Intégration des approches SOA et orientée objet pour...
147
Numéro d'ordre : 2010-ISAL-0060 Année 2010 Institut National des Sciences Appliquées de Lyon InfoMath : École Doctorale Informatique et Mathématiques Intégration des approches SOA et orientée objet pour modéliser une orchestration cohérente de services Thèse de Doctorat (Spécialité informatique) Par Alida ESPER Soutenue publiquement le 1 septembre 2010 devant la commission d'examen composée de : Dominique RIEU Professeur, Laboratoire LSR – IMAG, Saint Martin d’Hères présidente de jury Hervé PINGAUD Professeur, École des Mines d’Albi -Carmaux Rapporteur Samir TATA Professeur, TELECOM & Management SudParis Rapporteur Frédérique BIENNIER Professeur, LIESP – INSA de Lyon Directeur de thèse Youakim BADR Maître de Conférences, LIESP – INSA de Lyon Co-Directeur de thèse Laboratoire d’informatique pour l’entreprise et les systèmes de production
Transcript of Intégration des approches SOA et orientée objet pour...

Numéro d'ordre : 2010-ISAL-0060 Année 2010
Institut National des Sciences Appliquées de Lyon
InfoMath : École Doctorale Informatique et Mathématiques
Intégration des approches SOA et orientée objet pour
modéliser une orchestration cohérente de services
Thèse de Doctorat
(Spécialité informatique)
Par
Alida ESPER
Soutenue publiquement le 1 septembre 2010 devant la commission d'examen
composée de :
Dominique RIEU Professeur, Laboratoire LSR – IMAG, Saint Martin d’Hères présidente de jury
Hervé PINGAUD
Professeur, École des Mines d’Albi-Carmaux Rapporteur
Samir TATA Professeur, TELECOM & Management SudParis
Rapporteur
Frédérique BIENNIER
Professeur, LIESP – INSA de Lyon Directeur de thèse
Youakim BADR Maître de Conférences, LIESP – INSA de Lyon Co-Directeur de thèse
Laboratoire d’informatique pour l’entreprise et les systèmes de production


Aux plus chers à mon cœur : mes parents, mes sœurs mes frères

REMERCIMENT
Je tiens à remercier,
Mme Dominique RIEU de me faire l‟honneur de présider mon jury
de thèse.
M. Hervé PINGAUD et M. Samir TATA pour avoir accepté de lire
et d‟évaluer mon travail de thèse.
Mme. Frédérique BIENNIER pour ses conseils et son aide pendant
la rédaction de ma thèse.
Mr. Youakim BADR pour son apport tant au niveau des
connaissances, mais également pour ses encouragements, ainsi que son
soutien tout au long de la thèse.
Mes amis pour me supporter à avancer toujours.
Toute ma famille en Syrie, et plus particulièrement mes parents, mes
sœurs et mes frères qui m‟ont toujours encouragé.
Un grand merci à mes parents à qui je dois ce que je suis devenue.
Alida ESPER


Résumé
Pour faire face aux contraintes économiques, le développement de stratégies
« au plus juste » (lean manufacturing) impose à la fois un recentrage métier,
la mise en place de logistique de production « agile » et l‟organisation de
collaborations inter-entreprises. Ces collaborations conduisent à
l‟émergence d‟entreprises virtuelles et font largement appel aux
technologies de l‟information et de la communication. Or les réponses
technologiques apportées peuvent constituer un frein, les Systèmes
d‟Information (SI) d‟entreprise ne sont que peu agiles. Et manquent de
capacité d‟interopérabilité. En effet, l‟infrastructure informatique
(matérielle et logicielle, i.e. ERP, CRM, CAD, SCM, MES…) présente une
forte complexité technologique, manque d‟interopérabilité et limite donc les
possibilités « d‟interconnexion » entre les processus d‟entreprise et
l‟échange d‟information entre partenaires.
Pour surmonter ces limites, l‟implémentation du système d‟information
selon une architecture orientée services (SOA) définit une nouvelle
approche pour organiser les applications d'entreprise et optimiser les
processus métier.
Néanmoins, ces infrastructures sont essentiellement destinées à soutenir
l'interopérabilité intra-entreprise car elles reposent sur une définition mono-
contexte du processus d'affaires. Or un écosystème de services inclut un
environnement multi-contextuel d‟exécution de services.
Pour surmonter ces limites dans notre travail de recherche, nous proposons
d‟intégrer une architecture supportant différents contextes d‟exécution pour
favoriser le déploiement de systèmes d‟information interopérables au sein
de l‟entreprise et donc faciliter la collaboration des processus inter -
entreprises.
Pour cela, nous proposons d‟utiliser une architecture de collaboration à base
d‟hypergraphe. Afin de propager efficacement le contexte, nous proposons
de définir des règles de propagation des mécanismes d‟héritage issus de
l‟approche objet pour assurer une contextualisation des services à la
demande. Pour cela, notre modèle est basé sur trois concepts : le service, le
répertoire et le processus de collaboration (processus commun) qui est
défini par différents vues (gestion, sécurité et médiation). Ces différentes
vues permettent de composer simplement le service contextualisé.
Mots clés : Collaboration interentreprises, Architecture Orientée Services
(SOA), Service Web, composition de service, Approche Orienté Objet.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
vii
ABSTRACT
To face the economic constraints, the development of just in
time strategies (lean manufacturing) requires the organization of
collaborations between enterprises. These collaborations lead to the
emergence of virtual enterprise and needs the communication and
information technologies. However the technological answers can
constitute a brake as the enterprise Information systems (IS) lack of
agility. Indeed, the infrastructure (hardware and software, ie ERP
(Enterprise Resource Planning), CRM(Customer Relationship
Management), MES (Manufacturing Execution System)...) has a high
technological complexity, lack of interoperability and therefore limits
the potential interconnection between business processes and exchange
of information between partners.
To overcome these limits, the implementation of the
information system according to an orientated architecture services
(SOA) defines a new approach to organize the applications of enterprise
and to optimize the business processes. Nevertheless, these
infrastructures are primarily proposed to support the interoperability
inter-enterprise because they rely on a mono-context definition of the
business process. However an ecosystem of services includes a multi -
contextual environment of execution of services.
To overcome these limits, we propose to integrate an
architecture supporting various contexts of execution to support the
deployment of information systems interoperable within the enterprise
and improving interenterprise collaborative processes enactment.
Based on an hypergraph organisation, our architecture includes
context propagation rules and extends the inheritance mechanisms from
the object oriented approach to allow a simple service contextualisation.
Our model is based on three concepts: service, repository and
collaborative process (associated to the common process). Different
views (management, mediation, security) are used to support a simple
contextual service composition.
Key-words: Enterprise collaboration, Service Oriented Architecture
(SOA), Web service, service composition, and Approach objet oriented.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
viii
Table de matières
Chapitre 1 Introduction ............................................................................................................. 1
1.1 Problématique ................................................................................................................... 1
Chapitre 2 Etat de l’art ............................................................................................................. 5
2.1 Introduction ...................................................................................................................... 5
2.2 Méthodes de modélisation ................................................................................................. 6
2.2.1 CIMOSA ...................................................................................................................... 7
2.2.2 GRAI ............................................................................................................................ 9
2.2.3 PERA ......................................................................................................................... 11
2.2.4 GERAM...................................................................................................................... 12
2.2.5 Méthodes orientées « système d’information » ............................................................. 16
2.2.6 Conclusion .................................................................................................................. 20
2.3 Approche basée processus ............................................................................................... 20
2.3.1 Eléments caractéristiques d’un modèle de processus ..................................................... 21
2.3.2 Typologie des processus .............................................................................................. 24
2.3.3 Gestion de processus métier ......................................................................................... 26
2.3.4 ARIS : une méthode de modélisation orientée processus ............................................... 27
2.3.5 Stratégies d’interconnexion de processus ...................................................................... 29
2.3.6 Conclusion...................................................................................................................... 32
2.4 Architecture orientée service : une réponse à l’interopérabilité technologique .................... 32
2.4.1 Description de service ................................................................................................. 34
2.4.2 Communication entre service ....................................................................................... 37
2.4.3 Publication de service .................................................................................................. 37
2.4.4 Description de la partie opérative des services .............................................................. 39
2.4.5 Composition et orchestration de services ...................................................................... 42
2.4.6 Conclusion .................................................................................................................. 45
2.5 Démarches orientées objet ............................................................................................... 46
2.5.1 Concepts de base de l’approche objet ........................................................................... 46
2.5.2 Définition des Objets métier (Business objects) ........................................................... 49
2.5.3 Méthodes de modélisation orientée objet ..................................................................... 50
2.5.3.1 IEM ........................................................................................................................ 50
2.5.3.2 UML ....................................................................................................................... 51
2.5.4 Conclusion .................................................................................................................. 56
2.6 Des modèles au logiciel ................................................................................................... 56
2.7 Conclusion...................................................................................................................... 62
Chapitre 3 La collaboration des processus de l’entreprise ...................................................... 66
3.1 Introduction .................................................................................................................... 66
3.2 Architecture globale ........................................................................................................ 72
3.3 Spécification des différentes vues .................................................................................... 79
3.3.1 La vue de gestion ........................................................................................................ 79
3.3.2 La vue de médiation .................................................................................................... 85

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
ix
3.3.3 Vue de sécurité ........................................................................................................... 88
3.3.4 Conclusion .................................................................................................................. 90
3.4 Exploitation du modèle : ................................................................................................. 91
3.5 Conclusion...................................................................................................................... 95
Chapitre 4 Modélisation d'entreprises collaboratives par des graphes de d’héritages de
services .................................................................................................................. 96
4.1 Introduction .................................................................................................................... 96
4.2 Mécanismes d’héritage .................................................................................................... 99
4.3 Héritage entre services (objets) ...................................................................................... 100
4.3.1 Héritage avec les propriétés fonctionnelles ................................................................. 100
4.4 Les propriétés non fonctionnelles et le mécanisme d’héritage .......................................... 101
4.5 La construction de l’hypergraphe ................................................................................... 103
4.6 Construire l’arborescence des instances ......................................................................... 106
4.7 Collaboration entre les entreprises à base d’hypergraphe ................................................ 108
4.8 Orchestration contextualisée de “type de service“ ........................................................... 111
4.9 Les contraints de transition entre les types de service ..................................................... 114
4.10 L’enchaînement des types de services ............................................................................ 116
4.11 Les relations de dépendances entre les Services .............................................................. 118
4.11.1 La relation d’agrégation (A) ...................................................................................... 119
4.11.1.1 Les cardinalités ..................................................................................................... 120
4.11.1.2 La spécification de contraintes globales .................................................................. 120
4.11.1.3 La propagation des contraintes dans une composition .............................................. 121
4.11.2 La relation de recommandation (R) ............................................................................ 121
4.11.2.1 La relation de similarité (S) ................................................................................... 122
4.11.2.2 La relation de collaboration (C) ............................................................................. 123
4.12 Intégration des relations de dépendances dans les processus métiers ................................ 123
4.13 Conclusion.................................................................................................................... 125
Chapitre 5 Conclusion générale et perspectives .................................................................... 127
5.1 Conclusion général et perspective .................................................................................. 127

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
x
Table de figures
Figure 1 : Cube CIMOSA [16] page 138 .................................................................................... 7
Figure 2 : les outils GRAI ....................................................................................................... 10
Figure 3 : éléments méthodologiques de GERAM [20], page 5. ................................................ 14
Figure 4 : Cycle de vie de GERAM [21] page 10 ...................................................................... 15
Figure 5 : La modélisation d’une activité ................................................................................ 17
Figure 6 : Les éléments principaux pour la modélisation d’un processus métier [10] page 16. ... 22
Figure 7 : l'architecture d'ARIS [41] page 40 .......................................................................... 28
Figure 8 : Aris les niveaux de modélisation pour le processus de l’entreprise [41] page 3 ....... 28
Figure 9 : modèle de Service Web [51] page 5 ......................................................................... 33
Figure 10 : La description d’un service web grâce à WSDL [53] p86 ........................................ 35
Figure 11 : Ontologie OWL-S .................................................................................................. 36
Figure 12 : Mécanismes d’accès aux services fournis par un UDDI Registry [51] page 117. ..... 38
Figure 13 : Modèle structurel des données de UDDI Registry [51] page 119 ............................ 39
Figure 14 : La connexion entre un processus BPEL et des services [59] page 74. ...................... 40
Figure 15 : Le document XLANG [59] page 251 ...................................................................... 42
Figure 16 : Le model de coordination [53] page 4 ................................................................... 44
Figure 17 : exemple d'association ........................................................................................... 47
Figure 18 : Exemple d'agrégation ........................................................................................... 48
Figure 19 : exemple de généralisation ..................................................................................... 48
Figure 20 : Schéma d’un objet encapsulé ................................................................................. 49
Figure 21 : le modèle général d'activité d'IEM ......................................................................... 51
Figure 22 : Représentation des relations entre classes [34] page 20. ........................................ 52
Figure 23 : Exemple d'agrégation et de composition [34] page 21. ........................................... 52
Figure 24 : Exemple d'une collaboration dans un diagramme de structure composite [34] page
29 .......................................................................................................................................... 53
Figure 25 : Représentation d'un design pattern dans un diagramme de structure composite [34]
page 29 .................................................................................................................................. 54
Figure 26 : Les niveaux de modélisation .................................................................................. 57
Figure 27 : Les catégories de modèles dans MDA. ................................................................... 58
Figure 28 : Exemple de PIM [40] page 8. ................................................................................ 59
Figure 29 : Relation entre PIM et PSM en modélisation EJBexpanded [40] page 9 ................... 59
Figure 30 : Etapes du processus MDA [40] page 6. ................................................................ 60
Figure 31 : Exemple d’utilisation des modèles pour réaliser une applica tion [38] page 5. ......... 61
Figure 32 : Transformations des modèles [38] page 6. ............................................................. 61
Figure 33 : Comparaison entre processus collaborati fs traditionnels et multi-contextuels ......... 71
Figure 34 : Les concepts de base d’une collaboration contextualisée ........................................ 72
Figure 35 : Description du contexte permettant une sélection et exécution multi -contextuelles de
services .................................................................................................................................. 75
Figure 36 : Génération du processus concret en choisissant les services concrets convenables .. 76
Figure 37 : Vue d’agrégation du processus permettant la propagation des informations ............ 76

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
xi
Figure 38 : Architecture globale ............................................................................................. 78
Figure 39 : Relations entre le participant, le rôle, et le service abstrait .................................... 80
Figure 40 : les relations entre les concepts dans le processus de collaboration. ........................ 81
Figure 41 : les éléments de modèle de collaboration (génération le service) ............................. 81
Figure 42 : Exemple montrant la sélection du service abstrait à partir du rôle .......................... 83
Figure 43 : Exemple montrant la règle de sélection des services concrets à partir des services
abstraits ................................................................................................................................. 84
Figure 44 : Définition d’un service .......................................................................................... 85
Figure 45 : Mécanisme de propagation de contraintes de sécurités via le médiateur ................. 88
Figure 46 : Les droits d’accès et l’héritage entre les objets ...................................................... 89
Figure 47 : Construction du processus de collaboration par une série de transformation de
modèles (MDA) ....................................................................................................................... 91
Figure 48 : Modélisation des processus en termes d’hypergraphe ............................................. 98
Figure 49 : Le modèle de service vu comme un objet qui encapsule les propriétés et les méthodes
............................................................................................................................................ 100
Figure 50 : L’héritage entre les services ................................................................................ 101
Figure 51 : héritage avec les propriétés non fonctionnelles .................................................... 103
Figure 52 : Exemple d’arborescence ..................................................................................... 104
Figure 53 : Les attributs de la classe ..................................................................................... 105
Figure 54 : L’ensemble des attributs de l’objet ...................................................................... 106
Figure 55 : L’arborescence de l’objet .................................................................................... 107
Figure 56 : Les liens entre les classes et les objets ................................................................. 107
Figure 57 : Les liens avec des objets appartenant à différentes classes ................................... 108
Figure 58 : Principe de présenter les services ........................................................................ 109
Figure 59 : Arbre d'héritage de service <achat> ................................................................... 110
Figure 60 : rôle le médiateur ................................................................................................ 110
Figure 61 : Le rôle de médiateur pour sélectionner le service contextuel ................................ 111
Figure 62 : L’Orchestration de type de service ...................................................................... 113
Figure 63 : Les différents états de transition .......................................................................... 114
Figure 64 : Service composé l’acheter de produits informatiques ........................................... 117
Figure 65 : Vue statique du processus métier composite en relations d’agrégation .................. 120
Figure 66 : Relation de recommendation < RoomBookingWS, R, SightSeeingWS > ................. 122
Figure 67 : Relation de similarité < RoomBookingWS, S, RoomReservationWS > ................... 122
Figure 68 : Relation de collaboration < AirTicketPurchaseWS, C, 0,5, RoomBookingWS> ...... 123
Figure 69 : Un processus métier et les différentes types de relations de dépendances entre les
services ................................................................................................................................ 125

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
1
Chapitre 1
Introduction
1.1 Problématique
L‟évolution de la demande pour des associations
produits/services nécessite l‟organisation de collaborations « à la
demande » entre entreprises pour répondre aux besoins des clients. Ce
changement structurel au niveau du marché laisse donc prévoir une
croissance exponentielle des écosystèmes de services dans les
prochaines années et le développement de nouvelles structures
organisationnelles permettant de pouvoir organiser des collaborations
« à la demande » entre les entreprises. Ce changement de contexte
impose d‟accroître non seulement l‟agilité de l‟entreprise (définie
comme “the ability of an organization to sense environmental change
and respond efficiently and effectively to that change [1] page1 ") qui
constitue un élément clef de succès [2] pour les entreprises mais aussi de
résoudre les problèmes d‟interopérabilité tant au niveau organisationnel
qu‟en ce qui concerne le niveau technologique.
Pour ce qui concerne le niveau organisationnel, la mise en
place de stratégie de collaborations et de partenariat entre entreprises
impose de formaliser les différents processus afin de pouvoir ensuite
construire un processus commun interconnectant les processus propres
des différents partenaires. Pour cela, il faut modéliser à la fois les
processus (définis comme des séquences de tâches) et les échanges
d‟information entre ces tâches, ce qui nécessite la prise en compte de
différents points de vue :
1. La vue fonctionnelle permet de décrire les différentes
fonctions (en termes de processus, activités et opérations) et les
contraintes de cohérence liées à l‟enchaînement de différentes fonctions.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
2
2. La vue informationnelle est utilisée pour décrire les objets de
l‟entreprise et leur gestion mais aussi l‟échange d‟information en entrée
et sortie des fonctions et activités décrites précédemment
3. La vue des ressources est utilisée pour montrer les rôles des
ressources et leur mode de gestion (qui fait quoi et avec quoi).
4. La vue organisationnelle sert à la description des
responsabilités intervenant dans les prises de décision (qui est
responsable de quoi).
Cette phase de modélisation, si elle donne une vision globale et
précise du fonctionnement de l‟entreprise, est relativement lourde à
mettre en place. Or les règles de gestion des entreprises sont assez
souvent similaires aussi les différentes méthodes de modélisation
proposent elles une architecture intégrant des modèles génériques
(représentant des « bonnes pratiques ») à instancier et particulariser.
Toutefois, cette logique top-down ne permet pas de s‟adapter
dynamiquement aux différents contextes de collaboration puisque le
processus de modélisation, instanciation, particularisation doit être
repris depuis le début. De manière à atteindre le nécessaire niveau
d‟agilité, il faut donc réorganiser l‟entreprise pour permettre une
construction « incrémentale » des activités dans une logique plutôt
« bottom-up ».
Au niveau technologique, les Systèmes d‟Information (SI)
d‟entreprise ne sont que peu agiles et ne permettent pas d‟adapter les
processus internes de l‟entreprises pour répondre « à la demande » aux
changements structurels imposés par le marché. Or, l‟infrastructure
informatique (matérielle et logicielle) repose sur une large variété de
composants spécialisés ERP (Enterprise Ressource Planning),
CRM(Customer Relationship Management), SCM(Supply Chain
Management),…) et présente donc à la fois une forte complexité
technologique et un manque d‟interopérabilité. Or la formalisation d‟une
collaboration pour répondre à un objectif commun induit la création
d‟un processus collaboratif liant et coordonnant l‟ensemble des
processus mis en œuvre par les différents partenaires. Ceci impose donc
de fortes contraintes d‟agilité et d‟interopérabilité sur les différents
systèmes support pour permettre la combinaison et la bonne
synchronisation de ces différents éléments. Ceci explique que le
développement important des technologies de l‟information et de la

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
3
communication, au lieu de devenir un élément moteur de la
collaboration inter entreprise soit vu comme des freins puisqu‟elles
limitent les possibilités « d‟interconnexion » entre les processus
d‟entreprise et l‟échange d‟information entre partenaires. Pour remédier
aux problèmes d‟interopérabilité technologiques, le développement de
l'architecture orientée services (SOA) [3] permet aux entreprises
d‟organiser leur système d'information et les applications qui le
composent en termes de services assemblés les uns avec les autres.
L‟utilisation de standards d‟interface et de middleware (les Entreprise
Service Bus ou ESB) permettent d‟apporter une réponse technologique
au besoin d‟interopérabilité. Néanmoins, ces architectures à base de
services ne permettent pas de contextualiser les services et leur
assemblage dans une chaîne de service supportant un processus est dicté
par l‟organisation du processus lui-même, spécification issue des
activités de modélisation…
Pour surmonter ces limites, nous proposons d‟intégrer une
architecture orientée service allant du niveau technologique au niveau
d‟affaire. Pour cela, nous proposons de redéfinir les processus de
manière abstraite au niveau de la logique d‟affaire en exprimant les
différents rôles à jouer. Ceci permet de contourner la vision « top-
down » de la modélisation traditionnelle en apportant une vision de
composition incrémentale par composition de services abstraits en
fonction des besoins. De manière à fournir le support technologique
indispensable, ces processus abstraits sont utilisés pour sélectionner et
interconnecter les services technologiques. De manière à faciliter la
contextualisation, il importe de définir une logique d‟assemblage
permettant d‟intégrer différentes logiques de médiation, de sécurité… en
composant des services technologiques adaptés au contexte.
Pour cela, nous proposons une nouvelle logique
d‟instanciation : il ne s‟agit plus seulement de dériver un modèle
générique pour le particulariser puis transformer ce modèle particulier
en un code exécutable, mais d‟adopter une logique de composition de
services exécutables à partir de modèles abstraits ou d‟informations
contextuelle. Pour cela, nous proposons une vision en hypergraphe qui
nous permet de tirer partie à la fois des avantages de l‟approche objet
(héritage, agrégation,…), de l‟ingénierie des modèles (logique de
transformation) et de la composition de service. En effet, cette

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
4
architecture nous permet non seulement de relier étroitement services
abstraits et concrets mais aussi d‟intégrer un « tissage » de modèles de
sécurité, de médiation, des relations de similarité… qui permettront
d‟organiser au mieux le processus « concret » support de la
collaboration en guidant les différentes opérations de composition.
La suite de ce mémoire de thèse est organisée en 3 chapitres principaux :
dans chapitre 2 consacré à l'état de l'art, nous concentrons d'abord sur la
modélisation d'entreprise et présenterons différentes méthodes
généralistes avant de nous intéresser plus spécifiquement aux méthodes
de modélisation orientées système d‟information. Nous nous
intéresserons ensuite aux approches orientées processus et aux apports
des architectures orientées services avant de détailler les approches
orientées objets et l‟ingénierie dirigée par les modèles. En effet, la
plupart des méthodes de modélisation propose une démarche de type
instanciation à partir de modèles générique pour créer des modèles
spécifiques. Ce processus pourrait donc être amélioré en intégrant les
apports de ces deux technologies.
Le chapitre 3 présente globalement notre architecture
permettant de générer des services contextuels « au vol » en combinant
différents points de vue. L‟organisation des différents modèles associés
est définie dans une structure à base d‟hypergraphe présenté de manière
plus détaillée dans le chapitre 4.
Enfin, le chapitre 5 rappelle nos principales contributions et
présente les perspectives ouvertes par ce travail.

Chapitre 2 Etat de l’art
2.1 Introduction
Les évolutions rapides du contexte économique (notamment la
prise en compte de stratégies de personnalisation « de masse », le
développement de stratégies au plus juste, la recherche d’une rentabilité
maximale…) conduisent les entreprises à se recentrer sur leur cœur de
métier tout en développant une stratégie d’ouverture conduisant à des
organisations collaboratives. Ce nouveau contexte impose aux
entreprises de formaliser leur organisation (contraintes contractuelles)
mais aussi d’adapter leur organisation et leur système d’information de
manière à pouvoir construire de manière efficaces des processus
collaboratifs interopérables permettant à l’ensemble des partenaires
d’atteindre un but commun. Aussi, dans un premier temps, nous nous
intéresserons aux méthodes générales de modélisation de l’entreprise
avant de nous focaliser sur les approches centrées processus. Dans un
deuxième temps, nous prendrons en compte les contraintes
d’interopérabilité technologique et présenterons comment les approches
orientées services et les standard associés peuvent apporter une réponse
consistante au nécessaire besoin d’ouverture des systèmes
d’information. Enfin, de manière à faciliter la conception des processus
collaboratifs et de pallier les lourdeurs et difficultés inhérentes aux
méthodes de modélisation classique, nous étudierons plus précisément
les applications possibles des approches objets et de l’ingénierie dirigée
par les modèles pour permettre la génération de processus informatique
« support ».
Ce tour d’horizon nous permettra, en en identifiant les limites
de ces différentes approches dans la conclusion de ce chapitre,
d’esquisser les pistes de recherche qui serviront de base à notre
contribution.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
6
2.2 Méthodes de modélisation
Avant de présenter différentes approches de modélisation, il
convient d‟en préciser l‟objectif et le périmètre. La modélisation
d‟entreprise est l‟ensemble des activités et des processus utilisés pour
développer les différentes parties d‟un modèle d‟entreprise dans le but
de [13]:
• Construire une vision et une culture communes
communiquées lors de l‟utilisation de modèles.
• Offrir une meilleure représentation et une meilleure
compréhension du fonctionnement d‟une entreprise.
• Capitaliser la connaissance et le savoir-faire de l‟entreprise
pour une utilisation ultérieure.
• Rationaliser et structurer les échanges d‟information.
• Concevoir et spécifier une partie de l‟entreprise (aspects
structurels, organisationnels, informationnels, fonctionnels ou
comportementaux).
• Analyser certains aspects d‟une partie de l‟entreprise
(analyse économique, organisationnelle, quantitative, qualitative, etc.).
• Simuler le comportement d‟une partie de l‟entreprise.
• Offrir des éléments pour l‟aide à la décision pour le
contrôle et l‟évolution de l‟entreprise (des processus, par exemple).
Les approches de modélisation d‟entreprise sont nombreuses et
intègrent différents points de vue permettant d‟appréhender globalement
l‟organisation et le fonctionnement de l‟entreprise . Parmi elles, nous
présenterons d‟abord la vision « intégratrice » de CIMOSA avant de
nous intéresser à d‟autres méthodes se focalisant sur des points de vue
plus spécifiques comme GRAI (pour la modélisation des décisions),
PERA avant de terminer par le cadre fédérateur de GERAM. Nous nous
intéresserons ensuite plus précisément aux approches de modélisation
orientées système d‟information puisque le fonctionnement de
l‟entreprise fait largement appel au système d‟information qui agit lui -
même comme un élément structurant de l‟organisation. Nous dresserons
ensuite un bilan de ces méthodes dans le contexte particulier de la
modélisation d‟organisations collaboratives.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
7
2.2.1 CIMOSA
La méthode CIMOSA (Computer-Integrated Manufacturing
Open Systems Architecture) est issue d‟un projet européen Esprit.
L‟objectif était de fournir un cadre de modélisation et un ensemble de
modèles favorisant la mise en place du « Computer Integrated
Manufacturing » [14] [15]. CIMOSA prend en compte à la fois un cadre
de modélisation multi points de vue, une infrastructure facilitant la
communication entre les différents éléments et une démarche
méthodologique de modélisation. L‟infrastructure est chargée d‟apporter
un ensemble de services :
Les services de gestion assurent la gestion, le contrôle de
l‟exécution des tâches ou activité du système.
Les services de communication garantissent l‟accès aux données.
Les services d‟interface supportent une représentation cohérente
des différentes entités du domaine considéré.
Le cadre de modélisation de CIMOSA, connu sous le nom du
cube CIMOSA qui est montré dans la (figure 1) organise la modélisation
de l‟entreprise selon trois axes [16]:
Figure 1 : Cube CIMOSA [16] page 138

