
Cours 4 : Estimation non paramétrique de la loi d’une ...
88
Cours 4 : Estimation non paramétrique de la loi d’une durée de vie I- Généralités II- Estimation de la survie III- estimation de la fonction de hasard IV- Estimation du taux de hasard (restriction au cas censuré de type III, T et C indépendantes)
Transcript of Cours 4 : Estimation non paramétrique de la loi d’une ...

Cours 4 : Estimation non paramétrique de la loi d’une durée de vie
I- Généralités II- Estimation de la survie
III- estimation de la fonction de hasard IV- Estimation du taux de hasard
(restriction au cas censuré de type III, T et C indépendantes)

I- Généralités
ü Applicabilité On n’a pas d’idée a priori sur la forme paramétrique de la loi de T. On cherche donc à estimer directement cette fonction, dans un espace de dimension infinie
ü Contexte d’application • Population homogène de durées • Taille d’échantillon relativement grande

II- Estimation de la survie 1- Généralités
Modèle complet : de fdr F, survie S ü Estimateur ponctuel: avec fdr empirique.
• Rq : Ecriture des moments empiriques :
∀t ≥ 0, Sn (t) =1− Fn (t) =1n
1Ti>ti=1
n
∑
Fn (t) =1n
1Ti≤ti=1
n
∑
1( ,..., )nT T
Tn =1n
Tii=1
n
∑ = t dFn (t)0
∞
∫ dt

II- Estimation de la survie 1- Généralités
ü Propriétés:
• Absence de biais
• Cv p.s. uniforme (Glivenko-Cantelli)
• Normalité asymptotique (Donsker) Où W est un processus gaussien centré (pont Brownien) de fonction de var-cov :
E Sn (t)( ) = S(t)supt∈R Sn (t)− S(t) n→∞
% →%% 0 p.s.
n Sn (.)− S(.)( ) L% →%W (.)
( , ) ( ) ( ) ( ) ( )s t F s F t F s F tρ = ∧ −
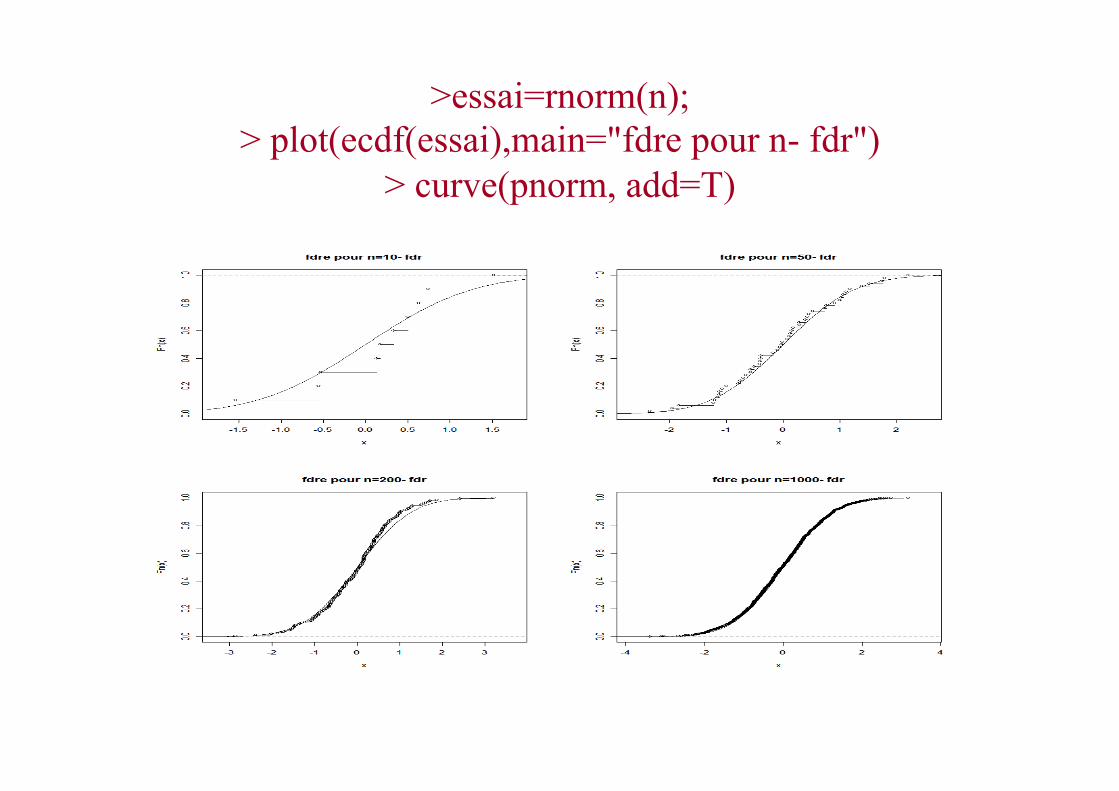
>essai=rnorm(n); > plot(ecdf(essai),main="fdre pour n- fdr")
> curve(pnorm, add=T)

II- Estimation de la survie 1- Généralités
Modèle censuré (type III):
L : fonction de répartition de X :
• Comment estimer S par une fonction constante par morceaux ?
( ) 1 11
, 1
, / ( ) i.i.d. , ( ) i.i.d. i ii i i i T C
i i i i n i i ni n
i i
X T C
X T F C GT C
δ
δ≤
≤ ≤ ≤ ≤≤ ≤
= ∧ =⎧⎪⎨⎪ ⊥⎩
1 (1 )(1 )L F G− = − −

II- Estimation de la survie 1- Généralités
Mauvaise idée : Estimateur naïf = estimateur empirique du sous-échantillon non censuré C’est un estimateur biaisé de S. En particulier, il n’est pas convergent :
Sn (t) =1 Ti>t ,δi=1{ }
i=1
n
∑
δii=1
n
∑
Sn (t)→P(T > t,δi =1)P(δi =1)
=(1−G(x)) f (x)dx
t
∞
∫P(T ≤C)
≠ f (x)dxt
∞
∫ = S(t)

II- Estimation de la survie 2- Construction d’estimateurs
ü Idée sous-jacente à l’estimation de S : Soit une discrétisation du temps et
ou = Probabilité de mourir dans Ii sachant qu’on n’est pas mort avant Les différents estimateurs proposés sont autant de manières d’estimer
∀t ∈ x( j ) ,x( j+1)#$ ), S(t) ≅ 1− qi( )i=1
j
∏
S(x( j ) ) = P(T > x( j ) |T > x( j−1) )P(T > x( j−1) ) = P(T > x(i ) |T > x(i−1) )i=1
j
∏
= 1− P(T ≤ x(i ) |T > x(i−1) )( )i=1
j
∏ = 1−P(x(i−1) <T ≤ x(i ) )P(T > x(i−1) )
$
%&&
'
())
i=1
j
∏ = 1− qi( )i=1
j
∏
(0) (1) ( )0 .... nx x x= ≤ ≤ ≤ =∞
⇒
iq
∀t ≥ 0, S(t) ≅ 1− qi( )i ,t≥x( i ){ }∏
iq

II- Estimation de la survie 2- Construction d’estimateurs
• mi=nombre de morts sur • ni=nombre de sujets entrant dans l’intervalle • ci=nombre de sujets censurés sur • ri=nombre de sujets à risque sur q Estimateur sur échantillon réduit (utilisé pour données groupées) PBME : Estimateur biaisé : surestime
q Estimateur actuariel (life-table estimator) (utilisé lorsque échelle de temps trop
grossière) On considère que les censures sont uniformément réparties sur l’intervalle (nombre moyen de cas à risque)
PBME : Estimateur non consistent en général (Breslow & Crowley, 1974).
( 1) ( )( , ]i ix x−
( 1) ( )( , ]i ix x−
S (1)n (t) = 1− qi(1)( )
x( i )≤t∏ , qi
(1) =mini − ci(1)ˆiq iq
S (2)n (t) = 1− qi(2)( )
x( i )≤t∏ , qi
(2) =mi
ni − ci / 2
qi =miri
( 1) ( )( , ]i ix x−

