
E.P.F.C. Chargé de cours: A.Alexandrowicz...
110
E.P.F.C. Chargé de cours: A.Alexandrowicz 2012-2013
Transcript of E.P.F.C. Chargé de cours: A.Alexandrowicz...

E.P.F.C. Chargé de cours: A.Alexandrowicz
2012-2013

Artemus Ward

Origines et définitions «Status», Etat en latin, apparaît en français en 1771. Initialement concerne les affaires de l’Etat
Historique Dès 3000 av J.C. en Mésopotamie, se poursuit en Chine
et dans l’Empire Romain Au XIXe Siècle 1er Congrès International de la Statistique uniformiser les techniques de compilation des statistiques (Adolphe Quételet)

Terminologie Statistiques ≠ Statistique Statistique descriptive v.s. Statistique inductive Population et recensement Les véhicules automobiles immatriculés en Belgique La population des P.M.E. d'un pays Les salariés d'une entreprise Les habitants d'un quartier
Individu, unité statistique

Critères (caractères): propriétés des individus
Ex1: Etude du personnel d’une entreprise d’après leur ancienneté Ex2: Parc automobile d’une entreprise d’après la marque des voitures
Peut être quantitatif (variable statistique) ou qualitatif (caractère statistique): Ex1: poids, taille, résultats d’examen,… Ex2: couleur de carrosserie d’une voiture, la nationalité,…
Variable statistique discrète ou continue EX1: Nombre d’enfants par famille,… Ex2: poids, taille, temps d’appels téléphoniques,…
Echantillon représentatif et sondage Biais statistique

Prédictions du Literary Digest en 1936 à l’aube des élections américaines
Exemple de biais statistique

Série statistique et série chronologique Tableau d’effectifs et/ou effectifs cumulés. Si variable discrète distribution des
fréquences/tableaux recensés Si variable continue distribution groupés des
fréquences/tableaux à classes

« Le statisticien moyen est marié à 1,75 femmes qui font leur possible pour l’éloigner de la maison 2,25 nuits dans la semaine avec seulement 50% de succès. L’inclinaison de son front est de 2% (dénotant une grande fermeté d’esprit), il possède 5/8 d’un compte en banque et 3.06 enfants qui le rendent à demi-fou; 1.65 de ses enfants sont des garçons. Seuls 0.07% de tous les statisticiens sont éveillés à leur petit déjeuner, au cours duquel ils consomment 1.68 tasses de café-et renversent les 0.32 restantes sur leur palstron…Le samedi soir il engage 1/3 de baby -sitter pour ses 3.06 chérubins, à moins qu’il ne soit affublé des 5/8 d’une belle-mère vivant à domicile et qui montera la garde pour la moitié du prix… »
W.F. Miksch(1950)

Exemple de données: on veut savoir le nombre d’examens oraux à présenter en fin d’année par des élèves de première année comptabilité. Données recueillies: 9, 11, 8, 10, 13, 12, 10, 11, 10
Soit n le nombre de valeurs observées d’une variable numérique discrète dont les valeurs possibles, rangées dans l’ordre croissant, sont x1, x2, x3,…xp n est l’effectif de la population( ou de l’échantillon), ici n=9 l’ensemble des données rassemblées sans se soucier de l’ordre
est un série statistique/tableau brut Une suite ordonnée est l’arrangement des données numériques
dans l’ordre croissant ou décroissant L’étendue est la différence entre la plus grande et la plus petite
valeur, ici l’étendue est de 5

La fréquence absolue d’une valeur xi est le nombre ni d’observations égales à xi. Dès lors:
p ∑ni=n
i=1 La fréquence relative fi d’une valeur xi est le rapport
ni /n. Dès lors: p
∑ fi =1 i=1 La fréquence relative est souvent exprimée en %:
fi %= 100 ni/ n

La fréquence (absolue ou relative) cumulée d’une valeur xi est la somme des fréquences( absolues ou relatives) de cette valeur et des valeurs inférieures.
Soit X une variable numérique discrète. On a donc les valeurs suivantes pour:
Freq.abs. cum. Val de X Freq.rel. cum. Ρ0=0 Si X<x1 Φ0=0 Ρ1=n1 Si x1≤X<x2 Φ1=f1
Ρ2 = n1+n2 Si x2≤X<x3 Φ2=f1+ f2
Ρp= n Φp=1

On constate que: Φi=ρi/n
La distribution des fréquences (absolues ou
relatives, cumulées ou non) d’une variable est un tableau contenant les valeurs possibles des cette variable, rangées par ordre croissant et pour chacune de ces valeurs la fréquence (absolue ou relative, cumulée ou non) correspondante. On parle de tableau recensé.

Exemple A partir des données brutes suivantes, établissez la distribution des fréquences correspondante
7 1 5 12 3 6 4 1 8 10 5 8 2 6 0 5 5 4 7 8 4 7 5 6 5 6 8 5 3 3 2 1 3 3 2 7 4 10 6 4

Valeurs de la variable(xi)
Freq. abs(ni)
Freq. relatives (ni/n)
Freq. relatives (%)
Freq. abs cumulées(ρi)
Freq.rel.cumulées(Φi)
Freq.rel. cum. (%)
0 1 0.025 2.50% 1 0.025 2.50% 1 3 0.075 7.50% 4 0.1 10.00% 2 3 0.075 7.50% 7 0.175 17.50% 3 5 0.125 12.50% 12 0.3 30.00% 4 5 0.125 12.50% 17 0.425 42.50% 5 7 0.175 17.50% 24 0.6 60.00% 6 5 0.125 12.50% 29 0.725 72.50% 7 4 0.1 10.00% 33 0.825 82.50% 8 4 0.1 10.00% 37 0.925 92.50% 9 0 0 0.00% 37 0.925 92.50%
10 2 0.05 5.00% 39 0.975 97.50% 11 0 0 0.00% 39 0.975 97.50% 12 1 0.025 2.50% 40 1 100.00%

Représentations graphiques Diagramme en bâtons Consiste à porter en abscisse les valeurs observées xi Tracer en regard de chacune d’elles et parallèlement à
l’axe des ordonnées un segment vertical, appelé bâton, de longueur égal à sa fréquence (absolue ou relative) non cumulée.

