
M2 Informatique – DAC – ASWS...
65
M2 Informatique DAC ASWS 2018/2019 Bernd Amann M2 Informatique DAC ASWS 2018/2019 Apprentissage Symbolique et Web SØmantique Bernd Amann SU 22 octobre 2018 293 / 357
-
Upload
nguyendang -
Category
Documents
-
view
213 -
download
0
Transcript of M2 Informatique – DAC – ASWS...

M2 Informatique DAC – ASWS 2018/2019 – – Bernd Amann
M2 Informatique – DAC – ASWS 2018/2019Apprentissage Symbolique et Web Sémantique
Bernd Amann
SU
22 octobre 2018
293 / 357

M2 Informatique DAC – ASWS 2018/2019 – – Bernd Amann
Systèmes RDF
1 Services de données RDF
2 Triple stores « SQL »
3 Systèmes RDF « noSQL »
4 Systèmes RDF fédérés
294 / 357

M2 Informatique DAC – ASWS 2018/2019 – Services de données RDF – Bernd Amann
Outline
1 Services de données RDF
2 Triple stores « SQL »
3 Systèmes RDF « noSQL »
4 Systèmes RDF fédérés
295 / 357

M2 Informatique DAC – ASWS 2018/2019 – Services de données RDF – Bernd Amann
Services de données RDFServices d’un système de données RDF
stockage et interrogation de graphes RDFimportation / exportation : fichiers RDF↔ graphes RDF« endpoint » SPARQL : interrogation à distance (service web/REST)service d’inférence RDFS et/ou OWL;interfaces de mises-à-jour (SPARQL Update)
Défis liés à la performance
taille des graphes ∼ nombre de triplets RDFoptimisation des requêtes (surtout le traitement des jointures)complexité des schéma RDFS et/ou ontologies OWL
inférence (matérialisation) avant l’interrogation→ taille des donnéesinférence (dynamique) pendant l’interrogation→ optimisation de requêtes
296 / 357

M2 Informatique DAC – ASWS 2018/2019 – Services de données RDF – Bernd Amann
Classification des systèmes RDFSystèmes RDF « non-natifs » : réutilisation
réutilisation de technologies existantes (relationnel, noSQL) :réutilisation au niveau logique : représentation de graphes dans des tables ettraduction de requêtes SPARQL en requêtes SQLréutilisation au niveau physique : structures d’index (arbres-B), opérateursphysiques (sélection, jointures, ...)
exemples : RDF-3X, Jena, Virtuoso, Graph DB, HBase/MapReduce,SPARK/Sparql SQL
Systèmes RDF « natifs » : spécialisation
systèmes spécialisés pour le traitement de données RDFreprésentation physique spécialisée (nouvelle)opérateurs conçus pour le traitement de graphes RDF
exemples : Sesame/rdf4j, WaterFowl, gStore
La séparation entre systèmes « natifs » et « non-natifs » n’est pas tou-jours évidente.
297 / 357

M2 Informatique DAC – ASWS 2018/2019 – Services de données RDF – Bernd Amann
Critères de comparaison de systèmes
Comment comparer les systèmes?
coûts de stockage du graphe (occupation disque/mémoire)coûts d’importation / pré-traitement de données (indexation,compression)coûts d’évaluation des requêtes (jointures !)mode de persistance : disque versus mémoire, distribution et réplicationcomplexité de déploiement : architecture, configuration du systèmeparallélisation des traitements
298 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Bernd Amann
Outline
1 Services de données RDF
2 Triple stores « SQL »
3 Systèmes RDF « noSQL »
4 Systèmes RDF fédérés
299 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Bernd Amann
SPARQL et SQLObjectif
Utiliser un moteur SQL pour évaluer des requêtes SPARQL :optimiseur : traduire requêtes SPARQL en SQL→ optimisation et évaluationSQLopérateurs physiques et index : traduire requêtes SPARQL en plan d’exécution→ optimisation SPARQL et évaluation SQL
→ définir un schéma de stockage relationnel pour des données RDF
Schéma de stockage relationnel pour RDF
schémas de stockage génériques :schémas relationnels fixes et indépendants du schéma RDFS (classes et propriétés)
schémas de stockage partitionnés :schémas relationnels dépendant du schéma RDFS (classes et propriétés)partitionnement structurelle du graphe en plusieurs tables
schémas de stockages étendus :modèle relationnel étendu (relationnel-objet, SQL3)structures et opérateurs (fonctions) spécifiques pour l’interrogation de graphes RDF
300 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage génériques Bernd Amann
2 - Triple stores « SQL »
Schémas de stockage génériquesSchémas de stockage partitionnéesSchémas de stockage étendus
301 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage génériques Bernd Amann
Solution 1 : Table de triplets
Schéma de stockage générique
une seule table principale : Triples(subject, property, object)tables « support » (dictionnaire) et indexVirtuoso, Jena, Sesame, 3store, Kaon, RStar
Avantages
importation / exportation simple et rapide (triplet = nuplet)traitement uniforme des données RDF et schémas RDFSreprésentation « naturelle » de propriétés multivaluées et optionnelles
Inconvénients
beaucoup d’auto-jointures sur une grande table
302 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage génériques Bernd Amann
Motifs simples = jointures SQLRequête optional1
PREFIX : < h t t p : / / example . org / ns#>SELECT ? t i t l e ?pr i ceFROM <bib l iosem . t t l >
WHERE { ?x : t i t l e ? t i t l e .?x : p r i ce ?pr i ce . }
