
Tests statistiques sous SPSS - Accueil de Cjoint.com · le test de Levene est significatif, il faut...
63
Tests statistiques sous SPSS
Transcript of Tests statistiques sous SPSS - Accueil de Cjoint.com · le test de Levene est significatif, il faut...

Tests statistiquessous SPSS
Analyses Uni-variées (tris à plat)…
Rappels:
L’analyse univariée permet de décrire et de synthétiser les résultats de l’étude enanalysant les variables une par une.
Analyse:
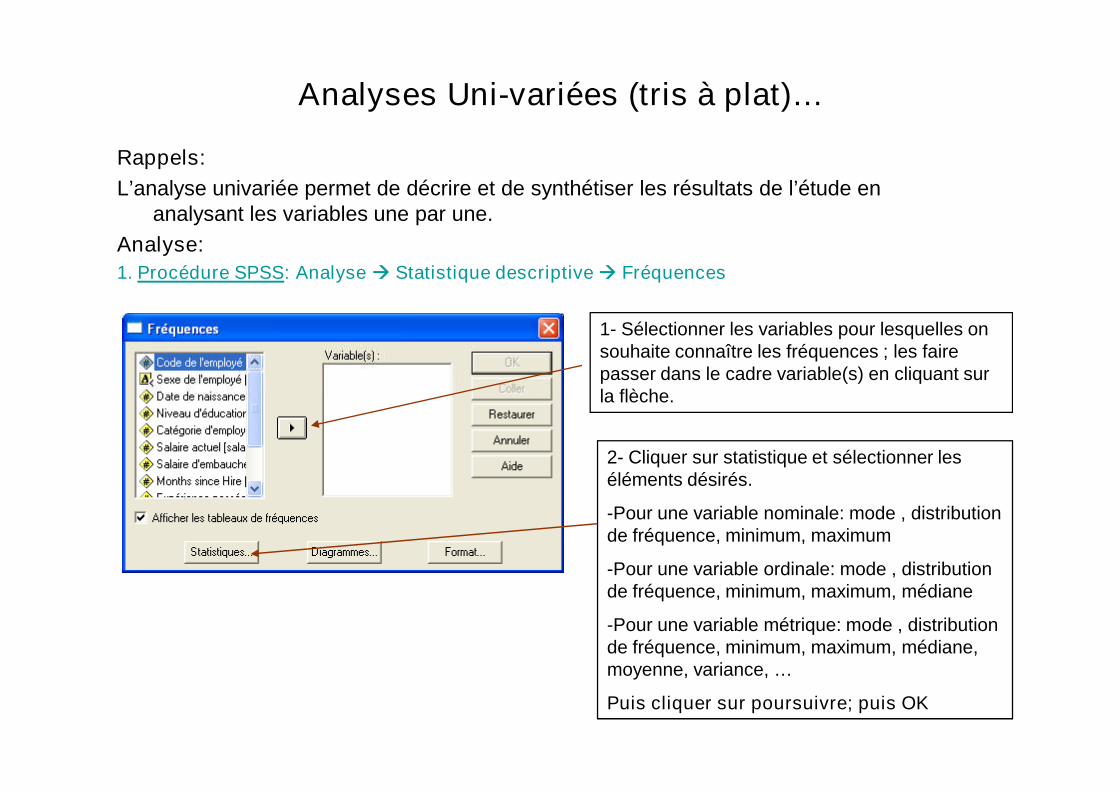
1. Procédure SPSS: Analyse Statistique descriptive Fréquences
1- Sélectionner les variables pour lesquelles onsouhaite connaître les fréquences ; les fairepasser dans le cadre variable(s) en cliquant surla flèche.la flèche.
2- Cliquer sur statistique et sélectionner leséléments désirés.
-Pour une variable nominale: mode , distributionde fréquence, minimum, maximum
-Pour une variable ordinale: mode , distributionde fréquence, minimum, maximum, médiane
-Pour une variable métrique: mode , distributionde fréquence, minimum, maximum, médiane,moyenne, variance, …
Puis cliquer sur poursuivre; puis OK
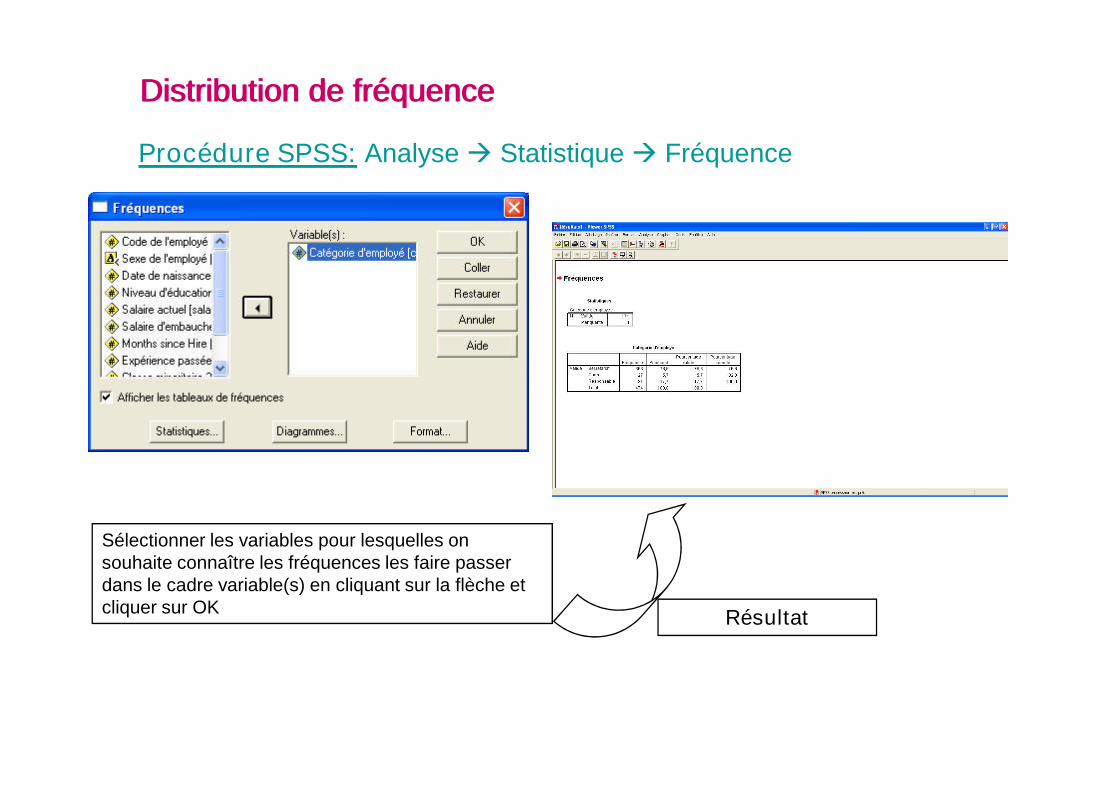
Procédure SPSS: Analyse Statistique Fréquence
Distribution de fréquenceDistribution de fréquence
Sélectionner les variables pour lesquelles onsouhaite connaître les fréquences les faire passerdans le cadre variable(s) en cliquant sur la flèche etcliquer sur OK
Résultat
Le cas des tableaux à réponses multiples …
Rappels :
Dans quel cas a-t-on un tableau multiple ?
Par exemple, dans le questionnaire sur les " Pratiques culturelles des étudiants" une question est : « parmi la liste des émissionsTV, ci-dessous, quelles sont vos 3 émissions préférées ? ».
Réponses possibles :•La marche du siècle, F3•Thalassa F3•Pyramide F2•Nulle part ailleurs, Canal+•Etc.
Le codage retenu est le suivant : nous avons créé autant de variables que d’émissions de TV proposées.Le codage retenu est le suivant : nous avons créé autant de variables que d’émissions de TV proposées.Lorsqu’une émission est mentionnée comme appartenant aux 3 émissions préférées, elle est codée « 1 », sinon « 0 ».
Dans ce cas, on a créé autant de variables que de modalités de réponses, chacune étant codée de façon binaire. Il serait fastidieuxde sortir un tableau de fréquences pour chaque variable ainsi créée. De plus l’interprétation ne serait pas aisée.
SPSS permet de faire les calculs pour l’ensemble des modalités de réponses en une seule opération.Analyse :
Pour calculer des fréquences sur un tableau multiple il faut
créer un vecteur (analyse réponses multiples définir les vecteurs),
Puis
demander les fréquences (analyse réponses multiples fréquences)
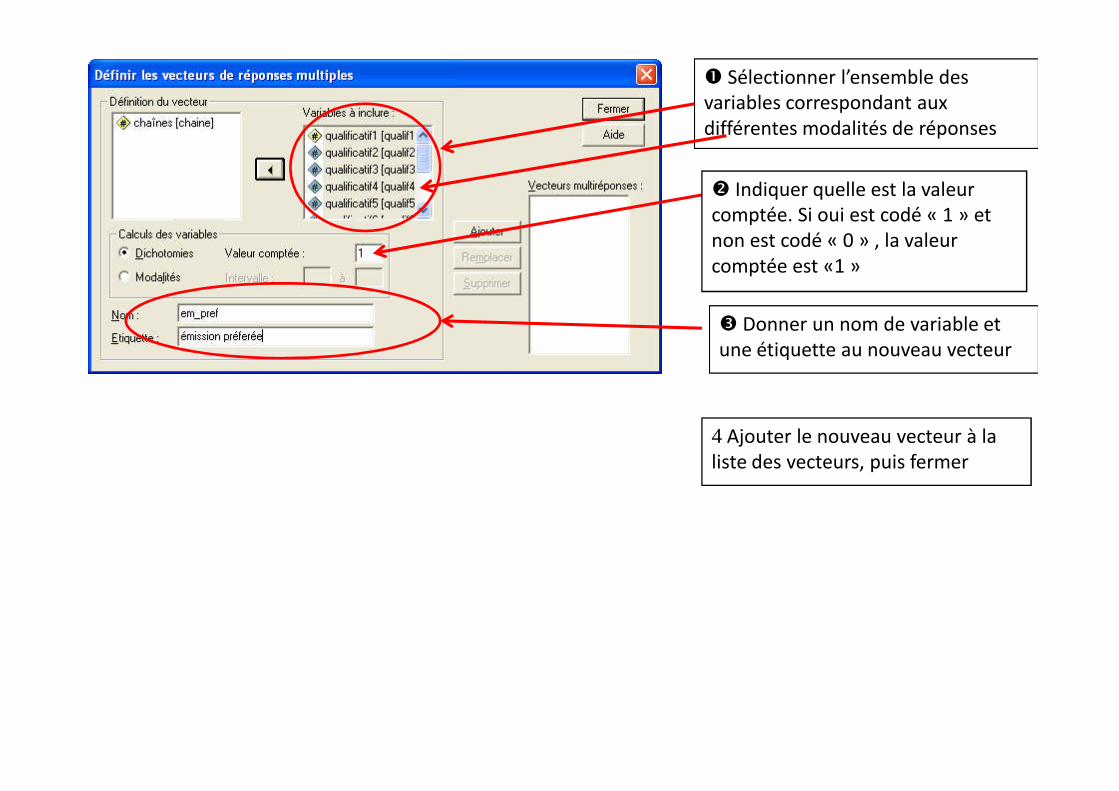
Sélectionner l’ensemble desvariables correspondant auxdifférentes modalités de réponses
Donner un nom de variable etune étiquette au nouveau vecteur
Indiquer quelle est la valeurcomptée. Si oui est codé « 1 » etnon est codé « 0 » , la valeurcomptée est «1 »
4 Ajouter le nouveau vecteur à laliste des vecteurs, puis fermer
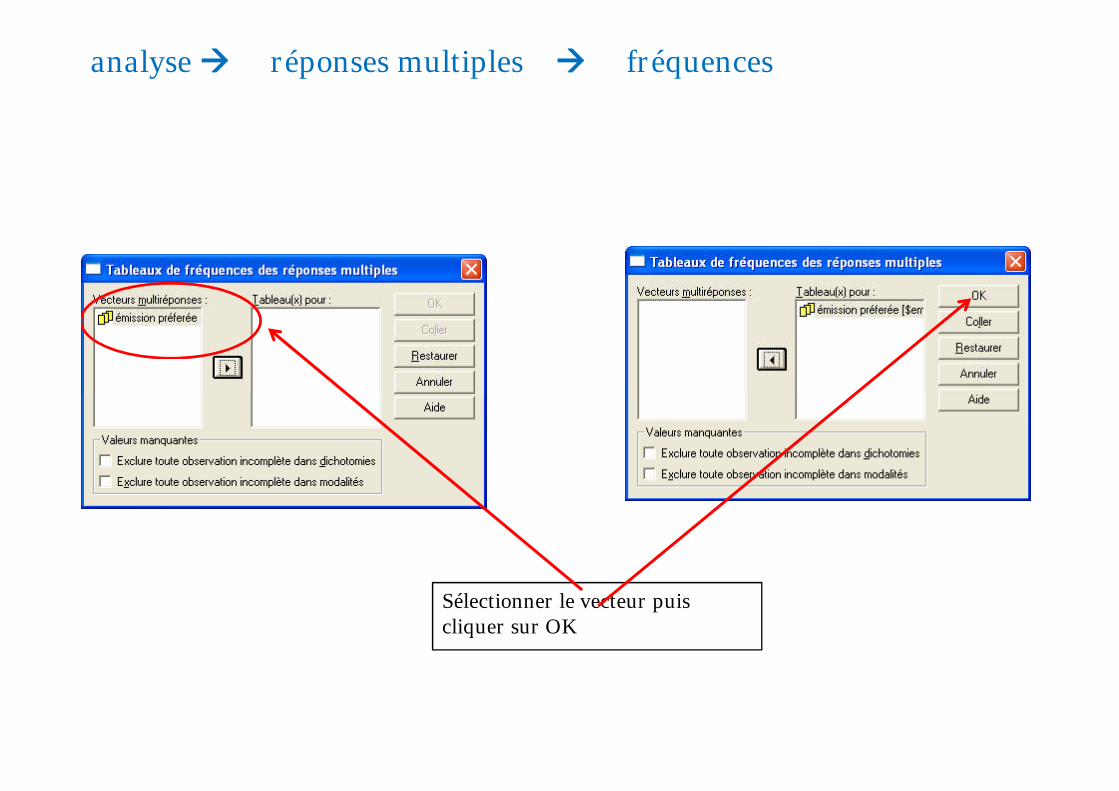
analyse réponses multiples fréquences
Sélectionner le vecteur puiscliquer sur OK
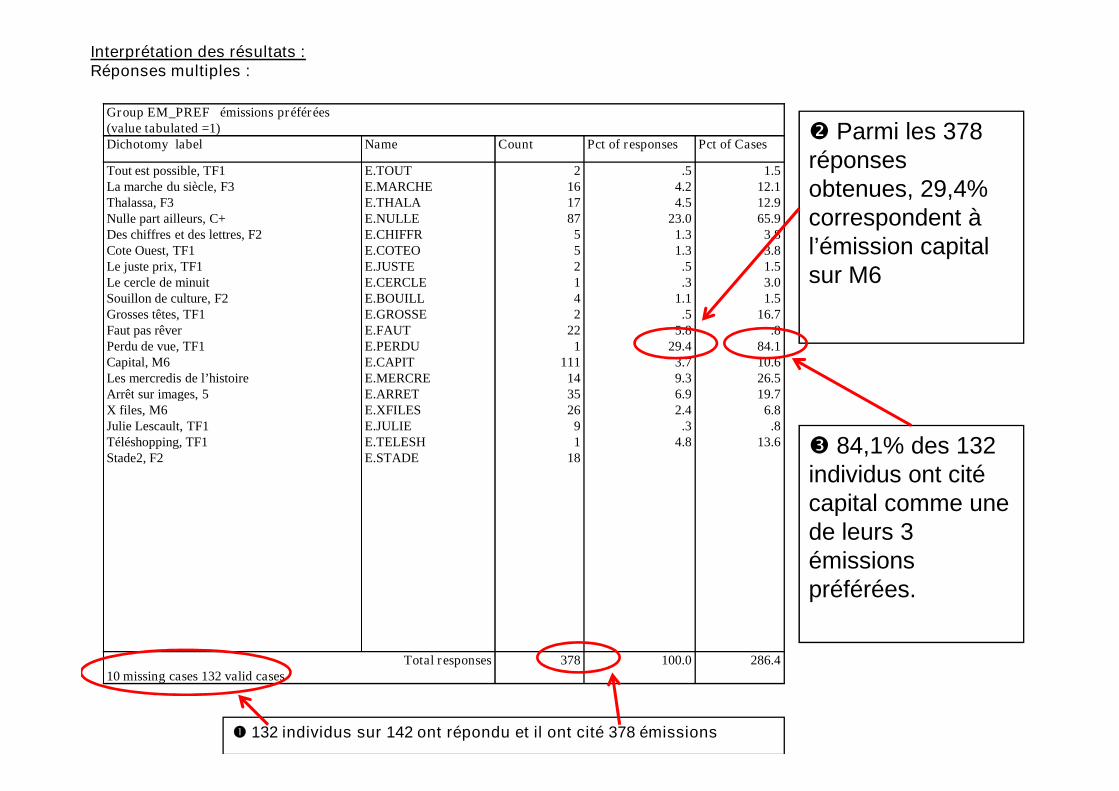
Group EM_PREF émissions préférées(value tabulated =1)Dichotomy label Name Count Pct of responses Pct of Cases
Tout est possible, TF1La marche du siècle, F3Thalassa, F3Nulle part ailleurs, C+Des chiffres et des lettres, F2Cote Ouest, TF1Le juste prix, TF1Le cercle de minuitSouillon de culture, F2Grosses têtes, TF1Faut pas rêverPerdu de vue, TF1Capital, M6Les mercredis de l’histoireArrêt sur images, 5
E.TOUTE.MARCHEE.THALAE.NULLEE.CHIFFRE.COTEOE.JUSTEE.CERCLEE.BOUILLE.GROSSEE.FAUTE.PERDUE.CAPITE.MERCREE.ARRET
2161787
552142
221
1111435
.54.24.5
23.01.31.3
.5
.31.1
.55.8
29.43.79.36.9
1.512.112.965.9
3.83.81.53.01.5
16.7.8
84.110.626.519.7
Parmi les 378réponsesobtenues, 29,4%correspondent àl’émission capitalsur M6
Interprétation des résultats :Réponses multiples :
Arrêt sur images, 5X files, M6Julie Lescault, TF1Téléshopping, TF1Stade2, F2
E.ARRETE.XFILESE.JULIEE.TELESHE.STADE
3526
91
18
6.92.4
.34.8
19.76.8
.813.6
Total responses10 missing cases 132 valid cases
378 100.0 286.4
84,1% des 132individus ont citécapital comme unede leurs 3émissionspréférées.
132 individus sur 142 ont répondu et il ont cité 378 émissions

