
Maîtrise d'Économétrie Cours de Séries empTorellesmath.univ-lille1.fr/~viano/economcours.pdf ·...
67
Transcript of Maîtrise d'Économétrie Cours de Séries empTorellesmath.univ-lille1.fr/~viano/economcours.pdf ·...

Université des Sciences et Technologies de Lille
U.F.R. de Mathématiques Pures et Appliquées
Maîtrise d'Économétrie
Cours de Séries Temporelles
Années 1999 à 2004
Texte : M.-C. Viano
Graphiques : A. Philippe


Table des matières
Table des �gures 5
Chapitre 1. Introduction 7
Chapitre 2. Qu'est ce qu'une série temporelle ? Exemples commentés.Tendances, saisonnalités 9
1. Exemples 92. Tendances, composantes saisonnières 12
Chapitre 3. Premiers indices descriptifs 141. Indices de tendance centrale 142. Indices de dispersion 143. Indices de dépendance 144. Comment utiliser l'auto-corrélation ? 18
Chapitre 4. Lissages exponentiels 221. Introduction 222. Lissage exponentiel simple 223. Lissage exponentiel amélioré, ou double 244. Méthode de Holt-Winters 28
Chapitre 5. Vers la modélisation : suites stationnaires de variables aléatoires 321. Dé�nitions. Auto-covariance et auto-corrélation 322. Exemples 333. Auto-corrélation partielle 354. Estimation de ces indices caractéristiques 37
Chapitre 6. Les processus ARMA 451. Les processus autorégressifs et leurs indices caractéristiques. 452. Les processus moyennes mobiles et leurs indices caractéristiques 493. Les ARMA mixtes 50
Chapitre 7. Comment prévoir dans un processus ARMA? 531. Principe général 532. Prévision à horizon 1 533. Prévision à horizon supérieur à 1 554. Comportement de l'erreur de prévision quand l'horizon croît 565. Intervalles de con�ance 576. Mise à jour 57
Chapitre 8. Identi�cation 581. Estimation des paramètres d'un modèle ARMA 58
3

TABLE DES MATIÈRES 4
2. Choix du modèle 593. Identi�cation et prévision 61
Chapitre 9. Récapitulons : les prévisions ARIMA et SARIMA 641. Résumé des étapes déjà vues 642. Filtrage inverse : modélisation ARIMA et SARIMA 64
Bibliographie 67

Table des �gures
2.1 Taches solaires 11
2.2 Ventes de champagne 11
2.3 Ventes de voitures 11
2.4 Consommation d'électricité 12
2.5 Tra�c aérien 12
2.6 Population des États-Unis 12
3.1 Série 1 16
3.2 Série 1 : Nuage de points Nk pour k = 1, . . . , 8 et auto-corrélation 16
3.3 Série 2 17
3.4 Série 2 : Nuage de points Nk pour k = 1, . . . , 8 et auto-corrélation 17
3.5 Série simulée non bruitée (en haut à droite), bruitée (en bas àdroite). Auto-corrélation de la série bruitée, de la série bruitéedi�érenciée, puis de la série bruitée di�érenciée et désaisonnalisée
20
3.6 Champagne : série et auto-corrélation 21
3.7 Champagne : série di�érenciée Xt −Xt−1 et auto-corrélation 21
3.8 Champagne : série di�érenciée et désaisonnalisée : Xt −Xt−12 etauto-corrélation 21
4.1 Lissage et prévision par la méthode de lissage exponentielsimple d'un bruit blanc [gauche] et d'une tendance linéaireX(t) = 0.5t + εt, εt ∼ N(0, 1) [droite](α = .1, .5, .9) 25
4.2 Lissage et prévision par la méthode de lissage exponentieldouble d'un bruit blanc [gauche] et d'une tendance linéaireX(t) = 0.5t + εt, εt ∼ N(0, 1).[droite] (α = .1, .5, .9) 27
4.3 Lissage et prévision par la méthode de lissage exponentiel doublesur la série X(t) = 0.5t + εt + 2 cos(tπ/6), εt ∼ N(0, 1).(α =.1, .5, .9) 27
4.4 Lissage et prévision par la méthode de Holt-Winters sur la sériex(t) = 0.5t + εt + 2 cos(tπ/6), εt ∼ N(0, 1). 30
4.5 Prévision par la méthode de Holt-Winters sur les données devente de champagne. 31
5

TABLE DES FIGURES 6
5.1 Comparaison des covariances théoriques et empiriques pour lemodèle ARMA(1,1) Xn + 0.8Xn−1 = εn − 0.8εn−1 40
5.2 bruit blanc gaussien : série, ACF et PACF 41
5.3 modele AR(1) a=0.8 : série, ACF et PACF 41
5.4 modele AR(1) a=-0.8 : série, ACF et PACF 42
5.5 modele MA(1) a=0.8 : série , ACF et PACF 42
5.6 modele MA(1) a=-0.8 : série, ACF et PACF 43
5.7 modele AR(2) Xn + 0.81Xn−2 = εn : série, ACF et PACF 43
5.8 modele ARMA(1,1) Xn + 0.8Xn−1 = εn − 0.8εn−1 : série, ACFet PACF 44
6.1 Auto-corrélation et auto-corrélation partielle de quelques ARMA51
8.1 Convergence des estimateurs de a1 et a2 dans un modèle AR2 59
8.2 Identi�cation et prévision dans un AR4 et un MA3 simulés 62
8.3 La série des lynx. Ajustement d'un AR8 et prévision 63
9.1 Série du tra�c aérien et série des ventes de champagne :ajustement d'un SARIMA et prévision 66

CHAPITRE 1
Introduction
Ce cours est une initiation aux méthodes statistiques de prévision.
• Pourquoi vouloir prévoir ?Très souvent pour des raisons économiques (prévoir l'évolution des ventes d'un
certain produit, prévoir la consommation d'électricité pour ajuster au mieux laproduction).
• Comment prévoir ?Toujours en s'appuyant sur ce qui s'est passé avant l'instant à partir duquel
démarre la prévision. Et parfois en utilisant des renseignements annexes. Dans laprévision des ventes pour l'année j+1 on s'appuiera sur l'évolution des ventes durantles années j, j − 1, · · · , mais on tiendra compte aussi, éventuellement, d'indices ex-ogènes (la conjoncture économique, certains événements récents inattendus etc....).
• Peut on prévoir parfaitement bien ?Jamais. Il y a toujours une erreur de prévision, et les bonnes méthodes four-
nissent non pas une prévision, mais un intervalle de prévision. Il arrive souventqu'une amélioration minime de la qualité de la prévision ait une grosse incidencesur les coûts.
• De quelles méthodes dispose-t-on pour prévoir ?Elles sont nombreuses.
1- Vous connaissez la plus rudimentaire, qui consiste à faire une régression età se baser sur elle pour prévoir. Par exemple on ajuste sur la série x1, · · · , xn unmodèle de type
xj = a1j2 + a2j + a3 + ej j = 1, · · · , n.
On estime les coe�cients par une méthode de régression. On valide le résultat, puison prévoit xn+1 par
a1(n + 1)2 + a2(n + 1) + a3,
et xn+2 ainsi que les suivants de façon analogue.
2- Les lissages exponentiels sont une batterie de procédures extrêmement sim-ples à mettre en ÷uvre. Ils sont exposés au chapitre 4.
3- Les méthodes de prévision les plus populaires depuis une trentaine d'an-nées sont celles liées à la modélisation ARMA. Elles consistent en gros à dégagerles tendances évidentes dans le phénomène qu'on observe (croissance, périodicitésetc...) et à se concentrer sur ce qui reste lorsqu'on les a supprimées. On procède àune modélisation �ne du résidu obtenu et on s'appuie sur cette modélisation pour
7

Cours de Séries Temporelles : M.-Cl. Viano 8
obtenir la prévision. Ces méthodes, plus sophistiquées mais plus performantes quela régression et que les lissages exponentiels, sont coûteuses en temps calcul. Leurutilisation systématique dans tous les domaines, que ce soit économique, indus-triel, physique etc..., est due au développement exponentiellement rapide de l'outilinformatique. Elles seront l'objet principal de ce cours.
Il y a bien d'autres méthodes dont on ne parlera pas ici.
Certaines données sont �faciles� et, sur elles, toutes les méthodes donnent debonnes prévisions. Tout l'art du statisticien, face à des données di�ciles, est deconfronter plusieurs méthodes et de choisir celle qui convient le mieux.

CHAPITRE 2
Qu'est ce qu'une série temporelle ? Exemples
commentés. Tendances, saisonnalités
Une série temporelle (ou encore une série chronologique) est une suite �nie(x1, · · · , xn) de données indexées par le temps. L'indice temps peut être selon lescas la minute, l'heure, le jour, l'année etc.... Le nombre n est appelé la longueur dela série. Il est la plupart du temps bien utile de représenter la série temporelle surun graphe construit de la manière suivante : en abscisse le temps, en ordonnée lavaleur de l'observation à chaque instant. Pour des questions de lisibilité, les pointsainsi obtenus sont reliés par des segments de droite. Le graphe apparaît donc commeune ligne brisée.
1. Exemples
Exemple 2.1. Les taches solaires. Il s'agit du nombre annuel de taches ob-servées à la surface du soleil pour les années 1700�1980. Il y a une donnée par an,soit donc 281 points reliés par des segments. C'est une des séries temporelles lesplus célèbres. On y distingue la superposition de deux phénomènes périodiques (unepériode d'à peu près 11 ans et une autre d'à peu près 60 ans, cette dernière étantmoins crédible que la première vu la longueur de la série). ‖
Exemple 2.2. Les ventes de champagne. Il s'agit du nombre mensuel de bouteillesvendues entre mars 1970 et septembre 1978. Soit 103 points. On distingue sur legraphe une augmentation moyenne, une dispersion croissante (les �pics� sont deplus en plus marqués) et deux saisonnalités superposées (1 an et 6 mois).
Cette série, comme les trois qui suivent, est assez typique de ce que l'on ren-contre dans le domaine de l'économétrie.
Elle est facile à modéliser et donne lieu à de �bonnes� prévisions pour toutesles méthodes couramment utilisées. ‖
Exemple 2.3. Les ventes de voitures. Les données courent sur 35 ans, et il yen a une par mois. Soit 420 points. On y voit une croissance non linéaire (peutêtre de type logarithmique). Les deux saisonnalités d'un an et de 6 mois se voientmoins que dans la série précédente à cause du plus grand resserrement des abscisses.On voit aussi une rupture très nette aux environs de l'année 1983. Cette rupturefait que la série est extrêmement di�cile à modéliser et donne de très mauvaisesprévisions quelle que soit la méthode utilisée. ‖
Exemple 2.4. La consommation d'électricité sur toute la France. Une donnéetoutes les demi-heures, pendant 35 jours en juin-juillet 1991. Soit 1680 données. Ony voit bien deux composantes périodiques correspondant à la journée (48 unités detemps) et à la semaine, ainsi qu'un e�et �week-end� massif. ‖
9

Cours de Séries Temporelles : M.-Cl. Viano 10
Exemple 2.5. Le nombre de passagers (en milliers) dans les transports aériens.Une donnée par mois de 1949 à 1960. Tendance linéaire (ou plus) très marquée,ainsi qu'une forte augmentation de la variabilité et une composante périodiquecorrespondant à l'année. ‖
Exemple 2.6. La population des États-Unis (une donnée tous les 10 ans, de1790 à 1980, soit 21 points). Le seul phénomène évident est la croissance qui semblenon-linéaire.‖
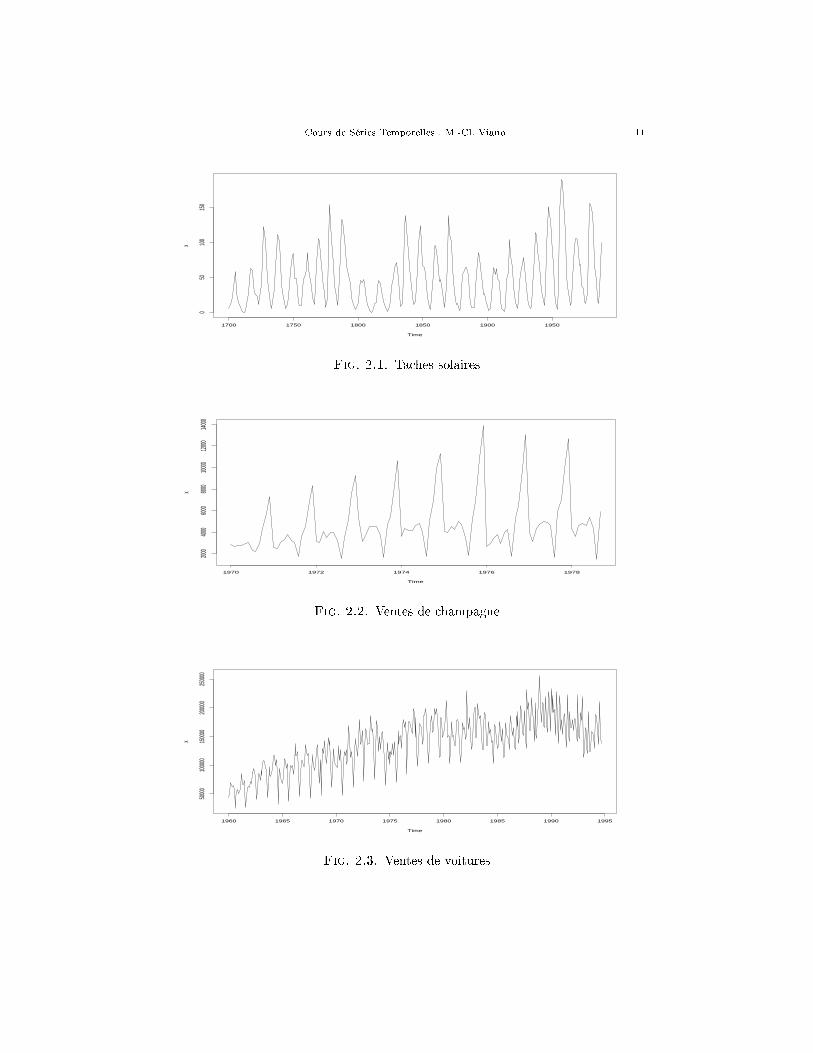
Cours de Séries Temporelles : M.-Cl. Viano 11
Time
x
1700 1750 1800 1850 1900 1950
050
100
150
Fig. 2.1. Taches solaires
Time
x
1970 1972 1974 1976 1978
2000
4000
6000
8000
1000
012
000
1400
0
Fig. 2.2. Ventes de champagne
Time
x
1960 1965 1970 1975 1980 1985 1990 1995
5000
010
0000
1500
0020
0000
2500
00
Fig. 2.3. Ventes de voitures
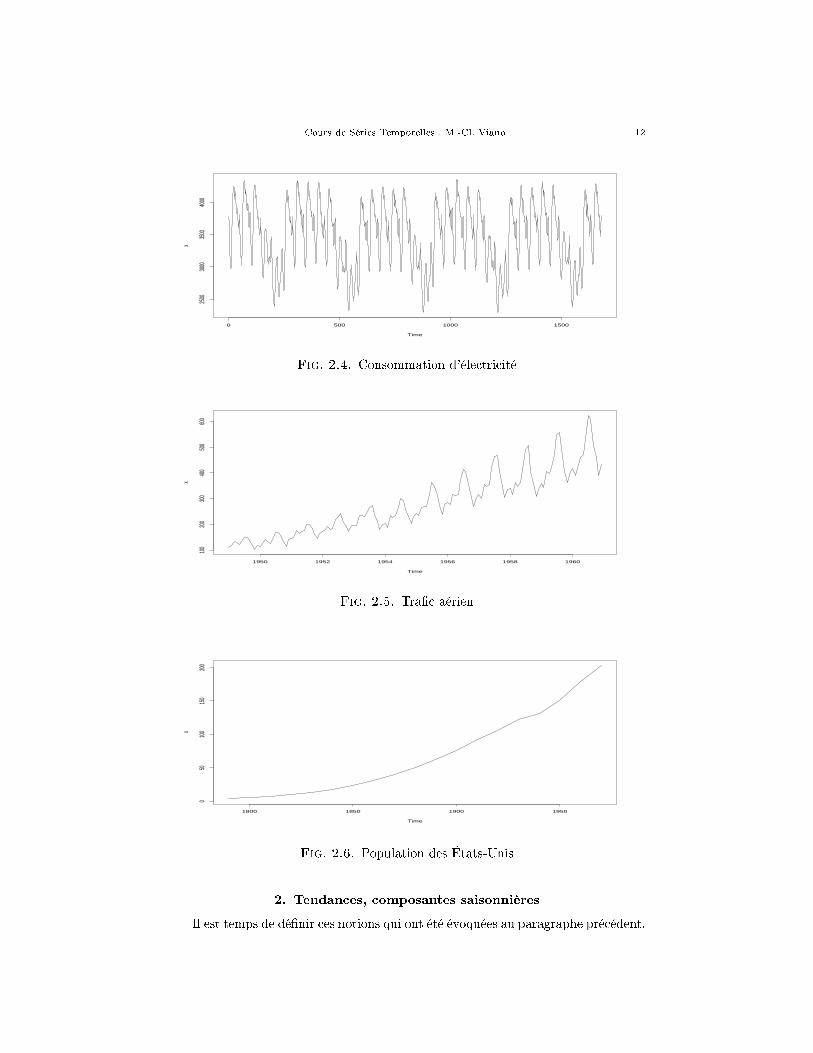
Cours de Séries Temporelles : M.-Cl. Viano 12
Time
x
0 500 1000 1500
2500
3000
3500
4000
Fig. 2.4. Consommation d'électricité
Time
x
1950 1952 1954 1956 1958 1960
100
200
300
400
500
600
Fig. 2.5. Tra�c aérien
Time
x
1800 1850 1900 1950
050
100
150
200
Fig. 2.6. Population des États-Unis
2. Tendances, composantes saisonnières
Il est temps de dé�nir ces notions qui ont été évoquées au paragraphe précédent.

Cours de Séries Temporelles : M.-Cl. Viano 13
2.1. Tendances.
• On parle de tendance linéaire lorsque la série peut se décomposer en
xn = an + b + en n = 1, 2, · · ·Plus généralement, on parle de tendance polynômiale lorsque la série peut se dé-composer en
xn = a1np + a2n
p−1 + · · ·+ ap+1 + en n = 1, 2, · · ·expression dans laquelle en est un résidu où ne �gure plus la tendance et qui, dece fait, a une allure relativement homogène dans le temps. Ceci sera précisé par lasuite.
De même on pourra dé�nir des tendances logarithmiques, exponentielles etc....Ainsi,le graphe de l'exemple 2.6 semble à première vue présenter une tendance polynômi-ale ou exponentielle. Pour trancher entre les deux, on peut tracer le graphe dulogarithme des données et voir si il présente une tendance linéaire.
• La tendance peut être multiplicative dans certaines séries :
xn = tnen n = 1, 2, · · ·où tn prend l'une des formes (linéaire, polynômiale etc...) évoquées plus haut. C'estalors le logarithme des données (si elles sont positives !) qui présente une tendanceadditive.
2.2. Composantes Périodiques, Saisonnalités.
• On parle de composante périodique, ou de périodicité, lorsque la série sedécompose en
xn = sn + en n = 1, 2, · · ·où sn est périodique (c'est à dire sn+T = sn pour tout n, où T est la période,supposée entière) et où en est un résidu non-périodique et sans tendance.
Par exemple sn = cos nπ6 a une période T = 12.
Lorsque la période T est de 6 mois ou un an, comme c'est le cas dans beaucoupde phénomènes socio-économiques, on a plutôt l'habitude de parler de saisonnalitéou de composante saisonnière.
• Comme précédemment, il arrive qu'on ait recours à un modèle multiplicatif.
2.3. Superposition de tendances et de périodes.
On peut bien imaginer des modèles de type
xn = s(1)n + s(2)
n + tn + en n = 1, 2, · · ·dans lequel se superposent deux séries périodiques de périodes T1 et T2 et une ten-dance. Moyennant une légère modi�cation (en l'occurrence le passage au logarithmequi gomme l'e�et d'augmentation de la dispersion) la série des ventes de champagne(exemple 2.2) est assez bien expliquée de cette façon, avec une tendance linéaireet la superposition de deux périodes de 6 mois et d'un an. Le commentaire est lemême pour le tra�c aérien. On y reviendra.