II- Estimation de la survie 3- Estimateur de Kaplan-Meier
q Estimateur de Kaplan-Meier (product-limit estimator) , Kaplan-Meier (1958):
ü Notations 1
RQ : sont des processus de comptages (processus à valeurs entières) , qui ne sautent qu’aux dates d’observations
. Ri (t)=1 Xi≥t{ } Ni(1) (t)=1 Xi≤t ,δi=1{ } Ni (t)=1 Xi≤t{ } Ni
(0) (t)=1 Xi≤t ,δi=0{ }
. R(t)= Ri (t)i=1
n
∑ =nombre de sujets à risque à t
. N (1) (t) = Ni(1) (t)
i=1
n
∑ = nombre de morts observées jusqu'à t
. N (t) = Ni (t)i=1
n
∑ = nombre d'évènements observés jusqu'à t
. M (t) = 1Xi=t ,δi=1i=1
n
∑ = nombre de morts à t(1) (1), , ,i iN N N N

II- Estimation de la survie 3- Estimateur de Kaplan-Meier
ü Notations 2
L(t) = P(X > t) =1− E(Ni (t))
L(1) (t) = P(X > t,δ =1) =1− E(Ni(1) (t))
L(0) (t) = P(X > t,δ = 0) =1− E(Ni(0) (t))

II- Estimation de la survie 3- Estimateur de Kaplan-Meier
q Définition : Fonction en escalier décroissante, continue à droite, qui ne saute qu’aux instants de morts réelles. Rq : Ici, les instants de discrétisation sont les instants, aléatoires, d’observations: et
=nombre de morts à X(i) =nombre de sujets à risque à X(i) (ni morts ni censurés
juste avant X(i))
( )
ˆ ( ) 1i
in
X t i
MS tR≤
⎛ ⎞= −⎜ ⎟
⎝ ⎠∏
(0) (1) ( )0 .... nX X X= ≤ ≤ ≤
(1)ˆ, ( ) 1nt X S t∀ < =
( )( )i iM M X=
( )( )i iR R X=
qi =Mi
Ri

II- Estimation de la survie 3- Estimateur de Kaplan-Meier
ü Expression en l’absence d’ex-aequos toujours vrai si les lois des durées et censures sont continues
Sn (t) = 1−δ(i )n− i +1
"
#$$
%
&''
X ( i )≤t∏
=n− in− i +1"
#$
%
&'
δ( i )
X ( i )≤t∏
= 1−δ(i )n− i +1
"
#$$
%
&''
i=1
n
∏1X ( i )≤t
( ) ( 1)1 1
j i j i
n n
i X X X Xj j
R n−≥ ≤
= =
= = −∑ ∑1 1

II- Estimation de la survie 3- Estimateur de Kaplan-Meier
ü Rq : autre formulation :
• Dém (sans ex-aequos) :
Sn (t) =1− Wii=1
n
∑ 1Xi≤t avec Wi =δi
n(1− G(Xi− ))
• W(i ) = Sn (X (i )−) − Sn (X (i ) ) = 1 − 1 −
δ(i )
n − i + 1
"
#$$
%
&''
"
#$$
%
&''
n − j
n − j + 1
"
#$
%
&'
δ( j )
X ( j )≤X ( i )−∏ =
δ(i )
n − i + 1
"
#$$
%
&''
n − j
n − j + 1
"
#$
%
&'
δ( j )
X ( j )≤X ( i )−∏
• 1 − G(X(i )−
) =n − j
n − j + 1
"
#$
%
&'
1−δ( j )
X ( j )≤X ( i )−∏
⇒ W(i ) × n × (1 − G(X−(i ) )) = n
δ(i )
n − i + 1
"
#$$
%
&''
n − j
n − j + 1
"
#$
%
&' =
j=1
i−1∏ δ(i )

II- Estimation de la survie 3- Estimateur de Kaplan-Meier
u Rq ü Le poids est nul pour les observations censurées : on ne saute qu’aux instants de
mort. ü Le poids attribué aux observations non censurées est d’autant plus grand que
l’observation est grande, afin de compenser le manque d’info dans les queues droites.
ü En données complètes, tous les poids sont égaux à 1/n, on retrouve l’estimateur classique.
ü L’estimateur n’atteint pas 1 lorsque la dernière observation est censurée. ü L’estimateur ne définit pas toujours une vraie distribution (<1). ü L’estimateur ne se comporte pas très bien en queue de distribution (biaisé)
u Estimation de :
⇒
θ = E( f (T ))
θ = f (t)dFn =∫ Wi f (Xi )j=1
n
∑

II- Estimation de la survie 3- Estimateur de Kaplan-Meier
ü Propriétés asymptotiques: Si T et C indépendantes, si les lois de T et de C n’ont aucune discontinuité communes (toujours vrai si ces lois sont continues),
• absence de biais asymptotique
• Cv uniforme p.s. (Stute & Wang, 93)
• Loi asymptotique (Breslow & Crowley, 74)
Où Z est un processus gaussien centré de fonction de var-cov :
ESn (t)( ) n→+∞
# →## S(t)
supt<τ LSn (t)− S(t) n→∞
# →## 0 p.s.
nSn − S( ) L# →# Z
0
( )( ( ), ( )) ( ) ( )( )²(1 ( ))
t s dF uCov Z s Z t S t S sS u G u
∧=
−∫
{ }inf 0, ( ) 1L x L xτ = ≥ =

II- Estimation de la survie 3- Estimateur de Kaplan-Meier
Pour n=50, 100, 200 library(survival) t=rnorm(n) c=rnorm(n,0,2) x=pmin(t,c) status=as.numeric(c>t) s=survfit(Surv(x,status) ~1) plot(s, conf.int=F)
-6 -4 -2 0
0.0
0.2
0.4
0.6
0.8
1.0
-5 -4 -3 -2 -1 0 1 2
0.0
0.2
0.4
0.6
0.8
1.0
-6 -4 -2 0 2
0.0
0.2
0.4
0.6
0.8
1.0

II- Estimation de la survie 3- Estimateur de Kaplan-Meier
ü Autres propriétés :
• Normalité asymptotique :
avec
∀t ∈ 0,τ#$ %&τ < τ L nSn (t)− S(t)( ) L( →( N (0,σ 2 (t))
σ 2 (t) = S(t)2 dF (u)S(u)2 (1−G(u))0
t∫ = S 2 (t) dH (u)
L(u)0
t
∫

II- Estimation de la survie 3- Estimateur de Kaplan-Meier
• L’estimateur de KM est l’unique estimateur cohérent de la survie :
la probabilité de décéder au-delà de t est la somme des probabilités d’être à risque à t et celle d’avoir été censuré avant t:
• L’estimateur de KM est l’estimateur du maximum de vraisemblance non-paramétrique de la survie dans l’espace des fonctions de survie (de dimension infinie).

II- Estimation de la survie 3- Estimateur de Kaplan-Meier
ü Estimateur de Greenwood (Estime la variance de KM) (utile pour calculer des intervalles de confiance)
En l’absence d’ex-Aequos L’estimateur de Greenwood est un estimateur consistent de la
variance
σ KM2 (t) =
Sn (t)
δi(n− i)(n− i +1)X ( i )≤t
∑
( )
2 ˆˆ ( ) ²( )( )
i
iKM n
X t i i i
Mt S tR R M
σ≤
=−∑

II- Estimation de la survie 3- Estimateur de Kaplan-Meier
ü Justification de la construction de cet estimateur
car On remplace ensuite par les estimateurs naturels (ne sautent qu’aux obs):
{ }
(1)2 (1)
, 10
( )( ) ²( ) avec ( ) ( , 1) 1 (1 )(1 ( )) ( )(1 ( ))
t
KM X udL un t S t L u P X u E
L u S u G u δσ δ ≤ =−
−= = > = = −
− −∫
(1)
0
( ) ( , ) ( , / ) ( ) (1 ( )) ( )u
L u P T u T C P t u C t T t dF t G t dF t∞ ∞
−= > ≤ = > ≥ = = −∫ ∫(1) ( ) (1 ( )) ( )dL u G u dF u−= − −
L(1) (u) ≅1− N(1) (u)n
S(u)(1−G(u− )) ≅ R(u)n
1− L(u) ≅ R(u+ )n
−dL(1) (u) ≅ dN(1) (u)n
=Mi
n1u=X ( i ){ }
d'où
σ KM2 (t) / S 2 =
X ( i−1)
X ( i )∫Mi
R(u)R(u+ )1u=X ( i ){ }
=X ( i )≤t∑ Mi
RiRi+1X ( i )≤t∑ =
Mi
Ri (Ri −Mi )X ( i )≤t∑

