
1. INTRODUCTION ET INFORMATIONS...
50
Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales Eric Crettaz - 1 - 1. INTRODUCTION ET INFORMATIONS PRATIQUES Pour me contacter, du lundi au mercredi et le vendredi : Eric Crettaz. Office fédéral de la statistique Section des analyses sociales Place de l’Europe 10, 2010 Neuchâtel. (Si vous envoyez quelque chose par écrit, n’oubliez pas d’ajouter une mention « personnel » dans l’adresse). [email protected] Le jeudi : PER21, Bureau G333. Organisation du cours : Jeudi, semaines paires, de 8h30 à 10h00, PER21, salle C140. Semestre d’automne 18 septembre 2008 2 octobre 2008 16 octobre 2008 30 octobre 2008 13 novembre 2008 27 novembre 2008 11 décembre 2008 Semestre de printemps 19 février 2009 26 février 2009 5 mars 2009 19 mars 2009 2 avril 2009 9 avril 2009 23 avril 2009 (remplace le 17 avril : Pâques) 30 avril 2009 14 mai 2009 28 mai 2009 Bibliographie : En plus du support de cours, il faut lire : DODGE Yadolah, Premiers pas en statistiques , Paris : Springer (2006). (Corrigé des exercices au secrétariat du DSS). Utile : FINK Arlene, How to Analyze Survey Data, Thousand Oaks : Sage Publications (1995).
-
Upload
vuongkhanh -
Category
Documents
-
view
218 -
download
0
Transcript of 1. INTRODUCTION ET INFORMATIONS...

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 1 -
1. INTRODUCTION ET INFORMATIONS PRATIQUES Pour me contacter, du lundi au mercredi et le vendredi : Eric Crettaz. Office fédéral de la statistique Section des analyses sociales Place de l’Europe 10, 2010 Neuchâtel. (Si vous envoyez quelque chose par écrit, n’oubliez pas d’ajouter une mention « personnel » dans l’adresse). [email protected] Le jeudi : PER21, Bureau G333. Organisation du cours : Jeudi, semaines paires, de 8h30 à 10h00, PER21, salle C140. Semestre d’automne 18 septembre 2008 2 octobre 2008 16 octobre 2008 30 octobre 2008 13 novembre 2008 27 novembre 2008 11 décembre 2008 Semestre de printemps 19 février 2009 26 février 2009 5 mars 2009 19 mars 2009 2 avril 2009 9 avril 2009 23 avril 2009 (remplace le 17 avril : Pâques) 30 avril 2009 14 mai 2009 28 mai 2009 Bibliographie : En plus du support de cours, il faut lire : DODGE Yadolah, Premiers pas en statistiques , Paris : Springer (2006). (Corrigé des exercices au secrétariat du DSS). Utile : FINK Arlene, How to Analyze Survey Data, Thousand Oaks : Sage Publications (1995).

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 2 -
2. OBJECTIFS DU COURS ET RÔLE DE LA STATISTIQUE « C’est une chose qu’on oublie, la sociologie a fait des progrès absolument formidables au point que c’est difficile pour un seul homme aujourd’hui de totaliser toutes les techniques mathématiques, statistiques, etc., qui sont à la disposition du sociologue – en utilisant un capital de savoirs, de connaissances, un mode de production très moderne auprès duquel la plupart des intellectuels, qui écrivent, entre autres, sur les sociologues, sont des artisans périmés. » Pierre Bourdieu, Si le monde social m’est supportable, c’est parce que je peux m’indigner. Entretien avec Antoine Spire, Paris : Editions de l’Aube, 2002, p.29. 3. NOTIONS DE BASE ET GRANDS CHAPITRES DE LA STATISTIQUE 3.1. Population, échantillon et variables Une des bases de la statistique, appliquée aux sciences de la société ou à bien d’autres disciplines, c’est qu’on peut étudier une population en se focalisant sur un échantillon, c’est-à-dire sur un sous-ensemble de cette population. Les variables (c-à-d. les caractéristiques « mesurables » de la population étudiée) sont indiquées par des lettres majuscules : souvent dans le cours nous utiliserons les lettres X, Y. Les différentes valeurs que peut prendre une variable sont les modalités. Pour désigner la valeur de la réalisation de X pour le ième individu de l’échantillon, on parle aussi d’observation, on utilisera la notation x i . Une variable indépendante est en fait une variable explicative et une variable dépendante est une variable expliquée. Généralement on utilise la notation n pour désigner la taille de l’échantillon et N pour la taille de la population. On distingue généralement deux grands types de variables : A. Les variables qualitatives ou catégorielles, qui elles-mêmes sont partagées en deux sous-groupes : - Les variables nominales (qui n’ont pas de vraie valeur numérique). - Les variables ordinales (il existe un ordre hiérarchique entre les catégories). B. Les variables quantitatives, elles aussi divisées en deux sous-groupes : - Les variables intervalles (échelles d’intervalles) - Les variables quotient (rapports) Une distinction importante doit encore être signalée : il existe des variables continues qui peuvent prendre n’importe quelle valeur (salaire p.ex.) et des variables discrètes qui ne

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 3 -
peuvent prendre que des valeurs déterminées, càd dont l’étendu des valeurs possibles est dénombrable (p.ex. le nombre d’enfants). Pour choisir une méthode d’analyse appropriée, il faut commencer par définir la finalité de l’étude, ensuite on détermine quelles sont les variables dépendantes et indépendantes et si ces variables sont nominales, ordinales ou quantitatives. 3.2. Les grands chapitres de la statistique La statistique descriptive / exploratoire : décrire et résumer l’information, mettre le doigt sur des phénomènes potentiellement intéressants. La statistique inférentielle : postuler un modèle jugé valable pour l’ensemble de la population et vérifier son adéquation avec les données de l’échantillon. 4. STATISTIQUE DESCRIPTIVE ET REPRÉSENTATIONS GRAPHIQUES 4.1. Mesures de tendance centrale On indique un point autour duquel les observations se concentrent. Les mesures les plus couramment utilisées sont la moyenne arithmétique, le mode et la médiane. 4.1.1. Moyenne arithmétique C’est la somme des observations divisée par le nombre d’observations. En langage mathématique on note :
∑=
=n
iix
nx
1
1
4.1.2. Le mode C’est la valeur d’une variable qui a la plus grande fréquence. Notons qu’il existe des cas où l’on a une distribution bimodale (2 valeurs sortent le plus fréquemment), voire multimodales. 4.1.3. La médiane Il s’agit du point qui divise la série ordonnée des observations en deux groupes de même taille, de l’ « observation du milieu ». Autrement dit, la moitié des observations sont en dessous de cette valeur, et l’autre moitié en dessus. Si n, la taille de l’échantillon, est paire, alors la médiane est la moyenne arithmétique des deux valeurs centrales. Si n est impaire, alors c’est plus simple puisqu’on a une valeur centrale.

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 4 -
De manière générale, la moyenne arithmétique est très influencée par les valeurs extrêmes, ce qui n’est pas le cas de la médiane. Si la répartition des points est symétrique, alors le mode, la médiane et la moyenne se confondent. 4.2. Quantiles, variance et dispersion des données En fait on peut généraliser l’idée de la médiane : il existe des points qui divisent l’échantillon en q groupes de « taille » égale. Ce sont les quantiles. On parle de quantile d’ordre α , avec α compris entre 0 et 1 (resp. entre 0 et 100%). Il y a une proportion α des observations en dessous de ce point et une proportion 1-α en dessus. Les quantiles souvent utilisés en sciences sociales sont les quartiles, les quintiles et les déciles. Prenons les quartiles (Définir des groupes contenant ¼ des observations ) : - q1 qui est le quantile d’ordre ¼, c’est-à-dire que ¼ des observations sont en dessous et ¾ en dessus. - q , c’est-à-dire que 2/4 des observations (donc la moitié) sont en dessus et 2/4 en dessous (l’autre moitié): il s’agit en fait de la médiane.
2
- q , ¾ des observations sont en dessous, ¼ en dessus. 3
Les quintiles sont les points qui divisent l’échantillon en groupes de 20% des observations (soit en 5 groupes), et les déciles en 10 groupes de 10%. La variance mesure la dispersion des observations Il s’agit de la moyenne arithmétique des écarts à la moyenne.
s =21
1
2
nx xi
i
n
( )=∑ −
On peut montrer que cela équivaut à :
s2 1= (
nx xi
i
n2
1
2)=∑ −
L’écart-type est la racine carrée de la variance empirique, et on le note s, et est plus souvent utilisé que la variance. D’autres indications de la variation: le maximum, le minimum et l’étendue empirique (Dodge: empan) soit la différence entre la plus grande et la plus petite observation. Cette indication est très sensible aux valeurs extrêmes, en toute logique. Autre élément, l’étendue interquartile, qui est en fait tout simplement l’écart entre q - q . C’est une indication intéressante que l’on utilise pour faire un graphique assez utile qu’on appelle un box-plot.
3 1

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 5 -
4.3. Forme, asymétrie, aplatissement Une distribution peut être étirée à droite (et oblique à gauche), ou inversément étirée à gauche (et oblique à droite). Si la distribution est asymétrique à droite (revenus par exemple), la moyenne est supérieure à la médiane, et si elle est asymétrique à gauche (âge auquel on atteint un poste de directeur), la moyenne est inférieure à la médiane. La base des mesures d’aplatissement et d’asymétrie sont les moments d’ordre r :
Moment d’ordre r = xn rn
iin∑=1
1 , si r=1 il s’agit de la moyenne arithmétique.
Moment centré d’ordre r = )(1
1 xxn inrn
ii −∑
=
Si r=2 c’est la variance empirique Si r=3 on a la base pour calculer une mesure de l’asymétrie (dans les logiciels en anglais : skewness). Si r=4 on a la base pour calculer une mesure de l’aplatissement (dans les logiciels en anglais: kurtosis). 4.4. Les représentations graphiques Le diagramme en bâton est utilisé pour les variables qualitatives ou quantitatives discrètes. Chaque bâton est proportionnel au pourcentage / à la fréquence d’une réponse. C’est un type de diagramme qui est très couramment utilisé en les sciences sociales. On peut aussi y recourir pour les questions avec plusieurs réponses possibles ou pour toute autre situation où le total ne fait pas 100%. L’histogramme repose sur le même principe, il représente la distribution d’une variable quantitative continue. Il faut ordonner les observations et ensuite déterminer un certain nombre de classes. On devrait avoir des classes d’une taille égale si l’on utilise des barres de même largeur ou alors il faut avoir des barres de „taille“ variable (pas pratique à faire sur PC). En outre, n’oubliez pas que souvent la barre la plus à droite du graphique est souvent une classe ouverte. Enfin, un graphique relativement peu utilisé dans la recherche, mais courant dans les sondages d’opinion est le pie-chart ou diagramme circulaire. C’est un graphique très simple : chaque tranche du gâteau a une taille proportionnelle au pourcentage qu’il représente. Ce graphique ne convient pas pour les questions „multiréponses“ !
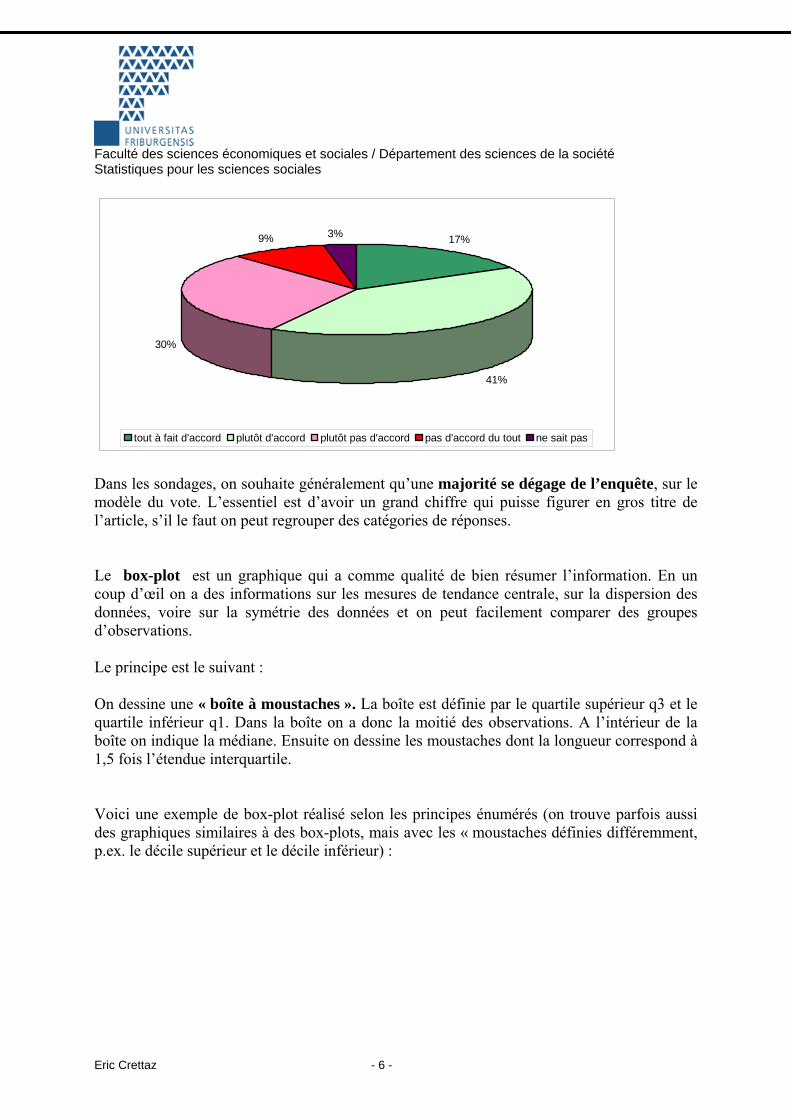
Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 6 -
17%
41%
30%
9% 3%
tout à fait d'accord plutôt d'accord plutôt pas d'accord pas d'accord du tout ne sait pas
Dans les sondages, on souhaite généralement qu’une majorité se dégage de l’enquête, sur le modèle du vote. L’essentiel est d’avoir un grand chiffre qui puisse figurer en gros titre de l’article, s’il le faut on peut regrouper des catégories de réponses. Le box-plot est un graphique qui a comme qualité de bien résumer l’information. En un coup d’œil on a des informations sur les mesures de tendance centrale, sur la dispersion des données, voire sur la symétrie des données et on peut facilement comparer des groupes d’observations. Le principe est le suivant : On dessine une « boîte à moustaches ». La boîte est définie par le quartile supérieur q3 et le quartile inférieur q1. Dans la boîte on a donc la moitié des observations. A l’intérieur de la boîte on indique la médiane. Ensuite on dessine les moustaches dont la longueur correspond à 1,5 fois l’étendue interquartile. Voici une exemple de box-plot réalisé selon les principes énumérés (on trouve parfois aussi des graphiques similaires à des box-plots, mais avec les « moustaches définies différemment, p.ex. le décile supérieur et le décile inférieur) :

