
Apprentissage de corrélations entre entrées et sorties … · et dynamique, comme peut l’être...
53
Apprentissage de corrélations entre entrées et sorties de systèmes dynamiques Rapport de Master 2 Recherche Intelligence Artificielle, Intelligence Collective, Interaction (IAICI) à l’Université Paul Sabatier (UPS) – Toulouse III 17 juin 2013 Simon Jambu Laboratoire d’accueil : Institut de Recherche en Informatique de Toulouse (IRIT) Directeur de recherche : Pierre Glize Responsables de stage : Carole Bernon, Luc Pons Equipe d’accueil : Systèmes Multi-Agents Coopératifs Soutenu le : 24/06/13 Mots-clés : Systèmes multi-agents, adaptation, auto-organisation, apprentissage Résumé : La complexité des systèmes informatiques actuels, notamment leurs propriétés dynamiques ainsi que la diversité de leurs utilisateurs, en font des systèmes de plus en plus imprévisibles donc plus difficiles à contrôler. Les jeux vidéo comptent parmi ces systèmes et il est aujourd’hui admis qu’il faut présenter à un joueur une expérience de jeu appropriée à ses besoins. Dans cette optique, une thèse, actuellement en cours dans l’équipe SMAC, propose une approche par système multi-agent auto- organisateur pour contrôler en temps réel les paramètres d’un jeu afin de respecter les objectifs (pédago- giques ou non) imposés au joueur. Dans ce système de contrôle, certains aspects peuvent être optimisés notamment lorsque la question de l’identification d’un paramètre à ajuster correspondant à une réponse souhaitée se pose. Jusqu’à présent, cette identification est faite a priori, ce qui demande une expertise du domaine que ne possède pas forcément le concepteur du jeu. Le but du travail entrepris dans ce stage est d’alléger la tâche de ce concepteur en proposant un système capable d’apprendre automatiquement les liens existant entre entrées et sorties d’un système complexe et dynamique, comme peut l’être un jeu vidéo. Cette étude a pour objet de concevoir et tester un système fondé sur la théorie des Adaptive Multi-Agent Systems (AMAS) afin de résoudre ce problème d’apprentissage.
Transcript of Apprentissage de corrélations entre entrées et sorties … · et dynamique, comme peut l’être...

Apprentissage de corrélations entre entrées et sorties desystèmes dynamiques
Rapport de Master 2 RechercheIntelligence Artificielle, Intelligence Collective, Interaction (IAICI)
à l’Université Paul Sabatier (UPS) – Toulouse III
17 juin 2013
Simon Jambu
Laboratoire d’accueil : Institut de Recherche en Informatique de Toulouse (IRIT)Directeur de recherche : Pierre Glize
Responsables de stage : Carole Bernon, Luc PonsEquipe d’accueil : Systèmes Multi-Agents Coopératifs
Soutenu le : 24/06/13
Mots-clés : Systèmes multi-agents, adaptation, auto-organisation, apprentissage
Résumé : La complexité des systèmes informatiques actuels, notamment leurs propriétés dynamiquesainsi que la diversité de leurs utilisateurs, en font des systèmes de plus en plus imprévisibles doncplus difficiles à contrôler. Les jeux vidéo comptent parmi ces systèmes et il est aujourd’hui admis qu’ilfaut présenter à un joueur une expérience de jeu appropriée à ses besoins. Dans cette optique, unethèse, actuellement en cours dans l’équipe SMAC, propose une approche par système multi-agent auto-organisateur pour contrôler en temps réel les paramètres d’un jeu afin de respecter les objectifs (pédago-giques ou non) imposés au joueur. Dans ce système de contrôle, certains aspects peuvent être optimisésnotamment lorsque la question de l’identification d’un paramètre à ajuster correspondant à une réponsesouhaitée se pose. Jusqu’à présent, cette identification est faite a priori, ce qui demande une expertisedu domaine que ne possède pas forcément le concepteur du jeu.Le but du travail entrepris dans ce stage est d’alléger la tâche de ce concepteur en proposant un systèmecapable d’apprendre automatiquement les liens existant entre entrées et sorties d’un système complexeet dynamique, comme peut l’être un jeu vidéo. Cette étude a pour objet de concevoir et tester unsystème fondé sur la théorie des Adaptive Multi-Agent Systems (AMAS) afin de résoudre ce problèmed’apprentissage.


Remerciements
Je tiens à remercier dans un premier temps Carole Bernon pour ses qualités d’encadrante, notam-ment pour l’aide et le soutien qu’elle m’a apporté au cours de ces 5 mois de stage. Je tiens surtout à laremercier pour la patience et la minutie dont elle a fait preuve pour relire et corriger ce document. Jesuis conscient du temps que cela lui a demandé et lui en suis extrêmement reconnaissant.
Je remercie également Luc Pons aussi pour ses qualités d’encadrant notamment concernant le suivide mon travail. Sa disponibilité, son intuition et ses qualités de chercheur mon permis d’avoir toujoursconseils et retours rapides sur mon travail. Je le remercie grandement pour sa disponibilité et son écouteattentive.
Un grand merci à Pierre Glize pour son humour et sa bonne humeur qui apportent convivialité etdécontraction lors des réunions. Je le remercie aussi et surtout pour son regard d’expert apportant uneconfiance dans la réalisation de mon travail.
Impossible de ne pas remercier Marie-Pierre Gleizes et Jean-Pierre Georgé qui m’ont enseigné leursavoir en terme de Systèmes Multi-Agents. Je les remercie pour leurs qualités de pédagogues car, enplus de leur savoir, ils savent transmettre leur passion pour ce domaine. Je voudrais enfin saluer leuroptimisme omniprésent qui ne manque pas d’apporter un courage non négligeable à tous les membresde l’équipe.
Merci à toute l’équipe SMAC de l’IRIT : Valérie Camps, Sylvain Lemouzy, Guy Camilleri, FredericMigeon ... pour leur accueil chaleureux et la bonne ambiance qui règne au sein de l’équipe, notammentautour de la machine à café.
Enfin je tiens particulièrement à remercier Teddy Bouziat, Alexandre Perles, Faustine Maffre, Ma-thieu Bonte, Ghazar Shahbandaryan qui m’ont accompagné et soutenu tout au long de cette année uni-versitaire. Nous avons alors eu l’occasion de tisser de forts liens d’amitié sans lesquels ma vie étudianteaurait été bien moins agréable.
iii


Table des matières
Introduction 1
1 Contexte de l’étude 31.1 Le contrôle de scénario dans les jeux sérieux . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.1.1 Les jeux sérieux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.1.2 Le contrôle de scénario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Les Systèmes Multi-Agents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.2.1 (Bref) Historique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.2.2 Caractéristiques des concepts associés aux Systèmes Multi-Agents . . . . . . . . . 5
1.2.2.1 Agent . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2.2.2 Environnement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2.2.3 Interaction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.2.2.4 Organisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.2.3 Émergence et auto-organisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2.3.1 Émergence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2.3.2 Auto-organisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.2.4 Théorie des AMAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2.4.1 Apprentissage par auto-organisation . . . . . . . . . . . . . . . . . . . . . 81.2.4.2 Situations Non Coopératives (SNC) . . . . . . . . . . . . . . . . . . . . . . 8
1.3 Les AMAS pour le contrôle de scénario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.3.1 Agents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.3.2 Matrice de corrélations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.4 Bilan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2 État de l’art 132.1 Apprentissage par renforcement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.2 Apprentissage par algorithme génétique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.3 Approche de type essais successifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.4 Programmation linéaire en nombres entiers . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3 Apprentissage de corrélations entre entrées et sorties de systèmes dynamiques 193.1 Le problème . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.1.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193.1.2 Formalisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.2 Conception du SMA d’apprentissage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203.2.1 Besoins préliminaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.2.2 Besoins finals . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.2.3 Analyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2.3.1 Agents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
v

Table des matières
3.2.3.2 Caractéristiques et fonctionnement . . . . . . . . . . . . . . . . . . . . . . 243.2.3.3 Situations Non Coopératives (SNC) . . . . . . . . . . . . . . . . . . . . . . 25
3.2.4 Conception . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253.2.4.1 Représentation et comportement des agents . . . . . . . . . . . . . . . . . 253.2.4.2 Vue modulaire du système . . . . . . . . . . . . . . . . . . . . . . . . . . . 283.2.4.3 Actes de communication . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283.2.4.4 Prototypage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2.5 Extension et système complet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283.3 Bilan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4 Résultats et discussion 314.1 Analyse des résultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 314.2 Bruitage du signal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 314.3 API et application réelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.3.1 Application Programming Interface (API) . . . . . . . . . . . . . . . . . . . . . . . . 324.3.2 Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.4 Discussion sur les résultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
Conclusion 37
Annexe 39
Bibliographie 45
vi

Introduction
L’équipe SMAC 1 s’intéresse actuellement à la problématique de l’adaptation du contenu d’un jeu àun utilisateur. En effet, que cela soit dans le cadre des jeux sérieux (c’est-à-dire des jeux ayant un autreobjectif que le simple divertissement) ou dans celui des jeux de divertissement, il est aujourd’hui admisqu’il faut présenter une expérience de jeu appropriée au joueur. Or, la complexité croissante des jeuxvidéo modernes, ainsi que la diversité des utilisateurs rend cette tâche fastidieuse et coûteuse. En effet,nous faisons face à des systèmes complexes aux multiples fonctionnalités soumis donc à nombre desituations imprévisibles. L’approche classique du Génie Logiciel, consistant à spécifier précisément unsystème avant de le concevoir, n’est alors plus valable.
Afin de répondre à ces nouveaux défis, l’intelligence artificielle distribuée qui donnera plus tardnaissance aux Systèmes Multi-Agents (SMA) a vu le jour. Inspirés des systèmes naturels complexes, telsque les fourmilières, les SMA sont composés d’une multitude d’agents logiciels plus ou moins simplesinteragissant entre eux afin d’accomplir une tâche commune. Les relations entre les différents agents dusystème sont dynamiques et aucun contrôle central ne supervise l’exécution globale. Ainsi, la fonction-nalité globale est distribuée et dépend essentiellement de l’organisation des agents au sein du systèmeétablie par les relations entre les agents. La possibilité de changer cette organisation de façon autonomepermet alors d’obtenir un système pouvant changer sa fonctionnalité globale au cours du temps. Onpeut alors qualifier un tel système d’adaptatif ou d’auto-organisateur.
L’équipe SMAC s’intéresse plus particulièrement à ces systèmes auto-organisateurs via l’étude desAMAS (ou Systèmes Multi-Agents Adaptatifs). La particularité des AMAS vient du fait qu’ils consistenten un système dont la fonctionnalité émerge des interactions d’entités autonomes. Ces entités –lesagents– sont dotées d’un but local et ne connaissent pas la fonction globale du système. En dotant cesagents de comportements dits coopératifs, l’équipe SMAC a pu adresser des problématiques jusque-làtrop complexes pour être résolues par des approches classiques.
Dans sa thèse, Luc Pons s’intéresse au contrôle adaptatif de scénario dans les jeux. Si un scénario estvu comme un ensemble de variables/paramètres d’un jeu, l’état du jeu est fortement dépendant de lavaleur de ces variables. D’une manière plus générale, les entrées d’un système modifient certains obser-vables du jeu, ici vus comme sorties du système. L’objectif de cette thèse est de concevoir un systèmede contrôle capable d’ajuster les paramètres d’un jeu afin de répondre au mieux aux performances dujoueur, et ceci en temps réel. Pour cela, des liens entre éléments d’un scénario sont pris en compte, cesliens sont appelés corrélations : une sortie est ainsi corrélée à une ou plusieurs entrées. Pour déterminerquelle(s) entrée(s) influe(nt) sur quelle(s) sortie(s), Luc Pons a choisi de remplir une matrice qui indiquesommairement les corrélations entres variables intervenant dans le jeu. Cependant, cette matrice estdéfinie a priori et nous ne disposons d’aucune information (notamment numérique) quant à la réelleinfluence d’une variable sur une autre ; ce qui signifie que cette matrice est potentiellement erronée ouincomplète. L’objectif originel du travail entrepris dans ce stage est donc d’améliorer le contenu de cettematrice en apprenant automatiquement les corrélations qui existent entre variables d’un jeu au fur età mesure que le jeu se déroule (avec ou sans contrôle). En effet, pouvoir disposer d’une matrice plusjuste que celle que pourrait donner le concepteur du jeu, ou tout autre expert, permettra d’effectuer un
1. Systèmes Multi-Agents Coopératifs
1

Introduction
contrôle de scénario encore plus efficace. En outre, comme nous le verrons dans le chapitre suivant, lesjeux (sérieux ou non) sont des systèmes complexes et dynamiques. Bien que nous mettions en avant leproblème de l’apprentissage d’une matrice de corrélations dans le contexte d’un jeu, notre probléma-tique est plus large que cela. Il s’agit, en effet, de savoir s’il est possible d’apprendre automatiquementdes corrélations entre entrées et sorties de systèmes dynamiques quelconques.
Ce document présente donc dans un premier temps, le contexte de notre étude c’est-à-dire les défini-tions et concepts de base indispensables à la bonne compréhension de notre problème, comme les SMAet la théorie des AMAS. Puis, nous dresserons un état de l’art décrivant quelques techniques jusqu’alorsutilisées pour résoudre des problèmes similaires au nôtre. Nous proposons alors une solution validéepar la suite par des résultats expérimentaux. Ce document se termine alors par une conclusion ainsiqu’une ouverture vers les enrichissements possibles de notre solution.
2

1 Contexte de l'étude
Le but de ce chapitre est de positionner le travail à réaliser au sein de ce stage par rapport à l’existant.Comme il a été introduit précédemment, ce stage vient en support d’une thèse portant sur le contrôletemps réel dans les jeux (sérieux) [Pons et al., 2012]. Dans un premier temps, ce chapitre s’intéresse doncaux jeux (sérieux). Lorsque le problème de leur contrôle se pose, ces systèmes informatiques présententdes propriétés particulières et nous verrons que l’approche descendante classique du génie logiciel nepermet pas une résolution du problème ; c’est pourquoi le concept de Système Multi-Agent (SMA) a étéutilisé et sera présenté. En effet, les caractéristiques de ces systèmes et, globalement, leur fonctionne-ment sont bien différents des systèmes informatiques conventionnels. Ensuite, nous verrons commentle système multi-agent de contrôle a été conçu et nous nous intéresserons à ses divers composants pouren retenir un en particulier, la matrice de corrélations. C’est en effet sur cette composante que va porternotre étude : l’apprentissage automatique de corrélations pour un système dynamique.
1.1 Le contrôle de scénario dans les jeux sérieux
1.1.1 Les jeux sérieux
Un jeu sérieux, de l’anglais serious game est une application informatique dont le but est de combiner,avec cohérence, une intention sérieuse, par exemple de type pédagogique (apprentissage, enseignement,communication) et un ressort ludique issu du jeu vidéo. Julian Alvarez, dans sa thèse [Alvarez, 2007],considère qu’un jeu sérieux résulte de l’intégration d’un scénario pédagogique à un jeu vidéo.
Du fait de cette intention sérieuse, il est important que le système tienne compte des préférences del’utilisateur et, surtout, sache identifier ses points forts et faibles. La problématique de l’adaptation dujeu à son utilisateur a donc été dressée [Westra et al., 2011a].
La plupart des jeux sérieux sur le marché utilisent une approche centralisée pour l’adaptation àl’utilisateur, or, bien que d’un point de vue contrôle du système la centralisation ait son avantage, celadevient un inconvénient lorsque le nombre de tâches à apprendre ainsi que leur complexité augmentent.Par ailleurs, du fait qu’un joueur joue de manière stochastique, il s’agit là d’un problème complexe donton ne peut établir de modèle prédictif.
Pour pallier ce problème, la technologie agent est donc de plus en plus utilisée [Westra et al., 2011b].En effet, l’aspect distribué de cette dernière permet d’aborder le problème de la complexité.
1.1.2 Le contrôle de scénario
Selon la conception d’un jeu sérieux établie par Luc Pons [Pons et al., 2012], ces derniers possèdentun moteur de jeu avec lequel le joueur interagit au travers de scénarios définis par expertise. Ces scé-narios définissent les objectifs à atteindre par le joueur ainsi que les conditions dans lesquelles il joue.Afin d’offrir une expérience optimale il convient de définir les bons scénarios, en d’autres termes, lesscénarios qui offriront les challenges les plus adéquats au joueur. Ces scénarios doivent aussi être conti-nuellement mis à jour afin de toujours préserver cette adéquation. D’un point de vue représentation,selon Luc Pons, les scénarios sont un ensemble de paramètres contrôlant chaque aspect/variable du jeu.
3

