
Éléments de bases de données IFT187 - Informatiquefrappier/ift187/notes-de-cours.pdf ·...
127
Université de Sherbrooke Département d’informatique Éléments de bases de données IFT187 Notes complémentaires et synthétiques Marc Frappier, Ph.D. professeur UNIVERSITÉ DE SHERBROOKE
Transcript of Éléments de bases de données IFT187 - Informatiquefrappier/ift187/notes-de-cours.pdf ·...

Université de SherbrookeDépartement d’informatique
Éléments de bases de donnéesIFT187
Notes complémentaires et synthétiques
Marc Frappier, Ph.D.professeur
UNIVERSITÉ DE SHERBROOKE

i

Avertissement
Ce document n’est pas un substitut au livre de référence du cours ni aux manuels de référencedes différents langages utilisés dans le cadre du cours.
ii

Contents
1 Les bases de données et leurs usages 11.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.1 Rôle des BDs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.1.2 Définitions de concepts de base . . . . . . . . . . . . . . . . . . . . . 1
1.2 Un exemple de BD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Services offerts par une BD . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3.1 Description des données . . . . . . . . . . . . . . . . . . . . . . . . . 31.3.2 Encapsulation des données . . . . . . . . . . . . . . . . . . . . . . . . 31.3.3 Partage des données entre plusieurs utilisateurs . . . . . . . . . . . . 3
1.4 Intervenants dans les systèmes de BD . . . . . . . . . . . . . . . . . . . . . . 41.5 Conséquences de l’usage de SGBD . . . . . . . . . . . . . . . . . . . . . . . . 41.6 Bref historique des BD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.7 Usage inapproprié des BDs . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Concepts et architecture des bases de données 62.1 Modèles de BD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.2 Catégories de modèle de données . . . . . . . . . . . . . . . . . . . . . . . . 62.3 Schéma . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.4 Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.5 Langages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.6 Composantes d’un SGBD . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
8 Le langage SQL 98.1 Langage de définition des données . . . . . . . . . . . . . . . . . . . . . . . . 9
8.1.1 Table . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98.1.2 Types en SQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108.1.3 Définition des tables . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
8.1.3.1 Syntaxe générale . . . . . . . . . . . . . . . . . . . . . . . . 138.1.3.2 Définition des attributs . . . . . . . . . . . . . . . . . . . . 148.1.3.3 Définition des contraintes . . . . . . . . . . . . . . . . . . . 14
8.1.3.3.1 Clé primaire . . . . . . . . . . . . . . . . . . . . . . 148.1.3.3.2 Clé unique . . . . . . . . . . . . . . . . . . . . . . . 158.1.3.3.3 Clé étrangère . . . . . . . . . . . . . . . . . . . . . 15
8.1.4 Modification des tables . . . . . . . . . . . . . . . . . . . . . . . . . . 168.1.4.1 Ajout d’attributs . . . . . . . . . . . . . . . . . . . . . . . . 16
iii

8.1.4.2 Modification d’attributs . . . . . . . . . . . . . . . . . . . . 168.1.4.3 Suppression d’attributs . . . . . . . . . . . . . . . . . . . . . 168.1.4.4 Ajout de contraintes . . . . . . . . . . . . . . . . . . . . . . 168.1.4.5 Suppression de contraintes . . . . . . . . . . . . . . . . . . . 17
8.1.5 Suppression des tables . . . . . . . . . . . . . . . . . . . . . . . . . . 178.1.5.1 L’exemple de la bibliothèque . . . . . . . . . . . . . . . . . 18
8.2 Langage de manipulation des données . . . . . . . . . . . . . . . . . . . . . . 218.2.1 Insert . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 218.2.2 Update . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 218.2.3 Delete . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 228.2.4 Select . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
8.2.4.1 Syntaxe générale . . . . . . . . . . . . . . . . . . . . . . . . 238.2.4.2 Sémantique . . . . . . . . . . . . . . . . . . . . . . . . . . . 238.2.4.3 La valeur spéciale NULL . . . . . . . . . . . . . . . . . . . . 238.2.4.4 Expressions . . . . . . . . . . . . . . . . . . . . . . . . . . . 248.2.4.5 Conditions (Expressions booléennes) . . . . . . . . . . . . . 248.2.4.6 Autres expressions (arithmétique, caractères, dates) . . . . . 258.2.4.7 Fonctions d’agrégation . . . . . . . . . . . . . . . . . . . . . 268.2.4.8 Opérations ensemblistes . . . . . . . . . . . . . . . . . . . . 278.2.4.9 Jointures . . . . . . . . . . . . . . . . . . . . . . . . . . . . 278.2.4.10 Quelques exemples de SELECT . . . . . . . . . . . . . . . . 30
8.3 Divers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 388.3.1 Table virtuelle : vue . . . . . . . . . . . . . . . . . . . . . . . . . . . 388.3.2 Contraintes d’intégrité . . . . . . . . . . . . . . . . . . . . . . . . . . 388.3.3 Index . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 388.3.4 Schéma . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 388.3.5 Oracle et la norme SQL . . . . . . . . . . . . . . . . . . . . . . . . . 39
3 Le modèle entité-association 403.1 Définition des concepts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403.2 Convention nominative . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 423.3 Notation de Chen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 433.4 Notation UML adaptée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 433.5 Exemples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.5.1 Gestion des cours . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 453.5.2 Gestion de projets . . . . . . . . . . . . . . . . . . . . . . . . . . . . 463.5.3 Gestion des statistiques au hockey . . . . . . . . . . . . . . . . . . . . 47
3.6 Erreurs fréquentes dans la modélisation entité-association . . . . . . . . . . . 47
7 Traduction d’un schéma E-R en un schéma relationnel 517.1 Algorithmes de traduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . 517.2 Exemples de traduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
iv

10 Conception et normalisation d’une BD 6310.1 Critères informels de conception de schéma . . . . . . . . . . . . . . . . . . . 63
10.1.1 Sémantique des relations . . . . . . . . . . . . . . . . . . . . . . . . . 6310.1.2 Information redondantes . . . . . . . . . . . . . . . . . . . . . . . . . 6410.1.3 Valeur nulle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6410.1.4 Tuples erronés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
10.2 Dépendance fonctionnelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6510.2.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6510.2.2 Règles d’inférence pour les dépendances fonctionnelles . . . . . . . . . 6510.2.3 Équivalence de dépendances fonctionnelles . . . . . . . . . . . . . . . 67
10.3 Formes normales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6910.3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6910.3.2 Première forme normale (1NF) . . . . . . . . . . . . . . . . . . . . . 6910.3.3 Deuxième forme normale (2NF) . . . . . . . . . . . . . . . . . . . . . 7010.3.4 Troisième forme normale (3NF) . . . . . . . . . . . . . . . . . . . . . 7010.3.5 Forme normale de Boyce-Codd (BCNF) . . . . . . . . . . . . . . . . 70
11 Autres formes normales 7111.1 Quatrième forme normale . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7111.2 Cinquième forme normale . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7111.3 Décomposition et préservation . . . . . . . . . . . . . . . . . . . . . . . . . . 7211.4 Algorithmes de décomposition de schéma . . . . . . . . . . . . . . . . . . . . 72
11.4.1 Algorithme 13.1 : décomposition en 3NF avecpréservation des dépendances fonctionnelles . . . . . . . . . . . . . . 73
11.4.2 Algorithme 13.3 : décomposition en BCNF avecjointure non additive . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
11.4.3 Algorithme 13.4 : décomposition en 3NF avecpréservation des dépendances fonctionnelles etjointure non additive . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
11.4.4 Algorithme 13.5 : décomposition en 4NF avecjointure non additive . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
11.4.5 Algorithme de décomposition en 5NF avecjointure non additive . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
A Diapositives de patrons de traduction 74
B Diapositives de normalisation 83
C Exercices de normalisation 118
v

Chapter 1
Les bases de données et leurs usages
1.1 Introduction
1.1.1 Rôle des BDs
• les BD jouent un rôle central dans les systèmes informatiques
– systèmes d’information traditionnels
∗ gouvernement∗ banque∗ assurances∗ commerce de détail
– nouveaux domaines d’application
∗ systèmes téléphoniques∗ systèmes multimédias (image, son, video)∗ géomatique (base de données géographiques)∗ entrepôt de données
• concepts de base communs à tous
• débute l’étude avec les systèmes traditionnels
1.1.2 Définitions de concepts de base
données : information pertinente pour un utilisateur du système.
base de données (BD) : collection de données structurée de manière à être exploitée.
• taille d’une BD varie beaucoup, de bytes à gigabytes (230 bytes), et même térabytes(240 bytes)
– 1 KB = 1024 bytes = 210 bytes– 1 MB = 1024 KB = 210 ∗ 210 bytes = 220 bytes
1

– 1 GB = 1024 MB = 210 ∗ 220 bytes = 230 bytes– 1 TB = 1024 GB = 210 ∗ 230 bytes = 240 bytes
• de type manuelle (Exemple: registre de naissance d’une paroisse)
• de type automatisée (Exemple: nouveau système québécois d’enregistrement desnaissances)
système de gestion de BD (SGBD) : collection de programmes qui permettent de créeret de maintenir une base de données.
ex: Oracle (relationnel), Object Store (orienté objets), MS Access (relationnel), In-formix (relationnel), IMS (hiérarchique), IDMS (réseau).
concevoir une BD : consiste à définir la structure des données (regroupement, type, con-traintes).
construire une BD : consiste à stocker les données dans la BD.
manipuler une BD : ajouter, modifier, supprimer, interroger les données de la BD.
naviguer dans une BD : parcourir les données en utilisant leurs liens.
Exemple: À partir d’un étudiant, accéder aux cours où il est inscrit, ensuite accéderà la description de ces cours, aux professeurs qui les enseignent, aux locaux utilisés,aux notes de l’étudiants.
application : programme qui fournit des services à l’utilisateur d’un système. Il ne fait paspartie du SGBD. Il est développé par des informaticiens d’une organisation. Il utiliseles services du SGBD pour accéder à une BD.
Synonyme : système d’information
Exemple: programme qui permet de gérer les inscription des étudiants, programmede préparation des payes, système de gestion des comptes d’une banque
système de BD : comprend l’application, le SGBD et la BD.
Voir figure 1.1
1.2 Un exemple de BDVoir figure 1.2
1.3 Services offerts par une BDpercevoir les distinctions entre le traitement de fichier et les bases de données
2

1.3.1 Description des données
catalogue : partie d’un SGBD; contient une description des données (méta-données : don-nées à propos des données);
• leur regroupement (structure);
• leur type;
• leur contrainte.
1.3.2 Encapsulation des données
• le SGBD encapsule les données (masque la manière dont les données sont stockées surdisque);
• le SGBD offre des services (interface) pour accéder facilement aux données et les main-tenir;
• interface : ensemble d’opérations avec leurs paramètres et leurs types;
• les programmes d’une application utilisent les services du SGBD;
• les utilisateurs peuvent aussi utiliser directement les services d’une BD (ex; requêteSQL).
• les programmes sont indépendants de la manière dont les données sont stockées surdisque (BD locale, répartie, réseau local, réseau internet, etc);
• facilite la maintenance des programmes d’une application;
• permet de présenter les données de plusieurs manières (vues (〈〈view 〉〉));
Voir figure 1.4
• permet de définir des contraintes d’intégrité sur les données;
• permet d’assurer la persistence des objets des programmes d’application (BD orientéeobjets);
• facilite l’archivage des données et les copies de sécurité.
1.3.3 Partage des données entre plusieurs utilisateurs
• une BD doit typiquement être utilisée par plusieurs personnes en même temps;
• le SGBD permet à plusieurs utilisateurs d’accéder (lecture et écriture) aux données enmême temps, tout en préservant l’intégrité des données;
• le SGBD assure la sécurité et la confidentialité des données.
3

1.4 Intervenants dans les systèmes de BDadministrateur de BDs (DBA) : s’occupe de
• la sécurité des données;
• la coordination et du contrôle de l’usage de la BD;
• la gestion du matériel et du logiciel du SGBD.
concepteur de BDs : s’occupe de définir la structure des données.
analystes et programmeurs : développent les systèmes de BD.
utilisateur : accède à la DB pour l’interroger et la modifier.
plusieurs niveaux de familiarité avec la BD
paramétrique : utilise les programmes d’application pour accéder à la BD.
sophistiqué : utilise directement les services du SGBD pour accéder à la BD.
autonome : développe et utilise de manière autonome ses propres systèmes de BD.
1.5 Conséquences de l’usage de SGBD• normalisation; facilite la communication entre les systèmes et les utilisateurs;
– nom des données
– type des données
– contraintes
• réduction des coûts et des délais de développement des applications;
• flexibilité : plus facile de modifier la structure des données pour répondre aux change-ments des besoins des utilisateurs;
• accès aux données en temps réel;
• économies d’échelle.
1.6 Bref historique des BDfichier indexé : fichier permettant un accès direct à un enregistrement en fonction d’une
clef, qui est un sous-ensemble des attributs de l’enregistrement. Accès très rapide à unenregistrement pour la mise à jour et l’interrogation. Peu souple pour l’interrogation àpartir d’un attribut autre que la clef, ou pour joindre plusieurs fichiers ensemble. Utiliséaujourd’hui dans l’implémentation des bases de données relationnelles et objets.
4

BD hiérarchique : stockage efficace des données pour favoriser certains accès, en utilisantles liens de hiérarchie entre les données. Moins souple pour l’interrogation des donnéeset la navigation à travers les données. Encore en opération aujourd’hui dans plusieursgrandes organisation (banques, assurances, gouvernement), à cause de leur efficacité,mais aussi à cause des investissements majeurs requis pour les remplacer.
BD réseau : les liens entre les données sont prédéterminés et spécifié dans le schéma debase de données. Navigation plus souple que dans les BD hiérarchiques, mais moinsflexible que celles des BD relationnelles.
BD relationnelle : les données sont regroupées sous formes de relations (tables). La nav-igation est très souple; les liens entre les tables ne sont pas prédéfinis; ils sont établisde manière dynamique, directement dans la requête d’interrogation. En contre-partie,si les requêtes ne sont pas optimisées, elles peuvent être très longues à exécuter.
BD orientée objets : les données sont représentées par des objets. Plus souple que lesBD relationnelles au niveau des structures de données admises. On peut y stocker lesobjets d’un programme orienté objets. Permet le partage des données entre plusieursprogrammes à la fois. Simplifie la programmation orientée objets pour assurer lapersistance des données, par rapport à une BD relationnelle. Navigation parfois pluscompliquée qu’une BD relationnelle. Moins standardisée que les BD relationnelles.Dépendante des languages de programmation.
BD relationnel objets : BD relationnel offrant en plus des mécanismes pour stocker desobjets, ou pour stocker des structures plus complexes. Par exemple, une table peut“contenir” une autre table, ou stocker un objet d’un programme Java ou C++. Toute-fois, les mécanismes d’accès aux objets sont moins souples que ceux des bases dedonnées orientées objets.
XML : 〈〈Extensible Markup Language〉〉 fichier texte ordinaire contenant des données struc-turées sous forme de balises que l’on peut imbriquer les unes dans les autres. On peutvisualiser son contenu, à l’aide d’outils, sous forme d’un arbre. Issu de SGML 〈〈StandardGeneralised Markup Language〉〉, et frère de HTML 〈〈HyperText Makup Language〉〉. Onpeut l’utiliser pour échanger des données entre des applications, ou pour stocker demanière simple des données d’une application.
1.7 Usage inapproprié des BDs• coûts fixes importants (SGBD, matériel, DBA); il faut que ce soit un investissement
rentable; faire une analyse coûts-bénéfices
• temps de réponse très rapide requis : on peut obtenir un temps de réponse plus courten implantant le système à l’aide de traitement de fichiers séquentiels indexés;
• très haute fiabilité requise : centrale nucléaire, avion, train, navette spatiale, etc.;peut-on garantir la fiabilité du SGBD?
5

Chapter 2
Concepts et architecture des bases dedonnées
2.1 Modèles de BDmodèle de données : collection de concepts qui permettent de caractériser la structure
d’une BD
• type de données
• relation entre les groupe de données
• contraintes sur les données
• services offerts (opérations, commandes du SGBD).
2.2 Catégories de modèle de donnéesconceptuel : représentation abstraite de l’information; utilise, entre autres, les notions
d’entité, d’attribut et de relations pour décrire la structure d’une BD;
représentationnel : représentation fréquemment utilisée dans les SGBD commerciaux;synonyme : modèle logique.
Exemple: modèle relationnel, modèle hiérarchique, modèle réseau
modèle objet : plus près des modèles conceptuels; représente une BD en terme d’objets,de relations entre les objets et de méthodes.
modèle physique : plus près de l’implémentation; décrit la structure interne de la BD: sesindex, sa répartition physique sur les processeurs, etc.
2.3 Schémaétablir une distinction entre la description de la structure de la BD et du contenu de la BD.
6

schéma :
• description de la structure d’une BD;
• typiquement représenté en partie par un diagramme;
• stocké dans le catalogue du SGBD.
Voir figure 2.1
état d’une BD : l’ensemble des données contenues dans une BD à un moment particulier
• aussi appelé instance du schéma de BD ;
• les opérations de mise à jour modifient l’état d’une BD.
2.4 ArchitectureArchitecture peut être décrite à trois niveaux.
interne : stockage physique des données;
conceptuel : décrit les entités, les relations, les opérations, les contraintes;
externe : décrit les vues des utilisateurs (pour une classe d’utilisateurs, on définit et re-groupe les entités désirées).
Cette séparation en trois facilite la maintenance du SGBD et des BDs.Voir figure 2.2
2.5 Langageslangage de définition des données (LDD) : permet de définir un schéma de BD;
Exemple: SQL (relationnel), ODL (orienté objets)
langage de manipulation des données (LMD) : permet de modifier ou d’interrogerl’état d’une BD;
Exemple: SQL (relationnel)
langage hôte (host language) : expression utilisée pour dénoter les langages externesaux LMD qui permettent de programmer des applications;
Exemple: Java, C++, COBOL, Visual Basic, PL/SQL
langage de requête (query language) : expression utilisée pour dénoter un LMD lorsqu’ilest utilisé de manière autonome;
Exemple: SQL avec SQL/PLUS d’Oracle (relationnel), OQL (orienté objets).
7

2.6 Composantes d’un SGBDcompilateur pour le LDD : met à jour le catalogue du SGBD en traitant un schéma;
compilateur pour le LMD : génère le code pour modifier l’état de la BD;
pré-compilateur pour un langage hôte : génère le code en langage hôte pour les énon-cés de LMD d’un programme d’application;
compilateur de requête : génère le code pour exécuter une requête d’interrogation de laBD;
processeur de requête : exécute les requêtes de mise à jour et d’interrogation de la BD;
gestionnaire des données stockées : gère les accès au disque pour le SGBD;
utilitaires : divers programmes permettant d’archiver, de prendre des copies de sécurité, decharger une BD à partir de fichiers séquentiels, de réorganiser l’espace physique d’uneBD, de faire le suivi de la performance;
outils d’aide au développement : permettent de générer des schémas à partir de mod-èles de haut niveau (Exemple: modèle relationnel à partir du modèle E-R) et dedévelopper des applications utilisant la BD (Exemple: Designer 2000 et Developper2000 d’Oracle).
Voir figure 2.3
8

Chapter 8
Le langage SQL
• le langage SQL est une norme de l’ANSI et de l’ISO pour les SGBD relationnels
• il comporte à la fois des énoncés de définitions des données (LDD) et de manipulationdes données (LMD).
• les fabricants de SGBD essaient de se conformer à cette norme, mais ils le font chacunà des niveaux différents de conformité;
• la version Oracle 10 est conforme à plusieurs éléments de la norme SQL, mais pascomplètement;
• dans le cours, nous utilisons Oracle et Postgres; il est possible que des requêtes SQLexécutant sur d’autres SGBD (comme Microsoft Access) ne puisse être exécutées sousOracle, et vice-versa;
• pour maximiser la portabilité des applications, il est préférable de se limiter au SQLnormalisé et ne pas utiliser de caractéristiques spécifiques à Oracle ou un autre SGBD.
8.1 Langage de définition des données
8.1.1 Table
• une table est un ensemble de tuples;
• on utilise aussi relation comme synonyme de table, et ligne ou enregistrement commesynonymes de tuple;
• tous les tuples d’une table ont le même format; ce format est défini par un ensembled’attributs;
• on peut représenter graphiquement une table par une matrice ou les colonnes sont les at-tributs; la première ligne comporte les noms des attributs, et les autres lignes représen-tent les tuples; l’ordre d’énumération des tuples ou des attributs n’a pas d’importance;
• la définition en SQL d’une table comporte les éléments suivants:
9