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
8
L‟axe de génération ou axe des vues est associé aux différents
points de vue :
a. La vue fonctionnelle permet de décrire les «
fonctionnalités », la structure de contrôle et le comportement de
l‟entreprise en termes d‟opération, activité et de processus.
b. La vue information permet la spécification du système
informatique de l‟entreprise, la création d‟une structure adaptée afin de
stocker / mettre à jour / traiter Les informations (données et
connaissances) pour les besoins des utilisateurs et des Applications
(mémoire de l‟entreprise).
c. La vue ressources est associée à la spécification et la
description des composants requis et/ou implantés dans le système de
production servant de réalisation des tâches de l‟entreprise. Il s‟agit
aussi bien des composants de la technologie manufacturière que de ceux
de la technologie informatique (qui fait quoi, quand et comment).
d. La vue organisation sert à la description de l‟organisation
et des responsabilités intervenant dans les prises de décision (qui est
responsable de quoi). L‟organisation de l‟entreprise est exprimée en
termes de cellules, d‟unités et de niveaux de prise de décision.
L‟axe de dérivation permet d‟intégrer les différentes phases d‟un projet de
modélisation selon trois phases :
e. Expression des besoins : c‟est la construction d‟un modèle
utilisateur qui définit ce qui doit être réalisé dans l‟entreprise (le QUOI).
f. Spécification de conception : c‟est la construction d‟un
modèle de l‟entreprise non ambigüe et cohérent. Différents modèles
peuvent être développés pour étudier diverses alternatives par le biais de
la simulation.
g. Description de l‟implantation : c‟est la construction d‟un
modèle exécutable de l‟entreprise (le COMMENT).
L‟axe d‟instanciation permet à partir d‟un modèle générique global de
construire différents modèles partiels avant de les particulariser pour
définir des modèles spécifiques de l‟entreprise.
Les différents points de vue proposés par cette méthode offrent
un cadre riche permettant de définir les différentes représentations
abstraites de l‟entreprise. La possibilité de générer des modèles
particuliers pour l‟entreprise à partir de modèles génériques peut
représenter un gain de temps appréciable et permettre de réutiliser des «

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
9
best practices ». Mais CIMOSA ne permet pas de se focaliser sur le
processus de décision, capital en cas de développement d‟une stratégie
de collaboration. Pour cela, on peut recourir à la méthode GRAI.
2.2.2 GRAI
L‟objectif de la méthode GRAI [17] (Graphe de Résultats et
Activités Inter-reliés) est de faciliter l‟identification de toutes les
activités de décision d‟un système lors de l‟analyse et de la conception
de son système pilotage. Pour cela, la méthode GRAI propose deux
outils principaux : la grille GRAI et les réseaux GRAI [18] qui sont
présentés dans la figure 2.
La grille GRAI permet d‟identifier les activités des centres de
décision suivant les dimensions fonctionnelles et temporelles. Les
colonnes représentent les fonctions d‟un processus de décision. Les
lignes correspondent à des niveaux de décision. Chaque niveau de
décision est défini par un couple (horizon/période). Chaque centre de
décision est défini par une activité de gestion.
Les réseaux GRAI représentent le fonctionnement de tout ou
partie d‟un centre de décision. Ils permettent de modéliser les activités
d‟exécution et de décision.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
10
Figure 2 : les outils GRAI
La démarche GRAI comporte deux phases :
L‟initialisation inclut la prise de contact avec l‟entreprise (pour
définir les conditions de la collaboration et les objectifs à
atteindre).
L‟analyse de l‟existant débute par l‟établissement des grilles
GRAI associées au système étudié. L‟étape suivante est
l‟analyse ascendante qui permet la création des réseaux
décrivant les processus utilisé dans le centre de décision
identifié. Enfin, cette phase se termine par la rédaction du
rapport d‟analyse.
La conception du futur système : la grille GRAI permet de
décrire l‟architecture du futur système de gestion de
l‟entreprise.
Cette modélisation des mécanismes de prise de décision (qui
décide de quoi et sur quel horizon) nous semble bien correspondre aux
problèmes soulevés par l‟organisation d‟organisations collaboratives car
cela permet de définir clairement les limites de responsabilité. En outre,

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
11
la collaboration interentreprises fait largement appel aux technologies de
l‟information et de la communication. Ce point est également pris en
compte par GRAI dans la mesure où cette méthode a fait l'objet de
plusieurs extensions en intégrant les méthodes orientées « système
d‟information » comme IDEF0 et MERISE au processus de modélisation
GRAI pour former la méthodologie GIM (GRAI Integrated Methodology
ou GRAI-IDEF0-MERISE) vers les années 90.
GIM apporte une réponse à la question de prise de décision,
cependant, il n'apporte pas une réponse complète de gestion de ressource
humaine et il ne prend pas en considération le cycle de vie d'un modèle.
Pour surmonter cette limite, la méthode PERA peut être envisagée de
manière complémentaire.
2.2.3 PERA
PERA (Purdue Enterpris Reference Architecture) est une
architecture pour la modélisation d‟entreprise développée à l‟université
de Purdue aux Etats-Unis [19]. La méthodologie est basée sur les étapes
associées au cycle de vie d‟un système :
- Identification de l‟entité modélisée : cette étape concerne la
caractérisation du domaine couvert par l‟étude : entreprise dans son
ensemble, partie d‟une usine, …
- Conceptualisation : il s‟agit ici d‟exprimer les objectifs et
politiques que l‟entreprise souhaite atteindre ou mettre en œuvre.
- Définition : c‟est l‟étape d‟analyse fonctionnelle qui permet
d‟identifier les besoins, les tâches à mettre en œuvre pour permettre la «
réalisation » de ses besoins et les liens entre ces tâches.
- Conception : cette étape débute par une phase de conception
fonctionnelle destinée à définir les choix initiaux ou concevoir
globalement les architectures organisationnelles, humaines, de
production et informatique. Ces architectures sont ensuite précisées dans
la phase de conception détaillée pour aboutir à des architectures
d‟implémentation.
- Installation et construction : il s‟agit ici de transformer les
spécifications détaillées en une implantation effective des moyens
nécessaires à la réalisation de la mission du système. C‟est lors de cette

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
12
étape que les ressources humaines sont formées et que les machines et
équipements sont testés.
- Mise en œuvre et maintenance : c‟est l‟exploitation effective
de l‟installation en y intégrant les tâches de maintenance.
PERA répond aux inconvénients observés dans GIM,
néanmoins, cette méthode ne couvre pas plus que GIM tous les aspects
nécessaires dans l‟organisation de collaboration. Elle doit donc être
utilisée de manière complémentaire.
Ceci pose donc le problème de mise en œuvre d‟un cadre
fédérateur permettant « d‟articuler » différentes méthodes de
modélisation pour tirer le meilleur partie de chacune d‟elle a obtenir un
modèle le plus complet possible. C‟est l‟objectif du développement de
GERAM.
2.2.4 GERAM
Comme nous venons de le voir, les différentes méthodes de
modélisation d‟entreprise utilisent une démarche méthodologique
similaire tout en permettant d‟appréhender des points de vue différents
(décision pour GRAI, fédération des architectures informatique,
organisationnelles et de production pour PERA alors que CIMOSA
juxtapose les différents composants du système). GERAM (Generic
Enterprise Reference Architecture and Methodology) [20][21] est une
initiative issue du groupe de travail (IFAC/IFIP Task Force) sur les
architectures pour l‟intégration d‟entreprises et repose sur une analyse
critique de ces différentes architecture pour fournir un cadre de
modélisation générique permettant de fédérer différentes méthodes et
outils de modélisation.
Le cadre de travail de GERAM est composé de plusieurs
entités [20] (voir figure 3).
Une architecture générique de référence pour l‟entreprise
(GERA : Generic Enterprise Reference Architecture) définit
le cycle de vie de l‟entreprise.
Une méthodologie générique d‟ingénierie de l‟entreprise
(GEEM : Generic Enterprise Engineering Methodology)

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
13
permet de présenter les différents éléments à développer
pour réaliser l‟intégration d‟une entreprise.
Des outils et langages de modélisation génériques pour la
modélisation de l‟entreprise (GEML : Generic Enterprise
Modelling Tools and Languages) offrent le support
nécessaire pour l‟activité de modélisaiton
Des modèles génériques d‟entreprise (GEMS pour Generic
Enterprise Models) : ils sont formés de méta-modèles,
ontologies et de modèles d‟entreprise réutilisables. Ils
constituent une base de « bonnes pratiques » qui peuvent
être utilisées pour faciliter la modélisation d‟une entreprise.
Des modules génériques d‟entreprise (GM pour Generic
Enterprise Modules). Ce sont des implémentations
standards d‟éléments qui peuvent être utilisé dans la phase
d‟intégration pour une entreprise.
Les EEMs (Enterprise Engineering Methodology) décrivent
le processus de l'ingénierie d'entreprise. Pour chaque type
d'activité du changement, elles décrivent des chemins
d'évolution, identifient les tâches ainsi que les outils
permettant ce changement.
Les EMLs (Enterprise Modelling Languages) définissent des
concepts (constructs) capables de modéliser à la fois la
partie humaine de l'activité de l'entreprise, les processus
métier et leurs technologies de support associées. Les
constructs définissent les objets qui seront utilisés dans les
vues définies dans GERA.
Les méthodologies et les langues utilisées pour la
modélisation d'entreprise sont supportés par les outils de
modélisation d'entreprise (Enterprise Engineering Tools,
EETs). Ces derniers permettent de gérer la création,
l'utilisation et la gestion des modèles d'entreprise. La
sémantique des langages de modélisation est assurée grâce à
Generic Enterprise Modelling Concepts (GEMCs).
Les modèles d'entreprise (Enterprise Models, EMs) qui
représentent l'ensemble ou une partie des opérations
d'entreprise, y compris son organisation et sa gestion ainsi
que ses systèmes de pilotage et d'information. Ces modèles

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
14
sont utilisés pour guider l'implémentation du système
opérationnel de l'entreprise (Particular Enterprise
Operational Systems, EOS). Ces modèles particuliers
peuvent être construits par « instanciation » puis adaptation
de modèles génériques
En fin Les modèles partiels (Partial Entreprise Model,
PEMs) représentent les modèles réutilisables pour les rôles
humaines, les processus ou les technologies.
Figure 3 : éléments méthodologiques de GERAM [20], page 5.
Outre ce cadre de référence, GERAM intègre aussi une
démarche de modélisation basée sur un cycle de vie en sept phases [21]
présenté dans la figure 4 :
Phase d‟identification du contenu : pour une entité
particulière, il s‟agit d‟identifier ses différentes activités, les
limites de responsabilité et les relations avec l‟environnement.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
15
Phase de définition des concepts de l'entité : C‟est l'ensemble
d'activités qui sont nécessaires pour développer les concepts
de l'entité fondamentale. Ces concepts incluent la définition
de la mission de l'entité, vision, ses objectifs, ses concepts
opérationnels, ses politiques, etc.
Phase de définition des besoins : Ce sont les activités
nécessaires pour définir les exigences opérationnelles de
l'entité de l'entreprise, ses processus et tous besoins
fonctionnels, comportementaux, informationnels.
Phase de conception : Ce sont les activités qui définissent la
spécification de l'entité avec l'ensemble de ses éléments qui
satisfont aux exigences de l'entité. Ces activités incluent la
conception de toutes les tâches humaines (tâches des individus
et des entités d'organisation), et toutes les tâches
automatisées.
Phase de démantèlement : Ce sont les activités qui définissent
toutes les tâches qui doivent être effectuées pour déconstruire
l'entité.
Phase de fonctionnement de l'entité : Ce sont les activités de
l'entité qui sont nécessaires au cours de son fonctionnement
pour fabriquer le produit demandé par les clients et réaliser au
bon fonctionnement de l‟entité.
Phase de recyclage de l'entité : ce sont les activités
nécessaires pour recycler, réaffecter ou dissoudre un
composant ou une entité toute entière en fin de sa vie.
Figure 4 : Cycle de vie de GERAM [21] page 10

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
16
Le cadre fédérateur de GERAM présente l‟avantage principale
de reposer sur une analyse critique des différentes architectures de
modélisation d‟entreprise pour fournir un cadre de modélisation
générique permettant de fédérer ces différentes méthodes et outils de
modélisation. En effet GERAM est fondé sur les concepts de trois
architectures (CIMOSA, GRAI-GIM et PERA) et a été définit dans un
but de généricité. GERAM devrait donc être applicable à n‟importe quel
type d‟entreprise [20] .
D‟autres avantages sont également présentés par GERAM (par
rapport aux autres méthodes) :
GERAM permet de présenter et fédérer les différents éléments à
développer pour réaliser l‟intégration d‟une entreprise.
le cadre méthodologique de GERAM couvre l‟ensemble du
cycle de vie non seulement d‟un projet de modélisation mais
surtout GERAM couvre la totalité du cycle de vie d‟une
organisation.
2.2.5 Méthodes orientées « système d’information »
Les entreprises créent de la valeur en gérant leurs Systèmes
d'Information (noté SI) qui représentent l'ensemble de tous les éléments
participant à la gestion, au traitement, au transport et à la diffusion de
l'information au sein de leurs organisations structurelles. La mise en
place d‟un système d‟information se révèle une démarche très difficile et
coûteuse. Il s‟agit dans un premier temps d‟étudier les différents
secteurs fonctionnels d'une entreprise (achat, production, administration,
ventes, maintenance, etc.) afin d‟aboutir à une structuration de ces
activités et à une capitalisation de l'ensemble de ces informations
échangées permettant ainsi d'en améliorer ses performances et son
évolutivité.
Il existe plusieurs méthodes d'analyse et de conception comme MERISE,
SADT, OSSAD ou UML. Les trois premières méthodes représentatives
de la conception du système d‟information dans une logique séparant
données et traitements ont été utilisées dans des projets de grande
ampleur de refonte d'un existant complexe ou le développement d‟un

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
17
nouveau système. La méthode UML en revanche respecte une logique
orientée objet et encapsule données et traitement dans des composants.
La méthode SADT (Structured Analysis and Design Technique) [22] est
une méthode graphique établie par Douglas T.Ross (Softech) vers 1974.
SADT distingue deux types de modèles : les actigrames qui représentent
les activités ou traitements du système modélisé et les datagrames,
représentant les données du système modélisé. SADT est basée sur le
principe de décomposition hiérarchique et structurée des fonctions de
l‟entreprise qui sont définies en termes d‟activité. Une activité peut être
considérée comme une fonction de transformation d‟entrées
(information ou matière) en sorties (informations ou matières) voir la
figure 5. Cette vision permet donc d‟agréger ces différentes vues.
Figure 5 : La modélisation d‟une activité
L‟exécution de l‟activité est déclenchée par un (ou plusieurs)
contrôle(s). La figure 6 représente une activité, les relations d‟une
activité avec les autres activités au moyen de flèches. Les flèches entrant
par le côté gauche du rectangle présentent les entrées de l‟activité, les
flèches sortant par le côté droit du rectangle représentent les sorties de
l‟activité. Les flèches entrant par la base du rectangle présent les
mécanismes utilisés par l‟activité (les ressources nécessaires au
déroulement de l‟activité. Enfin, les flèches entrant par le haut de
rectangle présent les contrôles de l‟activité.
En revanche, la méthode MERISE [23] [24,25] qui a été conçue pour
réaliser la conception et la mise en œuvre des systèmes d‟information
s‟appuie d‟une part sur la séparation des données et des traitements et
d‟autres parts sur l‟organisation de différents points de vue (conceptuel,

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
18
logique et physique). Basée sur la proposition du modèle
entité/association, la méthode MERISE, est très employée en France.
Cette approche entité / association a largement été diffusée à l‟échelle
mondiale par Peter CHEN. La méthode MERISE propose une démarche
d‟ingénierie des systèmes d‟information couplant approches bottom-up
et top-down : l‟étude de l‟existant doit permettre de remonter du niveau
physique (implémentation) jusqu‟à la construction d‟une vision
conceptuelle qui est ensuite améliorée. Une fois défini conceptuellement
les modèles de données et traitement, ceux-ci sont ensuite transformés
pour aboutir aux modèles physiques d‟implémentation.
Le niveau conceptuel permet la description de l‟entreprise
(objectifs généraux et contraintes). Il apporte la réponse à la
question “quoi“ (aspect fonctionnel) et représente le niveau le
plus stable du système-entreprise.
Le niveau organisationnel répond aux questions “ qui, où et
quand ?“. il décrit la structure à mettre en place pour satisfaire
les objectifs décrits au niveau précédent et représente un
deuxième niveau de variabilité du système.
Le niveau physique définit les moyens techniques à mettre en
œuvre pour réaliser le système d‟information. Il répond à la
question “ comment ?“.
Cette méthode initialement définie pour les grands systèmes a ensuite
été étendue pour y intégrer différentes évolutions technologiques.
La méthode OSSAD (Office Support System Analysis and Design) [26]
est une méthode de modélisation du système d‟information née dans le
contexte d‟un projet Européen ESPRIT (European Strategic Programme
for Research in Information Technology). Elle fonctionne suivant deux
niveaux :
Le modèle abstrait (MA) a comme objectif de formaliser les
caractéristiques stables et durables du système. Dans ce
modèle, on trouve des concepts qui sont liés à l‟activité. Il
s‟agit des concepts de Fonction (nom donnés aux processus),
de l‟organisation (exemple : marketing, production), de Sous-
fonction (sous processus) et d‟Activité. Notons que les
fonctions ou sous-fonctions échangent des messages qui sont
associés au concept de paquet d‟informations.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
19
Le modèle descriptif (MD) décrit la façon pratique dont le
travail est (ou sera) fait. Il propose les Rôles qui sont
l‟ensemble des Tâches/responsabilités confiées à une personne
: c‟est la “fonction“ professionnelle de l‟individu. Les Acteurs
sont des personnes remplissant un ou plusieurs Rôles. Les
unités sont des regroupements de rôles sur la base de
responsabilités identiques ou partagées.
Ces trois méthodes représentatives d'analyse et de conception
s‟articulent principalement autour de deux axes séparés à savoir les
modèles de données et les modèles de traitements (ou les activités).
Cette distinction entre les données et les activités nécessitent une
gestion particulière pour maintenir la cohérence entre les activités et les
données manipulées par ces activités. Cette gestion est fastidieuse
lorsque le métier d‟une entreprise évolue face aux changements
organisationnels, économiques ou technologiques.
De manière orthogonale, la méthode UML propose une stratégie de
modélisation orientée objet. L‟avantage de cette approche est
d‟encapsuler les données et les opérations qui les traitent sous forme de
classes. Ces classes représentent des objets métiers ayant un sens pour
des acteurs de l‟entreprise. Le modèle des objets métier, qui est
constitué d'un ou plusieurs classes (diagrammes de classe en UML), est
de très haut niveau par rapport au système d'information et permet de
donner une vision plus synthétique. Enfin, la large variété des modèles
proposés par UML permet d‟appréhender à la fois une description
statique portant sur les diagrammes de classes, de composants…
associés à l‟organisation effective de la solution et une vision
dynamique intégrant des cas d‟usage (les « use case »), l‟organisation
temporelle des échanges entre composants, une vision à base
d‟automates à états finis… En outre, les possibilités d‟instanciation et
d‟héritage entre classes permettent de synthétiser les descriptions et
améliorer la réutilisabilité.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
20
2.2.6 Conclusion
Comme nous venons de le voir, différentes méthodes de modélisation
d‟entreprise ont été proposées depuis les années 80. L‟organisation
d‟une entreprise regroupant différentes facettes, plusieurs méthodes
peuvent être nécessaires pour couvrir l‟ensemble des besoins. Ainsi, le
cadre de modélisation GERAM permet de les fédérer pour aboutir à une
vision la plus exhaustive possible tout en préservant la cohérence
globale. L‟ensemble de ces méthodes repose sur une conduite de projet
dans une logique « top-down » de construction de modèle et de
déploiement de la solution. Pour pallier les problèmes de complexité et
de lourdeur de la démarche de modélisation, ces méthodes reposent
toutes sur deux éléments invariants : l‟instanciation de modèles
générique et la transformation de modèles pour permettre d‟aboutir à
une solution déployable.
Si la modélisation d‟entreprise reste fondamentale pour décrire
globalement l‟entreprise et son organisation, la construction du système
d‟information (conditionnant fortement la structuration de l‟entreprise)
fait appel à d‟autres stratégies de modélisation se focalisant sur les
processus à mettre en œuvre et sur l‟organisation des données. Toutefois
ces méthodes spécialisées restent également complexes et lourdes à
mettre en œuvre.
Or l‟organisation collaborative repose sur la mise en place (rapide si
possible) d‟un processus commun permettant d‟aboutir au résultat global
souhaité objet de la collaboration et sur l‟organisation du support
technologique à la collaboration (i.e. modélisation du système
d‟information et organisation des interconnexions entre processus
différents). Pour cela, nous présenterons les caractéristiques principales
des approches basées processus dans la section suivante.
2.3 Approche basée processus
Le processus métier est au cœur de la collaboration entre les
entreprises : en effet, on peut le considérer comme un moyen pour
atteindre l‟objectif commun (à savoir répondre aux besoins du client).

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
21
Nous nous intéresserons d‟abord aux définitions usuelles d‟un processus
afin d‟en extraire les éléments de modélisation. Ensuite, nous
présenterons les différents types de processus. Une introduction sur les
technologies de workflow, qui permettent une mise en œuvre rapide des
modèles de processus sera ensuite présentée. Enfin, nous conclurons
cette section en repositionnant le processus dans un cadre plus large de
modélisation.
2.3.1 Eléments caractéristiques d’un modèle de processus
Différentes définitions du processus sont proposées dans la
littérature. Par exemple, [7] (p 9) définit le processus métier comme
« un ensemble de plusieurs activités reliées les unes aux autres pour
atteindre un objectif ». Cette définition, basée uniquement sur le but à
atteindre, peut être précisée par celle proposée par [8] en intégrant les
moyens nécessaires pour atteindre ce but : un processus est défini
comme un ensemble d‟activités ordonnées selon un ensemble de règles
procédurales pour réaliser un objectif précis au sein d‟une organisation
et réalisé par un groupe de personnes (par exemple, dans une entreprise).
Une vision plus « systémique » conduit à appréhender la notion de
processus comme un système composé d‟ensemble d‟éléments (activités,
rôles, acteurs, ressources, entrées, résultats…) qu‟il faudra prendre en
compte dans la modélisation du processus métier. On notera que ces
définitions sont essentiellement « descriptive » [9]. Or un processus peut
aussi être considéré comme un système dynamique orienté vers la
réalisation d‟un objectif [10].
Dans la figure 6 ci-après nous présentons une synthèse de ces
visions, intégrant à la fois les éléments statique (acteur, rôle, ressource,
activité…), la partie dynamique du système (événement, transition…) et
leur relations.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
22
Figure 6 : Les éléments principaux pour la modélisation d‟un processus métier
[10] page 16.
Le concept d‟activité peut être défini comme unité de
décomposition fonctionnelle du processus [10]. Les activités décrivent
comment l‟objectif d‟un processus (décrit de manière détaillée) pourra
être atteint.
Les concepts de rôle et d‟acteur sont fortement liés. On notera
d‟ailleurs que certains langages de modélisation n‟ont qu‟un seul
concept pour ces deux notions. Un acteur est un élément actif chargé
d‟une ou plusieurs activités dans le processus ([10] page 3). Un «
élément actif » peut être une personne physique, une entité
organisationnelle ou une machine. Ce sont les acteurs qui assurent
l‟exécution des travaux d‟un processus. Le concept d‟acteur permet de
faire apparaître les choix d‟automatisation (automate et / ou être
humains) et d‟organisation à plusieurs niveaux (individu, service,
département, etc.). Pour pouvoir être chargé d‟une ou plusieurs activités,

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
23
l‟acteur doit être capable d‟exécuter les travaux associés ou d‟en porter
la responsabilité.
Un rôle est un regroupement d‟activités (regroupement parfois
limité à une seule activité ou bien intégrant différentes activités
associées à des processus différents) données à un acteur unique. Le rôle
représente le comportement attendu de l‟élément actif à qui on a attribué
les activités associées à ce rôle.
Une transition exprime une contrainte d‟enchaînement entre
deux activités. On peut la considérer comme un lien orienté entre ces
activités. L‟ensemble des transitions d‟un processus représente
l‟ordonnancement de ses activités. Le concept de transition est utilisé
lorsque l‟on veut représenter un enchaînement de plusieurs activités. Si
la transition n‟est pas soumise à une condition, l‟enchaînement est
mécanique : la fin d‟une activité déclenche la suivante.
Une transition peut être soumise à condition. Elle peut être
utilisée simultanément avec ou à la place de concepts d‟événement,
d‟entrée et de résultat. Une condition peut être associée à une transition
et dans ce cas l la transition n‟est réalisée que lorsque la condition est
remplie. Cela signifie que la dernière tâche de l‟activité située au début
de la transition analyse l‟expression associée à la condition pour
déterminer si le passage à l‟activité suivante va s‟effectuer. Les
conditions sur les transitions permettent de représenter des chemins
alternatifs dans le déroulement du processus, ainsi que des boucles
d‟une activité ou un ensemble d‟activités tant qu‟une condition est
réalisée.
Une tâche est le plus petit élément de décomposition d‟une
activité. Lorsque l‟activité est décomposée, une activité peut être définie
comme un ensemble de tâches. La tâche n‟a pas d‟autonomie par rapport
à l‟activité dont elle dépend. Elle peut toutefois être soumise à une
condition d‟activation.
Une activité est activée par un événement. Cet événement
n‟implique aucun acteur de l‟activité et ne consomme aucune de ses
ressources. L‟événement métier “ déclencheur“ qui est à l‟origine de
l‟exécution du processus peut être un échange avec le monde extérieur
(par exemple : l‟événement “envoi d‟une lettre au client“ réclamant des
informations complémentaires pour traiter la demande est un événement
en sortie d‟une activité de l‟entreprise et sera « déclencheur » pour une

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
24
activité du client alors que l‟événement “réception de la réponse du
client“ est un événement déclencheur pour une activité de l‟entreprise
considérée). Un événement est toujours associé à au moins une activité
sur laquelle il agit. Un même événement peut agir sur plusieurs
activités : cela permet d‟activer des activités pouvant se dérouler en
parallèle. A l‟inverse, plusieurs événements peuvent être associés à la
même activité : celle-ci est alors dotée d‟une règle de synchronisation
qui indique si les événements doivent être ou non synchronisés.
On notera qu‟une condition peut être associée à un événement.
Cela signifie que certaines tâches sont implicites dans la description de
l‟activité. Ces tâches filtres analysent l‟expression conditionnelle
attachée à l‟événement pour décider de la prise en compte ou non de cet
événement. S‟il est interrupteur, cela signifie qu‟une tâche de
surveillance des événements peut arrêter le déroulement de l‟activité,
après réalisation éventuelle d‟une tâche spécifique d‟interruption,
soumise à une même condition. Si l‟événement est modificateur, il agit
sur le déroulement de l‟activité ; la condition se retrouve alors sur une
ou plusieurs tâches qui ne seront exécutées que si la condition est
remplie (ou à l‟inverse n‟est pas remplie).
Le résultat est un produit issu de l‟exécution d‟une activité. Il
est associé à l‟achèvement de l‟activité. Une activité peut produire
plusieurs résultats. Un résultat peut être de différentes natures : matériel,
documentaire, informationnel. Il peut également correspondre à un
changement d‟état d‟un élément du système.
Une ressource est un élément (matériel, documentaire,
informationnel, logiciel…) utilisé pour l‟exécution d‟une activité.
Selon la nature de l‟activité, plusieurs types de processus
peuvent être organisés. Le niveau de description a priori des activités va
dépendre directement du niveau de « répétitivité » de ces activités. Ceci
conduit donc à différents niveaux de modélisation. Dans le paragraphe
suivant nous présentons une synthèse sur les différents types de
processus métier.
2.3.2 Typologie des processus
D'après [9][11] les processus peuvent être classés selon quatre
catégories complémentaires :

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
25
1. Le processus d’administration : Il gère des processus
administratifs dont les règles de déroulement sont bien établies et
connues par chacun au sein de l‟organisation. Il est caractérisé par la
circulation de documents/formulaires à travers l‟organisation (par
exemple, demande de remboursement de frais de missions, demande
d‟inscription à une formation, etc.). De ce fait, il aide à transformer la
circulation de documents papiers en circulation de documents
électroniques. Les processus d‟administration ne sont pas d‟une très
grande valeur ajoutée pour une organisation d‟une part, et d‟autre part,
ils sont assez statiques si l‟on considère leur degré de répétition élevé.
2. Le processus de production : Il gère les processus de
production dans les entreprises. Il constitue généralement le cœur de
métier de l‟entreprise et la valeur ajoutée de l‟entreprise dépend
énormément de la qualité de ce processus. C‟est l‟efficacité de ce type
de processus qui assure à l‟entreprise des avantages compétitifs (par
exemple, processus de livraison pour une entreprise de vente en ligne,
processus de gestion des prêts dans une banque, processus de gestion
des demandes des dommages et intérêts au sein d‟une compagnie
d‟assurance, processus de gestion de la chaîne de production chez un
constructeur automobile, etc.).
3. Le processus de collaboration: Il gère la coordination au
sein du groupe lors d‟un projet commun (par exemple, conception
logicielle, réalisation d‟un plan de bâtiment, montage d‟un projet,
réalisation d‟une œuvre artistique, etc.). Il est caractérisé par une forte
valeur ajoutée au sein de l‟organisation, mais par un faible degré de
répétition. Il se distingue des autres processus par le grand nombre de
participants qui interagissent en permanence pour la réalisation du projet
en commun. La complexité de ce type de processus réside dans la
difficulté de modélisation de la méthodologie de travail à suivre surtout
qu‟il faut prévoir, pendant le déroulement du processus, l‟arrivée de
nouveaux participants, la création de nouvelles tâches à intégrer et à
gérer, etc. Il s‟agit par exemple, d‟un processus de coordination
apprenant-apprenant et apprenant-enseignant dans un environnement
d‟apprentissage coopératif (Computer Supported Cooperative Learning
ou CSCL), etc.
4. Le processus ad-hoc : Il représente une classe de processus
destinés à des situations spécifiques où la logique de déroulement à

