Price93], pour le travail d’évaluation. Cette taxonomie
s’avère la plus complète parmi l’ensemble des taxonomies que nous avons étudiées
(section 2.5). En effet, plusieurs auteurs ont suggéré des taxonomies pour les outils de
VL, mais ces taxonomies regroupent seulement une poignée de caractéristiques pour
décrire un domaine de travail grand et diversifié. Par contre, la taxonomie de Price et al.
couvre un grand nombre des aspects concrets qu’un outil de VL peut posséder. Notons
que cette taxonomie a été créée en 1993, et elle n’a été appliquée que pour évaluer des
outils développés pour la plupart au cours des années 80 et au début des années 90.
Malgré cela, les critères de cette taxonomie ne sont pas périmés et restent toujours
valables. En effet, notre travail démontre qu’ils continuent de s’appliquer aux outils de
VL de nos jours.
Deux sections majeures constituent ce chapitre. La première section (4.2) consiste à
décrire la taxonomie de Price et al. L’annexe A (Description de la taxonomie de Price et
al.) est associée à cette section. Quant à la deuxième section (4.3), elle présente
l’évaluation des sept outils de VL retenus et décrits au chapitre précédant. Elle met
l’emphase sur les points les plus saillants de cette évaluation qui est décrite de façon
détaillée dans les six tableaux de l’annexe B (Évaluation de sept outils de VL).

36
4.2 Description de la taxonomie de Price et al.
Comme il a déjà été précisé dans le chapitre 2 de ce mémoire, la taxonomie de Price et
al. [Price93] suggère une hiérarchie de six catégories de haut niveau. Chacune de ces
catégories est décomposée en un ensemble de sous-catégories à considérer pour
l’évaluation d’un outil de VL. Les sous-catégories se présentent sous forme de questions
et forment les différentes branches de la hiérarchie. L’annexe A expose la taxonomie de
Price et al. tout en indiquant pour chaque catégorie et sous-catégorie la question qui y
est associée. Une description brève de ces catégories et sous-catégories est donnée dans
les sous-sections ci-dessous.
4.2.1 Catégorie Scope
La catégorie Scope décrit l’intervalle de logiciels qui peuvent être visualisés par un outil
de VL donné. Elle comporte deux branches principales (Generality et Scalability):
• La première branche consiste à évaluer l’outil de VL par rapport au niveau de
généralité des logiciels dont il est capable de créer la visualisation. Un outil de VL
peut générer des visualisations de logiciels arbitraires à l’intérieur d’une classe
particulière (1er cas), comme il peut juste traiter un ensemble fixe d’exemples (2ième
cas). Quelques restrictions sont envisagées dans le premier cas. Ces restrictions
forment trois sous-niveaux de la branche Generality (Hardware, Operating system et
Language). Un quatrième sous-niveau (Applications) de cette branche s’applique à
chacun des deux cas décrits ci-dessus. Ils existent encore deux autres critères
(Concurrency et Speciality) classés plus bas dans la hiérarchie de cette branche.
• La deuxième branche consiste à préciser jusqu’à quel degré l’outil de VL permet de
visualiser des logiciels de grande taille. Elle comporte deux sous-niveaux (Program
et Data Sets).
4.2.2 Catégorie Content
La catégorie Content, quant à elle, décrit les aspects du logiciel que l’outil de VL permet
de visualiser. Elle est formée de quatre branches (Program, Algorithm, Fidelity and
completeness et Data gathering time):

37
• Les deux premières branches (Program et Algorithm) consistent à préciser jusqu’à
quel degré l’outil de VL permet respectivement de visualiser l’implantation du
logiciel et de visualiser l’algorithme de haut niveau qui se trouve en arrière du
logiciel. Chacune de ces deux branches est formée de deux sous-niveaux (Code (ou
Instructions) et Data) avec pour chacun des sous-niveaux un critère classé plus bas
dans la hiérarchie (respectivement, Control flow et Data flow).
• La branche Fidelity and completeness traite les métaphores visuelles. Son rôle est
d’évaluer jusqu’à quel degré ces dernières présentent le comportement vrai et
complet de la machine virtuelle sous-jacente. Un seul sous-niveau (Invasiveness) est
associé à cette branche.
• La dernière branche Data gathering time permet de préciser le moment durant lequel
les données de la visualisation sont rassemblées. Deux sous-niveaux lui sont liés
(Temporal control mapping et Visualization generation time).
4.2.3 Catégorie Form
L’élément le plus important du point de vue de l’utilisateur est la sortie (output) de la
visualisation qui est décrite dans la catégorie Form. Cette catégorie se concentre sur la
spécification des paramètres et des limitations qui régissent la sortie. Elle comporte cinq
branches (Medium, Presentation style, Granularity, Multiple views et Program
synchronization):
• La branche Medium permet de spécifier le moyen cible primaire pour la
visualisation. De nos jours, ce critère est presque évident. En effet, quasiment tous
les outils de VL utilisent un moniteur en couleur pour afficher la visualisation
produite.
• La branche Presentation style permet de préciser l’apparence générale de la
visualisation. Elle est formée de trois sous-niveaux (Graphical vocabulary,
Animation et Sound). Le premier sous-niveau traite deux critères (Colour et
Dimensions).
• La branche Granularity évalue jusqu’à quel degré l’outil de VL présente des détails
de coarse-granularity. Elle ne comporte qu’un seul sous-niveau (Elision).

38
• Les deux dernières branches (Multiple views et Program synchronization) ne
comportent aucun sous-niveau. D’une part, Multiple views permet de caractériser
l’outil de VL par rapport au nombre de vues synchronisées qu’il peut fournir des
différentes parties d’un même logiciel visualisé. D’autre part, Program
synchronization précise si l’outil de VL permet de générer simultanément des
visualisations synchronisées de plusieurs logiciels.
4.2.4 Catégorie Method
La catégorie Method caractérise les éléments importants de la spécification de la
visualisation. Elle comporte deux branches (Visualisation specification style et
Connection technique):
• La branche Visualisation specification style permet de préciser le style de
spécification de la visualisation utilisé et comporte deux sous-niveaux (Intelligence
et Tailorability). Le premier sous-niveau (Intelligence) ne s’applique que lorsque la
spécification de la visualisation est faite de façon automatique et consiste à évaluer
jusqu’à quel point l’outil de VL est avancé du point de vue Intelligence Artificielle
(IA). Le deuxième sous-niveau (Tailorability) traite un critère en particulier
(Customization language).
• La branche Connection technique comme son nom l’indique, permet de spécifier la
technique de connexion utilisée pour lier la visualisation au logiciel visualisé. Elle
est formée de deux sous-niveaux (Code ignorance allowance et System-code
coupling).
4.2.5 Catégorie Interaction
La catégorie Interaction traite des techniques utilisées par l’observateur (utilisateur de
l’outil de VL) pour interagir et contrôler l’outil de VL. Elle consiste en trois branches
(Style, Navigation et Scripting facilities):
• La branche Style consiste à spécifier la méthode que l’utilisateur emploie pour
donner des instructions à l’outil de VL.
• La branche Navigation précise jusqu’à quel degré l’outil de VL supporte la
navigation à travers une visualisation. Elle comporte deux sous-niveaux (Elision

39
control et Temporal control). Deux critères caractérisent le deuxième sous-niveau
(Direction et Speed).
• La branche Scripting facilities précise si l’outil de VL fournit des mécanismes pour
gérer l’enregistrement et le play-back des interactions avec des visualisations
particulières.
4.2.6 Catégorie Effectiveness
L’efficacité de l’outil de VL est déterminée par la catégorie Effectiveness. Des
évaluations empiriques sont requises dans cette catégorie qui comporte quatre branches
(Purpose, Appropriateness and clarity, Empirical evaluation et Production use) traitant
respectivement le but de l’outil de VL, la clarté de la visualisation, l’existence d’une
évaluation empirique pour l’outil de VL et son utilisation dans des milieux de production
fiables.
4.3 Évaluation de sept outils de VL
L’annexe B présente six tableaux. Chacun de ces tableaux correspond à une catégorie
bien particulière de l’ensemble des six catégories décrites dans la section précédente.
Nous retrouvons dans la première ligne de chaque tableau les propriétés (les critères)
associées aux différentes branches et sous-niveaux de la catégorie en question. Une
évaluation de chacune de ces propriétés est spécifiée pour les sept logiciels retenus.
Quelque fois, nous avons omis d’évaluer certaines des propriétés soit parce qu’elles sont
trop pointues et de bas niveau, soit parce qu’elles sont trop générales et de haut niveau:
• Dans le premier cas, ces propriétés étaient évaluées de façon large par la propriété
les englobant du niveau supérieur de la hiérarchie. Des exemples de telles propriétés
seraient Program et Data sets de la branche Scalability de la catégorie Scope. En
effet, nous nous sommes contentés d’évaluer la propriété Scalability en répondant à
la question suivante: “Jusqu’à quel degré l’outil de VL permet de visualiser des
logiciels de grande taille?” sans pour autant spécifier le plus grand programme qui
peut être visualisé ni le plus grand ensemble de données qui peut être manipulé.
• Pour le deuxième cas, une seule propriété a été identifiée: Presentation style de la
catégorie Form. Cette propriété est d’ailleurs présentée comme étant trop générale à

40
évaluer dans [Price93]. Elle englobe plusieurs autres propriétés plus spécifiques qui
la caractérisent et qui peuvent être évaluées.
Suite à cette évaluation présentée sous forme de tableaux, plusieurs éléments ont été
observés et retenus. Ces éléments regroupent les points essentiels de notre évaluation.
Les sous-sections qui suivent, présentent ces points pour chacune des catégories.
4.3.1 Catégorie Scope
Nous remarquons que tous les outils de VL étudiés peuvent manipuler un intervalle
généralisé de logiciels à visualiser. Pour rendre cette propriété plus compréhensible, un
contre-exemple serait SOS [Baecker81], un système déjà mentionné dans la section 2.4.
Ce système peut juste traiter un ensemble fixe d’exemples puisque sa présentation se
limite à une cassette-vidéo. Pour ce qui est du langage de programmation du logiciel à
visualiser, une évidence est la suivante: les outils qui prennent en entrée un format
particulier de fichier (par exemple, GML ou TR), acceptent que le logiciel à visualiser
soit écrit dans n’importe quel langage de programmation; il n’existe aucune restriction à
ce niveau à moins d’avoir un programme de transformation qui est associé à l’outil de
VL. Les outils correspondant sont VGJ et daVinci. L’outil VCG peut être considéré
comme ces deux derniers, mais l’utilisation du CGDI limite l’entrée à des fichiers C ou
C++. Par conséquent, si nous considérons les deux programmes de transformation que
nous avons créés respectivement pour VGJ et daVinci, ces deux outils n’accepteront en
entrée que des fichiers de format TA. A part les exigences liées au langage de
programmation des logiciels à visualiser, aucune restriction ne s’applique au domaine
d’application. Cependant, il existe un certain genre de logiciels qui est particulièrement
bon lors de la visualisation, par opposition à simplement être capable d’être visualisé. En
voici des exemples: les graphes dirigés pour daVinci, les graphes en général pour Swan
et les programmes avec beaucoup d’appels de fonctions pour VCG (en tenant compte du
CGDI).
Nous venons d’exposer les éléments essentiels tirés de l’évaluation des sept outils par
rapport à la première branche (Generality) de la catégorie Scope. Pour ce qui est de la

41
deuxième branche (Scalability) de cette catégorie, nous retenons la remarque suivante:
les outils commerciaux évalués n’exposent théoriquement aucun problème de
scalability. Ils peuvent visualiser des logiciels de grande taille. Par contre, pour la
plupart des outils de recherche (tous sauf VCG), le problème de scalability existe.
4.3.2 Catégorie Content
La première branche (Program) de la catégorie Content correspond à la visualisation du
code source d’un logiciel, donc à une visualisation de bas niveau. Par contre, la
deuxième branche (Algorithm) correspond au niveau d’abstraction lors de la
visualisation. Nous remarquons que plus un outil de VL permet de visualiser des
logiciels avec un bas niveau d’abstraction, plus le niveau de fidélité et de complétude
(troisième branche) est élevé. En effet, l’outil qui possède de façon évidente cette
propriété est xSuds. Ce dernier fournit une visualisation colorée du code source d’un
logiciel. Swan est un cas particulier pour la propriété Program. L’évaluation de cette
dernière dépend de l’annotation du logiciel à visualiser. VCG / CGDI quant à lui, ne
permet pas de visualiser le code source en tant que tel; cependant, la visualisation
supporte les appels de fonction et ainsi suggère un niveau d’abstraction relativement bas.
Le rassemblement des données pour créer la visualisation a lieu pour la plupart des
outils (xSuds, VGJ, daVinci, Swan et VCG) lors de la compilation. Trois de ces outils
(xSuds, Swan et VCG) recueillent aussi des informations lors de l’exécution du logiciel.
Ceci est évident pour xSuds et VCG (voir sections 3.3.1.1 et 3.3.1.2 pour xSuds et
3.3.7.1 pour VCG), alors que pour Swan, il en est moins. En effet, au fur et à mesure que
la visualisation avance, l’observateur a la possibilité d’interagir avec le SVI (Swan
Viewer Interface) à travers une ligne de commande, rassemblant ainsi de nouvelles
données pour la visualisation. Un sous-niveau à la propriété que nous venons d’évaluer
est le moment de génération de la visualisation. Dans le cas de quatre outils (xSuds,
VGJ, daVinci et VCG), la visualisation est produite en batch-job (post-mortem) à partir
des données enregistrées lors de la compilation ou de l’exécution. Par contre, la
visualisation dans Swan est produite live. En effet, après avoir compilé la version
annotée du programme, la visualisation est générée durant l’exécution dans le SVI.

42
4.3.3 Catégorie Form
Tel qu’il a été précisé dans la section 4.2.3, le moyen de visualisation pour tous les outils
étudiés est le moniteur en couleur. Une sortie en format PostScript (imprimable sur
papier) par exemple est parfois possible. Cependant, le moyen primaire d’affichage de la
visualisation reste le moniteur couleur. Tous les outils évalués offrent des vues
graphiques (nœuds, arcs, layouts particuliers, etc.), sauf xSuds qui est axé sur le code
source. La documentation de Discover n’offre malheureusement pas des détails qui nous
permettent d’évaluer cette propriété, cependant il est fort probable que cet outil offre des
vues de code source puisqu’il s’adresse entre autres aux développeurs. Tous les outils
répondent à la propriété couleur. Même pour daVinci, qui initialement n’offrait pas la
possibilité de visualiser en couleur, cette option fut rajoutée par le biais du Visualization
Research Group de l’Université de Durham en Grande Bretagne [VRG96]. Ceci suggère
fortement l’importance qu’offre la présence de couleur. La plupart des outils ne
supportent pas le 3D, ni l’animation, ni le son. Les seules exceptions que nous retenons
sont les suivantes: VGJ permet de visualiser des graphes avec des possibilités de 3D très
minimes, et Swan offre de l’animation de bas niveau lorsque l’observateur change de
layout. La coarse-granularity (par opposition à la granularité fine) est souvent possible
grâce aux Overview Windows qu’offrent la plupart des outils, mais non pas tous. Le nom
de cette option peut varier selon l’outil; par exemple, dans VCG nous retrouvons
l’option Panner qui n’est autre qu’une fenêtre d’overview. Dans xSuds, le scroll bar déjà
décrit dans la section 3.3.1.1, est considéré comme étant un support de visualisation
coarse-grain. Par contre, le viewing offset et le viewing angles de VGJ offrent
respectivement la possibilité de choisir la partie du graphe que nous voulons visualiser,
et l’angle (x, y, z) sous lequel nous voulons visualiser cette partie, mais n’offrent pas une
vue globale du logiciel. Elles ne sont donc pas considérées comme des fenêtres
d’overview. La possibilité de cacher temporairement l’information qui n’a pas un intérêt
immédiat est une caractéristique importante, mais malheureusement elle n’est pas
toujours supportée. Les trois seuls outils qui la supportent sont les produits de Tom
Sawyer (à travers les deux commandes hide children / parents et folding parents /
children), daVinci (à travers la commande hide edges / sub-graphs) et VCG (à travers la

43
commande folding sub-graph / region). Les deux propriétés Vues multiples et
Synchronisation ne sont supportées que par xSuds à l’aide de l’outil xDiff.
4.3.4 Catégorie Method
Le style de spécification de la visualisation peut être rendu automatique grâce à
l’écriture de programme prenant en entrée un certain format et donnant en sortie un
fichier de format requis par l’outil. Par exemple, xSuds prend une entrée en format .atac
qui est générée automatiquement par le compilateur ATAC inclus dans l’outil. Pour ce
qui est de daVinci, il accepte comme entrée un fichier de format bien particulier (TR)
pour lequel nous avons dû développer le programme de transformation correspondant
(passage de TA à TR). Il en est de même pour VGJ pour lequel le format GML est
requis. Cependant, VGJ comporte un éditeur de graphe incorporé qui permet de générer
un fichier GML. Swan, quant à lui, demande une connaissance préalable du code et
fournit une librairie SAIL que l’annotator utilise pour annoter le code source. Notons
que la technique d’annotation est dangereuse pour le code source du point de vue génie
logiciel. VCG requiert un format GDL pour lequel nous avons réussi à trouver un
ensemble d’outils connu sous le nom de CGDI qui permettent de passer d’un fichier C
ou C++ à un fichier de format GDL pour visualiser les graphes d’appel dynamique du
programme. Les sept outils évalués n’offrent aucune intelligence, par contre tous les
outils offrent la possibilité de particulariser la visualisation. Dans la plupart des cas, la
particularisation s’effectue de façon interactive entre l’utilisateur et l’outil, sauf dans le
cas de Swan, où elle est précisée sous forme procédurale (lors de l’annotation du code).
En effet, la possibilité de choisir dans xSuds le type de visualisation (par bloc, par
fonction, par décision, etc.), ou bien dans daVinci l’orientation du layout du graphe (top-
down, bottom-up, left to right ou right to left), peut être considérée comme un genre de
particularisation de la visualisation. Dans Swan, la particularisation de la visualisation
doit être permise par l’annotator.
4.3.5 Catégorie Interaction
La plupart des outils fournissent le même style (boutons, menus, etc.) pour recevoir des
instructions de l’utilisateur. Swan offre une ligne de commande en plus du style
commun. Pour ce qui est de la navigation, tous les outils, sauf VCG, permettent la

44
navigation. daVinci offre une navigation structurelle (nearest parent / child et left / right
sibling) en plus de la navigation ordinaire (previous, next et left / right neighbour level).
Pour ce qui est des trois propriétés: contrôle du temps, direction et vitesse, ils ne sont pas
applicables pour la plupart des outils, sauf pour Swan qui offre une visualisation lors de
l’exécution du programme. Cet outil ne permet pas de revenir aux étapes précédentes
lors de l’exécution du programme, et l’observateur ne peut pas contrôler la vitesse
d’exécution; cependant, il est capable de prendre son temps quant aux interactions avec
le système.
4.3.6 Catégorie Effectiveness
Le but primaire des outils étudiés reste la compréhension. D’ailleurs c’est le critère
principal sur lequel nous nous sommes basés pour identifier les outils de VL (section
3.2). Cependant, plusieurs autres buts existent, tel que le testing, le débogage, la
maintenance, etc. La clarté de la visualisation est une propriété très subjective. Il faut
évaluer si les métaphores visuelles utilisées inspirent rapidement la compréhension. Par
contre, les deux propriétés: évaluation empirique et utilisation dans la production sont
plus facilement évaluées. Aucune évaluation empirique et sérieuse n’a été effectuée pour
les sept outils étudiés. Trois de ces outils sont commerciaux (xSuds, les produits de Tom
Sawyers et Discover) et sont, par conséquent, utilisés dans des milieux de production.
Les quatre outils restants font partie du monde de recherche et ne sont pas utilisés de
façon répandue dans des milieux de production.
4.4 Conclusion
Suite à notre évaluation des sept outils de VL, nous remarquons que plusieurs des
caractéristiques de la taxonomie de Price et al. requièrent une évaluation subjective des
outils de VL dépendemment de notre compréhension de ces outils, ou encore de notre
opinion personnelle de leur performance. C’est le point faible de cette taxonomie et des
méthodes plus rigoureuses sont requises pour l’évaluation. En outre, la taxonomie de
Price et al. ne tient pas compte des éléments relatifs aux domaines de la science
cognitive et de la psychologie de logiciel. Par contre, ces éléments ont été traités de
façon exclusive, dans la taxonomie de Storey et al. Nous sommes d’accord sur le fait

45
que les deux domaines mentionnés ci-haut ont été sous-utilisés jusqu’à présent, par les
chercheurs lors de la construction d’outil de VL, et qu’en tenir compte lors de
l’évaluation semble prématuré. Cependant, une taxonomie bien conçue, qui regroupe à
la fois des éléments de la science cognitive ainsi que des aspects concrets d’outil de VL
obligera les développeurs de tels outils de commencer à tenir compte non seulement des
éléments techniques lors de la construction d’un outil de VL, mais aussi des éléments
cognitifs qui commencent à devenir de plus en plus importants de nos jours.
L’étude que nous venons de présenter nous a permis d’évaluer et de comprendre les
outils en question dans un cadre formel. Cependant, cette étude se limite à évaluer un
ensemble formé de sept outils. Bien qu’il soit représentatif, cet ensemble reste un
échantillon très minime étant donné le nombre élevé d’outils de VL existants. De plus,
tel qu’il a été évoqué ci-dessus, la plupart des fois l’évaluation des propriétés de la
taxonomie de Price et al. se faisait de façon subjective. Pour remédier à cela, une
évaluation quantitative des outils de VL, effectuée à partir d’un questionnaire s’est
avérée nécessaire. Cette évaluation permet de recueillir des points de vues d’un grand
nombre d’utilisateurs travaillant sur différents outils de VL. Elle permet aussi
d’identifier les besoins réels des utilisateurs surtout dans le domaine industriel, mais
aussi dans le domaine académique, pour but de comparaison. Les chapitres qui suivent
auront donc pour objectif de décrire l’enquête effectuée sur les outils de VL ainsi que de
présenter les résultats de l’analyse qui lui est associée.

Chapitre 5. Enquête sur les outils de VL
5.1 Introduction
Plusieurs évaluations qualitatives d’outils de VL ont déjà été effectuées. En effet, tel
qu’il a été précisé auparavant dans ce mémoire (section 2.5), un certain nombre de
taxonomies liées aux outils de VL [Myers90, Price93, Stasko92, Roman93, Storey99]
ont été suggérées. Certaines de ces taxonomies ont été employées pour caractériser et
évaluer officieusement des outils de VL. En outre, un certain nombre d’expériences ont
été effectuées sur des utilisateurs de tels outils. Storey et al. [Storey97], par exemple, ont
observés des utilisateurs résolvant des tâches de compréhension de programme, et par la
suite, ils ont essayé de décrire comment trois outils (Rigi [Müller88], SHriMP
[Storey95] et SNiFF+ [SNiFF+00]) ont supporté ou non un certain nombre de stratégies
de compréhension [Mayrhauser95]. Cependant, à nos connaissances, aucune enquête
formelle sur les outils de VL n’a été effectuée jusqu’à présent.
Pour mettre le projet SPOOL dans une plus large perspective, et pour fournir à Bell
Canada des informations à partir d’une étude quantitative sur les outils de VL, nous
avons pensé entreprendre une enquête sur ces outils. Nous avons donc décidé
d’interroger les utilisateurs de tels outils au sujet de leur perception sur ce qui a
fonctionné et ce qui n’a pas fonctionné en appliquant un outil de VL spécifique. En
profitant des taxonomies existantes et en utilisant des aspects techniques ainsi que des
aspects cognitifs d’outils de VL, nous avons créé un catalogue de propriétés de ces
outils. Puis, nous avons essayé d’arranger ces propriétés en un certain nombre de
questions, avec l’intérêt principal, tel qu’indiqué par Bell Canada, d’identifier les

47
propriétés désirables (ou non) des outils de VL, et d’évaluer leurs capacités pour réduire
l’effort de la compréhension de logiciel et de l’évaluation de conception.
Ce chapitre décrit de façon détaillée la conception d’un questionnaire sur les outils de
VL. Tout d’abord, une description générale du questionnaire est donnée (section 5.2).
Ensuite, nous détaillerons chacune des deux parties le constituant (sections 5.2.1 et
5.2.2), en discutant chacune des questions. Notons qu’une version du questionnaire est
donnée à l’annexe C.
5.2 Description du questionnaire sur les outils de VL
Une partie intégrale de notre enquête est la collecte de données via un questionnaire qui
se divise en deux grandes parties et qui est disponible en deux versions
(anglais/français). La première partie doit être remplie par tout participant, alors que la
seconde partie est facultative.
Un certain nombre d’éléments relatifs à l’élaboration d’une enquête [Cooper95] ont été
considérés lors de la conception du questionnaire. La plupart des questions dans les deux
parties du questionnaire sont fermées (closed questions) donnant un certain nombre de
réponses prédéfinies à partir desquelles les participants peuvent choisir. Cependant, pour
permettre aux participants d’exprimer leurs propres réponses, des champs vides sont
fournis pour quelques-unes des questions. De plus, à la fin de la première partie, deux
questions ouvertes (open-ended questions) sont présentées. Ces questions constituent la
dernière section de la partie I, où les participants sont invités à donner leurs avis quant
aux bénéfices et améliorations de l’outil de VL en main.
En outre, nous avons profité de l’expérience reportée dans [Desmarais94, Keller95,
Lethbridge00, Myers92]. Un brouillon du questionnaire a été distribué à l’intérieur de
notre groupe, et il a été envoyé à quelques-uns de nos collègues dans CSER, le
consortium auquel SPOOL participe. Par la suite, un ensemble de commentaires
intéressants ont été considérés et incorporés dans la version finale du questionnaire
(annexe C).

