
4METHODES PARAMETRIQUES : ESTIMATION …lpc2e.cnrs-orleans.fr/~theureau/Nezha_ElBakri_3.pdf ·...
28
4-METHODES PARAMETRIQUES : ESTIMATION D’UN MELANGE DE LOIS Méthode La loi de distribution d’ un ensemble d’ observations est le plus souvent définie comme une combinaison convexe de plusieurs lois de probabilités. Afin d’ estimer les paramètres de ce mélange de lois, la méthode de Monte Carlo par chaîne de Markov (MCMC) est de plus en plus utilisée. La méthode MCMC est un algorithme qui génère une chaîne de Markov (Yn, n=>0), stationnaire sous certaines conditions. Rappels : ( Yn, n=>0) est une chaîne de Markov si la loi de probabilité de l‘état Yn+1, ne dépend que de l’état de Yn : P (Yn+1 / Yn, Yn-1, .., Xo) = P (Yn+1 / Yn). Un état Yn représente la valeur des paramètres à estimer à la nième itération de l’algorithme. Le passage de l’état Yn à l’ état Yn+1 se fait grâce à une estimation Bayésienne. Cette méthode nécessite de connaître au préalable le nombre k de lois qui constituent le mélange. Nous allons appliquer cet algorithme à l’é chantillon 2. Les observations seront constituées des projections sur l’a xe 1 de l’ analyse en composantes principales. On suppose que ces observations sont une réalisation d’un e variable aléatoire X de loi Px. On suppose aussi que la distribution des points selon l’ axe 1 est un mélange de 2 lois normales (k=2). X ~ Px = p*Normale (mu_1, var_1) + (1-p)*Normale (mu_2, var_2). Soit f la densité de la loi normale du groupe 1 (gr1). Soit g la densité de la loi normale du groupe 1 (gr2). On pose théta = [p, (1-p), mu_1, mu_2, sigma_1, sigma_2], les paramètres à estimer. (théta est la chaîne de Markov) Le but est d’ estimer théta au vu des observations x1, ..., xN. Algorithme Etape 0. : Initialisation des paramètres : thêta (0) = thêta_0 (loi initiale de la chaîne de Markov) La chaîne de Markov est stationnaire si la loi initiale est la loi recherchée (i.e les valeurs de départ sont les vraies valeurs) [p, (1-p)] = [0.5, 0.5] Les probabilités a priori de chaque classe sont uniformes, égales à 1/ k, où k est le nombre de classes. [mu_1, mu_2] = [1, 2] [var_1, var_2] = [1, 1] 1
Transcript of 4METHODES PARAMETRIQUES : ESTIMATION …lpc2e.cnrs-orleans.fr/~theureau/Nezha_ElBakri_3.pdf ·...

4METHODES PARAMETRIQUES : ESTIMATION D’UN MELANGE DE LOIS
Méthode
La loi de distribution d’ un ensemble d’ observations est le plus souvent définie comme unecombinaison convexe de plusieurs lois de probabilités. Afin d’ estimer les paramètres de ce mélangede lois, la méthode de Monte Carlo par chaîne de Markov (MCMC) est de plus en plus utilisée. Laméthode MCMC est un algorithme qui génère une chaîne de Markov (Yn, n=>0), stationnairesous certaines conditions.
Rappels : ( Yn, n=>0) est une chaîne de Markov si la loi de probabilité de l‘état Yn+1, ne dépendque de l’état de Yn : P (Yn+1 / Yn, Yn1, .., Xo) = P (Yn+1 / Yn).
Un état Yn représente la valeur des paramètres à estimer à la nième itération de l’algorithme.Le passage de l’état Yn à l’état Yn+1 se fait grâce à une estimation Bayésienne.
Cette méthode nécessite de connaître au préalable le nombre k de lois qui constituent le mélange. Nous allons appliquer cet algorithme à l’é chantillon 2. Les observations seront constituées desprojections sur l’a xe 1 de l’ analyse en composantes principales. On suppose que ces observations sontune réalisation d’un e variable aléatoire X de loi Px.On suppose aussi que la distribution des points selon l’ axe 1 est un mélange de 2 lois normales (k=2).
X ~ Px = p*Normale (mu_1, var_1) + (1p)*Normale (mu_2, var_2).
Soit f la densité de la loi normale du groupe 1 (gr1).Soit g la densité de la loi normale du groupe 1 (gr2).On pose théta = [p, (1p), mu_1, mu_2, sigma_1, sigma_2], les paramètres à estimer. (théta est lachaîne de Markov)
Le but est d’ estimer théta au vu des observations x1, ..., xN.
Algorithme
Etape 0. : Initialisation des paramètres : thêta (0) = thêta_0 (loi initiale de la chaîne de Markov) La chaîne de Markov est stationnaire si la loi initiale est la loi recherchée (i.e lesvaleurs de départ sont les vraies valeurs)
[p, (1p)] = [0.5, 0.5] Les probabilités a priori de chaque classe sont uniformes, égales à 1/ k, où k est le nombre declasses.
[mu_1, mu_2] = [1, 2]
[var_1, var_2] = [1, 1]
1

Etape 1. : Mise à jour des paramètres. Il existe plusieurs méthodes : 1) estimation par maximum de vraisemblance. 2) estimation bayesienne.
Nous utiliserons ici une estimation bayesienne.La première partie de l’algorithme consiste à calculer les probabilités a posteriori de chaqueclasse, en tous les points, c'estàdire les probabilités d’être dans la classe j sachant l’observationxi : P (gr_j / xi)
Pour estimer P (gr_j / xi), on utilise la formule de Bayes :
P (gr_j)*P (xi / gr_j) P ( gr_j / xi) = ∑ P (gr_j)*P (xi / gr_j) j=1,2
Calculs intermédiaires :
Probabilité a priori de la classe j : P (gr_j) avec j dans {1, 2}.
Densité de probabilité pour la classe j, au point i :P (xi / gr_j) = f( xi )* dx. En prenant dx = 1, on a : P (xi / gr_j) = f (xi)
Les probabilités P (gr_j / xi) forment une matrice h :
h (i, j) =
i = 1..nj= 1, 2h (i, j) est la formule da Bayes : c’est la probabilité d’appartenir au groupe j lorsque l’on est aupoint xi.On peut donc réécrire la matrice h :
P (gr_j)*P (xi / gr_j) ∑ P (gr_j)*P (xi / gr_j) j=1,2
2