Chapitre 1. Contexte de l’étude
Trouver l’adéquation des scénarios signifie donc trouver les valeurs appropriées pour chaque paramètreselon un joueur donné. Le problème ici est qu’on ne peut prédire le comportement, l’évolution du sys-tème sans l’exécuter. En effet, on ne peut prévoir les actions du joueur et, de plus, la modification d’unparamètre peut entraîner des effets non désirés, l’approche Génie Logiciel classique visant à définir etconcevoir le système dans son intégralité avant exécution n’est donc pas adaptée. Luc Pons proposeainsi dans sa thèse une approche par Système Multi-Agent pour contrôler dynamiquement l’évolutiondu système le faisant tendre vers un état d’équilibre et ce, sans définition de modèle du joueur ni du jeu.
1.2 Les Systèmes Multi-Agents
1.2.1 (Bref) Historique
L’intelligence Artificielle (IA) se définit généralement comme la science qui vise à faire réaliser pardes machines des tâches complexes faisant intervenir les mécanismes d’intelligence humaine. Cette no-tion trouve son origine dans l’article d’Alan Turing « Computing Machinery and Intelligence » publié enOctobre 1950 [Turing, 1950]. Il existe en informatique des classes de problèmes que l’on ne peut résoudregrâce à des algorithmes classiques car d’une complexité en temps et/ou en espace trop forte (i.e. mêmeavec la puissance des machines actuelles ces problèmes ne peuvent être résolus en temps raisonnable oudépassent les capacités de mémoire). C’est le cas par exemple de la classe de problèmes NP-Complets[Cook, 1971] dont le jeu d’échec fait partie. La combinatoire de ce jeu est tellement grande qu’explo-rer entièrement l’espace des états possibles du jeu demande trop de temps. Des manières intelligentesd’aborder le problème sont donc nécessaires. Dans les années 70, les chercheurs sont convaincus qu’ex-plorer un espace d’état n’est pas une bonne pratique, même avec des explorations dites « informées »faisant intervenir des heuristiques. Ce type d’approche a certes de bon résultats sur certains problèmes,c’est le cas par exemple de l’algorithme A* [Hart, 1968] qui est optimal s’il est doté d’une heuristiqueadmissible. Il est nécessaire cependant que les programmes aient une connaissance approfondie du pro-blème et l’utilisent à bon escient.
Par la suite, [Jackson, 1999] définit un système expert comme un logiciel qui encode le savoir d’unexpert dans un domaine particulier et le représente sous forme de règles conditions-action. Il s’agit làd’une centralisation de l’expertise au sein d’un système unique. Le premier système expert est DEN-DRAL [Buchanan et Feigenbaum, 1978] qui permet d’identifier les constituants chimiques d’un maté-riau. Par la suite, viendra MYCIN [Buchanan et Shortliffe, 1984] qui est un système d’identification debactéries à l’origine de sévères infections telle que les méningites. A partir de symptômes MYCIN estcapable d’identifier une bactérie et donc de prescrire un ou des anti-biotiques. On commence plus tardà parler d’un nouveau paradigme : celui d’un ensemble d’experts humains permettant la cohabitationd’expertises multiples. On parle d’Intelligence Artificielle Distribuée. L’I.A.D permet de surmonter lesdifficultés d’un système intelligent unique (centralisation de la résolution, inefficacité sur les problèmescomplexes) en distribuant l’expertise au sein d’une société de systèmes intelligents. Cette distributionest similaire aux êtres humains accomplissant collectivement des tâches complexes qu’ils ne peuvent ac-complir individuellement. L’intelligence, ici, correspond à la capacité d’un groupe d’experts à collaboreret coordonner leurs actions pour arriver à accomplir leurs objectifs aussi bien individuels que collectifs.Deux approches sont alors retenues :
– le tableau noir : c’est un système à contrôle centralisé, où les entités intéragissent via le partage d’unmême espace de travail.
– les acteurs : c’est un système à distribution totale des connaissances et du contrôle où le traitementde l’information se fait localement et la communication s’effectue par envoi de messages.
Ce concept donnera ultérieurement naissance à des systèmes dont le comportement intelligent naîtde l’activité coopérative de plusieurs entités. Au début des années 80 est introduit la notion de Sys-tèmes Multi-Agents dont le modèle s’appuie sur la notion d’agent dont la caractéristique principale estl’autonomie. Sur le plan individuel, un agent se caractérise par une notion d’action persistante, tented’accomplir de manière autonome (avec initiative) une tâche qui lui a été assignée [Gasser et al., 1987].Sur le plan collectif, une tâche est assignée à un ensemble d’agents qui tentent de l’accomplir en co-
4

1.2. Les Systèmes Multi-Agents
opérant/collaborant. L’idée ici est donc pour un concepteur de déléguer, répartir le fonctionnement auxagents qui par interactions tenteront de résoudre un problème global [Weiss, 1995]. Une bonne orga-nisation des agents est donc nécessaire à la résolution du problème car de l’efficacité des interactionsdépend la réussite de cette dernière. En 1995, la notion d’agent se répand et est de plus en plus évoquéeà l’heure actuelle lorsque certaines approches classiques trouvent leurs limites.
1.2.2 Caractéristiques des concepts associés aux Systèmes Multi-Agents
La particularité des SMA est la distribution fonctionnelle par le concepteur au sein d’agents. Ainsi,bien que de l’interaction de ces derniers naisse la solution à un problème, la nature et les propriétés del’environnement dans lequel ils sont immergés a une grande importance et nécessite une attention touteaussi rigoureuse en terme d’analyse. Un SMA peut être observé à deux niveaux :
– Le macro-niveau qui correspond au point de vue de l’observateur qui ignore tous les mécanismesinternes de fonctionnement, il considère le système dans son ensemble.
– Le micro-niveau où, cette fois, l’observateur tient compte du comportement et des propriétés desagents ainsi que de la nature de leurs interactions.
La question maintenant est de savoir quelles sont les propriétés propres à un agent, comment définit-on ses interactions et finalement comment ces agents s’organisent-ils ?
1.2.2.1 Agent
Selon la définition communément admise [Ferber et Gurknecht, 1998], un agent est une entité phy-sique ou virtuelle autonome :
– capable d’agir dans un environnement ;– capable de percevoir une partie limitée de son environnement ;– possédant une représentation partielle, voire nulle de cet environnement ;– possédant des compétences et offrant des services ;– pouvant éventuellement se reproduire ;– se comportant pour atteindre ses objectifs en fonction des perceptions, représentations et commu-
nications qu’elle reçoit et grâce aux compétences et ressources qu’elle possède.Pour être autonome un agent doit satisfaire les conditions suivantes :– Son existence ne dépend pas de la présence d’autres agents.– Il est capable de maintenir sa viabilité dans des environnements dynamiques, sans contrôle exté-
rieur.– Son comportement est fonction de ses perceptions, ses connaissances et sa représentation de l’en-
vironnement.– Aucun contrôle extérieur ne peut accéder directement à ses représentations internes.Ainsi un agent possède des compétences (ce qu’il sait faire), des croyances (ses connaissances sur
son environnement, les autres et parfois sur lui-même), des accointances (ses relations sociales), desaptitudes (ses capacités de perception, d’action, de décision et d’apprentissage) et un objectif individuel(but implicite ou explicite). Il possède donc les moyens d’acquérir et de stocker des informations leconcernant. Le cycle de vie d’un agent se compose de trois phases : « Perception - Décision - Action ».L’agent perçoit son environnement (cf. Figure 1.1), décide de l’action qu’il va effectuer en fonction de sesconnaissances, de ses perceptions et de ses buts pour finalement agir [Wooldridge, 1999], ce qui a poureffet de le rapprocher de ses objectifs, voire, de les atteindre. Les agents sont de plus ou moins grossegranularité ; les plus simples ont des comportements de type réflexe, comme, par exemple une fourmi,qui, lorsqu’elle perçoit de la phéromone, la suit. Un agent de granularité plus élevée a une capacité deréflexion plus développée, il peut « réfléchir »sur une situation donnée.
1.2.2.2 Environnement
La définition de l’environnement est difficile à établir et souvent source d’ambigüité car selon lepoint de vue que l’on adopte, l’environnement est différent. On distingue donc trois types d’environne-
5

Chapitre 1. Contexte de l’étude
ment :
1. Point de vue du SMA : Du point de vue du SMA, l’environnement correspond à tout ce qui estextérieur au système. Par exemple si l’on considère une fourmilière, l’environnement correspondà tous les éléments de la nature à l’exception des fourmis de la fourmilière.
2. Point de vue de l’agent : Du point de vue de l’agent son environnement correspond à tout ce qui estextérieur à lui-même. Par exemple, l’environnement d’une fourmi correspond à l’environnementde la fourmilière et des autres fourmis.
3. Point de vue du concepteur : Du point de vue du concepteur, l’environnement n’a pas de liendirect avec le SMA, il s’agit plutôt de l’environnement d’exécution du programme (système infor-matique sur lequel s’exécute le SMA), l’environnement de simulation (outils logiciels permettantde simuler, visualiser, évaluer l’exécution du SMA) et l’environnement de développement.
[Russel et Norvig, 1995] propose de caractériser l’environnement d’un agent selon les critères sui-vants :
– Accessible : l’agent peut percevoir l’état complet, valide et à jour de son environnement. L’envi-ronnement réel et les environnements simulés sont inaccessibles par ce dernier.
– Déterministe : l’action d’un agent a un et un seul effet possible sur son environnement. L’état d’unenvironnement simulé déterministe est donc prévisible en fonction, et seulement en fonction, desactions des agents du système. L’environnement réel est non-déterministe car son état ne dépendpas seulement des actions des agents ; de nombreuses autres variables interviennent (météo, autresagents, etc.).
– Statique : lorsqu’un agent décide, l’état de son environnement est inchangé. C’est une contraintetrès forte car dans un monde réel, c’est-à-dire dans un environnement dynamique, il est fort pro-bable que l’état du monde perçu soit différent une fois un choix d’action effectué.
– Discret : le nombre d’actions que les agents peuvent entreprendre est limité.
FIGURE 1.1 — Interaction entre un agent et son environnement
1.2.2.3 Interaction
Dans un SMA, l’interaction est un moyen de communication entre agents afin d’exercer une activitécommune. L’interaction directe correspond à un envoi de message de proche en proche à un ou plusieursagents, l’interaction indirecte correspond à un partage d’information implicite via l’environnement (parexemple grâce à des phéromones, comme chez les fourmis). La figure 1.1 illustre l’interaction d’un agentavec son environnement.
1.2.2.4 Organisation
Une organisation est un ensemble d’individus, regroupés au sein d’une structure régulée, ayant unsystème de communication pour faciliter la circulation de l’information, dans le but de répondre à desbesoins et d’atteindre des objectifs déterminés. En général dans les systèmes multi-agents, l’organisation
6

1.2. Les Systèmes Multi-Agents
correspond à la structure du système ou à son architecture. Elle est définie par les liens d’échangesd’information et de requêtes entre les agents du système.
1.2.3 Émergence et auto-organisation
Le type de problèmes auquel nous nous intéressons a la particularité d’avoir une solution a priori« inconnue », ceci est dû en partie à l’aspect dynamique et non linéaire des systèmes étudiés. Résoudreces problèmes est donc difficile. L’auto-organisation permet de faire émerger une solution adéquate, quien plus soit adaptative. Nous nous intéressons dans cette partie à deux notions étroitement liées quesont l’émergence et l’auto-organisation, indispensables à l’obtention de la fonctionnalité recherchée.
1.2.3.1 Émergence
Cette notion vient principalement de l’observation de phénomènes naturels. Le terme émergencedésigne l’apparition soudaine et imprévisible de phénomènes au sein d’un système complexe. Suivant[Georgé, 2003] l’émergence possède les propriétés suivantes :
– Le phénomène est ostensible, il s’impose à l’observateur au macro-niveau.– Le phénomène est radicalement nouveau, il ne peut être expliqué par la connaissance du micro-
niveau.– Le phénomène est cohérent et corrélé, il a une identité propre mais liée aux parties du micro-niveau.– Le phénomène crée une dynamique particulière, il n’est pas prédéfini, il s’auto-crée et s’auto-
maintient. Cette notion est très intéressante dans le cadre des systèmes complexes car bien qu’onne puisse établir de modèle et donc prédire une solution, il est possible de faire émerger cettesolution en se concentrant essentiellement sur l’organisation des parties du micro-niveau.
1.2.3.2 Auto-organisation
Un Système Multi-Agent s’auto-organise lorsqu’il modifie de lui-même son organisation afin des’adapter à son environnement. L’auto-organisation est donc synonyme de flexibilité du système carcelui-ci est bien plus apte aux changements de l’environnement, c’est-à-dire à même de s’adapter auxperturbations. Il est ainsi primordial que les entités du système ne soient pas contrôlées de l’extérieur[Di Marzo Serugendo et al., 2006] (autonomie) et qu’elles communiquent car c’est bien de leurs interac-tions que naît une nouvelle organisation.
1.2.4 Théorie des AMAS
Maintenant que nous avons défini les principales caractéristiques et fonctionnalités des SMA, nousallons présenter un cas particulier de SMA utilisé par l’équipe SMAC : la théorie des AMAS [Caperaet al., 2003]. A l’heure actuelle, compte tenu de la puissance de calcul que les ordinateurs sont à mêmede nous offrir, nous sommes en mesure de traiter des applications complexes. Cette complexité vient no-tamment du nombre d’entités en interaction, entités autonomes, hétérogènes et évolutives. Par ailleursla généricité du matériel informatique rend le nombre de connexions possibles entre différents appareilsde plus en plus grand. Ainsi nous devons prendre en compte des environnements dynamiques, des sys-tèmes ouverts et hétérogènes. Bien que des théories formelles permettent de raisonner sur l’espace, letemps et la dynamique d’un monde évolutif, il s’avère que dans certaines situations ces spécificationssont impossibles :
– L’environnement du système est dynamique rendant inopérant l’énumération exhaustive des si-tuations que le système rencontrera.
– Le système a un nombre de composants variable dans le temps, il est ouvert et dynamique.– La tâche à réaliser par le système est trop complexe pour être spécifiée entièrement ce qui rend
une conception complète impossible.– La manière de réaliser cette tâche est difficile voire impossible à appréhender par un concepteur.
7