48
Les sous-sections qui suivent discutent de plus près chacune des deux parties du
questionnaire, tout en détaillant leurs différentes sections.
5.2.1 Description de la partie I
La partie I s’adresse à tout utilisateur d’outils de VL. Au départ, des renseignements sur
le contexte de travail du participant ainsi que sur les systèmes logiciels visualisés sont
demandés. Plusieurs de ces renseignements constituent l’ensemble des facteurs pouvant
influencer – ou non – les réponses aux questions des sections suivantes. Ensuite, des
questions sur les aspects fonctionnels et pratiques des outils de VL, souhaités – ou non –
sont posées. Les deux dernières sections de la partie I du questionnaire portent sur
l’“outil de VL en main”, c’est-à-dire, sur l’outil de VL avec lequel le participant est le
plus familier. Ainsi, une évaluation cognitive de l’outil de VL en main est effectuée, et
les participants seront invités à préciser les bénéfices retirés suite à l’utilisation de cet
outil, ainsi que les améliorations qui devraient lui être apportées.
Cette première partie comprend 21 questions (réparties en six sections). Les questions
liées à chacune des six sections seront détaillées dans les sous-sections suivantes.
5.2.1.1 Renseignements concernant le participant
Comme première question, il est important de connaître le milieu de travail du
participant. Il peut s’agir soit d’une compagnie, soit d’une université (milieu de
recherche). Ensuite, des informations plus personnelles sont demandées. Ces dernières
se limitent à la fonction professionnelle du participant, et à son adresse électronique qui
est nécessaire dans le cas où le participant souhaiterait avoir les résultats de notre
enquête. Une troisième question consiste à préciser le nombre de personnes affectées au
développement et à la maintenance dans l’équipe de travail du participant. Par cette
question, nous ne voulons pas connaître le nombre exact de personnes, mais plutôt la
taille (grande, moyenne, petite) de l’équipe de travail dont le participant fait partie. Nous
avons jugé qu’une petite équipe comporte moins de cinq personnes, alors qu’une grande
en comporte plus que vingt. Deux questions consistent respectivement à nommer les
trois outils de VL – ainsi que le distributeur correspondant (pour le seul but

49
d’identification de l’outil) – les plus utilisés dans l’équipe de travail et à déterminer le
niveau de connaissance de l’“outil de VL en main” après, bien sûr, l’avoir précisé
clairement. Cette expression (“outil de VL en main”) est bien définie dès le départ dans
le questionnaire. En effet, une note explicative précise qu’il s’agit de l’outil de VL que le
participant connaît le mieux et pour lequel il va remplir les sections V et VI du
questionnaire. Ces deux sections correspondent respectivement aux deux sous-sections
5.2.1.5 et 5.2.1.6 dans le présent mémoire. Le niveau de connaissance des systèmes
logiciels visualisés (familiarité avec le code source), de leur domaine d’application, ainsi
que du langage d’implantation relatif sont aussi demandés. Enfin, deux questions plus
générales sont posées. La première permet de savoir comment le participant a accédé au
questionnaire – où il en a entendu parler –, quant à la deuxième, elle lui donne la
possibilité de recevoir les résultats de notre étude.
5.2.1.2 Renseignements sur les systèmes logiciels visualisés
Dans cette section, un total de cinq questions liées aux systèmes logiciels visualisés
(SLV) sont présentées au participant. Par une première question, nous voulons connaître
le (les) style(s) de programmation des SLV. Nous différencions principalement entre
trois styles: orienté objet, procédural et déclaratif. Une deuxième question demande de
préciser le (les) domaine(s) d’application des SLV, tout en offrant un vaste choix de
réponses inspiré de [Jagannath93]. Ensuite, l’ordre de grandeur des SLV en KLOC est
demandé. Nous présentons au participant quatre intervalles (0-100, 100-500, 500-1000,
1000-++) parmi lesquels il peut choisir. Les SLV dont la taille appartient au premier
intervalle sont considérés comme étant des petits systèmes; ceux dont la taille appartient
au deuxième ou troisième intervalle sont considérés de taille moyenne; et finalement,
ceux dont la taille appartient au quatrième intervalle sont considérés des grands
systèmes. La quatrième question demande au participant d’estimer deux niveaux de
complexité: celui des SLV ainsi que celui de la tâche effectuée sur les SLV. Enfin,
comme dernière question, nous voulons connaître la disponibilité de la documentation
(au-delà du code source) pour les SLV.

50
5.2.1.3 Aspects fonctionnels des outils de VL
Suite aux deux sections que nous venons de décrire ci-haut, une section formée d’une
seule question comportant un ensemble de 34 fonctionnalités et capacités liées à des
outils de VL est fournie. Ces aspects fonctionnels sont présentés au participant, en lui
demandant de préciser jusqu’à quel point chacun d’eux lui est/serait utile pour effectuer
une certaine tâche sur un système logiciel. Le participant doit choisir entre quatre
options de réponses: “absolument essentiel”, “utile, mais non essentiel”, “pas du tout
utile”, “ne sais pas/non applicable”. Le tableau 2 présente ces 34 aspects fonctionnels
qui pour la plupart sont inspirés des travaux suivants [Burd96, Cain99, Lethbridge97,
Michail98, Mulholland95, Price93, Storey97, Storey99] ainsi que de notre propre
expérience avec les outils de VL (chapitres 3 et 4). Notons que certains des aspects
pratiques (section 5.2.1.4), de même que la plupart des aspects cognitifs (section
5.2.1.5), sont aussi inspirés de quelques-uns de ces travaux.
Deux notes explicatives sont rajoutées pour les deux aspects F21 et F26 qui ne semblent
pas assez compréhensibles. En effet, par navigation arbitraire (F21) nous entendons le
fait de pouvoir naviguer à des emplacements non nécessairement accessibles en suivant
des liens déjà définis. Ce type de navigation a été utilisé et défini pour une première fois
dans [Storey99] et peut être facilité par des outils de recherche (F14). Le program
slicing (F26) est une méthode pour décomposer un programme en des composantes où
chaque composante décrit certaines fonctionnalités du système; un “program slice”
contient seulement le code qui est pertinent à cette fonctionnalité [Weiser84]. Nous
estimons que le reste des aspects est assez clair et qu’un participant travaillant avec un
outil de VL devrait pouvoir les comprendre. Toutefois, nous avons donné la possibilité
de répondre “ne sais pas/non applicable” à un aspect non compris ou bien non applicable
aux tâches effectuées par le participant.

51
# Aspects fonctionnels
F1 Visualisation de code source (vues textuelles)
F2 Browsing de code source
F3 Accès direct (sans passer par des objets de haut niveau) au code source
F4Visualisation d’une liste de symboles (ex. les fichiers du logiciel visualisé, les fonctions définies et les types de données (variables,constantes, etc.))
F5 Accès facile, à partir de la liste de symboles, au code source correspondant
F6 Visualisation de graphes
F7 Browsing synchronisé de vues de même type ou de type différent (ex. browsing graphique et textuel synchronisé)
F8Passage d’une vue vers une autre de même type ou de type différent (ex. passage du code source à une fenêtre graphique ou vice-versa) (cross-referencing)
F9Possibilité d’avoir plusieurs vues de même type ou de type différent liées visuellement en mettant en évidence (highlighting) desinstances du même objet dans toutes les vues (ex. possibilité de lier les nœuds et les arcs dans des représentations graphiques au codesource correspondant)
F10 Capacités de layout automatique
F11 Capacités de scaling automatique
F12 Mécanismes d’abstraction (ex. affichage des nœuds de sous-système et les arcs composites dans un graphe)
F13 Fenêtres d’overview (ex. montrer la structure hiérarchique du logiciel visualisé)
F14 Outils de recherche d’éléments graphiques et/ou textuels
F15 Capacités de filtrage
F16 Capacités de zoom-in et zoom-out
F17 Visualisation dynamique (visualisation de l’exécution, animation)
F18 Représentations hiérarchiques (de sous-systèmes, de classes, etc.)
F19 Navigation de hiérarchies (de sous-systèmes, de classes, etc.)
F20 Navigation de style hypertexte
F21 Navigation arbitraire
F22 Possibilité de stocker les étapes d’une navigation arbitraire
F23 Possibilité de retour en arrière aux étapes de navigation précédentes
F24 Sauvegarde de vues, pour une utilisation future
F25 Possibilité d’afficher ou de cacher l’information selon les besoins
F26 Program slicing
F27Possibilité de voir le focus courant (ex. des vues de fish-eye, des vues détaillées de nœuds intéressants, des nœuds et arcs highlighted,des images thumbnail de code source, etc.)
F28 Possibilité de voir le chemin qui mène au focus courant (histories ou breadcrumb trails)
F29 Possibilité de particulariser la visualisation
F30 Possibilité de fournir une compréhension sommaire (coarse-grained)
F31 Possibilité de fournir une compréhension détaillée (fine-grained)
F32 Utilisation de couleurs
F33 Effets d’animation
F34 Représentations et layouts en 3D et techniques de réalité virtuelle
Tableau 2. Aspects fonctionnels des outils de VL.

52
5.2.1.4 Aspects pratiques des outils de VL
Une liste de 13 aspects pratiques liés aux outils de VL en général est exposée au
participant dans une section à part et sous forme d’une seule question. Nous lui
demandons de préciser l’importance qu’il accorde à chacun de ces aspects, en
choisissant entre les quatre choix de réponse suivants: “très important”, “relativement
important”, “pas important” et “ne sais pas”. Le tableau 3 donne l’ensemble de ces 13
aspects pratiques.
# Aspects pratiques
P1 Coût de l’outil
P2 Contenu et qualité de la documentation
P3 Disponibilité de documentation on-line
P4 Disponibilité de support technique
P5 Performance de l’outil (vitesse d’exécution de l’outil)
P6 Fiabilité de l’outil (absence d’erreurs)
P7 Facilité d’apprentissage et d’installation
P8 Facilité d’utilisation
P9 Facilité de visualiser des logiciels de grande taille
P10 Visualisation de logiciels écrits en langages différents
P11 Disponibilité sur plusieurs plate-formes
P12 Qualité de l’interface usager
P13 Possibilité de sortie (output) de la visualisation en fichiers de différents formats (postscript, pdf, bmp, etc.)
La plupart de ces aspects (tous sauf P9, P10 et P13) sont assez généraux, et de ce fait, se
trouvent applicables à une variété d’outils informatiques et non juste aux outils de VL.
Nous rencontrons par exemple certains de ces aspects dans [Jagannath93]. Par
conséquent, nous donnons la possibilité au participant d’exprimer ses propres aspects –
aspects liés de plus près aux outils de VL, qu’il a en tête et auxquels nous n’avons pas
pensé lors de la conception du questionnaire – dans des champs vides, avec trois
possibilités de réponse: “très important”, “relativement important” et “pas important”;
nous supprimons bien sûr la possibilité de répondre “ne sais pas”, puisque c’est un
aspect saisi et précisé par le participant lui-même.
Tableau 3. Aspects pratiques des outils de VL.

53
5.2.1.5 Évaluation cognitive de l’outil de VL en main
La section relative à l’évaluation cognitive des outils de VL comporte un total de cinq
questions. Cette section, ainsi que la section suivante du questionnaire, se rapportent à
l’outil de VL en main, tel que décrit dans les deux sous-sections 5.2.1 et 5.2.1.1. Une
première question dans cette section expose un ensemble de six caractéristiques et
demande au participant de préciser le degré (“haut”, “moyen”, “bas”, “ne sais pas”) de
chacune de ces caractéristiques par rapport à l’outil de VL en main. Voici la liste des six
caractéristiques: (1) facilité d’apprentissage, (2) facilité d’utilisation, (3) qualité des
effets visuels, (4) capacité de générer des résultats utiles, (5) confiance dans les résultats
générés, (6) connaissance requise du code source du logiciel visualisé, pour pouvoir
générer une visualisation.
Une deuxième question demande de préciser jusqu’à quel degré (“beaucoup”,
“moyennement”, “pas du tout”, “ne sais pas/non applicable”) l’outil de VL en main aide-
t-il le participant à effectuer chacune des huit tâches liées aux SLV: (1) maintenance, (2)
débogage, (3) test, (4) ajout de nouvelles fonctionnalités, (5) perfectionnement, (6)
analyse du code, (7) compréhension du code, et (8) création de la documentation.
Ensuite, un ensemble de cinq caractéristiques liées aux SLV ((1) complexité du code, (2)
taille du code, (3) interface très couplée, (4) documentation insuffisante, et (5) manque
de documentation sur l’intention de la conception) sont exposées, et nous demandons au
participant de préciser jusqu’à quel degré (“beaucoup”, “moyennement”, “pas du tout”,
“ne sais pas/non applicable”) chacune de ces caractéristiques diminue-t-elle l’efficacité
de l’outil de VL en main. Nous donnons aussi la possibilité au participant de saisir une
nouvelle caractéristique.
Finalement, les deux dernières questions de cette section demandent respectivement, si
selon le participant, l’outil de VL en main affecte l’approche prise pour effectuer une
tâche donnée et si les résultats obtenus lors de l’application de cet outil sont satisfaisants.
Pour chacune de ces deux questions, un choix de réponse avec échelle est donné. En
effet, l’échelle pour la première question comporte 5 niveaux et varie entre “beaucoup”,

54
“moyennement” et “pas du tout”. Il en est de même pour la deuxième question, mais
cette fois-ci les réponses varient entre “très satisfaisant”, “satisfaisant” et “non
satisfaisant”.
5.2.1.6 Bénéfices et améliorations de l’outil de VL en main
La dernière section du questionnaire est composée de deux questions ouvertes. Tel qu’il
a déjà été précisé dans l’introduction de la section 5.2.1, le participant est invité à
préciser les bénéfices qu’il a retirés suite à l’utilisation de l’outil de VL en main, ainsi
que les principales améliorations qui devraient être apportées à l’outil. Par ces deux
questions, nous cherchons principalement à détecter des patrons de réponse qui
formeront deux listes constituées respectivement des bénéfices et des améliorations.
5.2.2 Description de la partie II
La partie II s’adresse à des experts d’outils de VL, et permet de rassembler des
renseignements techniques associés à l’outil de VL en main. Notamment, des questions
portant sur le support de l’analyse du code par l’outil de VL en main seront demandées.
Cette deuxième partie comprend 17 questions (réparties en 2 sections). Nous décrirons
respectivement, dans chacune des deux sous-sections ci-dessous, les questions relatives
à chacune des deux sections de la partie II du questionnaire.
5.2.2.1 Renseignements techniques sur l’outil de VL en main
Les deux premières questions de la section rassemblant des renseignements techniques
sur les outils de VL en main demandent de saisir le nom et le distributeur de l’outil de
VL pour lequel le participant a choisi de compléter cette partie. Bien que le nom et le
distributeur de l’outil de VL en main aient déjà été demandés dans la partie I du
questionnaire, nous avons tenu à les redemander dans cette section. En effet, après avoir
rempli la partie I, un participant peut choisir de ne pas répondre de façon consécutive et
à partir du même poste de travail, dont nous détectons l’adresse IP, à la partie II. Par
conséquent, comme nous avons opté de rendre le questionnaire accessible on-line via le
web, sans toutefois demander dans la partie I des informations très personnelles au
participant permettant de l’identifier (par exemple, prénom et nom de famille), il s’est

55
avéré nécessaire d’exiger de façon redondante4 dans la partie II, le nom et le distributeur
de l’outil de VL en main. Une autre solution aurait pu être adoptée, c’est celle d’affecter
à chaque participant un login et un mot de passe lui permettant d’accéder au
questionnaire de façon plus personnalisée. Cette méthode d’accès – quoique non adopté
– sera discutée dans la section 6.5.
Pour ce qui est du reste de cette section, quelques-unes des questions sont inspirées de la
taxonomie de Price et al. [Price93]. En effet, quatre des huit questions restantes
correspondent à des propriétés de cette taxonomie: A.1.2, A.1.3, D.1 et F.1 (voir annexe
A). Pour chacune de ces quatre questions, un ensemble de réponses est fourni au
participant parmi lesquelles il peut choisir. De plus, nous lui donnons la possibilité de
saisir d’autres réponses non trouvées dans les choix de réponses fournis.
Finalement, quatre questions se rapportant respectivement au type de l’outil de VL (outil
commercial ou prototype de recherche), au nombre d’outils qui le forme (un seul grand
outil ou un ensemble d’outils), à son (ses) langage(s) d’implantation, ainsi que s’il est
(ou bien, s’il fait partie d’) un environnement de développement de logiciel ou non, sont
posées.
5.2.2.2 Support de l’analyse du code par l’outil de VL en main
Suite aux renseignements techniques adressés dans la section I de cette partie du
questionnaire, nous nous intéressons dans cette deuxième section aux capacités
d’analyse du code des SLV, supportées ou non par l’outil de VL en main. En effet, sept
aspects rassemblent 24 sous-aspects présentés dans le questionnaire sous forme de
questions (tableau 4). Chacun de ces sous-aspects est lié à l’un ou l’autre des sept
aspects de l’analyse du code considérés: (1) appels de fonctions, (2) clonage de
4 Lors de la compilation des réponses au questionnaire, nous avons remarqué que certains participants (un
nombre minime) ont rempli chacune des deux parties du questionnaire en considérant deux outils de
VL différents. Voilà donc une deuxième raison qui incite à demander deux fois le nom de l’outil de VL en
main, et à laquelle nous n’avions pas pensé lors de la conception du questionnaire.

56
fonctions, (3) graphes d’héritage, (4) graphes d’architecture de sous-systèmes, (5)
différents niveaux de détail, (6) métriques et (7) versions multiples.
Aspect # Sous-aspect1 Permettre de visualiser des appels de fonctions
2Permettre de visualiser le nombre de fois qu’une fonction est appelée par uneautre fonction
3 Fournir des fonctionnalités (un outil) pour identifier des chaînes de récursion
4 Éliminer les fonctions récursives simples
5Présenter comme un tout (dans un même graphe) une chaîne de récursioncomplexe
6 Représenter par des nœuds les fonctions de la chaîne de récursion
IAppels de fonctions
7 Accéder directement au code source à partir des nœuds
8 Permettre d’obtenir les clones d’une fonction
9 Voir le code source de ces clones
10 Différences mises en évidence par de changements de couleurs ou de polices
IIClonage de fonctions
11 Réduire la granularité des différences (un exemple le passage du mot à la lettre)
12 Visualiser des graphes d’héritage (des hiérarchies des classes du système)
13 Optimiser les positions des nœuds
14 Détecter un héritage multiple
IIIGraphes d’héritage
15 Détecter des branches profondes
16 Visualiser des graphes d’architecture de sous-systèmes
17Pouvoir lier l’architecture aux autres résultats de l’outil de VL en main (ex. zonesde couleurs différentes sur le graphe d’architecture)
18 Voir des clones de sous-systèmesIV
Graphes d’architecture de sous-systèmes
19Visualiser l’intérieur d’un sous-système (ex. les fichiers qui forment un sous-système)
VDifférents niveaux de détail
20 Voir différents niveaux de détail simultanément dans des fenêtres séparées
21 Calculer des métriquesVIMétriques 22 Intégrer les métriques et le code source
23 Travailler avec plusieurs versions simultanément
VIIVersions multiples 24
Calculer, pour chaque version, les différences par rapport aux versionsprécédentes (ex. le nombre de nouvelles fonctions, de fonctions non modifiées, defonctions modifiées, de fonctions effacées, etc.)
Pour chacune des questions, nous donnons au participant quatre choix de réponse: “oui”
(l’outil de VL en main fournit cet aspect), “non”, “ne sais pas/non applicable” et “non/je
ne sais pas, mais je souhaiterais cette propriété”, parmi lesquels il peut choisir. Notons
qu’à l’intérieur d’un même aspect, certaines dépendances existent; étant donné un aspect
principal, une réponse “non” à l’une de ses sous-aspects peut exclure des réponses “oui”
Tableau 4. Répartition des 24 sous-aspects de l’analyse du code par aspect.
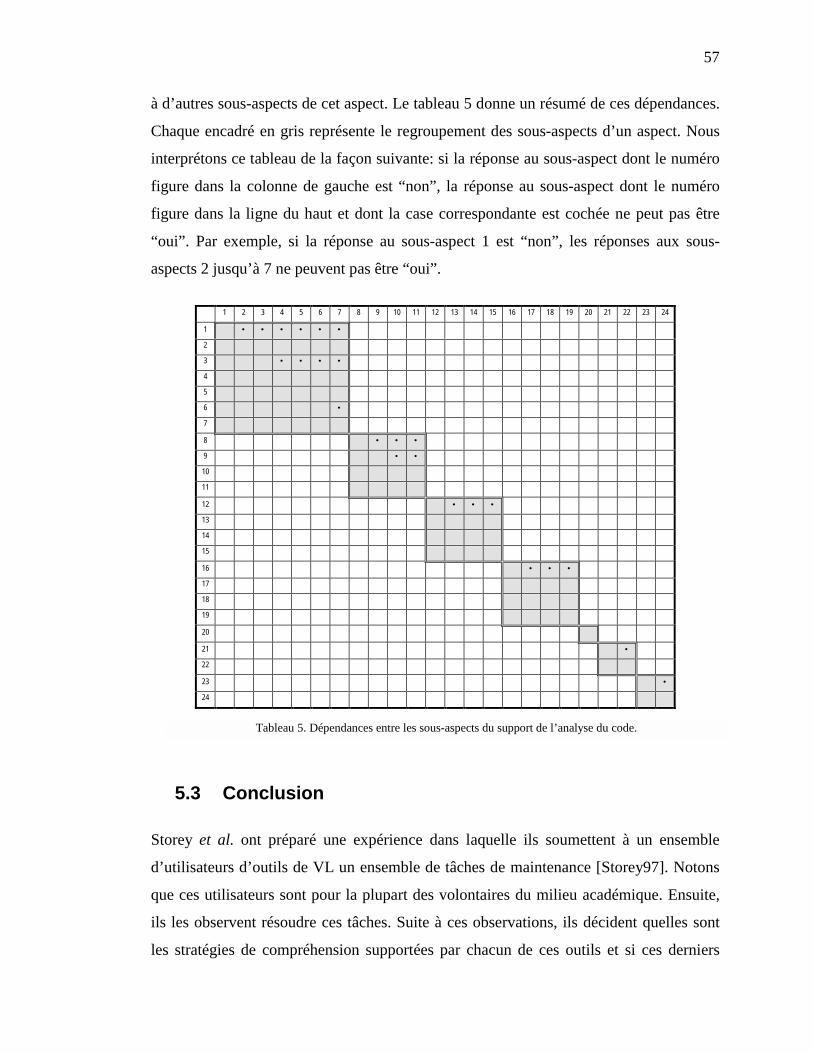
57
à d’autres sous-aspects de cet aspect. Le tableau 5 donne un résumé de ces dépendances.
Chaque encadré en gris représente le regroupement des sous-aspects d’un aspect. Nous
interprétons ce tableau de la façon suivante: si la réponse au sous-aspect dont le numéro
figure dans la colonne de gauche est “non”, la réponse au sous-aspect dont le numéro
figure dans la ligne du haut et dont la case correspondante est cochée ne peut pas être
“oui”. Par exemple, si la réponse au sous-aspect 1 est “non”, les réponses aux sous-
aspects 2 jusqu’à 7 ne peuvent pas être “oui”.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
1 • • • • • •
2
3 • • • •
4
5
6 •
7
8 • • •
9 • •
10
11
12 • • •
13
14
15
16 • • •
17
18
19
20
21 •
22
23 •
24
5.3 Conclusion
Storey et al. ont préparé une expérience dans laquelle ils soumettent à un ensemble
d’utilisateurs d’outils de VL un ensemble de tâches de maintenance [Storey97]. Notons
que ces utilisateurs sont pour la plupart des volontaires du milieu académique. Ensuite,
ils les observent résoudre ces tâches. Suite à ces observations, ils décident quelles sont
les stratégies de compréhension supportées par chacun de ces outils et si ces derniers
Tableau 5. Dépendances entre les sous-aspects du support de l’analyse du code.

58
permettent de passer d’une stratégie vers une autre. Bref, ce genre d’expérience se base
sur des observations pour évaluer certains aspects très spécifiques des outils de VL,
reliés à des éléments strictement cognitifs. Il serait bien sûr difficile de recueillir ce
genre d’information à partir d’un questionnaire. Cependant, plusieurs autres
informations telles que celles proposées dans les sections 5.2.1.3 à 5.2.1.6, de même que
celles proposées dans les sections 5.2.2.1 et 5.2.2.2, peuvent être facilement recueillies et
analysées à travers un questionnaire. En effet, la liste de questions aborde des
caractéristiques qu’offrent – ou non – les outils de VL. En combinant l’information
demandant si chacune de ces caractéristiques est jugée désirable ou inutile, et à savoir si
les participants utilisent déjà un outil de VL qui offre – ou non – la caractéristique
voulue, le questionnaire permet de retirer de façon ciblée, des informations quant aux
versions actuelles des outils de VL et de les comparer aux besoins réels des utilisateurs
de tels outils. Bien que le but principal de l’observation effectuée par Storey et al. soit
différent de celui visé par notre enquête, notons qu’il serait difficile d’appliquer une telle
étude axée à des observations dans le milieu industriel, que ce soit par manque de temps
pour les employés ou simplement par le fait qu’ils ne soient pas payés pour effectuer des
tâches “extra” à leur propre travail. Cependant, un questionnaire disponible via le web
peut être accessible toujours, et les participants peuvent répondre à leur guise, sans pour
autant être obligés d’arrêter leur travail.
Plusieurs itérations ont été nécessaires avant d’arriver à une version stable du
questionnaire. Comme nous l’avons laissé entendre à certaines places dans ce chapitre,
le questionnaire a été mis on-line. Les principaux avantages, les plus évidents d’ailleurs,
qui nous ont poussé à le rendre disponible via le web sont le fait de faciliter l’accès aux
participants pour ainsi recevoir le plus possible de réponses en un intervalle de temps
court. Une fois la collecte des données est terminée, un autre avantage serait le
traitement rapide de ces données. En effet, nous n’aurons pas à saisir les réponses des
participants avant de passer au traitement et analyse. Le chapitre suivant consiste à
discuter de façon plus prolongée l’implantation du questionnaire ainsi que les tâches qui
sont rendues automatiques étant donné le choix que nous avons adopté pour la
distribution du questionnaire.