Exemple diagramme en bâtons
0
1
2
3
4
5
6
7
8
0 1 2 3 4 5 6 7 8 9 10 11 12
Fréq
uanc
e Ab
solu
e( n
i)
Valeurs de la variable (xi)
Diagramme en bâton des fréquences absolues (ni)
Frequence Absolue
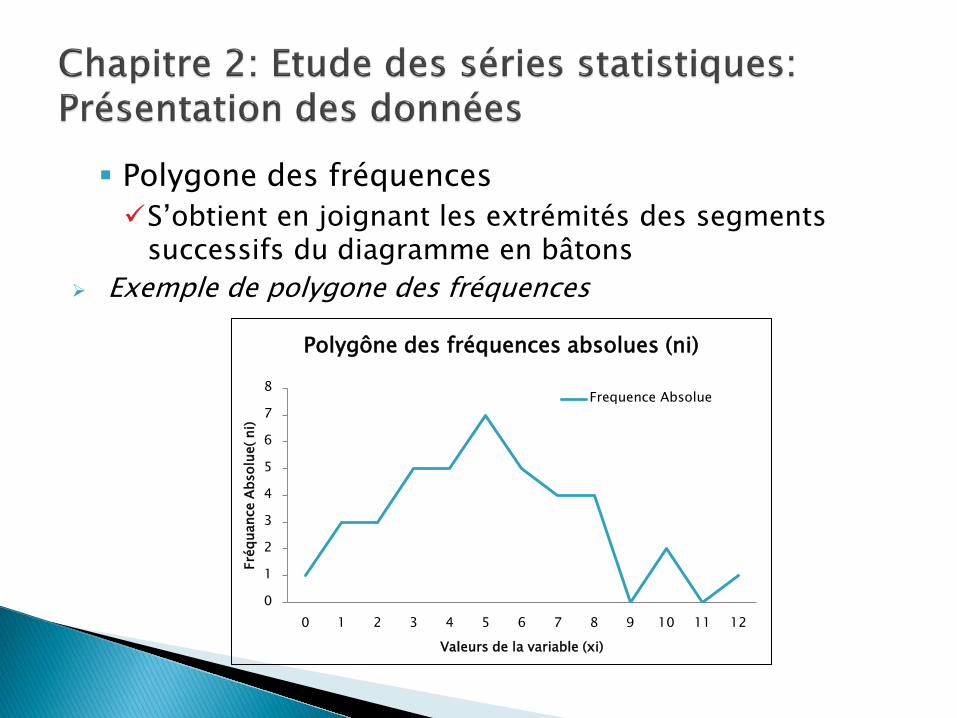
Polygone des fréquences S’obtient en joignant les extrémités des segments
successifs du diagramme en bâtons Exemple de polygone des fréquences
0
1
2
3
4
5
6
7
8
0 1 2 3 4 5 6 7 8 9 10 11 12
Fréq
uanc
e Ab
solu
e( n
i)
Valeurs de la variable (xi)
Polygône des fréquences absolues (ni)
Frequence Absolue
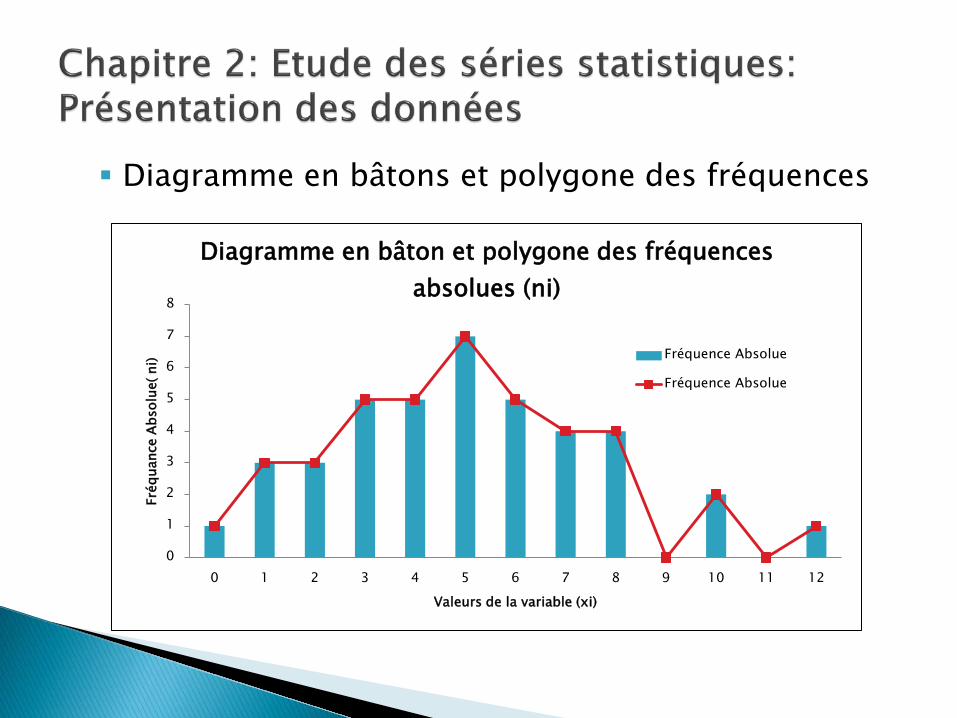
Diagramme en bâtons et polygone des fréquences
0
1
2
3
4
5
6
7
8
0 1 2 3 4 5 6 7 8 9 10 11 12
Fréq
uanc
e Ab
solu
e( n
i)
Valeurs de la variable (xi)
Diagramme en bâton et polygone des fréquences absolues (ni)
Fréquence Absolue
Fréquence Absolue

Polygone des fréquences relatives cumulées Fonction de distribution de la variable ou fonction de
répartition des fréquences Fonction en escalier, non décroissante, continue à
droite et variant de 0 à 1 Est le graphique de la fonction F(x) définie comme
suit: ∀X∈ ℝ,
0 Si X < x1
F(x)= (n1+ n2+…ni)/n
Si xi ≤ X <xi+1
1 Si x ≥ xp
avec i=1,2,…,p
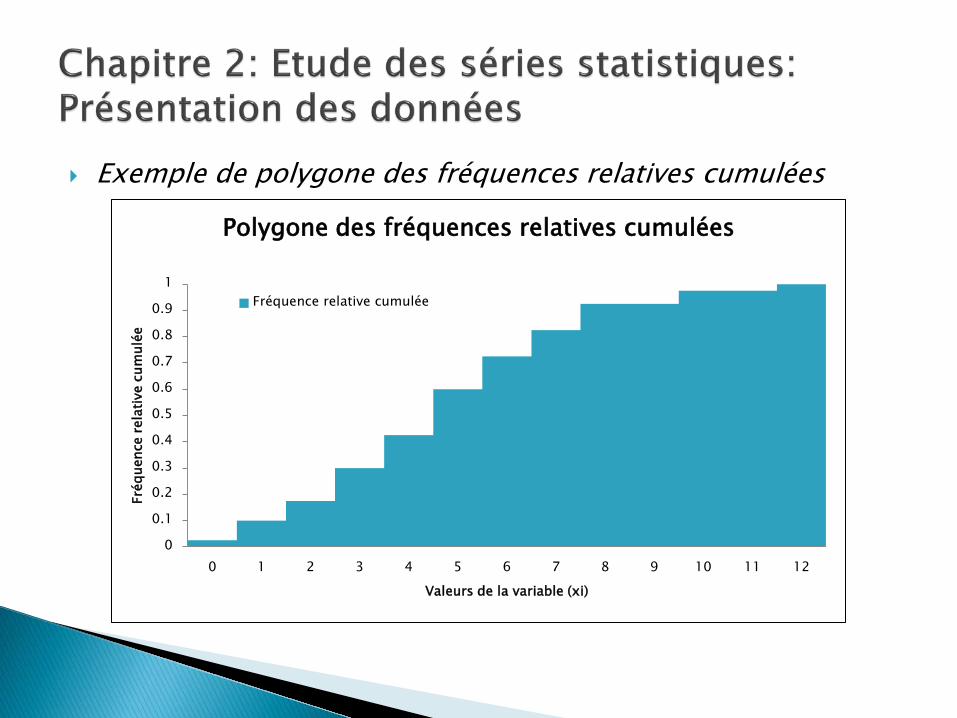
Exemple de polygone des fréquences relatives cumulées
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 1 2 3 4 5 6 7 8 9 10 11 12
Fréq
uenc
e re
lativ
e cu
mul
ée
Valeurs de la variable (xi)
Polygone des fréquences relatives cumulées
Fréquence relative cumulée

Diagramme sectoriel ou camembert Pour l’analyse des données en % Caractère Effectif Freq
rel. Célibataire 9 0.45 Divorcé 2 0.10 Marié 7 0.35 Veuf 2 0.10
45%
10%
35%
10%
Diagramme sectoriel (camembert)
Célibataire
Divorcé
Marié
Veuf

Le regroupement des données en classes ou catégories consiste à partitionner le domaine de la variable en intervalles contigus.
Si le nombre de valeurs observées distinctes devient grand Variables continues Fréquences absolues faibles
On définit:
La fréquence absolue d’une classe Ci est le nombre ni d’observations appartenant à l’intervalle Ci La fréquence relative d’une classe le Ci est le rapport ni/n
noté fi

La fréquence (absolue ou relative) cumulée d’une classe Ci est la somme des fréquences ( absolues ou relatives) de cette classe et des classes précédentes.
La distribution groupée des fréquences d’une variable est un
tableau contenant les classes de cette variable et, pour chacune de ces classes, les fréquences correspondantes( on parle aussi de tableau à classes)
L’étendue ou amplitude d’une classe est la différence entre ses
extrémités appelées borne supérieure et borne inférieure. Le centre ou la valeur centrale d’une classe Ci est le point
correspondant au milieu de cette classe. Il s’obtient en calculant la moyenne arithmétique des bornes de la classe.
Remarque: dans le cadre de ce cours on essaiera de choisir des classes de même amplitude afin de faciliter la comparaison des deux classes

Comment déterminer le nombre de classes? Pas de loi rigoureuse Dépend du problème considéré Pas trop grand, faible nombre d’individus par
classes Pas trop petit, sinon les classes sont trop larges et
risque de perte d’information Généralement entre 5 et 20 classes Quelques formules empiriques: Règle de Sturge: Nombre de classes = 1+ (3,3*log n) Règle de Yule: Nombre de classes = 2,5 ∜ n