– son nom
– ses attributs
– ses contraintes d’intégrité; il y a plusieurs types de contraintes d’intégrité:
∗ clé primaire, clé unique, clé étrangère∗ condition sur les valeurs des attributs (check(...), [not] null)
8.1.2 Types en SQL
La norme ANSI SQL définit des types de données. Il appartient aux fabricant de bases dedonnées (comme Oracle, IBM, Microsoft) de suivre cette norme. Le tableau 8.1 donne lesprincipaux types ANSI SQL.
• char(n)
– représente une chaîne de caractères de longueur fixe n;
– une chaîne de caractères est mise entre des apostrophes simples (’);
– pour inclure un ’ dans une chaîne de caractères, on utilise deux ’.
Exemple 8.1 La chaîne ’abc12’ est une valeur du type char(5). La chaîne ’ab”12’contient un ’ au milieu.
• numeric(p,s)
– p indique le nombre total de chiffres stockés pour un nombre; la valeur de p doitêtre entre 1 et 38;
– s > 0 indique le nombre total de chiffres après la virgule;
– s < 0 indique un arrondissement du nombre de s chiffre avant la virgule;
Exemple 8.2
– numeric(5,2) peut contenir une valeur comportant 5 chiffres, dont 3 avant lavirgule (soit 5-2) et 2 chiffres après la virgule; exemple de valeur : 123,45
– numeric(2,5) peut contenir une valeur comportant de 2 chiffres; comme p < sdans ce cas, on a seulement des chiffres après la virgule; les 3 premiers (soit 5-2)ont comme valeur 0; exemple de valeur : 0,00012
– numeric(5,-2) peut contenir une valeur comportant de 7 chiffres avant la vir-gule (soit 5 − −2), mais seulement les 5 premiers chiffres sont stockés, les 2derniers sont toujours 0; il n’y aucun chiffre après la virgule; exemple de valeur: 1234500;lorsqu’on stocke une valeur dans la base de données, elle est toujoursarrondie à deux chiffres avant la virgule; exemple 1234550 est stockée comme1234600 et 1234549 est stocké comme 1234500.
10

– numeric(2,-5) peut contenir une valeur comportant de 7 chiffres avant la virgule(soit 2−−5), mais seulement les 2 premiers chiffres sont stockés, les 5 dernierssont toujours 0; il n’y aucun chiffre après la virgule; exemple de valeur : 1200000;
• real
– permet de stocker un nombre en virgule flottant (c-a-d une valeur représentée parune mantisse et un exposant)
• varchar(n)
– permet de stocker une chaîne de caractères de longueur maximale n;
– par rapport à char(n), permet de mieux gérer l’espace disque si les chaînes decaractères ne sont pas toujours de longueur n;
• date et heure
– le type date de la norme SQL2 comprend seulement une date en formatYYYY-MM-DD;
– le type time de la norme SQL2 comprend seulement une heure en formatHH:MM:SS;
– le type timestamp de la norme SQL2 comprend la date et l’heureen format (YYYY-MM-DD HH:MM:SS.ffffff), où ffffff représente une fraction deseconde;
– le type date d’Oracle est presque équivalent au type timestamp de SQL2; ilcomprend la date et l’heure (YYYY-MM-DD HH:MM:SS), mais sans fraction deseconde; la valeur d’une date varie entre le 1er janvier 4712 avant J-C et 31décembre 4712 après J-C.
– la date sous Oracle est affichée selon le format donné par le paramètre globalnls_date_format;
– il existe plusieurs fonctions pour manipuler des dates en Oracle;
Exemple 8.3 to_date(’29-02-2000’,’DD-MM-YYYY’) retourne la valeur de la date29 février 2000 selon le type DATE d’Oracle.
Le tableau 8.2 donne les types spécifique à Oracle qui ne font pas partie de la norme etqu’il faut éviter d’utiliser par souci de portabilité; il est préférable d’utiliser les type ANSISQL supportés par Oracle.
11

Types de la norme SQL
Nom Espace Description Valeurs Exemples de constantes
smallint 2 bytes entier -32768 to +32767 518 et -312
integer 4 bytes entier -2147483648 to +2147483647
518 et -312
bigint 8 bytes entier -9223372036854775808 à 9223372036854775807
518 et -312
numeric(p,s) et decimal(p,s)!
variable
virgule fixe (ie, nombre fixe de positions décimales)
jusqu’à 131072 chiffres avant la virgule et 16383 après
9.76 et -5.412
real 4 bytes virgule flottante 6 chiffres de précision 0.123456e3 (ie, 0,123456 x 103) -0.515e-3 (ie, -0,515 x 10-3)
double precision 8 bytes virgule flottante 15 chiffres de précision
0.123456789012345e3 (ie, 0,123456789012345 x 103) -0.515e-3 (ie, -0,515 x 10-3)
char(n) n bytes chaine de caractères de longueur fixe n 'coucou'
'aujourd''hui'
varchar(n) n+2 bytes
chaine de caractères de longueur variable maximum n
'coucou' 'aujourd''hui'
date 4 bytes YYYY-MM-DD (année, mois, jour)
4713 avant JC, 294276 après JC
date '2013-08-23'
time 8 bytes HH:MM:SS (heures,mins,secs) time '23:59:59'
timestamp 8 bytes YYYY-MM-DD HH:MM:SS.ffffff
ffffff représente une fraction de seconde
timestamp '2013-12-23 23:59:59.123'
boolean 1 bit booléen true et false
!
Table 8.1: Les types de la norme SQL
12

Type de données ANSI SQL Type spécifique à Ora-cle (à éviter si possible,car non standard)
char(n)varchar(n) varchar2(n)numeric(p, s), decimal(p, s) number(p, s)integer, int, smallint number(38)real, double precision numberdate date contient une date et
une heure; pas d’autrechoix pour représenter unedate en Oracle
time inexistanttimestampboolean inexistant
Table 8.2: Types spécifiques à Oracle à éviter
8.1.3 Définition des tables
Notation utilisée pour décrire la syntaxe du langage SQL
• mot_cle : mot réservé du langage SQL;
• 〈symbole terminal〉 : peut être remplacé par un identificateur ou une constante (nom-bre, chaîne de caractère, etc);
• 〈〈symbole non terminal〉〉 : doit être remplacé par sa définition;
• 〈〈symbole non terminal〉〉 ::= . . . : définition d’un symbole non terminal;
• "{" et "}" : équivalent des parenthèses en mathématiques;
• + : une ou plusieurs occurrences;
• ∗ : zéro ou plusieurs occurrences;
• [ élément optionnel ]
• | : choix entre plusieurs options
8.1.3.1 Syntaxe générale
〈〈creation-table〉〉 ::=create table 〈nom-table〉 (〈〈liste-attributs〉〉[ , 〈〈liste-contraintes〉〉 ]
)
13

8.1.3.2 Définition des attributs
〈〈liste-attributs〉〉 ::=〈〈attribut〉〉 {, 〈〈attribut〉〉 }∗
〈〈attribut〉〉 ::=〈nom-attribut〉 〈type〉 [ default 〈〈expression〉〉 ][ not null ] [ check ( 〈〈condition〉〉 ) ]
• la valeur par défaut est utilisée si la valeur de l’attribut n’est pas spécifiée lors de lacréation d’un tuple;
• la condition doit être vérifiée lors de la création ou de la mise à jour d’un tuple;
• not null : la valeur de l’attribut ne peut contenir la valeur spéciale null;
• exemples de condition
– 〈nom-attribut〉 { = | > | >= | . . . } 〈〈expression〉〉– 〈nom-attribut〉 in (〈〈liste-valeurs〉〉)– 〈〈condition〉〉 { and | or } 〈〈condition〉〉– not 〈〈condition〉〉– plusieurs autres (voir manuel Oracle).
8.1.3.3 Définition des contraintes
〈〈liste-contraintes〉〉 ::=〈〈contrainte〉〉 {, 〈〈contrainte〉〉 }∗
〈〈contrainte〉〉 ::=〈〈cle-primaire〉〉 | 〈〈cle-unique〉〉 | 〈〈cle-etrangere〉〉
8.1.3.3.1 Clé primaire
〈〈cle-primaire〉〉 ::=constraint 〈nom-contrainte〉 primary key ( 〈〈liste-noms-attribut〉〉 )
• il ne peut y avoir deux tuples avec les mêmes valeurs pour les attributs de la cléprimaire;
• on peut définit une seule clé primaire pour une table;
• la valeur d’un attribut d’une clé primaire ne peut être null dans un tuple.
14

8.1.3.3.2 Clé unique
〈〈cle-unique〉〉 ::=constraint 〈nom-contrainte〉 unique ( 〈〈liste-noms-attribut〉〉 )
• il ne peut y avoir deux tuples dans la table avec les mêmes valeurs pour les attributsde la clé unique;
• on peut définir plusieurs clés uniques pour une table;
• un attribut d’une clé unique peut être null, toutefois, la combinaison de tous lesattributs non null doit être unique.
8.1.3.3.3 Clé étrangère On dénote deux cas possibles:
1. faire référence à la clé primaire d’une autre table
〈〈cle-etrangere〉〉 ::=constraint 〈nom-contrainte〉foreign key (〈〈liste-attributs〉〉)references 〈nom-table-referencee〉[ on delete cascade ]
• les types de 〈〈liste-attributs〉〉 doivent être les mêmes que les types des attributsde la clé primaire de 〈nom-table-référencée〉;• pour chaque tuple de la table dont les attributs de clé étrangère sont tous différents
de null, il doit exister un tuple dans 〈nom-table-référencée〉 avec la même valeurpour 〈〈liste-attributs〉〉;• on delete cascade : si un tuple dans 〈nom-table-référencée〉 est supprimé, tous
les tuples de la table qui le référence sont aussi supprimés.
2. faire référence à une clé unique d’une autre table
〈〈cle-etrangere〉〉 ::=constraint 〈nom-contrainte〉foreign key (〈〈liste-attributs〉〉)references 〈nom-table-referencee〉[ (〈〈liste-attributs-cle-unique〉〉) ][ on delete cascade ]
• les types de 〈〈liste-attributs〉〉 doivent être les mêmes que les types 〈〈liste-attributs-clé-unique〉〉;• pour chaque tuple de la table dont les attributs de clé étrangère sont tous différents
de null, il doit exister un tuple dans 〈nom-table-référencée〉 avec la même valeurpour 〈〈liste-attributs〉〉;• on delete cascade : si un tuple dans 〈nom-table-référencée〉 est supprimé, tous
les tuples de la table qui le référence sont aussi supprimés.
15

8.1.4 Modification des tables
alter table 〈relation〉 {〈〈ajout-attribut〉〉 |〈〈modification-attribut〉〉 |〈〈suppression-attribut〉〉 |〈〈ajout-contrainte〉〉 |〈〈suppression-contrainte〉〉 }
8.1.4.1 Ajout d’attributs
〈〈ajout-attribut〉〉 ::= add ( 〈〈liste-attributs〉〉 )
• ajoute les attributs de la liste à la table;
8.1.4.2 Modification d’attributs
〈〈modification-attribut〉〉 ::= modify ( 〈〈liste-attributs〉〉 )
• modifie le type, la valeur par défaut ou l’option null or not null des attributs de laliste;
• on spécifie seulement les parties à modifier;
• pour modifier le type, la valeur de chaque attribut doit être null pour tous les tuplesde la table;
• pour spécifier not null, il faut que l’attribut satisfasse déjà cette condition.
8.1.4.3 Suppression d’attributs
〈〈ajout-attribut〉〉 ::= drop ( 〈〈liste-noms-attribut〉〉 )
• supprime les attributs;
• non disponible en Oracle.
8.1.4.4 Ajout de contraintes
〈〈ajout-attribut〉〉 ::= add (〈〈liste-contraintes〉〉)
• ajoute les contraintes;
• les tuples de la table doivent satisfaire la contrainte.
16

8.1.4.5 Suppression de contraintes
〈〈ajout-attribut〉〉 ::= drop 〈nom-contrainte〉 [ cascade ]
• supprime la contrainte;
• cascade : supprime aussi toutes les contraintes qui dépendent de la contrainte sup-primée.
8.1.5 Suppression des tables
drop table 〈nom-table〉 [ cascade constraints ]
17

8.1.5.1 L’exemple de la bibliothèque
Voici le schéma relationnel.
1. editeuridediteur nom pays
2. auteuridauteur nom
3. livreidlivre titre idauteur idediteur dateAcquisition prix
4. membreidmembre nom telephone limitePret
5. pretidmembre idlivre datePret
6. reservationidreservation idmembre idlivre dateReservation
18

Voici le diagramme relationnel.
auteur
PK idauteur
nom
editeur
PK idediteur
nom pays
livre
PK idlivre
U2,U1 titreFK1,U1 idauteurFK2,U2 idediteur dateacquisition prix
membre
PK idmembre
nom telephone limitepret
pret
PK,FK1 idmembrePK,FK2 idlivrePK datepret
reservation
PK idreservation
FK1,U1 idmembreFK2,U1 idlivre datereservation
Figure 8.1: Diagramme relationnel de l’exemple de la bibliothèque
19

Voici les énoncés de création des tables.
-------------------------------------------- une ligne de commentaire commence par deux ’--’-- Exemple de la bibliotheque-- Marc Frappier , Universite de Sherbrooke-- 2001 -01 -08------------------------------------------
drop table editeur cascade constraints;create table editeur (idediteur numeric (3),nom varchar (10) not null ,pays varchar (10) not null ,constraint PKediteur primary key (idediteur));
drop table auteur cascade constraints;create table auteur (idauteur numeric (3),nom varchar (10) not null ,constraint PKauteur primary key (idauteur));
drop table livre cascade constraints;create table livre (idlivre numeric (3),titre varchar (10) not null
check(upper(substr(titre ,1,1)) = substr(titre ,1,1)),idauteur numeric (3) not null ,idediteur numeric (3) not null ,dateacquisition date ,prix numeric (7,2),constraint PKlivre primary key (idlivre),constraint UtitreAuteur unique (titre ,idauteur),constraint UtitreEditeur unique (titre ,idediteur),constraint FKlivreAuteur foreign key (idauteur) references auteur ,constraint FKlivreEditeur foreign key (idediteur) references editeur);
drop table membre cascade constraints;create table membre (idmembre numeric (3),nom varchar (10) not null ,telephone numeric (10)
20

check(telephone >= 8190000000and telephone <=8199999999) ,
limitepret numeric (2)check(limitepret > 0 and limitepret <= 10),
constraint PKmembre primary key (idmembre));
drop table pret cascade constraints;create table pret (idmembre numeric (3),idlivre numeric (3),datepret date not null ,constraint PKpret primary key (idmembre ,idlivre ,datepret),constraint FKpretMembre foreign key (idmembre) references membre ,constraint FKpretLivre foreign key (idlivre) references livre);
drop table reservation cascade constraints;create table reservation (idreservation numeric (3),idmembre numeric (3),idlivre numeric (3),datereservation date not null ,constraint PKreservation primary key (idreservation),constraint Ureservation unique (idmembre ,idlivre),constraint FKreservMembre foreign key (idmembre) references membre ,constraint FKreservLivre foreign key (idlivre) references livre);
8.2 Langage de manipulation des données
8.2.1 Insert
insert into 〈nom-table〉[ ( 〈〈liste-noms-attribut〉〉 ) ]{ values ( 〈〈liste-expressions〉〉 ) | 〈〈select〉〉 }
8.2.2 Update
update 〈nom-table〉set { 〈〈liste-affectation〉〉 | 〈〈affectation-select〉〉 }[ where 〈〈condition〉〉 ]
〈〈liste-affectation〉〉 ::=
21

〈〈affectation〉〉 [ , 〈〈affectation〉〉∗ ]
〈〈affectation〉〉 ::=〈nom-attribut〉 = 〈〈expression〉〉
〈〈affectation-select〉〉 ::=( 〈〈liste-noms-attribut〉〉 ) = 〈〈select〉〉
• 〈〈expression〉〉 peut être un énoncé select.
8.2.3 Delete
delete from 〈nom-table〉[ where 〈〈condition〉〉 ]
• si where n’est pas spécifié, l’énoncé delete supprime tous les tuples.
22

8.2.4 Select
8.2.4.1 Syntaxe générale
〈〈enonce-select-base〉〉 ::=select [ distinct ] 〈〈liste-expressions-colonne〉〉from 〈〈liste-expressions-table〉〉[ where 〈〈condition-tuple〉〉 ][ group by 〈〈liste-expressions-colonne〉〉 ][ having 〈〈condition-groupe〉〉 ][ order by 〈〈liste-expressions-colonne〉〉 ]
〈〈enonce-select-compose〉〉 ::=〈〈enonce-select-base〉〉
{ union [ all ] | intersect | minus }〈〈enonce-select-compose〉〉
8.2.4.2 Sémantique
Le résultat d’un énoncé select est égal au résultat des opérations suivantes. Note: chaqueSGBD utilise un algorithme propre pour exécuter un énoncé select. Toutefois, le résultatest le même que celui donné par la procédure ci-dessous.
1. évalue le produit cartésien des relations du from;
2. sélectionne les tuples satisfaisant la clause where;
3. tuples regroupés selon la clause group by;
4. sélectionne les groupes selon la condition having;
5. évalue les expressions du select;
6. élimine les doublons si clause distinct;
7. évalue l’union, l’intersection, ou la différence des selects (si nécessaire);
8. trie les tuples selon la clause order by.
8.2.4.3 La valeur spéciale NULL
• on utilise is null pour tester si une expression vaut null;
• on utilise is not null pour tester si une expression ne vaut pas null;
• une fonction évaluée sur une valeur null retourne une null (sauf la fonction nvl(e1, e2)qui retourne e2 si e1 vaut null, sinon elle retourne e1; de manière plus générale, lafonction coalesce(e1, . . . , en) retourne la première expression ei qui ne vaut pas null.
• dans toutes les fonctions de groupe sauf count(*), les valeurs null sont ignorées;
23

• count(*) compte le nombre de tuple (doublons inclus), incluant les valeurs NULL;
• une expression booléenne atomique utilisant une valeur null retourne la valeur in-connu;
• une expression booléenne composée est définie selon les tables suivantes:
not vrai faux inconnufaux vrai inconnu
and vrai faux inconnuvrai vrai faux inconnufaux faux faux faux
inconnu inconnu faux inconnu
or vrai faux inconnuvrai vrai vrai vraifaux vrai faux inconnu
inconnu vrai inconnu inconnu
• une clé primaire ne peut contenir de valeurs null pour les attributs d’un tuple;
• une clé unique peut contenir des valeurs null pour un tuple. Toutefois, l’unicité doitêtre préservée pour les valeurs non null.
8.2.4.4 Expressions
• expression élémentaire : nom d’attribut, fonction, constante;
• expression composée : opérateur ou fonction appliqué sur expressions élémentaires oucomposées;
• alias : renommer une expression ou une relation (table);
• * : retourne tous les attributs de toutes les tables du from
• R.* : retourne tous les attributs de la table R.
8.2.4.5 Conditions (Expressions booléennes)
• opérateurs logique : not, and, or
• opérateurs de comparaison : =, !=, <>, <, <=, >, >=
• is null, is not null (on écrit A is null, plutôt que A = null, qui retourne tou-jours INCONNU; idem pour A is not null, plutôt que A != null).
24

• 〈〈expr1〉〉 like 〈〈expr2〉〉 : vrai si 〈〈expr1〉〉 satisfait le patron 〈〈expr2〉〉; un patron est unechaîne de caractères pouvant contenir des caractères ayant une signification partic-ulière:
– ‘%’ dénote n’importe quelle chaîne de caractères, y compris la chaîne vide (i.e.,une chaîne de longueur 0),
– ‘_’ dénote n’importe quel caractère (i.e., une chaîne de caractères de longueur 1exactement).
Par exemple, l’expression A like ’%abc%def_8’ retourne vrai ssi A contient la chaîne’abc’ puis la chaîne ’def’ suivie de n’importe quel caractère et ensuite du caractère’8’; A peut contenir n’importe quelle chaîne de caractères avant l’occurrence du pre-mier ’abc’ (premier ’%’) et entre ’abc’ et ’def’ (deuxième ’%’), et exactement uncaractère (mais n’importe lequel) entre ’def’ et ’8’. Voici des exemples de valeurs deA qui satisfont le patron ’%abc%def_8’
– ’abcdefz8’
– ’qabc(deft8’
– ’qsxabc*h$def=8’
• condition appliquée à un subselect
– 〈expr〉 in (〈select〉) : vrai si 〈expr〉 est un élément de l’ensemble des tuples re-tournés par le select;
– 〈expr〉 not in (〈select〉) : vrai si 〈expr〉 n’appartient pas aux tuples retournés parle select;
– 〈expr〉 >any (〈select〉) : vrai s’il existe un tuple t ∈ 〈select〉 tel que 〈expr〉 > t;valable aussi pour tous les opérateurs de comparaison.
– 〈expr〉 >all (〈select〉) : vrai si pour tous les tuples t ∈ 〈select〉, 〈expr〉 > t;
– exists (〈select〉) : retourne vrai ssi le select retourne au moins un tuple;
– not exists (〈select〉) : retourne vrai ssi le select ne retourne aucun tuple;
8.2.4.6 Autres expressions (arithmétique, caractères, dates)
• tous les opérateurs arithmétiques de base et la plupart des fonctions mathématiquessont disponibles (voir le manuel de référence d’Oracle).
• sysdate retourne la date et l’heure courante.
• to_date(c, f) retourne la date correspondant à la chaîne de caractères c exprimée dansle format f .
Par exemple, to_date(’2012-08-27’,’YYYY-MM-DD’) retourne la date correspondantau 27 août 2012.
25