Chapitre 6. Conception technique du questionnaire
6.1 Introduction
Après avoir discuté le contenu du questionnaire, nous passons à sa conception technique.
Deux options sont possibles pour la présentation: (1) utiliser la méthode traditionnelle
des enquêtes sur papier, ou bien (2) profiter des techniques récentes liées à la collecte
d’informations à partir du web. Nous avons favorisé cette dernière option en raison des
avantages multiples déjà cités (section 5.3), soient la facilité d’accès, de remplissage, et
d’envoi des données, ainsi que le traitement rapide de ces données après réception. Le
questionnaire se trouve donc on-line à partir de l’adresse suivante: <http://
www.iro.umontreal.ca/labs/gelo/sv-survey/questionnaire.html>.
Les différentes étapes de la conception du questionnaire seront exposées dans les
prochaines sections de ce chapitre. En effet, la section suivante discute la génération des
fichiers HTML en mettant l’emphase sur l’utilisation de FrontPage. Dans les sections
6.3 et 6.4, nous présentons respectivement les deux genres de programmation
(JavaScript et Perl) auxquels nous avons eu recours pour contrôler les données avant de
les envoyer et puis pour recueillir ces données et les préparer pour le traitement. La
dernière section fournit une conclusion tout en discutant certains points du chapitre.
6.2 Génération des fichiers HTML
Nous avons utilisé l’utilitaire “Microsoft FrontPage®” [FrontPage00] inclus dans
“Microsoft Office 2000” pour la génération des fichiers HTML. Cet utilitaire est facile à
utiliser et permet de créer, d’éditer, et de visualiser un site web rapidement. En effet, il

60
offre un environnement de travail à trois options: (1) le “WYSIWYG” familier
(impression conforme à la visualisation; mode création normale), (2) la possibilité de
visualiser les étiquettes du code HTML tout en étant en mode création normale (reveal
tags), et (3) l’édition en mode HTML; il est aussi possible de visualiser le travail déjà
effectué utilisant l’une de ces trois options (preview).
Une caractéristique importante de FrontPage est la possibilité de choisir le(s) browser(s)
ainsi que les versions de browser sur lesquelles nous voulons exécuter notre site web. En
fait, pour rendre nos fichiers compatibles avec un browser bien spécifique, FrontPage
donne la possibilité de restreindre automatiquement les caractéristiques et technologies
non supportées par ce browser en particulier. Dans notre cas, nous avons précisé les
deux browsers: Netscape Navigator et Microsoft Internet Explorer, tout en spécifiant les
versions “3.0 browsers and later” pour ainsi être sûr que les participants n’auront pas
des problèmes de visualisation du questionnaire et d’envoi de données. Ce choix a bien
sûr exclu quelques-unes des nouvelles technologies telles que les contrôles ActiveX, les
VBScripts, et le HTML dynamique, qui ne sont pas supportées par des anciennes
versions de browsers. Cependant, les deux technologies les plus importantes, qui restent
supportées par ces derniers et auxquelles nous avons eu recours, sont le JavaScript et
l’utilisation des cadres (Frames).
Notre site comporte un total de 10 fichiers HTML logiquement5 différents, répartis
comme suit:
• Un fichier “couverture” bilingue (anglais/français) comportant des informations
générales telles que le nom du questionnaire, le nom des auteurs, leur adresse
électronique, etc., ainsi qu’un compteur permettant de visualiser le nombre de visites
à cette page. Ce premier fichier donne accès à chacune des deux versions du
questionnaire (anglaise ou française).
5 Puisqu’il existe deux versions du questionnaire (anglaise/française), nous distinguons entre fichiers
logiques et fichiers physiques.

61
• Trois fichiers permettant d’afficher une “introduction” au questionnaire: un fichier
divisant la page en deux cadres et affichant dans chacun de ces cadres les
informations d’un fichier bien particulier. Le premier cadre offre entre autres deux
liens hypertextes menant respectivement vers les deux parties du questionnaire
(partie I et partie II), alors que le deuxième cadre affiche un texte d’introduction
décrivant principalement chacune des deux parties.
• Trois fichiers affichant la partie I (respectivement, partie II) du questionnaire. Tout
comme l’introduction, nous divisons la page en deux cadres, le premier fournissant
des liens hypertextes permettant d’accéder directement à chacune des questions de
cette partie sans pour autant parcourir tout le formulaire, alors que le deuxième
affichant le formulaire comportant toutes les questions relatives à la partie I
(respectivement, partie II).
Chacun des deux formulaires, celui lié à la partie I et celui lié à la partie II, comporte
plusieurs types d’entrée dépendemment du genre de la question (question ouverte ou
fermée). Dans le cas d’une question fermée, nous déterminons le type d’entrée à utiliser
d’après le nombre total de choix fournis et le nombre de réponses que peut choisir le
participant (une seule ou plusieurs). En effet, pour saisir la réponses d’une question
ouverte nous utilisons une zone de texte déroulante (textarea) si la réponse à fournir peut
dépasser un mot ou une expression, c’est-à-dire si elle peut être un paragraphe. Dans le
cas d’un mot ou bien d’une expression se limitant à un nombre minime de caractères,
nous utilisons une zone de texte simple (text). Pour ce qui est d’une question fermée
offrant juste deux choix de réponse à partir desquels le participant ne peut choisir qu’une
seule, nous utilisons une paire de cases d’option (radio buttons). Dans le cas d’une
question fermée offrant plus que deux choix de réponse à partir desquels, encore une
fois, le participant ne peut choisir qu’une seule, nous utilisons les menus déroulants
(lists). Finalement, une question fermée offrant plusieurs choix de réponse à partir
desquels le participant peut choisir une ou plusieurs réponses, nous utilisons les cases à
cocher (checkboxes).

62
Un ensemble de propriétés peut être précisé à chacune de ces entrées, tel que le nom de
la variable, la valeur initiale, la largeur en caractères dans le cas d’une zone de texte
simple, le nombre de lignes dans le cas d’une zone de texte déroulante, l’état initial
d’une case d’option (respectivement, une case à cocher) qui peut être soit sélectionné
(respectivement, activé), soit non sélectionné (respectivement, non activé), etc.
Un fichier (dictionnaire des variables) comportant le nom de toutes les variables et le
type du champ relatif à chacune de ces variables, ainsi que les valeurs possibles dans le
cas d’une variable à choix (question fermée), a été généré. Les données de ce fichier
nous ont grandement aidés lors de la programmation des fonctions JavaScript dont les
différents buts seront cités dans la section qui suit.
6.3 Programmation JavaScript
Des fonctions JavaScript [JavaScript99, Kolbeck97] ont été implantées ayant pour but
principal la vérification des champs et l’interaction avec les participants en cas d’erreur.
En effet, certaines fonctions permettent de vérifier les champs requis lors de l’envoi d’un
formulaire; dans le cas où ces champs n’ont pas été remplis, le système refuse l’envoi du
formulaire et affiche un message d’alerte tout en renvoyant le participant au(x) champ(s)
en question.
D’autres fonctions permettent à des champs de devenir directement requis suite à une
action particulière ou bien à un changement particulier. Par exemple, le champ “adresse
électronique” devient requis lorsque le participant répond “oui” à la question “souhaitez-
vous avoir le résultat de cette étude?” Une vérification du format de l’adresse
électronique est aussi effectuée. Une adresse qui semble erronée n’est pas acceptée.
Les restrictions liées aux questions relatives à l’analyse du code (section 5.2.2.2, tableau
5) sont forcées par des fonctions JavaScript. En effet, lorsqu’un participant répond “oui”
à un sous-aspect pour lequel il ne peut pas le faire, il verra apparaître une alerte précisant
l’interdiction de choisir cette option, et le choix passera directement à “non” par défaut,

63
tout en laissant au participant la possibilité de changer pour “ne sais pas/non applicable”
ou bien pour “non/ne sais pas, mais je souhaiterais cette propriété”.
Ces fonctions JavaScript ont été incorporées à différents fichiers HTML. Ils continuent à
s’exécuter tant que les informations saisies par le participant ne sont pas complètes, ne
respectent pas un format donné ou bien ne satisfont pas à des restrictions bien
particulières. Lorsque les données d’un formulaire répondent à toutes les exigences
contrôlées par les fonctions JavaScript, elles deviennent alors prêtes à être envoyées, et
un programme CGI, écrit en Perl, permettant la communication entre le browser du
participant et le serveur où nous voulons garder les informations, s’exécute. La section
suivante expose plus en détail les caractéristiques de ce programme, ainsi que le rôle
d’un autre programme, écrit aussi en Perl, permettant de préparer nos données pour le
traitement.
6.4 Programmation CGI et préparation des données
Un fichier CGI (Common Gateway Interface) [CGI00] pour la collecte des données a été
programmé en Perl (version 5) [Perl00, Srinivasan96, Wall97]. Ce fichier constitue une
interface standard pour la communication entre le browser d’un utilisateur et un
programme s’exécutant sur un serveur. Il sera exécuté lors de la soumission du
formulaire (lorsque le participant appuie sur le bouton “Envoyer partie I (ou II)”, et
lorsque toutes les données envoyées répondent à toutes les exigences contrôlées par les
fonctions JavaScript) et a pour but de créer à partir des informations saisies par le
participant un querystring6 qui sera gardé dans un fichier texte, en ayant chaque fois le
soin de préciser au début de chaque querystring l’adresse IP et le host name de la
machine à partir de laquelle le participant a rempli le formulaire, ainsi que la date de
l’envoi. Ce programme a été placé sur le serveur www2 du DIRO qui reconnaît ce
6 Un querystring est une variable d’environnement de Perl, qui garde les informations sous forme de
paires séparées par des “&”, où chaque paire est formée du nom de la variable, suivi d’un “=” puis de la
valeur de cette variable; un exemple serait: milieuTravail=1&nomOrganisation=IBM+Canada&Titre=1.

64
fichier comme étant un script CGI. Des informations intéressantes à propos de la
programmation CGI peuvent être trouvées à partir de [Perl00, CGI00].
Un autre programme en Perl permet de passer directement du fichier texte où les
données sont présentées sous format querystring à un fichier texte où les données
relatives à un seul envoi sont séparées par des espaces, alors que des données provenant
de deux envois différents sont séparées par des retours à la ligne. Il est bien important
d’arriver de façon automatique à un fichier texte qui sera accepté par un tableur tel que
Excel ou bien SPSS [SPSS00]. En effet, ceci réduira les erreurs dues à la manipulation
manuelle des données, il diminuera aussi l’intervalle de temps entre la collecte des
données et l’analyse statistique. Notons que l’ordre des données est très important, et
que le programme qui permet de passer du format querystring à un format qui sera
accepté par un tableur tient compte de l’ordre de présentation des données.
Après l’exécution des deux programmes Perl décrits ci-dessus, nous préparons nos
données pour le traitement et l’analyse statistique utilisant SPSS. En effet, il s’agit de
s’assurer de l’ordre d’apparition des valeurs affectées aux différentes variables, tout en
complétant les champs manquants avec des valeurs par défaut. Notons qu’il aurait été
possible de conserver les données dans une base de données (BD) et de les traiter par un
système de gestion de bases de données (SGBD) au lieu d’un tableur. D’ailleurs
FrontPage, étant une application de Microsoft Office, permet la communication de façon
simple et rapide entre un formulaire qu’il crée et le SGBD Access. Cependant, deux
raisons principales nous ont conduits à garder nos données dans un tableur et de les
traiter utilisant un utilitaire statistique (SPSS) et non un SGBD. En effet, la première
raison est le fait de ne pas avoir besoin de recourir à une BD puisque nos données se
limitent à une centaine d’enregistrements seulement (107 participants pour la partie I, et
41 participants pour la partie II), qui peuvent facilement être acceptés et gérés par un
tableur tel que SPSS. La deuxième raison, la plus importante par ailleurs, est la
disponibilité des fonctions de calcul statistique prédéfinis dans l’utilitaire statistique,
alors que dans un SGBD ce genre de fonctions demande l’utilisation de Visual Basic (le
langage de programmation de Microsoft Office) pour l’écriture de macros.

65
6.5 Conclusion et discussion
Dans ce chapitre, nous venons de donner un aperçu rapide de la méthodologie et des
techniques utilisées pour la conception du questionnaire, ainsi que pour la collecte et la
préparation des données en vue du traitement et de l’analyse statistique. En effet, HTML
est un langage facile à apprendre et à utiliser, et l’utilisation de FrontPage a rendu la
génération des fichiers HTML encore plus rapide. De plus, connaissant bien HTML,
nous pouvons toujours faire des changements dans les fichiers HTML générés
automatiques par FrontPage. Pour ce qui est de JavaScript et de Perl, ce sont deux
langages de scripting qui fournissent beaucoup d’avantages, tels que le développement
rapide d’application web. Il est évident que dans notre cas la rapidité est un critère
important puisque le but final est non seulement de fournir un questionnaire, mais aussi
de recueillir les données, de les analyser et d’arriver à des résultats le plus rapidement
possible.
Du côté de l’interface du questionnaire, nous avons essayé de la rendre le plus possible
compréhensible, tout d’abord en différenciant entre les couleurs utilisées pour les zones
réservées aux questions et celles réservées aux réponses, mais aussi en fournissant un
accès direct à chacune des questions par des liens hypertextes. Un commentaire que
nous avons reçu est celui de la navigation entre la page “introduction” et chacune des
deux parties. En fait, quelques-uns des participants préféraient passer de l’introduction à
la partie I, et après avoir complété et envoyé le formulaire de cette partie, avoir le droit
de passer directement à la partie II. Ils trouvaient qu’il était en quelque sorte mélangeant
de donner la possibilité d’accéder aux deux parties directement à partir de
l’“introduction”, surtout qu’on avait bien précisé au début de la partie II la phrase
suivante: “Avez-vous rempli la partie I? Sinon, veuillez la compléter avant de remplir
cette partie! Merci.” Cependant, ne pas permettre à un participant d’accéder à la partie II
sauf à la suite de l’envoi du formulaire de la partie I, restreint en quelque sorte le nombre
de participants pour cette partie. En effet, nous avons remarqué plus tard qu’un certain
nombre de participants n’avaient pas rempli la partie II directement après avoir rempli la
partie I, mais bien à une date ultérieure. Une solution qui semble la plus intéressante
dans notre cas et qui a déjà était discutée à la section 5.2.2.1, est d’identifier un

66
participant en lui affectant un login et un mot de passe. Ainsi, la partie I étant déjà
remplie, le participant pourra accéder à la partie II lorsqu’il veut. De plus, il aura la
possibilité de sauvegarder ce qu’il a déjà rempli du formulaire pour une prochaine visite
du site, dans laquelle il complétera les sections/questions manquantes.
Finalement, le chapitre suivant donnera un aperçu des résultats de cette enquête. Une
interprétation de ces résultats sera aussi fournie. Une version plus détaillée des résultats
se trouve dans [Bassil00b, Bassil00c].

Chapitre 7. Analyse de l’enquête
7.1 Introduction
Ce chapitre présente les résultats de l’analyse des données collectées pour les deux
parties du questionnaire sur les outils de VL décrits au chapitre 5. Il est basé
principalement, sur deux rapports techniques créés à l’intérieur du laboratoire GÉLO
[Bassil00b, Bassil00c] de même que sur [Bassil01]. Ce dernier sera envoyé à un grand
nombre de participants (94%) qui avaient souhaité avoir les résultats de notre étude.
Plusieurs résultats intéressants liés à l’utilité et à l’importance accordée par une centaine
de participants à un ensemble d’aspects fonctionnels, pratiques et cognitifs ont été
générés. Aussi, un nombre considérable de nouveaux aspects non cités dans le
questionnaire ont été proposés. Nous avons remarqué que les participants étaient en
général satisfaits de l’outil de VL en main, ils en ont aussi précisé plusieurs bénéfices.
Cependant, une différence notable entre les aspects souhaités et les caractéristiques des
outils de VL d’aujourd’hui a été identifiée. En outre, une liste non négligeable
d’améliorations qui devront être apportées à ces outils a été exposée. Pour ce qui est de
la partie II du questionnaire, les données collectées suggèrent qu’en général des aspects
liés à l’analyse du code des systèmes logiciels visualisés n’étaient pas fortement
supportés par les outils pour lesquels nous avons reçu une réponse à cette partie.
Une liste complète des noms et références web des outils de VL pour lesquels nous avons reçu une ou
plusieurs réponses au questionnaire peut être trouvée à l’adresse suivante: <http://www.iro.umontreal.ca
/labs/gelo/sv-survey/list-of-tools.html>.

68
Les sections qui suivent exposent en détail les résultats de notre enquête, en mettant
parfois l’emphase sur la discussion et l’analyse de ces résultats. Nous commencerons par
présenter la méthodologie utilisée pour effectuer l’enquête (section 7.2). Ensuite, dans la
section 7.3, nous détaillerons les résultats liés aux aspects fonctionnels, pratiques et
cognitifs des outils de VL. La section 7.4 présentera quelques informations techniques
spécifiques à ces outils, en mettant l’emphase sur le support de l’analyse du code. La
dernière section (7.5) commencera par présenter quelques-unes des améliorations qui
peuvent être apportées à la version actuelle du questionnaire, et ensuite, elle discutera les
résultats principaux de notre enquête ainsi que leur impact.
7.2 Collecte de données et analyse
Une invitation a été envoyée sur plusieurs listes de messagerie électronique (SIGCHI,
Software Engineering Canada, Psychology of Programming Interest Group, Reverse-
Engineering, etc.) et newsgroups (comp.lang.visual, comp.software-eng, comp.lang.java,
comp.lang.c++, ibm.software.vajava.ide, etc.). De plus, un message a été envoyé
explicitement à un nombre de personnes utilisant des outils de VL bien spécifiques
(daVinci [daVinci00], Discover [Discover00], GraphViz [GraphViz00], Grasp
[Grasp00], PBS [PBS98], Rigi [Rigi00], SHriMP [SHriMPage00], TkSee [TkSee96],
Tom Sawyer Software [TomSawyer00a], VCG [VCG95a], xSuds [xSuds98], etc.)
Les réponses ont toutes été recueillies entre mars et mai 2000. L’échantillon consiste en
un total de 107 participants pour la partie I (100 ont rempli la version anglaise et 7 ont
rempli la version française), desquelles 41 ont rempli aussi la partie II (37 pour la
version anglaise et 4 pour la version française).
Pour analyser les données recueillies, nous avons appliqué des techniques statistiques
standards (voir annexe D), incluant la génération de fréquences (pourcentages) et de
moyennes pour des variables qualitatives, le calcul de corrélations entre des variables
ordinales, utilisant la corrélation tau-b ou tau-c de Kendall, aussi appelée “mesure
d’association”, et la vérification d’hypothèses utilisant la valeur du t-test. Dans le cas de
données ordinales, on suppose que l’échelle utilisée est en réalité un intervalle; ce qui

69
rend possible l’application de statistiques paramétriques tel que le calcul de la moyenne.
Tous les calculs ont été faits utilisant SPSS [SPSS00]. Les résultats générés suite à
l’application de ces techniques, s’appliquent à l’échantillon des 107 participants et ne
constituent pas une généralisation sur l’ensemble de la population.
7.3 Analyse de la partie I
7.3.1 Distribution des participants
Le questionnaire visait surtout les utilisateurs d’outils de VL du milieu industriel. Il n’est
donc pas surprenant de voir que les deux tiers des répondants travaillaient dans des
compagnies et le reste provenait du milieu académique. Considérant leur fonction
professionnelle, nous constatons encore une fois que les deux tiers faisaient partie de la
catégorie “développement et maintenance”, alors que le tiers restant était impliqué dans
des travaux de gestion ou de recherche. La distribution des participants selon la taille de
l’équipe de travail était comme suit : 35% des participants travaillaient dans une équipe
de moins de cinq personnes; 36% faisaient partie d’une équipe comportant cinq à 20
personnes, et 17% étaient impliqués dans de grands projets dont la taille des équipes
dépassait les 20 personnes. Les 12% restants n’avaient pas répondu à la question
concernant la taille de l’équipe de travail.
60% des participants avaient précisé que plus qu’un seul outil de VL (deux ou trois)
étaient utilisés dans leur équipe de travail. Ceci suggère qu’aucun outil dans ces équipes
ne fournit toutes les caractéristiques désirées et que des outils de VL complémentaires
sont nécessaires. De plus, la plupart de ces outils sont commerciaux. Plus des trois quarts
des participants estimaient avoir une bonne connaissance de l’outil de VL en main. Un
résultat similaire était trouvé pour la connaissance du SLV (familiarité avec le code
source). Notons qu’une corrélation positive significative nous permet d’affirmer qu’il
existe une relation non négligeable entre le niveau de connaissance du SLV et celui du
domaine d’application (tau-b = 0.458) et du langage d’implantation (tau-b = 0.489) du
SLV.

70
7.3.2 Caractéristiques des SLV
Un grand nombre des SLV ont été développés en utilisant un langage orienté objet (73
systèmes), contre 48 systèmes utilisant un langage procédural, et cinq systèmes utilisant
un langage déclaratif tel que Prolog. Le total de ces nombres (126) est supérieur au
nombre de participants (107), puisque les participants pouvaient indiquer plusieurs
langages. Considérant le type d’application des SLV et demandant aux participants de
choisir entre neuf réponses différentes proposées, nous avons trouvé que le type
d’application le plus fréquent était temps réel (21%), suivi par génie/scientifique (16%),
et systèmes d’information (15%). Un total de 52% a donc été calculé pour ces trois
réponses.
Du côté de l’ordre de grandeur, une répartition presque équitable de ces systèmes a été
remarquée. En effet, le tiers des SLV sont de grande taille avec plus de 1000 KLOC, le
tiers sont des systèmes de taille moyenne (entre 100 et 999 KLOC) et le tiers restant sont
de petits systèmes de moins de 100 KLOC. Ce n’est pas étonnant de trouver une
corrélation positive entre l’ordre de grandeur des SLV et la taille de l’équipe de travail
(tau-b = 0.250).
Nous avons remarqué qu’un grand nombre de participants (42%) affirment que les SLV
sont complexes, 36% estiment qu’ils sont de complexité moyenne, et 18% trouvent
qu’ils sont faciles, alors que les 4% restants n’avaient pas répondu à cette question. Des
pourcentages très proches ont été trouvés pour les tâches effectuées sur les SLV. Des
exemples de tâches seraient les tests, le débogage, l’ajout d’une nouvelle fonctionnalité
aux SLV, etc. En effet, une corrélation positive significative a été trouvée entre ces deux
variables (tau-b = 0.539); ceci laisse croire que les participants considèrent
probablement qu’un système complexe implique directement une certaine complexité
des tâches effectuées sur ce système et vice-versa.
Finalement, pour ce qui est de la disponibilité de la documentation (au-delà du code
source) pour les SLV, une répartition encore une fois équitable a été trouvée entre les

71
catégories “documentation presque complète”, “documentation incomplète”, et “presque
aucune documentation”.
7.3.3 Aspects fonctionnels d’outil de VL
Pour pouvoir évaluer l’utilité d’aspects fonctionnels et de caractéristiques liées aux
outils de VL, 34 fonctionnalités ont été présentées aux participants (voir tableau 2,
section 5.2.1.3) avec quatre choix de réponses possibles pour chacun d’eux (section
5.2.1.3).
Nous avons classifié ces fonctionnalités en procédant de deux manières différentes:
1. En identifiant les aspects qui ont été sélectionnés comme “absolument essentiels” par
au moins 50% des répondants.
2. En affectant un poids à chacune des réponses possibles (2 pour “absolument
essentielle”, 1 pour “utile, mais non essentielle”, et 0 pour “pas du tout utile”), en
calculant la moyenne des réponses pour chacun des 34 aspects et en sélectionnant les
aspects pour lesquels la moyenne est supérieure à 1.5. Nous avons retenu cette valeur
en nous basant sur la supposition qu’entre deux poids différents, il existe un
intervalle continu de valeurs. Une moyenne supérieure à 1.5 tend donc en quelque
sorte à la valeur 2 qui correspond à la réponse “absolument essentielle”.
L’utilité des aspects fonctionnels sera tout d’abord discutée indépendamment de tout
facteur d’influence (section 7.3.3.1), et puis en considérant quelques-uns de ces facteurs
(section 7.3.3.2). Ces derniers sont liés aux participants et aux SLV et sont identifiés
compte tenu des différents échantillons exclusifs de notre enquête:
• Échantillons liés à différents aspects des participants:
o Milieu de travail (“compagnie” versus “milieu académique”)
o Taille de l’équipe de travail (“petite” versus “grande”)
o Niveau de connaissance des SLV (“faible” versus “élevé”)
• Échantillons liés à différents aspects des SLV:
o Langage de programmation (“orienté objet” versus “procédural” versus
“déclaratif”)
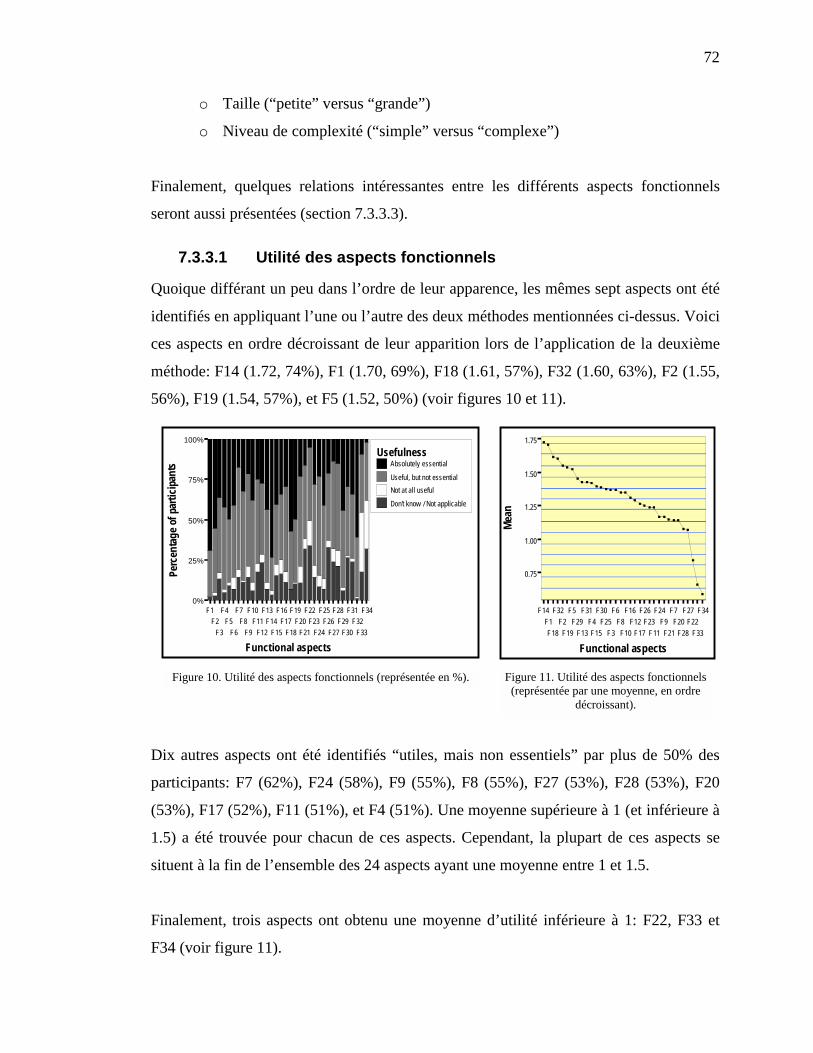
72
o Taille (“petite” versus “grande”)
o Niveau de complexité (“simple” versus “complexe”)
Finalement, quelques relations intéressantes entre les différents aspects fonctionnels
seront aussi présentées (section 7.3.3.3).
7.3.3.1 Utilité des aspects fonctionnels
Quoique différant un peu dans l’ordre de leur apparence, les mêmes sept aspects ont été
identifiés en appliquant l’une ou l’autre des deux méthodes mentionnées ci-dessus. Voici
ces aspects en ordre décroissant de leur apparition lors de l’application de la deuxième
méthode: F14 (1.72, 74%), F1 (1.70, 69%), F18 (1.61, 57%), F32 (1.60, 63%), F2 (1.55,
56%), F19 (1.54, 57%), et F5 (1.52, 50%) (voir figures 10 et 11).
Dix autres aspects ont été identifiés “utiles, mais non essentiels” par plus de 50% des
participants: F7 (62%), F24 (58%), F9 (55%), F8 (55%), F27 (53%), F28 (53%), F20
(53%), F17 (52%), F11 (51%), et F4 (51%). Une moyenne supérieure à 1 (et inférieure à
1.5) a été trouvée pour chacun de ces aspects. Cependant, la plupart de ces aspects se
situent à la fin de l’ensemble des 24 aspects ayant une moyenne entre 1 et 1.5.
Finalement, trois aspects ont obtenu une moyenne d’utilité inférieure à 1: F22, F33 et
F34 (voir figure 11).
Absolutely essential
Useful, but not essentialNot at all useful
Don't know / Not applicable
Usefulness
F1F2
F3
F4F5
F6
F7F8
F9
F10F11
F12
F13F14
F15
F16F17
F18
F19F20
F21
F22F23
F24
F25F26
F27
F28F29
F30
F31F32
F33
F34
Functional aspects
0%
25%
50%
75%
100%
Perc
entag
e of p
artic
ipant
s
Figure 10. Utilité des aspects fonctionnels (représentée en %).
F14F1F18
F32F2F19
F5F29
F13
F31F4F15
F30F25
F3
F6F8F10
F16F12
F17
F26F23
F11
F24F9F21
F7F20
F28
F27F22
F33
F34
Functional aspects
0.75
1.00
1.25
1.50
1.75
Mean
��
��
���
�
���
�����
��
��
����
�����
��
�
�
�
Figure 11. Utilité des aspects fonctionnels(représentée par une moyenne, en ordre
décroissant).

