Détecter les évènements populaires sur Twittermediamining.univ-lyon2.fr › people › guille ›...
15
PAGE: Date: Rennes, 30 janvier 2014 Auteurs: Adrien Guille et Cécile Favre Website: http://mediamining.univ-lyon2.fr/people/guille Détecter les évènements populaires sur Twitter Conférence EGC 2014 Rennes, 30 janvier 2014 - Adrien Guille ERIC LAB Université Lumière Lyon 2, France 1 sur 14
Transcript of Détecter les évènements populaires sur Twittermediamining.univ-lyon2.fr › people › guille ›...

PAGE:
Date: Rennes, 30 janvier 2014Auteurs: Adrien Guille et Cécile FavreWebsite: http://mediamining.univ-lyon2.fr/people/guille
Détecter les évènements populaires sur TwitterConférence EGC 2014
Rennes, 30 janvier 2014 - Adrien Guille
ERIC LABUniversité Lumière Lyon 2, France
1 sur 14

PAGE: Rennes, 30 janvier 2014 - Adrien Guille
ERIC LABUniversité Lumière Lyon 2, France
Détection d’évènements sur TwitterConférence EGC 2014
Motivation
2
• Pourquoi étudier Twitter ?• Beaucoup d’utilisateurs :
• 5,5 M en France (source : AFP)• +53% entre 2011 et 2012 (source : AFP)
• Publication des tweets en quasi temps-réel• Données (relativement facilement) accessibles
• Pourquoi détecter les évènements à partir de Twitter ?• Analyser les évènements qui intéressent le plus les utilisateurs de Twitter• Quantifier l’impact des évènements sur les utilisateurs de Twitter
• Tâche non-triviale• Les tweets rapportant les évènements importants sont noyés par un grand nombre de tweets sans rapport
sur 14

PAGE: Rennes, 30 janvier 2014 - Adrien Guille
ERIC LABUniversité Lumière Lyon 2, France
Contexte
3
• État de l’art• Méthodes basées sur la fréquence des mots
• Peaky Topics [CSCW ’11], tf-idf [IJWBC vol. 9:1 2013]• Méthodes à base de topic-models
• Online LDA [COLING ’12], ET-LDA [ICWSM ’12]• Méthodes à base de clustering de mots/n-grams de mots
• EDCoW [ICWSM ’11], TwEvent [CIKM ’12], ET [WWW ’13]
• Constats• Les méthodes se concentrent sur le contenu textuel, ignorant l’aspect social• La durée des évènements est fixée à l’avance (typiquement une journée)• Utilisation d’information externe (e.g. Wikipedia, médias traditionnels)
• Hypothèse de base• Les mentions, e.g. «@pseudonyme», insérées dans les tweets pour engager la discussion symbolisent un intérêt marqué pour la thématique abordée
Détection d’évènements sur TwitterConférence EGC 2014
sur 14

PAGE: Rennes, 30 janvier 2014 - Adrien Guille
ERIC LABUniversité Lumière Lyon 2, France
Proposition : formulation du problème
4
• Entrée• Un corpus C contenant N tweets• Partitionnement des tweets en n tranches temporelles
• Sortie• Les k évènements avec les k plus grandes magnitudes d’impact
• Définitions• Thématique «saillante» : étant donné un intervalle I, une thématique T est dite saillante si elle a attiré un niveau d’attention beaucoup plus élevé durant I que pendant le reste de la période d’observation. Une thématique T est définie par un mot principal, t, et un ensemble pondéré S de mots liés.
• Évènement : une thématique saillante et une valeur reflétant la magnitude d’impact sur les utilisateurs de Twitter
Détection d’évènements sur TwitterConférence EGC 2014
sur 14

PAGE: Rennes, 30 janvier 2014 - Adrien Guille
ERIC LABUniversité Lumière Lyon 2, France
Proposition : tour d’horizon
5
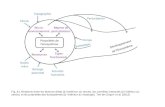
• MABED• i.e. Mention-Anomaly-Based Event Detection
• Deux phases et trois composants• Phase 1
Génération d’une liste ordonnée d’évènementse = [t,I,Ma, Ø] en analysant l’anomalie dans la fréquence de création de liens dynamiques (I)
• Phase 2Parcours de la liste et sélection des mots décrivant les évènements (II) jusqu’à ce que k évènements distincts aient été traités. Le composant (III) sauvegarde la description des évènements tout en gérant les évènements dupliqués à l’aide de graphes.
Détection d’évènements sur TwitterConférence EGC 2014
³�q<jIg
< D
IrdIEj<jQ][¥q<jIg¦
��Þ�§<�D¨
qq<jIgZ]][
���
������
���
���
���
< D
q<jIg�E]�]EEkgI[EI�
Z<jgQr
<����������������������������D���
���
"q<jIg
"Z]][
q
!<��
�KjIEjIg�YIh�KpJ[IZI[jh�=�d<gjQg�GI�Y�<[]Z<YQI
/KYIEjQ][[Ig�YIh�Z]jh�GKEgQp<[j�YIh�KpJ[IZI[jh
�
Og<dPI�GIh�gIG][G<[EIh
Og<dPI�GIh�jPKZ<jQfkIh
"
��
���
�Ykr�GI�jqIIjh
"�/�
QhjI�GIh�KpJ[IZI[jh�]gG][[Kh�hIY][�Y<�Z<O[QjkGI�GI�YIkg�QZd<Ej
7<jIg��Z]][�¥Á�ʦ��"�/��¥Á�ʦNg]Z�ÁÊ�ÂÂ�ÂÄ�ÂÁ<Zj]�ÁÊ�ÂÂ�ÂÆ�È�ÄÁ<Z
�K[KgIg�Y<�YQhjI�GIh�X�KpJ[IZI[jh�YIh�dYkh�Q[NYkI[jh�I[�OKg<[j�Y<�gIG][G<[EI
Z]][��"�/�
!<¥�¦
6IjIg<[h�hIgpIG�¥Á�ɦ��E]k[jgs�¥Á�ȦNg]Z�ÁÊ�ÂÂ�ÂÁ�ÅdZj]�ÁÊ�ÂÂ�ÂÃ�É<Z
0QOIg��7]]Gh��<EEQGI[j�¥Á�ʦ��E<g�¥Á�ʦNg]Z�ÁÊ�ÂÂ�ÃÈ�ÇdZj]�ÁÊ�ÂÂ�ÃÊ�Æ<Z
Q
Q
Q
�"0.
��+��/�
�Â+��/�
�Ã/$
.0��
sur 14

