Changement de cible d'inflation dans un modèle d'équilibre ...
58
CHARLES LAVOIE Changement de cible d'inflation dans un modèle d'équilibre général dynamique Mémoire présenté à la Faculté des études supérieures de l'Université Laval dans le cadre du programme de maîtrise en économique pour l'obtention du grade de Maître es arts (M.A.) Faculté des Sciences Sociales UNIVERSITÉ LAVAL QUÉBEC 2009 ©Charles Lavoie, 2009
Transcript of Changement de cible d'inflation dans un modèle d'équilibre ...

CHARLES LAVOIE
Changement de cible d'inflation dans un modèle d'équilibre général dynamique
Mémoire présenté à la Faculté des études supérieures de l'Université Laval dans le cadre du programme de maîtrise en économique
pour l'obtention du grade de Maître es arts (M.A.)
Faculté des Sciences Sociales UNIVERSITÉ LAVAL
QUÉBEC
2009
©Charles Lavoie, 2009

Résumé
Ce mémoire introduit une cible d'inflation non constante dans un modèle d'équilibre général pour vérifier si cet ajout permet d'améliorer la capacité de prévision du modèle. Les agents économiques du modèle sontAfin de modéliser la cible d'inflation, celle-ci est introduite dans la politique monétaire qui suit une règle de Taylor. On compare un modèle avec cible d'inflation non observée et un modèle avec cible d'inflation observée à un modèle contrôle traditionnel. Dans le modèle traditionnel, l'inflation à l'état stationnaire est retrouvée dans la règle de Taylor. On estime les différents modèles à l'aide de données canadiennes de 1981Q1 à 2006Q4. Les résultats de nos exercices de comparaison indiquent que l'introduction d'une cible d'inflation dans les modèles d'équilibre général permet de mieux expliquer les données que le modèle traditionel. De plus, le modèle avec cible d'inflation observée semble être la meilleure façon de modéliser la cible d'inflation.

Abstract
This thesis introduces an inflation target in a dynamic general equilibrium model to improve its forecasting capacity. The inflation target is introduced in the Taylor rule followed by the monetary authority. It is introduced in two ways. As an observed variable and as an unobserved variable. Both models are compared to a traditional control model that has the steady state inflation in the Taylor rule. The models are estimated with Canadian data from 1981Q1 to 2006Q4. We find that introducing an inflation target in the models improves them significantly. The model with the observed inflation target seems to be the preferred model.

Avant-propos
J'ai travaillé fort pendant deux ans sur ce mémoire. J'ai réussi à le compléter grâce à de nombreuse personnes qui m'ont soutenu durant ces deux ans et je souhaite les remercier.
Tout d'abord, je veux remercier Kevin Moran et Stephen Gordon de m'avoir dirigé tout le long de mon mémoire. Je remercie Kevin pour m'avoir fait découvrir et aimer la modélisation macroéconomique, particulièrement les modèles d'équilibre général. Je veux également le remercier de m'avoir employé comme assistant enseignant. Je remercie Stephen qui m'a fait découvrir et comprendre l'économétrie Bayesienne. Je suis très reconnaissant qu'il m'ait guidé durant l'estimation de mon mémoire.
Je souhaite également remercier M. Guy Lacroix, qui m'a offert un travail d'assistant enseignant pour la durée complète de mes études. C'était un plaisir de travailler pour lui et je lui offre toute ma reconnaissance.
Je désire remercier le CIRPÉE qui m'a soutenu financièrement à l'aide d'une bourse d'excellence.
Je désire aussi remercier mes collègues de travail à mon stage au Ministère des finances du Québec. Je remercie Patrick Perrier, Gilles Bélanger, Sébastien McMahon et Jean-Pierre Paré. Ils m'ont aidé à développer mon potentiel d'économiste et de chercheur.
Finalement, je désire remercier toutes les autres personnes qui m'ont supporté durant mes études. Mes parents, ma copine Lindsay, mes collègues étudiants et mes amis

Avant-propos
proches.
J'espère que vous allez apprécier la lecture de mon mémoire.

Table des matières
Résumé ii
Abstract iii
Avant-propos iv
Table des matières vi
Liste des tableaux viii
Table des figures ix
1 Introduction 1
2 Revue de l i t térature 3
3 Les modèles 5 3.1 Le consommateur 6 3.2 Le secteur du bien final 8 3.3 Le secteur des biens intermédiaires 9 3.4 L'autorité monétaire 11 3.5 Conditions d'équilibre du marché 13
4 Estimation du modèle 14 4.1 Introduction à l'estimation bayesienne 14 4.2 Fonctions a priori . . . 15 4.3 Distributions a posteriori 18 4.4 Données 19
5 Résultats des estimations 20
6 Comparaison des modèles 23
7 Conclusion 29

TaWe des matières vii
Bibliographie 30
A Système d'équations en équilibre symétrique 32
B Système d'équations stationnarisées 34
C Éta t stationnaire 36
D Décomposition Blanchard Kahn 37
E Le filtre de Kalman 44
F Estimations 47
G Prévisions 48

Liste des tableaux
4.1 Distributions a priori des paramètres 17
4.2 Distribution a priori de l'écart-type de la cible d'inflation 18
5.1 Résultats des estimations 21
6.1 Densité marginale conditionnelle au modèle 24
F.l Résultats des estimations avec écart-type 47
G.l Prévisions du modèle avec cible d'inflation non observée 48 G.2 Prévisions du modèle avec cible d'inflation observée 49

Table des figures
6.1 Prévisions des modèles pour le log du PIB 25 6.2 Prévisions des modèles pour le log de la monnaie 26 6.3 Prévisions des modèles pour le taux d'intérêt 27 6.4 Prévisions des modèles pour l'inflation 28

Chapitre 1
Introduction
Les modèles dynamiques d'équilibre général (DSGE) sont de plus en plus utilisés dans la littérature macroéconomique. Ces modèles combinent des éléments microéconomiques, comme la maximisation de l'utilité par les ménages, avec des concepts macroéconomiques comme l'équilibre général pour déterminer les prix et quantités d'équilibre. Les modèles d'équilibre général sont devenus de plus en plus complets durant les dernières années en incorporant de nombreux secteurs et chocs. Smets and Wouters (2003) et (2005)[18][19] en sont des exemples. Suite à des avancées technologiques importantes, il est maintenant possible d'estimer ces modèles plutôt que de les calibrer. En particulier, Gendron (2006) [8] est un bon exemple d'estimation d'un modèle DSGE. Ils sont également utilisés couramment par les banques centrales '.
Toutefois, en général, les modèles DSGE travaillent avec une cible d'inflation fixe2. Or, l'évidence est que la cible d'inflation bouge avec le temps. Notamment, en 1991, la Banque du Canada a introduit un nouvel objectif à leur politique monétaire. La Banque allait conduire la politique monétaire afin de viser une certaine cible d'inflation. La cible d'inflation actuelle est une fourchette de 1% à 3%.
Pour palier à cette faiblesse, ce mémoire incorpore une cible d'inflation qui n'est pas constante dans un modèle d'équilibre général et le modèle est estimé en utilisant des données canadiennes couvrant la période allant de 1981Q1 à 2006Q4. Une comparaison statistique est ensuite effectuée entre ce modèle et un autre dans lequel la cible d'infla-
!Le modèle d'équilibre général dynamique développé par la Banque du Canada est TOTEM, http ://www.banqueducanada.ca/fr/res/tr/2006/tr97.pdf
2Voir le papier de Gendron(2006)[8]

Chapitre 1. Introduction
tion est constante afin de déterminer le modèle qui explique le mieux les données.
Le cadre général de modélisation utilisé dans ce mémoire est basé sur les travaux de Dib, Gammoudi et Moran (2005)[6) et Gendron (2006) [8]. On modifie ces modèles en introduisant une cible d'inflation non constante. On estime ensuite les deux types de modèle à l'aide de techniques bayesiennes et on teste l'hypothèse que la cible d'inflation est constante en la confrontant à des modèles où la cible d'inflation évolue dans le temps. On peut ensuite trouver le modèle qui permet de mieux reproduire les données observées. Nos résultats montrent que les données concordent mieux avec la spécification du modèle avec cible d'inflation non constante.
Ce mémoire a la structure suivante : Le chapitre 2 offre une revue de littérature et résume brièvement le développement des modèles d'équilibre général. Le chapitre 3 développe les modèles qui seront analysés. Le chapitre 4 explique le fonctionnement de l'économétrie bayesienne ainsi que l'estimation du modèle. Le chapitre 5 explique comment on compare les différents modèles et détermine celui qui concorde le mieux avec les données. Le chapitre 6 conclut ce mémoire.

Chapitre 2
Revue de littérature
'Econometric Policy Evaluation : A Critique', un papier de Robert Lucas[14], est généralement considéré comme le point de départ du développement des modèles d'équilibre général. Dans ce papier, Lucas critique la façon de faire des modèles macroéconomiques de l'époque, particulièrement les systèmes d'équations modélisant les règles de décision des agents économiques. Le problème soulevé par Lucas est que le comportement des agents est modifié lorsqu'il y a un changement de politique. Ceci a pour effet de modifier les règles de décision des agents. Pour cette raison, Lucas suggère plutôt d'ancrer le développement de la macroéconomie dans la modélisation microéconomique du comportement des agents.
Durant les années 80, Kydland et Prescott|13] ont réussi à développer un modèle en réponse à la critique de Lucas. Ce modèle est nommé le modèle Real Business Cycle (RBC). Ce modèle macroéconomique est construit en modélisant le comportement microéconomique des agents individuels dans plusieurs différents secteurs économiques. Il corrigeait les défauts des anciens modèles en montrant clairement le changement dans le comportement des individus suite à des changements de politique et des chocs technologiques. De plus, il peut aisément être quantifié, à l'aide de simulations sur ordinateur, pour vérifier s'il est en mesure de répliquer le comportement des agrégats macroéconomiques observés.
Le modèle RBC était toutefois critiqué car il était plutôt limité. Il ne contenait qu'un choc technologique, alors que la littérature démontrait que d'autres chocs sont obervés dans l'économie. De plus, le modèle ne contenait pas de frictions nominales, ni de politique monétaire. En réponse à ces critiques, des chercheurs ont complexifié le

Chapitre 2. Revue de littérature
modèle durant les dernières années pour obtenir des modèles DSGE plus complets.
Aujourd'hui, les modèles DSGE sont devenus extrêmement flexibles et ils peuvent être ajustés pour tout les besoins. Ils peuvent être construits pour un modèle avec économie fermée ou ouverte, pour évaluer des changements dans la politique monétaire ou fiscale, etc. Même les modèles plus simples sont plutôt efficaces pour la prédiction et la simulation économique. Pour ces raisons, les modèles DSGE gagnent de la popularité parmi les macroéconomistes.
Plus récemment, une équipe de chercheurs dirigés par Michel Juillard a développé DYNARE, un sous-programme de Matlab qui permet de résoudre, solutionner et estimer les modèles d'équilibre général. DYNARE permet de programmer un modèle d'équilibre général en l'écrivant de manière symbolique plutôt que numérique : contraintes de budget, fonction de production et équations d'Euler. Ceci permet d'apporter des modifications rapidement au modèle et de voir les effets de ces modifications. L'utilisation de DYNARE est de plus en plus répandue dans la littérature macroéconomique et c'est ce programme qui a été utilisé pour estimer les différentes versions du modèle étudié dans ce mémoire.

