

Arbresudsmed.u-strasbg.fr/labiostat/IMG/pdf/V_diffusion_Arbres.pdf · – Croissance de l'arbre –...
55
Transcript of Arbresudsmed.u-strasbg.fr/labiostat/IMG/pdf/V_diffusion_Arbres.pdf · – Croissance de l'arbre –...

IntroductionIntroduction

SemStat 06/02/2007 3
GénéralitésGénéralités
• Dans les méthodes de data mining• Vocabulaire particulier• Deux grandes phases
– Croissance de l'arbre– Elagage ("pruning") : on regroupe des feuilles

SemStat 06/02/2007 4
Deux types d'arbresDeux types d'arbres
• Arbres de classification– Décision– Prédiction
• Arbres de régression• Définitions
– Nœuds– Branches– Feuilles
SemStat 06/02/2007 5
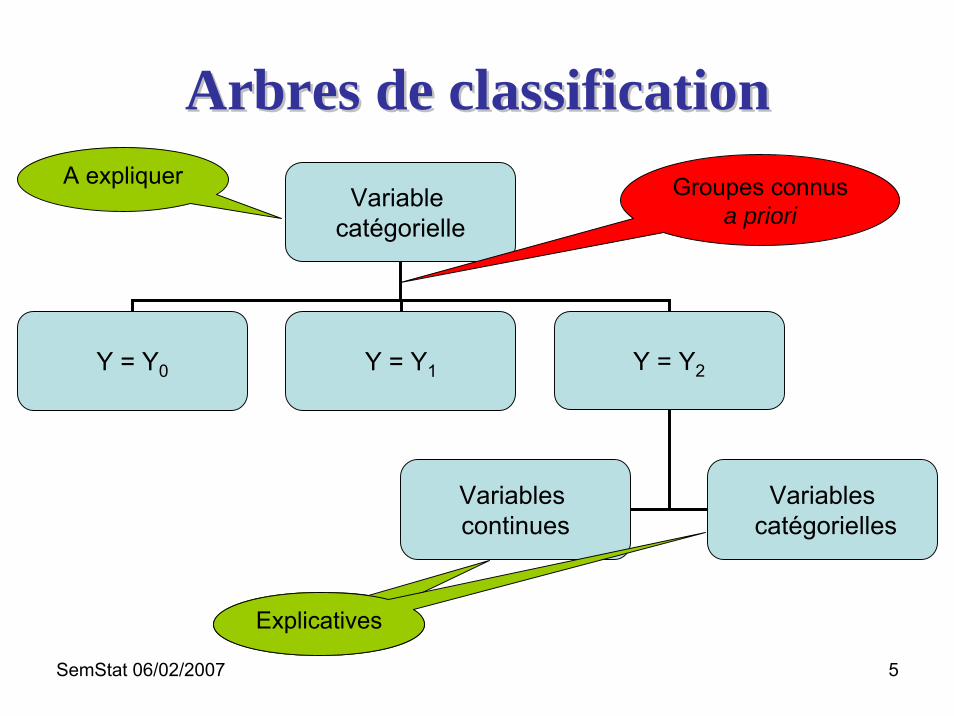
Arbres de classificationArbres de classification
Variable catégorielle
Y = Y0 Y = Y1 Y = Y2
Variables continues
Variablescatégorielles
Groupes connus a priori
A expliquer
ExplicativesExplicatives
SemStat 06/02/2007 6
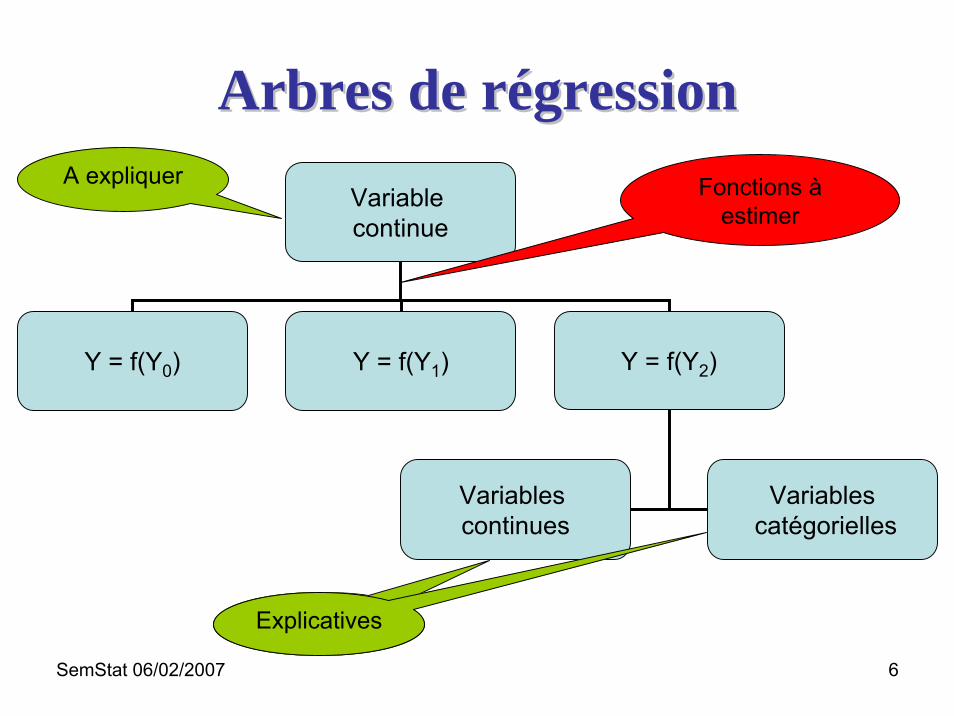
Arbres de régressionArbres de régression
Variable continue
Y = f(Y0) Y = f(Y1) Y = f(Y2)
Variables continues
Variablescatégorielles
A expliquer
ExplicativesExplicatives
Fonctions à estimer

SemStat 06/02/2007 7
Différences entre arbresDifférences entre arbres
• Classification1. Groupes définis a priori par la variable
catégorielle à expliquer2. Quelles variables classent le mieux les
observations dans les groupes?• Régression
1. Quelles variables prédisent le mieux la variable à expliquer?
2. Groupes définis a posteriori pour la variable continue à expliquer

SemStat 06/02/2007 8
VocabulaireVocabulaire
• Partitionnement– Un nœud (parent) donne naissance à d'autres nœuds
(enfants)– En réponse à une question sur une variable
explicative• Arbre binaire
– Chaque nœud parent n'a que deux nœuds enfants– Arbre m-aire
• Partitionnement récursif– Chaque nœud enfant peut devenir nœud parent