Expression algébrique de optional1
( p r e f i x ( ( : < h t t p : / / example . org / ns# > ) )( p r o j e c t ( ? t i t l e ?pr i ce )
( bgp( t r i p l e ?x : t i t l e ? t i t l e )( t r i p l e ?x : p r i c e ?pr i ce )
) ) )
SQL
s e l e c t t1 . ob jec t as t i t l e ,t2 . ob jec t as p r i ce
from T r i p l e s t1 , T r i p l e s t2where t1 . p roper ty = ’ : t i t l e ’
and t2 . p roper ty = ’ : p r i c e ’and t1 . sub jec t = t2 . sub jec t ;
ou
s e l e c t t1 . ob jec t as t i t l e ,t2 . ob jec t as p r i ce
from T r i p l e s t1 j o i n T r i p l e s t2on ( t1 . sub jec t = t2 . sub jec t )
where t1 . p roper ty = ’ : t i t l e ’and t2 . p roper ty = ’ : p r i c e ’ ;
303 / 357
M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage génériques Bernd Amann
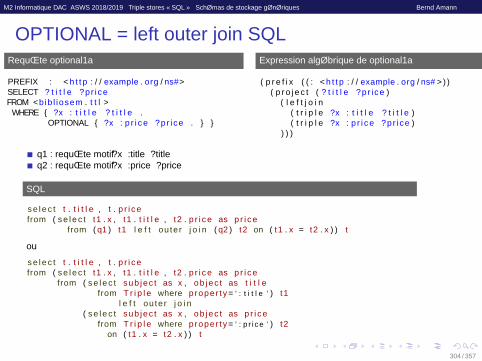
OPTIONAL = left outer join SQLRequête optional1a
PREFIX : < h t t p : / / example . org / ns#>SELECT ? t i t l e ?pr i ceFROM <bib l iosem . t t l >
WHERE { ?x : t i t l e ? t i t l e .OPTIONAL { ?x : p r i ce ?pr i ce . } }
Expression algébrique de optional1a
( p r e f i x ( ( : < h t t p : / / example . org / ns# > ) )( p r o j e c t ( ? t i t l e ?pr i ce )
( l e f t j o i n( t r i p l e ?x : t i t l e ? t i t l e )( t r i p l e ?x : p r i c e ?pr i ce )
) ) )
q1 : requête motif ?x :title ?titleq2 : requête motif ?x :price ?price
SQL
s e l e c t t . t i t l e , t . p r i cefrom ( s e l e c t t1 . x , t1 . t i t l e , t2 . p r i ce as p r i ce
from ( q1 ) t1 l e f t ou ter j o i n ( q2 ) t2 on ( t1 . x = t2 . x ) ) t
ou
s e l e c t t . t i t l e , t . p r i cefrom ( s e l e c t t1 . x , t1 . t i t l e , t2 . p r i ce as p r i ce
from ( s e l e c t sub jec t as x , ob jec t as t i t l efrom T r i p l e where proper ty= ’ : t i t l e ’ ) t1
l e f t ou ter j o i n( s e l e c t sub jec t as x , ob jec t as p r i ce
from T r i p l e where proper ty= ’ : p r i ce ’ ) t2on ( t1 . x = t2 . x ) ) t
304 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage génériques Bernd Amann
OPTIONAL imbriquéRequête optional5
PREFIX : < h t t p : / / example . org / ns#>SELECT ? t i t l e ? e d i t o r ?address
FROM <bib l iosem . t t l >WHERE { ?x : t i t l e ? t i t l e .
OPTIONAL { ?x : e d i t o r ? e d i t o rOPTIONAL { ? e d i t o r : address ?address } } }
q1 : requête motif ?x :title ?titleq2 : requête motif ?x :editor ?editorq3 : requête motif ?editor :address ?address
q1 ./ q2 ./ q3
SQL
s e l e c t t . t i t l e t . e d i t o r t . addressfrom ( s e l e c t t1 . x , t1 . t i t l e , t2 . e d i t o r
from q1 t1 l e f t ou ter j o i n( s e l e c t t2 . x , t2 . ed i t o r , t3 . addressfrom q2 t2 l e f t ou ter j o i n q3 t3
on ( t3 . e d i t o r = t2 . e d i t o r ) ) taon ( t1 . x = t2 . x ) ) t
305 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage partitionnées Bernd Amann
2 - Triple stores « SQL »
Schémas de stockage génériquesSchémas de stockage partitionnéesSchémas de stockage étendus
306 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage partitionnées Bernd Amann
Solution 2 : Tables partitionnéesSchéma de stockage partitionné
une table par type de propriété : Propertyi (Subject, Object)exemple : SW-Store [Abadi et.al. 07].
Avantages
import/export simple et rapide (triplet=nuplet)représentation « naturelle » de propriétés multivalués et optionnellesréutilisation de la technologie column tables (Vertica / Monet DB)jointures efficaces : tables trié par le sujet et merge-join
Inconvénients
beaucoup de jointuresnombre de tables importantes (beaucoup de « petites » tables)
307 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage partitionnées Bernd Amann
Schéma spécifique : Tables partitionnéesRequête simple1
PREFIX : < h t t p : / / example . org / ns#>SELECT ? t i t l e ?pr i ce ? e d i t o rFROM <bib l iosem . t t l >
WHERE { ?x : t i t l e ? t i t l e .?x : e d i t o r ? e d i t o r .?x : p r i c e ?pr i ce . }
SQL
s e l e c t t1 . t i t l e , t2 . ed i t o r , t3 . e d i t o rfrom t i t l e t1 , e d i t o r t2 , p r i ce t3
where t1 . sub jec t = t2 . sub jec tand t2 . sub jec t = t3 . sub jec t
308 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage partitionnées Bernd Amann
Solution 3 : Tables de propriétés
Schéma de stockage partitionné
regroupement (clustering) de sujets partageant des propriétésplusieurs tables : Proptablei (Subject, Property1, ..., Propertyn)
Avantages
fragmentation des données en plusieurs tablesregroupement de propriétés qui sont souvent interrogées ensembles→moins d’autojointures
Inconvénients
les propriétés partagées entre tables génèrent des unionsles propriétés multivalués ou optionnelles génèrent des valeurs NULL(ou des tables séparées)
309 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage partitionnées Bernd Amann
Tables de propriétés : Deux variantes
Cluster de propriétés
Propclusteri (Sujet, Property1, Property2, ..., Propertyn)le type RDF (classe) de la ressource est une propriété parmi d’autres.chaque propriété apparaît dans une seule table.
