
Data Miningpagesperso.univ-brest.fr/~bounceur/ecole_riir/presentations_pdf/... · - C4.5 - CART -...
71
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel 09-12 Décembre 2013 Data Mining Abdelmalek Amine Laboratoire GeCoDe - Universté de Saida
Transcript of Data Miningpagesperso.univ-brest.fr/~bounceur/ecole_riir/presentations_pdf/... · - C4.5 - CART -...

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Data Mining
Abdelmalek Amine
Laboratoire GeCoDe - Universté de Saida

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
2
Disponibilité croissante de donnéesdonnées sur les clientsdonnées sur les entreprisesnumérisation de documents textuels, images, vidéos, voix, etc.
Données en trop grandes quantités pour être traitées manuellement ou par des algorithmes classiques
nombre d’enregistrements en million ou milliarddonnées de grandes dimensions (trop de champs/attributs/caractéristiques)
Sources de données hétérogènes
Augmentation constante du volume d'information Croissance exponentielle
Émergence du Data Mining (fouille de données)

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Data Mining (fouille de données) est un processus de découverte de règle, relations, corrélations et/ou dépendances à travers une grande quantité de données, grâce à des méthodes statistiques, mathématiques, de reconnaissances de formes, ...
Data Mining (fouille de données) se définit comme un processus analytique destiné a explorer de large quantité de données dans différents domaines, afin de dégager une certaine structure et/ou des relations systématiques entre variables, puis en validant les conclusions et appliquant les structures trouvées à de nouveaux groupes de données
Data Mining (fouille de données) « un processus non-trivial d’identification de structures
inconnues, valides et potentiellement exploitables dans les bases de données » [Fayyad et al., 1996]
3

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Le Data Mining (fouille de données) renvoie à l’ensemble des méthodes et algorithmes pour l’exploration et l’analyse de gros volumes de données (bases de données informatiques) dans la perspective d’une aide à la prise de décision
Le Data Mining (fouille de données) repose sur la mise en évidence de règles, de tendances invisibles pour un analyste humain
4
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
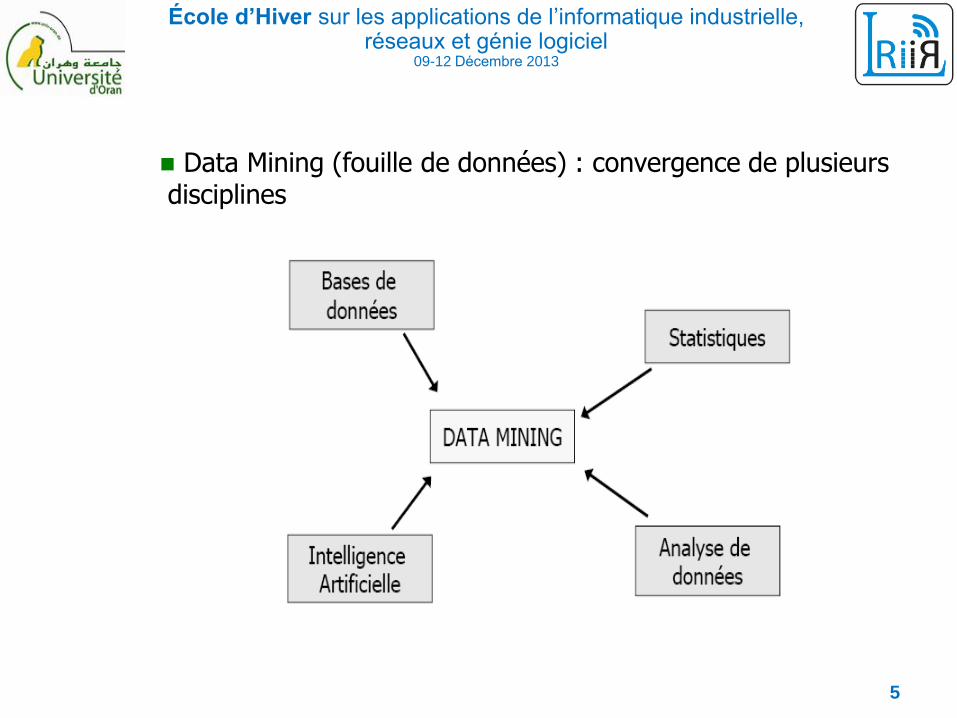
Data Mining (fouille de données) : convergence de plusieurs disciplines
5

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Processus du Data Mining(Étapes)
6

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
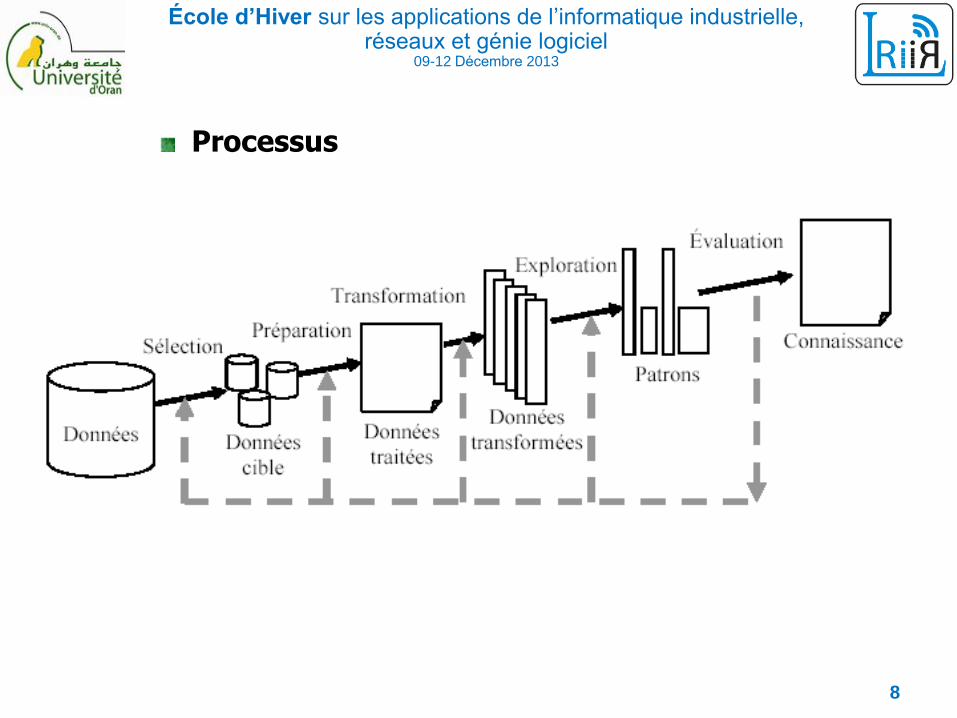
Processus
1. Identifier le problème cerner les objectifs
2. Préparer les donnéesCollecter les données
Nettoyer les données (suppression des doublons, des erreurs de
saisie, traitement des informations manquantes, ...)
Enrichir les données
Codage, normalisation
3. Fouille des donnéesChoisir un type de modèle (classification, …) et une technique (arbres
de décision, ...) pour construire ce modèle
Validation – Évaluation (Erreurs, …) : par un expert ou statistique
4. Utiliser le modèleVoir les résultats du modèle sur les données, Appliquer le modèle
pour prédire sur de nouvelles données, ...
7
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Processus
8

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Taches du Data Mining(Types de modèles)
9

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Selon les objectifs
Classification → examiner les caractéristiques d'un objet et lui
attribuer une classe
Prédiction → prédire la valeur future d'un attribut en fonction
d'autres attributs, par exemple prédire la "qualité" d'un client en fonction de son revenu
Association → consiste à déterminer les attributs qui sont corrélés :
analyse du panier de la ménagère
Segmentation → consiste à former des groupes homogènes à
l'intérieur d'une population. Tâche souvent faite avant les précédentes pour trouver les groupes sur lesquels appliquer la classification
10

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Selon le type d'apprentissage
Apprentissage supervisé → processus dans lequel l'apprenant reçoit des exemples d'apprentissage comprenant à la fois des données d'entrée et de sortie → classification, prédiction
Apprentissage non supervisé → processus dans lequel
l'apprenant reçoit des exemples d'apprentissage ne comprenant que des données d'entrée → Association, segmentation
11

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Selon le type de modèles obtenus
Modèles prédictifs → utilisent les données avec des résultats connus pour développer des modèles permettant de prédire les valeurs d'autres donnéesExemple: modèle permettant de prédire les clients qui ne rembourseront pas leur crédit → classification, prédiction
modèles descriptifs → proposent des descriptions des données
pour aider à la prise de décision. Les modèles descriptifs aident à la construction de modèles prédictifs → Association, segmentation
12

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Quelques algorithmes (méthodes):
- K-plus proches voisins (K-ppv ou Knn)
- K-moyennes (K-means)
- Naive Bayes
- Régression linéaire
- Réseau de neurones
- Arbre de décision
- Règles d’association…
13