PAGE: Rennes, 30 janvier 2014 - Adrien Guille
ERIC LABUniversité Lumière Lyon 2, France
Détecter les évènements à partir de l’anomalie dans la fréquence de création de mentions
6
• Anomalie en un point• Pour le mot t à la i ème tranche temporelle
•
• Magnitude d’impact d’un évènement• Pour un évènement décrit par le mot principal t et l’intervalle temporel I = [a;b]
•
Détection d’évènements sur TwitterConférence EGC 2014
2. The list is iterated through starting from the most influen-tial event. For each event, the second component selectsthe set S of words that best describe it. The selection relieson measures based on the co-occurrence and the tempo-ral dynamics of words tweeted during I . Each event pro-cessed by this component is then passed to the third com-ponent, which is responsible for storing event descrip-tions and managing duplicated events. Eventually, when kdistinct events have been processed, the third componentmerges duplicated events and returns the list L containingthe top k events.
Detection of Events Based on Mention AnomalyThe objective of this component is to precisely identifywhen events happened and to estimate the magnitude of theirimpact over the crowd. It relies on the identification of burstsbased on the computation of the anomaly in the frequency ofmention creation for each individual word in [email protected] of the anomaly at a point Before formu-lating the anomaly measure, we define the expected numberof mention creation associated to a word t for each time-slice i 2 [1;n]. We assume that the number of tweets thatcontain the word t and at least one mention in the ith time-slice, N i
@t, follows a generative probabilistic model. Thuswe can compute the probability P (N i
@t) of observing N i@t.
In (Fung et al. 2005), authors study word frequency in tex-tual streams and show that it is reasonable to model this kindof probability, if the corpus is large enough, with a bino-mial distribution; (Li, Sun, and Datta 2012) also employ thismodeling for tweet streams. Therefore we can write:
P (N i@t) =
✓N i
N i@t
◆pNi
@t@t (1� p@t)
Ni�Ni@t ,
where p@t is the expected probability of a tweet containingt and at least one mention in any time-slice. Because N i islarge we further assume that P (N i
@t) can be approximatedby a normal distribution, that is to say:
P (N i@t) ⇠ N (N ip@t, N
ip@t(1� p@t)).
It follows that the expected frequency of tweets containingthe word t and at least one mention in the ith time-slice isE[t|i] = N ip@t, with p@t = N@t/N . We then define theanomaly of the mention creation frequency related to theword t at the ith time-slice this way:
anomaly(t, i) = N i@t � E[t|i].
The anomaly is positive only if the observed mention cre-ation frequency is strictly greater than the expectation.Computation of the magnitude of impact The magnitudeof impact of an event associated with the time interval I =
[a; b] and the main word t is given by the formula below. Itcorresponds to the algebraic area of the anomaly function on[a; b].
Ma(t, I) =Z b
a
anomaly(t, i) di
=
bX
i=a
anomaly(t, i)
The algebraic area is obtained by integrating the discreteanomaly function, which in this case boils down to a sum.Identification of events For each word t 2 V@, we iden-tify the interval that maximizes the magnitude of impactby solving a “Maximum Contiguous Subsequence Sum”(MCSS) type of problem. The MCSS problem is well knownand finds application in many fields (Fukuda et al. 1996;Fan et al. 2003; Lappas et al. 2009). In other words, for agiven word t we want to identify the interval I = [a; b], suchthat:
Ma(t, I) = max{bX
i=a
anomaly(t, i)|1 6 a 6 b 6 n}.
This formulation permits the anomaly to be negative at somepoints in the interval, only if it permits extending the inter-val while increasing the total magnitude, which is a desirableproperty. More specifically, it avoids fragmenting events thatlast several days because of the lower activity on Twitter dur-ing the night, which can lead to low or negative anomaly.Another desirable property of this formulation is that a givenword can’t be considered as the main word of more than oneevent. This increases the readability of events for the fol-lowing reason. The bigger the number of events that can bedescribed by a given word, the less specific to each eventthis word is. Therefore, this word should rather be consid-ered as a related word than the main word. We solve thisMCSS type of problem using the linear-time algorithm de-scribed in (Bentley 1984). Eventually, each event detectedfollowing this process is described by: (i) a main word t (ii)a period of time I and (iii) the magnitude of its impact overthe tweeting behavior of the users, Ma(t, I).
Selection of Words Describing Events
In order to limit information overload, we choose to boundthe number of words used to describe an event. This boundis a manually fixed parameter noted p.Identification of the candidate words The set of candidatewords for describing an event is the set of the words with thep highest co-occurrence counts with the main word t duringthe period of time I . The most relevant words are selectedamongst the candidates based on the similarity between theirtemporal dynamics and the dynamics of the main word dur-ing I . For that, we compute a weight wt0q for each candidateword t0q . We propose to estimate this weight from the time-series for N i
t and N it0q
with the correlation coefficient pro-posed in (Erdem, Ceyhan, and Varli 2012). This coefficient,primarily designed to analyze stock prices, has two desir-able properties for our application: (i) it is parameter-freeand (ii) there is no stationarity assumption for the validity ofthis coefficient, contrary to common coefficients, e.g. Pear-son’s coefficient. Erdem’s coefficient takes into account thelag difference of data points in order to better capture the di-rection of the co-variation of the two time-series over time.For the sake of conciseness, we directly give the formula forthe approximation of the coefficient, given words t, t0q and
2. The list is iterated through starting from the most influen-tial event. For each event, the second component selectsthe set S of words that best describe it. The selection relieson measures based on the co-occurrence and the tempo-ral dynamics of words tweeted during I . Each event pro-cessed by this component is then passed to the third com-ponent, which is responsible for storing event descrip-tions and managing duplicated events. Eventually, when kdistinct events have been processed, the third componentmerges duplicated events and returns the list L containingthe top k events.
Detection of Events Based on Mention AnomalyThe objective of this component is to precisely identifywhen events happened and to estimate the magnitude of theirimpact over the crowd. It relies on the identification of burstsbased on the computation of the anomaly in the frequency ofmention creation for each individual word in [email protected] of the anomaly at a point Before formu-lating the anomaly measure, we define the expected numberof mention creation associated to a word t for each time-slice i 2 [1;n]. We assume that the number of tweets thatcontain the word t and at least one mention in the ith time-slice, N i
@t, follows a generative probabilistic model. Thuswe can compute the probability P (N i
@t) of observing N i@t.
In (Fung et al. 2005), authors study word frequency in tex-tual streams and show that it is reasonable to model this kindof probability, if the corpus is large enough, with a bino-mial distribution; (Li, Sun, and Datta 2012) also employ thismodeling for tweet streams. Therefore we can write:
P (N i@t) =
✓N i
N i@t
◆pNi
@t@t (1� p@t)
Ni�Ni@t ,
where p@t is the expected probability of a tweet containingt and at least one mention in any time-slice. Because N i islarge we further assume that P (N i
@t) can be approximatedby a normal distribution, that is to say:
P (N i@t) ⇠ N (N ip@t, N
ip@t(1� p@t)).
It follows that the expected frequency of tweets containingthe word t and at least one mention in the ith time-slice isE[t|i] = N ip@t, with p@t = N@t/N . We then define theanomaly of the mention creation frequency related to theword t at the ith time-slice this way:
anomaly(t, i) = N i@t � E[t|i].
The anomaly is positive only if the observed mention cre-ation frequency is strictly greater than the expectation.Computation of the magnitude of impact The magnitudeof impact of an event associated with the time interval I =
[a; b] and the main word t is given by the formula below. Itcorresponds to the algebraic area of the anomaly function on[a; b].
Ma(t, I) =Z b
a
anomaly(t, i) di
=
bX
i=a
anomaly(t, i)
The algebraic area is obtained by integrating the discreteanomaly function, which in this case boils down to a sum.Identification of events For each word t 2 V@, we iden-tify the interval that maximizes the magnitude of impactby solving a “Maximum Contiguous Subsequence Sum”(MCSS) type of problem. The MCSS problem is well knownand finds application in many fields (Fukuda et al. 1996;Fan et al. 2003; Lappas et al. 2009). In other words, for agiven word t we want to identify the interval I = [a; b], suchthat:
Ma(t, I) = max{bX
i=a
anomaly(t, i)|1 6 a 6 b 6 n}.
This formulation permits the anomaly to be negative at somepoints in the interval, only if it permits extending the inter-val while increasing the total magnitude, which is a desirableproperty. More specifically, it avoids fragmenting events thatlast several days because of the lower activity on Twitter dur-ing the night, which can lead to low or negative anomaly.Another desirable property of this formulation is that a givenword can’t be considered as the main word of more than oneevent. This increases the readability of events for the fol-lowing reason. The bigger the number of events that can bedescribed by a given word, the less specific to each eventthis word is. Therefore, this word should rather be consid-ered as a related word than the main word. We solve thisMCSS type of problem using the linear-time algorithm de-scribed in (Bentley 1984). Eventually, each event detectedfollowing this process is described by: (i) a main word t (ii)a period of time I and (iii) the magnitude of its impact overthe tweeting behavior of the users, Ma(t, I).
Selection of Words Describing Events
In order to limit information overload, we choose to boundthe number of words used to describe an event. This boundis a manually fixed parameter noted p.Identification of the candidate words The set of candidatewords for describing an event is the set of the words with thep highest co-occurrence counts with the main word t duringthe period of time I . The most relevant words are selectedamongst the candidates based on the similarity between theirtemporal dynamics and the dynamics of the main word dur-ing I . For that, we compute a weight wt0q for each candidateword t0q . We propose to estimate this weight from the time-series for N i
t and N it0q
with the correlation coefficient pro-posed in (Erdem, Ceyhan, and Varli 2012). This coefficient,primarily designed to analyze stock prices, has two desir-able properties for our application: (i) it is parameter-freeand (ii) there is no stationarity assumption for the validity ofthis coefficient, contrary to common coefficients, e.g. Pear-son’s coefficient. Erdem’s coefficient takes into account thelag difference of data points in order to better capture the di-rection of the co-variation of the two time-series over time.For the sake of conciseness, we directly give the formula forthe approximation of the coefficient, given words t, t0q and
2. The list is iterated through starting from the most influen-tial event. For each event, the second component selectsthe set S of words that best describe it. The selection relieson measures based on the co-occurrence and the tempo-ral dynamics of words tweeted during I . Each event pro-cessed by this component is then passed to the third com-ponent, which is responsible for storing event descrip-tions and managing duplicated events. Eventually, when kdistinct events have been processed, the third componentmerges duplicated events and returns the list L containingthe top k events.
Detection of Events Based on Mention AnomalyThe objective of this component is to precisely identifywhen events happened and to estimate the magnitude of theirimpact over the crowd. It relies on the identification of burstsbased on the computation of the anomaly in the frequency ofmention creation for each individual word in [email protected] of the anomaly at a point Before formu-lating the anomaly measure, we define the expected numberof mention creation associated to a word t for each time-slice i 2 [1;n]. We assume that the number of tweets thatcontain the word t and at least one mention in the ith time-slice, N i
@t, follows a generative probabilistic model. Thuswe can compute the probability P (N i
@t) of observing N i@t.
In (Fung et al. 2005), authors study word frequency in tex-tual streams and show that it is reasonable to model this kindof probability, if the corpus is large enough, with a bino-mial distribution; (Li, Sun, and Datta 2012) also employ thismodeling for tweet streams. Therefore we can write:
P (N i@t) =
✓N i
N i@t
◆pNi
@t@t (1� p@t)
Ni�Ni@t ,
where p@t is the expected probability of a tweet containingt and at least one mention in any time-slice. Because N i islarge we further assume that P (N i
@t) can be approximatedby a normal distribution, that is to say:
P (N i@t) ⇠ N (N ip@t, N
ip@t(1� p@t)).
It follows that the expected frequency of tweets containingthe word t and at least one mention in the ith time-slice isE[t|i] = N ip@t, with p@t = N@t/N . We then define theanomaly of the mention creation frequency related to theword t at the ith time-slice this way:
anomaly(t, i) = N i@t � E[t|i].
The anomaly is positive only if the observed mention cre-ation frequency is strictly greater than the expectation.Computation of the magnitude of impact The magnitudeof impact of an event associated with the time interval I =
[a; b] and the main word t is given by the formula below. Itcorresponds to the algebraic area of the anomaly function on[a; b].
Ma(t, I) =Z b
a
anomaly(t, i) di
=
bX
i=a
anomaly(t, i)
The algebraic area is obtained by integrating the discreteanomaly function, which in this case boils down to a sum.Identification of events For each word t 2 V@, we iden-tify the interval that maximizes the magnitude of impactby solving a “Maximum Contiguous Subsequence Sum”(MCSS) type of problem. The MCSS problem is well knownand finds application in many fields (Fukuda et al. 1996;Fan et al. 2003; Lappas et al. 2009). In other words, for agiven word t we want to identify the interval I = [a; b], suchthat:
Ma(t, I) = max{bX
i=a
anomaly(t, i)|1 6 a 6 b 6 n}.
This formulation permits the anomaly to be negative at somepoints in the interval, only if it permits extending the inter-val while increasing the total magnitude, which is a desirableproperty. More specifically, it avoids fragmenting events thatlast several days because of the lower activity on Twitter dur-ing the night, which can lead to low or negative anomaly.Another desirable property of this formulation is that a givenword can’t be considered as the main word of more than oneevent. This increases the readability of events for the fol-lowing reason. The bigger the number of events that can bedescribed by a given word, the less specific to each eventthis word is. Therefore, this word should rather be consid-ered as a related word than the main word. We solve thisMCSS type of problem using the linear-time algorithm de-scribed in (Bentley 1984). Eventually, each event detectedfollowing this process is described by: (i) a main word t (ii)a period of time I and (iii) the magnitude of its impact overthe tweeting behavior of the users, Ma(t, I).
Selection of Words Describing Events
In order to limit information overload, we choose to boundthe number of words used to describe an event. This boundis a manually fixed parameter noted p.Identification of the candidate words The set of candidatewords for describing an event is the set of the words with thep highest co-occurrence counts with the main word t duringthe period of time I . The most relevant words are selectedamongst the candidates based on the similarity between theirtemporal dynamics and the dynamics of the main word dur-ing I . For that, we compute a weight wt0q for each candidateword t0q . We propose to estimate this weight from the time-series for N i
t and N it0q
with the correlation coefficient pro-posed in (Erdem, Ceyhan, and Varli 2012). This coefficient,primarily designed to analyze stock prices, has two desir-able properties for our application: (i) it is parameter-freeand (ii) there is no stationarity assumption for the validity ofthis coefficient, contrary to common coefficients, e.g. Pear-son’s coefficient. Erdem’s coefficient takes into account thelag difference of data points in order to better capture the di-rection of the co-variation of the two time-series over time.For the sake of conciseness, we directly give the formula forthe approximation of the coefficient, given words t, t0q and
2. The list is iterated through starting from the most influen-tial event. For each event, the second component selectsthe set S of words that best describe it. The selection relieson measures based on the co-occurrence and the tempo-ral dynamics of words tweeted during I . Each event pro-cessed by this component is then passed to the third com-ponent, which is responsible for storing event descrip-tions and managing duplicated events. Eventually, when kdistinct events have been processed, the third componentmerges duplicated events and returns the list L containingthe top k events.
Detection of Events Based on Mention AnomalyThe objective of this component is to precisely identifywhen events happened and to estimate the magnitude of theirimpact over the crowd. It relies on the identification of burstsbased on the computation of the anomaly in the frequency ofmention creation for each individual word in [email protected] of the anomaly at a point Before formu-lating the anomaly measure, we define the expected numberof mention creation associated to a word t for each time-slice i 2 [1;n]. We assume that the number of tweets thatcontain the word t and at least one mention in the ith time-slice, N i
@t, follows a generative probabilistic model. Thuswe can compute the probability P (N i
@t) of observing N i@t.
In (Fung et al. 2005), authors study word frequency in tex-tual streams and show that it is reasonable to model this kindof probability, if the corpus is large enough, with a bino-mial distribution; (Li, Sun, and Datta 2012) also employ thismodeling for tweet streams. Therefore we can write:
P (N i@t) =
✓N i
N i@t
◆pNi
@t@t (1� p@t)
Ni�Ni@t ,
where p@t is the expected probability of a tweet containingt and at least one mention in any time-slice. Because N i islarge we further assume that P (N i
@t) can be approximatedby a normal distribution, that is to say:
P (N i@t) ⇠ N (N ip@t, N
ip@t(1� p@t)).
It follows that the expected frequency of tweets containingthe word t and at least one mention in the ith time-slice isE[t|i] = N ip@t, with p@t = N@t/N . We then define theanomaly of the mention creation frequency related to theword t at the ith time-slice this way:
anomaly(t, i) = N i@t � E[t|i].
The anomaly is positive only if the observed mention cre-ation frequency is strictly greater than the expectation.Computation of the magnitude of impact The magnitudeof impact of an event associated with the time interval I =
[a; b] and the main word t is given by the formula below. Itcorresponds to the algebraic area of the anomaly function on[a; b].
Ma(t, I) =Z b
a
anomaly(t, i) di
=
bX
i=a
anomaly(t, i)
The algebraic area is obtained by integrating the discreteanomaly function, which in this case boils down to a sum.Identification of events For each word t 2 V@, we iden-tify the interval that maximizes the magnitude of impactby solving a “Maximum Contiguous Subsequence Sum”(MCSS) type of problem. The MCSS problem is well knownand finds application in many fields (Fukuda et al. 1996;Fan et al. 2003; Lappas et al. 2009). In other words, for agiven word t we want to identify the interval I = [a; b], suchthat:
Ma(t, I) = max{bX
i=a
anomaly(t, i)|1 6 a 6 b 6 n}.
This formulation permits the anomaly to be negative at somepoints in the interval, only if it permits extending the inter-val while increasing the total magnitude, which is a desirableproperty. More specifically, it avoids fragmenting events thatlast several days because of the lower activity on Twitter dur-ing the night, which can lead to low or negative anomaly.Another desirable property of this formulation is that a givenword can’t be considered as the main word of more than oneevent. This increases the readability of events for the fol-lowing reason. The bigger the number of events that can bedescribed by a given word, the less specific to each eventthis word is. Therefore, this word should rather be consid-ered as a related word than the main word. We solve thisMCSS type of problem using the linear-time algorithm de-scribed in (Bentley 1984). Eventually, each event detectedfollowing this process is described by: (i) a main word t (ii)a period of time I and (iii) the magnitude of its impact overthe tweeting behavior of the users, Ma(t, I).
Selection of Words Describing Events
In order to limit information overload, we choose to boundthe number of words used to describe an event. This boundis a manually fixed parameter noted p.Identification of the candidate words The set of candidatewords for describing an event is the set of the words with thep highest co-occurrence counts with the main word t duringthe period of time I . The most relevant words are selectedamongst the candidates based on the similarity between theirtemporal dynamics and the dynamics of the main word dur-ing I . For that, we compute a weight wt0q for each candidateword t0q . We propose to estimate this weight from the time-series for N i
t and N it0q
with the correlation coefficient pro-posed in (Erdem, Ceyhan, and Varli 2012). This coefficient,primarily designed to analyze stock prices, has two desir-able properties for our application: (i) it is parameter-freeand (ii) there is no stationarity assumption for the validity ofthis coefficient, contrary to common coefficients, e.g. Pear-son’s coefficient. Erdem’s coefficient takes into account thelag difference of data points in order to better capture the di-rection of the co-variation of the two time-series over time.For the sake of conciseness, we directly give the formula forthe approximation of the coefficient, given words t, t0q and
2. The list is iterated through starting from the most influen-tial event. For each event, the second component selectsthe set S of words that best describe it. The selection relieson measures based on the co-occurrence and the tempo-ral dynamics of words tweeted during I . Each event pro-cessed by this component is then passed to the third com-ponent, which is responsible for storing event descrip-tions and managing duplicated events. Eventually, when kdistinct events have been processed, the third componentmerges duplicated events and returns the list L containingthe top k events.
Detection of Events Based on Mention AnomalyThe objective of this component is to precisely identifywhen events happened and to estimate the magnitude of theirimpact over the crowd. It relies on the identification of burstsbased on the computation of the anomaly in the frequency ofmention creation for each individual word in [email protected] of the anomaly at a point Before formu-lating the anomaly measure, we define the expected numberof mention creation associated to a word t for each time-slice i 2 [1;n]. We assume that the number of tweets thatcontain the word t and at least one mention in the ith time-slice, N i
@t, follows a generative probabilistic model. Thuswe can compute the probability P (N i
@t) of observing N i@t.
In (Fung et al. 2005), authors study word frequency in tex-tual streams and show that it is reasonable to model this kindof probability, if the corpus is large enough, with a bino-mial distribution; (Li, Sun, and Datta 2012) also employ thismodeling for tweet streams. Therefore we can write:
P (N i@t) =
✓N i
N i@t
◆pNi
@t@t (1� p@t)
Ni�Ni@t ,
where p@t is the expected probability of a tweet containingt and at least one mention in any time-slice. Because N i islarge we further assume that P (N i
@t) can be approximatedby a normal distribution, that is to say:
P (N i@t) ⇠ N (N ip@t, N
ip@t(1� p@t)).
It follows that the expected frequency of tweets containingthe word t and at least one mention in the ith time-slice isE[t|i] = N ip@t, with p@t = N@t/N . We then define theanomaly of the mention creation frequency related to theword t at the ith time-slice this way:
anomaly(t, i) = N i@t � E[t|i].
The anomaly is positive only if the observed mention cre-ation frequency is strictly greater than the expectation.Computation of the magnitude of impact The magnitudeof impact of an event associated with the time interval I =
[a; b] and the main word t is given by the formula below. Itcorresponds to the algebraic area of the anomaly function on[a; b].
Ma(t, I) =Z b
a
anomaly(t, i) di
=
bX
i=a
anomaly(t, i)
The algebraic area is obtained by integrating the discreteanomaly function, which in this case boils down to a sum.Identification of events For each word t 2 V@, we iden-tify the interval that maximizes the magnitude of impactby solving a “Maximum Contiguous Subsequence Sum”(MCSS) type of problem. The MCSS problem is well knownand finds application in many fields (Fukuda et al. 1996;Fan et al. 2003; Lappas et al. 2009). In other words, for agiven word t we want to identify the interval I = [a; b], suchthat:
Ma(t, I) = max{bX
i=a
anomaly(t, i)|1 6 a 6 b 6 n}.
This formulation permits the anomaly to be negative at somepoints in the interval, only if it permits extending the inter-val while increasing the total magnitude, which is a desirableproperty. More specifically, it avoids fragmenting events thatlast several days because of the lower activity on Twitter dur-ing the night, which can lead to low or negative anomaly.Another desirable property of this formulation is that a givenword can’t be considered as the main word of more than oneevent. This increases the readability of events for the fol-lowing reason. The bigger the number of events that can bedescribed by a given word, the less specific to each eventthis word is. Therefore, this word should rather be consid-ered as a related word than the main word. We solve thisMCSS type of problem using the linear-time algorithm de-scribed in (Bentley 1984). Eventually, each event detectedfollowing this process is described by: (i) a main word t (ii)a period of time I and (iii) the magnitude of its impact overthe tweeting behavior of the users, Ma(t, I).
Selection of Words Describing Events
In order to limit information overload, we choose to boundthe number of words used to describe an event. This boundis a manually fixed parameter noted p.Identification of the candidate words The set of candidatewords for describing an event is the set of the words with thep highest co-occurrence counts with the main word t duringthe period of time I . The most relevant words are selectedamongst the candidates based on the similarity between theirtemporal dynamics and the dynamics of the main word dur-ing I . For that, we compute a weight wt0q for each candidateword t0q . We propose to estimate this weight from the time-series for N i
t and N it0q
with the correlation coefficient pro-posed in (Erdem, Ceyhan, and Varli 2012). This coefficient,primarily designed to analyze stock prices, has two desir-able properties for our application: (i) it is parameter-freeand (ii) there is no stationarity assumption for the validity ofthis coefficient, contrary to common coefficients, e.g. Pear-son’s coefficient. Erdem’s coefficient takes into account thelag difference of data points in order to better capture the di-rection of the co-variation of the two time-series over time.For the sake of conciseness, we directly give the formula forthe approximation of the coefficient, given words t, t0q and
