
Utilisation du modele mapreduce dans les differents systemes nosql etude comparative

MapReduceRP*
Map
Reduce
RP* Framework pour le traitement parallèle de très grande quantité de données
Encadrer par:Mr.ARIDJ Mohamed Réaliser par:AMEUR Izzeddine
Juillet 2014

MapReduceRP* Le plan de travail
Partie théorique
Partie pratique
Conclusion
1

MapReduceRP* Vous la connaissez peut-être…
2

MapReduceRP* Deux gros problèmes
1. Données à très grande échelle2. Ressources financières limitées
3
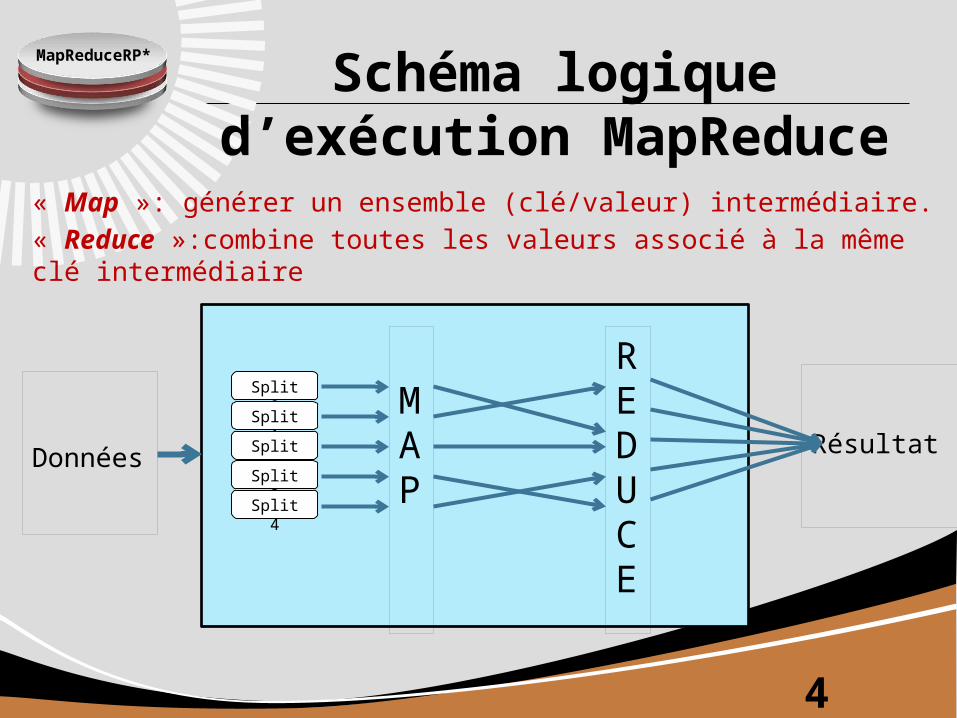
MapReduceRP* Schéma logique d’exécution MapReduce
« Map »: générer un ensemble (clé/valeur) intermédiaire.« Reduce »:combine toutes les valeurs associé à la même clé intermédiaire
Données
REDUCE
MAP
Résultat
Split 0
Split 1
Split 2
Split 3
Split 4
4

MapReduceRP* Schéma général d’exécution MapReduce
5

MapReduceRP* Exemple Word Count
Fonction de partitionnement
hash(Key) mod R
Ou R:nombre des tâches reduce
6

MapReduceRP* Structures de données classiques
Limite sur les performances d'accès Vulnérabilité aux pannes Scalabilité et Disponibilité Impossible pour un grand nombre de
clients
Serveurs
Clients
Répertoired'accès
7

MapReduceRP* Multi-ordinateurs
Une collection d'ordinateurs, Stations de travail, interconnectés par un réseau informatique (MAN, LAN, WAN)
Réseau
Besoin de Systèmes de Stockage Distribués et à Haute Disponibilité
8

MapReduceRP* SDDS
Conçues spécifiquement pour les multi-ordinateurs
pour des bases de données modernesdonnées complexes: spatiales, vidéo, Image, Son, …
9