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Knn
• Calcul de similarité
– Entre le nouveau exemple et les exemples pré-classés
– Similarité(d1,d2) = cos(d1,d2)
– Trouve les k exemples les plus proches
• Recherche des catégories candidates
– Vote majoritaire des k exemples
– Somme des similarités > seuil
• Sélection d'une ou plusieurs catégories
– Plus grand nombre de votes
– Score supérieur à un seuil
14
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
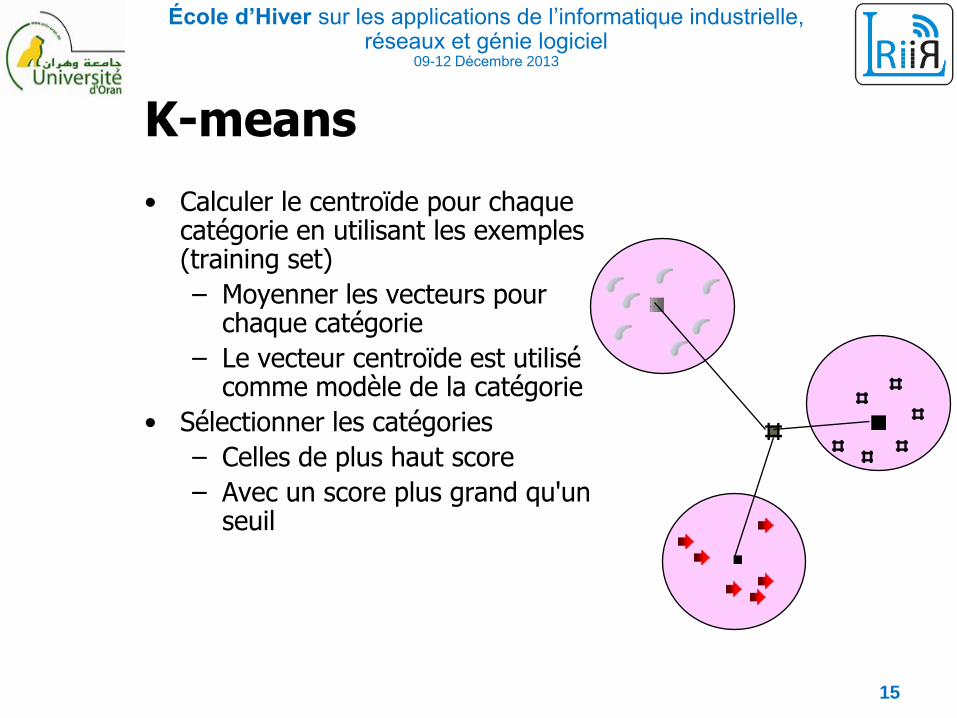
K-means
• Calculer le centroïde pour chaque catégorie en utilisant les exemples (training set)
– Moyenner les vecteurs pour chaque catégorie
– Le vecteur centroïde est utilisé comme modèle de la catégorie
• Sélectionner les catégories
– Celles de plus haut score
– Avec un score plus grand qu'un seuil
15

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Naïve Bayes
• Modèle probabiliste
– Basé sur l'observation de la présence des termes
• Suppose l'indépendance entre les termes
• La catégorie de plus grande probabilité est sélectionnée
– On peut utiliser un seuil pour en sélectionner plusieurs
16

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Le modèle probabiliste pour un classifieur est le modèle conditionnel
Où C est une variable de classe dépendante dont les instances
ou classes sont peu nombreuses, conditionnée par plusieurs
variables caractéristiques F1, …, Fn
=
À l'aide du théorème de Bayes, nous écrivons
=
17

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Exemple
Données Météo
Perspective Température Humidité Vent Jouer
Ensoleillé Chaude Elevée Faible Non
Ensoleillé Chaude Elevée Fort Non
Couvert Chaude Elevée Faible Oui
Pluvieux Tiède Elevée Faible Oui
Pluvieux Fraiche Normale Faible Oui
Pluvieux Fraiche Normale Fort Non
Couvert Fraiche Normale Fort Oui
Ensoleillé Tiède Elevée Faible Non
Ensoleillé Fraiche Normale Faible Oui
Pluvieux Tiède Normale Faible Oui
Ensoleillé Tiède Normale Fort Oui
Couvert Tiède Elevée Fort Oui
Couvert Chaude Normale Faible Oui
Pluvieux Tiède Elevée Fort Non
18
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
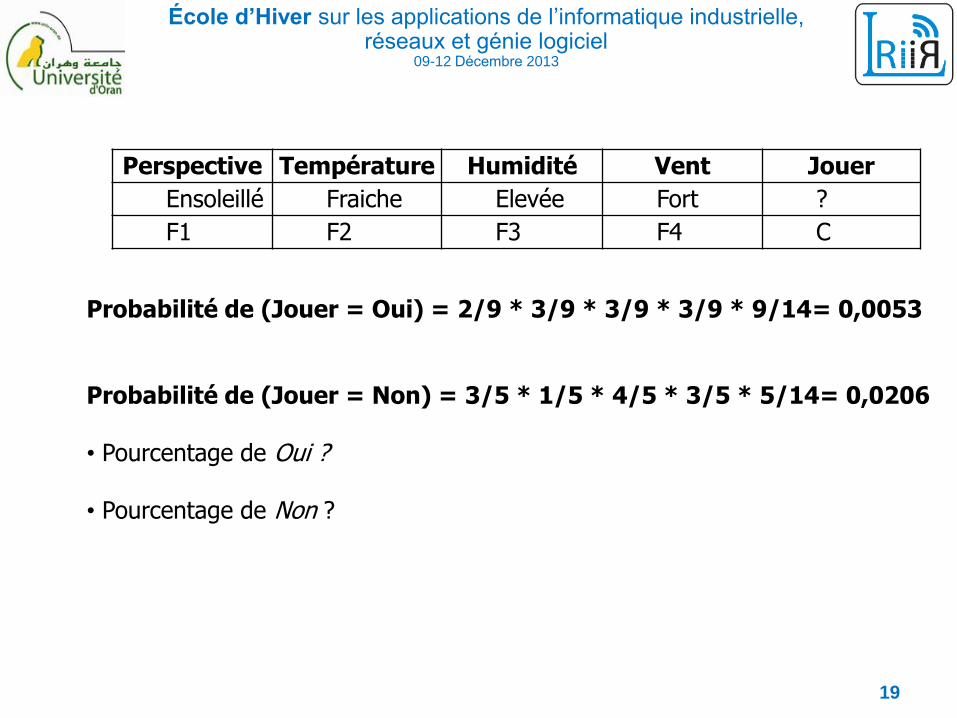
Probabilité de (Jouer = Oui) = 2/9 * 3/9 * 3/9 * 3/9 * 9/14= 0,0053
Probabilité de (Jouer = Non) = 3/5 * 1/5 * 4/5 * 3/5 * 5/14= 0,0206
• Pourcentage de Oui ?
• Pourcentage de Non ?
19
Perspective Température Humidité Vent Jouer
Ensoleillé Fraiche Elevée Fort ?
F1 F2 F3 F4 C

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Attributs Numériques
Pour les attributs numériques on va simplement listez les valeurs des instances, après on calcule L'espérance et la variance de chaque attribut numérique
• Espérance
• Variance
20
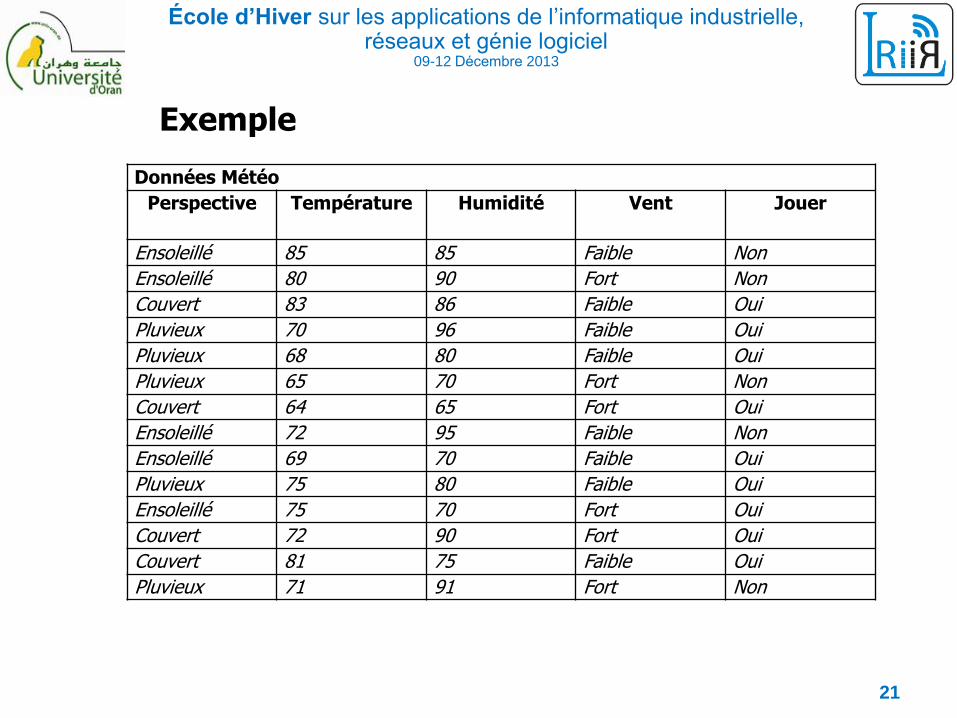
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Exemple
21
Données Météo
Perspective Température Humidité Vent Jouer
Ensoleillé 85 85 Faible Non
Ensoleillé 80 90 Fort Non
Couvert 83 86 Faible Oui
Pluvieux 70 96 Faible Oui
Pluvieux 68 80 Faible Oui
Pluvieux 65 70 Fort Non
Couvert 64 65 Fort Oui
Ensoleillé 72 95 Faible Non
Ensoleillé 69 70 Faible Oui
Pluvieux 75 80 Faible Oui
Ensoleillé 75 70 Fort Oui
Couvert 72 90 Fort Oui
Couvert 81 75 Faible Oui
Pluvieux 71 91 Fort Non

