
Yehudi Un environnement pour l’interopérabilité de...
166
N° d’ordre 02 ISAL 0094 Année 2002 Thèse Yehudi Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes Présentée devant L’Institut National des Sciences Appliquées de Lyon Pour obtenir Le grade de docteur École doctorale Informatique et Information pour la société (EDIIS) Par Alain BECAM Soutenue le 11 décembre 2002 devant la Commission d’examen Jury MM. Rapporteur M. SCHNEIDER Professeur (Université de Clermont-Ferrand II) Rapporteur K. YÉTONGNON Professeur (Université de Bourgogne) Président A. DUPAGNE Professeur (Université de Liège) R. LAURINI Professeur (INSA de Lyon) M. MIQUEL Maître de conférence (INSA de Lyon)
Transcript of Yehudi Un environnement pour l’interopérabilité de...

N° d’ordre 02 ISAL 0094 Année 2002
Thèse
Yehudi Un environnement pour
l’interopérabilité de modèles urbains distribués et hétérogènes
Présentée devant
L’Institut National des Sciences Appliquées de Lyon
Pour obtenir Le grade de docteur
École doctorale Informatique et Information pour la société (EDIIS)
Par Alain BECAM
Soutenue le 11 décembre 2002 devant la Commission d’examen
Jury MM.
Rapporteur M. SCHNEIDER Professeur (Université de Clermont-Ferrand II) Rapporteur K. YÉTONGNON Professeur (Université de Bourgogne) Président A. DUPAGNE Professeur (Université de Liège) R. LAURINI Professeur (INSA de Lyon) M. MIQUEL Maître de conférence (INSA de Lyon)

Mémoire de thèse
Page 2 sur 166

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 3 sur 166
MARS 2002
INSTITUT NATIONAL DES SCIENCES APPLIQUEES DE LYON
Directeur : STORCK.A Professeurs : AUDISIO S. PHYSICOCHIMIE INDUSTRIELLE BABOT D. CONT. NON DESTR. PAR RAYONNEMENT IONISANTS BABOUX J.C. GEMPPM*** BALLAND B. PHYSIQUE DE LA MATIERE BAPTISTE P. PRODUCTIQUE ET INFORMATIQUE DES SYSTEMES MANUFACTURIERS BARBIER D. PHYSIQUE DE LA MATIERE BASTIDE J.P. LAEPSI**** BAYADA G. MODELISATION MATHEMATIQUE ET CALCUL SCIENTIFIQUE BENADDA B. LAEPSI**** BETEMPS M. AUTOMATIQUE INDUSTRIELLE BIENNIER F. PRODUCTIQUE ET INFORMATIQUE DES SYSTEMES MANUFACTURIERS BLANCHARD J.M. LAEPSI**** BOISSON C. VIBRATIONS-ACOUSTIQUE BOIVIN M. (Prof. émérite) MECANIQUE DES SOLIDES BOTTA H. UNITE DE RECHERCHE EN GENIE CIVIL - Développement Urbain BOTTA-ZIMMERMANN M. (Mme) UNITE DE RECHERCHE EN GENIE CIVIL - Développement Urbain BOULAYE G. (Prof. émérite) INFORMATIQUE BOYER J.C. MECANIQUE DES SOLIDES BRAU J. CENTRE DE THERMIQUE DE LYON - Thermique du bâtiment BREMOND G. PHYSIQUE DE LA MATIERE BRISSAUD M. GENIE ELECTRIQUE ET FERROELECTRICITE BRUNET M. MECANIQUE DES SOLIDES BRUNIE L. INGENIERIE DES SYSTEMES D’INFORMATION BUREAU J.C. CEGELY* CAVAILLE J.Y. GEMPPM*** CHANTE J.P. CEGELY*- Composants de puissance et applications CHOCAT B. UNITE DE RECHERCHE EN GENIE CIVIL - Hydrologie urbaine COMBESCURE A. MECANIQUE DES CONTACTS COUSIN M. UNITE DE RECHERCHE EN GENIE CIVIL - Structures DAUMAS F. (Mme) CETHIL – Energétique et Thermique DOUTHEAU A. CHIMIE ORGANIQUE DUFOUR R. MECANIQUE DES STRUCTURES DUPUY J.C. PHYSIQUE DE LA MATIERE EMPTOZ H. RECONNAISSANCE DES FORMES ET VISION ESNOUF C. GEMPPM*** EYRAUD L. (Prof. émérite) GENIE ELECTRIQUE ET FERROELECTRICITE FANTOZZI G. GEMPPM*** FAVREL J. PRODUCTIQUE ET INFORMATIQUE DES SYSTEMES MANUFACTURIERS FAYARD J.M. BIOLOGIE APPLIQUEE FAYET M. MECANIQUE DES SOLIDES FERRARIS-BESSO G. MECANIQUE DES STRUCTURES FLAMAND L. MECANIQUE DES CONTACTS FLORY A. INGENIERIE DES SYSTEMES D’INFORMATION FOUGERES R. GEMPPM*** FOUQUET F. GEMPPM*** FRECON L. INFORMATIQUE GERARD J.F. MATERIAUX MACROMOLECULAIRES GERMAIN P. LAEPSI**** GIMENEZ G. CREATIS** GOBIN P.F. (Prof. émérite) GEMPPM*** GONNARD P. GENIE ELECTRIQUE ET FERROELECTRICITE GONTRAND M. CEGELY*- Composants de puissance et applications GOUTTE R. (Prof. émérite) CREATIS** GOUJON L. GEMPPM*** GOURDON R. LAEPSI****. GRANGE G. GENIE ELECTRIQUE ET FERROELECTRICITE GUENIN G. GEMPPM*** GUICHARDANT M. BIOCHIMIE ET PHARMACOLOGIE GUILLOT G. PHYSIQUE DE LA MATIERE GUINET A. PRODUCTIQUE ET INFORMATIQUE DES SYSTEMES MANUFACTURIERS
GUYADER J.L. VIBRATIONS-ACOUSTIQUE GUYOMAR D. GENIE ELECTRIQUE ET FERROELECTRICITE HEIBIG A. LAB. MATHEMATIQUE APPLIQUEES LYON JACQUET RICHARDET G. MECANIQUE DES STRUCTURES JAYET Y. GEMPPM***

Mémoire de thèse
Page 4 sur 166
JOLION J.M. RECONNAISSANCE DES FORMES ET VISION JULLIEN J.F. UNITE DE RECHERCHE EN GENIE CIVIL - Structures JUTARD A. (Prof. émérite) AUTOMATIQUE INDUSTRIELLE KASTNER R. UNITE DE RECHERCHE EN GENIE CIVIL - Géotechnique KOULOUMDJIAN J. INGENIERIE DES SYSTEMES D’INFORMATION LAGARDE M. BIOCHIMIE ET PHARMACOLOGIE LALANNE M. (Prof. émérite) MECANIQUE DES STRUCTURES LALLEMAND A. CENTRE DE THERMIQUE DE LYON - Energétique et thermique LALLEMAND M. (Mme) CENTRE DE THERMIQUE DE LYON - Energétique et thermique LAREAL P. UNITE DE RECHERCHE EN GENIE CIVIL - Géotechnique LAUGIER A. PHYSIQUE DE LA MATIERE LAUGIER C. BIOCHIMIE ET PHARMACOLOGIE LEJEUNE P. GENETIQUE MOLECULAIRE DES MICROORGANISMES MARS 2002 LUBRECHT A. MECANIQUE DES CONTACTS MAZILLE H. PHYSICOCHIMIE INDUSTRIELLE MERLE P. GEMPPM*** MERLIN J. GEMPPM*** MIGNOTTE A. (Mle) INGENIERIE, INFORMATIQUE INDUSTRIELLE MILLET J.P. PHYSICOCHIMIE INDUSTRIELLE MIRAMOND M. UNITE DE RECHERCHE EN GENIE CIVIL - Hydrologie urbaine MOREL R. MECANIQUE DES FLUIDES MOSZKOWICZ P. LAEPSI**** MOURA A. GEMPPM*** NARDON P. (Prof. émérite) BIOLOGIE APPLIQUEE NIEL E. AUTOMATIQUE INDUSTRIELLE NORTIER P. DREP ODET C. CREATIS** OTTERBEIN M. (Prof. émérite) LAEPSI****
PARIZET E. VIBRATIONS-ACOUSTIQUE
PASCAULT J.P. MATERIAUX MACROMOLECULAIRES PAVIC G. VIBRATIONS-ACOUSTIQUE PELLETIER J.M. GEMPPM*** PERA J. UNITE DE RECHERCHE EN GENIE CIVIL - Matériaux PERRIAT P. GEMPPM*** PERRIN J. ESCHIL – Equipe Sciences Humaines de l’Insa de Lyon PINARD P. (Prof. émérite) PHYSIQUE DE LA MATIERE PINON J.M. INGENIERIE DES SYSTEMES D’INFORMATION PONCET A. PHYSIQUE DE LA MATIERE POUSIN J. MODELISATION MATHEMATIQUE ET CALCUL SCIENTIFIQUE PREVOT P. GRACIMP – Groupe de Recherche en Apprentissage, Coopération et Interfaces Multimodales pour la Productique PROST R. CREATIS** RAYNAUD M. CENTRE DE THERMIQUE DE LYON - Transferts Interfaces et Matériaux REDARCE H. AUTOMATIQUE INDUSTRIELLE REYNOUARD J.M. UNITE DE RECHERCHE EN GENIE CIVIL - Structures RIGAL J.F. MECANIQUE DES SOLIDES RIEUTORD E. (Prof. émérite) MECANIQUE DES FLUIDES ROBERT-BAUDOUY J. (Mme) (Prof. émérite) GENETIQUE MOLECULAIRE DES MICROORGANISMES ROUBY D. GEMPPM*** ROUX J.J. CENTRE DE THERMIQUE DE LYON – Thermique de l’Habitat RUBEL P. INGENIERIE DES SYSTEMES D’INFORMATION RUMELHART C. MECANIQUE DES SOLIDES SACADURA J.F. CENTRE DE THERMIQUE DE LYON - Transferts Interfaces et Matériaux SAUTEREAU H. MATERIAUX MACROMOLECULAIRES SCAVARDA S. AUTOMATIQUE INDUSTRIELLE
SOUIFI A. PHYSIQUE DE LA MATIERE
SOUROUILLE J.L. INGENIERIE INFORMATIQUE INDUSTRIELLE THOMASSET D. AUTOMATIQUE INDUSTRIELLE UBEDA S. CENTRE D’INNOV. EN TELECOM ET INTEGRATION DE SERVICES THUDEROZ C. ESCHIL – Equipe Sciences Humaines de l’Insa de Lyon UNTERREINER R. CREATIS** VELEX P. MECANIQUE DES CONTACTS VIGIER G. GEMPPM*** VINCENT A. GEMPPM*** VRAY D. CREATIS** VUILLERMOZ P.L. (Prof. émérite) PHYSIQUE DE LA MATIERE Directeurs de recherche C.N.R.S. :

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 5 sur 166
BERTHIER Y. MECANIQUE DES CONTACTS CONDEMINE G. UNITE MICROBIOLOGIE ET GENETIQUE COTTE-PATAT N. (Mme) UNITE MICROBIOLOGIE ET GENETIQUE FRANCIOSI P. GEMPPM*** MANDRAND M.A. (Mme) UNITE MICROBIOLOGIE ET GENETIQUE POUSIN G. BIOLOGIE ET PHARMACOLOGIE ROCHE A. MATERIAUX MACROMOLECULAIRES SEGUELA A. GEMPPM*** Directeurs de recherche I.N.R.A. : FEBVAY G. BIOLOGIE APPLIQUEE GRENIER S. BIOLOGIE APPLIQUEE RAHBE Y. BIOLOGIE APPLIQUEE Directeurs de recherche I.N.S.E.R.M. : PRIGENT A.F. (Mme) BIOLOGIE ET PHARMACOLOGIE MAGNIN I. (Mme) CREATIS** * CEGELY CENTRE DE GENIE ELECTRIQUE DE LYON ** CREATIS CENTRE DE RECHERCHE ET D’APPLICATIONS EN TRAITEMENT DE L’IMAGE ET DU SIGNAL ***GEMPPM GROUPE D'ETUDE METALLURGIE PHYSIQUE ET PHYSIQUE DES MATERIAUX ****LAEPSI LABORATOIRE D’ANALYSE ENVIRONNEMENTALE DES PROCEDES ET SYSTEMES INDUSTRIELS

Mémoire de thèse
Page 6 sur 166
INSA DE LYON DEPARTEMENT DES ETUDES DOCTORALES ET RELATIONS INTERNATIONALES SCIENTIFIQUES MARS 2002
ECOLES DOCTORALES ET DIPLÔMES D’ETUDES APPROFONDIES HABILITÉS POUR LA PÉRIODE 1999-2003
ECOLES DOCTORALES
n° code national
RESPONSABLE
PRINCIPAL
CORRESPONDANT
INSA
DEA INSA
n° code national
RESPONSABLE
DEA INSA
CHIMIE DE LYON
(Chimie, Procédés, Environnement)
EDA206
M. D. SINOU UCBL1 04.72.44.62.63 Sec 04.72.44.62.64 Fax 04.72.44.81.60
M. R. GOURDON 87.53 Sec 84.30 Fax 87.17
Chimie Inorganique 910643
Sciences et Stratégies Analytiques
910634
Sciences et Techniques du Déchet 910675
M. R. GOURDON Tél 87.53 Fax 87.17
ECONOMIE, ESPACE ET MODELISA-
TION DES COMPORTEMENTS
(E2MC)
EDA417
M.A. BONNAFOUS LYON 2 04.72.72.64.38 Sec 04.72.72.64.03 Fax 04.72.72.64.48
Mme M. ZIMMERMANN 84.71 Fax 87.96
Villes et Sociétés 911218
Dimensions Cognitives et Modélisation
992678
Mme M. ZIMMERMANN Tél 84.71 Fax 87.96 M. L. FRECON Tél 82.39 Fax 85.18
ELECTRONIQUE, ELECTROTECHNI-
QUE, AUTOMATIQUE
(E.E.A.)
EDA160
M. G. GIMENEZ INSA DE LYON 83.32 Fax 85.26
Automatique Industrielle 910676
Dispositifs de l’Electronique Intégrée
910696
Génie Electrique de Lyon 910065
Images et Systèmes
992254
M. M. BETEMPS Tél 85.59 Fax 85.35 M. D. BARBIER Tél 85.47 Fax 60.81 M. J.P. CHANTE Tél 87.26 Fax 85.30 Mme I. MAGNIN Tél 85.63 Fax 85.26
EVOLUTION, ECOSYSTEME, MICRO-
BIOLOGIE , MODELISATION
(E2M2)
EDA403
M. J.P FLANDROIS UCBL1 04.78.86.31.50 Sec 04.78.86.31.52 Fax 04.78.86.31.49
M. S. GRENIER 79.88 Fax 85.34
Analyse et Modélisation des Systèmes Biologiques 910509
M. S. GRENIER Tél 79.88 Fax 85.34
INFORMATIQUE ET INFORMATION
POUR LA SOCIETE
(EDIIS)
EDA 407
M. J.M. JOLION INSA DE LYON 87.59 Fax 80.97
Documents Multimédia, Images et Systèmes d’Information Communicants
992774 Extraction des Connaissances à partir des Données
992099
Informatique et Systèmes Coopératifs pour l’Entreprise 950131
M. A. FLORY Tél 84.66 Fax 85.97 M. J.F. BOULICAUT Tél 89.05 Fax 87.13 M. A. GUINET Tél 85.94 Fax 85.38
INTERDISCIPLINAIRE SCIENCES-
SANTE
(EDISS)
EDA205
M. A.J. COZZONE UCBL1 04.72.72.26.72 Sec 04.72.72.26.75 Fax 04.72.72.26.01
M. M. LAGARDE 82.40 Fax 85.24
Biochimie 930032
M. M. LAGARDE Tél 82.40 Fax 85.24
Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 7 sur 166
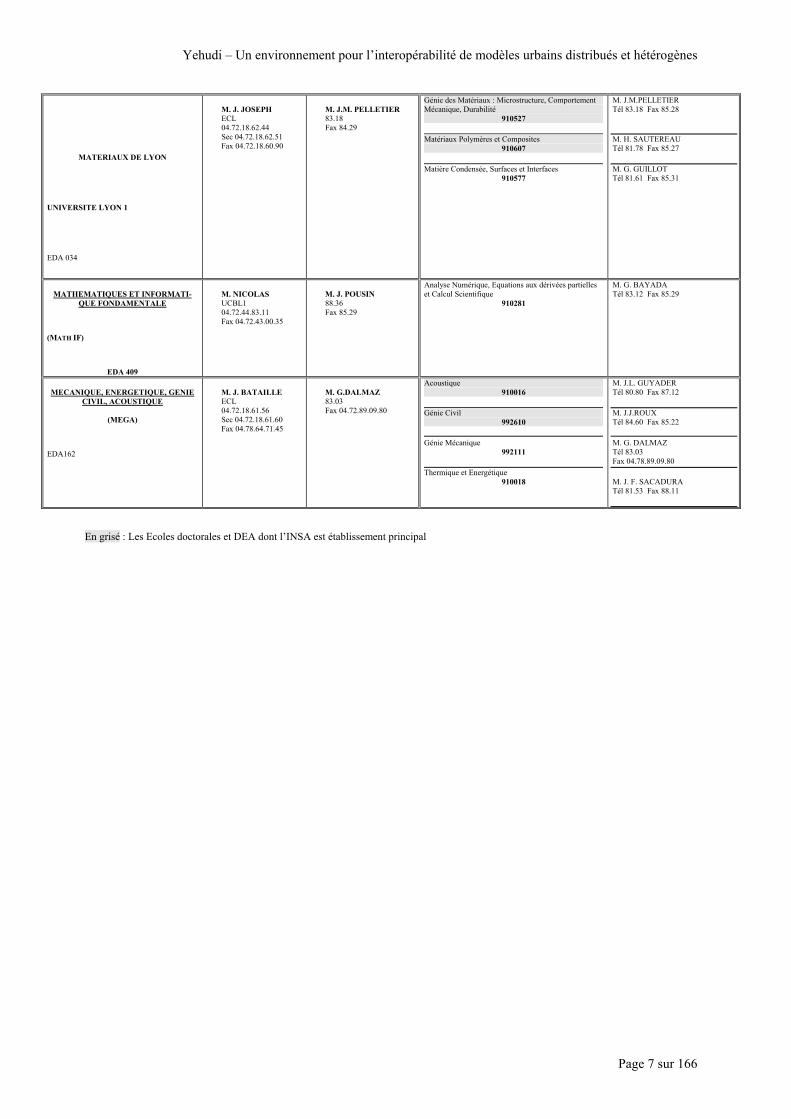
MATERIAUX DE LYON
UNIVERSITE LYON 1
EDA 034
M. J. JOSEPH ECL 04.72.18.62.44 Sec 04.72.18.62.51 Fax 04.72.18.60.90
M. J.M. PELLETIER 83.18 Fax 84.29
Génie des Matériaux : Microstructure, Comportement Mécanique, Durabilité
910527
Matériaux Polymères et Composites 910607
Matière Condensée, Surfaces et Interfaces
910577
M. J.M.PELLETIER Tél 83.18 Fax 85.28 M. H. SAUTEREAU Tél 81.78 Fax 85.27 M. G. GUILLOT Tél 81.61 Fax 85.31
MATHEMATIQUES ET INFORMATI-
QUE FONDAMENTALE
(MATH IF)
EDA 409
M. NICOLAS UCBL1 04.72.44.83.11 Fax 04.72.43.00.35
M. J. POUSIN 88.36 Fax 85.29
Analyse Numérique, Equations aux dérivées partielles et Calcul Scientifique
910281
M. G. BAYADA Tél 83.12 Fax 85.29
MECANIQUE, ENERGETIQUE, GENIE
CIVIL, ACOUSTIQUE
(MEGA)
EDA162
M. J. BATAILLE ECL 04.72.18.61.56 Sec 04.72.18.61.60 Fax 04.78.64.71.45
M. G.DALMAZ 83.03 Fax 04.72.89.09.80
Acoustique 910016
Génie Civil
992610 Génie Mécanique
992111
Thermique et Energétique 910018
M. J.L. GUYADER Tél 80.80 Fax 87.12 M. J.J.ROUX Tél 84.60 Fax 85.22 M. G. DALMAZ Tél 83.03 Fax 04.78.89.09.80 M. J. F. SACADURA Tél 81.53 Fax 88.11
En grisé : Les Ecoles doctorales et DEA dont l’INSA est établissement principal

Mémoire de thèse
Page 8 sur 166
REMERCIEMENTS Je ne pourrais terminer ma thèse sans parler de toutes les personnes qui m’ont soutenu ou aidé. Voilà donc une liste non exhaustive et non ordonnée. Que les oubliés me pardonnent. Je remercie tout d’abord Maryvonne Miquel et Robert Laurini pour leur enca-drement. Ils n’ont jamais été avares de patience, de travail, de compréhension et de conseils. Je remercie Michel Schneider et Kokou Yétongnon d’avoir accepté d’être mes rapporteurs et Albert Dupagne d’être de mon jury. Je remercie également mes collègues, principalement Franck, mais aussi Ahmed, Chirine, Elöd, Richard, Pierre, Béatrice, et tous les autres, doctorants, docteurs, maîtres de conférence ou professeurs, qui m’ont rendu la vie agréable au labora-toire. Je remercie encore tous les membres du LE2I I²BD et du LEMA. Je dois aussi dire un grand merci à ma famille, de France ou de Roumanie, pour son soutien permanent et sa confiance en moi. Je me permets d’élargir mes liens de parentés pour remercier Sébastien et sa famille. Pour finir, je tiens tout particulièrement à remercier la personne qui rend ma vie plus belle, me supporte tous les jours et m’a tant encouragé, ma femme Laura. Cette thèse est un peu la sienne.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 9 sur 166
PLAN GÉNÉRAL
TABLE DES FIGURES ........................................................................................................................ 13
INTRODUCTION.................................................................................................................................. 15
1. PROBLÉMATIQUE................................................................................................................................ 15 2. CONTRIBUTIONS DE LA THÈSE........................................................................................................... 16 3. PLAN DU RAPPORT .............................................................................................................................. 17
CHAPITRE I PROBLÉMATIQUE GÉNÉRALE............................................................................. 18
1. 1. NÉCESSITÉ DE MODÉLISER LE MONDE URBAIN ............................................................................ 18 1. 2. COMMENT SE PRÉSENTE UN MODÈLE ........................................................................................... 19 1. 2. 1. PRÉSENTATION............................................................................................................................. 19 1. 2. 2. DÉFINITION DES MODÈLES ........................................................................................................... 21 1. 2. 3. UTILISATION, RÉUTILISATION ET INTEROPÉRABILITÉ DE MODÈLES ............................................ 22 1. 2. 4. EXEMPLES DE MODÈLES............................................................................................................... 22 1. 3. SOLUTIONS ENVISAGEABLES ......................................................................................................... 29 1. 4. NOTRE OBJECTIF ............................................................................................................................ 29
CHAPITRE II OBJECTIF GÉNÉRAL.............................................................................................. 31
2. 1. LES DIFFÉRENTES HÉTÉROGÉNÉITÉS D’UN MODÈLE URBAIN...................................................... 31 2. 1. 1. ASSURER L’INTÉGRATION DES MODÈLES ET LEUR ACCÈS ........................................................... 32 2. 1. 2. METTRE EN COMMUNICATION LES MODÈLES............................................................................... 32 2. 1. 3. CONTRÔLER LES COMMUNICATIONS............................................................................................ 33 2. 1. 4. EXÉCUTER LES MODÈLES ............................................................................................................. 34 2. 1. 5. CONTRÔLER LA COHÉRENCE DE L’INTERCONNEXION.................................................................. 35 2. 1. 6. DU LOGICIEL AU SÉMANTIQUE..................................................................................................... 36 2. 2. CADRE DE TRAVAIL ........................................................................................................................ 37 2. 2. 1. CARACTÉRISTIQUES ..................................................................................................................... 37 2. 2. 2. PROBLÈMES LIÉS .......................................................................................................................... 37 2. 2. 3. HYPOTHÈSES DE TRAVAIL............................................................................................................ 38 2. 3. SOLUTIONS EXISTANTES................................................................................................................. 39 2. 3. 1. PARLER UN MÊME LANGAGE........................................................................................................ 39 2. 3. 2. TROUVER UN CONSENSUS ............................................................................................................ 43 2. 3. 3. PERMETTRE DES TRADUCTIONS ................................................................................................... 45 2. 3. 4. FORMALISER LES CONNAISSANCES.............................................................................................. 46 2. 3. 5. CONCLUSION ................................................................................................................................ 47 2. 4. INTEROPÉRABILITÉ DES MODÈLES URBAINS : APPROCHE GÉNÉRALE........................................ 47 2. 4. 1. SYNTHÈSE DES SOLUTIONS EXISTANTES...................................................................................... 47 2. 4. 2. LA SOLUTION YEHUDI.................................................................................................................. 48 2. 5. CONCLUSION................................................................................................................................... 49

Mémoire de thèse
Page 10 sur 166
CHAPITRE III INTÉGRATION DES MODÈLES .......................................................................... 50
3. 1. RÔLE DE L’INTÉGRATION .............................................................................................................. 50 3. 1. 1. ACCÉDER AUX MODÈLES.............................................................................................................. 50 3. 1. 2. LIER LES DIFFÉRENTS ÉLÉMENTS ................................................................................................. 51 3.2 ASPECT SEMI-COMPOSANT .............................................................................................................. 51 3. 2. 1. PRÉSENTATIONS DES TECHNOLOGIES EXISTANTES...................................................................... 52 3. 2. 2. APPORTS ET FAIBLESSES DE L’APPROCHE COMPOSANT............................................................... 54 3. 3. LES ENCAPSULATIONS.................................................................................................................... 56 3. 3. 1. PRINCIPE....................................................................................................................................... 56 3. 3. 2. L’ENCAPSULATION VUE COMME UNE CLASSE GÉNÉRIQUE À PARAMÉTRER ................................ 59 3. 3. 3. ÉCRITURE D’UN PILOTE................................................................................................................ 60 3. 3. 4. POSSIBILITÉS, LIMITES ET CONTRAINTES..................................................................................... 61 3.4. LES MÉTA-MODÈLES........................................................................................................................ 62 3. 4. 1. DÉCRIRE LES MODÈLES ET LES DONNÉES..................................................................................... 62 3. 4. 2. PRINCIPE....................................................................................................................................... 64 3. 4. 3. LA STRUCTURE DU MÉTA-MODÈLE .............................................................................................. 65 3. 4. 4. LE MÉTA-MODÈLE EN XML ......................................................................................................... 71 3. 4. 5. LES DONNÉES EN XML, CONVENTIONS D’ÉCRITURE................................................................... 73 3. 4. 6. SYNTHÈSE : LA PRÉSENCE DE LA SYNTAXE XML DANS YEHUDI ................................................ 73 3. 4. 7. LIEN ENTRE L’ENCAPSULATION ET LE MÉTA-MODÈLE................................................................. 74 3. 5. CONCLUSION................................................................................................................................... 76
CHAPITRE IV GÉRER L’INTERCONNEXION ............................................................................ 77
4. 1. LE SCHÉMA LOGIQUE ..................................................................................................................... 77 4. 1. 1. LES DIFFÉRENTS TYPES DE MODÈLES........................................................................................... 77 4. 1. 2. LE CATALOGUE ............................................................................................................................ 78 4. 1. 3. DESCRIPTION DU SCHÉMA LOGIQUE............................................................................................. 79 4. 1. 4. LE CHEF D’ORCHESTRE ................................................................................................................ 81 4. 1. 5. USAGE DU SCHÉMA LOGIQUE....................................................................................................... 82 4. 1. 6. MODES D’EXÉCUTION .................................................................................................................. 84 4. 1. 7. USAGE INTERACTIF DU SCHÉMA LOGIQUE OU COMME MODÈLE.................................................. 85 4. 2. COHÉRENCE DES INTERCONNEXIONS ET ADAPTATION................................................................ 86 4. 2. 1. REPRÉSENTATION DE CONNAISSANCE : TECHNIQUES ET LIMITES ............................................... 86 4. 2. 2. APPROCHES POSSIBLES ................................................................................................................ 88 4. 2. 3. RICHESSE OU ÉCHANGE................................................................................................................ 89 4. 3. UN RÉFÉRENTIEL PRATIQUE .......................................................................................................... 89 4. 3. 1. VÉRIFIER ET PERMETTRE LES INTERCONNEXIONS ....................................................................... 89 4. 3. 2. ÉLÉMENTS EXISTANTS ET ÉVOLUTION......................................................................................... 96 4. 3. 3. USAGE EN SESSION....................................................................................................................... 98 4. 3. 4. CONCLUSION ................................................................................................................................ 99 4. 4. GESTION DE LA QUALITÉ, CONTRÔLES LOGIQUES..................................................................... 100 4. 5. GESTION DU TEMPS ...................................................................................................................... 100 4. 6. CONCLUSION................................................................................................................................. 101
CHAPITRE V PRÉSENTATION DE L’ARCHITECTURE DISTRIBUÉE ............................... 102
5. 1. UNE ORGANISATION HIÉRARCHISÉE ........................................................................................... 102 5. 1. 1. UNE ARCHITECTURE TROIS COUCHES. ....................................................................................... 102 5. 1. 2. UNE PHILOSOPHIE TOUT CLIENT-SERVEUR. ............................................................................... 103 5. 2. GESTION LOCALE ......................................................................................................................... 105 5. 2. 1. PRÉSENTATION GÉNÉRALE......................................................................................................... 105

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 11 sur 166
5. 2. 2. LES ENCAPSULATIONS................................................................................................................ 107 5. 2. 3. LES SERVEURS DE MODÈLES ...................................................................................................... 108 5. 3. GESTION GLOBALE ....................................................................................................................... 110 5. 3. 1. PRÉSENTATION GÉNÉRALE......................................................................................................... 110 5. 3. 2. LE SERVEUR GLOBAL ................................................................................................................. 112 5. 3. 3. DE LA COUCHE LOGIQUE À LA COUCHE MÉDIANE : LE CHEF D'ORCHESTRE............................... 112 5. 4. COMMUNICATIONS ....................................................................................................................... 113 5. 4. 1. UN ENVIRONNEMENT FORTEMENT COMMUNICANT ................................................................... 113 5. 4. 2. HYPOTHÈSES ET CHOIX .............................................................................................................. 114 5. 4. 3. DEUX EXEMPLES : JAVA RMI ET E-MAILS................................................................................. 114 5. 5. INTERACTIVITÉ............................................................................................................................. 118 5. 5. 1. ADOPTION D’UN SERVEUR GRAPHIQUE...................................................................................... 118 5. 5. 2. FONCTIONNEMENT ..................................................................................................................... 119 5. 5. 3. UTILISATION D’UN MODÈLE COMPOSÉ....................................................................................... 119 5. 6. USAGE DE JAVA ET D’XML ......................................................................................................... 119 5. 6. 1. PARTICULARITÉS DE NOTRE SOLUTION...................................................................................... 119 5. 6. 2. JAVA........................................................................................................................................... 119 5. 6. 3. XML........................................................................................................................................... 121 5. 7. PARALLÉLISME ET USAGE MULTI-SESSION................................................................................. 121 5. 7. 1. PARALLÉLISME DE L’ENVIRONNEMENT ..................................................................................... 121 5. 7. 2. USAGE MULTISESSION................................................................................................................ 121 5. 8. CONCLUSION DU CHAPITRE ......................................................................................................... 122
CHAPITRE VI IMPLÉMENTATION............................................................................................. 123
6. 1. SPÉCIFICATIONS ........................................................................................................................... 123 6. 1. 1. ACCÉDER AUX MODÈLES............................................................................................................ 123 6. 1. 2. GÉRER LA DISTRIBUTION ........................................................................................................... 123 6. 1. 3. UNE EXÉCUTION ROBUSTE ......................................................................................................... 123 6. 1. 4. UN FORTE MODULARITÉ............................................................................................................. 123 6. 1. 5. TOUT XML................................................................................................................................. 124 6. 1. 6. ERGONOMIE ............................................................................................................................... 124 6. 1. 7. EXEMPLES D’UTILISATION ......................................................................................................... 124 6. 1. 8. ETUDE DE CAS : DEUX MODÈLES RÉELS..................................................................................... 125 6. 2. PROTOTYPE................................................................................................................................... 127 6. 2. 1. L’ENCAPSULATION DE MODÈLES ............................................................................................... 127 6. 2. 2. LES SERVEURS DE MODÈLES ...................................................................................................... 130 6. 2. 3. LE SERVEUR GLOBAL ET LE SERVEUR GRAPHIQUE .................................................................... 131 6. 2. 4. LE CHEF D'ORCHESTRE............................................................................................................... 133 6. 2. 5. LE MÉDIATEUR ........................................................................................................................... 136 6. 2. 6. GESTION D’XML........................................................................................................................ 136 6. 3. ÉVOLUTION DU PROTOTYPE ET POSSIBILITÉS FUTURES............................................................ 136 6. 3. 1. EVOLUTION DU PROTOTYPE ....................................................................................................... 136 6. 3. 2. TOUJOURS PLUS D'INTELLIGENCE .............................................................................................. 137 6. 3. 3. SUPPORTER UNE DISTRIBUTION MONDIALE ............................................................................... 137 6. 3. 4. UNE AUTRE MÉTA-MODÉLISATION............................................................................................. 137 6. 3. 5. VERS UN ENTREPÔT DE MODÈLES .............................................................................................. 137
CHAPITRE VII CONCLUSION ...................................................................................................... 139
7. 1. UNE INTÉGRATION LOGICIELLE .................................................................................................. 139 7. 2. UNE GESTION ROBUSTE................................................................................................................ 140 7. 3. CONTRIBUTIONS DE LA THÈSE..................................................................................................... 141

Mémoire de thèse
Page 12 sur 166
7. 4. VERS PLUS D’INTELLIGENCE ....................................................................................................... 142 7. 4. 1. PERMETTRE UN CHAÎNAGE ARRIÈRE DE MODÈLES .................................................................... 142 7. 4. 2. REVOIR LA CONCEPTION DES LOGICIELS.................................................................................... 143
BIBLIOGRAPHIE............................................................................................................................... 144
ANNEXE A PRÉSENTATION D’INVENTUR............................................................................... 150
PAGE DE SÉLECTION D’INVENTUR................................................................................................... 150 AFFICHAGE DE LA FICHE DE TOWNSCOPE.......................................................................................... 151 FICHE COMPLÈTE DE TOWNSCOPE ..................................................................................................... 151
ANNEXE B UN EXEMPLE DE MÉTA-MODÈLE........................................................................ 162

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 13 sur 166
TABLE DES FIGURES Figure 1.1 : L’interface conviviale de Townscope.................................................................................................. 23 Figure 1.2 : Quelques arbres générés par Genesis, exportés en format 3DS Max et affichés avec Cinéma 4D...... 25 Figure 1.3 : Positionnement des modèles en fonction de leurs capacités d’échange et de modularité.................... 28 Figure 1.4 : Un exemple d’interconnexions utile de quatres modèles..................................................................... 30 Figure 2.1 : Les éléments à interconnecter et l’interconnexion voulue................................................................... 31 Figure 2.2 : Sans perdre l’indépendance des modèles répartis, leur intégration les homogénéise. ......................... 32 Figure 2.3 : Les modèles sont connectés à un bus commun.................................................................................... 33 Figure 2.4 : Ajout d’éléments de copie (I), d’adaptations et gestion de la concurrence au niveau du modèle B. ... 34 Figure 2.5 : Gestion de l’exécution des modèles..................................................................................................... 35 Figure 2.6 : Les différents contrôles permettant la bonne intégration des modèles ................................................ 36 Figure 2.7 : Les cinq étapes de l’intégrations avec les trois aspects pris en compte. .............................................. 36 Figure 2.8 : Propriétés générales d’un modèle. ....................................................................................................... 39 Figure 3.1 : Détail d’une encapsulation et vue du paquetage d’interfaces et de pilotes.......................................... 57 Figure 3.2 : Décomposition d’un pilote type, communicant avec un modèle accessible via-C .............................. 58 Figure 3.3 : Accès de trois modules communicants à un modèle non-critique ....................................................... 58 Figure 3.4 : Accès de trois modules communicants à un modèle critique .............................................................. 59 Figure 3.5 : Les trois parties du méta-modèle et leur fonction................................................................................ 65 Figure 3.6 : Un méta-modèle et son usage pour une encapsulation. ....................................................................... 67 Figure 3.7 : Représentation du méta-modèle. Les sous-éléments sont détaillés en figure 3.8 et suivantes............. 68 Figure 3.8 : Détail des données en entrée................................................................................................................ 69 Figure 3.9 : Détail des descriptions de synchronisation. La synchronisation est aussi décrite sur les données,
comme le montre la figure précédente. ............................................................................................................ 70 Figure 3.10 : Description fine des exécutions multiples ......................................................................................... 70 Figure 3.11 : Détail des caractéristiques et de la description d’un modèle ............................................................. 71 Figure 3.12 : Les extensions sont extraites en pré-traitement. ................................................................................ 72 Figure 3.13 : La partie physique permet de paramétrer l’accès aux modèles mais également d’assurer le lien avec
la partie logique. .............................................................................................................................................. 75 Figure 3.14 : L’encapsulation réalise une abstraction du modèle, du monde physique au monde logique. Cette
abstraction permettra la prise en compte sémantique du modèle ..................................................................... 76 Figure 4.1 : Structure du catalogue. Le méta-modèle est représenté par sa partie logique. .................................... 78 Figure 4.2 : Exemple d’un schéma logique, avec quatre modèles réels, trois modèles d’interface homme-machine,
un modèle d’accès à une base de données et un modèle de copie, faisant appel à des paramètres et à une synchronisation. ............................................................................................................................................... 80
Figure 4.4 : Schématisation du traitement effectué par le chef d’orchestre après réception d’un évènement. Ce schéma est volontairement simplifié et les traitements sont en fait adaptés aux différents évènements et états possibles........................................................................................................................................................... 82
Figure 4.5 : Le schéma logique en utilisation. Une instance de modèle peut comporter plusieurs entrées, sorties, paramètres ou synchronisation. Chaque élément utilisé dispose d’un état, même s’il y a redondance : les instances de modèles, leurs éléments d’interface, les interconnexions, les données des interconnexions. ...... 83
Figure 4.6 : Comparaison des modes interactifs et non interactifs. Le schéma utilisé de manière interactive dispose d’éléments d’interfaces homme-machine et peut être contrôlé en temps réel. Le schéma utilisé de manière non interactive est considéré comme un modèle avec des liens avec l’extérieur définis comme « externes ». ...... 85
Figure 4.7 : Illustration des différents problèmes pouvant survenir dans une interconnexion. ............................... 90 Figure 4.8 : Un adaptateur, sa description au sein de la librairie et son usage dans une ontologie ......................... 92 Figure 4.9 : Cinq concepts et leurs parentés............................................................................................................ 93 Figure 4.10 : Exemple de parentés entre trois concepts réels.................................................................................. 93 Figure 4.11 : Description d’une parenté au sein de la librairie et son usage dans une ontologie ............................ 94 Figure 4.12 : Structure de la librairie ...................................................................................................................... 94 Figure 4.13 : Structure d’une ontologie .................................................................................................................. 95 Figure 4.14 : Utilisation d’un adaptateur « Somme » dans une librairie puis dans une ontologie. ......................... 97 Figure 4.15 : Lien entre le méta-modèle et une ontologie. Les concepts de l’ontologie permettent de définir les
types sémantiques des données en entrée, en sortie et en paramètre................................................................ 98 Figure 5.1 : Vue des trois couches : physique avec les modèles ainsi que les autres éléments hétérogènes, tel une
base de données, médiane avec les éléments proprement intégrés au système, logique avec une représentation de l’interconnexion souhaitée. ....................................................................................................................... 103
Figure 5.2 : Un exemple de configuration des différents éléments : le serveur global enregistre les serveurs de modèles et instancie les chefs d’orchestre. Les serveurs de modèles sont commandés par les chefs d’orchestre

Mémoire de thèse
Page 14 sur 166
et instancient les encapsulations. Les chefs d’orchestre demandent les encapsulations aux serveurs de modèles et pilotent les encapsulations.......................................................................................................................... 104
Figure 5.3 : Hiérarchie de l’environnement Yehudi.............................................................................................. 104 Figure 5.4 : Architecture d’une machine esclave en attente.................................................................................. 106 Figure 5.5 : L’enregistement d’un méta-modèle et la génération d’une encapsulation en cinq étapes. ................ 107 Figure 5.6 : Les éléments de base de la machine maître. ...................................................................................... 111 Figure 5.7 : Les éléments de la machine maître lors d’une session....................................................................... 111 Figure 5.8 : L’abstraction du support réseau......................................................................................................... 113 Figure 5.9 : Utilisation de Java RMI : schématisation, possibilités et impossibilités............................................ 115 Figure 5.10 : Les différents éléments nécessaires à une communication par e-mail............................................. 116 Figure 5.11. (a) et (b) : L’envoi et la réception de la requête. .............................................................................. 116 Figure 5.11. (c) et (d) : Les données sont transmises à l’objet distant qui renvoie ensuite le résultat. Ce résultat est
envoyé dans un message e-mail. .................................................................................................................... 117 Figure 5.11. (e) : Réception de la réponse............................................................................................................. 117 Figure 5.12 : Intégration d’un serveur graphique.................................................................................................. 118 Figure 6.1 : Deux possibilités pour calibrer un modèle. ....................................................................................... 125 Figure 6.2 : Interface de l’assistant de « découpage » d’un fichier. Le fichier traité est donné pour l’exemple et ne
correspond pas à un modèle urbain................................................................................................................ 126 Figure 6.3 : Les deux parties d’un pilote : le « leveur de modèle » et la partie spécifique, qui correspond au moins
à l’interface « modèle simple ». ..................................................................................................................... 128 Figure 6.4 : Les différents éléments d’une encapsulation ..................................................................................... 129 Figure 6.5 : Représentation d’un serveur de modèles selon une implémentation utilisant Java RMI et de ses
relations avec une encapsulation (pilote, spooler et module communicant). Un chef d’orchestre accèdera au serveur de modèles via son proxy. ................................................................................................................. 131
Figure 6.6 : Copie d’écran de l’interface graphique en développement................................................................ 132 Figure 6.7 : Les différents états prévus d’un modèle. ........................................................................................... 133 Figure 6.8 : Schématisation des différents éléments et de leurs relations ............................................................. 134 Figure 6.9 : Schématisation d’une substitution ..................................................................................................... 135 Figure 7.1 : Vue d’ensemble de l’architecture ...................................................................................................... 140

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 15 sur 166
INTRODUCTION
Une ville peut être vue comme un système composé de nombreux éléments en liaison
entre eux, tels que des humains, des équipements, des constructions, des phénomènes physiques et naturels, etc. Afin d’appréhender ces domaines séparément, les urbanistes utilisent des outils mathématiques et informatiques, permettant de les simuler ou de les évaluer, présentés sous la forme de modèles urbains sectoriels. Pour englober différents domaines, il est nécessaire d’utiliser plusieurs modèles conjointement. Cette conciliation n’est possible que si les modèles sont interopérables, c’est-à-dire capables de travailler et de communiquer ensemble.
Ce mémoire présente les résultats de notre thèse portant sur l’interopérabilité des mo-dèles urbains. Nous proposons une solution permettant d’intégrer et d’interconnecter des modèles urbains au sein d’un environnement distribué. L’approche définie utilise une abstraction du monde logiciel pour permettre sa manipulation à un niveau logique ainsi que l’usage d’un référentiel sémantique.
1. Problématique
En matière de gestion urbaine, lorsqu’un problème pratique se pose, notamment lors-qu’il s’agit d’évaluer les conséquences d’une décision, la solution consiste à interconnec-ter plusieurs modèles de développement urbain, chacun ayant été réalisé par des experts parlant des langages variés et ayant des vues sectorielles variées de la ville.
Par exemple, pour modifier le réseau d’assainissement d’une ville, il faut disposer d’un modèle d’estimation des précipitations, rédigé par des météorologistes, d’un modèle de rejets des eaux usées et d’un modèle d’écoulement rédigés par des hydrologues, et d’un modèle de calcul des coûts de modification du réseau conçu par des économistes. Pour éviter de fastidieuses manipulations, il est primordial d’automatiser leur intercon-nexion. Cependant, ces modèles sont réalisés selon des choix différents, tant dans la fa-çon de modéliser les phénomènes que dans l’écriture du modèle. Ils se présentent ainsi sous différentes formes, fonctionnent sous différents systèmes d’exploitation et manipu-lent des données différentes. Leur interconnexion n’est donc possible qu’après un grand effort d’intégration.
Plus largement, notre objectif sera d’apporter une solution permettant d’intégrer des modèles quelconques, préexistants et installés sur des machines réparties sur un réseau.
Pour ce faire, nous avons considéré les modèles selon leurs origines et leurs compor-tements pour permettre leur abstraction. Cette abstraction doit être suffisante pour cons-

Mémoire de thèse
Page 16 sur 166
truire un espace descriptif, permettant la gestion de la réalité recouverte, mais également à destination des utilisateurs. Une architecture supportant la répartition permet l’usage transparent de ces modèles sur différentes machines réparties.
2. Contributions de la thèse
Ces idées nous ont amené à développer une solution globale, nommée Yehudi, et nous pouvons présenter les contributions de cette thèse selon quatre points.
Tout d’abord, une encapsulation permet une abstraction forte d’un modèle, le présen-tant ainsi comme un élément logiciel homogène et doté de propriétés objets. Cette encap-sulation est complétée par un méta-modèle, qui permet d’une part d’adapter l’encapsulation au modèle en décrivant ses aspects physiques et d’autre part d’offrir une vue logique du modèle. Cette intégration du modèle minimise l’effort d’intégration en sé-parant l’encapsulation en trois parties distinctes, un pilote, un spooler et un module com-municant. Seul le pilote doit être adapté au modèle, le spooler et le module communicant prennent en charge les particularités d’un modèle. Le lien entre l’encapsulation et le mé-ta-modèle permet la manipulation apparente du modèle par ses seuls aspects logiques. Cette intégration a été présentée dans [Becam-Miquel 2000].
Ainsi rendu abstrait, le modèle est donc vu comme une entité homogène, comportant un aspect logique qui peut être manipulé et traité, en correspondance avec le modèle réel. Un système intégré est capable de manipuler différents modèles encapsulés, qui sont commandés par un acteur logiciel particulier, le chef d’orchestre. Celui-ci traite le ni-veau logique pour commander les éléments logiciels homogènes, composés des modèles encapsulés et des outils du système. L’utilisateur dispose alors des éléments présentés comme des modèles homogènes et documentés. Cette vue logique permet la définition simple d’un schéma d’interconnexion et son traitement lors d’une exécution.
Cette abstraction et ce niveau logique sont donc gérés afin de prendre en compte l’hétérogénéité sous-jacente. Le chef d’orchestre contrôle ainsi les éléments en utilisant un tableau de bord, qui est une représentation de l’avancement de l’activation des modè-les, mis à jour à chaque progression d’une exécution de session. Ce tableau de bord est utilisé pour déterminer l’action suivante à réaliser mais également pour la résolution des problèmes en adoptant une stratégie d’exécution prédéfinie. Le chef d’orchestre réagit à des évènements selon cette stratégie et en fonction des informations apportées par les mé-ta-modèles. Un timer permet la mise à jour des différents temps d’attente. L’exécution n’est jamais bloquante et offre, par ces mécanismes, une grande robustesse. Le chef d’orchestre apporte une réponse aux différents problèmes quand ils surviennent. Nous avons présenté cette gestion dans [Becam-Miquel-Laurini 2000] ainsi que l’architecture la supportant dans [Becam-Miquel-Laurini 2001].

