
Conservatoire National des Arts et...
276
Conservatoire National des Arts et Métiers Polycopié de cours et de travaux pratiques Version du 02/10/2013 Circuits logiques programmables C.ALEXANDRE
-
Upload
nguyenxuyen -
Category
Documents
-
view
214 -
download
0
Transcript of Conservatoire National des Arts et...

Conservatoire National des
Arts et Métiers
Polycopié de cours et de travaux pratiques
Version du 02/10/2013
Circuits logiques programmables
C.ALEXANDRE


i
1. LES CIRCUITS SPECIFIQUES A UNE APPLICATION ........ .............................................................. 1
1.1 INTRODUCTION .......................................................................................................................................... 1
1.2 TECHNOLOGIE UTILISEE POUR LES INTERCONNEXIONS ............................................................................... 3
1.2.1 Interconnexion directe ..................................................................................................................... 4
1.2.1.1 Interconnexion par fusible ...................................................................................................................... 4
1.2.1.2 Interconnexion par anti-fusible .............................................................................................................. 4
1.2.2 Interconnexion par cellule mémoire ................................................................................................ 5
1.2.2.1 La cellule EPROM ................................................................................................................................. 5
1.2.2.2 La cellule EEPROM ............................................................................................................................... 6
1.2.2.3 La cellule flash ....................................................................................................................................... 6
1.2.2.4 La cellule SRAM .................................................................................................................................... 6
1.3 LES CIRCUITS FULL CUSTOM ....................................................................................................................... 7
1.3.1 Les circuits à la demande ................................................................................................................ 7
1.3.2 Les circuits à base de cellules ......................................................................................................... 7
1.3.2.1 les cellules précaractérisées .................................................................................................................... 8
1.3.2.2 Les circuits à base de cellules compilées ................................................................................................ 8
1.4 LES CIRCUITS SEMI-CUSTOM ...................................................................................................................... 8
1.4.1 Les circuits prédiffusés .................................................................................................................... 8
1.4.1.1 Les circuits prédiffusés classiques .......................................................................................................... 8
1.4.1.2 Les circuits mer-de-portes ...................................................................................................................... 9
1.4.1.3 Les ASICs structurés ............................................................................................................................ 10
1.4.2 Les circuits programmables .......................................................................................................... 10
1.4.2.1 Les PROM ........................................................................................................................................... 11
1.4.2.2 Les PLA ............................................................................................................................................... 12
1.4.2.3 Les PAL ............................................................................................................................................... 13
1.4.2.4 Les EPLD ............................................................................................................................................. 18
1.4.2.5 Les FPGA ............................................................................................................................................. 20
1.4.2.6 Conclusion ........................................................................................................................................... 22
1.5 IMPLEMENTATION .................................................................................................................................... 22
1.6 COMPARAISON ENTRE LES FPGA ET LES AUTRES CIRCUITS SPECIFIQUES ................................................. 23
1.6.1 Comparaison entre les PLD et les ASIC. ....................................................................................... 24
1.6.2 Comparaison entre les FPGA et les EPLD.................................................................................... 24
1.6.3 Seuil de rentabilité entre un FPGA et un ASIC ............................................................................. 24
1.7 LES FAMILLES DE FPGA/EPLD ............................................................................................................... 26
1.7.1 Xilinx (52 % part de marché) ........................................................................................................ 27
1.7.2 Altera (34 % part de marché) ........................................................................................................ 28
1.7.3 Les autres fabricants ..................................................................................................................... 28
2. UN EXEMPLE DE FPGA : LA FAMILLE SPARTAN-3 ......... ............................................................ 29
2.1 CARACTERISTIQUES GENERALES .............................................................................................................. 29
2.2 BLOCS D’ENTREE-SORTIE (IOB) ............................................................................................................... 30

ii
2.2.1 Généralités ..................................................................................................................................... 30
2.2.2 Caractéristiques d’entrée ............................................................................................................... 32
2.2.3 Caractéristiques de sortie .............................................................................................................. 32
2.3 BLOC LOGIQUE CONFIGURABLE (CLB) ..................................................................................................... 32
2.3.1 Généralités ..................................................................................................................................... 32
2.3.2 Générateurs de fonctions ............................................................................................................... 34
2.3.3 Bascules ......................................................................................................................................... 34
2.3.4 Configuration en ROM, RAM et registre à décalage ..................................................................... 34
2.3.5 Logique de retenue rapide ............................................................................................................. 35
2.4 BLOCK RAM (SELECTRAM) ................................................................................................................... 35
2.5 MULTIPLIEURS DEDIES ............................................................................................................................. 36
2.6 GESTIONNAIRE D’HORLOGES .................................................................................................................... 36
2.7 RESSOURCES DE ROUTAGE ET CONNECTIVITE ........................................................................................... 37
2.7.1 Généralités ..................................................................................................................................... 37
2.7.2 Routage hiérarchique .................................................................................................................... 38
2.7.3 Lignes dédiées d’horloge ............................................................................................................... 40
2.8 CONFIGURATION....................................................................................................................................... 40
2.9 METHODOLOGIE DE PLACEMENT .............................................................................................................. 44
3. CONCEPTION D’UN FPGA .................................................................................................................... 45
3.1 SAISIE DU DESIGN ..................................................................................................................................... 45
3.1.1 Saisie de schéma ............................................................................................................................ 45
3.1.2 Langage de description de bas niveau ........................................................................................... 48
3.1.3 Langage de description matériel ................................................................................................... 49
3.2 LES OUTILS DE DEVELOPPEMENT XILINX .................................................................................................. 50
3.2.1 Le flot Xilinx .................................................................................................................................. 50
3.2.2 Mise en œuvre des contraintes ....................................................................................................... 52
3.2.3 Les modèles de timing .................................................................................................................... 54
3.2.4 Les librairies unifiées ..................................................................................................................... 56
3.2.5 Core Generator .............................................................................................................................. 59
3.3 LA MAQUETTE FPGA ............................................................................................................................... 60
3.3.1 Constitution .................................................................................................................................... 60
3.4 RECAPITULATIF DE LA CHAINE COMPLETE ................................................................................................ 62
4. DU VHDL A LA SYNTHESE ................................................................................................................... 67
4.1 LE LANGAGE VHDL ................................................................................................................................. 67
4.1.1 Définition ....................................................................................................................................... 67
4.1.2 Généralités ..................................................................................................................................... 67
4.1.2.1 Nécessité .............................................................................................................................................. 67
4.1.2.2 Un peu d'histoire .................................................................................................................................. 67

iii
4.1.3 Les principales caractéristiques du langage VHDL ...................................................................... 69
4.1.3.1 Un langage s'appliquant à plusieurs niveaux de descriptions ............................................................... 69
4.1.3.2 La portabilité ........................................................................................................................................ 70
4.1.3.3 La lisibilité ........................................................................................................................................... 70
4.1.3.4 La modularité ....................................................................................................................................... 70
4.1.3.5 Le couple entité architecture ................................................................................................................ 71
4.1.3.6 Les principaux objets manipulés .......................................................................................................... 72
4.1.3.7 Les types .............................................................................................................................................. 73
4.1.3.8 Fonctionnement concurrent .................................................................................................................. 74
4.1.3.9 Fonctionnement séquentiel ................................................................................................................... 75
4.1.4 VHDL par rapport aux autres langages ........................................................................................ 75
4.1.5 Normes et extensions ..................................................................................................................... 76
4.1.6 La synthèse .................................................................................................................................... 77
4.1.6.1 définition .............................................................................................................................................. 77
4.1.6.2 La synthèse automatique de circuits : dans quel but ? .......................................................................... 77
4.2 EXEMPLES COMMENTES DE CIRCUITS LOGIQUES ....................................................................................... 78
4.2.1 Portes combinatoires ..................................................................................................................... 79
4.2.2 multiplexeurs ................................................................................................................................. 82
4.2.3 Assignation inconditionnelle de signal : séquentiel contre concurrent ......................................... 89
4.2.4 compteur ........................................................................................................................................ 90
4.2.5 circuit diviseur d’horloge ............................................................................................................ 100
4.2.6 Circuit générateur de CE............................................................................................................. 102
4.2.7 registre ......................................................................................................................................... 103
4.2.8 buffer trois états ........................................................................................................................... 105
4.2.9 mémoire ROM.............................................................................................................................. 106
5. TRAVAIL PRATIQUE N°1 .................................................................................................................... 109
5.1 OUVERTURE DE SESSION ........................................................................................................................ 109
5.2 LANCEMENT DE « PROJECT NAVIGATOR » ............................................................................................. 109
5.3 CREATION DU PROJET ............................................................................................................................. 109
5.4 CREATION DU SCHEMA ........................................................................................................................... 112
5.5 GENERATION DU FICHIER DE STIMULI VHDL ......................................................................................... 123
5.6 SIMULATION FONCTIONNELLE ................................................................................................................ 129
5.7 SYNTHESE .............................................................................................................................................. 134
5.8 IMPLEMENTATION .................................................................................................................................. 138
5.9 SIMULATION DE TIMING .......................................................................................................................... 142
5.10 CONFIGURATION DE LA MAQUETTE ................................................................................................... 144
5.11 LE FLOT VHDL ................................................................................................................................. 150
5.12 FICHIER DE CONTRAINTES ................................................................................................................. 153
6. TRAVAIL PRATIQUE N°2 .................................................................................................................... 155

iv
6.1 INITIALISATION DU PROJET ..................................................................................................................... 155
6.2 CREATION DES LOGICORE ...................................................................................................................... 155
6.3 CREATION DU SCHEMA ........................................................................................................................... 163
6.4 LA SUITE DU TP...................................................................................................................................... 166
6.5 ECRITURE DU MODELE EN VHDL ........................................................................................................... 169
6.6 FICHIER DE CONTRAINTES ...................................................................................................................... 176
7. TRAVAIL PRATIQUE N°3 .................................................................................................................... 179
7.1 L’ EDITEUR DE FPGA ET LE FLOORPLANNER ........................................................................................... 179
7.2 LES RAPPORTS D’ IMPLEMENTATION ....................................................................................................... 186
7.3 L’ ANALYSE TEMPORELLE ....................................................................................................................... 188
7.4 LES CONTRAINTES .................................................................................................................................. 202
7.5 VERIFICATION DE LA PROGRAMMATION DU FPGA ................................................................................. 211
7.6 PROGRAMMATION DE LA MEMOIRE FLASH SERIE .................................................................................... 214
7.7 ACCES A L’ INFORMATION ....................................................................................................................... 221
8. TRAVAIL PRATIQUE N°4 .................................................................................................................... 225
8.1 OUVERTURE DU PROJET ......................................................................................................................... 225
8.2 CREATION DU DESIGN ............................................................................................................................. 226
8.3 LA SYNTHESE ......................................................................................................................................... 234
8.4 LA SUITE DU TP...................................................................................................................................... 237
8.5 L’ INTERET DES RESSOURCES DEDIEES .................................................................................................... 239
8.6 L’ ARCHITECTURE EN PIPELINE ................................................................................................................ 242
8.7 FICHIER DE CONTRAINTES ...................................................................................................................... 244
9. LE PROJET FREQUENCEMETRE ..................................................................................................... 247
9.1 LE MODE FREQUENCEMETRE .................................................................................................................. 247
9.2 LE MODE PERIODEMETRE ....................................................................................................................... 248
9.3 CREATION DU PROJET ............................................................................................................................. 249
9.4 METHODE DE TRAVAIL ........................................................................................................................... 250
9.5 LE COMPOSANT HORLOGE ...................................................................................................................... 254
9.6 LE COMPOSANT COUNT .......................................................................................................................... 254
9.7 LE COMPOSANT AFFICH .......................................................................................................................... 255
9.8 LE COMPOSANT CTRL ............................................................................................................................. 256
9.9 ANNEXE 1 : CARACTERISTIQUES DU 74148 ............................................................................................ 257
9.10 ANNEXE 2 : LISTING DU TOP LEVEL DESIGN FREQ ............................................................................. 259
9.11 ANNEXE 3 : LISTING DU PACKAGE FREQ_PKG ..................................................................................... 261

1
1. Les circuits spécifiques a une application
1.1 Introduction
Il existe une loi empirique, appelée loi de Moore, qui dit que la densité d’intégration dans les
circuits intégrés numériques à base de silicium double tous les 18 à 24 mois. Cette loi s’est
révélée remarquablement exacte jusqu'à ce jour. Durant les années 60, au début de l'ère des
circuits intégrés numériques, les fonctions logiques telles que les portes, les registres, les
compteurs et les ALU, étaient disponibles en circuit TTL. On parlait de composants SSI
(Small Scale Integration) ou MSI (Medium Scale Integration) pour un tel niveau d'intégration.
Dans les années 70, le nombre de transistors intégrés sur une puce de silicium augmentait
régulièrement. Les fabricants mettaient sur le marché des composants LSI (Large Scale
Integration) de plus en plus spécialisés. Par exemple, le circuit 74LS275 contenait 3
multiplieurs de type Wallace. Ce genre de circuit n'était pas utilisable dans la majorité des
applications. Cette spécialisation des boîtiers segmentait donc le marché des circuits intégrés
et il devenait difficile de fabriquer des grandes séries. De plus, les coûts de fabrication et de
conception augmentaient avec le nombre de transistors. Pour toutes ces raisons, les catalogues
de composants logiques standards (série 74xx) se sont limités au niveau LSI. Pour tirer
avantage des nouvelles structures VLSI (Very Large Scale Integration), les fabricants
développèrent 4 nouvelles familles :
• Les microprocesseurs et les mémoires RAM et ROM : les microprocesseurs et les circuits
mémoires sont attrayants pour les fabricants. Composants de base pour les systèmes
informatiques, ils sont produits en très grandes séries.
• Les ASSP (Application Specific Standard Product) : ce sont des produits sur catalogue qui
sont fabriqués en grande série. La fonction réalisée est figée par le constructeur, mais le
domaine d’utilisation est spécifique à une application. Exemple : un contrôleur Ethernet,
un encodeur MPEG-4, …
• Les circuits programmables sur site : n'importe quelle fonction logique, combinatoire ou
séquentielle, avec un nombre fixe d'entrées et de sorties, peut être implantée dans ces
circuits. A partir de cette simple idée, plusieurs variantes d'architecture ont été développées
(PAL, EPLD, FPGA,…).
2
• Les ASIC (Application Specific Integrated Circuit) réalisés chez le fondeur : le circuit est
conçu par l'utilisateur avec des outils de CAO, puis il est réalisé par le fondeur.
A l'heure actuelle, la majorité des circuits numériques est issue de ces 4 familles. Cependant,
certains éléments simples du catalogue standard (famille 74) sont toujours utilisés.
Plus simplement, on peut distinguer deux catégories de circuits intégrés : les circuits standards
et les circuits spécifiques à une application :
• Les circuits standards se justifient pour de grandes quantités : microprocesseurs,
contrôleurs, mémoires, ASSP, …
• Les circuits spécifiques sont destinés à réaliser une fonction ou un ensemble de fonctions
dans un domaine d’application particulier.
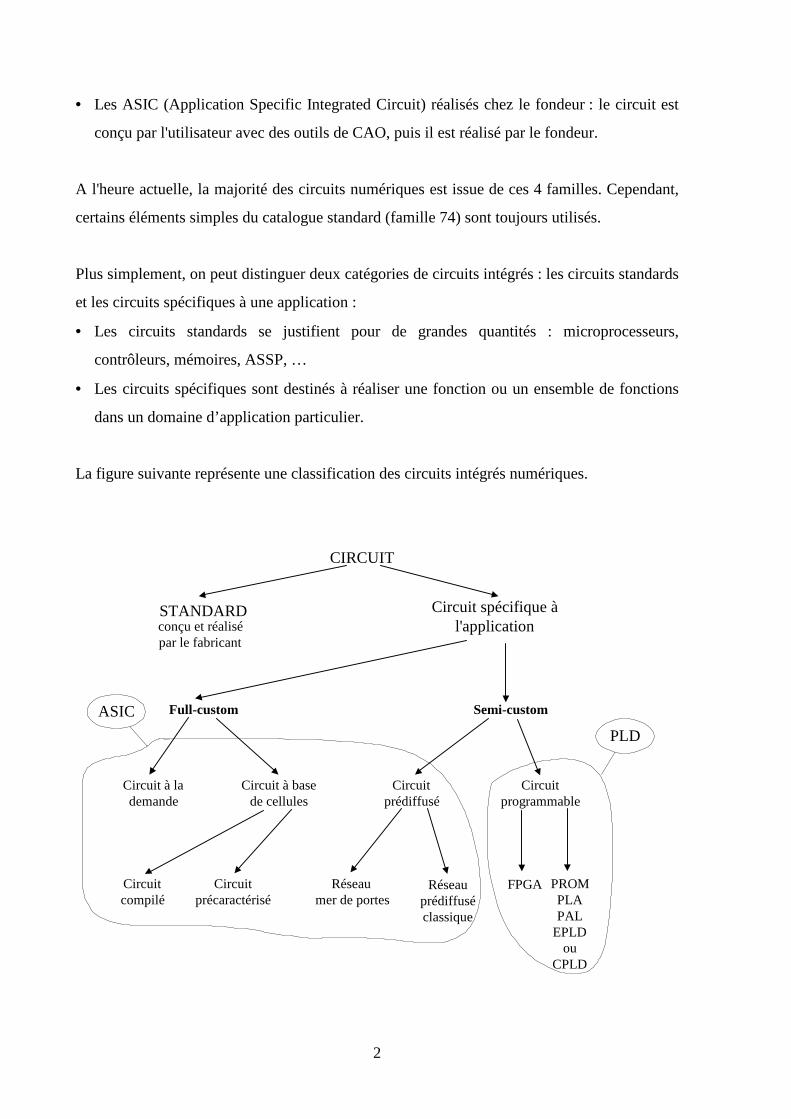
La figure suivante représente une classification des circuits intégrés numériques.
CIRCUIT
STANDARDconçu et réalisépar le fabricant
Circuit spécifique àl'application
Full-custom Semi-custom
Circuit à lademande
Circuit à basede cellules
Circuitprédiffusé
Circuitprogrammable
Circuitcompilé
Circuitprécaractérisé
Réseau mer de portes
Réseauprédiffuséclassique
FPGA PROMPLAPAL
EPLDou
CPLD
PLD
ASIC

3
Dans la littérature, le terme ASIC est employé pour décrire l’ensemble des circuits spécifiques
à une application. Or, dans le langage courant, le terme ASIC est presque toujours utilisé pour
décrire les circuits réalisés chez un fondeur. On désigne, par le terme générique PLD
(Programmable logic Device), l’ensemble des circuits programmables par l’utilisateur.
Parmi les circuits numériques spécifiques à une application, il faut distinguer deux familles :
• les circuits conçus à partir d’une puce de silicium « vierge » (Full-custom),
• les circuits où des cellules standards sont déjà implantées sur la puce de silicium (Semi-
custom).
Dans le premier groupe, les circuits appelés « Full custom », on trouve les circuits à la
demande et ceux à base de cellules (CBIC : Cell Based Integrated Circuit). Le fondeur réalise
l'ensemble des masques de fabrication. Dans le second groupe, les circuits appelés « Semi-
custom », on trouve les circuits prédiffusés (GA : Gate Array) et les circuits programmables.
Les cellules standards, déjà implantées sur la puce de silicium, doivent être interconnectées les
unes avec les autres. Cette phase de routage est réalisée, soit par masquage chez le fondeur
(prédiffusé), soit par programmation. Avant d’aborder le détail de la classification des circuits
numériques spécifiques à une application, un aperçu est donné sur les méthodes de réalisation
des interconnexions pour les circuits "Semi-custom".
1.2 Technologie utilisée pour les interconnexions
Les cellules standards implantées dans les circuits "Semi-custom" vont de la simple porte
jusqu'à une structure complexe utilisant un grand nombre de transistors. Il existe plusieurs
méthodes servant à interconnecter ces cellules :
• par masque (fondeur),
• par fusible,
• par anti-fusible,
• par cellule mémoire : EPROM, EEPROM, flash EPROM et SRAM.
Dans la méthode dite « interconnexion par masque », le fondeur réalise les interconnexions
par métallisation en créant les derniers masques de fabrication (2 masques par couches de
métallisation). Cette méthode n'est utilisée que pour les circuits prédiffusés.

4
Les autres méthodes sont utilisées dans les PLD. Dans ces circuits, les fils de liaison existent
déjà (organisée en lignes et en colonnes), mais ils ne sont reliés ni entre eux, ni avec les
éléments logiques du circuit. Il faut donc arriver à créer une interconnexion entre deux fils.
Deux possibilités existent : les interconnexions directes ou les interconnexions par cellule
mémoire.
colonne
ligne
Directe
colonne
ligne
Par cellule mémoire
mémoire
Fusible ou anti-fusible
1.2.1 Interconnexion directe
1.2.1.1 Interconnexion par fusible
C'est la technique des PROM bipolaires à fusibles (Programmable Read Only Memory). On
insère, entre chaque intersection, une diode en série avec un fusible. Pour supprimer la
connexion entre deux lignes, il suffit d'appliquer une tension élevée pour claquer le fusible. Le
boîtier n'est donc programmable qu'une seule fois par l'utilisateur. Cette méthode n’est plus
utilisée aujourd’hui.
1.2.1.2 Interconnexion par anti-fusible
Avec cette technique, c'est l'opération inverse qui est réalisée. On ne coupe pas une liaison,
mais on l'établit. L'anti-fusible isole deux lignes métalliques placées sur deux niveaux
différents grâce à une fine couche d'oxyde de silicium. Si on applique une impulsion élevée
(≈21V) calibrée en temps (moins de 5 ms), la couche d'oxyde est trouée et les deux lignes se
retrouvent en contact. La résistance entre les deux lignes passe alors de 100 MΩ à 100Ω.
Comme pour la technique du fusible, le boîtier n'est programmable qu'une seule fois par
l'utilisateur. Cette méthode est peu utilisée (à part par ACTEL).

5
1.2.2 Interconnexion par cellule mémoire
1.2.2.1 La cellule EPROM
Chaque cellule EPROM (Erasable Programmable Read Only Memory) est constituée d'un
transistor FAMOS (Floating gate Avalanche injection MOS, Intel 1971) qui est programmable
électriquement et effaçable aux rayons ultraviolets. La figure suivante montre que le transistor
FAMOS possède deux grilles.
La grille supérieure est utilisée pour la sélection et la grille inférieure entre la grille de
sélection et le substrat est dite flottante car elle n’est reliée à rien. Elle est entièrement isolée
par l’oxyde de silicium (SiO2). Par application d'une tension positive élevée sur la grille de
sélection, on communique aux électrons dans le canal une énergie suffisante qui leur permet
de passer au travers de cet isolant. Ces charges s'accumulent sur la grille isolée où elles se

6
trouvent piégées. La cellule mémoire est alors programmée. Pour l'effacement, on expose la
puce aux rayons ultra-violets. Les photons communiquent leur énergie aux électrons et leur
font franchir le diélectrique en sens inverse. La grille flottante du transistor perd alors sa
charge et la cellule redevient vierge. Pour cette technique, les boîtiers doivent posséder une
fenêtre en quartz pour laisser passer les U.V. Il existe une variante de cette technologie qui
n'est programmable qu'une seule fois par l'utilisateur : l'OTP (One Time Programming). Pour
des raisons de coûts du boîtier, la fenêtre en quartz servant à laisser passer les UV est
supprimée. La technologie EPROM n’est plus utilisée aujourd’hui.
1.2.2.2 La cellule EEPROM
La cellule EEPROM (Electrically Erasable Programmable Read Only Memory) est similaire à
la cellule EPROM, mais une deuxième grille recouvre la première grille flottante. La phase de
programmation reste identique. En revanche, le boîtier est effacé électriquement en appliquant
une tension suffisante sur la deuxième grille. Les électrons piégés dans la première grille sont
déchargés par effet tunnel. Les dimensions des cellules EEPROM étant beaucoup plus élevées
que celles des cellules EPROM, cette méthode n’est plus utilisée aujourd’hui.
1.2.2.3 La cellule flash
Comme pour la cellule EEPROM, la cellule flash se programme électriquement par injection
d'électrons et s'efface électriquement par effet tunnel. En revanche, la dimension de la cellule
est beaucoup plus réduite. C'est une technologie de mémoire morte reprogrammable
relativement récente (1985) qui connaît un fort développement. Cette solution non-volatile
serait idéale si les PLD basés sur de la mémoire Flash n’avaient pas deux générations de retard
sur les PLD basés sur de la mémoire SRAM (pour des raisons de procédé de fabrication).
1.2.2.4 La cellule SRAM
La cellule SRAM (Static Random Access Memory) consiste en deux inverseurs CMOS
connectés en boucle pour former un bistable. L'état de cette cellule peut être modifié par un
signal électrique externe (ligne B). La cellule RAM est une structure de stockage volatile. La
figure suivante représente la cellule d'une SRAM à 5 transistors (a) et une cellule à 6
transistors (b). Malgré son coût, C’est la méthode utilisée dans les FPGA les plus performants
à ce jour.

7
1.3 Les circuits full custom
Les circuits intégrés appelés full-custom ont comme particularité de posséder une architecture
dédiée à chaque application et sont donc complètement définis par les concepteurs. La
fabrication nécessite la création de l'ensemble des masques pour la réalisation (6 pour les
transistors plus 2 par couche métal). Les temps de fabrication de ces masques et de production
des circuits sont de ce fait assez long. Ces circuits sont ainsi appropriés pour de grandes
séries. L'avantage du circuit full-custom réside dans la possibilité d'avoir un circuit ayant les
fonctionnalités strictement nécessaires à la réalisation des objectifs de l'application, et donc un
nombre minimal de transistors (donc la surface de puce la plus petite et le coût le plus faible).
Parmi les circuits full-custom, on distingue :
• les circuits à la demande,
• les circuits à base de cellules.
1.3.1 Les circuits à la demande
Ces circuits sont directement conçus et fabriqués par les fondeurs. Ils sont spécifiques car ils
répondent à l'expression d'un besoin pour une application particulière. Le demandeur utilise le
fondeur comme un sous-traitant pour la conception et la réalisation et n'intervient que pour
exprimer le besoin. Ces circuits spécifiques utilisent au mieux la puce de silicium. Chaque
circuit conçu et fabriqué de cette manière doit être produit en très grande quantité pour amortir
les coûts de conception.
1.3.2 Les circuits à base de cellules
Les circuits à base de cellules (CBIC : Cell Based Integrated Circuit) permettent des
complexités d'intégration allant jusqu'à plusieurs dizaines de millions de portes. Dans cette
catégorie de circuits, on distingue les circuits à base de cellules précaractérisées et les
circuits à base de cellules compilées.

8
1.3.2.1 les cellules précaractérisées
Les cellules précaractérisées sont des entités logiques plus ou moins complexes. Il peut s'agir
de cellules de base (portes, bascules, etc.) mais aussi de cellules mémoires (ROM, RAM) ou
encore de sous-systèmes numériques complexes (UART, cœur de microprocesseur, PLA, ...).
Toutes ces cellules ont été implantées et caractérisées au niveau physique (d'où la notion de
cellules précaractérisées) par le fondeur. La fonctionnalité globale de l'application à réaliser
s'obtient en choisissant les cellules appropriées dans une bibliothèque fournie par le fondeur.
1.3.2.2 Les circuits à base de cellules compilées
Les circuits à base de cellules compilées sont en fait basés sur l'utilisation de cellules
précaractérisées. A la différence des circuits précaractérisés, les cellules ne sont pas utilisables
directement mais au travers de modules paramètrables ou modules génériques. Chaque
module est créé par la juxtaposition de n cellules de même type. La différence entre circuits
précaractérisés et circuits compilés provient essentiellement de l'outil utilisé pour générer les
dessins des masques de fabrication. Ces outils sont appelés des compilateurs de silicium.
1.4 Les circuits semi-custom
Dans la famille des circuits semi-custom, on distingue deux groupes :
• les circuits prédiffusés,
• les circuits programmables.
1.4.1 Les circuits prédiffusés
Parmi les circuits prédiffusés, on distingue les prédiffusés classiques (ou "gate-array"), les
réseaux mer-de-portes ( ou « sea of gates ») et les ASICs structurés.
1.4.1.1 Les circuits prédiffusés classiques
Les circuits prédiffusés classiques possèdent une architecture interne fixe qui consiste, dans la
plupart des cas, en des rangées de portes séparées par des canaux d'interconnexion.
L'implantation de l'application se fait en définissant les masques d'interconnexion pour la
phase finale de fabrication. Ces masques d'interconnexion permettent d'établir des liaisons
entre les portes et les plots d'entrées/sorties. Alors que pour un circuit standard ou "full-
custom" tous les masques sont nécessaires, la fabrication des prédiffusés ne nécessite que la
définition des masques de métallisation; les autres masques définissant l'architecture sont
fixes. Cette technique permet de diminuer les délais car les réseaux prédiffusés sont fabriqués

9
au préalable ; seule manque les couches d'interconnexions qui vont particulariser chaque
circuit. Par contre, les portes non utilisées sont perdues. Cette méthode est moins efficace
qu'un full-custom en terme d'utilisation de la surface de silicium.
Les circuits prédiffusés classiques intègrent de 50000 à 10000000 portes logiques et sont
intéressants pour des grandes séries. Pour des prototypes ou de petites séries, ils sont
abandonnés au profit des circuits programmables à haute densité d'intégration, comme les
FPGA. En effet, ceux-ci ont l'avantage indéniable d’être programmable sur site, c'est-à-dire
sans faire appel au fondeur. La figure suivante donne un exemple de structure pour un
prédiffusé classique. Les cellules internes sont de taille fixe et organisées en rangées ou
colonnes séparées par les canaux d'interconnexion.
1.4.1.2 Les circuits mer-de-portes
Contrairement aux prédiffusés classiques, les circuits mer-de-portes ne possèdent pas de
canaux d'interconnexion, ce qui permet d'intégrer plus d'éléments logiques pour une surface
donnée. Les portes peuvent servir, soit comme cellules logiques, soit comme interconnexions.
En fait, si ces circuits possèdent la structure logique équivalente à 250000 portes,
pratiquement, le nombre moyen de portes utilisables est de l'ordre de 100000, ce qui donne un
taux d'utilisation de 40% à 50%. En effet, si les canaux d'interconnexion ne sont pas imposés,
ils sont néanmoins nécessaires. Le gain des structures mer-de-portes est réalisé parce que ces
interconnexions ne sont pas imposées par l'architecture. En pratique, le taux d'utilisation
dépasse rarement 75%.

10
1.4.1.3 Les ASICs structurés
C’est le nième avatar du Gate Array traditionnel. Le principal problème des prédiffusés, c’est
qu’ils sont coincés entre les précaractérisés pour les grandes séries et les FPGA complexes.
L’idée de base de l’ASIC structuré, c’est d’offrir une offre logicielle simplifiée au client
(faible coût par rapport aux précaractérisés) mais avec la bibliothèque d’IPs (blocs de
propriété intellectuelle tels que les microprocesseurs, contrôleurs ethernet, …) des
précaractérisés : la simplicité et le coût des FPGA avec les potentialités du précaractérisé. La
réalité physique est bien entendue assez éloignée de la réalité marketing. Exemple de circuit :
RapidChip de LSI logic.
1.4.2 Les circuits programmables
Tous les circuits spécifiques détaillés jusqu'à présent ont un point commun ; il est nécessaire
de passer par un fondeur pour réaliser les circuits, ce qui introduit un délai de quelques mois
dans le processus de conception. Cet inconvénient a conduit les fabricants à proposer des
circuits programmables par l'utilisateur (sans passage par le fondeur) qui sont devenus au fil
des années, de plus en plus évolués. Rassemblés sous le terme générique PLD, les circuits
programmables par l'utilisateur se décomposent en deux familles :
1. les PROM, les PLA, les PAL et les EPLD,
2. les FPGA.
PLD(Circuit logiqueprogrammable)
PLA ou PAL(bipolaire
non effaçable)
PLD effaçable(circuit logique
effaçable)
FPGA(réseaux de portesprogrammables)
PAL CMOSou
GAL
EPLDou
CPLD
FPGAde typeRAM
FPGAà
anti-fusibles
PROM

11
1.4.2.1 Les PROM
Nous allons voir dans ce paragraphe la PROM sous l’angle de la réalisation d’une fonction
logique. Même si elle n’est plus utilisée pour cela aujourd’hui, elle est à la base de la famille
de PLA, des PAL et des EPLD.
Convention de notation
Afin de présenter des schémas clairs et précis, il est utile d'adopter une convention de notation
concernant les connexions à fusibles. Les deux figures suivantes représentent la fonction ET à
3 entrées. La figure b) n'est qu'une version simplifiée du schéma de la figure a).
c
a
a.b.cab a.b.c
a)
b c
b)
Un exemple de notation est donné sur la figure ci-dessous. La fonction réalisée est S = (a . c)
+ (b . d). Une croix, à une intersection, indique la présence d'une connexion à fusible non
claqué. L'absence de croix signifie que le fusible est claqué. La liaison entre la ligne
horizontale et verticale est rompue. La sortie S réalise une fonction OU des 2 termes produits
(a.c) et (b.d).
cba
S
d
Les premiers circuits programmables apparus sur le marché sont les PROM bipolaires à
fusibles. Cette mémoire est l'association d'un réseau de ET fixes, réalisant le décodage
d'adresse, et d'un réseau de OU programmables, réalisant le plan mémoire proprement dit. On
peut facilement comprendre que, outre le stockage de données qui est sa fonction première,
cette mémoire puisse être utilisée en tant que circuit logique. La figure ci-dessous représente
la structure logique d'une PROM bipolaire à fusibles.

12
Chaque sortie Oi peut réaliser une fonction OU de 16 termes produits de certaines
combinaisons des 4 variables A, B, C et D. Avec les PROM, les fonctions logiques
programmées sont spécifiées par les tables de vérités. Il suffit de mettre les variables d’entrées
sur les adresses et de récupérer la fonction logique sur le bit de donnée correspondant. Le
temps de propagation est indépendant de la fonction implantée (c’est le temps d’accès de la
mémoire).
1.4.2.2 Les PLA
Le concept du PLA a été développé, il y a plus de 20 ans. Il reprend la technique des fusibles
des PROM bipolaires. La programmation consiste à faire sauter les fusibles pour réaliser la
fonction logique de son choix. La structure des PLA est une évolution des PROM bipolaires.
Elle est constituée d'un réseau de ET programmables et d'un réseau de OU programmables. Sa
structure logique est la suivante :

13
Chaque sortie Oi peut réaliser une fonction OU de 16 termes produits des 4 variables A, B, C
et D. Avec cette structure, on peut implémenter n'importe quelle fonction logique
combinatoire. Ces circuits sont évidemment très souples d'emploi, mais ils sont plus difficiles
à utiliser que les PROM. Statistiquement, il s'avère inutile d'avoir autant de possibilité de
programmation, d'autant que les fusibles prennent beaucoup de place sur le silicium. Ce type
de circuit n'a pas réussi à pénétrer le marché des circuits programmables. La demande s'est
plutôt orientée vers les circuits PAL.
1.4.2.3 Les PAL
Contrairement aux PLA, les PAL (Programmable Array Logic) imposent un réseau de OU
fixes et un réseau de ET programmables. La technologie employée est la même que pour les
PLA. La figure qui suit représente la structure logique d'un PAL où chaque sortie intègre 4
termes produits de 4 variables.

14
L'architecture du PAL a été conçue à partir d'observations indiquant qu'une grande partie des
fonctions logiques ne requiert que quelques termes produits par sortie. L'avantage de cette
architecture est l'augmentation de la vitesse par rapport aux PLA. En effet, comme le nombre
de connexions programmables est diminué, la longueur des lignes d'interconnexion est
réduite. Le temps de propagation entre une entrée et une sortie est par conséquent plus faible.
En revanche, il arrive qu'une fonction logique ne puisse être implantée, car une sortie
particulière n'a pas assez de termes produits. Prendre un boîtier plus gros, peut être
préjudiciable en terme de prix et de rapidité, le temps de propagation étant proportionnel à la
longueur des lignes d'interconnexion du réseau de ET et donc au nombre d’entrées. Pour
remédier à cette limitation, il a fallu modifier les entrées/sorties du circuit. Le PAL possède
toujours des entrées simples sur le réseau de ET programmables, mais aussi des broches
spéciales (voir figure ci-dessous) qui peuvent être programmées :

15
• en entrée simple en faisant passer le buffer de sortie trois états en haute impédance,
• en sortie réinjectée sur le réseau de ET. Cela permet d’augmenter le nombre de termes
produits disponibles sur les autres sorties.
Les structures présentées jusqu'à maintenant ne font intervenir que de la logique combinatoire.
Les architectures des PAL ont évolué vers les PAL à registres. Dans ces PAL, la sortie du
réseau de fusibles aboutit sur l'entrée d'une bascule D. La sortie Q peut aller vers une sortie, la
sortie Q étant réinjectée sur le réseau via un inverseur/non inverseur.
Avec cette structure, la sortie ne peut pas être utilisée comme entrée sur le réseau. L'exemple
d'un PAL à registres 16R8 est donné à la page suivante. Il implémente 8 termes produits de 16
variables par sortie. D'après la notation employée par les fabricants, la référence 16R8
signifie :
• 16 : nombre d'entrées au niveau du réseau de ET.
• R : PAL à registres.
• 8 : nombre de sorties.
Les plus gros PAL standards sont les 20R8 et 20L8.

16
Le PAL versatile (polyvalent), dont le membre le plus connu est le 22V10, présente une
évolution des PAL vers les circuits logiques programmables de plus grande complexité. En
effet, ils continuent de respecter le principe de fonctionnement énoncé précédemment, mais ils
utilisent une structure de cellule de sortie qui s’apparente à celle d’un EPLD. D'après la figure
suivante, on remarque que la cellule de sortie dispose d'une bascule D pré-positionnable
associée à deux multiplexeurs programmables. Les connexions S0 et S1 sont réalisées grâce à
des fusibles internes.

17
Cette sortie peut adopter plusieurs configurations (d’où le terme polyvalent), le 22V10
pouvant être utilisé à la place de tous les PAL bipolaires classiques :
• sortie combinatoire active au niveau bas ou au niveau haut,
• sortie registre active au niveau bas ou au niveau haut,
• Entrée (broche bidirectionnelle).
Les premiers PAL pouvaient être assez facilement programmés à la main. Toutefois, la
réalisation de fonctions complexes est devenue rapidement inextricable. Des logiciels de
développement sont donc apparus afin de faciliter ce travail. Il en existait de nombreux, les
plus connus étant PALASM (société AMD) et ABEL (société DataIO). Au-delà d’un certain
niveau de complexité, l’utilisation de leur simulateur intégré permettait une mise au point
rapide de la fonction à réaliser.
Tous les PAL disposent d'un fusible ou bit de sécurité. Ce fusible, une fois claqué, interdit la
relecture d'un composant déjà programmé. En effet, il arrive que des entreprises indélicates
soient tentées de copier les PAL développés par leurs concurrents.
Un des inconvénients des circuits bipolaires à fusibles, est qu'ils ne peuvent pas être testés à la
sortie de l'usine. Pour tester leur fonctionnement, il faudrait en effet claquer les fusibles, ce
qui interdirait toute programmation ultérieure. A l'origine, les premiers PAL étaient bipolaires
puisqu'ils utilisaient la même technologie que les PROM bipolaires à fusibles. Il existe
maintenant des PAL en technologie CMOS (appelés GAL (Generic Array Logic) par certains
fabricants, ex : ISPGAL22V10 de Lattice), programmables et effaçables électriquement,
utilisant la même technologie que les mémoires EEPROM. Comme ils sont en technologie
CMOS, ils consomment beaucoup moins, en statique, que les PAL bipolaires de complexité
équivalente qui sont maintenant totalement abandonnés.

18
1.4.2.4 Les EPLD
Les EPLD (Erasable Programmable logic Device) sont des circuits programmables
électriquement et effaçables, soit par exposition aux UV pour les plus anciens, soit
électriquement. Ces circuits, développés en premier par la firme ALTERA, sont arrivés sur le
marché en 1985. Les EPLD sont une évolution importante des PAL CMOS. Ils sont basés sur
le même principe pour la réalisation des fonctions logiques de base. Les procédés physiques
d'intégration permis par les EPLD sont nettement plus importants que ceux autorisés par les
PAL CMOS. En effet, les plus gros EPLD actuellement commercialisés intègrent plusieurs
dizaines de milliers de portes utilisables par l'utilisateur. On peut ainsi loger dans un seul
boîtier, l'équivalent d'un schéma logique utilisant jusqu'à 50 à 100 PAL classiques.
Comme les PAL CMOS, les EPLD font appel à la notion de macro-cellule qui permet, par
programmation, de réaliser de nombreuses fonctions logiques combinatoires ou séquentielles.
Un exemple de schéma d’une macro-cellule de base d'un EPLD est présenté ci-dessous. On
remarque que le réseau logique est composé de 3 sous ensembles :
• le réseau des signaux d'entrées provenant des broches d'entrées du circuit,
• le réseau des signaux des broches d'entrées/sorties du circuit,
• le réseau des signaux provenant des autres macro-cellules.

19
Outre la logique combinatoire, la macro-cellule possède une bascule D configurable. Cette
bascule peut être désactivée par programmation d’un multiplexeur. Le signal d'horloge peut
être commun à toutes les macro-cellules ou bien provenir d'une autre macro-cellule via le
réseau logique.
Quelle que soit la famille d'EPLD, la fonctionnalité de la macro-cellule ne change guère. En
revanche, plus la taille des circuits augmente, plus les possibilités d'interconnexions et le
nombre de macro-cellules augmentent. On voit ci-dessous la structure d’un EPLD de la
famille MAX 5000 d’ALTERA

20
Il existe plusieurs types d'EPLD en technologie CMOS :
• Les circuits programmables électriquement et non effaçables. Ce sont les EPLD de type
OTP (One Time Programmable).
• Les circuits programmables électriquement et effaçables aux UV (obsolètes).
• Les circuits programmables électriquement et effaçables électriquement dans un
programmateur.
• Les circuits programmables électriquement et effaçables électriquement sur la carte (ISP :
In Situ Programmable), utilisant une tension unique.
Les plus rapides des EPLD ont des temps de propagation (entrée vers sortie sans registre) de
l'ordre de 5 ns. Le taux d'utilisation des ressources d'un EPLD dépasse rarement 80 %. Avec
les EPLD, il est possible de prédire la fréquence de travail maximale d'une fonction logique,
avant son implémentation. On rencontre parfois le terme CPLD (Complex Programmable
Logic Device). Ce terme est généralement utilisé pour désigner des EPLD ayant un fort taux
d'intégration.
1.4.2.5 Les FPGA
Lancé sur le marché en 1984 par la firme XILINX, le FPGA (Field Programmable Logic
Device) est un circuit prédiffusé programmable. Le concept du FPGA est basé sur l'utilisation
d'une LUT (LookUp Table) comme élément combinatoire de la cellule de base. En première
approximation, cette LUT peut être vue comme une mémoire (16 bits en général) qui permet
de créer n’importe quelle fonction logique combinatoire de 4 variables d’entrées. Chez Xilinx,
on appelle cela un générateur de fonction ou Function Generator. La figure suivante représente
la cellule type de base d'un FPGA.
S
D0
D1
D
CE
H
LUT 4 entrées
MUX 2:1
mémoire
Q
O

21
Elle comprend une LUT 4 entrées et une bascule D (D Flip-Flop). La bascule D permet la
réalisation de fonctions logiques séquentielles. La configuration du multiplexeur 2 vers 1 de
sortie autorise la sélection des deux types de fonction, combinatoire ou séquentielle. Les
cellules de base d'un FPGA sont disposées en lignes et en colonnes. Des lignes
d'interconnexions programmables traversent le circuit, horizontalement et verticalement, entre
les diverses cellules. Ces lignes d'interconnexions permettent de relier les cellules entre elles,
et avec les plots d'entrées/sorties. Les connexions programmables sur ces lignes sont réalisées
par des transistors MOS dont l'état est contrôlé par des cellules mémoires SRAM. Ainsi, toute
la configuration d'un FPGA est contenue dans des cellules SRAM.
Contrairement aux EPLD, on ne peut pas prédire la fréquence de travail maximale d'une
fonction logique, avant son implémentation. En effet, cela dépend fortement du résultat de
l'étape de placement-routage. Tous les FPGA sont fabriqués en technologie CMOS, les plus
gros d'entre eux intègrent jusqu'à 10000000 portes logiques utilisables.
Par rapport aux prédiffusés classiques, les interconnexions programmables introduisent des
délais plus grands que la métallisation (environ 3 fois plus lents). Par contre, les cellules

22
logiques fonctionnent à la même vitesse. Pour minimiser les délais de propagation dans un
FPGA, il faut donc réduire le nombre de cellules logiques utilisées pour réaliser une fonction.
Par conséquent, les cellules logiques d’un FPGA sont plus complexes que celles d’un
prédiffusé.
1.4.2.6 Conclusion
Pour éclaircir les idées, on peut classer les circuits numériques spécifiques à une application
suivant l'architecture du circuit. C'est-à-dire quels sont le ou les constituants de base mis à la
disposition de l'utilisateur et quelles sont les possibilités d'interconnexion de ces constituants
et par quelle technique? On parle en général de la « granularité » de l'architecture. La figure
suivante reprend la classification des circuits spécifiques à une application suivant leur
architecture.
1.5 Implémentation
Les PLD et les prédiffusés sont des circuits spécifiques dont les puces de silicium ont déjà des
cellules implantées. Durant l'étape d'implémentation, il faut résoudre les problèmes du
placement de la logique dans les cellules de base puis des interconnexions. L'implémentation

23
est réalisée une fois la saisie du design terminée. Le design peut être entré, soit graphiquement
(schématique), soit sous forme de langages de description matériel (VHDL, équations
booléennes, ...). Les étapes de l'implémentation sont :
1. La synthèse. La synthèse est l’opération qui permet de créer une netlist (EDIF ou NGC) à
partir d’une description de haut niveau écrite en VHDL (ou en Verilog). C’est la
transformation d’une description abstraite en une description physique. Une netlist est un
schéma sous forme texte. Elle répertorie toutes les fonctions logiques de base du design
(les primitives) ainsi que leurs interconnexions.
2. La translation. L'étape de translation consiste à établir une netlist sans hiérarchie interne (à
plat) et incorporant les contraintes à partir de la netlist précédente.
3. L'optimisation. L'étape d'optimisation reprend la netlist pour éliminer les portes inutiles et
la logique redondante.
4. Le partitionnement. Le design, une fois optimisé, est partitionné en blocs logiques pouvant
être implémenté dans les cellules de base du circuit spécifique.
5. Le placement-routage. Le placement détermine la position de chaque bloc logique
partitionné à l'intérieur du circuit spécifique. Les algorithmes de placement fonctionnent
par itérations. Ils essaient de réaliser le meilleur placement possible, c'est-à-dire qu'ils
regroupent dans une même zone du circuit une fonction nécessitant plusieurs cellules de
base, ceci afin de limiter les temps de propagation. Cependant, le résultat du placement
n'est pas toujours idéal, par exemple dans le cas des FPGA. Il est souvent nécessaire de
placer manuellement une partie du design (c'est le « Floorplanning »). Une fois la phase de
placement terminée, l'étape de routage doit être effectuée. Elle utilise les ressources de
routage du circuit pour réaliser les interconnexions entre les différentes cellules et les
broches d'entrée/sortie. Après l'étape de placement-routage, l'implémentation est terminée ;
le circuit spécifique peut être programmé à partir d'un fichier binaire de configuration
obtenu ou alors par masque chez le fondeur.
1.6 Comparaison entre les FPGA et les autres circui ts spécifiques
La comparaison et donc le choix entre les différentes technologies est une étape délicate car
elle conditionne la conception mais aussi toute l’évolution du produit à concevoir. De plus,
elle détermine le coût de la réalisation et donc la rentabilité économique du produit.
Généralement, les quantités à produire imposent leurs conditions de rentabilité, dans le
domaine du grand public par exemple. Par contre, dans le matériel professionnel, toutes les
options sont ouvertes. Il faut établir un rapport coût / souplesse d’utilisation le plus souvent

24
avec des données partielles (pour les quantités à produire par exemple). Nous allons nous
contenter dans ce paragraphe de comparer ce qui est comparable (PLD / ASIC, EPLD /
FPGA) et de donner une méthode de calcul des coûts des familles ASIC et PLD.
1.6.1 Comparaison entre les PLD et les ASIC.
Un premier choix doit être fait entre les ASIC et les PLD. Les avantages des PLD par rapport
aux ASIC sont les suivants :
• ils sont entièrement programmables par l'utilisateur,
• Ils sont généralement reprogrammables dans l'application, ce qui facilite la mise au point et
garantit la possibilité d'évolution,
• les délais de conception sont réduits, il n'y a pas de passage chez le fondeur.
En revanche, les inconvénients des PLD par rapport aux ASIC sont les suivants :
• ils sont moins performants en terme de vitesse de fonctionnement (d’un facteur 3),
• le taux d'intégration est moins élevé (d’un facteur 10 environ),
• Le programmation coûte les 2/3 de la surface de silicium.
De plus, le coût de l’ASIC est beaucoup plus faible que le coût du PLD (quoique les choses
évoluent très rapidement dans ce domaine, notamment dans la compétition entre FPGA et
prédiffusés). Au-delà d’une certaine quantité, l’ASIC est forcement plus rentable que le PLD.
Toute la question est donc de savoir quelle est cette quantité ?
1.6.2 Comparaison entre les FPGA et les EPLD
Si un PLD est choisi, il faut savoir si on doit utiliser un EPLD ou un FPGA. En réalité, le
choix est assez facile à faire. Le domaine d'utilisation des FPGA est celui des prédiffusés, par
exemple les fonctions logiques ou arithmétiques complexes ou le traitement du signal. Le
domaine d'utilisation des EPLD est plutôt celui des PAL, par exemple les machines d'état
complexes. Il est à noter qu'un marché important des PAL et des EPLD est la correction des
erreurs de conception dans les ASIC afin d'éviter un aller-retour coûteux chez le fondeur.
1.6.3 Seuil de rentabilité entre un FPGA et un ASIC
Avec un taux d'intégration de plus en plus important, les FPGA deviennent très intéressants
pour des productions en série par rapport aux ASIC. La question qui se pose au concepteur est

25
la suivante : combien d'unités doit-on produire, pour que l'ASIC soit plus rentable que le
FPGA ?
Le facteur principal qui détermine le coût d’un circuit intégré est la surface de la puce ou
encore le nombre de puces que l’on peut fabriquer sur une tranche de silicium. On travaille
aujourd’hui avec des tranches de 300 mm de diamètre et les plus grosses puces sont de
dimension 25x20 mm. Deux éléments peuvent fixer la taille de la puce : le nombre de portes
utilisées pour réaliser la fonction logique et le nombre d’entrées-sorties. Jusqu'à la technologie
0.5 µm, c’est la fonction logique qui détermine la taille de la puce et donc son prix. C’est la
raison pour laquelle, à fonctionnalité identique, le circuit full-custom est le moins cher alors
que le PLD est le plus coûteux à produire. Mais avec des circuits de plusieurs centaines de
broches, la taille de la puce tend à être fixée de plus en plus par les E/S et les différences de
prix s’estompent (notamment entre les FPGA et les prédiffusés).
Sans entrer dans les détails, une analyse rapide peut donner un ordre de grandeur du seuil de
rentabilité entre un FPGA et un ASIC. Prenons comme exemple un boîtier de 10 000 portes.
L'étude se base sur des données fournies par la société d'études de marché DATAQUEST en
1995. La formule de base du seuil de rentabilité est la suivante :
seuil de rentabilité = NRE + (développement et outils) + ( X unités * prix à l'unité)
Les NRE (Non Recurring Expenses) sont les frais fixes de mise en œuvre. On obtient pour les
ASIC et les FPGA les deux formules suivantes :
ASIC = $25 000 (NRE) + $79 000 (développement et outils) + ( X unités * $13)
FPGA = 0 NRE + $25 000 (développement et outils) + ( X unités * $79)
Il n'y a pas de NRE pour un FPGA. Les NRE sont imputés à chaque fois que l'on fait appel à
un fondeur. A partir des 2 équations ci-dessus, le seuil de rentabilité est atteint pour 1 196
unités. Le FPGA devient plus cher à produire qu'un ASIC au-delà de 1 196 unités. En fait, il
existe d'autres facteurs qui influent grandement sur le seuil de rentabilité :
• Le « time to market » (temps de mise sur le marché). C'est le temps écoulé entre le début de
l'étude et la phase de production. Prendre du retard sur le lancement d'un produit sur le

26
marché, en raison d'un cycle de développement et de mise au point trop long, a des effets
négatifs en termes de rentabilité. Le cycle moyen de développement d'un FPGA est de 11
semaines, il passe à 32 semaines pour un ASIC.
• La correction des erreurs. Environ 30 % des ASIC retournent chez le fondeur pour des
modifications (11 % sont des erreurs du fondeur et 19 % sont des modifications du design).
Ce nouveau cycle de développement introduit un délai supplémentaire de 12 semaines.
Pour un FPGA, une modification du design est très rapide, et n'apporte pratiquement pas de
surcoût.
• Les FPGA masqués. Les interconnexions programmables de ces FPGA sont remplacés par
des interconnexions fixes chez le fabricant (séries HardCopy chez Altera par exemple). Le
circuit n'est alors plus reprogrammable. Ils sont compatibles, broche à broche, avec les
FPGA programmables du même fabriquant mais ils sont moins chers, les NRE étant
beaucoup moins élevés que pour les ASIC. La méthode consiste à développer le prototype
avec un FPGA programmable puis à envoyer le fichier de configuration final chez le
fondeur. Celui-ci produit les FPGA HardCopy avec la configuration souhaitée mais il y a
une quantité minimum d’unités à commander.
Les chiffres permettant de quantifier les seuils de rentabilité entre les familles de circuits sont
difficiles à obtenir et parfois hautement subjectifs. Les ordres de grandeur des seuils de
rentabilité sont les suivants :
jusqu'à 5000 pièces entre 5000 et 50000 entre 50000 et 500000 plus de 500000
PLD prédiffusé précaractérisé full-custom
Il est important de noter qu’il existe une nette tendance visant à remplacer le prédiffusé par le
FPGA, certains fabricants (comme Xilinx) prétendant commercialiser des FPGA moins cher
que des prédiffusés pour des quantités de 100000 pièces. Il est difficile d’avoir une opinion
tranchée car les deux familles évoluent très rapidement.
1.7 Les familles de FPGA/EPLD
Le marché mondial des PLD représentait en 2004 3.3 Md$ dont 85 % pour les FPGA et 15 %
pour les CPLD à comparer avec un marché de 14 Md$ pour les ASIC.