Chapitre 1. Contexte de l’étude
L’approche globale descendante traditionnelle fondée sur des modèles du monde est impossible. Il estdonc nécessaire de se baser sur un autre axe de recherche. Ce nouvel axe repose sur le théorème de l’adé-quation fonctionnelle [Camps, 1998] [Glize, 2001] et propose d’utiliser le principe de l’auto-organisationpar coopération.
FIGURE 1.2 — Adéquation fonctionnelle
Un système est fonctionnellement adéquat s’il effectue « correctement » la tâche qui lui a été assignée.Le terme « correctement » sous-entend que l’observation est faite du point de vue du concepteur quiconnaît la finalité de la tâche.
Théorème. Pour tout système fonctionnellement adéquat, il existe au moins un système à milieu intérieur co-opératif qui réalise une fonction équivalente dans le même environnement.
Ce théorème montre que tout système réalisant une fonction possède un équivalent fonctionnel ausein duquel les agents qui le composent interagissent de manière coopérative. Ainsi, d’un point devue conceptuel, il faut se concentrer sur le comportement des agents afin qu’ils disposent de moyensd’interaction coopératifs avec leur environnement. La figure 1.2 illustre ce théorème.
1.2.4.1 Apprentissage par auto-organisation
Les systèmes fondés sur la théorie des AMAS voient leur fonction globale émerger de l’auto-organi-sation des entités qui les composent. D’un point de vue formel, une fonction globale fS d’un système Sest composée de fonctions partielles fi assurées par les entités Pi de S. On a donc fS = f1 ◦ f2 ◦ . . . ◦ fn.Or f1 ◦ f2 6= f2 ◦ f1, un changement d’organisation des entités donc de combinaison des fonctions par-tielles modifiera la fonction globale du système (cf. Figure 1.3). Le processus d’apprentissage par auto-organisation consiste donc à doter les entités du système de critères de réorganisation leur permettantde définir elles-mêmes leur rôle au sein du système, c’est-à-dire la faculté de modifier de manière auto-nome les relations qu’elles entretiennent entres elles afin de faire converger le système vers l’adéquationfonctionnelle. On peut noter que ces modifications de relations se font d’un point de vue local c’est-à-dire en fonction des perceptions propres aux entités, en aucun cas ces dernières ont pour but explicite defaire tendre le système vers son adéquation fonctionnelle. Ce mécanisme, du fait de l’émergence de sesstructures organisationnelles, rend le système robuste aux perturbations de l’environnement permettantde s’adapter à des situations non prévues lors de la conception.
1.2.4.2 Situations Non Coopératives (SNC)
Un agent agit de manière coopérative s’il occupe une place adéquate au sein du système, c’est-à-direque son comportement contribue à la résolution du problème et qu’il ne nuit pas aux autres agents.Dans le cas contraire on dit que l’agent est en situation non coopérative. Ce dernier doit donc agir afinde faire tendre son comportement vers une situation coopérative. C’est là toute la raison d’exister desagents dans un système adaptatif. On distingue plusieurs types de situations non coopératives [Georgé,2004]. Notamment lors des différentes phases du cycle de vie d’un agent :
– Perception :– L’incompréhension : l’agent reçoit une information qu’il ne comprend pas.
8

1.3. Les AMAS pour le contrôle de scénario
FIGURE 1.3 — Adaptation par auto-organisation
– L’ambiguïté : il y a ambigüité lorsqu’un agent attribue plusieurs significations à une informa-tion.
– Décision :– L’incompétence : l’agent n’est pas capable d’exploiter l’information perçue.– L’improductivité : l’agent est indifférent au signal, il ne conclut rien quant à l’information per-
çue.– Action :
– La concurrence : Deux agents font une action qui aboutit au même résultat.– Le conflit : Deux agents font une action incompatible.– L’inutilité : L’action d’un agent de fait pas progresser le système et ne rend service à aucun autre
agent.Un agent doit être capable de détecter ces situations afin de demeurer dans un état coopératif.
1.3 Les AMAS pour le contrôle de scénario
Comme établi précédemment, les propriétés complexes des jeux sérieux en font des systèmes im-possible à contrôler suivant l’approche descendante classique utilisée en génie logiciel. En conséquence,Luc Pons propose l’utilisation d’un AMAS afin de résoudre le problème du contrôle par une approchefondée sur l’émergence. Son système est consititué d’agents et d’une matrice de corrélations, élémentsqui sont décrits ci-après.
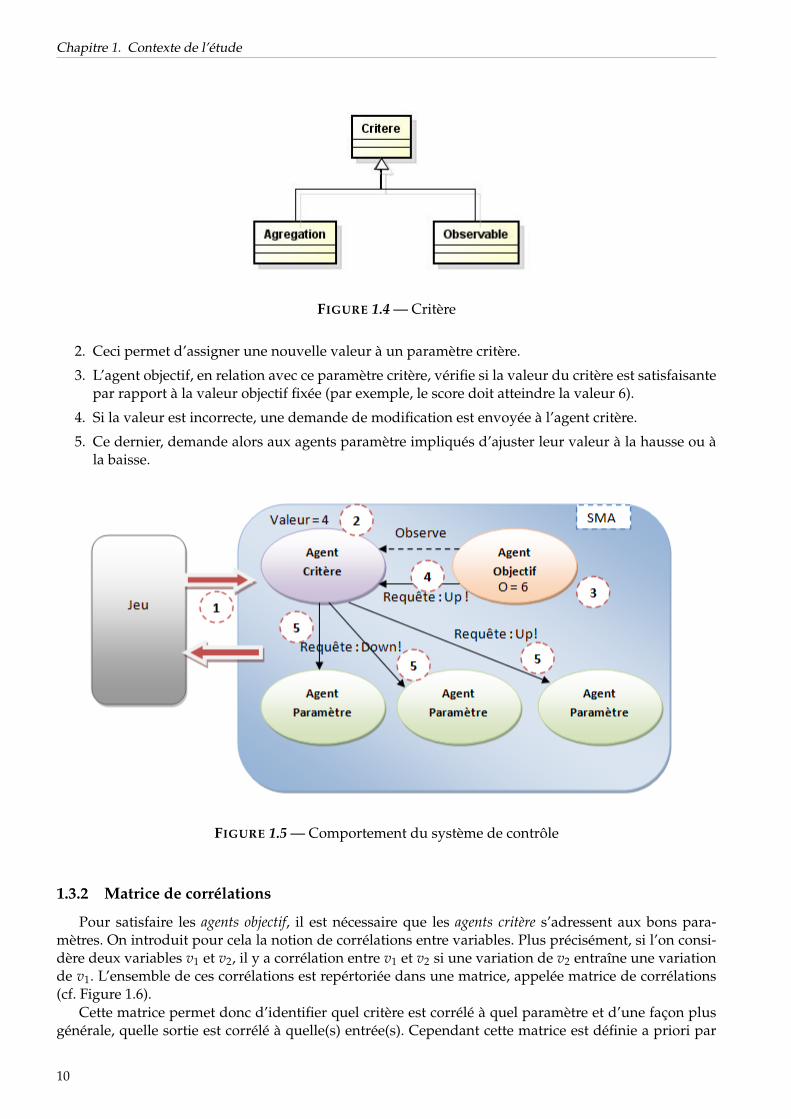
1.3.1 Agents
– Agent Critère (cf. Figure 1.4) : Un agent critère représente un observable (observation ou mesuresur le jeu) dont la valeur peut être obtenue en temps réel, ou des agrégations de paramètres oud’autres critères.
– Agent Objectif : Un agent objectif maintient une valeur souhaitée pour un critère, cette valeurcorrespond à l’objectif pédagogique à atteindre.
– Agent Paramètre : Un agent paramètre représente un paramètre effectif du jeu, la valeur qui luiest assignée influe directement sur l’état du jeu.
De plus, la notion de criticité est utilisée, elle représente le degré de non satisfaction d’un agent à uninstant donné. En effet, les agents étant coopératifs ils se doivent de traiter en priorité les demandesprovenant des agents dont l’état est le plus critique. Les agents objectif font connaître leur criticité auxagents critère qui, par requêtes de changement de valeur transmises aux agents paramètre, tentent derésorber cette criticité. La figure 1.5 illustre le comportement du système de contrôle.
1. Les informations en provenance du jeu sont mises à jour (par exemple, la valeur courante du scoredu joueur, qui vaut 4).
9
Chapitre 1. Contexte de l’étude
FIGURE 1.4 — Critère
2. Ceci permet d’assigner une nouvelle valeur à un paramètre critère.
3. L’agent objectif, en relation avec ce paramètre critère, vérifie si la valeur du critère est satisfaisantepar rapport à la valeur objectif fixée (par exemple, le score doit atteindre la valeur 6).
4. Si la valeur est incorrecte, une demande de modification est envoyée à l’agent critère.
5. Ce dernier, demande alors aux agents paramètre impliqués d’ajuster leur valeur à la hausse ou àla baisse.
FIGURE 1.5 — Comportement du système de contrôle
1.3.2 Matrice de corrélations
Pour satisfaire les agents objectif, il est nécessaire que les agents critère s’adressent aux bons para-mètres. On introduit pour cela la notion de corrélations entre variables. Plus précisément, si l’on consi-dère deux variables v1 et v2, il y a corrélation entre v1 et v2 si une variation de v2 entraîne une variationde v1. L’ensemble de ces corrélations est repértoriée dans une matrice, appelée matrice de corrélations(cf. Figure 1.6).
Cette matrice permet donc d’identifier quel critère est corrélé à quel paramètre et d’une façon plusgénérale, quelle sortie est corrélé à quelle(s) entrée(s). Cependant cette matrice est définie a priori par
10

1.4. Bilan
FIGURE 1.6 — Matrice de corrélations
expertise. Les informations qui s’y trouvent peuvent être potentiellement erronées ; de plus, aucuneinformation numérique quant à la force d’un paramètre sur un critère n’y est renseignée.
1.4 Bilan
Les jeux sont des systèmes dynamiques complexes non contrôlables par approche descendante clas-sique. L’approche par Système Multi-Agent Adaptatif a donc été proposée par Luc Pons pour réaliserun système capable d’ajuster les divers paramètres du jeu afin de réponde au mieux aux attentes dujoueur. Actuellement, ce système de contrôle donne des résultats pertinents en utilisant une matrice decorrélations qui n’est pas a priori la plus exacte possible. On peut penser que la qualité des corrélationsutilisées a un impact sur l’efficacité du contrôle réalisé. De plus, il est certainement souhaitable d’allégerla tâche du concepteur du jeu et/ou de l’expert du domaine. Pour cela, on propose donc d’enrichir lesystème de contrôle en le rendant capable d’apprendre par lui-même les corrélations de cette matrice.Le travail entrepris dans ce M2R est donc de proposer un mécanisme d’apprentissage automatique descorrélations entre entrées et sorties d’un système ayant des caractéristiques similaires à celles des jeuxconsidérés, à savoir un système dynamique.
11


2 État de l'art
Comme le chapitre précédent l’a expliqué, le but du travail entrepris dans ce stage est de concevoirun système capable d’apprendre les corrélations entre entrées et sorties d’un système dynamique. Eneffet, du fait de la dynamique particulière du type de systèmes que nous étudions, seul un système d’ap-prentissage peut répondre à notre problématique. Par conséquent, il est nécessaire qu’un ou plusieursagents apprennent les différentes actions à entreprendre face à l’évolution (imprévisible) du système.Ainsi nous présenterons dans un premier temps les principaux mécanismes d’apprentissage qui pour-raient être envisagés pour résoudre notre problème. Enfin nous nous intéresserons à une toute autretechnique de résolution de problèmes basée, elle, sur la satisfaction de contraintes appelée programma-tion linéaire en nombres entiers.
2.1 Apprentissage par renforcement
Présentation
Afin d’introduire le concept d’apprentissage par renforcement, prenons par exemple le problèmeconsistant à apprendre à jouer aux échecs. Selon une toute autre technique d’apprentissage, l’appren-tissage supervisé (méthodes des réseaux de neurones [Lippmann, 1988], arbres de décisions [Leo et al.,1984]), un agent nécessite la connaissance du résultat de chacune de ses actions possibles dans un étatdonné, mais un tel signal de retour est rarement disponible. En l’absence de ce signal, l’agent peut ap-prendre un modèle de transition pour ses propres actions et alors, peut-être, apprendre à prédire lesactions de son adversaire. Cela signifie que l’agent a besoin de savoir qu’il s’est produit quelque chosede bon s’il gagne et de mauvais s’il perd. Cette forme de retour de l’environnement s’appelle récom-pense ou renforcement.
L’apprentissage par renforcement est donc une technique d’apprentissage artificiel dont le but estd’apprendre, à partir d’expériences, ce qu’il convient de faire dans une situation donnée. Cela permet àun agent d’apprendre le comportement adéquat tout en interagissant avec un environnement incertain.Ce dernier doit en effet prendre une décision en fonction de son état courant et reçoit une réponse deson environnement qui peut être positive ou négative. La figure 2.1 illustre le fonctionnement.
Parmi les premiers algorithmes d’apprentissage par renforcement, on compte le TD-Learning (mé-thode de prédiction qui se base sur le principe que tout évènement est la conséquence d’un évènementprécédent), proposé par Richard Sutton en 1988 [Sutton, 1988], et le Q-learning (technique d’explorationpermettant la définition de politique de décision) [Watkins et Dayan, 1992].
Finalement l’apprentissage par renforcement c’est examiner comment un agent peut tirer des leçonsdu succès et de l’échec.
Fonctionnement
Dans un état donné, un agent teste de manière autonome les actions qu’il peut entreprendre afind’atteindre ou simplement s’approcher de son but. Une fois une action choisie et éxécutée il en déduitla pertinence de son action en y associant une récompense.
13

Chapitre 2. État de l’art
FIGURE 2.1 — Apprentissage par renforcement
Comme l’agent est en train d’apprendre, il se trouve régulièrement dans des états du monde incon-nus. En d’autres termes, il ne connaît pas les états successeurs de l’état du monde courant ou bien il n’aaucune préférence d’action. Ainsi son action est tirée au hasard, il l’exécute, associe une récompense àcette action (récompense positive ou négative) et enrichit sa base de connaissances. Lorsqu’un agent setrouve dans un état déjà expérimenté, il choisit l’action qui lui permet d’atteindre l’état dont la fonctionde valeur lui prédit un gain maximal. Après exécution de cette action, il y a soit renforcement de l’actionchoisie si elle a été à nouveau fructueuse, soit affaiblissement dans le cas contraire.
On distingue généralement trois types d’agents :
– Un agent fondé sur l’utilité dont le but est d’apprendre une fonction d’utilité sur des états etl’utilise pour sélectionner des actions qui maximisent l’utilité espérée du résultat.
– Un agent Q-learning qui apprend une fonction action-valeur qui donne l’utilité espérée de la réa-lisation d’une action donnée dans un état donné.
– Un agent réflexe qui apprend une politique qui associe directement les états aux actions.
Il est important de distinguer ces types de conceptions, en effet, un agent fondé sur l’utilité doit posséderun modèle de son environnement car il doit connaître les états auxquels ses actions vont conduire. Cen’est pas le cas d’un agent Q-Learning qui lui, peut comparer les valeurs des choix dont il dispose sansconnaître leur résultat. Cependant, étant donné qu’il ne sait pas où ses actions vont le mener, il ne peutpas anticiper.
D’une manière générale, ici, les fonctions apprises par les agents sont représentées sous forme tabu-laire, avec une sortie pour chaque n-uplet en entrée. Ce type d’approche marche raisonnablement bienpour les petits espaces d’états mais le temps de convergence et le temps par itération croît rapidement àmesure que l’espace d’état augmente. Les échecs et le backgammon sont de minuscules sous-ensemblesdu monde réel, et pourtant leur espace d’état contient de 1020 à 1040 états. Il serait donc absurde devouloir explorer tous les états pour apprendre à jouer.
Il existe cependant des méthodes comme les approximateurs de fonctions [Poggio et Girosi, 1989]pour palier ce problème.
Finalement, parce qu’il permet d’éliminer le codage manuel des stratégies de contrôle, l’apprentis-sage par renforcement continue à être un des domaines les plus actifs de la recherche en apprentissageartificiel. En ce qui concerne notre problématique, l’apprentissage par renforcement a un double avan-tage :
– C’est une approche qui permet d’apprendre à partir d’interactions avec l’environnement.– Cette approche est adéquate lorsqu’il s’agit d’apprendre en environnement inconnu.
14