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
• Espérance de l’attribut température pour Jouer = Oui
• Variance
22

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
• Densité de probabilité
23
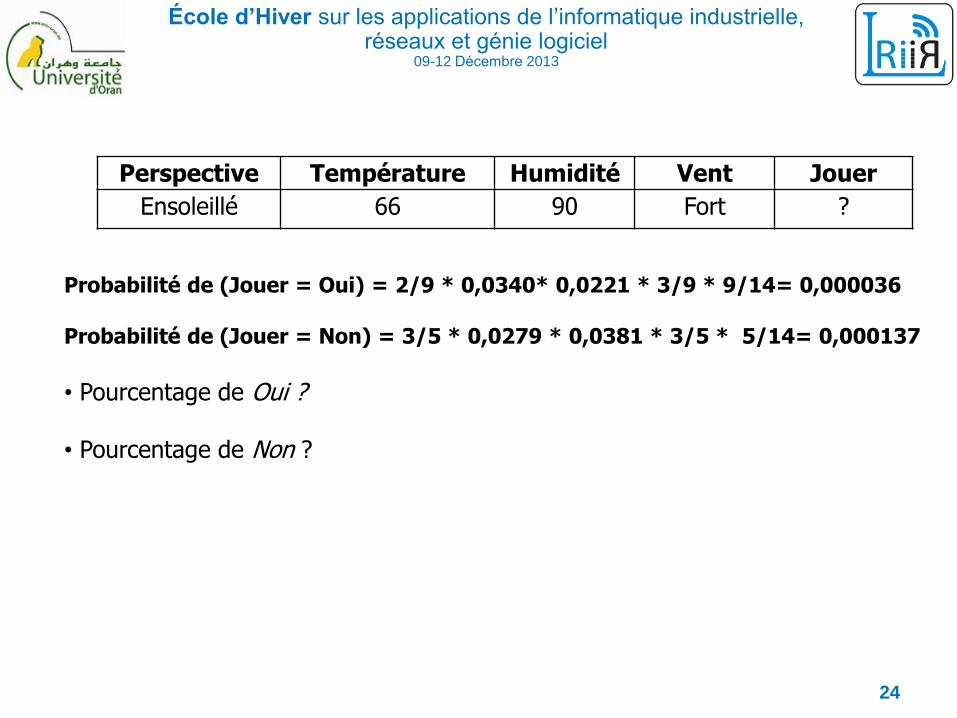
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Probabilité de (Jouer = Oui) = 2/9 * 0,0340* 0,0221 * 3/9 * 9/14= 0,000036
Probabilité de (Jouer = Non) = 3/5 * 0,0279 * 0,0381 * 3/5 * 5/14= 0,000137
• Pourcentage de Oui ?
• Pourcentage de Non ?
24
Perspective Température Humidité Vent Jouer
Ensoleillé 66 90 Fort ?