CHAPITRE 3
Premiers indices descriptifs
Il est bien utile de disposer de quelques indices numériques qui "résument" unesérie (x1, · · · , xn).
1. Indices de tendance centrale
Ce sont, classiquement, la moyenne et la médiane. Dans ce cours c'est lamoyenne qui sera systématiquement utilisée.
xn =1n
n∑j=1
xj
2. Indices de dispersion
Les plus courants sont la variance empirique (ou plus exactement l'écart typeempirique qui en est la racine carrée) et l'étendue (di�érence entre la plus grandevaleur et la plus petite). Elles indiquent la dispersion des observations autour deleur indice de tendance centrale. Dans ce cours c'est la variance empirique qui serautilisée :
σn(0) =1n
n∑j=1
(xj − xn)2.
3. Indices de dépendance
3.1. Auto-covariances empiriques.
Ces indices σn(1), σn(2), · · · donnent une idée de la dépendance entre les don-nées. Plus exactement
σn(1) =1n
n−1∑j=1
(xj − xn)(xj+1 − xn)
indique la dépendance entre deux données successives,
σn(2) =1n
n−2∑j=1
(xj − xn)(xj+2 − xn)
14

Cours de Séries Temporelles : M.-Cl. Viano 15
indique la dépendance entre deux données écartées de deux unités de temps et ainside suite jusqu'à
σn(n− 1) =1n
(x1 − xn)(xn − xn).
En réalité ce dernier indice, qui ne fait intervenir que la première et la dernièredonnée, n'a pas grand sens statistique, surtout si la longueur n de la série estgrande. Il en est de même pour σn(n−1). Le bon sens, ainsi que des considérationsde convergence dépassant la limite de ce cours, recommandent de ne prendre enconsidération que les auto-covariances empiriques σn(1), · · · , σn(h) pour un h "pastrop grand" par rapport à la longueur de la série.
3.2. Auto-corrélations empiriques.
Ce sont les quotients des covariances par la variance :
ρn(j) =σn(j)σn(0)
, j = 0, · · · , h.
Évidemment ρn(0) = 1, si bien qu'en passant des auto-covariances aux auto-corrélations on perd une information : la dispersion de la série autour de sa moyenne.Il faut garder ce fait en mémoire. Ceci dit, ce sont ces auto-corrélations qui carac-térisent les dépendances. Pour le voir, il faut remarquer par exemple que
ρn(1) =
∑n−1j=1 (xj − xn)(xj+1 − xn)∑n
j=1(xj − xn)2
est presque (à vous de ré�échir à ce qui di�ère) le coe�cient de corrélation entre lasérie (x1, x2, · · · , xn−1) et la série décalée d'une unité de temps (x2, x3, · · · , xn).
3.3. Visualisation graphique des auto-corrélations empiriques.
En rassemblant ce que vous savez sur la régression linéaire, vous pouvez déduirede la remarque précédente que le "nuage" N1 de points
(xj , xj+1), j = 1, · · · , n− 1,
(autre représentation de la série), constitue une bonne illustration de la valeur deρn(1). Si cette auto-corrélation est proche de ±1 le nuage est allongé selon unedroite. La pente de cette droite a le signe de ρn(1). Le nuage est d'autant plus"arrondi" que ρn(1) est plus proche de zéro.
Un commentaire analogue (en remplaçant ρn(1) par ρn(k)) peut être fait pourles nuages Nk pour k = 2, · · · , h :
(xj , xj+k), j = 1, · · · , n− k,
Les graphiques qui suivent représentent chacun une série simulée, (de longueur500), le graphe de son auto-corrélation, les nuages N1, · · · ,N8 et le graphe de sonauto-corrélation.
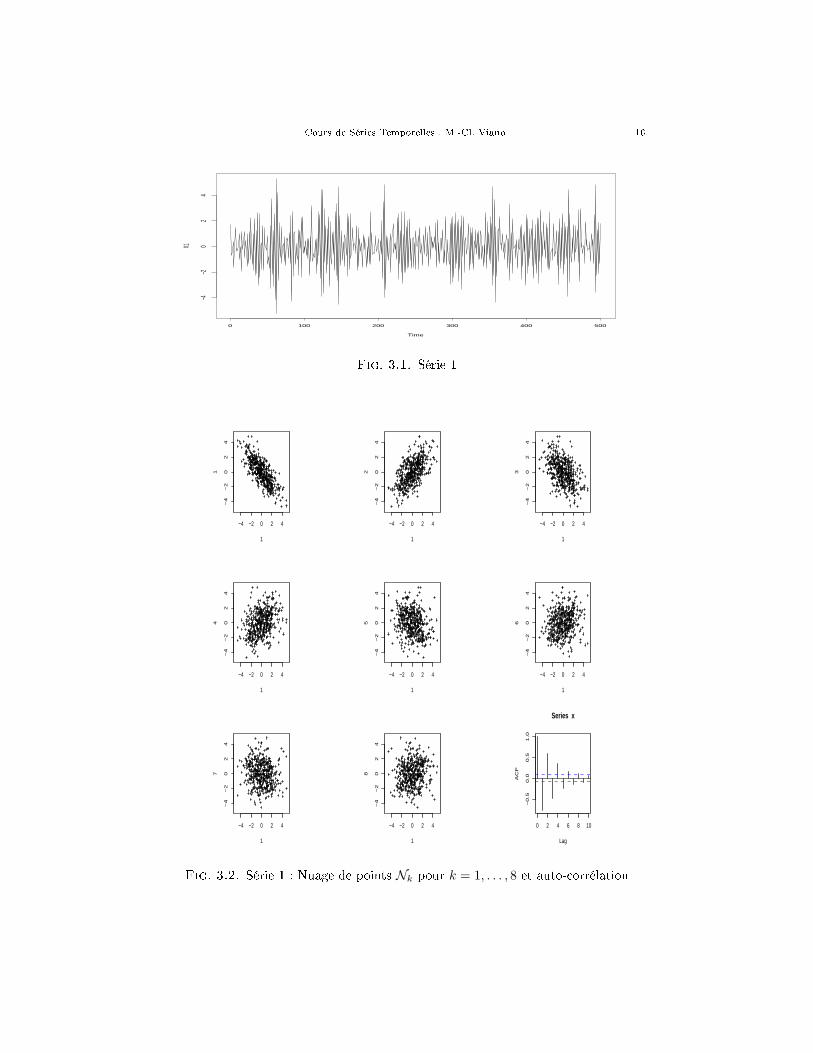
Cours de Séries Temporelles : M.-Cl. Viano 16
Time
X1
0 100 200 300 400 500
−4−2
02
4
Fig. 3.1. Série 1
−4 −2 0 2 4
−4
−2
02
4
1
1
−4 −2 0 2 4
−4
−2
02
4
1
2
−4 −2 0 2 4−
4−
20
24
1
3
−4 −2 0 2 4
−4
−2
02
4
1
4
−4 −2 0 2 4
−4
−2
02
4
1
5
−4 −2 0 2 4
−4
−2
02
4
1
6
−4 −2 0 2 4
−4
−2
02
4
1
7
−4 −2 0 2 4
−4
−2
02
4
1
8
0 2 4 6 8 10
−0
.50
.00
.51
.0
Lag
AC
F
Series x
Fig. 3.2. Série 1 : Nuage de points Nk pour k = 1, . . . , 8 et auto-corrélation
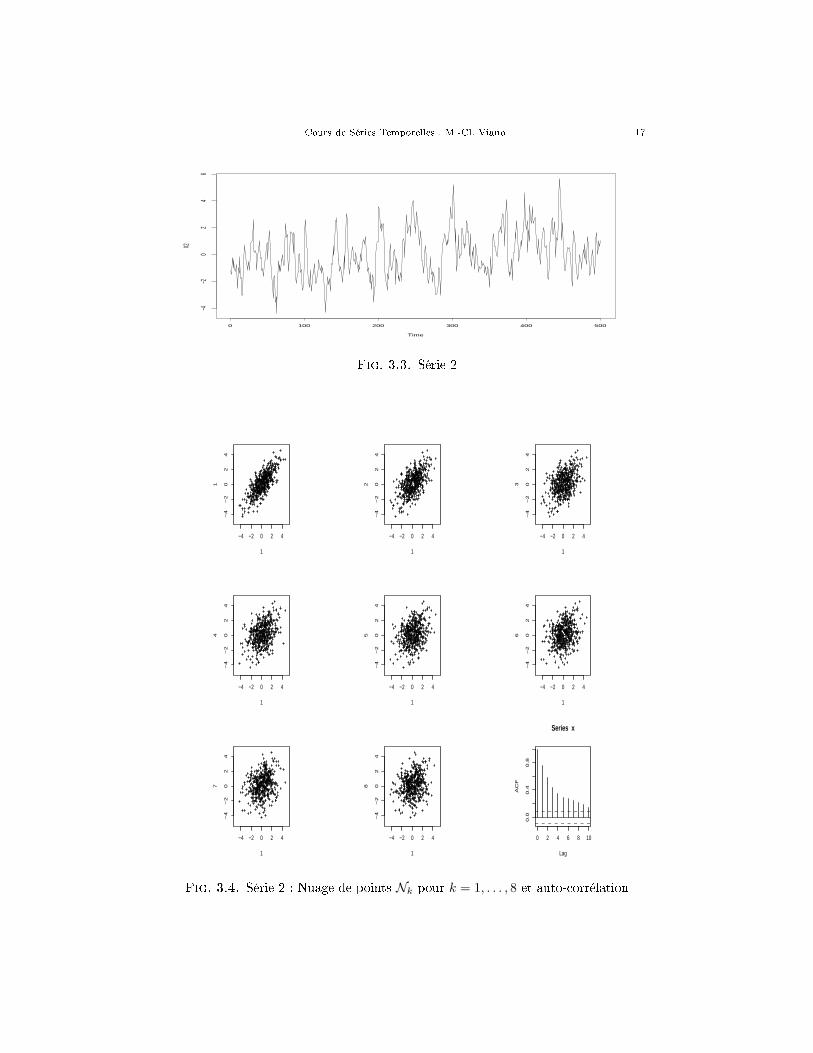
Cours de Séries Temporelles : M.-Cl. Viano 17
Time
X2
0 100 200 300 400 500
−4−2
02
46
Fig. 3.3. Série 2
−4 −2 0 2 4
−4
−2
02
4
1
1
−4 −2 0 2 4
−4
−2
02
4
1
2
−4 −2 0 2 4
−4
−2
02
4
1
3
−4 −2 0 2 4
−4
−2
02
4
1
4
−4 −2 0 2 4
−4
−2
02
4
1
5
−4 −2 0 2 4
−4
−2
02
4
1
6
−4 −2 0 2 4
−4
−2
02
4
1
7
−4 −2 0 2 4
−4
−2
02
4
1
8
0 2 4 6 8 10
0.0
0.4
0.8
Lag
AC
F
Series x
Fig. 3.4. Série 2 : Nuage de points Nk pour k = 1, . . . , 8 et auto-corrélation

Cours de Séries Temporelles : M.-Cl. Viano 18
4. Comment utiliser l'auto-corrélation ?
L'auto-corrélation est surtout utilisée sur les séries résiduelles en qui s'ajoutentaux tendances et aux saisonnalités. La démarche habituelle consiste à retirer de lasérie la tendance que l'on a détectée, puis, si il y a lieu, de la désaisonnaliser (cetraitement préalable des données est l'objet d'un autre cours). Sur la série résiduelleon calcule les auto-covariances empiriques qui serviront (voir chapitre 8) à mettreun modèle prédictif sur ces résidus.
Cependant il est très utile de comprendre quelle sera l'allure de cette auto-corrélation sur une série brute, comportant tendance ou/et saisonnalité. C'est lebut des propositions qui suivent.
Proposition 3.1. On considère une tendance linéaire pure :
xj = aj + b j = 1, · · · , n.
Pour k �xé, ρn(k) → 1 quand n tend vers l'in�ni.
La preuve est laissée en exercice. Donner d'abord l'expression de la moyenne.Montrer ensuite que ρn(k) ne dépend ni de a ni de b. En�n, utiliser les résultatsconnus sur les sommes de puissances d'entiers successifs
1 + 2 + · · ·+ N =N(N + 1)
2et 1 + 22 + · · ·+ N2 =
N(N + 1)(2N + 1)6
,
et terminer en évitant les calculs inutiles !Le résultat est le même pour toute tendance polynômiale. On l'admettra.
Proposition 3.2. On considère une série périodique pure :
xj = a cos2jπ
Tj = 1, · · · , n.
Pour k �xé, ρn(k) → cos 2kπT quand n tend vers l'in�ni.
On admettra ce résultat.Il indique que, si la série est assez longue, la période (T , en l'occurrence) se
voit aussi bien sur l'auto-corrélation que sur la série elle même.
En réalité, on n'a jamais à faire avec une tendance ou une composante péri-odique pures, mais les propositions précédentes donnent une bonne indication sur cequi se passe pour une série présentant une tendance ou une composante périodiqueadditives.
En résumé, pour une longue série présentant une tendance polynômiale, l'auto-corrélation ρn(k) est positive et assez proche de 1 lorsque k évolue tout en restantpetit devant n. Pour une série présentant une périodicité, cette périodicité se voitbien sur l'auto-corrélation. Ces deux constatations contrastent avec ce que l'onverra plus loin (chapitre 4) pour les séries résiduelles, où ρn(k) devient assez vitetrès petit quand k grandit.
On conclut que si l'auto-corrélation du résidu présente une des propriétés ci-dessus, c'est sans doute parce que l'on a oublié d'enlever une tendance ou que l'ona mal désaisonnalisé.
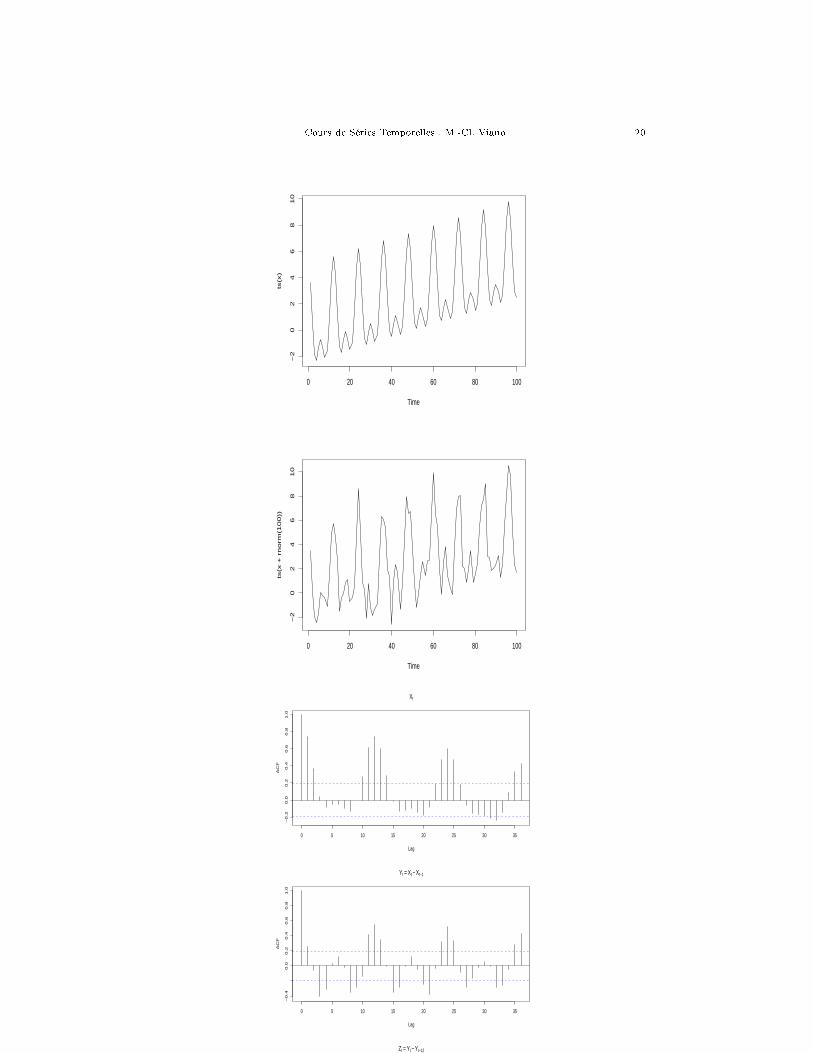
Les graphiques 3-5 montrent une série tn = an+b cos(πn3 )+c cos(πn
6 ), superpo-sition d'une tendance linéaire et de deux saisonnalités (périodes 6 et 12), puis unesimulation de la série bruitée xn = tn + en. On donne la fonction d'auto-corrélation

Cours de Séries Temporelles : M.-Cl. Viano 19
de cette série bruitée, puis l'auto-covariance de la série yn = xn − xn−1, et en�ncelle de la série zn = yn − yn−12.
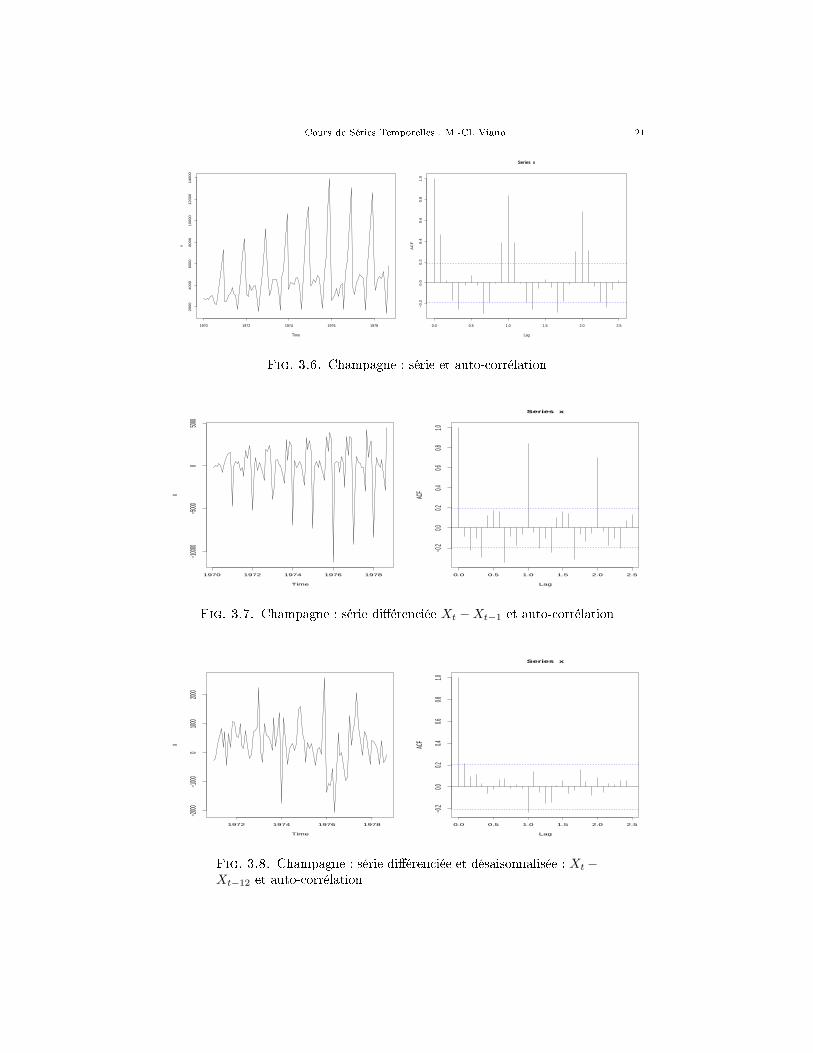
Les graphiques 3-6, 3-7 et 3-8 montrent l'auto-corrélation empirique des ventesde champagne, celle de la série di�érenciée (yn = xn − xn−1), puis celle de la sérieyn désaisonnalisée (zn = xn − xn−12).
Cours de Séries Temporelles : M.-Cl. Viano 20
Time
ts(x
)
0 20 40 60 80 100
−2
02
46
81
0
Time
ts(x
+ r
no
rm(1
00
))
0 20 40 60 80 100
−2
02
46
81
0
0 5 10 15 20 25 30 35
−0
.20
.00
.20
.40
.60
.81
.0
Lag
AC
F
Xt
0 5 10 15 20 25 30 35
−0
.40
.00
.20
.40
.60
.81
.0
Lag
AC
F
Yt = Xt − Xt−1
0 5 10 15 20 25 30 35
−0
.50
.00
.51
.0
Lag
AC
F
Zt = Yt − Yt−12
Fig. 3.5. Série simulée non bruitée (en haut à droite), bruitée (enbas à droite). Auto-corrélation de la série bruitée, de la série bruitéedi�érenciée, puis de la série bruitée di�érenciée et désaisonnalisée
Cours de Séries Temporelles : M.-Cl. Viano 21
Time
x
1970 1972 1974 1976 1978
2000
4000
6000
8000
10000
12000
14000
0.0 0.5 1.0 1.5 2.0 2.5
−0
.20
.00
.20
.40
.60
.81
.0
Lag
AC
F
Series x
Fig. 3.6. Champagne : série et auto-corrélation
Time
x
1970 1972 1974 1976 1978
−10000
−5000
0500
0
0.0 0.5 1.0 1.5 2.0 2.5
−0.2
0.00.2
0.40.6
0.81.0
Lag
ACF
Series x
Fig. 3.7. Champagne : série di�érenciée Xt −Xt−1 et auto-corrélation
Time
x
1972 1974 1976 1978
−2000
−1000
0100
0200
0
0.0 0.5 1.0 1.5 2.0 2.5
−0.2
0.00.2
0.40.6
0.81.0
Lag
ACF
Series x
Fig. 3.8. Champagne : série di�érenciée et désaisonnalisée : Xt −Xt−12 et auto-corrélation

