
simulium.bio.uottawa.casimulium.bio.uottawa.ca/bio4518/Documents%5CBiostatistiques%20... · I Table...
296
I Table des Matières INTRODUCTION 1 Objectifs du cours et philosophie d’enseignement 1 LE RÔLE DES STATISTIQUES DANS LA MÉTHODE SCIENTIFIQUE 3 La méthode hypothetico-déductive 3 Falsification d'hypothèses 3 Critères de qualité des hypothèses scientifiques 4 Pourquoi les scientifiques utilisent-ils les statistiques? 5 Ce que les statistiques peuvent faire pour vous 6 Ce que les statistiques ne peuvent faire pour vous 7 Critères de sélection des tests statistiques 8 QUELQUES COMMENTAIRES SUR LES TESTS STATISTIQUES 11 Le sens de p 11 Seuil de signification 11 Types d'erreur dans les tests statistiques 11 Tests unilatéraux et bilatéraux 13 QUELQUES CONCEPTS FONDAMENTAUX: STATISTIQUES ET DISTRIBUTIONS 17 Paramètres de position 17 Paramètres de dispersion 18 La distribution normale 19 Intervalles de confiance pour observations 20 La distribution du t de Student 22 Intervalles de confiance pour la moyenne 23 Effort d'échantillonnage requis pour estimer la moyenne 24 Intervalle de confiance pour la médiane 25 Intervalle de confiance pour la variance 26 TESTS D'AJUSTEMENT À UNE DISTRIBUTION THÉORIQUE 29 Tests du Khi-carré et de G 29 Facteurs de correction pour le test de khi-carré et de G lorsqu'il n'y a que deux catégories 30 Le test binomial 31 Tests de normalité à l'aide du Khi-carré ou de G 33 Le test de Kolmogorov-Smirnov 33 Test de normalité de Wilks-Shapiro 36 Test de normalité de Lilliefors 36 Commentaires sur les tests de normalité 36 LE CONCEPT D'ERREUR TYPE ET LE PRINCIPE FONDAMENTAL DU TEST DE T 39 Erreur type 39 Le principe du test de t 39 Effet de violations de l'hypothèse implicite de normalité 39 Transformation des données 41 COMPARAISONS DE DEUX MOYENNES, MÉDIANES, OU VARIANCES 43 Différences entre moyennes 43 Différences entre deux variances 44 Différences entre deux médianes 45 Autres tests nonparamétriques pour comparer la tendance centrale entre deux échantillons 45 Échantillons appariés 46 ANALYSE DE VARIANCE (ANOVA) À UN CRITÈRE DE CLASSIFICATION 49 Les trois types d’ANOVA (I, II et III) 50 Hypothèses implicites de l’ANOVA 51 Tests des conditions d’application 51 Le tableau d'ANOVA 53 La loi de Taylor pour trouver la meilleure transformation 54 Alternative non-paramétriques à l’ANOVA: le test de Kruskall-Wallis 54 COMPARAISONS MULTIPLES 57 Comparaisons planifiées et non-planifiées 57 Des approches différentes aux comparaisons multiples non-planifiées 57 Méthode de Bonferroni et Sidak 58 Méthode de Scheffé 58 Méthode de Tukey et GT2 59 Test de Student-Newman-Keuls (SNK) et de Duncan 60 Le test de Dunnett 60 Stratégies pour la sélection d’un test de comparaisons multiples a posteriori 60 Comparaisons multiples non-paramétriques 61 Intervalles de confiance pour les moyennes des groupes 61 Quelques points à retenir 62 ANALYSE DE VARIANCE À PLUSIEURS CRITÈRES DE CLASSIFICATION 63 Distinction entre l'ANOVA factorielle à deux critères de classification et l'ANOVA hiérarchique 63 Choisir entre l’ANOVA factorielle et l’ANOVA hiérarchique 64 ANOVA hiérarchique 65 ANOVA factorielle à deux facteurs de classification 67 Comparaisons multiples 69 ANOVA à deux critères de classification sans réplication 69 ANOVA à deux critères de classification non-paramétrique 70 Effectifs inégaux (Plan non-balancé) 71 CORRÉLATION 73 Hypothèses implicites 73 Test de signification 74 Intervalles de confiance 75 Comparaison de deux corrélations 76 Corrélation de rang 76 RÉGRESSION LINÉAIRE SIMPLE 79 Régression vs Corrélation 79 Le modèle général et les hypothèses implicites 79 Hypothèses implicites 80 Épreuves d’hypothèses 80 Test des hypothèses implicites 80 Erreur type de la pente 81 Intervalles de confiance en régression 82 Prédiction inversée 83 Régression avec réplication 84 Transformation des données 85 L’influence des valeurs extrêmes en régression 87 Régression pondérée 89 Quelques points à retenir 89
-
Upload
dangkhuong -
Category
Documents
-
view
219 -
download
0
Transcript of simulium.bio.uottawa.casimulium.bio.uottawa.ca/bio4518/Documents%5CBiostatistiques%20... · I Table...

