
Développement et mise en œuvre d’un algorithme de ... · Un grand merci à Monsieur Spetler et...
29
Institut Supérieur d’Informatique de Modélisation et de leurs Applications 24, avenue des Landais BP 10 125 63 173 AUBIERE cedex Manufacture Française des pneumatiques Michelin Place des Carmes Déchaux 63 040 CLERMONT FERRAND cedex 9 Rapport de projet de 3 ème année Filière F4 Développement et mise en œuvre d’un algorithme de traitement capable de trier différentes catégories de sols routiers Responsables du projet : Jérémy BUISSON & Frédéric SPETLER Auteurs : Morgan DESLANDES & Diyé DIA Année 2010-2011
Transcript of Développement et mise en œuvre d’un algorithme de ... · Un grand merci à Monsieur Spetler et...

Institut Supérieur d’Informatique
de Modélisation et de leurs Applications
24, avenue des Landais
BP 10 125
63 173 AUBIERE cedex
Manufacture Française des pneumatiques
Michelin
Place des Carmes Déchaux
63 040
CLERMONT FERRAND cedex 9
Rapport de projet de 3ème année
Filière F4
Développement et mise en œuvre d’un algorithme de
traitement capable de trier différentes catégories de
sols routiers
Responsables du projet : Jérémy BUISSON & Frédéric SPETLER
Auteurs :
Morgan DESLANDES & Diyé DIA
Année 2010-2011

Morgan DESLANDES & Diyé DIA
Manufacture Française des pneumatiques
Michelin
Place des Carmes Déchaux
63 040
CLERMONT FERRAND cedex 9
Rapport de projet de 3ème année
Filière F4
Développement et mise en œuvre d’un algorithme de
traitement capable de trier différentes catégories de
sols routiers
Responsables du projet :
Jérémy BUISSON & Frédéric SPETLER
Auteurs :
Morgan DESLANDES & Diyé DIA
Année 2010-2011
Institut Supérieur d’Informatique
de Modélisation et de leurs Applications
24, avenue des Landais
BP 10 125
63 173 AUBIERE cedex

Morgan DESLANDES & Diyé DIA
Remerciement
Nous tenons à remercier tout particulièrement Monsieur Jérémy Buisson pour sa
disponibilité et sa patience tout au long de ce projet. Il a été présent tout au long du projet, et
nous a orientés dans nos recherches. Il a été d’une grande patience lorsque les algorithmes ne
fonctionnaient pas. Il a toujours répondu rapidement et clairement à toutes les questions que
nous lui posions par mails ou durant nos réunions.
Un grand merci à Monsieur Spetler et à Mr Roux, qui ont répondu à nos questions et
nous ont éclairés tout au long de ce projet, en spécifiant de manière exacte les besoins du client
et l’importance de ces besoins.
Un grand merci également à Monsieur Barra qui nous a beaucoup aidés en nous
fournissant de précieux renseignements sur les pistes de recherche pour résoudre le problème.

Morgan DESLANDES & Diyé DIA
Résumé
Nous devons analyser des photos de route pour acquérir des données statistiques qui vont
permettre à Michelin de valider la fabrication ou l’amélioration de nouveaux produits. Les
photos prises, dans des conditions hivernales, doivent être triées selon le type de sol. Triées
manuellement auparavant, les photos doivent être triées automatiquement d’où la nécessité de
ce projet. Il existe, grossièrement, deux types de sols : sols dits « noirs » et sols dits « blancs ».
Pour éviter d’avoir des résultats biaisés, nous devons éliminer les photos dites
« inexploitables », à l’aide des données GPS, présentes sur les photos. Ensuite, la luminosité
étant un facteur important dans le traitement des images, un tri, qui sépare les photos de jour et
les photos de nuit, est proposé.
Enfin un tri, basé sur une méthode de binarisation, la méthode d’Otsu permet de séparer les
photos de sol « blanc » et les photos de sol « noir ». L’algorithme est implémenté avec le
langage MATLAB. Les résultats de tri des photos inexploitables sont très satisfaisants. Par
contre, l’utilisation de l’histogramme de l’image garantit un meilleur tri que l’application de la
méthode d’Otsu.
Mots-clés: tri, photos inexploitables, sol « blanc », sol « noir », méthode d’Otsu, histogramme
de l’image, MATLAB

Morgan DESLANDES & Diyé DIA
Abstract
We have to analyze photos to acquire statistical data which allow Michelin to validate the
manufacture or the improvement of new products. Photos should be sort out according to road
type. Photos are taken during winter. Before this project, photos are sorted out by hand, now it
is unattended. There are two road types: « white » road (with snow) and « black » road
(without snow). To have good results, we have to delete unusable photos by using GPS data.
GPS data are on the photos. Then, we share photos taken during the day and photos taken
during the night because the light effects are important in image processing. Finally, we use
Otsu’s method, a method of binarization, to separate photos with « white » road and photos
with « black » road. MATLAB is used to implement our algorithm. The results from the sort of
unusable photos are very good but some improvements have to be done about the algorithm
which uses Otsu’s method, because the use of image’s histogram gives better results.
Key-words: to sort out, unusable photos, road « white », road « black »,Otsu’s method,
image’s histogram, MATLAB

Morgan DESLANDES & Diyé DIA
Table des figures
FIGURE 1 : LE CELEBRE BIBENDUM, SYMBOLE DE LA MARQUE ....................................................... 1
FIGURE 2 : LES DIFFERENTS TYPES DE SOLS ENNEIGES ....................................................................... 3
FIGURE 3 : EXEMPLE DE PHOTOS INEXPLOITABLES ............................................................................. 4
FIGURE 4 : LE DISPOSITIF "BOITE NOIRE"................................................................................................. 4
FIGURE 5 : PHOTO DE SOL « NOIR » .............................................................................................................. 5
FIGURE 6 : ORGANISATION DE LA DECOMPOSITION ............................................................................. 5
FIGURE 7A : EXEMPLE D’UNE IMAGE COMPOSEE DE NIVEAUX DE GRIS ....................................... 6
FIGURE 7B : L’HISTOGRAMME ET LA PALETTE ASSOCIEE A L’EXEMPLE ..................................... 8
FIGURE 8A : UNE PHOTO A BINARISER AVEC LA METHODE D’OTSU ............................................... 8
FIGURE 8B : UNE PHOTO BINARISEE AVEC LA METHODE D’OTSU .................................................... 9
FIGURE 9A : PHOTO ENTIERE ......................................................................................................................... 9
FIGURE 9B : UNE PARTIE DE LA PHOTO INTERESSANTE .................................................................... 11
FIGURE 10 : HISTOGRAMMES ET COMPOSANTES HSV D’UNE PHOTO DE SOL « BLANC » DE
JOUR ...................................................................................................................................................................... 12
FIGURE 11A : HISTOGRAMMES ET COMPOSANTES HSV D’UNE PHOTO DE SOL « NOIR » DE
NUIT ....................................................................................................................................................................... 13
FIGURE 11B : PHOTO DE SOL « NOIR » DE NUIT ...................................................................................... 15