73
Certains participants ont opté pour la réponse “ne sais pas/non applicable” pour
quelques-uns des aspects fonctionnels. Deux explications sont probables: le participant
(1) ne comprenait ou ne connaissait pas l’aspect, ou bien (2) l’aspect ne s’appliquait pas
dans son cas. Un exemple de cette dernière explication serait le fait d’exposer le
participant à un aspect tel que F3 (“accès direct au code source”), alors que ses
principales tâches sont au niveau analyse et conception, utilisant un outil tel que
Together/J [TogetherJ00] ou Rational Rose [RationalRose00]. Pour ce qui est de la
première explication, il est fort probable que des aspects tels que F21, F22, F26, F30, ou
F31 ne soient pas assez compréhensibles pour tous les participants, malgré les notes
explicatives rajoutées dans le questionnaire pour F21 et F26. Finalement, l’aspect F34
est une propriété peu commune aux outils de VL, d’où le haut degré
d’incompréhensibilité (voir figure 10).
7.3.3.2 Facteurs d’influence sur l’utilité d’aspects fonctionnels
Dans cette section, les différents échantillons exclusifs de l’enquête, tel que décrits ci-
haut dans l’introduction de la section 7.3.3, sont examinés par rapport à l’utilité des
aspects fonctionnels. Nous discutons d’abord les trois échantillons reliés aux
participants, puis les trois échantillons concernant les SLV.
Nous avons remarqué que les participants du milieu académique accordent plus
d’importance aux deux aspects F33 et F34 que ceux du milieu industriel (F33: la
moyenne des réponses est 0.97 versus 0.49, valeur du t-test = -3.113, p < 0.003; F34:
0.77 versus 0.48, valeur du t-test = -2.202, p < 0.032). Comme nous pouvons le
constater, le t-test calculé permet de rejeter l’hypothèse nulle (H0) qui est l’égalité des
deux moyennes.
Une corrélation positive (quoique faible) a été identifiée entre F6 et la taille de l’équipe
de travail (tau-c = 0.206).
Plus le niveau de connaissance du SLV est bas, plus le participant a besoin d’avoir une
vue globale du système avant de manipuler son code source, et alors plus il accorde de

74
l’importance à F30 (tau-c < 0). Par contre, plus le niveau de connaissance du SLV est
élevé, plus il accorde de l’importance à F31 et F1 (tau-c > 0).
Considérons maintenant les échantillons liés aux caractéristiques des SLV. Le
pourcentage de participants qui ont choisi F1 (respectivement, F14) comme aspect
“absolument essentiel” s’élève respectivement à 82% (respectivement, 82%) lorsque les
SLV étaient implantés utilisant un langage procédural, et à 69% (respectivement, 79%)
dans le cas de SLV orientés objet. La différence qui existe suggère que le monde
procédural accorde plus d’importance à la visualisation du code source que le monde
orienté objet. Par contre, des pourcentages plus élevés ont été accordés aux deux aspects
F18 et F19 dans le cas de SLV orientés objet. Lorsque les SLV étaient du monde
déclaratif, les deux aspects F17 et F33 ont été identifiées comme les aspects les plus
essentiels par la plupart des participants (quatre sur cinq).
Les participants dont les SLV étaient de grande taille accordaient plus d’importance à
plus d’aspects fonctionnels que les participants dont les SLV étaient de petite taille. De
plus, le choix “ne sais pas/non applicable” a été plus largement choisi dans le cas de
SLV de petite taille que dans le cas de SLV de grande taille. Une corrélation positive a
été identifiée entre F6 et la taille des SLV. En revanche, une corrélation négative a été
identifiée entre F3 et cette dernière. Ceci suggère que plus le SLV est de grande taille,
plus il y a intérêt à le visualiser graphiquement et moins il est utile de passer directement
au code source. Lorsque les participants travaillaient avec des SLV de grande taille, ils
accordent en moyenne plus d’importance aux quatre fonctionnalités F4, F5, F6 et F24,
que lorsqu’ils travaillaient avec des SLV de petite taille (pour tous ces aspects, la valeur
du t-test suggère de rejeter H0; pour plus de détails, consulter [Bassil00b]).
Nous notons que lorsque les SLV étaient de complexité faible, les participants
attachaient de façon significative moins d’importance à la plupart des aspects
fonctionnels que lorsqu’ils étaient complexes. De plus, la réponse “ne sais pas/non
applicable” était largement sélectionnée. Une explication de ceci serait la faible
nécessité de recourir à des outils de VL pour comprendre un système non complexe.

75
Finalement, trois corrélations positives supérieures à 0.300 ont été identifiées entre le
niveau de complexité des SLV et trois aspects: F6 (tau-c = 0.321), F16 (tau-c = 0.320) et
F19 (tau-c = 0.314). Une grande différence entre les moyennes a aussi été détectée pour
ces trois aspects (le t-test calculé permet de rejeter H0).
7.3.3.3 Relations entre les aspects fonctionnels
Nous avons détecté un certain nombre de corrélations entre les différents aspects
fonctionnels. Quelques-unes de ces corrélations confirment simplement la cohérence des
données collectées. Des exemples de telles corrélations existent entre F4 et F5 (tau-b =
0.579), F4 et F15 (tau-b = 0.214), F21 et F22 (tau-b = 0.386), et F27 et F28 (tau-b =
0.417).
D’autres corrélations suggèrent des interdépendances plus intéressantes. Par exemple,
des corrélations positives significatives existent entre F6 et F7 (tau-b = 0.300), F6 et F8
(tau-b = 0.302), F7 et F8 (tau-b = 0.406). Ceci suggère que les utilisateurs sont axés sur
le code (code-centric); A chaque fois qu’ils souhaitaient avoir une visualisation
graphique, ils souhaitaient aussi avoir un accès au code source. Une autre corrélation
intéressante existe entre F14 et F21 (tau-b = 0.301), indiquant que les participants
réalisent le besoin d’outils de recherche pour une navigation arbitraire. Les deux aspects
F17 et F33 (tau-b = 0.379) sont liées en quelque sorte; en effet, la visualisation
dynamique est souvent effectuée en ayant recours à des techniques d’animation. Les
types de compréhension proposés par les deux aspects F30 et F31 (tau-b = 0.599), sont
complémentaires. Enfin, F33 et F34 (tau-b = 0.505) sont similaires; tous les deux sont
liées à des capacités étendues des outils de VL.
7.3.4 Aspects pratiques des outils de VL
Tout comme pour la classification des 34 aspects fonctionnels, les deux mêmes
méthodes (le calcul de la fréquence en pourcentage et le calcul de la moyenne) ont aussi
été utilisées pour classifier les 13 aspects pratiques.
En premier lieu, l’importance de ces aspects sera discutée indépendamment de tout
facteur d’influence (section 7.3.4.1). Ensuite, dans la section 7.3.4.2, nous tenons en
compte deux facteurs d’influence, notamment, l’environnement de travail du participant,

76
et la taille des SLV. Notons que les quatre autres facteurs spécifiés dans l’introduction
de la section 7.3.3 n’avaient pas influencé l’importance accordée aux aspects pratiques.
7.3.4.1 Importance des aspects pratiques
Parmi les 13 aspects pratiques, six ont été à la fois sélectionnés comme “très importants”
par plus de 50% des répondants et classifiés avec une moyenne du degré d’importance
supérieure à 1.5. Indépendamment de la méthode, nous avons obtenu l’ordre suivant: P6
(88%, 1.87), P8 (72%, 1.70), P12 (69%, 1.68), P9 (66%, 1.64), P3 (63%, 1.58), et P2
(62%, 1.56). En moyenne, aucun aspect n’a été classifié comme étant “non important”.
En effet, la moyenne du degré d’importance de chacun des aspects se trouve au-dessus
de la moyenne (1).
Après avoir affecté un degré d’importance spécifique à chacun des 13 aspects pratiques,
le participant pouvait saisir de nouveaux aspects qu’il considère – ou non – importants.
Cinq patrons principaux de réponse ont été détectés:
• Intégrer aux outils de VL des outils bien spécifiques, autres que des générateurs de
code (métriques, design partitioning, etc.) (10 participants)
• Intégrer aux outils de VL des outils de génération de code (plus ou moins
sophistiqués) (5 participants)
• Pouvoir importer de/exporter vers d’autres formats d’outil de VL (5 participants)
• Étendre l’outil de VL avec un langage macro (2 participants)
• Intégrer les outils de VL dans des environnements de développement et permettre
l’“aller-retour SV-IDE-SV” (2 participants)
D’autres aspects ont aussi été proposés. Quelques-uns ont simplement été repris et re-
formulés de la section sur les aspects fonctionnels et de la liste des 13 aspects pratiques.
Une vérification de la cohérence de ces réponses avec le degré d’importance accordé aux
aspects correspondants a été effectuée. Aucune incohérence n’a été détectée.
7.3.4.2 Facteurs d’influence sur l’importance d’aspects pratiques
Passons maintenant à la discussion de l’importance des aspects pratiques compte tenu du
facteur “milieu de travail des participants”. Nous avons constaté que les répondants du
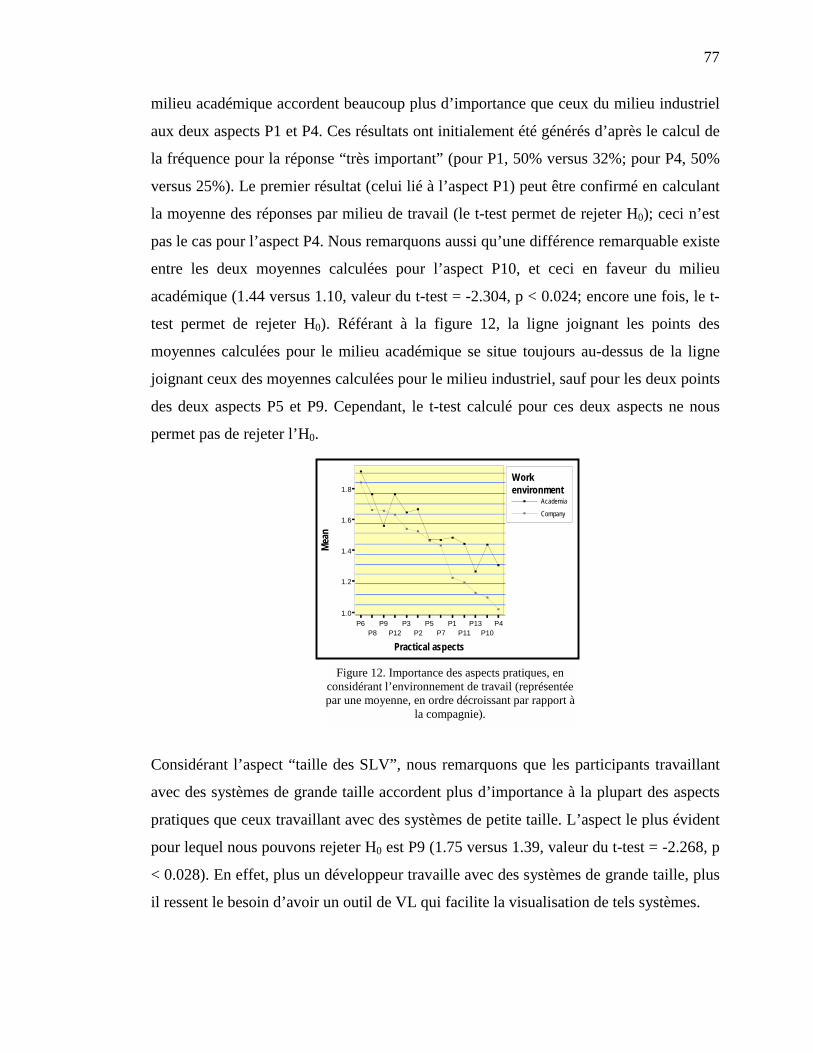
77
milieu académique accordent beaucoup plus d’importance que ceux du milieu industriel
aux deux aspects P1 et P4. Ces résultats ont initialement été générés d’après le calcul de
la fréquence pour la réponse “très important” (pour P1, 50% versus 32%; pour P4, 50%
versus 25%). Le premier résultat (celui lié à l’aspect P1) peut être confirmé en calculant
la moyenne des réponses par milieu de travail (le t-test permet de rejeter H0); ceci n’est
pas le cas pour l’aspect P4. Nous remarquons aussi qu’une différence remarquable existe
entre les deux moyennes calculées pour l’aspect P10, et ceci en faveur du milieu
académique (1.44 versus 1.10, valeur du t-test = -2.304, p < 0.024; encore une fois, le t-
test permet de rejeter H0). Référant à la figure 12, la ligne joignant les points des
moyennes calculées pour le milieu académique se situe toujours au-dessus de la ligne
joignant ceux des moyennes calculées pour le milieu industriel, sauf pour les deux points
des deux aspects P5 et P9. Cependant, le t-test calculé pour ces deux aspects ne nous
permet pas de rejeter l’H0.
Considérant l’aspect “taille des SLV”, nous remarquons que les participants travaillant
avec des systèmes de grande taille accordent plus d’importance à la plupart des aspects
pratiques que ceux travaillant avec des systèmes de petite taille. L’aspect le plus évident
pour lequel nous pouvons rejeter H0 est P9 (1.75 versus 1.39, valeur du t-test = -2.268, p
< 0.028). En effet, plus un développeur travaille avec des systèmes de grande taille, plus
il ressent le besoin d’avoir un outil de VL qui facilite la visualisation de tels systèmes.
� Academia� Company
Workenvironment
P6P8
P9P12
P3P2
P5P7
P1P11
P13P10
P4
Practical aspects
1.0
1.2
1.4
1.6
1.8
Mean
�
�
�
�
�
�
� ��
�
�
�
�
�
� �
�
��
�
�
�
�
�
�
�
Figure 12. Importance des aspects pratiques, enconsidérant l’environnement de travail (représentéepar une moyenne, en ordre décroissant par rapport à
la compagnie).

78
7.3.5 Évaluation cognitive d’outils de VL
Rappelons que pour remplir la section reliée aux aspects cognitifs (aussi bien que la
section sur les bénéfices et améliorations, et la partie II), les participants devaient choisir
un outil spécifique pour lequel ils répondront aux questions (“outil de VL en main”).
Nous avons reçu des réponses pour plus de 40 outils de VL différents. Étant donné le
nombre limité de participants (107), ceci conduit à un petit échantillon pour chaque
outil, et par conséquent, les résultats pour un outil spécifique sont peu significatifs.
Cependant, nous avons obtenu un certain nombre de résultats globaux intéressants, tel
que présentés ci-dessous.
Plus de 50% des répondants ont précisé que l’outil de VL en main est facile à utiliser,
qu’il est capable de générer des résultats utiles et qu’ils ont confiance dans les résultats
qu’il génère. Cependant, une différence notable a été identifiée entre quelques-unes des
aspects pratiques désirées (tableau 3) et les caractéristiques de l’outil de VL en main.
Spécifiquement, 69% des participants ont accordé la valeur “très important” à l’aspect
P12, alors que juste 43% ont répondu par “haut” à une question semblable dans les
aspects cognitifs. Une différence semblable a été trouvée pour l’aspect P8 (72% pour
“très important”, et juste 63% pour “haut”).
De plus, les résultats confirment notre intuition qu’un bon support pour la
compréhension du code facilite des tâches telles que la maintenance, le débogage, le test,
l’ajout de nouvelles fonctionnalités, le perfectionnement, la création de la documentation
et surtout l’analyse du code. En effet, des corrélations positives ont été trouvées entre le
support de chacune de ces tâches par un outil de VL et l’activité de compréhension du
code. La corrélation la plus significative est la corrélation entre l’analyse et la
compréhension du code (tau-b = 0.515).
Certaines caractéristiques des SLV ont été proposées, demandant aux répondants de
préciser pour chacune de ces caractéristiques le degré de diminution de l’efficacité
qu’elle apporte à l’outil de VL en main. Nous remarquons qu’une “documentation
insuffisante” est celle qui diminue le plus l’efficacité d’un outil de VL (57% des

79
participants ont répondu “beaucoup/moyennement”). Suite à celle-là vient la
caractéristique “complexité du code” (50%). En revanche, les répondants semblent être
satisfaits quant à la “scalability” des outils de VL en main (55% des participants ont
répondu à la caractéristique concernant la “taille du code” par “pas du tout”). D’autres
caractéristiques pouvant diminuer l’efficacité de l’outil de VL en main ont été
proposées. Ces caractéristiques sont liées à des outils bien particuliers tout comme
Fujaba [Fujaba98], UML Studio [UMLStudio00] et Rational Rose [RationalRose00].
Finalement, la plupart des participants (74%) trouvent que l’outil de VL en main affecte
en quelque sorte l’approche qu’ils prennent pour accomplir une certaine tâche sur le
SLV. La plupart (70%) aussi étaient très satisfaits quant aux résultats obtenus lors de
l’application de l’outil de VL en main. Aucun des répondants n’a été complètement non
satisfait de l’outil de VL qu’il utilise.
7.3.6 Bénéfices et améliorations des outils de VL
Deux questions ouvertes ont été posées aux participants pour saisir (1) les bénéfices
qu’ils ont retirées suite à l’utilisation de l’outil de VL en main, et (2) les principales
améliorations qui à leur avis, devraient être apportées à cet outil.
De façon générale, les patrons que nous avons détectés pour les bénéfices, et qui se
répétaient pour plusieurs des outils sont les suivants:
• Économie de temps (en effectuant une certaine tâche sur le SLV) (15 outils de VL)
• Meilleure compréhension (6 outils de VL)
• Augmentation de la productivité (vitesse de développement, etc.) (4 outils de VL)
• Gestion de la complexité (4 outils de VL)
• Aide à trouver des erreurs dans le code (3 outils de VL)
• Amélioration de la qualité (code, processus, etc.) (3 outils de VL)
• Économie financière (2 outils de VL)
D’autres bénéfices spécifiques à un seul outil ont aussi été évoqués. Par ailleurs, des avis
plus généraux non liés à un outil bien particulier ont aussi été précisés: (1) l’utilisation

80
de la VL rend le programmeur plus efficace, elle permet une économie de temps en
permettant un accès rapide au code dans des fichiers de grande taille, (2) la VL assiste
dans les phases suivantes: conception, implantation, maintenance, débogage, (3) en
général, les outils de VL rendent le génie logiciel une tâche facile et agréable.
Pour ce qui est des améliorations, la plupart – mais non pas toutes – ne sont qu’une
répétition des aspects et fonctionnalités cités tout le long de la partie I du questionnaire,
avec quelques aspects additionnels (qui ont été compilés et présentés comme patrons
dans la section 7.3.4.1). Certains répondants souhaitaient avoir ces propriétés (si elles
n’existaient pas dans l’outil) et d’autres souhaitaient avoir une amélioration de ces
propriétés (si elles existaient déjà dans l’outil). Quelques nouveaux aspects ont tout de
même été évoqués:
• Fournir un système d’aide (5 outils de VL)
• Adapter l’outil de VL à la compilation (4 outils de VL)
• Ajouter plus de fonctionnalités à l’outil de VL (3 outils de VL)
Le rapport [Bassil00b] donne des détails sur les bénéfices et améliorations proposés par
outil.
7.4 Analyse de la partie II
7.4.1 Aspects techniques des outils de VL
La partie II du questionnaire a été remplie par 41 participants pour un total de 24 outils
de VL différents. 16 des outils sont commerciaux, alors que huit sont des prototypes de
recherche. De plus, nous notons que 12 outils sont formés d’un seul grand outil, alors
que les 12 autres sont formés de plusieurs outils.
Les buts pour lesquels les outils peuvent être utilisés ont été demandés. Il semble que la
plupart des outils (18 des 24 outils) sont utilisés dans un but de compréhension des SLV.
Juste après, viennent le but d’analyse avec 17 outils puis les deux buts: maintenance et
ajout de nouvelles fonctionnalités avec pour chacun 16 outils. Le but le moins cité était

81
la conception avec juste quatre outils (Rational Rose [RationalRose00], Rhapsody
[Rhapsody00], Together/J [TogetherJ00], et UML Studio [UMLStudio00]). Au total, dix
participants ont profité de l’option “autre” pour spécifier d’autres buts pour lesquels
l’outil peut-être utilisé. Le participant de The Paislei IDE [PaisleiIDE00], par exemple, a
mentionné que l’outil est utilisé pour la conception et la visualisation de grammaires.
Les participants de aiSee [aiSee00] ont précisé les deux buts suivants: “pour vendre des
systèmes complexes” et “enseignement”. Les participants de Clarion [Clarion00], Grasp
[Grasp00] et UltraEdit [UltraEdit00] ont rajouté “création de code, développement et
écriture” comme but. Ce dernier but, quoique non précisé, est aussi supporté par d’autres
outils. Un exemple évident serait Emacs [Emacs99]. Finalement, le but “reverse
engineering” a été cité à plusieurs reprises et ceci pour les outils: UML Studio
[UMLStudio00], Fujaba [Fujaba98] et PBS [PBS98]. Nous sommes certains que,
quoique non précisé par les participants correspondants, d’autres outils (ex. SHriMP
[SHriMPage00], Rigi [Rigi00], etc.) couvrent aussi ce but.
Les deux styles les plus utilisés pour la spécification de la visualisation sont:
“automatique à partir du code source directement” (13 outils) et “utilisation d’un outil
d’édition graphique” (13 outils). Notons que pour certains des outils, plusieurs styles ont
été indiqués.
16 des 24 outils font partie d’un (ou bien sont des) environnement(s) de développement
de logiciel. Notons que dans la partie I, cet aspect a été fortement souhaité par les
participants. Par conséquent, nous sommes optimistes par rapport au résultat obtenu ici.
La dernière question de la section sur les renseignements techniques sur les outils de VL
demandait de préciser le(s) langage(s) de programmation dans lequel (lesquels) le SLV
peut être écrit. Nous remarquons que la plupart (17) des outils acceptent des systèmes
écrits en différents langages. Il est intéressant de noter que l’aspect pratique P10
correspondant à la “visualisation de logiciels écrits en langages différents” n’a pas été
classifié parmi les six aspects pratiques les plus importants (voir section 7.3.4.1). Les
sept outils restant soit qu’ils acceptent des systèmes écrits dans juste un des langages

82
suivants: C++, Pascal ou Java, soit qu’ils requièrent un traducteur approprié pour créer
des fichiers de format spécifique (ex. le graph description language pour VCG
[VCG95a], ou bien le term representation pour daVinci [daVinci00]). Nous remarquons
que la plupart des outils de VL visualisent surtout des systèmes orientés objet (Java et
C++). En effet, 20 des 24 outils supportent l’un ou l’autre de ces deux langages, ou bien
les deux.
7.4.2 Support de l’analyse du code par l’outil de VL
Dans la deuxième section de la partie II, nous étions intéressés par les capacités des
outils de VL pour l’analyse du code du SLV. Comme nous l’avons déjà précisé à la
section 5.2.2.2, le questionnaire couvre les sept aspects principaux: (1) appels de
fonctions, (2) clonage de fonctions, (3) graphes d’héritage, (4) graphes d’architecture de
sous-ensemble, (5) différents niveaux de détail, (6) métriques, et (7) versions multiples.
Ces aspects sont raffinés dans 24 sous-aspects. Dans les sous-sections qui suivent nous
expliquerons d’abord la procédure utilisée pour traiter des réponses multiples
(section 7.4.2.1). Puis, dans la section 7.4.2.2, nous discuterons quelques résultats pour
le support de l’analyse du code pour l’ensemble des 24 outils examinés.
7.4.2.1 Traitement de réponses multiples
Pour six outils, parmi les 24 couverts par les 41 participants, nous avons reçu plus d’une
seule réponse. Ces outils sont les suivants (avec le nombre de participants entre
parenthèses):
• Grasp [Grasp00] (6)
• pcGrasp [Grasp00] (5)
• aiSee [aiSee00] (5)
• PBS [PBS98] (3)
• Rational Rose [RationalRose00] (2)
• Software through Pictures [SoftwareThroughPictures98] (2)
Il n’est pas étonnant de voir apparaître, pour chacun de ces six outils, quelques réponses
contradictoires aux différents sous-aspects. Afin d’obtenir pour chaque sous-aspect et