Comment déterminer l’amplitude d’une classe? Amplitude des classes = (X max - X min) / Nombre de
classes avec X max et X min, respectivement la plus grande et la plus petite valeur de X dans la série statistique. A partir de Xmin on obtient les limites de classes ou bornes
de classes par addition successive de l’intervalle de classe. Les classes peuvent être désignées par leurs bornes ou par
leur centre si elles ont même amplitude Par convention la borne inférieure de chaque classe
appartient à la classe; la borne supérieure ne lui appartient pas

Exemple 1: A partir des données brutes suivantes, établissons une distribution des fréquences
72 51 56 95 68 66 77 81 83 75
41 79 92 78 85 55 104 76 80 61
65 70 83 92 88 59 75 75 81 69
71 96 101 87 65 74 68 73 78 68
73 86 84 51 85 75 79 90 68 71
75 74 81 64 88 78 77 66 91 75
69 73 82 76 76 71 74 96 72 74
102 74 80 82 86 78 87 61 80 78
48 68 71 66 59 92 77 76 81 70
85 77 68 82 78 75 91 77

Nombre de classes: Régle de Sturge: 1+ (3.3*log 98)=7.57 Règle de Yule: 2.5*∜ 98=7.87
Amplitude des classes: Xmax-Xmin/nombre de classes= 110-40/7= 10
Remarque: nous pouvons arrondir le nombre de classes en fonction des résultats obtenus et afin de faciliter de regroupement de données.

Distribution groupée des fréquences: On regroupe les données en classes d’amplitude 10 Classes Centres Freq
absolue Freq
relative Freq.
abs.cum Freq. rel.
cum. [40-50[ 45 2 2.0% 2 2.0% [50-60[ 55 6 6.1% 8 8.2% [60-70[ 65 16 16.3% 24 24.5% [70-80[ 75 40 40.8% 64 65.3% [80-90[ 85 22 22.4% 86 87.8% [90-100[ 95 9 9.2% 95 96.9% [100-110[ 105 3 3.1% 98 100.0%

Représentations graphiques Histogramme: Consiste à porter en abscisse, de façon équidistante, des points
correspondants aux bornes de chaque classe du tableau groupé.
Construire sur chaque intervalle de classe comme base un rectangle dont la hauteur est la fréquence absolue (ou relative) de cette classe. On dit un rectangle de hauteur proportionnelle à la fréquence de la classe considérée. Dès lors si toutes les classes ont même amplitude on obtient une
suite de rectangles de même base(=histogramme normé). Si on adopte l’amplitude de classes pour unité sur Ox et la
fréquence absolue 1 pour unité sur Oy, l’aire de chaque rectangle aura pour mesure la fréquence absolue ni de la classe Ci.
La mesure de l’aire total sous l’histogramme est donc n pour les fréquences absolues et 1 pour les fréquences relatives.

Exemple 2: A partir des données brutes suivantes qui représentent les cotes obtenues à un examen par 50 étudiants, constatons le changement « d’allure » de l’histogramme en fonction de l’amplitude pour les classes:
0.0 2.1 6.1 7.8 9.5 10.4 12.1 12.8 13.9 14.8
0.0 3.2 6.2 8.2 9.6 10.5 12.4 12.8 14.2 15.5
0.5 4.5 7.2 9.1 9.9 11.1 12.5 12.9 14.6 16.1
1.2 5.3 7.2 9.1 9.9 11.8 12.6 13 14.7 16.8
1.7 5.3 7.4 9.5 10.1 11.9 12.6 13.7 14.7 18.2
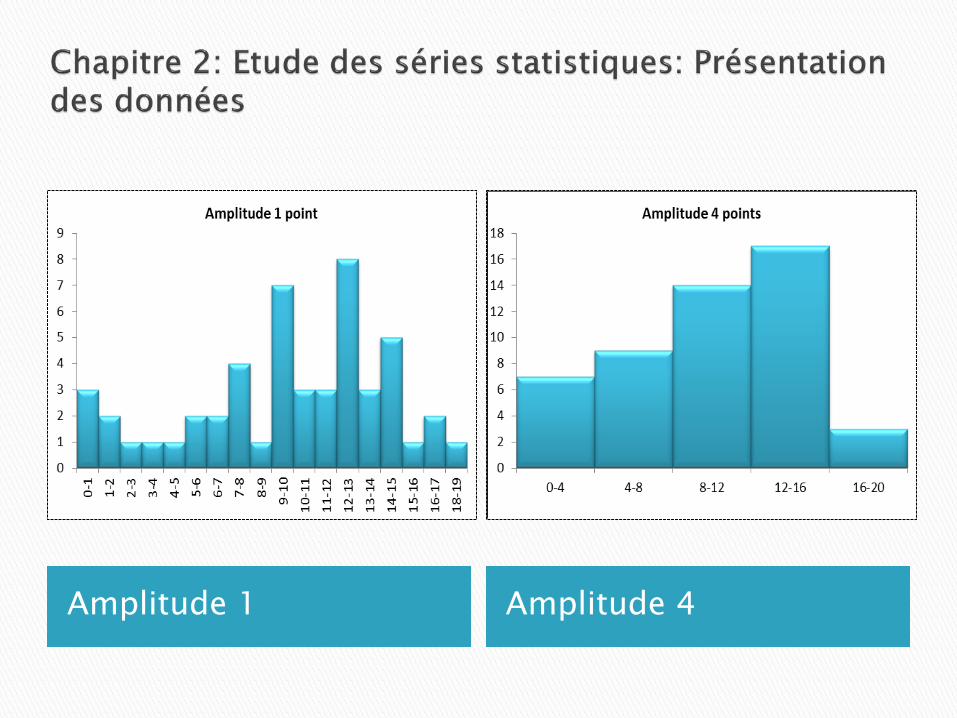
Amplitude 1 Amplitude 4

Amplitude 5 Amplitude 10

Exemple Histogramme des classes Exemple 1:

Exemple Polygone des fréquences

Polygone des fréquences (absolues ou relatives) Consiste à joindre par des segments de droite les centres
(ou milieux) des bases supérieures des rectangles successifs des histogrammes.
Remarque: on complète le polygone en le faisant commencer au point Q, abscisse 35(= valeur centrale de la classe [30,40[) et 0 en ordonnée(=fréquence nulle); et finir au point S d’abscisse 115(=valeur centrale de la classe [110,120[ ) et d’ordonnée 0. L’aire comprise entre le polygone et l’axe des abscisses est
égale à l’aire de l’histogramme, pour autant que toutes les classes soient de même amplitude!

Polygone des fréquences relatives(absolues) cumulées consiste à porter en regard des bornes supérieures des
classes des ordonnées égales aux fréquences relatives cumulées de ces classes
Remarque: Nous faisons l’hypothèse que toute la fréquence d’une classe est concentrée en sa borne supérieure
Consiste à joindre les points successifs obtenus par des segments de droite et compléter le graphe, aux extrémités, par des parallèles à l’axe des abscisses. On appelle ce graphe la fonction de distribution de la
variable

