Stéphane Tufféry Université Rennes 1 MASTER...
118
Stéphane Tufféry Université Rennes 1 MASTER 2 INGÉNIERIE ÉCONOMIQUE ET FINANCIÈRE COURS DE DATA MINING : Présentation
Transcript of Stéphane Tufféry Université Rennes 1 MASTER...

Stéphane Tufféry
Université Rennes 1MASTER 2INGÉNIERIE ÉCONOMIQUE ET FINANCIÈRE
COURS DE DATA MINING :Présentation

08/10/2010 2© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Présentation de l’intervenant• En charge de la statistique et du data mining
dans un grand groupe bancaire• Enseigne le data mining en Master 2 à l’Université
Catholique de l’Ouest (Angers) et à l’UniversitéRennes 1
• Docteur en Mathématiques• Auteur de :
• Data Mining et Statistique Décisionnelle, Éditions Technip, 2005, 3e édition 2010, préface de Gilbert Saporta
• Data Mining and Statistics for Decision Making, Éditions Wiley, janvier 2011
• Étude de cas en Statistique Décisionnelle, Éditions Technip, 2009

08/10/2010 3© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Plan du cours
• Qu’est-ce que le data mining ?• Préhistoire et histoire du data mining• Quelques ingrédients du data mining• A quoi sert le data mining ?• Comment faire du data mining ?• Quelques principes du data mining• Conclusion - Liens

08/10/2010 4© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Qu’est-ce que le data mining ?

08/10/2010 5© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
0 5 10
PCR1
-5
0
5
10
P
C
R
2
Classification automatique, ACP et segmentation de clientèle
forts revenusfaibles revenus
patrimoine - âge
crédit conso - CB
S1 (rouge) : peu actifsS2 (rose) : jeunesS3 (bleu) : consommateurs
S4 (orange) : seniorsS5 (noir) : aisésS6 (vert) : débiteurs
cycle de vie

08/10/2010 6© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Recherche d’associations et analyse du ticket de caisse
• Exemple (apocryphe !) de Wal-Mart : Les acheteurs de couches-culottes le samedi après 18h sont souvent aussi acheteurs de bière
• But : agencer les rayons et organiser les promotions en conséquence
• Dans l’ensemble de tickets de caisse :T1 A B C D ET2 B C E FT3 B ET4 A B DT5 C D
• l’indice de confiance de « B ⇒ E » = proba(B et E) / proba(B) = 3/4
• et son indice de support = proba(B et E) = 3/5

08/10/2010 7© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Scoring et prédiction des impayés à 12 mois
32,23
0,8
26,8
3,41
17,27
5,67
10,46
17,45
7,64
22,37
5,61
50,3
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
% clients % impayés
Score 1 Score 2 Score 3 Score 4 Score 5 Score 6
08/10/2010 8© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
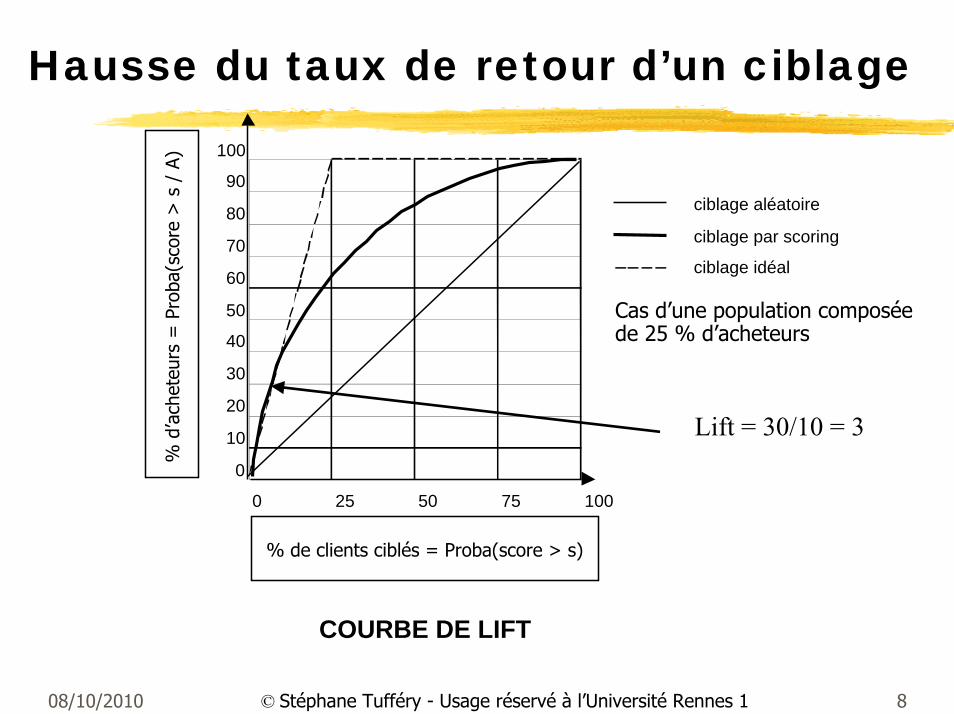
Hausse du taux de retour d’un ciblage
Lift = 30/10 = 3
100
90
80 ciblage aléatoire
70 ciblage par scoring
60 ciblage idéal
50
40
30
20
10
0
0 25 50 75 100
COURBE DE LIFT
% d
’ach
eteu
rs =
Pro
ba(s
core
> s
/ A
)
% de clients ciblés = Proba(score > s)
Cas d’une population composée de 25 % d’acheteurs

08/10/2010 9© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Détection du churn en téléphonie• Churn = attrition = départ d’un client vers la concurrence
• Critères d’attrition (exemple) :• Utilisation d’Internet• Appels vers mobiles• Appels vers l’international• C.A. supérieur de 30 % à la moyenne• Abonnement Numéris• Contacts plus nombreux avec le service clientèle
• On trouve 30 % des churners en sélectionnant 10 % des clients (lift = 3)

08/10/2010 10© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Définition• Le data mining est l’ensemble des :
• techniques et méthodes• … destinées à l’exploration et l’analyse• … de (souvent) grandes bases de données informatiques• … en vue de détecter dans ces données des règles, des
associations, des tendances inconnues (non fixées a priori), des structures particulières restituant de façon concise l’essentiel de l’information utile
• … pour l’aide à la décision
• Selon le MIT, c’est l’une des 10 technologies émergentes qui « changeront le monde » au XXIe siècle.

08/10/2010 11© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Data mining ≠ statistiques descriptives• On ne veut plus seulement savoir :
• « Combien de clients ont acheté tel produit pendant telle période ? »
• Mais :• « Quel est leur profil ? »• « Quels autres produits les intéresseront ? »• « Quand seront-ils intéressés ? »
• Les profils de clientèle à découvrir sont en général des profils complexes : pas seulement des oppositions « jeunes/seniors », « citadins/ruraux »… que l’on pourrait deviner en tâtonnant par des statistiques descriptives
> Le data mining fait passer• d’analyses confirmatoires• à des analyses exploratoires
08/10/2010 12© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
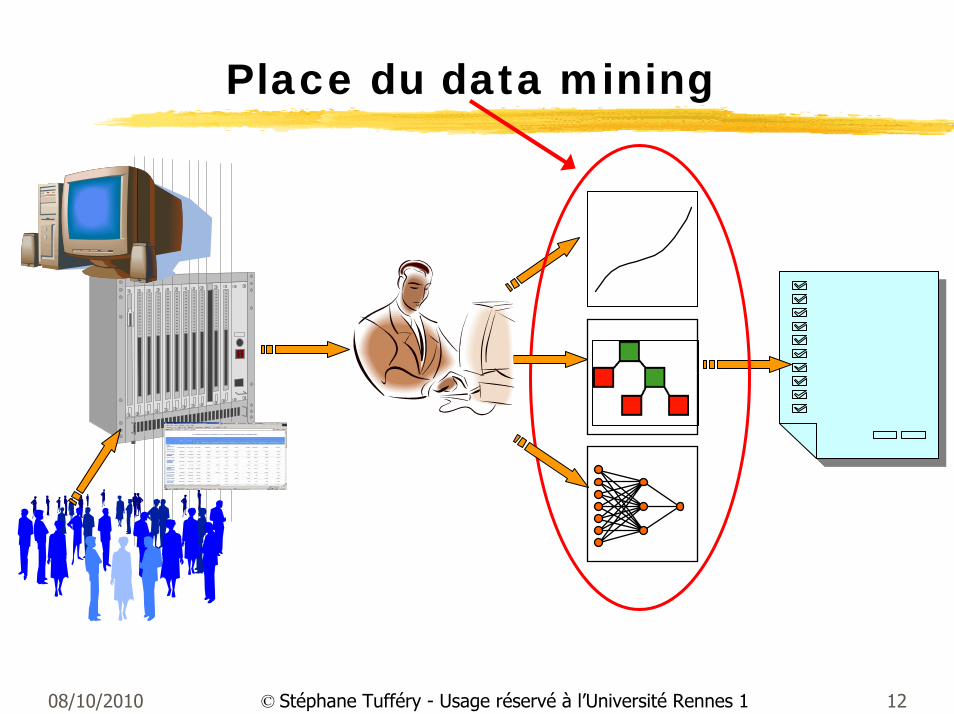
Place du data mining

08/10/2010 13© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Les 2 types de techniques de DM
• Les techniques descriptives (recherche de « patterns ») :• visent à mettre en évidence des informations
présentes mais cachées par le volume des données (c’est le cas des segmentations de clientèle et des recherches d’associations de produits sur les tickets de caisse)
• réduisent, résument, synthétisent les données• il n’y a pas de variable « cible » à prédire.
• Les techniques prédictives (modélisation) :• visent à extrapoler de nouvelles informations à partir
des informations présentes (c’est le cas du scoring)• expliquent les données• il y a une variable « cible » à prédire.

08/10/2010 14© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Principales méthodes descriptives et prédictives
• Les techniques descriptives :• analyse factorielle• classification automatique (clustering)• recherche d’associations (analyse du ticket de caisse)
• Les techniques prédictives :• classement / discrimination (variable « cible » qualitative)
• analyse discriminante / régression logistique• arbres de décision• réseaux de neurones
• prédiction (variable « cible » quantitative)• régression linéaire (simple et multiple)• ANOVA, MANOVA, ANCOVA, MANCOVA (GLM)• arbres de décision• réseaux de neurones
08/10/2010 15© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
0%
10%
20%
30%
40%
50%
60%D
ecis
ion
Tree
s
Clu
ster
ing
Sta
tistic
s
Neu
ral n
ets
Reg
ress
ion
Vis
ualiz
atio
n
Ass
ocat
ion
rule
s
Nea
rest
nei
ghbo
r
Bay
esia
nS
eque
nce
/ tim
e se
ries
anal
ysis
SV
M
Hyb
rid m
etho
ds
Gen
etic
alg
orith
ms
Boo
stin
g
Bag
ging
Oth
er
novembre 2003en % des votantsavril 2006 en %des votants
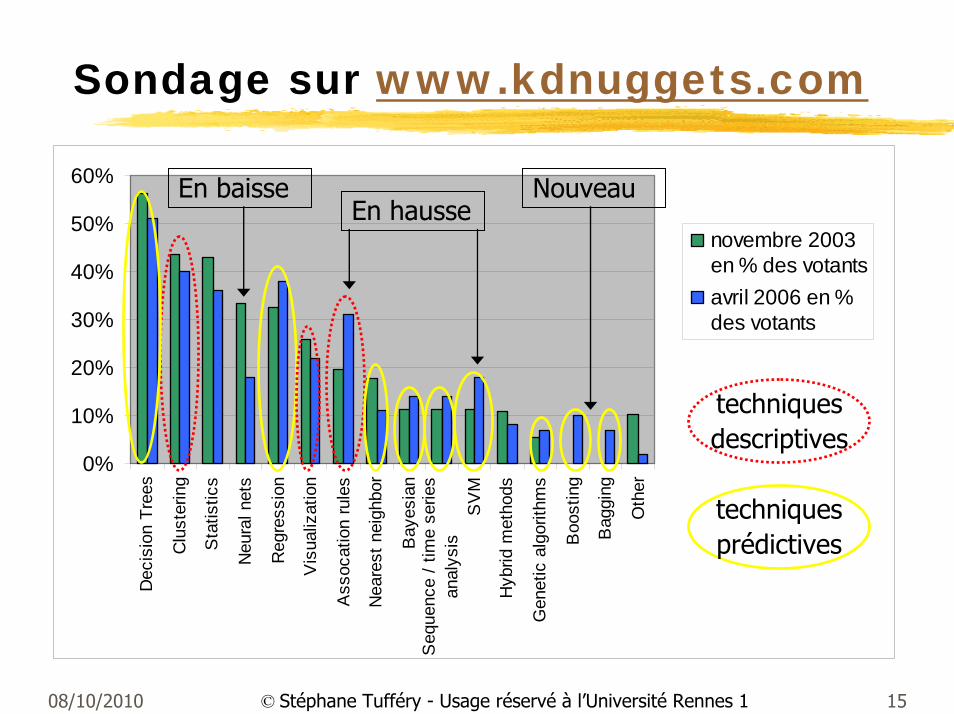
Sondage sur www.kdnuggets.com
techniquesdescriptives
techniquesprédictives
En baisse NouveauEn hausse

08/10/2010 16© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Le data mining aujourd’hui• Ces techniques ne sont pas toutes récentes• Ce qui est nouveau, ce sont aussi :
• les capacités de stockage et de calcul offertes par l’informatique moderne
• la constitution de giga-bases de données pour les besoins de gestion des entreprises
• la recherche en IA et en théorie de l’apprentissage• les logiciels universels, puissants et conviviaux• l’intégration du data mining dans les processus de production
>qui permettent de traiter de grands volumes de données et font sortir le data mining des laboratoires de recherche pour entrer dans les entreprises

08/10/2010 17© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Le data mining demain• Agrégation de modèles
• rééchantillonnage bootstrap, bagging, boosting…• Web mining
• optimisation des sites• meilleure connaissance des internautes• croisement avec les bases de données de l’entreprise
• Text mining• statistique lexicale pour l’analyse des courriers, courriels,
dépêches, comptes-rendus, brevets (langue naturelle)• Image mining
• reconnaissance automatique d’une forme ou d’un visage• détection d’une échographie anormale, d’une tumeur
• Données symboliques

08/10/2010 18© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Préhistoire et histoire du data mining

08/10/2010 19© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Préhistoire
• 1875 : régression linéaire de Francis Galton• 1896 : formule du coefficient de corrélation de Karl Pearson• 1900 : distribution du χ² de Karl Pearson• 1936 : analyse discriminante de Fisher et Mahalanobis• 1941 : analyse factorielle des correspondances de Guttman• 1943 : réseaux de neurones de Mc Culloch et Pitts• 1944 : régression logistique de Joseph Berkson• 1958 : perceptron de Rosenblatt• 1962 : analyse des correspondances de J.-P. Benzécri• 1964 : arbre de décision AID de J.P. Sonquist et J.-A. Morgan• 1965 : méthode des centres mobiles de E. W. Forgy• 1967 : méthode des k-means de Mac Queen• 1972 : modèle linéaire généralisé de Nelder et Wedderburn

08/10/2010 20© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Histoire
• 1975 : algorithmes génétiques de Holland• 1975 : méthode de classement DISQUAL de Gilbert Saporta• 1980 : arbre de décision CHAID de KASS• 1983 : régression PLS de Herman et Svante Wold• 1984 : arbre CART de Breiman, Friedman, Olshen, Stone• 1986 : perceptron multicouches de Rumelhart et McClelland• 1989 : réseaux de T. Kohonen (cartes auto-adaptatives)• vers 1990 : apparition du concept de data mining• 1991 : méthode MARS de Jerome H. Friedman• 1993 : arbre C4.5 de J. Ross Quinlan• 1996 : bagging (Breiman) et boosting (Freund-Shapire)• 1998 : support vector machines de Vladimir Vapnik• 2001 : forêts aléatoires de L. Breiman• 2005 : méthode elastic net de Zhou et Hastie

08/10/2010 21© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Statistique et data mining• Statistique (avant 1950) :
• quelques centaines d’individus• quelques variables recueillies
avec un protocole spécial (échantillonnage, plan d’expérience…)
• fortes hypothèses sur les lois statistiques suivies (linéarité, normalité, homoscédasticité)
• le modèle prime sur la donnée• Analyse des données (1960-1980) :
• quelques dizaines de milliers d’individus
• quelques dizaines de variables• construction des tableaux
Individus x Variables• importance du calcul et de la
représentation visuelle
• Data mining (depuis 1990) :• plusieurs millions d’individus• plusieurs centaines de variables• des variables non numériques• données recueillies avant l’étude,
et souvent à d’autres fins• données imparfaites, avec des
erreurs de saisie, des valeurs manquantes…
• populations évolutives difficiles àéchantillonner
• nécessité de calculs rapides, parfois en temps réel
• on ne recherche pas toujours l’optimum théorique, mais le + simple pour des non statisticiens
• la donnée prime sur le modèle

08/10/2010 22© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
De la statistique…
• Hier :• études de laboratoire• expérimentations cliniques• actuariat• analyses de risque - scoring
• Volumes de données limités• Analyse du réel pour mieux le comprendre• Démarche scientifique : les 1ères observations permettent
de formuler des hypothèses théoriques que l’on confirme ou infirme à l’aide de tests statistiques

08/10/2010 23© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
… au data mining• Aujourd’hui :
• de l’∞ petit (génomique) à l’∞ grand (astrophysique)• du plus quotidien (reconnaissance de l’écriture manuscrite)
au moins quotidien (aide au pilotage aéronautique)• du plus ouvert (e-commerce) au plus sécuritaire (prévention
du terrorisme, détection de la fraude)• du plus industriel (contrôle qualité…) au plus théorique
(sciences humaines, biologie…)• du plus alimentaire (agronomie et agroalimentaire) au plus
divertissant (prévisions d’audience TV)• Volumes de données importants• Systèmes d’aide à la décision + ou − automatiques• Démarche pragmatique : on cherche un modèle s’ajustant
le mieux possible aux données