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 17 sur 166
Enfin, la représentation logique de l’espace logiciel sert de base au développement d’un référentiel sémantique simple et adapté, une ontologie orientée document et inter-connexion. Cette dernière définit les concepts par leurs seules possibilités de liens avec d’autres concepts, par des considérations propres aux fonctionnalités de vérifications et d’adaptations recherchées. Les liens sont ainsi admis selon leur parenté (voisinage sémantique au sens large), selon une adaptation ou selon les deux. Une parenté permet la vérification de la validité d’un lien en indiquant si un lien parent d’un autre peut être uti-lisé comme ce dernier. Elle précise également les conséquences en terme de qualité et d’adaptation. Un adaptateur est un outil permettant la transformation d’une donnée en une autre. Les parentés et les adaptateurs sont décrits dans une librairie et peuvent ainsi être repris pour définir les liens entre concepts au sein d’une ontologie. Un médiateur est alors capable d’utiliser cette dernière pour vérifier et adapter une interconnexion.
3. Plan du rapport
Nous commençons ce mémoire par la description de la problématique, en présentant plus en détail les modèles urbains et les difficultés liées à leur réutilisation et à leur inter-connexion.
Le chapitre II présente l’objectif général, définit les hypothèses que nous avons po-sées, et donne une vue très générale de nos éléments de solutions.
Le chapitre III explique notre approche pour intégrer les modèles urbains d’une ma-nière logicielle avec l’apport d’un méta-modèle.
Nous insistons ensuite, dans le chapitre IV, sur notre gestion de l’interconnexion des modèles, par l’usage du niveau logique. Ce chapitre présente également le référentiel sé-mantique et son utilisation pour vérifier et adapter l’interconnexion.
Le chapitre V présente l’architecture distribuée supportant cette solution et le chapitre VI parle de l’actuelle implémentation de Yehudi.
En conclusion, nous récapitulons les possibilités actuelles et nos perpectives.

Mémoire de thèse
Page 18 sur 166
CHAPITRE I PROBLÉMATIQUE GÉNÉRALE
La ville est un univers complexe qui s’abstrait en nombreux sous-espaces, plus sim-
ples, plus appréhensibles, mais interdépendants, qui sont moins fidèles à la réalité quand on essaie de les considérer de façon isolée. Représenter ces réalités peut être un apport majeur pour la compréhension de l’espace urbain et de toutes ses composantes, naturel-les, artificielles et humaines. Dans ce chapitre, nous expliquons en quoi la modélisation est nécessaire puis nous présentons les modèles, leur usage, l’intérêt de les interconnecter et nous finissons par proposer un mode d’intégration.
1. 1. Nécessité de modéliser le monde urbain
Une ville est un système composé de nombreuses infrastructures, d’un tissu social ri-che et offrant une perpétuelle évolution. Elle subit et influence les évolutions de la société par la modification du paysage urbain, la mise en place de services sociaux et une gestion de ses différentes composantes.
Pour comprendre et gérer ces évolutions, les créateurs du paysage urbain, les décideurs au niveau d’une ville, les habitants et tout acteur de la vie d’une cité ont un besoin de connaissances, de prévision et de projection dans le futur.
Depuis plusieurs décennies, nous assistons donc à un cumul de connaissances venant de différents horizons : architectes, sociologues, physiciens, urbanistes, … L’informatique se trouve être un formidable outil pour supporter ces connaissances qui prennent ainsi le plus souvent la forme d’un modèle de représentation ou de connais-sance. Un modèle se définit comme une représentation plus ou moins fidèle d’une réalité. Nous considérons ici les modèles mathématiques et informatiques qui décrivent une réali-té par une série d’équations, par des procédures. Ces modèles utilisent des connaissances a priori pour, à partir de données fournies, générer des données qui apportent une infor-mation précise : une évaluation, une prévision, une projection…
De part la complexité des phénomènes en présence, nous pouvons imaginer la résolu-tion d’un problème donné par l’utilisation conjointe de plusieurs modèles spécialisés. L’objectif est de concilier des modèles afin d’appréhender des phénomènes complexes et d’étendre le domaine d’application. Dans un tel souci et également pour clarifier le do-maine de la modélisation urbaine, des inventaires ont été dressés, tel celui que nous utilisons, INVENTUR [Cerma 1999], mais encore IMT [Predit 2000] ou encore MDS [ETC/ACC 2001] et l’inventaire du COST 615 [Insti-

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 19 sur 166
tute for Meteorology of Hamburg 1998]. Ces inventaires fournissent une description as-sez claire et une typologie des modèles du champ urbain.
Cependant, cette description étant destinée aux utilisateurs, elle ne fait que recenser l’hétérogénéité des modèles, en fournissant des informations sur les choix des concep-teurs, les formats des données, également la nature et l’efficacité du traitement. Nous ai-merions permettre la gestion d’une collection de modèles, lesquels seraient suffisamment décrits pour pouvoir être retrouvés et reliés en fonction du problème posé.
Cet objectif nous a conduit à proposer une formalisation de la description d’un mo-dèle, sous la forme d’un méta-modèle, sorte de reflet logique, afin d’homogénéiser les différents modèles. Cette réalité logicielle homogène sera ensuite contrôlée par un chef d’orchestre et s’ouvrira à un possible traitement sémantique par des acteurs intelligents, des médiateurs, qui s’appuient sur un référentiel sémantique, la base d’ontologie1.
1. 2. Comment se présente un modèle
Notre projet s’intéresse à l’intégration de modèles urbains. Dans ce paragraphe, nous nous proposons de les présenter, en illustrant cette présentation par quelques exemples. Cette présentation nous amènera à parler de la modularité et des capacités d’échanges des modèles.
1. 2. 1. Présentation
D'une façon très générale, un modèle urbain est un programme qui permet d'approxi-mer un phénomène propre au monde urbain [Batty 1976].
INVENTUR [Cerma 1999] considère un modèle comme un outil capable de produire des connaissances sur un ou plusieurs phénomènes observables dans un champ donné. Ils doivent avoir fait l’objet d’un travail de validation et ainsi être destinés à un usage par d’autres que leurs concepteurs.
Le champ urbain est considéré au sein d’INVENTUR « comme l'ensemble des phé-nomènes naturels et anthropiques observables au niveau de fragments urbains significa-tifs, d'entités urbaines globales ou de systèmes de villes dans un territoire. Sont écartées a priori les échelles extrêmes, trop proches des entités architecturales, d'une part ou des grandes échelles géographiques d'autre part. Ces limites sont cependant laissées à l'appré-ciation des experts décrivant les modèles. »
1 Selon Thomas Gruber, une ontologie est une spécification explicite d’une conceptualisation, la conceptualisation étant une vue simplifiée du monde que nous souhaitons représenter. Une définition plus précise sera donnée au chapitre IV

Mémoire de thèse
Page 20 sur 166
Afin de mieux situer un modèle urbain, INVENTUR définit également huit domaines, eux-mêmes décomposés en champs. Un modèle peut s’adresser à plusieurs champs et domaines et à d’autres champs ou domaines qui ne seraient pas proposés dans INVEN-TUR. Ces domaines sont :
- la géographie et la dynamique spatiale, composée de sept champs, la dynamique spatiale intra-urbaine, la mobilité quotidienne, les choix résidentiels, l’utilisation du sol, la dynamique des systèmes de ville, les systèmes d’information géographique et le géo-marketing.
- l’économie et la gestion urbaine, composée du marché foncier et immobilier, du marché du travail, de la gestion urbaine et de la localisation des activités.
- la sociologie, avec les réseaux sociaux, l’intégration et l’exclusion ainsi que la crimi-nalité et la violence.
- les transports, comprenant la demande de transport, le choix modal, la logistique, l’interconnexion, les réseaux de transport intra-urbain et les réseaux de transport inter-urbain.
- les réseaux techniques, décomposés en 6 domaines, l’adduction d’eau, le rejet des eaux usées et l’assainissement, l’electricité, les réseaux hertziens et les télécommunica-tions, les réseaux de chaleur, les réseaux de transport de gaz et les réseaux de collecte de déchets urbains.
- la physique urbaine, avec la climatologie urbaine, l’aéraulique et la pollution de l’air, l’hydrologie et la pollution de l’eau, les sols, la mécanique des sols et la pollution des sols, la thermique et l’énergétique urbaine, l’acoustique urbaine, l’éclairage naturel et artificiel et la végétation.
- les risques et cindyniques, décomposés en risques naturels, risques épidémiologi-ques ou toxicologiques et en risques industriels.
- la morphologie urbaine, avec les modèles de terrain, les tissus urbains et l’architecture urbaine, l’urbanisme et le développement urbain, les modèles fractals, la té-lédétection et le radar, la photogrammétrie, la reconstruction 3D et l’imagerie urbaine.
Conjointement avec la description générale du modèle, INVENTUR fournit également une description scientifique et technique du modèle, permettant d’éclairer la création du modèle, son usage et la nature de ses résultats.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 21 sur 166
Il est ainsi possible de distinguer les modèles par leur type et par leur objectif. Pour modéliser un phénomène, deux approches sont possibles :
- à partir de connaissances sur le phénomène, essayer de reproduire toutes les carac-téristiques de celui-ci, en reproduisant un « monde virtuel », pour créer ainsi un modèle de connaissance,
- de manière plus ou moins empirique, retrouver un résultat par une méthode qui n'est pas nécessairement en rapport direct avec le phénomène à modéliser mais qui donne des résultats qui, semble-t-il, correspondent à la réalité. Cette approche per-met la création de modèles de représentation, nommés encore de fonctionnement.
Finalement, INVENTUR distingue trois objectifs du projet de modélisation du mo-dèle : l’analyse et la compréhension du phénomène, la simulation et l’expérimentation, la prédiction et l’aide à la décision.
Cependant, ces « classifications » ne sont qu’indicatives et de nombreux champs libres permettent une description précise d’un modèle.
1. 2. 2. Définition des modèles
Un modèle peut être considéré comme une règle permettant de calculer, à partir de grandeurs connues ou mesurées sur le système, d’autres grandeurs dont nous espérons qu’elles ressembleront aux grandeurs du système qui nous intéressent. De même, une si-mulation consiste en la « manipulation » du modèle mathématique avec différentes exci-tations ou sollicitations. La simulation est donc l’utilisation d’un modèle mathématique. Il est important de remarquer qu’une modélisation ne « contient » pas la réalité sous-jacente.Le résultat d’un modèle n’est jamais que l’ « addition » des données en entrée avec les données utilisées pour la construction du modèle.
Ainsi, par sa nature même, un modèle peut nécessiter un calibrage ou une vérification des résultats : il faut s’assurer que le résultat correspond à la réalité. Certains modèles peuvent ainsi diverger, c’est-à-dire s’éloigner de la réalité.
Tout modèle urbain est initialement conçu dans un objectif précis, par exemple repro-duire un phénomène pour pouvoir ensuite le simuler. En règle générale, lors de l’élaboration d’un modèle urbain, les objectifs sont fixés, l’approche de modélisation choisie et son cadre d’utilisation ultérieur parfaitement identifié. Les modèles répondent aux objectifs visés et cette notion de « réponse satisfaisante » n'est réellement ni qualita-tive ni quantitative. Ainsi, un modèle absolument satisfaisant pour l'utilisateur visé peut très bien générer des données qui ne sauraient être utilisées en entrée d'un autre modèle. Il convient donc de relativiser la notion de qualité des modèles, qui dépend de l’objectif vi-sé.

Mémoire de thèse
Page 22 sur 166
1. 2. 3. Utilisation, réutilisation et interopérabilité de modèles
Le monde urbain est d’une extrême richesse, ce qui interdit en soi l’existence d’un modèle global capable de décrire totalement une ville. De même, il n’existe pas d’organisation centralisant l’ensemble des connaissances actuelles en urbanisme. De ce fait, les modèles sont issus de nombreux groupes disparates et se présentent ainsi sous des formes différentes, traitent des problèmes peu ou prou différents en cristallisant l’expertise de leurs créateurs. Nous pouvons voir un modèle comme une capitalisation de compétences. Il peut être long et coûteux de réeffectuer ce travail.
Pour faire évoluer un modèle, créer un logiciel ayant quelques points communs, il peut être utile de réutiliser tout ou partie de ce modèle. Ce dernier effectue des traitements avancés et la difficulté d’intégration de ce programme existant est inférieure à la diffi-culté pour retrouver ces mêmes traitements. La réutilisation permet également de bénéfi-cier de modèles validés et créés par des experts.
Interconnecter des modèles présente également de nombreux avantages : combiner des modèles complémentaires pour traiter un problème plus vaste, affiner un résultat en utili-sant deux modèles concurrents, mettre au point un modèle correspondant sur certains points à des modèles réputés fiables.
Néanmoins, ce sont des programmes spécialisés et leur utilisation conjointe nécessite qu’ils gardent une certaine indépendance et puissent travailler ensemble en communi-quant : c’ets-à-dire interopérer.
La réutilisation d’un modèle demande un certain nombre d’informations sur le modèle, mais dans la limite de son usage seul. Faire interopérer des modèles nécessite d’avantages d’informations, pour être capable de les utiliser conjointement. Finalement, les utiliser dans le cadre d’une interconnexion nécessitent encore plus d’informations, pour pouvoir au mieux automatiser les échanges de données et les exécutions de modèles.
1. 2. 4. Exemples de modèles
Pour mieux introduire ce projet, nous présentons quelques modèles actuels, qui illus-trent bien la richesse et l’hétérogénéité de la modélisation urbaine.
1. Townscope
Townscope [Teller-Azar 2002] a été créé par le LEMA, le Laboratoire d’Étude Mé-thodologiques Architecturales de l’Université de Liège. Il s’intéresse à la morphologie et à la physique urbaine. C’est un outil d’analyse puissant d’aide à la décision pour le design urbain. Il permet l’évaluation du confort thermal, des risques d’inconfort liés au vent et des qualités perspectives des espaces ouverts, tels les places. Finalement, il offre un mo-dule de décision multicritère.
Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 23 sur 166
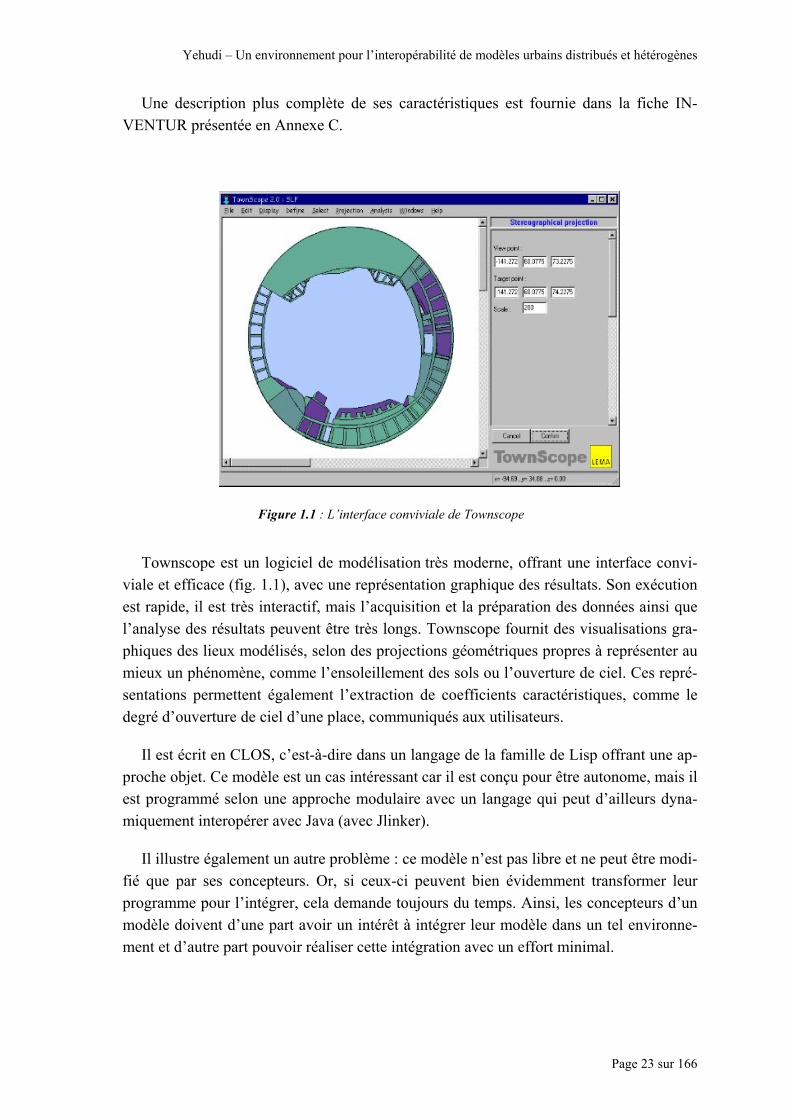
Une description plus complète de ses caractéristiques est fournie dans la fiche IN-VENTUR présentée en Annexe C.
Figure 1.1 : L’interface conviviale de Townscope
Townscope est un logiciel de modélisation très moderne, offrant une interface convi-viale et efficace (fig. 1.1), avec une représentation graphique des résultats. Son exécution est rapide, il est très interactif, mais l’acquisition et la préparation des données ainsi que l’analyse des résultats peuvent être très longs. Townscope fournit des visualisations gra-phiques des lieux modélisés, selon des projections géométriques propres à représenter au mieux un phénomène, comme l’ensoleillement des sols ou l’ouverture de ciel. Ces repré-sentations permettent également l’extraction de coefficients caractéristiques, comme le degré d’ouverture de ciel d’une place, communiqués aux utilisateurs.
Il est écrit en CLOS, c’est-à-dire dans un langage de la famille de Lisp offrant une ap-proche objet. Ce modèle est un cas intéressant car il est conçu pour être autonome, mais il est programmé selon une approche modulaire avec un langage qui peut d’ailleurs dyna-miquement interopérer avec Java (avec Jlinker).
Il illustre également un autre problème : ce modèle n’est pas libre et ne peut être modi-fié que par ses concepteurs. Or, si ceux-ci peuvent bien évidemment transformer leur programme pour l’intégrer, cela demande toujours du temps. Ainsi, les concepteurs d’un modèle doivent d’une part avoir un intérêt à intégrer leur modèle dans un tel environne-ment et d’autre part pouvoir réaliser cette intégration avec un effort minimal.

Mémoire de thèse
Page 24 sur 166
2. EnviMet
EnviMet est un modèle micro-climatique tri-dimensionnel développé par Michael Bruse du groupe de recherche de climatologie à l’institut géographique de Bochum [Bruse 2002].
Ce modèle est très éloigné de Townscope, malgré l’utilisation d’une interface convi-viale. En effet, les résultats et les données peuvent être exploités dans un logiciel séparé, Leonardo, et sont transmis en entrée et en sortie via des fichiers. La préparation des don-nées est rapide, ainsi que l’exploitation des résultats. En revanche, le traitement prend au minimum plusieurs heures.
EnviMet est un bon exemple de modèle propre à l’interopérabilité. Ses données sont clairement définies dans des fichiers textes, et son traitement est classique : il se base sur des calculs très complexes, peu compatibles avec une forte interactivité, du moins pas avant d’avoir des ordinateurs beaucoup plus puissants.
Il est programmé en C et en Pascal, privilégiant évidemment l’efficacité des calculs à une approche fortement modulaire. Par son fonctionnement, il peut aisément être assimilé à un programme batch, malgré l’interface graphique et peut aisément être intégré dans un environnement.
3. Quelques autres modèles « typiques »
Nous pouvons encore parler d’AMAP [Bionatics 2002], une collection de logiciels permettant la simulation de croissance de différentes plantes, avec le module Genesis, la modélisation numérique de terrains avec Altis et la mise en scène et le rendu dédié au paysage avec le module Orchestra. Un autre outil, Pixto 3D, permet le calage automati-que des maquettes virtuelles sur des vues réelles. Orchestra utilise un rendu basé sur une base de données dédiée permettant le dessin de scènes composées de plusieurs milliards de polygones. Altis quant à lui permet de travailler à partir de relevés numériques de ter-rains avec des triangulations, des interpolations, des déformations, offrant également le calcul de courbes de niveaux et la délimitation de parcelles. Mais AMAP est véritable-ment né du module Genesis. Ce dernier a été élaboré au sein du CIRAD, organisme fran-çais spécialisé en agronomie tropicale, pour permettre de simuler la croissance des plan-tes de manière réaliste. Le manque de logiciel de création de plantes réalistes en infogra-phie a fourni une application commerciale à Genesis, laquelle s’est étendue en AMAP, en association avec JMG Graphics. Depuis, JMG Graphics est devenu Bionatics et la tech-nologie AMAP est utilisée pour l’architecture, la modélisation temps-réel et les applica-tions multimédia telles que les jeux vidéo. Par sa grande ouverture, il est particulièrement compatible avec d’autres logiciels, fournissant ses données sous des formats répandues, 3ds Max, Autodesk VIS, Openflight, VRML, … De même, il peut utiliser des données variées, des cartes numériques, des ortho-photos, des dessins AutoCAD, ... Cependant, son usage avec d’autres modèles urbains est limité, car il fournit principalement des scè-

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 25 sur 166
nes tridimensionnelles composées de nombreux polygones, dont l’usage en entrée d’un autre modèle n’est pas encore compatible avec la puissance des ordinateurs. La figure 1.3 illustre cette complexité en présentant quelques arbres générés par Genesis. Orchestra gé-nère des images et est donc un modèle de fin de chaîne. Genesis et Altis pourraient être utilisés dans certains cas : la modification de terrains existants avec Altis, la création d’arbres réalistes avec Genesis. Ces terrains et ces arbres seraient utiles pour quelques modèles utilisant des données tridimensionnelles en entrée, tel EnviMet.
Figure 1.2 : Quelques arbres générés par Genesis, exportés en format 3DS Max et affichés avec Cinéma 4D
SubMeso [SubMeso 1996], quant à lui, présente la particularité d’être un super-modèle puisqu’il s’appuie déjà sur un ensemble de sous-modèles : prise en compte des sols et de la canopée, un processeur météo, la gestion de la dynamique et de la thermody-namique, calcul de la microphysique, traitement de la chimie et du transport, un mailleur et un post-processeur graphique. À partir de données géographiques, des cadastres des émissions et des données météorologiques, il calcule les champs 3D des concentrations de polluants. Il nécessite de ce fait une station de travail puissante et un travail d’extraction de données très important. De plus, il fonctionne dynamiquement, en réutili-sant les données générées et les données extraites pour évaluer l’écart entre les résultats et les estimations et continuer son traitement.
Piccolo [Safege 2001] ressemble quant à lui à un SIG tel ArcInfo. Il permet la gestion des réseaux d’eau dans une agglomération. Piccolo est, comme Townscope, un pro-gramme complet, non conçu pour être interopérable, offrant une interface utilisateur complète et puissante. De plus, il s’agit d’un modèle commercial.

Mémoire de thèse
Page 26 sur 166
Finalement, CAMx [Environ 2002], qui n’est pas décrit dans INVENTUR, est un mo-dèle permettant l’estimation de la qualité de l’air. Il est fourni sous forme de sources en Fortran 77 et de ce fait se compile sur presque toutes les plates-formes. Ce modèle est donc fortement interopérable, vis-à-vis de Java d’autant plus qu’il existe un compilateur de Fortran vers Java. Cependant, il faut préciser que de nombreux programmes fournis sous forme de sources ne sont pas modifiables pour des problèmes de droit, par contre le modèle peut être porté sur différentes plates-formes.
1. 2. 5. Modularité et échange
Certains modèles se présentent sous une forme particulièrement adaptée à leur intero-pérabilité : classe Java [Sun 2002d], code Visual Basic [Microsoft 2002b], compatibilité avec OLE [Microsoft 1998], avec CORBA [OMG 2000], ... Nous pouvons qualifier ces modèles d’intéropérables. Cette ouverture doit toutefois être relativisée. En effet, les techniques qui permettent d’implémenter ces modèles en tant que composants sont nom-breuses et non nécessairement compatibles entres-elles. En effet, un programme passant par OLE s’intègre difficilement à un environnement sous CORBA, un code Visual Basic ne s'exécute pas sous Java. De plus, les services pour l'échange ne traitent des problèmes d'hétérogénéité qu’à un certain niveau, tout du moins pas de manière automatique et satis-faisante, s’intéressant aux adaptations entre types informatiques de données, entiers, flot-tants, chaînes de caractères, et non entre des types correspondants à une réalité physique, la température, une distance, une portion de carte, … La composition est prévue sur un plan strictement informatique et n’offre pas de support à une connexion de programmes riches, qui utilisent des types particuliers et offrent un traitement riche. L’intéropérabilité supportée s’intéresse principalement à la représentation informatique des données.
En fait, d’un point de vue strictement informatique, ces technologies offrent deux ni-veaux distincts d’interopérabilité :
- intra-système, avec une communication immédiate, due à l’adoption du même sup-port, mais avec la nécessité d’assurer la correspondance des données. Cependant, la correspondance des types informatiques de données supportés peut être assurée au sein du système par des services.
- extra-système, avec la nécessité d’adapter la communication entre deux systèmes dif-férents, tout en devant également gérer les correspondances de données.
Malheureusement, cette prise en compte de l’interopérabilité est uniquement d’un point de vue informatique. Un modèle urbain est un programme spécifique et une inter-connexion de modèles urbains s’intéresse à cette spécificité, qui n’est en aucun cas sup-porté par ces technologies qui embrassent des problèmes de bas-niveau.
En revanche, il est toujours possible de réaliser un « pont », c’est-à-dire un programme utilisant des techniques compatibles avec celles utilisées par le modèle et répondant par-

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 27 sur 166
faitement aux spécifications pour l’intégrer à notre « monde ». Nous verrons par la suite que cette idée de « pont » constitue le fondement de l'encapsulation, la technique qui nous permet de rendre interconnectables et homogènes différents modèles. Dans le cas des modèles « interopérables », la fabrication de « ponts » est facilitée par le simple fait que c'est une technique tout à fait permise par les procédés mis en œuvre ici. De plus, certains « ponts » sont déjà construits, sous la forme d’API ou de librairies partagées par exemple.
Les modèles sous forme de classes sont presque des modèles interopérables. Nous avons d'ailleurs considéré les classes Java dans la précédente catégorie. En effet, les clas-ses Java disposent de mécanismes, dont les Java Beans ne sont qu'un reflet, qui permet-tent une utilisation dynamique et « in vivo » des classes.
La programmation dans des langages, tels que le C++, Delphi, repose sur une appro-che modulaire facilitant la réutilisation des classes. Disposant des sources, il est possible de réaliser des «ponts» vers ces programmes, simplement en programmant dans le même langage un lien avec notre système, voire, comme le permet Java Native Interface, d'inté-grer ce modèle comme s'il était natif à notre système.
Sans code source, il est tout de même envisageable d'utiliser un modèle de manière simple, pour peu qu'il ait été conçu pour permettre son utilisation de manière automati-que. Nous considérerons comme « procédures » tous les modèles pouvant facilement être utilisés via un autre programme, mais n'offrant pas de réelles facilités pour l'échange des données, leur récupération ou leur compréhension. Ces modèles sont donc interopérables, mais nécessitent un enrichissement conséquent pour une interconnexion satisfaisante.
Enfin, certains modèles se présentent sous la forme d'un produit fini destiné à un usage « final », c'est-à-dire disposant d'une interface utilisateur plus ou moins ergonomique et n'offrant d'interaction que, ou presque, via cette interface. Un tel modèle n'est pas conçu pour être interconnecté ni pour être utilisé via un autre programme. Leur interopérabilité est impossible a priori. Ces modèles sont des programmes intégrés.

Mémoire de thèse
Page 28 sur 166
Echange desdonnées
Modularité
Modèles intégrés
Procédures Classes
Composants
Townscope
EnviMet
CAMx
SubMeso
Amap
Figure 1.3 : Positionnement des modèles en fonction de leurs capacités d’échange et de modularité.
La figure 1.3 situe les modèles présentés selon les axes échanges de données et modu-larité. Les zones présentent également une classification des modèles selon ces deux axes. Ainsi, un composant offre des capacités d’échange et une grande modularité. Les classes perdent les capacités d’échanges mais gardent une forte modularité. Les procédures ont des capacités d’échanges autant limités que les classes et perdent en modularité. Finale-ment, les modèles intégrés sont peu modulaires et offrent des capacités d’échange plus ou moins grandes. Ainsi, CAMx, écrit en Fortran sous forme de modules, offre une modula-rité assez grande, mais des capacités d’échanges limitées et statiques. EnviMet, fournit sous la forme d’un programme complet, est quant à lui assez peu modulaire. En revanche, il génère et utilise des données stockées sous forme de fichiers textes, et permet donc des échanges de données assez simples. Townscope, écrit dans un langage modulaire et utili-sant des données dans des formats connus, offre un bon compromis entre échange et mo-dularité. SubMeso, par sa forme même, est relativement indépendant et offre donc de no-tre point de vue une modularité et des possibilités d’échanges de données assez faibles. AMAP est un peu un cas particulier. Il est en fait assez modulaire et permet des échanges de données, mais dans un contexte particulier, plus proche de l’infographie que de l’urbanisme. En effet, en tant que modèle urbain, il se suffit à lui-même.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 29 sur 166
1. 3. Solutions envisageables
Pour permettre l'interopérabilité des modèles urbains il est nécessaire de masquer leur hétérogénéité. Mais nous devons également connecter ces modèles, les faire vivre les uns avec les autres. Il ne suffit pas d'homogénéiser les données, il faut également piloter les modèles et leur enchaînement. Pour cela, il existe deux approches :
A priori, en fournissant un environnement qui permette de produire et d’exploiter des modèles homogènes :
- par une approche déclarative, utilisant des méta-modèles recouvrant intégralement la réalité des modèles, lesquels permettent la création du modèle lors de son utilisation. Ainsi, les modèles sont « virtuels », ils n'ont de réalité que pour la session en cours et les modèles générés sont naturellement compatibles. Cette approche interdit l'utilisation de modèle programmé existant, mais permet la réalisation de modèles interconnectables de manière simple [Maxwell 1999a, 1999b, Page-Parisel 2000],
- par fédération, les modèles sont différents mais doivent offrir un accès unifié. Ainsi, un système d'exploitation de modèles pourra les interconnecter sans problème, en temps réel si nécessaire. Cette approche est très performante, mais très difficile à réaliser, il s'agit d'un véritable système réparti multi-support, et les créateurs de modèles doivent respecter un cahier des charges. L'homogénéisation est assurée à la création du modèle en imposant un standard d'accès [DMSO 2002].
Dans ces deux approches, l'interopérabilité reste au niveau du modèle mais n’est pas réalisée ou peu au niveau des données. Il n'y a pas de médiation ou d'adaptation des don-nées. Les modèles sont forcément homogènes pour leur interconnexion.
Il existe donc une autre approche, a posteriori, qui tente d’intégrer des modèles exis-tants en se donnant les moyens de les faire communiquer. Ainsi, le système WebReuse décrit des modèles hétérogènes pour pouvoir les utiliser via le Web en traduisant les don-nées par des « wrappers » [Iazeolla-D’ambrogio 1998]. Nous adoptons également cette approche.
1. 4. Notre objectif
Pour ce projet, nous ne cherchons pas à offrir une utilisation interactive des modèles en réalisant leur interconnexion « à la volée », mais nous offrons la possibilité d'intercon-necter ces modèles selon un schéma donné par l'utilisateur, d’une façon semi-interactive, c’est-à-dire que l’utilisateur garde tout de même le contrôle de l’exécution. La figure 1.4 représente une interconnexion réaliste. Ces quatre modèles interconnectés peuvent être considérés comme un nouveau modèle ou comme un ensemble. Dans le premier cas, nous voulons offrir une gestion automatisée de l’ensemble qui permette à l’utilisateur d’utiliser

Mémoire de thèse
Page 30 sur 166
cette interconnexion de manière transparente, comme un seul modèle. Dans le deuxième cas, nous désirons apporter des possibilités de contrôles interactifs ainsi qu’offrir la pos-sibilité d’éditer dynamiquement le schéma. Ainsi, l’utilisateur pourra contrôler l’exécution du modèle « Estimation de la mobilité quotidienne en transports en com-mun », le mettre en pause, le relancer. Il pourra également enlever un modèle, le rempla-cer, ou en ajouter. Notre objectif est d’offrir la capacité d’intégrer des modèles existants dans un environnement intégré qui offre un maximum de possibilités à l’utilisateur, de composition, de réutilisation et d’usage interactif. Nous présentons plus en détail cet ob-jectif dans le chapitre II.
Estimationdu déplacement
piétonen agglomération
Estimation de la mobilitéquotidienne en voiture
Calculd’émissions
atmosphériques
Estimation de la mobilitéquotidienne en
transports en communInfrastructure
routière
Plan de circulation
Population/Tranche d’âge
Plan d’occupationdes tauxd’activité
Taux de fréquentationDes différents lieux
Nombre de passagepar type de lieu
Nombre de passagepar type de lieu
QualitéDe l’air
Figure 1.4 : Un exemple d’interconnexions utile de quatres modèles.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 31 sur 166
CHAPITRE II OBJECTIF GÉNÉRAL
Dans ce chapitre, nous précisons le cadre de travail, avec les problèmes liés et les hy-
pothèses que nous avons posées. Nous présentons alors les différentes approches cou-ramment utilisées, en précisant en quoi elles se complètent et pourquoi elles ne suffisent pas pour assurer l’interopérabilité des modèles urbains. Enfin, nous expliquons la philo-sophie de notre système.
2. 1. Les différentes hétérogénéités d’un modèle urbain
Pour mettre en évidence les difficultés inhérentes à l’intégration d’un modèle, nous pouvons détailler un exemple fictif comprenant trois modèles et une base de données. La figure 2.1 montre à sa gauche la réalité physique, avec trois machines respectivement sous Unix, Windows NT et Windows 98, trois modèles A, B, C et une base de données D. A droite, nous avons représenté l’interconnexion logique que nous souhaitons obtenir : les données sont extraites de la base de données D pour être traitées par les modèles A et C. Les données générées par A et C sont dupliquées par un élément I pour être utilisées par deux modèles B, qui sont paramétrés de manière différente, ce qui justifie leur double présence. Les données générées par les modèles B sont stockées dans un fichier. Le mo-dèle C réutilise ses résultats pour se calibrer, ce qui est représenté par le trait pointillé. Nous allons maintenant décrire cinq étapes pour intégrer ces modèles, en précisant ainsi leurs différents niveaux d’hétérogénéité.
Unix
Windows NT Windows 98
A
B
Synchronisation
D
D
AB
B
C
C
I
I
Figure 2.1 : Les éléments à interconnecter et l’interconnexion voulue

Mémoire de thèse
Page 32 sur 166
2. 1. 1. Assurer l’intégration des modèles et leur accès
Les modèles sont d’abord des programmes, écrits avec un certain langage pour un ou plusieurs systèmes d’exploitation et s’utilisant d’une manière particulière. Il faut donc tout d’abord pouvoir offrir une « interface » standardisée pour accéder aux modèles. Cette homogénéisation permet leur intégration au sein d’un environnement. Nous avons ainsi des éléments standardisés mais isolés, tels que représentés sur la figure 2.2. L’accès à la base de données se fait quant à lui en rajoutant un élément d’accès, qui pourra s’appuyer sur ODBC par exemple. Cet élément peut être vu comme un modèle standard. Cependant, il reste à gérer la distribution des modèles.
Unix
Windows NT Windows 98
A
B
Synchronisation
D
D
A
B
C
C
1. Intégration et accès
Figure 2.2 : Sans perdre l’indépendance des modèles répartis, leur intégration les homogénéise.
2. 1. 2. Mettre en communication les modèles
Lorsqu’il est possible d’accéder aux modèles de manière uniforme, il devient néces-saire de les mettre en communication. Il faut donc apporter une solution robuste pour abs-traire la réalité de la répartition et ainsi avoir un environnement de modèles distribués. À ce stade, les données sont transférées en aveugle, aucune fonctionnalité supplémentaire n’est disponible et le possible parallélisme n’est pas géré, ce qui s’illustre dans notre exemple par le fait qu’il n’y a qu’un seul modèle B connecté, contrairement à notre be-soin. Nous pouvons dire que les modèles sont en communication avec l’environnement mais non interconnectés. La figure 2.3 représente cet état.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 33 sur 166
Environnement
A
B
Synchronisation
D D
A B
CC
2. Mise en communication
Figure 2.3 : Les modèles sont connectés à un bus commun.
2. 1. 3. Contrôler les communications
Pour pouvoir utiliser les modèles conjointement, il est nécessaire de contrôler les don-nées circulantes et d’apporter des fonctionnalités supplémentaires, telle la copie de don-nées par les éléments I. Il faut également pouvoir gérer le parallélisme et les éventuels problèmes de concurrence, tel qu’ici avec le modèle B.
L’hétérogénéité des données est traitée par des éléments d’adaptation, qui sont repré-sentés sur la figure 2.4 à gauche en sortie de A et de C et en entrée de B. L’élément AB adapte les données générées par A pour qu’elles soient telles qu’attendues par B et l’élément CB fait de même pour C. Ces éléments sont des acteurs de l’environnement dis-tribué, schématisé à droite. Ces adaptations ne sont pas une conséquence naturelle de l’intégration des modèles. Il faut savoir les ajouter. Dans ce but, il faut pouvoir connaître précisément le type des données manipulées et si possible leur sémantique, ce qui n’est pas le cas actuellement. Cette étape offre un monde logiciel homogène qui doit être géré, c’est le rôle de la troisième étape.

Mémoire de thèse
Page 34 sur 166
Environnement
A
B
Synchronisation
D
D
A B
C
C
3. Gestion des communications
AB
AB
CB
CB
IIAB
CB
A
C
AB
CBB
Figure 2.4 : Ajout d’éléments de copie (I), d’adaptations et gestion de la concurrence au niveau du modèle B.
2. 1. 4. Exécuter les modèles
Nous possèdons maintenant des modèles vus comme des éléments homogènes et un environnement apportant les fonctionnalités permettant de les interconnecter. Cependant, leur exécution n’est pas triviale pour autant. Il faut en effet savoir quand commencer et quand finir le travail général. Le modèle C nécessite un calibrage qui doit également être prise en charge.
Il faut aussi apporter une gestion temporelle de l’environnement, pour contrôler et synchroniser l’exécution et la circulation des données. Ainsi l’exécution du programme A nécessite par exemple approximativement 3 heures, celle de C 1 heure et celle de B 2 jours.
Finalement, l’exécution des différents éléments demande de savoir gérer les problèmes pouvant survenir. L’exécution prend en charge l’aspect logique des différents éléments.
La figure 2.5 représente cette gestion.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 35 sur 166
D
AB
BC
I
I
4. Exécution
1 heure
3 heures2 jours
2 jours
Gestion du tempsd’exécution des
modèles
Prise en charge de la calibration
Figure 2.5 : Gestion de l’exécution des modèles
2. 1. 5. Contrôler la cohérence de l’interconnexion
Nous avons vu que certaines actions, telles l’adaptation des données et la gestion des pas de temps, nécessitent une connaissance des éléments en présence. Une intégration complète et automatique de modèles hétérogènes demande ainsi une gestion de la typolo-gie des données manipulées mais également de la réalité sémantique des données et des modèles urbains. Le système pourra ainsi vérifier la cohérence de l’interconnexion, savoir s’il n’existe pas de fortes incompatibilités entre deux modèles. Il est également utile, voire indispensable, de savoir comment obtenir des pas de temps identiques, comme nous le décrivons ci-après, et de savoir évaluer les pertes de qualités conséquentes. Ces vérifi-cations pourraient également être utilisées pour savoir ajouter automatiquement les né-cessaires calibrations. L’ensemble de ces contrôles est représenté en figure 2.6.
La gestion temporelle « interne » ne doit pas faire oublier une nécessaire gestion du temps de l’univers des modèles. Supposons que le modèle A évolue selon des pas de temps de 6 mois, le modèle C par intervalles de 3 mois et le modèle B tous les ans. Il faut savoir gérer les modèles A et C et leurs données générées pour que ces dernières suivent finalement un pas de temps identiques pour pouvoir être utilisées ensembles en entrée de B. L’intervalle de génération de B n’a pas forcément d’importance, ses données n’étant pas utilisées. La gestion de ce temps nécessite, ainsi que l’adaptation des données, une connaissance approfondie des modèles.

Mémoire de thèse
Page 36 sur 166
1 an
3 mois
6 mois
D
AB
BC
I
I
6. Contrôles de la cohérence
Vérification du temps de l’univers des modèles
Vérification de lacompatibilitédes modèles
Vérificationtypologique
et sémantiquedes données
Prise en charge de la calibration
Figure 2.6 : Les différents contrôles permettant la bonne intégration des modèles
2. 1. 6. Du logiciel au sémantique
Ces différentes étapes correspondent à une abstraction des modèles et des problèmes liés à leur intégration. Nous pouvons schématiser cette abstraction par une prise en compte successive des aspects logiciels, logiques puis sémantiques, telle que représentée en figure 2.7.
Intégration et accès
Mise en communication
Contrôle des communications
Exécution
Contrôle de cohérence
Aspects logiciels
Aspects logiques
Aspects sémantiques
Figure 2.7 : Les cinq étapes de l’intégrations avec les trois aspects pris en compte.
Dans cette partie, nous avons présenté les différents aspects du problème abordé. Nous allons maintenant parler des caractéristiques de celui-ci et des hypothèses que nous avons adoptées.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 37 sur 166
2. 2. Cadre de travail
Pour mieux cerner le problème posé, nous avons défini un cadre de travail en s’appuyant sur certaines hypothèses de travail. Nous décrivons celui-ci dans ce paragra-phe.
2. 2. 1. Caractéristiques
D’un point de vue logiciel, l’intégration des modèles urbains est limitée par le fait que ceux-ci sont des logiciels quelconques, qui ne suivent pas une règle précise de concep-tion. De plus, ils traitent leurs données en entrée ou en sortie de diverses manières, par fi-chier, par liaisons binaires, par interface graphique, …
Concernant les communications entre modèles, nous avons déjà précisé qu’ils sont ré-partis sur le réseau, sur des machines différentes, éventuellement sous des systèmes d’exploitation différents. Mais, comme nous le verrons bientôt, cette répartition sur un ré-seau disponible fait partie des hypothèses de travail. Ce qui ne veut pas dire que ces mo-dèles sont accessibles via le réseau, mais que la machine où ils résident l’est et qu’il est donc possible, via un autre logiciel, d’accéder à ce modèle. Ce qui signifie que les don-nées traitées ne sont pas elles non plus initialement conçues pour circuler sur le réseau.
Pour trouver un intérêt dans l’interconnexion de modèles, il faut également pouvoir les contrôler pour suivre l’enchaînement souhaité. Ce contrôle exige que le modèle soit déjà intégré et en communication mais également que cette intégration et cette mise en com-munication soient utilisables de manière automatique et que le système soit capable d’agencer ces exécutions pour respecter l’enchaînement.
Mais l’interopérabilité des modèles ne passe pas seulement par leur contrôle et la cir-culation des données. Les données manipulées sont complexes et elles recouvrent, ainsi que le traitement effectué par le modèle, une réalité sémantique complexe. Dans de nom-breuses applications, les données n’ont qu’une réalité informatique. Les modèles urbains, quant à eux, manipulent des données en rapport avec la réalité. Et la complexité des phé-nomènes représentés implique que les modélisations réalisent une approximation de la ré-alité.
2. 2. 2. Problèmes liés
Ces différentes caractéristiques engendrent de nombreux obstacles pour interconnecter des modèles urbains. Nous présentons maintenant les différents problèmes inhérents à ce projet, lesquels seront limités par les hypothèses de travail, présentées ci-après.