MapReduceRP* Classification des SDDS
RP*
10

MapReduceRP* La distribution des données
Utiliser algorithme distribition par intervalle RP* « Range Partitioning »
Basé sur paradigme B-arbres et intervalles (fichier ordonnée + accès rapide)
Admettant les requêtes à intervallesGarantie de bonnes performances
11

MapReduceRP* Algorithme RP*
Famille des SDDS, appelée RP* (Range Partitioning) : RP*N, RP*C et RP*S
RP*N :utilisation exclusive du Multicast RP*C :c’est un fichier RP*N avec une image au
niveau de chaque client. Utilisation de Unicast et Multicast
RP*S : c’est un fichier RP*C + un index distribué au niveau des serveurs indexant toutes les cases. Élimine le multicast.
12

MapReduceRP*
Algorithme d'éclatement d'une case
1/ Déterminer (Cm) la clé de l'enregistrement du milieu de la case de débordement2/ Créer une nouvelle case j 3/ Déterminer l'en-tête de la case j λj := Cm ; Copier dans la case j les enregistrements de la case i avec la clé C>Cm 4/ Modifier l'en-tête de la case i Effacer les enregistrements de la clé C>Cm
13

MapReduceRP* Exemple
Évolution d’un fichier RP*N avec des enregistrements de clé alphanumérique et pour b =4.
inséré clé a
totheof and
+ -
ofand
a
of-
tothe
+ of
Règle 1
Règle 2
Règle 3
Règle 4
14
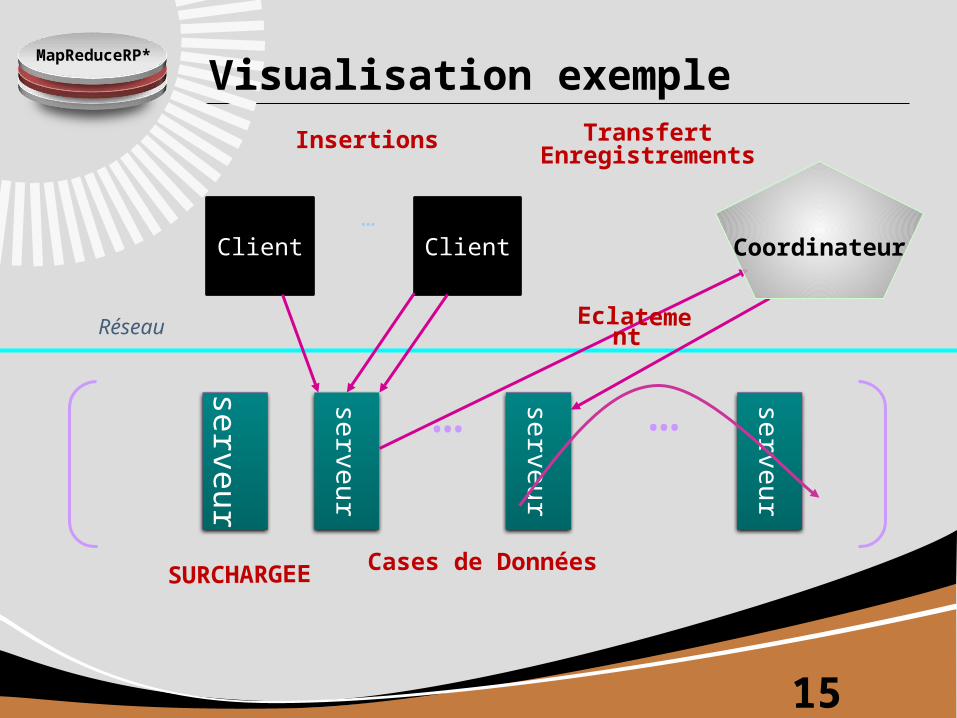
MapReduceRP*
serv
eu
r
Visualisation exemple
Client
Réseau
Client…
Cases de Données
…
SURCHARGEE
Eclatement
Insertions
…
serv
eu
r
serv
eu
r
serv
eu
r
Coordinateur
Transfert Enregistrements
15
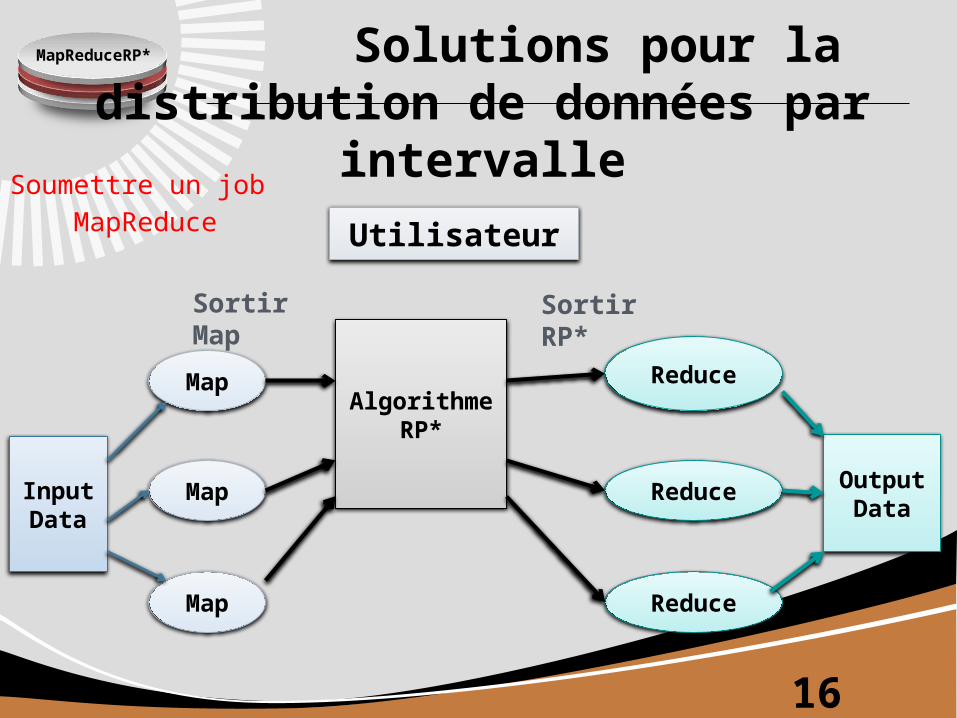
MapReduceRP* Solutions pour la distribution de données par
intervalleSoumettre un job MapReduce Utilisateur
InputData
OutputData
AlgorithmeRP*
Map
Map
Map
Reduce
Reduce
Reduce
Sortir Map
Sortir RP*
16

