ANALYSE NUMÉRIQUE -...
42
Université d’Orléans – Faculté des Sciences Licence de physique – 3ème année ANALYSE NUMÉRIQUE T. Dudok de Wit Université d’Orléans Janvier 2013
Transcript of ANALYSE NUMÉRIQUE -...

Université d’Orléans – Faculté des Sciences
Licence de physique – 3ème année
ANALYSE NUMÉRIQUE
T. Dudok de Wit
Université d’OrléansJanvier 2013

Table des matières
1 Introduction 4
1.1 Un exemple : le calcul dep
x . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Interpolation et extrapolation 5
2.1 L’interpolation polynomiale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Autres fonctions d’interpolation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.3 Extrapolation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.4 Interpolation en plusieurs dimensions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3 Différentiation numérique 13
3.1 Estimation de la dérivée première . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.2 Estimation de la dérivée seconde . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.3 Dériver dans la pratique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.3.1 Si f (x) est donnée par un tableau de valeurs . . . . . . . . . . . . . . . . . . . . . . . . 16
3.3.2 Si f (x) est donnée par son expression analytique . . . . . . . . . . . . . . . . . . . . . 16
3.3.3 Impact du bruit sur la dérivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4 Intégration numérique 19
4.1 Méthodes simples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.2 Méthodes composées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
4.3 Autres méthodes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.4 L’intégration dans la pratique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5 Recherche des racines d’une fonction 25
5.1 Méthode de la bisection ou de la dichotomie . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5.2 Méthode de la “Regula falsi” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
5.3 Méthode de la sécante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5.4 Méthode de Newton . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
5.5 La recherche de racines dans la pratique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
6 Intégration d’équations différentielles 33
6.1 Exemple . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
6.2 Les méthodes d’Euler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
6.3 Stabilité des méthodes d’Euler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
6.4 Méthodes de Runge-Kutta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
6.5 L’intégration dans la pratique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
6.6 Intégrer lorsque l’ordre > 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
6.7 Intégrer en présence de conditions de bord . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
2

Ce fascicule est un support au cours d’analyse numérique Il aborde : l’interpo-
lation, la dérivation et l’intégration numériques, la recherche de racines d’une
fonction et l’intégration d’équations différentielles. Deux autres chapitres de
l’analyse numérique (algèbre linéaire et optimisation) seront abordés dans le
cours de Nathalie Brun-Huret.
Les applications se feront avec le logiciel Scilab (un clone gratuit de matlab),
dont la documentation et les sources peuvent être téléchargées à l’adresse
http://www.scilab.org
Quelques références utiles disponibles à la BU sont :
• J.-Ph. Grivet, Méthodes numériques appliquées, EDP Sciences, 2009
(très proche du programme du cours, mais avec un contenu plus riche) :
http://www.edition-sciences.com/methodes-numeriques-appliquees.htm
• A. Fortin, Analyse numérique, Presses Internationales Polytechniques,
Montreal, 4ème édition, 2011 (bonne introduction, proche des applica-
tions) : http://giref.ulaval.ca/afortin.html
• C. Guilpin, Manuel de calcul numérique appliqué, EDP Sciences, 1999
(plus complet et plus théorique que le précédent).
• W. Press et al., Numerical Recipes in C, Cambridge University Press,
3ème édition, 2007 (LA référence sur les outils numériques) :
http://www.nr.com
Des références sur le logiciel Scilab
• Le site de Scilab : http://www.scilab.org
• Divers manuels d’introduction à Scilab :
http://www.scilab.org/resources/documentation/
• P. Depondt, Cours de physique numérique à l’ENS Cachan, 2011 (ex-
cellent cours en ligne, mais le niveau est plus proche d’un cours de mas-
ter) http://bit.ly/101JXn2
Pour me contacter : Thierry Dudok de Wit
email [email protected]
http://lpc2e.cnrs-orleans.fr/~ddwit/enseignement.html
3

1 Introduction
L’ordinateur est aujourd’hui un outil incontournable pour simuler et modéliser les sys-
tèmes, mais il faut encore savoir exprimer nos problèmes en langage formalisé des
mathématiques pures. Nous sommes habitués à résoudre les problèmes de façon ana-
lytique, alors que l’ordinateur ne travaille que sur des suites de nombres. On verra dès
lors qu’il existe souvent plusieurs approches pour résoudre un même problème, ce qui
conduit à des algorithmes 1 différents. Un des objectifs de ce cours est de fournir des
bases rigoureuses pour développer quelques algorithmes utiles dans la résolution de
problèmes en physique.
Un algorithme, pour être utile, doit satisfaire un certain nombre de conditions. Il doit
être :
• rapide : le nombre d’opérations de calcul pour arriver au résultat escompté doit
être aussi réduit que possible.
• précis : l’algorithme doit savoir contenir les effets des erreurs qui sont inhé-
rentes à tout calcul numérique. Ces erreurs peuvent être dues à la modélisation,
à la représentation sur ordinateur ou encore à la troncature.
• souple : l’algorithme doit être facilement transposable à des problèmes diffé-
rents.
1.1 Un exemple : le calcul dep
x
Sur ordinateur, l’addition de deux entiers peut se faire de façon exacte mais non le
calcul d’une racine carrée. On procède alors par approximations successives jusqu’à
converger vers la solution souhaitée. Il existe pour cela divers algorithmes. Le suivant
est connu depuis l’antiquité (mais ce n’est pas celui que les ordinateurs utilisent).
Soit x un nombre réel positif dont on cherche la racine carrée. Désignons par a0 la
première estimation de cette racine, et par ǫ0 l’erreur associée.
px = a0 +ǫ0
Cherchons une approximation de ǫ0. Nous avons
x = (a0 +ǫ0)2 = a20 +2a0ǫ0+ǫ2
0
Supposons que l’erreur soit petite face à a0, ce qui permet de négliger le terme en ǫ20
x ≈ a20 +2a0ǫ0
Remplaçons l’erreur ǫ0 par un ǫ′0, qui en est une approximation, de telle sorte que
x = a20 +2a0ǫ
′0
1. Le mot algorithme vient du mathématicien arabe Al-Khwarizmi (VIIIè siècle) qui fut l’un des premiers à
utiliser une séquence de calculs simples pour résoudre certaines équations quadratiques. Il est un des pionniers
de l’al-jabr (algèbre).
4

On en déduit que
ǫ′0 = (x/a0 −a0)/2
Le terme
a1 = a0 +ǫ′0 =1
2
(
x
a0+a0
)
constitue une meilleure approximation de la racine que a0, sous réserve que le dé-
veloppement soit convergent. Dans ce dernier cas, rien ne nous empêche de recom-
mencer les calculs avec a1, puis a2, etc., jusqu’à ce que la précision de la machine ne
permette plus de distinguer le résultat final de la véritable solution. On peut donc dé-
finir une suite, qui à partir d’une estimation initiale a0 devrait en principe converger
vers la solution recherchée. Cette suite est :
ak+1 =1
2
(
x
ak+ak
)
, a0 > 0
L’algorithme du calcul de la racine carrée devient donc
1. Démarrer avec une première approximation a0 > 0 dep
x
2. A chaque itération k, calculer la nouvelle approximation ak+1 = (x/ak +ak )/2
3. Calculer l’erreur associée ǫ′k+1
= (x/ak+1 −ak+1)/2
4. Tant que l’erreur est supérieure à un seuil fixé, recommencer en 2.
Le tableau ci-dessous illustre quelques itérations de cet algorithme pour le cas où x = 4.
i ai ǫ′i
0 4 -1.5
1 2.5 -0.45
2 2.05 -0.0494
3 2.00061 -0.000610
4 2.00000009 -0.000000093
etc
Nous voyons que l’algorithme converge très rapidement, et permet donc d’estimer la
racine carrée d’un nombre moyennant un nombre limité d’opérations élémentaires
(additions, soustractions, divisions, multiplications). Il reste encore à savoir si cet al-
gorithme converge toujours et à déterminer la rapidité de sa convergence. L’analysenumérique est une discipline proche des mathématiques appliquées, qui a pour ob-
jectif de répondre à ces questions de façon rigoureuse.
2 Interpolation et extrapolation
Problème : Une fonction f (x) n’est connue que par quelques-uns de ses points de
colocation :(
x0, f (x0))
,(
x1, f (x1))
, . . . ,(
xn , f (xn))
. Comment fait-on pour évaluer cette
fonction f en un x donné, proche des points de colocation ?
5