II- Estimation de la survie 3- Estimateur de Kaplan-Meier
ü Exemples de calcul
ü Exemple1 : On observe les durées de séjour de 10 épisodes de chômage exprimés en mois (* si censurées):
1 2 4* 5 7* 8 9 10* 11 13*
{ }(1,1),(2,1),(4,0),(5,1),(7,0),(8,1),(9,1),(10,0),(11,1),(13,0)Obs =

II- Estimation de la survie (fiabilité) 3- Estimateur de Kaplan-Meier
∀t ∈ [0,1)Sn (t) =1
∀t ∈ [1,2)Sn (t) = 1−
110
$
%&
'
()Sn (0) = 0.9
∀t ∈ [2,5)Sn (t) = 1−
19
$
%&
'
()Sn (1) = 0.8
∀t ∈ [5,8)Sn (t) = 1−
17
$
%&
'
()Sn (3) = 0,6857
∀t ∈ [8,9)Sn (t) = 1−
15
$
%&
'
()Sn (5) = 0,5485
∀t ∈ [9,11)Sn (t) = 1−
14
$
%&
'
()Sn (8) = 0,411
∀t ≥11Sn (t) = 1−
12
$
%&
'
()Sn (9) = 0,205

x=c(1,2,4,5,7,8,9,10,11,13); d=c(1,1,0,1,0,1,1,0,1,0))
i=1:10; ksp=d[i]/(10-i+1); km=cumprod(1-ksp)
k=c(1,km[d>0]); t=c(0,x[d>0]);plot(t,k)
s=1:6; Arrows(t[s],y[s],t[s+1],y[s],length=0.05)
arrows(11,0.205,12,0.205,length=0.05)
Ou bien library(survival); s=survfit(Surv(x,d) ~1) plot(s) summary(s) Call: survfit(formula = Surv(x, d)) time n.risk n.event survival std.err lower 95% CI upper 95% CI 1 10 1 0.900 0.0949 0.7320 1.00 2 9 1 0.800 0.1265 0.5868 1.00 5 7 1 0.686 0.1515 0.4447 1.00 8 5 1 0.549 0.1724 0.2963 1.00 9 4 1 0.411 0.1756 0.1782 0.95 11 2 1 0.206 0.1699 0.0408 1.00
Rq : mettre l’option conf.int=F pour enlever les IC
0 2 4 6 8 10
0.20.4
0.60.8
1.0
x
y
Estimateur de KM
ˆ ( )KM timeσ
ˆ ˆ( ) 1.96 ( )KM KMS time timeσ−

II- Estimation de la survie 3- Estimateur de Kaplan-Meier
ü Exemple2 :

II- Estimation de la survie 3- Estimateur de Kaplan-Meier

II- Estimation de la survie 3- Estimateur de Kaplan-Meier
ü Exemple 2 bis :
xx=c(6,6,6,6,7,9,10,10,11,13,16,17,19,20,22,23,25,32,32,34,35,1,1,2,2,3,4,4,5,5,8,8,8,8,11,11,12,12,15,17,22,23)
dd=c(1,1,1,0,1,0,1,0,0,1,1,0,0,0,1,1,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1) t=c(rep("6MP",21),rep("P",21)) f=data.frame(xx,dd,t)

library(survival) s=survfit(Surv(xx,dd)~t, data=f) plot(s, lty=c(1,3), xlab="Time", ylab="Survival Probability") legend(25, 1.0, c("6MP", "P") , lty=c(1,3) ) summary(s) Call: survfit(formula = Surv(xx, dd) ~ t, data = f) t=6MP time n.risk n.event survival std.err lower 95% CI upper 95% CI 6 21 3 0.857 0.0764 0.720 1.000 7 17 1 0.807 0.0869 0.653 0.996 10 15 1 0.753 0.0963 0.586 0.968 13 12 1 0.690 0.1068 0.510 0.935 16 11 1 0.627 0.1141 0.439 0.896 22 7 1 0.538 0.1282 0.337 0.858 23 6 1 0.448 0.1346 0.249 0.807 t=P time n.risk n.event survival std.err lower 95% CI upper 95% CI 1 21 2 0.9048 0.0641 0.78754 1.000 2 19 2 0.8095 0.0857 0.65785 0.996 3 17 1 0.7619 0.0929 0.59988 0.968 4 16 2 0.6667 0.1029 0.49268 0.902 5 14 2 0.5714 0.1080 0.39455 0.828 8 12 4 0.3810 0.1060 0.22085 0.657 11 8 2 0.2857 0.0986 0.14529 0.562 12 6 2 0.1905 0.0857 0.07887 0.460 15 4 1 0.1429 0.0764 0.05011 0.407 17 3 1 0.0952 0.0641 0.02549 0.356 22 2 1 0.0476 0.0465 0.00703 0.322 23 1 1 0.0000 NA NA NA

III- Estimation de la fonction de hasard 1- Generalites
ü Rappel sur la fonction de hasard :
ü Lorsque T est continue :
ü Dans le cas général
0
( )( )( )
t f uH t duS u
= ∫
0
( )( )( )
t dS uH tS u−
= −∫

III- Estimation de la fonction de hasard 1- Generalites
q Estimateur de Peterson (ou de Breslow) (Peterson, 1977) :
En l’absence d’ex-aequos
HnP (t) = − Log
X ( i )≤t∑ 1−
δin− i +1
$
%&
'
()
HnP (t) = − Log
X ( i )≤t∑ 1−
Mi
Ri
$
%&
'
()

III- Estimation de la fonction de hasard 2- Estimateur de Nelson-Aalen
q Estimateur de Nelson-Aalen, (Nelson, 1972) :
Fonction en escalier décroissante, continue à droite, qui ne saute qu’aux instants de morts réelles.
En l’absence d’ex-aequos, Possède de meilleures propriétés que Peterson .
( )
ˆ ( )1
i
in
X tH t
n iδ
≤
=− +∑
( )
ˆ ( )i
in
X t i
MH tR≤
⎛ ⎞= ⎜ ⎟
⎝ ⎠∑

III- Estimation de la fonction de hasard 2- Estimateur de Nelson-Aalen
ü Justification empirique à partir du Nelson : Pour n grand, et i pas trop grand les termes des deux sommes sont équivalents lorsqu’il n’y a pas d’ex-aequos
ü Justification théorique:
H (t) = − dL(1) (u)L(u− )0
t∫
Hn (t) =dN (1) (u)R(u)
=X ( i−1)
X ( i )∫i=1
n
∑ Mi
RiX ( i )≤t∑

III- Estimation de la fonction de hasard 2- Estimateur de Nelson-Aalen
ü Propriétés : Si les lois de T et de C n’ont pas de discontinuité commune (toujours vrai lorsque ces lois sont continues),
ü Absence de biais
ü Consistence
ü Normalité asymptotique
Où Z est un processus gaussien centré de var-cov :
( )
( )
(1)ˆ, ( ) ( )
ˆsup ( ) ( ) 0
ˆ ( ) ( ) ( )
n
psn
Ln
t X E H t H t
H t H t
n H t H t Z t
∀ > =
− ⎯⎯→
− ⎯⎯→
0
( )( ( ), ( ))( )(1 ( ))
t s dF uCov Z s Z tS u L u
∧
− −=
−∫

III- Estimation de la fonction de hasard 2- Estimateur de Nelson-Aalen
ü Estimateur de Tsiatis de la variance de Nelson-Aalen: En l’absence d’ex-Aequos Justification : et idem précédemment.
( )
( )
2
2
ˆ ( )²
ˆ ( )( 1)²
i
i
iNA
X t i
iNA
X t
MtR
tn i
σ
δσ
≤
≤
=
=− +
∑
∑
(1)2
20
( )( )(1 ( ))t
NAdL un tL u
σ−
=−∫