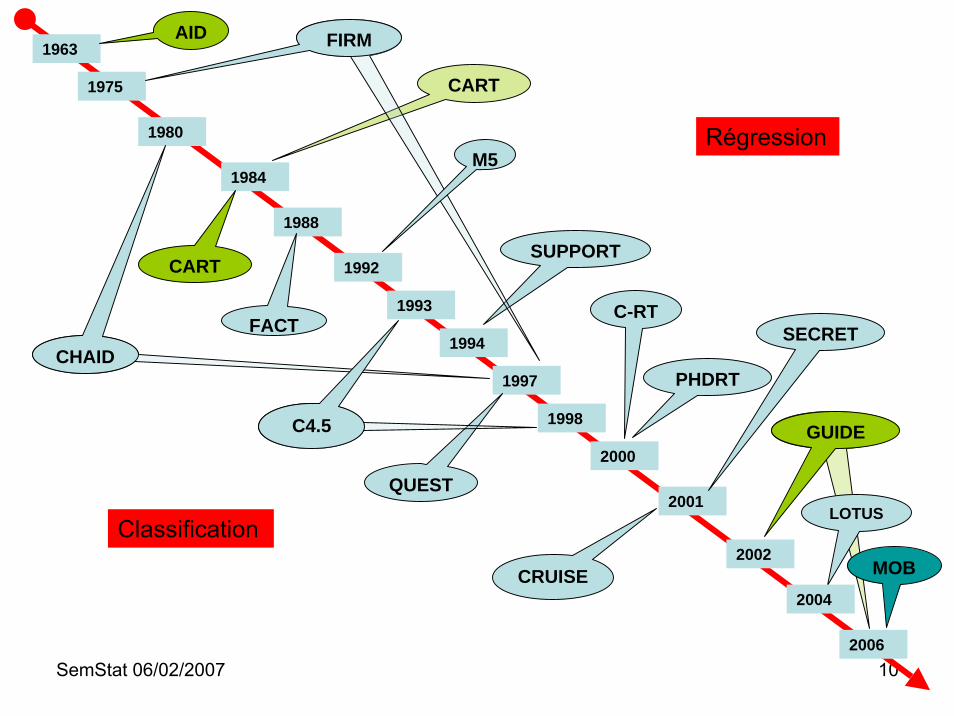
HistoriqueHistorique
SemStat 06/02/2007 10
Régression
Classification
GUIDE
1963AID
1984
1994
2002
2006
CART
CARTSUPPORT
GUIDE
MOB
2000
C-RT
FIRM
1975
1997
2001
FIRM
M5
1992
QUEST
PHDRT
CRUISE
SECRET
LOTUS
CHAID
C4.5
1988
FACT
1980
CHAID
1993
1998C4.5
2004

Arbres de classification et Arbres de classification et algorithme CARTalgorithme CART

SemStat 06/02/2007 12
CARTCART
• CART = Classification And RegressionTree
– Par essence classificatoire– Breiman, 1984
• Quatre grandes étapes1.Permettre à l'arbre de grandir2.Arrêter sa croissance3.Elaguer progressivement l'arbre4.Sélectionner le plus bel arbre

SemStat 06/02/2007 13
CART (1)CART (1)
• Position du problème– Variable dépendante catégorielle (à expliquer)– Variables indépendantes (explicatives)– Prédire la catégorie du résultat grâce aux
variables explicatives• Partitionnement binaire récursif
– Deux enfants question dont la réponse ne peut être que oui ou non
• Age < 64 ans ?

SemStat 06/02/2007 14
CART (1)CART (1)• Partitionnement ("splitting")
Y = Y0 (n=40)Y = Y1 (n=30)Y = Y2 (n=20)Y = Y3 (n=10)
Y = Y0 (n=40)Y = Y1 (n=30)Y = Y2 (n=20)Y = Y3 (n=10)
– Règle de Gini : isoler la catégorie la plus fréquente
A B
Y = Y0 (n=40)Y = Y1 (n=30)Y = Y2 (n=20)Y = Y3 (n=10)
Y = Y0 (n=40)Y = Y3 (n=10)
Y = Y1 (n=30)Y = Y2 (n=20)
– Règle de Twoing : équilibrer les enfants
A B
Quelle variable explicative?Quelles catégories ou bornes?
Quelle variable explicative?Quelles catégories ou bornes?
SemStat 06/02/2007 15
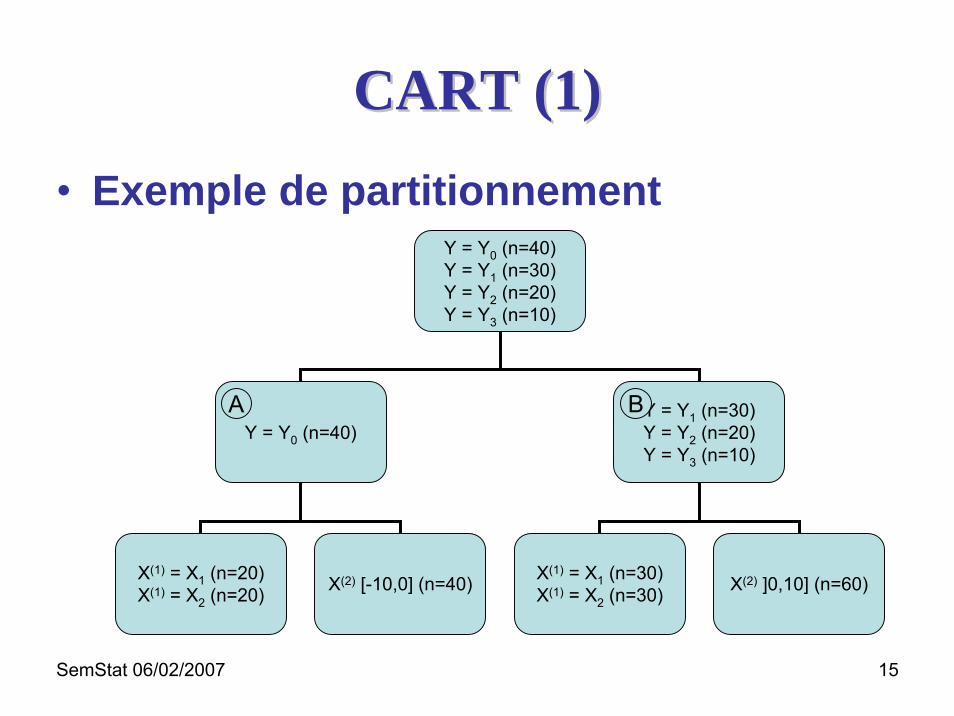
CART (1)CART (1)• Exemple de partitionnement
Y = Y0 (n=40)Y = Y1 (n=30)Y = Y2 (n=20)Y = Y3 (n=10)
Y = Y0 (n=40)Y = Y1 (n=30)Y = Y2 (n=20)Y = Y3 (n=10)
X(1) = X1 (n=30)X(1) = X2 (n=30)
X(1) = X1 (n=20)X(1) = X2 (n=20) X(2) [-10,0] (n=40) X(2) ]0,10] (n=60)
BA
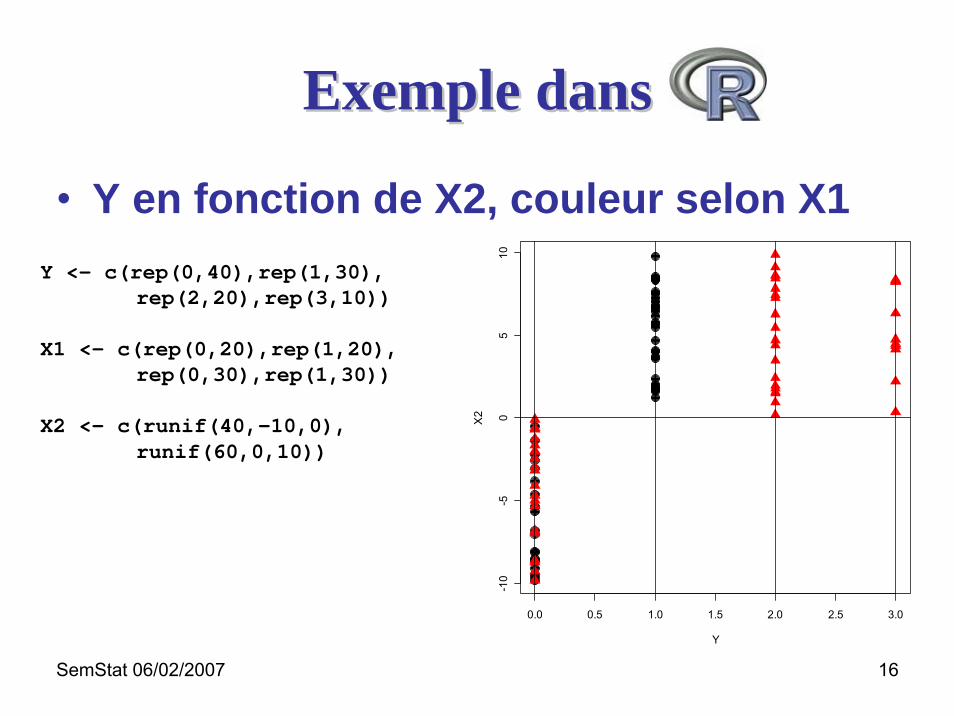
SemStat 06/02/2007 16
Exemple dansExemple dans
• Y en fonction de X2, couleur selon X1
0.0 0.5 1.0 1.5 2.0 2.5 3.0
-10
-50
510
Y
X2
Y <- c(rep(0,40),rep(1,30),rep(2,20),rep(3,10))
X1 <- c(rep(0,20),rep(1,20),rep(0,30),rep(1,30))
X2 <- c(runif(40,-10,0),runif(60,0,10))
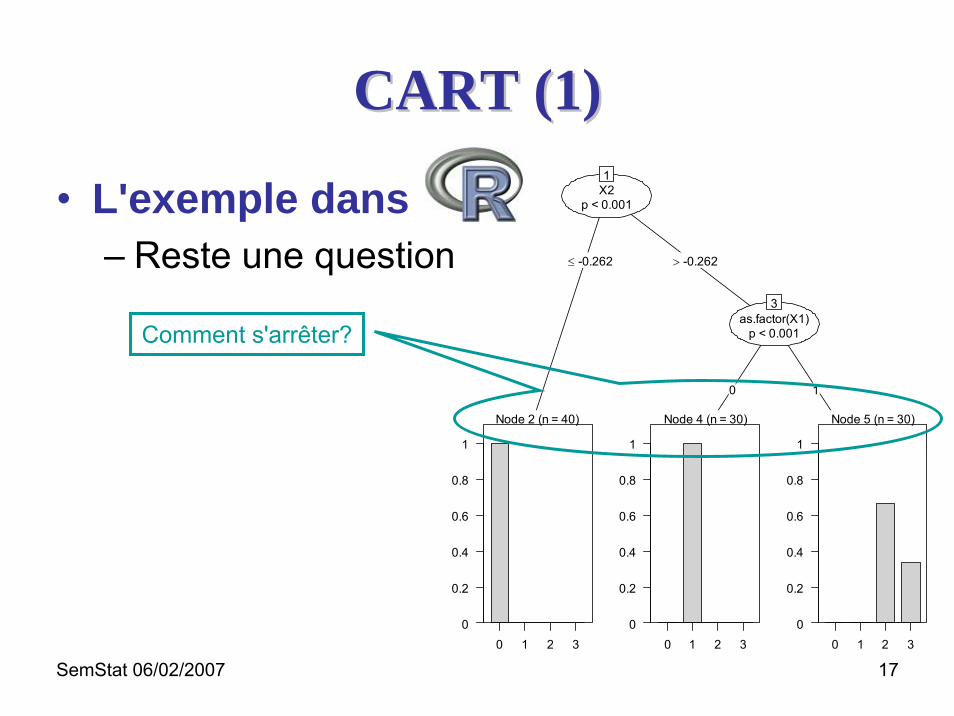
SemStat 06/02/2007 17
CART (1)CART (1)
• L'exemple dans– Reste une question
X2p < 0.001
1
≤ -0.262 > -0.262
Node 2 (n = 40)
0 1 2 30
0.2
0.4
0.6
0.8
1
as.factor(X1)p < 0.001
3
0 1
Node 4 (n = 30)
0 1 2 30
0.2
0.4
0.6
0.8
1
Node 5 (n = 30)
0 1 2 30
0.2
0.4
0.6
0.8
1
Comment s'arrêter?