CHAPITRE 4
Lissages exponentiels
Ce chapitre a été écrit en collaboration avec G. Oppenheim (U. de Marne la Vallée) et A.
Philippe (U. Lille 1)
1. Introduction
Dans l'industrie il est courant que l'on doive e�ectuer des prévisions de vente deproduction ou de stock pour une centaine de produits. Ces prévisions sont e�ectuéesà partir de données par exemple mensuelles et l'horizon de prévision est court, un anmaximum. Un certain nombre de techniques "autoprojectives" sont regroupées sousla rubrique du lissage exponentiel. Ces approches construisent des prévisions assezprécises. Elles sont peu coûteuses et les calculs peuvent être rendus très rapides parl'utilisation de formules récursives de mise à jour.
Elles ont beaucoup de succès dans les milieux dans lesquels un grand nombrede chroniques unidimensionnelles doivent être analysées séparément dans un but deprévision. Les succès sont importants malgré l'absence de bases théoriques solidescomparables à celles des méthodes ARMA, ARIMA et SARIMA.
Nous présentons les bases empiriques des techniques et précisons les conditionsd'utilisation optimales.
Les procédures automatiques présentent quelques dangers. On risque des mau-vaises prévisions si la technique utilisée n'est pas adaptée à la chronique analysée.
Le lissage exponentiel est brièvement présenté dans Gourieroux-Monfort ([3]).Une présentation détaillée �gure dans Mélard ([4]) page 139-170. Un article deGardner ([2]) fait un point sur la question.
1.1. Idées générales. On dispose d'une série chronologique x = (x1, . . . , xn)de longueur n enregistrée aux dates 1, . . . , n. On se situe à la date n et on souhaiteprévoir la valeur xn+h non encore observée à l'horizon h. On note cette prévision :xn,h.
L'entier n est parfois appelé base de la prévision.La plus ancienne des techniques est celle du lissage exponentiel simple. Dans
toutes ces techniques il s'agit d'ajuster à la chronique, localement, une fonctionsimple :
� une constante dans le lissage exponentiel simple,� une droite dans le lissage exponentiel double,� des fonctions polynomiales ou périodiques dans les lissages plus généraux.
2. Lissage exponentiel simple
Dans cette partie la prévision très simple, trop simple, ne dépend pas de l'hori-zon h de prévision. Nous conservons l'indice pour être cohérent avec la suite.
22

Cours de Séries Temporelles : M.-Cl. Viano 23
2.1. Dé�nition. La prévision xn,h est construite :� en prenant en compte toute l'histoire de la chronique,� de sorte que, plus on s'éloigne de la base n de la prévision, moins l'in�u-ence des observations correspondantes est importante. Cette décroissance del'in�uence est de type exponentiel. De là vient le nom de la technique.
On se donne α, appelé constante de lissage, avec 0 < α < 1, et on dé�nit (laprévision xn,h ne dépend pas de h) :
xn,h = (1− α)n−1∑j=0
αjxn−j . (1)
Remarquons que plus α est voisin de 1, plus l'in�uence des observations éloignéesdans le temps de la base n est grande.
2.2. Formules récursives de mise à jour. La dé�nition (1) véri�e les for-mules de récurrences suivantes
xn,h = (1− α)xn + αxn−1,h (2)
xn,h = xn−1,h + (1− α)(xn − xn−1,h) (3)
Par conséquent, la connaissance de la prévision à l'horizon sur la base n − 1, soitxn−1,h, et l'observation xn su�sent pour calculer immédiatement la prévision suiv-ante xn,h.
Cependant, l'utilisation des formules récursives nécessite d'initialiser la récur-rence en prenant par exemple x1,h = x1, on remarque que pour n assez grand lavaleur initiale a peu d'in�uence.
Remarquons aussi que la formule (2) permet d'interpréter xn,h comme le barycen-tre de xn et de xn−1,h a�ectés respectivement des masses 1−α et α. L'in�uence dela dernière observation est d'autant plus grande que α est proche de 0.
2.3. Interprétation géométrique. Asymptotiquement xn,h est la meilleureapproximation au sens des moindres carrés (pour des pondérations exponentielles)de x par le vecteur constant aδ où δ = (1, . . . , 1) ∈ Rn.
En e�et la valeur de a qui minimise
n−1∑j=0
αj(xn−j − a)2. (4)
est fournie par :
a(n) =1− α
1− αn
n−1∑j=0
αjxn−j .
Si l'on transforme légèrement le modèle en considérant que
x = (x1, . . . , xn) = (. . . , 0, . . . , 0, x1, . . . , xn)
c'est à dire que les coordonnées du nouveau vecteur sont nulles pour tous les indicesnégatifs ou nul. On cherche donc la valeur de a qui minimise
∞∑j=0
αj(xn−j − a)2.

Cours de Séries Temporelles : M.-Cl. Viano 24
la solution est fournie par
xn,h = (1− α)n−1∑j=0
αjxn−j .
Il est facile de montrer que les deux estimateurs sont asymptotiquement équivalents,on a
limn→∞
a(n) = limn→∞
xn,h.
Dans la minimisation de (4) là aussi, l'in�uence des observations décroît expo-nentiellement lorsqu'on s'éloigne de la base. On peut dire que l'ajustement par laconstante a est local et se fait au voisinage de n. La taille réelle de la plage desobservations in�uentes dépend de α. Plus α est grand plus la taille est grande.
2.4. Choix de la constante de lissage. La méthode n'est pas bonne enprésence de tendance, de composante saisonnière ou de �uctuations de hautesfréquences. En pratique le lissage exponentiel simple est assez peu utilisé.
Des valeurs de α comprises entre 0.7 et 0.99 produisent des prévisions quitiennent compte du passé lointain. Elles sont rigides et peu sensibles aux variationsconjoncturelles. Il n'en n'est plus de même si α est compris entre 0.01 et 0.3, laprévision est souple c'est à dire in�uencée par les observations récentes.
On peut aussi déterminer un α adapté à la prévision d'une série donnée.Pour un horizon h on cherche la valeur de α qui minimise
∑n−ht=1 (xt+h − (1 −
α)∑t−1
j=0 αjxt−j)2, c'est à dire la valeur qui en moyenne réalise la meilleure prévi-sion à l'horizon h sur les bases 1, 2, . . . , n − h en utilisant le critère des moindrescarrés. On choisit une grille de valeurs de α pour lesquelles on calcule le critère eton retient la valeur qui le minimise. Cette technique de choix de constante peut êtrereprise dans les méthodes qui vont suivre. Les calculs sont souvent plus longs car cen'est, en fait, plus une constante de lissage que nous sommes amenés à déterminermais souvent deux ou trois.
3. Lissage exponentiel amélioré, ou double
3.1. Dé�nition. On ajuste au voisinage de n une droite d'équation yt = a1 +a2(t− n). Le prédicteur sera :
xn,h = a1 + a2h. (5)
Les coe�cients a1, a2 sont solution de :
n−1∑j=0
αj(xn−j − (a1 − a2j))2 = infa1∈R,a2∈R
n−1∑j=0
αj(xn−j − (a1 − a2j))2. (6)
En remplaçant, comme dans le lissage simple, la sommation �nie par une sommede 0 à +∞, les équations précédentes deviennent
∞∑j=0
αj(xn−j − (a1 − a2j))2 = infa1∈R,a2∈R
∞∑j=0
αj(xn−j − (a1 − a2j))2.
Cours de Séries Temporelles : M.-Cl. Viano 25
0 10 20 30 40 50
−3
−2
−1
01
2
Index
x
alpha=0.1
0 10 20 30 40 50
−3
−2
−1
01
2
Index
x
alpha=0.5
0 10 20 30 40 50
−3
−2
−1
01
2
Index
x
alpha=0.9
0 10 20 30 40 50
05
10
15
20
25
Index
x
alpha=0.1
0 10 20 30 40 50
05
10
15
20
25
Index
x
alpha=0.5
0 10 20 30 40 50
05
10
15
20
25
Index
x
alpha=0.9
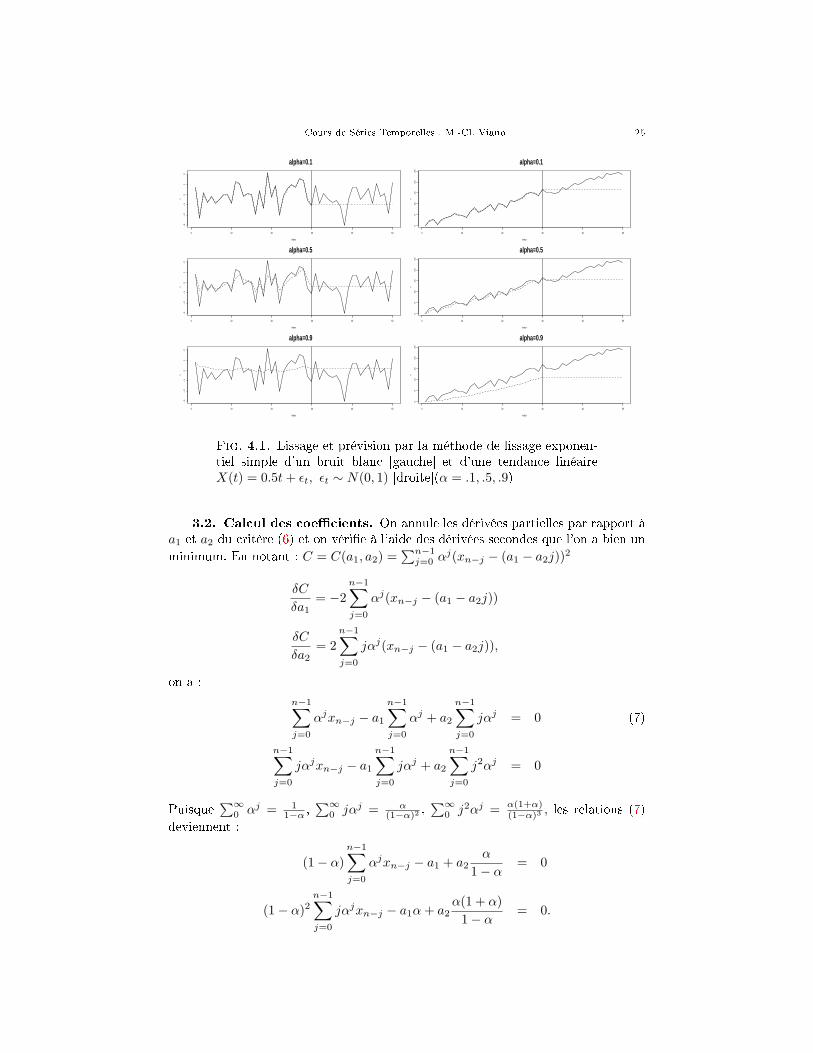
Fig. 4.1. Lissage et prévision par la méthode de lissage exponen-tiel simple d'un bruit blanc [gauche] et d'une tendance linéaireX(t) = 0.5t + εt, εt ∼ N(0, 1) [droite](α = .1, .5, .9)
3.2. Calcul des coe�cients. On annule les dérivées partielles par rapport àa1 et a2 du critère (6) et on véri�e à l'aide des dérivées secondes que l'on a bien unminimum. En notant : C = C(a1, a2) =
∑n−1j=0 αj(xn−j − (a1 − a2j))2
δC
δa1= −2
n−1∑j=0
αj(xn−j − (a1 − a2j))
δC
δa2= 2
n−1∑j=0
jαj(xn−j − (a1 − a2j)),
on a :
n−1∑j=0
αjxn−j − a1
n−1∑j=0
αj + a2
n−1∑j=0
jαj = 0 (7)
n−1∑j=0
jαjxn−j − a1
n−1∑j=0
jαj + a2
n−1∑j=0
j2αj = 0
Puisque∑∞
0 αj = 11−α ,
∑∞0 jαj = α
(1−α)2 ,∑∞
0 j2αj = α(1+α)(1−α)3 , les relations (7)
deviennent :
(1− α)n−1∑j=0
αjxn−j − a1 + a2α
1− α= 0
(1− α)2n−1∑j=0
jαjxn−j − a1α + a2α(1 + α)
1− α= 0.

Cours de Séries Temporelles : M.-Cl. Viano 26
Introduisons deux lissages exponentiels simples successifs, celui des x produit L1,celui de L1 produit L2 :
L1(n) = (1− α)n−1∑j=0
αjxn−j
L2(n) = (1− α)n−1∑j=0
αjL1(n− j).
On a donc
L2(n)− (1− α)L1(n) = (1− α)2n−1∑j=1
jαjxn−j ,
et L1 et L2 sont liés à a1 et a2 par les relations
L1(n)− a1 + a2α
1− α= 0
L2(n)− (1− α)L1(n)− a1α + a2α(1 + α)
1− α= 0.
Les solutions cherchées véri�ent donc,
a1(n) = 2L1(n)− L2(n) (8)
a2(n) =1− α
α[L1(n)− L2(n)].
Soit aussi :
L1(n) = a1(n)− α
1− αa2(n) (9)
L2(n) = a1(n)− 2α
1− αa2(n).
3.3. Formules récursives de mise à jour. Commençons par L1(n) et L2(n).
L1(n) = (1− α)t−1∑j=0
αjxn−j = (1− α)xn + αL1(n− 1) (10)
L2(n) = (1− α)L1(n− 1) + αL2(n− 1)= (1− α)2xn + α(1− α)L1(n− 1) + αL2(n− 1). (11)
récrivons (8) en utilisant (10) et (11).
a1(n) = 2[(1− α)xn + αL1(n− 1)]− [(1− α)2xn + α(1− α)L1(n− 1) + αL2(n− 1)]= (1− α2)xn + α(1 + α)L1(n− 1)− αL2(n− 1),
en tenant compte de (9)
a1(n) = (1− α2)xn + α(1 + α)[a1(n− 1)− α
1− αa2(n− 1)]
−α[a1(n− 1)− 2α
1− αa2(n− 1)]),
= (1− α2)xn + α2[a1(n− 1) + a2(n− 1)].
Cours de Séries Temporelles : M.-Cl. Viano 27
0 10 20 30 40 50
−2
−1
01
2
Index
x
alpha=0.1
0 10 20 30 40 50
−2
−1
01
2
Index
x
alpha=0.5
0 10 20 30 40 50
−2
−1
01
2
Index
x
alpha=0.9
0 10 20 30 40 50
51
01
52
02
5
Index
x
alpha=0.1
0 10 20 30 40 50
51
01
52
02
5
Index
x
alpha=0.5
0 10 20 30 40 50
51
01
52
02
5Index
x
alpha=0.9
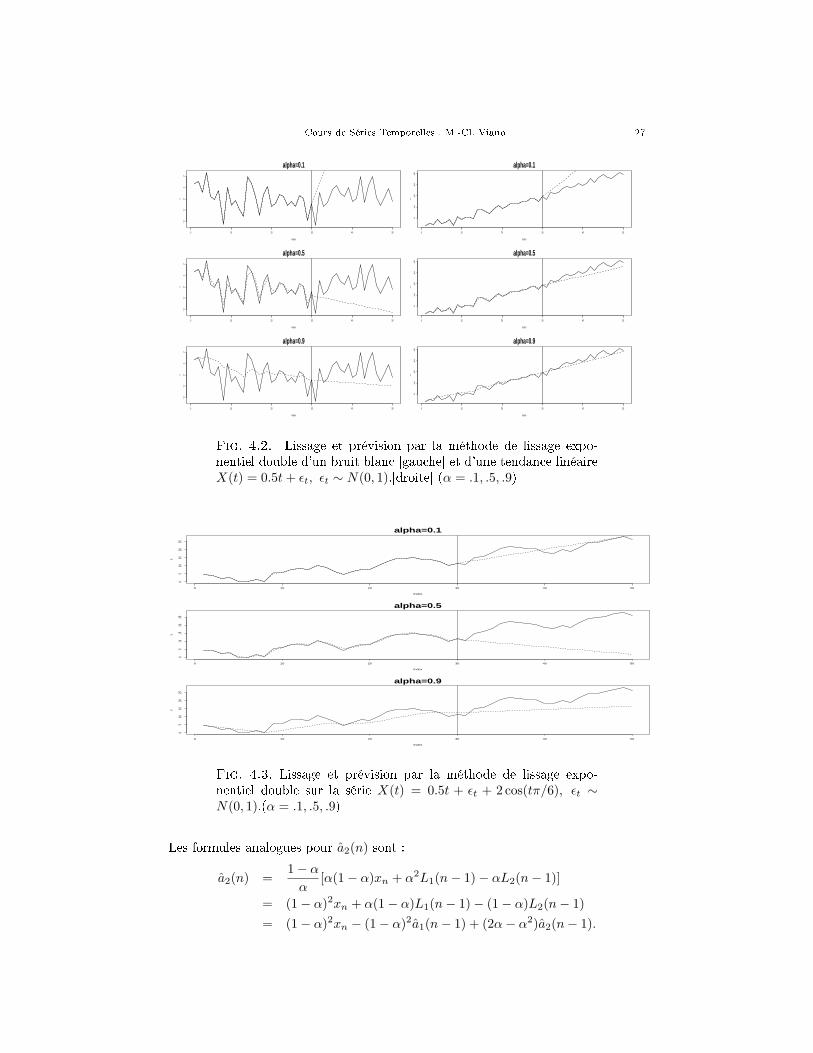
Fig. 4.2. Lissage et prévision par la méthode de lissage expo-nentiel double d'un bruit blanc [gauche] et d'une tendance linéaireX(t) = 0.5t + εt, εt ∼ N(0, 1).[droite] (α = .1, .5, .9)
0 10 20 30 40 50
05
1015
2025
Index
x
alpha=0.1
0 10 20 30 40 50
05
1015
2025
Index
x
alpha=0.5
0 10 20 30 40 50
05
1015
2025
Index
x
alpha=0.9
Fig. 4.3. Lissage et prévision par la méthode de lissage expo-nentiel double sur la série X(t) = 0.5t + εt + 2 cos(tπ/6), εt ∼N(0, 1).(α = .1, .5, .9)
Les formules analogues pour a2(n) sont :
a2(n) =1− α
α[α(1− α)xn + α2L1(n− 1)− αL2(n− 1)]
= (1− α)2xn + α(1− α)L1(n− 1)− (1− α)L2(n− 1)= (1− α)2xn − (1− α)2a1(n− 1) + (2α− α2)a2(n− 1).

Cours de Séries Temporelles : M.-Cl. Viano 28
En utilisant (5) avec h=1 et n− 1 comme instant de base, on obtient :
a1(n) = a1(n− 1) + a2(n− 1) + (1− α2)[xn − xn−1,1] (12)
a2(n) = a2(n− 1) + (1− α)2[xn − xn−1,1]. (13)
On peut prendre comme valeurs initiales a1(0) = x1, a2(0) = x2 − x1.
4. Méthode de Holt-Winters
4.1. Introduction. Cette approche a pour but d'améliorer et de généraliserle L.E.S. Nous étudions plusieurs cas particuliers de cette méthode :
� ajustement d'une droite a�ne (sans saisonnalité)� ajustement d'une droite a�ne + une composante saisonnière� ajustement d'une constante + une composante saisonnière
le dernier cas étant déduit du second. On ajuste au voisinage de l'instant n unedroite
xt = a1 + (t− n)a2.
La variante proposée par Holt-Winters porte sur les formules de mise à jour dansl'estimation de a1 et a2 par les formules (12) et (13). La formule (14) s'interprètecomme le barycentre de l'observation xn et de la prévision à l'horizon 1 à la daten − 1. La formule (15) s'interprète comme le barycentre de la pente estimée àl'instant n− 1 et la di�érence [a1(n)− a1(n− 1)] entre les ordonnées à l'origine auxdates n et n− 1.
Soit 0 < β < 1 et 0 < γ < 1 deux constantes �xées et les formules de mise àjour
a1(n) = βxn + (1− β)[a1(n− 1) + a2(n− 1)] (14)
a2(n) = γ[a1(n)− a1(n− 1)] + (1− γ)a2(n− 1)], (15)
La prévision prend la forme :
xn,h = a1(n) + ha2(n). (16)
Cette méthode est plus souple que le lissage exponentiel amélioré, dans la mesureoù elle fait intervenir deux constantes β et γ au lieu d'une α. Les équations (12) et(13) , qui sont un cas particulier des formules (14) et (15) peuvent s'écrire :
a1(n) = α2[a1(n− 1) + a2(n− 1)] ++(1− α2)[xn − xn−1,1 + a1(n− 1) + a2(n− 1)])
= α2[a1(n− 1) + a2(n− 1)] + (1− α2)xn
a2(n) = a2(n− 1) +(1− α)2
1− α2[a1(n)− α2[a1(n− 1) + a2(n− 1)]
−(1− α2)[a1(n− 1) + a2(n− 1)]]
= a2(n− 1) +(1− α)2
1− α2[a1(n)− a1(n− 1)− a2(n− 1)],
qui sont identiques à (14) et (15) si β = 1− α2 et γ = 1−α1+α . On remarque que si β
et γ sont petits, le lissage est fort puisqu'alors α est grand et que l'on tient comptedu passé lointain.