III- Estimation de la fonction de hasard 2- Estimateur de Nelson-Aalen
ü Remarque : estimateur de Fleming et Harrington de la Survie S
de variance estimée par :
Sn (t) = exp(−Hn (t))
( ) ( )
2ˆ ( ) exp 2²
i i
i iFH
X t X ti i
M MtR R
σ≤ ≤
⎛ ⎞= −⎜ ⎟⎜ ⎟
⎝ ⎠∑ ∑

III- Estimation de la fonction de hasard 2- Estimateur de Nelson-Aalen
ü Exemples
ü Exemple1 : On observe les durées de vie de 10 diodes exprimées en mois (* si censurées):
1 2 4* 5 7* 8 9 10* 11 13*
{ }(1,1),(2,1),(4,0),(5,1),(7,0),(8,1),(9,1),(10,0),(11,1),(13,0)Obs =

III- Estimation de la fonction de hasard 2- Estimateur de Nelson-Aalen
∀t ∈ [0,1)Hn (t) = 0
∀t ∈ [1,2)Hn (t) =
110
+Hn (0) = 0.1
∀t ∈ [2,5)Hn (t) =
19+Hn (1) = 0.21
∀t ∈ [5,8)Hn (t) =
17+Hn (3) = 0,35
∀t ∈ [8,9)Hn (t) =
15+Hn (5) = 0,55
∀t ∈ [9,11)Hn (t) =
14+Hn (8) = 0,80
∀t ≥11Hn (t) =
12+Hn (9) =1,3

III- Estimation de la fonction de hasard 2- Estimateur de Nelson-Aalen
x=c(1,2,4,5,7,8,9,10,11,13); d=c(1,1,0,1,0,1,1,0,1,0) n=cumsum(ksp) nn=c(0,n[d>0]); t=c(0,x[d>0]) plot(t,nn); s=1:6 arrows(t[s],nn[s],t[s+1],nn[s],length=0.05) ou bien library(survival) n=basehaz(coxph(Surv(x,d)~1)) Hazard time 1 0.1000000 1 2 0.2111111 3 3 0.3539683 5 4 0.5539683 8 5 0.8039683 9 6 1.3039683 11 plot(n[[2]],n[[1]], type="s")

III- Estimation de la fonction de hasard 2- Estimateur de Nelson-Aalen
ou encore library(survival) temp=summary(survfit(Surv(x,d) ~1,type="fh")) plot(temp$time, -log(temp$surv),type="s) temp Call: survfit(formula = Surv(x, d) ~1, type = "fh") time n.risk n.event survival std.err lower 95% CI upper 95% CI 1 10 1 0.905 0.0954 0.7359 1 2 9 1 0.810 0.1280 0.5939 1 5 7 1 0.702 0.1551 0.4552 1 8 5 1 0.575 0.1806 0.3103 1 9 4 1 0.448 0.1910 0.1939 1 11 2 1 0.271 0.2242 0.0538 1 -log(temp$surv) [1] 0.1000000 0.2111111 0.3539683 0.5539683 0.8039683 1.3039683

III- Estimation de la fonction de hasard 2- Estimateur de Nelson-Aalen
ü Exemple2 :

III- Estimation de la fonction de hasard 2- Estimateur de Nelson-Aalen
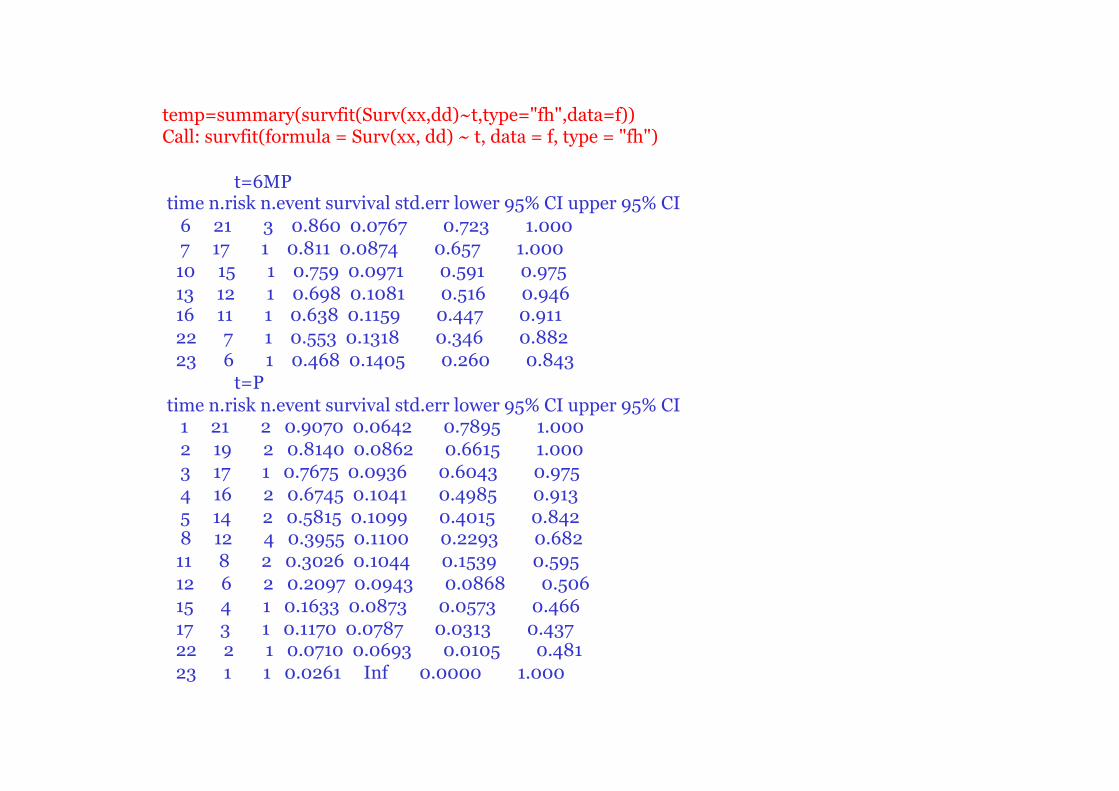
temp=summary(survfit(Surv(xx,dd)~t,type="fh",data=f)) Call: survfit(formula = Surv(xx, dd) ~ t, data = f, type = "fh") t=6MP time n.risk n.event survival std.err lower 95% CI upper 95% CI 6 21 3 0.860 0.0767 0.723 1.000 7 17 1 0.811 0.0874 0.657 1.000 10 15 1 0.759 0.0971 0.591 0.975 13 12 1 0.698 0.1081 0.516 0.946 16 11 1 0.638 0.1159 0.447 0.911 22 7 1 0.553 0.1318 0.346 0.882 23 6 1 0.468 0.1405 0.260 0.843 t=P time n.risk n.event survival std.err lower 95% CI upper 95% CI 1 21 2 0.9070 0.0642 0.7895 1.000 2 19 2 0.8140 0.0862 0.6615 1.000 3 17 1 0.7675 0.0936 0.6043 0.975 4 16 2 0.6745 0.1041 0.4985 0.913 5 14 2 0.5815 0.1099 0.4015 0.842 8 12 4 0.3955 0.1100 0.2293 0.682 11 8 2 0.3026 0.1044 0.1539 0.595 12 6 2 0.2097 0.0943 0.0868 0.506 15 4 1 0.1633 0.0873 0.0573 0.466 17 3 1 0.1170 0.0787 0.0313 0.437 22 2 1 0.0710 0.0693 0.0105 0.481 23 1 1 0.0261 Inf 0.0000 1.000

III- Estimation du taux de hasard
On se place dans le cadre de lois continues pour T et C Méthodes classiques : on lisse la fonction de hasard. - Estimateurs à noyaux ou par histogramme - Estimateur isotonique (si le taux de hasard est monotone) - (Estimation par les k points les plus proches) - Autres (splines, polynomes locaux,…)

III - Estimation du taux de hasard 1- estimateurs à noyaux d’une densité
q Estimateur à noyaux d’une densité f dans un modèle complet
ü Cas naif: estimateur de la fenêtre mobile (noyau uniforme): Pour estimer f en t, on compte le nombre d’observations dans une fenêtre de longueur autour de t
na
[ 1/ 2,1/ 2)1
nombre de décès dans ( / 2, / 2]ˆ ( )
ˆ ˆ( / 2) ( / 2)
1 où ( ) ( )
n nn
n
n n n n
n
ni
in n
t a t af tna
F t a F t aa
t TK K t tna a −
=
− +=
+ − −=
⎛ ⎞−= =⎜ ⎟
⎝ ⎠∑ 1