• to_char(d, f) retourne la chaîne de caractères correspondant à la date d exprimée dansle format f .
Par exemple, to_char(sysdate,’YYYY-MM-DD’) retourne la date courante sous formed’une chaîne de caractères.
• l’expression d+ n, où d est une date et n un nombre en point flottant (ie, un nombrerationnel) représentant un nombre de jours, retourne la date d incrémentée de n jours.
Par exemple to_date(’2012-08-27’,’yyyy-mm-dd’)+1 vaut le 28 août 2012.
De manière similaire, l’expression d− n retourne la date d decrémentée de n jours.
Par exemple to_date(’2012-08-27’,’yyyy-mm-dd’)-1 vaut le 26 août 2012.
• l’expression c1 || c1 retourne la concaténation des chaînes de caractères c1 et c2.
Par exemple, ’a’ || ’b’ vaut ’ab’.
• la fonction substring(c, i, j) retourne la sous-chaîne de caractères de c commençant àla position i et de longueur j.
Par exemple, substring(’abcdef’,2,3) vaut ’bcd’.
• la fonction decode(e0, e1, v1, . . . , en, vn, vn+1) se comporte commme suit: si e0 = e1,alors elle retourne v1, sinon si e0 = e2, alors elle retourne v2, et ainsi de suite. Si e0 6= eipour tout i de 1 à n, alors elle retourne vn+1.
• Il existe plusieurs autres fonctions; voir le manuel d’Oracle.
8.2.4.7 Fonctions d’agrégation
• appliquée à l’ensemble des tuples d’un select ou aux tuples d’un groupe quand la clausegroup by est utilisée.
• count(〈〈expr〉〉), sum(〈〈expr〉〉), avg(〈〈expr〉〉), min(〈〈expr〉〉), max(〈〈expr〉〉), etc;
• count(*) : compte aussi les valeurs null;
• count(attribut) : compte seulement les valeurs non null;
• count(distinct attribut) : une valeur est comptée une seule fois, même si plusieurstuples ont cette valeur;
• les autres fonction de groupe comme sum(x) ignorent les valeurs null; si toutes lesvaleurs sont null dans le groupe, alors la valeur null est retournée; utilisez nvl oucoalesce pour contourner ce problème.
26

8.2.4.8 Opérations ensemblistes
1. union : union de tous les tuples des subselects avec élimination des doublons;
2. union all : union de tous les tuples des subselects sans élimination des doublons;
3. intersect : intersection avec élimination doublon;
4. minus : différence, avec élimination doublon.
8.2.4.9 Jointures
La norme SQL propose une syntaxe pour exprimer les jointures dans la clause from.
CROSS JOIN
Le cross join retourne le produit cartésien de deux tables.
select ...from livre CROSS JOIN membre
est équivalent à
select ...from livre , membre
JOIN, INNER JOIN et NATURAL JOIN
inner join est un synonyme de join. Il retourne le produit cartésien de deux tablessuivi d’une sélection des lignes en fonction d’une égalité entre des attributs (clause using(...)) ou d’une condition spécifique (clause on 〈〈condition〉〉). Voici un exemple utilisantusing.
select ...from livre JOIN pret USING (idlivre)
est équivalent à
select ...from livre , pretwhere livre.idlivre = pret.idlivre
Voici un exemple utilisant ON.
select ...from livre JOIN pret
ON livre.idlivre = pret.idlivre andlivre.dateacquisition < pret.datepret
est équivalent à
27

select ...from livre , pretwhere livre.idlivre = pret.idlivre and
livre.dateacquisition < pret.datepret
Le natural join est équivalent à un using sur tous les attributs communs entre deux tables(ie, les colonnes portant le même nom dans les deux tables).
select ...from livre NATURAL JOIN pret
est équivalent à
select ...from livre JOIN pret USING (idlivre)
OUTER JOIN
Le outer join permet d’ajouter au résultat d’un join les lignes d’une des tables (leftpour la table de gauche, right pour la table de droite, full pour les deux tables) quin’apparaissent pas dans le résultat d’un join. L’exemple suivant retourne tous les livresde la table des livres, même ceux qui n’ont pas de prêt, et qui donc n’apparaitraient pas sion utilisait simplement un join. Les colonnes de l’autre table contiennent des valeurs nullpour les lignes ajoutées (ie, vu qu’elles n’ont pas de correspondance dans l’autre table).
select livre.idlivre , pret.datepretfrom livre LEFT OUTER JOIN pret USING (idlivre)
est équivalent à
select livre.idlivre , pret.datepretfrom livre , pretwhere livre.idlivre = pret.idlivreUNION(select livre.idlivre , nullfrom livrewhere NOT EXISTS
(select idlivrefrom pretwhere pret.idlivre = livre.idlivre)
);
Oracle permet aussi d’utiliser une syntaxe abbréviée pour un outer join, en utilisant un “+”dans la clause where. Un left outer join s’exprime en mettant un “+” du côté droit (etoui, c’est l’inverse ...). Un right outer join s’exprime en mettant un “+” du côté gauche.Un full outer join s’exprime en mettant un “+” de chaque côté. L’exemple précédents’exprime comme suit:
28

select livre.idlivre , pret.datepretfrom livre , pretwhere livre.idlivre = pret.idlivre (+)
29

8.2.4.10 Quelques exemples de SELECT
1. Sélection de colonnes d’une table : Afficher la liste des livres avec leur titre.
select idlivre , titrefrom livre
2. Sélection de lignes d’une table avec une condition élémentaire : Afficher laliste des livres avec leur titre pour l’auteur idauteur = 3.
select idlivre , titrefrom livrewhere idauteur = 3
3. Sélection de lignes d’une table avec une condition composée : Afficher la listedes livres avec leur titre pour les auteurs d’idauteur = 3 ou 5.
select idlivre , titrefrom livrewhere idauteur = 3 or idauteur = 5
ou bien
select idlivre , titrefrom livrewhere idauteur in (3,5)
4. Ordonnancement du résultat : Afficher la liste des livres avec leur titre pour leslivres des auteurs d’idauteur = 3 ou 5, triée en ordre croissant de idauteur et titre.
select idlivre , titrefrom livrewhere idauteur in (3,5)order by idauteur , titre
5. Spécification de colonnes calculées : Afficher la liste des livres avec leur titre et leprix incluant la TPS et la TVQ, pour les livres des auteurs d’idauteur = 3 ou 5, triéeen ordre croissant de idauteur et titre.
select idlivre , titre , prix *1.075*1.07 PrixTTCfrom livrewhere idauteur in (3,5)order by idauteur , titre
6. Sélection de lignes à partir d’expressions : Afficher la liste des livres avec leurtitre et le prix incluant la TPS et la TVQ, pour les livres des auteurs d’idauteur = 3ou 5 et dont le prix TTC est ≤ 100 $, triée en ordre croissant de idauteur et titre.
30

select idlivre , titre , prix *1.075*1.07 PrixTTCfrom livrewhere idauteur in (3,5) and
prix *1.075*1.07 <= 100order by idauteur , titre
7. Fonction d’agrégation : Afficher le nombre d’éditeurs dans la base de données.
select count(idediteur) "nb␣editeurs"from editeur
8. Fonction d’agrégation avec élimination des doublons : Afficher le nombred’éditeurs et le nombre d’auteurs dans la base de données.
select count(distinct idediteur) "nb␣editeurs",count(distinct idauteur) "nb␣auteurs"
from editeur , auteur
9. Jointure de plusieurs tables : Afficher la liste des livres avec leur titre, nom del’auteur et nom de l’éditeur, pour les idauteur = 3 ou 5, triée en ordre croissant deidauteur et titre
select livre.idlivre , livre.titre , auteur.nom , editeur.nomfrom livre , auteur , editeurwhere livre.idauteur = auteur.idauteur and
livre.idediteur = editeur.idediteur andlivre.idauteur in (3,5)
order by livre.idauteur , livre.titre
10. Calcul d’expressions de groupe : Afficher la liste des éditeurs avec le nombre delivres édités.
select editeur.idediteur , editeur.nom , count (*) "nb␣livres"from editeur , livrewhere editeur.idediteur = livre.idediteurgroup by editeur.idediteur , editeur.nomorder by editeur.idediteur
On note que si un éditeur n’a pas de livre édité, il n’apparaît pas dans le résultat duselect.
11. Sélection de groupes : Afficher la liste des éditeurs avec le nombre de livres édités,en sélectionnant les éditeurs qui ont édité 5 livres ou plus.
select editeur.idediteur , editeur.nom ,count(livre.idlivre) "nb␣livres"
from editeur , livrewhere editeur.idediteur = livre.idediteur
31

group by editeur.idediteur , editeur.nomhaving count(livre.idlivre) >= 5order by editeur.idediteur
12. Jointure externe (outer join) : Afficher la liste des éditeurs avec le nombre delivres édités. Si un éditeur n’a aucun livre, afficher 0.
select editeur.idediteur , editeur.nom ,count(livre.idlivre) "nb␣livres"
from editeur LEFT OUTER JOIN livre USING (idediteur)group by editeur.idediteur , editeur.nomorder by editeur.idediteur
Avec Oracle, on utilise parfois la notation (+), qui ne fait pas partie de la norme SQL.
select editeur.idediteur , editeur.nom ,count(livre.idlivre) "nb␣livres"
from editeur , livrewhere editeur.idediteur = livre.idediteur (+)group by editeur.idediteur , editeur.nomorder by editeur.idediteur
13. Opérateur any : Afficher les auteurs qui ont au moins un éditeur en commun avecl’auteur d’idauteur 1.
select distinct auteur.nom , auteur.idauteurfrom auteur , livrewhere auteur.idauteur = livre.idauteur and
livre.idediteur =any(select editeur.idediteurfrom editeur , livre lwhere editeur.idediteur = l.idediteur and
l.idauteur = 1)
14. Opérateur all : Afficher le (ou les) livre(s) dont le prix est le plus élevé (les élémentsmaximaux) pour chaque éditeur.
select editeur.idediteur , editeur.nom , livre.idlivre ,livre.titre , livre.prix
from editeur , livrewhere editeur.idediteur = livre.idediteur and
livre.prix >=all (select l.prixfrom livre lwhere l.idediteur = livre.idediteur)
order by editeur.idediteur , livre.idlivre
Si plusieurs livres ont le prix le plus élevé pour un éditeur donné, chacun est affiché.
32

15. Opérateur all Afficher le livre le plus cher (le supremum) de chaque éditeur, s’ilexiste.
select editeur.idediteur , editeur.nom , livre.idlivre ,livre.titre , livre.prix
from editeur editeur , livre livrewhere editeur.idediteur = livre.idediteur and
livre.prix >all (select l.prixfrom livre lwhere l.idediteur = livre.idediteur and
l.idlivre != livre.idlivre)order by editeur.idediteur , livre.idlivre
16. Opérateur exists : Afficher les auteurs qui ont publié au moins un livre avec l’éditeur1.
select auteur.idauteur , auteur.nomfrom auteurwhere exists (
select *from livrewhere livre.idauteur = auteur.idauteur and
livre.idediteur = 1)
L’énoncé ci-dessous est équivalent.
select distinct auteur.idauteur , auteur.nomfrom auteur , livrewhere auteur.idauteur = livre.idauteur and
livre.idediteur = 1
17. Opérateur not exists : Afficher le (ou les) livre(s) dont le prix est le plus élevé (leséléments maximaux) pour chaque éditeur.
select editeur.idediteur , editeur.nom , livre.idlivre ,livre.titre , livre.prix
from editeur , livrewhere editeur.idediteur = livre.idediteur and
not exists (select *from livre lwhere l.idediteur = livre.idediteur and
livre.prix < l.prix)order by editeur.idediteur , livre.idlivre
Si plusieurs livres ont le prix le plus élevé pour un éditeur donné, chacun est affiché.
33

18. Opérateur not exists Afficher le livre le plus cher (le supremum) de chaque éditeur,s’il existe.
select editeur.idediteur , editeur.nom , livre.idlivre ,livre.titre , livre.prix
from editeur , livrewhere editeur.idediteur = livre.idediteur and
not exists (select *from livre lwhere l.idediteur = livre.idediteur and
not (l.idlivre = livre.idlivre) andlivre.prix <= l.prix)
order by editeur.idediteur , livre.idlivre
19. Requête de type “pour tous” (Quantification universelle) Afficher les auteursqui ont publié un livre avec chaque éditeur.
select auteur.idauteur , auteur.nomfrom auteurwhere not exists (
select *from editeurwhere not exists (
select *from livrewhere livre.idauteur = auteur.idauteur and
livre.idediteur = editeur.idediteur ))
20. select imbriqué (clause from) : Afficher le (ou les) livre(s) ayant le plus grandnombre de prêts pour chaque éditeur (éléments maximaux).
select nbPretEditeurLivre.idediteur , nbPretEditeurLivre.nom ,nbPretEditeurLivre.idlivre , nbPretEditeurLivre.titre ,nbPretEditeurLivre.nbpret
from (select editeur.idediteur , editeur.nom , livre.idlivre ,
livre.titre , count(pret.idlivre) nbpretfrom editeur , livre , pretwhere editeur.idediteur = livre.idediteur (+) and
livre.idlivre = pret.idlivre (+)group by editeur.idediteur , editeur.nom ,
livre.idlivre , livre.titre) nbPretEditeurLivre
where not exists (select *
34

from livre l, pret pwhere l.idediteur = nbPretEditeurLivre.idediteur and
l.idlivre = p.idlivre (+)group by l.idlivrehaving count(p.idlivre) > nbPretEditeurLivre.nbpret)
order by nbPretEditeurLivre.idediteur
21. Operation ensemblistes (union) Afficher la liste de tous les auteurs et de tous lesediteurs en indiquant leur type (’auteur’ ou ’editeur’).
select a.nom nom_a_e , ’auteur ’ typefrom auteur aunion( select e.nom nom_a_e , ’editeur ’ type
from editeur e)order by nom_a_e
22. Requête “pour tous”: Afficher les membres m1, m2 tels que m1 a emprunté tous leslivres que m2 a emprunté. Effectué avec un double not exists
select m1.idmembre , m2.idmembrefrom membre m1, membre m2where
m1.idmembre != m2.idmembre ANDnot exists
(select *from
pret p2where
p2.idmembre = m2.idmembre andnot exists
(select *from
pret p1where
p1.idmembre = m1.idmembre ANDp1.idlivre = p2.idlivre
))
order by m1.idmembre , m2.idmembre;
23. Même requête “pour tous” que la précédente, effectuée avec un count
35

select m1.idmembre , m2.idmembrefrom membre m1, membre m2where m1.idmembre != m2.idmembre AND
exists(select p1.idmembrefrom
pret p1 , pret p2where-- calcule les livres que m1 et m2 ont empruntes
p1.idlivre = p2.idlivre ANDp1.idmembre = m1.idmembre ANDp2.idmembre = m2.idmembre
group byp1.idmembre
having-- nb total de livres que m1 et m2 ont en communcount(distinct p1.idlivre)
=-- calcule les livres que m2 a empruntes( select count(distinct p3.idlivre)
from pret p3where p3.idmembre = m2.idmembre
))
order by m1.idmembre , m2.idmembre;
36

24. Double requête “pour tous”: Afficher les membres m1, m2 tels que m1 et m2 ontemprunté exactement les mêmes livres. Effectuée avec un double not exists
select m1.idmembre , m2.idmembrefrom membre m1, membre m2where
m1.idmembre != m2.idmembre AND-- m1 a emprunte tous les livres de m2not exists
(select *from
pret p2where
p2.idmembre = m2.idmembre andnot exists
(select *from
pret p1where
p1.idmembre = m1.idmembre ANDp1.idlivre = p2.idlivre
)) AND
-- m2 a emprunte tous les livres de m1not exists
(select *from
pret p1where
p1.idmembre = m1.idmembre andnot exists
(select *from
pret p2where
p2.idmembre = m2.idmembre ANDp2.idlivre = p1.idlivre
))
order by m1.idmembre , m2.idmembre;
37

8.3 Divers
8.3.1 Table virtuelle : vue
• une vue est construite à partir d’un select;
• create view 〈nom-vue〉 as〈select〉 ;
• une vue peut-être utilisée dans un select; la vue est évaluée au moment où le from duselect est évalué;
• elle peut-être utilisé dans un update si la vue réfère à une seule table, et qu’un tuple dela vue correspond à exactement un tuple de la table originale (clé (primaire ou unique)incluse);
• elle permet de restreindre l’accès aux tables (Chap 20).
8.3.2 Contraintes d’intégrité
• create assertion 〈nom-contrainte〉check (〈condition〉)
• 〈condition〉 comme dans un where d’un select
• pas disponible en Oracle
• Oracle
CREATE [OR REPLACE] TRIGGER 〈nom-trigger 〉{BEFORE|AFTER} {INSERT|DELETE|UPDATE} ON 〈nom-table 〉[FOR EACH ROW [WHEN (〈condition 〉)]]〈enonce PL/SQL 〉
8.3.3 Index
CREATE [ UNIQUE ] INDEX <nom -index >ON TABLE <nom -table > (<liste -nom -attributs >)
8.3.4 Schéma
schéma : ensemble de tables, vues, domaines, séquences, procédures, synonymes, index,contraintes d’intégrité, et autres. create schema 〈nom-schéma〉
catalogue (dictionnaire de données en Oracle): ensemble de schémas.
domaine : create domain 〈nom-du-domaine〉 as 〈type〉 [ default 〈valeur〉 ]; (pas disponibleen Oracle)
38
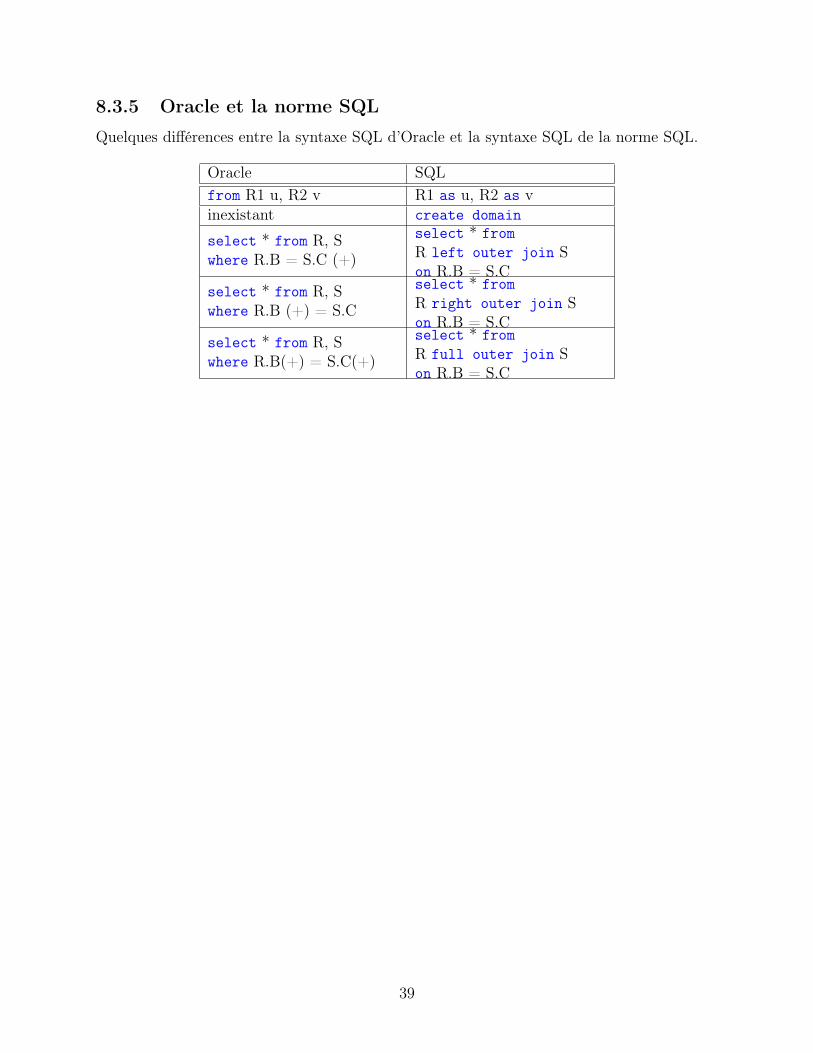
8.3.5 Oracle et la norme SQL
Quelques différences entre la syntaxe SQL d’Oracle et la syntaxe SQL de la norme SQL.
Oracle SQLfrom R1 u, R2 v R1 as u, R2 as vinexistant create domain
select * from R, Swhere R.B = S.C (+)
select * fromR left outer join Son R.B = S.C
select * from R, Swhere R.B (+) = S.C
select * fromR right outer join Son R.B = S.C
select * from R, Swhere R.B(+) = S.C(+)
select * fromR full outer join Son R.B = S.C
39