h =
Cette matrice h va nous permettre d’estimer tous les paramètres de la loi : [p, (1p), mu_1,mu_2, var_1, var_2]
Estimation des probabilités a priori de chaque groupe :
Afin d’estimer la probabilité P (gr_j), on utilise l’approximation de MonteCarlo :
P (gr_j) = nombre de points dans le groupe / nombre de points au total (N).
Le nombre de points dans le groupe j est approximé par :
P (gr_j / x1) + P (gr_j / x2) + … + P (g r_j / xN1) + P (gr_j / xN).
En effet, si P (gr_j / x1) est proche de 1, cela signifie que la probabilité d’être dans la groupe jsachant qu’on est au point x1 est grande : le point x1 a de grandes chances d’être dans le groupej. Cette probabilité exprime « la présence » du point dans le groupe j. On obtient donc unebonne approximation du nombre de points dans le groupe j.
Estimation des espérances dans chaque groupe :
Rappel : Un estimateur de l’espérance d’une variable aléatoire X, est la moyenne empirique (1/n ∑ xi) i=1..N.Avec 1/n, la probabilité uniforme sur chaque point.
On a donc la formule suivante pour mu_j :
P (gr_j / x1) P (gr_j / x2) P (gr_j / xN) mu_j = x1 * + x2* + … + xN * ∑ P (gr_j / xi) ∑ P (gr_j / xi) ∑ P (gr_j / xi) i=1…N i=1...N i=1...N
Les coefficients devant les xi, représentent le poids de chaque point dans le groupe j (Probabilité que le point soit dans le groupe j / somme des probabilités de tous les points dans legroupe j). Le coefficient remplace la valeur 1/n, dans le rappel cidessus.On note A1, A2, .., An, ces coefficients.
P (gr_1 / x1) P(gr_2 / x1) ... P (gr_k / x1) P (gr_1 / x2) P(gr_2 / x2) ... P (gr_k / x2) P (gr_1 / x3) P(gr_2 / x3) ... P (gr_k / x3)
… P (gr_1 / xN) P(gr_2 / xN) ... P (gr_k / xN)
3