III - Estimation du taux de hasard 1- estimateurs à noyaux d’une densité
ü Estimateur à noyau (cas général):
• Soit K une fonction de densité de probabilité paire integrable et bornée. L’estimateur à noyau de f de noyau K et de fenêtre an est :
Autour de chaque observation Ti on place une ‘bosse’ (la densité K). L’estimateur qui en résulte est simplement la somme de ces ‘bosses’. Le noyau K détermine la forme des ‘bosses’, et la fenêtre an détermine la largeur
des‘bosses’.
∀t ∈ R, fn (t) =1nan
Kt −Tian
$
%&
'
()
i=1
n
∑ =1an
K t −uan
$
%&
'
()dFn (u)∫

III- Estimation du taux de hasard 1- estimateurs à noyaux d’une densité
ü Propriétés asymptotiques:
Si K est de carré intégrable et
– Absence de biais asymptotique
– Normalité asymptotique
– Convergence en moyenne quadratique:
MSE( f ,an ) = E fn (t)− f (t)( )2=Var( fn (t))+ (Biais( fn (t)))
2 → 0
0,n na na→ → +∞| |lim ( ) 0t tK t→∞ =

III - Estimation du taux de hasard 1- estimateurs à noyaux d’une densité
ü Exemples de noyaux :
- Noyau gaussien
- Noyau quartic - Noyau d’Epanechnikov
- Noyau uniforme
- Noyau triangulaire
²21, ( )
2
u
u R K u eπ
−∀ ∈ =
( ) | | 115, ( ) 1 ² ²116 uu R K u u ≤∀ ∈ = −
( ) | | 13, ( ) 1 ² 14 uu R K u u ≤∀ ∈ = −
| | 11, ( ) 12 uu R K u ≤∀ ∈ =
( ) | | 1, ( ) 1 | | 1uu R K u u ≤∀ ∈ = −

III - Estimation du taux de hasard 1- estimateurs à noyaux d’une densité
q Cas de données censurées
Soit K une fonction de densité paire integrable et bornée. Soit le KM, la densité associée à et sa fdre ü Estimateur à noyau de f :
ü Estimateur à noyau de :
∀t ∈ R, fn (t) = −1an
K t −uan
$
%&
'
()dSn (u)∫ =
1an
Kt − X (i )an
$
%&&
'
())
i=1
n
∑δ(i )n− i +1
Sn (X (i )− )
ˆnS
(1)l (1) ( ) ( , 1)L t P X t δ= ≤ =(1)ˆnL
(1)l
∀t ∈ R, ln(1) (t) = 1
anK t −u
an
$
%&
'
()dLn
(1) (u)∫ =1nan
δiKt − Xian
$
%&
'
()
i=1
n
∑

III - Estimation du taux de hasard: 2- Estimateurs à noyau
q Cas de données complètes : obs=
ü Leadbetter, Watson (1964) : basé sur le noyau de la densité
ü Ramlau-Hansen (1983) : lissage du Nelson
1( ,..., )nT T
hn (t) =fn (t)
1− Fn (t)
Fn (t) = fn (u)du0
t∫
fn
hn (t) =
1anK t −u
an
"
#$
%
&'dHn (u) =∫ 1
an
1n− i +1
Kt − X (i )an
"
#$$
%
&''
i=1
n
∑

III - Estimation du taux de hasard: 2- Estimateurs à noyau
ü Propriétés : Si K est un noyau (densité) de carré intégrable et si
– Les estimateurs et sont asymptotiquement sans biais
– Ils convergent en moyenne quadratique :
– Ils sont asymptotiquement gaussiens centrés et ont la même variance asymptotique :
0,n na na→ → +∞
hnhn
( , ) 0nMSE h a →
Var( hn (t)) =Var(hn (t)) =
1nan
h(t)S(t)
K 2 (u)du∫
| |lim ( ) 0t tK t→∞ =

III - Estimation du taux de hasard: 2- Estimateurs à noyau
Modèle de censure aléatoire droite : obs=
ü Estimateurs de Foldes et al. (1981) : Si est un
estimateur à noyau ou histogramme de f et le KM :
Propriétés : Pour et K bien choisis et F et G admettant des propriétés de régularité, on a convergence presque sûre uniforme de vers h sur un compact.
hn (t) =fn (t)Sn (t)
fn (t)
( , )i iX δ
hn
na
ˆ ( )nS t

III - Estimation du taux de hasard: 2- Estimateurs à noyau
ü Estimateurs de Blum et Susarla. (1980) : Si est un
estimateur à noyau ou histogramme de et la fdr des Xi :
Propriétés : Pour et K bien choisis et F et G admettant des propriétés de régularité, on a convergence presque sûre uniforme de vers h sur un compact.
h *n (t) =ln(1) (t)
1− Ln (t)
ln(1)
hn
na
Ln(1)l

III - Estimation du taux de hasard: 2- Estimateurs à noyau
ü Estimateur de Tanner et Wong (1983) Propriétés : Si F et G n’ont pas de discontinuité commune, que h est 2
fois dérivable , si K est un noyau de carré intégrable et – L’ estimateur est asymptotiquement sans biais – Il converge en moyenne quadratique – Il est asymptotiquement normal en tout point t où h est continu avec
h(t)>0 et 0<L(t)<1 et de variance asymptotique équiv à:
hn (t) = K t − x
an
"
#$
%
&'dHn (x) =∫ 1
an
δin− i +1
Kt − X (i )an
"
#$$
%
&''
i=1
n
∑
0,n na na→ → +∞
Var(hn (t)) =
1nan
h(t)1− L(t)
K 2 (u)du∫
| |lim ( ) 0t tK t→∞ =
( , ) 0nMSE h a →

III - Estimation du taux de hasard: 2- Estimateurs à noyau
q Effets de bord (boundary effects)
La variance d’un estimateur à noyaux du taux tend vers l’infini lorsqu’on se rapproche du bord droit de l’intervalle , ce qui rend l’estimation de mauvaise qualité sur le bord droit. Une correction est alors nécessaire . Entre autres solutions,
• Utilisation d’une fenêtre locale an(t) (plus large au bord de
l’intervalle). • boundary kernel : Utilisation d’une fenêtre locale et d’un
noyau local . • Estimation par des polynomes locaux

III - Estimation du taux de hasard: 2- Estimateurs à noyau
q Construction pratique d’un estimateur à noyau:
Ø Qualité d’un estimateur :
Le biais est une fonction croissante de tandis que la variance est une fonction décroissante.
Ø Critères de perte classiques :
Erreur en moyenne quadratique (MSE) Risque quadratique moyen (MISE) Risque quadratique (ISE)
na
( )
( )( )( )
( , ) ( ) ( ) ²
( , ) ( ) ( ) ²
( , ) ( ) ( ) ²
.........................
n n
n n
n n
MSE a h E h t h t
MISE a h E h t h t dt
ISE a h h t h t dt
= −
= −
= −
∫∫
( , ) ²( , ) ( , ) ²n n n n n nR h a b h a v h a Biais Variance= + = +
( , )n nR h a

III - Estimation du taux de hasard: 2- Estimateurs à noyau
La qualité de l’estimation par noyau dépend :
ü peu du choix du noyau ü beaucoup du choix de la fenêtre : Si elle est trop petite, le bruit
sera élevée et l’estimation trop irrégulière. A l’inverse, le biais sera élevé, l’estimation sera trop lisse.
Ø Choisir K et la fenêtre , éventuellement locale, de manière à minimiser le critère de perte choisi. Impossible à faire en pratique à n fixé.
Ex : optimisation asymptotique pour le Tanner :
Ø En pratique : ü On choisit K arbitrairement ü On recherche une fenêtre optimale du critère de perte approchée
choisi. Généralement, on utilise une fenêtre locale à cause des effets de bord.
na
1/5( )na f h n−=

III - Estimation du taux de hasard: 2- Estimateurs à noyau
ü par validation croisée (MARRON et PADGETT [1987]) ou
bootstrap (minimisation du critère pour un estimateur de h construit par rééchantillonage) .
ü Par plug-in (on estime les paramètres inconnus dans l’expression de la fenêtre optimale asymptotique)
ü Fenêtre aléatoire (MIELNICZUK [1986]) dérivée de la méthode des k plus proches voisins.