Chapter 3
Le modèle entité-association
Le modèle entité-association est plus abstrait que le modèle relationnel (SQL). Il est réalisédans les phases d’analyse des besoins. Il peut être traduit durant la phase d’implémentationd’un système en un modèle relationnel en SQL, ou bien orienté-objet, ou tout autre modèlede base de données (hiérarchique, réseau, XML, documentaire, etc)
3.1 Définition des conceptsSynonyme d’entité-association : entité-relation, tiré de l’anglais 〈〈entity relationship〉〉
entité : c’est un objet qui permet à une application de fournir l’information désirée parl’utilisateur du système. Il peut être physique, virtuel, conceptuel, imaginaire, artificiel,etc. Le seul critère qui permet de juger de la pertinence d’une entité dans un modèleest son utilité pour l’utilisateur.
Exemple: un livre, un étudiant, un dieu de la mythologie grecque, etc
type d’entité : c’est la collection de toutes les entités de même structure.
Exemple: L’ensemble de tous les étudiants que l’on pourrait potentiellement stockerdans un système
Exemple: L’ensemble de tous les livres publiés et qui pourront être publiés dans toutel’histoire de l’Humanité.
ensemble d’entités : c’est l’ensemble des entités contenues dans un système à un momentdonné.
Exemple: L’ensemble de tous les étudiants inscrits à l’Université de Sherbrooke enjanvier 2004.
Exemple: L’ensemble de tous les livres contenus dans le catalogue de la bibliothèquede l’Université de Sherbrooke en décembre 2003.
Remarque: Il est courant d’entendre les expressions “entité” et “instance” au lieude “type d’entité” et “entité”. C’est une confusion fort malheureuse, à laquelle nousn’échapperons pas.
40

attribut : c’est une fonction A qui associe une valeur v ∈ V à une entité E.
A : E → V
Exemple: Le nom d’un étudiant est un attribut d’un étudiant.
type d’un attribut : c’est le domaine de la valeur d’un attribut; donc, c’est le codomainede la fonction A, c’est-à-dire V ).
Voici quelques catégories de types d’attribut
• atomique (synonyme : univalent)
• composé (agrégat)
• multivalué (synonyme : multivalent, plurivalent)
• dérivé
• mémorisé
clé d’un type d’entité : attribut injectif.
Soit K un attribut. Alors K est une clé ssi
K : E → P(V )
et (K est injective)K(e1) = K(e2)⇒ e1 = e2
ou bienK ◦K−1 = Id
type d’association 〈〈relationship type〉〉 : un type d’association de degré n > 1 met enrelation n types d’entité E1, . . . , En. C’est donc une relation mathématique R définiepar le produit cartésien E1 × . . .× En.
instance d’association : c’est un tuple (e1, . . . , en) de E1 × . . .× En.
ensemble d’association : c’est l’ensemble des instances (e1, . . . , en) contenus dans un sys-tème à un moment donné. Chaque tuple associe n entités e1, . . . , en.
Remarque: On dit qu’une association est récursive si E1 = E2.
cardinalité d’un type d’association : Elle indique le nombre d’instances auxquelles uneentité peut participer. Il existe trois manières de représenter ces contraintes.
1. La première, proposée par Chen, consiste à spécifier une borne maximale; ellene s’applique qu’aux associations binaires; les associations k-aire, avec k > 2 necomportent pas de cardinalités. Il y a donc trois cas de figure : 1:1, 1:N, N:N.
• E1—1—〈A〉—1—E2 : une instance de E1 est reliée par l’association A à auplus une instance de E2; une instance de E2 est reliée à au plus une instancede E1.
41

• E1—1—〈A〉—N—E2 : une instance E1 est reliée par l’association A à unnombre arbitraire d’instances de E2 (par convention, N indique qu’il n’y apas de maximum); le nombre 1 indique qu’une instance de E2 est reliée à auplus une instance de E1.• E1—N—〈A〉—N—E2 : une instance de E1 est reliée par l’association A à un
nombre arbitraire d’instances de E2; une instance de E2 est reliée à un nombrearbitraire d’instances de E1.
2. La deuxième, utilisée en UML, consiste à utiliser un intervalle i..j où i est uneborne inférieure et j une borne supérieure, avec j = ∗ s’il n’y a pas de bornesupérieure. Ainsi, une cardinalité
E1—i2..j2—〈A〉—i1..j1—E2
indique qu’une instance de E1 est reliée par l’association A à au moins i1 et auplus j1 instances de E2; une instance de E2 est reliée à au moins i2 et au plus j2d’instances de E1. Quanfd
3. La troisième manière, proposée par Jean-Raymond Abrial en 1974, et beaucoupmoins usitée, consiste à spécifier un couple (min,max) pour chaque composanteEi de l’association A, avec la signification suivante: chaque instance e de Ei doitapparaître dans au moins i tuples de l association, et au plus j fois. Lorsque j = ∗,il n’y a pas de borne supérieure sur le nombre de tuples où e peut apparaître. Cettenotation s’applique à une association de degré arbitraire (c-à-d, pas seulement lesbinaires).Remarque: La notation UML utilise malheureusement de manière inappropriéecette notation. En UML, le couple min..max est spécifié sur le côté opposé del’association, ce qui fait qu’il ne peut s’appliquer qu’aux associations binaires,en plus d’introduire une autre confusion dont la communauté informatique sepasserait bien :-).
type d’entité faible :
• une entité faible ne possède pas une clé complète, seulement d’une clé partielle;
• une entité faible doit hériter des clés de ses entités propriétaires pour former uneclé complète;
• un type d’entité faible dépend d’un ou plusieurs type d’entités propriétaires (pères);
• les entités propriétaires doivent exister avant que l’entité faible existe;
• il existe une relation d’identification entre l’entité faible et les entités propriétaires;
• cette relation est totale.
3.2 Convention nominative• type d’entité : nom
• association : verbe ou nom
42
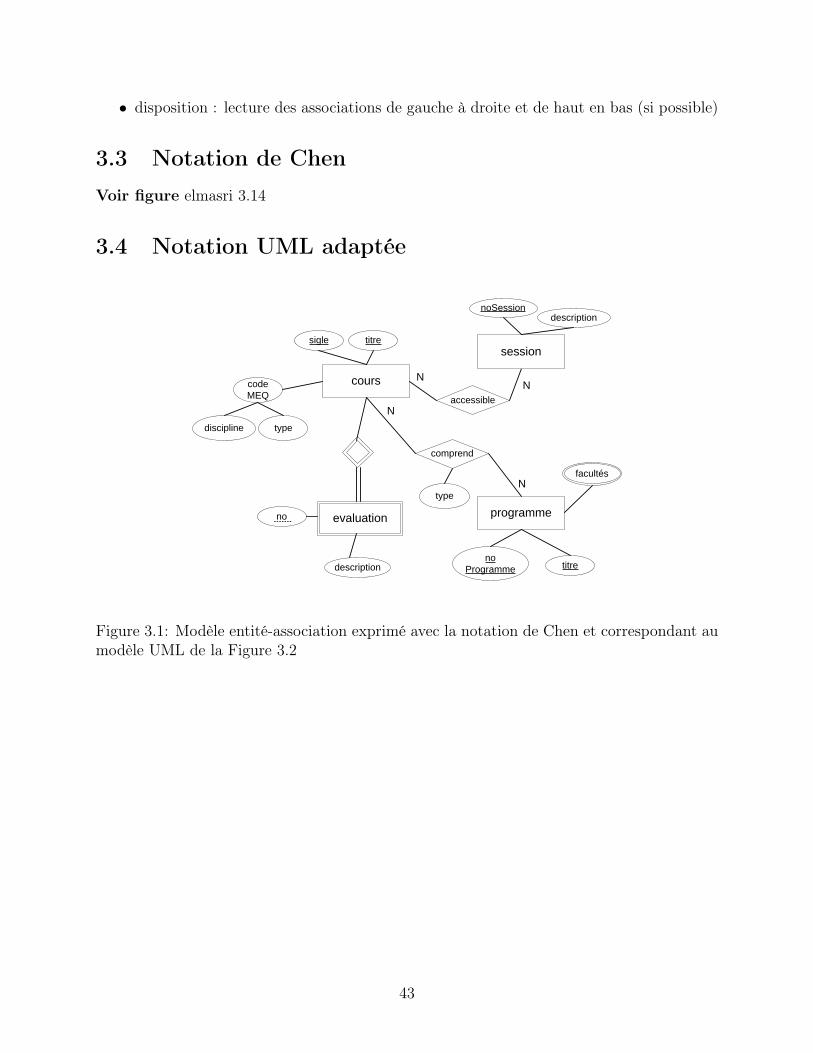
• disposition : lecture des associations de gauche à droite et de haut en bas (si possible)
3.3 Notation de ChenVoir figure elmasri 3.14
3.4 Notation UML adaptée
no
CHEN modèle ER UML
cours
sigle titre
sigle (c1)
titre (c2)
cours
evaluation no (cp1)
description
evaluation
description
accessible
session
noSession (c1)
descrip[tion
session
noSessiondescription
accessible
code
MEQ
discipline type
discipline
type
codeMEQ
programme
no
Programme
comprend
type
titre
noProgramme (c1)
titre (c2)
facultés : Set
programmetype
comprend
N
N
NN
* *
*
*
EK1
K11 K12
K2
K21 K22
Cas d'une clé formée de
plusieurs attributs :
dans cet exemple, on a deux
clés, chacune formée de 2
attributs
K11 (c1)
K12 (c1)
K21 (c2)
K22 (c2)
E
E1 A E21 N E1 E2A1..1 0..*
E1 A E2N 1
E1 A E21 N E1 E2A0..1 0..*
E1 E2A1..* 0..1
facultés
ratio de cardinalité et totalité
Figure 3.1: Modèle entité-association exprimé avec la notation de Chen et correspondant aumodèle UML de la Figure 3.2
43

no
CHEN modèle ER UML
cours
sigle titre
sigle (c1)
titre (c2)
cours
evaluation no (cp1)
description
evaluation
description
accessible
session
noSession (c1)
descrip[tion
session
noSessiondescription
accessible
code
MEQ
discipline type
discipline
type
codeMEQ
programme
no
Programme
comprend
type
titre
noProgramme (c1)
titre (c2)
facultés : Set
programmetype
comprend
N
N
NN
* *
*
*
EK1
K11 K12
K2
K21 K22
Cas d'une clé formée de
plusieurs attributs :
dans cet exemple, on a deux
clés, chacune formée de 2
attributs
K11 (c1)
K12 (c1)
K21 (c2)
K22 (c2)
E
E1 A E21 N E1 E2A1..1 0..*
E1 A E2N 1
E1 A E21 N E1 E2A0..1 0..*
E1 E2A1..* 0..1
facultés
ratio de cardinalité et totalité
Figure 3.2: Modèle entité-association exprimé avec la notation UML et correspondant aumodèle de la Figure 3.1
Attribut1 (c1)Attribut2 (c1,c2)Attribut3 (c2)Attribut4
Entité
Attribut1 (c1)AttriMultiv : Set
Entité
Attribut1Attribut2
AssociationBinaire
Attribut1 (cp1)Attribut2Attribut3
EntitéFaible
Attribut1 (c1)Attribut2
Entité
Attribut1Attribut2Attribut3
AttributComposé
0..1 0..*
Attribut1 (cp1)Attribut2
EntitéFaible
Attribut1 (c1)Attribut2
Entité
Attribut1 (c1)Attribut2
Entité
Attribut1Attribut2
AssocNAire
0..* 1..1
association_sans_attribut
Figure 3.3: Modèle entité-association exprimé avec la notation UML illustrant une associa-tion ternaire, ainsi que des entités faibles ayant plus d’un père
44

no
CHEN modèle ER UML
cours
sigle titre
sigle (c1)
titre (c2)
cours
evaluation no (cp1)
description
evaluation
description
accessible
session
noSession (c1)
descrip[tion
session
noSessiondescription
accessible
code
MEQ
discipline type
discipline
type
codeMEQ
programme
no
Programme
comprend
type
titre
noProgramme (c1)
titre (c2)
facultés : Set
programmetype
comprend
N
N
NN
* *
*
*
EK1
K11 K12
K2
K21 K22
Cas d'une clé formée de
plusieurs attributs :
dans cet exemple, on a deux
clés, chacune formée de 2
attributs
K11 (c1)
K12 (c1)
K21 (c2)
K22 (c2)
E
E1 A E21 N E1 E2A1..1 0..*
E1 A E2N 1
E1 A E21 N E1 E2A0..1 0..*
E1 E2A1..* 0..1
facultés
ratio de cardinalité et totalité
no
CHEN modèle ER UML
cours
sigle titre
sigle (c1)
titre (c2)
cours
evaluation no (cp1)
description
evaluation
description
accessible
session
noSession (c1)
descrip[tion
session
noSessiondescription
accessible
code
MEQ
discipline type
discipline
type
codeMEQ
programme
no
Programme
comprend
type
titre
noProgramme (c1)
titre (c2)
facultés : Set
programmetype
comprend
N
N
NN
* *
*
*
EK1
K11 K12
K2
K21 K22
Cas d'une clé formée de
plusieurs attributs :
dans cet exemple, on a deux
clés, chacune formée de 2
attributs
K11 (c1)
K12 (c1)
K21 (c2)
K22 (c2)
E
E1 A E21 N E1 E2A1..1 0..*
E1 A E2N 1
E1 A E21 N E1 E2A0..1 0..*
E1 E2A1..* 0..1
facultés
ratio de cardinalité et totalité
Figure 3.4: À gauche, une entité E possédant deux clés, K1 et K2, chacune formée de deuxattributs; à droite, E représentée en UML
no
CHEN modèle ER UML
cours
sigle titre
sigle (c1)
titre (c2)
cours
evaluation no (cp1)
description
evaluation
description
accessible
session
noSession (c1)
descrip[tion
session
noSessiondescription
accessible
code
MEQ
discipline type
discipline
type
codeMEQ
programme
no
Programme
comprend
type
titre
noProgramme (c1)
titre (c2)
facultés : Set
programmetype
comprend
N
N
NN
* *
*
*
EK1
K11 K12
K2
K21 K22
Cas d'une clé formée de
plusieurs attributs :
dans cet exemple, on a deux
clés, chacune formée de 2
attributs
K11 (c1)
K12 (c1)
K21 (c2)
K22 (c2)
E
E1 A E21 N E1 E2A1..1 0..*
E1 A E2N 1
E1 A E21 N E1 E2A0..1 0..*
E1 E2A1..* 0..1
facultés
ratio de cardinalité et totalité
Figure 3.5: Cardinalité exprimé avec la notation de Chen et correspondant au modèle UMLde la Figure 3.6
no
CHEN modèle ER UML
cours
sigle titre
sigle (c1)
titre (c2)
cours
evaluation no (cp1)
description
evaluation
description
accessible
session
noSession (c1)
descrip[tion
session
noSessiondescription
accessible
code
MEQ
discipline type
discipline
type
codeMEQ
programme
no
Programme
comprend
type
titre
noProgramme (c1)
titre (c2)
facultés : Set
programmetype
comprend
N
N
NN
* *
*
*
EK1
K11 K12
K2
K21 K22
Cas d'une clé formée de
plusieurs attributs :
dans cet exemple, on a deux
clés, chacune formée de 2
attributs
K11 (c1)
K12 (c1)
K21 (c2)
K22 (c2)
E
E1 A E21 N E1 E2A1..1 0..*
E1 A E2N 1
E1 A E21 N E1 E2A0..1 0..*
E1 E2A1..* 0..1
facultés
ratio de cardinalité et totalité
Figure 3.6: Modèle entité-association exprimé avec la notation UML et correspondant aumodèle de la Figure 3.5
3.5 Exemples
3.5.1 Gestion des cours
On désire développer un système pour gérer les inscriptions aux cours dans une université.Les cours offerts sont décrits dans l’annuaire de l’université. On désire affecter les cours selonles disponibilités des professeurs, leur compétence et l’accessibilité des cours par session. Unétudiant s’inscrit à un cours pour une session donnée s’il a complété tous ses préalables.On désire également y consigner la note d’un étudiant. On affecte un groupe-cours à un
45

étudiant inscrit à un cours. Un groupe-cours est donné par un professeur. Le modèle entité-association correspondant est représenté dans la Figure 3.7 avec la notation de Chen, et dansla Figure 3.8 avec la notation UML.
cours
sigle titre session
sessionaccessib
ilité
professeur
donneétudiant
N N
N
1
groupematricule
nom coteR
note
groupe
affecte1
N
1N N
inscription
sigle
session
matricule
clé
1
1
N
disponibilités
compétences
matricule
NN
N
N
préalables
NN
Figure 3.7: Modèle entité-association pour la gestion des cours selon la notation de Chen
3.5.2 Gestion de projets
Un projet est réalisé sur plusieurs phases, chaque phase ayant des dates de début et defin. Un projet est géré par un et un seul gestionnaire de projet. Le gestionnaire peuttoutefois autoriser d’autres personnes à modifier ou interroger son projet. Chaque phased’un projet se décompose en itérations. Une itération dure environ deux semaines. Chaqueitération comporte des tâches. Une tâche est affectée à une ou plusieurs personnes. Unetâche comporte un effort estimé (le nombre d’heures nécessaires pour réaliser la tâche). Ondésire connaître aussi le temps travaillé à chaque jour sur les tâches pour chaque personne.Chaque tâche est d’un certain type : analyse, programmation, test, formation, etc. Ondoit pouvoir spécifier pour chaque personne les types de tâches qu’elle peut accomplir. Onpeut affecter une tâche à une personne seulement si cette personne peut réaliser ce type detâche. Votre modèle doit pouvoir supporter les requêtes suivantes : connaître le temps totaltravaillé pour chaque projet, chaque phase, chaque itération et chaque tâche; déterminer laliste des tâches complétées; connaître l’effort total estimé d’un projet, d’une phase et d’uneitération; connaître le nombre d’heures travaillées pour chaque personne par semaine, parmois et par année; connaître le coût total estimé d’un projet (pour chaque type de tâche, ona un taux horaire prévu) et connaître le coût total réel; connaître le gestionnaire du projetet les personnes qu’il a autorisées pour modifier ou interroger le projet (pour chacune de
46

accessibilité
noSession (c1)
Session
note
Inscription
noGroupe (cp1)
GroupeCours
sigle (c1)titre (c2)
Cours0..*
affecte0..1
matricule (c1)coteRnom
Etudiant
matricule (c1)salairenom
Professeurcompétences disponibilités
0..*
0..* 0..*
0..*
0..*
préalables
donne
Figure 3.8: Modèle entité-association pour la gestion des cours selon la notation UML
ces personnes, on doit savoir s’il peut seulement interroger, ou bien interroger et modifier;si une personne peut modifier, elle peut alors interroger). Le modèle entité-associationcorrespondant est représenté dans la Figure 3.9 avec la notation UML.
3.5.3 Gestion des statistiques au hockey
La Figure 3.10 illustre le modèle relationel (SQL) d’une BD de gestion des statistiques auhockey; la Figure 3.11 illustre le modèle entité-association correspondant. On suppose qu’uneéquipe ne peut jouer qu’une seule partie par jour. Notez que de meilleurs modèles existentpour cet exemple; celui-ci illustre assez bien les entités faibles et les associations entre entitésfaibles.
3.6 Erreurs fréquentes dans la modélisation entité-association1. Un clé apparait dans plusieurs entités:
Dans un modèle entité-association, si une clé d’une entité apparait aussi comme unattribut d’une autre entité, il s’agit généralement d’une erreur de modélisation; dansce cas, on devrait plutôt utiliser une association entres ces deux entités. En général, uneclé d’une entité n’apparaît pas dans une autre entité. Cette remarque ne s’applique pasaux attributs génériques comme “titre” ou “description”, qui apparaissent dans plusieursentités, mais avec des sens différents (il ne s’agit pas du même titre ou de la mêmedescription). Ce problème est aussi symptomatique d’une mauvaise compréhension du
47