Classes de propriétés
Propclassei (Sujet, Property1, Property2, ..., Propertyn)classe RDFS = table relationnelleune propriété peut apparaître dans plusieurs tables.
310 / 357
M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage partitionnées Bernd Amann
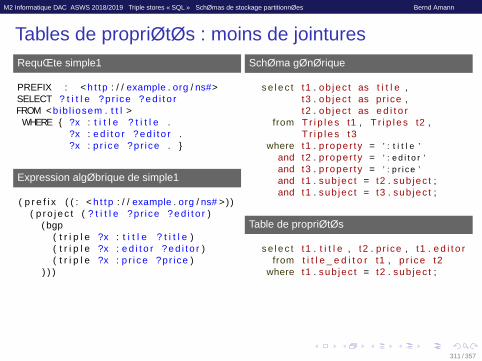
Tables de propriétés : moins de jointuresRequête simple1
PREFIX : < h t t p : / / example . org / ns#>SELECT ? t i t l e ?pr i ce ? e d i t o rFROM <bib l iosem . t t l >
WHERE { ?x : t i t l e ? t i t l e .?x : e d i t o r ? e d i t o r .?x : p r i ce ?pr i ce . }
Expression algébrique de simple1
( p r e f i x ( ( : < h t t p : / / example . org / ns# > ) )( p r o j e c t ( ? t i t l e ?pr i ce ? e d i t o r )
( bgp( t r i p l e ?x : t i t l e ? t i t l e )( t r i p l e ?x : e d i t o r ? e d i t o r )( t r i p l e ?x : p r i ce ?pr i ce )
) ) )
Schéma générique
s e l e c t t1 . ob jec t as t i t l e ,t3 . ob jec t as pr ice ,t2 . ob jec t as e d i t o r
from T r i p l e s t1 , T r i p l e s t2 ,T r i p l e s t3
where t1 . p roper ty = ’ : t i t l e ’and t2 . p roper ty = ’ : e d i t o r ’and t3 . p roper ty = ’ : p r i c e ’and t1 . sub jec t = t2 . sub jec t ;and t1 . sub jec t = t3 . sub jec t ;
Table de propriétés
s e l e c t t1 . t i t l e , t2 . p r ice , t1 . e d i t o rfrom t i t l e _ e d i t o r t1 , p r i ce t2
where t1 . sub jec t = t2 . sub jec t ;
311 / 357
M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage partitionnées Bernd Amann
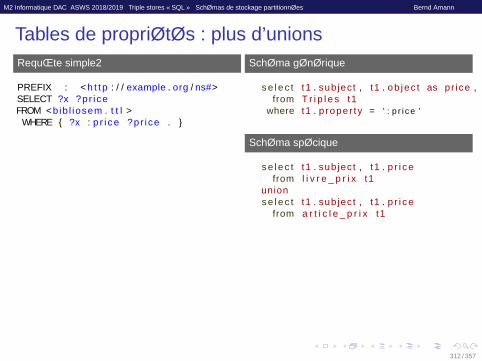
Tables de propriétés : plus d’unionsRequête simple2
PREFIX : < h t t p : / / example . org / ns#>SELECT ?x ?pr i ceFROM <bib l iosem . t t l >
WHERE { ?x : p r i ce ?pr i ce . }
Schéma générique
s e l e c t t1 . sub jec t , t1 . ob jec t as pr ice ,from T r i p l e s t1
where t1 . p roper ty = ’ : p r i c e ’
Schéma spécifique
s e l e c t t1 . sub jec t , t1 . p r i c efrom l i v r e _ p r i x t1
unions e l e c t t1 . sub jec t , t1 . p r i c e
from a r t i c l e _ p r i x t1
312 / 357
M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage étendus Bernd Amann
2 - Triple stores « SQL »
Schémas de stockage génériquesSchémas de stockage partitionnéesSchémas de stockage étendus
313 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage étendus Bernd Amann
Exemple : Oracle RDF
application du “Spatial Network Data Model” (Spatial NDM)graphe RDF = réseau logiquedeux packages :
SDO_RDF : manipulation de graphes RDF (modèles)SDO_RDF_INFERENCE : inférence et règles
314 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage étendus Bernd Amann
Schéma RDF étendu dans Oracle 10gDeux types abstraits
Interface SQL :SDO_RDF_TRIPLE (affichage)SDO_RDF_TRIPLE_S (stockage)
Plusieurs tables annexes
RDF_LINK$(LINK_ID, P_VALUE_ID, START_NODE_ID, END_NODE_ID,LINK_TYPE, ACTIVE, CONTEXT, REIF_LINK, MODEL_ID)RDF_MODEL$(MODEL_ID, MODEL_NAME)RDF_NAMESPACE$(NAMESPACE_ID, NAMESPACE_NAME)RDF_VALUE$(VALUE_ID,VALUE_NAME, VALUE_TYPE, LITERAL_TYPE) :
les URIs et valeurs sont stockées dans une table séparéeVALUE_TYPE : URI, blank node, literal (plain, typed)
RDF_NODE$(NODE_ID, ACTIVE)RDF_BLANK_NODE$(NODE_ID, NODE_VALUE, ORIG_NAME, MODEL_ID)
(invisibles pour le développeur)
315 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage étendus Bernd Amann
Utilisation du package SDO_RDF
Fonctionnalités principales
Génération d’un graphe RDF :création d’une table T avec un attribut de type SDO_RDF_TRIPLE_Spour stocker interroger des triplets RDF.création d’un modèle (graphe) RDF G : CREATE_RDF_MODEL :génération des tables annexes.