2.2. Apprentissage par algorithme génétique
Apport
Il est tout à fait concevable d’utiliser cette approche. En effet, ce type d’apprentissage est intéres-sant lorsqu’il s’agit d’apprendre dans un environnement inconnu où la solution même du problème estinconnue. Nous nous intéressons à l’apprentissage de corrélations inconnues a priori, il est donc envisa-geable de définir le comportement d’un agent de telle sorte qu’il essaie des valeurs pour les corrélationsjusqu’à trouver la bonne. Le problème ici est la définition de la récompense. En effet, il est difficile dedéfinir l’impact qu’une action peut avoir sur l’ensemble d’un système multi-agent. Par ailleurs, il estquestion d’apprendre dans un environnement dynamique. La récompense est donc d’autant plus diffi-cile à évaluer car elle est susceptible de varier au cours de l’évolution du système.
2.2 Apprentissage par algorithme génétique
Présentation
Les algorithmes génétiques appartiennent à la famille des algorithmes évolutionnistes. En effet, leurfonctionnement se rapproche des mécanismes d’évolution naturelle (croisement, mutation, sélectionetc.). Holland [Holland, 1975] a été le premier à s’inspirer des mécanismes de sélection et d’évolutiongénétique présents dans la nature. L’idée est de faire évoluer les paramètres des programmes par le biaisd’une sélection et d’un mécanisme de reproduction tel celui des êtres vivants.
Fonctionnement
La première étape vise, à partir d’une modélisation mathématique du problème, à trouver un codagepour les paramètres du programme. Le codage binaire (de par sa simplicité de représentation) a sou-vent été proposé comme encodage des entrées. Or il devient courant maintenant d’utiliser une notationréelle ou sous forme de nombres entiers. Vient ensuite le mécanisme de génération de la populationinitiale. La méthode utilisée pour générer cette population est importante car celle-ci conditionne la ra-pidité de convergence de l’algorithme. On constate ici la nécessité d’une fonction d’évaluation dont lafinesse dépend de l’heuristique utilisée. La suite de l’algorithme consiste à optimiser une fonction, paropérations successives sur la population de gènes. Ces opérations s’étendent de l’hybridation (obtentiond’un nouvel individu à partir de deux individus parents) à la mutation (modification d’un individu).
Pour en revenir à notre problème, la population initiale peut être un ensemble de valeurs prisealéatoirement pour les corrélations. Ainsi, au fur et à mesure des itérations de l’algorithme il s’agiraitde modifier ces valeurs voire d’en supprimer jusqu’à obtenir les valeurs réelles des corrélations.
Apport
L’utilisation des algorithmes génétiques est courante lorsque l’on cherche à résoudre des problèmescomplexes où la solution est a priori inconnue. Cependant la difficulté ici réside dans la définition d’unefonction d’évaluation. En effet, plus celle-ci sera précise, plus l’algorithme convergera rapidement. Cetype d’algorithme est donc tout à fait envisageable pour la résolution de notre problème d’apprentis-sage. Cependant il y a une contrainte lourde en terme de temps de résolution car une solution ne peutêtre obtenue qu’après un nombre important de générations. Ainsi il est fort probable que le temps derésolution croisse exponentiellement avec le nombre de corrélations. Par ailleurs, il ne s’agit pas ici derépartir l’algorithme sur plusieurs entités mais d’utiliser une résolution centralisée donc peu robuste. Eneffet, si l’environnement vient à changer (ajout ou suppression d’un paramètre, changement de valeurpour une corrélation), il est nécessaire de relancer l’algorithme à un état initial.
En conséquence, cette dernière remarque rend inexploitable les algorithmes génétiques.
15

Chapitre 2. État de l’art
2.3 Approche de type essais successifs
Présentation
Cette approche algorithmique, plus connue sous le nom de backtracking [Brassard et Bratley, 1996],consiste en l’exploration d’un espace d’états jusqu’à obtenir une ou plusieurs solutions. L’objectif est,à partir d’un espace d’états modélisé sous forme d’arbre, d’effectuer un parcours en profondeur enremplissant un vecteur solution constitué des solutions candidates évaluées lors du parcours.
Fonctionnement
Le principe de la résolution d’un problème par un algorithme à essais successifs est le suivant :– si l’état courant est solution du problème, le placer dans le vecteur solution ;– sinon :
1. énumérer les actions possibles dans l’état courant ;
2. choisir une des actions et l’exécuter (choix dépendant d’une heuristique) ;
3. ré-éxécuter l’algorithme à partir du nouvel état ;
4. rétablir le contexte d’avant l’appel (retour arrière, ou backtrack) ;
5. retourner au point étape 2 tant qu’il reste des actions possibles.
Ceci permet de trouver toutes les solutions du problème. Si on souhaite simplement trouver une solu-tion, il suffit de s’arrêter dès que l’étape 3 trouve une solution.
Apport
Cette approche est couramment utilisée pour des problèmes à espace d’état réduit, par exemple leproblème des n reines [Rivin et al., 1994]. Par ailleurs, il est possible d’enrichir l’exploration par ajoutd’une heuristique d’élagage qui permet d’éviter l’exploration d’états inutiles. Afin de trouver la solutionoptimale lors du parcours (et non renvoyer un vecteur de solutions candidates), une heuristique deguidage peut être utilisée.
Cette approche est similaire à l’approche par séparation et évaluation qui consiste à diviser le pro-blème en un certain nombre de sous-problèmes qui ont chacun leur ensemble de solutions réalisablesde telle sorte que tous ces ensembles forment un recouvrement (idéalement une partition) de l’ensembledes solutions. Ainsi, en résolvant tous les sous-problèmes et en prenant la meilleure solution trouvée,on est assuré d’avoir résolu le problème initial. L’algorithme A∗ fonctionne de la sorte.
En ce qui concerne notre problème, cette approche ne peut être retenue car la complexité en temps eten espace de ce type d’algorithme est exponentielle suivant le nombre d’entrées [Stone et Sipala, 1986].
2.4 Programmation linéaire en nombres entiers
Bien que cette technique n’est pas une technique d’apprentissage, nous verrons dans la suite del’étude que le problème à traiter peut se formaliser sous forme d’équation. Cette technique d’optimisa-tion est donc un bon élément de comparaison.
Présentation
La programmation linéaire, aussi connue sous le nom d’optimisation linéaire (OL) est une techniqued’optimisation visant à maximiser ou minimiser une fonction (linéaire). Cette fonction est généralementcomposée de plusieurs variables reliées par un ensemble de contraintes. Dans certains problèmes d’OL,on requiert en plus que les variables ne prennent que des valeurs entières. On parle alors de problèmed’optimisation linéaire en nombres entiers (OLNE).
La démarche classique de résolution de problèmes par programmation linéaire est la suivante :
16

2.4. Programmation linéaire en nombres entiers
1. définition de la fonction objectif (fonction linéaire à maximiser ou minimiser) ;
2. définition des contraintes ;
3. application d’un algorithme cherchant à maximiser ou minimiser la fonction objectif.
Il existe en effet des algorithmes polynomiaux efficaces (efficacité relative à la dimension du problèmeà résoudre). Nous détaillons maintenant les algorithmes les plus utilisés.
Fonctionnement
Algorithme du simplexe
Développé par Dantzig [Dantzig, 1963], l’algorithme du simplex est une méthode de résolution deproblèmes d’optimisation linéaire. Sûrement l’algorithme le plus connu en optimisation linéaire, il s’in-terprète assez simplement de manière géométrique. Les itérés (valeurs considérées par l’algorithmeà une itération donnée) se représentent sous forme de sommets d’un polyèdre convexe représentantl’ensemble des solutions admissibles (cf. figure 2.2). L’idée est donc, pour chaque itération, d’amélio-
FIGURE 2.2 — Représentation graphique des solutions possibles d’un problème etla solution optimale
rer (minimiser ou maximiser) la fonction objectif ou fonction coût en respectant les contraintes sur lesvariables, jusqu’à converger vers la solution optimale.
Bien que son fonctionnement soit simple et efficace, cet algorithme n’est pas polynomial. Il existe eneffet un problème [Klee et Minty, 1972] où l’algorithme est exponentiel. Ce problème a la particularitéd’avoir un ensemble de solutions admissibles qui se représente sous forme d’un cube pour lequel l’al-gorithme parcourt les 2n sommets. En effet, l’algorithme du simplexe prend des décisions à partir d’in-formations locales, ces décisions ont des effets globaux qui font que l’algorithme parcourt l’ensembledes sommets avant de trouver une solution.
Algorithme de points intérieurs
Proposé par Leonid Khachiyan [Khachiyan, 1979], cet algorithme est le premier algorithme polyno-mial en optimisation linéaire. Celui-ci se base sur une méthode géométrique appelée méthode de l’ellip-soïde proposée par Arkadi Nemirovski et David B. Yudin [Yudin et Nemirovski, 1976] (méthode d’op-timisation convexe visant à minimiser une fonction convexe). Bien que cette méthode se prête bien auxproblèmes d’optimisation non-linéaire, elle est moins rapide que le simplexe. C’est pourquoi, d’autresméthodes ont vu le jour comme la méthode projective de Narendra Karmarkar en 1984 [Karmarkar,1984] qui a une complexité au pire cas polynomiale.
17

Chapitre 2. État de l’art
Apport
Bien que l’algorithme du simplexe soit efficace, cette approche semble coûteuse lorsqu’il s’agit detraiter un grand nombre de paramètres. Par ailleurs, ce type d’approche n’est pas robuste (répond malaux perturbations). En effet, l’ajout ou le retrait d’une variable nécessite une révision du problème doncun retour à zéro dans le processus de résolution.
2.5 Conclusion
Parmi les techniques d’apprentissage présentées ci-dessus, seul l’apprentissage par renforcementpourrait convenir à notre problème. Cependant la définition de la récompense reste un point difficile.En effet, comme pour les autres techniques, il est nécessaire de définir une fonction d’évaluation dont laprécision conditionne la rapidité d’apprentissage. Par ailleurs, ces techniques ne sont pas adaptatives,un changement dans notre système impliquerait un ré-apprentissage à partir de zéro. C’est là le pointcritique car nous cherchons à mettre au point un système capable d’apprendre dans un environnementdynamique. Pour ce qui est de la programmation linéaire, cette méthode peut-être utilisée uniquementcomme élément de comparaison des performances (en terme de temps de résolution). Il ne s’agit pasd’une technique d’apprentissage.
On peut conclure cet état de l’art en disant qu’aucune des méthodes « classiques »d’apprentissageprésentées n’est donc réellement adaptée à la résolution du problème qui nous intéresse ici, à savoirl’apprentissage des corrélations entre entrées et sorties d’un système dynamique. En effet, le système àconcevoir doit être capable d’apprendre au sein d’environnements évolutifs, dynamiques. C’est pour-quoi, seule l’approche par systèmes multi-agents adaptatifs semble adaptée. Le chapitre suivant pré-sente donc une proposition de conception fondée sur ce type de système.
18

3 Apprentissage de corrélations entreentrées et sorties de systèmesdynamiques
Nous abordons maintenant le coeur de ce stage dont le but principal est de concevoir et réaliser unsystème capable d’apprendre des corrélations entre entrées et sorties d’un système dynamique. Afinqu’il n’existe aucune ambiguïté, il est important dans un premier temps de bien définir le problème etses caractéristiques formelles. Comme nous l’avons vu dans le chapitre précédent nous utiliserons uneméthodologie propre au développement système à fonctionnalité émergente appelée ADELFE. Nous laprésenterons puis nous l’appliquerons en détail afin de proposer une solution à notre problème initial.Nous pourrons ainsi conclure sur des résultats ainsi qu’une analyse détaillée de ces derniers.
3.1 Le problème
Nous allons maintenant définir en détail les caractéristiques de notre problème d’apprentissage.
3.1.1 Définitions
Système dynamique. Un système dynamique est un système informatique conventionnel dont l’état,à un instant donné, est uniquement lié aux évènements d’états passés. De plus, à chaque état, il ne cor-respond qu’un seul état futur possible. On dit qu’un système dynamique évolue de manière causale etdéterministe. La modélisation classique d’un système dynamique consiste en une équation différentiellefaisant intervenir la variable temps. Il s’agit là de la façon la plus naturelle de concevoir ces systèmescar la dynamique du système est fortement liée à l’évolution dans le temps.
Certains de ces systèmes sont dits « non linéaires »c’est-à-dire qu’ils ne respectent pas le principede superposition (la somme de deux entrées quelconques e1 et e2 ne correspond pas à la somme dedeux sorties correspondantes). Les systèmes non linéaires peuvent faire preuve de comportements im-prévisibles, ces derniers pouvant être de l’ordre de l’aléatoire. Cette branche des systèmes dynamiquess’appelle théorie du chaos.
Entrée et sortie. Une entrée est ici une information reçue par le système qui influence (ou pas) lecomportement de celui-ci. Cette modification de comportement se matérialise par une modification dessorties, une sortie étant donc un résultat produit par le système.
Corrélation. En probabilités et en statistiques, étudier la corrélation entre deux ou plusieurs va-riables aléatoires c’est étudier l’intensité de la liaison qui peut exister entre ces variables. Dans notrecas de figure les variables sont les entrées et les sorties du système. Ainsi nous cherchons à identifierl’influence réelle que peut avoir une entrée sur une ou plusieurs sorties. Pour reprendre l’exemple dujeu vidéo, la force des ennemis (entrée) peut avoir une influence sur la santé du joueur (sortie), on ditque la santé du joueur est corrélée à la force des ennemis. Ainsi, jouer sur la valeur en entrée entraînerades modifications sur la sortie.
19

Chapitre 3. Apprentissage de corrélations entre entrées et sorties de systèmes dynamiques
3.1.2 Formalisation
L’approche traditionnelle pour la résolution de problèmes en informatique consiste à trouver un mo-dèle mathématique permettant de formaliser ce problème. Dans un système dynamique, une variationd’une ou de plusieurs entrées à un instant t entraîne, à t + 1, une variation sur une ou plusieurs sorties :
4St+1i = 4Et
0 + · · ·+4Etn
Ainsi, numériquement nous avons choisi de modéliser cela sous forme de somme arithmétique :
St+1i = ∑n
0 Etj
Cependant, dans le cas d’une somme arithmétique tous les opérandes ont le même poids. Autrementdit, toutes les entrées ont la même influence sur la sortie. Or la réalité est toute autre, en effet, il seraittrès audacieux d’assumer le fait que toutes les entrées, bien qu’imprévisibles et de natures différentes,aient exactement la même force sur le système. Nous décidons donc d’introduire la notion de forced’une entrée, conventionnellement appelée poids d’une entrée. On peut donc modéliser notre problèmesous forme de combinaison linéaire. La valeur d’une sortie est donc le résultat d’une somme pondéréed’entrées :
St+1i = ∑n
0 wtj ∗ Et
j
Le système à concevoir a donc pour fonctionnalité d’apprendre les poids wj.Maintenant que notre problème est défini formellement nous pouvons entamer la démarche de ré-
solution. Cette dernière suit les étapes d’une méthodologie propre à la résolution de problèmes par lesAMAS appelée ADELFE.
3.2 Conception du SMA d’apprentissage
ADELFE 1 est une méthode de développement d’applications à fonctionnalité émergente basées surla théorie des AMAS. Cette méthode vise à guider le concepteur dans le cadre d’un processus de déve-loppement fondé sur le processus unifié. ADELFE couvre les phases habituelles de la conception d’unlogiciel, des exigences au codage, il utilise la notation UML et l’extension d’UML proposée dans AUML(Agent Unified Modeling Language). Ce processus de développement se divise en cinq étapes (cf. figure3.1) :
1. Besoins préliminaires : cette phase permet de concevoir un cahier des charges précis avec le client,de dégager les limites du système en devenir et de spécifier un vocabulaire commun lié au do-maine d’application du système.
2. Etude des besoins finals : elle permet, à partir du cahier des charges précédemment établi, d’iden-tifier les entités (actives ou passives) entrant en jeu dans le système et de déterminer celles quiconstitueront son environnement. Les interactions entre le système et ces entités sont étudiéesplus précisément.
3. Analyse : cette étape est particulièrement importante puisqu’elle permet de vérifier l’adéquationdu problème avec la théorie des AMAS et de fournir une première version de l’architecture logi-cielle.
4. Conception : cette phase est dédiée à la conception détaillée de l’application et notamment desagents et de leurs interactions. Elle permet également d’établir les situations non coopératives etde les décrire sous forme tabulaire.
5. Implémentation : cette phase correspond à l’implémentation du système.
20

3.2. Conception du SMA d’apprentissage
FIGURE 3.1 — ADELFE
La figure 3.1 illustre le processus de développement. Nous allons maintenant détailler les principalesparties nécessaires à la conception de notre système.
3.2.1 Besoins préliminaires
Bien que le but du travail entrepris ici soit de réaliser un système capable d’apprendre les corré-lations entre entrées et sorties de n’importe quel système dynamique, nous avons choisi d’appliquerADELFE en considérant un exemple plus concret. Le système considéré est celui pour lequel le travail aété envisagé à la base c’est-à-dire un jeu vidéo, celui sur lequel le contrôle est effectué dans les travauxde Luc Pons (voir chapitre 1.1.2).
Quelques mots-clés de notre simulation : corrélation, critère, paramètre. Notre système sera limitépar le nombre de critères et de paramètres représentés.
3.2.2 Besoins finals
Plusieurs entités (actives (A) ou passives (P)) composent l’environnement du système d’apprentis-sage que l’on va concevoir :
– Le moteur de jeu (A) : effecteur du SMA de contrôle, modifie la valeur des observables.– Le SMA de contrôle du système (A) : récupère la matrice de corrélations et ajuste les entrées du
jeu.– Le joueur (A) : l’état du jeu dépend du comportement de celui-ci.– La matrice de corrélations (P) : est utilisée par le SMA de contrôle pour savoir quels paramètres
ajuster.– Les objectifs (P) : correspondent aux objectifs pédagogiques du joueur, (i.e. valeurs ou intervalle
de valeurs souhaités pour un critère).
1. Atelier de DEveloppement de Logiciel à Fonctionnalité Émergente
21

