
Séminaire des doctorants de 2 année de l’équipe 2 · problème de déploiement des équipes...
22
Ecole Doctorale en Sciences de l’Ingénieur de l’ECP Formation doctorale en Génie Industriel Séminaire des doctorants de 2 ème année de l’équipe 2 Année universitaire 2012-2013 Résumés de thèse Laboratoire Génie Industriel Ecole Centrale Paris Le 29 Novembre 2012
Transcript of Séminaire des doctorants de 2 année de l’équipe 2 · problème de déploiement des équipes...

Ecole Doctorale en Sciences de l’Ingénieur de l’ECP Formation doctorale en Génie Industriel
Séminaire des doctorants de 2ème année de l’équipe 2
Année universitaire 2012-2013
Résumés de thèse Laboratoire Génie Industriel Ecole Centrale Paris
Le 29 Novembre 2012

2
Doctorants de 2ème année de l’équipe 2
Lina ABOUELJINANE
Performance et Optimisation Systémique de l’Aide Médicale Urgente
Yu CAO
The Optimization of Procurement Planning in Global Sourcing
Ayse Sena ERUGUZ
Contributions to Inventory Management Models for Multi-echelon Inventory Systems
Benjamin LEGROS
Gestion des Opérations dans un Centre d’Appel
Semih YALCINDAG
Modeling the Assignment and Routing Problems in the Home Health Care Context
Yueru ZHONG
Planification de la Production Flexible dans une Supply Chain

3
Mini CV
Lina Aboueljinane est née le 28/12/1984 à
Casablanca au Maroc. Elle a obtenu un
diplôme d’ingénieur en Recherche
Opérationnel en 2007 à l’Institut National
de Statistique et d’Economie Appliquée de
Rabat (Maroc) et un diplôme de master
recherche en Optimisation des Systèmes
Industriels et Logistiques en 2010 à l’Ecole
Centrale Paris.
Sa thèse a débuté en novembre 2010 au
sein du Laboratoire Génie Industriel à
l’ECP. En collaboration avec le SAMU-94
et l’Institut Géographique National, son
travail de recherche porte sur l’élaboration
d’un modèle de simulation pour la gestion
tactique et opérationnelle des systèmes
médicaux d’urgence.
Résumé
Les systèmes médicaux d’urgence sont des
services publics chargés de la stabilisation
pré-hospitalière et du transport médicalisé
de patients en état critique. Leur mission est
de fournir la réponse la mieux adaptée et
dans les plus brefs délais aux demandes de
soins qui leur sont soumises par une ligne
téléphonique d’urgence. Dans ce travail,
nous nous intéressons à la modélisation de
ces systèmes par l’outil de simulation à
événement discret ARENA. Nous avons
considéré dans cette modélisation le cas du
SAMU-94 (département du Val de Marne).
Cette approche permet la prise en compte
de divers facteurs de complexité liés à la
gestion de ce système et l’évaluation de
différents changements appliqués à sa
configuration initiale en vue d’atteindre des
objectifs de délai et de coût.
Mots-clés
Système médicaux d’urgence, modélisation,
évaluation de performances, optimisation,
déploiement et redéploiement
d’ambulances, santé
Performance et
Optimisation
Systémique de l’Aide
Médicale Urgente
Lina ABOUELJINANE
Contrat ANR
Laboratoire Génie Industriel,
Ecole Centrale Paris
Grande Voie des Vignes, 92295 Châtenay-
Malabry, France.
E-mail : [email protected]
Directeur de thèse
Evren Sahin
Co-encadrant de thèse Zied Jemai
Début de thèse Novembre 2010

4
Contexte et Problématique
Les systèmes médicaux d’urgence (SMU) sont des services publics chargés de la coordination des
soins pré-hospitaliers dans des conditions d’urgence dans une région géographique spécifique. Le
processus de soins est déclenché par le signalement de l’accident par un appel au centre d’écoute
téléphonique dans lequel la réponse la mieux adaptée à la nature de l’appel est déterminée. Cette
réponse peut prendre la forme d’un simple conseil médical par téléphone, ou de l’envoi d’une équipe
médicale composée de ressources humaines qualifiées (médecins urgentistes, infirmiers, etc.) à bord
d’un véhicule ambulancier. L’équipe médicale procède à la stabilisation et la prise en charge du
patient sur le lieu même de sa détresse et au besoin, à son transport médicalisé vers une structure
hospitalière appropriée. Elle peut également être appelée à assurer le transport entre deux structures
hospitalière d’un patient qui nécessite une surveillance médicale ou des soins intensifs pendant son
trajet.
Les prestations de soins fournis par les SMU ont pour objectif de réduire la mortalité, de prévenir
d’éventuelles séquelles et d’améliorer les chances de rétablissement des patients. En particulier, le
temps de réponse, défini comme la durée entre l’arrivée de l’appel et l’accès de l’équipe médicale à
l’emplacement de l’accident, est un aspect critique pour les gestionnaires des SMU, spécialement dans
les cas de défaillance majeure d’une fonction vitale comme les arrêts cardio-respiratoires (ACR).
(Cummins, 1989)1 affirme que la probabilité de survie suite à un ACR diminue de 7 à 10 % pour
chaque minute de retard dans le temps de réponse. Ainsi, avoir un temps de réponse inférieur à un
seuil spécifique est un objectif communément établi dans les SMU sous forme d’une obligation
légale/contractuelle ou comme une cible managériale. Pour atteindre cet objectif, les SMU disposent
ressources limitées liées à l’enjeu économique de réduction des dépenses considérables associées aux
installations, équipements et coûts opérationnels.
L’atteinte de ces objectifs de qualité et de coûts nécessite de prendre un certain nombre de décisions
étroitement reliées à tous les niveaux classiques de planification :
Le niveau stratégique : Détermination des objectifs de niveau de service, dimensionnement du
nombre de ressources humaines de différentes qualifications à embaucher, dimensionnement
des véhicules et des équipements médicaux à déployer, détermination de la localisation et de
la capacité du centre d’écoute téléphonique, détermination de la localisation et de la capacité
des postes d’attente potentiels, nommés bases, pour le stationnement des équipes médicales
entre deux interventions.
Le niveau tactique : Affectation des équipes médicales à chaque base (appelé problème de
déploiement), gestion des horaires du personnel.
Le niveau opérationnel : Règles d’affectation des équipes médicales aux interventions
appelées règles de dispatching, règles d’affectations des équipes médicales aux bases en
fonction des fluctuations de la demande dans une journée (appelé redéploiement multi-
période) ou de la variation du nombre et de la localisation des équipes disponibles (appelé
redéploiement dynamique), règles d’affectation des patients aux centres hospitaliers,
planification du nettoyage, vérification et réapprovisionnement des véhicules .
Objectif de la recherche
Dans la littérature, plusieurs approches ont été utilisées afin d’améliorer les performances des SMU.
Ainsi, les modèles issus de la programmation mathématique se sont essentiellement intéressés au
problème de déploiement des équipes médicales sous différents objectifs tels que la minimisation du
nombre d’équipes requis pour couvrir toute la demande dans un délai (distance) prescrit ou la
1 Cummins R.O. 1989. From concept to standard-of-care? Review of clinical experience with
automated external defibrillators. Ann. Emerg. Med. 18. pp 1269—1275