Chapitre 3
Les modèles
Trois modèles différents seront analysés. Partant d'une base identique, les trois versions du modèle sont différenciées par la politique monétaire de la banque centrale. Les agents économiques sont les consommateurs, les producteurs de biens intermédiaires, le producteur de bien final et l'autorité monétaire. Les consommateurs peuvent consommer ou investir le bien final. Afin de décourager des changements importants et trop rapides dans l'investissement, les consommateurs encourent un coût d'ajustement lorsqu'ils modifient le stock de capital. Ceci permet un lissage de l'investissement sur plusieurs périodes. Le marché du secteur du bien final utilise les biens intermédiaires comme intrant et fonctionne sous un environnement parfaitement compétitif. Le secteur des biens intermédiaires est en compétition monopolistique : chaque producteur produit un bien distinct dont la demande provient du secteur du bien final. Le secteur du bien intermédiaire prend la demande du bien final comme acquise et chaque producteur produit un bien distinct. Le producteur de bien intermédiaire fait face à des rigidités de prix : il peut optimiser son prix uniquement lorsqu'il reçoit un signal, comme dans Calvo(1983)[3]. Sinon, il ajuste son prix à l'inflation moyenne comme dans Yun (1996)[21). Les biens distincts sont ensuite combinés pour produire le bien final.
L'autorité monétaire suit une règle de décision qui modifie le taux d'intérêt à court terme selon une règle de Taylor (1993)(20j. Le taux d'intérêt s'ajuste à des variations de l'inflation, du PIB et de la croissance monétaire par rapport à l'état stationnaire. C'est cette règle monétaire qui différencie les trois modèles étudiés dans ce mémoire. L'autorité monétaire réagit aux déviations de nt par rapport à sa cible mais c'est dans la façon de définir la cible que les trois modèles sont différents. Le premier modèle tient compte du ratio de l'inflation par rapport à l'inflation à l'état stationnaire dans sa politique monétaire. Le deuxième modèle a un ratio de l'inflation par rapport à une cible

Chapitre 3. Les modèles 6
d'inflation endogène au modèle plutôt que l'inflation à l'état stationnaire. Finalement, le troisième modèle a un ratio de l'inflation par rapport à une cible d'inflation observée dans sa politique monétaire.
3.1 Le consommateur
Le consommateur maximise son utilité par rapport à sa consommation(Ct), ses heures travaillées(//t) et sa détention d'encaisses réelles (^r). Il maximise son utilité intertemporelle selon la fonction suivante :
t=o ^ t /
où j3 G (0,1) et la fonction d'utilité affiche la forme suivante :
Le paramètre r] dicte l'ampleur de l'utilité du loisir. Le paramètre 7 représente l'élasticité de substition entre la consommation et la détention d'encaisse réelle. Il y a également deux chocs dans cette fonction, zt et bt. Le choc zt peut être interprété comme un choc de préférence et bt est un choc de demande de monnaie. Les deux chocs suivent des processus autorégressifs :
log(zt) = p2logz l_1 + ezt;
log(ôt) = (1 -pb)\og(b) +p6log(6 t_i)+£W;
où on a pz et p& G (—1,1). De plus, ezt et eu sont des chocs indépendants distribués selon une loi normale de moyenne zéro et d'écart-type oz et ov
Les consommateurs doivent tenir compte de leur contrainte budgétaire lorsqu'ils maximisent leur utilité. Cette contrainte budgétaire est exprimée de la façon suivante :
Pt(Ct + h) + Mt + ^ < RktK t + WtHt + Mt_! + £,_! + Tt. rit
Le côté droit de l'équation représente les revenus de l'agent au temps t. Celui-ci reçoit un salaire (Wt) selon le nombre d'heures travaillées (H t). Son capital (Kt) lui

Chapitre 3. Les modèles
rapporte un certain rendement (Rkt) et le consommateur peut également recevoir un tranfert monétaire (T t). Le consommateur apporte aussi à la période t sa monnaie réelle détenue à la période précédente (M t i ) ainsi que ses bons du Trésor de la période précé
dente (i?t—i ) Le côté gauche de l'équation représente les dépenses de l'agent au temps t. L'agent peut consommer (C t) ou investir (I t) au prix P t . De plus, il peut choisir de détenir de la monnaie (M t) ou des bons du trésor (B t) dont le prix au temps t est ^.
Le consommateur fait également face à une contrainte d'accumulation de capital.
KM = (lS)Kt + I t [Zj i±g ( ! ) * ■
Le problème complet pour le consommateur est :
max Y^ B1
{Ct,Mt,Ht,K t+1,B t} j ^ 7 1 log c r +bï Mt
Pt
• . 1
+ r j \ o g ( l H t )
s.c.
Pt(C t + It) + M t + ^ = R k t K t + W tH t + M4_! + Bti + Tt; rit
K t + 1 = ( l S ) K t + I t K t + l
K t (I) Kr.
La solution de ce problème nous donne les cinq conditions du premier ordre suivantes

Chapitre 3. Les modèles
^ Z t C ! ' ^ = A,; (3.1)
<v +v(#) 7
f ^ l L ■ W«ffi*), O,) 77 = A , ? ; (3-3)
1 tf t ' Pt #t+i \ , i ,9 ici / ' V u (Rk,t+i . s . (Kt+2 \ K t+
Kt J V At y Pf+i V ' M + I / ^Ct+i
ffe-')"))' (3.6)
La variable At est le multiplicateur de Lagrange associé à la contrainte budgétaire.
3.2 Le secteur du bien final
Le bien final Yt est produit par de nombreuses firmes en compétition parfaite. Les firmes combinent un continuum de biens intermédiaires pour produire le bien final selon la fonction suivante :
*-( j fï*
V >*) y y >AJ\ ,e>i,
où 9 représente l'élasticité de substitution entre les biens intermédiaires. Les firmes dans ce secteur cherchent à maximiser leurs profits à chaque période ce qui donne le problème suivant :
nax (p t Y t / p j tY j tdj) (3.7) jt}j=o V Jo /
max {y3
S.C.

Chapitre 3. Les modèles
ry]dj (3.8) H S : ^ La solution pour ce problème nous donne la condition du premier ordre suivante pour Yjt, qui représente la demande globale pour le bien intermédiaire :
0 Pjt
Y j t = \P t ) Yt- ( 3-9 )
Puisque le secteur du bien final est un secteur en compétition parfaite et que la fonction de production est à rendements constants, on a aussi la condition que les profits économiques sont nuls. En insérant les équations (3.8) et (3.9) dans l'équation (3.7), nous obtenons la solution pour P t, l'indice des prix dans cette économie,
./o Pt = P n d j
3.3 Le secteur des biens intermédiaires
Le secteur des biens intermédiaires opère en situation de compétition monopolistique. La fonction de production pour chacun des biens intermédiaires est la suivante :
Y]t < A tK*(g tH J ty- a ,
dans lequel Kj t et Hjt représente la quantité de capital et de travail employé par l'entreprise, alors que At représente un choc cyclique de technologie. Finalement, gt est l'augmentation séculaire de la technologie.
Le choc cyclique At suit un processus auto-régressif stationnaire selon l'équation suivante :
log A - (1 - pA)\og(A) + pAlogAt-i +e A t .
Il est à noter que la croissance séculaire de la technologie au temps t est gt = g1 go, où <7o est le niveau initial de la technologie. Les firmes cherchent à minimiser leurs coûts en

Chapitre 3. Les modèles 10
choisissant le capital nécessaire (Kj t) et les heures travaillées (H j t) pour produire une quantité donnée (Yjt). Elles doivent donc résoudre le problème suivant :
{Kjt.Hjtj r t -r t
où mc t est le multiplicateur de Lagrange du problème.
La solution de ce problème nous donne les valeurs optimales pour les variables Kj t
Hjt-
^ = a m c t ^ - (3.10) f t t \ j t
^ = ( l - « ) m c t | i . (3.11) n rijt
Avec ces conditions du premier ordre, on peut obtenir le coût total de production.
RjuKjt ^ W tH j t
= ctmctYjt + (1 - a)mc tY j t ;
= mc tY j t.
Afin d'ajouter des frictions nominales au modèle, on fait l'hypothèse que les firmes dans le secteur intermédiaire ne peuvent pas modifier leur prix à chaque période. Elles changent plutôt leur prix selon le processus suivant : les firmes doivent recevoir un signal avec probabilité <p pour optimiser leur prix. Avec une probabilité 1 — 0, les firmes ne reçoivent pas le signal, mais peuvent ajuster leur prix au taux de l'inflation stationnaire. Une firme ayant reçu le signal d'optimisation doit donc résoudre le problème suivant :
max E Q {pjt}
OO y fc \
^(/?0)fcAm. ( ^ - m c A Yht+k £2 V Pt+k J
Ceci représente la valeur escomptée des profits durant la période pendant laquelle la firme ne sera pas en mesure de réoptimiser.
La condition du premier ordre de ce problème pour p j U une fois transformée, nous donne la valeur optimale de p j t ;

Chapitre 3. Les modèles 11
9 E t ET=o(^- e ) k ^kY t + kmc t + k Pf + k P j t 0 - 1 E t Y . Z v W W - ' ^ + k Y t + k P Î ï î [ ' '
A l'échelle de l'économie, la combinaison de firmes réoptimisant et des firmes indexant leur prix à l'inflation stationnaire implique que le niveau de prix Pt évolue selon :
P t1-0 = 0(7rPf
1i-0) + ( l - ^ 1 - â . (3.13)
En combinant les équations (3.12) et (3.13), il est possible de représenter l'évolution de l'inflation sous la forme suivante, souvent connue comme la courbe de Phillips néo-keynésienne.
_ ( 1 - 0 ) ( 1 - / ? < / > ) _ , 7Tt = Bir t^i -\ m c t .
3.4 L'autorité monétaire
L'autorité monétaire suit une règle monétaire représentée par la formule suivante :
l o g ( f ) - ^ t e ) +»**(T) +»-^ë)+log"" (314)
où log t est un choc de politique monétaire.
Dans cette équation, Rt est le taux d'intérêt contrôlé par l'autorité monétaire, irt est le niveau d'inflation et yt est le niveau de production. L'équation indique que l'autorité monétaire augmente le taux d'intérêt lorsque irt est plus grand que sa cible. Rt augmente également lorsque Yt est plus grand que son potentiel de long terme et lorsque la croissance de la monnaie, p t , est plus élevée que sa valeur à l'état stationnaire. Les trois modèles ont cette forme de politique monétaire en commun, mais diffèrent quant à la spécification de irCMe,t-
'Les variables avec le symbole tilde sont des variables exprimées en déviation par rapport à l'état stationnaire.