83
chaque outil une seule réponse, nous avons procédé en deux étapes. Dans un premier
temps, nous avons défini cinq heuristiques pour passer d’un ensemble de réponses
contradictoires à une seule réponse (“#” signifie le nombre d’éléments; “y”, “n”, “!” et
“?” correspondent respectivement à “oui”, “non”, “non/je ne sais pas, mais je
souhaiterais cette propriété”, et “ne sais pas/non applicable”; finalement, “yn” indique
que l’aspect est plus ou moins supporté par l’outil):
(1) (#y = 1 ∧ #n = 1) ∨ (#y > 1 ∧ #n > 1) � yn(2) [(#y ≤ 1 ∧ #n > 1) ∨ (#y = 0 ∧ #n = 1)] ∧ #! = 0 � n(3) (#y > 1 ∧ #n ≤ 1) ∨ (#y = 1 ∧ #n = 0) � y(4) [(#y < #n) ∨ (#y = 0 ∧ #n = 0)] ∧ #! ≥ 1 � !(5) #y = 0 ∧ #n = 0 ∧ #? ≥ 1 ∧ #! = 0 � ?
Après avoir appliqué ces heuristiques, nous sommes arrivés à quatre réponses “yn”.
Certaines restrictions (tableau 5) ont été violées par deux des quatre réponses “yn”. Par
conséquent, comme deuxième étape, nous avons essayé d’éliminer toutes les réponses
“yn”, en examinant étroitement le sous-aspect ainsi que la documentation liée à l’outil
de VL en main, et dans un cas, en consultant un participant connu. (Pour plus de détails
sur la procédure, référez-vous à [Bassil00c].)
7.4.2.2 Résultats pour le support de l’analyse du code
D’après nos résultats, parmi les sept aspects principaux, l’aspect lié à l’analyse du code,
supporté par le plus grand nombre d’outils de VL est “la visualisation des appels de
fonctions” (18 outils). L’aspect suivant est “la visualisation de graphes d’héritage
(hiérarchies des classes du système)” (17 outils), vient après, “la visualisation de
différents niveaux de détail simultanément dans des fenêtres séparées” (15 outils). Les
quatre aspects principaux restants sont supportés par moins de 12 outils. Notons qu’à
l’intérieur d’un aspect principal, des sous-aspects plus spécialisés ont été moins
supportés. Ceci a aussi été le cas pour les trois aspects cités ci-haut qui sont supportés
par plus que la moitié des outils de VL.
Les deux aspects les moins supportés par l’ensemble des 24 outils sont “la détection du
clonage de fonctions” (6 outils) et “le calcul de métriques” (5 outils). Quoique non

84
supportés, ces aspects ont rarement été souhaités. En effet, alors que 10 outils ne
supportent pas “la détection du clonage de fonctions”, nous avons juste trois outils pour
lesquels ce sous-aspect a été souhaité. De même pour “le calcul de métriques”, ces deux
nombres sont respectivement huit et trois. Nous nous sommes également rendus compte
qu’un nombre important de participants a répondu “?” pour ces deux aspects. En fait, les
trois aspects les moins connus sont: “le calcul de métriques” avec 7 outils, “la détection
du clonage de fonctions” avec 4 outils, et “la visualisation de graphes d’architecture de
sous-systèmes” avec 4 outils aussi.
Nos résultats suggèrent que les utilisateurs d’outils de VL spécifiques souhaitent souvent
avoir un raffinement des aspects qui sont déjà supportés:7 si un aspect n’existe pas dans
un outil, l’utilisateur de cet outil ressent rarement le besoin de l’avoir; par contre, s’il
existe, il souhaiterait avoir certains des sous-aspects qui lui sont liés. Il n’est donc pas
étonnant de voir apparaître les sous-aspects liés aux deux aspects les plus rencontrés
dans les outils de VL (“visualisation des appels de fonctions” et “visualisation de
graphes d’héritage”) parmi ceux les plus souhaités. Voici, en ordre décroissant, ces sous-
aspects, précédés par l’aspect principal correspondant:
• Appels de fonctions: Présenter comme un tout (dans un même graphe) une chaîne de
récursion complexe (5 outils ne supportent pas ce sous-aspect, et ce sous-aspect a été
souhaité pour 6 outils)
• Graphes d’héritage: Détecter des branches profondes (1 contre 6)
• Graphes d’architecture de sous-systèmes: Pouvoir lier l’architecture aux autres
résultats de l’outil de VL en main (ex. zones de couleurs différentes sur le graphe
d’architecture) (3 contre 5)
• Graphes d’héritage: Détecter un héritage multiple (1 contre 4)
• Appels de fonctions: Représenter par des nœuds les fonctions de la chaîne de
récursion et donner la possibilité d’accéder directement au code source à partir des
nœuds (4 contre 4)
7 Ceci nous rappelle le fameux proverbe français: “L’appétit vient en mangeant!”

85
Parmi les sous-aspects les moins supportés, nous retrouvons “l’élimination des fonctions
récursives simples” (supportées seulement par l’outil The Paislei IDE [PaisleiIDE00]), et
“la réduction de la granularité lors de la détection des différences qui existent dans les
clones d’une fonction” (supportée seulement par Rhapsody [Rhapsody00]). Enfin, aucun
des 24 outils ne permet d’“intégrer les métriques et le code source”.
Nous identifions parmi les 24 outils deux éditeurs de texte: Emacs [Emacs99] et
UltraEdit [UltraEdit00]. Notons que la majorité des sous-aspects liés à l’analyse du code
ne sont pas supportées par ces outils.
7.5 Discussion et perspectives
7.5.1 Améliorations du questionnaire
Comme avec la plupart des questionnaires, il reste toujours des améliorations à faire. Par
exemple, dans une version future du questionnaire, nous voudrions présenter des choix
plus raffinés pour quelques-unes des questions à choix multiples. En outre, puisque nous
avons obtenu beaucoup d’informations intéressantes à partir des questions ouvertes,
nous mettrions probablement encore plus d’emphase sur ce type de question. Par
exemple, pour ce qui est de l’utilité des aspects fonctionnels, des questions ouvertes
auraient pu rapporter des données complémentaires. Une autre amélioration serait de
fournir différentes versions du questionnaire pour différents genres d’outils de VL
(phase de conception, phase de programmation, etc.), pour ainsi obtenir des résultats
plus ciblés.
Pour ce qui est de l’évaluation cognitive des outils de VL, nous nous rendons compte
que, afin d’obtenir des résultats plus significatifs et spécifiques à chaque outil, il aurait
été nécessaire d’avoir plus de participants par outil que nous ne l’avons obtenu dans le
cas de notre enquête. Par ailleurs, un seul participant par outil aurait probablement été
suffisant pour la partie II du questionnaire. Ce participant devrait bien sûr être un vrai
expert de l’outil de VL.

86
7.5.2 Résumé et impact des résultats
En général, les participants étaient satisfaits de l’outil de VL qu’ils utilisent. Des aspects
fonctionnels tels que la recherche et le browsing, l’utilisation de couleurs, et l’accès
facile à partir d’une liste de symboles au code source correspondant, ont été évalués
comme aspects les plus essentiels. Des représentations hiérarchiques ainsi que la
navigation à travers les hiérarchies ont également été fortement désirées,
particulièrement quand le SLV était développé utilisant un langage orienté objet. D’autre
part, la visualisation de code source a été presque toujours souhaitée lorsque le SLV était
procédural. Les trois aspects les moins appréciés, particulièrement dans l’industrie,
étaient les effets d’animation, la visualisation en 3D et les techniques de réalité virtuelle.
Cependant, l’animation a été identifiée comme étant assez utile lorsque le SLV était
implanté utilisant un langage déclaratif.
Concernant les aspects pratiques des outils de VL, nous avons constaté que la fiabilité de
l’outil a été classifiée comme aspect le plus important, suivi de la facilité d’utilisation et
de la facilité de visualiser des logiciels de grande taille. Plusieurs participants ont
également évalué la qualité de l’interface usager comme très importante.
Malheureusement, nous avons trouvé une différence gênante entre la grande importance
accordée aux deux aspects: facilité d’utilisation et qualité de l’interface usager, et la
présence de ces aspects dans les outils de VL utilisés pratiquement. La documentation de
l’outil a également été estimée comme très importante, en termes du contenu, de la
qualité et de la disponibilité on-line. En outre, les participants ont indiqué une liste
intéressante d’aspects supplémentaires désirés. Plusieurs de ces aspects sont associés à
l’intégration des outils de VL dans d’autres outils, tels que des générateurs de code, des
outils de design partitioning, des éditeurs, des outils de métriques, des générateurs et des
gestionnaires de documentation, des schedulers, etc.
Aspects fonctionnels et aspects pratiques, tous les deux ont été influencés par les deux
facteurs: environnement de travail et taille du SLV. De plus, l’utilité des aspects
fonctionnels a aussi été influencée par la taille de l’équipe de travail et le niveau de
connaissance du SLV, aussi bien que par le langage d’implantation et le niveau de

87
complexité du SLV. Rappelons que ces derniers facteurs n’ont eu aucun impact
mesurable sur l’importance des aspects pratiques.
Évidemment, nous avons vérifié que la compréhension du code est considérée comme
élément principal pour effectuer des tâches de maintenance ainsi que d’autres tâches du
cycle de vie d’un logiciel. De plus, un certain nombre de patrons intéressants concernant
les bénéfices et les améliorations des outils de VL ont pu être dérivées.
Pour ce qui concerne les aspects de l’analyse du code, il semble qu’un nombre minime
de ces aspects est supporté par les outils actuels de VL. Parmi les 24 différents aspects,
seulement trois ont été identifiés comme étant supportés par plus que la moitié des outils
pour lesquels nous avons reçu des réponses. Ces trois aspects étaient: la visualisation
d’appels de fonctions, de graphes d’héritage, et de différents niveaux de détail dans des
fenêtres séparés. Les aspects liés au calcul de métriques étaient les moins supportés;
cependant, ils étaient parfois souhaités.
À partir de cette enquête, nous pouvons affirmer que les outils de VL actuels ont
beaucoup d’utilisations, notamment dans le processus de compréhension de logiciel. La
plupart des outils étudiés sont faciles à utiliser et génèrent des résultats utiles. Ces outils
affectent l’approche prise par les utilisateurs pour accomplir une certaine tâche sur le
SLV et présentent un certain nombre de bénéfices citées à la section 7.3.6. Côté
technique, les trois buts - liés aux tâches effectuées sur les SLV - pour lesquels les outils
sont les plus utilisés sont l’analyse de code, la maintenance et l’ajout de nouvelles
fonctionnalités. Un grand nombre de ces outils (1) fait partie d’un environnement de
développement de logiciel, (2) génère la visualisation automatiquement à partir du code
source ou bien via un outil d’édition graphique (3) et accepte des SLV écrits en
différents langages pour la plupart orientés objet.
En général, les utilisateurs sont satisfaits des résultats obtenus en appliquant l’outil de
VL en main. Ils ont indiqué beaucoup d’avantages liés à l’utilisation de cet outil. Les
deux bénéfices les plus cités étaient l’économie de temps en effectuant une certaine

88
tâche, et la meilleure compréhension du SLV. Cependant, beaucoup d’aspects souhaités
et de nombreuses améliorations de l’outil de VL en main ont également été indiqués par
les participants. Sans aucun doute, on s’attendrait à ce que ces éléments soient supportés
par les prochains outils de VL, ou même par les prochaines versions des outils de VL
d’aujourd’hui. Par conséquent, le défi pour les constructeurs des outils de VL futurs est
de fournir des outils qui (1) intègrent d’autres outils complémentaires, (2) rendent
possible d’importer/d’exporter vers d’autres formats d’outil de VL, et (3) sont plus
adaptés au(x) système(s) de compilation utilisé(s) pour le développement de code. Une
liste plus complète des améliorations qui devraient être faites aux outils de VL a été
présentée aux sections 7.3.4.1 et 7.3.6. Ces éléments concernent non seulement les
constructeurs d’outil de VL, mais certains d’entre eux constituent aussi des éléments de
recherche.

Chapitre 8. Conclusion
8.1 Synthèse
La science cognitive met l’emphase sur la force des formalismes visuels pour
l’apprentissage humain et la résolution de problème. En génie logiciel, une visualisation
claire d’un système logiciel aide à réduire l’effort de sa compréhension. L’utilisation
d’outils de VL a donc été proposée afin de fournir l’aide nécessaire pour accomplir
différentes activités liées aux différentes phases du cycle de vie d'un logiciel. Toutefois,
ces outils doivent surtout offrir aux utilisateurs un environnement favorable qui leur
permet avant tout de “comprendre” le système qu’ils ont entre les mains. Cependant,
nous manquons d’information sur les impacts positifs et les limitations de ce genre
d’outils. De plus, les propriétés désirées de tels outils n'ont guère été étudiées. Le travail
qui est décrit dans ce mémoire a donc commencé par identifier et évaluer
qualitativement des outils de VL. Suite à cette première étape, un catalogue d’aspects
fonctionnels, pratiques et cognitifs, ainsi que d’aspects liés à l’analyse de code, a été
créé pour ainsi former un questionnaire dont le but principal est de connaître les impacts
positifs et les limitations des outils de VL, ainsi que d’identifier les propriétés désirées
par les utilisateurs de tels outils.
8.1.1 Inventaire d’outils de VL et évaluation qualitative
Comme première étape dans ce travail, nous avons identifié une liste d’outils de VL à
partir de laquelle nous avons retenu sept outils que nous avons décrits. Le critère sur
lequel nous nous sommes basés pour l’identification de ces outils est le suivant: “un
outil de VL est tout outil qui aide d’une façon ou d’une autre à la compréhension de
logiciel.” Il n’était donc pas nécessaire que l’outil présente du graphisme comme le

90
suggèrent beaucoup des définitions rencontrées dans la littérature. Suite à l’étude de ces
outils, nous avons pu tirer un ensemble de conclusions comparant les deux catégories
d’outils (outils académiques et outils commerciaux). Cette liste se trouve à la section
3.4.
Les sept outils retenus et étudiés ont été par la suite évalués en utilisant la taxonomie de
Price et al. Cette taxonomie s’est avérée la plus complète parmi l’ensemble des
taxonomies que nous avons étudiées (section 2.5). Suite à notre évaluation, nous avons
remarqué qu’un grand nombre des caractéristiques de la taxonomie de Price et al.
requièrent une évaluation subjective des outils de VL. C’est d’ailleurs le point faible de
cette taxonomie. De plus, elle ne tient pas compte des aspects cognitifs d’un outil de VL,
qui ont cependant été traités de façon exclusive dans la taxonomie de Storey et al. Par
conséquent, nous pensons qu’une taxonomie qui regroupe à la fois des éléments de la
science cognitive ainsi que des aspects concrets d’outil de VL serait souhaitable pour la
communauté de personnes travaillant sur la VL.
Cette première étape du travail nous a permis d’évaluer de façon formelle un ensemble
d’outils de VL. Cependant, tel qu’il a déjà été précisé, l’évaluation de ces outils se faisait
le plus souvent de façon subjective. Pour remédier à cela, une enquête (évaluation
quantitative) sur les outils de VL, via un questionnaire, s’est avérée nécessaire.
8.1.2 Évaluation quantitative
Comme deuxième étape de notre travail, une enquête sur les outils de VL a été
développée, et elle a permis de recueillir le point de vue d’une centaine d’utilisateurs
travaillant sur différents outils de VL. Elle a aussi permis d’identifier les besoins réels de
ces utilisateurs.
Nous avons donc commencé par créer un catalogue de propriétés des outils de VL en
nous basant surtout sur les différents travaux qui ont été effectués dans le domaine de la
VL. A partir de ce catalogue, un certain nombre de questions ont été formulées, avec
toujours comme intérêt principal l’identification des propriétés désirables (ou non)

91
d’outils de VL, ainsi que l’évaluation de leurs capacités à réduire l’effort de la
compréhension de logiciel et de l’évaluation de conception. Plusieurs itérations ont été
nécessaires avant d’arriver à une version stable du questionnaire. Finalement, le
questionnaire a été mis on-line. Nous avons discuté au chapitre 6 l’implantation
technique du questionnaire tout en mettant l’emphase sur les techniques récentes liées à
la collecte d’informations à partir du web.
Plusieurs résultats intéressants ont été générés à partir de cette enquête. La section 7.5.2
discute en résumé les points les plus intéressants que nous avons tirés. En bref, un
ensemble d’aspects fonctionnels ont été retenus comme aspects très essentiels dans un
outil de VL. Certains facteurs ont influencé la classification de ces aspects. Il en était de
même pour l’importance accordée à un ensemble d’aspects pratiques. Malheureusement,
une différence gênante a été trouvée entre la grande importance accordée à certains de
ces aspects et leur présence dans les outils de VL utilisés en pratique. En outre, les
participants ont indiqué une liste intéressante d’aspects supplémentaires désirés.
Évidemment, nous avons vérifié que la compréhension du code est considérée comme
élément clé pour effectuer des tâches du cycle de vie d’un logiciel. De plus, un certain
nombre de bénéfices et d’améliorations des outils de VL ont pu être tirés. Pour ce qui
concerne les aspects de l’analyse du code, un nombre minime de ces aspects est supporté
par les outils actuels de VL. Bref, cette enquête nous a permis d’affirmer que les outils
de VL ont beaucoup d’utilisations, notamment dans le processus de compréhension de
logiciel.
8.2 Travaux futurs
Il y a deux directions principales dans lesquelles il serait souhaitable de continuer cette
étude. La première direction proposera une étude multi-phases des outils de VL
[Cooper95] pour ainsi compléter nos résultats actuels, alors que la deuxième direction
touchera de plus prés le processus d’évaluation de la qualité logicielle chez Bell Canada.
Tout d’abord, en profitant des résultats déjà recueillis à partir du questionnaire (chapitre
7), ainsi que des améliorations qui lui ont été proposées à la section 7.5.1, et par

92
l'intermédiaire de techniques d’études multi-phases [Cooper95], il va falloir
tenter d’identifier la population cible représentative pour différentes questions d’une
nouvelle enquête. Suite à cette identification, il va falloir essayer de tester un certain
nombre d’hypothèses, soit pour les accepter, soit pour les rejeter. Cette vérification
d’hypothèses se fera en ayant recours à des techniques statistiques standards telles que
celles déjà utilisées pour analyser les données collectées via le questionnaire actuel.
Comme deuxième direction des travaux futurs, les métaphores, techniques et outils de
VL déjà trouvés (tableau 1 de la section 3.2 et liste on-line des outils de VL8) et évalués
de façon qualitative et quantitative pendant les différentes phases de ce travail (chapitres
4 et 7 et première direction des travaux futurs) devront être reportés dans le processus
d’évaluation de la qualité logicielle chez Bell Canada, pour ainsi évaluer leur impact
positif et leurs limitations. Il va falloir chercher des synergies pour la visualisation de
l’impact de changement, des slices orientés objet, des patrons de conception, etc. Il va
falloir aussi étudier comment la visualisation peut guider l’évaluation quantitative d’un
logiciel, tel que la mesure de sa changeabilité et de son évolution.
8 Une liste complète des noms et références web des outils de VL pour lesquels nous avons reçu une ou
plusieurs réponses au questionnaire peut être trouvée à l’adresse suivante: <http://www.iro.umontreal.ca
/labs/gelo/sv-survey/list-of-tools.html>.

Bibliographie
[aiSee00] aiSee (AbsInt Angewandte Informatik GmbH). On-line at <http://www.absint.de/aisee.html>.
[Baecker75] Baecker, R. M., Two systems which produce animated representations of theexecution of computer programs. ACM SIGCSE Bulletin 7, pp. 158 - 167,1975.
[Baecker81] Baecker, R. M., Sorting Out Sorting. Morgan Kaufmann, Los Altos,California, Narrated colour videotape, 30 minutes, presented at ACMSIGCRAPH’81 and excerpted in ACM SIGGRAPH Video Review No. 7,1981.
[Baecker90] Baecker, R. M., and Marcus, A., Human factors and typography for morereadable programs. Addison-Wesley, Reading, Massachusetts, 1990.
[Barr96] Barr, J., Product review “Discover 3.0”. Software Development Magazine,March 1996. On-line at <http://www.sdmagazine.com/articles/1996/0003/0003n/0003n.htm>.
[Bassil00a] Bassil, S., and Keller, R., Inventaire d’outils de visualisation logicielle.Technical Report GELO-131, Université de Montréal, September 2000.
[Bassil00b] Bassil, S., and Keller, R., Analyse du questionnaire sur les outils devisualisation logicielle – Partie I. Technical Report GELO-132, Université deMontréal, September 2000.
[Bassil00c] Bassil, S., and Keller, R., Analyse du questionnaire sur les outils devisualisation logicielle – Partie II. Technical Report GELO-133, Universitéde Montréal, September 2000.
[Bassil01] Bassil, S., and Keller, R. K., Software visualization tools: Survey andanalysis. In Proceedings of the 9th International Workshop on ProgramComprehension (IWPC’01), Toronto, Ontario, Canada, May 2001. IEEE. Toappear.
[Bellay97] Bellay, B., and Gall, H., A comparison of four reverse engineering tools. InProceedings of the 4th Working Conference on Reverse Engineering(WCRE’96), Amsterdam, The Netherlands, pp. 2 - 11, 1997.
[Brooks83] Brooks, R., Towards a theory of the comprehension of computer programs.International Journal of Man-Machine Studies, 18 (6), pp. 543 - 554, 1983.

94
[Brown84] Brown, M. H., and Sedgewick, R., A system for algorithm animation.Proceedings of ACM SIGGRAPH’84 ACM Press, New York, pp. 177 – 186,1984
[Brown88] Brown, M. H., Exploring algorithms using Balsa-II. IEEE Computer, 21 (5),pp. 14 - 36, 1988.
[Brown93] Brown, M. H., and Najork, M. A., Algorithm animation using 3D interactivegraphics. DIGITAL, Systems Research Center, September 1993. On-line at<http://www.research.digital.com/SRC/publications/src-rr.html>.
[Burd96] Burd, E. L., Munro, M., and Young, P. J., The shape of software to come: Areview of preliminary investigations of the Visualisation Research Group. InProceedings of the 2nd UK Program Comprehension Workshop, Durham,1996.
[Cain99] Cain, J. W., and McCrindle, R. J., Software visualisation using C++ Lenses.In 7th International Workshop on Program Comprehension (IWPC’99), pp. 20– 26, Pittsburgh, Pennsylvania, USA, May 1999.
[CGDI96] Call Graph Drawing Interface Page. On-line at <http://www.ida.liu.se/~vaden/cgdi/>.
[CGI00] CGI Documentation. On-line at <http://stein.cshl.org/WWW/software/CGI/cgi_docs.html>.
[Clarion00] Clarion by SoftVelocity. On-line at <http://www.softvelocity.com/products/products.htm>.
[Cooper95] Cooper, D. R., and Schindler, P. S., Business research methods.Irwin/McGraw-Hill, sixth edition, 1995.
[Datrix99] Bell Canada. DATRIX abstract semantic graph – reference manual. Montreal,Quebec, Canada. January 1999. Available on request from<[email protected]>.
[daVinci00] The Graph Visualization System daVinci. On-line at <http://www.informatik.uni-bremen.de/daVinci/>.
[Desmarais94] Desmarais, M., Hayne, C., Jagannath, S., and Keller, R. K., A survey on userexpectations for interface builders. In Proceedings of the Conference onHuman Factors in Computing Systems (Conference Companion), pp. 279 –280, Boston, MA, April 1994. ACM.
[Discover00] Discover information set. On-line at <http://www.upspringsoftware.com/products/discover/index.html>.
[Domingue92] Domingue, J., Price, B. A., and Eisenstadt, M., A framework for describingand implementing software visualization systems. In Proceedings of GraphicsInterface’92, pp. 53 - 60, Vancouver, Canada, May 1992. On-line at <ftp://watson.open.ac.uk/pub/documents/Domingue-Viz-GI92.ps.Z>.
[Emacs99] GNU Emacs (Free Software Foundation) <http://www.gnu.org/software/emacs/emacs.html>.

95
[Fairchild88] Fairchild, K. M., Poltrock S. E., and Furnas, G. W., Semnet: Three-dimensional graphic representations of large knowledge bases. In CognitiveScience and Its Applications for Human-Computer Interaction, Fairlawn, NJ:Lawrence Erlbaum Associates, 1988. On-line at <http://panda.iss.nus.sg:8000/kids/fair/webdocs/semnet/semnet-1.hml>.
[FrontPage00] Microsoft Office – Microsoft FrontPage. On-line at <http://www.microsoft.com/frontpage/>.
[Fujaba98] Fujaba Homepage. On-line at <http://www.uni-paderborn.de/fachbereich/AG/schaefer/ag_dt/PG/Fujaba/>.
[Goldstein47] Goldstein, H. H., and Von Neumann, J., Planning and coding problems of anelectronic computing instrument. In Von Neumann, J., Collected Works (A.H. Taub, ed.) McMillan, New York, pp. 80 - 151, 1947.
[GraphViz00] GraphViz (AT&T Labs-Research). On-line at <http://www.research.att.com/sw/tools/graphviz/>.
[Grasp00] Grasp: Graphical Representations of Algorithms, Structures, and Processes.On-line at <http://www.eng.auburn.edu/department/cse/research/grasp/>.
[Green00] Green, S. B., Salkind, N. J., and Akey, T. M., Using SPSS for Windows:Analyzing and understanding data. Prentice-Hall Inc., second edition, 2000.
[GV3D95] The GraphVisualizer3D project. On-Line project overview, University ofNew Brunswick, 1995. On-line at <http://www.omg.unb.ca/hci/projects/hci-gv3D.html>.
[Haibt59] Haibt, L. M., A program to draw multi-level flow charts. In Proceedings of theWestern Joint Computer Conference. San Francisco, California, pp. 131 - 137,1959.
[Harel92] Harel, D., Biting the silver bullet. Toward a brighter future for systemdevelopment. IEEE Computer, 25(1), pp. 8 - 20, January 1992.
[Hendley95] Hendley, R. J., Wood, A. M., Beale, R., and Drew, N. S., Narcissus:Visualising information. University of Birmingham, 1995. On-line at <ftp://ftp.cs.bham.ac.uk/pub/authors/R.J.Hendley/ieeeviz.ps.Z>.
[Hueras77] Hueras, J., and Ledgard, H., An automatic formatting program for Pascal.ACM SIGPLAN Notices, 12 (7), pp. 82 - 84, 1977.
[Jagannath93] Jagannath, S., Questionnaire sur les outils de développement de l’interfaceusager. Centre de Recherche Informatique de Montréal (CRIM), October1993. Available also in English.
[JavaScript99] JavaScript Documentation. On-line at <http://developer.netscape.com/docs/manuals/index.html?content=javascript.html>.
[Jerding94] Jerding, D. F., and Stasko, J. T., Using visualisation to foster object-orientated program understanding. GVU Center, College of Computing,Georgia Institute of Technology, Technical Report GIT-GVU-94-33, July1994. On-line at <ftp://ftp.cc.gatech.edu/pub/gvu/tech-reports/94-33.ps.Z>.