08/10/2010 24© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Quelques ingrédients du data mining
08/10/2010 25© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
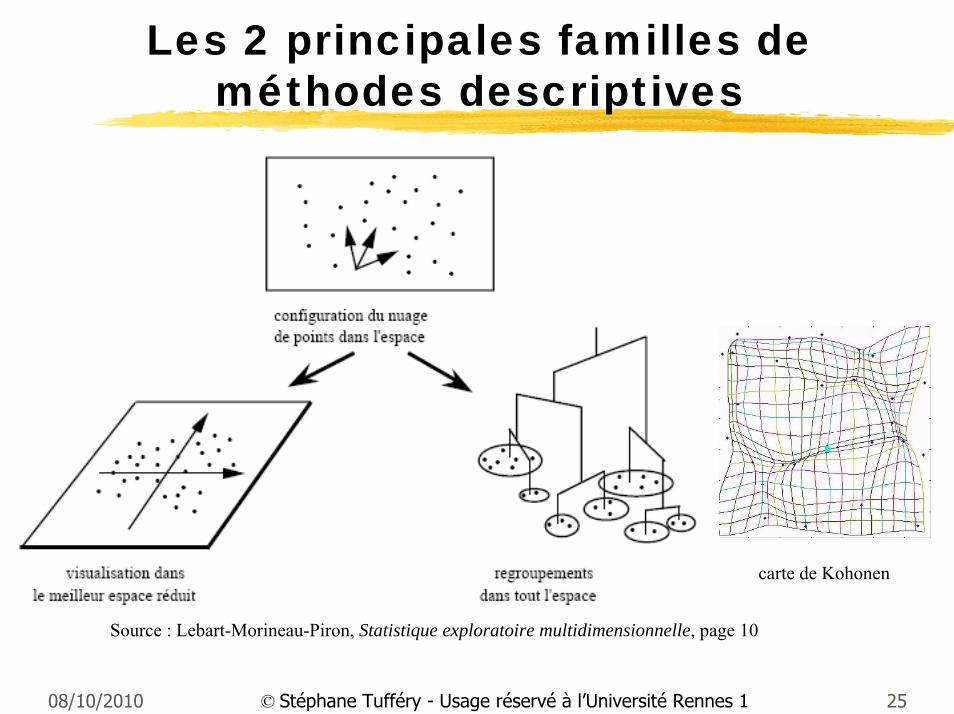
Les 2 principales familles de méthodes descriptives
Source : Lebart-Morineau-Piron, Statistique exploratoire multidimensionnelle, page 10
carte de Kohonen

08/10/2010 26© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Qu’est-ce que la classification ?
• Regrouper des objets en groupes, ou classes, ou familles, ou segments, ou clusters, de sorte que :• 2 objets d’un même groupe se ressemblent le + possible• 2 objets de groupes distincts diffèrent le + possible• le nombre des groupes est parfois fixé
• Méthode descriptive :• pas de variable cible privilégiée• décrire de façon simple une réalité complexe en la résumant
• Utilisation en marketing, médecine, sciences humaines…• Les objets à classer sont :
• des individus• des variables

08/10/2010 27© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Complexité du problème !
• Le nombre de partitions (non recouvrantes) de n objets est le nombre de Bell :
• Exemple : pour n = 4 objets, on a Bn = 15, avec• 1 partition à 1 classe (abcd)• 7 partitions à 2 classes (ab,cd), (ac,bd), (ad,bc), (a,bcd),
(b,acd), (c,bad), (d,abc)• 6 partitions à 3 classes (a,b,cd), (a,c,bd), (a,d,bc), (b,c,ad),
(b,d,ac), (c,d,ab)• 1 partition à 4 classes (a,b,c,d)
• Exemple : pour n = 30 objets, on a B30 = 8,47.1023
• Bn > exp(n) ⇒ Nécessité de définir des critères de bonne classification et d’avoir des algorithmes performants
∑∞
=
=1 !
1k
n
n kk
eB

08/10/2010 28© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Classification et classement• La classification consiste à
regrouper les individus d’une population en un nombre limité de classes qui :• ne sont pas prédéfinies
mais déterminées au cours de l’opération
• regroupent les individus ayant des caractéristiques similaires et séparent les individus ayant des caractéristiques différentes (forte inertie interclasse ⇔faible inertie intraclasse)
• Le classement consiste àplacer chaque individu de la population dans une classe, parmi plusieurs classes prédéfinies, en fonction des caractéristiques de l’individu indiquées comme variables explicatives
• Le résultat du classement est un algorithme permettant d’affecter chaque individu à la meilleure classe
• Le plus souvent, il y a 2 classes prédéfinies (« sain » et « malade », par exemple)

08/10/2010 29© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Prédiction
• La prédiction consiste à estimer• la valeur d’une variable quantitative (dite « à expliquer »,
« cible », « réponse », « dépendante » ou « endogène »)• en fonction de la valeur d’un certain nombre d’autres
variables (dites « explicatives », « de contrôle », « indépendantes » ou « exogènes »)
• Cette variable « cible » est par exemple :• le poids (en fonction de la taille)• la taille des ailes d’une espèce d’oiseau (en fonction de l’âge)• le prix d’un appartement (en fonction de sa superficie, de
l’étage et du quartier)• la consommation d’électricité (en fonction de la température
extérieure et de l’épaisseur de l’isolation)

08/10/2010 30© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Classement et prédiction
• Classement : la variable à expliquer est qualitative• on parle aussi de classification (en anglais) ou de
discrimination
• Prédiction : la variable à expliquer est quantitative• on parle aussi de régression• ou d’apprentissage supervisé (réseaux de neurones)
• Scoring : classement appliqué à une problématique d’entreprise (variable à expliquer souvent binaire)

08/10/2010 31© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
type famille sous-famille algorithme analyse en composantes principales ACP (variables continues)
analyse factorielle (projection sur un espace de dimension inférieure)
analyse factorielle des correspondances AFC (2 variables qualitatives) analyse des correspondances multiples ACM (+ de 2 var. qualitatives) méthodes de partitionnement (centres mobiles, k-means, nuées dynamiques)
analyse typologique (regroupement en classes homogènes) méthodes hiérarchiques
modèles géométriques
analyse typologique + réduction dimens.
classification neuronale (cartes de Kohonen)
modèles combinatoires
classification relationnelle (variables qualitatives)
méthodes descriptives
modèles à base de règles logiques
détection de liens détection d’associations
Tableau des méthodes descriptives
En grisé : méthodes « classiques »

08/10/2010 32© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Tableau des méthodes prédictivestype famille sous-famille algorithme
modèles à base de règles logiques
arbres de décision
arbres de décision (variable à expliquer continue ou qualitative)
réseaux de neurones
réseaux à apprentissage supervisé : perceptron multicouches, réseau à fonction radiale de base régression linéaire, ANOVA, MANOVA, ANCOVA, MANCOVA, modèle linéaire général GLM, régression PLS (variable à expliquer continue) analyse discriminante linéaire, régression logistique, régression logistique PLS (variable à expliquer qualitative) modèle log-linéaire, régression de Poisson (variable à expliquer discrète = comptage)
modèles à base de fonctions mathématiques
modèles paramétriques ou semi- paramétriques
modèle linéaire généralisé, modèle additif généralisé (variable à expliquer continue, discrète ou qualitative)
méthodes prédictives
prédiction sans modèle
k-plus proches voisins (k-NN)
En grisé : méthodes « classiques »

08/10/2010 33© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
A quoi sert le data mining ?

08/10/2010 34© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Sondage sur www.kdnuggets.com
Sondage effectué
en décembre
2009
Industries / Fields where you applied Data Mining in 2009 [180 votes total] CRM/ consumer analytics (59) 32.8% Banking (44) 24.4% Direct Marketing/ Fundraising (29) 16.1% Credit Scoring (28) 15.6% Telecom / Cable (26) 14.4% Fraud Detection (25) 13.9% Retail (21) 11.7% Health care/ HR (21) 11.7% Finance (20) 11.1% Science (19) 10.6% Advertising (19) 10.6% e-Commerce (18) 10.0% Insurance (18) 10.0% Web usage mining (15) 8.3% Social Networks (14) 7.8% Medical/ Pharma (14) 7.8% Biotech/Genomics (14) 7.8% Search / Web content mining (12) 6.7% Investment / Stocks (12) 6.7% Security / Anti-terrorism (9) 5.0% Education (8) 4.4% Government/Military (7) 3.9% Manufacturing (6) 3.3% Travel / Hospitality (5) 2.8% Social Policy/Survey analysis (3) 1.7% Entertainment/ Music (3) 1.7% Junk email / Anti-spam (1) 0.6% None (2) 1.1% Other (14) 7.8%

08/10/2010 35© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Utilité du data mining dans le CRM (gestion de la relation client)
• Mieux connaître le clientpour mieux le servir
pour augmenter sa satisfactionpour augmenter sa fidélité(+ coûteux d’acquérir un client que le conserver)
• La connaissance du client est encore plus utile dans le secteur tertiaire :• les produits se ressemblent entre établissements• le prix n’est pas toujours déterminant• ce sont surtout le service et la relation
avec le client qui font la différence

08/10/2010 36© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Exemple du credit scoring• Objectifs de la banque :
• vendre plus• en maîtrisant les risques• en utilisant les bons
canaux au bon moment
• Le crédit à la consommation• un produit standard• concurrence des sociétés
spécialisées sur le lieu de vente (Cetelem…)
• quand la banque a connaissance du projet du client, il est déjà trop tard
• Conclusion :•il faut être pro-actif•détecter les besoins des clients•et leur tendance à emprunter
>Faire des propositions commerciales aux bons clients, avant qu’ils n’en fassent la demande
+ Appétence
–
+ – Risque

08/10/2010 37© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Le data mining dans la banque• Naissance du score de risque en 1941 (David Durand)• Multiples techniques appliquées à la banque de détail et la
banque d’entreprise• Surtout la banque de particuliers :
• montants unitaires modérés• grand nombre de dossiers• dossiers relativement standards
• Essor dû à :• développement des nouvelles technologies• nouvelles attentes de qualité de service des clients• concurrence des nouveaux entrants (assureurs, grande
distribution) et des sociétés de crédit• pression mondiale pour une plus grande rentabilité• surtout : ratio de solvabilité Bâle 2

08/10/2010 38© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Le data mining dans l’assurance de risque
• Des produits obligatoires (automobile, habitation) :• soit prendre un client à un concurrent• soit faire monter en gamme un client que l’on détient déjà
• D’où les sujets dominants :• attrition• ventes croisées (cross-selling)• montées en gamme (up-selling)
• Besoin de décisionnel dû à :• concurrence des nouveaux entrants (bancassurance)• bases clients des assureurs traditionnels mal organisées :
• compartimentées par agent général• ou structurées par contrat et non par client

08/10/2010 39© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Le data mining dans la téléphonie• Deux événements :
• ouverture du monopole de France Télécom• arrivée à saturation du marché de la téléphonie mobile
• D’où les sujets dominants dans la téléphonie :• score d’attrition (churn = changement d’opérateur)• text mining (pour analyser les lettres de réclamation)• optimisation des campagnes marketing
• Problème du churn :• coût d’acquisition moyen en téléphonie mobile : 250 euros• plus d’un million d’utilisateurs changent chaque d’année
d’opérateur• la loi Chatel (juin 2008) facilite le changement d’opérateur en
diminuant le coût pour ceux qui ont dépassé 12 mois chez l’opérateur

08/10/2010 40© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Le data mining dans le commerce • Vente Par Correspondance
• utilise depuis longtemps des scores d’appétence• pour optimiser ses ciblages et en réduire les coûts• des centaines de millions de documents envoyés par an
• e-commerce• personnalisation des pages du site web de l’entreprise, en
fonction du profil de chaque internaute• optimisation de la navigation sur un site web
• Distribution
• analyse du ticket de caisse• détermination des meilleures implantations (géomarketing)

08/10/2010 41© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Exemples médicaux• Mettre en évidence des facteurs de risque ou de
rémission dans certaines maladies (infarctus et des cancers). Choisir le traitement le + approprié
• Déterminer des segments de patients susceptibles d’être soumis à des protocoles thérapeutiques déterminés, chaque segment regroupant tous les patients réagissant identiquement
• Décryptage du génome
• Tests de médicaments, de cosmétiques• Prédire les effets sur la peau humaine de nouveaux cosmétiques,
en limitant le nombre de tests sur les animaux

08/10/2010 42© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Exemples divers• Contrôle qualité
• recherche des facteurs expliquant les défauts de la production
• Prévisions de trafic routier (Bison futé)• Prédiction des parts d’audience pour une nouvelle
émission de télévision (BBC)• en fonction des caractéristiques de l’émission (genre,
horaire, durée, présentateur…), des programmes précédant et suivant cette émission sur la même chaîne, des programmes diffusés simultanément sur les chaînes concurrentes, des conditions météorologiques, de l’époque de l’année et des événements se déroulant simultanément
• Le classement en « étoile » ou « galaxie » d’un nouveau corps céleste découvert au télescope (système SKICAT)

08/10/2010 43© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Comment faire du data mining ?

08/10/2010 44© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Définition de la variable à expliquer• En médecine : définition souvent naturelle
• un patient a ou non une tumeur• Dans la banque : qu’est-ce qu’un client non risqué ?
• aucun impayé• 1 impayé• n impayés mais dette apurée ?
• Dans certains modèles, on définit une « zone indéterminée » non modélisée :• 1 impayé ⇒ variable à expliquer non définie• aucun impayé ⇒ variable à expliquer = 0• ≥ 2 impayés ⇒ variable à expliquer = 1
• Parfois encore plus problématique en appétence

08/10/2010 45© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Biais de sélection• En risque : certaines demandes sont refusées et on ne
peut donc mesurer la variable à expliquer• certaines populations ont été exclues de la modélisation et
on doit pourtant leur appliquer le modèle• il existe des méthodes « d’inférence des refusés », mais
dont aucune n’est totalement satisfaisante• En appétence, certaines populations n’ont jamais été
ciblées et on ne leur a pas proposé le produit• si on les modélise, elles seront présentes dans l’échantillon
des « mauvais » (clients sans appétence) peut-être à tort• contrairement au cas précédent, on peut mesurer la
variable à expliquer car il y a des souscriptions spontanées• envisager de limiter le périmètre aux clients ciblés
08/10/2010 46© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
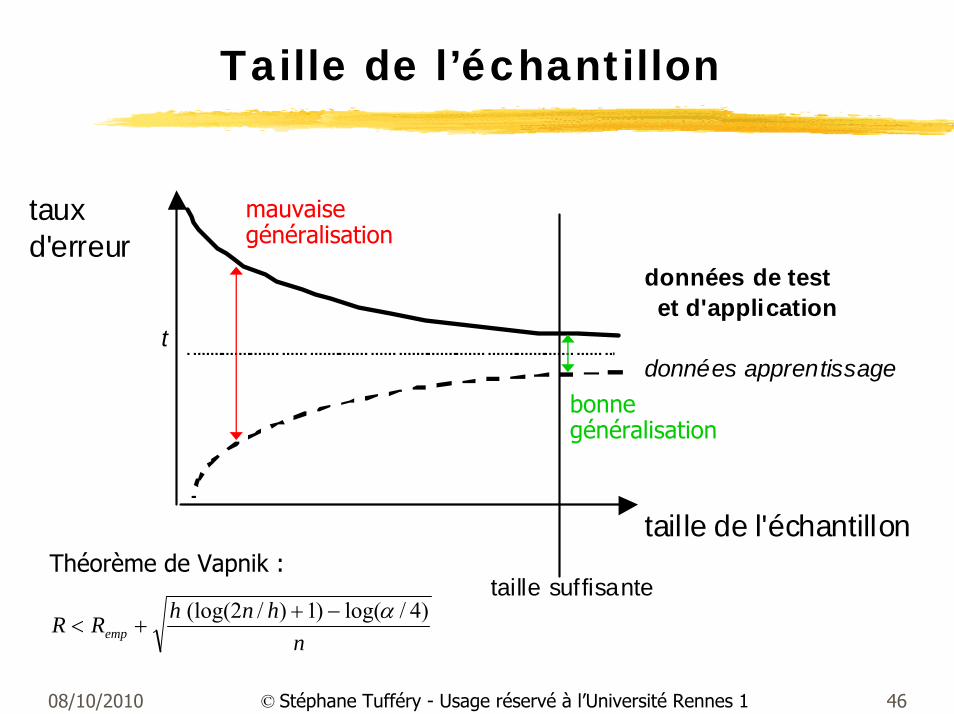
Taille de l’échantillon
tauxd'erreur
données de test et d'application
tdonnées apprentissage
taille de l'échantillon
taille suffisante
mauvaise généralisation
bonne généralisation
nhnhRR emp
)4/log()1)/2(log( α−++<
Théorème de Vapnik :

08/10/2010 47© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Représentativité de l’échantillon d’étude
• Hypothèse fondamentale :• l’échantillon d’étude est représentatif de la population à
laquelle sera appliqué le modèle• N’implique pas un échantillonnage aléatoire simple :
• événement à prédire rare ⇒ stratification non proportionnelle de l’échantillon sur la variable à expliquer
• parfois : 50 % de positifs et 50 % de négatifs• nécessaire quand on utilise CART pour modéliser 3 %
d’acheteurs, sinon CART prédit que personne n’est acheteur ⇒ excellent taux d’erreur = 3 % !
• change la constante du logit de la régression logistique• intéressant en cas d’hétéroscédasticité dans une analyse
discriminante linéaire

08/10/2010 48© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Construction de la base d’analyse
n° client
variable cible : acheteur (O/N)
âge PCS situation famille
nb achats
montant achats
… variable explicative m
échantillon
1 O 58 cadre marié 2 40 … … apprentissage2 N 27 ouvrier célibataire 3 30 … … test… … … … … … … … …… … … … … … … … …k O 46 technicien célibataire 3 75 … … test… … … … … … … … …… … … … … … … … …
1000 N 32 employé marié 1 50 … … apprentissage… … … … … … … …
variable à expliquer variables explicatives répartitionobservée année n observées année n-1 aléatoire
des clients O : au moins 500 clients ciblés dans l'année n et acheteurs entre les 2 N : au moins 500 clients ciblés dans l'année n et non acheteurs échantillons
f
au m
oins
100
0 ca
s
PREDICTION
08/10/2010 49© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
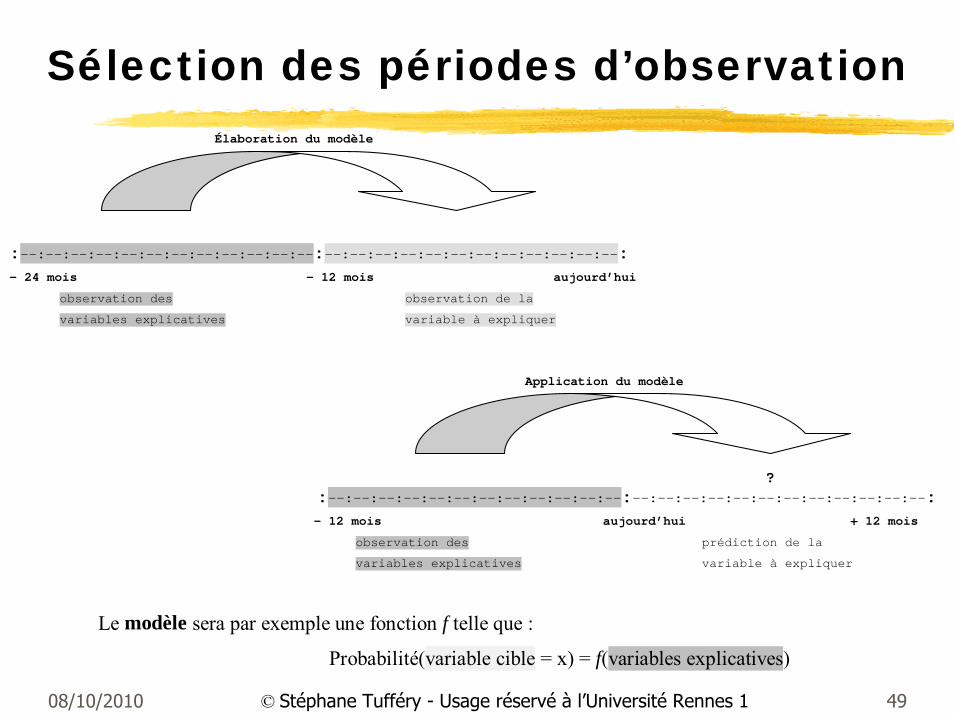
Sélection des périodes d’observation
Le modèle sera par exemple une fonction f telle que :
Probabilité(variable cible = x) = f(variables explicatives)
Élaboration du modèle
:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--: – 24 mois – 12 mois aujourd’hui
observation des observation de la
variables explicatives variable à expliquer Application du modèle
?
:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--:--: – 12 mois aujourd’hui + 12 mois
observation des prédiction de la
variables explicatives variable à expliquer