modèle entité-association, que l’on a souvent tendance à confondre avec le diagrammerelationnel, et de mettre des clés étrangères pour représenter les associations. Lesclés étrangères sont déduites du modèle entité-association; elles n’apparaissent pasexplicitement. La traduction d’un modèle E-A en un modèle relationnel est l’objet duprochain chapitre. Voir la figure 3.12, où l’attribut idMembre est ajouté par erreur àl’entité livre. C’est une erreur, car l’association pret identifie déjà l’emprunteur du livre.Au prochain chapitre, nous verrons qu’une association de cardinalité 0..* — 0..1 peutêtre représentée dans une table en ajoutant la clé de l’entité référencée au plus unefois en l’ajoutant comme clé étrangère (i.e., après traduction, l’attribut idMembre estajouté dans la table représentant l’entité livre en tant que clé étrangère vers membre).
2. Mauvaise cardinalité
noProjet (c1)
desccription
projet◄consulte
noPersonne (c1)
nom
personne
noPhase (cp1)
description
dateDebut
dateFin
phase
0..* 1..1
◄gère
0..* 1..1
noIteration (cp1)
description
dateDebut
dateFin
itération
noTache (cp1)
description
effortEstimé
complétée
tâche0..*
0..*
date (cp1)
effortRéel
tempsTravaillé
affe
ctée
►
noType (c1)
description
tauxHoraire
typeDeTâche
type de la tâche
pe
ut a
cco
mp
lir ►
mode
accès
0..*
0..*
1..1
0..*
Figure 3.9: Modèle entité-association pour la gestion de projets selon la notation UML
48

contrat
PK,FK1 nojoueurPK datedebut
FK2 noequipedatefinsalaire
equipe
PK noequipe
nomville
joueur
PK nojoueur
nom
marqueur
PK,FK1 nojoueurPK datepartie
nbbutsnbpasses
partie
PK,FK1 noequipe1PK,FK2 noequipe2PK datejouee
Figure 3.10: Modèle relationnel pour la gestion des statistiques au hockey
noJoueur (c1)
nom
joueur
dateJouee (cp1)
Partie
noEquipe (c1)
ville
nom
Équipe
0..*
signe
dateDebut (cp1)
dateFin
salaire
Contrat
1..1
datePartie (cp1)
nbButs
nbPasses
marqueur
Figure 3.11: Modèle entité-association pour la gestion des statistiques au hockey
3. Cardinalités inversées
4. Confusion de deux concepts distincts qui sont représentés avec une seule entité (ex:pièce et interprétation d’une pièce dans une bibliothèque de musique).
5. Distinction inutile entre deux entités, qui peuvent être fusionnées en une seule entité.
6. Incapacité de répondre à une requête en parcourant les associations.
7. Perte d’information en parcourant les associations: par exemple, on désire identifierle professeur donnant un groupe-cours comme ift187-groupe1, mais en naviguant dansun mauvais modèle, on obtient tous les profs qui donnent ift187.
49

Livre&
idLivre&(tre&idMembre&
Membre&
idMembre&nom&limitePret&
0..*& 0..1&pret&
Figure 3.12: Erreur typique : l’attribut idMembre est incorrectement ajouté à l’entité livre
8. Noms inappropriés pour les entités, les attributs et les associations.
9. Redondance : une association peut être déduite d’une autre association, avec exacte-ment le même sens.
10. Confusion: une seule association est utilisée pour représenter deux concepts distincts.
11. Représenter une clé formée de deux attributs par deux attributs, chacun étant identifiécomme une clé.
Pour valider un modèle, simulez les instances des entités et des associations.
50

Chapter 7
Traduction d’un schéma E-R en unschéma relationnel
7.1 Algorithmes de traduction1. un type d’entité E avec attributs univalents atomiques (A1, . . . , Ai, . . . , An) et clé Ai
devient un schéma de relation R(A1, . . . , Ai, . . . , An);
• Si la clé n’est pas atomique (i.e., Ai = (Ai1 , . . . , Aim)), alors on génère un at-tribut pour chaque attribut atomique Aij formant la clé; la clé primaire est alorsconstituée de tous ces attributs atomiques.
• S’il existe plusieurs clés pour une entité, on en choisit une comme clé primaire, etles autres deviennent des clés candidates (mot clé SQL UNIQUE).
• La traduction des attributs multivalués est décrite dans la suite de cette section.Voir étape 6
2. type d’entité faible E avec
• attributs univalents atomiques (A1, . . . , Ai, . . . , An),
• clé partielle Ai
• m entités propriétaires F1, . . . , Fm de clés AF1 , . . . , AFm
devient un schéma de relation R(A1, . . . , Ai, . . . , An, AF1 , . . . , AFm) avec clés étrangèresAF1 vers F1 et . . . et AFm vers Fm
3. association binaire E1 : E2 de cardinalité 1:1
• choisir entre E1 et E2 (choisir celle dont la participation est totale, s’il y a lieu,e.g., relation manages avec department et employees); soit S la relation choisie etT l’autre relation;
• ajouter la clé primaire de T au schéma de S; la définir comme clé étrangère;
• ajouter les attributs univalents de la relation au schéma de S.
51

Question 1: Nommez autre possibilité
Réponse: Une seule relation; inconvénients: mise à jour plus complexe
4. association binaire E11 R N E2, avec clé K1 de E1 et K2 de E2 et attributs univalents
A1, . . . , An de l’association R.
Il y a deux options:
• première option : importer la clé de E1 dans E2
– ajouter la clé K1 de E1 au schéma de E2 et en faire une clé étrangère ce(K1)réf. E1.
– ajouter les attributs univalents A1, . . . , An au schéma de E2.– Si la participation de E2 est totale, alors ajouter la contrainte NOT NULL
sur K1 dans E2
• deuxième option : créer une table pour l’association R– créer un schéma de relation R(K1, K2, A1, . . . , An) avec les clés étrangèresce(K1) réf. E1 et ce(K2) réf. E2.
– notons que la clé candidate ne comprend que K2, à cause du ratio 1 : N .– Ajouter la contrainte NOT NULL sur K1
5. association binaire E1M R N E2, avec clé K1 de E1 et K2 de E2 et attributs univalents
A1, . . . , An de l’association R.
• créer un schéma de relation R(K1, K2, A1, . . . , An) avec les clés étrangères ce(K1)réf. E1 et ce(K2) réf. E2.
6. attribut multivalué
• créer une relation R avec clé primaire les clés de l’entité (ou de l’association) etl’attribut multivalué.• Ajouter une clé étrangère vers l’entité ou l’association.
7. relation n-aire E1 : . . . : En avec n > 2
• créer une relation R de clé primaire formée avec les clés de E1, . . . , En et les clésétrangères vers E1, . . . , En.• ajouter les attributs univalents• pour les attributs multivalués, voir étape 6
7.2 Exemples de traductionLes figures 7.2 et 7.3 donnent la traduction en modèle relationnel du modèle entité-associationde la figure 7.1. Dans la figure 7.2, on a utilisé une table pour représenter les associations r2et r4, ce qui donne des tables qui se référencent mutuellement, à cause de la cardinalité 1..1.Le code SQL de ces tables est ensuite donné.
52
A5 (c1)A6
E2A8 (c1)A9 (c1)A10
E3
A7_1A7_2 : Set
R1
A12 (cp1)A13
E4
A1 (c1)A2 (c1)A3 (c2)A4 : Set
E1
A11_1A11_2
A11
0..1 0..*
A14 (cp1)A15
E5
A16A17
R3
0..* 1..1
R2
1
0..*
A18 (c1)A19
E6
R5
0..*
0..*
R4
0..*
1..1
role1
role2
Figure 7.1: Modèle E-A traduit dans les figures 7.2 et 7.3
53

e6
PK
a18
a19
r5
PK,FK
1a8
PK,FK
1a9
PK,FK
2a3
PK,FK
2a5
PK,FK
2a12
PK,FK
2a14
r1
PK,FK
2a8
PK,FK
2a9
a7_1
FK1a5
e1
PK
a1PK
a2
U1
a3
e1a4
PK,FK
1a3
PK
a4
r1a7_2
PK
a7_2
PK,FK
1a8
PK,FK
1a9
a5
e2
PK,FK
1a5
a6
e3
PK
a8PK
a9
a10
r2
PK,FK
1a5
FK2
a8FK2
a9e3a11
PK,FK
1a8
PK,FK
1a9
PK
a11_1
PK
a11_2
r3
PK,FK
1a3
PK,FK
1a5
PK,FK
1a12
PK,FK
1a14
PK,FK
3a8
PK,FK
3a9
PK,FK
2a18
a16
a17
e4
PK,FK
1,FK
3a3
PK,FK
2,FK
3a5
PK,FK
3a12
a13
r4
PK,FK
1a3_ro
le1
PK,FK
1a5_ro
le1
PK,FK
1a12_ro
le1
FK2
a3_ro
le2
FK2
a5_ro
le2
FK2
a12_ro
le2
e5
PK,FK
1a3
PK,FK
1a5
PK,FK
1a12
PK
a14
a15
Figure 7.2: Traduction du modèle E-A de la figure 7.154

r5
PK
,FK1
a8P
K,FK
1a9
PK
,FK2
a3P
K,FK
2a5
PK
,FK2
a12
PK
,FK2
a14
e5
PK
,FK1
a3P
K,FK
1a5
PK
,FK1
a12
PK
a14
a15
e1
PK
a1P
Ka2
U1
a3
e6
PK
a18
a19
e1a4
PK
,FK1
a3P
Ka4
r1
PK
,FK2
a8P
K,FK
2a9
a7_1
FK1a5
e2
PK
a5
a6
a8
a9
r1a7_2
PK
a7_2
PK
,FK1
a8P
K,FK
1a9
a5
e3
PK
a8P
Ka9
a10
e3a11
PK
,FK1
a8P
K,FK
1a9
PK
a11
_1P
Ka1
1_2
r3
PK
,FK1
a3P
K,FK
1a5
PK
,FK1
a12
PK
,FK1
a14
PK
,FK3
a8P
K,FK
3a9
PK
,FK2
a18
a16
a17
e4
PK
,FK1
a3P
K,FK
2a5
PK
a12
a13
FK3
a3_ro
le2
FK3
a5_ro
le2
FK3
a12
_role
2
Figure 7.3: Traduction du modèle E-A de la figure 7.1
55

Code SQL du modèle de la figure 7.2
---------------------------------------------------------drop table E1 cascade;create table E1 (a1 int ,a2 int ,a3 int ,primary key (a1,a2),unique (a3));
drop table E1A4 cascade;create table E1A4 (a3 int ,a4 int ,primary key (a3,a4),foreign key (a3) references E1 (a3));
drop table E2 cascade;create table E2 (a5 int ,a6 int ,primary key (a5));
drop table E3 cascade;create table E3 (a8 int ,a9 int ,a10 int ,primary key (a8,a9));
drop table E3A11 cascade;create table E3A11 (a8 int ,a9 int ,a11_1 int ,a11_2 int ,primary key (a8,a9,a11_1 ,a11_2),foreign key (a8,a9) references E3);
56

drop table R1 cascade;create table R1 (a7_1 int ,a5 int ,a8 int ,a9 int ,primary key (a8,a9),foreign key (a5) references E2,foreign key (a8,a9) references E3);
drop table R1A7_2 cascade;create table R1A7_2 (a7_2 int ,a5 int ,a8 int ,a9 int ,primary key (a8,a9,a7_2),foreign key (a8,a9) references R1);
drop table R2 cascade;create table R2 (a5 int ,a8 int not null ,a9 int not null ,primary key (a5),foreign key (a5) references E2 (a5),foreign key (a8,a9) references E3);
alter table E2 add constraint fkE2_R2 foreign key (a5) references R2;
drop table E4 cascade;create table E4 (a3 int ,a5 int ,a12 int ,a13 int ,primary key (a3,a5,a12),foreign key (a3) references E1 (a3),foreign key (a5) references E2);
drop table R4 cascade;
57

create table R4 (a3_role1 int ,a5_role1 int ,a12_role1 int ,a3_role2 int not null ,a5_role2 int not null ,a12_role2 int not null ,primary key (a3_role1 ,a5_role1 ,a12_role1),foreign key (a3_role1 ,a5_role1 ,a12_role1) references E4,foreign key (a3_role2 ,a5_role2 ,a12_role2) references E4);
alter table E4 add constraint fkE4_R4 foreign key (a3,a5 ,a12) references R4;
drop table E5 cascade;create table E5 (a3 int ,a5 int ,a12 int ,a14 int ,a15 int ,primary key (a3,a5,a12 ,a14),foreign key (a3,a5,a12) references E4);
drop table E6 cascade;create table E6 (a18 int ,a19 int ,primary key (a18));
drop table R3 cascade;create table R3 (a3 int ,a5 int ,a12 int ,a14 int ,a8 int ,a9 int ,a18 int ,a16 int ,a17 int ,primary key (a3,a5,a12 ,a14 ,a18 ,a8 ,a9),
58

foreign key (a3,a5,a12 ,a14) references E5,foreign key (a18) references E6,foreign key (a8,a9) references E3);
drop table R5 cascade;create table R5 (a8 int ,a9 int ,a3 int ,a5 int ,a12 int ,a14 int ,primary key (a8,a9,a3,a5,a12 ,a14),foreign key (a8,a9) references R1 ,foreign key (a3,a5,a12 ,a14) references E5);---------------------------------------------------------
59

Code SQL du modèle de la figure 7.3
---------------------------------------------------------drop table E1 cascade;create table E1 (a1 int ,a2 int ,a3 int ,primary key (a1,a2),unique (a3));
drop table E1A4 cascade;create table E1A4 (a3 int ,a4 int ,primary key (a3,a4),foreign key (a3) references E1 (a3));
drop table E2 cascade;create table E2 (a5 int ,a6 int ,a8 int not null ,a9 int not null ,primary key (a5),foreign key (a8,a9) references E3);
drop table E3 cascade;create table E3 (a8 int ,a9 int ,a10 int ,primary key (a8,a9));
drop table E3A11 cascade;create table E3A11 (a8 int ,a9 int ,a11_1 int ,a11_2 int ,primary key (a8,a9,a11_1 ,a11_2),
60

foreign key (a8,a9) references E3);
drop table R1 cascade;create table R1 (a7_1 int ,a5 int ,a8 int ,a9 int ,primary key (a8,a9),foreign key (a5) references E2,foreign key (a8,a9) references E3);
drop table R1A7_2 cascade;create table R1A7_2 (a7_2 int ,a5 int ,a8 int ,a9 int ,primary key (a8,a9,a7_2),foreign key (a8,a9) references R1);
drop table E4 cascade;create table E4 (a3 int ,a5 int ,a12 int ,a13 int ,a3_role2 int not null ,a5_role2 int not null ,a12_role2 int not null ,primary key (a3,a5,a12),foreign key (a3) references E1 (a3),foreign key (a5) references E2,foreign key (a3_role2 ,a5_role2 ,a12_role2) references E4);
drop table E5 cascade;create table E5 (a3 int ,a5 int ,a12 int ,a14 int ,
61

a15 int ,primary key (a3,a5,a12 ,a14),foreign key (a3,a5,a12) references E4);
drop table E6 cascade;create table E6 (a18 int ,a19 int ,primary key (a18));
drop table R3 cascade;create table R3 (a3 int ,a5 int ,a12 int ,a14 int ,a8 int ,a9 int ,a18 int ,a16 int ,a17 int ,primary key (a3,a5,a12 ,a14 ,a18 ,a8 ,a9),foreign key (a3,a5,a12 ,a14) references E5,foreign key (a18) references E6,foreign key (a8,a9) references E3);
drop table R5 cascade;create table R5 (a8 int ,a9 int ,a3 int ,a5 int ,a12 int ,a14 int ,primary key (a8,a9,a3,a5,a12 ,a14),foreign key (a8,a9) references R1 ,foreign key (a3,a5,a12 ,a14) references E5);---------------------------------------------------------
62

Chapter 10
Conception et normalisation d’une BD
• comment choisir un bon schéma de BD relationnelle?
• deux niveaux d’évaluation de la qualité
– point de vue utilisateur : sémantique des données
– point de vue développeur : manipulation et stockage des données
• théorie de la mesure de la qualité d’un schéma : dépendances fonctionnelles
Deux processus pour obtenir un schéma de BD relationnelle:
1. descendante
• définit modèle ERE
• transforme en modèle relationnel
• applique les critères informels vus au chapitre 12
2. synthèse relationnelle
• décompose les schémas de relation jusqu’à obtenir des schémas qui satisfont uncertain niveau de forme normale (3NF, BCNF, 4NF, 5NF);
• il existe des algorithmes pour faire cette décomposition.
10.1 Critères informels de conception de schéma
10.1.1 Sémantique des relations
• s’assurez que chaque relation corresponde à un concept ou un fait du domaine del’application
Voir figure 10.1,10.2
• ne pas mélanger des attributs de deux “entités” différentes dans la même relation
Voir figure 10.4
63

• il faut tenir compte de l’usage des entités
Exemple 10.1 gestion d’un dossier professeur au bureau de la recherche et gestiondes membres du centre sportif: doit-on créer une seule relation ou deux relations?
10.1.2 Information redondantes
• on vise à minimiser l’espace nécessaire pour stocker l’information Voir figure 10.3
• minimiser l’espace simplifie aussi les mises à jour
– ajout : ajoute l’information avec des valeur nulles ou ajoute l’information de deuxentités à la fois; doit s’assurer de la cohérence entre les duplications d’information.clé primaire nulle (ajout d’un département)
– modification : on doit modifier tous les tuples où l’information est dupliquée
– suppression : on doit supprimer tous les tuples où l’information est dupliquée,mais préserver au moins un tuple
• performance : on doit parfois avoir de la redondance pour améliorer la performance.
10.1.3 Valeur nulle
• éviter les valeurs nulles
• comment les traiter dans une fonction (ex: count, sum, etc?)
• elles ont 3 interprétations possibles
– l’attribut ne s’applique pas à ce tuple (ex: MGRSSN dans relation EMPLOYEE);
– la valeur de l’attribut est inconnue pour le tuple (elle le sera plus tard);
– la valeur de l’attribut est connue pour le tuple, mais elle n’est pas encore enreg-istrée (elle le sera plus tard);
• décomposer si la valeur est peu fréquente
10.1.4 Tuples erronés
• s’assurer que la jointure de deux relations sur des clés étrangères et des clés primairesne donnent pas de tuples erronés.
• considérer la relation EMP_PROJ (qui est obtenue à partir de la jointure naturelleEMPLOYEE on WORKS_ON on PROJECT. Voir figure 10.2,10.4,10.5
64

10.2 Dépendance fonctionnelle
10.2.1 Définition
• Définition 10.1 Soit R(Z) une relation. Il existe une dépendance fonctionnelle dansR entre deux ensembles d’attributs X ⊆ Z et Y ⊆ Z, notée X → Y , ssi pour toustuples t1, t2 de tout état r de R, on a
t1[X] = t2[X]⇒ t1[Y ] = t2[Y ]
• notation graphique Voir figure 10.3,
• une dépendance fonctionnelle impose une contrainte sur les états possibles r(R) de laBD.
• déterminée en fonction des besoins de l’application
10.2.2 Règles d’inférence pour les dépendances fonctionnelles
• on spécifie habituellement les dépendances fonctionnelles évidentes à partir de la de-scription du problème;
• on dénote par F l’ensemble de ces dépendances fonctionnelles
• on dénote par F+ la fermeture de F
• on peut calculer F+ à l’aide des règles suivantes. Soit W,X, Y, Z des ensemblesd’attributs.
réflexivité augmentation transitivitéX ⊇ Y
R1X → Y
X → YR2
XZ → Y ZX → Y Y → Z
R3X → Z
décomposition union pseudo-transitivitéX → Y Z
R4.1X → Y
X → Y ZR4.2
X → ZX → Y X → Z
R5X → Y Z
X → Y WY → ZR6
WX → Z
Les 3 premières règles sont suffisantes pour calculer F+ (théorème de Armstrong, 1974).
• on dénote par X+ la fermeture de X sous F , c’est-à-dire le plus grand ensembled’attributs Z tel que X → Z, à partir d’inférences sur F .
• à l’aide de cet opérateur de fermeture, on peut calculer si deux ensembles E et F dedépendances fonctionnelles sont équivalents.
• on peut calculer X+ avec l’algorithme suivant:
65

