
MODIFICATEURS DE LA MOTRICITE DIGESTIVE Dr HAMMAMI TURKI Serria FMS Laboratoire de Pharmacologie.

Rapport de Master
présenté pour obtenir
Le DIPLÔME MASTER 2 RECHERCHE
en Mathématiques Financières
par
A.Lokman ABBAS-TURKI
SUJET:
Pricing sur GPU
Encadrants :
Bernard Lapeyre Enseignant chercheur au CERMICS, ENPC
Renaud Keriven Directeur du CERTIS, ENPC
Septembre 2008


Aux deux femmes qui
ont rempli mon coeur
d’amour et d’affection.


Remerciements
Mes premiers remerciements vont à Monsieur Bernard Lapeyre, d’une part, de m’avoirproposé un sujet que j’ai énormément aimé pour sa richesse scientifique théorique et ap-pliquée et, d’autre part, pour ses conseils avisés, son aide et sa confiance continue en montravail.
Je remercie aussi très chaleureusement Monsieur Renaud Keriven qui a rendu, lui etson équipe, mon travail tellement agréable que j’ai eu l’impression de passer mes meilleuresvacances avec eux.
Ce travail a été effectué au CERMICS et principalement au sein de l’équipe du CER-TIS. Que tous les membres de ces départements trouvent ici l’expression de ma gratitude.Leur gentillesse et leur disponibilité ont grandement contribué à rendre ma tâche facile etmon séjour agréable.
Je suis très reconnaissant à tous les enseignants que j’ai eus durant mes dix-huit annéesd’étude et de formation, sans lesquels ce mémoire n’aurait pas eu son contenu actuel.
Enfin, on dit souvent que l’on ne choisit pas ses parents. En ce qui me concerne, sij’avais à le faire, j’aurais certainement retenu les miens. Qu’ils trouvent en moi l’enfantredevable toute sa vie.


Table des matières
0 Introduction générale 0-10.1 Contexte du projet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0-10.2 Objectif du projet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0-20.3 Organisation du manuscrit . . . . . . . . . . . . . . . . . . . . . . . . . . . 0-3
1 Le GPU et les finances 1-11.1 HPC sur GPU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-2
1.1.1 La gamme Geforce . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-21.1.2 La gamme Tesla . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-21.1.3 Cluster de cartes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-3
1.2 Programmer les GPU avec CG . . . . . . . . . . . . . . . . . . . . . . . . . 1-31.2.1 À propos du GPU . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-41.2.2 Monte Carlo sur GPU . . . . . . . . . . . . . . . . . . . . . . . . . 1-5
1.3 Put sur paniers d’actifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-8
2 Contrats Path Dependant 2-12.1 Contrats Standards . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-2
2.1.1 Modèle de diffusion . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-22.1.2 Option asiatique . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-22.1.3 Option Lookback . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-32.1.4 Option Barrière . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-4
2.2 Produits dérivés de taux . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-52.2.1 Modèle de diffusion . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-52.2.2 Target Redemption Risk Neutral . . . . . . . . . . . . . . . . . . . 2-72.2.3 Ratchet Product . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-9
2.3 Résultats de speedup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-9
3 Contrats Américains 3-13.1 Formulation du problème . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-23.2 Introduction au calcul de Malliavin . . . . . . . . . . . . . . . . . . . . . . 3-43.3 Généralisation en plusieurs dimensions . . . . . . . . . . . . . . . . . . . . 3-93.4 Implémentation numérique . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-12
Conclusion générale 4-1
A Caractéristiques techniques des Tesla dernière génération A-1

B Exemple de programme sur CG B-1
Liste des figures i
Liste des algorithmes i
Bibliographie i

Chapitre 0
Introduction générale
" La finance a envahi l’actualité. Sa complexité, l’énormité des sommes en jeu, larapidité des fortunes et des ruines, la valse des bourses et des monnaies, l’émergence depuissances hors contrôle des états, tout cela fascine ou inquiète. "
Catherine Lambert pour "Le Commerce Des Promesses"
Sommaire
0.1 Contexte du projet . . . . . . . . . . . . . . . . . . . . . . . . . 0-1
0.2 Objectif du projet . . . . . . . . . . . . . . . . . . . . . . . . . . 0-2
0.3 Organisation du manuscrit . . . . . . . . . . . . . . . . . . . . . 0-3
0.1 Contexte du projet
En quête de plus de rapidité dans les calculs, plusieurs institutions financières inves-tissent dans des machines multiprocesseurs très puissantes. La raison principale de cetinvestissement est double : D’une part, ces institutions veulent toujours être plus rapidesque la concurrence sur des produits standards. D’autre part, elles expriment le besoin demodèles plus sophistiqués et de contrats plus exotiques qui nécessitent un temps de calculplus important.
Parmi les méthodes les plus utilisées dans le domaine du "pricing" et de "hedging" decontrat, on trouve la simulation de Monte Carlo. Cette méthode est intuitive dès qu’il y aun problème d’intégration numérique. Elle est presque exclusivement la méthode utiliséedès qu’il s’agit d’un problème en grande dimension. Cependant, comme toute procédurede calcul scientifique, la simulation de Monte Carlo possède des avantages et des incon-vénients. L’obstacle majeur dans son utilisation reste sa lenteur de calcul qui s’accentueavec notre gourmandise pour la précision du résultat. Néanmoins, le fait qu’elle soit uneméthode parfaitement parallèle favorise son usage. En d’autres termes, on peut lancer
0-1
CHAPITRE 0. INTRODUCTION GÉNÉRALE
plusieurs processeurs, travaillant de manière indépendante, pour accélérer ainsi l’obten-tion du résultat.
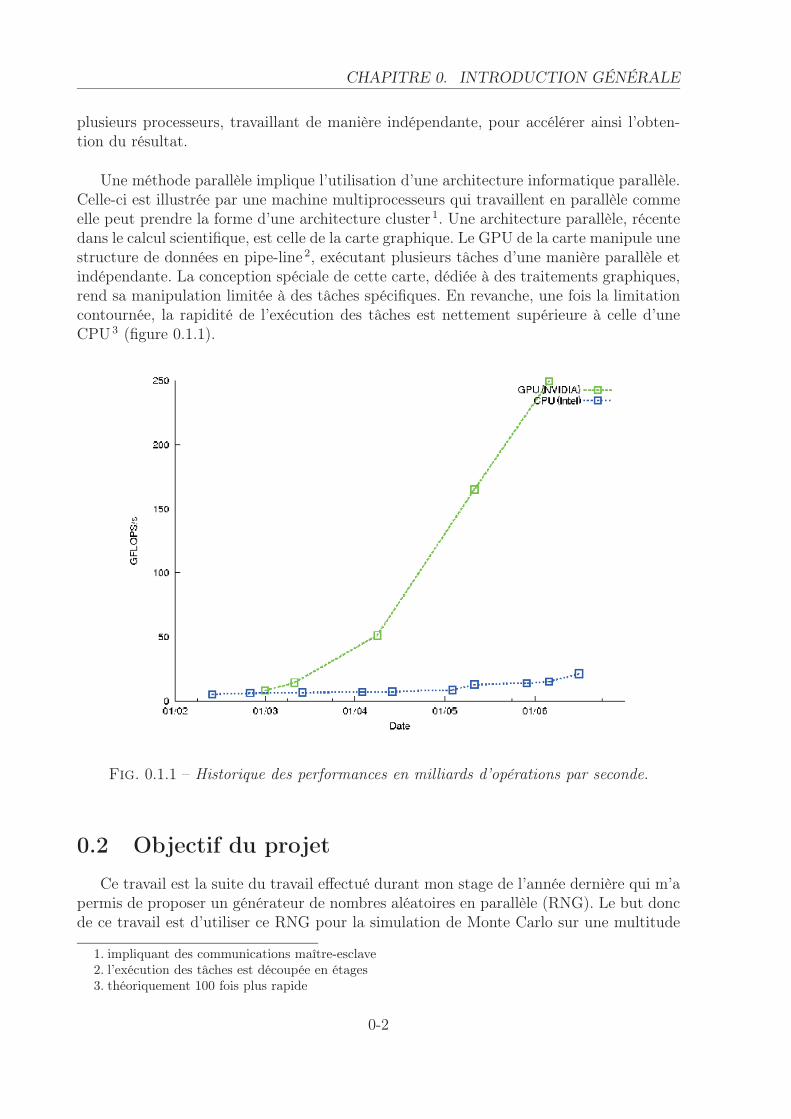
Une méthode parallèle implique l’utilisation d’une architecture informatique parallèle.Celle-ci est illustrée par une machine multiprocesseurs qui travaillent en parallèle commeelle peut prendre la forme d’une architecture cluster 1. Une architecture parallèle, récentedans le calcul scientifique, est celle de la carte graphique. Le GPU de la carte manipule unestructure de données en pipe-line 2, exécutant plusieurs tâches d’une manière parallèle etindépendante. La conception spéciale de cette carte, dédiée à des traitements graphiques,rend sa manipulation limitée à des tâches spécifiques. En revanche, une fois la limitationcontournée, la rapidité de l’exécution des tâches est nettement supérieure à celle d’uneCPU 3 (figure 0.1.1).
Fig. 0.1.1 – Historique des performances en milliards d’opérations par seconde.
0.2 Objectif du projet
Ce travail est la suite du travail effectué durant mon stage de l’année dernière qui m’apermis de proposer un générateur de nombres aléatoires en parallèle (RNG). Le but doncde ce travail est d’utiliser ce RNG pour la simulation de Monte Carlo sur une multitude
1. impliquant des communications maître-esclave2. l’exécution des tâches est découpée en étages3. théoriquement 100 fois plus rapide
0-2

0.3. ORGANISATION DU MANUSCRIT
de contrats financiers, avec un accent sur les algorithmes et les performances obtenuespour chaque contrat.
0.3 Organisation du manuscrit
Pour atteindre la majorité des objectifs fixés ci-dessus, le partage des chapitres a étéfait d’une manière croissante en difficulté : On commencera par introduire le matérielemployé et une description brève du RNG utilisé qui sera illustrée par l’exemple d’uncontrat vanille multidimensionnel. Puis, on passera sur des contrats européens faisantintervenir la trajectoire et enfin on terminera par traiter des contrats américains.
Chapitre 1
Cette partie fera le tour des évolutions de la carte graphique, en particulier, dans lemonde bancaire ainsi que de son utilisation via l’implémentation d’un cas simple.
Chapitre 2
Ce chapitre exposera l’implémentation de trois contrats standards dans le milieu finan-cier, il s’agit : d’une option asiatique sur un panier d’actifs et deux options sur maximumsur un panier d’actifs : lookback et barrière. En plus de ces contrats, je présenterai deuxautres contrats issus du "Fixed-Income" le premier est un Ratchet et le deuxième est unTarget, tous les deux utilisent un modèle HJM n-facteurs.
Chapitre 3
Pour explorer d’avantage l’utilité de la carte graphique dans le milieu financier, il m’asemblé incontournable de traiter les contrats américains. La difficulté de ce contrat estdouble : La première est une difficulté intrinsèque qui apparaît dès que l’on veut travaillersur plusieurs actifs. La deuxième difficulté est celle due à la parallélisation d’un contratdifficilement parallèlisable. On essayera de ce fait d’apporter une réponse double à cettedifficulté.
0-3

CHAPITRE 0. INTRODUCTION GÉNÉRALE
0-4

Chapitre 1
Le GPU et les finances
" Ces tests, faits avec la société de conseils ANEO, ont livrés des résultats pleins depromesses avec une accélération des performances et une exactitude exceptionnelle. Lagamme Tesla S1070 et C1060, qui apporte une double précision IEEE 754, est égalementun élément très important pour nous . "
Stéphane Tyc, Responsable de la recherche quantitative sur Equities & Derivates chezBNP Paribas
Sommaire
1.1 HPC sur GPU . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-2
1.2 Programmer les GPU avec CG . . . . . . . . . . . . . . . . . . 1-3
1.3 Put sur paniers d’actifs . . . . . . . . . . . . . . . . . . . . . . . 1-8
Depuis toujours, l’être humain veut disposer des outils les plus performants pour réa-liser ses tâches. Cette performance peut avoir plusieurs formes : la rapidité de l’obtentiondu résultat, la précision de ce résultat, le coût de fonctionnement de l’outil... De même,les institutions financières s’intéressent de plus en plus aux solutions alternatives à leursmachines énormes qui consomment énormément d’énergie et qui sont de plus en plus re-mises en cause au niveau de leur rapidité de calcul.
L’idée de proposer un processeur à peu près 100 fois plus rapide qui consomme pra-tiquement comme un processeur traditionnel séduit énormément. Le GPU de la cartegraphique propose une telle solution pour les professionnels dans le domaine de la simu-lation en parallèle. Nvidia qui est, jusqu’à maintenant, leader dans le domaine proposedepuis plus d’une année des cartes graphiques sans sortie vidéo dédiées à l’accélérationdu calcul. Le record de ces accélérations a été largement battu par la sortie de la gammeGeForce 8800 qui a bouleversé le monde du HPC (High-Cerformance Computing) parces speedup considérables et par l’originalité de pouvoir manipuler des entiers. Depuis,Nvidia a cherché à convaincre davantage sa clientèle en proposant une gamme encore pluslarge de cartes, jusqu’à deux fois plus rapides que la GeForce 8800, certaines même ma-nipulent la double précision.
1-1