08/10/2010 50© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Pré-segmentation
• Segmentation (classification) de la population étudiée :• en groupes forcément distincts selon les données
disponibles (clients / prospects)• en groupes statistiquement pertinents vis-à-vis des objectifs
de l’étude• selon certaines caractéristiques sociodémographiques (âge,
profession…) si elles correspondent à des offres marketing spécifiques
Méthode de classification Classification statistique Règles d’experts
Oui solution efficace solution pouvant être efficace
Données utilisées liées à l’événement à prédire
Non solution risquant d’être moyennement efficace
solution pouvant être efficace si les données sont bien choisies

08/10/2010 51© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Pré-segmentation : aspects opérationnels
• Simplicité de la pré-segmentation (pas trop de règles)• Nombre limité de segments et stabilité des segments• Tailles généralement comparables des segments• Homogénéité des segments du point de vue des variables
explicatives• Homogénéité des segments du point de vue de la variable
à expliquer

08/10/2010 52© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Analyse exploratoire des données 1/2
• Explorer la distribution des variables• Vérifier la fiabilité des variables
• valeurs incohérentes ou manquantes⇒ imputation ou suppression
• Détecter les valeurs extrêmes• voir si valeurs aberrantes à éliminer
• Variables continues• détecter la non-monotonie ou la non-linéarité justifiant la
discrétisation• tester la normalité des variables (surtout si petits effectifs) et
les transformer pour augmenter la normalité• éventuellement discrétiser : découper la variable en tranches

08/10/2010 53© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Analyse exploratoire des données 2/2
• Variables discrètes• regrouper certaines modalités aux effectifs trop petits
• Créer des indicateurs pertinents d’après les données brutes• prendre l’avis des spécialistes du secteur étudié• date de naissance + date 1er achat ⇒ âge du client au
moment de son entrée en relation avec l’entreprise• dates d’achat ⇒ récence et fréquence des achats• croisement de variables
• plafond ligne de crédit + part utilisée ⇒ taux d’utilisation du crédit
• Détecter les liaisons entre variables• entre variables explicatives et à expliquer (bon)• entre variables explicatives entre elles (colinéarité : à éviter
dans certaines méthodes)
08/10/2010 54© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
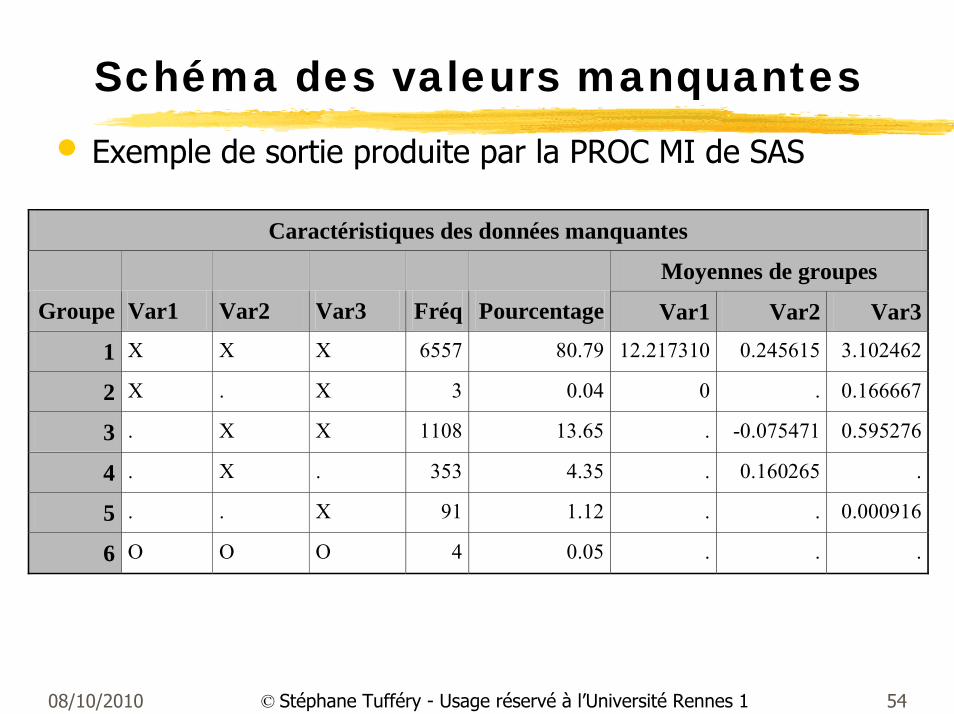
Schéma des valeurs manquantes• Exemple de sortie produite par la PROC MI de SAS
Caractéristiques des données manquantes
Moyennes de groupes
Groupe Var1 Var2 Var3 Fréq Pourcentage Var1 Var2 Var3
1 X X X 6557 80.79 12.217310 0.245615 3.102462
2 X . X 3 0.04 0 . 0.166667
3 . X X 1108 13.65 . -0.075471 0.595276
4 . X . 353 4.35 . 0.160265 .
5 . . X 91 1.12 . . 0.000916
6 O O O 4 0.05 . . .

08/10/2010 55© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Imputation des valeurs manquantes
• Solutions autres que l’imputation statistique :• suppression des observations (si elles sont peu nombreuses)• ne pas utiliser la variable concernée ou la remplacer par une
variable proche mais sans valeur manquante• traiter la valeur manquante comme une valeur à part entière• remplacement des valeurs manquantes par source externe
• Imputation statistique• par le mode, la moyenne ou la médiane• par une régression ou un arbre de décision• imputation simple (minore la variabilité et les intervalles de
confiance des paramètres estimés) ou multiple (remplacer chaque valeur manquante par n valeurs, par ex. n = 5, puis faire les analyses sur les n tables et combiner les résultats pour obtenir les paramètres avec leurs écart-types
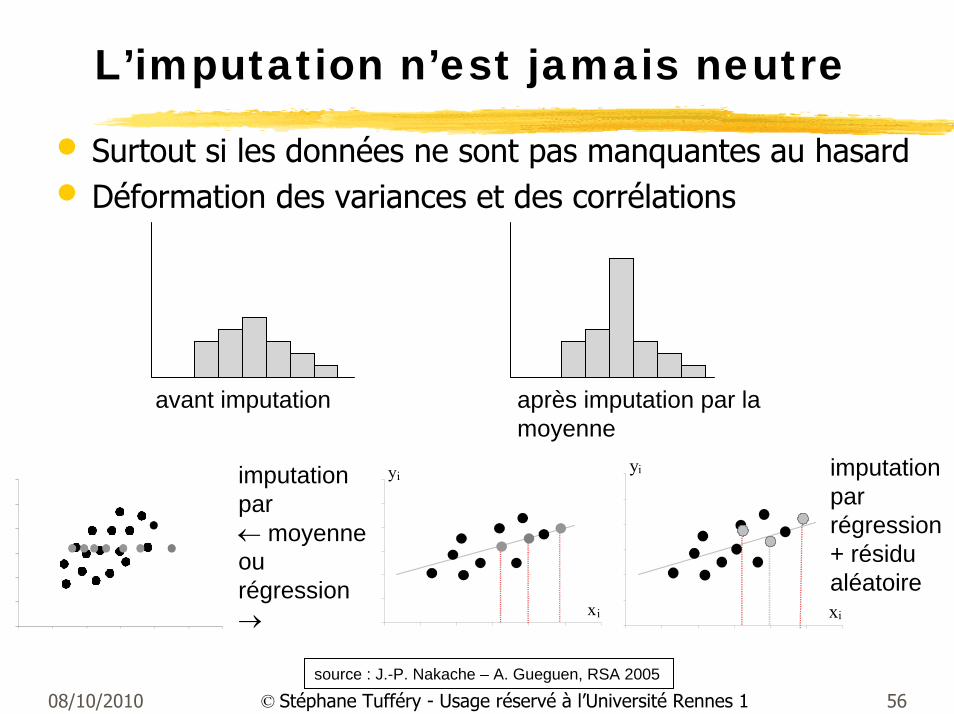
08/10/2010 56© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
L’imputation n’est jamais neutre
• Surtout si les données ne sont pas manquantes au hasard• Déformation des variances et des corrélations
0
1
2
3
4
5
6
0 1 2 3
xi
yi
0
1
2
3
4
5
6
0 1 2 3
xi
yiimputation par ← moyenne ou régression →
imputation par régression + résidu aléatoire
avant imputation après imputation par la moyenne
0 1 2 3 4 5 6
0 1 2 3
source : J.-P. Nakache – A. Gueguen, RSA 2005
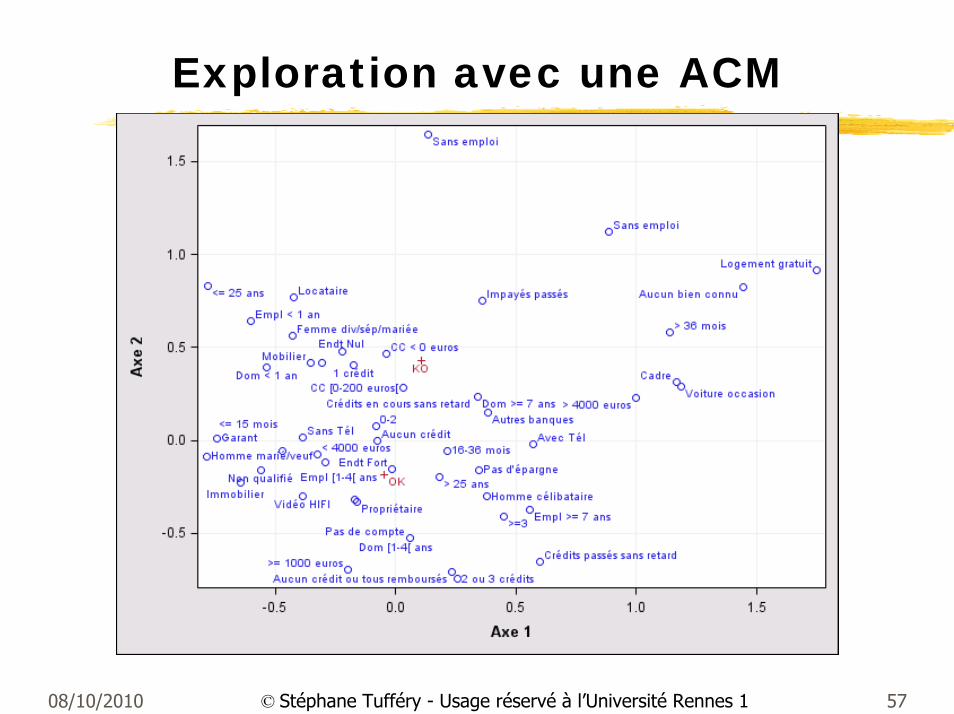
08/10/2010 57© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Exploration avec une ACM
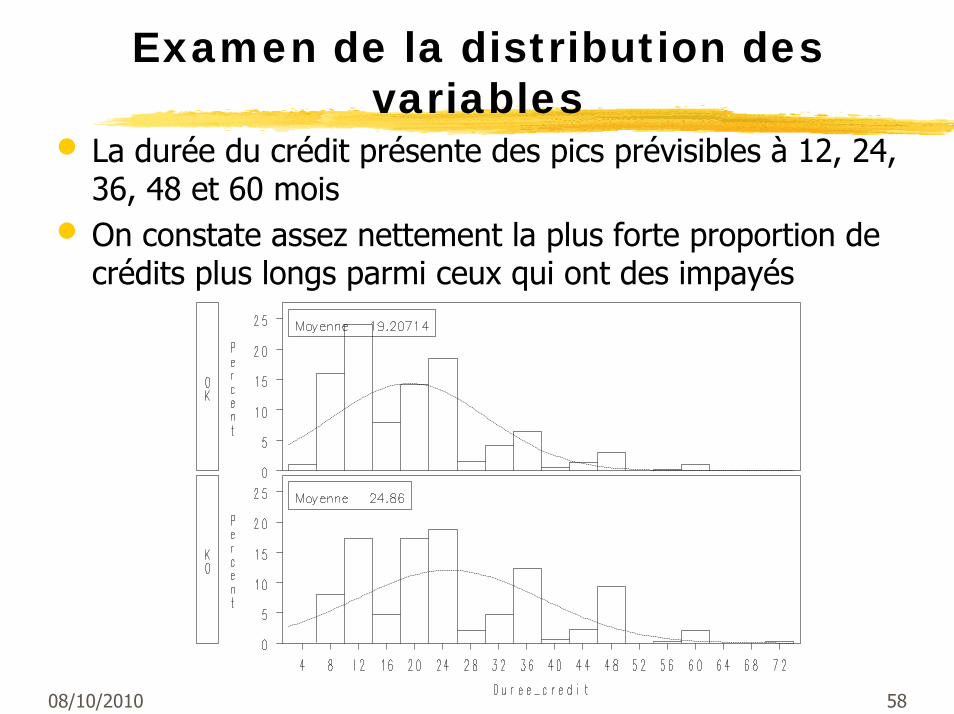
08/10/2010 58© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Examen de la distribution des variables
• La durée du crédit présente des pics prévisibles à 12, 24, 36, 48 et 60 mois
• On constate assez nettement la plus forte proportion de crédits plus longs parmi ceux qui ont des impayés

08/10/2010 59© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Normalisation : transformations
• Log (V)• transformation la plus courante pour corriger un
coefficient d’asymétrie > 0• Si V ≥ 0, on prend Log (1 + V)
• Racine carrée (V) si coefficient d’asymétrie > 0• -1/V ou –1/V² si coefficient d’asymétrie > 0• V2 ou V3 si coefficient d’asymétrie < 0• Arc sinus (racine carrée de V/100)
• si V est un pourcentage compris entre 0 et 100• Certains logiciels déterminent automatiquement la
transformation la plus adaptée• en utilisant la fonction de Box-Cox
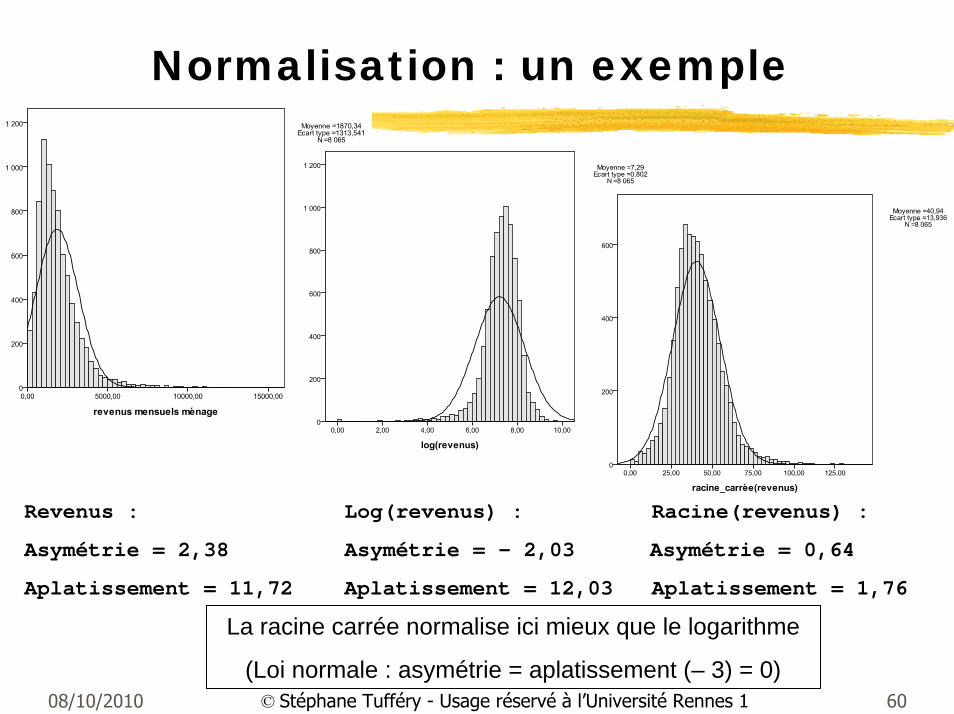
08/10/2010 60© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Normalisation : un exemple
Revenus : Log(revenus) : Racine(revenus) :
Asymétrie = 2,38 Asymétrie = - 2,03 Asymétrie = 0,64
Aplatissement = 11,72 Aplatissement = 12,03 Aplatissement = 1,76
La racine carrée normalise ici mieux que le logarithme
(Loi normale : asymétrie = aplatissement (– 3) = 0)

08/10/2010 61© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Utilité de la normalisation
• Une des hypothèses de l’analyse discriminante linéaire :• multinormalité de X/Gi et égalité des matrices de covariances
• N’est en pratique jamais satisfaite• Mais on constate une amélioration des performances de
l’analyse discriminante lorsque l’on s’en rapproche :• en neutralisant les « outliers »• en normalisant les variables explicatives susceptibles
d’entrer dans le modèle• Moralité : mieux vaut connaître les contraintes théoriques
pour se rapprocher des conditions optimales
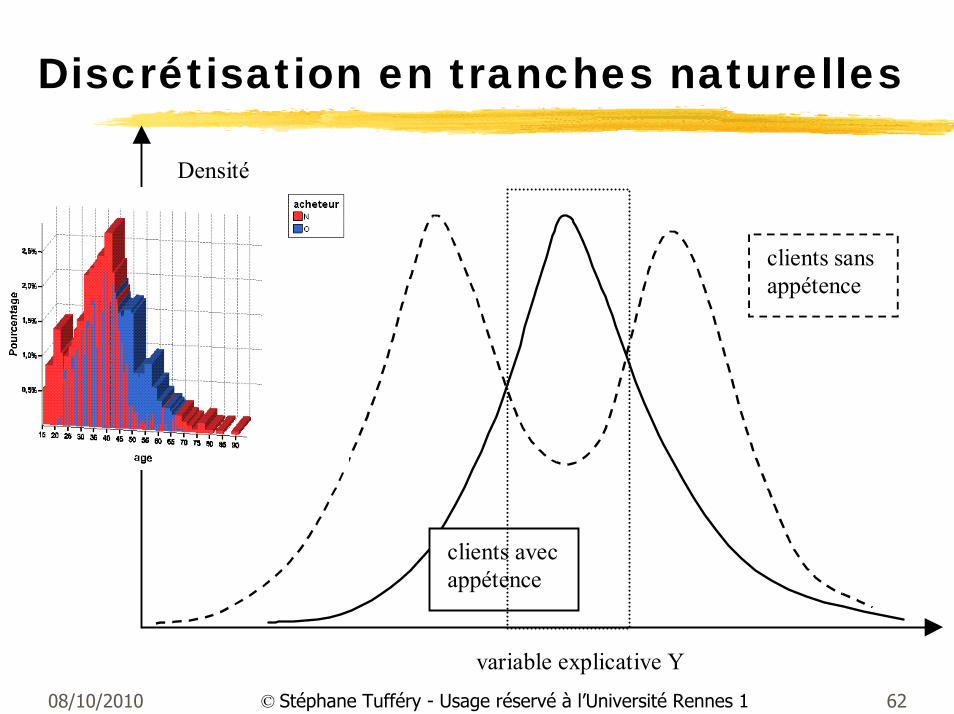
08/10/2010 62© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Densité
clients avecappétence
clients sansappétence
variable explicative Y
Discrétisation en tranches naturelles