96
[Keller95] Keller, R. K., User interface tools: A survey and perspective. In R. N. Taylorand J. Coutaz, editors, Software Engineering and Human-ComputerInteraction, pp. 225-231, 1995. Springer. LNCS 896.
[Keller99] Keller, R. K., Schauer, R, Robitaille, S., and Pagé, P., Pattern-based reverseengineering of design components. In Proceedings of the 21st InternationalConference on Software Engineering (ICSE’99), pp. 226 - 235, Los Angeles,CA, USA, May 1999.
[Kings95] Kings, N. J., Software visualisation. BT Corporate Research Programme,1995.
[Knowlton66a] Knowlton, K. C., L6: Bell telephone laboratories low-level linked listlanguage. Technical Information Libraries, Bell Laboratories, Inc., MurrayHill, New Jersey, 16 mm black and white sound film, 16 minutes, 1966.
[Knowlton66b] Knowlton, K. C., L6: Part II. An example of L6 programming. TechnicalInformation Libraries, Bell Laboratories, Inc., Murray Hill, New Jersey, 16mm black and white sound film, 30 minutes, 1966.
[Koike95] Koike Labs, VisuaLinda: 3D visualisation of parallel Linda programs. On-Line Project Abstract, Koike Labs, University of Electro-Communications inTokyo, 1995. On-line at <http://www.vogue.is.uec.ac.jp/vlinda.html>.
[Kolbeck97] Kolbeck, R. (traducteurs Reitz, F., Consavela, J.-C., et Elie, J.-P.) JavaScript.Micro Application, Paris, France, Collection Grand Livre, 1997.
[Kraemer93] Kraemer, E., and Stasko, J. T., The visualisation of parallel systems: Anoverview. Journal of Parallel and Distributed Computing, (18), pp. 105 - 117,1993.
[Ledgard75] Ledgard, H. F., Programming proverbs. Hayden, Rochell Park, New Jersey,1975.
[Lethbridge00] Lethbridge, T. C., What knowledge is important to a software professional?IEEE Computer, 33(5), pp. 44-50, May 2000.
[Lethbridge97] Lethbridge, T., and Singer, J., Understanding software maintenance tools:Some empirical research. In Workshop on Empirical Studies of SoftwareMaintenance (WESS’97), pp. 157 - 162, Bari, Italy, October 97.
[Linos93] Linos, P., Aubet, L., Dumas, Y., Helleboid, P., Lejeune, P., and Tuluba, P.Facilitating the comprehension of C programs: An experimental study. In 1st
International Workshop on Program Comprehension (IWPC’93), pp. 55 - 63,1993.
[Mayrhauser95] von Mayrhauser, A., and Vans, A. M., Program comprehension duringsoftware maintenance and evolution. IEEE Computer, 28(8), pp. 44-55,August 1995.
[Michail98] Michail, A., and Notkin, D., Illustrating object-oriented library reuse byexample: A tool-based approach. In 13th International Conference onAutomated Software Engineering (ASE’98), pp. 200 - 203, IEEE ComputerSociety Press, 1998.

97
[Miller93] Miller, B. P., What to draw? When to draw? An essay on parallel programvisualisation. Journal of Parallel and Distributed Computing, (18), pp. 258 -264, 1993.
[Mulholland95] Mulholland, P., A framework for describing and evaluating softwarevisualization systems: A case-study in Prolog. PhD Thesis, Knowledge MediaInstitute, The Open University, UK, 1995.
[Müller88] Müller, H., and Klashinsky, K., Rigi – A system for programming-in-the-large. In Proceedings of the 10th International Conference on SoftwareEngineering (ICSE’10), Singapore, pp. 80 – 86, April 1988.
[Muthukumarasamy95]Muthukumarasamy J., and Stasko, J. T., Visualising program executions onlarge data sets using semantic zooming. GVU Center, College of Computing,Georgia Institute of Technology, Technical Report GIT-GVU-95-02, 1995.On-line at <ftp://ftp.cc.gatech.edu/pub/gvu/tech-reports/95-02.ps.Z>.
[Myers90] Myers, B. A., Taxonomies of visual programming and program visualisation.Journal of Visual Languages and Computing, (1), pp. 97 - 123, 1990.
[Myers92] Myers, B. A., and Rosson, M. B., Survey on user interface programming. InProceedings of the Conference on Human Factors in Computing Systems(CHI’92), pp. 195-202, Monterey, CA, USA, May 1992.
[Norušis88] Norušis, M. J., The SPSS guide to data analysis for SPSSx. SPSS Inc.,Chicago, Illinois, 1988.
[PaisleiIDE00] The Paislei IDE and Laleh’s Pattern Matcher. On-line at <http://qtj.dhs.org/~lpm/>.
[PBS98] PBS (Portable Bookshelf). On-line at <http://www.turing.toronto.edu/pbs/>.
[Perl00] The Source for Perl, O’Reilly and Associates, Inc. On-line at <http://www.perl.com>.
[Price93] Price, B. A., Baecker, R. M., and Small, I. S., A principled taxonomy ofsoftware visualisation. Journal of Visual Languages and Computing, No. 4,pp. 211 - 266, 1993. On-line at <http://www-cs.open.ac.uk/~doc/jvlc/JVLC-Body.html>.
[PVMTrace95] The PVMTrace project. On-Line thesis proposal, University of NewBrunswick, 1995. On-line at <http://www.omg.unb.ca/hci/projects/hci-pvmtrace.html>.
[Rajlich94] Rajlich, V., Doran, J., and Gudla, R. T. S., Layered explanations of software:A methodology for program comprehension. In 2nd International Workshop onProgram Comprehension (IWPC’94), pp. 46 - 52, Washington, D.C., USA,1994.
[RationalRose00] Rational Rose. On-line at <http://www.rational.com/products/rose/index.jsp>.
[Reiss94] Reiss, S. P., 3-D Visualization of program information. In Proceedings ofGD’94: DIMACS International Workshop on Graph Drawing, pp. 12 - 24,Princeton, New Jersey, USA, October 1994.

98
[Rhapsody00] Rhapsody (I-Logix). On-line at <http://www.ilogix.com/>.
[Rigi00] Rigi: A Visual Tool For Understanding Legacy Systems. On-line at<http://www.rigi.csc.uvic.ca/>.
[Robitaille00] Robitaille, S., Schauer, R., and Keller, R. K., Bridging programcomprehension tools by design navigation. In Proceedings of the InternationalConference on Software Maintenance (ICSM’00), pp. 22 - 32, San Jose, CA,USA, October 2000.
[Roman92] Roman, G., and Cox, K. C., Program visualization: The art of mappingprograms to pictures. Department of Computer Science, WashingtonUniversity, 1992.
[Roman93] Roman, G., and Cox, K. C., A taxonomy of program visualisation systems.IEEE Computer, December 1993.
[Scanlan89] Scanlan, D. A., Structured flowcharts outperform pseudocode: Anexperimental comparison. IEEE Software, 6 (5), pp. 28 – 36, Septembre 1989.
[Schauer98] Schauer, R., and Keller, R. K., Pattern visualization for softwarecomprehension. In 6th International Workshop on Program Comprehension(IWPC’98), pp. 153 - 160, Ischia, Italy, June 1998.
[Shneiderman80] Shneiderman, B., Software psychology. Cambridge MA: Winthrop PublishersInc., 1980.
[SHriMPage00] SHriMPage. On-line at <http://www.csc.uvic.ca/~wjw/shrimpage.html>.
[SNiFF+00] SNiFF+ (TakeFive). On-line at <http://www.takefive.com/products/sniff+.html>.
[SoftwareThroughPictures98]Software through Pictures (Aonix). On-line at <http://www.aonix.com/Products/SMS/softbench_integ.html>.
[SPSS00] SPSS Statistical Package for the Social Sciences. On-line at <http://www.spss.com/>.
[Srinivasan96] Srinivasan, S. Advanced Perl Programming. O’Reilly and Associates,Sebastapol, California, 1996.
[Stasko92] Stasko, J. T., and Patterson, C., Understanding and characterizing softwarevisualisation systems. In Proceedings of the IEEE 1992 Workshop on VisualLanguages, Seattle, Washington, pp. 3 - 10, 1992.
[Stasko93] Stasko, J. T., and Wehrli, J. F., Three-dimensional computation visualisation.In Proceedings of IEEE/CS Symposium on Visual Languages, Bergen,Norway, pp. 24 - 27, 1993
[Steckel92] Steckel, M., Brade, K., Guzdial, M., and Soloway, E., Whorf: A visualizationtool for software maintenance. In Proceedings 1992 IEEE Workshop onVisual Languages, Seattle, Washington, pp. 148 - 154, 1992.

99
[Storey95] Storey, M.-A. D., and Müller, H. A., Manipulating and documenting softwarestructures using SHriMP views. In Proceedings of ICSM’95, pp. 275 - 284,Opio (Nice), France, October 17 - 20, 1995.
[Storey96] Storey, M.-A. D., Wong, K., Fong, P., Hooper, D., Hopkins, K., and Müller,H. A., On designing an experiment to evaluate a reverse engineering tool. InProceedings of the 3rd Working Conference on Reverse Engineering(WCRE’96), Monterey, California, pp. 31 - 40, 1996.
[Storey97] Storey, M.-A. D., Wong, K., and Müller, H. A., How do programunderstanding tools affect how programmers understand programs? InProceedings of the 4th Working Conference on Reverse Engineering(WCRE’97), pp. 12 - 21, Amsterdam, Holland, October 1997.
[Storey99] Storey, M.-A. D., Fracchia, F. D., and Müller, H. A., Cognitive designelements to support the construction of a mental model during softwareexploration. Journal of Systems and Software, 44 (3), pp. 171 - 185, January1999.
[Swan95] The Swan User’s Manual. On-line at <http://geosim.cs.vt.edu/Swan/manual.pdf>.
[Tilley97] Tilley, S. R., Discovering Discover. Technical Report CMU/SEI-97-TR-012,Pittsburgh, PA, October 1997. On-line at <http://www.sei.cmu.edu/publications/documents/97.reports/97tr012/97tr012title.htm>.
[TkSee96] TkSee (Knowledge-Based Reverse Engineering). On-line at <http://www.site.uottawa.ca/~tcl/kbre/>.
[TogetherJ00] TogetherSoft: Together/J. On-line at <http://www.togethersoft.com/together/togetherJ.html>.
[TomSawyer00a] Tom Sawyer Software: Products and Solutions documentation set. On-line at<http://www.tomsawyer.com/literature/index.html>.
[TomSawyer00b] Tom Sawyer Software: Product Demonstrations. On-line at <http://www.tomsawyer.com/download-soft.html>.
[UltraEdit00] UltraEdit (IDM Computer, Solutions, Inc.). On-line at <http://www.idmcomp.com/products/index.html>.
[UMLStudio00] Stringray UML Studio Product Page. On-line at <http://www.stingray.com/products/umlstudio/>.
[VCG95a] VCG Overview. On-line at <http://www.cs.uni-sb.de/RW/users/sander/html/gsvcg1.html>.
[VCG95b] VCG Documentation. On-line at <ftp://ftp.cs.uni-sb.de/pub/graphics/vcg/doc/vcgdoc.ps.gz>.
[VGJ98] Manual for VGJ. On-line at <http://www.eng.auburn.edu/department/cse/research/graph_drawing/manual/vgj_manual.html>.
[VRG96] Visualisation Research Group. On-line at <http://www.dur.ac.uk/~dcs0elb/visual/>.

100
[Wall97] Wall, L., Christiansen, T., and Schwartz, R. L. Programming Perl. O’Reillyand Associates, Sebastapol, California, 1997.
[Ware93] Ware, C., Hui, D., and Franck, G., Visualizing object oriented software inthree dimensions. In Proceedings of CASCON’93 (IBM Centre for AdvancedStudies), pp. 612 - 620, Toronto, Ontario, Canada, October 1993. On-line at<http://www.omg.unb.ca/hci/papers/IBM-CAS93-visualizing.ps.gz>.
[Watson95] Watson, A. B., and Buchanan, J. T., Towards supporting softwaremaintenance with visualisation techniques. Technical Report R5, Universityof Strathclyde, 1995.
[Weiser84] Weiser, M., Program slicing. IEEE Transactions on Software Engineering, SE- 10 (4), pp. 352 – 357, July 1984.
[Williams92] Williams, F., Reasoning with statistics: How to read quantitative research.Harcourt Brace College Publishers, fourth edition, 1992.
[xSuds98] Telcordia Software Visualization and Analysis Toolsuite documentation set.On-line at <http://xsuds.argreenhouse.com/manual.html>.
[Young96a] Young, P., Program comprehension, Internal Report, Centre for SoftwareMaintenance. University of Durham, May 1996. On-line at <http://www.dur.ac.uk/~dcs3py/pages/work/Documents/index.html>.
[Young96b] Young, P., Software visualisation. Internal Report, Centre for SoftwareMaintenance, University of Durham, June 1996. On-line at <http://www.dur.ac.uk/~dcs3py/pages/work/Documents/index.html>.

Annexe A. Description de la taxonomie de Price et al.
Cette annexe donne une explication brève des différentes propriétés de la taxonomie de
Price et al. [Price93]. Ces explications sont présentées sous forme de questions se
rapportant à chacune des six catégories de la hiérarchie ainsi qu’aux sous-niveaux qui
leur sont liés.
A. Scope (intervalle de logiciels qui peuvent être visualisés)
Quel est l’intervalle de logiciels que l’outil de VL peut prendre comme une entrée pour
la visualisation?
A.1. Generality
L’outil peut-il manipuler un intervalle généralisé de logiciels ou bien affiche-t-il un
ensemble fixe d’exemples?
Note 1: un outil généralisé peut générer des visualisations de logiciels arbitraires à
l’intérieur d’une classe particulière. Il va d’habitude avoir quelques restrictions régissant
ses possibilités (A.1.1. à A.1.4.).
Note 2: un outil exemple affiche une visualisation d’algorithmes particuliers, de
systèmes particuliers ou d’ensemble particulier de logiciels existants.
A.1.1. Hardware
Sur quel hardware s’exécute-t-il?
A.1.2. Operating System
Sur quel système d’exploitation s’exécute-t-il?

ii
A.1.3. Language
Dans quel langage de programmation les logiciels de l’utilisateur devront être écrits?
A.1.3.1. Concurrency
Si le langage de programmation supporte la concurrence, l’outil de VL peut-il visualiser
les aspects concurrents?
A.1.4. Applications
Quelles sont les restrictions sur le genre de logiciels utilisateurs qui peuvent être
visualisés? Ex. des algorithmes de tri, n’importe dans un langage bien particulier,
n’importe, graphe, liste, etc.
A.1.4.1. Specialty
Quel genre de logiciel se prête particulièrement bien à la visualisation (par opposition à
simplement capable d’être visualisé)? Ex. Graphes, algorithmes de tableau, etc.
A.2. Scalability (système à grande échelle)
Jusqu’à quel degré l’outil de VL monte-t-il pour manipuler de grands exemples?
A.2.1. Program
Quel est le plus grand logiciel qui peut être manipulé?
A.2.2. Data Sets
Quel est le plus grand ensemble de données en entrée qui peut être manipulé?
B. Content (les aspects à être visualisés tout comme le code et les types de
données)
Quel sous-ensemble d’information sur le logiciel est visualisé par l’outil de VL?
B.1. Program
Jusqu’à quel degré l’outil de VL visualise-t-il le logiciel implanté?

iii
B.1.1. Code
Jusqu’à quel degré l’outil de VL visualise-t-il les instructions dans le code source du
logiciel?
B.1.1.1. Control flow
Jusqu’à quel degré l’outil de VL visualise-t-il le flot de contrôle dans le code source du
logiciel?
B.1.2. Data
Jusqu’à quel degré l’outil de VL visualise-t-il les structures de données dans le code
source du logiciel?
B.1.2.1. Data flow
Jusqu’à quel degré l’outil de VL visualise-t-il le flot de données dans le code source du
logiciel?
B.2. Algorithm
Jusqu’à quel degré l’outil de VL visualise-t-il l’algorithme de haut niveau qui se trouve
en arrière du logiciel?
B.2.1. Instructions
Jusqu’à quel degré l’outil de VL visualise-t-il les instructions dans l’algorithme?
B.2.1.1. Control flow
Jusqu’à quel degré l’outil de VL visualise-t-il le flot de contrôle des instructions de
l’algorithme?
B.2.2. Data
Jusqu’à quel degré l’outil de VL visualise-t-il les structures de données de haut niveau
dans l’algorithme?
B.2.2.1. Data flow
Jusqu’à quel degré l’outil de VL visualise-t-il le flot de données dans l’algorithme?

iv
B.3. Fidelity and Completeness
Est-ce que les métaphores visuelles présentent-elles le comportement vrai et complet de
la machine virtuelle sous-jacente?
B.3.1. Invasiveness
Si l’outil de VL peut être utilisé pour visualiser des applications concurrentes, est-ce que
son utilisation perturbe la séquence d’exécution du programme?
B.4. Data gathering time
Est-ce que les données sur lesquelles dépend la visualisation sont rassemblées lors de la
compilation, lors de l’exécution ou bien lors des deux étapes?
B.4.1. Temporal control mapping
Quel est le rapport entre l’horloge du logiciel et celui de la visualisation?
B.4.2. Visualization generation time
Est-ce que la visualisation est produite comme étant un “batch job” (post-mortem) à
partir de données enregistrées durant une exécution préalable, ou bien elle est produite
“live” pendant que le logiciel s’exécute?
C. Form
Quelles sont les caractéristiques de la sortie de l’outil de VL (la visualisation)?
C.1. Medium
Quel est le medium cible primaire pour la sortie de l’outil de VL?
C.2. Presentation style
Quelle est l’apparence générale de la visualisation?
C.2.1. Graphical vocabulary
Quels sont les éléments graphiques utilisés dans la visualisation produite par l’outil de
VL?

v
C.2.1.1. Colour
Jusqu’à quel degré l’outil de VL utilise-t-il de la couleur dans les visualisations qu’il
produit?
C.2.1.2. Dimensions
Jusqu’à quel degré les extra-dimensions (3D, 4D) sont utilisées dans la visualisation?
C.2.2. Animation
Si l’outil de VL rassemble des données lors de l’exécution, jusqu’à quel degré la
visualisation résultante utilise l’animation?
C.2.3. Sound
Jusqu’à quel degré l’outil de VL utilise-t-il le son pour transférer l’information?
C.3. Granularity
Jusqu’à quel degré l’outil de VL présente-t-il des détails de coarse-granularity?
C.3.1. Elision
Jusqu’à quel degré l’outil de VL fournit-il des facilités pour cacher temporairement
l’information?
C.4. Multiple views
Jusqu’à quel degré l’outil de VL fournit-il plusieurs vues synchronisées des différentes
parties du logiciel visualisé?
C.5. Program synchronization
L’outil de VL peut-il générer simultanément des visualisations synchronisés de plusieurs
programmes?
D. Method
Comment est-ce que la visualisation est spécifiée?

vi
D.1. Visualisation specification style
Quel style de spécification de visualisation est utilisé? Ex. Fixe, librairie, automatique,
hard-coded.
D.1.1. Intelligence
Si la visualisation est automatique, jusqu’à quel degré l’outil de VL est-il avancé du
point de vue Intelligence Artificielle?
D.1.2. Tailorability
Jusqu’à quel degré l’utilisateur peut-il particulariser la visualisation?
D.1.2.1. Customization language
Si la visualisation est particularisable, comment peut-elle être spécifiée?
D.2. Connection technique
Comment la connexion est faite entre la visualisation et le logiciel visualisé? Ex.
Annotation, probes, etc.
D.2.1. Code ignorance allowance
Si le système de visualisation n’est pas complètement automatique, quel est le niveau de
connaissance du code requis pour produire une visualisation?
D.2.2. System-code coupling
Jusqu’à quel degré l’outil de VL est couplé avec le code?
E. Interaction
Comment l’utilisateur du système SV interagit-il avec le système et contrôle-t-il le
système?
E.1. Style
Quelle méthode l’utilisateur emploie-t-il pour donner des instructions à l’outil de VL?
E.2. Navigation
Jusqu’à quel degré l’outil de VL supporte-t-il la navigation à travers une visualisation?

vii
E.2.1. Elision control
L’utilisateur peut-il cacher de l’information ou supprimer des détails de l’affichage?
(notons que cette propriété n’est qu’une redondance par rapport à la propriété déjà vue
dans C.3.1.)
E.2.2. Temporal control
Jusqu’à quel degré l’outil de VL permet-il à l’utilisateur de contrôler les aspects
temporels de l’exécution d’un logiciel?
E.2.2.1. Direction
Jusqu’à quel degré l’utilisateur peut-il inverser la direction temporelle (revenir en
arrière) de la visualisation?
E.2.2.2. Speed
Jusqu’à quel degré l’utilisateur peut-il contrôler la vitesse d’exécution?
E.3. Scripting facilities
L’outil de VL fournit-il des facilités pour gérer l’enregistrement et le play-back des
interactions avec des visualisations particulières? (Cette facilité est importante lors des
démonstrations.)
F. Effectiveness
Jusqu’à quel degré l’outil de VL est-il capable de communiquer les informations
nécessaires à l’utilisateur?
F.1. Purpose
Pour quel but le système est-il approprié?
F.2. Appropriateness and clarity
Si des visualisations automatiques sont fournies, jusqu’à quel degré sont-elles capables
de communiquer les informations nécessaires sur le logiciel?

viii
F.3. Empirical evaluation
Jusqu’à quel degré l’outil de VL a été sujet à une bonne évaluation expérimentale?
F.4. Production use (publication, vente, distribution, utilisation continue par
des étudiants dans un cours)
Le système était-il en utilisation de production fiable pour une période significative de
temps?
Bibliographie de l’annexe A:
[Price93] Price, B. A., Baecker, R. M., and Small, I. S., A principled taxonomy ofsoftware visualisation. Journal of Visual Languages and Computing,No. 4, pp. 211 - 266, 1993. On-line at <http://www-cs.open.ac.uk/~doc/jvlc/JVLC-Body.html>.