III - Estimation du taux de hasard: 2- Estimateurs à noyau
ü Ex de validation croisée sur un estimateur du taux par
minimisation du ISE:
Le dernier terme ne dépend pas de an. Par ailleurs, que l’on peut remplacer par Un estimateur de type où le terme au numérateur est l’estimateur à noyaux de h estimé à
partir de tous les points sauf Xi.
h(t)h(t)dt =∫h(t)S(t)
f (t)dt∫1n
δih−i (Xi )SKM (Xi )i=1
n
∑
h

Noyau gaussien de TANNER et WONG noy=function(x,d,t,an) { i=1:length(x); ksp=d[i]/(length(x)-i+1); p=ksp[i]*dnorm((t-x[i])/an) noy=(1/an)*sum(p) } d=sample(c(0,1),100, rep=T,prob=c(0.1,0.9)) x=rweibull(100,0.5,2) s=seq(1,5,by=0.001) n=vector(length=length(s)) for(i in 1:length(s)){n[i]=noy(x,d,s[i],0.05)} plot(s,n,col="red", main="an=0.05",type="s") curve(dweibull(x,0.5,2)/(1-pweibull(x,0.5,2)),add=T) -------------------------------------- library(muhaz) b=muhaz(x,d,bw.method="local",b.cor="both"); plot(b,
col=“red”)

Exemple 1 : x=c(1,2,4,5,7,8,9,10,11,13); d=c(1,1,0,1,0,1,1,0,1,0) s=seq(0,10,by=0.01) n=vector(length=length(s)) for(i in 1:length(s)){ n[i]=noy(x,d,s[i],0.4)} plot(s,n,col="red”,main="an=0.4",type="s") ----------------------------------------- library(muhaz) b=muhaz(x,d,bw.method="local",b.cor="both") plot(b)



III - Estimation du taux de hasard: 3- Estimateur isotonique
Hypothèse : F est DFR (ou IFR) q Définition (Barlow et al., 1972): Soit le plus petit
majorant concave du Nelson L’estimateur isotonique est la dérivée continue à gauche de
C’est un histogramme à pas variable, spatialement adaptatif et
totalement « data-driven » q Propriétés
- meilleur histogramme - Normalité asymptotique
- convergence du risque quadratique
( )nH t( )nh t
( )nH t

III - Estimation du taux de hasard: 3- Estimateur isotonique
q Construction pratique de l’enveloppe concave (algorithme Pool Adjacent Violators) :
Soit la séquence des points de sauts de • On construit la linéarisée L(t) de comme la fonction affine par
morceaux entre les points • Soient la séquence des
pentes de L. Si elle est décroissante, alors =L(t). Sinon, on itère la règle suivante jusqu’à l’obtention d’une séquence décroissante:
( )nH t
(1) ( )..... kt t< <
l1,......lk−1, li =Hn (ti )−
Hn (ti−1)
ti − ti−1, t0 = 0
Hn (t)
Hn (t)
(t(i ) ,Hn (t(i ) ))
( )nH t

III - Estimation du taux de hasard: 3- Estimateur isotonique
Soit j le min des i / on définit à la place de L une nouvelle fonction obtenue en enlevant de la séquence des points de rupture de L: c’est une fonction affine par morceaux entre les points , de séquence de pentes
La fonction est concave, l’estimateur isotonique est sa pente continue à gauche.
1,i il l −>
( )nH t
1 1 2 2,..., * ..j j j kl l l l l− + −< < < 1 10
1 1
( ) ( )* , 0j jj
j j
L t L tl t
t t+ −
+ −
−= =
−
jt
(t(i ) ,Hn (t(i ) )) 1 ,i k i j≤ ≤ ≠

III - Estimation du taux de hasard: 3- Estimateur isotonique
L(t)
t b

Modèles de durée et processus ponctuels (GILL [1980] , FLEMING et HARRINGTON [1991])
L’étude d’une durée de vie s’effectue en étudiant la loi de la variable X, On peut raisonner différemment et de considérer le processus ponctuel naturellement associé à X : Rq : On a Lorsque l’on prend en compte la censure, on construit de même le processus des sorties non censurées
N (t) =1X ≤t
N 1(t) =1X ≤t ,δ=1
X > t{ } ⇔ N (t) = 0{ }

Modèles de durée et processus ponctuels Rappels sur les processus v Soit (Ω, F, P) un espace probabilisé. Un processus aléatoire est une fonction de
deux variables: où t représente le temps et w le hasard.
• Pour tout t € E, wàX(t,w) est une variable aléatoire (coordonnée à l’instant t). • Pour tout w € Ω, tàX(t,w) est une fonction (trajectoire de X). • Si pour presque tout w, tàX(w,t) est continue le processus est dit à trajectoires
continues • X est dit continu à droite (càd) (resp. admettant des limites à gauche (làg), resp. à
variations bornées resp. croissant, resp. positive…) si l’ensemble de ses trajectoires sont continues à droite (resp. làg resp. à variations bornées resp. croissantes, resp. positives…) avec une probabilité 1.
• X est dit intégrable ssi • X est dit de carré intégrable ssi
v
X = (Xt ) :E ×Ω→ R
(t,w)→ X (t,w)
supt∈EE( Xt ) <∞
supt∈EE(Xt
2 ) <∞

Modèles de durée et processus ponctuels v On appelle filtration (Ft ) toute suite croissante de sous-tribus (ie stable par
complémentation et réunion dénombrable) de F:
• NB : La filtration naturelle (histoire) de X est la tribu constituée des sous-tribus engendrées par les variables aléatoires Xs :
v X est un processus adapté à (Ft ) si pour tout t, Xt est Ft - mesurable
• NB : Un processus est toujours adapté à sa filtration naturelle.
v X est un processus prévisible pour (Ft ) si Xt est Ft- - mesurable. Avec Ex: un processus càg et adapté est prévisible du fait de la propriété de continuité. • Intuitivement, un processus prévisible est un processus dont la valeur en t est connue «
juste avant » t.
Ft−=∨s<t Fs (=σ (X s ,s < t) pour la filtration naturelle)
Fs ⊆ Ft ⊆ F
Ft =σ (X s ,s ≤ t)

Modèles de durée et processus ponctuels
Soit un processus càd-làg intégrable adapté à une filtration (Ft ) v M est une martingale Propriétés: Une martingale peut être vue comme un processus d’erreurs: • son espérance est constante (on pourra toujours supposer qu’elle est nulle) • ses incréments sont non corrélés : cov(Mt −Ms, Mv −Mu)=0, 0≤s≤t≤u≤v.
v M est une sous-martingale (resp sur-martingale)
• Par l’inégalité de Jensen, si M est une martingale alors M2 est une sous-martingale:
⇔ E(Mt Fs ) =Ms p.s,∀s ≤ t
⇔ E (Mt Fs ) ≥Ms p.s.,∀s ≤ t (resp.≤)
E(Mt2 Fs ) ≥ E(Mt Fs )( )
2
= Ms
M = Mt( )t≥0

Intégrale de Stieltjes (généralisation de l’intégrale ordinaire)
• Soient f continue g une fonction à variations finies (différence de deux fonctions croissantes bornées ) sur un intervalle fermé [a,b]. Soit a=x1<…<xi<…xn=b une subdivision, notée σ, de cet intervalle. On pose :
Alors, on montre que . Cette quantité, notée est appelé l'intégrale de Stieltjes de la fonction f par rapport à g. Rq : une fonction monotone bornée est à variations bornées.
S−( f ,σ ) = m
i(g(x
i)−
i=1
n
∑ g(xi−1)), S
+( f ,σ ) = M
i(g(x
i)−
i=1
n
∑ g(xi−1))
mi= inf
t∈[ xi−1,xi ]f (t), M
i= sup
t∈[ xi−1,xi ]f (t)
S−( f ) = inf
σS−( f ,σ ), S
+( f ) = sup
σS+( f ,σ )
f (x)dg(x)a
b
∫S−( f ) = S
+( f )