Morgan DESLANDES & Diyé DIA
Table des matières
REMERCIEMENT
RESUME
ABSTRACT
TABLE DES FIGURES
TABLE DES MATIERES
INTRODUCTION ................................................................................................................................................... 1
PRESENTATION DE MICHELIN ....................................................................................................................... 2
1 PRESENTATION DE L’ETUDE ................................................................................................................. 3
1.1 LA DESCRIPTION DU PROBLEME ................................................................................................................... 3 1.2 LA DECOMPOSITION DU PROBLEME .............................................................................................................. 6
2 LE LOGICIEL REALISE ............................................................................................................................. 8
2.1 LE TRI DES PHOTOS INEXPLOITABLES ........................................................................................................... 8 2.2 LE TRI JOUR/NUIT ......................................................................................................................................... 9 2.3 LE TRI NOIR/BLANC .................................................................................................................................... 10
3 RESULTATS ET DISCUSSIONS .............................................................................................................. 16
CONCLUSION ...................................................................................................................................................... 20
REFERENCES WEBOGRAPHIQUES
GLOSSAIRE

Morgan DESLANDES & Diyé DIA 1
Introduction
Dans le cadre de notre troisième année à l’Institut Supérieur d’Informatique, de
Modélisation et de leurs Applications (ISIMA), nous avons travaillé sur la mise en œuvre
d’un algorithme de traitement d’image. Nous avons réalisé notre projet de cent vingt
heures en partenariat avec Michelin. Il s’agit d’une entreprise de pneumatique, dont le
siège social se trouve à Clermont-Ferrand.
Dans un souci de satisfaire les besoins du client, Michelin, leader mondial du
pneumatique, doit acquérir des données statistiques sur les types de sols rencontrés par les
chauffeurs, en conditions hivernales. En triant les chaussées selon différentes catégories,
Michelin atteint son but c’est à dire quantifier l’usage des pneumatiques poids-lourd, en
hiver, en zone montagneuse. Une campagne sur un hiver et un véhicule fournit environ
10 000 photos. Ces données statistiques permettront de valider la mise sur le marché de
nouveaux produits ou d’axer leurs recherches sur d’autres types de produits.
Ces photos étaient triées manuellement. Notre travail consiste à automatiser ce tri.
Manuellement, ce tri se faisait en trois étapes. D’abord, ils éliminaient les photos multiples,
qui peuvent biaisées l’étude. Ensuite ils effectuent un tri grossier, qui sépare les sols dits
« noirs » (chaussée sèche ou humide) et des sols dits « blancs » (neige fraîche, verglacée,
fondante…) et enfin un tri plus fin, permet de ranger les sols « blancs » en plusieurs sous-
catégories.
Après avoir présenté Michelin, nous présentons notre étude. Pour l’automatisation du
tri, on élimine d’abord les photos inexploitables en utilisant des données GPS. Ensuite,
nous séparons les photos prises durant le jour et les photos prises durant la nuit. Enfin,
comme pour le tri manuel, nous effectuons un tri grossier qui sépare les sols dits « noirs »
et les sols dits « blancs ». Les algorithmes ont été implémentés avec Matlab. A la fin de
cette étude, nous présentons les résultats et une discussion à propos de ces résultats.

Morgan DESLANDES & Diyé DIA 2
Présentation de Michelin
Michelin est un fabricant français de pneumatiques. Fondée en 1889 par les frères
André et Édouard Michelin, c'est une multinationale dont le siège social est à Clermont-
Ferrand (Puy-de-Dôme), en France. Avec 20 % du marché mondial, elle est le leader
mondial du pneumatique. En effet, talonnée par ses concurrents, le Japonais Bridgestone
(18,2 % du marché mondial) et l'Américain Goodyear (16,5 %), l'entreprise familiale
clermontoise affiche depuis plus d'un siècle sa suprématie sur le marché mondial des
pneumatiques. Elle possède 71 sites industriels dans 19 pays. Elle emploie 129 000
personnes, dont environ un quart en France. Ces personnes produisent près de 200 millions
de pneumatiques par an. Le marché du remplacement pour les voitures, les camionnettes et
les poids lourds représente 70 % de ses ventes en volume.
La société mère, la Compagnie générale des établissements Michelin, est une société
en commandite par actions. Les sociétés du groupe « hors France » sont chapeautées par
une société holding, la Compagnie Financière Michelin, domiciliée à Granges-Paccot dans
le canton de Fribourg en Suisse.
Depuis sa création, l’entreprise Michelin s’est donnée pour mission de contribuer au
progrès de la mobilité des personnes et des biens et, au-delà, au progrès de la société. Elle
vise à satisfaire le besoin humain fondamental de rencontre, d’échange et de découverte.
Parmi ses nombreuses inventions, il y a le pneu démontable, le pneu ferroviaire
appelé le pneu rail, la carcasse radiale qui équipe tous les pneus contemporains et le pneu
dit "vert" qui réduit la consommation de carburant par moindre résistance à l'avancement
des véhicules. Michelin publie aussi une série populaire de cartes routières et le fameux
guide Michelin, qui mentionne des restaurants gastronomiques et se vend dans le monde
entier. En 2009, la manufacture fête la 100e édition de son guide.
Figure 1 : Le célèbre Bibendum, symbole de la marque

Morgan DESLANDES & Diyé DIA 3
1 Présentation de l’étude
1.1 La description du problème
L’enjeu du projet est d’ajuster le compromis de performances des pneumatiques à
l’usage de la clientèle. Les conditions hivernales posent un réel problème aux routiers.
Pour améliorer les conditions de voyage des habitués de la route, Michelin doit effectuer
des études pour estimer l’occurrence des types de route ainsi que la criticité du type de sol
considéré, afin de calculer la pénalisation. On entend par occurrence, le nombre de fois où
on compte une photo avec un type de sol défini. Il existe différents types de sol, répertoriés
par Michelin tel que les sols noirs, sols recouverts de neige fraiche, sols recouverts de
neige damée, sols recouverts de neige verglacée, sols recouverts de neige fondante. La
criticité, ici subjective, donne le degré d’importance, pour un type de sol donné, des
situations de conduite. Une situation de conduite peut être, par exemple, le besoin de
freiner sur un sol verglacé. On note qu’une situation de conduite est composée d’un type de
sol et d’un type de sollicitation. La pénalisation, qui est le produit de l’occurrence par la
criticité, donne un indice qui reflète les problèmes des routiers face aux conditions
hivernales c’est-à-dire à quel point leur situation est pénalisante.
Figure 2 : Les différents types de sols enneigés

Morgan DESLANDES & Diyé DIA 4
Nous devions traiter le problème de l’occurrence, c'est-à-dire analyser les photos via
divers algorithmes, à l’aide de l’outil de traitement d’image de MATLAB, ensuite les trier
grossièrement en deux catégories : les sols dits « blanc » et les sols dits « noir ». Comme
on l’a souligné plus haut, pour éviter de biaiser les résultats, nous devions mettre en
évidence une troisième catégorie : les photos inexploitables. Les photos inexploitables sont
les photos identiques qui ont été prises plusieurs fois, sur un même lieu, lorsque le véhicule
était en arrêt ou parfois dans un embouteillage, quand le véhicule avance très peu. Dans ce
cas une seule photo est utile pour notre étude. Le cas où l’appareil photo a pris une photo
du paysage ou d’un mur est considéré comme inexploitable aussi.
Sur la figure 3, on peut voir quatre photos dont les trois dernières vont être classées
« inexploitables » car elles sont identiques, seule la première va être considérée pour
l’étude.
Ces photos ont été prises à l’aide d’un système de prise de vues et d’acquisition de
données implanté sur les véhicules. Ce système prend des photos de la route telle que vue
par le conducteur de véhicule et stocke ces données. Ces données sont ensuite traitées à la
fin de la campagne. Les photos prises par ce dispositif sont enrichies par les données GPS
(la longitude, la latitude, la date…) et des données VBOX (la pente, la charge, le
dévers…). Les photos sont au format JPEG. On considère l’emplacement du dispositif sur
le véhicule, fixe.
Figure 3 : Exemple de photos inexploitables