27
Deux points importants sont à noter pour le concepteur en électronique et concernent
particulièrement les PLD:
Après 2000, la compatibilité 5V des E/S n’est plus obligatoire. Certains circuits le tolèrent
(avec une résistance série), d’autres non. Les tensions d’alimentations sont multiples
(exemple Spartan-3 : 3.3, 2.5 et 1.2 V).
Les boîtiers sont tous CMS. Quelques CPLD sont en boîtier PLCC et SOP. Pour les petits
FPGA faible coût, on trouve encore des QFP 100, 144 ou 208 broches. Pour les autres
circuits, il n’y a plus que des BGA (256 à 1760 broches).
Voyons maintenant les principaux fabricants de PLD ainsi que leur offre.
1.7.1 Xilinx (52 % part de marché)
Le tableau suivant dresse l’historique des PLD chez Xilinx. Les circuits en italique ne sont pas
supportés par le synthétiseur interne XST. Xilinx ne commence à fabriquer des CPLD qu’à
partir de 1995 pour avoir une offre complète. Dans cette optique, la société rachète la famille
de CPLD « Coolrunner » (basse consommation) à Philips en 1999.
FPGA (SRAM) FPGA faible coût CPLD (Flash)
XC2000 (1984)
XC3000 (1987)
XC4000 (1991) Spartan (1998)
Spartan-XL (1999)
XC9500 (1996)
XC9500XL (1998)
Virtex (1999) Spartan-2 (2000) CoolRunner (1999)
Virtex-E (2000) Spartan-2E (2002) XC9500XV (1999)
Virtex-II (2001) Spartan-3 (2004)
Spartan-3E (2005)
CoolRunner-II (2002)
Virtex-II pro (2003)
Virtex-4 (2005)
Outil logiciel : ISE.
Processeurs embarqués soft : Picoblaze, Microblaze.
Processeurs embarqués hard : PPC405.

28
1.7.2 Altera (34 % part de marché)
Le tableau suivant dresse l’historique des PLD chez Altera. Altera ne commence vraiment à
fabriquer des FPGA SRAM qu’à partir de la FLEX10K. Avant 1995, Altera ne vendait que
des CPLD.
FPGA (SRAM) FPGA faible coût CPLD (Flash)
FLEX8000 (1992) Classic (EP300 1984)
MAX 500 (1988)
FLEX10K (1995) FLEX6000 (1997) MAX 7000 (1991)
APEX20K (1999) MAX 9000 (1994)
APEX20KE, 20KC ACEX 1K (2000)
APEX II (2001)
Stratix (2002) Cyclone (2002)
Stratix-II (2004) Cyclone II (2005) MAX II (2004)
Outil logiciel : Max+plus II, Quartus II.
Processeur embarqué soft : NIOS.
1.7.3 Les autres fabricants
Les autres fabricants vivent sur des niches du marché des PLD, malgré tous leurs efforts pour
en sortir. Lattice (8 % part de marché) a racheté VANTIS à AMD qui avait elle-même racheté
MMI, le créateur des PAL. Lattice est le spécialiste des PAL.
FPGA (Flash) FPGA faible coût (Flash) CPLD (Flash)
ECP (2004) EC (2004) IspGAL, ispMACH, ispXPLD
Actel (6 % part de marché) est l’inventeur des FPGA à anti-fusibles.
FPGA (anti-fusible) FPGA (Flash) CPLD
Axcelerator (2002) ProASIC (2000)
Autres fournisseurs : Quicklogic, Atmel et Cypress.

29
2. Un exemple de FPGA : la famille Spartan-3
Ce paragraphe détaille la structure interne des FPGA de la famille Spartan-3 fabriqués par la
société XILINX.
2.1 Caractéristiques générales
La figure suivante représente la structure simplifiée de la famille Spartan-3. On reconnaît là,
une structure de type prédiffusé.
La famille Spartan-3 est une famille de FPGA CMOS SRAM faible coût basée sur la famille
Virtex-II (FPGA complexité élevée). La liste suivante résume ses caractéristiques :
• matrice de blocs logiques programmables ou CLB (Configurable Logic Block),
• blocs d'entrée/sortie programmables ou IOB (Input Ouput Block) dont le nombre varie
suivant le type de boîtier (QFP ou BGA). Ils supportent 23 standards d’E-S plus le contrôle
des impédances d’entrée et de sortie via DCI,
• réseau de distribution d'horloge avec une faible dispersion via les DCM,
• des blocs RAM 18 kbits,
• des multiplieurs 18 bits x 18 bits,
• de nombreuses ressources de routage.

30
Cette famille comprend 8 membres allant d’une capacité de 1728 à 74880 cellules logiques
(une LUT associée à une bascule D) :
Les boîtiers suivants sont disponibles :
Le circuit utilisé pour les TP est le XC3S200-FT256-4C. Nous allons maintenant reprendre
chaque point clé de ce FPGA plus en détail.
2.2 Blocs d’entrée-sortie (IOB)
2.2.1 Généralités
Des blocs d’entrée-sortie (IOB) configurables sont répartis sur toute la périphérie du boîtier.
Chaque IOB assure l'interface entre une broche d'entrée/sortie du boîtier et la logique interne.
La figure suivante représente le schéma bloc simplifié d'un IOB.
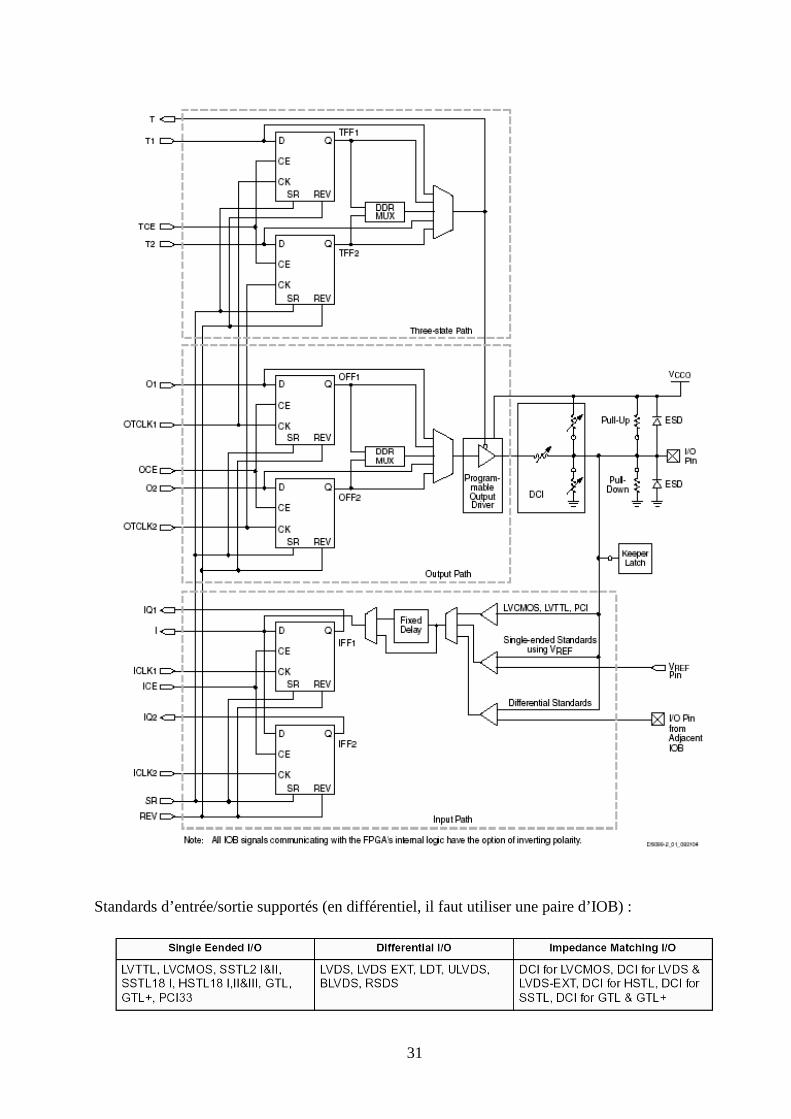
31
Standards d’entrée/sortie supportés (en différentiel, il faut utiliser une paire d’IOB) :

32
2.2.2 Caractéristiques d’entrée
Le signal sur la broche d'entrée (I/O pin) est amené vers les CLB soit directement via le signal
I, soit à travers une paire de bascules D (ou de latch) via IQ1 et IQ2. Les caractéristiques de
l'entrée de l’IOB sont les suivantes :
• diodes de protection ESD,
• résistance de "pull-up" ou "pull-down",
• Contrôle de l’impédance d’entrée (DCI),
• 23 standards d’entrée (différentiels ou non),
• horloge indépendante de la sortie,
• Un délai de quelques ns peut-être inséré dans le chemin de la donnée d'entrée pour
compenser le retard de l’horloge,
• Support du Double Data Rate pour écrire dans les SDRAM DDR.
2.2.3 Caractéristiques de sortie
Le signal de sortie peut être optionnellement inversé à l’intérieur de l’IOB et sortir
directement sur la broche ou bien être mis en mémoire par une paire de bascules D actives sur
un front. Les caractéristiques de la sortie d'un IOB sont les suivantes :
• buffer 3 états piloté par une paire de bascules D,
• sortie collecteur ouvert,
• 23 standards de sortie (différentiels ou non),
• contrôle de "slew-rate" (rapide ou lent),
• Contrôle de l’impédance de sortie (DCI),
• Support du Double Data Rate pour lire dans les SDRAM DDR.
• sortance de 24 mA max.
2.3 Bloc logique configurable (CLB)
2.3.1 Généralités
Le CLB est l'élément fonctionnel de base de ce FPGA. Sa programmation permet à
l'utilisateur de réaliser des fonctions logiques combinatoires ou séquentielles. Le schéma bloc
simplifié d'un CLB est représenté à la page suivante. Il est constitué de 4 SLICES, qui sont
eux-mêmes formés de deux cellules logiques.

33

34
Un slice (figure précédente) est constitué essentiellement de 2 générateurs de fonctions (LUT)
F et G et de 2 bascules D, FFX et FFY.
2.3.2 Générateurs de fonctions
Les deux générateurs de fonctions F et G peuvent réaliser chacun n’importe quelle fonction
combinatoire de 4 variables. En combinant les LUT des différents slices du CLB, il est aussi
possible de réaliser des multiplexeurs à grand nombre d’entrées : par exemple, un mux 4:1
dans un slice, un mux 16:1 dans un CLB ou encore un mux 32:1 dans deux CLB. La
polyvalence du CLB est la meilleure manière d’améliorer la vitesse de fonctionnement du
système à réaliser.
2.3.3 Bascules
Ces générateurs de fonctions peuvent être connectés directement vers les sorties du slice
(sorties X et Y), ou bien être mis en mémoire par deux bascules D (sorties XQ et YQ). Ces
deux bascules ont la même horloge (CLK), le même signal de validation (CE) et la même
logique de mise à 0 ou de mise à 1 asynchrone (SR). L’état de sortie de la bascule à la mise
sous tension est programmable. Les deux bascules peuvent être utilisées indépendamment
(entrée sur BX et BY) ou à la suite des générateurs de fonctions.
2.3.4 Configuration en ROM, RAM et registre à décalage
Tous les générateurs de fonctions F et G du CLB peuvent être utilisés comme des ROM. En
effet, chaque LUT est une ROM 16 bits et on peut donc former au maximum une ROM 128x1
dans un CLB. Chaque LUT des 2 Slices de gauche du CLB peut aussi être programmée en
RAM (simple et double port) ainsi qu’en registre à décalage.

35
Ainsi, on peut trouver au maximum dans un CLB :
• 4 mémoires 16x1 bits synchrones simple port,
• 2 mémoires 32x1 bits synchrones simple port,
• 1 mémoire 64x1 bits synchrone simple port,
• 2 mémoires 16x1 bits synchrones double port,
• 1 registre à décalage 64 bits.
Ces mémoires sont très rapides et elles ont l’avantage d’être situées au cœur de la fonction à
réaliser. Il n’y a donc pas de délais de routage. La mémoire synchrone est avantageuse car elle
est plus rapide et plus facilement exploitable que la mémoire asynchrone. La mémoire double
port possède deux ports (adresse, donnée, contrôle) indépendants. Elle peut être utilisée pour
réaliser des FIFO. Le contenu de ces RAM ou de ces ROM peut être initialisé à la mise sous
tension.
2.3.5 Logique de retenue rapide
Chaque slice contient une logique arithmétique dédiée pour générer rapidement une retenue
(carry). Cette logique dédiée accélère grandement toutes les opérations arithmétiques telles
que l’addition, la soustraction, l’accumulation, la comparaison... Elle accélère aussi la vitesse
de fonctionnement des compteurs. Chaque slice peut être configuré comme un additionneur 2
bits avec retenue qui peut être étendu à n’importe quelle taille avec d’autres CLB. La sortie
retenue (COUT) est passée au CLB se trouvant au-dessus. La retenue se propage en utilisant
une interconnexion directe.
2.4 Block RAM (SelectRAM)
Tous les FPGA de la famille Spartan-3 incorporent des blocs de mémoire RAM 18kbits
synchrones simple ou double ports (de 4 à 104 suivant la taille du circuit). Les 4 modes
suivants sont possibles :

36
Chaque BlockRAM peut être configuré dans les modes : 16kx1, 8kx2, 4kx4, 2kx8, 1kx16 et
512x32 en simple port ou double ports.
2.5 Multiplieurs dédiés
Associé à chaque BlockRAM, on trouve un multiplieur 18x18 = 36 bits signé en complément
à 2 (ou 17x17 = 34 non signé). On les utilisent surtout pour effectuer des opérations de
traitement du signal, mais ils peuvent aussi être utilisés avec profit pour réaliser des opérations
logiques (comme un décalage en un coup d’horloge par exemple).
2.6 Gestionnaire d’horloges
Le FPGA possède un gestionnaire d’horloge (Digital Clock Manager : DCM) particulièrement
élaboré. Il permet par exemple de créer des horloges décalées en phase (pour piloter des DDR
SDRAM par exemple), ou encore il élimine le skew (décalage des arrivées d’horloge sur les
bascules D) des horloges dans le FPGA ou bien encore il permet de synthétiser des horloges
avec des rapports (M x Fin) / D (avec M entier compris entre 2 et 32 et D entier compris entre
1 et 32). Vous pouvez par exemple créer une horloge sur CLKFX dont la fréquence est égale à
11/7 de CLKIN.
D’autre part, le FPGA possède 8 buffers spéciaux (BUFG) pour distribuer les horloges dans le
circuit.

37
2.7 Ressources de routage et connectivité
2.7.1 Généralités
Les FPGA de la série Spartan-3 disposent d'un nombre important de ressources de routage et
de connectivité, ce qui leur confère une très grande souplesse d'utilisation. Toutes les
connexions sont constituées de segments métalliques reliés par des matrices de contacts
programmables (Programmable Switch Matrix ou PSM). Chaque élément vu précédemment
est relié à une ou plusieurs PSM.
Chaque PSM est constituée de transistors permettant d’établir une connexion entre lignes
horizontales et verticales comme le montre le schéma suivant.
PSM 6 transistors par points de connexion

38
Après programmation, la PSM permet par exemple la configuration suivante :
L’objectif final est de relier les différents éléments logiques (LE) entre eux comme sur la
figure suivante :
LELE
LELE
LELE
LELE
LELE
LELE
SwitchMatrix
Switch Matrix
LELE
LELE
LELE
LELE
LELE
LELE
SwitchMatrix
Switch Matrix
2.7.2 Routage hiérarchique
Hélas, chaque passage par une PSM introduit un délai de propagation qui est très pénalisant
pour les liaisons à longue distance. Aussi les interconnexions ont été spécialisées en fonction
de la distance à parcourir. 4 types d’interconnexion sont disponibles :
• Les longues lignes qui connectent un CLB sur 6 et donc sautent 5 PSM sur 6.

39
• Les lignes triples qui connectent un CLB sur 3 et donc sautent 2 PSM sur 3.
• Les lignes doubles qui connectent un CLB sur 2 et donc sautent 1 PSM sur 1.
• Les lignes directes qui connectent un CLB avec ses voisins immédiats.
• Des lignes dédiées. Ce sont des connexions fixes utilisées pour propager les retenues,
cascader les registres à décalage formés dans les slices à gauche du CLB,... Il existe aussi
des lignes dédiées pour propager les horloges.

40
2.7.3 Lignes dédiées d’horloge
Il existe 8 entrées externes pour les horloges globales nommées GCLK0 à GCLK7. Il y a aussi
8 multiplexeurs (2:1) d’horloge globale BUFGMUX. Ces BUFGMUX acceptent en entrée soit
une horloge globale, soit une sortie de DCM, soit un signal créé à l’intérieur du FPGA. La
sortie des BUFGMUX attaque le réseau de distribution d’horloge. Une horloge globale dans
un design peut passer soit par un BUFGMUX, soit par un BUFG (Global Clock Buffer).
Pour minimiser la puissance dynamique dissipée, les lignes d’horloge non utilisées sont
désactivées.
2.8 Configuration
Il y a trois types de broches sur un FPGA :
• Les broches dédiées en permanence. Ce sont les broches d’alimentation et de masse (un
couple (VCC, GND) par coté), les buffers d’horloge...
• Les broches utilisables exclusivement par l’utilisateur pour réaliser son système.

41
• Les broches utilisables par l’utilisateur mais qui ont un rôle durant la configuration du
circuit.
La configuration est le processus qui charge le design dans la SRAM afin de programmer les
fonctions des différents blocs et de réaliser leurs interconnexions.
On voit, sur la figure ci-dessus, qu’il y a sous la logique dédiée à l’application une mémoire
de configuration qui contient toutes les informations concernant la programmation des CLB et
des IOB ainsi que l’état des connexions. Cette configuration est réalisée, à la mise sous
tension, par le chargement d’un fichier binaire dont la taille varie en fonction du nombre de
portes du circuit :

42
La configuration se fait en 4 étapes. A la mise sous tension, la mémoire de configuration est
effacée puis le circuit est initialisé. Ensuite a lieu la configuration qui est suivie du démarrage
du circuit programmé. Un CRC (« Cyclic Redundancy Check ») contenu dans le fichier de
configuration permet au circuit de vérifier l’intégrité des données au moment du chargement.
Le circuit peut se configurer en série (bit par bit) ou en parallèle (octet par octet). Il peut être
maître ou bien esclave en cas de configuration de plusieurs boîtiers. En mode maître, c’est lui
qui fournit les signaux nécessaires à sa propre configuration mais il peut aussi configurer un
ou plusieurs circuits esclaves montés en cascade (daisy chain). Le fichier de configuration
contient successivement tous les fichiers de configuration des circuits à programmer. Le mode
parallèle esclave correspond au mode périphérique microprocesseur. Les principaux modes
sont les suivants :
• En mode série maître, il faut utiliser une mémoire Flash série (XCF02S dans notre
maquette). On s'en sert en phase de production car c’est celui qui nécessite le moins de
câblage. Le FPGA génère une horloge CCLK pour lire les bits en série.
• En mode parallèle esclave, c’est un microcontrôleur externe qui charge la configuration
octet par octet. L’horloge est fournie par le microcontrôleur.
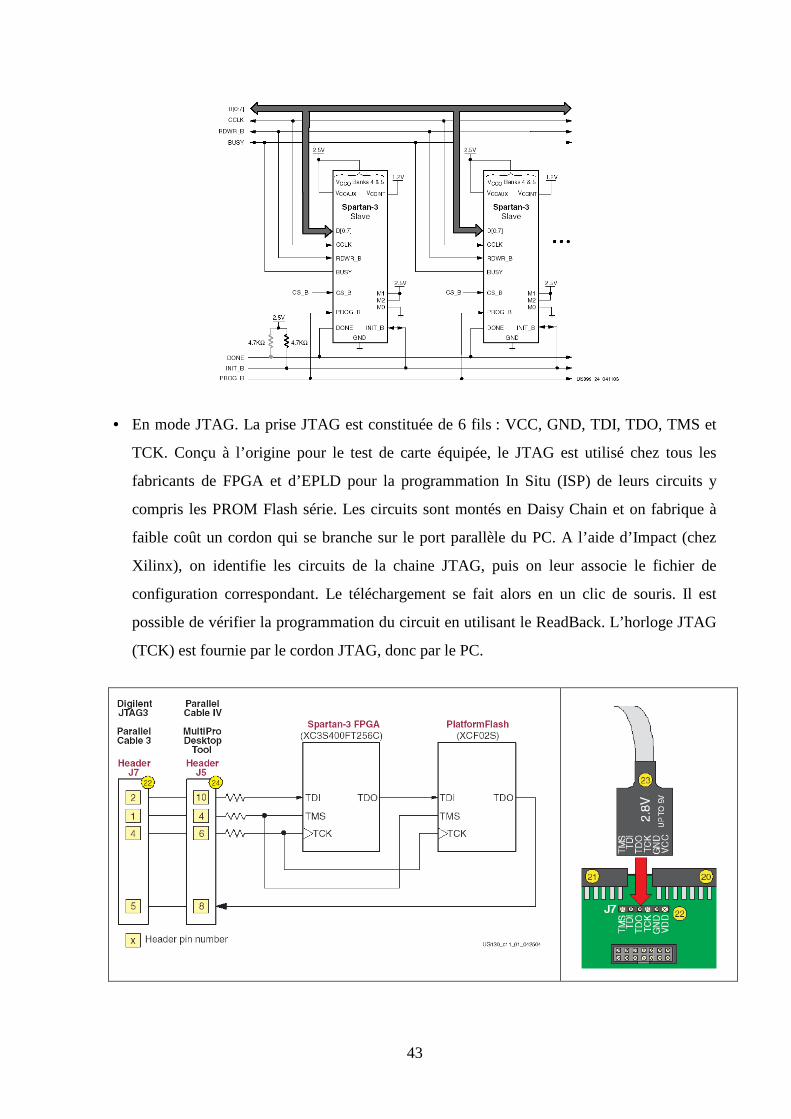
43
• En mode JTAG. La prise JTAG est constituée de 6 fils : VCC, GND, TDI, TDO, TMS et
TCK. Conçu à l’origine pour le test de carte équipée, le JTAG est utilisé chez tous les
fabricants de FPGA et d’EPLD pour la programmation In Situ (ISP) de leurs circuits y
compris les PROM Flash série. Les circuits sont montés en Daisy Chain et on fabrique à
faible coût un cordon qui se branche sur le port parallèle du PC. A l’aide d’Impact (chez
Xilinx), on identifie les circuits de la chaine JTAG, puis on leur associe le fichier de
configuration correspondant. Le téléchargement se fait alors en un clic de souris. Il est
possible de vérifier la programmation du circuit en utilisant le ReadBack. L’horloge JTAG
(TCK) est fournie par le cordon JTAG, donc par le PC.

44
2.9 Méthodologie de placement
Compte tenu de la structure du composant, il est préférable de placer les broches
d’entrées/sorties de la manière suivante :
Le point critique, ce sont les retenues qui montent dans le circuit, ce qui implique que les
additionneurs ont forcement le poids faible en bas et les bits dans l’ordre croissant en montant.
Les bus à l’entrée du FPGA doivent donc être mis dans l’ordre, LSB en bas et MSB en haut.
Ce point est toutefois bien moins critique que par le passé depuis que l’on peut effectuer des
changements dans l’affectation des broches du composant avec une faible pénalité temporelle.
Ce qui est vital quand on fabrique une carte avec des FPGA, c’est de placer :
1. Les alimentations,
2. les masses,
3. Les entrées d’horloges,
4. Les broches de configuration,
5. Les bus (dans le bon ordre de préférence s’il y a des problèmes de performance).
Le reste des fils peut être placé pour faciliter le routage de la carte. C’est le cas aussi pour les
bus s’ils ne sont pas très rapides.
Spartan 3

45
3. Conception d’un FPGA
3.1 Saisie du design
3.1.1 Saisie de schéma
Le rôle de la saisie de schéma est d’établir, à partir des composants utilisés et de leurs
interconnexions, une liste de connectivité (netlist). Cette netlist peut ensuite être utilisée par le
simulateur ou bien par les outils de placement–routage. L’utilisateur visualise son design à
l’aide de schémas graphiques faciles à interpréter. Les composants sont représentés par des
symboles graphiques. Les autres outils EDA (Electronic design automation) travaillent à partir
de la netlist ASCII (ou binaire). Les points suivants doivent être notés :
• Schéma multi-pages et hiérarchique. Un schéma peut occuper une ou plusieurs pages
(format A4 par exemple). C’est le schéma multi-pages. On utilise généralement
conjointement une autre méthode pour réduire la taille et la complexité du schéma : le
design hiérarchique. Dans un design hiérarchique, on a un schéma de plus haut niveau (top
level schematic) et des sous-schémas. Dans le schéma racine, on essaye d’avoir seulement
des blocs hiérarchiques. On associe à chacun de ces blocs un sous-schéma. On peut avoir
d’autres blocs hiérarchiques dans un sous-schéma et avoir ainsi un grand nombre de
niveaux hiérarchiques. L’exemple suivant vous montre un schéma racine composé de
deux symboles hiérarchiques HADD (demi-additionneur).
HADD
HADD
S
CO
CI
B
A A C
B DA C
B D
D
C
B
A
Top level schematic
Subschematic HADD

46
On appelle un design réalisé (ou mis) sur une seule page un design plat (flat design). On lui
associe une flat netlist.
• Librairies . Les composants utilisés dans le ou les schémas sont contenus dans une
librairie fournie par Xilinx. Il faut noter que l’utilisation de cette librairie rend impossible
le portage du design sur les composants d’un autre fabricant (Altera ou Lattice par
exemple). C’est le principal inconvénient de la saisie de schéma. En effet, même si on
retrouve les mêmes familles de composants dans les librairies des autres constructeurs de
FPGA, il y a toujours des différences dans l’appellation des composants ainsi que dans la
fonction réalisée.
• Nom d’instance. On utilise deux noms pour désigner un composant dans un schéma. Le
nom du composant et le nom d’instance. Le nom du composant est affecté au symbole (par
exemple AND) alors que le nom d’instance (instance name) est donné à chaque
instantiation de ce composant (and1, and2 et and3 dans l’exemple suivant) dans le
schéma.
and1
and3
and2
E
AND
AND
AND
D
C
B
A
noms d’instance
nom du composant
• Connecteurs. Il existe principalement trois types de connecteurs dans un design.
Le connecteur intra-page. A l’intérieur d’une page, il permet de relier ensemble
différentes connexions afin de clarifier le schéma.
Le connecteur multi-page. Sur un niveau hiérarchique donné, il permet de relier
ensemble différentes connexions se trouvant sur plusieurs pages d’un même schéma.
Le connecteur hiérarchique. Il permet d’établir les connexions entre deux niveaux
hiérarchiques adjacents (dans l’exemple précédent de bloc hiérarchique, les connecteurs
de HADD sont des connecteurs hiérarchiques).

47
• Symboles vectoriels. Lorsque l’on travaille sur un bus, on utilise des symboles vectoriels
pour pouvoir traiter le bus dans son ensemble et non pas traiter chaque fil séparément.
L’exemple suivant décrit un registre 4 bits.
FD4
FD
FD
FD
FD
Q1
H
D1 D Q
H
Q2D2 D Q
H
Q3D3 D Q
H
Q4D4 D Q
H
H
Q[1:4]D[1 :4] D Q
H
• Interconnexions. Il existe deux types d’interconnexions, le net et le bus. Le net
correspond à un fil reliant deux broches de composant, le bus est un ensemble de fils
reliant des symboles vectoriels. On peut relier (ou extraire) un net avec un bus grâce à un
extracteur de bus (ou bus ripper ou encore bus tap). On peut de la même manière relier (ou
extraire) un sous-bus avec un bus.
• Attributs . On peut placer un attribut (une propriété) sur un composant ou sur une
interconnexion afin par exemple de passer un paramètre aux outils de placement-routage.
C’est la commande « Object Properties…».
• Vérification . Un nombre élevé d’erreurs peut être éliminé en effectuant dans le schéma
des vérifications simples. C’est le rôle du programme « netlist screener » (Check
schematic dans ECS) qui vérifie quelques points élémentaires. L’absence d’erreurs ne
garantit en aucun cas que le design va fonctionner correctement.

48
• EDIF . L’« Electronic Design Interchange Format » est le seul standard de netlist existant
permettant d’échanger des données entre les différents outils EDA. La version 2.0.0,
quoique ancienne (il existe une version 3.0.0 et 4.0.0), est la plus utilisée pour cela. Les
outils des différents vendeurs (Mentor, Cadence, Synopsys, Viewlogic,…) permettent
généralement de lire ou d’écrire un schéma au format EDIF 2.0.0 au lieu de leur format
propriétaire habituel. Même Xilinx a prévu de passer du format XNF au format EDIF dans
ses outils de placement-routage. Mais le format EDIF ne règle en rien le problème de
l’incompatibilité entre les librairies.
3.1.2 Langage de description de bas niveau
La saisie de schéma est un moyen puissant pour spécifier un design car le schéma graphique
est une manière naturelle pour un électronicien de créer ou de lire un design. Elle a toutefois
trois inconvénients principaux :

49
• L’incompatibilité entre les librairies qui rend le portage d’un design entre deux fabricants
de FPGA quasiment impossible.
• La complexité d’un schéma devient très élevée quand le nombre de portes augmente. Au-
delà de 10000 portes, il devient généralement ingérable.
• Une modification importante au milieu d’une page du schéma nécessite généralement la
réécriture complète de la page.
Pour toutes ces raisons, on a essayé de développer des outils spécifiant le design avec une
entrée de type texte plutôt qu’avec une entrée de type graphique. Les premiers langages de bas
niveau ont été créés pour programmer les PAL puis les PLD. Il existe aujourd’hui un très
grand nombre de design élémentaires (et opérationnels) que l’on peut chercher à réutiliser. On
trouve principalement les deux langages suivants :
• PALASM . Il s’agit d’un langage de programmation de PAL conçu par AMD/MMI.
Aujourd’hui en version 2, les outils de développement ont l’immense avantage d’être
gratuits.
• ABEL . ABEL est un langage de programmation de PAL conçu par Data I/O. Il est très
utilisé au USA mais les outils de développement demeurent assez coûteux.
3.1.3 Langage de description matériel
Les deux langages précédents sont loin d’être assez puissants pour pouvoir spécifier un ASIC
ou un FPGA. Deux langages de description matériel sont apparus dans les années 80 : Verilog
et VHDL (VHSIC (Very High-Speed Integrated Circuit) Hardware Description Language). La
grande majorité des simulateurs ne travaille plus aujourd’hui qu’avec un de ces deux langages.
Le schéma graphique, quand il est utilisé, est simplement traduit dans un de ces langages (en
netlist VHDL avec ECS dans notre cas).
La synthèse est l’opération qui consiste, à partir du fichier texte, à produire la netlist contenant
le schéma électrique destiné aux outils de placement-routage (EDIF ou NGC). Cette étape est
particulièrement délicate dans le cas des FPGA à cause de la complexité élevée (granularité)
de la cellule de base du FPGA. La portabilité est bien meilleure qu’avec la saisie de schéma
(les langages VHDL et Verilog sont normalisés), mais toute la complexité du processus de
développement repose maintenant sur l’efficacité de la synthèse.

50
3.2 Les outils de développement Xilinx
3.2.1 Le flot Xilinx
Le flot standard Xilinx permet de générer le fichier PROM permettant la configuration du
FPGA à partir des fichiers de design NGC (Netlist format binaire Xilinx) ou EDIF (Netlist
format texte normalisée) issus de la CAO. L’organigramme suivant nous montre globalement
les différentes étapes du flot de conception d’un FPGA Xilinx.
A partir des fichiers issus de la synthèse, il faut quatre phases pour produire un fichier de
configuration (Design Implementation) :
• La translation (optimisation). Elle regroupe les différents fichiers de design NGC ou EDIF
ainsi que les fichiers de contraintes UCF pour générer un fichier de design unique NGD.
• Le mapping. A partir de ce fichier NGD, le mapper décompose le design en éléments
simples (primitives) qui sont effectivement disponibles dans le FPGA sélectionné.
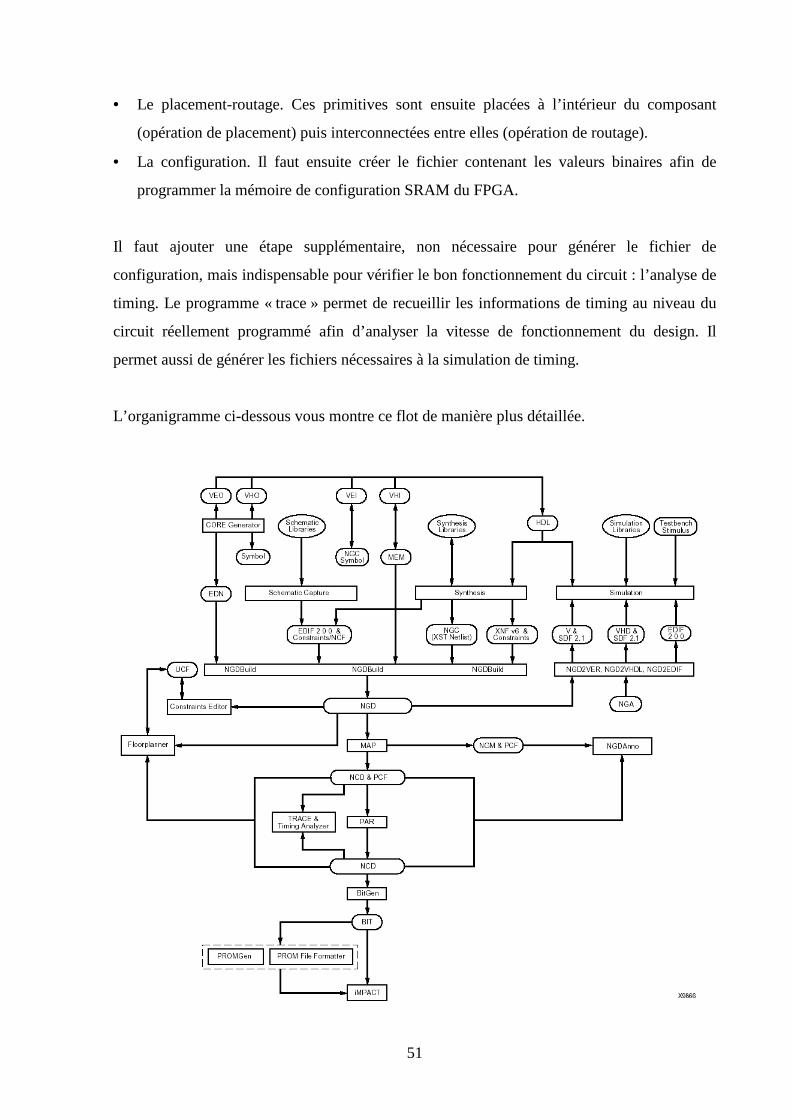
51
• Le placement-routage. Ces primitives sont ensuite placées à l’intérieur du composant
(opération de placement) puis interconnectées entre elles (opération de routage).
• La configuration. Il faut ensuite créer le fichier contenant les valeurs binaires afin de
programmer la mémoire de configuration SRAM du FPGA.
Il faut ajouter une étape supplémentaire, non nécessaire pour générer le fichier de
configuration, mais indispensable pour vérifier le bon fonctionnement du circuit : l’analyse de
timing. Le programme « trace » permet de recueillir les informations de timing au niveau du
circuit réellement programmé afin d’analyser la vitesse de fonctionnement du design. Il
permet aussi de générer les fichiers nécessaires à la simulation de timing.
L’organigramme ci-dessous vous montre ce flot de manière plus détaillée.

52
Les programmes NGDAnno, NGD2EDIF, NGD2VER et NGD2VHDL ne sont accessibles
qu’à partir de la ligne de commande (dans une fenêtre de commande). Ils permettent, après
mapping, de récupérer un modèle VHDL (ou EDIF, ou Verilog) représentant le design
décomposé en primitives. Il est possible d’incorporer à ce modèle les timings des primitives
(mais pas des interconnexions).
En plus du flot principal, quatre applications sont accessibles :
• Timing Analyzer. Cette application permet d’interroger le fichier de timing afin de vérifier
un temps de propagation sur un chemin particulier ou bien la fréquence de
fonctionnement maximale d’une horloge.
• IMPACT. Utilisée avec le câble JTAG (parallel cable III), cette application permet de
télécharger la configuration dans le FPGA mais aussi de transformer le fichier de
configuration design.bit spécifique à xilinx en un fichier plus standard (comme le MCS-
86 par exemple) pour pouvoir programmer une EEPROM.
• FPGA Editor. Cet éditeur de FPGA permet d’accéder à des informations de très bas
niveau sur le circuit ainsi que d’effectuer des opérations de placement-routage à la main
ou encore d’analyser des timings sur un net. A manier avec précaution.
• Xpower. C’est le logiciel qui estime la puissance consommée par le FPGA.
La mise en œuvre de certaines de ces applications sera vue dans les différents travaux
pratiques.
3.2.2 Mise en œuvre des contraintes
Les contraintes permettent à l’utilisateur de contrôler les opérations de mapping et de
placement-routage. L’organigramme suivant montre de manière détaillée les différentes
manières de spécifier des contraintes dans un design.
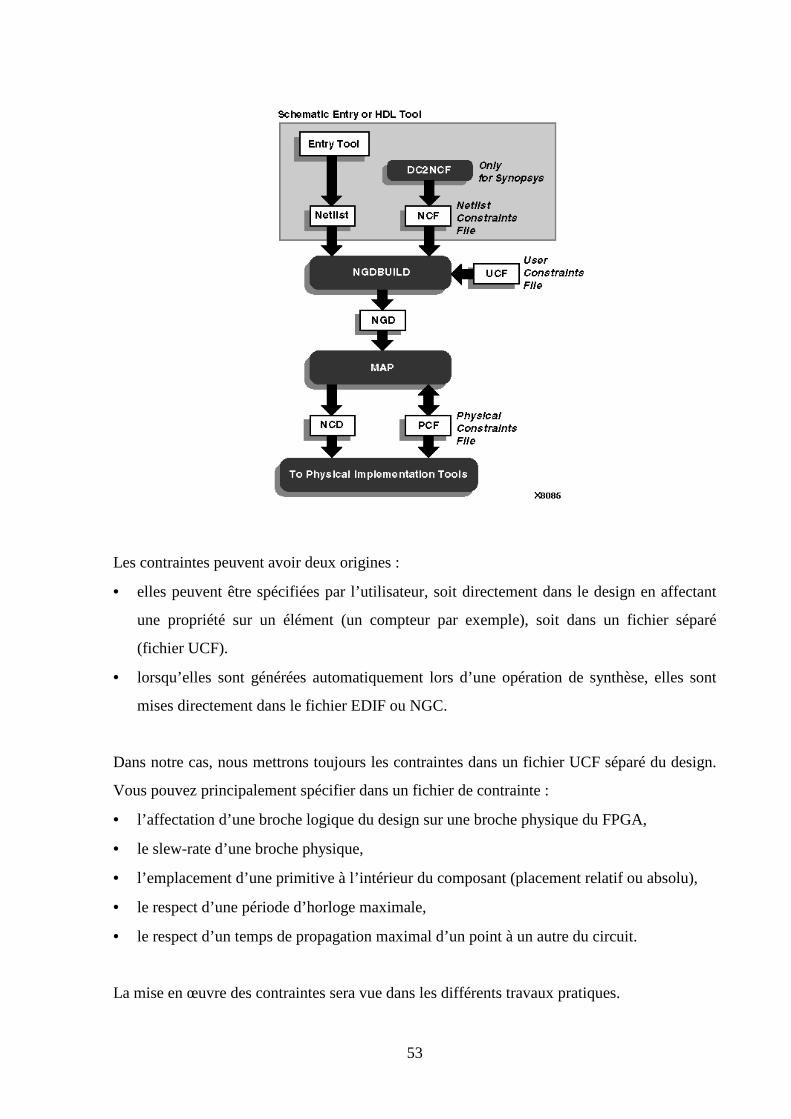
53
Les contraintes peuvent avoir deux origines :
• elles peuvent être spécifiées par l’utilisateur, soit directement dans le design en affectant
une propriété sur un élément (un compteur par exemple), soit dans un fichier séparé
(fichier UCF).
• lorsqu’elles sont générées automatiquement lors d’une opération de synthèse, elles sont
mises directement dans le fichier EDIF ou NGC.
Dans notre cas, nous mettrons toujours les contraintes dans un fichier UCF séparé du design.
Vous pouvez principalement spécifier dans un fichier de contrainte :
• l’affectation d’une broche logique du design sur une broche physique du FPGA,
• le slew-rate d’une broche physique,
• l’emplacement d’une primitive à l’intérieur du composant (placement relatif ou absolu),
• le respect d’une période d’horloge maximale,
• le respect d’un temps de propagation maximal d’un point à un autre du circuit.
La mise en œuvre des contraintes sera vue dans les différents travaux pratiques.

54
3.2.3 Les modèles de timing
Il existe 4 modèles de timing permettant de déterminer les caractéristiques temporelles d’un
design :
• Pad to Setup
Logiquecombinatoire
Clock
QD
interconnexionsPad
Pad to Setup
On a un signal sur une broche d’entrée (pad) et l’on souhaite qu’il soit pris en compte sur le
front actif d’une bascule D. Le temps « pad to Setup » est le temps de setup à prendre en
compte entre la broche d’entrée et le front actif de l’horloge. Dans l’exemple général ci-
dessus, il est égal à :
TPad to Setup = Tpropagation Pad + Tprop interconnexion + Tprop logique + Tprop interconnexion + Tsetup bascule
• Pad to pad
Logiquecombinatoire
Pad to pad
C’est le temps de propagation entre une broche d’entrée et une broche de sortie dans le cas
d’un circuit purement combinatoire. Dans l’exemple général ci-dessus, il est égal à :
TPad to pad = Tprop Pad + Tprop interconnexion + Tprop logique + Tprop interconnexion + Tprop Pad

55
• Clock to pad
Logiquecombinatoire
Clock
QD
Clock to pad
On souhaite mesurer le temps qui sépare le front actif de l’horloge et l’arrivée du signal de
sortie de la bascule sur une broche de sortie. Le temps « clock to pad » est le temps de
propagation du signal entre le front actif de l’horloge et son arrivée sur une broche de
sortie. Dans l’exemple général ci-dessus, il est égal à :
Tclock to pad = Tprop clock to Q + Tprop interconnexion + Tprop logique + Tprop interconnexion + Tprop Pad
• Clock to setup
Logiquecombinatoire
Clock
QD
clock to setup
Clock
QD
On a un signal sur une sortie de bascule D et l’on souhaite qu’il soit pris en compte sur le
front actif d’une deuxième bascule D, les deux bascules étant commandées par la même
horloge. Le temps « clock to Setup » est le temps à prendre en compte entre le front actif de
l’horloge et le front suivant de cette même horloge. Dans l’exemple général ci-dessus, il est
égal à :
Tclock to pad = Tprop clock to Q + Tprop interconnexion + Tprop logique + Tprop interconnexion + Tsetup bascule
Nous reverrons ces modèles lors de l’utilisation de l’application Timing analyzer ainsi que
lors de la spécification des contraintes temporelles.

56
3.2.4 Les librairies unifiées
Xilinx fournit des librairies contenant plusieurs centaines de composants « élémentaires » qui
sont généralement communes aux différentes familles de FPGA (Virtex, Spartan) et d’EPLD
(CoolRunner et XC9500) du fabricant. On appelle ces librairies des librairies unifiées. On
trouve principalement les familles suivantes :
• Les fonctions d’entrée / sortie (dans l’IOB).
Buffers d’entrée : IBUF, IBUF4, IBUF8, IBUF16.
Buffers de sortie : OBUF, OBUF4, OBUF8, OBUF16.
Contrôle trois états : OBUFT, OBUFT4, OBUFT8, OBUFT16.
Bascule d’entrée : IFD, IFD4, IFD8, IFD16.
Latches d’entrée : ILD, ILD4, ILD8, ILD16.
Bascules de sortie : OFD, OFD4, OFD8, OFD16.
Contrôle trois états : OFDT, OFDT4, OFDT8, OFDT16.
• Les fonctions logiques de base.
Inverseurs : INV, INV4, INV8, INV16.
Portes : AND, NAND, NOR, XOR, XNOR de 2 à 9 entrées.
Exemples : AND4 porte ET à 4 entrées.
AND5B3 porte ET à 5 entrées dont 3 inversées (B ≡ bubble).
NOR4B2 porte OU-NON à 4 entrées dont 2 inversées.
NAND9 porte ET-NON à 9 entrées.
• Les buffers.
Buffers : BUF, BUFE (avec enable), BUFE4, BUFE8, BUFE16.
Buffers d’horloge : BUFGP, BUFGS.
Buffers trois états internes : BUFT, BUFT4, BUFT8, BUFT16.
• Les mémoires.
RAM standard : RAM16x1, RAM16x8, RAM32x2, RAM32x4.
RAM double port : RAM16x1D, RAM16x2D, RAM16x4D, RAM16x8D.
RAM synchrone : RAM16x1S, RAM16x8S, RAM32x2S, RAM32x4S.
ROM : ROM16x1, ROM32x1.

57
• Les bascules.
Le nom de la bascule permet de retrouver ses fonctionnalités. La règle d’appellation est la
suivante :
Exemples :
Appellation Signification
FDC Flip-flop type D avec Clear asynchrone
FD4RE 4 Flip-flop type D avec Reset synchrone et clock enable
FDSRE Flip-flop type D avec Set et Reset synchrone et clock enable
FJKCE Flip-flop type JK avec Clear asynchrone et clock enable
FTSRE Flip-flop type T avec Set et Reset synchrone et clock enable
• Les registres à décalage. La règle d’appellation est la suivante :
Exemples : SR4CE registre 4 bits avec clear asynchrone et clock enable.
SR8RE registre 8 bits avec reset synchrone et clock enable.

58
• Les multiplexeurs. La règle d’appellation est la suivante :
Exemple : M4_1E multiplexeur 4 vers 1 avec enable.
• Les compteurs.
Exemples :
CB2RLE compteur binaire chargeable 2 bits avec reset synchrone et clock enable.
CB8CE compteur binaire 8 bits avec clear asynchrone et clock enable.
• Les décodeurs. La règle d’appellation est la suivante :
Exemple : D3_8E décodeur 3 vers 8 avec enable.

59
• Les comparateurs.
Comparateurs d’identité : COMP8.
Comparateurs de magnitude : COMPM8.
• Les circuits arithmétiques.
Additionneurs : ADD8.
Additionneurs / soustracteurs : ADSU8.
Accumulateurs : ACC16.
• Fonctions diverses.
Partitionnement logique : FMAP, HMAP.
Contrôleur boundary scan : BSCAN.
Mise à 0 : GND.
Mise à 1 : VCC.
3.2.5 Core Generator
En plus des librairies unifiées, Xilinx fournit un générateur de composants paramétrables,
CoreGen. Si vous ne trouvez pas le composant recherché dans les librairies unifiées, vous
pouvez utiliser CoreGen :

60
Voici par exemple la fenêtre de contrôle de CoreGen dans le cas d’une FFT :
De très nombreux paramètrages sont disponibles. Certains composants (on les appelle des IP
pour Intellectual Property) sont payant, mais la plupart sont fournis gratuitement par Xilinx
(comme la FFT).
3.3 La maquette FPGA
3.3.1 Constitution
La maquette FPGA est constituée :
• D’un FPGA Xilinx XC3S200-4C en boîtier BGA 256 broches.
• D’un CAN 8 bits 32 MSPS (AD9280) précédé d’un filtre anti-repliement (Tchebyscheff 5
MHz du 3ème ordre). Le niveau d’entrée sur la prise Din (adaptée 50 ΩΩΩΩ) ne doit pas
dépasser 1V crête à crête. Le FPGA doit fournir un signal d’horloge (niveau CMOS
3.3V) à ce composant.
• D’un CNA 8 bits 125 MSPS (AD9708) suivi d’un filtre de lissage (Tchebyscheff 5 MHz
du 3ème ordre). Le FPGA doit fournir un signal d’horloge (niveau CMOS 3.3V) à ce
composant.

61
SW0 SW7 BTN3
50 Ω
BTN0
FPGA XC3S200
CAN
CNA
fc = 5 MHz
téléchargement
fc = 5 MHz
Din
Dout
Hin
D U P
LD0 LD7
Hi
Lo
• De quatre afficheurs 7 segments multiplexés (dont trois nommés D (dizaine), U (unité) et
P (puissance)). Un segment s’allume quand la sortie du FPGA qui lui est connecté est au
niveau bas.
• De 8 leds nommées LD0 à LD7. Une led s’allume quand la sortie du FPGA qui lui est
connectée est au niveau haut.

62
• De 8 interrupteurs (Lo/Hi) nommés SW0 à SW7. Quand un interrupteur est sur Hi,
l’entrée du FPGA qui lui est connecté est au niveau haut.
• De quatre boutons poussoirs nommés BTN0 à BTN3. L’appui sur un de ces boutons
déclenche une impulsion positive (met au niveau 1 l’entrée correspondante).
• D’une entrée d’horloge Hin (niveau CMOS 3.3V adaptée 50 Ω).
• D’un oscillateur 50 MHz (100 ppm, niveau CMOS 3.3V) connecté sur le FPGA.
• D’une prise de téléchargement JTAG pour programmer le FPGA. Le téléchargement
s’effectue via une des prises parallèles du PC.
• D’un cordon d’alimentation. Il faut une alimentation 5 V, 1.6 A.
3.4 Récapitulatif de la chaîne complète
Nous allons maintenant revenir sur la chaîne de développement complète. Elle comprend les
étapes suivantes.
• En saisie de schéma :
1. Saisie du schéma (ECS). On peut résumer cette étape par les phases suivantes :
placement des symboles,
interconnexions des symboles,
affectation des labels,
vérification et sauvegarde.
ECS crée un fichier VHDL qui contient la liste des interconnexions entre les composants se
trouvant dans le schéma, plus les modèles VHDL (fournis par Xilinx avec les librairies
unifiées) de ces composants.

63
2. Ecriture du testbench (HDL Bencher). Pour pouvoir simuler le modèle VHDL de notre
design, il faut écrire des vecteurs (stimuli) de test qui forment le testbench. Cette
écriture se déroule en deux phases :
définition graphique des vecteurs de test,
sauvegarde de la saisie graphique et du fichier équivalent en langage VHDL.
3. Simulation fonctionnelle. A partir des fichiers design.vhf (modèle VHDL du design) et
design_tb.vhw (vecteurs de test en VHDL), nous pouvons effectuer la simulation
fonctionnelle du design. Il y a quatre phases :
compilation des fichiers,
lancement du simulateur,
exécution des vecteurs de test,
vérification du fonctionnement à l’aide des chronogrammes.
4. Traduction de la netlist VHDL en une netlist NGC. La génération du fichier NGC permet
de passer à l’implémentation. Le synthétiseur XST est ici utilisé en simple traducteur.
5. Implémentation. Le but de l’implémentation est de générer un fichier de configuration
permettant de programmer le FPGA à partir du fichier NGC. Le tableau suivant indique
les 5 étapes possibles ainsi que les rapports qui lui sont associés.
Etape Rapport Signification
Translation Translation report Création d’un fichier de design unique
Mapping Map report
Logic level timing report
Découpage du design en primitives
Timing sur primitives uniquement
Placement-routage Place & Route report
Pad report
Placement et routage des primitives
Assignation des broches du FPGA
Analyse de timing Asynchronous delay report
Post layout timing report
Timing sur certains nets
Timing sur primitives et interconnexions
configuration Bitgen report Génération du fichier de configuration
L’analyse de timing détaillée avec « timing analyzer » est optionnelle. Elle permet de
vérifier la fréquence maximale de fonctionnement du design.

64
6. Simulation temporelle. Après le placement-routage, on peut obtenir un modèle VHDL réel
du design (design_timesim.vhd) et le fichier de timings qui lui est associé
(design_timesim.sdf). On utilise le fichier de stimuli généré par HDL Bencher
(design_tb.timesim_vhw) pour effectuer la simulation de timing du design en quatre
phases :
compilation des fichiers,
lancement du simulateur,
exécution des vecteurs de test,
vérification du fonctionnement à l’aide des chronogrammes.
7. Téléchargement. Une fois le design entièrement testé, nous pouvons télécharger le fichier
de configuration du FPGA dans la maquette grâce au logiciel Impact :
Initialisation de la chaîne JTAG,
Association du fichier .bit avec le FPGA,
Téléchargement dans le FPGA.
8. Vérification sur la maquette. N’oubliez pas de respecter les adaptations d’impédance et les
niveaux nécessaires au bon fonctionnement de la maquette.
• En VHDL, les 4 premières étapes sont remplacées par :
1. Ecriture du modèle VHDL avec l’éditeur intégré du navigateur de projet. Nous allons voir
au chapitre suivant une introduction à l’écriture de modèles VHDL synthétisables. Il y a
deux parties à écrire :
L’entité (entrées/sorties),
L’architecture (la description du fonctionnement).
2. Ecriture du testbench (HDL Bencher). Cette étape est identique à celle vue en saisie de
schéma.
3. Simulation fonctionnelle. Cette étape est identique à celle vue en saisie de schéma.

65
4. Synthèse avec XST. Il s’agit ici d’une vraie opération de synthèse et pas d’une simple
traduction. Il faut bien comprendre la différence entre les deux cas :
En saisie de schéma, le design est composé de primitives simples contenues dans une
bibliothèque fournie par Xilinx. La netlist VHDL correspondante doit donc simplement
être traduite en une netlist NGC pour être compréhensible par les outils
d’implémentation. Le synthétiseur XST est utilisé comme un simple traducteur VHDL-
NGC.
La description VHDL n’utilise pas de bibliothèque propriétaire et elle est beaucoup
plus générale. Le rôle du synthétiseur est ici de comprendre et d’interpréter cette
description plus abstraite du compteur afin de générer un fichier NGC compréhensible
par les outils d’implémentation, c’est-à-dire une netlist NGC composée de primitives
simples.
la synthèse est l’opération qui permet de créer une netlist NGC à partir d’une
description de haut niveau écrite en VHDL.