CHAPITRE 1. LE GPU ET LES FINANCES
Dans ce qui suit, nous allons exposer certaines solutions informatiques fondées sur lesGPU, puis nous parlerons des difficultés de leurs programmations et des libertés offertes.Enfin, nous allons détailler un cas simple d’implémentation.
1.1 HPC sur GPU
Nous verrons dans ce qui suit deux types de solutions proposées par Nvidia pour lesamateurs des hautes performances. La première est la gamme Geforce destinée au grandpublic. La deuxième est la gamme Tesla consacrées aux professionnels même si elle estconstruite sur une technologie Geforce à peu de chose près. Enfin, nous terminerons cettesection par un paragraphe qui traite des perspectives de clusters utilisant les GPU.
1.1.1 La gamme Geforce
La gamme Geforce regroupe 3 séries de cartes graphiques à hautes performances :– Série 8 : Cette série est la moins récente. Elle contient, en particulier, les Geforce
8800 qui sont les premières cartes à proposer des speedup de l’ordre de 100. Cescartes sont munies d’une centaine d’unités de calcul et profitent d’un accès mémoirede l’ordre de deux fois plus rapide que les meilleures machines grand public.
– Série 9 : Bien que le nom diffère de la série précédente, elle n’est pas distincte auniveau des performances. Nvidia a voulu proposer avec cette catégorie une versionsur-cadencée de la série 8 mais avec des performances mémoires moins importantes.Cette série a été lancée principalement pour contrer les ATI Radeon vendues à unprix plus abordable 1.
– Série 200 : Cette série est très différente des deux précédentes de part ces per-formances qui doublent mais surtout par l’introduction de la double précision. Eneffet, cette double précision a été tellement demandée pour les problèmes mal condi-tionnés au sens de la propagation de l’erreur qu’il était impossible de la contourner.On distingue deux cartes dans cette série : la Geforce GTX 260 et la Geforce GTX280, la plus puissante sur le marché.
1.1.2 La gamme Tesla
La gamme Tesla est développée pour les professionnels. Elle regroupe deux séries decartes et de cluster de cartes :
– Série 8 : Âgée d’un an, elle est constituée de la soeur jumelle à la Geforce 8800 etde deux cluster de cette carte : le premier contient 2 cartes et le deuxième contient4 cartes.
– Série 10 : Cette gamme date de fin juin 2008 et elle est constituée de la Tesla C1060,qui est la soeur jumelle de la Geforce GTX 280, ainsi que du cluster Tesla S1070à 4 cartes Tesla C1060. La puissance de ce derniers cluster est supérieur à4 teraflops promettant un speedup de l’ordre de 1000 à 2000 fois celle
1. Etant donné que l’aspect mémoire est celui qui coûte le plus chère dans une carte.
1-2

1.2. PROGRAMMER LES GPU AVEC CG
d’une machine normale à un prix d’achat inférieur à 6000 euros. J’ai misen annexe A les descriptions techniques de ces calculateurs exceptionnels.
1.1.3 Cluster de cartes
La plus puissante machine au monde est le "Roadrunner" d’IBM acheté par Los Ala-mos National Laboratory à New Mexico, États-Unis. La puissance de calcul atteinte tourneautour de 1 petaflop 2 et son prix est de l’ordre de 100 Meuros. La solution actuelle possibleen GPU, pour atteindre une telle puissance de calcul, est de les assembler en cluster deGPU/CPU. Ainsi, on peut atteindre le petaflop avec un investissement inférieur à 2 Meu-ros ; le système résultant consomme beaucoup moins en terme d’énergie. Pour réaliser unemaquette réduite d’un tel système, un projet est en court de réalisation avec Supélec pourd’étudier l’asservissement d’une telle architecture. Le but final serait de faire communi-quer "N" machines en MPI 3 afin de réaliser "M" tâches dans une durée de temps optimale.
En plus de la réduction considérable de la consommation en terme d’énergie, l’intérêtd’une telle architecture, par rapport à une machine comme le "Roadrunner", se manifestedans la localisation de la machine par rapport au lieu de travail. En effet, plus la machineest proche de celui qui la manipule, plus c’est bénéfique. Ce qui, par exemple, réduit lescoûts d’intervention en terme logistique et budgétaire.
1.2 Programmer les GPU avec CG
Le modèle de carte graphique utilisée est la Geforce 8800 GTX. Comme ceci est men-tionné ci-dessus, elle diffère de la dernière génération sur la précision double et les per-formances qui sont de moitié. Dans ce qui suit, c’est la programmation de ce modèle quisera pris en compte. Les caractéristiques techniques importantes de cette carte sont :
– 128 flux de process– Fréquence de l’horloge du Shader : 1.35 GHz– Quantité de mémoire : 768 Mo– Fréquence de l’horloge de la mémoire : 900 Mhz– Manipulation des entiers et des flottants.
L’architecture d’une GPU est très spécifique et ne ressemble pas à celle d’une CPU.Les langages permettant de les manipuler autorisent moins de degrés de libertés 4 queceux existant pour CPU. Après avoir expliqué le fonctionnement d’une GPU dans lapremière partie de ce chapitre, nous exposons ensuite nos souhaits d’implémentation puisdéfinissons les solutions plausibles liées aux limitations matérielles et logicielles.
2. Soit 1000 teraflops3. Message Passing Interface4. même si une avancée considérable a été réalisée depuis les premières GPU. Cette progression ne
peut que durer à cause de l’appétence des jeunes pour les jeux vidéo d’une part et, d’autre part, à causede l’importance accordée depuis plus d’un an à la simulation scientifique sur ces cartes.
1-3

CHAPITRE 1. LE GPU ET LES FINANCES
1.2.1 À propos du GPU
La GPU est l’unité responsable du traitement de données sous format graphique.Le format graphique d’un flux de données vidéo est une séquence d’images alors que celuid’une image est un ensemble de fragments. L’élément graphique élémentaire constituantun fragment est un pixel. En d’autres termes, l’information est portée par un ensemblede pixels regroupés dans un fragment, dans une image ou dans un flux vidéo.
Une fois que l’on connaît l’objet qui conduit l’information, le traitement de cette in-formation prendra en compte la nature de l’objet qui la porte. Ainsi, si l’on veut dégagerune information de mouvement de rotation dans une séquence vidéo, il suffit d’afficherséquentiellement sur l’écran une trentaine d’images par seconde, de manière à ce que lavaleur portée par chaque pixel, dans chaque image, donne cette impression de mouvement.
Le langage openGL réalise l’inverse de la fonction de notre cerveau, du fait qu’iltraduit l’information du mouvement physique, comme la rotation, en une information deflux de pixels. La différence entre openGL et CG réside dans le lieu de cette traduction.En effet, le premier l’effectue au niveau du CPU et envoie cette traduction au GPU alorsque le deuxième envoie les informations utiles pour la traduction du CPU au GPU. C’estdonc cette dernière unité qui joue le rôle de l’interprète.
Le fait que CG ne sollicite le CPU que pour l’initialisation des données et le retour desrésultats, les communications CPU/GPU sont considérablement réduites. L’autre pointqui accélère la vitesse de traitement est celui dû au nombre de processeurs dans une GPUparticipant à la tâche de traduction.
Avec CG, la manipulation des données est découpée en plusieurs étages. Le shaderest la spécification des différentes opérations à réaliser au niveau d’un étage. L’ensembledes opérations est exécuté sur un groupe de pixels, dit texture. De ce fait, le shaderest l’élément principal du langage CG qui reçoit, en entrée, une texture et des donnéesnécessaires à la transformation puis renvoie une texture en sortie.
Les opérations réalisées par un shader sont, par défaut, exercées sur un pixel indépen-damment des autres appartenant à la même texture. L’expression par défaut remplaceici le fait que l’on peut créer une dépendance entre pixels de la même texture si l’on réussità trouver l’algorithme approprié.
Un shader n’accepte pas des appels récursifs pour la seule raison qu’il n’y a pas denotion de piles en manipulant des pixels. Un pixel peut contenir quatre valeurs rgba 5 int(resp float) dans une texture int (resp float). Contrairement à une allocation de int quipermet de représenter les entiers ∈ [0,232−1], c’est à dire 32 bits de précision, l’allocationfloat ne permet que 23 bits de précision.
5. Les trois couleurs principales et le niveau de gris
1-4

1.2. PROGRAMMER LES GPU AVEC CG
Fig. 1.2.1 – L’allocation float.
Nous donnons, à l’annexe B, un exemple de programmation d’un shader sur CG pourle schéma d’Euler avec un modèle de Black et Scholes.
1.2.2 Monte Carlo sur GPU
Rappelons que l’objectif principal du stage est : Réussir à généraliser la simula-tion de Monte Carlo proposée dans mon PFE [AT] (de l’année dernière) pourdivers contrats de la manière la plus optimale possible et que celle-ci soit fa-cilement évolutive pour une architecture cluster.
Pour atteindre ce but principal, la simulation de Monte Carlo que l’on doit généraliserdoit satisfaire les objectifs intermédiaires suivants :
– Un bon générateur parallèle de nombres aléatoires.– Une architecture qui permet de se rapprocher, le plus possible, des performances
optimales.– Un paradigme de programmation facilement généralisable pour d’autres contrats
ainsi qu’une architecture cluster.
La génération parallèle des nombres aléatoires fait l’objet de mon rapport de PFE[AT] de l’année dernière. Nous nous limiterons alors à donner l’idée générale de cetteparallélisation qui découle principalement de l’étude des deux articles : [Mas97] de Mi-chael Mascagni qui propose la parallélisation par un paramétrage et [Knu77] de DonaldE. Knuth qui permet, en amont, un bon choix de paramètres.
La récurrence de base que l’on considère est celle d’un LCG 6 particulier :
xn = axn−1 mod(231 − 1) (1.1)
Le premier avantage de ce générateur est certainement le fait qu’il soit très simple à réa-liser. Un autre intérêt est qu’il peut être parfaitement parallélisé en utilisant la techniquede paramétrage du multiplicateur a selon le procédé expliqué à la figure 1.2.2.
On considère à la figure 1.2.2 deux multiplicateurs a1 et a2, a1 étant plus grand quea2, alors a1 parcourt la période de l’anneau plus rapidement que a2. La diffculté principalede cette méthode est dans le choix des multiplicateurs appropriés pour paramétriser. Eneffet, il est possible de voir à la figure 1.2.2 qu’un multiplicateur comme a1 donne une
6. Linear Congruential Generator
1-5

CHAPITRE 1. LE GPU ET LES FINANCES
très grande corrélation 7 lors de la génération des nombres aléatoires. Le choix de cesmultiplicateurs est effectué au chapitre 6 de [AT].
Fig. 1.2.2 – Parallélisation par paramétrage.
0 20 40 60 80 10020
40
50
60
80
100
120
S0=
Textures successives rempliespar la valeur de
l’actif
Texture de générationde nombres aléatoires
Fig. 1.2.3 – Architecture que l’on veut réaliser.
Avoir un générateur pour chaque trajectoire nous procure une architecture raisonnablequi nous permettra de manipuler des trajectoires complètement parallèles d’actifs finan-ciers, comme cela est représenté à la figure 1.2.3. En effet, les trajectoires, dans un Monte
7. A l’oeil nu
1-6

1.2. PROGRAMMER LES GPU AVEC CG
Carlo, sont simulées de façon indépendante. Le meilleur moyen de tenir compte de cetteindépendance est d’associer une trajectoire et donc un générateur à chaque pixel. De cefait, la communication sera celle établie entre les pixels de textures différentes et non pasentre les pixels de la même texture.
Formellement, les textures, en noir, représentées sur la figure 1.2.3 sont des texturesfloat qui contiennent la valeur du sous-jacent à l’instant tn−1 et tn successivement. Cetactif sous-jacent suit une équation aux différences type Euler. De ce fait, le passage d’unetexture à une autre s’effectuera après une génération de nombres aléatoires sur la textureint en rouge. Cette dernière texture contient sur chaque pixel un générateur de nombresaléatoires. C’est comme si on avait N processeurs travaillant parallèlement, où N repré-sente le nombre de pixels utilisés.
Cette architecture permet aussi de décider du nombre de trajectoires nécessaires pourune précision donnée. Ainsi, avant de lancer la simulation, on spécifie la taille des texturespour un niveau de précision donné.
L’architecture présentée, pour le cas à une seule dimension, est parfaitement adaptéeà plusieurs types d’options sur plusieurs actifs, puisqu’il suffit d’utiliser plusieurs texturesrouges pour générer des nombres aléatoires, puis générer les browniens correspondantssur des textures noires. Enfin, il faut considérer une autre texture pour contenir l’actifqui sera calculé à partir d’une somme pondérée 8 des différents browniens, comme ceci estreprésenté à la figure 1.2.4.
1
2
3
1
2
3
1
1
1
2
2 3
1 2 3
1 2
1
Textures des browniens 1,2 et 3
Textures de génération de nombres aléatoires
Matrice triangulaire inférieure de Cholesky
Textures d’actifs
Fig. 1.2.4 – Architecture pour trois actifs.
8. par exemple celle utilisant la matrice de Cholesky
1-7