Fiche n° 2 :Test de la normalité des variables
Rappels: De nombreuses méthodes statistiques reposent sur la normalité des variables métriques(ou de certaines variables ordinales, considérées comme métriques telles que les variablesmesurées par des échelles de Likert).
Procédure SPSS, Analyse et interprétation des résultats:
Sélectionner : Analyse Statistiques descriptives Fréquences Statistique cocherasymétrie et aplatissement dans Distribution.
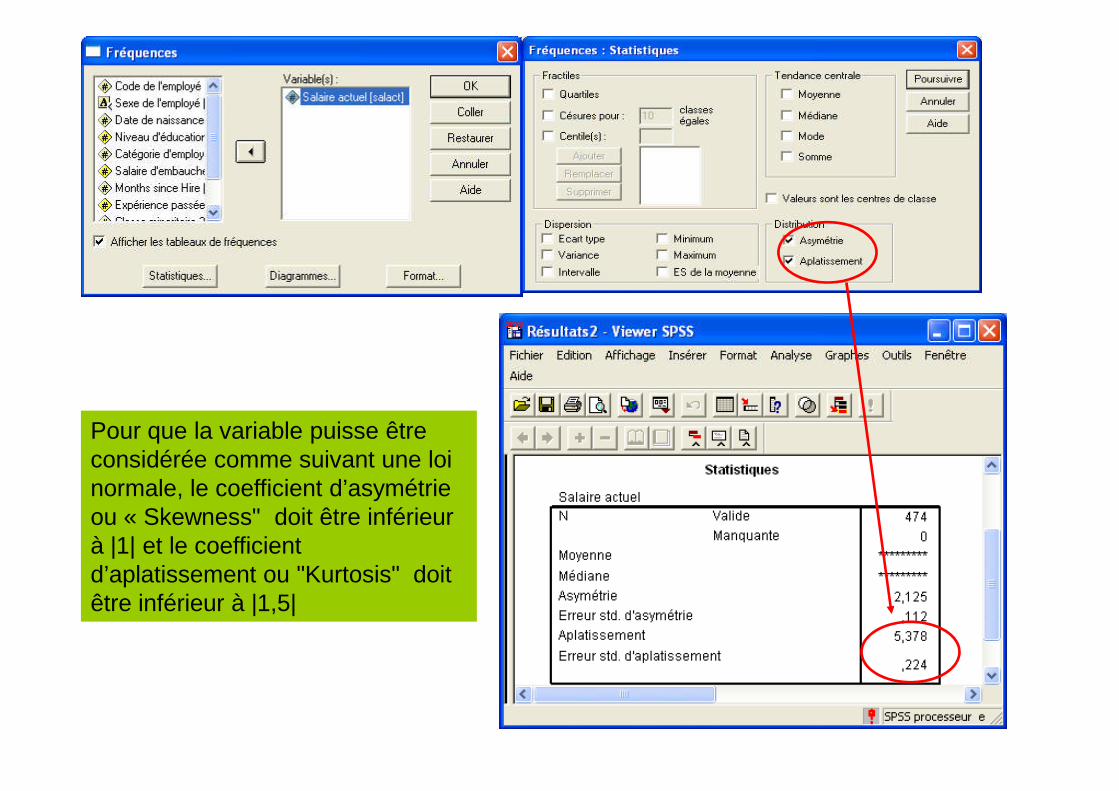
Pour que la variable puisse êtreconsidérée comme suivant une loinormale, le coefficient d’asymétrieou « Skewness" doit être inférieurà |1| et le coefficientd’aplatissement ou "Kurtosis" doitêtre inférieur à |1,5|
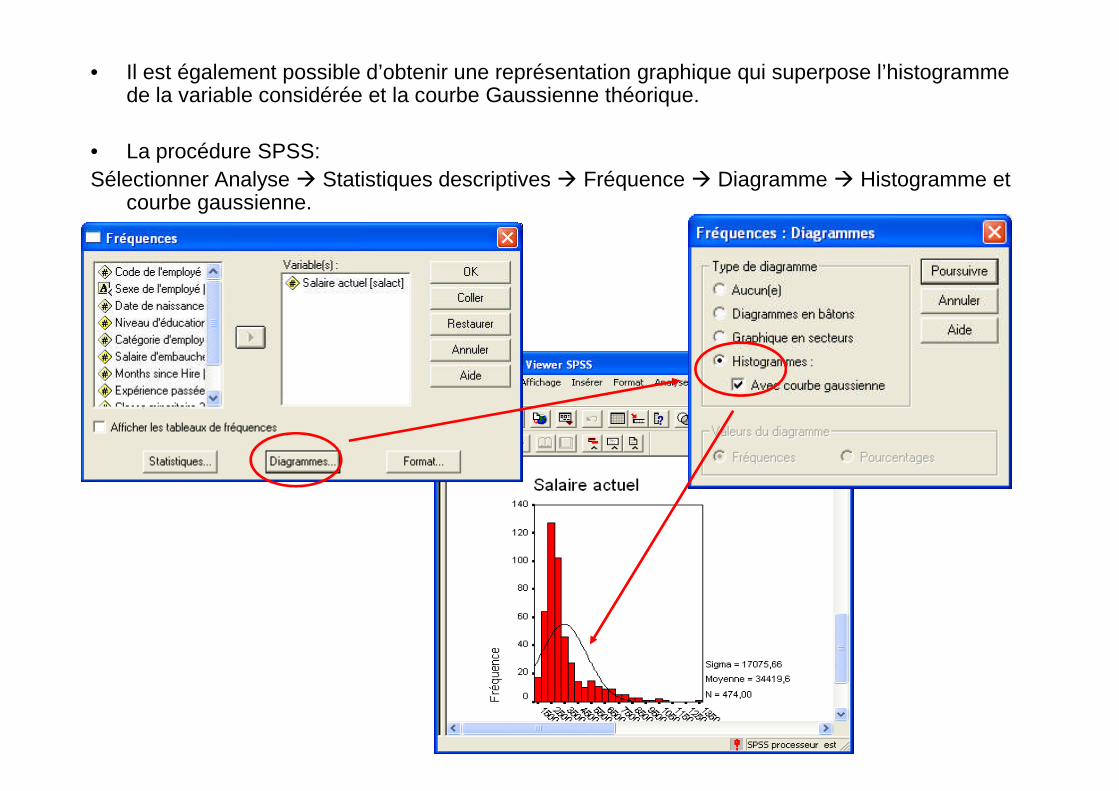
• Il est également possible d’obtenir une représentation graphique qui superpose l’histogrammede la variable considérée et la courbe Gaussienne théorique.
• La procédure SPSS:
Sélectionner Analyse Statistiques descriptives Fréquence Diagramme Histogramme etcourbe gaussienne.
Fiche n° 3:Les tris croisés et les tests d’indépendance du χ²
Rappels: Il est nécessaire de recourir au tests d’indépendance du χ² lorsque l’analyse porte surune relation bivariée comprenant deux variables non métrique (nominale et/ou ordinale).L’analyse de deux variables non métriques s’effectue à l’aide de fréquences conjointes (tableaude contingence).
Le tableau croisé contient les fréquences correspondant au croisement des caractéristiques quidéfinissent les deux variables.
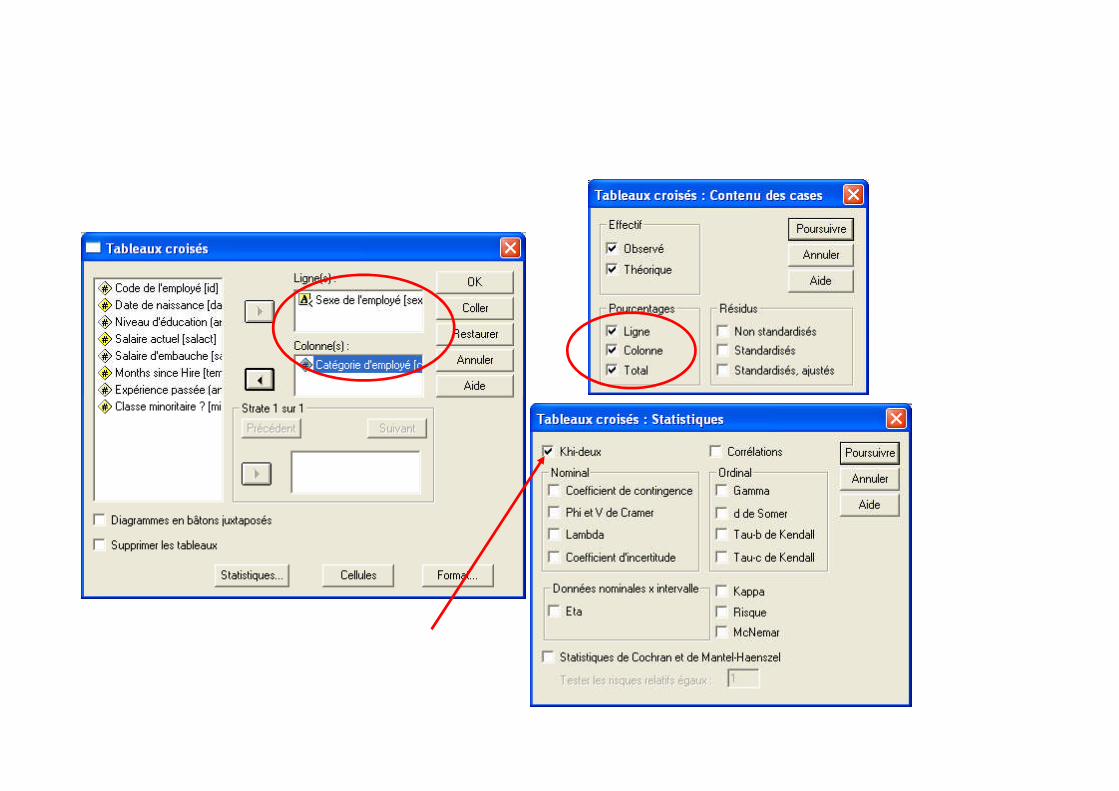
Faire des tris croisés et demander le test d’indépendance du χ²
définissent les deux variables.
Procédure SPSS : Pour obtenir un tableau croisé et faire le test d’indépendance du χ² la procédureSPSS est:
Sélectionner : Analyse Statistiques descriptives Tableaux croisés.

RESULTATS ET INTERPRETATION :Lecture d’un tableau croisé :
• Interpréter les résultats du test du χ² :
• Le test du χ² permet de vérifier si une relation entre
deux variables (non métriques) existe dans la population
• Le test du χ² permet donc d’accepter ou de rejeter• Le test du χ² permet donc d’accepter ou de rejeter
l’hypothèse H0 "il n’y a pas de relation entre les deuxvariables dans la population dont est issu l’échantillon".