On peut modéliser la probabilité d’observer avec la loi binomiale :
2. The list is iterated through starting from the most influen-tial event. For each event, the second component selectsthe set S of words that best describe it. The selection relieson measures based on the co-occurrence and the tempo-ral dynamics of words tweeted during I . Each event pro-cessed by this component is then passed to the third com-ponent, which is responsible for storing event descrip-tions and managing duplicated events. Eventually, when kdistinct events have been processed, the third componentmerges duplicated events and returns the list L containingthe top k events.
Detection of Events Based on Mention AnomalyThe objective of this component is to precisely identifywhen events happened and to estimate the magnitude of theirimpact over the crowd. It relies on the identification of burstsbased on the computation of the anomaly in the frequency ofmention creation for each individual word in [email protected] of the anomaly at a point Before formu-lating the anomaly measure, we define the expected numberof mention creation associated to a word t for each time-slice i 2 [1;n]. We assume that the number of tweets thatcontain the word t and at least one mention in the ith time-slice, N i
@t, follows a generative probabilistic model. Thuswe can compute the probability P (N i
@t) of observing N i@t.
In (Fung et al. 2005), authors study word frequency in tex-tual streams and show that it is reasonable to model this kindof probability, if the corpus is large enough, with a bino-mial distribution; (Li, Sun, and Datta 2012) also employ thismodeling for tweet streams. Therefore we can write:
P (N i@t) =
✓N i
N i@t
◆pNi
@t@t (1� p@t)
Ni�Ni@t ,
where p@t is the expected probability of a tweet containingt and at least one mention in any time-slice. Because N i islarge we further assume that P (N i
@t) can be approximatedby a normal distribution, that is to say:
P (N i@t) ⇠ N (N ip@t, N
ip@t(1� p@t)).
It follows that the expected frequency of tweets containingthe word t and at least one mention in the ith time-slice isE[t|i] = N ip@t, with p@t = N@t/N . We then define theanomaly of the mention creation frequency related to theword t at the ith time-slice this way:
anomaly(t, i) = N i@t � E[t|i].
The anomaly is positive only if the observed mention cre-ation frequency is strictly greater than the expectation.Computation of the magnitude of impact The magnitudeof impact of an event associated with the time interval I =
[a; b] and the main word t is given by the formula below. Itcorresponds to the algebraic area of the anomaly function on[a; b].
Ma(t, I) =Z b
a
anomaly(t, i) di
=
bX
i=a
anomaly(t, i)
The algebraic area is obtained by integrating the discreteanomaly function, which in this case boils down to a sum.Identification of events For each word t 2 V@, we iden-tify the interval that maximizes the magnitude of impactby solving a “Maximum Contiguous Subsequence Sum”(MCSS) type of problem. The MCSS problem is well knownand finds application in many fields (Fukuda et al. 1996;Fan et al. 2003; Lappas et al. 2009). In other words, for agiven word t we want to identify the interval I = [a; b], suchthat:
Ma(t, I) = max{bX
i=a
anomaly(t, i)|1 6 a 6 b 6 n}.
This formulation permits the anomaly to be negative at somepoints in the interval, only if it permits extending the inter-val while increasing the total magnitude, which is a desirableproperty. More specifically, it avoids fragmenting events thatlast several days because of the lower activity on Twitter dur-ing the night, which can lead to low or negative anomaly.Another desirable property of this formulation is that a givenword can’t be considered as the main word of more than oneevent. This increases the readability of events for the fol-lowing reason. The bigger the number of events that can bedescribed by a given word, the less specific to each eventthis word is. Therefore, this word should rather be consid-ered as a related word than the main word. We solve thisMCSS type of problem using the linear-time algorithm de-scribed in (Bentley 1984). Eventually, each event detectedfollowing this process is described by: (i) a main word t (ii)a period of time I and (iii) the magnitude of its impact overthe tweeting behavior of the users, Ma(t, I).
Selection of Words Describing Events
In order to limit information overload, we choose to boundthe number of words used to describe an event. This boundis a manually fixed parameter noted p.Identification of the candidate words The set of candidatewords for describing an event is the set of the words with thep highest co-occurrence counts with the main word t duringthe period of time I . The most relevant words are selectedamongst the candidates based on the similarity between theirtemporal dynamics and the dynamics of the main word dur-ing I . For that, we compute a weight wt0q for each candidateword t0q . We propose to estimate this weight from the time-series for N i
t and N it0q
with the correlation coefficient pro-posed in (Erdem, Ceyhan, and Varli 2012). This coefficient,primarily designed to analyze stock prices, has two desir-able properties for our application: (i) it is parameter-freeand (ii) there is no stationarity assumption for the validity ofthis coefficient, contrary to common coefficients, e.g. Pear-son’s coefficient. Erdem’s coefficient takes into account thelag difference of data points in order to better capture the di-rection of the co-variation of the two time-series over time.For the sake of conciseness, we directly give the formula forthe approximation of the coefficient, given words t, t0q and
2. The list is iterated through starting from the most influen-tial event. For each event, the second component selectsthe set S of words that best describe it. The selection relieson measures based on the co-occurrence and the tempo-ral dynamics of words tweeted during I . Each event pro-cessed by this component is then passed to the third com-ponent, which is responsible for storing event descrip-tions and managing duplicated events. Eventually, when kdistinct events have been processed, the third componentmerges duplicated events and returns the list L containingthe top k events.
Detection of Events Based on Mention AnomalyThe objective of this component is to precisely identifywhen events happened and to estimate the magnitude of theirimpact over the crowd. It relies on the identification of burstsbased on the computation of the anomaly in the frequency ofmention creation for each individual word in [email protected] of the anomaly at a point Before formu-lating the anomaly measure, we define the expected numberof mention creation associated to a word t for each time-slice i 2 [1;n]. We assume that the number of tweets thatcontain the word t and at least one mention in the ith time-slice, N i
@t, follows a generative probabilistic model. Thuswe can compute the probability P (N i
@t) of observing N i@t.
In (Fung et al. 2005), authors study word frequency in tex-tual streams and show that it is reasonable to model this kindof probability, if the corpus is large enough, with a bino-mial distribution; (Li, Sun, and Datta 2012) also employ thismodeling for tweet streams. Therefore we can write:
P (N i@t) =
✓N i
N i@t
◆pNi
@t@t (1� p@t)
Ni�Ni@t ,
where p@t is the expected probability of a tweet containingt and at least one mention in any time-slice. Because N i islarge we further assume that P (N i
@t) can be approximatedby a normal distribution, that is to say:
P (N i@t) ⇠ N (N ip@t, N
ip@t(1� p@t)).
It follows that the expected frequency of tweets containingthe word t and at least one mention in the ith time-slice isE[t|i] = N ip@t, with p@t = N@t/N . We then define theanomaly of the mention creation frequency related to theword t at the ith time-slice this way:
anomaly(t, i) = N i@t � E[t|i].
The anomaly is positive only if the observed mention cre-ation frequency is strictly greater than the expectation.Computation of the magnitude of impact The magnitudeof impact of an event associated with the time interval I =
[a; b] and the main word t is given by the formula below. Itcorresponds to the algebraic area of the anomaly function on[a; b].
Ma(t, I) =Z b
a
anomaly(t, i) di
=
bX
i=a
anomaly(t, i)
The algebraic area is obtained by integrating the discreteanomaly function, which in this case boils down to a sum.Identification of events For each word t 2 V@, we iden-tify the interval that maximizes the magnitude of impactby solving a “Maximum Contiguous Subsequence Sum”(MCSS) type of problem. The MCSS problem is well knownand finds application in many fields (Fukuda et al. 1996;Fan et al. 2003; Lappas et al. 2009). In other words, for agiven word t we want to identify the interval I = [a; b], suchthat:
Ma(t, I) = max{bX
i=a
anomaly(t, i)|1 6 a 6 b 6 n}.
This formulation permits the anomaly to be negative at somepoints in the interval, only if it permits extending the inter-val while increasing the total magnitude, which is a desirableproperty. More specifically, it avoids fragmenting events thatlast several days because of the lower activity on Twitter dur-ing the night, which can lead to low or negative anomaly.Another desirable property of this formulation is that a givenword can’t be considered as the main word of more than oneevent. This increases the readability of events for the fol-lowing reason. The bigger the number of events that can bedescribed by a given word, the less specific to each eventthis word is. Therefore, this word should rather be consid-ered as a related word than the main word. We solve thisMCSS type of problem using the linear-time algorithm de-scribed in (Bentley 1984). Eventually, each event detectedfollowing this process is described by: (i) a main word t (ii)a period of time I and (iii) the magnitude of its impact overthe tweeting behavior of the users, Ma(t, I).
Selection of Words Describing Events
In order to limit information overload, we choose to boundthe number of words used to describe an event. This boundis a manually fixed parameter noted p.Identification of the candidate words The set of candidatewords for describing an event is the set of the words with thep highest co-occurrence counts with the main word t duringthe period of time I . The most relevant words are selectedamongst the candidates based on the similarity between theirtemporal dynamics and the dynamics of the main word dur-ing I . For that, we compute a weight wt0q for each candidateword t0q . We propose to estimate this weight from the time-series for N i
t and N it0q
with the correlation coefficient pro-posed in (Erdem, Ceyhan, and Varli 2012). This coefficient,primarily designed to analyze stock prices, has two desir-able properties for our application: (i) it is parameter-freeand (ii) there is no stationarity assumption for the validity ofthis coefficient, contrary to common coefficients, e.g. Pear-son’s coefficient. Erdem’s coefficient takes into account thelag difference of data points in order to better capture the di-rection of the co-variation of the two time-series over time.For the sake of conciseness, we directly give the formula forthe approximation of the coefficient, given words t, t0q and
Comme est très grand, on suppose que peut être approximée par la loi normale suivante :
2. The list is iterated through starting from the most influen-tial event. For each event, the second component selectsthe set S of words that best describe it. The selection relieson measures based on the co-occurrence and the tempo-ral dynamics of words tweeted during I . Each event pro-cessed by this component is then passed to the third com-ponent, which is responsible for storing event descrip-tions and managing duplicated events. Eventually, when kdistinct events have been processed, the third componentmerges duplicated events and returns the list L containingthe top k events.
Detection of Events Based on Mention AnomalyThe objective of this component is to precisely identifywhen events happened and to estimate the magnitude of theirimpact over the crowd. It relies on the identification of burstsbased on the computation of the anomaly in the frequency ofmention creation for each individual word in [email protected] of the anomaly at a point Before formu-lating the anomaly measure, we define the expected numberof mention creation associated to a word t for each time-slice i 2 [1;n]. We assume that the number of tweets thatcontain the word t and at least one mention in the ith time-slice, N i
@t, follows a generative probabilistic model. Thuswe can compute the probability P (N i
@t) of observing N i@t.
In (Fung et al. 2005), authors study word frequency in tex-tual streams and show that it is reasonable to model this kindof probability, if the corpus is large enough, with a bino-mial distribution; (Li, Sun, and Datta 2012) also employ thismodeling for tweet streams. Therefore we can write:
P (N i@t) =
✓N i
N i@t
◆pNi
@t@t (1� p@t)
Ni�Ni@t ,
where p@t is the expected probability of a tweet containingt and at least one mention in any time-slice. Because N i islarge we further assume that P (N i
@t) can be approximatedby a normal distribution, that is to say:
P (N i@t) ⇠ N (N ip@t, N
ip@t(1� p@t)).
It follows that the expected frequency of tweets containingthe word t and at least one mention in the ith time-slice isE[t|i] = N ip@t, with p@t = N@t/N . We then define theanomaly of the mention creation frequency related to theword t at the ith time-slice this way:
anomaly(t, i) = N i@t � E[t|i].
The anomaly is positive only if the observed mention cre-ation frequency is strictly greater than the expectation.Computation of the magnitude of impact The magnitudeof impact of an event associated with the time interval I =
[a; b] and the main word t is given by the formula below. Itcorresponds to the algebraic area of the anomaly function on[a; b].
Ma(t, I) =Z b
a
anomaly(t, i) di
=
bX
i=a
anomaly(t, i)
The algebraic area is obtained by integrating the discreteanomaly function, which in this case boils down to a sum.Identification of events For each word t 2 V@, we iden-tify the interval that maximizes the magnitude of impactby solving a “Maximum Contiguous Subsequence Sum”(MCSS) type of problem. The MCSS problem is well knownand finds application in many fields (Fukuda et al. 1996;Fan et al. 2003; Lappas et al. 2009). In other words, for agiven word t we want to identify the interval I = [a; b], suchthat:
Ma(t, I) = max{bX
i=a
anomaly(t, i)|1 6 a 6 b 6 n}.
This formulation permits the anomaly to be negative at somepoints in the interval, only if it permits extending the inter-val while increasing the total magnitude, which is a desirableproperty. More specifically, it avoids fragmenting events thatlast several days because of the lower activity on Twitter dur-ing the night, which can lead to low or negative anomaly.Another desirable property of this formulation is that a givenword can’t be considered as the main word of more than oneevent. This increases the readability of events for the fol-lowing reason. The bigger the number of events that can bedescribed by a given word, the less specific to each eventthis word is. Therefore, this word should rather be consid-ered as a related word than the main word. We solve thisMCSS type of problem using the linear-time algorithm de-scribed in (Bentley 1984). Eventually, each event detectedfollowing this process is described by: (i) a main word t (ii)a period of time I and (iii) the magnitude of its impact overthe tweeting behavior of the users, Ma(t, I).
Selection of Words Describing Events
In order to limit information overload, we choose to boundthe number of words used to describe an event. This boundis a manually fixed parameter noted p.Identification of the candidate words The set of candidatewords for describing an event is the set of the words with thep highest co-occurrence counts with the main word t duringthe period of time I . The most relevant words are selectedamongst the candidates based on the similarity between theirtemporal dynamics and the dynamics of the main word dur-ing I . For that, we compute a weight wt0q for each candidateword t0q . We propose to estimate this weight from the time-series for N i
t and N it0q
with the correlation coefficient pro-posed in (Erdem, Ceyhan, and Varli 2012). This coefficient,primarily designed to analyze stock prices, has two desir-able properties for our application: (i) it is parameter-freeand (ii) there is no stationarity assumption for the validity ofthis coefficient, contrary to common coefficients, e.g. Pear-son’s coefficient. Erdem’s coefficient takes into account thelag difference of data points in order to better capture the di-rection of the co-variation of the two time-series over time.For the sake of conciseness, we directly give the formula forthe approximation of the coefficient, given words t, t0q and
2. The list is iterated through starting from the most influen-tial event. For each event, the second component selectsthe set S of words that best describe it. The selection relieson measures based on the co-occurrence and the tempo-ral dynamics of words tweeted during I . Each event pro-cessed by this component is then passed to the third com-ponent, which is responsible for storing event descrip-tions and managing duplicated events. Eventually, when kdistinct events have been processed, the third componentmerges duplicated events and returns the list L containingthe top k events.
Detection of Events Based on Mention AnomalyThe objective of this component is to precisely identifywhen events happened and to estimate the magnitude of theirimpact over the crowd. It relies on the identification of burstsbased on the computation of the anomaly in the frequency ofmention creation for each individual word in [email protected] of the anomaly at a point Before formu-lating the anomaly measure, we define the expected numberof mention creation associated to a word t for each time-slice i 2 [1;n]. We assume that the number of tweets thatcontain the word t and at least one mention in the ith time-slice, N i
@t, follows a generative probabilistic model. Thuswe can compute the probability P (N i
@t) of observing N i@t.
In (Fung et al. 2005), authors study word frequency in tex-tual streams and show that it is reasonable to model this kindof probability, if the corpus is large enough, with a bino-mial distribution; (Li, Sun, and Datta 2012) also employ thismodeling for tweet streams. Therefore we can write:
P (N i@t) =
✓N i
N i@t
◆pNi
@t@t (1� p@t)
Ni�Ni@t ,
where p@t is the expected probability of a tweet containingt and at least one mention in any time-slice. Because N i islarge we further assume that P (N i
@t) can be approximatedby a normal distribution, that is to say:
P (N i@t) ⇠ N (N ip@t, N
ip@t(1� p@t)).
It follows that the expected frequency of tweets containingthe word t and at least one mention in the ith time-slice isE[t|i] = N ip@t, with p@t = N@t/N . We then define theanomaly of the mention creation frequency related to theword t at the ith time-slice this way:
anomaly(t, i) = N i@t � E[t|i].
The anomaly is positive only if the observed mention cre-ation frequency is strictly greater than the expectation.Computation of the magnitude of impact The magnitudeof impact of an event associated with the time interval I =
[a; b] and the main word t is given by the formula below. Itcorresponds to the algebraic area of the anomaly function on[a; b].
Ma(t, I) =Z b
a
anomaly(t, i) di
=
bX
i=a
anomaly(t, i)
The algebraic area is obtained by integrating the discreteanomaly function, which in this case boils down to a sum.Identification of events For each word t 2 V@, we iden-tify the interval that maximizes the magnitude of impactby solving a “Maximum Contiguous Subsequence Sum”(MCSS) type of problem. The MCSS problem is well knownand finds application in many fields (Fukuda et al. 1996;Fan et al. 2003; Lappas et al. 2009). In other words, for agiven word t we want to identify the interval I = [a; b], suchthat:
Ma(t, I) = max{bX
i=a
anomaly(t, i)|1 6 a 6 b 6 n}.
This formulation permits the anomaly to be negative at somepoints in the interval, only if it permits extending the inter-val while increasing the total magnitude, which is a desirableproperty. More specifically, it avoids fragmenting events thatlast several days because of the lower activity on Twitter dur-ing the night, which can lead to low or negative anomaly.Another desirable property of this formulation is that a givenword can’t be considered as the main word of more than oneevent. This increases the readability of events for the fol-lowing reason. The bigger the number of events that can bedescribed by a given word, the less specific to each eventthis word is. Therefore, this word should rather be consid-ered as a related word than the main word. We solve thisMCSS type of problem using the linear-time algorithm de-scribed in (Bentley 1984). Eventually, each event detectedfollowing this process is described by: (i) a main word t (ii)a period of time I and (iii) the magnitude of its impact overthe tweeting behavior of the users, Ma(t, I).
Selection of Words Describing Events
In order to limit information overload, we choose to boundthe number of words used to describe an event. This boundis a manually fixed parameter noted p.Identification of the candidate words The set of candidatewords for describing an event is the set of the words with thep highest co-occurrence counts with the main word t duringthe period of time I . The most relevant words are selectedamongst the candidates based on the similarity between theirtemporal dynamics and the dynamics of the main word dur-ing I . For that, we compute a weight wt0q for each candidateword t0q . We propose to estimate this weight from the time-series for N i
t and N it0q
with the correlation coefficient pro-posed in (Erdem, Ceyhan, and Varli 2012). This coefficient,primarily designed to analyze stock prices, has two desir-able properties for our application: (i) it is parameter-freeand (ii) there is no stationarity assumption for the validity ofthis coefficient, contrary to common coefficients, e.g. Pear-son’s coefficient. Erdem’s coefficient takes into account thelag difference of data points in order to better capture the di-rection of the co-variation of the two time-series over time.For the sake of conciseness, we directly give the formula forthe approximation of the coefficient, given words t, t0q and
Comme est très grand, on suppose que peut être approximée par la loi normale suivante :
On définit alors la quantité «attendue» de tweets contenant au moins une mention et le mot t à la i ème tranche temporelle :
avec , la probabilité que n’importe quel tweet contienne au moins une mention et le mot t
2. The list is iterated through starting from the most influen-tial event. For each event, the second component selectsthe set S of words that best describe it. The selection relieson measures based on the co-occurrence and the tempo-ral dynamics of words tweeted during I . Each event pro-cessed by this component is then passed to the third com-ponent, which is responsible for storing event descrip-tions and managing duplicated events. Eventually, when kdistinct events have been processed, the third componentmerges duplicated events and returns the list L containingthe top k events.
Detection of Events Based on Mention AnomalyThe objective of this component is to precisely identifywhen events happened and to estimate the magnitude of theirimpact over the crowd. It relies on the identification of burstsbased on the computation of the anomaly in the frequency ofmention creation for each individual word in [email protected] of the anomaly at a point Before formu-lating the anomaly measure, we define the expected numberof mention creation associated to a word t for each time-slice i 2 [1;n]. We assume that the number of tweets thatcontain the word t and at least one mention in the ith time-slice, N i
@t, follows a generative probabilistic model. Thuswe can compute the probability P (N i
@t) of observing N i@t.
In (Fung et al. 2005), authors study word frequency in tex-tual streams and show that it is reasonable to model this kindof probability, if the corpus is large enough, with a bino-mial distribution; (Li, Sun, and Datta 2012) also employ thismodeling for tweet streams. Therefore we can write:
P (N i@t) =
✓N i
N i@t
◆pNi
@t@t (1� p@t)
Ni�Ni@t ,
where p@t is the expected probability of a tweet containingt and at least one mention in any time-slice. Because N i islarge we further assume that P (N i
@t) can be approximatedby a normal distribution, that is to say:
P (N i@t) ⇠ N (N ip@t, N
ip@t(1� p@t)).
It follows that the expected frequency of tweets containingthe word t and at least one mention in the ith time-slice isE[t|i] = N ip@t, with p@t = N@t/N . We then define theanomaly of the mention creation frequency related to theword t at the ith time-slice this way:
anomaly(t, i) = N i@t � E[t|i].
The anomaly is positive only if the observed mention cre-ation frequency is strictly greater than the expectation.Computation of the magnitude of impact The magnitudeof impact of an event associated with the time interval I =
[a; b] and the main word t is given by the formula below. Itcorresponds to the algebraic area of the anomaly function on[a; b].
Ma(t, I) =Z b
a
anomaly(t, i) di
=
bX
i=a
anomaly(t, i)
The algebraic area is obtained by integrating the discreteanomaly function, which in this case boils down to a sum.Identification of events For each word t 2 V@, we iden-tify the interval that maximizes the magnitude of impactby solving a “Maximum Contiguous Subsequence Sum”(MCSS) type of problem. The MCSS problem is well knownand finds application in many fields (Fukuda et al. 1996;Fan et al. 2003; Lappas et al. 2009). In other words, for agiven word t we want to identify the interval I = [a; b], suchthat:
Ma(t, I) = max{bX
i=a
anomaly(t, i)|1 6 a 6 b 6 n}.
This formulation permits the anomaly to be negative at somepoints in the interval, only if it permits extending the inter-val while increasing the total magnitude, which is a desirableproperty. More specifically, it avoids fragmenting events thatlast several days because of the lower activity on Twitter dur-ing the night, which can lead to low or negative anomaly.Another desirable property of this formulation is that a givenword can’t be considered as the main word of more than oneevent. This increases the readability of events for the fol-lowing reason. The bigger the number of events that can bedescribed by a given word, the less specific to each eventthis word is. Therefore, this word should rather be consid-ered as a related word than the main word. We solve thisMCSS type of problem using the linear-time algorithm de-scribed in (Bentley 1984). Eventually, each event detectedfollowing this process is described by: (i) a main word t (ii)a period of time I and (iii) the magnitude of its impact overthe tweeting behavior of the users, Ma(t, I).
Selection of Words Describing Events
In order to limit information overload, we choose to boundthe number of words used to describe an event. This boundis a manually fixed parameter noted p.Identification of the candidate words The set of candidatewords for describing an event is the set of the words with thep highest co-occurrence counts with the main word t duringthe period of time I . The most relevant words are selectedamongst the candidates based on the similarity between theirtemporal dynamics and the dynamics of the main word dur-ing I . For that, we compute a weight wt0q for each candidateword t0q . We propose to estimate this weight from the time-series for N i
t and N it0q
with the correlation coefficient pro-posed in (Erdem, Ceyhan, and Varli 2012). This coefficient,primarily designed to analyze stock prices, has two desir-able properties for our application: (i) it is parameter-freeand (ii) there is no stationarity assumption for the validity ofthis coefficient, contrary to common coefficients, e.g. Pear-son’s coefficient. Erdem’s coefficient takes into account thelag difference of data points in order to better capture the di-rection of the co-variation of the two time-series over time.For the sake of conciseness, we directly give the formula forthe approximation of the coefficient, given words t, t0q and
sur 14