Exemple Polygone des fréquences

Histogramme non normé Dans le cas ou les classes ne sont pas de même
amplitude, il faut ajuster la hauteur des rectangles Exemple 3: Voici le tableau des ouvriers d’une entreprise suivant leur âge:
Age Freq.abs.
(ni) [20,25[ 9 [25,30[ 27 [30,35[ 36 [35,40[ 45 [40,45[ 18 [45,50[ 9 [50,55[ 3 [55,60[ 3
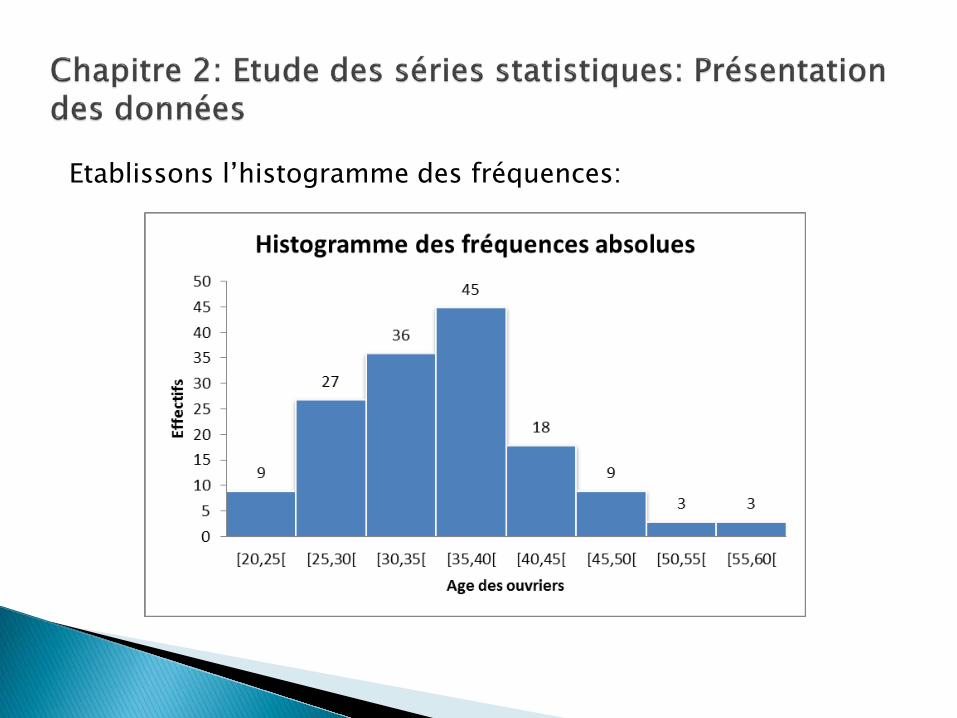
Etablissons l’histogramme des fréquences:

Supposons que les deux dernières classes aient été regroupées de la façon suivante: Age
Freq.abs ni
[20,25[ 9 [25,30[ 27 [30,35[ 36 [35,40[ 45 [40,45[ 18 [45,50[ 9 [50,60[ 6
Cet histogramme est faux!

En effet, cet histogramme est faux car il représente une série
statistique qui correspondrait aux fréquences absolues suivantes: On constate que l’amplitude de la classe [50,60[ étant double de
l’amplitude de chacune des autres classes, il faut représenter sur le segment [50,60[, un rectangle de hauteur moitié de la fréquence absolue donnée, autrement dit un rectangle de hauteur 6/2=3.
Dés lors, si une classe est d’amplitude k fois plus grande (ou plus petite) que l’amplitude prise pour l’unité, il faut diviser(ou multiplier) par k la fréquence correspondante à la classe concernée.
Lors de la représentation à l’aide de l’histogramme c’est l’aire des rectangles, et non leur hauteur, qui est proportionnelle à la fréquence (absolue ou relative).
[45,50[ 9 [50,55[ 6 [55,60[ 6

Exercices

Paramètres de position ( l’ordre de grandeur des observations)
Paramètres de dispersion (la variabilité des
observations) Paramètres de dissymétrie et d’aplatissement

Le mode Pour les données non groupées, le mode est le nombre
que l’on rencontre le plus fréquemment, c’est-à-dire celui qui a la plus grande fréquence absolue. Le mode peut ne pas exister ou ne pas être unique
Exemple: Une distribution n’ayant qu’un seul mode est appelée unimodale, deux modes bimodale,…
2 2 5 7 9 10 9 9 Mode=9 3 5 8 10 11 15 19 12 Pas de mode 4 2 2 9 7 9 10 18 Mode 2 et 9

Unimodal Bimodal

Interprétation graphique du mode diagramme en bâtons: abscisse correspondant au
bâton le plus long polygone des fréquences: point ayant l’ordonnée la
plus grande Pour les données groupées
La classe modale est la classe du plus grand effectif Si les classes sont d’amplitudes inégales il s’agit de la
classe de fréquence corrigée la plus élevée (effectif/amplitude).
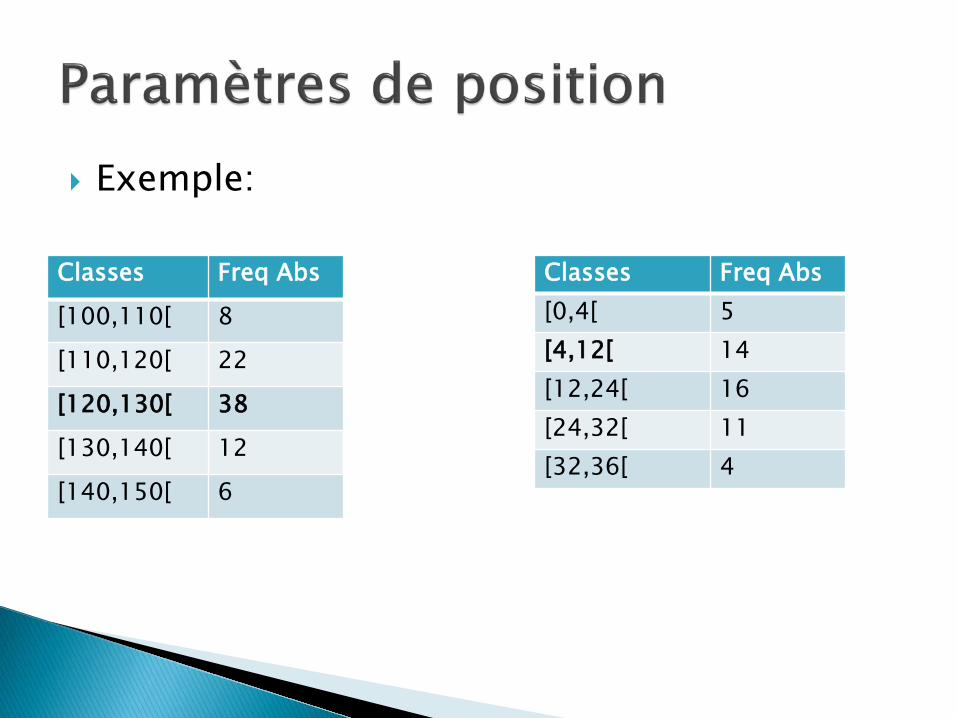
Exemple:
Classes Freq Abs [0,4[ 5 [4,12[ 14 [12,24[ 16 [24,32[ 11 [32,36[ 4
Classes Freq Abs
[100,110[ 8
[110,120[ 22
[120,130[ 38
[130,140[ 12
[140,150[ 6

Mode: valeur approximative: centre de la classe modale
Mode valeur exacte peut être calculée:


Valeur approchée du mode: ◦ [155,160[, avec ni=17
Valeur exacte: ◦ Mo=155+(5*8)/(1+8)=159,4
Avec: xm=155mm; ∆i=17-9=8;∆s=17-16=1;i=5mm

La médiane, Me, est la valeur du caractère pour laquelle la fréquence cumulée est égale à 0,5ou 50%. Elle correspond donc au centre de la série statistique classée par ordre croissant, ou à la valeur pour laquelle 50% des valeurs observées sont supérieures et 50% sont inférieures.
Pour les données non groupées on détermine la
médiane en: 1)classant les individus par ordre croissant 2)sélectionnant celui du milieu

Exemple1: ◦ Soit un échantillon de 9 personnes dont le poids
est: ◦ on les classe par ordre croissant:
45 68 89 74 62 56 49 52 63
45 49 52 56 62 63 68 74 89
4 4
Médiane

Exemple 2: ◦ Si le nombre d’individus est pair, on prend la
moyenne entre les deux valeurs centrales:
◦ Médiane= (56+62)/2= 59 kg Conclusion: ◦ si n est impair la médiane est l’observation de rang (n+1)/2 ◦ Si n est pair la médiane est par convention la moyenne des observations
xn/2 et (Xn/2)+1
45 49 52 55 56 62 63 68 74 89
5 5

Pour les données groupées, on détermine la médiane en: ◦ 1) déterminant le numéro d’ordre de la médiane ◦ 2) déterminant dans quelle classe elle se situe dans
le tableau groupé des fréquences ◦ 3) rangeant par ordre croissant les individus de
cette classe ◦ 4) Sélectionnant l’individu correspondant au
numéro choisi