Ici la valeur du χ² est relativement grande, ce qui lui permetd’être supérieure à la valeur critique correspondant auseuil de signification statistique de 0,05. ainsi, nousavons une signification de 0,000 ce qui nous permet derejeter H0 et de conclure qu’il existe bien une relationentre les deux variable dans la population
Remarque : dans la lecture du tableau du Khi-deux, il est préférable de seRemarque : dans la lecture du tableau du Khi-deux, il est préférable de seréférer au seuil de signification statistique qui est toujours le même (0,05)plutôt qu’à la valeur du χ² qui varie selon le nombre de degrés de liberté.
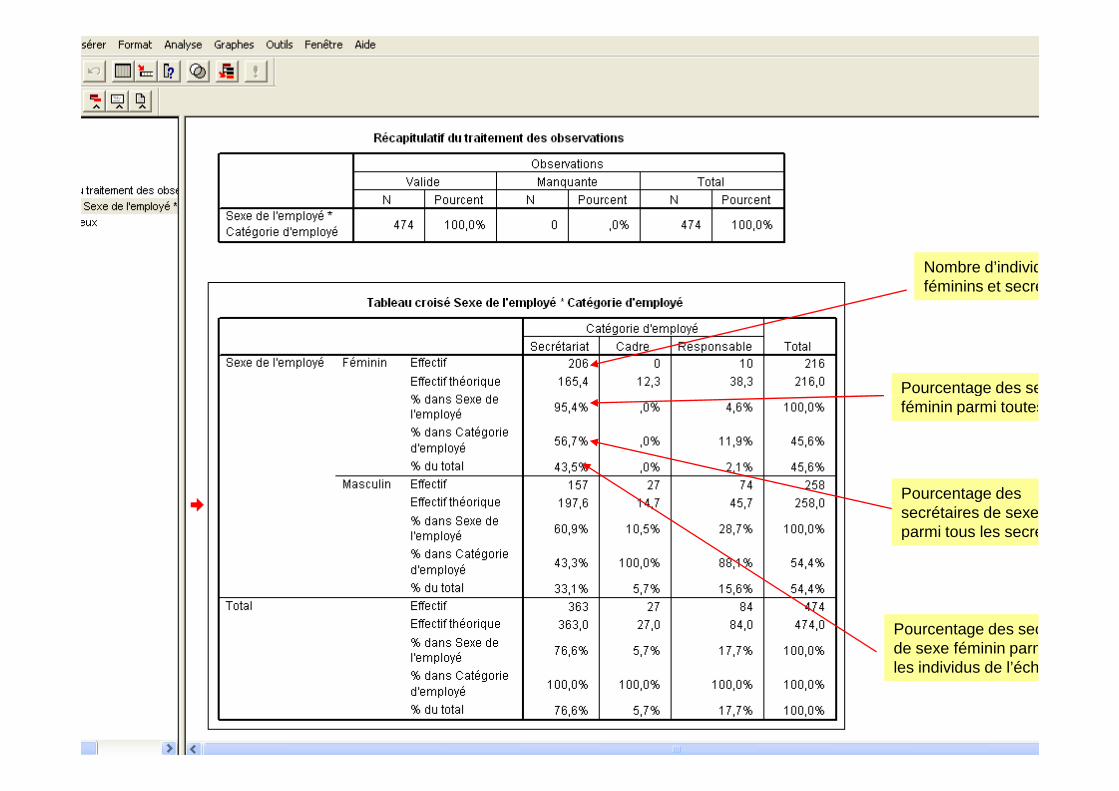
Nombre d’individusféminins et secrétaires
Pourcentage des secrétaires de sexePourcentage des secrétaires de sexeféminin parmi toutes les femme
Pourcentage dessecrétaires de sexe fémininparmi tous les secrétaires
Pourcentage des secrétairesde sexe féminin parmi tousles individus de l’échantillon
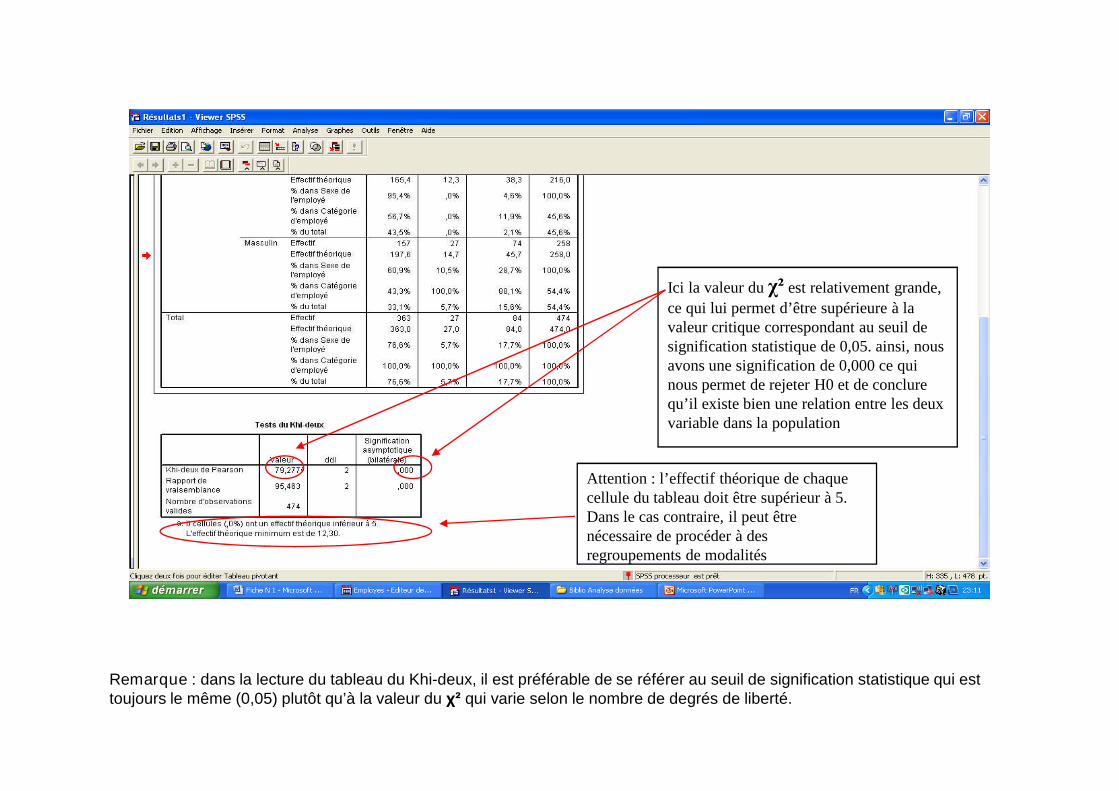
Ici la valeur du χ² est relativement grande,
ce qui lui permet d’être supérieure à lavaleur critique correspondant au seuil designification statistique de 0,05. ainsi, nousavons une signification de 0,000 ce quinous permet de rejeter H0 et de conclurequ’il existe bien une relation entre les deuxqu’il existe bien une relation entre les deuxvariable dans la population
Attention : l’effectif théorique de chaquecellule du tableau doit être supérieur à 5.Dans le cas contraire, il peut êtrenécessaire de procéder à desregroupements de modalités
Remarque : dans la lecture du tableau du Khi-deux, il est préférable de se référer au seuil de signification statistique qui esttoujours le même (0,05) plutôt qu’à la valeur du χ² qui varie selon le nombre de degrés de liberté.

FICHES N° 4LES TESTS DE COMPARAISON DE MOYENNES
Rappels
Il est nécessaire de recourir aux tests de comparaison de moyennes lorsque l’analyse porte surune relation bivariée comprenant une variable non métrique (nominale ou ordinale) et unevariable métrique (d’intervalle ou de ratio). Les tests de comparaison de moyennes sontégalement utilisables lorsque l’on a une variable métrique et une valeur de test.
Le test de comparaison de moyennes est approprié à l’analyse de relations de dépendance et
1. Les tests de comparaison de moyennes pour échantillons indépendants
Le test de comparaison de moyennes est approprié à l’analyse de relations de dépendance etd’interdépendance.
Il existe 3 types de tests de comparaison de moyennes selon la situation à analyser et la nature del’échantillon :
3. Les tests de comparaison de moyennes pour échantillon unique.
2. Les tests de comparaison de moyennes pour échantillons appariés

Le test de comparaison de moyennes pour échantillons indépendants…
Rappels :Le test de comparaison de moyennes pour échantillons indépendants suppose que lavariable non métrique (nominale ou ordinale) comporte seulement 2 modalités.Lorsque la variable non métrique comporte plus de 2 modalités (dans ce cas, il y a doncplus de 2 moyenne à comparer), il devient nécessaire de faire une analyse de varianceà un facteur.
L’hypothèse H0 est ici la suivante : "les moyennes observées dans les deux groupessont égales«l’hypothèse alternative est H1 "les moyennes observées dans les deux groupes sont
Exemple, on souhaite savoir si le salaire à l’embauche est égal chez les hommes et lesfemmes.
Procédure SPSS
Sélectionner : Analyse Comparer les moyennes Test t pour échantillons indépendants.
l’hypothèse alternative est H1 "les moyennes observées dans les deux groupes sontdifférentes".

1.on sélectionne la variablemétrique sur laquelle onsouhaite faire le test decomparaison de moyennes
2. on sélectionne la variablenon métrique à partir delaquelle on constitue les deuxsous-échantillonssous-échantillons
3. on définit les sous-échantillons àpartir des valeurs de la variable nonmétrique. Dans cet exemple, lepremier sous-échantillon estconstitué par les hommes « 1 » et lesecond par les femmes « 2 ».

Test-t
Sexe de l'employé N Moyenne Ecart-type
Erreur
standard
moyenne
Salaire d'embauche Féminin216 $13,091.97 $2,935.599 $199.742
Masculin258 $20,301.40 $9,111.781 $567.275
RESULTATS ET INTERPRETATION :
Nombre d’individus composantchaque sous-échantillon. Onconsidère généralement qu’il fautau minimum 30 individus parsous-groupe. Cette condition està vérifier, contrairement au testdu Chi-deux, SPSS ne donne pasd’indication dans ce sens
Moyenne de chaque sous-échantillon sous la variable àtester (variable métrique). Cetindicateur permet de se faireun première idée et de voirquel sous-groupe à lamoyenne la plus élevée.
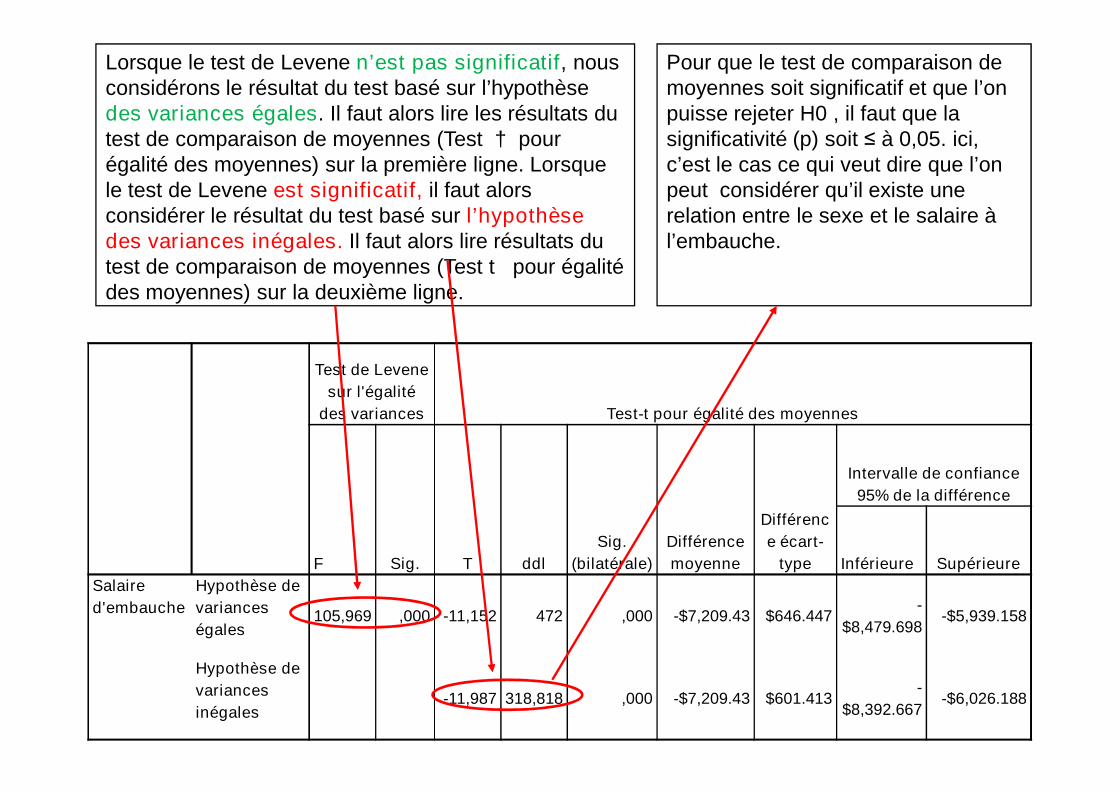
Test de Levene
sur l'égalité
Lorsque le test de Levene n’est pas significatif, nousconsidérons le résultat du test basé sur l’hypothèsedes variances égales. Il faut alors lire les résultats dutest de comparaison de moyennes (Test † pourégalité des moyennes) sur la première ligne. Lorsquele test de Levene est significatif, il faut alorsconsidérer le résultat du test basé sur l’hypothèsedes variances inégales. Il faut alors lire résultats dutest de comparaison de moyennes (Test t pour égalitédes moyennes) sur la deuxième ligne.
Pour que le test de comparaison demoyennes soit significatif et que l’onpuisse rejeter H0 , il faut que lasignificativité (p) soit ≤ à 0,05. ici,c’est le cas ce qui veut dire que l’onpeut considérer qu’il existe unerelation entre le sexe et le salaire àl’embauche.
sur l'égalité
des variances Test-t pour égalité des moyennes
F Sig. T ddl
Sig.
(bilatérale)
Différence
moyenne
Différenc
e écart-
type
Intervalle de confiance
95% de la différence
Inférieure Supérieure
Salaire
d'embauche
Hypothèse de
variances
égales105,969 ,000 -11,152 472 ,000 -$7,209.43 $646.447
-
$8,479.698-$5,939.158
Hypothèse de
variances
inégales-11,987 318,818 ,000 -$7,209.43 $601.413
-
$8,392.667-$6,026.188

Le test de comparaison de moyennes pour échantillons appariés…
Rappels :Le test de comparaison de moyennes pour échantillons appariés suppose que lavariable non métrique (nominale ou ordinale) comporte seulement deux modalités.Le test de comparaison de moyennes pour échantillons appariés est utilisé lorsque l’onsouhaite comparer deux moyennes calculées chez les mêmes individus.Par exemple, on peut souhaiter comparer l’attitude des spectateurs face à un produitmarocain et face à un produit étranger. Autre exemple, on peut souhaiter savoir si lesindividus dépensent plus dans un magasin A que dans un magasin B. Il est parfoiségalement nécessaire de faire des mesures "avant / après" , comme par exemple lorsd’une exposition à une publicité, pour voir si il y a un effet de la pub.d’une exposition à une publicité, pour voir si il y a un effet de la pub.Dans ce cas, on teste l’hypothèse H0 selon laquelle les moyennes observées dans lesdeux groupes sont égales.
Procédures SPSS :
Sélectionner Analyse Comparer les moyennes Test t pour échantillons appariés
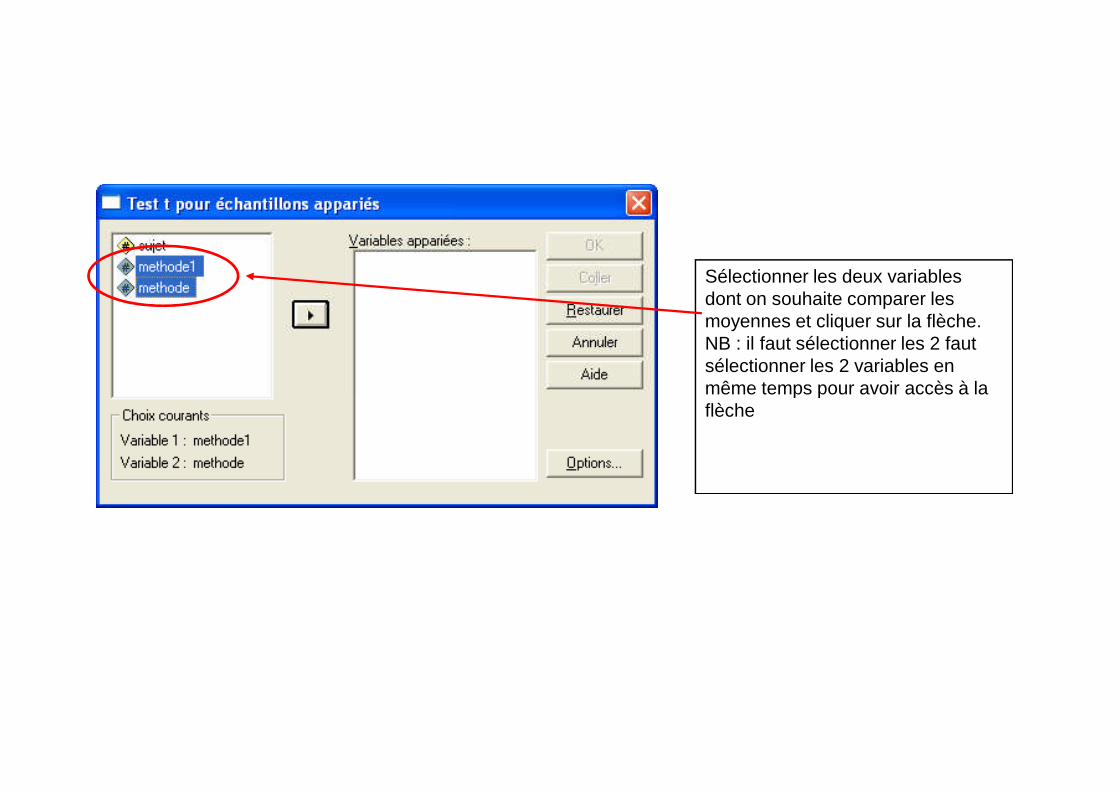
Sélectionner les deux variablesdont on souhaite comparer lesmoyennes et cliquer sur la flèche.NB : il faut sélectionner les 2 fautsélectionner les 2 variables enmême temps pour avoir accès à lamême temps pour avoir accès à laflèche

