Un mod¨le num©rique d'endommagement ductile orthotrope pour les transformations finies

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordres élevés
Institut Supérieur d’Informatique de Modélisation et de leurs Applications 24, Avenue des Landais BP 10 125 63 173 AUBIERE cedex.
Université Blaise Pascal -Laboratoire de Mathématiques UMR 6620 - CNRS
Campus des Cézeaux B.P. 80026 63171 Aubière cedex
Rapport de projet de 3ème année Calcul scientifique
Présenté par : Matthias Sentis Edouard IZARD Responsable ISIMA : Thierry Dubois
15 mars 2011

Remerciements Nous tenons à remercier le professeur et chercheur Thierry Dubois pour nous avoir proposé ce sujet. Sa disponibilité, ses explications ainsi que ses cours de parallélisme ont été d’un grand secours pour ce projet. Nous remercions également l’ISIMA pour nous avoir offert l’opportunité de réalisé ce projet très intéressant.

Résumé Pour comprendre le comportement d’un fluide, les équations de Navier-Stockes ou l’équation de la chaleur sont très utilisées, mais résoudre ces équations demande de nombreuses ressources. En effet, un ordinateur « basique » prend trop de temps pour trouver une solution à ce type de problème. Nous discuterons dans ce rapport, d’une méthode pour réduire le temps d’exécution pour de tels algorithmes. En collaboration avec Thierry DUBOIS (CNRS – LMA Clermont), nous avons utilisé MPI (Message Passing Interface), un langage de programmation qui permet aux processeurs de communiquer les uns avec les autres, sur un cluster (réseaux d’ordinateurs) pour réduire le temps d’exécution d’un programme existant pour la résolution des équations de Navier-Stockes. Nous avons implémenté l’environnement et les communications entre processeurs. Nous n’avons pas encore codé les calculs mais nous avançons que notre travail réduira le temps total d’exécution pour résoudre ces équations. Mots clés : équations de Navier-Stockes, Message passing Interface, cluster, communications.

Abstract
To understand a fluid behavior, the Navier-Stockes equation or the heat flow equations are very used but solving these equations take a lot of resources. Indeed, a basic computer takes too much time to calculate the solution. In this paper, we will discuss about a method to reduce the execution time for such an algorithm. In collaboration with Thierry DUBOIS (CNRS – LMA Clermont), we used Message Passing Interface (MPI), a programming language which allows processes to communicate with one another, on a cluster (computer network) to reduce the executing time of an existing program to solve the Navier-Stockes equation. We have implemented the environment and the communications between processes. We did not implement the calculus in the code but we assume that our work will decrease the total time execution to solve the equations. Keywords: Navier-Stockes equation, Message Passing Interface, cluster, communications.

Table des matières
Remerciements
Résumé
Abstract
Introduction ......................................................................................................................................... 1
1. Explication du problème ............................................................................................................... 2 1.1 Le problème physique étudié .......................................................................................................... 2 1.2 Les enjeux du projet et la parallélisation ....................................................................................... 3 1.3 Les directives du projet ..................................................................................................................... 3
2 La parallélisation .......................................................................................................................... 4 2.1 L’outil utilisé ......................................................................................................................................... 4 2.2 Structure du problème ....................................................................................................................... 5 2.3 Les communications ........................................................................................................................... 7
3 Résultats ...................................................................................................................................... 11 3.1 Résultats et explications ................................................................................................................. 11
3.1.1 Résultats pour un domaine cubique 128x128x128 ................................................................ 12 3.1.2 Résultats pour un domaine cubique 256x256x256 ................................................................ 14 3.1.3 Résultats pour un domaine cubique 512x512x512 ................................................................ 16
3.2 Améliorations possibles ................................................................................................................. 18 3.3 Ressenti .............................................................................................................................................. 18
Conclusion ......................................................................................................................................... 19
Glossaire
Table des illustrations
Annexe : Le code

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
1
Introduction
Dans le cadre de notre projet de troisième année au sein de l’ISIMA, nous avons travaillé au côté de Thierry Dubois. Ce dernier fait partie du laboratoire de Mathématiques Appliquées (LMA) rattaché au CNRS. La résolution des équations de Navier-Stockes pour un fluide compressible nécessite une discrétisation très précise. C'est-à-dire que le maillage utilisé doit être très fin, ce qui entraine un nombre d’inconnues important et donc un nombre très important de calculs. Dans cette optique, un algorithme séquentiel est inefficace car trop long. Il est donc nécessaire de passer par une parallélisation du code. Ceci est réalisable de par la mise en place d’un schéma de communication entre les différents processeurs d’un cluster. Nous avons implémenté ce schéma grâce à la librairie MPI. Nous verrons donc dans une première partie le contexte générale du projet, puis nous exposerons la manière dont nous avons implémenté le code pour enfin voir les résultats obtenus après essaie sur le cluster du LMA.
Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
2
1. Explication du problème
1.1 Le problème physique étudié
En fait, ce n’est pas uniquement un problème mais un ensemble de problèmes à géométrie identique auxquels on peut appliquer notre projet. On en cite seulement un dans cette section.
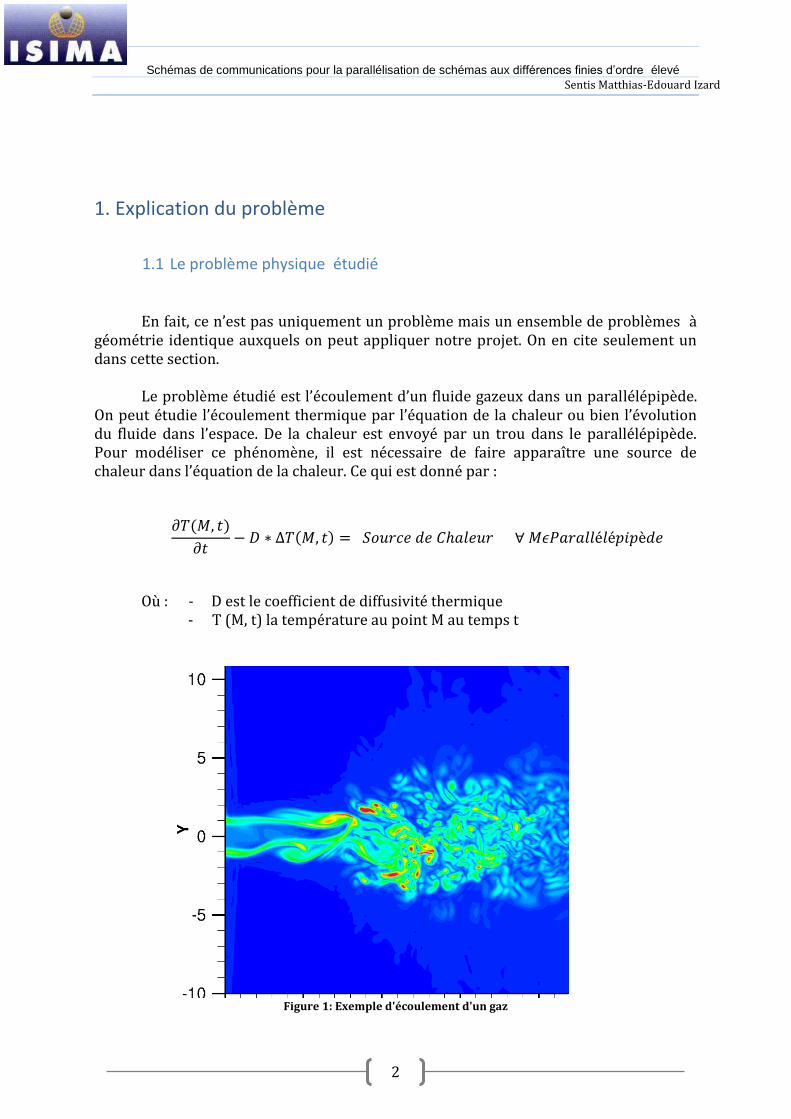
Le problème étudié est l’écoulement d’un fluide gazeux dans un parallélépipède.
On peut étudie l’écoulement thermique par l’équation de la chaleur ou bien l’évolution du fluide dans l’espace. De la chaleur est envoyé par un trou dans le parallélépipède. Pour modéliser ce phénomène, il est nécessaire de faire apparaître une source de chaleur dans l’équation de la chaleur. Ce qui est donné par :
Où : - D est le coefficient de diffusivité thermique - T (M, t) la température au point M au temps t
Figure 1: Exemple d'écoulement d'un gaz