5
maximisation de la demande couverte dans un délai (distance) prescrit en disposant d’un nombre
d’équipes limité. Les modèles issus de la théorie de files d’attente sont des modèles descriptifs qui
permettent généralement de calculer divers indicateurs de performance en fonction du nombre
d’équipe et leur déploiement. Les deux approches précitées nécessitent souvent un grand nombre
d’hypothèses simplificatrices afin de permettre la résolution de problèmes de taille réelle dans un délai
raisonnable. Dans ce travail, nous nous intéressons à une troisième approche qui permet l’évaluation et
la comparaison de différentes configurations et règles de gestions des SMU dans un cadre plus réaliste.
Ce type de modélisation permet la prise en compte de diverses sources d’incertitude à savoir
l’incertitude relatives à la fréquence et la distribution géographique et la gravité des appels, à la
disponibilité et la localisation précise des équipes médicales, à la disponibilité des lits d’hôpitaux dans
la structure hospitalière adéquate, et au temps de transport et de processus de soin suivant les
conditions de circulation ou l’état du patient.
Méthodologie de recherche
A ce jour, un modèle de simulation à événement discret, appliqué au SMU du département du Val-de-
Marne (SAMU-94), a été implémenté en utilisant le logiciel ARENA. Les données collectées pour
alimenter ce modèle sont issues du système d’information du SAMU-94 et correspondent à 13 mois
d’opérations. En collaboration avec l’Institut Géographique National, ces données ont été croisées
avec les traces GPS des véhicules sur la même période afin d’élaborer un module de calcul des temps
de parcours dans le Val-de-Marne entre un point de départ et un point de destination suivant le jour de
semaine et l’heure dans la journée. Ces données d’entrée ont ensuite été utilisées pour la construction
du modèle de simulation en respectant la méthodologie suivante :
Résultats de la recherche
L’analyse du fonctionnement et des données du SAMU-94 a permis de proposer divers scénarios pour
l’amélioration du système actuel en terme de temps de réponse. D’abord l’augmentation du nombre de
ressources (opérateurs téléphonique, équipes médicales..) améliore peu ou pas le temps de réponse,
alors que leur diminution dégrade la performance. Ceci confirme que le système a été bien
dimensionné pour faire face à la demande actuelle et les temps d’attente sont raisonnables dans un
contexte d’urgence. Nous avons également évalué un deuxième groupe de scenarios qui consiste à
délocaliser les postes d’attente des équipes médicales, actuellement situés dans les hôpitaux Henri-
Mondor et Villeneuve-Saint-Georges, dans trois autres hôpitaux du département. Les expérimentations
ont permis de montrer que ce groupe de scénarios permet d’obtenir de bons résultats. Finalement, nous
avons évalué l’impact de la réduction du temps de traitement des appels afin d’arbitrer sur l’intérêt
d’investir dans des moyens technologiques pouvant permettre cette amélioration.
Formulation du problème
•Spécification du périmètre et des objectifs de l'étude
•Cartographier le process à modeliser
•Selectionner les indicateurs de performances
Collecte et analyse des
données
•Spécification des paramètres du système
•Vérification de la cohérence des données
•Ajustement des données à des lois de probabilité théoriques ou empiriques
Construction et implémentation
du modèle
•Construction du modèle conceptuel
•Choix d'un logiciel adapté
•Implémentation du modèle informatisé
Vérification et Validation
•Validation du modèle conceptuel
•Verification du modèle informatisé
•Validation des résultats du modèle
Elaboration des scenarios
et analyse des résultats
•Elaboration, excecution et analysedes scénarios
•Documentation du modèle
•Implémentation des résultats
Erreurs
détectées Vérifier les
données
Vérifier le
process
Vérifier et mettre à
jour le modèle

6
Conclusion : limites et pistes de recherche
Une perspective intéressante au travail actuel serait de développer un modèle mathématique de
redéploiement dynamique qui permette d’assurer une meilleure couverture de la demande face à
l’indisponibilité et le mouvement des équipes. Les solutions de ce modèle pourront être évaluées grâce
au modèle de simulation existant. Un seconde piste serait d’utiliser des modèles de prévision de la
demande, en termes de fréquence et de localisation des appels, afin d’obtenir des solutions de
déploiement/redéploiement robustes pour couvrir la demande future au niveau de performance requis.

7
Mini CV
Yu Cao est née le 20/12/1986 à Jiangsu en
Chine. Elle a intégré à l’Université de
Tsinghua en 2004. Elle a participé au
programme cotutelle entre l’Ecole Centrale
de Lille et l’Université de Tsinghua de 2006
à 2008. En 2010, elle obtient les diplômes
d’Ingénieur Généraliste de l’Ecole Centrale
de Lille et de Master Scientifique en
mécanique et automatique de l’Univerisité
de Tsinghua. Elle débute sa thèse en 2010
au Laboratoire Génie Industriel à l’Ecole
Centrale Paris sur le sujet de « Management
des approvisionnements lointains ».
Abstract
In the practice of global sourcing, the
problem of long-term procurement planning
is difficult because of the large demand
uncertainty. This thesis presents an optimal
planning approach using a rolling horizon
scheme. The approach combines the
techniques of demand forecasting and
stochastic lot-sizing. The performance of
the proposed approach is analyzed
theoretically and evaluated by ex-post-facto
experiments. Promising results are shown
when the approach is applied on a long-
term procurement planning problem with
large unstructured demand uncertainty.
Key-words
Global sourcing, procurement planning,
inventory management, stochastic lot
sizing, demand forecasting
The Optimization of
Procurement Planning
in Global Sourcing
Yu CAO
Laboratoire Génie Industriel,
Ecole Centrale Paris
Grande Voie des Vignes, 92295 Châtenay-
Malabry, France.
Téléphone : 01 41 13 18 07
E-mail : [email protected]
Thesis Director
Chengbin Chu
Thesis start date September 2010