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 7 -
o Outliers/ valeurs atypiques / val.extrêmes o o
Q3 + 1,5*IQR (valeur la plus proche)
Q3
médiane
Q1
Q1 – 1,5* IQR (valeur la plus proche)
Dernière remarque : les cercles indiquent des points qu’on appelle « outliers », ou valeurs atypiques. En outre on parle parfois aussi de valeurs extrêmes. Le diagramme de dispersion est très utilisé pour comparer deux variables quantitatives. Le principe est très simple: on représente des couples de points . );( ii yx Y o o o
o oo );( ii yx o o o o o oo o
X
4.5. Pourcentages, proportions et description des évoluti
ons
Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 8 -
Jongler avec des pourcentages paraît être quelque chose d’évident. Pourtant beaucoup d’erreurs sont commises. On sait aussi que les pourcentages ne sont pas toujours bien compris dans l’ampleur qu’ils représentent. Souvent il sera plus parlant, dans un rapport, de dire qu’environ un répondant sur trois est d’accord, plutôt que 32,5%. En outre les pourcentages faibles sont souvent peu intuitifs. Donc, il est souvent plus parlant, surtout si l’on s’adresse à un public de non spécialistes, de décrire les résultats avec des proportions arrondies en termes de tiers, de quarts, de 1 répondant sur x, etc. Comment décrire l’évolution de moyennes, de proportions, etc. ? On doit d’abord décrire une tendance générale avant même d’entrer dans les détails : hausse, baisse, stagnation, volatilité ou stabilité, etc. On peut généraliser à trois principaux types de description des évolutions :
i) l’évolution en points de pourcentage, c’est la différence arithmétique entre les %. ii) l’écart arithmétique : c’est la variation des pourcentages exprimée en %, sur le modèle :
initialesituation initialesituation -finalesituation
iii) la progression géométrique : qui consiste à diviser la situation finale par la situation
initiale, pour voir de « combien de fois » un taux a augmenté (éventuellement diviser la situation initiale par la situation finale pour voir de combien de fois le taux a diminué).
5. VARIABLES ET QUESTIONNAIRE

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 9 -
5.1. Généralités et types de variables Le questionnaire est un outil tout à fait central pour les sciences sociales et beaucoup d’autres disciplines encore. Le questionnaire est non seulement un outil central, mais également jouissant d’une certaine légitimité et d’une certaine notoriété, notamment auprès du grand public. Un questionnaire est composé d’un certain nombre de questions posées dans un ordre structuré ayant une justification théorique et pratique. Concepts / hypothèses -> dimensions -> indicateurs (sur la base des variables contenues dans le questionnaire). Il y a quelques règles de base dont il faut tenir compte pour rédiger un questionnaire, au niveau de l’intitulé des questions et de la succession des questions. Nous les verrons en détail au cours de méthodologie. Nous avons déjà évoqué le fait qu’on peut diviser les variables en deux groupes : les variables quantitatives (intervalles ou quotient) et qualitatives (nominales ou ordinales). Nominales : il n’y a ni ordre ni distance entre les modalités Ordinales : il y a un ordre mais pas la distance entre les modalités Quantitatives (surtout quotient) : ordre et distances. Parmi les variables qualitatives, le nombre de réponses possibles c.-à-d. de modalités peut fortement varier. On peut avoir des variables dichotomiques. A l’opposé, on peut avoir un très grand nombre modalités. P.ex. la profession exercée par le répondant (ESPA). Dans ces cas-là, on recourt souvent à des nomenclatures. On peut formuler des questions ouvertes ou fermées. 5.2 Aspects pratiques et mathématiques En pratique, on attribue en général un code numérique à chaque réponse. Attention lorsque vous avez une matrice des données, la présence de codes numériques ne signifie pas qu’il s’agit d’une variable quantitative (p.ex. femme = 1, homme =2, le 1 et le 2 n’ont pas de valeur mathématique). Le format d’une variable est également un point important, en particulier pour les variables quantitatives. Les dates peuvent être des variables difficiles Autre point très important, il y a toujours un certain nombre de personnes interrogées qui ne donnent pas une réponse précise à la question. En général on définit des codes spéciaux et éventuellement un code « autre ». Les valeurs manquantes (ou missing) et aberrantes sont également très importantes, il faut toujours les analyser.

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 10 -
Tous les points traités ci-dessus le seront de façon beaucoup plus approfondie et à grand renfort d’exemples au cours de méthodologie, en deuxième année. 6. ECHANTILLONAGE, PONDERATION ET REPRESENTATIVITE 6.1. Population et échantillonnage 6.1.1. Définir la population de référence Cela constitue une première étape très importante dans l’optique de définir le tirage aléatoire d’un échantillon et les conclusions de l’étude ne pourront porter que sur cette population de référence et les unités statistiques qui la composent. 6.1.2. Recensements, dénombrement complet et échantillons Généralement un dénombrement complet de la population est très compliqué, très onéreux et très long. Le recensement fédéral de la population a lieu tous les 10 ans. Ceci est évidemment un exemple extrême ; si la population de référence n’est pas trop grande ou très hétérogène, cela peut valoir la peine de réaliser un relevé exhaustif. L’avantage d’un dénombrement complet est bien entendu que les paramètres de la population sont connus, alors que pour un échantillon il faut faire des estimations qui sont entachées d’une certaine erreur. Un échantillonnage aléatoire est basé sur des règles de sélection permettant de savoir a priori quelle est la probabilité pour un élément de la population de figurer dans l’échantillon. On peut en outre définir des règles fixes de sélection. Cela est en général conseillé pour les études à caractère scientifique. Enfin, il existe plusieurs manières de constituer un échantillon aléatoire, comme l’indique le schéma suivant :

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 11 -
Une classification possible des divers types d’échantillonnage :
i. Tous les éléments de la population sont-ils examinés ? NON : relevé partiel / échantillonnage OUI : relevé exhaustif
↓ ii. La sélection est-elle réalisée selon des règles fixes ?
OUI NON : sélection arbitraire ↓
iii. Si oui, ces règles reposent-elles sur un processus aléatoire ? OUI : sélection aléatoire NON : échant. par choix raisonné ↓
iv. Le processus se déroule-t-il en une étape ? OUI NON ↓
v. Le processus est-il basé sur une définition de groupes homogènes avant le tirage dans lesquels on tire au sort des échantillons aléatoires simples ?
NON OUI : échantillon stratifié ↓
i. Ou alors en unités spatiales et ensuite on relève l’information de tous les éléments de ces unités spatiales ?
NON : échantillon aléatoire simple OUI : échantillon par grappes La base de la plupart des processus aléatoires d’échantillonnage repose sur le fait d’avoir à disposition une liste exhaustive des éléments de la population de référence. En outre, l’autre élément absolument central réside dans le fait d’avoir la même probabilité d’être sélectionné ou non. Si cette probabilité varie d’une unité à l’autre, on doit généralement effectuer une pondération. En outre, il se peut que le processus de sélection et la réalisation de l’étude entraînent des biais, si les non-réponses, les refus, etc ne sont pas répartis de façon homogène. Il faut donc bien être conscient que l’échantillon obtenu est certes représentatif, mais d’une population peut-être légèrement différente de celle qu’on souhaiterait étudier. 6.1.2.1. Echantillon aléatoire simple On effectue un tirage de n éléments qui possèdent tous la même probabilité d’être sélectionnés. Si on opère à nouveau un tirage au sort à partir de cet échantillon (selon le modèle ci-dessus), le nouvel échantillon obtenu est également un échantillon aléatoire simple.

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 12 -
Les paramètres de la population peuvent être estimés par une mesure réalisée sur l’échantillon. Cette estimation est entachée d’une erreur que l’on peut estimer. On peut aussi calculer des intervalles de confiance. Nous y reviendrons. Les tirages reposent sur l’utilisation de nombres aléatoires. Ceux-ci sont soit disponibles dans des tables, soit générés par ordinateur. A côté de ces échantillonnages existent d’autres petits « trucs » utilisés dans la pratique (initiales, jour et mois de la naissance, etc.). 6.1.2.2. Echantillon stratifié Les éléments de la population sont regroupés en strates de façon à ce que chaque élément appartienne à une – et une seule – strate. Ensuite pour chaque strate on procède à un échantillonnage aléatoire. Deux avantages principaux : d’une part, si les strates se différencient par la dispersion d’une caractéristique intéressante, alors l’estimation de cette caractéristique est plus précise avec un échantillon stratifié (réduction de la variance). D’autre part, si les strates constituent en elles-mêmes un élément d’analyse intéressant (p.ex. des zones linguistiques ou des cantons pour la Suisse), on peut tirer des conclusions pour chaque strate. On peut également définir a priori le nombres de cas minimal qu’on doit avoir pour une strate donnée afin de pouvoir tirer des conclusions fiables. Désavantages : un échantillon stratifié nécessite une connaissance préalable de la population de base et de la répartition de certaines caractéristiques. D’autre part, la division en strates peut n’être idéale que par rapport à certaines (ou à une seule) caractéristique(s) et il est parfois difficile d’établir quelles sont les strates les plus intéressantes. 6.1.2.3. Echantillon par grappes Dans ce cas, le tirage aléatoire simple ne se base pas sur la population de base, mais sur un des agrégats, les grappes. On tire au sort un certain nombre de grappes et ensuite on collecte des données auprès de TOUS les éléments de chaque grappe. Cette approche a notamment un grand avantage lorsqu’on ne dispose pas d’une liste exhaustive de la population de référence. Problème si les grappes sont très différentes les unes des autres. Ainsi les éléments sont plus semblables à l’intérieur d’une grappe qu’ils ne le seraient dans un échantillon aléatoire et cela a pour conséquence une fiabilité moindre pour l’échantillon par grappes que celle d’un échantillon aléatoire simple. L’imprécision surgit donc lorsque les éléments sont très similaires à l’intérieur des grappes et que les grappes sont très différentes les unes des autres. La précision dépend également du nombre d’éléments dans chaque grappe : plus la grappe est homogène et plus elle compte d’éléments, moins l’échantillon par grappe est précis.

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 13 -
6.1.2.4. Plan de sondage à plusieurs degrés Jusqu’ici nous avons vu des procédés avec un seul tirage aléatoire. En général dans la recherche appliquée on recourt à des échantillonnages plus complexes. Très souvent, les études auprès de la population résidente sont basées sur des découpages géographiques. Ensuite on procède à un tirage aléatoire dans ces éléments primaires et on détermine ainsi des unités secondaires (p.ex. des foyers par le biais d’une base de sondage téléphonique), puis un autre tirage p.ex. un membre du foyer. En général le nombre des éléments varie fortement d’une unité primaire à l’autre, surtout lorsqu’il s’agit d’unités géographiques. Il faut en tenir compte dans l’échantillonnage et la pondération. 6.1.2.5. Sélection arbitraire Seuls les échantillons aléatoires garantissent l’utilisation de la statistique inférentielle. La sélection d’un élément de la population ne suit pas un plan d’échantillonnage précis, tel qu’on doit le faire pour les études à caractère scientifique. 6.1.2.6. Sélection par choix raisonné L’échantillon n’est pas sélectionné au hasard. Le cas le plus connu et probablement le plus utilisé est la méthode dite « des quotas ». Les instituts de sondages y recourent fréquemment. Les méthodes de la statistique inférentielle ne sont pas applicables. Quotas : l’échantillon est choisi de manière à ce que certaines caractéristiques aient dans l’échantillon exactement la même fréquence que dans la population. Cette méthode est beaucoup utilisée parce qu’elle présente de sérieux avantages en termes de temps, de budget et lorsque aucune base de sondage n’est disponible, mais n’est guère utilisée dans la recherche scientifique. 6.1.3. Panels et cohortes On peut réaliser une étude plusieurs années de suite, en procédant à un nouvel échantillonnage à chaque fois. Chaque prise d’information est désignée par le terme de « vague ». On peut ainsi observer l’évolution de phénomènes sociaux dans le temps, pour autant que l’échantillonnage et les outils de relevé des données restent identiques d’une année à l’autre. A chaque vague, on peut donc cerner l’évolution générale d’un phénomène, sans toutefois savoir comment la situation particulière d’un individu, d’un ménage, d’une entreprise, d’un canton, etc. évolue sur plusieurs années. Pour étudier ce genre de phénomènes, il faut recourir à des études basées sur des panels ou des cohortes.