Estimation des variances dans chaque groupe :
Rappel : un estimateur de la variance d’une variable aléatoire X est : (1/n)* ∑ (xi – xe) ^2 i=1..n xe est la moyenne empirique.
La variance dans le groupe j est :
var_j = ∑ Ai (xi – mu_j) ^2 i=1..NOn obtient ainsi des nouvelles valeurs pour pj, mu_j, var_j, à chaque itération de l’algorithme,qui ne dépendent que des valeurs précédentes. Cet algorithme converge vers les valeurs réelles. Application de l'algorithme MCMC à l'échantillon 2
Les données, sont sous forme d'un vecteur ligne : a. Ils représentent les coordonnées des galaxiessur l’axe 1 de l’ACPN. L’algorithme utilisé prend en paramètres un fichier contenant lesdonnées et le nombre d’itérations.
Lignes de commandes sur Scilab:
> A = read (‘data2.txt’, 1, 1);> A = A'; // les données A doivent être sous forme d'un vecteur ligne
// On exécute la fonction algo_em qui contient l’algorithme mcmc.
>em (A, 1500)
Afin d’analyser la convergence de l’algorithme, on construit les graphes représentant la valeurdu paramètre à estimer en fonction du nombre d’itération.
4
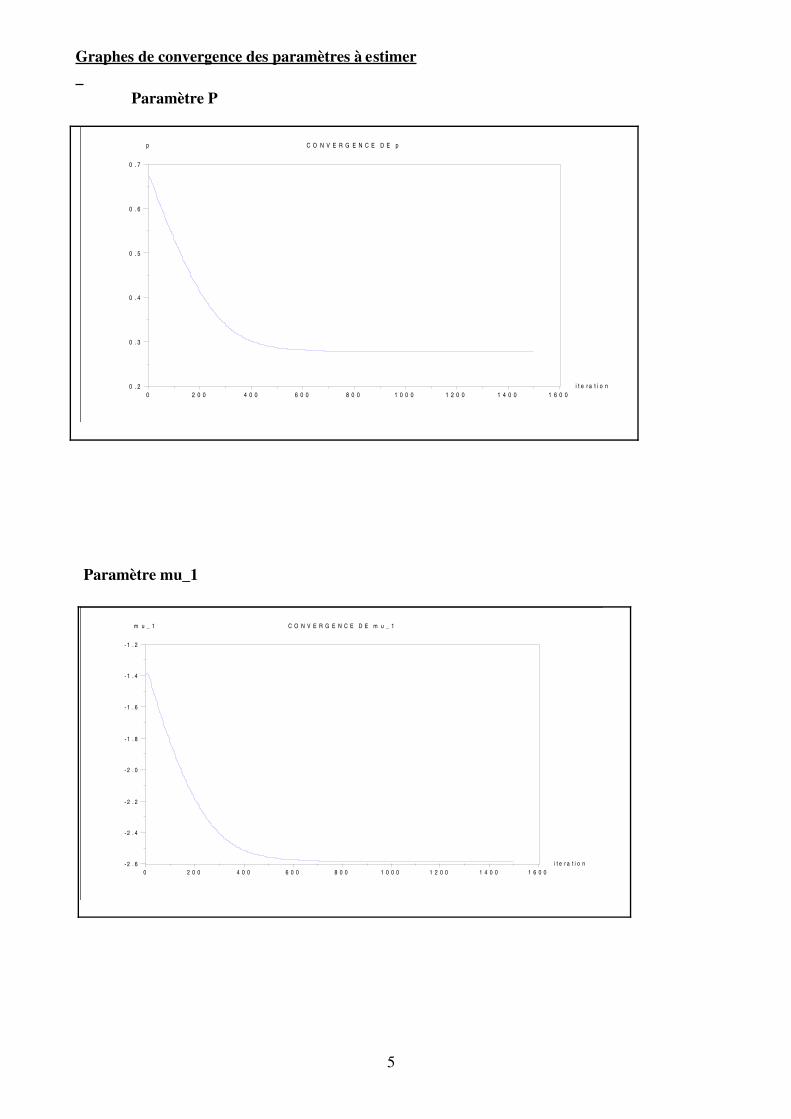
Graphes de convergence des paramètres à estimer Paramètre P
0 2 0 0 4 0 0 6 0 0 8 0 0 1 0 0 0 1 2 0 0 1 4 0 0 1 6 0 00 . 2
0 . 3
0 . 4
0 . 5
0 . 6
0 . 7
C O N V E R G E N C E D E p
i t e r a t i o n
p
Paramètre mu_1
0 2 0 0 4 0 0 6 0 0 8 0 0 1 0 0 0 1 2 0 0 1 4 0 0 1 6 0 0 2 . 6
2 . 4
2 . 2
2 . 0
1 . 8
1 . 6
1 . 4
1 . 2
C O N V E R G E N C E D E m u _ 1
i t e r a t i o n
m u _ 1
5
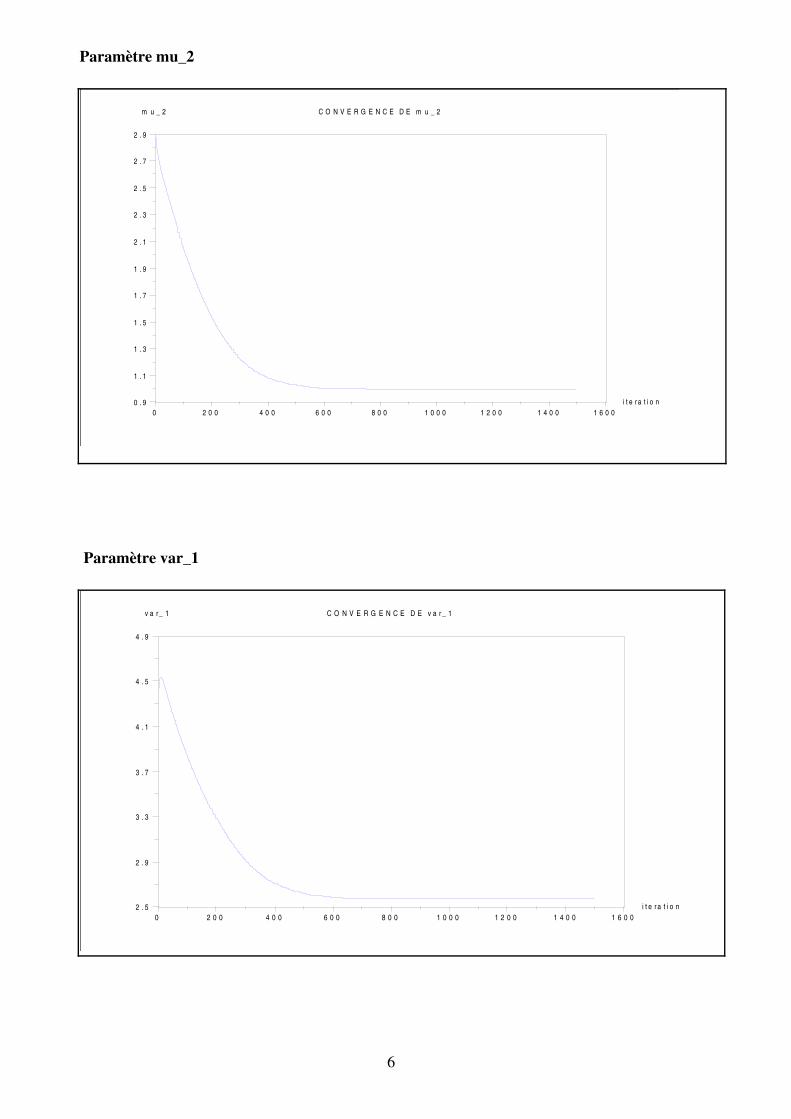
Paramètre mu_2
0 2 0 0 4 0 0 6 0 0 8 0 0 1 0 0 0 1 2 0 0 1 4 0 0 1 6 0 00 . 9
1 . 1
1 . 3
1 . 5
1 . 7
1 . 9
2 . 1
2 . 3
2 . 5
2 . 7
2 . 9
C O N V E R G E N C E D E m u _ 2
i t e r a t i o n
m u _ 2
Paramètre var_1
0 2 0 0 4 0 0 6 0 0 8 0 0 1 0 0 0 1 2 0 0 1 4 0 0 1 6 0 02 . 5
2 . 9
3 . 3
3 . 7
4 . 1
4 . 5
4 . 9
C O N V E R G E N C E D E v a r _ 1
i t e r a t i o n
v a r_ 1
6
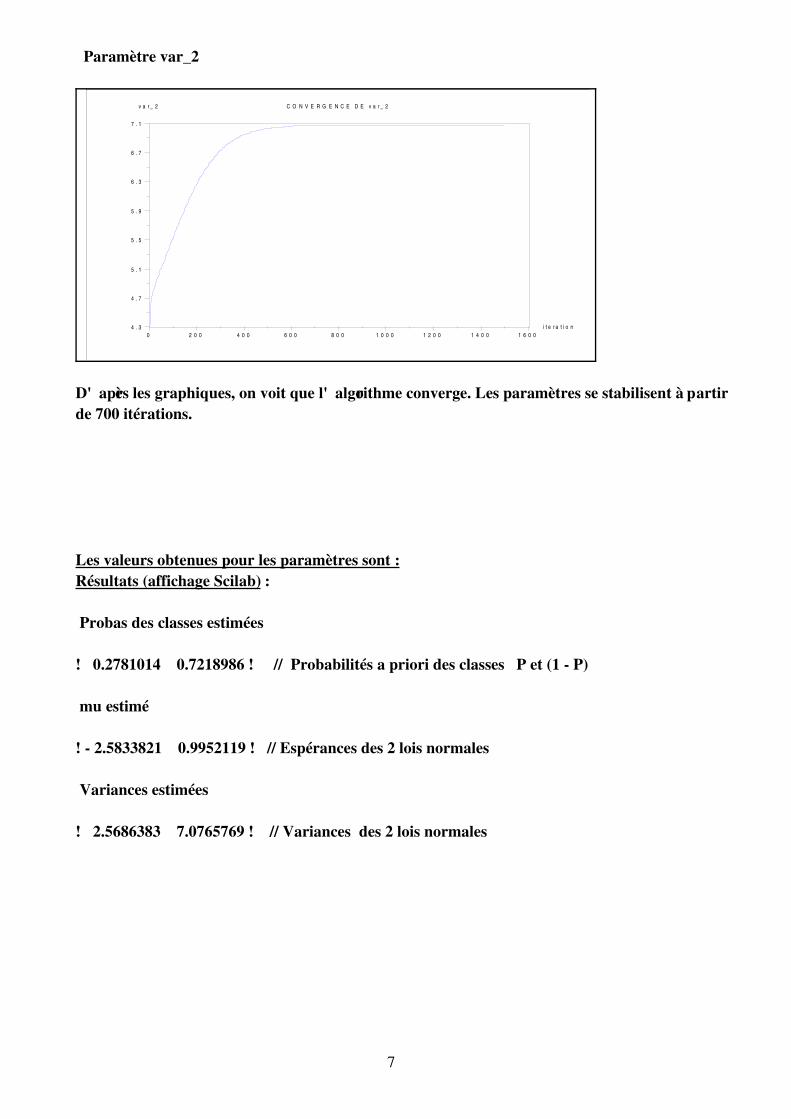