8
Context
Global sourcing is the practice of sourcing from the global market for goods or services under certain
geopolitical constraints. In virtually every industry, businesses have learnt that they are now all part of
some extended enterprises with trading partners from all around the world. Companies of all scales
may find that some part along their supply chain contains suppliers in distant locations, where the
costs of primary products or services are considerably low. In such an environment, global sourcing
has become a major issue that is worthy of attention. When developing sourcing strategies on a global
scale, companies have to consider not only the cost of manufacturing and the fluctuation of exchange
rates but also the availability of infrastructures such as transportation and energy. In addition, the
complex nature of global sourcing introduces many constraints to its successful execution. In
particular, logistics, inventory management and distance have become several major concerns for
multinational companies engaged in global sourcing.
Objective
Usually, global sourcing is associated with a centralized procurement planning strategy, under which a
central purchasing organization seeks an optimal balance among the costs on setup, inventory holding,
stock-out penalty, and so on. Procurement planning is, to some extent, similar to production planning.
The major difference comes from the large uncertainty and dramatic change of the demand in
procurement process. This is especially true when procurement planning is being considered for long
term and on a global scale. For production planning problems, dynamic lot-sizing has become a
mature and important tool. The techniques of dynamic lot-sizing determine the quantity of products to
produce in each period over a certain planning horizon, with the goal of satisfying the demand while
minimizing setup and inventory costs. In this sense, dynamic lot-sizing techniques may provide
reference to solve procurement planning problems. A major challenge, however, comes from the large
uncertainty and dramatic change of the demand in long-term procurement planning problems for
global sourcing. Most literature on dynamic lot-sizing assumes either no uncertainty or uncertainties
with known structures such as a fixed distribution, whereas in long-term procurement planning
problems for global sourcing, the demand uncertainty is usually unknown in the large. In regard to the
limited capability of conventional dynamic lot-sizing techniques on addressing uncertainties, the
objective of the thesis is to propose an optimal long-term procurement planning approach in global
sourcing which minimizes the total costs including ordering cost, inventory holding cost, stock-out
penalty and so on.
Methodology
The most distinctive feature of the long-term procurement planning for global sourcing is the large
uncertainty and dramatic change of the demand in procurement process. The demand can only be
estimated by prediction from the past data in previous periods. Although it is virtually impossible to
predict the future demand accurately, good predictions can bring a great help in the subsequent
procurement planning. Empirically, the forecast of demand in a certain period is gradually revised
over time. Motivated by this feature, a rolling horizon scheme is proposed in order to acquire the up-
to-date forecasts as far as possible.
In a rolling horizon scheme, the entire planning horizon is cut into multiple partly overlapping sub-
horizons along the time axis. In each phase, only a sub-horizon of certain fixed length is considered.
The distribution of demand lots over the considered sub-horizon can be predicted by applying some
forecasting techniques, and then the sub-problem corresponding to the aforementioned sub-horizon
can be considered as a stochastic lot sizing problem (SLSP) over a finite horizon. In the rolling
horizon scheme, the sub-problems corresponding to each sub-horizon are solved in a successive order.
Considering the long-term rolling horizon, the method adopted to solve the aforementioned SLSP in
each sub-horizon should be efficient. A heuristic algorithm is proposed in this thesis. The core idea of
the proposed heuristic is to decouple the deterministic part (mathematically described by the

9
expectations of demand distribution) and the stochastic part (described by the variances of demand
distribution) in the problem. The procurement planning for the sub-horizon can be determined in two
stages: (1) determine the optimal procurement planning while considering the deterministic part of
demand; (2) propose an adequate safety stock to cope with the probable stock-out caused by demand
uncertainty. In this manner, the proposed algorithm gives a high computational efficiency.
Results
Since the actual demand of each period can be all fixed only after the end of the entire planning
horizon, the ex-post-facto experiments are designed to evaluate the proposed approach. For each
scenario of demand, an ex-post-facto optimal solution can be determined at the end of the scenario
(when the demand lots of all the periods in this scenario are known), by employing any classical
deterministic dynamic lot-sizing algorithm. Let C* denote the ex-post-facto minimum total cost
figured out as aforementioned for the considered scenario. The total cost applying the proposed
optimization approach, C, can be determined at the end of the entire planning horizon of the
considered scenario. Regarding of the randomness of the problem, the final evaluation of the
proposed approach should be a statistical result and not decided by a single demand scenario. Letting
Ek(S) denote the statistical mean among the objective value S of k randomly generated demand
scenarios, we have two measures to evaluate the proposed approach, expressed respectively as Ek(C/C
*)
and Ek(C)/E
k(C
*). Promising results are demonstrated when the approach is applied to a long-term
procurement planning problem with large unstructured demand uncertainty, not being described here
in detail due to space limitations.
The performance of the proposed optimization approach can also be analyzed theoretically. In this
thesis, we seek to express E∞(C/C
*) and E
∞(C)/E
∞(C
*) analytically, which are strongly meaningful to
evaluate the proposed approach over an infinite procurement planning horizon. Moreover, the worst-
case performance analysis is important, which shows the robustness of the proposed approach. So far
we have proposed a polynomial algorithm to find the worst-case performance of the proposed heuristic
algorithm to solve the sub-problem corresponding to the optimal planning in each sub-horizon, which
demonstrates good robustness properties of the proposed heuristic. Besides, the high efficiency of the
proposed heuristic is approved through experiments by comparison with existing solutions to SLSP.
Future work
Future work will be conducted on more detailed theoretical analysis of the proposed optimization
approach. In addition, the proposed approach will be applied to scenarios with more sophisticated
uncertainties, e.g., lead time uncertainty.