SemStat 06/02/2007 18
CART (2)CART (2)
• Laisser croître l'arbre le plus possible– Une observation dans chaque nœud terminal– Nombre de division– Même valeur de Y dans les nœuds terminaux

SemStat 06/02/2007 19
CART (3)CART (3)
• Elagage– Paramètre de complexité de l'arbre– Réduction de complexité "coût" de
mauvaise classification (à définir)– Sélection de plusieurs arbres de moins en
moins complexes• Exemple dans
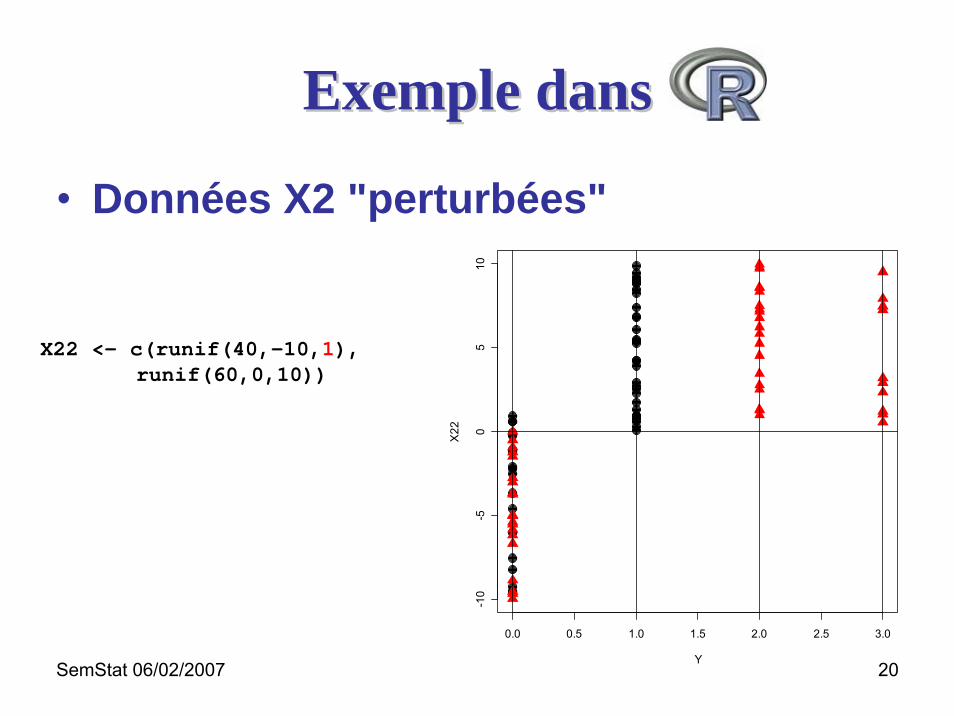
SemStat 06/02/2007 20
Exemple dansExemple dans
• Données X2 "perturbées"
0.0 0.5 1.0 1.5 2.0 2.5 3.0
-10
-50
510
Y
X22
X22 <- c(runif(40,-10,1),runif(60,0,10))
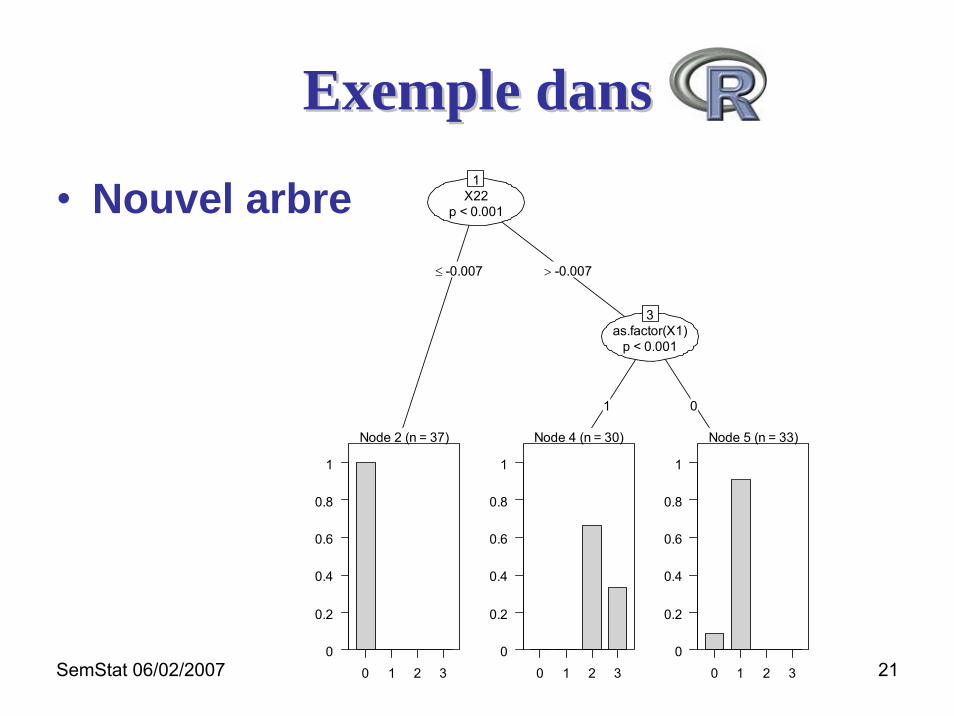
SemStat 06/02/2007 21
Exemple dansExemple dans
• Nouvel arbre X22p < 0.001
1
≤ -0.007 > -0.007
Node 2 (n = 37)
0 1 2 30
0.2
0.4
0.6
0.8
1
as.factor(X1)p < 0.001
3
1 0
Node 4 (n = 30)
0 1 2 30
0.2
0.4
0.6
0.8
1
Node 5 (n = 33)
0 1 2 30
0.2
0.4
0.6
0.8
1