Paramètre var_2
0 2 0 0 4 0 0 6 0 0 8 0 0 1 0 0 0 1 2 0 0 1 4 0 0 1 6 0 04 . 3
4 . 7
5 . 1
5 . 5
5 . 9
6 . 3
6 . 7
7 . 1
C O N V E R G E N C E D E v a r _ 2
i t e r a t i o n
v a r _ 2
D'après les graphiques, on voit que l'algorithme converge. Les paramètres se stabilisent à partirde 700 itérations.
Les valeurs obtenues pour les paramètres sont :Résultats (affichage Scilab) :
Probas des classes estimées
! 0.2781014 0.7218986 ! // Probabilités a priori des classes P et (1 P)
mu estimé
! 2.5833821 0.9952119 ! // Espérances des 2 lois normales
Variances estimées
! 2.5686383 7.0765769 ! // Variances des 2 lois normales
7
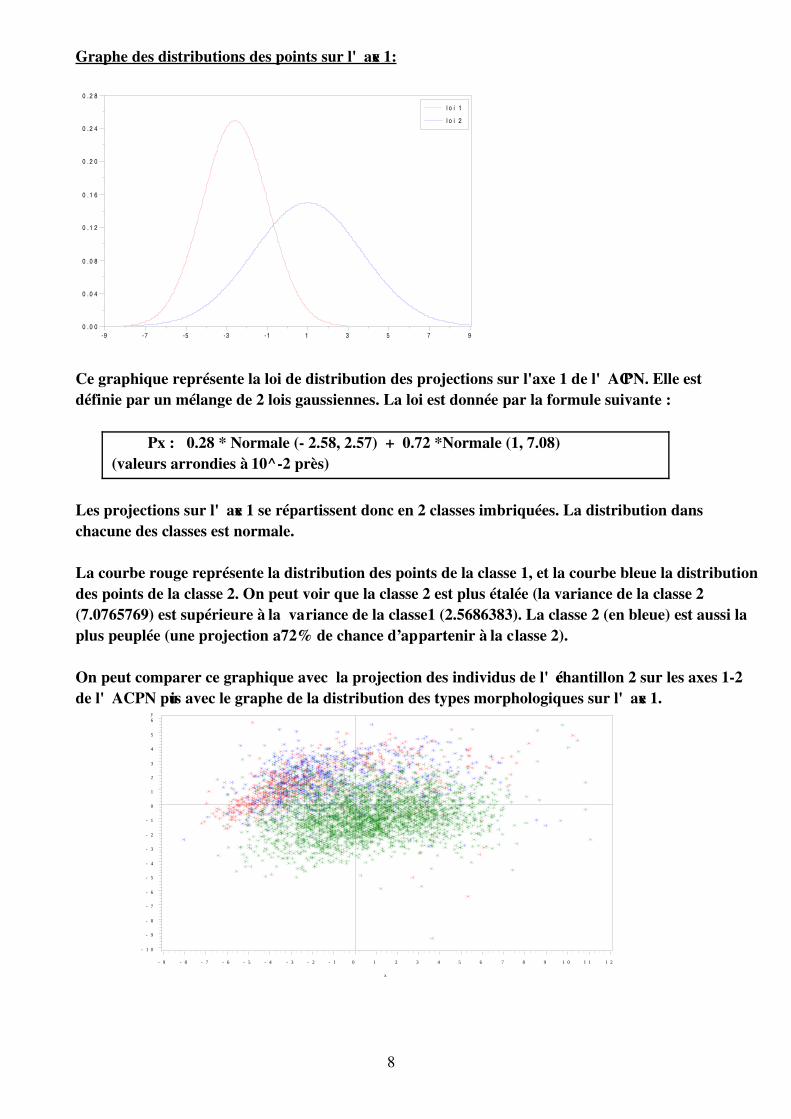
Graphe des distributions des points sur l'axe 1:
9 7 5 3 1 1 3 5 7 90 . 0 0
0 . 0 4
0 . 0 8
0 . 1 2
0 . 1 6
0 . 2 0
0 . 2 4
0 . 2 8
l o i 1
l o i 2
Ce graphique représente la loi de distribution des projections sur l'axe 1 de l'ACPN. Elle estdéfinie par un mélange de 2 lois gaussiennes. La loi est donnée par la formule suivante :
Px : 0.28 * Normale ( 2.58, 2.57) + 0.72 *Normale (1, 7.08) (valeurs arrondies à 10^2 près)
Les projections sur l'axe 1 se répartissent donc en 2 classes imbriquées. La distribution danschacune des classes est normale.
La courbe rouge représente la distribution des points de la classe 1, et la courbe bleue la distributiondes points de la classe 2. On peut voir que la classe 2 est plus étalée (la variance de la classe 2(7.0765769) est supérieure à la variance de la classe1 (2.5686383). La classe 2 (en bleue) est aussi laplus peuplée (une projection a72% de chance d’appartenir à la classe 2).
On peut comparer ce graphique avec la projection des individus de l'échantillon 2 sur les axes 12de l'ACPN puis avec le graphe de la distribution des types morphologiques sur l'axe 1.
y
- 1 0
- 9
- 8
- 7
- 6
- 5
- 4
- 3
- 2
- 1
0
1
2
3
4
5
6
x
- 9 - 8 - 7 - 6 - 5 - 4 - 3 - 2 - 1 0 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2
8