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
26
suivre est définie durant l‟exécution. Il forme une solution hybride
rassemblant des caractéristiques d‟administration, de production et de
collaboration. Ce type de processus gère des situations uniques ou
causées par des exceptions. Généralement, ce type de processus ne
possède pas de structure prédéfinie, l‟étape ultérieure à suivre est
déterminée essentiellement par les participants du processus. Par
exemple, si un coordinateur envoie une note d‟information aux membres
de son équipe, ces derniers ont le choix de faire ce qu‟ils veulent avec
cette note. Ils peuvent éventuellement la renvoyer à d‟autres personnes
qu‟elle peut intéresser (par exemple, par messagerie électronique, dans
les newsgroups, au sein d‟outils groupware, etc.).
Comme on peut le constater, ces différents types de processus
vont nécessiter des descriptions et modèles plus ou moins complexes . Ils
impliquent des stratégies de gestion adaptées mais aussi le recours à des
outils supports différents. Dans la suite, nous présentons rapidement les
stratégies de gestion de processus métier.
2.3.3 Gestion de processus métier
Le concept de processus métier est souvent associé au concept
de Gestion des processus métier (ou BPM: Business Process
Management). Le BPM consiste à modéliser des processus métier pour
donner une vision globale sur ces processus et de leurs interactions afin
de pouvoir les optimiser dans la mesure possible [12][35].
Dans le cadre du BPM, la gestion de processus métier comporte
essentiellement trois étapes: l‟identification des processus; la description
(modélisation) des processus en vue de leur mise en œuvre; le pilotage
du processus en vue de son amélioration.
- L‟identification des processus consiste à répertorier les
processus de l‟entreprise en distinguant les processus liés au cœur de
métier et les processus de support. Cette identification porte aussi sur la
nature du processus (processus manuels ou informatisables).
- La description (modélisation) des processus permet de
formaliser le processus avec des outils spécifiques de modélisation ou de
BPM. Deux approches complémentaires peuvent être appliquées :
approches descendante ou ascendante. L‟approche descendante part du

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
27
général vers le plus détaillé par raffinements successifs. Le processus est
d‟abord découpé en sous-processus et qui eux-mêmes sont découpés
progressivement en activités, tâches et actions. Une approche ascendante
part des parties de processus déjà modélisées, isolées comme des
composants pour reconstruire un processus global par assemblage de
composants de processus.
- Le pilotage des processus est le passage obligé de leur
amélioration. Il passe par la recherche de données pertinentes
d‟exécution des processus, leur enregistrement dans une base de données
et le calcul d‟indicateurs d‟analyse et de performance permettant
d‟apprécier leur pertinence.
- L‟orchestration des échanges interentreprises est une gestion
des flux de messages qui gère le protocole de la transaction électronique
entre les systèmes d‟information des entreprises impliquées.
- La gestion de processus métier permet d‟orchestrer les
interventions de personnes de l‟organisation et de logiciels du système
d‟information dans la réalisation d‟un processus métier complet de
l‟entreprise.
Ainsi, les activités de BPM concernent l‟ensemble du cycle de
vie d‟un processus métier, depuis son identification jusqu‟à son
exécution en passant par les activités de modélisation. Pour ce dernier
point, on peut recourir à une méthode « spécialisée processus » comme
ARIS que nous présentons dans la section suivante.
2.3.4 ARIS : une méthode de modélisation orientée processus
La méthode ARIS (Architecture of integrated Information
Systems) [16][41] est un framework pour le développement et
l‟optimisation des systèmes d‟information intégrés et permet de servir
de cadre pour la création, l‟analyse et l‟évaluation des processus de
gestion.
ARIS permet la description des processus métier et permet de
réduire leur complexité en les décomposant selon différentes vues
(fonction, données, organisation et contrôle voir figure 7) et trois
niveaux de modélisation (modèle conceptuel, modèle technique et
implémentation voir figure 8).
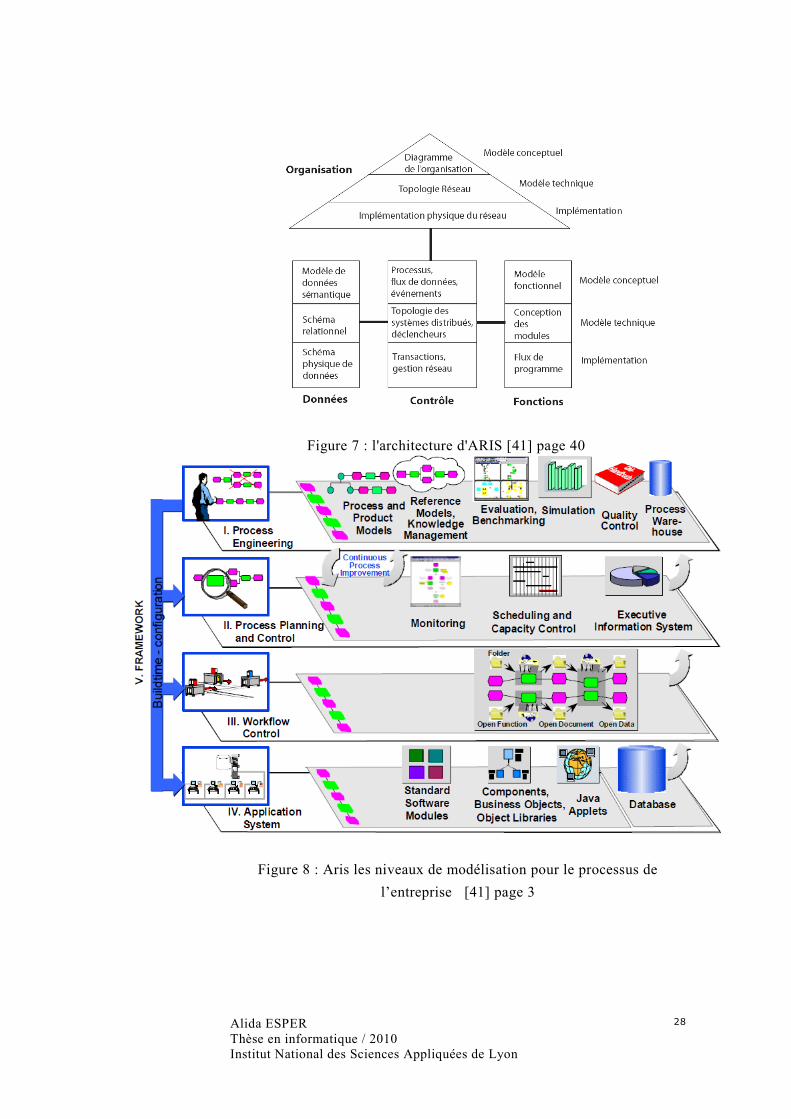
Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
28
Figure 7 : l'architecture d'ARIS [41] page 40
Figure 8 : Aris les niveaux de modélisation pour le processus de
l‟entreprise [41] page 3

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
29
Les différents niveaux peuvent être décrits comme suit :
- Niveau 1 : ingénierie du processus : Le processus
métier est modélisé selon le modèle organisationnel.
ARIS offre un cadre pour représenter tous les
aspects du processus métier, y Compris
l‟amélioration continue.
- Niveau 2 : planification et contrôle de processus. Le
processus métier est planifié et contrôlé selon les
méthodes d‟ordonnancements en prenant en compte
les contraintes de capacité et l‟analyse de coût.
- Niveau 3 : contrôle du Workflow. Les objets à
traiter sont transférés d‟un poste de travail au
suivant. Dans le cas où ces objets sont des
documents électroniques, les systèmes de gestion de
Workflow s‟occupent de ces transferts.
- Niveau 4 : systèmes d‟application. Les fonctions
impliquées dans un processus métier sont exécutées
via les systèmes d‟application, depuis les systèmes
d‟édition simples jusqu‟aux logiciels complexes
orientés objets de business.
Dans le cadre plus particulier des processus inter-entreprises, le
workflow représentant le processus commun est utilisé pour
interconnecter des processus propres à chaque entreprise associés à des
tâches à réaliser par l‟un ou l‟autre des partenaires. Cette interconnexion
pose un évident problème d‟organisation des communications et
échanges entre processus. Ce point est détaillé dans la section suivante.
2.3.5 Stratégies d’interconnexion de processus
L‟interconnexion des processus est un problème qui a été déjà
étudié depuis plusieurs années. L‟EDI (Electronic Data Interchange): est
défini comme un moyen d‟échange les données informatisées et les
documents commerciaux structurés entre différentes organisation [42].
L‟échange de données informatisées peut être utilisé pour transmettre de
manière dématérialisée des documents tels que des demandes d‟achat,
des avis d‟expédition et d‟autres types de correspondance commerciale
standardisée entre partenaire commerciaux. Il permet aussi de

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
30
transmettre des informations financières et des paiements sous forme
électronique.
Le standard principalement mis en œuvre dans le cadre de
l‟EDI est EDIFACT [43][44]. C‟est une norme de l‟UN/CEFACT
(Nations Unies) définissant les messages échangés dans les domaines du
commerce international, des achats, des transports, de la santé, etc.
Malgré les avantages liés à la dématérialisation, les
technologies traditionnelles d‟EDI sont considérées comme coûteux non
seulement dans le déroulement des échanges mais aussi pour ce qui
concerne les aspects de communication car ils recouraient fréquemment
à des Réseaux à Valeur Ajoutée (RVA “Value-Added Network VAN“).
Ceci a donc limité l‟adoption de cette solution, notamment par les
petites et moyennes entreprises.
Une stratégie plus légère consiste à construire de manière ad
hoc des modèles électroniques de collaboration permettant à différents
partenaires d‟interconnecter leurs processus. Pour cela, on peut utiliser
le langage XML (eXtensible Markup Language) [46] [47] pour définir
des échanges de documents structurés. Une solution basée sur XML est
moins difficile et moins coûteuse qu‟une solution EDI classique . XML
supporte, la structuration de données complexes en s‟appuyant sur des
principes simples et clairs qui sont :
La lisibilité à la fois par les machines et par les utilisateurs, la
définition sans ambiguïté du contenu et la structure d‟un document, la
séparation entre structure du document et présentation du document
constituent les principaux avantages de cette approche. Compte tenu de
son ouverture et des possibilités d‟extension de modèles, ce langage est
le standard le mieux standard adapté aux besoins actuels
d‟interopérabilité entre les processus d‟entreprise. Toutefois, si deux
processus utilisent XML, ils peuvent analyser les messages transmis,
mais cela n‟assure pas que le processus récepteur analyse correctement
les messages.
Ceci impose donc de revoir l‟organisation des processus et de
leur communication pour intégrer les contraintes de traitement sur les
données échangées dès la conception de ces processus. Ceci conduit de
facto à une multiplication des canaux de communication et introduit un
couplage fort entre les processus.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
31
De manière à permettre la communication entre applications et off rir un
couplage lâche, on peut utiliser un middleware (intergiciel) gérant
différentes interfaces. Les systèmes de type EAI (Entreprise Application
Integation) [45] offrent un ensemble de connecteurs permettant d‟éviter
l‟établissement de relations point à point spécifiques entre applications et
ainsi éviter le syndrome « spaghetti ».
D‟autres middleware sont orientés messages (Message Oriented
Middleware – MOM). Le message représente un contrat entre le serveur
qui gère le processus et le client invoquant les services du processus.
Ainsi, les interfaces des processus de l‟entreprise sont définies par ces
messages. L‟application cliente ne communique plus avec le serveur
mais directement avec le middleware. Ceci transforme donc le problème
d‟interconnexion entre processus en interconnexion du serveur et du
client avec le MOM. Ainsi, le client n‟a plus à gérer les informations du
module serveur (par exemple localisation, configuration, interface).
Il existe plusieurs plates-formes qui supportent cette stratégie
comme par exemple Microsoft MSMQ (Microsoft Message Queue
Server) ou le service d‟événement de CORBA (CORBA Event Service).
Une autre stratégie consiste à réorganiser le système
d‟information de l‟entreprise pour mettre en œuvre une architecture
orientée service. Outre un couplage lâche par échange de messages, ce
type d‟architecture présente également l‟avantage de séparer l‟interface
de l‟implémentation et offre plusieurs interfaces standardisées. Nous
détaillons cette approche dans la section 2.4.2.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
32
2.3.6 Conclusion
Comme nous l‟avons vu section 2.3, l‟organisation de
collaboration repose largement sur l‟organisation d‟un processus
commun. Ce processus collaboratif est organisé comme l‟interconnexion
des différents processus des entreprises partenaires. Cette stratégie
d‟analyse nous a conduit d‟abord à présenter la méthode ARIS, méthode
largement orientée processus avant d‟introduire les besoins de
communication entre processus. Si cette vision semble plus légère que
celle introduite par les stratégies de modélisation traditionnelles et
permet d‟aboutir plus rapidement à la génération d‟un système de
workflow support, le problème d‟interconnexion impose d‟utiliser une
stratégie de mise en œuvre recourant à des standards pour garantir
l‟interopérabilité technologique. Pour cela, les architectures orientées
services peuvent apporter une réponse.
2.4 Architecture orientée service : une réponse à l’interopérabilité
technologique
D‟après [48], un service peut être défini de la manière suivante:
“Services are autonomous platform-independent computational entities
that can be defined, published, discovered, selected, composed,
managed and programmed using XML artefacts for the purpose of
developing distributed interoperable applications“
Un service est un composant logiciel qui est représenté par
deux éléments séparés : son interface qui permet de définir les modalités
d‟accès au service (nom et paramètres des opérations publiques
définissant les signatures des opérations) et son implémentation. Les
éléments de l‟interface de chaque service sont : le nom du service, les
données d‟entrée et de sortie et les opérations. Les services sont
interconnectés via l‟échange de messages.
L‟ensemble des opérations associées à un service présente la
vue dynamique de ce service. Ces opération sont publié pour que être
retrouvée, composée puis invoquée.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
33
Chaque service peut être composé avec un autre service selon
une stratégie de composition séquentielle ou parallèle [49]. Dans une
logique de composition séquentielle, les services sont ordonnés et
présentés de manière séquentielle. Dans une logique de composition
parallèle, les services sont exécutés en parallèle
De manière plus spécifique, un Service Web est un système
logiciel identifié par une adresse URL, dont les interfaces publiques sont
définies et décrites à l'aide de XML. Sa définition peut être découverte
par d'autres systèmes logiciels. Ces systèmes peuvent alors interagir
avec le Service Web d‟une manière prescrite par sa définition, utilisant
les messages basé sur XML et transmis par les protocoles d'Internet [50]
page 7.
Le modèle d‟architecture à base de service Web se compose de
trois entités, le fournisseur de services, l‟annuaire de services et le
demandeur de services. La figure 9 représente une modèle de service
Web :
Figure 9 : modèle de Service Web [51] page 5
Le fournisseur de services crée ou offre simplement le service
Web. Le fournisseur de services doit décrire le Service Web dans un
format standard, qui est XML et publie cette description dans un
annuaire de services.
L‟annuaire de service contient des informations
supplémentaires sur le fournisseur de services, telles que l'adresse et des
détails techniques sur le service.
Le demandeur de service recherche l'information de l‟annuaire
et utilise la description de service obtenue pour se « lier » au service
(“Bind“) à et à invoquer le service Web.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
34
Les opérations de publication, recherche et liaison de services
permettent ainsi de supporter les communications entre applications
fonctionnant sur différentes plates-formes et écrites en différents
langages de programmation,
Le langage de description de service Web WSDL (Web
Services Description Language) utilise le format de XML pour décrire
les méthodes fournies par un Service Web. Cette description inclut aussi
les paramètres d'entrée et de sortie, les types de données et le protocole
de transport, qui est généralement HTTP. Le standard UDDI (Universal
Description Discovery and Integration ) permet de publier les services et
les informations concernant le fournisseur de service. Cet annuaire
représente une opportunité pour le demandeur de service pour trouver le
fournisseur de service et obtenir les détails sur le service Web.
Le protocole SOAP est utilisé pour l'échange de l'information
au format XML parmi les entités impliquées dans le modèle de service
Web.
Dans la suite de cette section nous présenterons les différents
standards permettant d‟atteindre un bon niveau d‟interopérabilité pour
les services.
2.4.1 Description de service
Afin de pouvoir interconnecter des services plusieurs formats
existent afin de décrire l‟interface de service (comme WSDL (Web
Service Definition Language)) ou de découvrir automatiquement un
service (comme OWL-S).
WSDL [52] est un format de description de l‟interface des services Web
basée sur XML. Le document WSDL définit les services comme des
collections de point finaux (points d‟entrée “endpoints“) de réseaux
aussi appelés “ports“. Via ces ports les services communiquent par
échange de message. Chaque port est associé à une liaison (binding)
spécifique.
C‟est la liaison (binding) qui détermine comment on peut naccéder à
l‟opération en utilisant un protocole de communication particulier
(SOAP, http, …).
Chaque opération est constituée d‟un ensemble de messages d‟entrée et
de sortie. Chaque message contient une ou plusieurs données définies

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
35
par des types. Une liaison (binding) établit une correspondance entre le
protocole utilisé pour communiquer, le port et l‟opération.
La description d‟un service web grâce à WSDL est montrée dans la
figure 10.
Figure 10 : La description d‟un service web grâce à WSDL [53] p86
Du fait du développement du web sémantique, un annuaire de
type UDDI ne suffit plus pour faire une sélection pertinente des
services. Pour cela, OWL-S (Web Ontology Language for Services) [54]
définit une ontologie de décrire les services en s‟appuyant sur le
framework OWL. Ce langage, standardisé par W3C est issu du
programme DAML-S du DARPA.
L‟initiative OWL-S issue du projet américain DARPA / DAML
vise à fournir une ontologie de service web basé sur OWL. Cette
description doit permettre d‟améliorer la découverte automatique de
services Web, leur invocation, composition… ainsi que la surveillance
de leur exécution.
Cette ontologie permet de fournir des informations sur l‟objet
du service et sur son fonctionnement. Pour ce qui concerne le premier
point, l‟accent est mis sur ce que fournit le service et ce qu‟il requière. Il
s‟agit majoritairement de son interface. Le deuxième point concerne le

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
36
comportement du service. Il se focalise sur la description des opérations
et des chemins possibles lors de l‟exécution.
Pour cela un service est défini selon 3 facette complémentaire
(service profile, service model et service grounding voir figure 11) que
nous détaillerons ci-après.
Figure 11 : Ontologie OWL-S
Le “ ServiceProfile“ fournit des informations sur un service qui peut
être utilisé par un agent pour déterminer si le service répond à ses
besoins, et s'il satisfait des contraintes telles que la sécurité, la localité,
l'accessibilité, etc.
Le profil d‟un service “ serviceProfiles “ se compose de trois types
d'information : une description du service et le fournisseur de services ;
le comportement fonctionnel du service; et plusieurs attributs
fonctionnels conçus pour l'automatisation de sélection.
Le profil inclut une description de haut niveau sur le service et son
fournisseur, qui typiquement serait présentée aux utilisateurs lors de la
navigation le registre de service.
Le ServiceModel permet à un agent : (1) d‟effectuer une analyse plus
détaillée pour savoir si le service répond à ses besoins ; (2) de composer
des descriptions de service pour exécuter une tâche spécifique ; (3) de
coordonner les activités des différents agents ; et (4) contrôler
l'exécution du service.
Les services sont accessibles au Web par des programmes ou
des périphériques. Leur opération est décrite en termes de modèle de
processus.
Les deux composants principaux du modèle de processus sont
“Process Ontology“ qui décrit un service en termes de ses entrées,
sorties, conditions antérieurs, effets, et “Process Control Ontology“ qui

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
37
décrit chaque processus en termes de son état, y compris l'activation,
l'exécution, et l'achèvement.
Le ServiceGrounding spécifie comment accéder aux détails de
service avec des formats de protocole et de message. Le
Servicegrounding présente comment invoquer le service. Dans DAML-
S, le ServiceProfile et le ServiceModel sont conçus comme des
représentations abstraites ; seulement le ServiceGrounding traite le
niveau concret de la spécification.
Dans la suite nous présenterons comment les services
échangent de messages grâce le protocole SOAP.
2.4.2 Communication entre service
SOAP (Simple Object Access Control) [53] [55] est un
protocole de communication et d‟échange de messages entre les Services
Web fondé sur XML. Le protocole SOAP permet d‟invoquer un objet
distance en communiquant les informations nécessaire à l‟appel (Nom
de la méthode et sa signature dans un message au format XML
communiqué via http). La réponse à la requête est aussi renvoyée
encapsulée au format XML.
Un message SOAP est une structure très simple qui comporte
une enveloppe (envelop) qui est la partie obligatoire du message et
contient le nom du message, l‟entête (header) est une partie optionnelle
utilisée lorsque le message doit être traité par plusieurs intermédiaires et
le corps du message. Le corps du message est une partie obligatoire et
peut contenir un ou plusieurs autres corps contenu dans le même
message. Il contient les données spécifiques à l‟application. Il permet
d‟échanger l‟information avec le destinataire final du message.
.
2.4.3 Publication de service
Universal Description Discovery and Integration (UDDI) est un
protocole qui permet non seulement la publication et l‟interrogation des
services Web mais aussi de découvrir des informations sur une
entreprise et ses services web. Le composant principal d‟UDDI est son
registre (figure 12. Il contient des documents XML où figurent des
informations sur les entreprises et les services publiés. L‟annuaire UDDI

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
38
facilite la localisation d‟un service web et l‟agrégation des services web
émanant d‟entreprises différentes.
Figure 12 : Mécanismes d‟accès aux services fournis par un UDDI
Registry [51] page 117.
UDDI encode de trois types d'informations sur les services Web :
1. Les pages blanches : elles comportent les informations sur les
entreprises et contiennent des informations sur le fournisseur de service
telles que le nom, les coordonnées (adresses), etc.
2. Les pages jaunes sont composées d‟informations permettant de
classifier l‟entreprise. Ces informations s‟appuient sur des standards de
classification industrielle normalisée.
3. Les pages vertes fournissent des informations techniques concernant
les services publiés. Ces pages contiennent des informations sur les
processus métier, des descriptions de service, et des informations de
liaison sur les services.
L‟UDDI comporte quatre structures de données définies sous forme de
schéma XML : BusinessEntity, businessService, bindingtemplate et
tmodel :
La structure BusinessEntity représente les informations sur
l‟entreprise qui offre les services dans l‟annuaire UDDI.
Le businessService inclut les informations relatives aux services
offerts par l‟entreprise.
BindingTemplate définit les informations concernant le lieu du
service, le point d‟entrées du service (URL) et comment accéder
au service (protocole d‟accès).
tModel : comprend l‟information concernant le mode d‟accès au
service.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
39
La figure 13 représente les principaux éléments et relations entre entités
du modèle d‟information UDDI sous forme de diagramme de classes
UML.
Figure 13 : Modèle structurel des données de UDDI Registry [51] page
119
Nous avons définit dans les sections précédentes que les services
communiquent en utilisant différent standards pour décrire leurs
interfaces et encoder leurs messages comme les protocoles SOAP,
UDDI, et WSDL pour réaliser l‟interconnexion. Ces standards utilisent
XML. Mais pour réaliser une interconnexion cohérente entre l‟ensemble
de services il faut bien définir l‟enchaînement des services selon un
canevas prédéfini afin de les composer dans un processus métier pour
répondre à des demandes qu‟un seul service ne peut pas la réaliser.
2.4.4 Description de la partie opérative des services
La prise en œuvre d‟un processus via des services web suppose non
seulement de pouvoir retrouver les services répondant aux besoins, les
composer dans une chaîne cohérente mais aussi de pouvoir définir
précisément le comportement de ces services. Comme nous l‟avons vu
précédemment, ces services interagissent en échangeant des messages

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
40
[Plusieurs standards proposent des langages permettant de décrire la
partie opérative des processus et des services [56].
Au niveau du processus, BPML (Business Process Markup language)
[57], il est destiné à la modélisation des processus métier. Il définit un
modèle formel pour l‟expression de processus exécutables ou abstraits
supports du processus métier.
BPEL (Buiness Process Execution Language) [58] est un standard à
permettre la description de l‟enchainement des actions pour réaliser un
processus en invoquant des entités comme des services. BPEL fournit
une sémantique riche qui permet d‟exprimer le comportement de
processus métier. Ce langage fait suite à des langages comme XLANG
ou WSFL développés par Microsoft ou IBM. WS-BPEL ou BPEL4WS
utilise donc un ensemble de balises pour définir l‟exécution de services.
Dans un scénario typique, le processus BPEL reçoit une requête puis il
invoque alors les services web impliqués et envoie la réponse au
demandeur. Les processus BPEL communiquent avec d‟autres services
web s‟appuient fortement sur la description WSDL.
BPEL introduit des extensions à WSDL qui permettent de spécifier
précisément dans le processus les relations entre plusieurs services web.
Ces relations sont appelées les liens vers des partenaires. La figure 14
montre ces connexions entre un processus BPEL et des services web
(liens vers des partenaires).
Figure 14 : La connexion entre un processus BPEL et des services [59]
page 74.
Tout processus BPEL précise l‟ordre exact dans lequel les services web
participants doivent être invoqués. Cette invocation peut être
séquentielle ou parallèle ou conditionnelle. L‟appel d‟un service peut

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
41
par exemple dépendre d‟une valeur provenant d‟une invocation
précédente.
Un processus BPEL est constitué d‟étapes. Chacune d‟elle est appelée
une activité. BPEL prend en charge les activités élémentaires et les
activités structurées. Les activités élémentaires sont utilisées pour
interagir avec une entité externe pour réaliser des tâches communes.
Les activités structurées gèrent le flot global du processus. Elles
indiquent quelle activité doit être exécutée et dans quel ordre.
XLANG est un langage qui a été créé par Microsoft pour l‟orchestration
de service Web [60]. XLANG est déjà implémenté dans le serveur
BizTalk. XLANG définit un langage de description du comportement
individuel d‟un service web qui participe à un processus métier. Il décrit
également comment combiner de tels services web pour produire un
processus métier multi participant Il s‟appuie sur la spécification WSDL
(figure 15) Etendant la description WSDL, XLANG s‟attache à prendre
en compte les fonctionnalités suivantes [60]:
La construction de flux de contrôle séquentiels et
parallèles,
Les transactions longues avec compensation,
La corrélation de messages,
La gestion des exceptions de traitement internes et
externes,
La référence de service dynamique,
WSFL est un langage également basé sur XML permettant de
décrire des orchestrations des services web. Proposé par IBM, WSFL
définit deux formes d‟orchestration de services web [59][61]. Le
premier décrit les processus d‟entreprise comme des chorégraphies des
services web comme XLANG, le second type définit les processus
métier en explicitant les relations producteur/consommateur de message
entre les différents services web constituant le processus global.
Pour illustrer le premier style de composition (processus métier ou
modèle de flux), nous proposons de prendre le cas d‟une entreprise
souhaitant mettre en place une application web pour le traitement de bon
de commande à l‟aide de services web externes et internes déjà
développés. Il s‟agit d‟identifier :

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
42
Les processus élémentaires (par exemple, la vérification du
crédit du donneur d‟ordre, le rejet d‟un bon de commande, le
traitement de la commande, l‟envoi des marchandises, etc.).
Les conditions d‟enchaînement des processus élémentaires,
qualifiées de règles métier dans la terminologie WSFL (tout
d‟abord, vérifier le crédit de l‟acheteur puis, suivant le résultat,
rejeter ou traiter la commande, puis envoyer les marchandises).
Le flot de données à chaque étape (prendre le bon de commande
comme paramètre d‟entrée et le passer à la procédure de rejet ou
de traitement, etc.).
Dans WSFL les étapes du processus sont appelées activités et sont
reliées par des liens de contrôle (passage explicite du contrôle d‟un
processus élémentaire à un autre) et des liens d‟information (passage de
données, avec transformation éventuelle, d‟un processus élémentaire à
un autre). On indique pour chaque activité l‟identité du service web
responsable de son exécution et les opérations à appeler grâce aux
éléments <Export> et <PlugLink>. Les activités sont exécutées sous la
responsabilité d‟un rôle qui les déroule dans un espace de travail
spécifique, appelé lane.
Figure 15 : Le document XLANG [59] page 251
2.4.5 Composition et orchestration de services
Lorsqu‟un service associé à un processus implique l‟interaction avec des
autre services (pour appeler leurs fonctionnalités), on parlera de service
composé ou composite. La composition de services permet de combiner