Mémoire de thèse
Page 38 sur 166
Tout d’abord, l’intégration logicielle d’un modèle s’oppose au fait qu’ils ne sont pas conçus pour cela. Nous ne souhaitons pas qu’il faille réécrire le modèle pour l’intégrer. Comment intégrer le modèle tel qu’il est ?
Dans un cadre distribué, l’utilisation de modèles tels qu’ils sont pose d’autres problè-mes. Pouvons-nous rendre le modèle mobile ou devons-nous gérer sa localisation ? Qui plus est, nous voulons que leur interconnexion soit décidée a posteriori. Ainsi, comment mémoriser l’enchaînement souhaité ? Comment exécuter les modèles dans l’ordre et en s’occupant des problèmes de compatibilité, de synchronisation et d’échange des don-nées ?
Ces deux premiers points nécessitent également que les modèles soient clairement connus. Or ils se présentent sous la forme de boîtes noires. Comment pouvons-nous ajou-ter l’information nécessaire à l’intégration et comment la stocker ?
Finalement, l’automatisation des interconnexions pose également de nombreux pro-blèmes. Les modèles sont des programmes complexes qui manipulent des données com-plexes. Il n’est pas possible de connecter n’importe quel modèle avec n’importe quel au-tre. Quelles informations devons-nous traiter pour permettre l’automatisation ? Comment vérifier les connexions ?
2. 2. 3. Hypothèses de travail
Cette interconnexion ne nous a paru possible, au moins dans un premier temps, qu’en dressant certaines hypothèses. Ainsi, nous considérons que :
- les modèles ont des comportements proches, il est possible de généraliser leur fonc-tionnement. La figure 2.8 montre notre schématisation : un modèle peut posséder des en-trées, des sorties, des paramètres. Il effectue un traitement qui peut être synchronisé et il peut générer des synchronisations. Nous pensons cette généralisation assez forte pour en-glober la majorité des modèles existants. A noter tout de même que cette généralisation « oublie » la possible interface graphique d’un modèle, ou la confond avec de simples en-trées, sorties et synchronisations. En fait, il s’avère souvent difficile de capturer les in-formations d’une interface graphique.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 39 sur 166
Modèlede
traitement
Entrées Sorties
Paramètres
Synchronisations
Figure 2.8 : Propriétés générales d’un modèle.
- ils sont localisés sur des machines connectées par réseau ou sur une seule machine. Nous ne voulons cependant pas nous limiter à un système d’exploitation ou à une connexion réseau particulière. Néanmoins, nous nous limiterons aux systèmes et connexions gérés par des technologies existantes. Nous ne fournirons pas de solution bas-niveau pour la communication ou le support système.
- intégrer des modèles existants impose qu’il existe une description suffisante pour pouvoir le faire. Nous ne pouvons attendre d’un concepteur qu’il fournisse une descrip-tion exhaustive d’un modèle, de ses traitements, des données traitées et des hypothèses sous-jacentes à son travail. Nous supposons donc pouvoir disposer d’une description mi-nimale des modèles, en acceptant que cette description ne décrive pas complètement le modèle.
- les utilisateurs savent utiliser les modèles. Nous considérons que, dans une certaine limite, ils peuvent superviser l’interconnexion de modèles. Ainsi, avant de totalement au-tomatiser l’interconnexion, nous souhaitons offrir un outil puissant et clair pour la facili-ter.
2. 3. Solutions existantes
L’interopérabilité n’est pas un problème nouveau. Elle suppose des possibilités d’échanges et des compatibilités entres éléments et systèmes différents. Nous exposons dans ce paragraphe les différentes méthodes existantes et nous verrons en quoi elles se révèlent complémentaires mais encore insuffisantes.
2. 3. 1. Parler un même langage
La solution la plus simple pour permettre à tous de se comprendre consiste à imposer un même langage pour tous. Cette méthode s’oppose néanmoins à plusieurs problèmes difficilement solvables. D’une part, l’informatique est un domaine où interviennent de

Mémoire de thèse
Page 40 sur 166
nombreux acteurs disposant de nombreux langages concurrents. Cette profusion peut être observée sur l’arbre généalogique des langages informatiques présenté en [Leve-nez 2002].
Aussi cette solution nécessiterait un langage qui soit suffisamment complet pour cou-vrir tous les domaines d’application. En général, la prise en compte de données com-plexes passe par la création de formats de données propres. Le langage ne fournit que des types de base, qui ne permettent donc pas d’avoir un support universel et clair pour l’ensemble des applications.
Mais la plus grande limitation vient du fonctionnement même de l’informatique : les logiciels sont très rarement des boîtes de cristal. Pour des besoins de performance, ils sont en effet écrits dans un langage informatique et le plus souvent compilés en langage ma-chine. Leur vie réelle sera ensuite gérée par le système d’exploitation. Traditionnelle-ment, ce dernier n’offre pas de voies de communication de haut niveau entre les logiciels. Et même si les systèmes évoluent pour offrir de telles possibilités, les solutions actuelles sont encore principalement orientées binaires, telle la solution OLE/DCOM de Microsoft [Microsoft 1998], qui utilisent des interfaces définies avant la compilation.
Il existe cependant certaines alternatives, une des plus connues étant Java [Sun 2002d], qui, en utilisant un langage intermédiaire, le byte-code, pour stocker les classes compi-lées, offre un support dynamique et introspectif beaucoup plus poussé. En fait, le byte-code est un langage machine avancé, interprété par une machine virtuelle. Mais cette in-terprétation a un coût et Java est un langage relativement lent. Cependant, l’universalité de ce langage est prévue par une autre caractéristique : le domaine couvert par les outils du langage est très large et régulièrement étendu. Ainsi, de nombreuses applications de haut niveau sont prises en compte directement au sein du langage, par des classes prédé-finis, robustes et optimisées. L’optimisation passe parfois par l’usage de méthodes nati-ves, c’est-à-dire compilées en C ou C++. Le vaste champ d’application traité en standard permet une compatibilité accrue entre les différents logiciels écrits en Java. De plus, la composition a été prévue par les Java Beans, des classes relativement standardisées. Ce-pendant, cette standardisation ne va pas jusqu’à prendre en compte des types de données complexes et des comportements particuliers. Finalement, les avancées de Java supposent l’avènement d’un univers tout Java, ce qui n’est pas encore compatible avec la réalité, surtout pour la réutilisation de programmes. Nous présentons Java plus en détail dans le chapitre V.
Ainsi, l’hégémonie d’un unique langage est une utopie, aussi bien dans le cadre de l’informatique que dans le monde réel. Il ne reste plus alors qu’à utiliser, comme dans le monde réel, un langage simple consensuel, des standards, des normes, des traducteurs et des interprètes.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 41 sur 166
a. Standards de faits
L’informatique est un domaine où les standards arrivent à se créer d’eux-mêmes, par un processus de sélection. En effet, certaines sociétés imposent un format qui devient quasi-universel par la seule importance de l’entreprise en question, comme les formats de documents de Microsoft. Dans certains cas, le format s’impose par ses qualités, tel le format d’image GIF.
Ces standards de fait n’offrent pas que des avantages. Ainsi, lorsqu’ils s’imposent pour des raisons indépendantes de leur qualité, ils peuvent remplacer des formats de meilleure qualité. De plus, et quelle que soit leur qualité, il se peut qu’ils ne soient pas libres de droits. Et la société qui possède ce format peut décider à tout moment du sort de ce der-nier.
Mais surtout, dans le domaine qui nous intéresse, il existe peu de standards de fait. Tout simplement parce que ces derniers ne se créent que par un usage répandu. Or, les données scientifiques ne sont utilisées que dans des cadres le plus souvent limités. Il existe ainsi certains standards pour des communautés scientifiques étendues, tels les as-tronomes, qui disposent du format FITS (Flexible Image Transport System) [FITS 2002]. Mais de nombreux modèles urbains utilisent leur propre format de données spécialisé.
b. Standards spécifiques
Il existe néanmoins des organismes de normalisation et des consortiums qui créent et proposent des standards ambitieux. En règle générale, les différents acteurs d’un domaine ont la possibilité de se regrouper pour définir des standards ou proposer des solutions concernant leur domaine. Ainsi, les standards proposés sont le fruit d’un consensus entre différents acteurs, ce qui est garant d’une qualité minimale. Ensuite, la mise en public d’une importante documentation permet d’utiliser un format accepté par une vaste com-munauté.
Cependant, il faut souligner certains points limitatifs. D’une part, les formats les plus marginaux ont peu de chance de se retrouver ainsi standardisés. D’autre part, afin de cou-vrir un domaine vaste, certaines normes et certains standards deviennent lourds d’utilisation et tous les acteurs n’ont pas forcément besoin de tout le potentiel proposé.
Les standards les plus communs sont documentaires, tel HTML, SGML, XML pour la syntaxe des documents, ISO Latin 1, Unicode pour les caractères, ou encore l’ISBN des livres. Il existe cependant de plus en plus de standards et de normes concernant des do-maines scientifiques, en particulier pour les systèmes d’information géographique. Ainsi, nous pouvons citer certains standards proches de notre domaine applicatif :

Mémoire de thèse
Page 42 sur 166
- Spatial Data Transfer Standard (SDTS) [USGS 2002], qui définie des méta-données permettant l’échange de données spatiales avec la possibilité de ne pas avoir de pertes d’information,
- Content Standard for Digital Geospatial Metadata (CSDGM) [FGDC 2002a] du Fe-deral Geographic Data Committee (FGDC) [FGDC 2002b], qui est un ensemble de ter-minologies et de définitions communes pour les données géo-spatiales digitales,
- Open GIS [OpenGIS 2002], qui fournit une spécification de caractéristiques de bases permettant l’intéropérabilité,
Le comité technique ISO/TC211 [ISO/TC 2002] est responsable de toutes les standar-disations en système d’information géographique, ainsi que le comité technique CEN/TC 287 [CEN/TC 1999] au niveau européen.
c. Même langage, même structure : cas des bases de données
Il existe tout de même un domaine qui a réussi à devenir pratiquement homogène : les bases de données. L’actuelle manipulation des bases de données repose sur un concept fort : l’algèbre relationnelle. Pour implémenter cette algèbre, un langage simple et effi-cace, le Structured Query Language (SQL) est utilisé de manière pratiquement systémati-que [Date 1990, Flory-Laforest 1996]. SQL est efficace et standardisé. Finalement, en correspondance avec ce concept et ce langage, la structure des bases est simple, sous forme de tables. Elles offrent un cadre où les données sont bien décrites, ainsi que les re-lations entre elles. Ainsi, passer d'une base de données à une autre est maintenant possi-ble.
Cette homogénéité est favorisée par la puissance de l’algèbre relationnelle et de SQL, à cause de la difficulté pour trouver mieux et par le tassement du marché : les solutions de gestion de bases de données relationnelles fonctionnent bien et sont très implantées. L’expérience malheureuse des bases de données-objets tend à démontrer la rigidité et la prudence de ce domaine. Malgré les années, les bases restent majoritairement relationnel-les, quitte à stocker des objets persistants.
Malgré tout cela, il existe des limites à cette homogénéité : certaines fonctions évo-luées sont propres à un système de base de données (SGBD), par exemple les interfaces graphiques ou la gestion des objets binaires de grande taille (BOB). Et concernant le contenu même d’une base, la migration vers une autre base est certes très simple mais né-cessite une supervision : une base est un contenant, bien structuré et avec des types pré-cis, mais sans autre connaissance sur la nature du contenu que le libellé de la table ou de la colonne.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 43 sur 166
2. 3. 2. Trouver un consensus
S’il n’est pas réaliste d’attendre que les différents acteurs parlent tous un même lan-gage, il est envisageable de leur demander d’utiliser un moyen commun de communica-tion. Ainsi, nous ne leur demandons plus d’être homogènes mais d’utiliser une voie de communication homogène.
a. Usage des interfaces
Une des solutions les plus répandues aujourd’hui consiste en l’usage d’interfaces. Il existe traditionnellement des interfaces homme/machine, mais également des interfaces machine/machine et ainsi des interfaces logiciel/logiciel. Ce sont ces dernières qui nous intéressent. Sans réaliser d’historique de l’usage des interfaces, nous pouvons dire qu’il s’agit d’une caractéristique avancée des langages orientés objets. Une interface comprend des méthodes « vides » qui doivent être « remplies » par quiconque implémente cette in-terface. Ainsi, l’élément intégrant cette dernière offre la garantie qu’il offre les possibili-tés décrites par l’interface.
Ce mode opératoire a également été repris par les langages de script tel REXX [Co-wlishaw 2002], d’IBM ou Visual Basic [Microsoft 2002b], pour ne citer qu’eux. Ces lan-gages sont conçus pour être « user-friendly », conviviaux, c’est-à-dire utilisables par le plus grand nombre de personnes moyennant une auto-formation simple. Pour être utilisés par un de ces langages de scripts, les logiciels doivent offrir des points d’entrée, de sortie et de contrôle dédiés au langage utilisé. Dans le cas de REXX, un programme peut ainsi se connecter à un port et est ensuite utilisable via REXX d’une façon simple et uniforme. Mais il peut également contrôler et utiliser d’autres programmes liés à un port REXX. Il est ainsi possible d’écrire un programme REXX qui précise qu’à chaque résultat d’un programme A, le programme B sera exécuté pour utiliser les données générées. Néan-moins cette liaison ne se fait pas automatiquement : le programme script doit être écrit et son écriture nécessite l’usage d’une documentation concernant l’ensemble des éléments à reliés. Qui plus est, cette solution impose que les programmes aient été écrits dans cet ob-jectif.
L’usage des interfaces en programmation objet est en général limité au langage même, et donc ne sert qu’au développement dans le cas de programmes compilés. De son côté, CORBA [OMG 2000] permet la collaboration entre différents objets écrits dans des lan-gages différents par l’usage d’un langage propre d’interface : l’IDL (Interface Description Language). Les langages supportés par CORBA peuvent ainsi utiliser une IDL pour défi-nir une interface publique. Ainsi, un programme rédigé en C++ pourra utiliser un pro-gramme en Fortran, en supposant qu’ils aient été tous les deux programmés en ce sens. En effet, l’usage de CORBA permet d’utiliser une classe préexistante sans avoir à la re-compiler, mais il faut que le programme l’utilisant passe par l’interface précise de cette classe.

Mémoire de thèse
Page 44 sur 166
D’une manière moins tolérante mais plus dynamique, Java [Sun 2002d] utilise l’introspection pour permettre des interactions interclasses. Ces classes doivent être de type Java mais peuvent retrouver les informations concernant les autres classes lors de l’exécution. Les classes précompilées en byte-code conservent pour se faire la description de leurs caractéristiques. En quelque sorte, les classes ont toujours une lisibilité, une in-terface lisible. Mais des interfaces au sens objet existent également et toute classe implé-mentant une interface peut être utilisée tel qu’indiqué dans l’interface. Cet ensemble de caractéristiques facilite grandement une interaction dynamique entre classes, d’autant plus qu’une distribution d’objet est offerte de manière simple par Java RMI et que Java offre maintenant une compatibilité totale avec CORBA.
D’une manière plus opaque, OLE/DCOM [Microsoft 1998], de Microsoft, utilise aussi une interface, mais sous une forme complexe. Cette solution présente en fait deux dé-fauts : elle est complexe et elle est fermée. En revanche, la version simplifiée d’OLE, Ac-tiveX, est très utilisée, principalement par ses capacités liées à Internet. L’évolution d’OLE/DCOM, .NET [Microsoft 2002a] se veut plus ouvert, utilisant entre autre XML et SOAP, respectivement un langage documentaire et un format de description de processus.
b. Fédération de données
D’une façon générale, les précédentes solutions exigent une écriture dédiée au système choisi. La fédération de données permet d’intégrer des acteurs préexistants avec la seule contrainte qu’ils soient capables d’exporter et d’importer leurs données selon un format imposé. Cette liaison peut ainsi être réalisée par un module supplémentaire, par une API ou par un programme existant. Ainsi, le consortium OpenGIS [OpenGIS 2002] offre des cadres de fédération sur proposition de ses différents membres. Cette proposition est examinée, testée puis approuvée, ce qui permet de proposer des spécifications couvrant un domaine. Ces spécifications permettent aux acteurs le désirant de créer leurs outils en suivant ce consensus. Comme le consortium OpenGIS est indépendant de toute société privée, les formats qu’il propose peuvent être adoptés par tous sans problèmes de concur-rence ou de droit. Ainsi, une société privée peut rajouter des filtres d’importation et d’exportation pour le format OpenGIS, ce qui permettra à ses logiciels d’être capables d’échanger des données sans avoir besoin de connaître d’autres formats.
c. Fédération de modèles
Si la fédération de données ne contraint pas vraiment les programmes, la fédération de modèles les transforment en modules interconnectés. Dans the High Level Architecture [DMSO 2002], une infrastructure d’exécution temps réel (Run Time Infrastructure, RTI), offre six groupes de services, permettant aux fédérés de s’intégrer dans une simulation globale. La RTI est une sorte de système d’exploitation de simulations, se greffant par-dessus les systèmes et le réseau et permettant une exploitation temps réelle de modèles,

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 45 sur 166
lesquels doivent respecter certaines règles pour être intégrables comme par exemple la gestion du temps.
Un autre système, ACE [Schmidt 2002], offre également un cadre pour l’intégration de programmes hétérogènes, en facilitant leur intégration par de nombreux services et par l’utilisation de patterns et de wrappers.
2. 3. 3. Permettre des traductions
Les solutions présentées précédemment exigent toutes une écriture logicielle, soit du programme proprement dit, soit d’un module s’ajoutant au programme. Ce sont des solu-tions demandant un travail d’informaticien. Pour éviter cette limitation, certaines appro-ches choisissent de laisser inchangés les programmes à intégrer mais de les connaître suf-fisamment pour traduire leurs différentes communications.
a. Médiations
Les approches par médiation [Wiederhold 1994] utilisent des informations fortes sur les différents éléments, principalement les données, pour permettre à un acteur intelligent, le médiateur, de vérifier les éventuels liens et, si possible, d’appeler un autre acteur, un adaptateur (wrapper) pour adapter les données. Cette solution nécessite que les différents éléments soient formellement décrits en rapport avec un référentiel, syntaxique mais aussi sémantique.
Cette description est malheureusement complexe et le référentiel, qui devrait être issu d’un consensus, pose de nombreux problèmes, de création mais également d’utilisation. Ce référentiel se présente de plus en plus sous la forme d’une base d’ontologie. L’ontologie se veut une représentation du « possible ». Elle représente ce que peut être un élément. Cette définition philosophique résume tous les problèmes des ontologies : com-ment décrire correctement un domaine d’application, pour que ce référentiel soit à la fois utile et utilisable. Les ontologies seront présentées plus en détail dans le paragraphe 4. 2.
Une variante, présentée par [Leclercq-Benslimane-Yétongnon 1997, 1999], propose d’instancier des contextes de médiations réalisés à partir des ontologies. Ces contextes permettent la médiation. Malgré ce niveau supplémentaire, l’enrichissement de ces réfé-rentiels reste problématique.
b. Usage de méta-données
Les méta-données permettent de rajouter des informations par dessus la réalité du do-maine. Les méta-données peuvent contenir une simple description textuelle, telle la bi-bliographie d’un document avec Dublin Core [DCMI 2002] mais également une formali-sation des caractéristiques utiles de l’élément décrit. Les méta-données peuvent ainsi

Mémoire de thèse
Page 46 sur 166
former un référentiel, qui n’est pas nécessairement sémantique. Il existe par exemple de nombreuses normes et standards de méta-données permettant une « encapsulation » de données particulières, telles FGDC pour les données géographiques mais également PIF et SOAP [PIF 1999, W3C 2000] qui décrivent des processus sur des données. Ainsi, les personnes désirant échanger leurs données en vue d’un traitement précis n’ont plus né-cessairement besoin de prévoir leur adaptation mais doivent les décrire conformément au standard correspondant.
Il existe également des méta-données sur les modèles tels UML [OMG 2002b], comme MOF et XMI [OMG 2002a, OMG 2002c]. Ainsi, MOF décrit plusieurs niveaux de descriptions, permettant de décrire un modèle informatique, ainsi que cette descrip-tion.
Récemment, des cadres de descriptions ont étés définis, tel the Ressource Description Framework (RDF) [W3C 2002b], utilisant des graphes représentés en syntaxe XML.
Avec le temps, les méta-données se répandent dans tous les domaines de l’informatique. La possibilité de décrire les données de manière plus précise est primor-diale pour l’échange de données et leur adaptation. Ainsi, les systèmes à base de média-tion utilisent le plus souvent des méta-données. Et nous pouvons considérer un référentiel sémantique comme des méta-méta-données.
2. 3. 4. Formaliser les connaissances
Les dernières solutions déjà présentées ajoutent une réalité logique pour permettre les échanges. Il est possible d’étendre ce principe pour recouvrir l’ensemble du domaine et ainsi s’occuper des interconnexions au seul niveau logique.
a. Usage de méta-modèles "purs"
De cette manière, « the Meta Model Langage » (MML) est un langage de haut niveau qui permet de capitaliser l’ensemble des connaissances nécessaires à une simulation. MML a évolué en deux projets séparés, « The Spatial Modeling Environment » (SME) et « The Simulation Module Markup Language » (SiMMaL) [Maxwell 1999a , 1999b]. Le projet ROMAN [Page-Parisel 2000] utilise lui aussi un langage de haut niveau, voisin de LISP, pour faire de même. Il est alors possible d’emmagasiner des « briques » décrivant des traitements précis. Les modèles de traitement sont générés lors de l’exécution d’une session et la formalisation de haut niveau « gomme » toute hétérogénéité. Cependant, cette approche considère les modèles comme des boîtes de cristal, ce qui est rarement le cas. Ces solutions sont donc utiles pour constituer une bibliothèque uniforme des modèles mathématiques communs. Leur évolution pourra cependant convaincre les experts de formaliser leurs modèles plutôt que de les écrire avec un langage de programmation.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 47 sur 166
b. Usage de méta-modèles comme abstraction de modèles
De ce fait, il existe aussi une solution intermédiaire. Dans ces systèmes, le méta-modèle formalise un modèle existant tout en considérant l’existence du modèle. La des-cription est alors utilisée pour intégrer le modèle et gérer ses interconnexions. Le méta-modèle est donc la réalité logique du modèle. Il reste difficile à écrire, car il doit être par-ticulièrement rigoureux, mais il est envisageable d’offrir des outils pour aider à sa créa-tion, en s’appuyant sur le modèle ou sur les sources du modèle et il n’a pas à formaliser les traitements. Cette solution est utilisée dans le cadre du projet WebReuse [Iazeolla-D’Ambrogio 1998], mais également dans le nôtre, présenté dans le cadre de cette thèse.
2. 3. 5. Conclusion
Nous pouvons conclure en remarquant que les dernières solutions présentées ont été créées pour palier aux insuffisances des premières. Et dans tous les cas, il faut, à un mo-ment ou à un autre, trouver un langage commun. Si ce n’est fait à la création d’un logiciel ou de données, cela doit être fait pour décrire le logiciel ou les données et permettre leur utilisation ainsi.
2. 4. Interopérabilité des modèles urbains : approche générale
Pour permettre l’interopérabilité des modèles urbains, nous avons développé une solu-tion particulière. Ce paragraphe fait la synthèse des solutions existantes, explique la spé-cificité de notre solution et présente sa philosophie générale.
2. 4. 1. Synthèse des solutions existantes
Nous venons de présenter des approches pratiquement équivalentes en terme de résul-tat mais différentes par les contraintes d’intégration : de la réécriture totale à la descrip-tion pure. Ainsi, les contraintes sur les éléments à ajouter diminuent en même temps qu’augmente la nécessité d’avoir une description formelle et riche. En quelque sorte, le problème est déplacé du logiciel au logique. Ce déplacement offre tout de même un avan-tage, car si la description est stockée dans un document lisible et traitable automatique-ment, l’intégration gagne en dynamisme.
En fait, ses solutions sont utilisables conjointement de façon réaliste et en ce sens, el-les facilitent le travail d’intégration. Malheureusement, leur développement non concerté crée encore une hétérogénéité. Et la puissance même d’une solution particulière rend dif-ficile sa collaboration avec une autre. Il faut donc essayer d’apporter une solution ou-verte, qui puisse à terme collaborer avec d’autres systèmes.

Mémoire de thèse
Page 48 sur 166
2. 4. 2. La solution Yehudi
Forts de cette considération, nous avons choisi d’apporter une réponse capable de prendre en compte l’ensemble des hétérogénéités. Pouc ce faire, le système développé fonctionne sur le modèle d’un orchestre.
a. Traiter toutes les hétérogénéités
Les approches présentées s'occupent soit d’homogénéiser des programmes, soit d’intégrer des données, soit d’intégrer les programmes. Elles ne s’occupent en général pas d’intégrer un programme hétérogène, de lui donner une réalité homogène puis d’intégrer les données. Qui plus est, elles passent le plus souvent par une réécriture sys-tématique ou par des logiciels bruts de conversion. Nous souhaitons intégrer les modèles sans obliger un changement au sein du modèle et si possible sans avoir à créer des logi-ciels supplémentaires spécifiques à chaque fois. Au minimum, nous souhaitons minimiser cette écriture.
Pour ce faire, nous avons cherché à considérer l’ensemble du problème pour apporter une solution qui soit capable de répondre à l’ensemble des difficultés rencontrées. C’est ainsi que nous avons comparé notre objectif à un orchestre.
b. La métaphore de l'orchestre
Nous nous sommes donc inspirés du fonctionnement d’un orchestre pour trouver un moyen efficace d’interconnecter des modèles urbains existants. Nous présentons mainte-nant cette solution.
Un orchestre est composé d’instruments physiques d’utilisations différentes et créant des sons différents. Un musicien est formé pour pouvoir utiliser cet instrument et suivre ainsi des instructions sous une forme standardisée : la partition sous la supervision d’un chef d’orchestre. Le chef d’orchestre connaît les caractéristiques des différents instru-ments et fait confiance en ses musiciens pour les manipuler. Ce faisant, il est capable de diriger les musiciens pour générer la musique de l’orchestre, en suivant la partition prin-cipale.
Dans notre cas, les instruments sont les modèles urbains, la partition principale est la description des interconnexions.
Nous allons donc manipuler les modèles urbains avec des éléments dédiés, qui corres-pondent aux musiciens, qui vont suivre des instructions dédiées, envoyées par un chef d’orchestre. Ces éléments seront vus comme le modèle, ils seront son abstraction logi-cielle et seront appelés encapsulations. Pour manipuler un modèle, ils utiliseront une des-cription propre à ce modèle : le méta-modèle, qui sera une abstraction logique du modèle.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 49 sur 166
Le chef d’orchestre sera donc l’élément logiciel principal de notre système. Il connaî-tra le but à atteindre, ayant à sa disposition une description des interconnexions, les capa-cités des encapsulations et les caractéristiques des instruments, données par le méta-modèle. Il aura à sa charge de mettre en place l’orchestre et de le commander pour attein-dre le but fixé : l’exécution de la session à son terme. La connaissance du chef d’orchestre est formalisée par une base d’ontologie.
Pour ne pas oublier la distribution des modèles à intégrer, le système sera basé sur un environnement réparti simple et fortement hiérarchique qui masquera les aspects réseaux.
Chaque modèle à intégrer devra être décrit par un méta-modèle. Ce dernier aura deux rôles distincts : il devra préciser comment utiliser physiquement le modèle et il décrira l’aspect logique du modèle, tel qu’il apparaîtra dans l’environnement : ses entrées, ses sorties, ses paramètres, ses synchronisations.
L’encapsulation utilisera la précision physique contenue dans un méta-modèle pour se spécialiser et se paramétrer pour accéder au modèle. Elle s’utilisera telle que décrite dans l’aspect logique du modèle.
Le chef d’orchestre devra finalement utiliser un schéma logique, indiquant l’interconnexion voulue à partir des descriptions logiques des modèles contenues dans les méta-modèles, pour créer et exécuter une session. Il aura à sa disposition un catalogue de modèles, enrichi à partir des méta-modèles et pourra ainsi créer et commander des encap-sulations.
Il devra s’assurer de la conformité des interconnexions, éventuellement s’occuper de l’adaptation des données et surtout être capable de faire face à un maximum de problè-mes. Il aura à sa charge les problèmes d’ordre logique et sémantique. Il pourra disposer d’un référentiel sémantique sous la forme de la base d’ontologie pour traiter les problè-mes sémantiques.
2. 5. Conclusion
Nous avons présenté dans ce chapitre l’objectif général de ce travail. La solution adop-tée s’appuie sur la métaphore de l’orchestre et suppose donc une intégration particulière des modèles permettant leur interconnexion. Le support de cette gestion est assurée par une architecture adaptée. Nous décrivons l’intégration des modèles dans le chapitre sui-vant, puis la gestion de l’interconnexion des modèles dans le chapitre IV, pour présenter ensuite l’architecture dans sa globalité au chapitre V.

Mémoire de thèse
Page 50 sur 166
CHAPITRE III INTÉGRATION DES MODÈLES
Pour permettre l’interopérabilité, l’hétérogénéité logicielle est traitée au plus tôt, c’est-
à-dire au niveau du modèle. Afin de gérer et de masquer l’hétérogénéité des modèles ur-bains, l’encapsulation apporte une vue logicielle standardisée des modèles et permet ainsi une manipulation à un niveau logique par l’introduction d’un méta-modèle. Cette idée à été présentée dans [Becam-Miquel 2000]. Nous présentons dans ce chapitre le rôle de l’intégration, son principe et son fonctionnement.
3. 1. Rôle de l’intégration
L’intégration des modèles doit répondre à deux besoins fondamentaux : accéder à des modèles hétérogènes de façon similaire et disposer d’une description des modèles qui permet leur utilisation.
3. 1. 1. Accéder aux modèles
L’accès aux modèles est bien entendu indispensable, mais nous devons trouver une so-lution qui minimise les difficultés pour rendre cet accès possible tout en proposant des fonctionnalités compatibles avec un usage automatique.
Nous allons proposer une solution qui prend en compte plusieurs points importants mais qui s’intéresse à une réalité logicielle comme dit auparavant. En tant que logiciel, un modèle urbain est très fortement hétérogène, par son mode d’utilisation, par les données qu’il traite et par la façon dont il fonctionne. Notre solution doit donc être capable de contrôler plusieurs types logiciels de modèles, d’importer et d’exporter des données de types et de formats différents, et de prévoir des comportements différents. Cependant, cet accès doit apparaître, du point de vue de l’environnement, homogène. Ainsi, l’intégration permettra d’abstraire la réalité logicielle du modèle.
La description du modèle, quant à elle, devra être suffisante pour « abstraire » le mo-dèle : il doit quitter son contexte logicielle propre pour intégrer notre environnement et être vu comme faisant partie d’un ensemble homogène.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 51 sur 166
3. 1. 2. Lier les différents éléments
Nous devons donc nous baser sur des fondements commune afin que les modèles aidés de leurs méta-modèles soient suffisamment homogènes pour rendre leur interconnexion possible. Pour ceci, nous devons envisager deux aspects complémentaires :
- l'utilisation d'une syntaxe imposée pour tous les méta-modèles. Quel que soit le contenu d'un méta-modèle, la syntaxe « de base » doit être la même pour tous. Ain-si, tout le monde pourra lire ce méta-modèle,
- le respect de règles, de sens et de concepts connus. Le méta-modèle, utilisant la syntaxe commune, devra être écrit suivant une vue unifiée de l'univers d'applica-tion. Cela signifie que nous disposons d'une description de l'univers de nos modè-les, comprenant les « lois » de cet univers, les concepts, les possibilités de liens, ... Pour cela, nous envisageons d’utiliser une ontologie, qui décrit les concepts et les liens entre eux [Chandrasekaran-Josephson-Benjamins 1999], et nous imposons une structure commune.
Mais si les modèles sont homogénéisés, il n'en demeure pas moins que les données qu'ils utilisent et qu'ils génèrent, restent particulières. En décrivant le modèle, nous appor-tons une connaissance du modèle et de ses données. Les données circulent, gagnant ainsi une indépendance, elles doivent également être décrites suivant la même syntaxe et en respectant l'ontologie définie.
Finalement, les modèles étant connus, leurs données également, il faut prévoir le pas-sage des données d'un modèle à un autre. Lors de cet échange, il faut parfois adapter la donnée, qui peut avoir une unité différente, ou différer sur d'autres points typologiques, et contrôler la conformité sémantique du lien créé. Pour ceci, des médiateurs et des traduc-teurs peuvent être créés. Les médiateurs se chargent de vérifier les liens, sémantiquement et typologiquement, et peuvent faire appel à un traducteur qui traitera la donnée en entrée pour la rendre conforme pour le modèle suivant en sortie. Il faut toutefois noter que cette approche peut varier dans sa forme.
3.2 Aspect semi-composant
Depuis quelques années, la programmation objet a évolué pour offrir des composants, des éléments logiciels utilisables comme des blocs auto-renseignés par d’autres éléments logiciels. Là où l’approche objet trouve sa principale utilité à la conception, les classes sont combinables et réutilisables, les composants permettent une modularité après conception. En effet, si les objets sont des instances de classes, a priori figées, les compo-sants sont des éléments autonomes disposant d’une description interne suffisante pour être utilisés sans être connus a priori. Bien sûr, un composant peut être un objet. Cepen-dant, un objet est rarement un composant. Nous verrons cependant que des propriétés in-

Mémoire de thèse
Page 52 sur 166
trospectives, comme celles offertes par Java, transforment potentiellement toute classe et tout objet en composant : chaque classe hérite de méthodes le décrivant, sauf désir contraire, et chaque objet est connu sous forme d’instance de classe. La frontière qui sé-pare alors les technologies objet des composants dépend de la qualité de la description : permet-elle vraiment l’usage a posteriori de l’élément logiciel ? Nous présentons mainte-nant les technologies existantes et nous expliquerons ensuite nos choix.
3. 2. 1. Présentations des technologies existantes
La modularité est maintenant considérée comme naturelle et primordiale. Les techno-logies ont donc évoluées pour augmenter l’indépendance des éléments logiciels. Dans le contexte distribué, nous pouvons distinguer deux approches principales :
- les technologies d’objets distribuées, CORBA (Common Object Request Broker Architecture), Microsoft OLE (Object Linking and Embedding)/DCOM(Distributed Component Object Model), COM+, NET, Java RMI (Remote Method Invocation), per-mettent d’utiliser des objets distants en s’appuyant sur une idée simple : à un niveau ou à un autre, l’élément doit offrir une interface connue qui permettra aux autres de l’utiliser, à distance ou non. La présence de l’interface permet au client d’avoir une « vue » de l’objet distant. Cette vue est souvent enrichie de copies des données échangées, pour offrir un objet proxy, un objet local que le serveur utilise comme un objet classique mais qui fera appel, pour chaque méthode, aux méthodes de l’objet distant, utilisant un système parti-culier pour l’échange de données (le « marshalling » pour Java RMI).
Java RMI ne fonctionne qu’avec des objets Java, les solutions Microsoft acceptent les éléments écrits spécialement pour elles et CORBA nécessite que l’élément fournisse une interface écrite selon le langage de CORBA, l’IDL (Interface Definition Language). l’IDL est la pièce d’identité permettant de connaître l’objet, elle exprime une facette pu-blique utilisable par les autres objets utilisant CORBA. De nombreux langages sont sup-portés par CORBA, qui propose de plus de nombreux services évolués, de nommage, de gestion de la persistance, de gestion des pannes, ... Une des limites de CORBA réside dans la nécessité d’utiliser un ORB (Object Request Broker), un négociateur d’objets, qui, installé sur plusieurs machines interconnectées, retrouve sur demande l’objet demandé, en le recherchant dans la base d’objets installés, lesquels disposent d’une IDL qui a été publiée.
Les services Microsoft sont inclus dans les systèmes d’exploitation Microsoft, ce qui élimine la nécessité de les installer. Cependant, lorsqu’un système concurrent est supporté par une technologie Microsoft, l’installation redevient obligatoire. La technologie OLE/COM/DCOM,COM+ est desservie par sa grande complexité, qui sera peut être ré-duite avec .NET, ainsi que par l’usage d’interfaces orientées binaires, complexes mais également peu propices à des usages externes. Finalement, ces technologies sont peu ou pas représentés sur les systèmes concurrents, ce qui constitue un frein évident. Et si Mi-

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 53 sur 166
crosoft fait mine de s’ « ouvrir » quelque peu, par exemple par l’usage de standards ou-verts tel XML ou SOAP, ses technologies, telles BizTalk, reposent sur des éléments pro-priétaires et fermés. Cette ouverture est tout de même positive car elle favorise les futures interopérabilités.
Java propose quant à lui un système assez basique, mais simple à mettre en place. En effet, le serveur Java, qui dispose des objets à distribuer, peut être exécuté à partir d’une classe. Il est possible d’offrir un environnement distribué qui s’installe simplement en exécutant des programmes, ce qui est d’une simplicité bien venue. Par contre, Java RMI nécessite de connaître l’emplacement des serveurs, ce qui est géré par l’ORB CORBA, et de s’occuper lui-même de la génération dynamique des objets. En effet, avec Java RMI, il est indispensable d’exporter les interfaces des objets distribués du serveur au client, ce qui n’est pas réalisé, a priori, à l’exécution mais bien à l’installation des classes. Il reste alors deux façons de réaliser soi-même un serveur d’objets : soit contraindre les objets par des interfaces connus, qui permettront d’utiliser des objets non définis à l’installation via ces interfaces en les retrouvant par les propriétés réflexives de Java, soit réaliser un objet distribué capable d’exporter à l’exécution les interfaces des objets à utiliser, ce qui est possible par l’aspect totalement dynamique de Java. La machine virtuelle vérifie l’existence des éléments à la demande. Néanmoins, deux solutions de serveurs de noms sont proposées, Java Naming and Directory Interface (JNDI) et JINI [Sun 2002b, Sun 2002c], qui est en fait une solution complète.
Il faut de plus apporter deux remarques importantes : Java supporte depuis longtemps CORBA et SUN développe deux solutions toutes intégrées : les Enterprises Java Bean (EJB) [Sun 2002a] et JINI. Les « beans » sont les composants de Java. En définissant ses classes selon des règles précises, l’objet sera utilisable à l’exécution par des points d’entrée bien définis. En fait, les propriétés introspectives de Java transforment toutes les classes n’interdisant pas l’introspection en composants utilisables de façon dynamique. Les beans normalisent encore un peu plus les classes. Les EJB étendent la notion de « beans » en gérant la persistance des objets. Un serveur s’occupe de fournir au client l’objet demandé en cachant totalement la réalité sous-jacente. Bien sûr, les EJB sont une solution tout Java. La politique de SUN semble être de proposer un monde futur tout composant, mais également tout SUN. Et c’est malheureusement la grande limite de Java. Cependant, les « mondes » Java pourront communiquer via CORBA ou par des voies plus primitives (JNI par exemple), mais aussi très efficaces. D’ailleurs, les EJB sont très complémentaires de CORBA. Et force est de reconnaître qu’au sein d’un monde Java, tout fonctionne relativement bien, tant que l’efficience n’est pas critique, car Java reste souvent un langage lent.
- les objets distribués, dans leur version simple, permettent une distribution des traitements, mais nécessite une connaissance de l’objet, et donc souvent une utilisation

Mémoire de thèse
Page 54 sur 166
prévue à l’écriture des programmes. Nous sommes encore dans une logique « figée ». Pour permettre des compositions hors conception, les objets sont amenés à devenir des composants. Selon [Orfali-Harkey-Edwards 1999], « un composant possède les propriétés suivantes :
- c’est une entité commercialisable,
- ce n’est pas une application complète, il peut être composé à d’autres composants pour former une application complète,
- il peut être utilisé en agencements non connus à l’avance,
- il possède une interface définie,
- c’est un objet qui sait interopérer, il est une entité logicielle indépendante des systè-mes,
- c’est un objet étendu. » Clemens Szyperski défini un composant par le fait qu’il s’agit d’une unité indépen-
dante du déploiement, également une brique de composition par des tiers parties et qu’il n’a pas d’état persistant [Szyperski 1999].
Nous pouvons également distinguer les composants techniques et les composants mé-tiers, en reprenant [Hassine-Khayati 2001]. Les composants techniques sont des compo-sants non fonctionnels offrant des fonctionnalités techniques. Un composant métier ré-pond aux besoins exprimés par l’utilisateur qui le manipule dans le cadre de leur métier.
A l’heure actuelle, CORBA propose déjà une gestion cohérente des composants. Les EJB sont une solution également, mais qui reste critiquable par l’imposition du tout Java. Les descriptions offertes par ces systèmes sont peu prolixes et fournissent donc des com-posants techniques, même si les EJB se veulent « métier ».
Un composant « idéal » doit être capable de se décrire soi-même. C’est ainsi qu’Open CORBA [Ledoux 1999], par exemple, se propose d’apporter des propriétés réflectives à CORBA, en rajoutant des méta-informations sur les objets. Java quant à lui, comme déjà dit, dispose déjà de propriétés réflectives simples mais utiles. Nous verrons que l’introspection est la base de la réutilisabilité et l’utilisation de méta-données extérieures aux objets permet de renforcer cette possibilité. Là où l’introspection s’attache à décrire la réalité de l’objet, les méta-données peuvent se permettre de décrire la réalité de l’objet et d’enrichir cette réalité, en lui fournissant une ou plusieurs nouvelles réalitées, logiques, sémantiques, ...
3. 2. 2. Apports et faiblesses de l’approche composant
Un composant présente de nombreux avantages liés à son usage dynamique et aisé :

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 55 sur 166
- les composants mettent leur interface à disposition et permettent ainsi leur usage dy-namique, y-compris via le réseau,
- ils s’utilisent conformément à l’approche objet, en s’instanciant,
- ils sont relativement autonomes.
Néanmoins, les composants gèrent encore mal certains points ou sont peu adaptés au
problème particulier de la réutilisabilité de logiciels existants, principalement, en ce qui nous concerne, les modèles. Ainsi :
- ils offrent une description typologique des données utilisées et une description tex-tuelle de base des méthodes utilisables (le nom de la méthode), leur usage est ainsi réser-vé à un développeur connaissant suffisamment le composant. Dans le cadre de la réutili-sation, nous aimerions que cette description soit suffisante pour pouvoir pleinement utili-ser le programme sous-jacent sans le connaître a priori,
- les méthodes proposées sont libres mais elles restent figées et propres au composant une fois celui-ci écrit. Le composant ne s’adapte ni n’évolue,
- l’utilisation est libre et sans contrainte, comme un objet, ce qui pose un problème si le composant « recouvre » un logiciel existant, qui peut être bloquant et critique,
- la description mélange l’aspect logique et l’aspect physique, ce qui est source de confusion et d’incompréhension pour un non-informaticien, qui ne devrait pas s’occuper de l’aspect physique,
- l’aspect sémantique est très pauvre ou absent,
- un composant est en général autonome, un programme existant l’est rarement. Il est délicat de déplacer un logiciel quelconque, car il peut utiliser des fichiers de données par-ticuliers, des fichiers de configuration, des librairies partagées, nécessiter des clés dans la base de registre Windows ou des définitions de variables d’environnement dans des fi-chiers «.profile» sous Unix, …
3. 2. 3 Principes retenus
Nous préférons offrir une vue dédiée, qui correspond à un « semi-composant », en sé-parant la gestion des accès au modèle par une encapsulation et la vue du modèle par un méta-modèle. Cette vue présente les caractéristiques suivantes :
- la description du modèle est plus large (autant que possible) et est clairement « sortie » de l’encapsulation,
- les méthodes sont contraintes par des interfaces correspondantes à des comporte-ments. Mais ces méthodes sont génériques et permettent une adaptation dynamique, pour correspondre à un modèle quelconque tout en restant standard,

Mémoire de thèse
Page 56 sur 166
- l’encapsulation demeure là où se trouve le modèle à intégrer. La description logique se déplace pour renseigner sur l’usage possible du modèle,
- l’utilisation des encapsulations est en général particulière, en correspondance avec un comportement de modèle de traitement. Une encapsulation implémentant l’ensemble des interfaces peut s’utiliser comme un élément logiciel dans une programmation graphique, mais ce sera très rarement le cas,
- le méta-modèle sépare explicitement la partie physique et la partie logique de la des-cription.
3. 3. Les encapsulations
L’intégration logicielle d’un modèle est réalisée par une encapsulation. Nous présen-tons dans ce paragraphe le principe de l’encapsulation avant de détailler ses caractéristi-ques.
3. 3. 1. Principe
La gestion de modèles urbains hétérogènes et répartis peut s’assimiler à la gestion de périphériques. En effet, un périphérique dispose d’une interface qui lui est propre, et im-pose au système d'exploitation qui l'utilise un certain nombre de contraintes, comme par exemple des temps de réponses précis, pour les imprimantes et les scanners un choix de résolution particulier, un certain nombre d’entrées d’un certain type, … Depuis plusieurs années, les systèmes d'exploitation ne dirigent plus directement les périphériques, mais utilisent des pilotes. Le système communique avec un pilote qui sait utiliser le périphéri-que auquel il est dédié. Le pilote est souvent écrit et fourni par le fabricant de périphéri-ques et non par l'éditeur du système d'exploitation mais peut également être développé par un expert.
L'encapsulation d’un modèle peut être en partie vue comme un pilote de modèle en as-surant la communication avec le modèle. Elle est également un élément standard et ho-mogène au sein de l’environnement. Ainsi, elle est composée d’une partie spécifique qui communique avec le modèle, le pilote, et d’une partie homogène qui sera réellement inté-grée à l’environnement, le module communicant. L’encapsulation se compose donc d’une partie spécifique (le pilote) et d’une partie générique (le module communicant). La figure 3.1 montre cette décomposition : un pilote composé d’une partie native, propre au type du modèle, d’une partie en Java, reliée par une interface propre au pilote, et le module com-municant générique. Cette décomposition permet de minimiser l’effort d’écriture : le mo-dule communicant offre toutes les opérations génériques, le pilote est dédicacé à un mo-dèle. Ainsi, seul le pilote est à réécrire ou à adapter pour un modèle. Pour prévoir diffé-rentes possibilités, le pilote est contraint par des interfaces correspondantes à une capaci-té. Ainsi, un pilote peut se conforter à une ou plusieurs de ces interfaces prédéfinis. Le

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 57 sur 166
module communicant implémente la totalité de ces interfaces et dispose de toutes les ca-pacités attendues, compensant au besoin les manques du pilote. Ainsi, pour ne jamais bloquer le système, l’exécution du pilote est toujours réalisée dans un processus léger. Ce choix offre deux avantages corrélés : l’écriture d’un pilote est plus simple, l’encapsulation est virtuellement toujours la même et donc utilisable de la même façon.
Paquetage Java
Encapsulation
Module communicant
Exécution(non bloquante)
Partie Java
Partie Native
PilotePilote
PilotePilote
Pilote
InterfaceInterface
InterfaceInterface
InterfaceInterface
Toutes interfacesstandards
Interfaces standards
Interface du pilote
Figure 3.1 : Détail d’une encapsulation et vue du paquetage d’interfaces et de pilotes
Une encapsulation type est donc composée :
- du pilote de modèle, choisi et spécialisé selon le type de modèle grâce aux infor-mations du méta-modèle,
- éventuellement d’un spooler, qui peut mettre plusieurs modules communicants en attente, dans le cas où le modèle serait critique et ne peut donc être utilisé plusieurs fois simultanément,
- d'un module communicant, qui sert d'interface entre le chef d'orchestre et le pilote et s'utilise comme un objet classique et générique, tout en offrant des facilités de communication, de stockage de données, en entrée et en sortie, et de reprise en cas d’erreur.
La figure 3.2 décompose un pilote selon ses parties génériques et spécifiques. La par-tie spécifique accède au pilote est peut donc être décomposée en une partie Java et en une partie plus proche du modèle, dans un autre langage. La partie générique est accédée par le module communicant.