Cours de Séries Temporelles : M.-Cl. Viano 29
4.2. Ajout d'une composante saisonnière. Décomposition additive.On ajuste au voisinage de n, la chronique
xt = a1 + (t− n)a2 + st
où st est une composante périodique de période T . Les formules récursives de miseà jour sont : soit 0 < β < 1,
a1(n) = β(xn − sn−T ) + (1− β)[a1(n− 1) + a2(n− 1)]a2(n) = γ[a1(n)− a1(n− 1)] + (1− γ)a2(n− 1)],
sn = δ[xn − a1(n)] + (1− δ)sn−T .
La prévision prend la forme :
xn,h = a1(n) + ha2(n) + sn+h−T 1 ≤ h ≤ T
xn,h = a1(n) + ha2(n) + sn+h−2T T + 1 ≤ h ≤ 2T
et ainsi de suite pour 2T < h. Dans cette procédure la di�culté de choisir lesconstantes de lissage est encore plus grande que pour les autres situations.
Initialisation : Les valeurs initiales suivantes permettent (mais on pourraiten proposer d'autres) de commencer le calcul récursif des prévisions à partir del'instant T + 2 :
a1(T + 1) = xT+1
a2(T + 1) =xT+1 − x1
Tsj = xj − (x1 + (T − 1)a2(T + 1))) pour j ∈ {1, · · · , T}

Cours de Séries Temporelles : M.-Cl. Viano 30
0 20 40 60
02
04
0
0.1 0.1 0.1
0 20 40 60
01
03
0
0.1 0.1 0.5
0 20 40 60
01
03
0
0.1 0.1 0.9
0 20 40 60
01
02
03
0
0.1 0.5 0.1
0 20 40 60
01
02
03
0
0.1 0.5 0.5
0 20 40 60
01
02
03
0
0.1 0.5 0.9
0 20 40 60
01
02
03
0
0.1 0.9 0.1
0 20 40 60
01
03
0
0.1 0.9 0.5
0 20 40 60
02
04
0
0.1 0.9 0.9
0 20 40 60
01
03
0
0.5 0.1 0.1
0 20 40 60
01
03
0
0.5 0.1 0.5
0 20 40 60
01
02
03
0
0.5 0.1 0.9
0 20 40 60
02
04
0
0.5 0.5 0.1
0 20 40 60
01
02
03
0
0.5 0.5 0.5
0 20 40 60
01
02
0
0.5 0.5 0.9
0 20 40 60
02
04
06
0
0.5 0.9 0.1
0 20 40 60
01
03
0
0.5 0.9 0.5
0 20 40 60
01
02
03
0
0.5 0.9 0.9
0 20 40 60
02
04
0
0.9 0.1 0.1
0 20 40 60
02
04
0
0.9 0.1 0.5
0 20 40 60
02
04
0
0.9 0.1 0.9
0 20 40 60
02
06
0
0.9 0.5 0.1
0 20 40 60
02
04
06
0
0.9 0.5 0.5
0 20 40 60
02
04
06
0
0.9 0.5 0.9
0 20 40 60
04
08
0
0.9 0.9 0.1
0 20 40 60
04
08
0
0.9 0.9 0.5
0 20 40 60
04
08
0
0.9 0.9 0.9
Fig. 4.4. Lissage et prévision par la méthode de Holt-Winters surla série x(t) = 0.5t + εt + 2 cos(tπ/6), εt ∼ N(0, 1).
Cours de Séries Temporelles : M.-Cl. Viano 31
0 20 40 60 80
2000
4000
6000
8000
1000
0
Index
vent
e de
cham
pagn
e
vente
prevision
beta=0.1,gamma=0.5, delta=0.7
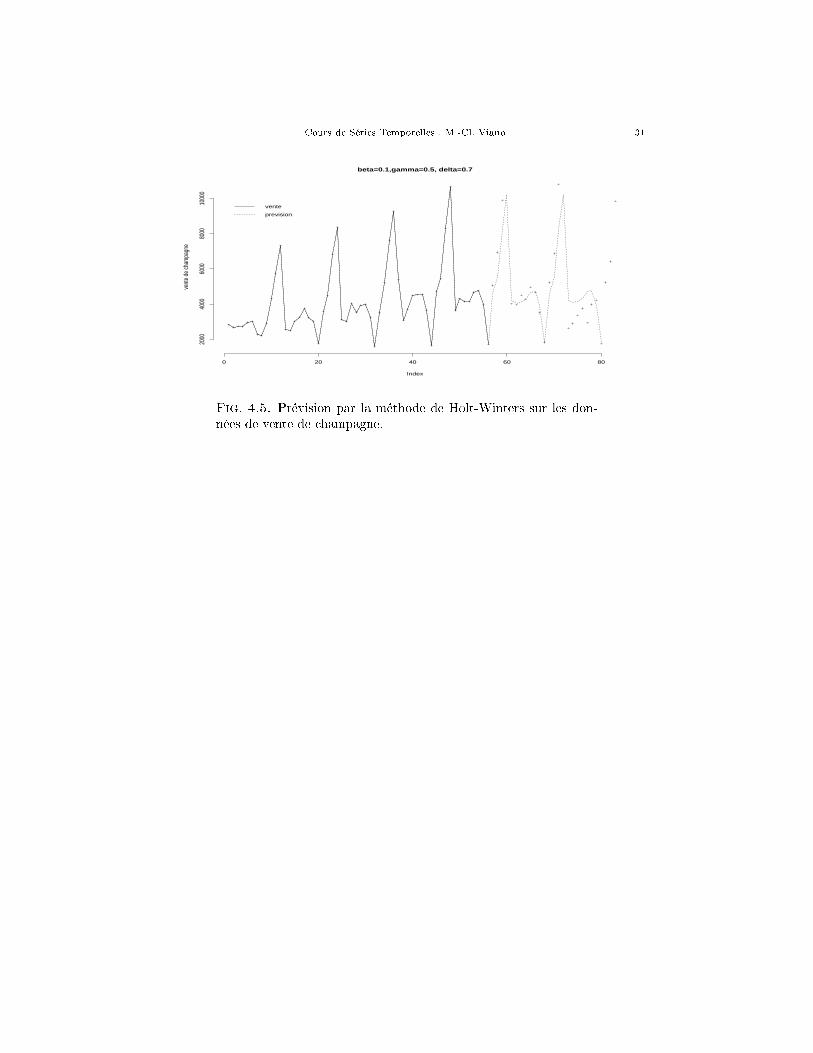
Fig. 4.5. Prévision par la méthode de Holt-Winters sur les don-nées de vente de champagne.

CHAPITRE 5
Vers la modélisation : suites stationnaires de
variables aléatoires
Ce chapitre est un premier pas vers la représentation de la série résiduelle parun modèle théorique qui se prête bien à la prévision. Il va permettre par la suitede travailler sur la série (x1, x2, · · · , xn) comme si elle était la réalisation des npremiers termes d'une suite in�nie (X1, X2, · · · ) de variables aléatoires. Pour mieuxcomprendre ce qui suit, il faut se rendre compte que pour pouvoir prévoir de façone�cace le futur d'une suite �nie (X1, · · · , Xn) de variables aléatoires, il faut queces variables admettent entre elles un peu de dépendance. Ce n'est par exemplepas la peine d'essayer de prévoir ce que va donner le cinquantième lancer d'unepièce de monnaie lorsqu'on a les résultas des quarante neuf précédents. L'erreur deprévision sera de toutes façons de 50%. Par contre, si on sait que la donnée n + 1dépend des données précédentes, et si par chance on a une idée de la nature decette dépendance, on pourra rechercher une procédure de prévision adaptée. Voilàpourquoi il faut consacrer quelque temps aux suites de variables dépendantes.
Par commodité mathématique, on considèrera des suites dont l'indice peut êtrenégatif.
1. Dé�nitions. Auto-covariance et auto-corrélation
Définition 5.1. On dit qu'une suite de variables aléatoires (· · · , X−1, X0, X1, · · · )est stationnaire si les espérances sont constantes
IE(Xn) =: µ ∀n
et si les covariances sont stables par translation du temps c'est-à-dire, pour tout h,
Cov(Xn, Xn+h) =: σ(h) ∀n,
où la covariance est dé�nie par
Cov(Xn, Xn+h) = IE(XnXn+h)−IE(Xn) IE(Xn+h) = IE ((Xn − IEXn)(Xn+h − IEXn+h)) .
Une telle suite est appelée processus stationnaire.On remarque que Var(Xn) = σ(0) pour tout n. Donc la variance est constante.Si l'espérance µ est nulle on dit que le processus est centré. Dans la suite, nos
processus seront centrés. C'est bien normal si on pense qu'ils sont censés modéliserdes résidus.
Définition 5.2.
32

Cours de Séries Temporelles : M.-Cl. Viano 33
1- La suite σ(h) est appelée fonction d'auto-covariance du processus station-naire.
2- La suite ρ(h) := σ(h)σ(0) est sa fonction d'auto-corrélation.
On remarque que σ(h) et ρ(h) ont les propriétés élémentaires suivantes :� Ces suites sont symétriques : pour tout h ≥ 0, σ(h) = σ(−h) ; même chosepour ρ(h).
� Puisque c'est une variance, σ(0) ≥ 0.� Par dé�nition, ρ(0) = 1.L'égalité à zéro de la variance σ(0) est possible mais tout à fait sans intérêt, car
alors la probabilité que Xn = µ est égale à 1 : la suite est constante. On supposeradans la suite que σ(0) > 0, ce qui justi�e l'utilisation de la corrélation.
Exercice 1. Soit (Xn)n=±1,··· une suite de variables aléatoires gaussiennes in-dépendantes, centrées et toutes de variance 1. Parmi les processus suivants, lesquelssont stationnaires ? Donner alors l'expression de leur fonction d'auto-covariance.• Yn = XnXn+1
• Yn = XnXn+1 · · ·Xn+k
• Yn = X2nX2
n+1 · · ·X2n+k
• Yn = X2n + X2
n+1 + X2n+2
• Yn = X1 cos(nπ2 )
• Yn = n + Xn
• Yn = nXn
• Yn = X2nX2
2n.44
2. Exemples
2.1. Bruits blancs.Ce sont les processus stationnaires les plus élémentaires. Ils ont une fonction
d'auto-covariance nulle (en dehors de σ(0)). Peu intéressants en eux-mêmes pour laprévision (voir la remarque en tête de chapitre), ils servent de base à la constructionde tous les modèles présentés dans ce cours.
Définition 5.3. Un bruit blanc est une suite de variables aléatoires non cor-rélées et d'espérance et de variance constante. Autrement dit, pour tout n
IE(Xn) = µ, Var(Xn) = σ2 et Cov(Xn, Xn+h) = 0 pour h 6= 0.
Si l'espérance µ est nulle, on dit que le bruit blanc est centré.Le cas particulier le plus courant est la suite de variables aléatoires gaussiennes
standard (espérance nulle et variance égale à 1) et indépendantes. C'est par exemplece qui a été choisi dans l'exercice 1.
2.2. Moyennes mobiles.Ce sont des processus obtenus à partir d'un bruit blanc.
Définition 5.4. Soit (εn)n=±1,··· un bruit blanc centré de variance σ2. Onappelle moyenne mobile un processus de la forme
Xn = εn + a1εn−1 + · · ·+ aqεn−q,

Cours de Séries Temporelles : M.-Cl. Viano 34
où q est un nombre entier �xé non nul, appelé l'ordre de la moyenne mobile.
Un processus moyenne mobile est évidemment stationnaire, et on a
σ(0) = σ2(1 + a21 + · · ·+ a2
q) (17)
σ(1) = σ2(a1 + a1a2 + · · ·+ aq−1aq)...
σ(q) = σ2a1aq
σ(q + 1) = σ(q + 2) = · · · = 0
Nous retrouverons ces processus au chapitre 6.
2.3. Processus autorégressif d'ordre 1.C'est l'exemple le plus simple de toute une famille qui sera introduite au
chapitre 6.
Définition 5.5. Soit (εn)n=±1,··· un bruit blanc centré de variance σ2 et a ∈] − 1, 1[ un paramètre �xé. Un processus autorégressif d'ordre 1 est un processusstationnaire centré qui véri�e les équations de récurrence
Xn = aXn−1 + εn ∀n = 0,±1, · · · (18)
Tout lecteur attentif aura remarqué que cette dé�nition implicite demande aumoins une information supplémentaire, à savoir : existe-t-il un processus stationnairecentré solution de la récurrence (18) ?
La réponse est oui, et la solution la plus intéressante est le processus dé�nicomme une suite de sommes de séries (la convergence de cette série sera admise) :
∀n, Xn = εn + aεn−1 + a2εn−2 + · · · (19)En regardant l'expression (19), on voit qu'un tel processus n'est guère qu'un
processus moyenne mobile d'ordre in�ni. Pour son espérance et son auto-covariance,on peut utiliser cette expression (la di�érence par rapport au paragraphe précédentest que les sommes �nies sont transformées ici en sommes de séries). On voit parexemple que
IE(Xn) = 0 (20)
Var(Xn) = σ2(1 + a2 + a4 + · · · ) = σ2 11− a2
(21)
σ(h) = σ(−h) = σ2(ah + ah+2 + · · · ) = σ2 ah
1− a2∀h ≥ 0 (22)
Cov(Xn, εn+k) = 0 ∀n et ∀k > 0. (23)
On remarque, comme conséquence de (21) et (22), que l'auto-corrélation tend verszéro à vitesse exponentielle quand l'écart h tend vers l'in�ni :
ρ(h) = a|h| ∀h(on évitera de dire qu'il s'agit d'une décroissance exponentielle car si a est négatif,la suite est alternativement positive et négative).
Exercice 2. Les expressions (20), (21) et (22) peuvent se retrouver facilementà partir de la récurrence (18) et, pour les covariances σ(h), en utilisant la nullité dela covariance entre le processus au temps n et le bruit futur (23). Faites ces calculs,ils vous aideront beaucoup par la suite. 44

Cours de Séries Temporelles : M.-Cl. Viano 35
3. Auto-corrélation partielle
Cette notion, importante dans le domaine des séries temporelles, est un peudélicate et demande quelque compréhension de la géométrie attachée à la covariance.
3.1. Un peu de géométrie.Souvenez vous du produit scalaire de deux vecteurs à n composantes < V, W >=
v1w1 + · · ·+ vnwn. Maintenant, remarquez que les variables aléatoires réelles sontaussi des vecteurs. On peut les ajouter, les multiplier par un scalaire, et ces deuxopérations ont les mêmes propriétés que lorsqu'elles agissent sur des vecteurs or-dinaires. On notera V l'espace vectoriel des variables aléatoires. Cet espace a unedimension in�nie, ce qui le rend très di�érent de l'espace vectoriel Rn des vecteursà n composantes. Cependant, les notions de géométrie sont aisément transposablesde l'un à l'autre.
• Produit scalaire. Remarquez que l'opération qui, à deux variables aléatoires Xet Y associe l'espérance du produit IE(XY ) a exactement les propriétés du produitscalaire (lesquelles ?).
• Orthogonalité. A partir de là, on dé�nit l'orthogonalité : deux variables X etY sont orthogonales lorsque IE(XY ) = 0. Ainsi, en notant 1I la variable constanteet égale à 1, on ré-interprète IE(X) = 0 comme étant l'orthogonalité de X et de 1I.
• Distance. De même on dé�nit la distance entre deux variables comme
d(X, Y ) =√IE ((X − Y )2).
• Espace engendré. On considère N variables aléatoires X1, · · · , XN . L'espacevectoriel engendré par ces variables, qui sera noté [X1, · · · , XN ] ou parfois [X]N1 , estl'ensemble de toutes les combinaisons linéaires λ1X1 + · · ·+λNXN de ces variables.
• Projection. Le projeté d'une variable aléatoire Y sur l'espace [X1, · · · , XN ],qui sera noté
P[X1,··· ,XN ](Y ),est la variable aléatoire de cet espace qui est la plus proche de Y au sens de ladistance vue plus haut. C'est donc la combinaison linéaire P[X1,··· ,XN ](Y ) = γ1X1+· · ·+ γNXN telle que
IE(Y − γ1X1− · · · − γNXN )2 ≤ IE(Y − λ1X1− · · · − λNXN )2 ∀λ1, · · · , λN . (24)
En quelque sorte, le projeté est la meilleure explication linéaire de la variable Yen termes de X1, · · · , XN . C'est pourquoi on l'utilise pour prévoir Y lorsqu'on neconnaît que X1, · · · , XN .
• Calcul du projeté. Il est commode, pour calculer le projeté, d'utiliser la pro-priété suivante, bien connue dans les espaces de dimension �nie, et facile à prouverdans ce cadre plus général (la preuve est laissée au lecteur)
Proposition 5.1. Le projeté P[X1,··· ,XN ](Y ) = γ1X1 + · · ·+ γNXN est carac-térisé par le fait que Y − P[X1,··· ,XN ](Y ) est orthogonal aux variables X1, · · · , XN .
Ceci signi�e que les coe�cients γ1, · · · , γN véri�ent les N équations
IE ((Y − γ1X1 − · · · − γNXN )Xk) = 0 ∀k = 1, · · · , N.
Soit aussi
γ1 IE(X1Xk) + · · ·+ γN IE(XNXk) = IE(Y Xk) ∀k = 1, · · · , N. (25)

Cours de Séries Temporelles : M.-Cl. Viano 36
On voit donc que, si ce système d'équations est régulier, c'est à dire si la matrice
Σ[X]N1=
IE(X21 ) . . . IE(X1XN )
......
...IE(X1XN ) . . . IE(X2
N )
est inversible, les coe�cients qui dé�nissent le projeté de la variable aléatoire Y surl'espace [X]N1 sont dé�nis par γ1
...γN
= Σ−1[X]N1
IE(Y X1)...
IE(Y XN )
. (26)
Avant de continuer, regardons un exemple facile.
Exercice 3. Reprendre le processus autorégressif de la section 2.3. A partirde la récurrence (18) et des propriétés (20) et (23), donner l'expression du projetéde Xn sur [X]n−1
n−2, puis sur [X]n−1n−3 et ainsi de suite.
Cet exercice sera repris plus généralement au chapitre 7 car c'est précisémentle projeté de Xn qui sera pris comme prédicteur de Xn. 44
• Propriétés.D'après la dé�nition il est facile de comprendre que, si Y est elle-même com-
binaison linéaire des variables X1, · · · , XN sur lesquelles se fait la projection, alorsY est son propre projeté. En termes de prévision : Y est dans ce cas sa propreprévision.
D'après (25), on voit que, si Y est orthogonale à toutes les Xj , le projeté de Yest nul. En termes de prévision, on prévoit alors Y par zéro.
En�n, l'expression (26) montre à l'évidence que l'opération qui consiste à pro-jeter est linéaire : le projeté d'une combinaison linéaire a1Y1 + · · · + amYm est lamême combinaison linéaire des projetés a1P[X]N1
(Y1) + · · ·+ amP[X]N1(Ym).
3.2. Coe�cient de corrélation partielle entre deux variables comptenon-tenu de l'in�uence d'un groupe de variables.
On se donne N ≥ 3 variables aléatoires X1, · · · , XN , et on va dé�nir uncoe�cient de corrélation entre X1 et XN qui fasse abstraction de l'in�uence deX2, · · · , XN−1.
Cette notion est une réponse à la question suivante : il arrive que deux phénomènessoient fortement corrélés, mais que cette corrélation traduise non pas un fort lienentre ces deux phénomènes, mais plutôt l'in�uence commune d'un facteur extérieur.Parmi les exemples célèbres (et, il faut le dire, un peu caricaturaux) il y a celui-ci :on note une forte corrélation entre le nombre de pasteurs baptistes et le nombred'arrestations pour ivresse sur la voie publique, aux États-Unis, à la �n du dix-neuvième siècle. Bien sûr cette corrélation n'est pas intéressante en elle-même, carl'augmentation simultanée de ces deux indices est simplement due à la forte aug-mentation de la population urbaine à cette époque (tiré de "Les quatre antilopes del'apocalypse" de S.J. Gould). Pour évacuer ce genre d'in�uences non pertinentes,on a dé�ni le coe�cient de corrélation partielle. Dans ce qui suit, corr(U, V ) désignele coe�cient de corrélation entre U et V , soit
corr(U, V ) =Cov(U, V )√VarU VarV