Chapitre 3. Les modèles 12
Le premier modèle représente la manière standard employée dans la littérature où flctWe.t = TT. Ceci signifie que la cible d'inflation est constante et elle est égale à l'inflation à l'état stationnaire.
Dans le deuxième modèle, on veut prendre en compte la possibilité que TTdUe.t n'est pas constant. La solution suggérée par les travaux de Ireland est la suivante :
Kciblct — TTcible,t-\ + E cible,t-
I Ceci signifie que les chocs à la cible, ffciWe,*, sont des chocs permanents. Ceci engendre
un problème, n, l'inflation à l'état stationnaire, n'est pas bien définie. L'estimation va trouver une valeur pour n, mais elle ne sera pas interprétable structurellement comme celle du premier modèle. La variable n estimée est plutôt un niveau d'inflation de référence parce que iTcibie,t n ' a P a s tendance à revenir à n, il n'y a que des chocs permanents qui affectent la cible.
Il y a beaucoup de données démontrant que iTcibie.t n'est pas constante, mais le modèle d'Ireland fait l'hypothèse que ircxbie,t n'est pas observée, ce qui est une hypothèse extrême. Le troisième modèle modifie donc cette hypothèse pour que iràUct soit une variable observée. En pratique, la variable irdbie.t est égale à la cible officielle de la Banque du Canada depuis 1991. Pour ce qui est des données avant 1991, nous utilisons les prévisions à long terme de la Banque du Canada. Les travaux de Amano et Murchisson ont ainsi établi une série pour 7rciWet et on l'utilise en faisant l'hypothèse suivante :
TTcible.t = TT + Ef
Ceci représente une décomposition de la cible entre l'inflation à l'état stationnaire et un facteur d'ajustement.

Chapitre 3. Les modèles 13
3.5 Conditions d'équilibre du marché
L'équilibre sur les marchés requiert que :
Kt = f Kjtdj; Jo
Ht = / HJtdj; Jo
Bt = 0; T, = MtMt ù Yt = Ct + If
Afin d'avoir un équilibre stationnaire, nous posons mt = j r , wt = yr et rkt = ^p1 ■ De manière à stationnariser les variables croissantes, les variables stationnarisées sont exprimées en minuscules (yt = — ).
Le modèle possède un équilibre unique lorsqu'on spécifie n, 7rdWe, A et b. irdUe est le cible d'inflation à l'état stationnaire et celleci équivaut à l'inflation à l'état stationnaire. Il faut stationnariser les variables Y, K, C, I et M par rapport à la croissance g. De plus, le modèle doit être log linéarisé autour de l'état stationnaire car le modèle n'a pas de solution analytique. Afin de résoudre le modèle, celuici est exprimé sous forme espaceétat comme démontré dans Blanchard et Kahn. La forme général du modèle en espaceétat est :
St+i — ^ l ^ t + fl2£t+l',
dt = Q3st.
Chacun des trois modèles comporte quatre chocs pouvant apporter des fluctuations au modèle. Puisqu'il y a quatre chocs dans l'économie, nous pouvons avoir quatre va
riables observées. Cellesci sont expliquées plus en détails dans le prochaine chapitre. Le vecteur st est un vecteur des variables exogènes et des variables prédéterminées du mo
dèle. Pour ces modèles, st = [k ti,rh ti, At,bt,Vt, Zt, Ttcibie.t] Le vecteur dt est composé des variables endogènes du modèle. Nous avons dt = [yt, rht, ht, Rt, rkt ct, rnct, At, ftt, wt, vrt] Le vecteur êt est composé des chocs du modèle. Nous avons êt = [EAI, £bt, Ezt, evt, £7rciWe,J Les vecteurs Qi, Jl2 et Q3 contiennent les paramètres du modèle. L'ensemble des para
mètres peut être exprimé avec O = [pA, pb, pz, pv, pn , p^, py, a A, o~b, °z, o~v,
aircible,Q, P, S, rj, g, 7,7T, x, A, b, a, </>]. Cette forme espaceétat du modèle nous permet de faire l'estimation bayesienne du modèle.

Chapitre 4
Estimation du modèle
Ce chapitre se concentre sur l'estimation des paramètres du modèle. Les paramètres sont estimés à l'aide de techniques bayesiennes. La première section est une introduction à l'estimation bayesienne. Les sections suivantes expliquent les étapes de l'estimation des trois modèles incluant une discussion à propos des distributions a priori et a posteriori des paramètres.
4.1 Introduction à l'estimation bayesienne
L'estimation bayesienne est à mi-chemin entre la calibration et le maximum de vraisemblance. L'estimation bayesienne retient une partie de la calibration avec les densités de probabilité a priori des paramètres et retient une partie du maximum de vraisemblance lorsqu'on veut confronter le modèle aux données. Les deux sont reliés par la loi de Bayes, d'où le nom estimation bayesienne.
D'un côté, nous avons la densité a priori des paramètres qui est exprimé comme p(O) et d'un autre côté, nous avons la fonction de vraisemblance p(dt\Q). Ce qui nous intéresse est la densité a posteriori, ce qui est représenté par p(Q\dt). En applicant le théorème de Bayes, nous pouvons obtenir la densité à posteriori des paramètres sachant les données est la suivante :
, n , n p(6;<*t) v m , ) = * T :

Chapitre 4. Estimation du modèle 15
où p(Q:dt) est la densité conjointe de 0 et dt et p(dt) est la distribution des données.
De plus, nous savons que
P(dt\Q) = ^ j ^ <=>p(6;d t) =p(d t \ e ) P ( e ) .
Avec les éléments ci-haut, il nous est possible d'obtenir notre densité de probabilité a posteriori. Celle-ci est exprimée à l'aide de la fonction de densité a priori et la fonction de vraisemblance comme
p ( e ^ l 4 A ) = pJdtJÂ) ' où p(dt\A) représente la densité de probabilité marginale des données conditionnelle au modèle A :
p(eA\d t ,A)= f p(GA;dt\A)deA. JeA
Nous pouvons finalement obtenir le noyau a posteriori,
p(GA\dt, A) <x p(d t\eA , A)p(QA\A) = K(GA\dt, A).
Cette équation est importante et nous permet de reproduire tous les moments a posteriori. L'idée est d'estimer la fonction de vraisemblance avec le filtre de Kalman et ensuite de simuler le noyau a posteriori à l'aide d'une méthode Monte Carlo par chaînes de Markov (MCMC) nommée Metropolis Hastings.
4.2 Fonctions a priori
Nous devons d'abord établir des distributions a priori pour les paramètres du modèle. Afin de prendre de bonnes distributions a priori, il faut faire un tour de la littérature macroéconomique. Les paramètres pA, pb, pz et pv sont les paramètres gouvernant le caractère autorégressif des chocs exogènes du modèle. Ceux-ci suivent une loi Beta, ce

Chapitre 4. Estimation du modèle 16
qui nous permet de maintenir les paramètres entre 0 et 1. Les valeurs de 0.8 pour pA, pb et pz sont tirées de Smets,Wouters(2003)[18] car on s'attend à ce que ces chocs affichent une persistence considérable. Un écart-type de 0.2 permet d'être peu contraignant et de d'allouer une large gamme de valeurs. Pour ce qui est de pv, le paramètre du processus auto-régressif du choc de politique monétaire, celui-ci devrait être moins élevé que les autres chocs. Il a donc une moyenne de 0.5 pour sa distribution et un écart-type de 0.2 également. Ensuite, les distributions a priori des écart-types des chocs sont distribués selon une Gamma Inverse. Cette loi nous permet d'avoir uniquement des valeurs positives pour les écart-types. En ce qui concerne les paramètres pn , p^ et py de la politique monétaire(voir équation (3.14)), les distributions a priori sont fortement influencées par les travaux de Taylor (1993)(20| et Ireland(1999)[10]. Ceux-ci ont estimé ces paramètres comme étant respectivement 1.5, 1.5 et 0.5. Ces valeurs sont donc la moyenne des distributions a priori et un écart-type de 0.5 pour ces paramètres est utilisé afin de ne pas être trop contraignant. Une loi normale est utilisée puisque les valeurs peuvent varier dans l'ensemble R.
Le paramètre 0 est l'élasticité de substitution entre les différents biens intermédiaires. Sa moyenne est basée sur Rotemberg and Woodford (1992)[17] qui ont établi le mark-up des prix à 20% environ, ce qui implique une valeur de 9 est 6. Ce paramètre a un écart-type de 1, ce qui est relativement petit puisque la littérature est assez certaine de ce paramètre. Les paramètres B, ô et a sont des paramètres classiques de la littérature macroéconomique. Ceux-ci ont été estimé à maintes reprises et leurs moyennes sont respectivement 0.97, 0.025 et 0.36. Les écart-types sont 0.2, 0.01 et 0.1. La variable n est un paramètre qui dicte l'ampleur du loisir dans la fonction d'utilité. Il a une moyenne de 1.35 ce qui fait que les gens passent un tiers de leur temps au travail, avec écart-type 0.1. Le taux de croissance de l'économie g affiche une moyenne de 1.005 dans le modèle, ce qui se traduit par un taux de croissance annualisé de 2%. Le taux de croissance g a un écart-type de 0.002. Le paramètre 7, l'élasticité de substitution intertemporelle de la monnaie réelle, est de moyenne 0.05 et d'écart-type 0.03. Cette faible moyenne est justifiée par les travaux de Mulligan, Martin(2000)[16] qui montrent que lorsque les taux d'intérêt sont bas, l'élasticité 7 est faible. Le paramètre \ dicte le coût de modifier la quantité de capital entre la période d'aujourd'hui et la période suivante. Une moyenne de 15 et un écart-type 5 sont utilisés et tirés de la calibration dans Ireland (2001)[10] et dans Dib (2001)[5].
L'inflation à l'état stationnaire, ir, suit une normale de moyenne 1.01 et d'écart-type 0.01. Ceci revient à un taux net annualisé de 4%. Ceci est également tiré de Ireland (2001). La technologie à l'état stationnaire, A, est plutôt un facteur d'échelle et peut

Chapitre 4. Estimation du modèle 17
T A B . 4.1 - Distributions a priori des paramètres Paramètre Distribution Moyenne Écart-type
PA Beta 0.8 0.2
Pb Beta 0.8 0.2 Pz Beta 0.8 0.2 Pv Beta 0.5 0.2 PlT Normale 1.5 0.5
Pu Normale 1.5 0.5
Py Normale 0.5 0.5 o-a Inverse gamma 0.0141 0.0009 °b Inverse gamma 0.0141 0.0009 o-z Inverse gamma 0.0141 0.0009 0~v Inverse gamma 0.0141 0.0009 e Normale 6 1
Q Beta 0.97 0.01 ô Beta 0.025 0.01
v Normale 1.35 0.1
9 Normale 1.005 0.002
7 Normale 0.05 0.03 X Normale 15 5 Tt Normale 1.01 0.01 A Normale 30 5 b Normale 0.5 0.2 a Beta 0.36 0.02
<t> Beta 0.5 0.3
prendre n'importe quelle valeur. Celui-ci suit une loi normale de moyenne 30 et écart-type 5. b est un paramètre de préférence pour les encaisses réelles dans la fonction d'utilité. Selon Dib(2003), la vélocité moyennne de M2 par rapport à la consommation est de moyenne 0.5 et écart-type 0.2. Sa distribution suivra donc une loi normale de moyenne 0.5 et écart-type 0.2. Finalement, le paramètre 0 suit une loi beta de moyenne 0.5 et écart-type 0.3. (p représente la durée des contrats pour les prix des biens intermédiaires. Sa moyenne est basé sur Bils et Klenow (2004) qui ont montré que les prix ont une durée d'environ 5.5 mois.
Pour le modèle avec la cible d'inflation non observée, les distributions a priori doivent être modifiées. En imposant une racine unitaire à la cible d'inflation, on ajoute une source potentielle de persistance distincte de celle présente dans la technologie. Par contre, ce sont les données qui vont décider laquelle de ces deux sources de persistance est importante. Il faut également ajouter une distribution a priori pour l'écart-type du