Résultats et Interprétation (exemple 1):Statistiques pour échantillons appariés
Moyenne
N Ecart-type
Erreur standardmoyenne
Paire Regarder la TV c’est une1. activité qui compte vraiment
beaucoup pour moi. j’aimeparticulièrement parler d’émissions deTV
2.502.69
139139
On a un écart de /0,19/Entre les 2 moyennes
P est à 0,05, on peut doncen conclure que la différenceentre les deux moyennes eststatistiquement significative
Différences
Moyenne Ecart-type Erreur standardmoyenne
Intervalle de confiance 95% de ladifférence
t ddl Sig (bilatérale)
Inférieur supérieure
Paire1
Regarder la TV c’est uneactivité qui comptevraiment beaucoup purmoi, j’aiparticulièrement parlerd’émission de TV
-19 1.06 9.01E609 -37 -1.61E-02 -2.156 138 033
La valeur de l’écart permet de calculer le t auquel on associe une significativité (p)
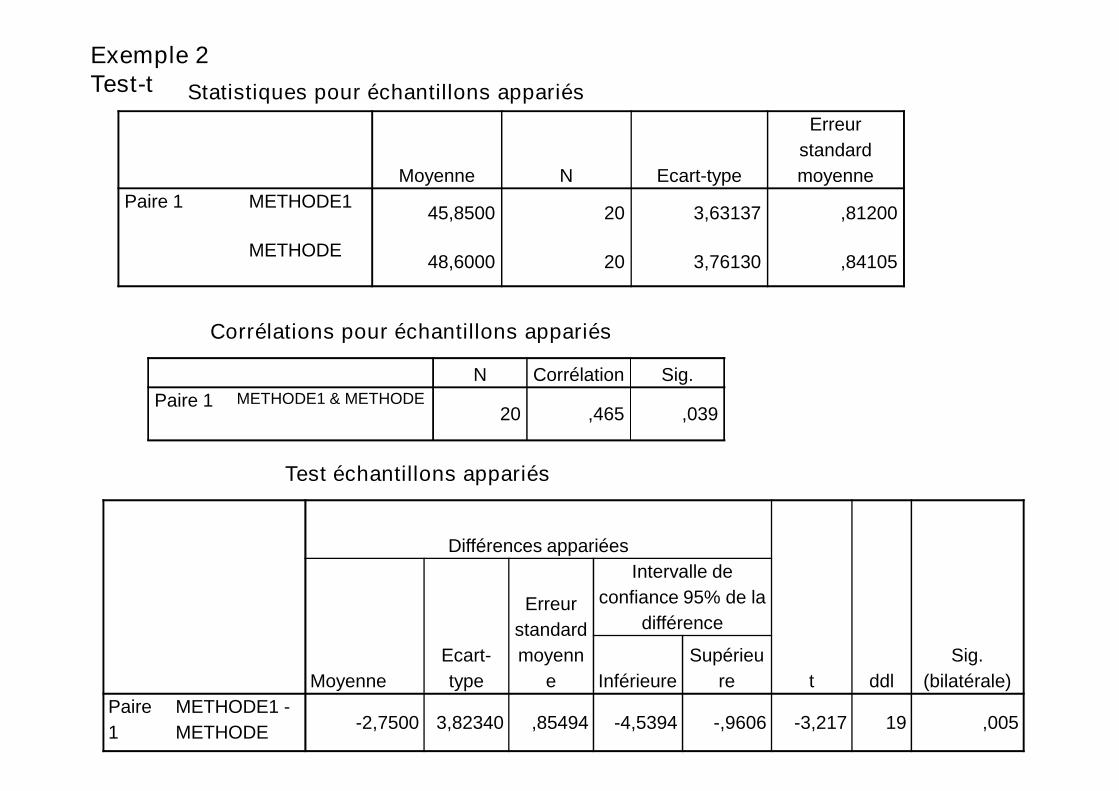
Exemple 2Test-t
Moyenne N Ecart-type
Erreur
standard
moyenne
Paire 1 METHODE145,8500 20 3,63137 ,81200
METHODE48,6000 20 3,76130 ,84105
Statistiques pour échantillons appariés
Corrélations pour échantillons appariés
N Corrélation Sig.
Paire 1 METHODE1 & METHODEPaire 1 METHODE1 & METHODE20 ,465 ,039
Test échantillons appariés
Différences appariées
t ddl
Sig.
(bilatérale)Moyenne
Ecart-
type
Erreur
standard
moyenn
e
Intervalle de
confiance 95% de la
différence
Inférieure
Supérieu
re
Paire
1
METHODE1 -
METHODE-2,7500 3,82340 ,85494 -4,5394 -,9606 -3,217 19 ,005
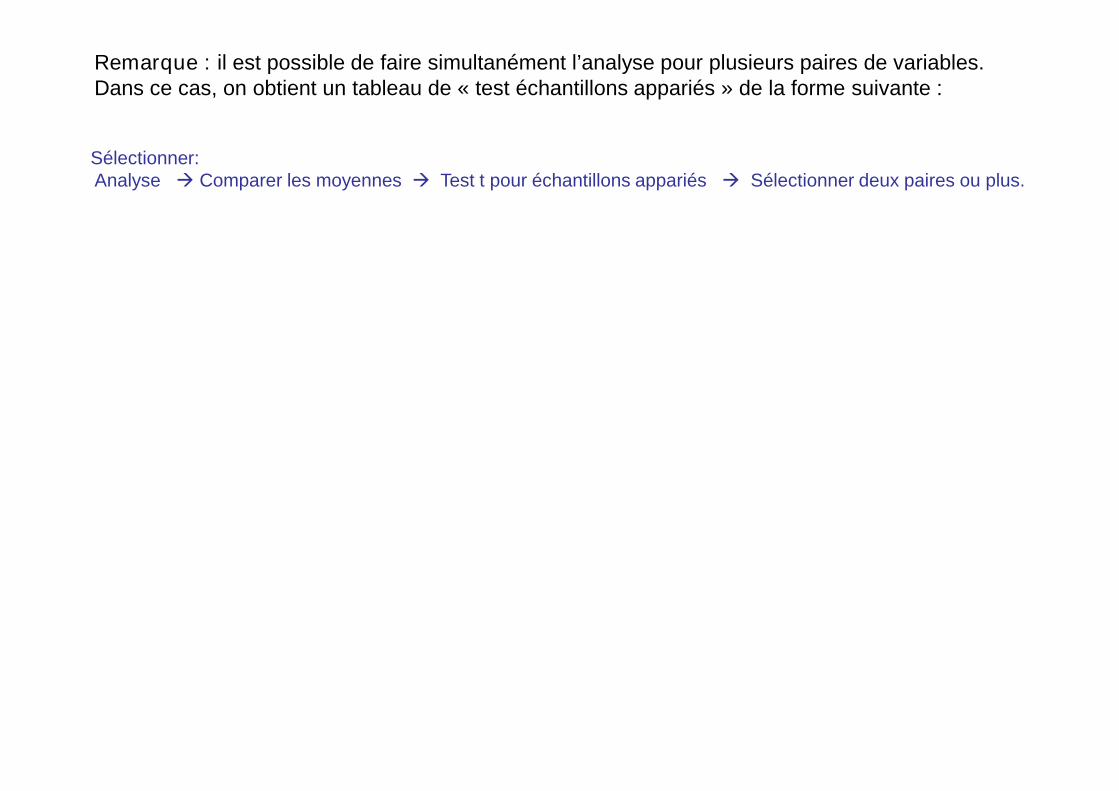
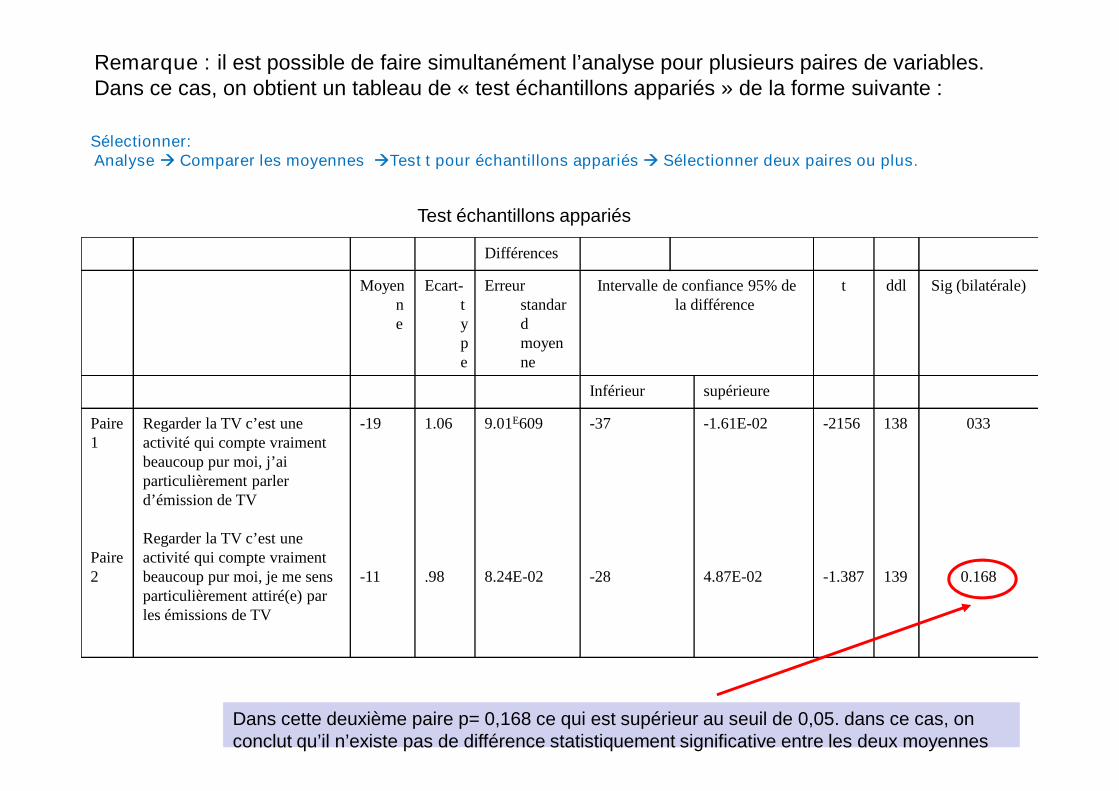
Remarque : il est possible de faire simultanément l’analyse pour plusieurs paires de variables.Dans ce cas, on obtient un tableau de « test échantillons appariés » de la forme suivante :
Sélectionner:Analyse Comparer les moyennes Test t pour échantillons appariés Sélectionner deux paires ou plus.
Test échantillons appariés
Différences
Moyenne
Ecart-type
Erreurstandardmoyenne
Intervalle de confiance 95% dela différence
t ddl Sig (bilatérale)
Inférieur supérieure
Remarque : il est possible de faire simultanément l’analyse pour plusieurs paires de variables.Dans ce cas, on obtient un tableau de « test échantillons appariés » de la forme suivante :
Sélectionner:Analyse Comparer les moyennes Test t pour échantillons appariés Sélectionner deux paires ou plus.
Dans cette deuxième paire p= 0,168 ce qui est supérieur au seuil de 0,05. dans ce cas, onconclut qu’il n’existe pas de différence statistiquement significative entre les deux moyennes
Inférieur supérieure
Paire1
Paire2
Regarder la TV c’est uneactivité qui compte vraimentbeaucoup pur moi, j’aiparticulièrement parlerd’émission de TV
Regarder la TV c’est uneactivité qui compte vraimentbeaucoup pur moi, je me sensparticulièrement attiré(e) parles émissions de TV
-19
-11
1.06
.98
9.01E609
8.24E-02
-37
-28
-1.61E-02
4.87E-02
-2156
-1.387
138
139
033
0.168