Chapitre 3. Apprentissage de corrélations entre entrées et sorties de systèmes dynamiques
Nous allons maintenant caractériser cet environnement selon les critères de Russel et Norvig. L’en-vironnement du système d’apprentissage des corrélations peut être qualifié de :
– Dynamique : la matrice de corrélations est régulièrement modifiée, au fur et à mesure que notresystème trouve de nouvelles corrélations, il les inscrit dans la matrice ;
– Non déterministe : le comportement du joueur est imprévisible ce qui rend les évènements obser-vés dans l’environnement imprévisibles aussi ;
– Discret : le nombre d’actions que nos entités (nos futurs agents) peuvent entreprendre est limité ;– Quasi-accessible : la vision de l’environnement est limitée. En effet, le SMA de contrôle et le moteur
de jeu sont des boîtes noires, or la matrice de corrélations est bien accessible.D’un point de vue interaction, notre système doit inscrire les corrélations qu’il découvre dans la
matrice. Cette dernière est directement utilisée par le SMA de contrôle qui peut ajuster les paramètresdu jeu. Suivant les actions du joueur, l’état du jeu est modifié, notre système observe donc directementles nouvelles valeurs des observables. La figure 3.2 illustre le couplage des différents systèmes.
FIGURE 3.2 — Couplage du système de contrôle et du système d’apprentissage
3.2.3 Analyse
Afin de vérifier que les AMAS sont adéquats pour résoudre le problème posé, il est impératif derépondre aux huit questions suivantes :
1. La tâche globale est-elle incomplètement spécifiée ? Un algorithme est-il inconnu a priori ? Dansnotre système, la tâche globale est spécifiée, il s’agit de remplir la matrice de corrélations doncd’apprendre les corrélations entre critères et paramètres or, les moyens et les solutions à mettre enoeuvre pour y arriver sont inconnus.
22

3.2. Conception du SMA d’apprentissage
2. Si plusieurs entités sont nécessaires pour résoudre la tâche globale, doivent-elles agir dans uncertain ordre ? Une activité corrélée est-elle nécessaire ? La coopération peut être une bonne so-lution pour gérer la collaboration entre composantes. L’ordonnancement des tâches est importantcar certaines ne peuvent être effectuées qu’après réception d’informations venant d’autres entités.
3. La solution est-elle, de manière générale, obtenue par essais successifs, plusieurs essais sont-ils requis avant de trouver une solution ? La solution optimale c’est-à-dire les poids réels desparamètres ne peut être trouvée directement car ils sont inconnus a priori, le système doit testerplusieurs valeurs pour les poids avant de se stabiliser.
4. L’environnement du système peut-il évoluer ? Il est envisageable de rajouter d’autres critèresou d’autres paramètres, en effet, le jeu évolue en fonction du comportement du joueur donc denouvelles corrélations peuvent apparaître, d’autres disparaître. Notre système peut donc évoluer.
5. Le traitement effectué par le système est-il fonctionnellement ou physiquement distribué ? Plu-sieurs entités physiquement réparties sont-elles utiles à la résolution de la tâche globale ? Une dis-tribution conceptuelle est-elle nécessaire ? Notre système est fonctionnellement distribué car nousconsidérons que chaque agent est responsable d’une tâche.
6. Est-il nécessaire d’avoir un grand nombre d’entités ? Notre système définit des corrélations entreentrées-sorties d’un système. Ce nombre d’entrées-sorties peut-être élevé, il est donc nécessaire deprévoir un nombre d’entités suffisamment pertinent pour gérer ces entrées-sorties.
7. Le système étudié est-il linéaire ? Notre système ne respecte pas le principe de superposition (cf.3.1.1), il n’est donc pas linéaire.
8. Le système est-il évolutif ou ouvert ? De nouvelles entités peuvent-elles apparaître ou dispa-raître dynamiquement ? Dans l’état actuel des choses nous n’envisageons pas l’ajout d’élémentsde scénario à la volée. Ainsi notre système est plus évolutif qu’ouvert.D’après les réponses données aux différentes questions ci-dessus, l’outil d’adéquation associé àAdelfe ([Picard, 2004]) permet de vérifier que les AMAS sont adéquats pour concevoir notre sys-tème.
3.2.3.1 Agents
L’étape suivante consiste à déterminer, parmi les entités identifiées, celles qui peuvent être considé-rées comme des agents.
– Les corrélations : Une corrélation est une relation binaire qui, sémantiquement, correspond à l’in-fluence qu’un paramètre possède sur un critère. Bien que la matrice soit vue comme une entitépassive, les informations renseignées dans cette dernière évoluent. La matrice est donc décompo-sable en entités actives. Ici, chaque case de la matrice est une corrélation qui prend une valeurréelle correspondant à son poids courant. De la satisfaction d’un critère dépend donc la valeurchoisie par les corrélations qui lui correspondent dans la matrice. Les corrélations sont donc lesagents moteurs de notre système c’est bien elles qui sont chargées d’apprendre des valeurs.
– Les observables : Les observables sont la source du feedback pour les corrélations. En effet, à uninstant t, ces agents sont capables de percevoir la variation qui s’est produite en sortie et la compa-rer avec le résultat obtenu (pour cette même sortie) suivant les valeurs courantes des corrélations.Pour cela ils maintiennent deux valeurs : la valeur réelle observée directement via le jeu et unevaleur théorique calculée via les valeurs courantes des corrélations.
Nous décidons de ne pas considérer les autres entités comme agents car les informations qu’elles main-tiennent ne sont pas nécessaires au comportement d’apprentissage. Nous n’avons pas besoin de leurattribuer de comportement autonome.
Au niveau local nous devons maintenant répondre aux questions suivantes :
1. Une entité n’a-t-elle qu’une rationalité limitée ? Dans notre cas, les agents n’ont qu’une vue par-tielle de l’environnement, ils perçoivent les valeurs des critères et objectifs et peuvent donc ignorercertaines informations (ils sont plutôt réactifs).
23
Chapitre 3. Apprentissage de corrélations entre entrées et sorties de systèmes dynamiques
2. Une entité est-elle de forte granularité ou non ? Est-elle capable d’effectuer de nombreusesactions, de raisonner beaucoup ? Doit-elle posséder beaucoup de capacités pour effectuer sapropre tâche ? Le nombre d’actions de nos agents est très réduit, les corrélations ne font qu’unajustement de leur valeur. Finalement, ils ont besoin de peu de capacités pour effectuer leur tâche.
3. Le comportement d’une entité peut-il évoluer ? L’entité doit-elle s’adapter aux changements deson environnement ? Nous sommes dans un environnement dynamique, le système évolue sui-vant le comportement imprévisible du joueur, nos entités doivent donc s’adapter aux changementsde l’environnement.
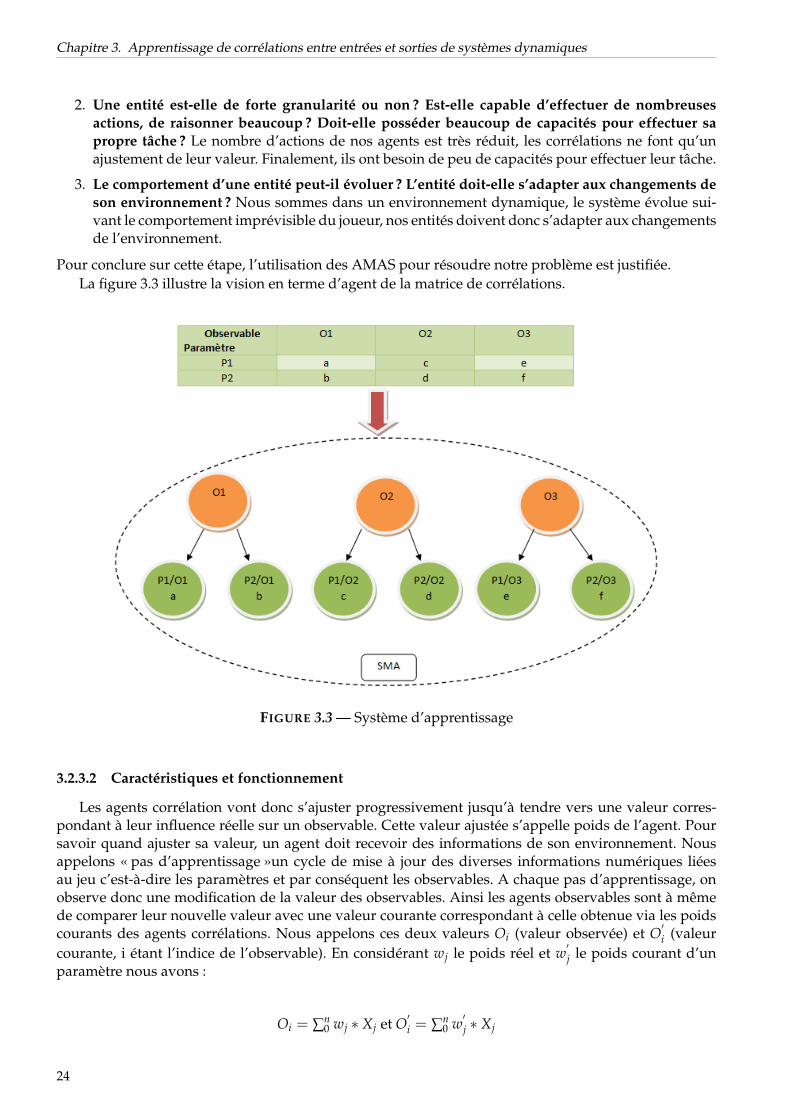
Pour conclure sur cette étape, l’utilisation des AMAS pour résoudre notre problème est justifiée.La figure 3.3 illustre la vision en terme d’agent de la matrice de corrélations.
FIGURE 3.3 — Système d’apprentissage
3.2.3.2 Caractéristiques et fonctionnement
Les agents corrélation vont donc s’ajuster progressivement jusqu’à tendre vers une valeur corres-pondant à leur influence réelle sur un observable. Cette valeur ajustée s’appelle poids de l’agent. Poursavoir quand ajuster sa valeur, un agent doit recevoir des informations de son environnement. Nousappelons « pas d’apprentissage »un cycle de mise à jour des diverses informations numériques liéesau jeu c’est-à-dire les paramètres et par conséquent les observables. A chaque pas d’apprentissage, onobserve donc une modification de la valeur des observables. Ainsi les agents observables sont à mêmede comparer leur nouvelle valeur avec une valeur courante correspondant à celle obtenue via les poidscourants des agents corrélations. Nous appelons ces deux valeurs Oi (valeur observée) et O
′i (valeur
courante, i étant l’indice de l’observable). En considérant wj le poids réel et w′j le poids courant d’un
paramètre nous avons :
Oi = ∑n0 wj ∗ Xj et O
′i = ∑n
0 w′j ∗ Xj
24

3.2. Conception du SMA d’apprentissage
Ainsi après comparaison de Oi et O′i un agent Oi peut spécifier aux agents corrélation dans quel sens
ils doivent s’ajuster. Nous appelons cette information le feedback :– Oi > O
′i : Feedback positif (les agents corrélations doivent augmenter leur poids)
– Oi < O′i : Feedback négatif (les agents corrélations doivent baisser leur poids)
– Oi = O′i : Feedback nul (La somme résultant des poids courants est correcte)
Par ce système de feedback nous avons donc à chaque pas d’apprentissage un ajustement des poidsdes corrélations. Il subsiste cependant un problème. En effet, Oi peut être égal à O
′i sans pour autant
que les poids courants des agents soient les poids réels. Exemple : 8 ∗ 3 + 2 ∗ 2 = 6 ∗ 3 + 5 ∗ 2 maispourtant 8 6= 6 et 2 6= 5. Cette situation ne peut arriver car à chaque pas il y a un nouvel exemple généré(nouvelle valeur pour les paramètres) donc un ajustement. Finalement, nous considérons que notresystème converge lorsqu’à chaque pas Oi = O
′i. Cela signifie que peu importe la valeur des paramètres,
les poids trouvés sont les bons.
3.2.3.3 Situations Non Coopératives (SNC)
Un agent corrélation est en situation non coopérative lorsque sa valeur est erronée. Suivant l’ap-proche par AMAS les agents sont coopératifs, les agents corrélation vont donc au cours de leur cycle devie tenter de trouver un moyen de redevenir coopératif en résolvant ces SNC.
Suivant [Bernon et al., 2009] l’approche par AMAS met à disposition du concepteur trois mécanismespermettant à un agent de rester coopératif et donc d’adapter la fonction du SMA :
– Le tuning de paramètre : les agents ajustent une ou plusieurs variables qu’ils maintiennent (cesvariables représentent leur état interne, il s’agit donc d’un changement d’état).
– La réorganisation : les agents changent leur structure d’interaction, c’est une modification de lastructure même du système.
– L’évolution : certains agents jugés inutiles peuvent disparaître ou à l’inverse, apparaître.Dans notre cas de figure nous nous intéressons au tuning de paramètre car les agents corrélation doiventuniquement ajuster leur poids. On peut dire qu’il sont coopératifs lorsqu’ils s’ajustent dans le sens dufeedback conditionnant ainsi la convergence du système vers un état stable. Sylvain Lemouzy montredans sa thèse [Lemouzy, 2011] que ce principe d’ajustement de paramètre répond au problème plusgénéral de recherche itérative de valeur, susceptible d’évoluer au cours du temps, en fonction d’infor-mations très restreintes de type « plus grand - plus petit ». Cette technique s’appelle Adaptive ValueTracker (AVT). L’AVT a pour but de rechercher une valeur réelle v où :
– v ∈ [vMin; vMax] avec vMin la borne minimale de l’espace de recherche et vMax la borne maximale.– La valeur v est dynamique (i.e. susceptible d’évoluer à tout moment).– La seule information permettant de trouver v est un feedback de l’environnement de type « plus
grand » (+), « plus petit » (-) ou « convenable » (=).Finalement, cette technique peut s’avérer efficace car nos agents cherchent effectivement une valeur
de manière itérative suite à des feedbacks de l’environnement et de plus cette valeur est dynamique carune corrélation peut évoluer dans le temps.
3.2.4 Conception
Cette partie vise à définir la représentation des agents ainsi que l’architecture globale du système enterme de paquetages, classes, agents et objets.
3.2.4.1 Représentation et comportement des agents
Représentation Les agents du système sont conçus suivant un cycle perception-décision-action, ils ontdonc les caractéristiques suivantes :
– Perceptions :◦ Agents observable : La nouvelle valeur de l’observable mise à jour par le système dynamique.◦ Agents corrélation : Le feedback de l’agent observable auquel ils sont rattachés afin de savoir
dans quel sens s’ajuster.
25