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
43
les fonctionnalités de plusieurs services dans un même processus métier
afin de répondre à des demandes complexes qu‟un seul service ne peut
pas réaliser. La composition nécessite les étapes suivantes :
Tout d‟abord il faut découvrir les services qui peuvent répondre aux
besoins de la composition. Cette opération de découverte se fait via les
annuaires. Il faut ensuite définir l‟ordre d‟invocation des différents
services et organiser l‟interaction entre les services qu‟on veut
composer : il s‟agit alors d‟orchestration et de chorégraphie [66].
L‟orchestration organise a priori les interactions entre plusieurs services
et organise à l‟avance la gestion des échanges de messages, condition
d‟activation… La chorégraphie quant à elle est réalisée « au fil de
l‟eau » et ne concerne donc qu‟un seul service.
Si on s‟intéresse maintenant au contrôle de l‟exécution, il faut prendre
en compte à la faut la spécification des conditions de coordination et de
gestion de transactions.
La coordination de séquences d'opérations est nécessaire pour assurer
l'exactitude et la cohérence. Pour cela, de nouveaux protocoles et
abstractions sont nécessaires. Afin de fournir des abstractions de
modélisation et de simplifier le développement de services Web,
différents efforts de standardisation ont été menés aboutissant par
exemple à la proposition de WS-Coordination [62] par IBM.
WS-Coordination décrivent un framework pour coordination de service
qui se compose de(figure 16):
Un service d'activation comportant une opération qui permet à
une application de créer un contexte de coordination.
Un service d'enregistrement comportant une opération qui
permet à une application d‟enregistre aux protocoles de
coordination.
un ensemble de protocoles de coordination.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
44
Figure 16 : Le model de coordination [53] page 4
Les applications utilisent le service d'activation pour créer le
contexte de coordination pour une activité. Une fois qu'un contexte de
coordination est défni par une application, il peut alors envoyé par tout
moyen à une autre application. Le contexte contient l' information
nécessaire pour s'enregistrer dans l'activité et spécifier le comportement
de coordination que l'application suivra.
Une application qui reçoit un contexte de coordination peut
utiliser le service d'enregistrement de l'application originale ou peut en
utiliser un qui est spécifié par un intermédiaire. De cette manière une
collection arbitraire de services Web peut coordonner leurs opérations
conjointement.
Outre les problèmes de coordination, l‟exécution d‟un service
composite peut nécessiter un temps long et des échecs peuvent survenir
lors de l‟exécution de certains services. Ceci conduit donc à devoir
annuler tout le processus. Pour cela, on peut s‟intéresser aux travaux
menés dans le domaine de la gestion de transaction. Une transaction est
un groupe d'opérations logiques qui doivent toutes réussir ou échouer
[63]. On peut dire qu‟une transaction est une séquence d‟opérations qui
permet de passer d‟un état stable à un autre état stable.
Les spécifications de Transaction de service se séparent en
deux parties les transactions atomiques (Atomic Transaction (AT)) et les
Activités métier (Business Activity (BA)).
Une transaction atomique est une transaction qui remplit les
propriétés ACID [64] [65] (Atomicité, Cohérence, Isolation, Durabilité)
qui sont utilisées pour coordonner les activités de courte durée. La
transaction atomique aussi garantit que tous les participants confirment
ou annulent la transaction dans une logique de type "tout ou rien". Une
transaction atomique est terminée soit dans l‟état "commit" (transaction

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
45
validée) soit dans l‟état "avort" (transaction annulée). Dans le cas d‟une
transaction validée, toutes les modifications liées à son exécution
deviennent durables. En revanche quand la transaction est avortée,
toutes les modifications amenées par son exécution doivent être
annulées.
Une activité métier est utilisée pour coordonner les activités de
longue durée. Des transactions de compensation sont utilisées dans cette
activité pour garantir la cohérence et remettre le système dans l‟état
stable initial si un utilisateur décide a posteriori d‟annuler une
transaction (par exemple un utilisateur commande un bien par internet
puis annule ultérieurement sa commande : il faut alors faire un
mécanisme de rollback pour annuler le payement). Cette nouvelle
transaction appelée transaction de compensation « compense » les effets
de la transaction originale. Il faut donc en prévoir la spécification lors de
la conception d‟un processus métier.
2.4.6 Conclusion
L‟approche orientée service présente plusieurs avantages dans le cadre
de l‟organisation d‟un processus collaboratif :
- La possibilité de publication de services permet
de diffuser largement une interface des
processus privés de l‟entreprise qui pourront
ensuite être « composés » dans une chaîne de
services correspondant au processus commun
- Le processus de sélection / composition permet
quant à lui d‟organiser rapidement une chaîne
de services répondant aux besoins exprimés
- L‟utilisation de standards permet d‟obtenir des
systèmes interopérables nativement
Toutefois, ces services ne peuvent être contextualisés ce qui conduit à
une multiplication des services correspondant aux différents contextes
d‟exécution et donc à des risques d‟incohérence puisqu‟aucune relation
ne peut être définie entre services ni entre services et modèles de
processus.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
46
2.5 Démarches orientées objet
La programmation orientée objet a été introduite dans les
années 70. Il s‟agissait alors d‟identifier des objets du monde réel et leur
associer des briques logicielles. L‟objet encapsule données et traitement
associé et permet de modéliser plus simplement le monde réel en
identifiant des objets et les relations entre eux. Dans le contexte de
travail collaboratif inter-entreprises, cette approche qui embarque
simultanément les données et processus dans des objets et ne doit
présenter qu‟une interface pour rendre l‟objet utilisable pourrait
permettre de garantir une relative indépendance entre les parties
publiques et privées. En effet, puisque tous les accès transitent par une
interface publique, il devient donc possible de « masquer » les éléments
internes (et donc de garantir le respect de contraintes de confidentialité
dans le cas d‟un processus inter-entreprise interconnectant plusieurs
objets privés propres aux différentes entreprises).
Outre ce premier avantage, l‟approche objet présente aussi une
certaine similarité avec les méthodes de modélisation d‟entreprise. En
effet, il est possible de construire de nouveaux objets en utilisant les
mécanismes d‟héritage de manière similaire à la génération de modèles
particulier par instanciation de modèles génériques. La définition des
instances lors de la création est donc largement facilitée puisque une
grande partie des informations et méthodes pourront être héritées des
classes de niveau supérieur.
Ce sont ces éléments qui motivent notre recours à l‟approche
orientée objet. Dans une première sous-section nous présenterons
d‟abord les points clef de cette démarche avant d‟introduire quelques
méthodes de modélisation basée sur cette approche.
2.5.1 Concepts de base de l’approche objet
L‟approche objet propose de modéliser un ensemble d‟entités
du monde réel sous forme objets, c.à.d. sous formes d‟unités atomiques
unissant un état, un comportement et une identité [27][28]. L‟état d‟un
objet est représenté par l‟ensemble de ses attributs (ou propriétés), c'est -

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
47
à-dire l‟ensemble des informations qui caractérisent l‟objet. Le
comportement d‟un objet est défini via des méthodes (ou opérations). Ce
sont ces opérations qui permettent à l‟objet de communiquer avec
l‟extérieur (par exemple avec d‟autres objets. A ce titre, l‟opération
(décrite par son nom de méthode) est l‟un des paramètres des messages
échangé lorsque deux objets communiquent. L‟identité permet de
distinguer cet objet des les autres objets (exemple : l‟identité d‟un objet
voiture peut être donné par son numéro d‟immatriculation).
Un objet comporte donc à la fois une partie statique (associée à
son état) et une partie dynamique décrivant son comportement (via les
opérations). Plusieurs objets peuvent posséder une structure et un
comportement communs. Il est alors possible de regrouper ces objet
dans un modèle générale (la “classe“). On dit alors que l‟objet est une
instance de la classe. Chaque classe est définie par un ensemble
d‟attributs (appelés variable d‟objet) qui décrivent la structure des objets
associés à cette classe, et des opérations, appelées méthodes.
Les liens qui relient les objets correspondent à une relation
entre leur classe. On distingue trois familles de relations ayant des
sémantiques différentes :
- l‟association et l‟agrégation,
- la généralisation et spécialisation,
- l‟héritage.
L‟association est utilisée pour lier les classes appartenant à des
environnements similaires (exemple : lier un étudiant et son université,
la relation entre l‟étudiant et l‟université est une association) voir la
figure 17.
Figure 17 : exemple d'association
La relation d‟agrégation permet de rassembler les propriétés et
de construire des objets complexes à partir d‟autres objets, appelé objets
composants. L‟agrégation exprime un assemblage fort entre les objets.
L‟agrégation est une relation de type “partie de“ ou “composé de“ (c.à.d.
une relation composant/composé) voir la figure 18.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
48
Figure 18 : Exemple d'agrégation
La généralisation et la spécialisation sont exprimées sur les
hiérarchies de classes. La généralisation permet de regrouper des classes
qui ont les mêmes caractéristiques dans une classe plus générale [28]
(voir la figure 19). Inversement, la spécialisation permet de créer des
classes plus spécialisées à partir d‟une classe existante.
Figure 19 : exemple de généralisation
La relation d‟héritage permet la réutilisation de propriétés par
spécialisation de classes. La classe spécialisée est appelée sous -classe et
la classe qu‟on spécialisé est appelée superclasse [28]. Ces liens
d‟héritage permettent de transférer des propriétés (attributs et méthodes)
de la class mère (superclasse) vers sous-classes. Ce dernier point nous
intéresse particulièrement dans notre travail dans la mesure où il permet
de générer des objets plus « précis ».
Enfin, l‟encapsulation permet de masquer les détails de l‟objet
pour n‟en présenter qu‟une interface. Ceci permet de préserver
l‟intégrité de l‟objet en différenciant l‟interface (publique) et
l‟implémentation (invisible) [29]. Ainsi un objet et les données qui lui
sont associées ne peuvent être manipulées que par les méthodes
explicitement définies (et donc dont les noms et paramètres de ces
méthodes figurent dans la spécification d‟interface) lors de la création
de cet objet (voir figure 20). L‟encapsulation définit donc deux
représentations de l‟objet : niveau externe (publique) et le niveau interne
(partie privée). La spécification d‟interface (niveau externe) regroupe la
partie visible de l‟objet c.à.d. les données communes et les méthodes
publiques (noms et paramètres) c'est-à-dire les méthodes qui peuvent

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
49
être invoquées depuis l‟extérieur. En revanche, les données et méthodes
figurant dans la partie privée ne peuvent être accédées que par des
méthodes de ce même objet.
Dans notre cas de processus collaboratif, la démarche objet
permet de protéger efficacement les informations, savoir et savoir faire
organisationnels privés d‟une entreprise en ne les rendant invocable
qu‟au travers d‟une interface publique. Ceci justifie donc de privilégier
des méthodes de modélisation orientée objet dans notre cas.
Figure 20 : Schéma d‟un objet encapsulé
2.5.2 Définition des Objets métier (Business objects)
L‟objet métier est un concept utilisé pour représenter des
ensembles d'information du Système d'Information de l‟entreprise. Un
objet métier est définit selon [30] page 4 “ A business object captures
information about a real world (business) concept, operations on that
concept, constraints on those operations, and relationships between that
concept and other business concepts. The business concept can then be
transformed into a software design and implementation. A business
application can be specified in terms of interactions among a
configuration of implemented business objects. “
Ce concept de “business object“ permet donc de modéliser des
entités (les « choses » qui existent dans l‟entreprise, ce sera par exemple
la notion d‟employé) et les activités qui y sont associées [31]. Comme
pour un objet traditionnel, l‟état d‟un objet métier est déf ini par les
attributs de cet objet et son comportement est défini par les actions que
cet objet métier peut exécuter pour atteindre un but [32]. Enfin, la prise
en compte de relations de composition permet aussi définir
récursivement les objets métier à partir d‟un objet pivot (représentant le

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
50
concept principal) et des éléments complémentaires (objets métier de
plus bas niveau).
L‟organisation de relations entre les objets permet de modéliser
un système par agrégation de plusieurs objets. Les opérations
représentent la vue dynamique de l‟objet métier [31][36].
2.5.3 Méthodes de modélisation orientée objet
Notre contexte d‟étude étant lié à l‟organisation de processus
collaboratifs inter-entreprises et à la possibilité de générer les
composants associés, nous limiterons notre présentation à deux
méthodes, l‟une IEM orientée modélisation d‟entreprise et l‟autre UML
orientée informatique.
2.5.3.1 IEM
IEM (Integrated Enterprise Modelling) utilise la modélisation orientée
objet pour modéliser des processus d‟entreprise [33][37]. Les concepts
principaux utilisés par IEM sont l‟encapsulation des fonctions et des
données dans un objet, le concept de classe et le principe d‟héritage.
IEM représente les différents aspects d‟une entreprise manufacturière au
travers d‟un modèle unique composé de 8 vues. Les vues fonctionnelle
et informationnelle sont axées sur la représentation des processus de
l‟entreprise indépendamment des aspects technologiques induits. Les
aspects technologiques sont détaillés dans quatre vues : applicatifs,
stockage de données, réseaux et matériel. Enfin deux vues, personnel et
qualifications d‟une part et unité d‟organisation d‟autre part sont
affectées à la gestion des ressources humaines.
La vue informationnelle regroupe les objets de l‟entreprise. Les
objets sont structurés en trois classes de base, selon leur usage dans les
processus modélisés : les produits, les commandes et les ressources.
La vue fonctionnelle représente les traitements effectués sur les
objets dans le cadre du processus de production. Le concept de base
utilisé pour la modélisation des traitements est l‟activité. Une activité
transforme des objets au moyen de ressources sous l‟action de contrôles.
IEM définit un modèle générique d‟activité, représenté en figure 21.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
51
Figure 21 : le modèle général d'activité d'IEM
Une activité avec toutes ses entrées et sorties définies est
appelée activité complète. Si seules les entrées et sorties d‟objets sont
définies, on parle de fonction. Enfin, en l‟absence d‟entrées et de sorties,
on dit qu‟on a affaire à une action.
En dehors des vues fonctionnelle et informationnelle, à chaque
vue additionnelle est associés une classe qui est la racine de tous les
objets compris dans ces vues.
La modélisation des processus est réalisée selon les cinq
étapes traditionnelles :
L‟identification des objets.
L‟identification des fonctions manipulant ces objets.
L‟organisation des fonctions. Leur enchaînement est défini au
moyen “ d‟opérateurs de connexion “ qui sont la séquence,
l‟exécution en parallèle, l‟alternative, la jointure et la boucle.
La description de chaque fonction au moyen des objets affectés,
c'est-à-dire la définition des entrées et des sorties de chaque
fonction.
La décomposition des fonctions en sous-fonctions si le niveau de
détail du modèle le requiert.
2.5.3.2 UML
The Unified Modeling Language (UML) [34] propose un
ensemble de diagrammes permettant de représenter un système
informatique et son utilisation prévue dans l‟entreprise.
UML couvre les différentes étapes du développement d‟un
objet en offrant différent types de diagramme.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
52
Le diagramme de structure définit les concepts statiques (ex :
classe, attribut, opération, composants, package) qui sont nécessaires
pour les diagrammes de classes, de composants et de déploiement . Cette
partie comporte trois packages (Class, Composite Structure,
Components).
Le diagramme de classe représente la structure d‟une
application orientée objet en montrant les classes et les relations qui
s‟établissent entre elles. La représentation d‟une classe comporte trois
parties, à savoir (1) le nom de la classe et ses propriétés, (2) les attributs
et (3) les opérations. Plusieurs types de relations permettent de relier les
classes : la généralisation, l‟association et la dépendance comme indique
dans la figure 22. Ce diagramme permet de définir toute la structure
conceptuelle d‟une application et toutes les contraintes ou règles de
gestion. Dans ce diagramme l‟agrégation et la composition sont deux
précisions supplémentaires de l‟association (relation qui peut s‟établir
entre instances de classes) qui introduisent la notion de composition
comme le montre par exemple la figure 23.
Figure 22 : Représentation des relations entre classes [34] page 20.
Figure 23 : Exemple d'agrégation et de composition [34] page 21.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
53
Dans cet exemple on présente une relation d‟agrégation “ une
zone “ inclut plusieurs stations c-à-d qu‟elle est implicitement composée
de plusieurs stations.“ La relation de composition est une relation de
type agrégation mais comporte en plus une règle sur la gestion du
modèle. Dans l‟exemple présenté, “ un client possède obligatoirement
un compte et la suppression d‟un client entraîne implicitement la
suppression de son compte.
Le package de type « Composite Structure » contient plusieurs
sous-packages qui permettent de spécifier la structure interne d‟une
classe. Il décrit deux types de composition possibles : la collaboration et
la classe structurée. La figure 24 représente la collaboration dans un
diagramme de structure composite.
Figure 24 : Exemple d'une collaboration dans un diagramme de
structure composite [34] page 29
Ce diagramme montre comment est réalisée la collaboration en
définissant les rôles et les classes qui y participent. Les rôles sont reliés
entre eux par un connecteur qui représente tous les moyens qui permet à
deux objets de se connaître afin de s‟échanger de l‟information : passage
d‟une référence, communication par opération, définition d‟une variable
commune, etc.
Les collaborations servent à exprimer les rôles des classes dans
la réalisation d‟un patron de conception (design pattern) voir la figure
25.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
54
Figure 25 : Représentation d'un design pattern dans un diagramme de
structure composite [34] page 29
Le package « Components » inclut plusieurs modèles :
Le diagramme de cas d‟utilisation (Use-Cases) définit
les concepts qui permettent de spécifier les cas
d‟utilisation d‟une application. Un cas d‟utilisation
représente une séquence d‟interactions entre
l‟application et ses utilisateurs.
Le diagramme d‟état consiste à décrire l‟évolution d‟un
système. Cette évolution est définie par les états(les
états sont des conditions ou situation durant la vie d‟un
objet qui satisfont certaines conditions, réalisent
certaines activités et attendent certains événements.)
Le diagramme d‟activité est destiné à modéliser les
processus et les fonctions sans nécessairement recourir
au concept d‟état.
Les diagrammes d‟interaction décrivent principalement
des objets échangeant des messages. Il y a deux types
de diagrammes d‟interaction.
Le diagramme de séquence décrit les échanges
de message entre les objets.
Le diagramme de communication permet de
spécifier l‟ordre de séquencement, les messages
sont numérotés suivant une logique
hiérarchique.
UML présente plusieurs avantages pour modéliser un processus
collaboratif :
- Le diagramme des cas d‟utilisation permet de
décrire précisément l‟organisation du processus

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
55
collaboratif et les interactions entre les
différents partenaires
- Le diagramme de composants permet de
présenter plusieurs niveaux de description
permettant de séparer l‟interface (associée à un
processus public publié par l‟entreprise) de
l‟implémentation réelle (processus privé de
l‟entreprise)
- Le diagramme de classe permet quant à lui de
spécialiser progressivement les différents
éléments. Cette approche hiérarchique peut
permettre de regrouper des services
« contextualisés » dans une même classe afin de
bénéficier des mécanismes d‟héritage et une
meilleure réutilisation.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
56
2.5.4 Conclusion
L’approche objet offre un ensemble de concepts et méthodes de
modélisation pouvant apporter une réponse pour modéliser des
processus collaboratifs entre entreprises. En effet, l’encapsulation
permet de protéger raisonnablement le patrimoine propre de chaque
entreprise (données et processus traduisant son savoir-faire) tout en
offrant la nécessaire ouverture sur le système (via la spécification des
interfaces).
Les nombreuses facettes permettant de décrire un objet proposé
par la méthode UML permet également de bien couvrir la spécification
d’un processus collaboratif. Le cas d’usage permet aux partenaires de
décrire effectivement ce qu’ils prévoient de faire de manière
« ponctuelle ». Les autres diagrammes permettent ensuite de préciser le
« comment » et le « qui fait quoi et quand ».
Toutefois, modéliser ne peut suffire à mettre en œuvre un
processus de collaboration. Il importe d’une part de pouvoir transformer
les modèles en logiciel support de ce processus.
2.6 Des modèles au logiciel
L‟ingénierie dirigée par les modèles propose un environnement
permettant d‟organiser les différentes étapes de modélisation pour
aboutir à un logiciel de qualité. Cette démarche permet de bénéficier des
possibilités d‟abstraction des modèles et d‟augmenter les possibilités de
réutilisation. Parmi les initiatives mettant en œuvre cette démarche,
l‟OMG, a proposé l‟approche MDA pour permettre d‟accroître
l‟interopérabilité des applications en séparant clairement les
spécifications fonctionnelles d‟un système des spécifications de son
implémentation sur une plate-forme donnée [38][39]. Plusieurs niveaux
de modélisation sont définis dans la figure 26 :
Le niveau M0 (ou instance) : il définit les informations correspondant
aux objets du monde réel.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
57
Le niveauM1(ou modèle): il décrit les informations de M0. Les modèles
UML appartiennent au niveau M1. Les modèles M1 sont des instances
de M2.
Figure 26 : Les niveaux de modélisation
Le niveau M2 (ou méta modèle) est composé de langages de
spécification de modèles, tels que UML, profil UML qui permet
d‟étendre le méta modèle UML.
Le niveau M3 (ou méta-méta-modèle) : est le plus haut niveau
d‟abstraction pour une architecture de méta modélisation. Il comporte
une entité unique qui s‟appelle MOF et qui permet de décrire la
structure des méta-modèles.
La démarche proposée par MDA est la construction d‟un ou plusieurs
modèles indépendants des plates-formes (Platform Independent Model,
PIM) suivie de la transformation de ces modèles en modèles dépendants
des plates-formes (Platform Specific Model, PSM). Les différents
niveaux de modélisation permettent de gérer les connaissances
nécessaires à ces transformations.
L‟approche MDA comporte différents modèles qui sont présentés dans
la figure 27 ci-après.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
58
Figure 27 : Les catégories de modèles dans MDA.
Le modèle d‟exigences CIM (Computation Independent Model
ou modèle indépendant de la programmation) est aussi appelé modèle de
domaine. Il modélise les exigences du système. Un modèle d‟exigences
ne contient pas d‟information sur la réalisation de l‟application n i sur les
traitements ce qui justifie son appellation CIM. Il montre simplement le
système dans l‟environnement organisationnel dans lequel il va être
exécuté. La première étape à faire pendant la construction d‟une
nouvelle application est de spécifier les besoins du client. L‟objectif de
ce modèle est d‟aider à comprendre le problème et permet de représenter
ce que doit être fait par le système. Les exigences qui sont exprimées
dans le CIM doivent être transmises dans le PIM et le PSM [38]
[39][40].
Le modèle de description de plateforme PDM (Plateform Description
Model) contient les informations nécessaires sur la plateforme afin de
transformer des modèles PIM en modèles PSM puis en code adapté pour
une plateforme spécifique [39].
La construction du modèle d‟analyse et de conception abstraite PIM
(Platform Independent Model) est la première étape de la démarche
MDA. Un exemple de PIM est présenté dans la figure 28. Cette famille
de modèles décrit le système sans montrer les détails des plateformes.
Un modèle de cette famille (représenté par un diagramme UML)
représente par exemple les différentes entités fonctionnelles du système
ainsi que les connexions entre celles-ci. Ce type de modèle peut aussi
être décrit avec un langage de contrainte comme OCL (Object Contraint
Language) [40]. Cette indépendance de la plateforme permet d‟assurer
une interopérabilité fonctionnelle.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
59
Figure 28 : Exemple de PIM [40] page 8.
Le modèle de code ou de conception concrète PSM (plateforme
Specific model) est quant à lui dépendant des plates-formes techniques.
Les modèles de cette famille servent de base à la génération de code
exécutable vers les plates-formes techniques. Il existe plusieurs niveaux
de PSM. Le premier est obtenu directement à partir de modèle PIM. Il
est représenté par un schéma UML. Les autre niveaux de PSM sont
obtenus via la transformation jusqu'à l‟obtention du système exécutable
(obtention du code dans un langage spécifique (Java,C++, etc) comme
c‟est montré dans la figure 29 [40].
Figure 29 : Relation entre PIM et PSM en modélisation EJBexpanded
[40] page 9
Les transformations de modèles (voir figure 30) concernent à la
fois les transformations de modèles d‟exigences (CIM) en modèles
fonctionnels (PIM) puis de modèles fonctionnels en modèles
« technologiques » liés à la plateforme (PSM) puis en code [40]. Ces
transformations sont essentielles à la pérennité des modèles : elles
garantissent les liens de traçabilité entre les modèles et les besoins
exprimé par le client.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
60
La transformation de CIM vers PIM permet de construire des
modèles de type PIM partiels à partir des informations contenues dans
les modèles d‟exigences (CIM). L‟objectif est de s‟assurer que les
besoins exprimés dans les modèles d‟exigence (CIM) sont retranscrits
dans les PIM.
Les transformations de modèles PIM à PIM sont généralement
appliquées pour ajouter (ou enlever) des informations à des modèles. Par
exemple quand on passe de la phase d‟analyse à la phase de conception,
cette transformation permet de raffiner les modèles pour améliorer la
précision des informations qu‟ils contiennent. Ces transformations qui
comportent une grande part de connaissances ne sont pas généralement
automatisable.
Figure 30 : Etapes du processus MDA [40] page 6.
Les transformations de modèles fonctionnels (PIM) vers des modèles
spécifiques des plateformes utilisées (PSM) sont les plus importantes de
la démarche MDA car elles garantissent la pérennité des modèles. Pour
réaliser ces transformations vers des modèles intégrant les spécificités
des plateformes il faut enrichir le modèle initial (de type PIM) pour le
spécialiser vers une plate forme donnée. Cette opération consiste à
ajouter des informations liées à une plateforme technique pour pouvoir
enfin générer le code. Les principales plates formes PSM possible sont
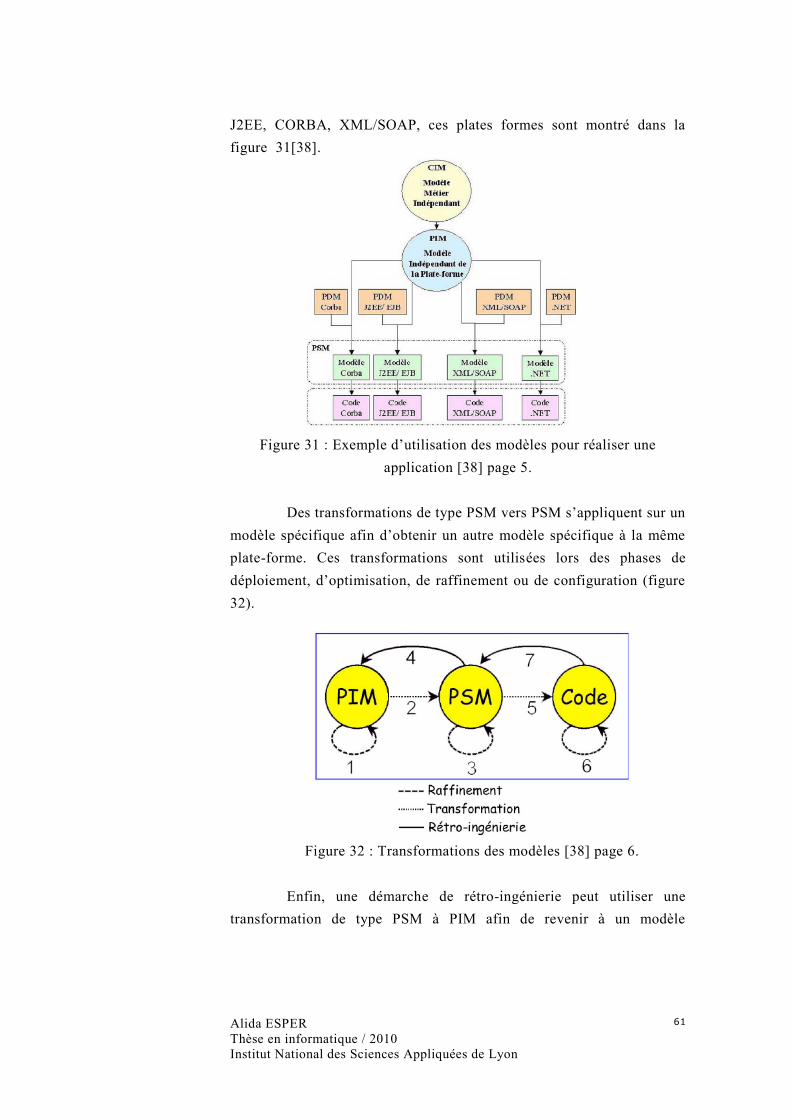
Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
61
J2EE, CORBA, XML/SOAP, ces plates formes sont montré dans la
figure 31[38].
Figure 31 : Exemple d‟utilisation des modèles pour réaliser une
application [38] page 5.
Des transformations de type PSM vers PSM s‟appliquent sur un
modèle spécifique afin d‟obtenir un autre modèle spécifique à la même
plate-forme. Ces transformations sont utilisées lors des phases de
déploiement, d‟optimisation, de raffinement ou de configuration (figure
32).
Figure 32 : Transformations des modèles [38] page 6.
Enfin, une démarche de rétro-ingénierie peut utiliser une
transformation de type PSM à PIM afin de revenir à un modèle

