Fabrice Bethuel Année Universitaire 2012-2013bethuel/LM256.pdf · LM256 : Analyse vectorielle,...
126
LM256 : Analyse vectorielle, intégrales multiples Fabrice Bethuel Année Universitaire 2012-2013
Transcript of Fabrice Bethuel Année Universitaire 2012-2013bethuel/LM256.pdf · LM256 : Analyse vectorielle,...

LM256 : Analyse vectorielle, intégrales multiples
Fabrice Bethuel
Année Universitaire 2012-2013

Table des matières
1 Fonctions d’une variable réelle 31.1 Généralités sur les applications et les fonctions . . . . . . . . . . . . . . . . . . . . . . 3
1.1.1 Premières définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.1.2 Composition des applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.1.3 Application réciproque . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.2 La notion de limite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3 La notion de continuité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.4 La notion de dérivée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.4.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.4.2 Calculs de dérivées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.4.3 Dérivées d’ordre supérieur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.5 Primitives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121.5.1 Opérations sur les primitives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131.5.2 Intégrales définies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.5.3 Aire d’un domaine du plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151.5.4 intégration de la relation ¿ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
1.6 Développements limités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2 Fonctions de deux variables 192.1 L’espace vectoriel R2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.2 Courbes paramétrées de R2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.3 Graphes, lignes de niveau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242.4 Limites, continuité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262.5 La notion de dérivée partielle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.5.1 Développement limité à l’ordre 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.5.2 Le gradient . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312.5.3 Dérivation des fonctions composées . . . . . . . . . . . . . . . . . . . . . . . . 322.5.4 La matrice Jacobienne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 342.5.5 Dérivées secondes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.6 Le théorème des fonctions implicites . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3 Champs de vecteurs 443.1 Premières définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.1.1 Changement de repère . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 453.1.2 Champ de gradient . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 463.1.3 Lignes de champ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3.2 Circulation d’un champ de vecteurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
1

3.2.1 Circulation d’un champ de gradient . . . . . . . . . . . . . . . . . . . . . . . . . 533.3 Le formalisme des formes différentielles . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.3.1 Formes linéaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 553.3.2 Forme différentielles de degré 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . 563.3.3 Intégrale curviligne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4 Intégrales doubles 594.1 Construction de l’intégrale double . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 594.2 Le Théorème de Fubini . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 604.3 Intégration par parties . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4.3.1 Calcul de l’aire d’un domaine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 674.3.2 Flux et divergence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 684.3.3 Autres formules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 694.3.4 La divergence en coordonnées polaires . . . . . . . . . . . . . . . . . . . . . . . 71
4.4 Changements de variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 724.4.1 Aire d’un parallélelogramme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 724.4.2 Aire de l’image d’un rectangle élémentaire . . . . . . . . . . . . . . . . . . . . . 734.4.3 La formule du changement de variable . . . . . . . . . . . . . . . . . . . . . . . 734.4.4 Invariances par changement de repère orthonormé. . . . . . . . . . . . . . . . 75
4.5 Calcul du volume d’un domaine de R3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 774.6 Interprétation de la divergence et du flux . . . . . . . . . . . . . . . . . . . . . . . . . . 78
5 Analyse vectorielle dans R3 825.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
5.1.1 Rappels sur R3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 825.2 Limites, continuités et dérivation dans R3 . . . . . . . . . . . . . . . . . . . . . . . . . 845.3 Courbes paramètrées dans R3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 865.4 Surfaces paramétrées dans R3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 865.5 Le théorème des fonctions implicites . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
5.5.1 Aire d’une surface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 915.5.2 Intégration sur les surfaces . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
5.6 Intégrales triples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 935.6.1 Construction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 935.6.2 Le Théorème de Fubini . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 935.6.3 Changements de variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
5.7 Formule flux-divergence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
6 Le rotationnel 1046.1 Champ de vecteurs, champs de gradient . . . . . . . . . . . . . . . . . . . . . . . . . . 104
6.1.1 Invariance du rotationnel par changement de repère orthonormé . . . . . . . 1066.2 Flux du rotationnel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
6.2.1 Surfaces fermées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1066.2.2 Surfaces dont le bord est une courbe . . . . . . . . . . . . . . . . . . . . . . . . 107
6.3 Champs à rotationnel nul . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1096.4 Champ à divergence nulle, potentiels vecteurs . . . . . . . . . . . . . . . . . . . . . . . 110
7 Sujets d’examen 113
2

Chapitre 1
Fonctions d’une variable réelle
Dans ce chapitre, nous rappelons quelques éléments de l’analyse des fonctions d’une variableréelle.
1.1 Généralités sur les applications et les fonctions
1.1.1 Premières définitions
Une application d’un ensemble E (dit "ensemble de départ") dans un ensemble F (dit "en-semble d’arrivée") est une correspondance qui associe à tout élément de E un élément de F et unseul . On note cette application :
f : E 7→ F ou encore f : x 7→ y = f (x).
L’élément y = f (x) de F est appelé l’image de x par f . On dit aussi que x est l’antécédent de y .Le graphe de f est la partie G du produit E ×F constituée des éléments de la forme (x, f (x)), où
x ∈ E .
Une fonction de E dans F est une application d’une partie D de E dans F . La partie D ⊂ E estalors appelée domaine de définition de la fonction f , et est souvent notée D f :
D =D f .
Comme précédemment le graphe de f est donnée par les éléments de la forme (x, f (x)), où x ∈D f .Dans ce chapitre, nous considérerons uniquement le cas où E = F =R. On parle alors de fonc-
tions réelle d’une variable réelle. En revanche, dans les chapitres suivants, nous considérons plusgénéralement les cas où E =RN , F =RK , avec N ∈ 1,2,3, K ∈ 1,2,3.
Pour les fonctions d’une variable réelle, la fonction f est souvent définie à l’aide d’une formule.L’ensemble de définition est donc représenté par les éléments x pour lesquels cette formule à unsens.
Exemple 1.– La fonctions x → ax , où a est donné, est une fonction linéaire. Son domaine de définition
est R tout entier. Son graphe est une droite du plan R2 passant par l’origine.
3

– la fonction x → ax +b où les nombres a et b sont donnés est une fonction affine. Son do-maine de définition est R tout entier. Son graphe est une droite du plan R2 passant par lepoint (0,b).
– la fonction x → ax2 +bx + c , où a 6= 0,b,c sont donné définit une fonction, polynôme dedegré 2. son domaine de définition est R tout entier. Son graphe est une courbe, appeléeparabole, qui passe par le point (0,c).
– La fonction f définie par la formule f (x) = 1
xest définie pour tout x non nul de R, son do-
maine de définition est donc D f =R\ 0.
– La fonction f définie par la formule f (x) =√
1−x2 est définie pour tout x de l’intervalle[−1,1]. Son domaine de définition D f est donc l’intervalle [−1,1].
Revenons au cas général, et considérons une application f : E → F , où E et F sont deux en-sembles. On dira que :
– L’application f est injective si chaque élément y de F a au plus un antécédent par f . End’autres termes, f est injective si et seulement si pour touséléments x et x ′ de E l’égalitéf (x) = f (x ′) entraîne nécessairement x = x ′.
– L’application f est surjective si chaque élément y de F a au moins un antécédent par f . End’autres termes, f est surjective si et seulement si pour touséléments y ′ de E il existe x ∈ Etel que y = f (x).
– L’application f est bijective si et seulement si chaque élément y de F a exactement un an-técédent et un seul par f . En d’autres termes, f est bijective si et seulement si pour toutélé-ment y de E il existe un unique élément x ∈ E tel que y = f (x).
On vérifiera sans mal qu’une application est bijective si et seulement si elle est injective et sur-jective.
Par exemple, l’application x → sin x est surjective si on la considère comme application de Rdans [−1,+1]. Elle n’est pas injective puisque, par exemple, si n0 = si n2π. En revanche, elle devientbijective si on la considère comme application de [−π
2 ,+π2 ] sur [1,+1].
1.1.2 Composition des applications
Considérons maintenant trois ensembles E ,F,G et des applications f : E → F et g : F →G . Pourtout élément x dans E , on peut alors définir l’élément z = g
(f (x)
)de G . Ceci définit une nouvelle
application de E dans G , notée g f .
Définition 1. On appelle application composée de f et de g et on note g f l’application de E versG définie par
g f (x) = g(
f (x))
, pour tout x ∈ E .
De même, on peut définir l’application composée de deux fonctions f : E → F et g : F → G .La fonction composée g f est alors une fonction de E vers G dont le domaine de définition estcomposée desélements de D f dont l’image par f appartient au domaine de définition de g .
Exemple 2. Prenons les fonctions d’une variable réelle f et g définies par
g (x) = 1
xet f (x) =
√1−x2.
4

La fonction g f est alors donnée par
g f (x) = 1p1−x2
.
Le domaine de définition de g f est donc ]−1,1[. Les points ±+1 appartiennent bien au domainede défintion de f , mais leur image par f vaut 0, qui n’est pas dans le domaine de définition de g .
1.1.3 Application réciproque
Soient E et F deux ensembles et f une application de E vers F que l’on supposera de plus bi-jective, c’est à dire que pour toutélément y de F il existe un uniqueélément x de E tel que y = f (x).
Définition 2. On appelle application réciproque de f et on note f −1 l’application de F vers E quià toutélément y de F associe l’uniqueélément x de E tel que y = f (x).
En d’autres termesx = f −1(y) si et seulement si y = f (x).
Il résulte de la définition quef −1 f = IdE et f f −1 = IdF ,
où IdE désigne l’application identité de E , c’est à dire l’application de E dans lui-même définie parIdE (x) = x, avec bien entendu une définition similaire pour IdF .
On peut vérifier la propriété suivante, dont la preuve est laissée en exercice
Proposition 1. Soient E ,F,G trois ensembles et des applications f : E → F et g : F → G supposéebijectives. Alors l’application composée g f est bijective de E vers G et l’application réciproquevérifie l’identité (
g f)−1 = f −1 g−1.
Exemple 3.– La fonction f : R+ → R+ définie par f (x) = x2, est une application bijective (elle ne le serait
pas si l’on prenait R comme ensemble de départ). Son application réciproque est donnéepar f −1 :R+ →R+, f −1(x) =p
x, qui n’est autre que la fonction racine carrée !– La fonction sin : [−π
2 , π2 ] → [−1,1] est une application bijective. On note arcsin l’applicationréciproque arcsin : [−1,1] → [−π
2 , π2 ]. On a donc pour x ∈ [−1,1], y = arcsin x si et seulementsi
y ∈ [−π2
,π
2] et x = sin y.
– De même, la fonction cos : [0,π] → [−1,1] est une application bijective. On note arccos l’ap-plication réciproque arccos : [−1,1] → [0,π]. On a donc pour x ∈ [−1,1], y = arccos x si etseulement si
y ∈ [0,π] et x = cos y.
– La fonction tan : [−π2 , π2 ] →R est une application bijective. On note arctan l’application réci-
proque arctan :R→ [−π2 , π2 ]. On a donc pour x ∈R, y = arctan x si et seulement si
y ∈ [−π2
,π
2] et x = tan y.
Notons par ailleurs que si f est une fonction d’une variable réelle bijective, le graphe de f −1
se déduit de celui de f en faisant agir une symétrie par rapport à la droite y = x, qui intervertit enparticulier les axes.
5

1.2 La notion de limite
Nous ne considérons dorénavant, et jusqu’à la fin de ce chapitre que des fonctions d’une va-riable réelle, c’est à dire le cas E = F =R.
Soit donc f et x0 un point donné de D f . On supposera de plus que f est définie sur un inter-valle ouvert non vide ]a,b[ contenant x0, sauf peut-être en x0, c’est à dire que ]a,b[\x0 ⊂D f .
Définition 3. On dit que la fonction f admet une limite L en x0, ou que f (x) tend vers L lorsque xtend vers x0, si et seulement si :
Pour tout nombre réel ε> 0, il existe un nombre α> 0 tel que la relation 0 < |x −x0| <α entraîne
| f (x)−L| < ε.
On vérifie que si une limite L existe, alors elle est forcément unique. On note alors
L = limx→x0
f (x) ou encore f (x) →x→x0
L.
Ceci signifie que pour un nombre ε> 0 aussi petit que l’on le désire, on peut trouver un nombreα> 0 qui dépend bien entendu de ε tel que si l’écart entre x0 et x (x étant distinct de x0) est infé-rieur à α, alors l’écart entre f (x) et L est inférieur à ε.
Voyons maintenant comment la notion de limite se comporte vis à vis des opérations clas-siques sur les fonctions (addition, multiplication et division). Rappelons que si f et g sont des
fonctions réelles, on définit les fonctions f ± g , f g , etg
fpar
( f ± g )(x) = f (x)± g (x), et ( f g )(x) = f (x)g (x),∀x ∈D f ∩Dg ,
g
f(x) = g (x)
f (x)pour x ∈D f ∩Dg tel que f (x) 6= 0.
Proposition 2. Soient f et g deux fonctions sur R telles que f et g admettent comme limites en x0
les nombres L et M respectivement. Les fonctions f ±g et f g admettent alors les limites suivantes enx0 :
limx→x0
( f ± g )(x) = L±M et limx→x0
( f g )(x) = LM .
de plus, si L 6= 0 alors on a
limx→x0
f
g(x) = L
M.
Démonstration (première partie). On commence par se donner ε > 0. Comme f (x) tend vers Lquand x tend vers x0, il existe un nombre α1 > 0 tel que, si 0 < |x−x0| <α1 alors on a | f (x)−L| < ε
2 .De la même manière, il existe un nombreα2 > 0 tel que si 0 < |x−x0| <α2, alors on a |g (x)−M | < ε
2 .Posons α= min(α1,α2). On a α> 0 et si 0 < |x − x0| <α, alors la définition de α entraîne que l’on a0 < |x −x0| <α1 et 0 < |x −x0| <α2 et donc
| f (x)+ g (x)−L−M | ≤ | f (x)−L|+ |g (x)−M |(inégalité triangulaire)
ε/2+ε/2 = ε.
6

Ceci montre donc quelim
x→x0( f + g )(x) = L+M .
Les autres relations se démontrent en utilisant des méthodes similaires.
Rappel. On a utilisé dans la preuve l’inégalité triangulaire
|a +b| ≤ |a|+ |b|.
Elle entraîne l’inégalité|a ±b| ≤ |a|− |b|.
Exemple 4. Des arguments géométriques élémentaires permettent d’établir que
limx→0
sin x
x= 1. (1.1)
On montreégalement que
limx→0
ex −1
x= 1. (1.2)
1.3 La notion de continuité
La notion de continuité découle directement de celle de limite.
Définition 4. On suppose que f est aussi définie en x0. On dit que f est continue en x0 si et seule-ment si f admet une limite en x0, égale à sa valeur f (x0) en ce point.
On dit que f est continue sur un intervalle ]a,b[ si elle est continue en tout point x0 de ]a,b[.
De manière intuitive, une fonction f est continue sur un intervalle ]a,b[ si on peut tracer legraphe de la restriction à cet intervalle sans lever la main.
Il résulte immédiatement de la Proposition 2 que si f et g sont deux fonctions continues en
un point x0, alors f + g , f − g et f g sont également continues en ce point. Si g (x0) 6= 0, alorsf
gest
également continue en x0.
Exemple 5.– Les fonctions constantes sont continues.– La fonction IdR est continue (prendre ε=α dans la Définition 6).– Les polynômes sont des fonctions continues (car obtenues à l’aide d’opérations de multipli-
cation et additions à partir de fonctions constantes et de la fonction IdR)– Les fractions rationnelles (quotient de deux polynômes) sont continues sur leur ensemble
de définition, qui est composé d’intervalles ouverts.– Les fonctions trigonométrique sin, cos sont continues sur R, ainsi que les fonction ex et log
sur leur ensemble de définition.
La notion de continuité a également de bonne propriétés vis à vis de la loi de composition.
Proposition 3. Soit f une fonction continue en x0 et soit g une fonction continue en f (x0). Alorsg f est continue en x0.
7

Démonstration Soit ε donné. Comme g est continue en f (x0), il existe un nombre η> 0 tel quesi |y − f (x0)| < η alors on a |g (y)− g ( f (x0))| = |g (y)− g f (x0)| < ε. Comme f est continue en x0, ilexiste un nombreα> 0 tel que si |x−x0| <α, alors | f (x)− f (x0)| < η. Il en résulte que si |x−x0| <α,alors |g ( f (x))− g f (x0)| < ε. La conclusion en découle.
Soit f une fonction définie sur un intervalle I =]a,b[ de R. Rappelons que l’on dit que f eststrictement croissante (resp. strictement décroissante sur I ) si et seulement, si pour tous nombresa < x1 < x2 < b, on a
f (x1) < f (x2) (resp. f (x1) > f (x2).
On dit que f est strictement monotone sur I si elle est strictement croissante ou strictement dé-croissante sur I . Lorsque f est strictement monotone sur I , il est facile de se convaincre qu’elleconstitue une bijection de I sur son image
f (I ) = y ∈R tel qu’il existe x ∈ I y = f (x).
Lorsque f est de surcroît continue, alors on a
Proposition 4. Soit I =]a,b[ un intervalle ouvert, et soit f une fonction continue sur I . Alors f (I ) estun intervalle de R. De plus, si f est strictement monotone, alors f (I ) est un intervalle ouvert, de laforme ] f (a), f (b)[ si f est strictement croissante (resp. ] f (b), f (a)[ si f est strictement décroissante),et de plus f est bijective de I sur f (I ). Son application réciproque est continue.
Nous admettrons ce résultat.
1.4 La notion de dérivée
1.4.1 Définition
Définition 5. Soit f une fonction. On dit que f possède une dérivée au point x0 si la limite suivante
limx→x0
f (x)− f (x0)
x −x0= lim
h→0
f (x0 +h)− f (x0)
h
existe et est finie. On note alors f ′(x0) cette limite. On dit aussi que f est dérivable au point x0.
Remarque 1. On utilise aussi parfois la notation
f ′ = d f
d x.
Lorsque la fonction est dérivable, le graphe possède au point (x0, f (x0)) une droite tangenteque est de pente f ′(x0) exactement. Plus précisement, la droite affine d’équation
y = f ′(x0)(x −x0)+ f (x0)
qui passe par le point (x0, f (x0)) est tangente à la courbe en ce point.
On déduit de la définition même de la dérivée, que l’on a le comportement suivant de la fonc-tion f près de x0
f (x0 +h) = f (x0)+ f ′(x0)h +hε(h), (1.3)
8

où ε désigne une fonction définie près de 0 et telle que
limh→0
ε(h) = 0,
Nous avons ici introduit la variable h = x −x0 qui tend vers 0 lorsque x tends vers x0.
La relation (1.3) nous fournit un premier exemple de développement limité. Dans ce contexte,il est utile de rappeler la définition suivante.
Définition 6. Soient f et g deux fonctions définies près de x0. On dit que f est négligeable devant gsi et seulement si il existe une fonction ε définie près de 0 telle que
f (x) = g (x)ε(x −x0) et limh→0
ε(h) = 0.
Si f est négligeable devant g , on écrit alors
f =x0
o(g ).
Si g ne s’annule pas près de x0 sauféventuellement en x0, alors f est négligeable devant g si etseulement si
limx→x0
f (x)
g (x)= 0.
Notons que la relation "être négligeable" est une relation d’ordre (qui n’est pas totale), en par-ticulier elle est transitive, c’est a dire si, f =
x0o(g ) et h =
x0o( f ) alors h =
x0o( f ). C’est pourquoi on
utiliseégalement, à la place de la notation f =x0
o(g ) la notation
f ¿x0
g ou de manière équivalente g Àx0
f .
La notion de fonction négligeable permet en particulier de comparer des infiniment petits près dex0, et éventuellement des échelles d’infiniments petits.
Exemple 6. si l’on prend g égale à la fonction constante 1 alors f =0
o(1) signifie tout simplementque
limx→0
f (x) = 0,
et de manière plus générale f tend vers L lorque x tend vers x0 peut s’écrire
f (x) =x0
L+o(1) ou de manière équivalente f (x0 +h) =0
L+o(1). (1.4)
On remarquera également que si m et n sont des nombres entiers tels que 0 ≤ m < n alors
xn ¿0
xm ,
ce qui nous fournit une échelle d’infiniment petits très utilisée pour comparer des fonctions
1 À0
x À0
x2 À0
x3 À0
x4 . . .
Revenons maintenant au développement (1.3) : ce dernier peut donc s’écrire, en utilisant lesnotations précédente comme
f (x0 +h) =0
f (x0)+ f ′(x0)h +o0
(h). (1.5)
La notion de dérivée permet donc d’effectuer un développement limité à l’ordre 1, alors que la no-tion de limite fournit un développement limité à l’ordre 0. Notons au passage que la comparaisonde (1.5) et de (1.4) permet immédiatement de démontrer :
9

Proposition 5. Si f est dérivable en x0, alors f est continue en x0.
La réciproque n’est pas vraie en général.
Rappelons également, pour finir avec les généralités sur la dérivation :
Proposition 6. Soit I un intervalle, f une fonction définie et dérivable sur I , de dérivée continuetelle que
f ′(x) > 0 sur I .
Alors f est strictement croissante sur I .
1.4.2 Calculs de dérivées
Proposition 7. Soient f et g deux fonctions dérivables en x0. Alors les fonctions f +g , f −g , f g sont
dérivables en x0, ainsi que la fonctionsf
g, si g (x0) 6= 0, les dérivées étant données par les formules :
( f ± g )′(x0) = f ′(x0)± g ′(x0)
( f g )′(x0) = f ′(x0)g (x0)+ f (x0)g ′(x0)(f
g
)′(x0) = f ′(x0)g (x0)− f (x0)g ′(x0)
g (x0)2si g (x0) 6= 0.
Si f est dérivable en x0 et g dérivable en f (x0) alors g f et dérivable en x0 et
(g f )′(x0) = g ′ ( f (x0))
f ′(x0).
Enfin si f possède une application réciproque et si f ′(x0) 6= 0 alors f −1 est dérivable en f (x0) et on a(f −1)−1 (
f (x0))= 1
f ′(x0).
Ces formules permettent de calculer de nombreuses dérivées : donnant quelques exemples.
Exemple 7. En utilisant directement la définition, on voit que la dérivée de la fonction f (x) = x estf ′(x) = 1 pour tout x. On utilisant la formule du produit, on en déduit que la derivée de la fonctionx 7→ x2 est
(x2)′ = 2x,
et de manière plus générale que la dérivée de la fonction x 7→ xn vaut pour tout n entier positif
(xn)′ = nxn−1.
En utilisant la formule pour les fractions, on s’aperçoit que cette formule reste valable pour toutn ∈Z.
On peut utiliser la formule de la fonction réciproque pour calculer la dérivée de la fonctionracine carré, réciproque de f (x) = x2. On trouve immédiatement(p
x)′ = 1
2p
x.
En fait, on peut montrer que pour tout α ∈R, on a la formule générale (xα)′ =αxα−1.
10

Pour les fonctions trigonométriques, on peut calculer directement la dérivées de la fonctionsin en utilisant la définition par quotient différentiel, et des formules de trigonométrie habituelles.On écrit, en utilisant le fait que (cosh)2 + (sinh)2 = 1
sin(x +h)− sin x = sin x cosh +cos x sinh − sin x
= (cosh −1)sin x +cos x sinh = −(sinh)2
1+cosh+cos x sinh
d’oùsi n(x +h)− si nx
h= −(sinh)2
(1+cosh)(h)+cos x
sinh
h
et ainsi, en utilisant (1.1)
limh→0
si n(x +h)− si nx
h= cos x.
On a donc montré que(sin x)′ = cos x.
Par une méthode similaire on obtient
(cos x)′ =−sin x.
En utilisant le fait que tan x = sin xcos x et la formule pour la dérivée du quotient de deux fonctions on
obtient
(tan x)′ = 1
(cos x)2= 1+ tan2 x.
Calculons maintenant la dérivée de la fonction arcsin en utilisant la formule pour la fonction ré-ciproque. Posons y = arcsin x de sorte que x = sin y . On a donc (arcsin x)′ = 1
cos y . Comme cos y =√1− sin y2 =
p1−x2, on en déduit que
(arcsin x)′ = 1p1−x2
.
Rappelons pour finir que
(ex)′ = ex , et (log x)′ = 1
x.
1.4.3 Dérivées d’ordre supérieur
La dérivée définit elle même une fonction réelle, et lorsque l’ensemble de définition de cettedernière contient des intervalles ouverts, on peut étudier ses propriétés de différentiabilité. Lors-qu’elle existe, on note f ′′ la dérivée f ′, et on l’appelle dérivée seconde. On définit ainsi itérative-ment la dérivée troisième notée f ′′′ ou f (3), et de manière générale la dérivée d’ordre n notée f (n).Par convention, on posera f (0) = f .
Un exemple remarquable est fourni par les polynômes, qui sont dérivables à tout ordre. Soitdonc P un polynôme de degré n
P (x) = an xn +an−1xn−1 +an−2xn−2 + . . . a1x +a0 =n∑
i=0ai xi .
11

Un bref calcul montre queP (0) = a0,P ′(0) = a1,P ′′(0) = 2a2
et de manière générale pour i = 0. . .nP (i )(0) = i !ai (1.6)
alors que P (i )(x) = 0 pour i > n et tout x dans R. On peut donc écrire
P (x) =n∑
i=0
P (i )(0)
i !xi . (1.7)
1.5 Primitives
L’opération de primitivation (ou d’intégration) est l’opération inverse de la dérivée.
Définition 7. Soit f une fonction définie sur un intervalle ]a,b[. On dit que F est une primitive def sur l’intervalle ]a,b[ si et seulement si
F ′(x) = f (x), pour tout x ∈]a,b[, (1.8)
Notons que pour f = 0, les fonctions constantes F (x) =C , pour tout x dans ]a,b[, où C désigneun nombre quelconque sont évidemment solutions et réciproquement, on démontre que si
F ′(x) = 0, pour tout x ∈]a,b[,
alors nécessairement il existe une constante C ∈ R telle que F = C . il en résulte que, si F est uneprimitive de f , alors il y a une infinité de primitives de f qui sont de la forme F +C . On désignepar le symbole ∫
f (x)d x
cet ensemble de fonctions (on parle aussi d’intégrale indéfinie, car définie seulement à une constanteprès).
Exemple 8. De nombreuses primitives s’obtiennent par inversion des formules de dérivation.Voici quelques exemples :
– Comme (xα)′ = αxα−1 pour tout α 6= 0 , on en déduit par inversion, sur tout intervalle où lafonction est définie, que∫
xαd x = xα+1
α+1+C , pour tout α 6= 1,où C désigne une constante arbitraire.
– Comme (ex)′ = ex , on en déduit, que sur R, on a∫exd x = ex +C .
– Comme (sin x)′ = cos x et (cos x)′ =−sin x on obtient, sur R∫sin xd x =−cosx +C et
∫cos xd x = si nx +C .
12

1.5.1 Opérations sur les primitives
On vérifie tout d’abord que l’on a bien∫( f ± g )(x)]d x =
∫f (x)d x +
∫g (x)d x,
et, pour tout λ 6= 0 ∫λ f (x)]d x =λ
∫f (x)d x.
La formule de dérivation de la multiplication donne lieu a une opération plus compliquée, l’inté-gration par partie. On a
Proposition 8 (intégration par parties). Soient f et g deux fonctions dérivables sur un intervalle]a,b[. On a ∫
f (x)g ′(x)d x = f (x)g (x)−∫
f ′(x)g (x)d x.
Démonstration. On part de la formule ( f g )′ = f g ′+ g f ′ d’ou il résulte que
f (x)g (x)+C =∫
f (x)g ′(x)d x +∫
f (x)g ′(x)d x.
(on peut ensuite absorber la constante C dans l’une des intégrales indéfinies).
Exemple 9. On utilise souvent la formule d’intégration par partie lorsque f ′g a une forme plussimple que f g ′. Donnons un exemple de calcul de primitive par cette méthode. Cherchons lesprimitives de la fonction xex . Posons f (x) = x et g (x) = ex , de sorte que g ′(x) = ex . On a donc∫
xexd x =∫
f (x)g ′(x)d x = f (x)g (x)−∫
exd x = xex −ex +C .
La loi de dérivation de la composée donne lieu, par inversion, à la formule dite de changementde variable. Soient f et g deux fonctions dérivables, telles que g soit définies sur l’image de f . SoitG une primitive de la fonction g . On a
(G f )′(x) =G ′( f (x)) f (x) = (g f )(x) f ′(x).
On a donc
Proposition 9 (changement de variable). Pour f , g ,G comme si dessus, on a
G( f (x)) =∫
(g f )(x) f ′(x)d x +C .
On a coutume d’écrire cette formule en introduisant la variable u = f (x) puis du = f ′(x)d x. Laformule de changement de variable devient alors facile a retenir.
Exemple 10. Cherchons à calculer une primitive de ex2x. Posons u = x2, d’où il résulte que du = 2x
et donc ∫ex2
xd x = 1
2
∫eudu = 1
2eu +C = 1
2ex2 +C .
Nous avons jusqu’à présent manipulé les intégrales, mais nous n’avons pas donné de résultatgénéral d’existence. Ce dernier est fourni par la théorie de l’intégrale définie, que nous présentonsci-dessous.
13

1.5.2 Intégrales définies
Considérons une fonction F continue sur un intervalle fermé [a,b]. Pour n donné dans N onpose h = b−a
n , puis on partage l’intervalle [a,b] en n intervalles de tailles égales au moyen despoints de subdivision
x0 = a, x1 = a +h, . . . xk = a +kh, . . . xn = b.
On définit ensuite les sommes
In = h[
f (x1)+ f (x2)+ . . . f (xn)]= h
n∑k=1
f (xk ) =n∑
k=1(x −xk ) f (xk )
Remarquons que, si f est positive, alors (xk−xk−1) f (xk ) représente l’aire du rectangle de base[xk−1, xk ]et de hauteur f (xk ). En sommant sur tous les k on obtient donc un nombre qui est une ap-proximation de l’aire limitée par la graphe de f , les droites verticales x = a, x = b, et l’axe Ox.
On peut démontrer que lorsque n tend vers +∞, la suite (In)n>0 converge, et que, si I désigne salimite
I = limn→∞ In ,
alors cette limite correspond bien à l’aire limitée par le graphe de f , les droites verticales x = a,x = b, et l’axe Ox.
Définition 8. On appelle I l’intégrale de f sur [a,b], et on la note
I =∫ b
af (x)d x.
Convention. On convient que ∫ a
bf (x)d x =−
∫ b
af (x)d x.
Explicitons maintenant le lien entre intégrale et primitive. Posons pour x0 ∈]a,b[
F (x) =∫ x
af (x)d x.
14

Pour h > 0 petit donné, F (x + h) − F (x) représente l’aire limitée par la graphe de f , les droitesverticales passant par x, x +h, et l’axe Ox, aire qui est proche de f (x)h. On a donc
F (x +h)−F (x)
h' f (x)
et donc
F ′(x) = limh→0
F (x +h)−F (x)
h= f (x),
F est donc une primitive de f : c’est la primitive de F qui s’annule en a. Réciproquement, si onconnaît une primitive quelconque F de f on a∫ b
af (x)d x = F (b)−F (a),
et donc les calculs d’intégrales se ramènent à trouver des primitives. Par exemple la formule d’in-tégration par parties s’écrit alors comme suit, pour les intégrales :
Proposition 10. On a ∫ b
af (x)g ′(x)d x = [ f g ]b
a −∫ b
af (x)g ′(x)d x
où on pose pour une fonction v quelconque
[v]ba = v(b)− v(a).
De même, la formule de changement de variable prend la forme suivante :
Proposition 11. On a, si g est continue sur f ([a,b])∫ f (b)
f (a)g (u)du =
∫ b
ag
(f (x)
)f ′(x)d x.
1.5.3 Aire d’un domaine du plan
Dans ce paragraphe, nous utilisons le calcul intégral pour calculer l’aire de domaines du plan.
Aire d’une arche de sinusoîde. Considérons le graphe de la fonction y = sin x pour x compris entre0 et π. Cette fonction est positive sur [0,π]. calculons l’aire de la surface limitée par le graphe decette fonction et l’axe Ox. Cette aire a pour valeur
S =∫ π
0sin xd x = [−cos x]π0 = (−cosπ)− (−cos0) = 2.
car comme nous l’avons vu, −cos x est une primitive de sin x.
Aire d’une ellipse. Considérons la surface bordée par la courbe
x2
a2+ y2
b2= 1 ⇔ y =±b
√1− x2
a2
15

où a et b sont strictement positifs. C’est une ellipse. La demie-ellipse supérieure est limitée parl’axe Ox et le graphe de la fonction positive
y = f (x) ≡ b
√1− x2
a2
qui est définie sur [−a, a]. La surface totale de l’ellipse est donc donnée par
S = 2∫ a
−af (x)d x.
On effectue le changement de variable
x = a cos t , t ∈ [0,π]
de sorte que y = f (x) = b sin t . Si t =π, on a x =−a et si t = 0 on a x = a. Donc
S =2∫ 0
π(b sin t )d(a cos t ) == 2
∫ 0
π(b sin t )(−a sin t )d t
=−2ab∫ 0
πsin t 2d t = 2ab
∫ π
0sin t 2d t
= ab∫ π
0(1−cos2t )d t = ab
[t − si n2t
2
]π0=πab.
où on a utilisé la relation 2sin2 t = 1−cos2t .
1.5.4 intégration de la relation ¿Contrairement à la dérivation, l’intégration à de bonnes propriétés vis à vis de la relation ¿.
On a
Proposition 12. Soient f et g deux fonctions définies près de zéro. On suppose de plus que
f ¿0
g .
On a alors ∫ x
0f (s)d s ¿
∫ x
0|g (s)|d s.
Démonstration. Par hypothèse f (x) = ε(x)g (x), où ε tend vers zéro lorsque x tend vers zéro on adonc
|∫ x
0f (s)d s| = |
∫ x
0ε(s)g (s)d s| ≤ sup
s∈[0,x]|ε(s)|
∫ x
0|g (s)|d s.
et la conclusion découle du fait que sups∈[0,x]
|ε(s) tend vers 0 lorsque x tend vers zéro.
Une conséquence intéressante de cette propriété est la suivante :
Proposition 13. Soit f une fonction définie près de zéro, ainsi que toutes ses dérivées jusqu’ ‘a l’ordren, que l’on suppose continues près de zéro. On suppose de plus que
f (k)(0) = 0 pour k = 0, . . . ,n.
Alors on af (x) ¿
0xn .
16