66

67
4. Du VHDL à la synthèse
4.1 Le langage VHDL
4.1.1 Définition
VHDL sont les initiales de VHSIC Hardware Description Langage, VHSIC étant celles de
Very High Scale Integrated Circuit. Autrement dit, VHDL signifie : langage de description
matériel s'appliquant aux circuits intégrés à très forte intégration.
4.1.2 Généralités
4.1.2.1 Nécessité
L'évolution des technologies induit une complexité croissante des circuits intégrés qui
ressemblent de plus en plus aux systèmes complets d'hier. Aujourd'hui, on intègre dans une
puce ce qui occupait une carte entière il y a quelques années. La simulation logique globale du
système au niveau "porte" n'est plus envisageable en terme de temps de simulation. C'est donc
tout naturellement que des simulateurs fonctionnels ont commencé à être utilisés en
microélectronique. Dans les années 70, une grande variété de langages et de simulateurs était
utilisée. Cette diversité avait pour conséquence une non portabilité des modèles et donc une
impossibilité d'échange entre les sociétés. Un des rôles de VHDL est de permettre l'échange de
descriptions entre concepteurs. Ainsi peuvent être mises en place des méthodologies de
modélisation et de description de bibliothèques en langage VHDL. L'effort de standardisation
d'un langage tel que VHDL était nécessaire par le fait qu'il ne s'agissait pas de construire un
seul simulateur VHDL (contrairement à la quasi-totalité des autres langages), mais de
permettre l'apparition d'une multitude d'outils (de simulation, de vérification, de synthèse, ...)
de constructeurs différents utilisant la même norme. Ceci garantit une bonne qualité (la
concurrence) et l'indépendance de l'utilisateur vis à vis des constructeurs de ces outils.
4.1.2.2 Un peu d'histoire
Les langages de description matériel (HDL ou Hardware Description Language) ont été
inventés à la fin des années 60. Ils s'appuyaient sur les langages de programmation et devaient
permettre la description et la simulation de circuits. Entre les années 1968 et 1975, une grande
diversité de langages et de simulateurs ont vu le jour. Cependant, leur syntaxe et leur
sémantique étaient incompatibles et les niveaux de descriptions étaient variés. En 1973, le

68
besoin d'un effort de standardisation s'est fait ressentir et c'est ainsi que le projet CONLAN
(pour CONsensus LANguage) a été mis en place. Les principaux objectifs de ce projet étaient
de définir un langage de description matériel permettant de décrire un système à plusieurs
niveaux d'abstractions, ayant une syntaxe unique et une sémantique formelle et non ambiguë.
En mars 1980, le département de la défense des Etats Unis d'Amérique (DoD ou Department
of Defense) lançait le programme VHSIC. En 1981, des demandes pour un nouveau langage
de description de systèmes matériels, indépendant de toute technologie et permettant de
couvrir tous les besoins de l'industrie microélectronique, ont été formulées. C'est en 1983, que
d'importantes sociétés telles que IBM, Intermetrics ou encore Texas Instruments se sont
investies dans ce projet et à la fin de l'année 1984, un premier manuel de référence du langage
ainsi qu'un manuel utilisateur ont été rédigés. En 1985, des remises en cause et des évaluations
ont donné naissance à la version 7.2 du langage VHDL, et en juillet 1986, Intermetrics a
développé un premier compilateur et un premier simulateur.
C'est en mars 1986, qu'un groupe chargé de la standardisation du langage VHDL a été créé. Il
s'agit du groupe américain VASG (VHDL Analysis and Standardization Group) qui est un
sous comité des DASS (Design Automation Standard Subcommittees), eux-mêmes émanant
de l'IEEE (Institute of Electrical and Electronics Engineers). La norme VHDL IEEE 1076 a
été approuvée le 10 décembre 1987. En tant que standard IEEE, le langage VHDL évolue tous
les cinq ans afin de le remettre à jour, d'améliorer certaines caractéristiques ou encore
d'ajouter de nouveaux concepts. Ainsi en 1991 a débuté le processus de re-standardisation :
regroupement et analyse des requêtes, définition des nouveaux objectifs du langage,
spécifications des changements à apporter au langage. La nouvelle norme du langage VHDL a
été votée en septembre 1993. La syntaxe et la sémantique de cette nouvelle norme ont donné
lieu à un nouveau manuel de référence.
Il est à souligner que la nouvelle version du langage VHDL généralement notée VHDL'93 est,
au moins théoriquement, la seule et unique version légale du langage. L'approbation de la
nouvelle norme VHDL en 1993 rend le standard précédent (IEEE Std 1076 voté en 1987)
désuet. Néanmoins, et heureusement, VHDL'93 reste compatible avec VHDL'87.

69
4.1.3 Les principales caractéristiques du langage VHDL
4.1.3.1 Un langage s'appliquant à plusieurs niveaux de descriptions
Le langage VHDL couvre tous les niveaux partant des portes logiques de base jusqu'aux
systèmes complets (plusieurs cartes, chacune comprenant plusieurs circuits). Il s'applique tout
aussi bien au niveau structurel qu'au niveau comportemental, en passant par le niveau
transferts de registres ou RTL (Register Transfer Logic).
La description comportementale
Le circuit est décrit sans tenir compte de la réalisation concrète sur un composant donné (par
exemple, on ne définit pas de signaux d’horloge). On utilise les fonctions de haut niveau
d’abstraction de VHDL. Le code est donc portable, mais il dépend entièrement du synthétiseur
pour le résultat (si un tel synthétiseur existe). Ce style de description permet en particulier de
spécifier le circuit sous forme d’un algorithme.
La description flot de données
Le circuit est décrit grâce à plusieurs couche de registres (bascules D) reliées par de la logique
combinatoire. On utilise généralement une liste d'instructions concurrentes d'affectations de
signaux du type "<signal> <= <expression> " où <expression> peut représenter un simple
signal, ou une expression utilisant des opérateurs logiques, arithmétiques ou relationnels, ou
une expression conditionnelle. C’est la manière traditionnelle d’écrire du VHDL et qui donne
généralement les meilleurs résultats avec les synthétiseurs commercialisés. Ce niveau de
description est souvent appelé "logiques à transfert de registres" ou RTL (Register Transfer
Logic).
La description structurelle de bas niveau
Le circuit est décrit par sa structure, sous forme d’une liste de composants instanciés et des
interconnexions les reliant. En fait, c’est l’équivalent littéral d’un schéma représentant
l’interconnexion de portes élémentaires issues d'une bibliothèque.
A
BC

70
La description structurelle de haut niveau
Le circuit est découpé en blocs fonctionnels de haut niveau qui sont reliés entre eux. Il s’agit
toujours d’un schéma, mais il représente des composants qui peuvent être écrit en
comportemental ou en RTL (mais aussi en structurel bas niveau). On retrouve en général ce
type de description dans le design supérieur d’une description hiérarchique (top level design).
4.1.3.2 La portabilité
La portabilité constituait un des objectifs principaux pendant la phase de définition du langage
VHDL. L'utilisation largement répandue de ce langage est essentiellement due au fait qu'il soit
un standard. Un standard offre beaucoup plus de garanties (stabilité, fiabilité, etc.) vis-à-vis
des utilisateurs que ne le permettrait un langage potentiellement précaire développé par une
société privée. La portabilité signifie dans le cadre des FPGA, qu’il est possible à tout moment
de changer de technologie cible (Altera, Xilinx, etc.) ou bien de famille au sein d’un même
fabricant ; ou même d’avoir une stratégie de conception qui consiste à réaliser un prototype
sur un circuit programmable (FPGA) avant de basculer sur des circuits spécifiques (ASIC ou
Application Specific Integrated Circuit).
4.1.3.3 La lisibilité
La représentation schématique n'est pas toujours d'une grande lisibilité. Il est difficile de saisir
rapidement le fonctionnement d'une machine d'état parmi un enchevêtrement de registres et de
portes logiques. Une documentation écrite est très souvent nécessaire à la compréhension d'un
schéma. VHDL apporte par son principe de modularité et d'interconnexion de composants une
grande lisibilité à la compréhension d'un système, sans pour autant supprimer l'utilité d'un
dessin fonctionnel.
4.1.3.4 La modularité
La modularité est une des caractéristiques essentielles de VHDL. Une description partitionnée
en plusieurs sous-ensembles est dite modulaire. VHDL supporte la conception modulaire et
hiérarchique, qui offre de nombreux avantages :
• les descriptions sont plus simples,
• les durées de simulation, de synthèse et de mise au point sont raccourcies,
• la fiabilité est améliorée : chaque sous-ensemble peut être testé exhaustivement,
• les sous-ensembles sont réutilisables.

71
En VHDL, une description peut donc faire appel à des modules externes et les interconnecter
de manière structurelle. Par exemple, la vision hiérarchique d’un additionneur consiste à
traiter les blocs, l’additionneur et le registre, comme assemblage d’objets plus élémentaires
comme le montre la figure suivante.
4.1.3.5 Le couple entité architecture
Un design quelconque (circuit intégré, carte électronique ou système complet) est
complètement défini par des signaux d’entrées et de sorties et par la fonction réalisée en
interne. L’élément essentiel de toute description en VHDL est formé par le couple entité
architecture qui décrit l’apparence externe d’un module et son fonctionnement interne.
Entité
L’entité décrit la vue externe du modèle : elle permet de définir les ports par où sont véhiculés
les informations (signaux) et les paramètres génériques. Le code suivant donne un exemple
d’entité définie pour un compteur N bits. Il est possible de définir des valeurs par défaut pour
les paramètres ; dans l’exemple, le paramètre WDTH correspond au nombre de bits du
compteur avec pour valeur par défaut 4.

72
entity compteur is generic (WDTH : integer :=4; STOP : integer := 10); port( CLK : in std_logic ; CE : in std_logic ; CLEAR : in std_logic;
CEO : out std_logic; DOUT : out std_logic_vector(WDTH -1 downt o 0)); end compteur;
Architecture
L’architecture définit la vue interne du modèle. Cette description peut être de type structurel,
flot de données, comportemental ou une combinaison des trois. Tous les fonctionnements ne
nécessitent pas le même degré de précision : tantôt une description globale permet d’obtenir
un résultat satisfaisant, tantôt une description très précise s’avère nécessaire.
A chaque entité peut être associée une ou plusieurs architectures, mais, au moment de
l’exécution (simulation ou synthèse), seule une architecture est utilisée. Ceci présente l’intérêt
majeur de comparer plusieurs architectures pour choisir la meilleure. L’architecture comprend
aussi une partie déclarative où peuvent figurer un certain nombre de déclarations (de signaux,
de composants, etc.) internes à l’architecture. A titre d’exemple, le code suivant donne une
description possible d’architecture associée à l’entité décrite précédemment pour un compteur
N bits.
architecture a1 of compteur is signal INT_DOUT : std_logic_vector(DOUT'range) ; begin process(CLK, CLEAR) begin if (CLEAR='1') then INT_DOUT <= (others => '0'); elsif (CLK'event and CLK='1') then if (CE='1') then if (INT_DOUT=STOP-1) then INT_DOUT <= (others => '0'); else INT_DOUT <= (INT_DOUT + 1); end if; end if; end if; end process;
CEO <= INT_DOUT(0) and not INT_DOUT(1) and not INT_ DOUT(2) and INT_DOUT(3) and CE; dout <= int_dout; end;
4.1.3.6 Les principaux objets manipulés
Les constantes : Une constante peut être assimilée à un signal interne (au circuit) auquel est
associée une valeur fixe et définitive. La constante peut être de tout type.

73
Les signaux : Les signaux sont spécifiques à la description matérielle. Ils servent à modéliser
les informations qui passent sur les fils, les bus ou, d’une manière générale, qui transitent
entre les différents composants. Les signaux assurent donc la communication.
Les variables : Une variable est capable de retenir une valeur pendant une durée limitée. Elle
ne peut être employée qu’à l’intérieur d’un process. A l’opposé d’un signal, une variable n’est
pas une liaison concrète et ne doit pas laisser de trace après synthèse.
4.1.3.7 Les types
Une des principales caractéristiques de VHDL est qu'il s'agit d'un langage fortement typé.
Tous les objets définis en VHDL doivent appartenir à un type avant d'être utilisés. Deux objets
sont compatibles s’ils ont la même définition de type. Un type définit l'ensemble des valeurs
que peut prendre un objet ainsi que l'ensemble des opérations disponibles sur cet objet.
Puisque VHDL s'applique au domaine logique, les valeurs '0' et '1' peuvent être considérées.
L'ensemble de ces deux valeurs définit le type BIT. Il est possible de définir d'autres valeurs
comme par exemple la valeur 'Z' désignant la valeur trois états. Un type plus complet,
englobant neuf valeurs logiques différentes décrivant tous les états d’un signal électronique
numérique, a été standardisé dans la librairie std_logic_1164 : le std_logic. Les valeurs que
peut prendre un signal de ce type sont :
• ‘U’ : non initialisé,
• ‘X’ : niveau inconnu, forçage fort,
• ‘0’ : niveau 0, forçage fort,
• ‘1’ : niveau 1, forçage fort,
• ‘Z’ : haute impédance,
• ‘W’ : niveau inconnu, forçage faible,
• ‘L’ : niveau 0, forçage faible,
• ‘H’ : niveau 1, forçage faible,
• ‘-‘ : quelconque.
Les valeurs ‘0’ et ‘L’ sont équivalentes pour la synthèse, tout comme les valeurs ‘1’ et ‘H’.
Les valeurs ‘U’, ‘X’ et ‘W’ ne sont utilisables que pour la simulation d’un design.

74
Il existe quatre familles de type en VHDL :
• les types scalaires, dont la valeur est composée d'un seul élément (integer, bit, std_logic,
boolean, etc.),
• les types composés, dont la valeur comprend plusieurs éléments (bit_vector,
std_logic_vector),
• les types accès, qui sont les pointeurs des langages de programmation,
• les types fichiers, qui ne sont utilisés que pour les objets fichiers.
Les deux dernières familles ne sont bien sûr pas utilisables pour le développement d’un circuit
intégré.
4.1.3.8 Fonctionnement concurrent
Le comportement d'un circuit peut être décrit par un ensemble d'actions s'exécutant en
parallèle. C'est pourquoi VHDL offre un jeu d'instructions dites concurrentes. Une instruction
concurrente est une instruction dont l'exécution est indépendante de son ordre d'apparition
dans le code VHDL. Par exemple, prenons le cas d'un simple verrou, comme le montre la
figure :
S
RS
Q
NQ
Les deux portes constituant ce verrou fonctionnent en parallèle. Une description possible de ce
circuit est donnée dans le code suivant (seule l'architecture est donnée).
architecture comportement of VERROU isbegin Q <= S nand NQ; NQ<= R nand Q;end comportement;

75
Ces deux instructions s'exécutent en même temps. Elles sont concurrentes ; leur ordre
d'écriture n'est pas significatif ; quel que soit l'ordre de ces instructions, la description reste
inchangée.
4.1.3.9 Fonctionnement séquentiel
Les instructions concurrentes qui viennent d’être présentées pourraient suffire à définir un
langage de description matériel. Cependant, certains circuits sont plus faciles à décrire en
utilisant des instructions séquentielles similaires à des instructions de langages classiques de
programmation. En VHDL, les instructions séquentielles ne s’utilisent qu’à l’intérieur des
processus. Un processus est un groupe délimité d’instructions, doté de trois caractéristiques
essentielles :
• Le processus s’exécute à chaque changement d’état d’un des signaux auxquels il est
déclaré sensible.
• Les instructions du processus s’exécutent séquentiellement.
• Les modifications apportées aux valeurs de signaux par les instructions prennent effet à la
fin du processus.
L’exemple de la description suivante montre une architecture (seule) d’un latch D contenant
un processus qui est exécuté lors du changement d’état de l’horloge CLK.
architecture comportement of basc_D isbegin
Process (CLK)Begin
If ( CLK= ‘1’) then Q <= D;
End if ;End process ;
end comportement;
4.1.4 VHDL par rapport aux autres langages
Bien que VHDL soit maintenant largement accepté et adopté, il n'est pas le seul langage de
description matériel. Pendant ces trente dernières années, beaucoup d'autres langages ont été
développés, ont évolués et sont encore utilisés aujourd'hui par les concepteurs de circuits
intégrés. Créé pour être un standard, VHDL doit son succès à la fois à ses prédécesseurs et à la
maturité de ses principes de base.

76
M et Verilog sont deux langages qui ont été développés par des compagnies privées pour leurs
propres besoins (langage de spécification pour leurs outils de simulation). Verilog a tout
d'abord été décrit par la société Gateway Design Automation qui a ensuite fusionné avec la
compagnie Cadence Design Systems. Pour que Verilog puisse faire face à VHDL, Cadence a
décidé de le rendre public en 1990. L'utilisation de Verilog est promue par le groupe Open
Verilog International (OVI) qui a publié en Octobre 1991 la première version du manuel de
référence du langage Verilog. En 1995, Verilog est devenu un standard sous la référence IEEE
1364. Contrairement à Verilog, M est toujours un langage privé. Il est la propriété de la
compagnie Mentor Graphics.
Du point de vue de leur syntaxe, VHDL s'est largement inspiré du langage ADA, Verilog
ressemble au langage C et Pascal, et M est totalement fondé sur le langage C. VHDL est
certainement le plus difficile à utiliser car il reste très général. De plus, il demande à
l'utilisateur d'avoir des habitudes de programmeur (compilation séparée, langage fortement
typé, notion de surcharge, etc.). Comparé à Verilog et M qui restent proches de la réalité
physique, VHDL est sans aucun doute plus complexe.
4.1.5 Normes et extensions
Les normes suivantes définissent le langage et ses extensions pour la simulation, la synthèse et
la rétro annotation.
Norme IEEE sujet
1076.1 1987 et 1993, IEEE Standard VHDL Language Reference Manual.
1076.2 1996, IEEE Standard VHDL Mathematical Packages.
1076.3 1997, IEEE Standard VHDL Synthesis Packages.
1076.4 1995, IEEE Standard VITAL Application-Specific Integrated Circuit (ASIC) Modeling Specification.
1164 1993, IEEE Standard Multivalue Logic System for VHDL Model Interoperability (Std_logic_1164).
P1497 Standard for (SDF) Standard Delay Format for the Electronic Design Process

77
Il y a deux versions de VHDL disponibles, VHDL-87 et VHDL-93. La version 93 devrait être
la seule utilisée, mais certains synthétiseur (notamment ceux de Synopsys) ne la respecte pas
entièrement. Il faut noter que :
• Le package IEEE 1076.3 concerne la synthèse. Il précise l’interprétation des nombres
(comment interpréter un nombre entier par exemple) ainsi que les packages arithmétiques
numeric_bit et numeric_std permettant de traiter les types signed et unsigned ainsi que de
nombreuses fonctions de conversion. Hélas, la normalisation a été tardive (1996) et a
permis la normalisation de fait des packages de Synopsys std_logic_unsigned,
std_logic_signed, std_logic_arith qui sont souvent utilisé à la place (notamment par
Synopsys).
• VITAL est une extension de la norme permettant la retro annotation en association avec
un fichier SDF. VITAL permet l’écriture de modèle physique de composant vérifiant entre
autres toutes ses caractéristiques de timing. Ces timings sont contenus dans le fichier SDF.
On écrit rarement soi même un modèle VITAL. C’est généralement l’outil de placement
routage qui écrit le modèle réel du design en VITAL et génère le fichier SDF. Ces deux
fichiers sont ensuite utilisés pour la simulation post-layout.
4.1.6 La synthèse
4.1.6.1 définition
La synthèse est définie comme une succession d'opérations permettant à partir d'une
description de circuit dans un domaine fonctionnel (description comportementale) d'obtenir
une description équivalente dans le domaine physique (description structurelle). Le processus
de synthèse peut être défini comme une boîte noire ayant en entrée une description abstraite en
termes de langages de description matériel, et comme sortie une description structurée en
termes de dispositifs interconnectés (une netlist).
4.1.6.2 La synthèse automatique de circuits : dans quel but ?
Le premier intérêt de la synthèse est de permettre une description la plus abstraite possible
d'un circuit physique. Le concepteur a de moins en moins de détails à donner. Par exemple,
pour décrire un compteur, la description détaillée des signaux de contrôle explicitement
utilisés n'est pas indispensable. Seule la fonctionnalité de comptage et les contraintes de
synthèse (qui peuvent être des contraintes de temps, d’optimisation, de circuit cible, etc.)
doivent être indiquées. Le but de l'abstraction est de réduire et de condenser les descriptions

78
au départ et, par conséquent, de faciliter leur correction en cas d'erreurs. L'autre avantage de
l'abstraction est la portabilité. Plus l'abstraction est élevée, plus la description est portable. En
effet, une abstraction élevée ne fait pas référence à un composant cible car elle ne spécifie pas
les détails.
Puisque les systèmes deviennent de plus en plus complexes, il ne sera bientôt plus possible
d'envisager leur conception en saisie de schéma. Avec la synthèse, le nombre d'informations
devant être fournies par le concepteur diminue. Ces informations consistent essentiellement en
la description comportementale du circuit et des contraintes correspondantes. La synthèse
amènera sans aucun doute dans les prochaines années, à des circuits plus sûrs, plus robustes et
devrait, à l’avenir, être considérée comme une marque de qualité dans le cycle de conception.
Puisque la synthèse permet de réduire la taille des descriptions, elle permet également de
faciliter les remises à jour, de rendre les corrections plus rapides, et de pouvoir explorer un
ensemble plus vaste de solutions architecturales. Dans ce contexte, le meilleur compromis
entre coût et performance peut plus facilement être atteint par le concepteur. Le grand nombre
de descriptions déjà existantes couplé avec la possibilité de les paramétrer amènent à la
création de ressources de bibliothèques réutilisables. Ceci permet d'améliorer encore plus la
productivité des circuits électroniques.
4.2 exemples commentés de circuits logiques
Le langage VHDL est un langage complexe dont les possibilités sont très étendues. Le sous-
ensemble que l’on a le droit d’utiliser pour la synthèse, c’est-à-dire pour réaliser un circuit
intégré, est beaucoup plus restreint. L’objectif de ce paragraphe est de vous apprendre la partie
du langage VHDL synthétisable qui nous sera nécessaire pour les travaux pratiques. Si vous
souhaitez approfondir vos connaissances sur ce sujet, les ouvrages suivants sont disponibles :
titre auteur éditeur niveau intérêt
VHDL : introduction à la synthèse logique
Philippe LARCHER Eyrolles débutant *
Le langage VHDL Jacques WEBER
Maurice MEAUDRE
Dunod Moyen à avancé
**
Fundamentals of digital logic with VHDL design
Stephen BROWN
Zvonko VRANESIC
Mc Graw Hill
Débutant à avancé
***

79
HDL chip design Douglas J.SMITH Hightext Publications
Débutant à avancé
***
Digital systems design with VHDL and synthesis
K.C. CHANG IEEE Computer Society
avancé ***
4.2.1 Portes combinatoires
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. entity GATE is 4. port(D1, D2, D3 : in std_logic; 5. Y1, Y2, Y3, Y4, Y5 : out std_logic); 6. end GATE; 7. architecture RTL of GATE is 8. signal tmp : std_logic ; 9. begin 10. Y1 <= D1 nor D2; 11. Y2 <= not (D1 or D2 or D3); 12. Y3 <= D1 and D2 and not D3; 13. Y4 <= D1 xor (D2 xor D3); 14. tmp <= D1 xor D2; 15. Y5 <= tmp nand D3 ; 16.end RTL;
• La ligne 1 définit l’appel à la librairie IEEE grâce à l’instruction « library
nom_de_la_librairie ». La ligne 2 indique l’utilisation de tous les éléments (fonctions ou
composants ou type comme std_logic) du paquetage (ou package) std_logic_1164 grâce à
l’instruction « use nom_de_la_librairie.nom_du_package.all ».
• Lignes 3 à 6 : définition des entrées-sorties du design GATE. Le mot clé port annonce la
liste des signaux d’interface. 4 modes sont possibles pour ces entrées-sorties: in, out, inout,
buffer.
IN
OUT
BUFFER
INOUT

80
On peut se passer du mode buffer en utilisant une variable temporaire interne (voir
exemple du compteur). En pratique, il n’est jamais utilisé.
Les types des signaux peuvent être les suivants :
Types prédéfinis : integer, natural (entier >= 0), positive (entier > 0), bit, bit_vector,
boolean, real, time, std_logic, std_logic_vector. Exemples :
NUM : in integer range -128 to 127 ; (NUM est compris entre –128 et +127)
DATA1 : in bit_vector(15 downto 0) ; (DATA1 est un bus 16 bits)
DATA2 : out std_logic_vector(7 downto 0) ; (DATA2 est un bus 8 bits)
Types définis par l’utilisateur :
Les types énumérés. Exemple :
type ETAT is (UN, DEUX, TROIS) ;
TOTO : out ETAT ;
Les tableaux. Exemple :
Type TABLEAU8x8 is array (0 to 7) of std_logic_vector(7 downto 0) ;
TAB8x8 : out TABLEAU8x8;
Les sous-types. Exemple :
subtype OCTET is bit_vector(7 downto 0) ;
BUS : inout OCTET ;
• Lignes 7 à 16 : La partie déclarative de l’architecture (entre les mots clés architecture et
begin) est destinée à la déclaration des objets internes (les E/S sont déclarées dans l’entity)
utilisés dans cette architecture. Ces objets sont généralement des signaux, constantes,
variables ou alias.
Les signaux. Ils représentent les fils d’interconnexion sur la carte. Exemple :
signal BUS : std_logic_vector(15 downto 0) ;

81
Les constantes. Une constante peut être assimilée à un signal interne ayant une valeur
fixe. Exemples :
constant ZERO : bit_vector(7 downto 0) := "00000000";
constant HIZ : bit_vector(15 downto 0) := (others => ‘Z’);
Les variables. Une variable est un objet capable de retenir une valeur pendant une durée
limitée. Ce n’est pas une liaison physique, mais un objet abstrait qui doit être interprété
par le synthétiseur. Elle ne doit être utilisée qu’à l’intérieur d’un process. Exemple :
variable TEMP : integer ;
Les alias. Ils permettent de nommer un objet de différentes manières. Exemples :
signal DBUS : bit_vector(15 downto 0) ;
alias OCTET0 : bit_vector(7 downto 0) is DBUS(7 downto 0) ;
La ligne 8 définit donc un signal temporaire tmp de type std_logic.
VHDL reconnaît les opérateurs logiques suivant : and, nand, or, nor, xor, xnor et not. Leur
signification est évidente. Il faut juste faire attention à leur associativité. Il est possible
d’écrire :
X <= A and B and C ; puisque le and est associatif (A . B . C = A . (B . C))
L’opérateur d’assignation ‘<=’ permet d’affecter une valeur à un signal. Par contre, on n’a
pas le droit d’écrire :
X <= A nor B nor C ; puisque le nor n’est pas associatif ( )( CBACBA ++≠++ )
Il faut obligatoirement mettre des parenthèses pour indique ce que l’on souhaite réaliser.
X <= A nor (B nor C) ;
Pour faire un vrai nor 3 entrées, il suffit d’écrire :

82
X <= not (A or B or C) ;
Compte tenu de ce qui précède, on voit que le circuit GATE réalise les fonctions logiques
suivantes :
tmp
D1
Y1
D2
D3
Y2
Y3
Y4
Y5
4.2.2 multiplexeurs
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. entity MUX is 4. port(Sel : in std_logic_vector(1 downto 0) ; 5. A, B, C, D : in std_logic; 6. Y1, Y2, Y3, Y4 : out std_logic); 7. end MUX; 8. architecture RTL of MUX is 9. signal tmp : std_logic ; 10.begin 11. Y1 <= A when Sel(0) = '0' else B;
12. p0 : process (A, B, Sel) 13. begin

83
14. if (Sel(0) = '0') then 15. Y2 <= A; 16. else 17. Y2 <= B; 18. end if; 19. if (Sel(1) = '1') then 20. Y3 <= A; 21. end if; 22. end process; 23. p1 : process (A, B, C, D, Sel) 24. begin 25. case Sel is 26. when "00" => Y4 <= A; 27. when "01" => Y4 <= B; 28. when "10" => Y4 <= C; 29. when "11" => Y4 <= D; 30. when others => Y4 <= A; 31. end case; 32. end process; 33.end RTL;
• Lignes 8 à 33. Les opérateurs relationnels suivants sont présents dans les instructions
conditionnelles de VHDL telles que « when … else », « if … then … else » ou « case » : =,
/=, <, <=, >, >=. Ils retournent un résultat booléen (vrai/faux). Exemple :
if (a > b) then …
Faites attention à ne pas confondre l’assignation X <= Y ; avec l’opérateur relationnel
inférieur ou égal. Les opérateurs relationnels peuvent être combinés aux opérateurs
logiques de la manière suivante :
if (a <= b and b=c) then …
L’opérateur de concaténation permet de juxtaposer deux objets de type std_logic ou
std_logic_vector. Exemples :
signal octet1, octet2 : std_logic_vector(7 downto 0) ;
signal mot1, mot2 : std_logic_vector(15 downto 0) ;
mot1 <= octet1&octet2 ;
mot2 <= "100"&octet1(3 downto 0)&octet2&’1’ ;

84
Il permet de simplifier l’écriture de :
if (A = ‘1’ and B = ’0’) then …
en écrivant :
if (A&B) = "10" then …
• La ligne 11 décrit un multiplexeur 2 entrées avec l’assignation conditionnelle when. En
effet, la phrase « Y1 prend la valeur de A si Sel(0) est égal à 0 sinon (Y1 prend la valeur
de) B » décrit bien un multiplexeur deux entrées A et B vers une sortie Y1 avec une entrée
de sélection reliée au bit de poids faible de Sel. La condition testée doit être booléenne ce
qui est bien le cas puisque les opérateurs relationnels fournissent un résultat booléen.
• Lignes 12 à 32 : fonctionnement concurrent et séquentiel. En électronique, les composants
fonctionnent simultanément (fonctionnement parallèle ou concurrent) alors qu’en
programmation traditionnelle, les instructions s’exécutent les unes à la suite des autres de
façon séquentielle. Les deux modes de fonctionnement coexistent dans VHDL suivant que
le code se trouve hors d’un processus (fonctionnement concurrent) ou dans un processus
(fonctionnement séquentiel). Prenons par exemple la séquence suivante :
A <= B ;
B <= C ;
En programmation traditionnelle, la séquence signifierait « A prend la valeur de B, puis B
prend la valeur de C ». A la fin du programme, A et B on des valeurs différentes. Si on
change l’ordre des instructions, la signification change. C’est le fonctionnement séquentiel.
En VHDL, il faut comprendre : à tout moment, A prend la valeur de B et à tout moment, B
prend la valeur de C. En clair A, B et C ont tout le temps la même valeur quel que soit
l’ordre des instructions. C’est le fonctionnement concurrent.

85
Voyons maintenant ce qu’est un processus. C’est un groupe délimité d’instructions doté de
trois caractéristiques :
1. Le processus s’exécute à chaque changement d’état d’un des signaux auxquels il est
déclaré sensible.
2. Les instructions dans le processus s’exécutent séquentiellement.
3. Les modifications apportées aux valeurs de signaux par les instructions prennent effet à
la fin du processus.
La structure d’un processus est la suivante :
Nom_de_processus : process (liste_de_sensibilité)
-- déclaration des variables locales du processus
begin
-- corps du processus
end process Nom_de_processus ;
Ligne 12 : le processus p0 se déclenche sur chaque changement d’état des signaux A, B et
Sel. Ligne 13 à 18 : on décrit à nouveau un multiplexeur 2 entrées avec l’assignation
conditionnelle « if … then … else … ». En effet, la phrase « si Sel(0) est égal à 0, Y2
prend la valeur de A sinon Y2 prend la valeur de B » décrit bien un multiplexeur deux
entrées A et B vers une sortie Y2 avec une entrée de sélection reliée au bit de poids faible
de Sel.
Ligne 23 : le processus p1 se déclenche sur chaque changement d’état des signaux A, B, C,
D et Sel. Lignes 25 à 31 : on décrit un multiplexeur 4 entrées avec l’assignation sélective
case.
Ligne 25 : le sélecteur est le bus Sel, de largeur 2 bits.
Ligne 26 : Quand Sel vaut 00, Y4 prend la valeur de A,
Ligne 27 : Quand Sel vaut 01, Y4 prend la valeur de B,
Ligne 28 : Quand Sel vaut 10, Y4 prend la valeur de C,
Ligne 29 : Quand Sel vaut 11, Y4 prend la valeur de D,
Ligne 30 : pour toutes les autres valeurs de Sel (n’oubliez pas que Sel est un
std_logic_vector dont chaque bit peut prendre 9 états), Y4 prend la valeur de A. C’est la

86
valeur par défaut qui est fortement recommandée. On verra un peu plus loin que cela
permet d’éviter d’inférer (de générer) un latch.
On a bien décrit un multiplexeur 4 entrées A, B, C, D une sortie Y4 et deux bits de
sélection Sel.
Nous allons maintenant lister les instructions séquentielles qui doivent se trouver
obligatoirement à l’intérieur d’un processus et les instructions concurrentes qui doivent
obligatoirement se trouver à l’extérieur d’un processus.
Instructions en mode concurrent.
Assignation inconditionnelle. Forme générale : signal <= expression ;.
A <= B and C ; -- A prend la valeur du résultat de l’opération (B and C).
X <= ‘0’ ; -- X prend la valeur 0.
Assignation conditionnelle. Forme générale : signal <= expression when condition else
expression ;.
Y1 <= A when Sel(0) = '0' else B; -- Y1 prend la valeur de A si Sel(0) est égal à 0
sinon (Y1 prend la valeur de) B.
Assignation sélective. Forme générale : with selecteur select signal <= expression
when valeur_selecteur, ;.
With ETAT select
X <= A when "00", -- X prend la valeur de A si le signal ETAT, utilisé comme
B when "01", -- sélecteur, vaut 00, B si ETAT vaut 01, etc.
C when "10",
D when others ;
Instanciation de composant. Forme générale : nom_d’instance : nom_du_composant
port map (liste_des_signaux_d’entréee et de sortie du composant) ;.

87
U0 : XOR4 port map (A, B, C, D, S) ; -- on insère le composant XOR4 dans le design (à
la manière d’un symbole dans un schéma). U0 est le nom d’instance. A, B, C, D sont les
entrée de U0, S est sa sortie.
Instruction generate. Cette instruction permet de générer plusieurs répliques d’un
composant ou d’une équation. Exemple, le composant ADDER dans le package de tp4.
gen : for j in 7 downto 0 generate -- pour j allant de 7 à 0
genlsb : if j = 0 generate -- génération de l’additionneur complet du bit de poids faible
fa0 : FullAdder port map (A => A(0), B => B(0), CI => CI, S => S(0), COUT =>
C(1));
end generate;
genmid : if (j > 0) and (j < 7) generate -- génération des autres additionneur
fa0 : FullAdder port map (A => A(j), B => B(j), CI => C(j), S => S(j), COUT =>
C(j+1));
end generate;
genmsb : if j = 7 generate -- génération de l’additionneur complet du bit de poids fort
fa0 : FullAdder port map (A => A(j), B => B(j), CI => C(j), S => S(j), COUT =>
COUT);
end generate;
end generate;
Instructions en mode séquentiel.
Assignation inconditionnelle de signal. Forme générale : signal <= expression ;.
A <= B and C ; -- A va prendre la valeur du résultat de l’opération (B and C) à la fin
du processus.
X <= ‘0’ ; -- X prend la valeur 0 à la fin du processus.
Assignation inconditionnelle de variable. Forme générale : var := expression ;.
X := ‘0’ ; -- X prend la valeur 0 immédiatement.

88
Assignation conditionnelle de signal ou de variable.
if (Sel(0) = '0') then -- si Sel(0) est égal à 0, Y2 prend la valeur de A
Y2 <= A;
else -- sinon Y2 prend la valeur de B
Y2 <= B;
end if;
Assignation sélective.
case Sel is
when "00" => Y4 <= A; -- si Sel vaut 00, Y4 prend la valeur de A
when "01" => Y4 <= B; -- si Sel vaut 01, Y4 prend la valeur de B
when "10" => Y4 <= C; -- si Sel vaut 10, Y4 prend la valeur de C
when "11" => Y4 <= D; -- si Sel vaut 11, Y4 prend la valeur de D
when others => Y4 <= A; -- pour toute autre valeur de Sel, Y4 prend la valeur de A
end case;
Boucles.
for i in 0 to 7 loop -- pour i allant de 0 à 7
datari(i) <= "000"&datar(i); -- datari(i) prend la valeur "000" concaténée avec datar(i)
end loop;
• Lignes 19 à 21 : mémorisation implicite. En VHDL, les signaux ont une valeur courante et
une valeur prochaine déterminée par l’opérateur d’assignation. Si lors d’une instruction
conditionnelle (concurrente ou séquentielle) un signal reçoit une assignation dans une
branche alors il doit recevoir une assignation dans toutes les autres branches. Si tel n’est
pas le cas, chaque absence d’assignation signifie que la prochaine valeur est identique à la
valeur courante et le synthétiseur doit générer une logique de mémorisation (bascule D ou
latch). Dans notre exemple, si Sel(1) vaut 1, Y3 prend la valeur de A et sinon, Y3 garde sa
valeur courante. Le synthétiseur infère donc un latch au lieu d’un multiplexeur.

89
Le circuit MUX réalise donc les fonctions logiques suivantes :
AY1
B
C
Y2
Y4
Y3
D
Sel[1:0]
Sel[0]
Sel[1]
4.2.3 Assignation inconditionnelle de signal : séquentiel contre concurrent
Le design suivant tente d’éclaircir un point parfois un peu obscur, c’est-à-dire la différence de
comportement des assignations inconditionnelles de signal entre le mode séquentiel (dans le
process) et le mode concurrent (hors process).
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. entity conc_seq is 4. port( A, B : in std_logic; 5. Yconc : out std_logic; 6. Yseq : out std_logic); 7. end conc_seq; 8. architecture a1 of conc_seq is 9. begin 10. Yconc <= A; 11. Yconc <= B; 12. process(A, B) begin 13. Yseq <= A; 14. Yseq <= B; 15. end process; 16.end a1 ;

90
En mode concurrent, les deux fils A et B sont reliés ensemble sur Yconc. Quand A et B sont
dans un état différent (01 ou 10), Yconc passe à l’état indéterminé X puisqu’il y a conflit entre
A et B. C’est le fonctionnement électronique traditionnel.
En mode séquentiel, A et B sont copiés dans Yseq. Mais il n’y a pas de conflit, car comme
nous sommes en séquentiel, c’est la dernière assignation qui est prise en compte (Yseq <= B).
Il faut comprendre qu’avec des signaux (ce n’est pas vrai pour des variables), toutes les
assignations sont préparées dans le process, puis exécutées en même temps en sortant du
process. Sil y a plusieurs assignations sur un même signal (Yseq dans notre cas), elles sont
toutes exécutées, mais c’est la dernière qui est prise en compte.
4.2.4 compteur
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. use IEEE.std_logic_arith.all; 4. use IEEE.STD_LOGIC_UNSIGNED.all; 5. entity compteur is 6. generic (WDTH : integer :=4; STOP : integer :=10) ; 7. port( CLK : in std_logic ; 8. CE : in std_logic ; 9. CLEAR : in std_logic; 10. CEO : out std_logic; 11. DOUT : out std_logic_vector(WDTH -1 downto 0 )); 12.end compteur; 13.architecture a1 of compteur is 14. signal INT_DOUT : std_logic_vector(DOUT'range) ; 15.begin 16. process(CLK, CLEAR) begin 17. if (CLEAR='1') then 18. INT_DOUT <= (others => '0'); 19. elsif (CLK'event and CLK='1') then 20. if (CE='1') then 21. if (INT_DOUT=STOP-1) then 22. INT_DOUT <= (others => '0'); 23. else 24. INT_DOUT <= (INT_DOUT + 1); 25. end if; 26. end if; 27. end if; 28. end process; 29. CEO <= INT_DOUT(0) and not INT_DOUT(1) and not INT_DOUT(2) and
INT_DOUT(3) and CE; 30. dout <= int_dout; 31.end;

91
32.library IEEE; 33.use IEEE.std_logic_1164.all; 34.entity gen_cnt is 35. port(Clock : in std_logic; 36. Reset : in std_logic; 37. add : out std_logic_vector(3 downto 0); 38. adu : out std_logic_vector(3 downto 0)) ; 39.end gen_cnt; 40.architecture comporte of gen_cnt is 41. COMPONENT compteur 42. generic (WDTH : integer :=4; STOP : integer :=10); 43. port( CLK : in std_logic ; 44. CE : in std_logic ; 45. CLEAR : in std_logic; 46. CEO : out std_logic; 47. DOUT : out std_logic_vector(WDTH -1 dow nto 0)); 48. END COMPONENT; 49. signal ceo : std_logic; 50. constant zero : std_logic := '0'; 51. signal zeros : std_logic; 52. constant un : std_logic := '1'; 53. signal uns : std_logic; 54.begin 55. zeros <= zero; 56. uns <= un; 57. cd4d : compteur generic map(4,10) port map(Clo ck, ceo, Reset, open,
add); 58. cd4u : compteur generic map(4,10) port map(Clo ck, uns, Reset, ceo,
adu); 59.end comporte ;
• Lignes 3 à 4. Le package std_logic_1164 définit le type std_logic, mais pas les opérateurs
arithmétiques qui vont avec. Les packages propriétaires synopsys std_logic_arith et
std_logic_unsigned (il y a aussi un std_logic_signed), abusivement placé dans la librairie
IEEE, définissent ces opérateurs. L’IEEE a normalisé assez tardivement des packages
similaires dans la norme 1076.3 (numeric_bit et numeric_std). Tous les synthétiseurs
reconnaissent donc les packages synopsys, mais synopsys ne reconnaît toujours pas les
packages IEEE. Cette déclaration est obligatoire par exemple pour effectuer l’opération :
INT_DOUT <= (INT_DOUT + 1);
avec INT_DOUT un signal std_logic_vector.

92
• Lignes 6, 11 et 57 : paramètres génériques. Il est possible de passer des paramètres au
composant au moment de son instanciation. On peut donc écrire un modèle générique d’un
composant (ici, un compteur) et définir ses caractéristiques au moment de son appel dans le
design. Voyons notre exemple. L’entité compteur déclare deux paramètres, la largeur du
compteur en bits WDTH et le nombre d’état du compteur STOP. On peut définir des
valeurs par défaut pour ces deux paramètres (ici, 4 pour WDTH et 10 pour STOP) utilisés
si on ne passe pas de valeurs au moment de son appel.
ligne 6. generic (WDTH : integer :=4; STOP : intege r :=10);
Au moment de l’instanciation, on passe les deux valeurs dans l’ordre après le mot clé
« generic map ». Si on omet le generic map, les paramètres par défaut sont utilisés.
ligne 57. cd4d : compteur generic map(4,10) port ma p(Clock, ceo, Reset, open, add);
Ces paramètres peuvent être utilisés soit dans la déclaration des entrées sorties (ici, on
définit la largeur du bus de sortie) :
ligne 11. DOUT : out std_logic_vector(WDTH -1 downt o 0));
soit dans l’architecture du composant (ici, la valeur d’arrêt du compteur) :
ligne 21. if (INT_DOUT=STOP-1) then
Les paramètres génériques apportent une grande flexibilité aux descriptions de composants
et permettent l’écriture de bibliothèques standardisées.
• Ligne 14 : l’attribut range. Il fait partie des nombreux attributs de VHDL. Si le signal A est
défini par un std_logic_vector(X downto Y), alors A’range est équivalent à X downto Y et
peut être utilisé à la place. Dans notre exemple :
ligne 14. signal INT_DOUT : std_logic_vector(DOUT'r ange) ;
INT_DOUT à la même largeur que DOUT (de WDTH-1 à 0). L’attribut range simplifie
l’écriture des modèles génériques.

93
• Ligne 18 : initialisation à 0 d’un vecteur. La ligne suivante :
INT_DOUT <= (others => '0');
signifie que tous les bits de INT_DOUT prennent la valeur 0 à la fin du processus déclaré à
la ligne 16.
• Ligne 19. L’attribut event. Accolé à un signal, il retourne un booléen qui sera vrai si un
événement (c’est à dire un changement d’état) s’est produit sur ce signal. Par exemple, la
forme :
if (CLK'event and CLK='1') then
sera utilisée pour détecter un front montant d’horloge (s’il y a eu changement d’état sur
CLK et si CLK vaut 1). La forme :
if (CLK'event and CLK='0') then
sera utilisée pour détecter un front descendant d’horloge (s’il y a eu changement d’état sur
CLK et si CLK vaut 0). Le package std_logic_1164 définit deux fonctions équivalentes
rising_edge(CLK) et falling_edge(CLK) qui pendant longtemps n’ont pas été reconnus par
synopsys. C’est pourquoi beaucoup de designers utilisent toujours la forme (CLK'event and
CLK='1').
• Lignes 13 à 31 : fonctionnement du compteur. Nous avons vu à la fin de l’exemple
précédent (multiplexeur) le problème de la mémorisation implicite qui générait un latch
quand toutes les branches d’une instruction conditionnelle n’étaient pas définies. Cela
pouvait paraître être un inconvénient majeur. En fait, cette mémorisation implicite permet
la simplification de la description de circuits séquentiels synchrones. Voyons l’exemple
suivant. Le process est activé (ligne 1) par l’horloge clock. Si le front montant de l’horloge
arrive (ligne 2) alors Out prend la valeur de in (la ligne 3). Sinon (le « if… then… else… »
est incomplet), out garde son état précédent. Il s’agit là de la description d’une bascule D.

94
1. process(clock) begin 2. if (clock 'event and clock ='1') then 3. out <= in; 4. end if; 5. end process;
Il suffit donc de mettre une assignation entre deux signaux dans la branche « if (clock
'event and clock ='1') then » pour générer un registre. La description est équivalente au
schéma :
in out
clock
On peut ajouter un reset asynchrone de la manière suivante :
1. process(clock, clear) begin -- clock et clear active le process 2. if (clear ='1') then -- si clear vaut 1 3. out <= '0'; -- alors out prend la valeur 0 4. elsif (clock 'event and clock ='1') then – sinon, si front montant sur clock 5. out <= in; -- alors out prend la valeur de in 6. end if; -- sinon out garde sa valeur précédente 7. end process;
Le clear est bien asynchrone puisque le “ if (clear ='1') “ est en dehors de la branche “ elsif
(clock 'event and clock ='1') “. S’il était dans cette branche, alors le clear serait synchrone.
Cette description est équivalente au schéma :
in
clock
out
clear
On peut de plus ajouter un signal de validation “ce” de la manière suivante :

95
1. process(clock, clear) begin -- clock et clear active le process 2. if (clear ='1') then -- si clear vaut 1 3. out <= '0'; -- alors out prend la valeur 0 4. elsif (clock 'event and clock ='1') then – sinon, si front montant sur clock 5. if (ce ='1') then -- si ce vaut 1 6. out <= in; -- alors out prend la valeur de in 7. end if; -- sinon out garde sa valeur précédente 8. end if; 9. end process;
On pourrait en toute logique ajouter la condition sur le “ce” directement dans la condition
“elsif (clock 'event and clock ='1')“. Ce type de description a une nette tendance a perturber
le synthétiseur. Il vaut mieux décomposer les conditions. Cette description est équivalente
au schéma :
in
clock
clear
ceout
Pour comprendre le fonctionnement du compteur, il reste deux choses à voir : le calcul du
CEO et l’utilisation d’une variable temporaire int_dout.
Le signal CEO passe à 1 quand l’état final de la séquence de comptage est atteint (ici, la
valeur 9) et quand le signal de validation d’entrée CE vaut 1. Ceci est traduit par
l’assignation :
60. CEO <= INT_DOUT(0) and not INT_DOUT(1) and not INT_ DOUT(2) and INT_DOUT(3) and CE;
Pourquoi cette assignation n’est-elle pas dans le processus synchrone ? parce que CEO
passerait à 1 sur le front d’horloge qui suit le déclenchement de la condition (c’est à dire
quand la sortie du compteur est égale à 0. N’oubliez pas la bascule D qui est
automatiquement générée ! Il faudrait donc détecter l’état final –1 pour que CEO passe à 1
sur l’état final, ce qui ne serait pas très clair pour la compréhension du design. La solution
consiste donc à réaliser une détection purement combinatoire de l’état final, donc en dehors
du process synchrone.

96
Il est impossible en VHDL d’utiliser la valeur d’un signal dans l’architecture d’un
composant s’il a été déclaré en sortie pure dans l’entité. L’assignation suivante ne peut pas
être effectuée sur le signal dout.
Ligne 24. int_dout <= (int_dout + 1);
On effectue donc l’assignation sur un signal déclaré localement, puis on assigne ce signal
temporaire int_dout à la sortie dout en dehors du process (pour ne pas générer une bascule
de trop).
Ligne 30. dout <= int_dout;
On aurait pu contourner ce problème en déclarant dout en mode buffer, ce qui aurait
autorisé son utilisation dans l’architecture. On n’utilise jamais ce mode, car il faudrait que
le design qui appelle ce composant déclare aussi un signal en mode buffer pour se
connecter à dout et ceci sans aucune raison apparente. Cette bizarrerie se propagerait
d’ailleurs si l’architecture appelante était à son tour instanciée par une autre. Le mode
buffer n’est plus utilisé en VHDL, la déclaration d’un signal temporaire comme int_dout
donne une représentation strictement équivalente.
Vous avez maintenant toutes les éléments pour comprendre le fonctionnement du
composant compteur.
• Description modulaire sans package. Un design est généralement constitué d’un design
racine (root design ou bien top level design) qui instancie plusieurs composants de base.
Dans notre exemple, ces composants sont écrits au début du fichier (ligne 1 à 31). On a
écrit ensuite le root design gen_cnt avec, dans la partie déclarative de l’architecture, la
définition des E/S des composants de base via l’instruction component (ligne 41 à 48) qui a
la même forme que la déclaration de l’entité correspondante. Il ne reste plus ensuite qu’à
instancier les composants (lignes 57 et 58). Cette méthode d’écriture, quoique modulaire,
devient relativement fastidieuse quand la taille du design augmente. D’où l’idée de
regrouper les composants dans un paquetage (ou package) et dans un fichier séparé.

97
• Description modulaire avec package. La déclaration du composant compteur est
maintenant dans un fichier séparé cnt_pkg.vhd. On trouve au début de ce fichier la
déclaration des entrées sorties de tous les composants du package gen_cnt_pkg (lignes 3 à
12) puis la description complète de ces composants (entité et architecture, lignes 13 à 43).
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. package gen_cnt_pkg is 4. COMPONENT compteur 5. generic (WDTH : integer :=4; STOP : integer :=1 0); 6. port( CLK : in std_logic; 7. CE : in std_logic; 8. CLEAR : in std_logic; 9. CEO : out std_logic; 10. DOUT : out std_logic_vector(WDTH -1 downto 0)); 11. END COMPONENT; 12. end gen_cnt_pkg; 13. library IEEE; 14. use IEEE.std_logic_1164.all; 15. use IEEE.std_logic_arith.all; 16. use IEEE.STD_LOGIC_UNSIGNED.all; 17. entity compteur is 18. generic (WDTH : integer :=4; STOP : integer :=10) ; 19. port( CLK : in std_logic; 20. CE : in std_logic; 21. CLEAR : in std_logic; 22. CEO : out std_logic; 23. DOUT : out std_logic_vector(WDTH -1 downto 0 )); 24. end compteur; 25. architecture a1 of compteur is 26. signal INT_DOUT : std_logic_vector(DOUT'range) ; 27. begin 28. process(CLK, CLEAR) begin 29. if (CLEAR='1') then 30. INT_DOUT <= (others => '0'); 31. elsif (CLK'event and CLK='1') then 32. if (CE='1') then 33. if (INT_DOUT=STOP-1) then 34. INT_DOUT <= (others => '0'); 35. else 36. INT_DOUT <= (INT_DOUT + 1); 37. end if; 38. end if; 39. end if; 40. end process; 41. CEO <= INT_DOUT(0) and not INT_DOUT(1) and not IN T_DOUT(2) and
INT_DOUT(3) and CE; 42. dout <= int_dout; 43. end;
Le root design se trouve dans le fichier cnt.vhd (les noms des fichiers utilisés sont sans
importance). Le simulateur ou le synthétiseur va compiler le package dans la librairie par

98
défaut work. Pour pouvoir l’utiliser dans gen_cnt, il suffit de déclarer use
work.gen_cnt_pkg.all;. Les composants peuvent ensuite être instanciés comme
précédemment.
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. use work.gen_cnt_pkg.all; 4. entity gen_cnt is 5. port( 6. Clock : in std_logic; 7. Reset : in std_logic; 8. add : out std_logic_vector(3 downto 0); 9. adu : out std_logic_vector(3 downto 0)); 10. end gen_cnt; 11. architecture comporte of gen_cnt is 12. signal ceo : std_logic; 13. constant zero : std_logic := '0'; 14. signal zeros : std_logic; 15. constant un : std_logic := '1'; 16. signal uns : std_logic; 17. begin 18. zeros <= zero; 19. uns <= un; 20. cd4d : compteur generic map(4,10) port map(Clock, ceo, Reset, open,
add); 21. cd4u : compteur generic map(4,10) port map(Clock, uns, Reset, ceo,
adu); 22. end comporte ;
Il faut noter que :
a) un paquetage peut contenir un nombre quelconque d’éléments.
b) un paquetage peut contenir autre chose que des composants : par exemple, des
définitions de types.
c) on met en général dans un paquetage des éléments utilisables dans des applications
similaires.
d) Une description peut faire appel à plusieurs paquetages. Il suffit d’inclure autant de
clause use qu’il y a de paquetages.
e) Il est tout à fait possible de compiler un paquetage dans une libraire autre que la librairie
work et de le rendre accessible à d’autres développeurs. C’est nécessaire quand le projet
nécessite plusieurs designers. C’est le cas notamment pour la librairie IEEE et les
paquetages std_logic_1164 ou numeric_bit par exemple.

99
La description modulaire avec package est la méthode normale d’organisation du travail
quand on développe un projet en VHDL.
• Lignes 50 à 58 : définition des constantes 0 et 1. Lors de l’instanciation d’un composant, il
peut être nécessaire de mettre une de ses entrées à la valeur permanente 1. On n’a hélas pas
le droit d’écrire directement :
cd4u : compteur generic map(4,10) port map(Clock, ‘1’ , Reset, ceo, adu);
car c’est un signal qui doit être connecté sur l’entrée. On n’a pas non plus le droit de
déclarer :
signal uns : std_logic := ‘1’ ;
puis d’écrire :
cd4u : compteur generic map(4,10) port map(Clock, uns , Reset, ceo, adu);
car le synthétiseur ignore la valeur initiale ‘1’. Il faut donc écrire :
constant un : std_logic := '1'; signal uns : std_logic;
puis
uns <= un; cd4u : compteur generic map(4,10) port map(Clock, u ns, Reset, ceo, adu);
ce qui n’a rien de très agréable. C’est un des inconvénients de VHDL qui est langage
fortement typé, c’est à dire que le type des variables qui se trouve de part et d’autre d’une
assignation doit être identique.
• Ligne 57 : le mot clé open. Lors de l’instanciation d’un composant, il peut être nécessaire
d’indiquer qu’une de ses sorties est non connectée. C’est le rôle du mot clé open. La ligne
57 vous donne un exemple de son utilisation.