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 14 -
Panel : on étudie les mêmes variables auprès des mêmes personnes à plusieurs moments dans le temps. Cela permet de mettre en valeur des processus, comme la volatilité ou la permanence d’une situation. La question du meilleur espacement entre les vagues est un point très délicat et très important. Les défauts des panels :
- Difficile d’assurer la constance des instruments de mesure sur une période de temps assez longue
- la mortalité du panel - le coût est généralement très élevé - les effets de panel : les participants changent de comportement à force d’être
interrogés. Les cohortes : On sélectionne des personnes pour qui le même événement est survenu au même moment de leur existence. L’exemple le plus connu est celui de cohortes basées sur l’année de naissance (personnes nées la même année). 6.2. Quelques remarques sur la notion de représentativité Les échantillons aléatoires constituent la seule garantie que l’on puisse tirer des conclusions sur les paramètres de la population de référence sur la base des caractéristiques de l’échantillon, du moins dans les limites de certaines erreurs statistiques. En principe c’est la seule dimension vraiment scientifique du terme « représentativité ». En pratique, par contre, on utilise ce terme à tort et à travers. Il ne s’agit pas d’un critère de qualité bien défini. Pour juger de la qualité d’une procédure d’échantillonnage, il faut au moins disposer d’informations exactes sur : la population de référence, le processus de sélection, les valeurs manquantes, les non-réponses, la distribution de certaines valeurs structurelles et les instruments utilisés En aucun cas on ne peut se contenter, en sciences sociales, de constater que certaines caractéristiques de l’échantillon sont réparties de la même manière que dans la population de référence et d’en déduire que c’est le cas pour toutes les caractéristiques. Il faut donc se méfier de la méthode des quotas, mais aussi des échantillons aléatoires contenant des non-réponses qui peuvent générer une distorsion.

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 15 -
6.3. Non-réponse, valeurs manquantes et valeurs extrêmes : plausibilisation et contrôles de qualité Dans chaque étude on trouve des ménages qui ont été sélectionnés mais qui n’aboutissent pas dans l’échantillon. C’est le problème de la non-réponse. En général, on distingue le cas où on n’a pas pu récolter la moindre information sur l’unité d’enquête (foyer, personne, entreprise, commune, etc.) du cas où on a pu contacter l’unité en question mais quelques réponses font défaut. Dans le premier cas, on parle de non-réponse totale (par unité) et dans le second de non-réponse partielle (par item). Les causes de la non-réponse totale :
- mauvaise information de contact : les n° de tél ne sont pas valables, il s’agit de n° de fax, l’adresse est fausse ou inexistante, etc
- absence du répondant (à l’étranger, en vacances, au service militaire, communes touristiques, etc.)
- refus de participer, la personne contactée raccroche, claque la porte ou passe son chemin
- déménagement - problèmes de langue, notamment pour les personnes ne maîtrisant aucune des
langues officielles suffisamment - le fardeau du répondant est trop élevé. C’est particulièrement vrai si le
questionnaire est long ou s’il y a plusieurs vagues. Participation obligatoire ou volontaire ?
- manque d’intérêt du répondant pour le sujet ou manque de temps Les causes de la non-réponse partielle :
- le répondant n’a pas compris la question - il refuse de répondre, notamment parce que la question paraît indiscrète, gênante - ne sait pas la réponse, ne peut pas se prononcer - l’interviewer a oublié de poser la question
Dans ce cas on peut aussi obtenir des réponses impossibles, incohérentes, inutilisables, ce sont des problèmes qui s’ajoutent aux valeurs manquantes stricto sensu. En bref, on recense les 4 cas suivants : - Non répondants - Réponses partielles - Réponses incohérentes, impossibles - Répondants

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 16 -
A chaque étape d’une recherche on peut prévenir en partie la non-réponse : - Lors de la planification - Lors de la création de la base de sondage, en la nettoyant le plus possible et en ayant des informations valables, ainsi que l’information de classification (p.ex. secteur d’activité) - Lors de l’élaboration du plan de sondage (par expérience) - Dans la conception du questionnaire, certaines questions ou structures peuvent générer la non-réponse - Pendant la collecte des données, par la formation des enquêteurs, par des tests, en envoyant des courriers avant la collecte, etc. Effectuer un suivi de la non-réponse. En fait il existe trois mécanismes :
1) uniforme / missing completely at random : la probabilité de réponse ne dépend d’aucune variable. Peu réaliste.
2) ignorable / missing at random : la variable dépend de certaines variables auxiliaires, mais pas de la variable d’intérêt (la variable qu’on veut expliquer, la variable centrale de l’étude)
3) non-ignorable / not missing at random : c’est la cas le plus grave qui peut entraîner de graves distorsions, parfois très difficiles à corriger.
En outre on peut distinguer les personnes difficilement atteignables, les personnes incapables de répondre / non-interviewables et les personnes qui refusent. Ceci implique donc un nécessaire travail de plausibilisation et de contrôle de qualité. On peut identifier 3 étapes :
1) l’analyse des données manquantes, nous en avons déjà parlé plus haut. 2) l’analyse des valeurs extrêmes pour les variables quantitatives. Rappel : les outliers
sont des valeurs se trouvant soit en dessus de + 1.5* IQR ou en dessous de -
1.5* IQR. Parfois on s’intéresse aux valeurs vraiment extrêmes et on peut les définir au moyen de 3 fois l’écart interquartile au lieu d’une fois et demie. Certains utilisent parfois la moyenne et 3 fois l’écart-type, càd
q3 q1
σ*3±x .
3) L’analyse des réponses incohérentes, incorrectes et douteuses. Les incohérences surgissent souvent par la combinaison de plusieurs variables.

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 17 -
6.4. Probabilité de sélection, non-réponse et pondération Le calcul repose en général sur l’inverse de la probabilité d’inclusion et / ou sur l’inverse du taux de réponse, ce qui donne plus de poids aux sous-groupes de la population ayant davantage de refus, c’est-à-dire étant sous-représentés dans l’échantillon. Si l’on utilise p.ex. un échantillon stratifié disproportionnel, les diverses strates doivent être soumises à une pondération, afin de pouvoir tirer des conclusions fiables à partir des données de l’échantillon. Le principe est simple: les éléments ayant une probabilité élevé d’être sélectionnés se voient attribuer un faible poids et vice versa. Le principe consiste à multiplier par l’inverse de la probabilité d’inclusion, c’est-à-dire la probabilité d’être dans l’échantillon.
On note souvent : )(
1inclusionp
wi = .
En règle générale, la pondération des études ayant un plan d’échantillonnage bien précis se déroule en plusieurs étapes, ou selon l’une ou l’autre des étapes suivantes : - la pondération qui tient compte de la probabilité d’inclusion, telle que décrite dans l’exemple ci-dessus. Le rapport 1/p(inclusion) est le poids de sondage. Dans le cas de strates
régionales, la probabilité d’inclusion = irégion la de adressesd' nombres
irégion la dans choisies adressesd' nombre
- la pondération qui tient compte du taux de non-réponse et des facteurs qui influencent le
plus ces non-réponses. Il s’agit l’approche traditionnelle consistant à utiliser le rapport pw
i
i
ˆ , le
numérateur étant le poids de sondage défini ci-dessus et le dénominateur est une estimation du taux de réponse. P.ex. si on considère les ménages ayant refusé de répondre dans la région i :
la probabilité de réponse = irégion la dans choisies adressesd' nombre
répondu ayant irégion la de ménages de nombre
- le calage qui est une approche plus récente. Le but est de pondérer par l’inverse des probabilités de réponse, en utilisant des poids wi
~ étant les plus proches possibles de poids
initiaux tout en assurant des totaux et des taux conformes à ceux observés dans les recensements sur les variables considérées.
wi
Les sondeurs utilisent souvent le redressement, qui consiste à pondérer de telle façon que certaines caractéristiques de l’échantillon correspondent exactement à celles de la population (sexe, âge, région, etc). D’un point de vue scientifique on doit dire que le redressement tend davantage à masquer le problème de la non-réponse plutôt qu’à le résoudre.

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 18 -
7. PROBABILITES 7.1. Notions fondamentales des probabilités L’ensemble fondamental d’une expérience aléatoire se compose de l’ensemble des résultats possibles. On le note Ω = a,b,c,d,... , ces lettres désignant chaque événement élémentaire. P.ex. on tire un dé, l’ensemble des résultats possibles est Ω = 1,2,3,4,5,6. Dans ce cas il s’agit d’une ensemble fini et dénombrable. Cet ensemble peut dans certains cas être dénombrable mais infini, p.ex. le nombre de fois nécessaire pour obtenir face lorsqu’on lance une pièce et qu’on joue à pile ou face : Ω = P, PF, PPF, PPPF, ..., PPPPPPPPPF, ..... Il y a même des cas ou les événements possibles ne sont pas dénombrables, car ils sortent de l’ensemble des nombres entiers naturels, comme par exemple le revenu d’une personne, qui peut prendre une infinité de valeurs, puisqu’il s’agit d’une variable continue comme nous l’avons déjà vu. Un événement est généralement la combinaison de plusieurs résultats possibles. Lorsqu’on traite de la question des « working poor », l’ensemble des événements possibles peut être défini comme: (non-pauvre, actif), (non-pauvre, non-actif), (pauvre, non-actif), (pauvre, actif). Ceci dit, il existe des événements simples, constitués d’un seul résultat, p.ex. on lance un dé une fois. Chaque valeur du dé constitue un événement simple. Il existe des cas particuliers, l’événement impossible que l’on note ∅ (l’ensemble vide), et l’événement certain que l’on note Ω . 7.2. Théorie des ensembles et probabilités Ω
A
A est un événement, symbolisé par l’ellipse et le rectangle symbolise l’ensemble fondamental. On peut de même représenter deux événements d’un ensemble fondamental. Parfois les ensembles sont disjoints, car il n’y a pas d’intersection, parfois il y en a une. Si A est l’événement « être pauvre », B « être non pauvre », C « être actif » et D « être working poor », alors on note A B∩ = ∅ et A C D∩ = . Dans la première figure ci-dessous les deux ensembles ne se recoupent pas, dans le second au contraire il y a une intersection, qui est l’événement D.
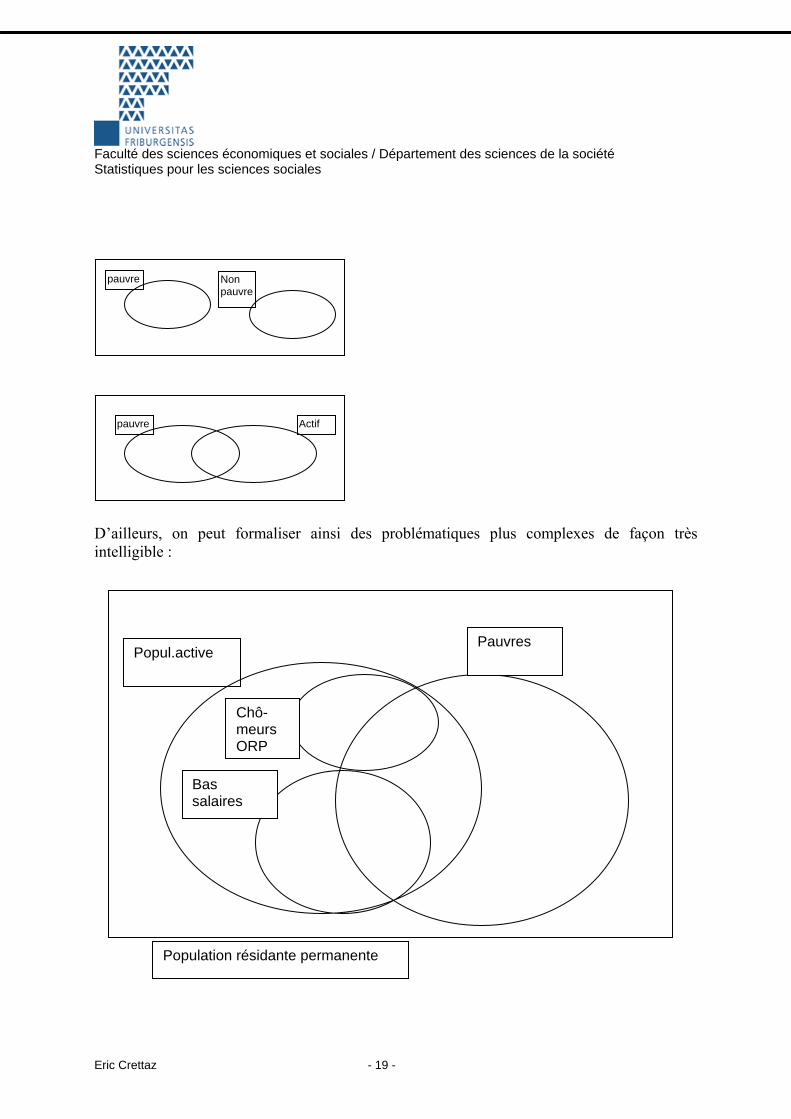
Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz
D’ailleurs, on peut formaliser ainsi des problématiques plus complexes de façon très intelligible :
Pauvres Popul.active
Bas salaires
Chô-meurs ORP
pauvre Non pauvre
pauvre Actif
Population résidante permanente- 19 -