Mémoire de thèse
Page 58 sur 166
Interface Standard Pilote JAVA Pilote JNI-C
Modèle brut
JAVA
Partie générique Partie spécifique
Figure 3.2 : Décomposition d’un pilote type, communicant avec un modèle accessible via-C
Le pilote dialogue directement avec le module communicant, qui s'instancie tel un ob-jet et offre des fonctions utiles telles que le stockage de données en attente. Si le modèle ne peut pas être dupliqué, le pilote est unique, mais la partie communicante peut être ins-tanciée autant de fois que possible. Les accès concurrents au pilote sont gérés par un spooler qui travaille tel un spooler d'imprimante. Le modèle est alors géré comme une ressource critique. La figure 3.3 montre un exemple d’un accès parallèle non critique. Lorsque le modèle n’est pas critique, une demande de trois modèles simultanés se tradui-ra par la création de trois modèles avec pour chacun un pilote et un module communicant.
Modèlenon-critique
B - 1
Modèlenon-critique
B - 2
Modèlenon-critique
B - 3
Pilote
Pilote
Pilote
Schéma logique
B
B’
B’’
Modulecommunicant 1
Modulecommunicant 1
Modulecommunicant 1
Figure 3.3 : Accès de trois modules communicants à un modèle non-critique
Lorsque le modèle est critique, la même demande, schématisée en figure 3.4, se tradui-ra par la création d’un seul modèle avec un pilote correspondant et un spooler, qui garde

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 59 sur 166
la référence du pilote. Ce pilote sera accédé par un seul module communicant à la fois pendant que le spooler mettra les autres en attente.
En attenteModèlecritique
BPilote
Schéma logique
B
B’
B’’
Modulecommunicant 1
Modulecommunicant 2
Modulecommunicant 3
Spooler
Actif
Figure 3.4 : Accès de trois modules communicants à un modèle critique
Ainsi, le chef d'orchestre peut utiliser un modèle autant de fois que nécessaire, la ges-tion des accès multiples est faite au niveau de l'encapsulation. Cette gestion est également une facilité pour l’intégration de modèle non critique mais délicats à contrôler de façon concurrente.
3. 3. 2. L’encapsulation vue comme une classe générique à paramétrer
L’encapsulation est une interface logicielle entre un modèle quelconque et l’environnement qui va l’utiliser. Il est assez simple d'écrire une encapsulation dédiée à un modèle pour un concepteur qui connaît très bien à la fois le modèle et l’environnement. Pour l’utilisateur ou le concepteur d’un modèle, c’est un travail sup-plémentaire qui n’est pas réaliste de laisser à sa charge malgré les possibilités offertes par la suite. Aussi proposons-nous deux voies complémentaires :
- il n'est jamais nécessaire de réécrire la totalité d'une encapsulation. Les parties qui gèrent les communications et la concurrence ne changent jamais, seule la partie qui ac-cède au modèle est spécifique.
- la partie accédant au pilote peut être écrite pour un type de modèles. Elle est ensuite spécialisée pour un modèle.
Dans tous les cas, les parties "invariantes" de l'encapsulation doivent être dédicacées à la partie spécifique, qui répond tout de même à une ou plusieurs interfaces précises. Le modèle est connu par une ou plusieurs caractéristiques précises mais génériques et décri-tes dans le méta-modèle.
Les interfaces disponibles correspondent pour certaines à des comportements nécessai-res et pour d’autres à des comportements optionnel. Elles sont au nombre de quatre :

Mémoire de thèse
Page 60 sur 166
- l’interface modèle simple, qui doit toujours être implémentée et correspond à un comportement de base : entrées, sorties, paramètres et traitements. Cette interface com-prend des méthodes d’écriture et de lecture de données, des méthodes d’exécution et une méthode pour vérifier l’état du modèle, prêt ou non. Les méthodes d’exécution permet-tent une exécution générale du modèle, plusieurs exécutions générales et des exécutions numérotées et donc différenciées.
- une interface pour les synchronisations, qui indique que le modèle est capable de se synchroniser et/ou de synchroniser, en comportant des méthodes d’acceptation de syn-chronisations, identifiées par un numéro de port ou par un nom, et en supposant l’utilisation de méthodes externes de synchronisations.
- une interface sauvegarde, le modèle peut sauver et restaurer son état,
- une interface modèle XML, le modèle est capable d’échanger ses données sous la forme de portions XML.
3. 3. 3. Écriture d’un pilote
L’intégration d’un programme préexistant dans un environnement d’interconnexion pose de nombreux problèmes qui se traduisent au niveau du pilote par la nécessitée de gé-rer l’exécution d’un modèle au mieux, le démarrer, le stopper, savoir s’il a rencontré un problème. Lors de son exécution, il est également possible qu’il évolue, qu’il génère des données selon un échéancier précis. De fait, le pilote doit également savoir importer les données du modèle et lui exporter les données venant de l’environnement. Finalement, il doit fournir les données sous une forme échangeable.
Ainsi, l’écriture d’un pilote nécessite de savoir isoler les entrées, sorties et paramètres
utiles et de savoir comment elles vont être introduites ou extraites du modèle. Ensuite, il est nécessaire de déterminer comment le pilote contrôlera le modèle, d’une exécution simple à un contrôle par synchronisation. Par exemple, un modèle s’utilisant de manière simple avec un seul traitement sur des données stockées dans un fichier et générant éga-lement un fichier avec les résultats sera exécuté de manière simple par la commande sys-tème adaptée. En revanche, les structures des fichiers de données en entrée et sortie de-vront être précisées pour pouvoir générer les entrées et, de même, extraire les sorties. Si le modèle a un comportement plus complexe et dispose d’une interface de contrôle, comme par exemple un composant OLE/DCOM, il sera nécessaire de passer par ces in-terfaces.
Pour créer le pilote, nous pouvons distinguer trois méthodes :
- automatique, à partir d’un modèle, un outil est capable de générer automatiquement le pilote ou de trouver les paramètres pour un pilote type,

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 61 sur 166
- semi-automatique, l’aide d’un utilisateur est obligatoire mais le système est capable de réaliser une bonne partie du travail,
- manuel, l’utilisateur doit alors écrire lui-même le pilote et le méta-modèle ou le mé-ta-modèle pour un pilote type.
Le lien entre Java et les différents modèles s’effectue en utilisant différents outils. Le principal est Java Native Interface, qui réalise le lien entre Java et les systèmes d’exploitation en permettant l’utilisation de programmes C/C++ et fortran en lien avec des objets Java. Cette liaison peut même être dynamique si le lien se fait avec une librai-rie partagée.
Les liaisons peuvent aussi se faire par des ponts avec des technologies de composants, CORBA et OLE/DCOM. CORBA est supporté par Java et OLE/DCOM par des APIs spécifique, comme JACOB.
Nous reviendrons sur ces techniques dans le chapitre VI.
3. 3. 4. Possibilités, limites et contraintes
L'encapsulation est un processus puissant qui permet l'utilisation d'un grand nombre de modèles différents. C'est une solution assez légère, très extensible et propre. Du point de vue du chef d'orchestre, l'encapsulation est un objet communicant. Dans un même sché-ma, cette approche permet d’avoir autant de modèles que voulu, sans se soucier de la na-ture du modèle. Qui plus est, il y a autant de modules communicants que de modèles sou-haités et ces modules sont identifiés de manières uniques. Ainsi, les possibilités multi-sessions sont offertes localement par l’instanciation d’un module communicant à chaque apparition du modèle dans les différents schémas. Nous présenterons plus loin les méca-nismes qui rendent cette utilisation possible.
Néanmoins, cette solution offre certaines limites et contraintes. Tout d'abord, une en-capsulation type est très difficile à écrire pour certains modèles. En effet, elle dépend alors du système des modèles et de leurs fonctionnements. Cette encapsulation type peut également avoir un fonctionnement peu satisfaisant, ne pas pouvoir contrôler l’exécution d’un modèle trop fermé, ne pas être capable d’importer ou d’exporter certaines données d’un type trop complexe, … De plus, la gestion des modèles « critiques » est à double tranchant. En effet, elle masque la réalité au chef d'orchestre, ce qui permet une utilisa-tion parallèle virtuelle mais cache également le temps d'exécution, qui sera forcément augmenté. Il faut arriver à estimer ce temps d'exécution, ce qui n'est pas forcément possi-ble.

Mémoire de thèse
Page 62 sur 166
3.4. Les méta-modèles
Pour adapter les encapsulations et décrire les modèles, un méta-modèle est écrit pour chaque modèle à intégrer. Celui-ci suit une structure précise basée sur les comportements prévus.
3. 4. 1. Décrire les modèles et les données
Nous devons apporter une description suffisamment précise des domaines et éléments concernés par notre système, dans un premier temps les modèles utilisés et les données manipulées. Dans une première optique, cette description n'a pas à être sémantique mais simplement pratique.
1. Quel niveau de description ?
Dès lors, nous pouvons envisager d'utiliser une description plus ou moins complète et utile :
- une simple description, c'est-à-dire un simple texte décrivant le modèle, en lan-gage humain, avec peut-être un identifiant pour les traitements. Cette description n'est donc pas utile pour un traitement automatique, mais seulement pour une utili-sation par un humain. Il faut toutefois noter que cette description, bien que non suf-fisante, est indispensable dans nombre de cas. En effet, il faut toujours pouvoir ren-seigner l'utilisateur.
- une simple description d'usage, qui indique, dans des fins de traitement automati-que, les paramètres pour l'usage du modèle. Si tous les modèles sont fortement ho-mogènes et s'utilisent donc pratiquement de la même façon, cette description est suffisante. Néanmoins, pour notre projet, ce niveau de description ne suffit qu'à no-tre premier prototype qui travaille sur des faux modèles. Avec des vrais modèles quelconques, l'hétérogénéité est trop grande pour se contenter d'un tel niveau de description. Il faudrait prévoir énormément de paramètres possibles pour couvrir tous les modèles existants et indiquer convenablement leur usage, ce qui n'est pas concevable.
- une description pour le partage, qui se réfère à une base d'informations possibles, et éventuellement de liens entres elles, pour permettre l'échange des modèles. Leur description se référant à un référentiel, il suffit d'avoir le même référentiel pour « comprendre » la description du modèle. Cette notion est utile mais plutôt com-plémentaire qu'alternative. Destiner une description à un échange influe sur la mé-thode de fabrication, pas sur le rôle de la description.
- une description pour un traitement typologique et sémantique, qui apporte une vé-ritable précision sur les données traitées, sur leur type et sur leur sens. Cette des-

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 63 sur 166
cription offre la possibilité, avec l'utilisation d’un référentiel, d'une base de connais-sance et de techniques de traitement, d'adapter de manière « intelligente » les don-nées et de contrôler ainsi le modèle en assurant une cohérence.
2. Quelle description pour quel usage ?
Selon l'utilisation souhaitée des modèles, le niveau de description nécessaire change. Pour une utilisation par un utilisateur, une description textuelle est suffisante mais néces-saire. Pour des programmes semblables qui doivent être utilisés par la machine, une des-cription d'usage est suffisante. Il en est de même pour chaque problème.
Dans notre projet, il nous faut une description qui puisse :
- apporter une explication claire sur l'usage du modèle,
- permettre son contrôle automatique,
- donner une description suffisante des données en entrée, en sortie et en paramètres pour permettre leur contrôle et leur adaptation typologique et sémantique,
- préciser les limites de l'utilisation possible du modèle grâce à cette description.
- être échangeable.
Donc, il nous faut une description qui réponde à tous les points énumérés auparavant.
3. Nécessité d'un méta-modèle
Il nous est ainsi apparu que nous avions besoin d'un méta-modèle, c'est-à-dire une des-cription qui soit réellement le reflet descriptif du modèle. Cela signifie que cette descrip-tion n'est pas seulement un apport d'information sur le modèle, mais véritablement une vue la plus complète possible du modèle. Cette description doit être suffisante pour que, sans même avoir le modèle, nous puissions avoir une « image » précise de lui.
4. Utilité d'un méta-modèle, possibilités
Un méta-modèle offre plusieurs possibilités qui expliquent clairement son utilité :
- comme « vue » du modèle, il permet la préparation du travail à faire avec le mo-dèle, sur le modèle, sans avoir besoin du modèle,
- il apporte une connaissance des éléments utiles du modèle, éléments qui ne sont pas, a priori, connus si le modèle est seul,
- il est le côté logique du modèle et peut être plus que le simple reflet du modèle : nous pouvons apporter un supplément virtuel au modèle, voire définir un modèle virtuel pur, qui sera créé à l'usage,

Mémoire de thèse
Page 64 sur 166
- il est une description du modèle, à usage de la machine mais aussi de l’utilisateur.
L'utilisation d'un méta-modèle nous apporte la possibilité de décrire de manière suffi-sante la plus grande partie des modèles. Malgré tout, il ne faut pas perdre de vue le fait qu'il faille créer ce méta-modèle, ce qui n'est pas nécessairement simple. De même, vou-lant interconnecter ces modèles, nous devons les « standardiser », pour qu'ils puissent être utilisés conjointement.
3. 4. 2. Principe
Le méta-modèle suit donc un principe simple : il est une vue logique du modèle. Plus précisément, il doit contenir toutes les informations nécessaires à son intégration dans l’univers de notre système.
Le méta-modèle est composé de trois parties distinctes, qui prennent en compte l’intégration par encapsulation, et contraint le modèle par l’usage d’un pilote spécialisa-ble.
Ainsi, tel que représenté en figure 3.5, le méta-modèle comprend tout d’abord une par-tie logique, qui est la vue logique du modèle, seule existence du modèle en dehors de l’encapsulation. La partie logique est contrainte, elle doit respecter une structure donnée. Afin que le modèle encapsulé soit utilisé de façon transparente, le méta-modèle fournit une vue logique de modèle, une description de l'apparent élément homogène obtenu. Comme déjà dit, nous « encadrons » les différents modèles en prévoyant leur comporte-ment. La partie logique du méta-modèle décrit le modèle selon un cadre structurel précis et commun à tous les modèles, prévoyant des fonctionnalités bien définies. La partie lo-gique correspond aux interfaces définis pour intégrer les modèles, ce qui permet une correspondance exacte entre la vue logique et la réalité logicielle. Une partie typologique précise également le type de modèle, ce qui permettra de choisir un pilote. Finalement, une partie physique, dont le contenu dépend du pilote choisi est utilisée pour paramétrer le pilote, pour qu’il puisse accéder au modèle et apporter les fonctionnalités décrites dans la partie logique.
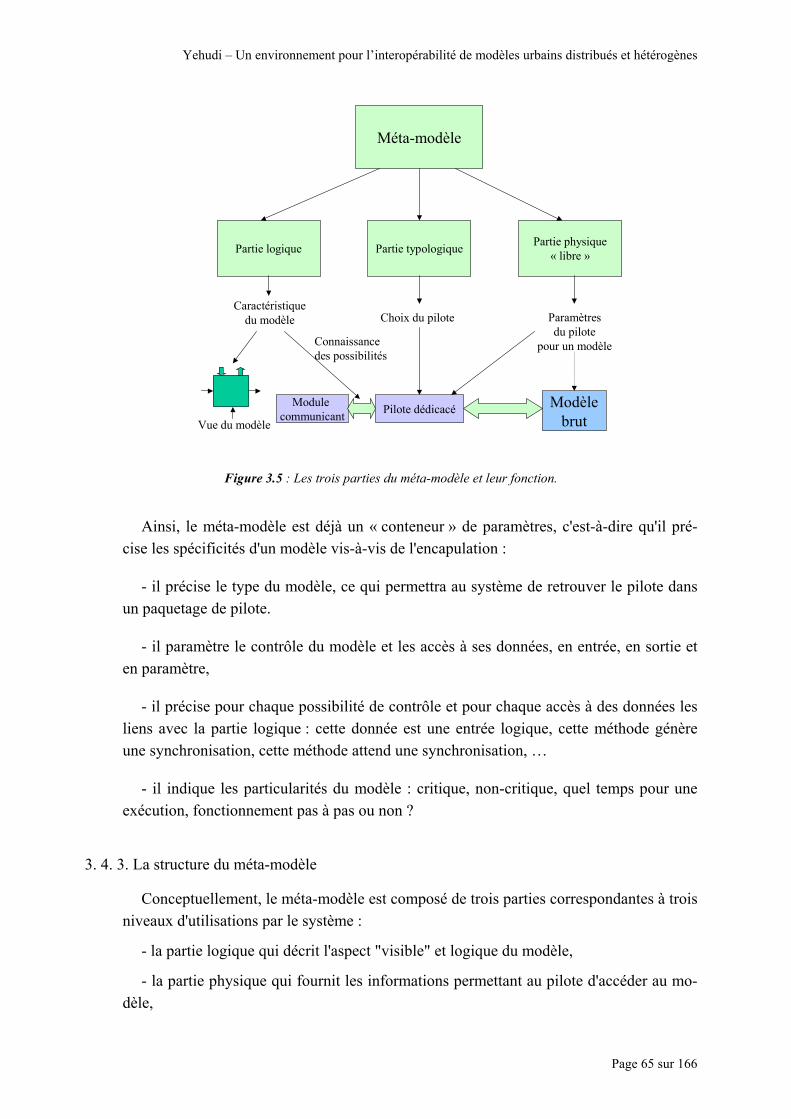
Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 65 sur 166
Pilote dédicacé
Méta-modèle
Partie logique Partie typologique Partie physique« libre »
Caractéristiquedu modèle Choix du pilote Paramètres
du pilotepour un modèle
ModèlebrutVue du modèle
Module communicant
Connaissancedes possibilités
Figure 3.5 : Les trois parties du méta-modèle et leur fonction.
Ainsi, le méta-modèle est déjà un « conteneur » de paramètres, c'est-à-dire qu'il pré-cise les spécificités d'un modèle vis-à-vis de l'encapulation :
- il précise le type du modèle, ce qui permettra au système de retrouver le pilote dans un paquetage de pilote.
- il paramètre le contrôle du modèle et les accès à ses données, en entrée, en sortie et en paramètre,
- il précise pour chaque possibilité de contrôle et pour chaque accès à des données les liens avec la partie logique : cette donnée est une entrée logique, cette méthode génère une synchronisation, cette méthode attend une synchronisation, …
- il indique les particularités du modèle : critique, non-critique, quel temps pour une exécution, fonctionnement pas à pas ou non ?
3. 4. 3. La structure du méta-modèle
Conceptuellement, le méta-modèle est composé de trois parties correspondantes à trois niveaux d'utilisations par le système :
- la partie logique qui décrit l'aspect "visible" et logique du modèle,
- la partie physique qui fournit les informations permettant au pilote d'accéder au mo-dèle,

Mémoire de thèse
Page 66 sur 166
- le type de modèle, qui indique quel pilote est nécessaire pour accéder au modèle.
Ainsi, la partie physique est utilisée par le pilote pour le paramétrage, le type de mo-dèle est utilisé pour choisir le pilote et la partie logique est utilisée par presque tous les éléments du système :
- pour l'enrichissement d’un catalogue de modèle et son utilisation. Le catalogue sera utilisé pour retrouver les modèles.
- pour la création interactive (et son exécution) d’un schéma d’interconnexion. Les parties logiques sont utilisées pour une édition précise du schéma, correspondant aux pos-sibilités réelles des modèles, tel que prévu dans le système, sans nécessiter une communi-cation « tendue » avec les encapsulations utilisées.
- pour l'instanciation des différentes encapsulations et l'exécution d'une session. La partie logique indique les possibilités et les limites de l’encapsulation correspondante et précise les points d’accès, pour les données, pour les synchronisations et pour les exécu-tions. Cette même description correspond aux possibilités couvertes par la partie physi-que. Ainsi, elle permet l’instanciation d’une encapsulation en renseignant le module communicant.
La partie physique a une structure qui dépend totalement du pilote. La figure 3.6 pré-sente un exemple de méta-modèle.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 67 sur 166
Vue du modèle
Pilote
Modèle brut
Environnement
Partie logique
<LOGICAL_PART><MODEL_NAME>District Occupation</MODEL_NAME><DATA_INPUTS>
<INPUT>...</INPUT>
</DATA_INPUTS><DATA_OUTPUTS>...</DATA_OUTPUTS><AUTHOR>Ernest Dupont</AUTHOR><DESCRIPTION>...</DESCRIPTION><REMARK>...</REMARK>
</LOGICAL_PART>
Type du modèle <MODEL_TYPE>JNI_C++
</MODEL_TYPE>
<PHYSICAL_PART><FUNCTION>
<FUNCTION_NAME>setMap</FUNCTION_NAME><DATA_INPUTS>
<INPUT>...
<IS>MAP</IS>
</INPUT></DATA_INPUTS><RETURN>...</RETURN>
...</FUNCTION>
</LOGICAL_PARTL>
Partie physique
Figure 3.6 : Un méta-modèle et son usage pour une encapsulation.
Le type du modèle est juste précisé par le nom du pilote.
Le pilote a une obligation : une méthode non utilisée ne doit jamais provoquer d'er-reur, elle est non bloquante et retourne un résultat nul. La partie correspondante à une in-terface, si elle est implémentée, va décrire quelles méthodes sont réellement implémen-tées ou non. Ainsi, le méta-modèle apporte la souplesse qui manque : au mieux le pilote permet tout ce que l'interface prévoit, au pire, il ne l'implémente pas. Tous les autres cas de figure situés entre ces deux extrémités sont possibles.
Ainsi, le méta-modèle, tel que représenté en figure 3.7, est obligatoirement composé d’une partie logique qui comporte obligatoirement le nom du modèle. Tous les autres éléments sont facultatifs. En plus de sa partie logique, un méta-modèle indique en général le type de modèle et comporte une partie physique. Le contenu de la partie physique dé-pend du type de modèle. En revanche, la partie logique doit suivre une structure précise. Elle pourra ainsi décrire les données en entrée, en sortie et en paramètre, des synchronisa-tions en entrée et en sortie, préciser les caractéristiques du modèle, apporter une descrip-tion supplémentaire pour un utilisateur et dispose d’un conteneur libre « Autre ».

Mémoire de thèse
Page 68 sur 166
Méta-modèle
Partie logique
Partie physique
Type de modèle
Données en entrée
Données en sortie
Paramètres
Synchronisationsen entrée
Synchronisationsen sortie
Description
Nom du modèle
Autre
Caractéristiques
LégendeLégende
ou
Lien obligatoireLien optionnel
Lien multiple
Exclusion
Nœud
Père Fils
Figure 3.7 : Représentation du méta-modèle. Les sous-éléments sont détaillés en figure 3.8 et suivantes.
Les descriptions des données en entrée, en sortie ou en paramètre, ont la même struc-ture, représentée pour les données en entrée en figure 3.8. Une donnée dispose obligatoi-rement d’un nom et d’un type. Elle peut avoir une valeur fixée. Éventuellement, elle peut réagir à des synchronisations, internes ou externes, pour des effets différents. Les syn-chronisations sont connues par leur numéro de port ou par le nom du port : un port est propre à un modèle, la synchronisation est gérée au niveau logique. Finalement, les don-nées peuvent avoir des propriétés XML spécifiques, être exclusivement en XML, être aussi en XML et avoir une valeur fixée en XML. Nous verrons l’utilisation d’XML un peu plus loin.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 69 sur 166
Donnée en entrée
Nom de la donnée
Type de la donnée
Type sémantique
Valeur
Est XML
Est Aussi XML
Valeur XML
LégendeLégende
ou
Lien obligatoireLien optionnel
Lien multiple
Exclusion
Nœud
Père Fils
Utilisée sur synchronisationinterne
Passée par synchronisationexterne
Nom du port
Numéro du port
Nom du port
Numéro du portou
ou
Passée sur synchronisationinterne
Nom du port
Numéro du portou
Effacée sur synchronisationinterne
Nom du port
Numéro du portou
Utilisée par synchronisationexterne
Nom du port
Numéro du portou
Effacée par synchronisationexterne
Nom du port
Numéro du portou
Figure 3.8 : Détail des données en entrée
Les synchronisations sont décrites séparément selon qu’elles sont en entrée ou en sor-tie (fig. 3.9). Une synchronisation a obligatoirement soit un nom de port soit un numéro. Lorsqu’elles sont utilisées par des données, il n’y a pas nécessairement d’autres descrip-tions. Une synchronisation sur une donnée en entrée peut effacer une donnée, provoquer son utilisation, c’est-à-dire qu’elle est passée au modèle sans être effacée, ou déclencher son passage au modèle, ce qui signifie qu’elle sera effacée. Les possibilités sur les don-nées en sorties sont similaires, avec une communication vers le système et non vers le modèle. Une donnée peut être synchronisée par un élément externe (synchronisation ex-terne) ou par le modèle lui-même (synchronisation interne). Les synchronisations peuvent être en relation avec des exécutions séparées du modèle. En effet, le pilote peut proposer plusieurs exécutions d’un modèle, soit pour correspondre à des changements d’état du modèle, soit pour une quelconque autre raison. De ce fait, une synchronisation en entrée peut provoquer une exécution ou forcer la fin d’une exécution et une synchronisation en sortie peut être générée par la fin d’une exécution, par un problème, par un blocage

Mémoire de thèse
Page 70 sur 166
d’exécution ou par un refus d’exécution. Comme le schématise la figure 3.10, une exécu-tion est décrite dans les caractéristiques du modèle par son numéro, par son temps estimé d’exécution et si elle est bloquante ou non. Les synchronisations ainsi que les exécutions multiples couvrent un grand nombre de cas possibles.
Synchronisations en entrée Synchronisation
ou
Nom du port
Numéro du portou
Première Exécution
Exécution
Fin exécution ou
Numéro d’exécution
Numéro d’exécution
Synchronisations en sortie Synchronisation
Nom du port
Numéro du portou
ou
ouFin Exécution générale
Fin Exécution
Problème Exécution ou
Numéro d’exécution
Numéro d’exécution ou
Blocage Exécution
Pas prêt pour Exécution
Numéro d’exécution
Numéro d’exécution
LégendeLégende
ou
Lien obligatoireLien optionnel
Lien multiple
Exclusion
Nœud
Père Fils
Figure 3.9 : Détail des descriptions de synchronisation. La synchronisation est aussi décrite sur les données, comme le montre la figure précédente.
Exécutions multiples ExécutionNuméro d’exécution
Temps d’exécution
Bloquante (O/N)
LégendeLégende
ou
Lien obligatoireLien optionnelLien multipleExclusion
Nœud
Père Fils
Figure 3.10 : Description fine des exécutions multiples
Comme représentée en figure 3.11, la partie logique peut également contenir les carac-téristiques du modèle, préciser s’il est critique ou non, donner une estimation du temps global d’exécution, préciser les exécutions multiples et indiquer si son exécution globale est bloquante ou non. Par défaut, le modèle sera pris au pire : critique, avec un temps d’exécution arbitrairement long.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 71 sur 166
Finalement, la description permet de préciser l’auteur du modèle, le propriétaire du modèle, d’ajouter une description libre et une remarque. A noter que des remarques peu-vent être rajoutées à tous les niveaux du méta-modèles, elles servent en quelque sorte de commentaire.
Description
Nom de l’auteur
Nom du propriétaire
Description
Remarque
Caractéristiques
Critique (O/N)
Temps d’exécution
Exécutions multiples Exécution
Exécution bloquante (O/N)
Figure 3.11 : Détail des caractéristiques et de la description d’un modèle
Cette structure générale trouve sa correspondance avec des interfaces logicielles et avec une gestion logique. Son arborescence nous a amené à utiliser une syntaxe simple et adaptée. Nous avons donc adopté XML.
3. 4. 4. Le méta-modèle en XML
XML (eXtended Markup Language) est dérivé de SGML, il permet de définir soi-même la structure de son document. XML n’impose cependant pas l’utilisation d’une structure fixe. Nous utilisons XML pour sa clarté, pour son extensibilité et parce qu’un document XML est facilement traitable.
XML est un méta-langage à balises. Sa structure peut être définie par un autre docu-ment, une DTD ou un Schéma XML. C’est un standard proposé par le World Wide Web Consortium (W3C). Il est largement accepté et la nébuleuse XML est devenue vaste, pro-posant de nombreux standards et presque autant d’API pour les traiter.
Le méta-modèle est ainsi écrit avec XML, reportant sa structure arborescente en bali-ses et contenu. Cette syntaxe simple permet également la gestion des extensions. En effet, la partie logique est une combinaison de comportements types prédéfinis. Elle peut être enrichie par blocs (fig. 3.12) : les parties inconnues sont simplement ignorées par le cœur

Mémoire de thèse
Page 72 sur 166
du système et éventuellement traitées par d’autres éléments. Bien sûr, elles ne doivent pas remettre en compte la structure attendue.
Partie logique étendue
Yehudi Meta-modèle
Partie logique
Partie physique
Type de modèle
Données en entrée
Données en sortie
Paramètres
Synchronisations en entrée
Synchronisations en sortie
Description
Nom du modèle
Autre
Caractéristiques
Extension A
Extension A - 1
Extension A - 5
Extension A - 4
Extension A - 3
Extension A - 2
Extension B
Extension B - 3
Extension B - 2
Extension B - 1
Extensions
Partie logique conforme
Yehudi Meta-modèle
Partie logique
Partie physique
Type de modèle
Données en entrée
Données en sortie
Paramètres
Synchronisations en entrée
Synchronisations en sortie
Description
Nom du modèle
Autre
Caractéristiques
Extension A
Extension A - 1
Extension A - 5
Extension A - 4
Extension A - 3
Extension A - 2
Extension B
Extension B - 3
Extension B - 2
Extension B - 1
Pré-traitement
Figure 3.12 : Les extensions sont extraites en pré-traitement.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 73 sur 166
3. 4. 5. Les données en XML, conventions d’écriture
Les données de Yehudi peuvent être décrites en XML et les méta-données le sont sys-tématiquement. Nous avons adopté une écriture simple mais extrêmement cohérente. Les fichiers Yehudi, le catalogue, les schémas, les méta-modèles et les fichiers de configura-tion, suivent tous la même structure. Le document est encadré par la racine YEHUDI, chaque balise est sans attribut et doit avoir un nom clair. Une partie de document n’a de contenu seulement si elle est une feuille terminale. Nous pouvons schématiser cette syn-taxe ainsi :
<YEHUDI> < SECTION> <NOM_DE_LA_SECTION> Texte </NOM_DE_LA_SECTION> <SOUS_SECTION> <CARACTERISTIQUE_DE_SOUS_SECTION> Texte </CARACTERISTIQUE_DE_SOUS_SECTION> </SOUS_SECTION> </SECTION> </YEHUDI>
Cette notation correspond à un arbre à nœuds et à liens non valués, avec ses seules feuilles comme conteneur de données.
Cela correspond à notre souhait de séparer clairement les éléments structurels, qui ont un lien avec l’environnement, et les données contenues, qui sont traités par les éléments de l’environnement.
De plus, cette syntaxe « bavarde » est très claire.
3. 4. 6. Synthèse : la présence de la syntaxe XML dans Yehudi
XML est présent partout où l’environnement utilise des documents, pour :
- le méta-modèle, tel que présenté auparavant,
- si possible les données, « encapsulée » proprement dans un fichier XML pour leur circulation. Cela impose malheureusement une gestion d’un codage/décodage au niveau du pilote, qui est à charge du développeur du pilote,
- le catalogue de modèles, qui reprend la liste des modèles utilisables, décrits par leur partie logique, et des renseignements pratiques. La structuration par balise permet la constitution du catalogue par simple fusion de texte.
- le schéma d’interconnexion, qui indique les modèles à instancier ainsi que tous les liens. Les modèles sont encore représentés par leur partie logique,

Mémoire de thèse
Page 74 sur 166
- les schémas d’états, qui sont une « photographie » d’une session à un moment donné et qui correspondent donc au schéma d’interconnexion enrichi des états des différents éléments ainsi qu’éventuellement du codage des données, si disponible,
- les sauvegardes d’états, qui, localement à un élément, sauve lors d’une session toutes les données nécessaires pour reprendre le traitement au moment de la sauvegarde ou au dernier moment précédant la sauvegarde,
- les fichiers de configuration, qui indique les préférences de l’utilisateur.
Cet usage sera mis en valeur dans le chapitre 4, où nous présentons la gestion des in-terconnexions de modèles au sein de l’environnement Yehudi.
3. 4. 7. Lien entre l’encapsulation et le méta-modèle
Le pilote est accessible via des interfaces standards, les mêmes qu’implémente le mo-dule communicant. Ce dernier répercutera tout accès par ses interfaces au même accès aux même interfaces du pilote, éventuellement de façon différée. Le pilote doit donc être seul capable de fournir les données attendues à partir des données extraites. Ainsi, la par-tie physique précise pour chaque donnée accédée, en entrée, en sortie ou en paramètre, à quelle donnée logique elle correspond et paramètre les voies d’accès au modèle. La figure 3.13 illustre les deux fonctions de la partie physique : elle permet d’extraire les données A et D et elle précise que ces données sont les données attendues A logique et D logique, ce qui permet au pilote de les fournir en interface. Cette correspondance sera en général décrite par un descriptif "IS", qui précise que telle donnée physique "EST" la donnée lo-gique. La définition de cette précision est cependant à la seule charge du pilote. Les partie génériques de l'encapsulation ne se fient qu'à la partie logique. Le pilote doit s'assurer de fournir le support adapté à cette description. Ces définitions de liens physiques/logiques permettront de compléter l’interface du pilote.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 75 sur 166
A
B
C
D
Pilote
AL
DL
Modulecommunicant
AL
DL
Méta-modèlePartie physique
Paramètres d’accès
Liens physique/logique
Figure 3.13 : La partie physique permet de paramétrer l’accès aux modèles mais également d’assurer le lien avec la partie logique.
Ce choix permet au pilote de « composer » les données : une donnée logique peut correspondre à plusieurs données physiques ou une donnée physique peut être décompo-sée en plusieurs données logiques. Nous pouvons par exemple traiter un modèle qui cal-cule des résultats sous une forme matricielle, lesquels pourraient être transformés sous une forme linéaire.
Pour des raisons de simplicité, nous recommandons cependant l'usage prioritaire du champ "IS" pour l'écriture d'un pilote. Le mieux est l'ennemi du bien et nous favorisons la robustesse.
L'ajout d'un pré ou d'un post-traitement devrait donc être limité aux cas où les données du modèle ne peuvent pas être intégrées telles quelle à l'environnement.
L’encapsulation est ainsi une abstraction du modèle, telle que représentée en figure 3.14. L’annexe B présente un méta-modèle décrivant un modèle simple sous forme de classe Java. Il a été généré automatiquement par un outil développé en Java.
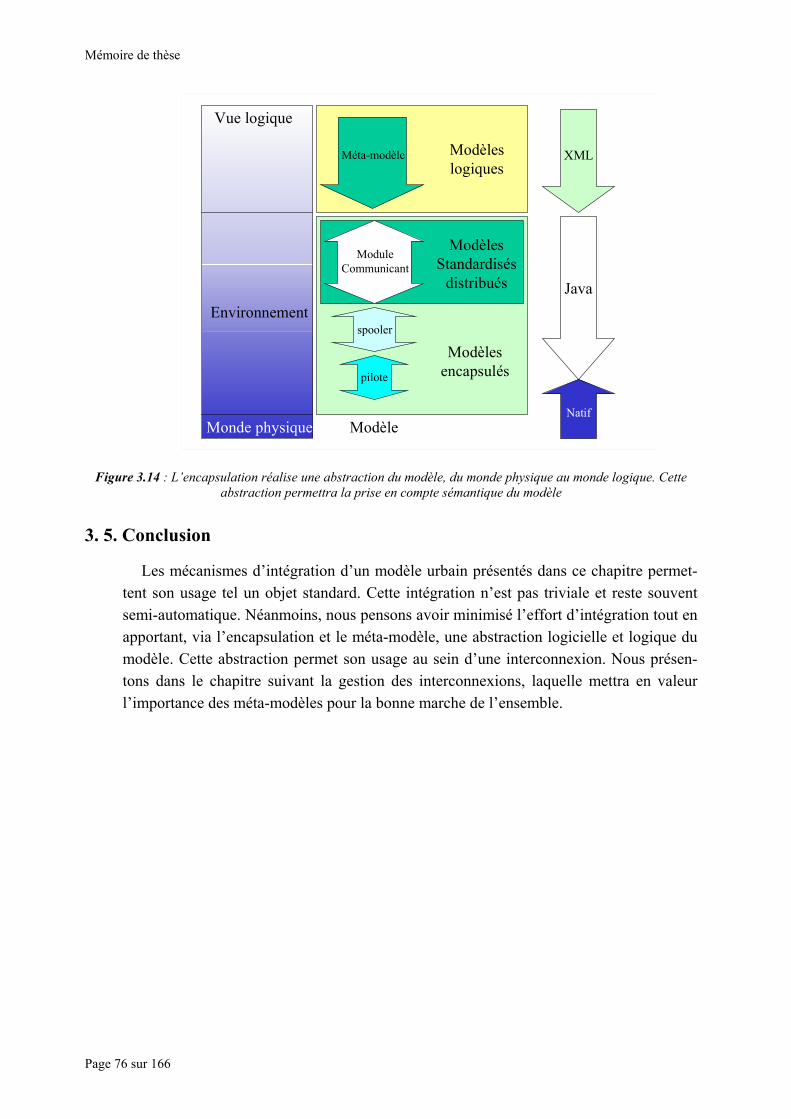
Mémoire de thèse
Page 76 sur 166
Environnement
Monde physique
Vue logique
ModèlesStandardisés
distribués
Modèle
Modèlesencapsuléspilote
spooler
ModuleCommunicant
Natif
Java
Modèleslogiques
Méta-modèle XML
Figure 3.14 : L’encapsulation réalise une abstraction du modèle, du monde physique au monde logique. Cette abstraction permettra la prise en compte sémantique du modèle
3. 5. Conclusion
Les mécanismes d’intégration d’un modèle urbain présentés dans ce chapitre permet-tent son usage tel un objet standard. Cette intégration n’est pas triviale et reste souvent semi-automatique. Néanmoins, nous pensons avoir minimisé l’effort d’intégration tout en apportant, via l’encapsulation et le méta-modèle, une abstraction logicielle et logique du modèle. Cette abstraction permet son usage au sein d’une interconnexion. Nous présen-tons dans le chapitre suivant la gestion des interconnexions, laquelle mettra en valeur l’importance des méta-modèles pour la bonne marche de l’ensemble.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 77 sur 166
CHAPITRE IV GÉRER L’INTERCONNEXION
Afin de décrire et de gérer l’interconnexion des modèles, nous introduisons un schéma
d’interconnexion ou schéma logique à l’usage du chef d’orchestre. Sa fonction et son uti-lisation sont ensuite décrites. Enfin, pour faciliter l’interconnexion des modèles et leur in-teropérabilité, nous proposons l’utilisation d’une base d’ontologie et de médiateurs. Nous avons présenté cette approche dans [Becam-Miquel-Laurini 2000].
4. 1. Le schéma logique
L’utilisateur désirant interconnecter différents modèles doit sélectionner les modèles qu’il souhaite utiliser, et indiquer comment ils sont liés. Ces informations sont regroupées dans le schéma logique, un document particulier décrivant une interconnexion de modè-les. Il sera utilisé lors d’une session tel un planning dont le chef d’orchestre doit assurer la bonne marche.
4. 1. 1. Les différents types de modèles
Les seuls modèles encapsulés ne suffisent pas pour concevoir une application com-plète. Nous avons donc défini d’autres modèles additionnels. Ainsi, l’utilisateur peut dis-poser :
- des modèles urbains encapsulés, gérés par le système qui s’occupe donc de leur as-pect distribué et de leurs contraintes éventuelles,
- des modèles utilitaires, des programmes spécifiques vus comme des modèles et of-frant une fonctionnalité particulière, par exemple l’accès à une base de données, la lecture de données GPS, l’adaptation de données, …
- des modèles d’IHM, des éléments simples d’interface graphique, en entrée ou en sortie, pouvant être reliés à un modèle pour saisir des données, attendre l’appui sur un bouton, ou encore afficher un résultat,
- des modèles élémentaires, offrant des fonctionnalités élémentaires, comme la copie de données, la comparaison de plusieurs entrées, … Ces modèles permettent de simplifier le schéma logique et d’offrir des fonctions simples mais très utiles pour la conception d’une application complète.
Ces quatre types de modèles sont utilisables de manière similaire.

Mémoire de thèse
Page 78 sur 166
4. 1. 2. Le catalogue
L’ensemble des modèles disponibles est listé dans un catalogue, en précisant sur quelle machine se trouve chaque modèle. Le catalogue est unique et statique, la disponi-bilité réelle d’un modèle ou d’une machine est vérifiée à la mise en place d’une session.
Le catalogue est composé des parties logiques des méta-modèles ainsi que d’informations envoyées par chaque machine et utilisées par le système : URL, système d’exploitation, processeur, … Il se présente sous la forme d’un fichier XML et suit la structure présentée en figure 4.1.
Catalogue Modèle
Machines
Partie logique
LégendeLégende
ou
Lien obligatoireLien optionnel
Lien multiple
Exclusion
Nœud
Père Fils
Machine
Nom
URL
Version Java
Répertoire Java
Java ClassPath
Nom du système
Vesrion du système
Architecture
Répertoire Utilisateur
Répertoire de travail
Figure 4.1 : Structure du catalogue. Le méta-modèle est représenté par sa partie logique.
Le catalogue contient donc une liste de modèles. Chaque modèle est caractérisé par sa partie logique et par les machines où ce modèle est disponible. Une machine est principa-lement caractérisée par son URL mais d’autres informations sont disponibles, permettant d’améliorer la connaissance de la machine. L’architecture permettra par exemple de choi-sir la machine la plus performante pour un modèle.
Actuellement, il n’existe qu’un seul catalogue, présent sur la machine principale pour la gestion générale des modèles.
Il sera utilisé par le système pour proposer la liste de modèle à la création d’un schéma puis pour retrouver un modèle à la mise en place d’une session.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 79 sur 166
4. 1. 3. Description du schéma logique
Le schéma logique est créé par l’utilisateur et décrit le schéma complet de l’application développé par l’utilisateur. Il est ensuite utilisé pour exécuter une session.
Le schéma logique est composé de trois parties :
- les parties logiques des méta-modèles associées aux modèles interconnectés, pour ne pas répéter cette information en cas d’usage multiple d’un modèle,
- l’ensemble des modèles utilisés dans le schéma, comprenant la liste des modè-les encapsulés, des modèles utiles, des modèles d’IHM et des modèles de facilité utilisés. Un même modèle présent plusieurs fois est numéroté.
- la description des interconnexions. Une sortie d’une instance de modèles correspond à une entrée ou à un paramètre d’une autre instance ou à la sortie du schéma d’interconnexion. Une synchronisation en sortie correspond à une synchronisation en en-trée ou à une action sur un modèle. Les liens peuvent également être marqués « obligatoire », « facultatif » ou « interdit ». Par défaut, ils sont obligatoires, c’est-à-dire que le modèle en aval doit obtenir une donnée de ce lien avant de s’exécuter. S’ils sont facultatifs, le modèle peut s’exécuter sans cette donnée et s’ils sont interdits, la présence de cette donnée interdit l’exécution du modèle.
La figure 4.2 présente un exemple de schéma logique en démographie urbaine. Il dé-crit un traitement complexe pour l’évaluation du nombre de places en crèche. Dans ce cas, des pyramides des âges sont extraites d’une base de données via un modèle spécialisé pour des accès JDBC. Ces données sont utilisées par des modèles d’estimation d’âge, qui effectuent un traitement statistique simple consistant, à partir d’une pyramide des âges, à estimer une population type. En paramètres, il est possible de leur spécifier quelle tranche d’âge nous intéresse ainsi que la population globale. En sortie, ces deux modèles donnent le nombre de personnes dans la tranche d’âge pour la population spécifiée. Dans ce schéma, nous utilisons deux modèles d’estimations d’âge pour permettre l’utilisation de paramètres différents, à des fins de comparaison. Les résultats sont ensuite transmis à deux modèles calculant le nombre de crèches nécessaire pour une quantité de population donnée. Finalement, les résultats sont affichés dans des modèles spécifiques d’interface homme-machine. Comme tous les modèles de ce schéma sont légers, rapides et non-critiques, ce schéma introduit un moyen de synchronisation du début de traitement : un bouton en IHM, qui va synchroniser les modèles d’estimation d’âge. Ce bouton permet d’attendre la sollicitation de l’utilisateur pour afficher les résultats.
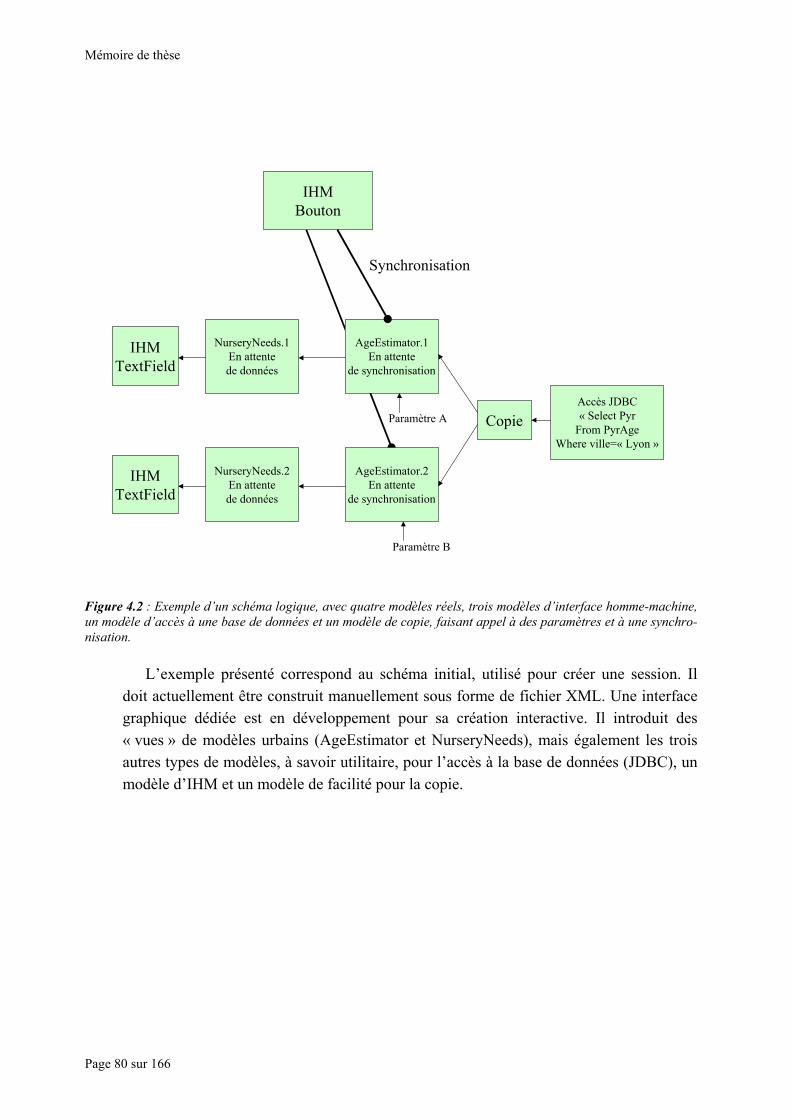
Mémoire de thèse
Page 80 sur 166
AgeEstimator.1En attente
de synchronisation
AgeEstimator.2En attente
de synchronisation
NurseryNeeds.1En attentede données
NurseryNeeds.2En attentede données
CopieAccès JDBC« Select Pyr
From PyrAgeWhere ville=« Lyon »
IHMBouton
IHMTextField
IHMTextField
Synchronisation
Paramètre A
Paramètre B
Figure 4.2 : Exemple d’un schéma logique, avec quatre modèles réels, trois modèles d’interface homme-machine, un modèle d’accès à une base de données et un modèle de copie, faisant appel à des paramètres et à une synchro-nisation.
L’exemple présenté correspond au schéma initial, utilisé pour créer une session. Il doit actuellement être construit manuellement sous forme de fichier XML. Une interface graphique dédiée est en développement pour sa création interactive. Il introduit des « vues » de modèles urbains (AgeEstimator et NurseryNeeds), mais également les trois autres types de modèles, à savoir utilitaire, pour l’accès à la base de données (JDBC), un modèle d’IHM et un modèle de facilité pour la copie.
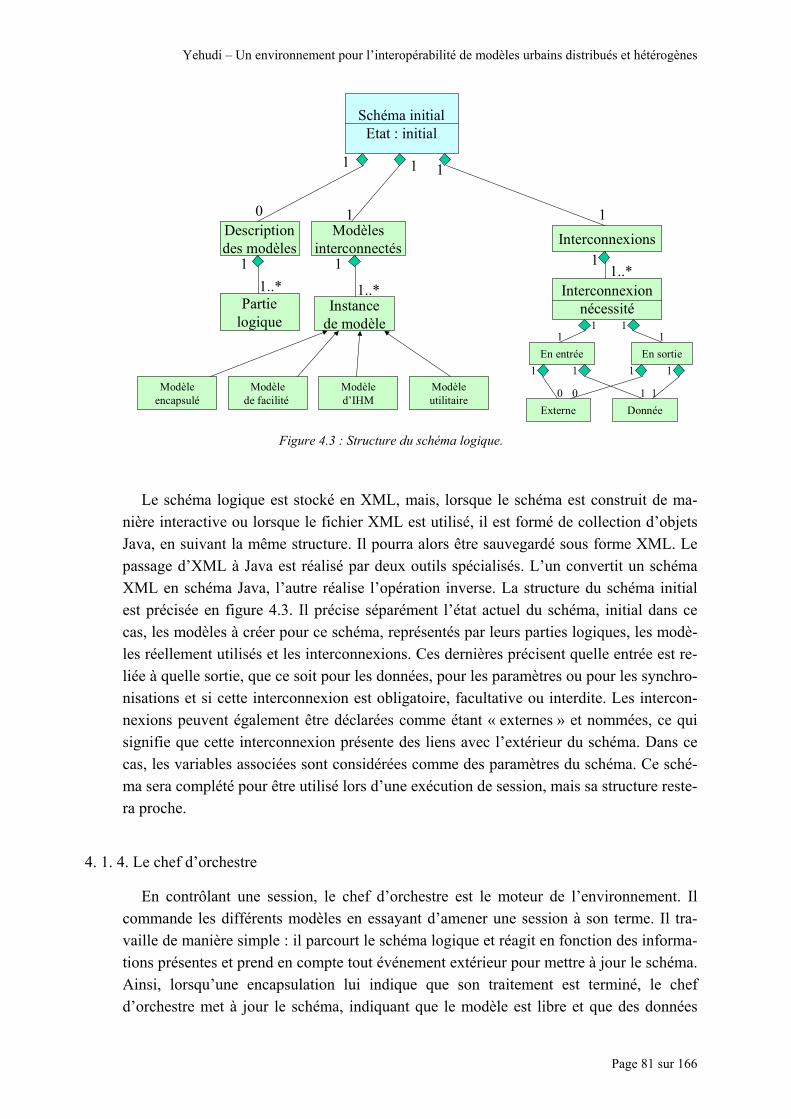
Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 81 sur 166
Schéma initialEtat : initial
Descriptiondes modèles
Modèlesinterconnectés Interconnexions
Partielogique
Instancede modèle
Interconnexionnécessité
Modèlede facilité
Modèled’IHM
Modèleutilitaire
Modèleencapsulé
En entrée En sortie
Externe Donnée
1
0
1
1
1
1
11..*
1
1..*1..*
1
11
11
1 1 1 1
0 0 1 1
Figure 4.3 : Structure du schéma logique.
Le schéma logique est stocké en XML, mais, lorsque le schéma est construit de ma-nière interactive ou lorsque le fichier XML est utilisé, il est formé de collection d’objets Java, en suivant la même structure. Il pourra alors être sauvegardé sous forme XML. Le passage d’XML à Java est réalisé par deux outils spécialisés. L’un convertit un schéma XML en schéma Java, l’autre réalise l’opération inverse. La structure du schéma initial est précisée en figure 4.3. Il précise séparément l’état actuel du schéma, initial dans ce cas, les modèles à créer pour ce schéma, représentés par leurs parties logiques, les modè-les réellement utilisés et les interconnexions. Ces dernières précisent quelle entrée est re-liée à quelle sortie, que ce soit pour les données, pour les paramètres ou pour les synchro-nisations et si cette interconnexion est obligatoire, facultative ou interdite. Les intercon-nexions peuvent également être déclarées comme étant « externes » et nommées, ce qui signifie que cette interconnexion présente des liens avec l’extérieur du schéma. Dans ce cas, les variables associées sont considérées comme des paramètres du schéma. Ce sché-ma sera complété pour être utilisé lors d’une exécution de session, mais sa structure reste-ra proche.
4. 1. 4. Le chef d’orchestre
En contrôlant une session, le chef d’orchestre est le moteur de l’environnement. Il commande les différents modèles en essayant d’amener une session à son terme. Il tra-vaille de manière simple : il parcourt le schéma logique et réagit en fonction des informa-tions présentes et prend en compte tout événement extérieur pour mettre à jour le schéma. Ainsi, lorsqu’une encapsulation lui indique que son traitement est terminé, le chef d’orchestre met à jour le schéma, indiquant que le modèle est libre et que des données