Exemple: Soit les % obtenus par 49 élèves à un examen rangés par classes de 10% de large N=49: La médiane porte le numéro 25 ((49+1)/2) Se situe dans la classe 41-51 contient les individus portant les numéros de 20 à 26
Classes Freq abs Freq abs
cum. 1-11 2 2
11-21 4 6
21-31 5 11
31-41 8 19
41-51 7 26
51-61 9 35
61-71 6 41
71-81 6 47
81-91 2 49
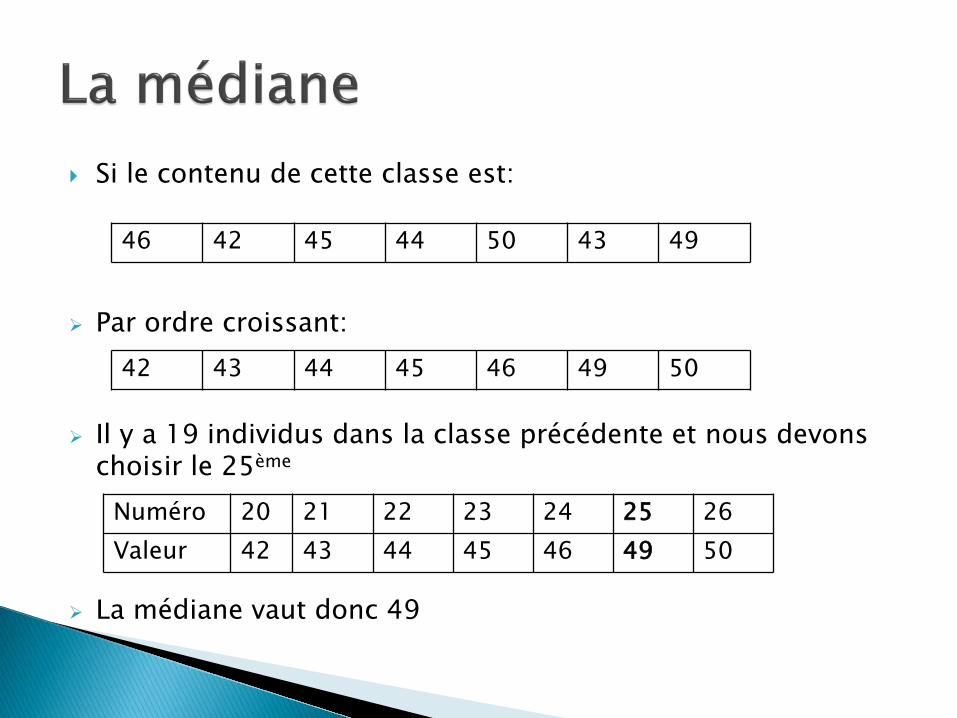
Si le contenu de cette classe est: Par ordre croissant:
Il y a 19 individus dans la classe précédente et nous devons choisir le 25ème
La médiane vaut donc 49
46 42 45 44 50 43 49
42 43 44 45 46 49 50
Numéro 20 21 22 23 24 25 26 Valeur 42 43 44 45 46 49 50

Quid si effectif très grand?
x= L1 + (N/2-(∑f)) * c f médian où L1: borne inférieure de la classe médiane N: effectif ∑f: somme des fréq. abs. de toutes les classes inférieures à la classe médiane f médian: fréquence absolue de la classe médiane c: amplitude de la classe médiane

Exemple: x= 41 +((49/2 -19)/7)*10 =41+((11/2)/7)*10 =41+(11/14)*10 =41+110/14=41+7.85=48.85
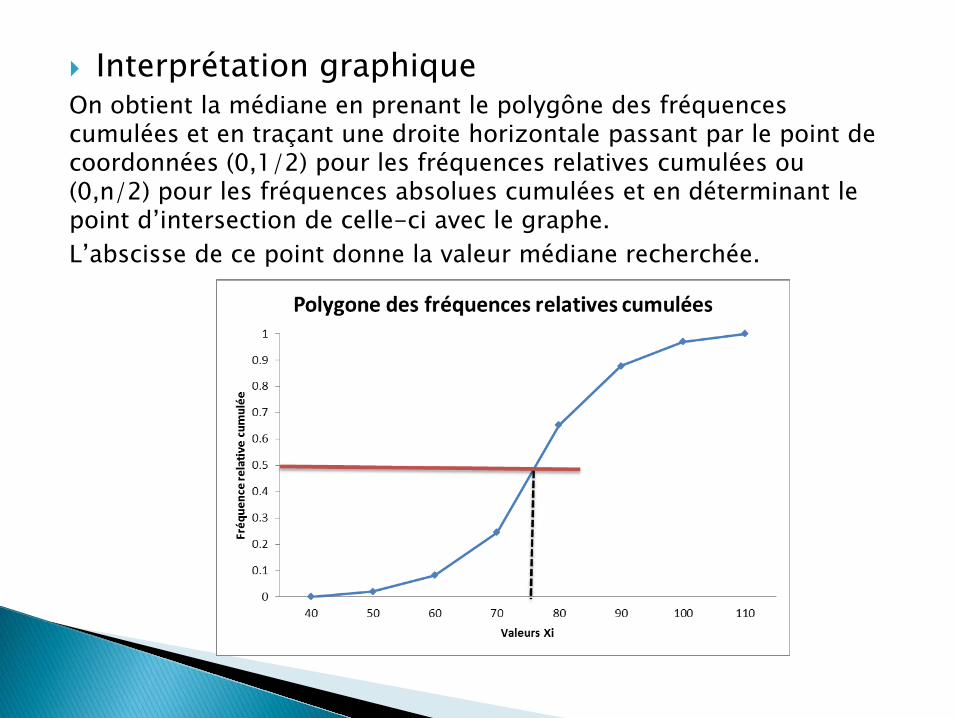
Interprétation graphique On obtient la médiane en prenant le polygône des fréquences cumulées et en traçant une droite horizontale passant par le point de coordonnées (0,1/2) pour les fréquences relatives cumulées ou (0,n/2) pour les fréquences absolues cumulées et en déterminant le point d’intersection de celle-ci avec le graphe. L’abscisse de ce point donne la valeur médiane recherchée.

Unique Grande stabilité par rapport aux valeurs
extrêmes Elle est déterminée par le nombre
d’observations et pas par leurs valeurs

Somme des grandeurs mesurées divisée par le nombre d’individus Si données non groupées: où n est l’effectif de l’échantillon xi sont les différentes valeurs de la variable ni sont les fréq. abs. des différents xi p est le nombre de valeurs observées

Pour les valeurs groupées On suppose que tous les individus d’une
classe se situent au centre de celle-ci
où n est l’effectif de l’échantillon xi sont les centres des différentes classes ni sont les fréq. abs. de chaque classe p est le nombre de classes
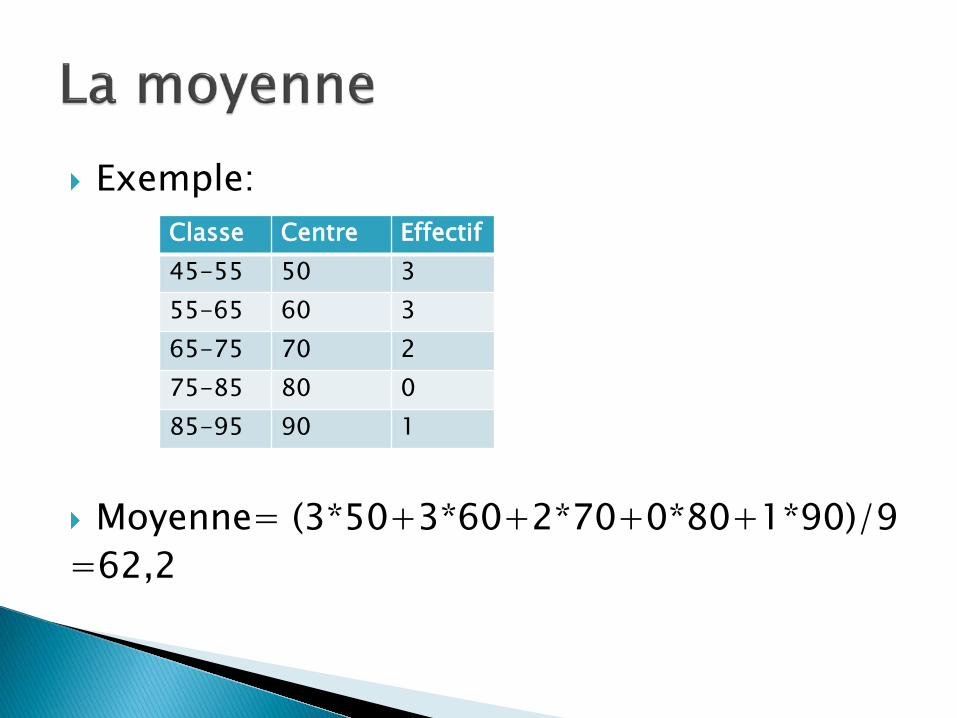
Exemple:
Moyenne= (3*50+3*60+2*70+0*80+1*90)/9 =62,2
Classe Centre Effectif 45-55 50 3 55-65 60 3 65-75 70 2 75-85 80 0 85-95 90 1