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 20 -
7.3. Propriétés des probabilités P est une probabilité si elle satisfait les propriétés suivantes : 1) 0 ≤ P(A) ≤ 1 , avec A un événement et sachant que P(∅ )=0 et P(Ω )=1. Pour être concret, la probabilité d’un événement doit être comprise entre 0 et 100% 2) A ∪B signifie que soit l’événement A se produit, soit l’événement B se produit , soit les deux simultanément. 3) Il existe un événement complémentaire qu’on note A , qui signifie en fait que A ne se réalise pas. Exemple : ne pas être pauvre. La probabilité de l’événement complémentaire est vaut donc P( A )=1-P(A). Il arrive que tous les événements de l’ensemble fondamental aient la même probabilité, on parle alors d’équiprobabilité, p.ex. lorsqu’on lance un dé, s’il n’est pas pipé, chaque valeur du dé a la même probabilité. La probabilité de n’importe quel événement se calcule de la même façon : P(A) = nombre de cas favorables nombre de cas possibles Une propriété importante est la suivante : P(A B) = P(A) + P(B) - P(A B) . ∪ ∩ 7.4. Indépendance et probabilités conditionnelles Soit deux événements A et B. On se demande si la probabilité que A se réalise influence la probabilité que B se réalise. On note P(A / B) la probabilité que A se réalise sachant que B est réalisé. Il s’agit d’une probabilité conditionnelle. Si l’événement B est possible (c’est-à-dire si P(B)>0), on sait que
P(A / B) = P(A B)
P(B)∩
Notons que P(A / B) = 1 - P( A / B) Souvent se pose la question, notamment en sciences sociales, de savoir si deux variables sont indépendantes l’une de l’autre. C’est un point crucial, et on définit cette indépendance de la façon suivante :

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 21 -
Deux événements sont indépendants si P(A / B) = P(A), en d’autres termes si la variable B n’a pas d’influence sur la probabilité que A se réalise. On peut montrer que si A et B sont des événements indépendants, P(A B) = P(A) * P(B), ∩ en effet, compte tenu de la formule de calcul d’une probabilité conditionnelle définie ci-dessus : P(A∩B) = P(A / B) * P(B) or si A et B sont indépendant P(A / B) = P(A), donc P(A∩B) = P(A) * P(B). 7.5. Analyse combinatoire Lire pp. 145 à 148 du Dodge. 8. LES VARIABLES ALEATOIRES : PROBABILITES, REPARTITION ET DENSITE Une variable aléatoire est une variable dont les valeurs sont déterminées par une « expérience aléatoire ». Nous en distinguerons deux types : les variables aléatoires discrètes et continues. Nous verrons également les principales distributions de v.a. continues et discrètes utilisées en statistique : la loi binômiale, la loi de Poisson, la loi normale (parfois centrée réduite). 8.1. Les variables aléatoires discrètes Il s’agit de variables dont chaque valeur a une probabilité strictement positive ou nulle. On écrit pour la variable aléatoire discrète X ayant ses valeurs dans un ensemble fini , , ..., :
1x 2xkx
0 ≤ = ≤P X ix( ) 1
Définition : la fonction XF X( ) = P (X≤ ix ) = est appelée la fonction de
répartition, et elle varie entre 0 et 1.
P Xx
ix
xi
( =≤∑ )
La loi de probabilité est une fonction qui associe à chaque valeur de la variable X la probabilité P(X= ). On représente la densité de cette variable au moyen d’un graphique avec des rectangles dont la largeur doit faire une unité, pour que la surface totale des rectangles soit égale à 1.
ixix

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 22 -
Densité
0,390,44
0,14
0,03
00,050,1
0,150,2
0,250,3
0,350,4
0,45
nombre d'enfants
prob
abili
tés 1 enfant
2 enfants3 enfants4 enfants
On peut résumer l’information nécessaire dans un tableau : X=x 1 2 3 4 enfants ou
plus P(X=x) 0.39 0.44 0.14 0.03
XF X( ) 0.39 0.83 0.97 1
Et la fonction de répartition est représentée de la manière suivante :
Fonction de répartition
00,10,20,30,40,50,60,70,80,9
1
0 1 2 3 4
nombre d'enfants
pour
cent
age

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 23 -
Autre exemple, la fonction de répartition du lancer de dé :
Une propriété importante doit être soulignée ici. Soient deux valeurs a et b telles que a<b, alors P(a < x b) = ≤ XF b( ) - XF a( ) . Dans l’exemple précédent, prenons la probabilité d’avoir plus d’un enfant et au maximum 4 enfants. Il s’agit ici de calculer P( 1 < x ≤4) = XF ( )4 - XF ( )1 = 1 - 0.39 = 0.61 = 61% 8.2. Les variables aléatoires continues Il s’agit de variables dont chaque valeur admise a une probabilité nulle. En effet, puisque cette variable est continue, elle peut prendre une infinité de valeurs. Il faut définir des probabilités sur un intervalle. Comme il s’agit de variables continues, la fonction de répartition prend la forme suivante :
Cette fonction remplit le même but que l’ « escalier » pour les v.a. discrètes. Donc cette fonction de répartition indique, pour chaque valeur x de la variable X, la probabilité d’avoir des valeurs inférieures à x, c.-à-d. P(X≤x).
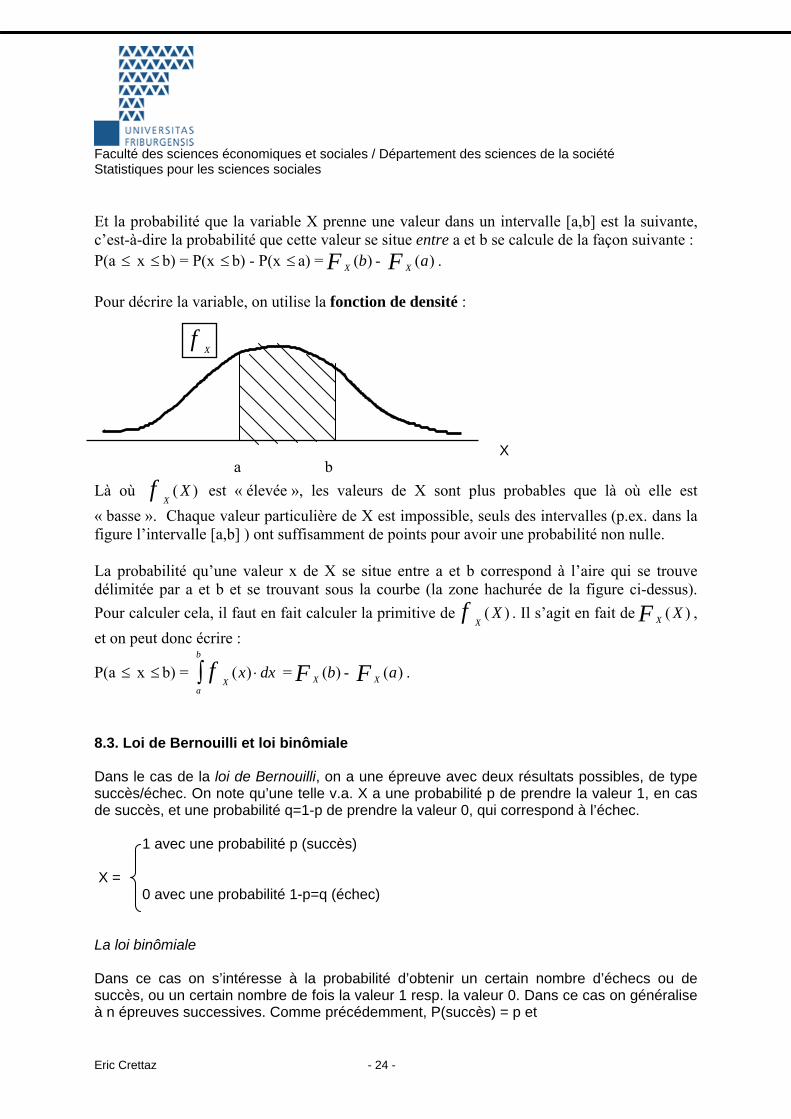
Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 24 -
Et la probabilité que la variable X prenne une valeur dans un intervalle [a,b] est la suivante, c’est-à-dire la probabilité que cette valeur se situe entre a et b se calcule de la façon suivante : P(a x b) = P(x b) - P(x ≤ a) =≤ ≤ ≤ XF b( ) - XF a( ) . Pour décrire la variable, on utilise la fonction de densité :
f X
X a b Là où est « élevée », les valeurs de X sont plus probables que là où elle est « basse ». Chaque valeur particulière de X est impossible, seuls des intervalles (p.ex. dans la figure l’intervalle [a,b] ) ont suffisamment de points pour avoir une probabilité non nulle.
Xf X( )
La probabilité qu’une valeur x de X se situe entre a et b correspond à l’aire qui se trouve délimitée par a et b et se trouvant sous la courbe (la zone hachurée de la figure ci-dessus). Pour calculer cela, il faut en fait calculer la primitive de
Xf X( ) . Il s’agit en fait de XF X( ) ,
et on peut donc écrire :
P(a x b) = =≤ ≤X
a
b
f x dx( )∫ ⋅ XF b( ) - XF a( ) .
8.3. Loi de Bernouilli et loi binômiale Dans le cas de la loi de Bernouilli, on a une épreuve avec deux résultats possibles, de type succès/échec. On note qu’une telle v.a. X a une probabilité p de prendre la valeur 1, en cas de succès, et une probabilité q=1-p de prendre la valeur 0, qui correspond à l’échec.
1 avec une probabilité p (succès) X =
0 avec une probabilité 1-p=q (échec)
La loi binômiale Dans ce cas on s’intéresse à la probabilité d’obtenir un certain nombre d’échecs ou de succès, ou un certain nombre de fois la valeur 1 resp. la valeur 0. Dans ce cas on généralise à n épreuves successives. Comme précédemment, P(succès) = p et
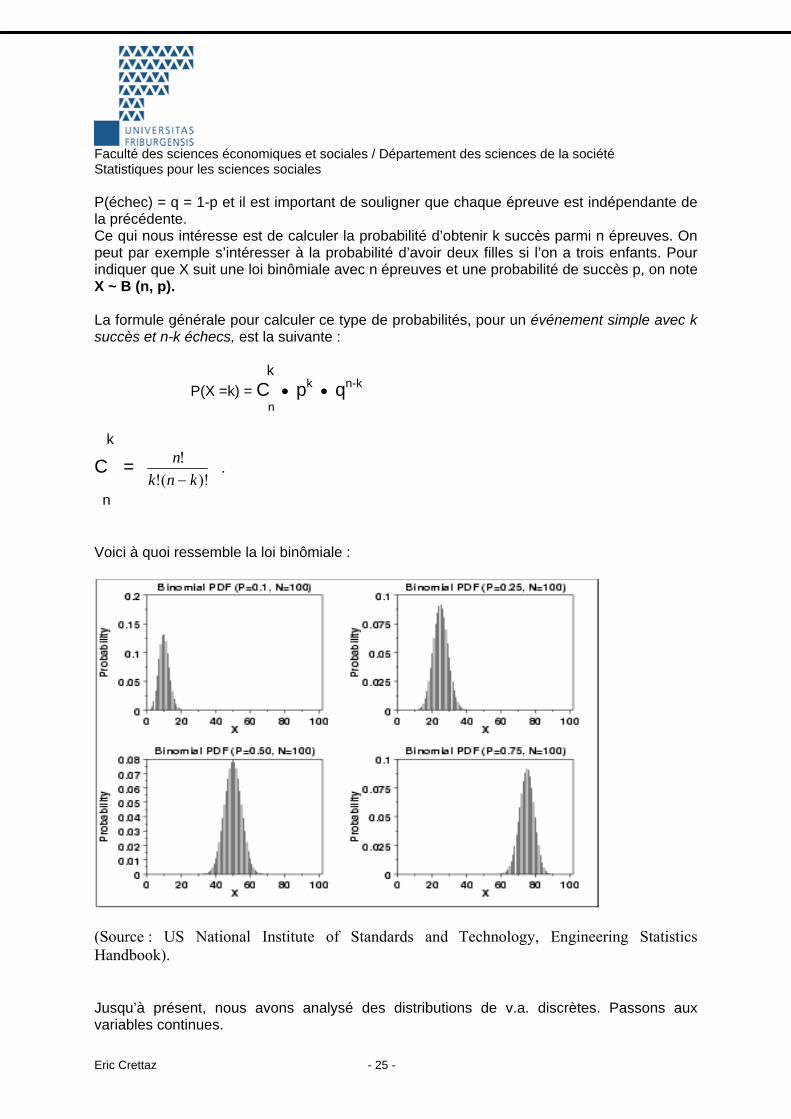
Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 25 -
P(échec) = q = 1-p et il est important de souligner que chaque épreuve est indépendante de la précédente. Ce qui nous intéresse est de calculer la probabilité d’obtenir k succès parmi n épreuves. On peut par exemple s’intéresser à la probabilité d’avoir deux filles si l’on a trois enfants. Pour indiquer que X suit une loi binômiale avec n épreuves et une probabilité de succès p, on note X ~ B (n, p). La formule générale pour calculer ce type de probabilités, pour un événement simple avec k succès et n-k échecs, est la suivante :
k
P(X =k) = C p• k q• n-k n
k
C = )!(!
!knk
n−
.
n
Voici à quoi ressemble la loi binômiale :
(Source : US National Institute of Standards and Technology, Engineering Statistics Handbook).
Jusqu’à présent, nous avons analysé des distributions de v.a. discrètes. Passons aux variables continues.
Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 26 -
8.5. La loi normale 8.5.1. Distribution La distribution d’une v.a. continue peut prendre p.ex. les formes suivantes :
La densité d’une v.a. suivant une loi normale a la forme d’une cloche symétrique, c’est la fameuse courbe de Gauss. Toute loi normale se caractérise par 2 paramètres : µ et σ2, et on note X ~ N (µ, σ2), qu’on estime de la façon suivante
pour µ : n
xn
ii∑
= 1 et pour σ2 : n
xxn
ii∑
=
−1
2)(
La formule de la loi normale est la suivante :
⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
−=2
21exp
21)(
σµ
πσxxf x
Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 27 -
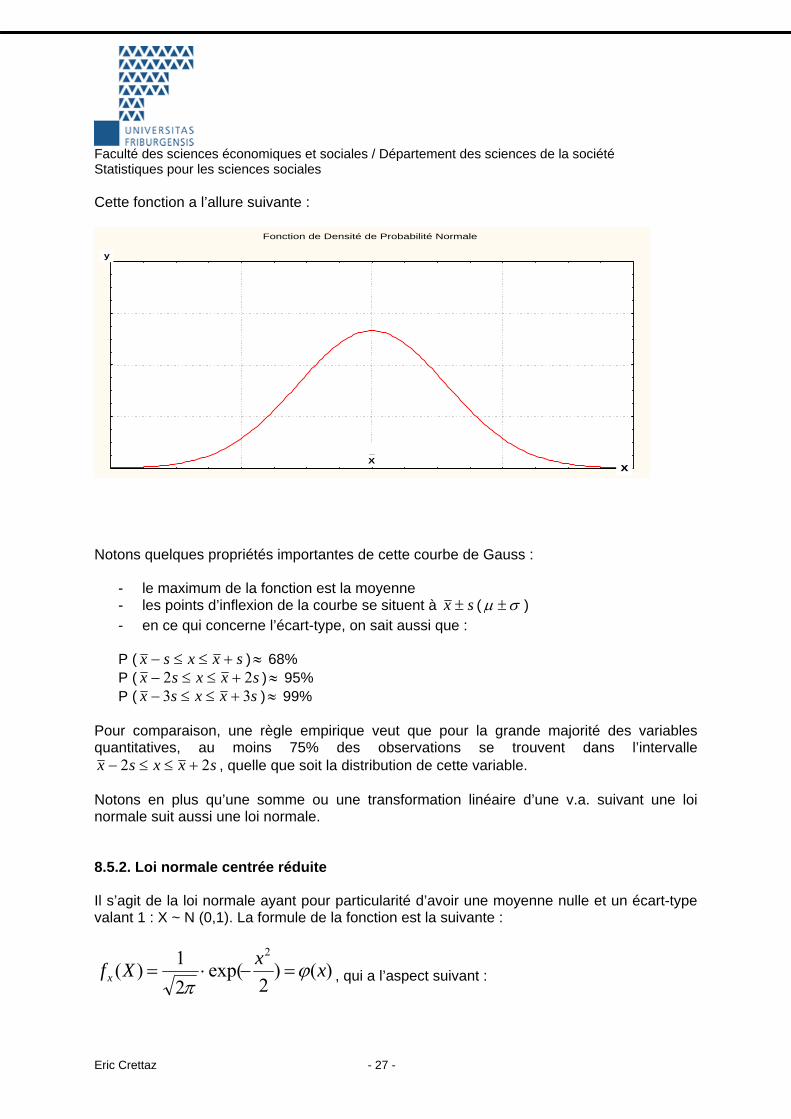
Cette fonction a l’allure suivante :
Fonction de Densité de Probabilité Normale
x
y
X_
Notons quelques propriétés importantes de cette courbe de Gauss :
- le maximum de la fonction est la moyenne - les points d’inflexion de la courbe se situent à sx ± ( σµ ± ) - en ce qui concerne l’écart-type, on sait aussi que : P ( sxxsx +≤≤− ) 68% ≈P ( sxxsx 22 +≤≤− ) 95% ≈P ( sxxsx 33 +≤≤− ) 99% ≈
Pour comparaison, une règle empirique veut que pour la grande majorité des variables quantitatives, au moins 75% des observations se trouvent dans l’intervalle
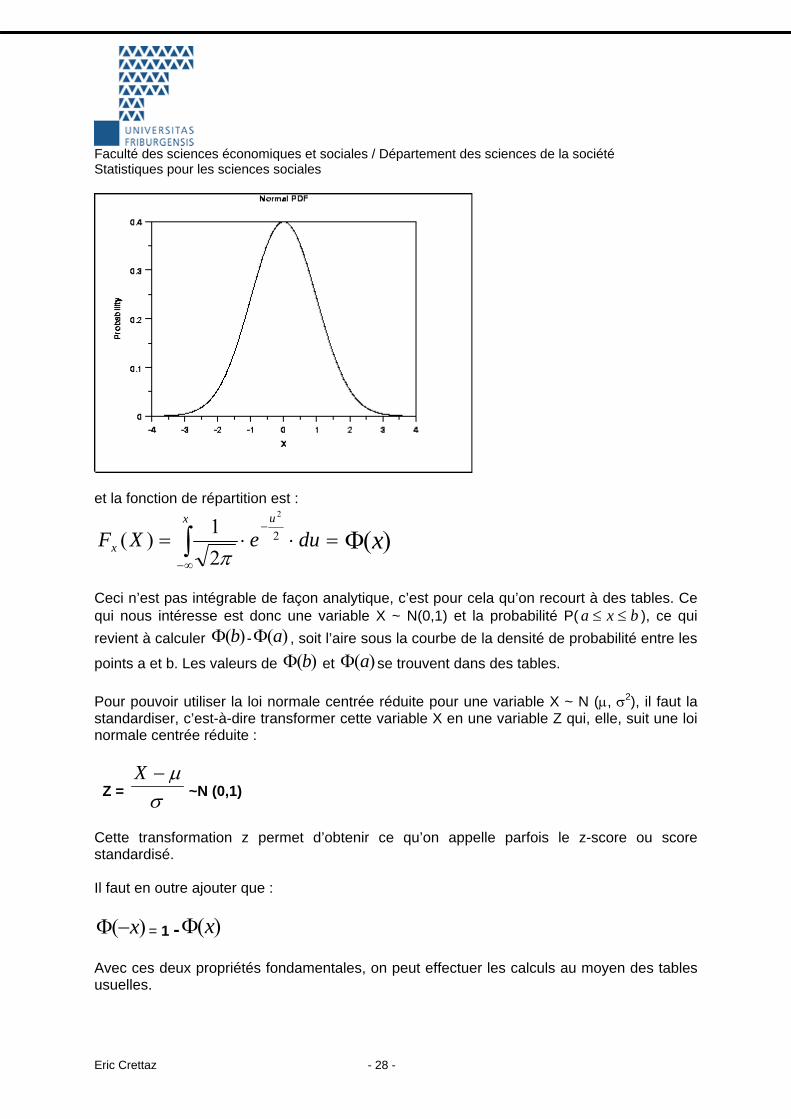
sxxsx 22 +≤≤− , quelle que soit la distribution de cette variable. Notons en plus qu’une somme ou une transformation linéaire d’une v.a. suivant une loi normale suit aussi une loi normale. 8.5.2. Loi normale centrée réduite Il s’agit de la loi normale ayant pour particularité d’avoir une moyenne nulle et un écart-type valant 1 : X ~ N (0,1). La formule de la fonction est la suivante :
)()2
exp(21)(
2
xxXfx ϕπ
=−⋅= , qui a l’aspect suivant :
Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 28 -
et la fonction de répartition est :
=⋅⋅= ∫∞−
−dueXF
x u
x2
2
21)(π
)(xΦ
Ceci n’est pas intégrable de façon analytique, c’est pour cela qu’on recourt à des tables. Ce qui nous intéresse est donc une variable X ~ N(0,1) et la probabilité P( ), ce qui revient à calculer - , soit l’aire sous la courbe de la densité de probabilité entre les
points a et b. Les valeurs de et
bxa ≤≤)(bΦ )(aΦ
)(bΦ )(aΦ se trouvent dans des tables. Pour pouvoir utiliser la loi normale centrée réduite pour une variable X ~ N (µ, σ2), il faut la standardiser, c’est-à-dire transformer cette variable X en une variable Z qui, elle, suit une loi normale centrée réduite :
Z = σµ−X
~N (0,1)
Cette transformation z permet d’obtenir ce qu’on appelle parfois le z-score ou score standardisé. Il faut en outre ajouter que :
)( x−Φ = 1 - )(xΦ Avec ces deux propriétés fondamentales, on peut effectuer les calculs au moyen des tables usuelles.