Mémoire de thèse
Page 82 sur 166
sont disponibles en sortie. Il parcourt ensuite le schéma, rééxécute le modèle si nécessaire et fait circuler les données si elles sont connectées. Ce traitement est schématisé en figure 4.4. Le schéma est donc constamment utilisé pour l’exécution d’une session.
Vérifier un modèleSelon état
Événement
Schéma logique
Vérification des modèles
Vérifier les données enentrée/sortie/paramètre
Selon résultat
Vérifier le modèlePossibilité d’action ?
Augmenter letemps d’attentesur les données Action
Augmenter letemps d’attentesur le modèle
Mise à jourdes compteurs
Fin dela vérification
du modèle
Vérifier tempslimite
Dépassé ?
Vérifier tempslimite
Dépassé ?
Changer l’étatproblème
Changer l’étatproblème
ouinonoui non
nonoui
Figure 4.4 : Schématisation du traitement effectué par le chef d’orchestre après réception d’un évènement. Ce schéma est volontairement simplifié et les traitements sont en fait adaptés aux différents évènements et états possi-bles.
4. 1. 5. Usage du schéma logique
Le schéma logique est d’abord utilisé pour générer une session et décrire une inter-connexion de modèles, il correspond alors au schéma initial. À partir de ce schéma, le

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 83 sur 166
chef d’orchestre instancie les modèles listés, qu’ils s’agissent de modèles encapsulés par des utilisateurs ou de modèles utilitaires, d’IHM ou de facilité.
Ensuite, le chef d’orchestre utilise le schéma pour vérifier les interconnexions.
Schéma utiliséEtat : utilisé
Descriptiondes modèles
Modèlesinterconnectés Interconnexions
Partielogique
Instancede modèle
InterconnexionEtat Nécessité
Modèleutilitaire
Etat Temps
Modèled’IHM
Etat Temps
Modèlede facilité
Etat Temps
Modèleencapsulé
Etat Temps
En entrée En sortie
Externe DonnéeEtat Temps
1
0
1
1
1
1
11..*
1
1..*1..*
1
11
11
1 1 1 1
0 0 1 1
EntréeEtat
SortieEtat
ParamètreEtat
SynchronisationEtat
1
0..*
Figure 4.5 : Le schéma logique en utilisation. Une instance de modèle peut comporter plusieurs entrées, sorties, paramètres ou synchronisation. Chaque élément utilisé dispose d’un état, même s’il y a redondance : les instances de modèles, leurs éléments d’interface, les interconnexions, les données des interconnexions.
Le schéma initial va alors être complété pour pouvoir être utilisé par l’environnement, tel que représenté en figure 4.5. La plupart des éléments demeurent, mais avec un rensei-gnement sur leur état. Ce dernier permet au chef d’orchestre de gérer le schéma. A la structure initiale ont été précisés les entrées, sorties, paramètres et synchronisations des différents modèles, ce qui permet de suivre leur état. L’attribut « Temps » des modèles et des données permet de savoir depuis combien de temps ils se trouvent dans cet état. Le schéma logique est modifié au fur et à mesure de l’avancement de l’exécution de la ses-sion pour refléter l’état des différents éléments et des différentes connexions. Le chef d’orchestre utilise ce schéma pour savoir que faire : quelle donnée transmettre, quel mo-dèle exécuter, quel problème gérer…

Mémoire de thèse
Page 84 sur 166
Par sécurité, il est possible de sauvegarder une session sous la forme de schémas d’état, qui représentent l’état d’une session à un moment donné. Ces schémas peuvent être générés automatiquement, à chaque étape majeure d’exécution, ou sur demande de l’utilisateur. Ainsi l’ensemble des données utilisées par la session, en entrée, en sortie ou en paramètre d’un modèle est stocké régulièrement. Pour pouvoir reprendre une session interrompue, il faut pouvoir également sauvegarder les données utilisées au niveau d’une encapsulation. Cette sauvegarde peut s’effectuer localement sur la machine où réside le modèle encapsulé ou de façon centralisée avec les schémas d’état. Actuellement, c’est cette dernière opération qui a été privilégiée. Ce choix s’explique principalement par l’indépendance entre un schéma et l’agencement des machines interconnectées. Lors de la mise en place d’une session, le chef d’orchestre utilise le catalogue pour retrouver les modèles, pouvant choisir une machine plutôt qu’une autre si un modèle est disponible sur plusieurs machines. La centralisation de la sauvegarde permet de garder cette indépen-dance et donc de reprendre une session y-compris si une des machines précédemment uti-lisées n’est plus disponible. En contrepartie, ce choix impose une charge du réseau impor-tante lors de l’opération de sauvegarde.
4. 1. 6. Modes d’exécution
Nous avons défini deux modes d’exécutions possibles d’une session.
Dans le mode automatique, l’utilisateur n’interagit pas avec le système sauf dans le cas d’un arrêt urgent ou de changement de mode d’exécution. Le système déclarera une session terminée si un des événements suivants survient :
- épuisement des données en entrée. Le système attend que toutes les données en en-trée soient utilisées. L’utilisateur doit dans un premier temps s’assurer lui-même de la possibilité de cet épuisement. En effet, certaines sources de données ne peuvent s’épuiser.
satisfaction des modèles terminaux. Le système attend que tous les modèles en fin d’interconnexion aient terminé leur traitement.
Dans le mode par contrôle, l’utilisateur contrôle lui-même l’exécution ou ajoute des modèles spécifiques qui vont contrôler l’exécution.
Le mode est choisi par l’utilisateur avant ou lors d’une exécution. Le système n’offre pas actuellement de contrôle de la validité du mode choisi. Cependant, l’exécution d’une session est interactive et l’utilisateur peut contrôler et stopper une session à tout moment.
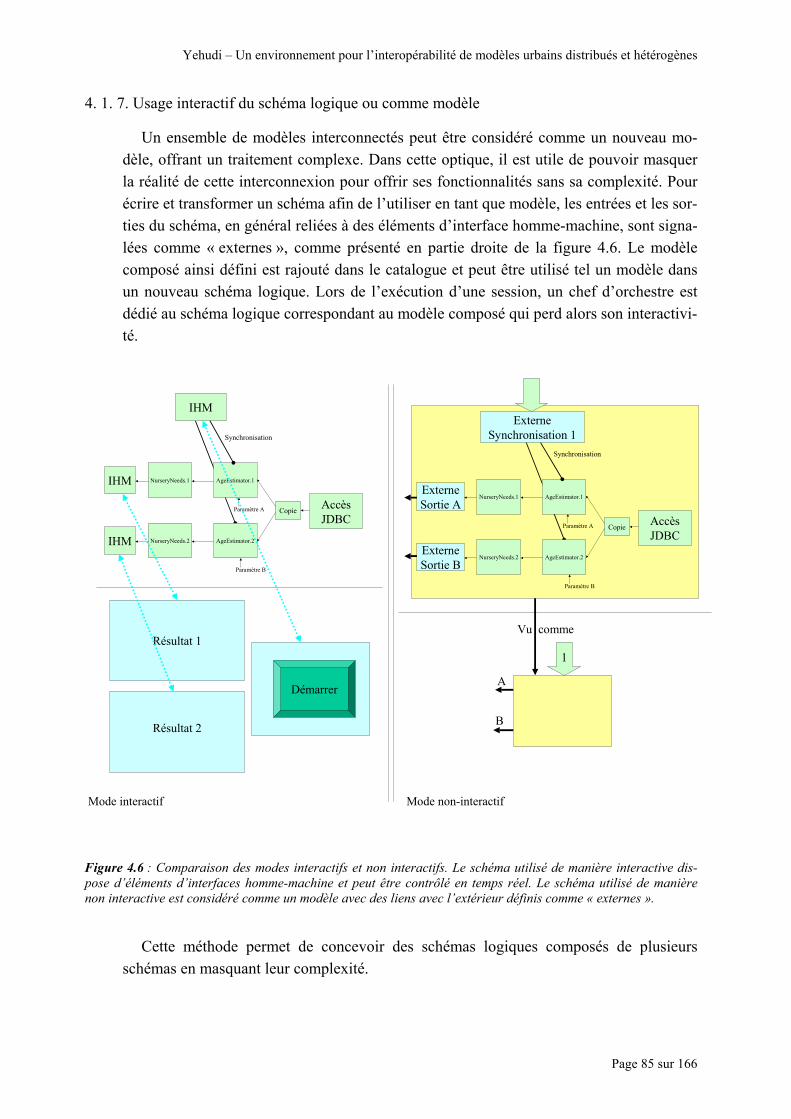
Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 85 sur 166
4. 1. 7. Usage interactif du schéma logique ou comme modèle
Un ensemble de modèles interconnectés peut être considéré comme un nouveau mo-dèle, offrant un traitement complexe. Dans cette optique, il est utile de pouvoir masquer la réalité de cette interconnexion pour offrir ses fonctionnalités sans sa complexité. Pour écrire et transformer un schéma afin de l’utiliser en tant que modèle, les entrées et les sor-ties du schéma, en général reliées à des éléments d’interface homme-machine, sont signa-lées comme « externes », comme présenté en partie droite de la figure 4.6. Le modèle composé ainsi défini est rajouté dans le catalogue et peut être utilisé tel un modèle dans un nouveau schéma logique. Lors de l’exécution d’une session, un chef d’orchestre est dédié au schéma logique correspondant au modèle composé qui perd alors son interactivi-té.
AgeEstimator.1
AgeEstimator.2
NurseryNeeds.1
NurseryNeeds.2
Copie AccèsJDBC
IHM
IHM
IHM
Synchronisation
Paramètre A
Paramètre B
Résultat 1
Résultat 2
Démarrer
Mode interactif
AgeEstimator.1
AgeEstimator.2
NurseryNeeds.1
NurseryNeeds.2
Copie AccèsJDBC
ExterneSynchronisation 1
ExterneSortie A
ExterneSortie B
Synchronisation
Paramètre A
Paramètre B
1
A
B
Mode non-interactif
Vu comme
Figure 4.6 : Comparaison des modes interactifs et non interactifs. Le schéma utilisé de manière interactive dis-pose d’éléments d’interfaces homme-machine et peut être contrôlé en temps réel. Le schéma utilisé de manière non interactive est considéré comme un modèle avec des liens avec l’extérieur définis comme « externes ».
Cette méthode permet de concevoir des schémas logiques composés de plusieurs schémas en masquant leur complexité.

Mémoire de thèse
Page 86 sur 166
4. 2. Cohérence des interconnexions et adaptation
Les données générées et utilisées par les modèles ne sont pas semblables. Elles peu-vent varier par leur type, par leur échelle, par leur sens. Ainsi, une connexion entre deux modèles n’est pas forcément possible ou valide. Pour pouvoir vérifier ces interconnexions et éventuellement apporter une solution, le chef d’orchestre a besoin d’un repère ainsi que d’outils capables d’utiliser ce repère.
Ce repère doit permettre deux opérations : la vérification du schéma et l’ajout d’outils pour l’adaptation des données qui peuvent l’être. Lors de l’interconnexion de deux modè-les, les données doivent être vérifiées et adaptées tant du point de vue typologique que sémantique. L’adaptation typologique bénéficie d’une formalisation claire et d’une rela-tive absence d’ambiguïté. Nous avons donc considéré celle-ci comme incluse dans les adaptations sémantiques et nous les supporterons de manière identique.
Pour le traitement sémantique, nous avons choisi d’apporter un référentiel sémantique sous la forme d’une base d’ontologie. Cette base représente des connaissances d’un uni-vers donné, lesquelles seront utilisées sur les méta-modèles qui représentent eux-mêmes, en respectant la base d’ontologie, le modèle correspondant. Dans le cadre de notre travail, nous souhaitons représenter les connaissances du domaine d’application des modèles ur-bains, afin de fournir un référentiel et de contribuer à l’homogénéisation sémantique des modèles. Le référentiel est utilisé pour vérifier les interconnexions et permettre la modifi-cation du schéma logique et son enrichissement si besoin est.
Pour justifier nos choix, nous présentons les deux techniques les plus utilisées pour la représentation des connaissances, les graphes conceptuels et les logiques de description.
4. 2. 1. Représentation de connaissance : techniques et limites
Il existe actuellement deux techniques proches très utilisées pour représenter des connaissances.
La première approche, proposée par Sowa [Sowa 2000], définie un réseau sémantique utilisant un support, avec :
- une hiérarchie de types de concepts, structurée en treillis, partant de l’entité, qui est le type universel, vers le néant, qui est le type absurde : tout est entité, rien n’est néant,
- des types de relations, numérotés et contraints par un graphe,
- un ensemble de marqueurs structurés en treillis également,
- une relation de conformité entre la hiérarchie de marqueurs et celle de concepts.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 87 sur 166
Cette représentation est compatible avec des techniques d’inférences relativement effi-caces. Cependant, c’est une représentation qui reste complexe, même si elle peut être re-présentée graphiquement, et qui devient très difficile à gérer si les concepts deviennent très nombreux.
La deuxième approche est en réalité la représentation textuelle d’un réseau sémanti-que. La logique de description correspond donc à l’expression des connaissances avec une notation linéaire, qui se rapproche en ce sens des prototypage des langages objets [Kayser 1997]. De nombreuses variations existent, apportant une simplification ou une spécialisation du langage. Nous pouvons citer l’usage de langage proche des langages ob-jets tels que C/C++, par exemple dans l’approche de [Leclercq-Benslimane-Yétongnon 1999], l’adoption de la syntaxe LISP par KIF [Genese-reth], ou l’usage de la syntaxe XML par IFF, XOL, OIL [IFF 1999, XOL 1999, Fensel-Horrocks-Van Harmelen et al. 2000]. De même, il faut noter que des langages de méta-données, tel RDF, se rapprochent des logiques de description.
Nous pouvons encore citer d’autres langages utilisant ces représentations : Ontolingua, KADS et CommonKADS, Loom et Powerloom [Farquhar-Fikes-Rice 1996, KADS, LOOM 2002], ainsi que des outils permettant leur édition, tel ceux d’Ontolingua et Pro-tégé [Grosso-Eriksson-Fergerson et al. 1999] . Quelle que soit la forme choisie pour re-présenter les connaissances, le problème esssentiel demeure la construction de ces repré-sentations. Ainsi, dans le domaine des modèles urbains, le concepteur de l’environnement ne peut construire seul le référentiel sémantique. Nous devons permettre aux experts d’enrichir une base dont le noyau est initialement défini. Dans le cadre de notre projet, nous avons choisi de manipuler le modèle comme une boîte noire. Nous avons donc fait deux choix complémentaires :
- d’une part, et cela a déjà été présenté, abstraire la réalité logicielle pour offrir une ré-alité logique aux données et aux modèles. Ce monde logique n’a pas la prétention de re-présenter le monde physique mais d’être une vue suffisante pour permettre la pleine utili-sation (dans la limite du possible) du monde physique. Cette vue offre ensuite un cadre homogène et transparent pour une gestion sémantique. Métaphoriquement, nous pouvons considérer l’espace logiciel comme une bibliothèque. Nos yeux nous offrent une vue de la bibliothèque et nous utilisons les images perçues pour pouvoir appréhender les élé-ments présents. Il est important de bien préciser que le traitement cérébral effectué par après ne concerne pas réellement la bibliothèque mais bien la perception que nous en avons. Notre couche logique est donc une image de la réalité. Cette image est nécessaire, même si elle est imparfaite, car nous ne savons pas appréhender « directement » la réalité, sans perception. L’idéal serait bien évidemment d’offrir un dispositif de perception de la réalité logicielle. Mais cet idéal se heurte à deux difficultés : un programme est un en-semble complexe, qui réunit des traitements de différents ordres (nous pouvons par exemple opposer les interactions de l’interface graphique aux opérations « internes »), et un programme compilé, sous forme de code machine, repose sur des opérations basiques,

Mémoire de thèse
Page 88 sur 166
qui trouvent leur consistance dans leur combinaison : par exemple le tracé d’une lettre à l’écran nécessite plusieurs opérations simples, qui n’intéressent pas un concepteur ou un utilisateur ne souhaitant pas agir sur ce tracé. Nous n’affirmons pas que cette perception est impossible, mais il n’existe pas actuellement de telles techniques efficaces et simples. De plus, l’apport manuel ou semi-manuel d’une description logique ajoute des informa-tions qui sont simplement absentes du logiciel ou qui seraient très difficiles à retrouver. Ces informations peuvent dépasser la simple vue pour être d’ordre contextuel et sémanti-que.
- D’autre part, nous avons cherché une solution qui simplifierait la création et l’usage d’une ontologie. Pour cela, nous proposons une structure logicielle simple, qui est compa-tible avec l’usage d’un langage existant, tel IFF, XOSL ou OIL. Cependant, pour permet-tre la création d’un environnement fonctionnel, nous avons réduit cette structure et utili-sons la syntaxe XML pour des documents fonctionnels et clairs, utilisant des outils pré-existants.
L’ontologie est un type de référentiel sémantique, qui a l’ambition de définir le « possible », c’est-à-dire de préciser, pour le domaine représenté, les potentialités concep-tuelles des entités représentées. Bien sûr, il s’agit là d’un but idéal. L’ontologie est donc un document qui utilise un langage de description de connaissance et qui est construit se-lon deux approches distinctes : du concept de plus haut niveau vers l’application ou de l’application vers le concept de plus haut niveau, en reliant tous les différents niveaux. En général, ces deux constructions ne se rejoignent pas : les ontologies construites à partir d’un concept de haut niveau sont trop complexes pour être utilisées ou ne descendent pas jusqu’au niveau applicatif, les ontologies construites à partir de l’application n’arrivent pas à un concept « réunificateur ».
Il convient donc de préciser le rôle de l’ontologie dans notre environnement, pour fournir une réponse adaptée. Elle doit être utilisée par le chef d’orchestre, sur le niveau logique, pour concilier les modèles et leurs données. Elle doit donc d’abord permettre la vérification de l’adéquation des données et offrir au chef d’orchestre les moyens de trou-ver le cas échéant des solutions d’adaptation des données.
4. 2. 2. Approches possibles
Nous pouvons opposer deux manières de construire une ontologie : proposer une seule ontologie, la plus complète possible, ou une ontologie décomposée en plusieurs parties, soit avec un noyau et des extensions, comme pour OML/CKML/IFF [Ontolo-gos 1999], soit par couches pyramidales, comme proposés par [Benslimane-Leclercq-Savonnet et al. 2000].
Dans tous les cas, le problème reste le même : offrir une référence satisfaisante et suf-fisante, donnant un choix correct pour la conception des méta-modèles et permettant des

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 89 sur 166
traitements. Cependant, une base d'ontologie complète décrivant tout l’univers des modè-les et de leurs données serait très grande, pratiquement impossible à réaliser et très diffi-cile à utiliser, car les « voisinages » de concepts seraient nombreux, ambiguës et subjec-tifs.
4. 2. 3. Richesse ou échange
Dans toutes les étapes de conception de la base d'ontologie, pour le noyau ou un do-maine plus réduit, il faut essayer d'être assez précis et complet, mais également de per-mettre un échange des connaissances. Les définitions doivent satisfaire tous les utilisa-teurs du domaine concerné. Or, plus la base est riche, plus il devient difficile d'avoir des concepts suffisamment généraux pour faire l'unanimité. Ainsi, il faut nécessairement trouver un compromis entre les possibilités d'échange, l’utilisation de la base, et la ri-chesse de la base, forcément plus sujet à la subjectivité de chacun. Ce problème impose une réflexion sur la nécessité d’offrir un outil avancé pour construire une ontologie com-plète ou d’adopter une solution moins ambitieuse mais plus fonctionnelle. Sans renier une future utilisation d’une ontologie « classique », nous avons ainsi choisi une structure dé-diée.
4. 3. Un référentiel pratique
Pour profiter au mieux des choix déjà effectués pour l’interconnexion de modèles, nous avons mis au point une ontologie orientée document et interconnexion.
4. 3. 1. Vérifier et permettre les interconnexions
En fonction de notre problématique, nous avons exprimé nos besoins afin de proposer une réponse adaptée.
1. Problématique
L’interconnexion de modèles existants pose des problèmes de conformités des connexions. Nous voulons vérifier ces connexions pour éventuellement les permettre ou les adapter.
L’approche boîte noire choisie pour décrire un modèle implique que celui-ci se carac-térise par les données entrantes et sortantes. Plus ces données sont caractérisées de façon syntaxique et sémantique et plus le modèle est décrit. Interconnecter deux modèles pose alors différents types de problèmes, représentés en figure 4.7 :
- syntaxique, les données générées et utilisées ont des structures différentes, des types différents, sont agrégées ou non, … Ainsi dans l’exemple (a) un modèle générant une ma-trice 2-2, doit être connecté à un modèle acceptant une ligne de cette matrice. Dans

Mémoire de thèse
Page 90 sur 166
l’exemple (b) un premier modèle fournit en sortie une structure, représentant un quartier, et comprenant un champ « rue » que nous désirons utiliser pour une interconnexion. Les différences syntaxiques nécessitent une opération pour adapter les données.
- d’unités, les données suivent un type identique mais correspondent à une unité phy-sique différente. L’exemple (c) est l’interconnexion entre un modèle générant un entier représentant des mètres et un modèle utilisant un entier représentant des kilomètres. Le problème d’unité rejoint les problèmes syntaxiques et il faut en général adapter les don-nées.
- sémantique, deux données peuvent avoir un sens différent et, malgré une compatibili-té syntaxique, ne pas être utilisables conjointement. L’exemple (d) montre deux modèles, l’un générant des données représentant une rue et l’autre attendant des données représen-tant une impasse. Selon l’usage qu’il en est fait, ces données peuvent ou non être considé-rées comme équivalentes dans une interconnexion.
- de pas de temps, les données sont générées de manière régulière, mais avec des pas de temps différents : dans l’exemple (e) un modèle travaille avec des pas de temps d’un an, un autre avec des pas de temps d’un mois. Il faut donc interpoler ou extrapoler les données. La gestion du temps sera abordé dans une section ultérieure.
- de dénomination, deux données ont un même nom mais recouvrent une réalité diffé-rente. Nous n’avons pas traité ce problème et supposons que les données possède un nom unique.
rue
quartierrue
Matrice 2*2 Matrice 2*1Différence syntaxiques
Différence syntaxiques
rue impasse Différence sémantique
500 m 0,5 km Différence d’unité
Différence temporelleHabitantspar pas de 1 an
Habitantspar pasde 1 mois
(a)
(b)
(c)
(d)
(e)
Figure 4.7 : Illustration des différents problèmes pouvant survenir dans une interconnexion.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 91 sur 166
Pour répondre à cette problématique, la solution retenue utilise les potentialités du sys-tème : le méta-modèle qui fournit des informations logiques sur un modèle et ses don-nées, l’approche tout modèle qui permet d’utiliser des modèles pour des besoins de ges-tion.
2. Besoins
Dans un premier temps, il s’agit donc de vérifier la validité de l’interconnexion, c’est-à-dire la compatibilité entre entrées et sorties. Dans un deuxième temps, on doit tenter de rendre l’interconnexion possible. Dans notre approche, nous considérons qu’une inter-connexion lie un concept à un autre et il est donc nécessaire de définir et faciliter ces liens.
Ce lien pourra être défini soit par une parenté, indiquant qu’un lien est possible ou non selon les parentés entre concepts, soit par une adaptation, qui permet d’adapter des don-nées, soit par les deux.
Ainsi, notre solution repose d’une part sur l’apport possible d’adaptateurs, des modè-les utilitaires qui peuvent être incorporés dans le schéma d’interconnexion et qui rendent donc une interconnexion possible malgré une différence syntaxique ou d’unité. D’autre part, nous définissons des parentés possibles entre concepts pour vérifier la véracité de certaines interconnexions.
3. L’adaptation
L’adaptation a pour objectif de transformer une sortie correspondante à un concept pour pouvoir être utilisée à une entrée correspondant à un autre concept semblable ou lé-gèrement différent.
Lorsque deux modèles quelconques sont interconnectés, l’adaptation utilise des adap-tateurs qui sont des modèles intercalés entre les deux modèles nécessitant l’adaptation au niveau du schéma logique, puis générés et gérés comme tout autre modèle par le chef d’orchestre. L’intégration d’un adaptateur est donc principalement un pré-traitement du schéma s’appuyant sur l’utilisation de modèles utilitaires.
Pour pouvoir être insérés automatiquement, les adaptateurs sont décrits, ainsi que leurs types, dans une librairie. Cette description indique le type en entrée, le type en sortie et les conséquences qualitatives de l’adaptation. La librairie est suffisante pour décrire des adaptations d’un point de vue purement syntaxique, mais ne permet pas d’aborder le pro-blème d’un point de vue sémantique. Pour cela, nous avons défini des parentés et utili-sons une (ou plusieurs) ontologies.

Mémoire de thèse
Page 92 sur 166
Concernant les adaptations, l’ontologie précise quel adaptateur est nécessaire pour passer d’un concept à un autre. La figure 4.8 montre un adaptateur xy2z, qui adapte deux entrées de type x et y en une sortie de type z. La librairie décrit simplement les types utili-sés et l’adaptateur xy2z. Finalement, l’ontologie, construite selon les informations de la librairie, précise qu’il existe un lien entre deux concepts A et B qui nécessite une adapta-tion via l’adaptateur xy2z.
Adaptateurxy2z
Type xType y Type z
Librairietypes
x : descriptiony : descriptionz : description
adaptateursxy2z : de x,y à z
Ontologieconcepts
A : descriptionB : description
lienA à Badaptation : par xy2z
Figure 4.8 : Un adaptateur, sa description au sein de la librairie et son usage dans une ontologie
Pour compléter cette possibilité d’adaptation, nous avons apporté une gestion de la pa-
renté.
4. Les parentés
Les concepts peuvent avoir des liens de parentés qu’il s’agit de décrire. Les parentés entre concepts permettent surtout des vérifications, une parenté exprime la possibilité ou l’impossibilité de « substituer » un lien parent avec un autre en précisant les éventuelles conséquences en terme de qualité et d’adaptation. Cette définition peut aussi être vue ain-si : si un concept A est parent avec un concept B, alors le système accepte ou n’accepte pas d’utiliser le concept A à la place du concept B avec une éventuelle adaptation de A à B via un adaptateur et une éventuelle perte de qualité. La figure 4.9 montre cinq concepts ainsi que leurs parentés.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 93 sur 166
Concept C
Concept D Concept E
Concept F Concept GCousins
Fils
Père
Fils
Père
Père Père
Fils FilsFrères
Oncle
Neveu
Figure 4.9 : Cinq concepts et leurs parentés
Ces parentés peuvent être décrites dans la librairie en précisant si un concept peut être
accepté à la place d’un concept parent. Par exemple, un concept fils peut souvent être uti-lisé à la place d’un concept père mais l’inverse est rarement vrai. Un concept est parfois parfaitement équivalent à un concept cousin, parfois pas. Une parenté est ainsi rattachée à une action qui sera effectuée lorsque cette parenté est retrouvée dans une interconnexion. Cette action peut être l’acceptation, le refus ou un avertissement.
Bâtiment
Maison Villa
Père Père
Fils FilsFrères
Figure 4.10 : Exemple de parentés entre trois concepts réels.
Une parenté permet principalement l’affichage d’informations à destination de l’utilisateur : « le concept F est cousin du concept G que le lien E à G attend, voulez-vous accepter le concept F ? ». La figure 4.10 présente trois concepts réels et leurs parentés. Les définitions de parentés permettront de déterminer si une villa peut être considérée comme une maison ou comme un bâtiment, selon qu’elles autorisent les liens « frère de » et « fils de ».
La figure 4.11 présente un exemple de parenté, défini dans la librairie par son nom, l’action demandée lors de la vérification et les conséquences possibles en terme de qualité et d’adaptation. L’ontologie se contente de préciser la parenté entre deux concepts.
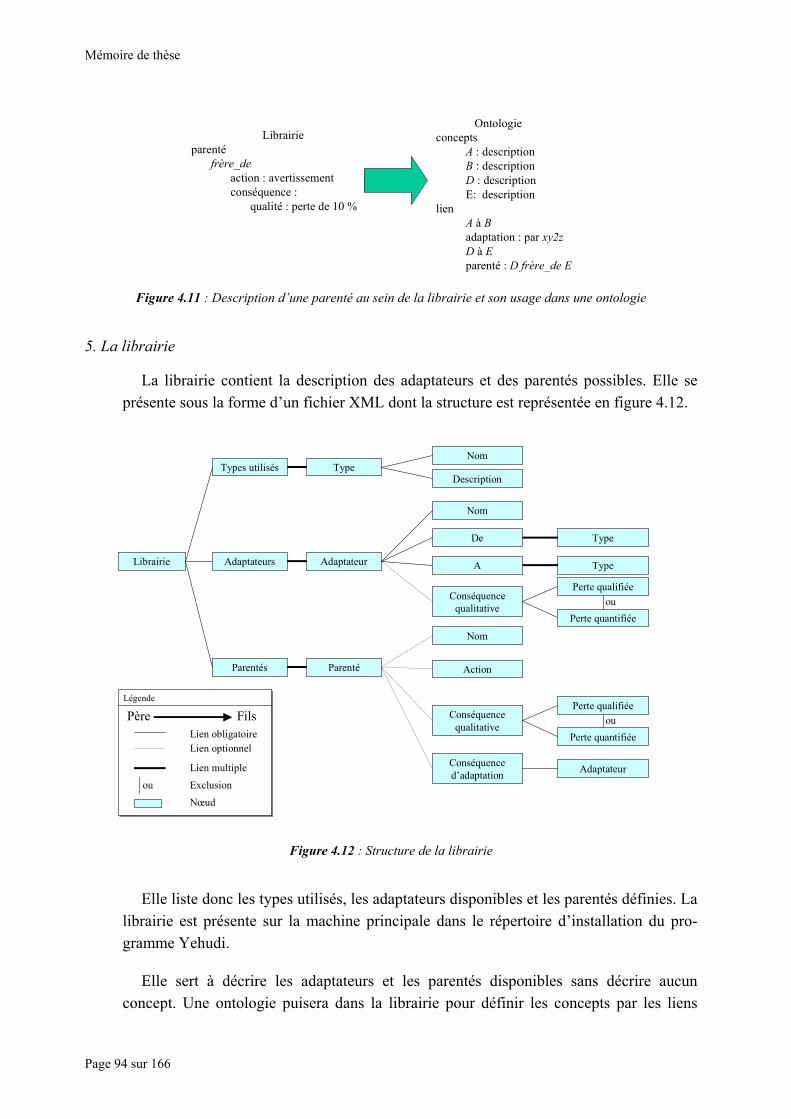
Mémoire de thèse
Page 94 sur 166
Librairieparenté
frère_deaction : avertissementconséquence :
qualité : perte de 10 %
Ontologieconcepts
A : descriptionB : descriptionD : descriptionE: description
lienA à Badaptation : par xy2zD à Eparenté : D frère_de E
Figure 4.11 : Description d’une parenté au sein de la librairie et son usage dans une ontologie
5. La librairie
La librairie contient la description des adaptateurs et des parentés possibles. Elle se présente sous la forme d’un fichier XML dont la structure est représentée en figure 4.12.
Librairie Adaptateur
Parentés
Type
De
A
Conséquence qualitative
Nom
Conséquencequalitative
Description
Conséquenced’adaptation
Action
LégendeLégende
ou
Lien obligatoireLien optionnel
Lien multiple
Exclusion
Nœud
Père Fils
Types utilisés
Adaptateurs
Parenté
Nom
Nom
Perte qualifiée
Perte quantifiéeou
Perte qualifiée
Perte quantifiéeou
Adaptateur
Type
Type
Figure 4.12 : Structure de la librairie
Elle liste donc les types utilisés, les adaptateurs disponibles et les parentés définies. La librairie est présente sur la machine principale dans le répertoire d’installation du pro-gramme Yehudi.
Elle sert à décrire les adaptateurs et les parentés disponibles sans décrire aucun concept. Une ontologie puisera dans la librairie pour définir les concepts par les liens

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 95 sur 166
possibles entre eux, ces liens étant possibles via une parenté et/ou un adaptateur. La li-brairie précise avec quels types travaillent les adaptateurs et quelles sont les conséquen-ces d’une adaptation ou d’une parenté.
Pour des raisons de gestion et de partage, il peut y avoir plusieurs librairies, une librai-rie de référence et des librairies utilisateurs. En effet, si un utilisateur souhaite rajouter un adaptateur ou une parenté, il a la possibilité d’enrichir la librairie fournie avec le système. Cependant, s’il désire partager cette contribution, il sera mieux qu’il définisse une autre librairie, qui pourra être échangée sans remettre en cause la librairie de référence. S’il le désire, il pourra contacter des concepteurs de Yehudi pour proposer l’ajout de sa contri-bution dans la librairie de référence.
De plus, cette séparation permet de mettre au point une portion de librairie sans risquer d’invalider les librairies fonctionnelles.
6. L’ontologie
L’ontologie est orientée interconnexion et ne définit les concepts que par leur possibi-lités de lien avec d’autres concepts : soit par adaptation, soit par parenté, soit les deux. Elle permet le passage d’un concept à un autre au niveau sémantique. Elle est utilisée lors de la vérification du schéma logique. Les concepts définis seront utilisés pour définir le type sémantique des méta-modèles. Un lien entre deux concepts sera accepté s’il est défi-ni au sein de l’ontologie et si cette définition est favorable. Si besoin est, le lien sera adapté et les conséquences en terme de qualité rajoutées au schéma.
Ontologie
Lien
Concept
De
A
Adaptation
Description
LégendeLégende
ou
Lien obligatoireLien optionnel
Lien multipleExclusion
Nœud
Père Fils
Concepts décrits
Liens
Parenté
Nom
Nom
Concept
Concept
librairieDescription
Librairiesutilisées
Nom
Adaptateur
Figure 4.13 : Structure d’une ontologie

Mémoire de thèse
Page 96 sur 166
Elle est composée, comme le montre la figure 4.13, de la liste des librairies utilisées, de la liste des concepts décrits, sans précision autre qu’une description textuelle, puis de la définition des liens possibles entre concepts : selon une adaptation, une parenté ou les deux.
Elle se réfère donc à une ou plusieurs librairies et définit ses liens à partir des adapta-teurs et des parentés ainsi définis.
L’ontologie est également un document XML, présent sur la machine principale.
L’utilisateur a la possibilité d’écrire des ontologies séparées, pour des raisons de ges-tion et de partage mais également pour définir un domaine précis. Comme une ontologie ne définie ses concepts que par des liens dans notre solution, il n’y a pas vraiment de ni-veaux d’ontologies : elles définissent les liens qu’elles désirent. Néanmoins, pour que ces ontologies soient utiles, il faut que les concepts des différents domaines soient liés. Ac-tuellement, cette condition doit être remplie à la construction des ontologies par l’expert. Pour faciliter une bonne définition des ontologies, un outil de création et d’édition per-formant pourra être écrit.
4. 3. 2. Éléments existants et évolution
Ce référentiel est basé sur des possibilités d’évolution simplifiées. Nous fournissons donc des éléments de base et permettons leurs extensions.
1. Éléments de base
Les éléments de base sont une librairie d’adaptateurs et de liens de parentés et l’ontologie décrivant les éléments existants.
Cette solution est conçue pour être aisément extensible. Nous fournissons donc un en-semble jouant deux rôles :
- il apporte un minimum de concepts, de parentés et d’adaptation, en correspondance avec les connaissances à un moment donné,
- il est une base pour de futures extensions, en fournissant un exemple clair de chaque élément.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 97 sur 166
2. Ajout d’un adaptateur
Un adaptateur est un modèle classique, si possible écrit en java sous la forme d’un modèle utilitaire. Dans certains cas où la vitesse d’exécution est primordiale, il est possi-ble d’encapsuler un modèle en C/C++.
Ce modèle est intégré comme tout autre modèle, via son méta-modèle. Il doit ensuite être référencé dans la librairie. La figure 4.14 présente un exemple d’adaptateur et son utilisation.
SommeQuelconque Entier
Méta-modèleNom : SommeDonnée en entier : QuelconqueDonnée en sortie : Entier
...
Librairie existanteTypes:
String : chaîne de caractèreEntier : entier 32 bitsEntier16 : entier 16 bits
…Adaptations:...
Librairie mise à jourTypes:
String : chaîne de caractèreEntier : entier 32 bitsEntier16 : entier 16 bitsQuelconque : un type quelconque
…Adaptations:…
Adaptateur : SommeDe : QuelconqueA : Entier
OntologieConcepts:
PersonnePopulation
…Lien:…
De : PersonneA : Populationadaptation : Somme
Méta-modèleNom : donnepersonneDonnée en sortie : string
Type sémantique : Personne
Méta-modèleNom : utilisepopulationDonnée en entrée : entier
Type sémantique : Population
Figure 4.14 : Utilisation d’un adaptateur « Somme » dans une librairie puis dans une ontologie.
L’adaptateur « Somme » est un modèle utilitaire acceptant en entrée un type quel-conque et en sortie un entier, comme le précise son méta-modèle. Il fait la somme du nombre d’arrivées de données en entrée et renvoie cette somme. Le type « entier » est dé-jà présent dans la librairie, il ne faut donc pas le décrire à nouveau. La librairie mise à jour décrit donc le type « quelconque » et l’adaptateur « Somme », par son nom et par ses types en entrée et en sortie. Une fois défini dans la librairie, l’adaptateur peut être utilisé dans une ontologie pour permettre un lien, ici entre « Personne » et « Population » : une somme de personnes forment une population. Ce lien sera utilisé lorsqu’une intercon-nexion met en relation deux données de types sémantiques « Personne » et « Population ». Ce type sémantique est donné dans le méta-modèle.