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
3
Le problème est alors discrétisé par un schéma aux différences finies d’ordre six. Ces types de schéma calculent la valeur du point courant avec les valeurs voisines en faisant des approximations sur les termes dérivés.
1.2 Les enjeux du projet et la parallélisation
A temps fixé, on a un système linéaire { résoudre qui a autant d’inconnues que de points du maillage. Pour un maillage petit et donc un nombre de points conséquents, l’écriture séquentielle du schéma est mal appropriée parce qu’elle s’exécute en un temps trop long. C’est ainsi que la parallélisation intervient pour réduire le temps de calcul. De manière générale, la parallélisation divise le temps d’exécution au mieux par le nombre de processeurs utilisés. L’idée est d’envoyer des données sur chaque processeur afin qu’ils effectuent les calculs en même temps. Plusieurs méthodes existent pour paralléliser : GP/GPU, OpenMP, MPI. Notre tuteur, M. Dubois, nous a proposé de le faire avec la librairie MPI (Message Passing Interface) utilisée dans le langage FORTRAN 90. Ce genre de librairie est efficace pour ces problèmes car les calculs à faire sont identiques sur chaque sous-espace.
1.3 Les directives du projet
Les directives étaient assez libres puisqu’on on faisait le cours de MPI en même temps que l’on commençait le projet. Ainsi nos premières directives furent d’installer l’outil MPI sur nos ordinateurs. Une fois cette étape réalisé, nous avons commencé à implémenté le code. Cependant la structuration du code n’était pas très claire, M. Dubois nous a alors montré et expliqué comment structurer un programme en fortran (module, subroutine…). Les paramètres étant nombreux, il devient vital de structurer le code pour sa compréhension et sa réutilisabilité. Nous avons alors vérifié les communications que nous avions implémentées. Pour finir, nous avons testé notre programme sur un cluster pour pouvoir constater l’augmentation des temps de communication en faisant varier le nombre de processeurs utilisé.

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
4
2 La parallélisation
2.1 L’outil utilisé
L’outil utilisé est donc Message Passing Interface(MPI) qui est disponible sur le site suivant : http://www.open-mpi.org/software/ompi/v1.4/
Expliquons un peu le fonctionnement de l’outil utilisé. Il n’existe qu’un programme sur tous les processeurs. L’écriture d’un programme MPI nécessite donc l’écriture d’un seul fichier FORTRAN. Pour utiliser la librairie MPI, il suffit de la télécharger et de faire un « use mpi »sur le programme principal. Il faut ensuite initialiser l’environnement MPI et récupérer certains attributs de base : Initialisation de MPI : call mpi_init(i_err) call mpi_comm_size(mpi_comm_world, nb_proc, i_err) call mpi_comm_rank(mpi_comm_world, i_num, i_err) Maintenant, on connaît le nombre total de processeurs utilisés (nb_proc) spécifié à l’exécution du programme et le rang du processeur courant (i_num). On peut maintenant travailler sur les processeurs, faire des calculs et des communications. Pour finir, on doit rendre le contexte initial de MPI par : call mpi_finalize(i_err)

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
5
2.2 Structure du problème
On doit mettre en place différents paramètres avant de faire quoi que ce soit. L’initialisation des paramètres doit être facilement détectable (pour la lisibilité du code) et l’utilisation de ceux-ci doit être rendu simple d’utilisation (si réutilisation).
On doit initialiser le nombre de processeurs utilisés (p1, p2, p3), la taille du
maillage, la grille, le champ de vitesse initial, les bordures pour les communications. Pour cela, le langage FORTRAN nous permet de les initialiser une fois pour toute grâce au module qui comprend la déclaration des paramètres qui sont initialisés et qui peuvent être modifiés. Ces paramètres sont accessibles dans tout le reste du programme, il suffit d’inclure le module dans la partie désirée. Ces modifications sont faites par l’appel de sous-fonctions (subroutine) dans le programme principal. Ainsi voici les modules implémentés nécessaires { l’initialisation de nos paramètres :
* module.size.f90 pour la taille du maillage nx, ny, nz.
* module.grid.f90 pour la taille de la grille x,y,z * module.velocity.f90 pour les vitesses u,v,w * module.border.f90 pour la taille des bords à envoyer lors des
communications : SpeedGx, SpeedDx, SpeedGy, SpeedDy, SpeedGz, SpeedDz
Une fois tout défini, il faut remplir les valeurs initiales. Pour cela nous avons implémenté les fonctions d’initialisations. A chaque module correspond une fonction d’initialisation. Les voici :
* size_init.f90 * grid_init.f90 * velocity_init.f90 * border_init.f90
Ces fonctions sont appelées à partir du programme principal. A cette étape, tous les processeurs ont tous les paramètres initialisés nécessaires pour la suite du codage.
Il est aussi nécessaire d’initialiser l’environnement MPI avant toute initialisation. Pour cela un module sert { la déclaration des paramètres pour l’utilisation de MPI : mpi_param.f90. L’initialisation des paramètres vu au 1 de cette section sont faite par la fonction mpi_env.f90 avec le paramètre i_flag =0. Dans ce même module, il y a aussi la déclaration de p1, p2, p3 que nous expliquerons dans la section suivante. Cette même fonction avec le paramètre i_flag =1 sert à la fin de l’utilisation de MPI pour rendre le contexte d’origine.
Attelons-nous à expliquer la géométrie du problème. Le problème initial a pour
géométrie un parallélépipède rectangle. L’idée est de scinder le problème en sous

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
6
problèmes identiques sur des parallélépipèdes de taille inférieur. Le nombre de sous-problèmes est égal au nombre de processeurs utilisés. Nous faisons donc face au problème de scinder le parallélépipède en un nombre de parallélépipèdes nb_proc. On pose (p1, p2, p3) l’indice du processeur dans le parallélépipède. On a donc p1*p2*p3 = nb_proc.
Ainsi, trois choix de découpe s’offre { nous : * couper selon x uniquement : p2 =1 et p3 = 1.
Figure 2: Exemple de découpage du domaine selon x
Ici, dans l’exemple, p1= 4. * couper selon x et y : p3 = 1
Figure 3: Exemple de découpage du domaine selon x et y
Ici, dans l’exemple, p1= 4 et p2 = 5.

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
7
* couper selon x, y et z :
Figure 4: Exemple de découpage du domaine selon x, y et z
Ici, dans l’exemple, p1= 4, p2= 5 et p3= 2. Tout ceci est lié { l’initialisation des variables p1, p2 et p3 dans la fonction mpi_env.f90. Cette initialisation est automatisée par la lecture dans un fichier input_parameters. Ce fichier permet aussi de rentrer la taille globale du parallélépipède Lx (la longueur), Ly (la largeur) et Lz (la hauteur) Ces paramètres servent au remplissage de nx,ny et nz dans l’initialisation de la grille sur chaque processeur. Récapitulons, chaque processeur possède un identifiant (p1, p2, p3) et est donc facilement détectable, a un nombre nx*ny*nz points et a une vitesse (u,v,w) sur chacun des point du maillage x,y,z. Il est évident que x= 1..nx, y= 1..ny et y= 1..nz.
2.3 Les communications
Il est vrai que l’on a beaucoup parlé des communications mais pourquoi les processeurs ont-ils besoin de communiquer ? Le problème vient du fait que pour calculer le point courant, on a besoin des points voisins. Ainsi, sur un processeur, quand on calcule un point sur l’un des bords, un des points voisins se situe sur un des processeurs voisins. D’ou la communication du processeur courant avec le processeur voisin concerné. On peut faire le même raisonnement sur tous les points du bord. Ainsi, on s’aperçoit que l’on doit envoyer les plans voisins au processeur courant.
Il est donc nécessaire de définir les processeurs voisins. Dans notre programme, les voisins sont définis dans le module mpi_param.f90 et stockés dans la variable i_send. On fait les calculs de voisins, en utilisant les p1, p2 et p3 rentrés par l’utilisateur, dans la