CHAPITRE 1. LE GPU ET LES FINANCES
1.3 Put sur paniers d’actifs
Cette dernière partie achève l’explication de la méthode de simulation, présentée ci-dessus, par un exemple illustratif. L’exemple considéré est un put sur la moyenne géomé-trique de 40 actifs, ainsi, nous pourrons comparer le résultat numérique de la simulationavec les formules explicites.
Soit St le prix du panier d’actif que l’on suppose de la forme St =(∏40
i=1 Sit
)1/40.On
considère la dynamique suivante pour chaque actif Sit :
Sit = Si
0 exp
[(ri − di −
σ2i
2
i∑
k=1
ρ2ik
)t + σi
i∑
k=1
ρikWkt
](1.2)
où :
Si0 est la valeur initiale de l’actif i.ri est le taux de l’actif i.di est le dividende de l’actif i.σi est la volatilité de l’actif i.
W kt est le kiem mouvement brownien.
ρik est le coefficient associé à l’actif i dans la matrice corrélative diagonale inférieurequi pondère le mouvement brownien W k
t .
La matrice corrélative que l’on choisit est la racine carré 9 de :
A =
1 0.5 . . . 0.5
0.5 1. . .
......
. . . . . . 0.50.5 . . . 0.5 1
Associons le strike Ki pour tout actif i, alors le prix via la simulation du put géomé-trique sur 40 actifs est donné par :
PutMC = E
[e−rT
(40∏
i=1
K140 −
40∏
i=1
(Si
T (ε)) 1
40
)
+
](1.5)
Dans (1.5), ε représente la gaussienne multidimensionnelle qui sert à simuler le com-portement du panier d’actifs ST . D’autre part, ce prix est obtenu par l’expression explicitesuivante :
Putexplicite = e−rT
[(40∏
i=1
K140
)N(α) −
(40∏
i=1
Si0
140
)N(α −
√TV )eTβ
](1.6)
où:
α =1√V
(40∑
i=1
γi
)(1.7)
9. Au sens de la factorisation de Cholesky
1-8

1.3. PUT SUR PANIERS D’ACTIFS
γi =1
40√
T
[ln
(Ki
Si0
)−
(r − di −
σ2i
2
i∑
k=1
ρ2ik
)T
](1.8)
V =40∑
i=1
(1
40
40∑
k=i
σkρik
)2
(1.9)
β =V
2+
1
40
40∑
i=1
(r − di −
σ2i
2
i∑
k=1
ρ2ik
)(1.10)
N(x) =
∫ x
−∞
1√2π
exp
(−t2
2
)dt (1.11)
Sur le tableau 1.1 et 1.2, nous faisons la comparaison entre la simulation en utilisant(1.5) et la formule explicite (1.6) pour différentes valeurs de strike Ki et de volatilité σi.
K PutMC ǫMC Putexplicite
80 0.0621 0.0023 0.061090 0.5115 0.0078 0.5068100 2.1862 0.0178 2.1723110 5.9433 0.0299 5.9208120 11.9023 0.0407 11.8810
Tab. 1.1 – Comparaison de la valeur de si-mulation avec la vraie valeur pour les para-mètres : ri = r = 0.1, T = 1, di = 0, σi =0.2, Si
0 = 100, Ki = K avec ∀1 ≤ i ≤ 40. Onchoisit l’intervalle de confiance à 95%.
Malgré le fait que l’on intègre sur un espace très grand en dimension, on remarque surles tableaux 1.1 et 1.2 que la valeur de la simulation est toujours comprise dans l’intervallede confiance.
σ PutMC ǫMC Putexplicite
0.1 0.2729 0.0027 0.27040.2 2.1862 0.0178 2.17230.3 4.9271 0.0315 4.90240.5 8.0521 0.0445 8.01840.6 11.4249 0.0565 11.3833
Tab. 1.2 – Comparaison de la valeur de si-mulation avec la vraie valeur pour les para-mètres : ri = r = 0.1, T = 1, di = 0, σi = σ,Si
0 = 100, Ki = 100 avec ∀1 ≤ i ≤ 40. Onchoisit l’intervalle de confiance à 95%.
L’algorithme de simulation est le suivant :
1-9

CHAPITRE 1. LE GPU ET LES FINANCES
Algorithme 1 : Prix d’un put sur pondération géométrique d’actifs.Entrée : Paramètres du modèleSortie : PutMC
/* */
/* Partie C++ */
/* */
/* Initialisation des textures d’actifs par la valeur initiale de
chaque actif */
pour i ∈ 1, . . . 40 faire1
Si ←− texture de taille N × N ;2
pour ij ∈ 1, . . . N faire3
pour ik ∈ 1, . . . N faire4
Si[ij][ik] ←− S0;5
fin6
fin7
fin8
/* Initialisation de la texture des multiplicateurs et de la graine
*/
A ←− texture de taille N × N ;9
X0 ←− texture de taille N × N ;10
pour ij ∈ 1, . . . N faire11
pour ik ∈ 1, . . . N faire12
A[ij][ik] ←− valeurs chargées d’un fichier;13
X0[ij][ik] ←− valeurs chargées d’un fichier;14
fin15
fin16
/* */
/* Instructions de transferts de données entre CPU et GPU */
/* */
/* */
/* Partie CG */
/* */
pour i ∈ 1, . . . 40 faire17
/* Génération de nombres aléatoires */
Xi ←− AXi−1 mod(231 − 1) ;18
/* Passage d’uniforme à guassienne */
Gi ←− BoxMuller(Xi) ;19
/* Actualisation du prix */
SiT ←− Si
0 exp( l’expression (1.2) avec t = T ) ;20
fin21
PutMC ←− 1nb de simulations
∑nb de simulationsk=1 e−rT
(∏40k=1 K
140 − ∏40
i=1 (SiT (εk))
140
)+
;22
1-10

1.3. PUT SUR PANIERS D’ACTIFS
La non utilisation des boucles 10 dans la partie CG de l’algorithme peut surprendrele lecteur. Cependant ceci est bien réel puisqu’en utilisant CG, par exemple, écrire unemultiplication directe des textures implique implicitement une multiplication pixel parpixel qui est réalisée par les différentes unités de calcul. En d’autres terme, chaque fois oùil y a une tâche SIMD à réaliser, nous le faisons pour avoir de très bonnes performanceset pour simplifier la syntaxe.
Les temps d’exécutions sont comparés avec ceux de la machine suivante :
– Core Duo cadencé à 2.80 GHz– Quantité de mémoire 3 Go– Fréquence de l’horloge de la mémoire 400 MHz
Une comparaison avec la machine ci-dessus indique une performance de l’ordre de dix.Ce facteur, petit par rapport au nombre de process, peut être expliqué par le fait quele problème d’origine n’est pas un bon benchmark pour mesurer la rapidité. En effet,le put géométrique sur 40 actifs consomme seulement 30 secondes sur CPU alors que lechargement des donnée entre CPU et GPU est de l’ordre de la seconde. De ce fait, mêmesi le temps d’exécution sur GPU est inférieur à la seconde, la communication entre CPUet GPU réduit le speedup qu’on devrait obtenir.
10. à part la boucle sur la dimension
1-11

CHAPITRE 1. LE GPU ET LES FINANCES
1-12

Chapitre 2
Contrats Path Dependant
" Est-ce que les centaines d’unités de process sur la GPU peuvent remplacer unecentaine de CPU? "
Christophe Michel, Responsable de la recherche quantitative sur Rates & HybridDerivatives chez Calyon
Sommaire
2.1 Contrats Standards . . . . . . . . . . . . . . . . . . . . . . . . . 2-2
2.2 Produits dérivés de taux . . . . . . . . . . . . . . . . . . . . . . 2-5
2.3 Résultats de speedup . . . . . . . . . . . . . . . . . . . . . . . . 2-9
Cette question est tellement pertinente dans le domaine industriel 1 et tellement trivialedans le milieu informatique qu’une réponse donnée par un informaticien peut ne pas ras-surer l’industriel 2. Une connaissance des deux domaines est donc presque incontournablepour apporter une solution satisfaisante en soi et capable d’engendrer une collaborationentre celui qui interroge et celui qui répond. Cette solution doit argumenter sa négationou son affirmation et utiliser ces mêmes arguments pour proposer une solution.
Dans ce chapitre, nous allons traiter cinq contrats dont les prix dépendent de la simu-lation des trajectoires. Ces contrats vont non seulement nous donner un ordre de grandeurde l’accélération impressionnante que l’on peut tirer d’un GPU et qui va être tangentielleà l’accélération théorique, mais aussi donner une impression de facilité de programma-tion 3, déjà introduite dans le chapitre précédent, qui va pratiquement bluffer le lecteur.Une fois les performances maximales exposées, on essayera d’apporter une réponse à laquestion posée par Monsieur Christophe Michel.
Dans la première partie, seront exposés trois contrats standards 4 dans le monde des
1. Dans notre cas l’industrie financière2. C’est le problème : "Ce qui est évident pour certains ne l’est pas pour d’autres"3. par rapport à d’autres architectures parallèles, par exemple par MPI4. Tirés de la recherche quantitative dans les "equities"
2-1

CHAPITRE 2. CONTRATS PATH DEPENDANT
finances qui utilisent le modèle de Black et Scholes. Les deux autres sont des dérivées detaux construits sur des modèles HJM n-dimensionnels (HJMn) qui seront développés enseconde partie. Pour rendre plus clair l’exposé de ce chapitre, ces deux sections indépen-dantes seront chacune partagée en une sous-section sur le modèle de diffusion plus unesous-section pour chaque payoff qui traite l’algorithmique et le résultat obtenu.
2.1 Contrats Standards
Comme ceci est signalé ci-dessus, nous allons donner le modèle utilisé puis traiter uncontrat sur moyenne et deux contrats sur maximum. Le document support de cette sectionest [Jou07].
2.1.1 Modèle de diffusion
Le modèle utilisé pour chaque actif Si est un modèle de mouvement brownien géomé-trique décrit par l’équation stochastique suivante :
dSi
t = (ri − di)Sitdt + σiS
itdBt
S0 = x(2.1)
La solution d’une telle équation passe par une décorrélation de browniens puis par uncalcul d’Itô élémentaire sur la variable aléatoire Y = ln(X) qui donne :
Sit = Si
0 exp
[(ri − di −
1
2
i∑
j=1
σ2ij
)t +
i∑
j=1
σijWjt
](2.2)
Ce modèle est utilisé comme benchmark. Il va de soi que si on remplace dans (2.1)la volatilité et le drift constants par une volatilité et un drift variables 5 ceci ne rajouterarien à la complexité de l’implémentation sur la GPU à part celle due intrinsèquement auproblème 6.
2.1.2 Option asiatique
Le contrat asiatique fait intervenir la moyenne de la trajectoire dans l’expression deson payoff. Il peut, en outre, avoir plusieurs expressions comme celles données au le ta-bleau ci-dessous où l’expression meanT St(ε) signifie 1
T
∫ T
0St(ε)dt. Comme dans le chapitre
précédent, ε représente la gaussienne multidimensionnelle qui sert à simuler le comporte-ment du panier d’actifs ST .
Dans notre cas, puisque c’est le modèle de Black-Scholes qui est pris en considéra-tion, aucun schéma de discrétisation n’est nécessaire pour la simulation. Il suffit d’utiliserl’expression (2.2) pour obtenir la valeur de chaque actif X i
t à tout instant t. La moyennetrajectorielle est ensuite approchée par une moyenne discrète sur la trajectoire en utilisantla méthode des trapèzes, comme ceci est proposé dans [Lap01].
5. par exemple une volatilité locale ou stochastique6. par exemple l’utilisation d’un schèma d’Euler pour la volatilité stochastique
2-2

2.1. CONTRATS STANDARDS
Noms de contrats Payoffs
Call asiatique de strike flottant (ST (ε) − meanT St(ε))+
Put asiatique de strike flottant (meanT St(ε) − ST (ε))+
Call asiatique de strike fixé (meanT St(ε) − K)+
Put asiatique de strike fxé (K − meanT St(ε))+
Étant donné que la partie initialisation est semblable à celle exposée dans l’algorithme1, dans le suivant nous n’allons exposer que la partie exécutée sur la carte graphique.
Algorithme 2 : Put asiatique à strike flottantEntrée : Paramètres du modèleSortie : PutAs = E
(e−rT (meanT St(ε) − ST (ε))+
)
pour t ∈ 0,δt,2δt, . . . 1δt faire1
pour i ∈ 1, . . . 40 faire2
/* Génération de nombres aléatoires */
Xt∗40+i ←− AXt∗40+i−1 mod(231 − 1);3
/* Passage d’uniforme à gaussienne */
Gi ←− BoxMuller(Xi) ;4
/* Actualisation du prix */
Sit ←− Si
0 exp( l’expression (2.2) ) ;5
/* Implémentation récursive de la somme en utilisant la méthode
des trapèze */
Si
t ←− ((t − 1)/t)Si
t−1 + (1/t)Si
t ;6
fin7
fin8
PutAs ←− 1nb de trajectoires
∑nb de trajectoiresk=1
(e−rT (meanT St(εk) − ST (εk))+
);9
2.1.3 Option Lookback
Afin de simuler ce contrat nous allons énoncer un lemme et une proposition dont lesdémonstrations peuvent-être trouvées dans [Jou07]. Ces deux résultats sont nécessairespour la simulation du maximum fondée sur la technique du pont brownien. Commençonspar donner le payoff de ce contrat :
PayoffLookback = maxt∈[0,T ]
Xt − XT
Proposition 2.1 Conditionnellement à (X0,Xt1 ,...,XT ) = (x0,x1,...,xN), les variablesaléatoires maxt∈[tk,tk+1] Xt, k ∈ 0,...,N − 1 sont indépendantes et ont respectivement
la même loi que xk + σ(xk) maxt∈[0,t1]] Wt conditionnellement à Wt1 = xk+1−xk
σ(xk).
2-3