Démonstration Le cas n = 1 a déjà été traité. Si n = 2, alors on a f ′′(0) = 0 et donc par le casn = 1, on obtient
f ′(x) ¿0
x.
Comme f (x) = ∫ x0 f ′(x)d x, la proposition 12 nous donne
f (x) ¿0
x2.
ce qui est la conclusion désirée pour k = 2. Le cas général se traite de même.
1.6 Développements limités
Définition 9. Soit f une fonction définie au voisinage d’un point x0 ∈ R. On dit que f admet undéveloppement limité d’ordre n au voisinage de x0 si l’on peut écrire
f (x) = a0 +a1(x −x0)+ . . .+an(x −x0)n + (x −x0)nε(x)
où ε est une fonction qui tend vers 0 lorsque x tend vers x0.
Le polynôme DLn( f , x0) de degré inférieur ou égal à n défini par
DLn( f , x0) ≡ a0 +a1(x −x0)+ . . .+an(x −x0)n
est appelé partie régulière du développement limité, et (x − x0)nε(x) le reste que l’on peut doncécrire o(x −x0)n .
Le développement limité, lorsqu’il existe, est unique. Notons que l’on a
DLn( f ± g , x0) = DLn( f , x0)±DLn(g , x0)
et pour toute constante λ ∈RDLn(λ f , x0) =λDLn( f , x0).
Pour calculer DLn( f g , x0) on développe le produit DLn( f , x0)DLn(g , x0) et on ne garde que lestermes de degré inférieur à n. Le résultat suivant est fondamental.
Théorème 1 (développement de Taylor). Supposons que f ainsi que toutes ses dérivées jusqu’àl’ordre n soient définies, continues près de x0. Alors f possède un développement limité à l’ordren près de x0 donné par
f (x) =x0
f (x0)+ f ′(x0)(x −x0)+ . . .+ f (n)(x0)
n!(x −x0)n +o((x −x0)n).
Démonstration. Supposons pour simplifier que x0 = 0 (sinon, on fait un changement de variable),et considérons le polynôme
P (x) = f (0)+ f ′(0)x + . . . f (n)(0)
n!xn .
On a vu que, pour tout k = 0, . . . ,n, on a
P (k)(0) = f (k)(0) et donc ( f −P )(k)(0) = 0.
17

la conclusion résulte alors de la Proposition 12.
Voici quelques exemple classiques de développements limités près de 0
1
1−x= 1+x +x2 + . . . xn +o(xn)
sin x = x − x3
3!+ x5
5!+ . . .+ (−1)p x2p+1
(2p +1)!+o(x2p+1)
cos x = 1− x2
2!+ x4
4!+ . . .+ (−1)p x2p
(2p)!+o(x2p )
ex = 1+x + x2
2!+ . . .+ xn
n!+o(xn)
log(1+x) = x − x2
2+ x3
3+ . . .+ (−1)n xn
n+o(xn).
18

Chapitre 2
Fonctions de deux variables
On considère dans cette partie des fonctions de deux variables à valeurs dans R ou éventuel-lement dans R2 c’est à dire des fonctions de E = R2 vers F = R ou F = R2. Avant d’aller plus loin,commençons par quelques rappels sur les propriétés de R2 ainsi que sur la notion de courbe pa-ramètrée.
2.1 L’espace vectoriel R2
L’espace R2 est un espace vectoriel lorsqu’on le munit de la loi d’addition
(x1, x2)+ (y1, y2) = (x1 + y1, x2 + y2),∀X = (x1, x2) ∈R2,∀Y = (y1, y2) ∈R2,
et de la loi de multiplication par un scalaire
λ.(x1, x2) = (λx1,λx2),∀X = (x1, x2) ∈R2,λ ∈R.
On note 0 = (0,0) l’élément neutre pour l’addition ci-dessus, c’est à dire tel que 0+X = X +0 = X .
On munit par ailleurs R2 d’un produit scalaire noté "." défini par
(x1, x2).(y1, y2) = x1.y1 +x2.y2, ∀X = (x1, x2) ∈R2,∀Y = (y1, y2) ∈R2.
On vérifie immédiatement que le produit scalaire a les propriétés suivantes :
Proposition 1. On a pour tous vecteurs X ,Y , Z de R2 et tout scalaire λ de R2
X .Y = Y .X
(X +Y ).Z = X .Y +Y .Z
X .(Y +Z ) = X .Y +X .Z
(λX ).Y =λ(X .Y )
X .X ≥ 0
avec égalité si et seulement si X = 0.
On définit la norme euclidienne ‖ ·‖ par
‖X ‖ =p
X .X =√
x21 +x2
2 ≥ 0, ∀X = (x1, x2) ∈R2,
19

de sorte que ‖X ‖ = 0 si et seulement si X est nul. L’inégalité triangulaire est une propriété trèsintéressante de la norme, à savoir
‖X +Y ‖ ≤ ‖X ‖+‖Y ‖. (2.1)
Si θ désigne l’angle entre les vecteurs X et Y , on a par ailleurs
X .Y = ‖X ‖.‖Y ‖cosθ,
de sorte que|X .Y | ≤ ‖X ‖.‖Y ‖, (2.2)
avec égalité si et seulement si les vecteurs sont colinéaires. Cette dernière inégalité s’appelle l’in-égalité de Cauchy-Schwarz.
La norme euclidienne permet de définir une distance, dite euclidienne également, entre les élé-ments de R2 :
dist(X ,Y ) = ‖X −Y ‖.
Notons que cette distance majore la différence des coordonnées
|x1 − y1| ≤ dist(X ,Y ) = ‖X −Y ‖, |x2 − y2| ≤ dist(X ,Y ) = ‖X −Y ‖,
et que la somme de la différence des coordonnées majore la norme
dist(X ,Y ) = ‖X −Y ‖ ≤ |x1 − y1|+ |x2 − y2|.
Remarque 1. Si A = (a1, a2) et B = (b1,b2) sont deux éléments de R2 alors on note souvent
−→AB = B − A = (b1 −a1,b2 −a2)
La norme de−→AB donnée par
‖−→AB‖ =√
(b1 −a1)2 + (b2 −a2)2
représente donc la longueur du segment AB . Notons par ailleurs qu’avec ces notations, on a éga-
lement X =−−→OX .
20

2.2 Courbes paramétrées de R2
Nous serons amenés dans de nombreuses circonstances à formaliser la notion de courbe dansle plan R2. Nous verrons essentiellement deux méthodes pour réaliser un tel objectif : la méthodeparamétrique et la méthode implicite. La méthode paramétrique que nous allons voir dans ceparagraphe, s’inspire de la notion de trajectoire. Elle permet de plus de définir une orientationnaturelle à la courbe.
Définition 1. Soit I un intervalle de R non vide. Soit M1 et M2 deux applications continues de Idans R, et soit l’application M : I →R2 définie par M(t ) = (M1(t ), M2(t )), pour t ∈ I . Soit C l’imagede I par M , c’est à dire l’ensemble des points de R2 de la forme (x1, x2) = (M1(t ), M2(t )) où t ∈ I ouencore
C = t ) = (M1(t ), M2(t )), t ∈ I .
On dit que C est une courbe paramètrée du plan.
Exemple 1. La courbe définie par les fonctions
M1(t ) = a1t +b1, M2(t ) = a2t +b2 pour t ∈R
définie une droite affine du plan. Si a1 = 0 c’est la droite verticale x = b1, si a2 = 0 on obtient ladroite horizontale y = b2.
La courbe définie par x1 = cos t et x2 = sin t pour t ∈ I = [0,2π] est le cercle de centre 0 et derayon 1.
La courbe définie par x1 = a cos t et x2 = b sin t , où a > b > 0 sont des paramètres pour t ∈ I =[0,2π] est une ellipse de centre 0, dont le grand axe est horizontal, de longueur 2a.
Le graphe de fonction de I dansR fournit un autre exemple élémentaire de courbe paramètrée.Si f est une fonction de I dans R son graphe est la courbe paramétrée par
M1(t ) = t
M2(t ) = f (t ), t ∈ I .
Remarque 2. On peut paramètrer une même courbe C de plusieurs manières différentes. Parexemple la droite y = x peut être paramètrée par
x1 = t x2 = t , t ∈R
mais aussi parx1 = 2t x2 = 2t , t ∈R.
De manière plus générale, si J est un intervalle de R et ϕ une application continue strictementmonotone bijective de J vers I , la courbe C peut être paramétrée comme
x1 = ( f1 ϕ)(s), x2 = ( f2 ϕ)(s), s ∈ J .
Supposons maintenant que les fonctions M1 et M2 sont dérivables.
21

Définition 2. Le point M(t ) = (M1(t ), M2(t )) de la courbe C est dit ordinaire si(M ′
1(t ), M ′2(t )
) 6= (0,0).
Il est dit stationnaire si(M ′
1(t ), M ′2(t )
)= (0,0).
Définition 3. Soit M(t0) = (M1(t0), M2(t0)) un point ordinaire. La droite passant par M(t0) et devecteur directeur
(M ′
1(t0), M ′2(t0)
), c’est à dire la droite paramétrée par
x1(s) = M ′1(t0)s +M1(t0) et x2(s) = M ′
2(t0)s +M2(t0), s ∈R
est appelée droite tangente en M(t0) à la courbe C .
Tout vecteur non nul colinéaire au vecteur((M ′
1(t0), M ′2(t0)
)est appelée vecteur tangent en
M(t0). Il est souvent d’usage de représenter un tel vecteur en prenant un point P de la droite
tangente à C , choisi de sorte que le vecteur−−−−−→M(t0)P d’origine M(t0) et d’extrémité P soit égal au
vecteur tangent donné. Réciproquement, tout vecteur de cette forme est bien un vecteur tangent.
Exemple 2. Considérons le cercle unité S 1 défini par
x1(t ) = cos t , x2(t ) = sin t , t ∈ [0,2π].
et le point M0 = M(π4 ), c’est à dire M0 =(1/p
2,1/p
2). La droite tangente à S 1 en M0 a pour vecteur
directeur(−1/
p2,1/
p2)
et peut être paramètrée de la façon suivante
x1 =− tp2+ 1p
2, x2 = tp
2+ 1p
2t ∈R.
Il s’agit aussi de la droite qui a pour équation
x1 +x2 =p
2.
Considérons maintenant de manière plus générale une courbe donnée sous forme de graphe x2 =ϕ(x1), où ϕ est une fonction d’une variable réelle dérivable. Un vecteur tangent à cette courbe aupoint M = (m1,m2) est donné par
~T = (1,ϕ′(m1)
). (2.3)
La droite tangente a pour équation
x2 =ϕ′(m1)(x1 −m)+ϕ(m1).
Notons pour finir que si tous les points sont ordinaires, alors le vecteur M ′(t ) ne s’annule ja-mais, et le paramètrage nous fournit également une orientation de la courbe C . On introduit dansce contexte la définition suivante :
Définition 4. On dit que le paramètrage t 7→ M(t ) est naturel si et seulement si on
‖M ′(t )‖ = 1. (2.4)
22

Bien entendu, dans un paramétrage naturel, tous les points sont ordinaires. Réciproquement,si pour un paramétrage tous les points sont ordinaires, on peut reparamétrer la courbe en intro-duisons un paramétrage naturel, sous la forme
M(s) = M ϕ(s).
On a en effetd M
d s(s) = M ′(ϕ(s)).ϕ′(s)
de sorte que
‖d M
d s(s)‖ = ‖M ′(ϕ(s))‖ϕ′(s),
de sorte que le réparamétrage doit vérifier l’équation
ϕ′(s) = 1
‖M ′(ϕ(s))‖ ,
équation que l’on peut intégrer, grâce en particulier au Théorème de Cauchy-Lipschitz.
Lorsque le paramètrage est naturel, on note souvent s la variable du paramètrage (que l’onappelle abscisse curviligne) et
~T (s) = d M
d s(s),
le vecteur tangent, qui est alors unitaire, car ‖~T (s)‖ = 1.
Longueur d’une courbe. Soit C une courbe paramètrée par t 7→ M(t ), t ∈ I = [a,b]. On supposeque tous les points sont ordinaires, c’est à dire que M ′ ne s’annule pas sur I , et qu’il est bijectivede I vers C .
Définition 5. On appelle longueur de C la quantité
L(C ) =∫ b
a‖M ′(t )‖d t .
Cette quantité est positive, éventuellement infinie, et ne dépend pas de l’orientation. On vérifiepar ailleurs que L(C ) est indépendant du paramètrage choisi. Si le paramètrage est naturel, on adonc
L(C ) =∫ b
ad s.
Exemple 3. Si une courbe est définie comme graphe d’une fonction f = [a,b] sur un intervalle,c’est à dire C = (x,ϕ(x), x ∈ I , alors, on a
L(C ) =∫ b
a‖~T (x)‖d x,
où le vecteur tangent T (x) est donné par la formule (2.3), c’est à dire T (x) = (1,ϕ′(x)) de sorte que‖~T (x)‖ =√
1+ϕ′(x)2. Il en résulte que
L(C ) =∫ b
a
√1+ϕ′(x)2d x.
23

Exemple 4. Calculons la longueur du cercle SR de rayon R. Un paramétrage est fourni par l’appli-
cation M : [0,2π[→R2,t 7→ (R cos t ,R sin t ) de sorte ded
d tM(t ) = (−R sin t ,R cos t ) et donc ‖M(t )‖ =√
R2 cos2 t +R2 sin2 t = R. Il vient ainsi
L(SR ) =∫ 2π
0Rd t = 2πR.
Exemple 5. Calculons la longueur d’une ellipse Ea,b , où a ≥ b > 0, paramétrée par M : [0,2π[→R2,
t 7→ M(t ) = (a cos t ,b sin t ). On a doncd
d tM(t ) = (−a sin t ,b cos t ), et ainsi
‖ d
d tM(t )‖ =
√a2 sin2 t +b2 cos2 t =
√a2 + (b2 −a2)cos2 t ,
et donc
L(Ea,b) =∫ 2π
0
√a2 + (b2 −a2)cos2 td t = 2I , où I =
∫ π
0
√a2 + (b2 −a2)cos2 td t ,
intégrale que l’on ne sait pas intégrer explicitement...
2.3 Graphes, lignes de niveau
Soit F une fonction de R2 dans R, D = D f son domaine de définition. Si X ∈ D est un point decoordonnées(x1, x2), on notera indifférement f (X ) ou f (x1, x2) son image.
Exemple 6. Souvent, comme dans le cas réel, les fonctions seront données à l’aide de formules.– f (x1, x2) = ax1 +bx2, a et b donnés, est une fonction linéaire– f (x1, x2) = ax1 +bx2 + c avec a,b,c donnés, est une fonction affine– f (x1, x2) = x3
1 −x22 +x1x2 +x1 +2x1 −1 est un polynôme.
La fonction
f (x1, x2) =√
1−x21 +
√1−x2
2
est définie quand |x1| ≤ 1 et |x2| ≤ 1 c’est à dire sur le carré de centre 0 = (0,0) et de taille 2×2 avecbord. La fonction
f (x1, x2) = 1√1−x2
1 +√
1−x22
est définie pour |x1| ≤ 1 et |x2| ≤ 1 sauf pour |x1| = |x2| = 1 c’est à dire le carré de centre 0 = (0,0) etde taille 2×2 avec bord, mais privé de ses quatres sommets. Enfin, la fonction
f (x1, x2) = 1√1−x2
1 −x22
est définie pour x21 +x2
2 < 1 c’est à dire sur le disque sans bord de centre 0 = (0,0) et de rayon 1.
Des exemples de fonctions sur R2 abondent aussi dans de la vie courante : c’est le cas la fonc-tion qui atout point d’une carte associe l’altitude (carte IGN) en ce point, ou la température(cartemétéo).
24

Le graphe Γ f de la fonction f est un sous-ensemble de R3 = R2 ×R donné par l’ensemble despoints de coordonnées (x1, x2, f (x1, x2)), où (x1, x2) parcours le domaine de définition :
Γ f = (x1, x2, x3) ∈R3, tels que (x1, x2) ∈D f , x3 = f (x1, x2)
= (x1x2, f (x1, x2)
), (x1, x2) ∈D f ⊂ R3
C’est en générale une surface. Par exemple, dans le cas des fonctions affines, le graphe est un planaffine de R3.
Une autre idée introduite pour identifier la distribution des valeurs de f c’est de représenterles lignes de niveau. Elle est notamment utilisée en cartographie, et est un moyen particulièrementcommode pour porter les altitudes sur une carte.
Une ligne de niveau, est, pour une valeur c donnée, constituée par l’ensemble des points (x1, x2)du domaine de définition de f dont l’image par f a pour valeur c. C’est donc l’ensemble de R2
défini par la relationf (x1, x2) = c.
A chaque valeur de c correspond bien entendu une ligne de niveau, notée f c . Une ligne de ni-veau peut être, entre autres, l’ensemble vide, réduite à un point, ou encore être une courbe ou unensemble de courbes.
Exemple 7. Soit f la fonction affine donnée par f (x1, x2) = x1 + x2 +1. Les lignes de niveau sontdonc les droites du plan d’équation
x1 +x2 = c −1.
Si f est la fonction d’équation f (x1, x2) = x21 +x2
2 , alors la ligne de niveau c a pour équation
x21 +x2
2 = c.
elle est donc vide si c < 0, réduite au point 0 si c = 0, enfin pour c > 0, il s’agit du cercle centré àl’origine de rayon
pc.
25

2.4 Limites, continuité
Les définitions que nous avons introduites au Chapitre 1 se transposent facilement au casmulti-dimensionnel.
Soit f une fonction sur R2 et M0 un point donné de R2. On supposera de plus que f est définiesur un disque ouvert non vide
D(M0,R) ≡ X ∈R2, ‖X −M0‖ > r
r > 0, contenant M0, sauf peut-être en M0, c’est à dire que
D(M0,R) \ M0 ⊂D f .
Définition 6. On dit que la fonction f admet une limite L en M0, ou que f (X ) tend vers L lorsqueX tend vers M0, si et seulement si :
Pour tout nombre réel ε > 0, il existe un nombre α > 0 tel que la relation 0 < ‖X − M0‖ < α
entraîne| f (X )−L| < ε.
On vérifie que si une limite L existe, alors elle est forcément unique. On note alors
L = limX→M0
f (X ) ou encore f (X ) →X→M0
L.
La propriété précédente exprime le fait que si X 6= X0 se trouve à une distance de M0 infé-rieure àα> 0, qui dépend bien entendu de ε, alors la différence entre f (X ) et L est nécessairementinférieure à ε. On a, comme au chapitre 1 :
Proposition 2. Soient f et g deux fonctions sur R2 telles que f et g admettent comme limite en M0
les nombres L et K . Les fonctions f ± g et f g admettent alors les limites suivantes en X0 :
limX→X0
( f ± g )(X ) = L±K et limX→X0
( f g )(X ) = LK .
de plus, si K 6= 0 alors on a
limX→X0
f
g(X ) = L
K.
La notion de continuité découle directement de celle de limite.
Définition 7. On suppose que f est aussi définie en X0. On dit que f est continue en M0 si et seule-ment si f admet une limite en M0, égale à sa valeur f (M0) en ce point.
Il résulte immédiatement de la Proposition 2 que si f et g sont deux fonctions continues en
un point M0, alors f + g , f − g , f g sontégalement continues en ce point. Si g (M0) 6= 0, alorsf
gest
également continue en X0.
26

Exemple 8. Les fonctions polynômiales, c’est a dire du type
f (x1, x2) =n∑
i , j=0ai j xi
1x j2
sont continues en tout point de R2. Les exemples les plus simples de telles fonctions sont les fonc-tions affines, de la forme
f (x1, x2) = a1x1 +a2x2 +b.
Par ailleurs, si g est une fonction d’une variable réelle continue sur un intervalle ouvert I , alors lafonction de deux variables f définie par
f (x1, x2) = g (x1) (2.5)
est continue sur I ×R.
Nous aurons à plusieurs reprises à considérer des fonctions F deR2 à valeurs dansR2. Une tellefonction peut donc s’écrire
F (x1, x2) = (f1(x1, x2), f2(x1, x2)
)où f1 et f2 désignent des fonctions de deux variables à valeurs réelles, c’est à dire de R2 vers R2.Nous dirons que F est continue en X0 si et seulement si les deux fonctions f1 et f2 sont continuesen X0.
Remarque 3. On pourra vérifier que F est continue en X0 si et seulement si pour tout nombre réelε> 0, il existe un nombre α> 0 tel que la relation 0 < ‖X −X0‖ <α entraîne
‖F (X0)−F (X )‖ < ε.
Passons maintenant à la loi de composition , pour laquelle il convient de distinguer plusieurscas, au vu des divers types de fonctions que nous avons considérés jusqu’ à présent.
Considérons tout d’abord une fonction à deux variables f , c’est à dire de R2 à valeurs dans R,supposée continue en un point X0 de D f . Soit ensuite une fonction h d’une variable réelle, c’est àdire de R vers R, définie en f (X0) et continue en ce point de R. On a alors
Proposition 3. Si f , h, X0 sont comme ci-dessus, alors la fonction h f , définie par (h f )(X ) =h
(f (X )
)est continue en X0.
Exemple 9. la fonction g définie par
g (x1, x2) = ex21+x2
2
est définie sur tout R2. On peutécrire g = h f , où f est la fonction polynômiale de deux variablesdéfinie par f (x1, x2) = x2
1+x22 et la fonction h est la fonction d’une variable réelle définie par h(x) =
ex , pour tout x ∈R. Ces deux fonctionsétant continues, il en résulte que g l’est également.
Considérons maintenant un deuxième type de composition celui où on commence par unefonction h de R à valeurs dans R2 c’est à dire de la forme
h(x) = (h1(x),h2(x))
Si F est une fonction de deux variables. Soit x0 in point de R. On suppose que h1 et h2 sont conti-nues en x0 et que F est continue en h(x0). on a
27

Proposition 4. Si f , h, x0 sont comme ci-dessus, alors la fonction f h, définie par ( f h)(x) =f (h(x)) est continue en x0.
Considérons enfin un dernier cas, celui ou on a deux fonctions F et H de R2 vers R2 telles queF est continue en X0 et H continue en F (x0). alors
Proposition 5. La fonction F H, définie par (F H)(x) = F (H(x)) est continue en X0.
2.5 La notion de dérivée partielle
Considérons une fonction de deux variables réelles et un point M = (m1,m2) de R2. Si l’on fixel’une des variables, et que l’on fait varier l’autre, on obtient une fonction d’une variable réelle. Plusprécisément, posons pour t ∈R
f1(t ) = f (m1 + t ,m2)
f2(t ) = f (m1,m2 + t ).
Pour définir la fonction f1 on se restreint donc à la droite horizontale D1 passant par M d’équa-tion x2 = m2, ou encore de paramétrage x1 = m1 + t , x2 = m2 et et de même pour définir f2 onse restreint à la droite verticale D2 passant par M et d’équation x1 = m1, encore de paramétragex1 = m1, x2 = m2+ t . On suppose par ailleurs que les fonctions f1 et f2 sont dérivables en t = 0. Lesdérivées partielles correspondent alors aux dérivées en 0 des fonctions précédentes.
Définition 8. On appelle dérivée partielle de f en M0 par rapport à la variable x1 la dérivée f ′1(0).
On la note
f ′x1
(M0), ∂x1 f (M0) ou encore∂ f
∂x1(M0).
On a donc∂ f
∂x1(M0) = lim
t→0
f (m1 + t ,m2)− f (m1)
t.
De même, on appelle dérivée partielle de f en M par rapport à la variable x2 la dérivée f ′2(0). On la
note f ′x2
(M0), ∂x2 f (M0) ou encore∂ f
∂x2(M0). On a donc
∂ f
∂x2(M0) = lim
t→0
f (m1,m2 + t )− f (m1)
t.
28

Remarque 4. Notons, par ailleurs que si f1 est dérivable, alors
f ′1(t ) = ∂ f
∂x1(m1 + t ,m2)
et de même si f2 est dérivable, alors
f ′2(t ) = ∂ f
∂x1(m1,m2 + t ).
Lorsque les dérivées partielles existent en tout point du domaine D, elles définissent des fonc-tions à deux variables sur ce domaine, que l’on note
f ′x1
, f ′x2
, ou ∂x1 f ,∂x2 , f ou encore∂ f
∂x1,∂ f
∂x2.
Exemple 10. Considérons le polynôme f (x1, x2) = x21 +x3
2 +x1x −2. On a
f ′x1
(x1, x2) = 2x1 +x2 et f ′x2= 3x2
2 +x2.
Comme dans le cas de fonctions d’une seule variable, on a les règles de calcul suivantes :
Proposition 6. On a pour i = 1,2
( f ± g )xi = f ′xi± g ′
xi, ( f g )xi = f ′
xig + f g ′
xi.
De plus si là où g ne s’annule pas (f
g
)′xi
= f ′xi
g − f g ′xi
g 2.
Notons également la propriété suivante :
Proposition 7. Soit f une fonction dérivable sur R2. On suppose que
∂ f
∂x1= 0.
alors il existe une fonction g :R→R telle que
f (x1, x2) = g (x2),
c’est à dire que f ne dépend que de la variable x2. De plus, on a
g ′(x2) = ∂ f
∂x2(x1, x2).
Démonstration. Par intégration, on a
f (x1, x2) = f (0, x2)+∫ x1
0
∂ f
∂x1(s, x2)d s = f (0, x2).
En posant g (x2) = f (0, x2) la conclusion en découle.
29

2.5.1 Développement limité à l’ordre 1
Afin de pouvoir écrire un developpement limité au premier ordre près d’un point M = (m1,m2)donné, il faut, non seulement supposer que la fonction possède des dérivées partielles en ce point,mais également que ces dernières soient définies et continues dans un voisinage de ce point : leshypothèses sont donc plus exigeantes qu’en dimension 1. Dans ces conditions, on a
Proposition 8. On supposee que f ′xi
est définie et continue près de M = (m1,m2), pour i = 1,2. Alorson a pour h = (h1,h2) petit
f (M +h) = f (m1 +h1,m2 +h2) = f (m1,m2)+h1 f ′x1
(m1,m2)+h2 f ′x2
(m1,m2)+‖h‖ε(h), (2.6)
où la fonction ε est définie près de 0 et vérifie
limh→0
ε(h) = 0.
Idée de la démonstration. On se déplacant selon des lignes horizontales et verticales unique-ment, on peut décomposer :
F (M +h)−F (M) = [f (m1 +h1,m2 +h2)− f (m1,m2 +h2)
]+ [f (m1,m2 +h2)− f (m1,m2)
]=
∫ h1
0f ′
x1(m1 + s,m2 +h2)d s +
∫ h2
0f ′
x2(m1,m2 + s)d s
= h1 f ′x1
(M)+h2 f ′x2
(M)+∫ h1
0
[f ′
x1(m1 + s,m2 +h2)− f ′
x1(M)
]d s +
∫ h2
0
[f ′
x2(m1,m2 + s)− f ′
x2(M)
]d s
(2.7)
Posons pour r > 0 etε(r ) = sup
X∈D(M ,r ),i=1,2| f ′
xi(X )− f (M)|.
Comme f ′xi
est supposée continue en M , nous obtenons
limr→0
ε(r ) = 0.
Par ailleurs, en revenant à (2.7), on trouve
|F (M +h)−F (M)−h1 f ′x1
(M)−h2 f ′x2
(M)| ≤ (|h1|+ |h2|)ε(‖h‖),
d’o û la conclusion découle.
30

2.5.2 Le gradient
Si f est dérivable au point M , alors on introduit le vecteur gradient de f , noté ∇ f ou−−−→grad f par
−−−→grad f (M) = (
f ′x1
(M), f ′x2
(M))
.
Si f est dérivable sur tout le domaine D , on définit ainsi une nouvelle fonction de deux variables àvaleurs dans R2. Sous les mêmes hypothèses qu’au paragraphe précédent sur f , on peut écrire ledéveloppement (2.6) sous la forme condensée
f ′(M +h)− f (M) = h.−−−→grad f (M)+‖h‖ε(h). (2.8)
Considérons maintenant une droite quelconque D passant par M , de vecteur directeur~e, supposéde norme 1, c’est à dire ‖e‖ = 1. Si on paramètre la droite par M(t ) = M + t~e, et que s’intéresse à larestriction fD définie par
fD (s) = f (M + s~e)
la formule (2.8) montre alors que fD est dérivable en 0 et
f ′D (0) =~e.
−−−→grad f (m).
On peut en conclure que f est dérivable dans toutes les directions, et que la direction dans laquellela fonction croît le plus est celle du gradient.
On a par ailleurs :
Proposition 9. Soit f une fonction dérivable sur R2 telle que
−−−→grad f = 0.
Alors la fonction f est constante, c’est à dire il existe une constante c ∈R telle que
f = c.
Démonstration. La propriété résulte directement de la Proposition 7. En effet, comme ∂ f∂x1
= 0, on a
f (x1, x2) = g (x2),
pour une fonction d’une variable g . Comme par ailleurs
g ′(x2) = ∂ f
∂x2(x1, x2) = 0,
la fonction g est constante et la conclusion en découle.
Remarque 5. On montre de même que si−−−→grad f = (a1, a2) est un vecteur constant sur R2 alors la
fonction f est nécessairement une fonction affine. Pour s’en convaincre, Il suffit de considérer la
fonction g (x1, x2) = f (x1, x2)− (a1x1 +a2x2) et de vérifier que−−−→grad g = (0,0).
31

2.5.3 Dérivation des fonctions composées
Nous avons rencontré plusieurs exemples de fonction composées à la Section 2.4. Voyons main-tenant comment dériver de telles fonctions, en commençant par quelques situations simples.
Premièr exemple. Soit f une fonction de R2 dans R2 et g une fonction de R dans R. On considère lafonction G définie par G = g f :R2 →R, M 7→G(M) = g
(f (M)
), pour M ∈R2. On a alors
Proposition 10. On supose f dérivable en M et g dérivable en f (M). Alors G est dérivable en M et
G ′xi
(M) = g ′( f (M)) f ′xi
(M), pour i = 1,2,
et donc−−−→gradG(M) = g ′( f (M))
−−−→grad f (M).
Preuve. Pour i = 1, et t ∈R petit, on a, si M = (m1,m2)
G(m1 + t ,m2)−G(m1,m2) = g ( f (m1 + t ,m2))− g ( f (m1,m2)) = g ( f1(t ))− g ( f1(0)),
et donc
limt→0
G(m1 + t ,m2)−G(m1,m2)
t= (g f1)′(0) = g ′( f1(0)) f ′
1(0) = g ′( f (M). f ′x1
(M).
Deuxième exemple. Soit f une fonction de R2 dans R, dérivable dans le voisinage d’un point M , dedérivées continues, et soit ~n une fonction d’une variable s à valeur dans R2
~n(s) = (n1(s),n2(s)) ,
telle que ~n(s0) = M . On suppose h dérivable en s0. Une telle fonction ~n représente par exemple leparamétrage d’une courbe C , ou la trajectoire d’une particule se déplaçant le long de C au coursdu temps désigné par la variable s. On s’intéresse ici à fonction φ :R→R définie pae
φ(s) = f ~n(s) = f (~n(s)).
Si on reprend l’image de la particule se déplaç ant sur la courbe C , alors φ(s) désigne la valeur def au temps s mésurée sur la particule.
Proposition 11. La fonction φ= f ~n de R à valeur dans R est dérivable en s0 et
φ′(s) = ( f ~n)′(s0) =~n′(s0) .−−−→grad f (M) =~n′(s0) .
−−−→grad f (~n(s0))
= f ′x1
(~n(s0))n′1(x0)+ f ′
x2(~n(s0))n′
2(s0).
32