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
8
fonction mpi_env avec le paramètre i_flag=0. Dans le ca général, l’indice du processeur courant (i_proc, j_proc, k_proc) est donné par :
k_proc = i_num/ (p1*p2) j_proc = (i_num - p1*p2*k_proc)/p1 i_proc = i_num - p1*j_proc - p1*p2*k_proc
Les voisins sont alors définis par : i_send(1) = i_proc-1 i_send(2) = i_proc+1 i_send(3) = j_proc-1 i_send(4) = j_proc+1 i_send(5) = k_proc-1 i_send(6) = k_proc+1 Les deux premiers sont les voisins sur x, les deux suivants sont les voisins sur y et les deux derniers sont les voisins sur z. Une fois les voisins définis, il faut définir les plans à envoyer. Pour cela, on doit définir des types MPI. Ces types servent à un envoi plus simple des plans. Dans notre cas, 3 types sont nécessaires pour tous les envois. Un type par axe d’envoi. Les types sont différents car on a un stockage de donnée particulier en FORTRAN. Pour un tableau en trois dimensions du type Tab(x, y, z), les donnés sont stockés de manière contiguë en x puis en y et enfin en z. Voici un exemple du stockage contigu pour un tableau Tab (2, 2,2) : Tab(1,1,1) Tab(2,1,1) Tab(1,2,1) Tab(2,2,1) Tab(1,1,2) Tab(2,1,2) Tab(1,2,2) Tab(2,2,2) Ainsi, voici les types utilisés pour les envois dans notre programme : * Définition du type pour envoyer sur l'axe x call mpi_type_vector(ny*nz,1,nx,mpi_double_precision,type_tabX,i_err) On enverra un vecteur de nx*ny points (double précision) qui sont définies en partant du point d’envoi, spécifié lors de l’envoie, et en prenant un point tout les nx éléments contiguës en mémoire. Le type a alors pour nom type_tabX.
* Définition du type pour envoyer sur l'axe y call mpi_type_vector(nz,nx,nx*ny,mpi_double_precision,type_tabY,i_err) On enverra un vecteur de nz éléments de nx éléments (double précision) contiguës en partant du point d’envoi, spécifié lors de l’envoie, et en faisant un saut de nx*ny octets en mémoire. Le type a alors pour nom type_tabY.

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
9
* Définition du type pour envoyer sur l'axe z call mpi_type_contiguous(nx*ny,mpi_double_precision,type_tabZ,i_err) On enverra nx*ny éléments (double précision) contiguës en mémoire en partant du point d’envoi, spécifié lors de l’envoie. Le type a alors pour nom type_tabZ. Les plans à envoyer définies, il reste à mettre en place le schéma de communication. Pour cela, on a utilisé uniquement des communications bloquantes. Dans ce mode de fonctionnement, lorsqu’un processeur envoi quelque chose, il doit attendre la réception de son message pour continuer. De la même façon, quand un processeur arrive sur une ligne du code qui lui dit de recevoir un message de quelqu’un, il doit attendre ce message du bon processeur qui a envoyé avant de continuer la suite du programme. Ce mode de fonctionnement est le plus sécurisant pour les communications. Regardons comment marche les fonctions mpi qui permettent d’envoyer et de recevoir des messages. La fonction MPI_SEND sert { l’envoi, voici son prototype : MPI_SEND (BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR) BUF : élément de départ de l’envoi (adresse d’envoi). COUNT : le nombre d’élément de type DATATYPE à envoyer DEST : le rang du processeur récepteur TAG : le label de l’envoi (le label est le nombre qui doit être le même { la réception)
COMM : communicateur sur lequel on travaille, dans notre cas, c’est mpi_comm_world IERROR : entier pour savoir si tout c’est bien passé. La fonction MPI_RECV sert à la réception, voici son prototype : MPI_RECV (BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS,
IERROR) BUF : élément de réception. COUNT : le nombre d’élément de type DATATYPE à recevoir DEST : le rang du processeur émetteur TAG : le label de la réception (le label est le nombre qui doit être le même { l’envoi)
COMM : communicateur sur lequel on travaille, dans notre cas, c’est mpi_comm_world STATUS : donne des informations en plus si la communication c’est mal passé
IERROR : entier pour savoir si tout c’est bien passé. Dans notre cas, les DATATYPE sont les types prédéfinis auparavant. C’est { dire type_tabX, type_tabY et type_tabZ. Le rang des processeurs à spécifier { l’envoi ou { la réception est déterminé grâce à i_send. Raisonnons uniquement sur l’axe x. L’idée est de faire des envois et réceptions dirigés imbriqués. Prenons un exemple simple pour expliquer. On se place dans le cas où on fait une coupe sur x avec p1=3, p2=1 et p3=1.

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
10
Le processeur 0 envoie, en utilisant son voisin de droite stocké dans i_send(2), son plan droite au processeur 1. Le processeur 1 reçoit, en utilisant i_send(1), le plan est envoi son plan gauche au processeur 0. Le processeur 0 le reçoit (i_send) et finis ces communications sur x. Le processeur 1 envoie son plan de droite au processeur 2, le processeur 2 le reçoit et envoie son plan gauche à 1. Le processeur 1 le reçoit est fini ces communications sur x. Le processeur 2 envoie son plan de droite au processeur 3, le processeur 3 le reçoit et envoie son plan gauche à 2. Le processeur 2 reçoit le plan et finit ces communications sur x. Le processeur 3 finit ces communications sur x. Le schéma de communication est le même sur les axes y et z. Une fois qu’un processeur finit ces communications sur x, il communique sur y (si p2 différent de 1), puis sur z (si p2 différent de 1) si toute fois l’utilisateur le spécifie en rentrant les valeurs de (p1, p2, p3). Cela permet de faire un gain de temps. Toute l’implémentation des communications sont dans le fichier mpi_single_comm.f90.