CHAPITRE 2. CONTRATS PATH DEPENDANT
Lemme 2.1 Soit Wt un mouvement brownien réel,
P( maxt∈[0,t1]
Wt ≥ y|Wt1 = x) =
1 si y ≤ max(0,x)
e−
2y(y−x)t1 sinon
En particulier, si U suit une loi uniforme sur [0,1], alors conditionnellement à Wt1 = x,maxt∈[0,t1] Wt a même loi que 1
2(x +
√x2 − 2t1 ln(U)).
L’algorithme de simulation pour 40 actifs est le suivant :
Algorithme 3 : Option LookbackEntrée : Paramètres du modèleSortie : PutLB = E
(e−rT (maxt∈[0,T ] Xt − XT )
)
pour t ∈ 0,δt,2δt, . . . 1δt faire1
pour i ∈ 1, . . . 40 faire2
/* Génération de nombres aléatoires */
Xt∗80+2∗i ←− AXt∗80+2∗i−1 mod(231 − 1);3
/* Passage d’uniforme à guassienne */
Gt∗80+i ←− BoxMuller(Xt∗80+i) ;4
/* Actualisation du prix */
Sit ←− Si
0 exp( l’expression (2.2) ) ;5
/* Génération des variables uniformes qui interviennent dans la
simulation du maximum */
Xt∗80+2∗i+1 ←− AXt∗80+2∗i mod(231 − 1)6
/* Normalisation des variables uniformes */
U ←− Xt∗80+2∗i+1/(231 − 1)7
/* Simulation du maximum */
loc1 = 140
∑40i=1 Si
t−1 , loc2 = 140
∑40i=1 Si
t8
loc3 = 0.5 ∗ (loc1 + loc2 +√
(loc2 − loc1) ∗ (loc2 − loc1) − 2 ∗ σ ∗ t ∗ log(U))9
/* Actualisation récursive sur les trajectoires */
St = max(St−1,loc3);10
fin11
fin12
PutLB ←− 1nb de trajectoires
∑nb de trajectoiresk=1
(e−rT (St(εk) − ST (εk))
);
13
2.1.4 Option Barrière
Puisque ce contrat est aussi un contrat sur maximum, il est nécessaire d’utiliser laproposition 2.1 et le lemme 2.1 afin de simuler le prix. Ici, on détaillera la simulationd’une version up and out appliquée à un payoff de put, soit :
Payoffbarriere = (K − XT )+1maxt∈[0,T ] Xt<L
2-4

2.2. PRODUITS DÉRIVÉS DE TAUX
L représente la barrière.
En utilisant la technique de conditionnement, le prix à estimer est le suivant :
E[e−rT (K − ST (ε))+1ST <L
]= E
[e−rT (K − ST (ε))+G
](2.3)
avec ST = max0≤t≤T St(ε)et :
G = 1St0<L
N−1∏
k=0
1Stk+1<L
[1 − exp
(−2(L − Stk)(L − Stk+1
)
t0σ2
)](2.4)
L’algorithme de simulation pour 40 actifs est le suivant :
Algorithme 4 : Put up and outEntrée : Paramètres du modèleSortie : PutBar = E
[e−rT (K − ST (ε))+G
]
pour t ∈ 0,δt,2δt, . . . 1δt faire1
pour i ∈ 1, . . . 40 faire2
/* Génération de nombres aléatoires */
Xt∗40+i ←− AXt∗40+i−1 mod(231 − 1) ;3
/* Passage d’uniforme à gaussienne */
Gt∗40+i ←− BoxMuller(Xt∗40+i) ;4
/* Actualisation du prix */
Sit ←− Si
0 exp( l’expression (2.2) ) ;5
/* Actualisation récursive de la variable G selon (2.4) */
loc1 = 140
∑40i=1 Si
t−1, loc2 = 140
∑40i=1 Si
t6
loc3 = 2(L − loc1)(L − loc2)/(t0σ2) G = G ∗ 1loc2<L [1 − exp (−loc3)]7
fin8
fin9
PutBar ←− 1nb de trajectoires
∑nb de trajectoiresk=1
(e−rT ((K − ST (εk))+G)
);10
2.2 Produits dérivés de taux
Le but de ce paragraphe est de prendre des produits utilisés dans le fixed income etde tester leur simulation sur le GPU de la carte graphique. Ce travail reprend un modèleutilisé par la banque Calyon qui va être présenté dans le paragraphe suivant.
2.2.1 Modèle de diffusion
Dans ce qui suit, nous allons développer le prix du zéro-coupon à partir d’une construc-tion HJM n-facteurs utilisant le taux forward instantané f(t,T ). Soit σ(t,T ) la volatilité
2-5

CHAPITRE 2. CONTRATS PATH DEPENDANT
de ce taux forward et posons :
Γ(s,t) =
∫ t
s
σ(s,u)du
Le prix du zéro-coupon B(t,T ) est donné par :
B(t,T ) =B(0,T )
B(0,t)exp
−1
2
∫ t
0
(−→Γ (s,T )2 −−→
Γ (s,t)2)
ds +
∫ t
0
(−→Γ (s,T ) −−→
Γ (s,t))
d−→W s
où d−→W s est un mouvement brownien de dimension n. Nous donnons à la volatilité la forme
suivante :
σ(s,u) = a(s)−→b (u)
où−→b (u) est un vecteur de norme b(u) qui s’écrit :
−→b (u) = b(u)
−→ψ
avec :
−→ψ =
ψ1
ψ2...
ψn
=
cos(θ1)sin(θ1) cos(θ2)
...sin(θ1) · · · sin(θn−1) cos(θn)
Les courbes de a(s) et de b(u) sont supposées constantes par morceaux. En tenant comptede ces hypothèses :
−→Γ (s,t) = a(s)
∫ t
s
−→b (u)du
et∫ t
0
(−→Γ (s,T ) −−→
Γ (s,t))
d−→W s =
∫ t
0
a(s)
(∫ T
t
−→b (u)du
)d−→W s
=
(∫ T
t
−→b (u)du
)(∫ t
0
a(s)d−→W s
)
Posons :
−→X (t) =
∫ t
0
a(s)d−→W s,
−→β (t) =
∫ t
0
−→b (u)du
afin d’obtenir :∫ t
0
(−→Γ (s,T ) −−→
Γ (s,t))
d−→W s =
(−→β (T ) −−→
β (t))−→
X (t)
D’autre part :
2-6

2.2. PRODUITS DÉRIVÉS DE TAUX
∫ t
0
(−→Γ (s,T )2 −−→
Γ (s,t)2)
ds =
∫ t
0
a2(s)
[(∫ T
s
−→b (u)du
)2
−(∫ t
s
−→b (u)du
)2]
ds
=
∫ t
0
a2(s)
[(∫ T
t
−→b (u)du
)2
+ 2
(∫ T
t
−→b (u)du
∫ t
s
−→b (u)du
)]ds
=
(∫ T
t
−→b (u)du
)2 (∫ t
0
−→a (s)ds
)+ 2
(∫ T
t
−→b (u)du
)[∫ t
0
a2(s)
(∫ t
s
−→b (u)du
)ds
]
Posons aussi :
α(t) =
∫ t
0
a2(s)ds,−→λ (t) =
∫ t
0
a2(s)−→β (s)ds
afin d’obtenir :
∫ t
0
(−→Γ (s,T )2 −−→
Γ (s,t)2)
ds = α(t)(−→
β (T ) −−→β (t)
)2
+
+2(−→
β (T ) −−→β (t)
)[∫ t
0
a2(s)(−→
β (T ) −−→β (t)
)ds
]
= α(t)(−→
β (T ) −−→β (t)
)2
+ 2(−→
β (T ) −−→β (t)
) [α(t)
−→β (t) −−→
λ (t)]
= α(t)−→β
2(T ) − α(t)
−→β
2(t) − 2
(−→β (T ) −−→
β (t))−→
λ (t)
=(−→
β (T ) −−→β (t)
) [α(t)
(−→β (T ) +
−→β (t)
)− 2
−→λ (t)
]
La formule de reconstruction des zéro-coupons est donc donnée par :
B(t,T ) =B(0,T )
B(0,t)exp
(−→β (T ) −−→
β (t))[
−1
2α(t)
(−→β (T ) −−→
β (t))
+−→X (t) −−→
λ (t)
](2.5)
Pour évaluer les contrats suivants, en plus de la dynamique des zéro-coupon ci-dessus,on a besoin d’utiliser le taux Libor forward qui a pour expression :
L(t,T,T + ∆T ) =1
∆T
(B(t,T )
B(t,T + ∆T )− 1
)(2.6)
2.2.2 Target Redemption Risk Neutral
Le payoff de ce contrat à des instants Ti fixés est donné par :
Fi = ∆T (K − L(Ti,Ti,Ti + ∆T ))+ (2.7)
M représente le target associé à ce contrat. Le prix associé à un échéancier de taille Nest donc donné par :
N∑
i=1
E
(i∏
j=1
B(Tj−1,Tj)1∑i−1k=0 Fk<MFi
)
2-7

CHAPITRE 2. CONTRATS PATH DEPENDANT
L’algorithme de simulation pour 5 facteurs est le suivant :
Algorithme 5 : TargetEntrée : Paramètres du modèleSortie : Tar =
∑Ni=1 E
(∏ij=1 B(Tj−1,Tj)1∑i−1
k=0 Fk<MFi
)
/* Initialisations des textures qui vont permettre de dérouler
l’algorithme */
/* Texture qui contient la somme∑i−1
k=0 Fk */
TexSum1
/* Texture qui contient le produit∏i
j=1 B(Tj−1,Tj) */
TexProd2
/* Texture qui contient le payoff Fi */
TexPay3
/* Texture qui contient le résultat∏i
j=1 B(Tj−1,Tj)1∑i−1k=0 Fk<MFi */
TexResul4
/* Déroulement de l’algorithme */
pour t ∈ 0,δt,2δt, . . . 1δt faire5
pour i ∈ 1, . . . 5 faire6
/* Génération de nombres aléatoires */
Xt∗5+i ←− AXt∗5+i−1 mod(231 − 1) ;7
/* Passage d’uniforme à gaussienne */
Gt∗5+i ←− BoxMuller(Xt∗5+i) ;8
fin9
/* Calcul du prix du Bond */
B(t,t + δt) ←− B(0,t+δt)B(0,t)
exp( l’expression (2.5) ) ;10
/* Actualisation du payoff en utilisant (2.6) et (2.7) */
TexPay ←− Ft+δt ;11
/* Actualisation de la somme */
TexSum ←− TexSum + Ft+δt ;12
/* Test sur la somme */
B(t,t + δt) ←− B(t,t + δt) ∗ (TexSum < M) ;13
/* Actualisation du taux */
TexProd ←− TexProd ∗ B(t,t + δt) ;14
/* Actualisation du résultat */
TexResul ←− TexResul + TexProd ∗ TexPay ;15
fin16
Tar ←− TexResul.sum()/N17
2-8

2.3. RÉSULTATS DE SPEEDUP
2.2.3 Ratchet Product
Le payoff de ce contrat à des instants Ti fixés est donné par la récurrence suivante :
Fi = ∆T (K + Fi−1 − L(Ti,Ti,Ti + ∆T ))+ (2.8)
Le prix associé à un échéancier de taille N est donc donné par :
N∑
i=1
E
(i∏
j=1
B(Tj−1,Tj)Fi
)
La simulation du Ratchet est effectué dans l’algorithme 6.
2.3 Résultats de speedup
Les résultats de speedup pour le contrat asiatique et les contrats sur maximum sont del’ordre de 200. Ce speedup peut-être expliqué par le fait que l’accès mémoire est deux foisplus rapide sur la carte graphique. En effet, les opérations exécutées sur la carte sont trèssimples et la rapidité est donc corrélée à l’accès mémoire beaucoup plus qu’à la fréquenced’exécution. En ce qui concerne le ratchet, on retrouve une accélération de l’ordre de 30alors que pour le target le speedup est de l’ordre de 100.
Les résultats de speedup sont très bons, ils permettent de faire chuter le temps desimulation de l’ordre de la minute, voire presque une demi-heure pour l’option asiatique,à des simulations de l’ordre de la seconde. L’ensemble de ces simulations prouve que l’onpeut être très proche des performances théoriques de l’ordre de 100. Cependant, ceci neveut aucunement dire que les 100 unités de calcul sur GPU peuvent remplacer 100 CPUpour n’importe quelle tâche. En fait, si on avait à donner un exemple de collaborationentre CPU et GPU, ce sera celui d’une entreprise dans laquelle le GPU représente uneéquipe d’ouvriers alors que le CPU est le cadre ou le manager de celle-ci. Il va de soi qu’uncadre est beaucoup plus qualifié qu’un ouvrier pour des tâches plus diverses. Néanmoins,la prestation d’un cadre vaut plus chère. Par conséquent, la meilleure solution consiste àdonner à l’ouvrier tous les emplois qu’il peut réaliser et garder le reste pour le cadre. Untel système correspond parfaitement à un cluster de CPU et de GPU.
2-9