Chapitre 4. Estimation du modèle 18
TAB. 4.2 - Distribution a priori de l'écart-type de la cible d'inflation Paramètre
Vcible
Distribution Inverse gamma
Movenne 0.0141
Écart-type 0.0009
choc de cible d'inflation.
4.3 Distributions a posteriori
Afin de calculer les fonctions de probabilité a posteriori, nous utilisons l'algorithme d'acceptation-rejet Metropolis Hastings. L'objectif est de simuler la fonction de probabilité a posteriori à l'aide de Metropolis Hastings. Nous utilisons cette technique car le noyau a posteriori est une fonction complexe non-linéaire du vecteur de paramètres O et ne possède pas de forme explicite. Il est donc plus simple de simuler la fonction de probabilité a posteriori. Dynare suit les étapes suivantes lorsqu'il utilise la technique Metropolis Hastings :
1. On choisit un point de départ O0. Ce point de départ devrait être le mode de la fonction de probabilité a posteriori calculé par le maximum du log vraisemblance.
2. Nous tirons un vecteur de paramètres O* d'une distribution
J(Q*\Qt-l) = N ( Q t - l c ^ 2 )
où V m est l'inverse de la matrice hessienne calculée au mode de la densité a posteriori.
3. On calcule le ratio d'acceptation :
p(Q*\YT) K(e,\YT) r = P(&^ \Y T ) K(et-i\YT)
4. On accepte ou rejette le candidat selon la règle de décision suivante :
el = 5. Répéter les étapes 2 à 4.
O*, avec probabilité min(r,l) ; sinon. e*-1.
À l'étape 1, on choisit notre premier candidat O* avec le mode de la distribution a posteriori. À l'étape 2, on tire un nouveau candidat d'une distribution normale centrée

Chapitre 4. Estimation du modèle 19
en O' - 1 . À l'étape 3, on calcule la valeur du noyau a posteriori du candidat O* comparé à la valeur du noyau a posteriori de O' - 1 . L'étape 4 nous permet de décider si on conserve le candidat ou non. Si le ratio d'acceptation est plus grand que 1, alors on conserve le candidat. Sinon, le candidat est conservée avec probabilité r et rejeté avec probabilité 1 — r. Si le nouveau candidat est rejeté, on conserve O' - 1 pour le prochain tour. Après de nombreuses itérations de ce processus, il est possible de faire un histogramme représentant les candidats retenus durant chaque itération du processus acceptation rejet. L'idée est d'avoir un très grand nombre de différentes colonnes pour l'histogramme de sorte que l'on obtienne une distribution lisse de la fonction de probabilité a posteriori.
Il est important qu'on balaie complètement le domaine de la distribution a posteriori et le taux d'acceptation est la mesure pour s'assurer que ceci a été fait. Les candidats doivent donc être tirés un peu partout dans le domaine afin de trouver un maximum global. Le paramètre le plus important pour avoir un bon taux d'acceptation est le facteur d'échelle c, qui influence la variance de la fonction pour choisir les candidats. Si le facteur d'échelle est trop bas, le taux d'acceptation sera élevé. Ceci augmente le temps pour que la distribution converge vers la distribution a posteriori car il y a de fortes chances que la distribution demeure coincée sur un maximum local. Un facteur d'échelle trop élevé et le taux d'acceptation sera trop bas et il est probable qu'on conserve longtemps un candidat dans les queues de la distribution. Selon la littérature, un taux d'acceptation idéal se situe entre 0.25 et 0.40.
4.4 Données
L'exercice d'estimation est fait avec des données canadiennes. Les données utilisées sont tirées de CANSIM II de Statistique Canada. Les données sont celles du PIB, des encaisses réelles, du taux d'intérêt à court terme et de l'inflation. Le PIB est mesuré par la demande domestique finale réelle. La monnaie réelle est M2 divisé par le déflateur du PIB. On utilise les données de la population pour trouver le PIB et M2 par habitant. Le taux d'intérêt à court terme est le taux des bons du Trésor à court terme (trois mois). Finalement, l'inflation est le taux de croissance du déflateur du PIB. Le PIB et la monnaie réelle sont exprimés en logarithme1. De plus, toutes les données ont une fréquence trimestrielle. Les données pour la cible d'inflation proviennent de la base de donnée construite par Robert Amano et Stephen Murchison pour la Banque du Canada.
'La série V1992078 est utilisé pour le PIB, V37128 pour l'aggrégat M2, V122531 pour le taux d'intérêt, V1997756 pour le déflateur du PIB et V2091037 pour les données sur la population. Les séries peuvent être retrouvées sur le site de Statistique Canada, www.statcan.ca

Chapitre 5
Résultats des estimations
Pour ce mémoire, DYNARE a performe cinq itérations de Metropolis-Hastings pour chaque modèle. Les tests univiariés et multivariés de Brooks-Gelman démontrent qu'il y a convergence pour tout les paramètres. DYNARE calcule ensuite la moyenne de la distribution a posteriori des paramètres. Les résultats sont présentés dans le tableau 5.1 à la page suivante.
Un total de 23 paramètres sont estimés dans le modèle contrôle et dans le modèle avec cible d'inflation observée. Le modèle avec cible d'inflation non observée, quant à lui, a 24 paramètres estimés, l'écart-type dans les changements de cible étant le paramètre ajouté. La plupart des paramètres varient peud'un modèle à l'autre ce qui indique une certaine stabilité. De plus, les valeurs estimées ressemblent aux valeurs calibrées de ces paramètres dans la littérature. Les paramètres qui sont très variables sont les paramètres de la politique monétaire, l'inflation à l'état stationnaire et le paramètre de la persistance du choc technologique. Pour le paramètre p- (la réponse du taux d'intérêt aux déviations de l'inflation par rapport à sa cible), le modèle avec cible d'inflation non observée (CINO) obtient une valeur considérablement plus élevée que les autres modèles. Celui-ci a une valeur de 0.5836, comparé à 0.9725 avec le modèle contrôle (C) et 0.758 pour le modèle avec cible d'inflation observée (CO). Ceci implique que lorsque la cible d'inflation est variable, la politique monétaire réagit fortement aux différences entre l'inflation et la cible d'inflation. Le paramètre p^ demeure relativement constant dans les modèles C et CO, 1.1042 pour le modèle C, 1.1346 pour le modèle CO. Par contre, le modèle CINO accorde une forte importance à la croissance de la monnaie, avec une valeur estimée de 2.7818. La variable py est plutôt surprenante. Elle a peu d'influence dans le modèle C (0.0641) et le modèle CO (0.0145) mais elle a une influence importante dans le modèle CINO (1.1994). De plus, le modèle CINO a une autre différence majeure comparé aux modèles C et CO. La persistance du choc technologique est beaucoup plus

Chapitre 5. Résultats des estimations 21
TAB. 5.1 - Résultats des estimations Modèle
Paramètre Contrôle Cible d'inflation observée Cible d'inflation non observée PA 0.8955 0.9045 0.1149 Pb 0.8181 0.8148 0.8579 Pz 0.9008 0.9016 0.9408 Pv 0.1866 0.2101 0.4562 Pir 0.9725 0.758 0.5836 Pu 1.1042 1.1346 2.7818 Py 0.0641 0.0145 1.1994 e 6.6949 6.7631 6.6769 P 0.9901 0.9903 0.9902 ô 0.0428 0.042 0.0617 V 1.3157 1.3095 1.3142 9 1.0074 1.0076 1.0072 7 0.0524 0.053 0.0686 X 23.15 23.329 26.181 TTss 1.0088 1.0075 1.0239 ASs 29.912 29.89 30.1 bss 0.2114 0.2481 0.974 a 0.3884 0.3874 0.3819 4> 0.6472 0.6433 0.658 o-A 0.0102 0.0103 0.0128 °b 0.0094 0.0096 0.0094
°z 0.0147 0.0158 0.0106 av 0.0134 0.0131 0.0114 Otarg - - 0.009

Chapitre 5. Résultats des estimations 22
faible dans le modèle CINO (0.1149) que dans les modèles C (0.8955) et CO (0.9045). Ceci peut être expliqué par la présence de la cible d'inflation qui suit un processus avec racine unitaire. Ceci implique que la persistance du modèle est passée de la technologie à la cible d'inflation. Finalement, l'inflation à l'état stationnaire est considérablement différente entre le modèle CINO (1.0239), le modèle C(1.0088) et le modèle CO(1.0075). Ceci implique un taux d'inflation annuel de 9.9%, 3.4% et 3.11%, respectivement. La valeur de 9.9% pour le modèle CINO ne semble pas une valeur réaliste, mais elle est une conséquence de la racine unitaire. Ceci à pour conséquence qu'il est difficile pour le modèle de fixer une valeur à n.
Pour ce qui est des paramètres dont la valeur estimée varie moins d'un modèle à l'autre, on a Pb, qui prend la valeur 0.8181 (modèle C), 0.8148 (modèle CO) et 0.8579 (modèle CINO). La persistance du choc z, pz est élevé dans les trois modèles. Il prend les valeurs 0.9008 (modèle C), 0.9016 (modèle CO) et 0.9408 (modèle CINO). La persistance du choc de politique monétaire, pv, est légèrement différent dans le modèle CINO (0.4562) que dans le modèle C (0.1866) et le modèle CO (0.2101). Par contre, la persistance est tout de même peu élevée dans les trois modèles. 6 prend les valeurs 6.6949 (modèle C), 6.7631 (modèle CO) et 6.6769 (modèle CINO). Le mark-up des producteurs intermédiaires sur le coût marginal demeure donc le même darts les trois modèles, autour de 20%, comme dans Rotemberg et Woodford (1992)|17). La dépréciation du capital, 5, est 0.0428 (modèle C), 0.042 (modèle CO) et 0.0617 (modèle CINO). Le poids du loisir dans la fonction d'utilité, représenté par rj, prend la valeur 1.3157 (modèle C), 1.3095 (modèle CO) et 1.3142 (modèle CINO). Ceci implique que les ménages passent un tiers de leur temps au travail ce qui est une valeur fréquente dans la calibration. La croissance économique, g, est estimée à 1.0074 (modèle C), 1.0076 (modèle CO) et 1.0072 (modèle CINO). Ceci représente un taux de croissance annualisé de, 3%, 3.1% et 2.9% respectivement. La variable 7 est estimée à 0.0524 (modèle C), 0.053 (modèle CO) et 0.0686 (modèle CINO). La variable 7 est donc légèrement plus élevée dans le modèle CINO, mais la valeur 0.0686 reste similaire à Dib, Gammoudi, Moran (2005). La part du capital dans la production, a, prend les valeurs 0.3884, 0.3874 et 0.3819. La distribution a priori de a était assez restrainte afin d'assurer une valeur comme celles estimées dans les trois modèles. Ces valeurs reflètent donc la calibration dans la littérature. La durée des contrats de prix, (f>, est estimée à 0.6472 (modèle C), 0.6433 (modèle CO) et 0.658 (modèle CINO). Ceci reflète respectivement une durée de contrat de 7 mois pour le modèle C et CO ainsi qu'une durée de 6.7 mois dans le modèle CINO.