Idée de la démonstration. On passe par les développements limités à l’ordre 1. On écrit tout d’abordle développement limité de ~n près de s0, à savoir pour h petit
~n(s0 +h) =~n(s0)+h.~n′(s0)+hε(h), o ù ε(h) → 0lorsque h → 0.
Posons~k(h) =~n(s0 +h)−M = h(~n′(s0)+ε(h)),
de sorte que ‖k(h)‖ ≤C |h| pour h petit, où C est une constante. Utilisons maintenant 2.8, à savoir
f (n(s0 +h))− f (M) = f (M +k(h))− f (M) =~k(h).−−−→grad f (M)+‖~k(h)‖ε(~k(h)),où ε(~k) → 0 lorsque~k → 0,
= h(~n′(s0).−−−→grad f (M)+h.ε2(h),
où ε2(h) → 0 lorsque h → 0.
Troisième exemple. Voyons maintenant une autre situation tout aussi importante, et qui corres-pond en particulier à des changements de variables. Soit U une fonction de R2 dans R2, qui peutdonc s’écrire sous la forme
U (X ) = (u1(X ),u2(X ))
qui sera supposé dérivable près d’un point M donné, de dérivées continues, c’est à dire telle que u1
et u2 sont dérivables, de dérivées partielles continues. Soit f une fonction de R2 dans R dérivableprès de U (M) de dérivées partielles continues. Considérons la fonction F = f U
F (M) = f (u1(M),u2(M)).
Proposition 12. La fonction F = f U est différentiable en M. De plusF ′
x1(M) = f ′
u1(U (M))(u1)′x1
(M)+ f ′u2
(U (M))(u2)′x1(M)
F ′x2
(M) = f ′u1
(U (M))(u1)′x2(M)+ f ′
u2(U (M))(u2)′x2
(M).(2.9)
Idée de la démonstration. Pour t ∈R petit, on a
F (m1 + t ,m2) = f ~n(t ),
où ~n une une fonction de R dans R2 définie par ~n(t ) = (u1(m1 + t ,m2),u2(m1 + t ,m2)). On a
~n′(0) = ((u1)′x1
(M), (u2)′x1(M)
),
On a donc, en utilisant la Proposition 11 il vient
F ′x1
(M) = ( f ~n)′(0) =~n′(0).−−−→grad f (M),
ce qui donne le résultat.
Remarque 6. Nous verrons plus loin que ce résultat s’écrit de manière plus condensée en utilisantla matrice jacobienne de U donnée par
DU (M) =(
(u1)′x1(u1)′x2
(u2)′x1(u2)′x2
)Les relations (2.9) s’écrivent alors sous forme matricienne
−−−→gradF (M) =−−−→
grad f (U (M)) ·DU (M), (2.10)
où le point · désigne la multiplication des matrices et−−−→grad f est considéré comme un vecteur ligne.
33

Exemple 11. Illustrons le calcul précédent en voyons comment différentier une fonction en coor-données polaires. Rappelons que si X = (x1, x2) est un point du plan R2 de coordonnées polaires(r,θ), avec r ≥ 0, alors
x1 = r cosθ, x2 = r sinθ.
Ceci nous conduit à introduire l’applicationΦ de D =R+×R dans R2 définie par
Φ(r,θ) = (Φ1(r,θ),Φ2(r,θ) = (r cosθ,r sinθ). (2.11)
On vérifie que Φ est dérivable sur son domaine de définition et que ses dérivées partielles sontcontinues. En effet, on a
(Φ1)′r (r,θ) = cosθ, (Φ1)′θ(r,θ) =−r sinθ
(Φ2)′r (r,θ) = sinθ, (Φ2)′θ(r,θ) = r cosθ.
Si f est une fonction définie en coordonnées cartésiennes, son expression en coordonnées po-laires sera F = f Φ. On aura donc
F ′r (r,θ) = f ′
x1(M)sinθ+ f ′
x2(M)cosθ (2.12)
etF ′θ(M) = f ′
x1(M)r cosθ− f ′
x2r sinθ. (2.13)
On peut réecrire ces formules en introduisant les vecteurs unitaires
~er = M
‖M‖ = (cosθ, sinθ), et ~eθ = (−sinθ,cosθ)
qui sont orthogonaux, de sorte que
Fr (r,θ) =~er .−−−→grad f et Fθ(r,θ) = r~eθ.
−−−→grad f .
Remarquons que l’on peut déduire de ces calculs l’expression de−−−→grad f en coordonnées polaires,
à savoir −−−→grad f = Fr (r,θ)~er + 1
rFθ(r,θ)~eθ.
Remarque 7. Remarquons que l’on peut également écrire la formule (2.12) sous la forme
r∂F
∂r= x1
∂ f
∂x1+x2
∂ f
∂x2
et la formule (2.13) sous la forme∂F
∂θ= x2
∂ f
∂x1−x1
∂ f
∂x2.
2.5.4 La matrice Jacobienne
Il est possible de donner une forme plus concise aux résultats précédents en introduisant lamatrice Jacobienne. Considérons de manière générale une application ~f de Rk vers Rn , où lesnombres k et n peuvent prendre les valeurs 1, 2, voire 3 dans les chapitres ultérieurs. On peutécrire
~f (x1, . . . , xk ) = (f1(x1, . . . , xk ), . . . , fn(x1, . . . , xk )
).
34

On dira que ~f est dérivable si et seulement si toutes les fonctions fi le sont, pour i = 1, . . . ,k. Onintroduit alors la matrice D~f à n lignes et k colonnes, matrice dont les lignes sont composées desgradients des fonctions fi , i = 1, . . . ,n. On a donc
D f =
∂ f1∂x1
. . . ∂ f1∂xk
.... . .
...∂ fn∂x1
. . . ∂ fn∂xk
. (2.14)
Exemple 12. Soit F est une application linéaire de Rk vers Rn définie par une matrice
A = (ai , j )1≤i≤n, 1≤ j≤k
à n lignes et k colonnes, c’est à dire telle que
t f (~X ) = At~X . (2.15)
Ici t f et t~X désignent les vecteurs colonnes associés aux vecteurs lignes ~f (x) et ~X respectivement(ce sont aussi leurs matrices transposée, si on considère ces vecteurs lignes comme des matrices).Plus précisement, on a
t~X =
x1...
xk
et t~f (X ) =
f1(X )...
fn(X )
la relation matricielle (2.15) donne donc fi (X ) = ai ,1x1 + . . . a1,k xk . Alors
D f (X ) = A,∀X ∈Rk .
Si par ailleurs, on note comme précedemment
t~h =
h1...
hk
alors les développements limités du type (2.8) peuvent s’écrire
~f (M +h)−~f (M) = D f (M) ·t ~h +‖h‖ε(h), (2.16)
où ε tend vers 0 lorsque h tend vers 0 (c’est à dire chacune de ses composantes), et où le produitD f (M) ·t ~h désigne la multiplication des matrices, c’est à dire
D f (M)~h =
∂ f1∂x1
. . . ∂ f1∂xn
.... . .
...∂ fk∂x1
. . . ∂ fk∂xn
·
h1...
hk
.
Le produit précédent définit une application linéaire
~h 7→ D f (M) ·t ~hde Rk à valeurs dans Rn . Cette application est appelée application linéaire tangente à f au pointM . L’application affine
~h 7→ D f (M) ·~h +~f (M)
est une appproximation à l’ordre 1 de f près de M .
35

Proposition 13. SiΦ est une fonction Rn vers Rk dérivable de dérivées continues près de M et F unefonction de Rk vers R`, dérivable de dérivées continues près deΦ(M) alors F Φ est dérivable près deM et la matrice Jacobienne de la composée F Φ en M est donnée par
D f Φ(M) = D f (Φ(M)) ·DΦ(M). (2.17)
Si Φ est une une fonction de Rn vers Rn , dérivable de dérivées continues près de M, telle que Φ−1
existe près deΦ(M) et telle que dΦ(M) soit inversible, alors
DΦ−1 (Φ(M)) = (DΦ(M))−1.
Exemple 13. Reprenant l’application Φ donnée par (2.11) et qui exprime les coordonnées carté-siennes en fonctions des coordonnées polaires. Sa matrice jacobienne est donc
dΦ(r,θ) =(
∂x1∂r
∂x1∂θ
∂x2∂r
∂x2∂θ
)=
(cosθ −r sinθsinθ r cosθ
)La matrice inverse de cette matrice se calcule comme(
cosθ sinθ−1
r sinθ 1r cosθ
).
Il résulte donc de la proposition que l’on a(∂r∂x1
∂r∂x2
∂θ∂x1
∂θ∂x2
)=
(cosθ sinθ
−1r sinθ 1
r cosθ
)=
( x1r
x2r
− x2r 2
x1r 2
).
(2.18)
2.5.5 Dérivées secondes
Lorsque f est dérivable sur l’ensemble de son domaine de définition, ceci définit de nouvellesfonctions, les dérivées partielles. Lorsque ces dernières sont elles-mêmes dérivables, les dérivéesde ces dernières sont appelées les dérivées secondes. Ainsi, si f est une fonction sur R2 on a 4dérivées partielles d’ordre 2, à savoir
f ′′x1x1
= ( f ′x1
)x1, f ′′
x1x2= ( f ′
x1)x2
, f ′′x2x1
= ( f ′x2
)x1et f ′′
x2x2= ( f ′
x2)x2
on utilise aussi souvent les notations
∂2 f
∂2x1,
∂2 f
∂x1∂x2,
∂2 f
∂x2∂x1et
∂2 f
∂2x2.
En guise d’exemple on peut remarquer que si f est une fonction affine, toutes les dérivéessecondes sont nulles. C’est d’aileurs une condition nécessaire et suffisante, lorsque le domaineest connexe.
Dans l’exemple 10 ci-dessus, on obtient, dans l’ordre, les fonctions suivantes :.
2, 1, 1, 6x2.
On constate sur cet exemple que les dérivées secondes "croisées" sontégales. Ceci est en fait uneconséquence du résultat général suivant, souvent appelé Théorème de Schwarz ou de Clairaut-Schwarz.
36

Théorème 1. Si les dérivées secondes existent et sont continues près d’un point M donné, alors on al’identité
∂
∂x1
(∂ f
∂x2
)(M) = ∂
∂x2
(∂ f
∂x1
)(M).
c’est à diref ′′
x1x2(M) = f ′′
x2x1(M).
Idée de la démonstration. Supposons pour simplifier que M = 0 et, de plus, que f (0) et les dérivéespartielles premières de f sont nulles en M = 0 : on peut toujours se ramener à ce dernier cas ensoustrayant à f l’application affine tangente en M = 0, les dérivés secondes restant inchangées.Dans ces conditions, réécrivons, pour h = (h1,h2) donnés, la décomposition (2.7) sous la forme
f (h) =∫ h2
0
∂ f
∂x2(0, s)d s +
∫ h1
0
∂ f
∂x1(s,h2)d s. (2.19)
Par intégration on peut écrire pour 0 ≤ s ≤ h2
∂ f
∂x2(0, s) =
∫ s
0
∂2 f
∂2x2(0, t )d t = s
∂2 f
∂2x2(0,0)+‖h‖ε1(h), (2.20)
o û la fonction ε1 tend vers 0 quand h tend vers 0. De même, on a pour 0 ≤ s ≤ h1
∂ f
∂x1(s,h2) = ∂ f
∂x1(0,h2)+
∫ s
0
∂2 f
∂2x1(t ,h2)d t .
Comme on a par ailleurs
∂ f
∂x1(0,h2) =
∫ h2
0
∂2 f
∂x2∂x1(0, t )d t = h2
∂2 f
∂x2∂x1(0,0)+‖h‖ε2(h)
où la fonction ε2 tend vers 0 quand h tend vers 0, de sorte que
∂ f
∂x1(s,h2) = s
∂2 f
∂2x1(0,0)+h2
∂2 f
∂x2∂x1(0,0)+‖h‖ε3(h). (2.21)
où la fonction ε3 tend vers 0 quand h tend vers 0. En reportant les développements (2.20) et (2.21)dans (2.19), on obtient après intégration, le développement limité
f (h) = 1
2h2
1∂2 f
∂2x1(0,0)+h1h2
∂2 f
∂x2∂x1(0,0)+ 1
2h2
2∂2 f
∂2x2(0,0)+‖h‖2ε(h). (2.22)
où la fonction ε tend vers quand h tend vers 0. Rappelons que nous avons obtenu cette formule enpartant de l’égalité (2.19), qui correspond à une intégration en suivant le chemin vert ci-dessous
37

Si nous remplaçons le chemin en trait plein vert par le chemin en pointillés rouge, alors nousobtenons la formule
f (h) =∫ h1
0
∂ f
∂x1(s,0)d s +
∫ h2
0
∂ f
∂x2(h1, s)d s. (2.23)
qui par des arguments analogues à ceux développés plus haut mènent au développement limité
f (h) = 1
2h2
1∂2 f
∂2x1(0,0)+h1h2
∂2 f
∂x1∂x2(0,0)+ 1
2h2
2∂2 f
∂2x2(0,0)+‖h‖2ε(h). (2.24)
où la fonction ε tend vers quand h tend vers 0. Comme on peut identifier les premiers termes desdeux développements, la conclusion en résulte.
Remarque 8. Lorsque f admet toutes les dérivées jusqu’à l’ordre n et lorsque ces dérivées sontcontinues, alors l’ordre dans lequel on effectue les dérivation n’a aucune importance. Pour n déri-vations où interviennent p la variable x1 et q fois la variable x2, avec n = p +q on note
∂n f
∂p x1∂q x2
la dérivée partielle correspondante. Par exemple pour n = 3 les dérivées partielles d’ordre 3 sont
∂3 f
∂3x1,
∂3 f
∂2x1∂x2,
∂3 f
∂x1∂2x2,∂3 f
∂3x2.
Notons que nous avons obtenu lors de la preuve du Théorème 1 le développement d’ordre 2d’une fonction à deux variables. On a donc :
Théorème 2. Si les dérivées secondes existent et sont continues près d’un point M donné, alors on apour h = (h1,h2)
f (M +h) = f (M)+h.−−−→grad f (M)+ 1
2h2
1∂2 f
∂2x1(M)+h1h2
∂2 f
∂x2∂x1(M)+ 1
2h2
2∂2 f
∂2x2(M)
+‖h‖2ε(h)
= f (M)+h.−−−→grad f (M)+ 1
2Hess f (M) · (h,h)+‖h‖2ε(h),
(2.25)
38

o û la fonction ε tend vers quand h tend vers 0, où Hess f (M) désigne la matrice symétrique
Hess f (M) = ∂2 f
∂2x1(M) ∂2 f
∂x2∂x1(M)
∂2 f∂x2∂x1
(M) ∂2 f∂2x2
(M)
.
et l’expression Hess f (M) · (~h,~h) la forme quadratique associée, c’est à dire
Hess f (M) · (~h,~h) =~h ·Hess f (M)t~h
= (h1,h2) · ∂2 f
∂2x1(M) ∂2 f
∂x2∂x1(M)
∂2 f∂x2∂x1
(M) ∂2 f∂2x2
(M)
·(
h1
h2
).
2.6 Le théorème des fonctions implicites
Nous avons vu jusqu’à présent deux manièrse de représenter la notion intuitive de ligne dansR2 : les courbes paramétrée d’une part, les lignes de niveau d’autre part. Les résultats de cette par-tie vont nous convaincre que pour une large part, ces deux notions coïncident.
On considère une fonction f supposée dérivable sur son domaine de définition. On s’intéresseà l’équation
f (x1, x2) = 0, (2.26)
et à l’ensemble de ses solutions, à savoir
C = (x1, x2), f (x1, x2) = 0, (2.27)
qui correspond à l’ensemble de niveau f c pour c = 0. Comme nous l’avons vu, notre intuition nousamène à penser que C est une courbe. Or nous avons jusqu’à présent représenté les courbes sousforme de paramètrage, et l’on peut se demander si il est possible de paramétrer localement C .
Exemple 14. Nous avons déjà vu que le cercle S 1 pouvaitêtre paramètré par une application de[0,2π] à valeur dans R2, à savoir
t 7→ M(t ) = (cost , si nt ),
mais on a aussiS 1 = (x1, x2), x2
1 +x22 −1 = 0
c’est à dire de la forme (2.27) avec f (x1, x2) = x21 +x2
2 −1.
Une question naturelle est donc la suivante :
Sous quelles conditions C est-elle une courbe paramétrée ?
En fait, nous allons voir que, sous des hypothèses adéquates, on peut pour les éléments de C
exprimer localement une des variables, par exemple x2, en fonction de l’autre, ici x1 de sorte quelocalement C est un graphe.
Pour fixer les idées, commençons par regarder le cas où la fonction f est affine, c’est à diresupposons que l’équation a la forme
a1x1 +a2x2 +b = 0.
39

Si a2 6= 0, on obtient immédiatement x2 connaissant x1 à savoir
x2 =−a1x1 +b
a2.
de sorte que l’ensemble des solutions de (2.26) est le graphe de la fonction ϕ de la variable x1
donnée par
ϕ(x1) = a1x1 +b
a2,
et l’ensemble des solutions est donc une courbe paramétrique
C = (x1,φ(x1), x1 ∈R.
En revanche a2 = 0, alors, on ne peut plus exprimer x2 en fonction de x1. En revanche, on peutexprimer x1 en fonction de x2 si a1 6= 0, et dans ce cas là également on obtient aussi une courbeparamétrée. Le seul cas où on n’obtient pas de courbe est celui o ù
(a1, a2) = (0,0)
cas, où en fonction de c on obtient soit l’ensemble vide, soit l’espace tout entier. Notons au passage
que (a1, a2) =−−−→grad f , qui est bien la quantité à étudier. On a en effet le résultat général suivant, que
nous admettons :
Théorème 3. Soit f une fonction qui admet des dérivées partielles sur son ensemble de définition,et soit M = (m1,m2) solution de (2.26). Supposons que
∂ f
∂x2(M) 6= 0. (2.28)
Alors il existe un voisinage U de M dans R2, un intervalle ouvert I contenant m1, une fonctionϕ : I →R telle que l’ensemble des solutions de (2.26) dans U soit exactement de la forme
(x1,ϕ(x1)), x1 ∈ I .
Sous l’hypothèse (2.28), et près de M l’ensemble des solutions est donc un graphe, celui de lafonction ϕ. Si on a
∂ f
∂x1(M) 6= 0,
alors on peut changer le rôle de x1 et x2 et trouver une fonction ψ telle que x1 =ψ(x2) près de M ,et de nouveau la courbe est localement un graphe, donc paramétrée. Le seul cas où on ne peutconclure est celui où −−−→
grad f (M) = 0.
Le résultat précédent permet de calculer les vecteurs tangents au solutions de (2.26). On a toutd’abord
Proposition 14. Sous les hypothèses du Théorème 3 on a
ϕ′(s) =− f ′x1
(s,ϕ(s))
f ′x2
(s,ϕ(s)).
40

Démonstration. On a pour s ∈ I , f (s,ϕ(s)) = 0. Posons pour s ∈ I , ~n(s) = (n1(s),n2(s)) de sorte quela relation précédente s’écrit
f ~n(s) = 0, ∀s ∈ I ,
d’ou il resulte, en dérivant par rapport à s que
( f ~n)′(s) = 0,∀i u ∈ I .
. On peut calculer cette dérivée grâce à la proposition 11 de sorte que
( f ~n)′(s) =~n′(s).−−−→grad f (~n(s)) = f ′
x1(s,ϕ(s))+ f ′
x2(s,ϕ(s))ϕ′(s)) = 0.
La conclusion en découle.Ceci permet finalement d’établir
Théorème 4. Soit M une solution de (2.26) telle que
−−−→grad f (M) 6= 0. (2.29)
Alors il existe un voisinage U de M telle que M ∩U soit une courbe paramétrée. De plus, le vecteur
−−−→grad⊥ f (M) = (− f ′
x2(M), f ′
x1(M)
)(2.30)
est alors tangent à la courbe f (x1, x2) = 0 en M.
Démonstration. Supposons pour commencer que∂ f
∂x2(M) 6= 0. Dans ce cas, l’ensemble des so-
lutions est localement donné par le graphe x2 =ϕ(x1), et il résulte alors de (2.3) que le vecteur
(1,ϕ′(m1)) = (1,− f ′x1
(M)
f ′x2
(M))
est tangent à ce graphe. En multipliant par f ′x2
(M) on obtient la résultat.
Si∂ f
∂x2(M) = 0, alors nécessairement, comme le gradient ne s’annule pas en M , on doit avoir
∂ f
∂x1(M) 6= 0, et on reprend le même raisonnement en échangeant les rôles de x1 etx2.
Remarque 9. On a −−−→grad⊥ f (M).
−−−→grad f (M) = 0 (2.31)
Exemple 15. Revenons au cas du cercle S1, avec f (x1, x2) = x21 + x2
2 − 1. On a ∂ f∂x2
= 2x2, et donc,les deux seuls points où cette dérivée s’annule sont (1,0) et (−1,0). Si x2 > 0, alors on peutécrirel’équation du cercle comme
x2 =√
1−x21 ,
et on a donc
ϕ(x1) =√
1−x21 ,
et de même si x2 < 0, alors on a ϕ(x1) =−√
1−x21 . un vecteur tangent à la courbe est donné par
−−−→grad⊥ f (x1, x2) = (2x2,2x1) = 2(−x2, x1).
41

Remarque 10. La condition (2.29) est une condition suffisante pour que C soit localement près deM une courbe paramétrée, ce n’est cependant pas une condition nécessaire. Pour s’en convaincre,on peut remarquer que C correspond également à l’ensemble de niveau de la fonction f 2, à savoir
C = (x1, x2) ∈R2, f 2(x1, x2) = 0.
Or on a pour tout M ∈R2, −−−→grad f 2(M) = 2 f (M)
−−−→grad f (M),
de sorte que −−−→grad f 2(M) = 0 pour M ∈C .
Exercices
Exercice I
Soit f une fois deux fois dérivables de dérivées secondes continues. On suppose que
Hess f (M) = 0, pour tout M ∈R2.
montrer que f est une fonction affine.
Exercice II
Soit f une fonction dérivable de R2 dans R et ~n une fonction de R dans R2 telle que
d
d t~n(t ) =−−−−→grad f (~n(t )).
calculer dd t f (n(t )).
Exercice III
Soit f une fonction dérivables sur R2 de dérivées continues. On suppose que
∂ f
∂x1+2
∂ f
∂x2= 0.
On pose u1 = 2x1 −x2, u2 = 2x1 +x2, et F (u1,u2) = f (x1, x2). Montrer que
∂F
∂u1= 0.
en déduire qu’il existe une fonction d’une varibale réelle g telle que
f (x1, x2) = g (2x1 −x2).
42

Exercice IV
A) Soit F une fonction sur R2 ayant des dérivées secondes continues. On suppose que
∂2F
∂x1∂x2= 0.
Montrer qu’il existe des fonctions f1 et f2 une variable réelle telles que
F (x1, x2) = f1(x1)+ f2(x2).
B) Soit g une fonction définie sur R2 telle que
∂2 f
∂2x1− ∂2 f
∂2x2= 0.
On considère le changement de variable linéaire de R2 →R2 défini par
(u1,u2) 7→ (x1, x2) =(u1 −u2
2,
u1 +u2
2
),
et on pose G(u1,u2) = g (x1, x2). Montrer que
∂2G
∂u1∂u2= 0.
C) En déduire qu’il existe des fonctions g1 et g2 telles
g (x1, x2) = g1(x1 −x2)+ g2(x1 +x2).
43

Chapitre 3
Champs de vecteurs
3.1 Premières définitions
Soit D un domaine de R2.
Définition 1. On appelle champ de vecteurs sur D toute application ~V d’un domaine D de R2 àvaleur dans R2 :
M ∈D 7→ ~V (M) = (V1(M),V2(M)) ,
où les fonctions V1 et V2 sont des applications scalaires sur D, c’est à dire des applications de D versR.
Nous avons déjà rencontré cette notion lors du chapitre précédent. En réalité, la terminologierelève en partie de la physique, où les applications de D versR sont appelées par contraste champsscalaires.
Comme exemple de tels champs, considérons par exemple la carte d’une région, notée ici D, etque l’on peut considérer comme un domaine de R2. En chaque point de cette carte, nous pouvonspar exemple considérer la température au sol : il s’agit alors d’une fonction T de D à valeurs dansR,c’est à dire un champ scalaire. En revanche, si à chaque point M de la carte, on associe la directionet la vitesse du vent, que l’on peut représenter par un vecteur ~V (M), alors on a défini un champ devecteurs. On représente en général le vecteur ~V (M) sous forme de vecteur attaché au point M .
44

3.1.1 Changement de repère
Nous avons représenté jusqu’à présent les vecteurs de R2 dans la base canonique (~e1,~e2). Quece passe-t-il lorsque l’on désire exprimer les champs de vecteurs dans une nouvelle base (~e ′
1,~e ′2) ?
les champs de Cette opération correspond tout simplement à l’opération usuelle de changementde coordonnées de vecteurs dans un changement de base que nous rappelons ici brièvement.
Soit e la base initiale (~e1,~e2) deR2, et considérons la nouvelle base e′formée des vecteurs (~e ′
1~e′2).
Supposons que nous connaissions les coordonnées des vecteurs de la nouvelle base dans la baseinitiale, c’est à dire suposons que nous connaissions des décomposition suivantes :
~e ′1 = p1,1~e1 +p2,1~e2
~e ′2 = p1,2~e1 +p2,2~e2
Formons la matrice carrée P (e→ e′), appelée matrice de passage de la base e vers la base e′
P (e→ e′) =(
p1,1 p1,2
p2,1 p2,2
)Notons que la i -ème colonne de cette matrice est composée des coordonnées du vecteur~e ′
i dans
la base initiale e. Considérons maintenant un vecteur ~X de R2, qui se décompose comme
~X = x1~e1 +x2~e2
dans la base initiale , et comme~X ′ = x ′
1~e′1 +x2~e
′2.
Un bref calcul montre alors que (x1
x2
)=
(p1,1 p1,2
p2,1 p2,2
)(x ′
1x2
),
que l’on peut écrire, sous forme plus condensée, en posant
t X =(
x1
x2
)et t X ′ =
(x ′
1x ′
2
)sous la forme
t X = P (e→ e′)t X ′. (3.1)
La matrice de passage P (e→ e′) et la relation (3.1) permettent donc de calculer les coordonnéesinitiales lorsque l’on connaît les nouvelles coordonnées : en général, c’est plutôt l’inverse que l’ondésire faire. Nous déduisons de (3.1) que
t X ′ = P−1(e→ e′)t X , (3.2)
et ainsiP (e′ → e) = P−1(e→ e′).
On peut en effet vérifier que les matrices de passage d’une base à l’autre sont toujours inversibles.Ainsi si on veut calculer les nouvelles coordonnées en fonctions des coordonnées initiales, noussommes amenés à calculer l’inverse de la matrice de passage P−1(e→ e′).
45

Remarque 1. On peut également se demander comment se transforme le produit scalaire d’ori-gine dans un changement de base, c’est à dire qu’elle est l’expression du produit scalaire dans lenouvelle base. Soient ~X = (x1, x2) et ~Y = (x1, x2) deux vecteurs de R2 et ~X . ~Y = x1.x2 + y1.y2 leurproduit scalaire. C e dernier peut s’écrire pour forme matricielle comme
~X .~Y = X .t Y = (x1, x2)
(y1
y2
)Si (x ′
1, x ′2) et(y ′
1, y ′2) sont les coordonnées dans la nouvelle base e/,′ alors
~X .~Y = (x ′1, x ′
2)t P (e→ e′)P (e→ e′)(
y ′1
y ′2
).
Si la base e′
est elle-même orthonormée, alors la matrice P verifie t PP = I et on a donc
~X .~Y = x ′1.x ′
2 + y ′1.y ′
2.
L’expression du produit scalaire est donc la même dans toute les bases orthonormées.
Remarque 2. Notons qu’un champ de vecteur est homogène àune longueur.
Remarque 3. Dans certains problèmes, on peut être amenéà écrire à considérer des repères mo-bile, c’est à dire des bases orthonormées e
′(M) qui dépendent elle-même du point considéré M .
C’est par exemple le cas lorsqu’on considère le repère mobile associé aux coordonnées polaires
e′(M) = (~er (M),~eθ(M))
où
~er (M) = M~‖M‖ , eθ(M) =~e⊥
r (M).
Un exemple fondamental de champ de vecteur est fourni par les champs de gradient.
3.1.2 Champ de gradient
Définition 2. Soit f une application d’un domaine D de R2 supposée dérivable en tout point du
domaine. On appelle champs de gradient associé à f le champs de vecteurs−−−→grad f défini par
−−−→grad f (M) = (
f ′x1
(M), f ′x2
(M))
. (3.3)
Nous avons déjà rencontré cette notion au chapitre précédent. La propriété suivante exprimele fait que le gradient est orthogonal aux lignes de niveau. Posons à cet effet, pour c ∈R
Lc = M ∈D, f (M) = c.
Proposition 1. Soit c ∈ R tel que Lc est non vide, et soit M ∈ Lc tel que−−−→grad f (M) 6= 0. Alors, pour
tout vecteur ~T tangent à Lc en M, ona
~T ⊥−−−→grad f (M).
Démonstration. la proposition est une conséquence immédiate du Théorème 4, et de la remarquequi le suit.
46

Remarque 4. Si on dessine les lignes de niveau pour des valeurs de c espacées régulièrement, alorsle gradient est orthogonale aux lignes de niveau, pointe vers les ensembles de valeurs de niveaucroissant, et son module est plus élevé aux endroits où ces courbes se resserrent.
Il est naturel de se demander si tout champ de vecteur peut se représenter sous forme de gra-dient d’une fonction, ce qui est le cas pour les fonctions d’une variable réelle, qui sont la dérivée deleur primitive. En réalité, il est facile de se convaincre que ce n’est pas le cas pour tous les champsde vecteurs, comme le montre le résultat suivant :
Proposition 2. Soit ~V = (V1,V2) un champ de vecteurs dérivable, de dérivée continue, défini sur undomaine D. Une condition nécessaire pour que ~V soit un champ de gradient est que
∂V2
∂x1= ∂V1
∂x2. (3.4)
Démonstration. Supposons qu’il existe une fonction f définie sur D telle que
~V =−−−→grad f , c’est à dire V1 = ∂ f
∂x1, et V2 = ∂ f
∂x2.
Par le Théorème de Schwarz, on doit avoir
∂
∂x1
(∂ f
∂x2
)= ∂
∂x2
(∂ f
∂x2
),
ce qui même directement à (3.4).
Nous verrons par la suite que, si le domaine est sans trou, alors la condition (3.4) est aussi unecondition suffisante, c’est à dire tout champ de vecteurs qui vérifie (3.4) est un champ de gradient.
Exemple 1. Considérons tout d’abord un champ de vecteur constant V (x1, x2) = (a1, a2), pour tout(x1, x2) dans R2, où a1 et a2 sont deux constantes données. Alors on a V ′
x1(x1, x2) = 0 et V ′
x2(x1, x2) =
0 de sorte que (3.4) est satisfaite. On peut par ailleurs vérifier que V est le champ de gradient de lafonction linéaire
f (x1, x2) = a1x1 +a2x2,∀(x1, x2) ∈R2,
de sorte que tout champ de vecteur constant est bien un champ de gradient.
47