insertion / suppression de triplets RDF dans la table T : INSERT /DELETEinterrogation motifs SPARQL : requête SQL sur des tables générées parSDO_RDF_MATCH sur G
Autres fonctionnalités
gestion d’espaces de noms, collections, noeuds blancs, réification
316 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage étendus Bernd Amann
Exemple : Création Graphe Vide
Création d’une table pour stocker les triplets
CREATE TABLE fam i l y_ rd f_da ta (i d NUMBER,t r i p l e SDO_RDF_TRIPLE_S ) ;
Création des tables annexes
SDO_RDF.CREATE_RDF_MODEL( model_name ,table_name , column_name ) ;
Exemple
EXECUTE SDO_RDF.CREATE_RDF_MODEL( ’ f a m i l y ’ ,’ f am i l y_ rd f_da ta ’ , ’ t r i p l e ’ ) ;
317 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage étendus Bernd Amann
Le type SDO_RDF_TRIPLE_S
SDO_RDF_TRIPLE_S
Type abstrait pour triplets RDF.
Méthodes SDO_RDF_TRIPLE_S
SDO_RDF_TRIPLE_S(model, subject, property, object)constructeur
SDO_RDF_TRIPLE_S.GET_TRIPLE()SDO_RDF_TRIPLE_S.GET_SUBJECT()SDO_RDF_TRIPLE_S.GET_PROPERTY()SDO_RDF_TRIPLE_S.GET_OBJECT()
318 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage étendus Bernd Amann
Exemple : Insertion triplets
INSERT INTO fam i l y_ rd f_da ta VALUES (1 ,SDO_RDF_TRIPLE_S( ’ f a m i l y ’ ,
’ h t t p : / / www. example . org / f a m i l y / John ’ ,’ h t t p : / / www. example . org / f a m i l y / f a the rO f ’ ,’ h t t p : / / www. example . org / f a m i l y / Suzie ’ ) ) ;
INSERT INTO fam i l y_ rd f_da ta VALUES (20 ,SDO_RDF_TRIPLE_S( ’ f a m i l y ’ ,
’ h t t p : / / www. example . org / f a m i l y / Male ’ ,’ r d f s : subClassOf ’ ,’ h t t p : / / www. example . org / f a m i l y / Person ’ ) ) ;
INSERT INTO fam i l y_ rd f_da ta VALUES (25 ,SDO_RDF_TRIPLE_S( ’ f a m i l y ’ ,
’ h t t p : / / www. example . org / f a m i l y / s i b l i n g O f ’ ,’ r d f : type ’ ,’ r d f : Proper ty ’ ) ) ;
319 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage étendus Bernd Amann
Évaluation de Motifs de GraphesFonction SDO_RDF_MATCH
SDO_RDF_MATCH(query VARCHAR2,models SDO_RDF_MODELS, ru lebases SDO_RDF_RULEBASES,a l i ases SDO_RDF_ALIASES,f i l t e r VARCHAR2
) RETURN ANYDATASET;
Exemple
SELECT mFROM TABLE(SDO_RDF_MATCH(
’ (?m r d f : type : Male ) ’ ,SDO_RDF_Models ( ’ f a m i l y ’ ) , n u l l ,SDO_RDF_Aliases ( SDO_RDF_Alias ( ’ ’ , ’ h t t p : / / www. example . org / f a m i l y / ’ ) ) ,
n u l l ) ) ;
Réponse
M−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−h t t p : / /www. example . org / f a m i l y / Jackh t t p : / /www. example . org / f a m i l y /Tom
320 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage étendus Bernd Amann
Utilisation du package SDO_RDF_INFERENCESDO_RDF_INFERENCE
Package pour la définition et l’exécution de règles RDF.
Application
création de bases de règles : CREATE_RULEBASEinsertion / suppression de règles : INSERT / DELETEapplication de règles (matérialisation) : CREATE_RULES_INDEX
forward chaining : génération de l’ensemble de triplets qu’on peut déduire à partir desrègles
Bases de règles par défaut (Oracle 11gR2)
RDFS : RDF/RDFS entailmentRDFS++ : RDFS et owl :InverseFunctionalProperty, owl :sameAsOWLSIF : RDFS++ et owl :FunctionalProperty, owl :SymmetricProperty,owl :TransitiveProperty, owl :inverseOf, owl :equivalentClass,owl :equivalentProperty, owl :hasValue, owl :someValuesFrom,owl :allValuesFromOWLPrime : OWLSIF + owl :disjointWith, owl :complementOfOWL2RL http://www.w3.org/TR/owl-profiles/#OWL_2_RL
321 / 357

M2 Informatique DAC – ASWS 2018/2019 – Triple stores « SQL » – Schémas de stockage étendus Bernd Amann
Exemple : Interrogation avec Inférence
Règles utilisateurs
EXECUTE SDO_RDF_INFERENCE.CREATE_RULEBASE( ’ f am i l y_ rb ’ ) ;INSERT INTO MDSYS.RDFR_FAMILY_RB VALUES(
’ g randparent_ru le ’ ,’ (? x : parentOf ?y ) (? y : parentOf ?z ) ’ ,NULL, ’ (? x : grandParentOf ?z ) ’ ,SDO_RDF_Aliases ( SDO_RDF_Alias ( ’ ’ ,
’ h t t p : / / www. example . org / f a m i l y / ’ ) ) ) ;
Requêtes avec Inférence
SELECT m FROM TABLE(SDO_RDF_MATCH( ’ (?m r d f : type : Male ) ’ ,SDO_RDF_Models ( ’ f a m i l y ’ ) ,SDO_RDF_Rulebases ( ’RDFS ’ ) ,SDO_RDF_Aliases ( SDO_RDF_Alias ( ’ ’ ,
’ h t t p : / / www. example . org / f a m i l y / ’ ) ) , n u l l ) ) ;
322 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF « noSQL » – Bernd Amann
Outline
1 Services de données RDF
2 Triple stores « SQL »
3 Systèmes RDF « noSQL »
4 Systèmes RDF fédérés
323 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF « noSQL » – RDF et noSQL Bernd Amann
3 - Systèmes RDF « noSQL »
RDF et noSQLSystèmes RDF/noSQLRDF/SPARQL en MapReduce
324 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF « noSQL » – RDF et noSQL Bernd Amann
Systèmes not-only SQLDonnées RDF
données volumineuses, complexes et faiblement structuréesrequêtes complexes (motifs de graphes)cohérence faible (données web, schéma = description)
Systèmes « SQL »
structuration forte : schéma = contraintesalgèbre physique complexe→ distribution et parallélisation difficilegestion de cohérence coûteuse (ACID)
Systèmes « noSQL »
favoriser la scalabilité et la disponibilitéstructuration faible : schéma = description et validation des donnéescohérence à terme (eventual consistency) au lieu de cohérence forte (lecture/écriture)
Les systèmes noSQL sont bien adaptés pour le stockage et l’interrogation detrès grands graphes RDF.