Chapitre 6
Comparaison des modèles
Afin de comparer les modèles entre eux, nous allons utiliser le rapport de cotes a posteriori. Celui-ci nous permet de voir lequel des modèles concorde le mieux avec les données. En supposant que nous connaissons les distributions a priori d'un modèle A (p(A)) et d'un modèle B (p(B)), la loi de Bayes nous indique que nous pouvons trouver la distribution a posteriori d'un modèle avec
P W T ) «*MM Ei=A,BP(dr\I)p(lY
où I = A,B.
Cette formule peut être généralisée pour autant de modèles qu'on veut. On peut ensuite comparer deux modèles avec la formule suivante, dérivée de la précédente
p(A\dT) p(A)p(dT\A) p(B\dT) p(B)p(dT\BY
Ce qu'il nous manque est la densité marginale des données conditionnelle au modèle (p(dT\I)). En supposant que p(A) = p(B)(i.e. qu'on accorde autant de poids à un modèle qu'à l'autre), il ne reste qu'à trouver la valeur de ^pffy- Heureusement, DYNARE peut calculer le log de la densité marginale des données conditionnelle au modèle. Par contre, ce test n'a pas de p-value précise qui permet une décision d'acceptation ou de rejet d'un modèle en faveur d'un autre. C'est plutôt une mesure relative pour décider lequel explique mieux les données.

Chapitre 6. Comparaison des modèles 24
TAB. 6.1 - Densité marginale conditionnelle au modèle Contrôle Cible d'inflation observée Cible d'inflation non observé
log(p(YT\I)) 1477.2 1819.1 1495 Différences des logarithmes - 341.8 17.8
En faisant la différence des logarithmes, \ogp(dr\A) — \ogp(dr\B), nous obtenons une mesure nous permettant de comparer les modèles. Lorsque la valeur de cette mesure est plus élevée que 10, il y a de bonnes raisons de rejeter le modèle B en faveur du modèle A. Lorsque l'on compare le modèle avec cible constante à celui de cible d'inflation variable mais non observée, il y a une différence de 17.8 en faveur du modèle avec cible d'inflation non observée. Une différence aussi importante laisse croire que le modèle avec cible d'inflation non observée concorde mieux avec les données que le modèle sans cible d'inflation. Par contre, le modèle avec cible d'inflation observée a une différence beaucoup plus considérable que le modèle contrôle et le modèle avec cible d'inflation non observée. Il dépasse de 324 le modèle avec cible d'inflation non observée et de 341.8 le modèle contrôle. Cette méthode a des limites. Le problème est que le rapport de cotes a posteriori dépend fortement des données utilisées et puisque les données sont différentes entre le modèle avec cible d'inflation observée et les autres modèles, il n'y a pas de sens à les comparer. L'ajout de la cible d'inflation observée rend nécessairement le modèle plus explicatif que les autres. Pour déterminer lequel des deux modèles avec cible d'inflation est meilleur que l'autre, nous allons comparer leur performance pour la prévision hors-échantillon des données observées. Nous enlevons une donnée de notre échantillon, le modèle est réestimé et on prédit la donnée enlevée. On peut ensuite comparer notre prévision à la donnée réelle. On répète le processus en retirant une autre donnée à notre échantillon, on refait une autre estimation et on fait une nouvelle prédiction qu'on peut comparée à la donnée retirée. L'équation qui suit explique comment nous obtenons une prévision des données pour la période suivante avec les données de la période présente. Celle-ci nous donne la distribution de la prévision.
p(dt+i\dt) = Jp(dt+i\dt,ô)p(9\dt)de
On calcule l'espérance de la distribution de notre prévision :
E[dt+i\dt] = j p(d t+i\d t)dd t+\.
Ceci peut être calculé avec notre représentation espace-état en faisant une moyenne de l'ensemble des candidats 6l. On calcule dt+i à l'aide de l'équation
Chapitre 6. Comparaison des modèles 25
dt+i = P(G)s t
de la représentation espace-état. On fait ensuite la moyenne des d t+i pour obtenir notre prévision.
Les figures 6.1 à 6.4 montre les données comparées aux prévisions du modèles avec cible d'inflation observée et le modèle avec cible d'inflation non observée.
2004Q4 Période
1 1 ■ _ i 1 1
<£.
i /V--— — "" '/ ^ N _ - " " " ' " ' " " * , . . • ' '
i /V--— ■ ' " ' • ■ / \ ... - - • -. _ _ _:-,' • • " " /
1\ ,;/V / ■ ■ ■
/ \ ^ - ^ \ • / /
i i V' '
■ / ■ -
i 1 1 1 1
Traditionnel
- - Cible observée Données
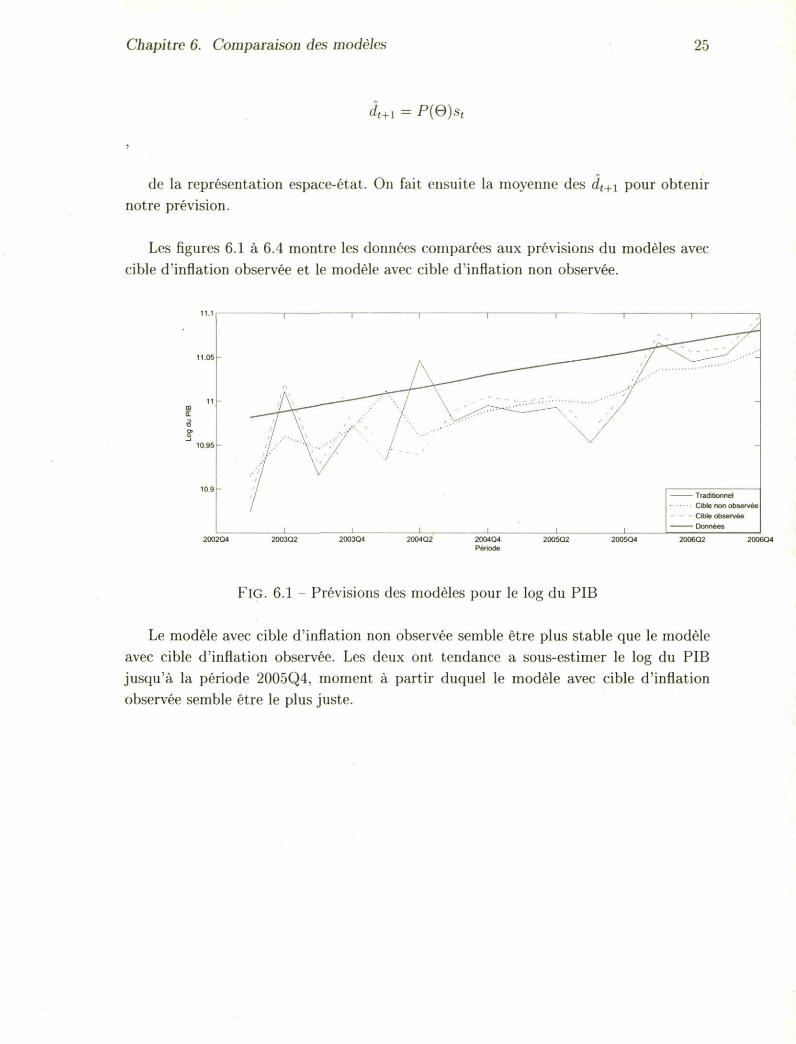
FlG. 6.1 - Prévisions des modèles pour le log du PIB
Le modèle avec cible d'inflation non observée semble être plus stable que le modèle avec cible d'inflation observée. Les deux ont tendance a sous-estimer le log du PIB jusqu'à la période 2005Q4, moment à partir duquel le modèle avec cible d'inflation observée semble être le plus juste.
Chapitre 6. Comparaison des modèles 2G
94
9.35
93
9.25
i
9.2
I
9.15
2004Q2 2004Q4 Période
-
i i i i I i
-— . . - ■ ■ / = = :
^
: „ _ - - ~ - . - ' / ' -
: \ ' S - ^
- ' / ' -
_ J>^~- / ^ \ ^y - - - _
- ""f \> - ""f \> Traditionnel
-
i i I
Cible observée Données
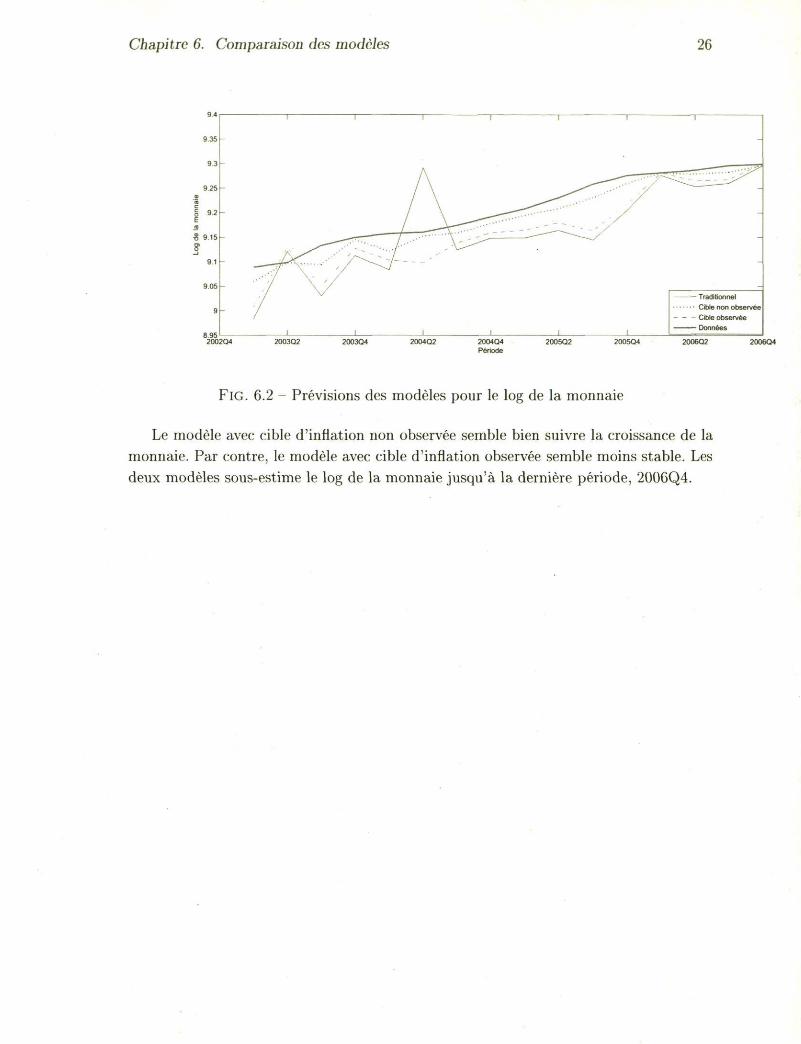
FlG. 6.2 Prévisions des modèles pour le log de la monnaie
Le modèle avec cible d'inflation non observée semble bien suivre la croissance de la monnaie. Par contre, le modèle avec cible d'inflation observée semble moins stable. Les deux modèles sousestime le log de la monnaie jusqu'à la dernière période, 2006Q4.
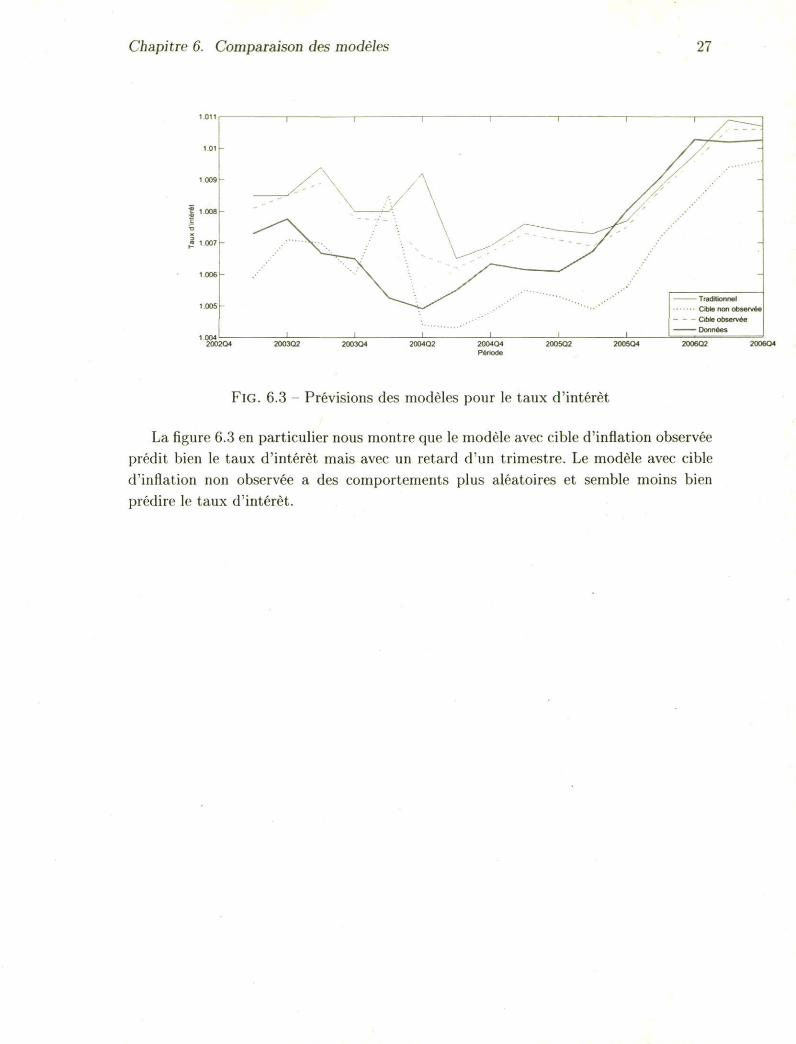
Chapitre 6. Comparaison des modèles 27
2003Q2 2003Q4
FlG. 6.3 - Prévisions des modèles pour le taux d'intérêt
La figure 6.3 en particulier nous montre que le modèle avec cible d'inflation observée prédit bien le taux d'intérêt mais avec un retard d'un trimestre. Le modèle avec cible d'inflation non observée a des comportements plus aléatoires et semble moins bien prédire le taux d'intérêt.