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
11
3 Résultats Quand nous avons terminé d’implémenter les communications, sur notre ordinateur, nous avons vérifié que celles-ci étaient correctes avant de tester notre programme sur le cluster. Le cluster utilisé regroupe plusieurs ordinateurs, au total 24. Ces ordinateurs sont vus comme des nœuds. Sur chaque nœud nous disposons de 4 cœurs. Au total, on peut donc exécuter le programme sur un total de 96 cœurs. Le plus rapide reste d’utiliser les nœuds sans en parcourir les cœurs. Par exemple si on veut lancer le programme sur 24 processeurs (cœur par abus de langage), il est plus efficace d’utiliser les 24 nœuds que d’utiliser 12 nœuds avec chacun 2 cœurs. Dans cette partie, nous exposerons donc les tests réalisés sur le cluster ainsi que l’explication des résultats.
3.1 Résultats et explications Nous allons faire des tests pour différentes tailles de domaine. Nous prendrons un cube 128x128x128 puis 256x256x256 et enfin 512x512x512 pour comparer les temps de communications. Pour chaque test nous fixerons le nombre de processeur selon une direction (p1, p2 ou p3) et nous mettrons en évidence le temps de communication nécessaire { l’exécution du programme parallélisé. Cependant, beaucoup de résultat sont faussé. En effet, lors des tests nous avons remarqué des temps de communications soit trop élevés soit trop petits. Nous avons supposé que le temps de latence du réseau dans le cluster en était la cause.
Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
12
3.1.1 Résultats pour un domaine cubique 128x128x128
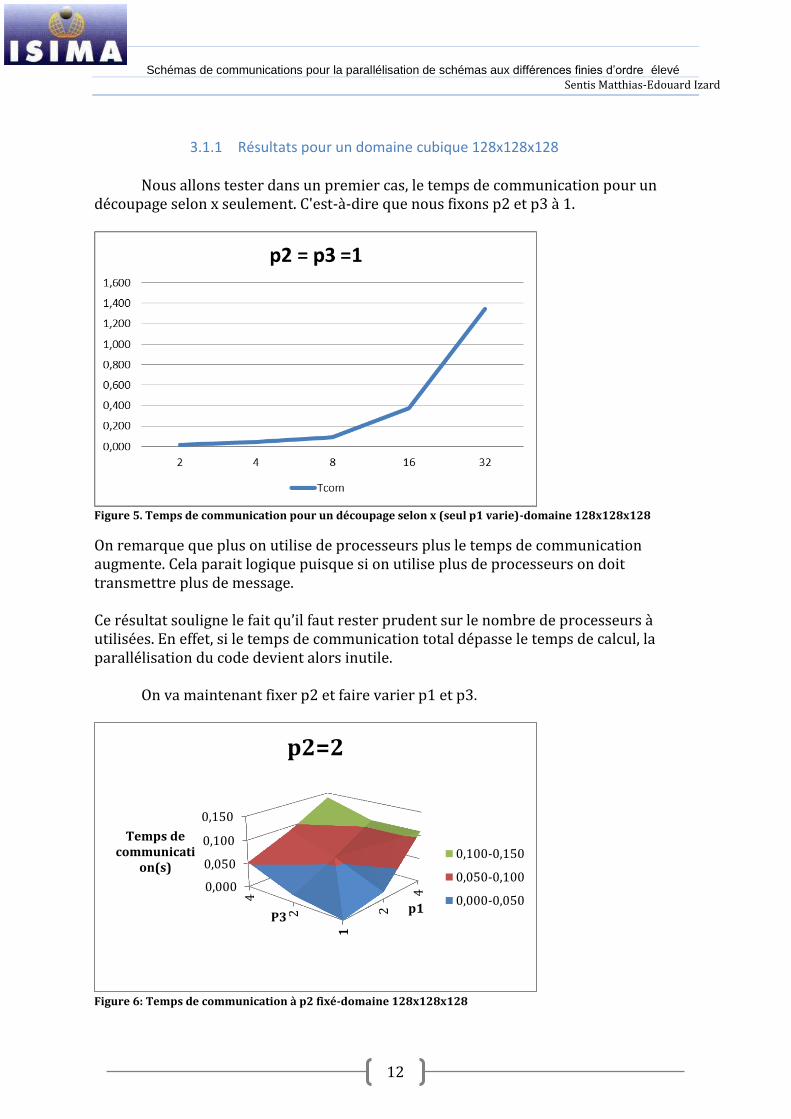
Nous allons tester dans un premier cas, le temps de communication pour un découpage selon x seulement. C'est-à-dire que nous fixons p2 et p3 à 1.
Figure 5. Temps de communication pour un découpage selon x (seul p1 varie)-domaine 128x128x128
On remarque que plus on utilise de processeurs plus le temps de communication augmente. Cela parait logique puisque si on utilise plus de processeurs on doit transmettre plus de message. Ce résultat souligne le fait qu’il faut rester prudent sur le nombre de processeurs { utilisées. En effet, si le temps de communication total dépasse le temps de calcul, la parallélisation du code devient alors inutile.
On va maintenant fixer p2 et faire varier p1 et p3.
Figure 6: Temps de communication à p2 fixé-domaine 128x128x128
1
2
4
0,000
0,050
0,100
0,150
1
2
4
P3
Temps de communicati
on(s)
p1
p2=2
0,100-0,150
0,050-0,100
0,000-0,050
Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
13
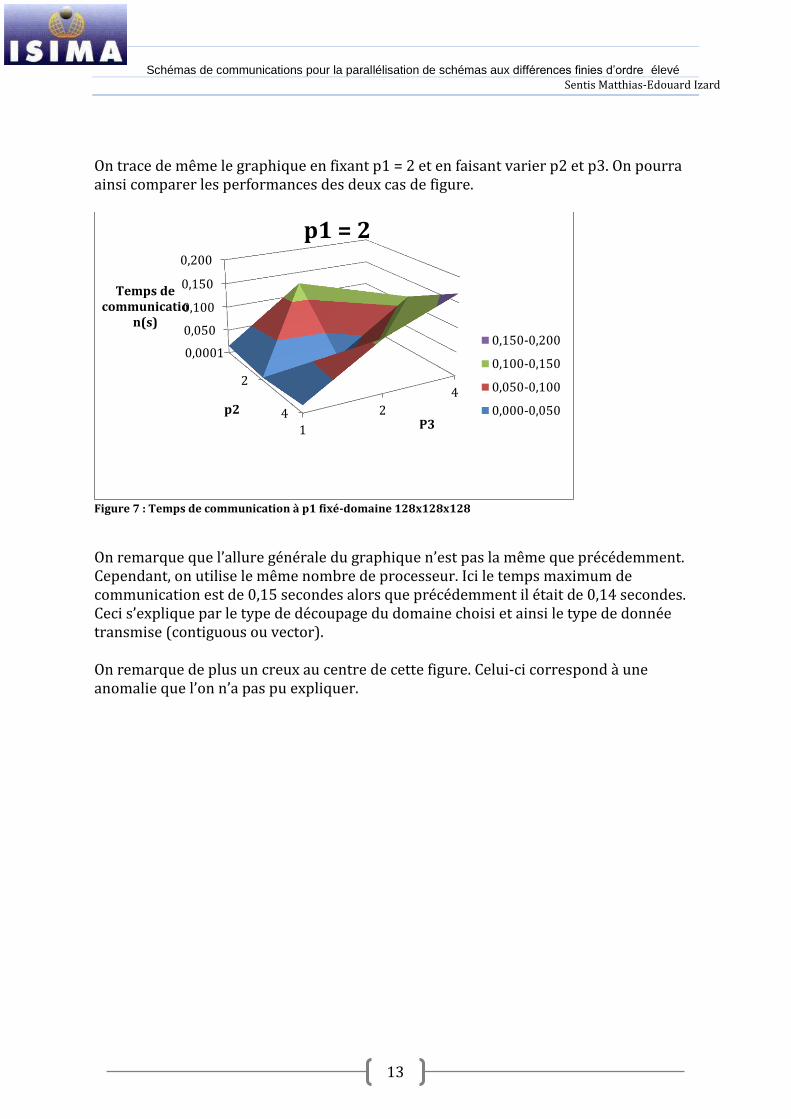
On trace de même le graphique en fixant p1 = 2 et en faisant varier p2 et p3. On pourra ainsi comparer les performances des deux cas de figure.
Figure 7 : Temps de communication à p1 fixé-domaine 128x128x128
On remarque que l’allure générale du graphique n’est pas la même que précédemment. Cependant, on utilise le même nombre de processeur. Ici le temps maximum de communication est de 0,15 secondes alors que précédemment il était de 0,14 secondes. Ceci s’explique par le type de découpage du domaine choisi et ainsi le type de donnée transmise (contiguous ou vector). On remarque de plus un creux au centre de cette figure. Celui-ci correspond à une anomalie que l’on n’a pas pu expliquer.
1
2
4
0,000
0,050
0,100
0,150
0,200
1
2
4P3
Temps de communicatio
n(s)
p2
p1 = 2
0,150-0,200
0,100-0,150
0,050-0,100
0,000-0,050
Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
14
3.1.2 Résultats pour un domaine cubique 256x256x256
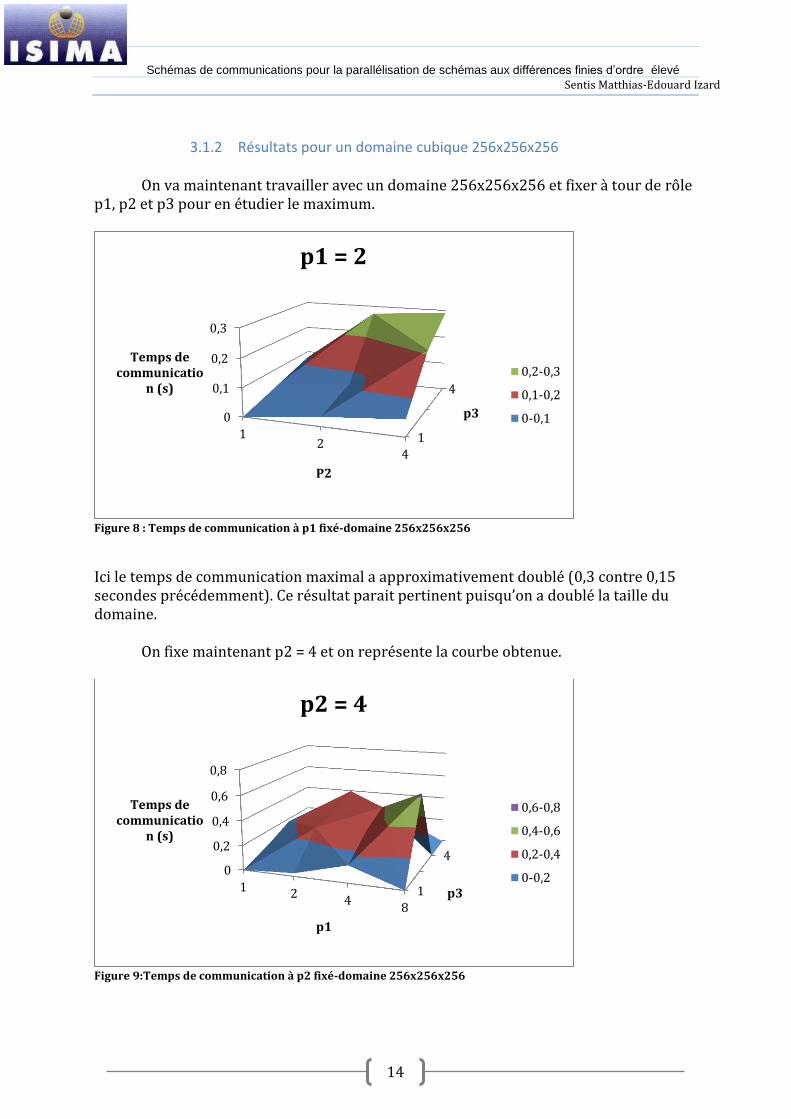
On va maintenant travailler avec un domaine 256x256x256 et fixer à tour de rôle p1, p2 et p3 pour en étudier le maximum.
Figure 8 : Temps de communication à p1 fixé-domaine 256x256x256