Chapitre 3. Apprentissage de corrélations entre entrées et sorties de systèmes dynamiques
– Décision :◦ Agents corrélation : Compte tenu des informations perçues, la seule décision que ces agents
doivent prendre est d’ajuster leur poids ou non.– Actions :◦ Agents observable : Diffuser le feedback aux corrélations.◦ Agents corrélation :
. Incrémenter leur poids.
. Le décrémenter.
. Ne pas le modifier.Ainsi, un agent corrélation doit maintenir les informations suivantes :– poids : valeur courante du poids de l’agent.– Xj : valeur courante du paramètre.– f eedback : feedback de l’agent observable (représentée sous forme de valeurs entières : 0 pour un
feedback null, 1 pour un feedback positif, -1 négatif).– avt : stratégie d’ajustement du poids (cf. chapitre 3.2.3.3).
Comportement La fonction d’un agent corrélation est de déterminer la valeur correcte du poids d’unparamètre. A chaque valeur reçue d’un agent observable tous les agents corrélation pourraient modifierleur valeur courante pour que la somme globale réduise l’écart indiqué par le feedback. Mais ils sontainsi tous en situation de concurrence selon la théorie des AMAS. Ils vont donc, au fur et à mesurede leurs ajustements, maintenir une valeur symbolisant la tendance d’ajustement de l’agent. Comme lesagents sont coopératifs, ils s’ajustent dans le sens du feedback. Or ce feedback est général (concerneun ensemble d’agents), ainsi il est nécessaire qu’ils personnalisent leur comportement afin d’éviter unajustement systématique dans le sens du feedback. Par exemple, si un agent s’ajuste régulièrement versle haut et qu’à certains moments l’observable demande moins, il ne prendra pas en compte ce feedbackcar compte tenu de sa tendance il considèrera que cette demande ne le concerne pas. Cette notion estétroitement liée à l’apprentissage par renforcement (cf. chapitre 2.1). En effet, on peut dire que les agentscorrélation apprennent l’action adéquate dans une situation donnée (plus un agent s’ajuste dans un sensplus il faut qu’il renforce cette tendance à s’ajuster dans ce sens). Cette tendance est fonction de plusieurscritères :
1. Le signe du f eedback. Si le signe est celui de tendance, alors tendance doit s’éloigner de 0 (si on luidemande + et qu’il à tendance à faire + il faut qu’il renforce cette tendance) ; s’en rapprocher sinon.
2. implication = |poids ∗ Xj|/O′i. Le changement de tendance doit être d’autant plus important que
l’agent a pris une grande responsabilité dans le calcul de Oi. Cela personnalise les comportementsdes agents : leurs dynamiques seront potentiellement différentes.
3. DYN = 0, 5. Cette variable (constante) représente la dynamique du système. Si l’on considère quel’environnement est très évolutif, il faut que tendance tienne une grande importance du dernierfeedback (feedback envoyé par l’agent observable au temps t − 1). En d’autres termes il s’agitd’une plage de mémorisation des feedbacks (plus la dynamique est élevée, plus le système estinstable, plus il est important de ne considérer que les feedbacks récents).
Ceci nous amène au calcul suivant : tendance = ( f eedback ∗ implication ∗DYN)+ ((1−DYN) ∗ tendance)L’agent n’effectue d’ajustement de son poids que si tendance est du signe de Feedback. L’agent fondesa décision sur le signe d’un nombre pour obtempérer ou pas à la demande de l’observable. Lorsquece nombre tend vers 0 c’est-à-dire que l’agent n’a pas une place importante dans le calcul, faire ou pasun ajustement n’a pas de sens. Il faut donc définir une plage autour de 0 (un SEUIL) pour laquelle, sitendance y est inclus, l’agent ne s’ajustera pas.
L’algorithme 1 décrit le processus de décision des agents corrélation. A titre d’exemple nous prenonsdes valeurs de paramètre entre -50 et 50.
26

3.2. Conception du SMA d’apprentissage
Algorithm 1 Comportement1: Let PLUS = 12: Let MOINS = −13: Let SEUIL = 0, 14: Let DYN = 0, 55: Let tendance← 0 //sens d’ajustement habituel6: Let poids← Random(1, 200) //poids initial aléatoire entre 1 et 2007: Let Xj ← Random(−50, 50) //valeur de paramètre entre -50 et 508: Let avt //outil d’ajustement du poids (cf. chapitre 3.2.3.3)9: Let resAbs← max(|agent(j).getPoids() ∗ agent(j).getXj()|) //calcul de la borne maximale
10: Let implication← |poids ∗ Xj|/resAbs //calcul de l’implication de l’agent dans resAbs11: Let f eedback← observable.getFeedback() //demande de feedback a l’observable12: if f eedback = PLUS then13: if tendance > 0∧ tendance > SEUIL then14: if Xj > 0 then15: poids ← avt.ajustValue(Feedback.GREATER) // j’augmente mon poids (GREATER) si on
me demande +, que j’ai tendance à faire + et que mon Xj est positif16: else17: poids ← avt.ajustValue(Feedback.LOWER) // je diminue mon poids (LOWER) si on me
demande +, que j’ai tendance à faire + et que mon Xj est négatif18: end if19: end if20: end if21: if f eedback = MOINS then22: if tendance < 0∧ |tendance| > SEUIL then23: if Xj > 0 then24: poids ← avt.ajustValue(Feedback.LOWER) // je diminue mon poids (LOWER) si on me
demande -, que j’ai tendance à faire - et que mon Xj est positif25: else26: poids ← avt.ajustValue(Feedback.GREATER) // j’augmente mon poids (GREATER) si on
me demande -, que j’ai tendance à faire - et que mon Xj est négatif27: end if28: end if29: end if30: tendance← ( f eedback ∗ implication ∗DYN)+ ((1−DYN) ∗ tendance) //mise a jour de ma tendance
d’ajustement
27

Chapitre 3. Apprentissage de corrélations entre entrées et sorties de systèmes dynamiques
3.2.4.2 Vue modulaire du système
Afin que notre système soit fonctionnellement distribué et respecte une architecture modulaire faci-lement extensible nous l’avons divisé en plusieurs modules :
– Control : paquetage lié aux agents observable– Sync : paquetage de synchronisation des agents– Agent : paquetage lié aux agents corrélation
Le diagramme statique de classes A.1 présent en annexe illustre une première version de notre système.Pour des raisons de propreté de conception nous avons utilisé les patrons de conception suivants :
– Command : sépare le code initiateur d’une action, du code de l’action elle-même (utilisé pour lagénéricité des actions utilisateur).
– Observer : utilisé pour la gestion des évènements au sein du système.– State : utilisé pour la gestion des états des modules et les traitements associés.
3.2.4.3 Actes de communication
D’un point de vue interaction des entités, nous simulons le travail du SMA de contrôle (dont le rôleest l’ajustement des paramètres) par l’assignation d’une valeur aléatoire aux paramètres à chaque pas.Cette modification de valeur provoque directement un changement de valeur pour les observables quipeuvent transmettre un feedback.
3.2.4.4 Prototypage
Le premier prototype réalisé permet de visualiser l’évolution du poids recherché par les agents corré-lations ainsi que leur erreur maximale au cours du temps. L’idée étant de spécifier les poids recherchéset d’observer l’ordre de grandeur en terme de pas d’apprentissage pour lequel le système converge.Cette première expérimentation concerne plusieurs entrées mais qu’une seule sortie.
Par ailleurs, nous avons opté pour une stratégie d’ajustement des poids par pas fixes (qui régressenéanmoins au fur et à mesure que l’erreur maximale diminue). En effet, l’AVT est conçue initialementpour optimiser une recherche de valeur dynamique ce qui ne concerne pas notre problématique.
A titre d’exemple, les agents corrélation commencent avec un pas de deux, si l’erreur maximale estinférieure à dix, il passe à un etc.
3.2.5 Extension et système complet
Par la suite nous avons étendu notre système afin qu’il accepte plusieurs observables et représenteainsi une matrice de corrélations. La figure 3.4 illustre le lancement du système qui demande de spéci-fier une matrice afin que l’on observe l’évolution de l’apprentissage au cours du temps. L’objectif ici estde spécifier une matrice à apprendre et vérifier par observation que le système l’apprend. Ce cas d’utili-sation permet aussi de donner un ordre de grandeur concernant le temps de converge du système. Il estpossible de suivre l’évolution de l’erreur maximale (distance au poids à apprendre la plus grande parmil’ensemble des agents cf. Figure A.2) ainsi que l’évolution de l’erreur pour chaque agent (cf. Figure A.3).
Afin d’étudier nos divers résultats nous avons aussi ajouté un module de génération de données(paramètres de la simulation et temps de convergence du système). Celui-ci exporte ces dernières afinde permettre des analyses plus poussées en fonction de divers paramètres du système comme la dyna-mique du système, le nombre d’entrées. Le diagramme statique de classes A.4 présent en annexe illustrenotre système complet.
3.3 Bilan
Nous avons conçu et réalisé un module d’apprentissage de corrélations entre entrées et sorties d’unsystème. Nous avons suivi la méthodologie ADELFE pour assurer que notre système se base sur la tech-
28

3.3. Bilan
FIGURE 3.4 — Matrice de corrélation à apprendre
nologie des AMAS. Nous disposons maintenant de résultats que nous allons exposer dans le chapitresuivant.
29