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
62
indépendant de plate forme(PIM) à partir d‟un modèle spécifique de
plate forme (PSM). Ce type de transformation complexe à réaliser et
plus difficile à automatiser.
Cette démarche dirigée par les modèles est très riche dans la
mesure où elle permet de prendre en compte les différents points de vue
de modélisation. Sa richesse constitue à la fois son principal atout et son
principal handicap pour le domaine qui nous concerne, à savoir la
collaboration entre entreprises. Nous identifions trois limites pour ce
contexte particulier. D‟une part la modélisation de collaboration entre
entreprise s‟appuie principalement sur une vision « processus » et ne
doit pas remettre en cause la totalité du système d‟information. D‟autre
part la complétude de ces démarches imposent une durée d‟ingénierie
d‟autant plus élevée que nombre de transformations ne sont pas
automatisables. Cette durée peut s‟avérer incompatible avec la durée de
vie du « projet de collaboration » (en d‟autres termes, il ne faudrait pas
que la mise à disposition de l‟environnement de collaboration soit plus
long que la collaboration elle-même). Enfin, sir la démarche de
transformation permet d‟organiser une certaine interopérabilité
applicative au niveau fonctionnelle, elle ne permet pas de définir une
réelle interopérabilité au niveau technologique.
2.7 Conclusion
L‟organisation de collaborations inter-entreprises (voire de co-
industrie) conduit à l‟émergence d‟entreprises virtuelles et fait
largement appel aux technologies de l‟information et de la
communication. Ces pratiques collaboratives sont limitées à la fois en
raison de la nécessaire modélisation et structuration des processus et des
contraintes technologiques liées aux systèmes d‟information
d‟entreprise, organisés en silo fonctionnels, et limitant la mise en place
des collaborations du fait de leur rigidité (ils ne répondent donc pas au
besoin d‟agilité) et de leur manque d‟ouverture (ce qui pose un problème
d‟interopérabilité).
La première limite, liée à la formalisation les processus de
collaboration et les informations échangées suppose que chaque
partenaire dispose de modèles permettant de décrire son activité et son

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
63
SI. Or les méthodes de modélisation traditionnelles sont souvent lourdes
et nécessitent une durée de projet incompatible avec l‟horizon court ou
moyen terme impliqué par une collaboration. Pour faciliter cette activité
d‟ingénierie, la plupart des méthodes proposent des architectures
permettant d‟utiliser un modèle générique puis de le particulariser. Cette
approche, assez similaire au processus d‟instanciation de l‟approche
objet, permet effectivement de simplifier l‟ingénierie en définissant des
« bonnes pratiques » mais ne permet pas de s‟adapter à l‟organisation de
l‟entreprise et aux changements de contexte : les modèles sont
particularisés dans une approche top-down et tout changement impose
de recommencer l‟activité d‟ingénierie. En outre, les méthodes de
modélisation d‟entreprise n‟interfèrent que peu avec les méthodes de
modélisation permettant la génération de code, introduisant ainsi une
dichotomie entre espace de business et espace technologique. De la
même manière, les processus de générations proposés dans la démarche
MDA sont aussi organisés de manière hiérarchisée dans une logique top-
down et ne permettent pas de « tisser » dynamiquement différents
modèles contextuels.
La deuxième limite que nous avons identifié concerne la
réponse technologique : outre les coûts liés à l‟infrastructure
informatique (matérielle et logicielle), les Systèmes d‟Information (SI)
d‟entreprise ne sont que peu agiles et ne prennent pas réellement en
compte les logiques de production. Les démarches d‟urbanisation et
l‟organisation d‟architectures orientées services, visant à rendre les SI
agiles, sont basées sur une organisation « métier » de l‟entreprise,
reflétant plus l‟organigramme (achat, production, relation client…), que
l‟organisation industrielle ce qui ne permet ni de pouvoir construire à la
demande des organisations de co-production efficientes ni de rendre le
système d‟information réellement adaptable (pour suivre de manière
continuelle les stratégies industrielles) et pervasif (pour s‟adapter aux
différents modes de suivi et de traçabilité de la production).. Si les
architectures à base de services assurent une interopérabilité
« syntaxique » et technologique, elles n‟apportent pas de réponse au
niveau organisationnel. En outre, elles ne permettent pas de gérer des
services contextualisés.
Pour pallier les limites, il faudrait pouvoir apporter la
flexibilité et l‟agilité des opérations de composition de service aux

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
64
stratégies de modélisation. Pour cela, nous proposons d‟étendre les
travaux de thèse de Sodki Chaari [69] réalisés dans notre équipe. Il
s‟agit de transformer l‟organisation traditionnelle de l‟entreprise en une
organisation « d‟entreprise orientée service ». Ainsi, une entreprise
pourrait publier ses offres de services comme base pour établir des
collaborations. L‟organisation d‟un processus collaboratif entre
entreprises reviendrait ainsi à sélectionner et « composer » les services
d‟entreprises pour former une chaîne répondant aux besoins du client
puis générer le support informatique correspondant à ce contexte de
collaboration.
Pour offrir le meilleur niveau d‟interopérabilité possible, nous
proposons de coupler plus étroitement les niveaux d‟affaire et
technologique : l‟expression des besoins du client permet de définir les
rôles et services qui devront être combinés pour former le processus
collaboratif correspondant. Une fois identifiés ces services d‟affaire, ils
sont composés dans une logique de processus et en fournissent donc un
modèle abstrait. Pour aboutir au modèle « concret » du système support,
il faut pouvoir transformer ces services abstraits en services
technologiques composés en prenant en compte les contraintes de
contexte. Pour cela, nous proposons de dépasser le simple cadre « top-
down » de l‟ingénierie dirigée par les modèles pour passer à une logique
de composition issue de l‟architecture orientée services d‟une part et de
l‟héritage purement hiérarchique de l‟approche objet d‟autre part pour
permettre de composer (ou « tisser ») des modèles selon le contexte et
être capable de propager ces contraintes contextuelles le long de la
chaîne de services. Pour ce faire, il importe de définir une organisation
non plus hiérarchique mais mixte en hypergraphe permettant d‟une part
d‟améliorer la génération de services particuliers en utilisant pleinement
les mécanismes d‟héritage et d‟autres part d‟utiliser les relations
« latérales » pour propager les contraintes de contextes et améliorer les
possibilité de substitution de services. Notons également que les
possibilités d‟encapsulation apportées par la structure d‟hypergraphe
peut permettre de masquer la complexité et le savoir-faire des processus
propres de l‟entreprise en n‟en publiant que la vision « publique », c'est-
à-dire le service de haut niveau.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
65
Dans le chapitre 3, nous présenterons globalement le principe
et l‟architecture retenue avant de détailler les différentes relations et
mécanismes de construction de l‟hypergraphe dans le chapitre 4.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
66
Chapitre 3
La collaboration des processus de
l’entreprise
3.1 Introduction
L‟organisation d‟un système de collaborations entre entreprise
suppose d‟abord une analyse de cette stratégie de collaboration : si dans
le passé les entreprises pouvaient opérer seules dans des environnements
relativement stables, les évolutions du marché (prise en compte de la
dimension produit service, customisation de masse, recherche de
réduction des coûts, globalisation,…) les conduisent à se recentrer sur
leur cœur de métier et à construire de plus en plus de relations de
collaborations plus ou moins durables avec des partenaires industriels.
Les défis principaux de cette stratégie de collaboration sont (1) la
sélection de partenaires industriels et / ou commerciaux appropriés, (2)
l‟organisation et la mise en œuvre de processus appropriés en réponse
aux besoins exprimés par les clients et ce avec des coûts de production
acceptables et (3) disposer des moyens informatique nécessaires pour
supporter ces fonctions de sélection et disposer rapidement des outils
supports nécessaires pour l‟exécution de ce processus commun. Le
premier défi suppose de pouvoir identifier les « services » proposés par
les partenaires potentiels de manière à pouvoir les sélectionner. Le
deuxième défi quant à lui impose une réorganisation des processus de
l‟entreprise à la fois pour améliorer la productivité mais aussi pour avoir
plus de souplesse et d‟agilité afin de répondre rapidement aux

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
67
changements de contextes liés au marché. Le troisième défi est quant à
lui lié au développement des TIC induisant une nouvelle stratégie
économique (économie numérique) et facilitant les échanges
dématérialisés d‟information. Cette possibilité de recourir à une
distribution des informations à large échelle a permis de faire émerger
des entreprises virtuelles, c‟est à dire des entreprises regroupant dans
une organisation collaboratives plusieurs partenaires partageant des
ressources et travaillant ensemble pour atteindre un objectif commun.
Le développement de ces stratégies de collaboration implique
souplesse et agilité des entreprises tant en ce qui concerne leur
organisation qu‟en ce qui concerne leur système d‟information. Ce
développement bénéficie largement du développement des TIC et des
technologies basées sur l‟Internet. En effet, le développement des
services et des technologies de services web permet aux entreprises de
pouvoir développer de manière plus rapide les supports informatiques
nécessaires au développement de leurs processus en combinant des
services mais cela pose d‟évidents problèmes d‟interopérabilité. Ainsi,
un processus collaboratif peut être développé en construisant une chaîne
de services intégrant des services offerts par différents fournisseurs à
condition de pouvoir sélectionner puis « interconnecter » ces services,
c'est-à-dire à condition que les entreprises publient ces services et
développent des interfaces standardisées (ce qui est le cas lorsqu‟on
utilise des technologies à base de services web). L‟enjeu principal est
alors la capacité de s‟organiser pour collaborer et de partager de
l'information entre les entreprises. Ceci pose alors le problème de
l‟interopérabilité, tant en ce qui concerne l‟organisation (ce qui impacte
l‟organisation et les conditions de travail) qu‟en ce qui concerne les
technologies utilisées dans le système d‟information support.
Pour répondre à ces exigences, nous nous focaliserons sur deux
dimensions importantes : l‟agilité du système d‟information d‟une part
et la construction de processus de collaboration d‟autre part. En effet,
les systèmes d‟information d‟entreprises étant constitués de nombreux
outils dédiés à des espaces métier particuliers (ERP, SCM, CRM…), il
existe une forte complexité technologique et chaque système est
relativement « figé » ce qui ne permet pas des (re)configurations
rapides. En outre, ces systèmes étant relativement « fermés » et les
formats d‟interfaces étant définis de manière spécifique (et souvent

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
68
incompatible), les échanges d‟informations (compréhensibles) entre
partenaires sont donc limités. Dépasser cette limite impose d‟obtenir un
niveau d‟interopérabilité suffisant. L‟interopérabilité dans l‟entreprise
est définie comme la capacité des systèmes d‟information et des
processus à supporter l‟échange des données et de permettre le partage
d‟information et des connaissances [67].
Depuis quelques années, de nombreux travaux ont porté sur
l‟interopérabilité, principalement pour ce qui concerne les applications.
De nombreuses approches dans ce domaine ont pour but l‟adaptation des
types et structures des paramètres d'appel quand un processus
d‟entreprise doit invoquer un autre processus. Ceci a par exemple
conduit au développement des architectures orientées services (SOA) [1]
en réponse aux problématiques d'interopérabilité entre les différents
systèmes qui implémentent les systèmes d'information des entreprises.
Si cette approche apporte une solution adaptée au problème
d‟interopérabilité dans l‟entreprise (donc interopérabilité entre les
différents systèmes « métier »), elle reste limitée par une vision « mono-
contexte » du service, ce qui ne correspond pas réellement aux besoins
d‟une collaboration inter-entreprises. En effet, un écosystème de
services inclut un environnement multi-contextuel d‟exécution de
services. Ainsi, l‟approche SOA impose de multiplier les services :
chaque entreprise doit fournir plusieurs services, chacun relié à un
contexte particulier, pour pouvoir intégrer convenablement les fonctions
selon des besoins propres à chaque contexte. Ceci augmente donc la
complexité du système et les risques d‟incohérence.
Pour s‟adapter au contexte de collaboration inter-entreprises, il
faut réorganiser l‟entreprise pour présenter une structure interopérable à
tous les niveaux, i.e. niveaux organisation, d‟affaires (métier) et,
technologiques :
o L‟interopérabilité du niveau organisation impose d‟adapter les
structures et les moyens d'organisation pour pouvoir
construire des organisations dynamiques capables de fournir
des réponses appropriées aux différents scénarios de
collaboration.
o L‟interopérabilité du niveau d‟affaire doit permettre la
construction de processus de collaboration (pour la fabrication
de produits ou de services) à partir des différents processus

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
69
appartenant aux différents partenaires. Les éléments
industriels doivent être décrits, publiés et rendus accessibles
par des plates-formes adaptées.
o Enfin, l‟interopérabilité du niveau technique concerne les
choix et moyens technologiques. Les entreprises doivent alors
analyser leur système d'information afin de les adapter aux
stratégies dynamiques de collaboration et faciliter
l‟interopérabilité.
Nos propositions pour améliorer l‟interopérabilité reposent sur
un modèle multi-vues (gestion, médiation et sécurité) pour réaliser une
bonne interconnexion entre les différents processus d‟entreprise. Comme
dans la thèse de Mlle Rajsiri (voir [76]), nous proposons que le
processus collaboratif soit conçu comme une chaîne de services. Ceci
impose donc que chaque entreprise publie les services, pouvant
intervenir dans un processus de collaboration, dans un répertoire propre.
Ainsi, le processus de conception du processus collaboratif repose donc
sur une sélection / composition. Comme dans [76], cet espace de
conception s‟apparente à un modèle de type CIM : les services sont alors
définis de manière abstraite et associé à des rôles. La transformation de
ce modèle CIM en PIM puis PSM impose de transformer ces services
abstraits en services concrets puis en services exécutables. Toutefois, à
la différence de [76], notre modèle vise d‟une part une génération
contextuelle des services et d‟autre part à faciliter la réutilisation, les
processus de sélection/composition en ajoutant différentes relations
entre les services d‟autres part.
Tout d‟abord, nous lions la transformation du service abstrait
en service concret au contexte (qui invoque le service, à partir de quel
mode d‟accès, quand, avec quels besoins en qualité de service et sous
quelles politiques de sécurité). Par exemple, un service abstrait d‟achat
en ligne peut être réutilisé par plusieurs processus avec un rôle
« Achat ». Selon le contexte d‟accès au service (accès par un client final,
un professionnel partenaire, un personnel de l‟entreprise) et
l‟infrastructure d‟accès utilisé (PC et réseau privé, accès via internet,
accès par téléphone portable…) différentes politiques de sécurité et
différents services concrets (gérant des interface utilisateur spécialisées )
pourront être déployés.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
70
Ensuite, de manière à assurer la cohérence des services générés
(modèles d‟interface, règles opératoires communes…) selon le contexte,
nous avons choisi d‟encapsuler des services dans des objets pour utiliser
pleinement le mécanisme d‟héritage (ce qui assure la cohérence entre les
objets et facilite les opérations de mise à jour).
Enfin, la structure du registre est enrichie par différents types
de relations :
- La relation d‟agrégation permet de définir des
services comme englobant un chaîne de services
élémentaire ce qui permet de gérer simplment
plusieurs niveaux de détail dans la spécification
des services et augmente les possibilités de
réutilisation
- La relation de similarité permet de définir des
équivalences entre les services ce qui accélère
notablement la sélection d‟un service adapté au
moment de l‟exécution (sous réserve de
disposer d‟un système de « late binding »
adapté) ce qui est très important dans une
logique de passage à l‟échelle (problème de
scalabilité)
- La relation de collaboration permet de disposer
d‟informations objectives sur les collaborations
précédentes pour sélection le(s) bon(s)
partenaire(s)
- La relation de recommandation permet enfin
d‟assister l‟utilisateur dans la conception de la
chaîne de service en indiquant quels autres
services ont pu être utilisés conjointement.
Ces relations et différentes descriptions permettent de sélectionner
les services en fonction des besoins et de construire le processus commun
comme une chaîne de services abstraits comme illustré dans la Figure33.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
71
F
i
g
u
re 33 : Comparaison entre processus collaboratifs traditionnels et multi -
contextuels
L‟intégration des différentes vues permet de « superposer »
différents éléments de contexte et, grâce à un « arbre d‟héritage », de
contexualiser le service abstrait et donc aboutir à un service et un
processus concrets. Pour cela, on intègre les contraintes de médiation
entre les services (issues de la vue médiation) et les éléments de sécurité
(déduit des politiques de sécurité exprimées dans la vue sécurité). Pour
répondre à la contrainte de dynamicité, nous proposons que ces politiques
soient exprimées dans une logique ECA (Event, Condition, Action) :
l‟action est effectuée quand un événement donné se produit et que la
condition est satisfaite.
Pour prendre en compte ces différentes dimensions et permettre
des héritages multiples, notre modèle est basé sur un hypergraphe
permettant d‟introduire différentes stratégies d‟héritage et de multiples
niveaux de description.
Dans ce chapitre, nous présentons d‟abord l‟architecture
globale avant de détailler les différentes vues et le processus de
transformation avant de présenter le principe de construction d‟un
Vue Médiation
Vue Gestion
Vue Médiation
Processus à base de services concrets
Contexte
Processus à base de services abstraits multi-contextuels
VS

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
72
processus collaboratif. Le fonctionnement de l‟hypergraphe et son
utilisation pour une orchestration cohérente seront quant à eux détaillés
dans le chapitre suivant.
3.2 Architecture globale
Notre architecture propose un modèle destiné à supporter la
collaboration en sélectionnant les services nécessaires pour construire le
processus collaboratif. Ce modèle repose sur les concepts suivants
comme illustrés en Figure 34.
Figure 34 : Les concepts de base d‟une collaboration contextualisée
1. Le service abstrait : ce service fournit une description abstraite
d‟une activité métier sans une description technique de son
implémentation et son invocation. Il manipule les objets métiers
passés comme des entrées et aide les partenaires à se concentrer
sur la conception de processus de collaboration sans maitrise
technique des services concrets.
2. Le service concret : est un service informatique qui implémente
un service abstrait en respectant un modèle architectural
(Service Web, DCOM, composant CORBA, etc.) et un langage
de programmation (Java, C#, etc.). Dans notre approche les
services concrets respectent la propriété du couplage lâche pour
faciliter la réutilisation mais ils sont reliés par des relations
sémantiques qui permettent de contextualiser l‟exécution
(relation d‟héritage), faciliter la propagation des contraintes
(relation d‟agrégation) et enrichir la robustesse et disponibilité
(relation de similarité et relation de substitution).
Service Abstrait Services concrets Répertoire local Répertoire public
Répertoire partagé de processus
collaboratifs communs

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
73
3. Le répertoire local de services concrets : ce répertoire contient
les services concrets et maintient les relations entre services. Il
est interne à l‟entreprise et n‟est pas partagé avec les
partenaires.
4. Le répertoire public de services abstraits : ce répertoire
contient les services abstraits qu‟une entreprise souhaite
partager avec ses partenaires. Les services abstraits pointent sur
des services concrets interconnectés par les relations entre
services (graphes de services). Il contient également les objets
métiers manipulés par ces services abstraits. C‟est au moment de
l‟exécution,
5. Le répertoire de processus collaboratifs communs : le
processus collaboratif est conçu conjointement par les
partenaires à partir de leurs services abstraits. Ce processus est
vu comme une chaîne de services dont les informations
contextuelles se propagent. Il est similaire à un patron
(template) qui représente d'une manière abstraite les descriptions
des services à sélectionner au moment de l‟exécution en tenant
de compte des informations contextuelles et en s‟appuyant sur
les différentes vues (gestion, médiation et sécurité).
En général, nous considérons le service comme un objet
représenté par son interface qui permet de donner accès au service
abstrait. Les éléments associés à l‟interface d‟un service sont le nom du
service, les paramètres en entrée et sorties et les opérations. Seules les
noms, paramètres et opérations publiques sont présentées dans le
répertoire destiné à la collaboration (ce qui permet de préserver les
visions processus public et processus privé). Le service abstrait
représente l‟interface publique publiée par l‟entreprise : ceci permet de
masquer les implantations réelles et donc respecte la séparation publique
/ privée. Chaque service abstrait est ensuite lié aux services concrets qui
représentent des instances de services « concrets » qui seront
effectivement exécutés. La sélection du service concret est faite au
moment de l‟exécution. L‟interconnexion entre les services offre une
possibilité de couplage lâche qui repose sur l‟échange de messages.
Le répertoire public, propre à chaque entreprise, permet de
lister les services qu‟elle désire exposer. Ce répertoire permet de

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
74
présenter les services abstraits et leur interface. Notons que la
description des échanges entre les services est prise en compte en
associant les messages à la description des services (messages en entrée
et en sortie).
Lorsque plusieurs entreprises veulent collaborer, elles créent un
répertoire commun intégrant les différents services proposés par les
partenaires. Au cours du temps, d‟autres entreprises peuvent rejoindre ce
groupe et publier également leurs services dans ce répertoire commun.
Ceci permet d‟organiser des communautés de collaboration (breeding
virtual organisation) [68]).
Ensuite on peut créer un processus de collaboration (associé à
un répertoire commun) qui comporte les services qui venant de
différents partenaires. Dans ce répertoire au lieu de présenter les
services comme une liste, des relations d‟agrégation, de similarité…
détaillées dans le chapitre suivant permettent de compléter une stratégie
d‟héritage et de composition pour créer le processus commun . Ceci
représente le concept clef de notre architecture. Ce processus commun
permet de matérialiser les « opérations » nécessaires pour la réalisation
de la collaboration et atteindre l‟objectif fixé.
Le processus de collaboration est un concept clef de notre
architecture. Ce processus est construit pour répondre à une demande
spécifique et suppose que les entreprises partenaires soient d‟accord
pour collaborer et donc créer le processus abstrait. Ce processus est
constitué par assemblage de services abstraits qui viennent de différents
partenaires. Ces services sont associés à des rôles ce qui permet de
préciser la responsabilité de chaque partenaire dans l‟organisat ion du
processus commun. Ce processus est défini par un ensemble de vues :
gestion, médiation et sécurité, qui permettent de définir son contexte, dit
contexte global. De la même manière, nous proposons d‟associer ces
vues aux services abstraits constituant le processus ce qui permet de
décrire leur contexte propre. Par composition, ces différents contextes
permettent de construire le contexte global du processus commun.
La Figure 35 présente le contexte du processus collaboratif en
citant succinctement quelques éléments associés à ces vues.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
75
La vue de gestion permet de gérer le service abstrait. Un
ensemble de règles logiques est défini pour gérer les communications
entre services et la collaboration entre participants en permettant ensuite
de contextualiser le service.
Figure 35 : Description du contexte permettant une sélection et exécution
multi-contextuelles de services
Comme nous l‟avons déjà dit, ces services abstraits ne sont pas
associés à une implantation effective mais définissent l‟interface
publique d‟un service concret (entrées, sorties…), ce qui permet de
préserver la confidentialité sur les processus privés des entreprises. De
la sorte, un service abstrait peut être implémenté de manière « variable »
selon le contexte en masquant le processus « concret » effectivement
réalisé par chaque partenaire.
Processus collaboratif
Information Contextuelle
Vue Gestion
Qualité de service
- quantitatifs
- qualitatif
Préférences
Objets métiers
Règles métiers
Vue Sécurité
Authentification
Autorisation
Chiffrement
Certificat
Rôles
.
Vue Médiation
Appariement
- entrées
- sorties
Adaptation
- messages
- objets métiers

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
76
Figure 36 : Génération du processus concret en choisissant les services concrets
convenables
La vue de médiation permet transformer de le processus abstrait
en processus concret (ou d‟affaire). Pour chaque service abstrait il faut
trouver au moins un service concret en tenant en compte les
informations contextuelles au moment du déploiement. Au fur et à
mesure que le processus s‟exécute, le choix de chaque service concret
est révisé si les informations contextuelles sont changées. La sélection
est réalisé à partir du répertoire local de chaque entreprise : une requête
où figure les entrées et sorties nécessaires pour chaque service abstra it
est construite ce qui permet d‟extraire les services concrets
correspondants. Par ce biais, on peut composer dynamiquement une
chaîne de services concrets associés au processus de collaboration. La
Figure 36 illustre brièvement la génération du processus concret.
Chaque service abstrait dans le répertoire public est associé aux services
concrets qui les implémentent. C‟est la médiation qui trouve le service
convenable parmi les services concrets « candidats » en tenant compte
du contexte.
Figure 37 : Vue d‟agrégation du processus permettant la propagation des
informations
Les services concrets candidats
Médiation
Processus abstrait Processus concret
contexte

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
77
Enfin, la vue de sécurité permet d‟intégrer les contraintes de
sécurité dans la chaîne de services. Pour cela, chaque service concret
hérite d‟une politique de sécurité correspondant au contexte (rôle joué par
ce service, qui invoque ce service). Ceci permet d‟améliorer la gestion des
droits d‟accès en définissant globalement des politiques cohérentes
sélectionnées en fonction du contexte. La Figure 37 illustre comment un
processus collaboratif peut être représenté par la relation d‟agrégation
(top-down) qui relie ses services abstraits. Cette vue hiérarchisée permet
également de définir les informations contextuelles qui doivent se
propager moment de l‟exécution dans la chaine de services. A ce niveau, il
est possible de vérifier si les contraintes de sécurité, par exemple, peuvent
être s‟appliquées de bout en bout et si le médiateur devrait intervenir pour
assurer les transitions/transformations entre les contraintes à respecter par
chaque service. Dans la Figure 37 le rôle associé au processus est
„salesman‟ tandis que le rôle associé au service „S22‟ est „online
salesman‟. La médiation vérifie si le rôle „online salesman‟ peut avoir les
mêmes droits que le rôle „salesman‟ et elle assure ensuite la transition au
cours de l‟exécution.
Ces vues, qui seront détaillées dans la section suivante, sont
assemblées dans un Méta-Modèle d'entreprise (EMMA “Enterprise
Meta-Model Architecture“) pour permettre de générer des services
« contextualisés ». L‟architecture globale de notre approche est
présentée par la Figure 38. Elle présente deux répertoires publics de
deux entreprises (E1 et E2) qui contiennent respectivement leurs
services abstraits. Le répertoire partagé contient les processus
collaboratifs communs sous forme d‟hypergraphe conjointement conçus
par E1 et E2, et qui sont reliés aux services abstraits. Le médiateur qui
génère les objets contextes en tenant compte des trois vues, les rôles, et
les services abstraits.
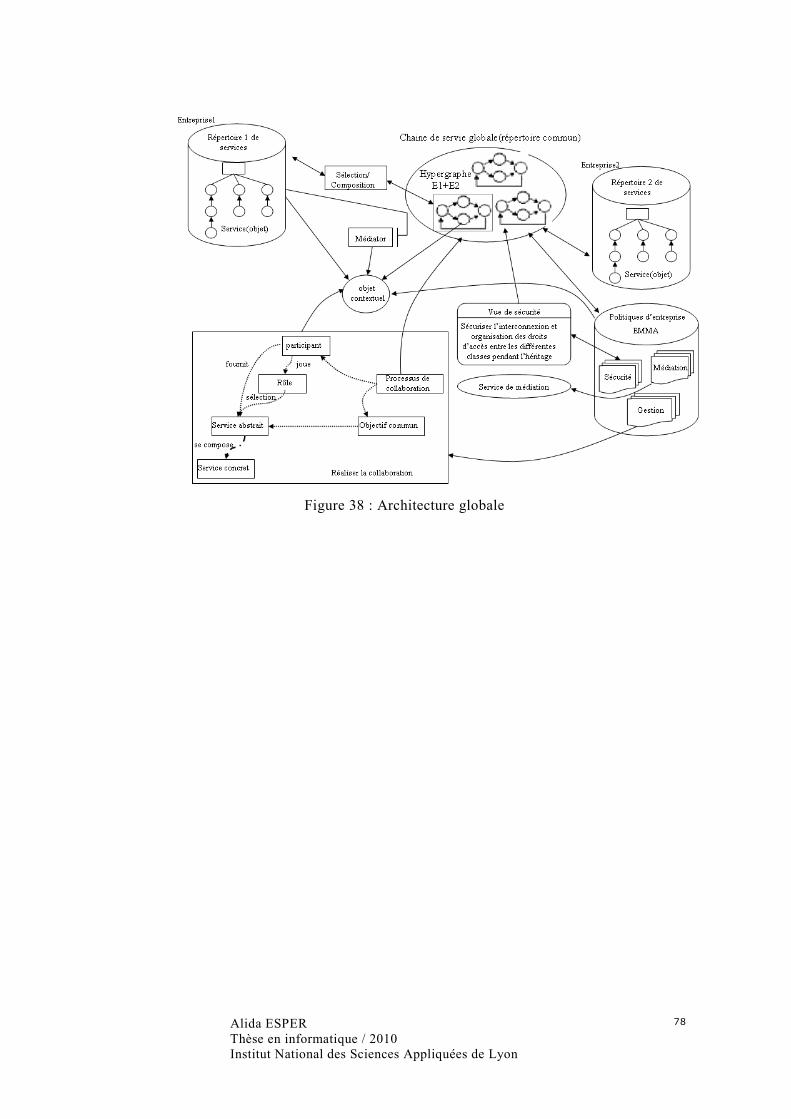
Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
78
Figure 38 : Architecture globale