Algorithme 10.1X+ := X;répéteroldX+ := X+
pour chaque Y → Z de F fairesi Y ⊆ X+ alors X+ := X+Z
jusqu’à oldX+ = X+
Exemple 10.2 SoitF = {
A1 → A2,A3 → {A4, A5},{A1, A3} → A6,
}AlorsA+
1 = {A1, A2}A+
3 = {A3, A4, A5},{A1, A3}+ = {A1, A2, A3, A4, A5, A6}
• On peut prouver à l’aide des règles d’inférence que d’une dépendance fonctionnelle estdéduite à partir d’un ensemble de dépendances fonctionnelles. On utilise la notationsuivante :
F |= X → Y
pour énoncer que X → Y peut être déduite à partir de l’ensemble des dépendancesfonctionnelles F en appliquant les règles d’inférence. Par exemple, on prouve
{A→ B,B → C,CD → EF, F → G} |= AD → G
comme suit:
A→ B B → CR3
A→ C CD → EFR6
AD → EFR4.1
AD → F F → GR3
AD → G
La preuve est représentée avec un arbre de déduction. La racine de l’arbre est ladépendance fonctionnelle à déduire (i.e., la conclusion de la preuve, soit AD → Gdans l’exemple ci-dessus). Les feuilles de l’arbre sont les dépendances fonctionnellede F (i.e., les hypothèses de la preuve, soit {A → B,B → C,CD → EF, F → G}).Chaque dépendance intermédiaire est obtenue en appliquant une règle d’inférence à deshypothèses ou des dépendances déjà déduites. Il n’est pas nécessaire d’utiliser toutesles dépendances de F dans la preuve. Une hypothèse peut être utilisée plusieurs foisdans une preuve.
66

La preuve de F |= X → Y peut aussi être faite en utilisant l’algorithme 10.1 en vérifiantsi Y ∈ X+ sous F . Toutefois, dans les examens, vous devez être capable de produireun arbre si cela est expressément demandé dans une question. Vous pouvez vérifierrapidement si F |= X → Y est vrai en utilisant l’algorithme 10.1. Pour l’exempleprécédent, on note que G ∈ (AD)+ = ABCDEFG.Pour infirmer un énoncé F |= X → Y , on doit donner un contre-exemple. Pour donnerun contre-exemple, il suffit de donner une table contenant deux lignes où F est satisfaitet X → Y n’est pas satisfaite. Une dépendance X → Y n’est pas satisfaite si la valeurde X est la même sur les deux lignes de la table, mais les valeurs de Y sont distinctes.En effet, si la dépendance X → Y est satisfaite dans une table, alors chaque valeur deX est associé à exactement une valeur de Y . Par exemple, l’énoncé suivant:
{A→ B,BC → DE,E → A} |= B → A
est faux; voici un contre-exemple.
A B C D Ea1 b1 c1 d1 e1a2 b1 c2 d2 e2
On note que A 6∈ B+ = B. Bien sûr, si un énoncé est vrai, il est impossible de trouverun contre-exemple, sinon cela invaliderait les règles d’inférence d’Armstrong.
10.2.3 Équivalence de dépendances fonctionnelles
Définition 10.2 Soit E ,F des ensembles de dépendances fonctionnelles. On dit que Fcomprend E si pour toute dépendance X → Y de E, on a Y ⊆ X+ sous F .
Exemple 10.3 SoitE = {
A1 → A3,A2 → A4,A3 → A4,A4 → A3
}etF = {
A1 → A4,A2 → A3,A3 → A4,A4 → {A3, A5}
}Si on calcule A+
1 , A+2 , A
+3 , A
+4 sous F , on obtient
A+1 = {A1, A3, A4, A5}
A+2 = {A2, A3, A4, A5}
A+3 = {A3, A4, A5}
A+4 = {A3, A4, A5}}
67

On observe que F comprend E.Si on calcule A+
1 , A+2 , A
+3 , A
+4 sous E, on obtient
A+1 = {A1, A3, A4}
A+2 = {A2, A3, A4}
A+3 = {A3, A4}
A+4 = {A3, A4}}
On observe que E ne comprend pas F , car pour A4 → {A3, A5}, on a
{A3, A5} 6⊆ {A3, A4}
Définition 10.3 Soit E ,F des ensembles de dépendances fonctionnelles. On dit que E et Fsont équivalents ssi E comprend F et F comprend E.
Exemple 10.4 On observe que E et F de l’exemple 10.3 ne sont pas équivalents, car Fcouvre E, mais E ne couvre pas F . SoitF ′ = {
A1 → A4,A2 → A3,A3 → A4,A4 → A3
}Si on calcule A+
1 , A+2 , A
+3 , A
+4 sous F ′, on obtient
A+1 = {A1, A3, A4}
A+2 = {A2, A3, A4}
A+3 = {A3, A4}
A+4 = {A3, A4}}
Donc, E et F ′ sont equivalents.
Définition 10.4 Une dépendance fonctionnelle X → Z est dite minimale ssi il n’existe pasde dépendance fonctionnelle Y → Z telle que Y ⊂ X.
Définition 10.5 Un ensemble d’attributs X est une clé candidate d’une relation R(X, Y )ssi il existe une dépendance fonctionnelle minimale X → Y .
Définition 10.6 Un ensemble d’attributs X est une super clé d’une relation R(X, Y ) ssi ilexiste une dépendance fonctionnelle X → Y .
Une clé candidate est donc une super clé. Une super clé minimale est une clé candidate. Lorsde la définition des contraintes d’intégrité dans une table, on choisit une des clé candidatescomme clé primaire; les autres clés candidates sont représentées par des clés uniques.
Définition 10.7 Un ensemble de dépendances fonctionnelles F est minimal ssi
1. pour chaque X → A ∈ F , A est un singleton;
2. on ne ne peut enlever une dépendance de F et obtenir un ensemble de dépendancesfonctionnelles équivalent;
3. on ne peut remplacer une X → A ∈ F par Y → A ∈ F , avec Y ⊂ X.
68

10.3 Formes normalesIl existe plusieurs formes normales. Dans ce chapitre, on s’intéresse aux formes normalessuivantes:
• 1NF : première forme normale
• 2NF : deuxième forme normale
• 3NF : troisième forme normale
• BCNF : forme normale de Boyce-Codd
Ces formes normales représentent des contraintes sur des schémas de relation. Elles sontordonnées comme suit. Soit rel(FN) l’ensemble des relations satisfaisant la forme normaleFN . On a
rel(2NF) ⊇ rel(3NF) ⊇ rel(BCNF)
Donc, si une relation est en forme BCNF, alors elle est aussi en forme 3NF, 2NF; si unerelation est en 3NF, elle est aussi en 2NF.
10.3.1 Introduction
• La normalisation est un processus qui consiste à transformer des schémas de relationafin qu’ils satisfassent les formes normales.
• La normalisation permet:
– d’éviter les anomalies de maj
– de réduire la redondance
• rappels et définitions
– attribut premier : attribut qui appartient à une clé candidate
– attribut non premier : attribut qui n’appartient pas à une clé candidate
10.3.2 Première forme normale (1NF)
Par définition, un schéma de relation est en première forme normale.
Définition 10.8 Une relation R est en première forme normale (1NF) ssi tous les attributsde R sont atomiques (pas d’ensemble, de tuple ou autre structure vectorielle comme type d’unattribut)
Voir figure 10.8,10.9,10.3Les versions récentes de RDBMS (ex: Oracle 10) supporte maintenant des attributs qui
sont des relations (i.e., des relations qui ne sont pas en première forme normale)
69

10.3.3 Deuxième forme normale (2NF)
Définition 10.9 Une dépendance fonctionnelle X → Y est complète ssi pour tout A ∈ X,X − {A} 6→ Y (i.e., il n’y a pas de dépendance fonctionnelle entre X − {A} et Y ).
Définition 10.10 Une relation R est en deuxième forme normale (2NF) ssi tous les at-tributs non premiers de R sont en dépendance fonctionnelle complète de chaque clé de R.
Voir figure 10.10
10.3.4 Troisième forme normale (3NF)
Définition 10.11 Une relation R est en troisième forme normale (3NF) ssi pour toutedépendance fonctionnelle X → A de R, une des conditions suivantes est satisfaite:
1. X est une super clé
2. A est un attribut premier
Voir figure 10.10,10.11
10.3.5 Forme normale de Boyce-Codd (BCNF)
Définition 10.12 Une relation R est en forme normale Boyce-Codd (BCNF) ssi pour toutedépendance fonctionnelle X → A de R, X est une super clé.
Voir figure 10.12
70

Chapter 11
Autres formes normales
11.1 Quatrième forme normaleDéfinition 11.1 Soit R un schéma de relation et X, Y ⊆ R. Il existe une dépendanceplurivalente entre X et Y , notée X→→Y ssi, pour tout état r de R,
πX∪Y (r) on πR−Y (r) = r
On note que si X→→Y est vrai, alors X→→(R − Y ) est aussi vrai, et vice-versa. Pour cela,on note souvent une DP par X→→Y/Z, où Z = R− (X ∪ Y ).
Définition 11.2 Une dépendance plurivalente X→→Y est triviale ssi
• Y ⊆ Xou
• X ∪ Y = R
Définition 11.3 Une relation R est en quatrième forme normale (4NF) ssi, pour toutedépendance plurivalente non triviale X→→Y de R, X est une super clé.
Voir figure 13.4
11.2 Cinquième forme normaleDéfinition 11.4 Soit R un schéma relationnel. Une décomposition de R est un ensemblede schémas relationnels D = {R1, . . . , Rn}. On dit que D préserve les attributs de A ssi
n⋃i=1
Ri = R
Définition 11.5 Soit R un schéma de relation avec F comme ensemble de dépendancesfonctionnelles, et D = {R1, . . . , Rn} une décomposition de R. Il existe une dépendance dejointure, notée JD(R1, . . . , Rn) dans R ssi, pour tout état r de R satisfaisant F ,
πR1(r) on . . . on πRn(r) = r
71

Notons qu’une DP est un cas particulier de dépendance de jointure avec n = 2.
Définition 11.6 Une dépendance de jointure JD(R1, . . . , Rn) est triviale ssi ∃i : Ri = R.
Définition 11.7 Une relation R est en cinquième forme normale (5NF) ssi, pour toutedépendance de jointure non triviale JD(R1, . . . , Rn) de R, chaque Ri est une super clé.
Voir figure 13.4
11.3 Décomposition et préservationDéfinition 11.8 Soit F un ensemble de dépendances fonctionnelles F sur R, et Ri ⊆ R.La projection de F sur Ri, notée πF (Ri), est un ensemble F ′ de dépendances fonctionnellesdéfini comme suit:
F ′ = {X → Y | X → Y ∈ F+ ∧ X ∪ Y ⊆ Ri}
Définition 11.9 Une décomposition D = {R1, . . . , Rn} de R préserve les dépendances fonc-tionnelles F dans R ssi
(n⋃
i=1
πF (Ri))+ = F+
Définition 11.10 Une décomposition D = {R1, . . . , Rn} de R satisfait la propriété de join-ture non additive par rapport à F ssi, pour tout état r de R satisfaisant F ,
πR1(r) on . . . on πRn(r) = r
11.4 Algorithmes de décomposition de schéma1. décomposition en 3NF avec préservation des dépendances fonctionnelles (algorithme
13.1)
2. décomposition en BCNF avec jointure non additive (algorithme 13.3)
3. décomposition en 3NF avec préservation des dépendances fonctionnelles et jointure nonadditive (algorithme 13.4)
4. décomposition en 4NF avec jointure non additive (algorithme 13.5)
5. décomposition en 5NF avec jointure non additive
72

11.4.1 Algorithme 13.1 : décomposition en 3NF avecpréservation des dépendances fonctionnelles
Soit F un ensemble de dépendances fonctionnelles minimal sur R.
pour chaque X tel que ∃A : X → A ∈ F fairecréer un schéma de relation RX(X,A1, . . . , Am),où X → Ai ∈ F
créer une relation R(B1, . . . , Bn),où Bi est un attribut de R qui n’a pas été inclusdans aucune relation à l’étape précédente
11.4.2 Algorithme 13.3 : décomposition en BCNF avecjointure non additive
D := {R}tant qu’il existe un schéma de relation Q dans D non en BCNF fairesoit X → Y une DF en Q qui viole BCNFremplacer Q par les deux schémas X ∪ Y et Q− Y .
11.4.3 Algorithme 13.4 : décomposition en 3NF avecpréservation des dépendances fonctionnelles etjointure non additive
faire algorithme 13.1si aucun des schémas ne comporte une clé pour R,ajouter un schéma de relation avecdes attributs qui forment une clé pour R
11.4.4 Algorithme 13.5 : décomposition en 4NF avecjointure non additive
D := {R}tant qu’il existe un schéma de relation Q dans D non en 4NF fairesoit X→→Y une DP en Q qui viole BCNFremplacer Q par les deux schémas X ∪ Y et Q− Y .
11.4.5 Algorithme de décomposition en 5NF avecjointure non additive
D := {R}tant qu’il existe un schéma de relation Q dans D non en 5NF fairesoit JD(Q1, . . . , Qm) une DP en Q qui viole 5NFremplacer Q par les schémas Q1, . . . , Qm.
73

Annexe A
Diapositives de patrons de traduction
74
2014-‐08-‐12
1
Cas 0..1 — 0..1 Associa1on représentée par une table
E1
A1 (c1) A2
E2
A3 (c1) A4
0..1 0..1
create table E1 ( A1 A2 PK (A1) )
A
create table A ( A1 PK (A1) FK (A1) REF E1 A3 not null UN (A3) FK (A3) REF E2 )
create table E2 ( A3 A4 PK (A3) )
La table A a deux clés: A1 comme PK, et A3 en UNIQUE NOT NULL (ie, équivalent à une PK) 2
Cas 0..1 — 1..1 et 1..1 — 1..1 Associa1on représentée par une table • Même solu1on que le cas précédent 0..1—0..1
3

2014-‐08-‐12
2
Cas 0..1 — 0..1 Associa1on représentée dans une en1té par1cipante
E1
A1 (c1) A2
E2
A3 (c1) A4
0..1 0..1
create table E1 ( A1 PK (A1) A2 A3 FK (A3) REF E2 )
A
create table E2 ( A3 PK (A3) A4 )
On peut choisir E1 ou E2 pour implémenter la clé étrangère qui représente l’associa1on 4
Cas 0..1 — 1..1 Associa1on représentée dans une en1té par1cipante
E1
A1 (c1) A2
E2
A3 (c1) A4
0..1 1..1
create table E1 ( A1 PK (A1) A2 A3 NOT NULL FK (A3) REF E2 )
A
create table E2 ( A3 PK (A3) A4 )
La différence avec le cas précédent est notée en bleu: le NOT NULL est requis pour représenter la cardinalité minimale 1
5
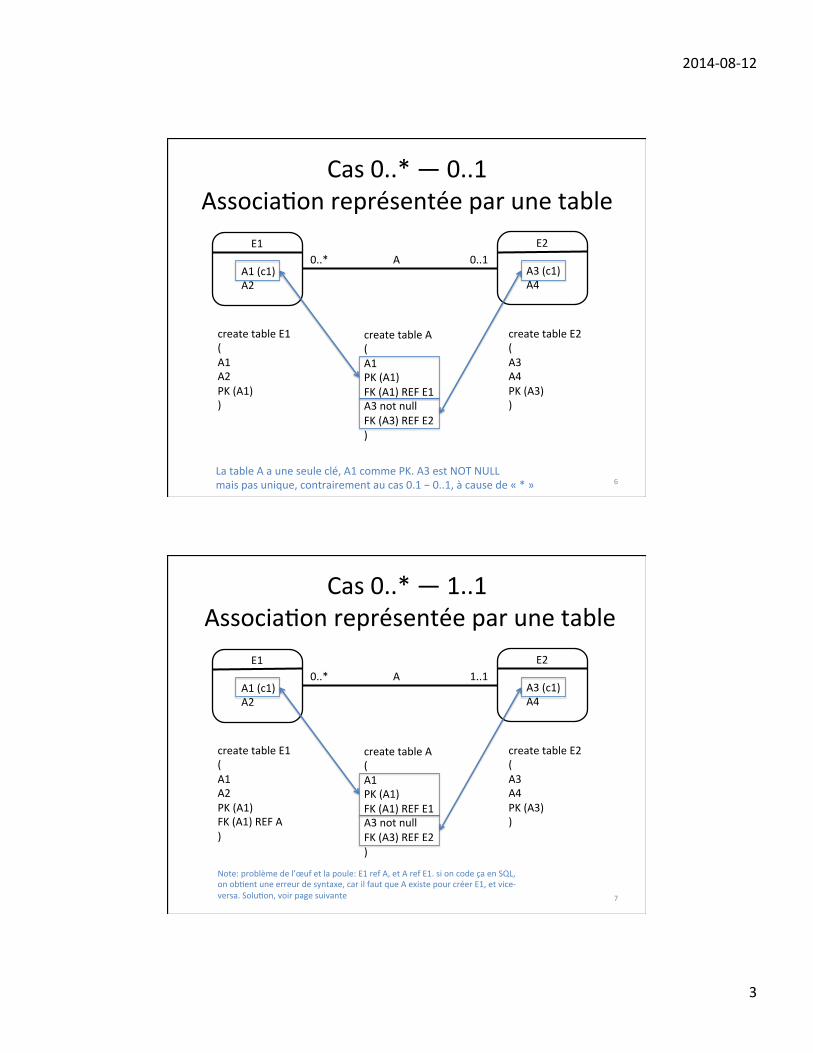
2014-‐08-‐12
3
Cas 0..* — 0..1 Associa1on représentée par une table
E1
A1 (c1) A2
E2
A3 (c1) A4
0..* 0..1
create table E1 ( A1 A2 PK (A1) )
A
create table A ( A1 PK (A1) FK (A1) REF E1 A3 not null FK (A3) REF E2 )
create table E2 ( A3 A4 PK (A3) )
La table A a une seule clé, A1 comme PK. A3 est NOT NULL mais pas unique, contrairement au cas 0.1 − 0..1, à cause de « * » 6
Cas 0..* — 1..1 Associa1on représentée par une table
7
E1
A1 (c1) A2
E2
A3 (c1) A4
0..* 1..1
create table E1 ( A1 A2 PK (A1) FK (A1) REF A )
A
create table A ( A1 PK (A1) FK (A1) REF E1 A3 not null FK (A3) REF E2 )
create table E2 ( A3 A4 PK (A3) )
Note: problème de l’œuf et la poule: E1 ref A, et A ref E1. si on code ça en SQL, on ob1ent une erreur de syntaxe, car il faut que A existe pour créer E1, et vice-‐versa. Solu1on, voir page suivante