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 29 -
8.5.3. Le théorème central limite TCL C’est l’un des théorèmes fondamentaux de la statistique. Il dit que si on a une grand nombre de variables aléatoires x 1 , x , …, x identiquement distribuées, alors leur somme x 1 + x +…+ x suit approximativement une loi normale. On estime que ce théorème est applicable à partir de n = 30.
2 n
2 n
Cela signifie notamment que la moyenne d’un échantillon aléatoire suit une loi normale,
c’est-à-dire x ~ N (2, xx σµ ).
Supposons que vous voulez calculer la moyenne d’âge des habitants d’un pays et que vous tirez aléatoirement 1000 échantillons différents et calculez chaque fois la moyenne. Les moyennes calculées vont se répartir sur une courbe en forme de cloche, une courbe de Gauss. Nous y reviendrons lorsque nous parlerons des intervalles de confiance. 8.5.4. Vérifier la normalité des données et transformations On peut de façon qualitative considérer le Q-Q plot (Quantile-Quantile) qui est un graphique qui compare les quantiles théoriques de la loi normale et les quantiles observés. Si les points de ce graphique sont plus ou moins alignés le long d’une droite alors on peut partir du principe que la variable suit une loi normale. Un Q-Q plot à l’aspect suivant, en prenant l’exemple des revenus des foyers :
Valeur gaussienne théorique
Valeur observée du revenu
Sur cet exemple on constate très clairement que les revenus des foyers ne suivent pas une distribution normale, car les points (en rouge) s’éloignent de la droite à partir d’un certain niveau de revenus.

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 30 -
En fait beaucoup de tests statistiques sont basés sur l’hypothèse de la normalité des données. Cette hypothèse mène à des tests qui sont simples et puissants comparés à certains autres tests n’étant pas basés sur cette hypothèse. Malheureusement, beaucoup de jeux de données n’ont pas une distribution normale. C’est pour cela qu’on procède à des transformations de manière à obtenir une variable transformée suivant à peu près une loi normale. Il y a beaucoup de possibilités de transformations : - racine carrée, - logarithme naturel ln(x)
- transformations de Box-Cox (λ
λ 1−X )
- etc. 9. VALEURS CARACTERISTIQUES, ESTIMATIONS ET INTERVALLES DE CONFIANCE En statistique inférentielle, on recourt à deux types d’approches pour cerner un paramètre d’une population θ : soit on calcule un estimateur (on fait une estimation) en sachant que, très vraisemblablement le chiffre obtenu (c’est-à-dire l’estimateur ) n’est pas la valeur réelle, ou alors on calcule un intervalle ayant une probabilité (dans les sciences sociales 95%) de couvrir la valeur réelle du paramètre qu’on cherche à évaluer.
θ
Commençons par définir quelques valeurs caractéristiques très importantes : l’espérance mathématique, la variance et l’écart-type. 9.1. L’espérance mathématique Illustrons par un exemple. On jette 100 fois un dé et on obtient 14 fois un 1, 20 fois un 2, 18 fois un 3, 21 fois un 4, 13 fois un 5 et 14 fois un 6. Calculons : 14x1 + 20x2 + 18x3 + 21x4 + 13x5 + 14x6 = 14 + 40 + 54 + 84 + 65 + 84 = 341 341/100= 3,41. Si on lançait un nombre infini de fois le dé, on obtiendrait exactement 3,5. Cette moyenne théorique est l’espérance mathématique notée E(x) ou µ. Le calcul de l’espérance mathématique, pour une v.a. discrète dans et ayant P(X= ), P(X= ), …, P( ) est le suivant :
kxxx ,...,, 21
1x 2x kx
E(X) = ∑=
⋅=k
iii xxXP
1)(

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 31 -
C’est une mesure de tendance centrale pour une distribution de probabilités. Remarque : pour une v.a. continue, on a la même définition, mais qui prend la forme d’une intégrale de la densité de la variable :
E(X) = ∫+∞
∞−⋅⋅ duuuf x )(
Estimation : Le paramètre θ à estimer est donc l’espérance mathématique E(X) =µ. Son estimateur
est la moyenne arithmétique
θ
∑=
=n
iix
nx
1
1
9.2. La variance Nous avons déjà étudié la variance empirique, c’est-à-dire celle observée directement sur un échantillon. Ici on définit une variance théorique, liée aux probabilités d’une v.a. X :
Var (X) = = E [(X – E(X)) ], soit l’espérance mathématique de (X - E(X)) , qu’on peut également noter Var(X) = E [(X-µ) ], et on peut montrer que cela équivaut à
2σ 2 2
2
E(X2) – E(X)2 . L’écart-type est la racine carrée de la variance, c’est-à-dire σ . Estimation : Le paramètre θ à estimer est donc la variance Var(X)= . Son estimateur est la
variance empirique s =
2σ θ
2 11
2
nx xi
i
n
( )=∑ − .
Notons qu’on peut aussi faire la même estimation mais avec 1/n-1 (estimateur sans biais) plutôt que 1/n. Faites donc toujours attention quand vous utilisez une calculatrice, vous pouvez avoir deux touches, l’une notée 1−nσ et l’autre nσ . Une remarque importante : dans le cas de la loi binômiale la variance vaut np(1-p), et l’espérance mathématique vaut np. 9.3. Les intervalles de confiance (I.C) 9.3.1. Intervalle de confiance pour la moyenne
Selon le TCL, x ~ N (2, xx σµ ), même si on ne connaît pas la distribution exacte des . ix
Ceci nous permet de calculer le risque d'erreur lié à l'échantillonnage. Notre but n’est pas seulement de connaître la moyenne dans l’échantillon mais aussi de tirer des conclusions sur la population de référence. x est un estimateur (sans biais) de µ. Si n > 30 alors les moyennes calculées suivent approximativement une loi normale, selon le TCL.