• En raisonnant trajectoire par trajectoire, on peut également définir une intégrale de Stieljes par rapport à tout processus à variations bornées.
• Si X est mesurable et Y à variations bornées sur (s,t], on peut définir
• Rq : ca marche pour Y martingale, Y processus de comptage • Si X prévisible et Y martingale cad, l’intégrale est un processus prévisible
X dY =s
t∫
X s dMs0
t∫ = X s
2d M0
t∫ s

Modèles de durée et processus ponctuels
v Décomposition de Doob-Meyer :
Soit X une sous-martingale positive càd adaptée. Alors, il existe une martingale M càd et un processus prévisible croissant càd A satisfaisant tels que • Le processus A est appelé compensateur de X • Si A0=0, cette décomposition est unique. • Si X0=0, on a E(Xt)=E(At) pour tout t. On en déduit en particulier que si M est une martingale de carré intégrable, M2 (qui est alors une sous-martingale) possède un unique compensateur nul en zero noté <M> :
Théorème: Soit M une martingale positive càd adaptée et de carré intégrable alors il existe une unique processus prévisible croissant nul en zero <M>, tel que <M> est appelé le processus à variations prévisibles ou crochet de M et
E(At ) <∞
∀t, Xt =Mt + At
E(<M >t ) <∞M 2 − M est une martingale càd
E(dMt−2 / F
t−) = d M
t

Modèles de durée et processus ponctuels
Processus de comptage v Soit (Ft ) une filtration sur un espace probabilisé. Un processus de comptage (N(t))t ≥ 0
est un processus • Ft – adapté • càd-lag • tel que N(0) = 0 , N(t ) < ∞ p.s. • Croissant • à trajectoires constantes par morceaux et ne présentent que des sauts d’amplitude +1. En pratique on considérera souvent pour (Ft ) la filtration naturelle associée à N: Ft =σ (N (u), 0 ≤ u ≤ t). Ex: Le processus de Poisson ; les processus introduits en début de chapitre N ,N (1) ,N ,N (1)

• Remarque : Les processus de comptage sont à trajectoires croissantes et bornées sur [0,t], donc à variation bornée, et on peut donc définir pour un processus adapte X à trajectoires continues (ou càd) l’intégrale de stieljes
Ex :
X (s)dN (s)s
t∫ = X (ti )
ti∈S( s ,t ]
∑ où S est l'ensemble des sauts de N sur l'intervalle (s,t]
Ni (t)=1 Xi≤t{ }
Ci (t) =1t<Ci
Ci (s)0
t
∫ dNi (s) = Ci (Xi )Xi≤t∑ = 1 Xi≤t ,δi=1{ } = Ni
(1) (t)

• Propriétés : Un processus de comptage est une sous-martingale (car il est croissant):
D’un point de vue heuristique, la décomposition N (t ) = Λ (t ) + M (t ) exprime que le processus N « oscille » autour de la tendance prévisible Λ L’équation N (t)= Λ(t)+ M (t) peut donc se lire comme « observations = modèle + terme d’erreur ».
Modèles de durée
ISFA Support de cours - 6 -
� � � � � �³ t
udNuCtN0
1
avec � � > @� �suC C,01 . La censure agit donc comme un filtre. Comme un processus ponctuel est une sous-martingale (puisqu’il est croissant), on lui associe son compensateur prévisible, qui est donc un processus prévisible croissant, de sorte que la différence entre le processus ponctuel et son compensateur soit une martingale. De manière plus formelle on a le résultat suivant : Proposition : Si un processus ponctuel � �� �0tttN , adapté à la filtration � � 0t t
Ft
est tel que � �> @ f�tNE , alors il existe un unique processus croissant continu à droite / tel que
� � 00 / , � �> @ f�/ tE et � � � � � �ttNtM /� est une martingale.
Lorsque / peut se mettre sous la forme � � � �0
t
t u duO/ ³ , le processus O s’appelle
l’intensité du processus ponctuel. Par exemple le compensateur d’un processus de Poisson homogène est � � tt O / , ou, de manière équivalente, l’intensité d’un processus de Poisson homogène est constante égale à O . D’un point de vue heuristique, la décomposition � � � � � �N t t M t / � exprime que le processus N « oscille » autour de la tendance prévisible / de sorte que la différence entre le processus d’intérêt N et sa tendance soit assimilable à un résidu, dont on maîtrise les variations. L’équation � � � � � �N t t M t / � peut ainsi se lire comme « observations = modèle
+ terme d’erreur ». On a en particulier � � � �t tE N E / . On cherche maintenant à déterminer le compensateur prévisible du processus � � ^ `tXtN d 1 .
On note � � � �uNtNtun
� lim la limite à gauche de � �tN et on s’intéresse à la loi de la variable
aléatoire � �� �1tP dN N t � , en ayant noté formellement � � � �tNdttNdNt �� avec dt
« petit ». La variable aléatoire � �tdN ne peut prendre que les valeurs 0 et 1. Par définition de la fonction de survie et de la fonction de hasard, on a :
� �� � � �1tP dN N t h t dt � avec la probabilité � �tS
et � �� � 01 � tNdNP t avec la probabilité � �tS�1 .
En effet, si � � 1 �tN , la sortie s’est déjà produite et le processus ne peut plus sauter. Cet événement se produit avec la probabilité � �tS�1 . Le processus N ne peut sauter entre t et
dtt � que si � � 0 �tN (événement de probabilité � �tS ) et la probabilité de saut est � �dtth . On pose alors � � � � ^ `tXtht t 1O , produit de la fonction de hasard en t et de l’indicatrice de
présence juste avant t, � � ^ `tXtY t 1 . Le processus � �tO est prévisible et � � 1Y t est
∀t > s,N (t) ≥ N (s)⇒ E(N (t) / Fs ) ≥ E(N (s) / Fs ) = N (s)

• M0=0 • On a E(N(t) )= E(Λ(t) ). • Rq : Lorsque Λ peut se mettre sous la forme Λ (t ) = ∫ λ (u ) du , le processus λ
s’appelle l’intensite du processus ponctuel. Si N est intégrable et que λ est cadlag, on montre que
• Dém: Cette quantité Représente, sachant le passé la probabilité infinitésimale de sauter à t
dΛ(t) = λ(t)dt = P(dNt−=1/ F
t−)
E(dMt−/ F
t−) = E(dNt− / Ft− )− dΛ(t) = 0

• Exemple : Processus de Poisson homogène : Λ(t ) = λt • L’intensité d’un processus de Poisson homogène est constante égale à λ . • Ce processus est caractéristique d’un système qui ne vieillit pas: la probabilité
de sauter à t sachant le passé est constante
• Exemple : Processus de Poisson non-homogène : Λ(t ) est déterministe

Processus de comptage dans les durées de vie :
• Dém : On cherche • Soit • On a :
Ni (t)=1 Ti≤t{ } ; Yi (t) =1Ti≥t ⇒Λi (t) = h(u)Yi (u)du0
t∫
P(dNt−
=1/Nt−=1) = 0 avec la probabilité 1− S(t− )
P(dNt−
=1/Nt−= 0) = P(t− <T ≤ t− + dt /T > t− ) = h(t− )dt avec la probabilité S(t− )
⇒ P(dNt−=1/ N
t−) = h(t− )1
N (t− )=0dt = h(t− )Y (t)dt = dΛ(t)⇒Λ(t) = h(u− )Y (u)du
0
t
∫ ≡ h(u)Y (u)du0
t
∫
λ / P(dNt−=1/ F
t−) = λ(t)dt
dNt = Nt+dt − Nt

• On vérifie : Λi(t ) est croissant, il est prévisible par construction
• Mi (t ) = Ni (t ) − ∫ λi (u ) du = Ni (t ) − ∫ h (u )Yi (u ) du = Ni (t ) − H (t ∧ Ti ) est une martingale centrée E(dMt/ N(t−))=0