10
Mini CV
Ayse Sena Eruguz was born in Istanbul,
Turkey in 1987. She received her B.Sc. in
Industrial Engineering from the Galatasaray
University in Istanbul, Turkey in 2009. She
received her M.Sc. with a specialty in
―Industrial and Logistics Systems
Optimization‖ from Ecole Centrale Paris,
France in 2010. At present, she is pursuing
her Ph.D. degree in the Industrial
Engineering Laboratory of Ecole Central
Paris. Her current research interests include
supply chain management, inventory
management and multi-echelon inventory
systems.
Abstract
Inventory management is about specifying
the size, the reorder interval and the
placement of stocked goods to balance the
need for product availability against the
need for minimizing related costs (e.g., the
cost of carrying products in inventory, the
ordering or setup costs). The problem
complexity increases when a supply chain
contains more than one echelon of
processing activity and storage with
stochastic components. In this thesis, we
aim at developing mathematical models to
improve the economic performance in such
multi-echelon systems. We mainly consider
general multi-echelon structures in order to
have a representation of industrial
configurations encountered in practice.
Keywords
Supply chain management, inventory
management, multi-echelon inventory
systems
Contributions to
Inventory Management
Models for Multi-
echelon Inventory
Systems
Ayse Sena ERUGUZ
Allocation de recherche
Laboratoire Génie Industriel,
Ecole Centrale Paris
Grande Voie des Vignes, 92295 Châtenay-
Malabry, France.
Telephone: 01 41 13 18 12
E-mail: [email protected]
Thesis Director
Yves Dallery
Co-directors Zied Jemai
Evren Sahin
Thesis start date November 2010

11
Introduction
Inventory management is an important challenge for all enterprises. Many real world supply chains
represent complex multi-echelon systems for which it is not obvious how to determine an optimal
policy under external demand uncertainty. Researchers proposed the Stochastic Model (SM) and the
Guaranteed-Service Model (GSM) approach in order to dimension inventory in multi-echelon systems
facing stochastic demand. The related research on the SM approach mostly focuses on small-scale
multi-echelon systems (e.g., two-echelon systems) since this approach becomes computationally
intractable for more complex systems. However, real-world supply chains are usually composed of
several echelons and exhibit a general complex multi-echelon structure. The GSM enables to consider
this type of systems due to the assumptions it uses and becomes applicable for industrial-scale
problems. Therefore, the GSM has gained interest in the last decade and has been used in different
industrial applications (see, Eruguz et al. 2012a).
Research Objectives
This thesis aims at developing mathematical models in order to improve the performance related to
inventory management, in general complex multi-echelon systems. In such systems, traditionally the
performance is measured in terms of economic efficiency. Since the GSM approach enables to
consider such systems our primary intent is to study this approach for (1) evaluating the model
performance, (2) proposing solutions to new extensions.
The Studied Problems
The original GSM aims at determining the optimal placement and amount of safety stocks that ensures
a high service level at the lowest cost. Key assumptions of this model are that we can model the supply
chain as a network, that demand is bounded, that each stage in the supply chain operates with a
periodic-review base-stock policy, and that there is a guaranteed service time between every stage and
its customers. Since now, we realized two studies concerning the GSM approach, that are described
below:
1. Assessment of the Cycle-Service-Level
In this study, we investigate the effectively observed service level at final customer stages for multi-
echelon supply chains operating under the GSM assumptions. The GSM assumes that demand is
bounded at each stage of the considered supply chain. In the GSM research, demand bounds are
usually defined in terms of a service measure which reflects the percentage of time that the safety
stock covers demand variation during a coverage time. This service measure is known in the literature
as the Cycle Service Level (CSL). However, using the GSM assumptions, the effectively observed
CSL at final customer stages would be less than the one used to define the demand bounds. The gap is
due to the fact that the CSL at a final customer stage is affected by the demand bounds of its supplier
stages. Particularly, this may happen when the coverage times at customer-supplier stages are
different. To the best of our knowledge, the gap between the effective CSL at final customer stages
and the CSL used to define the demand bounds has neither been discussed nor measured in the
literature. In this study, we first identify the reason of this gap. Then, we illustrate the gap on a two-
stage system example and on two real-world supply chain examples. Besides, for the two-stage system
example, we propose an approximation method to evaluate the gap.
2. Optimizing Reorder Intervals
The original GSM assumes that the reorder intervals are known input parameters and the model only
considers holding costs. To the best of our knowledge, there is no existing GSM enabling to determine
the optimal reorder intervals that minimize the total cost of a multi-echelon system including fixed
ordering costs. In this study, we provide an extension of the GSM by considering the fixed ordering
costs associated with each stage. We propose a deterministic optimization model for general multi-

12
echelon systems to determine the optimal reorder intervals and the corresponding service times. This
is a Non Linear Integer Programming (NLIP) problem with a neither convex nor concave objective
function. The NILP problem becomes difficult to solve for general multi-echelon systems. Therefore,
we propose a Sequential Optimization Procedure (SOP) to solve this NILP model and to obtain near
optimal solutions with reasonable computational time. We measure the performance of this procedure
on randomly generated instances pertaining to five-echelon serial and five-echelon general acyclic
supply chain systems.
Research Methodologies
We use simulation and optimization tools in our studies. In our first study, we developed simulation
models using Arena and Excel in order to evaluate the service level performance of the guaranteed-
service supply chains. In our second study, the global optimizer BARON is used to obtain global and
sequential optimal solutions for the relevant NLIP problems.
Research Results
In our first study, simulation results showed that the gap between the effective CSL at final customer
stages and the CSL used to define the demand bounds may be important for real-world supply chains.
Besides, for the two-stage system example, the accuracy of the proposed approximation method is
confirmed by simulation results (see, Eruguz et al 2012b).
In our second study where we propose an extension of the GSM and a SOP to solve the relevant
model, computational studies demonstrated that the SOP provides near optimal solutions within a few
seconds for the considered supply chains (see, Eruguz et al. 2012c).
Limits and Future Research Directions
Some additional issues remain for future consideration. In our first study, we proposed an
approximation method to estimate the gap between the effective CSL at final customer stages and the
CSL used to define the demand bounds for a two-stage system example. This method can be
considered as a basis in estimating the gap by an analytical method. Further research may be able to
propose new analytical methods to evaluate the gap for more complex real-world supply chains. In our
second study, we illustrated the performance of the SOP for five-echelon serial and five-echelon
general acyclic systems. The performance evaluation of the SOP for large-scale multi-echelon systems
may be provided in further research. For those systems, a faster global optimization method must be
developed in order to realize this analysis.
Besides, other extensions for the GSM such as proposing new alternatives to model the demand
bounds, including supply uncertainties and stochastic lead times, including issues related to multi-
product case may be considered. These extensions represent challenging future research directions for
general multi-echelon systems facing stochastic demand.
References
Eruguz, A.S., Jemai, Z., Sahin, E. and Dallery, Y. 2012a. A review of the guaranteed-service model
for multi-echelon inventory systems. In: Proceedings of the 14th IFAC symposium on
information control problems in manufacturing, pp.1439-1444.
Eruguz, A.S., Jemai, Z., Sahin, E., Yves, D., 2012b. Optimizing reorder intervals and order-up-to
levels in guaranteed service supply chains. Technical report (Cahiers de recherche 2012-07),
Ecole Centrale Paris, Laboratoire Génie Industriel.
Eruguz, A.S., Jemai, Z., Sahin, E., Dallery, Y., 2012c. Contribution to the assessment of cycle-service-
level for the guaranteed-service model. Paper to submit to IESM’13.