Dans toutes les expériences où on est amené à évaluer une fonction f (x) pour dif-
férentes valeurs de x (par exemple la pression p(T ) en fonction de la température T
dans une machine thermique) il est fastidieux voire impossible d’évaluer une fonction
f (x) pour un grand nombre de valeurs de x. L’interpolation devient nécessaire chaque
fois que l’on veut estimer f (x) pour une valeur de x autre que celles dont on dispose.
Comme nous le verrons plus bas, l’interpolation se trouve aussi à la base de nombreux
algorithmes.
Exemple : Lors d’un balayage de fréquence, la réponse en amplitude d’un filtre
passe-haut a été mesurée à quelques fréquences différentes (cf. tableau ci-dessous).
Estimez la fréquence de coupure de ce filtre, sachant que la fonction de transfert du
filtre varie régulièrement avec la fréquence. Il faut donc interpoler les données et dé-
terminer à quelle fréquence correspond le gain de -3 [dB]. La figure 1 suggère que cette
fréquence de coupure vaut environ fc = 6500 Hz.
gain [dB] xk -0.39 -1.39 -1.73 -4.01 -3
fréquence [Hz] f (xk ) 2000 4000 4800 7500 ?
0 2000 4000 6000 8000 10000−6
−5
−4
−3
−2
−1
0
1
?
frequence [Hz]
gain
[dB
]
FIGURE 1 – Les trois mesures ainsi que l’emplacement approximatif de la fréquence de coupure du filtre,
pour un gain de -3 dB
Avant d’interpoler ces données, il convient d’abord de
• changer les unités : les fréquences sont exprimées ici en Hz, mais il est plus com-
mode de les convertir en kHz de sorte à ne pas avoir à gérer des valeurs qui
s’écartent trop de l’unité.
• changer de représentation. Notre objectif est en effet d’évaluer la fréquence pour
un gain donné. Il est donc préférable de traiter la fréquence comme une fonction
du gain ( f = f (g )) plutôt que l’inverse (g = g ( f )).
6
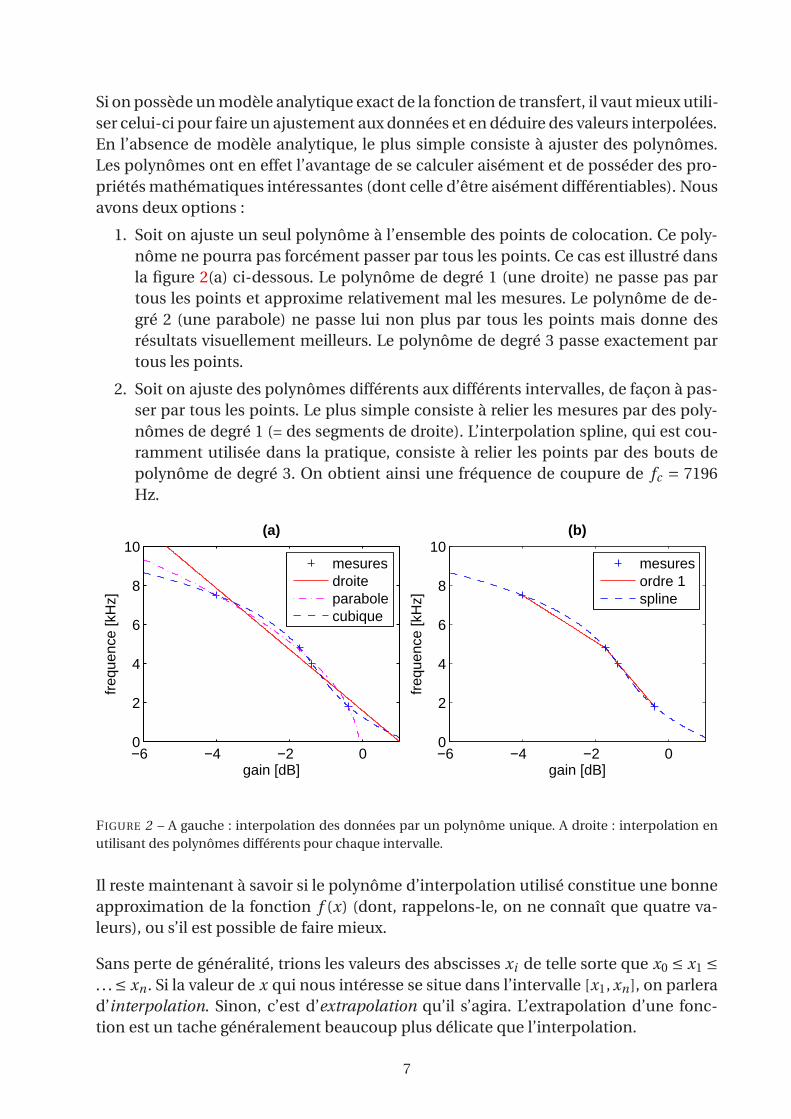
Si on possède un modèle analytique exact de la fonction de transfert, il vaut mieux utili-
ser celui-ci pour faire un ajustement aux données et en déduire des valeurs interpolées.
En l’absence de modèle analytique, le plus simple consiste à ajuster des polynômes.
Les polynômes ont en effet l’avantage de se calculer aisément et de posséder des pro-
priétés mathématiques intéressantes (dont celle d’être aisément différentiables). Nous
avons deux options :
1. Soit on ajuste un seul polynôme à l’ensemble des points de colocation. Ce poly-
nôme ne pourra pas forcément passer par tous les points. Ce cas est illustré dans
la figure 2(a) ci-dessous. Le polynôme de degré 1 (une droite) ne passe pas par
tous les points et approxime relativement mal les mesures. Le polynôme de de-
gré 2 (une parabole) ne passe lui non plus par tous les points mais donne des
résultats visuellement meilleurs. Le polynôme de degré 3 passe exactement par
tous les points.
2. Soit on ajuste des polynômes différents aux différents intervalles, de façon à pas-
ser par tous les points. Le plus simple consiste à relier les mesures par des poly-
nômes de degré 1 (= des segments de droite). L’interpolation spline, qui est cou-
ramment utilisée dans la pratique, consiste à relier les points par des bouts de
polynôme de degré 3. On obtient ainsi une fréquence de coupure de fc = 7196
Hz.
−6 −4 −2 00
2
4
6
8
10
freq
uenc
e [k
Hz]
gain [dB]
(a)
mesuresdroiteparabolecubique
−6 −4 −2 00
2
4
6
8
10
freq
uenc
e [k
Hz]
gain [dB]
(b)
mesuresordre 1spline
FIGURE 2 – A gauche : interpolation des données par un polynôme unique. A droite : interpolation en
utilisant des polynômes différents pour chaque intervalle.
Il reste maintenant à savoir si le polynôme d’interpolation utilisé constitue une bonne
approximation de la fonction f (x) (dont, rappelons-le, on ne connaît que quatre va-
leurs), ou s’il est possible de faire mieux.
Sans perte de généralité, trions les valeurs des abscisses xi de telle sorte que x0 ≤ x1 ≤. . .≤ xn . Si la valeur de x qui nous intéresse se situe dans l’intervalle [x1, xn], on parlera
d’interpolation. Sinon, c’est d’extrapolation qu’il s’agira. L’extrapolation d’une fonc-
tion est un tache généralement beaucoup plus délicate que l’interpolation.
7
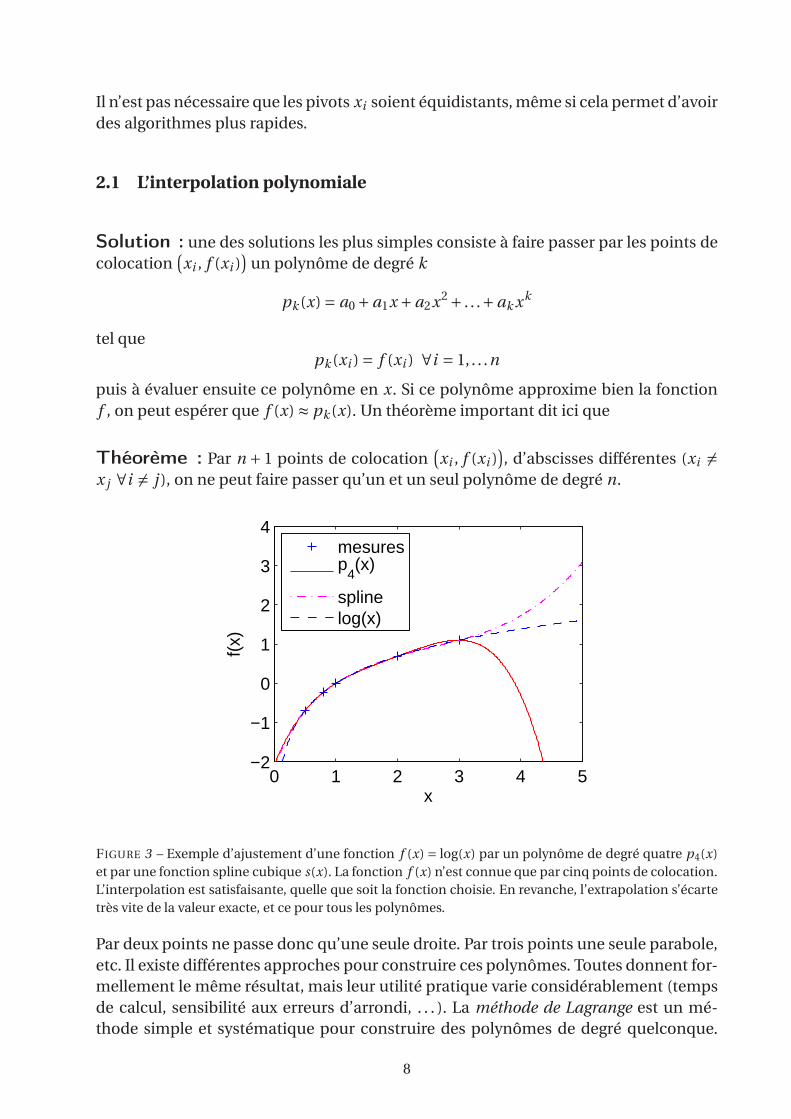
Il n’est pas nécessaire que les pivots xi soient équidistants, même si cela permet d’avoir
des algorithmes plus rapides.
2.1 L’interpolation polynomiale
Solution : une des solutions les plus simples consiste à faire passer par les points de
colocation(
xi , f (xi ))
un polynôme de degré k
pk (x) = a0 +a1x +a2x2 + . . .+ak xk
tel que
pk (xi ) = f (xi ) ∀i = 1, . . .n
puis à évaluer ensuite ce polynôme en x. Si ce polynôme approxime bien la fonction
f , on peut espérer que f (x) ≈ pk (x). Un théorème important dit ici que
Théorème : Par n + 1 points de colocation(
xi , f (xi ))
, d’abscisses différentes (xi 6=x j ∀i 6= j ), on ne peut faire passer qu’un et un seul polynôme de degré n.
0 1 2 3 4 5−2
−1
0
1
2
3
4
x
f(x)
mesuresp
4(x)
splinelog(x)
FIGURE 3 – Exemple d’ajustement d’une fonction f (x) = log(x) par un polynôme de degré quatre p4(x)
et par une fonction spline cubique s(x). La fonction f (x) n’est connue que par cinq points de colocation.
L’interpolation est satisfaisante, quelle que soit la fonction choisie. En revanche, l’extrapolation s’écarte
très vite de la valeur exacte, et ce pour tous les polynômes.
Par deux points ne passe donc qu’une seule droite. Par trois points une seule parabole,
etc. Il existe différentes approches pour construire ces polynômes. Toutes donnent for-
mellement le même résultat, mais leur utilité pratique varie considérablement (temps
de calcul, sensibilité aux erreurs d’arrondi, . . . ). La méthode de Lagrange est un mé-
thode simple et systématique pour construire des polynômes de degré quelconque.
8

Elle n’est cependant guère utilisée aujourd’hui en raison de son coût en temps de cal-
cul.
• Pour une fonction définie par deux points de colocation uniquement (n = 2), le
polynôme de Lagrange est de degré 1 et s’écrit
p1(x) = f (x0)x −x1
x0 −x1+ f (x1)
x −x0
x1 −x0
On vérifie que ce polynôme passe bien par les deux points de colocation puisque
p(x = x0) = f (x0) et p(x = x1) = f (x1).
• Pour une fonction définie par trois points de colocation, le polynôme de La-
grange est une parabole d’équation
p2(x) = f (x0)(x −x1)(x −x2)
(x0 −x1)(x0 −x2)+ f (x1)
(x −x0)(x −x2)
(x1 −x0)(x1 −x2)+ f (x2)
(x −x0)(x −x1)
(x2 −x0)(x2 −x1)
Pour une fonction définie par n +1 points de colocation, l’expression gé-
nérale du polynôme de Lagrange de degré n s’écrit
pn(x) =n∑
k=0
f (xk )Lk (x)
où Lk (x) désigne le polynôme de degré n
Lk (x) =(x −x0)(x −x1) · · ·(x −xk−1)(x −xk+1) · · ·(x −xn)
(xk −x0)(xk −x1) · · ·(xk −xk−1)(xk −xk+1) · · ·(xk −xn)
On vérifie que Lk (x) satisfait toujours la condition
Lk (xl ) ={
0 si l 6= k
1 si l = k
Erreur d’interpolation : l’interpolation polynomiale peut aisément générer des
valeurs absurdes, si elle n’est pas effectuée correctement. Il est donc essentiel de quan-
tifier l’erreur d’interpolation pour interpréter les résultats.
En analyse numérique , il est généralement impossible de connaître exactement l’erreur.
En effet, si tel était le cas, alors la solution exacte serait elle aussi connue. En revanche,
il est souvent possible d’estimer l’ordre de grandeur de l’erreur et de savoir comme cette
dernière se comporte dans différentes conditions. Cette information est nécessaire (mais
non suffisante) pour évaluer la fiabilité d’une méthode.
Appelons ǫn(x) l’écart ou erreur définie par
f (x) = pn(x)+ǫn(x)
9

Tout le problème consiste à estimer l’erreur sans disposer de la valeur de f (x) en tout
x. On supposera dans ce qui suit que les valeurs des points de colocation sont connues
exactement, ce qui n’est pas toujours vrai dans la pratique. Le théorème suivant est
alors utile
Théorème : Soit un ensemble de n + 1 points de colocation {(
x0, f (x0))
,(
x1, f (x1))
, . . . ,(
xn , f (xn))
}. On suppose que la fonction f (x) est définie dans l’intervalle
[x0, xn] et qu’elle est (n + 1)-fois dérivable dans l’intervalle ]x0, xn[. Il existe alors une
abscisse ξ ∈ [x0, xn] telle que
ǫn(x) =f (n+1)(ξ)
(n +1)!(x −x0)(x −x1) · · ·(x −xn)
où l’expression f (n+1)(ξ) désigne la dérivée (n + 1)-ième de f (x), évaluée en une abs-
cisse ξ inconnue.
Ce théorème nous apprend que
• l’erreur ǫn(x) est d’autant plus petite que la fonction f (x) est "lisse" (ses dérivées
supérieures restent petites).
• l’erreur ǫn(x) diminue quand x est proche d’un des points de colocation. Elle est
naturellement nulle aux points de colocation : ǫn(xi ) = 0, i = 0, . . . ,n
• pour un degré n élevé, le polynôme dans l’expression de l’erreur tend à osciller,
ce qui peut affecter l’interpolation.
0 2 4 6
0
5
10
15
x
f(x)
mesuresp
10(x)
FIGURE 4 – Exemple d’interpolation avec un polynôme de degré 10. Plus le degré est élevé, plus le poly-
nôme a tendance à osciller.
La figure 4 illustre ce qui se passe quand on interpole avec des polynômes de degré
élevé. Non seulement le calcul de ces polynômes de degré élevé présente des instabili-
tés numériques, mais en plus on voit apparaître des oscillations indésirables. Augmen-
ter le degré du polynôme ne fait qu’amplifier ces oscillations. D’où la règle générale
10
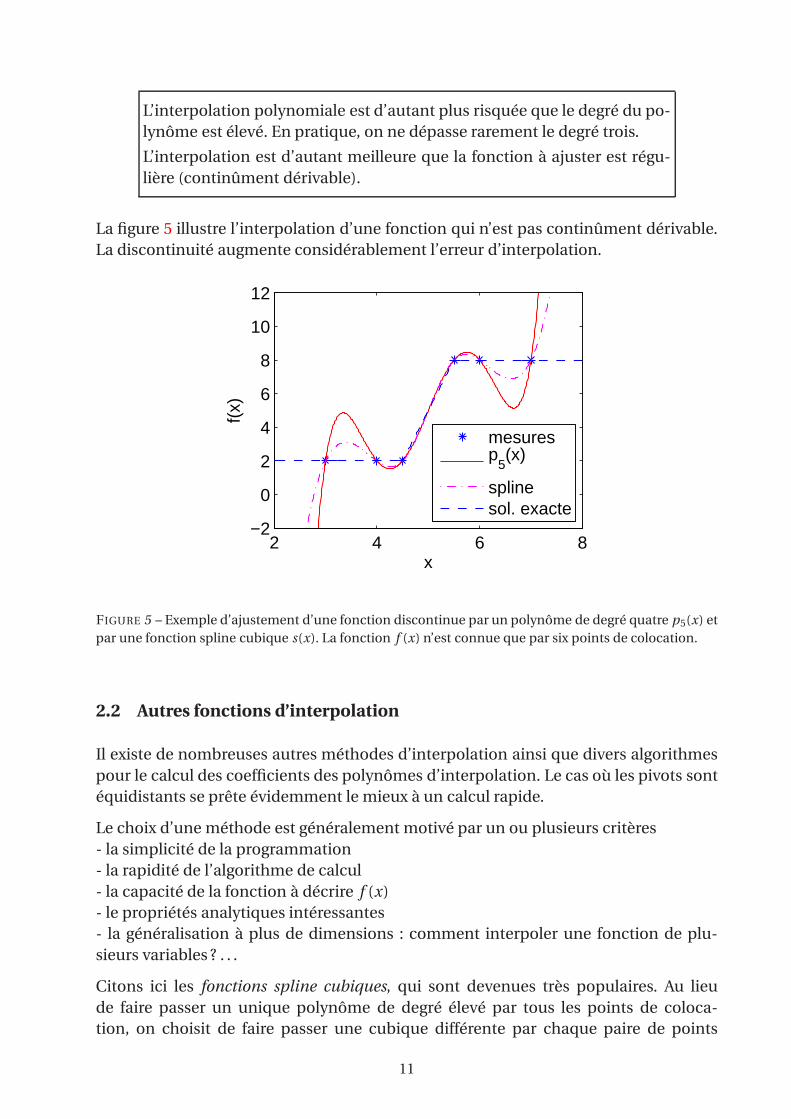
L’interpolation polynomiale est d’autant plus risquée que le degré du po-
lynôme est élevé. En pratique, on ne dépasse rarement le degré trois.
L’interpolation est d’autant meilleure que la fonction à ajuster est régu-
lière (continûment dérivable).
La figure 5 illustre l’interpolation d’une fonction qui n’est pas continûment dérivable.
La discontinuité augmente considérablement l’erreur d’interpolation.
2 4 6 8−2
0
2
4
6
8
10
12
x
f(x)
mesuresp
5(x)
splinesol. exacte
FIGURE 5 – Exemple d’ajustement d’une fonction discontinue par un polynôme de degré quatre p5(x) et
par une fonction spline cubique s(x). La fonction f (x) n’est connue que par six points de colocation.
2.2 Autres fonctions d’interpolation
Il existe de nombreuses autres méthodes d’interpolation ainsi que divers algorithmes
pour le calcul des coefficients des polynômes d’interpolation. Le cas où les pivots sont
équidistants se prête évidemment le mieux à un calcul rapide.
Le choix d’une méthode est généralement motivé par un ou plusieurs critères
- la simplicité de la programmation
- la rapidité de l’algorithme de calcul
- la capacité de la fonction à décrire f (x)
- le propriétés analytiques intéressantes
- la généralisation à plus de dimensions : comment interpoler une fonction de plu-
sieurs variables ? . . .
Citons ici les fonctions spline cubiques, qui sont devenues très populaires. Au lieu
de faire passer un unique polynôme de degré élevé par tous les points de coloca-
tion, on choisit de faire passer une cubique différente par chaque paire de points
11
(x0, x1), (x1, x2), . . . , (xn−1, xn). Le problème est a priori sous-déterminé, car il existe une
infinité de cubiques pouvant passer par deux points. Toutefois, si on impose en chaque
xi la continuité de f (x) ainsi que la continuité de la dérivée première f ′(x), la solution
devient unique. Le résultat est souvent plus satisfaisant qu’avec un polynôme de La-
grange, comme le montrent les figures 3 et 4. Il existe en outre des algorithmes rapides
pour le calcul des coefficients des splines.
2.3 Extrapolation
L’extrapolation est une tâche encore bien plus délicate que l’interpolation, car la rapide
divergence des fonctions polynômiales tend rapidement à donner des valeurs qui sont
totalement dénuées de sens. Contrairement à l’interpolation, il est indispensable de
disposer d’un modèle analytique de la fonction à étudier si on veut extrapoler celle-ci.
Sans un tel modèle, l’extrapolation sera peu crédible.
1800 1900 2000 21000
5
10
15
20
25
annee
effe
ctif
[mill
iard
]
mesuresp
5(x)
splineexponentielle
FIGURE 6 – Extrapolation de l’effectif de la population mondiale jusqu’en 2100.
Exemple : Le tableau ci-dessous donne quelques valeurs de la popu-
lation mondiale. Différentes hypothèses de fécondité donnent des extra-
polations fort différentes. Selon le scénario malthusien (taux de natalité
constant), la concentration devrait continuer de croître de façon exponen-
tielle n(t) = n0e t/τ. Ce cas est illustré par la courbe en traitillé dans la figure
6. Une réduction progressive de ce taux permettrait au contraire de stabili-
ser l’effectif. Les extrapolation polynomiales dans la figure 6 ne s’appuient
sur aucun modèle et n’ont donc aucune valeur, même si le hasard veut que
le modèle spline soit en bon accord avec le modèle mathusien pour le siècle
à venir.
12