Distribution des elliptiques/lenticulaires sur l’axe 1
P E R C E N T
0
1 0
2 0
3 0
x MI D P O I N T
-7.8
-6.6
-5.4
-4.2
-3.0
-1.8
-0.6
0.6
1.8
3.0
4.2
5.4
6.6
7.8
9.0
10.2
Distribution des spirales sur l’axe 1
P E R C E N T
0
1
2
3
4
5
6
7
8
9
1 0
1 1
1 2
x MI D P O I N T
-6.4
-5.6
-4.8
-4.0
-3.2
-2.4
-1.6
-0.8
0.0
0.8
1.6
2.4
3.2
4.0
4.8
5.6
6.4
7.2
8.0
8.8
9.6
10.4
11.2
En comparant la distribution des types sur l'axe 1 et les classes, on remarque que la classe 1correspond majoritairement aux elliptiques/lenticulaires; alors que la classe 2 est constituée engrande partie par les spirales. Les 2 classes formées par l'algorithme reproduisent la séparationmorphologique : les spirales d'une part et les elliptiques/ lenticulaires d'autre part. Pourpréciser ce résultat, il est nécessaire d’appliquer l’algorithme sur un espace à 2 dimensions.
Remarques : >Les résultats sont (dans cet exemple) indépendants des conditions initiales. >Nous avons fait l'hypothèse pour l'échantillon 2 d'un mélange de 2 classes (donc 2 loisnormales). On peut cependant supposer un nombre de classes plus important (3 ou 4 par exemple). Onremarque que si l'on désire un nombre de classes strictement supérieur à 2, une classe disparaîtà chaque fois. Ainsi pour obtenir 3 classes, on doit déclarer k=4. Etc.C'est pourquoi on préfèrera conserver une répartition en 2 classes.
9
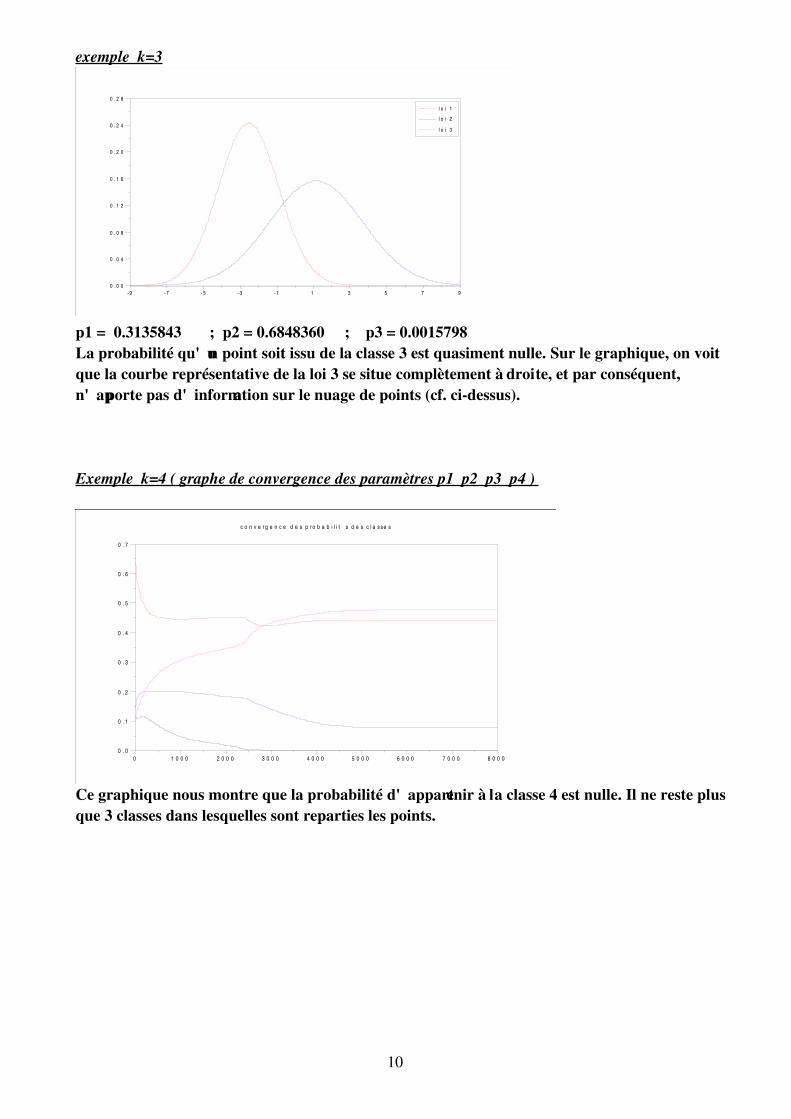
exemple k=3
9 7 5 3 1 1 3 5 7 90 . 0 0
0 . 0 4
0 . 0 8
0 . 1 2
0 . 1 6
0 . 2 0
0 . 2 4
0 . 2 8
l o i 1
l o i 2
l o i 3
p1 = 0.3135843 ; p2 = 0.6848360 ; p3 = 0.0015798 La probabilité qu'un point soit issu de la classe 3 est quasiment nulle. Sur le graphique, on voitque la courbe représentative de la loi 3 se situe complètement à droite, et par conséquent,n'apporte pas d'information sur le nuage de points (cf. cidessus).
Exemple k=4 ( graphe de convergence des paramètres p1 p2 p3 p4 )
0 1 0 0 0 2 0 0 0 3 0 0 0 4 0 0 0 5 0 0 0 6 0 0 0 7 0 0 0 8 0 0 00 . 0
0 . 1
0 . 2
0 . 3
0 . 4
0 . 5
0 . 6
0 . 7
c o n v e r g e n c e d e s p r o b a b i l i t s d e s c l a s se s
Ce graphique nous montre que la probabilité d'appartenir à la classe 4 est nulle. Il ne reste plusque 3 classes dans lesquelles sont reparties les points.
10
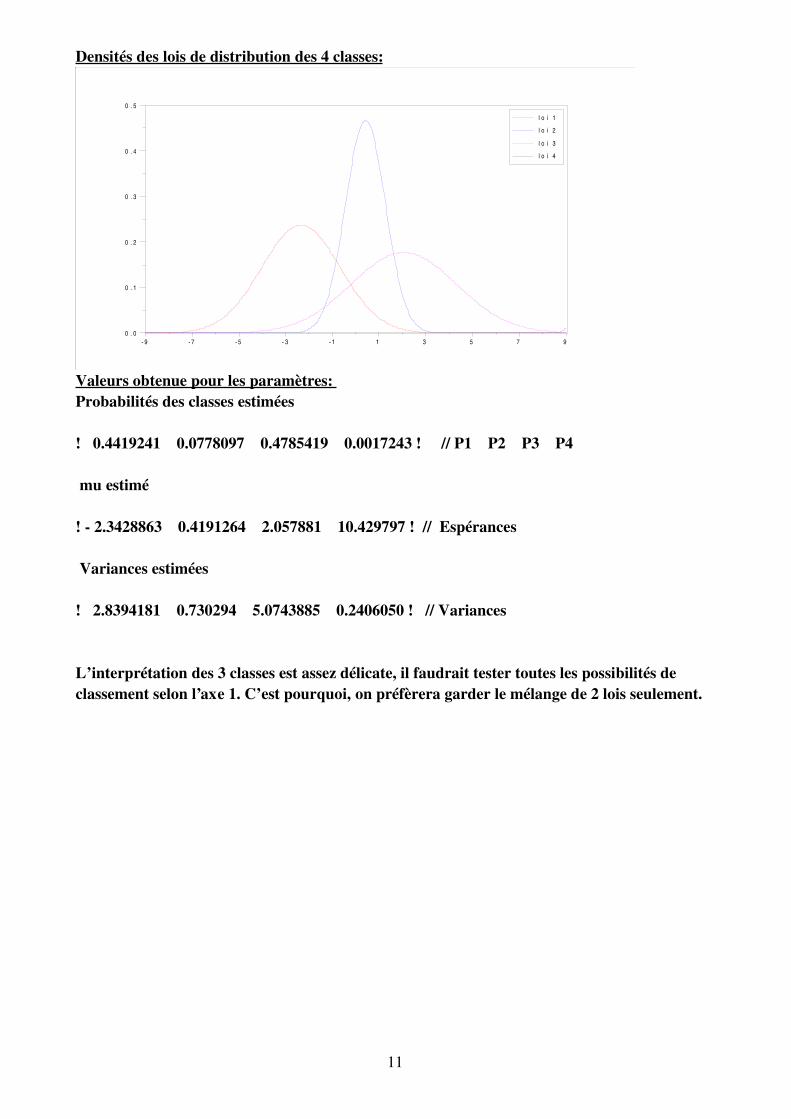
Densités des lois de distribution des 4 classes:
9 7 5 3 1 1 3 5 7 90 . 0
0 . 1
0 . 2
0 . 3
0 . 4
0 . 5
l o i 1
l o i 2
l o i 3
l o i 4
Valeurs obtenue pour les paramètres: Probabilités des classes estimées
! 0.4419241 0.0778097 0.4785419 0.0017243 ! // P1 P2 P3 P4
mu estimé
! 2.3428863 0.4191264 2.057881 10.429797 ! // Espérances
Variances estimées
! 2.8394181 0.730294 5.0743885 0.2406050 ! // Variances
L’interprétation des 3 classes est assez délicate, il faudrait tester toutes les possibilités declassement selon l’axe 1. C’est pourquoi, on préfèrera garder le mélange de 2 lois seulement.
11