2014-‐08-‐12
4
Tables qui se référencent mutuellement
8
Il faut procéder en 3 étapes. 1-‐ On crée E1 sans sa FK vers A. 2-‐ On crée A 3-‐ On ajoute la FK manquante à E1 create table E1 ( A1 A2 PK (A1) ); create table A ( A1 PK (A1) FK (A1) REF E1 A3 not null FK (A3) REF E2 ); ALTER TABLE E1 ADD CONSTRAINT i_E1_A FOREIGN KEY (A1) REFERENCES A;
Cas 0..* — 0..1 Associa1on représentée dans une en1té par1cipante
E1
A1 (c1) A2
E2
A3 (c1) A4
0..* 0..1
create table E1 ( A1 PK (A1) A2 A3 FK (A3) REF E2 )
A
create table E2 ( A3 PK (A3) A4 )
Iden1que au cas 0..1 − 0..1, sauf qu’on n’a pas le choix du côté où implémenter la clé étrangère; on doit la meore du côté « * » de l’associa1on. 9
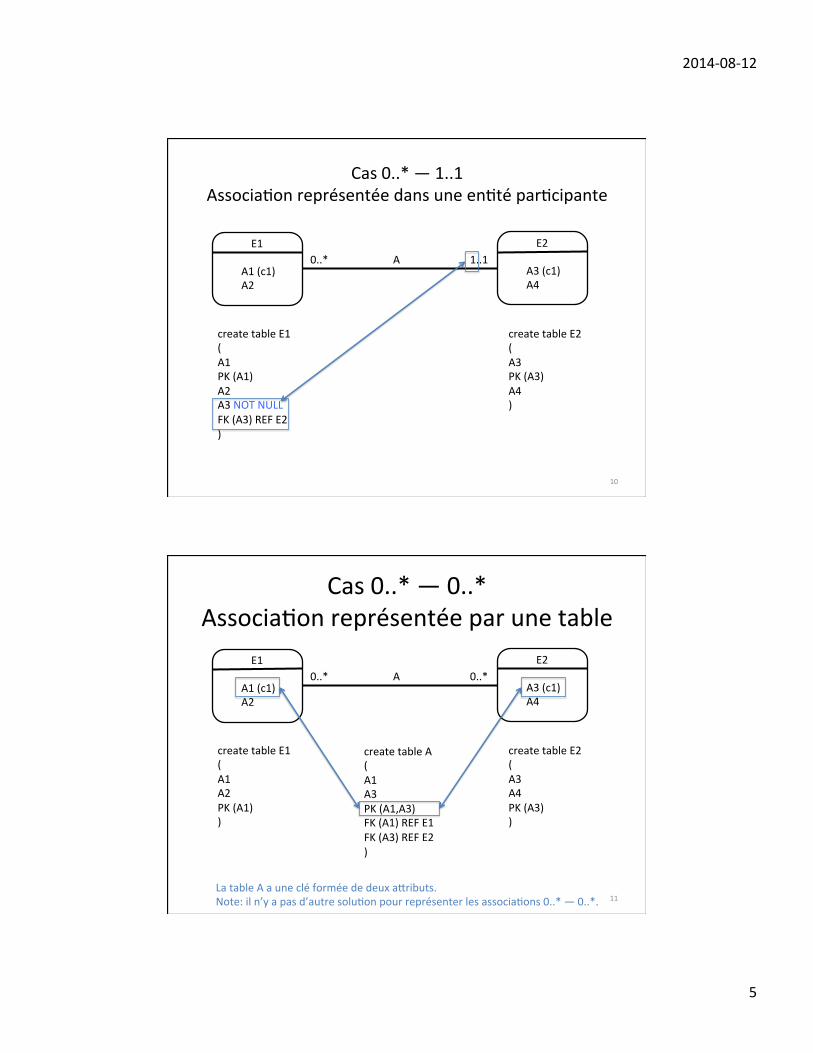
2014-‐08-‐12
5
Cas 0..* — 1..1 Associa1on représentée dans une en1té par1cipante
E1
A1 (c1) A2
E2
A3 (c1) A4
0..* 1..1
create table E1 ( A1 PK (A1) A2 A3 NOT NULL FK (A3) REF E2 )
A
create table E2 ( A3 PK (A3) A4 )
10
Cas 0..* — 0..* Associa1on représentée par une table
E1
A1 (c1) A2
E2
A3 (c1) A4
0..* 0..*
create table E1 ( A1 A2 PK (A1) )
A
create table A ( A1 A3 PK (A1,A3) FK (A1) REF E1 FK (A3) REF E2 )
create table E2 ( A3 A4 PK (A3) )
La table A a une clé formée de deux aoributs. Note: il n’y a pas d’autre solu1on pour représenter les associa1ons 0..* — 0..*. 11

2014-‐08-‐12
6
Associa1on n-‐aire (n > 2)
create table A ( A1 A3 A5 PK (A1,A3,A5) FK (A1) REF E1 FK (A3) REF E2 FK (A5) REF E3 )
12
E1
A1 (c1) A2
E3
A5 (c1) A6
E2
A3 (c1) A4
A
La clé de la table A est formée de l’union des clés des en1tés par1cipant dans l’associa1on (généralisa1on du cas n=2). Si on u1lisait les cardinalités d’Abrial, qui donnent plus d’informa1ons que les cardinalités de UML et Chen, on pourrait être plus précis sur la forma1on de la clé primaire.
En1té ayant plusieurs clés candidates
• On en choisit une pour la clé primaire (arbitrairement), et les autres sont représentées par des clés uniques (une clé unique pour chaque clé candidate restante)
• Pour représenter la par1cipa1on à une associa1on, on peut choisir n’importe quelle clé candidate
13

2014-‐08-‐12
7
Aoribut mul1valué d’une en1té E1
A1 (c1) A2 A3 : Set
create table E1 ( A1 A2 PK (A1) )
14
create table E1A3 ( A1 A3 PK (A1,A3) FK (A1) REF E1 )
E1
A1 (c1) A2
A3
A31 A32
0..*
create table E1A3 ( A1 A31 A32 PK (A1,A31,A32) FK (A1) REF E1 )
Aoen1on: il faut créer une table par aoribut mul1valué d’une en1té.
Aoribut mul1valué d’une associa1on
15
E1
A1 (c1) A2
E3
A5 (c1) A6
E2
A3 (c1) A4
A
A7 A8 : Set
create table A ( A1 A3 A5 A7 PK (A1,A3,A5) FK (A1) REF E1 FK (A3) REF E2 FK (A5) REF E3 )
create table A8 ( A1 A3 A5 A8 PK (A1,A3,A5,A8) FK (A1,A3,A5) REF A )
Il faut créer une autre table pour représenter l’aoribut mul1valué de l’associa1on. Les aoributs monovalués comme A7 sont stockés dans la table de l’associa1on. Chaque aoribut mul1valué a sa propre table.
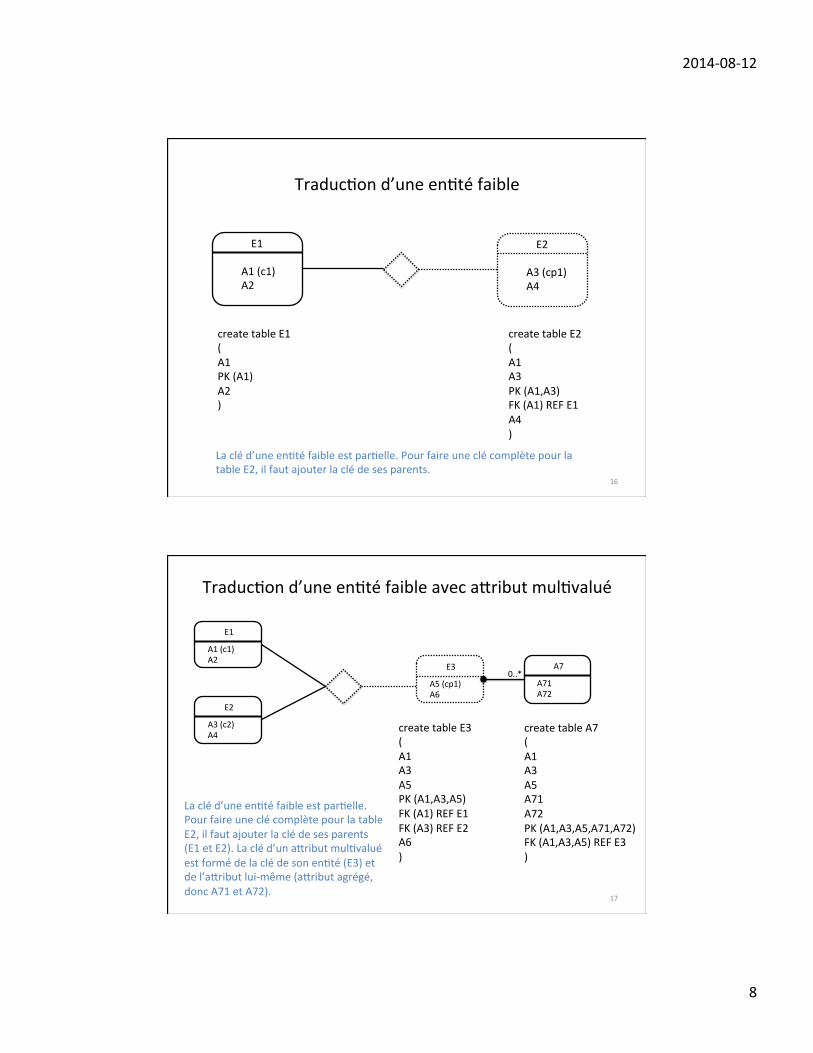
2014-‐08-‐12
8
Traduc1on d’une en1té faible
E1
A1 (c1) A2
E2
A3 (cp1) A4
create table E1 ( A1 PK (A1) A2 )
create table E2 ( A1 A3 PK (A1,A3) FK (A1) REF E1 A4 )
La clé d’une en1té faible est par1elle. Pour faire une clé complète pour la table E2, il faut ajouter la clé de ses parents.
16
Traduc1on d’une en1té faible avec aoribut mul1valué
create table E3 ( A1 A3 A5 PK (A1,A3,A5) FK (A1) REF E1 FK (A3) REF E2 A6 )
17
E1
A1 (c1) A2
E2
A3 (c2) A4
E3
A5 (cp1) A6
A7
A71 A72
0..*
create table A7 ( A1 A3 A5 A71 A72 PK (A1,A3,A5,A71,A72) FK (A1,A3,A5) REF E3 )
La clé d’une en1té faible est par1elle. Pour faire une clé complète pour la table E2, il faut ajouter la clé de ses parents (E1 et E2). La clé d’un aoribut mul1valué est formé de la clé de son en1té (E3) et de l’aoribut lui-‐même (aoribut agrégé, donc A71 et A72).

Annexe B
Diapositives de normalisation
83

1
2012/03/12 1
Modélisation de données (modèle relationnel)
2012/03/12 2
Modélisation de données
• On peut créer un modèle relationnel des données de deux manières:
1. Modèle entité-relation et traduction du modèle entité-relation en modèle relationnel
2. Produit directement un modèle relationnel qui est ensuite raffinné pour s’assurer de sa qualité
• Dans cette partie, on utilisera la deuxième

2
2012/03/12 3
Normalisation des données
• Permet produire un modèle relationnel de qualité – Sans redondance de données – Base de données facile à mettre à jour et à
interroger
2012/03/12 4
Modèle entité-relation
• Modèle abstrait (conceptuel) • Peut être traduit en un
– Modèle relationnel – Modèle objet – Modèle hiérarchique, réseau, XML, etc
• Les algorithmes de traduction du modèle entité-relation en modèle relationnel produise généralement un modèle relationnel normalisé

3
2012/03/12 5
Identifier les entités
• une relation est un objet d’intérêt pour l’utilisateur du système
• une relation peut représenter un objet physique ou virtuel (artificiel) du monde
• critères de pertinence – la relation a-t-elle une valeur pour le processus
d’affaires? – est-elle référencée par une fonction de maj et une
fonction d’interrogation? – y a-t-il plusieurs instances de l’entité?
2012/03/12 6
Sources pour l’identification des entités
• texte de l’étude de faisabilité • diagramme des fonctions • rapport ou autre document que l’on désire
informatiser • procédures
4
2012/03/12 7
La modélisation dans le processus de développement
Étude de faisabilité
1
Analyse fonctionnelle
2
Réalisation3
donnéesfonctions
modèle logiquede données
diagramme desfonctions
ébauche dumodèle
de données
modèlede données
complet
2012/03/12 8
Processus de modélisation Identifier
fonctions etentités
1
Élaborermodèlelogique
2
Élaborermodèle
physique
3
liste d'entitésliste de fonctions
modèle logiquedes données
modèled'un monde
"idéal"optimisation dela performance
modèle physiquede données

5
2012/03/12 9
Modélisation de données et modélisation des fonctions
• le modèle de données et le diagramme des fonctions se développent en parallèle – l’identification d’une relation entraîne
l’identification de fonctions (maj, interrogation) – l’identification d’une fonction entraîne
l’identification de relations • choisir l’approche la plus naturelle selon le
domaine d’application
2012/03/12 10
Exemple d’identification des entités
• “On désire développer un système pour gérer les inscriptions aux cours dans une université. Les cours offerts sont décrits dans l’annuaire de l’université. On désire affecter les cours selon les disponibilités des professeurs, leur compétence et l’accessibilité des cours par session. Un étudiant s’inscrit à un groupe d’un cours pour une session donnée s’il a complété tous ses préalables. On désire également y consigner la note d’un étudiant.”

6
2012/03/12 11
Exemple candidats d’entité
• “On désire développer un système pour gérer les inscriptions aux cours dans une université. Les cours offerts sont décrits dans l’annuaire de l’université. On désire affecter les cours selon les disponibilités des professeurs, leur compétence et l’accessibilité des cours par session. Un étudiant s’inscrit à un groupe d’un cours pour une session donnée s’il a complété tous ses préalables. On désire également y consigner la note d’un étudiant.”
2012/03/12 12
Exemple d’élicitation de la liste des entités
• inscription – oui (elle a une valeur pour le processus d’affaires)
• cours – oui (valeur, idem)
• université – non – aucune valeur; – le système s’applique toujours à la même université; – si on gérait les cours pour un réseau d’université, ou
pour des programmes multi-universitaires, l’entité université serait alors pertinente)

7
2012/03/12 13
Exemple d’élicitation de la liste des entités
• annuaire – oui (il a une valeur, il contient la liste des cours)
• professeur – oui (valeur)
• disponibilités des professeurs – c’est un attribut de professeur; il a une valeur pour
gérer l’affectation des cours • compétence
– c’est un attribut de professeur; il a une valeur pour gérer l’affectation des cours
2012/03/12 14
Exemple d’élicitation de la liste des entités
• accessibilité – oui (valeur pour gérer l’affectation des cours)
• session – non; pas nécessaire de gérer les sessions; il s’agit plutôt
d’un attribut de plusieurs entités • étudiant
– oui (valeur) • note
– oui (valeur)

8
2012/03/12 15
Exemple d’élicitation de la liste des entités
• groupe – oui (valeur)
• préalables – non (considérons le comme un attribut de
cours)
2012/03/12 16
Représentation graphique cours
groupe
inscription
professeur
etudiant
accessibilité
annuaire
note

9
2012/03/12 17
Définition des attributs des entités
• pour chaque attribut, il faut – nom – type – contraintes d’intégrité
• pour l’instant, on se concentre sur le nom • représentation textuelle des attributs d’une
entité – entité(attribut1, ..., attributn)
2012/03/12 18
Exemple d’identification des attributs
• inscription(sigle, session, groupe, matricule) • cours(sigle, titre, préalables) • annuaire
– c’est un ensemble de cours, donc déjà traité par l’entité cours; on élimine cette entité
• professeur(nom, matricule, salaire, disponibilités, compétences)

10
2012/03/12 19
Exemple d’identification des attributs
• accessibilité(sigle, session) • étudiant(matricule, nom, coteZ) • groupeCours(sigle, session, groupe,
matricule) – matricule du prof qui enseigne le cours
2012/03/12 20
Exemple d’identification des attributs
• note (sigle, session, groupe, matricule, note) • on peut combiner l’entité note avec
inscription, car tous les attributs d’inscription sont inclus dans note
• inscription(sigle, session, groupe, matricule,note)

11
2012/03/12 21
Le modèle logique de gestion des cours avant normalisation
sigletitrepréalables
cours
siglesessiongroupematricule
groupeCours
siglesessionmatriculegroupenote
inscription
matriculenomsalairecompétencesdisponibilités
professeur
matriculenomcoteZ
etudiant
siglesession
accessibilité
Clé étrangère
2012/03/12 22
Normalisation des entités
• la normalisation des entités permet d’obtenir un schéma de BD relationnelle de bonne qualité
• la normalisation – minimise la redondance des données – facilite la mise à jour des données – facilite l’interrogation des données

12
2012/03/12 23
Formes normales
• une forme normale dénote un niveau de normalisation pour une entité
• il existe plusieurs formes normales – 1FN, 2FN, 3FN, BCNF, 4FN, 5FN
• on a – 1FN – BCNF ⇒ 3FN ⇒ 2FN – 5FN⇒ 4FN
• la plus courante est la 3FN • les deux premières (1FN et 2FN) sont à éviter
2012/03/12 24
Définition de 1FN
• Une relation E est en 1FN (première forme normale) ssi tous les attributs de E sont scalaires (ou atomiques) – attribut scalaire : attribut dont le type est
élémentaire (char, varchar, numeric, etc) – attribut vectoriel : ensemble, liste (c-à-d une
structure comportant des répétitions)

13
2012/03/12 25
Exemples et contre-exemples de 1FN
• les relations groupeCours, inscription, étudiant, et accessibilité sont en 1FN
• la relation cours n’est pas en 1FN, car l’attribut préalables est un ensemble de sigles
• la relation professeur n’est pas en 1FN, car les attributs compétences et disponibilités sont des ensembles
2012/03/12 26
Normalisation en 1FN
• si une relation E1 n’est pas en 1FN, on la normalise en créant une nouvelle relation E2 pour chaque attribut vectoriel
• les attributs de E2 sont : – la clé primaire de E1
– les attributs des éléments de la structure vectorielle
• on enlève de la relation E1 les attributs vectoriel

14
2012/03/12 27
Normalisation en 1FN de cours
sigle titre préalablesIFT286 Lab. de BD IFT178
IFT486 BD IFT286IFT339
cours
courssigle titreIFT286 Lab. de BD
IFT486 BD
préalablesCourssigle préalablesIFT286 IFT178IFT486 IFT286IFT486 IFT339
2012/03/12 28
Normalisation en 1FN de professeur
matricule salaire nom1 35 000 $ xyz2 25 000 $ abc
professeur
matricule salaire nom disponibilités compétences
1 35 000 $ xyz A01E02
IFT286IFT339
2 25 000 $ abc H01 IFT178
professeur
matricule session1 A011 E022 H01
disponibilitésmatricule sigle
1 IFT2861 IFT3392 IFT178
compétences

15
2012/03/12 29
Le modèle logique de cours après normalisation en 1FN
sigletitre
cours
siglesiglePrealable
prealableCours
siglesessiongroupematricule
groupeCours
siglesessionmatriculegroupenote
inscription
matriculesalairenom
professeur
matriculecoteZnom
etudiant
siglematricule
competence
matriculesession
disponibilite
siglesession
accessibilité
2012/03/12 30
Pourquoi normaliser en 1FN?
• parce que le modèle relationnel ne permet pas de stocker une structure vectorielle dans un attribut d’une table
• d’autres modèles permettent les répétitions – modèle relationnel étendu ou relationnel objet
(SQL3) – modèle orienté objets

16
2012/03/12 31
Dépendance fonctionnelle
• les définitions de 2FN, 3FN, BCNF reposent sur la notion de dépendance fonctionnelle
• une dépendance fonctionnelle est une fonction entre des listes d’attributs
• on dénote une dépendance fonctionnelle comme suit :
(A1, ..., An) → An+1 on dit que An+1 dépend de A1, ..., An
2012/03/12 32
Que représente une dépendance fonctionnelle?
• c’est une fonction, donc elle associe à une liste de valeurs des attributs A1, ..., An une et une seule valeur dans An+1
• exemple – dans une université, étant donné le matricule d’un étudiant, on peut
donner son nom – il existe donc une dépendance fonctionnelle entre matricule et nom
matricule → nom
– l’inverse n’est pas vrai : étant donné un nom, on ne peut déterminer le matricule d’un étudiant, car il peut y avoir plusieurs matricules, puisque plusieurs étudiants peuvent avoir le même nom

17
2012/03/12 33
Que représente une dépendance fonctionnelle?
• attention! la dépendance matricule → nom ne signifie pas que le nom associé à un matricule ne change jamais; le nom peut changer, mais, en tout temps, on peut déterminer le nom d’un étudiant à partir de son matricule
• cela ne signifie pas non plus que si on a deux matricules différents, alors leurs noms associés doivent être différents
• cela signifie que deux étudiants ne peuvent avoir le même matricule
2012/03/12 34
Dépendance fonctionnelle minimale
• si (A1, ..., An) → B
alors on a aussi (A1, ..., An, An+1) → B
• pour les fins de normalisation, on considère seulement les dépendances qui sont minimales selon la liste de gauche

18
2012/03/12 35
Dépendance fonctionnelle et clé candidate
• s’il existe une dépendance fonctionnelle minimale entre (A1, ..., An) et tous les autres attributs de la relation, alors on peut conclure que (A1, ..., An) est une clé candidate
• une dépendance fonctionnelle sera donc traduite en une contrainte primary key ou unique
2012/03/12 36
Quelques lois sur les dépendances fonctionnelles
Soit W, X, Y et Z des ensembles d’attributs Par soucis de concision, on dénote par XY l’union X ∪ Y de deux ensembles d’attributs X et Y

19
2012/03/12 37
Comment déterminer les dépendances fonctionnelles?
• les dépendances fonctionnelles sont des contraintes du domaine d’application
• on les détermine à partir de notre connaissance des faits (règles, conditions, etc) du domaine d’application
• on peut déterminer s’il y a une dépendance fonctionnelle (A1, ..., An) → An+1 en répondant à la question suivante: – étant donné une liste de valeurs pour A1, ..., An , peut-
on toujours associer une et une seule valeur pour An+1?
2012/03/12 38
Représentation graphique
• sigle → titre
• (sigle,session,groupe) → matricule
sigle titre
sigle session groupe matricule