CHAPITRE 2. CONTRATS PATH DEPENDANT
Algorithme 6 : RatchetEntrée : Paramètres du modèleSortie : Rat =
∑Ni=1 E
(∏ij=1 B(Tj−1,Tj)Fi
)
/* Initialisations des textures qui vont permettre de dérouler
l’algorithme */
/* Texture qui contient le produit∏i
j=1 B(Tj−1,Tj) */
TexProd1
/* Texture qui contient le payoff Fi */
TexPay2
/* Texture qui contient le résultat∏i
j=1 B(Tj−1,Tj)Fi */
TexResul3
/* Déroulement de l’algorithme */
pour ti ∈ 0,δt,2δt, . . . 1δt faire4
pour i ∈ 1, . . . 5 faire5
/* Génération de nombres aléatoires */
Xt∗5+i ←− AXt∗5+i−1 mod(231 − 1) ;6
/* Passage d’uniforme à gaussienne */
Gt∗5+i ←− BoxMuller(Xt∗5+i) ;7
fin8
/* Calcul du prix du Bond */
B(t,t + δt) ←− B(0,t+δt)B(0,t)
exp( l’expression (2.5) ) ;9
/* Actualisation du payoff en utilisant (2.6) et (2.8) */
TexPay ←− Fi ;10
/* Actualisation du taux */
TexProd ←− TexProd ∗ B(t,t + δt) ;11
/* Actualisation du résultat */
TexResul ←− TexResul + TexProd ∗ TexPay ;12
fin13
Tar ←− TexResul.sum()/N14
2-10

Chapitre 3
Contrats Américains
" The computation of American option prices is a challenging problem, especiallywhen several underlying assets are involved. The mathematical problem to solve is anoptimal stopping problem. In classical diffusion models, this problem is associated with avariational inequality, for which, in higher dimensions, classical PDE methods areineffective. "
Emmanuelle Clément, Damien Lamberton de l’Equipe dAnalyse et de mathéematiquesappliquéees, Universitée de Marne-la-Vallée et Philip Protter de l’Operations Researchand Industrial Engineering Department, Cornell University.
Sommaire
3.1 Formulation du problème . . . . . . . . . . . . . . . . . . . . . . 3-2
3.2 Introduction au calcul de Malliavin . . . . . . . . . . . . . . . . 3-4
3.3 Généralisation en plusieurs dimensions . . . . . . . . . . . . . 3-9
3.4 Implémentation numérique . . . . . . . . . . . . . . . . . . . . . 3-12
L’intérêt accordé aux problèmes avec exercice prématuré a fait l’objet d’une très richelittérature. Ceci est certainement dû à sa difficulté qui relève un challenge constant, maissurtout à ces retombées économiques qui attirent même l’attention des moins curieux.
En feuilletant les livres et articles qui parlent des contrats américains, j’ai trouvé quela méthode fondée sur le calcul de Malliavin est la plus attirante de part sa théorie, quitraite les deux problèmes de pricing et de headging, et de son implémentation qui, jusqu’àprésent, me semble la plus judicieuse pour une architecture parallèle.
Ce chapitre est très largement fondé sur [Bal] et [BCZ03], le dernier étant le supportde cours que j’ai suivi sous la direction de Monsieur Vlad Bally. Contrairement à l’article[BCZ03], je n’utiliserai pas un raisonnement fondé sur l’intégration par partie pour établirles différents résultats théoriques, même si le premier lemme 1 l’énonce implicitement. Ce
1. c’est le lemme clef, il sollicite pour sa démonstration toute la théorie du calcul de Malliavin
3-1

CHAPITRE 3. CONTRATS AMÉRICAINS
chapitre est partagé en quatre parties : La première exposera la formulation du problèmeà traiter. la deuxième donnera les outils du calcul de Malliavin nécessaires à la résolutiondu problème. La troisième partie généralise les résultats en plusieurs dimensions. Enfin,la dernière partie donne l’implémentation numérique adaptée à la carte graphique ainsique les résultats obtenus.
3.1 Formulation du problème
Commençons tout d’abord par la formulation du problème des contrats américains.Soit (Ω,F ,P) un espace de probabilité filtré et soit la filtration Ft = σ(Ws,s ≤ t) associéeau mouvement brownien d-dimensionnel W . Soit Xt un processus de diffusion modélisantle comportement du sous-jacent :
dXt = b(Xt)dt + σ(Xt)dBt
X(0) = x(3.1)
Le prix à l’instant t d’un contrat américain de maturité T et de payoff Φ : Rd+ → R
est donné par :
Pt(x) = supθ∈Tt,T
Et,x
(e−r(θ−t)Φ(Xθ)
)(3.2)
tel que : Tt,T est l’ensemble des temps d’arrêt prenant leurs valeurs sur (t,T ) et r est le tauxrisque neutre. Le principe de la programmation dynamique pour résoudre numériquement(3.2) approxime l’ensemble des valeurs prises dans Tt,T par un ensemble fini 0 = t0 < t1 <... < tn = T et effectue la décente backward suivante :
PT (XT ) = Φ(XT )
∀k ∈ 0,...,n − 1, Ptk(Xtk) = max(Φ(Xtk),e−r(tk+1−tk)
E(Ptk+1
(Xtk+1) |Xtk))
(3.3)
Afin de dérouler (3.3), la seule inconnue dont on veut avoir la valeur est l’espéranceconditionnelle E
(Ptk+1
(Xtk+1) |Xtk) . De façon générale on veut estimer la valeur de :
E (Φ(Xt) |Xs = x) (3.4)
où 0 < s < t, x ∈ R+ et Φ est une fonction à croissance polynomiale, de sorte qu’elleappartient à l’ensemble :
Eb(R) = f ∈ M(R) : ∃C > 0 et m ∈ N t.q f(y) ≤ C(1 + |y|m) (3.5)
avec : M(R) = f : R → R t.q f est mesurable.
3-2

3.1. FORMULATION DU PROBLÈME
Le modèle de l’actif Xt est un modèle de Black et Scholes :
Xt = x exp
((b − σ2
2
)t + σBt
)(3.6)
La valeur de l’expression (3.4) est donnée par les deux théorèmes suivants : le premierénonce une forme non localisée alors que le deuxième utilise la technique de localisation.
Théorème 3.1 Pour tout 0 < s < t, Φ ∈ Eb et x > 0 :
E(Φ(Xt)|Xs = x) =Ts,t[Φ](x)
Ts,t[1](x)
avec :
Ts,t[f ](x) = E
(f(Xt)
H(Xs − x)
σs(t − s)Xs
∆Ws,t
)(3.7)
H est une fonction définie sur R t.q : H(ξ) = 1ξ≥0, et :
∆Ws,t = (t − s)(Ws + σs) − s(Wt − Ws)
Théorème 3.2 Soit ψ : R → [0, + ∞) de sorte que∫
Rψ(ξ)dξ = 1 et Ψ sa fonction de
répartition : Ψ(y) =∫ y
−∞ψ(ξ)dξ. Alors, pour tout 0 < s < t, Φ ∈ Eb et x > 0, on a :
E(Φ(Xt)|Xs = x) =Ts,t[Φ](x)
Ts,t[1](x)
avec :
Ts,t[f ](x) = E(f(Xt)Ψ(Xs − x)) + E
(f(Xt)
H(Xs − x) − Ψ(Xs − x)
σs(t − s)Xs
∆Ws,t
)(3.8)
H est une fonction définie sur R t.q : H(ξ) = 1ξ≥0, et :
∆Ws,t = (t − s)(Ws + σs) − s(Wt − Ws)
Lemme 3.1 Pour toute distribution φ et toute fonction test Φ ∈ Eb(R), on a pour 0 <s < t :
E(φ′(Xs)Φ(Xt)) = E(φ(Xs)πXs(Φ(Xt))) = E
(Φ(Xt)
φ(Xs)
σs(t − s)Xs
∆Ws,t
)(3.9)
avec :
πXs=
Φ(Xs)
σs(t − s)Xs
∆Ws,t ∆Ws,t = (t − s)(Ws + σs) − s(Wt − Ws)
3-3

CHAPITRE 3. CONTRATS AMÉRICAINS
En supposant le lemme 3.1, nous allons démontrer les deux théorèmes précédents.Preuve Théorème 3.1:
E(Φ(Xt)|Xs = x) = E
(Φ(Xt)
δ0(Xs − x)
E(δ0(Xs − x))
)=
E(Φ(Xt)H′(Xs − x))
E(H ′(Xs − x))
En utilisant (3.9), le résultat découle directement.¥
Preuve Théorème 3.2:
E(H(Xs −x)πXs(Φ(Xt))) = E(ψ(Xs)Φ(Xt))−E(ψ(Xs)Φ(Xt))+E(H(Xs −x)πXs
(Φ(Xt)))
=E (ψ(Xs)Φ(Xt)) + E(H(Xs − x)πXs(Φ(Xt))) − E(Ψ′(Xs)Φ(Xt))
=E (ψ(Xs)Φ(Xt)) + E(H(Xs − x)πXs(Φ(Xt))) − E(Ψ(Xs − x)πXs
(Φ(Xt)))
=E (ψ(Xs)Φ(Xt)) + E((H(Xs − x) − Ψ(Xs − x))πXs(Φ(Xt)))
Ce qui justifie l’égalité de l’expression (3.8) et (3.9) puisque la première donne :
Ts,t[Φ](x) = E(H(Xs − x)πXs(Φ(Xt)))
et la deuxième donne :
Ts,t[Φ](x) = E(ψ(Xs)Φ(Xt)) + E((H(Xs − x) − Ψ(Xs − x))πXs(Φ(Xt)))
¥
Dans la sous-section suivante, on exposera une introduction du calcul de Malliavin quiva nous permettre de définir deux opérateurs : La dérivée de Malliavin et l’intégrale deSkorohod. Ces opérateurs vont être la source de la démonstration du lemme 3.1 .
3.2 Introduction au calcul de Malliavin
On considère l’espace (Ω,F ,P) qui est un espace de probabilité filtré et soit la filtra-tion Ft = σ(Ws,s ≤ t) associée au mouvement brownien d-dimensionnel W . L’intervalletemporel que l’on utilise par la suite est t ∈ [0,1] qui est discrétisé en tkn = k2−n aveck,n ∈ N. Grâce à cette discrétisation, on introduit le vecteur accroissement brownien∆n = (∆0
n,...,∆2n−1n ) avec :
∆kn = W (tk+1
n ) − W (tkn) , k = 0,...,2n − 1.
Définition 3.1 On définit une fonctionnelle simple d’ordre n comme une variablealéatoire de la forme :
F = f(∆n), f ∈ C∞p (R2n
,R)
tel que C∞p (R2n
,R) représente l’ensemble des fonctions infiniment différentiables qui ontune croissance polynomiale ainsi que toutes ses dérivées qui ont une croissance polyno-miale. On note par Sn l’espace des fonctionnelles simples d’ordre n et par S =
⋃n∈N
Sn
l’espace des fonctionnelles simples.
3-4

3.2. INTRODUCTION AU CALCUL DE MALLIAVIN
On remarque que cette définition implique l’inclusion Sn ⊂ Sn+1, S est un sous-espacelinéaire dense dans L2(Ω,F1,P) avec : F1 = σ(Ws,s ≤ 1).
Définition 3.2 Un processus simple U : [0,1]×Ω → R d’ordre n est un processus quia la forme suivante :
Ut =∑2n−1
k=0 Uk1[tkn,tk+1n )(t), Uk ∈ Sn
On note par Pn l’espace des processus simples d’ordre n et par P =⋃
n∈NPn l’espace des
processus simples.
On remarque que pour tout ω ∈ Ω, t → Ut est un élément de L2([0,1],B([0,1]),dt : R)muni du produit scalaire :
< U,V >= E
(∫ 1
0UsVsds
)
De la même manière que ce qui précède, on remarque que P est un sous-espace linéaireet dense dans L2([0,1],B([0,1]),dt : R).
Définition 3.3 L’opérateur dérivée de Malliavin D : Sn → Pn est défini pour unélément f(∆n) ∈ Sn comme suit :
Dsf(∆n) =2n−1∑
k=0
∂f
∂xk(∆n)1[tkn,tk+1
n )(s)
Une notation plus intuitive est de dire que :
Dsf(∆n) =∂f
∂∆sn
(∆n)
avec : ∆sn = ∆k
n pour s ∈ [tkn,tk+1n )
La dérivée de Malliavin ne dépend pas de l’ordre de l’espace des fonctions simples puisquepour tout n : si f(∆n) ∈ Sn alors f(∆n+1) ∈ Sn+1 et :
∂f
∂∆sn
(∆n) =∂f
∂∆sn+1
(∆n+1)
car : ∆kn = ∆2k
n+1 + ∆2k−1n+1
Définition 3.4 L’opérateur divergence 2 δ : Pn → Sn est défini pour un élément Ut =∑2n−1k=0 Uk1[tkn,tk+1
n )(t) ∈ Sn comme suit :
δ(U) =2n−1∑
k=0
(uk(∆n)∆k
n − ∂uk
∂xk(∆n)
1
2n
)
De la même manière, l’intégrale de Skorohod ne dépend pas de l’ordre de l’espace Pn.D’autre part, on utilisera la notation :
δ(U) =∫ 1
0UsdWs
2. Intégrale de Skorohod
3-5