Ici le temps de communication maximal a approximativement doublé (0,3 contre 0,15 secondes précédemment). Ce résultat parait pertinent puisqu’on a doublé la taille du domaine.
On fixe maintenant p2 = 4 et on représente la courbe obtenue.
Figure 9:Temps de communication à p2 fixé-domaine 256x256x256
1
4
0
0,1
0,2
0,3
12
4
p3
Temps de communicatio
n (s)
P2
p1 = 2
0,2-0,3
0,1-0,2
0-0,1
1
40
0,2
0,4
0,6
0,8
1 24
8p3
Temps de communicatio
n (s)
p1
p2 = 4
0,6-0,8
0,4-0,6
0,2-0,4
0-0,2
Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
15
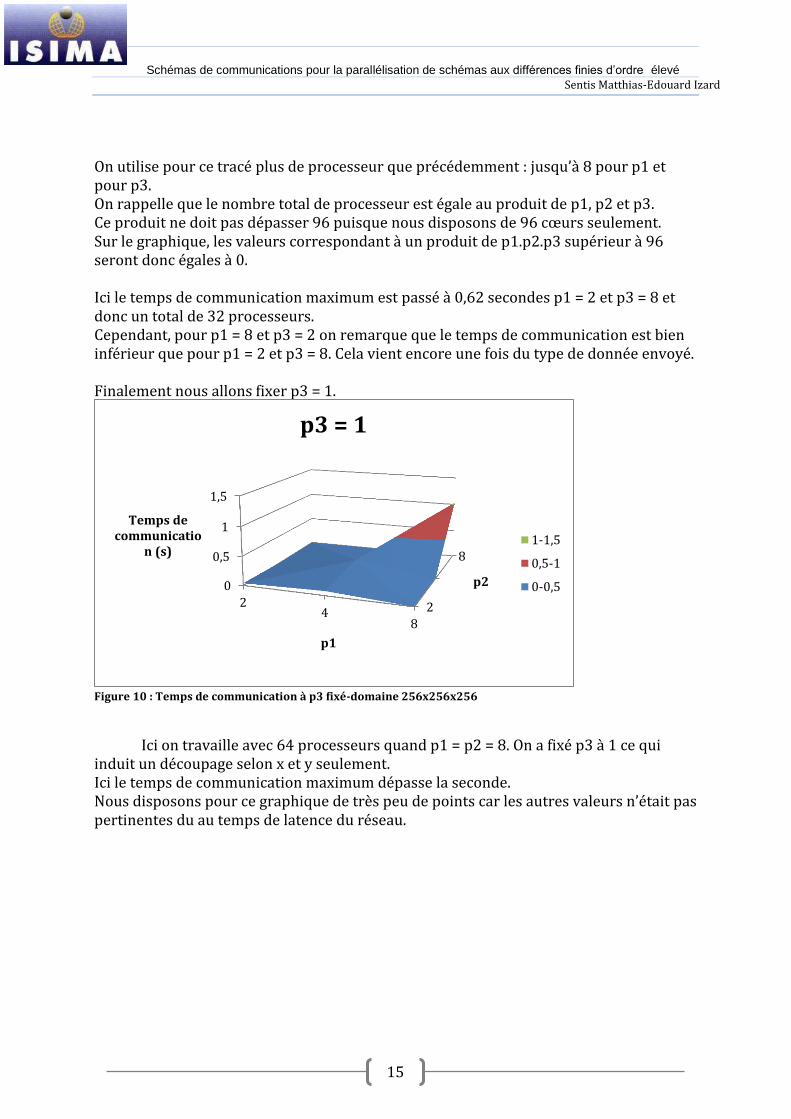
On utilise pour ce tracé plus de processeur que précédemment : jusqu’{ 8 pour p1 et pour p3. On rappelle que le nombre total de processeur est égale au produit de p1, p2 et p3. Ce produit ne doit pas dépasser 96 puisque nous disposons de 96 cœurs seulement. Sur le graphique, les valeurs correspondant à un produit de p1.p2.p3 supérieur à 96 seront donc égales à 0. Ici le temps de communication maximum est passé à 0,62 secondes p1 = 2 et p3 = 8 et donc un total de 32 processeurs. Cependant, pour p1 = 8 et p3 = 2 on remarque que le temps de communication est bien inférieur que pour p1 = 2 et p3 = 8. Cela vient encore une fois du type de donnée envoyé. Finalement nous allons fixer p3 = 1.
Figure 10 : Temps de communication à p3 fixé-domaine 256x256x256
Ici on travaille avec 64 processeurs quand p1 = p2 = 8. On a fixé p3 à 1 ce qui
induit un découpage selon x et y seulement. Ici le temps de communication maximum dépasse la seconde. Nous disposons pour ce graphique de très peu de points car les autres valeurs n’était pas pertinentes du au temps de latence du réseau.
2
8
0
0,5
1
1,5
24
8
p2
Temps de communicatio
n (s)
p1
p3 = 1
1-1,5
0,5-1
0-0,5
Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
16
3.1.3 Résultats pour un domaine cubique 512x512x512
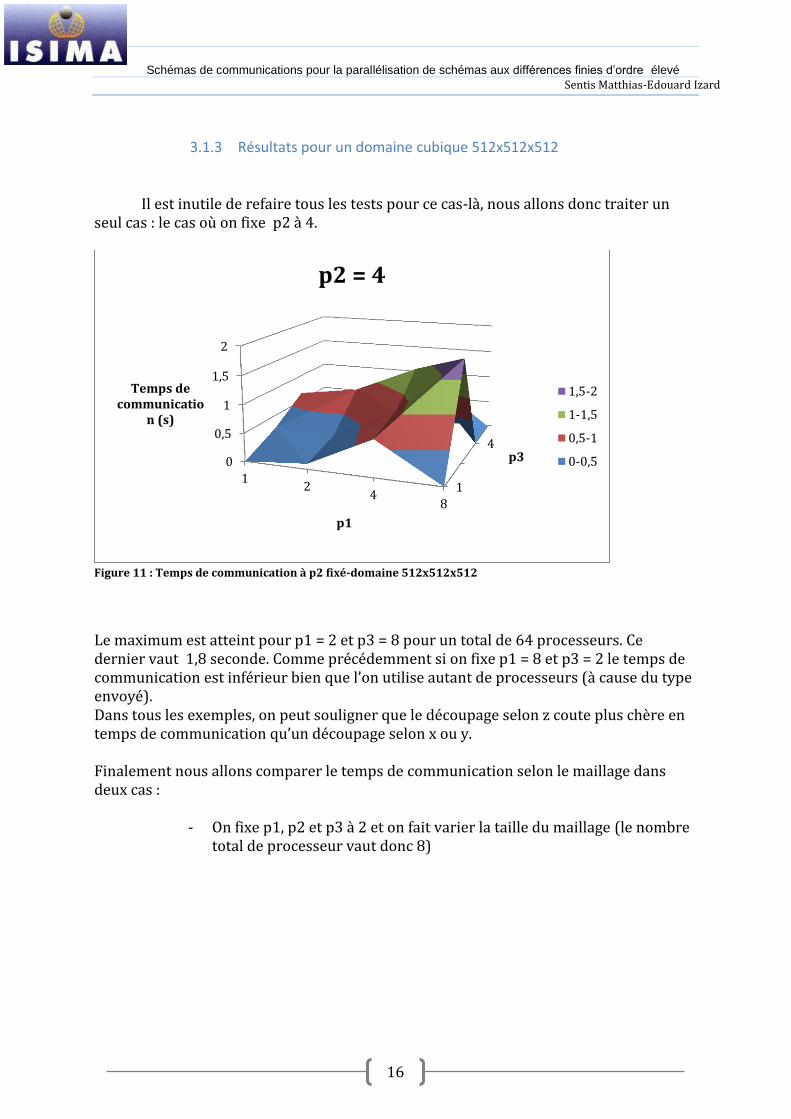
Il est inutile de refaire tous les tests pour ce cas-là, nous allons donc traiter un seul cas : le cas où on fixe p2 à 4.
Figure 11 : Temps de communication à p2 fixé-domaine 512x512x512
Le maximum est atteint pour p1 = 2 et p3 = 8 pour un total de 64 processeurs. Ce dernier vaut 1,8 seconde. Comme précédemment si on fixe p1 = 8 et p3 = 2 le temps de communication est inférieur bien que l’on utilise autant de processeurs ({ cause du type envoyé). Dans tous les exemples, on peut souligner que le découpage selon z coute plus chère en temps de communication qu’un découpage selon x ou y. Finalement nous allons comparer le temps de communication selon le maillage dans deux cas :
- On fixe p1, p2 et p3 à 2 et on fait varier la taille du maillage (le nombre total de processeur vaut donc 8)
1
4
0
0,5
1
1,5
2
12
48
p3
Temps de communicatio
n (s)
p1
p2 = 4
1,5-2
1-1,5
0,5-1
0-0,5
Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
17
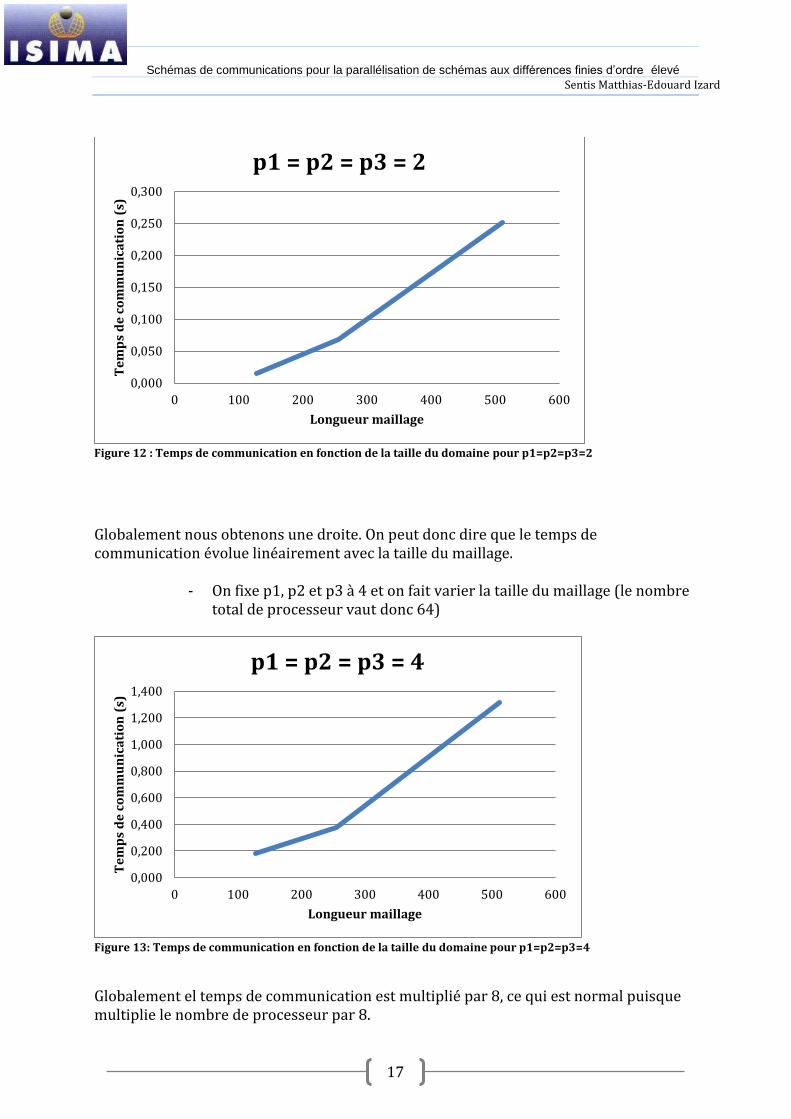
Figure 12 : Temps de communication en fonction de la taille du domaine pour p1=p2=p3=2
Globalement nous obtenons une droite. On peut donc dire que le temps de communication évolue linéairement avec la taille du maillage.
- On fixe p1, p2 et p3 à 4 et on fait varier la taille du maillage (le nombre total de processeur vaut donc 64)
Figure 13: Temps de communication en fonction de la taille du domaine pour p1=p2=p3=4
Globalement el temps de communication est multiplié par 8, ce qui est normal puisque multiplie le nombre de processeur par 8.
0,000
0,050
0,100
0,150
0,200
0,250
0,300
0 100 200 300 400 500 600
Te
mp
s d
e c
om
mu
nic
ati
on
(s)
Longueur maillage
p1 = p2 = p3 = 2
0,000
0,200
0,400
0,600
0,800
1,000
1,200
1,400
0 100 200 300 400 500 600
Te
mp
s d
e c
om
mu
nic
ati
on
(s)
Longueur maillage
p1 = p2 = p3 = 4