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 32 -
On va donc chercher à calculer un I.C. tel que la probabilité que cet intervalle couvre la valeur réelle du paramètre de la population s’élève à 95%, cet I.C étant de la forme [ x ± e], ± e étant la marge d'erreur. On peut dire qu’un I.C. fournit un étendue plausible pour la vraie valeur. On trouve notamment ces indications dans les sondages d’opinions : si vous y prêtez attention, il y a en général un % dans l’article. Notons que cela présuppose que la façon dont a été conduite le sondage respecte les lois de la statistique inférentielle basée sur le tirage d’un échantillon aléatoire ; c’est loin d’être toujours le cas.
e±
Posons α le risque d'erreur de notre intervalle de confiance, en règle générale 5% dans les sciences sociales. Mais on peut se montrer plus exigeant selon l’importance de la précision de l’I.C., p.ex. 99%. On écrit: P(µ - e ≤ x ≤ µ + e) = 0.95 = 1 - α On va recourir à la loi normale centrée réduite pour faire ce calcul. Il faut chercher a et b t.q. P(Z ≤ b) = 97.5% et P(Z ≤ a) = 2.5% . ⇒a = -1,96 et b = 1.96
Posons σ x = l'écart-type de la distribution des moyennes d'échantillon.
P(-1,96 ≤ x
xσµ−
≤ 1,96) = 0,95 ,avec xσ =nσ
L’ I.C. pour la moyenne arithmétique vaut :
[ x - 1,96 n
S ; x + 1,96
nS
]
Deux remarques fondamentales :
i) cette formule ne s’applique que pour n≥30 ii) cette formule n’est valable que pour des échantillons aléatoires simples.
De ce qui précède on déduit que plus la variance est grande, c.-à-d. plus les réponses sont hétérogènes et dispersées, plus l’intervalle de confiance est grand. On voit aussi que plus la taille de l’échantillon est grande, plus l’IC est petit. Et surtout que l’IC ne dépend pas de la taille de la population de référence. Prudence : n ne désigne pas toujours la taille de l’échantillon dans son entier, il peut s’agir d’un sous-échantillon sur lequel on estime un paramètre. Donc plus le sous-groupe de l'échantillon sur lequel est calculé la moyenne est petit, plus l’IC est large.

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 33 -
Rappelons aussi que le problème de constitution de l’échantillon reste entier même si on a une faible marge d’erreur : la base de sondage utilisée, le taux de non-réponse, les biais dans la collecte des données, etc. 9.3.2. Intervalle de confiance pour une proportion La formule de l’IC avec un niveau de confiance de 95% (probabilité de couvrir la valeur) pour une proportion vaut donc :
nsp
nsp
22
96,196,1 +≤≤− π
Avec s2 = p(1-p) et n la taille de l’échantillon ou du sous-groupe de l’échantillon considéré, donc l’IC peut s’écrire :
nppp )1(96.1 −⋅
⋅± , la marge d’erreur maximale vaut : n
250096.1 ⋅± .
C’est la marge d’erreur qui est généralement indiquée dans les sondages d’opinion. Notons toutefois que les formules évoquées ci-dessus ne fonctionnent que pour les cas où l’échantillon n’excède pas 5% de la taille de la population de référence, sinon il faut recourir à un facteur correctif
1−−
NnN .
Notons encore que, lorsqu’on compare deux proportions, si leur I.C. ne se recouvrent pas, il y a des différences. Si une proportion est contenue dans l’I.C. de l’autre proportion, alors il n’y a pas de différence.
10. VARIABLES CATÉGORIELLES ET TABLEAUX DE CONTINGENCE 10.1. Généralités Il s’agit d’un aspect particulièrement important de la statistique appliquée aux sciences sociales. En effet, les variables nominales ou ordinales jouent un rôle important, et les tableaux croisés, les tableaux de contingence sont très fréquents dans les publications. Abordons tout d’abord un point fondamental : l’interprétation de tableaux croisés. Cela paraît évident, malheureusement des fautes sont commises très fréquemment. Quand on lit des pourcentages dans un tableau croisé, il faut s’interroger : s’agit-il de pourcents en ligne, en colonne ou sur le total ? C’est LA question cruciale ! Reste encore les pourcentages sur le total, plus faciles à interpréter. Nous les abordons dans la section suivante.

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 34 -
10.2. Tableaux de contingence Un tableau de contingence croisant deux variables A et B est un tableau qui a la forme suivante : 1 2 j c total 1 n11
n12 n j1
n c1 n +1
2 n21 n +2
i ni1 nij ni+
l nl1 nlc
nl+
total n 1+ n 2+
n j+ n c+
n
nij est l’élément de la ième ligne et de la jème colonne.
ni+ est le nombre d’éléments sur la ième ligne = ∑=
c
iijn
1
n j+est le nombre d’éléments dans la jème colonne = ∑
=
l
jijn
1
Si les deux variables sont indépendantes, on sait par les lois des probabilités que P(A∩B)=P(A)*P(B), donc :
P(ligne=i et colonne=j)=P(ligne=i)*P(colonne=j) ⇒nn
nn
nn jiij ++ ⋅= ⇒
nnnn ji
ij++
⋅=
Donc la valeur attendue, vaut nnn ji ++⋅
,
soit le nombre de personnes de toute la ième ligne multiplié par le nombre de personnes de toute la jème colonne, divisé par le nombre total d’individus. 10.3. Sur-représentation et sous-représentation La première façon de mesurer ces écarts entre les effectifs théoriques et les effectifs observés, c’est de calculer le ratio :
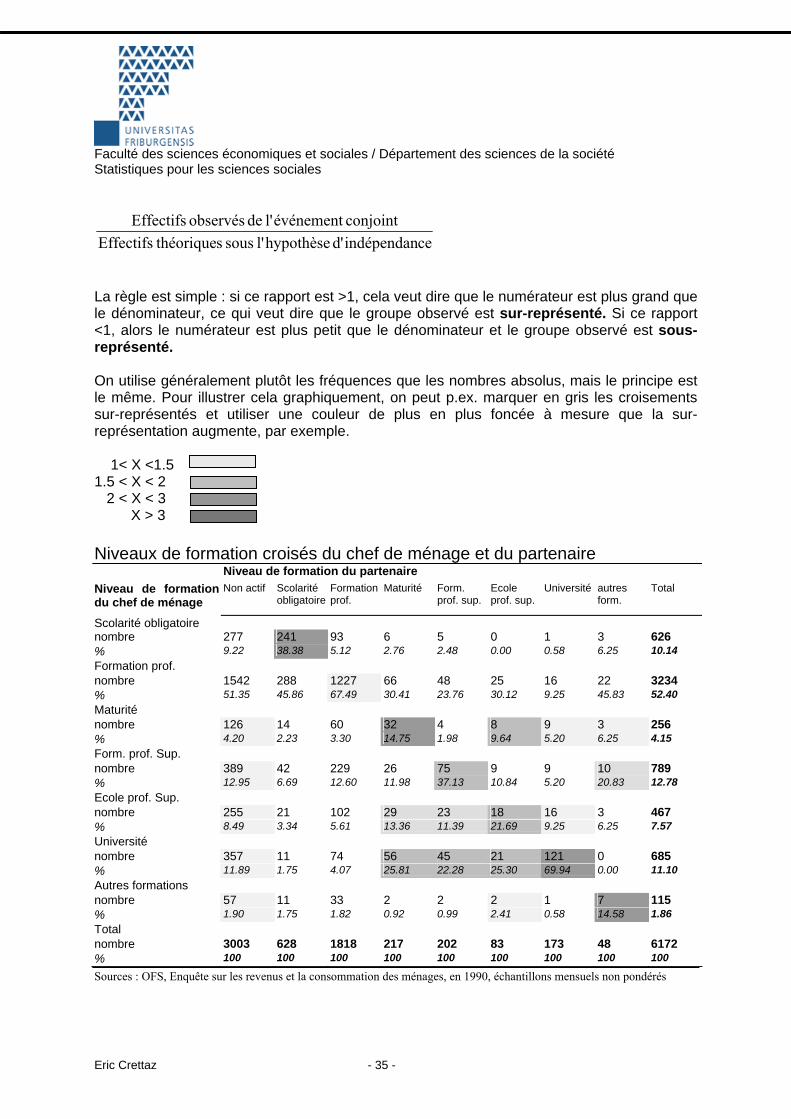
Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 35 -
ceindépendand' hypothèsel' sous s théoriqueEffectifsconjointévénement l' de observés Effectifs
La règle est simple : si ce rapport est >1, cela veut dire que le numérateur est plus grand que le dénominateur, ce qui veut dire que le groupe observé est sur-représenté. Si ce rapport <1, alors le numérateur est plus petit que le dénominateur et le groupe observé est sous-représenté. On utilise généralement plutôt les fréquences que les nombres absolus, mais le principe est le même. Pour illustrer cela graphiquement, on peut p.ex. marquer en gris les croisements sur-représentés et utiliser une couleur de plus en plus foncée à mesure que la sur-représentation augmente, par exemple. 1< X <1.5 1.5 < X < 2 2 < X < 3 X > 3 Niveaux de formation croisés du chef de ménage et du partenaire Niveau de formation du partenaire Niveau de formation du chef de ménage
Non actif Scolarité obligatoire
Formation prof.
Maturité Form. prof. sup.
Ecole prof. sup.
Université autres form.
Total
Scolarité obligatoire nombre 277 241 93 6 5 0 1 3 626 % 9.22 38.38 5.12 2.76 2.48 0.00 0.58 6.25 10.14 Formation prof. nombre 1542 288 1227 66 48 25 16 22 3234 % 51.35 45.86 67.49 30.41 23.76 30.12 9.25 45.83 52.40 Maturité nombre 126 14 60 32 4 8 9 3 256 % 4.20 2.23 3.30 14.75 1.98 9.64 5.20 6.25 4.15 Form. prof. Sup. nombre 389 42 229 26 75 9 9 10 789 % 12.95 6.69 12.60 11.98 37.13 10.84 5.20 20.83 12.78 Ecole prof. Sup. nombre 255 21 102 29 23 18 16 3 467 % 8.49 3.34 5.61 13.36 11.39 21.69 9.25 6.25 7.57 Université nombre 357 11 74 56 45 21 121 0 685 % 11.89 1.75 4.07 25.81 22.28 25.30 69.94 0.00 11.10 Autres formations nombre 57 11 33 2 2 2 1 7 115 % 1.90 1.75 1.82 0.92 0.99 2.41 0.58 14.58 1.86 Total nombre 3003 628 1818 217 202 83 173 48 6172 % 100 100 100 100 100 100 100 100 100
Sources : OFS, Enquête sur les revenus et la consommation des ménages, en 1990, échantillons mensuels non pondérés

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 36 -
11. LES TESTS STATISTIQUES, TEST D’INDÉPENDANCE DU , TEST DU T SUR DEUX PROPORTIONS.
χ 2
11.1. Les tests en statistique inférentielle Toute démarche strictement scientifique repose sur la formulation d’une hypothèse sur la population, suivie d’une collecte de données puis du rejet ou du non-rejet de l’hypothèse à de l’écart existante entre les données observées et les valeurs prédites par l’hypothèse. Nous avons déjà parlé des estimations (ponctuelles ou par intervalle de confiance) : il s’agissait d’une démarche de quantification. Dans le cas d’un test d’hypothèse, il s’agit d’une validation. On formule une hypothèse de départ, qu’on appelle hypothèse nulle et qu’on note . La conclusion du test contient un risque d’erreur. En fait il y en a deux :
0H
α : Probabilité de rejeter l’hypothèse alors qu’elle est vraie, c’est l’erreur de 10H ère espèce
β : Probabilité d’accepter alors qu’elle est fausse, c’est l’erreur de 20H ème espèce. Les deux autres cas de figures sont bien évidemment ceux qu’on recherche : ne pas rejeter
quand elle est vraie et rejeter quand elle est fausse. 0H 0H La marche à suivre est la suivante :
i) formuler et définir son alternative 0H 1Hii) définirα , en général 5% iii) définir un critère qui nous permet de tirer une conclusion : c’est la statistique
du test dont on devra connaître la distribution (N, t, , F, etc.) χ 2
iv) définir une région de rejet telle que si la statistique du test est plus grande (ou plus petite) qu’une valeur critique, alors l’hypothèse est rejetée.
v) prélever un échantillon vi) calculer la statistique du test sur l’échantillon et tirer une conclusion.
Il existe de nombreux tests en statistique inférentielle : des tests d’indépendance, des tests d’adéquation, des tests sur des hypothèses techniques d’autres tests, des tests sur les moyennes, sur la variance, etc. Une autre approche est possible, qui est celle dite de la « p-valeur » ou valeur p. Plutôt que de définir une zone de rejet, on calcule la probabilité de trouver une valeur aussi « extrême » que la statistique du test calculée. Si cette probabilité est petite, on rejette l’hypothèse, c’est-à-dire si la valeur p est < α , qui vaut généralement 0.05 ou 0.01. La valeur p n’est pas :
- une indication de l’importance du phénomène qu’on étudie, elle dit seulement s’il y a ou non un effet
- la probabilité que l’hypothèse soit vraie