Cours de Séries Temporelles : M.-Cl. Viano 37
Définition 5.6. Le coe�cient de corrélation partielle entre X1 et XN abstrac-tion faite de l'in�uence de X2, · · · , XN−1 est le coe�cient de corrélation entre lesdeux variables auxquelles on a retranché leurs meilleures explications en terme deX2, · · · , XN−1, soit
r[X]N−12
(X1, XN ) = corr(X1 − P[X]N−1
2(X1), XN − P[X]N−1
2(XN )
).
• Propriété. Il est facile de voir, à partir de la formule (26), que r[X]N−12
(X1, XN )ne dépend que des espérances des produits XiXj .
Un exemple permet de comprendre la simplicité de la notion.
Exercice 4. Considérons trois variables indépendantes X, Z1, Z2 centrées etde variance 1. On considère les variables
X1 = X + Z1 et X2 = X + Z2.
Calculer ρ(X1, X2), puis r[X](X1, X2), et commenter. 44
3.3. Auto-corrélation partielle d'un processus stationnaire.On considère maintenant un processus stationnaire centré (· · · , X−1, X0, X1, · · · ).
On dé�nit la fonction d'auto-corrélation partielle r(h), pour h 6= 0, de la façon suiv-ante
Définition 5.7.
r(h) = r(−h) ∀h 6= 0, (27)
r(1) = ρ(1) (28)
r(h) = r[X]h2(X1, Xh+1) ∀h ≥ 2. (29)
La dé�nition de r(1) est bien conforme à (29) puisque, si on fait h = 1 danscette formule, on constate qu'il n'y a pas de variable entre X1 et X2. D'autre part,dans (29), le coe�cient peut aussi bien se dé�nir comme
r(h) = r[X]k+h−1k+1
(Xk, Xk+h) ∀k ≥ 1.
En e�et, on a vu que la corrélation partielle ne dépend que des espérances desproduits des variables en jeu (ici, de leurs covariances, puisque les espérances sontnulles). Or ces covariances ne changent pas si on translate les indices puisque leprocessus est stationnaire.
Exercice 5. Reprendre le processus autorégressif d'ordre 1 de la section 2.3.Prendre h > 1. Quelle est la projection de Xh+1 sur [X]h2 ? (utiliser l'exercice 2).En déduire Xh+1 − P[X]h2
(Xh+1), puis, sans plus de calculs, la valeur du coe�cientr(h). 44
4. Estimation de ces indices caractéristiques
Jusqu'ici, dans ce chapitre, on a travaillé sur des suites (· · · , X−1, X0, X1, · · · )de variables aléatoires, c'est à dire des êtres mathématiques abstraits. Maintenanton va considérer les réalisations (x1, x2, · · · , xn) de ces suites de variables aléatoires.On parlera de trajectoire de longueur n du processus. Entrent dans cette rubriqueles séries obtenues par simulation. Par exemple on dispose de simulateurs de bruitsblancs gaussiens. A partir d'eux on peut évidemment simuler des trajectoires deprocessus moyennes mobiles (voir 2.2). On peut aussi simuler des trajectoires de

Cours de Séries Temporelles : M.-Cl. Viano 38
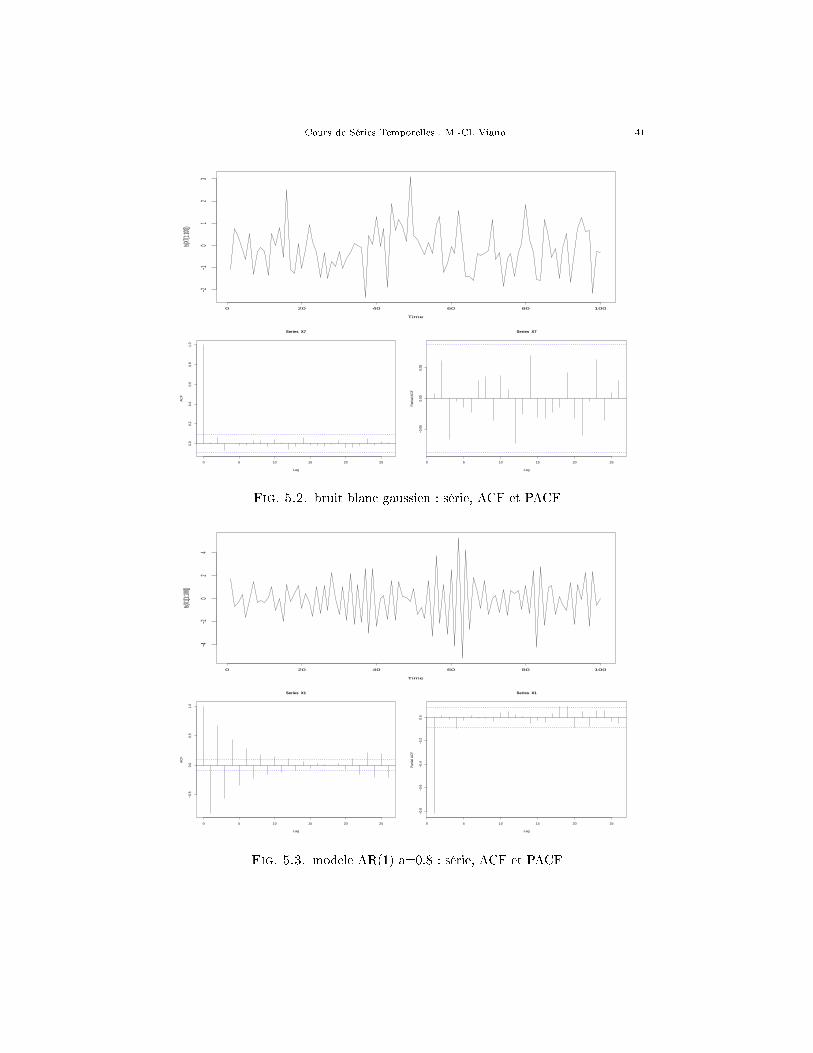
processus autorégressif d'ordre 1. Pour cela on simule une trajectoire de longueurvoulue d'un bruit blanc, on choisit arbitrairement une valeur de x0, puis on faitagir la récurrence (18). Voir les �gures 5.2 à 5.8 où le graphique du haut représentela série obtenue par simulation.
On considérera aussi bien sûr les résidus de séries temporelles auxquelles on aenlevé les tendances et que l'on a désaisonnalisées.
Dans le premier cas (simulations) on va se demander comment estimer lesparamètres µ, σ(h), ρ(h) et r(h) correspondant à chaque modèle.
Dans le second on va se demander comment des indices bien choisis, calculés surla série des résidus, peuvent permettre d'ajuster un modèle de processus stationnairesur cette série.
Les deux problèmes sont en fait les mêmes et les indices empiriques introduitsau chapitre 3 sont de bons estimateurs.
4.1. Estimation de l'espérance, des auto-covariances et des auto-corrélations.• On estime µ par la moyenne empirique xn = 1
n
∑nj=1 xj .
• On estime l'auto-covariance σ(h) par l'auto-covariance empirique
σn(h) =1n
n−h∑j=1
(xj − xn)(xj+h − xn)
• �nalement, on estime l'auto-corrélation ρ(h) par l'auto-corrélation empiriqueρn(h) = σn(h)
σn(0) .On peut se demander ce qui permet de dire que ces indices empiriques sont de
bons estimateurs des indices théoriques correspondants. La proposition suivante,qui va au delà des limites de ce cours, est éclairante.
Proposition 5.2. Si (· · · , X−1, X0, X1, · · · ) est un des processus ARMA dé�-nis au chapitre 6, les indices aléatoires
Xn =1n
n∑j=1
Xj ,
σn(h) =1n
n−h∑j=1
(Xj −Xn)(Xj+h −Xn),
ρn(h) =σn(h)σn(0)
convergent respectivement, lorsque la taille n de la trajectoire tend vers l'in�ni, versles valeurs théoriques correspondantes (c'est-à-dire respectivement vers µ = 0, σ(h)et ρ(h)). Cette convergence a lieu avec la probabilité 1.
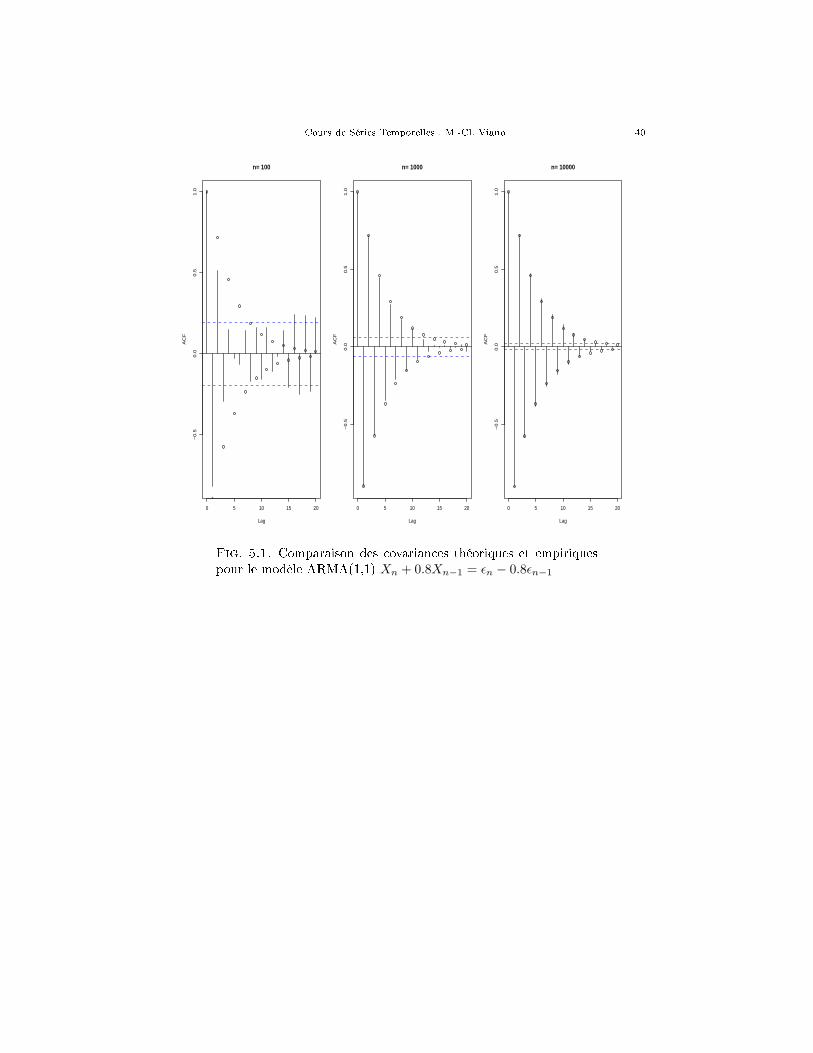
Ceci signi�e que, pour des longueurs de séries assez grandes, les indices em-piriques approchent bien les indices théoriques. Le graphique 5.1 montre l'évolutionde l'auto-corrélation empirique vers la théorique quand la longueur de la série croît.
4.2. Estimation des auto-corrélations partielles.Il existe un algorithme très commode, l'algorithme de Durbin-Watson, qui per-
met, pour tout h ≥ 2, de calculer l' auto-corrélation partielle r(h) d'un processusstationnaire à partir de ses auto-corrélations (ρ(1), · · · , ρ(h)).

Cours de Séries Temporelles : M.-Cl. Viano 39
On obtient les estimateurs rn(h) des auto-corrélations partielles en appliquant cetalgorithme aux auto-corrélations empiriques ρn(1), · · · , ρn(h). On montre que lesbonnes propriétés données par la proposition 5.2 sont aussi valables pour les esti-mateurs ainsi obtenus.
Cours de Séries Temporelles : M.-Cl. Viano 40
0 5 10 15 20
−0
.50
.00
.51
.0
Lag
AC
F
n= 100
0 5 10 15 20
−0
.50
.00
.51
.0
Lag
AC
F
n= 1000
0 5 10 15 20
−0
.50
.00
.51
.0
Lag
AC
F
n= 10000
Fig. 5.1. Comparaison des covariances théoriques et empiriquespour le modèle ARMA(1,1) Xn + 0.8Xn−1 = εn − 0.8εn−1
Cours de Séries Temporelles : M.-Cl. Viano 41
Time
ts(X7[1
:100])
0 20 40 60 80 100
−2−1
01
23
0 5 10 15 20 25
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
F
Series X7
0 5 10 15 20 25
−0.0
50.
000.
05
Lag
Par
tial A
CF
Series X7
Fig. 5.2. bruit blanc gaussien : série, ACF et PACF
Time
ts(X1[1
:100])
0 20 40 60 80 100
−4−2
02
4
0 5 10 15 20 25
−0.5
0.0
0.5
1.0
Lag
AC
F
Series X1
0 5 10 15 20 25
−0.8
−0.6
−0.4
−0.2
0.0
Lag
Par
tial A
CF
Series X1
Fig. 5.3. modele AR(1) a=0.8 : série, ACF et PACF
Cours de Séries Temporelles : M.-Cl. Viano 42
Time
ts(X2[1
:100])
0 20 40 60 80 100
−4−3
−2−1
01
2
0 5 10 15 20 25
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
F
Series X2
0 5 10 15 20 25
0.0
0.2
0.4
0.6
0.8
Lag
Par
tial A
CF
Series X2
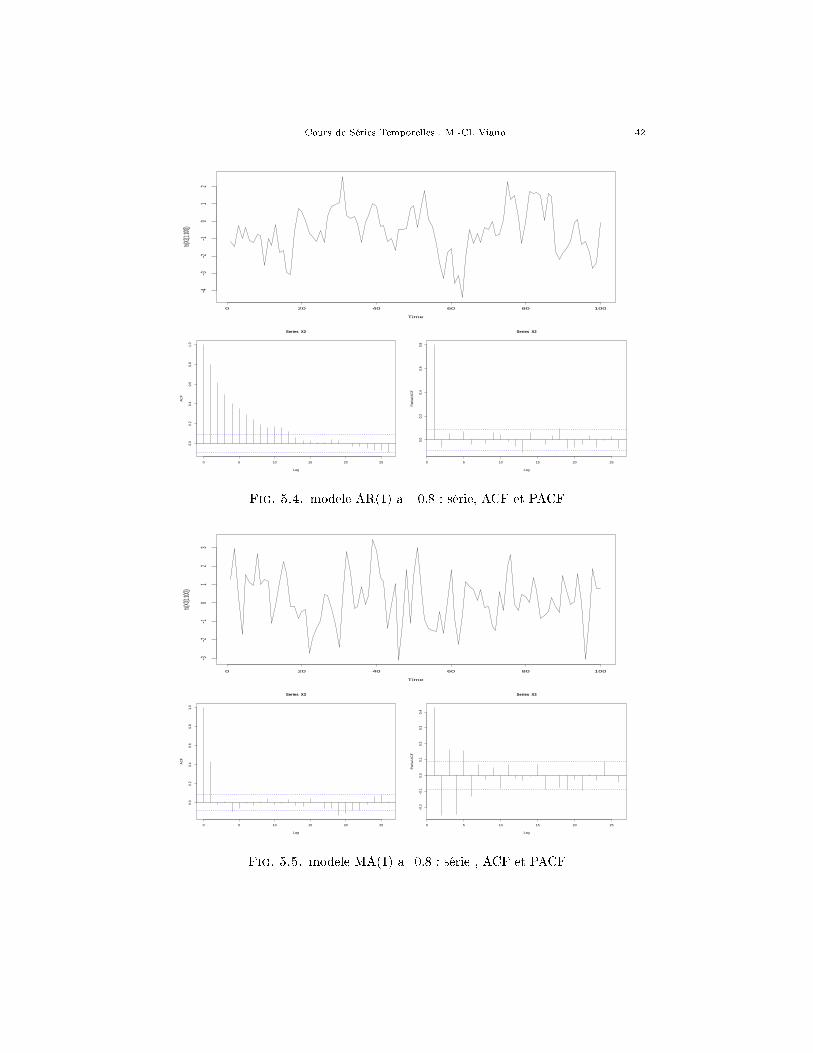
Fig. 5.4. modele AR(1) a=-0.8 : série, ACF et PACF
Time
ts(X3[1
:100])
0 20 40 60 80 100
−3−2
−10
12
3
0 5 10 15 20 25
0.0
0.2
0.4
0.6
0.8
1.0
Lag
AC
F
Series X3
0 5 10 15 20 25
−0.2
−0.1
0.0
0.1
0.2
0.3
0.4
Lag
Par
tial A
CF
Series X3
Fig. 5.5. modele MA(1) a=0.8 : série , ACF et PACF
Cours de Séries Temporelles : M.-Cl. Viano 43
Time
ts(X4[1
:100])
0 20 40 60 80 100
−2−1
01
23
0 5 10 15 20 25
−0.5
0.0
0.5
1.0
Lag
AC
F
Series X4
0 5 10 15 20 25
−0.5
−0.4
−0.3
−0.2
−0.1
0.0
0.1
Lag
Par
tial A
CF
Series X4
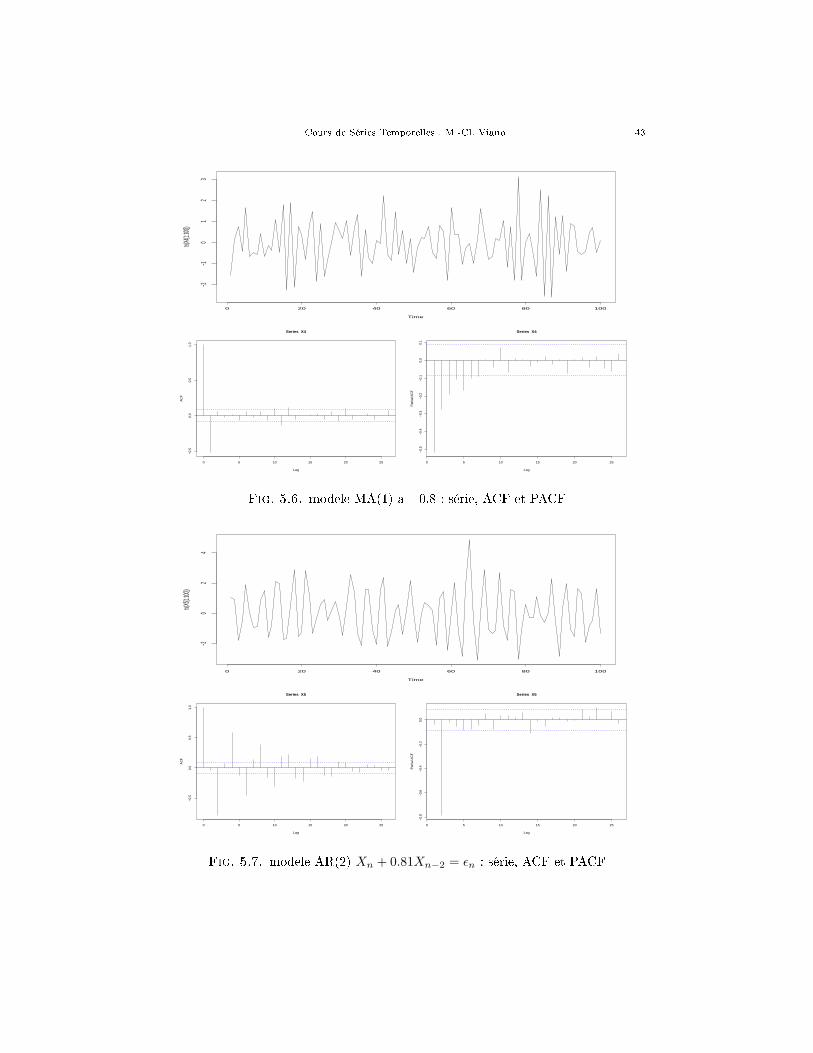
Fig. 5.6. modele MA(1) a=-0.8 : série, ACF et PACF
Time
ts(X5[1
:100])
0 20 40 60 80 100
−20
24
0 5 10 15 20 25
−0.5
0.0
0.5
1.0
Lag
AC
F
Series X5
0 5 10 15 20 25
−0.8
−0.6
−0.4
−0.2
0.0
Lag
Par
tial A
CF
Series X5
Fig. 5.7. modele AR(2) Xn + 0.81Xn−2 = εn : série, ACF et PACF
Cours de Séries Temporelles : M.-Cl. Viano 44
Time
ts(X6[1
:100])
0 20 40 60 80 100
−6−4
−20
24
6
0 5 10 15 20 25
−0.5
0.0
0.5
1.0
Lag
AC
F
Series X6
0 5 10 15 20 25
−0.8
−0.6
−0.4
−0.2
0.0
Lag
Par
tial A
CF
Series X6
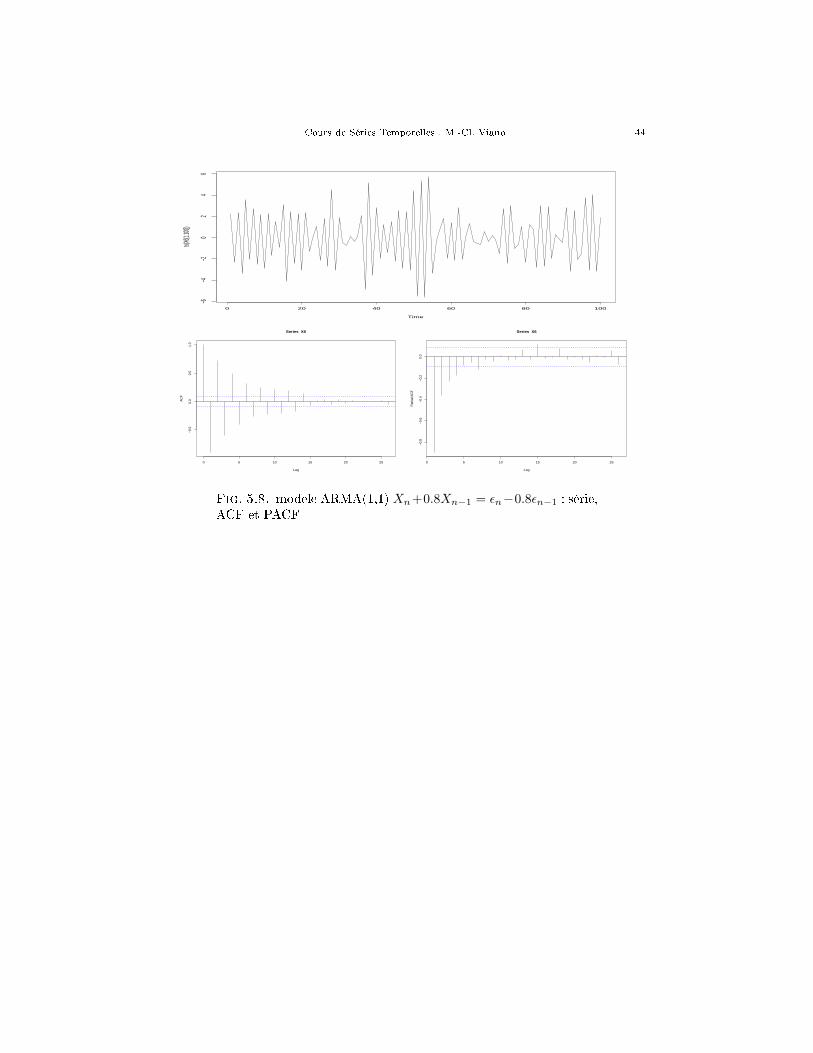
Fig. 5.8. modele ARMA(1,1) Xn+0.8Xn−1 = εn−0.8εn−1 : série,ACF et PACF