325 / 357
M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF « noSQL » – Systèmes RDF/noSQL Bernd Amann
3 - Systèmes RDF « noSQL »
RDF et noSQLSystèmes RDF/noSQLRDF/SPARQL en MapReduce
326 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF « noSQL » – Systèmes RDF/noSQL Bernd Amann
Column StoresSystèmes no-SQL
Bigtable/Google, Hbase/Apache, Cassandra/Apache, SimpleDB
Modèle
tables avec familles de colonnes / couples (clé,valeur) imbriquéskeyspace→ column family (table)→ row key (ligne)→ column key (attribut)→valeurindexation par « hachage cohérent » sur un anneau
Avantages et Inconvénients
+ favorise la cohérence et la tolérance aux pannes- complexité de la mise-en-oeuvre
Column Stores RDF
20 (Hexastore + HBase), CumulusRDF [21] (Cassandra), Stratusstore [22](SimpleDB)
327 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF « noSQL » – Systèmes RDF/noSQL Bernd Amann
Document Stores
Systèmes
Lotus notes, mongodb/10gen, couchDB/Apache, Terrastore, JSON stores
Modèle
collection de documents indépendants et identifiés par des clésdocument = instance JSON : imbrication, liste, ...
Avantages et Inconvénients
+ contrôle sur la fragmentation de données en documents indépendants- distribution à la charge du développeur (sharding)
Document Stores RDF
rdf-couchdb, MongoDB-RDF
328 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF « noSQL » – Systèmes RDF/noSQL Bernd Amann
Graph DB
Systèmes
Neo4j, InfiniteGraph, Trinity (Microsoft), FlockDB
Modèle
graphes dirigés et étiquetés
Avantages et Inconvénients
+ implémentation « directe » du modèle graphe RDF : jointure parnavigation, expressions de chemins
- parallélisation compliquée : partitionnement de graphes
Graph Stores RDF
Neo4J (support natif de SPARQL), gStore, AMBER
329 / 357
M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF « noSQL » – RDF/SPARQL en MapReduce Bernd Amann
3 - Systèmes RDF « noSQL »
RDF et noSQLSystèmes RDF/noSQLRDF/SPARQL en MapReduce
330 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF « noSQL » – RDF/SPARQL en MapReduce Bernd Amann
Performance et passage à l’échelleScalabilité
Implémenter des systèmes RDF qui sont capables d’adapter « enproportion » leurs besoins en ressources aux demandes (requêtes) et auxvolumes de données RDF à gérer.
Scalabilité⇔ distribution et parallélisation
Partitionnement et distribution des données :schémas de stockage partitionnés (hash, graph)indexation distribuée
Évaluation parallèle de requêtes (jointures)
Problème d’optimisation
Deux problèmes équivalents :Minimiser l’échange de données (shuffling) entre les noeudsMaximiser la localité des données par rapport aux traitements
331 / 357
M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF « noSQL » – RDF/SPARQL en MapReduce Bernd Amann
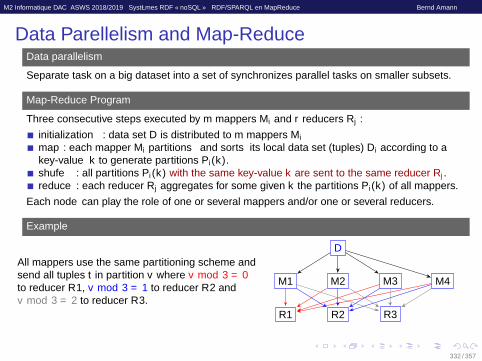
Data Parellelism and Map-ReduceData parallelism
Separate task on a big dataset into a set of synchronizes parallel tasks on smaller subsets.
Map-Reduce Program
Three consecutive steps executed by m mappers Mi and r reducers Rj :initialization : data set D is distributed to m mappers Mimap : each mapper Mi partitions and sorts its local data set (tuples) Di according to akey-value k to generate partitions Pi(k).shuffle : all partitions Pi(k) with the same key-value k are sent to the same reducer Rj .reduce : each reducer Rj aggregates for some given k the partitions Pi(k) of all mappers.
Each node can play the role of one or several mappers and/or one or several reducers.
Example
All mappers use the same partitioning scheme andsend all tuples t in partition v where v mod 3 = 0to reducer R1, v mod 3 = 1 to reducer R2 andv mod 3 = 2 to reducer R3.