I
Table des MatièresINTRODUCTION 1
Objectifs du cours et philosophie d’enseignement 1
LE RÔLE DES STATISTIQUES DANS LA MÉTHODE SCIENTIFIQUE 3
La méthode hypothetico-déductive 3Falsification d'hypothèses 3Critères de qualité des hypothèses scientifiques 4Pourquoi les scientifiques utilisent-ils les statistiques? 5Ce que les statistiques peuvent faire pour vous 6Ce que les statistiques ne peuvent faire pour vous 7Critères de sélection des tests statistiques 8
QUELQUES COMMENTAIRES SUR LES TESTS STATISTIQUES 11
Le sens de p 11Seuil de signification 11Types d'erreur dans les tests statistiques 11Tests unilatéraux et bilatéraux 13
QUELQUES CONCEPTS FONDAMENTAUX: STATISTIQUES ET DISTRIBUTIONS 17
Paramètres de position 17Paramètres de dispersion 18La distribution normale 19Intervalles de confiance pour observations 20La distribution du t de Student 22Intervalles de confiance pour la moyenne 23Effort d'échantillonnage requis pour estimer la moyenne 24Intervalle de confiance pour la médiane 25Intervalle de confiance pour la variance 26
TESTS D'AJUSTEMENT À UNE DISTRIBUTION THÉORIQUE 29
Tests du Khi-carré et de G 29Facteurs de correction pour le test de khi-carré et de G lorsqu'il n'y a que deux catégories 30Le test binomial 31Tests de normalité à l'aide du Khi-carré ou de G 33Le test de Kolmogorov-Smirnov 33Test de normalité de Wilks-Shapiro 36Test de normalité de Lilliefors 36Commentaires sur les tests de normalité 36
LE CONCEPT D'ERREUR TYPE ET LE PRINCIPE FONDAMENTAL DU TEST DE T 39
Erreur type 39Le principe du test de t 39Effet de violations de l'hypothèse implicite de normalité 39Transformation des données 41
COMPARAISONS DE DEUX MOYENNES, MÉDIANES, OU VARIANCES 43
Différences entre moyennes 43Différences entre deux variances 44Différences entre deux médianes 45Autres tests nonparamétriques pour comparer la tendance centrale entre deux échantillons 45Échantillons appariés 46
ANALYSE DE VARIANCE (ANOVA) À UN CRITÈRE DE CLASSIFICATION 49
Les trois types d’ANOVA (I, II et III) 50Hypothèses implicites de l’ANOVA 51Tests des conditions d’application 51Le tableau d'ANOVA 53La loi de Taylor pour trouver la meilleure transformation 54Alternative non-paramétriques à l’ANOVA: le test de Kruskall-Wallis 54
COMPARAISONS MULTIPLES 57Comparaisons planifiées et non-planifiées 57Des approches différentes aux comparaisons multiples non-planifiées 57Méthode de Bonferroni et Sidak 58Méthode de Scheffé 58Méthode de Tukey et GT2 59Test de Student-Newman-Keuls (SNK) et de Duncan 60Le test de Dunnett 60Stratégies pour la sélection d’un test de comparaisons multiples a posteriori 60Comparaisons multiples non-paramétriques 61Intervalles de confiance pour les moyennes des groupes 61Quelques points à retenir 62
ANALYSE DE VARIANCE À PLUSIEURS CRITÈRES DE CLASSIFICATION 63
Distinction entre l'ANOVA factorielle à deux critères de classification et l'ANOVA hiérarchique 63Choisir entre l’ANOVA factorielle et l’ANOVA hiérarchique 64ANOVA hiérarchique 65ANOVA factorielle à deux facteurs de classification 67Comparaisons multiples 69ANOVA à deux critères de classification sans réplication 69ANOVA à deux critères de classification non-paramétrique 70Effectifs inégaux (Plan non-balancé) 71
CORRÉLATION 73Hypothèses implicites 73Test de signification 74Intervalles de confiance 75Comparaison de deux corrélations 76Corrélation de rang 76