Mémoire de thèse
Page 98 sur 166
4. 3. 3. Usage en session
Les ontologies ainsi définies peuvent être utilisées pour enrichir les méta-modèles puis vérifier et adapter les interconnexions au sein d’un schéma logique.
1. Enrichir les méta-modèles
En utilisant les ontologies disponibles, et si celles-ci couvrent le bon domaine, l’utilisateur qui intègre un modèle a la possibilité de rajouter des types sémantiques aux définitions d’entrées, de sorties et de paramètres dans la partie logique. Pour cela, une on-tologie est vue comme un document qui définit des concepts. L’utilisateur doit alors pré-ciser quelle(s) ontologie(s) le méta-modèle utilise, puis utiliser les concepts de l’ontologie pour définir les types sémantiques des entrées/sorties/paramètres du méta-modèle. Le ré-férentiel fourni par ce système d’ontologies ne sera utiles que lorsque suffisamment de méta-modèle définiront des types sémantiques pour leur données en entrée, sorties et pa-ramètres. La figure 4.15 illustre cette possibilité.
Donnée en entrée
Nom de la donnée
Type de la donnée
Type sémantique
Valeur
LégendeLégende
Lien obligatoireLien optionnel
Nœud
Père Fils
concept Aconcept Bconcept C
OntologieMéta-modèle (détail)
Figure 4.15 : Lien entre le méta-modèle et une ontologie. Les concepts de l’ontologie permettent de définir les
types sémantiques des données en entrée, en sortie et en paramètre.
L’enrichissement d’un méta-modèle met en relief l’intérêt des descriptions textuelles
au sein des ontologies. Les concepts doivent en effet être définis clairement pour ne pas être utilisés lorsqu’ils ne conviennent pas.
Le méta-modèle ainsi complété est utilisé normalement pour construire un schéma. Ces informations sont alors utilisées lors de la vérification du schéma.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 99 sur 166
2. Contrôle des interconnexions
Sur demande de l’utilisateur, le chef d’orchestre vérifie les interconnexions. Pour cha-que interconnexion, si les deux données reliées ont des types sémantiques définis mais non identiques, le chef d’orchestre appelle le médiateur en lui donnant la référence du schéma logique.
Le médiateur est un acteur particulier qui, utilisant la description des données à adap-ter et le référentiel sémantique, est capable de rechercher une solution pour permettre l’adaptation et également vérifier la validité du lien sémantique.
Il commence par retrouver les types sémantiques contenus dans les méta-modèles. Il va ensuite rechercher un lien entre les deux types sémantiques dans les ontologies dispo-nible. S’il trouve ce lien, il utilise les informations pour éventuellement ajouter un adapta-teur et vérifier la parenté. L’ajout d’un adaptateur se fait en modifiant le schéma logique. C’est le chef d’orchestre qui utilisera vraiment l’adaptateur, sans le différencier des au-tres. Si nécessaire, le médiateur informe l’utilisateur et peut également lui demander des confirmations ou des choix.
Dans sa première version, le médiateur recherche un adaptateur ou une parenté entre deux concepts. Une ontologie définit un graphe entre concepts. La recherche actuelle consiste à trouver des liens simples, sans profondeur. Il pourra être amélioré pour effec-tuer des recherches en profondeur dans ce graphe, en construisant un nouveau adaptateur résultant du chaînage d’adaptateurs existants.
Le médiateur offre des fonctionnalités suffisantes pour les besoins de la plupart des utilisateurs, compensant sa simplicité par une facilité d’emploi et d’enrichissement des ontologies, des librairies et des méta-modèles. Il pourra toutefois être amélioré pour sup-porter des recherches plus intelligentes.
4. 3. 4. Conclusion
Cette solution est fortement orientée document, facilitant ainsi son enrichissement, sa consultation et l’usage futur de nombreux outils d’aide à la création et à l’édition. L’adaptation se fait en utilisant les possibilités de gestion du système ce qui permet l’utilisation de modèles quelconques.
En revanche, nous avons fait le choix d’avoir une ontologie orientée connexion et nous ne pouvons pas considérer que cette solution utilise un moteur d’inférence : les recher-ches sont limitées. Finalement, mais c’est le lot commun de tout référentiel, cette solution n’est pas infaillible, et repose surtout sur la bonne définition puis sur la complète com-préhension des différentes descriptions par les concepteurs et utilisateurs. Nous pouvons

Mémoire de thèse
Page 100 sur 166
considérer que cette solution permet à des experts d’enrichir le système en vue d’utiliser au mieux les modèles dont ils ont l’expertise.
4. 4. Gestion de la qualité, contrôles logiques
Pour gérer la qualité des données, le système ne peut évaluer simplement la perte ef-fectuée par un traitement ou une adaptation. En effet, cette évaluation nécessiterait soit la parfaite implémentation de cette fonction par tous les modèles, soit une connaissance des conséquences de tous les traitements possibles. En fait, les résultats d’un modèle répon-dent à un besoin donné. Leur qualité n’est donc pas exprimé autrement que comme « répondant aux objectifs ». Ainsi, nous offrons une vérification logique de la qualité. Chaque méta-modèle peut exprimer la perte éventuelle de qualité sur ses données en sor-tie. Cette perte sera reflétée sur le schéma d’interconnexion.
Malheureusement, l’évaluation de la qualité ne peut se faire sur une chaîne de modèles que si tous les méta-modèles correspondants renseignent cette perte. Pour faciliter cette gestion, la perte est évaluée quantitativement et qualitativement, en apportant une corres-pondance arbitraire entre le qualitatif et le quantitatif. La perte est donc exprimée en pourcentage.
La gestion de la qualité correspond à un contrôle logique.
4. 5. Gestion du temps
La gestion du temps est également à prendre en compte dans l’interconnexion de mo-dèles. Si un modèle utilise un pas de temps différent d’un autre, l’adaptation des données nécessite un changement de comportement pour l’exécution des modèles d’une session. Pour cela, nous avons prévu, dans un premier temps, des techniques par interpolation li-néaire et par intégration. Ces opérations sont effectuées par des adaptateurs particuliers s’occupant de types de données compatibles avec une telle opération. Les uns, s’occupant des interpolations, utilisent un tampon de données en entrée pour offrir les données inter-polées en sortie. Les autres, s’occupant de l’intégration, accumulent les données en entrée jusqu’à dépasser le pas de temps attendu, stockent ce résultat en tampon puis réalisent eux aussi une interpolation pour suivre le pas exact. Ces deux adaptateurs sont en exécu-tion constante et ne travaillent qu’avec un nombre minimal de données en entrée.
Bien sûr, ces techniques dégradent les données et peuvent même être tout à fait inexactes, car elles supposent un « échantillonnage » fin des données qui sont générées par un modèle, pour respecter au mieux le théorème de Shannon1. ce qui n’est pas forcé-
1 Le théorème de Shannon est à la base de la théorie de l’information, il énonce la condition d’un échantillonnage sans perte : « L'information véhiculée par un signal dont le spectre est à support borné n'est pas modifiée par l'opé-ration d'échantillonnage à condition que la fréquence d'échantillonnage soit au moins deux fois plus grande que la plus grande fréquence contenue dans le signal.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 101 sur 166
ment le cas. Nous pouvons améliorer le traitement en offrant une interpolation non-linéaire, cependant certains modèles génèrent simplement des données trop éloignées dans le temps, masquant donc une réalité « accidentée » entre les deux pas, et leurs don-nées ne peuvent donc pas être interpolées ni intégrées. La garantie d’une interpolation sans pertes ou à pertes minimes demande une connaissance sur le traitement effectué.
De ce fait, le concepteur de modèle pourra préciser, si le modèle génère des données selon un pas de temps, si les données du modèles sont interpolables ou non.
4. 6. Conclusion
Nous avons présenté dans ce chapitre des acteurs logiciels et des solutions techniques qui s’appuient sur une architecture distribuée simple à mettre en œuvre et fortement mo-dulaire. La gestion des interconnexions ne sera possible qu’avec l’apport d’un environ-nement logiciel efficace qui sera le support de cette interconnexion. Nous présentons ain-si l’architecture distribuée de Yehudi dans le chapitre V.
La reconstitution du signal original peut être effectuée par un filtre passe-bas idéal de fréquence de coupure égale à la moitié de la fréquence d'échantillonnage. »

Mémoire de thèse
Page 102 sur 166
CHAPITRE V PRÉSENTATION DE L’ARCHITECTURE DISTRIBUÉE
Yehudi s’appuie sur une architecture qui gère la distribution des modèles. Elle est pré-
sentée dans [Becam-Miquel-Laurini 2001]. Ce chapitre présente le principe de cette ar-chitecture avant de présenter sa spécification dans le détail.
5. 1. Une organisation hiérarchisée
L’architecture choisie est constituée de trois couches complémentaires et utilise des outils logiciels de type client-serveur fortement hiérarchisés.
5. 1. 1. Une architecture trois couches.
Notre solution s’appuie sur la complémentarité de trois couches : une couche physi-que, comprenant les modèles urbains, qui sont encapsulés pour être utilisés de manière uniforme au sein de la couche médiane. Celle-ci est composée des différents éléments lo-giciels de l’environnement, offrant des capacités de gestion distribuée et de communica-tion. Le chef d’orchestre pilote les éléments de cette couche pour respecter le schéma d’interconnexion qui compose, avec les différents autres éléments logiques, la couche lo-gique. Ces trois couches sont schématisées dans la figure 5.1.
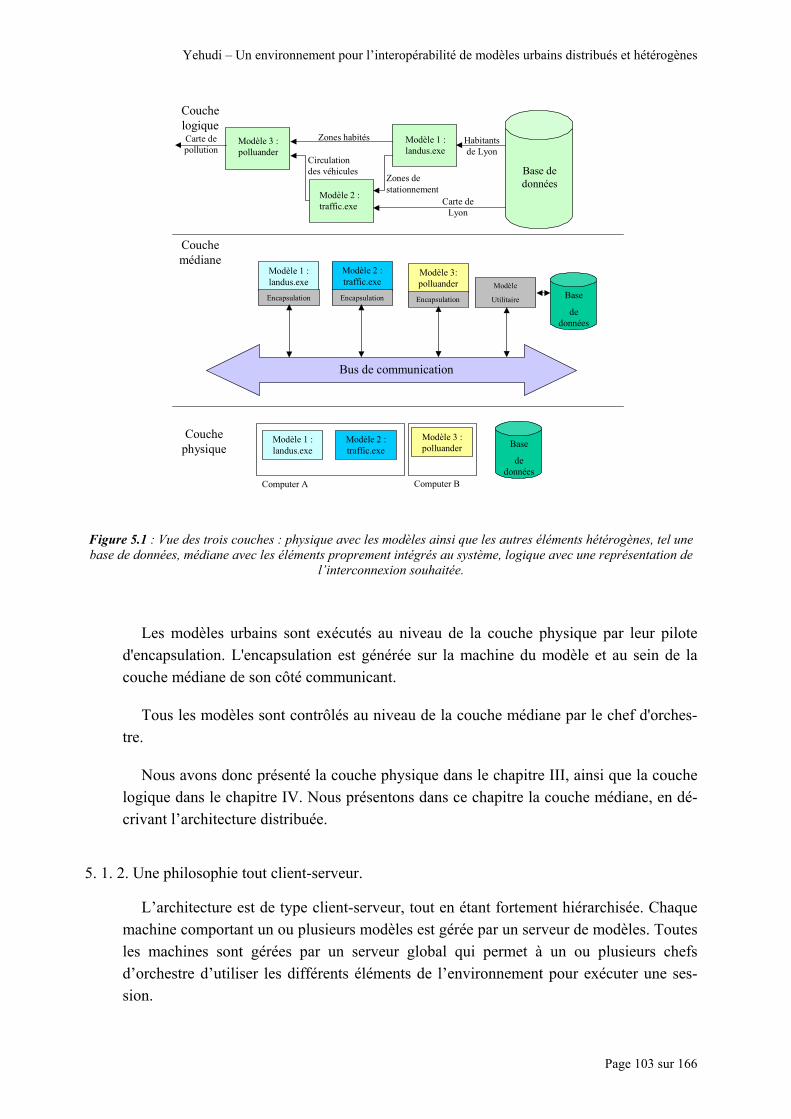
Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 103 sur 166
Couche logique
Modèle 1 : landus.exe
Modèle 2 : traffic.exe
Modèle 3 : polluander
Base de données
Habitants de Lyon
Zones de stationnement
Carte de Lyon
Circulation des véhicules
Zones habitésCarte de pollution
Modèle 1 : landus.exe
Modèle 2 : traffic.exe
Modèle 3: polluander
Base
de données
Encapsulation Encapsulation Encapsulation
Modèle
Utilitaire
Bus de communication
Couche médiane
Modèle 1 : landus.exe
Modèle 2 : traffic.exe
Modèle 3 : polluander
Computer A Computer B
Couche physique Base
de données
Figure 5.1 : Vue des trois couches : physique avec les modèles ainsi que les autres éléments hétérogènes, tel une base de données, médiane avec les éléments proprement intégrés au système, logique avec une représentation de
l’interconnexion souhaitée.
Les modèles urbains sont exécutés au niveau de la couche physique par leur pilote d'encapsulation. L'encapsulation est générée sur la machine du modèle et au sein de la couche médiane de son côté communicant.
Tous les modèles sont contrôlés au niveau de la couche médiane par le chef d'orches-tre.
Nous avons donc présenté la couche physique dans le chapitre III, ainsi que la couche logique dans le chapitre IV. Nous présentons dans ce chapitre la couche médiane, en dé-crivant l’architecture distribuée.
5. 1. 2. Une philosophie tout client-serveur.
L’architecture est de type client-serveur, tout en étant fortement hiérarchisée. Chaque machine comportant un ou plusieurs modèles est gérée par un serveur de modèles. Toutes les machines sont gérées par un serveur global qui permet à un ou plusieurs chefs d’orchestre d’utiliser les différents éléments de l’environnement pour exécuter une ses-sion.

Mémoire de thèse
Page 104 sur 166
Nous avons donc deux types de serveurs : les serveurs globaux et les serveurs de mo-dèles. Les chefs d'orchestre (fig. 5.2) sont les clients et s’appuient sur les différents ser-veurs pour mener une session à terme.
Machine maître
BUS
Machine esclave 2Machine esclaveMachine esclave 1
Encapsulation 4
Serveur de modèle 3
Encapsulation 2
Serveur global
Chef d’orchestre 1
Chef d’orchestre 2
Serveur de modèles 1 Serveur de modèles 2
Encapsulation 1 Encapsulation 3
Catalogue de modèles
Figure 5.2 : Un exemple de configuration des différents éléments : le serveur global enregistre les serveurs de modèles et instancie les chefs d’orchestre. Les serveurs de modèles sont commandés par les chefs d’orchestre et instancient les encapsulations. Les chefs d’orchestre demandent les encapsulations aux serveurs de modèles et pilotent les encapsulations.
La machine comportant le serveur global est l’ordinateur maître de la distribution. Les autres ordinateurs utilisés sont des ordinateurs esclaves : ils sont sous le contrôle du maî-tre. Cette hiérarchie est représentée en figure 5.3.
Ordinateurmaître
Ordinateuresclave 1
Ordinateuresclave 2
Ordinateuresclave 3
Gestion généraleSupport des chefs d’orchestreInterface de contrôle
Gestion localeSupport des encapsulations
Figure 5.3 : Hiérarchie de l’environnement Yehudi.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 105 sur 166
5. 2. Gestion locale
Sur chaque machine comportant un ou plusieurs modèles, un serveur de modèle s’occupe de la gestion locale, avec l’aide d’outils dédiés, pour mettre à disposition les modèles installés.
5. 2. 1. Présentation générale
L’adoption d’une approche tout modèle, des modèles encapsulés aux modèles utilitai-res, de facilité ou d’IHM, nous a amené à concevoir un système fortement modulaire. De ce fait, les modèles sont tous gérés par des serveurs de modèles, où qu’ils soient. Ces der-niers sont des éléments fortement communicants, en vue d’un usage réseau. Chaque ma-chine esclave comporte ainsi des éléments communs lui permettant de s’insérer dans l’architecture générale.
La figure 5.4 représente les éléments d’une machine esclave lorsque aucune session n’utilise la machine. Sur chaque machine, un paquetage doit donc être installé, compor-tant un ensemble minimal assurant la gestion locale : le serveur de modèles, l’ensemble des pilotes disponibles et des modèles de gestion.
Les modèles de gestion sont des outils conçus comme des modèles utilitaires. Ils of-frent des traitements nécessaires au système, comme la lecture d’un fichier, la récupéra-tion d’informations concernant une machine, l’extraction d’une partie d’un fichier XML. Ils ne sont pas à l’heure actuelle renseignés par un méta-modèle et donc utilisable par un utilisateur.

Mémoire de thèse
Page 106 sur 166
Modèlede gestion
Modèlede gestion
Modèlede gestionModèle
de gestion
Modèlede gestion
Modèlede gestion Partie
Dédiée
PartieDédiée
PartieDédiée
Serveur demodèles dédié
BUSPartieDédiée
Modèlede gestion
ouModèle
de gestion
Méta-modèleMéta-modèleMéta-modèle
Figure 5.4 : Architecture d’une machine esclave en attente
Cette figure montre un serveur de modèles en attente, les méta-modèles qu’il peut lire ainsi que les modèles de gestion à sa disposition. Pour garder une architecture de base la plus générale possible, un serveur de modèles général a été écrit, capable d’utiliser tous les éléments d’une machine mais accessible seulement de manière locale. Ce serveur gé-néral est hérité pour écrire des serveurs de modèles dédiés à un protocole réseau particu-lier, par exemple Java RMI.
Selon le protocole utilisé, les modèles sont gérés directement par le serveur de modèle, ou transformés en objets distribués. Dans ce dernier cas, ils sont alors gérés directement par le système choisi, par exemple CORBA ou Java RMI. Pour des raisons pratiques, un objet distribué doit être écrit spécifiquement pour le système choisi. Dans ce cas là, une partie spécifique au protocole rajouté est rajoutée à chaque modèle. Cette partie est une simple interface entre le modèle et le système d’objets distribués.
Le serveur de modèles gère les éléments de sa machine selon les demandes de la ma-chine maître. Les modèles de gestion lui permettent certaines opérations supplémentaires, comme par exemple des opérations fichiers nécessaires pour choisir et lire un méta-modèle.
Pour son usage au sein de l’environnement, le serveur de modèles supporte toutes les opérations nécessaires à la gestion des encapsulations. Les principales étapes sont sché-matisées en figure 5.5.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 107 sur 166
Serveur demodèle
BUS
Partie logiquePartie typologique
Partie physique
Méta-modèle
Pilote APilote APilote BPilote A
Pilote A ouMC
MCSpooler
13
23
1
54
4
Figure 5.5 : L’enregistement d’un méta-modèle et la génération d’une encapsulation en cinq étapes.
Le serveur de modèles est tout d’abord chargé d’enregistrer les méta-modèles (1). Pour cela, il envoie la partie logique à la machine maître qui va mettre à jour le catalogue. Lorsqu’une demande de création d’encapsulation arrive (2), le serveur utilise la partie ty-pologique du méta-modèle pour chercher le bon pilote (3). Il utilise la partie logique pour créer et paramétrer le module communicant avec ou sans spooler (4). Finalement, il transmet la partie physique au pilote pour permettre à ce dernier de s’adapter au mo-dèle (5).
Cet enchaînement ne montre pas le cas d’un modèle critique déjà utilisé. Dans ce cas, le pilote et le spooler sont conservés alors que le module communicant créé est mis en at-tente.
Les deux éléments principaux des machines esclaves sont donc les encapsulations et le serveur de modèles.
5. 2. 2. Les encapsulations
Les encapsulations sont vues par leur module communicant. Le module communicant est la partie devant répondre à l’interface donnée pour un modèle homogène. Il se charge d’effectuer le lien entre les demandeurs, extérieurs, et le pilote de modèle. Cet objet, lié directement au pilote, stocke ses données, en cas de mise en attente et les fournit ensuite au demandeur. Il donne également des informations sur son fonctionnement et celui du pilote.

Mémoire de thèse
Page 108 sur 166
Les encapsulations, comme les modèles utilitaires, peuvent également comporter une partie spécifique au protocole réseau choisi, qui complète le module communicant.
5. 2. 3. Les serveurs de modèles
Un serveur de modèles est un outil fortement communicant. Il est a priori exécuté ma-nuellement sur la machine à intégrer et se charge de s’enregistrer au près de la machine maître. Cet enregistrement se fait en fonction du protocole choisi, mais en envoyant des informations communes : nom de la machine (URL), système d’exploitation, processeurs, utilisateur, emplacement de Java, … Ces informations sont fournies par un modèle de gestion.
Le serveur de modèles supporte différentes fonctionnalités permettant l’utilisation de sa machine dans l’environnement :
- le choix et l’enregistrement d’un méta-modèle, via des outils adaptés à la distribu-tion et des modèles utilitaires de gestion de fichiers,
- l’instanciation et l’exécution de modèles de gestion. La décomposition de traite-ments de base en différents modèles de gestion permet d’ajouter ou d’améliorer des fonctions sur l’ensemble des machines sans avoir à réécrire les serveurs de modèle et donc sans changer la configuration d’une machine.
- l’instanciation, l’exécution et la gestion des encapsulations. Le serveur de modèles garde la liste des encapsulations, des pilotes et des spoolers créés et répond aux sol-licitations du chef d’orchestre. Le tableau 1 présente quelques échanges prévus en-tre un serveur de modèles et un chef d’orchestre.
Chef d’orchestre Serveur de modèles Désire la création d’un modèle
okForModel ( nom du modèle, identification obtenue): le modèle a été généré. Son identification est passée en paramètre.
notOkForModel ( identification voulue, problème) : le modèle n’a pas pu être généré
askForModel (nom du modèle, identification voulue): méthode permettant la génération d’un modèle selon les contraintes.
Si la création à réussi
Sinon

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 109 sur 166
Chef d’orchestre Serveur de modèles Désire contrôler l’état des modèles d’une machine
modelsAre(états) : fournit un tableau d’états des modèles.
howAreModels(identification de session) : donne l’état des modèles.
Désire relâcher un modèle
workingModel (identification du modèle) : le modèle est occupé et ne peut être relâché.
okModelReleased (identification du modèle) : le modèle a été relâché.
modelNotReleased (identification du modèle) : le modèle n’a pas pu être relâchée pour une raison inconnue.
releaseModel (identification du modèle): tente de tuer une encapsulation. Si cette dernière est occupée, ne tente rien et averti le chef d’orchestre.
Si le modèle a été relâché
Si l’encapsulation ne peut pas être tuée pour une raison inconnue
Désire tuer un modèle
okModelKilled (idModel) : le modèle a été tué.
modelNotKilled (idModel) : le modèle n’a pas pu être tué pour une raison inconnue.
killModel (identification du modèle) : tue sans condition une encapsulation.
En cas de succès.
Si l’encapsulation ne peut pas être tuée pour une raison inconnue..
Tableau 1 : Quelques exemples d’échanges entre un chef d’orchestre et un serveur de modèles.

Mémoire de thèse
Page 110 sur 166
Bien que le serveur de modèle ignore l’identité de la session, tous les modèles créés ou encapsulés ont un identifiant unique qui contient l’identifiant de session. Ainsi, est-il pos-sible de filtrer les modèles utilisés pour isoler les différentes sessions. De cette façon, un serveur de modèles est capable de tuer tous les éléments d’une session.
Ainsi, chaque machine esclave offre un ensemble de fonctionnalités suffisantes pour mettre ses modèles à disposition. La machine maître s’occupe de gérer cet ensemble.
5. 3. Gestion globale
La machine maître s’occupe du contrôle général de l’ensemble des constituants de l’architecture. Ce contrôle est d’abord effectué par le serveur global, qui enregistre les serveurs de modèles et les nouveaux modèles, et crée les chefs d’orchestre. Ces derniers utilisent les informations fournies par le serveur global pour exécuter leur session.
5. 3. 1. Présentation générale
La gestion globale consiste à assurer l’intégration de tous les éléments distribués, en tenant à jour le catalogue de modèles. La figure 5.6 montre les différents éléments pré-sents sur la machine maître lorsque aucune session n’est en cours. Le serveur global gère l’intégralité des éléments et s’occupe du catalogue de modèles. Les serveurs de modèles sont enregistrés grâce à des enregistreurs dédiés à un protocole réseau, qui attendent que les nouveaux serveurs de modèles se signalent. Lorsqu’un nouveau serveur de modèles est accepté, un proxy adapté au protocole réseau choisi est créé et lui est rattaché. Le ser-veur de modèles distant sera toujours appelé via le serveur proxy qui lui est dédié. Un ou-til de gestion de fichiers distants est complémentaire des outils des machines esclaves et permet des manipulations distantes, comme la recherche et le rajout de méta-modèles. Un serveur de modèles est également implanté sur la machine maître. Il est utilisé pour gérer les modèles locaux, principalement utilitaires, d’IHM ou de facilité, mais également en-capsulés, si besoin est.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 111 sur 166
Serveur Global
Proxy deserveur demodèles 1
Proxy deserveur demodèles 2
Proxy deserveur demodèles 3
Cataloguede modèles
EnregistreurProtocole 1
EnregistreurProtocole 2
BUS
Outil XML
Outil Fichier
Outil XMLOutil XML
Outil FichierOutil Fichier
Serveurde
modèles
Gestionde fichiers
distants
Figure 5.6 : Les éléments de base de la machine maître.
Pour l’exécution d’une session, le serveur global instancie un chef d’orchestre, lequel
s’occupe de l’exécution d’un schéma. La figure 5.7 schématise une machine maître s’occupant d’une session simple. Un chef d’orchestre lit un schéma sous forme XML, le transcrit sous forme Java en utilisant un outil séparé pour gérer les éventuelles extensions. Il a également la possibilité d’appeler un médiateur pour réaliser les vérifications séman-tiques. Pour cela, ce dernier dispose d’une ou de plusieurs ontologies ainsi qu’une ou plu-sieurs librairies.
Serveur Global
Proxy deserveur demodèles 1
Proxy deserveur demodèles 2
Proxy deserveur demodèles 3
Cataloguede modèles
BUS
Outil XML
Outil Fichier
Outil XMLOutil XML
Outil FichierOutil Fichier
Serveurde
modèles
Chefd’orchestre
SchémaXML
Schéma« Java »
Gestiondes extensions
TimerMédiateur
Ontologie Librairie
Figure 5.7 : Les éléments de la machine maître lors d’une session.

Mémoire de thèse
Page 112 sur 166
Pour mettre en place une session, le chef d’orchestre communique avec les serveurs de modèles distants via leurs proxies et directement avec le serveur de modèles local. Il uti-lise le catalogue de modèles pour choisir le serveur à appeler. Lors de l’exécution, il uti-lise un modèle très particulier : le timer, qui appelle le chef d’orchestre à intervalle régu-lier pour permettre une gestion temporelle.
La gestion globale s’articule ainsi autour du serveur global et des chefs d’orchestre.
5. 3. 2. Le serveur global
Le serveur global est l'élément minimal de notre environnement. Il a la connaissance de son univers et peut commander à tous les autres acteurs. Il crée les chefs d’orchestre ainsi que les proxies de serveurs de modèles, les enregistreurs et le serveur de modèles local. Il met à la disposition des chefs d’orchestre l’ensemble des informations utiles : les serveurs de modèles disponibles, l’emplacement du catalogue.
Le rôle du serveur global est assez limité. Il sert surtout à la réunion de tous les élé-ments du système et s’appuie sur différents outils : les proxies de serveurs de modèles, les enregistreurs. Il laisse les gestions de sessions aux chefs d’orchestre.
5. 3. 3. De la couche logique à la couche médiane : le chef d'orchestre
Le chef d’orchestre est l’acteur majeur d’une session. Il commande les modèles ho-mogènes de la couche médiane selon la lecture du schéma logique. Le serveur global ins-tancie le chef d’orchestre et lui offre l’accès au catalogue de modèles. Selon le schéma logique, en utilisant le catalogue de modèles pour localiser les modèles voulus, le chef d’orchestre demande des encapsulations, des modèles utilitaires et de facilité aux diffé-rents serveurs de modèles. Un modèle d’IHM doit toujours être présent sur la machine maître, parce qu’il est impossible de faire circuler l’interface graphique.
Pour exécuter une session, le chef d’orchestre suit le schéma logique pour commander les différents modèles. Il utilise également un timer pour faire évoluer le schéma logique. Il compare alors les différents temps d’attente avec les informations apportées par le mé-ta-modèle et réagit en fonction. Les éléments commandés ont une exécution indépendante du chef d’orchestre. Ainsi, si un dépassement de temps survient, le chef d’orchestre inter-roge l’élément fautif et réagit en fonction de la réponse. S’il n’obtient pas d’information, il interroge le serveur de modèles responsable ou le serveur global, en dernier recours.
Pour des raisons pratiques, nous devons préciser que le chef d’orchestre accède rare-ment directement aux encapsulations. Chaque proxy associé à un serveur de modèles of-fre également une vue « locale » de chaque encapsulation gérée, en générant des objets que le chef d’orchestre utilise directement mais qui font appel aux encapsulations distri-
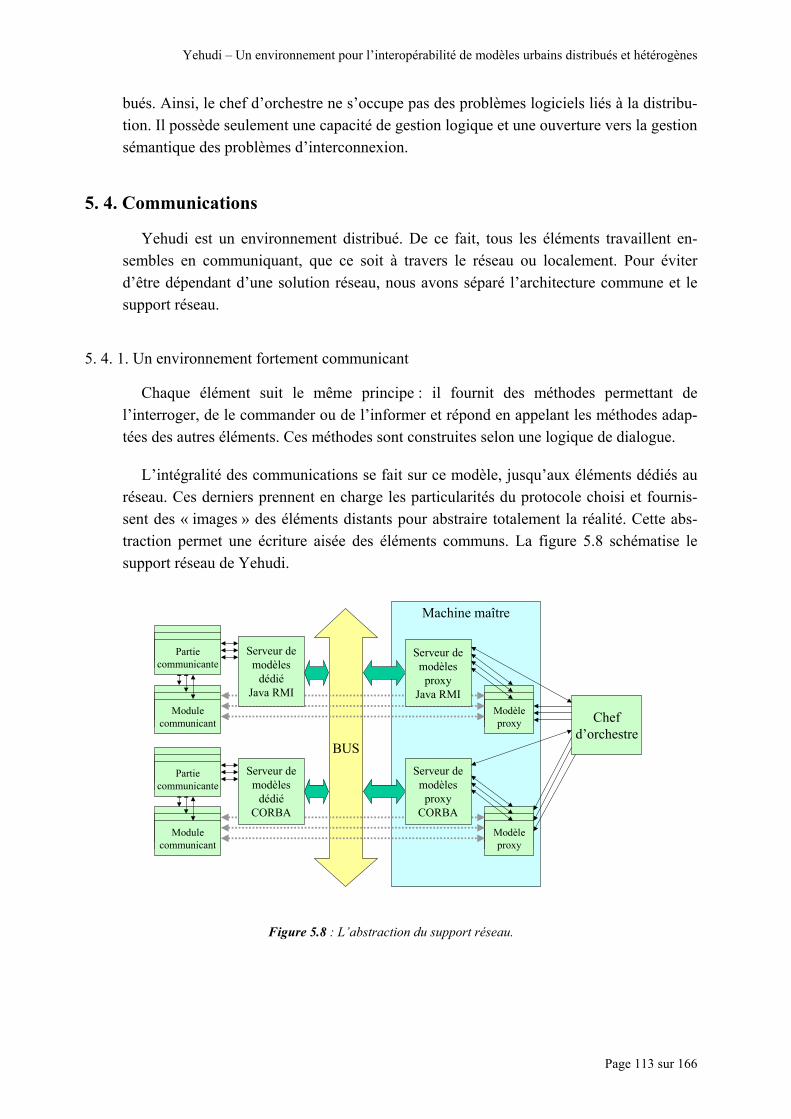
Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 113 sur 166
bués. Ainsi, le chef d’orchestre ne s’occupe pas des problèmes logiciels liés à la distribu-tion. Il possède seulement une capacité de gestion logique et une ouverture vers la gestion sémantique des problèmes d’interconnexion.
5. 4. Communications
Yehudi est un environnement distribué. De ce fait, tous les éléments travaillent en-sembles en communiquant, que ce soit à travers le réseau ou localement. Pour éviter d’être dépendant d’une solution réseau, nous avons séparé l’architecture commune et le support réseau.
5. 4. 1. Un environnement fortement communicant
Chaque élément suit le même principe : il fournit des méthodes permettant de l’interroger, de le commander ou de l’informer et répond en appelant les méthodes adap-tées des autres éléments. Ces méthodes sont construites selon une logique de dialogue.
L’intégralité des communications se fait sur ce modèle, jusqu’aux éléments dédiés au réseau. Ces derniers prennent en charge les particularités du protocole choisi et fournis-sent des « images » des éléments distants pour abstraire totalement la réalité. Cette abs-traction permet une écriture aisée des éléments communs. La figure 5.8 schématise le support réseau de Yehudi.
BUS
PartiecommunicantePartiecommunicante
ModulecommunicantModulecommunicantModulecommunicant
Partiecommunicante
PartiecommunicantePartiecommunicante
ModulecommunicantModulecommunicantModulecommunicant
Partiecommunicante
Machine maître
ModèleproxyModèleproxyModèleproxy
ModèleproxyModèleproxyModèleproxy
Serveur demodèles
dédiéJava RMI
Serveur demodèles
proxyJava RMI
Serveur demodèles
dédiéCORBA
Serveur demodèles
proxyCORBA
Chefd’orchestre
Figure 5.8 : L’abstraction du support réseau.

Mémoire de thèse
Page 114 sur 166
Dans la figure présentée, deux serveurs de modèles apportent un support de Java RMI et de CORBA. La machine maître a deux serveurs proxies en correspondance, qui offrent eux-mêmes des « modèles proxies ». Ces derniers sont pilotés par le chef d’orchestre en répercutant chaque demande au modèle distant. Il n’ont pas a priori de réelle capacité de proxy.
Cette solution est particulière et s’appuie sur un certain nombre d’hypothèses.
5. 4. 2. Hypothèses et choix
Encore une fois, nous avons choisi d’adapter au mieux notre environnement aux carac-téristiques des modèles urbains. Cela nous a amené à émettre deux hypothèses. D’une part, nous pensons qu’en général le temps de calcul d’un modèle est supérieur au temps nécessaire à la circulation des données sur le réseau, quel que soit le protocole choisi. De plus, nous considérons que le volume de données est en général assez faible. Cette hypo-thèse s’appuie sur notre connaissance des modèles, la plupart génèrent des données d’une taille raisonnable, mais également sur les limites des réseaux les plus communs : il n’existe pas de moyen adapté pour faire circuler des grands volumes de données dans le cadre d’une interconnexion. En effet, de telles circulations génèrent une charge réseau très importante et il convient donc de les limiter au mieux.
Nous avons donc choisi d’apporter une solution qui privilégie la robustesse des échan-ges. Notre solution s’appuie ainsi sur une indépendance vis-à-vis des protocoles choisis, ce qui ne permet pas d’avoir des échanges optimisés mais offre la possibilité de choisir le protocole le plus adapté : peu communicant mais gérant de grands volumes de données, par FTP par exemple, par boîte aux lettres pour éviter les pare-feux, par objets distribués pour une meilleure rapidité, …
5. 4. 3. Deux exemples : Java RMI et e-mails
Pour illustrer le support de la distribution, nous présentons ici deux exemples.
Tout d’abord, la figure 5.9 schématise l’utilisation de Java RMI.
Java RMI est le système d’objets distribués standard de Java. Il est le support réseau par défaut de Yehudi. C’est un système simple qui utilise un système d’interfaces pour permettre l’utilisation de méthodes d’objets distants. Le client utilise une interface qui correspond à l’objet distant, les serveurs Java s’occupent du codage/décodage des objets circulant sur le réseau, si ceux-ci en ont la capacité.
À première vue, c’est un système assez basique, qui nécessite l’enregistrement d’un objet distant en deux temps, en copiant d’abord les interfaces nécessaires du côté du ser-veur et du client puis en enregistrant l’objet avec RMIregistry, qui est en quelque sorte le

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 115 sur 166
serveur chargé de mettre à disposition les objets qu’il enregistre. Il faudra ensuite gérer les objets distribués en utilisant les possibilités de Java. Pour une meilleure intégration, le RMIregistry peut être exécuté à partir d’une classe.
Pour permettre l’utilisation d’objets qui ne sont pas écrits spécifiquement pour Java RMI, il est possible de gérer la circulation des interfaces, car Java ne charge une classe qu’à la demande. Il est également possible d’utiliser des objets intermédiaires, implémen-tant les interfaces distribuées, qui vont correspondre des objets utilisant un autre système d’interfaces. Yehudi utilise cette dernière solution, en utilisant le méta-modèle pour ca-ractériser des éléments offrant des interfaces uniformes.
RMIInterface réseau serveur
Interface réseau client
BUS
Appel de méthode
Objet distribuéStructures composés
Objets IHM
Firewall
Firewall
Figure 5.9 : Utilisation de Java RMI : schématisation, possibilités et impossibilités.
Comme le schématise la figure 5.9, l’utilisation d’une technologie d’objets permet des appels de méthodes virtuellement directs. Nous pouvons donc utiliser des structures com-posées sans trop de difficultés. En revanche, il n’est pas possible de faire circuler des ob-jets IHM, nous ne pouvons donc pas avoir de modèles d’IHM qui s’exécuteraient à dis-tance tout en s’affichant sur la machine maître. Ceci s’explique par la très grande charge du réseau engendrée par de telles opérations, mesurable par exemple par l’usage d’un serveur X distant. Un problème plus grand concerne la difficulté inhérente aux technolo-gies objets quant à la sécurité : permettre un usage réparti présente un risque. Ainsi, les pare-feux, ou firewalls, interdisent souvent la circulation d’objets distribués.
Le support de communications par e-mails permet de contourner ce problème. La fi-gure 5.10 présente les éléments nécessaires pour cette communication.

Mémoire de thèse
Page 116 sur 166
Serveur de modèles
Proxy de serveur de modèle
Client POP3
Client SMTP
BUS
Envoi de requête
Objet distribué
Firewall
FirewallClient POP3
Client SMTP
Gestionnaire d’e-mails
Résultat
Boîteau lettreserveur
Boîteau lettre
client
Figure 5.10 : Les différents éléments nécessaires à une communication par e-mail.
Un appel pour un objet distant se fait alors, au niveau du proxy du serveur de modèles, par un envoi de requêtes sous la forme d’e-mail. Le résultat sera également renvoyé sous la forme d’un e-mail. Les figures suivantes détaillent les différentes étapes intermédiaires.
Client POP3
Client SMTP
Envoi de requête
Modèle distant
Client POP3
Client SMTP
Serveur de modèles
Résultat
Boîteau lettreserveur
Boîteau lettre
client
RequêteXML
(a)
Client POP3
Client SMTP
Envoi de requête
Modèle distant
Client POP3
Client SMTP
Serveur de modèles
Résultat
Boîteau lettreserveur
Boîteau lettre
client
RequêteXML
(b)
Figure 5.11. (a) et (b) : L’envoi et la réception de la requête.
La demande est envoyée dans un e-mail en syntaxe XML (a). Elle est reçue par la boîte aux lettres du serveur. À intervalles réguliers, le serveur de modèles dédié lit sa boîte aux lettres et rapatrie les e-mails qui lui sont destinés (b).
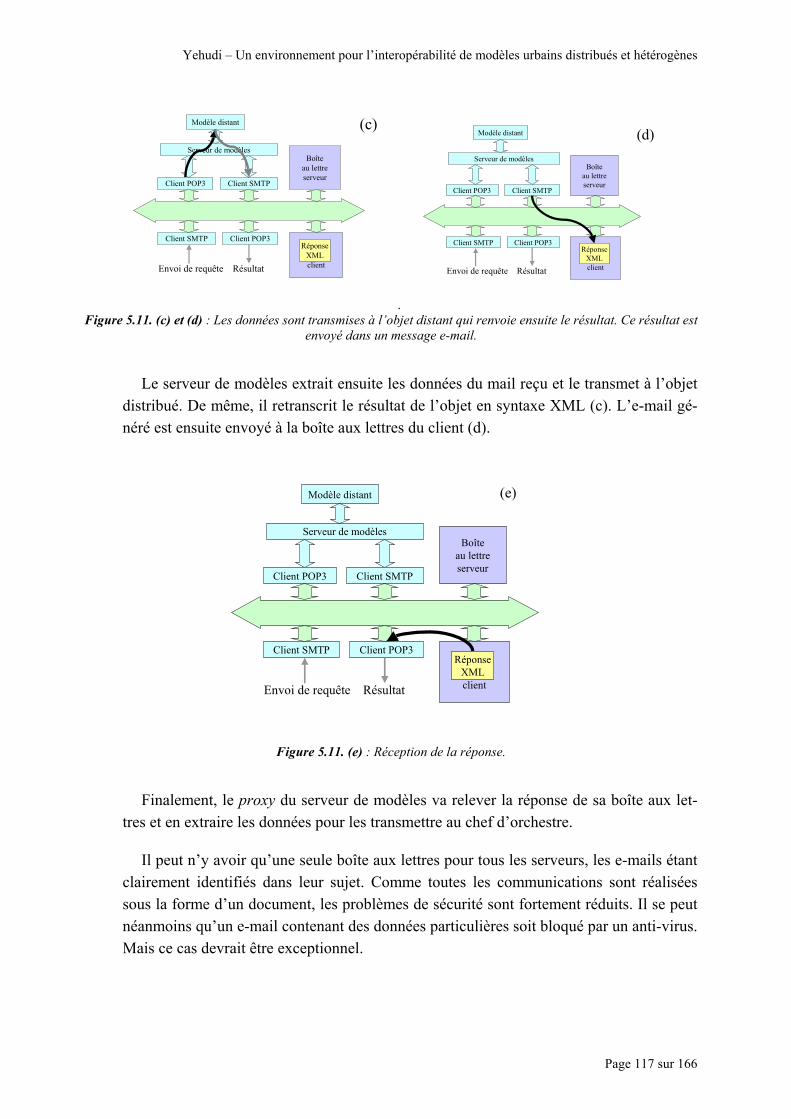
Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 117 sur 166
Client POP3
Client SMTP
Envoi de requête
Modèle distant
Client POP3
Client SMTP
Serveur de modèles
Résultat
Boîteau lettreserveur
Boîteau lettre
client
RéponseXML
(c)
.
Client POP3
Client SMTP
Envoi de requête
Modèle distant
Client POP3
Client SMTP
Serveur de modèles
Résultat
Boîteau lettreserveur
Boîteau lettre
client
RéponseXML
(d)
Figure 5.11. (c) et (d) : Les données sont transmises à l’objet distant qui renvoie ensuite le résultat. Ce résultat est
envoyé dans un message e-mail.
Le serveur de modèles extrait ensuite les données du mail reçu et le transmet à l’objet distribué. De même, il retranscrit le résultat de l’objet en syntaxe XML (c). L’e-mail gé-néré est ensuite envoyé à la boîte aux lettres du client (d).
Client POP3
Client SMTP
Envoi de requête
Modèle distant
Client POP3
Client SMTP
Serveur de modèles
Résultat
Boîteau lettreserveur
Boîteau lettre
client
RéponseXML
(e)
Figure 5.11. (e) : Réception de la réponse.
Finalement, le proxy du serveur de modèles va relever la réponse de sa boîte aux let-tres et en extraire les données pour les transmettre au chef d’orchestre.
Il peut n’y avoir qu’une seule boîte aux lettres pour tous les serveurs, les e-mails étant clairement identifiés dans leur sujet. Comme toutes les communications sont réalisées sous la forme d’un document, les problèmes de sécurité sont fortement réduits. Il se peut néanmoins qu’un e-mail contenant des données particulières soit bloqué par un anti-virus. Mais ce cas devrait être exceptionnel.

Mémoire de thèse
Page 118 sur 166
5. 5. Interactivité
Suivant le principe d’éléments communicants, nous avons souhaité apporter une inter-face ergonomique et extensible. Pour cela, nous avons défini un serveur graphique qui s’appuie sur les fonctionnalités du système.
5. 5. 1. Adoption d’un serveur graphique
Pour permettre la mise au point et le suivi d’une session, une interface graphique est utilisable sur la machine maître. Elle doit permettre l’édition d’un schéma, le contrôle de l’exécution d’une session et centraliser les données générées par les modèles pour offrir leur affichage.
L’interface graphique est gérée par un ou plusieurs serveurs graphiques. Celui-ci fait le lien entre les éléments graphiques et le reste du système : il commande un chef d’orchestre pour l’exécution d’une session. La figure 5.11 présente une machine maître comportant un serveur graphique.
Serveur Global
Cataloguede modèles
Chefd’orchestre
SchémaXML
Schéma« Java »
ServeurGraphique
Conteneurgraphique
Listede modèles
Affichaged’information
Schémainteractif
Tableaud’entrée/sortie
Figure 5.12 : Intégration d’un serveur graphique.
Le serveur graphique est indépendant du chef d’orchestre et manipule seul le catalogue et le schéma pour permettre l’édition du schéma avant l’exécution d’une session. Il com-munique avec des éléments graphiques, les renseigne et répond à leur sollicitations. Ain-si, le serveur graphique permet de créer ou de modifier un schéma avant son utilisation. Ensuite, il appelle un chef d’orchestre pour l’exécution d’une session et communique avec ce dernier pour permettre une totale interaction : les éléments graphiques peuvent contrôler l’exécution d’une session.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 119 sur 166
5. 5. 2. Fonctionnement
Le serveur graphique gère les éléments graphiques qui se placent dans un conteneur graphique. Ces éléments sont tous, excepté la barre de menu, des modèles d’IHM particu-liers. La capacité de cette interface est basée sur le support du « drag’n’drop » et sur de nombreuses communications : chaque élément dispose d’une méthode lui indiquant qu’un changement est survenu. Il peut alors interroger le serveur graphique pour avoir des détails. Lors d’une action d’un utilisateur, l’élément informe le serveur graphique qui peut modifier ses informations : concernant la structure du schéma, sur l’élément sélec-tionné, … Lorsque ces changements concernent le chef d’orchestre, l’information lui est transmise.
5. 5. 3. Utilisation d’un modèle composé
Un schéma logique peut comporter un modèle composé, c’est-à-dire une intercon-nexion considérée comme un modèle. Dans ce cas, un chef d’orchestre est créé pour exé-cuter l’interconnexion composant ce modèle. Si l’utilisateur souhaite vérifier l’exécution du modèle composé, un serveur graphique est créé pour afficher cette sous-session. Il y a toujours un seul chef d'orchestre par schéma et également un seul serveur graphique.
5. 6. Usage de Java et d’XML
L’architecture présentée a été construite en prévoyant l’adoption de deux technologies complémentaires : Java et XML. Nous présentons dans ce paragraphe les raisons de ce choix.
5. 6. 1. Particularités de notre solution
Notre solution s’articule sur deux axes particuliers. Elle est d’une part orientée réseau, s’appuyant sur des invocations dynamiques, sur des propriétés d’introspection et sur l’indépendance générale vis à vis du système et du réseau. D’autre part, elle est orientée document, avec des documents fortement mais simplement structurés. Elle se base sur de nombreux échanges de données et de méta-données, lesquelles sont à la destination du système mais également des utilisateurs et des concepteurs.
5. 6. 2. Java
Java est un langage objets s’inspirant de Smalltalk, de Scheme 84 mais principalement de C++, avec un typage plus fort et un aspect objet plus marqué. Les améliorations les plus significatives sont l’usage de formats de données figés et standards, la disparition de l’héritage multiple, source de confusion, au profit des interfaces, élégantes et efficaces et l’apport systématique et standard de librairies très complètes et de haut niveau gérant des

Mémoire de thèse
Page 120 sur 166
domaines vastes : les collections d’objets, la gestion du temps, le multi-threading, la ré-partition, l’IHM, les fonction sonores, graphiques en 2D et 3D, ...
Mais la caractéristique principale consiste en l’usage d’une machine virtuelle, Java Virtual Machine. Une classe Java est compilée dans un format particulier, le byte-code, qui sera exécuté exclusivement par la machine virtuelle Java. Il est néanmoins possible de compiler définitivement ou à la volée une classe Java en format assembleur classique. Le passage par une machine virtuelle offre deux avantages décisifs :
- pour passer d’une machine à une autre, seule la machine virtuelle et les méthodes de bas niveaux, nommées natives, doivent être réécrites. Les méthodes natives sont le plus souvent écrites en C++,
- le byte-code est le reflet d’une classe et s’auto-décrit dans la plupart des cas, sauf souhait inverse à la création de la classe. Ainsi, une classe peut s’utiliser de manière dy-namique, permettant bien sûr les instanciations mais autorisant également d’être utilisée sans être connue a priori, car pouvant être retrouvée dynamiquement, par son nom ou par une exploration des classes disponibles. Les classes héritées, les interfaces implémentées et les méthodes offertes sont également décrites.
De plus, l’interface JNI, Java Native Interface, permet à des classes Java d’utiliser des méthodes natives à un système, comme précisé auparavant, mais également à des pro-grammes non-Java d’utiliser les classes Java et de profiter également du dynamisme of-fert par l’usage de la JVM.
Sun Microsystem est un acteur majeur des technologies liées aux réseaux, par ses ma-chines et ses solutions logicielles. Java ne déroge pas à la règle et offre un support effi-cace du réseau. Non seulement Java supporte bien les différents services les plus connus, des sockets à la technologie CORBA, mais il offre également sa propre technologie d’objets distribuées, Java Remote Methode Invocation, Java RMI, moins performante et complète mais simple à mettre en oeuvre et souple. Java s’accommode également de nouvelles technologies développées autour de Java RMI, telles que JINI ou les EJB.
Sans rentrer dans le détail de ces technologies, il nous paraît important de dire que l’intérêt de Java pour la distribution des objets n’est pas tant l’adoption de telle ou telle technologie de répartition mais bien l’abstraction système offerte par la JVM, qui permet d’exécuter une classe Java sur tout système. Quel que soit le moyen de communication, tous les acteurs sont dans le même monde et non dans différents mondes dialoguant au-tour d’un même protocole. Ainsi, s’il est toujours possible de s’échapper du monde Java, soit localement par JNI ou par l’usage de protocoles réseaux tels les sockets ou http, il est possible et souvent avantageux de regrouper toutes les machines dans un monde Java uni-forme et cohérent.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 121 sur 166
5. 6. 3. XML
Nous avons déjà présenté XML dans le chapitre III. Sans revenir sur sa présentation, nous pouvons dire qu’XML offre l’avantage d’être un langage conçu pour définir des do-cuments tout en étant suffisamment cohérent et structuré pour permettre des traitements automatiques. La libre définition de sa structure offre la possibilité de décrire l’intégralité des données et des méta-données avec la même syntaxe.
5. 7. Parallélisme et usage multi-session
Pour conclure la présentation de l’architecture, nous présentons le parallélisme offert et l’usage multisession de l’environnement.
5. 7. 1. Parallélisme de l’environnement
L’environnement offre un véritable parallélisme en s’appuyant sur des communica-tions non bloquantes. Pour cela, les processus bloquants sont isolés dans un processus lé-ger et un chef d’orchestre ne se bloque pas pour attendre une réponse.
5. 7. 2. Usage multisession
L’usage multisession de Yehudi est facilité par le mécanisme des encapsulations. Comme un module communicant, muni d’un identifiant unique, est toujours instancié pour correspondre à un modèle logique, plusieurs chefs d’orchestre peuvent demander plusieurs instances sans aucun problème. Néanmoins, l’utilisation de modèles critiques, avec une mise en file d’attente par un spooler, peut entraîner des interblocages ou des temps d’attente très longs.
Un chef d’orchestre est toujours sur une machine comportant un serveur global, car ce dernier génère le chef d’orchestre et lui fournit les informations lui permettant de travail-ler. Pour ne pas limiter l’usage d’un chef d’orchestre à une seule machine, Yehudi permet l’usage de plusieurs serveurs globaux. Leur gestion se fait sous forme de chaîne. Le pre-mier serveur créé est toujours le maître et renseigne les nouveaux arrivants en leur four-nissant toutes les informations dont il dispose : le catalogue de modèles, la liste des ser-veurs de modèles, et éventuellement la liste des sessions en cours. Ce serveur maître est le seul à pouvoir enregistrer un serveur de modèles, un nouveau chef d'orchestre, et donc une session, un modèle via un serveur de modèles ou un autre serveur global. Les autres serveurs doivent toujours en référer à lui pour toute demande d'enregistrement.
Lors de l’arrêt du serveur global maître, s’il est seul serveur global, il demande la fin de tous les serveurs de modèles. Sinon, il contacte les autres serveurs globaux dans l’ordre de chaînage et nomme le premier contacté comme nouveau maître avant de

Mémoire de thèse
Page 122 sur 166
s’arrêter seul. Un autre serveur global que le maître s’arrête seul après avoir informer le maître.
5. 8. Conclusion du chapitre
L’architecture présentée permet la réalisation d’un environnement complet et adapté aux contraintes qui nous étaient données. Elle met en valeur un point commun à toutes les architectures distribuées reposant sur des éléments hétérogènes répartis : le travail d’ingénierie est très grand. Nous présentons dans le chapitre VI notre implémentation mais nous verrons en conclusion que la possibilité d’intégrer des éléments quelconques sans compromis et en réduisant au minimum le travail d’ingénierie pour l’intégrateur de modèles nécessiterait une réflexion profonde sur la façon même de concevoir les logiciels et sur les fonctionnalités indispensables d’un système d’exploitation.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 123 sur 166
CHAPITRE VI IMPLÉMENTATION
Notre travail nous a amené à conceptualiser un environnement d’interconnexion de
modèles. Dans le cadre de cette thèse, nous présentons également un prototype qui inté-gre l’ensemble des principaux concepts définis. Dans ce chapitre, nous aborderons les spécifications de ce prototype puis l’implémentation effectuée. Finalement, nous parle-rons des évolutions futures.
6. 1. Spécifications
Le prototype développé doit permettre la validation des différents choix effectués. Pour cela, nous avons défini une spécification minimale.
6. 1. 1. Accéder aux modèles
Le prototype devra intégrer des encapsulations complètes et offrir quelques pilotes. Ainsi, nous avons voulu développer les trois parties de l’encapsulation : des pilotes, le spooler et le module communicant.
6. 1. 2. Gérer la distribution
Le prototype doit pouvoir gérer des systèmes différents et la distribution des modèles. Il utilisera un seul protocole réseau mais respectera l’architecture présentée pour ne pas être dépendant de la technologie choisie. L’ensemble des outils permettant une gestion répartie d’une session devra être présenté.
6. 1. 3. Une exécution robuste
L’exécution de la session doit être suffisamment robuste pour que le prototype soit uti-lisable dans des cas réalistes. En ce sens, les stratégies de base de gestion des problèmes devront être implémentées.
6. 1. 4. Un forte modularité
Le prototype sera développé par modules, en respectant exactement la conception et en suivant des interfaces imposées. Ainsi, chaque module devrait pouvoir être amélioré sans devoir changer le reste du prototype.