CHAPITRE 3. CONTRATS AMÉRICAINS
Cependant, il faut comprendre que cette intégrale est anticipante, elle ne coïncide doncavec l’intégrale d’Itô que dans le cas où le processus intégré est adapté.
Proposition 3.1 Soient F ∈ S et U ∈ P , nous avons la relation de dualité suivante :
E(<DF,U>) = E(F δ(U))
Preuve Proposition 3.1:On suppose, sans perte de généralité, que F ∈ Sn et U ∈ Pn avec le même ordre n, alors :
E(< DF,U >) =2n−1∑
k=0
E(∂xkf(∆k
n,∆kn)uk(∆
k
n,∆kn))
1
2n(3.10)
de sorte que ∆k
n représente toutes les variables aléatoires qui interviennent dans ∆n excepté∆k
n et puisque ∆k
n et ∆kn sont indépendantes et que ∆k
n ∼ N(0,h) avec h = 2−n alors :
E(∂xkf(∆k
n,∆kn)uk(∆
k
n,∆kn)) =
1√2πh
E
(∫
R
∂xkf(∆k
n,y)uk(∆k
n,y)e−y2/2hdy
)
= − 1√2πh
E
(∫
R
f(∆k
n,y)(∂xkuk(∆k
n,y) − y
huk(∆
k
n,y))e−y2/2hdy
)
= E
(f(∆
k
n,∆kn)(uk(∆
k
n,∆kn)
∆kn
h− ∂xkuk(∆
k
n,∆kn))
)
et en remplaçant dans (3.10), on obtient le résultat voulu.¥
Lemme 3.2 L’opérateur D est fermable i.e : Si Fn ∈ S
– Fn → 0 en L2(Ω)
– DFn → G dans L2([0,1] × Ω)
alors G=0
Preuve lemme 3.2:Soient la suite Fn considérée dans l’énoncé du lemme et U ∈ P , on a alors :
E(< G,U >) = limn E(< DFn,U >) = limn E(Fnδ(U)) = 0
Le résultat étant vrai pour tout U ∈ P et donc aussi pour G.¥
En utilisant la dualité, on peut aussi démontrer la fermabilité de l’opérateur divergencequi est énoncée dans le lemme suivant.
Lemme 3.3 L’opérateur δ est fermable i.e : Si Un ∈ P
– Un → 0 en L2([0,1] × Ω)
– δ(Un) → F dans L2(Ω)
alors F=0
Définition 3.5 On dit que F ∈ DomD s’il existe une suite Fn ∈ S, n ∈ N de sorte que :
limn Fn = F dans L2(Ω) et limn DFn = G dans L2([0,1] × Ω)
3-6

3.2. INTRODUCTION AU CALCUL DE MALLIAVIN
pour certain G ∈ L2([0,1] × Ω). Dans ce cas, on écrit : DF = G = limn DFn
L’espace DomD est un espace Hilbertien 3 muni du produit scalaire :
< F,G >1,2= E(FG) + E
(∫ 1
0
DsF × DsG ds
)
Définition 3.6 On dit que U ∈ Domδ s’il existe une suite Un ∈ P , n ∈ N de sorte que :
limn Un = U dans L2([0,1] × Ω) et limn δ(Un) = F dans L2(Ω)
pour certain F ∈ L2(Ω). Dans ce cas, on écrit : δ(Un) = F = limn δ(Un)
Proposition 3.2 (Dérivation en chaîne) Soit F = (F1,...,Fm) avec pour tout i Fi ∈DomD et soit φ ∈ C1
b (Rm,R), alors φ(F ) ∈ DomD et :
Dφ(F ) =m∑
k=1
∂kφ(F )DFk (3.11)
Preuve Proposition 3.2:Dans le cas où (F1,...,Fm) ∈ Sm, alors φ(F ) ∈ S et la dérivation en chaîne standardimplique le résultat. Si (F1,...,Fm) ∈ DomDm, alors on prend F n
k ∈ S, n ∈ N de sorte que||F n
k − Fk||1,2 → 0. Puisque φ possède des dérivées bornées, alors ||φ(F n) − φ(F )||2 → 0et on a la convergence suivante :
∣∣∣∣∣
∣∣∣∣∣Dφ(F n) −m∑
k=1
∂kφ(F )DFk
∣∣∣∣∣
∣∣∣∣∣L2([0,1]×Ω)
=
∣∣∣∣∣
∣∣∣∣∣
m∑
k=1
∂kφ(F n)DF nk −
m∑
k=1
∂kφ(F )DFk
∣∣∣∣∣
∣∣∣∣∣L2([0,1]×Ω)
→ 0
Puisque pour tout k :
||∂kφ(F n)DF nk − ∂kφ(F )DFk||L2([0,1]×Ω) ≤ an + bn
avec :an = E
(|∂kφ(F n) − ∂kφ(F )|2
∫ 1
0|DsFk|2ds
)et bn = E
(|∂kφ(F n)|2
∫ 1
0|Ds(Fk − F n
k )|2ds)
bn converge par bornétude de ∂kφ, an converge en utilisant le théorème de Lebesgue etune suite F n qui converge presque sûrement vers F .En conclusion, la définition de DomD entraine que φ(F ) ∈ DomD et que Dφ(F ) =∑m
k=1 ∂kφ(F )DFk.
¥
Proposition 3.3 Soient F ∈ DomD et U ∈ Domδ de sorte que le produit FU ∈ Domδet :
δ(FU) = Fδ(U)+ < DF,U >L2[0,1] (3.12)
3. on renvoie le lecteur à [BCZ03] pour la démonstration
3-7

CHAPITRE 3. CONTRATS AMÉRICAINS
Preuve Proposition 3.3:Pour tout G ∈ S :
E(Gδ(FU)) = E
(∫ 1
0
DsG × (FUs)ds
)= E
(∫ 1
0
Ds(FG)Usds − GDsF × Usds
)
= E
(G(Fδ(U) −
∫ 1
0
DsF × Usds)
)
Dans la première et la troisième égalité, on utilise la relation de dualité. Dans la deuxièmeégalité on remplace FDsG = Ds(FG) − GDsF .
¥
Application En considérant le processus stochastique de dynamique (3.6) soit :
Xt = x exp
((b − σ2
2)t + σBt
)
et pour 0 < s < t :
DsXt = σXt
Preuve Application:En appliquant la dérivation en chaîne (3.11), on obtient : DsXt = σXtDsBt
Il reste donc à montrer que DsBt = 1. On introduit la fenêtre suivante :
ηn(t) =
(k − 1)/2n si (k − 1)/2n ≤ t < k/2n
0 sinon
et on pose Fn = Bηn(t) qui converge clairement en L2(Ω) vers F = Bt. D’autre part,Fn =
∑2nηn(t)+1k=1 ∆k
n ce qui implique :
DsFn =∂Fn
∂∆sn
=
1 si s ≤ ηn(t)0 sinon
D’où DsFn = 1[0,ηn(t))(s) qui converge lui aussi vers 1[0,t)(s) et le fait que s < t achève ladémonstration.
¥
Preuve lemme 3.1:Soit u < s < t
Duφ(Xs) = φ′(Xs)DuXs = φ′(Xs)σXs
d’où :
φ′(Xs) =1
σXs
Duφ(Xs) =1
tσXs
∫ t
0
Duφ(Xs)du
3-8

3.3. GÉNÉRALISATION EN PLUSIEURS DIMENSIONS
E(φ′(Xs)Φ(Xt)) = E
(1
sσXs
∫ s
0
Duφ(Xs)Φ(Xt)du
)= E
(φ(Xs)
∫ s
0
1
sσXs
Φ(Xt)dWu
)
= E
(φ(Xs)
[Φ(Xt)
σsXs
Ws −∫ s
0
Du
(Φ(Xt)
σsXs
)du
])
Dans la deuxième égalité on utilise la relation de dualité et dans la troisième on utilise(3.12).
Du
(Φ(Xt)
Xs
)=
Φ′(Xt)DuXt
Xs
− Φ(Xt)
X2s
DuXt =Φ′(Xt)σXt
Xs
− Φ(Xt)
Xs
σ
E(φ′(Xs)Φ(Xt)) = E
(φ(Xs)
Φ(Xt)
sσXs
(Ws − σs)
)− E
(φ(Xs)
Φ′(Xt)
Xs
Xt
)(3.13)
E
(φ(Xs)
Φ′(Xt)
Xs
Xt
)= E
(φ(Xs)
Xs
E(Φ′(Xt)Xt/Fs)
)
DuΦ(Xt) = Φ′(Xt)DuXt = φ′(Xt)σXt
φ′(Xt)Xt =1
σDuΦ(Xt) =
1
σ(t − s)
∫ t
s
DuΦ(Xt)du
E(Φ′(Xt)Xt/Fs) =1
σ(t − s)E
(∫ t
s
DuΦ(Xt)du/Fs
)=
1
σ(t − s)E(Φ(Xt)(Wt − Ws)/Fs)
En remplaçant la valeur de E(Φ′(Xt)Xt/Fs) dans (3.13) :
E(φ′(Xs)Φ(Xt)) = E(φ(Xs)πXs(Φ(Xt))) = E
(Φ(Xt)
φ(Xs)
σs(t − s)Xs
∆Ws,t
)(3.14)
avec :
∆Ws,t = (t − s)(Ws + σs) − s(Wt − Ws)
¥
3.3 Généralisation en plusieurs dimensions
Dans cette section, nous allons généraliser les théorèmes énoncés dans la premièresection sur les cas multidimenssionnels. On traite de ce fait un panier d’actifs corrélésXt. Chaque actif X i
t possède une dynamique lognormale semblable à celle utilisée dans lechapitre précédent, soit donc :
X it = X i
0 exp
[(ri − di −
1
2
i∑
j=1
σ2ij
)t +
i∑
j=1
σijWjt
](3.15)
3-9

CHAPITRE 3. CONTRATS AMÉRICAINS
La première étape consiste à introduire un processus auxiliaire X qui, contrairement àXt, possède des composantes X i
t indépendantes et dont l’espérance conditionnelle se metsous la forme d’un produit. Une fois la formule pour X établie, on reviendra au processusoriginal X. Afin de ne pas alourdir la notation, posons :
hi =
(ri − di −
1
2
i∑
j=1
σ2ij
)
Soit lt = (l1t ,...,ldt ) une fonction C1 fixée et soit :
X it = xi exp
(hit + lit + σiiW
it
)(3.16)
Lemme 3.4 ∀ t ≥ 0, ∃ Ft(·) : Rd+ → R
d+ de sorte que Ft est inversible et que :
Xt = Ft(Xt), Xt = F−1t (Xt) = Gt(Xt)
avec :
F it (y) = e−
∑ij=1 σij ljt
i−1∏
j=1
(yj
xj
e−hjt
)σij
, i = 1,...,d, y ∈ Rd+ (3.17)
Git(z) = elitzi
i−1∏
j=1
(zj
xj
e−hjt
)σij
, i = 1,...,d, z ∈ Rd+ (3.18)
Preuve lemme 3.4:Soient t,l,x fixés de (3.16), on a :
W it =
1
σii
(ln
X it
xi
− hit − lit
)
En insérant ceci dans (3.15), on obtient :
X it = xi exp
(hit −
i∑
j=1
σij
σjj
(hjt + ljt )
)i∏
j=1
(Xj
t
xj
)σij/σjj
On pose : σij = σij/σjj et on utilise la notation vectorielle ln ξ = (ln ξ1,..., ln ξd) pourξ = (ξ1,...,ξd) ∈ R
d, alors Ft = (F 1t ,...,F d
t ) satisfait :
ln Ft(y) = −σlt + σ ln y + (I − σ)(ln x + ht)
En posant : σ = σ−1, la fonction inverse satisfait :
ln F−1t (z) = lt + σ ln z + (I − σ)(ln x + ht)
3-10