Annexe B. Évaluation de sept outils de VL
Dans cette annexe, nous présentons les six tableaux comportant l’évaluation des sept
outils de VL retenus à la section 3.3 (xSuds, Tom Sawyer Products, Discover, VGJ,
daVinci, Swan et VCG / CGDI). Chacun des tableaux est lié à une catégorie bien
particulière de la taxonomie de Price et al. [Price93] déjà décrite à l’annexe A et
regroupe un grand nombre des caractéristiques de cette catégorie ainsi que leur
applicabilité sur les outils de VL retenus. Il existe des caractéristiques, marquées par des
“?”, pour lesquelles nous n’avons pas pu répondre par manque de connaissance de l’outil
(par exemple, Discover que nous n’avons pas pu évaluer de façon pratique). D’autres
caractéristiques ne s’appliquent pas pour un outil en particulier; les cases
correspondantes sont marquées par “NA”. Une discussion de ces tableaux est présentée à
la section 4.3.
A. Scope
Critères����
Nom del’outil de
VL����
Gén
éral
ité
Syst
ème
d’ex
ploi
tatio
n (+
com
pila
teur
néce
ssai
re si
cec
i est
appl
icab
le)
Lan
gage
App
licat
ions
Spéc
ialit
é
Scal
abili
ty
xSuds Oui Windows 95/NTavec MicrosoftVisual C++
C,C++
N’importe ? Théoriquement, ilsemble ne pas avoirde problème
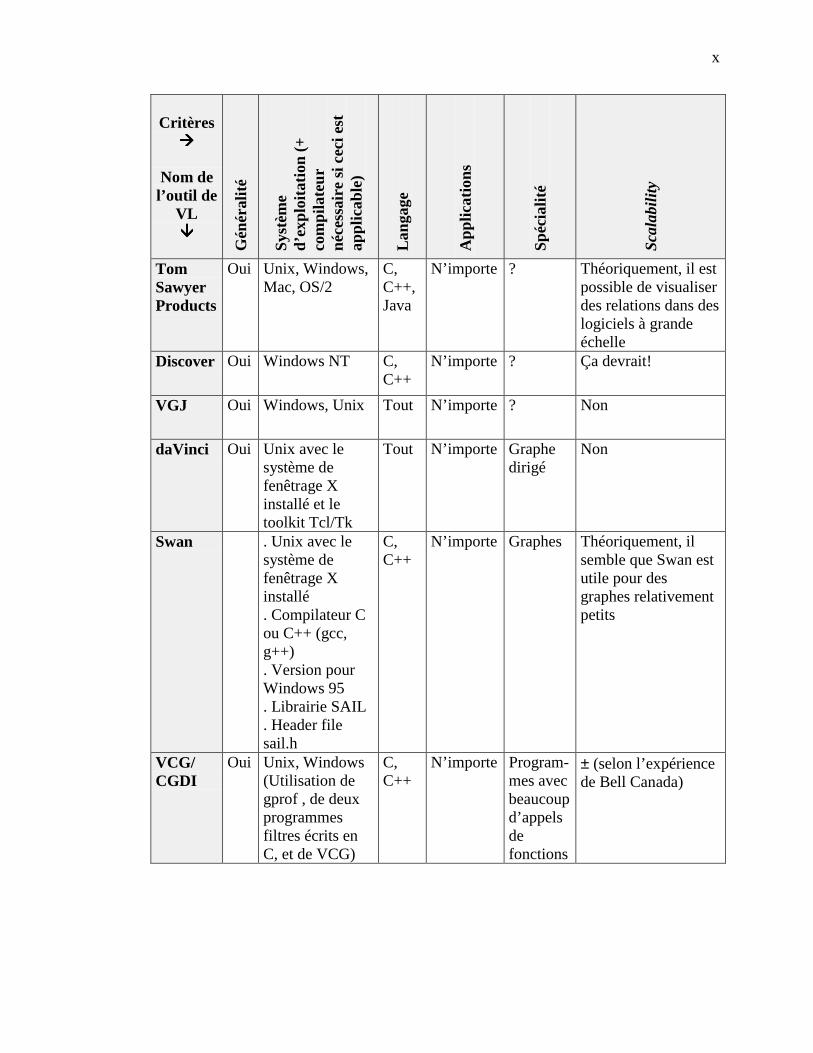
x
Critères����
Nom del’outil de
VL����
Gén
éral
ité
Syst
ème
d’ex
ploi
tatio
n (+
com
pila
teur
néce
ssai
re si
cec
i est
appl
icab
le)
Lan
gage
App
licat
ions
Spéc
ialit
é
Scal
abili
ty
TomSawyerProducts
Oui Unix, Windows,Mac, OS/2
C,C++,Java
N’importe ? Théoriquement, il estpossible de visualiserdes relations dans deslogiciels à grandeéchelle
Discover Oui Windows NT C,C++
N’importe ? Ça devrait!
VGJ Oui Windows, Unix Tout N’importe ? Non
daVinci Oui Unix avec lesystème defenêtrage Xinstallé et letoolkit Tcl/Tk
Tout N’importe Graphedirigé
Non
Swan . Unix avec lesystème defenêtrage Xinstallé. Compilateur Cou C++ (gcc,g++). Version pourWindows 95. Librairie SAIL. Header filesail.h
C,C++
N’importe Graphes Théoriquement, ilsemble que Swan estutile pour desgraphes relativementpetits
VCG/CGDI
Oui Unix, Windows(Utilisation degprof , de deuxprogrammesfiltres écrits enC, et de VCG)
C,C++
N’importe Program-mes avecbeaucoupd’appelsdefonctions
± (selon l’expériencede Bell Canada)
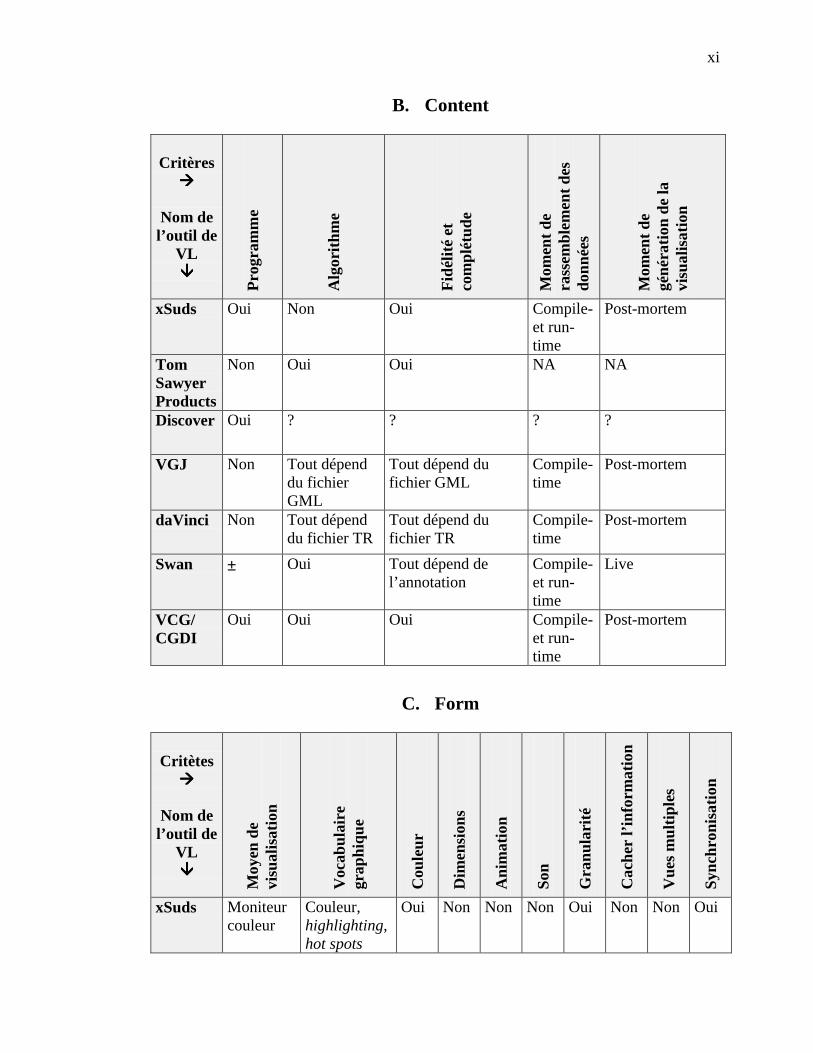
xi
B. Content
Critères����
Nom del’outil de
VL����
Prog
ram
me
Alg
orith
me
Fidé
lité
etco
mpl
étud
e
Mom
ent d
era
ssem
blem
ent d
esdo
nnée
s
Mom
ent d
egé
néra
tion
de la
visu
alis
atio
n
xSuds Oui Non Oui Compile-et run-time
Post-mortem
TomSawyerProducts
Non Oui Oui NA NA
Discover Oui ? ? ? ?
VGJ Non Tout dépenddu fichierGML
Tout dépend dufichier GML
Compile-time
Post-mortem
daVinci Non Tout dépenddu fichier TR
Tout dépend dufichier TR
Compile-time
Post-mortem
Swan ± Oui Tout dépend del’annotation
Compile-et run-time
Live
VCG/CGDI
Oui Oui Oui Compile-et run-time
Post-mortem
C. Form
Critètes����
Nom del’outil de
VL����
Moy
en d
evi
sual
isat
ion
Voc
abul
aire
grap
hiqu
e
Cou
leur
Dim
ensi
ons
Ani
mat
ion
Son
Gra
nula
rité
Cac
her
l’inf
orm
atio
n
Vue
s mul
tiple
s
Sync
hron
isat
ion
xSuds Moniteurcouleur
Couleur,highlighting,hot spots
Oui Non Non Non Oui Non Non Oui
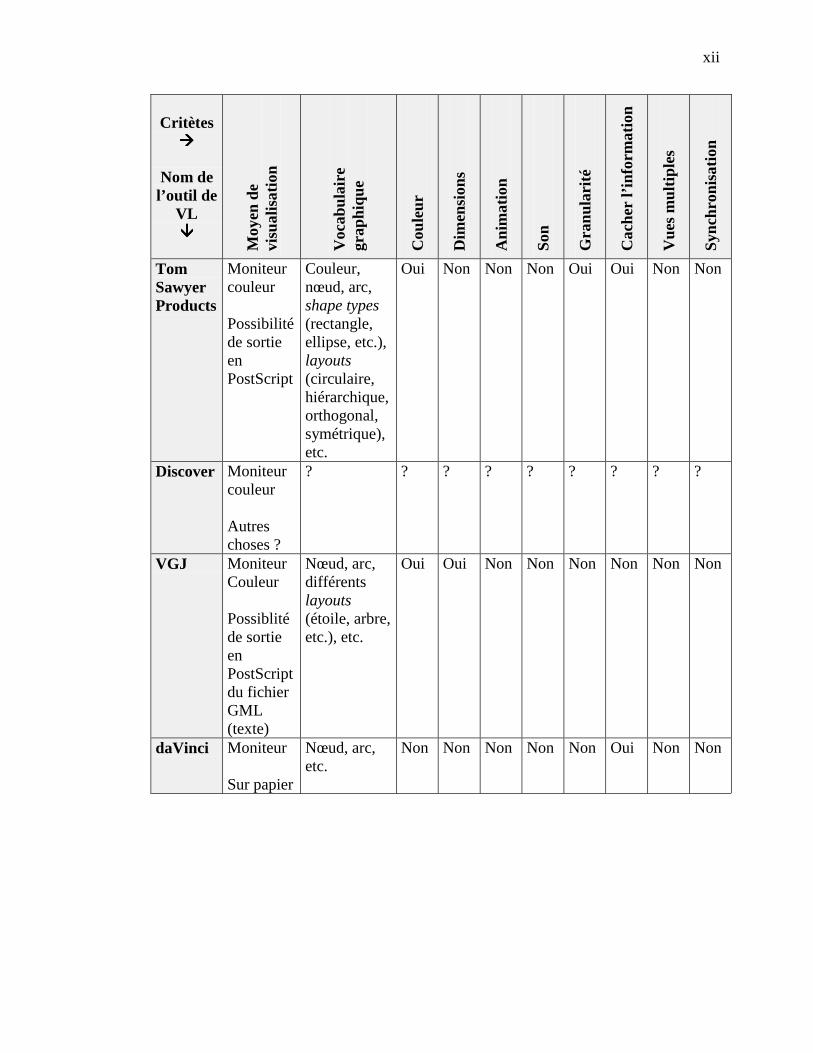
xii
Critètes����
Nom del’outil de
VL����
Moy
en d
evi
sual
isat
ion
Voc
abul
aire
grap
hiqu
e
Cou
leur
Dim
ensi
ons
Ani
mat
ion
Son
Gra
nula
rité
Cac
her
l’inf
orm
atio
n
Vue
s mul
tiple
s
Sync
hron
isat
ion
TomSawyerProducts
Moniteurcouleur
Possibilitéde sortieenPostScript
Couleur,nœud, arc,shape types(rectangle,ellipse, etc.),layouts(circulaire,hiérarchique,orthogonal,symétrique),etc.
Oui Non Non Non Oui Oui Non Non
Discover Moniteurcouleur
Autreschoses ?
? ? ? ? ? ? ? ? ?
VGJ MoniteurCouleur
Possiblitéde sortieenPostScriptdu fichierGML(texte)
Nœud, arc,différentslayouts(étoile, arbre,etc.), etc.
Oui Oui Non Non Non Non Non Non
daVinci Moniteur
Sur papier
Nœud, arc,etc.
Non Non Non Non Non Oui Non Non
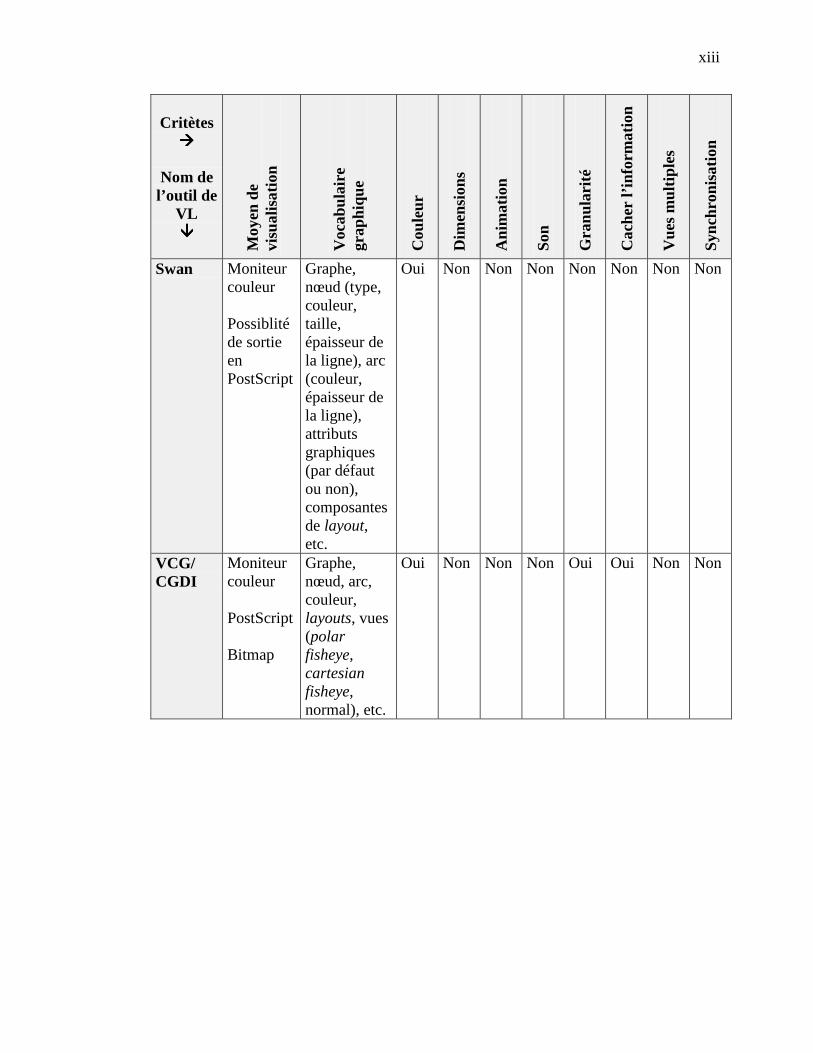
xiii
Critètes����
Nom del’outil de
VL����
Moy
en d
evi
sual
isat
ion
Voc
abul
aire
grap
hiqu
e
Cou
leur
Dim
ensi
ons
Ani
mat
ion
Son
Gra
nula
rité
Cac
her
l’inf
orm
atio
n
Vue
s mul
tiple
s
Sync
hron
isat
ion
Swan Moniteurcouleur
Possiblitéde sortieenPostScript
Graphe,nœud (type,couleur,taille,épaisseur dela ligne), arc(couleur,épaisseur dela ligne),attributsgraphiques(par défautou non),composantesde layout,etc.
Oui Non Non Non Non Non Non Non
VCG/CGDI
Moniteurcouleur
PostScript
Bitmap
Graphe,nœud, arc,couleur,layouts, vues(polarfisheye,cartesianfisheye,normal), etc.
Oui Non Non Non Oui Oui Non Non
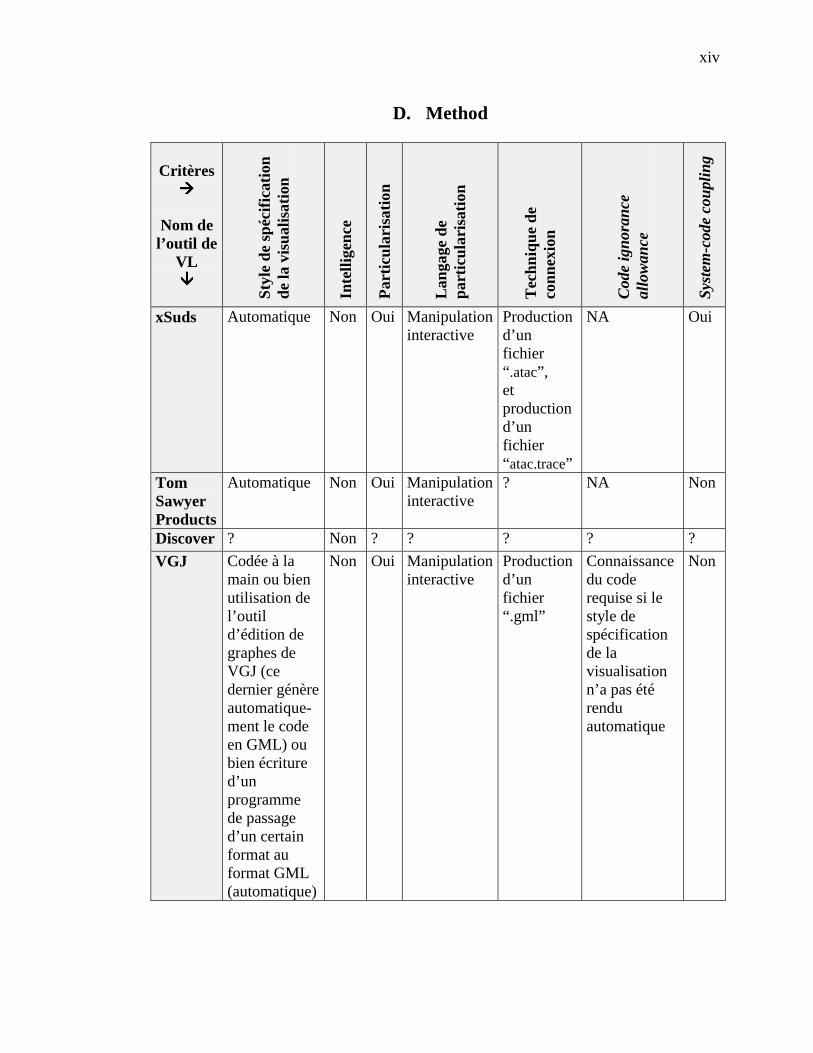
xiv
D. Method
Critères����
Nom del’outil de
VL����
Styl
e de
spéc
ifica
tion
de la
vis
ualis
atio
n
Inte
llige
nce
Part
icul
aris
atio
n
Lan
gage
de
part
icul
aris
atio
n
Tec
hniq
ue d
eco
nnex
ion
Code
igno
ranc
eal
lowa
nce
Syste
m-c
ode
coup
ling
xSuds Automatique Non Oui Manipulationinteractive
Productiond’unfichier“.atac”,etproductiond’unfichier“atac.trace”
NA Oui
TomSawyerProducts
Automatique Non Oui Manipulationinteractive
? NA Non
Discover ? Non ? ? ? ? ?VGJ Codée à la
main ou bienutilisation del’outild’édition degraphes deVGJ (cedernier génèreautomatique-ment le codeen GML) oubien écritured’unprogrammede passaged’un certainformat auformat GML(automatique)
Non Oui Manipulationinteractive
Productiond’unfichier“.gml”
Connaissancedu coderequise si lestyle despécificationde lavisualisationn’a pas étérenduautomatique
Non
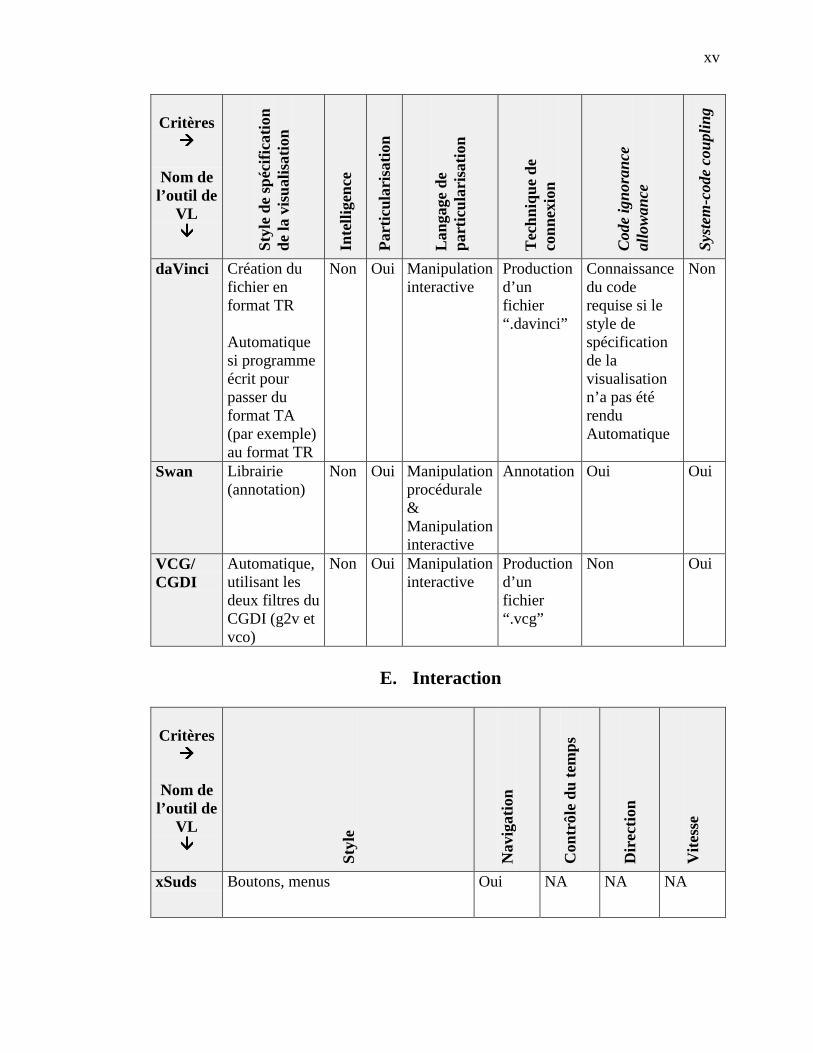
xv
Critères����
Nom del’outil de
VL����
Styl
e de
spéc
ifica
tion
de la
vis
ualis
atio
n
Inte
llige
nce
Part
icul
aris
atio
n
Lan
gage
de
part
icul
aris
atio
n
Tec
hniq
ue d
eco
nnex
ion
Code
igno
ranc
eal
lowa
nce
Syste
m-c
ode
coup
ling
daVinci Création dufichier enformat TR
Automatiquesi programmeécrit pourpasser duformat TA(par exemple)au format TR
Non Oui Manipulationinteractive
Productiond’unfichier“.davinci”
Connaissancedu coderequise si lestyle despécificationde lavisualisationn’a pas étérenduAutomatique
Non
Swan Librairie(annotation)
Non Oui Manipulationprocédurale&Manipulationinteractive
Annotation Oui Oui
VCG/CGDI
Automatique,utilisant lesdeux filtres duCGDI (g2v etvco)
Non Oui Manipulationinteractive
Productiond’unfichier“.vcg”
Non Oui
E. Interaction
Critères����
Nom del’outil de
VL����
Styl
e
Nav
igat
ion
Con
trôl
e du
tem
ps
Dir
ectio
n
Vite
sse
xSuds Boutons, menus Oui NA NA NA
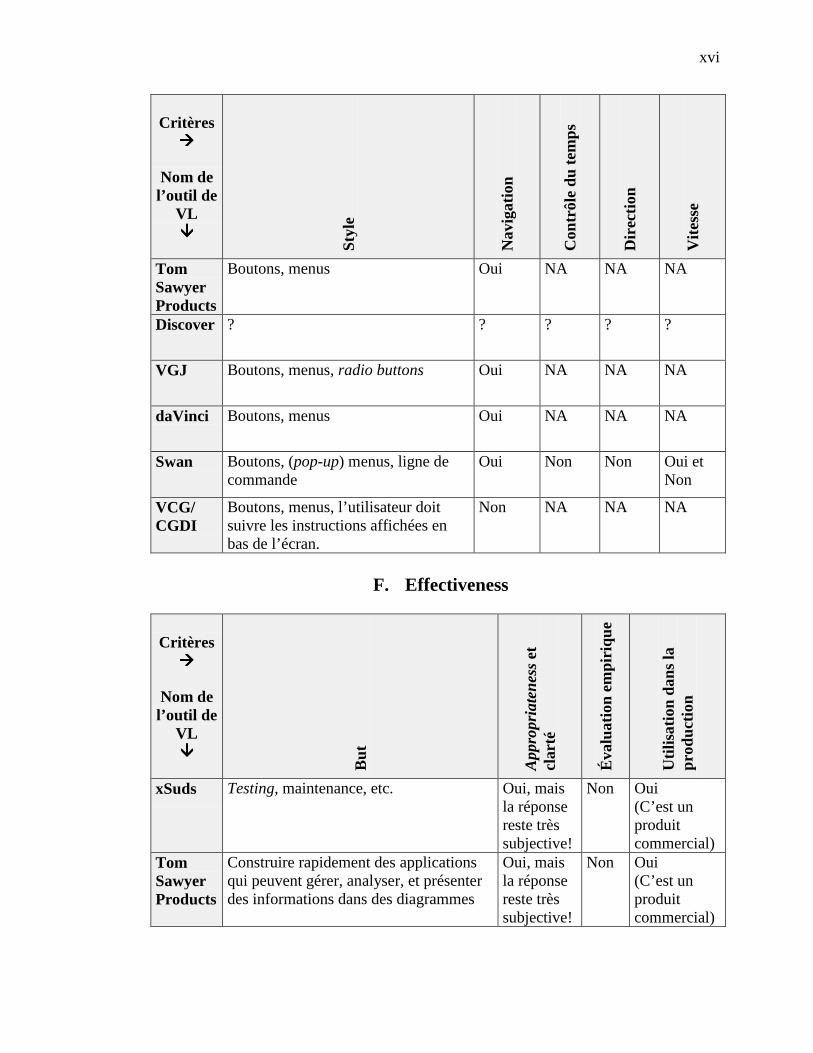
xvi
Critères����
Nom del’outil de
VL����
Styl
e
Nav
igat
ion
Con
trôl
e du
tem
ps
Dir
ectio
n
Vite
sse
TomSawyerProducts
Boutons, menus Oui NA NA NA
Discover ? ? ? ? ?
VGJ Boutons, menus, radio buttons Oui NA NA NA
daVinci Boutons, menus Oui NA NA NA
Swan Boutons, (pop-up) menus, ligne decommande
Oui Non Non Oui etNon
VCG/CGDI
Boutons, menus, l’utilisateur doitsuivre les instructions affichées enbas de l’écran.
Non NA NA NA
F. Effectiveness
Critères����
Nom del’outil de
VL����
But
Appr
opria
tene
ss e
tcl
arté
Éva
luat
ion
empi
riqu
e
Util
isat
ion
dans
lapr
oduc
tion
xSuds Testing, maintenance, etc. Oui, maisla réponsereste trèssubjective!
Non Oui(C’est unproduitcommercial)
TomSawyerProducts
Construire rapidement des applicationsqui peuvent gérer, analyser, et présenterdes informations dans des diagrammes
Oui, maisla réponsereste trèssubjective!
Non Oui(C’est unproduitcommercial)
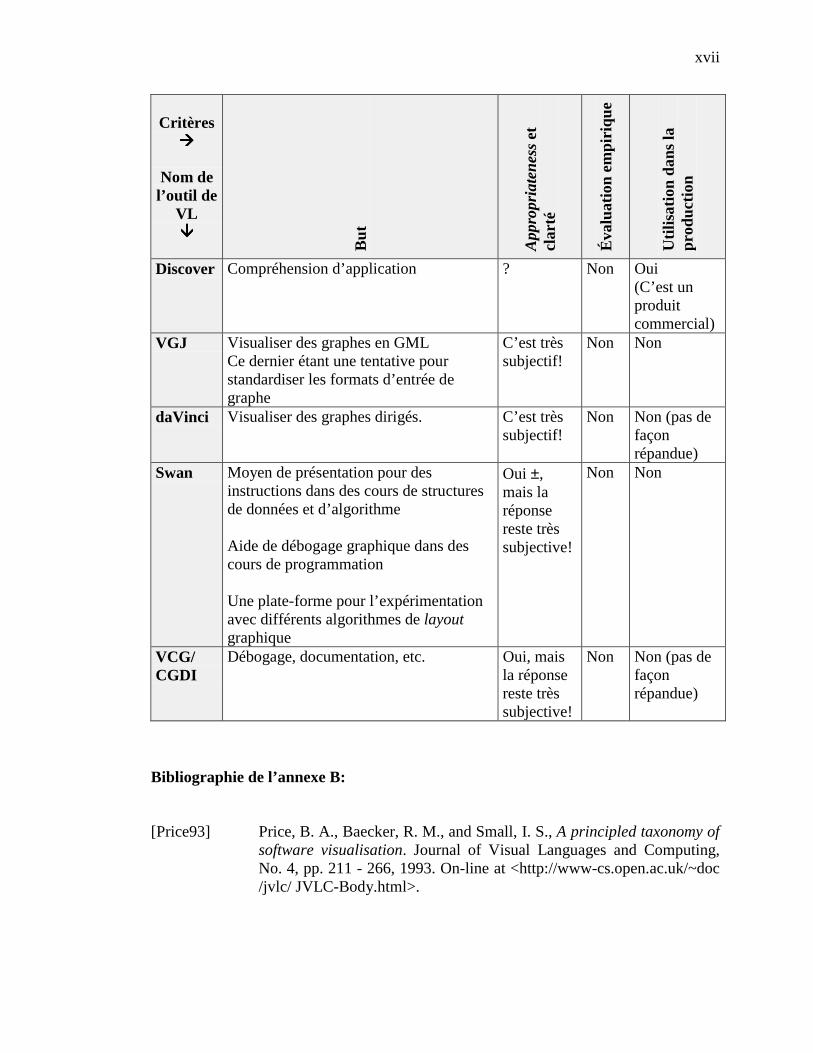
xvii
Critères����
Nom del’outil de
VL����
But
Appr
opria
tene
ss e
tcl
arté
Éva
luat
ion
empi
riqu
e
Util
isat
ion
dans
lapr
oduc
tion
Discover Compréhension d’application ? Non Oui(C’est unproduitcommercial)
VGJ Visualiser des graphes en GMLCe dernier étant une tentative pourstandardiser les formats d’entrée degraphe
C’est trèssubjectif!
Non Non
daVinci Visualiser des graphes dirigés. C’est trèssubjectif!
Non Non (pas defaçonrépandue)
Swan Moyen de présentation pour desinstructions dans des cours de structuresde données et d’algorithme
Aide de débogage graphique dans descours de programmation
Une plate-forme pour l’expérimentationavec différents algorithmes de layoutgraphique
Oui ±,mais laréponsereste trèssubjective!
Non Non
VCG/CGDI
Débogage, documentation, etc. Oui, maisla réponsereste trèssubjective!
Non Non (pas defaçonrépandue)
Bibliographie de l’annexe B:
[Price93] Price, B. A., Baecker, R. M., and Small, I. S., A principled taxonomy ofsoftware visualisation. Journal of Visual Languages and Computing,No. 4, pp. 211 - 266, 1993. On-line at <http://www-cs.open.ac.uk/~doc/jvlc/ JVLC-Body.html>.