PAGE: Rennes, 30 janvier 2014 - Adrien Guille
ERIC LABUniversité Lumière Lyon 2, France
Détecter les évènements à partir de l’anomalie dans la fréquence de création de mentions
7
• Anomalie en un point• Pour le mot t à la i ème tranche temporelle
•
• Magnitude d’impact d’un évènement• Pour un évènement décrit par le mot principal t et l’intervalle temporel I = [a;b]
•
Détection d’évènements sur TwitterConférence EGC 2014
2. The list is iterated through starting from the most influen-tial event. For each event, the second component selectsthe set S of words that best describe it. The selection relieson measures based on the co-occurrence and the tempo-ral dynamics of words tweeted during I . Each event pro-cessed by this component is then passed to the third com-ponent, which is responsible for storing event descrip-tions and managing duplicated events. Eventually, when kdistinct events have been processed, the third componentmerges duplicated events and returns the list L containingthe top k events.
Detection of Events Based on Mention AnomalyThe objective of this component is to precisely identifywhen events happened and to estimate the magnitude of theirimpact over the crowd. It relies on the identification of burstsbased on the computation of the anomaly in the frequency ofmention creation for each individual word in [email protected] of the anomaly at a point Before formu-lating the anomaly measure, we define the expected numberof mention creation associated to a word t for each time-slice i 2 [1;n]. We assume that the number of tweets thatcontain the word t and at least one mention in the ith time-slice, N i
@t, follows a generative probabilistic model. Thuswe can compute the probability P (N i
@t) of observing N i@t.
In (Fung et al. 2005), authors study word frequency in tex-tual streams and show that it is reasonable to model this kindof probability, if the corpus is large enough, with a bino-mial distribution; (Li, Sun, and Datta 2012) also employ thismodeling for tweet streams. Therefore we can write:
P (N i@t) =
✓N i
N i@t
◆pNi
@t@t (1� p@t)
Ni�Ni@t ,
where p@t is the expected probability of a tweet containingt and at least one mention in any time-slice. Because N i islarge we further assume that P (N i
@t) can be approximatedby a normal distribution, that is to say:
P (N i@t) ⇠ N (N ip@t, N
ip@t(1� p@t)).
It follows that the expected frequency of tweets containingthe word t and at least one mention in the ith time-slice isE[t|i] = N ip@t, with p@t = N@t/N . We then define theanomaly of the mention creation frequency related to theword t at the ith time-slice this way:
anomaly(t, i) = N i@t � E[t|i].
The anomaly is positive only if the observed mention cre-ation frequency is strictly greater than the expectation.Computation of the magnitude of impact The magnitudeof impact of an event associated with the time interval I =
[a; b] and the main word t is given by the formula below. Itcorresponds to the algebraic area of the anomaly function on[a; b].
Ma(t, I) =Z b
a
anomaly(t, i) di
=
bX
i=a
anomaly(t, i)
The algebraic area is obtained by integrating the discreteanomaly function, which in this case boils down to a sum.Identification of events For each word t 2 V@, we iden-tify the interval that maximizes the magnitude of impactby solving a “Maximum Contiguous Subsequence Sum”(MCSS) type of problem. The MCSS problem is well knownand finds application in many fields (Fukuda et al. 1996;Fan et al. 2003; Lappas et al. 2009). In other words, for agiven word t we want to identify the interval I = [a; b], suchthat:
Ma(t, I) = max{bX
i=a
anomaly(t, i)|1 6 a 6 b 6 n}.
This formulation permits the anomaly to be negative at somepoints in the interval, only if it permits extending the inter-val while increasing the total magnitude, which is a desirableproperty. More specifically, it avoids fragmenting events thatlast several days because of the lower activity on Twitter dur-ing the night, which can lead to low or negative anomaly.Another desirable property of this formulation is that a givenword can’t be considered as the main word of more than oneevent. This increases the readability of events for the fol-lowing reason. The bigger the number of events that can bedescribed by a given word, the less specific to each eventthis word is. Therefore, this word should rather be consid-ered as a related word than the main word. We solve thisMCSS type of problem using the linear-time algorithm de-scribed in (Bentley 1984). Eventually, each event detectedfollowing this process is described by: (i) a main word t (ii)a period of time I and (iii) the magnitude of its impact overthe tweeting behavior of the users, Ma(t, I).
Selection of Words Describing Events
In order to limit information overload, we choose to boundthe number of words used to describe an event. This boundis a manually fixed parameter noted p.Identification of the candidate words The set of candidatewords for describing an event is the set of the words with thep highest co-occurrence counts with the main word t duringthe period of time I . The most relevant words are selectedamongst the candidates based on the similarity between theirtemporal dynamics and the dynamics of the main word dur-ing I . For that, we compute a weight wt0q for each candidateword t0q . We propose to estimate this weight from the time-series for N i
t and N it0q
with the correlation coefficient pro-posed in (Erdem, Ceyhan, and Varli 2012). This coefficient,primarily designed to analyze stock prices, has two desir-able properties for our application: (i) it is parameter-freeand (ii) there is no stationarity assumption for the validity ofthis coefficient, contrary to common coefficients, e.g. Pear-son’s coefficient. Erdem’s coefficient takes into account thelag difference of data points in order to better capture the di-rection of the co-variation of the two time-series over time.For the sake of conciseness, we directly give the formula forthe approximation of the coefficient, given words t, t0q and
2. The list is iterated through starting from the most influen-tial event. For each event, the second component selectsthe set S of words that best describe it. The selection relieson measures based on the co-occurrence and the tempo-ral dynamics of words tweeted during I . Each event pro-cessed by this component is then passed to the third com-ponent, which is responsible for storing event descrip-tions and managing duplicated events. Eventually, when kdistinct events have been processed, the third componentmerges duplicated events and returns the list L containingthe top k events.
Detection of Events Based on Mention AnomalyThe objective of this component is to precisely identifywhen events happened and to estimate the magnitude of theirimpact over the crowd. It relies on the identification of burstsbased on the computation of the anomaly in the frequency ofmention creation for each individual word in [email protected] of the anomaly at a point Before formu-lating the anomaly measure, we define the expected numberof mention creation associated to a word t for each time-slice i 2 [1;n]. We assume that the number of tweets thatcontain the word t and at least one mention in the ith time-slice, N i
@t, follows a generative probabilistic model. Thuswe can compute the probability P (N i
@t) of observing N i@t.
In (Fung et al. 2005), authors study word frequency in tex-tual streams and show that it is reasonable to model this kindof probability, if the corpus is large enough, with a bino-mial distribution; (Li, Sun, and Datta 2012) also employ thismodeling for tweet streams. Therefore we can write:
P (N i@t) =
✓N i
N i@t
◆pNi
@t@t (1� p@t)
Ni�Ni@t ,
where p@t is the expected probability of a tweet containingt and at least one mention in any time-slice. Because N i islarge we further assume that P (N i
@t) can be approximatedby a normal distribution, that is to say:
P (N i@t) ⇠ N (N ip@t, N
ip@t(1� p@t)).
It follows that the expected frequency of tweets containingthe word t and at least one mention in the ith time-slice isE[t|i] = N ip@t, with p@t = N@t/N . We then define theanomaly of the mention creation frequency related to theword t at the ith time-slice this way:
anomaly(t, i) = N i@t � E[t|i].
The anomaly is positive only if the observed mention cre-ation frequency is strictly greater than the expectation.Computation of the magnitude of impact The magnitudeof impact of an event associated with the time interval I =
[a; b] and the main word t is given by the formula below. Itcorresponds to the algebraic area of the anomaly function on[a; b].
Ma(t, I) =Z b
a
anomaly(t, i) di
=
bX
i=a
anomaly(t, i)
The algebraic area is obtained by integrating the discreteanomaly function, which in this case boils down to a sum.Identification of events For each word t 2 V@, we iden-tify the interval that maximizes the magnitude of impactby solving a “Maximum Contiguous Subsequence Sum”(MCSS) type of problem. The MCSS problem is well knownand finds application in many fields (Fukuda et al. 1996;Fan et al. 2003; Lappas et al. 2009). In other words, for agiven word t we want to identify the interval I = [a; b], suchthat:
Ma(t, I) = max{bX
i=a
anomaly(t, i)|1 6 a 6 b 6 n}.
This formulation permits the anomaly to be negative at somepoints in the interval, only if it permits extending the inter-val while increasing the total magnitude, which is a desirableproperty. More specifically, it avoids fragmenting events thatlast several days because of the lower activity on Twitter dur-ing the night, which can lead to low or negative anomaly.Another desirable property of this formulation is that a givenword can’t be considered as the main word of more than oneevent. This increases the readability of events for the fol-lowing reason. The bigger the number of events that can bedescribed by a given word, the less specific to each eventthis word is. Therefore, this word should rather be consid-ered as a related word than the main word. We solve thisMCSS type of problem using the linear-time algorithm de-scribed in (Bentley 1984). Eventually, each event detectedfollowing this process is described by: (i) a main word t (ii)a period of time I and (iii) the magnitude of its impact overthe tweeting behavior of the users, Ma(t, I).
Selection of Words Describing Events
In order to limit information overload, we choose to boundthe number of words used to describe an event. This boundis a manually fixed parameter noted p.Identification of the candidate words The set of candidatewords for describing an event is the set of the words with thep highest co-occurrence counts with the main word t duringthe period of time I . The most relevant words are selectedamongst the candidates based on the similarity between theirtemporal dynamics and the dynamics of the main word dur-ing I . For that, we compute a weight wt0q for each candidateword t0q . We propose to estimate this weight from the time-series for N i
t and N it0q
with the correlation coefficient pro-posed in (Erdem, Ceyhan, and Varli 2012). This coefficient,primarily designed to analyze stock prices, has two desir-able properties for our application: (i) it is parameter-freeand (ii) there is no stationarity assumption for the validity ofthis coefficient, contrary to common coefficients, e.g. Pear-son’s coefficient. Erdem’s coefficient takes into account thelag difference of data points in order to better capture the di-rection of the co-variation of the two time-series over time.For the sake of conciseness, we directly give the formula forthe approximation of the coefficient, given words t, t0q and
Comme est très grand, on suppose que peut être approximée par la loi normale suivante :
Pour chaque mot t du vocabulaire V@ on identifie l’intervalle I=[a;b] qui maximise la magnitude d’impact :
2. The list is iterated through starting from the most influen-tial event. For each event, the second component selectsthe set S of words that best describe it. The selection relieson measures based on the co-occurrence and the tempo-ral dynamics of words tweeted during I . Each event pro-cessed by this component is then passed to the third com-ponent, which is responsible for storing event descrip-tions and managing duplicated events. Eventually, when kdistinct events have been processed, the third componentmerges duplicated events and returns the list L containingthe top k events.
Detection of Events Based on Mention AnomalyThe objective of this component is to precisely identifywhen events happened and to estimate the magnitude of theirimpact over the crowd. It relies on the identification of burstsbased on the computation of the anomaly in the frequency ofmention creation for each individual word in [email protected] of the anomaly at a point Before formu-lating the anomaly measure, we define the expected numberof mention creation associated to a word t for each time-slice i 2 [1;n]. We assume that the number of tweets thatcontain the word t and at least one mention in the ith time-slice, N i
@t, follows a generative probabilistic model. Thuswe can compute the probability P (N i
@t) of observing N i@t.
In (Fung et al. 2005), authors study word frequency in tex-tual streams and show that it is reasonable to model this kindof probability, if the corpus is large enough, with a bino-mial distribution; (Li, Sun, and Datta 2012) also employ thismodeling for tweet streams. Therefore we can write:
P (N i@t) =
✓N i
N i@t
◆pNi
@t@t (1� p@t)
Ni�Ni@t ,
where p@t is the expected probability of a tweet containingt and at least one mention in any time-slice. Because N i islarge we further assume that P (N i
@t) can be approximatedby a normal distribution, that is to say:
P (N i@t) ⇠ N (N ip@t, N
ip@t(1� p@t)).
It follows that the expected frequency of tweets containingthe word t and at least one mention in the ith time-slice isE[t|i] = N ip@t, with p@t = N@t/N . We then define theanomaly of the mention creation frequency related to theword t at the ith time-slice this way:
anomaly(t, i) = N i@t � E[t|i].
The anomaly is positive only if the observed mention cre-ation frequency is strictly greater than the expectation.Computation of the magnitude of impact The magnitudeof impact of an event associated with the time interval I =
[a; b] and the main word t is given by the formula below. Itcorresponds to the algebraic area of the anomaly function on[a; b].
Ma(t, I) =Z b
a
anomaly(t, i) di
=
bX
i=a
anomaly(t, i)
The algebraic area is obtained by integrating the discreteanomaly function, which in this case boils down to a sum.Identification of events For each word t 2 V@, we iden-tify the interval that maximizes the magnitude of impactby solving a “Maximum Contiguous Subsequence Sum”(MCSS) type of problem. The MCSS problem is well knownand finds application in many fields (Fukuda et al. 1996;Fan et al. 2003; Lappas et al. 2009). In other words, for agiven word t we want to identify the interval I = [a; b], suchthat:
Ma(t, I) = max{bX
i=a
anomaly(t, i)|1 6 a 6 b 6 n}.
This formulation permits the anomaly to be negative at somepoints in the interval, only if it permits extending the inter-val while increasing the total magnitude, which is a desirableproperty. More specifically, it avoids fragmenting events thatlast several days because of the lower activity on Twitter dur-ing the night, which can lead to low or negative anomaly.Another desirable property of this formulation is that a givenword can’t be considered as the main word of more than oneevent. This increases the readability of events for the fol-lowing reason. The bigger the number of events that can bedescribed by a given word, the less specific to each eventthis word is. Therefore, this word should rather be consid-ered as a related word than the main word. We solve thisMCSS type of problem using the linear-time algorithm de-scribed in (Bentley 1984). Eventually, each event detectedfollowing this process is described by: (i) a main word t (ii)a period of time I and (iii) the magnitude of its impact overthe tweeting behavior of the users, Ma(t, I).
Selection of Words Describing Events
In order to limit information overload, we choose to boundthe number of words used to describe an event. This boundis a manually fixed parameter noted p.Identification of the candidate words The set of candidatewords for describing an event is the set of the words with thep highest co-occurrence counts with the main word t duringthe period of time I . The most relevant words are selectedamongst the candidates based on the similarity between theirtemporal dynamics and the dynamics of the main word dur-ing I . For that, we compute a weight wt0q for each candidateword t0q . We propose to estimate this weight from the time-series for N i
t and N it0q
with the correlation coefficient pro-posed in (Erdem, Ceyhan, and Varli 2012). This coefficient,primarily designed to analyze stock prices, has two desir-able properties for our application: (i) it is parameter-freeand (ii) there is no stationarity assumption for the validity ofthis coefficient, contrary to common coefficients, e.g. Pear-son’s coefficient. Erdem’s coefficient takes into account thelag difference of data points in order to better capture the di-rection of the co-variation of the two time-series over time.For the sake of conciseness, we directly give the formula forthe approximation of the coefficient, given words t, t0q and
• Permet d’étendre l’intervalle, même si l’anomalie est ponctuellement négative (typiquement la nuit), à condition que la magnitude totale soit augmentée
• Un mot donné ne peut être le mot principal que d’un seul évènement : augmente la lisibilité, car si un mot est associé à plusieurs évènements, alors il est moins spécifique à chacun. Il semble donc plus pertinent de le considérer comme un mot lié pour les autres évènements
sur 14