Le test de comparaison de moyennes pour échantillon unique …
Rappels :
Le test de comparaison de moyennes pour échantillon unique est un peu différent des deuxprécédents. Il permet de comparer la moyenne d’une variable métrique avec une valeur, issue dedonnées secondaires.
Gardons l’exemple du cas « Pratiques culturelles des étudiants de la FSTG ». Imaginons qu’unorganisme de sondage ait récemment fait une enquête auprès de la population étudiante du Marocet que cette étude a montré que les étudiants marocains dépensent en moyenne 50 Dh par joursen « produits alimentaires ».
L’hypothèse H0 testée est alors la suivante : la moyenne obtenue pour l’échantillon des étudiants àà la FSTG est égale à celle relevée pour l’ensemble des étudiants marocains.
Procédures SPSS
Sélectionner : Analyse Comparer les moyennes Test t pour échantillon unique
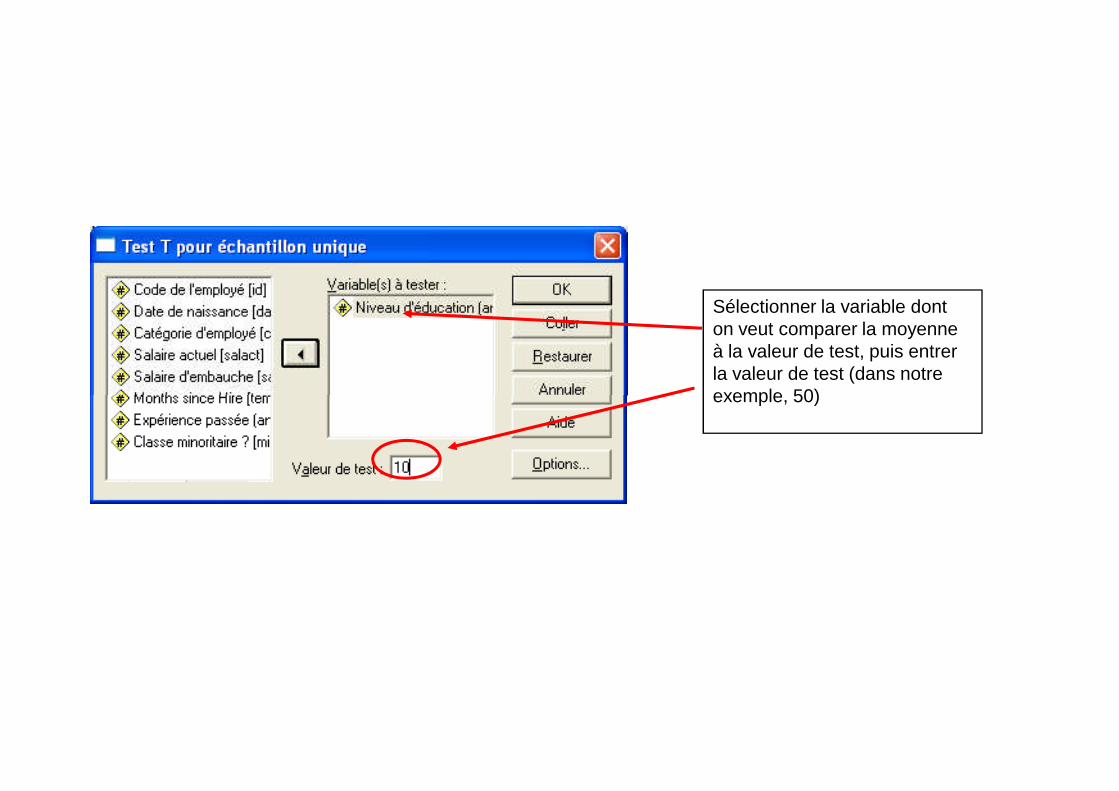
Sélectionner la variable donton veut comparer la moyenneà la valeur de test, puis entrerla valeur de test (dans notreexemple, 50)exemple, 50)
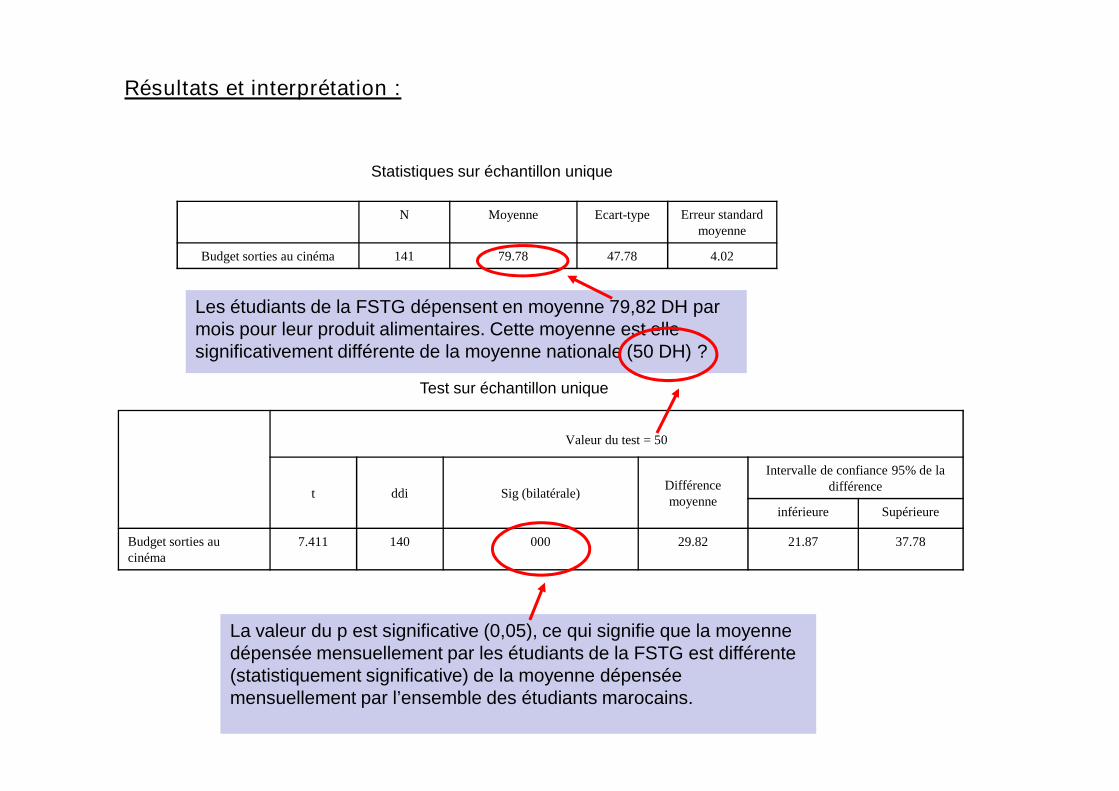
Les étudiants de la FSTG dépensent en moyenne 79,82 DH parmois pour leur produit alimentaires. Cette moyenne est ellesignificativement différente de la moyenne nationale (50 DH) ?
Résultats et interprétation :
N Moyenne Ecart-type Erreur standardmoyenne
Budget sorties au cinéma 141 79.78 47.78 4.02
Test sur échantillon unique
Statistiques sur échantillon unique
La valeur du p est significative (0,05), ce qui signifie que la moyennedépensée mensuellement par les étudiants de la FSTG est différente(statistiquement significative) de la moyenne dépenséemensuellement par l’ensemble des étudiants marocains.
Test sur échantillon unique
Valeur du test = 50
t ddi Sig (bilatérale)Différencemoyenne
Intervalle de confiance 95% de ladifférence
inférieure Supérieure
Budget sorties aucinéma
7.411 140 000 29.82 21.87 37.78

Rappels :Un coefficient de corrélation r est une mesure d’association (d’interdépendance) entre deuxvariables métriques. Elle mesure l’intensité de la co-variation entre les deux variables. Cettemesure est standardisée (i.e,. elle ne dépend pas de l’unité utilisée pour chaque variable), et estcomprise entre -1et +1.
La corrélation…
FICHE N° 6 : CORRELATION ET REGRESSION LINEAIRES
Plus le coefficient est proche de 1 en valeur absolue, plus les variables sont dites corrélées :si r est proche de +1, ceci signifie que les deux variables varient dans le même sens (ex., « lesdépenses de loisirs et le revenu ») ;si r est proche de -1, ceci signifie que les deux variables varient en sens inverse l’une de l’autresi r est proche de -1, ceci signifie que les deux variables varient en sens inverse l’une de l’autre(ex., « plus on s’éloigne du centre de Casa, moins les loyers sont élevés ») ;
Plus r est proche de 0, moins les variables sont corrélées. 0 signifie l’absence de corrélation entreles deux variable (attention d’autres relations restant toujours possibles, exemple : relationssinusoïdale de type y = sin x).
Dans la mesure où l’on travaille sur un échantillon (et non sur la population totale, donc lacorrélation observée peut être due à la fluctuation), SPSS teste, si le coefficient obtenu estsignificativement différent de 0 (autrement dit, si le coefficient obtenu est différent de 0 dans lapopulation). Il indique le risque d’erreur de première espèce (sig.), à savoir, le risque de rejeter àtort l’hypothèse de non corrélation (ou ce qui revient au même, l’hypothèse H0 suivante : r = 0). SiH0 est rejetée, alors on conclut que les variables sont corrélées.
SPSS permet de représenter sur un tableau croisé les mesures de corrélation deux à deux d’unnombre illimité de variables (par rapport à des besoins usuels, j’entend).

Fichier utilisé : Voitures.sav ou utiliser les données du TD2 exo 13 (poidset tailles des bébés)
Procédure SPSS :
Analyse Corrélation Bivariée
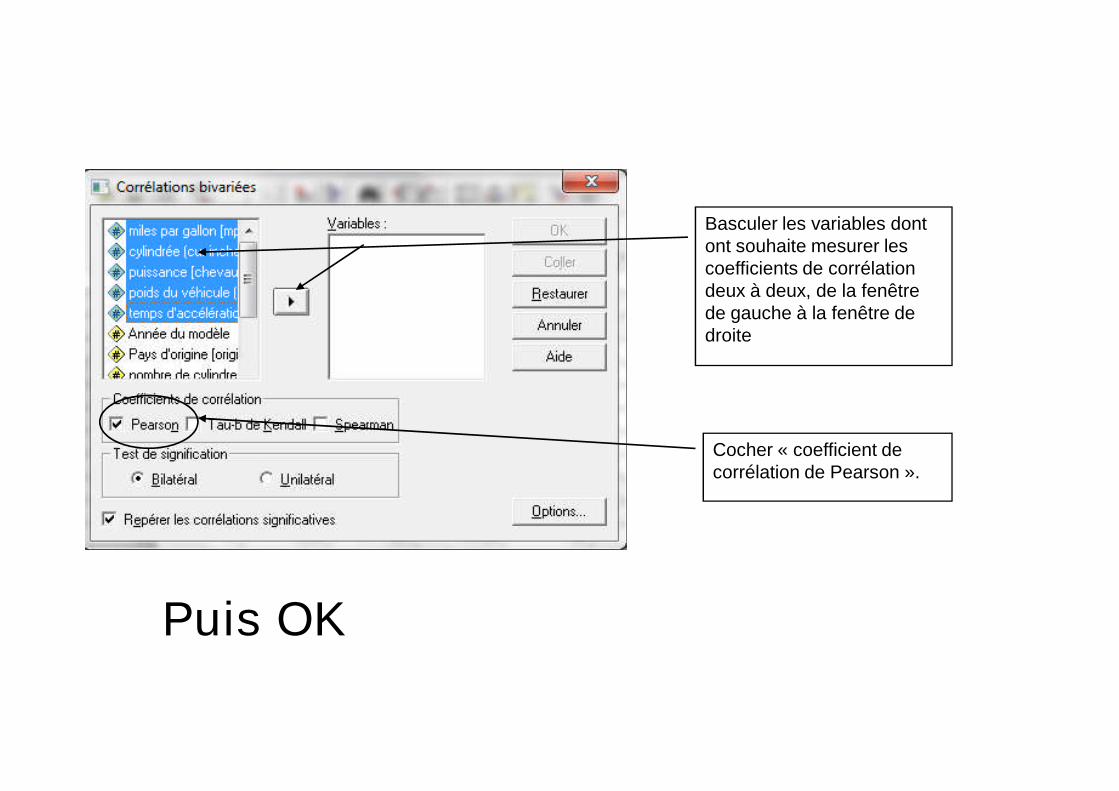
Basculer les variables dontont souhaite mesurer lescoefficients de corrélationdeux à deux, de la fenêtrede gauche à la fenêtre dedroite
Cocher « coefficient decorrélation de Pearson ».
Puis OK

Corrélations
1,000 -,789** -,771** -,807** ,434**
, ,000 ,000 ,000 ,000
398 398 392 398 398
-,789** 1,000 ,897** ,933** -,545**
,000 , ,000 ,000 ,000
398 406 400 406 406
-,771** ,897** 1,000 ,859** -,701**
,000 ,000 , ,000 ,000
Corrélation de Pearson
Sig. (bilatérale)
N
Corrélation de Pearson
Sig. (bilatérale)
N
Corrélation de Pearson
Sig. (bilatérale)
miles par gallon
cylindrée (cu. inches)
puissance
miles pargallon
cylindrée(cu. inches) puissance
poids duvéhicule (lbs.)
tempsd'accélérationde 0 à 60 mph
(sec)
Résultats et interprétation :
,000 ,000 , ,000 ,000
392 400 400 400 400
-,807** ,933** ,859** 1,000 -,415**
,000 ,000 ,000 , ,000
398 406 400 406 406
,434** -,545** -,701** -,415** 1,000
,000 ,000 ,000 ,000 ,
398 406 400 406 406
Sig. (bilatérale)
N
Corrélation de Pearson
Sig. (bilatérale)
N
Corrélation de Pearson
Sig. (bilatérale)
N
poids du véhicule (lbs.)
temps d'accélérationde 0 à 60 mph (sec)
La corrélation est significative au niveau 0.01 (bilatéral).**.
Pour chaque couple de variable (xi, xj), les résultats indiquent le coefficient (de Pearson) estimé, et le risque d’erreurde première espèce ou signification (sig.)-soit le risque de se tromper sur le sens de la corrélation-. Si sig. ‹0,05, onpeut conclure à l’existence d’un corrélation, au seuil 0,05 entre les deux variables (au seuil de signification indiqué par lastatistique sig.) le symbole **indique tous les sig. Inférieurs à 0.05. Ceci permet une lecture rapide du tableau.

Création du diagramme interactif
Cet exercice présente les procédures de base permettant de créer desdiagrammes interactifs à l’aide du sous-menu Interactif du menu Graphes.
Il illustre les opérations suivantes :•Création d’un diagramme en bâtons interactif récapitulant des groupesd’observations
•Modification de la légende pour créer un diagramme en bâtons juxtaposés
•Affichage des valeurs moyennes dans un diagramme en bâtons
•Application d’un modèle de graphiques
•Collage d’un diagramme interactif dans une autre application

Les diagrammes standard (non interactifs) sont présentés après. si vous souhaitezmodifier un diagramme crée par une procédure statistique comme fréquences, suivezles instructions relatives aux diagrammes standard."Glisser-déplacer". En ce qui concerne les diagrammes interactifs, la technique du« glisser- déplacer » permet de déplacer les variables à l’intérieur des boîtes de
Cet exercice utilise le fichier Employes data.sav
« glisser- déplacer » permet de déplacer les variables à l’intérieur des boîtes dedialogue. (Dans les autres boîtes de dialogue du système, l’utilisateur doit cliquer sur unbouton fléché pour déplacer une variable).
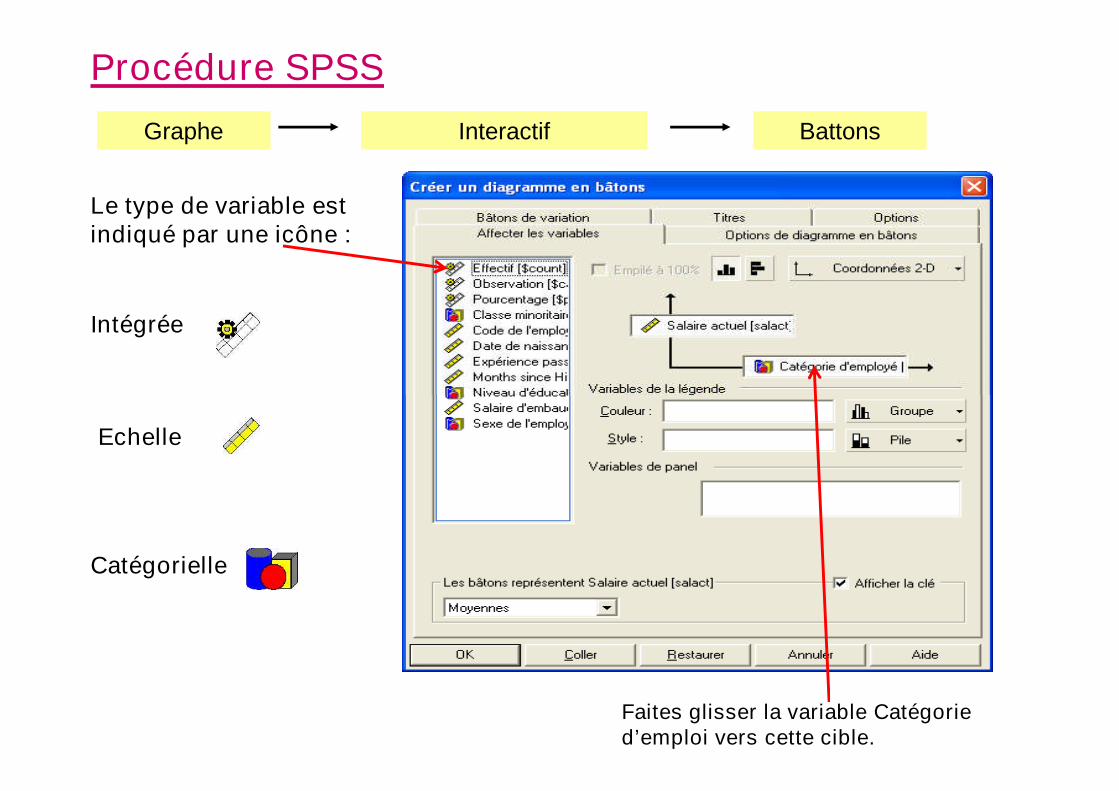
Graphe Interactif Battons
Procédure SPSS
Le type de variable estindiqué par une icône :
Intégrée
Echelle
Catégorielle
Faites glisser la variable Catégoried’emploi vers cette cible.
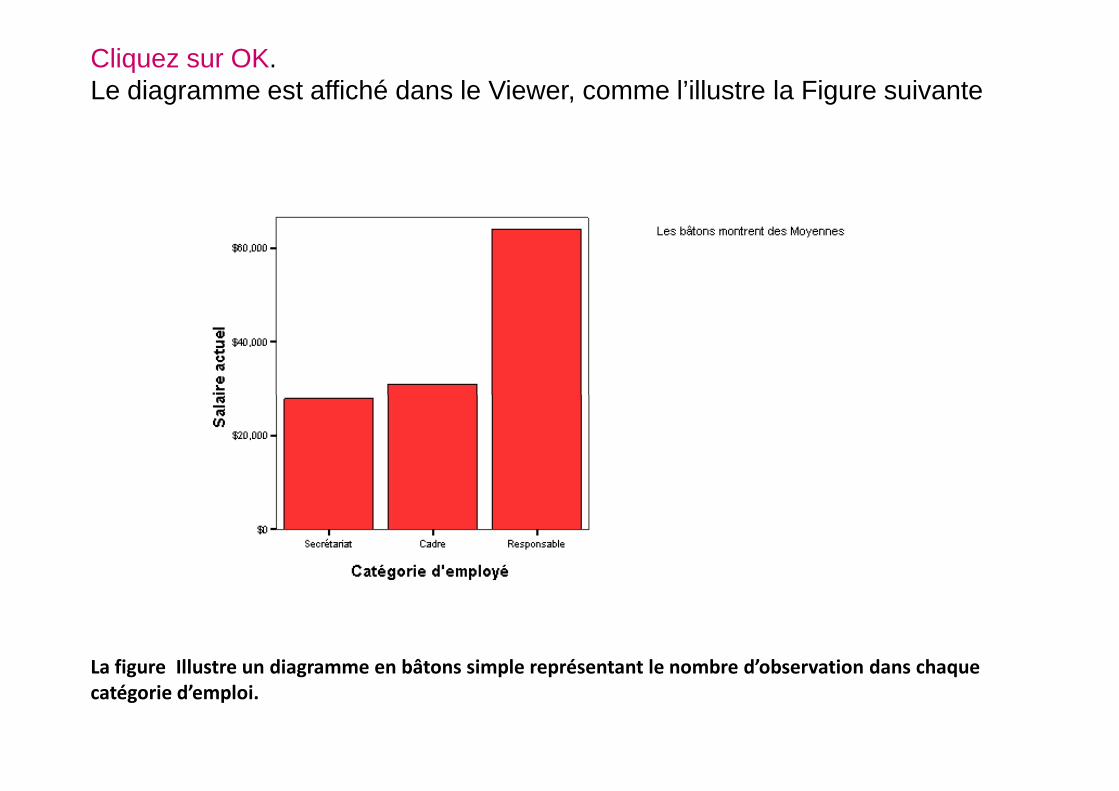
Cliquez sur OK.Le diagramme est affiché dans le Viewer, comme l’illustre la Figure suivante
La figure Illustre un diagramme en bâtons simple représentant le nombre d’observation dans chaquecatégorie d’emploi.