100
Le design gen_cnt réalise donc la fonction logique suivante :
ceo
Clock
Reset
Add[3:0]
Adu[3:0]
compteur
CE
CLK
DOUT[wdth-1:0]
CEO
CLEAR
compteur
CE
CLK
DOUT[wdth-1:0]
CEO
CLEAR
Les deux compteurs BCD montés en cascade fonctionnent suivant le chronogramme :
4.2.5 circuit diviseur d’horloge
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. use IEEE.std_logic_arith.all; 4. use IEEE.STD_LOGIC_UNSIGNED.all; 5. entity clk_div_N is 6. generic (div : integer := 8); 7. port (clk_in : in std_logic; 8. clear : in std_logic; 9. clk_out : out std_logic); 10.end clk_div_N;

101
11.architecture RTL of clk_div_N is 12. signal clk_tmp : std_logic; 13. signal compte : integer range 0 to (div/2)-1; 14.begin 15. PROCESS (clk_in, clear) BEGIN 16. if (clear = '1') then 17. clk_tmp <= '0'; 18. compte <= 0; 19. elsif (clk_in'event and clk_in='1') then 20. if compte = ((div/2)-1) then 21. compte <= 0; 22. clk_tmp <= not clk_tmp; 23. else 24. compte <= compte + 1; 25. end if; 26. end if; 27. END PROCESS; 28. clk_out <= clk_tmp; 29.end;
A ce stade du cours, le fonctionnement de ce circuit diviseur d’horloge ne doit pas vous poser
de problème de compréhension. Il ne fonctionne que pour des valeurs paires de div. Le signal
« compte » évolue entre les valeurs 0 et div/2 – 1 (voyez sa déclaration à la ligne 13). Vous
noterez qu’il s’agit d’un entier et pas d’un type std_logic. Cela permet une réalisation plus
simple du diviseur. Quand « compte » atteint la valeur finale div/2 – 1, le signal « clk_tmp »
est inversé. Le chronogramme suivant explique le fonctionnement du circuit avec une
division par 8 (valeur par défaut) :
Si vous utilisez le type std_logic, les bascules sont toutes à l’état U (unknown) au démarrage.
Vous devez obligatoirement prévoir une mise à zéro ou bien une mise à un pour pouvoir
utiliser votre design. C’est un avantage de ce type vis à vis du type bit car il est proche du
fonctionnement réel d’un circuit intégré. En effet, à la mise sous tension, les éléments de
mémorisation (dont les bascules) sont dans un état indéterminé. Vous ne devez jamais
supposer que l’état de départ de vos bascules est connu quand vous concevez un design.
L’emploi du type std_logic vous y oblige, d’où son intérêt. La question qui se pose maintenant
est : reset synchrone ou reset asynchrone ? Vous pouvez bien sur utiliser un reset synchrone,
mais celui-ci consomme des ressources de routage. Or il existe des ressources de routages
dédiées pour le reset asynchrone dans les FPGA xilinx, le GSR. En réalisant un reset

102
asynchrone comme c’est le cas dans cet exemple, le synthétiseur va inférer un module startup
et le connecter au reset. Au moment du placement routage, l’outil Xilinx va automatiquement
relier le reset aux ressources dédiées du FPGA. Vous ne consommez donc pas de ressources
de routage et vous pouvez relier le reset à un interrupteur extérieur pour initialiser le circuit. Il
faut savoir qu’un reset asynchrone implicite est effectué au moment de la mise sous tension du
FPGA. Ceci dit, il n’est pas garanti que toutes les bascules seront initialisées exactement en
même temps (et notamment que la fin de cette initialisation sera parfaitement simultanée sur
toutes les bascules). Votre design ne doit pas reposer sur cette hypothèse pour fonctionner
correctement.
4.2.6 Circuit générateur de CE
Il existe deux manières de traiter le cas où un design doit fonctionner avec une fréquence plus
faible que l’horloge entrante du FPGA :
1. Avec le circuit diviseur d’horloge précédent (clk_div_N ), on crée une nouvelle horloge
qui sera utilisée comme horloge du design. Le design sera synchrone avec cette nouvelle
horloge, mais pas avec l’horloge entrante. S’il y a dans le design plusieurs blocs qui
travaillent à des fréquences différentes, on crée autant d’horloges que de blocs, chaque bloc
étant synchrone avec son horloge. Cette méthode a pour avantage de minimiser la
consommation du circuit, car chaque bascule travaille à sa fréquence minimale. Son
principal inconvénient est que le design n’est plus synchrone avec une seule horloge, mais
synchrone par bloc. Tout le problème (très délicat dans le cas général) va consister à
échanger de manière fiable des données entre les différents blocs, chaque bloc travaillant
avec sa propre horloge.
2. Il y a une autre manière de traiter le problème ; la méthode full synchrone. Tout le design
travaille avec l’horloge entrante de fréquence élevée (si les performances du FPGA le
permettent), et on crée un signal de validation (CE_x) pour chacun des blocs avec un
circuit générateur de CE (gen_ce_div_N ). Ce signal de validation qui vaut 1 toutes les
N périodes de l’horloge sera connecté aux différentes bascules D des blocs. Les bascules
seront donc activées à une cadence plus faible que l’horloge. Cette méthode a pour
avantage de faciliter l’échange des données entre les blocs. En effet, tous les échanges sont
synchrones puisqu’il n’y a plus qu’une seule horloge. Le seul inconvénient de cette
méthode, c’est une consommation élevée puisque toutes les bascules du montage
travaillent à la fréquence maximale.

103
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. use IEEE.std_logic_arith.all; 4. use IEEE.STD_LOGIC_UNSIGNED.all; 5. entity gen_ce_div_N is 6. generic (div : integer := 4); 7. port (clk_in : in std_logic; 8. clear : in std_logic; 9. ce_out : out std_logic); 10. end gen_ce_div_N; 11. architecture RTL of gen_ce_div_N is 12. signal compte : integer range 0 to div-1; 13. begin 14. PROCESS (clk_in, clear) BEGIN 15. if (clear = '1') then 16. compte <= 0; 17. ce_out <= '0'; 18. elsif (clk_in'event and clk_in = '1') then 19. if (compte = div-1) then 20. ce_out <= '1'; 21. compte <= 0; 22. else 23. ce_out <= '0'; 24. compte <= compte + 1; 25. end if; 26. end if; 27. END PROCESS; 28. end;
Le fonctionnement du montage est évident. ce_out vaut 0 sauf quand compte est égal à la
valeur div-1 (3 dans le chronogramme ci-dessous). Il passe alors à 1.
Une bascule D reliée à l’horloge clk_in dont le chip enable (CE) serait connecté à ce_out
serait donc activée un front d’horloge sur 4.
4.2.7 registre
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. package tp4_pkg is 4. TYPE data8x8 IS ARRAY (0 TO 7) OF std_logic_vecto r(7 DOWNTO 0); 5. end tp4_pkg;

104
6. library IEEE; 7. use IEEE.std_logic_1164.all; 8. use IEEE.std_logic_arith.all; 9. use IEEE.STD_LOGIC_UNSIGNED.all; 10.use work.tp4_pkg.all; 11.entity regMxN is 12. generic (NbReg : integer :=8; NbBit : integer :=8); 13. port( CLK : in std_logic ; 14. CLEAR : in std_logic; 15. CE : in std_logic; 16. DIN : in std_logic_vector(NbBit -1 downt o 0); 17. datar : out data8x8); 18.end regMxN; 19.architecture RTL of regMxN is 20. signal datari : data8x8; 21.begin 22. process(CLK, CLEAR) begin 23. if (CLEAR='1') then 24. for i in 0 to 7 loop 25. datari(i) <= (others => '0'); 26. end loop; 27. elsif (CLK'event and CLK='1') then 28. if (ce = '1') then 29. for i in 1 to 7 loop 30. datari(8-i) <= datari(7-i); 31. end loop; 32. datari(0) <= DIN; 33. end if; 34. end if; 35. end process; 36. datar <= datari; 37.end;
Le type data8x8 définit un tableau de 8 signaux de largeur 8 bits. L’initialisation d’un signal
de ce type se fait à l’aide d’une boucle for (lignes 24 à 26). Le décalage du registre est réalisé
aux lignes 28 à 33. Si CE vaut 1, alors on copie datari(6) dans datari(7), puis datari(5) dans
datari(6), puis datari(4) dans datari(5), …, puis datari(0) dans datari(1). Il suffit ensuite de
copier din dans datari(0) pour terminer le décalage. Le design regMxN réalise donc la fonction
logique suivante :
Le chronogramme suivant montre l’évolution des signaux avec les valeurs par défaut (8,8) :

105
4.2.8 buffer trois états
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. use work.gen_cnt_pkg.all; 4. entity gen_cntZ is 5. port( 6. Clock : in std_logic; 7. Reset : in std_logic; 8. Sel : in std_logic; 9. add : out std_logic_vector(3 downto 0); 10. adu : out std_logic_vector(3 downto 0)); 11.end gen_cntZ; 12.architecture comporte of gen_cntZ is 13. signal ceo : std_logic; 14. signal addi : std_logic_vector(3 downto 0); 15. signal adui : std_logic_vector(3 downto 0); 16. constant zero : std_logic := '0'; 17. signal zeros : std_logic; 18. constant un : std_logic := '1'; 19. signal uns : std_logic; 20.begin 21. zeros <= zero; 22. uns <= un; 23. add <= addi when Sel='0' else (others => 'Z'); 24. adu <= adui when Sel='0' else (others => 'Z'); 25. cd4d : compteur generic map(4,10) port map(Clo ck, ceo, Reset, open,
addi); 26. cd4u : compteur generic map(4,10) port map(Clo ck, uns, Reset, ceo,
adui); 27.end comporte ;
L’exemple « compteur » a été repris avec son package. On a simplement inséré des buffers
trois états sur les sorties des deux compteurs BCD. Pour cela, deux signaux intermédiaires
« addi » et « adui » ont été ajoutés aux lignes 14 et 15. Les buffers trois états, définis aux
lignes 23 et 24, ressemblent fortement à un multiplexeur dans leur description :
add <= addi when Sel='0' else (others => 'Z');
Il faut traduire par : add prend la valeur de addi si Sel est égal à 0 sinon (add prend la valeur)
Z, ce qui est bien la description d’un buffer trois état. Le design gen_cntZ réalise donc la
fonction logique suivante :

106
adui[3:0]
addi[3:0]
Clock
Reset
compteur
CE
CLK
DOUT[wdth-1:0]
CEO
CLEAR
compteur
CE
CLK
DOUT[wdth-1:0]
CEO
CLEAR
OBUFT4
out[3:0]
sel
in[3:0]
OBUFT4
out[3:0]
sel
in[3:0] Adu[3:0]
Add[3:0]
Sel
Le chronogramme suivant montre l’évolution des signaux :
4.2.9 mémoire ROM
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. use IEEE.std_logic_arith.all; 4. use IEEE.std_logic_unsigned.all; 5. entity mem is 6. port (addr : in std_logic_vector(3 downto 0); 7. dout : out std_logic_vector(7 downto 0)); 8. end mem;

107
9. architecture a1 of mem is 10. TYPE mem_data IS ARRAY (0 TO 15) OF std_logic_ vector(7 DOWNTO 0); 11. constant data : mem_data := ( 12. ("01000000"), 13. ("01111001"), 14. ("00100100"), 15. ("00110000"), 16. ("00011001"), 17. ("00010010"), 18. ("00000010"), 19. ("01111000"), 20. ("00000000"), 21. ("00010000"), 22. ("00000000"), 23. ("00000000"), 24. ("00000000"), 25. ("00000000"), 26. ("00000000"), 27. ("00000000")); 28.begin 29. PROCESS (addr) BEGIN 30. dout <= data(CONV_INTEGER(addr)); 31. END PROCESS; 32.end;
Le type mem_data définit un tableau de 16 cases de largeur 8 bits. La constante data qui
représente le contenu de la mémoire est initialisée aux lignes 11 à 27. La ligne 30 définit le
fonctionnement de la mémoire. Elle utilise une fonction de conversion définie dans le package
synopsys, CONV_INTEGER. En effet, l’index du tableau data doit être un nombre entier
alors que le signal data est de type std_logic_vector. La conversion std_logic_vector vers
entier est obligatoire. Le chronogramme suivant montre le fonctionnement de la mémoire :

108

109
5. Travail pratique N°1
Ce premier TP a pour but de permettre la prise en main des outils de CAO Xilinx sur un
exemple simple : un compteur 8 bits avec reset et sortie sur les leds de la maquette FPGA.
Nous allons passer en revue toutes les phases du développement d’un design en mode saisie
de schéma puis en VHDL. Ce texte a pour but de vous indiquer l’enchaînement des tâches
nécessaires, les explications détaillées concernant la finalité des commandes vous seront
données oralement au fur et à mesure du déroulement des travaux pratiques.
5.1 Ouverture de session
Appuyer sur control+Alt+Sup pour ouvrir une session sur l’ordinateur. Le nom de l’utilisateur
est fpga, le mot de passe est fpga.
5.2 Lancement de « Project Navigator »
Le lancement de l’application principale « Project Navigator » s’effectue en cliquant deux fois
sur l’icône se trouvant sur le bureau.
5.3 Création du projet
Après un long moment (30 secondes la première fois), la fenêtre de « Project Navigator »
s’ouvre. Cliquez sur le menu « File » et le sous-menu « New Project…».
La fenêtre de création du projet apparaît.
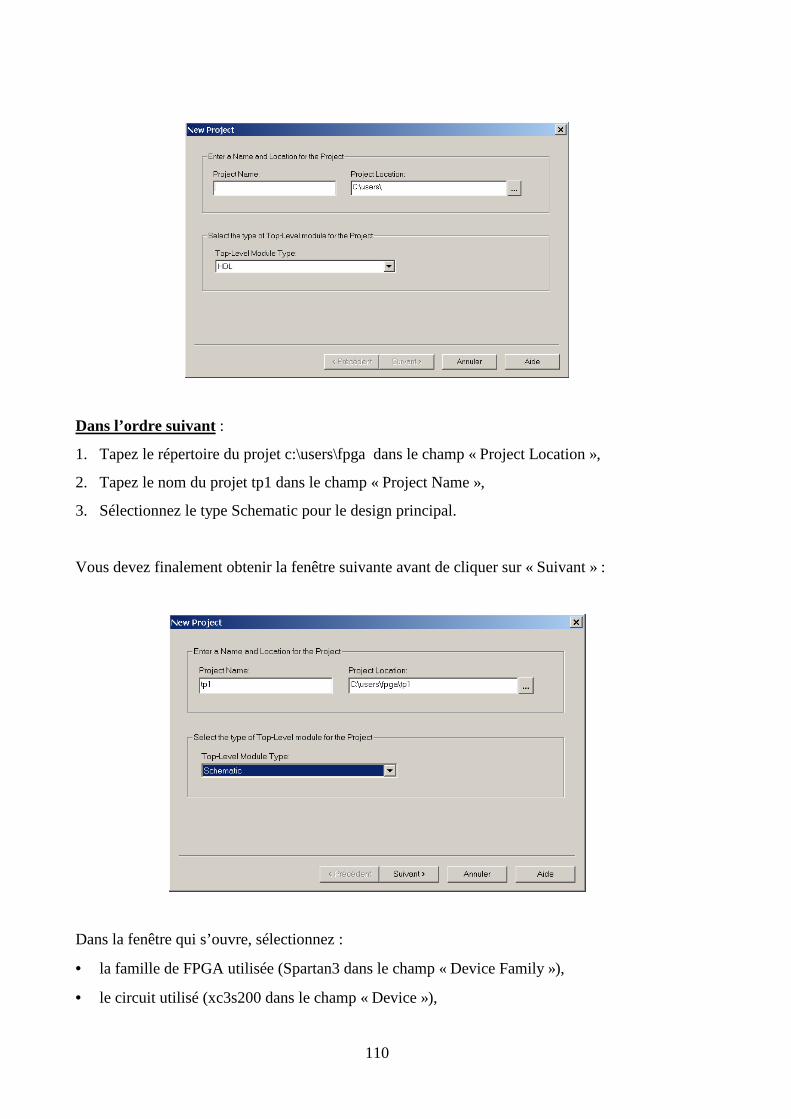
110
Dans l’ordre suivant :
1. Tapez le répertoire du projet c:\users\fpga dans le champ « Project Location »,
2. Tapez le nom du projet tp1 dans le champ « Project Name »,
3. Sélectionnez le type Schematic pour le design principal.
Vous devez finalement obtenir la fenêtre suivante avant de cliquer sur « Suivant » :
Dans la fenêtre qui s’ouvre, sélectionnez :
• la famille de FPGA utilisée (Spartan3 dans le champ « Device Family »),
• le circuit utilisé (xc3s200 dans le champ « Device »),

111
• le boîtier (ft256 dans le champ « Package »),
• la vitesse (-4 dans le champ « Speed Grade »),
• les outils du flot de développement (synthétiseur : XST, simulateur : modelsim, langage
VHDL).
Vous devez finalement obtenir la fenêtre suivante avant de cliquer sur « Suivant » :
Cliquez sur « Suivant » dans les deux fenêtres suivantes, puis sur « Terminer » dans la fenêtre
finale :
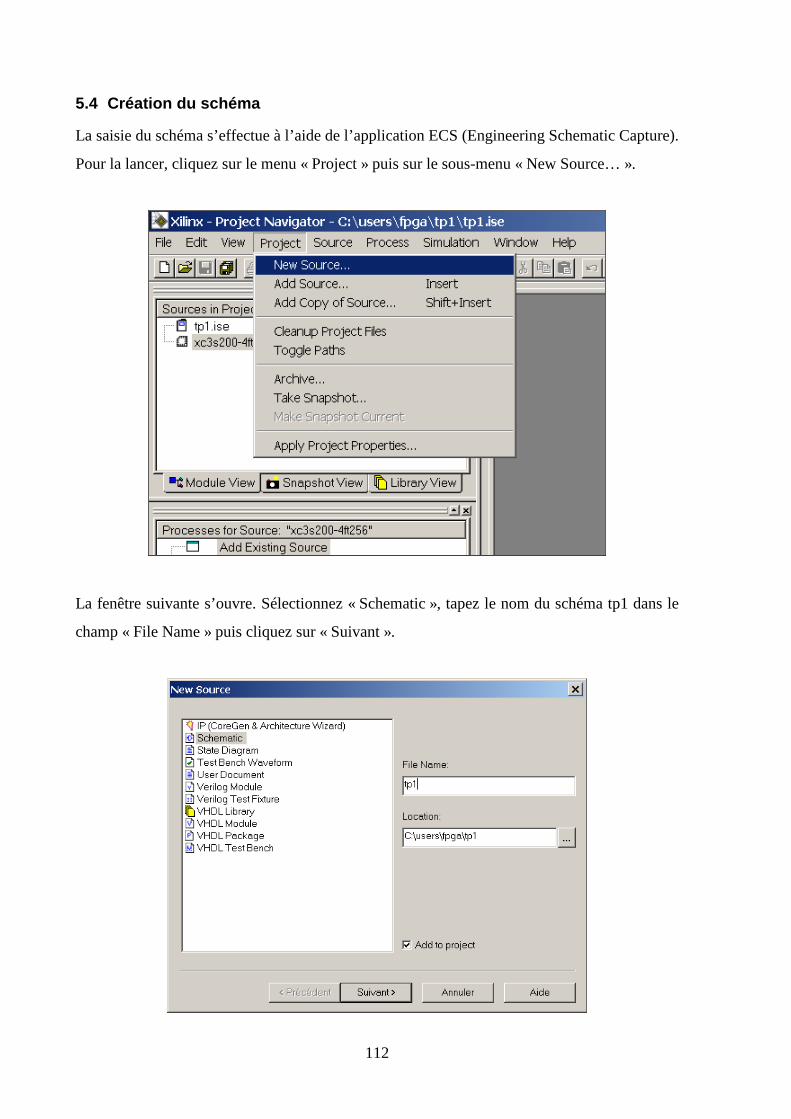
112
5.4 Création du schéma
La saisie du schéma s’effectue à l’aide de l’application ECS (Engineering Schematic Capture).
Pour la lancer, cliquez sur le menu « Project » puis sur le sous-menu « New Source… ».
La fenêtre suivante s’ouvre. Sélectionnez « Schematic », tapez le nom du schéma tp1 dans le
champ « File Name » puis cliquez sur « Suivant ».

113
Dans la fenêtre d’information qui s’ouvre alors, cliquez sur « Terminer ».
La fenêtre de saisie de schéma apparaît dans Project Navigator.

114
Pour travailler plus à votre aise, vous allez détacher la fenêtre d’ECS du navigateur de projet
en cliquant sur le bouton >> en haut à droite de la fenêtre :
ECS est maintenant séparé du navigateur. Si vous souhaitez le rattacher à nouveau, cliquez sur
. La fenêtre est séparée en 4 zones : les menus déroulants, les 2 niveaux de barre d’outils,
la zone de saisie de schéma et la fenêtre options/symbols. Dans ce premier TP, nous allons
réaliser une fonction simple pour apprendre à maîtriser les différents outils logiciels ; un
compteur 8 bits. Le schéma suivant doit être obtenu avant de passer à la simulation.

115
Il comprend les symboles :
Categories Symbol Label
general STARTUP_SPARTAN3 (interface utilisateur vers les ressources globales GSR, GTS et horloge de configuration)
VCC (force au niveau 1)
GND (force au niveau 0)
Stp
counter CB8CE (compteur binaire 8 bits avec chip enable et clear actifs à 1)
Cnt8
Nous allons maintenant apprendre à nous servir de la saisie de schéma. Passons en revue les
commandes de la barre d’outils qui vont nous être utiles dans ce TP :
Icône Nom Fonction
Save Sauve le schéma en cours
Check Schematic Vérifie la conformité du schéma
Zoom Full View (F6) Affiche plein cadre le schéma actif
Zoom In (F8) Augmente l’agrandissement du schéma
Zoom Out (F7) Diminue l’agrandissement du schéma
Zoom To Box Agrandissement avec sélection de zone
Zoom to Selected Agrandissement de la partie sélectionnée
Push Into Symbol or Return to Calling Schematic
Visualise l’intérieur d’un symbole (descend d’un niveau hiérarchique) ou remonte d’un niveau hiérarchique
Add Wire Place un fil entre deux symboles
Undo Annule la dernière action
Redo Exécute la dernière action annulée
Add I/O Marker Ajoute un connecteur d’entrée-sortie

116
Il existe trois possibilités de zoom.
• Avec F7 et F8, vous agrandissez ou réduisez le schéma autour du pointeur de la souris.
Avec F6, vous visualisez immédiatement l’ensemble du schéma sur l’écran.
• Quand l’icône « Zoom To Box » est activée, sélectionnez la zone (de gauche à droite)
que vous voulez agrandir (placer le curseur de la souris en haut à gauche de la zone à
agrandir, cliquer sur le bouton gauche et déplacer le curseur vers le bas à droite tout en
maintenant le bouton gauche appuyé, relâcher le bouton de la souris), le zoom s’effectue
automatiquement sur la zone sélectionnée. Si vous refaites cette opération du bas à droite
vers le haut à gauche (donc en sens inverse), vous annulez le zoom précédent.
• Sélectionnez la zone du schéma que vous voulez agrandir puis cliquez sur le bouton
« Zoom to Selected » . L’agrandissement est alors automatique.
Pour déplacer le schéma dans la fenêtre de saisie, utilisez les barres de défilement horizontale
et verticale. Le schéma se déplace alors en sens inverse du mouvement de la souris. Pour
désactiver (si nécessaire) un mode de placement (symbole ou wire) ou de zoom, cliquez une
fois avec le bouton de droite de la souris puis une fois avec le bouton de gauche ou bien
appuyez sur la touche « Echap » du clavier.
Les composants à utiliser pour réaliser la fonction souhaitée se trouvent dans des librairies
fournies par Xilinx. Pour faire apparaître la liste des symboles disponibles, cliquez sur l’onglet
« symbols » dans la fenêtre de gauche d’ECS :
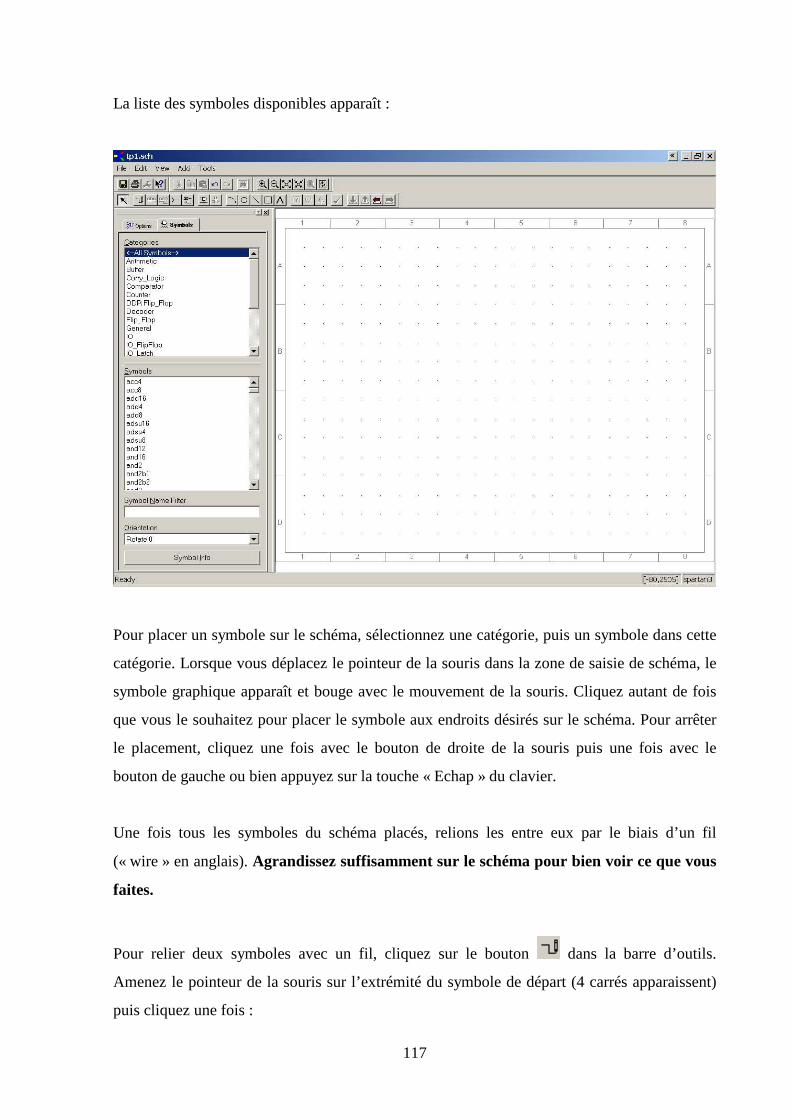
117
La liste des symboles disponibles apparaît :
Pour placer un symbole sur le schéma, sélectionnez une catégorie, puis un symbole dans cette
catégorie. Lorsque vous déplacez le pointeur de la souris dans la zone de saisie de schéma, le
symbole graphique apparaît et bouge avec le mouvement de la souris. Cliquez autant de fois
que vous le souhaitez pour placer le symbole aux endroits désirés sur le schéma. Pour arrêter
le placement, cliquez une fois avec le bouton de droite de la souris puis une fois avec le
bouton de gauche ou bien appuyez sur la touche « Echap » du clavier.
Une fois tous les symboles du schéma placés, relions les entre eux par le biais d’un fil
(« wire » en anglais). Agrandissez suffisamment sur le schéma pour bien voir ce que vous
faites.
Pour relier deux symboles avec un fil, cliquez sur le bouton dans la barre d’outils.
Amenez le pointeur de la souris sur l’extrémité du symbole de départ (4 carrés apparaissent)
puis cliquez une fois :

118
Un fil apparaît, relié à cette extrémité. Amenez l’autre extrémité du fil sur le symbole
d’arrivée (4 carrés doivent alors apparaître) puis cliquez à nouveau. La liaison est réalisée.
Si le fil doit effectuer un angle droit, cliquez simplement sur l’origine et sur la destination ;
ECS se charge d’effectuer le tournant automatiquement. Placez les fils nécessaires sur le
schéma.
Occupons-nous maintenant des connecteurs d’entrée-sortie. Vous ne pouvez placer un
connecteur sur un fil que si celui-ci existe déjà. Prenons l’exemple de la sortie Data(7:0). Il
faut placer le fil à la sortie du compteur et laisser l’autre extrémité non connectée. Pour cela,
cliquez une fois sur l’extrémité de l’inverseur, puis double cliquez pour arrêter le placement
du fil.

119
Pour placer le connecteur, cliquez sur l’icône puis amenez le pointeur sur le carré rouge à
l’extrémité du fil. Lorsque les 4 carrés apparaissent, cliquez une fois. Le connecteur est placé.
Pour changer le nom des connecteurs, double-cliquez sur le symbole pour faire apparaître la
fenêtre des propriétés de l’objet :
Cliquez sur le champ Name et tapez Data(7:0). Vous devez obtenir la fenêtre suivante avant
de cliquer sur OK.

120
Le schéma est maintenant modifié.
Vous pouvez maintenant placer les deux connecteurs Clock et Reset. Vous devez aussi placer
des labels (des noms d’instance) sur les symboles CB8CE et STARTUP_SPARTAN3 (voir
tableau des symboles). Pour cela, double cliquez sur le symbole (ou sur le fil) et modifiez son
nom. Par exemple, double cliquez sur le compteur et tapez Cnt8 dans le champ InstName :
Attention, ne changez pas le nom des fils connectés aux symboles VCC et GND. Laissez
la valeur par défaut.
Vous pouvez visualiser l’intérieur d’un symbole en le sélectionnant puis en cliquant sur le
bouton dans la barre d’outils. Si la fenêtre suivante s’ouvre, cliquez sur « OK » pour
ignorer l’erreur. C’est un problème de date de fichier.

121
Le schéma correspondant au symbole (Cnt8 dans cet exemple) apparaît alors :

122
Vous pouvez remonter au schéma racine en cliquant sur le bouton dans la barre d’outils.
A ce point de la manipulation, vous avez normalement obtenu le schéma désiré grâce aux trois
phases de la saisie de schéma :
1. Placement des symboles,
2. Liaisons entre les symboles par le biais de fils,
3. Affectations des labels.
Vous devez maintenant vérifier la cohérence de votre schéma grâce au bouton de la barre
d’outils. Le menu suivant apparaît si vous n’avez pas commis d’erreurs :
En cas d’erreurs, sélectionnez le message. La zone qui pose problème apparaît sur le schéma
surlignée en jaune. Corrigez l’erreur, puis refaites une vérification.
Le schéma est maintenant vérifié et doit être sauvé. Cliquez sur le bouton de la barre
d’outils puis fermez la saisie de schéma :

123
Le schéma apparaît maintenant dans les sources du navigateur de projet :
5.5 Génération du fichier de stimuli VHDL
Nous avons maintenant un design prêt à être simuler et nous devons écrire un fichier en
langage VHDL décrivant les signaux d’entrées (dans ce TP, il s’agit seulement d’un signal
d’horloge et du Reset). Ce fichier s’appelle un fichier de stimuli (un testbench en VHDL) qui
contient des vecteurs de test. Il y a parmi les outils Xilinx un outil graphique pour définir les
stimuli : Waveform Editor. Pour lancer cette application, cliquez sur le menu « Project » puis
sur le sous-menu « New Source… ».

124
La fenêtre suivante apparaît alors à l’écran. Sélectionner le type « Testbench waveform » et
tapez tp1_tb comme nom de fichier pour notre testbench :
Cliquez sur suivant pour associer le testbench avec le design tp1 :
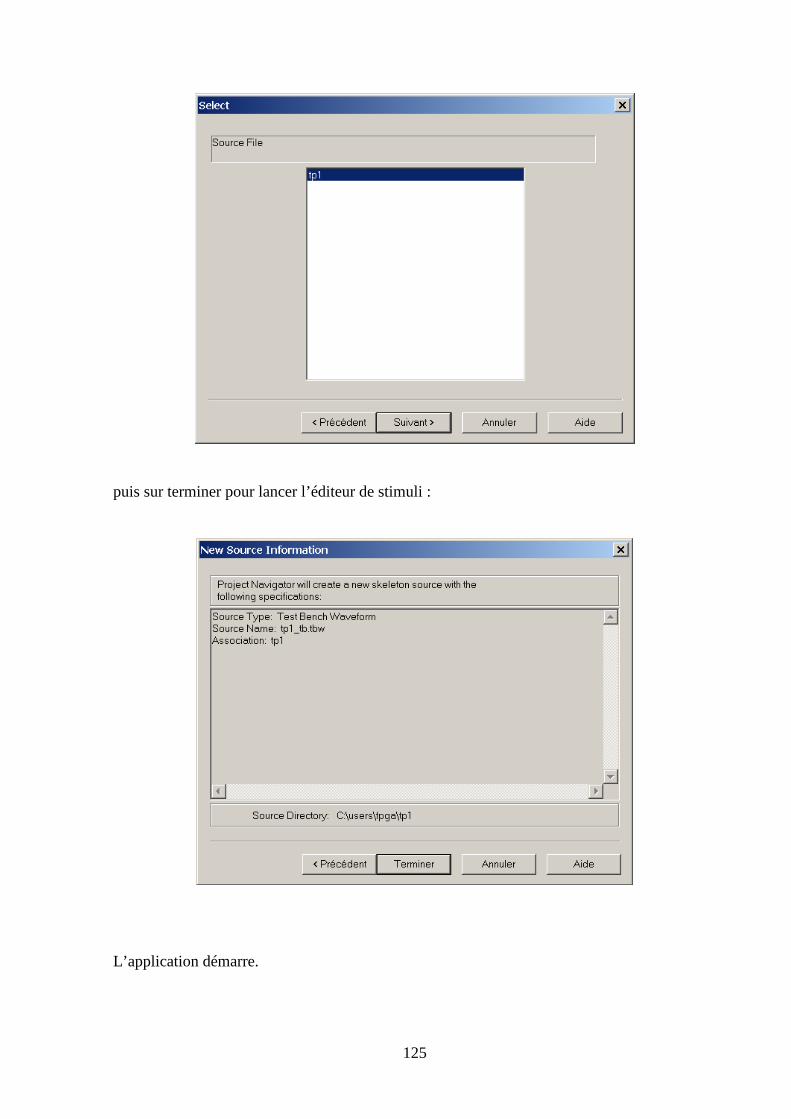
125
puis sur terminer pour lancer l’éditeur de stimuli :
L’application démarre.

126
L’horloge du design tp1 est bien Clock. Nous souhaitons une horloge à 10 MHz, avec un
temps mort de 100 ns au démarrage (pour faire le reset) et une durée de simulation égale à
2000 ns. Remplissez les différents champs comme sur la fenêtre suivante avant de cliquez sur
« OK » :
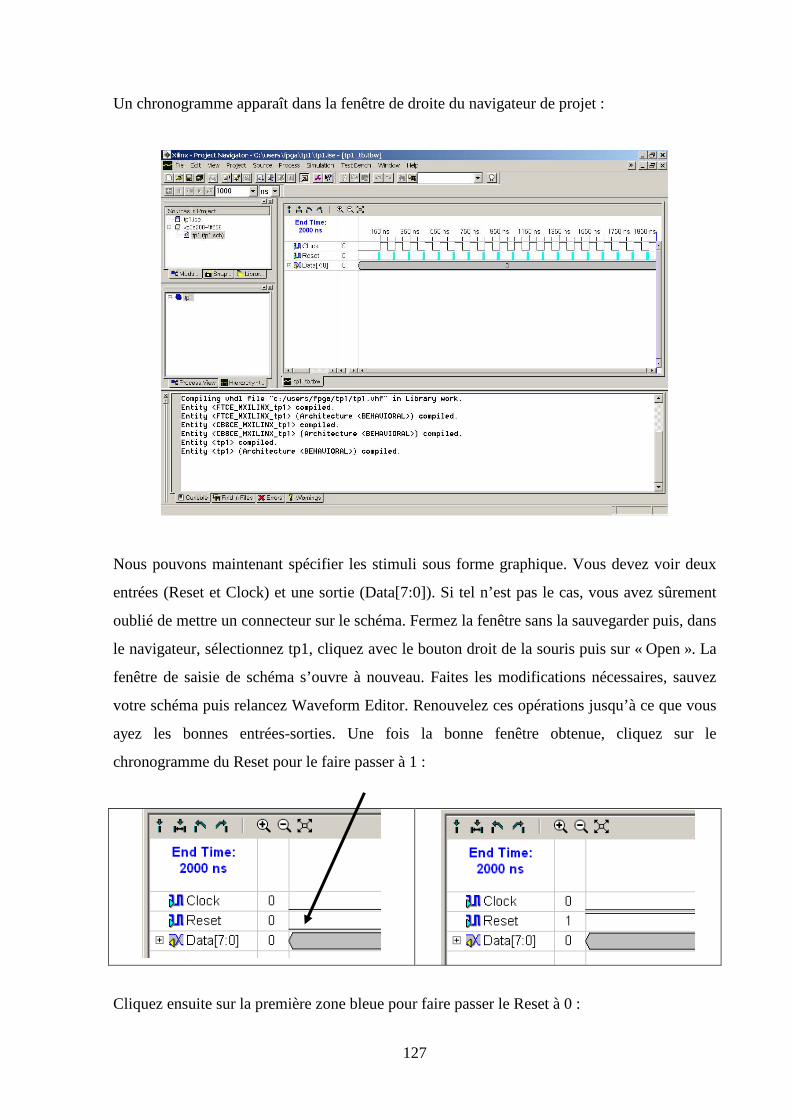
127
Un chronogramme apparaît dans la fenêtre de droite du navigateur de projet :
Nous pouvons maintenant spécifier les stimuli sous forme graphique. Vous devez voir deux
entrées (Reset et Clock) et une sortie (Data[7:0]). Si tel n’est pas le cas, vous avez sûrement
oublié de mettre un connecteur sur le schéma. Fermez la fenêtre sans la sauvegarder puis, dans
le navigateur, sélectionnez tp1, cliquez avec le bouton droit de la souris puis sur « Open ». La
fenêtre de saisie de schéma s’ouvre à nouveau. Faites les modifications nécessaires, sauvez
votre schéma puis relancez Waveform Editor. Renouvelez ces opérations jusqu’à ce que vous
ayez les bonnes entrées-sorties. Une fois la bonne fenêtre obtenue, cliquez sur le
chronogramme du Reset pour le faire passer à 1 :
Cliquez ensuite sur la première zone bleue pour faire passer le Reset à 0 :

128
Cliquez sur l’icône pour sauver le testbench, puis sur le menu « File », « Close » pour
quitter l’application :
Le testbench apparaît maintenant dans les sources du navigateur de projet. Vous pouvez à tout
moment relancer Waveform Editor en double cliquant sur tp1_tb.tbw.
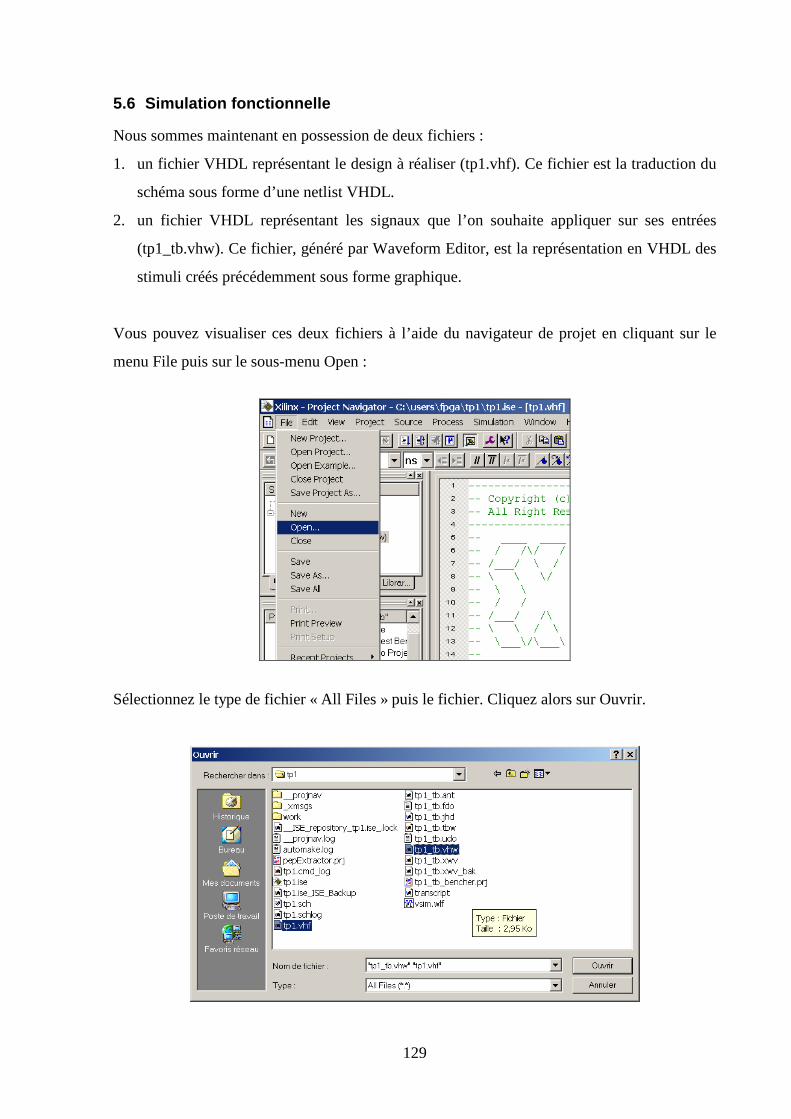
129
5.6 Simulation fonctionnelle
Nous sommes maintenant en possession de deux fichiers :
1. un fichier VHDL représentant le design à réaliser (tp1.vhf). Ce fichier est la traduction du
schéma sous forme d’une netlist VHDL.
2. un fichier VHDL représentant les signaux que l’on souhaite appliquer sur ses entrées
(tp1_tb.vhw). Ce fichier, généré par Waveform Editor, est la représentation en VHDL des
stimuli créés précédemment sous forme graphique.
Vous pouvez visualiser ces deux fichiers à l’aide du navigateur de projet en cliquant sur le
menu File puis sur le sous-menu Open :
Sélectionnez le type de fichier « All Files » puis le fichier. Cliquez alors sur Ouvrir.
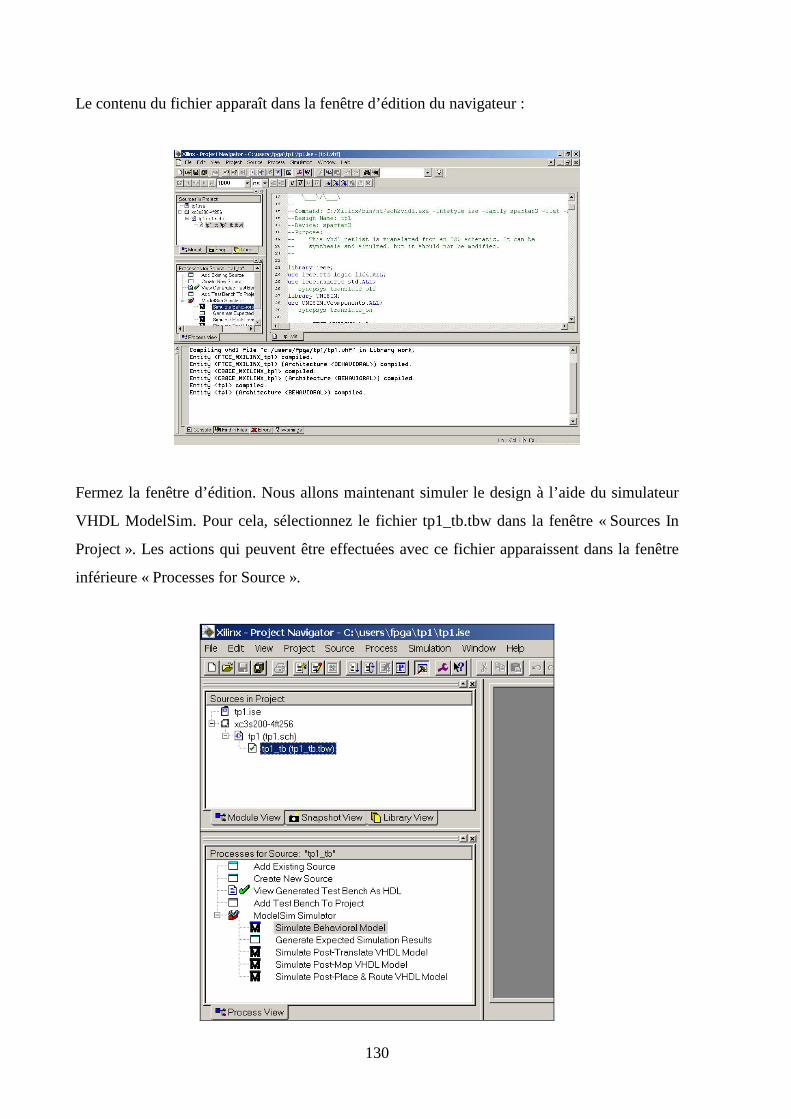
130
Le contenu du fichier apparaît dans la fenêtre d’édition du navigateur :
Fermez la fenêtre d’édition. Nous allons maintenant simuler le design à l’aide du simulateur
VHDL ModelSim. Pour cela, sélectionnez le fichier tp1_tb.tbw dans la fenêtre « Sources In
Project ». Les actions qui peuvent être effectuées avec ce fichier apparaissent dans la fenêtre
inférieure « Processes for Source ».

131
Sélectionnez le process « Simulate Behavorial Model » puis cliquez avec le bouton droit de la
souris sur le menu Run :
Le simulateur VHDL ModelSim démarre et la fenêtre suivante s’ouvre à l’écran. Si tel n’est
pas le cas, c’est parce que ModelSim s’exécute sous le navigateur de projet. Il faut alors
cliquer sur son icône dans la barre de tache de Windows pour le mettre au premier plan.
ModelSim va enchaîner automatiquement :
• la compilation du design et des stimuli,
• le lancement du simulateur,
• la simulation jusqu’à l’arrêt automatique du testbench.

132
Sélectionnez la fenêtre Wave (là où se trouvent les chronogrammes) en cliquant sur le menu
Windows, Memory-wave :
Nous allons détacher la fenêtre Wave de la fenêtre principale de Modelsim afin de mieux voir
les chronogrammes. Pour cela, cliquez sur le bouton du milieu (en haut à droite de
la fenêtre wave) puis mettez la fenêtre wave plein écran.
Cliquez sur le bouton « Zoom Full » de la barre d’outils de cette fenêtre pour visualiser
du début à la fin de la simulation (de 0 à 2100 ns). Vous pouvez maintenant vérifier le
fonctionnement de votre montage à l’aide des chronogrammes.

133
Sélectionnez le bus data puis cliquez avec le bouton droit de la souris sur le menu Radix, puis
sur Hexadecimal.
Le bus contient maintenant des valeurs hexadécimales au lieu de valeurs binaires.
Faîtes un zoom sur le chronogramme en cliquant en haut et à gauche de la zone à agrandir
avec le bouton du milieu de la souris. Maintenez cliqué et déplacez la souris en bas et à droite
de la zone (un rectangle bleu apparaît). Relâchez le bouton du milieu. Le zoom s’exécute.
Cliquez n’importe où sur le chronogramme. Un curseur jaune apparaît :

134
Cliquez sur le bouton « Insert Cursor » de la barre d’outils. Un deuxième curseur apparaît.
Vous voyez en bas de la fenêtre « Wave » le temps correspondant à la position de chaque
curseur ainsi que l’écart qui les sépare. Sur l’exemple suivant, on mesure la période de
l’horloge.
Quand la vérification est terminée, faites apparaître la fenêtre de ModelSim, puis cliquez sur
le menu « File » dans la fenêtre principale, puis sur « Quit ». Quand le message suivant
apparaît à l’écran, cliquez sur Oui.
5.7 Synthèse
Nous avons fini la première phase de création et de vérification du design. Vous pouvez voir à
tout moment le résumé des différentes étapes du design en sélectionnant tp1, puis en double-
cliquant sur « View Design Summary » :

135
La page de résumé s’affiche à droite du navigateur de projet :
Elle contient pour l’instant peu d’informations, mais elle va s’enrichir au fur et à mesure de
l’avancement du projet. Il faut maintenant traduire la netlist VHDL en une netlist NGC. C’est
le rôle du synthétiseur XST. En réalité, la synthèse est l’opération qui permet de créer une
netlist NGC à partir d’une description de haut niveau écrite en VHDL (ou en Verilog).
Comme nous partons ici d’un schéma (donc d’une netlist), la synthèse est beaucoup plus
facile puisque le fichier VHDL contient déjà des composants qui peuvent être compris par les
outils de placement-routage.
Sélectionnez le design tp1.sch dans la fenêtre « Sources » puis « Synthesize » dans la fenêtre
« Processes ». Cliquez avec le bouton droit de la souris puis cliquez sur « Run » :
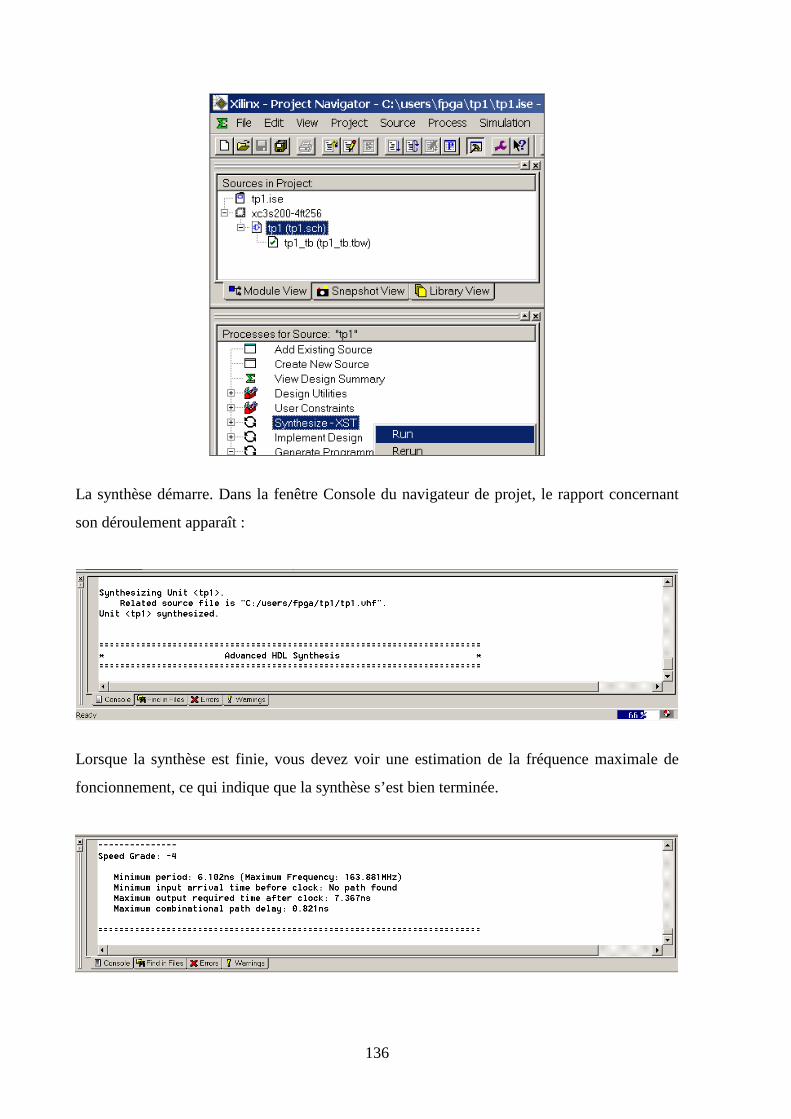
136
La synthèse démarre. Dans la fenêtre Console du navigateur de projet, le rapport concernant
son déroulement apparaît :
Lorsque la synthèse est finie, vous devez voir une estimation de la fréquence maximale de
foncionnement, ce qui indique que la synthèse s’est bien terminée.