D
M1 M2 M3 M4
R1 R2 R3
332 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF « noSQL » – RDF/SPARQL en MapReduce Bernd Amann
Map-Reduce Joins and Graph PatternsMap-Reduce and RDF
RDF data set can be partitioned and distributed over a given set of computation nodesGraph pattern ∼ many joins
Observations
Map-Reduce step naturally implements a « join » on the hash values.Joins with Map-Reduce is a well-known problem;Two main join processing strategies : partitioned join and broadcast (replicated) join
Example
All mappers partition their tupes on joinattribtute a and send all tuples in partitiont .a = v where t .a mod 3 = 0 to reducerR1, t .a mod 3 = 1 to reducer R2 andt .a mod 3 = 2 to reducer R3.
D
M1 M2 M3 M4
R1 R2 R3
333 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF « noSQL » – RDF/SPARQL en MapReduce Bernd Amann
Partitioned Triple joinJoin t 1?x t ′
initialization (executed once) : data set D is distributed to the mappers Mi .map : each mapper Mi partitions the triples matching patterns t and t ′ according to thebindings k of variable ?x to generate partitions Pi(t , k) and Pi(t ′, k).shuffle : all partitions Pi(t , k) and Pi(t ′, k) with the same key-value k are sent to the samereducer Rj .reduce : reducer Rj joins the partitions Pi(t , k) and Pi(t ′, k) received from all mappers Mifor a given join value k of .
Example : t=(?x :p :r1), t’=(?a :q ?x)
all results for triple patterns (?x :p :r1 and (?a :q ?x) contaning the same binding for ?xare sent to the same reducer R which computes the join.data transfer cost : O(b + b′) where b and b′ is the size of all bindings for both patterns tand t ′.the result is partitioned on ?x
Data locality depends on initialization step
For example, if all triples with the same subject s are distributed to the same mapper nodeM(s) and each mapper node M(s) is also the reducer M(s) = R(s) of the triples with subjectS ⇒ star queries are executed locally (without any data exchange)
334 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF « noSQL » – RDF/SPARQL en MapReduce Bernd Amann
Broadcast joinJoin t 1?x t ′
initialization (executed once) : data set D is distributed to the mappers Mi .map : each mapper Mi partitions the triples matching patterns t according to thebindings k of variable ?x to generate partitions Pi(t , k) and Pi(t ′, k).shuffle : each mapper Mi broadcasts the partition corresponding to the smallerdata set, say Pi(t , k), to all computation nodes (reducers).reduce : each reducer Rj joins all received partitions Pi(t , k) bindings with itslocal partition Pj(t ′, k).
Example : t=(?x :p :r1), t’=(?a :q ?x)
for a given node (mapper) N, all bindings produced by N for triple pattern t(small) are sent to all nodes (reducers) which compute the join.data transfer cost : O(b ∗ n) where b is the size of bindings for t and n is thenumber of computation nodes.the result preserves the initial (target) partitioning.
335 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF « noSQL » – RDF/SPARQL en MapReduce Bernd Amann
Example : RDF-3X + Hadoop [9]
Data distribution
partition RDF graph : METIS graph partitionereach Hadoop node stores one or several partitions in a local RDF-3Xinstance(partial) replication to reduce inter-machine communication (N-hopguarantee)
Parallel query processing
Query is parallelizable without communication?yes : result = union of locally evaluated sub-queriesno :
1 decompose query pattern into subqueries (minimal edge partionining ofquery graph)
2 evaluate subqueries3 integrate subquery results globally
336 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF « noSQL » – RDF/SPARQL en MapReduce Bernd Amann
RDF-3X + Hadoop : Node Cut PartitioningGraphe RDF
:r1 :r2 :r3 :r4 :r13
:r6 :r7 :r8 :r5
:r9 :r10 :r11 :r12
:p:q :r
:s
:t
:r:q
:p
:t
:s
:t
:r
:s
trois partitions :
p1 p2 p3
les noeuds repliqués sonten rouge (1-hopreplication).
Motifs SPARQL
M1 :
?b
?a
?c
:r
:s
M2 :
?b
?a ?c ?d
?e
:r:t :t
:s
M1 : évaluation localementdans les trois partitions etunion des mappingsobtenusM2 : décomposition ensous-motifs qui sontévalués localement ; leursréponses sont jointsglobalement.
337 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF fédérés – Bernd Amann
Outline
1 Services de données RDF
2 Triple stores « SQL »
3 Systèmes RDF « noSQL »
4 Systèmes RDF fédérés
338 / 357
M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF fédérés – LOD et SPARQL endpoints Bernd Amann
4 - Systèmes RDF fédérés
LOD et SPARQL endpointsExemple : SPLENDID
339 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF fédérés – LOD et SPARQL endpoints Bernd Amann
LOD
Linked Open Data Cloud
http://lod-cloud.net/
graphe de 1 224 datasets RDFreliés par 16 113 liens (Juin 2018)chaque dataset RDF évolueindépendamment et est lié àd’autres dataset RDFrafraîchir les donnéesrégulièrement est coûteux→architectures fédérées
"Linking Open Data cloud diagram 2017, by Andrejs Abele, John P. McCrae, PaulBuitelaar, Anja Jentzsch and Richard Cyganiak. http ://lod-cloud.net/"
340 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF fédérés – LOD et SPARQL endpoints Bernd Amann
SPARQL EndpointsSPARQL endpoint
Service Web (REST) qui exécute des requêtes SPARQL sur un datasetRDF :
HTTP GET avec requête SPARQL comme paramètrerésultat en XML, JSON, Turtle, textAPIs : PHP (ARC, RAP), Java (ARQ-Jena, Sesame), Python(PySPARQL, SPARQL wrapper)
Exemples
https://www.wikidata.org/wiki/Wikidata:SPARQL_query_service
http://data.gov/
http://www4.wiwiss.fu-berlin.de/dblp/
http://dbpedia.org/
Liste : https://www.w3.org/wiki/SparqlEndpoints341 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF fédérés – LOD et SPARQL endpoints Bernd Amann
Interroger plusieurs SPARQL endpoints
1 programmes avec des requêtes paramétrées : bouclesrequêtes/sous-requêtes+ données à jour- inefficace : composition de requêtes ad-hoc par un programme