Exemple 2. Considérons un champ de vecteur ~V linéaire, c’est à dire de la forme
t~V (~X ) = A ·t ~X ,
où A est une matrice 2
A =(
a1,1 a1,2
a2,1 a2,2.
)On vérifie que V1(x1, x2) = a1,1x1 +a1,2x2, V2(x1, x2) = a2,1x1 +a2,2x2,
∂V2
∂x1= a2,1,
et que∂V1
∂x2= a1,2.
Le champ V est donc un champ de gradient si et seulement a1,2 = a2,1, c’est à dire si et seulementsi la matrice A est symétrique.
Remarque 5. pour une fonction f donnée, nous avons introduit au chapitre précédent le champde vecteurs −−−→
grad⊥ f = (− ∂ f
∂x2,∂ f
∂x1),
qui correspond au champ gradient auquel on a fait subir une rotation de π/2 dans le plan. Pour untel champ de vecteurs, la condition (3.4) s’écrit
− ∂
∂x1
(∂ f
∂x1
)=− ∂
∂x2
(∂ f
∂x2
)c’est à dire
∆ f = 0, (3.5)
où ∆ désigne l’opérateur Laplacien, qui s’écrit
∆F = ∂2 f
∂2x1+ ∂2 f
∂2x2.
Par exemple, si on prend la fonction f (x1, x2) = x21 +x2
2 , alors
∆ f (M) = 2,
et−−−→grad⊥ f (M) = (2m2,−2m1) n’est donc pas un champ de gradient.
Invariance du gradient par changement de repère orthonormé.
La question de l’invariance par changement de repère est une question centrale, tant en ma-thématique que dans les domaines applicatifs. Nous avons vu qu’un gradient est un champ devecteur, à ce titre il se transforme dans un changement de base par les règles de l’algèbre linéaire,voir le paragraphe 3.1.1. Que devient alors dans le nouveau repère la définition (3.3) ?
La définition (3.3) associé en effet à une fonction f sur R2 le champ de vecteur−−−→grad f : cette dé-
finition repose sur l’expression dans un repère donné de la fonction f et de ses dérivées partielles,
48

elle donc a priori relative à un choix de repère orthonormé (~e1,~e2), qui détermine les coordonnéescartésiennes (x1, x2). Elle s’exprime donc, pour une fonction f donnée sur un domaine D par larelation −−−→
grad f = ∂ f
∂x1~e1 + ∂ f
∂x2~e2.
Introduit un nouveau repère orthonormé (~e ′1,~e ′
2) et des coordonnées x ′1, x ′
2 correspondantes desorte que
x1~e1 +x2~e2 = x ′1~e
′1 +x ′
2~e′2
Cherchons l’expression du gradient dans cette nouvelle base. Posons
f (x ′1, x ′
2) = f (x1, x2) = f (x1~e1 +x2~e2) = f (x ′1~e
′1 +x ′
2~e′2).
Proposition 3. On a pour tout (x1, x2) ∈D
−−−→grad f (x1, x2) = ∂ f
∂x ′1
~e ′1 +
∂ f
∂x ′2
~e ′2,
ses coordonnées dans la base (~e ′1,~e ′
2) sont donc f ′x ′
1et f ′
x ′2.
L’expression du gradient dans la nouvelle base est donc identique à celle dans l’ancienne base.
Preuve. On a f = f Φ où Φ désigne l’application de R2 dans lui-même qui aux nouvelles coor-données associe les anciennes (x ′
1, x ′2) 7→ Φ(x ′
1, x ′2)) = (x1, x2). Il s’agit d’une application linéaire,
associe à une matrice P carrée 2×2. Posons ~X = (x1, x2) et ~X ′ = (x ′1, x ′
2). On a
t~X =Φ(~X ′) = P t X ′,
où A désigne la matrice de passage de la nouvelle base vers l’ancienne. Comme Φ est linéaire, ona DΦ = P , et donc par la formule (2.10)
−−−→grad f (x ′
1, x ′2) =−−−→
grad f (x1, x2)P
Comme A est orthonormée , on a P−1 =t P , et donc−−−→grad f (x1, x2) = −−−→
grad f (x ′1, x ′
2) t P , soit, entransposant
t−−−→grad f (x1, x2) = P t −−−→grad f (x ′1, x ′
2).
Ceci montre que les coordonnées du gradient se transforment comme celles des vecteurs, et donnela relation désirée.
Remarque 6. Attention, l’énoncé n’est valable que pour des changements de bases orthonormées.
Remarque 7. La proposition 3 peut aussi s’interpréter en revenant à la formule du développementlimité (2.8)
f (M +~h)− f (M) '~h.−−−→grad f (M).
la conservation du produit scalaire par changement de repère orthonormé comme celle du membrede gauche explique alors que la forme du gradient reste elle-même inchangée.
49

FIGURE 3.1 – Champ électrique généré par des charges de même signe et de signes opposés.
FIGURE 3.2 – la limaille de fer dessine des lignes de champ magnétique.
3.1.3 Lignes de champ
Considérons un champ de vecteurs ~V défini sur un domaine D, et C une courbe tracée dansle domaine D.
Définition 3. On dira que C est une ligne de champ du champ de vecteurs ~V si et seulement si ~Vest tangent à C en tout point de C .
Les lignes de champ sont souvent utilisées en physique pour représenter des champs de vec-teurs, par exemple des champs électriques ou magnétiques, comme dans la figure ci-dessous, quireprésente le champ électrique crée par des charges ponctuelles de même signe puis de signe op-posé. Notons par ailleurs que le champ électrique est un champ gradient, associé à l’opposé dupotentiel électrique.
En mathématiques, se pose bien entendu le problème de l’existence de telles lignes de champs.
Proposition 4. Soit ~V un champ de vecteurs dérivable de dérivées continues sur un domaine D, etsoit M0 un point de D. Alors il existe une ligne de champ C et une seule qui passe par M0.
Idée de la démonstration. Pour construire la ligne de champ, on introduit l’équation différentielleavec condition initiale
d M
d t(t ) = ~V (M(t )), t ∈ I
M(0) = M0,(3.6)
50

où I désigne un intervalle de R contenant 0, et où l’inconnue est la fonction t 7→ M(t ) ∈D. Notonsque l’équation (3.6) est en fait un système de deux équations différentielles lorsqu’on l’exprime encoordonnées.
Les méthodes de résolution des équations différentielles, et en particulier le Théorème deCauchy-Lipschitz montrent alors que l’équation (3.6) possède toujours une solution, qui existetant que M(t ) ne sort pas d’un voisinage de M0. La fonction t 7→ M(t ) ∈D fournit alors le paramé-
trage d’une courbe C , dont un vecteur tangent n’en autre qued M
d t(t ) en M(t ) c’est à dire, au vu de
(3.6), le vecteur ~V (M(t )).
Remarque 8. En mathématiques, on utilise souvent le terme courbes intégrales du champ de vec-teurs ~V pour désigner les lignes de champ. Ceci fait références à l’intégration de l’équation diffé-rentielle (3.6).
Remarque 9. L’équation (3.6) modélise de nombreux phénomènes, en particulier en mécaniquedes fluides, comme nous allons le voir.
Considérons un fluide, qui pourra être un liquide comme l’eau ou un gaz, comme l’air occu-pant un domaine D (ici de R2). Supposons que le champ de vecteurs ~V représente le champ desvitesses du fluide, c’est à dire qu’on chaque point M du domaine, ~V (M) désigne la vitesse des par-ticules élémentaires, par exemple les molécules, constituant ce fluide. Alors les lignes de champou courbes intégrales de ~V correspondent aux trajectoires suivies par les particules élémentaires :plus précisément, les particules présentes au temps 0 en M0 seront transportées par le fluide aupoint M(t ) au temps t . La donnée du champ de vecteurs ~V permet donc de reconstituer entière-ment les trajectoires des particules du fluide.
En guise d’exercice, voyons maintenant comment les quantités physiques sont transportéespar le champ de vecteurs. Soit f une quantité scalaire physique que l’on peut mesurer dans lefluide : f (M , t ) représente donc la quantité mesurée au point M , au temps t . La température dufluide peut être un exemple d’une telle quantité. Considérons une particule située au temps t = 0en M0 et essayons de voir comment varie la quantité f mesurée sur la particule : nous noterons fcette quantité qui dépend uniquement du temps.
On a par définitionf (t ) = f (M(t ), t )
et doncd f
d t(t ) = d
d tf (M(t ), t ).
Si on applique donc la règle de dérivation des fonctions composées, il vient, si−−−→gradM désigne
uniquement les dérivées par rapport aux variables spatiales
d f
d t(t ) = d M
d t(t ).
−−−→gradM f (M(t ), t )+ ∂ f
∂t(M(t ), t ),
soit finalementd f
d t(t ) = ∂ f
∂t(M(t ), t )+~V (M(t )).
−−−→gradM f (M(t ), t ). (3.7)
On parle alors de dérivée particulaire.
51

3.2 Circulation d’un champ de vecteurs
Soit ~V un champ de vecteurs dérivable, de dérivées continues. On considère ici une courbeparamétrée t 7→ ~M(t ) par un segment fermée [a,b]
x1 = M1(t ) x2 = M2(t ), où t ∈ [a,b].
Les extrémités de cette courbes sont notées A = (M1(a), M2(a)) , B = (M1(b), M2(b)), et la courbeelle-même sera notée AB . Notons que l’on considère ici des courbes orientées, c’est à dire avec unedirection allant de A vers B 1. On introduit alors la quantité suivante :
I =∫ b
a
~V (M(t )).~M ′(t )d t
=∫ b
a
[V1(M(t ))M ′
1(t )+V2(M(t )).M ′2(t )
]d t
Proposition 5. La valeur de l’intégrale I ne dépend pas du paramétrage choisi de la courbe AB, s’ilrespecte l’orientation. On la note ∫
AB
~V (M)d ~M , (3.8)
et on l’appelle circulation du champs de vecteurs ~V le long de la courbe AB.
Démonstration. Considérons un autre paramétrage de la courbe : on peut l’obtenir en considéronsun intervalle [c,d ], et une application ϕ : [c,d ] → [a,b] dérivable telle que ϕ(c) = a, ϕ(d) = b , desorte que
s 7→ N (s) ≡ ~M(ϕ(s)
)fournit bien le paramétrage désiré. On a∫ d
c
~V (N (s)).~N ′(s)d s =∫ d
c
~V (M(ϕ(s)).~M ′(ϕ(s))ϕ′(s)d s
=∫ b
a
~V (M(t )).~M ′(t )d t
(3.9)
o û on a utilisé la formule de changement de variable pour la dernièreégalité.
Remarque 10. Dans la notation (3.8) on a écrit implicitement d ~M = ~M ′(t )d t , où M ′(t ) = (M ′
1(t ), M ′2(t )
).
Passons maintenant en revue, sans démonstration, quelques propriétés utiles.
Proposition 6. On a, si ~V est un champ de vecteurs et AB une courbe paramétrée– Si C est un point sur la courbe AB on a∫
AB
~V (M)d ~M =∫AC
~V (M)d ~M +∫
C B
~V (M)d ~M .
1. on ne considère pour simplifier que des paramétrages monotones, c’est à dire qui forment une bijection del’intervalle [a,b] vers AB et tels que la dérivée ne s’annule pas
52

– si λ ∈R, on a ∫AB
λ~V (M)d ~M =λ∫
AB
~V (M)d ~M .
et si ~V1 et V2 sont deux champs de vecteurs∫AB
(~V1(m)+V2(M)
)d ~M =
∫AB
~V1(M)d ~M +∫
AB
~V2(M)d ~M
Par ailleurs, si t 7→ M(t ) est un paramétrage de la courbe AB , alors l’application t 7→ M(b+a−t )est un paramétrage de la courbe orientée B A et on a∫
AB
~V (M)d ~M =−∫
AB
~V (M)d ~M .
3.2.1 Circulation d’un champ de gradient
Considérons le cas particulier où ~V =−−−→grad f est un champ de gradient. On a alors
Proposition 7. Soit f une fonction dérivable, de dérivées continues, et AB une courbe orientée. Ona ∫
AB
−−−→grad f (M)d ~M = f (B)−F (A).
En particulier, la valeur de la circulation d’un champ de gradient ne dépend que des extrémités, etpas du chemin suivi.
Démonstration ; On a ∫AB
−−−→grad f (M)d ~M =
∫ b
a
−−−→grad f (M(t )).~M ′(t )d t .
Or, par la formule de dérivation des fonction composées, il vient
d
d tf (M(t )) =−−−→
grad f (M(t )).~M ′(t ).
Il en résulte que∫AB
−−−→grad f (M)d ~M =
∫ b
a
d
d tf (M(t ))d t = f (M(b))− f (M(a)) = f (B)− f (A).
Il résulte de la proposition précédente que si C est une courbe fermée, qui correspond au casA = B , alors la circulation d’un champ de gradient est nulle∫
C
−−−→grad f (M)d ~M = 0.
On dit parfois, surtout dans le langage physique, qu’un champ de gradient est à circulation conser-vative.
Définition 4. Un champ de vecteurs est dit à circulation conservative si sa circulation le long detoute courbe fermée est nulle.
En fait, il s’avère que les champs à circulation conservative sont exactement les champs degradient. Pour le démontrer on vérifie successivement les propriétés suivantes :
53

Proposition 8. Soit A et B deux points du domaine supposé connexe. La circulation d’un champde vecteurs ~V à circulation conservative le long d’une courbe allant de A vers B ne dépend pas de lacourbe choisie, elle ne dépend que des extrêmités.
Démonstration. Soit C1 et C2 deux courbes paramètrées reliant A et B . Notons C3 la courbe d’orien-tation inversée de C2. La réunion C =C1∪C3 forme donc une courbe fermée et orientée, de sorteque
0 =∫C
~V (M)d ~M =∫C1
~V (M)d ~M +∫C3
~V (M)d ~M
=∫C1
~V (M)d ~M −∫C2
~V (M)d ~M .(3.10)
.Prenons maintenant un point de référence quelconque O dans le domaine et posons, pour
x ∈D
f (X ) =∫
OX
~V (M)d ~M , (3.11)
o û OX désigne une courbe orientée quelconque reliant 0 et X (nous venons de voir que le résultatest indépendant du choix de la courbe).
Proposition 9. Soit V un champ de vecteurs à circulation conservative sur un domaine D. Alors Vest un champ de gradient, car
~V =−−−→grad f ,
où la fonction f est donnée par la formule (3.11).
Démonstration. Soit X un point quelconque dans D . Soit~e1 le vecteur de la base canonique de R2
défini par~e1 = (1,0). pour h ∈ R petit, considérons le point Xh = x +h~e1 et le segment [X , Xh], quipeutêtre paramètré par
s 7→ X + s~e1, s ∈ [0,h].
Si OX est une courbe quelconque reliant O à X , alors OX ∪ [X , Xh] est une courbe orientée reliant0 à Xh et
f (Xh) =∫
OX∪[X ,Xh ]
~V (M)d ~M = f (X )+∫
[X ,Xh ]
~V (M)d ~M
= f (X )+∫ h
0V1(X + s~e1)d s
(3.12)
On a doncf (X +h~e1)− f (X )
h= 1
h
∫ h
0V1(X + s~e1)d s →V1(X ) lorsque h → 0,
d’ou il résulte que∂ f
∂x1=V1(X ).
On démontre de même que∂ f
∂x2=V2(X ),
ce qui termine la preuve.
54

Remarque 11. Si on a~V =−−−→
grad f , (3.13)
alors pour toute constante c ∈ R on a aussi
~V =−−−→grad( f + c),
de sorte qu’il n’y a pas unicité de la fonction f qui vérifie (3.13). Par ailleurs, on vérifie, au vu durésultat de la Proposition 9, que toutes les solutions de l’équation (3.13) on la forme f + c, c ∈R.
3.3 Le formalisme des formes différentielles
3.3.1 Formes linéaires
La notion de forme linéaire est une notion de base de l’algèbre linéaire. Considérons de ma-nière générale l’espace vectoriel Rn , où n ∈ N∗ est donné. Rappelons qu’une base (dite cano-nique) de Rn est donnée par la famille (e1, . . . ,en), où e1 = (1,0,0, . . . ,0), e2 = (0,1,0,0, . . . ,0), . . . ,en = (0,0, . . . ,0,1).
Définition 5. On appelle forme linéaire sur Rn toute application linéaire L de Rn vers R.
On notera par la suite⟨L,u⟩
l’image d’un vecteur u de Rn par l’application linéaire L, de sorte que la linéarité s’exprime par lacondition
⟨L,λ1u1 +λ2u2⟩ =λ1⟨L,u1⟩+λ2⟨L,u2⟩,pour tous vecteurs u1,u2 dans Rn , et tous nombres λ1,λ2.
Exemple 3. Un exemple fondamental de forme linéaire est fourni par les forme coordonnées e∗k
pour k = 1, . . . ,n. Ces dernières sont définies, par les relations
⟨e∗k ,em⟩ = 0, si k 6= m et ⟨e∗
k ,ek⟩ = 1,
ou encore pour x = (x1, . . . , xn)⟨e∗
k , x⟩ = xk .
Par ailleurs, si v est un vecteur donné de Rn on peut lui associer de manière naturelle la formelinéaire Lv définie par
⟨Lv ,u⟩ = u.v, pour tout u ∈Rn .
On pourra vérifier quee∗
k = Lek .
Proposition 10. L’ensemble des formes linéaires sur Rn forme un espace vectoriel noté (Rn)∗ de di-mension n , et appelé le dual de Rn . Une base de (Rn)∗ est fournie par la famille (e∗
1 ,e∗2 , . . . ,e∗
n).
Dans le contexte qui suit, on utilisera souvent la notation
d xk = e∗k .
55

3.3.2 Forme différentielles de degré 1
Soit D in domaine de R2. Les formes différentielles de degré 1 sont des formes linéaires dontles coefficients varient en fonction du point.
Définition 6. On appelle forme différentielle (de degré 1) définie sur D une application de D dansl’espace vectorielle (R2)∗.
Soit ω une forme linéaire sur D. En exprimant les formes linéaires dans la base (e∗1 ,e∗
2 ) =(d x1,d x2), on peut doncécrire
ω(M) = f1(M)d x1 + f2(M)d x2,
ou si on préfèreω(x1, x2) = f1(x1, x2)d x1 + f2(x1, x2)d x2, (3.14)
o û f1 et f2 sont deux fonctions définies sur D.
Exemple 4. Un exemple intéressant de forme différentielle de degré 1 est fourni par la différen-tielle d’une fonction. Si f est une fonction dérivable sur D, alors sa différentielle d f est la formedifférentielle notée d f définie par
d f (M) = ∂ f
∂x1(M)d x1 + ∂ f
∂x2(M)d x2.
Définition 7. On dit d’une forme différentielle ω de degré 1 qu’elle est exacte, si et seulement si ilexiste une fonction f telle que
ω= d f .
On peut définir une correspondance entre forme différentielles et champs de vecteurs. A laforme ω définie en (3.14), on peut associer de manière biunivoque le champ de vecteurs ~V (M) =( f1(M), f2(M)). Dans cette correspondance, les champs de gradients correspondent aux formesexactes. En particulier une condition nécessaire pour qu’une forme différentielle
ω= f1d x1 + f2d x2
soit exacte est que∂ f2
∂x1= ∂ f1
∂x2.
3.3.3 Intégrale curviligne
Soit AB une courbe orientée dans D, et soitω une forme différentielle de degré 1 définie sur D.si T 7→ M(t ) = (m1(t ),m2(t )) est une paramétrisation de AB sur un intervalle I = [a,b], on consi-dère
I =∫ b
a⟨ω(x), M ′(t )⟩d t =
∫ b
a
[f1(M(t ))m′
1(t )+ f2(M(t ))m′2(t )
]d t .
On vérifie alors
56

Proposition 11. L’intégrale I ne dépend pas du paramétrage. Elle est appelée intégrale curvilignede la forme ω le long de la courbe AB. On la note∫
ABω ou
∫AB
f1d x1 + f2d x2.
On a de plus ∫ABω=
∫AB
~V (M)d ~M ,
o û le champ de vecteurs ~V est défini par
~V (M) = (f1(M), f2(M)
).
On montre par ailleurs que ∫AB
d f = f (B)− f (A).
Remarque 12. Le formalisme des formes différentielles est particulièrement agréable pour fairedes calculs : en effet si la courbe est donnée de mani ère param ’ etrée x1 = M1(t ), x2 = M2(t ), alorson écrit sur la courbe au M(t) d M1 = M ′
1(t )d t , d M2 = M ′2(t )d t de sorte que∫
Cω=
∫ b
af1(M(t ))d M1(t )+ f2(M(t ))d M2(t )
=∫ b
a
[f1(M(t ))M ′
1(t )+ f2(M(t ))M ′2(t )
]d t .
Exemple 5. On considère la courbe C d’équation
x2 +x22 −2x2 = 0,
orientée dans le sens trigonométrique positif. On désire calculer l’intégrale curviligne∫C
x1x22 d x2 −x2x2
1 d x1.
La première étape du calcul consiste à trouver un paramétrage de C : tout d’abord en écrivantl’équation comme
x21 + (x2 −1)2 = 1,
on reconnaît l’équation du cercle de centre (0,1) et de rayon 1, de sorte qu’un paramétrage nousest fournit par
x1 = cos t , x2 = 1+ sin t t ∈ [0,2π].
On a donc
I =∫ 2π
0cos t (1+ sin t )2d(1+ sin t )− (1+ sin t )cos2 td( cost )
=∫ 2π
0
[(1+ sin t )2 cos2 t + (1+ sin t )cos2 t sin t
]d t
=∫ 2π
0cos2 t
[1+3sin t +2sin2 t
]d t
=∫ 2π
0cos2 td t +3
∫ 2π
0cos2 t sin td t +2
∫ 2π
0cos2 t sin2 td t .
57

On utilise ensuite les formules de trigonmétrie classiques
cos2 t = 1
2(1+cos2t ), et sin t cos t = 1
2sin2t
de sorte que
(sin t cos t )2 = 1
4sin2 t = 1
8(1−cos4t ),
où on a utilisé également la relation 1−cos2θ = 2sin2θ. Par ailleurs, comme la fonction t 7→ cos2 t sin test impaire, 2π périodique, son intégrale sur une période est nulle. On a donc
I = 1
2
∫ 2π
0(1+cos2t )d t + 1
4
∫ 2π
0(1−cos4t )d t = 3π
2.
Exercices
Exercice I
Soit ~A un vecteur de R2, et ~V le champ de vecteur constant défini pour tout M ∈R2 par
~V (M) = ~A.
1) Soit C une courbe fermée de R2. Montrer que la circulation de V le long de C est nulle.
2) En déduire qu’il existe une fonction f telle que ~V =−−−→grad f .
3) Calculer f .
58

Chapitre 4
Intégrales doubles
4.1 Construction de l’intégrale double
Considérons un domaine D deR2, limité par une courbe régulière C . Soit f une fonction conti-nue définie sur D. On divise le plan R2 en petits rectangles de taille ∆x1 ×∆x2 parallèles aux axesOx1 et Ox2 de la manière suivante. ‘
On découpe d’abordR2 en plusieurs tranches Ti de longueur de hauteur∆x2 grâce à des droitesparallèles à l’axe Ox1. Ensuite, on découpe chaque chaque tranche par des droites parallèles à l’axeOx2, ce qui forme les rectangles que nous avons mentionnés plus haut. Nous ne garderons que lesrectangles Ri , j qui sont contenus dans le domaine D. Notons Mi , j le centre du rectangle Ri , j . Onpondère l’aire ∆x1 ×∆x2 du rectangles Ri , j par le poids f (Mi , j ) et on fait la somme sur tous lesrectangles inclus dans le domaine D, à savoir∑∑
f (Mi , j )∆x1∆x2. (4.1)
Notons que si f = 1 alors on obtient ainsi l’aire de la réunion des rectangles Ri , j inclus dans D, airequi tend, lorsque ∆x1 et ∆x2 tendent vers 0, vers l’aire de D. Dans le cas général on montre :
lorsque∆x1 et∆x2 tendent vers 0, la somme ci-dessus converge vers une quantité que nous note-rons Ï
Df (x1, x2)d x1d x2.
59

Définition 1. On appelle I l’intégrale double de la fonction f sur le domaine D.
Interprétation. Nous avons déjà vu que lorsque f est identiquement égale à 1, alors l’intégraledouble donne l’aire de D, c’est à dire
Aire de D =Ï
D1d x1d x2 =
ÏD
d x1d x2.
Dans le cas général, on trouve donc une aire pondérée. Par exemple, si D représente un objet ayantla forme d’une plaque, de densité variable f , I représente son poids totale.
Par ailleurs, de même que nous avions vu que l’intégrale d’une fonction d’une variable réellepermettait de calcul l’aire située sous le graphe, l’intégrale double d’une fonction f représente levolume situé sous le graphe de cette fonction f . Supposons pour simplifier que f est positive etnotons S le graphe de f au dessus de D. Cette surface et les parallèles à Ox3 menées par les pointsdu contour C limite un domaine V de R3. L’intégrale I fournit alors la mesure de ce domaine V .En effet, le volume limité dans V par le rectangle Ri , j et les plans parallèles à Ox3 qui s’appuientsur son périmètre a pour valeur approchée
f (Mi , j )∆x1∆x2.
La somme ∑∑f (Mi , j )∆x1∆x2
représente donc une valeur approchée du volume de V . La limite I est donc le volume exacte.
Voici quelques propriétésélémentaires :
Proposition 1. Soit D un domaine donné de R2. Si f est une fonction continue sur D, λ ∈R alors ona Ï
Dλ f (x2, x1)d x1d x2 =λ
ÏD
f (x2, x1)d x1d x2,
et si f1 et f2 sont deux fonctions continues sur D, alorsÏD
( f1 + f2) f (x2, x1)d x1d x2 =Ï
Df1(x2, x1)d x1d x2 +
ÏD
f2(x2, x1)d x1d x2.
Si l’on divise le domaine D en deux domaines D1 et D2, alorsÏD
f (x2, x1)d x1d x2 =Ï
D1
f (x2, x1)d x1d x2 +Ï
D2
f (x2, x1)d x1d x2.
Ces propriétés se démontrent en établissant des propriétés similaires pour les approximationsdes intégrales doubles données par les sommes (4.1).
4.2 Le Théorème de Fubini
Le théorème de Fubini parmet de ramener des calculs d’intégrales doubles à des intégralessimples.
Soit un domaine D sur lequel on désire intégrer une fonction. Lorsque l’on consid ‘ere lespoints de D, fixe une des variables, par exemple x2, alors l’autre variable varie sur des réunions
60

d’intervalles : pour simplifier, nous allons considérer le cas où x1 varie dans un seul intervalle[ϕ(x2),ψ(x2)] dont les bornes sont des fonctions de x2. On suppose par ailleurs que si x2 prend desvaleurs au delà de deux nombres c < d , alors l’intervalle est vide. En terme plus mathématiques,ceci signifie que la projection orthogonale de D sur l’axe Ox2 est égale à l’intervalle [c,d ] et que
D∩ x2 = m2 = (x1,m2), x1 ∈ [ϕ(m2),ψ(m2)].
pour tout m2 ∈ [c,d ].
On a alors
Théorème 1. On a l’identitéÏf (x1, x2)d x1d x2 =
∫ d
c
(∫ ψ(x2)
ϕ(x2)f (x1, x2)d x1
)d x2.
Remarque 1. La quantité entre parenthèses dans le membre de droite est bien une fonction quine dépend que de la variable x2 par l’intermédiaire de f et des bornes d’intégration.
Remarque 2. Bien entendu les variables x1 et x2 jouent des roles équivalents. Supposons que surle domaine D la variable x1 varie sur un intervalle [a,b], et que, lorsque x1 est fixé, la variable x2
varie sur un intervalle [ζ(x1),ξ(x1)] alors on aÏD
f (x1, x2)d x1d x2 =∫ b
a
(∫ ξ(x1)
ζ(x1)f (x1, x2)
)d x1
Intuition de la démonstration. Pour comprendre la formule, revenons à la somme (4.1). Considé-rons une tranche Ti de D, et une valeur yi de x2 donnée, telle que les points d’ordonnée x2 = yi
soient dans cette tranche. Alors l’abscisse x1 varie dans l’intervalle [ϕ(yi ),ψ(yi )]. Considéronsmaintenant tous les rectangles Ri , j de la tranche Ti et la somme∑
jf (Mi , j )∆x1.
Cette somme représente la valeurt approchée de l’intégrale simple∫ ψ(yi )
ϕ(yi )f (x1, yi )d x1.
61

Cette intégrale ne dépend que du nombre yi . Posons
F (x2) =∫ ψ(x2)
ϕ(x2)f (x1, x2)d x1,
de sorte que ∑j
f (Mi , j )∆x1 ' F (yi ).
Pour la somme double que nous considérons, on a∑∑f (Mi , j )∆x1∆x2 '
∑F (yi )∆x2.
Sur le domaine D, yi varient sur un certain intervalle [c,d ]. On a∑∑f (Mi , j )∆x1∆x2 '
∑F (yi )∆x2 '
∫ d
cF (y)d y.
Le théorème s’obtient en faisant tendre ∆x1 et ∆x2 vers 0.
Exemple 1. On prend pour domaine le triangle rectangle D défini par
D = (x1, x2), x1 ≥ 0, x2 ≥ 0, x1 +x2 ≤ 1.
On veut calculer
I =Ï
Dx1x2d x1d x2.
on voit que x2 varient sur l’intervalle [c,d ] = [0,1], et que pour une valeur de x2 donnée, x1 prendses valeurs dans [ϕ(x2),ψ(x2)] = [0,1−x2]. En intégrant d’abord par rapport à x2, on a donc
I =∫ 1
0
(∫ 1−x2
0x1x2d x1
)d x2 =
∫ 1
0
(∫ 1−x2
0x1d x1
)x2d x2.
On calcule d’abord l’intégrale dans la parenthèse : on a∫ 1−x2
0x1d x1 =
[x2
1
2
](1−x2)
0
= 1
2(1−x2)2.
Il en résulte, en utilisant une intégration par parties, que
I =∫ 1
0
1
2x2(1−x2)2d x2 =
[x2(1−x2)3
6
]1
0+
∫ 1
0
(1−x2)3
6d x = 1
24.
62

4.3 Intégration par parties
Rappelons que dimension un d’espace la formule d’intégration par partie se déduit de la for-mule fondamentale
f (b)− f (a) =∫ b
af ′(x)d x, (4.2)
qui précise le lien entre la dérivation et l’intégration. Voyons ce qu’il advient de ce type de formuleen dimension deux, à savoir que donne l’intégration d’une dérivée partielle, par exemple
I1 =Ï
D
∂ f
∂x1(x1, x2)d x1d x2,
où f désigne une fonction dérivable de deux variables x1 et x2, sur un domaine D de contour C .Plaçons nous sous les mêmes hypothèses que dans la Section 4.2, c’est à dire supposons que l’ona
D = (x1, x2) ∈R2, tels que ,c ≤ x2 ≤ d et ϕ(x2) ≤ x1 ≤ψ(x2).
On peut alors écrire, grâce au Théorème de FubiniÏD
∂ f
∂x1(x1, x2)d x1d x2 =
∫ d
c
(∫ ψ(x2)
ϕ(x2)
∂ f
∂x1(x1, x2)d x1
)d x2
=∫ d
c
(f (x2,ψ(x2))− f (x2,ϕ(x2))
)d x2.
(4.3)
Orientons maintenant le contour C dans le sens trigonométrique positif. Nous allons vérifier quele membre de droite de (4.3) peut s’interpréter comme une intégrale curviligne, à savoir
I1 =∫ d
c
(f (x2,ψ(x2))− f (x2,ϕ(x2))
)d x2 =
∫C
f d x2. (4.4)
En effet, on remarque tout d’abord que le contour C est le réunion de deux courbes paramètréesC1 et C2. La première, C1 peut être paramètrée explicitement par t 7→ M1(t ) = (t ,ψ(t )), t ∈ [c,d ]alors que C2 peutêtre paramètrée, si l’on respecte l’orientation, par t 7→ M1(t ) = (c+d −t ,ϕ(c+d −t ), t ∈ [c,d ]. On a de plus
M ′1(t ) = (
1,ψ′(t ))
et M ′2(x2) = (
1,−ϕ′(c +d − t ))
.
63

On a donc
⟨ f (M1(t ))d x2, M ′1(t )⟩ = f (M1(t ))) et ⟨ f (M2(t )d x2, (M ′
2(t )⟩ =− f (M2(t )).
Le résultat (4.4) s’en déduit par intégration.Un calcul similaire montre queÏ
D
∂ f
∂x2(x1, x2)d x1d x2 =−
∫C
f d x1,
et on obtient ainsi la formule dit de Green-Riemann
Théorème 2 (Formule de Green-Riemann). Soient f et g deux fonctions dérivables sur un domaineD de R2. On a la relationÏ
D
[∂g
∂x1(x1, x2)− ∂ f
∂x2(x1, x2)
]d x1d x2 =
∫C
f d x1 + g d x2.
Remarque 3. Bien entendu, on peut aussi utiliser, si on préfère, le langage des champs de vecteurs,qui est probablement plus intuitif et écrireÏ
D
[∂V2
∂x1(x1, x2)− ∂V1
∂x2(x1, x2)
]d x1d x2 =
∫C
~V (M)d ~M . (4.5)
où ~V est le champ de vecteurs ~V (M) = (V1(M),V2(M)).
Voyons une application intéressante de la formule de Green-Riemann.
Théorème 3. Supposons que le domaine D sans trou. Soit ~V = (V1,V2) un champ de vecteurs déri-vable sur D. On suppose que
∂V2
∂x1= ∂V1
∂x2sur D. (4.6)
Alors V est un champ de gradient, c’est à dire qu’il existe une fonction f dérivable sur D tellle que
~V =−−−→grad f .
Remarque 4. Au chapitre précédent, nous avions déjà vu que la condition (4.6)était nécessairepour qu’un champ de vecteurs soit un champ de gradient. Le résultat précédent montre doncqu’elle est aussi nécessaire, si le domaine ne possède pas de trou.
Démonstration. Nous allons montrer que si ~V vérifie la relation (4.6), alors V est un champ devecteurs conservatif, ce qui entraîne la conclusion, grâce à la proposition 9 du chapitre précédent.Soit C0 une courbe fermée quelconque incluse dans D, nous devons montrer que∫
C0
~V (M)d ~M = 0. (4.7)
Soit D0 le domaine intérieur limité par D . On a grâce à la Remarque 3 et l’hypothèse (4.6)
0 =Ï
D0
[∂V2
∂x1(x1, x2)− ∂V1
∂x2(x1, x2)
]d x1d x2 =
∫C0
~V (M)d ~M ,
ce qui donne la conclusion.
64