Chapitre 6. Comparaison des modèles 28
1 1 1 1 1 1 Traditionnel Cible non observée Cible observée
-
— ^ Données
-
_
►
\ / \ /
/ \
/ /^v^»
\ S \ . /
►
\ / \ /
/ \
/ \ N.
\ S \ . /
►
\ / \ /
/
/ \ N.
\ S \ . /
-
1 ' ■■
1 1 1 1 i i 1 2004Q4 Période
FlG. 6.4 Prévisions des modèles pour l'inflation
La figure 6.4 semble encore donner raison au modèle avec cible d'inflation observée qui suit les mêmes chocs à l'inflation mais avec un retard d'un trimestre. Le modèle avec cible d'inflation non observée prédit constamment une inflation moindre que 1.
L'ensemble de ces graphiques semblent donner raison au modèle avec cible d'inflation observée plutôt que le modèle avec cible d'inflation non observée. Particulièrement le graphique de prévision de l'inflation, où le modèle avec cible d'inflation non observée prédit constamment une baisse des prix.

Chapitre 7
Conclusion
L'objectif du mémoire était d'incorporer une cible d'inflation non constante dans un modèle dynamique d'équilibre général estimé, pour vérifier si cette modification améliore la performance du modèle. Pour atteindre cet objectif, on a commencé avec un modèle ayant une politique monétaire traditionnelle dont la cible d'inflation était constante dans le temps. Un deuxième modèle a été ensuite développé, incorporant une cible d'inflation stochastique dans la politique monétaire suivant les travaux de Ireland(2007)[12]. Le troisième modèle incorporait une cible d'inflation non constante mais observée utilisant pour cela des travaux effectués à la Banque du Canada. Suite à l'estimation, on peut conclure que le modèle avec cible d'inflation non observée et celui avec cible d'inflation observée concordent mieux avec les données que le modèle contrôle dans lequel la cible d'inflation est constante. Puisque les données sont différentes entre le modèle avec cible d'inflation observée et les deux autres modèles, il est définitivement plus explicatif puisqu'il a plus de données, donc plus d'information. Suite à des comparaisons des capacités de prévision des deux modèles avec cible d'inflation, on conclut que le modèle avec cible d'inflation observée serait le modèle préféré.
Les prochaines étapes possibles pourraient être d'incorporer le modèle avec cible d'inflation observéee en économie ouverte. Il pourrait également être intéressant de reprendre le modèle avec cible d'inflation non observée et faire des modifications qui pourraient améliorer sa capacité de prévision.

Bibliographie
[2
[3
M
[5
[6
[7
[8
[9
[10
[H
112
David Andolfatto, Scott Hendry, and Kevin Moran. Are inflation expectations rational ? January 2005. Olivier Jean Blanchard and Charles M Kahn. The solution of linear difference models under rational expectations. Econometrica, 48(5) :1305—11, July 1980. Guillermo A. Calvo. Staggered prices in a utility-maximizing framework. Journal of Monetary Economics, 12(3) :383-398, September 1983.
Lawrence J. Christiano, Martin Eichenbaum, and Charles Evans. Nominal rigidities and the dynamic effects of a shock to monetary policy. Journal of political economy, 2005.
Ali Dib. An Estimated Canadian DSGE Model with Nominal and Real Rigidities. 2001. Ali Dib, Mohamed Gammoudi, and Kevin Moran. Forecasting Canadian time series with the new-keynesian model. 2005.
Christopher J. Erceg and Andrew T. Levin. Imperfect credibility and inflation persistence. Journal of Monetary Economics, 50(4) :915-944, May 2003.
Debbie Gendron. Model stability under a policy shift : Are DSGE models really structural ? Université Laval, 2006. S. Gordon and G. Bélanger. Echantillonnage de Gibbs et autres application économétriques des chaînes markoviennes. Cahiers de recherche 9509, Université Laval - Département d'économique, (9509), 1995.
Peter N. Ireland. Sticky-price models of the business cycle : Specification and stability. Journal of Monetary Economics.
Peter N. Ireland. A small, structural, quarterly model for monetary policy evaluation. Carnegie-Rochester Conference Series on Public Policy, pages 83 108, December 1997.
Peter N. Ireland. Changes in the Federal Reserve's Inflation Target : Causes and Consequences. Journal of Money, Credit and Banking, 39(8) :1851-1882, December 2007.

Bibliographie 31
113
[14
[15
[16
[17
[18
[19
[20
[21
Finn E. Kydland and Edward C. Prescott. Time to build and aggregate fluctuations. Econometrica, 50(6) : 1345 1370, 1982.
Robert Jr Lucas. Econometric policy evaluation : A critique. Carnegie-Rochester Conference Series on Public Policy, 1(1) : 19-46, January 1976.
T. Mancini Griffoli. Dynare User Guide, An introduction to the solution and estimation of DSGE models. 2007.
Casey B. Mulligan and Xavier Sala i Martin. Extensive margins and the demand for money at low interest rates. The Journal of Political Economy, 108(5) :961-991, 2000.
Julio J Rotemberg and Michael Woodford. Oligopolistic pricing and the effects of aggregate demand on economic activity. Journal of Political Economy, 100(6) :1153-1207, December 1992.
Frank Smets and Raf Wouters. An Estimated Dynamic Stochastic General Equilibrium Model of the Euro Area. Journal of the European Economic Association, 1(5) :1123-1175, 09 2003.
Frank Smets and Raf Wouters. Comparing shocks and frictions in US and Euro area business cycles : a Bayesian DSGE Approach. Journal of Applied Econometrics, 20(2) :161-183, 2005. John B. Taylor. Discretion versus policy rules in practice. Carnegie-Rochester Conference Series on Public Policy, 39(1) :195-214, December 1993.
Tack Yun. Nominal price rigidity, money supply endogeneity, and business cycles. Journal of Monetary Economics, 37(2-3) :345 370, April 1996.

Annexe A
Système d'équations en équilibre symétrique
On définit rkt = ^p- Les conditions d'équilibre du marché sont K% = f0 Kj tdj, Ht = £ Hjtdj et Yt = /J Yjtdj.
h C r y - l 1
TET = Af (A.l)
C, ; + W ( f )
— - A t -0£ , t ( — — L_r = A t - / ? ^ t { ^ ± i ] (A.2)
V = A , ^ (A.3) 1 - Ht 'P t
I ^ t + l \ , 1 « 177 / A t + 1 f Rk,t+\ , , r . ( K t+2 \ Kt+2 X\—f? 5 + 1 = 0-Ei -L— - S + 1 - 5 + X "rT 9 Kt V ^ V P+: V^t+J V ^ + i
2 V ^ + i X / ^ t + 2
(A.5)

Annexe A. Système d'équations en équilibre symétrique 33
P~k t Yjt f . V — = a m c t — (A.6)
^ = (l-a)mct^- (A.7) -Tt # j t
0 E t ZZo(P4>«~9)k*t+kYt+kmct+kPte+k
Yt A ^ ^ Z / t ) 1 " 0 (A.9) 2
Kl+i = >l-6)K, + I , - ( ! ^ - g \ ( f ) K , (A.10)
ï, . fa+M>Lt% (A.n)
M t
log(f) = P. log(^)+p y log^)+P / i log^+log^ (A.13)
log(zt) = pz\ogzt-i +ez t (A.14) log(fet) = {l-pb)\og(b) + pblog{bt-i)+ebt (A.15) log At = (l-pA) log(A)+ /9 / 1 logA t_1+^ t (A.16) logut = -dylogvt-i + evt (A.17)
Pour les modèles avec cible d'inflation, la politique monétaire est plutôt
log ( § ) = * log ( j i - ) + p , log ( j £ ) + ft log ( & ) + log „
Dans le modèle avec cible d'inflation non observée, on ajoute l'équation suivante :
TTtarget.t = ^ target^—l ~r E-tTtarget.t
Dans le modèle avec cible d'inflation observée, on ajoute l'équation suivante :
TTtarget.t = 7T + £-Ktarget,t