Paramètre de position le plus utilisé Il existe toujours et est unique il dépend de toutes les valeurs observées sa valeur peut être biaisé par des valeurs
extrêmes la somme des écarts entre les valeurs
observées et la moyenne est nulle( à démontrer)


Définition: un ensemble de données numériques tend généralement à s’étaler autour d’un valeur centrale, que l’on appelle dispersion ou variabilité des données.
Plusieurs mesures: étendue, intervalle interquartile, écart moyen absolu, écart type, la variance et le coefficient de variation.

A quoi ça sert? Exemple: on désire comparer les revenus des ouvriers d’une
usine à ceux de l’ensemble de la population de leur région dont voici les résultats:

Dans ce cas, les deux distributions ont le même centre mais elles sont manifestement différentes:
elles diffèrent par leur dispersion
Exemple 2: on compare les salaires journaliers accordés aux employés par deux établissements différents, qui comptent chacun 5 salariés, dont voici les valeurs rangées par ordre croissant:
Etablissement A: 220; 228; 248; 260; 272 Etablissement B: 188; 192; 248; 256; 344
Quelles sont les caractéristiques de tendance centrale? ◦ Meme médiane= 248€ ◦ Meme moyenne= 246€
Les deux entreprises accordent-elles les mêmes salaires?

La réponse est non! Dans le second établissement les valeurs sont plus étalées, plus dispersées autour des valeurs centrales que dans le premier établissement.
Les caractéristiques de tendance centrale sont insuffisants nécessité de calculer des caractéristiques de dispersion pour pouvoir comparer
NB: une faible dispersion des valeurs de la variable autour dune valeur centrale, ex la moyenne, donne une signification plus grande à cette valeur que si la dispersion est élevée.

Définition: l’étendue est la différence entre la plus grande et la plus petite des valeurs observées
Exemple: ◦ Soit la série ordonnée: 2; 3; 3; 5; 5; 5; 8; 10; 12 Etendue= 12-2=10
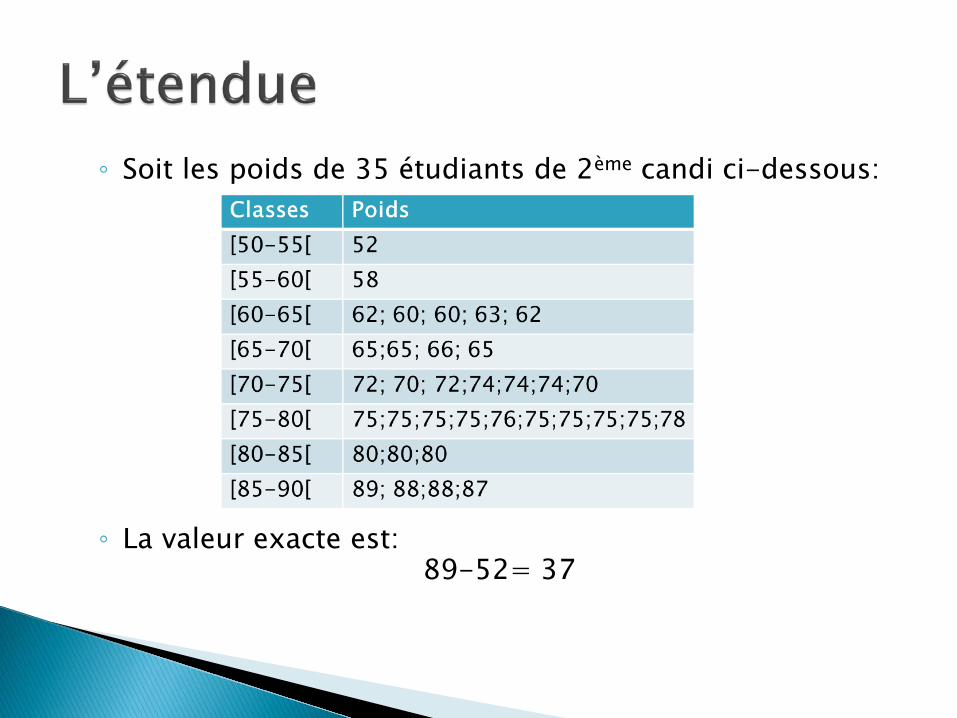
◦ Soit les poids de 35 étudiants de 2ème candi ci-dessous:
◦ La valeur exacte est: 89-52= 37

◦ La valeur approchée, prenant en compte le centre des classes donne:
87-52= 35 Dans le cas de données groupées l’étendue
est la différence entre le centre de la dernière classe et celui de la première.

Simple à calculer N’implique que les valeurs extrêmes Sensible aux valeurs aberrantes Ne peut être retenu que pour des séries dont
les valeurs sont réparties « convenablement »(= sans valeurs extrêmes). Il sert de première approche dans la mesure de la dispersion

Définitions: ◦ On appelle Premier Quartile( ou Quartile inférieur) d’une
distribution statistique et on désigne par Q1, la valeur telle que 25% des valeurs prises par la variable( donc 25% de l’effectif total de la population étudiée) lui soient inférieures, et 75% supérieures.
◦ On appelle Troisième Quartile( ou Quartile supérieur) d’une distribution statistique et on désigne par Q3, la valeur telle que 75% des valeurs prises par la variable lui soient inférieures, et 25% supérieures.
◦ Par conséquent le Second Quartile, noté Q2, se confond avec la médiane.

L’intervalle interquartile est la différence entre le Troisième et le Premier Quartile:
Intervalle interquartile= Q3-Q1
Les observations étant rangées par ordre croissant:
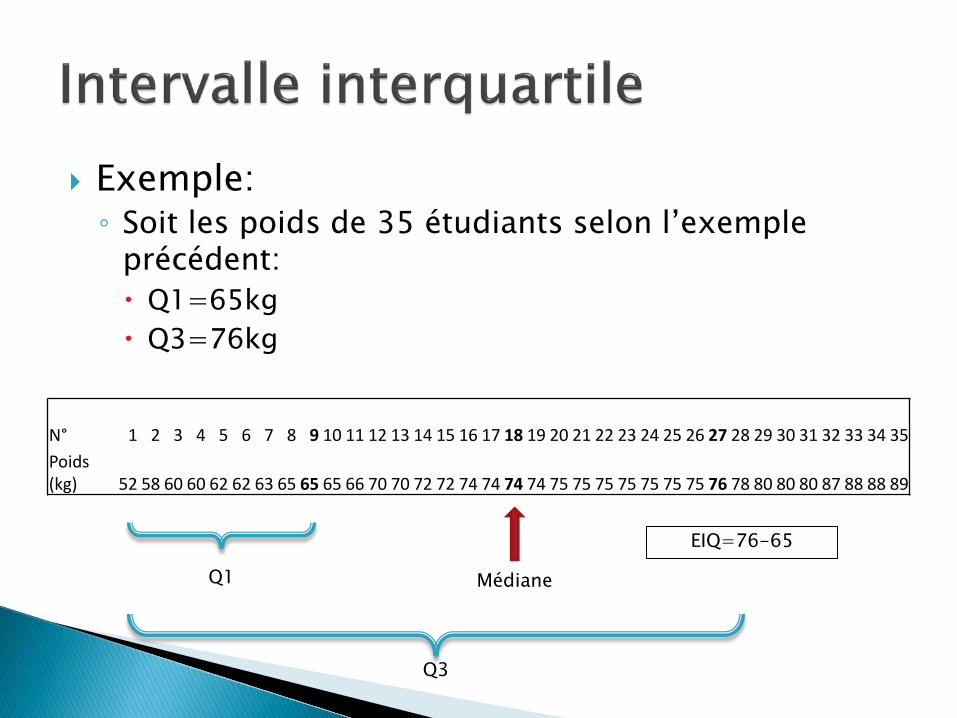
Exemple: ◦ Soit les poids de 35 étudiants selon l’exemple
précédent: Q1=65kg Q3=76kg
N° 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
Poids (kg) 52 58 60 60 62 62 63 65 65 65 66 70 70 72 72 74 74 74 74 75 75 75 75 75 75 75 76 78 80 80 80 87 88 88 89
Médiane Q1
Q3
EIQ=76-65