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
18
On peut remarquer que le premier point pour un maillage de 128x128x128 à la quasiment la même valeur que précédemment. En fait, plus le maillage est grossier, moins le nombre de processeur a un impact sur le temps de communication.
3.2 Améliorations possibles
Les améliorations possibles résident principalement sur les tests effectués. En effet, comme nous l’avons dit précédemment, certains temps de communications nous ont paru absurde et cela à cause du temps de latence du réseau. Il faudrait donc faire plus de tests pour comprendre le fonctionnement du réseau et ainsi garder seulement les valeurs pertinentes trouvées.
Un autre défaut notable réside dans l’attribution de sous domaine au processeur. C'est-à-dire que si l’on prend un domaine de taille flottante ou un domaine de taille égale { un nombre premier, notre algorithme n’est plus valable. Cependant, l’utilisation qui en sera fait ne prend pas en compte ces cas-là, cette amélioration ne sera donc utile que pour une généralisation du programme { d’autres cas.
3.3 Ressenti
Nous expliquerons ici le déroulement du projet, nos impressions générales ainsi que les difficultés rencontrées.
Ce sujet nous a beaucoup intéressés puisqu’il a été en quelques sortes la continuité du cours de Thierry Dubois. Le parallélisme étant de plus en plus utilisé pour les calculs haute performance, il nous a semblé très utile d’en connaitre plus { travers ce projet.
Dans l’ensemble le projet s’est très bien déroulé grâce { l’aide de M. Dubois. Les difficultés principales au niveau de l’implémentation ont été les communications ainsi que les types de donnée à utiliser. En effet, nous avons dû comprendre la manière dont les données sont stockées en mémoire pour créer un type approprié. L’autre difficulté rencontrée réside dans les tests qui nous ont données beaucoup de mauvaises valeurs. Il nous a fallu trier ces données et en retenir le plus pertinent.