année t 1804 1927 1960 1974 1987 1999
effectif n(t) [milliard] 1 2 3 4 5 6
2.4 Interpolation en plusieurs dimensions
De nombreuses applications sont de grosses consommatrices d’interpolations à plu-
sieurs dimensions : les programmes faisant appel à des éléments finis, la CAO, les lo-
giciels utilisés pour générer des effets spéciaux dans les films, . . . La plupart des outils
(et en particulier les fonctions spline) peuvent être générées à plusieurs dimensions,
au prix d’une plus grande complexité.
3 Différentiation numérique
Une fonction f (x) continûment dérivable est connue par quelques-uns de ses points
de colocation. Comment fait-on pour évaluer la dérivée première f ′(x) et/ou les dé-
rivées d’ordre supérieur ? Ce besoin de différentiation numérique s’exprime dans de
nombreux domaines.
Exemple : La tension aux bornes d’un condensateur qui se décharge
est mesurée à des intervalles réguliers, donnant une suite de valeurs
{U0,U1,U2, . . . ,Un}. Pour estimer le courant de décharge I =CU , il faut déri-
ver une fonction dont on ne connaît que les points de colocation. Comment
procéder ?
La solution consiste ici à faire passer par les points de colocation un polynôme d’inter-
polation, puis à dériver celui-ci le nombre de fois nécessaire. On peut ainsi estimer la
dérivée aux points de colocation ou entre deux.
3.1 Estimation de la dérivée première
Le cas le plus simple est celui où il n’y a que deux points de colocation :(
x0, f (x0))
et(
x1, f (x1))
. Par ces points passe la droite d’équation
p1(x) =f (x1)− f (x0)
x1 −x0(x −x0)+ f (x0)
L’estimation de la dérivée première équivaut donc au coefficient directeur de la droite
f ′(x) ≈ p′1(x) =
f (x1)− f (x0)
x1 −x0, x ∈ [x0, x1]
Notons qu’elle prend la même valeur en tout point de l’intervalle [x0, x1]. Par ailleurs,
la dérivée seconde et toutes les dérivées supérieures sont nulles.
13

Estimation de l’erreur : Pour savoir quelle confiance accorder à l’expression
ci-dessus, il faut connaître l’erreur. Du chapitre précédent, nous tirons
f (x) = pn(x)+ǫn(x) ⇒ f ′(x) = p′n(x)+ǫ′n(x)
Supposons dorénavant que les abscisses des points de colocation sont régulièrement
réparties, et appelons h = xi+1 − xi l’écartement ou pas entre deux abscisses voisines.
On peut alors montrer que
ǫ′n(x) = (−1)n f (n+1)(ξ)
(n +1)!hn , ξ ∈ [x0, xn]
L’erreur varie donc comme ǫ′n(x) ∼ hn . On dira qu’elle est d’ordre n et on écrira fré-
quemment de façon abrégée ǫ′n(x) ∼O (hn)
Avec deux points de colocation, l’expression de la dérivée première d’ordre 1 peut
s’écrire de deux façons différentes. Soit on estime la pente de la droite qui passe par
le point de colocation suivant (différence avant), soit on prend la pente de la droite
passant par le point qui précède (différence arrière).
f ′(xk ) =f (xk+1)− f (xk )
h+O (h) différence avant d’ordre 1
f ′(xk ) =f (xk )− f (xk−1)
h+O (h) différence arrière d’ordre 1
Avec trois points de colocation, le polynôme d’interpolation devient une parabole. A
partir de cette dernière, on peut évaluer la dérivée première en chacun des trois points
f ′(xk−1) =− f (xk+1)+4 f (xk )−3 f (xk−1)
2h+O (h2) différence avant d’ordre 2
f ′(xk ) =f (xk+1)− f (xk−1)
2h+O (h2) différence centrée d’ordre 2
f ′(xk+1) =3 f (xk+1)−4 f (xk )+ f (xk−1)
2h+O (h2) différence arrière d’ordre 2
Pour les différences d’ordre 2, l’erreur varie asymptotiquement comme h2 alors que
pour les différences d’ordre un, elle varie comme h. Pour une fonction f suffisamment
lisse et pour un petit pas h donné, la différence d’ordre 2 donnera généralement une
erreur plus petite.
Trois raisons nous poussent à préférer la différence centrée d’ordre 2 :
1. D’abord, son terme d’erreur est en O (h2) et non en O (h)
2. Un calcul plus détaillé montre ensuite que parmi les trois estimateurs d’ordre 2,
c’est la différence centrée qui possède en moyenne l’erreur la plus petite.
3. Enfin, et c’est là un point crucial : la différence centrée d’ordre 2 ne nécessite
que la connaissance de deux points de colocation. En effet, la valeur du point en
lequel on estime la dérivée n’entre pas en jeu. Le coût en calcul est donc identique
à celui d’une différence d’ordre 1, pour un résultat meilleur.
14

x0 x1 x2
f(x0)
f(x1)
f(x2)
diff. avantdiff. centreediff. arriere
FIGURE 7 – Illustration des dérivées avant et arrière d’ordre 1, et de la dérivée centrée d’ordre 2 au point
d’abscisse x = x1.
Exemple : L’estimation de la dérivée de f (x) = 1/x en x = 2 par différentes
méthodes donne les résultats ci-dessous. On constate que pour h suffisam-
ment petit, réduire le pas d’un facteur 10 revient à diminuer l’erreur d’un
facteur 10 pour la méthode d’ordre 1 et d’un facteur 100 pour la méthode
de d’ordre 2. En revanche, pour des grands pas h, la méthode d’ordre 1 est
plus proche de la réalité. La différence centrée d’ordre 2 est donc plus inté-
ressante, à condition que le pas soit suffisamment petit, et pour autant que
la fonction f à dériver soit suffisamment continue.
pas différence centrée différence avant
d’ordre 2 d’ordre 1
h f ′(x = 2) |ǫ| f ′(x = 2) |ǫ|1.50000000 -0.57142857 0.32142857 -0.14285714 0.10714286
1.00000000 -0.33333333 0.08333333 -0.16666667 0.08333333
0.10000000 -0.25062657 0.00062657 -0.23809524 0.01190476
0.01000000 -0.25000625 0.00000625 -0.24875622 0.00124378
0.00100000 -0.25000006 0.00000006 -0.24987506 0.00012494
0.00010000 -0.25000000 0.00000000 -0.24998750 0.00001250
0.00001000 -0.25000000 0.00000000 -0.24999875 0.00000125
3.2 Estimation de la dérivée seconde
La procédure reste la même pour les dérivées secondes, sauf que le polynôme d’in-
terpolation doit être dérivé deux fois. Comme ce polynôme doit être au minimum de
degré 2 (sinon sa dérivée seconde est nulle), on en déduit qu’il faut au minimum trois
points de colocation.
15