Morgan DESLANDES & Diyé DIA 5
On note que, sur à peu près 25 000 photos que Michelin nous ont données à
traiter, les photos de sol « noire » sont majoritaires. D’après le tri manuel, ces photos
représentent plus de 80 % des photos utilisables.
Nous avons résolu le problème de tri de toutes ces photos, en nous posant des
questions pratiques. D’abord, nous avons traité les données que nous possédions à savoir
les données GPS, principalement. Ensuite nous avons effectué des recherches dans le
domaine du traitement d’image, afin d’analyser les photos à notre disposition. Les
similitudes et différences que l’on a remarquées, sur les photos, nous ont aussi aidés, à
mener à bien notre tâche. Cette démarche, à première vue simple, nous a permis de
répondre à la question : comment séparer les photos en différentes catégories ?
Figure 4 : Le dispositif « boîte noire »
Figure 5 : Photo de sol « noir »

Morgan DESLANDES & Diyé DIA 6
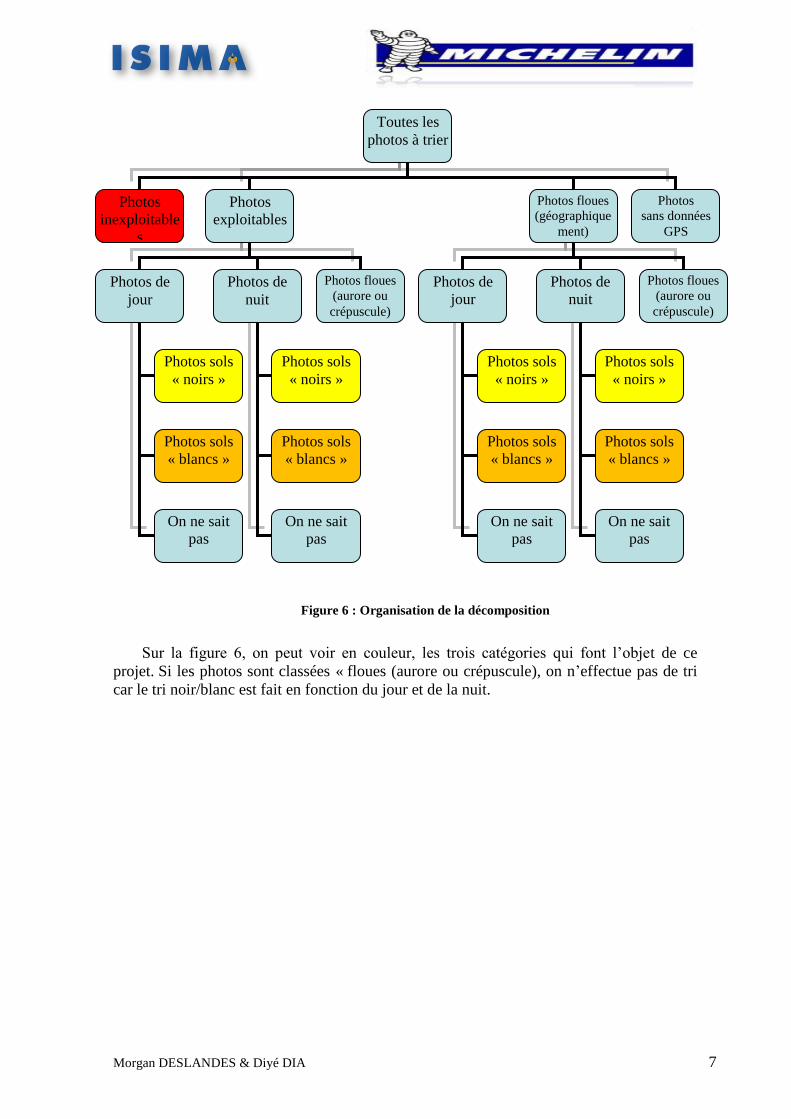
1.2 La décomposition du problème
Pour rendre le problème plus facile à résoudre, la décomposition en de plus petits
éléments semblait une bonne idée. En effet, il est plus facile de travailler sur l’ensemble
des photos de jour, par exemple, que sur toutes les photos. Les photos sont triées suivant
des similitudes, des points communs. Cette décomposition nous a permis d’avoir une vue
générale du projet et de répertorier tous les cas à étudier.
Décomposition au premier niveau
La première décomposition se fait grâce aux données GPS présentes sur les photos. Les
données sont lues à l’aide de l’application ExifPro, qui est destinée à afficher, manipuler et
voir des photographies. En plus d'afficher des images, ExifPro peut également présenter
des informations intégrées dans les photos JPEG, telles que la date ou un mot-clé, par
exemple. Cette étude nous a permis de séparer les photos inexploitables et les photos
utilisables. Ce n’est pas tout, l’analyse des informations nous a permis aussi de se rendre
compte qu’il existe une zone de floue dans laquelle on ne peut pas se prononcer. L’analyse
des photos nous a aussi autorisés à dire qu’il existait des photos qui ne possédaient pas de
données GPS. La distinction de ces cas partage l’ensemble des photos en quatre catégories.
Décomposition au deuxième niveau
Pour chaque catégorie, nous avons essayé de trier les photos, en formant d’autres sous-
catégories lorsque c’est possible. Pour les photos sans données GPS, nous n’avons pas
assez d’informations pour l’exploiter en profondeur. Notre projet a pour but,
grossièrement, de classer les photos en trois catégories : les photos inexploitables, les
photos de sols dits « noir » et les photos de sols dits « blanc ». La catégorie « photos
inexploitables » est le premier ensemble fini de notre tri. On n’a plus à exploiter cette
catégorie. Pour les deux dernières catégories, on a encore utilisé les données GPS, pour
séparer les photos prises durant la journée et les photos prises durant la nuit. La luminosité
de la photo n’étant pas la même que l’on soit de jour ou de nuit, il est préférable de
distinguer les deux cas pour un traitement optimal des images. Il existe, aussi, lors de ce tri,
une zone de floue (l’aurore et le crépuscule).
Décomposition au troisième niveau
Nous avons effectué des recherches pour pouvoir établir la décomposition à ce niveau.
Des techniques de traitement d’image ont été utilisées comme la binarisation avec la
méthode d’Otsu. Les photos de jour sont donc séparées en photos de sols dits « noir » et en
photos de sols dits « blanc ». Les photos de nuit sont divisées de la même manière
également. Ce tri, étant basé sur des techniques statistiques, qui seront détaillées plus tard,
crée aussi une catégorie de photos dites « incertain », c'est-à-dire l’algorithme ne permet
pas de les classer, sol « noir » ou sol « blanc ». Une autre méthode, utilisant l’histogramme
de l’image, est aussi utilisée dans cette partie pour le tri noir / blanc. Le tri de la catégorie
« incertain », générée au deuxième niveau, pourrait optimiser le résultat mais nous
pouvons pas le faire par manque de critère de tri.
Morgan DESLANDES & Diyé DIA 7
Toutes les
photos à trier
Photos
inexploitable
s
Photos
exploitables
Photos
sans données
GPS
Photos de
jour
Photos floues
(géographique
ment)
Photos de
nuit
Photos sols
« noirs »
Photos sols
« blancs »
Photos sols
« noirs »
Photos sols
« blancs »
On ne sait
pas
On ne sait
pas
Photos floues
(aurore ou
crépuscule)
Photos de
jour
Photos de
nuit
Photos floues
(aurore ou
crépuscule)
Photos sols
« noirs »
Photos sols
« blancs »
On ne sait
pas
Photos sols
« noirs »
On ne sait
pas
Photos sols
« blancs »
Sur la figure 6, on peut voir en couleur, les trois catégories qui font l’objet de ce
projet. Si les photos sont classées « floues (aurore ou crépuscule), on n’effectue pas de tri
car le tri noir/blanc est fait en fonction du jour et de la nuit.
Figure 6 : Organisation de la décomposition