PAGE: Rennes, 30 janvier 2014 - Adrien Guille
ERIC LABUniversité Lumière Lyon 2, France
Sélectionner les mots décrivant chaque évènement
8
• Identification des mots «candidats»• On choisit de limiter la taille de l’ensemble S à p• Les p mots les plus cooccurents avec t dans les tweets publiés pendant I
• Sélection des mots les plus pertinents• Calcul d’un poids wq pour chaque mot candidat t’q
• Mesure de la corrélation entre les valeurs Nit et Nit’q sur l’intervalle I avec le coefficient de Erdem [MAF ’12]• L’ensemble S contient les mots t’q, tq wq > θ
• et
Détection d’évènements sur TwitterConférence EGC 2014
the period of time I = [a; b]:
⇢Ot,t0q =
bX
i=a+1
At,t0q
(b� a� 1)AtAt0q
,
where At,t0q = (N it �N i�1
t )(N it0q�N i�1
t0q),
A2t =
Pbi=a+1(N
it �N i�1
t )
2
b� a� 1
, and
A2t0q
=
Pbi=a+1(N
it0q�N i�1
t0q)
2
b� a� 1
.
This practically corresponds to the first order auto-correlation of the time-series for N i
t and N it0q
. The proof that⇢O satisfies |⇢O| 6 1 using the Cauchy-Schwartz inequalityappears in (Erdem, Ceyhan, and Varli 2012). Eventually, wedefine the weight of the term t0q as an affine function of ⇢O toconform with the definition of bursty topic, i.e. 0 6 wq 6 1:
wq =
⇢Ot,t0q + 1
2
Because the temporal dynamics of very frequent words areless impacted by a particular event, this formulation – muchlike tf · idf – diminishes the weight of words that occur veryfrequently in the stream and increases the weight of wordsthat occur less frequently, i.e. more specific words.Selection of the most relevant words The final set ofwords retained to describe an event is the set S, such that8t0q 2 S, wq > ✓. The parameters p and ✓ 2 [0; 1] allow theusers of MABED to adjust the level of information and detailthey require.
Generating the List of the Top k EventsEach time an event has been processed by the second com-ponent, it is passed to the third component. It is responsi-ble for storing the description of the events while manag-ing duplicated events. For that, it uses two graph structures:the topic graph and the redundancy graph. The first is a di-rected, weighted, labeled graph that stores the descriptionsof the detected events. The representation of an event e inthis graph is as follows. One node represents the main wordt and is labeled with the interval I and the score Ma. Each re-lated word t0q is represented by a node and has an arc towardthe main word, which weight is wq . The second structure isa simple undirected graph that is used to represent the rela-tions between the eventual duplicated events, represented bytheir main words. See Figure 1 for an illustration of thesestructures.
Let e1 be the event that the component is processing. First,it checks whether it is a duplicate of an event that is alreadystored in the topic graph or not. If it isn’t the case, the eventis introduced into the graph and the count of distinct eventsis incremented by one. Otherwise, assuming e1 is a duplicateof the event e0, a relation is added between t0 and t1 in theredundancy graph. When the count of distinct events reachesk, the duplicated events are merged and the list of the top k
most influential events is returned. We describe how dupli-cated events are identified and how they are merged togetherhereafter.Detecting duplicated events The event e1 is consideredto be a duplicate of the event e0 already stored in the topicgraph if (i) the main words t1 and t0 would be mutually con-nected and (ii) if the periods of time I1 and I0 significantlyoverlap. It is so if |I1\I0|
min(I1,I0)exceeds a threshold � 6 1. In
this case, the description of e1 it stored aside and a relationis added between t1 and t0 in the redundancy graph.Merging duplicated events Identifying which duplicatedevents should be merged together is equivalent to identi-fying the connected components in the redundancy graph.This is done in linear time using the algorithm describedin (Hopcroft and Tarjan 1973). In each connected compo-nent, there is exactly one node that corresponds to an eventstored in the topic graph. The definition of this event is up-dated according to the extra information brought by dupli-cated events. The main word becomes the aggregation of themain words of all duplicated events. The words describingthe updated event are the p words among all the words de-scribing the duplicated events with the p highest weights.
EvaluationIn this section we present the main results of the extensivequalitative and quantitative studies we performed to eval-uate MABED. We show that the proposed method is ableto extract an accurate and meaningful retrospective view ofthe events discussed in real Twitter data. To study preci-sion and recall, we ask human judges to judge whether thedetected events are indeed meaningful and significant real-world events. We also empirically demonstrate the relevanceof the mention-anomaly-based approach, by showing thatthe precision achieved by MABED is greater in all our teststhan the precision achieved by a variant of MABED that ig-nores mentions.
Experimental SetupData Since the Twitter corpora used in prior work aren’tavailable, we base our experiments on two different Twittercorpora. One contains 1,437,126 tweets written in English,which correspond to all the tweets published by 52,494 U.S.based users in November 2009. These data were collectedby (Yang and Leskovec 2011) and were widely available be-fore Twitter changed its T.O.S. This corpus is noted Cen. Theother corpus contains 2,086,136 tweets written in French1.We collected these tweets with the aim to capture the politi-cal conversation ongoing on Twitter during the campaign forthe 2012 French presidential elections. We crawled tweetsfor a month using the Twitter streaming API based on a listof keywords established by French political scientists priorto the crawling phase. This corpus is noted Cfr in the follow-ing. No preprocessing is applied for both corpus but trivialwords are ignored when iterating through each corpus’ vo-cabulary based on English and French standard stop-word
1This corpus can be reconstructed based on the list of tweets’ID available at http://anonymized.url
the period of time I = [a; b]:
⇢Ot,t0q =
bX
i=a+1
At,t0q
(b� a� 1)AtAt0q
,
where At,t0q = (N it �N i�1
t )(N it0q�N i�1
t0q),
A2t =
Pbi=a+1(N
it �N i�1
t )
2
b� a� 1
, and
A2t0q
=
Pbi=a+1(N
it0q�N i�1
t0q)
2
b� a� 1
.
This practically corresponds to the first order auto-correlation of the time-series for N i
t and N it0q
. The proof that⇢O satisfies |⇢O| 6 1 using the Cauchy-Schwartz inequalityappears in (Erdem, Ceyhan, and Varli 2012). Eventually, wedefine the weight of the term t0q as an affine function of ⇢O toconform with the definition of bursty topic, i.e. 0 6 wq 6 1:
wq =
⇢Ot,t0q + 1
2
Because the temporal dynamics of very frequent words areless impacted by a particular event, this formulation – muchlike tf · idf – diminishes the weight of words that occur veryfrequently in the stream and increases the weight of wordsthat occur less frequently, i.e. more specific words.Selection of the most relevant words The final set ofwords retained to describe an event is the set S, such that8t0q 2 S, wq > ✓. The parameters p and ✓ 2 [0; 1] allow theusers of MABED to adjust the level of information and detailthey require.
Generating the List of the Top k EventsEach time an event has been processed by the second com-ponent, it is passed to the third component. It is responsi-ble for storing the description of the events while manag-ing duplicated events. For that, it uses two graph structures:the topic graph and the redundancy graph. The first is a di-rected, weighted, labeled graph that stores the descriptionsof the detected events. The representation of an event e inthis graph is as follows. One node represents the main wordt and is labeled with the interval I and the score Ma. Each re-lated word t0q is represented by a node and has an arc towardthe main word, which weight is wq . The second structure isa simple undirected graph that is used to represent the rela-tions between the eventual duplicated events, represented bytheir main words. See Figure 1 for an illustration of thesestructures.
Let e1 be the event that the component is processing. First,it checks whether it is a duplicate of an event that is alreadystored in the topic graph or not. If it isn’t the case, the eventis introduced into the graph and the count of distinct eventsis incremented by one. Otherwise, assuming e1 is a duplicateof the event e0, a relation is added between t0 and t1 in theredundancy graph. When the count of distinct events reachesk, the duplicated events are merged and the list of the top k
most influential events is returned. We describe how dupli-cated events are identified and how they are merged togetherhereafter.Detecting duplicated events The event e1 is consideredto be a duplicate of the event e0 already stored in the topicgraph if (i) the main words t1 and t0 would be mutually con-nected and (ii) if the periods of time I1 and I0 significantlyoverlap. It is so if |I1\I0|
min(I1,I0)exceeds a threshold � 6 1. In
this case, the description of e1 it stored aside and a relationis added between t1 and t0 in the redundancy graph.Merging duplicated events Identifying which duplicatedevents should be merged together is equivalent to identi-fying the connected components in the redundancy graph.This is done in linear time using the algorithm describedin (Hopcroft and Tarjan 1973). In each connected compo-nent, there is exactly one node that corresponds to an eventstored in the topic graph. The definition of this event is up-dated according to the extra information brought by dupli-cated events. The main word becomes the aggregation of themain words of all duplicated events. The words describingthe updated event are the p words among all the words de-scribing the duplicated events with the p highest weights.
EvaluationIn this section we present the main results of the extensivequalitative and quantitative studies we performed to eval-uate MABED. We show that the proposed method is ableto extract an accurate and meaningful retrospective view ofthe events discussed in real Twitter data. To study preci-sion and recall, we ask human judges to judge whether thedetected events are indeed meaningful and significant real-world events. We also empirically demonstrate the relevanceof the mention-anomaly-based approach, by showing thatthe precision achieved by MABED is greater in all our teststhan the precision achieved by a variant of MABED that ig-nores mentions.
Experimental SetupData Since the Twitter corpora used in prior work aren’tavailable, we base our experiments on two different Twittercorpora. One contains 1,437,126 tweets written in English,which correspond to all the tweets published by 52,494 U.S.based users in November 2009. These data were collectedby (Yang and Leskovec 2011) and were widely available be-fore Twitter changed its T.O.S. This corpus is noted Cen. Theother corpus contains 2,086,136 tweets written in French1.We collected these tweets with the aim to capture the politi-cal conversation ongoing on Twitter during the campaign forthe 2012 French presidential elections. We crawled tweetsfor a month using the Twitter streaming API based on a listof keywords established by French political scientists priorto the crawling phase. This corpus is noted Cfr in the follow-ing. No preprocessing is applied for both corpus but trivialwords are ignored when iterating through each corpus’ vo-cabulary based on English and French standard stop-word
1This corpus can be reconstructed based on the list of tweets’ID available at http://anonymized.url
sur 14