MapReduceRP* Structure RP*
17

MapReduceRP* Architecteur HDFS
18
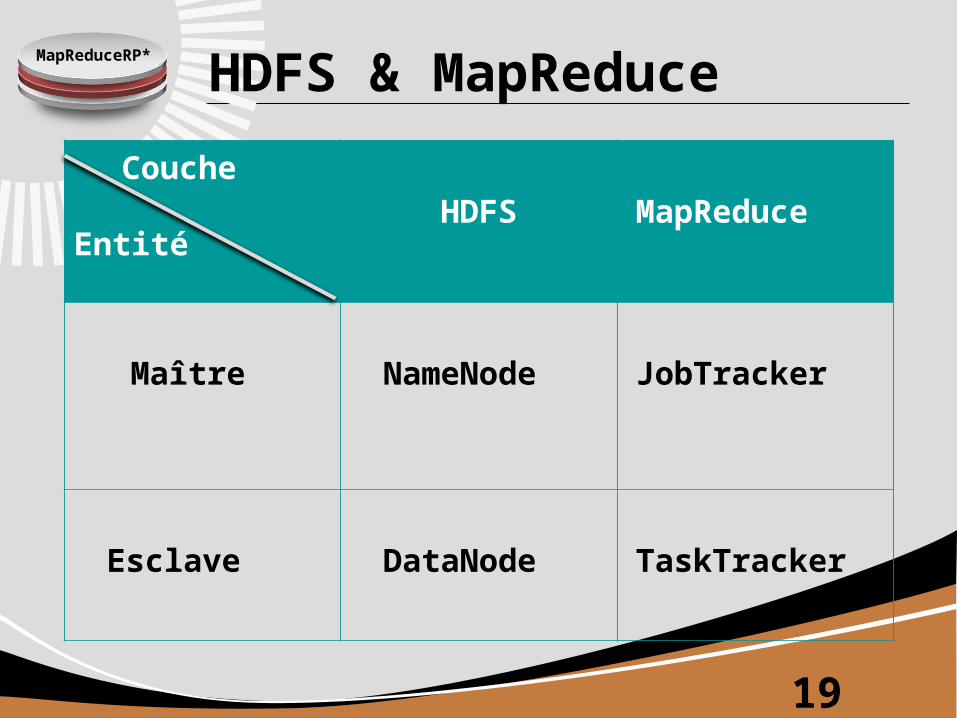
MapReduceRP* HDFS & MapReduce
Couche
Entité HDFS MapReduce
Maître NameNode JobTracker
Esclave DataNode TaskTracker
19