Annexe B
Système d'équations stationnarisées
Cette section présente les équations sans la tendance g. Pour ce faire, nous avons M, W t
que ct = ^ ,ht = Ht,kt = & , y t = * ,mt = -%-,wt = -g- et Xt = Xtgt.
i
ztct
et"1 + W m t ' T = A( (B.l)
Ct" + W m t " y7Tt+1
V 1 - H t
= Xtwt (B.3)
1 „ ^ ( At+i
X fkt+2 x ' 9 2 \kt+i

Annexe B. Système d'équations stationnarisées 35
rkt = ormct-jf- (B.6) Kt
wt = ( l - a ) m c ^ (B.7) ht
~ 0 Et Y .Zo(^ - e ) k X t + ky t^mct + k P! + k P ] t ~ 9 - 1 Et l Z Z o ( ^ - e ) k X t + k y t + k P & ' ' yt = Atk^gïht)1-" (B.9)
gkt+i = (l-ô)kt + yt-Ct-(^--g) (|) ht (B.10)
it = ^t-1 + ( 1 - ^ - ^ 4 C t (B.ll)
IH = ^ (B+2) m t _ i
log(zt) = p z \ ogz t - i+£ z t (B.14) log(6£) = (l ~ pb)\og(b) + pb\og(b t.i) + eu (B.15) log A = ( l -p A ) \og(A) + p A l ogA t - i+£ A t (B.16) logvt = ^ logu t - i + e^ (B.17)
Pour les modèles avec cible d'inflation, la politique monétaire est plutôt
RA '-fjLUo,loeW+fl,.k^ l oS "F ) = Ar log + py log + pM log — + log vt \ R J \TTtargetJ \Vt-\ J \ P j
Dans le modèle avec cible d'inflation non observée, on ajoute l'équation suivante
TTtarget.t ^target, t—l i £irtarget,t
Dans le modèle avec cible d'inflation observée, on ajoute l'équation suivante
TTtarget.t — 7T + E-rrtarget.t

Annexe C
État stationnaire
l + ( l «5
P = gir (Cl) R =
n
P (C.2)
mc = 9 1
9 (C.3)
rk = ?♦ ' ' (C.4)
amc rk
k y
(C.5)
k g ) =
y c y
(C.6)
Xc = i (C.7) Xc = / \ ,y~ i
(C.7) 1 + b f a )
Xm = Scn^n B)~^b (C.8) h
1 h Xc(l — a)mc
' G ) (C.9)
y = ( ( ) ^ U ^ f t y
(CIO)
w = (la)mc(f ) ( C i l )
Dans les modèles avec cible d'inflation, la cible d'inflation est égale à l'inflation à l'état stationnaire.

Annexe D
Décomposition Blanchard Kahn
L'équation statique est :
Afr = Bdt + Cx t
L'équation dynamique est :
Dd t+i + Eft+i = Fd t + G ft + Hx t
Les chocs sont exprimés comme :
xt+i = pxt + &+i, o£ ~ N(0, a)
On commence en isolant / dans l'équation statique
ft = A-1Bd t + A-1Cx t
et on avance le tout d'une période :
f t+i = A - 1 B d t + i + A - 1 C x t + i

Annexe D. Décomposition Blanchard Kahn 38
On peut maintenant remplacer ft et / t + 1 dans l'équation dynamique :
Ddt+i + ElA^Bdt+i + A^Cxt+i] = Fd t + G[A~l Bdt + A^Cxt]
Sachant que E t(x t+i) = pxt, on peut remplacer dans l'équation et obtenir :
Dd t+i + E[A~ lBd t+i + A- lCpx t] = Fd t + G{A~xBdt + A~lCxt}
En réarrangeant les variable, on obtient :
[D + EA~1B]dt+i = [F + GA~lB]dt + [GA~lC - EA- lCp\x t
On isole d t+i
dt+i = [D + E A ^ B Y ^ F + GA~1B}dt + [D + EA- l B\- l [GA~ lC - EA~xCp\xt
On peut exprimer cette équation de façon plus élégante :
dt+i = Kdt + Lxt
On diagonalise K tel que K = M 1NM, M étant les vecteurs propres et N étant les valeurs propres,
Ni 0 0 N2
où Ni < 1 et N2 > 1.

Annexe D. Décomposition Blanchard Kahn 39
M = Mu Mi 2 M2i M22
où Mij sont des vecteurs.
On définit L comme étant :
L = Ly L-2
Nous avons donc
d t+i = M lNMd t + Lxt
On multiplie par la matrice M :
Mdt+i = NMd t + MLx t
ce qui s exprime comme :
M n M n \ d Ni 0 \ Mn M 1 2 \ ( M u M12 \ / Lx
Mai M22 j t + 1 "" l 0 N2 \ M21 M22 ' l M21 M22 j l L2
De plus, on définit Qi = M11Z/1 + M i2L2 et Q2 = M2XLi + M22L2. Nous avons aussi dt = [ktXt]'. kt représente les variables prédéterminées du modèle et Xt représente les autres variables. Nous avons donc que Ni est associé à kt et Af2 est associé à Xt.
On définit ensuite :
kt = M u k t + MnX t
et

Annexe D. Décomposition Blanchard Kahn 40
Ât = M2ik t + M22Xt
Donc :
kt+i = Nikt + QiXt
Ât+i = N2Xt + Q2x t
Pour annuler l'effet des valeurs propres instables N2 > 1, nous avons que lini/v—oo Xt 0.
On peut isoler A( de l'équation At+i = N2Xt + Q2x t .
Xt = N2- lX t +i - N2~ lQ2x t
On peut développé cette équation récursivement :
Ât = N 2 - \N 2 - l X t + 2 - N 2l Q 2 x t + i ) - N 2
l Q 2 x t
En continuant, nous obtenons :
At — N2 A t + n + 1 — 2_^ N2 ' Q2x t+S
s = 0
Par contre, nous avons que
lim N2- { n + 1 )X t + n + i = 0 N—>oo
et Et(x t + S) = p sx t , donc :

Annexe D. Décomposition Blanchard Kahn 41
Ât = - x>2- ( s+ l W5*, s=0
Qu'on peut exprimer de façon plus simple :
At = px t
On peut maintenant retourner à l'équation At = M2Xkt + M22Xt pour isoler Xt.
Xt = M22lXt - M22
lM2Xkt
On peut remplacer Xt,
Xt = M2 2ux t - M22M2Xkt
Qu'on peut écrire :
At = s2xt + sikt
On peut maintenant remplacer Xt
Mukt+i + Mx2Xt+i = NiMnkt + Qxxt
On peut remplacer Xt+i,
Mnkt+i + MX2[s2xt+x + sxkt+x] = NxMxxkt + Qxxt
On peut isoler kt+x :

Annexe D. Décomposition Blanchard Kahn 42
kt+x = [Mu + M u s ^ N x M n k t + [Mu + MX2sx]l[Qx MX2s2p]xt
Qu'on peut exprimer comme :
kt+i = s^kt + s^Xt
On peut maintenant retourner à l'équation statique et remplacer A :
ft = A' lBdt + A lCx t
h = A ' B \ £ \+A~1Cx t
i k l ^A~ SXKt + S2Xt
ft = A~1B[ J \kt + [AlC + A l B . t ^ )]xt
Qu'on peut écrire de façon plus brève :
ft = s$kt + s6xt
Nous avons donc la forme matricielle de équation statique :
:;;: H r ; :; + >+■ Nous avons aussi
ft \ f s5 s6 \ / kt Xt \ sx s2 j \ xt

Annexe D. Décomposition Blanchard Kahn 43
Equation d'observation :
dt = 03s (
Equation d'état :
s t+i = 6 i St + O2&+1

Annexe E
Le filtre de Kalman
Nous avons les équations exprimées sous la forme espace-état :
St+l = 0 i s t + 02et+i
dt = ©3Sf
où tt ~7V(0,E).
Le filtre de Kalman est utilisé pour faire des prévisions par moindres carrés linéaires du vecteur s à l'aide des données de la période t. Le processus est récursif et nous permet de faire des projections à l'aide de Si|0 jusqu'à sT\T_x.
On peut calculer le carré moyen de l'erreur de chaque projection avec :
Pt+i|t = E[(st+i\t - St+i|t)(st+i|t - st+i|t)']
où P[st+i|rf(] représente la projection linéaire de s t sur dt.
Pour commencer le processus, il faut trouver sx\o qui est la prévision de Si sans données. Dans ce cas-ci, puisqu'il n'y a pas d'observation, s\ correspond à la moyenne inconditionnelle de sx.
si = E[si]

Annexe E. Le filtre de Kalman 45
Pilo = E[(s i -E[s i})(s i -E[s x}y}
On peut tirer de l'équation statique que la moyenne inconditionnelle est :
E[sx] = E[Gxst-X}
Il est également possible d'avoir la variance inconditionnelle :
E(Sts't) = E[(e1st_1+e2et)(s;_1e/1 + e;e'2)] (E.I)
= 6is t_i/i - i e ; + e 2 s e 2 (E.2)
où V est la matrice variance covariance de s,
v = oxve\ + Q2ze'2
On peut maintenant obtenir V,
vec(V) = [Ir2 - ex ® e,]-1 * vec(e2se2)
Il est maintenant possible d'avoir une projection de dt de l'équation d'observation,
^t | t - l = 03St | t - l
et l'erreur de prévision est :
dt ~ d t\t-\ = ©3St - 03Sf|t-l = Q3(s t - St | t- l)
On a aussi le carré moyen de l'erreur :
E[(dt - dt\t-x)(dt - dt\t-i)'] = P[03(s t+i |{ - st+x\t){s(+x\t - st+i\ty&3]