4 Résultats et discussion
Ce chapitre vise à exposer et discuter des résultats obtenus après exploitation du système préalable-ment conçu. Nous allons donc présenter les différents tests que nous avons effectués dans des conditionsstandard (pas de perturbation du système) puis dans des conditions où certaines informations sont brui-tées. Enfin nous présenterons l’API que nous avons mise en place afin que ce système soit utilisé pard’autres personnes.
4.1 Analyse des résultats
La figure 4.1 illustre le temps de convergence c’est-à-dire le nombre de pas d’apprentissage à partirduquel notre système ne fait plus d’erreur (i.e. les corrélations sont correctes) en fonction du nombrede paramètres. On remarque qu’il s’agit d’une évolution linéaire. Ainsi la complexité en temps ne croîtpas exponentiellement en fonction de la taille des entrées comme pourrait le faire un algorithme de typeessais successifs. Les caractéristiques de notre méthode ont été explorées statistiquement par de nom-breuses expériences jusqu’à 100 inconnues pour une seule sortie (100 paramètres donc 100 corrélationsinconnues).
On observe qu’en moyenne la solution est trouvée en moins de 1000 essais lorsqu’il s’agit d’ap-prendre 10 corrélations, 7000 essais pour 100 corrélations. La question était de savoir s’il existait unethéorie mathématique à même de résoudre ce genre de problème, ce qui nous permettrait d’avoir uncritère de comparaison : il s’agit de la programmation linéaires en nombre entier (cf. chapitre 2.4). Pourcette technique de résolution, suivant des travaux préliminaires effectués sur cette thématique [Moyal,2001], il faudrait statistiquement environ 600 000 essais pour qu’elle trouve la solution avec 10 incon-nues. Par ailleurs un des résultats pertinent de ces travaux est qu’au-delà d’un espace de recherche de1012 la programmation linéaire ne résolvait plus l’équation car l’espace mémoire disponible était saturé(à l’époque de la simulation).
La théorie des AMAS a surtout été explorée pour 100 inconnues ce qui définit un espace de recherchede l’ordre de 10230, ce qui est bien au-delà de ce que peut faire la programmation linéaire et avec unnombre de pas sans commune mesure.
4.2 Bruitage du signal
Une autre question que nous nous sommes posée consistait à savoir si le système est sensible aubruit. Nous avons donc ajouté un système de génération de bruit et étudié le comportement du systèmed’apprentissage.
Ajouter du bruit dans un système signifie ajouter de mauvaises informations ou fausser des infor-mations existantes, ceci dans le but de tester le comportement d’un système dans un environnementperturbé. En d’autres termes, il s’agit de tester la robustesse du système. Ainsi l’information que nousdécidons de bruiter est le feedback des observables. En effet, dans un environnement fortement perturbéil se peut qu’un agent observable envoi un feedback erroné faussant ainsi le processus de décision desagents corrélation. Pour fausser ce feedback nous procédons à un tirage uniforme de probabilité entre
31
Chapitre 4. Résultats et discussion
FIGURE 4.1 — Temps de convergence en fonction du nombre de paramètres doncde corrélations a priori inconnues
zéro et cent. Si le résultat obtenu est inférieur à un certain seuil (nombre donné a priori représentant lepourcentage de bruit) alors l’agent observable chargé de renvoyer le feedback le fausse (il prend l’op-posé). L’algorithme 2 illustre le tirage aléatoire servant à l’algorithme de décision de l’agent observable(algorithme 3).
Algorithm 2 bruitageSignal1: Let BRUIT = 50 //Pourcentage de bruit défini a priori à 502: Let random← Random(0, 100) //Tirage aléatoire d’un nombre entre 0 et 1003: return random < BRUIT
4.3 API et application réelle
4.3.1 Application Programming Interface (API)
Notre système tel qu’il est réalisé n’offre pas de portabilité. Afin que celui-ci puisse être utilisé dansn’importe quel système dynamique présentant des caractéristiques similaires au système de Luc Pons,une API à été développée afin de ne retenir que le module d’apprentissage. L’idée ici est de pouvoirinstancier le module, lui spécifier des entrées et des sorties, spécifier des valeurs pour ces variables et,à partir de ces dernières, le module apprend les corrélations entre entrées et sorties. Il est important denoter que la précision de la valeur des corrélations dépend du nombre d’entrées (de valeurs) fournie aumodule.
4.3.2 Applications
A l’heure actuelle notre système est utilisé dans un projet d’optimisation au sein de l’équipe. Lesystème d’apprentissage récupère des données exportées préalablement dans un fichier, et apprend lescorrélations entre les variables (les données sont des valeurs numériques pour des entrées et sorties dusystème à optimiser).
32
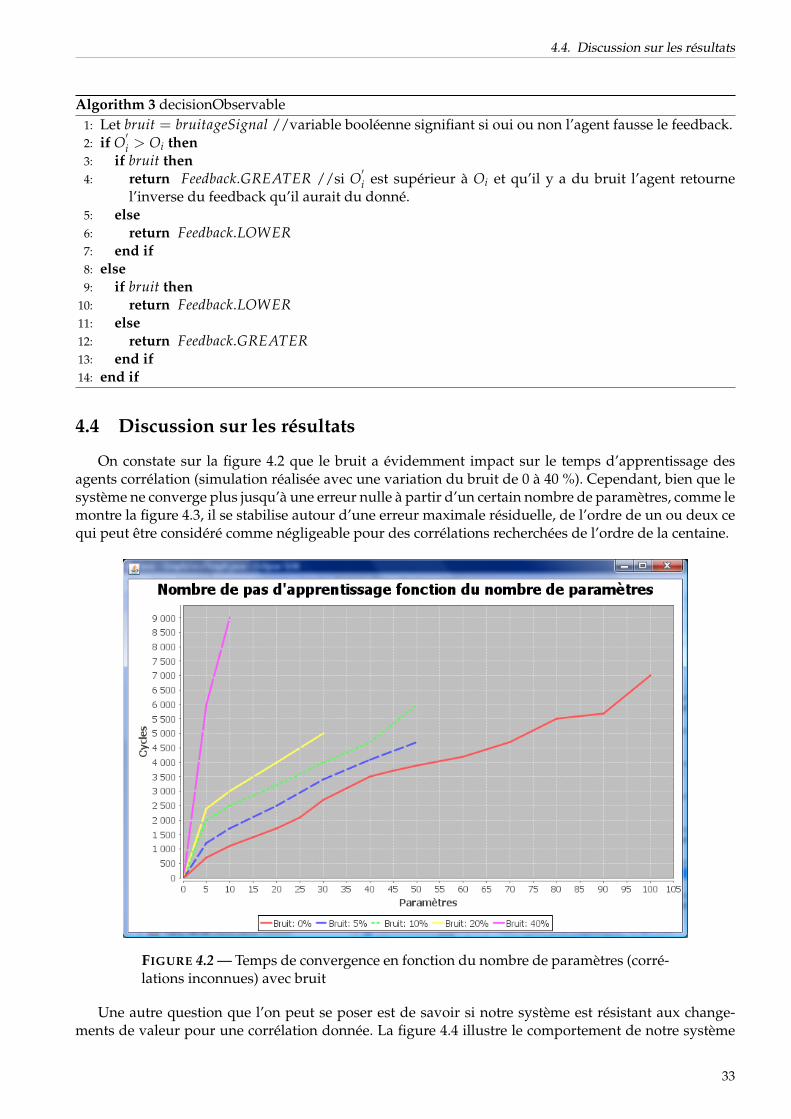
4.4. Discussion sur les résultats
Algorithm 3 decisionObservable1: Let bruit = bruitageSignal //variable booléenne signifiant si oui ou non l’agent fausse le feedback.2: if O
′i > Oi then
3: if bruit then4: return Feedback.GREATER //si O
′i est supérieur à Oi et qu’il y a du bruit l’agent retourne
l’inverse du feedback qu’il aurait du donné.5: else6: return Feedback.LOWER7: end if8: else9: if bruit then
10: return Feedback.LOWER11: else12: return Feedback.GREATER13: end if14: end if
4.4 Discussion sur les résultats
On constate sur la figure 4.2 que le bruit a évidemment impact sur le temps d’apprentissage desagents corrélation (simulation réalisée avec une variation du bruit de 0 à 40 %). Cependant, bien que lesystème ne converge plus jusqu’à une erreur nulle à partir d’un certain nombre de paramètres, comme lemontre la figure 4.3, il se stabilise autour d’une erreur maximale résiduelle, de l’ordre de un ou deux cequi peut être considéré comme négligeable pour des corrélations recherchées de l’ordre de la centaine.
FIGURE 4.2 — Temps de convergence en fonction du nombre de paramètres (corré-lations inconnues) avec bruit
Une autre question que l’on peut se poser est de savoir si notre système est résistant aux change-ments de valeur pour une corrélation donnée. La figure 4.4 illustre le comportement de notre système
33
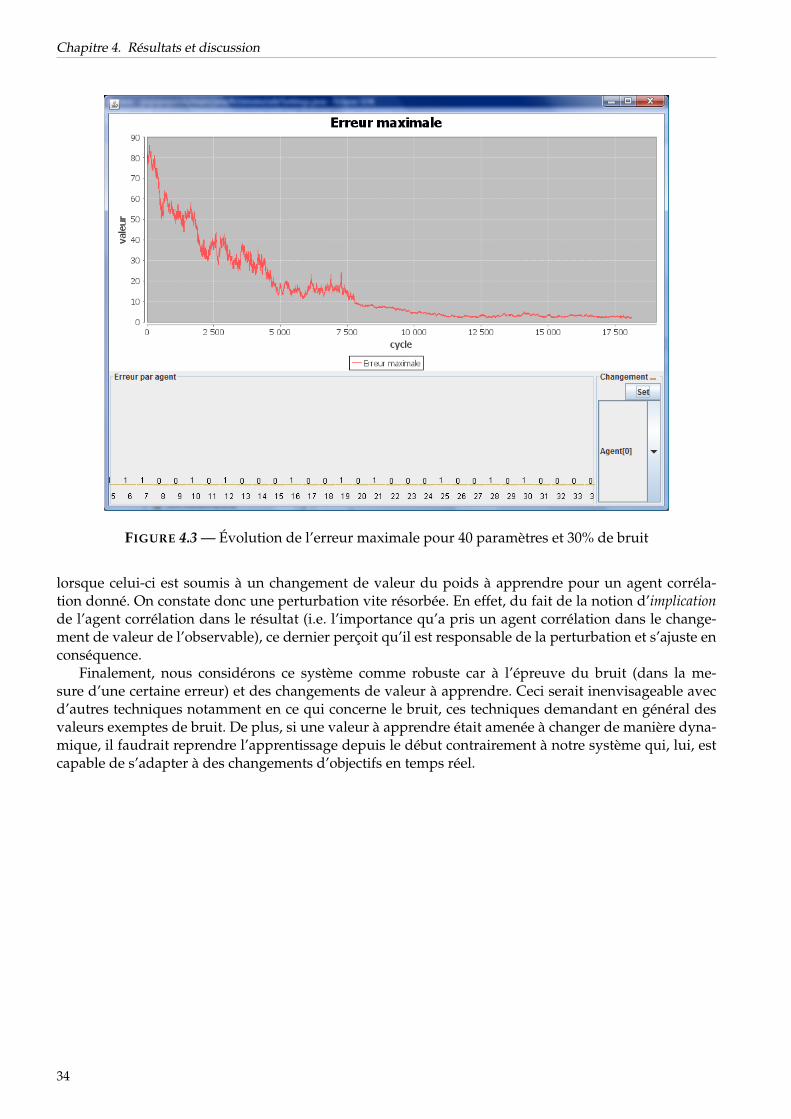
Chapitre 4. Résultats et discussion
FIGURE 4.3 — Évolution de l’erreur maximale pour 40 paramètres et 30% de bruit
lorsque celui-ci est soumis à un changement de valeur du poids à apprendre pour un agent corréla-tion donné. On constate donc une perturbation vite résorbée. En effet, du fait de la notion d’implicationde l’agent corrélation dans le résultat (i.e. l’importance qu’a pris un agent corrélation dans le change-ment de valeur de l’observable), ce dernier perçoit qu’il est responsable de la perturbation et s’ajuste enconséquence.
Finalement, nous considérons ce système comme robuste car à l’épreuve du bruit (dans la me-sure d’une certaine erreur) et des changements de valeur à apprendre. Ceci serait inenvisageable avecd’autres techniques notamment en ce qui concerne le bruit, ces techniques demandant en général desvaleurs exemptes de bruit. De plus, si une valeur à apprendre était amenée à changer de manière dyna-mique, il faudrait reprendre l’apprentissage depuis le début contrairement à notre système qui, lui, estcapable de s’adapter à des changements d’objectifs en temps réel.
34
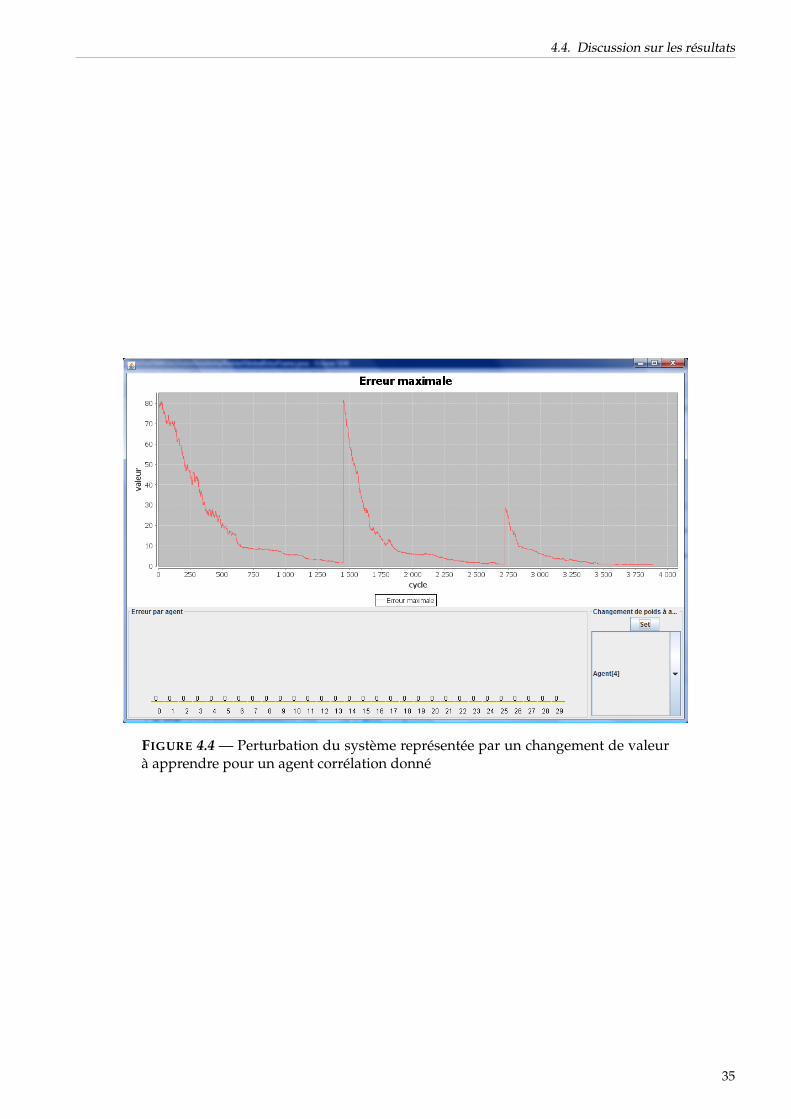
4.4. Discussion sur les résultats
FIGURE 4.4 — Perturbation du système représentée par un changement de valeurà apprendre pour un agent corrélation donné
35


Conclusion
Bilan
Arrivé au terme de cette étude, le premier bilan que nous dressons est que les solutions multi-agents,basées sur la théorie des AMAS, permettent non seulement de concevoir des systèmes fiables et robustesmais aussi d’obtenir l’émergence de solutions très pertinentes face à des problèmes incomplètementspécifiés.
En effet, nous avons dans une première partie présenté les techniques classiques d’apprentissage.Celles-ci concernent en général un seul agent et ont prouvé leur efficacité dans certains cas. Or, en cequi concerne la problématique de cette étude, une centralisation de l’apprentissage n’est pas efficace caril est question de l’apprentissage d’un grand nombre de variables ayant toutes une influence différentesur le système global. L’approche par systèmes multi-agents adaptatifs fondée sur l’émergence nous adonc semblé être la plus appropriée. En effet, par délégation de la fonction d’apprentissage à chaqueagent, premièrement on se dispense des inconvénients liés à la centralisation (manque de souplesse etde robustesse) et en second lieu, il n’y a aucune exploration d’espace d’état. En effet, par un mécanismesimple de calcul d’implication d’un agent dans un système, celui-ci apprend de lui-même son impor-tance et s’ajuste afin de rester coopératif, c’est-à-dire ajuster sa valeur (son poids) afin que le systèmereste stable.
Ayant constaté qu’un travail antérieur dans l’équipe SMAC avait appliqué avec succès la théorie desAMAS à un problème d’apprentissage de pondérations dans des systèmes d’inéquations [Brax et al.,2013], nous avons décidé de nous inspirer de cette démarche afin de résoudre notre problème.
Pour cela et afin de concevoir un système conforme aux AMAS, nous avons suivi la méthode deconception ADELFE développée dans l’équipe SMAC. En effet, cette méthode permet de savoir si ouiou non notre problème se prête bien à une résolution par les AMAS. C’est donc une fois le système conçuet conforme aux AMAS que nous l’avons soumis à divers tests donnant des résultats très probants.
En effet, durant la phase d’analyse des résultats, nous avons pu tout d’abord confirmer la conver-gence de notre système vers une solution stable et adéquate. De plus, nous avons pu comparer cesrésultats aux résultats d’une expérimentation ayant été faites sur un problème similaire avec la pro-grammation linéaire. Il s’avère que notre système est plus performant que cette méthode. Puis nousavons mis en évidence sa capacité d’adaptation face à des environnements évolutifs par bruitage dusignal. Bien que notre système ne converge que pour un pourcentage de bruit faible lorsque le nombrede paramètres est élevé, il est difficilement envisageable de trouver une quelconque solution avec uneautre méthode ; en effet, ces dernières requièrent des valeurs exactes.
Perspectives
Il reste toutefois un certain nombre d’améliorations à apporter au système. En effet, ce dernier à ététesté avec un nombre de paramètres et observables fixe, l’étude de son évolution lors de l’ajout à la voléede paramètres ou observables serait une prochaine étape intéressante.
Une étude du comportement de l’erreur maximale de nos agents lorsque le système est bruité peus’avérer aussi intéressante. En effet, les résultats exposés ne montrent que le nombre de variables pour
37

Conclusion
lequel notre système converge vers une erreur maximale nulle. Or nous avons constaté que même s’ilne converge pas vers une erreur nulle, cette dernière est toujours faible.
Par ailleurs, le fait de changer à chaque pas d’apprentissage la valeur des paramètres simule uneréalité utopique. En effet, dans un système réel tel un jeu vidéo, nous ne pouvons disposer d’autantde valeurs à moins de soumettre l’utilisateur à une phase de pré-traitement. Cette méthode permetaussi d’éviter le sur-apprentissage. En effet, il peut être envisageable que notre système soit confrontéà des données similaires sur plusieurs cycles induisant l’apprentissage de mauvaises valeurs. Un pointintéressant serait donc de coupler notre système à un réel système de contrôle, tel le système de contrôledéveloppé dans la thèse de Luc Pons, afin d’en étudier son comportement.
Après étude de la régression de l’erreur des agents corrélation, nous avons constaté que celle-ciévolue de manière différente selon la valeur du pas d’ajustement. Ainsi, lorsque cette erreur est grande,cette régression est très rapide c’est-à-dire que l’agent corrélation tend très vite à trouver sa place dans lesystème (i.e. calcul de son implication et ajustement de son poids). Une fois l’erreur maximale moindre,le système met plus de temps à converger vers une erreur nulle. Ainsi, nous fonctionnons avec un pasd’ajustement fixe qui est réduit suivant une valeur de l’erreur définie a priori. Or il serait intéressantde mettre au point une stratégie de contrôle dynamique de ce pas d’ajustement. Une étude du seuilde l’erreur à partir duquel l’agent commence à se stabiliser s’avèrerait intéressante afin de gérer d’unemanière optimale le pas d’ajustement et ainsi amener à une convergence plus rapide.
Notre étude représente donc une première étape encourageante dans l’apprentissage de corrélationsentre variables mais qui peut encore donner lieu à de nombreuses améliorations.
Bilan personnel
Depuis le début de ma formation d’informaticien, j’ai été attiré par deux mondes :– le Génie Logiciel– l’Intelligence ArtificielleMes deux années de DUT et mon année de Master 1 spécialisée en Génie Logiciel m’ont permis
d’apprendre et maîtriser les bonnes pratiques de conception et développement de systèmes informa-tiques. C’est au cours de cette même année de Master 1 que j’ai pu me familiariser avec les systèmesmulti-agents. C’est alors durant mon année de Master 2 spécialisée en Intelligence Artificielle que j’aipu approfondir mes connaissances de ces systèmes. Les concepts de résolution locale, d’adaptation etd’émergence de fonctionnalité inspirés de la nature m’ont alors séduit et j’ai ainsi décidé de suivre monstage de Master 2 recherche au sein de l’équipe SMAC de l’IRIT.
Ce stage m’a tout d’abord permis d’approfondir ma connaissance des systèmes multi-agents adap-tatifs tels que les conçoit l’équipe SMAC. J’ai en effet dû tout d’abord prendre connaissance de la théoriequi fait office de cadre de leurs travaux mais j’ai dû également apprendre la méthode développée spé-cialement pour ces systèmes. Une fois ce travail effectué, j’ai alors pu appréhender ce qu’est réellementun travail de recherche. Cela débute tout d’abord par un travail nécessaire d’état de l’art, puis vientalors les phases plus dynamiques : l’étude même de la problématique, la conception, l’implémentationet l’analyse des résultats. J’ai alors appris que cela ne peut se faire sans une coopération et une confron-tation d’idées avec les membres de son équipe. En effet, bien qu’une grande partie de mon temps detravail se soit écoulée devant mon ordinateur, les décisions importantes et les conclusions pertinentesconcernant mon travail n’auraient pu émerger sans les réunions de travail que nous avons faites. Pourmoi, la recherche est donc avant tout un travail d’équipe.
Par ailleurs, une bonne partie du stage étant consacrée à la conception, j’ai eu l’occasion de mettreen pratique mon expérience et mes qualités en terme de Génie Logiciel.
Enfin, mon étude a abouti à des résultats encourageants. En plus de la satisfaction que j’ai pu enretirer, cela m’a persuadé de l’efficacité et des avantages des phénomènes émergents. Je suis maintenantconvaincu que l’avenir de l’informatique offre une grande place à ce concept encore mal maîtrisé. C’estpour cela que j’envisage à présent de consacrer mes prochaines années à l’étude des systèmes multi-agents à fonctionnalité émergente.
38