13
Mini CV
Rédaction de deux ouvrages ;
« Mathématiques pour la gestion » et
« Mathématiques Financières» adressés à
des étudiants d’études de commerce ou
d’ingénieur. Enseignement en
Mathématiques Financières, Statistiques,
Probabilités et Marchés Financiers à l’ESG,
l’ESGF, l’EFREI, l’EPF et Paris 13.
Enseignement en contrôle de gestion et
outils mathématiques de gestion au CFA
ACE, en DCG et DSCG et à l’ESGF.
Enseignement de GI (Génie Industriel) à
Centrale Paris. Enseignement en Recherche
Opérationnelle à l’ESG MS. Encadrement
de projet de recherche et mémoires de fin
d’étude (Centrale Paris et ESGMS).
Organisation du concours d’entrée à
l’ESGMS. Etudes à l’Ecole Centrale Paris.
Résumé
Modélisation et mesure de Performance de
la Flexibilité dans les centres d’appels
téléphoniques dans le cadre d’une thèse.
Mission de modélisation des performances
dans la réalisation de tâches en simultané
dans un centre d’appel Multi canal.
Mots-clés
Centres d’appels, multicanal, flexibilité.
Gestion des opérations
dans un centre d’appel
Benjamin LEGROS
Financement par entreprise
Laboratoire Génie Industriel,
Ecole Centrale Paris
Grande Voie des Vignes, 92295 Châtenay-
Malabry, France.
Téléphone : 06 84 11 23 59
E-mail : [email protected]
Directeur de thèse
Yves Dalery
Co-encadrant de thèse Oualid Jouini
Début de thèse Avril 2010

14
Project 1: A Flexible Architecture for Call Centers with Skill-Based Routing
(Submitted article)
Abstract
We focus on architectures with limited flexibility for multi-skill call centers. The context is that of call
centers with asymmetric parameters: unbalanced workload, different service requirements, a
predominant customer type, high costs of cross-training, etc. The most knowing architectures with
limited flexibility such as chaining fail in resisting to such asymmetry. In this paper, we propose a new
architecture refereed to as single pooling with only two skills per agent and we prove its efficiency.
We conduct a comprehensive comparison between this novel architecture and chaining. As a function
of the different parameters of arrivals and service requirements, we delimit the regions where either
chaining or single pooling is the best. Single pooling leads to a better performance than chaining while
being less costly than chaining under various situations of asymmetry: asymmetry in the number of
arrivals of different customer types, in the service durations, in the variability of inter-arrival or service
times, in the service level requirements, etc. It is also shown that these observations are more apparent
for big call centers
The models
Results and future work
The results of the comparison between SP and chaining have significant managerial implications. We
showed that SP resits in most cases against asymmetry in the parameters, while having a low degree of
flexibility and it is less costly than chaining. There might be then opportunities for managers of call
centers to improve performance using the single pooling architecture. Although we have supported our
conclusions with some simple analytical models, the analysis in this project is mainly based on
simulation experiments. In a future research, it would be interesting to go further by analytically
analyzing queueing models that are closer to the simulated ones. It would be also useful to extend the
use of the fixed point algorithm (in the online supplement) to evaluate the performance of customers 0.