137
Un point d’exclamation jaune apparaît dans la fenêtre Processes :
Il indique que des messages d’avertissement (Warnings) ont été émis pendant la synthèse.
Vous pouvez voir ces Warnings en faisant défiler le rapport dans la Console à l’aide de la
barre de défilement de droite. Ils concernent des sorties du compteur qui sont non-connectées.
C’ est normal, nous pouvons donc les ignorer.
Vous ne pouvez pas visualiser le fichier NGC issu de la synthèse car il s’agit d’un format de
netlist binaire qui ne peut donc être visualisé avec un éditeur ASCII. La fenêtre de résumé a
évoluée et reflète maintenant les informations de synthèse :
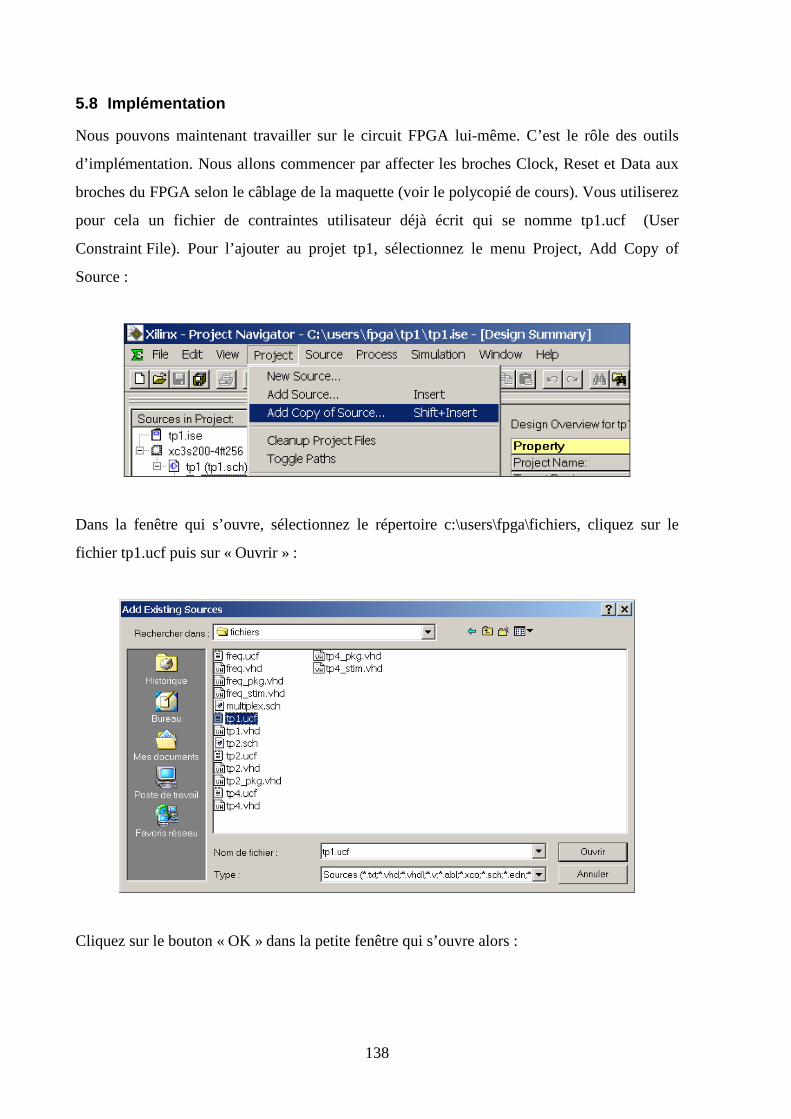
138
5.8 Implémentation
Nous pouvons maintenant travailler sur le circuit FPGA lui-même. C’est le rôle des outils
d’implémentation. Nous allons commencer par affecter les broches Clock, Reset et Data aux
broches du FPGA selon le câblage de la maquette (voir le polycopié de cours). Vous utiliserez
pour cela un fichier de contraintes utilisateur déjà écrit qui se nomme tp1.ucf (User
Constraint File). Pour l’ajouter au projet tp1, sélectionnez le menu Project, Add Copy of
Source :
Dans la fenêtre qui s’ouvre, sélectionnez le répertoire c:\users\fpga\fichiers, cliquez sur le
fichier tp1.ucf puis sur « Ouvrir » :
Cliquez sur le bouton « OK » dans la petite fenêtre qui s’ouvre alors :

139
Le fichier est maintenant inclus dans le projet :
Pour voir le contenu de ce fichier, il suffit de le sélectionner dans la fenêtre « Sources », puis
de double-cliquer dans la fenêtre Processes sur « Edit Constraints (Text) » :
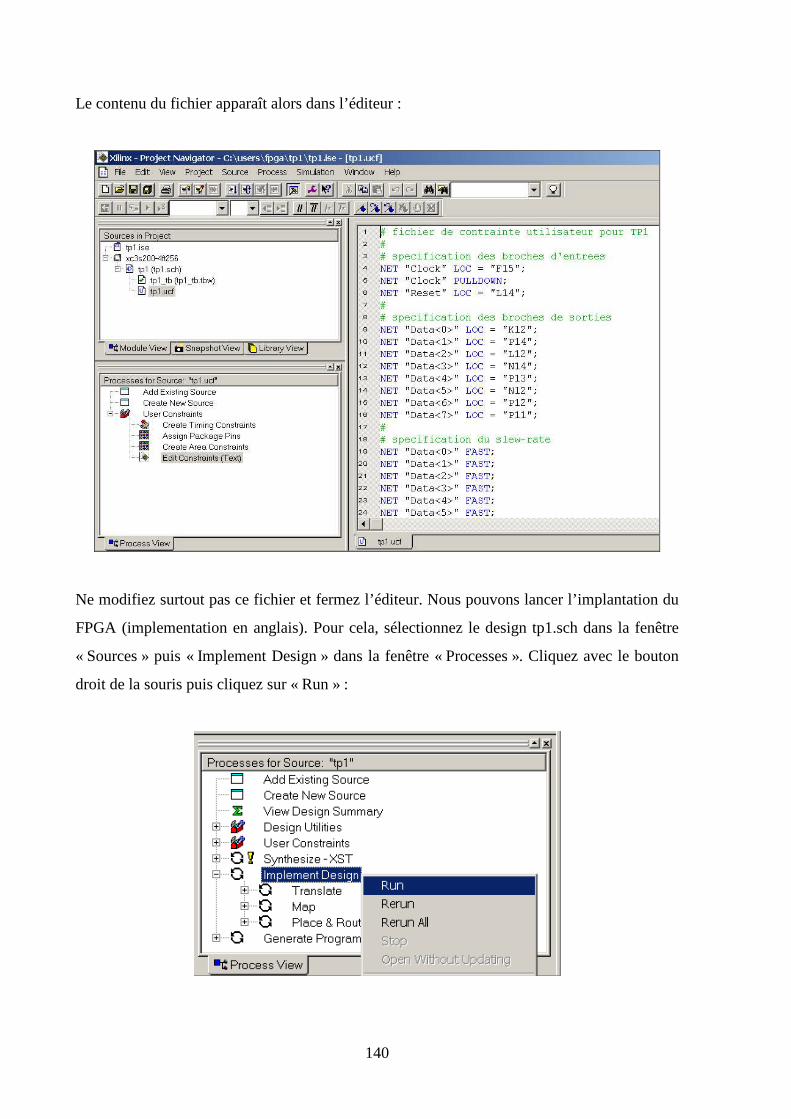
140
Le contenu du fichier apparaît alors dans l’éditeur :
Ne modifiez surtout pas ce fichier et fermez l’éditeur. Nous pouvons lancer l’implantation du
FPGA (implementation en anglais). Pour cela, sélectionnez le design tp1.sch dans la fenêtre
« Sources » puis « Implement Design » dans la fenêtre « Processes ». Cliquez avec le bouton
droit de la souris puis cliquez sur « Run » :
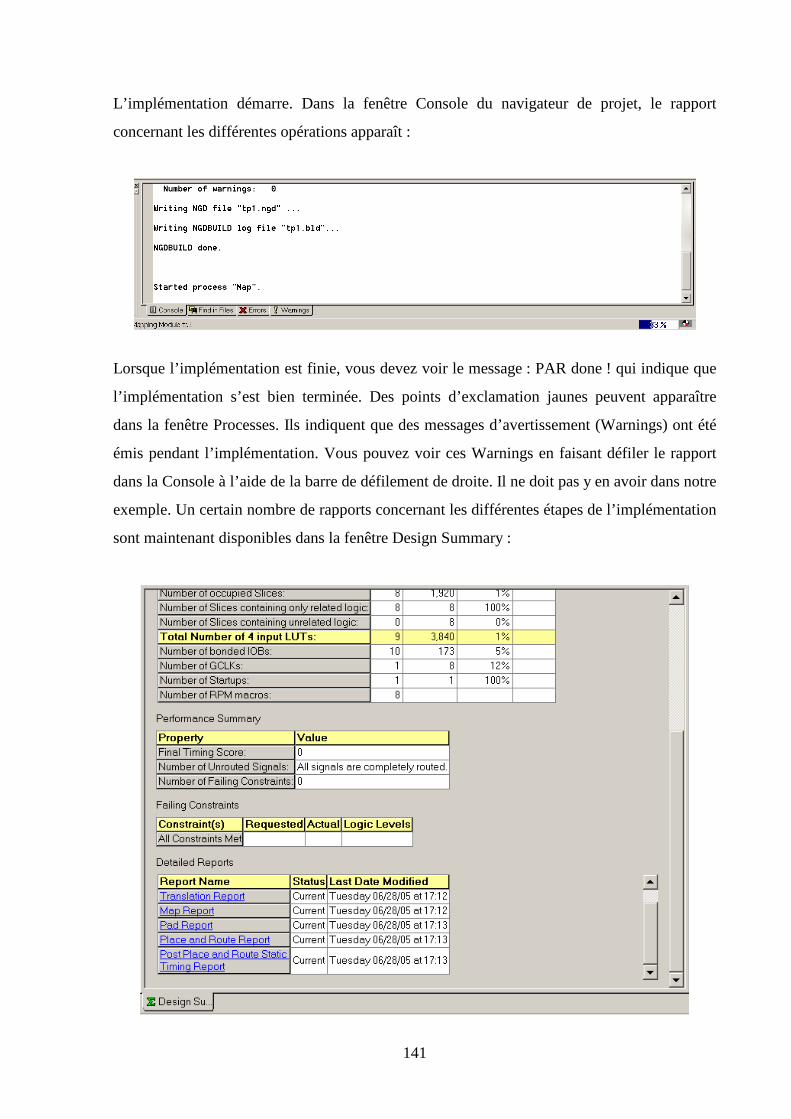
141
L’implémentation démarre. Dans la fenêtre Console du navigateur de projet, le rapport
concernant les différentes opérations apparaît :
Lorsque l’implémentation est finie, vous devez voir le message : PAR done ! qui indique que
l’implémentation s’est bien terminée. Des points d’exclamation jaunes peuvent apparaître
dans la fenêtre Processes. Ils indiquent que des messages d’avertissement (Warnings) ont été
émis pendant l’implémentation. Vous pouvez voir ces Warnings en faisant défiler le rapport
dans la Console à l’aide de la barre de défilement de droite. Il ne doit pas y en avoir dans notre
exemple. Un certain nombre de rapports concernant les différentes étapes de l’implémentation
sont maintenant disponibles dans la fenêtre Design Summary :

142
Le tableau suivant vous indique le rôle des différentes étapes de l’implémentation ainsi que
les rapports associés :
Etape Rapport Signification
Translation Translation report Création d’un fichier de design unique
Mapping Map report Découpage du design en primitives
Placement-routage Place & Route report
Post Place & Route static timing report
Pad report
Placement et routage des primitives
Respect des contraintes temporelles et fréquence max de fonctionnement
Assignation des broches du FPGA
5.9 Simulation de timing
Les outils de placement-routage peuvent fournir un nouveau modèle VHDL
(tp1_timesim.vhd) qui correspond au modèle de simulation réel du circuit ainsi qu’un fichier
contenant tous les timings du FPGA (tp1_timesim.sdf). On l’appelle le modèle VITAL . A
l’aide de ces deux fichiers et du fichier de stimuli tp1_tb.timesim_vhw (généré précédemment
par Waveform Editor), nous allons pouvoir vérifier le fonctionnement réel de notre design.
C’est la simulation de timing (ou simulation Post-Place&Route ou encore simulation Post-
layout).
Pour lancer cette simulation, sélectionnez le fichier tp1_tb.tbw dans la fenêtre « Sources In
Project ». Sélectionnez le processus « Simulate Post-Place&Route VHDL Model » puis
cliquez avec le bouton droit de la souris sur le menu Run :

143
Le simulateur VHDL ModelSim démarre. Il va enchaîner automatiquement :
• la compilation du design et des stimuli,
• le lancement du simulateur,
• la simulation jusqu’à l’arrêt automatique du testbench.
A la fin, la fenêtre Modelsim est la suivante :
Sélectionnez la fenêtre Wave (là où se trouvent les chronogrammes) puis détachez-la de la
fenêtre ModelSim. Cliquez sur le bouton « Zoom Full » de la barre d’outils de cette
fenêtre pour visualiser du début à la fin de la simulation (de 0 à 2100 ns). Vous pouvez
maintenant vérifier le fonctionnement de votre montage à l’aide des chronogrammes.
Sélectionnez le bus data puis cliquez avec le bouton droit de la souris sur le menu Radix, puis
sur Hexadécimal.

144
Faîtes un zoom sur le chronogramme en cliquant en haut et à gauche de la zone à agrandir
avec le bouton du milieu de la souris. Maintenez cliqué et déplacez la souris en bas et à droite
de la zone (un rectangle bleu apparaît). Relâchez le bouton du milieu. Le zoom s’exécute. Sur
l’exemple de chronogramme suivant, on voit clairement apparaître le décalage entre l’horloge
et les sorties. Utilisez les curseurs temporels pour mesurer l’écart entre le front d’horloge actif
et le changement en sortie.
Quand la vérification est terminée, cliquez sur le menu « File » dans la fenêtre ModelSim,
puis sur « Quit». Quand le message ci-dessous apparaît à l’écran, cliquez sur Oui.
5.10 Configuration de la maquette
A ce point du TP, le design est entièrement vérifié. Nous pouvons maintenant le télécharger
dans le FPGA. Sélectionnez le design tp1.sch dans la fenêtre « Sources » puis « Configure
Device » dans la fenêtre « Processes ». Cliquez avec le bouton droit de la souris puis cliquez
sur « Run » :
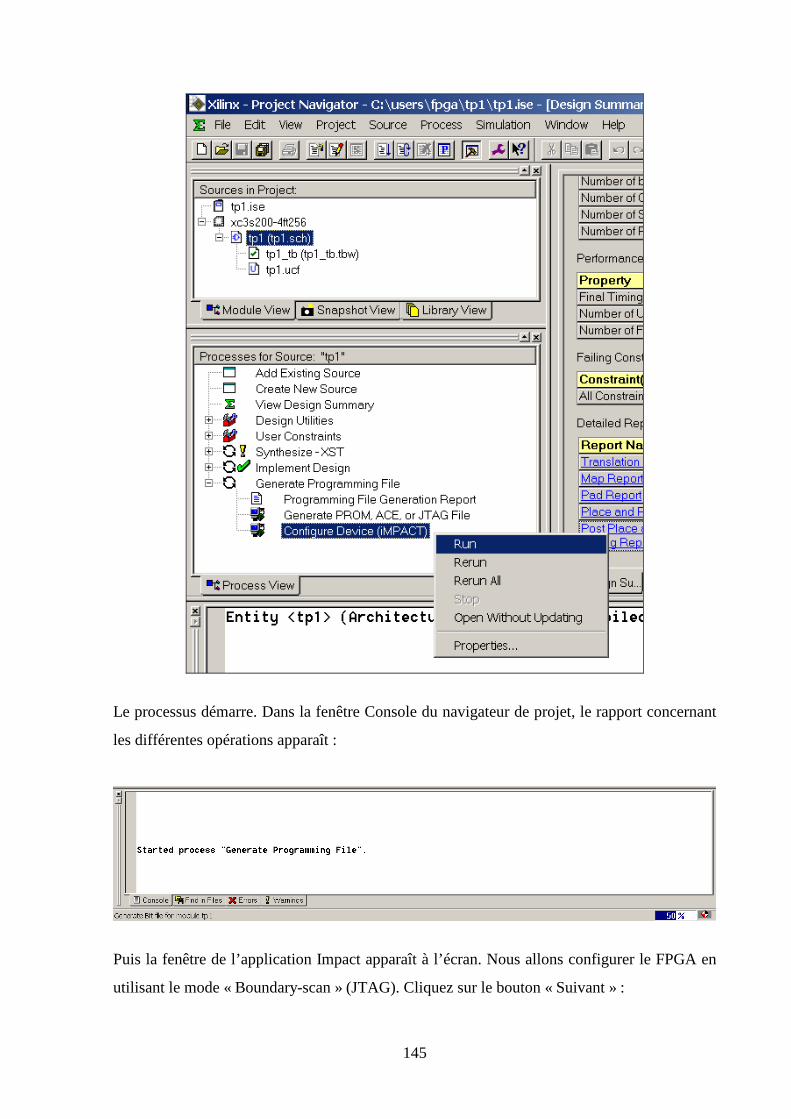
145
Le processus démarre. Dans la fenêtre Console du navigateur de projet, le rapport concernant
les différentes opérations apparaît :
Puis la fenêtre de l’application Impact apparaît à l’écran. Nous allons configurer le FPGA en
utilisant le mode « Boundary-scan » (JTAG). Cliquez sur le bouton « Suivant » :
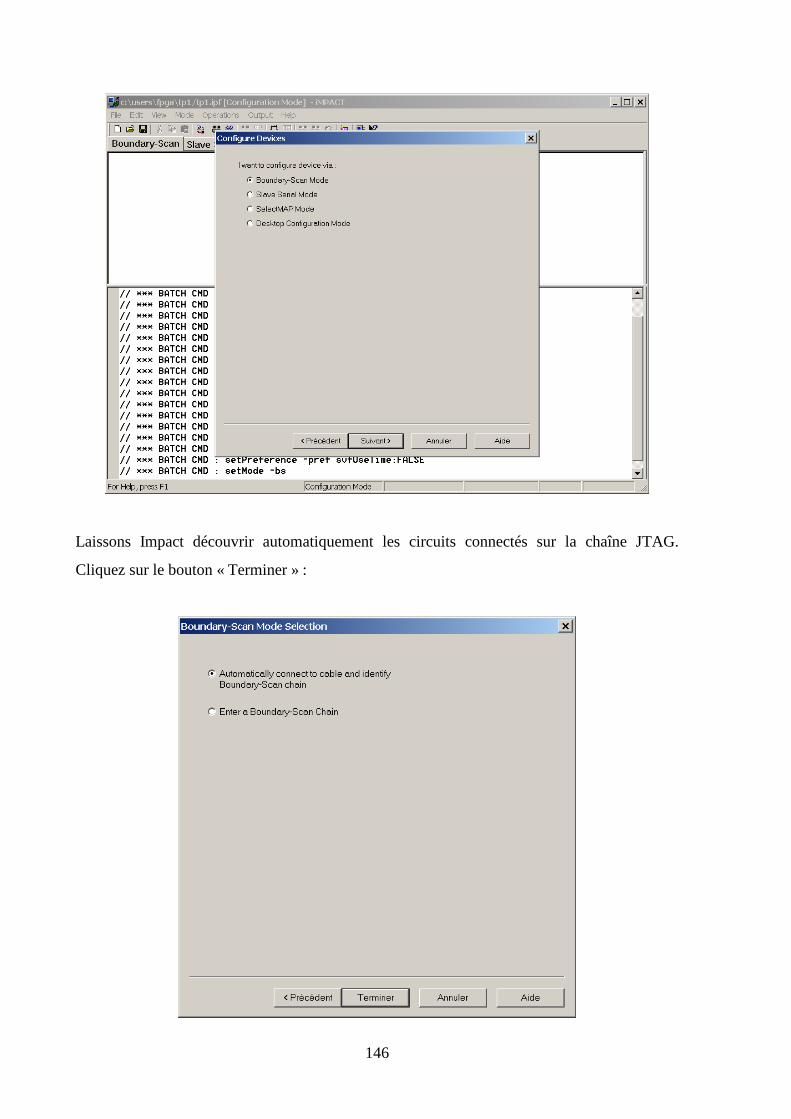
146
Laissons Impact découvrir automatiquement les circuits connectés sur la chaîne JTAG.
Cliquez sur le bouton « Terminer » :
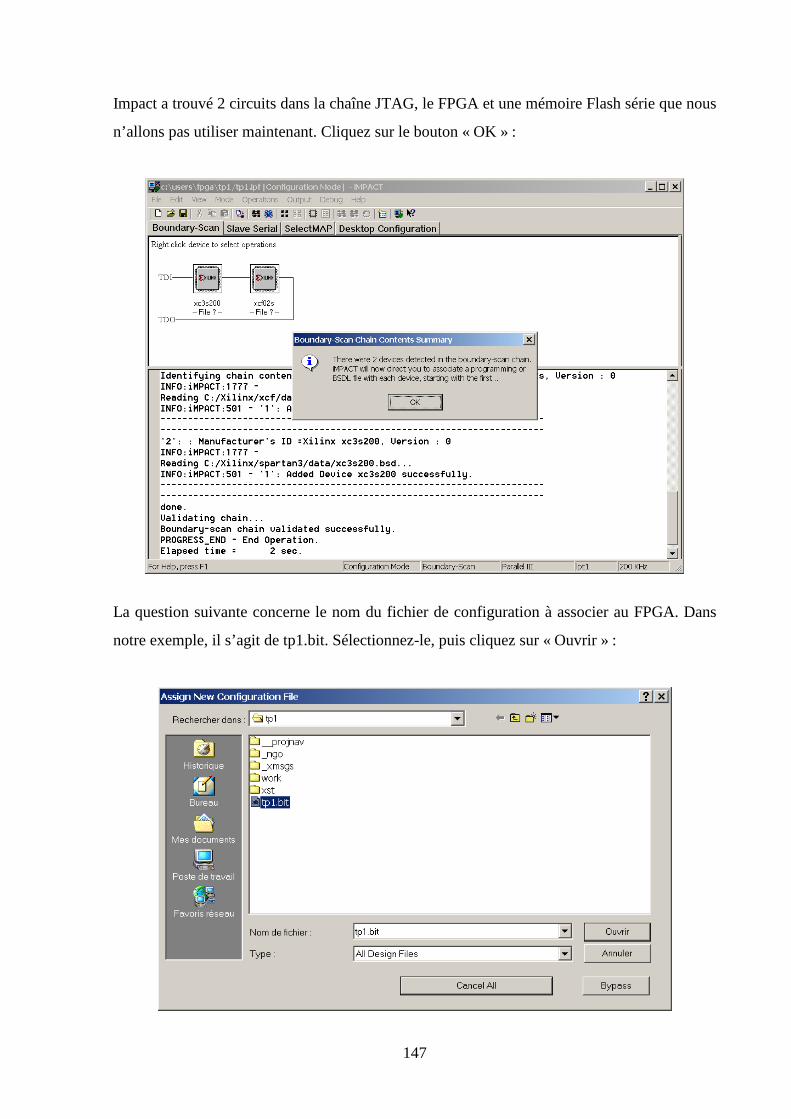
147
Impact a trouvé 2 circuits dans la chaîne JTAG, le FPGA et une mémoire Flash série que nous
n’allons pas utiliser maintenant. Cliquez sur le bouton « OK » :
La question suivante concerne le nom du fichier de configuration à associer au FPGA. Dans
notre exemple, il s’agit de tp1.bit. Sélectionnez-le, puis cliquez sur « Ouvrir » :

148
Par défaut, le FPGA est en mode maître, c’est à dire qu’il génère l’horloge CCLK de lecture
de la configuration. Comme en JTAG, le FPGA est esclave, la fenêtre suivante vous avertit
que l’horloge dans le fichier de configuration tp1.bit a été passée en mode JTAG (sur la copie
en mémoire seulement). Cliquez sur « OK » pour poursuivre :
Impact demande ensuite quel fichier va être associé avec la mémoire Flash série. Comme nous
n’avons pas créé le fichier pour la PROM (format MCS-86), cliquez sur « Bypass » pour
sauter cette étape :
Finalement, on obtient la fenêtre suivante :
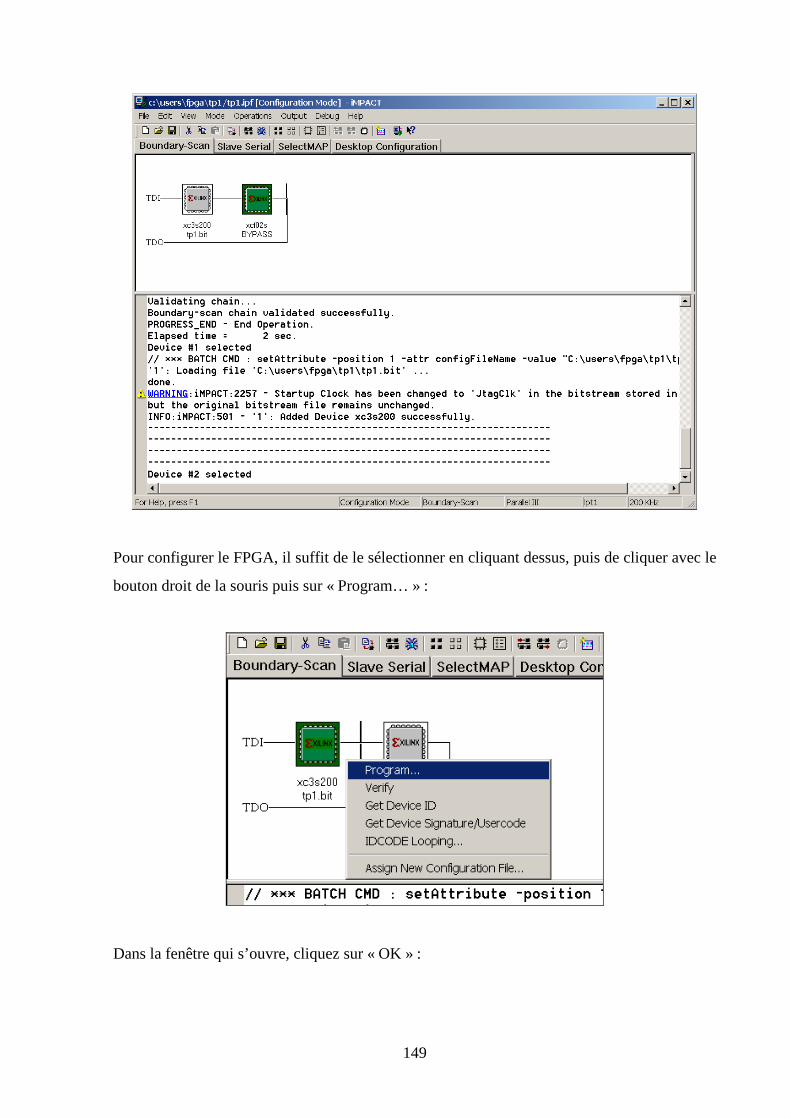
149
Pour configurer le FPGA, il suffit de le sélectionner en cliquant dessus, puis de cliquer avec le
bouton droit de la souris puis sur « Program… » :
Dans la fenêtre qui s’ouvre, cliquez sur « OK » :

150
En moins de 10 secondes, le téléchargement est terminé. Fermez la fenêtre Impact sans sauver
le projet. Connectez un générateur d’horloge compatible CMOS 3.3V (entre 0 et 3 Volt,
fréquence ≈ 10 Hz) sur l’entrée Hin (qui est chargée sur 50 Ω). Vérifiez le comptage sur les
LED. Le bouton poussoir BTN3 (User Reset) réinitialise le montage.
5.11 Le flot VHDL
Nous allons maintenant refaire le même TP avec un design écrit directement en langage
VHDL. Pour cela, fermez le projet TP1 (menu « File », « Close Project ») puis créez en un
nouveau appelé TP1V (Top-Level Module Type : HDL). Le compteur 8 bits est déjà écrit en
VHDL (tp1.vhd) et se trouve dans le répertoire c:\users\fpga\fichiers. Pour l’insérer dans le
projet TP1V, cliquez sur « Project », « Add Copy of Source ».
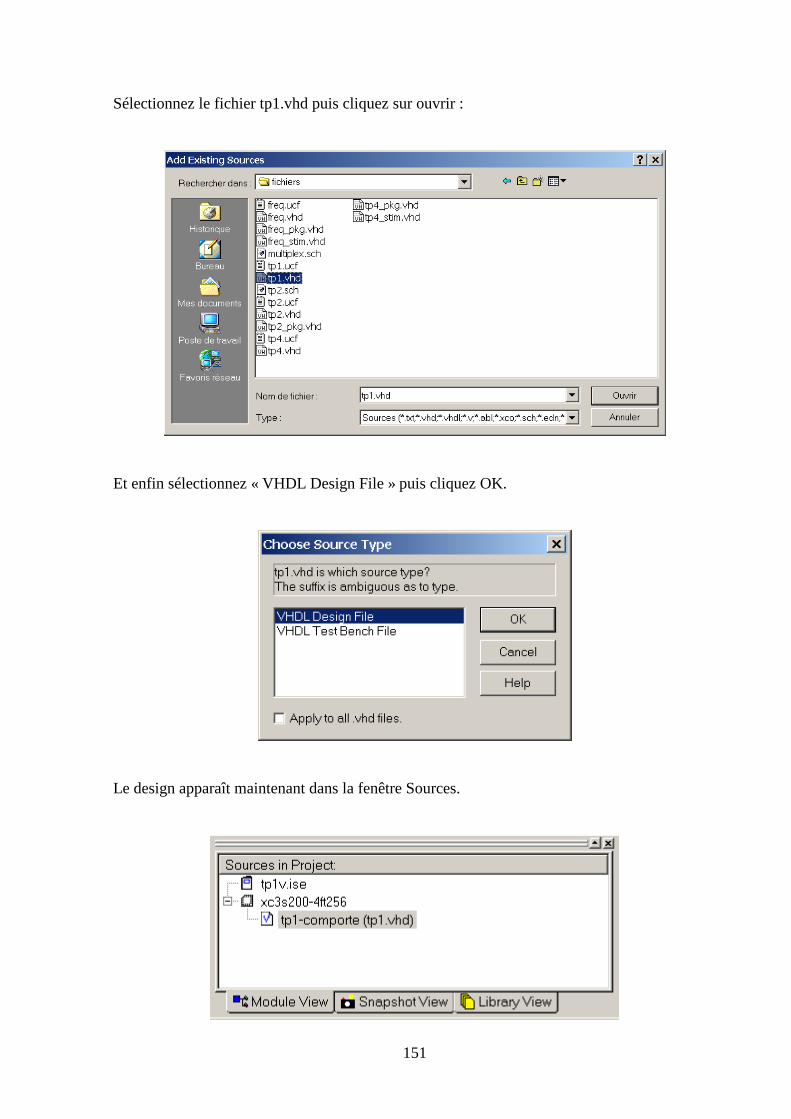
151
Sélectionnez le fichier tp1.vhd puis cliquez sur ouvrir :
Et enfin sélectionnez « VHDL Design File » puis cliquez OK.
Le design apparaît maintenant dans la fenêtre Sources.

152
Pour l’éditer, sélectionnez-le, cliquez avec le bouton droit de la souris puis sur « Open ». Le
contenu du fichier apparaît dans la fenêtre d’édition.
Il faut bien comprendre que le schéma dans le TP précédent était sauvegardé sous la forme
d’une netlist écrite en VHDL alors que dans ce TP, le code VHDL est d’un niveau
d’abstraction bien plus élevé. Dans les deux cas, la synthèse est obligatoire, mais pas pour la
même raison.
En saisie de schéma, le design est composé de primitives simples contenues dans une
bibliothèque fournie par Xilinx. La netlist VHDL correspondante doit donc simplement être
traduite en une netlist NGC pour être compréhensible par les outils d’implémentation. Le
synthétiseur XST est utilisé comme un simple traducteur VHDL-NGC.
La description VHDL tp1.vhd n’utilise pas de bibliothèque propriétaire et elle est beaucoup
plus générale. Le rôle du synthétiseur est ici de comprendre et d’interpréter cette description
plus abstraite du compteur afin de générer un fichier NGC compréhensible par les outils
d’implémentation, c’est-à-dire une netlist NGC composée de primitives simples.
153
A par cette différence importante sur le rôle du synthétiseur, le flot de conception est
identique :
écriture en VHDL ou
saisie du schéma
Ecriture des stimuli
Simulation fonctionnelle
Synthèse
Placement-routage
Simulation de timing
Configuration
Le déroulement de ce TP est identique au précédent. Reportez-vous au texte de tp1 pour
poursuivre tp1v.
5.12 Fichier de contraintes
# fichier de contrainte utilisateur pour TP1
#
# specification des broches d'entrees
NET "Clock" LOC = "F15";
NET "Clock" PULLDOWN;
NET "Reset" LOC = "L14";
#
# specification des broches de sorties
NET "Data<0>" LOC = "K12";
NET "Data<1>" LOC = "P14";
NET "Data<2>" LOC = "L12";
NET "Data<3>" LOC = "N14";
NET "Data<4>" LOC = "P13";
NET "Data<5>" LOC = "N12";

154
NET "Data<6>" LOC = "P12";
NET "Data<7>" LOC = "P11";
#
# specification du slew-rate
NET "Data<0>" FAST;
NET "Data<1>" FAST;
NET "Data<2>" FAST;
NET "Data<3>" FAST;
NET "Data<4>" FAST;
NET "Data<5>" FAST;
NET "Data<6>" FAST;
NET "Data<7>" FAST;

155
6. Travail pratique N°2
Nous n’allons passer en revue dans ce texte que les phases qui diffèrent avec TP1. Vous vous
reporterez au texte du premier TP pour le reste des informations. Ce deuxième TP a deux
objectifs :
• la mise en œuvre des Logicore en saisie de schéma, sur un exemple simple : un compteur
BCD avec sortie sur deux afficheurs 7 segments.
• L’écriture du modèle VHDL équivalent (nous verrons que les Logicore n’ont pas à être
utilisés) avec utilisation d’un paquetage (ou package).
6.1 Initialisation du projet
Ouvrez une session « fpga » sur votre ordinateur. Lancez « Project Navigator », fermez
l’ancien projet puis créez un nouveau projet « tp2 » (Top-Level Module Type : Schematic)
dans le répertoire « c:\users\fpga ».
6.2 Création des Logicore
Premièrement, nous souhaitons créer un bloc mémoire morte (16 x 8 bits) qui assure la
conversion BCD–7 segments afin de commander un afficheur 7 segments à partir d’un
compteur BCD. Le segment s’allume quand le signal qui le commande est au niveau bas
(voir : documentation maquette). Le tableau suivant nous donne le contenu de la mémoire :
g
d
a B7S
e A[3:0] D[6:0]
b
c
f
dp
D[7:0]
A[3:0] dp
g f e d c b a
0 0 1 0 0 0 0 0 0
1 0 1 1 1 1 0 0 1
2 0 0 1 0 0 1 0 0
3 0 0 1 1 0 0 0 0
4 0 0 0 1 1 0 0 1
5 0 0 0 1 0 0 1 0
6 0 0 0 0 0 0 1 0
7 0 1 1 1 1 0 0 0
8 0 0 0 0 0 0 0 0
9 0 0 0 1 0 0 0 0

156
Pour créer un Logicore, cliquez avec le bouton droit de la souris dans la fenêtre Sources puis
cliquez sur « New Source… » :
Dans la fenêtre qui apparaît, sélectionnez le type « IP », tapez le nom de fichier b7s puis
cliquez sur « Suivant » :
Dans la fenêtre de sélection du type de composant paramétrable, double-cliquez sur
« Memories » puis sur « RAMs & ROMs » et enfin sélectionnez « Distributed Memory ».
Cliquez sur « Suivant » :
157
Cliquez sur « Terminer » dans la fenêtre d’information :
Après un long moment (au moins 30 s !!! C’est normal, c’est du Java : c’est le progrès), la
fenêtre Logicore « Distributed Memory » apparaît à l’écran.
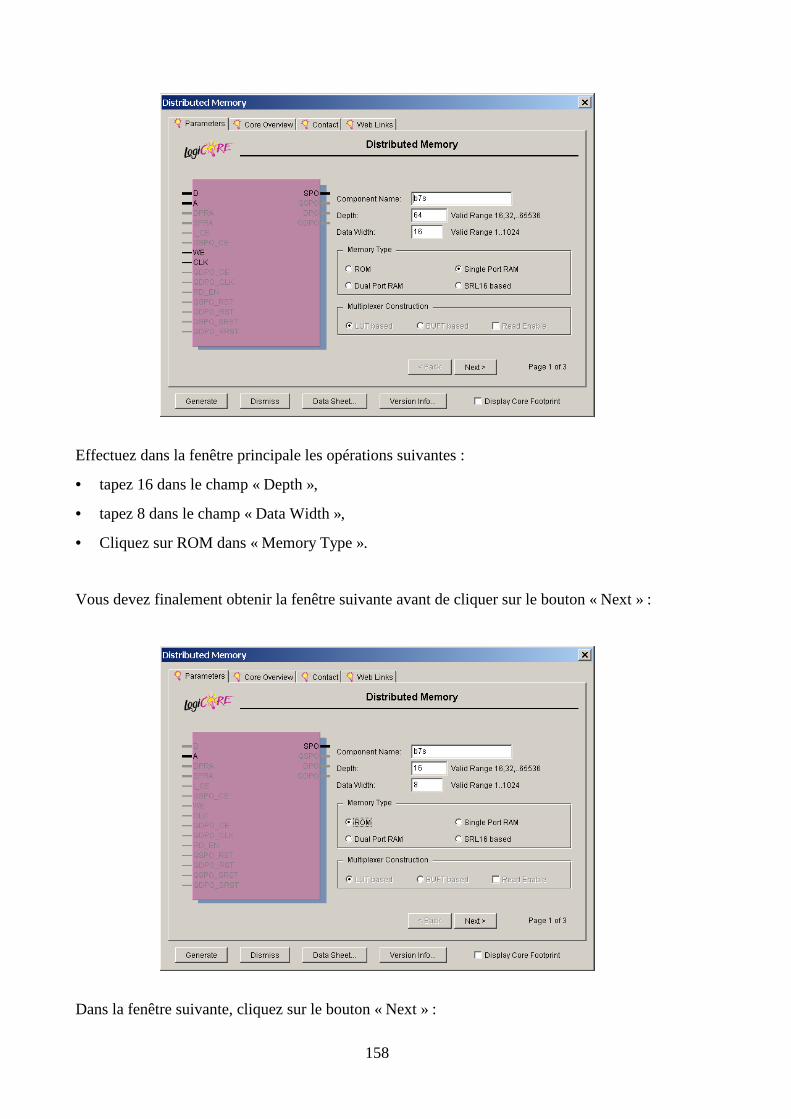
158
Effectuez dans la fenêtre principale les opérations suivantes :
• tapez 16 dans le champ « Depth »,
• tapez 8 dans le champ « Data Width »,
• Cliquez sur ROM dans « Memory Type ».
Vous devez finalement obtenir la fenêtre suivante avant de cliquer sur le bouton « Next » :
Dans la fenêtre suivante, cliquez sur le bouton « Next » :
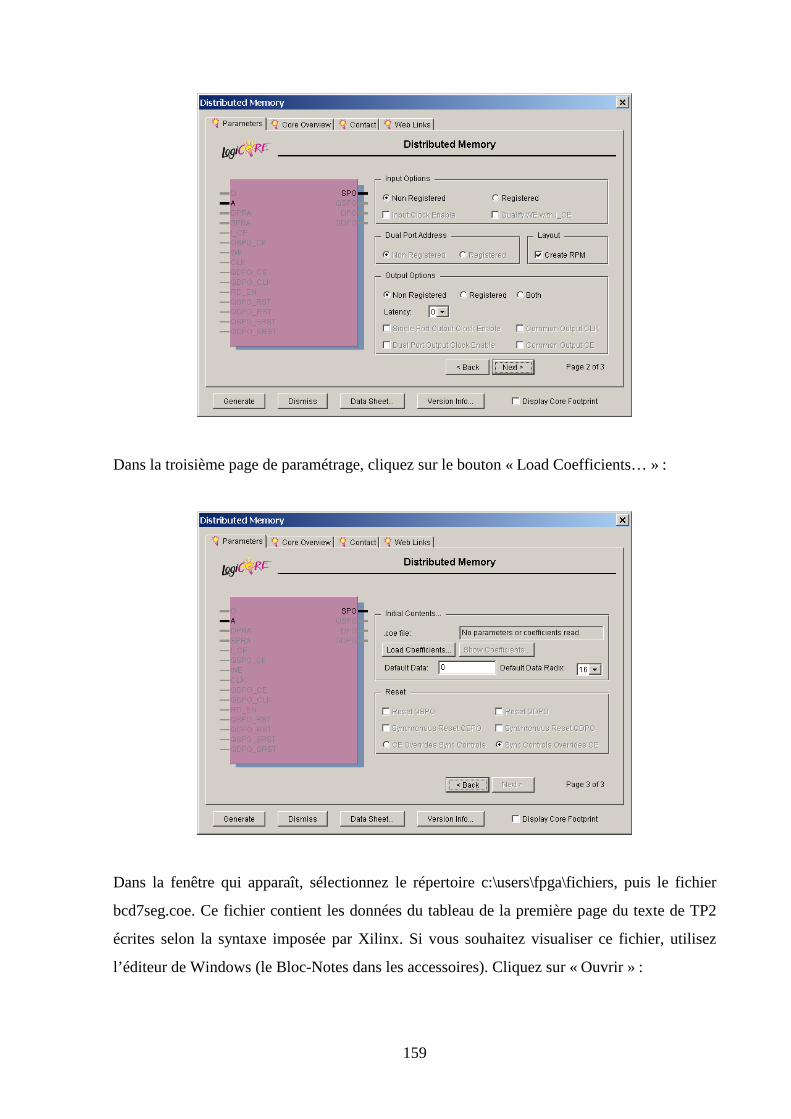
159
Dans la troisième page de paramétrage, cliquez sur le bouton « Load Coefficients… » :
Dans la fenêtre qui apparaît, sélectionnez le répertoire c:\users\fpga\fichiers, puis le fichier
bcd7seg.coe. Ce fichier contient les données du tableau de la première page du texte de TP2
écrites selon la syntaxe imposée par Xilinx. Si vous souhaitez visualiser ce fichier, utilisez
l’éditeur de Windows (le Bloc-Notes dans les accessoires). Cliquez sur « Ouvrir » :

160
Vous devez obtenir la fenêtre suivante avant de cliquer sur le bouton « Generate » :
La fenêtre Logicore se ferme. Après un moment (assez long, c’est toujours du Java), l’IP
apparaît dans le navigateur de projet :
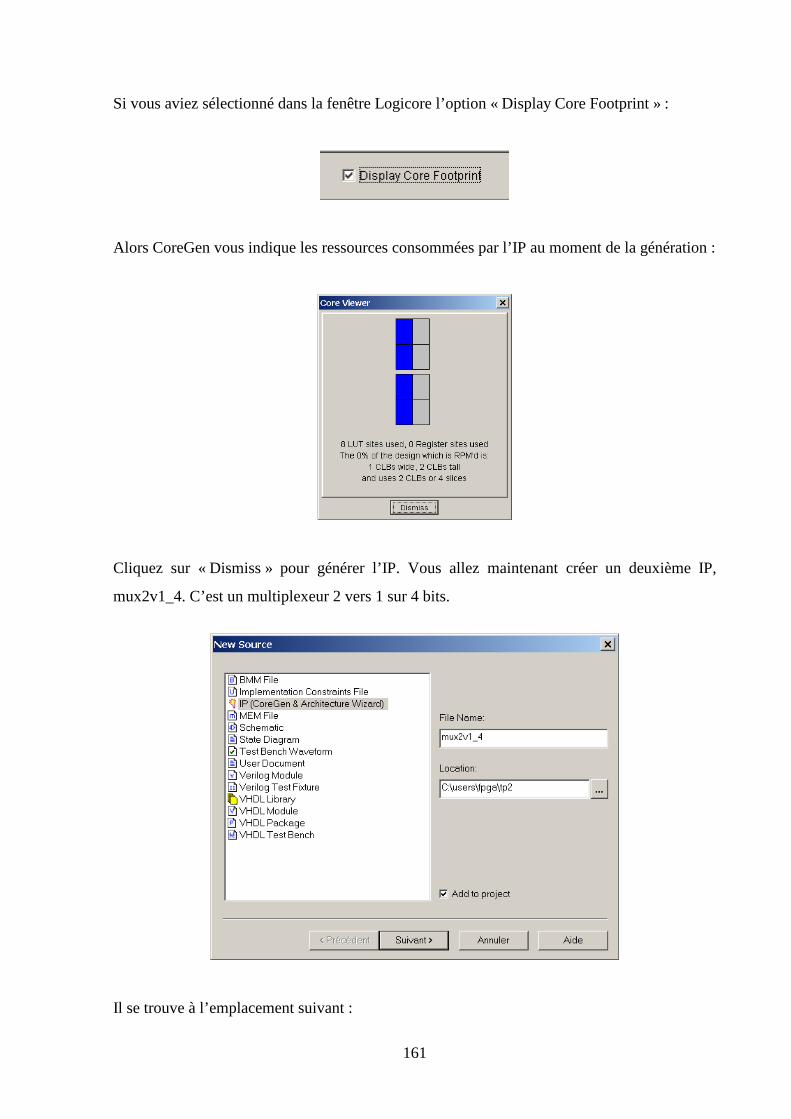
161
Si vous aviez sélectionné dans la fenêtre Logicore l’option « Display Core Footprint » :
Alors CoreGen vous indique les ressources consommées par l’IP au moment de la génération :
Cliquez sur « Dismiss » pour générer l’IP. Vous allez maintenant créer un deuxième IP,
mux2v1_4. C’est un multiplexeur 2 vers 1 sur 4 bits.
Il se trouve à l’emplacement suivant :
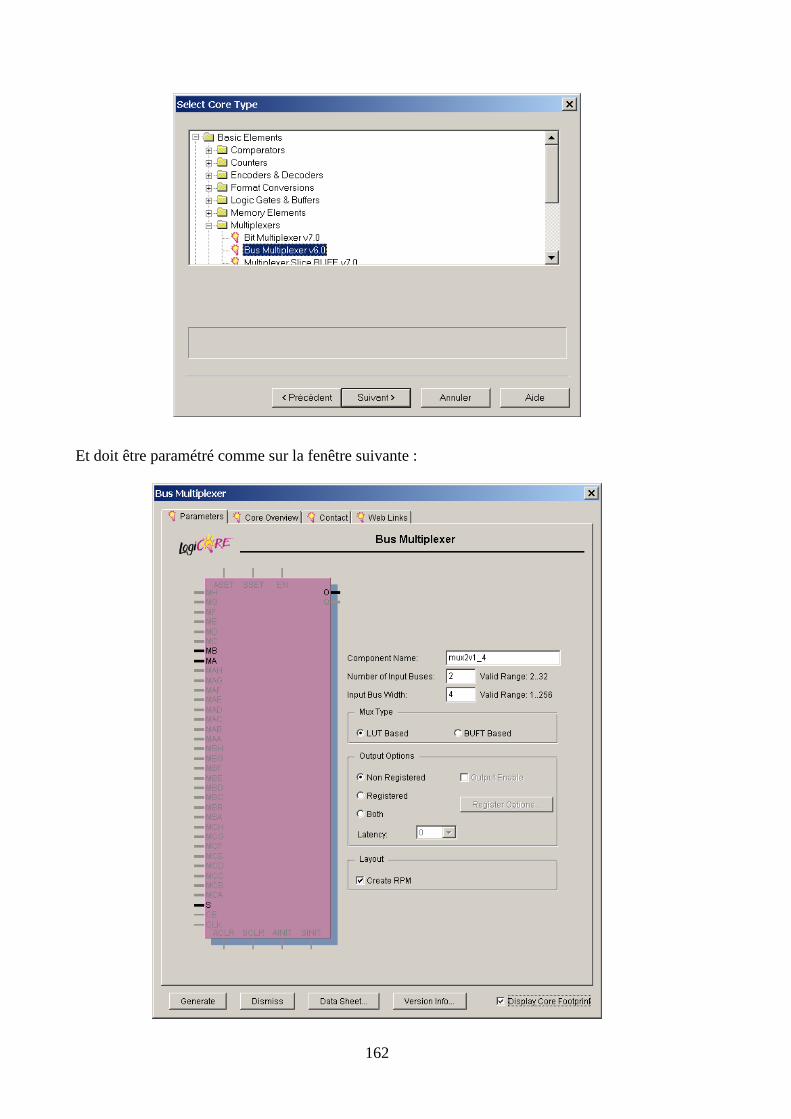
162
Et doit être paramétré comme sur la fenêtre suivante :
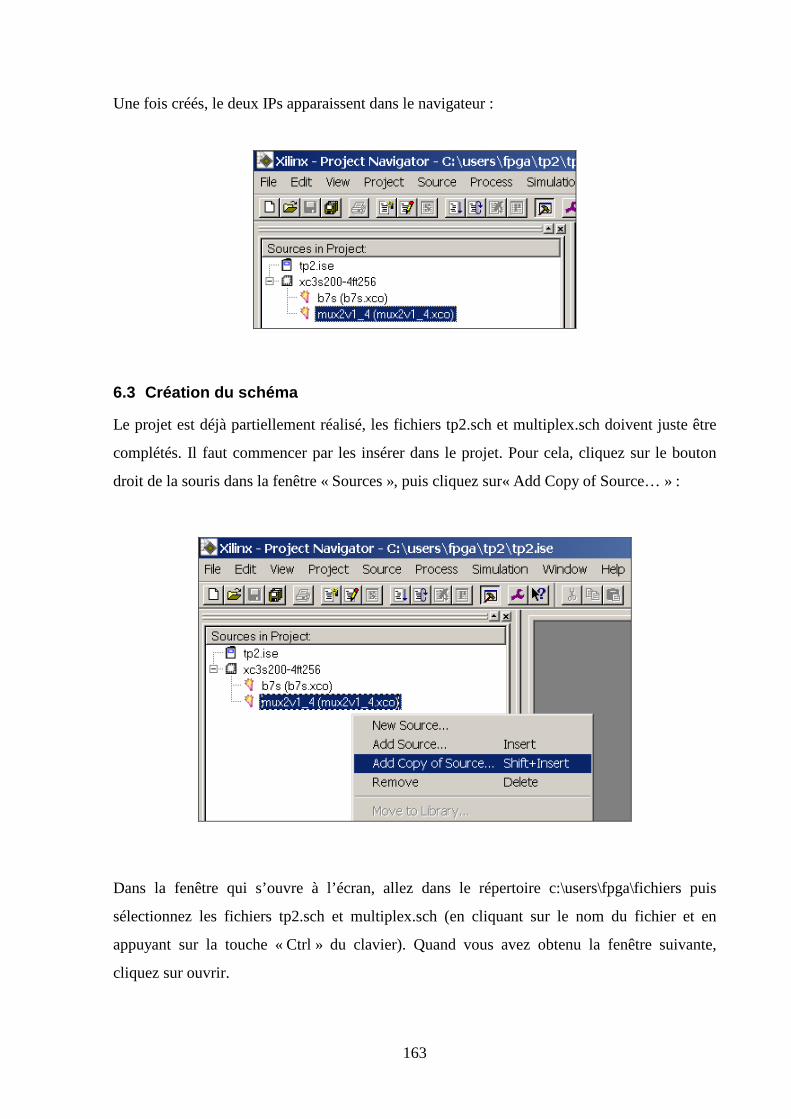
163
Une fois créés, le deux IPs apparaissent dans le navigateur :
6.3 Création du schéma
Le projet est déjà partiellement réalisé, les fichiers tp2.sch et multiplex.sch doivent juste être
complétés. Il faut commencer par les insérer dans le projet. Pour cela, cliquez sur le bouton
droit de la souris dans la fenêtre « Sources », puis cliquez sur« Add Copy of Source… » :
Dans la fenêtre qui s’ouvre à l’écran, allez dans le répertoire c:\users\fpga\fichiers puis
sélectionnez les fichiers tp2.sch et multiplex.sch (en cliquant sur le nom du fichier et en
appuyant sur la touche « Ctrl » du clavier). Quand vous avez obtenu la fenêtre suivante,
cliquez sur ouvrir.
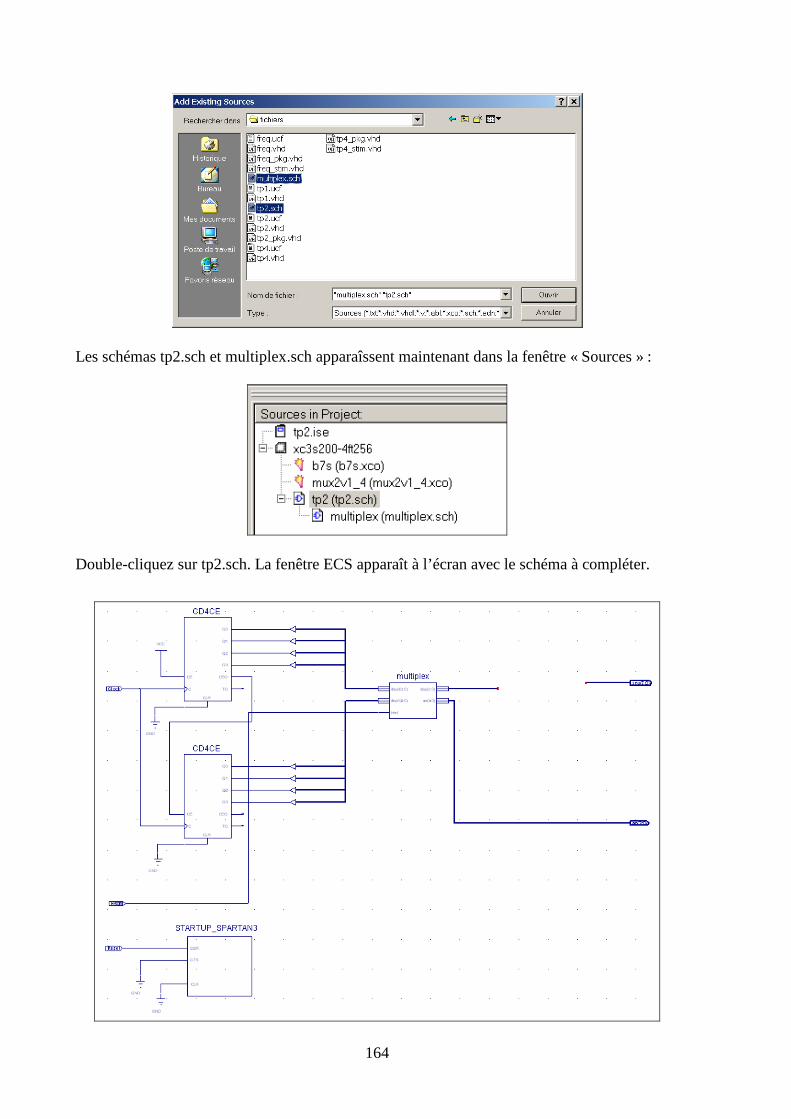
164
Les schémas tp2.sch et multiplex.sch apparaîssent maintenant dans la fenêtre « Sources » :
Double-cliquez sur tp2.sch. La fenêtre ECS apparaît à l’écran avec le schéma à compléter.
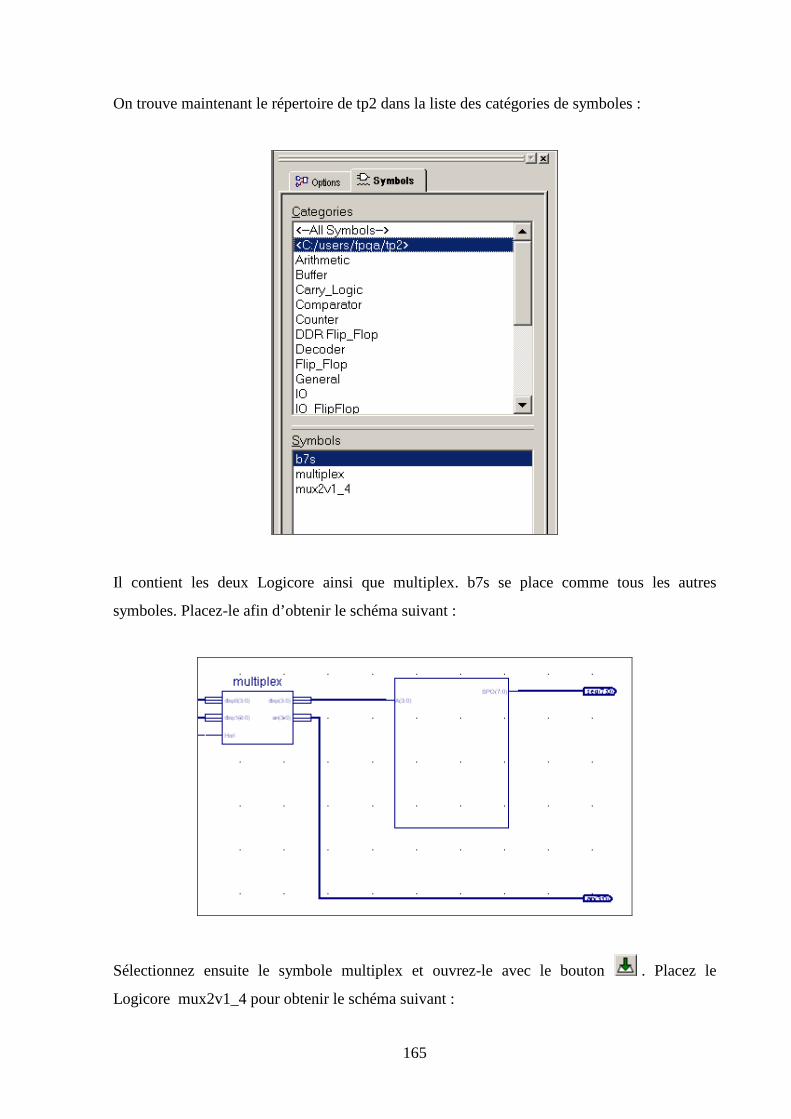
165
On trouve maintenant le répertoire de tp2 dans la liste des catégories de symboles :
Il contient les deux Logicore ainsi que multiplex. b7s se place comme tous les autres
symboles. Placez-le afin d’obtenir le schéma suivant :
Sélectionnez ensuite le symbole multiplex et ouvrez-le avec le bouton . Placez le
Logicore mux2v1_4 pour obtenir le schéma suivant :

166
Sauvez les deux schémas, puis fermez ECS.
6.4 La suite du TP
A ce point du TP, vous devez voir dans la fenêtre « Sources » du navigateur de projet :
Passons maintenant à la génération du fichier de stimuli VHDL.