SemStat 06/02/2007 22
CART (4)CART (4)
• Arbre optimal– Décider de la complexité à garder– "Overfit" des arbres sur les données
d'apprentissage– Données de test
• Véritable jeu de données• Validation croisée (10)

SemStat 06/02/2007 23
CARTCART
• Inconvénients– Algorithme glouton ("greedy")
• Etudie toutes les partitions binaires– Biais dans la sélection des variables
• Nombreuses modalités favorisées
• Alternative– Modèle logistique polytomique
• Exemple
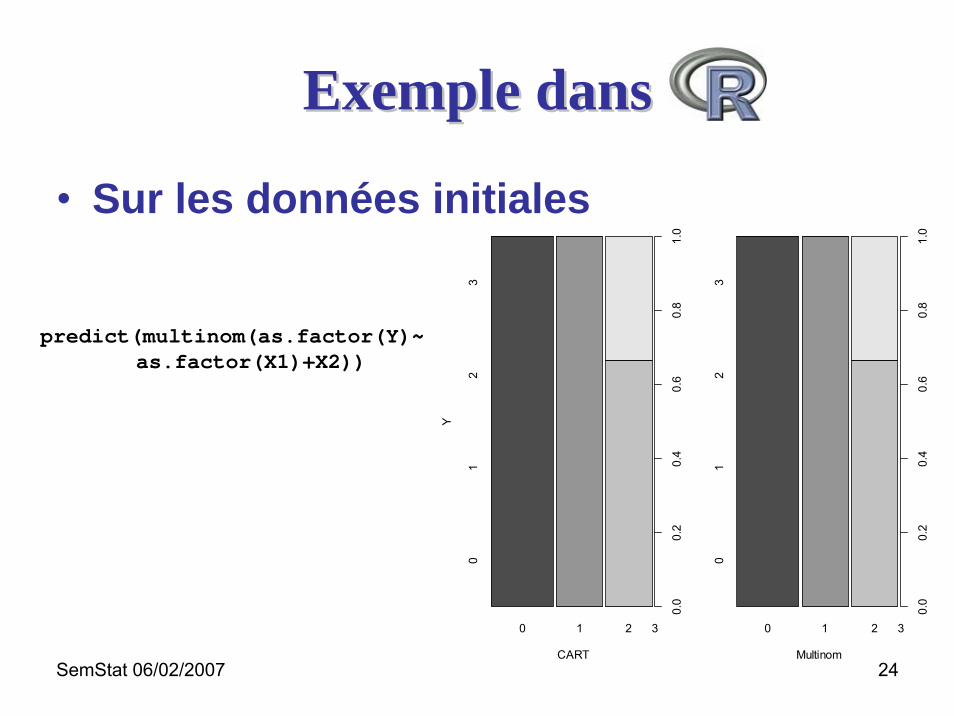
SemStat 06/02/2007 24
Exemple dansExemple dans
• Sur les données initiales
CART
Y
0 1 2 3
01
23
0.0
0.2
0.4
0.6
0.8
1.0
Multinom
0 1 2 3
01
23
0.0
0.2
0.4
0.6
0.8
1.0
predict(multinom(as.factor(Y)~as.factor(X1)+X2))