3.3. GÉNÉRALISATION EN PLUSIEURS DIMENSIONS
Si on note Gt = F−1t , le calcul suivant peut être fait facilement puisque σ et σ sont
triangulaires pour obtenir :
F it (y) = e−
∑ij=1 σij ljt
i−1∏
j=1
(yj
xj
e−hjt
)σij
, i = 1,...,d, y ∈ Rd+
Git(z) = elitzi
i−1∏
j=1
(zj
xj
e−hjt
)σij
, i = 1,...,d, z ∈ Rd+
¥
Théorème 3.3 Pour tout 0 < s < t, Φ ∈ Eb et x > 0 alors :
E(Φ(Xt)|Xs = x) =Ts,t[Φ](x)
Ts,t[1](x)
avec :
Ts,t[f ](x) = E
(f(Xt)
d∏
i=1
H(X is − xi)
σiis(t − s)X is
∆W is,t
)(3.19)
avec Xs = Gs(Xs) et x = Gs(x)
∆W is,t = (t − s)(W i
s + σs) − s(W it − W i
s), i = 1,...,d
Preuve Théorème 3.3:Posons Φt(y) = Φ Ft(y), y ∈ R
d+, Ft étant définie en (3.18). Puisque Xt = Ft(Xt) pour
tout t, alors :
E(Φ(Xt)|Xs = x) = E(Φ(Xt)|Xs = x)
Il suffit donc de démontrer que :
E(Φ(Xt)|Xs = x) =Ts,t[Φ](x)
Ts,t[1](x)(3.20)
Commençons par supposer que : Φ(y) = Φ1(y1)···Φd(yd), de sorte que Φ puisse être séparéen produit :
E(Φ(Xt)|Xs = x) =d∏
i=1
E(Φi(Xit)|X i
s = xi)
En aplliquant le Théorème 3.1 sur chaque composante X it , on retrouve le résultat requis.
Dans le cas général, le résultat est vrai par un argument de densité : ∀ Φ ∈ Eb(Rd),
∃Φnn ⊂ Eb(Rd) de sorte que Φn(Xt) → Φ(Xt) dans L2 et tel que Φn soit une combinaison
de fonctions à variables séparées comme ci-dessus. Comme (3.20) est vrai pour Φn, alorselle l’est aussi pour Φ par passage à la limite.
¥
3-11

CHAPITRE 3. CONTRATS AMÉRICAINS
Théorème 3.4 Soit ψ(x) =∏d
i=1 ψi(xi) avec ψi : R → [0,+∞) de sorte que∫
Rψi(ξ)dξ =
1 et Ψi sa fonction de répartition Ψi(y) =∫ y
−∞ψi(ξ)dξ. Alors pour tout 0 < s < t, Φ ∈ Eb
et x > 0 on a :
E(Φ(Xt)|Xs = x) =Ts,t[Φ](x)
Ts,t[1](x)
avec :
Ts,t[f ](x) = E
(f(Xt)
d∏
i=1
[Ψ(X i
s − xi) +H(X i
s − xi) − Ψ(X is − xi)
σs(t − s)X is
∆W is,t
])(3.21)
et :
∆W is,t = (t − s)(W i
s + σs) − s(W it − W i
s), i = 1,...,d
Preuve Théorème 3.4:La preuve de ce théorème s’effectue de la même manière que pour le Théorème 3.2. Afinde séparer les coordonnées, il suffit d’utiliser un conditionnement par rapport à toutes lescoordonnées restantes.
¥
3.4 Implémentation numérique
L’implémentation numérique utilise le principe de la programmation dynamique im-posée par la nature du contrat. On renvoie le lecteur à l’article [BCZ03], pour consulterl’implémentation ordinaire du contrat américain qui ne va pas être traîtée dans cette sec-tion. En revanche, nous proposons ici une méthode plus optimisée en temps de calculpour l’architecture du GPU. Même si cette méthode reprend les grandes lignes de l’al-gorithme de base, elle propose une étape d’approximation ayant pour but d’accélérer lecalcul pour une architecture parallèle. En outre, étant donné que l’algorithme pour plu-sieurs dimensions ressemble à l’algorithme pour une seule dimension, le payoff traité seraun put unidimensionnel.
La phase qui consomme le plus de temps dans la simulation des contrats américains estl’estimation des espérances conditionnelles. En effet, chaque tirage i de la variable X i
tkest
associé à une espérance conditionnelle E(Ptk+1
(Xtk+1)∣∣X i
tk
)donc, si on veut augmenter
le nombre de tirages, on sera contraint par augmenter le nombre d’espérances condition-nelles à estimer ce qui alourdit rapidement l’algorithme. Sachant que si X i
tkest proche de
Xjtk
, alors E(Ptk+1
(Xtk+1)∣∣X i
tk
)≈ E
(Ptk+1
(Xtk+1)∣∣Xj
tk
), on peut réduire le nombre d’es-
pérances conditionnelles pour un nombre de tirages donné. Cette idée d’approximationdes espérances est à l’origine de l’algorithme qui va être présenter par la suite.
Afin de comprendre l’origine des termes qui vont intervenir dans l’algorithme, on vaeffectuer sa présentation de manière rétrograde en plusieurs étapes :
3) La dernière étape est l’approximation des N espérances conditionnelles par N/n es-pérances conditionnelles ce qui s’écrit comme :
3-12

3.4. IMPLÉMENTATION NUMÉRIQUE
E
(Ptk+1
(Xtk+1)∣∣X i
tk
)← E
(Ptk+1
(Xtk+1)∣∣∣X⌈ i
n⌉∗n−1
tk
)(3.22)
2) La deuxième étape consiste à calculer E
(Ptk+1
(Xtk+1)∣∣∣X⌈ i
n⌉∗n−1
tk
)soit :
E(Ptk+1(Xtk+1
)|X⌈ in⌉∗n−1
tk) =
∑Nj=1 Ptk+1
(Xjtk+1
)H(Xj
tk−X
⌈ in ⌉∗n−1
tk)
Xjtk
∆W jk
∑Nj=1
H(Xjtk−X
⌈ in ⌉∗n−1
tk)
Xjtk
∆W jk
(3.23)
1) L’expression (3.22) n’est valide que si X⌈ i
n⌉∗n−1
tket X i
tkproviennent du même Xtk+1
en utilisant la programmation dynamique backward. On obtient donc les expressionssuivante :
– W itk← k
k+1W
⌈ in⌉∗n−1
tk+1+
√tk
k+1U i avec U i des gaussiennes indépendantes.
– X itk←− X0 exp
[(r − d − 1
2σ2
)tk + σW i
tk
]
– ∆W ik ← (tk+1 − tk)W
itk− tk(W
⌈ in⌉∗n−1
tk+1− W i
tk) + tk(tk+1 − tk)σ
Comme la récurrence (3.3) est similaire pour toute la plage temporelle, nous allonsexpliquer ce qui se produit à l’instant arbitraire tk+1 dans la récurrence (3.3). Par souci declarté nous diviserons l’algorithme en deux, chacun des algorithmes résultant sera associéà une figure
– Le premier algorithme expose la simulation de la valeur du payoff : Φ(Xtk).
– Le deuxième algorithme traite la simulation de l’espérance conditionnelle :E
(Ptk+1
(Xtk+1) |Xtk)
En outre, on ne reprendra pas la partie simulation des variables gaussiennes déjà exposéeprécédemment.
En notant par i l’indice de la trajectoire, l’algorithme de simulation de la valeur dupayoff est le suivant :
3-13

CHAPITRE 3. CONTRATS AMÉRICAINS
Algorithme 7 : Simutation de la valeur du payoff pour un put américain unidimen-sionnelEntrée : Paramètres du modèleEntrée : Variable gaussienne UEntrée : L’ensemble des browniens W i
tk+1associés à chaque trajectoire i
Sortie : Φ(X itk
)
/* Génération des W itk
*/
W itk← k
k+1W
⌈ in⌉∗n−1
tk+1+
√tk
k+1U i ;
1
/* Prix de l’actif X itk
*/
X itk←− X0 exp
[(r − d − 1
2σ2
)tk + σW i
tk
]2
/* Calcul du payoff */
Φ(X itk
) ←− (K − X itk
)+ ;3
La première ligne de l’algorithme ci-dessus est expliquée dans la figure 3.4.1.
Pour simplifier l’algorithme, nous exposerons une version non localisée du calcul del’espérance conditionnelle.
Algorithme 8 : Espérance conditionnelle pour un put américainEntrée : Paramètres du modèleEntrée : W i
tk+1, W i
tk, X i
tk, Ptk+1
(X itk+1
)
Sortie : E(Ptk+1
(Xtk+1)∣∣X i
tk
)
/* Accroissements browniens */
∆W ik ← (tk+1 − tk)W
itk− tk(W
⌈ in⌉∗n−1
tk+1− W i
tk) + tk(tk+1 − tk)σ1
/* Calcul du l’espérance conditionelle */
2
E(Ptk+1(Xtk+1
)|X⌈ in⌉∗n−1
tk) ←
∑Nj=1 Ptk+1
(Xjtk+1
)H(Xj
tk−X
⌈ in ⌉∗n−1
tk)
Xjtk
∆W jk
∑Nj=1
H(Xjtk−X
⌈ in ⌉∗n−1
tk)
Xjtk
∆W jk
/* Approximation */
E(Ptk+1
(Xtk+1)∣∣X i
tk
)← E
(Ptk+1
(Xtk+1)∣∣∣X⌈ i
n⌉∗n−1
tk
)3
L’utilité de l’algorithme précédent par rapport à un algorithme ordinaire réside dans lefait que, d’une part, il nous permet de réduire le nombre d’espérances conditionnelles cal-culées par rapport à l’algorithme ordinaire et, d’autre part, les espérances conditionnellessont obtenues en utilisant un nombre important de points pour une meilleure précision.
3-14

3.4. IMPLÉMENTATION NUMÉRIQUE
Fig. 3.4.1 – Payoff : n = 3
Fig. 3.4.2 – Espérance conditionnelle : n = 3
L’utilisation de cet algorithme permet donc de gagner considérablement sur une archi-tecture SIMD. Par exemple le temps de calcul d’un put américain en utilisant 10 pas detemps et ∼ 250000 trajectoires consomme ∼ 10 heures sur CPU alors qu’il ne consommeque ∼ 2 minutes sur GPU. Ce speedup peut-être expliqué non seulement par la puissancede la GPU, mais aussi par l’algorithme proposé.
Malgré la meilleure convergence des espérances conditionnelles (figure 3.4.1), les ré-sultats de simulation sont similaires à ceux obtenus par le CPU dans l’article [BCZ03].Néanmoins, le fait d’utiliser beaucoup plus de points que dans [BCZ03] nous a permis
3-15

CHAPITRE 3. CONTRATS AMÉRICAINS
d’accélérer la convergence en agissant sur le nombre de tirages de la simulation. En effet,nous avons remarqué empiriquement que :
E(Ptk+1(Xtk+1
)|X⌈ in⌉∗n−1
tk) =
∑Nj=1 Ptk+1
(Xjtk+1
)H(Xj
tk−X
⌈ in ⌉∗n−1
tk)
Xjtk
∆W jk
∑N ′
j=1
H(Xjtk−X
⌈ in ⌉∗n−1
tk)
Xjtk
∆W jk
(3.24)
converge plus rapidement vers la valeur voulue pour un bon choix de N et de N ′ dans(3.24) tels que N 6= N ′. Ce dernier résultat a été vérifié pour des puts géométriques àdimensions variant entre 1 et 6, et un échéancier comportant de 10 à 100 pas de temps.En revanche, la preuve théorique est toujours en cours d’élaboration.
0 2 4 6 8 10 12 14
x 104
2
4
6
8
10x 10
−3
Nombre de tirages
Esp
éran
ces
Convergences
Fig. 3.4.3 – Convergence de l’espérance conditionnelle.
3-16

Conclusion générale
Ce travail se situe entre les mathématiques financières et l’informatique de haut niveau.Le déroulement de son contenu commence par une motivation d’accélérer la simulation deMonte Carlo, puis s’étale sur une présentation de plusieurs exemples, afin de comprendrel’intérêt de l’architecture utilisée, et, enfin, expose le travail fourni actuellement pour laparallélisation des contrats américains.
L’intérêt des algorithmes proposés se traduit par leur simplicité et surtout leur conve-nance avec l’architecture en pipe-line de la GPU. De ce fait, les performances de calculsont convaincantes puisqu’elles sont proches de la théorie.
Contributions
La contribution apportée à travers ce stage est double :– Explorer le speedup obtenu sur plusieurs produits financiers par Monte Carlo, afin
de justifier l’utilité de programmer sur des GPU.
– Proposer une méthode de simulation de contrats américains qui soit la plus optimiséepossible et qui fait profiter de l’architecture utilisée.
Perspectives
Relativement au travail fourni, on résume les perspectives dans les points suivants :
1) Continuer des essais sur des produits plus exotiques.2) Procurer plus d’efforts pour asservir un cluster de machines disposant de plusieurs
GPU.3) Poursuivre le problème de la parallélisation des contrats américains en asseyant, non
seulement, d’apporter des preuves aux les résultats empiriques utilisant la méthodedu calcul de Malliavin, mais aussi d’explorer d’autres méthodes comme la régressionde Longstaff-Schwarz ou aussi la quantification.
4-1

4-2

Annexe A
Caractéristiques techniques des Tesla
dernière génération
Dans les pages suivantes, le lecteur trouvera la description de la carte Tesla C1060 etcelle de la Tesla S1070.
A-1