CHAPITRE 6
Les processus ARMA
Il s'agit d'une très large famille de processus stationnaires qui présente deuxavantages : d'une part ces processus sont d'excellents outils de prévision, et d'autrepart on dispose de méthodes parfaitement au point pour estimer leurs paramètres.
1. Les processus autorégressifs et leurs indices caractéristiques.
Ces processus généralisent les processus autorégressifs d'ordre 1 introduitsen 2.3. Reprenons cet exemple. En regardant les équations (18) et (19), et en serappelant que la fonction (1− az)−1 se développe au voisinage de zéro en
11− az
= 1 + az + a2z2 + · · ·+ akzk + · · · ,
on constate que l'expression (19) est tout simplement obtenue en remplaçant les zk
par les εn−k dans le développement. A partir de cette constatation, on obtient uneméthode de construction de la famille des processus autorégressifs.
1.1. Dé�nition, polynôme caractéristique.
Définition 6.1. Étant donné un polynôme A(z) = 1 + a1z + · · · + apzp de
degré exactement p (c'est à dire que ap 6= 0) dont toutes les racines sont de modulestrictement supérieur à 1, la fonction A(z)−1 se développe au voisinage de zéro en
1A(z)
=1
1 + a1z + · · ·+ apzp= 1 + α1z + α2z
2 + · · ·+ αkzk + · · · .
Soit (εn)n=0,±1,··· un bruit blanc centré dont la variance sera notée σ2. Le processusdé�ni par
Xn = εn + α1εn−1 + · · ·+ αkεn−k + · · · ∀n (30)
est appelé processus autorégressif d'ordre p (ou encore processus ARp) de polynômecaractéristique A et de bruit d'innovation (εn).
Avant d'examiner les diverses propriétés de ces processus, faisons quelques re-marques.
Remarque 6.1. Le polynôme A se décompose en A(z) = (1−z1z) · · · (1−zpz),où les zj sont les inverses des racines de A et sont, de ce fait, de module strictementinférieur à 1 (et non nécessairement réelles, évidemment). Du développement dechaque facteur (1− zjz)−1 = 1 + zjz + z2
j z2 + · · · on peut déduire celui de A(z)−1,ce qui permet le calcul des coe�cients αj , comme on le voit dans l'exercice qui suit.
Exercice 6. Expliciter l'expression du processus autorégressif de polynômecaractéristique A dans chacun des cas suivants :• A(z) = 1− z + 1
2z2.
45

Cours de Séries Temporelles : M.-Cl. Viano 46
• A(z) = 1− 56z + 1
6z2.• A(z) = 1− 1
2z2. 44
Remarque 6.2. Comme pour le processus autorégressif d'ordre 1, la conver-gence de la série dans (30) sort des limites de ce cours. Cette convergence a lieugrâce à l'hypothèse faite sur les racines de A.
1.2. Stationnarité.De la représentation en série (30), on déduit que IE(Xn) = 0 quel que soit n.
Quant à l'auto-covariance, elle s'écrit
Cov(Xn, Xn+h) = Cov(εn + · · ·+ αkεn−k + · · · , εn+h + · · ·+ αkεn+h−k + · · · )= σ2(αh + αh+1α1 + · · ·+ αh+kαk + · · · ),
puisque Cov(εj , εk) est nul si j 6= k et est égal à σ2 si j = k.L'expression obtenue est loin d'être explicite. Cependant elle montre à l'évi-
dence que la covariance ne dépend que de h. Donc le processus proposé en (30)est stationnaire. Nous verrons plus loin une façon plus commode de calculer cettecovariance.
1.3. Expression autorégressive.De même que le processus autorégressif d'ordre 1 véri�e l'équation de récurrence
(18), il est assez facile de voir que le processus dé�ni par (30) véri�e l'équation derécurrence
Xn + a1Xn−1 + · · ·+ apXn−p = εn ∀n. (31)
En e�et
Xn + a1Xn−1 + · · ·+ apXn−p = εn + α1εn−1 + α2εn−2 + · · ·+ a1(εn−1 + α1εn−2 + α2εn−3 + · · · )+ a2(εn−2 + α1εn−3 + α2εn−4 + · · · )+ · · ·+ ap(εn−p + α1εn−p−1 + α2εn−p−2 + · · · )
Soit
Xn + a1Xn−1 + · · ·+ apXn−p = εn + εn−1(α1 + a1) + εn−2(α2 + a1α1 + a2)+ · · ·+ εn−p(αp + αp−1a1 + αp−2a2 + · · ·+ · · ·+ ap)+ · · ·
Or, les coe�cients α1 + a1, α2 + a1α1 + a2, etc... sont tous nuls, car les aj et les αj
sont reliés par la relation
(1 + a1z + · · ·+ apzp)(1 + α1z + α2z
2 + · · · ) = 1 ∀z,
qui nécessite que le coe�cient de z dans le produit soit nul (soit α1 + a1 = 0), ainsique le coe�cient de z2 (soit α2 + a1α1 + a2 = 0), et ainsi de suite.
La représentation (31), qui fait apparaître les coe�cients du polynôme carac-téristique, est bien sûr préférée à la représentation en série in�nie (30). C'est ellequi justi�e le nom de processus autorégressif : en e�et (31) peut se lire formelle-ment comme un modèle de régression où l'observation est Xn, où les variables surlesquelles on régresse sont Xn−1, · · · , Xn−p, les coe�cients étant −a1, · · · ,−ap, etoù le bruit résiduel est εn.

Cours de Séries Temporelles : M.-Cl. Viano 47
1.4. L'innovation.De la représentation en série (30) on déduit que, quelque soit n et pour tout
h > 0,
Cov(εn+h, Xn) = IE(εn+hXn) = IE(εn+hεn) + α1 IE(εn+hεn−1) + · · · = 0,
parce que εn est un bruit blanc.
Proposition 6.1. Dans le modèle ARp (30), le bruit d'innovation est tel que,pour tout n, εn est orthogonal à toutes les variables Xj dont l'indice j est strictementinférieur à n.
C'est d'ailleurs pour cela que l'on parle de bruit d'innovation (il représente ceque Xn+1 apporte de vraiment nouveau à ce qui s'est passé observé jusqu'à l'instantn). Comme dans l'exercice 2, cette propriété importante va permettre de trouverla fonction d'auto-covariance du processus.
1.5. Auto-covariance des processus ARp.On part de la récurrence (31). Pour tout h et pour tout n, on a
Cov(Xn+h + a1Xn+h−1 + · · ·+ apXn+h−p, Xn) = Cov(εn+h, Xn). (32)
Si h est strictement positif, le second membre est nul, ce qui conduit à
Proposition 6.2. La fonction d'auto-covariance d'un processus ARp de polynômecaractéristique
1 + a1z + · · ·+ apzp
satisfait à l'équation de récurrence linéaire sans second membre
σ(h) + a1σ(h− 1) + · · ·+ apσ(h− p) = 0 ∀h > 0. (33)
Évidemment, puisque l'auto-corrélation est proportionnelle à l'auto-covariance,cette proposition est aussi valable pour ρ(h), c'est à dire que
ρ(h) + a1ρ(h− 1) + · · ·+ apρ(h− p) = 0 ∀h > 0. (34)
Supposons que l'on ait à déterminer la suite des auto-covariances ou des auto-corrélations. La récurrence ci-dessus implique que chacune de ces deux suites estconnue dès que sont connues ses p premières valeurs σ(0), · · · , σ(p − 1) ou ρ(0) =1, ρ(1), · · · , ρ(p− 1). Par ailleurs, supposons que toutes les racines du polynôme Asont simples (ce sont les 1
zj, cf. la remarque 6.1). On sait que les suites un solutions
de la récurrence
uh + a1uh−1 + · · ·+ apuh−p = 0 ∀h > 0.
sont toutes de la formeuh = λ1z
h1 + · · ·+ λpz
hp .
Donc la suite des auto-covariances est aussi de cette forme, ainsi que celle des auto-corrélations. Pour chacune de ces suites, les coe�cients λj se déterminent à partirdes p valeurs initiales de la suite (remarquer que les calculs sont plus faciles pourl'auto-corrélation puisque ρ(0) = 1 n'a pas à être déterminé).
Le fait important est que les deux suites ρ(h) et σ(h) tendent vers zéro lorsqueh tend vers l'in�ni. De plus cette convergence est assez rapide puisqu'elle se fait à lavitesse |zm|h, (où |zm| est le plus grand des modules des zj) c'est à dire à la vitessed'une suite géométrique. Par exemple, dans l'exercice 10 ci-dessous, la vitesse est2−h/2.

Cours de Séries Temporelles : M.-Cl. Viano 48
Exercice 7. On considère le processus autorégressif d'ordre deux, de représen-tation
Xn + a1Xn−1 + a2Xn−2 = εn ∀n.
Montrer que
ρ(1) =−a1
1 + a2,
et queρ(2) = −a1ρ(1)− a2.
44
Exercice 8. Quelle est la fonction d'auto-covariance du processus autorégressifde représentation
Xn −12Xn−2 = εn.
44
Exercice 9. On considère le processus autorégressif de représentation
Xn −56Xn−1 +
16Xn−2 = εn.
Donner les valeurs de σ(0) et σ(1). Trouver les racines du polynôme 1− 56z + 1
6z2
et en déduire l'expression de σ(h) pour h ≥ 1. 44
Exercice 10. On considère le processus autorégressif de représentation
Xn −Xn−1 +12Xn−2 = εn.
Donner les expressions de σ(0) et σ(1). Trouver les racines du polynôme 1−z+ 12z2
et en déduire que
ρ(h) = 2−h/2
(cos
(hπ
4
)+
13
sin(
hπ
4
))∀h ≥ 0.
44
1.6. Auto-corrélation partielle d'un processus autorégressif.Dans l'exercice 5 on a vu que, pour un processus AR1, le coe�cient r(h) est
nul pour h ≥ 2.Plus généralement, considérons un processus ARp de représentation (31). Soit
h ≥ 1. Le projeté de Xp+h+1 sur l'espace [X]p+h2 est −a1Xp+h − a2Xp+h−1 − · · · −
apXh+1, puisque cette combinaison linéaire est dans l'espace sur lequel se fait laprojection et puisque la di�érence Xp+h+1−(−a1Xp+h−a2Xp+h−1−· · ·−apXh+1) =εp+h+1 est orthogonale aux variables X2, · · · , Xp+h. En conséquence,
Cov(Xp+h+1 − P[X]p+h
2(Xp+h+1), X1 − P[X]p+h
2(X1)
)= Cov
(εp+h+1, X1 − P[X]p+h
2(X1)
)= 0,
ce qui prouve que le coe�cient d'auto-corrélation partielle r(h) est nul pour h =p + 1, p + 2, · · ·
De plus on montre que r(p) = −ap. Véri�ons le pour p = 2 (et on l'admettrasans preuve pour p ≥ 3). D'après la dé�nition (29), on a
r(2) = r[X2](X1, X3) = corr(X1 − γ1X2, X3 − γ2X2),

Cours de Séries Temporelles : M.-Cl. Viano 49
où γ1X2 et γ2X2 sont les projections respectives de X1 et de X3 sur l'espace [X2].Pour calculer γ1 on écrit que X1 − γ1X2 est orthogonal à X2, c'est à dire
IE(X2(X1 − γ1X2)) = 0 = σ(1)− γ1σ(0).
D'où γ1 = ρ(1). On trouve le même résultat pour γ2. Il en résulte que
r(2) = corr(X1 − ρ(1)X2, X3 − ρ(1)X2) =Cov(X1 − ρ(1)X2, X3 − ρ(1)X2)√Var(X1 − ρ(1)X2)Var(X3 − ρ(1)X2)
=ρ(2)− ρ(1)2
1− ρ(1)2.
Dans l'exercice 7, on a vu que ρ(1) = −a11+a2
. En utilisant (33), on en déduit que
ρ(2) = −a1ρ(1)− a2 = −a2 +a21
1 + a2.
En reportant ces deux résultats dans l'expression de r(2) on trouve le résultatannoncé.
Pour résumer, on peut énoncer la
Proposition 6.3. La fonction d'auto-corrélation partielle r(h) d'un proces-sus autorégressif d'ordre p est nulle pour p > h. De plus, si la représentation duprocessus est Xn + a1Xn−1 + · · ·+ apXn−p = εn, on a r(p) = −ap.
Exercice 11. Les �gures 5.3, 5.4 et 5.7 représentent, pour trois processusautorégressifs di�érents (deux AR1 et un AR2) une trajectoire simulée de longueur100 (en fait ce sont les 100 premiers termes d'une trajectoire de longueur 500, surla quelle son calculés les indices empiriques), l'auto-corrélation empirique et l'auto-corrélation partielle empirique. Commentez soigneusement ces �gures et retrouvez(approximativement !) les valeurs des paramètres des processus qui ont servi demodèles aux simulations. 44
2. Les processus moyennes mobiles et leurs indices caractéristiques
Définition 6.2. Étant donné un polynôme B(z) = 1+b1z+ · · ·+bqzq de degré
exactement q (donc, bq 6= 0) et dont toutes les racines sont de module strictementsupérieur à 1, et étant donné un bruit blanc centré (εn)n=±1,···, on appelle processusmoyenne mobile d'ordre q (on dit aussi MAq, "MA" correspondant à "movingaverage") de polynôme caractéristique B et d'innovation εn, le processus dé�ni par
Xn = εn + b1εn−1 + · · ·+ bqεn−q, ∀n.
En réalité, l'hypothèse faite sur les racines du polynôme B est inutile pourl'instant. On l'utilisera pour des questions de prévision.
Un processus moyenne mobile est évidemment stationnaire, centré et on a
IE(Xnεn+h) = 0 ∀h > 0,
ce qui justi�e l'utilisation du terme innovation pour le bruit blanc.De plus, (voir section 2.2 du chapitre 5)
σ(h) = 0 ∀h > q.

Cours de Séries Temporelles : M.-Cl. Viano 50
On voit donc que l'auto-corrélation d'un processus moyenne mobile a le même typede comportement (annulation systématique au dessus d'un certain écart h) quecelui de l'auto-corrélation partielle d'un processus autorégressif.
L'auto-corrélation partielle d'un processus moyenne mobile est compliquée àcalculer, on ne le fera pas ici. Par exemple le processus moyenne mobile d'ordre 1
Xn = εn + bεn−1
a pour fonction d'auto-corrélation partielle
r(h) = −(
−b
1 + b2
)h
∀h ≥ 1.
Comme −1 < −b1+b2 < 1, on voit que cette suite tend vers zéro à vitesse exponentielle
lorsque h →∞ (en oscillant ou pas selon le signe de b), comme le fait ρ(h) pour unprocessus autorégressif.
On admettra que ceci est toujours vrai, c'est à dire que l'auto-corrélation par-tielle d'un processus moyenne mobile a le même type de comportement que celuide l'auto-corrélation d'un processus autorégressif (décroissance exponentiellementrapide de la valeur absolue avec ou sans oscillations).
Les graphiques 5.5 et 5.6 représentent les 100 premières valeurs de deux sériesde longueur 500 simulées à partir de modèles de moyennes mobiles, ainsi que lesauto-corrélations et les auto-corrélations partielles correspondantes.
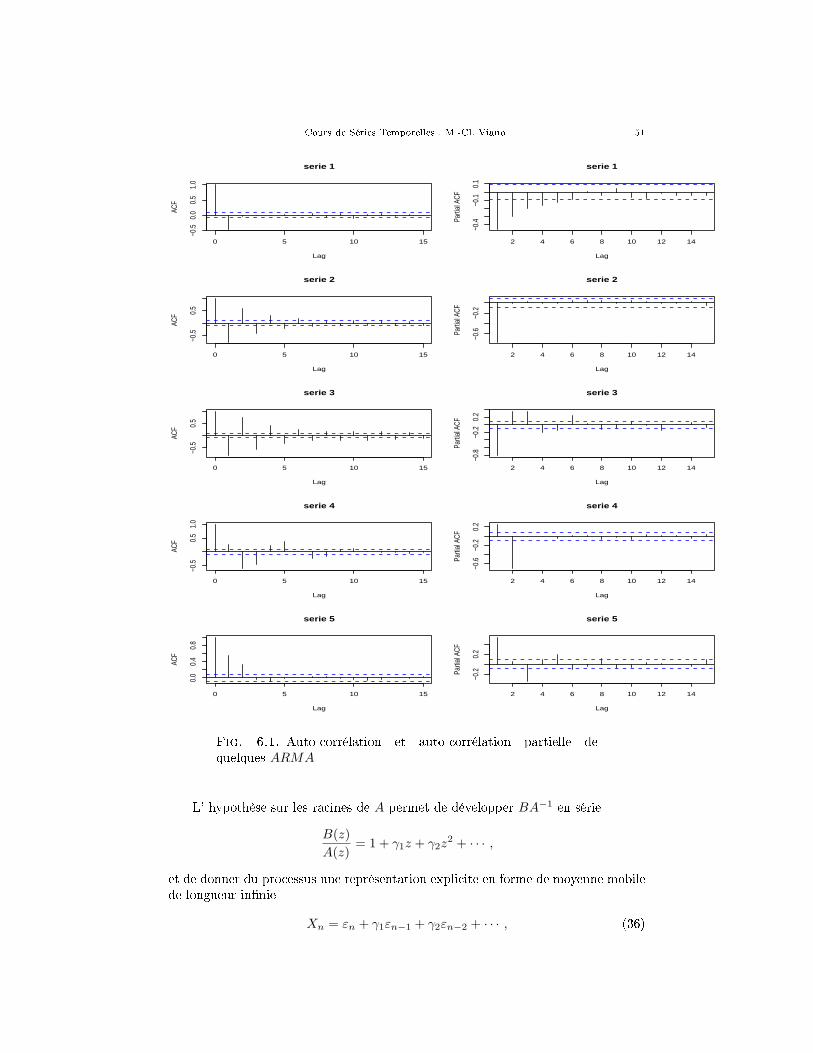
2.1. Un peu de reconnaissance de formes.En se basant sur ce qu'on sait des comportements comparés des auto-corrélations
et des auto-corrélations partielles des AR et des MA, il arrive qu'on puisse se faireune idée de la modélisation adéquate aux données simplement en regardant les auto-corrélations empiriques et les auto-corrélations partielles empiriques. Les graphiques6.1 montrent ces deux indices empiriques pour 5 séries simulées. Arrivez vous à direquel type de modèle convient à chaque série ?
3. Les ARMA mixtes
Ce sont des processus qui se représentent sous la forme d'une récurrenceauto-régressive à second membre de type moyenne mobile (d'où le sigle ARMA)
Xn + a1Xn−1 + · · ·+ apXn−p = εn + b1εn−1 + · · ·+ bqεn−q, ∀n. (35)
où (εn)n=0,±1,··· est un bruit blanc centré. Il y a donc deux polynômes caractéris-tiques A(z) = 1 + a1z + · · · + apz
p et B(z) = 1 + b1z + · · · + bqzq. On suppose
pq 6= 0 et on dit qu'on a a�aire à un processus ARMAp,q. Les racines de A et de Bsont toutes de module strictement supérieur à 1 et ces deux polynômes n'ont pasde racine commune. L'hypothèse sur les racines de B est inutile pour le moment,on l'utilisera pour faire de la prévision. Demander que A et B n'aient pas de racinecommune revient à s'assurer qu'il n'y a pas une représentation plus courte. Parexemple le processus qui véri�e
Xn + aXn−1 = εn + aεn−1
véri�e aussi Xn = εn. C'est donc un bruit blanc, et utiliser la récurrence ARMA1,1
serait très maladroit car cela demanderait l'estimation d'un paramètre a qui en faitn'existe pas.
Cours de Séries Temporelles : M.-Cl. Viano 51
0 5 10 15
−0.5
0.0
0.5
1.0
Lag
ACF
serie 1
2 4 6 8 10 12 14
−0.4
−0.1
0.1
Lag
Parti
al A
CF
serie 1
0 5 10 15
−0.5
0.5
Lag
ACF
serie 2
2 4 6 8 10 12 14
−0.6
−0.2
Lag
Parti
al A
CF
serie 2
0 5 10 15
−0.5
0.5
Lag
ACF
serie 3
2 4 6 8 10 12 14−0
.8−0
.20.
2Lag
Parti
al A
CF
serie 3
0 5 10 15
−0.5
0.5
1.0
Lag
ACF
serie 4
2 4 6 8 10 12 14
−0.6
−0.2
0.2
Lag
Parti
al A
CF
serie 4
0 5 10 15
0.0
0.4
0.8
Lag
ACF
serie 5
2 4 6 8 10 12 14
−0.2
0.2
Lag
Parti
al A
CF
serie 5
Fig. 6.1. Auto-corrélation et auto-corrélation partielle dequelques ARMA
L' hypothèse sur les racines de A permet de développer BA−1 en série
B(z)A(z)
= 1 + γ1z + γ2z2 + · · · ,
et de donner du processus une représentation explicite en forme de moyenne mobilede longueur in�nie
Xn = εn + γ1εn−1 + γ2εn−2 + · · · , (36)