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 37 -
La valeur p vaut F−1 0 (x), ou F 0 , selon le type d’hypothèse à vérifier.
11.2. Le test d’indépendance du χ 2
Jusqu’à présent, nous avons analysé de façon qualitative la différence existant entre les effectifs observés et les effectifs attendus. Ici il s’agit d’une approche plus « dure », basée sur la statistique inférentielle et les tests. Nous avons vu que, dans le fond, le critère de décision sur l’éventuelle indépendance de ces deux variables dépend de la différence entre les fréquences observées et les fréquences attendues. C’est en comparant ces deux grandeurs que nous avons déterminé quelle couleur attribuer à une case. Il nous faut déterminer une mesure globale des écarts entre les effectifs observés et les effectifs attendus, en utilisant les notations :
nij pour les fréquences observées
nij
∗pour les fréquences attendues (ou théoriques)
T est la statistique du test, qu’on calcule de la manière suivante :
T =∑∑= =
c
i
l
j1 1 nnnij
ijij∗
∗− 2)(
C’est-à-dire la somme de (effectifs observés – effectifs attendus)2 / effectifs attendus, pour chaque case du tableau de contingence.
On sait que T suit une distribution , on note T ~ . C’est une loi dont le calcul est assez compliqué, mais on dispose de tables, comme pour la loi normale centrée réduite.
χ 2 χ 2
On rejette l’hypothèse si T > k = 0H χ α
2
),1()1( −⋅− cl
Cela dépend donc, entre autres, du nombre de lignes et de colonnes du tableau de contingence, ce qui est logique puisque plus il y a de cases dans le tableau, plus le nombre de différences possibles est élevé. Ce calcul dépend également de l’erreur de première espèce, bien entendu. Cela veut dire que PH 0
(T>K) = PH 0(rejeter l’hypothèse) = α et en toute logique
PH 0(T≤K) = 1 - α .
Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 38 -
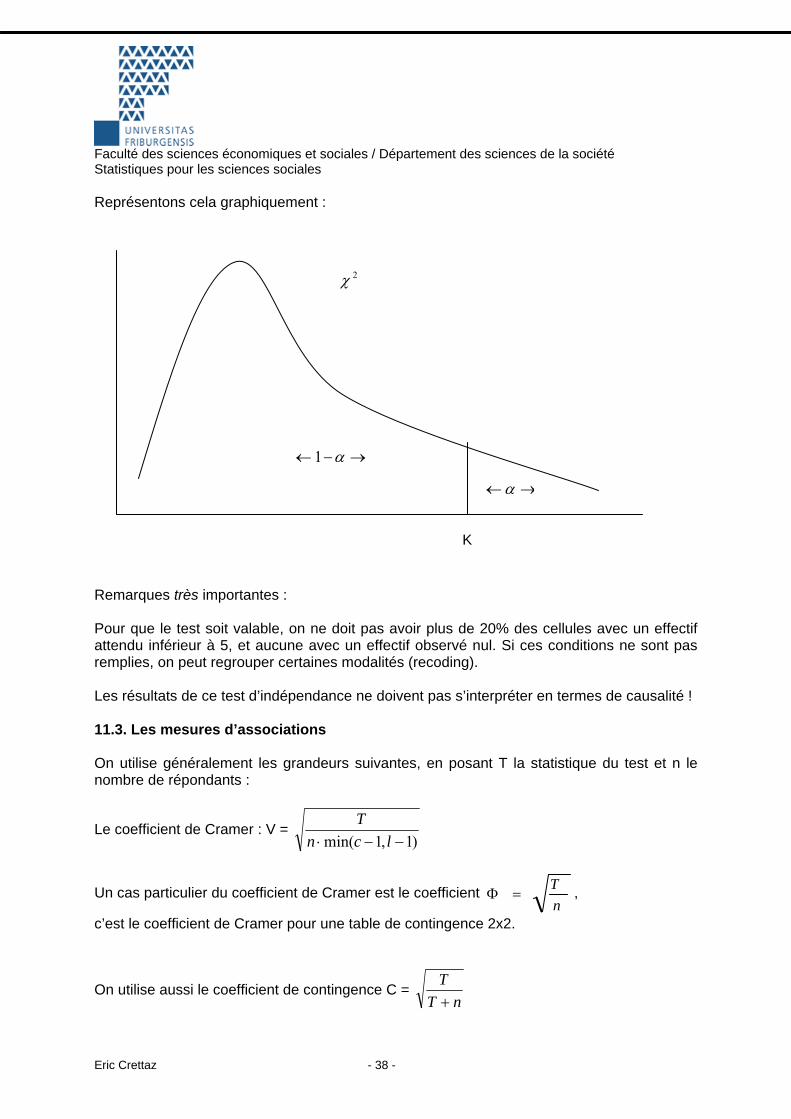
Représentons cela graphiquement :
2χ
→−← α1
→←α
K
Remarques très importantes : Pour que le test soit valable, on ne doit pas avoir plus de 20% des cellules avec un effectif attendu inférieur à 5, et aucune avec un effectif observé nul. Si ces conditions ne sont pas remplies, on peut regrouper certaines modalités (recoding). Les résultats de ce test d’indépendance ne doivent pas s’interpréter en termes de causalité ! 11.3. Les mesures d’associations On utilise généralement les grandeurs suivantes, en posant T la statistique du test et n le nombre de répondants :
Le coefficient de Cramer : V = )1,1min( −−⋅ lcn
T
Un cas particulier du coefficient de Cramer est le coefficient nT
=Φ ,
c’est le coefficient de Cramer pour une table de contingence 2x2.
On utilise aussi le coefficient de contingence C = nT
T+

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 39 -
Ces mesures prennent des valeurs entre 0 et 1. En fait il y a deux logiques :
- la relation est-elle forte ? mesures d’association →- y a-t-il une relation significative ? test d’indépendance →
11.4. Test d’adéquation Sur le même modèle, on peut calculer les effectifs observés d’une variable et les effectifs attendus selon une distribution. Il suffit de découper les observations en un certain nombre de classes (k classes qui ne se recoupent pas). L’hypothèse : la variable étudiée suit une certaine loi 0HL’hypothèse : la variable ne suit pas la loi en question. 1H La statistique du test est la même que ci-dessus :
T =∑∑= =
c
i
l
j1 1 nnnij
ijij∗
∗− 2)(
C’est-à-dire la ∑∑ −attendus
attendusobservés 2)(
On rejette l’hypothèse si T > k = 0H χ α
2
,1−k
11.5. Le test du t sur deux proportions Il est fréquent, en sciences sociales, de constater que le taux d’individus dans un groupe A ayant une propriété a et différent du taux d’individus dans un groupe B ayant une propriété b. On constatera ainsi que les femmes choisissent moins les études scientifiques de type polytechnique que les hommes, que les personnes sans formation postobligatoire ont un risque de pauvreté plus élevé que les universitaires, que le taux d’assistance est plus élevé dans les centres urbains que dans les communes de plus petites tailles, etc. On peut se contenter du simple constat descriptif. De façon plus intéressante, et pour pouvoir « trancher » de manière univoque, on peut recourir à un test nous permettant de savoir si l’écart observé entre ces deux proportions (taux d’hommes et de femmes à l’école polytechnique, taux de pauvreté des personnes sans formation et taux de pauvreté des universitaires, etc.) est statistiquement significatif. L’hypothèse à vérifier, ainsi que l’hypothèse alternative, sont les suivantes :

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 40 -
210 : ppH =
211 : ppH ≠ (ce qu’on appelle un test bilatéral). La statistique du test vaut :
2
22
1
11
21
)ˆ1(ˆ)ˆ1(ˆˆˆ
npp
npp
pp
t−
+−
−=
Avec les deux sous-échantillons sur lesquels on a calculé , les deux barres verticales symbolisant la valeur absolue. Cette formule est valable pour deux (sous-) échantillons indépendants.
21 , nn 21 ˆ,ˆ pp
Bien entendu, si on travaille avec des proportions exprimées en pourcents, il faut remplacer 1 par 100 dans la formule ci-dessus. On sait que cette statistique du test suit une distribution t de Student, et que la valeur critique
est t nn 2,2
21α
−+ .
Il se trouve que la distribution t, à partir d’une certain nombre de degrés de liberté, c’est-à-dire à partir d’une certaine taille d’échantillon, ressemble beaucoup à une loi normale centrée réduite. Pour être précis, on peut chercher la valeur critique dans une table de la loi normale à partir de et (ou 301 =n 302 =n 4021 =+ nn ).
Donc le seuil pour 05,0=α est z 2α de la loi normale centrée réduite, c’est-à-dire z 75.0 ,
qui vaut 1,96. Si l’on fixe 01,0=α , cette valeur critique devient 2,58. Donc si la statistique ci-dessus est supérieure à 1,96 (ou 2,58), on rejette l’hypothèse nulle, donc il y a un écart significatif entre les deux proportions. Il est assez courant de voir des tableaux contenants des pourcentages observés sur deux échantillons accompagnés d’une étoile si l’écart est significatif pour 05,0=α et deux étoiles pour 01,0=α . Remarques : Il faut souligner ici que les échantillons sont indépendants. Si deux échantillons sont liés (p.ex. deux mesures sont réalisées sur la même population), le test est un peu différent. On peut également réaliser un test du t sur des moyennes de deux échantillons indépendants, mais ce dernier a des hypothèse techniques « ennuyeuses » : les données doivent suivre une loi normale et l’écart-type doit être le même dans les deux échantillons. Sinon, il faut utiliser des tests non-paramétriques.

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 41 -
12. CORRELATIONS ET REGRESSIONS Nous retournons maintenant aux variables quantitatives continues. Nous nous intéressons aux liens linéaires qui peuvent unir deux variables de ce type. 12.1. Covariance et coefficient de corrélation de Pearson Avant de passer au coefficient de Pearson r, nous devons introduire le concept de covariance. La covariance mesure le lien qui peut unir deux variables en tenant compte des écarts à la moyenne de chaque variable :
Covariance de X et Y (empirique) = Cov (X,Y) = ))((11
yyxxn i
n
ii −−⋅∑
=
, le paramètre étant
E[(X- xµ )(Y- xµ )] . On peut montrer que ce dernier terme équivaut à E(XY) - xµ xµ . Cette valeur peut varier entre -∞ et +∞ .
Si on calcule Cov(X,X), on obtient ))((11
xxxxn i
n
ii −−⋅∑
=
= 2
1)(1 xx
n
n
ii −⋅∑
=
, qui est en fait la
variance de X. Le coefficient de corrélation de Pearson (ou Bravais-Pearson) vaut :
r = )var()var(),(YX
YXCov=
∑ ∑ ∑ ∑
∑ ∑ ∑
= = = =
= = =
−•−
⋅−⋅
n
1i 1 1
2
1
222i
1 1 1
))(())(x(n
)()(
n
i
n
i
n
iiii
n
i
n
i
n
iiiii
yynx
yxyxn
r ]1;1[−∈ Si les couples de points ( , ) sont à peu près alignés sur une droite alors r s’approche de 1 ou de -1.
ix iy
Il vaut 1 si y augmente quand x augmente (p.ex. taille et poids) et vaut -1 si y diminue quand x augmente. Lorsque r a une valeur proche de 0, on peut considérer que le lien est très faible voire inexistant le long d’une droite. Cela ne signifie pas nécessairement qu’il n’existe aucun lien entre les variables ! Il se peut qu’il existe un lien curvilinéaire. En outre il faut dire que si les deux variables sont indépendantes, alors la corrélation sera nulle, mais la réciproque n’est pas vraie, et on note :

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 42 -
X, Y indépendantes corr(X,Y)=0 ⇒
corr (X,Y) = 0 X, Y indépendantes. ⇒ Par contre la contraposée est vraie : corr(X,Y) 0 X, Y ne sont pas indépendantes ≠ ⇒ Donnons quelques exemples graphiques, sous forme de diagrammes de dispersion :
x xxx x x x x xx xxx xx x x x xxxxxxxx x x x x x x x x x x x x x x xxx xx xxxxx
Dans ce cas, c.-à-d. un nuage de points dans lequel ne se dégage aucune tendance linéaire, on obtient une valeur du coefficient de Pearson r 0≅
x x xx xxx xx xx xxx x xx xxx
xx xxx x xx xxx x xx xx x xx
Dans ces deux cas, dans lesquels les points sont plus ou moins alignés, r resp. 1. 1−≅
Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 43 -
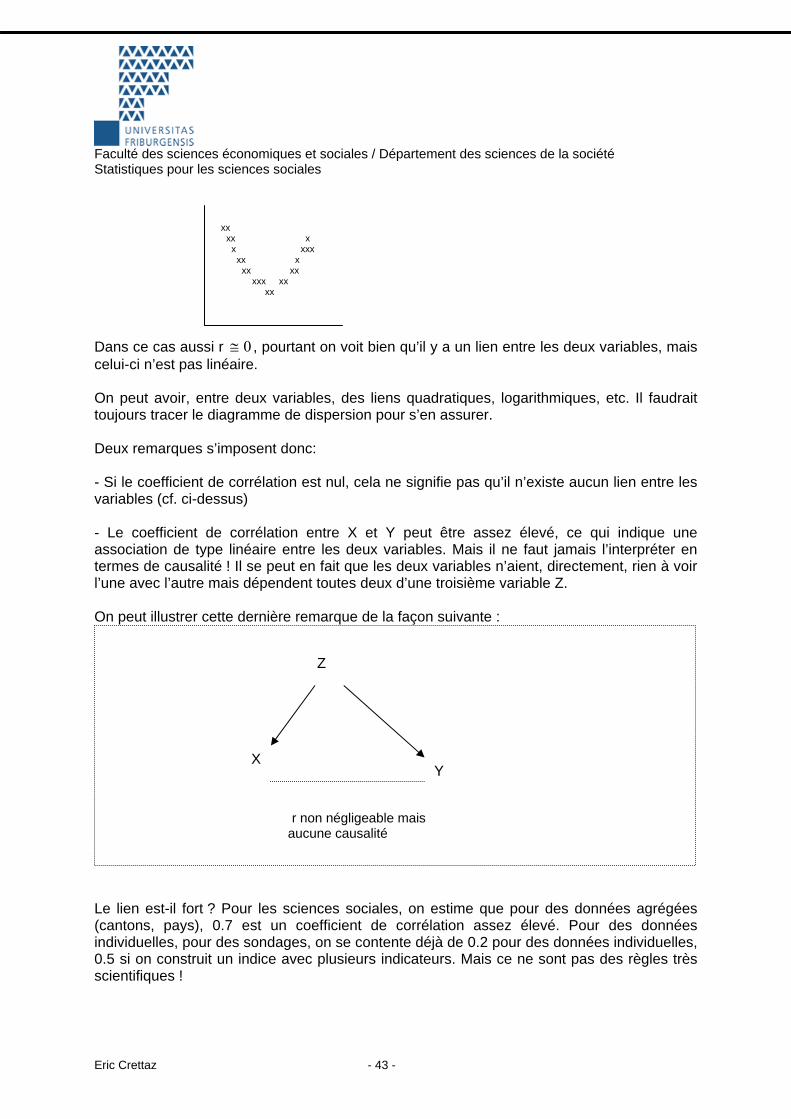
xx xx x x xxx xx x xx xx xxx xx xx
Dans ce cas aussi r , pourtant on voit bien qu’il y a un lien entre les deux variables, mais celui-ci n’est pas linéaire.
0≅
On peut avoir, entre deux variables, des liens quadratiques, logarithmiques, etc. Il faudrait toujours tracer le diagramme de dispersion pour s’en assurer. Deux remarques s’imposent donc: - Si le coefficient de corrélation est nul, cela ne signifie pas qu’il n’existe aucun lien entre les variables (cf. ci-dessus) - Le coefficient de corrélation entre X et Y peut être assez élevé, ce qui indique une association de type linéaire entre les deux variables. Mais il ne faut jamais l’interpréter en termes de causalité ! Il se peut en fait que les deux variables n’aient, directement, rien à voir l’une avec l’autre mais dépendent toutes deux d’une troisième variable Z. On peut illustrer cette dernière remarque de la façon suivante :
Z
X Y
r non négligeable mais aucune causalité
Le lien est-il fort ? Pour les sciences sociales, on estime que pour des données agrégées (cantons, pays), 0.7 est un coefficient de corrélation assez élevé. Pour des données individuelles, pour des sondages, on se contente déjà de 0.2 pour des données individuelles, 0.5 si on construit un indice avec plusieurs indicateurs. Mais ce ne sont pas des règles très scientifiques !