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
19
Conclusion Le cahier des charges initialement proposé a été respecté. En effet, nous avons réussi à mettre en place le schéma de communication entre les processeurs grâce à MPI. Un contexte particulier a été défini : la géométrie parallélépipédique et ses paramètres propres modifiables par l’utilisateur. Les communications au sein du réseau ont été vérifiées et validées sur un ordinateur classique. Nous avons aussi pu constater, grâce à M. DUBOIS et à l’accès au cluster, l’augmentation des temps de communication quand on augmente le nombre de processeurs utilisés ou la variation de celui-ci selon le type de l’envoie. L’analyse générale est cohérente et soutient le fait que l’on a implémenté un programme utilisable même si des améliorations sont possibles. En effet, ce programme ne peut pas traiter tous les types de maillage. Notre programme semble, malgré ses limites, correspondre aux attentes de notre tuteur et sera donc utilisé pour la résolution des équations de Navier-Stockes compressibles.

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
Glossaire Cluster : ensemble de machines interconnectées par un réseaux. Equations de Navier-Stockes : équations régissant le mouvement des fluides incompressibles. MPI : acronyme de Message Passing Interface qui signifie interface de passage de messages. C’est une bibliothèque du FORTRAN 90 qui permet de paralléliser du code. Prototype : cela désigne la syntaxe d’une fonction. Processeur : c’est l’élément d’un ordinateur qui exécute les programmes informatiques.

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
Table des illustrations Figure 1: Exemple d'écoulement d'un gaz ............................................................................................. 2 Figure 2: Exemple de découpage du domaine selon x ..................................................................... 6 Figure 3: Exemple de découpage du domaine selon x et y .............................................................. 6 Figure 4: Exemple de découpage du domaine selon x, y et z .......................................................... 7 Figure 5. Temps de communication pour un découpage selon x (seul p1 varie)-domaine 128x128x128 ................................................................................................................................................. 12 Figure 6: Temps de communication à p2 fixé-domaine 128x128x128 ................................... 12 Figure 7 : Temps de communication à p1 fixé-domaine 128x128x128 .................................. 13 Figure 8 : Temps de communication à p1 fixé-domaine 256x256x256 .................................. 14 Figure 9:Temps de communication à p2 fixé-domaine 256x256x256 .................................... 14 Figure 10 : Temps de communication à p3 fixé-domaine 256x256x256 ............................... 15 Figure 11 : Temps de communication à p2 fixé-domaine 512x512x512 ............................... 16 Figure 12 : Temps de communication en fonction de la taille du domaine pour p1=p2=p3=2 ................................................................................................................................................... 17 Figure 13: Temps de communication en fonction de la taille du domaine pour p1=p2=p3=4 ................................................................................................................................................... 17

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
Annexe : Le code Module Border et subroutine d’initialisation de border module border
use size
implicit none
!
real(kind=8) , dimension(:,:), allocatable :: SpeedGx, SpeedDx
!Définition vitesse selon x pour 1D, 2D
et 3D
real(kind=8) , dimension(:,:), allocatable :: SpeedGy, SpeedDy
!Définition vitesse selon y pour 2D et 3D
real(kind=8) , dimension(:,:), allocatable :: SpeedGz, SpeedDz
!Définition vitesse selon z 3D
!
end module border
subroutine border_init()
use border; use size
implicit none
!
if (p1*p2*p3 == nb_proc) then
allocate(SpeedGx(ny,nz)); allocate(SpeedDx(ny,nz))
if(p2 /= 1) then
allocate(SpeedGy(nx,nz)); allocate(SpeedDy(nx,nz))
end if
if(p3 /= 1) then
allocate(SpeedGz(nx,ny)); allocate(SpeedDz(nx,ny))
end if
endif
!
end subroutine border_init

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
Module grid et subroutine d’initialisation de grid module grid
use size
implicit none
!
integer, dimension (:), allocatable :: x
integer, dimension (:), allocatable :: y
integer, dimension (:), allocatable :: z
!
end module grid
subroutine grid_init ()
!
use grid; use size
implicit none
!
integer :: i
!
allocate(x(nx)) ; allocate(y(ny)) ; allocate(z(nz))
!
do i = 1,nx
x(i) = i
end do
!
do i = 1,ny
y(i) = i
end do
!
do i = 1,nz
z(i) = i
end do
!
end subroutine grid_init

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
Module size et subroutine d’initialisation de size module size
use param
use mpi_param
implicit none
!
integer :: nx,ny,nz
!
end module size
subroutine size_init ()
!
use param ; use mpi_param ; use size
implicit none
!!
call read_int("Px",p1) ; call read_int("Py",p2) ; call read_int
("Pz",p3)
call read_real("Lx",Lx) ; call read_real ("Ly",Ly) ; call
read_real ("Lz",Lz)
nx = INT(Lx/p1)
ny = INT(Ly/p2)
nz = INT(Lz/p3)
!
end subroutine size_init

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
Module velocity et subroutine d’initialisation de velocity module velocity
use size
implicit none
!
real (kind=8), dimension (:,:,:), allocatable :: u,v,w
!
end module velocity
subroutine field_init () !
use size; use velocity
!
implicit none
!
integer :: i,j,k
!
allocate (u(nx,ny,nz)) ; allocate (v(nx,ny,nz)) ; allocate
(w(nx,ny,nz))
!
do i = 1,nx
do j = 1,ny
do k = 1,nz
if (i==1) then
u(i,j,k) = i*j*k
else
u(i,j,k) = 1000*i*j*k
end if
v(i,j,k) = sin(REAL(i*j*k))
w(i,j,k) = i*j*k/100.0
end do
end do
end do
!
end subroutine field_init

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
Fichier input parameters ! Number of processors !
10 Px ! indice du processeur sur x
4 Py ! indice du processeur sur y
2 Pz ! indice du processeur sur z
! Domain size and mesh !
50.00 Lx ! domain length
40.00 Ly ! domain largeur
4.00 Lz ! domain height
1 imesh ! Uniform (0) or non-uniform mesh (1)
! Flow and numerical parameters !
1.0 Re ! Reynolds
1.0 alpha ! Alpha
1 itest ! Polynomial solution (0) or cosine solution (1)
1 isave ! Frequency for ouptut
1.0e-16 Tol_cg ! Tolerence parameter for CG method
2.0 beta !
5.0 gamma !

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
Module mpi-param et module param module mpi_param
use mpi
implicit none
!
integer :: i_num,nb_proc
integer :: p1, p2,p3
integer :: i_proc, j_proc, k_proc, i_err
integer, dimension(mpi_status_size) :: i_etat
integer, dimension (1:6) :: i_send
!
end module mpi_param
module param
!
implicit none
!
real(kind=8) :: Lx,Ly,Lz !Longueur respectives des trois dimensions
!
end module param

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
Subroutine pour l’initialisation de l’environnement mpi subroutine mpi_env (i_flag)
!
use mpi_param
!
implicit none
!
integer, intent(in) :: i_flag
!
if (i_flag==0) then
!
call mpi_init(i_err)
call mpi_comm_size(mpi_comm_world, nb_proc, i_err)
call mpi_comm_rank(mpi_comm_world, i_num, i_err)
!
call read_int("Px",p1) ; call read_int("Py",p2) ; call read_int
("Pz",p3)
!
if (p1*p2*p3 == nb_proc) then
!
if(p2==1 .and. p3==1) then
i_proc = i_num
i_send(1) = i_proc-1
i_send(2) = i_proc+1
!
else if(p3 == 1) then
!
j_proc = i_num/p1
i_proc = i_num - p1 * j_proc
i_send(1) = i_proc-1
i_send(2) = i_proc+1
i_send(3) = j_proc-1
i_send(4) = j_proc+1
!
else
!
k_proc = i_num/(p1*p2)
j_proc = (i_num - p1*p2*k_proc)/p1
i_proc = i_num - p1*j_proc - p1*p2*k_proc
i_send(1) = i_proc-1
i_send(2) = i_proc+1
i_send(3) = j_proc-1
i_send(4) = j_proc+1
i_send(5) = k_proc-1
i_send(6) = k_proc+1
!
end if
end if
else if (i_flag==1) then
call mpi_finalize(i_err)
else
print*,' Wrong value for i_flag in mpi_env' ; stop

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
end if
end subroutine mpi_env