MapReduceRP*
Interface : Applications - SDDS
send Request
Socket
Network
Response
Request
ReceiveResponse
file client(n)
,,,,,, ,,,,,, ,,,,, ,,,,,,,,
Server Address
ReceiveRequest
ReturnResponse
Request
Response
Server
Architecture Client
20
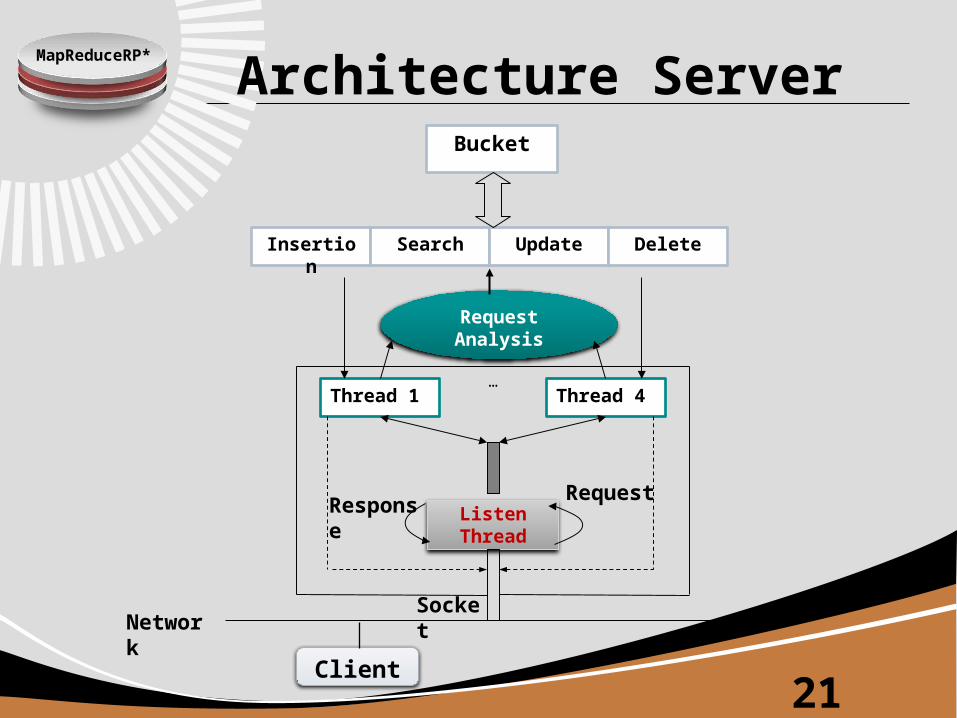
MapReduceRP*
Bucket
Insertion Search Update Delete
Thread 1 Thread 4…
Request Analysis
Listen Thread
Socket
Client
Network
Request
Response
Architecture Server
21

MapReduceRP*
Requête simple Coté client :Envoyée à l’aide d’un message
Multicast. Reçue par tous les serveurs. Coté serveur : Chaque serveur S, d’intervalle [, ], procède comme suit :
Si clé « c » [, ] alors S exécute la requête, puis envoie éventuellement une réponse au client à l’aide d’un message Unicast, sinon ignore la requête
Cette réponse contient le résultat de l’exécution de la requête( par exemple : l’enregistrement de clé « c » trouvé avec succès )
22