L’étendue de 35 kg (87-52) contient 100% des individus, alors que l’intervalle interquartile, d’amplitude 11 kg contient 50% des individus.
Moyen d’apprécier la dispersion autour des valeurs
centrales des observations faites. Dans cet exemple la moitié des individus se trouve regroupée dans un intervalle (11 kg) d’amplitude inférieure au tiers de l’étendue (35kg)
Remarque: en matière de caractéristiques de tendance
centrale ou de position, nous cherchions sur l’axe des abscisses, des points, par exemple le point dont l’abscisse donnait la valeur médiane, alors que pour des caractéristiques de dispersion nous cherchons à déterminer des segments traduisant des intervalles.

A partir du polygône des fréquences cumulées, on trace deux droites horizontales l’une passant par le point (0,1/4) et l’autre par le point (0,3/4) et on détermine les points d’intersection de celles-ci avec le graphe.

Comment mesurer les écarts entre toutes les observations et une valeur centrale?
Par rapport à la valeur centrale choisie qui est la moyenne arithmétique, on peut en effet définir l’ écart moyen absolu:
e.m.=1
𝑛∑ 𝑛𝑖𝑝𝑖=1 *|xi-x|
où n est l’effectif de l’échantillon xi sont les différentes valeurs de la variable ni sont les fréq. abs. des différents Xi p est le nombre de valeurs distinctes observées xest la moyenne arithmétique

La moyenne des écarts à la moyenne est nulle!
Démonstration: Σ Χ − Χ = (x1 –x)+( x2-x)+…
=(x1+x2+…)-(x+x+…) =∑x-nx
=∑x-n(1𝑛∑x)
=0 et donc la moyenne 0/n= 0

Peut se définir comme la moyenne des valeurs absolues des différences entre les observations( ou centres) et la valeur moyenne x.
Permet de mesurer la dispersion des séries Exemple: Si Alice a obtenu 5,10,15 pour notes et Bob, 9,10,11, leur moyennes sont les mêmes mais leurs cas sont très différents. L’écart moyen d’Alice est de 10/3, tandis que celui de Bob est de 2/3

Example: Soit le poids de 35 étudiants de 2ème candi. Analysons la moyenne arithmétique x= 72,285
e.m.= 135
*(1*|52.5-72,285|+1*|57.5-72;285|+….+ 4*|87.5-72,285|)
=6,987 En moyenne, les poids des étudiants s’écartent d’environ 7 kg de la moyenne arithmétique des poids. Conclusion: Un écart moyen absolu de mesure plus faible (ou plus élevée) serait évidemment l’indicateur d’une dispersion plus faible( ou plus élevée).

Pour des raisons mathématiques, il est possible afin d’éliminer les signes -, de calculer le carré des écarts de chaque valeur de la variable à la moyenne arithmétique.
Dès lors on définit la variance grâce à:
s2=1𝑛 ∑ 𝑛𝑖𝑝
𝑖=1 (xi-x)2
où n est l’effectif de l’échantillon xi sont les différentes valeurs de la variable ni sont les fréq. abs. des différents Xi p est le nombre de valeurs distinctes observées xest la moyenne arithmétique

En développant le carré, cette formule devient plus simple à utiliser:
s2=( 1𝑛 ∑ 𝑛𝑖𝑝
𝑖=1 xi2)-x2
Désavantages de ce paramètre: L’unité dans laquelle il s’exprime vaut le carré des unités utilisées pour les valeurs observées. C’est pour cette raison que l’on définit l’écart type comme étant la racine carré positive de la variance:
s= 𝑆2

Dans l’exemple du cours( données non groupées): rappel x=5,025
s2= 140
*(1*02+3*1+3*22+…+1+122)-(5,025)2
= 1291
40 - 25,250625=7,024375
s=2,6503

C’est la mesure de dispersion la plus utilisée Tout comme la variance, s dépend de toutes
les observations Il présente l’avantage de s’exprimer dans les
mêmes unités que les observations

Echantillon représentatif Le but principal de la statistique est de déterminer les
caractéristiques d’une population donnée à partir de l’étude d’une partie de cette population, appelée échantillon.
La façon de sélectionner l’échantillon est donc aussi
importante que la manière de l’analyser.
Il faut que l’échantillon soit représentatif de la population, et l’échantillonnage aléatoire est le meilleur moyen d’y parvenir.
Un échantillon aléatoire est un échantillon tiré au hasard dans lequel tous les individus ont la même chance de se retrouver. Si ce n’est pas le cas, l’échantillon est biaisé.
Un petit échantillon représentatif est de loin préférable à un grand échantillon biaisé.

On désire étudier la taille moyenne des étudiants de 2ème candi à partir d’un échantillon de 10 individus. La population totale étant de 86 étudiants (51 filles et 35 garçons) dont la moyenne est de 174 cm. Nous choisissons un échantillon de 5 filles et 5 garçons choisis au hasard:
La moyenne de l’échantillon obtenue est de 177,2 cm soit 3,2
cm de plus que la valeur exacte
Taille des filles (cm)
Taille des garçons (cm)
171 193 165 187 173 180 174 185 166 178

Le choix de l’échantillon était-il judicieux? ◦ Chaque garçon a plus de chances d’être choisi que chaque
fille: 5 garçons sur 35( 0,143) ◦ Alors que chaque fille a 5 chances sur 51 d’être choisie
(0,098) donc plus faible que celle des garçons.
L’échantillon est biaisé Il faut donc choisir au hasard sans
considération de sexe ou utiliser la technique des quotas, c’est- à dire appliquer les mêmes proportions à l’échantillon: 40% des garçons(35/86) et 60% des filles (51/86).

Les échantillons suivants sont-ils représentatifs de la population? ◦ Pour connaitre les opinions politiques de la
population d’une ville on envoie 5 enquêteurs interroger les gens à la sortie de 5 grands magasins. Ils doivent questionner les clients jusqu’à ce qu’ils obtiennent un échantillon de 200 personnes.
◦ On désire faire une enquête sur les goûts musicaux de la population belge. Pour cela on choisit au hasard 1000 numéros de téléphone dans l’ensemble des annuaires et on les appelle pendant les heures de bureau.

Supposons que l’échantillon soit représentatif de la population, comment approcher la moyenne de la population grâce à la moyenne de l’échantillon?
La précision dépendra de: ◦ La taille de l’échantillon ◦ La dispersion de la population
Dans une population peu dispersée, toutes les valeurs de
l’échantillon seront forcément proches de la moyenne. Tandis que dans une population plus dispersée, les
valeurs de l’échantillon seront généralement plus éloignées de la moyenne. La moyenne de l’échantillon pourra donc s’écarter plus fortement de celle de la population.

La précision de la moyenne peut être mesurée par un écart type sur la moyenne:
𝜎(X)= 𝜎𝑛
n: nombre d’individus dans l’échantillon 𝜎: écart type de la population La précision sur la valeur moyenne sera donc d’autant meilleure
que ◦ La population sera peu dispersée (écart type petit) ◦ L’échantillon sera grand ( n grand)
Pour une précision 2 fois meilleure, il faut un échantillon 4 fois
plus grand, et si on veut qu’elle soit 10 fois meilleure, il faut un échantillon 100 fois plus grand.
La précision coûte cher!