Pour trois points de colocation, on obtient les expressions
f ′′(xk−1) =f (xk+1)−2 f (xk )+ f (xk−1)
h2+O (h2) différence avant d’ordre 2
f ′′(xk ) =f (xk+1)−2 f (xk )+ f (xk−1)
h2+O (h2) différence centrée d’ordre 2
f ′′(xk+1) =f (xk+1)−2 f (xk )+ f (xk−1)
h2+O (h2) différence arrière d’ordre 2
A titre de comparaison, la différence centrée d’ordre 4 s’écrit
f ′′(xk ) =− f (xk−2)+16(xk−1)−30 f (xk )+16 f (xk+1)− f (xk+2)
h4+ O (h4)
3.3 Dériver dans la pratique
3.3.1 Si f (x) est donnée par un tableau de valeurs
Si la fonction à dériver est spécifiée par un ensemble de points de colocation (= son
expression analytique n’est pas connue) alors le pas est imposé. Le seul degré de li-
berté dont on dispose reste le degré du polynôme d’interpolation utilisé pour évaluer
la dérivée.
Augmenter le degré du polynôme peut sembler intéressant, mais nous avons vu que
les polynômes d’interpolation de degré supérieur à 3 sont rarement recommandables.
Par ailleurs, un telcalcul nécessitera davantage d’opérations de calcul.
3.3.2 Si f (x) est donnée par son expression analytique
La situations est fort différente lorsque l’expression analytique de la fonction à dériver
est connue. En effet les points de colocation peuvent alors être choisis librement et on
peut prendre un pas h aussi petit que souhaité.
On pourrait penser qu’il vaut mieux choisir un pas h très petit pour augmenter la préci-
sion du calcul. C’est souvent vrai. Toutefois, lorsque h devient trop petit, le résultat est
entaché par des erreurs d’arrondi. En effet, suivant le type de fonction à dériver, il arri-
vera un moment où l’écart f (x +h)− f (x) sera inférieur à la précision du calculateur.
Le résultat sera alors erroné.
Il existe donc une valeur optimale du pas qui dépendra de la fonction f (x) à dériver
et de la précision du calculateur. Pour une calculette de poche, la valeur relative du
pas se situera typiquement entre h/x = 10−2 et h/x = 10−6. Pour un calcul en double
précision, le pas relatif pourra parfois descendre jusqu’à h/x = 10−12.
16
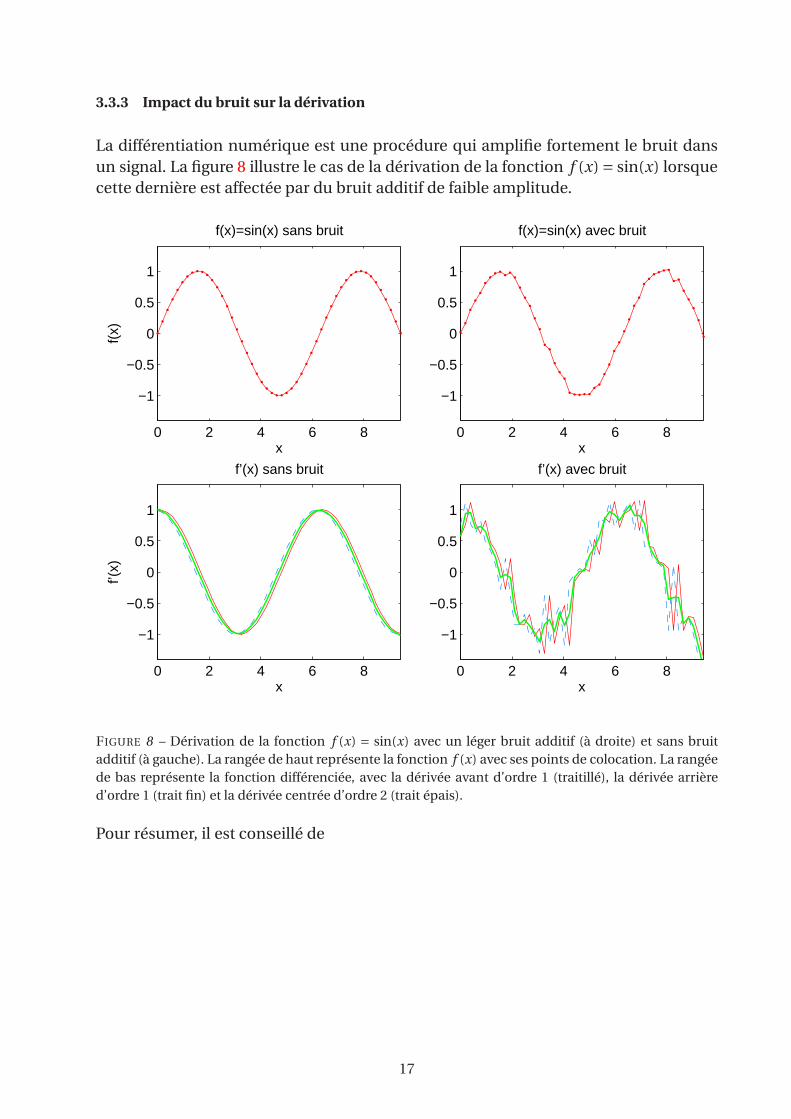
3.3.3 Impact du bruit sur la dérivation
La différentiation numérique est une procédure qui amplifie fortement le bruit dans
un signal. La figure 8 illustre le cas de la dérivation de la fonction f (x) = sin(x) lorsque
cette dernière est affectée par du bruit additif de faible amplitude.
0 2 4 6 8
−1
−0.5
0
0.5
1
x
f(x)
f(x)=sin(x) sans bruit
0 2 4 6 8
−1
−0.5
0
0.5
1
x
f(x)=sin(x) avec bruit
0 2 4 6 8
−1
−0.5
0
0.5
1
x
f’(x)
f’(x) sans bruit
0 2 4 6 8
−1
−0.5
0
0.5
1
x
f’(x) avec bruit
FIGURE 8 – Dérivation de la fonction f (x) = sin(x) avec un léger bruit additif (à droite) et sans bruit
additif (à gauche). La rangée de haut représente la fonction f (x) avec ses points de colocation. La rangée
de bas représente la fonction différenciée, avec la dérivée avant d’ordre 1 (traitillé), la dérivée arrière
d’ordre 1 (trait fin) et la dérivée centrée d’ordre 2 (trait épais).
Pour résumer, il est conseillé de
17

Pour les dérivées d’ordre 1 et 2, les expressions les plus intéressantes sont
les différences centrées d’ordre 2
f ′(xk ) =f (xk+1)− f (xk−1)
2h+O (h2)
f ′′(xk ) =f (xk+1)−2 f (xk )+ f (xk−1)
h2+O (h2)
En général, plus le terme d’erreur O (hp ) est d’ordre élevé, plus le résultat
tendra à être précis. Mais ceci n’est pas toujours vrai lorsque les données
sont affectées de bruit. De fait, les dérivées d’ordre supérieur et les expres-
sions d’ordre supérieur à 2 sont rarement utilisées.
A titre d’exemple, un programme de calcul simplifié de la dérivée par différence cen-
trée s’écrit en Scilab
1 function [dydx] = derivee(y,h)
2
3 // y : vecteur de valeurs a deriver
4 // h : pas de derivation
5 // dydx : difference centree de y(x) (vecteur colonne )
6
7 y = y(:);
8 n = length(y);
9 dydx = zeros(n,1);
10 dydx(1) = y(2)-y(1);
11 dydx(n) = y(n)-y(n-1);
12 dydx(2:n-1) = (y(3:n)-y(1:n-2)) / 2;
13 dydx = dydx / h;
14 endfunction
où y est un vecteur d’ordonnées obtenues pour des abscisses espacées de h. Voici la
même fonction, écrite sous une forme plus compacte
1 function [dydx] = derivee(y,h)
2
3 // y : vecteur de valeurs a deriver
4 // h : pas de derivation
5 // dydx : difference centree de y(x) (vecteur colonne )
6
7 y = y(:); // met y en vecteur colonne
8 dydx = [y(2)-y(1); (y(3:$)-y(1:$-2))/2; y($)-y($-1)]/h;
9 endfunction
Si l’expression analytique de la fonction f (x) est connue, alors on peut procéder diffé-
remment :
18

1 function [dfdx] = derivee(f,x)
2
3 // f : nom de la fonction a deriver
4 // x : vecteur d’abscisses ou il faut evaluer la derivee
5 // dfdx : valeur de la derivee (vecteur colonne)
6
7 x = x(:); // met x en vecteur colonne
8 dx = [x(2)-x(1); (x(3:$)-x(1:$-2))/2; x($)-x($-1)]; // le pas
9 y = f(x); // evalue en x la fonction dont le nom est dans f
10 dfdx = [y(2)-y(1); (y(3:$)-y(1:$-2))/2; y($)-y($-1)] ./ dx;
11 endfunction
Il faut ensuite définir la fonction à dériver. Par exemple pour f (x) = xe−x nous aurions
function f = mafonction(x)// definit la fonction dont il faut evaluer la deriveef = exp(-x).*x;endfunction
Et le résultat s’obtient en exécutant dans la console
z = derivee(mafonction,x);
4 Intégration numérique
Le problème de l’intégration numérique (ou quadrature) peut se présenter de deux
façons différentes :
Problème 1 : Une fonction f (x) est connue par quelques-uns de ses points de
colocation {(
xi , f (xi ))
}ni=0
(qui sont régulièrement espacés ou non). Comment fait-on
pour estimer la valeur de l’intégrale∫xn
x0f (x)d x, alors que l’expression analytique de
f (x) n’est pas connue ?
Un exemple : la décharge d’un courant I (t) dans une bobine d’inductance L
est étudiée en mesurant le courant des intervalles de temps réguliers. Cela
donne une suite {I0, I1, . . . , In}. Comment estimer l’énergie W = 12
L∫
I 2 d t ?
Problème 2 : On cherche la valeur de l’intégrale définie∫b
a f (x) d x lorsque l’ex-
pression analytique de l’intégrand f (x) est connue, mais non sa primitive.
Un exemple : calculer∫b
a e−x2d x
19
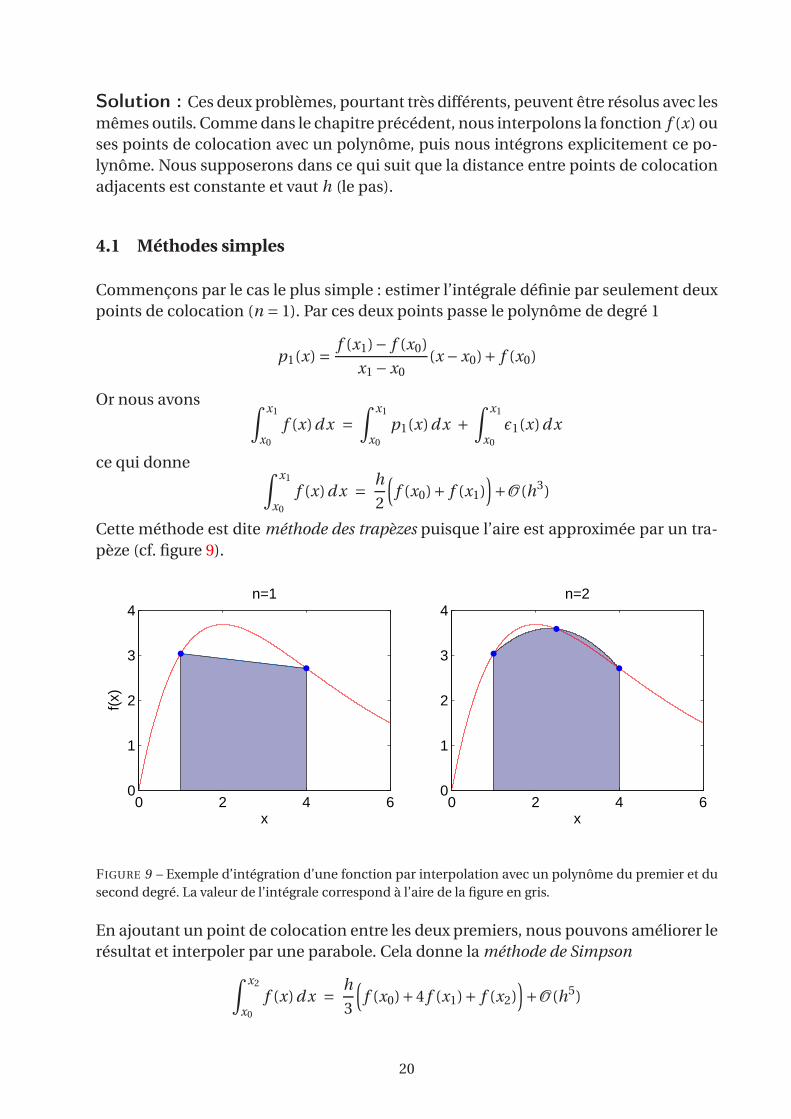
Solution : Ces deux problèmes, pourtant très différents, peuvent être résolus avec les
mêmes outils. Comme dans le chapitre précédent, nous interpolons la fonction f (x) ou
ses points de colocation avec un polynôme, puis nous intégrons explicitement ce po-
lynôme. Nous supposerons dans ce qui suit que la distance entre points de colocation
adjacents est constante et vaut h (le pas).
4.1 Méthodes simples
Commençons par le cas le plus simple : estimer l’intégrale définie par seulement deux
points de colocation (n = 1). Par ces deux points passe le polynôme de degré 1
p1(x) =f (x1)− f (x0)
x1 −x0(x −x0)+ f (x0)
Or nous avons∫x1
x0
f (x)d x =∫x1
x0
p1(x)d x +∫x1
x0
ǫ1(x)d x
ce qui donne∫x1
x0
f (x)d x =h
2
(
f (x0)+ f (x1))
+O (h3)
Cette méthode est dite méthode des trapèzes puisque l’aire est approximée par un tra-
pèze (cf. figure 9).
0 2 4 60
1
2
3
4
x
f(x)
n=1
0 2 4 60
1
2
3
4
x
n=2
FIGURE 9 – Exemple d’intégration d’une fonction par interpolation avec un polynôme du premier et du
second degré. La valeur de l’intégrale correspond à l’aire de la figure en gris.
En ajoutant un point de colocation entre les deux premiers, nous pouvons améliorer le
résultat et interpoler par une parabole. Cela donne la méthode de Simpson
∫x2
x0
f (x)d x =h
3
(
f (x0)+4 f (x1)+ f (x2))
+O (h5)
20
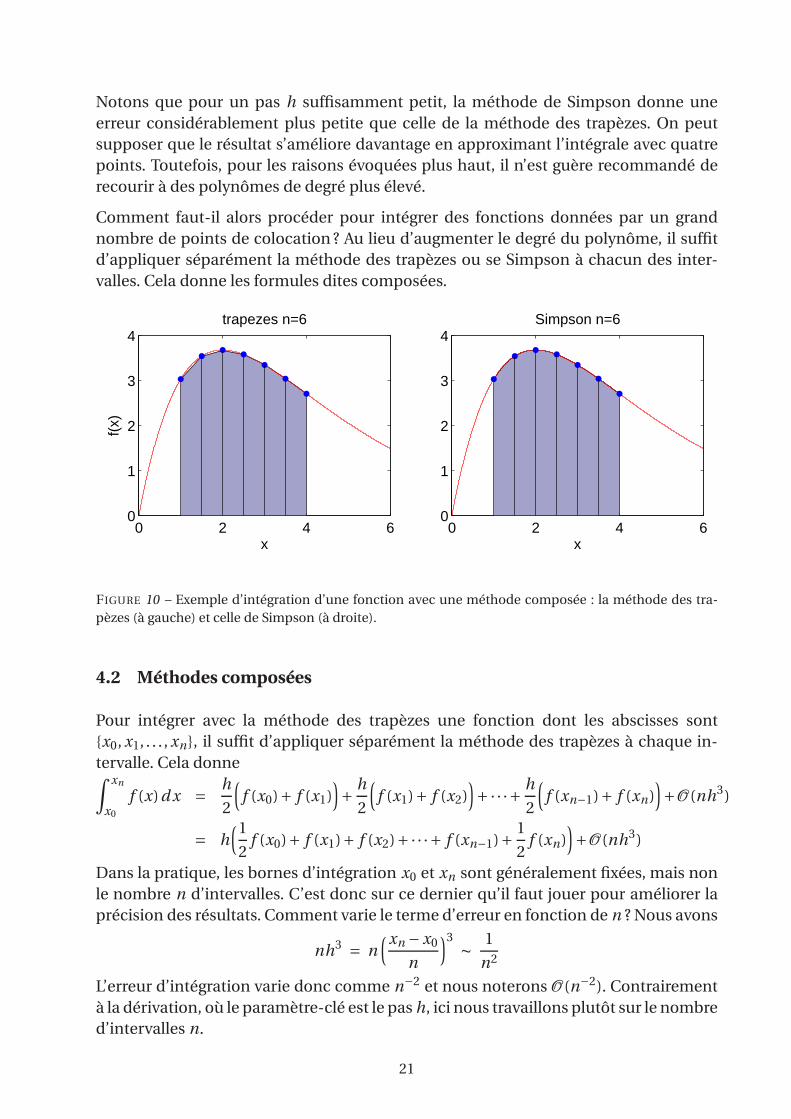
Notons que pour un pas h suffisamment petit, la méthode de Simpson donne une
erreur considérablement plus petite que celle de la méthode des trapèzes. On peut
supposer que le résultat s’améliore davantage en approximant l’intégrale avec quatre
points. Toutefois, pour les raisons évoquées plus haut, il n’est guère recommandé de
recourir à des polynômes de degré plus élevé.
Comment faut-il alors procéder pour intégrer des fonctions données par un grand
nombre de points de colocation ? Au lieu d’augmenter le degré du polynôme, il suffit
d’appliquer séparément la méthode des trapèzes ou se Simpson à chacun des inter-
valles. Cela donne les formules dites composées.
0 2 4 60
1
2
3
4
x
f(x)
trapezes n=6
0 2 4 60
1
2
3
4
x
Simpson n=6
FIGURE 10 – Exemple d’intégration d’une fonction avec une méthode composée : la méthode des tra-
pèzes (à gauche) et celle de Simpson (à droite).
4.2 Méthodes composées
Pour intégrer avec la méthode des trapèzes une fonction dont les abscisses sont
{x0, x1, . . . , xn}, il suffit d’appliquer séparément la méthode des trapèzes à chaque in-
tervalle. Cela donne∫xn
x0
f (x)d x =h
2
(
f (x0)+ f (x1))
+h
2
(
f (x1)+ f (x2))
+·· ·+h
2
(
f (xn−1)+ f (xn))
+O (nh3)
= h(1
2f (x0)+ f (x1)+ f (x2)+·· ·+ f (xn−1)+
1
2f (xn)
)
+O (nh3)
Dans la pratique, les bornes d’intégration x0 et xn sont généralement fixées, mais non
le nombre n d’intervalles. C’est donc sur ce dernier qu’il faut jouer pour améliorer la
précision des résultats. Comment varie le terme d’erreur en fonction de n ? Nous avons
nh3 = n(xn −x0
n
)3∼
1
n2
L’erreur d’intégration varie donc comme n−2 et nous noterons O (n−2). Contrairement
à la dérivation, où le paramètre-clé est le pas h, ici nous travaillons plutôt sur le nombre
d’intervalles n.
21