12

CONCLUSION Durant ce stage, j’a i réalisé une analyse de données détaillée des échantillons à l’ aide du logicielSAS. Ainsi, une analyse en composantes principales, plusieurs méthodes de classification et uneanalyse discriminante ont été appliquées aux données. Pour chaque technique, j’ ai écrit unprogramme réalisant le calcul d’ indicateurs (contributions aux axes, qualités de représentation),facilitant l’int erprétation des résultats. De plus, l’e xpérimentation de l’a lgorithme de Monte Carlo(MCMC) a été l’o ccasion d’ approfondir mes bases en probabilités/statistiques, et surtout de découvrirles applications actuelles des outils statistiques. L’ ouverture à une nouvelle discipline : l’ astronomie,vient compléter mes enseignements. Afin de rechercher des outils de classifications de galaxies, j’ ai donc effectué une analysemathématique des échantillons tout en intégrant des aspects importants de l’ astronomie. L’a nalyse de données a été une étape importante pour l’é tude des échantillons. En effet, lesplans de projections issus de l’ ACPN ont joué un rôle essentiel ; ils ont servi de bases pour lesméthodes de classification. Il a été intéressant de constater que les principaux facteurs caractérisants les morphologies,apparaissent dans les résultats des classifications automatiques comme des paramètres discriminants.La séparation très subjective des morphologies peut être donc modélisée par des fonctionsmathématiques des paramètres physiques. Des outils ont été créés, permettant d’ extraire l’in formation morphologique à partir d’unensemble de données physiques. Ces méthodes automatiques seront utilisées sur la base de donnéesHyperleda extragalactique (http//wwwobsLyon1.fr/hypercat) d’où ont été extraits les échantillons. On suppose ici que l'échantillon 2, à partir duquel les fonctions ont été calculées, est représentatif del'ensemble des galaxies de la base.
L’a pplication de l’ algorithme de Monte Carlo par Chaîne de Markov sur l’ axe 1, a montré unestabilité pour 2 lois mélangées. Cette méthode paramétrique s’int erprète difficilement en dimension 1.Cependant, en confrontant la distribution théorique avec la distribution empirique des morphologieson a pu expliciter les deux classes obtenues. Pour aller audelà, il serait intéressant d’ expérimenter un peu plus la méthode paramétrique surun espace non plus à 1 dimension mais à 2 dimensions. Ceci permettrait une visualisation optimaledes classes obtenues sur un plan. Des variantes de l’a lgorithme peuvent être testées, en modifiant parexemple, les hypothèses initiales sur les lois de distributions, et en remplaçant la méthode Bayésiennepar une estimation par maximum de vraisemblance.
13

14

Bibliographie :
Combes F., Boissé P., Mazure A., Blanchard A, Astrophysique, Galaxies et cosmologie, 1997.
Robert C.P., Soubiran C., Estimation of a normal mixture model through Gibbs sampling and PriorFeedback, URA CNRS 1378, Université de Rouen, Vol. 2, No. 12, p.125126, 1993.
Cornebise J, Maumy M, Girard P., A Practical Implementation of the Gibbs sampler for Mixtureof Distributions: Application to the Determination of Specifications in Food Industry, p.828836.
Elie L. Lapeyre B., Introduction aux Méthodes deMonteCarlo, Septembre 2001.
Mazet V., Introduction aux Méthodes de Monte Carlo par Chaînes de Markov,CRAN CNRS UMR 7039, Université Henri Poincaré, mai 2003.
Pinçon B., Une introduction à Scilab, Institut Elie Cartan Nancy E.S.I.A.L, Université HenryPoincaré.
Sites web : (guides d’utilisa tion de SAS)
http://www.ecn.ulaval.ca/pages/ressources/aide/sas/
http://www.lsp.upstlse.fr/Besse/enseignement.html
http://www.cmi.univmrs.fr/~mcroubau/MaitMASSAD.html
Photo de couverture : Mosaïque de Galaxies extraites du relevé photographique du Mont Palomar.
15

16

Annexes :
Quelques détails de programmation sur SAS : utilisation des procédures Princomp et IML.
Création d’une table SASIl existe plusieurs manières de créer une table SAS. Lorsque les données sont stockées dans un fichiertexte (c’ est d’a illeurs souvent le cas), la syntaxe est : Data sample1; //création d’une table pour l’échantillon 1//Infile 'C:\mes documents\sample_1.txt';input bi bj jk spi sbb sbj sbh sbk c31j c31h c31k ;run ;Cette étape crée une table SAS temporaire qui sera détruite à la fin de la session. Il est cependantpossible d’e nregistrer une table SAS pour pouvoir l’ut iliser ultérieurement (voir programme enannexe).
Utilisation de la procédure Princomp de SASLa procédure Princomp effectue une ACPN ; les principales sorties affichées sont les statistiquesdescriptives, les valeurs propres et les coordonnées des variables sur les axes crées. Pour obtenir lesgraphiques de projections des galaxies et des variables, indispensables à l’i nterprétation, il faudraprogrammer ;
La syntaxe générale de la procédure Princomp est :PROC PRINCOMP <options>.BY variablesFREQ variablesPARTIAL variablesVAR variablesWEIGHT variable
L’ instruction PROC PRINCOMP est obligatoire, les autres instructions sont optionnelles.Pour une ACPN classique sur l’ échantillon 1, la syntaxe est la suivante :
PROC PRINCOMP data = sample1 outstat = sortie1 out = sortie1; VAR bi bj jk spi sbb sbj sbh sbk c31j c31h c31k ;
La table sortie1 contient moyennes, écartstypes pour chaque variable ; matrice des corrélations,valeurs propres et vecteurs propres de la matrice des corrélations.La table sortie2 est une table contenant les données de départ et les coordonnées des individus sur lesaxes. Transformer une table SAS en fichier texteOn peut vouloir conserver une base de données dans un autre format que celui de SAS; dans ce cas,la syntaxe est :Data _null_ ; // _null_ indique qu’ aucune base sas ne sera créée//Set toto ; // toto est la table à transformer//File ‘C:\ Mes Documents\ résultats.txt’ ; // résultats est le fichier texte crée à partir de // // la base sas toto//
17