08/10/2010 63© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Pourquoi discrétiser ?• Appréhender des liaisons non linéaires (de degré >1), voire
non monotones, entre les variables continues• par une ACM, une régression logistique ou une analyse
discriminante DISQUAL• Neutraliser les valeurs extrêmes (« outliers »)
• qui sont dans la 1ère et la dernière tranches• Gérer les valeurs manquantes (imputation toujours délicate)
• rassemblées dans une tranche supplémentaire spécifique• Gérer les ratios dont le numérateur et le dénominateur
peuvent être tous deux > 0 ou < 0• Traiter simultanément des données quantitatives et
qualitatives
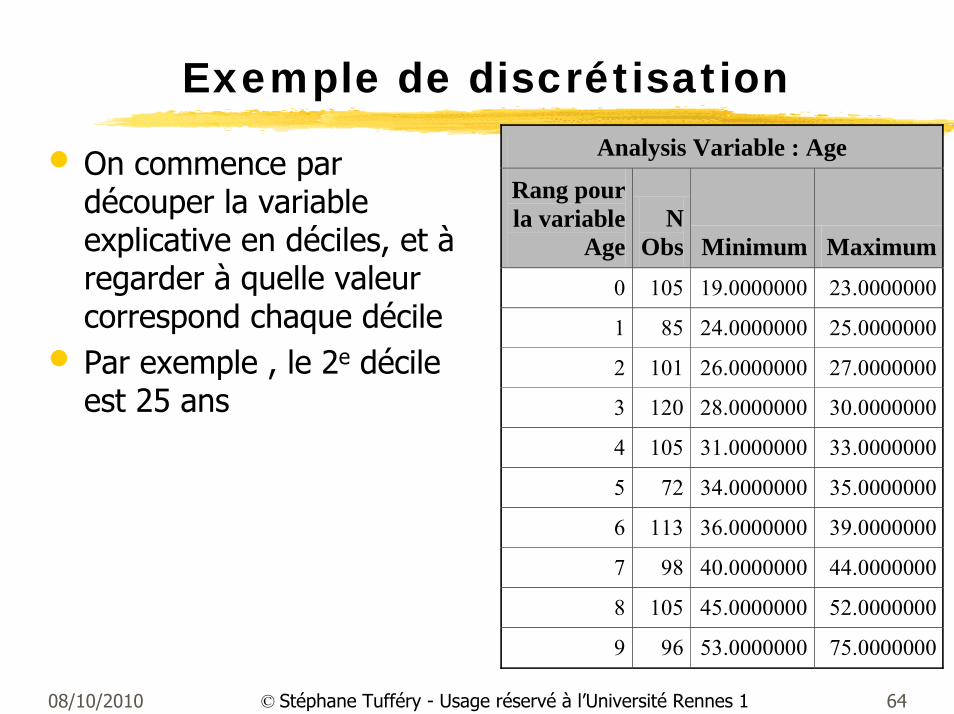
08/10/2010 64© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Exemple de discrétisation
• On commence par découper la variable explicative en déciles, et àregarder à quelle valeur correspond chaque décile
• Par exemple , le 2e décile est 25 ans
Analysis Variable : Age
Rang pour la variable
AgeN
Obs Minimum Maximum 0 105 19.0000000 23.0000000
1 85 24.0000000 25.0000000
2 101 26.0000000 27.0000000
3 120 28.0000000 30.0000000
4 105 31.0000000 33.0000000
5 72 34.0000000 35.0000000
6 113 36.0000000 39.0000000
7 98 40.0000000 44.0000000
8 105 45.0000000 52.0000000
9 96 53.0000000 75.0000000
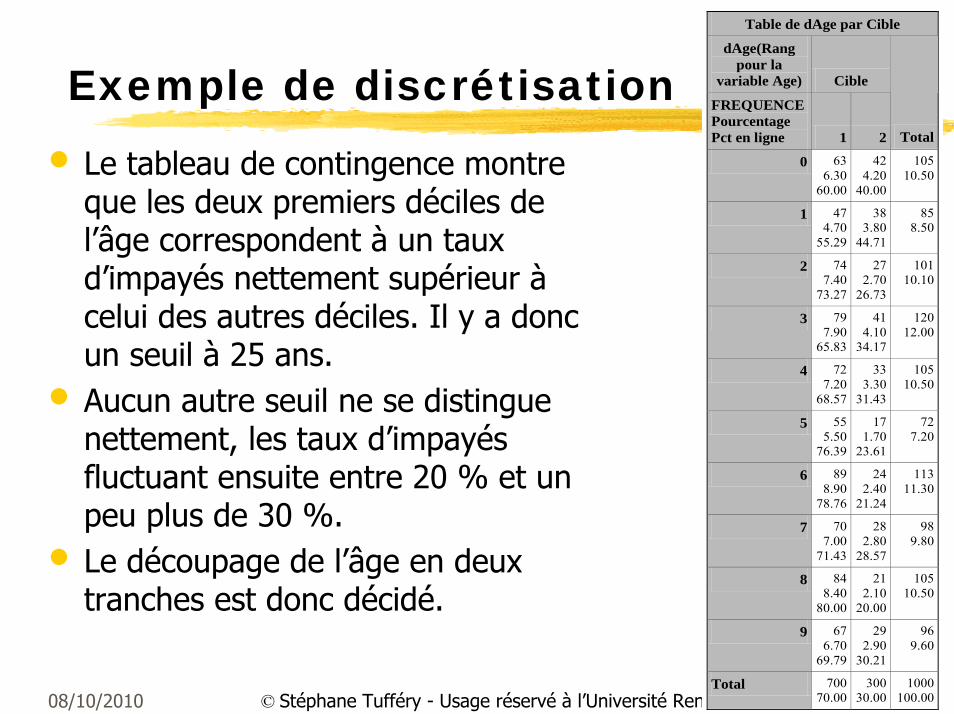
08/10/2010 65© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Exemple de discrétisation
• Le tableau de contingence montre que les deux premiers déciles de l’âge correspondent à un taux d’impayés nettement supérieur àcelui des autres déciles. Il y a donc un seuil à 25 ans.
• Aucun autre seuil ne se distingue nettement, les taux d’impayés fluctuant ensuite entre 20 % et un peu plus de 30 %.
• Le découpage de l’âge en deux tranches est donc décidé.
Table de dAge par Cible
dAge(Rang pour la
variable Age) Cible
FREQUENCEPourcentage Pct en ligne 1 2 Total
0 636.30
60.00
424.20
40.00
105 10.50
1 474.70
55.29
383.80
44.71
85 8.50
2 747.40
73.27
272.70
26.73
101 10.10
3 797.90
65.83
414.10
34.17
120 12.00
4 727.20
68.57
333.30
31.43
105 10.50
5 555.50
76.39
171.70
23.61
72 7.20
6 898.90
78.76
242.40
21.24
113 11.30
7 707.00
71.43
282.80
28.57
98 9.80
8 848.40
80.00
212.10
20.00
105 10.50
9 676.70
69.79
292.90
30.21
96 9.60
Total 70070.00
30030.00
1000 100.00

08/10/2010 66© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Exemple de regroupement de modalités
• Regroupement de « < 100 » et « [100-500 euros[ dont les taux d’impayés sont proches (35,99% et 33,01%)
• Regroupement de « [500-1000 euros[ et « >= 1000 euros » : leurs taux d’impayés sont moins proches mais la 2e modalité est trop petite pour rester seule
• On pourrait même regrouper ces deux modalités avec « Pas d’épargne »
Table de Epargne par Cible
Epargne Cible
FREQUENCE Pourcentage Pct en ligne OK KO Total
Pas d'épargne 15115.1082.51
323.20
17.49
183 18.30
< 100 38638.6064.01
21721.7035.99
603 60.30
[100-500 euros[ 696.90
66.99
343.40
33.01
103 10.30
[500-1000 euros[ 525.20
82.54
111.10
17.46
63 6.30
>= 1000 euros 424.20
87.50
60.60
12.50
48 4.80
Total 70070.00
30030.00
1000 100.00

08/10/2010 67© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Autre exemple de regroupement de modalités
• Le regroupement des modalités « Locataire » et « Logement gratuit »est évident
• Elles sont associées à des taux d’impayés proches et élevés (39,11% et 40,74%)
• Les propriétaires sont moins risqués, surtout s’ils ont fini leur emprunt, mais pas seulement dans ce cas, car ils sont généralement plus attentifs que la moyenne au bon remboursement de leur emprunt
Table de Statut_domicile par Cible
Statut_domicile Cible
FREQUENCE Pourcentage Pct en ligne OK KO Total
Locataire 10910.9060.89
707.00
39.11
179 17.90
Propriétaire 52752.7073.91
18618.6026.09
713 71.30
Logement gratuit 646.40
59.26
444.40
40.74
108 10.80
Total 70070.00
30030.00
1000 100.00
08/10/2010 68© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
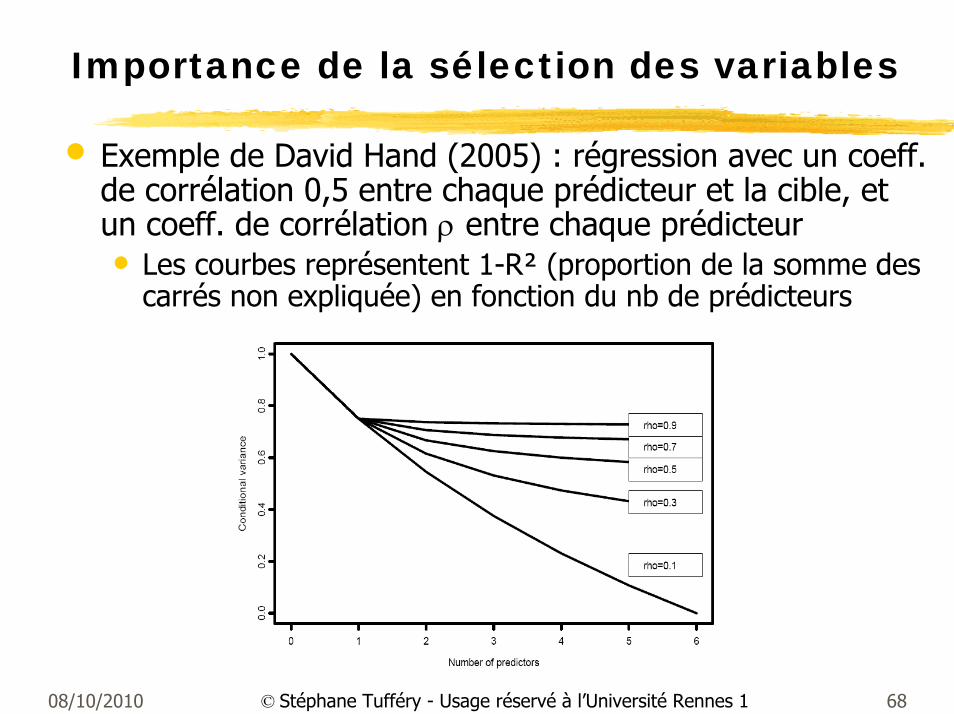
Importance de la sélection des variables
• Exemple de David Hand (2005) : régression avec un coeff. de corrélation 0,5 entre chaque prédicteur et la cible, et un coeff. de corrélation ρ entre chaque prédicteur• Les courbes représentent 1-R² (proportion de la somme des
carrés non expliquée) en fonction du nb de prédicteurs

08/10/2010 69© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Limiter le nombre de variables sélectionnées
• En présence de colinéarité entre les prédicteurs, l’apport marginal de chaque prédicteur décroît très vite
• Et pourtant, ici chaque prédicteur est supposé avoir la même liaison avec la cible, ce qui n’est pas le cas dans une sélection pas à pas réelle où la liaison décroît !
• Conclusion :• Éviter au maximum la colinéarité des prédicteurs• Limiter le nombre de prédicteurs : souvent moins de 10• Alternative : la régression PLS ou régularisée (ridge…)
• Remarque :• Dans une procédure pas à pas, le 1er prédicteur peut occulter
un autre prédicteur plus intéressant
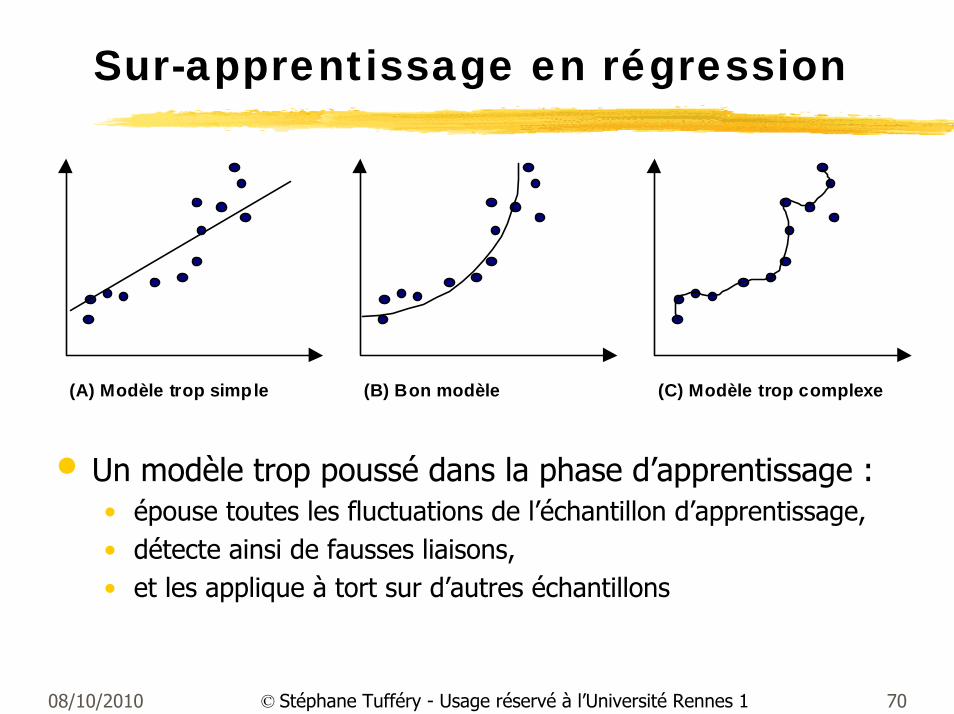
08/10/2010 70© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Sur-apprentissage en régression
(A) Modèle trop simple (B) Bon modèle (C) Modèle trop complexe
• Un modèle trop poussé dans la phase d’apprentissage :• épouse toutes les fluctuations de l’échantillon d’apprentissage,• détecte ainsi de fausses liaisons,• et les applique à tort sur d’autres échantillons

08/10/2010 71© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Sur-apprentissage en classement
Source : Olivier Bousquet
(A) Mod
èle tro
p simple
(B) Bon modèle
(C) Modèle trop complexe
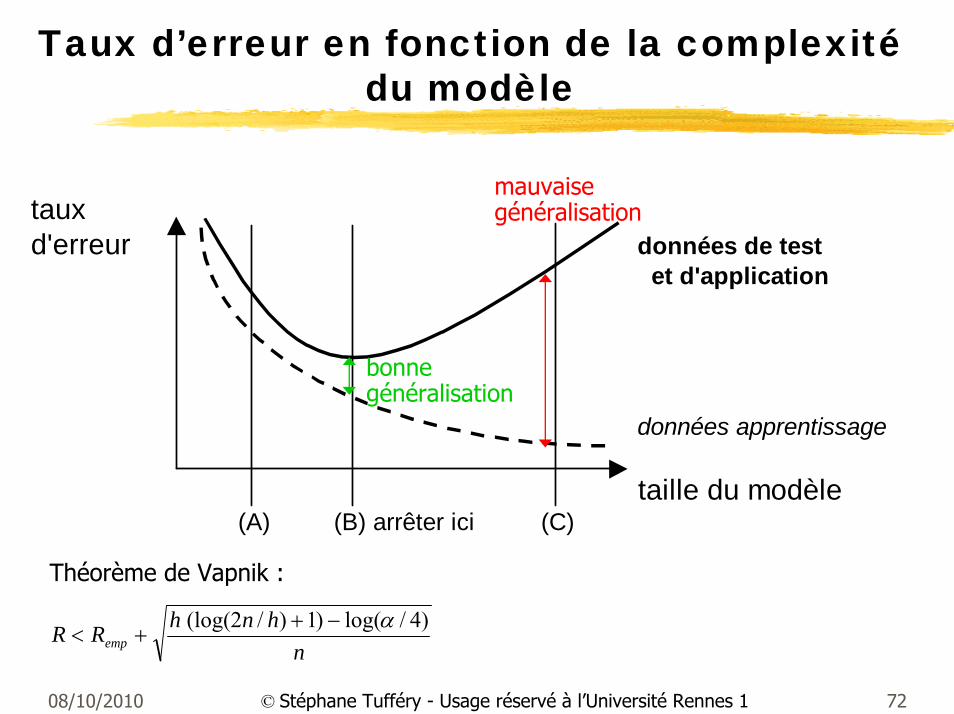
08/10/2010 72© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Taux d’erreur en fonction de la complexitédu modèle
tauxd'erreur données de test
et d'application
données apprentissage
taille du modèle(A) (B) arrêter ici (C)
mauvaise généralisation
bonne généralisation
nhnhRR emp
)4/log()1)/2(log( α−++<
Théorème de Vapnik :