Exemple 2. Considérons un champ de vecteur ~V linéaire, c’est à dire de la forme
~V (~X ) = A ·~X ,
où A est une matrice 2×2
A =(
a1,1 a1,2
a2,1 a2,2
).
On a donc V1(x1, x2) = a1,1x1 +a1,2x2 et V2(x1, x2) = a2,1x1 +a2,2x2, de sorte que
∂V2
∂x1− ∂V1
∂x2= a2,1 −a1,2.
~V est donc un champ de gradient si et seulement si
a2,1 = a1,2,
c’est à dire si et seulement si la matrice A est symétrique. Cherchons maintenant une fonction f
telle que ~V =−−−→grad f , c’est à dire telle que
∂ f
∂x1(x1, x2) = a1,1x1 +a1,2x2
∂ f
∂x2(x1, x2) = a2,1x1 +a2,2x2.
(4.8)
On intégre la première équation en traitant la varibale x2 comme un paramètre. Ceci donne
f (x1, x2) = 1
2a1,1x2
1 +a1,2x2x1 +ϕ(x2). (4.9)
o ù la constante d’intégration ϕ(x2) est une fonction de x2 uniquement. En prenant la dérivéepartielle par rapport à x2 de cette expression on obtient
∂ f
∂x2(x1, x2) = a1,2x1 +ϕ′(x2.)
En reportant dans la deuxième équation du système (4.10) on trouve donc
ϕ′(x2) = a2,1x1 −a1,2x1 +a2,2x2 = a2,2x2
qui donne en intégrant
ϕ(x2) = 1
2a2,2x2
2 + c,
o û c ∈R est une constante d’intégration. Il en résulte donc que
f = 1
2
(a1,1x2
1 +a2,2x22 +2a1,2x1x2
)+ c.
On vérifie ainsi que l’on a ~V =−−−→grad f , avec
f (X ) = 1
2A ·~X .~X + c
la forme quadratique associée à la matrice symétrique A.
65

Exemple 3. Considérons le champ de vecteurs ~V défini sur R2 par
~V (x1, x2) = (V1(x1, x2),V2(x1, x2)) = (x4
2 +3x31 , 4x1x3
2 +2x22
).
On a∂V2
∂x1− ∂V1
∂x2= 4x3
2 −4x32 = 0,
de sorte qu’il existe une fonction f telle que−−−→grad f = ~V .
Pour trouver f , il faut donc résoudre le système de deux équations∂ f
∂x1(x1, x2) = x4
2 +3x31
∂ f
∂x2(x1, x2) = 4x1x3
2 +2x22 .
(4.10)
On intégre la première équation en traitant la variable x2 comme un paramètre. On trouve donc
f (x1, x2) = x1x42 +
3
4x4
1 +ϕ(x2),
la constante d’intégrationϕ(x2) étant une fonction de x2 seulement. En prenant la dérivée partiellepar rapport à x2 de cette expression on obtient
∂ f
∂x2(x1, x2) = 4x1x3
2 +ϕ′(x2.)
En reportant dans la deuxième équation du système (4.10) on trouve donc
ϕ′(x2) = 4x1x32 +2x2
2 −4x1x32 = 2x2
2 ,
qui donne en intégrant
ϕ(x2) = 2
3x3
2 − c,
o û c ∈R est une constante d’intégration. Il en résulte donc que
f = 2
3x3
2 +x1x42 +
3
4x4
1 + c.
En guise d’exercice, voyons comment on peut retrouver la valeur de f par la formule (3.11) surune courbe appropriées, par exemple
OX = [O, X1]∩ [X1, X ],
où X1 = (x1,0). On peut paramétrer le segment [0, X1] par s 7→ M(s) = (s,0) de sorte que ~M ′(s) =(1,0) et donc, sur ce segment, on a
~V (M)d ~M = ~V (s,0) · (1,0)d s =V1(s,0)d s = 3s3d s.
De même, on paramètre le segment [X1, X ] par s 7→ M(s) = (x1, s), de sorte que ~M ′(s) = (0,1) et
~V (M)d ~M = ~V (x1, s) · (0,1)d s =V2(x1, s)d s = (4x1s3 +2s2)d s.
66

On a donc
f (x1, x2) =∫ x1
0V1(s,0)d s +
∫ x2
0V2(x1, s)d s
=∫ x1
03s3d s +
∫ x2
0(4x1s3 +2s2)d s
= 3
4x4
1 +x1x42 +
2
3x3
2 ,
et toutes les solutions de l’équation−−−→grad f = ~V ont donc la forme 3
4 x41 +x1x4
2 + 23 x3
2 + c, c ∈R.
4.3.1 Calcul de l’aire d’un domaine
On peut utiliser la formule (4.5) pour calculer l’aire du domaine. En effet, le membre de droitede cette identité représente l’aire, si on choisit le champ de vecteurs de sorte que
∂V2
∂x1(x1, x2)− ∂V1
∂x2(x1, x2) = 1 sur D. (4.11)
On peut chercher de tels champs sous forme de champs linéaires. On vérifier en particulier queles champs
~V = (0, x1), ~V = (0,−x2) ou encore ~V = 1
2(−x2, x1)
sont des solutions de l’équation (4.11). En en déduit, en revenant à (4.5)
Proposition 2. L’aire du domaine D est donnée par
A ire(D) =∫C
x1d x2 =−∫C
x2d x1 = 1
2
∫C
x1d x2 −x2d x1, (4.12)
où la courbe C est orientée dans le sens trigonométrique.
Exemple 4. Nous allons recalculer l’aire de l’ éllipse limitée par la courbe C d’équation
x1 = a cos t , x2 = b sin t t ∈ [0,2π], a,b > 0
qui fournit bien l’orientation demandée. Ainsi l’aire S de l’ellipse est donnée par
S = 1
2
∫C
x1d x2 −x2d x1
= 1
2
∫ 2π
0a cos td(b sin t )−b sin td(a cos t )
= 1
2
∫ 2π
0ab cos2 td t +ab sin2 d t
= 1
2
∫ 2π
0ab(cos2 t + sin2 t )d t
= 1
2
∫ 2π
0abd t
=πab.
67

4.3.2 Flux et divergence
Supposons dans cette section que nous ayons un paramétrage naturel s 7→ M(s) de la courbeC , où s ∈ [0,L], et M(0) = M(L), orientée dans le sens trigonométrique positif. On a donc
‖~T (s)‖ = ‖d M
d s(s)‖ = 1.
Soit ~n(s) le vecteur unitaire orthogonal à ~T sortant de D au point M(s). On peut aussi exprimercette condition en disant que les vecteurs (~T (s),~n(s)) forment une base orthonormée directe deR2. En coordonnées, on a
~n(s) = (M ′
2(s),−M ′1(s)
).
Définition 2. On appelle flux du champ de vecteurs ~V à travers la courbe C l’intégrale
Flux(V ,C ) =∫ L
0
~V (M(s)) .~n(s)d s.
Par abus de notation, on notera cette intégrale
Flux(V ,C ) =∫C
~V (M(s)) .~n(s)d s
Introduisons maintenant la divergence d’un champ de vecteurs.
Définition 3. Soit ~V un champ de vecteurs dérivable sur un domaine D, de dérivées continues.On appelle divergence du champ de vecteurs ~V la fonction définie sur D par
div~V (M) = ∂V1
∂x1(M)+ ∂V2
∂x2(M)
Exemple 5. Si ~V (x1, x2) = (x1, x2) alors div~V = 2, alors que si V (x1, x2) = (−x2, x1), alors div~V = 0.De manière plus générale, si ~V est un champ linéaire, c’est à dire de la forme
~V (~X ) = A.~X ,
où A est une matrice 2×2, alors on vérifie (exercice) que div~V est une fonction scalaire constante,et que
div~V = Tr A.
ainsi, si A est antisymétrique, alors div~V = 0.
68

Avec ces notations le Théorème 4.5 peut se formuler comme suit :
Théorème 4. On a, sous les hypothèses ci-dessusÏD
div~V (M)d x1d x2 = Flux(V ,C ) =∫C
~V (M(s)) .~n(s)d s.
L’intégrale de la divergence est donc égale au flux à travers le contour. On appelle parfois ce ré-sultat le théorème flux-divergence ou encore le théorème de Green-Ostrogradski. Nous verrons plusloin les interprétations physiques de cette relation.
Démonstration. Introduisons le champ de vecteurs ~V ⊥ = (V ⊥1 ,V ⊥
2 ) qui se déduit du champ ~V par
~V ⊥(M) = (−V2(M),V1(M),
de sorte que
div~V (M) = ∂V ⊥2
∂x1(x1, x2)− ∂V ⊥
1
∂x2(x1, x2).
La relation (4.5) nous donne alorsÏD
div~V (M)d x1d x2 =∫C
~V (M)⊥d ~M .
=∫ L
0V (M)⊥.~M ′(s)d s
On remarque que
~V (M(s))⊥.~M ′(s) =−V2(M(s)).M ′1(s)+V1(M(s)).M ′
2(s)) = ~V (M).~n(s).
La conclusion en découle.
4.3.3 Autres formules
Nous donnons dans ce paragraphe quelques formules dérivées des relations précédentes.
Proposition 3. Soit f une fonction et ~V un champ de vecteurs définis, dérivables et de dérivéescontinues sur D.
– Le champ de vecteurs f ~V défini par f ~V (M) = f (M)~V (m) pour tout M ∈ D est un champ devecteurs dérivable sur D dont la divergence est la fonction qui s’écrit
div( f ~V ) = f divV +~V ·−−−→grad f . (4.13)
– si f est deux fois dérivable alors
div(−−−→grad f ) =∆ f (4.14)
etdiv(
−−−→grad⊥ f ) = 0. (4.15)
– Si f et g sont des fonctions deux fois dérivables alors
g∆ f = div(g .−−−→grad f )−−−−→
gradg ·−−−→grad f . (4.16)
69

Démonstration. Pour (4.13) on applique la formule de Taylor qui donne
div( f ~V ) = ∂( f V1)
∂x1+ ∂( f V2)
∂x2
= f
[∂V1
∂x1+ ∂V2
∂x2
]+V1
∂ f
∂x1+V2
∂ f
∂x2
= f divV +~V ·−−−→grad f .
Pour (4.14) on a comme−−−→grad f = ( fx1 , fx2 )
div(−−−→grad f ) = ∂ fx1
∂x1+ ∂ fx2
∂x2
= ∂2 f
∂2x1+ ∂2 f
∂2x2=∆ f .
Pour (4.15) on a comme−−−→grad⊥ f = (− fx2 , fx1 )
div(−−−→grad⊥ f ) =−∂ fx2
∂x1+ ∂ fx1
∂x2
= ∂2 f
∂x1∂x2+ ∂2 f
∂x2∂x1= 0.
Enfin pour (4.16), on utilise (4.13) et (4.14) pourécrire
g∆ f = g div(−−−→grad f )
= div(g .−−−→grad f )−−−−→
gradg .−−−→grad f
De ces formules, on peut déduire un certain nombre de formules intégrales :
Proposition 4. Soit f une fonction et ~V un champ de vecteurs définis, dérivables et de dérivéescontinues sur D.
– On a pour i = 1,2 et en écrivant ~n(s) = (n1(s),n2(s))ÏD
∂ f
∂xid x1d x2 =
∫C
f (M(s)) .ni (s)d s
et donc ÏD
−−−→grad f d x1d x2 =
∫C
f ~n(s)d s.
[Attention : il s’agit d’une égalité de vecteurs !]– On a Ï
Df divV d x1d x2 =
∫C
f (M(s))~V (M(s))d s −Ï
D
−−−→grad f ·V d x1d x2.
Démonstration. Pour la première identité, on prend le champ de vecteurs V = ( f ,0) si i=1, et ~V =(0, f ) si i = 2 puis on applique le Théorème 4. Pour la dernière, on part de la formule (4.13) et onapplique de nouveau le Théorème 4.
70

4.3.4 La divergence en coordonnées polaires
Comme nous l’avons déjà vu, la base de référence pour faire des calculs en coordonnées po-laire, c’est la base (~er ,~eθ). Il s’agit d’un repère mobile, puisqu’il dépend du point ou il est considéré.Supposons donc que le champ de vecteurs considéré ~V soit exprimé en coordonnées polaires aupoint M = (r cosθ,r sinθ)
~V (M) =Vr (r,θ)~er (M)+Vθ(r,θ)~eθ(M).
o ù~er = (cosθ, sinθ) et~eθ = (−sinθ,cosθ).
Si on écrit maintenant ~V = (V1,V2) en coordonnées cartésiennes, on obtient
V1 =Vr (r,θ)cosθ−Vθ(r,θ)sinθ
etV2 =Vr (r,θ)sinθ+Vθ(r,θ)cosθ.
Il vient alors, par la règle des fonctions composées, et en utilisant l’expression de la matrice Jaco-bienne (2.18)
∂V1
∂x1= ∂V1
∂r
∂r
∂x1+ ∂V1
∂θ
∂θ
∂x1= cosθ
∂V1
∂r− 1
rsinθ
∂V1
∂θ
= cosθ
[∂Vr
∂rcosθ− ∂Vθ
∂rsinθ
]− 1
rsinθ
[[∂Vr
∂θcosθ−Vr sinθ− ∂Vθ
∂θsinθ−Vθ cosθ
]= cos2θ
∂Vr
∂r+ Vr
rsin2θ+ 1
rsin2θ
∂Vθ∂θ
− 1
rsinθcosθ
[r∂Vθ∂r
+ ∂Vθ∂r
−Vθ
]et
∂V2
∂x2= ∂V2
∂r
∂r
∂x2+ ∂V2
∂θ
∂θ
∂x2= sinθ
∂V2
∂r+ 1
rcosθ
∂V2
∂θ
= sinθ
[∂Vr
∂rsinθ+ ∂Vθ
∂rcosθ
]+ 1
rcosθ
[[∂Vr
∂θsinθ+Vr cosθ+ ∂Vθ
∂θcosθ−Vθ sinθ
]= sin2θ
∂Vr
∂r+ Vr
rsin2θ+ 1
rcos2θ
∂Vθ∂θ
+ 1
rsinθcosθ
[r∂Vθ∂r
+ ∂Vθ∂r
−Vθ
]En faisant la somme, on trouve finalement
divV = ∂V1
∂x1+ ∂V2
∂x2= ∂Vr
∂r+ Vr
r+ 1
r
∂Vθ∂θ
ou encore
div~V = 1
r
∂ (r Vr )
∂r+ 1
r
∂Vθ∂θ
.
71

4.4 Changements de variables
Commençons par quelques rappels de géométrieélémentaire.
4.4.1 Aire d’un parallélelogramme
Considérons tout d’abord le parallélogramme O AC B ci dessous :
Ces cotés sont deux à deux paralléles, on donc,
~X =−−→O A =−→
BC
et~Y =−−→
OB =−→AC .
Cherchons maintenant à calculer l’aire A de ce parallèlélogramme. La géométrie élémentairenous enseigne que
A = ‖~X ‖.‖~Y ‖sinθ.
Ce résultat peut aussi s’écrire en utilisant la théorie du déterminant, à savoir
A = |det(~X ,~Y )| =∣∣∣∣ ∣∣∣∣x1 y1
x2 y2
∣∣∣∣ ∣∣∣∣= ∣∣x1 y2 −x2 y1∣∣ .
Considérons maintenant une application linéaire T de R2 vers R2, et calculons l’aire de l’imagepar T du carré C = [0,1]2. L’image de ce carré est un parallèlélogramme porté par les vecteurs T (e1)et T (e2) de sorte que l’aire (algébrique cette fois) se calcule comme
A ire(T ([0,1]2)
)= |det(T )| . (4.17)
De manière plus générale, si on considère le rectangle [0,`1]× [0,`2], alors l’aire algébrique de sonimage par T
A ire(T ([0,`1]× [0,`2])) = `1`2 |det(T )| . (4.18)
72

4.4.2 Aire de l’image d’un rectangle élémentaire
Considérons maintenant une application Φ d’un domaine Ω de R2 vers un domaine D de R2
également, supposée dérivable de dérives continues. On suppose de que Φ est de plus une bijec-tion de Ω sur D, de sorte que Ω peut être considéré comme un paramétrage de D par le domaineΩ. Il s’agit de la situation typique que l’on rencontre lorsqu’on fait un changement de variable : siM = (M1, M2) un point quelconque de D, et si
U = (u1,u2) =φ−1(M), c’est à dire M1 =Φ1(u1,u2) et M2 =φ2(u1,u2).
alors les valeurs de u1 et u2 correspondent aux nouvelles coordonnées de M .
Soit donc M = (M1, M2) un point quelconque de D, et U = (u1,u2) comme ci dessus. Il résultedes résultats de la Section 2.5.4 du Chapitre 2, qu’au premier ordre l’applicationΦ est bien appro-chée, près de U par l’application affineΦ(U )+DΦ(U )h, plus précisément on a
Φ(U +~h)) =Φ(U )+DΦ(U )~h +‖h‖ε(h),
où DΦ désigne la matrice jacobienne deΦ c’est à dire
DΦ =(
∂Φ1∂u1
∂Φ1∂u2
∂Φ2∂u1
∂Φ2∂u2
).
Considérons maintenant un rectangle élémentaire de cotés de longueurs ∆u1 et ∆u2 dont undes sommets est U . On a d’après les résultats de la section précédente et le développement limité(4.4.2)
A ire(Φ ([u1,u1 +∆u1]× [u2,u2 +∆u2])) = det(DΦ(U ))∆u1∆u2 +o(∆u1∆u2). (4.19)
4.4.3 La formule du changement de variable
On considère une fonction f définie sur D. La fonction f Φ est donc définie surΩ. On a alors
Théorème 5. On aÏD
f (x1, x2)d x1d x2 =ÏΩ
f (Φ (u1,u2)) |det(DΦ(u1,u2))|du1du2
73

où detDΦ désigne le déterminant jacobien
detDΦ(u1,u2) =∣∣∣∣∣
∂Φ1∂u1
(u1,u2) ∂Φ1∂u2
(u1,u2)∂Φ2∂u1
(u1,u2) ∂Φ2∂u2
(u1,u2).
∣∣∣∣∣ .
Remarque 5. Notons qu’il faut prendre ici la valeur absolue du déterminant Jacobien (qui peutbien entendu être négatif).
Idée de la démonstration. Elle s’appuie sur l’interprétation de l’intégrale comme l’aire pondérée.Dans cette interprétation, l’intégrale du membre de droiteÏ
Rf (x1, x2)d x1d x2 (4.20)
représente donc l’aire de D, pondérée par la fonction f . Par ailleurs, la fonctionΦ nous permet deparamétrer D par Ω. Si on découpe, comme nous l’avons fait pour (4.1) sur D, le domaine Ω enrectangles élémentaires Ri , j de cotés de tailles ∆u1 et ∆u2, alors l’aire de l’image par Φ de Ri , j estapproximativement l’aire d’un parallélogramme donnée par (4.19), c’est à dire
|det(DΦ(Ui , j ))|∆u1∆u2,
o û Ui , j est un des sommets du rectangle Ri , j . En pondérant cette aire par f (Φ(Ui , j ) et en sommanton trouve donc une approximation de (4.20), à savoirÏ
Df (x1, x2)d x1d x2 '
∑i , j
f (Φ(Ui , j )|det(DΦ(Ui , j ))|∆u1∆u2,
ce qui mène directement au résultat.
Remarque 6. On utilise aussi la notation
detDΦ(u1,u2) = D(Φ1,Φ2)
D(u1,u2)= D(x1, x2)
D(u1,u2)
pour désigner le déterminant Jacobien. en particulier si
Remarque 7. Il résulte de la formule de changement de variables, en prenant f = 1 que
A ire(D) =ÏΩ|detDΦ(u1,u2)|du1du2.
En particulier, si |detDΦ(u1,u2)| = 1 surΩ alors
A ire(D) =A ire(Ω).
Coordonnées polaires. Le calcul des intégrales en coordonnées polaires fournit un exemple inté-ressant d’application de la formule de changement de variable.
Considérons le disque Da de centre 0 et de rayon a. Si on paramètre ce domaine en coor-données polaires, c’est à dire que l’on fait correspondre aux nombres (r,θ) le point M2 de D decoordonnées cartésiennes
M1 = r cosθ et M2 = r sinθ,
74

alors nous sommes exactement dans la situation que nous avons décrite plus haut : iciΩ= [0, a]×[0,2π[, D = Da et
Φ1(r,θ) = r cosθ etΦ2(r,θ) = r sinθ.
Calculons le déterminant Jacobien deΦ :
detDΦ(r,θ) =∣∣∣∣∣ ∂Φ1
∂r (r,θ) ∂Φ1∂θ (r,θ)
∂Φ2∂r (r,θ) ∂Φ2
∂θ(r,θ)
∣∣∣∣∣ .
Si on procède au calcul effectif, il vient
detDΦ(r,θ) =∣∣∣∣ cosθ −r sinθ
sinθ r cosθ.
∣∣∣∣= r
Soit maintenant f une fonction définie sur Da . Posons f (r,θ) = f Φ(r,θ) = f (r cosθ,r sinθ). Ilvient Ï
Da
f (x1, x2)d x1d x2 =Ï
[0,a]×[0,2π[f (r,θ)r dr dθ
=Ï
[0,a]×[0,2π[f (r cosθ,r sinθ)r dr dθ.
en termes abrégés, on dit souvent que l’élément de volume s’écrit, en coordonnées polaires commer dr dθ.
Exemple 6. Calculons l’intégrale double
I =Ï
D
1
1+x21 +x2
2
d x1d x2,
où D = (x1, x2) ∈R2, x21 +x2
2 < 1. En coordonnées polaires, on a donc
I =Ï
[0,1]×[0,2π]
1
1+ r 2r dr dθ =
Ï[0,1]×[0,2π]
r
1+ r 2dr dθ.
En utilisant la formule de Fubini on trouve donc
I =∫ 2π
0
(∫ 1
0
r
1+ r 2dr
)dθ = 2π
∫ 1
0
r
1+ r 2dr.
Pour calculer cette dernière intégrale posons u = r 2 de sorte que du = 2r dr et
I =π∫ 1
0
1
1+udu =π[
log(1+u)]1
0 =π log2.
4.4.4 Invariances par changement de repère orthonormé.
La formule du changement de variables montre immédiatement que les intégrales sont inva-riantes par changement de repères orthonormés. Montrons qu’il en est de même pour la diver-gence. La discussion que nous menons ici est tout àfait parallèle à celle menée dans la section(3.1.2) pour le gradient.
75

Comme pour le gradient que la définition (3) est relative à un choix de repère orthonormé(~e1,~e2), qui détermine les coordonnées cartésiennes (x1, x2). Introduisons un nouveau repère or-thonormé (~e ′
1,~e ′2) et des coordonnées x ′
1, x ′2 correspondantes de sorte que x1~e1+x2~e2 = x ′
1~e′1+x ′
2~e′2 ?
Soit ~V un champs de vecteur donné sur D. Ce champ s’exprime dans la base (~e1,~e2) comme
~V (M) =V1(x1, x2)~e1 +V2(x1, x2)~e2, pour M de coordonnées (x1, x2) dans (~e1,~e2)
Son expression dans la nouvelle base sera alors
~V (M) =V ′1(x ′
1, x ′2)~e ′
1 +V2(x ′1, x ′
2)~e ′2, pour M de coordonnées (x ′
1, x ′2) dans (~e ′
1,~e ′2).
En posant ~X = (x1, x2) et ~X ′ = (x ′1, x ′
2) on a
t~X = P t X ′,
où P = P (e → e′
désigne la matrice de passage de l’ancienne base vers la nouvlele. De même, ilvient
~V ′(x ′1, x ′
2) =(V ′
1(x ′1, x ′
2, )V ′
2(x ′1, x ′
2)
)= P
(V1(x1, x2)V2(x1, x2)
)= p~V (x1, x2). (4.21)
Quelle est l’expression de la divergence dans cette nouvelle base ?
Proposition 5. On a pour tout M ∈D
div~V (M) = ∂V ′1
∂x ′1
(x ′1, x ′
2)+ ∂V2
∂x ′2
(x ′1, x ′
2),
où (x1, x ′2) désigne les coordonnées de M dans la base (~e ′
1,~e ′2).
L’expression de la divergence dans la nouvelle base est donc identique à celle dans l’anciennebase.
Preuve. L’expression (6.6) s’écrit comme
~V ′(~X ′) = P~V (P t~X ′).
On utilsant la règle de dérivation composée on trouve∂V ′1
∂x ′1
∂V ′1
∂x ′2
∂V ′2
∂x ′1
∂V ′2
∂x ′2
(x ′1, x ′
2) = P
∂V1∂x1
∂V1∂x ′
2∂V2∂x ′
1
∂V2∂x2
(x1, x2).P t
et donc comme P t = P−1,∂V1∂x1
∂V1∂x ′
2∂V2∂x ′
1
∂V2∂x2
(x1, x2) = P t
∂V ′1
∂x ′1
∂V ′1
∂x ′2
∂V ′2
∂x ′1
∂V ′2
∂x ′2
(x ′1, x ′
2)P
la divergence correspond à la trace de la matrice du membre de gauche de cette expression. Commeune trace est invariante par conjugaison, c’est a dire
TrA = tr PAP−1
pour toute matrices A et P , si P est inversible, le résultat en découle.
Remarque 8. Attention, l’énoncé n’est valable que pour des changements de bases orthonormé.
76

4.5 Calcul du volume d’un domaine de R3
Soit f une fonctions de deux variables définie sur un domaine D, limité par une courbe C .Nous avons déjà vu que si f est une fonction positive définie sur D, et Γ f la surface de R3 repré-sentant le graphe de f , alors l’intégrale de f sur D fournit le volume du domaine V de R3 délimitépar Γ f et les parallèles à Ox3 menées par les points de C . Ceci permet de calculer des volumesdans R3. Donnons un exemple.
Considérons la boule B de R3 centrée à l’origine (0,0,0) et de rayon R. La demi-boule supé-rieure est limitée par le graphe de la fonction
x3 =√
R2 −x21 −x2
2
au dessus du disque DR de R2 de centre 0 et de rayon R. Le volume de B est donc donné par
Vol(B) = 2Ï
DR
√R2 −x2
1 −x22d x1d x2.
Pour calculer cette intégrale effectuons le changement de variables polaires
x1 = r cosθ, x2 = r sinθ,
o û (r,θ) prend ces valeurs dans le domaineΩ= [0,R]× [0,2π[, et
D(x1, x2)
D(r,θ)= r.
On obtient √R2 −x2
1 −x22 =
√R2 − r 2
de sorte que
Vol(B) = 2ÏΩ
√R2 − r 2r dr dθ.
En appliquant le théorème de Fubini il vient
Vol(B) = 2∫ R
0
(∫ 2π
0
√R2 − r 2r dθ
)dr.
On intègre d’abord par rapport à θ. Commep
R2 − r 2r ne dépend pas de θ, on obtient∫ 2π
0
√R2 − r 2r dθ = 2π
√R2 − r 2r,
d’où
Vol(B) =2∫ R
02π
√R2 − r 2r dr
= 4π∫ R
0
√R2 − r 2r dr.
Pour calculer cette intégrale, on peut faire le changement de variable t = R2 − r 2. On a alors d t =−2r dr , c’est à dire r dr =−1
2 d t , et t varie entre R2 et 0. On obtient
Vol(B) = 4π∫ 0
R2t
12 (−1
2)d t = 2π
∫ R2
0t
12 d t = 2π
[2
3t
32
]R2
0= 4
3πR3.
77

4.6 Interprétation de la divergence et du flux
Nous avons introduit l’opérateur "divergence" dans la Section 4.3.2. Cet opérateur intervientdans de nombreuses modélisations, en physique, en mécanique, ou en biologie. Le but de cettesection est d’éclairer un mécanisme dans lequel cet operateur intervient de manière naturelle.
Considérons un domaine D de R2, et un champ de vecteurs ~V défini sur D. Reprenons l’ana-logie avec le champs de vitesse d’un fluide, développée à la Section 3.1.3, c’est à dire supposonsque le champ de vecteurs ~V représente le champ des vitesses du fluide : pour chaque point M dudomaine, ~V (M) désigne la vitesse des particules élémentaires constituant ce fluide en ce point.Les particules du fluides sont donc régies par l’équation (3.6)
d M
d t(t ) = ~V (M(t )), t ∈ I
M(0) = M0,(4.22)
La particule étant au temps 0 en M0 se retrouve au temps t en M(t ). Soit Ω0 un domaine inclusdans D strictement, et soitΩt le domaine occupé au temps t par les particules présentes au temps0 dansΩ0. La question que nous nous posons alors est la suivante :
Q : Comment l’aire deΩt notée A ire(Ωt )évolue-t-elle au cours du temps ?
Essayons de calculer en particulier la variation
dA ire(Ωt )
d t |t=0
.
A cet effet, remarquons tout d’abord que
A ire(Ωt ) =ÏΩt
d x1d x2,
intégrale dont le domaine change au cours du temps. Afin de nous ramener à un domaine fixe,nous allons paramétrer le domaine Ωt par le domaine au temps 0, à savoir Ω0. Notons Φt l’appli-cation qui au point M0 associe sa position M(t ) au temps t , c’est à dire
Φt (M0) = M(t )
o û M(t ) est la solution de l’équation différentielle (4.22). La formule du changement de variablenous donne alors Ï
Ωt
d x1d x2 =ÏΩ0
|JΦt (m1,m2)|dm1dm2,
ou en a poseJΦt = det(DΦt ).
On a donc
dA ire(Ωt )
d t |t=0
= d
d t
[ÏΩ0
JΦt (m1,m2)dm1dm2
]|t=0
=ÏΩ0
d
d t
[JΦt (m1,m2)
]|t=0
dm1dm2.
(4.23)
où nous nous sommes autorisés, sans le justifier, à dériver sous le signe somme. On a alors lerésultat suivant
78

Proposition 6. On ad
d t
[JΦt (m1,m2)
]|t=0
= div~V (m1,m2).
Justification. Nous n’allons pas fournir de preuve rigoureuse de ce résultat, mais, en revanche,essayer d’en indiquer une justification intuitive. Au vu de (4.22) on a envie d’écrire pour t petit
Φt (M0)−M0 ' t~V (M(t ))
et donc
JΦt (m1,m2) '∣∣∣∣∣ 1+ t ∂V1
∂m1t ∂V1∂m2
∂V2∂m1
1+ t ∂V2∂m2
∣∣∣∣∣' 1+ t
(∂V1
∂m1+ ∂V2
∂m2
)+ t 2
(∂V1
∂m1
∂V2
∂m2− ∂V1
∂m2
∂V2
∂m1
).
Le résultat s’en déduit.
Revenons à (4.23), que nous pouvons maintenantécrire sous la forme
dA ire(Ωt )
d t |t=0
=ÏΩ0
div~V (m1,m2)dm1dm2. (4.24)
On peut donc interpréter l’intégrale de la divergence comme la dérivée de l’aire occupée par lesparticules, lorsqu’elles sont transportées par le champ de vecteurs. Notons que si la divergence duchamp de vecteurs est nulle, alors le volume occupé par les particule est invariant au cours dutemps. C’est par exemple approximativement le cas pour des liquides comme l’eau. Les gaz, enrevanche, sont compressibles.
Interprétation du flux. Considérons un variation de temps élémentaire ∆t , qui fait passer le do-maine Ω0 à Ω∆t . Si l’on compare le volume occupé par les deux domaines, on s’aperçoit que ladifférence entre les deux domaines est due, au premier ordre, aux particules près de la frontières,transportées par le champ de vecteurs ~V . Une particule présente au temps 0 en M se retrouveau temps ∆t au point M + ~V (M)∆t . La différence entre les deux domaines, est représentée, enpremière approximation, par la courbe C que l’on munit d’une "épaisseur " en chaque point del’ordre de ~V .~n ∆t . La différence de volume est donc
∆t∫C
~V .~n(s)d s.
qui est précisement le flux multiplié par ∆t .
79