2 SPARQL endpoint universel qui réunit plusieurs RDF datasets(http://lod.openlinksw.com/sparql)+ efficace : données locales, optimisation SPARQL- données obsolètes
3 systèmes RDF « fédérés » qui optimisent et propagent les requêtes+ données à jour+ optimisation de requêtes distribuées- mise-en-place complexe
342 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF fédérés – LOD et SPARQL endpoints Bernd Amann
Architectures d’intégration de données RDF
1 entrepôts de données RDF :chargement de datasets dans un serveur centralisé ;données, indexation et interrogation localesOpenLink Virtuoso, AllegroGraph, Jena TDB, Stardog
2 systèmes fédérés :fédération de serveurs RDF (endpoints SPARQL)données distribuées, index centralisé, interrogation distribuéeFedX, SPLENDID, Anapsid, Avalanche
3 protocole « link-traversal » :exploration dynamique du graphe pendant l’interrogationdonnées distribuées, pas d’index, interrogation distribuée
4 réseaux pair-à-pairréseau P2P structuré (overlay network, DHT)données, indexation et interrogation distribuésRDFPeers, Atlas
343 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF fédérés – LOD et SPARQL endpoints Bernd Amann
Distribution de données RDF
Distribution de données RDF
RDF permet de différents « schémas de distribution » :toutes les propriétés et valeurs (objets) d’une entité (sujet) sont localesavec des liens owl:sameAs vers des entités distants ;toutes les propriétés d’une entité sont locales avec des valeurs (objets)locales et distants ;les propriétés et valeurs d’une entité (sujet) sont distribuées librement ;
Défis
Chaque type de distribution nécessite des solutions spécifiques pourdécouvrir/identifier les sources (SPARQL endpoint) pertinentes pourune requêteréécrire, optimiser et évaluer les requêtes
344 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF fédérés – LOD et SPARQL endpoints Bernd Amann
Systèmes RDF fédérés : cataloguesCatalogue de sources
statique : catalogue de sources (portail http://thedatahub.org)dynamique : moteur de recherche RDF (Sindice)
Catalogue de données
Description du contenu des sources :les classes et propriétés couvertes avec des statistiques (schema index)les chemins de propriétés couverts (structure index)des informations sur les instances (par ex., histogramme de valeurs)
Informations difficiles et coûteuses à obtenir et à maintenir :publication par les serveurscollecte dynamique (requêtes SPARQL) par les clients (cache)
Problème : manque de standard de publication.
345 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF fédérés – Exemple : SPLENDID Bernd Amann
4 - Systèmes RDF fédérés
LOD et SPARQL endpointsExemple : SPLENDID
346 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF fédérés – Exemple : SPLENDID Bernd Amann
Évaluation de requêtes
catalogue de sources/données : statique ; format VOIDsélection des sources : schema index, requêtes ASKoptimisation de requêtes (modèle de coût)exécution de requêtes : bind join, hash join
347 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF fédérés – Exemple : SPLENDID Bernd Amann
Sélection de sources
IP : propriétés→ sourcesIt : types (classes)→ sourcesrésultat : motif de triplet→ sources
348 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF fédérés – Exemple : SPLENDID Bernd Amann
Évaluation de motifs de graphes I
Algorithme général
Entrée : un motif de graph P = {t1, ..., tn} où chaque motif de triplet ti estlié à un ensemble de sources D(ti) ⊆ D :
Étapes :1 décomposition : générer des partitionnements Π de P × D en couples
(Pi ,Dj ) où Pi est un sous-graphe connexe (pas de produits cartésiens) etévaluée par la source Dj .
2 pour chaque couple (pi ,Dj ) dans la décomposition Π : évaluer pi sur Dj etjoindre localement avec le résultat intermédiaire
3 résultat : union des résultats partiels obtenus dans les deux étapesprécédentes
349 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF fédérés – Exemple : SPLENDID Bernd Amann
Optimisation de requêtes fédérées
Optimisation de requêtes
trouver des décompositions efficaces (qui calculent le résultat correct)chaque décomposition représente un plan de jointure avec des sourcesdistantes
Problèmes liés à la distribution
coût d’évaluation dominé par le coût de communicationréduire le nombre de sous-requêtes évaluées à distanceréduire la taille des résultats intermédiaires
modèle d’estimationprécision de méta-données/statistiques limitéejointures : estimation des coûts et des tailles des résultats difficiles(variables dépendantes)
350 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF fédérés – Exemple : SPLENDID Bernd Amann
Optimisation : Stratégies de décompositionDécomposition complète
évaluer chaque motif ti sur toutes ses sources D(ti)inefficace : beaucoup de requêtes et de résultats redondants
Décomposition par groupes exclusifs
hypothèse : certains motifs sont couvertes par une seule sourceregrouper les motifs de triplets qui sont couvertes par une seule source
Regroupement par ressources (sujets)
hypothèse : pour chaque ressource (sujet) il existe une source qui couvre toutes ses propriétésregrouper les motifs partageant le même sujet (star queries) et choisir les sources partagées partous ces motifsrésultats potentiellement incomplets (hypothèse trop forte)
Regroupement owl:sameAs
hypothèse : les sources sont connectées uniquement par des liens owl:sameAsregrouper les motifs de triplets (?y owl:sameAs ?z) avec tous les autres motifs contenant lavariable ?y et choisir les sources partagées par tous les motifsrésultats potentiellement incomplets (hypothèse trop forte)
351 / 357

M2 Informatique DAC – ASWS 2018/2019 – Systèmes RDF fédérés – Exemple : SPLENDID Bernd Amann
Optimisation : Jointures distribuées
Objectif
Réduire la taille des données échangées entre le site local et le sitedistant.