08/10/2010 73© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
• Tests paramétriques• supposent que les variables suivent une loi
particulière (normalité, homoscédasticité)• ex : test de Student, ANOVA
• Tests non-paramétriques• ne supposent pas que les variables suivent une loi particulière• se fondent souvent sur les rangs des valeurs des variables
plutôt que sur les valeurs elles-mêmes• peu sensibles aux valeurs aberrantes• ex : test de Wilcoxon-Mann-Whitney, test de Kruskal-Wallis
• Exemple du r de Pearson et du ρ de Spearman :• r > ρ ⇒ présence de valeurs extrêmes ?• ρ > r ⇒ liaison non linéaire non détectée par Pearson ?
• ex : x = 1, 2, 3… et y = e1, e2, e3…
Rappel sur les tests
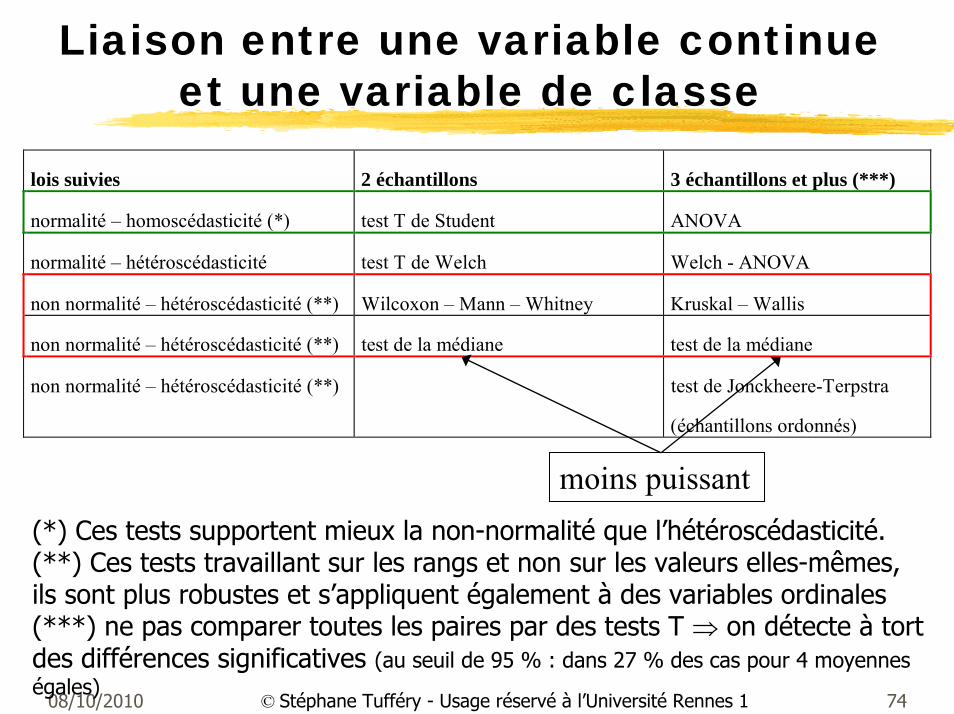
08/10/2010 74© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Liaison entre une variable continue et une variable de classe
(*) Ces tests supportent mieux la non-normalité que l’hétéroscédasticité.(**) Ces tests travaillant sur les rangs et non sur les valeurs elles-mêmes,ils sont plus robustes et s’appliquent également à des variables ordinales(***) ne pas comparer toutes les paires par des tests T ⇒ on détecte à tort des différences significatives (au seuil de 95 % : dans 27 % des cas pour 4 moyennes égales)
lois suivies 2 échantillons 3 échantillons et plus (***)
normalité – homoscédasticité (*) test T de Student ANOVA
normalité – hétéroscédasticité test T de Welch Welch - ANOVA
non normalité – hétéroscédasticité (**) Wilcoxon – Mann – Whitney Kruskal – Wallis
non normalité – hétéroscédasticité (**) test de la médiane test de la médiane
non normalité – hétéroscédasticité (**) test de Jonckheere-Terpstra
(échantillons ordonnés)
moins puissant

08/10/2010 75© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Sélection des variables discriminantes
• Dans la sélection des variables discriminantes d’un modèle, le test de Kruskal-Wallis est souvent plus apte que l’ANOVA paramétrique à détecter des variables qui seront efficaces, une fois mises en classes, dans une régression logistique• notamment les variables hautement non normales que sont
les ratios X/Y• Idée de présentation des variables discriminantes :
• R² = Σ des carrés interclasse / Σ totale des carrés• χ² KW = χ² de Kruskal-Wallis (à 1 d° de liberté)
variable χ² KWrang KW R²
rang R² χ² CHAID
nb nœudsCHAID ddl proba CHAID
rang CHAID
rang CART
X 2613,076444 1 0,0957 1 1023,9000 5 4 2,3606E-220 1 1
Y 2045,342644 2 0,0716 2 949,0000 5 4 4,0218E-204 2 11
Z 1606,254491 3 0,0476 5 902,3000 4 3 2,8063E-195 4 12
… 1566,991315 4 0,0491 4 920,4000 4 3 3,3272E-199 3 4

08/10/2010 76© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
ODS OUTPUT KruskalWallisTest = kruskal ; PROC NPAR1WAY WILCOXON DATA = exemple; CLASS segment ; VAR &var ; DATA kruskal (keep = Variable nValue1 RENAME=(nValue1=KWallis)) ; SET kruskal ; WHERE name1 = '_KW_' ; PROC SORT DATA = kruskal ; BY DESCENDING KWallis ; RUN;
Automatisation de la sélection
• Avec l’ODS de SAS ou l’OMS de SPSS :
OMS /SELECT TABLES /IF COMMANDS = ["NPar Tests"] SUBTYPES = ["Kruskal Wallis Test Statistics"] /DESTINATION FORMAT = SAV OUTFILE = "C:\temp\kw.sav" /COLUMNS DIMNAMES=['Statistics'].
NPAR TESTS /K-W= !var BY segment (0 1) /MISSING ANALYSIS.
OMSEND.
GET FILE = "C:\temp\kw.sav".
SELECT IF(Var1 = 'Khi-deux'). EXE.
SORT CASES Var3 (D) .
SAVE OUTFILE = "C:\temp\kw.sav" /KEEP=Var2 Var3.
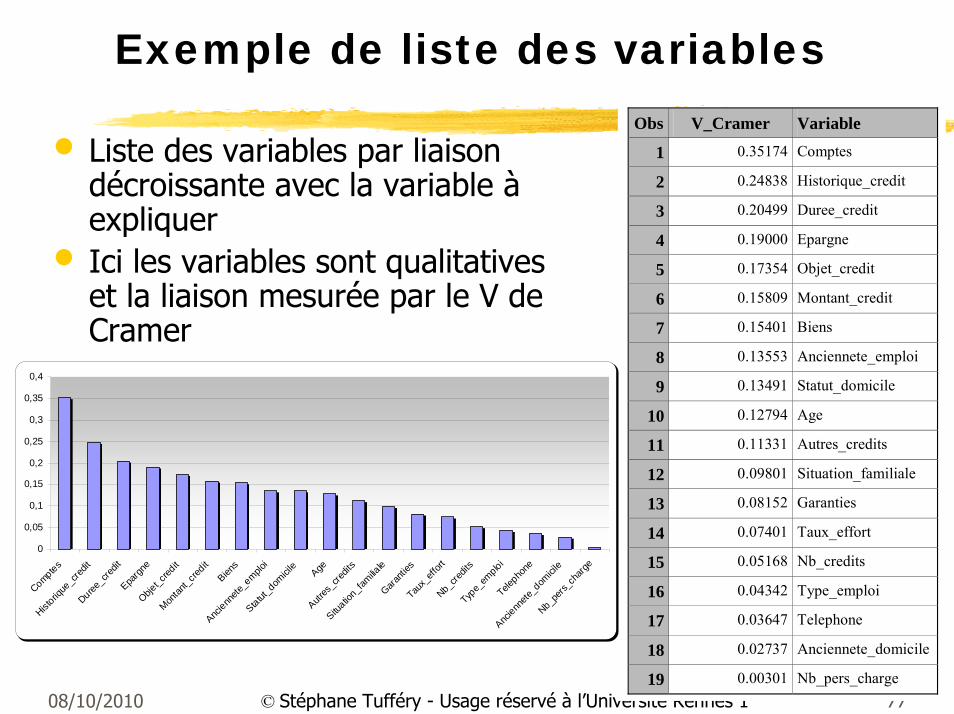
08/10/2010 77© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Exemple de liste des variables
• Liste des variables par liaison décroissante avec la variable àexpliquer
• Ici les variables sont qualitatives et la liaison mesurée par le V de Cramer
Obs V_Cramer Variable
1 0.35174 Comptes
2 0.24838 Historique_credit
3 0.20499 Duree_credit
4 0.19000 Epargne
5 0.17354 Objet_credit
6 0.15809 Montant_credit
7 0.15401 Biens
8 0.13553 Anciennete_emploi
9 0.13491 Statut_domicile
10 0.12794 Age
11 0.11331 Autres_credits
12 0.09801 Situation_familiale
13 0.08152 Garanties
14 0.07401 Taux_effort
15 0.05168 Nb_credits
16 0.04342 Type_emploi
17 0.03647 Telephone
18 0.02737 Anciennete_domicile
19 0.00301 Nb_pers_charge
0
0,05
0,1
0,15
0,2
0,25
0,3
0,35
0,4
Comptes
Historiq
ue_c
redit
Duree_cre
ditEpa
rgne
Objet_c
redit
Montan
t_cred
itBien
s
Ancienn
ete_e
mploi
Statut_d
omicil
e
AgeAutr
es_c
redits
Situatio
n_familia
leGara
nties
Taux_
effort
Nb_cred
itsTyp
e_em
ploiTele
phone
Ancienn
ete_d
omicil
e
Nb_pers
_cha
rge
08/10/2010 78© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Constant
e
V05 V
09
V14
V01
V03 V
13
V02
V04
V18
V22
V19
V17
V24
V08
V36
V28
V07
V25
V26
V15
V12
V29
V31
V10
V20
V06
V16
V32
V37
V11
V21
V23
V27
V34
V35
0
10
20
30
40
50
60
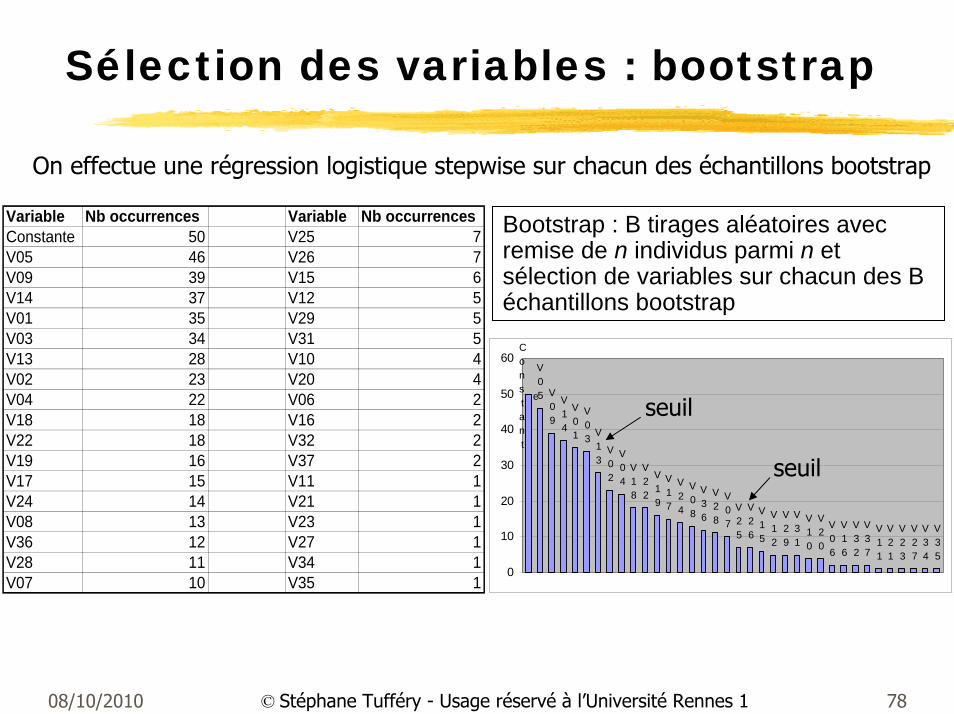
Sélection des variables : bootstrap
Variable Nb occurrences Variable Nb occurrencesConstante 50 V25 7V05 46 V26 7V09 39 V15 6V14 37 V12 5V01 35 V29 5V03 34 V31 5V13 28 V10 4V02 23 V20 4V04 22 V06 2V18 18 V16 2V22 18 V32 2V19 16 V37 2V17 15 V11 1V24 14 V21 1V08 13 V23 1V36 12 V27 1V28 11 V34 1V07 10 V35 1
seuil
seuil
Bootstrap : B tirages aléatoires avec remise de n individus parmi n et sélection de variables sur chacun des B échantillons bootstrap
On effectue une régression logistique stepwise sur chacun des échantillons bootstrap

08/10/2010 79© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Sélection des variables : classification à l’aide d’une ACP
évolution consommation0.78700.00270.2151evolconsom
relation (ancienneté client)0.36620.03360.6461relation
âge0.39670.00000.6033ageCluster 2
règlements à crédit0.76890.00020.2312utilcredit
abonnement autre service0.74950.00420.2537abonnement
revenus du client0.55800.02340.4551revenus
nb achats0.40530.00070.5950nbachats
nb produits0.38820.01830.6189nbproduits
nb points fidélité0.34580.00110.6546nbpointsCluster 1
NextClosest
OwnCluster
VariableLabel
1-R**2Ratio
R-squared with
VariableCluster
évolution consommation0.78700.00270.2151evolconsom
relation (ancienneté client)0.36620.03360.6461relation
âge0.39670.00000.6033ageCluster 2
règlements à crédit0.76890.00020.2312utilcredit
abonnement autre service0.74950.00420.2537abonnement
revenus du client0.55800.02340.4551revenus
nb achats0.40530.00070.5950nbachats
nb produits0.38820.01830.6189nbproduits
nb points fidélité0.34580.00110.6546nbpointsCluster 1
NextClosest
OwnCluster
VariableLabel
1-R**2Ratio
R-squared with
VariableCluster
PROC VARCLUS DATA=fichier_client;VAR age relation nbpoints nbproduits nbachats revenus abonnement evolconsom utilcredit; RUN;
08/10/2010 80© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
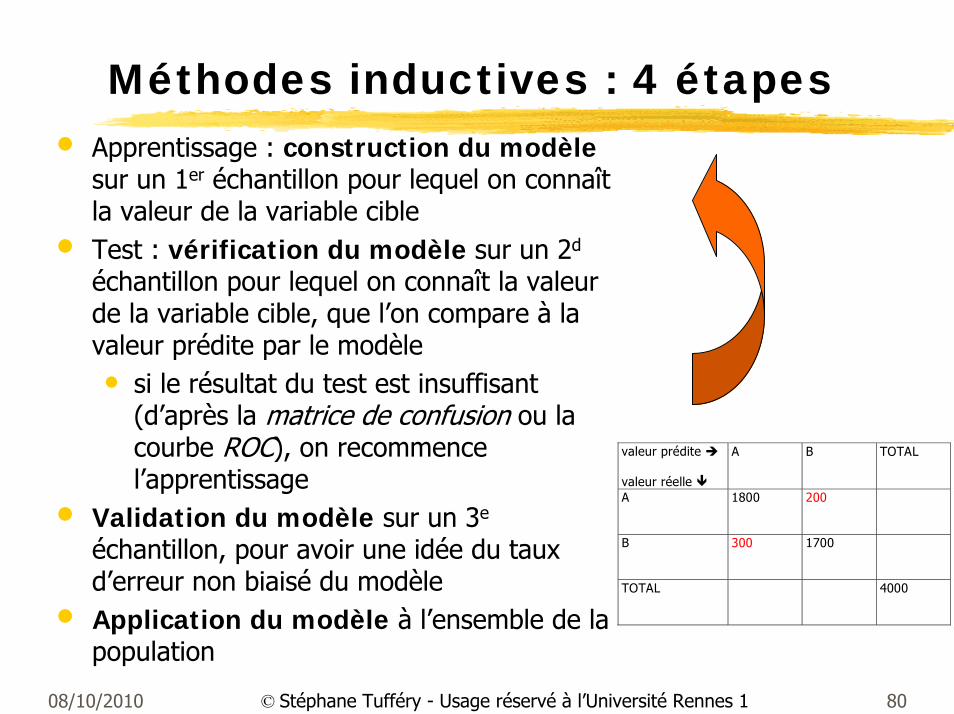
Méthodes inductives : 4 étapes• Apprentissage : construction du modèle
sur un 1er échantillon pour lequel on connaît la valeur de la variable cible
• Test : vérification du modèle sur un 2d
échantillon pour lequel on connaît la valeur de la variable cible, que l’on compare à la valeur prédite par le modèle• si le résultat du test est insuffisant
(d’après la matrice de confusion ou la courbe ROC), on recommence l’apprentissage
• Validation du modèle sur un 3e
échantillon, pour avoir une idée du taux d’erreur non biaisé du modèle
• Application du modèle à l’ensemble de la population
valeur prédite
valeur réelle
A B TOTAL
A 1800 200
B 300 1700
TOTAL 4000

08/10/2010 81© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Phase de modélisation
• Régression logistique (généralité – concision – précision)
• Analyse discriminante (simplicité – concision – précision)• Arbre de décision (généralité – lisibilité)
logit = - 0.98779849 - (0.00005411 * liquidités)
+ (0.01941272* mouvements) + (0.12187987* produits)
- (0.00001503 * patrimoine);
score = exp(logit) / (1 + exp(logit));
logit = - 0.98779849 - (0.00005411 * liquidités)
+ (0.01941272* mouvements) + (0.12187987* produits)
- (0.00001503 * patrimoine);
score = exp(logit) / (1 + exp(logit));
logit = - 0.98779849 - (0.00005411 * liquidités)
+ (0.01941272* mouvements) + (0.12187987* produits)
- (0.00001503 * patrimoine);
score = exp(logit) / (1 + exp(logit));