Equation de conservation (hors programme). Supposons que le fluide ait une densité ρ(t , M) parunité de surface. au point M . La masse contenue dansΩt s’écrit donc
M (t ) =ÏΩt
ρ(t , x1, x2)d x1d x2 =ÏΩ0
ρ (t ,Φt (m1,m1)) JΦt (m1,m2)dm1dm2 (4.25)
la conservation de la masse s’écritd
d tM (t ) = 0. (4.26)
En dérivant l’expression (4.25) on trouve
d
d tM (t )|t=0 =
ÏΩ0
d
d t
[ρ (t ,Φt (m1,m1))
]|t=0
JΦ0 (m1,m2)dm1dm2
+ÏΩ0
ρ (0,m1,m1))d
d t
[JΦt (m1,m2)
]|t=0
dm1dm2.(4.27)
CommeΦ0 = Id, on a JΦ0 (m1,m2) = 1. Par ailleurs, on a
d
d t
[ρ (t ,Φt (m1,m1))
]= ∂ρ
∂t((t ,Φt (m1,m1))+ d
d t(Φt (M(t )) ·−−−→gradρ
= ∂ρ
∂t((t ,Φt (m1,m1))+~V (Φt (m1,m1)) ·−−−→gradρ,
d’o ûd
d t
[ρ (t ,Φt (m1,m1))
]|t=0
= ∂ρ
∂t((t ,m1,m1)+~V (m1,m2) ·−−−→gradρ(0,m1,m2).
En reportant ces relations ainsi que (4.24) dans (4.27) on obtient finalement
d
d tM (t )|t=0 =
ÏΩ0
[∂ρ
∂t+~V .
−−−→gradρ+ρ.divV
](0,m1,m1)dm1dm2.
Comme~V .
−−−→gradρ+ρ.divV = div(ρ~V ]
et en utilisant maintenant la conservation de la masse (4.26) on obtientÏΩ0
[∂ρ
∂t+div(ρ~V )
)](0,m1,m2)dm1dm2 = 0.
Cette identité étant vraie pour tout domaine Ω0, on en déduit finalement l’équation locale deconservation de la masse
∂ρ
∂t+div(ρ~V ) = 0. (4.28)
Remarque 9. Dans de nombreuse application, le champ de vecteurs ~V dépend également de t .Cependant, cela ne change pas le résultat des calculs précédents, et en particulier (4.28) reste va-lable.
Exercices
80

Exercice I
1) Soit A une matrice 2×2 :
A =(
a1,1 a1,2
a2,1 a2,2
).
1) On note At la matrice transposée. Montrer que l’on peut decomposer la matrice A de manièreunique sous la forme
A = B +C ,
o ù la matrice B est symétrique, c’est à dire B = B t , et la matrice C est antisymétrique, c’est à direC t =−C . Donner les expressions de B et C .2) On considère le champ de vecteur linéaire
~V (X ) = A. ·X ,
et une courbe fermée C , orientée dans le sens trigonométrique. Calculer∫C
~V (M)d ~M
en fonction de l’aire du domaine D entouré par C et des coefficients de A.
81

Chapitre 5
Analyse vectorielle dans R3
5.1 Introduction
Le but de ce chapitre est de voir comment les notions développées dans le cadre des fonctionsà deux variables se généralisent aux fonctions de trois variables. Pour de nombreuses notions,cette généralisation se fait sans peine, car elle est assez directe. Certaines notions en revanche re-quierent l’introduction de nouveaux concepts, et de nouveaux outils.
Commençons par quelques rappels sur l’espace R3.
5.1.1 Rappels sur R3
Comme R2, l’espace R3 est un espace vectoriel lorsqu’on le munit de la loi d’addition
(x1, x2, x3)+ (y1, y2, y3) = (x1 + y1, x2 + y2, x3 + y3),∀X = (x1, x2, x3) ∈R3,∀Y = (x1, x2, x3) ∈R3.
et de la loi de muliplication par un scalaire
λ.(x1, x2) = (λx1,λx2,λx3),∀X = (x1, x2, x3) ∈R3λ ∈R.
Le produit scalaire noté "." devient
X .Y = x1.y1 +x2.y2 +x3.y3, ∀X = (x1, x2, x3) ∈R3,∀Y = (y1, y2, y3) ∈R3,
et la norme associée dite norme euclidiennne ‖ ·‖ est alors donnée par
‖X ‖ =p
X .X =√
x21 +x2
2 +x23 ≥ 0, ∀X = (x1, x2, x3) ∈R3.
Les propriétés présentées dans la Proposition 1 du Chapitre 2, ou dans les inégalités (2.1) et (2.2)restent valables.
Le produit vectoriel. Cette opération est spécifique à R3 : elle associe à un couple de vecteurs deR3 un vecteur de R3.
Définition 1. Soit ~X = (x1, x2, x3) et ~Y = (y1, y2, y3) deux vecteurs de R3. Le produit vectoriel de ~Xpar ~Y est le vecteur, noté ~X ∧~Y défini par
~X ∧~Y = (x2 y3 − y2x3, x3 y1 − y3x1, x1 y2 − y1x2).
82

Par exemple, si ~e1 = (1,0,0),~e2 = (0,1,0),~e3 = (0,0,1) sont les vecteurs de la base canonique,alors on a
~e1 ∧~e2 =~e3, ~e2 ∧~e3 =~e1 et~e3 ∧~e1 =~e2.
Remarque 1. Pour se souvenir de l’ordre dans lequel on doit prendre les coordonnées, on écritsouvent l’opération ∧ en utilisant des vecteurs colonnes
~X ∧~Y =x1
x2
x3
∧y1
y2
y3
=x2 y3 − y2x3
x3 y1 − y3x1
x1 y2 − y1x2
.
La première ligne du produit vectoriel est obtenu en "cachant" la première ligne des vecteurs ~X et~Y et en prenant le déterminant des éléments restants, et de même pour les autres lignes.
On vérifie les propriétés suivantes :
Proposition 1. On a pour tous vecteurs ~X ,~Y ,~Z de R3 et tout nombre λ
~X ∧~Y =−~Y ∧X
(~X +~Y )∧~Z = ~X ∧~Z +~Y ∧~Z .
~X ∧ (~Y +~Z ) = ~X ∧~Y +~X ∧~Z(λ~X )∧~Y =λ(~X ∧~Y ).
On a également
Proposition 2. On a ~X ∧~Y = 0 si et seulement si ~X et ~Y sont colinéaires, c’est à dire qu’on a ~X =λYou ~Y =λ~X pour une constante λ.
Démonstration. Montrons d’abord que la condition est suffisante. Supposons par exemple que~X =λY , le cas =λ~X se traitant de même. On a alors x1 =λy1, x2 =λy2, x3 =λy3. Ceci entraîne
~X ∧Y = ((x2 y3 − y2x3, x3 y1 − y3x1, x1 y2 − y1x2) = (0,0,0).
Montrons maintenant que la condition est nécessaire. Supposons que ~X ∧~Y = 0, et montrons queles vecteurs sont colinéaires. Si X = 0, on ~X = 0~Y et la propriété est donc démontrée. Sinon on a
83

(x1, x2, x3) 6= (0,0,0). Supposons que x1 6= 0 (les cas x2 6= 0 ou x3 6= 0 se traitent de la même façon).Comme on a supposé que
~X ∧~Y = (x2 y3 − y2x3, x3 y1 − y3x1, x1 y2 − y1x2) = (0,0,0)
on a en particulier x3 y1 − y3x1 = 0 etx1 y2 − y1x2 = 0. Comme x1 6= 0, il en résulte que y3 = x3 y1/x1
et y2 = y1x2/x1. D’o û~Y = (y1, y1x2/x1, x3 y1/x1) = y1
x1(x1, x2, x3) =λ~X
où λ= y1/x1. La propriété est donc démontrée.Finalement nous avons (résultat que nous admettrons)
Proposition 3. Le vecteur ~X ∧~Y est orthogonal aux vecteurs ~X et ~Y . La norme ‖~X ∧~Y ‖ est égale àl’aire du parallélélogramme de cotés ~X et ~Y .
Interprétation géométrique du déterminantSoient ~X , ~Y , et ~Z trois vecteurs de R3. La valeur absolue du déterminant det(~X ,~Y ,~Z ) s’interprètecomme le volume du parallèlépipède P dont les côtés sont parallèles à ~X ,~Y et ~Z
|Vol(P )| = det(~X ,~Y ,~Z )|.Le déterminant est le produit vectoriel sont reliés par la formule suivant
Proposition 4. Soient ~X , ~Y , et ~Z trois vecteurs de R3. On a
det(~X ,~Y ,~Z ) = ~X ∧~Y .~Z .
5.2 Limites, continuités et dérivation dans R3
La notion de limite, présentée dans le cas des fonctions sur R2 au Chapitre 2 dans la définition2.4, se transpose presque mot pour mot au cas des fonction f surR3. Il en est de même de la notionde continuité.
La notion de dérivée partielle se généralise également sans peine. Soit f une fonction déiniesur R3 et M0 un point du domaine de définition tels que f est définie près de M0.
84

Définition 2. Soit i = 1,2 ou 3. On appelle dérivée partielle de f en M0 par rapport à la variable xi
la limite suivante, lorqu’elle existe
∂ f
∂xi(M0) = lim
t→0
f (M0 + t~ei )− f (M)
t.
on la note
f ′xi
(M0), ∂xi f (M0) ou encore comme ci-dessus∂ f
∂xi(M0).
On conserve bien entendu les mêmes règles de calcul :
Proposition 5. On a pour i = 1,2 ou 3
( f ± g )xi = f ′xi± g ′
xi, ( f g )xi = f ′
xig + f g ′
xi.
De plus si là où g ne s’annule pas (f
g
)′xi
= f ′xi
g − f g ′xi
g 2.
On a également le développement limité suivant :
Proposition 6. On suppose que f ′xi
est définie et continue près de M, pour i = 1,2 ou 3. Alors on apour h = (h1,h2,h3) petit
f (M +h) = f (m1 +h1,m2 +h2) = f (M)+h1 f ′x1
(M)+h2 f ′x2
(M)+h3 f ′x3
(M)+‖h‖ε(h), (5.1)
où la fonction ε est définie près de 0 et vérifie
limh→0
ε(h) = 0.
On peut écrire le développement (5.1) sous la forme condensée
f ′(M +h)− f (M) = h.−−−→grad f (M)+‖h‖ε(h). (5.2)
où on définit le champ de vecteurs−−−→grad comme en dimension deux par la formule
−−−→grad f (M) = ( f ′
x1(M), f ′
x2(M), f ′
x3(M)).
Enfin, pour calculer la dérivées de fonctions composées, on calcule les matrices Jacobiennes,et on utilise comme en dimension deux la formule (2.17).
Lorsque f est dérivable près d’un point de son domaine de définition et que les dérivées par-tielles y sont dérivables, les dérivées de ces dernières sont appelées les dérivées secondes. On notepour i = 1,2,3 et j = 1,2,3
∂2 f
∂xi∂x j= ∂
∂x1
(∂ f
∂x j
), pour i 6= j
et∂2 f
∂x2i
= ∂
∂x1
(∂ f
∂xi
),
85

Théorème 1. Si les dérivées secondes existent et sont continues près d’un point M donné, alors on a
∂
∂xi
(∂ f
∂x j
)(M) = ∂
∂x j
(∂ f
∂xi
)(M).
La démonstration est similaire à celle de la dimension 2. Elle nous fournit de plus, comme endimension deux :
Théorème 2. Si les dérivées secondes existent et sont continues près d’un point M donné, alors on apour h = (h1,h2,h3)
f (M +h) = f (M)+h.−−−→grad f (M)+ 1
2
3∑i ,i
∂2 f
∂xi∂x j(M +‖h‖2ε(h). (5.3)
5.3 Courbes paramètrées dans R3
Les définitions sont semblables à celle données pour les courbes de R2. Soit I un intervalle deR et soit une application M : I → R3 définie par M(t ) = (M1(t ), M2(t ), M3(t )), pour t ∈ I . Soit C
l’image de I par M , c’est à dire l’ensemble des points de R3 de la forme
C = t ) = (M1(t ), M2(t ), M3(t )), t ∈ I .
On dit alors que C est une courbe paramètrée par M . La notion de point ordinaire est identiqueau cas du plan, à savoir qu’un point M(t ) est dit ordinaire si et seulement si
M ′(t ) = (M ′1(t ), M ′
2(t ), M ′3(t )) 6= (0,0,0).
Pour un point ordinaire M(t ) les vecteurs tangents en M(t ) à la courbe sont les vecteurs non nulscolinéaires à M ′(t ), et la droite tangente se définie comme en dimension deux. Il en est de mêmede la notion de longueur, ou de paramètrage naturel.
5.4 Surfaces paramétrées dans R3
La définition des surfaces paramètrées de R3 s’inspire de celle des courbes paramètrées, à ladifférence notable qu’elles ne sont pas paramètrées par des intervalles, mais par des domaines deR2.
Soit doncΩ un domaine de R2 et soit M = (M1, M2, M3) une application deΩ dans R3
~M :Ω→R3, (u1,u2) 7→ (M1(u1,u2), M2(u1,u2), M3(u1,u2)) pour (u1,u2) ∈Ω.
La surface paramètrée S est l’image deΩ par M , c’est à dire l’ensemble
S = (M1(u1,u2), M2(u1,u2), M3(u1,u2)) (u1,u2) ∈Ω.
Nous supposerons de plus que les applications M1, M2, M3 sont dérivables de dérivées continues.Posons alors
∂~M
∂u1=
(∂M1
∂u1,∂M2
∂u1,∂M3
∂u1
)et
∂~M
∂u1=
(∂M1
∂u1,∂M2
∂u1,∂M3
∂u1
).
(5.4)
86

Ces deux vecteurs sont tangents à la surface S au point ~M . Le vecteur
~m = ∂~M
∂u1∧ ∂~M
∂u2
est orthogonal à la surface S au point M . Nous supposerons dans toute la suite qu’il n’est pasnul. 1 Posons
~n = ~m
‖~m‖ =∂~M∂u1
∧ ∂~M∂u2∥∥∥ ∂~M
∂u1∧ ∂~M∂u2
∥∥∥ .
Le vecteur ~n est un vecteur unitaire, car‖~n| = 1
et de plus il est orthogonal à la surface. Ce vecteur dépend du point ~M(u1,u2) de manière continue.Nous dirons que la surface S est orientée suivant le vecteur ~n. 2
Remarque 2. Pour changer l’orientation, il faut changer~n en −~n, et donc définir un nouveau para-mètrage. Par exemple, pour le faire, on peut permuter les variables u1, et u2, de sorte que la surfaceest paramètrée par (u2,u1).
On appelle plan tangent en M(u1,u2) le plan affine passant par M(u1,u2) et parallèle au sous-
espace vectoriel engendré par les vecteurs ∂~M∂u1
et ∂~M∂u2
. Il est donc orthogonal au vecteur ~n au pointM . On a donc
Proposition 7. Soit M0 = M((u01,u0
2)] ≡ (M 01 , M 0
2 , M 03 ) un point de S . Soit ~m0 et ~n0 les vecteurs or-
thogonaux associés comme ci-dessus. alors le plan tangent en M0 admet pour équation
(x1 −M 01 , x2 −M 0
2 , x3 −M 03 ).~m0 = 0
ou encore(x1 −M 0
1 , x2 −M 02 , x3 −M 0
3 ).~n0 = 0
Exemple 1. Soit~e1 et~e1 deux vecteurs de R3, non colinéaires, et soit~b un vecteur quelconque deR3. Alors, l’ensemble
S = s~e1 + t~e2 +~b, s ∈R, t ∈R
est bien une surface paramétrée, il s’agit du plan affine passant par~b, et dont le plan directeur estengendré par les vecteurs~e1 et~e2. Son plan tangent est identique à lui-même.
Le cas des graphes. Un exemple de surface paramètrée de R3 est fourni par le graphe d’une fonc-tion f du domaineΩ de R2 ves R. Un paramétrage est alors donné par l’application
M : Ω→R3, (x1, x2) 7→ M(x1, x2) = (x1, x2, f (x1, x2)
).
On a ∂~M
∂x1=
(1,0,
∂ f
∂x1(x1, x2)
)∂~M
∂x2=
(0,1,
∂ f
∂x2(x1, x2)
),
1. cette condition pour les surfaces est l’équivalent de celle de point ordinaire pour les courbes2. On peut imaginer que ~n indique le côté on se trouve par rapport à la surface
87
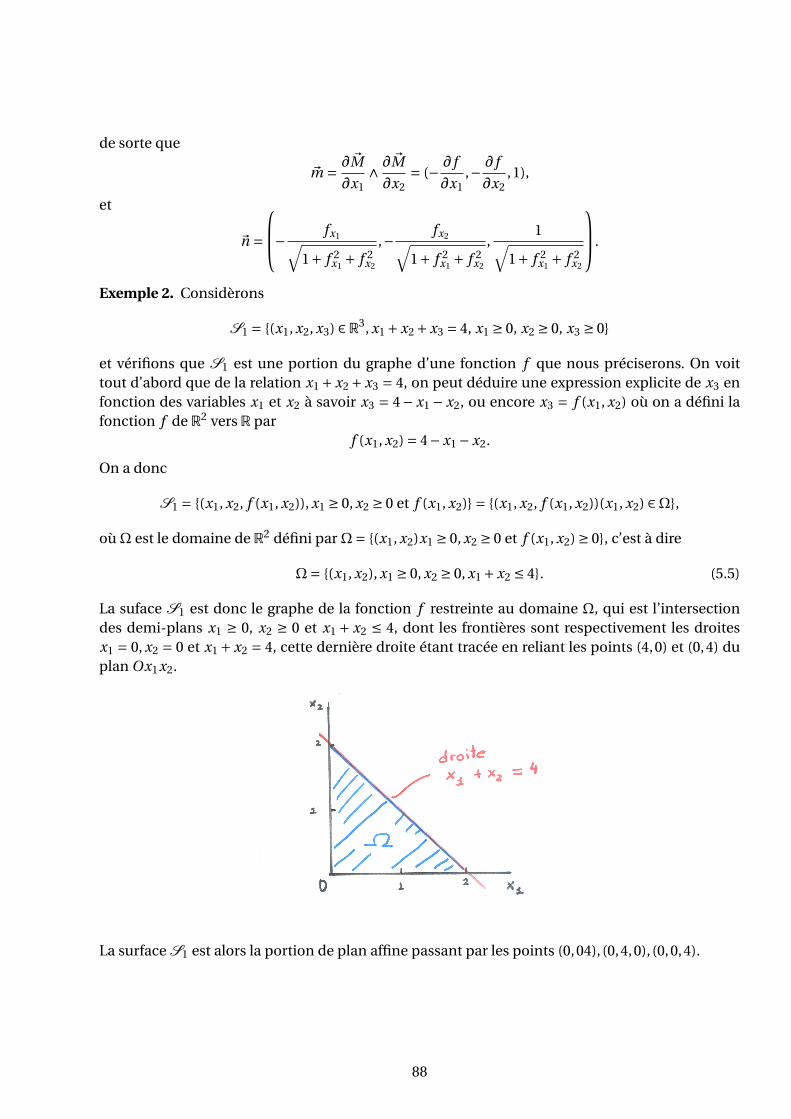
de sorte que
~m = ∂~M
∂x1∧ ∂~M
∂x2= (− ∂ f
∂x1,− ∂ f
∂x2,1),
et
~n =
− fx1√1+ f 2
x1+ f 2
x2
,− fx2√1+ f 2
x1+ f 2
x2
,1√
1+ f 2x1+ f 2
x2
.
Exemple 2. Considèrons
S1 = (x1, x2, x3) ∈R3, x1 +x2 +x3 = 4, x1 ≥ 0, x2 ≥ 0, x3 ≥ 0
et vérifions que S1 est une portion du graphe d’une fonction f que nous préciserons. On voittout d’abord que de la relation x1 + x2 + x3 = 4, on peut déduire une expression explicite de x3 enfonction des variables x1 et x2 à savoir x3 = 4− x1 − x2, ou encore x3 = f (x1, x2) où on a défini lafonction f de R2 vers R par
f (x1, x2) = 4−x1 −x2.
On a donc
S1 = (x1, x2, f (x1, x2)), x1 ≥ 0, x2 ≥ 0 et f (x1, x2) = (x1, x2, f (x1, x2))(x1, x2) ∈Ω,
oùΩ est le domaine de R2 défini parΩ= (x1, x2)x1 ≥ 0, x2 ≥ 0 et f (x1, x2) ≥ 0, c’est à dire
Ω= (x1, x2), x1 ≥ 0, x2 ≥ 0, x1 +x2 ≤ 4. (5.5)
La suface S1 est donc le graphe de la fonction f restreinte au domaine Ω, qui est l’intersectiondes demi-plans x1 ≥ 0, x2 ≥ 0 et x1 + x2 ≤ 4, dont les frontières sont respectivement les droitesx1 = 0, x2 = 0 et x1 + x2 = 4, cette dernière droite étant tracée en reliant les points (4,0) et (0,4) duplan Ox1x2.
La surface S1 est alors la portion de plan affine passant par les points (0,04), (0,4,0), (0,0,4).
88

On a−−−→grad f = (−1,−1), donc un vecteur normal à la surface au point ~M(x1, x2) est donné par
~m = (1,1,1), et un vecteur unitaire normal par
~n = 1p3
(1,1,1).
Exemple 3. Un autre exemple est fourni par la projection stéréographique, qui est un moyen uti-lisé pour cartographier la sphère privée du pôle nord. Considérons la sphère unité de R3 définiepar
S 2 = (x1, x2, x3) ∈R3, x21 +x2
2 +x23 = 1.
Soit P le plan Ox1x2, qui est donc un plan équatorial de la sphère S 2.. Pour U = (u1,u2) considé-rons le point M = M(u1,u2), intersection de S 2 et de la droite U N , où N = (0,0,1) désigne le pôlenord. A chaque point (u1,u2) du plan P correspond un unique point de S 2 \ N , et l’application
M : P →S 2 \ N , (u1,u2) 7→ M(u1,u2)
est bien un paramétrage de S 2 \ N . On peut d’ailleurs l’expliciter comme
M(u1,u2) =(
2u1
1+u21 +u2
2
,2u2
1+u21 +u2
2
,1−u2
1 −u22
1+u21 +u2
2
).
Remarque 3. Pour une surface donnée S , on peut parfois avoir à diviser S en plusieurs mor-ceaux, dont chacun est une surface paramétrée au sens précédent.
5.5 Le théorème des fonctions implicites
Les surfaces deR3 peuvent aussi être définies comme l’ensemble des solutions d’une équation.Soit F une fonction sur R3 définie sur un domaine D. Considérons l’ensemble
S = (x1, x2, x3) ∈R3 tels que F (x1, x2, x3) = 0. (5.6)
Soit M = (m1,m2,m3) un point de S tel que les dérivées partielles de F soient continues près deM . Nous allons voir que
89

Théorème 3. Soit M = (m1,m2,m3) un point de S tel que
−−−→gradF (M) 6=~0.
Alors localement près de M, S est une surface paramétrée. De plus, un vecteur orthogonal à S en M
est donnée par−−−→grad f (M) et un vecteur orthonogonal unitaire par
~n =−−−→gradF (M)
‖−−−→gradF (M)‖.
Par ailleurs l’équation du plan tangent en M a la forme simple suivante
fx1 (M)(x1 −m1)+ fx2 (M)(x2 −m2)+ fx1 (M)(x2 −m1) = 0. (5.7)
Retenons donc que les vecteurs orthogonaux ainsi qu’une équation d’un plan tangent sont parti-culièrement simples à établir lorsque la surface est donnée sous forme d’équation (5.6).
La preuve du Théorème (3) repose , comme en dimension 2, sur le théorème des fonctionsimplicites, dont voici un énoncé
Théorème 4. Soit M = (m1,m2,m3) un point de S tel que les dérivées partielles de F soient conti-nues près de M On suppose de plus que
∂F
∂x3(M) 6= 0. (5.8)
Alors il existe un voisinage U de M = (m1,m2) dans R2 et une fonction ϕ : U →R tel que
ϕ(m1,m2) = m3 et F (x1, x2,ϕ(x1, x2)) = 0.
Il en résulte que près de M , S peut alors se représenter comme le graphe d’une fonction. Uncalcul similaire à celui effectué en dimension 2 montre alors que les dérivées partielles de ϕ secalculent comme suit :
ϕx1 (x1, x2) = F ′x1
(x1, x2,ϕ(x1, x2)
)F ′
x3
(x1, x2,ϕ(x1, x2)
)et
ϕx2 (x1, x2) = F ′x2
(x1, x2,ϕ(x1, x2)
)F ′
x3
(x1, x2,ϕ(x1, x2)
) .
(5.9)
Exemple 4. SoitS = (x1, x2, x3) ∈R3, a1x1 +a2x2 +a3x3 = b
où a1, a2, a3 et b sont des nombres réels donnés, tels que (a1, a2, a3) 6=~0. Ici la fonction F est donnéepar
F (x1, x2, x3) = a1x1 +a2x2 +a3x3 −b,
de sorte que−−−→gradF = (a1, a2, a3) 6=~0. La surface obtenue est ici un plan affine, dont le plan tangent
est identique à elle même en tout point, et un vecteur normal est (a1, a2, a3).
90

Exemple 5. Le graphe d’une fonction f d’un domaine D de R2 dans R est donnée par une équa-tion. Si
Γ f = (x1, x2, x3) ∈R3, (x1, x2) ∈D, x3 = f (x1, x2), x3 = f (x1, x2)
est le graphe de f alorsΓ f = (x1, x2, x3) ∈R3, ,F (x1, x2, x3) = 0
où la fonction F est définie de D×R vers R par
F (x1, x2, x3) = x3 − f (x1, x2).
On a alors −−−→gradF (x1, x2, x3) = (− f ′
x1(x1, x2), (− f ′
x1(x1, x2),1).
de sorte qu’un vecteur unitaire orthogonal au graph de f est donné par
~n =
− fx1√1+ f 2
x1+ f 2
x2
,− fx2√1+ f 2
x1+ f 2
x2
,1√
1+ f 2x1+ f 2
x2
.
L’équation du plan affine tangent au graphe en (m1,m2,m3) avec m3 = f (m1,m2) est alors donnéepar
− f ′x1
(m1,m2)(x1 −m1)− f ′x2
(m1,m2)(x2 −m2)+ (x3 −m3) = 0.
Exemple 6. Considérons l’éllipsoide d’équation
x21
a21
+ x22
a22
+ x23
a23
= 1,
où a1, a2 et a3 sont des réels non nuls. Un vecteur orthogonal au point M = (m1,m2,m3) est donnépar
−−−→gradF (m1,m2,m3) =
(2m1
a21
,2m2
a22
,3m3
a23
).
L’équation du plan tangent en (m1,m2,m3) est alors donnée par
m1
a21
(x1 −m1)+ m2
a22
(x2 −m2)+ m3
a23
(x3 −m3) = 0 où (x1, x2, x3) ∈R3.
5.5.1 Aire d’une surface
Considérons une surface S paramètrée par une fonction
M :Ω→R3, U = (u1,u2) 7→ M(U ).
Considérons U un point quelconque de Ω, et un rectangle élémentaire R de cotés ∆u1 et ∆u2,dont un des sommets est U . L’image par M de ce rectangle est proche, au premier ordre, d’un
parallélogramme dont les cotés sont donnés par les deux vecteurs ∆u1∂~M
∂u1et ∆u2
∂~M
∂u2. On a donc,
en invoquant la Proposition 3
A ire(M(R)) '∆u1∆u2
∥∥∥∥∥∂~M∂u1∧ ∂~M
∂u2
∥∥∥∥∥ .
91

Il en résulte que si on diviseΩ en petites rectangles de cotés ∆u1 et ∆u2, que l’on somme sur tousles rectangles, et enfin que l’on fait tendre∆u1 et∆u2vers zéro, alors on obtient l’aire de la surface,c’est à dire
A ire(S ) =ÏΩ
∥∥∥∥∥∂~M∂u1∧ ∂~M
∂u2
∥∥∥∥∥du1du2. (5.10)
On vérifie ensuite que cette formule est indépendante du paramètrage choisi. Lorsque l’on a be-soin de diviser S en plusieurs morceaux pour pouvoir la paramètrer, on fait alors la somme desaires des différents morceaux.
Le cas des graphes. Si la surface est décrite sous forme de graphe d’une fonction f :Ω→R commeci-dessus, alors
A ire(S ) =ÏΩ
√1+ f 2
x1+ f 2
x2d x1d x2.
Exemple 7. Considèrons de nouveau la surface S1 définie dans l’example 2 S1 = (x, y, z) ∈R3, x1+x2 + x3 = 4, x1 ≥ 0, x2 ≥ 0, X3 ≥ 0. Nous avons vu qu’il s’agit du graphe de la fonction f (x1, x2) =4−x1 −x2 pour le domaineΩ défini en (5.5). On asqr t1+ f 2
x1+ f 2
x2=p
3, d’où
A ire(S1) =ÏΩ
p3d x1d x2.
On peut calculer cette intégrale en utilisant le théorème de Fubini,
A ire(S1) =p3∫ 4
0
(∫ 4−x1
0d x2
)d x1 =
p3∫ 4
0(4−x1)d x1 =−p3
[(4−x1)2
2
]2
0= 8
p3.
5.5.2 Intégration sur les surfaces
Considérons une surface S paramètrée par une fonction M(U ) : Ω→ R3, et f une fonctiondéfinie sur S . Posons
I =ÏΩ
f (M(u1,u2))
∥∥∥∥∥∂~M∂u1∧ ∂~M
∂u2
∥∥∥∥∥du1du2.
la valeur I est appelée intégrale de f sur S . On vérifie que cette quantité est indépendante duparamètrage choisi. On la note souvent
I =Ï
Sf dσ,
o û dσ désigne l’élément d’aire élémentaire sur S . La valeur calculée ici ne tient pas compte del’orientation.
Exemple 8. Calculons I1 =Ï
S1
x21dσ, où S1 est la portion de surface définie dans l’exemple 2. On
trouve, en utilisant le théorème de Fubini
I1 =p
3ÏΩ
p3x2
1d x1d x2
=p3∫ 4
0
(∫ 4−x1
0x2
1d x2
)d x1 =
p3∫ 4
0(4−x1)x2
1d x1
=p3
[4
3x3
1 −1
4x4
1
]4
0=p
3(4
364−64) = 6
43p
3 = 64p3
.
92

5.6 Intégrales triples
5.6.1 Construction
Les intégrales de fonctions à trois variables se définissent de manière similaire à celui du cas dedeux variables. Soit D un domaine deR3 limité par une surface S . Soit f une fonction continue surD avec son bord. On divise l’espace R3 en petits parallélépipèdes rectangles Ri , j ,k de taille ∆x1 ×∆x2 ×∆x3 parallèles aux axes Ox1, Ox2 et Ox3 On considère les parallélépipèdes Ri , j ,k contenusdans D. Notons Mi , j ,k le centre de Ri , j ,k . Considérons la somme∑∑∑
f (Mi , j ,k )∆x1∆x2∆x3.
Notons que ∆x1∆x2∆x3 représente la mesure du volume de Ri , j ,k . Nous admettons la propriétésuivante : Lorsque ∆x1 , ∆x2 et ∆x3 tendent vers 0, la somme ci-dessus converge vers une quantitéque nous noterons
I =Ñ
Df (x1, x2, x3)d x1d x2d x3.
Définition 3. On appelle I l’intégrale triple de la fonction f sur le domaine D.
Notons que pour f = 1, on obtient la mesure du volume de D, c’est à dire
Vol(D) =Ñ
Dd x1d x2d x3.
On alors les propriétes suivantes.
Proposition 8. On a pour un domaine D fixéÑD
( f1 + f2)(x1, x2, x3)d x1d x2d x3 =Ñ
Df1(x1, x2, x3)d x1d x2d x3 +
ÑD
f2(x1, x2, x3)d x1d x2d x3ÑD
(λ f1)(x1, x2, x3)d x1d x2d x3 =λÑ
Df (x1, x2, x3)d x1d x2d x3.
Si l’on divise D en deux domaines D1 et D2 alors∫∫∫∫D
f (x1, x2, x3)d x1d x2d x3 =Ñ
D1
f (x1, x2, x3)d x1d x2d x3 +Ñ
D2
f (x1, x2, x3)d x1d x2d x3.
5.6.2 Le Théorème de Fubini
Il permet de ramener des calculs d’intégrales triples à des intégrales doubles.
Soit un domaine D sur lequel on désire intégrer une fonction. On suppose par ailleurs que six3 prend des valeurs dans un intervalle [c0,c1], c’est àdire que
D ⊂R2 × [c0,c1].
Pour chaque nombre m3 fixé, on suppose que (x1, x2) varie dans un domaine T (x3) de R2, où
T (m3) = (x1, x2) tels que (x1, x2,m3) ∈D
de sorte que T (m3) ≡ (x1, x2,m3) tels que (x1, x2) ∈ T (m3) =D∩ (x1, x2,m3). On a alors
93