Arbres de régressionArbres de régression

SemStat 06/02/2007 26
Arbres de régressionArbres de régression
• Principe général– Variable à prédire ("class") continue– Variables prédictives ("attributes") discrètes et
continues– Y = f(X1, …, XJ)
• Evolution de CART pour régression : C-RT
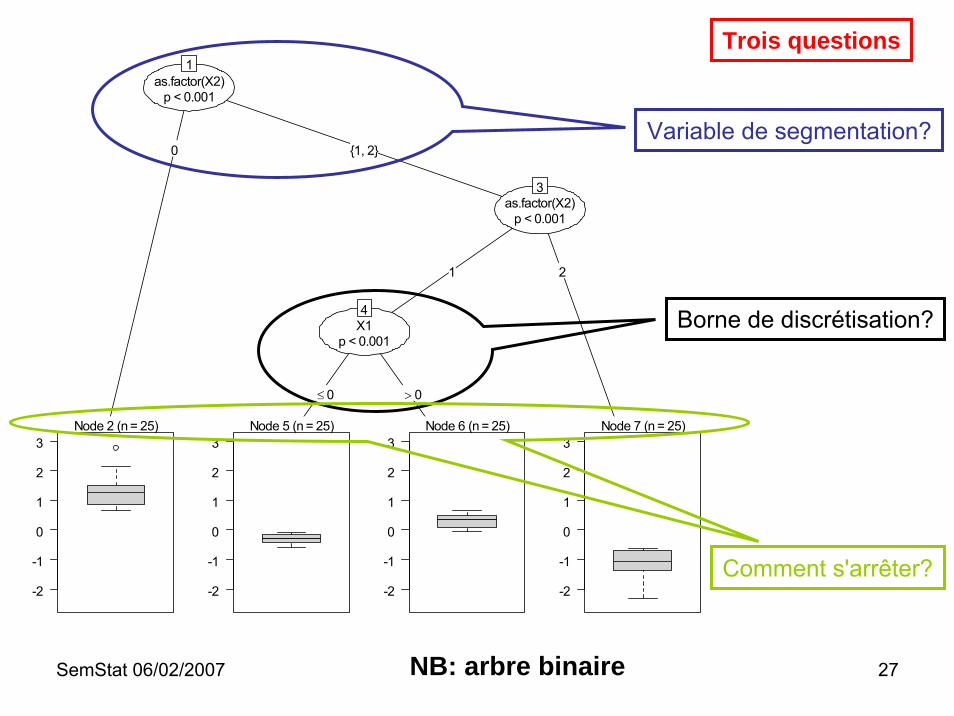
SemStat 06/02/2007 27
as.factor(X2)p < 0.001
1
0 {1, 2}
Node 2 (n = 25)
-2
-1
0
1
2
3
as.factor(X2)p < 0.001
3
1 2
X1p < 0.001
4
≤0 > 0
Node 5 (n = 25)
-2
-1
0
1
2
3Node 6 (n = 25)
-2
-1
0
1
2
3Node 7 (n = 25)
-2
-1
0
1
2
3
Variable de segmentation?
Borne de discrétisation?
Comment s'arrêter?
Trois questions
NB: arbre binaire

SemStat 06/02/2007 28
Trois questionsTrois questions
• Choix des variables de segmentation?– ANOVA
SCT = SC"B" + SC"W"
– Xj = arg max(SC"B"(X))– Maximisation de la disparité entre les groupes
( ) ( ) ( )∑∑∑∑ −+−=−jn G
jijG
jjn
i yyyynyy 222
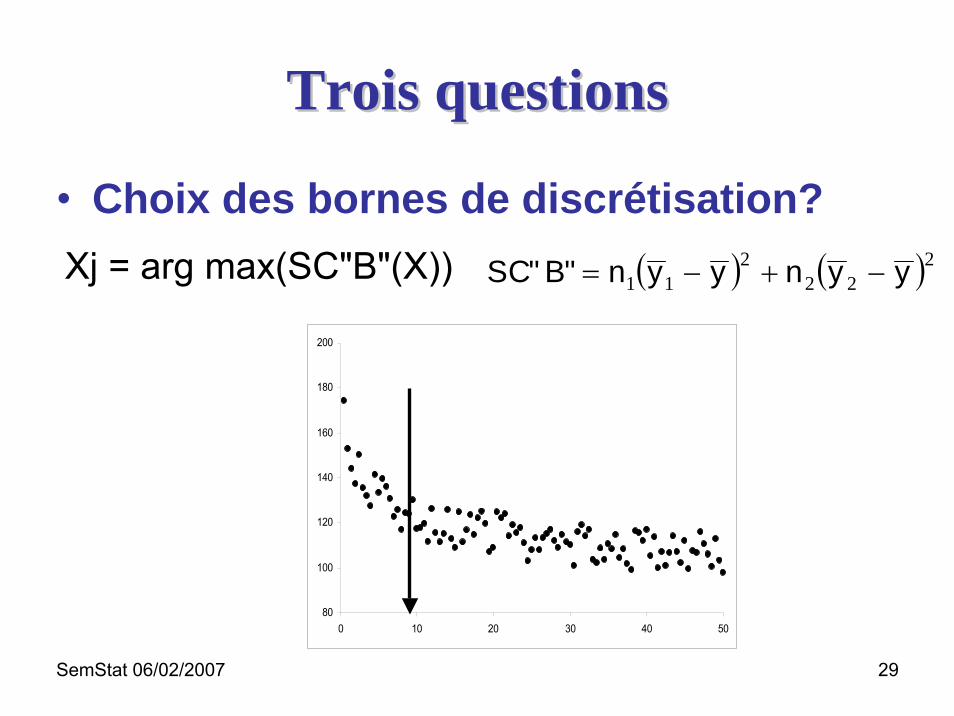
SemStat 06/02/2007 29
Trois questionsTrois questions
• Choix des bornes de discrétisation?
80
100
120
140
160
180
200
0 10 20 30 40 50
Xj = arg max(SC"B"(X)) ( ) ( )2222
11 yynyyn"B"SC −+−=

SemStat 06/02/2007 30
Trois questionsTrois questions
• Règles d'arrêt– Critères empiriques
• Effectif minimum pour segmenter• Nombre de niveaux de l'arbre
– Critères statistiques (AID)• On segmente si la signification de l'ANOVA est
inférieure à un seuil fixé
• Elagage– Minimiser l'erreur de prédiction ∑ −
Nii )yy( 2

SemStat 06/02/2007 31
InconvénientsInconvénients
• Greedy = gourmand– Comparer tous les découpages possibles– Temps machine– Toutes sortes de trucs pour gagner du temps– Autres algorithmes utilisant des statistiques
• SUPPORT (1994): test sur le signe des résidus pour séparer deux classes
• GUIDE (2002, 2006)

SemStat 06/02/2007 32
SUPPORTSUPPORT
• Première utilisation de résidus– ri = yi – mean(Y)– Deux séries de résidus : positifs et négatifs
• Test de comparaison de moyenne (variances inégales)– Pour toutes les variables : retenir la
signification le plus faible• Séparer au mieux deux groupes de part
et d'autre de la moyenne de Y

SemStat 06/02/2007 33
GUIDEGUIDE
• Wei-Yin Loh, Statistica Sinica 2002• Tests sur les variables et leurs interactions
– Chi² (Pearson)– Tableaux par catégorie ou quantile
• Algorithme de choix des variables– Signification des tests de variables– Signification des tests d'interaction– Type de variables (continues ou discrètes)
• Biais de sélection diminué

SemStat 06/02/2007 34
Arbres conditionnelsArbres conditionnels
• Principe général– Tests de permutation– Distribution conditionnelle des statistiques
• Sans biais

SemStat 06/02/2007 35
AlternativeAlternative
• Régression linéaire multiple– Lissage par splines – Avantage des arbres: estimations locales des
moyennes de Y
• Exemple dans