08/10/2010 82© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Principales méthodes de scoring
• Analyse discriminante linéaire• Résultat explicite P(Y/ X1, … , Xp) sous forme d’une formule• Requiert des Xi continues et des lois Xi/Y multinormales et
homoscédastiques (attention aux « outliers »)• Optimale si les hypothèses sont remplies
• Régression logistique• Sans hypothèse sur les lois Xi/Y, Xi peut être discret, nécessaire
absence de colinéarité entre les Xi
• Précision parfois légèrement inférieure à l’analyse discriminante• Arbres de décision
• Règles complètement explicites• Traitent les données hétérogènes, éventuellement manquantes,
sans hypothèses de distribution• Détection de phénomènes non linéaires• Moindre robustesse
08/10/2010 83© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
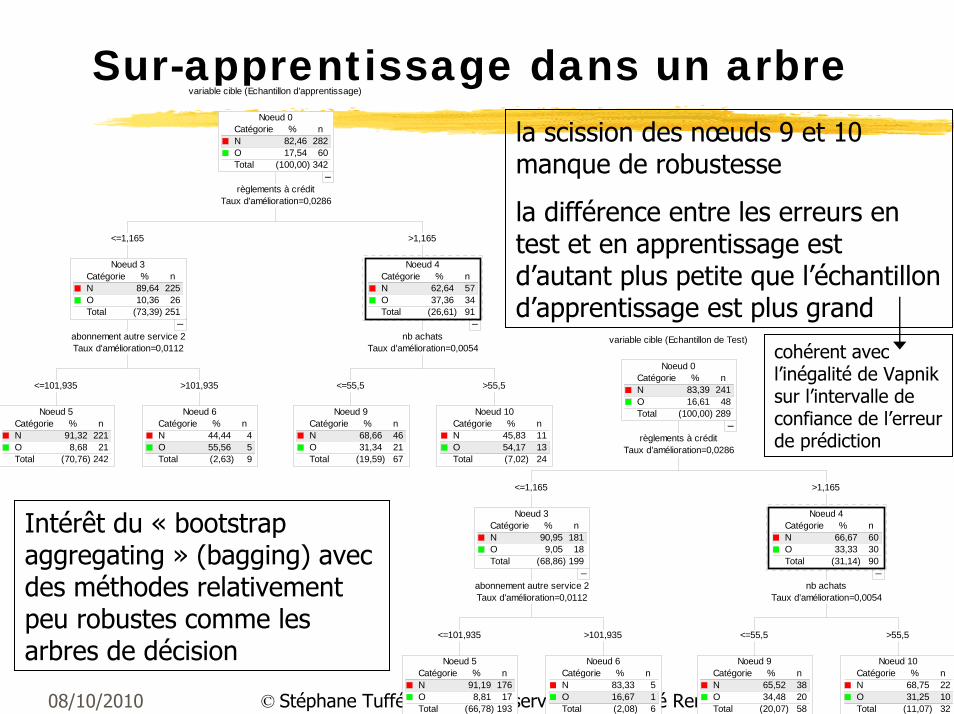
Sur-apprentissage dans un arbreCatégorie % nN 82,46 282O 17,54 60Total (100,00) 342
Noeud 0
Catégorie % nN 62,64 57O 37,36 34Total (26,61) 91
Noeud 4
Catégorie % nN 45,83 11O 54,17 13Total (7,02) 24
Noeud 10Catégorie % nN 68,66 46O 31,34 21Total (19,59) 67
Noeud 9
Catégorie % nN 89,64 225O 10,36 26Total (73,39) 251
Noeud 3
Catégorie % nN 44,44 4O 55,56 5Total (2,63) 9
Noeud 6Catégorie % nN 91,32 221O 8,68 21Total (70,76) 242
Noeud 5
variable cible (Echantillon d'apprentissage)
règlements à créditTaux d'amélioration=0,0286
>1,165
nb achatsTaux d'amélioration=0,0054
>55,5<=55,5
<=1,165
abonnement autre service 2Taux d'amélioration=0,0112
>101,935<=101,935Catégorie % nN 83,39 241O 16,61 48Total (100,00) 289
Noeud 0
Catégorie % nN 66,67 60O 33,33 30Total (31,14) 90
Noeud 4
Catégorie % nN 68,75 22O 31,25 10Total (11,07) 32
Noeud 10Catégorie % nN 65,52 38O 34,48 20Total (20,07) 58
Noeud 9
Catégorie % nN 90,95 181O 9,05 18Total (68,86) 199
Noeud 3
Catégorie % nN 83,33 5O 16,67 1Total (2,08) 6
Noeud 6Catégorie % nN 91,19 176O 8,81 17Total (66,78) 193
Noeud 5
variable cible (Echantillon de Test)
règlements à créditTaux d'amélioration=0,0286
>1,165
nb achatsTaux d'amélioration=0,0054
>55,5<=55,5
<=1,165
abonnement autre service 2Taux d'amélioration=0,0112
>101,935<=101,935
la scission des nœuds 9 et 10 manque de robustesse
la différence entre les erreurs en test et en apprentissage est d’autant plus petite que l’échantillon d’apprentissage est plus grand
Intérêt du « bootstrap aggregating » (bagging) avec des méthodes relativement peu robustes comme les arbres de décision
cohérent avec l’inégalité de Vapnik sur l’intervalle de confiance de l’erreur de prédiction
08/10/2010 84© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
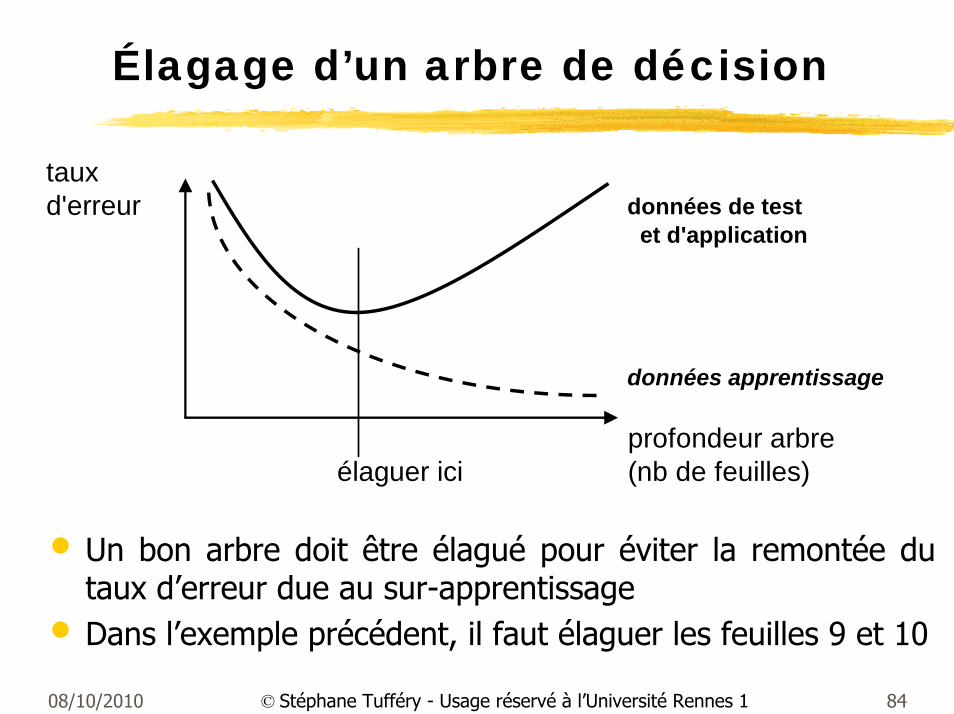
Élagage d’un arbre de décision
• Un bon arbre doit être élagué pour éviter la remontée du taux d’erreur due au sur-apprentissage
• Dans l’exemple précédent, il faut élaguer les feuilles 9 et 10
tauxd'erreur données de test
et d'application
données apprentissage
profondeur arbreélaguer ici (nb de feuilles)

08/10/2010 85© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Grille de score
• Passage de coefficients (« Estimation ») à des pondérations dont la somme est comprise entre 0 et 100
Variable Modalité Nb points
Age > 25 ans 0
Age ≤ 25 ans 8
Autres_credits Aucun crédit extérieur 0
Autres_credits Crédits extérieurs 7
Comptes Pas de compte 0
Comptes CC ≥ 200 euros 13
Comptes CC [0-200 euros[ 19
Comptes CC < 0 euros 25
Duree_credit ≤ 15 mois 0
Duree_credit 16-36 mois 13
Duree_credit > 36 mois 18
Epargne pas épargne ou > 500 euros 0
Epargne < 500 euros 8
Garanties Avec garant 0
Garanties Sans garant 21
Historique_credit Jamais aucun crédit 0
Historique_credit Crédits sans retard 6
Historique_credit Crédits en impayé 13
Analyse des estimations de la vraisemblance maximum
Paramètre DF EstimationErreur
stdKhi 2
de Wald Pr > Khi 2
Intercept 1 -3.1995 0.3967 65.0626 <.0001
Comptes CC >= 200 euros 1 1.0772 0.4254 6.4109 0.0113
Comptes CC < 0 euros 1 2.0129 0.2730 54.3578 <.0001
Comptes CC [0-200 euros[ 1 1.5001 0.2690 31.1067 <.0001
Comptes Pas de compte 0 0 . . .
Historique_credit Crédits en impayé 1 1.0794 0.3710 8.4629 0.0036
Historique_credit Crédits sans retard 1 0.4519 0.2385 3.5888 0.0582
Historique_credit Jamais aucun crédit 0 0 . . .
Duree_credit > 36 mois 1 1.4424 0.3479 17.1937 <.0001
Duree_credit 16-36 mois 1 1.0232 0.2197 21.6955 <.0001
Duree_credit <= 15 mois 0 0 . . .
Age <= 25 ans 1 0.6288 0.2454 6.5675 0.0104
Age > 25 ans 0 0 . . .
Epargne < 500 euros 1 0.6415 0.2366 7.3501 0.0067
Epargne pas épargne ou > 500 euros 0 0 . . .
Garanties Avec garant 1 -1.7210 0.5598 9.4522 0.0021
Garanties Sans garant 0 0 . . .
Autres_credits Aucun crédit extérieur 1 -0.5359 0.2439 4.8276 0.0280
Autres_credits Crédits extérieurs 0 0 . . .

08/10/2010 86© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Exemples de notations
• Note d’un jeune de moins de 25 ans, qui demande pour la première fois un crédit dans l’établissement et qui n’en a pas ailleurs, sans impayé, avec un compte dont le solde moyen est légèrement positif (mais < 200 €), avec un peu d’épargne (< 500 €), sans garant, qui demande un crédit sur 36 mois :• 8 + 0 + 19 + 13 + 8 + 21 + 0 = 69 points
• Note d’un demandeur de plus de 25 ans, avec des crédits à la concurrence, sans impayé, avec un compte dont le solde moyen est > 200 €, avec plus de 500 € d’épargne, sans garant, qui demande un crédit sur 12 mois :• 0 + 7 + 13 + 0 + 0 + 21 + 0 = 41 points
• On constate la facilité de l’implémentation et du calcul du score

08/10/2010 87© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Validation des modèles
• Etape très importante car des modèles peuvent :• donner de faux résultats (données non fiables)• mal se généraliser dans l’espace (autre échantillon) ou le
temps (échantillon postérieur)• sur-apprentissage
• être peu efficaces (déterminer avec 2 % d’erreur un phénomène dont la probabilité d’apparition = 1 % !)
• être incompréhensibles ou inacceptables par les utilisateurs• souvent en raison des variables utilisées
• Principaux outils de comparaison :• matrices de confusion, courbes ROC, de lift, et indices
associés

08/10/2010 88© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Sensibilité et spécificité
• Pour un score devant discriminer un groupe A (les positifs; ex : les risqués) par rapport à un autre groupe B (les négatifs ; ex : les non risqués), on définit 2 fonctions du seuil de séparation s du score :• sensibilité = α(s) = Proba(score ≥ s / A) = probabilité de
bien détecter un positif• spécificité = β(s) = Proba(score < s / B) = probabilité de
bien détecter un négatif• Pour un modèle, on cherche s qui maximise α(s) tout en
minimisant les faux positifs 1 - β(s) = Proba(score ≥ s / B)• faux positifs : négatifs considérés comme positifs à cause du
score• Le meilleur modèle : permet de capturer le plus possible
de vrais positifs avec le moins possible de faux positifs
08/10/2010 89© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
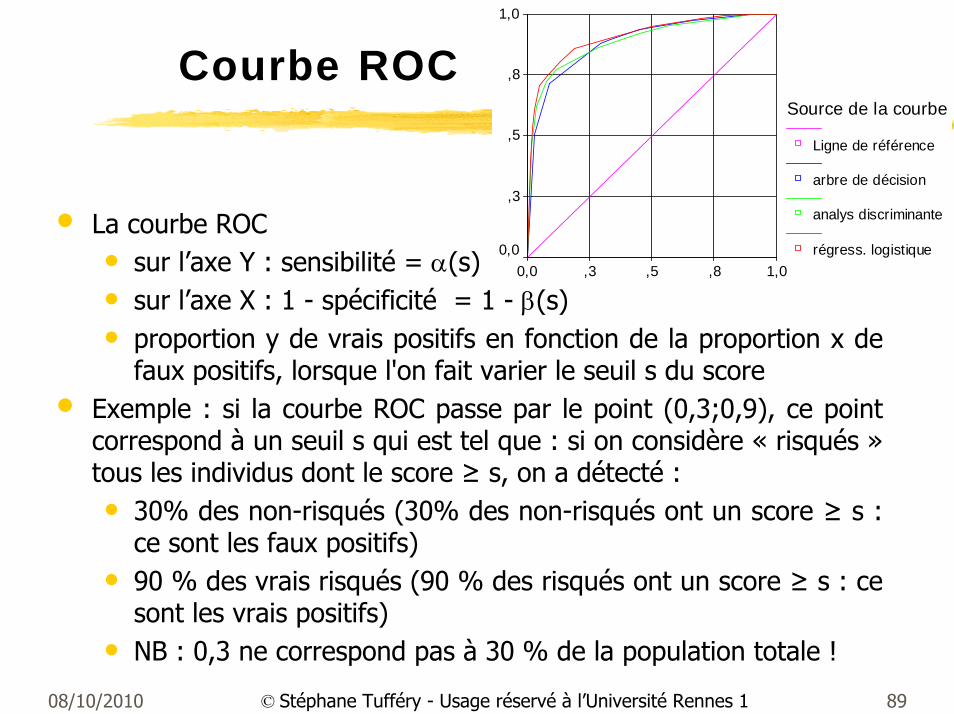
Courbe ROC
• La courbe ROC• sur l’axe Y : sensibilité = α(s)• sur l’axe X : 1 - spécificité = 1 - β(s) • proportion y de vrais positifs en fonction de la proportion x de
faux positifs, lorsque l'on fait varier le seuil s du score• Exemple : si la courbe ROC passe par le point (0,3;0,9), ce point
correspond à un seuil s qui est tel que : si on considère « risqués »tous les individus dont le score ≥ s, on a détecté :• 30% des non-risqués (30% des non-risqués ont un score ≥ s :
ce sont les faux positifs)• 90 % des vrais risqués (90 % des risqués ont un score ≥ s : ce
sont les vrais positifs)• NB : 0,3 ne correspond pas à 30 % de la population totale !
1,0,8,5,30,0
1,0
,8
,5
,3
0,0
Source de la courbe
Ligne de référence
arbre de décision
analys discriminante
régress. logistique
08/10/2010 90© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
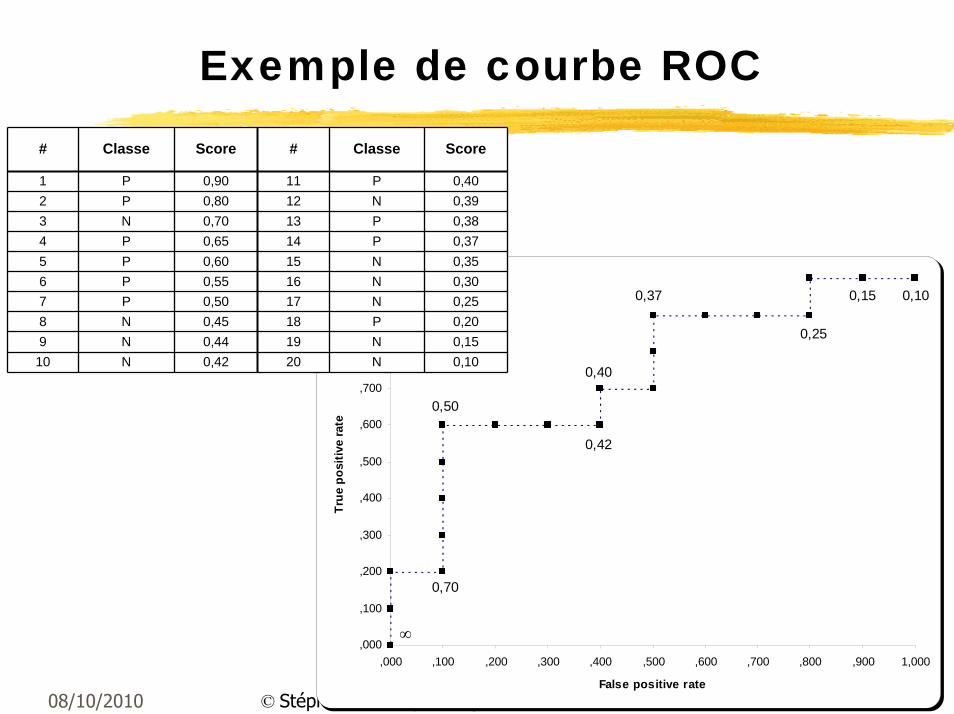
Exemple de courbe ROC
,000
,100
,200
,300
,400
,500
,600
,700
,800
,900
1,000
,000 ,100 ,200 ,300 ,400 ,500 ,600 ,700 ,800 ,900 1,000
False positive rate
True
pos
itive
rate
0,15 0,10
0,70
0,50
0,42
0,40
0,37
0,25
∞
# Classe Score # Classe Score
1 P 0,90 11 P 0,402 P 0,80 12 N 0,393 N 0,70 13 P 0,384 P 0,65 14 P 0,375 P 0,60 15 N 0,356 P 0,55 16 N 0,307 P 0,50 17 N 0,258 N 0,45 18 P 0,209 N 0,44 19 N 0,1510 N 0,42 20 N 0,10
08/10/2010 91© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
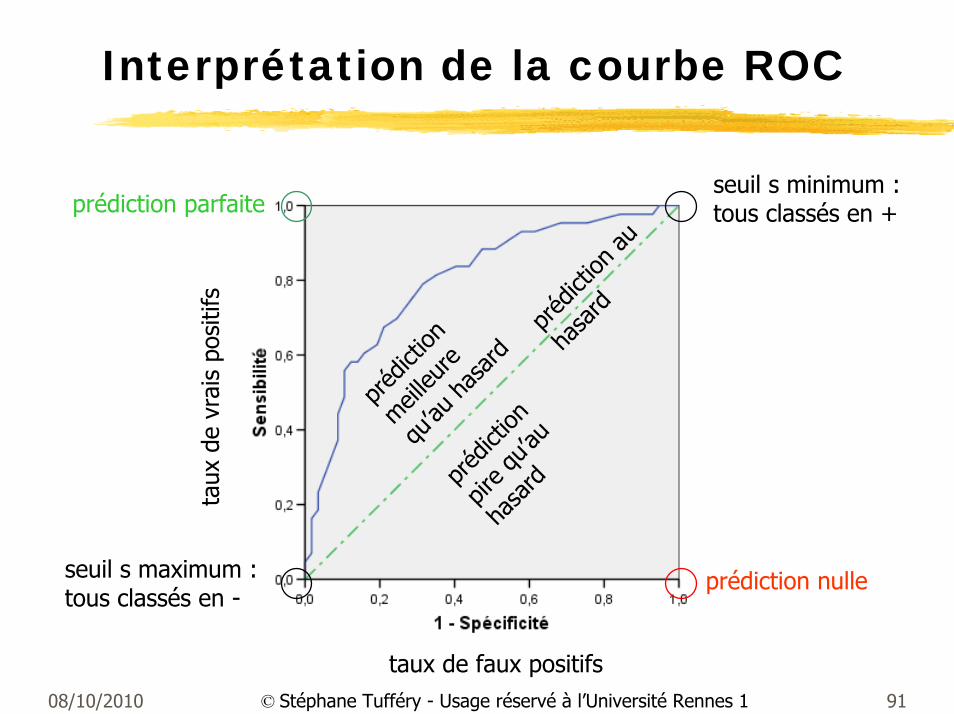
Interprétation de la courbe ROC
taux
de
vrai
s po
sitif
s
taux de faux positifs
préd
iction
meilleu
re
qu’au
hasa
rd
préd
iction
pire q
u’au
hasa
rd
prédiction nulle
prédiction parfaiteseuil s minimum :tous classés en +
seuil s maximum :tous classés en -
préd
iction
au
hasa
rd
08/10/2010 92© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
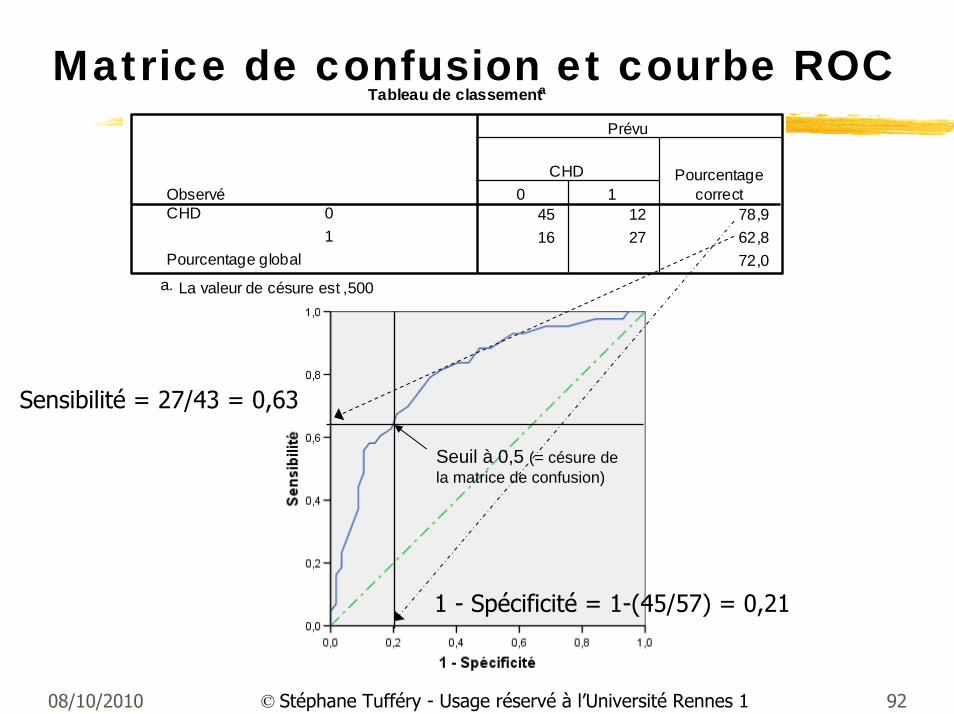
Tableau de classementa
45 12 78,916 27 62,8
72,0
Observé01
CHD
Pourcentage global
0 1CHD Pourcentage
correct
Prévu
La valeur de césure est ,500a.
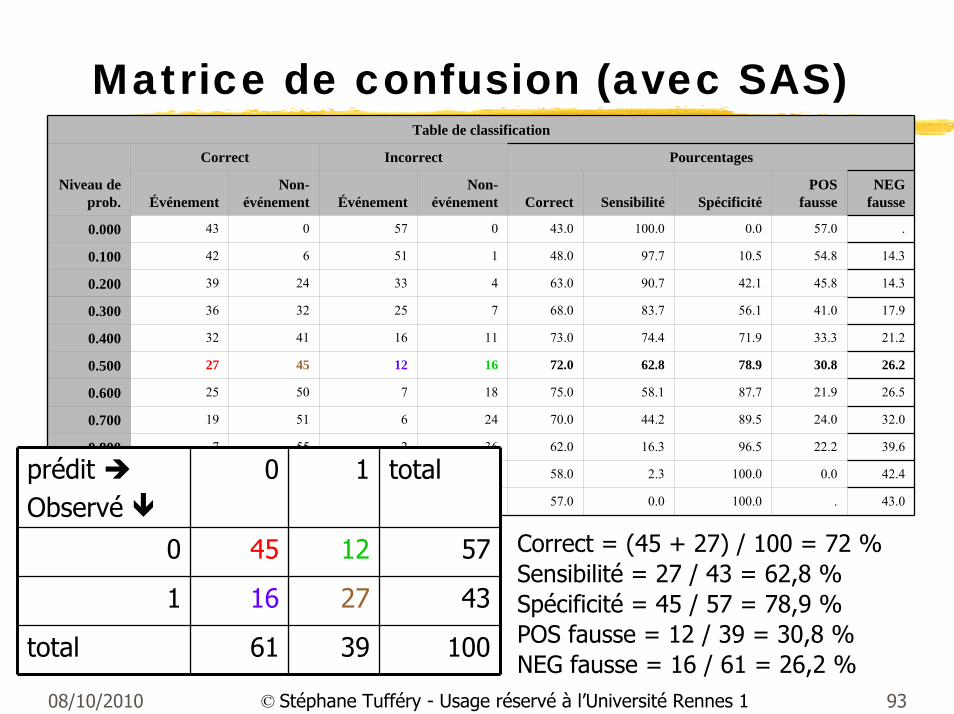
Matrice de confusion et courbe ROC
Seuil à 0,5 (= césure de la matrice de confusion)
Sensibilité = 27/43 = 0,63
1 - Spécificité = 1-(45/57) = 0,21
08/10/2010 93© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Matrice de confusion (avec SAS)Table de classification
Correct Incorrect Pourcentages
Niveau deprob. Événement
Non-événement Événement
Non-événement Correct Sensibilité Spécificité
POSfausse
NEGfausse
0.000 43 0 57 0 43.0 100.0 0.0 57.0 .
0.100 42 6 51 1 48.0 97.7 10.5 54.8 14.3
0.200 39 24 33 4 63.0 90.7 42.1 45.8 14.3
0.300 36 32 25 7 68.0 83.7 56.1 41.0 17.9
0.400 32 41 16 11 73.0 74.4 71.9 33.3 21.2
0.500 27 45 12 16 72.0 62.8 78.9 30.8 26.2
0.600 25 50 7 18 75.0 58.1 87.7 21.9 26.5
0.700 19 51 6 24 70.0 44.2 89.5 24.0 32.0
0.800 7 55 2 36 62.0 16.3 96.5 22.2 39.6
0.900 1 57 0 42 58.0 2.3 100.0 0.0 42.4
1.000 0 57 0 43 57.0 0.0 100.0 . 43.0
prédit Observé
0 1 total
0 45 12 57
1 16 27 43
total 61 39 100
Correct = (45 + 27) / 100 = 72 %Sensibilité = 27 / 43 = 62,8 %Spécificité = 45 / 57 = 78,9 %POS fausse = 12 / 39 = 30,8 %NEG fausse = 16 / 61 = 26,2 %