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
79
3.3 Spécification des différentes vues
3.3.1 La vue de gestion
Cette vue est destinée à supporter la première étape de sélection des
services pour construire un processus de collaboration puis d‟intégrer
leur spécification d‟interface pour composer une chaîne de services
cohérents, comme nous l‟avons vu dans la modélisation d‟entreprise,
nous proposons un logique d‟héritage pour permettre la définition de
services “particuliers“ instanciés à partir de modèles générique. Il faudra
définir d‟autres relations et règles de propagation car le seul mécanisme
d‟héritage seulement ne peut pas permettre la propagation des éléments
liés au contexte sur la chaîne de service qui représente le processus.
Dans la suite de cette section, nous présentons notre modèle de service
abstrait construit à partir d‟un modèle de collaboration défini ci -après.
Notre modèle de collaboration regroupe plusieurs participants
(donc plusieurs entreprises) désirant atteindre un objectif commun via la
collaboration. Un rôle définit la responsabilité d'un participant dans
l‟organisation du processus commun (par exemple dans l‟organisation
d‟une collaboration supportant une chaîne logistique, on trouvera des
rôles de vente, achat, production). Pour chaque rôle, on associe des
services abstraits qui permettent de remplir le cahier des charges fixé.
Un service abstrait est donc associé aux compétences liées au rôle. Ce
service peut aussi être associé à plusieurs services concrets qui décrivent
comment ce service abstrait sera mis en œuvre. Par exemple pour un
service de production (d‟un bien ou service), on pourra associer la
gestion de l‟approvisionnement, la production et la gestion des
expéditions). Cette modélisation réutilise pleinement les travaux de Mlle
Rajsiri [76] qui propose une ontologie CNO (collaborative network
ontology) qui couvre à la fois la collaboration d'interentreprises et les
domaines de collaboration des processus. Cette ontologie se compose
des concepts, relations et des règles de déduction propres au domaine de
l‟entreprise. Elle permet de représenter les comportements collaboratifs
entre les partenaires. Cette ontologie fédère plusieurs sous-ontologies, à
savoir :
- l'ontologie de collaboration (CO) est organisée en deux
parties principales : le participant et la collaboration.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
80
I) Le participant comprend trois concepts : le participant qui
peut être un acteur physique ou une entreprise qui utilise le réseau pour
atteindre un objectif commun avec d'autres participants, le rôle qui
définit le rôle d'un participant dans le réseau. Par exemple : vendeur,
acheteur et le service abstrait qui est un service qui décrit les
compétences du participant.
2) La partie de collaboration concerne les critères de
caractérisation de la collaboration : un objectif commun, participant,
relation.
- L'Ontologie de processus de collaboration CPO se réfère à la
conceptualisation d'un processus de collaboration.
Comme dans ce travail, le processus de transformation du
modèle CIM en modèle PIM puis PSM passe par un remplacement des
services abstraits par des services concrets (dits services de Business
dans les travaux de Mlle Rajsiri). Comme nous l‟avons dit dans la
présentation de notre architecture, nous enrichissons l‟approche de Mlle
Rajsiri en intégrant le contexte (cad qui invoque quel service, dans
quelles conditions en utilisant quels moyens d‟accès et avec quelles
exigences de qualité de service) dans le processus de recherche des
services concrets substituables aux services abstraits. Ceci nous conduit
donc à coupler la notion de contexte aux services abstraits.
La Figure 39 illustre les relations entre ces concepts.
Figure 39 : Relations entre le participant, le rôle, et le service abstrait
Un processus de collaboration est associé à un groupe d‟au
moins deux participants qui voudraient travailler ensemble en réponse à
un ou plusieurs objectifs communs. Une relation définit l'interaction
entre les participants comme par exemple une relation client/fournisseur,
une relation de type donneur d‟ordre / sous-traitance. Ces relations

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
81
permettent d‟intégrer le type de collaboration dans la spécification du
contexte global (Figure 40). La juxtaposition de ce contexte de
collaboration à la définition du service abstrait permet de construire le
modèle global (Figure 41).
Figure 40 : les relations entre les concepts dans le processus de collaboration.
Figure 41 : les éléments de modèle de collaboration (génération le service)
A partir de ce modèle, nous avons défini des règles logiques
destinées à représenter le service : une première permet de sélectionner
les services abstraits associés à des rôles alors qu‟une autre règle permet
de retrouver les services d‟affaire (donc les services concrets)
correspondant au contexte.
1) Sélection des services abstraits à partir du rôle : Cette
première règle de sélection des services abstraits repose d‟abord sur
l‟identification des rôles associés au participant pour ensuite extraire les
services abstraits pouvant être invoqué avec ces rôles. Si la liste de
services sélectionnés en fonction du rôle et du contexte n‟est pas vide,

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
82
la règle retourne le premier service de la liste. Ceci nous conduit à la
formalisation suivante :
Partner(x) HasRole(x, y) ListOfAbstractServicesByRole (y, z) Context(v)
SelectContextuelAbstractService(x, y, z, v).
La partie B de la Figure 42 montre comment la règle ci-dessus
fonctionne à partir d‟un exemple.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
83
Figure 42 : Exemple montrant la sélection du service abstrait à partir du rôle
Le participant A peut jouer un rôle de vendeur. A ce rôle, on
associe plusieurs services abstraits comme vendre un produit ou vendre
un service. Ces services abstraits sont différenciés car ils correspondent
à des processus différents dans l’entreprise, même si leur rôle dans une
chaîne de service est identique
2) Règle de sélection des services concrets (appelé aussi
services d’affaire) à partir des services abstraits : Soit un participant
x dans un processus collaboratif qui fournit un service abstrait, y, dans
un contexte bien défini, v. Il important de choisir le service concret
approprié. Cette règle commence par rechercher les services concrets qui
correspondent aux services abstraits fournis par le participant avant de
renvoyer la liste de services d‟affaire que le participant devrait utiliser
pour implémenter le service abstrait contextualisé.
Partner(x) HasContextuelAbstractService(x, z) ListOfConcretServices(y, z)
SelectConcretService(x, y, v).

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
84
La partie B de la Figure 43 montre comment la règle ci-dessus
fonctionne à partir d‟un exemple.
Figure 43 : Exemple montrant la règle de sélection des services concrets
à partir des services abstraits
Le participant A joue un rôle de vendeu. A ce rôle on associe
plusieurs service abstrait (vendre prouduit). A chaque service abstrait
on peutr associer un ou plusieurs services concrets élémentaires ou
composites. La recherche du service concret est réalisée en fonction du
contexte et peut nécessiter la composition de plusieurs services
élementaires pour supporter le processus effectif (depuis la gestion de la
commande, jusqu’à la préparation de la livraison et la facturation).
Une fois sélectionné, une règle contrôle l‟exécution du service.
Soit deux partenaires P1 et P2, fournissant des services abstraits x et y. Il
faut s‟assurer de la compatibilité des entrées et sorties pour permettre
une bonne composition :
Soient deux Participant P1, et P1, et respectivement leur service
concret s1 et s2. L‟exécution de s2 dépend de la compatibilité entre les
propriétés fonctionnelles et non fonctionnelles de deux services, du
contexte actuel et en particulier du rôle de chaque partenaire au moment
de l‟exécution. La règle de médiation est la suivante
PartnerConcreteService(P1, s1) PartnerConcreteService(P2, s2)
MediateFunctionalPropertiesBetween(Output(s1), Input(s2))
MediateNonFunctionalPropertiesBetween(Role(s1), Role(s2))
PropagateContext(s1, s2) InvokeService(s2)
Cette formalisation logique permet de raisonner sur les
services, d‟automatiser la sélection des services abstraits, concrets

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
85
contextualisés et la médiation avant l‟invocation. Ceci nécessite un
ensemble d‟ontologies décrivant, les propriétés fonctionelles et non
fonctionelles, le contexte et les rôles, et un ensemble de règles pour
implémenter les prédicats utilisés dans ces règles logiques.
En conclusion, nous avons vu comment la vue de gestion
permet de gérer la communication entre les services. Dans la section
suivante, nous nous focaliserons sur la vue de médiation avant de
prendre en compte les politiques de sécurité.
3.3.2 La vue de médiation
Dans cette vue nous considérons le service comme une boîte noire. Il
consomme un message et produit un autre message. Un message se
compose de plusieurs propriétés ou attributs. Chaque attribut est associé
à un type de données. Nous schématisons un service en fonction de ses
entrées et sorties comme montrer dans la Figure 44.
Nous avons vu dans la section précédente comment
sélectionner un service concret à partir d‟une liste de services concrets
qui implémentent réellement un service abstrait contextuel. Dans la
suite, nous expliquons comment construire cette liste de services
concrets qui correspond à un service abstrait identifié par les partenaires
pendant dans la construction du processus collaboratif commun. Dans un
premier temps, la construction de cette liste est basée sur les propriétés
fonctionnelles du service abstrait-- notamment les attributs d‟entrée et
de sortie --, la notions de sous-typage et la transformation des ces
attributs pour qu‟elles correspondent respectivement aux attributs
d‟entrée/sortie des services concrets.
Figure 44 : Définition d‟un service

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
86
Nous définissons le service concret noté S de la manière
suivante en prenant en compte ses entrée/sortie: S= {D entrée, D sortie}, où
D entrée= {di/di est l‟attribut de la donnée d‟entrée de type ti}
D sorties= {di/di est l‟attribut du donné de sortie de type ti}
De la même manière, nous définissons un service abstrait, noté
R par ses attributs d‟entrée/sortie R={R entrée, R sortie} où
R entrée= {d i/d i est l‟attribut d‟entrée du service abstrait de type t i}
R sortie= {d i/d i est l‟attribut de sortie du service abstrait de type ti}
Pour trouver le service concret (ou les services concrets) qui correspond
(correspondent) à un service abstrait R, nous proposons un mécanisme
de médiation entre les attributs d‟entrée et sortie du service abstrait et
les attributs d‟entrée et sortie de tous les services concrets du répertoire
local. Cette médiation s‟appuie sur la similarité sémantique (noté ) et
la similarité de typage (noté ): La similarité sémantique estime le
degré de proximité entre la signification de deux attributs et évalue la
relation sémantique qui les relie [73]. Le typage consiste à associer à un
attribut le type de sa valeur. Le type définit les valeurs que peut prendre
une donnée, ainsi que les opérateurs qui peuvent lui être appliqués. Un
type pourrait être un booléen (valeurs vrai ou faux), un entier (signé ou
non signé), un réel en virgule flottante et une chaîne de caractères.
Certains types correspondent à d'autres structures de données plus
complexes. Par exemple, le type composé adresse postale est composé
de numéro de rue, nom de la rue, et code postale. Le typage signifie en
plus que tout attribut a un type et que les attributs ne peuvent se
combiner qu'en respectant des règles de "typage". Par exemple,
concaténer une adresse (chaîne de caractères) et un numéro de téléphone
(entier positive). La similarité de typage entre deux attributs s‟assure
que leur types sont identiques ou bien qu‟il est possible de détecter une
conversion de type implicite (par exemple, un entier est un réel, un réel
est transformable en une chaîne de caractères, etc..). Nous nous
appuyons sur les travaux développés dans le cadre de la thèse de Patrick
Hoffmann [74] pour renforcer notre mécanisme de médiation et
implémenter la similarité sémantique et la similarité de typage en
utilisant des ontologies basées sur le contexte.
Etant donnée un service abstrait, il faut découvrir les services concrets
dont les attributs d‟entrée et sortie sont similaires. Ceci nous conduit à
la formulation suivante :

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
87
D entrée de service d‟affaire (concret) R entrée de service abstrait
D sortie de service d‟affaire R sortie de service abstrait
D entrée de service d‟affaire (concret) R entrée de service abstrait
D sortie de service d‟affaire R sortie de service abstrait
A partir d‟une chaîne de services abstraits, on peut alors utiliser
cette règle de médiation pour découvrir les services concrets candidats
qui peuvent implémenter le service abstrait . Puisque les services
concrets peuvent être implicitement interconnectés par des relations
d‟héritage pour exprimer une variation dans leur contexte d‟utilisation
(généralisation ou spécialisation), il s‟avère important de sélectionner
parmi les services concrets candidats le service correspondant au
contexte courant d‟exécution. Ceci se traduit par le parcours de l‟arbre
d‟héritage de ces services et la comparaison entre le contexte du service
abstrait et le contexte associé à chacun de ces services concrets.
On répète cette procédure pour chaque service abstrait. Ceci
permet donc transformer étape par étape la chaîne de services abstraits
en chaîne de services concrets. Il ne reste alors plus qu‟à intégrer les
contraintes de sécurité.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
88
3.3.3 Vue de sécurité
Pour sécuriser l‟interconnexion entre les différents services abstraits et
par conséquences entre les différents services concrets nous traiterons
les exigences de sécurité par le moniteur.
Pour améliorer la gestion des droits d‟accès et répondre aux exigences
de sécurité de manière cohérente entre les chaînes de service, nous
définissons deux classes de droits d‟accès liés à deux rôles différents :
propriétaire et membre. Chaque service a un propriétaire unique à un
moment donné. Le propriétaire définit le niveau de sécurité du service,
les niveaux d‟authentification et les droits d'accès affectés aux
utilisateurs ou services. Les membres sont considérés comme des
utilisateurs ou autres services qui ont l‟autorisation de manipuler le
service en question via son interface et via les méthodes d'accès.
Pour gérer les différents contextes, nous proposons d‟utiliser un
ensemble de services interconnectés par une relation d‟agrégation afin
de composer le processus collaboratif commun (i.e. la chaîne de
service). Chacun d‟eux est associé à un contexte particulier. En plus, le
processus collaboratif est associé à son tour à un contexte globale.
Figure 45 : Mécanisme de propagation de contraintes de sécurités via le médiateur
contexte
local
contexte global
S2
S3
S4
S5
Processus métier
S22
S21
S2
Processus métier
S5
S4
S3
contraintes sécurités
locales
contraintes sécurités
globales

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
89
Dans le contexte de la sécurité, la relation d‟héritage définit une relation
de référentiel entre les services dérivés pour traiter la propagation de
contraintes de sécurité d‟une façon similaire à l‟approche orientée objet .
A titre d‟exemple, nous considérons deux hiérarchies de services
(classes) C et D, et une relation d‟agrégation entre D et C. Chaque
service dans chacune de ces deux hiérarchies encapsule les méthodes
d‟accès aux données et les méthodes spécifiques utilisées pour
manipuler ses attributs. Comme illustré dans la figure, les deux services,
S1 et S2, font respectivement partie de C et D. S1 hérite les propriétés,
en particulier la sécurité des composants et des méthodes, de son service
de base (superclasse) dans l‟hiérarchie d‟héritage de C. Il en va de même
pour D. Comme il existe une relation d‟agrégation entre C et D, (c-à-d
C est un service composite ayant parmi ses constituants, un service de la
hiérarchie d‟héritage de D), la médiation (et par la suite le médiateur)
assure la comptabilité de sécurité et la propagation de ses contraintes
(par exemple, rôle, token, etc) du service composite au service
composant comme illustré dans la Figure 46.
Figure 46 : Les droits d‟accès et l‟héritage entre les objets
Les droits d'accès tels que l‟invocation d‟une méthode de
lecture ou d‟une méthode de modification de valeurs d‟attributs sont
principalement gérés par le propriétaire du service. Il accorde ses droits
aux membres identifiés par leurs rôles. Les droits sont présentés par un
triplet de règles d'accès définies par la relation suivante < R, S, m, o >
qui définit que le membre ayant le rôle R, sont autorisés à manipuler
l‟hiérarchie d‟héritage de services S (qui pourrait être un singleton), via

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
90
la méthode m selon les modes o de lecture (r), écriture (w), ou rien (x).
Ci-dessous un exemple de droits d'accès qui peuvent être modifiés et
ajustés, y compris en ajoutant de nouveaux droits d'accès et où en en
révoquant par le propriétaire du service AchatEnligne et le service
GestionVente.
< Salesman, AchatEnligne, validerCommande, r >
< Client, GestionVente, annulerCommande, x >
< Anonyme, AchatEnLigne, PasserCommande,w >
Les listes des droits d'accès sont continuellement ajustées : quand une
classe est modifiée, les sous-classes et les droits d'accès à l‟objet sont
également adaptés (ajout ou révocation dans la liste d'accès), sauf si le
propriétaire de l‟objet a manuellement changé cette liste.
La mise en place de cette vue permet donc d‟adapter
dynamiquement le contrôle d‟accès au contexte d‟invocation du service
et de simplifier la spécification de ces droits d‟accès.
3.3.4 Conclusion
Dans cette section, nous avons présenté les différentes vues de
notre modèle qui permettront de faciliter la contextualisation des
services. Ainsi, nous avons défini une vue de gestion associée à des
services abstraits, eux-mêmes associés à des rôles. La notion de contexte
(qui accède à quoi avec quelles exigences de qualité et via quels moyens
d‟accès) a été utilisée pour permettre de « tisser » les différentes
politiques et sélectionner les services concrets adaptés. Ceci est réalisé
grâce à la vue de médiation qui permet de définir des relations vers des
services concrets. Enfin, la vue de sécurité permet de définir les
éléments liés à la politique de sécurité. Cette organisation multi -vues
enrichie la démarche de Mlle Rajsiri [76] en permettant une
contextualisation des services lors de la transformation CIM vers PIM
puis PSM et prolonge la séparation multi-niveaux introduite par [69]: en
spécifiant des relations de rôles entre service, il devient plus « simple »
de sélectionner les services abstraits répondant à un besoin puis
d‟exploiter les relations existants avec les services concrets et éléments
de sécurité pour permettre de construire un processus concret

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
91
contextualisé. Ces différents principes sont présentés dans la section
suivante.
3.4 Exploitation du modèle :
Pour montrer comment les différentes vues de ce modèle sont
exploitées pour former un processus collaboratif, nous allons nous
intéresser à la phase de conception de ce type de processus. En effet,
lorsque des partenaires veulent collaborer, ils décrivent un processus
abstrait qui servira de base aux contrats de collaboration. Pour cela, la
notation graphique BPMN est fréquemment utilisée. Plusieurs travaux
de recherche ont porté sur la transformation d‟un modèle décrit en
BPMN (donc de manière abstraite) en processus concret BPEL.
Figure 47 : Construction du processus de collaboration par une série de
transformation de modèles (MDA)

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
92
Notre démarche est différente comme l‟indique la Figure 47:
dans un premier temps, la chaîne de services abstraits est conçue en
utilisant la notation BPMN. A la différence des autres travaux, la
transformation en BPEL n‟est pas réalisée en interprétant le processus
défini en BPMN mais en procédant par substitution. Ensuite, nous allons
rechercher dans les répertoires les services abstraits correspondant au
besoin en nous intéressant aux opérations qui doivent être réalisées par
le participant en fonction du rôle qu‟il doit jouer dans le processus
Transformation
Processus à base de services abstraits multi-contextuels (BPEL abstrait)
Vue Médiation
Vue Gestion
Vue Sécurité
Contexte
Processus à base de services concrets multi-contextuels (BPEL Concret)
Moteur BPEL étendu
Processus collaboratif commun (BPMN)
Transformation
Exécution

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
93
collaboratif : on procède d‟abord à une extraction du rôle du participant
puis on extrait les services abstraits utilisables avec ce rôle : on utilise
alors la vue de gestion. Ensuite, pour chaque service abstrait, on va
rechercher les services d‟affaire qui peuvent le mettre en œuvre : il
s‟agit alors d‟exploiter la vue de médiation. Pour chaque service
abstrait, on recherche alors les services d‟affaire substituable dans le
répertoire du partenaire concerné. De cette manière, les interfaces sont
respectées. Ceci nous conduit à formaliser la règle suivante :
Soit un processus de collaboration PC composé de services
abstraits yi et Soit un partenaire P i pouvant fournir un service concret x i
permettant de mettre en œuvre les fonctionnalités du service abstrait yi.
On dira que si le service xi concret correspond au service yi abstrait
alors le service concret x i peut être substitué au service abstrait y i.
Pour établir une collaboration, les partenaires sélectionnent les
services abstraits et construisent ensemble le processus collaboratif
commun. On établit des relations entre services abstraits qu‟on répercute
ensuite entre les services concrets. Nous notons P i un partenaire offrant
un ensemble de services (abstraits et concrets) s (s Pi) noté pi(x). Ces
services sont répartis en services abstraits yi et services concrets xi
associés aux services abstraits. Si y1 est un service abstrait de partenaire
P1, y2 est un service abstrait du partenaire P2 et que y1et y2 sont liés par
une relation R, alors cette relation R est répercutée entre les services
concrets associés aux services abstraits : une relation R’ est créée entre
les services concrets x1 et x2 associés respectivement aux services
abstraits y1 et y2.
Cette logique de transformation par substitution de services
permet à la fois de respecter la séparation entre processus publics
(publiés comme des services abstraits) et privés (services qui seront
effectivement exécuté et intègre des connaissances sur le
fonctionnement exact de l‟entreprise) et de composer et orchestrer le
processus de collaboration « au vol » et donc de choisir le service
concret qui sera invoqué en fonction du contexte exact.
Une fois réalisée la sélection du service concret convenable, la
dernière étape consiste à intégrer les services « techniques » de sécurité.
En effet, si la séparation entre services publics et privés offre un premier
niveau de protection aux entreprises, il importe également de prendre en
compte les politiques de sécurité (gestion des droits d‟accès en

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
94
particulier). Pour cela, nous définissons deux services « techniques »
d‟authentification et d‟autorisation qui peuvent être ajoutés lors de
l‟opération de composition avant d‟invoquer un service concret :
1) Le service d‟authentification : Ce service vise à établir de
manière certaine l‟identité de celui qui invoque un service
soit pour conserver la trace « nominative » de l‟invocation
soit en préalable d‟une demande d‟autorisation. Lors de la
récupération des informations nécessaires à
l‟authentification, ce service prend en charge la protection
de ces informations (chiffrement des échanges, signature
du message…) afin de garantir qu‟aucune capture
d‟information conduisant à une usurpation d‟identité
ultérieure ne puisse être faite. De même, les bases
contenant ces informations seront protégées.
2) Le service d‟autorisation définit les droits d'un service et
les autorisations sur un système. Une fois l‟identité prouvé
(donc après l‟invocation du service d‟authentification), le
service d‟autorisation détermine ce que l‟utilisateur du
service invoqué (humain ou service appelant) peut
effectuer sur le service invoqué (utilisation d‟une opération
particulière par exemple).
Par exemple dans le cadre d‟un processus d‟achat en ligne de
pièces détachées, on aura une chaîne de différents services : présentation
et sélection des produits, gestion de la commande, gestion du paiement.
Dans le cadre du service de paiement, on devra échanger de manière
sécurisée des informations financières (numéro de carte de crédit,
gestion de l‟authentification du client). Pour cela, il faudra donc
composer les services d‟authentification et de gestion des autorisations
auprès de la banque pour poursuivre la transaction. En revanche, lorsque
le processus d‟achat est mené par une entité de l‟entreprise (par exemple
commande interne de pièces détachées par le SAV), le processus de
facturation interne n‟impose que l‟authentification de l‟utilisateur qui
invoque le service et non une quelconque demande d‟autorisation
bancaire.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
95
3.5 Conclusion
Pour faciliter la collaboration entre entreprise, nous avons proposé de
recourir à une stratégie « orientée service » permettant de composer un
processus commun. En dotant chaque entreprise d‟un répertoire, des
services abstraits (représentant son offre de collaboration) peuvent être
exposés. L‟organisation en hypergraphe permet de définir différentes
vues pour permettre, grâce à la spécification de relations typées, de
faciliter la définition de services concrets contextualisés. L‟organisation
précise de ces mécanismes est présentée dans le chapitre suivant.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
96
Chapitre 4
Modélisation d'entreprises collaboratives
par des graphes de d’héritages de
services
4.1 Introduction
Afin d‟assurer la collaboration et l‟interconnexion de processus
inter entreprises, nous avons introduit une approche originale qui
s‟appuie sur une collaboration à base de services multi-contextuels. Les
services métiers qui sont partagés par les partenaires sont modélisés
selon trois vues différentes et complémentaires à savoir la vue de
gestion, la vue de médiation et la vue de sécurité. En plus, nous ne
considérons pas ces services comme des composants fonctionnels
indépendants facilitant ainsi la composition de processus collaboratifs
mais nous introduisons plusieurs types de relations implicites et non
intrusives entre les services. Ces relations, qui sont maintenues par des
répertoires, facilitent la découverte des services, enrichissent la
composition et permettent l‟exécution en tenant compte du contexte.
Dans ce chapitre nous définissons le concept d‟hypergraphe d‟un
service. En effet, les hypergraphes sont des grappes de graphes qui
permettent de spécialiser des relations sémantiques entre les services et
les processus offerts par les partenaires. Les relations visent à faciliter la
mise en place des processus collaboratifs et mieux gérer leurs
interactions. En particulier, nous considérons les relations de type
héritage qui sont vues comme un procédé de partage et d‟échange

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
97
d‟information dans une structure hiérarchique regroupant des sous
ensembles d‟entités (services ou processus métiers). Dans ce contexte,
les services sont décrits par des caractéristiques ou propriétés
fonctionnelles et non fonctionnelles. La structuration hiérarchique nous
permet de factoriser les propriétés communes à plusieurs entités afin de
faciliter leur définition et la maintenance de l‟ensemble (meilleure
cohérence). Ainsi, une propriété qui caractérise une entité est héritée par
toutes ses sous entités inférieures. Chaque sous entité se définit par ses
propres propriétés ainsi que par les propriétés héritées des entités
supérieures. Dans cette organisation, il est possible d‟associer un
mécanisme capable de restituer la définition complète d‟une entité à
partir de ses propriétés propres et héritées. De façon plus abstraite, nous
regroupons les entités en graphes : un arc représentent une relation
d‟ordre partiel appelée relation d‟héritage et les nœuds représentent les
sommets du graphe annotés par des propriétés fonctionnelles et non
fonctionnelles. La relation d‟héritage est unidirectionnelle et orientée du
plus spécifique au plus générique. Elle exige en plus que chaque nœud
hérite des propriétés des nœuds les plus génériques. Dans notre contexte,
la collaboration entre les entreprises s‟appuie sur un répertoire commun
comprenant des structures d‟hypergraphes permettant la réalisation des
objectifs métiers et des scénarios de collaboration. Une entreprise
pourrait aussi être représentée par des hypergraphes représentant ses
activités en termes de processus ou services à partager. Les relations
d‟héritage permettent d‟offrir une variété d‟utilisation de ces processus
ou services dans des différents scénarios d‟utilisation. Figure 48, illustre
un hypergraphe contenant les processus ou services métiers composites
(nœuds) et des liens génériques d‟interconnexion entre eux.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
98
Figure 48 : Modélisation des processus en termes d‟hypergraphe
Dans les sections suivantes, nous présentons la collaboration
entre les entreprises en utilisation les hypergraphes afin de construire les
chaînes de collaboration globale à base de services. Nous également
discutons l‟enchainement des services et les contraintes de transaction
entre eux. Enfin, nous enrichissons la construction d‟hypergraphe en
utilisant différents types de relations entre les services à savoir les
relations d‟héritage, d‟agrégation, etc…