167
Le fichier de stimuli doit être associé au top level design tp2 :
Clock est l’horloge principale de notre design. On va lui affecter une fréquence égale à 10
MHz, avec un temps mort au démarrage de 100 ns. La durée de simulation égale à 2000 ns.
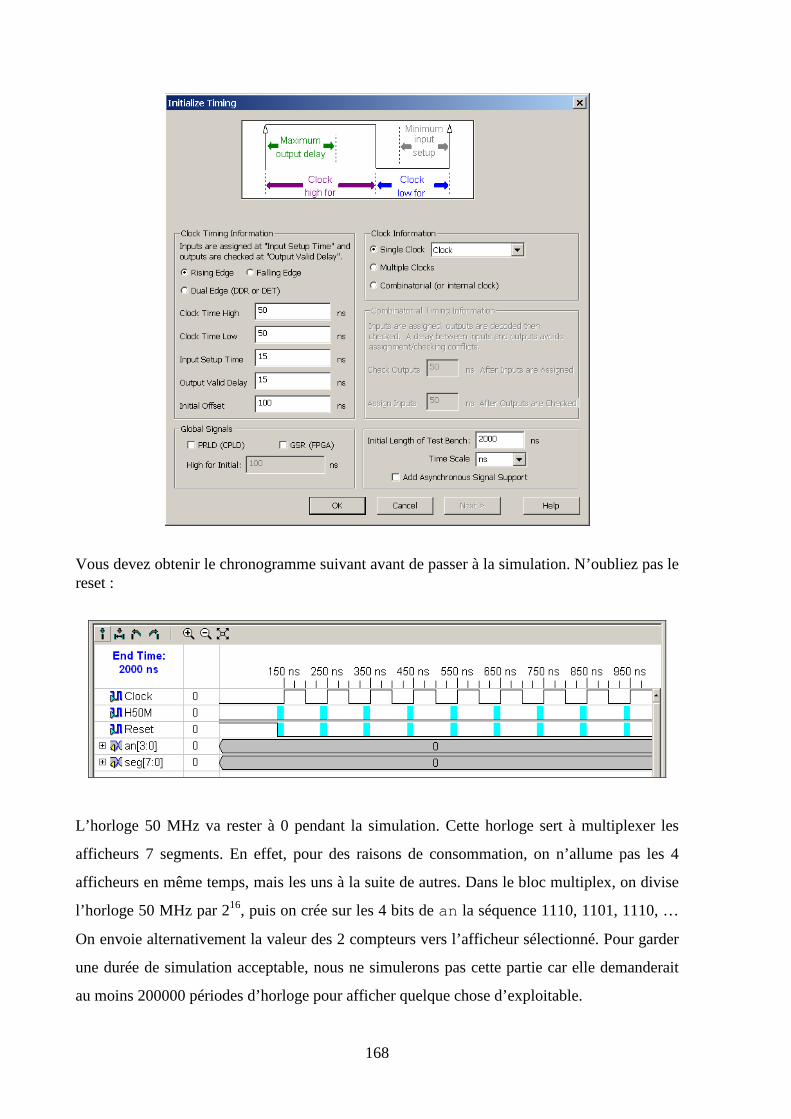
168
Vous devez obtenir le chronogramme suivant avant de passer à la simulation. N’oubliez pas le reset :
L’horloge 50 MHz va rester à 0 pendant la simulation. Cette horloge sert à multiplexer les
afficheurs 7 segments. En effet, pour des raisons de consommation, on n’allume pas les 4
afficheurs en même temps, mais les uns à la suite de autres. Dans le bloc multiplex, on divise
l’horloge 50 MHz par 216, puis on crée sur les 4 bits de an la séquence 1110, 1101, 1110, …
On envoie alternativement la valeur des 2 compteurs vers l’afficheur sélectionné. Pour garder
une durée de simulation acceptable, nous ne simulerons pas cette partie car elle demanderait
au moins 200000 périodes d’horloge pour afficher quelque chose d’exploitable.

169
Le reste du TP est similaire à TP1 avec les étapes :
• Simulation fonctionnelle.
• Synthèse.
• Placement-routage. Le fichier de contrainte s’appelle tp2.ucf.
• Simulation de timing.
• Configuration de la maquette et test.
6.5 Ecriture du modèle en VHDL
Nous allons maintenant refaire le même TP avec un design écrit en langage VHDL. Pour cela,
fermez le projet TP2 (menu « File », « Close Project ») puis créez en un nouveau appelé
TP2V (Top-Level Module Type : HDL). Le projet doit comporter 2 fichiers : le top level
design (tp2.vhd) et un paquetage contenant les composants nécessaires à son fonctionnement
(tp2_pkg.vhd). Ces deux fichiers sont déjà partiellement écris et se trouvent dans
c:\users\fpga\fichiers. Pour les insérer dans le projet TP2V, cliquez sur « Project », « Add
Copy of Source ». Sélectionnez les 2 fichiers (cliquez sur le nom du premier, appuyez sur la
touche Ctrl du clavier et cliquez sur le nom du deuxième) puis cliquez sur ouvrir :
La première fenêtre qui s’ouvre demande quel est le type du fichier tp2_pkg.vhd. Comme il
s’agit d’un fichier de design, sélectionnez « VHDL Design File », puis cliquez sur OK :
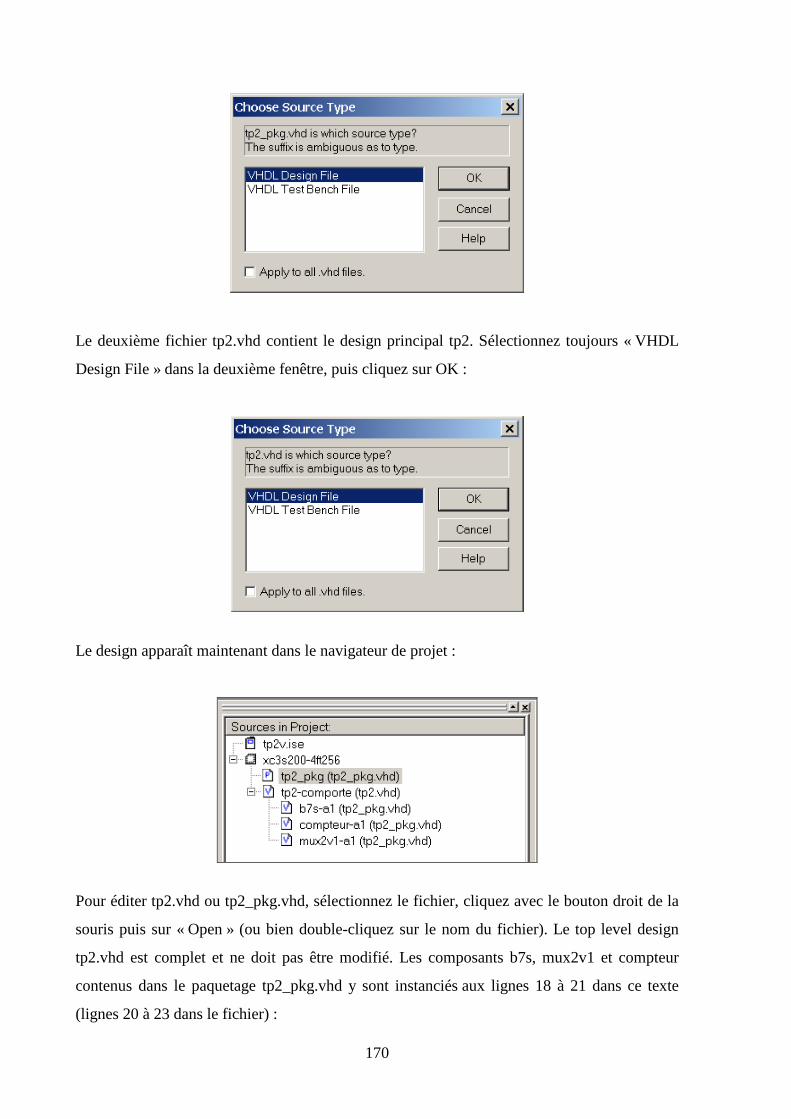
170
Le deuxième fichier tp2.vhd contient le design principal tp2. Sélectionnez toujours « VHDL
Design File » dans la deuxième fenêtre, puis cliquez sur OK :
Le design apparaît maintenant dans le navigateur de projet :
Pour éditer tp2.vhd ou tp2_pkg.vhd, sélectionnez le fichier, cliquez avec le bouton droit de la
souris puis sur « Open » (ou bien double-cliquez sur le nom du fichier). Le top level design
tp2.vhd est complet et ne doit pas être modifié. Les composants b7s, mux2v1 et compteur
contenus dans le paquetage tp2_pkg.vhd y sont instanciés aux lignes 18 à 21 dans ce texte
(lignes 20 à 23 dans le fichier) :

171
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. use work.tp2_pkg.all; 4. entity tp2 is 5. port( 6. Clock : in std_logic; 7. H50M : in std_logic; 8. Reset : in std_logic; 9. an : out std_logic_vector(3 downto 0); 10. seg : out std_logic_vector(7 downto 0)); 11. end tp2; 12. architecture comporte of tp2 is 13. signal dizaine : std_logic_vector(3 downto 0); 14. signal unite : std_logic_vector(3 downto 0); 15. signal chiffre : std_logic_vector(3 downto 0); 16. signal ceo : std_logic; 17. begin 18. cd4d : compteur generic map(4,10) port map(Clock, ceo, Reset, open,
dizaine); 19. cd4u : compteur generic map(4,10) port map(Clock, ’1’, Reset, ceo,
unite); 20. b7seg : b7s port map(chiffre, seg); 21. mux : mux2v1 port map(H50M, Reset, unite, dizaine , chiffre, an); 22. end comporte ;
Il vous reste à compléter dans tp2_pkg.vhd les architectures des composants b7s et compteur
(lignes 38 et 49 dans ce texte, lignes 46 et 60 dans le fichier) en vous inspirant des exemples
donnés au §4.2 du polycopié de cours. Pour cet exemple assez simple, vous allez mettre au
point votre design de la manière suivante :
1. Complétez le fichier tp2_pkg.vhd.
2. Simulez le design en fonctionnel (après avoir généré le fichier de stimuli associé à tp2).
3. En cas de différences de simulation avec tp2 (saisie de schéma), modifiez les architectures
des deux composants b7s et compteur.
4. C’est seulement lorsque la simulation fonctionnelle est correcte que vous poursuivez le
TP.
Pour un design plus important, on ne peut plus procéder de cette manière. Il faut synthétiser
après chaque développement de composant, implémenter le morceau de design puis faire une
simulation de timing pour vérifier que tout fonctionne bien. Il ne faut pas développer
l’ensemble du design en fonctionnel et synthétiser seulement à la fin sinon vous vous
exposez à un véritable désastre au moment de l’implémentation du design.

172
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. package tp2_pkg is 4. COMPONENT compteur 5. generic (WDTH : integer :=4; STOP : integer :=1 0); 6. port( CLK : in std_logic ; 7. CE : in std_logic ; 8. CLEAR : in std_logic; 9. CEO : out std_logic; 10. DOUT : out std_logic_vector(WDTH -1 dow nto 0)); 11. END COMPONENT; 12. COMPONENT b7s 13. port (addr : in std_logic_vector(3 downto 0) ; 14. dout : out std_logic_vector(7 downto 0 )); 15. END COMPONENT; 16. COMPONENT mux2v1 17. port( H50M : in std_logic ; 18. CLEAR : in std_logic; 19. unite : in std_logic_vector(3 downto 0) ; 20. dizaine : in std_logic_vector(3 downto 0) ; 21. chiffre : out std_logic_vector(3 downto 0 ); 22. an : out std_logic_vector(3 downto 0 )); 23. END COMPONENT; 24.end tp2_pkg; 25.library IEEE; 26.use IEEE.std_logic_1164.all; 27.use IEEE.std_logic_arith.all; 28.use IEEE.STD_LOGIC_UNSIGNED.all; 29.entity compteur is 30. generic (WDTH : integer :=4; STOP : integer := 10); 31. port( CLK : in std_logic ; 32. CE : in std_logic ; 33. CLEAR : in std_logic; 34. CEO : out std_logic; 35. DOUT : out std_logic_vector(WDTH -1 downt o 0)); 36.end compteur; 37.architecture a1 of compteur is 38.--complétez l'architecture 39.end; 40.library IEEE; 41.use IEEE.std_logic_1164.all; 42.use IEEE.std_logic_arith.all; 43.use IEEE.std_logic_unsigned.all; 44.entity b7s is 45. port (addr : in std_logic_vector(3 downto 0); 46. dout : out std_logic_vector(7 downto 0)); 47.end b7s; 48.architecture a1 of b7s is 49.--complétez l'architecture 50.end; 51.library IEEE; 52.use IEEE.std_logic_1164.all; 53.use IEEE.std_logic_arith.all; 54.use IEEE.STD_LOGIC_UNSIGNED.all;
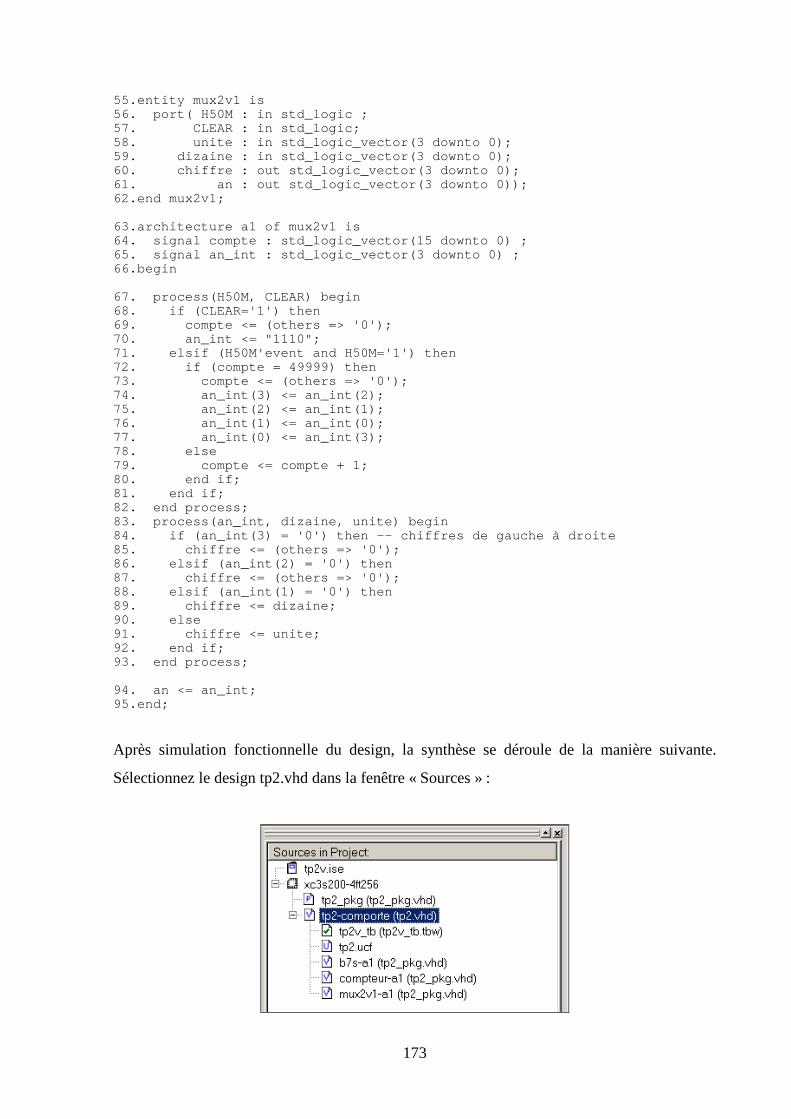
173
55.entity mux2v1 is 56. port( H50M : in std_logic ; 57. CLEAR : in std_logic; 58. unite : in std_logic_vector(3 downto 0); 59. dizaine : in std_logic_vector(3 downto 0); 60. chiffre : out std_logic_vector(3 downto 0); 61. an : out std_logic_vector(3 downto 0)) ; 62.end mux2v1; 63.architecture a1 of mux2v1 is 64. signal compte : std_logic_vector(15 downto 0) ; 65. signal an_int : std_logic_vector(3 downto 0) ; 66.begin 67. process(H50M, CLEAR) begin 68. if (CLEAR='1') then 69. compte <= (others => '0'); 70. an_int <= "1110"; 71. elsif (H50M'event and H50M='1') then 72. if (compte = 49999) then 73. compte <= (others => '0'); 74. an_int(3) <= an_int(2); 75. an_int(2) <= an_int(1); 76. an_int(1) <= an_int(0); 77. an_int(0) <= an_int(3); 78. else 79. compte <= compte + 1; 80. end if; 81. end if; 82. end process; 83. process(an_int, dizaine, unite) begin 84. if (an_int(3) = '0') then -- chiffres de gau che à droite 85. chiffre <= (others => '0'); 86. elsif (an_int(2) = '0') then 87. chiffre <= (others => '0'); 88. elsif (an_int(1) = '0') then 89. chiffre <= dizaine; 90. else 91. chiffre <= unite; 92. end if; 93. end process; 94. an <= an_int; 95.end;
Après simulation fonctionnelle du design, la synthèse se déroule de la manière suivante.
Sélectionnez le design tp2.vhd dans la fenêtre « Sources » :

174
puis faites apparaître les sous-menus de « Synthesize » dans la fenêtre « Processes ».
Cliquez avec le bouton droit de la souris sur « Synthesize » puis cliquez sur « Run… » :
Après un moment, la synthèse s’achève. Vous pouvez voir un point d’exclamation jaune à
coté du nom du processus. Cela indique la présence d’un warning pendant la synthèse :

175
Le rapport dans la fenêtre « Console » vous indique, pour chaque composant du package, les
éléments utilisés (compteurs, registres,…) ainsi que le nombre et le type d’éléments de
mémorisation utilisés (ici, des bascules D ou flip-flop). Cette fenêtre est capitale pour
comprendre ce que vous avez fait dans le modèle VHDL. Il faut que vous prévoyiez les
éléments utilisés dans le modèle et que vous vérifiez votre prévision dans cette fenêtre. Le
principal danger quand on écrit un design en VHDL est de commencer à penser logiciel
au lieu de penser matériel.
Le rapport de synthèse vous indique aussi globalement les ressources logiques utilisées :
ainsi que l’utilisation des ressources du FPGA :

176
Vous pouvez voir aussi que le design utilise deux entrées d’horloge globale (GCLK) du FPGA
(pour les signaux Clock et H50M) et que le synthétiseur a inséré deux buffers d’horloge
(BUFGP) sur ces entrées :
Le rapport de synthèse complet est accessible à tout moment en lançant :
Ce rapport est à consulter en priorité en cas de mauvais fonctionnement du design en
simulation de timing ou dans la maquette.
A la fin de la synthèse, XST a créé une netlist NGC à destination des outils d’implémentation.
Le reste du TP s’effectue comme dans TP2 (n’oubliez pas le fichier de contrainte
c:\users\fpga\fichiers\tp2.ucf).
6.6 Fichier de contraintes
# fichier de contrainte utilisateur pour TP2
#
# specification des broches d'entrees
NET "Clock" LOC = "F15";
NET "Clock" PULLDOWN;
NET "H50M" LOC = "T9";
NET "Reset" LOC = "L14";

177
#
# specification des broches de sorties
NET "seg<0>" LOC = "e14";
NET "seg<1>" LOC = "g13";
NET "seg<2>" LOC = "n15";
NET "seg<3>" LOC = "p15";
NET "seg<4>" LOC = "r16";
NET "seg<5>" LOC = "f13";
NET "seg<6>" LOC = "n16";
NET "seg<7>" LOC = "p16";
NET "an<0>" LOC = "d14";
NET "an<1>" LOC = "g14";
NET "an<2>" LOC = "f14";
NET "an<3>" LOC = "e13";

178

179
7. Travail pratique N°3
Ce troisième TP a pour but de vous exposer 6 aspects importants de l’implémentation d’un
FPGA :
1. L’éditeur de FPGA et le Floorplanner,
2. Les rapports après implémentation,
3. L’analyse de timing,
4. Les contraintes,
5. La vérification de la programmation du FPGA,
6. La programmation de la mémoire Flash série,
7. L’accès à l’information.
Nous allons pour cela utiliser les fichiers générés dans les deux premiers TP.
7.1 L’éditeur de FPGA et le floorplanner
Nous allons voir quelques fonctionnalités de l’application FPGA Editor en analysant le projet
TP1. Cet éditeur possède de nombreuses fonctions très puissantes (notamment en ce qui
concerne le placement–routage manuel), mais il vaut mieux être expérimenté pour les utiliser.
Nous allons nous contenter dans ce paragraphe de visualiser l’intérieur du FPGA dans un but
pédagogique. Ouvrez le projet TP1, sélectionnez tp1.sch dans la fenêtre « Sources… » puis
lancez FPGA Editor.
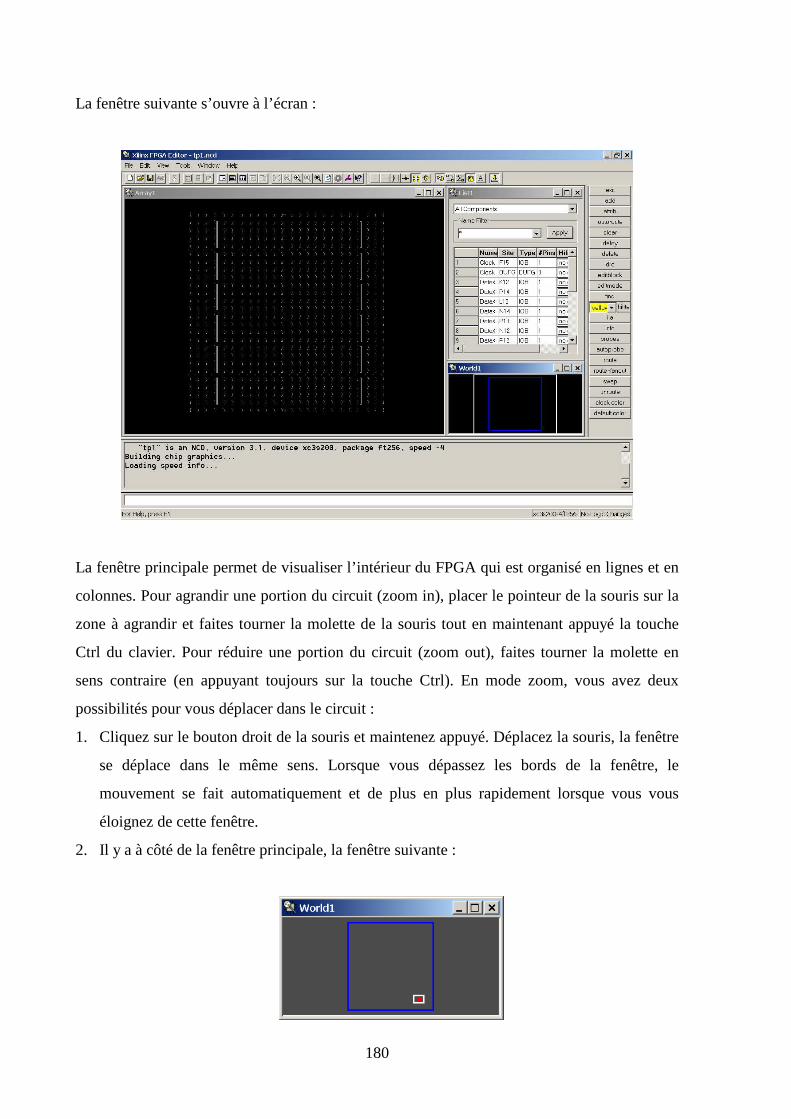
180
La fenêtre suivante s’ouvre à l’écran :
La fenêtre principale permet de visualiser l’intérieur du FPGA qui est organisé en lignes et en
colonnes. Pour agrandir une portion du circuit (zoom in), placer le pointeur de la souris sur la
zone à agrandir et faites tourner la molette de la souris tout en maintenant appuyé la touche
Ctrl du clavier. Pour réduire une portion du circuit (zoom out), faites tourner la molette en
sens contraire (en appuyant toujours sur la touche Ctrl). En mode zoom, vous avez deux
possibilités pour vous déplacer dans le circuit :
1. Cliquez sur le bouton droit de la souris et maintenez appuyé. Déplacez la souris, la fenêtre
se déplace dans le même sens. Lorsque vous dépassez les bords de la fenêtre, le
mouvement se fait automatiquement et de plus en plus rapidement lorsque vous vous
éloignez de cette fenêtre.
2. Il y a à côté de la fenêtre principale, la fenêtre suivante :

181
Le grand carré bleu représente l’ensemble du circuit alors que le petit carré blanc se
trouvant à l’intérieur représente la zone agrandie. Placez le pointeur de la souris sur le
petit carré, cliquez sur le bouton droit de la souris et maintenez appuyé. Déplacez
maintenant la souris, le petit carré se déplace de la même manière sur une nouvelle zone
du FPGA. Quand vous relâchez le bouton droit de la souris, cette zone apparaît dans la
fenêtre principale.
Au démarrage de l’éditeur, le FPGA semble vide. En fait, le design est tellement petit qu’il
n’apparaît pas à l’écran. Il faut agrandir suffisamment pour voir les éléments internes du
FPGA, puis sélectionner un slice du design dans la fenêtre :
Le slice apparaît en rouge dans la fenêtre :
Déplacez le carré blanc pour faire apparaître le slice dans la fenêtre principale :
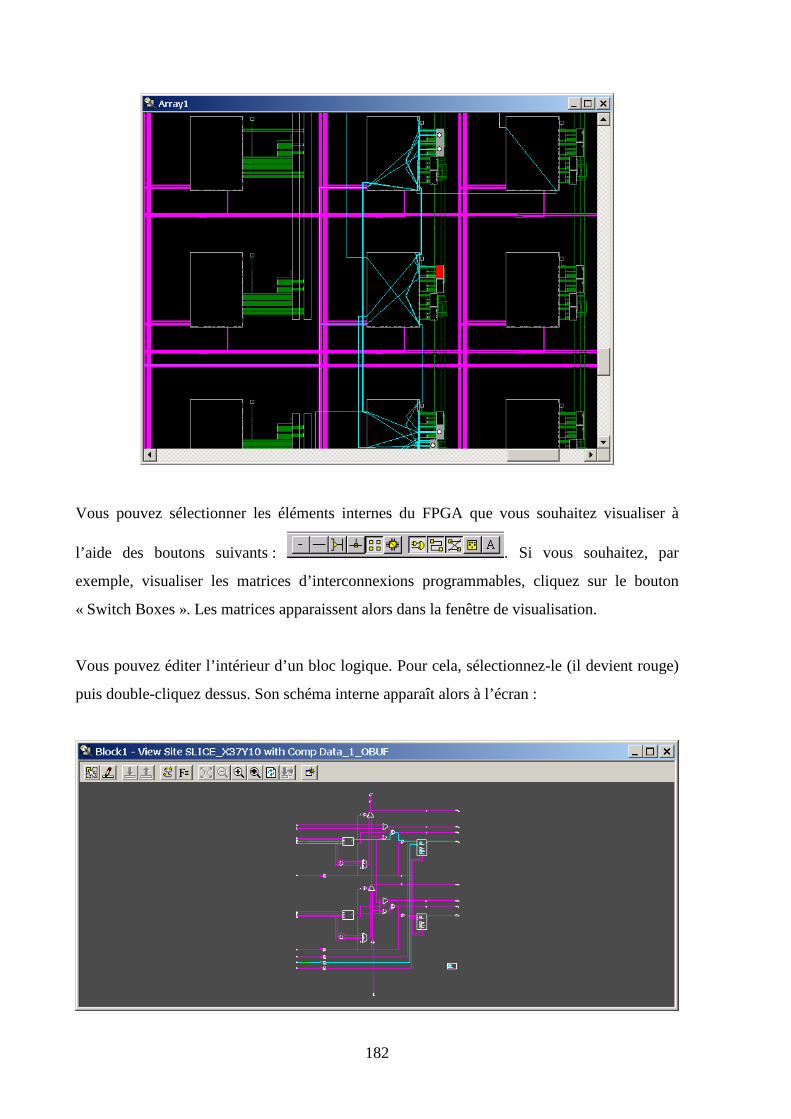
182
Vous pouvez sélectionner les éléments internes du FPGA que vous souhaitez visualiser à
l’aide des boutons suivants : . Si vous souhaitez, par
exemple, visualiser les matrices d’interconnexions programmables, cliquez sur le bouton
« Switch Boxes ». Les matrices apparaissent alors dans la fenêtre de visualisation.
Vous pouvez éditer l’intérieur d’un bloc logique. Pour cela, sélectionnez-le (il devient rouge)
puis double-cliquez dessus. Son schéma interne apparaît alors à l’écran :
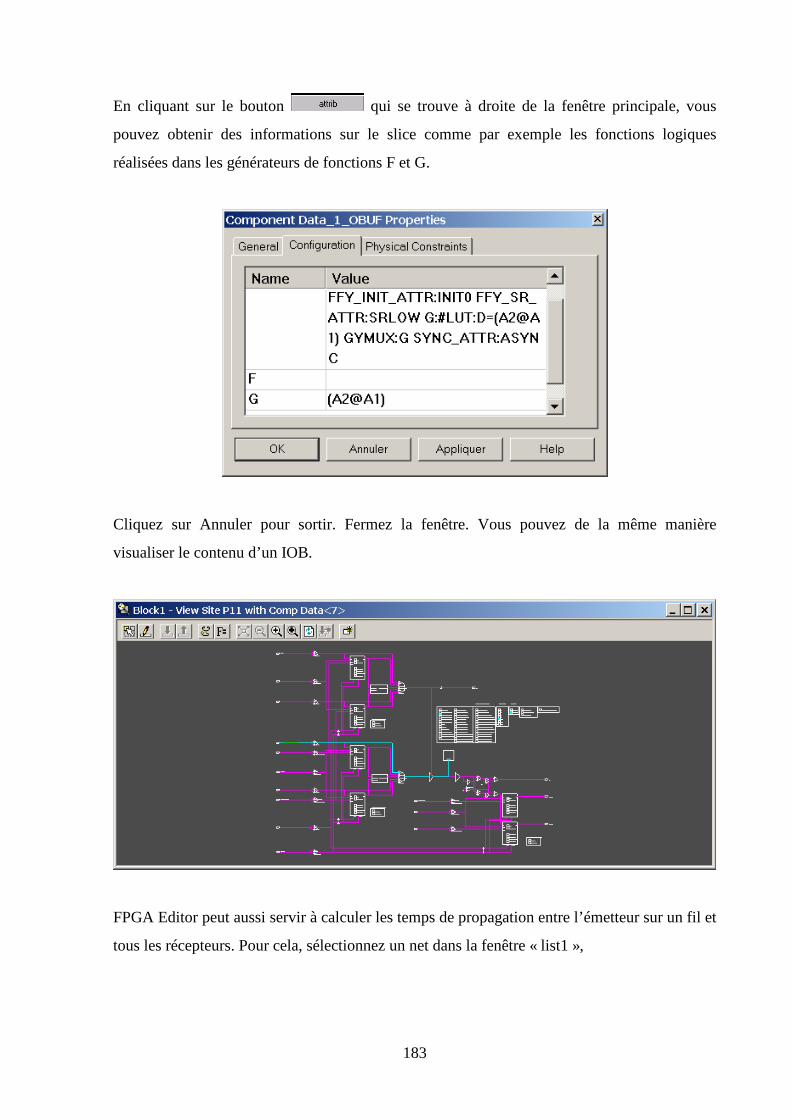
183
En cliquant sur le bouton qui se trouve à droite de la fenêtre principale, vous
pouvez obtenir des informations sur le slice comme par exemple les fonctions logiques
réalisées dans les générateurs de fonctions F et G.
Cliquez sur Annuler pour sortir. Fermez la fenêtre. Vous pouvez de la même manière
visualiser le contenu d’un IOB.
FPGA Editor peut aussi servir à calculer les temps de propagation entre l’émetteur sur un fil et
tous les récepteurs. Pour cela, sélectionnez un net dans la fenêtre « list1 »,

184
puis cliquez sur le bouton . Vous obtenez alors, dans la fenêtre de dialogue se
trouvant sous la fenêtre principale de visualisation :
On voit, sur la ligne driver, une sortie de slice (c’est le driver sur le fil). Les autres lignes (les
récepteurs) correspondent soit à une entrée de slice, soit à une broche de sortie du FPGA. Le
temps au début de la ligne correspond au temps de propagation sur le net reliant le slice
Data_0_OBUF sortie YQ et le récepteur considéré. Par exemple, sur la dernière ligne, il y a un
temps de propagation de 0,787 ns entre la sortie YQ du slice Data_0_OBUF et l’entrée G2 du
slice Data_4_OBUF.
Il y a dans FPGA Editor de nombreuses autres fonctionnalités (notamment pour placer la
logique ou pour router un fil à la main), mais elles sortent du cadre de cette étude.

185
Il existe un autre outil permettant de visualiser l’intérieur d’un FPGA d’une manière plus
symbolique : le Floorplanner. Fermez la fenêtre de FPGA Editor, puis lancez l’application :
La fenêtre suivante s’ouvre :

186
Le floorplanner est un outil de plus haut niveau que FPGA Editor dont l’étude, encore une
fois, sort du cadre de ce cours. Son but est d’augmenter la fréquence maximale de
fonctionnement du design en minimisant les délais de routage. Il permet de placer les
fonctions logiques critiques à la main, puis de laisser « Place and Route » finir le placement-
routage. Sélectionnez une partie du design en cliquant en haut à gauche de la zone puis en
tirant le rectangle noir en bas à droite de cette même zone. Cliquez sur le bouton « Zoom to
selected » pour agrandir la zone puis sur pour faire apparaître les éléments internes
des slices. Si vous sélectionnez un élément logique de la fenêtre « Design Hierarchy », les
CLB correspondants apparaissent hachurés. Fermez la fenêtre sans rien sauvegarder.
7.2 Les rapports d’implémentation
Vous pouvez consulter dans le navigateur de projet de nombreux rapports concernant les
différentes phases de l’implémentation. Il faut pour cela regarder toutes les icônes de type
texte ( ) dont le nom se termine par Report dans la fenêtre « Processes for Current
Sources : ». Une marque verte ou encore un ! jaune signale que le rapport concernant le
processus est disponible. Si le rapport n’existe pas, c’est parce que le processus correspondant
n’a pas été exécuté. Pour lire un rapport, double-cliquez sur son nom.

187
Le tableau suivant vous indique la signification de ces rapports :
Etape Rapport Signification
Translate Translation report Création d’un fichier de design unique
Map Map report
Post Map Static timing report
Découpage du design en primitives
Timing sur primitives uniquement (pas de délais de routage)
Place&Route Place & Route report
Pad report
Placement et routage des primitives
Assignation des broches du FPGA
Asynchronous delay report
Post Place&Route static timing report
Timing sur certains nets
Fréquence maximale de fonctionnement, respect des contraintes
Generate Programming File
Programming File Generation report
Génération du fichier de configuration
La fenêtre de résumé, accessible en double-cliquant sur :
vous permet d’accéder plus rapidement aux rapports les plus importants. Dans quelles
conditions les utilise-t-on ? Il y a plusieurs cas possibles :
1. Le flot d’implémentation s’arrête en cours d’exécution sur une erreur. Le dernier rapport
généré contient le message d’erreur (le processus correspondant est signalé avec une
marque rouge). Il doit être consulté pour remédier au problème.

188
2. Le flot d’implémentation s’exécute correctement, mais le design ne fonctionne pas une
fois téléchargé dans la maquette. Les rapports suivants doivent être consultés pour trouver
le problème :
Pad report. Vérifier l’affectation des broches.
Post Place&Route static timing report. Vérifier le respect des contraintes temporelles.
Map report. Ce rapport est très important car il explique la manière dont le mapper a
optimisé le design. Cette phase d’optimisation modifie le design puisqu’elle consiste
en la suppression de la logique jugée inutile pour la réalisation du design. Par
exemple, les sorties CEO et TC du compteur CB8CE dans TP1 ne sont pas utilisées,
donc la logique correspondante peut être supprimée lors de l’implémentation. Le
rapport est séparé en sections. Parmi celles-ci, la section « Removed Logic » peut
s’avérer particulièrement intéressante.
3. Le design fonctionne une fois téléchargé dans la maquette. Seul le «Post Place&Route
static timing report » doit être lu pour vérifier le respect des contraintes temporelles. Il faut
généralement le compléter par une analyse de timing pour être certain du bon
fonctionnement du design dans le pire des cas.
Editez les différents rapports pour les projets TP1 et TP2.
7.3 L’analyse temporelle
L’analyse temporelle permet de calculer les différents temps de propagation à l’intérieur du
FPGA en vue de calculer la fréquence de fonctionnement du design. Pour comprendre le
fonctionnement de l’application « Timing Analyzer », nous allons travailler sur le projet TP1.
Le compteur CB8CE est formé à partir de bascules T (FTCE) constituées d’une bascule D
(FDCE) et d’un ou exclusif :
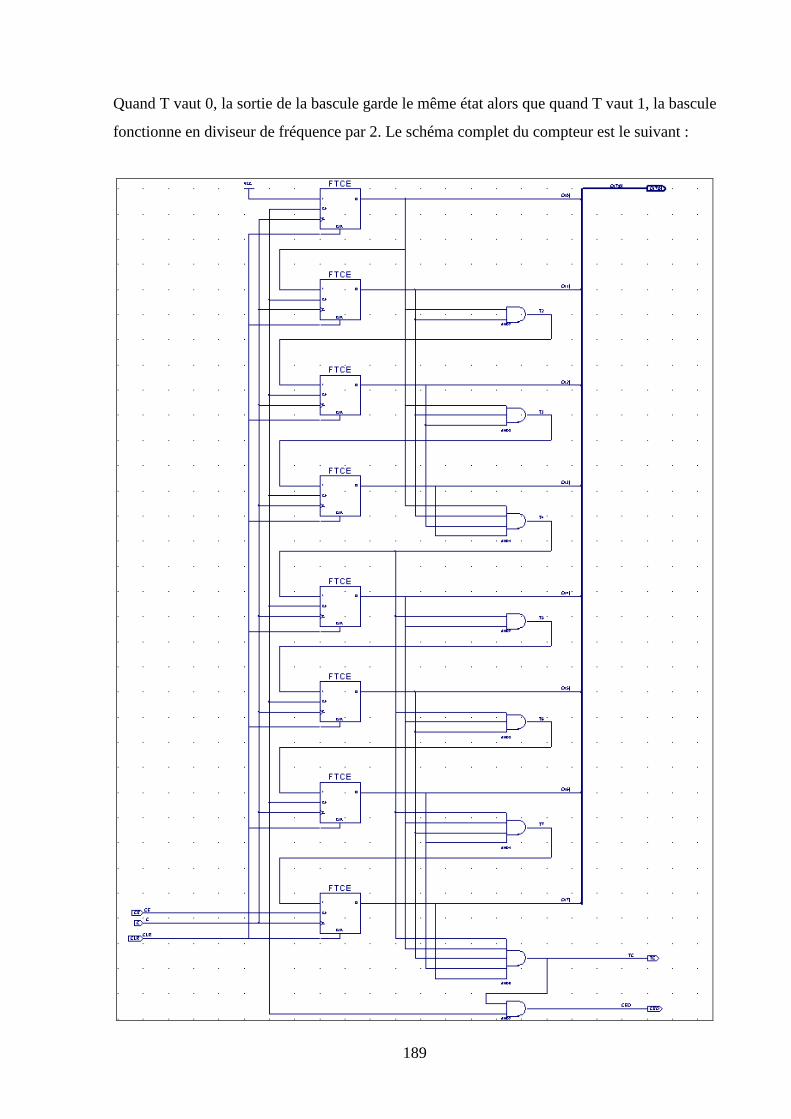
189
Quand T vaut 0, la sortie de la bascule garde le même état alors que quand T vaut 1, la bascule
fonctionne en diviseur de fréquence par 2. Le schéma complet du compteur est le suivant :

190
Pour comprendre une analyse de timing, il faut avoir en mémoire le schéma d’un CLB :

191
ainsi que les timings qui lui sont associés :
L’entrée de la huitième bascule T du compteur est un ET des sorties des 7 bascules de poids
faibles. Ces 7 sorties suivies du ET (constitué de deux AND4 en cascade) puis du fil reliant la
sortie du ET à l’entrée de la bascule constituent le chemin critique, c’est-à-dire le chemin
combinatoire le plus long à l’intérieur du compteur. C’est le temps de propagation sur ce
chemin critique qui détermine la fréquence maximale de fonctionnement du compteur.
Sélectionnez le design tp1.sch dans le navigateur de projet, puis lancez l’application « Timing
Analyzer » :

192
La fenêtre de l’analyseur temporel s’ouvre à l’écran :
193
Commençons d’abord par modifier certains réglages par défaut. Cliquez sur le menu « Edit »
puis sur « Preferences… » :
Dans la fenêtre qui apparaît, cochez toutes les cases avant de cliquer sur le bouton OK.
Analysons maintenant la fréquence maximale de fonctionnement du design. Pour cela, cliquez
sur le menu « Analyze », sur le sous-menu « Against User Specified Paths » puis sur « by
Defining EndPoints… » :

194
Nous allons sélectionner les bascules D (flip-flop) comme source et destination de l’analyse
temporelle à effectuer. Pour cela, sélectionnez Flip-Flops dans « Resources » puis cliquez sur
la flèche dans Sources et Destinations. Vous devez obtenir la fenêtre suivante avant de
cliquer sur OK :

195
Le rapport d’analyse apparaît. En sélectionnant les flip-flops comme source et destination de
l’analyse, nous avons en fait sélectionné l’horloge Clock comme source et comme destination
de l’analyse temporelle puisque dans une bascule D, c’est l’horloge qui sert de référence
unique pour toutes les actions. Nous allons donc mesurer un temps Clock to Setup qui va nous
donner la fréquence maximale de fonctionnement du design. Timing Analyzer a analysé tous
les chemins (il y en a 36) correspondant à la sélection (source, destination) et indique les
timings des 3 chemins les plus critiques classés par ordre décroissant (vous pouvez suivre ce
chemin à l’aide de FPGA Editor).
Nous pouvons vérifier sur le schéma du compteur cette analyse temporelle. La durée minimale
entre deux coups d’horloge de Clock est égale à :
Description Symbole
Valeur [ns]
Clock CLK to outputs YQ
(de Clock vers SLICE_X37Y9.YQ)
TCKO 0,720
Temps de propagation sur un fil
(de SLICE_X37Y9.YQ vers SLICE_X36Y7.G1)
net 0,787

196
Propagation time : F/G inputs to X/Y outputs
(de SLICE_X36Y7.G1 vers SLICE_X36Y7.Y)
TILO 0.608
Temps de propagation sur un fil
(de SLICE_X36Y7.Y vers SLICE_X34Y4.G1)
net 1,025
Propagation time : F/G inputs to X/Y outputs
(de SLICE_X34Y4.G1 vers SLICE_X34Y4.Y)
TILO 0.608
Temps de propagation sur un fil
(de SLICE_X34Y4.Y vers SLICE_X34Y4.F4)
net 0,015
Temps de setup : F/G inputs to CLK
(de SLICE_X34Y4.F4 vers SLICE_X34Y4.CLK)
Tfck 0,69
total 4,453 ns
Tous les temps sont maximums, ce qui implique une fréquence de fonctionnement d’environ
224 MHz dans le pire des cas.
Nous allons maintenant travailler sur un phénomène qui a été vu lors de la simulation de
timing sur TP1. Nous avions vu un écart temporel entre l’arrivée de la donnée sur Data<0> et
l’arrivée de la donnée sur Data<1>. La fenêtre des chronogrammes était la suivante :
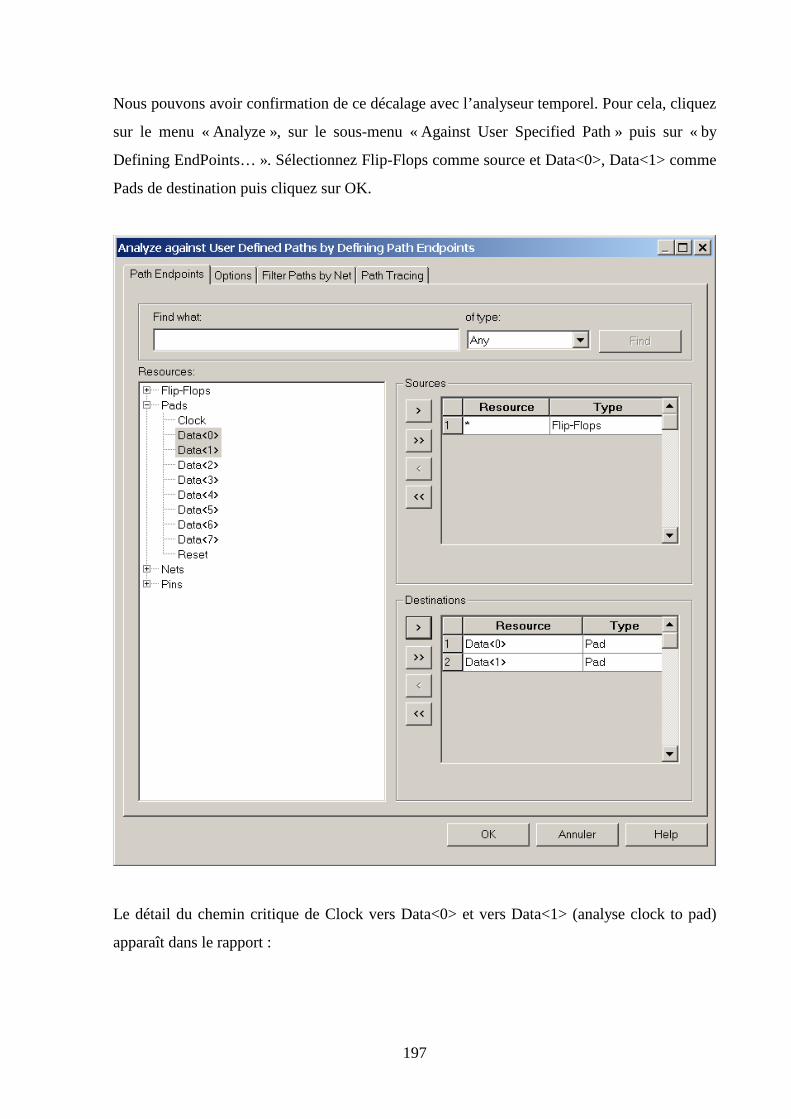
197
Nous pouvons avoir confirmation de ce décalage avec l’analyseur temporel. Pour cela, cliquez
sur le menu « Analyze », sur le sous-menu « Against User Specified Path » puis sur « by
Defining EndPoints… ». Sélectionnez Flip-Flops comme source et Data<0>, Data<1> comme
Pads de destination puis cliquez sur OK.
Le détail du chemin critique de Clock vers Data<0> et vers Data<1> (analyse clock to pad)
apparaît dans le rapport :
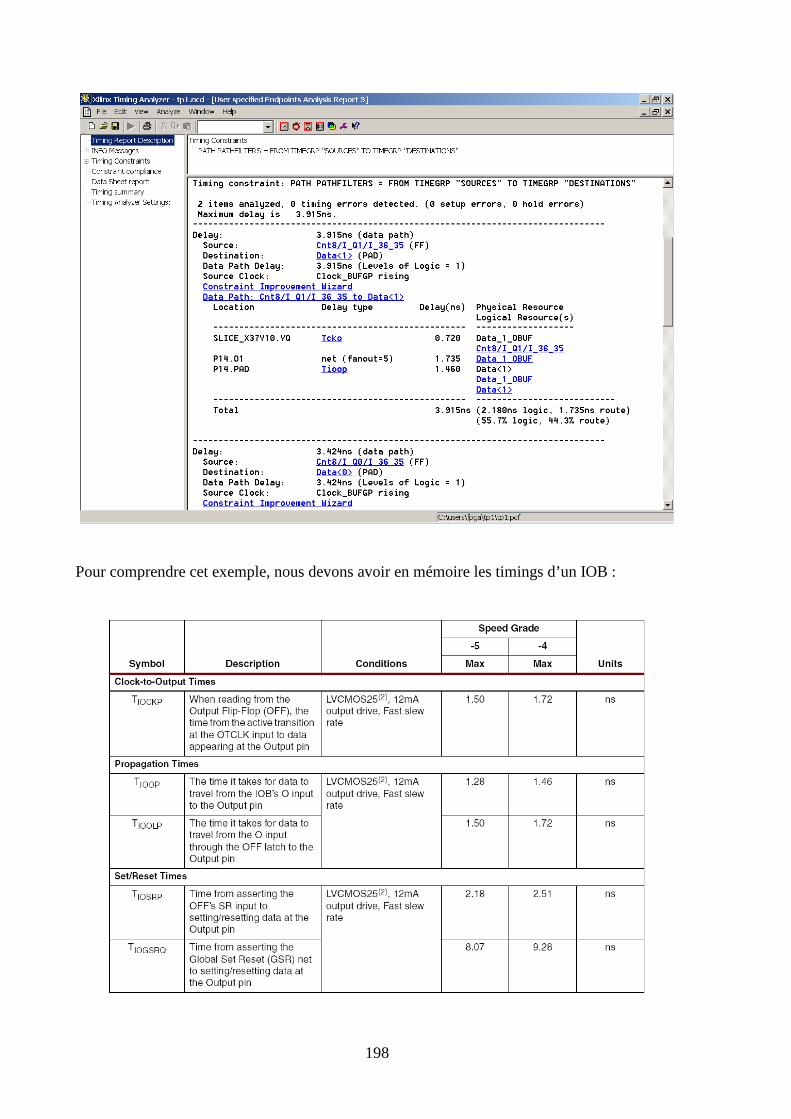
198
Pour comprendre cet exemple, nous devons avoir en mémoire les timings d’un IOB :
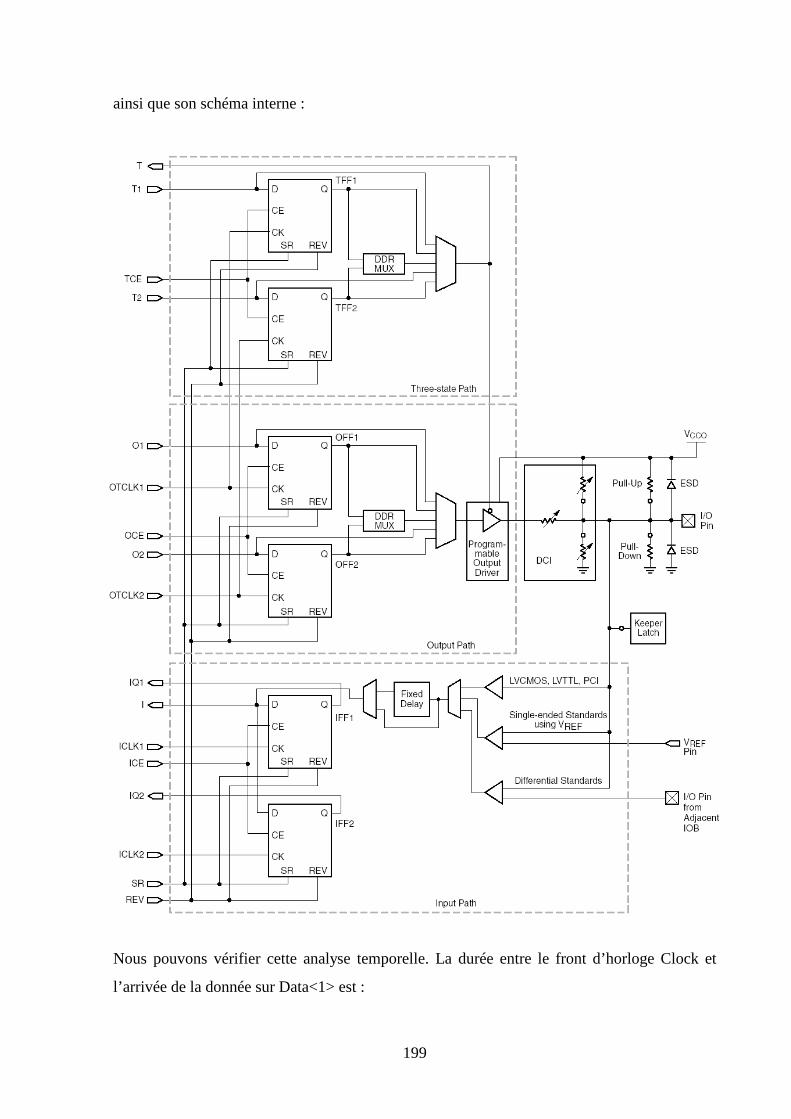
199
ainsi que son schéma interne :
Nous pouvons vérifier cette analyse temporelle. La durée entre le front d’horloge Clock et
l’arrivée de la donnée sur Data<1> est :

200
Description Symbole Valeur [ns]
Clock CLK to outputs YQ
(de Clock vers SLICE_X37Y10.YQ)
TCKO 0,720
Temps de propagation sur un fil
(de SLICE_X37Y10.YQ vers P14.O1)
net 1,735
Propagation time : output (O) to pad
(de P14.O1 vers P14.PAD)
TIOOP 1,460
total 3,915
En réalisant la même analyse sur Data<0>, on obtient un temps total égal à 3,424 ns. Vous
pouvez vérifier la différence (491 ps) entre les arrivées des deux signaux à l’aide de la
simulation de timing. On peut aussi expliquer l’intervalle de 9,337 ns entre le front montant
de Clock et l’arrivée de la donnée sur Data<0>. Il faut rajouter aux 3,424 ns précédentes le
temps de propagation entre le pad F15 et le net Clock. A l’aide de l’analyseur (source : Pads
(clock), destination : Flip-Flops), on trouve un temps de propagation égal à 5,913 ns :
Ce qui nous donne bien un total de 9,337 ns. L’analyseur temporel possède une fonctionnalité
intéressante pour sélectionner la vitesse du circuit nécessaire à la réalisation du design. Nous
allons analyser à nouveau la fréquence de fonctionnement maximale du montage :
201
en sélectionnant les flip-flop comme source et destination de l’analyse temporelle à effectuer.
Nous obtenons une période égale à 4.453 ns. Si vous voulez savoir à quelle vitesse tournerait
le design dans un XC3S200-5, fermez ce rapport, et relancez l’analyse. Dans la fenêtre
suivante, cliquez sur l’onglet « Options », sélectionnez une vitesse -5 (Speed Grade) puis
cliquez sur OK.
La période minimale vaut maintenant 3,887 ns. Fermez l’analyseur temporel.