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
Fichier mpi-single-comm pour les communications subroutine mpi_single_comm(Speed)
use mpi ; use mpi_param ; use size ; use border
implicit none
real(kind = 8), dimension(nx,ny,nz), intent(in) :: Speed
integer::type_tabX, type_tabY, type_tabZ
!
if (p1*p2*p3 == nb_proc) then
!
! Definition du type pour envoyer sur l'axe x
call mpi_type_vector(ny*nz,1,nx,mpi_double_precision,type_tabX,i_err)
call mpi_type_commit(type_tabX,i_err)
!
! Definition du type pour envoyer sur l'axe y
call
mpi_type_vector(nz,nx,nx*ny,mpi_double_precision,type_tabY,i_err)
call mpi_type_commit(type_tabY,i_err)
! Definition du type pour envoyer sur l'axe z
!
call mpi_type_contiguous(nx*ny,mpi_double_precision,type_tabZ,i_err)
call mpi_type_commit(type_tabZ,i_err)
!
!Dans les trois cas, on envoie qulque chose selon x, donc on alloue
!
!
if(p2 == 1 .AND. p3 == 1) then
!
! Cas 1 D :
!
! Envois et Receptions selon x :
!
if(i_proc /= 0) then
call mpi_recv(SpeedGx, ny*nz, mpi_double_precision,
i_send(1),1, mpi_comm_world,i_etat,i_err)
call mpi_send(Speed(1,1,1), 1, type_tabX, i_send(1),1,
mpi_comm_world,i_err)
end if
!
if(i_proc /= p1-1) then
call mpi_send(Speed(nx,1,1), 1, type_tabX,
i_send(2),1, mpi_comm_world,i_err)
call mpi_recv(SpeedDx, ny*nz, mpi_double_precision,
i_send(2),1, mpi_comm_world,i_etat,i_err)
end if
!
else if(p3 == 1) then
!
! Cas 2 D :
!
! Envois et Receptions selon x :
!
if (i_proc /= 0) then

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
!
call mpi_recv(SpeedGx, ny*nz, mpi_double_precision,
i_send(1)+p1*j_proc,1, mpi_comm_world,i_etat,i_err)
call mpi_send(Speed(1, 1, 1), 1,type_tabX,
i_send(1)+p1*j_proc,1, mpi_comm_world,i_err)
end if
!
if(i_proc /= p1-1) then
call mpi_send(Speed(nx,1,1), 1, type_tabX,
i_send(2)+p1*j_proc,1, mpi_comm_world,i_err)
call mpi_recv(SpeedDx, ny*nz,
mpi_double_precision,i_send(2)+p1*j_proc,1,
mpi_comm_world,i_etat,i_err)
end if
!
!
! Envois et Receptions selon y :
!
if(j_proc /= 0) then
call mpi_recv(SpeedGy, nx*nz, mpi_double_precision,
i_proc+p1*i_send(3),10, mpi_comm_world,i_etat,i_err)
call mpi_send(Speed(1,1,1), 1, type_tabY,
i_proc+p1*i_send(3),10, mpi_comm_world,i_err)
end if
!
if(j_proc /= p2-1) then
call mpi_send(Speed(1,ny,1), 1, type_tabY,
i_proc+p1*i_send(4),10, mpi_comm_world,i_err)
call mpi_recv(SpeedDy, nx*nz, mpi_double_precision,
i_proc+p1*i_send(4),10, mpi_comm_world,i_etat,i_err)
end if
!
else
!
! Cas 3 D :
!
! Envois et Receptions selon x :
!
if(i_proc /= 0) then
call mpi_recv(SpeedGx, ny*nz, mpi_double_precision,
i_send(1)+p1*j_proc+p1*p2*k_proc,1, mpi_comm_world, &
i_etat,i_err)
call mpi_send(Speed(1,1,1), 1, type_tabX,
i_send(1)+p1*j_proc+p1*p2*k_proc,1, mpi_comm_world,i_err)
end if
!
if(i_proc /= p1-1) then
call mpi_send(Speed(nx,1,1), 1, type_tabX,
i_send(2)+p1*j_proc+p1*p2*k_proc,1, mpi_comm_world,i_err)
call mpi_recv(SpeedDx, ny*nz, mpi_double_precision,
i_send(2)+p1*j_proc+p1*p2*k_proc,1, mpi_comm_world,i_etat,i_err)
end if
!
!
! Envois et Receptions selon y :

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
!
if(j_proc /= 0) then
call mpi_recv(SpeedGy, nx*nz, mpi_double_precision,
i_proc+p1*i_send(3)+p1*p2*k_proc,10, mpi_comm_world, &
i_etat,i_err)
call mpi_send(Speed(1,1,1), 1, type_tabY,
i_proc+p1*i_send(3)+p1*p2*k_proc,10, mpi_comm_world,i_err)
end if
!
if(j_proc /= p2-1) then
call mpi_send(Speed(1,ny,1), 1, type_tabY,
i_proc+p1*i_send(4)+p1*p2*k_proc,10, mpi_comm_world,i_err)
call mpi_recv(SpeedDy, nx*nz, mpi_double_precision,
i_proc+p1*i_send(4)+p1*p2*k_proc,10, mpi_comm_world, &
i_etat,i_err)
end if
!
! Envois et Receptions selon z :
!
if(k_proc /= 0) then
call mpi_recv(SpeedGz, nx*ny, mpi_double_precision,
i_proc+p1*j_proc+p1*p2*i_send(5),100, mpi_comm_world, &
i_etat,i_err)
call mpi_send(Speed(1,1,1), 1, type_tabZ,
i_proc+p1*j_proc+p1*p2*i_send(5),100, mpi_comm_world,i_err)
end if
!
if(k_proc /= p3-1) then
call mpi_send(Speed(1,1,nz), 1, type_tabZ,
i_proc+p1*j_proc+p1*p2*i_send(6),100, mpi_comm_world,i_err)
call mpi_recv(SpeedDz, nx*ny, mpi_double_precision,
i_proc+p1*j_proc+p1*p2*i_send(6),100, mpi_comm_world, &
i_etat,i_err)
end if
end if
!
! On desaloue les types crees
!
call mpi_type_free(type_tabX,i_err)
call mpi_type_free(type_tabY,i_err)
call mpi_type_free(type_tabZ,i_err)
!
end if
!
end subroutine mpi_single_comm

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
Programme main program projet
!
use mpi
use mpi_param; use size; use velocity; use border
!
implicit none
real(kind=8) :: start, fin, res, res2, tempsInit, tempsCom
!
start = MPI_Wtime()
call archive_read("input.parameters") ! Parametres d'entree du
programme
!
call mpi_env(0)! Initialisation de l'environnement mpi et des voisins
!
call size_init () ! Initialisation de la taille du maillage sur un
processeur
!
call grid_init () ! Initialisation de la grille
!
call field_init () ! Initialisation du champ de vitesse
!
call border_init()! Initialisation des bords pour les communications
!
fin = MPI_Wtime()
res = fin-start
start = MPI_Wtime()
call mpi_single_comm(u) ! Communications entre les processeurs
call mpi_barrier(mpi_comm_world,i_err)
call mpi_single_comm(v)
call mpi_barrier(mpi_comm_world,i_err)
call mpi_single_comm(w)
fin = MPI_Wtime()
res2 = fin-start
! Calcul des temps d'initialisation et de communication.
call
mpi_reduce(res,tempsInit,1,mpi_double_precision,mpi_sum,0,mpi_comm_worl
d,i_err)
call
mpi_reduce(res2,tempsCom,1,mpi_double_precision,mpi_sum,0,mpi_comm_worl
d,i_err)
if(i_num == 0) then
print*, "Initialisation:", tempsInit, "secondes"
print*, "Initialisation moyen pour 1 proc:", tempsInit/(p1*p2*p3),
"secondes"
print*, "Communications:", tempsCom, "secondes"
print*, "Communications moyen pour 1 proc:", tempsCom/(p1*p2*p3),
"secondes"
endif
!
call mpi_env(1) ! Finalisation de l'environnement mpi
!
end program projet

Schémas de communications pour la parallélisation de schémas aux différences finies d’ordre élevé Sentis Matthias-Edouard Izard
Fichier pour la compilation
/bin/rm *.o x.run
FLAGS=''
comp='mpif90'
echo $comp $FLAGS
$comp -c $FLAGS module.size.f90 module.param.f90 module.grid.f90
module.velocity.f90 module.mpi_param.f90 module.border.f90
$comp -c $FLAGS archive.f90 unit.counter.f90
$comp -c $FLAGS size_init.f90 grid_init.f90 field_init.f90
main_init.f90 border_init.f90
$comp -c $FLAGS mpi_env.f90 mpi_single_comm.f90
$comp $FLAGS main.f90 *.o -o x.run