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
99
4.2 Mécanismes d’héritage
Dans notre contribution nous proposons d‟adopter le
mécanisme d‟héritage développé dans l‟approche orientée-objet et
l‟appliquer aux développements de services métiers et aux
collaborations contextuelles. En effet, dans la vie pratique de
l‟entreprise, nous avons constaté que la plupart de services métiers qui
sont mis à disposition des partenaires ont subi des modifications
successives selon la variété d‟utilisation dans des contextes différents.
Cette tendance est bien connue dans le secteur de l‟innovation qui
favorise la différenciation de produits existants en ajoutant quelques
fonctionnalités afin de fournir de nouveaux produits et conquérir de
nouveaux marchés. La relation d‟héritage permet ainsi d‟établir un lien
indiquant qu‟un service est une spécialisation d‟un service plus
générique (super-service). La spécialisation d‟un service existant décrit
un contexte plus restreint pour son utilisation tout en gardant le
sémantique métier hérité de son super-service. Ce recours à l‟approche
et le sémantique objet est issu du constat que le concept service
ressemble au concept classe de l‟approche orienté-objet, qui s‟avère être
utile dans le domaine de génie logiciel.
Nous expliquons dans cette section le mécanisme d‟héritage
pour innover et développer de services contextuels. Il s‟agit d‟une
approche incrémentale pour différencier les services à fournir aux
partenaires ainsi que leurs intégrations dans des processus collaboratifs.
A l‟exécution, les informations contextuelles pourraient guider le
moteur d‟exécution d‟un processus collaboratif à bien choisir un service
convenable sans mettre en cause la construction entière du processus.
Avant d‟introduire le mécanisme d‟héritage entre services et en
particulier l‟héritage de propriétés fonctionnelles et non fonctionnelles,
nous rappelons que le concept classe ou objet est définit par identifiant,
type et méthodes :
L‟objet est défini par son nom et les propriétés associées à
lui. Par exemple : O1 : [nom : Jaque, numéro compte : 1993]
et O2 : [nom : Eric, numéro compte : 2404]

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
100
Type d‟objet : La structure d‟un objet comporte des
propriétés (attributs) simples (entier, réel, chaîne, etc..) ou
complexes et les méthodes (opérations). Un objet est dit de
type complexe s‟il est une structure qui regroupe plusieurs
types simples ou complexes (récursives).
Les méthodes (ou opérations) : chaque objet est spécifié par
un ensemble de méthodes. Exemple d‟un attribut pour
réserver un avion [numéro : intègre, nom : string, date allé :
date, prix de billet : real] et une méthode pour payer le prix
d‟un ticket, payer(montant : real).
4.3 Héritage entre services (objets)
Afin de détailler le mécanisme d‟héritage, nous nous intéressons aux
propriétés des objets qui représentent les services dans notre contexte.
Dans chaque service il existe des propriétés fonctionnelles (messages
d‟entrée, messages de sortie, conditions, etc.) et des propriétés non
fonctionnelles (sécurité, QoS, etc.). La Figure 49 illustre une vue
abstraite du modèle service.
Figure 49 : Le modèle de service vu comme un objet qui encapsule les propriétés et les
méthodes
4.3.1 Héritage avec les propriétés fonctionnelles
Le mécanisme d‟héritage entre les services permet d‟hériter
les propriétés et les opérations. Notons que les propriétés héritées

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
101
peuvent être redéfinies ou renommées. Ce mécanisme permet la
transmission de propriétés, attributs et méthodes des services/objets qui
sont dans les super-classes (services) vers les services/objets qui sont
dans les sous-classes (services). En conclusion, les sous-services
pourraient redéfinir, renommer les attributs ou modifier le
comportement de certaines opérations. Dans notre cas quand le
service 2S hérite du service 1S , 2S peut garder les mêmes paramètres
mais on peut aussi ajouter de nouveaux paramètres. Par exemple
l‟héritage entre les deux servies 1S (consulter compte en France) et
2S (consulter compte depuis l‟étranger), nécessite de prendre en compte
un nouveau paramètre (pays) comme illustré dans la Figure 50.
Figure 50 : L‟héritage entre les services
4.4 Les propriétés non fonctionnelles et le mécanisme d’héritage
Les propriétés non-fonctionnelles de services fournissent des
informations supplémentaires pour que les services s‟exécutent dans les
meilleures conditions possibles et dans différents contextes. Ces
propriétés incluent à titre d‟exemple les paramètres de qualité de
service QoS tels que la fiabilité, la sécurité, la performance, le temps de
réponse etc.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
102
Selon [70] la qualité de service est définie comme “quality is
expressed referring to observable parameters, relating to non-
functional property“.
La qualité de service peut être divisée en deux catégories
comprenant la qualité d'exécution et la qualité métier.
1) La qualité d'exécution représente la mesure de propriétés qui
sont liées à l'exécution d'une opération, Nous distinguons cinq
catégories de qualité d‟exécution à savoir: le temps de réponse, la
fiabilité, la disponibilité, l'accessibilité et l'intégrité [71][72][56].
Temps de réponse : mesure le délai prévu entre le
moment où une opération envoie une requête et le moment
où les résultats sont reçus.
Fiabilité : concerne les échanges des messages entre les
différents services. Elle assure les messages envoyés et
reçus par les demandeurs de service et les fournisseurs de
services ne sont ni perdus ni erronés.
La disponibilité : elle concerne la capacité du système à
offrir les fonctionnalités pour lesquels il a été conçu. Il
s‟agit de s‟assurer que le service est opérationnel au
moment où il est sollicité [56]..
L'accessibilité : elle mesure le degré selon lequel une
opération d‟un service est capable de répondre à une
requête venant d‟un service web. L‟accessibilité peut être
exprimée comme une probabilité mesurant le pourcentage
de succès ou la chance de succès d‟instanciation du service
à un instant donnée. (on différencie le cas où le service
Web est fonctionnellement disponible mais ne peut être
effectivvement instancié (manque de ressources locales…)
[56].
L'intégrité : mesure la capacité d‟une opération de service
à assurer correctement l'interaction.
L’exactitude : est définie comme le taux d'erreur produit
(généré) par le service dans un intervalle de temps. Cette
variable doit être minimisée.
La performance : est mesurée en termes de débit
(throughput) et de latence (latency). Le débit représente le
nombre de demandes de service Web servis dans une

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
103
période donnée. La latence : est le temps qui s‟écoule
entre l'envoi d'une requête et la réception de la réponse
([75] page 44).
La qualité métier permet l'évaluation d'une opération de
service d‟un point de vue métier. Par exemple : le coût
mesure le prix qu'un demandeur de service doit payer pour
invoquer l'opération de service.
Dans l‟héritage de propriétés non fonctionnelles, les besoins sont hérités
de la super-classe. Par exemple, quand le service 2S hérite du service 1S
il prend les valeurs des attributs de sécurité de S1 mais aussi les valeurs
associées aux exigences non fonctionnelles en ce qui concerne le
contexte d‟exécution (temps de réponse, coût,…), voir la Figure 51.
Figure 51 : héritage avec les propriétés non fonctionnelles
4.5 La construction de l’hypergraphe
Afin de réaliser les interconnexions entres les différents
services, nous nous sommes basés sur le mécanisme d‟héritage. Par la
suite, nous généralisons ce concept pour construire un hypergraphe de
service contenant tous les services métier de l‟entreprise. L‟hypergraphe
est composé par les services interconnectés par différents types de
relations à savoir : la relation d‟agrégation, la relation de
recommandation, et la relation de collaboration.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
104
Nous définissons l‟hypergraphe Ch comme un ensemble de
services concrets qui forment les nœuds et qui sont reliés par des arcs.
Les arcs désignent les relations d‟interdépendance entre les services
(nœuds). Soient deux services ci et cj de l‟hypergraphe, l‟arc qui relie
ces deux services est noté par cjci a =( ic , jc ).
Pour permettre de contextualiser les services concrets, nous
organisons le répertoire locale de chaque entreprise dans un hypergraphe.
Nous définissons l‟hypergraphe Ch comme un tuple (C, A) ; c-à-d
Ch =(C,
A) sachant que C désigne l‟ensemble de tous les services concrets de
l‟hypergraphe Ch tel que C = {ci} et A l‟ensemble de tous les arcs entre les
services de l‟ensemble C tel que A = { cjci a }.
La Figure 52 présent graphiquement un exemple d‟arborescence d‟un
hypergraphe Ch et montre que la relation ciacj relie sémantiquement les
deux services ci et cj. Par analogie à l‟approche orienté objet, les
services sont similaires aux classes, les arcs sont similaires aux relations
d‟interdépendance (par exemple héritage). Chaque service peut être
exécuté en parallèle plusieurs fois dans un contexte de montée en charge
ou en gestion transactionnelle ce qui ressemble aux objets instanciés
d‟une classe donnée. Les services sont présentés par des rectangles et les
instances sont présentées par des cercles. Par exemple, le service ci a
deux instances qui s‟exécutent en concurrence.
Figure 52 : Exemple d‟arborescence

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
105
Nous notons par Mi l‟ensemble de tous les attributs d‟un service ci. Mi,p
désigne l‟attribut p du service ci Dans notre contexte, les attributs
représentent les messages d‟entrée et de sortie et les propriétés non
fonctionnelles d‟un service. Par exemple dans la Figure 53, le service ci
possède implicitement par le mécanisme d‟héritage l‟ensemble des
attributs des tous ses services supérieures, notamment les attributs mo,1 et
mo,2 du service co, mh,1 du service ch et mi,1, mi,2 et mi,3 du service ci.
Figure 53 : Les attributs de la classe
A l‟exécution, un service peut être exécuté en plusieurs
instances. Pour cela, nous proposons de différentier les instances de
services dans un hypergraphe afin d‟apporter un traitement individuel à
chaque instance et établir de relations inter-instances de services qui
reflètent la situation réelle de l‟exécution à un moment donné. Dans la
section suivante nous construisons l‟hypergraphe des instances et nous
montrons son utilité. Dans le paragraphe suivant nous expliquons
comme noter les instances d‟un service de l‟hypergraphe.
Nous notons par oim l‟instance appelée m du service ci.
L‟ensemble de tous les instances du service ci est noté par oi tel que oi
= { oim } et oi
m oi. La notion d‟instance est importante dans le
contexte d‟une gestion transactionnelle et d‟exécution répartie de
service. En effet, certains fournisseurs de services exécutent en
parallèle plusieurs instances d‟un service pour monter en charge et

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
106
répondre aux requêtes avec un temps de réponse acceptable, même en
cas d'affluence massive. L'équilibrage de charges consiste à distribuer
un service sur un pool de machines afin de s'assurer de la disponibilité
d‟un service, en n'envoyant des requêtes qu'aux instances en mesure de
répondre.
En conséquence, les attributs d‟une instance oim d‟un service ci
est noté aipm pour p=1, ..,n Toute instance oi
m possède implicitement,
de plus de ses attributs, les attributs de l‟ensemble de toutes ses super-
instances. Elles constituent l‟ensemble aipm des attributs de l‟instance
oim (voir Figure 54)
Figure 54 : L‟ensemble des attributs de l‟objet
Une instance possède autant d‟attributs que son service et hérite
aussi les attributs aim de toutes les instances qui la précédent dans
la hiérarchie d‟héritage.
4.6 Construire l’arborescence des instances
Après la construction de l‟hypergraphe nous présentons la
construction de l‟arborescence des instances. L‟arborescence des
instances constitue une vue réelle d‟un ensemble de services au cours
de l‟exécution à un moment précis. Cette vue est utile pour décrire les
cycles de vies des services en termes d‟états de transition (activé,
annulé, échoué, compensé, terminé, etc..) et expliquer comment les
contraintes sont propagés au cours de l‟exécution. Le mécanisme de
transition et la propagation seront introduits plus tard dans ce chapitre.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
107
Soient l‟arborescence hc et deux sommets ci et cj tels que cj est
le successeur direct de ci , tout sommet oim peut être relié à un ou
plusieurs sommets ojn par un arc
nj
mi
o
cj
o
ci a à condition que les attributs ain
de l‟instance ojn soient identiques à l‟ensemble des attributs ai
m de
l‟instance oim
O={m
io },
nj
mi
o
cj
o
ci a =(m
io ,n
jo ), a=
nj
mi
o
cj
o
ci a2o , oh =<o, a>, voir la Figure 55.
Figure 55 : L‟arborescence de l‟objet
Le service ci peut joindre un ou plusieurs services par
l‟intermédiaire des relations. Une relation joignant ci à cj est
noté : ),( jicck ccL
ji . Si deux services ci et cj possèdent une
relationjicc
kL , les instances respectives de ces deux classes peuvent
être reliées par un arc noté nj
mi oo
cicjL et qui désigne un lien entre ces
instances. La Figure 56 montre que le service ci est interconnecté
au service cj par la relation cijL , et inversement le service cj est
relié au service ci par la relation cjiL , les instances oim du service ci
peut être reliée aux instances ojn du service cj par la relation
nj
mi oo
cicjL .
Figure 56 : Les liens entre les classes et les objets

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
108
Une instance d‟un service peut avoir des liens avec des instances
appartenant à différents services à condition qu‟il existe des liens entre ce
service et les services correspondants aux instances considérées (voir
Figure 57). En effet, l‟instance oim possède des liens avec plusieurs
instances d‟un même service.
Figure 57 : Les liens avec des objets appartenant à différentes classes
Une instance oim peut être lié à des instances oj
n et ok
p appartenant
à différents services, s‟il existe des liens respectivement entre les services
ci , cj et ck.
4.7 Collaboration entre les entreprises à base d’hypergraphe
Pour établir une collaboration entre deux entreprises, nous avons
proposé dans le chapitre précédent que chaque entreprise gère son
répertoire local de services concrets et publie ses services abstraits dans
un répertoire global. Le répertoire global contient les informations
génériques sur ses activités, l‟ensemble de services abstraits et de
processus à partager ainsi que leurs interfaces afin de faciliter leur
découverte et déploiement. Il est important de noter que ce répertoire
local ne contient pas la liste de services indépendamment les uns des
autres mais prend aussi en compte des relations d‟héritage et d‟autres
types de relations sous forme d‟hypergraphes. L‟architecture globale est
illustrée en Figure 58 et montre que les hypergraphes de services dans
les répertoires locaux sont utilisés pour établir des chaînes de services
de collaboration enregistrées dans un répertoire commun. Les chaînes de
services sont également représentées en tant que hypergraphes grâce à
des relations comme la relation d‟héritage. Ainsi, la relation d‟héritage
dans un hypergraphe permet la réutilisation des propriétés de services

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
109
par une relation de généralisation/spécialisation similaire à l‟approche
orientée-objets : la classe spécialisée, c.à.d. la sous-classe, hérite les
propriétés et les méthodes de la classe que l‟on spécialise, c.à.d. super -
classe. L‟héritage entre les classes permet la transmission de propriétés
(attributs et méthodes) de la super-classe vers les sous-classes.
Figure 58 : Principe de présenter les services
Supposons que les entreprises E1 et E2 souhaitent collaborer.
Pour cela, elles négocient et établissent une chaîne de services à partir
de leurs services abstraits. Elles déposent dans le répertoire commun la
chaîne de service globale en tant que “hypergraphe“ de services.
D‟autre part, nous désignons par le terme “type de service“ un
arbre d‟héritage d‟un service particulier comprenant l‟ensemble de ses
services hérités. Le type de service pointe sur le service racine et tous
ses sous-services hérités. Le schéma dans la Figure 59 montre l‟arbre
d‟héritage du service d‟achat, noté “<achat>“ et qui inclut plusieurs
sous-services tels que achat en ligne, achat par portable ou bien achat
sur web :
<achat> = achat online achat portable achat web.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
110
Figure 59 : Arbre d'héritage de service <achat>
Au moment de la génération du processus de collaboratif
correspondant à le chaîne de services concrets à partir de la spécification
ne com :portant que les services abstraits, le médiateur cherche le type
de services qui correspond au service abstrait en tenant compte du
contexte (par exemple, le contexte d‟exécution, les périphériques
d‟accès, le profil de l‟utilisateur etc.). Le médiateur permet de choisir le
service contextualisé en s‟appuyant sur son type de service (voir Figure
60).
Figure 60 : rôle le médiateur
Par exemple, lorsqu‟un utilisateur décide d‟acheter un ticket de
train en utilisation son portable, le médiateur choisit de l‟arbre
d‟héritage du service Achat (type de service <Achat>), le service
“Achat Portable ».
Sachant que la chaîne de service globale désigne un processus
de collaboration générique qui décrit le flux d‟information et le sens
d‟exécution de services, la prise ne compte du contexte permet de
développer des services contextuels qui nécessitent un mode

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
111
d‟orchestration ou de composition particulière. Le médiateur devient un
élément essentiel pour une orchestration proactive qui s‟appuie sur les
relations entre les services. L‟architecture présentée Figure 61 montre
une vue globale d‟un processus générique à base de type de services et
le rôle du médiateur qui consiste à choisir tardivement et en fonction du
contexte le service à exécuter. Dans la section suivante, nous détaillons
le mécanisme d‟orchestration de service.
Figure 61 : Le rôle de médiateur pour sélectionner le service contextuel
4.8 Orchestration contextualisée de “type de service“
L‟orchestration de services permet explicitement de décrire
l‟enchaînement de l‟exécution des services. Elle permet également de
spécifier les messages échangés et les interactions qui se produisent au
niveau de ces messages [63].

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
112
Pour réaliser une orchestration contextualisée en se basant sur
le concept “type de service“, nous définissons formellement un type de
service par un triplet de trois nœuds(ne(s), nrc(s), ns (s)) tels que :
ne(s): désigne l‟ensemble des “attributs d‟entrée“, ne1,ne2,…..nen du
service S.
ns : désigne l‟ensemble des “attributs de sortie“, ns1, ns2,… nsm du
service S.
nrc : désigne l‟ensemble de règles de contrôle qui s‟appliquent sur les
attributs d‟entrée et sortie. Les règles nrc1, nrc2,… nrcn contraignent
l‟exécution du service S en posant des conditions sur les attributs,
conditions à satisfaire avant l‟exécution et après l‟exécution .
A titre d‟exemple, les règles de contrôle pour une réservation
d‟un billet d‟avion sont définies en termes de ses ressources et leurs
propriétés sont listées dans le Tableau 1.
Tableau 1 : Règles de contrôle pour une réservation de billet
d‟avion
Dans ce cas, les règles de contrôle sont définies comme suit :
a. le service « Acheter un billet d‟avion » est exécuté si les
conditions prix<500 euro et le jour de départ est “dimanche“ sont
valides.
b. le service « AutoriserRéservation » est exécuté si la condition
« passeport du client n‟est pas expiré » est valide.
En cours d‟exécution, un service est prêt à être exécuté si et
seulement si toutes les valeurs des attributs d‟entrée sont fournies et que
toutes les conditions définies par les règles de contrôle (nrc) sont
accomplies ou réalisées. Dans le cas contraire, le service est considéré
“non disponible“. Les règles de contrôle sont considérées comme une
condition préalable (pré-condition) sur la disponibilité d‟un service.
Nous définissons le mécanisme d‟orchestration comme une
extension à l‟orchestration BPEL en redéfinissant les activités (invoke)

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
113
pour appeler le médiateur et détecter les informations du contexte avant
de choisir un service dans la hiérarchie de l‟hypergraphe du type de
service en question.
Afin de passer les messages d‟un “type de service“ à un autre
“type de service“ comme indiqué dans la Figure 62, le médiateur
applique les règles de contrôle pour assurer une cohérence dans
l‟exécution.
D‟autre part, nous proposons un mécanisme de gestion
transactionnelle générique qui s‟applique sur un hypergraphe d‟un type
de services. Ce mécanisme s‟appuie sur un ensemble de contraintes de
transition et des états pour que le processus collaboratif fonctionne
malgré une défaillance ou une monté de charge. Grâce à ce mécanisme,
le médiateur choisit ou réplique les instances d‟un service et met à jour
l‟hypergraphe des instances.
Figure 62 : L‟Orchestration de type de service

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
114
4.9 Les contraints de transition entre les types de service
La gestion transactionnelle joue un rôle très important dans la mise en
place de processus collaboratifs. Elle est un facteur déterminant pour la
robustesse, la fiabilité et l‟intégrité des données manipulées par les
services. Elle définit le comportement d‟un service dans les cas
d‟inconsistance des données ou de concurrence d‟accès. Les aspects
importants de la gestion transactionnelle locale par rapport à un type de
service est le diagramme d‟état qui décrit les différents états possibles
de son cycle de vie. Pour contrôler l‟exécution d‟un type de service,
nous définissons les transitions possibles qui relient ses différents états.
On note par :
“E “ l‟ensemble de tous les états possible
“ T “ l‟ensemble de toutes les transitions
SE,T = { S. E S*T }/ e E , t T, S. E le type de service dans l‟état E et
S*T : est la transition de type de service S.
Nous définissons les états suivants {début, abandonné, activé, annulé,
échoué, terminé, compensé} et les transitions entre ces états par le
diagramme dans la Figure 63.
Une fois qu‟un service particulier est déployé, il est en état “début“,
ensuite il transite dans plusieurs états, par exemple abandonné (avant
d‟être exécuté) ou activé s‟il est en cours d‟exécution. Dans l‟état activé,
le service continue son exécution ou décide d‟annuler à cause d‟un
problème. Si le service n‟est pas annulé pendant son exécution, il
s‟exécute jusqu‟à son terme en succès ou il échoue.
Figure 63 : Les différents états de transition
La transition indique le changement d‟état d‟un service.
L‟activation d‟une transition contrôle le comportement d‟un service.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
115
Nous définissons la transition T sur un type de service S qui s‟applique
en exécution sur ses services choisi par l‟orchestrateur comme suite :
Nous définissons la transition d‟un type de service par :
Les transitions entre les différents états sont définies de la manière
suivante:
1) La transition abandonner permet d‟abandonner l‟exécution du type
de service avant d‟être activé et lui permettre de passer d‟un état début à
l‟état abandonné.
2) La transition activer permet d‟activer un type de service et lui
permettre de passer de l‟état début à l‟état activé.
3) La transition annuler permet d‟annuler un type de service pendant son
exécution et permet de transiter l‟état activé à l‟état annulé.
4) La transition échouer permet d‟indiquer l‟échec de type de service et
permet de transiter de l‟état activé à l‟état échoué.
5) La transition terminer permet d‟indiquer la transition d‟un type de
service avec succès, transiter de l‟état activé à l‟état terminé.
6) La transition ressayer permet d‟activer un type de service après son
échec et transiter de l‟état échoué (avorter) à l‟état activé.
S*annuler= S. activé S. annulé.
S*T = {E1 E (S) ; E(S) est un ensemble états de S, E2 E (S)} ; E1 E2 où E1 est l’état de S
avant l’activation S*T et E2 est l’état de S après l’activation de S*T
S*T T : S. ES. E ; S. E est le type de service dans l’état E.
S*abandonner : S. début S. abandonné.
S*activer = S. débutS. activé.
S*échouer = S. activé S. échoué
S*terminer= S. activéS. terminé
S*essayer= S. échoué S. activé

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
116
7) La transition compenser, après que la transition ressayer se termine
avec un échec, elle permet de transiter de l‟état échoué (avorter) à l‟état
compensé.
La gestion transactionnelle locale implique un choix de la stratégie
adéquate et appropriée à adopter pour soutenir une collaboration robuste
et performante. Dans la suite nous présenterons un exemple qui montre
l‟enchaînement transactionnel du service.
4.10 L’enchaînement des types de services
Nous illustrons le mécanisme de transition par un exemple pour mieux
comprendre l‟enchainement transactionnel du service. Nous considérons
une application d‟achat en ligne de produits informatiques, par exemple
l'ordinateur personnel et USB Bluetooth. Cette application est réalisée
par un processus collaboratif à savoir :
S1 : Le service de spécifications des besoins de client. Ce service est
utilisé pour passer la commande du client.
S2 : Le service d‟achat de clés USB Bluetooth.
S3 : Le service d‟achat d‟ordinateur personnel.
S4 : Le service de paiement par carte de crédit. Ce service est utilisé
pour payer par la carte en ligne.
S5, S6 : deux services pour conditionner et livrer les produits achetés
(par exemple un ordinateur et une clé USB). Un type de service
composé peut être définit comme ensemble de type de service
composants. Pour définir l‟enchainement de type de services, nous
définissons les pré-conditions sur les types de services.
Par exemple le service composite présenté dans la Figure 64
spécifie que le type de service S4 (paiement en line) va être activé après
la terminaison des services acheter USB et acheter l’ordinateur. La pré-
condition de l‟activation de la transition activer du type de service
S*compenser= S. échoué S. compensé

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
117
paiement en line sera dans ce cas : La terminaison le service acheter
USB et la terminaison du service acheter ordinateur.
Figure 64 : Service composé l‟acheter de produits informatiques
1) Dans cet exemple, l‟enchainement et l‟activation du type de
service S1 (spécification les besoins du client) et le type de service S2
(acheter USB) indiquent que le type de service S2 (acheter USB) est
activé après le type de service S1 (spécification des besoins du client est
terminé). Cet enchainement exprime une relation de succession entre les
deux types de services. L‟enchaînement d‟activation de S1 vers S2 existe
si et seulement si la terminaison de S1 peut déclencher l‟activation de
S2.
L‟enchaînement d‟activation S1 vers S2 est définit de la manière
suivante: Enchact(S1,S2)=(pré-condition de S1, transition S2).
La pré-condition de S1 S1.PT et la transition S2 S2 T.
2) un enchainement d‟abandon du service S1 vers le service
S2 indique que S2 est abandonné lorsque S1 échoue, annule ou
abandonne. Cet ensemble {échoué, annulé, abandonné} est la pré-
condition de S1. Cet enchaînement est défini par :
3) un enchainement alternatif entre le type de service S5 vers
le type de service S6 indique que le S6 est activé lorsque le service S5 est
dans l‟état échoué. Cet enchaînement spécifie S6 comme un service
alternatif de livraison. Ainsi, l‟enchaînement d‟alternatives permet
d‟exprimer des alternatives d‟exécution. Dans ce cas, un enchaînement
Ench act(S1,S2) = Ench(S1.p terminer,S2 activer).
Enchaban(S1,S2)=Ench(S1.p abandoner,S2 abandonner) Ench(S1.p
échouer,S2 abandonner) Ench(S1.p annuler,S2 abandonner).

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
118
alternatif de S5 vers S6 existe si et seulement si l‟échec de S5 peut
déclencher l‟activation de S6.
4) l‟enchaînement de compensation de S2 vers S3 indique que S3
est compensé quand S2 échoué. On note
5) l‟enchaînement d‟annulation de S2 vers S3 indique que S3 est
annulé en cours d‟exécution quand S2 est échoué à son tour. On note
Enfin, nous avons présenté dans cette section la
collaboration entre les entreprises en nous appuyant sur le concept des
hypergraphes de type de services. Nous avons défini une architecture
basée sur un médiateur qui permet de contextualiser l‟exécution des
services et qui s‟intègre dans une orchestration proactive en fonction du
contexte d‟exécution. Le moteur d‟orchestration est supporté par un
mécanisme de gestion transactionnelle à base d‟états pour plus
d‟autonomie en tenant compte de l‟approche d‟hypergraphe.
Dans la section suivante nous présentons la construction d‟un
hypergraphe en utilisation les éléments issus de l‟approche-objet.
4.11 Les relations de dépendances entre les Services
Les répertoires, tels que les annuaires UDDI, sont limités aux
descriptions fonctionnelles des services et ne permettent pas la
représentation des dépendances ou les relations inter-services. Modéliser
les interactions entre les services s‟avère utile dans plusieurs cas
d‟utilisation. Par exemple, un système de recommandation en
s‟appuyant sur certains types de relations pourrait remplacer un service
défectueux ou non disponible par un service similaire, ou bien proposer
un ou plusieurs services facultatifs pour enrichir la composition d‟un
nouveau processus métier.
Nous présentons dans la section suivante plusieurs types de relations
entre services. Ces relations peuvent être définies à priori et utilisées au
Ench alt(S5,S6)=Ench(S5.p échouer, S6 activer).
Ench comp(S2,S3) = Ench(S2.p échouer, S3 compenser).
Ench annul(S2,S3)=Ench(S2.p échouer, S3 annuler).