SemStat 06/02/2007 36
Exemple dansExemple dans
• Données les plus simples as.factor(X1)p < 0.001
1
1 0
Node 2 (n = 50)
-3
-2
-1
0
1
2
Node 3 (n = 50)
-3
-2
-1
0
1
2
Y <- sort(rnorm(100))X1 <- c(rep(0,50),rep(1,50))
> mean(Y);sd(Y)[1] -0.1007885[1] 0.9287044
> mean(Y[slot(m.0,"where")==2]);sd(Y[slot(m.0,"where")==2])[1] 0.63834[1] 0.5565293
> mean(Y[slot(m.0,"where")==3]);sd(Y[slot(m.0,"where")==3])[1] -0.839917[1] 0.5638619
SemStat 06/02/2007 37
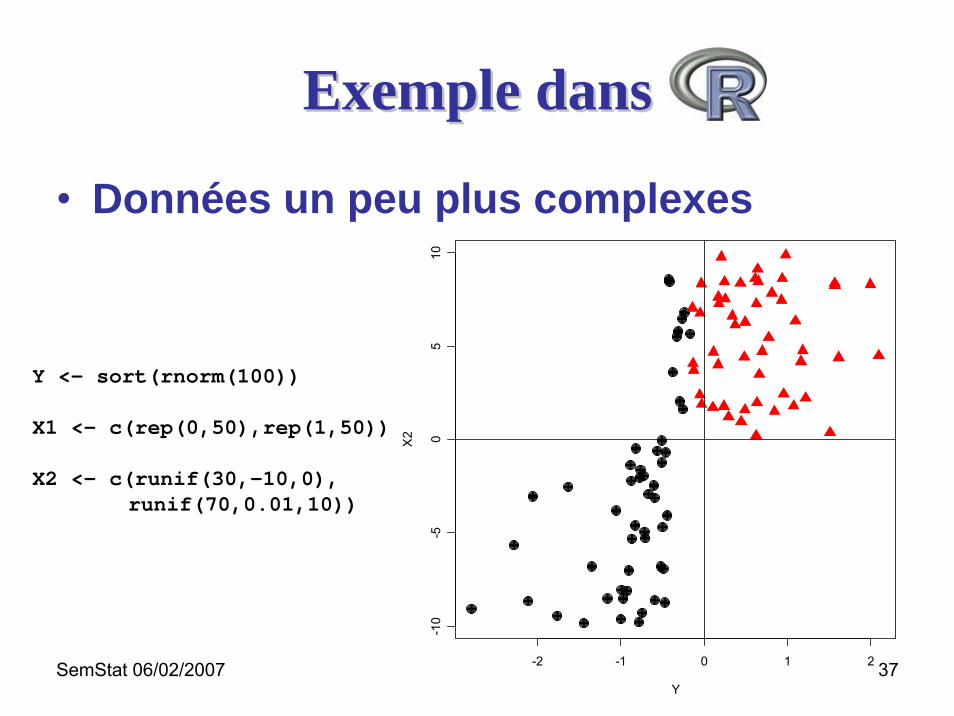
Exemple dansExemple dans
• Données un peu plus complexes
Y <- sort(rnorm(100))
X1 <- c(rep(0,50),rep(1,50))
X2 <- c(runif(30,-10,0),runif(70,0.01,10))
-2 -1 0 1 2
-10
-50
510
Y
X2
SemStat 06/02/2007 38
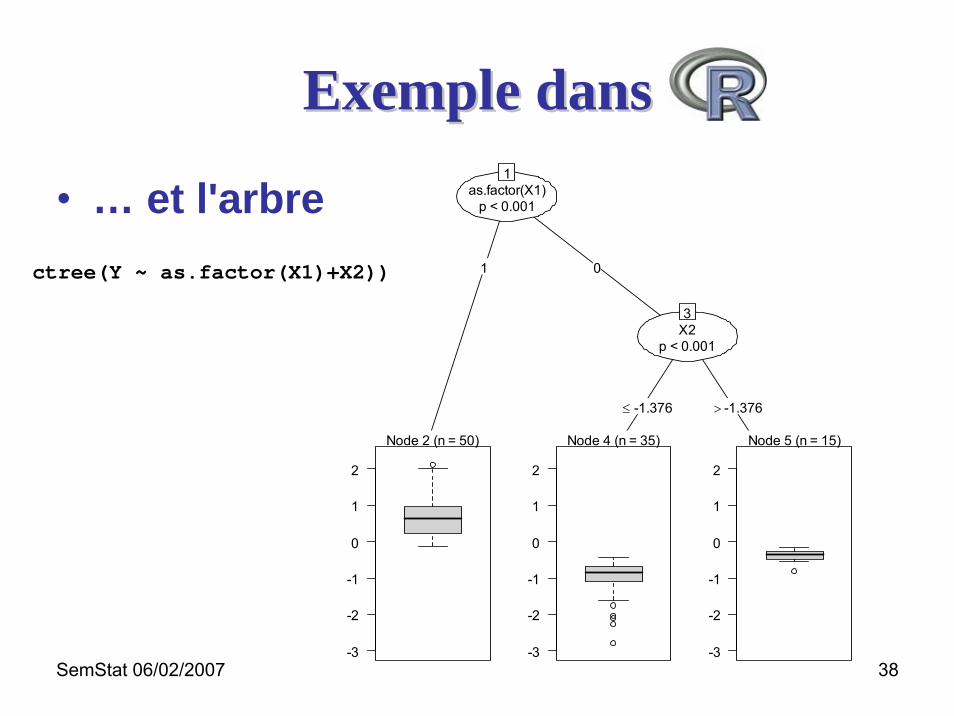
Exemple dansExemple dans
• … et l'arbrectree(Y ~ as.factor(X1)+X2))
as.factor(X1)p < 0.001
1
1 0
Node 2 (n = 50)
-3
-2
-1
0
1
2
X2p < 0.001
3
≤ -1.376 > -1.376
Node 4 (n = 35)
-3
-2
-1
0
1
2
Node 5 (n = 15)
-3
-2
-1
0
1
2

SemStat 06/02/2007 39
LimiteLimite
• Données complexes– Multiples nœuds terminaux
• Classification versus régression– On reste avec des "boîtes"– Se rapprocher d'une vision continue

SemStat 06/02/2007 40
AméliorationsAméliorations• Combinaison linéaire d'arbres
– Plus difficilement lisible qu'un arbre– Bagging
• Breiman, 1996• Plusieurs arbres sur échantillons boostrappés
– Random forest• Breiman, 2001• Plusieurs arbres sur échantillons boostrappés• A chaque nœud, partitionnement sur échantillon aléatoire de
variables explicatives (!!)– Boosting
• Défavorise (sous-pondère) les arbres moins prédictifs

SemStat 06/02/2007 41
Version bayésienneVersion bayésienne
• BART : Bayesian Additive Regression Trees– Chipman, 2005– Y = f(X1, …, XJ) + N(0,σ²)– f(X) est une somme d'arbres
• Numéro d'arbre• Estimateur de Y dans chacun des nœuds terminaux
– Priors• Chaque arbre et chaque estimateur de Y• σ²

SemStat 06/02/2007 42
AméliorationsAméliorations
• Arbres basés sur des modèles– Zeileis 2005, GUIDE 2006
– Spécification• Y = f(X1, …, XJ | Z1, …, ZL)• Variable dépendante : Y• Régresseurs : X• Variables "d'ajustement" : Z
– Ajuster des modèles Y = f(X) dans chacun des nœuds terminaux, déterminés par le partitionnement sur les Z
• Bayesian treed GLM