15
Project 2: Managing Operations in a Multichannel Call Center (About to be
Submitted)
Abstract
We consider a call center model with one agent and two channels, calls and emails. Because the ―urge
to answer‖ is higher for calls we suppose that calls have a priority over the emails. However this
priority is supposed to be non preemptive since agents do not appreciate to cut a task in progress. The
agent has the possibility to do emails during the second stage of a call service and between two calls.
Our target is to optimize the emails’ treatment while respecting an objective service level on calls. We
propose to solve this problem in a general Probabilistic Model (PM) and in a limited choice to extreme
cases more applicable in managing practice.
Modeling
Results and future work
The intuition conducts managers to use the time between calls to do emails. We show in this section
that the use of the break inside a call can be a good opportunity also. Especially when the workload is
important, the use of the break instead of the blending times can increase the email throughput while
respecting a constraint on the service level on calls. The choice on the nature of the quality of service
is important, a choice of the average waiting time favourite choices of blending tasks, a choice of
probability of waiting less than a period set increases the spaces in which imbricating tasks is better
than blending. The order of first blending and second imbricating when the workload on calls is
increasing is quite intuitive and our Models confirm this intuition in a large range of parameters.
However our Models also show that this order is not always the good one. We propose indicators that
enable the manager to make a practical choice for the treatment of the emails. The use of those
coefficients can be extended to situations with more than one agent with an approximation.
Future research will fucus on the Modelling of the other channels like the chat by services composed
with a succession of stages with breaks. The routing policies will also be developed in order to
ameliorate the proposition of the probabilistic Model.
16
Project 3: Adaptative Call Center Blending (Far from being Submitted)
Résumé
Je considère le modèle proposé par Bhulaï avec deux tâches distinctes. Un flux d’arrivées d’appels
(inbound), un stock infini de mails (outbound), une priorité non préemptive des appels sur les emails et
une politique de seuil de c serveurs occupés (mails ou appels) au minimum. L’objectif est de
maximiser le débit d’emails tout en respectant une contrainte de qualité de service pour les emails. La
question est de savoir à quelle fréquence et selon quel règle changer le seuil :
L’optimal se situe toujours entre deux états définis par c et c+1, le travail en cours consiste à
comprendre les paramètres intervenant sur le choix du nombre d’intervalle optimal, de proposer un (ou
des) indicateurs permettant à l’ACD de découper une plage de temps en un nombre idéal d’intervalles.
La difficulté est de proposer des indicateurs à partir de grandeurs mesurées et non de paramètres
constants définissant une loi aléatoire.
Résultats
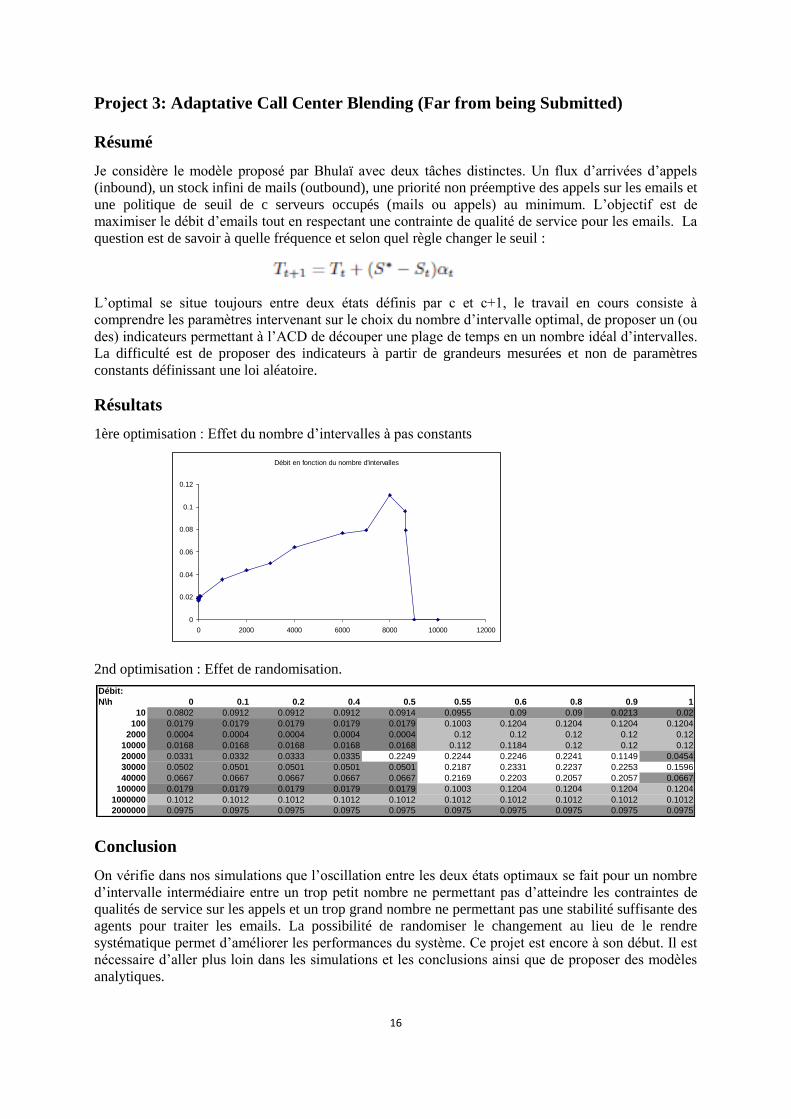
1ère optimisation : Effet du nombre d’intervalles à pas constants
2nd optimisation : Effet de randomisation.
Conclusion
On vérifie dans nos simulations que l’oscillation entre les deux états optimaux se fait pour un nombre
d’intervalle intermédiaire entre un trop petit nombre ne permettant pas d’atteindre les contraintes de
qualités de service sur les appels et un trop grand nombre ne permettant pas une stabilité suffisante des
agents pour traiter les emails. La possibilité de randomiser le changement au lieu de le rendre
systématique permet d’améliorer les performances du système. Ce projet est encore à son début. Il est
nécessaire d’aller plus loin dans les simulations et les conclusions ainsi que de proposer des modèles
analytiques.
Débit en fonction du nombre d'intervalles
0
0.02
0.04
0.06
0.08
0.1
0.12
0 2000 4000 6000 8000 10000 12000
Débit:
N\h 0 0.1 0.2 0.4 0.5 0.55 0.6 0.8 0.9 1
10 0.0802 0.0912 0.0912 0.0912 0.0914 0.0955 0.09 0.09 0.0213 0.02
100 0.0179 0.0179 0.0179 0.0179 0.0179 0.1003 0.1204 0.1204 0.1204 0.1204
2000 0.0004 0.0004 0.0004 0.0004 0.0004 0.12 0.12 0.12 0.12 0.12
10000 0.0168 0.0168 0.0168 0.0168 0.0168 0.112 0.1184 0.12 0.12 0.12
20000 0.0331 0.0332 0.0333 0.0335 0.2249 0.2244 0.2246 0.2241 0.1149 0.0454
30000 0.0502 0.0501 0.0501 0.0501 0.0501 0.2187 0.2331 0.2237 0.2253 0.1596
40000 0.0667 0.0667 0.0667 0.0667 0.0667 0.2169 0.2203 0.2057 0.2057 0.0667
100000 0.0179 0.0179 0.0179 0.0179 0.0179 0.1003 0.1204 0.1204 0.1204 0.1204
1000000 0.1012 0.1012 0.1012 0.1012 0.1012 0.1012 0.1012 0.1012 0.1012 0.1012
2000000 0.0975 0.0975 0.0975 0.0975 0.0975 0.0975 0.0975 0.0975 0.0975 0.0975

17
Mini CV
Semih YALCINDAG was born on 2nd
February 1985 in Istanbul, Turkey. In 2003,
he joined the Yeditepe University in Turkey
where he got his engineering degree. He
obtained his master’s degree in 2010 in
Sabanci University in Turkey. He started
his joined Ph.D degree in the Industrial
Engineering Laboratory of Ecole Centrale
Paris and Mechanical Engineering
Department of Politecnico di Milano on
December 2010.
Abstract
In recent years, Home Health Care (HHC)
service systems have been developed as
alternatives to conventional hospitalization.
Human resource planning in HHC services
is a critical activity on which the quality of
the delivered care depends. Two of the
main issues encountered while planning
human resources of HHC services is the
assignment (i.e., deciding which operator
will take care of which patient) and routing
problems, (i.e., deciding the visiting
sequence of each operator). This work
addresses the assignment and routing
problems for HHC services with the
development of new models considering
also several peculiarities of HHC services
(e.g. continuity of care). While considering
large areas, it may not be possible to know
the relative travel times between patients
during the assignment phase. Thus,
estimation of travel times is crucial. To this
end, we propose some new methods to
estimate the travel times of operators.
Keywords
Home Health Care, Service systems,
Optimization, Human Resource Planning,
Assignment, Routing, Travel Time
Estimation
Modeling the
Assignment and
Routing Problems in
the Home Health Care
Context
Semih YALCINDAG
Joint Ph.D
LGI, ECP and MECC, POLIMI
E-mail: [email protected],
Supervisor:
Evren Sahin
Co-supervisor: Andrea Matta
Thesis start date December 2010