La variable Effectif est affectée par défaut à l’axe vertical. Trois types devariable sont disponibles dans la liste des variables : variables intégrées,d’échelle et catégorielles. Une dimension de données intégrée crée undiagramme sur la base des effectifs ou des pourcentages des observationstrouvées dans vos données. Par exemple, la variable Effectif produit undiagramme sur la base des effectifs des observations dans chaque catégorie.Une dimension de données d’échelle produit un diagramme dans lequel unefonction de la variable est représentée (la valeur moyenne, par exemple). Lafonction de la variable est représentée (la valeur moyenne, par exemple). Lavariable Salaire actuel est une variable d’échelle. Une dimension de donnéescatégorielle produit un diagramme avec des graduations indiquant des valeursdiscrètes, sans valeurs entre les graduations. La variable Catégorie d’emploiest une variable catégorielle. Ses catégories sont Employé de bureau,Personnel pénitentiaire et Cadre.Cliquez sur la variable catégorielle Catégorie d’emploi, maintenez le boutongauche de la souris enfoncé et faites glisser la variable vers la cible de l’axehorizontal.

Modification de la légende
Supposons que vous souhaitez visualiser la répartition des sexes dansles catégories d’emploi. Vous pouvez modifier la légende pour produireune répartition par sexe dans le diagramme.•Double-cliquez sur le diagramme pour l’activer.•Cliquer sur l’outil Affecter les variables du diagramme pour ouvrir laboîte de dialogue du même nom.
Faites glisser la variablesexe vers la cible couleur
Boîte de dialogue Affecter les variables du diagramme
sexe vers la cible couleursous variable de la légende.Dans la liste déroulante,sélectionnez Juxtaposer
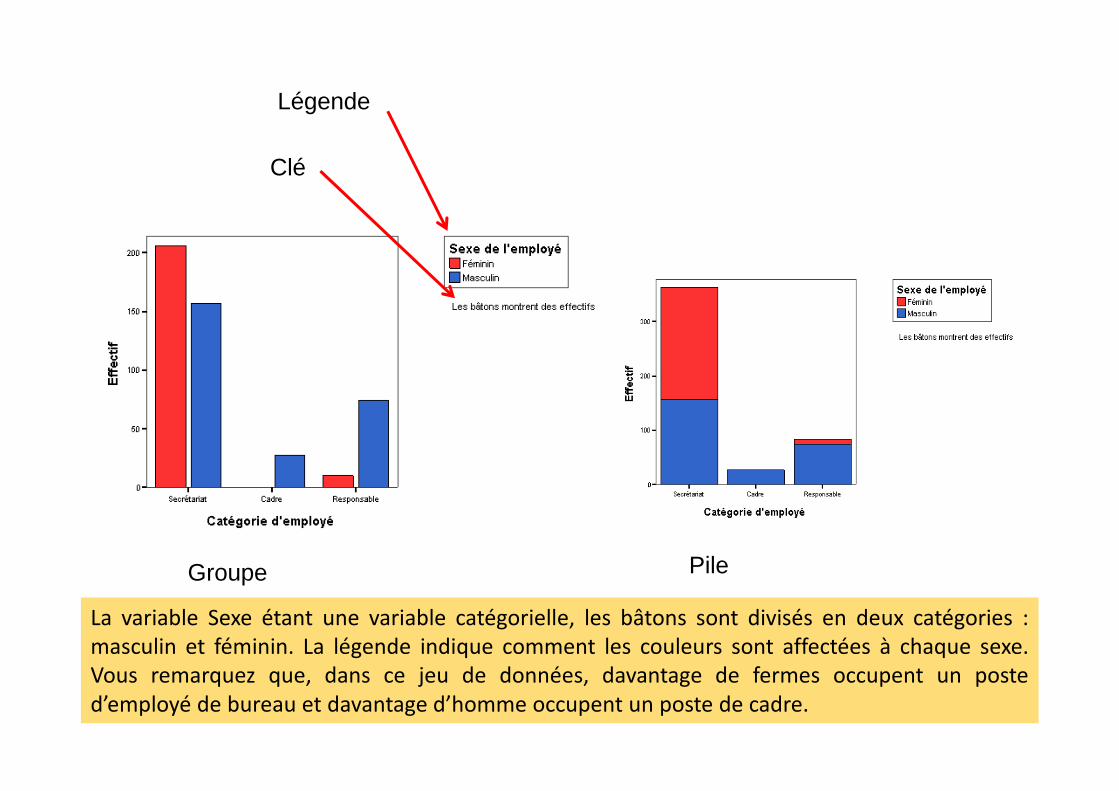
Clé
Légende
Groupe Pile
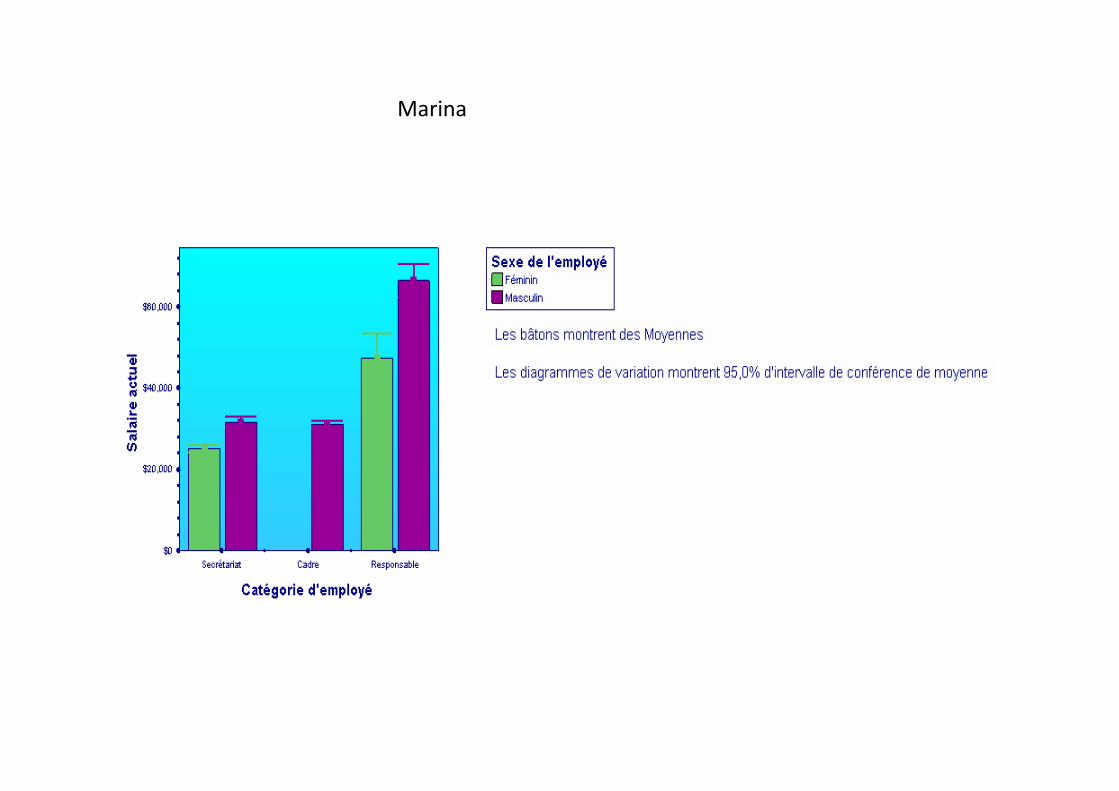
La variable Sexe étant une variable catégorielle, les bâtons sont divisés en deux catégories :masculin et féminin. La légende indique comment les couleurs sont affectées à chaque sexe.Vous remarquez que, dans ce jeu de données, davantage de fermes occupent un posted’employé de bureau et davantage d’homme occupent un poste de cadre.
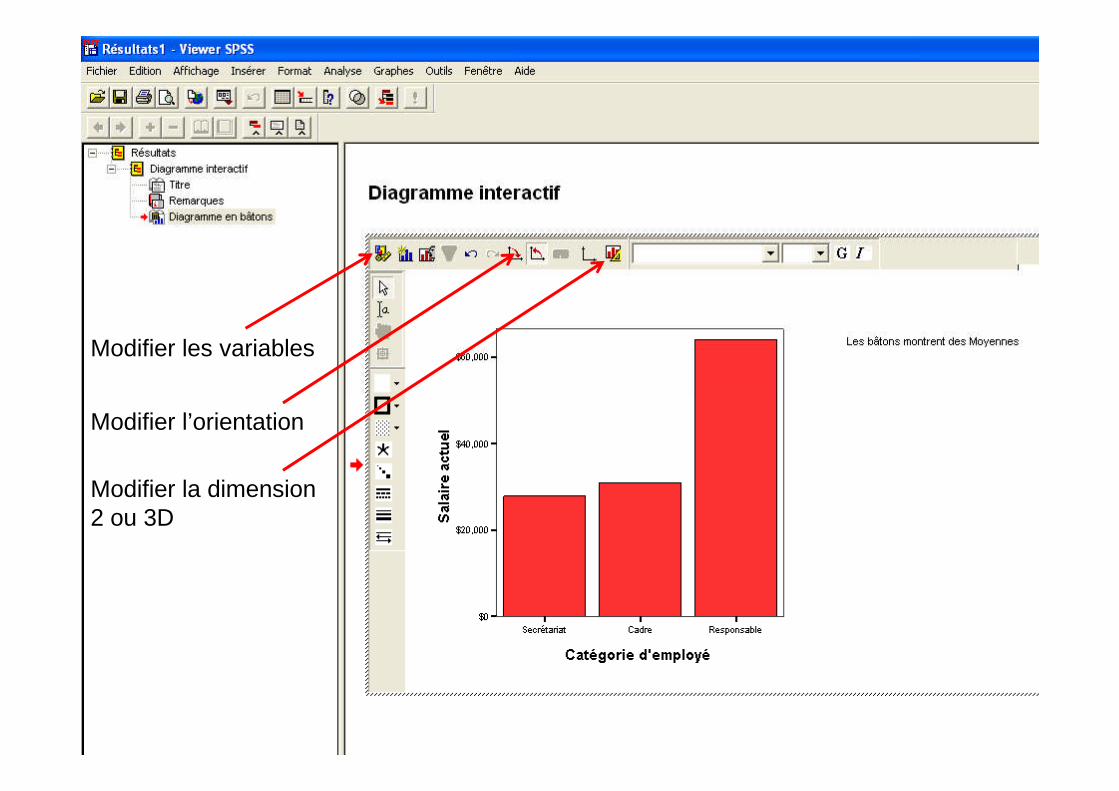
Modifier les variables
Modifier la dimension2 ou 3D
Modifier l’orientation