Annexe
39
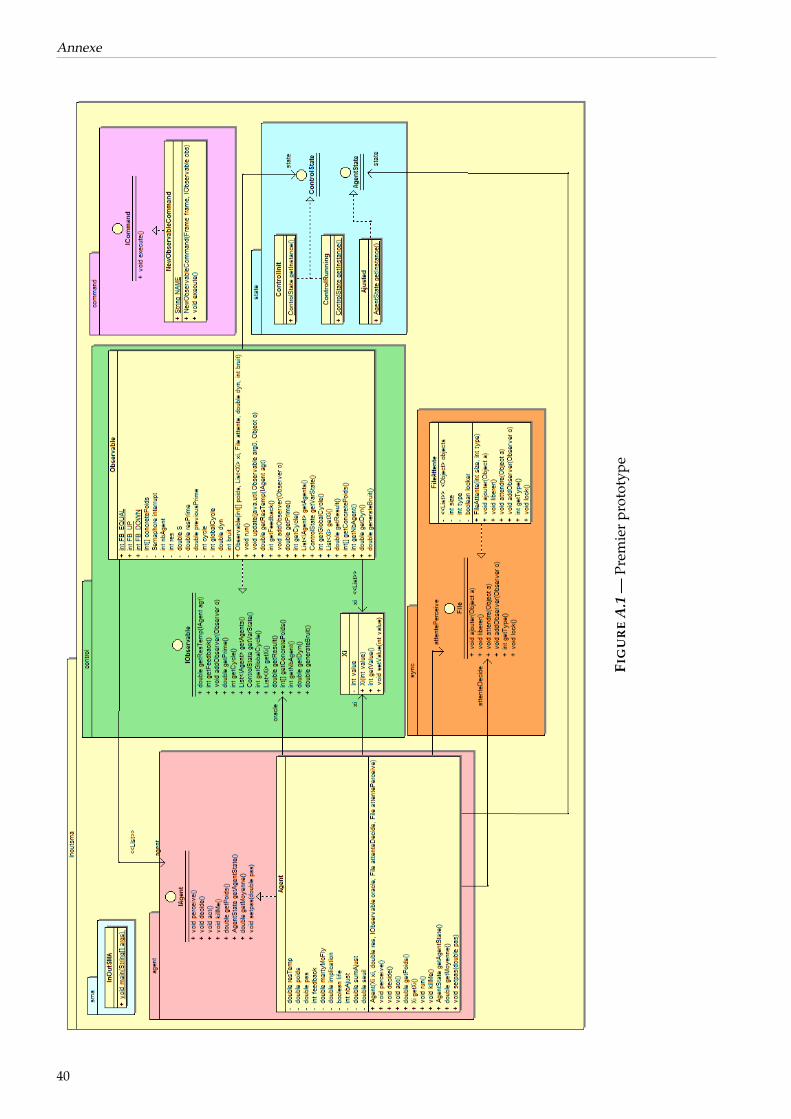
Annexe
FIG
UR
EA
.1—
Prem
ier
prot
otyp
e
40
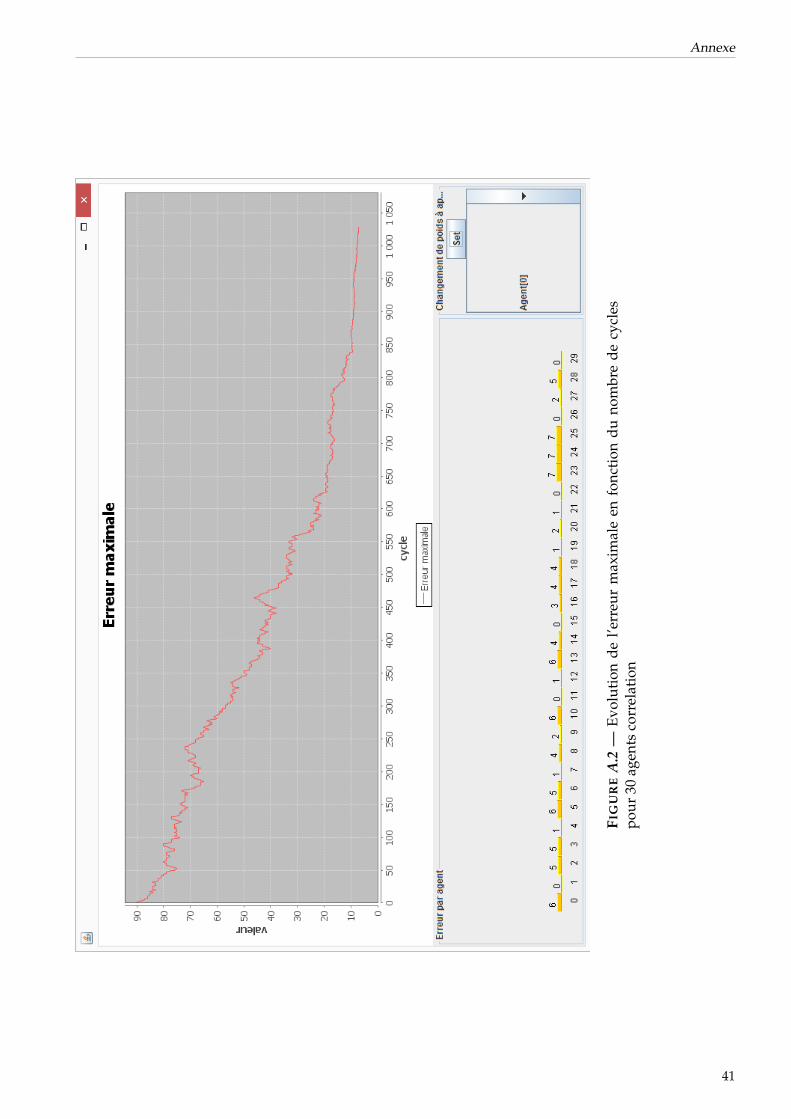
Annexe
FIG
UR
EA
.2—
Evol
utio
nde
l’err
eur
max
imal
een
fonc
tion
duno
mbr
ede
cycl
espo
ur30
agen
tsco
rrel
atio
n
41
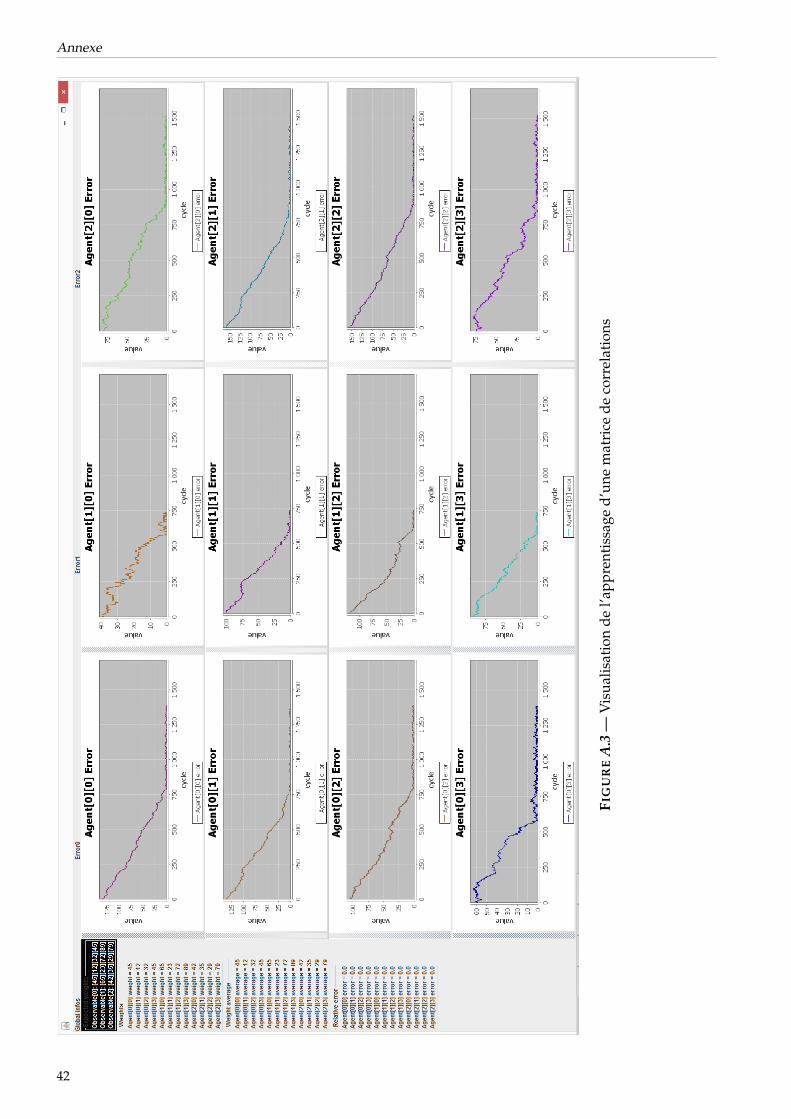
Annexe
FIG
UR
EA
.3—
Vis
ualis
atio
nde
l’app
rent
issa
ged’
une
mat
rice
deco
rrel
atio
ns
42
Annexe
FIG
UR
EA
.4—
Syst
eme
com
plet
43


Bibliographie
J. ALVAREZ : Du jeu vidéo au Serious Game. Approches culturelle, pragmatique et formelle. Thèse de doctorat,Université de Toulouse-le-Mirail, Toulouse, France, décembre 2007.
C. BERNON, D. CAPERA et J.P. MANO : Engineering Self-Modeling Systems : Application to Biology. InA. ARTIKIS, G. PICARD et L. VERCOUTER, éditeurs : International Workshop on Engineering Societies inthe Agents World (ESAW), numéro 5485 in LNCS, pages 236–251. Springer-Verlag, 2009.
G. BRASSARD et P. BRATLEY : Fundamentals of algorithmics. Prentice-Hall, Inc., Upper Saddle River, NJ,USA, 1996. ISBN 0-13-335068-1.
N. BRAX, E. ANDONOFF, J-P. GEORGÉ, M-P. GLEIZES et J-P. MANO : MAS4AT : un SMA auto-adaptatifpour le déclenchement d’alertes dans le cadre de la surveillance maritime. Revue d’Intelligence Artifi-cielle, n°3/2013, juin 2013.
B.G. BUCHANAN et E.A. FEIGENBAUM : Dendral and meta-dendral : Their applications dimension.Artif. Intell., 11(1-2):5–24, 1978.
B.G. BUCHANAN et E.H. SHORTLIFFE : Rule Based Expert Systems : The MYCIN Experiments of the StanfordHeuristic Programming Project. Reading, Mass. : Addison-Wesley, 1984.
V. CAMPS : Vers une théorie de l’auto-organisation dans les systèmes multi-agents basée sur la coopération :application à la recherche d’information dans un système d’information répartie. Thèse de doctorat, UPSToulouse 3, Janvier 1998.
D. CAPERA, J-P. GEORGÉ, M-P. GLEIZES et P. GLIZE : The AMAS Theory for Complex Problem SolvingBased on Self-organizing Cooperative Agents. In 12th IEEE International Workshops on Enabling Techno-logies, Infrastructure for Collaborative Enterprises, Linz, Austria, pages 383–388. IEEE Computer Society2003, June 2003.
S.A. COOK : The complexity of theorem-proving procedures. STOC ’71 Proceedings of the third annualACM symposium on Theory of computing, 1971.
G. DANTZIG : Linear Programming and Extensions. Princeton University Press, 1963. ISBN 0691059136.
G. DI MARZO SERUGENDO, M-P GLEIZES et A. KARAGEORGOS : Self-Organisation and Emergence inMulti-Agent Systems : An Overview. Informatica, 30(1):45–54, janvier 2006.
J. FERBER et O. GURKNECHT : Aalaadin : a Meta-Model for the Analysis and Design of Organizations inMulti-Agent Systems. In Y. DEMAZEAU, éditeur : 3rd International Conference on Multi-Agent Systems,pages 128–135, Paris, 1998. IEEE.
L. GASSER, C. BRAGANZA et N. HERMAN : MACE : A Flexible Testbed for Distributed AI Research, cha-pitre 5, pages 119–152. Pitman, San Francisco, 1987.
J-P. GEORGÉ : L’émergence. Rapport technique, Institut de Recherche en Informatique de Toulouse,Décembre 2003.
45

Bibliographie
J.P. GEORGÉ : Résolution de problèmes par émergence, Etude d’un Environnement de Programmation émergente.Thèse de doctorat, Université Paul Sabatier, Toulouse, France, juillet 2004.
P. GLIZE : L’adaptation des systèmes à fonctionnalité émergente par auto-organisation coopérative. Hdr,Université Paul Sabatier, Toulouse III, Juin 2001.
P.E. HART : A Formal Basis for the Heuristic Determination of Minimum Cost Paths. Systems Scienceand Cybernetics, IEEE Transactions on, 1968.
J.H. HOLLAND : Adaptation in Natural and Artificial Systems. University of Michigan Press, 1975.
P. JACKSON : Introduction to Expert Systems, 3rd Edition. Addison-Wesley, 1999.
N. KARMARKAR : A new polynomial-time algorithm for linear programming. In Proceedings of thesixteenth annual ACM symposium on Theory of computing, STOC ’84, pages 302–311, New York, NY,USA, 1984. ACM. ISBN 0-89791-133-4.
L. G. KHACHIYAN : A polynomial algorithm in linear programming. Doklady Akademii Nauk SSSR,244:1093–1096, 1979.
V. KLEE et G. J. MINTY : How Good is the Simplex Algorithm ? In O. SHISHA, éditeur : Inequalities III,pages 159–175. Academic Press Inc., New York, 1972.
S. LEMOUZY : Systèmes interactifs auto-adaptatifs par systèmes multi-agents auto-organisateurs : application àla personnalisation de l’ ?accès à l ?’information. Thèse de doctorat, Université Paul Sabatier, Toulouse,France, juillet 2011.
B. LEO et al. : Classification and Regression Trees. Chapman & Hall, New York, 1984. ISBN 0-412-04841-8.URL http://www.crcpress.com/catalog/C4841.htm.
R.P. LIPPMANN : An introduction to computing with neural nets. SIGARCH Comput. Archit. News, 16(1):7–25, mars 1988. ISSN 0163-5964. URL http://doi.acm.org/10.1145/44571.44572.
Yanaï MOYAL : Résolution graphique d’équations par amas sous oris. Stage DUT Informatique Tou-louse, Juin 2001.
G. PICARD : Méthodologie de développement de systèmes multi-agents adaptatifs et conception de logiciels àfonctionnalité émergente. Thèse de doctorat, UPS Toulouse 3, Décembre 2004.
T. POGGIO et F. GIROSI : A theory of networks for approximation and learning. Laboratory, MassachusettsInstitute of Technology, 1140, 1989.
L. PONS, C. BERNON et P. GLIZE : Scenario Control for (Serious) Games using Self-organizing Multi-Agent Systems (regular paper). In International Conference on Complex Systems (ICCS), pages 1–6.IEEExplore digital library, 2012.
I. RIVIN, I. VARDI et P. ZIMMERMAN : The n-queens problem. The American Mathematical Monthly, 101(7):pp. 629–639, 1994. ISSN 00029890. URL http://www.jstor.org/stable/2974691.
S. RUSSEL et P. NORVIG : Artificial Intelligence : a modern approach. Informatique, Intelligence Artificielle.Prentice-Hall, 1995.
H.S. STONE et P. SIPALA : The average complexity of depth-first search with backtra-cking and cutoff. IBM J. Res. Dev., 30(3):242–258, mai 1986. ISSN 0018-8646. URLhttp://dx.doi.org/10.1147/rd.303.0242.
R.S. SUTTON : Learning to predict by the methods of temporal differences. Mach. Learn., 3(1):9–44, août1988. ISSN 0885-6125.
46

Bibliographie
A. TURING : Computing Machinery and Intelligence. Mind : A Quarterly Review of Psychology and Philo-sophy, October 1950.
Christopher J. C. H. WATKINS et P. DAYAN : Q-learning. Machine Learning, 8(3-4):279–292, 1992.
G. WEISS : Multiagent Systems. A Modern Approach to Distributed Artificial Intelligence. MIT Press, 1995.
J. WESTRA, F. DIGNUM et V. DIGNUM : Agents for games and simulations ii. chapitre Guiding useradaptation in serious games, pages 117–131. Springer-Verlag, Berlin, Heidelberg, 2011a. ISBN 978-3-642-18180-1.
J. WESTRA, F. DIGNUM et V. DIGNUM : Scalable adaptive serious games using agent organizations.In The 10th International Conference on Autonomous Agents and Multiagent Systems - Volume 3, AAMAS’11, pages 1291–1292, Richland, SC, 2011b. International Foundation for Autonomous Agents andMultiagent Systems. ISBN 0-9826571-7-X, 978-0-9826571-7-1.
M. WOOLDRIDGE : Intelligent Agents, pages 27–78. The MIT Press, Cambridge, MA, USA, 1999.
D. YUDIN et A. NEMIROVSKI : Informational complexity and effective methods of solution of convexextremal problems. Economics and mathematical methods, 12:357–369, 1976.
47


