08/10/2010 94© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Syntaxe SAS de la régression logistique
ods rtf file= « c:\logistic_sas.doc »;proc logistic data=matable.ascorer outmodel=mon.modele;
classvar_quali_1 (ref=‘A1’) … var_quali_i (ref=‘Ai’) / param=ref;model cible (ref=‘0’)=var_quali_1 … var_quali_i var_quanti_1 var_quanti_j/ selection=forward sle=.05 maxiter=25 outroc=roc rsquare lackfitctable;output out=matable.scoree predicted=proba resdev=deviance;
run;symbol1 i=join v=none c=blue;proc gplot data=roc;
where _step_ in (1 7);title ‘Courbe ROC’;plot _sensit_*_1mspec_=1 / vaxis=0 to 1 by .1 cframe=ligr;
run;ods rtf close ;proc logistic inmodel=mon.modele; score data= autretable.ascorer;run;
niv. de signif. en entrée
Hosmer-Lemeshow
R²
enregistre la probabilitéprédite pour l’événement
matrice de confusion
08/10/2010 95© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
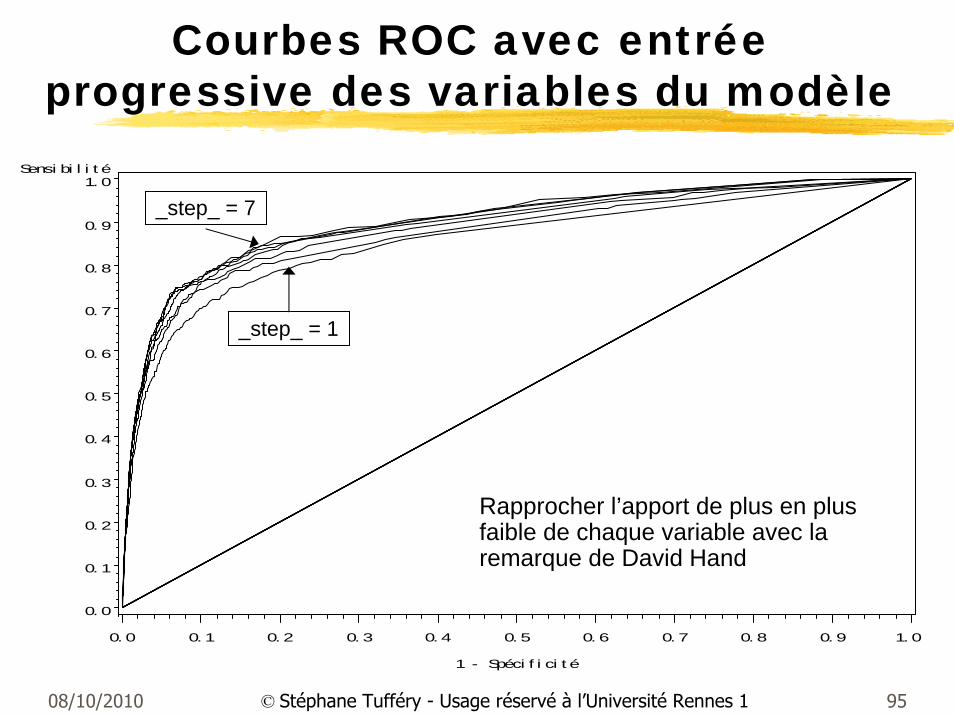
Courbes ROC avec entrée progressive des variables du modèle
Sensi bi l i t é
0. 0
0. 1
0. 2
0. 3
0. 4
0. 5
0. 6
0. 7
0. 8
0. 9
1. 0
1 - Spéci f i ci t é
0. 0 0. 1 0. 2 0. 3 0. 4 0. 5 0. 6 0. 7 0. 8 0. 9 1. 0
_step_ = 1
_step_ = 7
Rapprocher l’apport de plus en plus faible de chaque variable avec la remarque de David Hand

08/10/2010 96© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
AUC : Aire sous la courbe ROC
• Aire AUC sous la courbe ROC = probabilité que score(x) > score(y), si x est tiré au hasard dans le groupe A (àprédire) et y dans le groupe B
• 1ère méthode d’estimation : par la méthode des trapèzes• 2e méthode d’estimation : par les paires concordantes
• soit n1 (resp. n2) le nb d’observations dans A (resp. B)• on s’intéresse aux n1n2 paires formées d’un x dans A et
d’un y dans B• parmi ces t paires : on a concordance si score(x) >
score(y) ; discordance si score(x) < score(y)• soient nc = nb de paires concordantes ; nd = nb de paires
discordantes ; n1n2 - nc - nd = nb d’ex aequo• aire sous la courbe ROC ≈ (nc + 0,5[t - nc - nd]) / n1n2
• 3e méthode équivalente : par le test de Mann-Whitney• U = n1n2(1 – AUC) ou n1n2AUC

08/10/2010 97© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
AUC : calcul avec SAS
U est la statistique de Mann-Whitney, qui se déduit des effectifs ni et de la somme des rangs Ri fournis par la proc NPAR1WAY de SAS
nb de fois où un score du groupe 1 > un score du groupe 2
( ) ( )⎭⎬⎫
⎩⎨⎧ −
++−
++= 2
22211
1121 2
1,2
1min RnnnnRnnnnU
Obs Class N SumOfScores n2 R2 n1 R1 U1 U2 U AUC
1 1 711 1038858.0 711 1038858 . . . . . .
2 0 1490 1384443.0 1490 1384443 711 1038858 273648 785742 273648 0.74169
ODS OUTPUT WilcoxonScores = wilcoxon;
PROC NPAR1WAY WILCOXON DATA=&data CORRECT=no;CLASS &cible;VAR &score;RUN;
DATA auc;SET wilcoxon;n2 = N; R2 = SumOfScores ;n1 = LAG(N); R1 = LAG(SumOfScores) ;u1 = (n1*n2) + (n1*(n1+1)/2) - R1 ;u2 = (n1*n2) + (n2*(n2+1)/2) - R2 ;u = MAX(u1,u2);AUC = ROUND(u/(n1*n2),0.001);RUN;
PROC PRINT DATA=auc (KEEP = AUC) ;TITLE "Aire sous la courbe ROC de &data";WHERE AUC > .;RUN;
08/10/2010 98© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
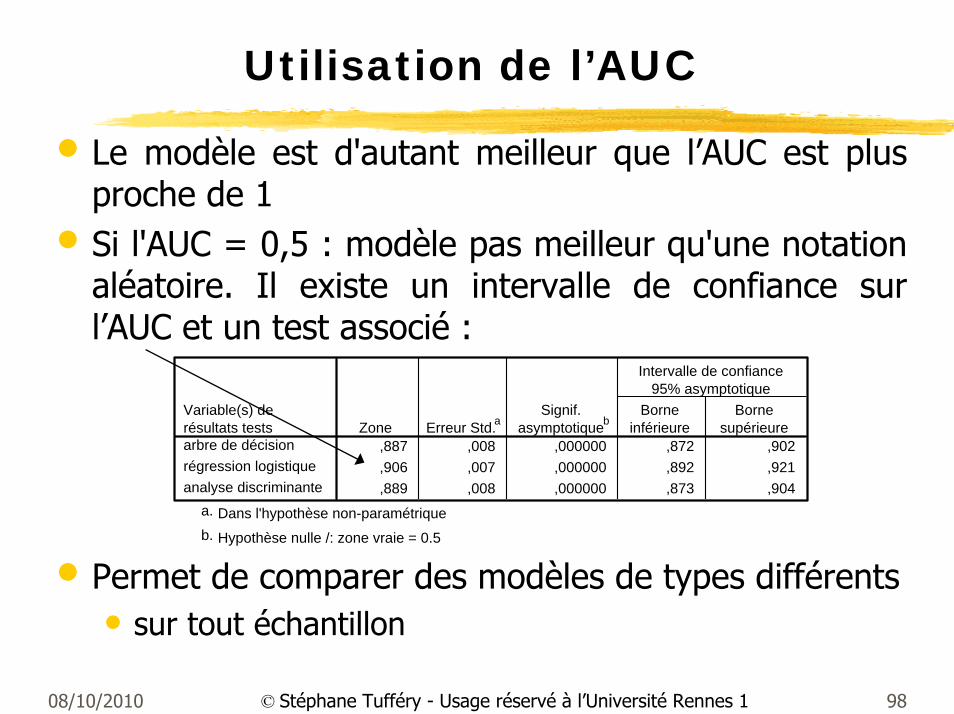
Utilisation de l’AUC
• Le modèle est d'autant meilleur que l’AUC est plus proche de 1
• Si l'AUC = 0,5 : modèle pas meilleur qu'une notation aléatoire. Il existe un intervalle de confiance sur l’AUC et un test associé :
• Permet de comparer des modèles de types différents• sur tout échantillon
,887 ,008 ,000000 ,872 ,902,906 ,007 ,000000 ,892 ,921,889 ,008 ,000000 ,873 ,904
Variable(s) derésultats testsarbre de décisionrégression logistiqueanalyse discriminante
Zone Erreur Std.aSignif.
asymptotiquebBorne
inférieureBorne
supérieure
Intervalle de confiance95% asymptotique
Dans l'hypothèse non-paramétriquea.
Hypothèse nulle /: zone vraie = 0.5b.

08/10/2010 99© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Courbe de lift
• La courbe de lift :• sur l’axe Y : sensibilité = α(s) = Proba(score ≥ s / A)• sur l’axe X : Proba(score ≥ s)• proportion de vrais positifs en fonction de la proportion
d’individus sélectionnés, en faisant varier le seuil s du score• même ordonnée que la courbe ROC, mais une abscisse
généralement plus grande>la courbe de lift est en général
sous la courbe ROC• Très utilisée en marketing
100
90
80 ciblage aléatoire
70 ciblage par scoring
60 ciblage idéal
50
40
30
20
10
0
0 25 50 75 100
% d
'indi
vidu
s ré
pond
ants
% d'individus ciblés
Lift = 40/10 = 4

08/10/2010 100© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Lien entre courbe de lift et ROC
• Relation entre l’aire AUL sous la courbe de lift et l’aire AUC :• AUC – AUL = p(AUC – 0,5) AUL = p/2 + (1 – p)AUC• où p = Proba(A) = probabilité a priori de l’événement dans la
population (=0,25 dans l’exemple précédent)• Cas particuliers :
• AUC = 1 ⇒ AUL = p/2 + (1 – p) = 1 – p/2 (modèle parfait !)• AUC = 0,5 ⇒ AUL = p/2 + 1/2 – p/2 = 0,5• p petit ⇒ AUC et AUL sont proches• AUC1 > AUC2 AUL1 > AUL2
• Ces indicateurs sont des critères universels de comparaison de modèles
08/10/2010 101© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
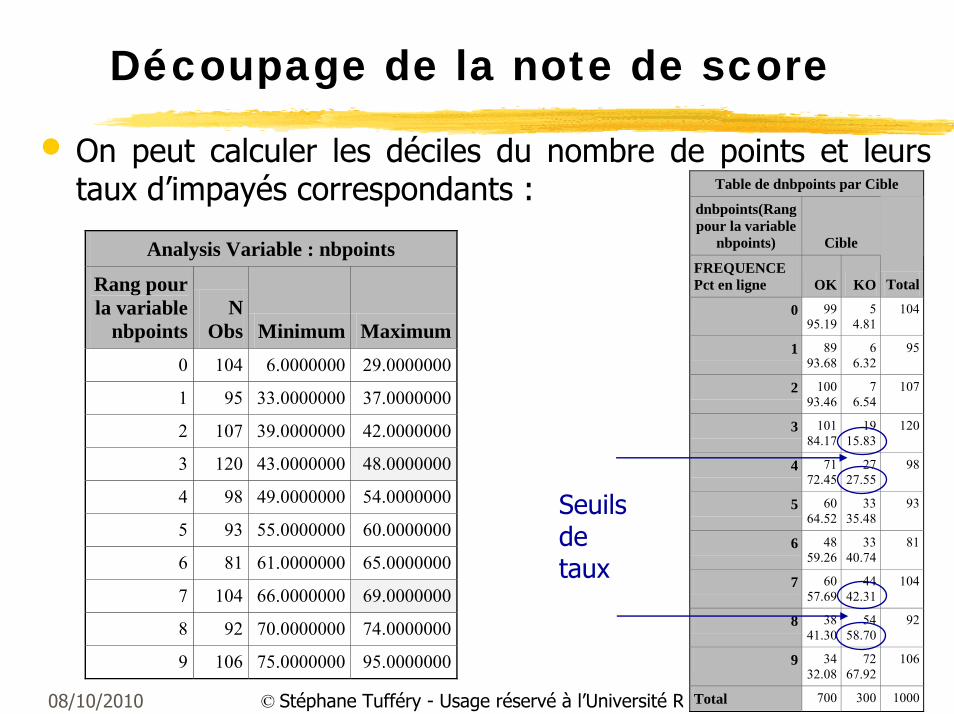
Découpage de la note de score
• On peut calculer les déciles du nombre de points et leurs taux d’impayés correspondants :
Analysis Variable : nbpoints
Rang pour la variable
nbpoints N
Obs Minimum Maximum0 104 6.0000000 29.0000000
1 95 33.0000000 37.0000000
2 107 39.0000000 42.0000000
3 120 43.0000000 48.0000000
4 98 49.0000000 54.0000000
5 93 55.0000000 60.0000000
6 81 61.0000000 65.0000000
7 104 66.0000000 69.0000000
8 92 70.0000000 74.0000000
9 106 75.0000000 95.0000000
Table de dnbpoints par Cible
dnbpoints(Rang pour la variable
nbpoints) Cible
FREQUENCE Pct en ligne OK KO Total
0 9995.19
54.81
104
1 8993.68
66.32
95
2 10093.46
76.54
107
3 10184.17
1915.83
120
4 7172.45
2727.55
98
5 6064.52
3335.48
93
6 4859.26
3340.74
81
7 6057.69
4442.31
104
8 3841.30
5458.70
92
9 3432.08
7267.92
106
Total 700 300 1000
Seuils de taux