Affichage des valeurs moyennesSupposons que vous souhaitez les salaires actuels moyens pour chaque catégoried’emploi.•Dans la boîte de dialogue Affecter les variables du diagramme, replacez la variablesexe dans la liste des variables.Faites glisser la variable salaire actuel vers l’axe vertical et déposez-la sur lavariable Effectif. Dans la boîte de dialogue, les variables permutent. La variableEffectif retourne automatiquement dans la liste des variables.
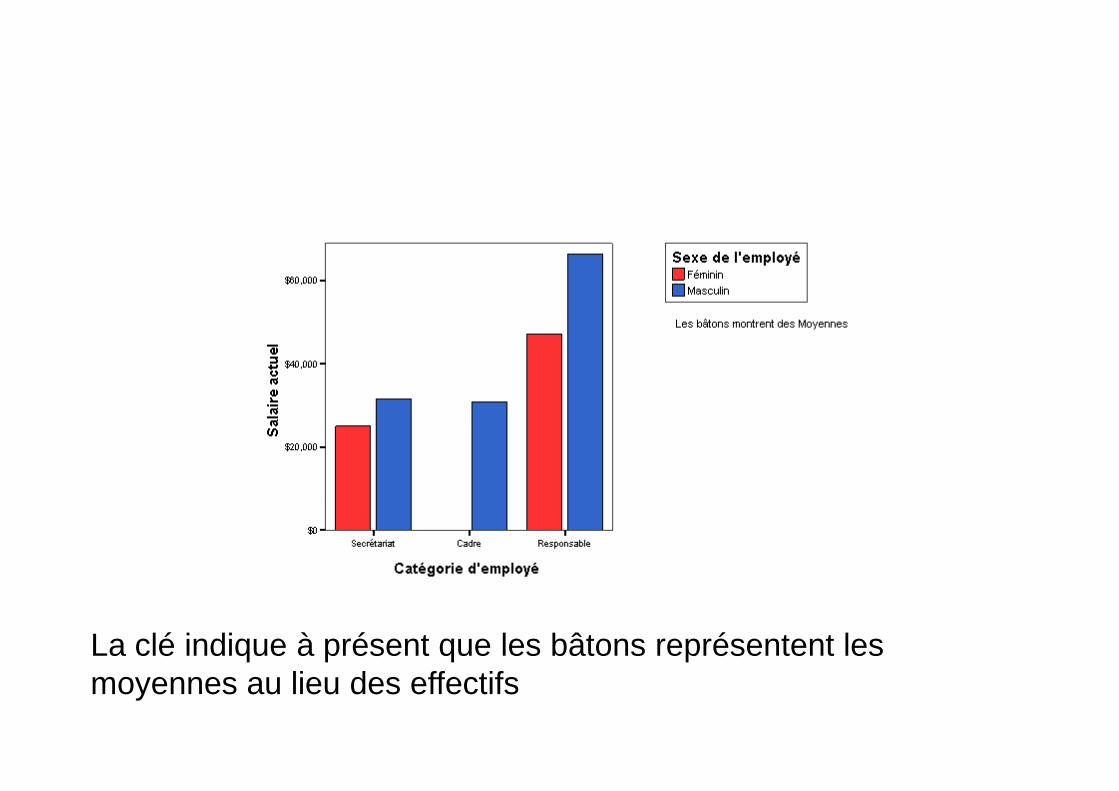
La clé indique à présent que les bâtons représentent lesmoyennes au lieu des effectifs
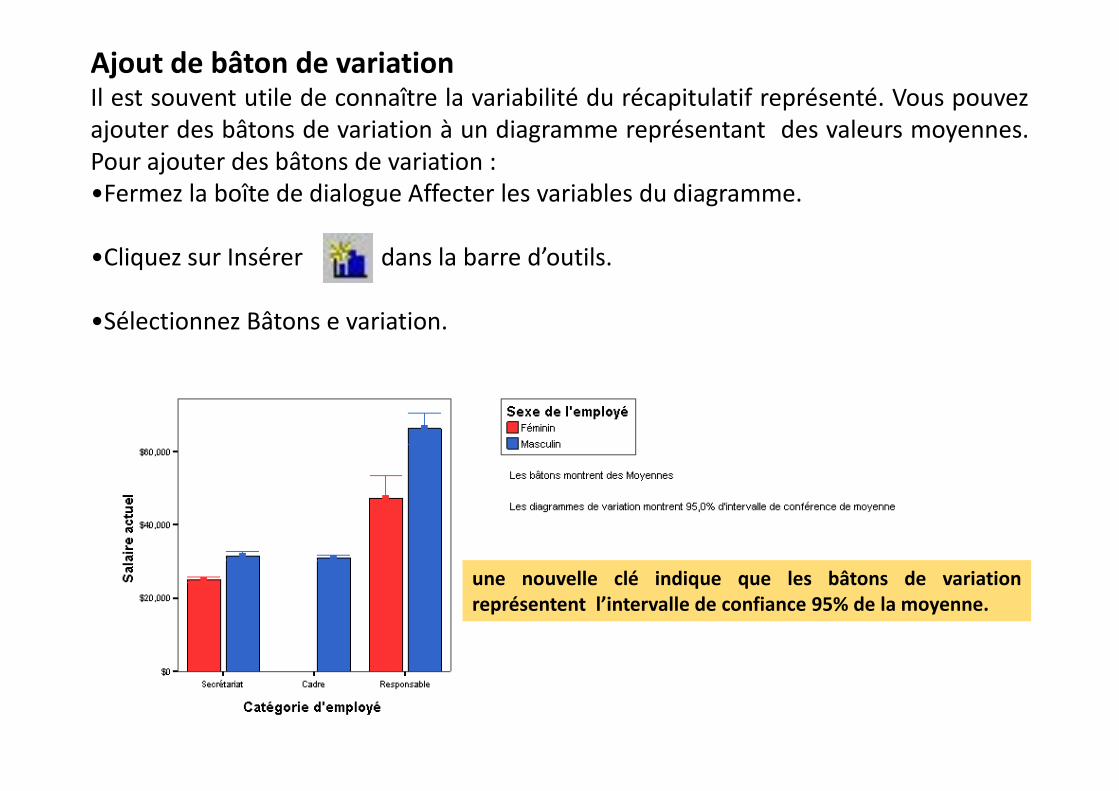
Ajout de bâton de variationIl est souvent utile de connaître la variabilité du récapitulatif représenté. Vous pouvezajouter des bâtons de variation à un diagramme représentant des valeurs moyennes.Pour ajouter des bâtons de variation :•Fermez la boîte de dialogue Affecter les variables du diagramme.
•Cliquez sur Insérer dans la barre d’outils.
•Sélectionnez Bâtons e variation.
une nouvelle clé indique que les bâtons de variationreprésentent l’intervalle de confiance 95% de la moyenne.
Application d’un modèle de graphiquesVous pouvez personnaliser l’aspect d’un diagramme en appliquant un modèle degraphique. Vous pouvez utiliser des modèles de graphiques pour améliorer l’aspectdes diagrammes en vue de présentations et de rapports, ou pour standardiser desfonctions comme la couleur et la taille.•Dans le Viewer, double-cliquez sur le diagramme pour l’activer.•A partir du menu, sélectionnez :FormatModèle de graphiquesLa boîte de dialogue Modèle de graphiques apparaît, comme l’illustre la figuresuivante. Elle contient la liste des modèles de graphiques stockés dans le répertoiresuivante. Elle contient la liste des modèles de graphiques stockés dans le répertoireLooks.
Figure : Boîte de dialogue modèle de graphiques
•Dans la liste des modèles de graphiques,sélectionnez Classique ou marina
•Cliquez sur appliquer, puis sur fermer.
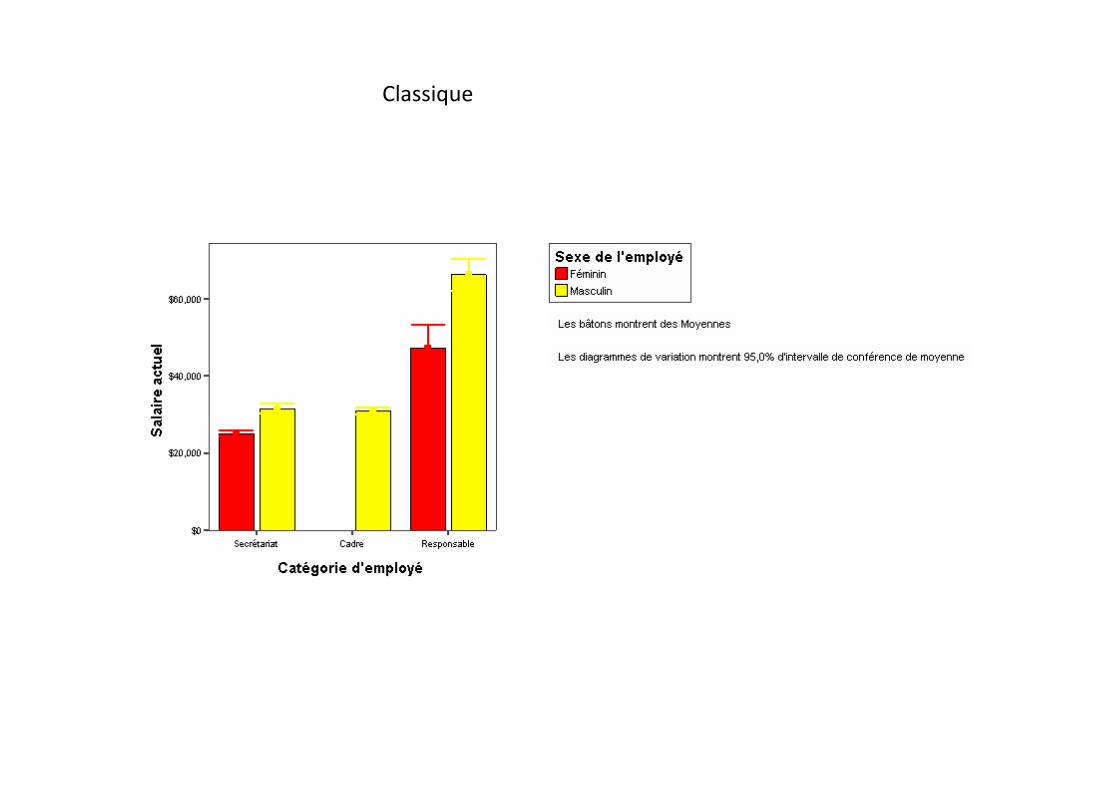
Classique
Marina
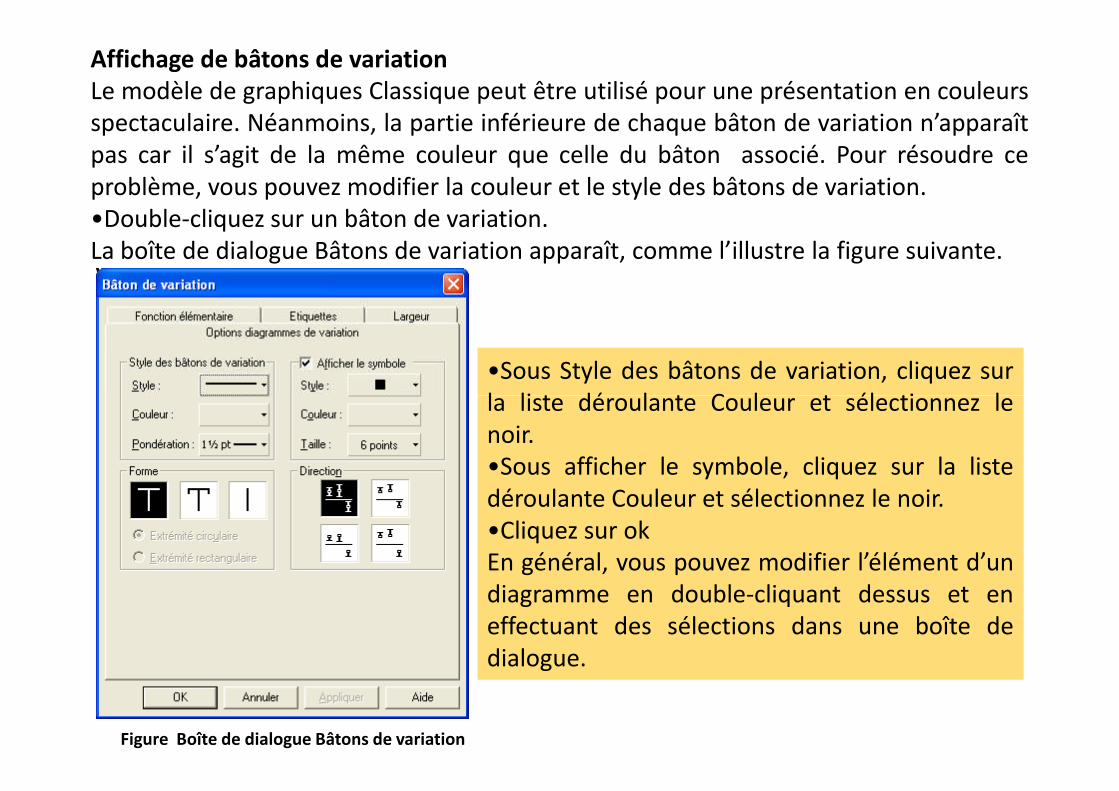
Affichage de bâtons de variationLe modèle de graphiques Classique peut être utilisé pour une présentation en couleursspectaculaire. Néanmoins, la partie inférieure de chaque bâton de variation n’apparaîtpas car il s’agit de la même couleur que celle du bâton associé. Pour résoudre ceproblème, vous pouvez modifier la couleur et le style des bâtons de variation.•Double-cliquez sur un bâton de variation.La boîte de dialogue Bâtons de variation apparaît, comme l’illustre la figure suivante.
•Sous Style des bâtons de variation, cliquez surla liste déroulante Couleur et sélectionnez le
Figure Boîte de dialogue Bâtons de variation
la liste déroulante Couleur et sélectionnez lenoir.•Sous afficher le symbole, cliquez sur la listedéroulante Couleur et sélectionnez le noir.•Cliquez sur okEn général, vous pouvez modifier l’élément d’undiagramme en double-cliquant dessus et eneffectuant des sélections dans une boîte dedialogue.

Collage d’un diagramme dans une autre applicationVous pouvez coller votre diagramme dans une autre application, et imprimer ledocument final en noir et blanc. Vous devez d’abord sélectionner un modèle degraphiques approprié pour l’impression en noir et blanc (comme Niveau de gris).•Dans le Viewer, double-cliquez sur le diagramme pour l’activer.•A partir du menu, sélectionnez :FormatModèle de graphiques•Dans la liste des modèles de graphiques, sélectionnez niveaux de gris.•Cliquez sur appliquer, puis sur fermer.Cette opération applique un modèle de graphiques en niveaux de gris dontCette opération applique un modèle de graphiques en niveaux de gris dontl’impression en noir et blanc est très réussie.•Cliquez dans le Viewer hors du diagramme pour désactiver ce dernier.•Cliquez une fois à dans le diagramme pour le sélectionner•A partir des menus de l’application cible, sélectionnez :AffichageCollerVous pouvez maintenant imprimer le diagramme dans l’autre application. (une fois lediagramme collé dans l’autre application, vous ne pouvez plus le modifier).

Exercice : Création et modification de diagrammes de dispersion interactifs
Cet exercice présente les bases de la création d’un diagramme en partant de zéro et del’ajout d’objets de façon interactive. Il illustre les opérations suivantes :
•Démarrage avec un diagramme vide•Création d’un diagramme de dispersion interactif•Etiquetage de points dans un diagramme de dispersion•Ajout d’une ligne de régression à un diagramme de dispersion•Ajout de courbes de prévision de la moyenne ajustables
Cet exercice utilise le fichier Employée data.sav

Création d’un diagramme de dispersionUn diagramme de dispersion montre la relation entre deux variables continues commesalaire actuel et salaire d’embauche, comme l’illustre la figure suivante.

Cet exercice débute par un diagramme contenant une zone de données vide.Les menus appropriés figurent dans le Viewer.•Si le Viewer n’est pas affiché, à partir des menus, sélectionnez :
FichierNouveauRésultat
Une nouvelle fenêtre du Viewer apparaît
•A partir du menu, sélectionnez :InsérerGraphique 2 D interactifCette opération insère un diagramme bidimensionnel vide, comme l’illustre la figuresuivante
Figure Diagramme bidimensionnel vide
Cliquez sur l’icône affecter les variables du diagramme pour ouvrir laboîte de dialogue du même nom.