18
Problem
Home Health Care (HHC) service is an alternative to the conventional hospitalization and consists of
delivering medical, paramedical and social services to patients at their homes. The goal is to help
patients to improve or keep their best clinical, social and psychological conditions. The development
of this concept can be attributed to the ageing of populations, social changes in families, the increase
in the number of people with chronic disease, the improvement in medical technologies, the advent of
new drugs and the governmental pressures to contain health care costs. Many resources are involved in
the HHC service delivery, including operators (e.g., nurses, physicians, etc.). The planning of
operators is very important and can be done through different steps: resource dimensioning,
partitioning of a territory into districts, allocation of resources to districts, assignment of operators to
patients (or to visits) and routing. We focus more specifically on the assignment and the routing
problems encountered in HHC services.
Objectives
The assignment problem refers to the decision of which operators will take care of which patients. The
routing problem specifies the sequence in which the patients are visited. In particular, the continuity of
care is pursued by several HHC providers to assign a patient to only one operator who is responsible
for the care during his/her stay in the HHC service. Since loss of information between is avoided and
the patient does not need to develop new relations with new operators, the continuity of care is
considered as a crucial indicator of the service quality. Despite the importance of both assignment and
routing problems, the number of works in the literature dealing with these problems in the HHC
context is still limited (Yalcindag et al. 2011). Moreover, few works focus on the continuity of care
context (Lanzarone et. al. 2012). In order to make good assignment and routing plans, patient and their
locations are important aspects to be considered. In particular, when the HHC provider serves large
areas, the locations of patients and correspondingly the travel times from each patient to other may
have a significant impact on obtaining feasible/improved plans. In some cases, considering travel
times may not be possible since the visiting sequences of patients are not available and so the relative
travel times between patients are not know. Thus, in these cases, accurate estimations of the travel
times are necessary to obtain the assignment lists as well as the visiting sequences.
Methodology
To obtain the routes for operators first the assignment lists of operators should be known. Then with
the lists obtained, the visiting sequences of operators can be found. There are two main approaches;
the first one is solving them independently by a two-stage procedure (Yalcindag et al. 2012) and the
second one is solving them simultaneously in a single model. In the first case, the output of the
assignment problem is integrated as an input to the routing problem. To do this, a single
assignment model (involving all operators and all patients) and several (as the number of operators)
independent routing models are solved. In the second case, the simultaneous decision is obtained by
using a single model. Both methods have some advantages and drawbacks. The main advantage of the
simultaneous approach is to provide more accurate solutions since the model aims at solving both the
assignment and routing decisions at the same time. Although this approach seems to be the best
alternative, in terms of complexity it requires demanding solution procedures. On the other hand, the
sequential approach is easier to solve since the assignment and routing decisions are held separately.
But there can be infeasibilities between the two stages. In the assignment model, the exact travel times
cannot be directly included, so some estimates should be used. Since this output is used as an input to
the routing problem where the routes are based on the exact distances, it is possible to observe some
infeasibilities between two stages. To overcome this issue, both assignment and routing solutions
should be repeated until the feasible solution is obtained. Thomsen (2006) formulated the
simultaneous decision of the assignment and routing problem. Since obtaining solutions are time
consuming, they develop heuristics to obtain the solutions. Although heuristics are fast, they might not
still be accurate enough. Since, the simultaneous approach is hard to solve, using a sequential
approach can be better alternative. But good estimations on travel times, still have not been developed,

19
should be used to find similar assignment and routing solutions as it can be found by the simultaneous
approach. Travel times can be estimated either by using an average values or by using a set of data.
The average values either can be calculated with a weight proportional to the requirement of the
patient (frequency of required visits) or with equal weights where each patient is considered as
equally. It is also possible to use available data sets. The data set can either be a real data (observed) or
randomly generated data (i.e., Monte Carlo simulation method). With these data sets especially with
the real one, usually detailed information for given periods are available such as all the assignment
lists of operators, requested visit numbers from each patient and the visiting sequences of operators
according to their assignment lists. Thus, based on this information, it might be possible to obtain the
total travel times of operators in each period. To do this, development of a function based on the
available data to calculate the estimated total travel times of each operator can be useful and
contributing. The development of such function can be done by different statistical fitting methods like
kernel smoothing (Wand and Jones 1995). The performance of the estimator can be shown with the
comparison of the estimated value with the real travel time obtained with the routing process. Since
exact distances are used in the routing process, this comparison would make sense in order to evaluate
the performance of the estimator.
Conclusion and Future Research Perspectives
Although there are some works related to the assignment and routing problems of the HHC services,
dependent or independent interaction of these problems with new attributes (e.g., more than one
patient pathology, etc.) still needs more attention. Thus, we try to develop new models and algorithms
to fill this gap in the literature. In particular, since estimation of travel times in the cases where relative
travel times between patients are not known is also important, we try to provide new methods for
travel time estimation alternatives.
References
Lanzarone, E., Matta, A., and Sahin E. (2012) Operations Management Applied to Home Care
Services: The Problem of Assigning Human Resources to Patients, Systems, Man and
Cybernetics, Part A: Systems and Humans, IEEE Transactions, 42 (6), 1346-1363.
Thomsen, K. (2006) Optimization on Home Care, Thesis (MSc), Technical University of Denmark.
Yalcindag, S., Matta, A. and Sahin, E. (2011) Human Resource Scheduling and Routing Problems in
Home Health Care Context: A Literature Review, In: Proceedings of ORAHS 2011, Cardiff,
UK, 8–22.
Yalcindag, S., Matta, A. and Sahin, E. (2012) Operator Assignment and Routing Problems in Home
Health Care Services, In: Proceedings of CASE 2012, Seoul, Korea, 325–330.
Wand, M.P. and Jones, M.C.(1995) Kernel Smoothing. London: Chapman and Hall.

20
Mini CV
Yueru ZHONG est née le 6 février à
Guangyuan en Chine. Elle a obtenu le
diplôme de licence en ingénierie d’avions
en 2007 à Université d’Aéronautique et
d’Astronautique à Nanjing. Elle suivait un
programme d’échange à l’Ecole Centrale de
Lyon et a obtenu le diplôme d’ingénieur en
2009 en option Transport Terrestre et en
métier Logistique. Pour terminer ses études,
elle a effectué un stage de longue durée
chez Renault sur la modélisation et la
simulation d’une nouvelle supply chain
pour un nouveau véhicule électrique.
Intégrant dans la Chaire Supply Chain en
2010, elle travaille sur la planification de la
production dans une supply chain et la
flexibilité concernée.
Résumé
Les travaux présentés dans ce papier portent
sur l’étude de l’optimisation de la
planification de la production. En
particuliers un cas d’étude est réalisé avec
Evian pour une optimisation combinatoire
en synchronisant le plan de production et le
plan de transport. Nous avons aussi étudié
la flexibilité dans une supply chain. En
utilisant la méthode d’analogie d’un
système supply chain à un système
mécanique, nous avons étudié et visualisé le
comportement de flexibilité dans un
maillon de supply chain chez LV.
Mots-clés
Optimisation combinatoire, Flexibilité,
Anagogie mécanique, Planification de la
production
Planification de la
Production Flexible
dans une Supply Chain
Yueru ZHONG
Centrale Paris Développement
Laboratoire Génie Industriel,
Ecole Centrale Paris
Grande Voie des Vignes, 92295 Châtenay-
Malabry, France.
Téléphone : 01 41 13 16 59
E-mail : [email protected]
Directeur de thèse
Chengbin CHU
Co-encadrant de thèse Zied Jemai
Début de thèse Mai 2010