La taille moyenne de la population de 51 filles de 2ème candi communication est de
𝜇 = 167,9 𝑐𝑐 (nous noterons 𝜇 la valeur moyenne pour la population et X la valeur moyenne pour l’échantillon) L’écart type est de
𝜎 = 5,3 𝑐𝑐 Si on estime la taille moyenne à partir de 4 personnes, on
aura une précision(écart type) sur la moyenne de : 𝜎 𝑋 = 5,3
4= 2,65 cm
A partir d’un échantillon de 10 personnes, la précision serait de :
𝜎 𝑋 = 5,310
= 1,7 cm

Nous désirons déterminer la taille moyenne des hommes belges âgés d’une vingtaine d’années.
Nous disposons d’un échantillon représentatif de 35 étudiants de 2ème candi communication. Sa moyenne est une estimation de celle de la population et elle est de 182,9 cm.
Pour estimer la précision de cette moyenne il faudrait connaitre
l’écart type de la taille de la population hors ce n’est pas le cas. Si l’échantillon n’est pas trop petit, nous pouvons remplacer
l’écart type σ de la population par l’écart type s de l’échantillon.
Dans ce cas il vaut s = 6,7 cm La précision sur la moyenne serait donc de :
𝜎 𝑋 = 6,7
35= 1,1 cm

Donc si l’écart type de la grandeur analysée dans la population n’est pas connu, on peut le remplacer par l’écart type calculé dans l’échantillon, pour autant que cet échantillon soit suffisamment grand
𝜎 𝑋 =𝑠𝑛
(𝑠𝑖 𝑛 𝑒𝑠𝑒 𝑔𝑔𝑔𝑛𝑔,≥ 100) Comme pour la moyenne, nous réservons les lettre
grecques pour les grandeurs relatives à la population et les caractères romains pour les grandeurs correspondant à l’échantillon:
Moyenne population: 𝜇 Ecart type population: 𝜎 Moyenne échantillon: X Ecart type échantillon: s

Une application courante des sondages statistiques est l’estimation de l’audience des émissions de télévision. Passez en revue quelques-unes des méthodes utilisées en présentant leurs principaux avantages et inconvénients.

Ajustement Technique qui consiste à ajuster une série statistique, c’est-à-dire de substituer aux fréquences effectivement observées des fréquences calculées selon certains procédés. Exemples:

On conçoit à l’aide de ces exemples graphiques simples, que la première étape d’ajustement soit la recherche de la forme générale de la courbe d’ajustement et la seconde étant la détermination de l’équation de la courbe d’ajustement. Cette équation sera de la forme:
Fréq ajustés= fonction de la variable x ou f(x)=x
où: f(x)=y

A partir du tableau de distribution des fréquences on place dans un système d’axes cartésiens les points (xi, ni) obtenus.
Lorsqu’on observe le nuage de points, on peut intuitivement tracer à main levée sur le graphique une courbe simple régulière telle que se compensent à peu près les écarts positifs ou négatifs, pour une même abscisse, entre les ordonnées ajustées et les ordonnées réelles. Une telle courbe est appelée courbe d’ajustement.
Ainsi les deux exemples précédents conduiraient à des ajustements manuels qui se présenteraient comme suit:

Sur la figure de gauche les points semblent se répartir de façon linéaire. Les données semblent donc être parfaitement approchées par une droite. Nous l’appellerons droite d’ajustement.
Sur la figure de droite les points se répartissent de façon non linéaire. Les données semblent être parfaitement approchées par une parabole. nous appellerons cette courbe d’ajustement parabole d’ajustement.

Si on connait l’équation de la courbe, on peut obtenir les constantes qui figurent dans l’équation en choisissant autant de points sur la courbe qu’il y a de constantes. Si la courbe est pas exemple, une droite, deux points suffisent; si c’est une parabole trois points sont nécessaires.
L’inconvénient de la méthode est que des
observateurs différents pourront obtenir des courbes et des équations différents en fonction des points sélectionnés. Cette méthode n’est donc pas objective!

Soit la distribution des fréquences suivante:
La représentation graphique de cette série est faite de cinq points
Xi yi(ni)
2 8
3 10
4 10
5 14
6 15 02468
10121416
0 1 2 3 4 5 6 7
N
M

Déterminons l’équation y=ax+b de cette droite en indiquant que celle-ci comprend les deux points M et N de coordonnées:
M= (2,8) et N(6,15)
L’équation de la droite sera: y-y1= (x-x1)*((y2-y1)/(x2-x1))
y-8=(x-2)*((15-8)/(6-2)) y-8=(7/4)*(x-2) y=1,75x-3,5+8 (donc a= 1,75 et b= 4,5) y= 1,75x+4,5

Il faut déterminer les différents paramètres d’une fonction qui ajuste de la façon la plus satisfaisante les observations faites. La fonction retenue devra conduire à une courbe d’ajustement aussi simple que possible.
Pour cela considérons la figure ci-dessous où les points de
coordonnées (X1,Y1), (X2, Y2),…(Xn, Yn) proviennent du tableau de distribution des fréquences.

Pour une valeur donnée de X, soit X1, il y aura une différence entre la valeur vraie observée Y1 et la valeur correspondante déterminée par la courbe y=f(x). Càd. qu’à chaque observation (X1,Y1) correspond sur la courbe d’ajustement un point (X1, f(X1)). Appelons cette différence D1, quelquefois appelé l’écart, l’erreur ou le résidu et peut être positif ou négatif ou nul. De la même façon, on obtient pour X2, X3, …, Xn des écarts D2, D3,…, Dn D2
1+D22+…D2
n est une mesure de « l’efficacité de l’ajustement » de la courbe C pour les données. Si celle-ci est petite, l’ajustement est bon si elle est grande l’ajustement est mauvais. Il faut donc que:
Min (D21+D2
2+…D2n)

Quand une courbe vérifie cette propriété on dit qu’elle ajuste les données au sens des moindres carrés. On l’appelle alors courbe des moindres carrée. Ainsi, s’il s’agit d’une droite, on parle de la droite des moindres carrés, et si c’est une parabole, de la parabole des moindres carrés.
Nous devons donc chercher la fonction y=f(x) qui permettra de calculer la série des fréquences ajustées telles que:
∑{𝑦𝑖 − 𝑓(𝑥𝑖)} 2 soit minimum

Soit la distribution des fréquences suivante:
Soit les points (xi, yi) provenant du tableau des distributions des fréquences (observations réelles). Supposons qu’on puisse ajuster les données à l’aide d’une droite y= ax+b.
Mais on souhaite minimiser l’écart entre les valeurs observées (yi) et les valeurs de la droite ajustée (a+bxi).
On minimise donc la somme des carrées des écarts entre chaque valeur observée et la valeur de la droite ajustée.
Xi Yi X1 Y1 X2 Y2 X3 Y3 … … Xn Yn

Nous devons rendre minimum l’expression: (a+bx1-Y1)2+ (a +bx2-y2)2+…..+ (a+bxn-Yn)2
et donc trouver les coefficients a et b de la droite idéale: Par résolution mathématique nous trouvons les coefficients de la droite des moindres carrés: a=∑(𝒙𝒙−𝒙)(𝒚𝒙−𝒚)
∑(𝒙𝒙−𝒙)𝟐
b= 𝒚 − 𝒂𝒙











![ATELIER: Science Acoustique · CV dur V dur F 0 SPL C +[i] 0.3 s 0.2s 230Hz dB C + [i9] 0.1 s 0.07 s 90 Hz 66.5 dB C + [u] 0.3 s 0.2 s 130 Hz 67 dB C + [u9] 0.2 s 0.09 s 82 Hz 65](https://static.fdocuments.fr/doc/165x107/5f5dee02b5a0f9063d69202c/atelier-science-cv-dur-v-dur-f-0-spl-c-i-03-s-02s-230hz-db-c-i9-01-s.jpg)
![Indicaons de réanimaon en oncologie thoracique€¦ · 2.4 [0.5 – 10] 13.1 [2.72 – 62] p < 0.001 p = 0.23 p = 0.001 Chimiothérapie en réa 0.24 [0.07 – 0.83] p = 0.02 Barth,](https://static.fdocuments.fr/doc/165x107/60716417bf8df77a2367c458/indicaons-de-ranimaon-en-oncologie-thoracique-24-05-a-10-131-272-a.jpg)