Mémoire de thèse
Page 124 sur 166
6. 1. 5. Tout XML
Comme précisé dans la conception, l’ensemble des documents utiles, les méta-modèles, le catalogue, les schémas, les fichiers de configuration seront écrits en syntaxe XML. Cependant, Yehudi utilise des documents XML sans attributs, car leurs structures suit une arborescence avec liens non valués. Le prototype devra utiliser XML pour tous ces documents, les lire évidemment mais également les générer parfois.
6. 1. 6. Ergonomie
La conception de Yehudi s’est faite avec un soucis constant d’ergonomie. Nous pen-sons en effet que l’ergonomie est fortement corrélée à une conceptualisation cohérente. Une apparente simplicité n’est pas un défaut mais une preuve que le système a été clai-rement défini. Nous espérons que notre conception répond à ce souhait.
De même, l’abstraction effectuée par notre système ne doit se faire qu’en fournissant une vue correspondant à la réalité logique que nous avons voulu extraire. L’utilisateur, sans connaître les mécanismes qui permettent l’interconnexion, doit pouvoir appréhender sans problème la réalité exprimée par le mécanisme d’intégration et ainsi comprendre ce qu’il contrôle. Le prototype devra répondre au mieux à ces exigences.
6. 1. 7. Exemples d’utilisation
Pour illustrer l’usage possible de l’environnement proposé, nous présentons trois exemples caractéristiques.
1. Exécution simple
Pour une exécution simple, le prototype devra juste vérifier les interconnexions, ins-tancier les différents éléments, puis contrôler ces éléments pour tenter d’offrir le résultat attendu. Ce cas nécessite les mécanismes suivants :
- la gestion simple de la distribution, la plus transparente possible pour l’utilisateur,
- une interface évoluée, interactive et claire,
- un affichage cohérent des résultats.
2. Calibrage
L’environnement pourra être utilisé pour comparer des données calculées et des don-nées réelles. Cette possibilité est illustrée en figure 6.1. À gauche (a), un utilisateur a la possibilité d’utiliser deux modèles d’IHM pour calibrer le modèle comme il le désire. À droite (b), un modèle utilitaire extrait des données d’une base de données, lesquelles sont comparées avec les données générées par un modèle urbain. La comparaison est effectuée

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 125 sur 166
par un modèle de corrélation. Le résultat de la corrélation est utilisé pour calibrer le mo-dèle. Lorsque le modèle est calibré, le schéma peut être modifié pour utiliser le modèle.
Modèle
IHMOUT
IHMIN Modèle
AccèsJDBC
corrélation
(a) (b)
Figure 6.1 : Deux possibilités pour calibrer un modèle.
3. Mise au point d’une interconnexion
Finalement, l’usage d’un environnement dédié pour interconnecter des modèles per-met de modifier aisément le schéma d’interconnexion. Ainsi, est-il possible de mettre au point des modèles ou des interconnexions en modifiant un schéma existant pour exécuter plusieurs sessions.
6. 1. 8. Etude de cas : deux modèles réels
Il est intéressant d’expliquer comment deux modèles réels peuvent techniquement être intégrés. Pouc cela, nous considérons Townscope et EnviMet, présentés au chapitre I.
1. Townscope
Par son interactivité forte, Townscope peut être utilisé, sans être modifié, en bout de chaîne : créer des données réutilisables ou utiliser des données générées. Dans ces cas là, il serait pratiquement indépendant de Yehudi, car nécessitant une supervision directe, mais son méta-modèle permettrait une gestion automatique des données en entrée et en sortie.
Pour être intégré sans réécriture majeure, il peut être modifié selon deux axes :
- création de ports d’entrées-sorties, en CORBA par exemple,
- intégration complète à un environnement Java par Jlinker [Franz 2002] ou une autre technologie similaire.

Mémoire de thèse
Page 126 sur 166
Dans ces deux cas, il faudrait soit annihiler l’interface, soit la séparer nettement et permettre l’utilisation du modèle sans son interface, quitte à réintégrer l’interface par des modules Java, ce qui représente malheureusement un certain travail.
Ceci met en relief un fait bien établi : l’intégration « forte » d’un modèle conçu comme un produit fini nécessite le plus souvent une réécriture, l’intégration « faible » au minimum une description stricte. Et même dans le cas de modèles programmés de façon modulaire, tel Townscope, qui peuvent donc aisément être modifiés, l’effort d’intégration est suffisant pour n’être justifié que par des avantages réels. Un système d’intégration doit donc être abouti pour pouvoir être proposé et adopté par la communauté d’experts.
2. EnviMet
Comme nous l’avons déjà précisé, EnviMet s’utilise via des fichiers, ce qui peut per-mettre son utilisation de façon « batch ». Son intégration consiste à savoir lire et écrire les fichiers de données utilisés et à simplement exécuter le modèle. Les fichiers sont traités par rapport à des règles de séparation, de cycles, devant permettre de « remplir » des données de type précis. La figure 6.2 montre l’outil que nous développons pour assister l’extraction de données et leur réintégration. Les deux fenêtres en bas montrent à gauche le fichier à utiliser et à droite les données extraites. Différentes options permettent d’extraire les données à partir de différents critères : séparateurs, longueur de champ, po-sition des séparateurs (préfix, postfix, infix), distance des champs. Finalement, il est pos-sible d’ajouter les déclarations des données attendus, avec leur format. Lorsque l’utilisateur considère que les paramètres d’extraction sont bons, l’outil doit être capable de générer un fichier XML qui pourra être utilisé pour construire une partie physique de méta-modèle.
Figure 6.2 : Interface de l’assistant de « découpage » d’un fichier. Le fichier traité est donné pour l’exemple et ne correspond pas à un modèle urbain.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 127 sur 166
L’interface de cet outil montre le problème de cette intégration : l’extraction peut être complexe et reste limitée aux cas « prévus ».
6. 2. Prototype
Le prototype est une pré-version de l’ensemble de l’environnement Yehudi. Il est composé des différents serveurs présentés avec une utilisation de Java RMI pour la ges-tion de la distribution ainsi que d’un fonctionnement tout modèle avec encapsulation tel que décrit auparavant. L’ensemble des éléments présentés en chapitre V existent dans ce prototype, mais offrent des fonctionnalités minimales ainsi que peu ou pas de contrôle d’erreurs et ne gèrent pas les possibles problèmes liés à la distribution.
Ce prototype a toutefois été développé en vue d’un développement complet et il peut être finalisé sans changements majeurs.
6. 2. 1. L’encapsulation de modèles
L’encapsulation est liée aux méta-modèles. Pour ce faire, elle est séparée en plusieurs classes et utilise les propriétés introspectives de Java. Nous présentons maintenant le dé-tail de son implémentation.
1. L’interface des modèles
Les modèles ne sont connus que par leurs interfaces. Ils doivent implémenter au moins une des interfaces de modèles décrites au chapitre III. Ainsi, les méthodes définies par ces interfaces définissent l’interface du modèle.
2. L’utilisation de l’introspection : le « leveur » de modèles
Le pilote d’un modèle est retrouvé par son nom, en utilisant la réflexion de Java. Ain-si, une classe particulière, nommée RaiseModel, est chargée de « lever » le pilote, c’est à dire de retrouver ce dernier par son nom, vérifier l’existence des interfaces, instan-cier le pilote. RaiseModel implémente toutes les interfaces d’un modèle « complet » et les méthodes de ce « leveur » appellent les méthodes du pilote levé, quand elles sont im-plémentées. Ensuite, le module communicant utilise RaiseModel à la place du pilote. La figure 6.3 montre l’ensemble constituant un pilote.

Mémoire de thèse
Page 128 sur 166
RaiseModel SimpleModèle
Modèle
1 1
1
1
correspond
accède
Figure 6.3 : Les deux parties d’un pilote : le « leveur de modèle » et la partie spécifique, qui correspond au moins à l’interface « modèle simple ».
La classe « RaiseModel » doit s’assurer que n’importe quelle demande ne posera pas de problème. Elle est le seul élément entre le pilote, qui peut être écrit d’une manière relativement quelconque, et le système, qui attend un pilote stable et standard. Ainsi, Rai-seModel doit prévoir les différentes erreurs possibles.
3. Le spooler
Le spooler est une classe qui gère les accès à un pilote. Il travaille avec des référen-ces : celle du pilote, celle du module communicant utilisant le pilote et celles des modules en attente, stockées dans un vecteur. Quand un module communicant d’une encapsulation demande l’accès à un pilote, il fournit sa référence. Le spooler regarde si le pilote est li-bre :
- Si ce n’est pas le cas, la référence du module communicant est placée en fin de vec-teur et le spooler utilise une méthode du module communicant pour lui demander d’attendre,
- Si c’est le cas, il appelle une méthode du module communicant pour lui spécifier que le pilote est libre en lui donnant également la référence du pilote. Le pilote est alors considéré comme utilisé et le spooler garde la référence de ce module communicant. Quand le module communicant a terminé l’utilisation du pilote, il informe le spooler qui libère le premier module communicant du vecteur.
Le spooler est créé par le serveur local en même temps que le premier pilote et le pre-mier module communicant d’un modèle critique. Le module communicant d’un modèle critique est appelé avec la référence du spooler et est obligé de passer par le spooler, qui est ainsi lié pour pouvoir donner la main et recevoir ensuite le message de fin d’utilisation et libérer le pilote.
Le spooler peut également être forcé d’effectuer certaines opérations, comme le réar-rangement des modules en attente, sur ordre d’un chef d’orchestre.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 129 sur 166
4. Le module communicant
Le module communicant s’occupe des communications avec l’extérieur. Il implémente lui-aussi les quatre interfaces d’un modèle complet, en appelant toujours pour ces métho-des les méthodes du pilote sous-jacent. Pour ne pas être dépendant du protocole, il utilise une classe dédiée au protocole qui contient les mêmes méthodes dérivées des interfaces, spécialement écrites pour un protocole réseau particulier.
Le module communicant exécute toujours le pilote dans un processus nommé « exécutable », pour ne pas bloquer le système. À la fin de l’exécution, le processus in-forme le module qui va à son tour informer le serveur local et, si nécessaire, le spooler.
Si le modèle est critique, le module communicant copie systématiquement les données en transit, pour s’assurer de leur persistance malgré l’éventuelle mise en attente.
5. Vue générale
La figure 6.4. montre un diagramme de classe de l’encapsulation. L’encapsulation est en fait un paquetage composé de ses différents éléments.
Pilote
Spooler
Modulecommunicant
LèveModèle
SimpleModèle
ModèleExécutable
0..*
0..11
1
11
11
1
1 1
11
0..1accède à>
exécute>Thread
<g è re
à l ’ accè s a
Encapsulation
Figure 6.4 : Les différents éléments d’une encapsulation
6. Précisions techniques pour l’écriture d’un pilote
Le pilote est bien la partie critique du système. Java fonctionnant sur une machine vir-tuelle, qui sert de couche homogène au-dessus du système d’exploitation, les accès avec le monde extérieur à Java nécessite des ponts. Heureusement, il en existe un grand nom-

Mémoire de thèse
Page 130 sur 166
bre, de Java Native Interface (JNI) [Sun 1999], qui est intégré à Java pour assurer les liens entre la machine virtuelle et le système d’exploitation via C/C++ ou Fortran, à JA-COB [Adler 2001] pour lier Java à OLE/DCOM ou encore JLinker [Franz 2002] pour les liens avec Lisp (malheureusement avec le seul Lisp Allegro de Franz Inc.). Finalement, le support du réseau par Java permet également ce passage, du puissant CORBA aux soc-kets et datagrammes. La difficulté, à part dans le cas de CORBA et de JLinker, qui of-frent tous deux des possibilités dynamiques évoluées, réside dans l’écriture des pilotes. Cette écriture est toujours délicate, même si nous avons minimisé les demandes sur le pi-lote et nous sommes encore en phase de développement pour la validation de pilotes ty-pes. Un pilote type très simple est un pilote pour fonctionnement en batch. Il se contente d’offrir un ou plusieurs fichiers en entrée, formatés correctement, d’exécuter le modèle et de lire le ou les fichiers en sortie. Le formatage d’un fichier de données se décrit aisément au sein d’un document XML.
Une solution simple existe parfois également pour les modèles disponibles en source. En effet, il existe de plus en plus des outils de transformation de source à source. Nous pouvons citer fortran2java, qui transforme du Fortran 77 en Java, dans le but premier de traduire une librairie logicielle de calcul numérique initialement en fortran en classes Ja-va. Guillaume Desnoix offre un système plus ambitieux, ALMA [Desnoix 2002], qui tra-duit les sources de plusieurs langages en source pour n’importe lequel des autres langages traités. Malgré tout, la traduction source pose des problème également, car souvent, les modèles s’appuie sur des caractéristiques du langage, sur des librairies partagées (acces-sibles seulement via JNI avec Java) ou encore sur une API. Dans de nombreux cas, une traduction de la source ne sera pas possible, et dans d’autres cas, elle sera suffisamment difficile pour ne pas être intéressante.
6. 2. 2. Les serveurs de modèles
Le serveur de modèle générique est une classe Java qui permet la gestion de modèles mais n’est accessible que localement. Elle est héritée pour créer des serveurs de modèles dédiés à un protocole particulier. Dans le cas de Java RMI, il faut implémenter une inter-face qui sera utilisée pour l’usage distant. L’objet distant utilisant le serveur de modèle est un proxy. Ce dernier est utilisé par un chef d’orchestre comme un serveur de modèle générique, mais en réalisant le lien avec le serveur de modèles distant.
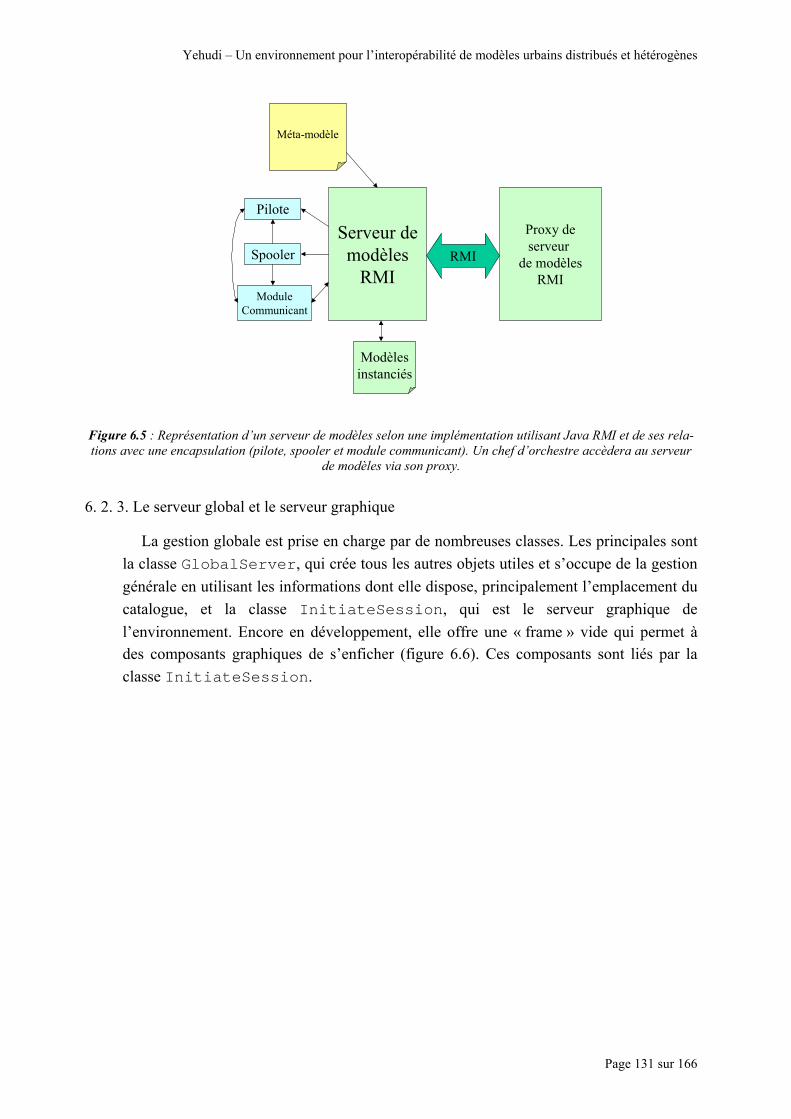
Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 131 sur 166
Serveur demodèles
RMI
Proxy deserveur
de modèlesRMI
RMI
Méta-modèle
Modèlesinstanciés
Pilote
Spooler
ModuleCommunicant
Figure 6.5 : Représentation d’un serveur de modèles selon une implémentation utilisant Java RMI et de ses rela-tions avec une encapsulation (pilote, spooler et module communicant). Un chef d’orchestre accèdera au serveur
de modèles via son proxy.
6. 2. 3. Le serveur global et le serveur graphique
La gestion globale est prise en charge par de nombreuses classes. Les principales sont la classe GlobalServer, qui crée tous les autres objets utiles et s’occupe de la gestion générale en utilisant les informations dont elle dispose, principalement l’emplacement du catalogue, et la classe InitiateSession, qui est le serveur graphique de l’environnement. Encore en développement, elle offre une « frame » vide qui permet à des composants graphiques de s’enficher (figure 6.6). Ces composants sont liés par la classe InitiateSession.

Mémoire de thèse
Page 132 sur 166
Figure 6.6 : Copie d’écran de l’interface graphique en développement.
Ces composants permettent une utilisation interactive de Yehudi. Les principaux sont :
- la liste des modèles disponibles, visible en haut à gauche, qui affiche les modèles en masquant la réalité sous-jacente, cette liste accepte le « glisser » de ses éléments. Les éléments glissés sont une représentation précise d’un modèle non instancié, correspondante à la réalité de l’environnement, mais masquée pour l’utilisateur. La sélection d’un élément informe InitiateSession de la sélection de ce premier, pour l’utilisation de composants contextuels,
- la fenêtre d’édition/visualisation/utilisation du schéma, en haut à droite. Cette fe-nêtre accepte le glisser-déposé, de modèles non instanciés et de modèles instanciés. L’édition du schéma se fait de façon simple et graphique. La visualisation du sché-ma permet de suivre et de contrôler l’exécution d’une session. Les différents états d’un modèle sont représentés en figure 6.7. Actuellement, ils ne sont pas dessinés. La sélection d’un élément informe InitiateSession de la sélection de ce premier. Ainsi, les composants contextuels pourront être utilisés :
- la fenêtre de contrôle global, non présente sur la figure, qui permet de générer les éléments de session, d’exécuter une session, de la mettre en pause, d’obtenir des in-formations, ...
- la fenêtre de contrôle contextuel, en bas à gauche, qui permet des contrôles sur un élément sélectionné, suppression d’un modèle non-instancié du catalogue, ajout

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 133 sur 166
d’une machine portant ce modèle, mise en pause d’un modèle instancié, demande d’information, ...
- la fenêtre d’informations contextuelles, en bas à droite, qui offre des informations sur un élément sélectionné,
- la fenêtre d’informations générales, non présente sur la figure, qui apporte des in-formations sur le nombre de modèles instanciés, le nombre de modèles critiques, le temps d’exécution général, les pertes estimés de qualité, le nombre d’erreurs, ...
- le tableau offert aux modèles, en bas à gauche, qui gère la visualisation des modè-les d’IHM.
?
n
n
n
n
n
? n
xn
x
!
m n
État inconnu
En attente depuis n minute(s)
Travaildepuis n minute(s)
En attente de donnéesdepuis n minute(s)
Pas de réponsedepuis n minutes
En attente de lasynchronisation xdepuis n minutes
Génération de lasynchronisation x
Plus de modèle réel
En attente d’accèsau modèle réeldepuis n minute(s)En attente d’expéditionde données depuisn minute(s)Manque n connexion(s) en entréeet/ou m connexion(s) en sortie
Plus de serveur local
Problème inconnu
Figure 6.7 : Les différents états prévus d’un modèle.
InitiateSession agit comme un intermédiaire entre le chef d’orchestre et l’interface. Elle offre des méthodes qui peuvent être utilisés de façon indifférente par les différents composants et qui lui permettent de s’informer des actions de l’utilisateur ou d’informer les éléments d’interface, par événement ou à temps donné (lors d’un top du timer).
6. 2. 4. Le chef d'orchestre
Le chef d’orchestre est tout d’abord une classe qui gère une session. Il communique avec les proxies des serveurs locaux, connus par le serveur global, pour instancier et exé-cuter une session. C’est lui qui fait l’intelligence du système en permettant, par exemple, d’appeler deux exécutions d’un même modèle critique sur deux machines à la fois pour offrir un parallélisme relatif.

Mémoire de thèse
Page 134 sur 166
La figure 6.8 schématise l’ensemble des éléments et leurs relations, sans présenter de médiateurs ni le serveur de modèles présent sur la machine maître.
Gestionde
sessiongraphique
Chefd ’orchestre
Schémalogique
Serveur globalCatalogue
demodèles
Interface
Timerde
session
Proxiesde serveursde modèles
serveursde
modèles Modulecommunicant
OU
SpoolerPilote
Modèle « brut »
Figure 6.8 : Schématisation des différents éléments et de leurs relations
Le travail le plus important du chef d’orchestre reste l’exécution d’une session. Utili-sant les événements reçus par les différents éléments et un signal d’un timer interne, qui est un modèle spécifique, le chef d’orchestre tente de mener une session à terme. Pour ce-la, il suit une stratégie très simple :
Sur événement ou sur signal du timer :
1. Trouver toutes les données disponibles à la sortie d’un modèle et les envoyer à l’entrée liée, mettre à jour les états correspondants,
2. Trouver toutes les données disponibles à l’entrée d’un modèle,
3. Chercher pour chaque modèle exécutable si ce modèle a toutes les données dési-rées,
4. Pour chaque modèle disposant de toutes les données voulues, en entrée et en pa-ramètre :
- si ce modèle n’attend pas une synchronisation, le modèle est exécuté,
- sinon, le modèle est prêt à être exécuté sur synchronisation.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 135 sur 166
Dans tous les cas, mettre à jour l’état du modèle.
5. Pour tous les autres éléments, incrémenter leur temps d’état actuel :
- si le nouveau temps est supérieur au temps prévu, l’élément doit avoir un pro-blème, le placer dans cet état, la session est considérée comme ayant un problème,
- sinon, on passe au modèle suivant.
Ensuite vient la phase de résolution des erreurs, si un problème au moins a été détec-té :
1. Pour chaque modèle ayant un problème :
- interroger le module communicant, attendre sa réponse,
- en cas de réponse, traiter le cas donné,
- sinon, interroger le serveur local, puis le serveur global.
Il existe un cas particulier, offert par un système de substitution, qui permet de rem-placer un modèle par un autre après un certain temps, représenté en figure 6.9. Dans ce cas là, si A dépasse un temps donné (qui peut être inférieur au temps estimé d’exécution), alors B lui est substitué. B peut déjà avoir été exécuté, alors il transmet directement ses données en sortie, sinon il est exécuté dès que possible. Les sorties passent alors dans un modèle OU qui renvoie les données de A ou de B. Le schéma de substitution est exclusif au niveau des sorties, évidemment.
A
B
OU B à substituer à Aaprès n minutes
Figure 6.9 : Schématisation d’une substitution
2. Pour chaque donnée ayant un problème de transmission :
- réaliser ou demander une nouvelle transmission.

Mémoire de thèse
Page 136 sur 166
Enfin, et simplement, sur synchronisation en sortie, le système tente une synchronisa-tion sur le modèle relié. Le modèle relié ne possède pas nécessairement de synchronisa-tion en entrée, car le signal peut être utilisé pour exécuter/terminer/mettre en pause un modèle quelconque.
6. 2. 5. Le médiateur
Le médiateur est une classe bien particulière, travaillant sur demande du chef d’orchestre et capable de traiter le schéma logique avec des ontologies et des médiateurs. Il fonctionne comme expliqué en chapitre IV.
6. 2. 6. Gestion d’XML
Actuellement, la gestion d’XML passe par des modèles utilitaires simples, capables principalement d’isoler ou d’extraire une partie encadrée par un tag. Nous envisageons d’utiliser des API répandues, telles JDOM ou SAX, mais l’utilisation de modèles utilitai-res permet une très grande légèreté, un contrôle complet du traitement et une compatibili-té accrue avec les différentes versions de Java.
6. 3. Évolution du prototype et possibilités futures
La conception de ce système, dans sa spécification actuelle, sera longue. Nous présen-tons ici l’évolution future du prototype ainsi que les possibilités qui pourraient être rajou-tées dans un avenir plus lointain.
6. 3. 1. Evolution du prototype
Une évolution utile serait d’utiliser l’approche protocolaire pour supporter des techno-logies répandues telles CORBA, OLE ou même les communications par simples mails.
Le chef d’orchestre pourrait également devenir plus efficace en adoptant, comme dé-crit dans la spécification, des stratégies d’exécution différentes. Il serait bon de trouver un format qui permette la définition d’heuristique.
Notre système pourra aussi être optimisé en prévoyant des plans d’action pour diffé-rents problèmes.
Finalement, l’évolution devra se faire en développant des outils pratiques, des modèles utilitaires variés et des pilotes types.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 137 sur 166
6. 3. 2. Toujours plus d'intelligence
Naturellement, l’utilisation de ce système, ainsi que les apports d’informations de-mandés aux experts, bénéficieraient toujours de davantage d’intelligence. Nous pourrons concevoir une description sémantique des modèles par l’intermédiaire de questions en langage claire déduites de la base d’ontologie, apporter une gestion sémantique précise de la qualité, vérifier la cohérence des descriptions, les liens de parentés, fusionner des bases d’ontologie, ...
6. 3. 3. Supporter une distribution mondiale
L’architecture actuelle de Yehudi est particulièrement adaptée à un usage sur un ré-seau local. Il n’est d’ailleurs pas nécessaire d’envisager un usage plus vaste tant que l’environnement n’est pas suffisamment éprouvé.
Pour permettre son utilisation en dehors d’un réseau local, il faudrait rajouter la possi-bilité d’installer des serveurs de modèles sans les enregistrer auprès d’un serveur global. Ils seraient ainsi mis à disposition. Un serveur global devrait alors être capable de de-mander à un serveur local existant de s’enregistrer.
Cette évolution demanderait également d’adapter l’environnement pour gérer au mieux les problèmes de sécurité.
6. 3. 4. Une autre méta-modélisation
Notre méta-modèle est actuellement descriptif en se basant sur des références strictes. Nous pouvons prévoir, comme dit précédemment, une méta-modélisation pour la généra-tion « in vivo » de programmes. Il est assez aisé d’adjoindre la possibilité d’interprétation d’un langage encapsulé dans le méta-modèle, procédural ou déclaratif. C’est par contre un travail assez considérable. Et nous pouvons aussi imaginer une méta-modélisation « pure », qui définit un rôle. À partir de cette définition, le système sait créer un modèle répondant à ce rôle.
6. 3. 5. Vers un entrepôt de modèles
Nous pouvons rêver d’un entrepôt de modèles, où il suffit de choisir un modèle dans cet entrepôt pour l’utiliser. Yehudi, dans sa forme actuelle ne correspond pas à une telle réalité. En effet, les modèles ne sont pas des composants, ils sont installés sur une ma-chine particulière et dépendent peut-être d’une façon inconnue de librairies partagées, de fichiers de configuration, voire d’autres logiciels. Et nous pensons que la réutilisation de modèles existants n’a pas suffisamment à gagner en permettant le « stockage » de modè-les dans un entrepôt vis-à-vis du travail à fournir pour permettre cela : incorporation de toutes les « dépendances » du modèle, réinstallation de l’ensemble à l’exécution, restauration du système après exécution, éventuellement simulation d’un système

Mémoire de thèse
Page 138 sur 166
ration du système après exécution, éventuellement simulation d’un système manquant, ... En fait, il apparaît que la réécriture d’un modèle, en offrant peut-être des outils de haut niveaux, qui pourraient s’appuyer sur le méta-modèle, pour le transformer en composant dans un langage prévu pour cet usage tel que Java, serait alors moins difficile.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 139 sur 166
CHAPITRE VII CONCLUSION
Nous vous avons présenté Yehudi dans sa conception et son implémentation actuelle.
Pour conclure, nous récapitulons les possibilités actuelles de notre solution et nous par-lons des possibles perspectives.
7. 1. Une intégration logicielle
Actuellement, Yehudi offre principalement une gestion logicielle de l’interopérabilité des modèles. Nous pouvons ainsi noter que :
- cette approche offre une très forte extensibilité et flexibilité,
- cette architecture est très puissante, totalement multi-session, permet le parallé-lisme et offre une bonne robustesse,
- les différents éléments sont absolument génériques, s’appuyant toujours sur des interfaces,
- les pilotes restent très difficiles à écrire, ce travail dépend du système du modèle, de son fonctionnement, et reste donc une opération de bas niveau nécessitant une bonne connaissance informatique,
- pour une situation mettant en œuvre un grand nombre de modèles, la mise en œu-vre est toujours délicate et l'exécution d'une session peut être très insatisfaisante,
- les erreurs d’une session peuvent influer sur toutes les autres sessions,
- ce système est très ouvert et n’offre pas forcément des garanties de validité des traitements des pilotes de modèles, des modèles, ...
La figure 7.1 montre une vue d’ensemble de cette architecture.
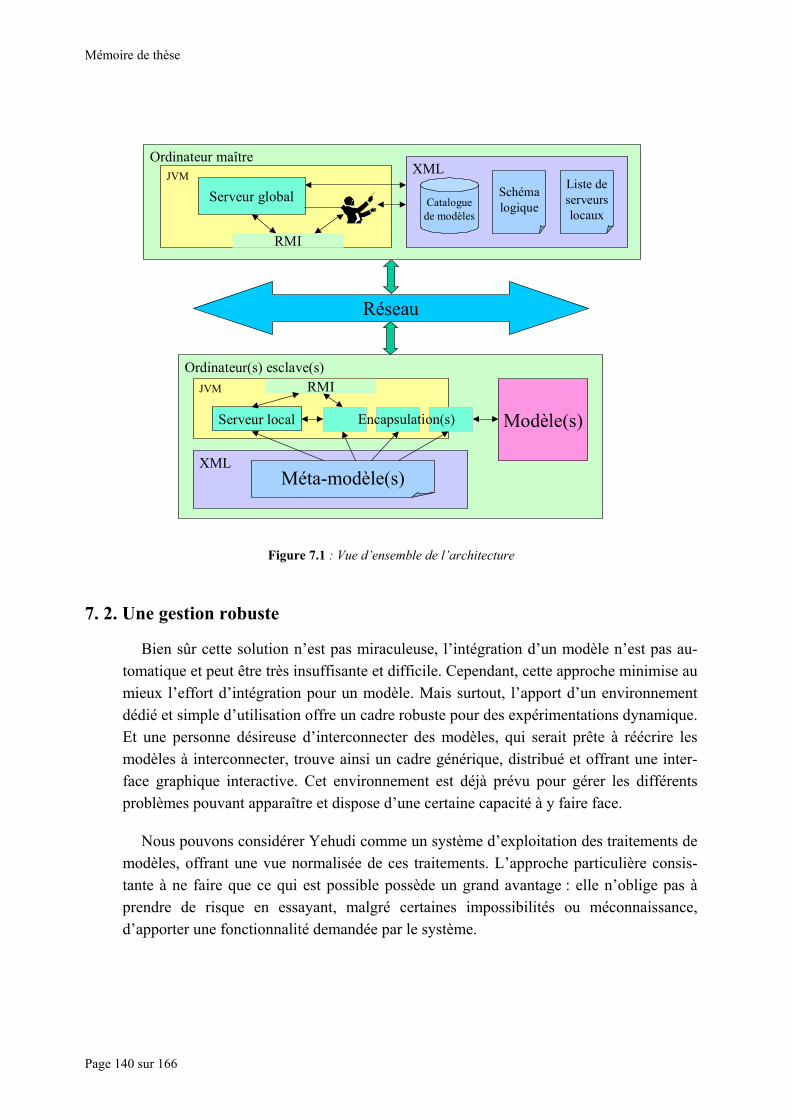
Mémoire de thèse
Page 140 sur 166
Réseau
Ordinateur maîtreJVM
Serveur global
RMI
XML
Cataloguede modèles
Schémalogique
Liste deserveurslocaux
Ordinateur(s) esclave(s)JVM
Serveur local Encapsulation(s)
RMI
Modèle(s)
XMLMéta-modèle(s)
Figure 7.1 : Vue d’ensemble de l’architecture
7. 2. Une gestion robuste
Bien sûr cette solution n’est pas miraculeuse, l’intégration d’un modèle n’est pas au-tomatique et peut être très insuffisante et difficile. Cependant, cette approche minimise au mieux l’effort d’intégration pour un modèle. Mais surtout, l’apport d’un environnement dédié et simple d’utilisation offre un cadre robuste pour des expérimentations dynamique. Et une personne désireuse d’interconnecter des modèles, qui serait prête à réécrire les modèles à interconnecter, trouve ainsi un cadre générique, distribué et offrant une inter-face graphique interactive. Cet environnement est déjà prévu pour gérer les différents problèmes pouvant apparaître et dispose d’une certaine capacité à y faire face.
Nous pouvons considérer Yehudi comme un système d’exploitation des traitements de modèles, offrant une vue normalisée de ces traitements. L’approche particulière consis-tante à ne faire que ce qui est possible possède un grand avantage : elle n’oblige pas à prendre de risque en essayant, malgré certaines impossibilités ou méconnaissance, d’apporter une fonctionnalité demandée par le système.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 141 sur 166
7. 3. Contributions de la thèse
Les contributions de cette thèse à l’intégration des modèles existants se présentent se-lon quatre axes.
En premier lieu, le modèle est abstrait par un mécanisme logiciel particulier, l’encapsulation. Cette dernière est liée à une vue logique, le méta-modèle, qui est suffi-sant pour permettre la manipulation du modèle par ses aspects logiques. L’encapsulation minimise l’effort d’intégration en considérant le modèle tel un périphérique et en prenant en charge les limitations de celui-ci. De ce fait, elle homogénéise le modèle.
Les méta-modèles représentant les modèles réels s’intègrent alors dans un niveau logi-que, homogène et reflet de la réalité. La mise à disposition d’outils sous la forme de mo-dèles permet une approche unifiée qui simplifie la création et l’usage d’un schéma d’interconnexion. Ce dernier présente des modèles clairement documentés. Un outil logi-ciel particulier, le chef d’orchestre, manipule un schéma logique pour commander les dif-férents éléments le constituant et ainsi exécuter une session.
Cette exécution se fait en utilisant le schéma logique comme un tableau de bord. Le chef d’orchestre prend en compte l’hétérogénéité sous-jacente en fonction des informa-tions apportées au sein du schéma-logique par les méta-modèles et en suivant une straté-gie d’exécution prédéfinie. Le chef d’orchestre réagit aux évènements qui sont soit issus des éléments interconnectés soit les « tops » d’un timer, lesquels permettent la mise à jour des temps d’attente. À partir de ces évènements, le chef d’orchestre réagit selon la straté-gie établie et met à jour le schéma logique. Cette approche permet une exécution robuste en gérant les problèmes quand ils surviennent.
Finalement, l’abstraction logique des différents éléments d’une interconnexion et l’approche tout modèle permettent l’usage d’une ontologie adaptée. Dans cette ontologie orientée document et interconnexion, les concepts sont définis par leur possibilité de liens avec d’autres concepts. Les liens sont possibles selon une parenté, selon un adaptateur ou selon les deux. Une parenté indique si un concept qu’elle lie avec un autre peut être ac-cepté comme ce dernier et possède une conséquence en terme de perte de qualité ou d’adaptation. Un adaptateur est un modèle utilitaire qui transforme une donnée en une au-tre. Une librairie décrit les adaptateurs et définit les parentés. Un médiateur est capable d’utiliser cette ontologie et effectue ainsi un pré-traitement du schéma logique, en véri-fiant les liens, en répercutant les conséquences qualitatives et en insérant les adaptateurs dans le schéma logique.

Mémoire de thèse
Page 142 sur 166
7. 4. Vers plus d’intelligence
Nous avons introduit dans notre solution une abstraction forte de la réalité logicielle. Ainsi, les éléments trouvent une existence logique complète et cohérente. Nous pensons que cette première étape est essentielle pour permettre la gestion intelligente du système. En effet, un système informatique classique n’a qu’une existence physique, avec pour seul « contact » avec l’extérieur des interfaces « logicielles », dont la plus simple est la possibilité d’exécution. En retrouvant une réalité logique, auparavant intrinsèque aux programmes informatiques, nous offrons une existence logique nécessaire pour un traite-ment sémantique. Notre vision nous offre une représentation riche de l’univers qui nous entoure. Nos sens nous permettent d’embrasser le monde qui nous entoure. Notre enri-chissement logique est la lumière de la grotte de Platon, elle montre une réalité cachée. Bien sûr, cette représentation est comme une ombre, elle n’offre pas une représentation exacte, mais tente de s’en rapprocher au mieux.
Ce monde logique est une base forte pour des traitements sémantiques efficaces. Sans extrapoler à l’ensemble de l’informatique, nous pouvons préciser tout ce que notre sys-tème peut attendre d’un enrichissement sémantique :
- améliorer la gestion sémantique des données, permettre ainsi des adaptations cohé-rentes et fines,
- contrôler la cohérence des connexions vis-à-vis des théories sous-jacentes aux modè-les,
- apporter une connaissance de la répartition des modèles et des données,
- permettre l’intégration intelligente des modèles, par la paramétrisation assistée ou au-tomatique de pilote type ou par la création dynamique d’un pilote dédié,
- informer « intelligemment » l’utilisateur,
- répondre à des questions complexes, être capable de faire un chaînage arrière des modèles à partir d’une requête exprimée en langage naturel ou pseudo-naturel.
Pour cela, il faut offrir une base d’ontologie très complète, ce qui n’est possible que si nous créons des outils performant de création d’ontologie.
7. 4. 1. Permettre un chaînage arrière de modèles
Si l’adaptation et la vérification des liens est possible pour tous les éléments intégrés au système, nous pouvons imaginer d’utiliser ces description pour répondre à un pro-blème seulement en connaissant le résultat voulu. Ensuite, les systèmes rechercheraient les modèles à relier en fonction de leurs transformations, cherchant un moyen, venant des données destinations voulues, d’arriver à des données sources disponibles via des modè-les disponibles eux aussi. Malheureusement, ce chaînage pose de nombreux problèmes :

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 143 sur 166
- si les modèles répertoriés sont nombreux, la recherche peut rapidement devenir très longue, surtout si de nombreux modèles créent des données semblables,
- le système doit pouvoir éviter des boucles, ce qui est possible par des astuces de pro-grammation : gérer un historique, limiter la profondeur de recherche,
- si les descriptions sont incorrectes, surtout trop imprécises, le chaînage perd de son sens. L’ontologie présentée porte une réalité sémantique pauvre, elle est conçue pour être opérationnelle. Ainsi, si les pertes de qualités doivent être précisées, nous pouvons assis-ter à une imprécision sémantique, des pertes de qualités sémantiques, c’est-à-dire que les modèles liés ne correspondent pas vraiment au modèle souhaité. Bien sûr, la connais-sance de ce souhait est très difficile à gérer correctement. Malheureusement, lors d’un chaînage automatique, ces écarts vont sans doute s’amplifier,
- comment l’utilisateur peut exprimer sa requête.
Pour tenter d’apporter un premier chaînage arrière, nous pensons proposer une interro-gation par un choix de modèle. L’utilisateur choisi un ou plusieurs modèles et le système tente de compléter le schéma autour de ce ou ces modèles pour permettre leur exécution. La recherche sera simple et de profondeur réduite mais pourrait compenser cette simplici-té par le choix de plusieurs solutions. Ainsi, dans un premier temps, ce chaînage arrière serait plutôt une assistance pour l’utilisateur, lui permettant de retrouver facilement des modèles de toute façon fortement corrélés.
7. 4. 2. Revoir la conception des logiciels
La conception de cet environnement nous a amené à utiliser des techniques récentes et à les utiliser pour recréer une couche logique qui disparaît à la conception des logicielles. Et il nous semble que des techniques telles que l’introspection et les interfaces sont des palliatifs à cette absence. Il serait bénéfique d’étendre ces techniques et des les mêler pour permettre la conservation de la réalité logique dès la conception d’une application. À la manière de Javadoc pour Java, qui génère des documentations à partir des commen-taires, il faudrait pouvoir enrichir les codes sources d’informations claires permettant une compilation directe de l’application sous la forme de compositions d’éléments connus et réutilisables. Pour cela, nous pensons qu’il ne faut pas, comme la plupart des techniques actuelles, considérer les informations sur le logiciel comme des données accessibles par des méthodes communes car héritées d’une classe de très haut niveau, mais comme une facette particulière du logiciel, un document qui représente sa réalité logique. Les systè-mes d’exploitation devraient également évoluer pour être capable d’utiliser cette facette et gérer les applications comme des compositions d’éléments logiciel. L’abstraction of-ferte par un système dépasserait alors le simple usage de points d’entrées et d’interfaces de composants à destination d’autres logiciels pour offrir les éléments logiciels sous la forme de fonctionnalités utilisables librement. Ces éléments pourraient être vus comme des composants métiers.