Théorème 5. On a l’identitéÑf (x1, x2, x3)d x1d x2d x2 =
∫ c1
c0
(ÏT (x3)
f (x1, x2, x3)d x1d x2
)d x3.
Remarque 4. La quantité entre parenthèses dans le membre de droite est bien une fonction quine dépend que de la variable x3 par l’intermédiaire de f et du domaine d’intégration T (x3) :Ï
T (x3)f (x1, x2, x3)d x1d x2
Pour calculer une telle intégrale double, on peut appliquer de nouveau le théorème de Fubini pourle cas de deux variables.
Remarque 5. Bien entendu les variables x1, x2 et x3 jouent des rôles équivalents.
Donnons une autre version du Théorème de Fubini. supposons que (x1, x2) varie dans un cer-tain domaine∆ de R2 et pour chaque point (x1, x2) de∆ supposons que x3 varie dans un intervalle[ϕ(x1, x2),ψ(x1, x2)].
Théorème 6. On aÑD
f (x1, x2, x3)d x1d x2d x3 =Ï∆
(∫ ψ(x1,x2)
ϕ(x1,x2)f (x1, x2, x3)d x3
)d x1d x2.
Exemple 9. Calculons en utilisant le théorème de Fubini le volume d’un cône.
94

SoitΩ un domaine deR2 =Ox1x2, soit A = (a1, a2, a3) un point donné deR3. On considère pourdomaine D le cône de sommet A de baseΩ, c’est à dire l’ensemble suivant :
D = X = (x1, x2, x3) ∈R3 tels que X ∈ [A, X ′], où X ′ ∈Ox1x2 est un point deΩ
.
Ici [A, X ′] désigne le segment joignant A et X ′. On désire calculer le volume de D, c’est à dire l’in-tégrale triple
I = Vol(D) =Ñ
Dd x1d x2d x3.
En utilisant le théorème de Fubini a on donc
I =∫ a3
0
(∫Ωh
d x1d x2
)dh =
∫ a3
0A ire(Ωh)dh, (5.11)
où Ωh = (xh1 , xh
2 ) ∈R2 tels que Xh = (xh1 , xh
2 ,h),∈D. Essayons maintenant de décrire ces tranches
Ωh . Soit Xh = (xh1 , xh
2 ) un point quelconque de Ω, Mh = (xh1 , xh
2 ,h) ∈ D. On a−→
AMh = (xh1 − a1, xh
2 −a2,h −a3). La droite Dh passant par A et Mh a donc pour forme
Dh = (a1 + s(xh1 −a1), a2 + s(xh
2 −a2), a3 + s(h −a3), s ∈R
= (1− s)a1 + sxh1 , (1− s)a2 + sxh
2 , (1− s)a3 + sh, s ∈R,
Soit Ah son intersection avec le plan 0x1x2. Elle correspond à la valeur s0 = a3
a3 −hdu paramètre
qui annule la troisième coordonnée. On a donc par hypothèses Ah ∈Ω et
Ah = (1− s0)a1 + s0xh1 , (1− s0)a2 + s0xh
2 , (1− s0)a3 + s0h,
= (1− s0)A+ s0Xh ∈Ω par hypothèse.
Ω est donc l’image deΩh par l’application affine bijective de R2 vers R2 définie par
Φh(Xh) = (1− s0)A+ s0Xh , avecΦh(Ω) =Ω.
On a
DΦh = s0IdR2 et donc |JΦh | = s20 =
(a3
a3 −h
)2
.
Ainsi par la formule du changement de variable
A ire(Ω) =ÏΩ
d x1d x2 =ÏΩh
|JΦh |d x1d x2
=(
a3
a3 −h
)2 ÏΩh
d x1d x2 =(
a3
a3 −h
)2
A ire(Ωh).
Il en résulte que
A ire(Ωh) =(1− h
a3
)2
A ire(Ω)
En revenant à (5.11) on trouve donc
I =A ire(Ω)∫ a3
0
(1− h
a3
)2
dh =−A ire(Ω)
3a23
[(a3 −h)3]a3
0 = 1
3a3A ire(Ω).
95

5.6.3 Changements de variables
La règle générale est analogue au cas à deux variables. Soit D un domaine de R3 que l’on pa-ramètre par un domaine Ω de R3 à l’aide d’une application Φ : Ω→ D, u = (u1,u2,u3) 7→ Φ(U ) =(Φ1(U ),Φ2(U ),Φ3(U )) = X = (x1, x2, x3), bijective et dérivable de dérivées continues. On considèrealors le Jacobien
JΦ =∣∣∣∣∣∣
(Φ1)u1 (Φ1)u2 (Φ1)u3
(Φ2)u1 (Φ2)u2 (Φ2)u3
(Φ3)u1 (Φ3)u2 (Φ3)u3
∣∣∣∣∣∣On le notera également
JΦ = D(x1, x2, x3)
D(u1,u2,u3).
On a alors
Théorème 7. On aÑD
f (x1, x2, x3)d x1d x2d x3 =Ñ
Ωf (Φ(u1,u2,u3)) |JΦ(u1,u2,u3)|du1du2du3.
Attention. Dans la formule précédente, on prend la valeur absolue du Jacobien.
Coordonnées cylindriques. Soit D le cylindre de R3 défini par
x21 +x2
2 ≤ R2, x3 ∈ [c0,c1].
On effectue le changement de variable
x1 = r cosθ, x2 = r sinθ, x3 = x3.
Les nouvelles variables sont donc (r,θ, x3). Le domaineΩ est donné par
Ω= (r,θ, x3), tels que 0 ≤ r ≤ R, 0 ≤ θ < 2π,c0 ≤ x3 ≤ c1,
c’est à dire le parallélépipède [0,R]× [0,π]× [c0,c1]. L’applictionΦ s’écrit donc
Φ1 = r sinθ, Φ2 = r cosθ, Φ3 = x3,
et le Jacobien de ce changement de variable est
JΦ =∣∣∣∣∣∣
cosθ −r sinθ 0sinθ r cosθ 0
0 0 1
∣∣∣∣∣∣= r.
On a donc ÏD
f (x1, x2, x3)d x1d x2d x3 =Ñ
Ω( f Φ)(r,θ, x3)r dr dθd x3
=Ñ
Ωf (r cosθ,r sinθ, x3)r dr dθd x3.
96

Exemple 10. Calcul du volume d’un tore de révolution. On considere ici le domaine U de R3
intérieur à un tore de révolution
U = (x1, x2, x3) ∈R3, tels que (r −a)2 +x23 ≤ R2,
où a > R > 0 sont des constantes données, et où on a posé, comme ci-dessus r =√
x21 +x2
2 . Il s’agitdonc du domaine engendré par la rotation autour de l’axe Ox3 d’un cercle du plan Ox1x3 de centre(a,0) et de rayon R.
On désire donc calculer
I = Vol(U ) =Ñ
Ud x1d x2d x2
=Ï
DR (a)×[0,2π]r dr ddθd x3 =
∫ 2π
0
(ÏDR (a)
dr d x3
)dθ
= 2πÏ
DR (a)r dr d x3 = 2πJ (a,R)
où
J (a,R) =Ï
DR (a)r dr d x3.
et où Dr (a) désigne le disque de centre a et de rayon R c’est à dire
DR (a) = (r, x3) ∈R2 tels que (r −a)2 +x23 ≤ R2.
Il reste donc a calculer l’intégrale double J (a,R). On remarque tout d’abord queÏDR (a)
(r −a)dr d x3 = 0,
car le domaine DR (a) est symétrique par rapport à verticale passant par (a,0) et r −a impaire parrapport àcet axe. On a donc
J (a,R) = aÏ
DR (a)dr d x3 = aπR2.
le volume de l’intérieur du tore de révolution est donc
Vol(U ) = 2π2aR2.
97

Exemple 11. Calcul de la surface d’un tore de tore de révolution. On considere ici la surface T
de R3
T = (x1, x2, x3) ∈R3, tels que (r −a)2 +x23 ≤ R2,
où a > R > 0 sont des constantes données, et où on a posé r =√
x21 +x2
2 . Cette surface est un torede révolution. On désire calculer l’aire de T : à cet effet introduisons un paramétrage de T . Oncommence par paramétrer le cercle C = (x, y) ∈R2(x −a)2 + y2 ≤ R2 par exemple par un angle α,c’est à dire on considère l’application de [0,2π] à valeurs dans R2 définie par
~N (α) = (N1(α), N2(α)) = (a +R cosα,R sinα).
On en déduit le paramétrage ~M : [0,2π]× [0,2π] 7→R3 défini par
~M(θ,α) = (N1(α)cosθ, N1(α)sinθ, N2(α)) = ((a +R cosα)cosθ, (a +R cosα)sinθ,R sinα) .
On a alors ∂~M
∂θ= (−(a +R cosα)sinθ, (a +R cosα)cosθ,0)
∂~M
∂α= (−R sinαcosθ,−R sinαsinθ,R cosα)
et un rapide calcul donne
‖∂~M
∂θ∧ ∂~M
∂α‖ = R(a +R cosα)
Il vient ainsi
A ire(T ) =Ï
[0,2π]×[0,2π]R(a +R cosα)dθdα= R
∫ 2π
0
(∫ 2π
0(a +R cosα)dα
)dθ
= 4π2Ra. =Remarque 6. Les coordonnées sont particulièrement utiles en présence de certaines symétries,comme la symétrie cylindrique. Par exemple, si une fonction f possède la symétrie radiale, c’est àdire si il existe une fonction f de [0,R]× [c0,c1] à valeurs dans R telle que
f (x1, x2, x3) = f (r, x3), r =√
x21 +x2
2 .
On a alors
I =Ñ
BR
f (x1, x2, x3)d x1d x2d x3 =Ñ
[0,R]×[0,2π[×[c0],c1
f (r, x3)r dr dθd x3
En utilisant le théorème fe Fubini, il vient
I =∫ 2π
0
(Ï[0,R]×[c0,c1i ]
f (r, x3)r dr d x3
)dθ
= 2πÏ
[0,R]×[0,2π]f (r ), x3r dr dθ
Coordonnées sphériques. On considère ici comme domaine la boule D = BR où BR désigne laboule de centre 0 et de rayon R, dont l’équation est donnée par
BR = (x1, x2, x3) ∈R3, tels que x21 +x2
2 +x23 ≤ R2.
On effectue alors le changement de variable
x1 = r sinϕcosθ, x2 = r sinϕsinθ, x3 = r cosϕ.
98

Les nouvelles variables sont donc (r,θ,ϕ). Le domaineΩ est ici donné par
Ω= (r,θ,ϕ), 0 ≤ r ≤ R, 0 ≤ θ < 2π,0 <ϕ≤π,
c’est à direΩ est le parallélépipède [0,R]× [0,2π[×[0,π[. On a
Jφ =∣∣∣∣∣∣
sinϕcosθ −r sinϕsinθ r cosϕcosθsinϕsinθ r sinϕcosθ r cosϕsinθ
cosϕ 0 −r sinϕ
∣∣∣∣∣∣=−r 2 sinϕ.
On a doncÑD
f (x1, x2, x3)d x1d x2d x3 =Ñ
Ωf (r sinϕcosθ,r sinϕsinθ,r cosϕ)r 2 sinϕdr dθdϕ.
Ici la valeur absolue du Jacobien est égale à r 2 sinϕ, car sinϕ≥ 0 (puisque 0 ≤ϕ≤π).
Remarque 7. Les coordonnées sphériques sont particulièrement utiles en présence de certainessymétries, comme la symétrie radiale. Par exemple, si une fonction f possède la symétrie radiale,c’est à dire si il existe une fonction f de [0,R] à valeurs dans R telle que
f (x1, x2, x3) = f (r ), r =√
x21 +x2
2 +x23 .
On a alors
I =Ñ
BR
f (x1, x2, x3)d x1d x2d x3 =Ñ
[0,R]×[0,2π[×[0,π]f (r )r 2 sinϕdr dθdϕ
En utilisant le théorème fe Fubini, il vient
I =∫ π
0
(Ï[0,R]×[0,2π]
f (r )r 2dr dθ
)sinϕdϕ
=(Ï
[0,R]×[0,2π]f (r )dr dθ
)(∫ π
0sinϕdϕ
)= 2
Ï[0,R]×[0,2π]
f (r )r 2dr dθ
= 4π∫ R
0f (r )r 2dr.
99

par exemple, si on prend pour f = 1,alors f = 1, et on retrouve le calcul du volume de la sphère, àsavoir
volB(R) =Ñ
BR
d x1d x2d x3 = 4π∫ R
0r 2dr = 4
3πR3.
Exemple 12. Les coordonnées sphériques peuvent aussi être utiles pour param/’etrer certainesportions de sphères comme le montre l’exemple ci-dessous. Soit
S2 = (x, y, z) ∈R3, x2 + y2 + z2 = 4, x ≥ 0, y ≥ 0, z ≥ 0.
On voit que la surface S 2 correspond à une partie de la sphère de rayon 2. En fait en coordonnéessphériques on a
S2 =
2sinϕcosθ,2sinϕsinθ,r cosϕ) θ ∈ [0,π
2],ϕ ∈ [0,
π
2]
.
On trouve donc, en utilisant les coordonnées sphériques, et en posant Ω2 = (0, π2 ]× [0, π2 ] le para-
métrage ~M :Ω2 →S2 de S2
(θ,ϕ) 7→ M(θ,ϕ) = 2sinϕcosθ,2sinϕsinθ,r cosϕ).
On peut utiliser ce paramétrage pour calculer l’intégrale
I3 =Ï
S2
x2 y zdσ.
On a ∂~M
∂θ= (−2sinθ sinϕ,2cosθ sinϕ,0)
∂~M
∂ϕ= (2cosθcosϕ,2sinθcosϕ,−2sinϕ)
et donc
‖∂~M
∂θ∧ ∂~M
∂ϕ‖ = 4sinϕ.
On a donc
I2 =Ï
[0,π2 ]×[0,π2 ](4cos2θ sin2ϕ)(2sinθ sinϕ)(2cosϕ)(4sinϕ)dθdϕ
= 64∫ π
2
0cos2θ sinθdθ
∫ π2
0sin4ϕcosϕdϕ= 64
[−cos3θ
3
]π2
0
[sin5ϕ
5
]π2
0
= 64
15.
5.7 Formule flux-divergence
La formule flux-divergence que nous avons vue au Chapitre 3 pour la dimension 2 s’étendau cas de la dimension trois. Si ~V est un champ de vecteurs sur R3 dérivable, la divergence de~V = (V1,V2,V3) est la fonction scalaire définie par
div~V = ∂V1
∂x1+ ∂V2
∂x2+ ∂V3
∂x3=
3∑i=1
∂Vi
∂xi.
100

Si S est une surface de R3 on définit le flux à travers cette surface comme l’intégrale
Flux(V ,S) =Ï
S
~V (σ) ·~n(σ)dσ,
où ~n(σ) désigne un vecteur unitaire orthogonale à la surface en un point donné σ de cette sur-face. Bien entendu, une telle définition suppose un choix du vecteur unitaire : lorsque la surfaceest fermée, la convention est de prendre le vecteur unitaire orthogonal sortant. le théorème flux-divergence s’énonce alors de la manière suivante : considérons un domaine D de R3 dont la fron-tière S est une surface paramétrée. On a
Théorème 8. Soit ~V un champ de vecteurs continu ainsi que ses dérivées sur D avec sa frontière S .on a l’égalité Ñ
DdivV (x1, x2, x3)d x1d x2d x3 = Flux(V ,S) =
ÏS
~V (σ) ·~n(σ)dσ,
o ù l’orientation est choisie de sorte que ~n est dirigé vers l’extérieur de D.
On peut obtenir ces résultats en étendant à la dimension trois l’interprétation qui est fourniede la formule flux-divergence en dimension deux dans la Section 4.3.2.
Exercices
Exercice I
On considère l’applicationΦ de R3 dans R3 définie par
Φ(u1,u2,u3) = (a1u1, a2u2, a3u3),
où a1, a2 et a3 sont des nombres réels donnés.a)Montrer que l’image de la boule B1 est données par l’ellipsoide E défini par l’équation
x21
a21
+ x22
a22
+ x23
a23
< 1.
b) En déduire volE .
101

Exercice II
Théorème de Guldin
A) On considère un domaine bornéΩ du plan Ox1x3 inclus dans le demi-plan x1 ≥ 0.1) Montrer qu’il existe un point et un seul A = (a1, a3) de ce plan tel queÏ
Ω(xi −ai )d x1d x3 = 0 pour i = 1 et i = 3.
On appelle ce point le centre de gravité deΩ.2) On considère le volume U engendré par la rotation deΩ autour de l’axe Ox3, c’est à dire
UΩ = (x1, x2, x3) ∈R3 tels que (r, x3) ∈Ω,
où on a posé r =√
x21 +x2
3 . Montrer que Vol(UΩ) = 2πa1A ire(Ω).B) On considère dans cette question le domaineΩ défini pout R > a > 0 par
Ω= (x1, x3) ∈R2, x1 ≥ 0 et (x1 −a)2 +x23 ≤ R2.
1) Calculer l’aire deΩ ainsi que l’intégrale I =ÏΩ
x1d x1d x3.
1) en déduire que les coordonnées du gravité deΩ.2) Calculer la valeur de Vol(UΩ) dans le cas considéré.
Exercice III
Surface de révolution
On considère ici une surface engendrée par la rotation d’une courbe fermée autour d’un axe.Soit C une courbe paramétrée de R2,
C = ~N (s), s ∈ I ,
où ~N = (N1, N2) est une application de I vers R2, où I désigne un intervalle de R. On Considère
S = (x1, x2, x3) ∈R3 tels que (r, x3) ∈C ,
102

où r =√
x21 +x2
2 .
1) Montrer que l’application M : [0,2π]× I →R3 définie pour θ ∈ [0,2π[ et s ∈ I par
~M(θ, s) = (N1(s)cosθ, N1(s)sinθ, N2(s))
est un paramétrage de S .2) Montrer que
∂~M
∂θ= (−N1(s)sinθ, N1(s)cosθ,0)
∂~M
∂s=
(d N1
d s(s)cosθ,
d N1
d s(s)sinθ,
d N2
d s(s)
).
Vérifier que ces deux vecteurs sont orthogonaux.3) Montrer que
‖∂~M
∂θ∧ ∂~M
∂s‖ = |N1(θ)|‖d ~N
d s‖.
4) Montrer que
A ire(S ) = 2π∫
IN1(s)dl .
103

Chapitre 6
Le rotationnel
6.1 Champ de vecteurs, champs de gradient
Les champs de vecteurs sur R3 se définissent comme en dimension deux, c’est à dire il s’agitd’applications ~V = (V1,V2,V3) d’un domaine D de R3 à valeurs dans R3. Si C est une courbe orien-tée dans R3 paramétrée sur un intervalle I par une application M : I →R3, t 7→ M(t ) pour t ∈ I , onpeut définir la circulation de ~V comme en dimension deux par la formule∫
I
~V (M(t )).~M ′(t )d t .
que l’on note ∫C
~V (M)d ~M .
Si f est une fonction dérivable sur R3, alors son gradient est défini par
−−−→grad f = (
∂ f
∂x1,∂ f
∂x2,∂ f
∂x3).
Si AB est une courbe orientée, on a alors, comme en dimension deux∫C
−−−→grad f (M)d ~M = f (B)− f (A).
Comme en dimension deux, la question suivante se pose :
Q : A quelle condition un champ de vecteurs est-il un champ de gradient ?
Le Théorème de Schwarz impose des conditions nécessaires.
Proposition 1. Soit ~V = (V1,V2,V3) un champ de vecteurs dérivable, de dérivées continues, définisur un domaine D. Une condition nécessaire pour que ~V soit un champ de gradient est que
∂V3
∂x2= ∂V2
∂x3,∂V1
∂x3= ∂V3
∂x1et∂V2
∂x1= ∂V1
∂x2. (6.1)
Nous verrons plus loin que (6.1) est aussi une condition suffisante, si on fait des hypothèsesadéquates sur le domaine.
104

Définition 1. Soit ~V = (V1,V2,V3) un champ de vecteurs dérivable défini sur un domaine D de R3.On appelle rotationnel de ~V le champ de vecteur noté
−→rot~V défini sur D par
−→rot~V =
(∂V3
∂x2− ∂V2
∂x3,∂V1
∂x3− ∂V3
∂x1,∂V2
∂x1− ∂V1
∂x2
).
Remarque 1. Pour désigner le rotationnel, on utilise aussi souvent la notation~∇∧~V .Si on écrit lesvecteurs sous forme colonne, cette notation a un avantage mnémotechnique appréciable, car enpeut utiliser la même règle que pour le produit vectoriel
~∇∧~V =
∂∂x1∂∂x2∂∂x3
∧V1
V2
V3
=
∂V3∂x2
− ∂V2∂x3
∂V1∂x3
− ∂V3∂x1
∂V2∂x1
− ∂V1∂x2
.
Exemple 13. Champ planaire. Considéons un champ planaire, c’est à dire dans les coomposantessont dans le plan 0x1x2,et supposons de plus qu’il est indépendant de la variable x3. Il a donc laforme
~V (x1, x2, x3) = (V1(x1, x2),V2(x1, x2),0) . (6.2)
On obtient−→rotV (x1, x2, x3) =
(0,0,
(∂V2
∂x1− ∂V1
∂x2
)(x1, x2)
)=
(∂V2
∂x1− ∂V1
∂x2
)~e3.
Le rotationnel est donc orthogonal au plan 0x1x2, parallèle au vecteur~e3 = (0,0,1).
Voyons deux propriétés importantes :
Proposition 2. Soit f une fonction deux fois dérivable de dérivées secondes continues sur D do-maine de R3. On a −→
rot(−−−→grad f ) = 0. (6.3)
Si ~V est un champ de vecteurs deux fois dérivable sur D de dérivées secondes continues, alors on a
div(−→rot~V ) = 0 (6.4)
et −→rot
(−→rot~V
)=−−−→
grad(div~V )−∆V. (6.5)
Démonstration. La première identité, et une conséquence immédiate de la Proposition 1, c’est àdire le théorème de Schwarz. Un bref calcul permet de vérifier les deux autres formules.
Remarque 2. la condition (6.4) fournit en particulier une condition necessaire pour qu’un champsoit un rotationnel : seul les champs à divergence nulle peuvent être des rotationnels. Par exemplesi
~V (M) = (x1, x2, x3)
alors div~V = 3 et ~V n’est donc pas un rotationnel.
Voyons maintenant d’autres propriétés élémentaires :
Proposition 3. Soit f une fonction et V un champ de vecteurs dérivables de dérivée continues surD domaine de R3. On a −→
rot( f ~V ) = f−→rot~V +−−−→
grad f ∧~V .
105

6.1.1 Invariance du rotationnel par changement de repère orthonormé
Comme pour le gradient et la divergence, la forme du rotationnel est la même pour tous lesrepères orthonormés. Soit (~e ′
1,~e ′2,~e ′
3) une nouvelle base orthonomée, et des coordonnées x ′1, x ′
2, x ′3
correspondantes de sorte que x1~e1 +x2~e2 +x3e3 = x ′1~e
′1 +x ′
2~e′2 +x ′
3~e′3. Soit ~V un champs de vecteur
donné sur D. Ce champ s’exprimera dans la base (~e1,~e2,~e3) comme
~V (M) =V1(x1, x2, x3)~e1 +V2(x1, x2, x3)~e2 +V3(x1, x2, x3)~e3
pour M de coordonnées (x1, x2, x3) dans (~e1,~e2,~e3). Son expression dans la nouvelle base sera alors
~V (M) =V ′1(x ′
1, x ′2, x ′
3)~e ′2 +V2(x ′
1, x ′2, x ′
3)~e ′2 +V3(x ′
1, x ′2, x ′
3)~e ′3,
pour M de coordonnées (x ′1, x ′
2, x ′3) dans (~e ′
1,~e ′2,~e ′
3). En posant ~X = (x1, x2, x3) et ~X ′ = (x ′1, x ′
2, x ′3) on
at~X = At X ′,
où A désigne la matrice de passage de la nouvelle base vers l’ancienne. De même, il vient
~V ′(x ′1, x ′
2, x ′3) =
V ′1(x ′
1, x ′2, x ′
3)V ′
2(x ′1, x ′
2, x ′3)
V ′3(x ′
1, x ′2, x ′
3)
= A
V1(x1, x2, x3)V2(x1, x2, x3)V3(x1, x2, x3)
= A~V (x1, x2, x3). (6.6)
Quelle est l’expression du champ rotationnel dans la nouvelle base ?
Proposition 4. . Soit M ∈D. Alors on a
−→rotV (M) = ∂V ′
3
∂x ′2
− ∂V ′2
∂x ′3
~e ′1 +
∂V ′1
∂x ′3
− ∂V ′3
∂x ′1
~e ′2
∂V ′2
∂x ′1
− ∂V ′1
∂x ′2
~e ′3
La forme du rotationnel ne dépend donc pas de la base orthonormée choisie.
6.2 Flux du rotationnel
6.2.1 Surfaces fermées
Nous avons vu dans la section précédente que le rotationnel est un champ à divergence cenulle
div(−→rot~V ) = 0.
Il résulte alors
Proposition 5. Soit S une surface fermée deR3, c’est à dire bordant un domaine D deR3. Alors pourtout champ de vecteur ~V défini sur D on a
Flux(−→rot~V ,S ) = 0.
Preuve. Ceci est une conséquence directe de la formule flux-divergence vu dans le champprécédent : si S est une surface fermée de R3 limitant un domaine D, alors on a pour tout champde vecteurs ~V dérivable
Flux(−→rot~V ,S ) =
ÏS
−→rot~V (σ).~n(σ)dσ=
ÑD
div(−→rot~V )(x1, x2, x3)d x1d x2d x3 = 0.
106

6.2.2 Surfaces dont le bord est une courbe
Considérons maintenant une courbe fermée C dansR3 et S une surface deR3 dons le bord estC . Si on s’est donné une orientation sur C , on choisit alors le sens correspondant pour le vecteurunitaire normal ~n(σ) à la surface au point σ de cette surface, en s’assurant que l’orientation de lacourbe soit celle du sens trigonométrique, lorsque l’on regarde dans la direction donnée par ~n.
Il résulte de la Proposition 5 que la quantité
Flux(−→rot~V ,S ) =
ÏS
−→rot~V (σ).~n(σ)dσ
ne dépend pas de la surface S mais uniquement du contour C . Considérons en effet une autresurface S0 de bord C , et soit D0 le domaine dont le bord est S ∪S0. En effet, on a par (5)
Flux(−→rot~V ,S ∪S0) =
ÑD0
div(−→rot~V )(x1, x2, x3)d x1d x2d x3 = 0.
OrFlux(
−→rot~V ,S ∪S0) = Flux(
−→rot~V ,S )−Flux(
−→rot~V ,S0),
le signe moins dans le terme de droite provenant du fait que les vecteurs normaux sont orientédifféremment. Il en résulte que
Flux(−→rot~V ,S ) = Flux(
−→rot~V ,S0).
la valeur du Flux est donc, la même pour toute surface dont le contour est C : il s’agit donc d’unefonction de C uniquement.
Théorème 1. On a l’identité ÏS
−→rot~V ·~n dσ=
∫C
~V (M)d ~M .
Quelques indications sur la démonstration. Commençons par considérer la cas planaire, c’est àdire le cas où la courbe est incluse dans un plan.
Le cas planaire. Il correspond au cas où la courbe est incluse dans un plan P de l’espace, ainsique la surface S . Quitte hanger de repère orthonormée, on peut supposer que ce plan P contientl’origine, et qu’il est engendré par les vecteurs (~e1,~e2) d’un repère orthonormé (~e1,~e2,~e3). Comme
107

S est inclus dans P , P est le plan tangent à S en tout point de S , et en orientant la courbe dansle sens trigonométrique on a donc
~n(σ) =~e3, pour tout point σ ∈S .
Il en résulte, comme l’expression du rotationnel est la même dans tous les repères que
−→rot~V (σ).~n(σ) =
(∂V2
∂x1− ∂V1
∂x2
)(σ),
et que
Flux(−→rotV ,S ) =
ÏS
(∂V2
∂x1− ∂V1
∂x2
)(x1, x2)d x1d x2 =
∫C
~V (M)d ~M ,
où la dernière identité provient du théorème de Green-Riemann vu au chapitre 4. Ceci démontredonc la propriété dans le cas planaire.
Le cas où S est incluse dans la réunion de deux plans. Traitons maintenant un autre cas particulier,celui ou S est incluse dans la réunion de deux plans P1 et P2, dont l’intersection est une droite D ,comme sur le dessin ci-dessous
Soit S est une surface de P1 ∪P2. On a S = S1 ∪S2 où S1 = S ∩P1 et S2 = S ∩P2 de sorteque
Flux(−→rotV ,S ) = Flux(
−→rotV ,S1)+Flux(
−→rotV ,S2) (6.7)
108

Soit C1 la courbe bordant S1 et soit Soit C2 la courbe bordant S2. Chacune des deux surfaces étantplanaire, on a par l e résultat de la première partie de cette démonstration
Flux(−→rotV ,Si ) =
∫Ci
~V (M)d ~M pour i = 1,2. (6.8)
Enfin on vérifie que ∫C
~V (M)d ~M =∫C1
~V (M)d ~M +∫C2
~V (M)d ~M . (6.9)
En effet, la réunion des courbes C1 et C2 nous donne la courbe C , à lquelle il faut ajouter unearête commun sur la droite D . Cette dernière est parcouru dans des sens opposés sur chacune descourbes, de sorte que leurs contributions s’annule dans la somme du membre de droite de (6.9) .En combinant les relation (6.7), (6.8) et (6.9) on obtient la relation du théorème.
Le cas général. En s’inspirant du deuxième cas, on peut démontrer que le théorème est vrailorsque la surface est tracée sur une réunion finie de plan. On montre ensuite que toute surfacepeut être approchée par des surfaces qui ont cette propriété.
6.3 Champs à rotationnel nul
Corollaire 1. Soit ~V un champ de vecteurs dérivable de dérivées continues, sur un domaine D de R3
sans trou. Si −→rot~V = 0,
alors ~V est un champ de gradient, c’est à dire qu’il existe une fonction f définie sur D telle que
~V =−−−→grad f .
Démonstration. Soit C une courbe fermée quelconque de D. Si le domaine est sans trou, alors onpeut toujours trouver une surface parmètrée S dont C est le bord. Si de plus
−→rot~V = 0, alors il
résulte du Théorème 1 que ∫C
~V (M)d ~M = 0.
Comme ceci est vrai pour toute courbe fermée C , il en résulte que le champ de vecteurs ~V estconservatif, et donc un champ de gradient.
Remarque 3. Comme en dimension 2, les seules solutions de l’équation
−−−→grad g = 0
sont les fonctions g constantes. Il en résulte que si f et f sont tels que ~V = −−−→grad f = −−−→
grad f alorsnécessairement
f = f + c,
où c est une constante.
Exemple 14. Considérons un champ de vecteur ~V linéaire, c’est a dire de la forme
~V (~V ) = A ·~X ,
109

où A est une matrice 3×3.
A =a1,1 a1,2 a1,3
a2,1 a2,2 a2,3
a3,1 a3,2 a3,3
.
On a donc V1(x1, x2) = a1,1x1 + a1,2x2 + a1,3x3, V2(x1, x2) = a2,1x1 + a2,2x2 + a2,3x3, et V3(x1, x2) =a3,1x1 +a3,2x2 +a3,3x3 de sorte que
∂V3
∂x2− ∂V2
∂x3= a3,2 −a2,3
∂V1
∂x3− ∂V3
∂x1= a1,3 −a3,1
∂V2
∂x1− ∂V1
∂x2= a2,1 −a1,2
V est donc un champ de gradient si et seulement si
a2,1 = a1,2, a 1,3 = a3,1 et a2,1 = a1,2
c’est à dire si et seulement si la matrice A est symétrique. Dans ce cas, on vérifie, comme en di-
mension deux, que l’on a ~V =−−−→grad f , avec
f (X ) = 1
2A ·~X .~X ,
la forme quadratique associée à la matrice symétrique A.
6.4 Champ à divergence nulle, potentiels vecteurs
Définition 2. On dit d’un champ de vecteurs ~V qu’il est un champ de rotationnel s’il existe unchamp de vecteur ~A tel que
~V =−→rot~A.
Le champ de vecteur A est alors dit potentiel vecteur dont dérive le champ ~V .
Dans la remarque 2 nous avons vu qu’une condition nécessaire pour être un champ de rota-tionnel était
div~V = 0.
Si le domaine n’a pas de trou, il s’avère alors que cette condition est également suffisante.
Théorème 2. Soit ~V un champ de vecteur dérivable sur un domaine D sans trou. On suppose que
div~V (M) = 0, ∀M ∈D.
Alors il existe un champ de vecteur ~A défini sur D tel que
~V =−→rot A.
Le champ de vecteurs ~A est donc un potentiel vecteur dont dérive le camp de vecteurs ~V .
110