Morgan DESLANDES & Diyé DIA 8
2 Le logiciel réalisé
2.1 Le tri des photos inexploitables
Le classement des photos dans l’ordre chronologique
Nous avons crée plusieurs fonctions, pour résoudre notre problème. Ces fonctions sont
utilisées, toutes, dans un programme principal. La fonction « classement » est la première
utilisée par la fonction principale. Le but de cette fonction est de ranger les photos dans
l’ordre chronologique à l’aide des données GPS. Ce rangement va faciliter le tri des photos
« inexploitables » dans une deuxième fonction qui est la fonction « inexploitable ». Elle
prend en paramètre le chemin du dossier dans lequel se trouvent les photos que l’on veut
analyser et retourne trois variables qui seront ensuite utilisées par les autres fonctions du
programme principal.
La première variable que retourne la fonction « classement » est un vecteur appelé
vecteur « ordre », de la taille du nombre de photos contenues dans le dossier donné en
paramètre. La composante i de ce vecteur donne l’indice de la iième image dans le dossier
chronologiquement. La deuxième variable est la liste des photos contenues dans le dossier
et la troisième variable est le nombre de photo dans le dossier. Le tri chronologique des
images se fait par insertion dichotomique. Voici l’algorithme de la fonction
« classement » :
Pour chaque image faire
Initialiser les indices inf et sup
Tant que inf est inférieur à sup faire
Calculer le milieu de ces indices qui correspond à l’indice mil
Comparer la date de l’image courante avec celle de l’image à l’indice mil
(position chronologiquement)
Si l’image est antérieure alors
Mettre à jour l’indice sup à mil
FinSi
Si l’image est postérieure alors
Mettre à jour l’indice inf à mil+1
FinSi
// L’indice chronologique de l’image courante est ‘sup’
FinTantque
FinPour
Le tri par la fonction « inexploitable »
Cette fonction a pour but de repérer les photos qui sont à peu près identiques, par
exemple, lorsque le véhicule s’arrête sur un parking et que le dispositif continue de prendre
des photos. Une seule de ces photos est utilisée et les autres sont considérées
inexploitables. Pour cela, la fonction parcourt toutes les images dans l’ordre
chronologique, grâce à la fonction « classement ». Grâce aux données GPS, elle calcule la
distance entre l’image courante et l’image précédente. Selon la valeur de cette distance, la
photo est considérée comme « inexploitable » si la distance est inférieure à vingt mètres,
« incertain (distance)» si la distance est comprise entre vingt mètres et cinquante mètres, et
« exploitable » si la distance est supérieure à cinquante mètres. Les photos pour lesquelles

Morgan DESLANDES & Diyé DIA 9
le véhicule est à l’arrêt, peuvent être exploitées avec la vitesse qui doit être nulle. Cette
donnée est contenue dans les données VBOX mais nous n’avons pas pu accéder à ces
données.
Pour effectuer l’algorithme de tri des photos « inexploitable », la fonction a besoin, en
paramètre, du vecteur « ordre », de la liste des photos et du nombre de photos, tous les trois
générés par la fonction précédente, c’est-à-dire la fonction « classement ». En sortie, la
fonction retourne un vecteur qui indique pour chaque photo si elle est « inexploitable »,
« incertain », « exploitable », ou si elle ne possède pas de données GPS.
Tant que parcourir les images dans l’ordre chronologique faire
Initialiser la première image possédant des données GPS à prec
Pour chaque image faire
Si l’image courante et prec possèdent des données GPS alors
Calculer la distance entre les deux images
Mise à jour de prec avec l’image courante
FinSi
FinPour
FinTantque
2.2 Le tri jour/nuit
Le tri par la fonction « nuitjour »
La fonction « nuitjour » sert à savoir si la photo a été prise de jour ou de nuit. Elle
fonctionne en calculant les heures de lever et de coucher du soleil grâce aux données GPS
qui permettent de connaître le lieu et l’heure à laquelle a été prise la photo (utilisation de
latitude et longitude). Cette fonction n’est donc utilisée que sur les images qui possèdent
des données GPS, et elle retourne un vecteur qui indique pour chacune de ces images s’il
fait nuit, jour ou si elle se trouve dans la zone d’incertitude. La zone d’incertitude
correspond à une heure avant l’heure de lever du soleil, qui a été calculée, et une heure
après l’heure de coucher du soleil, qui a été calculée. La fonction prend, en paramètre, la
liste des images à traiter et le vecteur obtenu avec la fonction « inexploitable ». Ce qui
permet de traiter que les photos « exploitable » et « incertain (distance)», les deux
catégories qui nous intéresse pour la suite de notre étude. On ne peut pas traiter les photos
sans données GPS puisqu’on n’a pas les moyens de les traiter et les traiter pourrait fausser
l’étude ou bien l’améliorer mais c’est incertain, donc on ne les traite pas.
Tant que parcourir les images considérées comme « exploitable » faire
Récupérer la date et l’heure de prise de vue, la latitude et la longitude
Calculer l’heure de lever et l’heure de coucher du soleil
Remplir le vecteur résultat en comparant l’heure de prise de vue avec celle de
lever et de coucher du soleil
FinTantque
Le programme principal et la fonction de rangement des photos « trie_photos »
Dans le programme principal, on fait appel à toutes les fonctions c'est-à-dire les
fonctions « classement », « inexploitable », « nuitjour », « blancnoirh » qu’on va présenter
plus tard, et la fonction « trie_photos ».

Morgan DESLANDES & Diyé DIA 10
On a construit une fonction « trie_photos » qui crée des répertoires et range les photos
triées dans les répertoires. Ainsi, l’utilisateur met le chemin où se trouvent les photos à
trier et exécute le programme principal, les photos sont triées et rangées dans le même
répertoire où se trouvent les photos à trier.
2.3 Le tri noir/blanc
Cette partie constitue le cœur du problème, en effet, le but du projet était de séparer
les photos de sol « blanc » et les photos de sol »noir ». Des méthodes de seuillages simples
ont d’abord été envisagées pour détecter la route, ensuite des méthodes de binarisation
comme la méthode d’Otsu ont été choisies. Enfin, l’exploitation de l’histogramme de
l’image a été expérimentée.
La méthode d’Otsu : principe et intérêt
En vision par ordinateur et traitement d'image, la méthode d'Otsu est utilisée pour
effectuer un seuillage automatique à partir de la forme de l'histogramme de l'image, ou la
réduction d'une image à niveaux de gris en une image binaire. Un histogramme de l’image
est un graphique statistique permettant de représenter la distribution des intensités des
pixels d'une image, c'est-à-dire le nombre de pixels pour chaque intensité lumineuse. Par
convention un histogramme représente le niveau d'intensité en abscisse en allant du plus
foncé (à gauche) au plus clair (à droite). Ainsi, l'histogramme d'une image en 256 niveaux
de gris sera représenté par un graphique possédant 256 valeurs en abscisses, et le nombre
de pixels de l'image en ordonnées. Prenons par exemple l'image suivante composée de
niveaux de gris :
L'histogramme et la palette associés à cette image sont respectivement les suivants :
L’histogramme fait apparaître que les tons gris clairs sont beaucoup plus présents dans
Figure 7a : Exemple d’une image composée de niveaux de gris
Figure 7b : L’histogramme et la palette associée à l’exemple