RÉGRESSION LINÉAIRE SIMPLE 79Régression vs Corrélation 79Le modèle général et les hypothèses implicites 79Hypothèses implicites 80Épreuves d’hypothèses 80Test des hypothèses implicites 80Erreur type de la pente 81Intervalles de confiance en régression 82Prédiction inversée 83Régression avec réplication 84Transformation des données 85L’influence des valeurs extrêmes en régression 87Régression pondérée 89Quelques points à retenir 89

II TABLE DES MATIÈRES
ANALYSE DE COVARIANCE (ANCOVA) 91Le modèle d’ANCOVA 91Hypothèses implicites 91L’ajustement des modèles en ANCOVA 92
RÉGRESSION MULTIPLE 97Le modèle général 97Hypothèses implicites 98Épreuves d'hypothèses 98Multicolinéarité 99Détection de la multicolinéarité 100Solutions au problème de multicolinéarité 101Sélection des variables indépendantes 102Régression curvilinéaire (polynomiale) 104Variables indicatrices 106
RÉGRESSION PONDÉRÉE, PROBIT, NORMIT, LOGIT ET NON-LINÉAIRE 109
Régression pondérée 109Régression probit, normit et logit 109Régression non-linéaire 113
TABLEAUX DE CONTINGENCE ET MODÈLES LOG-LINÉAIRES 115
X 2 et test de G 115Modèles log-linéaires 117
PERMUTATION ET BOOTSTRAP 121Tests de permutation 121Bootstrap 122Commentaires 123
EXERCICES DE LABORATOIRE 125
LABO- INTRODUCTION À SYSTAT 127Le cahier de bord, une habitude à prendre 127Ouvrir un fichier de données SYSTAT 128Création de diagrammes de dispersion 128Calculer des statistiques descriptives 131 Importer/Exporter des fichiers 131Manipulation de données dans le chiffrier 132Trouver des cas 133Sélectionner des cas 133Transformer des données 134Trier des données 137Produire des graphiques 137Sauvegarder et imprimer les fichiers de sortie 140
LABO- COMPARAISON DE DEUX ÉCHANTILLONS 143
Éprouver l'hypothèse de normalité 143Comparer les moyennes de deux échantillons indépendants : comparaisons paramétriques et non paramétriques 147Comparer les moyennes de deux échantillons appareillés 148Comparer la médiane et la variance de deux échantillons 151Comparer la distribution de deux échantillons 153Références 154
LABO- ANOVA À UN CRITÈRE DE CLASSIFICATION 155
ANOVA à un critère de classification et comparaisons multiples 155Vérifier si les conditions d'application de l'ANOVA paramétrique sont rencontrées 161Transformations de données et ANOVA
non-paramétrique 167
LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES 171
Plans hiérarchiques 171Plan factoriel à deux facteurs de classification et réplication 177Plan factoriel à deux facteurs de classification sans réplication 185ANOVA avec mesures répétées 189ANOVA non paramétrique avec deux facteurs de classification 193Comparaisons multiples 196
LABO- CORRÉLATION LINÉAIRE ET RÉGRESSION LINÉAIRE SIMPLE 207
Diagrammes de dispersion 207Transformations et le coefficient de corrélation 209Corrélations non paramétriques : r de Spearman et tau de Kendall 212Matrices de corrélations et correction de Bonferroni 214Régression linéaire simple 219Vérifier les conditions d'application de la régression 221Transformation des données en régression 223
LABO- ANCOVA 227Homogénéité des pentes 227Le modèle d'ANCOVA 233
LABO- RÉGRESSION MULTIPLE 239Conseils généraux 239Sélection des variables indépendantes 239Détecter la multicolinéarité 251Régression polynomiale 253
LABO- TABLEAUX DE CONTINGENCE ET MODÈLES LOG-LINÉAIRES. 259
Création du fichier de données 259Éprouver une hypothèse extrinsèque 262Épreuve d'indépendance pour tableau à deux critères de classification 264Modèles log-linéaires et tableaux de contingence à critères de classification multiples. 265Exercice 271