20
2012/03/12 39
Exercice
• identifiez les dépendances fonctionnelles entre les attributs suivants – sigle, titre, matricule, nom, session, groupe,
note, salaire, coteR
2012/03/12 40
Définition de 2FN
• une relation E est en deuxième forme normale ssi tous les attributs non premiers de E sont en dépendance fonctionnelle complète de chaque clé candidate de E – attribut premier : attribut d’une clé candidate – dépendance fonctionnelle complète : l’attribut
dépend de toute la clé (c-à-d il n’existe pas de dépendance fonctionnelle entre une partie d’une clé candidate et un attribut non premier)

21
2012/03/12 41
Modèle logique de cours sigletitre
cours
siglesiglePrealable
prealableCours
siglesessiongroupematricule
groupeCours
siglesessionmatriculegroupenote
inscription
matriculesalairenom
professeur
matriculecoteZnom
etudiant
siglematricule
competence
matriculesession
disponibilite
siglesession
accessibilité
2012/03/12 42
Exemples de 2FN
• les relations suivantes sont en 2FN
– cours – prealablesCours – accessibilité – groupeCours – inscription
– professeur – competence – disponibilite – etudiant

22
2012/03/12 43
Contre-exemple de 2FN
une entité E est en deuxième forme normale ssi tous les attributs non premiers de E sont en dépendance fonctionnelle complète de chaque clé candidate de E
sigle session groupe matricule titre nom
titre ne dépend pas de toute la clé; il dépend seulement de sigle
2012/03/12 44
Normalisation en 2FN
• les attributs non premiers en dépendance partielle sont extraits – pour former une nouvelle relation
ou bien
– sont ajoutés à une relation ayant une clé primaire appropriée
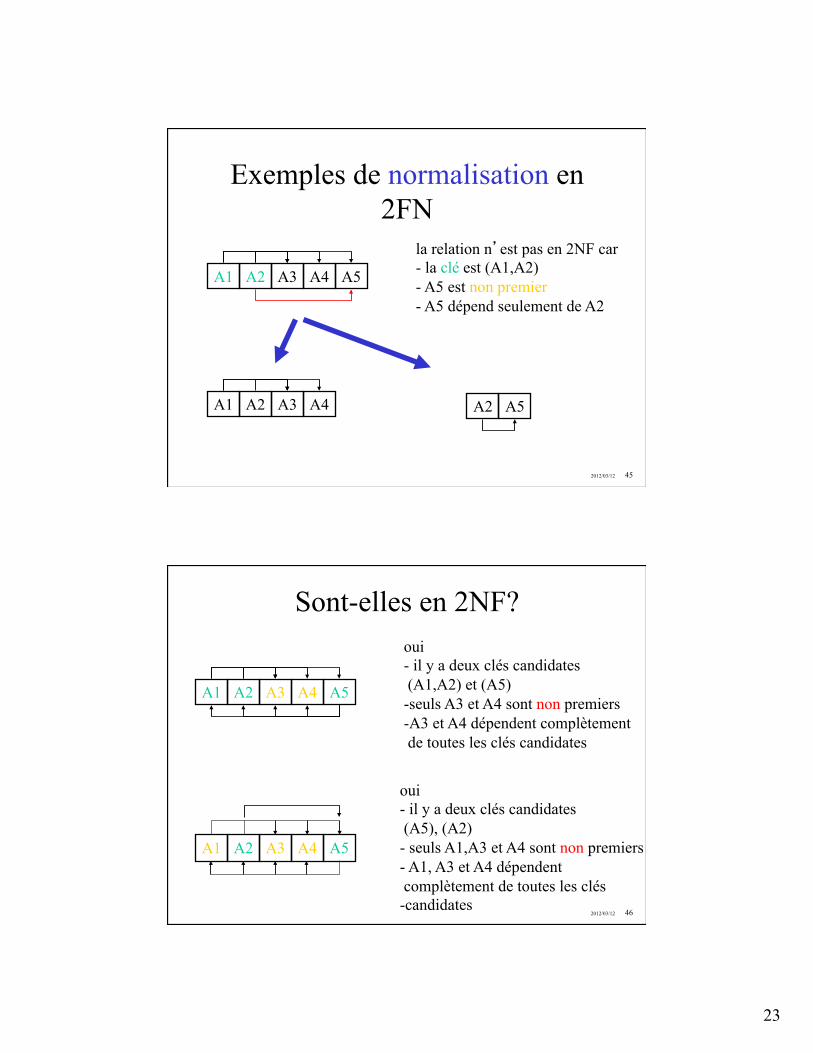
23
2012/03/12 45
Exemples de normalisation en 2FN
A1 A2 A3 A4 A5
la relation n’est pas en 2NF car - la clé est (A1,A2) - A5 est non premier - A5 dépend seulement de A2
A1 A2 A3 A4 A2 A5
2012/03/12 46
Sont-elles en 2NF?
A1 A2 A3 A4 A5
oui - il y a deux clés candidates (A1,A2) et (A5) - seuls A3 et A4 sont non premiers - A3 et A4 dépendent complètement de toutes les clés candidates
A2 A3 A4 A5
oui - il y a deux clés candidates (A5), (A2) - seuls A1,A3 et A4 sont non premiers - A1, A3 et A4 dépendent complètement de toutes les clés - candidates
A1

24
2012/03/12 47
Pourquoi normaliser en 2FN?
• parce que cela élimine la redondance des données
• cela assure une meilleure intégrité des données tout en simplifiant les mise à jour
• on ne perd aucune information; on peut recréer la relation originale avec une jointure des deux relations normalisées
2012/03/12 48
Définition de 3FN
• Une relation E est en troisième forme normale ssi pour toute dépendance fonctionnelle X → A de E, une des conditions suivantes est satisfaite: – X est une super clé – A est un attribut premier
• super clé : liste d’attributs contenant une clé candidate

25
2012/03/12 49
Exemples de 3FN
• les relations suivantes sont en 3FN
– cours – prealablesCours – accessibilité – groupeCours – inscription
– professeur – competence – disponibilite – etudiant
2012/03/12 50
Contre-exemple de 3FN
sigle session groupe matricule nom
Une relation E est en troisième forme normale ssi pour toute dépendance fonctionnelle X → A de E, une des conditions suivantes est satisfaite:
– X est une super clé – A est un attribut premier
cette relation n’est pas 3FN car : • matricule n’est pas une super clé • nom n’est pas premier
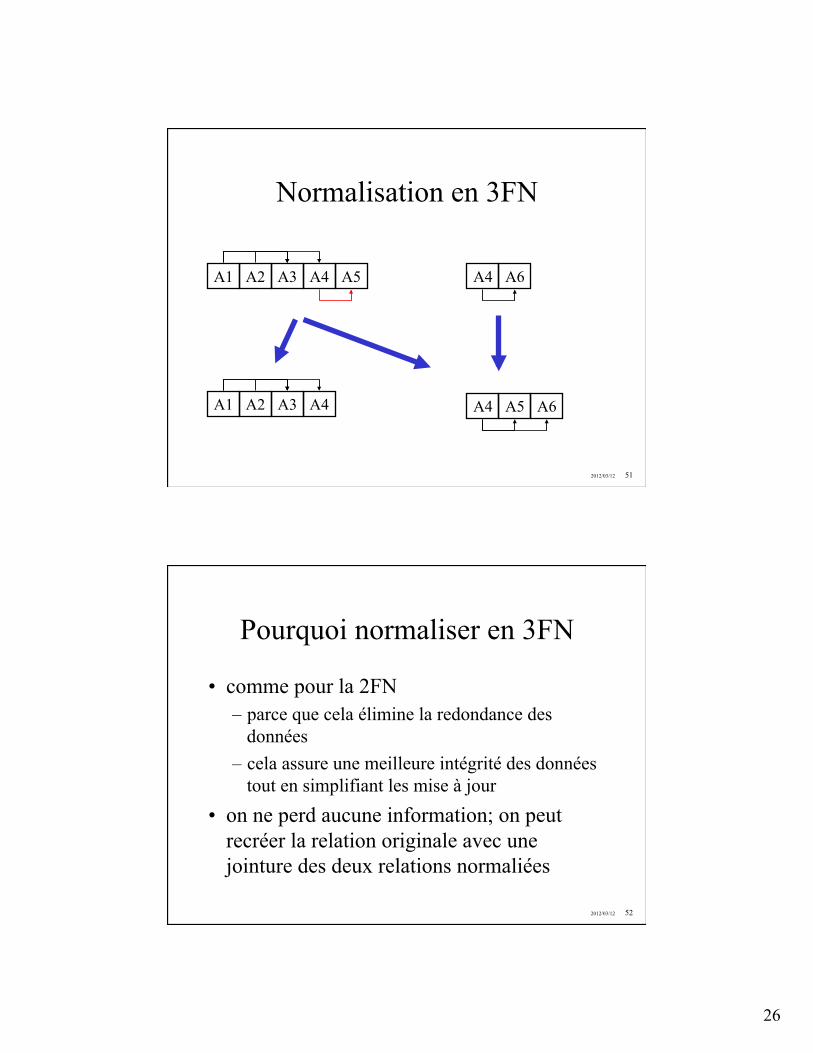
26
2012/03/12 51
Normalisation en 3FN
A1 A2 A3 A4 A5
A1 A2 A3 A4 A4 A5
A4 A6
A6
2012/03/12 52
Pourquoi normaliser en 3FN
• comme pour la 2FN – parce que cela élimine la redondance des
données – cela assure une meilleure intégrité des données
tout en simplifiant les mise à jour • on ne perd aucune information; on peut
recréer la relation originale avec une jointure des deux relations normaliées

27
2012/03/12 53
Définition de BCNF
• Une relation E est en forme normale de Boyce-Codd ssi pour toute dépendance fonctionnelle X → A de E, la condition suivante est satisfaite: – X est une super clé
2012/03/12 54
Exemples de BCNF
• les relations suivantes sont en BCNF
– cours – prealablesCours – accessibilité – groupeCours – inscription
– professeur – competence – disponibilite – etudiant

28
2012/03/12 55
Contre-exemple de BCNF
• supposons qu’une institution d’enseignement décerne un seul diplôme (SEC, DEC, ou BAC) et qu’une personne obtient un diplôme d’une et une seule institution; on a les DF suivantes – (personne,diplôme) → institution – institution → diplôme
2012/03/12 56
Contre-exemple de BCNF
personne diplôme institution
cette entité n’est pas en BCNF, car il y a la DF institution → diplôme, et institution n’est pas une super clé
Une entité E est en forme normale de Boyce-Codd ssi pour toute dépendance fonctionnelle X → A de E, la condition suivante est satisfaite:
– X est une super clé

29
2012/03/12 57
Normalisation en BCNF
personne diplôme institution
personne institution diplôme institution
note: - on ne perd pas d’information, - on diminue la redondance - on perd une contrainte d’intégrité (personne,diplôme) → institution
2012/03/12 58
Définition de 5FN
• Une relation E est en cinquième forme normale ssi E ne peut être obtenue par une jointure de relations E1, ..., En telle que l’une des Ei n’est pas une clé de E
• la quatrième forme normale est un cas particulier de 5FN; nous omettons sa définition

30
2012/03/12 59
Exemple de 5FN
• les relations suivantes sont en 5FN
– cours – prealablesCours – accessibilité – groupeCours – inscription
– professeur – competence – disponibilite – etudiant
2012/03/12 60
Contre-exemple de 5FN
• offreDeCours(sigle,session,matricule) représente le fait qu’un professeur peut enseigner le cours à une session donnée
• cette relation peut être obtenue par la jointure des 3 relations suivantes: – disponibilité(matricule, session) – compétence(matricule, sigle) – accessibilite(sigle, session)

31
2012/03/12 61
Contre-exemple de 5FN
sigle sessionIFT286 H01IFT286 E01
accessibilitématricule session
1 E012 E01
disponibilitématricule sigle
1 IFT2862 IFT286
compétence
sigle session matriculeIFT286 E01 1IFT286 E01 2
offreDeCours
⧓ ⧓
=
2012/03/12 62
Normalisation en 5FN
sigle session matriculeoffreDeCours
sigle sessionaccessibilité
matricule sessiondisponibilité
matricule siglecompétence

32
2012/03/12 63
Normalisation vs Modèle ER
• Il arrive parfois que la traduction d’un modèle ER ne donne pas un modèle relationnel normalisé
• Exercice – Produisez le modèle ER du système de gestion des
inscriptions aux cours – Traduisez votre modèle en modèle relationnel – Comparez le modèle relationnel obtenu avec le modèle
normalisé
2012/03/12 64
Modèle ER (erroné) de la gestion des cours
cours
sigle titre préalables session
sessionaccessibilité
professeur
donne
étudiantinscription
N N
N
1
groupematricule
nom coteZ
matricule
note
groupe1 N
N
N
N
N
disponibilité
compétence
N

33
2012/03/12 65
Modèle relationnel obtenu par traduction
sigletitre
cours
siglesiglePrealable
prealableCours
siglesessiongroupematricule
groupeCours
siglesessionmatriculegroupenote
inscription
matriculesalairenom
professeur
matriculecoteZnom
etudiant
siglematricule
competence
matriculesession
disponibilite
siglesession
accessibilité
2012/03/12 66
Modèle logique nornalisé de la gestion des cours
sigletitre
cours
siglesiglePrealable
prealableCours
siglesessiongroupematricule
groupeCours
siglesessionmatriculegroupenote
inscription
matriculesalairenom
professeur
matriculecoteZnom
etudiant
siglematricule
competence
matriculesession
disponibilite
siglesession
accessibilité

34
2012/03/12 67
Modèle ER correspondant au modèle normalisé
cours
sigle titre session
sessionaccessibilité
professeur
donneétudiant
N N
N
1
groupe matricule
nom coteR
note
groupe
affecte1
Ninscription
sigle
session
matricule
clé
1
N
disponibilités
compétences
matricule
NN
N
N
préalables
NN
NN
11
2012/03/12 68
Modèle UML correspondant au modèle normalisé
accessibilité
noSession (c1)
Session
note
Inscription
noGroupe (cp1)
GroupeCours
sigle (c1)titre (c2)
Cours0..*
affecte0..1
matricule (c1)coteRnom
Etudiant
matricule (c1)salairenom
Professeurcompétences disponibilités
0..*
0..* 0..*
0..*
0..*
préalables
donne

Annexe C
Exercices de normalisation
Voici d’abord un rappel des règles d’inférence R1 à R6.
réflexivité augmentation transitivitéX ⊇ Y
R1X → Y
X → YR2
XZ → Y ZX → Y Y → Z
R3X → Z
décomposition union pseudo-transitivitéX → Y Z
R4.1X → Y
X → Y ZR4.2
X → ZX → Y X → Z
R5X → Y Z
X → Y WY → ZR6
WX → Z
1. Prouvez ou infirmez les énoncés suivants. Pour une preuve, vous pouvez utiliser lesrègles R1 à R6; pour infirmer, donnez un contre-exemple.
(a) {A→ B,C → D} |= AC → BD
(b) {A→ BC,B → E,CD → EF} |= AD → F
(c) {A→ B,BC → DE,AEF → G} |= ACF → DG
(d) {A→ B,BC → DE,AEF → G} |= AF → D
2. Soit R(A,B,C,D,E, F,G) avec les dépendances fonctionnelles F = {A → BC,C →DE,F → G}.
(a) Calculez la fermeture de A,AC,B,C, F sous F .(b) Identifiez toutes les clés candidates de R.
3. Soit R(A,B,C,D,E) avec les dépendances fonctionnelles suivantes.
F1 = {A→ B,AB → C,D → AC,D → E}
F2 = {A→ BC,D → AE}
(a) Déterminez si F1 et F2 sont équivalents.
(b) Identifiez les clés candidates de R.
118

4. Déterminez si les relations suivantes sont en 1FN. Justifiez votre réponse. Normalisezla relation si elle n’est pas en 1FN.
• personne(noPersonne,nom,prénom,surnoms)
• équipe(noEquipe, nom, entraineurChef, entraineursAdjoints, joueurs)
• vin(codeBarre,appelationContrôlée, producteur)
5. Normalisez les relations suivantes jusqu’en BCNF. Procédez par étape : normaliser lesd’abord en 2FN, puis en 3FN et finalement en BCNF. Pour chaque étape : a) identifiezles clés candidates; b) identifiez les dépendances fonctionnelles qui font qu’une relationne satisfait pas le niveau de normalisation; c) normalisez la relation. Voici un exemple.Soit R(ABCD) et F = {AB → CD,B → C,C → D}
• 2FN : clé candidate de R : AB.La relation R n’est pas en 2FN à cause de B → CD.Normalisation en 2FN : R1(AB) et R2(BCD).
• 3FN : clé candidate de R1: AB; clé candidate de R2 : B.La relation R2 n’est pas en 3FN à cause de C → D.Normalisation en 3FN : R1(AB), R21(BC) et R22(CD).
• BCNF : clé candidate de R1 : AB; clé candidate de R21 : B; clé candidate deR22 : C.Les relations sont en BCNF.
Voici les relations à normaliser.
(a) R(ABCD) et F = {A→ B,B → C,C → D}(b) R(ABCDE) et F = {AB → CD,CD → AB,D → E}(c) R(ABCDE) et F = {AB → CD,CD → AB,CD → E}(d) R(ABCDE) et F = {ABC → DE,E → A}(e) R(ABCDE) et F = {ABC → DE,DE → ABC,E → A}(f) R(ABCDE) et F = {AB → D,BC → E}
6. Chez un fabricant d’automobiles, chaque modèle de voiture possède plusieurs options.Par exemple, on peut commander une Skoda de couleur bleu ou rouge avec un moteurde 1,5L ou de 1,3L. L’analyste de chez Skoda propose le schéma suivant pour représentertous les modèles avec leurs options : modèle(noModèle, moteur, couleur). Critiquezet normalisez ce modèle selon les hypothèses suivantes (produisez une réponse pourchaque hypothèse).
(a) Toutes les couleurs sont disponibles pour tous les types de moteurs.
(b) Seules certaines combinaisons (couleur,type de moteur) sont valides pour un mod-èle de voiture donné.
119

7. Définissez un schéma de BD en 5ième forme normale pour le problème suivant. Pourchaque table, donnez seulement les informations suivantes:
nomTable(A1, . . . , An0)clé candidate1 (A1, . . . , An1). . .clé candidatek (A1, . . . , Ank
)clé étrangère1 (A1, . . . , An1) référence nomTable(A1, . . . , An1). . .clé candidatej (A1, . . . , Anj
) référence nomTable(A1, . . . , Anj)
Description du problème
Une compagnie a un ensemble de départements. Chaque département a un ensembled’employés, un ensemble de projets et un ensemble de bureaux. Chaque employé a unhistorique de travail, constitué des postes occupés par l’employé dans cette compagnie.Pour chaque poste occupé, un employé a un historique de salaire, représentant lesdifférents échelons salariaux obtenus par l’employé. Chaque bureau a un ensemble detéléphones.
La base de données doit contenir les informations suivantes. Utilisez les noms d’attributidentifiés entre ().
• pour un département : le no du département (noDept), son budget (budgetDept),et le no d’employé (noEmpChef) du chef du département.
• pour un employé : le numéro d’employé (noEmp), le numéro du projet (noProj)pour lequel il travaille présentement, no de bureau (noBureau) et no de téléphone(noTel); de plus, on doit aussi avoir le titre de chaque poste occupé par l’employé(poste), la date de début de ce poste (dateDebut), et tous les échelons salariaux(salaire) obtenus par l’employé avec la date de début (dateDebut).
• pour un projet : no de projet (noProjet) et budget (budgetProjet)
• pour un bureau : no de bureau (noBureau) , localisation (ex: D4) (localisation)et numéros de téléphone (noTel).
On pose les hypothèses suivantes.
• Les numéros de département, d’employé, de projet, de bureau et de téléphonesont uniques lorsque considéré individuellement.
• Un employé ne gère qu’un seul département à la fois.
• Un employé ne travaille que dans un seul département à la fois.
• Un employé ne travaille que dans un seul projet à la fois.
• Un employé n’occupe qu’un seul bureau à la fois.
• Un employé n’a qu’un seul téléphone à la fois.
• Un employé n’occupe qu’un seul poste à la fois.
120

• Un projet est sous la responsabilité d’un seul département.
• Un bureau n’est affecté qu’à un seul département à la fois.
• Un bureau peut être inoccupé.
• Un poste n’est pas unique; par exemple, on peut être directeur du départementdes ventes et ensuite directeur du département de production.
121


