Annexe C. Questionnaire sur les outils de VL
Nous présentons dans cette annexe les deux parties (I et II) du questionnaire sur lesoutils de VL. Notons que les “o” désignent que le participant ne peut choisir qu’uneseule réponse parmi les choix donnés, alors que les “�” donnent la possibilité de choisirune ou plusieurs réponses.
Cette version (Microsoft Word) n’a servi que pour s’échanger les différentes versions(itérations) du questionnaire. Nous n’avons jamais publié le questionnaire utilisant ceformat. Le chapitre 6 donne les détails de l’implantation du questionnaire qui est baséesur HTML, JavaScript et Perl. Enfin, notons que le questionnaire est disponible on-line,dans des versions anglaises et françaises, à l’adresse <http://www.iro.umontreal.ca/labs/gelo/sv-survey/questionnaire.html>.
Partie I
(I) Renseignements concernant le participant
1 Informations sur le milieu de travail.
o Compagnie
o Université (milieu de recherche)
Nom de l’organisation : ____________________
2 Informations personnelles.
Fonction professionnelle
o Analyste
o Concepteur
o Programmeur
o Testeur

xix
o Débogeur
o Maintainer
o Autre, précisez : ____________________
Adresse électronique : ____________________
3 Taille de l’équipe de travail dont vous faîtes partie (Nombre de personnes affectées
au développement et à la maintenance dans votre équipe de travail).
o <5
o Entre 5 et 10
o Entre 11 et 20
o >20
o Ne sais pas
4 Où avez-vous entendu parler de ce questionnaire?
o Invitation par les auteurs
o Newsgroup
Autre, précisez : ____________________
5 Souhaitez-vous avoir le résultat de cette étude?
o Oui
o Non
6 Veuillez nommer les trois outils de VL les plus utilisés dans votre équipe de travail.
Nom d’outil Nom du distributeurcorrespondant Outil de VL en maina
____________________ ____________________ o
____________________ ____________________ o
____________________ ____________________ o
a L’outil de VL que vous connaissez le mieux et pour lequel vous allez remplir les sections V et VI de
cette partie du questionnaire.

xx
7 A quel niveau se situe votre connaissance…
Trèsbonne Bonne Moyenne Faible Très
faible Aucune
… de l’outil de VL en main? o o o o o o
… des logiciels visualisés
(familiarité avec le code source)?o o o o o o
... du domaine d’application des
logiciels visualisés?o o o o o o
... de programmation dans le langage
d’implantation des logiciels
visualisés?
o o o o o o
(II) Renseignements sur les logiciels visualisés
8 Style(s) de programmation des Logiciels visualisés...
� Orienté Objet
� Procédural
� Déclaratif
� Autre, précisez : ____________________
9 Domaine(s) d’application des Logiciels visualisés...
� Conception assistée par ordinateur
� Application d’entrée de données
� Système de support à la décision
� Système de diagnostique
� Système d’information
� Application multimédia
� Application en temps réel
� Application génie/scientifique
� Simulation
� Autre, précisez : ____________________

xxi
10 Ordre de grandeur (KLOC) des Logiciels visualisés...
0 __ o __ 100 __ o __ 500 __ o __ 1000 __ o __ ++
11 Niveau de complexité...
Complexe Complexitémoyenne Facile Ne sais pas
… des logiciels visualisés o o o o
… de la tâche effectuée sur les
logiciels visualiséso o o o
12 Disponibilité de documentation (au-delà du code source) pour les logiciels
visualisés...Aucune documentation ___ Documentation incomplète ___ Documentation complète
o o o o o
(III) Aspects fonctionnels des outils de VL
13 Voici des fonctionnalités et des capacités liées à des outils de VL. Jusqu’à quel point
ces propriétés vous sont/seraient utiles pour effectuer une certaine tâche?
Absolumentessentielle
Utile, maisnon
essentielle
Pas dutout utile
Ne saispas/Non
applicableVisualisation de code source (vues
textuelles)o o o o
Browsing de code source o o o o
Accès direct (sans passer par des objets de
haut niveau) au code sourceo o o o
Visualisation d’une liste de symboles (ex. les
fichiers du logiciel visualisé, les fonctions définies
et les types de données (variables, constantes,
etc.))
o o o o
Accès facile, à partir de la liste de
symboles, au code source correspondanto o o o

xxii
Visualisation de graphes o o o o
Browsing synchronisé de vues de même
type ou de type différent (ex. browsing
graphique et textuel synchronisé)
o o o o
Passage d’une vue vers une autre de
même type ou de type différent (ex.
passage du code source à une fenêtre
graphique ou vice-versa) (cross-
referencing)
o o o o
Possibilité d’avoir plusieurs vues de
même type ou de type différent liées
visuellement en mettant en évidence
(highlighting) des instances du même
objet dans toutes les vues (ex. possibilité
de lier les nœuds et les arcs dans des
représentations graphiques au code source
correspondant)
o o o o
Capacités de layout automatique o o o o
Capacités de scaling automatique o o o o
Mécanismes d’abstraction (ex. affichage
des nœuds de sous-système et les arcs
composites dans un graphe)
o o o o
Fenêtres d’overview (ex. montrer la
structure hiérarchique du logiciel
visualisé)
o o o o
Outils de recherche d’éléments graphiques
et/ou textuelso o o o
Capacités de filtrage o o o o
Capacités de zoom-in et zoom-out o o o o
Visualisation dynamique (visualisation de
l’exécution, animation)o o o o
xxiii
Représentations hiérarchiques (de sous-
systèmes, de classes, etc.)o o o o
Navigation de hiérarchies (de sous-
systèmes, de classes, etc.)o o o o
Navigation de style hypertexte o o o o
Navigation arbitraireb o o o o
Possibilité de stocker les étapes d’une
navigation arbitraireo o o o
Possibilité de retour en arrière aux étapes
de navigation précédenteso o o o
Sauvegarde de vues, pour une utilisation
futureo o o o
Possibilité d’afficher ou de cacher
l’information selon les besoinso o o o
Program slicingc o o o o
Possibilité de voir le focus courant (ex.
des vues de fish-eye, des vues détaillées
de nœuds intéressants, des nœuds et arcs
highlighted, des images thumbnail de
code source, etc.)
o o o o
Possibilité de voir le chemin qui mène au
focus courant (histories ou breadcrumb
trails)
o o o o
Possibilité de particulariser la
visualisationo o o o
Possibilité de fournir une compréhension o o o o
b Navigation à des emplacements non nécessairement accessibles en suivant des liens déjà définis.c Méthode pour décomposer un programme en des composantes où chaque composante décrit certaines
fonctionnalités du système (un “program slice” contient seulement le code qui est pertinent à cette
fonctionnalité).
xxiv
sommaire (coarse-grained)
Possibilité de fournir une compréhension
détaillée (fine-grained)o o o o
Utilisation de couleurs o o o o
Effets d’animation o o o o
Représentations et layouts en 3D et
techniques de réalité virtuelleo o o o
(IV) Aspects pratiques des outils de VL
14 Veuillez préciser l’importance que vous accordez à chacun des aspects suivants liés
aux outils de VL en général.
Trèsimportant
Relativementimportant
Pasimportant
Ne saispas
Coût de l’outil o o o o
Contenu et qualité de la documentation o o o o
Disponibilité de documentation on-line o o o o
Disponibilité de support technique o o o o
Performance de l’outil (vitesse
d’exécution de l’outil)o o o o
Fiabilité de l’outil (absence d’erreurs) o o o o
Facilité d’apprentissage et d’installation o o o o
Facilité d’utilisation o o o o
Facilité de visualiser des logiciels de
grande tailleo o o o
Visualisation de logiciels écrits en
langages différentso o o o
Disponibilité sur plusieurs plate-formes o o o o
Qualité de l’interface usager o o o o
Possibilité de sortie (output) de la
visualisation en fichiers de différentso o o o

xxv
formats (postscript, pdf, bmp, etc.)
Autre, précisez : ____________________ o o o
Autre, précisez : ____________________ o o o
Autre, précisez : ____________________ o o o
(V) Évaluation cognitive de l’outil de VL en main
15 Veuillez préciser le degré de chacune de ces caractéristiques par rapport à l’outil de
VL en main (celui que vous avez indiqué à la question 6).
Haut Moyen Bas Ne sais pasFacilité d’apprentissage o o o o
Facilité d’utilisation o o o o
Qualité des effets visuels o o o o
Capacité de générer des résultats utiles o o o o
Confiance dans les résultats générés o o o o
Connaissance requise du code source du
logiciel visualisé, pour pouvoir générer
une visualisation
o o o o
16 Jusqu’à quel degré l’outil de VL en main vous aide-t-il à effectuer chacune des
tâches suivantes (liées aux logiciels visualisés)?
Beaucoup Moyennement Pas dutout
Ne saispas/Non
applicableMaintenance o o o o
Débogage o o o o
Testing o o o o
Ajout de nouvelles fonctionnalités o o o o
Perfectionnement o o o o
Analyse du code o o o o
Compréhension du code o o o o
Création de la documentation o o o o

xxvi
17 Selon vous, jusqu’à quel degré les caractéristiques des logiciels visualisés
mentionnées ci-dessous diminuent-elles l’efficacité de l’outil de VL en main?
Beaucoup Moyennement Pas dutout
Ne saispas/Non
applicableComplexité du code o o o o
Taille du code o o o o
Interface très couplée o o o o
Documentation insuffisante o o o o
Manque de documentation sur
l’intention de la conceptiono o o o
Autre, précisez : __________________ o o o o
18 Selon vous, l’outil de VL en main affecte-t-il l’approche prise pour effectuer une
tâche donnée?
Beaucoup ______________ Moyennement ______________ Pas du tout
o o o o o
19 Les résultats obtenus lors de l’application de l’outil en main sont (degré de
satisfaction)…
Très satisfaisants ______________ Satisfaisants ______________ Non satisfaisants
o o o o o
(VI) Bénéfices et améliorations de l’outil de VL en main
20 Veuillez préciser les bénéfices que vous avez retirés suite à l’utilisation de l’outil de
VL en main (Économie financière, économie de temps, etc.).
____________________________________________________________________
____________________________________________________________________
____________________________________________________________________

xxvii
21 Selon vous, quelles sont les principales améliorations qui devraient être apportées à
l’outil de VL en main?
____________________________________________________________________
____________________________________________________________________
____________________________________________________________________
Partie II
(I) Renseignements techniques sur l’outil de VL en main
1 Nom de l’outil de VL dont vous êtes expert et pour lequel vous allez remplir cette
partie du questionnaire (outil de VL en main).
______________________
2 Nom du distributeur de l’outil de VL en main.
______________________
3 L’outil de VL en main est…
o Un outil commercial
o Un prototype de recherche
4 L’outil de VL en main est formé…
o D’un seul grand outil
o D’un ensemble d’outils
5 Sur quel(s) système(s) d’exploitation l’outil de VL en mains s’exécute-t-il?
� UNIX
� UNIX avec le système de fenêtrage X
� DOS
� DOS avec le système de fenêtrage Microsoft
� OS/2

xxviii
� Windows 95/98
� Windows NT
� Macintosh
� Autre, précisez : ______________________
6 Pour quel(s) but(s) est-ce que l’outil de VL en main peut être utilisé?
� Analyse
� Test
� Débogage
� Maintenance
� Compréhension du logiciel visualisé
� Ajout de nouvelles fonctionnalités
� Création de la documentation
� Autre, précisez : ______________________
7 Dans quel(s) langage(s) de programmation l’outil de VL en main est-il écrit?
� C++
� Java
� Ne sais pas
� Autre, précisez : ______________________
8 Quel est (sont) le(s) style(s) utilisé(s) pour la spécification de la visualisation?
� Automatique à partir du code source directement
� Automatique à partir du code source via la génération de fichiers
intermédiaires
� Annotation manuelle du code source (supportée ou non par une librairie)
� Utilisation d’un outil d’édition graphique
� Autre, précisez : ______________________

xxix
9 L’outil de VL en main est-il (ou bien, fait-il partie d’) un environnement de
développement de logiciel?
o Oui
o Non
10 Dans quel(s) Langage(s) de programmation le logiciel visualisé peut-il être écrit?
� Ada
� C
� C++
� Cobol
� Fortran
� Java
� Pascal
� Prolog
� Smalltalk
� Langage de quatrième génération, précisez : ______________________
� Autre, précisez : ______________________
(II) Support de l’analyse du code par l’outil de VL en main
11 Appels de fonctions
L’outil de VL en main… Oui NonNe saispas/Non
applicable
Non/Ne sais pas,mais je
souhaiteraiscette propriété
... permet-il de visualiser des appels de fonctions? o o o o
... permet-il de visualiser le nombre de fois
qu’une fonction est appelée par une autre
fonction?
o o o o
... fournit-il des fonctionnalités (un outil) pour
identifier des chaînes de récursion?o o o o
... élimine-t-il les fonctions récursives simples? o o o o
xxx
... présente-t-il comme un tout (dans un même
graphe) une chaîne de récursion complexe?o o o o
... représente-t-il par des nœuds les fonctions de la
chaîne de récursion?o o o o
Peut-on accéder directement au code source à
partir des nœuds?o o o o
12 Clonage de fonctions
L’outil de VL en main… Oui NonNe saispas/Non
applicable
Non/Ne sais pas,mais je
souhaiteraiscette propriété
... permet-il d’obtenir les clones d’une fonction? o o o o
Est-il possible de voir le code source de ces
clones?o o o o
Les différences sont-elles mises en évidence par
des changements de couleurs ou de polices?o o o o
Peut-on réduire la granularité des différences?(un
exemple serait le passage du mot à la lettre)o o o o
13 Graphes d’héritage
L’outil de VL en main… Oui NonNe saispas/Non
applicable
Non/Ne sais pas,mais je
souhaiteraiscette propriété
... permet-il de visualiser des graphes d’héritage
(des hiérarchies des classes du système)?o o o o
... optimise-t-il les positions des nœuds? o o o o
... permet-il de détecter un héritage multiple? o o o o
... permet-il de détecter des branches profondes? o o o o

xxxi
14 Graphes d’architecture de sous-systèmes
L’outil de VL en main… Oui NonNe saispas/Non
applicable
Non/Ne sais pas,mais je
souhaiteraiscette propriété
... permet-il de visualiser des graphes
d’architecture de sous-systèmes?o o o o
Existe-t-il un moyen pour pouvoir lier
l’architecture aux autres résultats de l’outil de VL
en main (ex. zones de couleurs différentes sur le
graphe d’architecture)?
o o o o
Est-il possible de voir des clones de sous-
systèmes?o o o o
... permet-il de visualiser l’intérieur d’un sous-
système (ex. les fichiers qui forment un sous-
système)?
o o o o
15 Différents niveaux de détail
L’outil de VL en main… Oui NonNe saispas/Non
applicable
Non/Ne sais pas,mais je
souhaiteraiscette propriété
... permet-il de voir différents niveaux de détail
simultanément dans des fenêtres séparées?o o o o
16 Métriques
L’outil de VL en main… Oui NonNe saispas/Non
applicable
Non/Ne sais pas,mais je
souhaiteraiscette propriété
... permet-il de calculer des métriques? o o o o
... permet-il d’intégrer les métriques et le code
source?o o o o

xxxii
17 Versions multiples
L’outil de VL en main… Oui NonNe saispas/Non
applicable
Non/Ne sais pas,mais je
souhaiteraiscette propriété
... permet-il de travailler avec plusieurs versions
simultanément?o o o o
... permet-il de calculer, pour chaque version les
différences par rapport aux versions précédentes
(ex. le nombre de nouvelles fonctions, de
fonctions non modifiées, de fonctions modifiées,
de fonctions effacées, etc.)?
o o o o

Annexe D. Techniques statistiques
Dans cette annexe, nous expliquons de façon brève les différentes techniques statistiques
utilisées pour l’analyse des données recueillis à partir du questionnaire sur les outils de
VL. Nous avons tenu à présenter un bref aperçu de ces techniques puisque le chapitre 7
en fait souvent référence.
Les techniques statistiques utilisées sont considérées standards par les connaisseurs du
domaine. Elles comportent:
• Des statistiques descriptives, notamment la génération de fréquences
(pourcentages) et de moyennes pour des variables qualitatives. Une variable
qualitative, par opposition à quantitative, est toute variable non numérique, tel que
l’information sur le milieu de travail (compagnie, université), la fonction
professionnelle (analyste, concepteur, etc.), etc.
• Des relations entre des variables ordinales (où l’ordre est important). Un exemple
de variable ordinale serait le “niveau de connaissance” dans la question 7 de la partie
I du questionnaire (voir l’annexe C). En effet, la connaissance dans cette question
varie entre “très bonne” et “aucune” (très bonne, bonne, moyenne, faible, très faible,
aucune). Ces relations sont identifiées d’après le calcul du coefficient de corrélation
bivariée tau-b ou tau-c de Kendall, aussi appelé “mesure d’association”. Notons
qu’un tau-b est calculé lorsqu’on a une table carrée (même nombre de choix de
réponses pour les deux variables pour lesquelles la corrélation est calculée), alors
qu’un tau-c est calculé lorsque la table est rectangulaire (nombre de choix de
réponses différent pour les deux variables pour lesquelles la corrélation est calculée).
Les valeurs de ce coefficient s’étalent entre -1 et 1. Une corrélation de 1 entre deux
variables indique que plus la valeur d’une variable augmente, plus la valeur de
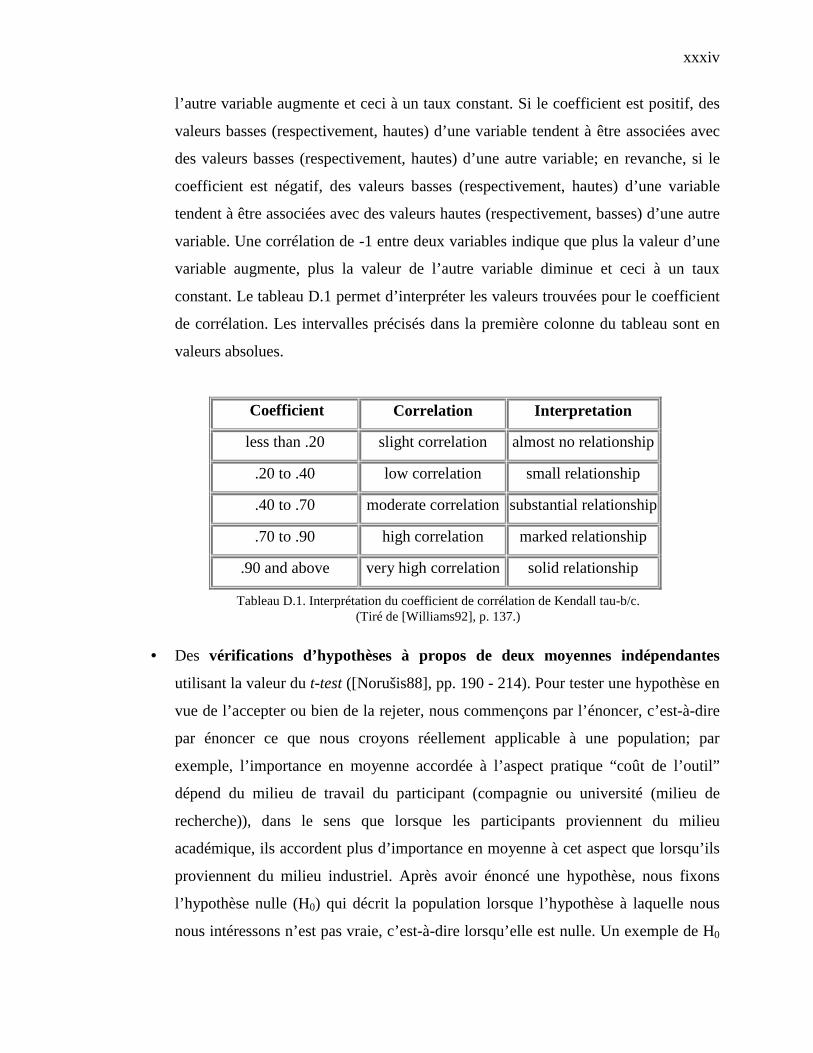
xxxiv
l’autre variable augmente et ceci à un taux constant. Si le coefficient est positif, des
valeurs basses (respectivement, hautes) d’une variable tendent à être associées avec
des valeurs basses (respectivement, hautes) d’une autre variable; en revanche, si le
coefficient est négatif, des valeurs basses (respectivement, hautes) d’une variable
tendent à être associées avec des valeurs hautes (respectivement, basses) d’une autre
variable. Une corrélation de -1 entre deux variables indique que plus la valeur d’une
variable augmente, plus la valeur de l’autre variable diminue et ceci à un taux
constant. Le tableau D.1 permet d’interpréter les valeurs trouvées pour le coefficient
de corrélation. Les intervalles précisés dans la première colonne du tableau sont en
valeurs absolues.
Coefficient Correlation Interpretation
less than .20 slight correlation almost no relationship
.20 to .40 low correlation small relationship
.40 to .70 moderate correlation substantial relationship
.70 to .90 high correlation marked relationship
.90 and above very high correlation solid relationship
• Des vérifications d’hypothèses à propos de deux moyennes indépendantes
utilisant la valeur du t-test ([Norušis88], pp. 190 - 214). Pour tester une hypothèse en
vue de l’accepter ou bien de la rejeter, nous commençons par l’énoncer, c’est-à-dire
par énoncer ce que nous croyons réellement applicable à une population; par
exemple, l’importance en moyenne accordée à l’aspect pratique “coût de l’outil”
dépend du milieu de travail du participant (compagnie ou université (milieu de
recherche)), dans le sens que lorsque les participants proviennent du milieu
académique, ils accordent plus d’importance en moyenne à cet aspect que lorsqu’ils
proviennent du milieu industriel. Après avoir énoncé une hypothèse, nous fixons
l’hypothèse nulle (H0) qui décrit la population lorsque l’hypothèse à laquelle nous
nous intéressons n’est pas vraie, c’est-à-dire lorsqu’elle est nulle. Un exemple de H0
Tableau D.1. Interprétation du coefficient de corrélation de Kendall tau-b/c.(Tiré de [Williams92], p. 137.)

xxxv
pour l’hypothèse que nous venons de citer ci-dessus serait de dire que les
participants du milieu académique et ceux du milieu industriel accordent la même
moyenne d’importance à l’aspect pratique “coût de l’outil”. Ensuite, nous calculons
la probabilité de voir une différence au moins aussi grande que celle observée dans
notre échantillon si H0 est vraie, c’est-à-dire s’il n’y a pas de différence dans notre
population. Si cette probabilité (appelée “the observed significance level” ou bien “le
niveau de signification observé”) est petite (inférieure à 0.05), nous rejetons H0. Par
contre, si elle est grande (supérieure à 0.05), nous ne pourrons pas rejeter H0; ceci ne
signifie pas que nous l’acceptons, mais que nous restons incertains.
En bref, le t-test est utilisé pour tester l’hypothèse que deux moyennes d’une
population (deux moyennes de deux échantillons exclusifs) sont égales. De façon
technique, il s’agit de calculer ces deux moyennes, puis de calculer la valeur du t-test
(qui est égale à la différence entre les deux moyennes divisée par l’erreur standard de
la différence) avec la probabilité liée à cette valeur, et finalement de comparer cette
probabilité avec 0.05. Si elle est inférieure, nous rejetons H0 qui est l’égalité de ces
deux moyennes.
Finalement, tous nos calculs et graphes sont effectués en utilisant la version 10.0 de
SPSS sous Windows NT [Green00, SPSS00].
Bibliographie de l’annexe D:
[Green00] Green, S. B., Salkind, N. J., and Akey, T. M., Using SPSS for Windows:Analyzing and understanding data. Prentice-Hall Inc., second edition,2000.
[Norušis88] Norušis, M. J., The SPSS guide to data analysis for SPSSx. SPSS Inc.,Chicago, Illinois, 1988.
[SPSS00] SPSS Statistical Package for the Social Sciences. On-line at <http://www.spss.com/>.
[Williams92] Williams, F., Reasoning with statistics: How to read quantitativeresearch. Harcourt Brace College Publishers, fourth edition, 1992.