Cours de Séries Temporelles : M.-Cl. Viano 52
qui permet de voir que le processus est centré, stationnaire, et que , pour tout n,Xn est orthogonal aux εj d'indice strictement supérieur à n. Ces propriétés sontdonc communes à tous les processus ARMA.
Question de vocabulaire. Les processus ARMA sont ceux qui véri�ent la récur-rence (35), avec les conditions restrictives qui l'accompagnent. parmi ces processusil y a les AR, ceux pour les quels les bj sont nuls, et les MA, ceux pour les quels lesaj sont nuls. Pour les distinguer de ces deux cas extrèmes simples, les autres serontappelés par la suite ARMA mixtes.
3.1. Auto-covariance, auto-corrélation et auto-corrélation partielledes processus ARMA mixtes.
En reprenant (35), on trouve que
Cov(Xn+h + a1Xn+h−1 + · · ·+ apXn+h−p, Xn) = σ(h) + a1σ(h− 1) + · · ·+ apσ(h− p)= Cov(εn+h + b1εn+h−1 + · · ·+ bqεn+h−q, Xn),
qui est nul dès que h dépasse q. Donc on peut énoncer
σ(h) + a1σ(h− 1) + · · ·+ apσ(h− p) = 0 si h > q. (37)
Ceci signi�e que l'auto-covariance (et l'auto-corrélation) d'un processus ARMAmixte évolue selon la même récurrence linéaire que celle du processus autorégressifdont la représentation s'obtient en annulant les bj . La di�érence est que la récurrenceest valable dès que h = 1 pour l'autorégressif alors qu'il faut attendre h = q+1 pourl'ARMAp,q. Mais à cette di�érence près, les deux auto-covariances se comportentde façon analogue si h est grand.
3.2. Les ARMA1,1.On se contentera ici d'étudier en détail le cas le plus simple p = q = 1.
Exercice 12. On étudie ici les processus ARMA1,1
Xn + aXn−1 = εn + bεn−1
où |a| < 1, |b| < 1, et où (εn) est un bruit blanc.• Écrire le développement en moyenne mobile in�nie de ces processus.• Calculer σ(0), σ(1), · · · à partir de l'expression précédente.• Directement, sans utiliser l'expression en moyenne mobile in�nie, calculer σ(0),montrer que σ(1) + aσ(0) = bσ2, et que
σ(h) + aσ(h− 1) = 0 ∀h > 1.
En déduire de nouveau les valeurs des covariances.• Donner l'expression de ρ(1).• La �gure 5.8 montre les 100 premières valeurs d'une trajectoire de longueur 500obtenue par simulation d'un processus ARMA1,1, ainsi que les auto-corrélationset auto-corrélations partielles empiriques. Comment pourriez vous reconstituer lavaleur du paramètre a à partir de ces graphiques ? 44

CHAPITRE 7
Comment prévoir dans un processus ARMA?
1. Principe général
On cherche à prévoir la valeur que va prendre la variable aléatoire Xn+h, et pourcela on s'appuie sur les variables Xn, Xn−1, · · · que l'on suppose avoir été observées.On dit que h est l'horizon de la prévision. Comme au chapitre 4, on note Xn,h leprédicteur que l'on va choisir. Ce prédicteur est donc, ici, une variable aléatoirefonction des Xj d'indices au plus n. En fait, dans le cadre de la modélisationARMA on choisit de prendre pour prédicteur une combinaison linéaire de ces Xj .Autrement dit
Xn,h = c1,hX1 + · · ·+ cn,hXn.
Dans le cadre choisi il est bien naturel de prendre celle de ces combinaisons linéairesqui est "la plus proche" de la variable aléatoire Xn+h. La projection de Xn+h
sur l'espace engendré [X]n1 est toute indiquée car c'est la combinaison linéaire quiminimise
IE(c1X1 + · · ·+ cnXn −Xn+h)2.On prendra donc
Xn,h = P[X]n1(Xn+h),
et le reste du chapitre est consacré aux méthodes de calcul (ou de calcul approché)de cette projection lorsque le processus (Xn)n∈Z est un ARMA. Le calcul est trèssimple pour un processus autorégressif, un peu plus compliqué pour les moyennesmobiles et les ARMA mixtes (dans ce cas, on fera un calcul approché).
2. Prévision à horizon 1
2.1. Prévision dans un processus autorégressif.Comme εn+1 est orthogonal aux Xj pour j = n, n− 1, · · · , et comme
Xn+1 = −a1Xn − · · · − apXn+1−p + εn+1,
on voit directement que
Xn,h = P[X]n1(Xn+1) = −a1Xn − · · · − apXn+1−p.
De ce fait, l'erreur de prévision, c'est à dire la di�érence entre Xn+1 et son pré-dicteur, est
Xn+1 − Xn,1 = Xn+1 + a1Xn − · · ·+ apXn+1−p = εn+1.
Donc le bruit d'innovation est aussi l'erreur de prévision à horizon 1.
53

Cours de Séries Temporelles : M.-Cl. Viano 54
On déduit de ce qui précède que cette erreur est une variable aléatoire centréeet de variance σ2. Si on suppose en plus que le bruit εn est gaussien, on sera capablede donner un intervalle de con�ance pour la prévision (cette question sera abordéeau paragraphe 5 de ce chapitre).
2.2. Prévision dans les processus moyenne mobile et dans les proces-sus mixtes.
Pour ces processus, il est plus facile de projeter non pas sur [X]n1 mais sur[X]n−∞, espace engendré par tous les Xj d'indice au plus n. Cet espace est en quelquesorte le passé in�ni linéaire du processus. Projeter sur cet espace est évidemmentpeu réaliste sur le plan pratique car X0, X−1, · · · ne sont pas accessibles à l'obser-vateur, ce qui rend incalculable toute expression qui les utilise. On reviendra surcette question plus loin.
2.2.1. Préliminaires.On va d'abord montrer que les deux espaces [X]n−∞ et [ε]n−∞ sont égaux. Tout
d'abord, pour un processus moyenne mobile, l'inclusion [X]n−∞ ⊂ [ε]n−∞ vient dela dé�nition elle même. Pour un processus autorégressif ou pour un ARMA mixte,elle découle des développements (30) et (36). Dans l'autre sens, l'inclusion [ε]n−∞ ⊂[X]n−∞ vient, pour un AR, de son expression autorégressive. Dans les autres cas onutilise la proposition suivante, qui sera admise, et dont la preuve repose sur le faitque les racines de B sont de module strictement plus grand que 1.
Proposition 7.1. Les processus moyenne mobile et les processus mixtes ad-mettent une expression de type autorégressif de longueur in�nie
εn = Xn + β1Xn−1 + β2Xn−2 + · · · , (38)
dont les coe�cients βj sont ceux du développement
A(z)B(z)
=1 + a1z + · · ·+ apz
p
1 + b1z + · · ·+ bqzq= 1 + β1z + β2z
2 + · · ·
Ici encore, la convergence de la série de terme général βjXn−j sort des limitesdu cours.
Exercice 13. Déterminer le développement autorégressif in�ni d'un processusMA1 et d'un processus ARMA1,1. 44
2.2.2. Prévision et erreur de prévision.On peut maintenant résumer ce qui vient d'être dit et en tirer les conséquences.
Pour simpli�er l'écriture, dans la proposition qui suit, on note Xn = εn +α1εn−1 +α2εn−2 + · · · les représentations en moyenne mobile (�nie, si le processus est unMAq, in�nies dans les autres cas) des processus ARMA.
Proposition 7.2.1) Les passés linéaires d'un processus ARMA et de son bruit d'innovation sont
égaux :[X]n−∞ = [ε]n−∞ ∀n,
2)Pour tout n, le prédicteur à horizon 1, Xn,1 est
Xn,1 = P[X]n−∞(Xn+1) = P[ε]n−∞
(Xn+1) = α1εn + α2εn−1 + · · · (39)
3) l'erreur de prévision à horizon 1 est
Xn+1 − Xn,1 = Xn+1 − α1εn − α2εn−1 − · · · = εn+1.

Cours de Séries Temporelles : M.-Cl. Viano 55
4) l'expression du prédicteur en fonction des Xj s'obtient en remplaçant, dans (39),les εj par leur développement (38).
Démonstration. Le 1) a déjà été prouvé, le 2) vient du fait que la di�érenceXn+1−(−α1εn−α2εn−1−· · · ), qui est εn+1 (voir le 3)) est orthogonale à [X]n−∞. �
Cette proposition établit entre autres que l'erreur de prévision à horizon 1 estle bruit d'innovation. C'est le résultat qui avait déjà été obtenu pour la prévisiondans un processus autorégressif.
Pour bien comprendre cette proposition, le mieux est de la tester sur des ex-emples simples.
Exercice 14. Exprimer Xn,1 pour un processus MA1 et pour un ARMA1,1
44Comme il a été dit plus haut, pour les processus mixtes ou pour les moyennes
mobiles, on obtient une expression du prédicteur qui dépend de tous les Xj d'indicesau plus n. De ce fait ce prédicteur n'est pas calculable par le statisticien puisquecelui ci ne connaît que les valeurs de Xn, · · · , X1. La solution adoptée consiste àposer X0 = X−1 = · · · = 0 dans l'expression fournie par la proposition. On obtientainsi un prédicteur approché, Xn,1, qui n'est ni P[X]n−∞
(Xn+1) ni P[X]n1(Xn+1), mais
qui n'est pas loin de P[X]n−∞(Xn+1) si n est grand.
Exercice 15. Faire le calcul de Xn,1 pour un processus MA1 et pour unprocessus ARMA1,1. Montrer que la di�érence Xn,1 − Xn,1 entre ce prédicteurapproché et celui trouvé dans l'exercice précédent tend vers zéro quand n → ∞.44
3. Prévision à horizon supérieur à 1
La situation est un peu particulière pour les processus moyennes mobiles.Nous commençons par eux.
3.1. Les processus moyenne mobile. Pour ceux-là, on voit tout de suite,à partir de la représentation
Xn+h = εn+h + b1εn+h−1 + · · ·+ bqεn+h−q, ∀n,
que le prédicteur est nul dès que l'horizon h dépasse q. En e�et, la di�érence
Xn+h − 0 = εn+h + b1εn+h−1 + · · ·+ bqεn+h−q
est orthogonale à l'espace [X]n−∞ = [ε]n−∞ puisque n + h− q > n. L'erreur est alors
Xn+h − Xn,h = Xn+h,
et la variance de l'erreur est σ(0).
3.2. Les processus autorégressifs et les ARMA mixtes.La projection sur un espace donné est, comme on l'a vu, une opération linéaire.
Donc, si Xn est un processus ARMA de représentation (35), on a
P[X]n−∞(Xn+h) + a1P[X]n−∞
(Xn+h−1) + · · ·+ apP[X]n−∞(Xn+h−p)
= P[X]n−∞(εn+h) + · · ·+ bqP[X]n−∞
(εn+h−q). (40)

Cours de Séries Temporelles : M.-Cl. Viano 56
Mais on sait que P[X]n−∞(Y ) = Y si Y ∈ [X]n1 et que P[X]n−∞
(Y ) = 0 si Y estorthogonale à [X]n−∞ c'est à dire si IE(Y Xn) = IE(Y Xn−1) = · · · = 0. Il en résulteque, dans (40),
P[X]n−∞(Xn+h−l) = Xn+h−l et P[X]n−∞
(εn+h−l) = εn+h−l si l ≥ h,
tandis que P[X]n−∞(εn+h−l) = 0 si h > l.
Notamment, si h > q, le second membre de (40) est nul et on a
Xn,h + a1Xn,h−1 + · · ·+ apXn,h−p = 0.
Tout d'abord, cela donne la possibilité de calculer la prévision à horizon h lorsqu'ona calculé toutes les prévisions à horizon plus petit.Ensuite, on note que la prévision Xn,h évolue (n étant �xé, h croissant) selon lamême récurrence que la fonction d'auto-covariance. Donc, comme elle, elle tend verszéro à vitesse exponentielle quand h → ∞. Il est donc inutile de prévoir à horizontrop grand.
Exercice 16. Faites les calculs des prévisions à horizon 2 et 3 pour un proces-sus AR1,un processus AR2, un processus MA1, et un processus mixte ARMA1,1.44
4. Comportement de l'erreur de prévision quand l'horizon croît
Le problème abordé est le suivant : les variables observées étant celles d'indiceau plus n, comment se comporte l'erreur de prévision à horizon h quand h croît.
4.1. Évolution de l'erreur.On reprend l'expression en moyenne mobile in�nie, écrite au rang n + h
Xn+h = εn+h + α1εn+h−1 + · · ·+ αhεn + · · ·On a vu que le prédicteur est
Xn,h = αhεn + αh+1εn−1 + · · ·Il s'ensuit que l'erreur de prévision est
Xn+h − Xn,h = εn+h + α1εn+h−1 + · · ·+ αh−1εn+1,
variable aléatoire centrée et de variance Varh = σ2(1 + α21 + · · ·+ α2
h−1).
4.2. Évolution de la variance d'erreur pour les AR ou les ARMAmixtes.
On voit clairement que la variance d'erreur de prévision croît avec h. La valeurσ2 obtenue pour h = 1 est la plus petite. Lorsque h →∞, la variance d'erreur tendvers
Var∞ = σ2 limh→∞
(1 + α21 + · · ·+ α2
h−1) = σ2(1 +∞∑
j=1
α2j ) = σ(0),
ce qui est bien normal puisque, étant donné que le prédicteur tend vers zéro quandl'horizon tend vers l'in�ni, l'erreur de prévision �nit par ressembler à Xn+h (pourun processus moyenne mobile, cette valeur est atteinte dès que l'horizon dépassel'ordre).
Pour résumer

Cours de Séries Temporelles : M.-Cl. Viano 57
Proposition 7.3. La variance d'erreur de prévision à horizon h dans un pro-cessus ARMA croît depuis la variance du bruit d'innovation (valeur prise pourh = 1) jusqu'à la variance du processus lui même.
5. Intervalles de con�ance
Supposons maintenant que le bruit est gaussien. Autrement dit les εj sont desvariables aléatoires gaussiennes, centrées, indépendantes et de variance σ2. Il enrésulte que toutes les variables considérées ici (ce sont des combinaisons linéaires�nies ou in�nies de ces εj) sont aussi gaussiennes. Notamment l'erreur de prévision
Xn+h − Xn,h = εn+h + α1εn+h−1 + · · ·+ αh−1εn+1
est gaussienne, centrée, et sa variance est, comme on l'a vu Varh = σ2(1 + α21 +
· · ·+ α2h−1).
Il en résulte que l'intervalle aléatoire
[Xn,h − zα/2σ√
1 + α21 + · · ·+ α2
h−1 , Xn,h + zα/2σ√
1 + α21 + · · ·+ α2
h−1]
a une probabilité 1 − α de contenir Xn+h. Cet intervalle est donc un intervalle decon�ance de niveau 1 − α pour prévoir Xn+h lorsqu'on a observé les Xj d'indiceau plus n. Et on remarque, comme on s'y attendait, que la largeur de cet intervallecroît avec h.
6. Mise à jour
Le problème est le suivant. On a, en se basant sur les observations antérieuresà n, prévu Xn+1, Xn+2, · · · , Xn+h. On observe maintenant Xn+1. Non seulementon n'a plus à le prévoir, mais encore on connaît maintenant la valeur de l'er-reur de prévision Xn+1 − Xn,1. De plus, on va pouvoir modi�er les prévisions deXn+2, · · · , Xn+h. De quelle façon ?
On écrit le développement en moyenne mobile
Xn+h = εn+h + α1εn+h−1 + · · ·+ αh−1εn+1 + αhεn + · · · .
Le prédicteur est
Xn+1,h−1 = P[X]n+1−∞
(Xn+h) = αh−1εn+1 + αhεn + · · ·
= αh−1εn+1 + P[X]n−∞(Xn+h) = αh−1εn+1 + Xn,h.
Donc la prévision de Xn+h s'obtient en ajoutant αh−1εn+1 à la prévision précédem-ment obtenue. Or on connaît la valeur de ce terme complémentaire. En e�et, εn+1
est, on l'a vu, l'erreur de prévision Xn+1 − Xn,1. On a donc le résultat suivant
Proposition 7.4. Lorsque l'observation Xn+1 vient s'ajouter aux précédentes,la mise à jour des prévisions se fait de la façon suivante :
Xn+1,h−1 = Xn,h + αh−1(Xn+1 − Xn,1).
Autrement dit, on ajoute au prédicteur précédent de Xn+h une correction pro-portionnelle à l'erreur que l'on avait faite en prédisant, avant de l'avoir observée, ladonnée que l'on vient de recueillir.