202
7.4 Les contraintes
Nous n’avons pour l’instant donné aucune indication à l’outil de placement-routage
concernant les performances du design. La manière la plus élémentaire (et a priori une des
plus efficaces) de spécifier une fréquence de fonctionnement est la contrainte PERIOD placée
dans le fichier de contraintes. Continuons de travailler avec TP1. L’éditeur de contraintes
permet de modifier le fichier tp1.ucf. On le lance en sélectionnant tp1.sch dans la fenêtre
« Sources » puis en lançant « Create Timing Constraints » dans la fenêtre « Processes » :
La fenêtre suivante apparaît :

203
Sur la ligne Clock (onglet « Global » de la fenêtre supérieure), double-cliquez sur la case
« Period ». Dans la fenêtre qui s’ouvre, tapez 3.6 dans la case « Time » puis cliquez sur OK.
La nouvelle case « Period » doit maintenant ressembler à :

204
Cliquez sur « File », « Exit » pour sortir de l’éditeur de contraintes. Cliquez sur Yes quand la
fenêtre suivante apparaît :
Les marques vertes ont été remplacées par des points d’interrogation dans les différentes
phases de l’implémentation.
Il faut la relancer pour prendre en compte la contrainte temporelle sur l’horloge Clock.

205
Comparons en détail les timings du chemin critique. Lancez l’analyseur temporel et cliquez
sur le bouton pour réaliser l’analyse de la contrainte sur l’horloge.
Pas de contrainte Période = 3.6 ns
TCKO 0,720 ns 0,720 ns
net 0,787 ns 0,725 ns
TILO 0,608 ns 0,551 ns
net 1,025 ns 0,291 ns
TILO 0,608 ns 0,608 ns
net 0,015 ns 0,015 ns
TFCK 0,69 ns 0,69 ns
total 4,453 ns 3,600 ns
Le tableau précédent vous donne les valeurs des timings avec et sans contraintes. On voit bien
que l’outil de placement-routage optimise les délais des interconnexions pour satisfaire la
contrainte. Bien entendu, les délais logiques ne sont pas modifiés (sauf le 1er TILO, mais le
fanout du net qui l’attaque est passé de 6 à 3). Il faut noter qu’il y a des différences entre deux
essais successifs d’implémentation car le processus de placement-routage est initialisé par une
valeur pseudo-aléatoire qui change à chaque essai. Une période égale à 3,6 ns semble être le
minimum possible.
Nous allons maintenant voir un autre exemple en utilisant le projet TP2. Nous allons placer
une contrainte sur l’horloge Clk de ce design ainsi que sur le temps de propagation de
l’horloge vers les sorties od[7] à od[0] et ou[7] à ou[0]. Pour cela, nous allons utiliser la
syntaxe des éléments suivants :
Signification du mot clé Nom du mot clé
Mot clé pour désigner un fil NET
Timing Name Net (attribution d’un label à un net) TNM_NET
Time Group (attribution d’un label à un groupe d’objet) TIMEGRP
206
Mot clé pour désigner une broche PADS
Time Specification (définition d’une spécification temporelle)
TIMESPEC
Définition d’un temps maximal entre un point de départ et un point d’arrivée
FROM : TO
Définition d’une période maximale PERIOD
Nous allons spécifier ces contraintes sans utiliser l’éditeur de contraintes, mais en modifiant
directement à la main le fichier tp2.ucf. Il s’agit là d’une autre méthode pour indiquer une
contrainte. Pour cela, sélectionnez tp2.sch dans la fenêtre « Sources » puis lancez « Edit
Constraints » dans la fenêtre « Processes » :
Le fichier tp2.ucf s’ouvre dans l’éditeur. Ajoutez à la fin du fichier les lignes suivantes (les
explications sont données en italique) :
NET Clock TNM_NET = CK; # définit un nom de timing (label CK) pour l’horloge
Clock.
TIMEGRP OPADS = PADS(seg*); # définit un nom de groupe (label OPADS) pour
toutes les broches dont le nom commence par seg.

207
TIMESPEC TS01 = FROM CK TO OPADS 10; # définit la spécification de timing TS01
comme un temps de propagation de 10 ns de l’horloge Clock vers les sorties commandant
les afficheurs 7 segments.
TIMESPEC TS02 = PERIOD CK 3.7; # définit dans la spécification de timing TS02 une
période de 3.7 ns pour l’horloge Clock.
La dernière ligne est équivalente à la commande PERIOD vue précédemment. Une fois le
fichier tp2.ucf sauvegardé et l’éditeur fermé, relancez l’implémentation.
Le tableau suivant (cliquez sur le bouton de l’analyseur temporel) donne l’évolution de
TS01 en fonction de la contrainte :
Pas de contrainte 10 ns
TCKO 0,720 ns 0,720 ns
net 0,684 ns 0,611 ns
TILO 0,551 ns 0,551 ns
net 2,110 ns 1,396 ns
TILO 0,608 ns 0,608 ns
net 1,534 ns 1,647 ns
TIOOP 4,362 ns 4,362 ns
total 10,569 ns 9,895 ns
Le tableau suivant donne l’évolution de TS02 en fonction de la contrainte :
Pas de contrainte 3.7 ns
TCKO 0,720 ns 0,720 ns
net 1,026 ns 0,723 ns
TILO 0,608 ns 0,608 ns
net 0,821 ns 1,042 ns
TCECK 0.602 ns 0.602 ns
total 3,777 ns 3,695 ns

208
Il existe d’autres manières de spécifier des contraintes temporelles (par exemple, le retard
maximal sur un net avec NET "clock" MAXDELAY = 20 ns). Vous vous reporterez à la
documentation Xilinx pour de plus amples renseignements.
Une autre catégorie de contraintes existe, les contraintes physiques. Ces contraintes sont
généralement placées dans le fichier *.ucf. Nous en avons déjà vu certaines telles que
l’affectation d’une broche du FPGA ou d’un slice :
NET "Clock" LOC=F15;
INST "and1" LOC= SLICE_X36Y7;
ou bien la valeur du slew-rate d’une broche :
NET "Data<0>" FAST;
Vous pouvez aussi interdire l’utilisation d’une broche ou d’un slice :
CONFIG PROHIBIT = P10 ;
CONFIG PROHIBIT = SLICE_X36Y7;
Il existe une méthode très puissante pour placer des fonctions logiques dans les générateurs de
fonctions d’un slice particulier en utilisant le composant FMAP. En effet, l’outil de
placement-routage (PAR) ne va pas nécessairement ranger les fonctions combinatoires d’une
manière optimale dans les générateurs de fonctions F, G existants. On peut donc forcer un
ensemble de fonctions combinatoires à prendre place dans un générateur donné en affectant au
composant FMAP les mêmes noms de signaux en entrée et en sortie. Le schéma suivant
montre, comme exemple, une partie d’un composant ADD4 que vous pouvez visualiser avec
ECS :

209
On peut ensuite indiquer à PAR la localisation d’un FMAP ou d’une bascule en affectant une
propriété LOC au composant correspondant. Dans le tableau suivant, on affecte les 2
générateurs de fonctions et les deux flip-flops au SLICE_X0Y0 :
LOC composant Affectation dans le CLB
SLICE_X0Y0.F FMAP Générateur de fonctions F
SLICE_X0Y0.G FMAP Générateur de fonctions G
SLICE_X0Y0.FFX FDCE ou FD Bascule avec sortie sur XQ
SLICE_X0Y0.FFY FDCE ou FD Bascule avec sortie sur YQ
La propriété RLOC (Relative Location) permet de réaliser des RPM (Relationally Placed
Macros). Dans un schéma, on affecte à un couple FMAP (ainsi éventuellement qu’à deux
bascules) la position de référence X0Y0. On affecte ensuite aux autres composants (FMAP ou
bascules) du schéma, des RLOC indiquant un placement relatif à cette référence. Lors du
placement-routage, PAR va placer le slice de référence en fonction des contraintes, puis il
placera les autres éléments du schéma (ayant une propriété RLOC) en fonction de la position
du premier slice. Le design peut donc être le plus compact possible, ce qui assure les liaisons
les plus courtes et donc la fréquence de fonctionnement la plus élevée.
Dans le processus de réalisation d’un FPGA, un design est implémenté de nombreuses fois. Il
y a généralement de nombreuses parties du design qui ne changent pas d’une implémentation
à l’autre. De plus, quand la contrainte temporelle a été respectée sur une partie critique du

210
design, on souhaite souvent que l’ajout de fonctionnalités nouvelles ne change pas les parties
déjà réalisées. C’est le développement incrémental. Il est possible de sélectionner une
implémentation précédente pour guider l’implémentation en cours. Il faut pour cela
sélectionner les propriétés du processus d’implémentation, puis cliquer sur l’onglet
« Place&Route Properties » :
Il faut alors sélectionner un fichier NCD correspondant à l’implémentation précédente dans le
champ « PAR Guide Design File » et sélectionner Exact dans le champ « PAR Guide Mode »
pour préserver totalement la partie du design déjà implémentée. Dans le mode Leverage, les
opérations de mapping, placement et routage de la logique existante peuvent être modifiées si
cela est indispensable.
Il faut noter que le développement incrémental n’était utilisable à l’origine qu’en saisie de
schéma car les synthétiseurs avaient une fâcheuse tendance à changer le nom d’instance des
composants primitifs et le nom des signaux à chaque nouvelle synthèse du design. Pour l’outil
de placement routage, tout se passait comme s’il s’agissait d’un nouveau design à chaque
synthèse. Le guidage ne pouvait donc pas fonctionner correctement. Il existe aujourd’hui un
mode incrémental pour chaque synthétiseur du commerce, mais son utilisation demande une
étude détaillée (notamment pour vérifier s’il fonctionne correctement).
211
7.5 Vérification de la programmation du FPGA
Reprenons le design TP1V. Lors de la programmation du FPGA, nous n’avions pas coché la
case « Verify ». Si vous essayez maintenant :
Vous obtenez le message d’erreur suivant :
Puis :
Finalement, la programmation échoue :
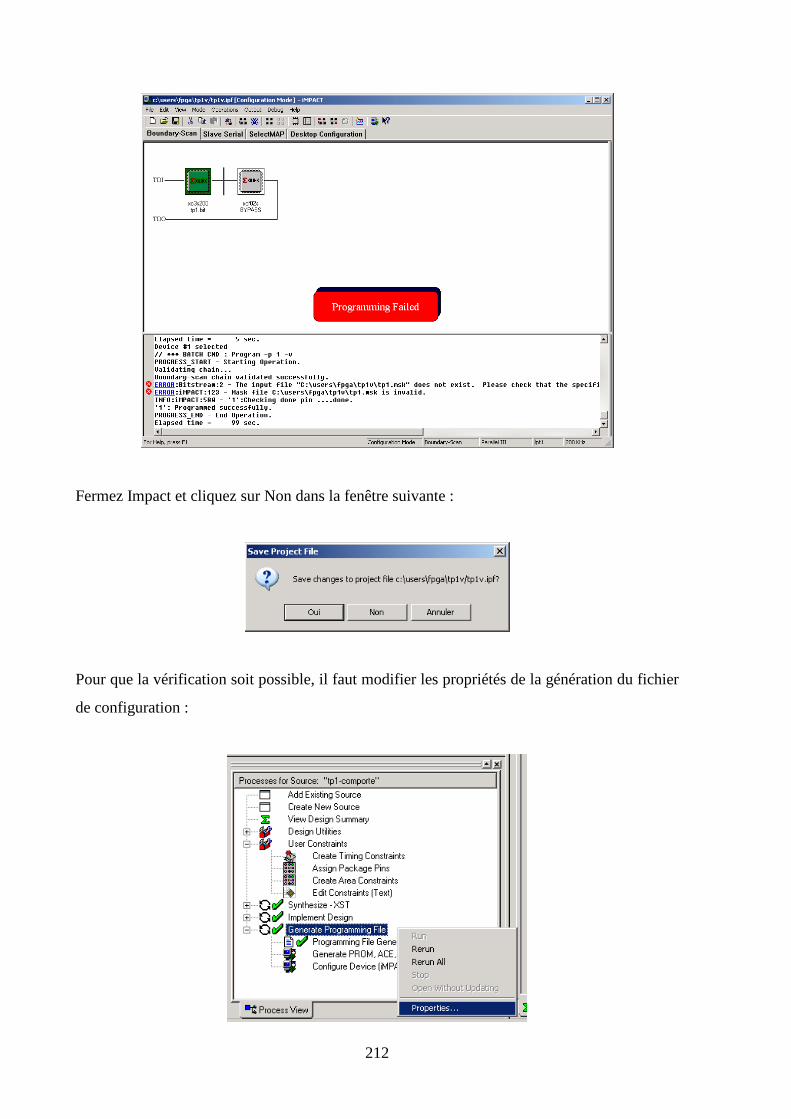
212
Fermez Impact et cliquez sur Non dans la fenêtre suivante :
Pour que la vérification soit possible, il faut modifier les propriétés de la génération du fichier
de configuration :

213
Dans l’onglet « Readback Options », sélectionnez « Create ReadBack Data Files » puis
« Create Mask File » et cliquez sur OK :
Relancez Impact :
Vous pouvez maintenant lancer la vérification. Impact configure le FPGA avec le fichier .bit
en passant par le JTAG, puis il vérifie la programmation (toujours par le JTAG) en relisant le
contenu de la SRAM du FPGA et en comparant ce contenu avec celui du fichier .bit (C’est là
qu’il utilise le fichier .msk).

214
Il arrive parfois que la vérification échoue sans pour cela que la programmation soit forcément
mauvaise. La fiabilité du téléchargement via le cordon JTAG n’est pas toujours excellente.
Elle dépend des paramètres suivants :
• la qualité du cordon JTAG,
• la vitesse de la programmation,
• l’alimentation du cordon JTAG,
• la qualité du port parallèle du PC,
• la qualité du circuit imprimé de la carte FPGA.
Il y a parfois un aspect un peu « magique » derrière tout cela, certains PC s’obstinant à refuser
tout téléchargement fiable à travers le port parallèle (quand il existe encore, notamment sur les
portables). Pour assurer une programmation de bonne qualité, il est souvent nécessaire de
programmer la mémoire Flash série sur la carte plutôt que le FPGA directement. La fiabilité
est en général bien meilleure avec la Flash qu’avec le FPGA.
7.6 Programmation de la mémoire Flash série
Continuons avec le design TP1V. La programmation de la Flash s’effectue avec un fichier au
format MCS-86. Pour le créer, il faut lancer :
Dans la fenêtre qui s’ouvre (il s’agit toujours d’Impact), sélectionnez « PROM File », puis
cliquez sur « Suivant » :
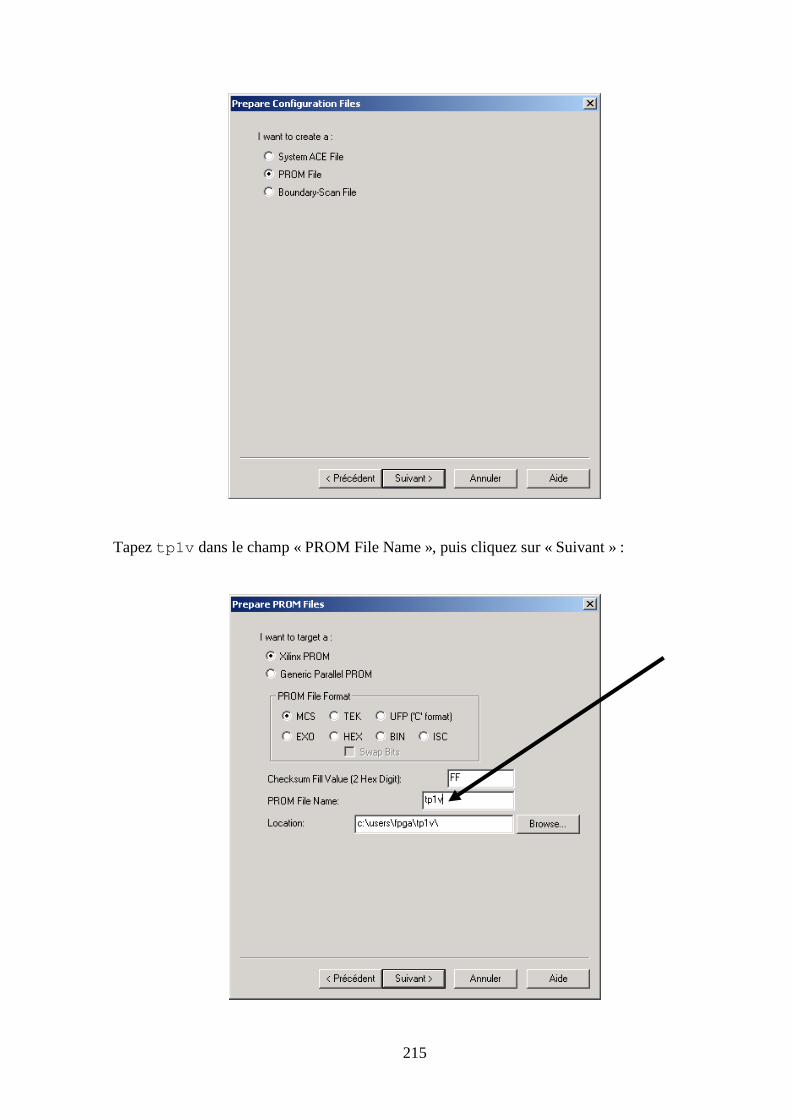
215
Tapez tp1v dans le champ « PROM File Name », puis cliquez sur « Suivant » :

216
Sélectionnez xcf02s puis cliquez sur le bouton « Add ». Vous devez obtenir cette fenêtre avant
de cliquer sur « Suivant » :
Vérifiez sur la page de résumé que tout est correct avant de cliquer sur « Suivant » :

217
Dans la fenêtre qui s’ouvre alors, cliquez sur « Add File… » :
Puis sélectionnez le fichier tp1.bit dans le répertoire c:\users\fpga\tp1v et cliquez sur
« Ouvrir » :
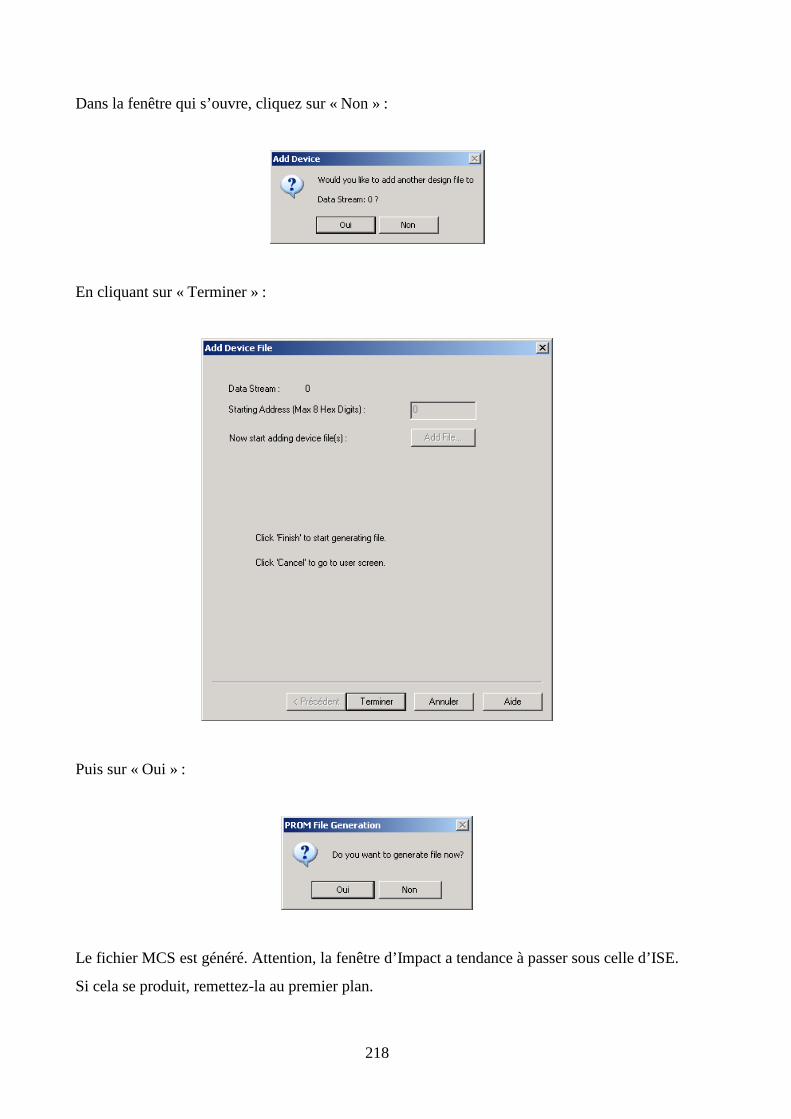
218
Dans la fenêtre qui s’ouvre, cliquez sur « Non » :
En cliquant sur « Terminer » :
Puis sur « Oui » :
Le fichier MCS est généré. Attention, la fenêtre d’Impact a tendance à passer sous celle d’ISE.
Si cela se produit, remettez-la au premier plan.
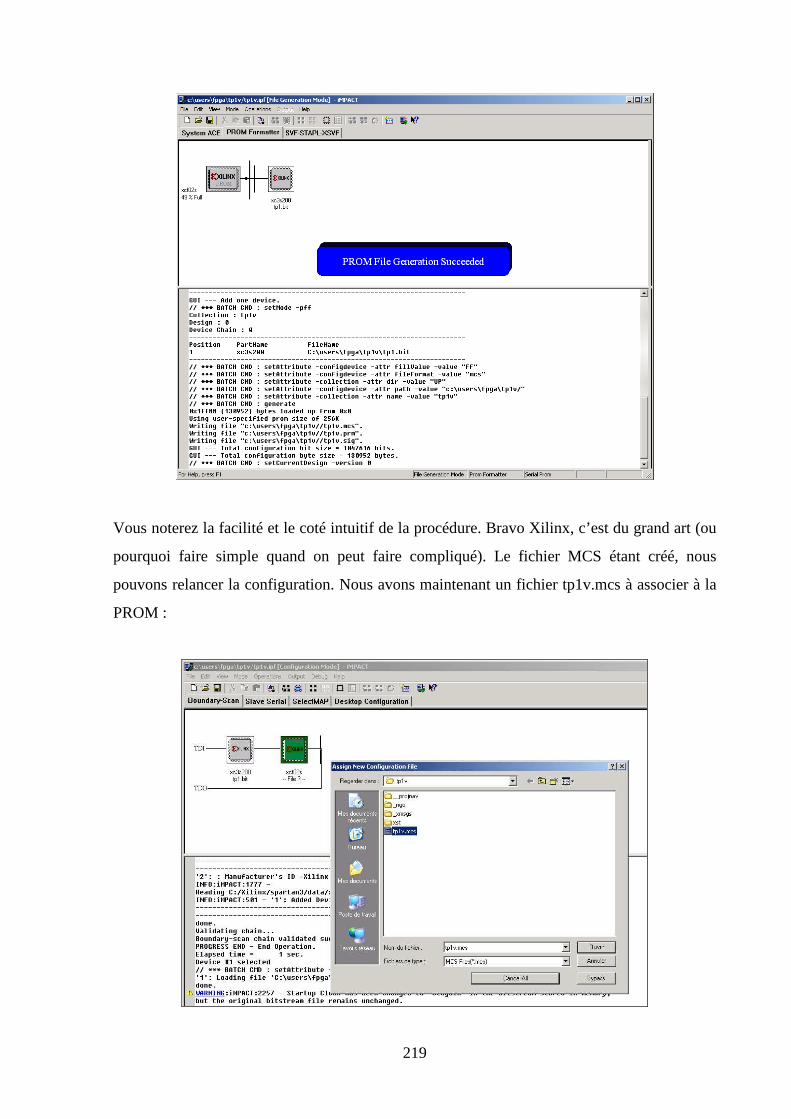
219
Vous noterez la facilité et le coté intuitif de la procédure. Bravo Xilinx, c’est du grand art (ou
pourquoi faire simple quand on peut faire compliqué). Le fichier MCS étant créé, nous
pouvons relancer la configuration. Nous avons maintenant un fichier tp1v.mcs à associer à la
PROM :
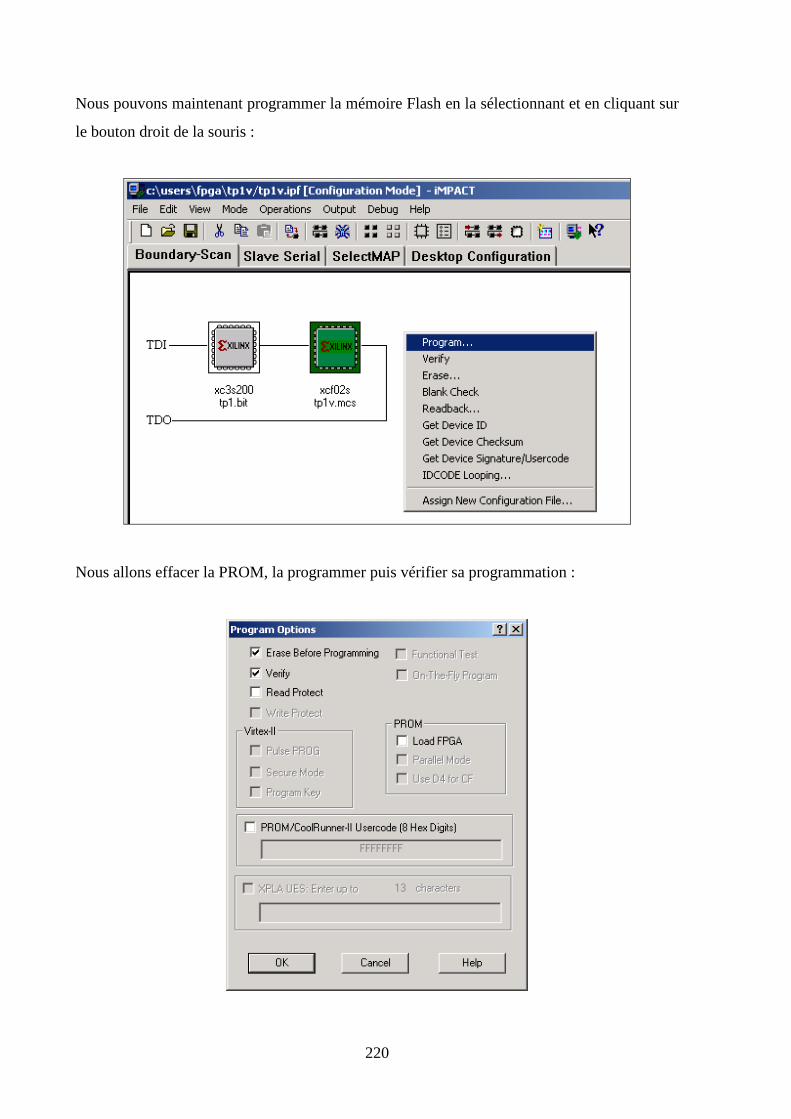
220
Nous pouvons maintenant programmer la mémoire Flash en la sélectionnant et en cliquant sur
le bouton droit de la souris :
Nous allons effacer la PROM, la programmer puis vérifier sa programmation :

221
L’opération dure environ 40 secondes. Si vous éteignez puis rallumez la carte, vous voyez
que le design est bien rechargé dans le FPGA. Si maintenant vous effacez la PROM :
Vous constaterez en éteignant puis en rallumant la carte qu’aucun design n’est plus chargé
dans le FPGA. Effacez la PROM avant de passer à la suite du TP.
7.7 Accès à l’information
Il est très important de bien connaître les différents emplacements où se trouve l’information.
L’accès à l’information est vital pour le concepteur de circuit intégré. Il y a deux grandes
sources d’informations :
• Première source : la documentation installée avec ISE qui doit être consultée en premier.

222
Elle est au format PDF et décrit de manière complète le fonctionnement des outils ainsi que
les différentes étapes du développement.
Concernant VHDL, il y a aussi la documentation interne de ModelSim qui est très
complète :
Concernant la syntaxe et les possibilités des différents langages utilisés, vous avez accès à
un assistant dans ISE :

223
Cet assistant est un aide mémoire très puissant concernant l’écriture des fichiers UCF,
VHDL ou Verilog.
• Deuxième source de documentation : Internet. Le site de Xilinx est accessible à travers
ISE.

224
Ou bien de préférence directement sur le Web (www.xilinx.com).
On trouve sur ce site :
• Les datasheets des composants,
• Des notes d’application,
• La documentation des outils,
• Les mises à jour des logiciels,
• Une base de connaissance pour faire des recherches en cas de problème,
• Un service de support en ligne (webcase),
• De forums de discussion internes à Xilinx,
• Et bien d’autres choses encore.
Il existe aussi des forums de discussion publics spécialisés dans les FPGA
(comp.arch.fpga) et dans VHDL (comp.lang.vhdl) qui sont de véritables mines
d’informations.

225
8. Travail pratique N°4
Ce quatrième TP a pour but d’effectuer entièrement en VHDL un traitement du signal simple :
une moyenne mobile sur 8 coefficients successifs.
Registre 8 bits
8
12.5 MHz
CAN
CNA
D Q Din
Dout
Additionneur 8 bits
D Q 8
12.5 MHz
D Q D Q D Q D Q D Q D Q D Q
TRAVAIL PREALABLE A REMETTRE AU DEBUT DE LA SEANCE (les
développements mathématiques sont inutiles pour répondre à ces questions) :
1. Analysez le fonctionnement théorique de ce montage.
2. On applique à l’entrée de ce montage : Din = 0, 1, 2, 3, 4, 5, …, 16, 255, 255, …
Quelle suite de valeurs trouve-t-on sur la sortie Dout (en numérique sans les
convertisseurs, registres initialisés à 0 au départ. C’est un simple calcul arithmétique,
voir chronogramme page 126) ?
3. Tracez la courbe de la réponse en fréquence (la formule ne nous intéresse pas).
4. Complétez les parties manquantes dans le fichier VHDL tp4_pkg.vhd.
5. Dessinez le schéma interne du bloc addit8x8 (le composant ADDER est un
additionneur générique sur N bits).
8.1 Ouverture du projet
Nous n’allons passer en revue dans ce texte que les phases qui diffèrent avec TP1 et TP2.
Reportez-vous aux textes des premiers TP pour plus de détails.
• Ouvrez une session « fpga » sur votre ordinateur.
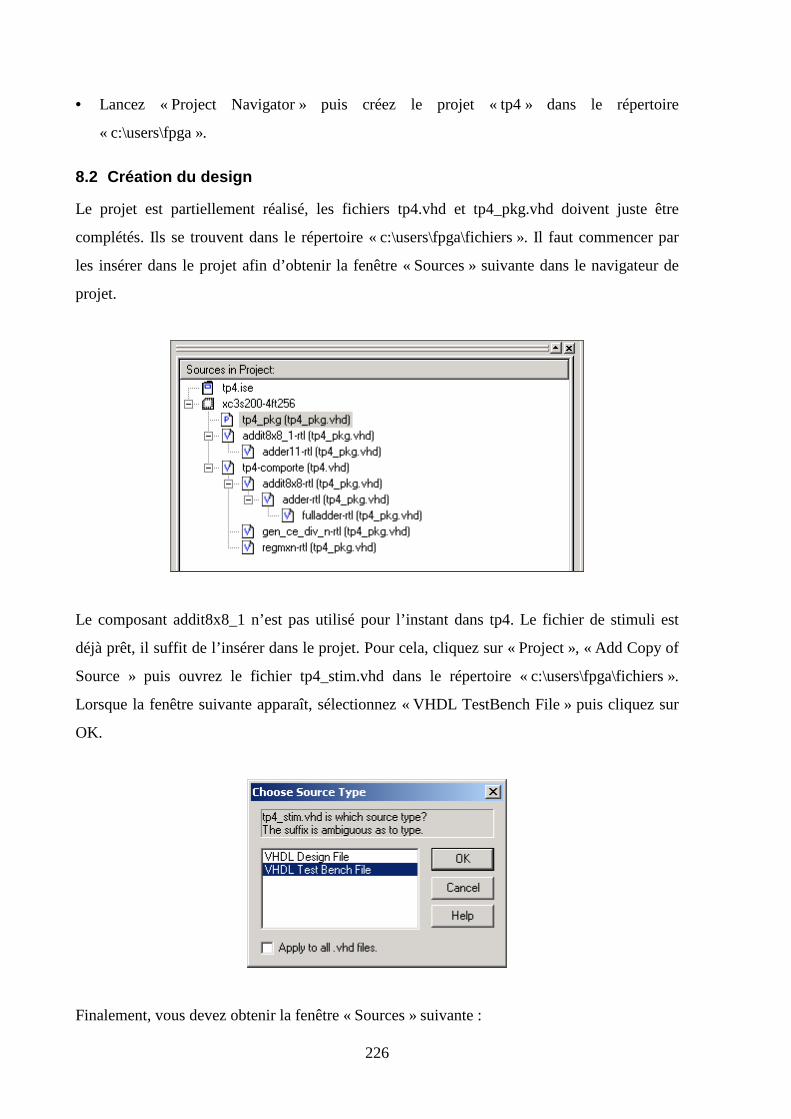
226
• Lancez « Project Navigator » puis créez le projet « tp4 » dans le répertoire
« c:\users\fpga ».
8.2 Création du design
Le projet est partiellement réalisé, les fichiers tp4.vhd et tp4_pkg.vhd doivent juste être
complétés. Ils se trouvent dans le répertoire « c:\users\fpga\fichiers ». Il faut commencer par
les insérer dans le projet afin d’obtenir la fenêtre « Sources » suivante dans le navigateur de
projet.
Le composant addit8x8_1 n’est pas utilisé pour l’instant dans tp4. Le fichier de stimuli est
déjà prêt, il suffit de l’insérer dans le projet. Pour cela, cliquez sur « Project », « Add Copy of
Source » puis ouvrez le fichier tp4_stim.vhd dans le répertoire « c:\users\fpga\fichiers ».
Lorsque la fenêtre suivante apparaît, sélectionnez « VHDL TestBench File » puis cliquez sur
OK.
Finalement, vous devez obtenir la fenêtre « Sources » suivante :

227
Le top level design tp4.vhd est complet et ne doit pas être modifié. Trois composants
gen_ce_div_N, addit8x8 et regMxN y sont instanciés aux lignes 21 à 23 dans le listing ci-
dessous (lignes 23 à 25 dans le fichier).
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. use work.tp4_pkg.all; 4. library unisim; 5. use unisim.all; 6. entity tp4 is 7. port( 8. H50_I : in std_logic; 9. Reset : in std_logic; 10. data_i : in std_logic_vector(7 downto 0); 11. CLK_CAN : out std_logic; 12. CLK_CNA : out std_logic; 13. data_o : out std_logic_vector(7 downto 0) ); 14.end tp4; 15.architecture comporte of tp4 is 16. signal data : data8x8; 17. signal ce_symb : std_logic; 18.begin 19. CLK_CAN <= ce_symb; 20. CLK_CNA <= ce_symb; 21. div4 : gen_ce_div_N generic map(4) port map(H 50_I, Reset, ce_symb); 22. addit8 : addit8x8 port map(H50_I, Reset, ce_sym b, data, data_o); 23. reg8 : regMxN generic map(8,8) port map(H50_I, Reset, ce_symb, data_i, data); 24.end comporte ;

228
Ce design correspond au schéma suivant :
Le design est entièrement synchrone avec l’horloge externe à 50 MHz. Le signal de validation
ce_out, créé par le composant gen_ce_div_N, vaut 1 toutes les 4 périodes du 50 MHz, soit une
période d’activation de 12,5 MHz. Il active le registre regMxN (8 bits de profondeur, 8
coefficients stockés simultanément) ainsi que le composant qui réalise l’addition de ces 8
coefficients sur 8 bits, addit8x8. ce_out est aussi copié sur les horloges CLK_CNA et
CLK_CAN qui servent à piloter les convertisseurs de la maquette. Le fichier tp4_pkg.vhd
contient la définition des composants utilisés dans le montage. Vous devez compléter
l’architecture de gen_ce_div_N (ligne 133 dans ce texte, ligne 146 dans le fichier) ainsi que
celle de regMxN (ligne 266 dans ce texte, ligne 287 dans le fichier) en vous inspirant des
exemples donnés au §4 du polycopié de cours.
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. package tp4_pkg is 4. 5. TYPE data8x8 IS ARRAY (0 TO 7) OF std_logic_vecto r(7 DOWNTO 0); 6. TYPE data8x11 IS ARRAY (0 TO 7) OF std_logic_vect or(10 DOWNTO 0); 7. 8. component FullAdder 9. port (A : in std_logic; 10. B : in std_logic; 11. CI : in std_logic; 12. S : out std_logic; 13. COUT : out std_logic); 14. end component; 15. 16. component ADDER 17. generic (N : in integer := 8); 18. port (A : in std_logic_vector(N-1 downto 0) ; 19. B : in std_logic_vector(N-1 downto 0) ; 20. CI : in std_logic;

229
21. S : out std_logic_vector(N-1 downto 0) ; 22. COUT : out std_logic); 23. end component; 24. 25. component ADDER11 26. port (A : in std_logic_vector(10 downto 0); 27. B : in std_logic_vector(10 downto 0); 28. S : out std_logic_vector(10 downto 0)) ; 29. end component; 30. 31. component gen_ce_div_N 32. generic (div : integer := 4); 33. port (clk_in : in std_logic; 34. clear : in std_logic; 35. ce_out : out std_logic); 36. end component; 37. 38. COMPONENT addit8x8 39. port( CLK : in std_logic ; 40. CLEAR : in std_logic; 41. ce : in std_logic; 42. datar : in data8x8; 43. DOUT : out std_logic_vector(7 downto 0) ); 44. END COMPONENT; 45. 46. COMPONENT addit8x8_1 47. port( CLK : in std_logic ; 48. CLEAR : in std_logic; 49. ce : in std_logic; 50. datar : in data8x8; 51. DOUT : out std_logic_vector(7 downto 0) ); 52. END COMPONENT; 53. 54. COMPONENT regMxN 55. generic (NbReg : integer :=8; NbBit : intege r :=8); 56. port( CLK : in std_logic ; 57. CLEAR : in std_logic; 58. ce : in std_logic; 59. DIN : in std_logic_vector(NbBit -1 dow nto 0); 60. datar : out data8x8); 61. END COMPONENT; 62. 63.end tp4_pkg; 64.library IEEE; 65.use IEEE.std_logic_1164.all; 66.entity FullAdder is 67. port ( 68. A, B, CI : in std_logic; 69. S, COUT : out std_logic); 70.end FullAdder; 71.architecture RTL of FullAdder is 72.begin 73. S <= A xor B xor CI; 74. COUT <= (A and B) or (A and CI) or (B and CI); 75.end; 76.library IEEE; 77.use IEEE.std_logic_1164.all; 78.use work.tp4_pkg.all; 79.entity ADDER is 80. generic (N : in integer := 8); 81. port (

230
82. A, B : in std_logic_vector(N-1 downto 0); 83. CI : in std_logic; 84. S : out std_logic_vector(N-1 downto 0); 85. COUT : out std_logic); 86.end ADDER; 87.architecture RTL of ADDER is 88. signal C : std_logic_vector(A'length-1 downto 1); 89.begin 90. gen : for j in A'range generate 91. 92. genlsb : if j = 0 generate 93. fa0 : FullAdder port map (A => A(0), B => B(0), 94. CI => CI, S => S(0), COUT => C(1)); 95. end generate; 96. 97. genmid : if (j > 0) and (j < A'length-1) gen erate 98. fa0 : FullAdder port map (A => A(j), B => B(j), 99. CI => C(j), S => S(j), COUT => C(j+1 )); 100. end generate; 101. 102. genmsb : if j = A'length-1 generate 103. fa0 : FullAdder port map (A => A(j), B => B(j ), 104. CI => C(j), S => S(j), COUT => COUT); 105. end generate; 106. 107. end generate; 108. end; 109. library IEEE; 110. use IEEE.std_logic_1164.all; 111. use IEEE.std_logic_arith.all; 112. use IEEE.STD_LOGIC_UNSIGNED.all; 113. entity ADDER11 is 114. port ( 115. A, B : in std_logic_vector(10 downto 0); 116. S : out std_logic_vector(10 downto 0)); 117. end ADDER11; 118. architecture RTL of ADDER11 is 119. begin 120. S <= A + B; 121. end; 122. library IEEE; 123. use IEEE.std_logic_1164.all; 124. use IEEE.std_logic_arith.all; 125. use IEEE.STD_LOGIC_UNSIGNED.all; 126. entity gen_ce_div_N is 127. generic (div : integer := 4); 128. port (clk_in : in std_logic; 129. clear : in std_logic; 130. ce_out : out std_logic); 131. end gen_ce_div_N; 132. architecture RTL of gen_ce_div_N is 133. -- complétez l'architecture 134. end; 135. library IEEE; 136. use IEEE.std_logic_1164.all; 137. use work.tp4_pkg.all;

231
138. entity addit8x8 is 139. port( CLK : in std_logic ; 140. CLEAR : in std_logic; 141. ce : in std_logic; 142. datar : in data8x8; 143. DOUT : out std_logic_vector(7 downto 0)); 144. end addit8x8; 145. architecture RTL of addit8x8 is 146. signal suma1 : std_logic_vector(7 downto 0) ; 147. signal sumb1 : std_logic_vector(7 downto 0) ; 148. signal sumc1 : std_logic_vector(7 downto 0) ; 149. signal sumd1 : std_logic_vector(7 downto 0) ; 150. signal couta1 : std_logic; 151. signal coutb1 : std_logic; 152. signal coutc1 : std_logic; 153. signal coutd1 : std_logic; 154. signal dina2 : std_logic_vector(8 downto 0) ; 155. signal dinb2 : std_logic_vector(8 downto 0) ; 156. signal dinc2 : std_logic_vector(8 downto 0) ; 157. signal dind2 : std_logic_vector(8 downto 0) ; 158. signal suma2 : std_logic_vector(8 downto 0) ; 159. signal sumb2 : std_logic_vector(8 downto 0) ; 160. signal couta2 : std_logic; 161. signal coutb2 : std_logic; 162. signal dina3 : std_logic_vector(9 downto 0) ; 163. signal dinb3 : std_logic_vector(9 downto 0) ; 164. signal suma3 : std_logic_vector(9 downto 0) ; 165. signal couta3 : std_logic; 166. begin 167. process(CLK, CLEAR) begin 168. if (CLEAR='1') then 169. DOUT <= (others => '0'); 170. elsif (CLK'event and CLK='1') then 171. if (ce = '1') then 172. DOUT <= couta3 & suma3(9 downto 3); 173. end if; 174. end if; 175. end process; 176. 177. adda1 : ADDER generic map(8) port map(datar(0), d atar(1), zeros,
suma1, couta1); 178. addb1 : ADDER generic map(8) port map(datar(2), d atar(3), zeros,
sumb1, coutb1); 179. addc1 : ADDER generic map(8) port map(datar(4), d atar(5), zeros,
sumc1, coutc1); 180. addd1 : ADDER generic map(8) port map(datar(6), d atar(7), zeros,
sumd1, coutd1); 181. dina2 <= couta1&suma1; 182. dinb2 <= coutb1&sumb1; 183. dinc2 <= coutc1&sumc1; 184. dind2 <= coutd1&sumd1; 185. 186. adda2 : ADDER generic map(9) port map(dina2, dinb 2, zeros, suma2,
couta2); 187. addb2 : ADDER generic map(9) port map(dinc2, dind 2, zeros, sumb2,
coutb2); 188. dina3 <= couta2&suma2; 189. dinb3 <= coutb2&sumb2; 190. 191. adda3 : ADDER generic map(10) port map(dina3, din b3, zeros, suma3,
couta3); 192. 193. end;

232
194. library IEEE; 195. use IEEE.std_logic_1164.all; 196. use work.tp4_pkg.all; 197. entity addit8x8_1 is 198. port( CLK : in std_logic ; 199. CLEAR : in std_logic; 200. ce : in std_logic; 201. datar : in data8x8; 202. DOUT : out std_logic_vector(7 downto 0)); 203. end addit8x8_1; 204. 205. architecture RTL of addit8x8_1 is 206. signal datari : data8x11; 207. signal suma1 : std_logic_vector(10 downto 0) ; 208. signal sumb1 : std_logic_vector(10 downto 0) ; 209. signal sumc1 : std_logic_vector(10 downto 0) ; 210. signal sumd1 : std_logic_vector(10 downto 0) ; 211. signal suma1r : std_logic_vector(10 downto 0) ; 212. signal sumb1r : std_logic_vector(10 downto 0) ; 213. signal sumc1r : std_logic_vector(10 downto 0) ; 214. signal sumd1r : std_logic_vector(10 downto 0) ; 215. signal suma2 : std_logic_vector(10 downto 0) ; 216. signal sumb2 : std_logic_vector(10 downto 0) ; 217. signal suma2r : std_logic_vector(10 downto 0) ; 218. signal sumb2r : std_logic_vector(10 downto 0) ; 219. signal suma3 : std_logic_vector(10 downto 0) ; 220. begin 221. process(CLK, CLEAR) begin 222. if (CLEAR='1') then 223. DOUT <= (others => '0'); 224. elsif (CLK'event and CLK='1') then 225. if (ce = '1') then 226. DOUT <= suma3(10 downto 3); 227. end if; 228. end if; 229. end process; 230. 231. process(datar) begin 232. for i in 0 to 7 loop 233. datari(i) <= "000"&datar(i); 234. end loop; 235. end process; 236. 237. adda1 : ADDER11 port map(datari(0), datari(1), su ma1); 238. addb1 : ADDER11 port map(datari(2), datari(3), su mb1); 239. addc1 : ADDER11 port map(datari(4), datari(5), su mc1); 240. addd1 : ADDER11 port map(datari(6), datari(7), su md1); 241. suma1r <= suma1; 242. sumb1r <= sumb1; 243. sumc1r <= sumc1; 244. sumd1r <= sumd1; 245. adda2 : ADDER11 port map(suma1r, sumb1r, suma2); 246. addb2 : ADDER11 port map(sumc1r, sumd1r, sumb2); 247. suma2r <= suma2; 248. sumb2r <= sumb2; 249. adda3 : ADDER11 port map(suma2r, sumb2r, suma3); 250. end; 251. library IEEE; 252. use IEEE.std_logic_1164.all; 253. use IEEE.std_logic_arith.all; 254. use IEEE.STD_LOGIC_UNSIGNED.all; 255. use work.tp4_pkg.all;
233
256. entity regMxN is 257. generic (NbReg : integer :=8; NbBit : integer :=8 ); 258. port( CLK : in std_logic ; 259. CLEAR : in std_logic; 260. ce : in std_logic; 261. DIN : in std_logic_vector(NbBit -1 downto 0 ); 262. datar : out data8x8); 263. end regMxN; 264. 265. architecture RTL of regMxN is 266. -- complétez l'architecture 267. end;
Comme pour tp2, vous utiliserez la méthodologie de développement simplifiée, à savoir :
1) Complétez le fichier tp4_pkg.vhd.
2) Simulez tp4 en fonctionnel. Avant de lancer la simulation, sélectionnez le fichier de stimuli
tp4_stim.vhd puis faites apparaître la fenêtre des propriétés de la simulation fonctionnelle :
Dans cette fenêtre, cochez la case « Use Custom Do File » et décochez la case « Use
Automatic Do File ». Sélectionnez ensuite dans le champ « Custom Do File », le fichier
C:\users\fpga\fichiers\tp4.do (afin de corriger un bug Xilinx dans le pilotage du simulateur
ModelSim). Cliquez sur OK, puis lancez ModelSim.
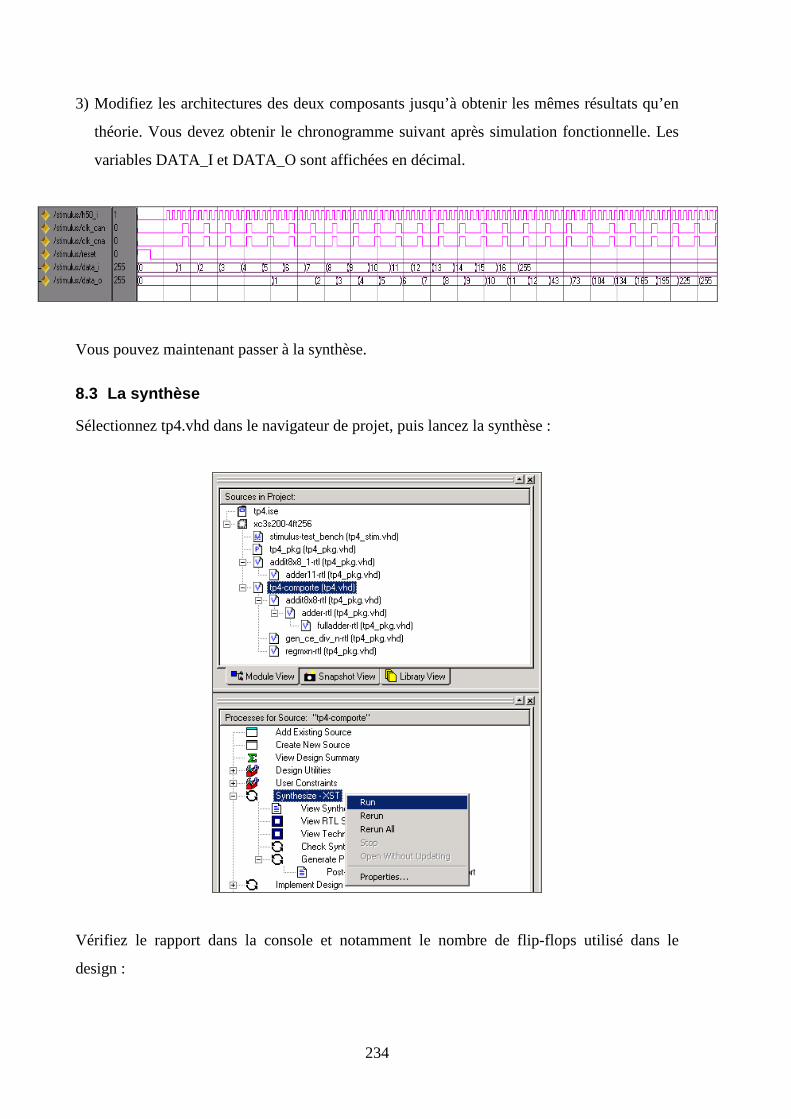
234
3) Modifiez les architectures des deux composants jusqu’à obtenir les mêmes résultats qu’en
théorie. Vous devez obtenir le chronogramme suivant après simulation fonctionnelle. Les
variables DATA_I et DATA_O sont affichées en décimal.
Vous pouvez maintenant passer à la synthèse.
8.3 La synthèse
Sélectionnez tp4.vhd dans le navigateur de projet, puis lancez la synthèse :
Vérifiez le rapport dans la console et notamment le nombre de flip-flops utilisé dans le
design :