Morgan DESLANDES & Diyé DIA 11
l'image que les tons foncés. Le ton de gris le plus utilisé est le 11ème
en partant de la
gauche. Pour les images en couleur plusieurs histogrammes sont nécessaires. Par exemple
pour une image codée en RGB : un histogramme représentant la distribution de la
luminance et trois histogrammes représentant respectivement la distribution des valeurs
respectives des composantes rouges, bleues et vertes.
L'algorithme d’Otsu suppose alors que l'image à binariser ne contient que deux
classes de pixels, (c'est-à-dire le premier plan et l'arrière-plan) puis calcule le seuil optimal
qui sépare ces deux classes afin que leur variance intra-classe soit minimale. Le nom de
cette méthode provient du nom de son initiateur, Nobuyuki Otsu. Cette méthode de
binarisation nécessite au préalable le calcul de l'histogramme, comme on l’a expliqué plus
haut. Puis, la séparation en deux classes est effectuée. Elle se fait à partir de la moyenne et
l'écart-type. On calcul un seuil pour les 256 niveaux de gris (en utilisant la probabilité
qu'un pixel se trouve dans une classe) ensuite on prend le seuil max qui va être le critère de
séparabilité (sépare le premier plan et l’arrière plan). En appliquant cette méthode à la
partie de la photo qui nous intéresse, c'est-à-dire la route, on obtient un critère utilisable
pour séparer les photos de sol dit « noir » et les photos de sol dit « blanc » en utilisant les
marqueurs de la route, par exemple. L’application de cette méthode à notre problème n’est
pas très fiable, on distingue la route par rapport au reste de l’image mais, elle nous dit pas
si c’est « noir » ou « blanc ».
Figure 8a : Une photo à binariser avec la méthode d’Otsu
Figure 8b : Une Photo binarisée avec la méthode d’Otsu

Morgan DESLANDES & Diyé DIA 12
L’application de cette méthode : algorithme
On a fait des recherches pour trouver des méthodes de détection de contour (droite), on
a trouvé des méthodes de détections classiques comme la méthode qui utilise la transformée
de Hough (technique de reconnaissance de forme) mais comme sur une route il peut y avoir
d’autres véhicules devant le conducteurs, les résultats pouvaient être biaisés. Pour faire plus
simple et plus sûr, nous avons décidé de prendre le premier quart de l’image et de faire notre
étude sur cette partie. Cette partie de l’image intéressante peut être différente suivant le
placement du dispositif sur le véhicule. Voici l’image suivante, obtenue après découpage :
Après avoir déterminé sur quelle partie de l’image on va appliquer la méthode
d’Otsu, nous avons fait plusieurs tests pour savoir quel seuil correspond à un sol dit
« noir » et quel seuil peut-on associer à un sol dit « blanc ». L’algorithme, qui met en
Figure 9a : Photo entière
Figure 9b : Une partie de la photo intéressante