Mémoire de thèse
Page 144 sur 166
BIBLIOGRAPHIE
[Adler 2001] ADLER D. The JACOB Project: A JAva-COM Bridge [en ligne]. 2001. Disponible sur <http://danadler.com/jacob/> (consulté le 16.10.2002). [AFNOR 2002] AFNOR ASSOCIATION FRANÇAISE DE NORMALISATION. Paris : Groupe AFNOR [en ligne]. 2002. Disponible sur <http://www.afnor.fr> (consulté le 13.10.2002). [Batty 1976] BATTY M. Urban Modeling: Algorithms, Calibrations, Predictions. Cambridge : Cambridge University Press, 1976, 381 p. [Becam-Miquel 2000] BECAM A., MIQUEL M. : Model's Encapsulation for Interoperability between Urban Data and Models. In : Spaccapietra S. Ed. Proceedings of the International Workshop on Emerging Technologies for Geo-Based Applications, Ascona, Switzerland, May 22-25, 2000. Lausanne : EPFL, 2000, pp 275-282. [Becam-Miquel-Laurini 2000] BECAM A., MIQUEL M., LAURINI R. : A Distributed Environment using Ontology for the Interoperability of Urban Data and Models. In : Geographical Domain & Geographical Information systems-EuroConference on the Ontol-ogy and Epistemology for Spatial Data Standards, 22 - 27 September 2000, La Londe-les-Maures (France), pp 11-15. (GeoInfo n°19) [Becam-Miquel-Laurini 2001] BECAM A., MIQUEL M., LAURINI R. Yehudi: An Orchestrated System for the Interoperability of Urban Data and Models. In : Sha E. Ed., 14th International Conference on Parallel and Distributed Computing Systems, 2001, 8-10 August, Dallas, Texas USA. Cary : ISCA, 2001, pp 272-277. ISBN 1-880843-39-0 [Benslimane-Leclercq-Savonnet et al. 2000] BENSLIMANE D., LECLERCQ E., SAVONNET M., TERRASSE M.N., YÉTONGNON K. On the Definition of Generic Multi-Layered Ontologies for Urban Applications. International Journal of Computers, Environment and Urban Systems, 2000, vol. 24, pp 191-214. [Bionatics 2002] BIONATICS. Bionatics, spécialiste de modélisation en 3D de plantes [en ligne] 2002. Disponible sur <http://www.bionatics.com> (consulté le 16.10.2002). [Bruse 2002] BRUSE M. ENVI-met 2 [en ligne] 2002. Disponible sur <http://www.envi-met.com/> (consulté le 16.10.2002). [CEN/TC 1999] CEN/TC 287. CEN/TC 287 [en ligne]. 1999. Disponible à partir de <http://www.isotc211.org/organizn.htm> (consulté le 16.10.2002). [CERMA 1999] CENTRE DE RECHERCHE MÉTHODOLOGIQUE D'ARCHITECTURE (CERMA). INVENTUR Inventaire des modèles du champ urbain [en ligne]. 1999. Disponible sur <http://www.cerma.archi.fr/inventur/inventur.html> (consulté le 16.10.2002). [Chandrasekaran-Josephson-Benjamins 1999] CHANDRASEKARAN B., JOSEPHSON J.R., BENJAMINS V.R. What are Ontologies, and why do we Need them? IEEE Intelligent Systems, January/February 1999, vol. 14, n° 1, pp. 20-26.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 145 sur 166
[Cowlishaw 2002] COWLISHAW M. The Rexx Language [en ligne]. IBM UK Laboratories, 2002. Disponible sur <http://www2.hurlsey.ibm.com/rexx> (consulté le 13.10.2002). [Date 1990] DATE C. J. An Introduction to Database Systems, Fifth Edition . Reading : Addison-Wesley Publishing Company, 1990, 845 p. (The system programming series) ISBN 0-201-51381-1 [DCMI 2002] DUBLIN CORE METADATA INITIATIVE (DCMI). Dublin Core Metadata Initiative [en ligne]. 2002. Disponible sur <dublincore.org> (consulté le 13.10.2002). [Desnoix 2002] DESNOIX G. Alma, atelier logiciel de modélisation et d'analyse [en ligne]. 2002. Disponible sur <http://www.memoire.com/guillaume-desnoix/alma/> (consulté le 16.10.2002). [DMSO 2002] DEFENSE MODELING AND SIMULATION OFFICE (DMSO). High Level Architecture [en ligne]. 2002. Disponible sur <www.dmso.mil/public/transition/hla> (consulté le 13.10.2002). [ENVIRON 2002] ENVIRON. CAMx Comprehensive Air Quality Model with Extensions [en ligne] 2002. Disponible sur <www.camx.com> (consulté le 16.10.2002). [ETC/ACC 2001] EUROPEAN TOPIC CENTRE ON AIR AND CLIMATE CHANGE (ETC/ACC) -TOPIC CENTRE OF EUROPEAN ENVIRON-MENT AGENCY. MDS - Model Documentation System [en ligne] 2001. Disponible sur <http://air-climate.eionet.eu.int/databases> (consulté le 16.10.2002). [Farquhar-Fikes-Rice 1996] FARQUHAR A.,FIKES R., RICE J. The Ontolingua Server: A Tool for Collaborative Ontology Construction. Knowl-edge Systems Laboratory, 1996. [Fensel-Horrocks-Van Harmelen et al. 2000] FENSEL D., HORROCKS I., VAN HARMELEN F., DECKER S., ERDMANN M., KLEIN M.: OIL in a Nutshell. In : R. Dieng et al. eds. Knowledge Acquisition, Modeling, and Management, Proceedings of the European Knowledge Acquisition Conference (EKAW-2000), Juan-les-Pins, France, pp 1-16 (Lecture Notes in Artificial Intelligence, vol. 1937). [FITS 2002] THE FITS SUPPORT OFFICE. The FITS Support Office Home Page [en ligne]. 2002. Disponible sur : <http://fits.gsfc.nasa.gov> (consulté le 13.10.2002). [FGDC 2002a] FEDERAL GEOGRAPHIC DATA COMMITEE (FGDC). Content Standard for Digital Geospatial Metadata (CSDGM) [en ligne]. 2002. Disponible sur <www.fgdc.gov/metadata/contstan.html> (consulté le 16.10.2002). [FGDC 2002b] FEDERAL GEOGRAPHIC DATA COMMITEE (FGDC). Federal Geographic Data Committee [en ligne]. 2002. Dispo-nible sur <www.fgdc.gov> (consulté le 13.10.2002). [Flory-Laforest 1996] FLORY A., LAFOREST F. Les bases de données relationnelles. Paris : Economica, 1996, 111 p. ISBN 2-7178-3115-0 [Franz 2002] FRANZ Inc. jLinker - A Dynamic Link between Lisp and Java [en ligne]. 2002. Disponible sur <http://www.franz.com/support/documentation/6.2/doc/jlinker.htm> (consulté le 16.10.2002).

Mémoire de thèse
Page 146 sur 166
[Genesereth] GENESERETH R. Knowledge Interchange Format (KIF) [en ligne], Disponible sur <http://logic.stanford.edu/kif> (consulté le 16.10.2002). [Grosso-Eriksson-Fergerson et al. 1999] GROSSO W. E., ERIKSSON H., FERGERSON R. W., GENNARI J. H., TU S. W. & MUSEN,M. A.. Knowledge Modeling at the Millennium (The Design and Evolution of Protege-2000) [en ligne], Rapport. 1999. Disponible sur : <http://smi-web.stanford.edu/pubs/SMI_Abstracts/SMI-1999-0801.html> (consulté le 7.11.2002). [Hassine-Khayati 2001] HASSINE I., KHAYATI O. Modèles à base de composants métier : Analyse & Etude Comparative. In : actes de la journée de travail bi-thématique du GDR-PRC I3, Lyon 2001, pp. 85-102. [Iazeolla-D’Ambrogio 1998] IAZEOLLA G., D'AMBROGIO A. A Web-based Environment for the Reuse of Simulation Models. Simulation series, 1998, vol. 30, n°1, pp. 37-44. [IFF 1999] THE ONTOLOGY CONSORTIUM. Information Flow Framework (IFF) [en ligne]. 1999. Disponible sur <http://www.ontologos.org/IFF/IFF.html> (consulté le 16.10.2002). [Institute for Meteorology of Hamburg 1998] INSTITUTE FOR METEOROLOGY - UNIVERSITY OF HAMBURG. The Models Inventory [en ligne] 1998. Disponible sur <http://www.mi.uni-hamburg.de/technische_meteorologie/cost/cost_615/models_inventory/index.html> (consulté le 16.10.2002). [ISO 2002] INTERNATIONAL ORGANIZATION FOR STANDARDIZATION (ISO). Welcome to ISO Online [en ligne]. 2002. Disponi-ble sur <http://www.iso.org> (consulté le 13.10.2002). [ISO/TC 2002] ISO/TC 211. ISO/TC 211 Geographic information/Geomatics [en ligne]. 2002. Disponible sur <http://www.isotc211.org> (consulté le 13.10.2002). [KADS] ARTIFICIAL INTELLIGENCE LABORATORY (ARTI). KADS-II ESPRIT Project P5248 [en ligne]. Disponible sur <http://arti.vub.ac.be/kads/> (consulté le 16.10.2002) [Kayser 1997] KAYSER D. La représentation des connaissances. Paris : Hermès , 1997, 308 p. ISBN 2-86601-647-5 [Leclercq-Benslimane-Yétongnon 1997] LECLERCQ E., BENSLIMANE D., YÉTONGNON K. A Distributed Object Oriented Model for Heterogeneous Spatial Databases. In : A. El-Amawy and S. Q. Zhenf Eds Proceedings of the 10 th International Conference on Parallel and Distributed Computing Systems PDCS, 1997, New Orleans, Louisiana, USA. Cary : ISCA, 1998, pp. 625-629. ISBN 1-880843-21-8 [Leclecq-Benslimane-Yétongnon 1999] LECLERCQ E., BENSLIMANE D., YÉTONGNON K. HORUS: a Semantic Broker for GIS Interoperability. In : Telegeo 99, Mai 1999, Villeurbanne, pp. 61-70. [Ledoux 1999] LEDOUX T. OpenCorba : A Reflective Open Broker. Lecture Notes in Computer Science, 1999, vol. 1616, pp 197-214.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 147 sur 166
[Levenez 2002] LÉVÉNEZ E. Computer Languages History [en ligne] 2002. Disponible sur <http://www.levenez.com/lang/> (consulté le 16.10.2002). [LOOM 2002] UNIVERSITY OF SOUTHERN CALIFORNIA'S INFORMATION SCIENCES INSTITUTE. Loom Project Home Page [en li-gne]. 2002. Disponible sur <http://www.isi.edu/isd/LOOM/LOOM-HOME.html> (Consulté le 16.10.2002). [Maxwell 1999a] MAXWELL T.P. Current Development Projects [en ligne] 1999) Disponible sur <http://www.uvm.edu/giee/Tom/Projects.html> (consulté le 16.10.2002). [Maxwell 1999b] MAXWELL T.P. Selected Papers [en ligne] 1999. Disponible sur <http://www.uvm.edu/giee/Tom/Papers.html> (consulté le 16.10.2002). [Microsoft 1998] MICROSOFT CORP. Distributed Component Object Model (DCOM) [en ligne]. 1998. Disponible sur <http://www.microsoft.com/com/tech/dcom.asp> (consulté le 13.10.2002). [Microsoft 2002a] MICROSOFT CORP. .NET Framework Home Page [en ligne]. 2002. Disponible sur <http://msdn.microsoft.com/netframework> (consulté le 13.10.2002). [Microsoft 2002b] MICROSOFT CORP. Visual Basic .NET Home Page [en ligne]. 2002. Disponible sur <http://msdn.microsoft.com/vbasic> (consulté le 13.10.2002). [OMG 2000] OBJECT MANAGEMENT GROUP (OMG). CORBA [en ligne]. 2000. Disponible sur <http://www.corba.org> (consul-té le 13.10.2002). [OMG 2002a] OBJECT MANAGEMENT GROUP (OMG). Meta Object Facility (MOF) Specification [en ligne]. 2002. Disponible sur <http://www.omg.org/technology/documents/formal/mof.htm> (consulté le 13.10.2002). [OMG 2002b] OBJECT MANAGEMENT GROUP (OMG). Unified Modelling Language (UML) [en ligne]. 2002. Disponible sur <http://www.uml.org> (consulté le 13.10.2002). [OMG 2002c] OBJECT MANAGEMENT GROUP (OMG). XML Metadata Interchange (XMI), Version 1.2 [en ligne]. 2002. Disponi-ble sur <http://www.omg.org/technology/documents/formal/xmi.htm> (consulté le 13.10.2002). [Ontologos 1999] THE ONTOLOGY CONSORTIUM. Ontologos. [en ligne]. 1999. Disponible sur <http://www.ontologos.org/> (consulté le 16.10.2002). [OpenGIS 2002] OPEN GIS CONSORTIUM. OGC – Open GIS Consortium, Inc. [en ligne]. 2002. Disponible sur <http://<www.opengis.org> (consulté le 16.10.2002) [Orfali-Harkey-Edwards 1999] ORFALI R., HARKEY D., EDWARDS J. Client/Server Survival Guide. Norwood : Wiley, John and Sons, 1999, 800 p. ISBN: 0471316156 [Page-Parisel 2000] PAGE M., PARISEL C. Modélisation automatique dans les domaines faiblement formalisés. In : Actes Reconnais-sance des Formes et Intelligence Artificielle (RFIA 2000), 1-3 février 2000, Paris, France. Paris : TELECOM Paris, Dépt. Traitement du Signal et des Images, 2000, pp 391-398 (II).

Mémoire de thèse
Page 148 sur 166
[PIF 1999] THE PIF WORKING GROUP. Process Interchange Format (PIF) [en ligne]. 1999. Disponible sur <http://ccs.mit.edu/pif> (consulté le 13.10.2002). [Predit 2000] PROGRAMME NATIONAL DE RECHERCHE ET D'INNOVATION DANS LES TRANSPORTS TERRESTRES (PREDIT). Inven-taire des modèles de transport (IMT) [en ligne]. 2000. Disponible sur <http://www.predit.prd.fr/02-Predit/Imt/> (consulté le 16.10.2002). [Safege 2001] SOCIÉTÉ ANONYME FRANÇAISE D'ETUDES ET DE GESTION – SAFEGE. Piccolo [en ligne] 2001. Disponible sur <http://www.safege.fr/french/dom/logiciel/reseaux/piccolo/present.htm> (consulté le 16.10.2002). [Sowa 2000] SOWA J. F. Knowledge Representation: Logical, Philosophical, and Computational Foundations. Pacific Grove : Brooks Cole Publishing Co., 2000, 594 p. [Schmidt 2002] SCHMIDT D.C. The ADAPTIVE Communication Environment (ACE) [en ligne]. 2002. Disponible sur <www.cs.wustl.edu/~schmidt/ACE.html> (consulté le 13.10.2002). [SubMeso 1996] GDR SUB-MESO. Le code SUB-MESO [en ligne]. 1996. Disponible sur <http://terac712.hmg.inpg.fr/GDR/code.htm> (consulté le 16.10.2002). [Sun 1999] SUN MICROSYSTEMS. Java Native Interface [en ligne]. 1999. Disponible sur <http://java.sun.com/products/jdk/1.2/docs/guide/jni/> (consulté le 16.10.2002). [Sun 2002a] SUN MICROSYSTEMS. Enterprise JavaBeans Technology [en ligne]. 2002. Disponible sur <http://wwws.sun.com/products/ejb/> (consulté le 16.10.2002). [Sun 2002b] SUN MICROSYSTEMS. Jini[tm] Network Technology [en ligne]. 2002. Disponible sur <http://wwws.sun.com/software/jini/> (consulté le 16.10.2002). [Sun 2002c] SUN MICROSYSTEMS. Java Naming and Directory Interface (JNDI) [en ligne]. 2002. Disponible sur <http://java.sun.com/products/jndi/> (consulté le 16.10.2002). [Sun 2002d] SUN MICROSYSTEMS. The Source for Java Technology [en ligne]. 2002. Disponible sur <http://java.sun.com> (consulté le 13.10.2002). [Szyperski 1999] SZYPERSKI C. Components and Objects Together. Software Development, May 1999, Vol. 7, N° 5, pagination inconnue. [Teller-Azar 2002] TELLER L., AZAR S. TOWNSCOPE II Presentation [en ligne]. 2002. Disponible sur <http://www.lema.ulg.ac.be/tools/townscope/> (consulté le 16.10.2002). [USGS 2002] U.S. GEOLOGICAL SURVEY (USGS). Welcome to the Spatial Data Transfer Standard (SDTS) Information Site [en ligne]. 2002. Disponible sur : <http://mcmcweb.er.usgs.gov/sdts> (consulté le 13.10.2002).

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 149 sur 166
[W3C 2000] WORLD WIDE WEB CONSORTIUM (W3C). Simple Object Access Protocol (SOAP) 1.1 [en ligne]. 2000. Disponible sur <http://www.w3.org/TR/SOAP> (consulté le 13.10.2002). [W3C 2002a] WORLD WIDE WEB CONSORTIUM (W3C). Extensible Markup Language (XML) [en ligne]. 2002. Disponible sur <http://www.w3.org/XML> (consulté le 13.10.2002). [W3C 2002b] WORLD WIDE WEB CONSORTIUM (W3C). Resource Description Framework (RDF) [en ligne]. 2002. Disponible sur <http://www.w3.org/RDF> (consulté le 13.10.2002). [Wiederhold 1994] WIEDERHOLD G. Interoperation, Mediation and Ontologies. In : International Symposium on 5th Generation Com-puter Systems; Workshop on Heterogeneous Cooperative Knowledges-Bases, 1994, Tokyo, Japan, volume W3, pp 33-48. [XOL 1999] THE ONTOLOGY CONSORTIUM. XOL [en ligne]. 1999. Disponible sur <http://www.ontologos.org/Ontology/XOL.htm> (consulté le 16.10.2002).

Mémoire de thèse
Page 150 sur 166
ANNEXE A PRÉSENTATION D’INVENTUR
INVENTUR se présente sous la forme d’un page web. Un choix multi-modal permet
d’afficher la fiche d’un modèle. L’ajout d’un modèle se fait en téléchargeant un formu-laire en RTF, à renvoyer aux responsables d’INVENTUR.
Page de sélection d’INVENTUR
Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 151 sur 166
Affichage de la fiche de Townscope
Fiche complète de Townscope
INVENTUR
MODÈLE « TOWNSCOPE »
Présentation générale Description scientifique et technique
Description libre Rédacteur
1. PRÉSENTATION GÉNÉRALE
Identification du modèle
Nom :TOWNSCOPE
Année de création :1998 Numéro de version actuel :II

Mémoire de thèse
Page 152 sur 166
Conditions d'utilisation : Le modèle existe-t-il sous la forme d'un logiciel diffusable ? Oui Non
Si oui, est-il : Libre de droits ? Soumis à une licence ?
Le cas échéant, précisez les conditions particulières d'utilisation du modèle (droits d'utilisation de bibliothèques séparées, données à acquérir, brevets associés, etc.) :
• en coours d'élaboration
Auteurs
Identité et coordonnées :
• LEMA - Universite de Liege 15, avenue des Tilleuls, D1, 4000, Liege Belgique tel 32 4 366 93 94 fax 32 4 366 95 62
Statut : Recherche Organisme institutionnel Privé
Personne à contacter préférentiellement :
Nom : Albert Dupagne E-mail : [email protected] Lien Web : http://www.ulg.ac.be/lema
Domaine(s) et champ(s) d'application du modèle
Pour chacun des domaines de compétence du modèle, cochez le(s) champ(s) principal(aux) d'application. Utilisez éventuellement les zones autres pour décrire un champ d'application qui n'est pas spécifié.
Utilisez les zones Autre(s) domaine(s) et Autre(s) champ(s) pour préciser, le cas échéant, des domaine(s) et champ(s) particuliers.
Géographie et dynamique spatiale
Dynamique spatiale intra-urbaine Mobilité quotidienne Choix résidentiels Utilisation du sol Dynamique des systèmes de villes Systèmes d'information géographique Géomarketing
Autre :
Economie et gestion urbaine
Marché foncier et immobilier Marché du travail Gestion urbaine Localisations des activités
Autre :
Sociologie Réseaux sociaux Intégration / Exclusion Criminalité / Violence

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 153 sur 166
Autre :
Transports
Demande de transport Choix modal Logistique Interconnexion Réseaux de transport intra-urbain Réseaux de transport inter-urbain
Autre :
Réseaux techniques
Eau / Eaux usées / Assainissement Electricité Réseaux hertziens / Télécommunications Réseaux de chaleur Réseaux de transport de gaz Réseaux de collecte de déchets urbains
Autre :
Physique urbaine
Climatologie urbaine Aéraulique / Pollution de l'air Hydrologie / Pollution de l'eau Sols / Mécanique des sols / Pollution des sols Thermique et énergétique urbaine Acoustique urbaine Eclairage naturel et artificiel Végétation
Autre :
Risques et cindyniques
Risques naturels Risques épidémiologiques ou toxicologiques Risques industriels
Autre :
Morphologie urbaine
Modèles de terrain Tissus urbains / Architecture urbaine Urbanisme / Développement urbain Modèles fractals Télédétection / Radar Photogrammétrie / Reconstruction 3D Imagerie urbaine
Autre :
Autre(s) domaine(s) : •
Autre(s) champ(s) :
• Physique urbaine - consommation energetique des batiments morphologie urbaine - etudes d'impact visuel

Mémoire de thèse
Page 154 sur 166
Phénomènes étudiés, objectifs et opérationnalité
Quel(s) phénomène(s) le modèle permet-il de simuler, d'évaluer ?
• - eclairement radiatif dans les espaces urbains - confort thermique dans les espaces ouverts - consommation energetique des batiments - confinement dans les espaces ouverts
Quels sont les objectifs du projet de modélisation de ces phénomènes ?
L'analyse et la compréhension du(es) phénomène(s) La simulation et l'expérimentation La prédiction ou l'aide à la décision
Précisez éventuellement : •
Diriez-vous qu'il s'agit plutôt :
d'un modèle de connaissance (modèle qui cherche à imiter le plus fidèlement les mécanis-mes élémentaires expliquant le fonctionnement de l'objet modélisé, modèles descriptifs ou ex-plicatifs),
d'un modèle de fonctionnement (modèle qui reproduit les relations constatées entre les en-trées et les sorties de l'objet modélisé comme un système, modèles prédictifs ou prospectifs).
Précisez éventuellement votre point de vue : •
Opérationnalité : Par rapport à ses objectifs (analyse, simulation et expérimentation, prédiction ou aide à la décision), diriez-vous que le modèle est opérationnel ?
Oui Non
Précisez éventuellement les capacités et les limites opérationnelles du modèle : •
Echelle(s) d'application dans le champ urbain, dimensions
Echelle(s) : A quelle(s) échelle(s) le modèle appréhende-t-il le champ urbain ?
Fragments urbains Ville Systèmes de villes
Précisez éventuellement ces échelles :
• L'echelle de travail de TOWNSCOPE correspond a ce que les anglo-saxons appellent l'urban design, c'est-à-dire une échelle intermédiaire entre la planification urbaine et l'architecture. Echelle du quartier et de l'espace public.
Dimensions : Quelles sont les dimensions du champ urbain prises en compte dans le modèle ?

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 155 sur 166
Dans l'espace : 2D 3D
Dans le temps : Stationnaire Dynamique
Quelle est la résolution spatiale du modèle (ordre de grandeur), ou bien quelles sont les unités spatiales de référence ?
• De l'ordre de 10 cm
Le cas échéant, quelle est sa résolution temporelle ? •
Précisez éventuellement ces éléments :
• L'echelle est fixée par l'utilisateur, mais on considère généralement qu'une précision de l'ordre de 10 cm correspond à la précision des données de base que l'on peut trouver dans les plans, relevés urbains, des SIG, disponibles auprès des utilisateurs du modèle.
Famille, antécédents et filiation
Famille : Considérez-vous que le modèle appartient à une famille de modèles ? Si oui, comment désigneriez-vous cette famille ?
• modèles d'aide à la décision énergétique solaire
Connaissez-vous un ou plusieurs autre(s) modèle(s) de la même famille dans des domaines proches ? Si oui, préci-sez le(s)quel(s) :
• Solène, SOMBRERO
Quelle est la spécificité du modèle décrit ici au sein de sa famille ?
• Le développement d'interfaces visuelles pour l'explicitation des phénomènes étudiés et des résultats obte-nus.
Antécédents : Le modèle décrit ici est-il lié directement à un ou plusieurs autres modèles développés antérieurement ? Si oui, précisez le(s)quel(s) et l'année de sa (leur) création :
• CAM.UR (Computer Aided Management System for Urban Renewal), développé dans le cadre du pro-gramme "CCE-DGXII, 3rd European R&D non nuclear energy programme, PASTOR sub-programme".
Filiation : Le modèle décrit ici a-t-il permis d'engendrer d'autres modèles ? Si oui, précisez le(s)quel(s) :
• Modèles d'analyse paysagère, basés sur le calcul d'intervisibilités Gisement énergétique solaire en site vierge
2. DESCRIPTION SCIENTIFIQUE ET TECHNIQUE
2.1 Modélisation

Mémoire de thèse
Page 156 sur 166
Problématique et hypothèses
Problématique : Décrivez brièvement la problématique qui a conduit au développement du modèle :
• voir publications du lema
Hypothèses : Notez ici de manière simple les principales hypothèses utilisées par le modèle. Précisez éventuellement les théo-ries, paradigmes, principes ou lois générales auxquels il se réfère :
• - Utilisation de méthodes analytiques (Dogniaux) pour la détermination des énergies solaires disponibles afin de minimiser le volume de données météo à définir - Eclairement diffus isotrope ou ciel CIE - Une seule inter-reflection est prise en compte dans le calcul de l'energie reflechie - Application des equations de Fanger aux espaces ouverts - Utilisation du concept d'ouverture de ciel pour qualifier le confinement des espaces ouverts
Formalisation
Décrivez ici les principes de formalisation utilisés dans le modèle. Spécifiez le cas échéant les méthodes em-ployées (méthodes statistiques, réseaux de neurones, système multi-agents, etc.) ou précisez les éléments originaux de conception du modèle (analogie avec un phénomène physique, par exemple).
• - Le modèle est basé sur la géométrie sphérique, afin de prendre en considération l'ensemble de l'envi-ronnement "visible" à partir d'un point. En outre la géométrie sphérique se prète particulièrement bien à la calibration des interfaces de visualisation des résultats.
Construction
Le modèle a-t-il été construit par l'agencement d'autres modèles (composants ou modules autonomes) ? Précisez le cas échéant les principaux modules utilisés et l'architecture de l'ensemble. Indiquez si ces modules sont antécé-dents ou s'ils ont été développés pour ce modèle.
• Le logiciel a été entièrement développé en CLOS (Common Lisp Object System) qui est un language orienté-objet dynamique. L'interface utilisateur ainsi que les algorithmes de simulation sont intégrés dans le même code.
Résolution
Décrivez succinctement les méthodes utilisées dans les modules de résolution : méthodes du calcul numérique, solutions analytiques, formules (semi)-empiriques, etc.
• - méthodes de calcul basées sur la résolution d'équations en géométrie sphérique
Sensibilité
Connaissez-vous la sensibilité du modèle, soit aux données d'entrée, soit aux paramètres utilisés ? Si oui, donnez les principales indications à ce sujet. Précisez également la méthode utilisée pour l'analyse de sensibilité.
• - Sensibilite assez forte à la qualité des donnees climatiques, mais dans la mesure ou le modele sert es-sentiellement a la comparaison d'alternatives de design, cela ne prete pas vraiment a consequence. D'au-tant que la sensibilite aux donnes geometriques de base est relativement faible.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 157 sur 166
Validation
Indiquez le niveau actuel de validation du modèle :
Niveau 1 : Validation définitive Niveau 2 : Incertitudes inhérentes au modèle ou aux mesures disponibles Niveau 3 : Validation partielle (voir ci-dessous) Niveau 4 : Travail de validation en cours Niveau 5 : Aucune validation
En cas de validation partielle, précisez les cas ou types de cas sur lesquels le modèle a été validé :
• Le modele a ete valide sur base de mesures in-situ realisees dans un lotissement de la province de Liege (CCE DGXII, 1st & 2nd European R&D non nuclear energy pgm, under contract EE-5-600-B(G) - un-published report).
Indiquez le cas échéant la(es) méthode(s) de calibration ou de calage utilisée(s) : •
La validation du modèle pose-t-elle des difficultés ? Si oui, décrivez les problèmes rencontrés :
• Sensibilite tres forte des donnees mesurees in-situ au mode d'occupation des espaces, particulierement des espaces interieurs.
Limites et perspectives
Limites : Indiquez ici les principales limites du modèle. Précisez si elles résultent de la formalisation ou des hypothèses utilisées (limites permanentes), ou bien des techniques de résolution ou du niveau de validation actuel (limites temporaires) :
• - transposabilite des equations de Fanger aux espaces exterieurs est une hypothese assez discutable
Perspectives : Signalez éventuellement les recherches en cours ou à effectuer pour améliorer le modèle. Donnez éventuellement les échéances prévisibles pour l'aboutissement de ces recherches :
• - calibration des mesures relatives a la qualite des espaces ouverts (confinement, longueurs de vue) sur base d'enquetes psycho-sociales. - validation des interfaces de visualisation aupres d'utilisateurs neophites.
2.2 Données et résultats
Données
Nature : Détaillez ici le(s) type(s) des données nécessaires en entrée du modèle :
• - données geometriques relatives à la volumetrie du site - données météo : altitude, latitude, turbidité, humidité, nébulosité mensuelle
Interopérabilité : Certaines des données d'entrée sont-elles issues d'un ou plusieurs autre(s) modèle(s) ? Si oui, précisez lesquels (données et modèles) :
•

Mémoire de thèse
Page 158 sur 166
Acquisition : Pour les autres données, quelles sont les méthodes d'acquisition employées ?
• SIG commerciaux pour l'acquisition des données 2D. Le modèle comporte également une interface d'entrée DXF, pour les échanges de données 3D avec des modeleurs de solides existants sur le marché.
Résultats
Nature des résultats : Indiquez ici la nature des résultats fournis :
• - visualisation graphique des parcours solaires, des niveaux d'eclairement (par heure, par jour ou par annee), des niveaux de confort thermique, distribution des longueurs de vue, visualisation sphérique (équidistante, cylindrique, orthogonale, isoaire, etc)
Post-traitements : Indiquez ici le(s) type(s) de traitements possibles des résultats :
• Si les post-traitements ne sont pas gérés en interne par le modèle, indiquez (le cas échéant) quels autres outils peuvent être utilisés :
•
Interopérabilité : Les résultats sont-ils utilisés par un ou plusieurs autre(s) modèle(s) ? Si oui, précisez lesquels (résultats et modè-les) ou donnez les conditions pour ce faire :
•
2.3 Mise en oeuvre
Matériel, système et code
En pratique, le modèle nécessite au minimum :
Un super calculateur Une station de travail Un ordinateur personnel
Précisez éventuellement quels autres matériels sont nécessaires, notamment en matière d'acqui-sition des données (interfaces spécifiques) :
• - tablette de digitalisation (optionnel)
Le choix de ce matériel résulte avant tout :
de la puissance de calcul qu'il offre du volume important de données à traiter de la disponibilité d'outils spécifiques à ce support (langages, bibliothèques, autres modèles,
etc.)

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 159 sur 166
Précisez éventuellement :
• La raison de ce choix est la volonté de plus grande diffusabilité du modèle
Le modèle est utilisable sous :
Unix / Linux MS Dos Windows MacOs Un autre système
Précisez le cas échéant quelles autres ressources sont nécessaires : •
Le code source est principalement écrit dans le langage : CLOS
Lors du développement, le code spécifique du modèle a-t-il été dissocié du code permettant sa mise en oeuvre (interface, calcul, etc.) ? Précisez éventuellement leur degré d'interdépendance :
• Exploitation de la technologie orienté-objet pour dissocier le code selon différents modules (interface, calcul, visualisation etc.) et faciliter son adaptation à différentes plate-formes et différentes applications.
Le code fait-il appel à des bibliothèques extérieures spécialisées (calcul, graphiques, maillages, etc.) ? Précisez le cas échéant :
• - bibliothèque de saisie graphique de bitmaps écran
Le code est-il public ? Oui Non
Temps de mise en oeuvre
Précisez le temps de mise en oeuvre pour chacune des étapes :
Acquisition et préparation des données Résolution Post-traitements, analyse des
résultats
Moins d'une heure Moins d'une journée Plusieurs jours
Moins d'une heure Moins d'une journée Plusieurs jours
Moins d'une heure Moins d'une journée Plusieurs jours
Documentation
Indiquez le niveau de documentation actuellement disponible :
Niveau 1 : Description scientifique. Manuel d'utilisation, détails du code... Niveau 2 : Description scientifique. Manuel d'utilisation plus ou moins complet Niveau 3 : Description scientifique fondamentale Niveau 4 : Documentation en cours d'élaboration Niveau 5 : Aucune documentation

Mémoire de thèse
Page 160 sur 166
La documentation est-elle soumise à certaines restrictions de diffusion dues à son caractère confidentiel ? Précisez le cas échéant :
• Pas de restrictions relatives a la diffusion, si ce n'est que le logiciel n'est pas supporte (debug, on-line suport etc.) par le laboratoire.
Utilisation
Niveau d'utilisabilité : Expert Public informé Tout public
Précisez éventuellement le(s) type(s) d'utilisateur(s) :
• architectes, ingénieurs, designers urbains
Connaissez-vous approximativement le temps de formation au modèle pour ces utilisateurs ?
• une journée
Communauté d'utilisateurs : Le modèle a-t-il été diffusé auprès d'autres équipes ? Existe-t-il de fait une communauté d'utilisateurs du modèle ? Précisez le cas échéant le nombre d'utilisateurs et le mode d'existence de la communauté (réunions régulières, mailing-list, intranet, etc.) :
• Le modèle est en cours de diffusion auprès de nos partenaires de recherche (Université d'Athènes, Uni-versité de Seville, BRE). Il sera mis a la disposition du public a la fin de cette annee.
Exemples d'application : Décrivez ici, le cas échéant, quelques exemples significatifs d'application du modèle dans le champ urbain :
• Application à des projets urbains en cours de realisation ou realise, dans le cadre du design ou de contentieux juridiques : - LISBOA'98 international exhibit (PT) ; - place du Marché à Liège (BE) ; - lotissement a Bethencourt-sur-mer (FR) ; - place Saint-Lambert à Liège (BE).
3. DESCRIPTION LIBRE Notez ici des informations sur le modèle qui n'apparaissent pas précédemment. Copiez par exemple le résumé d'un article concernant le modèle ou proposez-en une représentation synthétique (rubrique Abstract). Donnez les références des principales publications concernant le modèle. Ajoutez éventuelle-ment d'autres commentaires.
Abstract :
• TOWNSCOPE II is a computer system devoted to support solar access decision-making in a sustainable urban design perspective. The software consists in a three-dimensional urban information system coupled with solar evaluation tools. It’s been especially considered that numerical results interpretation proves to be all but trivial in complex built environments. It is nevertheless a crucial aspect in decision-making, es-pecially for current negotiated urban design practices. So the point of developing visual instruments in order to unveil the geometrical mechanisms lying behind the final results. Various spherical projections were thereby developed, each of them presenting specific advantages and disadvantages for solar access visualisation and/or evaluation purposes.

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 161 sur 166
Principales publications relatives au modèle :
• [DUPA-91] DUPAGNE A., "A computer package to facilitate inhabitants' participation in urban re-newal", Environment and Planning B : Planning and Design, 1991, volume 18, pages 119-134. [DUPA-95] DUPAGNE A., FERNANDES E., "Urban design and environmental integration”, The EXPO'98-LISBOA Experiment", Sustainable and energy efficient building, James&James, 1995. [DUPA-95] DUPAGNE A., LECLERCQ P., "La climatologie comme facteur modifiant du projet urbain", 8e Colloque International de Climatologie, Université de Liège, septembre 1995. [DUPA-96] DUPAGNE A., TELLER J., "Représentation de l'espace ouvert dans un système d'informa-tion de projet urbain", Ingéniérie des Systèmes d'Information, vol 5 n. 2, juin 1997.
D'autres commentaires ? •
VOUS (FACULTATIF)
Votre statut par rapport au modèle décrit
Vous êtes :
Utilisateur du modèle décrit ? Concepteur et/ou développeur du modèle décrit ?
Précisez éventuellement : •
Votre champ de compétence principal est :
Celui du modèle Un autre (précisez) :
Votre appréciation de la situation du modèle Selon vous, le modèle décrit ici est-il bien accepté dans la communauté scientifique ? Existe-t-il des alternatives à ce modèle pour répondre au même type de question ? Le cas échéant, quelles autres équipes y travaillent ?
•
Dans le cadre de cet inventaire, des séminaires de restitution de type « workshop » seront programmés. Souhaitez-vous participer à l'un de ces séminaires ?
Non Oui, sous les conditions suivantes :
Votre nom et vos coordonnées (si vous le souhaitez)
• Albert Dupagne et Jaques Teller, LEMA-ULg
Page composée automatiquement d'après la description reçue de Jacques Teller 10:47 17/09/98

Mémoire de thèse
Page 162 sur 166
ANNEXE B UN EXEMPLE DE MÉTA-MODÈLE
Le méta-modèle suivant décrit un modèle en Java et a été généré automatiquement par
un outil Java très simple. Cet outil recherche les méthodes « get » et « set » de la classe choisie pour construire le méta-modèle. De par la spécificité de Java, la partie physique est très proche de la partie logique.
<?xml version="1.0"?> <YEHUDI version="0.2"> <METAMODEL> <LOGICALPART> <MODEL_NAME> modelssimples.SaisieMot </MODEL_NAME> <MODEL_TYPE> java </MODEL_TYPE> <DATA_INPUTS> <DATA_INPUT> <NAME>setDataIN.java.util.Hashtable </NAME> <TYPE>java.util.Hashtable </TYPE> </DATA_INPUT> <DATA_INPUT> <NAME>setParam.java.util.Hashtable </NAME> <TYPE>java.util.Hashtable </TYPE> </DATA_INPUT> </DATA_INPUTS> <DATA_OUTPUTS> <DATA_OUTPUT> <NAME>getDataOUT.return.java.util.Hashtable </NAME> <TYPE>java.util.Hashtable </TYPE> </DATA_OUTPUT> <DATA_OUTPUT> <NAME>getDescOUT.return.java.util.Vector </NAME> <TYPE>java.util.Vector </TYPE> </DATA_OUTPUT> <DATA_OUTPUT> <NAME>getState.return.boolean </NAME> <TYPE>boolean </TYPE> </DATA_OUTPUT> <DATA_OUTPUT> <NAME>getClass.return.java.lang.Class </NAME> <TYPE>java.lang.Class </TYPE> </DATA_OUTPUT> <DATA_OUTPUT> <NAME>getDescIN.return.java.util.Vector </NAME> <TYPE>java.util.Vector </TYPE> </DATA_OUTPUT> <DATA_OUTPUT> <NAME>getDescParam.return.java.util.Vector </NAME> <TYPE>java.util.Vector </TYPE> </DATA_OUTPUT> </DATA_OUTPUTS> <CHARACTERISTIC>

Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Page 163 sur 166
<CRITICAL> FALSE </CRITICAL> </CHARACTERISTIC> <DESCRIPTION> Automatically generated from modelssimples.SaisieMot </DESCRIPTION> </LOGICALPART> <TYPEOFMODEL> Java </TYPEOFMODEL> <PHYSICAL_DESCRIPTION> <INTERFACES> <INTERFACE> modelssimples.ModelsSimples </INTERFACE> <INTERFACE> modelssimples.ModelsAutoDecrits </INTERFACE> </INTERFACES> <SUPER> java.lang.Object </SUPER> <METHODS> <METHOD> <METHOD_NAME> getDataOUT </METHOD_NAME> <RETURN> java.util.Hashtable </RETURN> </METHOD> <METHOD> <METHOD_NAME> getDescOUT </METHOD_NAME> <RETURN> java.util.Vector </RETURN> </METHOD> <METHOD> <METHOD_NAME> getState </METHOD_NAME> <RETURN> boolean </RETURN> </METHOD> <METHOD> <METHOD_NAME> getClass </METHOD_NAME> <RETURN> java.lang.Class </RETURN> </METHOD> <METHOD> <METHOD_NAME> getDescIN </METHOD_NAME> <RETURN> java.util.Vector </RETURN> </METHOD> <METHOD> <METHOD_NAME> getDescParam </METHOD_NAME> <RETURN> java.util.Vector </RETURN> </METHOD> <METHOD> <METHOD_NAME> setDataIN </METHOD_NAME> <PARAMETER> java.util.Hashtable </PARAMETER> <RETURN> void </RETURN> </METHOD> <METHOD> <METHOD_NAME> setParam </METHOD_NAME> <PARAMETER> java.util.Hashtable </PARAMETER> <RETURN> void </RETURN> </METHOD> </METHODS> </PHYSICAL_DESCRIPTION> </METAMODEL> </YEHUDI>

Mémoire de thèse
Page 164 sur 166
FOLIO ADMINISTRATIF
THESE SOUTENUE DEVANT L'INSTITUT NATIONAL DES SCIENCES APPLIQUEES DE LYON
NOM : BECAM DATE de SOUTENANCE : 11/12/2002 (avec précision du nom de jeune fille, le cas échéant) Prénoms : Alain TITRE : Yehudi – Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes NATURE : Doctorat Numéro d'ordre : 02 ISAL 0094 Formation doctorale : École doctorale Informatique et Information pour la société (EDIIS) Cote B.I.U. - Lyon : T 50/210/19 / et bis CLASSE : RESUME : Le monde urbain est un ensemble complexe, mêlant des problèmes sociaux, économiques, architecturaux, environnemen-taux, … Depuis de nombreuses années, la modélisation des phénomènes propres à la ville est une aide indispensable pour la compréhension des phénomènes ainsi que pour la prise de décision. De nos jours, les modèles urbains se présentent souvent sous la forme d’un logiciel informatique complet, répondant bien aux objectifs visés. Malheureusement, il n’existe pas de cadre uniforme de création de modèle et ceux-ci sont fortement hétérogènes. Néanmoins, une interconnexion des modèles existants apporterait des possibilités très étendues et profiterait de la connaissance d’experts venant d’horizons différents. Partant de l’hypothèse que les modèles offrent des similarités suffisantes pour être représentés par des comportements com-muns, nous avons considéré une telle interconnexion comme un orchestre, qui comporterait des instruments différents, les modèles, utilisés par des musiciens pour suivre les instructions d’un chef d’orchestre. Ainsi, chaque modèle est intégré par un composant logiciel spécialisé, nommé encapsulation, qui offre une vue homogène et s’occupe de la répartition réseau, des problèmes de concurrence et de l’accès au modèle. Ce dernier est géré tel un périphérique. Pour supporter cette encapsulation et permettre une interconnexion efficace, nous avons défini une couche logique, composée de méta-données représentantes la réalité logicielle recouverte mais également la réalité logique et, éventuellement, la réalité sémantique des différents éléments. Les méta-données les plus importantes sont les méta-modèles, représentants les modèles urbains, le schéma logique, décrivant l’interconnexion des modèles et utilisé pour l’exécution d’une session, et le catalogue de modèles. Un élément logiciel primordial, le chef d’orchestre, est capable d’utiliser ces informations pour contrôler les différents éléments du système et ainsi réaliser une interconnexion de modèle. Le chef d’orchestre est réactif et tente toujours d’amener une session à son terme. Il dispose d’une capacité limitée pour résoudre les problèmes quand ils surviennent et continuer tout de même le travail. Les méta-données utilisent la syntaxe XML, pour la clarté et la souplesse de ce langage. Les méta-modèles profitent particuliè-rement de l’usage des balises pour offrir deux vues clairement séparées : une partie physique, indiquant comment accéder au modèle, et une partie logique, qui représente le modèle et est détachée de la partie physique pour être la seule vue du modèle au sein de l’environnement. La partie logique décrit le comportement du modèle et les données traitées. Elle peut également contenir des descriptions textuelles et des descriptions sémantiques. Cette abstraction offre donc une vue logique cohérente de l’ensemble des éléments du système, laquelle est utilisable pour ajouter une gestion sémantique de l’ensemble, avec l’introduction d’un référentiel sémantique simple mais extensible, la base d’ontologie. Ce référentiel est utilisé pour vérifier les connexions et, éventuellement, pour les adapter. Pour cela, le chef d’orchestre fait appel à un médiateur, lequel peut traiter les informations sémantiques et intégrer des adaptateurs au schéma. Les encapsulations et les différentes méta-données sont utilisées au sein d’une architecture dédiée. Celle-ci est fortement hié-rarchisée et répartie. Elle repose ainsi sur des serveurs locaux, qui s’occupent de la gestion des modèles de leur machine et sur un serveur global, qui contrôle les serveurs locaux ainsi que tous les autres éléments du système. Un chef d’orchestre est un client de cet environnement et travaille ainsi principalement à un niveau logique. Un serveur graphique assure le lien entre le chef d’orchestre et l’utilisateur. Pour valider cette solution, nous avons développé un prototype complet, écrit en Java et utilisant Java RMI pour la distribution. Différentes technologies, par exemple CORBA, JACOB avec des liaisons OLE, permettent d’offrir des encapsulations pour des modèles écrits avec d’autres langages que Java. MOTS-CLES : interopérabilité, méta-modèle, encapsulation, ontologie, architecture distribuée Laboratoire (s) de recherches : Laboratoire d'Ingénierie des Systèmes d'Information (LISI) Directeur de thèse: Robert Laurini – Maryvonne Miquel Président de jury : Albert Dupagne Composition du jury : Michel Schneider, Kokou Yétongnon, Robert Laurini, Maryvonne Miquel


Yehudi Un environnement pour l’interopérabilité de modèles urbains distribués et hétérogènes
Ce mémoire de thèse présente le résultat de nos travaux concernant l’interopérabilité des modè-les urbains existants. Ces derniers sont des outils mathématiques et informatiques utilisés par les urbanistes pour appréhender les différents phénomènes concernant la ville. Leur hétérogé-néité est multiple et interdit leur usage conjoint. Pour pouvoir bénéficier de leurs spécificités, nous avons défini un environnement intégré permettant leur intégration et leur interconnexion. Cet environnement s’appuie sur un mécanisme d’encapsulation des modèles qui, avec l’adjonction d’un méta-modèle, permet leur abstraction logicielle et logique. Un outil particu-lier, le chef d’orchestre, commande alors les différents éléments présents en s’appuyant sur ce niveau logique grâce à une architecture distribuée dédiée. Finalement, un référentiel sémanti-que adapté permet la vérification et l’adaptation de l’interconnexion. Mots clés : interopérabilité, méta-modèle, encapsulation, ontologie, architecture distribuée Title: Yehudi: an Environment for the Interoperability of Distributed and Heterogeneous Urban Models. Abstract: This thesis presents the results of our work concerning the interoperability of exiting urban models. The urban models are mathematical and software tools used to simulate or esti-mate phenomena relevant to the urban domain. The direct interconnection of existing models is not possible due to their multiple heterogeneities. To be able to use several models together, we have developed an integrated environment capable of integrating and interconnecting them. A model is integrated by an encapsulation, which is linked to a meta-model in order to offer a software and logical abstraction. The supervisor is a software tool, which controls the different elements by using the logical layer. A distributed architecture offers a strong management and a semantic referential allows the verification and the adaptation of the interconnection. Keywords: interoperability, meta-model, encapsulation, ontology, distributed architecture. Thèse préparée au Laboratoire d'Ingénierie des Systèmes d'Information (LISI), INSA
Campus de la Doua, Bâtiment Blaise Pascal (501), 20 avenue Albert Einstein 69621 VILLEURBANNE CEDEX


