• De façon équivalente :
• De même pour les processus cumulés
Ni(1) (t)=1 Xi≤t ,δi=1{ } ; Ri (t) =1Xi≥t ⇒Λi
(1) (t) = h(u)R(u)du0
t∫
N (t)= 1 Xi≤t ,δi=1{ }∑ ; Y (t) = 1∑ Ti≥t⇒Λ(t) = h(u)Y (u)du
0
t∫
N (1) (t)= 1 Xi≤t ,δi=1{ }∑ ; R(t) = 1Xi≥t∑ ⇒Λ(1) (t) = h(u)R(u)du0
t∫

• Le fait que soit une martingale centrée suggère de proposer N1(t) comme estimateur de
• Par ailleurs, Le processus est également une martingale dès lors que R(t)> 0 . Donc L+H est un estimateur naturel de H. Cet estimateur s’appelle l’estimateur de Nelson-Aalen. V(H)=V(L)=E(<L>)=
M (t) = N1(t)− h(u)R(u)du0
t∫
h(u)R(u)du0
t∫
L(t) =1R(u)>uR(u)
dM (u)0
t∫ =
1R(u)>uR(u)
dN1(u)−0
t∫ H (t)
1R(u)>uR2 (u)
d <M > (u) =0
t∫
1R(u)>uR2 (u)
h(u)du(u)0
t∫

Modèles de durée
ISFA Support de cours - 10 -
3.1.2. Variance de l’estimateur de Nelson-Aalen
Il résulte de l’approximation effectuée à la section précédente que l’accroissement du processus � �tN1 entre t et ut � suit approximativement une loi de Poisson de paramètre
� � � � � � � �t u
t
R s h s ds R t h t u�
|³ . En effet, on avait vu que conditionnellement au « passé
immédiat », l’accroissement de � �1N t entre t et dtt � suit donc une loi de Bernouilli de
paramètre � � � �h t R t dt . La somme sur les différents individus conduit donc à une variable
binomiale, que l’on peut approcher par une loi de Poisson en choisissant udtn
. On en déduit
donc que, conditionnellement à � �tR , � � � �
� �� �� �
1 1N t u N t h t uV
R t R t§ ·� �
|¨ ¸¨ ¸© ¹
; or on a vu à la section
précédente que � �h t u pouvait être estimé par � � � �� �
1 1N t u N tR t� �
, d’où l’estimateur de la
variance � � � �� �
� � � �� �
1 1 1 1
2ˆ N t u N t N t u N t
VR t R t
§ ·� � � �|¨ ¸¨ ¸
© ¹, qui conduit finalement à proposer
comme estimateur de la variance de H :
� �� � � �� �^ `
1
2/
ˆ ˆi
i
i T t i
N TV H t
R Td
' ¦
qui peut s’écrire avec les notations simplifiées, en l’absence d’ex aequo :
� �� � � �� �^ `
21/
ˆ ˆi
i
i T t
d TV H t
n id
� �
¦ .
3.1.3. Un exemple
Freireich, en 1963, a fait un essai thérapeutique pour comparer les durées de rémission, en semaines, de patients atteints de leucémie selon qu’ils ont reçu ou non un médicament appelé 6 M-P ; le groupe témoin a reçu un placebo. Les résultats obtenus sont les suivants6 :
6 M-P : 6, 6, 6, 6+, 7, 9+, 10, 10+, 11+, 13, 16, 17+, 19+, 20+, 22, 23, 25+, 32+, 32+, 34+, 35+.
Placebo : 1, 1, 2, 2, 3, 4, 4, 5, 5, 8, 8, 8, 8, 11, 11, 12, 12, 15, 17, 22, 23. Les nombres suivis du signe + correspondent à des données censurées. L’application des formules ci-dessus à ces données conduit à :
6 Durée de rémission, en semaines.

• L’estimateur de Kaplan-Meier (KAPLAN et MEIER [1958]) peut également être introduit via les processus ponctuels, en remarquant que la fonction de survie de base du modèle est l’unique solution de l’équation intégrale suivante : t S(t)=1−∫S(u−)h(u)du.
L’équation ci-dessus exprime simplement le fait que la somme des survivants en t et des individus sortis avant t est constante. En remplaçant h(u)du par son estimateur dN1(u)/R(u) introduit à la section précédente on peut proposer un estimateur de la fonction de survie en cherchant une solution à l’équation : S(t)=1− ∫tˆ Shat(u−) dN1(u)/ R(u) . On peut montrer qu’il existe une unique solution à cette équation, et on obtient alors l’estimateur de Kaplan-Meier de la fonction de survie. Cet estimateur peut s’exprimer à l’aide de l’estimateur de Nelson-Aalen de la manière suivante :

où ΔH(s)=H(s)−H(s−). On peut toutefois proposer une
construction explicite plus intuitive de cet estimateur, décrite
infra.
Modèles de durée
ISFA Support de cours - 13 -
On peut montrer qu’il existe une unique solution à cette équation, et on obtient alors l’estimateur de Kaplan-Meier de la fonction de survie. Cet estimateur peut s’exprimer à l’aide de l’estimateur de Nelson-Aalen de la manière suivante :
� � � �� �1ˆ ˆs t
S t H sd
� '�
où � � � � � �ˆ ˆ ˆH s H s H s' � � . On peut toutefois proposer une construction explicite plus intuitive de cet estimateur, décrite infra. La construction heuristique de l’estimateur de Kaplan-Meier s’appuie sur la remarque suivante : la probabilité de survivre au-delà de st ! peut s’écrire :
� � � � � � � � � �S t P T t T s P T s P T t T s S s ! ! ! ! ! . On peut renouveler l’opération, ce qui fait apparaître des produits de termes en � �P T t T s! ! ; si on choisit comme instants de conditionnement les instants où se produit
un événement (sortie ou censure), on se ramène à estimer des probabilités de la forme :
� �1( ) ( )i i ip P T T T T � ! !
ip est la probabilité de survivre sur l’intervalle @ @)()( , ii TT 1� sachant qu’on était vivant à l’instant
)( 1�iT . Un estimateur naturel de ii pq � 1 est 1
ˆ i ii
i
d dq
r n i
� �.
On observe alors qu’à l’instant )(iT , et en l’absence d’ex aequo, si 1 )(iD alors il y a sortie
par décès donc 1 id , et dans le cas contraire l’observation est censurée et 0 id . L’estimateur de Kaplan-Meier s’écrit donc finalement :
� � 111
( )
( )
ˆi
i
D
T t
S tn id
§ · �¨ ¸� �© ¹�
En pratique cependant on est confronté à la présence d’ex æquo ; on suppose alors par convention que les observations non censurées précèdent toujours les observations censurées. On obtient l’expression suivante de l’estimateur :
� � 1( )
ˆi
i
T t i
dS t
rd
§ · �¨ ¸
© ¹�
Remarque n°1 : on travaille ici avec la version continue à droite de la fonction de survie ; certains auteurs utilisent la version continue à gauche. Dans ce cas, les expression ci-dessus restent valables en remplaçant le terme tT i d)( par tT i �)( .


• On notera en préambule que la distribution peut être, comme on l’a vu, caractérisée par différentes fonctions : fonction de hasard, fonction de hasard cumulée, fonction de répartition, densité... Il est évident que l’estimation de la fonction de hasard est du même degré de complexité que l’estimation de la densité ; on se tournera donc de manière privilégiée vers l’estimation empirique du hasard cumulé ou de la fonction de survie, a priori plus simple.
• L’estimation de la fonction de hasard nécessitera alors de régulariser l’estimateur de la fonction de hasard cumulée, qui sera en général discontinu. Ces aspects ne sont pas abordés ici4. Les deux estimateurs principaux dans ce contexte sont l’estimateur de Nelson-Aalen du taux de hasard cumulé et l’estimateur de Kaplan-Meier de la fonction de survie.

• Andersen, P.K., Borgan, , Gill, R.D. and Keiding, N. (1993). Statistical Models Based on Counting Processes. New York: Springer-Verlag.
• Diehl, S. and Stute, W. (1988). Kernel density and hazard function • estimation in the presence of censoring. J. Mult. Analy. 25, 299-310. • Anderson, J. and Senthilselvan, A. (1980). Smooth estimates for the • hazard function. J. R. Statist. Soc. B 42, 322-327. • M¨uller, H.G. and Wang, J.L. (1994). Hazard rate estimation under
random censoring with varying kernels and bandwidths. Biometrics 50, 61-76.


