Morgan DESLANDES & Diyé DIA 13
place la méthode d’Otsu, et que l’on ne va pas donner ici, donne en sortie un critère de
séparabilité ou seuil. Notre étude nous a conduits à la conclusion, que si le seuil trouvé
pour un sol « noir » appartient à un intervalle que l’on définit, on classe cette photo dans
photos « noirs ». Ainsi nous avons définit plusieurs intervalles. Voici notre algorithme qui
traite le tri des photos en photos « noirs » et photos « blancs ». Dans cet algorithme, on ne
prendra que deux intervalles pour simplifier, le principe étant le même.
Pour chaque photo faire
Lire l’image
La découper et garder le premier quart
Appliquer la méthode d’Otsu
Récupérer le seuil
Si (seuil_défini1 < seuil < seuil_défini2) alors
Mettre la photo dans le répertoire « photos noirs »
Sinon si (seuil_défini3 < seuil < seuil_défini4) alors
Mettre la photo dans le répertoire « photos blancs »
Sinon
Mettre la photo dans le répertoire « on ne sait pas »
FinSi
FinPour
Un moyen plus simple et fiable pour résoudre ce problème : exploitation de
l’histogramme
Comme présenté plus haut l’histogramme de l’image permet d’avoir le nombre de
pixel présent dans une teinte de couleur. Le pic maximum de l’histogramme de l’image,
signifie qu’il y a un nombre maximum de pixel dans le niveau de gris correspondant au
pic. Il existe 256 niveaux de gris. On définit une fonction histo qui va construire
l’histogramme. L’algorithme se déroule comme suivant :
Pour chaque photo faire
Lire l’image
La découper et garder le premier quart
Transformer l’image RGB en image HSV
Construire l’histogramme de l’image HSV (h = histo (imageValue,256))
Prendre le niveau de gris associé au pic max de l’histogramme = seuil
Si (seuil < seuil_défini1) alors
Mettre la photo dans le répertoire « photos noirs »
Sinon si (seuil > seuil_défini2) alors
Mettre la photo dans le répertoire « photos blancs »
Sinon
Mettre la photo dans le répertoire « on ne sait pas »
FinSi
FinPour
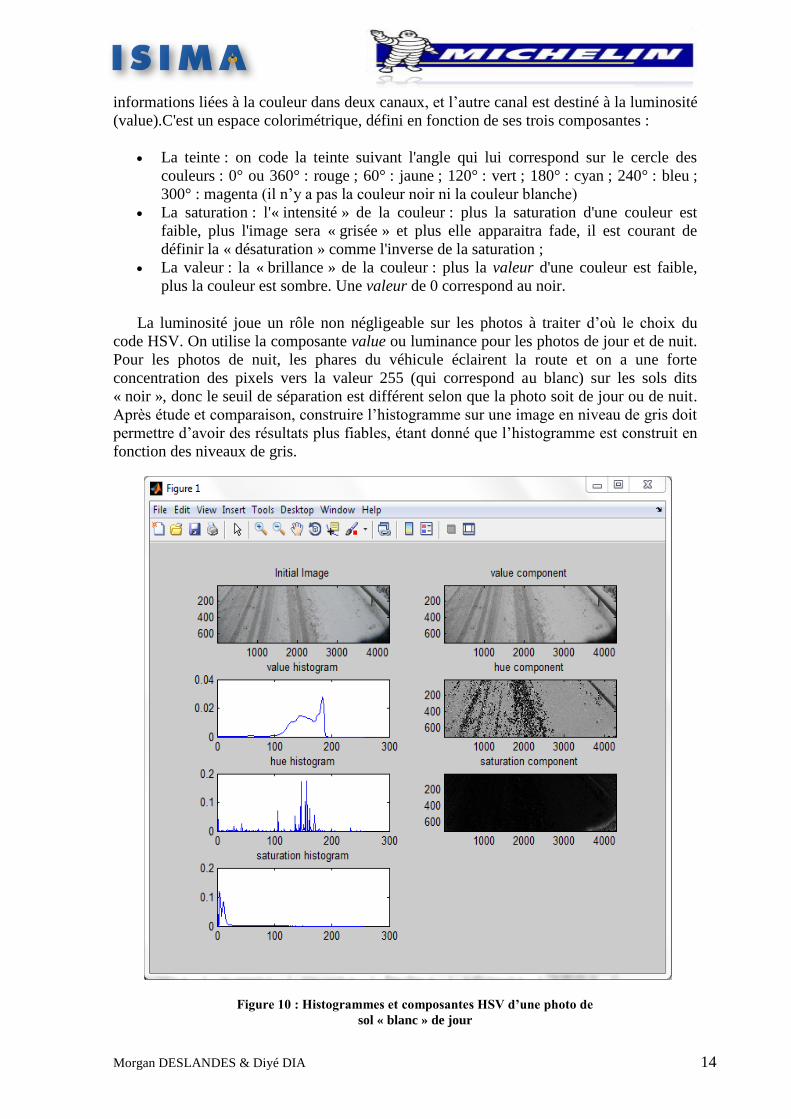
Dans cet algorithme, nous avons transformé l’image codée RGB en une image codée HSV
(H : hue ou teinte, S : saturation, V : value ou luminance). Ce code sépare la composante
de chrominance de la composante de luminance. L’image codée HSV, garde les
Morgan DESLANDES & Diyé DIA 14
informations liées à la couleur dans deux canaux, et l’autre canal est destiné à la luminosité
(value).C'est un espace colorimétrique, défini en fonction de ses trois composantes :
La teinte : on code la teinte suivant l'angle qui lui correspond sur le cercle des
couleurs : 0° ou 360° : rouge ; 60° : jaune ; 120° : vert ; 180° : cyan ; 240° : bleu ;
300° : magenta (il n’y a pas la couleur noir ni la couleur blanche)
La saturation : l'« intensité » de la couleur : plus la saturation d'une couleur est
faible, plus l'image sera « grisée » et plus elle apparaitra fade, il est courant de
définir la « désaturation » comme l'inverse de la saturation ;
La valeur : la « brillance » de la couleur : plus la valeur d'une couleur est faible,
plus la couleur est sombre. Une valeur de 0 correspond au noir.
La luminosité joue un rôle non négligeable sur les photos à traiter d’où le choix du
code HSV. On utilise la composante value ou luminance pour les photos de jour et de nuit.
Pour les photos de nuit, les phares du véhicule éclairent la route et on a une forte
concentration des pixels vers la valeur 255 (qui correspond au blanc) sur les sols dits
« noir », donc le seuil de séparation est différent selon que la photo soit de jour ou de nuit.
Après étude et comparaison, construire l’histogramme sur une image en niveau de gris doit
permettre d’avoir des résultats plus fiables, étant donné que l’histogramme est construit en
fonction des niveaux de gris.
Figure 10 : Histogrammes et composantes HSV d’une photo de
sol « blanc » de jour
Morgan DESLANDES & Diyé DIA 15
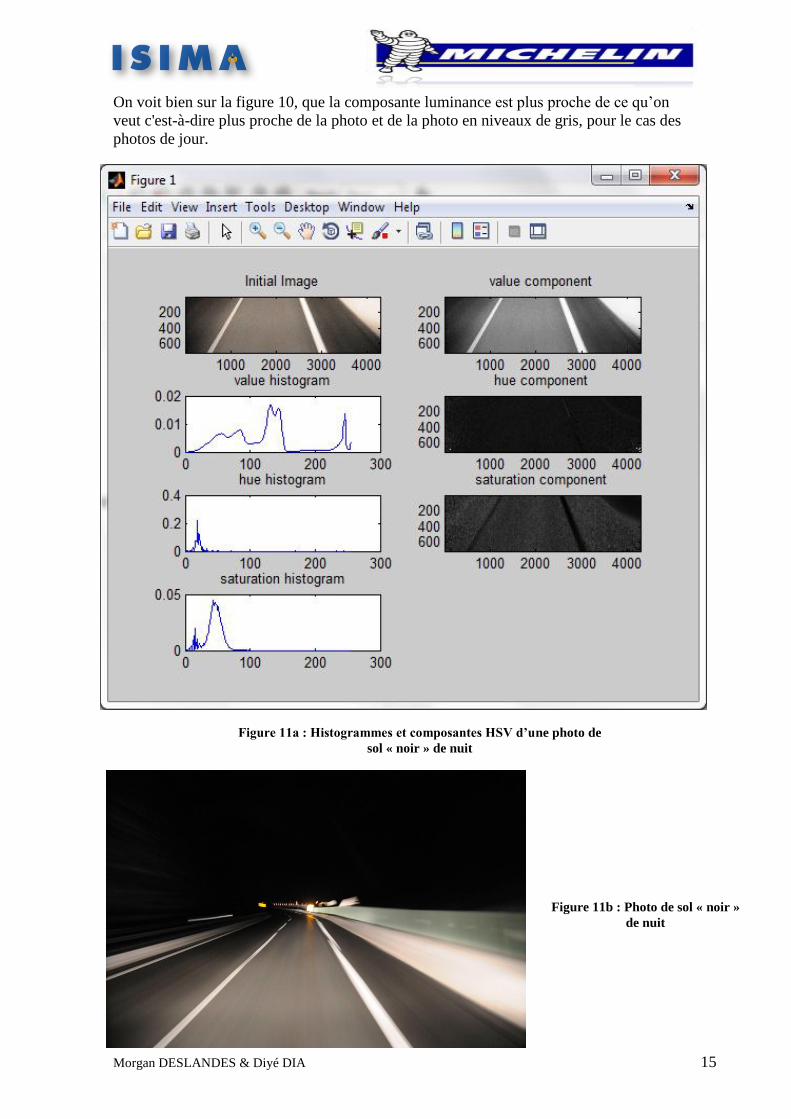
On voit bien sur la figure 10, que la composante luminance est plus proche de ce qu’on
veut c'est-à-dire plus proche de la photo et de la photo en niveaux de gris, pour le cas des
photos de jour.
Figure 11b : Photo de sol « noir »
de nuit
Figure 11a : Histogrammes et composantes HSV d’une photo de
sol « noir » de nuit