08/10/2010 102© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Taux d’impayés par tranches de score
• Tranche de risque faible :• 8,69% d’impayés• octroi du crédit avec un
minimum de formalités• Tranche de risque moyen :
• 36,44% d’impayés• octroi du crédit selon la
procédure standard• Tranche de risque élevé :
• 63,64% d’impayés• octroi du crédit interdit sauf
par l’échelon hiérarchique supérieur (directeur d’agence)
Table de nbpoints par Cible
nbpoints Cible
FREQUENCE Pourcentage Pct en ligne OK KO Total
risque faible [0 , 48] points
38938.9091.31
373.708.69
42642.60
risque moyen [49 , 69] points
23923.9063.56
13713.7036.44
37637.60
risque fort ≥ 70 points
727.20
36.36
12612.6063.64
19819.80
Total 70070.00
30030.00
1000100.00

08/10/2010 103© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Reprenons nos exemples
• Demandeur de moins de 25 ans, qui demande pour la première fois un crédit dans l’établissement et qui n’en a pas ailleurs, sans impayé, avec un compte dont le solde moyen est légèrement positif (mais < 200 €), avec un peu d’épargne (< 500 €), sans garant, qui demande un crédit sur 36 mois :• 69 points ⇒ risque moyen• On est à la limite du risque élevé et cette limite aurait
été franchie avec un crédit sur plus de 36 mois• Demandeur de plus de 25 ans, avec des crédits à la
concurrence, sans impayé, avec un compte dont le solde moyen est > 200 €, avec plus de 500 € d’épargne, sans garant, qui demande un crédit sur 12 mois :• 41 points ⇒ risque faible
08/10/2010 104© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
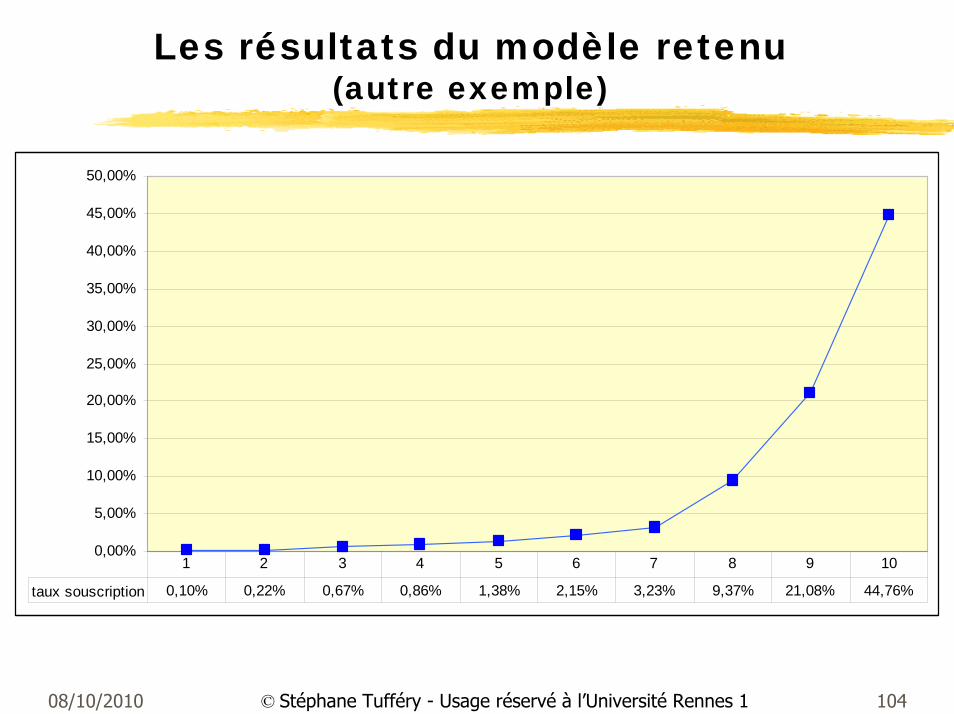
Les résultats du modèle retenu(autre exemple)
0,00%
5,00%
10,00%
15,00%
20,00%
25,00%
30,00%
35,00%
40,00%
45,00%
50,00%
taux souscription 0,10% 0,22% 0,67% 0,86% 1,38% 2,15% 3,23% 9,37% 21,08% 44,76%
1 2 3 4 5 6 7 8 9 10

08/10/2010 105© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Quelques principes du data mining

08/10/2010 106© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Les 8 principes de base de la modélisation
• La préparation des données est la phase la plus longue, pas la plus passionnante mais la plus importante
• Il faut un nombre suffisant d’observations pour en inférer un modèle• Validation sur un échantillon de test distinct de celui d’apprentissage
(ou validation croisée)• Arbitrage entre la précision d’un modèle et sa robustesse (« dilemme
biais – variance »)• Limiter le nb de variables explicatives et surtout éviter leur colinéarité• Perdre de l’information pour en gagner
• découpage des variables continues en classes
• La performance d’un modèle dépend plus de la qualité des données et du type de problème que de la méthode• cf. match « analyse discriminante vs régression logistique »
• On modélise mieux des populations homogènes• intérêt d’une classification préalable à la modélisation

08/10/2010 107© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Qualités attendues d’une technique prédictive 1/2
• La précision• le taux d’erreur doit être le plus bas possible, et l’aire sous
la courbe ROC la plus proche possible de 1• La robustesse
• être le moins sensible possible aux fluctuations aléatoires de certaines variables et aux valeurs manquantes
• ne pas dépendre de l’échantillon d’apprentissage utilisé et bien se généraliser à d’autres échantillons
• La concision• les règles du modèle doivent être les plus simples et les
moins nombreuses possible

08/10/2010 108© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Qualités attendues d’une techniqueprédictive 2/2
• Des résultats explicites• les règles du modèle doivent être accessibles et
compréhensibles• La diversité des types de données manipulées
• toutes les méthodes ne sont pas aptes à traiter les données qualitatives, discrètes, continues et… manquantes
• La rapidité de calcul du modèle• un apprentissage trop long limite le nombre d’essais possibles
• Les possibilités de paramétrage• dans un classement, il est parfois intéressant de pouvoir
pondérer les erreurs de classement, pour signifier, par exemple, qu’il est plus grave de classer un patient malade en « non-malade » que l’inverse
08/10/2010 109© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
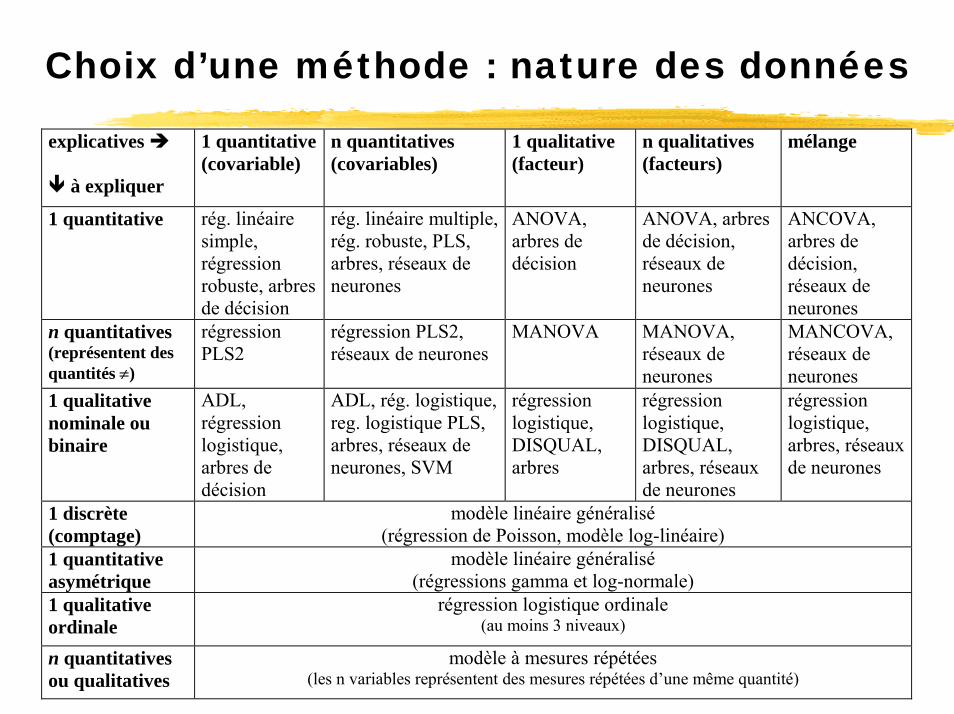
Choix d’une méthode : nature des données
explicatives
à expliquer
1 quantitative(covariable)
n quantitatives (covariables)
1 qualitative (facteur)
n qualitatives (facteurs)
mélange
1 quantitative rég. linéaire simple, régression robuste, arbres de décision
rég. linéaire multiple, rég. robuste, PLS, arbres, réseaux de neurones
ANOVA, arbres de décision
ANOVA, arbres de décision, réseaux de neurones
ANCOVA, arbres de décision, réseaux de neurones
n quantitatives (représentent des quantités ≠)
régression PLS2
régression PLS2, réseaux de neurones
MANOVA MANOVA, réseaux de neurones
MANCOVA, réseaux de neurones
1 qualitative nominale ou binaire
ADL, régression logistique, arbres de décision
ADL, rég. logistique, reg. logistique PLS, arbres, réseaux de neurones, SVM
régression logistique, DISQUAL, arbres
régression logistique, DISQUAL, arbres, réseaux de neurones
régression logistique, arbres, réseaux de neurones
1 discrète (comptage)
modèle linéaire généralisé (régression de Poisson, modèle log-linéaire)
1 quantitative asymétrique
modèle linéaire généralisé (régressions gamma et log-normale)
1 qualitative ordinale
régression logistique ordinale (au moins 3 niveaux)
n quantitatives ou qualitatives
modèle à mesures répétées (les n variables représentent des mesures répétées d’une même quantité)

08/10/2010 110© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Choix d’une méthode : précision, robustesse, concision, lisibilité
• Précision : privilégier la régression linéaire, l’analyse discriminante et la régression logistique, et parfois les réseaux de neurones en prenant garde au sur-apprentissage (ne pas avoir trop de neurones dans la ou les couches cachées)
• Robustesse : éviter les arbres de décision et se méfier des réseaux de neurones, préférer une régression robuste à une régression linéaire par les moindres carrés
• Concision : privilégier la régression linéaire, l’analyse discriminante et la régression logistique, ainsi que les arbres sans trop de feuilles
• Lisibilité : préférer les arbres de décision et prohiber les réseaux de neurones. La régression logistique, DISQUAL, l’analyse discriminante linéaire et la régression linéaire fournissent aussi des modèles faciles à interpréter

08/10/2010 111© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Choix d’une méthode : autres critères
• Peu de données : éviter les arbres de décision et les réseaux de neurones
• Données avec des valeurs manquantes : essayer de recourir à un arbre, à une régression PLS, ou à une régression logistique en codant les valeurs manquantes comme une classe particulière
• Les valeurs extrêmes de variables continues n’affectent pas les arbres de décision, ni la régression logistique et DISQUAL quand les variables continues sont découpées en classes et les extrêmes placés dans 1 ou 2 classes
• Variables explicatives très nombreuses ou très corrélées : arbres de décision, régression régularisée ou PLS
• Mauvaise compréhension de la structure des données : réseaux de neurones (sinon exploiter la compréhension des données par d’autres types de modèles)
08/10/2010 112© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
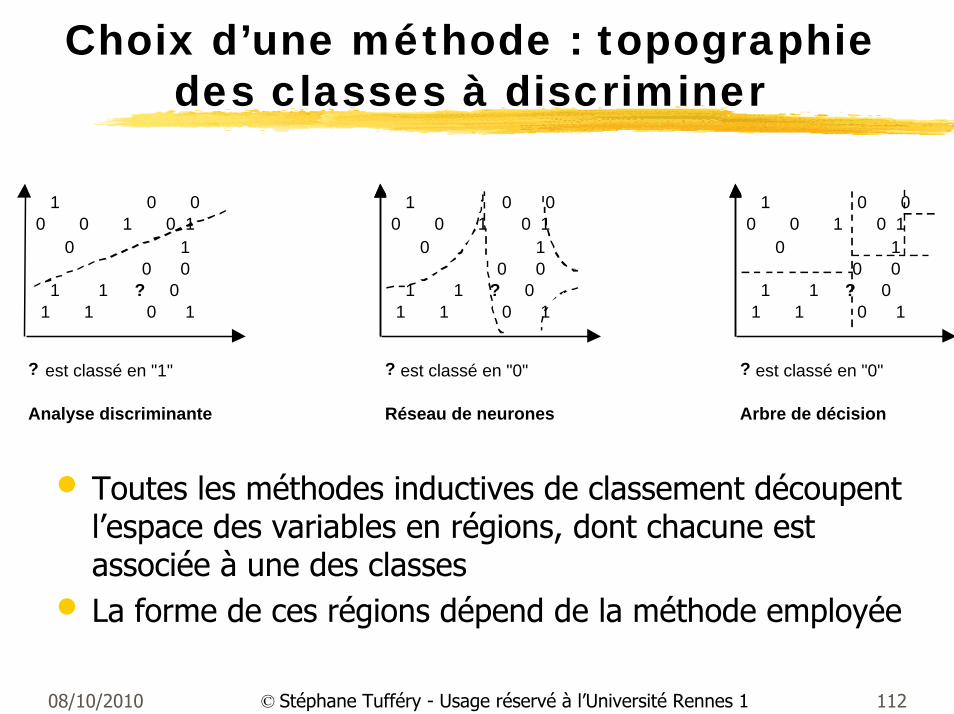
Choix d’une méthode : topographie des classes à discriminer
? est classé en "1" ? est classé en "0" ? est classé en "0"
Analyse discriminante Réseau de neurones Arbre de décision
1 0 00 0 1 0 1
0 10 0
1 1 ? 01 1 0 1
1 00 0 1 1
1 1 1? 0 0
+ + 0+ 0 1
1 00 0 1 1
1 1 1? 0 0
+ + 0+ 0 1
1 0 00 0 1 0 1
0 10 0
1 1 ? 01 1 0 1
1 0 00 0 1 0 1
0 10 0
1 1 ? 01 1 0 1
• Toutes les méthodes inductives de classement découpent l’espace des variables en régions, dont chacune est associée à une des classes
• La forme de ces régions dépend de la méthode employée

08/10/2010 113© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Influence des données et méthodes
• Pour un jeu de données fixé, les écarts entre les performances de différents modèles sont souvent faibles• exemple de Gilbert Saporta sur des données d’assurance
automobile (on mesure l’aire sous la courbe ROC) :• régression logistique : 0,933• régression PLS : 0,933• analyse discriminante DISQUAL : 0,934• analyse discriminante barycentrique : 0,935
• le choix de la méthode est parfois affaire d’école• Les performances d’un modèle dépendent :
• un peu de la technique de modélisation employée• beaucoup plus des données !
• D’où l’importance de la phase préliminaire d’exploration et d’analyse des données• et même le travail (informatique) de collecte des données
08/10/2010 114© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Conclusion

08/10/2010 115© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Quelques idées fausses sur le data mining
• Aucun a priori n'est nécessaire• On n'a plus besoin de spécialistes du métier• On n'a plus besoin de statisticiens (« Il suffit d'appuyer
sur un bouton »)• Le data mining permet de faire des découvertes
incroyables• Le data mining est révolutionnaire• Il faut utiliser toutes les données disponibles et ne
jamais échantillonner ou éliminer des variables

08/10/2010 116© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Perspectives professionnelles• Finance
• Réglementation Bâle II (et bientôt Bâle III)• Évolution des marchés boursiers
• Marketing• Dont marketing direct et sur le web• Étude des préférences et des comportements des
consommateurs• Assurance (scoring et actuariat)• Industrie pharmaceutique, santé
• Tests cliniques, pharmacovigilance, épidémiologie• Médecine
• Analyses de survie, causes, prévention et traitement des maladies
• Environnement et Météorologie• Études sur le climat, la pollution
• Recherche scientifique• …

08/10/2010 117© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Limites légales au data mining
• CNIL : des pouvoirs renforcés en 2004• par la loi n° 2004-801 relative à la protection des personnes physiques à
l’égard des traitements de données à caractère personnel, transposant la directive européenne 95/46/CE en remaniant la loi n° 78-17
• Données sensibles• données génétiques, infractions et condamnations, numéro NIR (hors
du cadre normal de certains traitements : paie du personnel, assurance maladie), données biométriques, difficultés sociales des personnes (absence de revenus, chômage…)
• Quelques points à surveiller• variables des scores• noms des segments de clientèle• utilisation des données et des modèles qui les utilisent• information et droit d’accès du client
• Limitations• données géodémographiques (très peu de données à l’îlot)

08/10/2010 118© Stéphane Tufféry - Usage réservé à l’Université Rennes 1
Quelques liens
• Site de la Société Française de Statistique : www.sfds.asso.fr• Site de Gilbert Saporta (contenu riche, avec de nombreux cours) :
http://cedric.cnam.fr/~saporta/• Site de Philippe Besse (très complet sur les statistiques et le data
mining) : www.math.univ-toulouse.fr/~besse/• Site de la revue MODULAD : www.modulad.fr• Site de Statsoft (statistiques et data mining) :
www.statsoft.com/textbook/stathome.html• StatNotes Online Textbook (statistiques) :
www2.chass.ncsu.edu/garson/pa765/statnote.htm• Statistique avec R : http://zoonek2.free.fr/UNIX/48_R/all.html• Aide en ligne SAS : http://support.sas.com/documentation/onlinedoc/• Ressources sur SPSS : www.spsstools.net/• Site d’Olivier Decourt (spécialiste de SAS) : www.od-datamining.com/



![Monnaies grecques, inédites et incertaines. [4] / [J.P. Six]](https://static.fdocuments.fr/doc/165x107/577cc6c31a28aba7119f18d2/monnaies-grecques-inedites-et-incertaines-4-jp-six.jpg)







![Monnaies grecques, inédites et incertaines. [1] / [J.P. Six]](https://static.fdocuments.fr/doc/165x107/577cc6cf1a28aba7119f2ffa/monnaies-grecques-inedites-et-incertaines-1-jp-six.jpg)