MapReduceRP* Requête à intervalle Il s’agit de la recherche de l’ensemble des
enregistrements de clés « c » appartenant à un intervalle donné [a, b] (a <b)
Elle est envoyée à tous les serveurs à l’aide d’un message Multicast.
Elle est traitée sur chaque serveur d’intervalle (, ] tel que (, ] [a, b] {}.
Les enregistrements sélectionnés sont ensuite envoyés au client .
23

MapReduceRP* Visualisation RequêteLoad Data Load Data
Démarrer Réponse
Serveur Concerné
Transfert Réponse
24

MapReduceRP* Partie pratique
25

MapReduceRP* Résultats de simulation-1-
10000 30000 50000 1000000
10000
20000
30000
40000
50000
60000
70000
80000
90000
100000100005000
-Temps de distribution (ms)- 26

MapReduceRP* Résultats de simulation-2-
5000 10000 1000000
10000
20000
30000
40000
50000
60000
100000500003000010000
-Temps de distribution (ms) en fonction de nombre de clés
insérés - 27
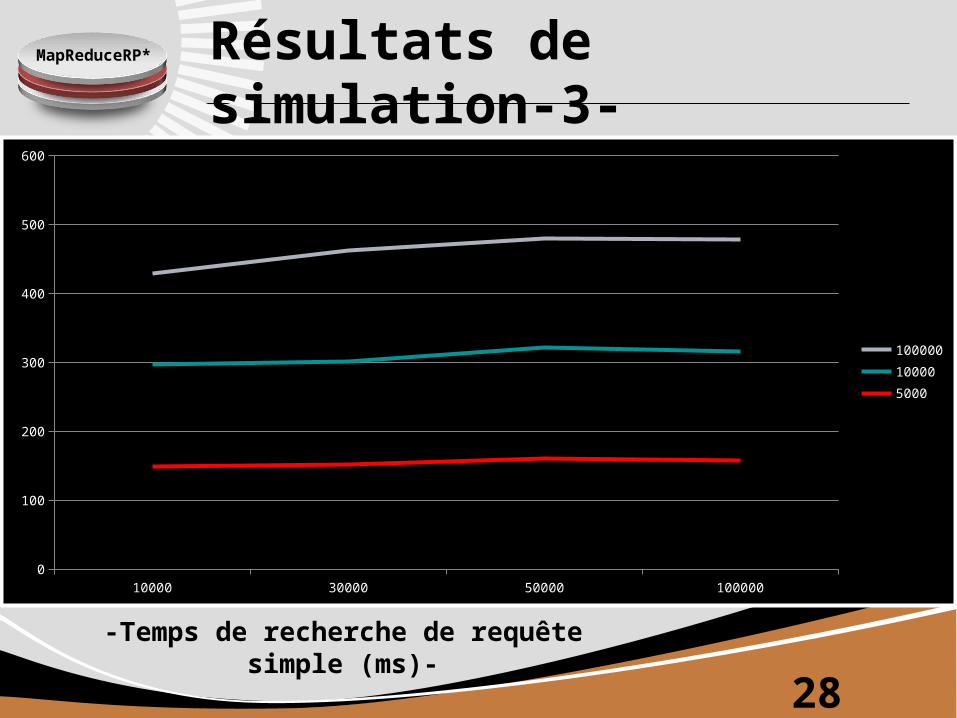
MapReduceRP* Résultats de simulation-3-
10000 30000 50000 1000000
100
200
300
400
500
600
100000100005000
-Temps de recherche de requête simple (ms)-
28

MapReduceRP* Résultats de simulation-4-
10000 30000 50000 1000000
200
400
600
800
1000
1200
1400
1600
100000100005000
-Temps de recherche de requête à intervalle (ms)-
29

MapReduceRP* Conclusion
Nos travaux ont porté sur le couplage des
algorithmes SDDS avec paradigme MapReduce,
et afin de profiter au maximum des ressources de
stockage et de traitement de ces réseaux
d’ordinateurs il faut assurer que les données sont
stockées de façon ordonnée.
30

MapReduceRP* Perspectives
Implémenter d’autres variantes de RP* tel que : la variante RP*c, RP*s
Implémenter notre système avec une base de données NoSql
L’adaptation d’un outil en ligne permet ordonné donnée de façon périodiquement
31

MapReduceRP*
www.izzeddineameur.netne.net
Merci


