Morgan DESLANDES & Diyé DIA 16
3 Résultats et Discussions
Pour valider nos résultats, nous avons implémenté des fonctions de comparaison. Pour
faire cela, il nous fallait récupérer les « tags » ou mots-clés, présents sur les photos et
affectés par Michelin, à la suite du tri manuel. Les mots-clés « inexploitable » ou « noir »,
par exemple, sont des méta-données IPTC. Ces méta-données vont nous permettre de
comparer nos résultats, lors du tri pour extraire les photos « inexploitable », les photos
« noir » et les photos « blanc », avec les résultats du tri manuel. C'est-à-dire la qualité du tri
« ISIMA » est évaluée en comparant le résultat « ISIMA » et le tag déjà affecté
manuellement par Michelin (les différentes catégories de sol noir (sec, mouillé) ou blanc
(damée, fraiche, fondante…) définies par Michelin ne sont pas interprétées au-delà de noir
ou blanc).
Notre fonction qui sépare les photos inexploitables et les autres catégories
(« incertain », « photos sans GPS » et « exploitable »), marche bien. Pour la comparaison
des tags, lorsque nous mettons le tag « inexploitable », le tag Michelin est le même mais il
existe des tags Michelin « inexploitables » que nous ne mettons pas. Nous ne mettons le
tag « inexploitable » que pour les photos qui correspondent à notre critère de distance, mais
il existe des photos inexploitables qui le sont parce que c’est une photo de paysage sans
route, par exemple, et donc le critère de distance classe cette photo dans les photos
exploitables. Si on avait un critère de vitesse, notre tri des photos « inexploitable» serait
amélioré.
Nous avons testé notre programme sur un premier jeu de données de 200 photos, les
résultats sont en pourcentage :
Tri « ISIMA » en % Tri « Michelin » en %
Inexploitable 20 38.5
Sans GPS 4 -
Incertain (distance) 2.5 -
Exploitable 73.5 61.5
38.5 % des photos sont inexploitables d’après le tri à la main. Ce résultat est à
comparer avec l’ensemble « inexploitable », « sans GPS » et « incertain » qui regroupent
26.5 %. En accord avec nos dires, il existe des photos qui sont inexploitables pour d’autres
causes différentes du critère de distance. Ces photos que notre algorithme n’a pas traitées,
par manque de critères, de données, représentent 31% des photos considérées
«inexploitables» par Michelin. Donc en comparaison au tri « Michelin », 69% des photos
« inexploitable » sont bien triées par notre tri, le tri « ISIMA ».
Tri « ISIMA » en % Tri manuel en %
Incertain (distance)/Jour 0 -
Incertain (distance)/Nuit 100 -
Incertain
(distance)/incertain
0 -
Exploitable/Jour 1.3 0
Exploitable/Nuit 85.7 93.8
Exploitable/Incertain 13 6.2

Morgan DESLANDES & Diyé DIA 17
Nous avons effectué un tri manuel pour les photos de jour et de nuit pour
comparer les résultats obtenus.
Le tri jour/nuit « ISIMA » nous donne les résultats suivante : Sur les photos traitées,
c’est-à-dire sur lesquelles on applique notre algorithme, 86.2 % sont classées photos de
nuit contre 93.8 % pour le tri Michelin ce qui est explicable par le fait que l’aurore et le
crépuscule à des minutes près, semble être des photos de nuit à l’œil.
Nous allons présenter les résultats du tri « ISIMA » pour le tri noir/blanc, toujours
pour le premier jeu de données.
Catégories de photos
Exploitables
Méthode
d’Otsu en %
L’histogramme de
l’image
HSV en %
Exploitable/Jour/Noir 100 50
Exploitable/Jour/Blanc 0 50
Exploitable/Jour/Onnesaitpas 0 0
Exploitable/Nuit/Noir 82.6 27
Exploitable/Nuit/Blanc 17.4 73
Exploitable/Nuit/Onnesaitpas 0 0
Résultants surprenants dû aux lumières très claires des phares dans ce jeu de donnée.
D’où la proposition de choix de la teinte au lieu de la luminance, dans le cas des photos de
nuit, ou tout simplement de construire l’histogramme à partir de l’image en niveau de gris.
Dans le répertoire « noir » on trouve que 41% des photos de ce répertoire sont affectées du
tag « inexploitable » de Michelin. Dans le répertoire « blanc » on trouve que 15% des
photos de ce répertoire sont affectées du tag « inexploitable » de Michelin.
A la fin de ce tri, la méthode d’Otsu compte que 53% de photos de sols dits « noir »,
20% de photos « inexploitables », et 11% de photos de sols dits « blanc », 16% de photos
non classées. Pour le tri, la méthode de l’histogramme de l’image HSV, nous donne 18%
de photos de sols dits « noir » et 48.5% de photos de sols dits « blanc ».
Catégories de photos
Exploitables
Méthode Michelin en %
Exploitable/Noir 60.5
Exploitable/Blanc 1
Nous avons testé notre programme sur un deuxième jeu de données de 200 photos
différent de la première, les résultats sont en pourcentage :
Tri « ISIMA » en % Tri « Michelin » en %
Inexploitable 10.5 33
Sans GPS 2.5 -
Incertain (distance) 0.5 -
Exploitable 86.5 67
Comme pour le premier jeu de données, on a moins de photos « inexploitable » par rapport
au tri « Michelin ». L’explication est la même.

Morgan DESLANDES & Diyé DIA 18
Tri « ISIMA » en % Tri manuel en %
Incertain(distance)/Jour 100 -
Incertain(distance)/Nuit 0 -
Incertain(distance)/Incertain 0 -
Exploitable/Jour 59.6 56
Exploitable/Nuit 28.3 40.3
Exploitable/Incertain 12.1 3.7
On peut dire que c’est résultat tri nuit/jour est le fruit du tri précédent. En effet le
nombre de photos exploitables étant différent, ça a un impact sur le tri suivant.
Catégories de photos
Exploitables
Méthode
d’Otsu en %
L’histogramme de
l’image HSV en %
L’histogramme
de l’image en
niveau de gris
en %
Exploitable/Jour/Noir 65 76.7 76.7
Exploitable/Jour/Blanc 35 16.5 16.5
Exploitable/Jour/Onnesaitpas 0 6.8 6.8
Exploitable/Nuit/Noir 83.7 28.6 36.7
Exploitable/Nuit/Blanc 16.3 71.4 61.2
Exploitable/Jour/Onnesaitpas 0 0 2.1
Avec Otsu, sur les photos présentes dans les catégories « jour » et « nuit », on obtient
50.6% de photos de sols dits « noir » et 29% de sols « blanc » avec le tri « ISIMA » tandis
qu’avec le tri « Michelin » on a 69% de sols « noir » et 7.2% de sols « blanc ». Les
catégories sols « noir » contiennent que des sols réellement noirs, il existe un taux
d’erreurs dans les catégories sols « blanc ».
Avec la méthode de l’histogramme avec image HSV, on a toujours le même
problème des phares du véhicule qui fausse le traitement. Mais les photos de jour sont bien
triées. En effet, sur les photos de jour, 69% sont réellement « noir » d’après le tri Michelin
et 9% sont « blanc » conter 76.7% et 16.5% pour notre tri. Donc, l’algorithme trie bien les
sols « noir », dans la catégorie « noir », on ne trouve que des sols « noir » ou
« inexploitable » bien sûr. Tandis que pour l’histogramme en niveau de gris, les résultats
sont améliorés pour le tri de nuit, bien qu’on reste loin de la réalité.
Catégories de photos
Exploitables
Méthode Michelin en %
Exploitable/Noir 61
Exploitable/Blanc 6
Concernant la qualité du tri, le tri des photos de jour par l’histogramme et très fiable,
nous l’avons essayé sur plusieurs jeu de données, les résultats sont satisfaisants. Le tri des
photos inexploitables, aussi, est satisfaisant. Par contre nous restons sceptiques sur les
résultats d’Otsu. Bien que proche de la réalité, comme nous l’avons vu sur les résultats,
théoriquement, l’objectif de cette méthode ne correspond pas à l’objectif de notre tri. Le tri
utilisant l’histogramme de l’image pose quelques soucis lorsqu’on est de nuit. Nous avons
essayé de l’améliorer en passant en image en niveau de gris. Il y a eu une amélioration
mais qui reste loin de la réalité. Sur l’ensemble des photos exploitables, d’après le tri
Michelin, on doit avoir à peu près 80% de sols dits « noir ». Sur le tri « ISIMA », on 50%
de photos de sols « noir » avec la méthode de l’histogramme en HSV.