SemStat 06/02/2007 43
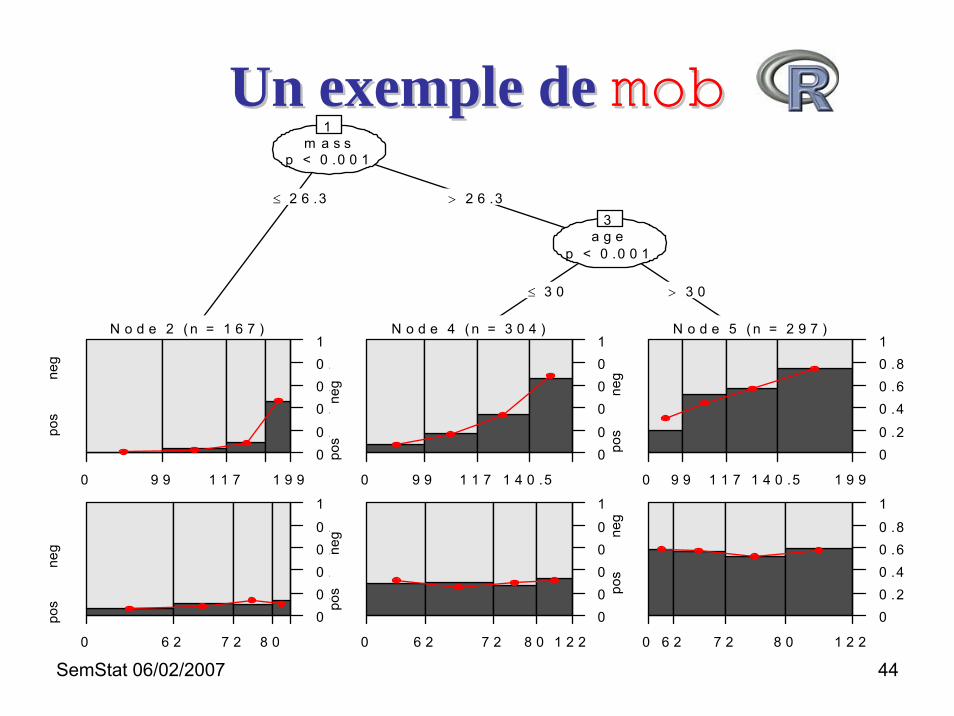
Un exemple de Un exemple de mobmob
• Pima Indians diabetes
• Modèle logistique
pregnant Nombre de grossesse Zglucose Glucose plasmatique Xpressure Pression sanguine diastolique (mm Hg) Xtriceps Epaisseur du pli cutané au triceps (mm) Zinsulin Insuline plasmatique (mu U/ml) Zmass Indice de masse corporelle Zpedigree "Diabetes pedigree function" Zage Age (années) Zdiabetes Diabète (test positif vs test négatif) Y
SemStat 06/02/2007 44
Un exemple de Un exemple de mobmobm a s s
p < 0 .0 0 1
1
≤ 2 6 .3 > 2 6 .3
N o d e 2 ( n = 1 6 7 )
0 9 9 1 1 7 1 9 9
pos
neg
00 .2
0 .40 .60 .81
0 6 2 7 2 8 0
pos
neg
00 .20 .40 .60 .8
1
a g ep < 0 .0 0 1
3
≤ 3 0 > 3 0
N o d e 4 ( n = 3 0 4 )
0 9 9 1 1 7 1 4 0 .5
pos
neg
00 .2
0 .40 .60 .81
0 6 2 7 2 8 0 1 2 2
pos
neg
00 .20 .40 .60 .8
1
N o d e 5 ( n = 2 9 7 )
0 9 9 1 1 7 1 4 0 .5 1 9 9
pos
neg
00 .2
0 .40 .60 .81
0 6 2 7 2 8 0 1 2 2
pos
neg
00 .20 .40 .60 .8
1

SemStat 06/02/2007 45
ConcurrentsConcurrents
• Régressions linéaire et logistique• MARS
– Multivariate Adaptive polynomial RegressionSpline
• Neural networks– Généralisation des modèles régressifs– Data mining

SemStat 06/02/2007 46
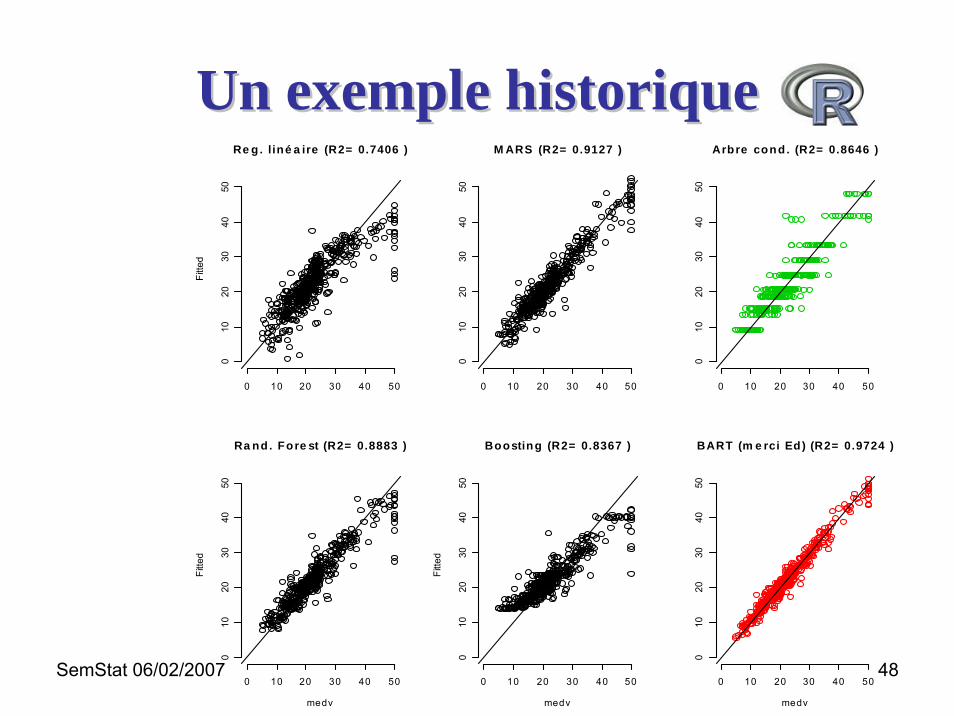
Un exemple historiqueUn exemple historique• Boston housing data (par unité de recensement)
crim Taux de crime par habitantzn Proportion de résidences indus Proportion d'industrie dans l'acrechas = 1 si la région est sur la Charles rivernox Concentration oxyde nitrique (parties par 10 millions)rm Nombre moyen de pièces par logementage Proportion d'unités occupées par le propriétaire établies avant 1940dis Distances aux centres d'emploi de Bostonrad Index d'accessibilité (routes radiales)tax Taux plein de taxe foncière (par $10.000)ptratio Rapport élève-professeur black 1000(Bk - 0.63)^2 où Bk est la proportion de noirslstat pourcentage de bas statut de la populationmedv Valeur médiane des maisons occupées par le propriétaire (par $1000)