21
Contexte et Problématique
La planification et l’ordonnancement de la production consistent à planifier les activités dans le temps
à l’aide des ressources disponibles (machine, labour, matière...) qui sont de capacité limitée
(Vollmann, 1997), tout en respectant les contraintes ou en optimisant un ou plusieurs critères donnés,
souvent antagonistes : minimisation du coût, maximisation du niveau de service aux clients, etc. Ces
problèmes font partie des problèmes d’optimisation combinatoire NP-difficiles, même pour le
problème single item lot-sizing à capacité limité (Florian, 1980), pour lesquels ils n’existent pas de
méthodes de résolution efficaces universelles.
Un autre volet de recherche est ajouté dans le cadre de cette thèse, la flexibilité dans la supply chain,
qui ne se cantonne pas au champ de production. Upton (1994) considère la flexibilité comme la
capacité d’agir et de réagir contre le changement d’environnement avec peu de pénalité en termes de
temps, coût, efforts, etc. Comment mesurer et évaluer la flexibilité et comment implémenter
correctement la flexibilité dans l’industrie sont des sujets à explorer.
Objectif de la recherche
L’objectif de la recherche est de développer des méthodes de résolution efficaces en exploitant les
propriétés des problèmes à résoudre, par la modélisation appropriée et des algorithmes programmés
pour obtenir des résultats optimaux ou proche-optimaux. Il faut définir la quantité à produire pendant
les périodes d’un horizon considéré à partir d’un grand nombre de références partageant les mêmes
ressources à capacité limitée. Il est aussi important de chercher et développer des méthodes à évaluer
la flexibilité dans la supply chain de l’industrie, identifier ses indicateurs, utiliser et installer
proprement la flexibilité pour répondre à la variabilité de la demande et de l’incertitude prévisionnelle,
etc. Les méthodes développées doivent être testées à l’aide des données fournis par les partenaires de
la Chaire.
Méthodologie de recherche
Pour un système de production de bouteille qui ne fait pas de stock pas sur place, on doit déployer les
produits finis aux entrepôts rapidement après leur fabrication (Fig.1). Soit par train, soit par camion,
les quantités envoyées et les quantités produites s’attachent réciproquement. Un modèle multi-produit
basé sur les coûts de changement de campagne de la production, de pénalité du stock, de transport par
train et par camion est ainsi établi.
Figure 1: Production et transportation des eaux embouteillés chez Evian Figure 2 : Analogie mécanique
Une grande variété d’approches a été étudiée pour le problème de la planification multi-produit à
capacité limité (Karimi, Fatemi Ghomi & Wilson 2003). Ceci est un mix-integer-problem, souvent
difficile d’avoir des résultats dans une durée raisonnable à la méthode classique. On se propose d’une
problème-spécifique heuristique pour le résoudre. On commence par la construction de la première
Ligne 1
Ligne 2
Ligne 14

22
solution faisable, et puis dans la deuxième phase l’amélioration de la solution avec une politique de
terminaison.
Pour la partie de flexibilité, on pense à faire analogie d’un système supply chain à un système
mécanique de vibration, soumis aux excitations extérieures (Alexopoulos, 2007, 2008). On peut
assimiler la demande comme l’excitation et la livraison comme la sortie (Fig.2). Après une
transformation fourrière de la fonction du transfert, le facteur de l’amortisseur ζ peut être calculé. Ceci
est bien équivalent à une mesure de la flexibilité du système supply chain, qui indique la sensibilité de
ce système. Pour éliminer l’influence de différentes paternes d’entrées, et prenant en compte de
multiples changements de configuration du système, on effectue à l’avance une différenciation en
mettent du poids à chaque période dans l’horizon.
Résultats de la recherche
1. Résultats du cas d’Evian plus efficace que le solveur Cplex
Plan de production : quantité de produit i sur ligne de production k dans la période t ;
nombre de changement de campagne sur ligne de production k de produit i à l’autre
produit dans la période t ; niveau de stock pour produit i
Plan de transport : quantité de wagon à réserver dans la direction de l’entrepôt l dans
la période t ; quantité de camion à utiliser dans la direction de l’entrepôt l dans la
période t ; taux de remplissage
2. Taxonomie de la flexibilité dans la supply chain ; Mesure de la flexibilité chez LV : Détection
de la différenciation des périodes t ; Comparer le comportement de la sensibilité aux
demandes par magasin i et par la différenciation des périodes
Conclusion : limites et pistes de recherche
Dans la première étude de cas, l’heuristique qu’on a proposée est très efficace mais problème-
spécifique. L’approche de trouver la première solution faisable par ce type d’heuristique, puis
l’encastrer comme solution initiale dans le programme par cplex, est plus efficace à trouver la solution
optimale que dans cplex seul, donc a plus d’intérêt à utiliser pour résoudre d’autres problèmes. Pour
l’analogie mécanique sur la flexibilité, le prochain point est de creuser sur la correspondance entre
différentes modes de vibration et différentes types de flexibilité. De plus, un système vibration avec
des ressorts en série ou en parallèle pourrait aussi représenter les phénomènes dans la supply chain.
Bibliographie
Alexopoulos, K., et al. (2007) Quantifying the flexibility of a manufacturing system by applying the
transfer function. International Journal of Computer Integrated Manufacturing. 20 (6) p.538–
547.
Alexopoulos, K., et al.. (2008) Oscillator analogy for modeling the manufacturing systems dynamics.
International Journal of Production Research. 46 (10) p.2547–2568.
Florian, M. (1980) Deterministic production planning: Algorithms and complexity. Management
science. 26 (7) p.669–679.
Karimi, B., Fatemi Ghomi, SMT. and Wilson, JM. (2003) The capacitated lot sizing problem: a review
of models and algorithms, Omega. 31 (5) p.365-378.
Upton, D.M. (1994) The management of manufacturing flexibility. California Management Review.
36 (2) p.72–89.
Vollmann, T.E., Berry, W.L. and Whybark, C.D. (1997) Manufacturing planning and control systems,
4th edition. New York: Irwin/Mcgraw-Hill


