Morgan DESLANDES & Diyé DIA 19
La consigne qu’aucun sol « blanc » ne soit trié comme « noir » et que les photos de
sol « blanc » dans la catégorie inexploitable sont bien des photos redondantes dont un
exemplaire est présent dans la catégorie sol blanc a été bien respecté. Pour les cas des
photos classées « on ne sait pas « ou « floue », le cahier des charges nous imposait des
contraintes. 10% des photos doivent faire partie de cette catégorie, nous avons à peu près
17% de photos dans cette catégorie. L’utilisateur doit juste choisir le répertoire des photos
à trier. Le tri est bien automatisé. Concernant les performances, notre algorithme trie 20
photos à la minute, environ.
Difficultés et améliorations
L’une de nos premières difficultés a été de récupérer les tags IPTC sur les photos.
Aucune fonction sur Matlab ne permet de les extraire, il a fallut utiliser un autre logiciel :
ExifPro, pour extraire les tags sous forme de fichier texte que l’on lit ensuite avec Matlab.
Cette méthode permet de pouvoir lire les tags mais pas de les écrire. C’est pourquoi les
fichiers sont déplacés dans des dossiers qui correspondent au tag que l’on veut leur donner.
Mais le déplacement des fichiers prend du temps et peut-être qu’écrire les tags dans un
fichier texte aurait été mieux bien que surement moins pratique.
Nous avons également eu quelques difficultés avec la date et l’heure de prise de vue
des photos. Avec Matlab, nous avons trouvé plusieurs façons différentes de récupérer ces
données mais certaines peuvent provenir des paramètres de l’appareil photos alors que l’on
veut la date et l’heure données par le GPS. Sur les images que nous avons traitées, toutes
les valeurs étaient les mêmes, nous n’avons donc pas pu les différencier et savoir quelle
méthode utiliser pour avoir la date et l’heure provenant du GPS.
Nous avons aussi passé du temps pour améliorer la méthode d’Otsu. Du point de vue
théorique cette méthode nous paraissait adéquate mais en pratique les résultats n’étaient
pas satisfaisants. Nous avons essayé de l’améliorer en affinant la valeur des seuils et en
ciblant une partie spécifique de l’image mais les résultats n’étaient toujours pas bons.
Donc nous avons revu les bases de cette méthode et nous avons compris pourquoi nos
résultats n’étaient pas satisfaisants. Nous avons donc essayé d’amélioré cette partie en
exploitant l’histogramme de l’image, qui est elle-même à l’origine de la méthode d’Otsu.
Nous avons pensé à des améliorations qui pourraient être ajoutées à notre programme,
mais nous avons manqué de temps. On aurait pu, par exemple, utiliser les marqueurs sur
les routes pour pouvoir délimiter la route et avoir un histogramme plus représentatif de la
chaussée, mais cette technique ne concerne que des routes particulières et il y aurait donc
un tri à faire au préalable. On aurait pu aussi trouver une méthode pour classer de jour ou
de nuit les photos sans données GPS et pouvoir ainsi les traiter malgré tout. Les photos qui
ne sont classé ni jour ni nuit, on ne sait pas encore les traiter, il y a une amélioration à faire.

Morgan DESLANDES & Diyé DIA 20
Conclusion
L’objectif qui consistait à trier les photos de sols dits « noir », les photos de sols
dits « blancs » et les photos inexploitables est atteint. Les taux d’erreurs peuvent encore
être améliorés. En effet, tout au long de l’étude, par de multiples recherches, nous avons pu
améliorer le taux d’erreur, par l’application de différentes méthodes. Le tri, plus fin, des
différents types de sols dits « blancs » c'est-à dire sols recouverts de neige fraiche, damée
ou fondante, n’a pas pu être fait.
Nous avons rencontré des difficultés techniques. La lecture de données pour
construire les algorithmes, l’amélioration de la fonction de tri noir/blanc sont ces
difficultés entre autres. Au niveau de l’organisation, le rapport envoyé sous forme de mail,
était hebdomadaire et on a manqué d’organisation (retard des mails par manque de
temps…). Des améliorations à tous les niveaux sont à faire pour optimiser le tri et
l’automatiser davantage.
L’utilisation du programme réalisé va permettre à Michelin de trier les photos de
route de manière plus rapide. Bien que le programme ne soit pas parfait, il réduit le temps
de travail manuel. Ce projet pourrait donner lieu à un autre projet d’amélioration du
produit.

Morgan DESLANDES & Diyé DIA
Références webographiques
Documentation Matlab Central et Otsu [Ressource électronique]
Disponible sur : http://www.mathworks.com
Disponible sur :http://www.biomecardio.com/matlab/otsu.html
Documentation données IPTC [Ressource électronique]
Disponible sur: http://www.developpez.net/forums/d755571/environnements-
developpement/matlab/images/ecrire-tag-image-tif/
Documentation données Exif [Ressource électronique]
Disponible sur : http://www.exif.org/
Documentation heure de coucher et de lever du soleil [Ressource électronique]
Disponible sur : http://jean-paul.cornec.pagesperso-orange.fr/heures_lc.html
Documentation sur calcul de distance coordonnées GPS [Ressource électronique]
Disponible sur : http://www.clubic.com/forum/programmation

Morgan DESLANDES & Diyé DIA
Glossaire
Application : désigne à la fois, en informatique, l'activité d'un utilisateur susceptible d'être
automatisée et le logiciel qui automatise cette activité : le logiciel applicatif.
Binarisation : une opération qui produit deux classes de pixels, en général, ils sont
représentés par des pixels noirs et des pixels blancs.
Dichotomie : (« couper en deux » en grec) c’est, en algorithmique, un processus itératif ou
récursif de recherche où, à chaque étape, on coupe en deux parties (pas forcément égales)
un espace de recherche qui devient restreint à l'une de ces deux parties.
Données GPS : données issues du système de positionnement par satellite.
Données IPTC : C’est en 1979 que l’I.P.T.C. (International Press Telecommunications
Council) lance le premier « standard » de description de documents textes pour les partages
d’information au sein de la Presse Internationale. En 1991, l’I.I.M (Information
Interchange Model) est proposé comme entête électronique intégré, pour les documents
électroniques multimédia, et en 1994, donne naissance à la première norme dédiée aux
images numérique : les IPTC Headers (littéralement : entêtes IPTC), très largement
utilisées depuis sur les formats JPEG et TIF notamment pour la description des images.
Image RGB : une image est composée de plusieurs pixels. Un pixel est représenté par trois
canaux : rouge, vert, et bleu.
MATLAB : Il est à la fois un langage de programmation et un environnement de
développement développé et commercialisé par la société américaine MathWorks.
MATLAB est utilisé dans les domaines de l'éducation, de la recherche et de l'industrie pour
le calcul numérique mais aussi dans les phases de développement de projets.
Niveau de gris : en imprimerie, désigne la concentration des points de trame et est donc
directement en rapport avec le rendu de l'image. Un niveau de gris va alors varier du blanc
au noir. Cela est également valable pour toutes les autres couleurs (cyan, magenta, jaune).
On fera alors varier la densité du cyan du blanc jusqu'au cyan foncé. Dans le cas d'une
image numérique, le niveau de gris représente l'intensité lumineuse d'un pixel, lorsque ses
composantes de couleur sont identiques en intensité lumineuse.
Traitement d’image : discipline de l'informatique et des mathématiques appliquées qui
étudie les images numériques et leurs transformations, dans le but d'améliorer leur qualité
ou d'en extraire de l'information.


