ANNEXE A. CARACTÉRISTIQUES TECHNIQUES DES TESLA DERNIÈREGÉNÉRATION
Avec la carte NVIDIA ® Tesla™ C1060, bénéficiez d’une
solution de supercalcul parallèle écoénergétique, et
intégrez dans une seule station de travail les
performances traditionnellement réservées aux clusters
d’entreprise.
La carte NVIDIA® Tesla™ C1060 transforme une station
de travail en un supercalculateur haute performance plus
puissant qu’un cluster standard. Les professionnels
bénéficient ainsi d’une ressource de bureau dédiée bien
plus rapide et écoénergétique qu’un cluster partagé dans
un centre de données. La carte Tesla C1060 est équipée
du processeur Tesla T10P massivement parallèle et
multi-coeurs et couplée au standard de programmation
CUDA C afin de simplifier la programmation multi-coeur.
Prise en charge complète et performante de la technologie HPC
Traitez les demandes de calcul les plus exigeantes et complexes,
notamment dans le domaine de la recherche médicale, des industries du
pétrole et du gaz, et des opérations financières.
Architecture multi-coeur pour une mise à l’échelle optimale des
applications HPC
L’architecture multi-coeur Tesla répond à toutes les demandes de calcul
des applications trop complexes pour une simple prise en charge par le
CPU.
Efficacité de calcul maximale pour les entreprises à la recherche desmeilleures solutions écoénergétiques
Bénéficiez des meilleures performances et de capaci tés de traitement
avancées pour résoudre les problèmes les plus compl exes avec des
ressources et une consommation plus faibles.
Technologie NVIDIA CUDA™, pour libérer la puissance des produitsTesla multi-coeur
Le seul environnement en langage C capable d’exploiter toute la puissance
multi-coeur des GPU pour répondre aux défis les plu s avancés de
l’industrie en matière de traitement informatique.
A-2

Architecture massivement parallèle etmulti-cœur avec 240 unités detraitement
Résolvez sur une simple station de travail les défi s auparavant uniquementà la portée des environnements en cluster des serveurs d’entreprise.
MØmoire 4 Go haute vitesseStockez des données étendues en local sur chaque pro cesseur, et profitezde vitesses de transfert mémoire de 102 Go/s tout en minimisant lesdéplacements des blocs de données dans votre système.
Environnement de programmationCUDA C, ouvert et faciled’apprentissage
Exploitez facilement les parallélismes inter-applications et tirez parti del’architecture multi-coeur du GPU.
Gestion simultanée de plusieurs GPUpour exploiter des centaines d’unitésde traitement
Résolvez des problèmes d’envergure en mettant à l’é chelle des centainesd’unités de traitement à travers plusieurs GPU.
Conformité norme IEEE754 en virguleflottante simple et double précision
Avec une seule puce, atteignez des performances maximales en virguleflottante, tout en répondant aux exigences de préci sion de vos applications.
Capacité de transfert asynchroneBoostez vos performances système en exécutant simultanément lestraitements logiciels et les transferts de données.
Interface mémoire de 512-bits pouroptimiser GPU et mémoire embarquée
Interface mémoire GDDR3 512-bits ultra-rapide délivrant un taux detransfert incroyable de 102 Go/s.
MØmoire partagéePlusieurs groupes d’unités de traitement peuvent collaborer tout en utilisantde faibles paramètres de latence mémoire.
Taux de données haut débit PCI-Express Gen 2.0
Communications rapides à haut débit entre le CPU et le GPU.
Facteur de forme flexibleDécouvrez des stations de travail et des systèmes 1U adaptés à undéploiement flexible dans une gamme étendue d’environnements.
Format 10.5" x 4.376", Dual Slot
# de GPU Tesla 1
# d’unités de traitement 240
Fréquence des unités de traitement 1.3 Ghz
Précision en virgule flottante Conformité norme IEEE754 en virgule flottante simple et double précision
Mémoire dédiée totale 4 GB
Vitesse de la mémoire 800 MHz
Interface mémoire 512-bit GDDR3
Bande passante 102 GB/sec
Consommation maximale 225 W (consommation maximale), 160 W (consommation standard)
Interface système PCIe 16x Gen2
Connecteurs de puissance auxiliaires 6-broches + 8-broches (possibilité d’utiliser deux connecteurs 6-broches)
Solution thermique Refroidissement actif
Environnement de programmation C(CUDA)
A-3

ANNEXE A. CARACTÉRISTIQUES TECHNIQUES DES TESLA DERNIÈREGÉNÉRATION
Le châssis 1U NVIDIA® Tesla™ S1070 (connexion dual
PCIe Gen2) est un supercalculateur alimenté par quatre
processeur Tesla C10P qui offre une puissance de calcul
cumulée de quatre teraflops.
Avec le premier processeur multi-coeur au monde
disposant d’une puissance d’un téraflop, le NVIDIA ®
Tesla™ S1070 accélère la transition vers les
supercalculateurs parallèles écoénergétiques. Avec 960
(4x240) unités de traitement et un compilateur C
simplifiant le développement des applications, le Tesla
S1070 permet de répondre rapidement et efficacement
aux défis les plus avancés de l’industrie en matière de
traitement informatique.
Prise en charge complète et performante de la technologie HPC
Traitez les demandes de calcul les plus exigeantes et complexes,
notamment dans le domaine de la recherche médicale, des industries du
pétrole et du gaz, et des opérations financières.
Architecture multi-coeur pour une mise à l’échelle optimale des
applications HPC
Profitez d’une architecture évolutive et des performances parallèles de
2x240 unités de traitement (capables d’exécuter des centaines de tâches
en simultané), afin de répondre à toutes les demand es de calcul des
applications trop complexes pour une simple prise en charge par le CPU.
Efficacité de calcul maximale pour les entreprises à la recherche desmeilleures solutions écoénergétiques
Bénéficiez des meilleures performances et de capaci tés de traitement
avancées pour résoudre les problèmes les plus compl exes avec une
utilisation plus faible de vos ressources.
Technologie NVIDIA CUDA™, pour libérer la puissance des produitsTesla multi-coeur
Le seul environnement en langage C capable d’exploiter toute la puissance
multi-coeur des GPU pour répondre aux défis les plus avancés de
l’industrie en matière de traitement informatique.
A-4

Quatre processeurs d ’untéraflop dans un système 1Uhaute densité
Bénéficiez des performances cumulées de 4 téraflops dans un système de racks en1U pour des résultats encore inégalés.
Architecture parallèle multi-coeur
240 unités de traitement par processeur (soit un total de 960) permettent d’exécuterdes centaines de threads simultanés. .
Mise à l’échelle multi GPUGérez simultanément plusieurs GPU pour exploiter de s centaines d’unités detraitement et traiter des opérations d’envergure.
Programmation GPU en NVIDIACUDA™: C
Programmez en CUDA, la plateforme de développement incontournable pour lessolutions multi-coeur.
Intégration de virgule flottanteà double précision
Répondez aux normes de précision de vos application s les plus exigeantes avecl’intégration des unités IEEE 754 64-bits à double précision.
Transfert de donnéesasynchrone
Boostez vos performances système en exécutant simultanément les transferts dedonnées et les traitements logiciels par les unités de traitement.
MØmoire 16 Go ultra-rapideStockez des données étendues en local sur les 4 Go alloués à chaque processeur,et maximisez les performances tout en minimisant les déplacements des blocs dedonnées dans votre système.
Taux de données haut dØbitPCI-Express 2.0
Avec une latence réduite et une large bande-passante, bénéficiez d’un taux detransfert optimal avec une architecture PCI-Express standard pour le traitement detoutes vos applications.
Montage sur rail à une visProfitez d’un système de montage simplifié sur rail à une vis, ne nécessitant pasd’outil et offrant la sécurité et la rigidité d’un maintien solide du rail sur le rack.
Fonctions de contrôle système
Un système de gestion et de contrôle post-installation aide votre équipeinformatique à gérer le système très facilement. Des fonctionnalités distantes ainsique des indicateurs lumineux de statut à l’avant et à l’arrière du rack permettentd’assurer une administration matérielle et logicielle performante.
Connexion Dual PCI-Express2.0
Maximisez la bande-passante entre le processeur-hôte et les processeurs Teslaavec des vitesses de transfert jusqu’à 12,8 Go/s (jusqu’à 6,4 Go/s par connexionPCI Express).
Carte adaptateur hôte Small-form-factor (SFF)
La carte adaptateur hôte (à basse consommation) permet aux systèmes Tesla detravailler avec tout système hôte répondant à la norme PCIe et disposant d’unconnecteur PCIe Gen2 libre (16x ou 8x)
# de processeurs Tesla 4
# d’unités de traitement 960 (240 par processeur)
Précision en virgule flottante Conformité norme IEEE754 en virgule flottante simple et double précision
Mémoire dédiée totale 16 Go (4 Go par GPU)
Interface mémoire Interface de mémoire 2048-bits GDDR3 (512-bits par GPU)
Bande passante 408 Go/sec (102 Go/s par GPU vers mémoire locale)
Consommation maximale 700 W
Interface système PCIe 16x Gen2 ou 8x Gen2
Environnement de programmation CUDA
A-5


Annexe B
Exemple de programme sur CG
Dans le programme suivant, nous aurons en entrée d’une part, une texture int conte-nant deux nombres aléatoires affectés aux deux coordonnées rg 1 de chaque pixel. D’autrepart, une texture float qui contient la valeur de l’actif sur une coordonnée de chaque pixel.La sortie ne sera que la valeur de l’actif, selon une discrétisation du modèle de Black etScholes, qui remplie une texture float semblable à celle en entrée.
float main (in float2 coords : TEXCOORD0, // coordnnees de la texture en sortie
uniform float div, // dividende
uniform float mu, // taux sans risque
uniform float dt, // pas de temps
uniform float sigma, // ecart type
uniform float pi,
uniform usamplerRECT UIn, // texture des nombres aleatoires
uniform samplerRECT FIn // texture de l'actif en entree
) : COLOR
1. couleurs rouge et verte
B-1

ANNEXE B. EXEMPLE DE PROGRAMME SUR CG
// La valeur de l'actif a l'instant t_k-1
float input = f1texRECT(FIn,coords);
// Les valeurs aleatoires
unsigned int2 aleat = texRECT(UIn, coords).rg;
// Choix de bits comme cela est explique au chapitre 6
aleat.r = bitChoice(aleat.r);aleat.g = bitChoice(aleat.g);
// Le module aprys choix de bits et reduction
float m = 8388607;
// Reduction
aleat.r>>=8;aleat.g>>=8;
// Gaussienne via Box-Muller
float2 gaush;gaush.r = sqrt(-2*log(((float) aleat.r)/m))*cos(2*pi*(((float) aleat.g)/m));gaush.g = sqrt(-2*log(((float) aleat.g)/m))*cos(2*pi*(((float) aleat.r)/m));
B-2

L’initialisation des arguments de notre shader et le retour du résultat s’effectue viaune communication CPU/GPU spécifiée dans un code C++ ordinaire.
B-3


Table des figures
0.1.1 Historique des performances en milliards d’opérations par seconde. . . . . . 0-2
1.2.1 L’allocation float. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-51.2.2 Parallélisation par paramétrage. . . . . . . . . . . . . . . . . . . . . . . . . 1-61.2.3 Architecture que l’on veut réaliser. . . . . . . . . . . . . . . . . . . . . . . . 1-61.2.4 Architecture pour trois actifs. . . . . . . . . . . . . . . . . . . . . . . . . . 1-7
3.4.1 Payoff :n = 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-153.4.2 Espérance conditionnelle :n = 3 . . . . . . . . . . . . . . . . . . . . . . . . 3-153.4.3 Convergence de l’espérance conditionnelle. . . . . . . . . . . . . . . . . . . 3-16
i


Liste des Algorithmes
1 Prix d’un put sur pondération géométrique d’actifs. . . . . . . . . . . . . . . 1-102 Put asiatique à strike flottant . . . . . . . . . . . . . . . . . . . . . . . . . 2-33 Option Lookback . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-44 Put up and out . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-55 Target . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-86 Ratchet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-107 Simutation de la valeur du payoff pour un put américain unidimensionnel . 3-148 Espérance conditionnelle pour un put américain . . . . . . . . . . . . . . . 3-14
i


Bibliographie
[AT] A. Lokman ABBAS-TURKI. Monte Carlo sur GPU. Septembre 2007.[Bal] Vlad Bally. An elementary introduction to malliavin calculus. Preprint INRIA.[BCZ03] V. Bally, L. Caramellino, and A. Zanette. Pricing and hedging american options
by monte carlo using a malliavin calculus approach. Preprint INRIA, 2003.[FI86] George S. Fishman and Louis R. Moore III. An exhaustive analysis of multipli-
cative congruential random number generators with modulus 231 − 1. SIAM J.SCI. STAT. COMPUT., 7:24–45, 1986.
[FK] Randima Fernando and Mark J Kilgard. The CG Tutorial : The Definitive GuideTo Programmable Real-Time Graphics. NVIDIA, Addison-Wesley.
[Gir01] Pierre-Noël Giraud. Le Commerce des Promesses. Seuil, 2001.[Jou07] Benjamin Jourdain. Méthodes de Monte Carlo pour les Processus Financier.
ENPC, 2007.[Knu77] Donald E. Knuth. Notes on generalized dedekind sums. Acta Arithmetica,
33:297–325, 1977.[Lap01] Temam E. Lapeyre, B. Competitive monte carlo for the pricing of asian options.
Journal of Computational Finance, 2001.[Mas97] Michael Mascagni. Parallel linear congruential generators with prime moduli.
Parallel Computing, 24:923–936, 1997.
i


