SemStat 06/02/2007 47
Un exemple historiqueUn exemple historique
• Modèles– Régression linéaire– Polymars – Arbre de régression (conditionnel) puis MOB– Random forest– Boosting– BART
• Sans analyse de sensibilité• Paramétrage pour des conditions semblables
SemStat 06/02/2007 48
Un exemple historiqueUn exemple historique
0 10 20 30 40 50
010
2030
4050
Re g. l iné a ire (R2= 0.7406 )
Fitte
d
0 10 20 30 40 50
010
2030
4050
M ARS (R2= 0.9127 )
0 10 20 30 40 50
010
2030
4050
Arbre cond. (R2= 0.8646 )
0 10 20 30 40 50
010
2030
4050
Ra nd. Fore st (R2= 0.8883 )
medv
Fitte
d
0 10 20 30 40 50
010
2030
4050
Boosting (R2= 0.8367 )
medv
Fitte
d
0 10 20 30 40 50
010
2030
4050
BART (m e rci Ed) (R2= 0.9724 )
medv
SemStat 06/02/2007 49
Un exemple historiqueUn exemple historique
0 10 20 30 40 50
010
3050
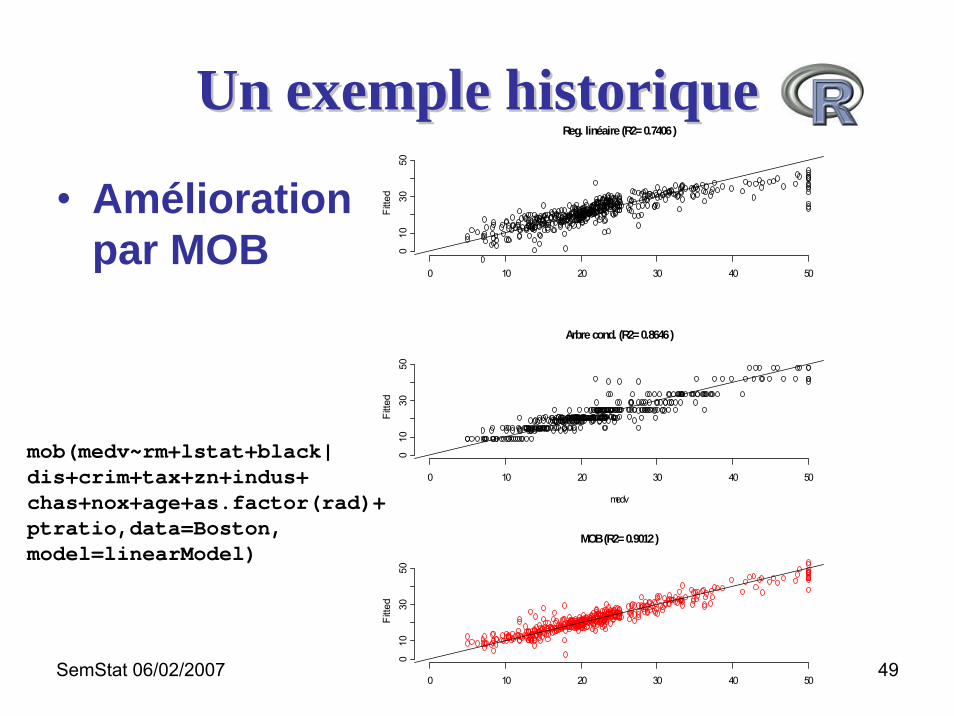
Reg. linéaire (R2= 0.7406 )
Fitte
d
0 10 20 30 40 50
010
3050
Arbre cond. (R2= 0.8646 )
medv
Fitte
d
0 10 20 30 40 50
010
3050
MOB (R2= 0.9012 )
Fitte
d
• Amélioration par MOB
mob(medv~rm+lstat+black|dis+crim+tax+zn+indus+chas+nox+age+as.factor(rad)+ptratio,data=Boston,model=linearModel)

SemStat 06/02/2007 50
ExtensionsExtensions
• Autres situations que Y continues– Survie– Multivarié– Classification sur Y catégorielle ordonnée

SemStat 06/02/2007 51
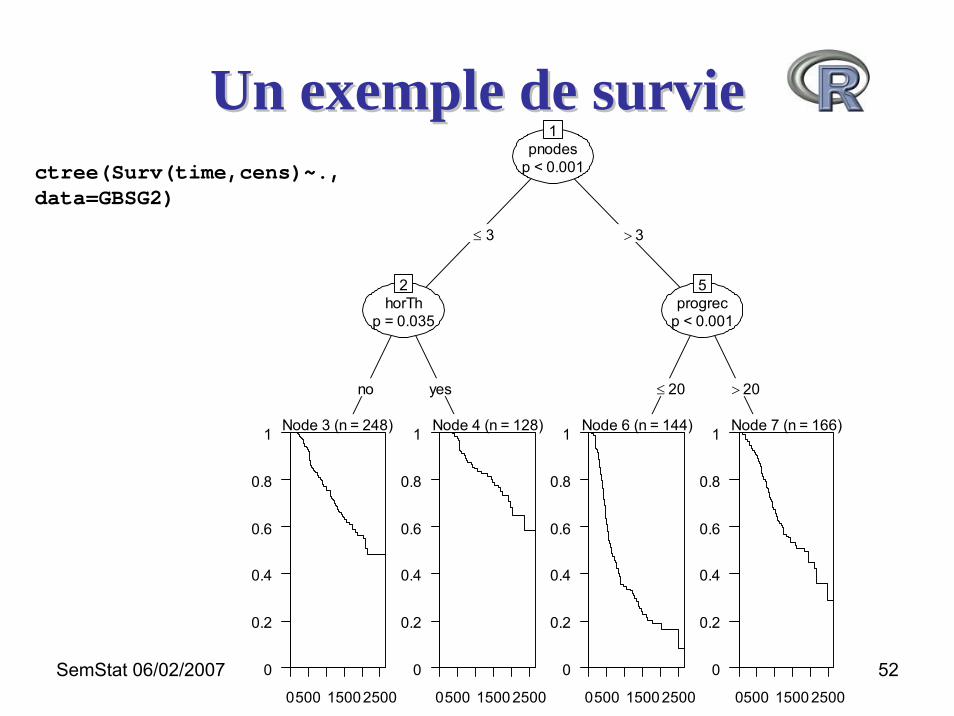
Un exemple de survieUn exemple de survie
• German Breast Cancer Study Group
horTh Thérapie hormonale (oui/non) age Age des patientes (annees)menostat Statut ménopausique (pré-/post-) tsize Taille de la tumeur (mm)tgrade Grade tumoral (I < II < III)pnodes Nombre de nodules envahisprogrec Récepteurs à la progestérone (fmol)estrec Récepteurs aux estrogènes (fmol)time Survie sans récidive (jours)cens Statut (0- censuré, 1- événement)
SemStat 06/02/2007 52
Un exemple de survieUn exemple de surviectree(Surv(time,cens)~.,data=GBSG2)
pnodesp < 0.001
1
≤ 3 > 3
horThp = 0.035
2
no yes
Node 3 (n = 248)
0500 15002500
0
0.2
0.4
0.6
0.8
1 Node 4 (n = 128)
0500 15002500
0
0.2
0.4
0.6
0.8
1
progrecp < 0.001
5
≤ 20 > 20
Node 6 (n = 144)
0500 15002500
0
0.2
0.4
0.6
0.8
1 Node 7 (n = 166)
0500 15002500
0
0.2
0.4
0.6
0.8
1

LogicielsLogiciels

SemStat 06/02/2007 54
Packages RPackages R
• Majeurs– tree, maptree, rpart (inspiration CART)– party (inférence conditionnelle, mob)
• Mais aussi– gbm (boosting)– gbev (boosting, erreur de mesure)– randomForest– tgp (mob bayésien)

SemStat 06/02/2007 55
Autres logicielsAutres logiciels
• Logiciels spécifiques– Pour quasiment chaque algorithme– Des logiciels de data mining
• Tanagra• Orange
• Logiciels généraux : SAS, SPSS

![Fouille de données - Institut de Recherche en ...Yoann.Pitarch/Docs/SID/Fouille/slides_dm_sid... · Arbres de décision Algorithme C4.5 [Quinlan J.,1993] 22 Quilan J. C4.5: ... Arbres](https://static.fdocuments.fr/doc/165x107/5b9d0eb609d3f2443d8b6456/fouille-de-donnees-institut-de-recherche-en-yoannpitarchdocssidfouilleslidesdmsid.jpg)
