235
Vous pouvez aussi voir le schéma logique de la structure obtenue. Il suffit pour cela de
lancer :
Le schéma apparaît :
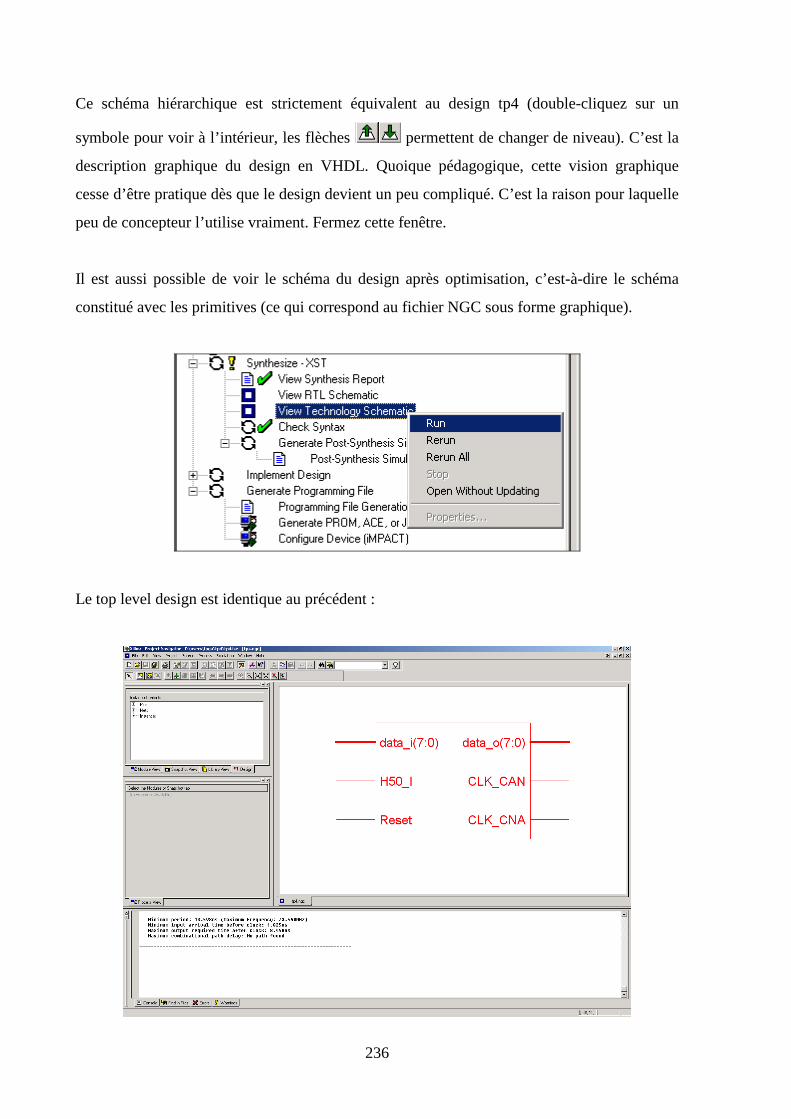
236
Ce schéma hiérarchique est strictement équivalent au design tp4 (double-cliquez sur un
symbole pour voir à l’intérieur, les flèches permettent de changer de niveau). C’est la
description graphique du design en VHDL. Quoique pédagogique, cette vision graphique
cesse d’être pratique dès que le design devient un peu compliqué. C’est la raison pour laquelle
peu de concepteur l’utilise vraiment. Fermez cette fenêtre.
Il est aussi possible de voir le schéma du design après optimisation, c’est-à-dire le schéma
constitué avec les primitives (ce qui correspond au fichier NGC sous forme graphique).
Le top level design est identique au précédent :
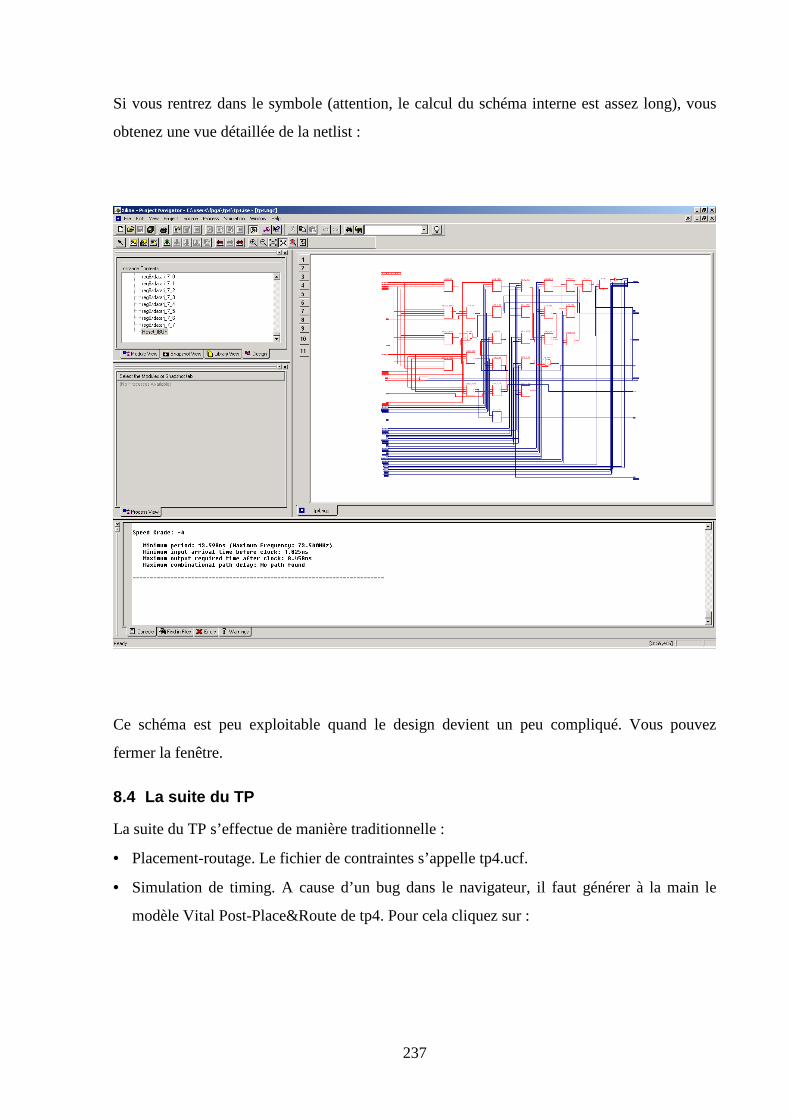
237
Si vous rentrez dans le symbole (attention, le calcul du schéma interne est assez long), vous
obtenez une vue détaillée de la netlist :
Ce schéma est peu exploitable quand le design devient un peu compliqué. Vous pouvez
fermer la fenêtre.
8.4 La suite du TP
La suite du TP s’effectue de manière traditionnelle :
• Placement-routage. Le fichier de contraintes s’appelle tp4.ucf.
• Simulation de timing. A cause d’un bug dans le navigateur, il faut générer à la main le
modèle Vital Post-Place&Route de tp4. Pour cela cliquez sur :

238
Les fichiers tp4_timesim.vhd et tp4_timesim.sdf sont maintenant créés. Avant de lancer la
simulation Post-Place&Route, sélectionnez tp4_stim.vhd dans la fenêtre « Sources », puis
faites apparaître la fenêtre des propriétés de la simulation :

239
Dans cette fenêtre, cochez la case « Use Custom Do File » et décochez la case « Use
Automatic Do File ». Sélectionnez ensuite dans le champ « Custom Do File », le fichier
C:\users\fpga\fichiers\tp4_pl.do. Cliquez sur OK, puis lancez ModelSim.
• Configuration de la maquette et test. Entrez un signal sinusoïdal sur Din (± 500 mV crête)
et visualisez la sortie sur Dout. Vous devez noter une annulation du niveau de sortie pour
une fréquence égale à 1562,5 kHz.
8.5 L’intérêt des ressources dédiées
Dans le design précédent, l’additionneur était réalisé de manière classique comme il aurait été
conçu pour un ASIC. Le composant de base est FullAdder qui n’est autre que l’additionneur
complet (sur 1 bit) que vous devez déjà connaître. Cet additionneur est constitué de portes
logiques élémentaires comme le montre le schéma suivant :

240
Cette structure d’additionneur est tout à fait valable, mais elle a un inconvénient important ;
elle n’utilise pas les ressources dédiées du FPGA pour réaliser la propagation de la retenue.
Dans FullAdder, la retenue est calculée avec :
COUT <= (A and B) or (A and CI) or (B and CI);
Le synthétiseur utilise donc des générateurs de fonction pour réaliser les portes demandées, ce
qui consomme beaucoup plus de ressources et est plus lent que si on utilisait la logique dédiée
existant dans le CLB. Dans le composant ADDER11 (additionneur 11 bits), la description est
beaucoup plus simple que dans le composant ADDER. Il n’y a ni retenue entrante, ni retenue
sortante (additionner 8 coefficients codés avec 8 bits donne un résultat sur 11 bits). L’addition
est réalisée à l’aide de l’opérateur d’addition de VHDL. Le synthétiseur va choisir la manière
la plus efficace pour réaliser l’addition et va donc utiliser la logique dédiée de propagation de
la retenue.
1. entity ADDER11 is 2. port ( 3. A, B : in std_logic_vector(10 downto 0); 4. S : out std_logic_vector(10 downto 0)); 5. end ADDER11; 6. architecture RTL of ADDER11 is 7. begin 8. S <= A + B; 9. end;
La description de ADDER est d’un niveau assez bas qui ressemble à du code structurel alors
que la description de ADDER11, plus proche du comportemental, est d’un niveau
d’abstraction beaucoup plus élevé. Ceci implique une remarque générale concernant
l’utilisation du synthétiseur :
Plus la description est de bas niveau et moins le synthétiseur a de liberté
pour optimiser le design. C’est le concepteur qui impose sa volonté à l’outil.
Plus la description est de haut niveau et plus le synthétiseur peut choisir
la meilleure manière d’obtenir le résultat.
Dans cet exemple, nous allons voir qu’il vaut mieux laisser le synthétiseur faire le travail, le
résultat étant beaucoup plus efficace. Ce n’est pas toujours vrai et il est parfois plus
efficace de faire soi-même le travail.

241
Nous allons évaluer les performances du design tp4 précédent. Il y a une contrainte égale à 15
ns sur l’horloge 50 MHz. Dans le « Map Report », nous trouvons les ressources utilisées :
Design Summary -------------- Logic Utilization: Number of Slice Flip Flops: 59 out of 3,84 0 1% Number of 4 input LUTs: 214 out of 3,84 0 5% Logic Distribution: Number of occupied Slices: 145 out o f 1,920 7% Number of Slices containing only related logic: 145 out of 145 100% Number of Slices containing unrelated logic: 0 out of 145 0% Total Number of 4 input LUTs: 214 out of 3,840 5% Number of bonded IOBs: 20 out of 173 11% IOB Flip Flops: 16 Number of GCLKs: 1 out of 8 12%
Et dans le « Place And Route Report », nous trouvons les performances suivantes :
--------------------------------------------------- ---------------------------- Constraint | Requested | Actual | Logic Levels --------------------------------------------------- ---------------------------- TS_H50_I = PERIOD TIMEGRP "H50_I" | 15.000ns | 14.655ns | 7 15 ns H IGH 50% | | | --------------------------------------------------- ----------------------------
Nous allons maintenant modifier tp4.vhd et instancier le composant addit8x8_1 à la place de
addit8x8.
Modifiez la contrainte (de 15 ns à 13 ns) sur le 50 MHz dans tp4.ucf. Lancez ensuite
l’implémentation. En utilisant les ressources dédiées du FPGA, tp4 consomme les ressources
suivantes :
Design Summary -------------- Logic Utilization: Number of Slice Flip Flops: 60 out of 3,840 1% Number of 4 input LUTs: 62 out of 3,840 1% Logic Distribution: Number of occupied Slices: 62 out of 1,9 20 3% Number of Slices containing only related logic: 62 out of 62 100% Number of Slices containing unrelated logic: 0 out of 62 0% Total Number of 4 input LUTs: 62 out of 3,840 1% Number of bonded IOBs: 20 out of 173 11% IOB Flip Flops: 15 Number of GCLKs: 1 out of 8 12%

242
Avec les performances suivantes :
--------------------------------------------------- --------------------------------- Constraint | Reque sted | Actual | Logic Levels --------------------------------------------------- --------------------------------- TS_H50_I = PERIOD TIMEGRP "H50_I" 13 ns | 13.00 0ns | 12.834ns | 6 HIGH 50% | | | --------------------------------------------------- ---------------------------------
Le gain dû à l’utilisation des ressources dédiées de propagation de retenue est important
puisque le nombre de LUT utilisé passe de 214 à 62 (de 145 à 62 slices). Par contre, la
fréquence maximale de fonctionnement est peu améliorée (de 68 à 78 MHz). Nous allons voir
maintenant une méthode très importante permettant d’accélérer la fréquence maximale de
fonctionnement d’un design (mais qui consomme toutefois beaucoup plus de bascules D).
8.6 L’architecture en pipeline
Quand on dispose d’un circuit intégré ayant de nombreuses bascules, on a tout intérêt à utiliser
une architecture de type pipeline pour augmenter la fréquence de fonctionnement du design.
L’objectif de l’architecture en pipeline est de placer des registres entre chaque couche de
fonctions combinatoires afin de diminuer le temps clock to setup. Dans le schéma suivant, il y
a deux couches logiques (deux niveaux de CLB par exemple) entre les deux bascules.
Logiquecombinatoire
1Clock
QD
clock to setup
Clock
QDLogique
combinatoire2
On a donc la relation :
Tclock to setup = Tp clock to Q + Tp net + Tp logique 1 + Tp net + Tp logique 2 + Tp net + Tsetup
En modifiant le design de la manière suivante :

243
Logiquecombinatoire
1Clock
QD
Clock
QDLogique
combinatoire2
Clock
QD
clock to setup 1 clock to setup 2
On obtient les relations :
Tclock to setup 1 = Tp clock to Q + Tp net + Tp logique 1 + Tp net + Tsetup
Tclock to setup 2 = Tp clock to Q + Tp net + Tp logique 2 + Tp net + Tsetup
Le plus élevé de ces deux temps (Tclock to setup X) correspond à la période minimale de l’horloge.
Il est évident que Tclock to setup X est toujours inférieur au Tclock to setup du premier montage. Le
pipeline a bien augmenté la fréquence de fonctionnement du design. En contrepartie, on a
retardé le signal de sortie d’un coup d’horloge. Tout ce passe comme si on échangeait une
fréquence de fonctionnement plus élevée contre un temps de latence supplémentaire. Ce retard
est égal au nombre de couches de bascules inséré multiplié par la période de l’horloge.
Pour mettre en évidence ce phénomène, nous allons modifier le bloc addit8x8_1 de façon à
insérer une ligne de registres entre chaque niveau d’additionneurs. Il suffit pour cela de
déplacer les lignes 241 à 244 et 247-248 du listing du §4.2 (lignes 274-277 et 280-281 dans le
fichier) dans le process synchrone du composant et d’initialiser à 0 ces signaux quand clear
vaut 1 (sinon le synthétiseur ne peut pas insérer de module startup dans le design). Faites la
simulation fonctionnelle et notez le décalage de deux coups d’horloge par rapport aux deux
design précédents. Placez une contrainte de 7 ns sur H50 puis relancez l’implémentation. Le
design tp4 avec pipeline utilise les ressources suivantes :
Design Summary -------------- Logic Utilization: Number of Slice Flip Flops: 127 out of 3,840 3% Number of 4 input LUTs: 62 out of 3,840 1% Logic Distribution: Number of occupied Slices: 81 out of 1,920 4% Number of Slices containing only related logic: 81 out of 81 100% Number of Slices containing unrelated logic: 0 out of 81 0% Total Number of 4 input LUTs: 62 out of 3,840 1% Number of bonded IOBs: 20 out of 173 11% IOB Flip Flops: 15 Number of GCLKs: 1 out of 8 12%

244
Avec les performances suivantes :
--------------------------------------------------- --------------------------------- Constraint | Reque sted | Actual | Logic Levels --------------------------------------------------- --------------------------------- TS_H50_I = PERIOD TIMEGRP "H50_I" 6.7 ns | 6.700 ns | 6.647ns | 3 HIGH 50% | | | --------------------------------------------------- ---------------------------------
Par rapport au design précédent, la fréquence maximale passe de 78 à 150 MHz et on passe de
62 à 81 slices utilisés, ce qui est relativement peu compte tenu du fait que le nombre de
bascules utilisé est passé de 75 à 142. Cette faible augmentation du nombre de slices utilisé
est due au fait qu’un additionneur 8 bits consomme 4 slices qu’il soit accompagné de registres
ou non. L’utilisation des bascules D inutilisées dans TP4 est donc quasiment gratuite et c’est
pourquoi la méthode du pipeline est souvent utilisée dans les FPGA.
8.7 Fichier de contraintes
# fichier de contrainte utilisateur pour TP4
#
# specification des broches d'entrees
NET "H50_I" LOC = "T9";
NET "Reset" LOC = "L14";
NET "data_i<0>" LOC = "c12";
NET "data_i<1>" LOC = "r10";
NET "data_i<2>" LOC = "d11";
NET "data_i<3>" LOC = "p10";
NET "data_i<4>" LOC = "c11";
NET "data_i<5>" LOC = "n11";
NET "data_i<6>" LOC = "e10";
NET "data_i<7>" LOC = "t3";
#
# specification des broches de sorties
NET "data_o<0>" LOC = "d12";
NET "data_o<1>" LOC = "t7";
NET "data_o<2>" LOC = "e11";
NET "data_o<3>" LOC = "r7";
NET "data_o<4>" LOC = "b16";
NET "data_o<5>" LOC = "n6";
NET "data_o<6>" LOC = "r3";

245
NET "data_o<7>" LOC = "m6";
NET "CLK_CAN" LOC = "c10";
NET "CLK_CNA" LOC = "d15";
#
# specification du slew-rate
NET "data_o<0>" FAST;
NET "data_o<1>" FAST;
NET "data_o<2>" FAST;
NET "data_o<3>" FAST;
NET "data_o<4>" FAST;
NET "data_o<5>" FAST;
NET "data_o<6>" FAST;
NET "data_o<7>" FAST;
NET "CLK_CAN" FAST;
NET "CLK_CNA" FAST;
#
# specification de timings
NET "H50_I" TNM_NET = "H50_I";
TIMESPEC "TS_H50_I" = PERIOD "H50_I" 15 ns HIGH 50 %;

246

247
9. Le projet fréquencemètre
Le but de ce projet est de réaliser un appareil permettant de mesurer une fréquence (de 10 Hz
à 1 MHz) ou une période (entre 100 et 1000 ms). L’affichage s’effectuera de la manière
suivante :
D U P
Valeur affichée = D.Ux10P
Exemples :
F=1586 Hz ⇒ valeur affichée = 1.5 3
T=412 ms ⇒ valeur affichée = 4.1 2
9.1 Le mode fréquencemètre
Le signal d’entrée du fréquencemètre est un signal LVCMOS (0 – 3V) dont la fréquence varie
entre 10 Hz et 1 MHz. La durée de la mesure (la fonction porte) sera égale à 1 seconde. Un
signal RESET remettra à 0 les afficheurs et démarrera la mesure. Une diode LED clignotera
au rythme de la porte. En cas de dépassement de capacité (overflow ou underflow), les
afficheurs 7 segments devront s’éteindre. Le schéma synoptique suivant montre le principe de
fonctionnement de l’appareil :
reset 1 ≤ D ≤ 9 0 ≤ U ≤ 9 1 ≤ P ≤ 5
Porte = 1 s
50 MHz
Hin Compteur 0 → 106
Reset sur front montant de la porte
Registre
Diviseur de fréquence
Gestion
afficheurs
D U P
Le tableau ci-dessous récapitule l’action des interrupteurs ainsi que la fonction des LEDs de la
maquette dans ce mode :

248
BTN3 Reset
SW0 = Hi Mode fréquencemètre
LD0 allumée, LD1 éteinte Mode fréquencemètre
LD2 allumée Underflow (f < 10 Hz)
LD3 allumée Overflow (f ≥ 1 MHz)
LD4 Clignote au rythme de la porte (1 s)
9.2 Le mode périodemètre
Le signal d’entrée du périodemètre est un signal LVCMOS (0 – 3V) dont la fréquence varie
entre 1 Hz et 10 Hz. Dans ce mode, c’est la période du signal Hin qui sert de fonction porte et
on compte le nombre de coups d’horloge à 1 kHz pendant cette durée. Cela nous donne la
période de Hin directement en millisecondes. Le schéma synoptique suivant montre le
principe de fonctionnement de l’appareil :
reset 1 ≤ D ≤ 9 0 ≤ U ≤ 9
P = 2
Horloge 1 kHz
50 MHz
Hin
Compteur 0 → 106 Reset sur front montant
de la porte
Registre
Diviseur de fréquence
Gestion
afficheurs
D U P
Le tableau ci-dessous récapitule l’action des interrupteurs ainsi que la fonction des LEDs de la
maquette dans ce mode :
BTN3 Reset (au relâchement de S1)
SW0 = Lo Mode périodemètre
LD0 éteinte, LD1 allumée Mode périodemètre
LD2 allumée Underflow (T < 100 ms)
LD3 allumée Overflow (T ≥ 1000 ms)
LD4 Clignote au rythme de la porte (Hin)

249
9.3 Création du projet
Créez un nouveau projet (nom du projet : projet ) dans « c:\users\fpga » puis insérez dans ce
projet les fichiers de design freq.vhd et freq_pkg.vhd se trouvant dans
« c:\users\fpga\fichiers ». Ce projet est constitué principalement de 4 composants :
• Horloge, qui génère toutes les horloges nécessaires au projet.
• Count, qui contient le compteur 0 → 106 et le registre.
• Affich, qui gère les trois afficheurs 7 segments.
• Ctrl, qui adapte les signaux d’overflow et d’underflow et qui crée bli.
Le design principal Freq et le composant Horloge sont complets. Le listing du fichier freq.vhd
et son schéma bloc se trouvent à l’annexe 2. Le listing du fichier freq_pkg.vhd et le schéma
bloc du composant horloge se trouvent à l’annexe 3. Les autres composants existent dans
freq_pkg.vhd, mais vous devez compléter leur architecture aux lignes suivantes :
• 201, 206, 210, 218 et 222 pour le composant Count,
• 243 pour le composant Ctrl,
• 281 pour le composant Affich.
Le projet comprend les entrées-sorties suivantes :
Entrée Rôle
Hin Signal à mesurer
H50 50 MHz
FP Mode fréquencemètre, FP_I = 1
Mode périodemètre, FP_I = 0
Reset Actif à 1
Sortie Rôle
Led_porte Led porte LD4
Led_freq Led mode fréquencemètre LD0
Led_per Led mode périodemètre LD1
O_F Led overflow LD3
U_F Led underflow LD2

250
an[3:0] Commande de multiplexage des afficheurs 7 segments
seg[7:0] Afficheur
Le fichier de contraintes correspondant freq.ucf se trouve dans le répertoire
« c:\users\fpga\fichiers ».
9.4 Méthode de travail
Après insertion des deux fichiers VHDL, le gestionnaire de projet ressemble à ceci :
Les 3 buffers d’horloge (BUFG) ont été instanciés à la main ainsi que le module
d’initialisation (STARTUP_SPARTAN3). Il est souvent nécessaire de procéder ainsi car le
synthétiseur produit parfois des résultats surprenants quand le design devient compliqué. Les
3 composants qui se trouvent en dehors du design (gen_cnt, Mux8vers1_4b,
priority_encoder_8vers3) seront instanciés dans les composants count et affich.
Le fichier de stimuli vous est fourni (c:\users\fpga\fichiers\freq_stim.vhd). Il y a dans ce
fichier une horloge à 50 MHz sur H50 et une horloge à 500 kHz sur Hin. Les deux signaux
sont théoriquement asynchrones (dans un vrai fréquencemètre) mais le simulateur gère
difficilement les asynchronismes en simulation de timing car il vérifie le bon respect des
temps de setup des bascules et produit un X en cas de violation. Dans ce fichier, Hin change
sur le front descendant de H50 et est donc synchrone avec le signal Gate. On va démarrer en
mode fréquencemètre (FP = 1).

251
Le problème avec ce design, c’est qu’il faut normalement attendre 1 seconde de simulation
pour obtenir un résultat en sortie, soit 50.106 coups d’horloge, ce qui est beaucoup trop long.
Pour mettre au point le design, nous allons tricher en transformant div50M à la ligne 133 du
fichier freq_pkg.vhd en diviseur par 5000.
Ainsi, la porte ne durera plus que 100 µs au lieu d’une seconde et le nombre de coups
d’horloge nécessaire sera divisé par 10000. Bien entendu, au lieu de compter 500000 périodes
de Hin, le fréquencemètre n’en comptera plus que 50. Cela sera largement suffisant pour
effectuer les tests. La simulation durera 200 µs avec les stimuli suivants :
Nous pouvons tout de suite simuler freq pour comprendre le fonctionnement du bloc horloge.
Vous utiliserez pour cette simulation fonctionnelle le fichier freq.do :
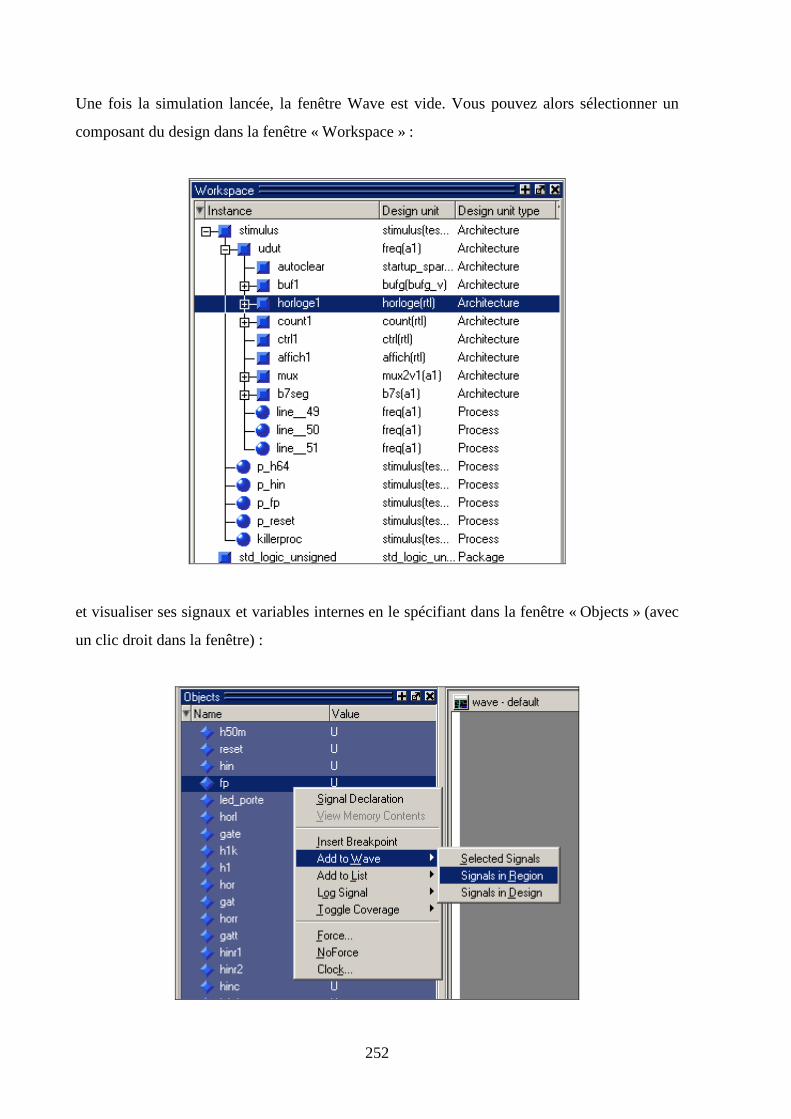
252
Une fois la simulation lancée, la fenêtre Wave est vide. Vous pouvez alors sélectionner un
composant du design dans la fenêtre « Workspace » :
et visualiser ses signaux et variables internes en le spécifiant dans la fenêtre « Objects » (avec
un clic droit dans la fenêtre) :

253
Les signaux apparaissent alors dans la fenêtre Wave. Vous pouvez maintenant lancer la
simulation ( : run -all). Il n’est absolument pas nécessaire d’attendre que le design soit
complet pour commencer les simulations (à condition toutefois que les entrées-sorties de
chaque composant soient définies). Vérifiez et corrigez votre préparation concernant le
composant horloge.
Nous pouvons passer à la synthèse. Il est normal que des avertissements apparaissent dans la
fenêtre inférieure puisque le design n’est pas complet.
Vous pouvez maintenant compléter les composants dans l’ordre suivant : count, affiche puis
ctrl. Commencez par la mise au point du premier composant avec le simulateur, puis
synthétisez le design et vérifiez soigneusement le résultat. Passez ensuite au composant
suivant. Quand tout est terminé, vous vérifierez les résultats de simulation du design complet,
vous synthétiserez puis vous effectuerez le placement routage (n’oubliez pas le fichier de
contraintes freq.ucf). Vous pourrez ensuite télécharger le fichier de configuration dans la
maquette et vérifier le fonctionnement réel. En cas de problème, effectuez une simulation
post-layout (à l’aide de freq_pl.do). Finalement le projet doit ressembler à ceci :

254
9.5 Le composant Horloge
Ce composant existe déjà et il faut que vous analysiez son fonctionnement. Son rôle est de
créer trois signaux en mode fréquencemètre et périodemètre :
• Le signal actionnant la led porte,
• Les signaux Gate et Horl.
On pose FP = 1. Déterminez les chronogrammes (simplifiés) des signaux Led_porte, Gate et
Horl.
Même question avec FP = 0.
9.6 Le composant Count
Le synoptique du composant Count est le suivant :
4
Compteur BCD 6 décadesavec Clear asynchrone
Horl CLR
Gate
Registre 6x4 bits
Gate
4
4
4
4
4
Détection d’overflow O_F
Décade0
Décade5
Décade4
Décade3
Décade2
Décade1
FP
Expliquez à l’aide de chronogrammes simplifiés le rôle de chacun des éléments de ce bloc.
Complétez le composant Count à l’aide de l’éditeur VHDL (vous disposez dans le package
d’un compteur générique gen_cnt pour réaliser un compteur BCD sur 4 bits).
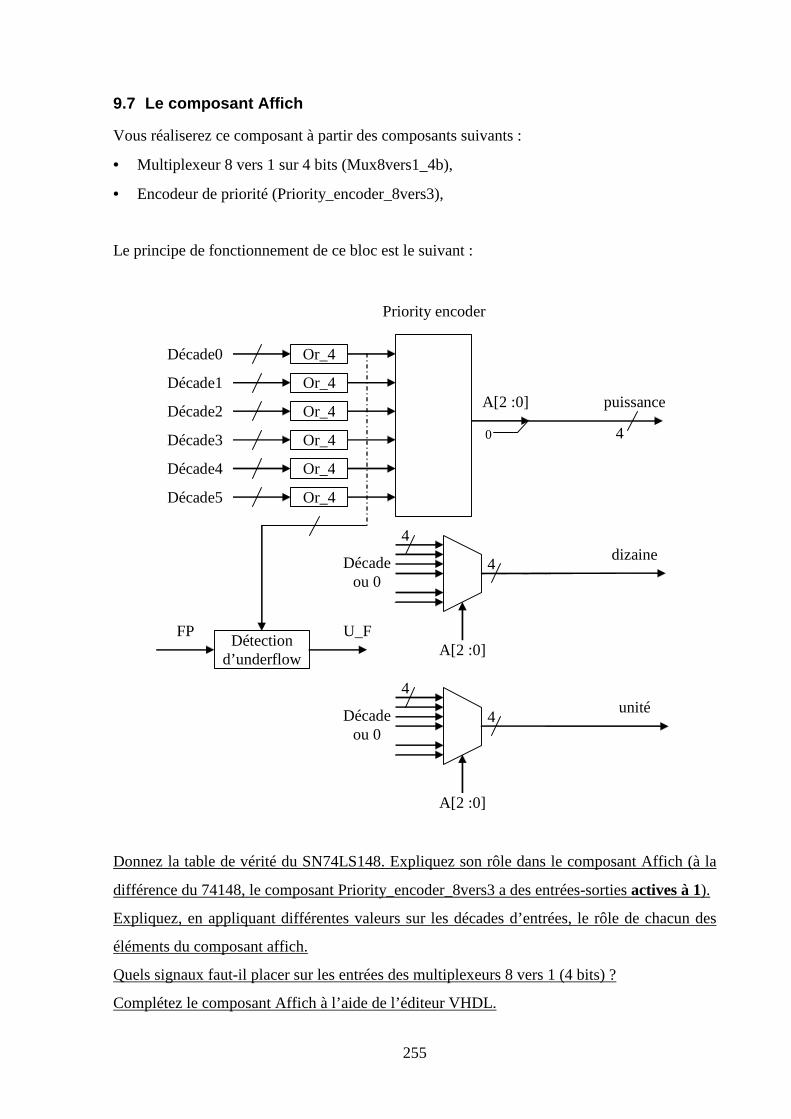
255
9.7 Le composant Affich
Vous réaliserez ce composant à partir des composants suivants :
• Multiplexeur 8 vers 1 sur 4 bits (Mux8vers1_4b),
• Encodeur de priorité (Priority_encoder_8vers3),
Le principe de fonctionnement de ce bloc est le suivant :
0
4
4
4
4
Priority encoder
Décade0
Décade5
Décade4
Décade3
Décade2
Décade1
Or_4
Or_4
Or_4
Or_4
Or_4
Or_4
A[2 :0] puissance
dizaine
A[2 :0]
Décade
ou 0
unité
A[2 :0]
Décade
ou 0
Détection d’underflow
U_F FP
4
Donnez la table de vérité du SN74LS148. Expliquez son rôle dans le composant Affich (à la
différence du 74148, le composant Priority_encoder_8vers3 a des entrées-sorties actives à 1).
Expliquez, en appliquant différentes valeurs sur les décades d’entrées, le rôle de chacun des
éléments du composant affich.
Quels signaux faut-il placer sur les entrées des multiplexeurs 8 vers 1 (4 bits) ?
Complétez le composant Affich à l’aide de l’éditeur VHDL.

256
9.8 Le composant Ctrl
Ce composant permet de créer, à partir du signal d’overflow du composant Count et du signal
d’underflow du composant Affich, les signaux bli (commande d’extinction des afficheurs 7
segments), O_F (commande de la led d’overflow) et U_ F (commande de la led d’underflow).
Complétez le composant Ctrl à l’aide de l’éditeur VHDL.

257
9.9 Annexe 1 : caractéristiques du 74148
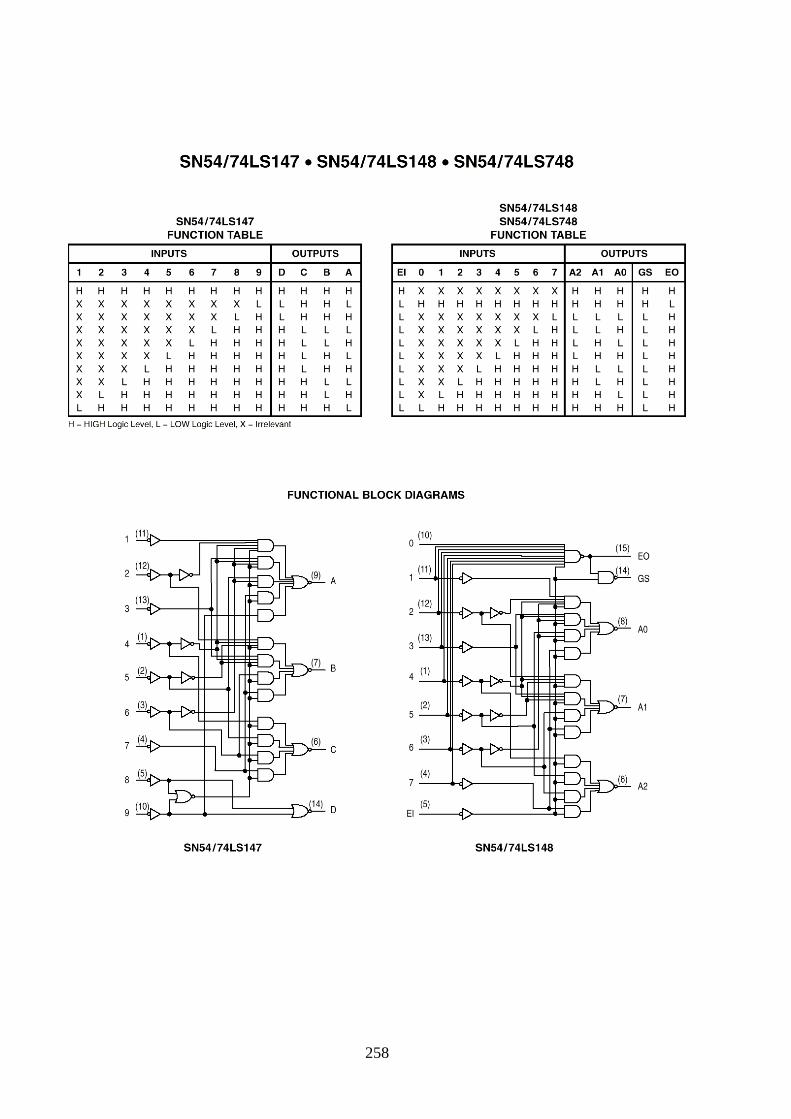
258

259
9.10 Annexe 2 : listing du top level design FREQ
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. use work.freq_pkg.all; 4. library unisim; 5. use unisim.all; 6. 7. entity freq is 8. port(H50 : in std_logic; 9. Reset : in std_logic; 10. Hin : in std_logic; 11. FP : in std_logic; 12. an : out std_logic_vector(3 downto 0); 13. seg : out std_logic_vector(7 downto 0); 14. Led_freq : out std_logic; 15. Led_per : out std_logic; 16. Led_porte : out std_logic; 17. O_F : out std_logic; 18. U_F : out std_logic); 19. end freq; 20. 21. architecture a1 of freq is 22. signal Gate : std_logic; 23. signal H50M : std_logic; 24. signal Horl : std_logic; 25. signal O_Flow : std_logic; 26. signal U_Flow : std_logic; 27. signal Bli : std_logic; 28. signal OD : std_logic_vector(3 downto 0); 29. signal OU : std_logic_vector(3 downto 0); 30. signal OP : std_logic_vector(3 downto 0); 31. signal DCD0 : std_logic_vector(3 downto 0); 32. signal DCD1 : std_logic_vector(3 downto 0); 33. signal DCD2 : std_logic_vector(3 downto 0); 34. signal DCD3 : std_logic_vector(3 downto 0); 35. signal DCD4 : std_logic_vector(3 downto 0); 36. signal DCD5 : std_logic_vector(3 downto 0); 37. signal anode : std_logic_vector(3 downto 0); 38. signal chiffre : std_logic_vector(3 downto 0); 39. component STARTUP_SPARTAN3 40. port (GSR, GTS, CLK : in std_logic); 41. end component; 42. component BUFG 43. port (I : in std_logic; 44. O : out std_logic); 45. end component; 46. begin 47. autoclear : STARTUP_SPARTAN3 port map(Reset, '0', '0'); 48. buf1 : BUFG port map(H50, H50M); 49. Led_freq <= FP; 50. Led_per <= not FP; 51. an <= anode when Bli='0' else (others => 'Z'); 52. 53. horloge1 : horloge port map(H50M, Reset, Hin, FP, Led_porte, Horl, Gate); 54. count1 : count port map(FP, Reset, Gate, Horl, DC D5, DCD4, DCD3, DCD2, DCD1,
DCD0, O_Flow); 55. Ctrl1 : Ctrl port map(U_Flow, O_Flow, Bli, O_F, U _F); 56. affich1 : affich port map(DCD5, DCD4, DCD3, DCD2, DCD1, DCD0, FP, U_Flow, OD,
OU, OP); 57. 58. mux : mux2v1 port map(H50M, Reset, OU, OD, OP, ch iffre, anode); 59. b7seg : b7s port map(chiffre, seg); 60. end;

260
Schéma bloc de freq

261
9.11 Annexe 3 : listing du package freq_pkg
1. library IEEE; 2. use IEEE.std_logic_1164.all; 3. 4. package freq_pkg is 5. 6. TYPE multibus8_4b IS ARRAY (0 TO 7) OF std_logic_v ector(3 DOWNTO 0); 7. 8. component horloge 9. port(H50M : in std_logic; 10. Reset : in std_logic; 11. Hin : in std_logic; 12. FP : in std_logic; 13. Led_porte : out std_logic; 14. Horl : out std_logic; 15. Gate : out std_logic); 16. end component; 17. 18. component count 19. port(FP : in std_logic; 20. Reset : in std_logic; 21. Gate : in std_logic; 22. Horl : in std_logic; 23. DCD5 : out std_logic_vector(3 downto 0); 24. DCD4 : out std_logic_vector(3 downto 0); 25. DCD3 : out std_logic_vector(3 downto 0); 26. DCD2 : out std_logic_vector(3 downto 0); 27. DCD1 : out std_logic_vector(3 downto 0); 28. DCD0 : out std_logic_vector(3 downto 0); 29. O_F : out std_logic); 30. end component; 31. 32. component Ctrl 33. port(U_Flow : in std_logic; 34. O_Flow : in std_logic; 35. Bli : out std_logic; 36. O_F : out std_logic; 37. U_F : out std_logic); 38. end component; 39. 40. component affich 41. port(DCD5 : in std_logic_vector(3 downto 0); 42. DCD4 : in std_logic_vector(3 downto 0); 43. DCD3 : in std_logic_vector(3 downto 0); 44. DCD2 : in std_logic_vector(3 downto 0); 45. DCD1 : in std_logic_vector(3 downto 0); 46. DCD0 : in std_logic_vector(3 downto 0); 47. FP : in std_logic; 48. U_F : out std_logic; 49. OD : out std_logic_vector(3 downt o 0); 50. OU : out std_logic_vector(3 downt o 0); 51. OP : out std_logic_vector(3 downt o 0)); 52. end component; 53. 54. component clk_div_N 55. generic (div : integer := 8); 56. port (clk_in : in std_logic; 57. clear : in std_logic; 58. clk_out : out std_logic); 59. end component; 60. 61. component gen_cnt 62. generic (modulo : integer := 16; wdth : intege r := 4); 63. port (clk : in std_logic ; 64. clear : in std_logic ;

262
65. en : in std_logic ; 66. dout : out std_logic_vector(wdth - 1 down to 0); 67. rco : out std_logic); 68. end component; 69. 70. component b7s 71. port (addr : in std_logic_vector(3 downto 0 ); 72. dout : out std_logic_vector(7 downto 0)); 73. end component; 74. 75. component Mux8vers1_4b 76. port (DataIn : in multibus8_4b; 77. MuxSelect : in std_logic_vector(2 downto 0 ); 78. MuxOut : out std_logic_vector(3 downto 0 ) ); 79. end component; 80. 81. component Priority_encoder_8vers3 82. port (DataIn : in std_logic_vector(7 downto 0 ); 83. DataOut : out std_logic_vector(2 downto 0 ) ); 84. end component; 85. 86. COMPONENT mux2v1 87. port( H50M : in std_logic ; 88. CLEAR : in std_logic; 89. unite : in std_logic_vector(3 downto 0); 90. dizaine : in std_logic_vector(3 downto 0); 91. puissance : in std_logic_vector(3 downto 0); 92. chiffre : out std_logic_vector(3 downto 0) ; 93. an : out std_logic_vector(3 downto 0)); 94. END COMPONENT; 95. 96.end freq_pkg; 97. 98.library IEEE; 99.use IEEE.std_logic_1164.all; 100. use work.freq_pkg.all; 101. library unisim; 102. use unisim.all; 103. 104. entity horloge is 105. port(H50M : in std_logic; 106. Reset : in std_logic; 107. Hin : in std_logic; 108. FP : in std_logic; 109. Led_porte : out std_logic; 110. Horl : out std_logic; 111. Gate : out std_logic); 112. end horloge; 113. 114. architecture RTL of horloge is 115. component BUFG 116. port (I : in std_logic; 117. O : out std_logic); 118. end component; 119. attribute clock_signal : string; 120. signal H1k : std_logic; 121. signal H1 : std_logic; 122. signal hor : std_logic; 123. signal gat : std_logic; 124. signal horr : std_logic; 125. signal gatt : std_logic; 126. signal Hinr1 : std_logic; 127. signal Hinr2 : std_logic; 128. signal Hinc : std_logic; 129. signal H1r1 : std_logic; 130. signal Porte : std_logic;

263
131. begin 132. div50k : clk_div_N generic map(50000) port map(H 50M, Reset, H1K); 133. div50M : clk_div_N generic map(50000000) port ma p(H50M, Reset,
H1); 134. Led_porte <= H1 when FP='1' else Hin; 135. hor <= Hin when FP='1' else H1k; 136. gat <= Porte when FP='1' else Hinc; 137. buf1 : BUFG port map(hor, horr); 138. buf2 : BUFG port map(gat, gatt); 139. Horl <= horr; 140. Gate <= gatt; 141. 142. process(H50M, Reset) begin 143. if (Reset='1') then 144. H1r1 <= '0'; 145. Porte <= '0'; 146. elsif (H50M'event and H50M='1') then 147. H1r1 <= H1; 148. Porte <= H1 and not H1r1; 149. end if; 150. end process; 151. 152. process(horr, Reset) begin 153. if (Reset='1') then 154. Hinr1 <= '0'; 155. Hinr2 <= '0'; 156. Hinc <= '0'; 157. elsif (horr'event and horr='1') then 158. Hinr1 <= Hin; 159. Hinr2 <= Hinr1; 160. Hinc <= Hinr1 and not Hinr2; 161. end if; 162. end process; 163. 164. end; 165. 166. library IEEE; 167. use IEEE.std_logic_1164.all; 168. use work.freq_pkg.all; 169. 170. entity count is 171. port(FP : in std_logic; 172. Reset : in std_logic; 173. Gate : in std_logic; 174. Horl : in std_logic; 175. DCD5 : out std_logic_vector(3 downto 0); 176. DCD4 : out std_logic_vector(3 downto 0); 177. DCD3 : out std_logic_vector(3 downto 0); 178. DCD2 : out std_logic_vector(3 downto 0); 179. DCD1 : out std_logic_vector(3 downto 0); 180. DCD0 : out std_logic_vector(3 downto 0); 181. O_F : out std_logic); 182. end count; 183. 184. architecture RTL of count is 185. signal DC5 : std_logic_vector(3 downto 0); 186. signal DC4 : std_logic_vector(3 downto 0); 187. signal DC3 : std_logic_vector(3 downto 0); 188. signal DC2 : std_logic_vector(3 downto 0); 189. signal DC1 : std_logic_vector(3 downto 0); 190. signal DC0 : std_logic_vector(3 downto 0); 191. signal rco5 : std_logic; 192. signal rco4 : std_logic; 193. signal rco3 : std_logic; 194. signal rco2 : std_logic; 195. signal rco1 : std_logic;

264
196. signal rco0 : std_logic; 197. signal ceo_f : std_logic; 198. signal O_Fa1 : std_logic; 199. begin 200. 201. -- complétez ici 202. 203. process(Horl, Gate) begin 204. if (Gate='1') then 205. 206. -- complétez ici 207. 208. elsif (Horl'event and Horl='1') then 209. 210. -- complétez ici 211. 212. end if; 213. end process; 214. 215. process(Gate, Reset) begin 216. if (Reset='1') then 217. 218. -- complétez ici 219. 220. elsif (Gate'event and Gate='1') then 221. 222. -- complétez ici 223. 224. end if; 225. end process; 226. 227. end; 228. 229. library IEEE; 230. use IEEE.std_logic_1164.all; 231. 232. entity Ctrl is 233. port(U_Flow : in std_logic; 234. O_Flow : in std_logic; 235. Bli : out std_logic; 236. O_F : out std_logic; 237. U_F : out std_logic); 238. end Ctrl; 239. 240. architecture RTL of Ctrl is 241. begin 242. 243. -- complétez ici 244. 245. end; 246. 247. library IEEE; 248. use IEEE.std_logic_1164.all; 249. use work.freq_pkg.all; 250. 251. entity affich is 252. port(DCD5 : in std_logic_vector(3 downto 0); 253. DCD4 : in std_logic_vector(3 downto 0); 254. DCD3 : in std_logic_vector(3 downto 0); 255. DCD2 : in std_logic_vector(3 downto 0); 256. DCD1 : in std_logic_vector(3 downto 0); 257. DCD0 : in std_logic_vector(3 downto 0); 258. FP : in std_logic; 259. U_F : out std_logic; 260. OD : out std_logic_vector(3 downto 0); 261. OU : out std_logic_vector(3 downto 0);

265
262. OP : out std_logic_vector(3 downto 0)); 263. end affich; 264. 265. architecture RTL of affich is 266. signal d5 : std_logic; 267. signal d4 : std_logic; 268. signal d3 : std_logic; 269. signal d2 : std_logic; 270. signal d1 : std_logic; 271. signal d0 : std_logic; 272. signal SelectP : std_logic_vector(7 downto 0); 273. signal Power3 : std_logic_vector(2 downto 0); 274. signal DataP : std_logic_vector(3 downto 0); 275. signal DataU : multibus8_4b; 276. signal DataD : multibus8_4b; 277. signal DoutU : std_logic_vector(3 downto 0); 278. signal DoutD : std_logic_vector(3 downto 0); 279. begin 280. 281. -- complétez ici 282. 283. end; 284. 285. library IEEE; 286. use IEEE.std_logic_1164.all; 287. use IEEE.std_logic_arith.all; 288. use IEEE.STD_LOGIC_UNSIGNED.all; 289. 290. entity clk_div_N is 291. generic (div : integer := 8); 292. port (clk_in : in std_logic; 293. clear : in std_logic; 294. clk_out : out std_logic); 295. end clk_div_N; 296. 297. architecture RTL of clk_div_N is 298. signal clk_tmp : std_logic; 299. signal compte : integer range 0 to div-1; 300. begin 301. PROCESS (clk_in, clear) BEGIN 302. if (clear = '1') then 303. clk_tmp <= '0'; 304. compte <= 0; 305. elsif (clk_in'event and clk_in='1') then 306. if compte = ((div/2)-1) then 307. compte <= 0; 308. clk_tmp <= not clk_tmp; 309. else 310. compte <= compte + 1; 311. end if; 312. end if; 313. END PROCESS; 314. clk_out <= clk_tmp; 315. end; 316. 317. library IEEE; 318. use IEEE.std_logic_1164.all; 319. use IEEE.std_logic_arith.all; 320. use IEEE.STD_LOGIC_UNSIGNED.all; 321. 322. entity gen_cnt is 323. generic (modulo : integer := 16; wdth : integer := 4); 324. port (clk : in std_logic ; 325. clear : in std_logic ; 326. en : in std_logic ; 327. dout : out std_logic_vector(wdth - 1 downto 0);

266
328. rco : out std_logic); 329. end gen_cnt ; 330. 331. architecture comporte of gen_cnt is 332. signal state : std_logic_vector(dout'range); 333. begin 334. process(clk, clear) 335. begin 336. if clear = '1' then 337. state <= (others => '0'); 338. elsif (clk'event and clk = '1') then 339. if (en = '1') then 340. if (state = modulo - 1) then 341. state <= (others => '0'); 342. else 343. state <= (state + 1); 344. end if; 345. end if; 346. end if ; 347. end process; 348. rco <= en when state = modulo - 1 else '0' ; 349. dout <= state ; 350. end comporte ; 351. 352. library IEEE; 353. use IEEE.std_logic_1164.all; 354. use IEEE.std_logic_arith.all; 355. use IEEE.std_logic_unsigned.all; 356. 357. entity b7s is 358. port (addr : in std_logic_vector(3 downto 0); 359. dout : out std_logic_vector(7 downto 0) ); 360. end b7s; 361. 362. architecture a1 of b7s is 363. TYPE mem_data IS ARRAY (0 TO 15) OF std_logic_vec tor(7 DOWNTO 0); 364. constant data : mem_data := ( 365. ("01000000"), 366. ("01111001"), 367. ("00100100"), 368. ("00110000"), 369. ("00011001"), 370. ("00010010"), 371. ("00000010"), 372. ("01111000"), 373. ("00000000"), 374. ("00010000"), 375. ("11111111"), 376. ("11111111"), 377. ("11111111"), 378. ("11111111"), 379. ("11111111"), 380. ("11111111")); 381. begin 382. PROCESS (addr) BEGIN 383. dout <= data(CONV_INTEGER(addr)); 384. END PROCESS; 385. end; 386. 387. library IEEE; 388. use IEEE.std_logic_1164.all; 389. use IEEE.std_logic_arith.all; 390. use IEEE.std_logic_unsigned.all; 391. use work.freq_pkg.all; 392. 393. entity Mux8vers1_4b is

267
394. port (DataIn : in multibus8_4b; 395. MuxSelect : in std_logic_vector(2 downto 0); 396. MuxOut : out std_logic_vector(3 downto 0) ); 397. end Mux8vers1_4b; 398. architecture a1 of Mux8vers1_4b is 399. begin 400. Muxout <= datain(CONV_INTEGER(UNSIGNED(Muxselec t))); 401. end; 402. 403. library IEEE; 404. use IEEE.std_logic_1164.all; 405. use IEEE.std_logic_arith.all; 406. use IEEE.std_logic_unsigned.all; 407. 408. entity Priority_encoder_8vers3 is 409. port (DataIn : in std_logic_vector(7 downto 0); 410. DataOut : out std_logic_vector(2 downto 0) ); 411. end Priority_encoder_8vers3; 412. 413. architecture a1 of Priority_encoder_8vers3 is 414. begin 415. PROCESS (DataIn) BEGIN 416. DataOut <= (others => '0'); 417. Search : for I in DataIn'range loop 418. if DataIn(I) = '1' then 419. DataOut <= std_logic_vector(CONV_UNSIGNED(I,3)) ; 420. exit Search; 421. end if; 422. end loop Search; 423. END PROCESS; 424. end; 425. 426. library IEEE; 427. use IEEE.std_logic_1164.all; 428. use IEEE.std_logic_arith.all; 429. use IEEE.STD_LOGIC_UNSIGNED.all; 430. 431. entity mux2v1 is 432. port( H50M : in std_logic ; 433. CLEAR : in std_logic; 434. unite : in std_logic_vector(3 downto 0); 435. dizaine : in std_logic_vector(3 downto 0); 436. puissance : in std_logic_vector(3 downto 0); 437. chiffre : out std_logic_vector(3 downto 0); 438. an : out std_logic_vector(3 downto 0)); 439. end mux2v1; 440. 441. architecture a1 of mux2v1 is 442. signal compte : std_logic_vector(15 downto 0) ; 443. signal an_int : std_logic_vector(3 downto 0) ; 444. begin 445. 446. process(H50M, CLEAR) begin 447. if (CLEAR='1') then 448. compte <= (others => '0'); 449. an_int <= "0111"; 450. elsif (H50M'event and H50M='1') then 451. if (compte = 49999) then 452. compte <= (others => '0'); 453. an_int(3) <= an_int(2); 454. an_int(2) <= an_int(1); 455. an_int(1) <= an_int(0); 456. an_int(0) <= an_int(3); 457. else 458. compte <= compte + 1; 459. end if;

268
460. end if; 461. end process; 462. 463. process(an_int, dizaine, unite, puissance) begin 464. if (an_int(3) = '0') then -- chiffres de gauche à droite 465. chiffre <= dizaine; 466. elsif (an_int(2) = '0') then 467. chiffre <= unite; 468. elsif (an_int(1) = '0') then 469. chiffre <= (others => '1'); 470. else 471. chiffre <= puissance; 472. end if; 473. end process; 474. 475. an <= an_int; 476. end;
269
Schéma bloc d’horloge

270


