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Arbre de Décision
• Méthode de classification
• Représentation graphique d’une procédure de classification
25
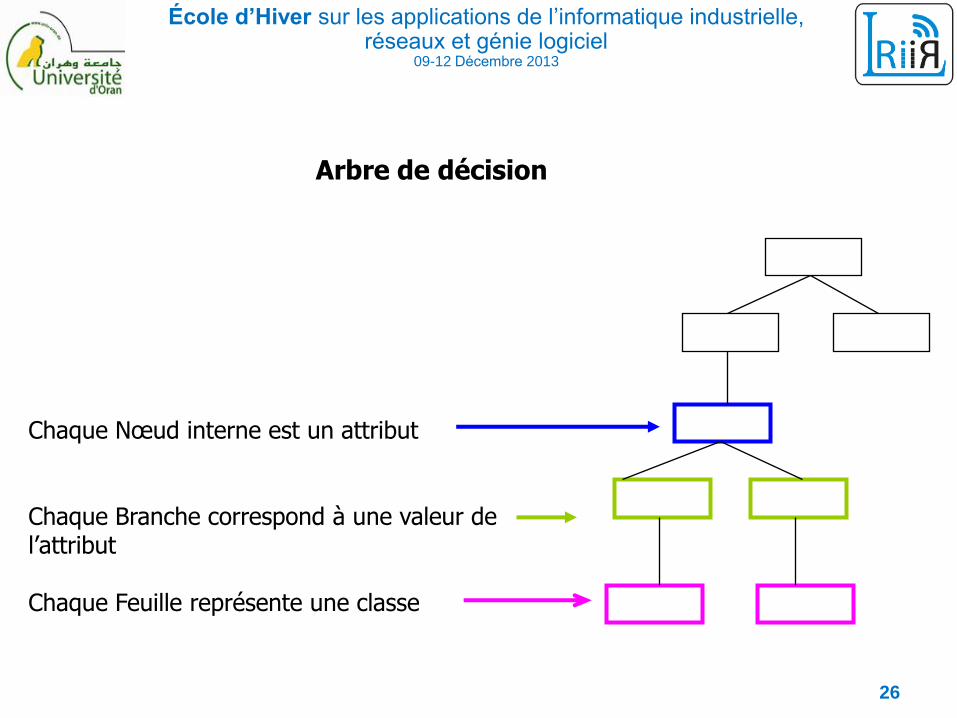
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Arbre de décision
Chaque Nœud interne est un attribut
Chaque Branche correspond à une valeur de l’attribut
Chaque Feuille représente une classe
26
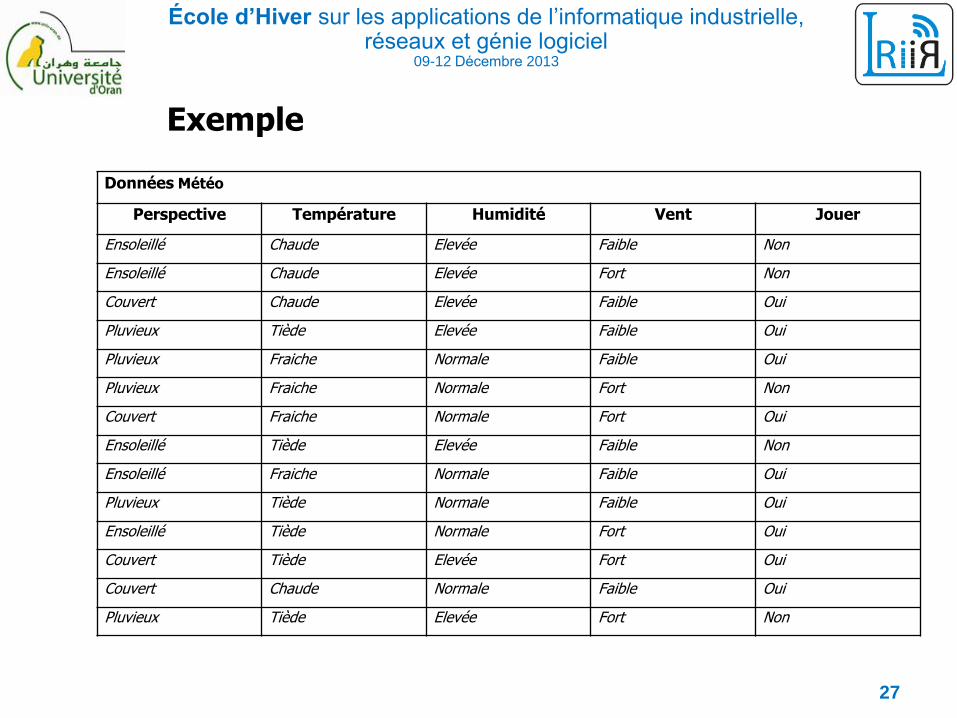
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Exemple
Données Météo
Perspective Température Humidité Vent Jouer
Ensoleillé Chaude Elevée Faible Non
Ensoleillé Chaude Elevée Fort Non
Couvert Chaude Elevée Faible Oui
Pluvieux Tiède Elevée Faible Oui
Pluvieux Fraiche Normale Faible Oui
Pluvieux Fraiche Normale Fort Non
Couvert Fraiche Normale Fort Oui
Ensoleillé Tiède Elevée Faible Non
Ensoleillé Fraiche Normale Faible Oui
Pluvieux Tiède Normale Faible Oui
Ensoleillé Tiède Normale Fort Oui
Couvert Tiède Elevée Fort Oui
Couvert Chaude Normale Faible Oui
Pluvieux Tiède Elevée Fort Non
27
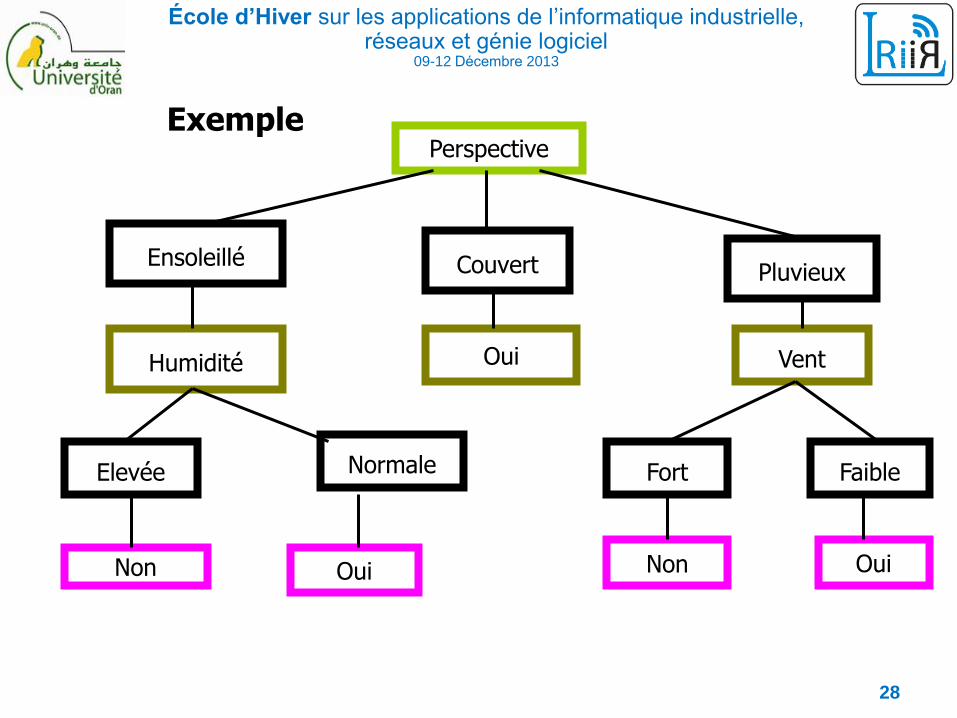
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
NormaleElevée FaibleFort
Non Oui Non Oui
Humidité
Perspective
Oui Vent
Ensoleillé Couvert Pluvieux
Exemple
28
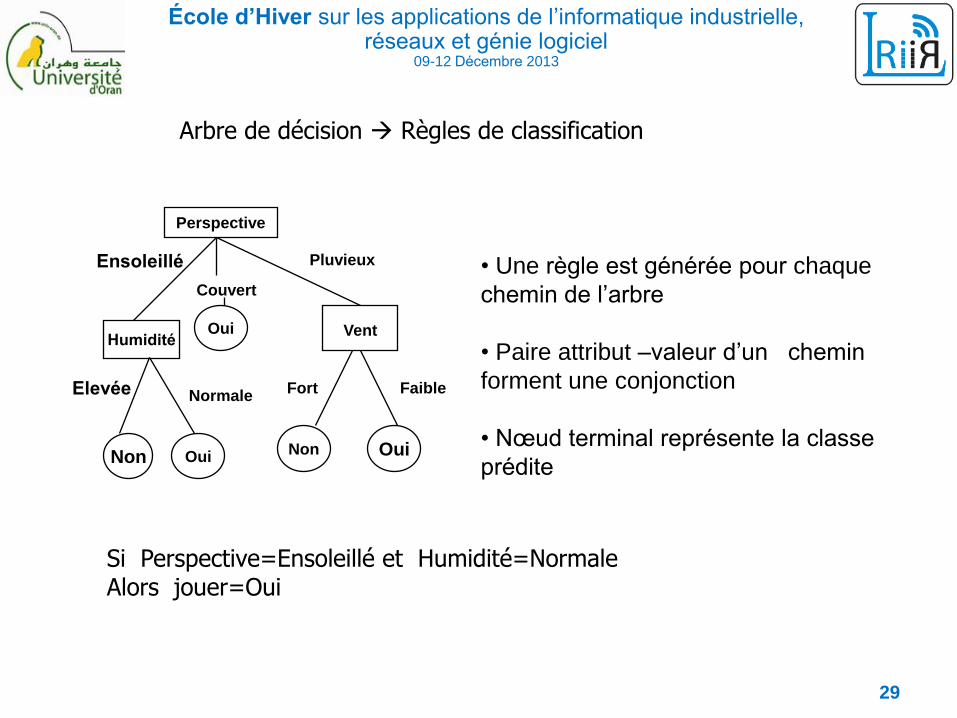
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
• Une règle est générée pour chaque
chemin de l’arbre
• Paire attribut –valeur d’un chemin
forment une conjonction
• Nœud terminal représente la classe
prédite
Ensoleillé
Elevée
Vent
Perspective
Humidité
Couvert
Oui
Oui NonNon Oui
NormaleFort Faible
Pluvieux
Arbre de décision Règles de classification
Si Perspective=Ensoleillé et Humidité=NormaleAlors jouer=Oui
29

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Plusieurs algorithmes pour les arbres de décision
• Algorithme de base
- Construction récursive d’un arbre de manière « diviser – pour- régner »- Attributs considérés énumératifs
• Plusieurs variantes
- ID3- C4.5 - CART - CHAID- …
30