Avec la méthode de Simpson (en prenant des intervalles qui ne se chevauchent pas),
on obtient la formule de Simpson composée. Comme chaque intervalle nécessite trois
points de colocation, le nombre n d’intervalles doit obligatoirement être pair. Cela
donne∫xn
x0
f (x)d x =h
3
(
f (x0)+4 f (x1)+2 f (x2)+4 f (x3)+·· ·+4 f (xn−1)+ f (xn))
+O (n−4)
4.3 Autres méthodes
On utilise aujourd’hui plus couramment des méthodes adaptatives qui, pour un
nombre d’intervalles n donné, offrent une erreur plus petite ou bien qui permettent de
sélectionner le meilleur nombre d’intervalles (pour une précision donnée) en procé-
dant par itérations. La méthode de Romberg consiste à combiner astucieusement une
interpolation par des polynômes de différents degrés pour réduire davantage le terme
d’erreur. Les méthodes de quadrature de Gauss cherchent à minimiser l’erreur d’in-
tégration en choisissant convenablement les abscisses xi (qui ne sont plus forcément
réparties uniformément). Enfin, il existe des méthodes spécialement adaptées à l’inté-
gration de fonctions qui présentent des singularités, comme par exemple f (x) = x−1/2.
4.4 L’intégration dans la pratique
Les problèmes d’intégration numérique sont comparables à ceux rencontrés dans la
différentiation numérique. Augmenter le nombre n d’intervalles (lorsque c’est pos-
sible) améliore généralement les résultats. Toutefois, lorsque n devient trop grand, le
temps de calcul devient prohibitif et le résultat est corrompu par les erreurs d’arrondi.
Suivant le type de fonction, n peut varier de n = 100− 106 ou plus. Il existe des mé-
thodes qui permettent de déterminer le nombre n optimal de façon récursive.
Exemple de calcul avec un intégrand connu
On cherche la valeur de l’intégrale I =∫1
0 e−x d x donne
méthode des trapèzes méthode de Simpson
n I ǫ I ǫ
2 0.6452351 -0.0131 0.6323336 -0.000213
4 0.6354094 -0.00328 0.6321341 -0.0000136
10 0.6326472 -0.000526 0.6321209 -0.000000351
100 0.6321258 -0.00000526 0.6321209 -0.0000000000351
1000 0.6321206 -0.0000000526 0.6321209 -0.00000000000000351
22
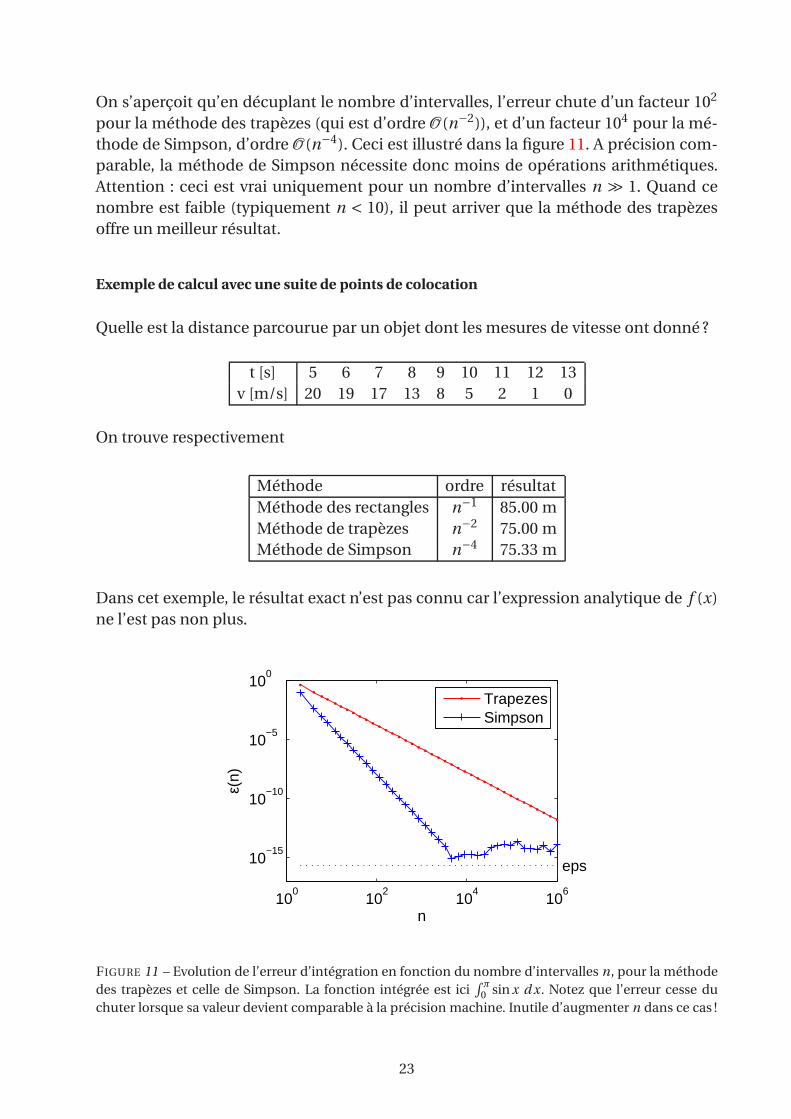
On s’aperçoit qu’en décuplant le nombre d’intervalles, l’erreur chute d’un facteur 102
pour la méthode des trapèzes (qui est d’ordre O (n−2)), et d’un facteur 104 pour la mé-
thode de Simpson, d’ordre O (n−4). Ceci est illustré dans la figure 11. A précision com-
parable, la méthode de Simpson nécessite donc moins de opérations arithmétiques.
Attention : ceci est vrai uniquement pour un nombre d’intervalles n ≫ 1. Quand ce
nombre est faible (typiquement n < 10), il peut arriver que la méthode des trapèzes
offre un meilleur résultat.
Exemple de calcul avec une suite de points de colocation
Quelle est la distance parcourue par un objet dont les mesures de vitesse ont donné ?
t [s] 5 6 7 8 9 10 11 12 13
v [m/s] 20 19 17 13 8 5 2 1 0
On trouve respectivement
Méthode ordre résultat
Méthode des rectangles n−1 85.00 m
Méthode de trapèzes n−2 75.00 m
Méthode de Simpson n−4 75.33 m
Dans cet exemple, le résultat exact n’est pas connu car l’expression analytique de f (x)
ne l’est pas non plus.
100
102
104
106
10−15
10−10
10−5
100
n
ε(n)
eps
TrapezesSimpson
FIGURE 11 – Evolution de l’erreur d’intégration en fonction du nombre d’intervalles n, pour la méthode
des trapèzes et celle de Simpson. La fonction intégrée est ici∫π
0 sin x d x. Notez que l’erreur cesse du
chuter lorsque sa valeur devient comparable à la précision machine. Inutile d’augmenter n dans ce cas !
23

Avant d’intégrer une fonction, il faut la visualiser au préalable, afin détermi-
ner si elle se prête bien à une intégration numérique (régularité, disconti-
nuités, singularités,. . . ) et pour estimer le pas.
Le pas doit toujours être choisi h ≪ T , où T est l’échelle caractéristique sur
laquelle la fonction f (x) varie. Pour une fonction périodique, par exemple,
T sera la période.
Les méthodes d’intégration classiques sont la méthode des trapèzes et celle
de Simpson. La seconde offre, à temps de calcul équivalent, un résultat gé-
néralement meilleur.∫xn
x0
f (x)d x = h(1
2f (x0)+ f (x1)+ f (x2)+·· ·+ f (xn−1)+
1
2f (xn)
)
+O (n−2)
∫xn
x0
f (x)d x =h
3
(
f (x0)+4 f (x1)+2 f (x2)+4 f (x3)+·· ·+4 f (xn−1)+ f (xn))
+O (n−4)
Un programme de calcul simplifié de l’intégrale par la méthode des trapèzes, lorsque
l’expression analytique de l’intégrand est connue, est donné ci-dessous. On pourrait
aussi passer le nom de l’intégrand comme argument.
1 function [y] = trapezes (f,a,b,n)
2
3 // f : nom de la fonction a integrer
4 // a : borne inferieure
5 // b : borne superieure
6 // n : nombre d’intervalles
7 // y : integrale
8
9 x = linspace (a,b,n+1)’;
10 y = f(x); // evalue en x la fonction dont le nom est dans f
11 h = x(2)-x(1); // le pas
12 I = (sum(y) - 0.5*(y(1)+y($)))*h;
13 endfunction
La même fonction, basée sur la méthode de Simpson, donne
1 function [I] = simpson(f,a,b,n)
2
3 // f : nom de la fonction a integrer
4 // a : borne inferieure
5 // b : borne superieure
6 // n : nombre d’intervalles (pair)
7 // I : integrale
8
9 n = 2*int(n/2); // garantit que n soit pair
10 x = linspace (a,b,n+1)’;
11 y = f(x); // evalue en x la fonction dont le nom est dans f
12 h = x(2)-x(1); // le pas
13 I = y(1)+y($) + 4*sum(y(2:2:$-1)) + 2*sum(y(3:2:$-2));
24

14 I = I*h/3;
15 endfunction
Par intégrer, il fait leur fournir le nom de la fonction qui définit l’intégrand. Par
exemple, pour calculer∫1
0 e−x2d x avec la méthode des trapèzes en prenant 400 noeuds,
on commence par définir l’intégrand
function f = integrand(x)// definit l’integrand pour le calcul d’integralef = exp(-x.*x);endfunction
ou encore définir dans la console une fonction avec la commande deff
deff(’[y]=integrand(x)’,’y=exp(-x.*x)’)
puis dans la console on exécute la commande
I = trapezes(integrand,0,1,400)
5 Recherche des racines d’une fonction
Problème : Une fonction f (x) connue en chacun de ses points possède une ou plu-
sieurs racines (ou zéros) {xi | f (xi ) = 0}. Comment fait-on pour déterminer ces racines ?
Il existe de nombreuses méthodes de recherche de racines. Toutes sont itératives : par-
tant d’une ou de plusieurs estimations de la racine, ces méthodes convergent en prin-
cipe par itérations successives. Le problème consiste à trouver un compromis entre
la vitesse (il faut limiter le nombre d’opérations de calcul) et la fiabilité (il faut que la
méthode converge sûrement vers la valeur souhaitée).
Dans la pratique, on est souvent amené à alterner différentes méthodes en fonction des
caractéristiques de la fonction. Notons aussi que le problème courant de la recherche
de zéros en plusieurs dimensions {(xi , yi , . . .) | f (xi , yi , . . .) = 0} est nettement plus com-
plexe et fait aujourd’hui encore l’objet d’intenses recherches.
5.1 Méthode de la bisection ou de la dichotomie
Supposons que l’intervalle dans lequel se situe la racine soit connu. La méthode de
la bisection offre une convergence lente mais sûre vers la racine. Cette méthode est
recommandée lorsque la fonction présente des discontinuités ou des singularités.
25