Put x +4 y ; // les colonnes gardées sont x et y //Run ;Sur SAS, les données les données sont considérées uniquement comme des tableaux ; pour pouvoirfaire des calculs matriciels sur les bases de données, il faut utiliser la procédure IML. Comme pourSAS, je ne vais décrire que les principales lignes de programmation dont j’ ai eu besoin.
Utilisation de la procédure IML
Proc IML ; // appelle la procédure (après avoir exécuter cette ligne un message « IML ready » s’af fiche sur la fenêtre blog.Reset print ; // pour afficher toutes les sorties
Use toto ; // toto est une base SAS. On va transformer cette base en un matrice pour pouvoir travailler dessus sous IML.
Read all var {var1, var2, …v arN} into mat // mat est une matrice contenant les donnée de lamatrice toto. Si on ne précise pas var {}, toutes les variables sont prises en compte.
(Opérations sur la matrice mat)
// Pour sauvegarder une matrice en table SAS cname = {"pgc" "project"}; // nom des colonnes à créees create out from g [ colname=cname ]; // creation d’une table sas “ out” à partir de la matrice g append from g;
quit ;
La syntaxe de programmation est classique et proche de scilab ; toutes les opérations sur les matricessont les mêmes : ‘* ‘ produit scalaire ‘*. ‘ produit terme à terme ‘ ||’ c oncaténation de 2 matrices …e tc.
18

Programme SAS pour l’analyse de données sur l’échantillon 2data sample2; **lit les donnees;infile 'C:\Documents and Settings\theureau\Bureau\samples\sample2.txt' LRECL=600;input pgc bm im jm hm km ag ai logd logr bi bj jk spi sbb sbj sbh sbk c31j c31h c31k typ mb mi mj mh mk logda dens dk;run;
data sample2; **ne garde que les donnees intrinseques;set sample2;keep pgc bi bj jk spi sbb sbj sbh sbk c31j c31h c31k typ mb mi mj mh mk logda dens dk;run;
data sample2; /** les valeurs manquantes sont notées par des points**/set sample2;if bi=99.99 or bi=99 then bi=.;if bj=99.99 or bj=99 then bj=.;if jk=99.99 or jk=99 then jk=.;if spi=99.99 or spi=99 then spi=.;if sbb=99.99 or sbb=99 then sbb=.;if sbj=99.99 or sbj=99 then sbj=.;if sbh=99.99 or sbh=99 then sbh=.;if sbk=99.99 or sbk=99 then sbk=.;if c31j=99.99 or c31j=99 then c31j=.;if c31h=99.99 or c31h=99 then c31h=.;if c31k=99.99 or c31k=99 then c31k=.;if mb=99.99 or mb=99 then mb=.;if mi=99.99 or mi=99 then mi=.;if mj=99.99 or mj=99 then mj=.;if mh=99.99 or mh=99 then mh=.;if mk=99.99 or mk=99 then mk=.;if logda=99.99 or logda=99 then logda=.;if dens=99.99 or dens=99 then dens=.;run;
data sample2;set sample2;if bi=. or bj=. or jk=. or spi=. or sbb=. or sbj=. or sbh=. or sbk=. or c31j=. or c31h=. or c31k=. or typ=. or mb=. or mi=. or mj=. or mh=. or mk=. or logda=. or dens=. then delete;run;
/**** pour l’ acpn, on enlève les variables typ, dk, pgc ***/proc princomp data = sample2 outstat = outstat out = sortie;var bi bj jk spi sbb sbj sbh sbk c31j c31h c31k mb mi mj mh mk logda dens ;run;
19

data outstat;set outstat;if _type_='EIGENVAL' then _name_='VP';
run;proc transpose data = outstat out = transtat; run;
/**recuperation des valeurs propres ds des macrovariables**/data _null_;set transtat;if vp and _name_='bi' then do;V1=vp;call symput('VP1',left(V1));end;if vp and _name_='bj' then do;V2=vp;call symput('VP2',left(V2));end;if vp and _name_='jk' then do;V3=vp;call symput('VP3',left(V3));end;if vp and _name_='spi' then do;V4=vp;call symput('VP4',left(V4));end;if vp and _name_='sbb' then do;V5=vp;call symput('VP5',left(V5));end;if vp and _name_='sbj' then do;V6=vp;call symput('VP6',left(V6));end;if vp and _name_='sbh' then do;V7=vp;call symput('VP7',left(V7));end;if vp and _name_='sbk' then do;V8=vp;call symput('VP8',left(V8));end;if vp and _name_='c31j' then do;V9=vp;call symput('VP9',left(V9));end;if vp and _name_='c31h' then do;V10=vp;call symput('VP10',left(V10));end;
20

if vp and _name_='c31k' then do;V11=vp;call symput('VP11',left(V11));end;if vp and _name_='mb' then do;V12=vp;call symput('VP12',left(V12));end;
if vp and _name_='mi' then do;V13=vp;call symput('VP13',left(V13));end;if vp and _name_='mj' then do;V14=vp;call symput('VP14',left(V14));end;if vp and _name_='mh' then do;V15=vp;call symput('VP15',left(V15));end;if vp and _name_='mk' then do;V16=vp;call symput('VP16',left(V16));end;if vp and _name_='logda' then do;V17=vp;call symput('VP17',left(V17));end;if vp and _name_='dens' then do;V18=vp;call symput('VP18',left(V18));end;run;
/**on etudie les 3 premiers axes , contenant le maximum de l’ information**//**on calcule les coordonnées des variables sur les axes (1, 2, 3), la contribution , la qualité cereprésentation des var**/data transtat;set transtat;/**coordonnées**/projv1=prin1*sqrt(&vp1);projv2=prin2*sqrt(&vp2);projv3=prin3*sqrt(&vp3);/**contributions**/contrv1=prin1*prin1;contrv2=prin2*prin2;contrv3=prin3*prin3;/**cosinus**/cosv1=projv1*projv1;
21

cosv2=projv2*projv2;cosv3=projv3*projv3;/**qualité de représentation sur les axes 12, 13****/qual_12=cosv1+cosv2;qual_13=cosv1+cosv3;run;proc print data=transtat;run;
/**on centre et on reduit les donnees**/proc standard data = sample2 out = stand mean = 0 std =1;var bi bj jk spi sbb sbj sbh sbk c31j c31h c31k mb mi mj mh mk logda dens ;run;
/**calcul de la norme 2 au carré**/data norme; set stand;norme=(bi*bi)+(bj*bj)+(jk*jk)+(spi*spi)+(sbb*sbb)+(sbj*sbj)+(sbh*sbh)+(sbk*sbk)+(c31j*c31j)+(c31h*c31h)+(c31k*c31k)+(mb+mb)+(mi+mi)+(mj+mj)+(mh+mh)+(mk+mk)+(logda+logda)+(dens+dens);run;
proc sort data=sortie ;by pgc;run;proc sort data=norme;by pgc;run;
/**on calcule les contribution des individus sur les axes 1, 2, 3 **/ /**les coordonnées des individus sont : prin1, prin2, prin3**/ /*** la qualité de représentation des individus : **/data sortie;merge sortie norme;by pgc;contri1=(prin1*prin1)/(&vp1); /**contributions = (vecteur propre1)^2 / (valeur propre )**/contri2=(prin2*prin2)/(&vp2);contri3=(prin3*prin3)/(&vp3);
contri1=contri1/4014; /**on divise par le poids**/contri2=contri2/4014;contri3=contri3/4014;
/**cosinus carrés = vect*vect / par norme 2 au carré**/coscai1=(prin1*prin1)/norme;coscai2=(prin2*prin2)/norme;
/**qualité des info sur axe 1 et 2**/quali=coscai1+coscai2;keep contri1 contri2 pgc typ sbb sbj mj spi bj c31j logda prin1 prin2 coscai1 coscai2 quali;run;
22