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
- Gain d’information ( ID3 , C 4.5)
- Indice Gini (CART)
-Table de contingence statique x2 (CHAID)
- …
31
Mesures de sélection d’attributs
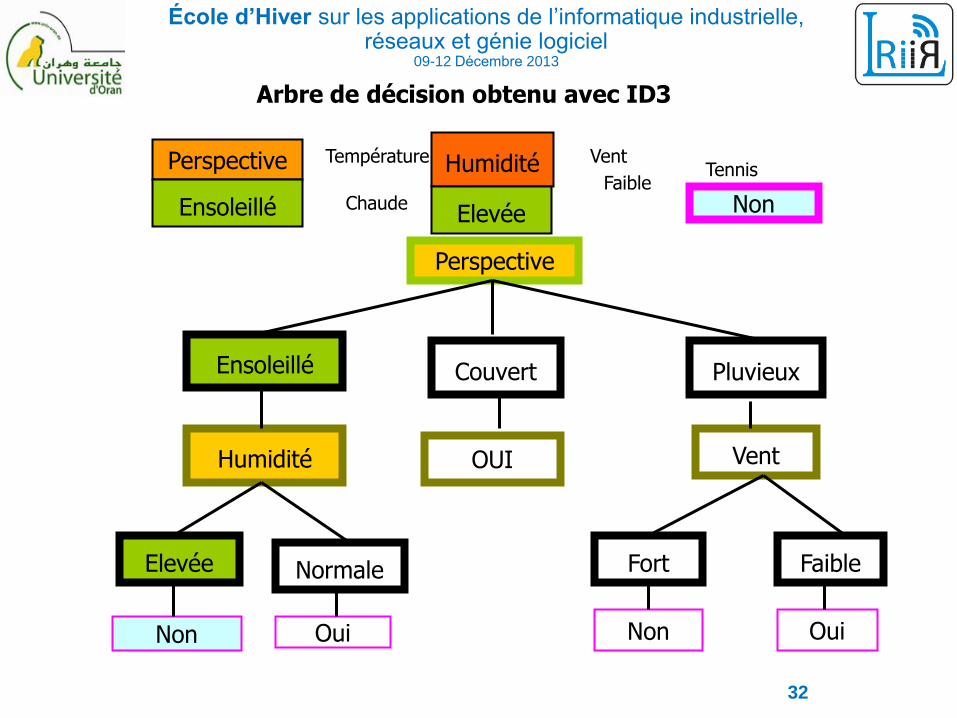
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
NormaleElevée FaibleFort
Non Oui Non Oui
Humidité
Perspective
OUI Vent
Ensoleillé Couvert Pluvieux
Perspective
Ensoleillé
Humidité
Elevée Non
Température
Chaude
Vent
FaibleTennis
Arbre de décision obtenu avec ID3
32
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
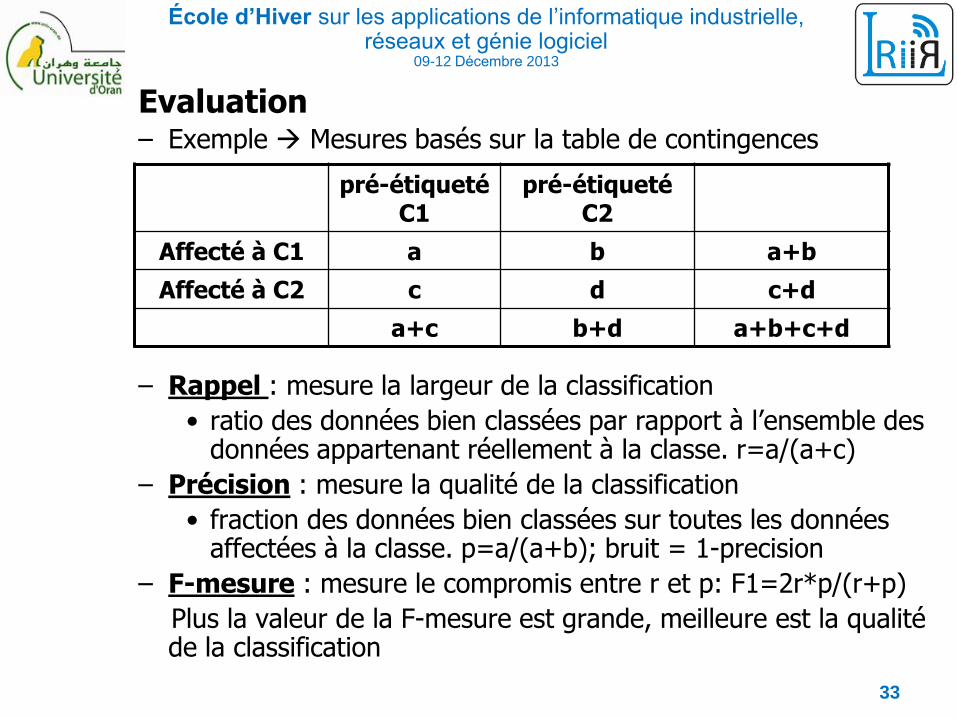
Evaluation– Exemple Mesures basés sur la table de contingences
– Rappel : mesure la largeur de la classification
• ratio des données bien classées par rapport à l’ensemble des données appartenant réellement à la classe. r=a/(a+c)
– Précision : mesure la qualité de la classification
• fraction des données bien classées sur toutes les données affectées à la classe. p=a/(a+b); bruit = 1-precision
– F-mesure : mesure le compromis entre r et p: F1=2r*p/(r+p)
Plus la valeur de la F-mesure est grande, meilleure est la qualité de la classification
pré-étiqueté C1
pré-étiqueté C2
Affecté à C1 a b a+b
Affecté à C2 c d c+d
a+c b+d a+b+c+d
33

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
34
Text Mining

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Structurées: 10% - augmentent de 4% par anNon structurées: 90% - augmentent de 6400% par an
Le traitement des données non structurées constitue un
enjeu colossal pour aujourd’hui et plus encore pour demain
35

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Lorsque les données considérées se présentent sous la forme de textes (qu’ils soient non structurés ou semi-structurés)
Données non structurées (textes bruts) :
- Fichiers textes (TXT, RTF, DOC, …)
- Pages web (article Wikipédia, blog, site institutionnel, …)
Données semi-structurées :
- SGML, XML, HTML…
- RDF, …
Text Mining (Text Data Mining) ou fouille de textes (fouille de données textuelles)
36

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Text Mining (fouille de données textuelles)
« l’ensemble des tâches qui, par analyse de grandesquantités de textes et la détection de modèles fréquents,essaie d’extraire de l’information probablement utile »
[Sebastiani, 2002].
37

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Le Text Mining est l’ensemble des techniques et méthodes destinées au traitement automatique de données textuelles disponibles sous forme informatique (Internet, Intranet, bibliothèques numériques, DVD, …) en assez grande quantité, en vue d’en dégager et structurer le contenu et les thèmes dans une perspective d’analyse rapide, de découverte d’informations cachées ou de prise automatique de décision.
Le Text Mining est un procédé consistant à synthétiser (classer, structurer, résumer, …) les textes en analysant les relations, les patterns et les règles entre unités textuelles (mots, groupes, phrases, documents)
38
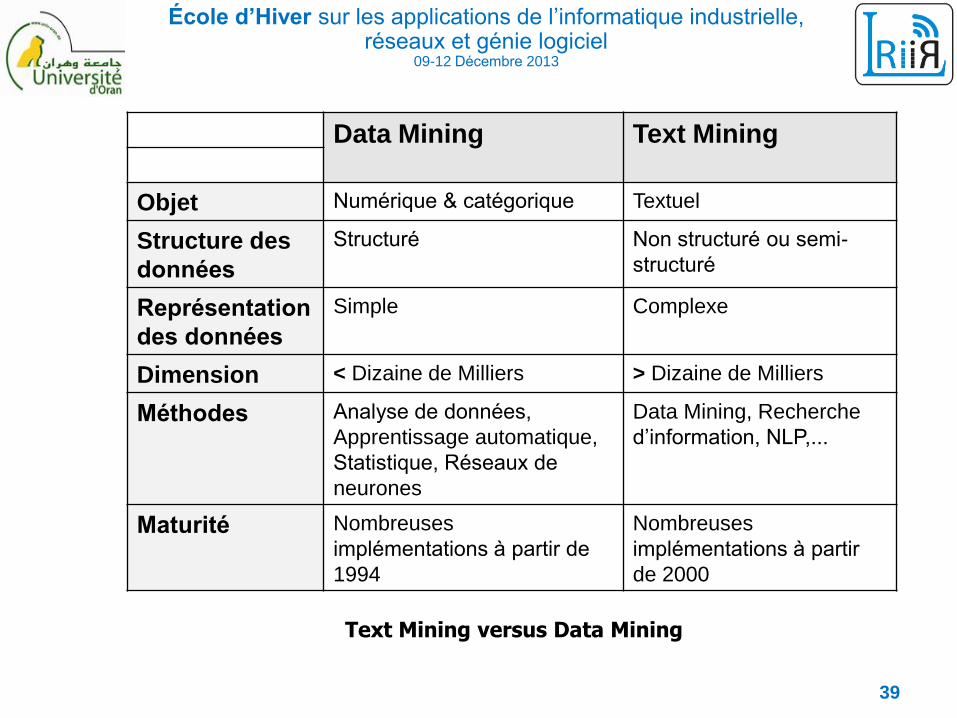
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Data Mining Text Mining
Objet Numérique & catégorique Textuel
Structure des
données
Structuré Non structuré ou semi-
structuré
Représentation
des données
Simple Complexe
Dimension < Dizaine de Milliers > Dizaine de Milliers
Méthodes Analyse de données,
Apprentissage automatique,
Statistique, Réseaux de
neurones
Data Mining, Recherche
d’information, NLP,...
Maturité Nombreuses
implémentations à partir de
1994
Nombreuses
implémentations à partir
de 2000
Text Mining versus Data Mining
39

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
La démarche du Text Mining ne se différencie pas de celle du Data Mining, elle est similaire
Sa particularité réside dans les étapes spécifiques de préparation des données, qui permettent de passer du texte à la forme, et de la forme au nombre.
40
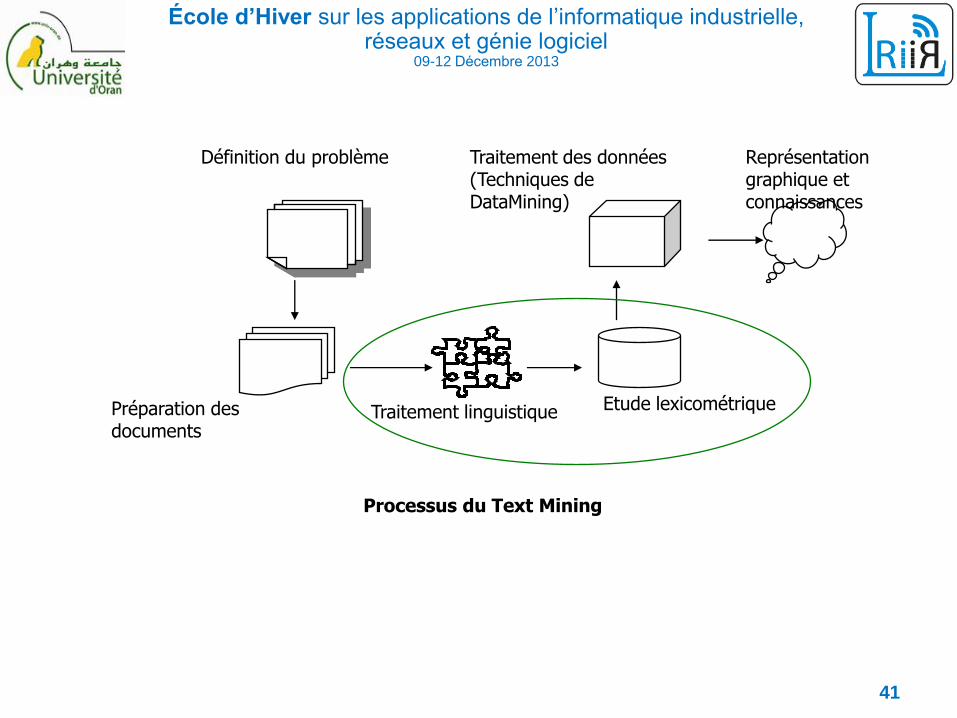
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Processus du Text Mining
Définition du problème Traitement des données (Techniques de DataMining)
Représentation graphique et connaissances
Préparation des documents
Traitement linguistique Etude lexicométrique
41