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 44 -
Une autre approche consiste à réaliser un test ayant pour hypothèse nulle : r = 0 et l’hypothèse alternative r . Cela nous dit si le coefficient de corrélation est significativement différent de zéro.
0≠
La statistique du test vaut 212
rnrt−−
= , avec n le nombre d’observations.
Cette statistique suit une distribution t de Student et a n-2 degrés de liberté. Si cette statistique est supérieure à la valeur critique (t=1,645 pour n grand et 05,0=α ), on rejette l’hypothèse : r = 0. 0H 12.2. Diagramme de dispersion et régression linéaire simple
Nous avons déjà eu l’occasion de décrire des diagrammes de dispersion, qui sont de la
forme suivante :
x xxx x x x x x x xx x xx x x x xx x xx xxx x x x x x x x x x x x x x x xx x xx xxxxx
Variable Y
Variable X
Un tel diagramme permet de visualiser un ensemble de couples d’observations ( , ) ix iyDans le cas de la régression, on souhaite calculer la droite qui s’approche le plus du nuage de points :
x x x x x xx x x xx x xx x x x xx x
Cette droite est la droite de régression. Son équation peut s’écrire y = a + bx. En fait y est une fonction de x : y est la variable dépendante (c.-à-d. la variable qu’on veut expliquer) et x est la variable indépendante ou explicative. Le terme a indique quelle est l’ordonnée à l’origine, c.-à-d. la valeur que prend y quand x vaut 0, et b est la pente de la droite.

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 45 -
Il faut donc calculer une droite telle que la somme des écarts de chaque point à cette droite soit la plus petite possible. En effet, la plupart des points ne sont pas sur la droite de régression. Il faut donc additionner les termes )( ii bxay +− . On recourt à la méthode des moindres carrés :
Q(a,b) = )∑=
n
i 1
( ( ii bxay +− ) 2 . On doit trouver le minimum de cette somme.
On élève les écarts à la droite de régression au carré pour que les distances des points se trouvant au-dessus de la droite ne s’annulent pas avec les distances des points se trouvant en dessous de la droite.
On obtient les paramètres suivants (pour alléger la notation, on écrit ∑ pour ) : ∑=
n
i 1
â = xby ⋅− ˆ
= b∑ ∑
∑ ∑ ∑−
⋅−22 )(
)(
ii
iiii
xxnyxyxn
= r ∑∑
−
−⋅ 2
2
)()(
xxyy
i
i
Cette droite passe par les points (0, â) et ( yx, ). Notons la valeur observée de la variable Y correspondant à l’abscisse et la valeur prédite par la droite de régression. Les résidus valent = -
iy ix iy
ie iy iy On peut démontrer que la variation totale = variation au niveau des résidus + la variation expliquée par la régression. Cela peut s’écrire :
222 )ˆ()ˆ()( yyyyyy iiii ∑∑ ∑ −+−=− Somme des carré, total (SCT) = Somme des carrés liés aux résidus, c.-à-d. les termes e (SCE) + somme des carrés liés à la régression (SCR). Ces termes permettent de juger la régression :
En effet le terme R2 = SCTSCR
, qui varie entre 0 et 1,
s’appelle le coefficient de détermination et s’interprète comme le pourcentage de la variabilité/variation de la variable expliquée/dépendante qui est associée à la variation de la

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 46 -
variable explicative/indépendante expliqué par la régression. Dans le cas de la régression simple, R2=r2. L’expérience montre que, en sciences sociales, 30% de variabilité expliquée est satisfaisant. Le but de la régression est double : d’une part il s’agit de résumer le lien qui existe entre deux variables, et d’autre part il s’agit de prédire quelle valeur prendrait y pour un x qui n’a pas été observé. Notons que c’est l’aspect le plus délicat de la régression, c.-à-d. la prédiction en dehors des valeurs observées de x, car rien ne nous assure que la tendance linéaire observée se poursuit partout. Il y a des hypothèses techniques à respecter : - Les résidus ~ N(0, ) ie 2σ - l’hypothèse de l’homoscédasticité, c’est-à-dire que Var(ε )= 2σ
résidus
xx x x x x xx x x x xxx x x x x x x x x xx x x xx x Valeurs
prédites x x x xx x x x
- en plus il faut vérifier que les termes d’erreur sont indépendants E( iε jε )=0, pour i j ≠
résidus xx x x x x xx x x x xxx x x x x x x x x xx x x xx x x x x xx x x x
i Donnons un exemple : Expliquer l’espérance de vie par le taux de mortalité infantile en Amérique latine, centrale et dans les Caraïbes :

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 47 -
MORT_ENF
876543210
ES
P_V
IE
80
70
60
50
Calculons la droite de régression : Espérance_vie = 78.002 – 2,514*mortalité_infantile Vérifions certaines hypothèses techniques : normalité
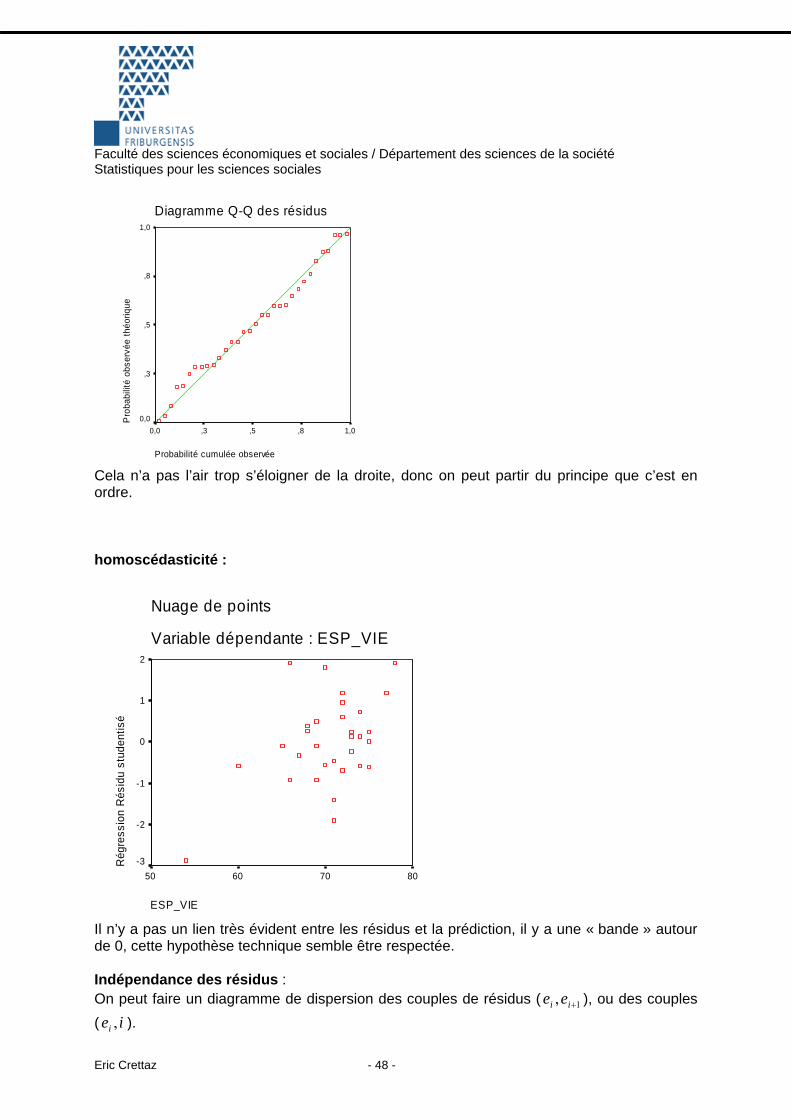
Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 48 -
Diagramme Q-Q des résidus
Probabilité cumulée observée
1,0,8,5,30,0
Pro
babi
lité
obse
rvée
théo
rique
1,0
,8
,5
,3
0,0
Cela n’a pas l’air trop s’éloigner de la droite, donc on peut partir du principe que c’est en ordre. homoscédasticité :
Nuage de points
Variable dépendante : ESP_VIE
ESP_VIE
80706050
Rég
ress
ion
Rés
idu
stud
entis
é
2
1
0
-1
-2
-3
Il n’y a pas un lien très évident entre les résidus et la prédiction, il y a une « bande » autour de 0, cette hypothèse technique semble être respectée. Indépendance des résidus : On peut faire un diagramme de dispersion des couples de résidus ( ), ou des couples ( ).
1, +ii eeiei ,

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 49 -
On peut également calculer la statistique de Durbin-Watson = 2.482 dans notre cas, ce n’est pas trop mal.
La statistique de ce test (D) est la suivante ∑∑=
=
−−n
in
jj
ii
e
ee2
1
2
21 )(
et l’hypothèse d’indépendance n’est pas rejettée si D 2≈ . Partons donc du principe que les hypothèses techniques sont vérifiées. En réalité, on pourrait être plus rigoureux (il existe des tests pour la normalité et l’homoscédasticité). La droite de régression, rappelons-le, peut donc s’écrire : Espérance_vie = 78.002 – 2,514*mortalité_infantile Avec R2 = 0.803, donc environ 80% de la variance est expliquée par ce modèle. 12.3. Régressions quasi-linéaires Lorsque les paramètres de régression sont sous forme linéaire et les variables explicatives sous forme non-linéaire, le modèle est globalement linéaire. Parfois on parle de régressions quasi-linéaires. Quelques exemples :
Y= est linéaire, mais pas Y= . ε++⋅+ 2210 )ln( XaXaa ε+++ 21
0aa XXa
En d’autres termes on peut avoir une fonction curvilinéaire de la variable indépendante dans l’équation et considérer que le modèle est globalement linéaire. Des variables peuvent avoir des liens non linéaires entre elles, comme dans les exemples ci-dessous :

Faculté des sciences économiques et sociales / Département des sciences de la société Statistiques pour les sciences sociales
Eric Crettaz - 50 -
En partant du graphique en haut à gauche, et en allant dans le sens des aiguilles d’une montre, les courbes de régression pourraient avoir une formule de type : Y = a + bx + cx2 (quadratique) Y = a + b ln(x) (logarithmique) Y = ab1/x
Y = a +bx+cx2+dx3
12.4. Régressions multiples Une régression multiple est de la forme :
ε+++++= nn xaxaxaay ...22110 , c’est-à-dire que plusieurs variables expliquent la variable dépendante. Ce type de modèle est le plus couramment utilisé en sciences sociales ; en effet, il est rare qu’on puisse expliquer un phénomène de façon satisfaisante par une seule variable. Ce type de modèle rajoute toutefois une quatrième hypothèse technique : il ne doit pas y avoir de problème de multicolinéarite, c’est-à-dire que les variables explicatives ne doivent pas trop être corrélées entre elles. Nous en reparlons dans le cadre du cours de méthodologie de 2ème année.








![19980702-F Donovan-TC-Martin Walser, Guerre de Fink-[Allemagne]](https://static.fdocuments.fr/doc/165x107/55cf9167550346f57b8d4042/19980702-f-donovan-tc-martin-walser-guerre-de-fink-allemagne.jpg)



![Datove struktury I´fink/teaching/data_structures...BB[ ]-strom 2 Splay strom 3 (a,b)-strom a cerveno-ˇcern´y strom 4 Haldy 5 Cache-oblivious algorithms 6 Hesovˇ an´ı 7 Geometricke](https://static.fdocuments.fr/doc/165x107/60d97a82bbad87169e55701c/datove-struktury-i-finkteachingdatastructures-bb-strom-2-splay-strom.jpg)