CHAPITRE 8
Identi�cation
Le statisticien à qui on demande de faire la prévision d'un certain phénomènedispose des données x1, · · · , xn. Par contre il n'a pas idée, en général, d'un modèlede processus bien adapté à ces données. Il va chercher dans l'ensemble des modèlesARMA celui qui convient le mieux. On dit qu'il identi�e le modèle. Pour cela il doittout d'abord choisir les ordres p et q du modèle ARMA, puis, lorsque ces ordressont choisis, il doit estimer les paramètres a1, · · · , ap, b1, · · · , bq, et la variance σ2
du bruit d'innovation. En réalité il (ou plutôt le logiciel dont il se sert) procède ensens inverse. Il choisit deux valeurs à ne pas dépasser p∗ et q∗ pour les ordres. Puis,pour chaque couple p ≤ p∗, q ≤ q∗, il estime les paramètres a1, · · · , ap, b1, · · · , bq,et σ2 du modèle ARMAp,q. Ensuite seulement il choisit le meilleur parmi tous cesmodèles.
1. Estimation des paramètres d'un modèle ARMA
1.1. Estimation préliminaire.1.1.1. Exemple.Considérons le processus AR2 de l'exercice 7. Montrons que les paramètres
a1, a2, σ2 sont fonction de σ(2), σ(1), σ(0).
On a vu que
σ(1) =−a1
1 + a2σ(0), σ(2) = −a1σ(1)− a2σ(0).
De ces deux équations on peut déduire l'expression des paramètres a1 et a2 enfonction de σ(2), σ(1) et σ(0). On trouve
a1 = σ(1)σ(2)− σ(0)
σ(0)2 − σ(1)2, a2 = σ(1)
σ(1)− σ(2)σ(0)2 − σ(1)2
.
Par ailleurs, en calculant la variance des deux membres de l'équation
Xn = −a1Xn−1 − a2Xn−2 + εn,
on obtient
σ(0)(1− a21 − a2
2) = 2a1a2σ(1) + σ2,
qui permet d'exprimer la variance du bruit en fonction de σ(2), σ(1) et σ(0).Comme on dispose d'estimateurs convergents de ces auto-covariances (voir
chapitre 5, paragraphe 4), on peut estimer a1, a2 et σ2 de façon convergente enremplaçant les σ(j) par les σn(j) dans les trois expressions précédentes.
58
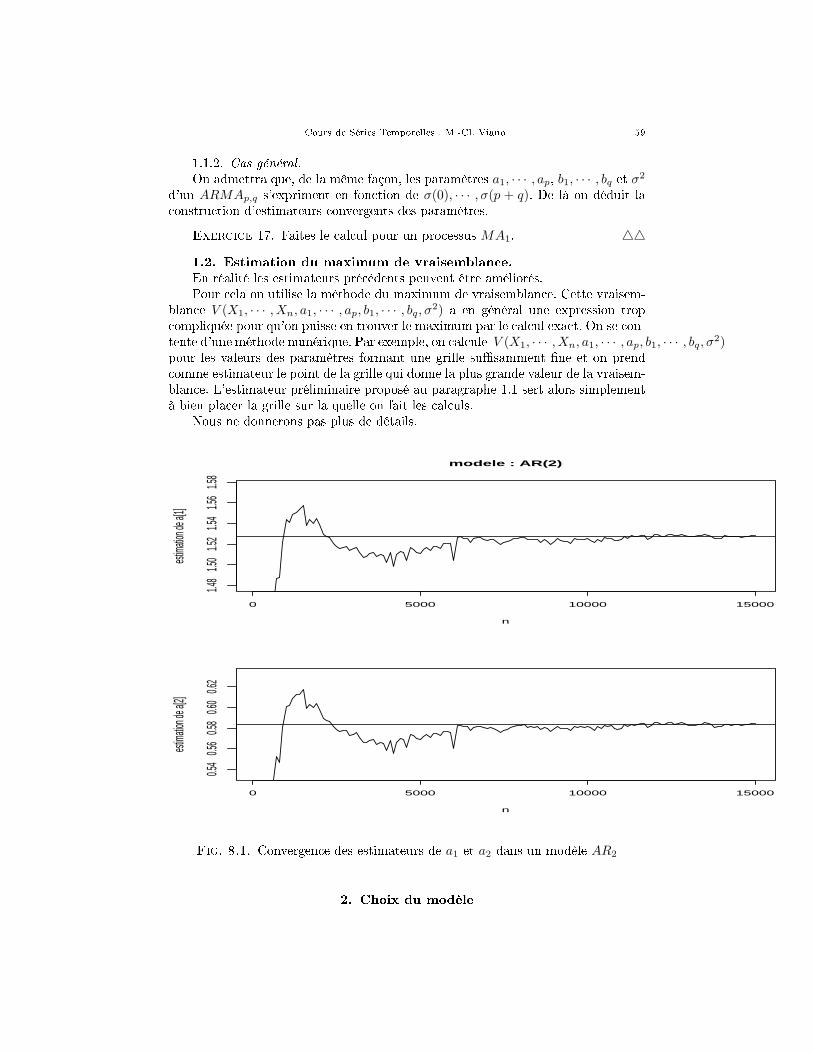
Cours de Séries Temporelles : M.-Cl. Viano 59
1.1.2. Cas général.On admettra que, de la même façon, les paramètres a1, · · · , ap, b1, · · · , bq et σ2
d'un ARMAp,q s'expriment en fonction de σ(0), · · · , σ(p + q). De là on déduit laconstruction d'estimateurs convergents des paramètres.
Exercice 17. Faites le calcul pour un processus MA1. 44
1.2. Estimation du maximum de vraisemblance.En réalité les estimateurs précédents peuvent être améliorés.Pour cela on utilise la méthode du maximum de vraisemblance. Cette vraisem-
blance V (X1, · · · , Xn, a1, · · · , ap, b1, · · · , bq, σ2) a en général une expression trop
compliquée pour qu'on puisse en trouver le maximum par le calcul exact. On se con-tente d'une méthode numérique. Par exemple, on calcule V (X1, · · · , Xn, a1, · · · , ap, b1, · · · , bq, σ
2)pour les valeurs des paramètres formant une grille su�samment �ne et on prendcomme estimateur le point de la grille qui donne la plus grande valeur de la vraisem-blance. L'estimateur préliminaire proposé au paragraphe 1.1 sert alors simplementà bien placer la grille sur la quelle on fait les calculs.
Nous ne donnerons pas plus de détails.
0 5000 10000 15000
1.48
1.50
1.52
1.54
1.56
1.58
n
estima
tion de
a[1]
modele : AR(2)
0 5000 10000 15000
0.54
0.56
0.58
0.60
0.62
n
estima
tion de
a[2]
Fig. 8.1. Convergence des estimateurs de a1 et a2 dans un modèle AR2
2. Choix du modèle

Cours de Séries Temporelles : M.-Cl. Viano 60
Après la procédure décrite plus haut, on a obtenu, pour tout choix des ordresp et q, un modèle ARMAp,q estimé. Il reste à choisir le meilleur de ces modèles.
2.1. Critères d'information.Toutes les méthodes de choix commencent par l'optimisation d'un certain critère
(AIC, BIC, etc...). Ces critères sont tous basés sur les deux idées suivantes :• Étant donné que σ2 est la variance d'erreur de prévision à horizon 1, on
aimerait choisir, parmi les modèles estimés, celui qui fournit la plus petite valeurde σn
2.• On ne peut pas, pour des raisons statistiques, choisir un modèle présentant
un grand nombre de paramètres (p et q grands). Pour un tel modèle, la qualité del'estimation risque d'être mauvaise si la série n'est pas assez longue.
Or, ces deux exigences, pouvoir prédictif et réalisme statistique, sont antago-nistes. On prédit mieux avec un ARMA long, mais on l'estime moins bien.
Les critères utilisés permettent d'équilibrer ces deux exigences. Pour les détails,consulter par exemple [1] et [4].
2.2. Véri�cation.L'optimisation du critère conduit à la sélection de deux ordres p et q et à
l'estimation des p + q + 1 paramètres correspondants. On obtient donc à partir desdonnées x1, · · · , xn un modèle estimé
Xj + a1,nXj−1 + · · ·+ ap,nXj−p = εj + b1,nεj−1 + · · ·+ bq,nεj−q
où la variance du bruit est σn2.
Il est alors tout à fait possible d'estimer les εj . Par exemple, si le modèle estautorégressif (q = 0), il est naturel de prendre
εj = xj + a1,nxj−1 + · · ·+ ap,nxj−p, j = p + 1, · · · , n,
où les xj sont les observations. Pour un modèle mixte ou pour un MAq, il faut faireappel au développement autorégressif in�ni donné au chapitre 6 (Proposition 7.1),en posant xj = 0 si j ≤ 0.
On véri�e alors que le modèle choisi est convenable en testant que le bruit ainsiestimé est bien blanc, c'est à dire que ses auto-corrélations empiriques des résidussont statistiquement nulles.
Exercice 18. De quelle façon estimeriez vous le bruit si le modèle ajusté estun MA1 ? Même question pour un ARMA1,1. 44

Cours de Séries Temporelles : M.-Cl. Viano 61
3. Identi�cation et prévision
Dans ce paragraphe on se contente d'illustrer ce qui précède sur trois exemples.Les résultats sont représentés dans les �gures 8.2 et 8.3.
• Figure 8.2.Sur des séries simulées (un AR4 en haut et un MA3 en bas) de longueur 1000 on
a ajusté un modèle, puis e�ectué les prévisions à horizon 1, 2, · · · , 10. Le graphiquede gauche représente la série, les prévisions faites à partir de n = 990, et les in-tervalles de con�ance sur la prévision. Le graphique de gauche représente l'auto-corrélation des résidus.
• Figure 8.3.Il s'agit ici d'une série réellement observée : le nombre annuel de lynx cap-
turés par piégeage au Canada entre 1820 et 1935. Cette série, représentée dansle graphique du haut, a une allure périodique (son auto-corrélation et son auto-corrélation partielle sont représentés dans les graphiques du milieu).
On pourrait penser à estimer la période et ensuite à supprimer la composantepériodique. En fait, il est di�cile de travailler avec une période estimée, ne serait-ce que parcequ'elle n'est pas forcément entière (comment désaisonnaliser, alors ?).On choisit donc de lancer un programme d'identi�cation ARMA. Le modèle quioptimise le critère AIC est un AR8.
Les graphiques du bas représentent l'auto-corrélation des résidus (à droite), etles prévisions (et intervalles de prévision) à horizon allant de 1 à 10 calculés sur la�n de la série.
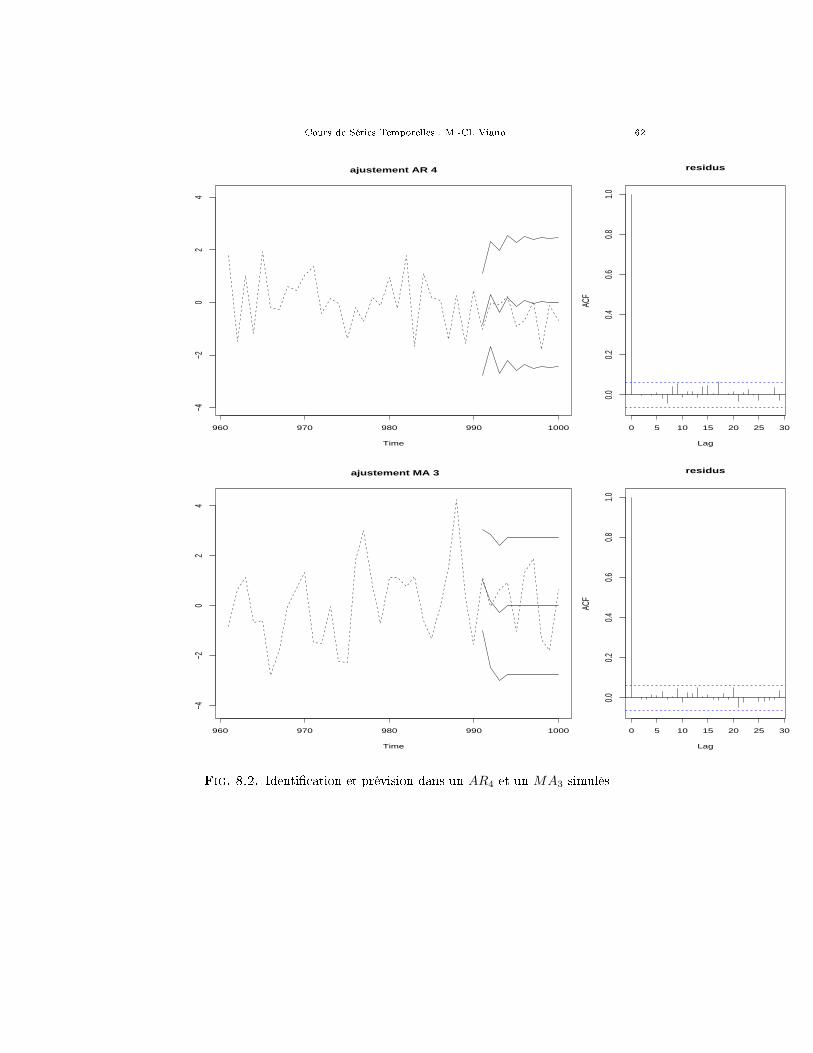
Cours de Séries Temporelles : M.-Cl. Viano 62
Time
960 970 980 990 1000
−4−2
02
4
ajustement AR 4
0 5 10 15 20 25 30
0.00.2
0.40.6
0.81.0
Lag
ACF
residus
Time
960 970 980 990 1000
−4−2
02
4
ajustement MA 3
0 5 10 15 20 25 30
0.00.2
0.40.6
0.81.0
Lag
ACF
residus
Fig. 8.2. Identi�cation et prévision dans un AR4 et un MA3 simulés
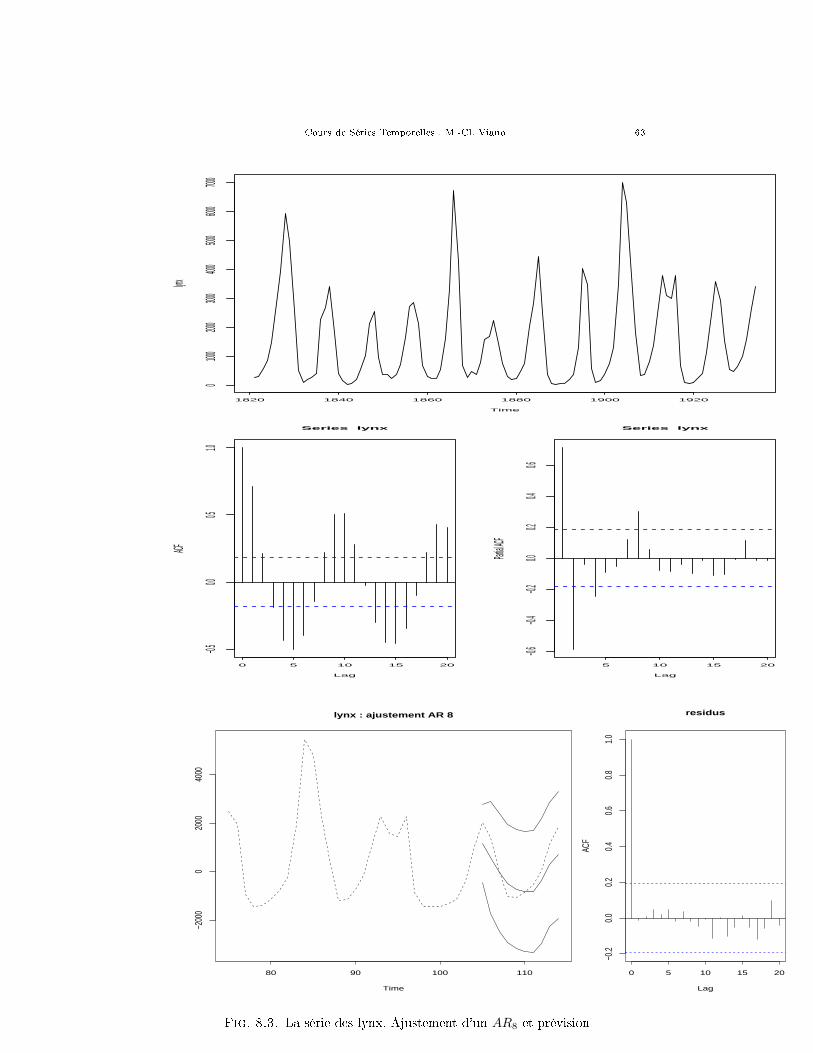
Cours de Séries Temporelles : M.-Cl. Viano 63
Time
lynx
1820 1840 1860 1880 1900 1920
01000
20003000
40005000
60007000
0 5 10 15 20
−0.50.0
0.51.0
Lag
ACF
Series lynx
5 10 15 20
−0.6−0.4
−0.20.0
0.20.4
0.6
Lag
Partial AC
F
Series lynx
Time
80 90 100 110
−200
00
2000
4000
lynx : ajustement AR 8
0 5 10 15 20
−0.2
0.00.2
0.40.6
0.81.0
Lag
ACF
residus
Fig. 8.3. La série des lynx. Ajustement d'un AR8 et prévision

CHAPITRE 9
Récapitulons : les prévisions ARIMA et SARIMA
Reprenons la procédure depuis le début. Un statisticien est chargé de faire laprévision d'un certain phénomène. L'unique information dont il dispose est la sérietemporelle observée x1, · · · , xn.
1. Résumé des étapes déjà vues
Étape 1. Suppression des tendances et désaisonnalisation.Par exemple, si la série n'est pas centrée et présente une période de longueur
12, on la transforme en
yj = xj − xj−12, j = 13, · · · , n
Étape 2. Ajustement d'un modèle ARMA adapté à la série yj (voir chapitre 8).Étape 3. Prévision de yn+1, · · · , yn+h en s'appuyant sur le modèle identi�é à
l'étape 2 (voir chapitre 7).Étape 4. Retour à la série xj d'origine.C'est cette dernière étape qu'il nous reste à détailler.
2. Filtrage inverse : modélisation ARIMA et SARIMA
2.1. Exemple.Reprenons l'exemple donné à l'étape 1. Pour tout j ∈ {13, · · · , n}, on a xj =
yj + xj−12. D'où xj = yj + yj−12 + xj−24, puis xj = yj + yj−12 + yj−24 + xj−36 etainsi de suite jusqu'à obtenir
xj = yj + yj−12 + yj−24 + · · ·+ yr(j)+12 + xr(j)
où l'indice r(j) n'est autre que le reste de la division de j par 12.Puisque le statisticien dispose des xj , j ≤ n ainsi que des prévisions de
yn+1, · · · , yn+h, on en déduit les prévisions cherchées. Par exemple, pour un horizonh = 1,
xn,1 = yn,1 + yn−11 + yn−23 + · · ·+ yr(n+1)+12 + xr(n+1).
Exercice 19. Reprendre ce qui précède pour une série xj qui présente unetendance linéaire sans saisonnalité. 44
64

Cours de Séries Temporelles : M.-Cl. Viano 65
2.2. Les modèles ARIMA et SARIMA.Il s'agit simplement de formaliser ce qui vient d'être décrit sur un exemple.
Pour simpli�er les écritures, on notera ∆ l'opération de di�érenciation associant(Xn − Xn−1)n∈Z au processus (Xn)n∈Z. Ainsi le processus Xn − 2Xn−1 + Xn−2,obtenu en di�érenciant deux fois de suite, sera noté ∆2Xn. On dé�nit de même ∆d,l'opération qui consiste à di�érencier d fois de suite.
L'opération qui fait passer de (Xn) à (Xn − Xn−D) est notée ∆D (à ne pasconfondre avec ∆D !).
Vous savez que ∆2 annule les tendances linéaires et que ∆D annule les suitesD-périodiques et remet la moyenne à zéro.
Définition 9.1. On dit que (Xn) est un processus ARIMAp,d,q si le processus
Yn = ∆dXn
est un processus ARMAp,q.
Ce type de modèle convient bien aux séries chronologiques présentant une ten-dance polynômiale de degré d− 1.
Définition 9.2. On dit que (Xn) est un processus SARIMAp,d,D,q si le pro-cessus
Yn = ∆D ◦∆dXn
est un processus ARMAp,q. (Ici, ∆D ◦∆d est l'opération qui consiste à di�érencierd fois, suivie de ∆D, ce qui, d'ailleurs, peut se faire dans l'ordre inverse).
Ce type de modèle convient bien aux séries chronologiques présentant une péri-ode de longueur D superposée à une tendance polynômiale de degré d.
Il existe évidemment des modèles plus compliqués, tenant compte notammentde la présence éventuelle de plusieurs périodes di�érentes. On trouvera une descrip-tion complète des modèles SARIMA dans [4].
2.3. Que font les logiciels de prévision, que fait le statisticien ?• Le statisticien décide du pré-traitement qu'il veut faire subir à la série : il
décide par exemple d'appliquer une transformation logarithme (exemple des ventesde champagne), et il choisit d et D, c'est à dire le type de désaisonnalisation et lenombre de di�érenciations et successives qu'il désire faire subir à la série.• Le logiciel di�érencie et désaisonnalise comme on le lui a demandé. Sur la sérieainsi modi�ée il ajuste un modèle ARMA (voir chapitre 8). Le statisticien peutencore intervenir dans le choix du modèle car il arrive que le meilleur modèle ausens du critère en cours dans le logiciel (AIC, BIC, etc...) ne soit pas celui qui donnele résidu le plus �blanc�.• S'appuyant sur le modèle estimé, le logiciel fournit la prévision de la série modi�ée(et l'intervalle de prévision) à l'horizon demandé (voir chapitre 7).• En�n il revient à la prévision sur la série d'origine en e�ectuant les �ltragesinverses comme on l'a vu sur deux exemples au début du présent paragraphe.
La �gure 9.1 illustre ce qui précède sur la série du tra�c aérien (graphique duhaut) et la série des ventes de champagne (deuxième ligne). Les graphiques du basreprésentent les résidus des ajustements (à gauche, le tra�c aérien).
Pour les ventes de champagne, on a identi�é un SARIMA0,0,12,13. Plus pré-cisément, on choisit de modéliser ∆12Xn par un processus moyenne mobile d'ordre13 de la forme
Yn = εn + b1εn−1 + b2εn−1 + b1b2εn−13.
Cours de Séries Temporelles : M.-Cl. Viano 66
Time
1957 1958 1959 1960 1961
300
400
500
600
700
Time
6 7 8 9
050
0010
000
1500
0
0.0 0.5 1.0 1.5
−0
.20
.00
.20
.40
.60
.81
.0
Lag
AC
F
residus
0.0 0.5 1.0 1.5
−0
.20
.00
.20
.40
.60
.81
.0
Lag
AC
F
residus
Fig. 9.1. Série du tra�c aérien et série des ventes de champagne :ajustement d'un SARIMA et prévision

Bibliographie
[1] Brockwell P. J. , Davis R. A. (1991) Time Series : Theory and Methods. Springer.
[2] Gardner E.S Jr. Exponential Smoothing : The State of the Art. Journal of Forcasting, 4(1) :1�28, 1985.
[3] Gourieroux C.- Monfort A. Cours de series temporelles. Economica, 1983.
[4] Mélard G. (1990) Méthodes de prévision à cour terme. Ed. Ellipses.
67


