Annexe E. Le filtre de Kalman 46
Ce qui peut se simplifier à :
E[(dt - dt\t-i){dt - dt\t-i)') = ©svv.e; .
On peut maintenant mettre notre prévision à jour :
St|t = st\t-i + E[(st - st\t-i)(dt - dt\t-i)']E[(dt - dt\t-i)(dt - dt\t-i)'} * (dt - e £L3)) = st\t-1-rVtït-ie'3(e3vt[t-1e'3)*(dt-dt\t-l) (EA)
Ensuite, on peut faire la prévision :
st+i|t = 0ist|t-i + ©iVViO^OsVtit©;,)-1 * (dt ~ dtit-i)
vt+X\t = o2se2 + eiVt\t-iQ'i - e1yt,t_1e/3(e3vi|t_10^-103v;it-i0/
1
Finalement, on obtient la log vraisemblance de dt alors que dt ~ N(dt\t-X,Q3Vt\t-XQ'3) peut être exprimée sous la forme :
NT 1 T 1 T
InL = -—ln(2n) - -^2ln\e3V03 \ - - ]T[K - d - t\t - l)'(e3VtG'3)(dt - dtlt.x)} t=i t=i
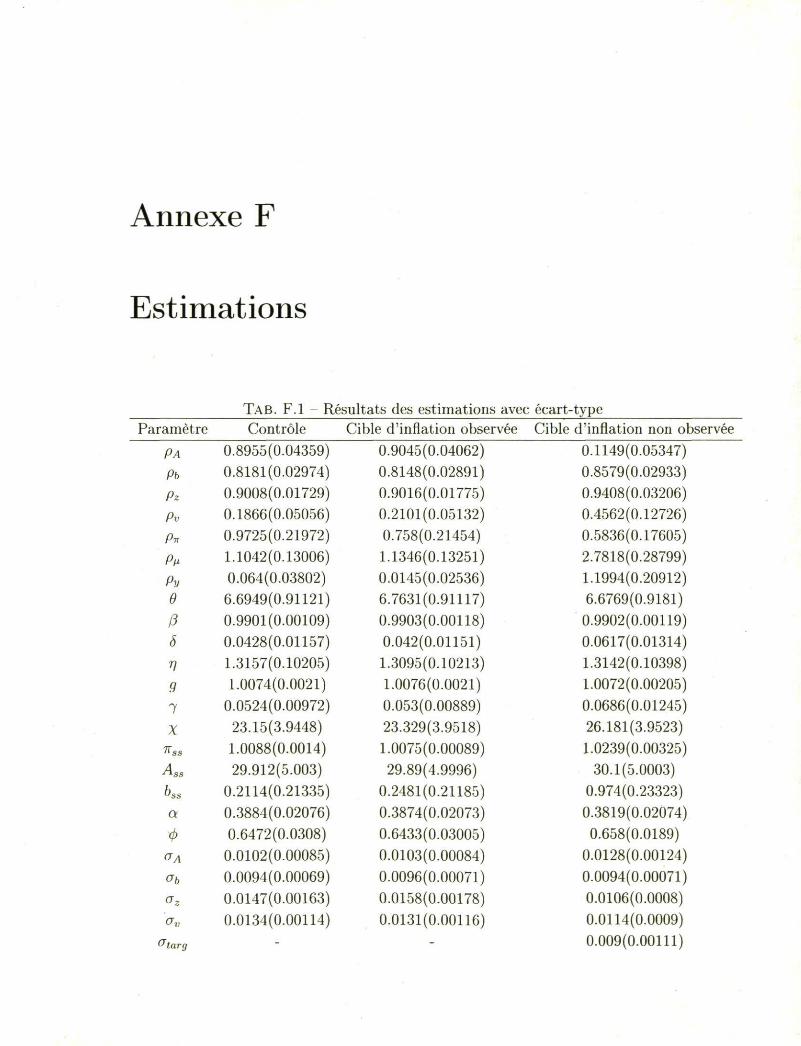
Annexe F
Estimations
TAB. F.l Résultats des estimations avec écart-type Paramètre Contrôle Cible d'inflation observée Cible d'inflation non observée
PA 0.8955(0.04359) 0.9045(0.04062) 0.1149(0.05347) Pb 0.8181(0.02974) 0.8148(0.02891) 0.8579(0.02933) Pz 0.9008(0.01729) 0.9016(0.01775) 0.9408(0.03206) Pv 0.1866(0.05056) 0.2101(0.05132) 0.4562(0.12726) P-K 0.9725(0.21972) 0.758(0.21454) 0.5836(0.17605) P» 1.1042(0.13006) 1.1346(0.13251) 2.7818(0.28799) Py 0.064(0.03802) 0.0145(0.02536) 1.1994(0.20912) 6 6.6949(0.91121) 6.7631(0.91117) 6.6769(0.9181) P 0.9901(0.00109) 0.9903(0.00118) 0.9902(0.00119) 8 0.0428(0.01157) 0.042(0.01151) 0.0617(0.01314) V 1.3157(0.10205) 1.3095(0.10213) 1.3142(0.10398) 9 1.0074(0.0021) 1.0076(0.0021) 1.0072(0.00205) 7 0.0524(0.00972) 0.053(0.00889) 0.0686(0.01245) V 23.15(3.9448) 23.329(3.9518) 26.181(3.9523)
Kss 1.0088(0.0014) 1.0075(0.00089) 1.0239(0.00325) ASs 29.912(5.003) 29.89(4.9996) 30.1(5.0003) bss 0.2114(0.21335) 0.2481(0.21185) 0.974(0.23323) a 0.3884(0.02076) 0.3874(0.02073) 0.3819(0.02074) i> 0.6472(0.0308) 0.6433(0.03005) 0.658(0.0189)
O-A 0.0102(0.00085) 0.0103(0.00084) 0.0128(0.00124) <Jb 0.0094(0.00069) 0.0096(0.00071) 0.0094(0.00071)
°z 0.0147(0.00163) 0.0158(0.00178) 0.0106(0.0008) n,. 0.0134(0.00114) 0.0131(0.00116) 0.0114(0.0009)
rJtarg - - 0.009(0.00111)
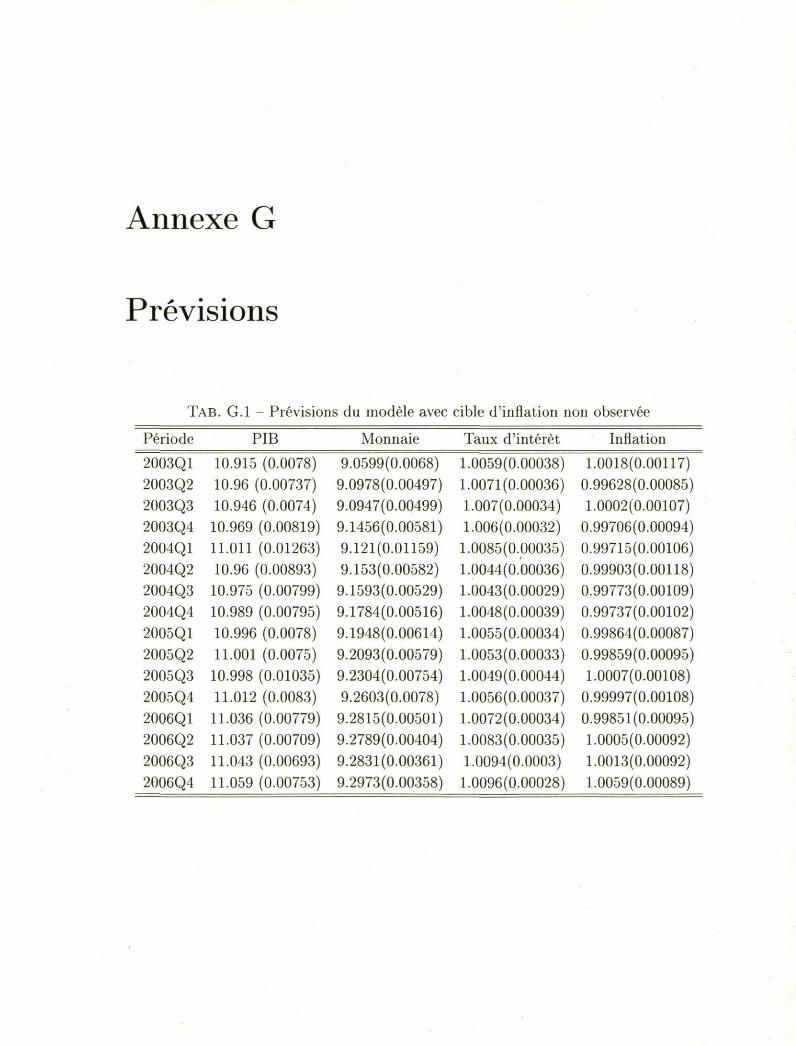
Annexe G
Prévisions
TAB. G.l Prévisions du modèle avec cible d'inflation non observée
Période PIB Monnaie Taux d'intérêt Inflation
2003Q1 2003Q2 2003Q3 2003Q4 2004Q1 2004Q2 2004Q3 2004Q4 2005Q1 2005Q2 2005Q3 2005Q4 2006Q1 2006Q2 2006Q3 2006Q4
10.915 (0.0078) 10.96 (0.00737) 10.946 (0.0074) 10.969 (0.00819) 11.011 (0.01263) 10.96 (0.00893) 10.975 (0.00799) 10.989 (0.00795) 10.996 (0.0078) 11.001 (0.0075) 10.998 (0.01035) 11.012 (0.0083) 11.036 (0.00779) 11.037 (0.00709) 11.043 (0.00693) 11.059 (0.00753)
9.0599(0.0068) 9.0978(0.00497) 9.0947(0.00499) 9.1456(0.00581) 9.121(0.01159) 9.153(0.00582) 9.1593(0.00529) 9.1784(0.00516) 9.1948(0.00614) 9.2093(0.00579) 9.2304(0.00754) 9.2603(0.0078) 9.2815(0.00501) 9.2789(0.00404) 9.2831(0.00361) 9.2973(0.00358)
1.0059(0.00038) 1.0071(0.00036) 1.007(0.00034) 1.006(0.00032) 1.0085(0.00035) 1.0044(0.00036) 1.0043(0.00029) 1.0048(0.00039) 1.0055(0.00034) 1.0053(0.00033) 1.0049(0.00044) 1.0056(0.00037) 1.0072(0.00034) 1.0083(0.00035) 1.0094(0.0003) 1.0096(0.00028)
1.0018(0.00117) 0.99628(0.00085) 1.0002(0.00107) 0.99706(0.00094) 0.99715(0.00106) 0.99903(0.00118) 0.99773(0.00109) 0.99737(0.00102) 0.99864(0.00087) 0.99859(0.00095) 1.0007(0.00108) 0.99997(0.00108) 0.99851(0.00095) 1.0005(0.00092) 1.0013(0.00092) 1.0059(0.00089)

Annexe G. Prévisions 49
TAB. G.2 - Prévisions du modèle avec cible d'inflation observée
Période PIB Monnaie Taux d'intérêt Inflation 2003Q1 10.889(0.0153) 9.0078(0.0153) 1.0081(0.00036) 1.0097(0.00078) 2003Q2 11.021(0.01279; 9.1279(0.01109) 1.0085(0.00025) 0.99737(0.00096) 2003Q3 10.927(0.01294; 9.0508(0.01353) 1.0089(0.00032) 1.0075(0.0007) 2003Q4 10.986(0.01292; 9.1277(0.01176) 1.0078(0.00024) 1.0023(0.00078) 2004Q1 10.946(0.01447; 9.1034(0.01421) 1.0077(0.00034) 1.0067(0.00086) 2004Q2 10.939(0.01337; 9.098(0.01383) 1.0066(0.00035) 1.0079(0.00087) 2004Q3 10.989(0.01317; 9.1392(0.01208) 1.0062(0.00029) 1.0032(0.00082) 2004Q4 11.005(0.01282; 9.1591(0.01151) 1.0067(0.00024) 1.0031(0.00081) 2005Q1 10.999(0.01275; 9.1648(0.0122) 1.0073(0.00025) 1.0049(0.00089) 2005Q2 11.006(0.01259; 9.18(0.01114) 1.0071(0.00025) 1.005(0.00074) 2005Q3 10.965(0.01401; 9.1629(0.01487) 1.0069(0.00033) 1.0099(0.00091) 2005Q4 11.008(0.01283; 9.2184(0.01288) 1.0075(0.00024) 1.007(0.0008) 2006Q1 11.076(0.01371; 9.2818(0.0106) 1.0087(0.00026) 1.002(0.0009) 2006Q2 11.056(0.0114) 9.2651(0.00945) 1.0096(0.00022) 1.0049(0.00067) 2006Q3 11.061(0.01019; 9.2677(0.0091) 1.0106(0.00021) 1.0059(0.00073) 2006Q4 11.097(0.01051; 9.3013(0.00837) 1.0106(0.0002) 1.0028(0.00077)