Figure : Boîte de dialogue affecter les variables du diagramme
•Faites glisser la variable salaire d’embauche de la liste de variables vers l’axehorizontal.•Faites glisser la variable salaire actuel de la liste des variables vers l’axe vertical.La diagramme est toujours vide car nous n’avons pas sélectionnée son type .•A partir du menu sélectionnez :InsérerNuageCette opération créé un diagramme de dispersion, come l’illustre la figure suivante
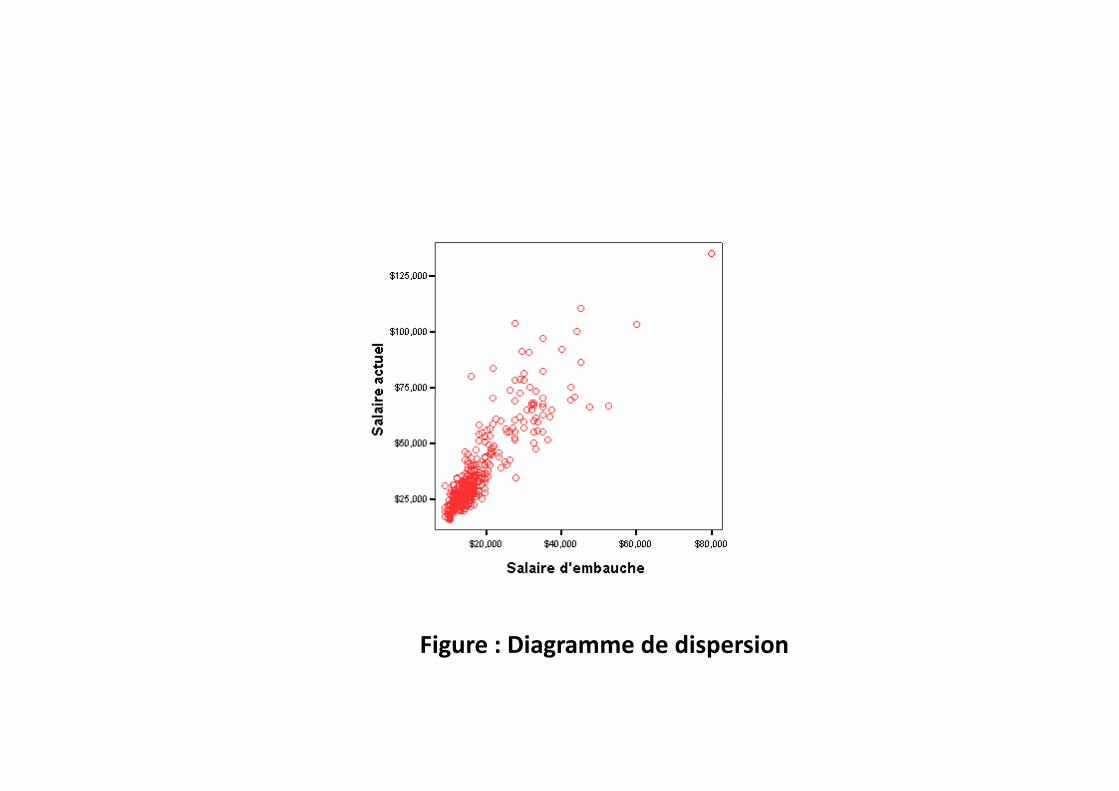
Figure : Diagramme de dispersion

• Etiquetage de points dans le diagramme de dispersion
• Supposons que vous souhaitiez étiqueter tout ou partie des pointsde la variable Expérience passée (nombre de mois).
• Dans la boîte de dialogue Affecter les variables du diagramme,sélectionnez l’onglet observations.
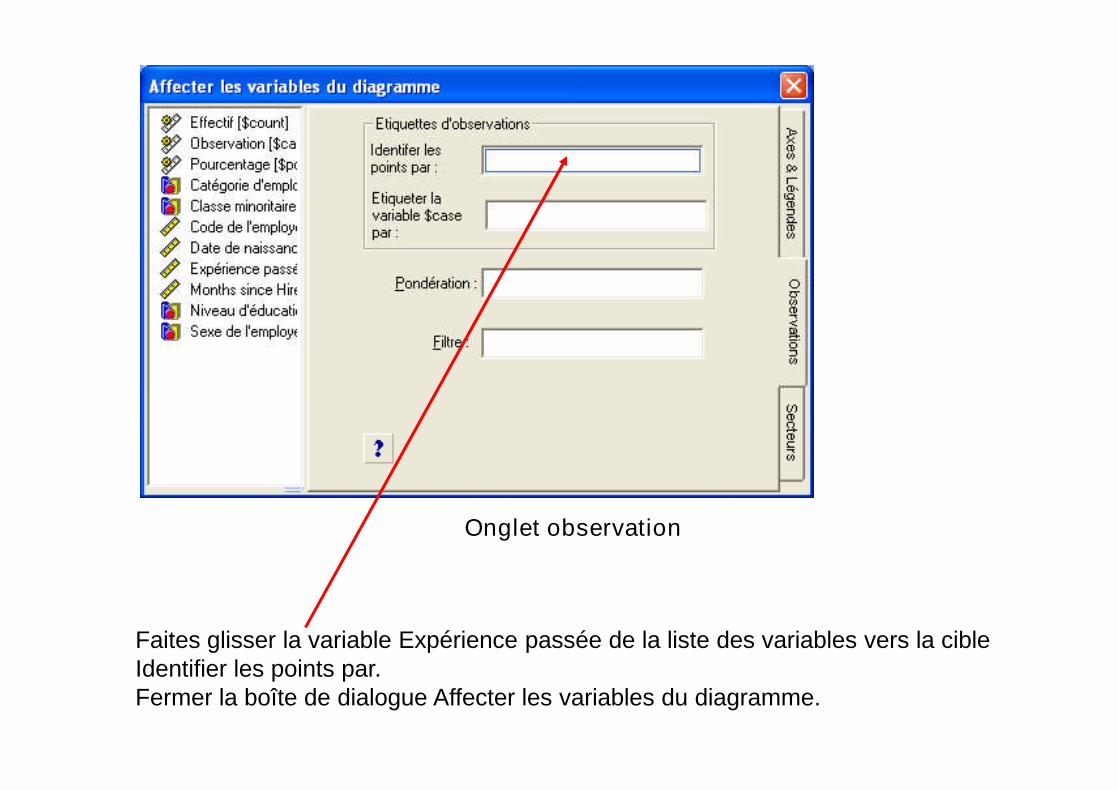
Onglet observation
Faites glisser la variable Expérience passée de la liste des variables vers la cibleIdentifier les points par.Fermer la boîte de dialogue Affecter les variables du diagramme.
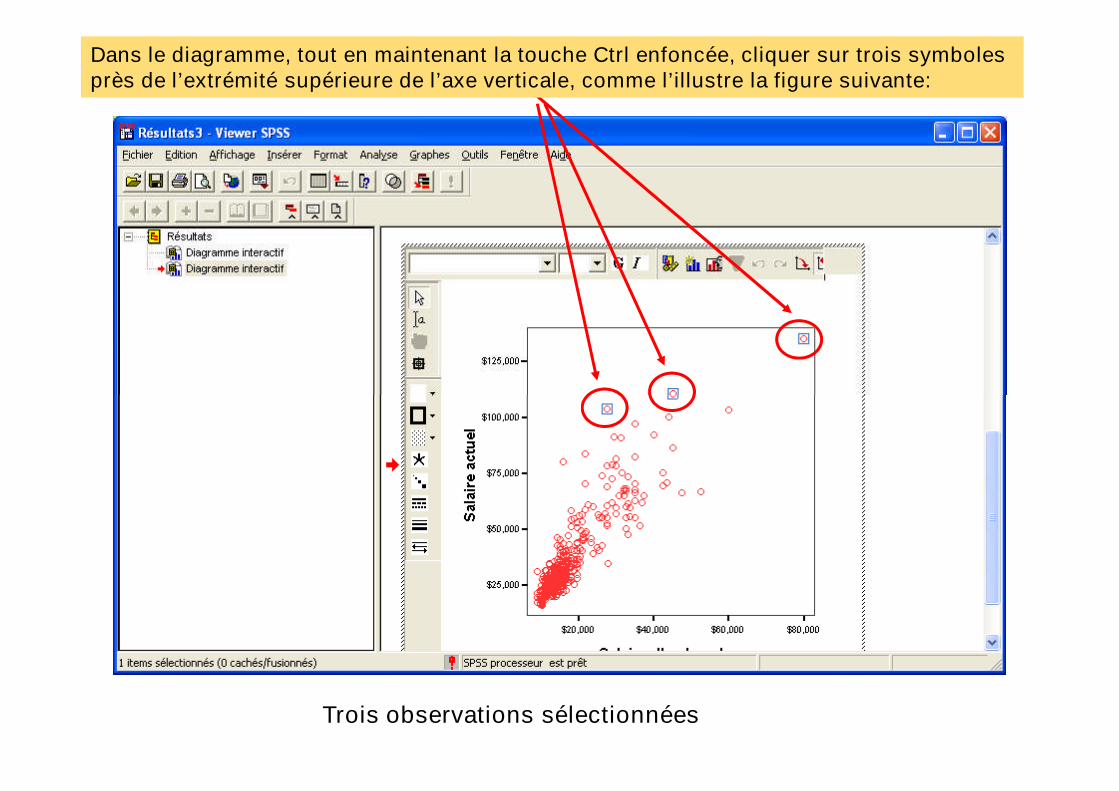
Dans le diagramme, tout en maintenant la touche Ctrl enfoncée, cliquer sur trois symbolesprès de l’extrémité supérieure de l’axe verticale, comme l’illustre la figure suivante:
Trois observations sélectionnées
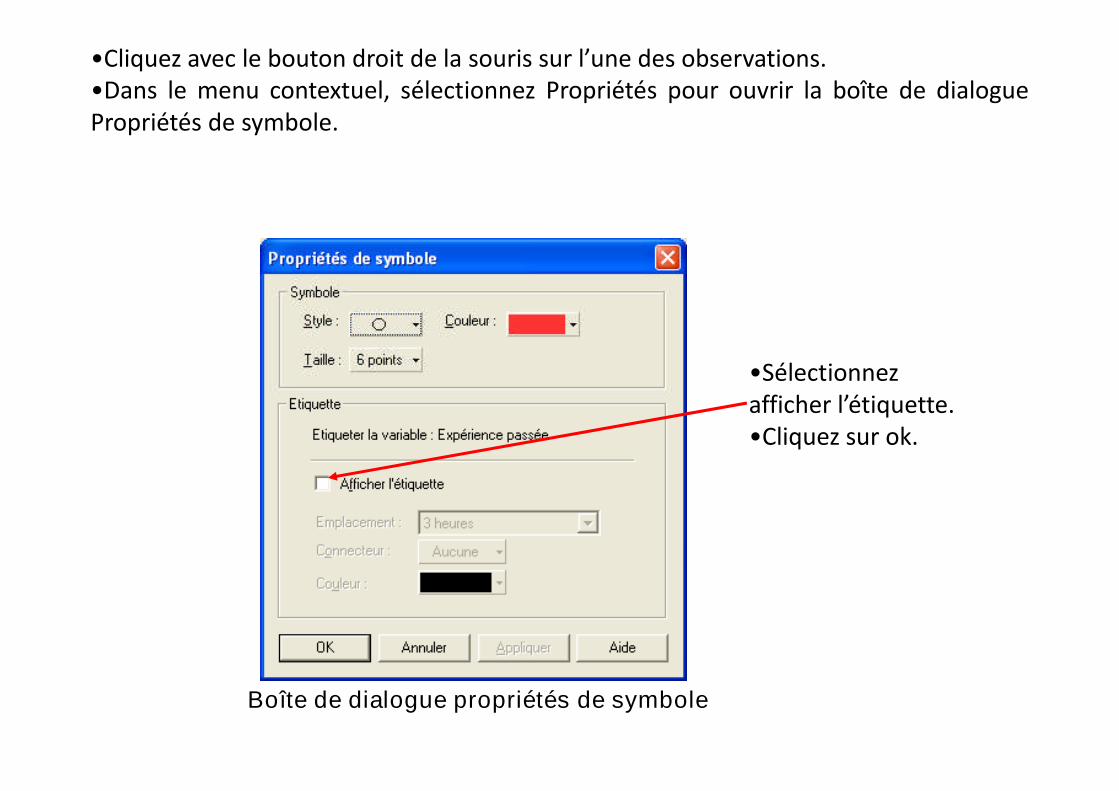
•Cliquez avec le bouton droit de la souris sur l’une des observations.•Dans le menu contextuel, sélectionnez Propriétés pour ouvrir la boîte de dialoguePropriétés de symbole.
•Sélectionnezafficher l’étiquette.
Boîte de dialogue propriétés de symbole
afficher l’étiquette.•Cliquez sur ok.
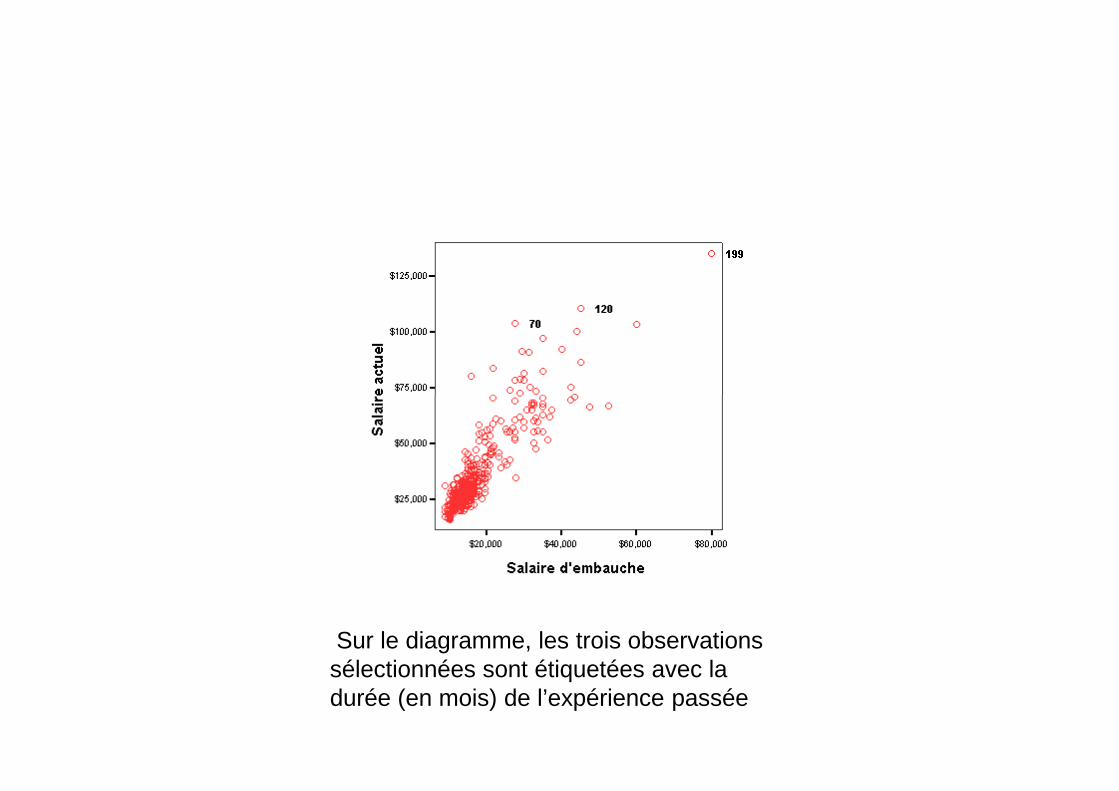
Sur le diagramme, les trois observationssélectionnées sont étiquetées avec ladurée (en mois) de l’expérience passée

Dans la boîte de dialogue propriétés desymbole, vous pouvez également modifierle style, la couleur et la taille des symbolesdu diagramme.du diagramme.

• Ajout d’une ligne de régression
• Les points du diagramme de dispersion semblent plus ou moinsdisposés le long d’une ligne droite. Plusieurs méthodes permettentd’ajuster ne ligne aux points. Une méthode d’ajustement de lignecouramment utilisée est appelée régression.
• Pour tracer une ligne ajustée à la distribution des points, à partir desmenus, sélectionne :
• Insérer
• Courbe d’ajustement
• Régression• Régression
• Cette opération insère une ligne de régression dans le diagrammede dispersion, comme l’illustre la figure 7.9. Des étiquettesapparaissent également : elles contiennent l’équation de la ligne etune valeur pour R-eux, statistique qui inique la qualité d’ajustementde la ligne. Les valeurs de R-deux peuvent aller de 0 à 1 : pluscette valeur est proche de 1, meilleur est l’ajustement.


