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Le processus du Text Mining comprend la succession d’étapes suivantes:
La définition du problème et identification des buts : Définition des buts attendus et des résultats souhaités.
La préparation des données : Les textes doivent être recueillis en utilisant, par exemple, des outils
automatique de récupération de l'information, ou de façon manuelle à partir de différentes sources.
Le traitement linguistique : Les textes utilisés en entrée sont des textes en langue naturelle. Pour réussir un
traitement juste de ces textes et extraire des connaissances à partir de ceux-ci, il faut qu’ils passent des étapes
appelées généralement prétraitement. L’étape de prétraitement des textes appartient au domaine du traitement
automatique de la langue naturelle. Elle comporte en général les phases suivantes :
Détection de la langue du texte : Pour commencer le traitement il faut d’abord savoir dans quelle
langue chaque document est écrit et comment cette langue est encodée. Il est important de
détecter avec précision la langue dans laquelle le texte est rédigé, car une erreur à ce niveau voue
à l’échec les étapes suivantes. Il existe deux familles d’approches dans l’identification de la langue
: linguistique et statistique.
Nettoyage des données : Habituellement, le nettoyage consiste à éliminer les mots vides (stop-
words). Ces mots vides sont des mots ne jouant qu’un rôle syntaxique, contribuant peu au sens
des documents. On les élimine pour deux raisons : (a) Minimiser la taille du fichier traité
(contrainte d’espace). (b) Rendre le traitement plus rapide (contrainte de temps).
Lemmatisation : La lemmatisation est l’opération qui consiste à ramener les variantes
(flexionnelles) d’un même mot à une forme canonique, le lemme. Elle s’appuie sur une analyse
grammaticale des textes afin de remplacer les verbes par leur forme infinitive et les noms par leur
forme au singulier. Cette opération permet de réduire le nombre de termes dans un index, ce qui
est intéressant du point de vue du stockage des données.
L’étude lexicométrique : La lexicométrie est l’étude quantitative du vocabulaire ; elle consiste à mesurer la
fréquence d’apparition des mots dans un même texte, et il en résulte une représentation mathématique du texte.
Le traitement des données (techniques de Data Mining) : On choisit l’une des techniques du Data Mining
telles que les arbres de décisions, les algorithmes génétiques ou les réseaux de neurones, pour l’appliquer aux
textes transformés (représentation mathématique), ce qui permettra de réaliser plusieurs tâches telles que: la
classification, la traduction automatique, l’identification de la langue, etc.
42

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
1. Sélection du corpus de documents
2. Extraction des termes
3. Transformation
4. Traitement des données
5. Visualisation des résultats
6. Interprétation des résultats
43

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Quelques « grands » noms :
Claude Shannon (1916-2001)- Fondateur de la théorie de l’information- Entropie (définit la quantité d’information contenue
dans un document)
Gerard Salton (1927-1995)
- Modèle d’espaces vectoriels
Karen Sparck Jones (1935-2007)
- IDF (Inverse Document Frequency)
Cornelis Joost van Rijsbergen (1943)
- Modèles probabilistes en recherche d’information
44

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Représentation des documents textuels
45

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
La plupart des algorithmes d’apprentissage sont incapables de traiter
directement des données non structurées
Les documents textuels sont par nature sous un format non
structuré
Une étape préliminaire est indispensable dite de représentation
La particularité du Text Mining réside dans les étapes spécifiques
de préparation des données, qui permettent de passer :
du texte à la forme au nombre
46

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Hypothèse fondamentale des travaux sur l’extraction et la sélection
d’informations :
« le contenu textuel d’un document discrimine le type et la valeur
des informations qu’il véhicule »
Analyse de la fréquence d’apparition des termes dans un texte
(corpus de textes)
47
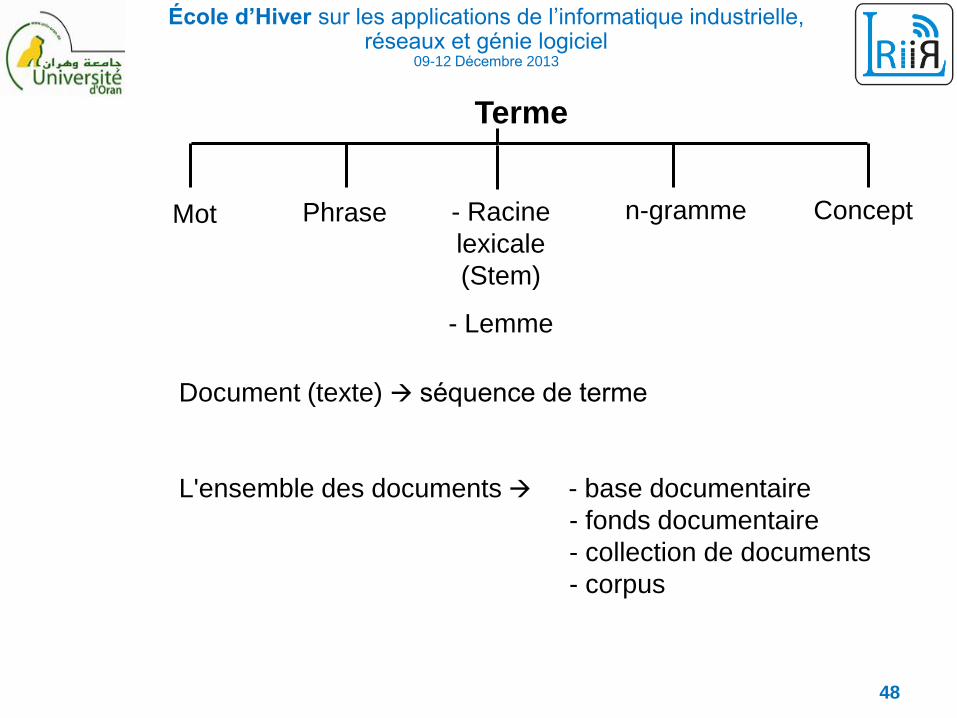
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Terme
Phrase - Racine
lexicale
(Stem)
- Lemme
n-grammeMot Concept
Document (texte) séquence de terme
L'ensemble des documents - base documentaire
- fonds documentaire
- collection de documents
- corpus
48

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Deux modèles de représentation de textes pour le
calcul de cette fréquence le modèle probabiliste
le modèle vectoriel
Le modèle vectoriel VSM pour Vector Space Model, ([Salton
and McGill, 1983], [Salton et al., 1975]) le plus utilisé
sert de base à la représentation des données textuelles par des
vecteurs dans l'espace euclidien. Un document est représenté par
un vecteur de termes
.
49