Opérateurs de Jointure distribués
semi-join : envoyer uniquement les valeurs de jointure au site distantbloom-join : envoyer un filtre Bloom qui encode les valeurs de jointureau site distantbind-join : nested-loop avec passage de liaisons de variables
352 / 357

M2 Informatique DAC – ASWS 2018/2019 – Bibliographie – Bernd Amann
Bibliographie I1 D. Abadi, A. Marcus, S. Madden and K. Hollenbach. SW-Store : a
vertically partitioned DBMS for Semantic Web data management.VLDBJ 18(2), 2009.
2 Marcelo Arenas, Jorge Pérez, Querying semantic web data withSPARQL, Proceedings of the thirtieth ACM SIGMOD-SIGACT-SIGARTsymposium on Principles of database systems, June 13-15, 2011,Athens, Greece
3 Bornea, Mihaela A., Julian Dolby, Anastasios Kementsietsidis, KavithaSrinivas, Patrick Dantressangle, Octavian Udrea, and BishwaranjanBhattacharjee. Building an Efficient RDF Store over a RelationalDatabase. In Proceedings of the 2013 International Conference onManagement of Data - SIGMOD ’13, 121. New York, New York, USA :ACM Press, 2013.
4 Aluc, Günes, Tamer M. Ozsu, Khuzaima Daudjee, and Olaf Hartig.Executing Queries over Schemaless RDF Databases. Proceedings -International Conference on Data Engineering 2015-May (2015) :807-818.
353 / 357

M2 Informatique DAC – ASWS 2018/2019 – Bibliographie – Bernd Amann
Bibliographie II
5 Chebotko, Artem, Shiyong Lu, and Farshad Fotouhi. SemanticsPreserving SPARQL-to-SQL Translation. Data & KnowledgeEngineering 68, no. 10 (October 2009) : 973-1000.
6 Goasdoué, François, Zoi Kaoudi, Ioana Manolescu, Jorge-ArnulfoQuiané-Ruiz, and Stamatis Zampetakis. CliqueSquare : Flat Plans forMassively Parallel RDF Queries. In 2015 IEEE 31st InternationalConference on Data Engineering, 771-782. IEEE, 2015.
7 C. Guttierez, C. Hurtado, A. Mendelzon, Foundations of Semantic WebDatabases, PODS 2004
8 Harth, Andreas, Katja Hose, and Ralf Schenkel. Database Techniquesfor Linked Data Management. In Proceedings of the 2012 ACMSIGMOD International Conference on Management of Data, 597-600.ACM, 2012.
9 Huang et al : Scalable SPARQL Querying of Large RDF Graphs. VLDB2011
354 / 357

M2 Informatique DAC – ASWS 2018/2019 – Bibliographie – Bernd Amann
Bibliographie III
10 Kaoudi, Zoi, and Ioana Manolescu. RDF in the Clouds : A Survey. TheVLDB Journal 24, no. 1 (2015) : 67-91.
11 Andrés Letelier, Jorge Pérez, Reinhard Pichler, Sebastian Skritek, Staticanalysis and optimization of semantic web queries, ACM Transactionson Database Systems (TODS), v.38 n.4, p.1-45, 2013.
12 H. Naacke, O. Curé, B. Amann, SPARQL query processing with ApacheSpark, arXiv preprint arXiv :1604.08903
13 T. Neumann and G. Weikum. RDF-3X : a RISC-style engine for RDF.VLDBJ 19(1), 2010.
14 Özsu, M. Tamer. A Survey of RDF Data Management Systems.Frontiers of Computer Science, 2016, 1-15.
15 Reinhard Pichler, Sebastian Skritek, Containment and equivalence ofwell-designed SPARQL, Proceedings of the 33rd ACMSIGMOD-SIGACT-SIGART symposium on Principles of databasesystems, June 22-27, 2014, Snowbird, Utah, USA.
355 / 357

M2 Informatique DAC – ASWS 2018/2019 – Bibliographie – Bernd Amann
Bibliographie IV
16 Schätzle, Alexander, Martin Przyjaciel-Zablocki, Simon Skilevic, andGeorg Lausen. S2RDF : RDF Querying with SPARQL on Spark. arXivPreprint arXiv :1512.07021, 2015. http ://arxiv.org/abs/1512.07021.
17 Schmidt, Michael, Michael Meier, and Georg Lausen. Foundations ofSPARQL Query Optimization. In Proceedings of the 13th InternationalConference on Database Theory - ICDT ’10, 4. New York, New York,USA : ACM Press, 2010.
18 Petros Tsialiamanis, Lefteris Sidirourgos, Irini Fundulaki, VassilisChristophides, Peter Boncz, Heuristics-based query optimisation forSPARQL, Proceedings of the 15th International Conference onExtending Database Technology, March 27-30, 2012, Berlin, Germany
19 Lei Zou, M. Tamer Özsu, Lei Chen, Xuchuan Shen, Ruizhe Huang,Dongyan Zhao, gStore : A Graph-based SPARQL Query Engine, VLDBJournal, 23(4) : 565-590, 2014.
20 Sun et al. Scalable RDF Store Based on HBase and MapReduce.ICACTE 2010
356 / 357

M2 Informatique DAC – ASWS 2018/2019 – Bibliographie – Bernd Amann
Bibliographie V
21 G. Ladwig et al. CumulusRDF : Linked Data Management on NestedKey-Value Stores. SSWS 2011
22 R. Stein et al : RDF On Cloud Number Nine. NeFoRS 2010
23 Kaoudi, Zoi, and Ioana Manolescu. Cloud-Based RDF DataManagement. In Proceedings of the 2014 ACM SIGMOD InternationalConference on Management of Data, 725-729. ACM, 2014.
24 Görlitz, O. (2015). Distributed Query Processing for Federated RDFData Management.
357 / 357

