/** on construit les graphiques d’ aide a l'interpretation ***/
data ano;set transtat;x=projv1;y=projv2;xsys='2';ysys='2';text=_name_;size=1.5; run;
symbol1 v=square c=pink;symbol2 i=spline c=blue v=none;
data cercle;do i=1 to 100;
x=cos(arcos(1)*i/10);z=sin(arcos(1)*i/10);output; end; run;
data correl;set ano cercle;run;
title"representation des variables";proc gplot data=correl;
plot y*x=1 z*x=2 / overlay annotate=ano
frame href=0 vref=0; run;
data ano;set sortie;x=prin1;y=prin2;xsys='2';ysys='2';text=pgc;size=1;keep pgc x y xsys ysys text size;
run;proc sort data=ano;by pgc;run;proc sort data=sample2;by pgc;run;data ano ; merge ano sample2; by pgc;run;
23

data ano; set ano; keep pgc typ sbb sbj mj spi bj c31j logda x y xsys ysys text size;run;
symbol1 v=dot c=green;
title"representation des individus";proc gplot data=ano;
plot y*x=1 /annotate=anoframehref=0 vref=0; run;
/**************************************************************************//***** on veut representer les 3 morphologies de differentes couleurs******/data plan_12;set sortie;drop prin3prin18;run;data plan_12;set plan_12;keep pgc typ prin1 prin2;run;
data elliptique;set plan_12;if 5<=typ<2;run;
data lenticulaire;set plan_12;if 2<=typ<1;run;
data spirale;set plan_12;if 1<=typ<=10;run;
data elliptique;set elliptique;x=prin1;y=prin2;xsys='2';ysys='2';text=pgc;size=1;keep pgc typ x y xsys ysys text size;
run;
24

data lenticulaire;set lenticulaire;x=prin1;z=prin2;xsys='2';zsys='2';text=pgc;size=1;keep pgc typ x z xsys zsys text size;
run;
data spirale;set spirale;x=prin1;h =prin2;xsys='2';hsys='2';text=pgc;size=1;keep pgc typ x h xsys hsys text size;
run;
data graph;set elliptique lenticulaire spirale;run;goptions reset=all;symbol1 c=red v=star;symbol2 c=blue v=star;symbol3 c=green v=star;
proc gplot data=graph;plot y*x=1 z*x=2 h*x=3 / overlay annotate=graph frame vref=0 href=0 ; run;
25

Simulation de l’algorithme de monte Carlo par chaîne de Markov sur Scilab :
// Valeurs de la densité de probabilité d'une loi normale, aux points du vecteur Xfunction f = gauss(m, sq, x)f=exp(((xones(x)*m)^2)./(2*sq))/ sqrt (2*%pi*sq)endfunction;
//Algorithme em : Prend en paramètres un échantillon d'observations : echant//et le nombre d'itération de l'algorithme : iter
function em ( echant , iter )k=2 //nombre de classes constituant le mélangeX=echant n=length(X)P=ones(1,k)/k //initialisation des probas a priori des classesmu=[1:k] //initialisation des espérances de chaque loisq=ones(1,k) //initialisation des variances de chaque loih=zeros(n,k)
for i=1:iter//etape 0.Estimation des probabilités conditionnelles// P("classe j sachant xi")(par la formule de Bayes) for l=1:k
26

h(:,l)=(P(l)*gauss(mu(l),sq(l),X))' end sumc=sum(h,'c') for l=1:k h(:,l)=h(:,l)./sumc end//etape 1. Mise a jour des paramètres s=sum(h,'r') P=s/n for l=1:k mu(l)=(X*h(:,l))/s(l) sq(l)=(((Xmu(l)*ones(1,n)).^2)*h(:,l))/s(l) endend
//On affiche les paramètres estimésdisp('probas des classes estimées')disp(P)
disp('mu estimé')disp(mu)
disp('variances estimées')disp(sq)// Tracé des deux densitésxbasc()x=[9:.01:9]Y=zeros(x)Z=zeros(x)
Y=gauss(mu(1),sq(1),x) z=gauss(mu(2),sq(2),x)
plot2d(x,Y,5)plot2d(x,z,2)legends(['loi 1','loi 2'],[5,2],1)endfunction;
27

Utilisation des Matrices :
La projection des galaxies de l'échantillon 2 sur les axes 1 et 2 est donnée par la tableprojection_individus_s2, qui est de la forme : pgc X Y classe
X est l'abscisse, Y est l'ordonnée.La classe vaut e pour elliptique (en rouge) l pour lenticulaires (en bleu) s pour spirales (en vert)
La projection des variables de l'échantillon 2 sur les axes 1 et 2 est donnée par la tableprojection_var_s2, qui est de la forme : X Y nom de la variable (bi, bj, spi, ..)
La répartition de l'échantillon dans les 11 groupes représenté dans le plan 12 de l'acpn est donnéepar la table 11_groupes_s2 : pgc no du groupe X Y
Le no du groupe donne la couleur : 1 (gris), 2 (bleu), 3 (vert), 4 (jaune), 5 (or), 6 (violet), 7 (orange),8 (marron), 9(vert kaki), 10 (rose), 11 (noir).
La représentation de ces groupes sur le plan de TullyFisher est donnée par la table TFisher_s3s : pgc X Y no du groupe
La corrélation entre le paramètre typ (type morphologique) et le paramètre To est donnée par la tablecorr_typ_To qui est de la forme : pgc To typ
La corrélation entre le résidus de TullyFisher et le paramètre bj pour les spirales à forte brillance desurface, est donnée par la table corr_resbj_ forte qui est de la forme : pgc bj res
La corrélation entre le résidus de TF et le paramètre bj pour les spirales à faible brillance de surface,est donnée par la table corr_resbj_ faible qui est de la forme : pgc bj res
Pour centrer et réduire un ensemble de galaxies par rapport au barycentre de l'échantillon 2 , on doit utiliser le fichier "centrer et réduire par rapport à s2".
La table vecteur_prop donne les 18 vecteurs propres (en colonne) nécessaires pour le calcul descoordonnées d'une galaxie quelconque sur les 18 axes créées par l'ACPN sur l'échantillon 2. Ils sontutilisés si on veut projeter une galaxie sur le plan 12 de l'ACPN de l'échantillon2.
La base orthonormale de la droite des types est donnée par le vecteur : type_base. Il sert à obtenir lesprojections (notées To) des galaxies sur cet axe.
28