Remarque 4. SidivV = 0,
alors il n’y a pas unicité du potentiel vecteur. En effet, si ~A, est un tel potentiel vecteur, c’est à diresi
~V =−→rot~A,
alors il en est de même de~A f = ~A+−−−→
grad f , (6.10)
pour toute fonction f , car−→rot(
−−−→grad f ) = 0. Il résulte du Corollaire 1 que tous les potentiels vecteurs
dont dérive ~V ont la forme (6.10).
Exemple 15. Champs planaires. Reprenons les champs planaires introduits dans l’exemple 13,sans supposer ici qu’il sont indépendants de la variable x3 : ils ont donc la forme
~V (x1, x2, x3) = (V1(x1, x2, x3),V2(x1, x2, x3),0) . (6.11)
Supposons de plus que div~V = 0. Ceci signifie, comme la troisième composante est nulle que
∂V1
∂x1(x1, x2, x3)+ ∂V2
∂x1(x1, x2, x3) = 0
En considérons le champs de vecteurs sur R3
~V ⊥(x1, x2) = (V2(x1, x2, x3),−V1(x1, x2, x3),0)
on obtient∂V ⊥
2
∂x1(x1, x2, x3)− ∂V ⊥
1
∂x2(x1, x2, x3) = 0
Si l’on fixe la troisième variable x3 et deux l’on ne considère que les deux premières composantesde ~V ⊥, aloes on obtient un champ de vecteur sur le plan x3 = Cte : On peut donc appliquer lesrésultats du Chapitre 4 sur les champs de vecteurs à deux variables, qui montrent ~V ⊥ est un champde gradient par rapport aux deux premères variables, c’est à dire qu’il il existe donc une fonctionf :R3 →R telle que
~V ⊥ = (∂ f
∂x1,∂ f
∂x2,0),
soit~V (x1, x2, x3) = (− ∂ f
∂x2(x1, x2),
∂ f
∂x1(x1, x2),0).
Posons~A(x1, x2, x3) = (0,0,− f (x1, x2)).
On vérifie alors que l’on a bien −→rot~A = ~V .
Exercices
Exercice I
111

Soit ~A un vecteur de R3. déterminer la divergence et le rotationnel du champ de vecteur
~V (~X ) = ~A∧~X .
Exercice II
Soient ~A et ~B deux vecteurs de R3. On définit sur R3 le champ de vecteur
~V (~X ) = (~A ·~X )~B .
Exprimer la divergence et le rotationnel de ~V .
112

Chapitre 7
Sujets d’examen
113

UNIVERSITÉ PIERRE ET MARIE CURIE ANNÉE UNIVERSITAIRE 2011-2012L2-PEIP2-LM256
Examen du 5 Juin 2012
Durée : 2 heures.
Les notes de cours et les calculatrices ne sont pas autorisées. Le sujet comprend quatre exercices,qui sont indépendants.
Exercice III
On considère la fonction de deux variables F (x, y) = x4 +3y2 −4x2 y , et on note C l’ensemble (x, y) ∈R2,F (x, y) = 0.
1) Calculer−−−→gradF . Quels sont les points de R2 où
−−−→gradF s’annule ?
2) Montrer que A = (1,1) ∈ C . Calculer le gradient de F en ce point. Montrer que près de F , C estle de la forme y =ϕ(x), c’est à dire le graphe d’une fonction ϕ.3) Donner un vecteur tangent en C en A, puis un vecteur unitaire tangent.4) Donner l’équation de la droite affine tangente à C en A.5) Calculer ϕ′(1).
Exercice IV
On considère la courbe paramétrée C de l’espace R3 donnée par le paramétrage suivant :
x(t ) = cost , y(t ) = si nt , z(t ) = t ,où 0 ≤ t ≤ 2π.
1) Calculer un vecteur tangent à C au point M(t ) = (x(t ), y(t ), z(t )
), puis un vecteur unitaire tan-
gent.
2) soit V1 le champ de vecteurs défini par ~V1(x, y, z) = (x + z, y2, x). Calculer∫C
~V1(M)d ~M .
3) Soit V2 le champ de vecteur défini par ~V2(x, y, z) = (y2 cos x,2y sin x+ez , yez). Montrer qu’il existe
une fonction f telle que ~V2 =−−−→grad f .
4) Calculer f .
5) Calculer∫C
~V2(M)d ~M .
Exercice V
1) Soit D = (x, y) ∈ R2,1 ≤ y ≤ 10, y ≤ x ≤ y2. Calculer en utilisant le théorème de Fubini les inté-
grales doubles I1 =Ï
D
1
x2 yd xd y et I2 =
ÏD
y
(x + y)2d xd y .
2) Soit D = (x, y) ∈ R2, x2 + y2 < 1 le disque unité de R2. Calculer en utilisant un changementde variables approprié
I3 =Ï
D
x2
1+x2 + y2d xd y.
114

3) Soit V1 = (x, y, z) ∈R3, x2 + y2 < 1,0 < z < 1. Calculer en utilisant des coordonnées cylindriques
l’intégrale I4 =Ñ
V1
(x2 + y2 + z2)d xd yd z.
4)Soit V2 = (x, y, z) ∈R3, x2 + y2 < 1, 0 < z < x2 + y2 +1. Calculer le volume de V2.5) Soit B+ = (x, y, z) ∈ R3, x2 + y2 + z2 < 1, 0 ≤ z < 1. Calculer, en utilisant des coordonnées sphé-
riques l’intégrale I5 =Ñ
B+zd xd yd z.
Exercice VI
1) Soit S1 = (x, y, z) ∈R3, x + y + z = 4, x ≥ 0, y ≥ 0, z ≥ 0. Vérifier que S est une portion du graphe
d’une fonction que l’on précisera. Calculer I1 =Ï
S1
x2dσ.
2) Soit S2 = (x, y, z) ∈R3, x = y2 +2z2, 0 ≤ y ≤ 1, 0 ≤ z ≤ 1. L’ensemble S est-il un graphe ?3) Calculer
I2 =Ï
S2
y zdσ.
115

UNIVERSITÉ PIERRE ET MARIE CURIE ANNÉE UNIVERSITAIRE 2011-2012L2-PEIP2-LM256
Corrigé de l’examen du 5 Juin 2012
Exercice I
1) on a−−−→gradF = (4x3 −8x y, 6y −4x2). Pour avoir
−−−→gradF = (0,0), il faut donc 4x3 = 8x y et 6y = 4x2.
Si x 6= 0,alors la premier équation donne y = 12 x2 ce qui est incompatible avec la seconde. La seule
solution est donc (x, y) = (0,0).
2) On vérifie que F (1,1) = 0 et on calcule−−−→gradF (1,1) = (−4,2). Comme F ′
y (a) = 2 6= 0, la conclusiondécoule du théorème des fonctions implicites.
3)Un vecteur tangent est donné par−−−→grad⊥F (A) = (−2,−4), et un vecteur unitaire tangent par
−−−→grad⊥F (A)
‖−−−→grad⊥F (A)‖c’est à dire (
−1p5
,−2p
5).
4) L’équation est donnée par −4(x −1)+2(y −1) = 0, ou encore −4x +2y =−2.5) On a ϕ′(1) = 2.
Exercice II
1) Un vecteur tangent à la courbe C est donné par M ′(t ) = (x ′(t ), y ′(t ), z ′(t )), c’est à dire M ′(t ) =(−sin t ,cos t ,1). Comme ‖M ′(t )‖2 = (sin t )2 + (cos t )2 +1 = 2, un vecteur unitaire tangent est donc
donné par1p2
(−sin t ,cos t ,1).
2) on a
I ≡∫C
~V (M)d ~M =∫ 2π
0
[(x(t )+ z(t )) x ′(t )+ y2(t )y ′(t )+x(t )z ′(t )
]d t
=∫ 2π
0
[(cos t + t )(−sin t )+ (sin2 t )(cos t )+cos t
]d t
=∫ 2π
0
[−cos t sin t − t sin t + (1−cos2 t )(cos t )+cos t]
d t
=−∫ 2π
0t sin td t = [t cos t ]2π
0 −∫ 2π
0cos td t = 2π
les autres parties de l’intégrale dans la troisième ligne étant nulles pour des raison de périodicité,parité (en se ramenant à la période [−π,π] , etc... ) et où la dernière intégrale est calculée parintégration par parties.3) On calcule
−→rot~V2 = (ez −2ez ,0−0,2y cos x −2y cos x) = (0,0,0) et la conclusion en découle par
un résultat du cours (Corollaire 1, Chapitre 6).4) On doit avoir f ′
x = y2 cos x de sorte que par intégration f (x, y, z) = y2 sin x+g (y, z). De la relationf ′
y = 2y si nx + ez on déduit alors que g ′y = 2y sin x + ez − 2y sin x = ez , d’ou g (y, z) = yez +h(z).
enfin, la relation f ′z = yez donne h′(z) = yez − yez = 0 d’ou h = c, constante arbitraire. On a donc
f (x, y, z) = y2 sin x + yez + c.5) Comme ~V2 est un champ de gradient, on obtient pour résultat f (M(2π))− f (M(0)) = f (1,0,2π)−f (1,0,0) = 0.
116

Exercice III
I1 =∫ 10
1
(∫ y2
y
1
x2 yd x
)d y =
∫ 10
0
1
y[
1
y− 1
y2]d y =
[1
2y−2 − y−1
]10
1= 81
200= 0,405.
I2 =∫ 10
1
(∫ y2
y
y
(x + y)2d x
)d y =
∫ 10
1y
[1
y + y− 1
y + y2
]d y =
∫ 10
1[1
2− 1
1+ y]d y
= [1
2y − log(1+ y)]10
1 = 9
2− log
11
2.
I3 =Ï
[0,1]×[0,2π]
r 2 cos2θ
1+ r 2r dr dθ =
∫ 2π
0
(∫ 1
0
r 3
1+ r 2dr
)cos2θdθ =
(∫ 1
0
r 3
1+ r 2dr
)(∫ 2π
0cos2θdθ
)=
[1
2(r 2 − log(1+ r 2))
]1
0
[∫ 2π
0
1
2(1+cos2θ)dθ
]= π
2[1− log2].
I4 =Ñ
[0,1]×[0,2π]×[0,1](r 2 + z2)r dr dθd z = 2π
∫ 1
0
(∫ 1
0r (r 2 + z2)dr
)d z = 2π
∫ 1
0
[1
4+ 1
2z2
]d z = 5π
6.
Vol(V2) =Ï
V2
d xd yd z =∫ 2π
0
(∫ 1
0
(∫ r 2+1
0r d z
)dr
)dθ = 2π
∫ 1
0
(∫ r 2+1
0d z
)r dr = 2π
∫ 1
0(r 3+r )dr = 3π
2.
I5 =Ñ
[0,1]×[0,2π]×[0,π2 ](r cosϕ)r 2 sinϕdr dθdϕ= 2π
(∫ 1
0r 3dr
)(∫ π2
0sinϕcosϕdϕ
)
= π
4
∫ π2
0sin2ϕdϕ= π
4
[−cos2ϕ
2
]π2
0= π
4.
Exercice IV
1) S1 et le graphe de la fonction f (x, y) = 4− x − y . on a donc√
1+ f ′2x + f ′2
y = p1+1+1 = p
3.
Considérons D = (x, y), x ≥ 0, y ≥ 0, x + y ≤ 4 (intérieur d’un triangle) . Alors S1 est le graphe de fau dessus de D, et en utilisant le Théorème de Fubini
I1 =p
3Ï
Dx2d xd y =p
3∫ 4
0
(∫ 4−y
0x2d x
)d y =p
3∫ 4
0
(4− y)3
3d y =p
3.44
12= 64p
3.
2) S2 est le graphe g (y, z) = y2 +2z2. On a√
1+ g ′2y + g ′2
z =√
1+4y2 +8z2.
I2 =∫ 1
0
(∫ 1
0y√
1+4y2 +8z2d y
)zd z = 1
12
∫ 1
0
[(1+4y2 +8z2)
32
]1
0zd z
= 1
12
∫ 1
0[(5+8z2)
32 − (1+8z2)
32 ]zd z = 1
480
[(5+8z2)
52 − (1+8z2)
52
]1
0
= 1
480[13
52 −9
52 −5
52 +1].
117

UNIVERSITÉ PIERRE ET MARIE CURIE ANNÉE UNIVERSITAIRE 2011-2012L2-PEIP2-LM256
Examen du 26 Juin 2012Durée : 2 heures.
Les notes de cours et les calculatrices ne sont pas autorisées. Le sujet comprend trois exercices, quisont indépendants.
Exercice I
On considère la courbe paramétrée C de l’espace R3 donnée par :
x(t ) = e t , y(t ) = e2t , z(t ) = t ,où 0 ≤ t ≤ 1.
1) Calculer un vecteur tangent à C au point M(t ) = (x(t ), y(t ), z(t )
), puis un vecteur unitaire tan-
gent.
2) soit V1 le champ de vecteurs défini par ~V1(x, y, z) = (x2 + y, z2, y3). Calculer I1 =∫C
~V1(M)d ~M .
3) Soit ~V2 le champ de vecteur défini par
~V2(x, y, z) = (−2x z2 sin x2 +2x sin y2, 2x2 y cos y2 +3y2ez , 2z cos x2 + y3ez).
3) Calculer−→rotV2. Que peut-on en déduire ?
4) Trouver une fonction f telle que ~V2 =−−−→grad f .
5) Calculer I2 =∫C
~V2(M)d ~M .
Exercice II
On considère la fonction de deux variables F (x, y) = x4 + y4ex2 −1, le domaine
D = (x, y) ∈R2, F (x, y) < 0
ainsi que son contour C , c’est à dire l’ensemble C = (x, y) ∈R2,F (x, y) = 0.1) Montrer que 0 = (0,0) appartient à D,et que le point A = (0,1) appartient à C .2) Montrer que si (x, y) ∈ D (resp. C ), alors les points (x,−y), (−x, y) (−x,−y) appartiennent à D
(resp. C ).3) Montrer que D ⊂ [−1,1]× [−1,1].
4) Calculer−−−→gradF . Quels sont les points où
−−−→grad F s’annule ?
5) Calculer−−−→gradF (A). Donner un vecteur tangent à C en A.
6) Donner l’équation de la droite affine tangente à C en A.7) Montrer que C ∩ (x, y), y ≥ 0 est le graphe d’une fonction que l’on déterminera. On pose D+ =D∩ (x, y), y ≥ 0, et on note C + le contour de D+.
8) Calculer I1 =Ï
D+y3ex2
(2x2 −x)d xd y .
9) Soit ~V (x, y) = (V1(x, y),V2(x, y)) = (x2 y4ex2, y3ex2
). Calculer g = ∂V2
∂x− ∂V1
∂y.
10) Calculer I2 =∫C +~V2(M)d ~M , où C + est orientée dans le sens trigonométrique.
118

Exercice III
A) Soit D1 le triangle dans R2 de sommets (0,0), (1,0) et (0,1). Calculer l’intégrale double I1 =ÎD1
x2 y2d xd y.
B) Soit V1 la partie de R3 définie par
V1 = (x, y, z) ∈R3,6−x2 − y2 ≥ z ≥ 4x2 +4y2 +1.
Calculer le volume de V1 [on pourra utilser des coordonnées polaires ou cylindriques].
C) Soit S1 = (x, y, z) ∈R3,3x +2y + z = 6, x ≥ 0, y ≥ 0, z ≥ 0.C 1) Montrer que S1 est une portion de graphe d’une fonction que l’on explicitera.C 2) Montrer que le point A1 = (1,1,1) appartient à S1. Donner l’équation du plan affine tangent àS1 en A1.
C 3) Calculer I2 =Ï
S1
cos(x + y + z)dσ.
D) Soit S2 = (x, y, z) ∈R3, x2 + y2 + z2 = 4, x ≥ 0, y ≥ 0, z ≥ 0.D 1) Montrer que le point A2 = (1,1,
p2) appartient à S2. Donner l’équation du plan affine tangent
à S2 en A2.D 2)Quelles sont les coordonnées sphériques du point A2 ?
D3 ) En utilisant des coordonnées sphériques, calculer I3 =Ï
S2
x2 y zdσ.
119

UNIVERSITÉ PIERRE ET MARIE CURIE ANNÉE UNIVERSITAIRE 2011-2012L2-PEIP2-LM256
Corrigé de l’examen du 26 Juin 2012
Exercice I
1) Un vecteur tangent à la courbe est donné pard
d tM(t ) = (e t ,2e2t ,1). Un vecteur unitaire est donc
donné par1p
e2t +4e4t +1(e t ,2e2t ,1).
2) On a
I =∫C
~V1(M)d ~M =∫ 1
0
[(e2t +e2t )e t + t 2 2e2t +e6t ]d t =
∫ 1
0
(2e3t +2t 2e2t +e6t )d t .
On a par intégration par parties∫ 1
0t 2e t d t = [t 2 e2t
2]10 −
∫ 1
0te2t = e2
2− [t
e2t
2]10 +
∫ 1
0
e2t
2= [
e2t
4]10 =
e2
4et donc
I = 2
3e3 + 1
4e2 + 1
6e6.
3) Comme−→rotV = 0, ~V est un champ gradient.
4) On a fx =−2xz2 sin x2 +2x sin y2, d’où par intégration f = z2 cos x2 + x2 sin y2 + g (y, z). Commefy = 2x2 y cos y2 + 3y2ez = 2x2 y cos y2 + g y (y, z) on en déduit g y (y, z) = 3y2ez , et en intégrant denouveau g (y, z) = y3ez +h(z). Enfin fz = 2z cos x2 + y3ez = 2z cos x2 + y3ez +h′(z) d’où h′(z) = 0.On a donc f = z2 cos x2 +x2 sin y2 + y3ez +C .5) on a
∫C~V1(M)d ~M = f (M(1))− f (M(0)) = f (e,e2,1)− f (1,1,0) = (cose2 +e2 sine4 +e7 − sin1.
Exercice II
1) On a F (0,0) =−1 et donc (0,0) ∈D. F (0,1) = 1.e0 −1 = 0 et donc A ∈C .2) La propriété résulte de la parité de F par rapport à x et par rapport à y .3) (x, y) ∈D ssi x4 + y4ex2 ≤ 1 et donc x4 ≤ 1 et y4 ≤ e−x2 ≤ 1, d’où la proriété.
4)−−−→gradF = (4x3 +2x y4ex2
,4y3ex2). le gradient s’annule ssi 4y3ex2 = 0 et x3 +2x y4ex2 = 0. la pre-
mière condition entraîne y = 0 et en reportant dans la seconde on obtient x = 0. Le seul point oùle gradient s’annule est donc (0,0).
5) On a−−−→gradF (A) = (0,4), de sorte qu’un vecteur tangent est
−−−→grad⊥F (A) = (−4,0), et un vecteur uni-
taire tangent est donc (1,0) =~e1.6) la droite affine tangente a pour équation y = 1.
7) Si (x, y) ∈ C on a y4 = (1− x4)e−x2. Si de plus y ≥ 0, alors y = (1− x4)
14 e− x2
4 , on obtient donc le
graphe de f (x) = (1−x4)14 e− x2
4 .8) On utilise Fubini :
I1 =∫ 1
−1
(∫ f (x)
0y3(2x2 −x)ex2
d y
)d x =
∫ 1
−1
[y4
4
] f (x)
0(2x2 −x)ex2
d x
=∫ 1
−1
1
4(1−x4)(2x2 −x)d x = 1
4
[2x7
7+ x6
6+ 2x3
3− x2
2
]1
−1= 1
7+ 1
3= 10
21.
120

9) On trouve g = 2x y3ex2 −4x2 y3ex2 =−2y3ex2(2x2 −x).
10) O n trouve I2 = 2I1 grâce au théorème de Green-Riemann.
Exercice III
A) On a D1 = (x, y), x + y ≤ 1, x, y ≥ 0. Il vient par Fubini I1 =∫ 1
0 x2(∫ 1−x
0 y2d y)d x = ∫ 10 [ y3
3 ]1−x0 d x =
13
∫ 10 (1−x)3x2d x = 1
3 [− x6
6 + 3x5
5 − 3x4
4 + x3
3 ]10 = 1
3 (−16 + 3
5 − 34 + 1
3 ) = 1180 .
B)Utilisons des coordonnées cylindriques : ~V1 est donc caractérisé par 6− r 2 ≥ z ≥ 4r 2 +1,et il fautdonc 5 ≥ 5r 2, c’est à dire 0 ≤ r ≤ 1. Il vient
Vol(V1) = ∫ 2π0 (
∫ 10 (
∫ 6−r 2
4r 2+1 d z)r dr )dθ = 2π∫ 1
0 (5−5r 2)r dr = 10π[ r 2
2 − r 4
4 ]10 = 5π
2 .C1) S1 est le graphe de la fonction affine f (x, y) = 6−3x −2y au dessus de Ω1 = (x, y) ∈ R2, x, y ≥0,3x +2y ≤ 6. On a
√1+ f 2
x + f 2y =p
1+9+4 =p15.
C2) On vérifie que 3+2+1=6. Comme S1 est un portion de plan affine, l’équation du plan tangentest donc 3x +2y + z = 6.
C3) On a I2 =ÎΩ cos(x+y+(6−3x−2y)
p15d xd y =Î
Ω cos(6−2x−y)p
15d xd y =p15
∫ 30 (
∫ 6−3x2
0 cos(6−2x−y)d y)d x =p
15∫ 3
0 [−sin(6−2x−y)]6−3x
20 d x =−p15
∫ 30 (sin( 1
2 (3−x))−sin(6−2x))d x =−p15[2cos( 32−
x2 )− 1
2 cos(6−2x)]30
D1) On a 12 +12 + (p
2)2 = 4, A appartient donc à S2.D2) Soient r A,θA,ϕA les coordonnées sphériques de A. On a r A = 2, et
p2 = 2sinϕA, d’où ϕA = π
2 .Comme 1 = 2cosθA cosϕA on obtient θA = π
2 .
D3 )On parmétre S2 en utilisant les coordonn’es sphériques ~M : [0, π2 ] × [0, π2 ] → S2, (θ,ϕ) 7→M(θ,ϕ) = (2cosθ sinϕ,2sinθ sinϕ,2cosϕ). On a ~Mθ = (−2sinθ sinϕ,2cosθ sinϕ,0), ~Mϕ = (2cosθcosϕ,2sinθcosϕ,−2sinϕ),et ‖Mθ∧Mϕ‖ = 4sinϕ. On a donc I2 =
Î[0,π2 ]×[0,π2 ](4cos2θ sin2ϕ)(2sinθ sinϕ)(2cosϕ)(4sinϕ)dθdϕ=
64∫ π
20 cos2θ sinθdθ
∫ π2
0 sin4ϕcosϕdϕ= 64[− cos3θ3 ]
π20 [ sin5ϕ
5 ]π20 = 64
15 .
121

UNIVERSITÉ PIERRE ET MARIE CURIE ANNÉE UNIVERSITAIRE 2012-2013L2-PEIP2-LM256
Examen du 14 mai 2013Durée : 2 heures.
Les notes de cours et les calculatrices ne sont pas autorisées. Le sujet comprend quatre exercices, quisont indépendants.
Exercice I
On considère la fonction F définie sur R3 par F (x, y, z) = x4 +2y2 +4z4 − x2z2 −6 et on considèrel’ensemble S = (x, y, z) ∈R3,F (x, y, z) = 0.
1) Calculer−−−→gradF . Quels sont les points de R3 où
−−−→gradF s’annule ?
2) Montrer que le point A = (1,1,1) ∈ S . Donner l’équation du plan tangent en A, ainsi qu’unvecteur unitaire normal à S en A.3) Donner deux vecteurs non colinéaires tangents en A à S .
Exercice II
On considère dans R2 la courbe C1 =
(x, y) ∈R2, y = ex +e−x
2, 0 ≤ x ≤ 1
.
1) Calculer la longueur de la courbe C1.2) On considère le champ de vecteurs ~V1(x, y) = (2y,2x2). Calculer I1 =
∫C1~V1(M)d ~M .
3) Calculer de même I2 =∫C2~V1(M)d ~M où C2 désigne le segment orienté joignant les points (0,1)
et(1, 1
2 (e +e−1)).
4) Le champ de vecteur ~V1 est-il un champ de gradient ?5) On considère sur D =]0,+∞[×]0,+∞[ le champ de vecteurs
~V2(x, y) =(
3x4 +2x2 y2 − y4
x2 y,
3y4 +2x2 y2 −x4
y2x
).
Montrer que ~V2 est un champ de gradient. Trouver une fonction f telle que ~V2 =−−−→grad f .
6) Montrer que∫C1~V2(M)d ~M = ∫
C2~V2(M)d ~M .
Exercice III
On considère surR2 les ensembles D =
(x, y) ∈R2, 0 ≤ r ≤ cos2θ, θ ∈ [−π4
,π
4]
et C =
(x, y) ∈R2, r = cos2θ, θ ∈ [−π4
,π
4]
,
où (r,θ) désigne des coordonnées polaires sur R2 telles que x = r cosθ et y = r sinθ.1) Dessiner l’allure des ensembles D et C . Possèdent-t-ils des symétries ?2) Montrer que C est une courbe paramétrée, que l’on peut paramétrer en fonction de l’angle θ.
3) Vérifier que le point A = (p
34 , 1
4 ) appartient à C (on rappelle que cos π6 =p
32 ). Donner un vecteur
tangent à C en A.
4) Calculer l’aire de D, c’est à dire A ire(D) =Ï
Ddxdy.
5) Calculer les intégrales I1 =Ï
Dx dxdy et I2 =
ÏD
ydxdy.
122

6) Calculer∫C
xd y , où C est orientée dans le sens trigonométrique.
7) Calculer le volume du domaine U = (x, y, z) ∈R3, tels que (√
x2 + y2, z) ∈D.
Exercice IV
On considère dans R3 le domaine U = (x, y, z) ∈R3, x2 + y2 ≥ z2, x2 + y2 + z2 ≤ 1. 1) Dessiner l’al-lure du domaine U . S’agit-il d’un domaine de révolution ?2) Décrire U en coordonnées sphériques.3) Calculer le volume de U .
4) Calculer l’intégrale I1 =Ñ
U(x2 + y2 + z2)
32 dxdydz.
5) On note S la surface délimitant U . Calculer l’aire de S .
123

UNIVERSITÉ PIERRE ET MARIE CURIE ANNÉE UNIVERSITAIRE 2012-2013L2-PEIP2-LM256
Corrigé de l’examen du 14 Mai 2013
Exercice I
1) On a−−−→gradF = (4x3−2xz2,4y,16z3−2x2z). Pour que
−−−→gradF = 0, il faut 4x3−2xz2 = 0, y = 0,16z3−
2x2z = 0, d’où 2x2 = z2, y = 0, 8z2 = x2 qui entraîne y = 0,2x2 = z2 = 16z2, soit y = 0, y = 0, z = 0. Iln’y a donc que solution évidente (0,0,0).
2) On a−−−→gradF (A) = (2,4,14), d’où l’équation du plan tangent affine en A : 2(x−1)+4(y−1)+14(z−
1) = 0.3) Le vecteur
−−−→gradF (A) est orthogonal à S en A, le vecteur
~n =−−−→gradF (A)
‖−−−→gradF (A)‖= 1p
216(2,4,14) est donc unitaire et orthogonal.
4) Les vecteurs~t1 =−−−→gradF (A)∧~e1 et~t2 =
−−−→gradF (A)∧~e2 sont par exemple de tels vecteurs tangents,
soit~t1 = (0,14,−4) et~t2 = (0,−14,2).
Exercice II
1) La courbe C1 est le graphe de la fonction f donnée par f1(x) = 12 (ex +e−x). Sa longueur est donc
donnée par l’intégrale L = ∫ 20
√1+ f ′(x)2d x. On calcule
1+ f ′(x)2 = 1
4(e2x +e−2x −2)+1 = 1
4(ex +e−x)2. On obtient donc L = 1
2
∫ 20 ((ex+e−x)dx = 1
2 [ex−e−x]10 =
12 (e −e−1).2) Comme la courbe est un graphe, on la paramètre par x, avec d y(x) = 1
2 (ex−e−x)d x. Il vient ainsi,en utilisant des intégrations par parties
I1 =∫ 1
0(ex +e−x)d x + (x2)(ex −e−x)d x = [ex −e−x+(x2(ex+e−x)−2x(ex−e−x)+2(ex+e−x)]1
0 = 2e+4e−1 +4.3) Le segment C2 est également un graphe, celui de la fonction affine f2(x) = x( 1
2 (e + e−1)−1)+1.Sur cette courbe d y = a d x, où a = 1
2 (e +e−1 −1)) et donc,
I2 =∫ 1
02(ax +1)d x +2x2ad x = [a(x2 + 2x3
3)+2x]1
0 = 2+ 5
3a. Les deux quantités ne sont pas égales,
on n’a donc pas un champ de gradient.4) Si on écrit ~V2 = (V 1
2 ,V 22 ) alors
∂V 22
∂x=−3y2
x2+2−3
x2
y2= 3y4 +x2 y2 +3x4
x2 y2et de même
∂V 12
∂y= 3y4 +x2 y2 +3x4
x2 y2Comme ces deux
quantités sont égales, ~V2 est bien un champ de gradient.
5) On doit avoir∂ f
∂x=V 1
2 donc, f (x, y) =∫
(3x2
y+2y − y3
x2)d x = x3
y+2x y + y3
x+ g (y). En dérivant
par rapport à y on trouve∂ f
∂y=−x3
y2+2x + 3y2
x+ g ′(y) d’ou
g ′(y) =V 22 + x4 −2x2 y2 −3y4
x y2= 0. On donc f (x, y) = x3
y +2x y + y3
x + c = (x2+y2)2
x y + c.
124

Exercice III
1) Le domaine est symétrique par rapport à l’axe 0x.2) un paramétrage de C est donné par l’application ~M : [−π
4 , π4 ] →R2, θ 7→ ~M(θ) = (cos2θcosθ, cos2θ sinθ).
3) Pour A, on a r = 14
p3+1 = 1
2 = cos(π3 ) . On vérifie ensuite que l’on a bien A = ~M(π6 ) = (cos π3 cos π6 ,cos π3 sin π6 ).
Un vecteur tangent au point ~M(θ) est donnée par ~M ′(θ) = (−2sin2θcosθ−cos2θ sinθ,−2sin2θ sinθ+cos2θcosθ), soit pour θ = π
6 , ~M ′(π6 ) = (−(2p
32 .
p3
2 + 12 . 1
2 ),−2.p
32 . 1
2 + 12 .
p3
2 ) = (−74 ,−
p3
4 ).4) Soit Ω = (r,θ),0 ≤ r ≤ cos2θ, θ ∈ [−π
4 , π4 ]. Par la formule de changement de variable il vientai r e(D) = ∫
Ω r drdθ =∫ π4
−π4
(∫ cos2θ0 r dr
)dθ = 1
2
∫ π4
−π4
(cos2θ)2dθ = 14
∫ π4
−π4
(1+cos4θ)dθ = π8 .
5) Par symétrie I2 = 0. Pour I1 on écrit x = r cos θ d’où il vient
I1 =∫Ω r 2 cosθdrdθ = ∫ π
4
−π4
(∫ cos2θ0 r 2 cosθdr
)dθ = 1
3
∫ π4
−π4
(cos2θ)3 cosθdθ. Or on a
16(cos2θ)3 cosθ = (exp2iθ+exp−2iθ)3(exp iθ+exp−iθ) = [(exp6iθ+exp−6iθ)+3(exp2iθ+exp−2iθ)](exp iθ+exp−iθ) = 2(cos7θ + cos5θ + 3cos3θ + 3cosθ). Il en résulte que I1 = 1
24 [ sin7θ7 + sin5θ
5 + 3 sin3θ3 +
3sinθ]π4
−π4=
p2
24 [−17− 1
5+1+3] = 128p
235.24 . 6) on a par la formule de Green-Riemann
∫C xd y =A ire(D) =
π8 .7) Le domaine U est un domaine revolution autour de l’axe 0z, engendé par la rotation de D. Ona donc en raisonnant comme dans le chapitre 5 Vol(U ) = 2πI1.
Exercice IV
1) Le domaine U est de révolution autour de l’axe Oz.2) U = (x, y, z) tels que 0 ≤ r ≤ 1, π4 ≤ϕ≤ 3π
4 ,0 ≤ θ ≤ 2π.
3) On a Vol(U ) =ÎU dxdydz = ∫ 1
0 (∫ 2π
0 (∫ 3π
4π4
sinϕdϕ)dθ)r 2dr = 2π[cos(ϕ)]3π4π4
[ r 3
3 ]10 = 2
p2
3 π.
4) on a I =ÎU r 3dxdydz = ∫ 1
0 (∫ 2π
0 (∫ 3π
4π4
sinϕdϕ)dθ)r 5dr = 2π[cos(ϕ)]3π4π4
[ r 6
6 ]10 =
p2
6 π.
125