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
119
moment de la composition ou de l‟exécution de services. Ces relations
sont caractérisées par des liens symétriques ou asymétriques entre deux
ou plusieurs services (nœuds). Le graphe constitué par ces relations nous
permet d'identifier des communautés homogènes de services selon les
types de relations sous-adjacentes. Ces communautés regroupent les
modes d'interaction (patterns) entre les types de services Web dans le
but d'offrir une meilleure interactivité et autonomie à l'avenir dans
différents contextes de composition ou d‟exécution de services Web.
Nous définissons plusieurs types de relations entre les services pour
construire l‟hypergraphe à savoir, la relation d‟agrégation, la relation de
recommandation, la relation de similarité et la relation de collaboration.
4.11.1 La relation d’agrégation (A)
Un processus métier (ou un servie composite) est souvent
représenté par ses services/composants reliés par un flux d‟information
qui véhiculent les messages d‟entrée/sortie et détermine l‟ordre
d‟exécution de ces services. Il s‟agit d‟une vue dynamique qui
représente la composition à un seul niveau de profondeur et qui ne
contient que les services atomiques et composites. Cette vue ne permet
pas de présenter récursivement les services composants de certains
services composites. La relation d‟agrégation permet de construire une
vue statique et hiérarchique contenant à la fois les services composites
ainsi que leurs services atomiques. Les services qui se trouvent en bas
de la hiérarchie sont exclusivement atomiques tandis que les services
intermédiaires et la racine sont des services composites.
La relation d‟agrégation est présentée par un n-tuple <S1, A,
S11, S12, S1n>. Elle signifie que S1 est un service composite et S11, ….
S1n sont respectivement ses composants. Notons que cette définition
s‟applique récursivement aux services composants qui pourraient être
eux-mêmes des services composites. La relation d‟agrégation est
asymétrique et non récursive.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
120
Figure 65 : Vue statique du processus métier composite en relations d‟agrégation
La (Figure 65) présente un processus métier (service
composite) sous le perspective d‟une vue dynamique. Dans cet exemple,
S1, S3, S4 et S5 sont des services atomiques alors que le service S2 est un
service composite. Ce processus est représenté à droite par une
hiérarchie d‟agrégations qui révèle les composants de S2 (S21 et S22) et
les composants de S22 (S221, S222 et S223).
4.11.1.1 Les cardinalités
La relation d‟agrégation permet en outre de spécifier des
contraintes au niveau de services composants qui doivent les respecter.
Par exemple, la paire de cardinalité (min, max) permet de préciser que le
service composant doit créer entre min et max instances pendant
l‟exécution pour compenser une montée en charge. La cardinalité (1,1)
est la cardinalité par défaut d‟une relation reliant un composite à un
composant.
4.11.1.2 La spécification de contraintes globales
En outre, la relation d‟agrégation permet de spécifier
facilement des contraintes de qualités de services (QoS) globales sur le
service composite où les services composants doivent ensemble les
satisfaire. Par exemple, si le temps de réponse du service composite doit
être inférieur à 5 secondes, la somme de temps de réponses de tous ses
services composants ne devrait pas dépasser 5 secondes. Cette contrainte

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
121
globale est prise en considération au moment de la composition et c‟est
grâce au contrat de service (SLA) de chaque service que chaque sous
service doit s‟engager à fournir un temps de réponse individuel
acceptable. Le système de composition devrait prendre en considération
la vérification du temps de réponse globale.
4.11.1.3 La propagation des contraintes dans une composition
La relation d‟agrégation permet d‟élaborer un mécanisme de
propagation de contraintes dans une hiérarchie de composition. Nous
définissions deux types de propagation à savoir la propagation molle et
la propagation dure (ou explicite). Une propagation dure permet de
spécifier un ensemble de contraintes sur un service composite et de les
propager récursivement jusqu‟aux services composants atomiques qui
occupent les feuilles dans la hiérarchie d‟agrégation. Les services
composites intermédiaires ne peuvent pas réécrire les valeurs de ces
contraintes. Par exemple, la contrainte « Binding » qui précise que le
protocole de transmission est HTTP pour échanger les messages SOAP,
est spécifiée au niveau de la racine dans la (Figure 60). Dans une
propagation dure, tous les services composants doivent garantir une
implémentation du protocole SOAP-HTTP. Si la propagation est molle,
la valeur de la contrainte « Binding » pourrait être réinitialisée par les
services composants et intermédiaires à n‟importe quel niveau. Par
exemple, si SOAP-RPC est la nouvelle valeur de la contrainte « Binding
» au niveau du service S22, ses services composants, notamment S221,
S222 et S223, doivent implémenter le protocole SOAP-RPC et non le
protocole SOAP-HTTP.
4.11.2 La relation de recommandation (R)
Elle établit une dépendance simple entre deux services. Cette
relation permet au moment de la composition de services de proposer au
concepteur des services susceptibles de l‟intéresser pour enrichir sa
composition avec des fonctionnalités supplémentaires. Le concepteur est
libre d‟accepter ou de refuser les services recommandés dans sa
composition finale. La relation de recommandation est présentée par un

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
122
triplet <S1, R, S2> qui signifie que S1 recommande S2. La relation de
Recommandation est asymétrique.
La (Figure 66) montre que le service SightSeeingWS est relié
par une relation de recommandation au service RoomBookingWS. Si le
service RoomBookingWS participe dans une composition, il pourrait
recommander le service SightSeeingWS pour enrichir le processus par
un service susceptible d‟être intéressant.
Figure 66 : Relation de recommendation < RoomBookingWS, R,
SightSeeingWS >
4.11.2.1 La relation de similarité (S)
Elle permet de rassembler en communauté les services ayant
des fonctionnalités similaires. Cette relation permet au moment de
l‟exécution de proposer un service alternatif pour le substituer à un
service faisant partie d‟une composition en cours d‟exécution. Le
service sera substitué suite à une défaillance ou à un changement externe
ou interne qui ne garantit plus les paramètres de qualité de services
(QoS) entre le fournisseur du service et le consommateur du service.
La relation de similarité est présentée par un triplet <S 1, S, S2>.
Elle signifie que S1 similaire à S2. La relation de similarité est
symétrique.
La Figure 67 montre que les services RoomBookingWS et
RoomReservationWS sont reliés par une relation de similarité. Pendant
l‟exécution le service RoomBookingWS pourrait être remplacé par le
service RoomReservationWS sous certaines conditions contextuelles.
Les deux services appartiennent à la même communauté.
Figure 67 : Relation de similarité < RoomBookingWS, S,
RoomReservationWS >

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
123
4.11.2.2 La relation de collaboration (C)
Le système de composition mémorise les interactions entre
services pour établir les relations de collaborations. Elles correspondent
souvent aux flux d‟information échangés entre les services. En se basant
sur la qualité des interactions précédentes entre deux services, le
système met à jour les poids pondérés affectés à leur relation de
collaboration. Ceci permet d‟ajuster le processus de composition en
choisissant les services qui ont le mieux collaboré dans des
compositions précédentes et accroître la confiance sur la collaboration
entre deux services. La relation de collaboration est présentée par un
quadruple <S1, C, w, S2>. Elle signifie que S1 et S2 ont déjà collaboré et
leur degré de collaboration a une valeur de w. Cette relation est
symétrique et le poids de la relation de collaboration est défini de la
manière suivante.
W(S1, S2)= Ci/Cn
Ci= nombre de fois S1 et S2 sont réellement collaborés
Cn= nombre de fois S1 et S2 sont sélectionnés pour collaborer,
La Figure 68 montre que les services AirTicketPurchaseWS et
RoomBookingWS sont en collaboration. Au moment d‟une composition
de services, la requête qui interroge le registre UDDI pour sélectionner
les services similaires d‟une communauté (à collaborer avec
AirTicketPurchaseWS par exemple) se base sur le poids de collaboration
le plus élevé pour favoriser le choix d‟un service particulier parmi
plusieurs services de même type (RoomBookingWS).
Figure 68 : Relation de collaboration < AirTicketPurchaseWS, C, 0,5,
RoomBookingWS>
4.12 Intégration des relations de dépendances dans les processus
métiers
La découverte des services Web dans un répertoire s‟appuie sur des
langages de requêtes qui spécifient les propriétés fonctionnelles
notamment les messages d‟entrée et sorties, les pré- et post-conditions et

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
124
les propriétés non-fonctionnelles dont entre autres les préférences de
sécurité. Les types de relations entre les services favorisent la création
de processus collaboratifs qui s‟adaptent aux changements du contexte
de collaboration. Le processus a un comportement dynamique ajusté au
fil du temps. Figure 69 montre que le processus métier n‟est plus isolé
mais ses différents services sont interconnectés par les différents types
de relations de dépendances. Ces relations sont exploitées au moment de
la composition et de l‟exécution de la manière suivante :
1- Exploitation des relations au moment de la conception des
services : Tout d'abord, le concepteur établit différents types de relations
entre les services Web atomiques/simples. Ensuite, il interroge le
répertoire par des requêtes pour sélectionner les services susceptibles de
participer à une composition afin de créer un nouveau processus métier
(service composite). Les requêtes ne doivent pas seulement prendre en
considération les propriétés fonctionnelles et non- fonctionnelles mais
elles devraient aussi traiter les relations de dépendances entre les
services Web pour ajuster la sélection.
2- Exploitation des relations au moment de l'exécution des
services : Le moteur d'exécution des processus métiers (moteur BPEL)
pourrait prendre certaines actions (situations d‟échec par exemple) en
s‟appuyant sur les relations de dépendances et les scénarios de
compositions précédentes.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
125
Figure 69 : Un processus métier et les différentes types de relations de
dépendances entre les services
Les relations ne sont pas seulement préservées au moment de la
conception mais elles sont également exploitées pendant l‟exécution et
elles sont enrichies pendant le cycle de vie de chaque pair de services.
Les relations acquièrent donc une importance égale aux services-mêmes.
4.13 Conclusion
Nous avons défini la collaboration entre les entreprises en
utilisant l‟hypergraphe. Nous avons aussi défini la construction de notre
hypergraphe que nous exploitons ensuite pour introduire des stratégies
d‟héritage antre les services. Ensuit nous avons défini l‟orchestration
entre les services et les contraints de transition entre eux avant .de
définir le mécanisme d‟héritage entre les services et les différentes
relations entre les services.
Dans le chapitre suivant nous présenterons la conclusion
générale et notre perspective.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
126

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
127
Chapitre 5 Conclusion générale et
perspectives
5.1 Conclusion général et perspective
L‟évolution de la demande pour des associations produits/services
nécessite l‟organisation de collaborations « à la demande » entre
entreprises pour répondre aux besoins des clients. Ce changement
structurel au niveau du marché laisse donc prévoir une croissance
exponentielle des écosystèmes de services dans les prochaines années et
impose de pouvoir organiser des collaborations « à la demande » entre
les entreprises ce qui implique des changements radicaux dans la
structure organisationnelle des entreprises. Ces collaborations
conduisent à l‟émergence d‟entreprises virtuelles et font largement appel
aux technologies de l‟information et de la communication. Or les
réponses technologiques apportées peuvent constituer un frein : les
Systèmes d‟Information (SI) d‟entreprise ne sont que peu agiles et
manquent de capacité d‟interopérabilité. En effet, l‟infrastructure
informatique (matérielle et logicielle, i.e. ERP, CRM, CAD, SCM,
MES…) présente une forte complexité technologique, manque
d‟interopérabilité et limite donc les possibilités « d‟interconnexion »
entre les processus d‟entreprise et l‟échange d‟information entre
partenaires.
Pour surmonter ces limites, l‟implémentation du système d‟information
selon une architecture orientée services (SOA) définit une nouvelle
approche pour organiser les applications d'entreprise et optimiser les
processus métier. Néanmoins, ces infrastructures sont essentiellement
destinées à soutenir l'interopérabilité intra-entreprise car elles reposent
sur une définition mono-contexte du processus d'affaires. Or un
écosystème de services inclut un environnement multi -contextuel

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
128
d‟exécution de services. Chaque entreprise fournit plusieurs services
reliés à des contextes d‟exécution particuliers. Cette approche qui vise à
développer des services multi-contextuels est un environnement
complexe à mettre en place. En plus, il est exposé à des risques
d‟incohérence entre les différents services qui offrent les mêmes
fonctionnalités.
Dans notre travail de recherche, nous proposons un cadre générique qui
s‟appuie sur la composition de chaînes de services multi -contextuels
(i.e. supportant différents contextes d‟exécution) et qui favorise le
déploiement de systèmes d‟information interopérables et collaboratifs.
Pour cela, nous avons présenté une approche qui permet la réalisation de
plusieurs scénarios de collaboration inter entreprises en se basant sur les
concepts clés tels que le service, l‟hypergraphe, les relations
d‟interdépendance et différentes vues notamment la vue de gestion, la
vue de médiation, et la vue de sécurité. Ces concepts visent à enrichir la
composition de services et assurer une exécution contextuelle. Dans
notre travail, nous proposons que chaque entreprise maintienne un
répertoire local de services à partager avec ses partenaires et participe à
la gestion d‟un répertoire commun contenant les chaînes de services
fournies par les différents partenaires. L‟originalité de notre approche
consiste à conserver la propriété du « couplage lâche » qui est nécessaire
pour le mécanisme d‟orchestration, et proposer plusieurs types de
relations entre les services afin d‟enrichir la composition et assurer une
exécution tardive et contextuelle en fonction des informations perçues
par l‟environnement d‟exécution. Dans notre travail de recherche, nous
avons défini les types de relations suivants : la relation d‟agrégation, la
relation de recommandation, la relation de similarité, la relation de
collaboration et la relations d‟héritage.
Les travaux réalisés dans le cadre de cette thèse ouvrent
diverses perspectives et plusieurs travaux futurs peuvent être envisagés :
Améliorer les relations de dépendances inter-services :
Nous nous sommes limités dans la démarche que nous avons
présentée dans cette thèse à plusieurs types de relations entre les
services. Ceci constitue un point de départ important pour associer à
chaque type de relation un poids qui mesure son importance. Par
exemples, un service sélectionné pourrait recommander plusieurs

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
129
services grâce à la relation de recommandation. Or ces relations peuvent
avoir de poids différents et le service sélectionné pourrait choisir le
service avec le poids le plus élevé. Nous envisageons aussi d‟introduire
plusieurs formules pour calculer les poids associés à ces relations.
Etendre la conception de services multi-contextuels :
La modélisation de services multi-vues que nous avons
développée prend en compte l‟environnement multi-contextuel
d‟exécution. Ces vues sont assez simples et indépendantes et plusieurs
extensions peuvent être prises en compte. Nous voudrions introduire un
modèle holistique de vues interconnectées où la modification d‟une vue
entrainerait la mise à jour de tous les vues. L‟enchainement de ces vues
nécessite une intégration cohérente et une transformation de modèles qui
décrivent ces vues.
Améliorer les capacités de l’orchestrateur pour une
exécution multi-contextuelle:
L'idée de développer un médiateur pour supporter une
exécution multi-contextuelle s'avère être très intéressante vue
l'importance d'une telle médiation dans la mise en place d'une
orchestration SOA. Nous envisageons d‟étudier ce type d‟orchestration
pour prendre en compte les différentes vues et leurs propriétés non-
fonctionnelles. Un point important à développer sera la gestion
transactionnelle de ces services en se basant sur les types de relations
afin d‟assurer une autonomie dans l‟exécution de chaînes de services.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
130
Bibliographie
[1] E. Overby, A. Bharadwaj, and V. Sambamurthy, “A Framework for Enterprise
Agility and the Enabling Role of Digital Options,” Business Agility and
Information Technology Diffusion, vol.180,Springer,Boston, 2005, pp. 295-312.
[2] E. Overby, A. Bharadwaj, and V. Sambamurthy, “Enterprise agility and the
enabling role of information technology,” European Journal of Information
Systems, vol. 15, 2006, pp. 120-131.
[3] T. Erl, “Service-Oriented Architecture: Concepts, Technology, and Design,”
Prentice Hall PTR, August 2005, pp. 792.
[4] A. Esper, L. Sliman, Y. Badr, and F. Biennier, “Towards Secured and
Interoperable Business Services,” Enterprise Interoperability III,Springer,Berlin
2008, pp. 301-312.
[5] A. Esper, Y. Badr, and F. Biennier, “Organization of Contextual Enterprise -
Service Bus,” Proceeding of the 3rd International Conference on Information &
Communication Technologies: from Theory to Applications (ICTTA‟08),
Damascus , Syria , Avril 2008, pp. 1-5.
[6] A. Esper, Y. Badr, and F. Biennier , “ Hypergraph of Services for Business
Interconnectivity and Collaboration,“APMS (International Conference on
Advances in Production Management Systems à Bordeaux, France, 2009.
[7] Modélisation des processus de l‟entreprise: Etat de l'art et conseils pratiques,
projet SPINOV, 2006, disponible à
http://www.citi.tudor.lu/SI/Livrable.nsf/96F59447CF
4CCF05C125701C004C6BA9/$File/RS_BP%20Modeling_Etat%20art%20et%20c
onseils%20pratiques_1.0.pdf, la dernière visite 14/06/2010.
[8] M. Brahimi and L. Bouzidi, “Eléments d‟architecture pour une mémoire
d‟entreprise orientée processus métier.” Revue électronique suisse de science de
l'information, 2007, disponible à http://cours.ebsi.umontreal.ca/sci6144/lecture/

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
131
seance%208/S%C3%A9ance%2008%20%C3%89l%C3%A9ments%20d'architectu
re%20pour%20une%20m%C3%A9moire%20d'entreprise.pdf, la dernière visite
14/06/2010.
[9] D. Georgakopoulos, M. Hornick, and A. Sheth, “An overview of workflow
management: From process modeling to workflow automation infrastructure,”
Distributed and Parallel Databases, vol. 3, 1995, pp. 119–153.
[10] C. Morley, “Un cadre unificateur pour la représentation des processus,”
International Conference on Information Systems Pre-ICIS, Washington, USA,
décembre 2004, disponible à http://www-dsi.int-evry.fr/files/chap2.pdf, la
dernière visite 14/06/2010.
[11] BPMI, The Business Process Management Initiative. 2007 disponible à
http://www.bpmi.org/" la dernière visite 14/06/2010.
[12 ] L. Fischer , “Innovation and Excellence in Workflow and Business Process
Management,” Excellence in Practice, Volume V, ISBN 0-9703509-5-3.
[13] F. Vernadat, “Enterprise Modeling and Intergration: Principles and
Applications,” (Champan& Hall, london) ,1996,455 P.
[14] K. Kosanke, “CIMOSA: Overview and status,” Comput. Ind., vol. 27, 1995,
pp. 101-109.
[15] K. Kosanke, F. Vernadat, and M. Zelm, “CIMOSA: enterprise engineering
and integration,” Comput. Ind., vol. 40, 1999, pp. 83-97.
[16] W.S. August, ARIS - Business Process Frameworks, Springer, Berlin: 1998.
[17] G. Goumeingts, “ Méthode GRAI : méthode de conception des systèmes en
productique, thèse d‟Etat, Université de Bordeaux 1,” 1984.
[18] D. Chen, B. Vallespir, and G. Doumeingts, “GRAI integrated methodology
and its mapping onto generic enterprise reference architecture and methodology,”
Comput. Ind., vol. 33, 1997, pp. 387-394.
[19] T.J. Williams, “The Purdue Enterprise Reference Architecture,” Comput.
Ind.,USA, vol. 24, 1994, pp. 141-158.
[20] IFIP-IFAC, GERAM: Generalised Enterprise Reference Architecture and
Methodology, 1999, disponible à:

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
132
http://www.cit.griffith.edu.au/~bernus/taskforce/geram/versions/geram1-6-
3/GERAMv1.6.3.pdf, la dernière visite 14/06/2010.
[21] P. Bernus and L. Nemes, “Requirements of the generic enterprise reference
architecture and methodology,” Annual Reviews in Control, vol. 21, 1997, pp.
125-136.
[22] SADT & IDEF une méthode de spécification,” 2010; availabla at
http://psylon.free.fr/formatio/doc/sadt.doc, la dernière visite 14/06/2010.
[23] M. DIVINÉ, “MERISE:60 Affaires classées,” Paris, Eyrolles, 2008,291P.
[24] H. Tradieu, A. ROCHFELD, R. COLLETTI, La méthode MERISE, principes
et outils, Ed. d‟Organisation, Paris, 1986.
[25] H. TARDIEU, A. ROCHFELD, R. COLLETTI, La méthode MERISE :
Principes et outils, Paris, les Ed. d'Organisation, 1998, 344 p.
[26] P. Dumas and G. Charbonnel, La méthode OSSAD, éditions d'organisation,
1990, disponible à http://dumas.univ tln.fr/Docs_PDF/ OSSAD %20vol1
%20020315.pdf, la dernière visite 14/06/2010.
[27] W.P. M. Blaha, “A catalog of object model transformations,” In 3rd Working
Conference on Reverse Engineering, november 1996
[28] J. Ferber, Conception et programmation par objets, Hermè, paris, 1991, 50P.
[29] C. Pasquier, P. Roucoulet, and M. Lin Lanaspèze, l'approche objet. Hermes,
1995, 217 P.
[30] “OMG Business Object DTF Common Business Objects,” 1997, disponible à
http://www.omg.org/docs/bom/97-12-01.pdf, la dernière visite 14/06/2010.
[31] W.V.D. Heuvel, M.P. Papazoglou, and M.A. Jeusfeld, “Configuring Business
Objects from Legacy Systems,” Proceedings of the 11th International Conference
on Advanced Information Systems Engineering, Springer-Verlag, 1999, pp. 41-
56.
[32] A. Caetano, A.R. Silva, and J. Tribolet, “Using roles and business objects to
model and understand business processes,” Proceedings of the 2005 ACM
symposium on Applied computing, USA, March 2005, pp. 1308-1313.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
133
[33] K. Mertins, R. Jochem, Planning of enterprise-related CIMstructures, in:
Proceedings of 8th International Conference CARS and FOF, Metz, France, 17-19
August 1992.
[34] F. Vallée, “ UML pour les décideurs“ Paris, Eyrolles, 2005, 273 P.
[35] H. Smith and P. Fingar, Business Process Management: The Third Wave,
Meghan-Kiffer Press, 2003, disponible à http://www.bpm3.com/, la dernière
visite 14/06/2010.
[36] M.H. Dodani, “From Objects to Services: A Journey in Search of
Component Reuse Nirvana.” Journal of Object Technology, 2004, disponible à
http://www.jot.fm/issues/issue_2004_09/column5/, la dernière visite 14/06/2010.
[37] K. Mertins, R. Jochem, and F. Jäkel, “A tool for object-oriented modelling
and analysis of business processes,” Comput. Ind., vol. 33, 1997, pp. 345-356.
[38] S. Andre, “MDA (Model Driven Architecture) principes et états de
l‟art,”Technical report, 2004, disponible à
http://wwwesto.ump.ma/mounir/mda/these%20mda/MDAv1.8.pdf, la dernière
visite 14/06/2010.
[39] H. Kadima, MDA:Conception orientée objet guidée par les modèles,
Numilog, Dunod, 2005, 240 P.
[40] X. Blanc, MDA en action, Paris Eyrolles,1ère édition,2005, 270 P.
[41] A. Wilhelm Scheer, ARIS: des processus de gestion au systeme integré
d'applications , Springer-Verlag, 2002.
[42] M.A. Emmelhainz, EDI = L'échange de données informatisées, Masson,
1993, 267P.
[43] Berge, J., The EDIFACT Standards. Manchester, England, NCC Blackwell,
1991.
[44] C. Huemer, G. Quirchmayr, and A.M. Tjoa, “A Meta Message Approach for
Electronic Data Interchange (EDI),” Proceedings of the 8th International
Conference on Database and Expert Systems Applications, Springer-Verlag,
1997, pp. 377-386.
[45] D. Linthicum. Enterprise Application Integration. Addison-Wesley, 2000,
377 pp.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
134
[46] T. Bray, J. Paoli, C. M. Sperberg-McQueen, E. Maler, and Y. François,
Extensible markup language (XML) 1.0 (second edition)- W3C recommendation“.
Disponible à http://www.w3.org/TR/REC-xml/, la dernière visite 15/06/2010.
[47] B. Alexendre, XML, Paris, Eyrolles,2007, 240P.
[48] J. Yang, “Service oriented computing: the challenges and opportunities in
business development, 2005, disponible à
http://www.ict.csiro.au/MU/Trends/Presentations/Jian%20Yang.pdf , la dernière
visite 14/06/2010.
[49] J. Yang and M.P. Papazoglou, “Service components for managing the life -
cycle of service compositions,” Inf. Syst., vol. 29, 2004, pp. 97-125.
[50] D. Booth, H. Haas, F. McCabe, E. Newcomer, M. Champion, C. Ferris, and
D. Orchard, “Web Services Architecture, W3C Working Group Note 11,
February, W3C Technical Reports and Publications,” 2004.
[51] H. Kadima and V. Monfort, Les Web services - Techniques, démarches et
outils : XML-WSDL-SOAP-UDDI-Rosetta-UML, Dunod/01 Informatique, 2003,
411.
[52] E. Christensen, F. Curbera, G. Meredith, and S. Weerawarana, “Web
Services Description Language (WSDL) 1.1,”,W3C, Mar. 2001, disponible à
http://www.w3.org/TR/wsdl, la dernière visite 15/06/2010.
[53] J.M. Chauvet, Service Web avec SOAP,WSDL, UDDI,ebXML , 2002,528P.
[54] D. Martin, A. Ankolekar , M. Burstein , G. Denker , D. Elenius, J. Hobbs , L.
Kagal , O. Lassila , D. McDermott , D. McGuinness , S. McIlraith , M. Paolucci ,
B. Parsia , T. Payne , M. Sabou , C. Schlenoff , E. Sirin , M. Solanki , N.
Srinivasan , K. Sycara , and R. Washington , “OWL-S Coalition, OWL-S
Specification,” 2004,disponible à http://www.daml.org/services/owl-s/, la
dernière visite 15/06/2010.
[55] D. Box, D. Ehnebuske, G. Kakivaya, A. Layman, N. Mendelsohn, H. F.
Nielsen, S. Thatte, and D. Winer, “Simple object access protocol (SOAP) 1.1,”
http://www.w3.org/TR/SOAP/, la dernière visite 15/06/2010.
[56] Q. Yu, X. Liu, A. Bouguettaya, and B. Medjahed, “Deploying and managing
Web services: issues, solutions, and directions,” The VLDB Journal, vol. 17,
2008, pp. 537-572.

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
135
[57] A. Arkin, “Business Process Modeling Language, Version 1.0,” Business
Process Management Initiative (BPMI.org), Tech. Rep., June 2002.
[58] A.Tony, C. Francisco, D. Hitesh, G. Yaron, K. Johannes, L. Frank, L. Kevin,
R. Dieter, S.Doug, T. Satish, T. Ivana, and W. Sanjiva.“ Business process
execution language for web services version 1.1“. Technical report, May 2003.
http://www.oasisopen.org/committees/download.php/2046/BPEL%20V11%20Ma
y%205%202003%20Final.pdf, la dernière visite 15/06/2010.
[59] D. Djidel, B. Mathew, and M. Juric, Orchestration de services web avec
BPEL, guide pour architectes et développeurs, Packt, 2004, 413P.
[60] S. Thatte, “XLANG : Web Services for Business Process Design,” Microsoft.
2001.
[61] F. Leymann. Web Services Flow Language (WSFL 1.0). IBM, May 2001.
[62] S. Felipe, G. Copeland, M. Feingold, T. Freund, J. Johnson, C. Kaler, J.
Klein, D. Langworthy, A. Nadalin, D. Orchard, I. Robinson, J. Shewchuk, and T.
Storey, “Web Services Coordination (WS-Coordination),” 2004,disponible à
http://schemas.xmlsoap.org/ws/2004/10/wscoor/ la dernière visite 15/06/2010.
[63] F. Cabrera, G. Copeland, B. Cox, T. Freund, J. Klein, T. Storey, and S.
Thatte, “Web Services Transaction (WS-Transaction),” 2002, disponible à
http://xml.coverpages.org/WS-Transaction2002.pdf, la dernière visite 15/06/2010
[64] J. Gray and A. Reuter, “Transaction processing Concepts and Techniques",
Morgan Kaufmann, 1993, 887P.
[65] J. Gray, “The transaction concept: virtues and limitations (invited paper),”
Proceedings of the seventh international conference on Very Large Data Bases -
Volume 7, Cannes, France: VLDB Endowment, 1981, pp. 144-154.
[66] C. Peltz, “Web Services Orchestration and Choreography,” Computer, vol.
36, 2003, pp. 46-52.
[67] F. Vernadat, Interoperable enterprise systems: Principles, concepts, and
methods, Annual Reviews in Control, 31(1), 2007, pp. 137-145.
[68] H. Afsarmanesh, L.M. Camarinha-Matos: A framework for management of
virtual organizations breeding environments. Proceedings of PRO-VE'05 -

Alida ESPER
Thèse en informatique / 2010
Institut National des Sciences Appliquées de Lyon
136
Collaborative networks and their breeding environments, Springer, Valencia,
Spain, 26-28 Sept, 2005, pp. 35-48.
[69] C. Sodki., Interconnexion des processus Interentreprises: une approche
orientée services, thèse INSA Lyon, 2008,198 P .
[70] H. Ludwig, “Web services QoS: external SLAs and internal policies or: how
do we deliver what we promise?,” Web Information Systems Engineering
Workshops, 2003. Proceedings. Fourth International Conference on, 2003, pp.
115-120.
[71] J. Cardoso, A. Sheth, J. Miller, J. Arnold and K. Kochut, Quality of service
for workflows and web service processes, Web Semantics: Science, Services and
Agents on the World Wide Web,2004, pp. 281-308.
[72] M. Conti, M. Kumar, S. K. Das and B.A, Shirazi, Quality of service issues
in Internet web services, IEEE Transactions on Computers, 2002, pp. 593-594.
[73] P. Resnik, Semantic Similarity in Taxonomy: An information-based measure
and its application to Problems of Ambiguity in Natural language. Journal of
Artificial Intelligence 11 (1999): 95-130
[74] P. Hoffmann, Similarité sémantique inter-ontologies basée sur le contexte,
thèse de doctorat, 1999. 82 pages.
[75] L.B. Yanne., Towards the conception of extended information systems
organized around a web service platform, Univesité Lyon 1, 2008, 127 P.
[76] Rajsiri V., Knowledge-based system for collaborative process specification,
Thèse de doctorat, Thèse de l‟Ecole des Mines d‟Albi-Carmaux, 2009, 223 P.