PAGE: Rennes, 30 janvier 2014 - Adrien Guille
ERIC LABUniversité Lumière Lyon 2, France
Générer la liste d’évènements et gérer la redondance
9
• Le graphe des thématiques• Stocke les descriptions des k évènements distincts• Détecte les duplicats sur la base des mots principaux et des intervalles temporels
• Le graphe des redondances• Mémorise les évènements dupliqués à fusionner à la fin du processus
• Identification des évènements à fusionner
• Identifier les composantes connexes du graphe des redondances [CACM 16:6]
Détection d’évènements sur TwitterConférence EGC 2014
sur 14
³�q<jIg
< D
IrdIEj<jQ][¥q<jIg¦
��Þ�§<�D¨
qq<jIgZ]][
���
������
���
���
���
< D
q<jIg�E]�]EEkgI[EI�
Z<jgQr
<����������������������������D���
���
"q<jIg
"Z]][
q
!<��
�KjIEjIg�YIh�KpJ[IZI[jh�=�d<gjQg�GI�Y�<[]Z<YQI
/KYIEjQ][[Ig�YIh�Z]jh�GKEgQp<[j�YIh�KpJ[IZI[jh
�
Og<dPI�GIh�gIG][G<[EIh
Og<dPI�GIh�jPKZ<jQfkIh
"
��
���
�Ykr�GI�jqIIjh
"�/�
QhjI�GIh�KpJ[IZI[jh�]gG][[Kh�hIY][�Y<�Z<O[QjkGI�GI�YIkg�QZd<Ej
7<jIg��Z]][�¥Á�ʦ��"�/��¥Á�ʦNg]Z�ÁÊ�ÂÂ�ÂÄ�ÂÁ<Zj]�ÁÊ�ÂÂ�ÂÆ�È�ÄÁ<Z
�K[KgIg�Y<�YQhjI�GIh�X�KpJ[IZI[jh�YIh�dYkh�Q[NYkI[jh�I[�OKg<[j�Y<�gIG][G<[EI
Z]][��"�/�
!<¥�¦
6IjIg<[h�hIgpIG�¥Á�ɦ��E]k[jgs�¥Á�ȦNg]Z�ÁÊ�ÂÂ�ÂÁ�ÅdZj]�ÁÊ�ÂÂ�ÂÃ�É<Z
0QOIg��7]]Gh��<EEQGI[j�¥Á�ʦ��E<g�¥Á�ʦNg]Z�ÁÊ�ÂÂ�ÃÈ�ÇdZj]�ÁÊ�ÂÂ�ÃÊ�Æ<Z
Q
Q
Q
�"0.
��+��/�
�Â+��/�
�Ã/$
.0��

PAGE: Rennes, 30 janvier 2014 - Adrien Guille
ERIC LABUniversité Lumière Lyon 2, France
Évaluation
10
• Données• C-en : 1,5M tweets publiés par 50K twittos américains en novembre 2009• C-fr : 2M tweets publiés durant la campagne présidentielle en mars 2012• Pas de pré-traitement (e.g. stemming, identification des n-grams)• Mots vides retirés du vocabulaire
• Choix des paramètres• Tranches temporelles de 30 minutes• Taille maximale de l’ensemble S : p = 6• Nombre d’évènements k = 40• Autres paramètres : θ = 0,7 et σ = 0,85
• α-MABED• Variante de MABED ignorant les mentions• Détecte les évènements et estime leur impact en analysant Nit au lieu de Ni@t
Détection d’évènements sur TwitterConférence EGC 2014
sur 14

PAGE: Rennes, 30 janvier 2014 - Adrien Guille
ERIC LABUniversité Lumière Lyon 2, France
Évaluation qualitative
11
• Extrait des résultats• 20 top évènements• Ordonnés par impact décroissant
Détection d’évènements sur TwitterConférence EGC 2014
# Time-span Topic (main words are in bold and the weight of each related word is given in parentheses)1 from 25 09:30 thanksgiving, turkey: hope (0.72), happy (0.71)
to 28 06:30 Twitter users celebrated Thanksgiving2 from 25 09:30 thankful: happy (0.77), thanksgiving (0.71)
to 27 09:00 Related to event #13 from 10 16:00 veterans: served (0.80), country (0.78), military (0.73), happy (0.72)
to 12 08:00 Twitter users celebrated the Veterans Day that honors people who have served in the U.S. Armed Forces4 from 26 13:00 black: friday (0.95), amazon (0.75)
to 28 10:30 Twitter users were talking about the deals offered by Amazon the day before the “Black Friday”5 from 07 13:30 hcr, bill, health, house, vote: reform (0.92), passed (0.91), passes (0.88)
to 09 04:30 The House of Representatives passed the health care reform bill on November 7, 20096 from 05 19:30 hood, fort: ft (0.92), shooting (0.83), news (0.78), army (0.75), forthood (0.73)
to 08 09:00 The Fort Hood shooting was a mass murder that took place in a U.S. military post on November 5, 20097 from 19 04:30 chrome: os (0.95), google (0.87), desktop (0.71)
to 21 02:30 On November 19, Google released Chrome OS’s source code for desktop PC8 from 27 18:00 tiger, woods: accident (0.91), car (0.88), crash (0.88), injured (0.80), seriously (0.80)
to 29 05:00 Tiger Woods was injured in a car accident on November 27, 20099 from 28 22:30 tweetie, 2.1, app: retweets (0.93), store (0.90), native (0.89), geotagging (0.88)
to 30 23:30 The iPhone app named Tweetie (v2.1), hit the app store with additions like retweets and geotagging10 from 29 17:00 monday, cyber: deals (0.84), pro (0.75)
to 30 23:30 Twitter users were talking about the deals offered by online shops for the “Cyber Monday”11 from 10 01:00 linkedin: synced (0.86), updates (0.84), status (0.83), twitter (0.71)
to 12 03:00 Starting from November 10, LinkedIn offered users the possibility to sync their status updates with Twitter12 from 04 17:00 yankees, series: win (0.84), won (0.84), fans (0.78), phillies (0.73), york (0.72)
to 06 05:30 The Yankees baseball team defeated the Phillies to win their 27th World Series on November 4, 200913 from 15 09:00 obama: chinese (0.75), barack (0.72), twitter (0.72), china (0.70)
to 17 23:30 During a visit to China Barack Obama admitted that he’d never used Twitter but Chinese should be able to14 from 25 10:00 holiday: shopping (0.72)
to 26 10:00 Twitter users started talking about the “Black Friday”, a shopping day and is a holiday in some states.15 from 19 21:30 oprah, end: talk (0.81), show (0.79), 2011 (0.73), winfrey (0.71)
to 21 16:00 On November 19, Oprah Winfrey announced her talk show will end in September 201116 from 07 11:30 healthcare, reform: house (0.91), bill (0.88), passes (0.83), vote (0.83), passed (0.82)
to 09 05:00 Related to event #517 from 11 03:30 facebook: app (0.74), twitter (0.73)
to 13 08:30 No clear corresponding event18 from 18 14:00 whats: happening (0.76), twitter (0.73)
to 21 03:00 Twitter started asking ”What’s happening?” instead of ”What are you doing?” from November 18, 200919 from 20 10:00 cern: lhc (0.86), beam (0.79)
to 22 00:00 On November 20, proton beams were successfully circulated in the ring of the LHC (CERN) for the 2nd time20 from 26 08:00 icom: lisbon (0.99), roundtable (0.98), national (0.88)
to 26 15:30 The I-COM roundtable about market issues in Portugal took place on November 26, 2009
Table 3: Top 20 events with highest magnitude of influence over the crowd, detected by MABED in Cen.
Quantitative EvaluationBecause the corpora don’t come with ground truth, we askedtwo human judges to judge whether the detected events aremeaningful and significant events, by assigning 0 (i.e. notrelevant) and 1 (i.e. relevant) rates. The judges are Frenchgraduate students who aren’t involved in this project. We fol-low the definition of precision used in (Weng and Lee 2011;Li, Sun, and Datta 2012), defined as the fraction of the de-tected events that are related to a realistic event. Only eventsthat got assigned a total score of 2 are considered relevant.For a similar reason, we can’t measure recall and again fol-low (Li, Sun, and Datta 2012). Instead we report the DER-ate, defined as the fraction of the detected events that areduplicates. Considering this is a time consuming task forthe judges, we choose to set k = 40. In other words weask the judges to rate the top 40 most influential events de-tected with MABED and ↵-MABED in both corpora. The
inter-rater agreement measured with Cohen’s Kappa is '0.76, showing a strong agreement. The precision@k andDERate@k for values of k ranging from 5 to 40 are givenby Figure 4. MABED yields a precision@40 of 82.5% onCfr and 77.5% on Cen. The DERate stays under 20% on Cenwhile there is no duplicate among the 40 events detectedin Cfr. It appears that MABED yields slightly better perfor-mance on Cfr. We explain this because of the crawling strat-egy: Cfr is keyword-centered whereas Cen is user-centered.It is thus legitimate to assume that the latter contains a sig-nificantly higher proportion of tweets that are not related toevents. According to the study presented in (PearAnalytics2009), this proportion could be as high as 50%.
Relevance of the mention-anomaly-based ap-proach MABED achieves a greater precision than↵-MABED in all our tests with an overall gain of precisionof 46.5%. This empirically verify our main assumption,
sur 14