Procédure à suivre : La racine se trouve initialement dans l’intervalle de re-
cherche [xk , xk+1]. On a donc f (xk ) · f (xk+1) ≤ 0. L’algorithme devient
1. choisir comme nouvelle abscisse xk+2 = (xk + xk+1)/2, le point milieu de l’inter-
valle :
2. si f (xk ) · f (xk+2) ≤ 0, la solution se trouve dans l’intervalle [xk , xk+2], qui devient
alors le nouvel intervalle de recherche
3. au contraire, si f (xk ) · f (xk+2) ≥ 0, le nouvel intervalle de recherche devient
[xk+2, xk+1]
4. revenir au point 1. jusqu’à ce qu’il y ait convergence.
0 0.5 1 1.5 2 2.5 3
−4
−2
0
2
4
6
x
f(x)
x0
x1
x2
x3
x4x
∞
FIGURE 12 – Représentation des premières itérations avec la méthode de la bisection pour f (x) = x2 −4.
On peut montrer que cette méthode possède une convergence linéaire : si ǫk = |x −xk |est l’écart à la k-ième itération entre xk et la racine x∞, alors en moyenne ǫk+1 = c ǫk ,
où 0 < c < 1 est une constante.
Exemple : reprenons l’exemple de l’introduction, qui consiste à calculer la racine
carrée de 4. Posons f (x) = x2 −4 = 0, dont la solution est la racine recherchée. L’inter-
valle de départ est [0.5,3]. Cela donne
itération intervalle nlle valeur erreur
k xk+2 f (xk+2) |ǫk+2|0 [0.5000, 3.0000] 1.7500 -0.9375 0.2500
1 [1.7500, 3.0000] 2.3750 1.6406 0.3750
2 [1.7500, 2.3750] 2.0625 0.2539 0.0625
3 [1.7500, 2.0625] 1.9062 -0.3662 0.0938
4 [1.9062, 2.0625] 1.9844 -0.0623 0.0156
5 [1.9844, 2.0625] 2.0234 0.0943 0.0234
6 [1.9844, 2.0234] 2.0039 0.0156 0.0039
etc
26
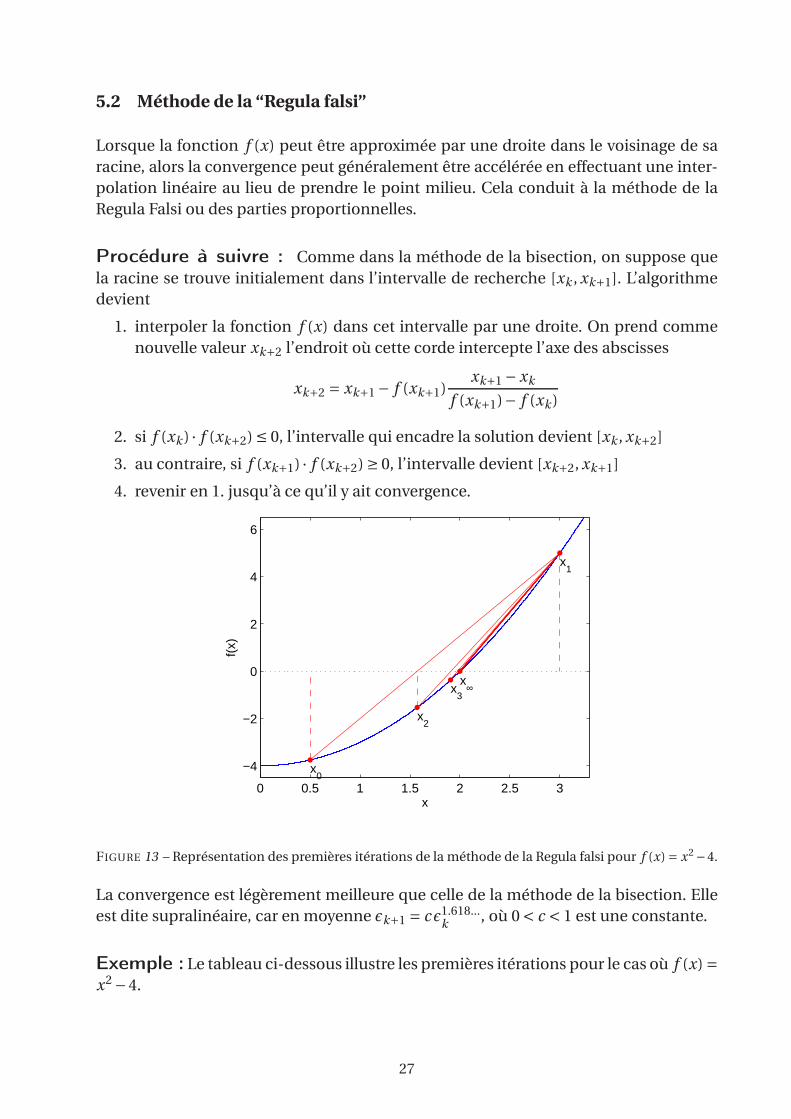
5.2 Méthode de la “Regula falsi”
Lorsque la fonction f (x) peut être approximée par une droite dans le voisinage de sa
racine, alors la convergence peut généralement être accélérée en effectuant une inter-
polation linéaire au lieu de prendre le point milieu. Cela conduit à la méthode de la
Regula Falsi ou des parties proportionnelles.
Procédure à suivre : Comme dans la méthode de la bisection, on suppose que
la racine se trouve initialement dans l’intervalle de recherche [xk , xk+1]. L’algorithme
devient
1. interpoler la fonction f (x) dans cet intervalle par une droite. On prend comme
nouvelle valeur xk+2 l’endroit où cette corde intercepte l’axe des abscisses
xk+2 = xk+1 − f (xk+1)xk+1 −xk
f (xk+1)− f (xk )
2. si f (xk ) · f (xk+2) ≤ 0, l’intervalle qui encadre la solution devient [xk , xk+2]
3. au contraire, si f (xk+1) · f (xk+2) ≥ 0, l’intervalle devient [xk+2, xk+1]
4. revenir en 1. jusqu’à ce qu’il y ait convergence.
0 0.5 1 1.5 2 2.5 3
−4
−2
0
2
4
6
x
f(x)
x0
x1
x2
x3
x∞
FIGURE 13 – Représentation des premières itérations de la méthode de la Regula falsi pour f (x) = x2 −4.
La convergence est légèrement meilleure que celle de la méthode de la bisection. Elle
est dite supralinéaire, car en moyenne ǫk+1 = c ǫ1.618...k
, où 0 < c < 1 est une constante.
Exemple : Le tableau ci-dessous illustre les premières itérations pour le cas où f (x) =x2 −4.
27

itération intervalle nlle valeur erreur
k [a,b] xk+2 |ǫk+2|0 [0.5000, 3.0000] 1.5714 0.42857
1 [1.5714, 3.0000] 1.9062 0.09375
2 [1.9062, 3.0000] 1.9809 0.01911
3 [1.9809, 3.0000] 1.9962 0.00384
4 [1.9962, 3.0000] 1.9992 0.00077
etc
Voici un exemple de code Scilab qui estime la racine d’une fonction (dont l’expres-
sion analytique est connue) par la méthode de la Regula falsi.
1 function [x2] = regulafalsi(f,x0,x1,epsilon)
2
3 // f : nom de la fonction a etudier
4 // x0 : borne inferieure de l’intervalle
5 // x1 : borne superieure de l’intervalle
6 // epsilon : tolerance sur la solution
7 // x2 : racine
8
9 maxiter = 50; // nombre maximum d’iterations
10 k = 1;
11 f0 = f(x0);
12 f1 = f(x1);
13
14 while k<maxiter
15 x2ancien = x0;
16 x2 = x0 - f0*(x1-x0)/(f1-f0+%eps);
17 f2 = f(x2);
18 disp([x2 f2])
19 if f1*f2 <0
20 x0 = x2;
21 f0 = f2;
22 else
23 x1 = x2;
24 f1 = f2;
25 end
26 k = k+1;
27 if abs(x2-x2ancien )<epsilon , break , end
28 end
29 if k==maxiter , disp(’**␣pas␣de␣convergence␣**’), end
30 endfunction
Il faut ensuite définir séparément la fonction à étudier. Par exemple, pour f (x) = e−x +x/5−1, on prend
function [f] = racine(x)// definit la fonction dont on veut la racinef = exp(-x) + x/5 - 1;endfunction
28

et pour lancer la recherche de racines dans l’intervalle [0,10] il faut écrire dans la
console
z = regulafalsi(racine,0,10,1e-6);
5.3 Méthode de la sécante
Cette méthode est très proche de la précédente. Toutefois, au lieu de prendre à chaque
itération l’intervalle qui encadre la racine, on définit le nouvel intervalle à partir des
deux dernières valeurs.
Procédure à suivre : On suppose que la racine se trouve initialement à proximité
(mais pas forcément dans) de l’intervalle de recherche [xk , xk+1]. L’algorithme devient
1. interpoler la fonction f (x) dans cet intervalle par une droite. On prend comme
nouvelle valeur xk+2 l’endroit où cette corde intercepte l’axe des abscisses
xk+2 = xk+1 − f (xk+1)xk+1 −xk
f (xk+1)− f (xk )
2. le nouvel intervalle de recherche devient [xk+1, xk+2]
3. revenir en 1. jusqu’à ce qu’il y ait convergence.
0 0.5 1 1.5 2 2.5 3
−4
−2
0
2
4
6
x
f(x)
x0
x1
x2
x3
x∞
FIGURE 14 – Représentation des premières itérations de la méthode de la sécante pour f (x) = x2 −4.
La convergence est légèrement plus rapide qu’avec la méthode de la Regula falsi. En
revanche, la méthode de la sécante est moins robuste car il n’est plus garanti que la
solution se trouve à l’intérieur de l’intervalle.
Exemple : Le tableau ci-dessous illustre les premières itérations pour le cas où f (x) =x2 −4.
29