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
L'étape d'indexation analyser les documents afin de créer une
représentation de leur contenu textuel qui soit exploitable
Chaque document est alors associé à un vecteur représenté par
l'ensemble des termes d'indexation extraits (descripteurs)
Fréquence
Soit on associe un poids au terme
soit on l'enregistre simplement comme «présent»/« non
présent » dans le document courant
valeur 1 s’il est présent et 0 autrement
50
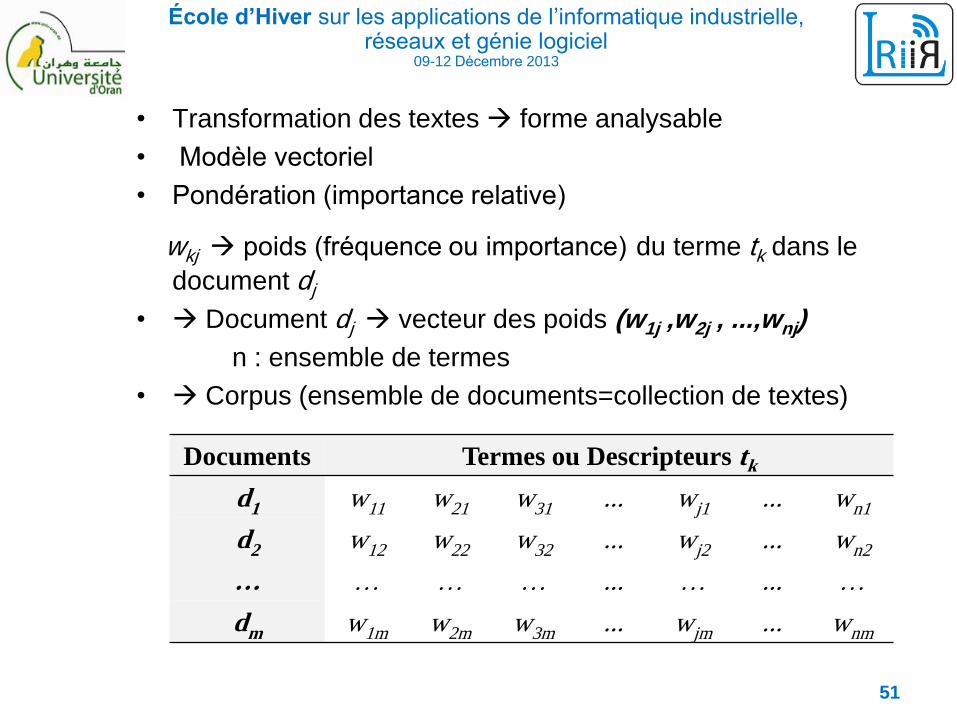
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
• Transformation des textes forme analysable
• Modèle vectoriel
• Pondération (importance relative)
wkj poids (fréquence ou importance) du terme tk dans le
document dj
• Document dj vecteur des poids (w1j ,w2j , ...,wnj)
n : ensemble de termes
• Corpus (ensemble de documents=collection de textes)
Documents Termes ou Descripteurs tk
d1 w11 w21 w31 ... wj1 ... wn1
d2 w12 w22 w32 ... wj2 ... wn2
… … … … ... … ... …
dm w1m w2m w3m ... wjm ... wnm
51

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
• Occ(tk, dj): nombre d’occurrences du terme tk dans
le document dj
• Nbre_doc: nombre total de documents du corpus
• Nbre_doc(tk): nombre de documents de cet ensemble dans lesquels
apparaît au moins une fois le terme tk
Calcul du poids wkj (Pondération TFxIDF)
Mesure l'importance d’un terme dans un document relativement à l’ensemble des documents
)t(doc_Nbre
doc_NbreLog)d,t(Occd,tIDFTF
k
jkjk
52

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
• Un terme qui apparait plusieurs fois dans un document est
plus important qu’un terme qui apparaît une seule fois
• Un terme qui apparaît dans peu de documents est un meilleur
discriminant qu’un terme qui apparaît dans tous les documents
53
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
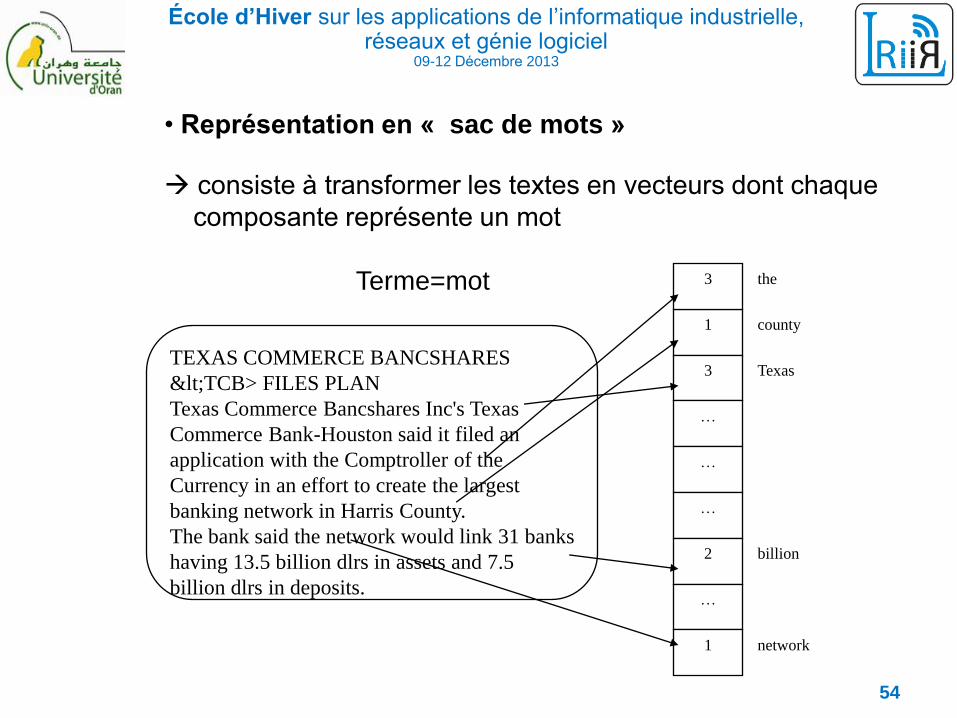
• Représentation en « sac de mots »
consiste à transformer les textes en vecteurs dont chaque
composante représente un mot
Terme=mot
1
TEXAS COMMERCE BANCSHARES
<TCB> FILES PLAN
Texas Commerce Bancshares Inc's Texas
Commerce Bank-Houston said it filed an
application with the Comptroller of the
Currency in an effort to create the largest
banking network in Harris County.
The bank said the network would link 31 banks
having 13.5 billion dlrs in assets and 7.5
billion dlrs in deposits.
3
…
…
…
2
…
1
3 the
county
Texas
billion
network
54

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
• Représentation des textes par des phrases
une sélection des phrases des séquences de mots se suivant
dans le texte en privilégiant celles qui sont susceptibles de porter
un sens important (pas l'unité lexicale «phrase » telle qu'on
l’entend habituellement)
« the sweet little boy plays with a yellow ball »
Les séquences :
« sweet little boy », « yellow ball », « little boy » sont porteuses
de sens.
Les séquences :
« the sweet », « a yellow » ne sont pas intéressantes
55

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
• Représentation des textes avec des racines lexicales (stems)
et des lemmes
modèle « sac de mots » chaque flexion d'un mot est considérée
comme un descripteur (terme) différent (Dimensionnalité)
Stemming : considérer uniquement la racine des mots plutôt que
les mots entiers (stem en anglais) le défaut principal des racines
est de regrouper trop de mots différents sous une même racine
lemmatisation : remplacer les verbes par leur forme infinitive et
les noms par leur forme au singulier plus difficile à mettre en
œuvre que la recherche de racines (stemming) elle nécessite
une analyse grammaticale des textes
56

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
TEXA COMMERC BANCSHAR <TCB> FILE
PLAN
Texa Commerc Bancshar Inc's Texa
Commerc Bank-Houston said it file an applic with the
Comptrol of the Currenc in an effort to creat the largest
bank network in Harri Counti.
The bank said the network would link 31 bank have
13.5 billion dlr in asset and 7.5 billion dlr in deposit.
TEXAS COMMERCE BANCSHARES LT TCB>
FILE PLAN
Texas Commerce Bancshares inc's Texas
Commerce Bank Houston say it file an application with
the comptroller of the currency in an effort to create the
large banking network in Harris County
The bank say the network would link bank have
@card@ billion dlrs in asset and @card@ billion dlrs
in deposit
TEXAS COMMERCE BANCSHARES <TCB>
FILES PLAN
Texas Commerce Bancshares Inc's Texas
Commerce Bank-Houston said it filed an application
with the Comptroller of the Currency in an effort to
create the largest banking network in Harris County.
The bank said the network would link 31 banks
having 13.5 billion dlrs in assets and 7.5 billion dlrs in
deposits.
Exemple de texte
Stemming : mots remplacés par leur racine
(algorithme de Porter)
Lemmatisation : mots remplacés par lemme
(algorithme TreeTagger)
57

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
• Représentation des textes avec la méthode des n-grammes
Un n-gramme peut désigner aussi bien un n-uplet de caractères
(n-gramme de caractères) qu’un n-uplet de mots (n-gramme de
mots)
Un n-gramme est une séquence de n caractères consécutifs.
Pour un document quelconque, l’ensemble des n-grammes que
l’on peut générer est le résultat que l’on obtient en déplaçant une
fenêtre de n cases sur le corps du texte. Ce déplacement se fait
par étapes ; une étape correspond à un caractère pour les n-
grammes de caractères, à un mot pour les n-grammes de mots
58

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
• Exemple de n-grammes de mots dans la phrase
« document clustering using ngrams » :
- un-gramme: « document », « clustering », « using », « ngrams »,
- bi-grammes: « document clustering », « clustering using », « using ngrams »,
- tri-grammes: « document clustering using », « clustering using ngrams »
• Exemple de 5-grammes de caractères de la phrase
« document clustering using ngrams » :
« docum, ocume, cumen, ument, ment_, ent_c, nt_cl, t_clu, _clus, clust, luste, uster, steri, terin, ering, ring_, ing_u, ng_us, g_usi, _usin, using, sing_, ing_n, ng_ng, g_ngr, _ngra, ngram, grams »
Le caractère « _ » représente un blanc
59