PAGE: Rennes, 30 janvier 2014 - Adrien Guille
ERIC LABUniversité Lumière Lyon 2, France
Évaluation qualitative
12
• Étude de cas•
• Lisibilité des évènements• Mise en valeur des mots principaux• Souvent des entités nommées
• Précision temporelle• Évènements précisément localisés• Dans ce cas : évènement réel entre 19h34 et 19h44 le 5 novembre 09• α-MABED le détecte le 7 novembre 09
• Redondance• Limite la fragmentation des évènements discutés plusieurs jours
0
0,13
0,25
0,38
0,50
<12 [12;24] ]24;36] ]36;48] ]38;60] >60
C-fr C-en
Durée (en heures)
Pour
cent
age
d’év
ènem
ents
Détection d’évènements sur TwitterConférence EGC 2014
lists. All timestamps are in GMT. Table 2 gives further de-tails about each corpus, namely the proportion of tweets con-taining mentions and the proportion of tweets that are re-tweets.
Corpus N @ prop. RT prop.Cen 1,437,126 0.54 0.17Cfr 2,086,136 0.68 0.43
Table 2: Statistics on the corpora.
Parameter setting There are several parameters that couldaffect the performance of MABED. We choose to partitionboth corpus using 30 minutes time-slices, which allows fora good temporal precision while keeping the number oftweets in each time-slice large enough. The maximum num-ber of words describing each event, p, is set to 6. The weightthreshold for selecting relevant words, ✓, and the fusionthreshold for redundant events, �, should intuitively be closeto 1 to obtain the best performance. We empirically find that✓ = 0.7 and � = 0.85 give the best results and therefore weuse these values for all the experiments presented hereafter.↵-MABED We compare the performance of MABED witha variant that ignores mentions, ↵-MABED. This means thatthe first component detects events and estimates their mag-nitude of impact based on the values of N i
t instead of N i@t.
Qualitative EvaluationTable 3 lists the top 202 events with highest magnitude ofinfluence over the crowd in Cen. From this table, we makeseveral observations along three axes: readability, temporalprecision and redundancy.Readability We argue that highlighting main words al-lows for an easy reading of the description, more especiallyas main words often correspond to named entities, e.g. FortHood (# 6), Chrome (# 7), Tiger Woods (# 8), Obama (# 13).This favors the quick understanding of events by putting intolight the key places/products/actors at the heart of the events.Temporal precision MABED dynamically estimates theperiod of time during which each event is discussed on Twit-ter. This improves the temporal precision as compared toexisting methods that typically report events on a daily ba-sis. We illustrate how this improves the quality of the resultswith the following example. The 6th event corresponds toTwitter users reporting the Fort Hood shooting that, accord-ing to Wikipedia3, happened on November 5, 2009 between13:34 and 13:44pm CST (i.e. 19:34 and 19:44 GMT). Theburst of activity engendered by this event is first detectedby MABED in the time-slice covering the 19:30-20:00 GMTperiod. MABED gives this description:(i) 11-05 19:30 to 11-08 9:00; (ii) hood, fort; (iii) ft (0.92),shooting (0.83), news (0.78), army (0.75), forthood (0.73).We can clearly understand that (i) something happenedaround 7:30pm GMT, (ii) at the Hood Fort and that (iii) it
2Due to page limitation, only the top 20 events are listed. Thecomplete lists of events for both corpora are available at http://anonymized.url
3Source: http://en.wikipedia.org/wiki/Fort Hood shooting
Nov. 5 #6 (13:30) Nov. 6 Nov. 70
max
Time (CST)
Ano
mal
y
“hood”“fort”
“shooting”
Figure 2: Measured anomaly for the words “hood”, “fort”and “shooting” between Nov. 5 and Nov. 7 midnight (CST).
0
0.2
0.4
<12 [12;24] ]24;36] ]36;48] ]48;60] >60
Event duration (in hours)
Perc
enta
geof
even
ts CenCfr
Figure 3: Event duration distribution.
is a shooting. In contrast, ↵-MABED fails at detecting thisevent on November 5 but reports it on November 7 when themedia coverage was the highest.Redundancy Some events have several main words, e.g.events #1, 5, 6, 8. This is due to merges operated by thethird component of MABED to avoid duplicated events. Re-dundancy is further limited because of the dynamic estima-tion of each event duration. We keep using event #6 for il-lustrating that. Figure 2 plots the evolution of the anomalymeasured for the words “hood”, “fort” and “shooting” be-tween November 5 and November 7. We see that the mea-sured anomaly is closer to 0 during the night, giving a “dual-peak” shape to the curves. Nevertheless, MABED reports aunique event which is discussed for several days, instead ofreporting distinct consecutive 1-day events. The importanceof dynamically estimating the duration of events is further il-lustrated by Figure 3, which shows the distributions of eventduration for both corpus. It reveals that they follow a nor-mally distributed pattern and that some events are discussedduring less than 12 hours whereas some are discussed formore than 60 hours. We note that the politics related eventsdetected in Cfr tend to be discussed for a longer time thanthe events detected in Cen. This is consistent with the em-pirical study presented in (Romero, Meeder, and Kleinberg2011), which states that controversial and more particularlypolitical topics are more persistent than the other topics onTwitter.
sur 14

PAGE: Rennes, 30 janvier 2014 - Adrien Guille
ERIC LABUniversité Lumière Lyon 2, France
Évaluation quantitative
13
• Méthodologie• 2 juges attribuant des 0 et 1• Kappa de Cohen κ = 0,76
• Résultats• P@40 : 0,83 (C-fr) et 0,78 (C-en)
• DERate@40 : 0 (C-fr) et 0,15 (C-en)
• Gain par rapport à α-MABED• Précision +46,5%• Temps d’exécution -31,3%
0
0,25
0,50
0,75
1,00
5 10 15 20 25 30 35 40
P(C-en) MABED P(C-fr) MABEDP(C-en) α-MABED P(C-fr) α-MABEDDERate(C-en) MABED DERate(C-fr) MABED
Valeur de k
Préc
isio
n /
DER
ate
@ k
Détection d’évènements sur TwitterConférence EGC 2014
sur 14

PAGE: Rennes, 30 janvier 2014 - Adrien Guille
ERIC LABUniversité Lumière Lyon 2, France
Conclusion
14
• Implémentation• Utilisation «offline» et «online»• Trois interfaces utilisateur, une pour chaque dimension des évènements
• Travaux futurs• Incorporer d’autres connaissances, e.g. capitalistes sociaux [CN ’13]• Étudier la relation entre réseau social et réseau «thématique»
Détection d’évènements sur TwitterConférence EGC 2014
sur 14

Rennes, 30 janvier 2014 - Adrien Guille
ERIC LABUniversité Lumière Lyon 2, France
Références
• État de l’art• [CSCW ’11] Shamma, D. A.; Kennedy, L.; and Churchill, E. F. 2011. Peaks and persistence: modeling the shape of microblog conversations.• [ICWSM ’11] Weng, J., and Lee, B.-S. 2011. Event detection in twitter.• [CIKM ’12] Li, C.; Sun, A.; and Datta, A. 2012. Twevent: Segment- based event detection from tweets.• [COLING ’12] Lau, J. H.; Collier, N.; and Baldwin, T. 2012. On-line trend analysis with topic models: #twitter trends detection topic model online.• [ICWSM ’12] Yuheng, H.; Ajita, J.; Dore e, D. S.; and Fei, W. 2012. What were the tweets about? topical associations between public events and twitter feeds.• [WWW ’13] Parikh, R., and Karlapalem, K. 2013. Et: events from tweets.• [IJWBC vol. 9:1] Benhardus, J., and Kalita, J. 2013. Streaming trend detection in twitter.
• Proposition• [CACM 27:9] Bentley, J. 1984. Programming pearls: algorithm design techniques. Communications of the ACM 27:9• [MAF ’12] Erdem, O.; Ceyhan, E.; and Varli, Y. 2012. A new correla- tion coefficient for bivariate time-series data.• [CACM 16:6] Hopcroft, J., and Tarjan, R. 1973. Algorithm 447: efficient algorithms for graph manipulation. Communications of the ACM 16:6
• Conclusion• [CN ’13] Nicolas Dugué; Anthony Perez, 2013. Detecting social capitalists on Twitter using similarity measures.
Détection d’évènements sur TwitterConférence EGC 2014