itération intervalle nlle valeur erreur
k [xk , xk+1] xk+2 |ǫk+2|0 [0.5000, 3.0000] 1.5714 0.42857
1 [3.0000, 1.5714] 1.9062 0.09375
2 [1.5714, 1.9062] 2.0116 0.01155
3 [1.9062, 2.0116] 1.9997 0.00028
etc
5.4 Méthode de Newton
La méthode de Newton s’applique aux fonctions donc on connaît l’expression analy-
tique de la dérivée première f ′(x). Contrairement aux deux méthodes précédentes, il
suffit de connaître une seule estimation initiale x de la racine x∞. Supposons que cette
estimation soit suffisamment proche de la racine pour justifier un développement li-
mité
f (x∞) = f (x +δ) = f (x)+δ f ′(x)+1
2δ2 f ′′(x)+O (δ3) = 0
Siδ est suffisamment petit, on peut négliger les termes d’ordre supérieur à 2, pour avoir
f (x)+δ f ′(x)+O (δ2) = 0
soit
δ=−f (x)
f ′(x)
ce qui donne enfin la suite
xk+1 = xk −f (xk )
f ′(xk )
Procédure à suivre : Connaissant une estimation initiale xk de la racine, il faut
donc
1. calculer δ=− f (xk )
f ′(xk )
2. la nouvelle estimation de la racine devient xk+1 = xk +δ
3. poursuivre en 1. jusqu’à ce qu’il y ait convergence
La convergence de cette méthode est quadratique, car en moyenne ǫk+1 = c ǫ2k
où
0 < c < 1 est une constante. Mais cette propriété n’est assurée que dans un voisinage
immédiat de la racine. Ailleurs, la convergence peut devenir nettement moins favo-
rable.
Exemple : reprenons toujours le même exemple du calcul de la racine, avec f (x) =x2 −4. Alors
xk+1 = xk −f (xk )
f ′(xk )= xk −
x2k−4
2xk=
1
2
(
xk +2
xk
)
Partant de l’estimation initiale x0 = 3, on obtient successivement
30
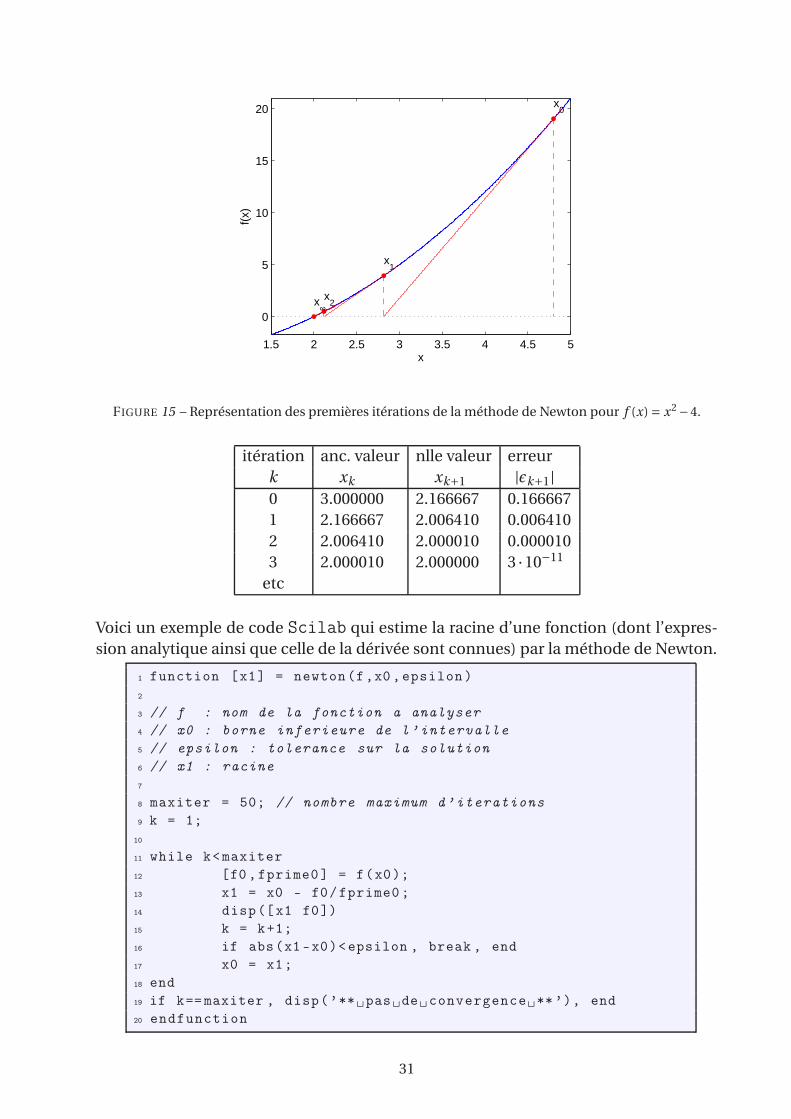
1.5 2 2.5 3 3.5 4 4.5 5
0
5
10
15
20
x
f(x)
x0
x1
x2x
∞
FIGURE 15 – Représentation des premières itérations de la méthode de Newton pour f (x) = x2 −4.
itération anc. valeur nlle valeur erreur
k xk xk+1 |ǫk+1|0 3.000000 2.166667 0.166667
1 2.166667 2.006410 0.006410
2 2.006410 2.000010 0.000010
3 2.000010 2.000000 3 ·10−11
etc
Voici un exemple de code Scilab qui estime la racine d’une fonction (dont l’expres-
sion analytique ainsi que celle de la dérivée sont connues) par la méthode de Newton.
1 function [x1] = newton(f,x0,epsilon)
2
3 // f : nom de la fonction a analyser
4 // x0 : borne inferieure de l’intervalle
5 // epsilon : tolerance sur la solution
6 // x1 : racine
7
8 maxiter = 50; // nombre maximum d’iterations
9 k = 1;
10
11 while k<maxiter
12 [f0,fprime0] = f(x0);
13 x1 = x0 - f0/fprime0;
14 disp([x1 f0])
15 k = k+1;
16 if abs(x1-x0)<epsilon , break , end
17 x0 = x1;
18 end
19 if k==maxiter , disp(’**␣pas␣de␣convergence␣**’), end
20 endfunction
31

Il est ipportant que la fonction à analyser restitue à la fois la valeur f (x) et la dérivée
f ′(x). Par exemple
function [f,fprime] = racine(x)// definit la fonction dont on cherche la racinef = exp(-x) + x/5 - 1;fprime = -exp(-x) + 1/5;endfunction
5.5 La recherche de racines dans la pratique
La recherche de racines sans inspection préalable de la fonction f est une opération
risquée. Comme le montre la figure 16, les pièges sont nombreux.
0 0.2 0.4 0.6 0.8 1−1
−0.5
0
0.5
1
x
f(x)
0 0.2 0.4 0.6 0.8 1−1
−0.5
0
0.5
1
x
0 0.2 0.4 0.6 0.8 1−1
−0.5
0
0.5
1
x
f(x)
0 0.2 0.4 0.6 0.8 1−1
−0.5
0
0.5
1
x
FIGURE 16 – Quelques fonctions pour lesquelles la recherche des racines risque de poser des problèmes
si l’intervalle de recherche initial et la méthode ne sont pas soigneusement choisis.
32

Avant de rechercher les racines d’une fonction, il est indispensable de vi-
sualiser cette fonction.
Dans le doute, mieux vaut opter pour une méthode dont la convergence
est lente mais sûre. Avec la méthode de la bisection, on est assuré de voir
l’intervalle se réduire de moitié à chaque itération, ce qui n’est pas le cas
avec les autres méthodes.
La convergence sera d’autant meilleure que la fonction pourra être ap-
proximée par une droite (méthode de la sécante ou de la Regula falsi) dans
le voisinage de la racine. La méthode de Newton permet de converger plus
rapidement lorsque l’expression de la dérivée première est connue.
La meilleure stratégie consiste généralement à démarrer par une mé-
thode lente mais sûre (bisection) pour ensuite accélérer la convergence
dans le voisinage de la racine avec une méthode de Newton.
6 Intégration d’équations différentielles
Problème : Une variable y(t) est décrite par une équation différentielle ordinaire
du premier ordre d y(t)/d t = f(
y(t), t)
. On connaît la condition initiale y(t = t0) = y0.
Comment déterminer y(t) à des temps autres que t0 ?
6.1 Exemple
Un condensateur se décharge dans une résistance non-linéaire, dont la valeur dépend
du courant. Ce genre de situation surgit par exemple avec les tubes fluorescents. Le
circuit est décrit par l’équationd I
d t=−
I
C R(I )
avec la condition initiale I (t0) = I0. Cette équation est facile à intégrer lorsque R =cte.
En revanche, il devient très difficile de trouver une solution analytique dans le cas où R
varie. Il faut alors procéder à une intégration numérique. Tous les logiciels de concep-
tion de circuits par ordinateur comprennent des modules plus ou moins sophistiqués
pour résoudre de tels problèmes.
Représentons la solution recherchée I (t) en fonction de t . La valeur initiale I (t0) ainsi
que la dérivée première en ce point I ′(t0) sont connues. Faisons un développement
33
limité de la solution (en supposant que celle-ci soit suffisamment continue) pour dé-
terminer la valeur que prend le courant à un instant ultérieur t0 +δt ,
I (t0 +δt) = I (t0)+δtd I (t0)
d t+
1
2δt2 d2I (t0)
d t2+ . . .
= I (t0)+δtd I (t0)
d t+O (δt2)
= I (t0)+δt f(
I (t0), t0
)
+O (δt2)
Avec un pas de temps δt suffisamment petit, on peut donc approximer la valeur que
prend le courant au temps t0 +δt . Or l’opération peut maintenant être répétée en t =t0 + δt puisque la valeur de la dérivée première en ce point peut être calculée. Cela
nous permet de passer au point t = t0+2δt , et ainsi de suite. La méthode d’intégration
consiste donc à estimer les valeurs successives de I (t) en procédant par petits pas de
temps.
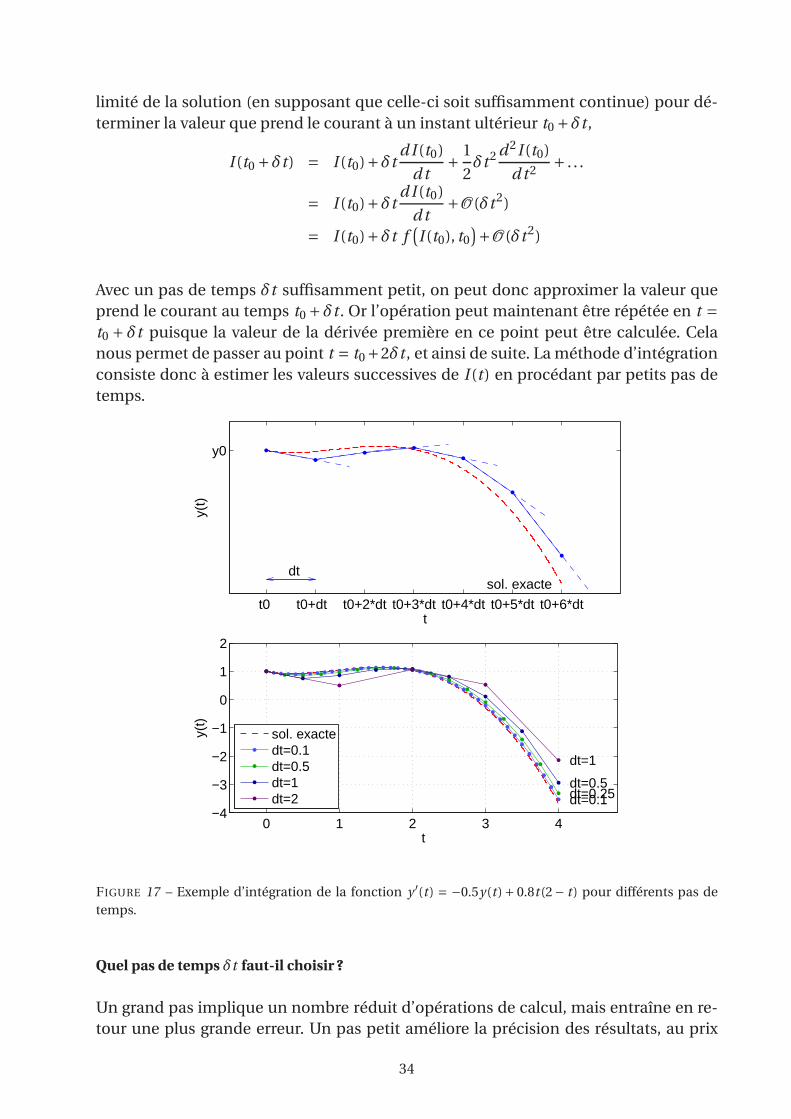
t0 t0+dt t0+2*dt t0+3*dt t0+4*dt t0+5*dt t0+6*dt
y0
t
y(t)
sol. exactedt
0 1 2 3 4−4
−3
−2
−1
0
1
2
t
y(t)
dt=0.1dt=0.25dt=0.5
dt=1
sol. exactedt=0.1dt=0.5dt=1dt=2
FIGURE 17 – Exemple d’intégration de la fonction y ′(t ) = −0.5y(t )+ 0.8t (2− t ) pour différents pas de
temps.
Quel pas de temps δt faut-il choisir ?
Un grand pas implique un nombre réduit d’opérations de calcul, mais entraîne en re-
tour une plus grande erreur. Un pas petit améliore la précision des résultats, au prix
34