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
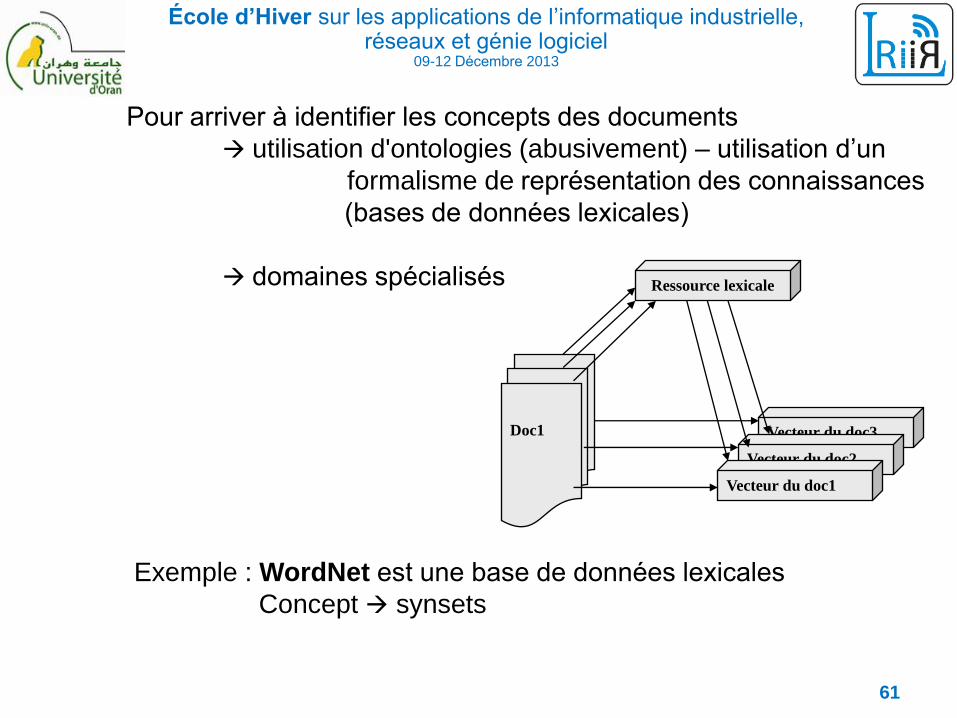
• Représentation par concepts
Le processus de représentation ou d'indexation dans la majorité des
systèmes actuels
indexation classique basée sur les mots
le sens des mots n'est pas pris en compte
Concept termes synonymes …
Exemple :
60
École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Doc1 Vecteur du doc3
Vecteur du doc2
Vecteur du doc1
Ressource lexicale
Exemple : WordNet est une base de données lexicales
Concept synsets
Pour arriver à identifier les concepts des documents
utilisation d'ontologies (abusivement) – utilisation d’un
formalisme de représentation des connaissances
(bases de données lexicales)
domaines spécialisés
61

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
• Traitements complémentaires, Analyse et préparation
- Corrections orthographiques (fautes de frappe ) processus de
correction orthographique
- Conversion de caractères majuscules en minuscules - conversion
des caractères diacritiques
- Reconnaissance de mots composés Utilisation d’une table de
mots composés du langage identifier ceux ne formant qu'un seul
mot Ex : foot ball (foot et ball)
- Elimination des mots-vides (mots-outils ou Stop-words)
prépositions, at, of - les articles : the, an, a - les pronoms : her, him -les auxiliaires : be , have peut être étendu aux mots très fréquents
au sein d'une collection de textes
62

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Une liste de mots-vides :
a , beaucoup, comment, encore, lequel, moyennant, près, ses, toujours, afin, ça,
concernant, entre, les, ne, puis, sien, tous, ailleurs, ce, dans, et, lesquelles, ni,
puisque, sienne, toute, ainsi, ceci, de, étaient, lesquels, non, quand, siennes, toutes,
alors, cela, dedans, était, leur, nos, quant, siens, très, après, celle, dehors, étant,
leurs, notamment, que, soi, trop, attendant, celles, déjà, etc, lors, notre, quel, soi-
même, tu, au, celui, delà, eux, lorsque, notres, quelle, soit, un, aucun, cependant,
depuis, furent, lui, nôtre, quelqu’un, sont, une, aucune, certain, des, grâce, ma,
nôtres, quelqu’une, suis, vos, au-dessous, certaine, desquelles, hormis, mais, nous,
quelque, sur, votre, au-dessus, certaines, desquels, hors, malgré, nulle, quelques-
unes, ta, vôtre, auprès, certains, dessus, ici, me, nulles, quelques-uns, tandis,
vôtres, auquel, ces, dès, il, même, on, quels, tant, vous, aussi, cet, donc, ils,
mêmes, ou, qui, te, vu, aussitôt, cette, donné, jadis, mes, où, quiconque, telle, y,
autant, ceux, dont, je, mien, par, quoi, telles, autour, chacun, du, jusqu, mienne,
parce, quoique, tes, aux, chacune, duquel, jusque, miennes, parmi, sa, tienne,
auxquelles, chaque, durant, la, miens, plus, sans, tiennes, auxquels, chez, elle,
laquelle, moins, plusieurs, sauf, tiens, avec, combien, elles, là, moment, pour, se,
toi, à, comme, en, le, mon, pourquoi, selon, ton
63

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
• Réduction de l’espace de représentation
Problème de la dimension (malédiction de la dimensionnalité)
pour un corpus de taille raisonnable
le nombre de descripteur plusieurs centaines de milliers
Nécessité d’utiliser une méthode statistique pour déterminer les
mots utiles
64

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Principe
calculer pour chaque terme une valeur statistique qui
représente son utilité
(un score est associé à chaque terme)
sélectionner les termes les plus importants
(les attributs avec les scores les plus faibles seront éliminés)
Il existe de nombreuses statistiques pour mesurer cette quantité
d’information
un point commun à toutes ces statistiques est la nécessité de
choisir un seuil Peu importe le critère choisi pour la sélection, il
faut déterminer à partir de quelle valeur on élimine ou on conserve
un terme
65

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
La Fréquence-document (Document Fréquency)
L’information mutuelle (mutual information)
Le gain d’information (information gain)
Le Chi-deux
La force du terme (term strength)
66

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
• Similarité entre documents
• Document Vecteur
• Le nombre de termes présents dans les documents du corpus détermine la dimension de l’espace
• Dans l’espace vectoriel de dimension V, les vecteurs
représentant les textes forment un faisceau de même origine
• Documents similaires les textes qui se ressemblent contiennent
les mêmes termes ou des termes qui apparaissent dans les mêmes
contextes (les termes qui ont des contextes identiques sont
similaires)
• Vecteurs similaires dans l’espace vectoriel, ils correspondent à
des vecteurs proches
67

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
• Le cosinus de l’angle est
souvent utilisé
> cos()<cos()
• d2 est plus proche de d1
que de d3
• Permet de ranger les
documents par pertinence
• documents similaires
proches
Des vecteurs proches ont des directions
quasi-identiques ou dont les extrémités
sont proches
68

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
Similarité entre documents Estimée par une fonction calculant
la distance entre les vecteurs de ces
documents
Quelques mesures:
22
,,
,
ji
k
jkik
ji
dd
t
dtIDFTFdtIDFTF
ddCos
Distance du Cosinus
n
1
kjki2
ji ) w- w( )d,dEuclidean(Distance Euclidienne
n
1
n
1
n
1
n
1
) w- w(ww
)w w( )d,Sim(d
kjkikjki
kjki.
jiJaccard
d = 1 − s
69

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
• Classification de documents
La classification est la tâche la plus importante en Text Mining
Application des méthodes classiques aux vecteurs de
documents
(Knn, Centroid, Naïve Bayes, SVM, Arbre de décision…)
Segmentation des documents
Evaluation
70

École d’Hiver sur les applications de l’informatique industrielle, réseaux et génie logiciel
09-12 Décembre 2013
• Weka (Waikato Environment for Knowledge Analysis)
(Environnement Waikato pour l'analyse de connaissances)
• Tanagra
• Rapid Miner YALE (Yet Another Learning Environment)
• Orange
• …
Outils
71







![Data Mining Modèles et Algorithmes - Erick STATTNER · Induction d'un arbre de décision ID3 [Quinlan 1986] a évolué jusqu'aux versions C4.5 et C5.0 principe de base : construire](https://static.fdocuments.fr/doc/165x107/5b9d0eb609d3f2443d8b6432/data-mining-modeles-et-algorithmes-erick-induction-dun-arbre-de-decision.jpg)