d’un temps de calcul plus élevé. Un pas trop petit risque d’amplifier les erreurs de tron-
cature. Il existe donc un pas idéal, qui peut éventuellement varier au cours du temps.
Nous verrons qu’il existe divers algorithmes pour traiter ce genre de problème.
6.2 Les méthodes d’Euler
Les méthodes d’Euler sont les plus simples pour intégrer une équation différentielle.
Cependant, ces méthodes sont rarement utilisées en raison de manque de précision et
de leur instabilité. Nous avons au départ{
y ′(t) = f(
y(t), t)
y(t0) = y0
Discrétisons d’abord le temps en prenant des pas de même durée h : tk = t0 +kh. Po-
sons pour simplifier y(tk ) = yk . Il s’agit désormais de trouver la suite {yk } définie par
y ′(tk ) = f (yk , tk )
y(t0) = y0
tk = t0 +kh
Exprimons la dérivée de y(t) par une différence finie (cf. chapitre 3). Cela conduit à
trois expressions différentes suivant qu’on prend la différence avant, arrière ou centrée.
Chacune possède des propriétés différentes.
y ′(tk ) =yk+1 − yk
h+O (h) différence avant
y ′(tk ) =yk − yk−1
h+O (h) différence arrière
y ′(tk ) =yk+1 − yk−1
2h+O (h2) différence centrée
• La méthode d’Euler explicite s’obtient en prenant la différence avant. Cela donne
une équation simple à résoudre en yk+1
yk+1 = yk +h f (yk , tk )+O (h2)
Cette méthode, quoique simple, est peu utilisée. D’abord, elle est relativement
peu précise. Mais surtout, elle est instable puisque l’erreur a généralement ten-
dance à croître. Cette instabilité, illustrée dans la figure 18, peut survenir même
si le pas h est très petit.
• La méthode d’Euler implicite s’obtient en prenant la différence arrière. Cela
donne une équation plus difficile à résoudre en yk
yk −h f (yk , tk ) = yk−1 +O (h2)
Cette équation n’admet pas toujours de solution analytique, ce qui est un sérieux
handicap. En revanche, la méthode est stable puisque l’erreur n’a plus tendance
à croître indéfiniment.
35
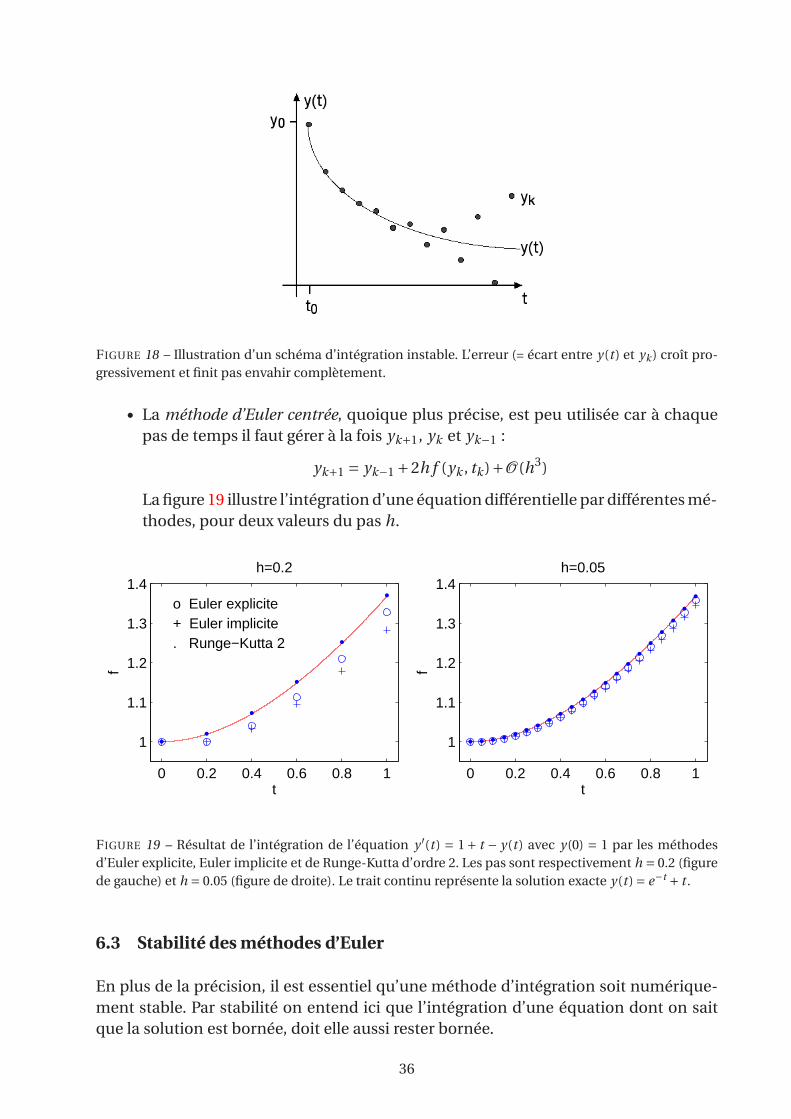
FIGURE 18 – Illustration d’un schéma d’intégration instable. L’erreur (= écart entre y(t ) et yk ) croît pro-
gressivement et finit pas envahir complètement.
• La méthode d’Euler centrée, quoique plus précise, est peu utilisée car à chaque
pas de temps il faut gérer à la fois yk+1, yk et yk−1 :
yk+1 = yk−1 +2h f (yk , tk )+O (h3)
La figure 19 illustre l’intégration d’une équation différentielle par différentes mé-
thodes, pour deux valeurs du pas h.
0 0.2 0.4 0.6 0.8 1
1
1.1
1.2
1.3
1.4
t
f
h=0.2
o Euler explicite+ Euler implicite. Runge−Kutta 2
0 0.2 0.4 0.6 0.8 1
1
1.1
1.2
1.3
1.4
t
f
h=0.05
FIGURE 19 – Résultat de l’intégration de l’équation y ′(t ) = 1+ t − y(t ) avec y(0) = 1 par les méthodes
d’Euler explicite, Euler implicite et de Runge-Kutta d’ordre 2. Les pas sont respectivement h = 0.2 (figure
de gauche) et h = 0.05 (figure de droite). Le trait continu représente la solution exacte y(t )= e−t + t .
6.3 Stabilité des méthodes d’Euler
En plus de la précision, il est essentiel qu’une méthode d’intégration soit numérique-
ment stable. Par stabilité on entend ici que l’intégration d’une équation dont on sait
que la solution est bornée, doit elle aussi rester bornée.
36

L’étude de la stabilité d’une méthode est une tâche complexe. L’exemple suivant per-
met cependant d’illustrer l’origine des instabilités. Intégrons l’équation y ′ =−y avec la
condition initiale y0 = 1.
1. Avec la méthode d’Euler explicite, on obtient
yk+1 = yk −hyk ⇒ yk = (1−h)k y0
Cette suite converge à condition que |1−h| < 1. Cela implique soit h > 0 (tou-
jours vrai) soit h < 2. Il n’est donc pas possible de choisir des pas h arbitrairement
grands, sous risque de voir la suite diverger.
2. Avec la méthode d’Euler implicite, on obtient
yk+1 = yk −hyk+1 ⇒ yk = (1+h)−k y0
La stabilité est ici vérifiée pour tout h > 0. Plus généralement, on peut montrer
que la méthode d’Euler implicite est toujours stable.
3. Avec la méthode d’Euler centrée, on obtient
yk+1 = yk−1 −2hyk
et la condition de stabilité devient | −h ±p
1+h2| < 1. Cette méthode peut elle
aussi devenir instable.
6.4 Méthodes de Runge-Kutta
Les méthodes de Runge-Kutta sont couramment utilisées car elles allient précision,
stabilité et simplicité. Toutes nécessitent plusieurs itérations pour effectuer un pas.
La méthode de Runge-Kutta d’ordre 2 est la plus simple ; elle combine deux itérations
successives de la méthode d’Euler explicite. Dans un premier temps la dérivée en
(tk , yk ) est évaluée pour faire une première estimation du point suivant (noté A dans la
figure 20). L’estimation provisoire de yk+1 en ce point est ensuite utilisée pour affiner
la calcul de la dérivée. Une nouvelle approximation de celle-ci est obtenue en prenant
sa valeur à mi-parcours (prise au point B). C’est cette valeur de la dérivée qui sera en-
suite utilisée pour estimer le prochain pas yk+1 (point C). La procédure d’intégration
se résume àα = h f (yk , tk )
β = h f
(
yk +α
2, tk +
h
2
)
yk+1 = yk +β+O (h3)
Même si cette méthode demande deux fois plus opérations de calcul que la méthode
d’Euler explicite pour effectuer un seul pas, le résultat est plus précis et plus stable.
37

FIGURE 20 – Principe de fonctionnement de la méthode de Runge-Kutta du second ordre pour effectuer
un seul pas. Le lettres réfèrent au texte.
La méthode de Runge-Kutta d’ordre 4 combine quatre itérations successives. Sa préci-
sion est généralement encore meilleure. La procédure d’intégration devient
α = h f (yk , tk )
β = h f
(
yk +α
2, tk +
h
2
)
γ = h f
(
yk +β
2, tk +
h
2
)
δ = h f(
yk +γ, tk +h)
yk+1 = yk +1
6(α+2β+2γ+δ)+O (h5)
38

Le code suivant décrit un exemple d’intégration par la méthode de Runge-Kutta
d’ordre 2. La fonction à intégrer est définie par integrand.
1 function [y,t] = rungekutta2(t0,tn,h,y0)
2
3 // t0 : temps initial
4 // tn : temps final
5 // h : pas de temps
6 // y0 : conditions initiales (vecteur )
7 // y : solution (une colonne par variable )
8 // t : vecteur temps correspondant
9
10 n = ceil((tn-t0)/h)+1; // nombre de pas
11 ordre = length(y0); // ordre = nbre de cond initiales
12 y = zeros(n,ordre);
13 t = zeros(n,1);
14 y(1,:) = y0(:)’;
15 t(1) = t0;
16
17 for i=1:n-1
18 t(i+1) = t(i) + h;
19 delta1 = h*integrand (t(i), y(i,:));
20 delta2 = h*integrand (t(i)+h/2, y(i,:)+delta1 /2);
21 y(i+1,:) = y(i,:) + delta2;
22 end
23 endfunction
24
25 function yprime = integrand (t,y)
26 // definit le systeme a integrer
27 k = 4;
28 yprime (1) = y(2);
29 yprime (2) = -k*y(1);
30 endfunction
6.5 L’intégration dans la pratique
Le choix du pas est un point essentiel. S’il est trop grand, la méthode choisie, aussi
bonne soit-elle, donnera des résultats erronés (cf. figure 21). Si le pas est trop petit, on
perdra du temps de calcul et on risquera d’être affecté par des erreurs d’arrondi. D’où
les règles générales
Le pas h doit toujours être choisi nettement inférieur au temps caracté-
ristique de la fonction y(t) à intégrer. Par exemple, pour une fonction pé-
riodique de période T , il faudra prendre h ≪T .
Parmi les méthodes d’intégration qui existent, celles de Runge-Kutta
offrent souvent un bon compromis entre précision et temps de calcul.
39

0 2 4 6 8 10−2
−1
0
1
2
t
f
. Euler h=1 + Euler h=0.5 o Runge−Kutta 2 h=1
f(x)
FIGURE 21 – Intégration d’une équation différentielle dont la solution est y(t ) = sin(2πt /5). Cette équa-
tion a délibérément été intégrée avec des pas trop grands pour en montrer les conséquences. Les mé-
thodes utilisées sont : Euler explicite avec un pas de h = 1 (points), Euler explicite avec un pas de h = 0.5
(croix), et Runge-Kutta d’ordre 2 avec un pas de h = 1.
Le problème de l’intégration des équations différentielles est fait encore l’objet de re-
cherches intensives. Une solution intéressante consiste à adapter le pas h à l’allure de
la fonction y(t) pour gagner du temps. Lorsque la fonction y(t) est régulière avec ses
dérivées d’ordre > 2 sont petites, alors on peut se contenter de choisir un pas élevé, qui
sera progressivement réduit dans le voisinage de brusques variations de y(t).
Les méthodes de Runge-Kutta peuvent aussi aisément se généraliser à la résolution
d’équations différentielles d’ordre supérieur à 1.
6.6 Intégrer lorsque l’ordre > 1
Les équations différentielles d’ordre supérieur à 1 peuvent aisément être transformées
en des systèmes d’équations d’ordre 1, moyennant la définition de nouvelles variables.
Ainsi, le modèle de l’oscillateur harmonique amorti
d2
d t2f (t)+λ
d
d tf (t)+ω2 f (t) = 0
peut d’écrire
d
d tf (t) = u(t)
d
d tu(t) = −λu(t)−ω2 f (t)
où u(t) est la nouvelle variable, qui s’apparente à une vitesse. Cette paire d’équations
couplées d’ordre 1 peut maintenant être intégrée à l’aide des méthodes discutées pré-
cédemment.
40

Plus généralement, toute équation différentielle différentielle d’ordre N
d N f
d xN+aN (x)
d N−1 f
d xN−1+aN−1(x)
d N−2 f
d xN−2+·· ·+a2(x)
d f
d x+a1(x) f (x)+a0(x) = 0
peut être transformé en un système de N équations différentielles d’ordre 1, moyen-
nant la création de N −1 nouvelles variables
d
d xf (x) = u1(x)
d2
d x2f (x) = u2(x)
d3
d x3f (x) = u3(x)
...
d N−1
d xN−1f (x) = uN−1(x)
d N
d xNf (x) = −aN (x)uN−1(x)−aN−1(x)uN−2(x)−·· ·−a2(x)u1(x)−a1(x) f (x)−a0(x)
Les conditions initiales
f (x0) = f0,d f
d x
∣
∣
∣
∣
x=x0
= f ′0,
d2 f
d x2
∣
∣
∣
∣
x=x0
= f ′′0 , etc.
deviennent alors
f (x0) = f0, u1(x0) = u1,0, u2(x0) = u2,0, etc.
6.7 Intégrer en présence de conditions de bord
L’intégration est plus difficile lorsque le problème est spécifié par des conditions de
bord (ou aux limites) et non par des conditions initiales. Par exemple, le problèmed2
d x2 f (x)+ dd x
f (x)+ g (x) = 0 possède des conditions initiales si f (0) = a, dd x
f (x = 0) = b,
car il suffit d’intégrer depuis x = 0. On parlera au contraire de conditions de bord si
f (0) = a, f (x = 1) = b.
Il existe plusieurs stratégies pour intégrer de tels problèmes. L’une consiste à recourir
aux éléments finis (au programme de master). Une autre stratégie consiste à remplacer
les conditions initiales manquantes par des valeurs estimées, puis à intégrer l’équation
jusqu’à ce que la solution atteigne le bord. En fonction de l’écart observé entre la va-
leur finale de la solution et la condition de bord imposée, on corrigera la solution en
adaptant ses conditions initiales. Ceci s’apparente à la correction qu’un tireur applique
à l’angle de tir lorsqu’il souhaite atteindre sa cible ; c’est la raison pour laquelle la mé-
thode porte le nom de méthode du tir.
41

Exemple : Une équation différentielle doit être intégrée de xi à x f . Le conditions de
bord imposées sont{
f (xi ) = fi
f (x f ) = f f
Soit, a(1) la valeur initiale de la condition de bord manquante ; par exemple f ′(xi ) = a(1)
s’il s’agit d’une équation d’ordre 2. L’équation est intégrée avec ces deux conditions
initiales jusqu’à l’abscisse x f pour donner en ce point f (x f ) = f (1)f
. Un second essai
avec une autre condition initiale a(2) donne f (x f ) = f (2)f
.
Le problème se réduit alors à une recherche de racines. Nous pouvons en effet définir
une fonction F (a) telle que
F (a(1)) = f (1)f
− f f
F (a(2)) = f (2)f
− f f
Le problème se réduit alors à la recherche de la valeur a(∞) telle que
F (a(∞)) = f (∞)f
− f f = 0
où la fonction F n’est connue que pour les quelques valeurs de a(i ). Il suffit dès lors
d’itérer à l’aide d’une méthode de recherche de racines (sécante, ou autre) jusqu’à
converger vers la racine. Toutefois, rien ne garantit que la racine existe ou soit unique.
42