LABO- RÉGRESSION PONDÉRÉE, LOGISTIQUE ET NON-LINÉAIRE 279
Régression pondérée 279Régression logistique 281Régression non-linéaire 284
RÉFÉRENCES 287
GLOSSAIRE 289Biais 289Conservateur 289Erreur α 289Erreur β 289Exactitude 289Libéral 289Paramètre 290Puissance 290Précision 290Robustesse 290Sensibilité 290
INDEX 291

INTRODUCTION - 1
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Introduction
Objectifs du cours et philosophie d’enseignementL’objectif principal de ce cours est de vous aider à acquérir ou à augmenter votre gros bon sens en statistiques, et de vous aider à analyser vos données. Vous avez tous suivi au moins un cours de statistiques mais peu d’entre vous ont vraiment apprécié l’expérience. Il en a été de même pour nous. Nous ne nous sommes réellement intéressé aux statistiques que lorsque nous avons commencé à faire de la recherche. Le désir de présenter les résultats d'une manière convaincante nous a mené à la réalisation que les statistiques étaient l'outil le plus logique et le plus puissant pour le faire. Malheureusement, dans notre cas, il était trop tard et plusieurs aspects intéressants de nos premières recherches ne purent être développés parce que nous n'avions pas tenu compte de certaines considérations statistiques lors de la planification des expériences. Nous espérons que ce cours évitera au moins à certains d'entre vous de commettre les mêmes erreurs.
Nous ne sommes pas des vrais statisticiens, seulement des écologistes qui utilisent les statistiques presque quotidiennement. Notre attitude face aux statistiques (sans doute parce que nous avons peu de formation formelle en mathématiques et en statistiques) est similaire à celle que nous avons face à notre voiture: nous ne sentons pas le besoin de comprendre tous les détails de son fonctionnement pour la conduire, mais néanmoins trouvons la logique et le gros bons sens fort utiles lorsqu'elle refuse de démarrer. Il n'y aura pas de preuves ou de démonstrations de théorèmes statistiques dans ce cours. D'un autre côté, il y aura beaucoup d'exemples et de descriptions visuelles des concepts les plus importants de manière à vous y familiariser avant que vous ayez à les utiliser pour vos propres analyses. Au laboratoires vous aurez l'occasion de mettre en pratique les concepts vus en classe, d'analyser des données avec un logiciel de première classe (SYSTAT) et d'obtenir de l'aide pour l'analyse de vos propres données.
Pour que ce cours vous soit utile, vous devrez y mettre du temps. Nous savons que tous les professeurs vous disent cela et que vous journées sont déjà bien remplies. Il y a cependant deux stratégies qui peuvent vous aider à maintenir votre intérêt et réduire un peu votre tâche: d'abord, essayez de mettre la main sur des données qui vous intéressent, ensuite utilisez ce cours pour analyser pour vous aider dans un autre cours où vous devez faire une analyse de données.

2 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

LE RÔLE DES STATISTIQUES DANS LA MÉTHODE SCIENTIFIQUE - 3
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Le rôle des statistiques dans la méthode scientifique
La méthode hypothetico-déductiveLe progrès en science peut être mesuré par le taux auquel les possibilités logiques sont éliminées. Une des approches les plus couronnées de succès pour maximiser ce taux est la méthode hypothetico-déductive, qui est pour certains la méthode scientifique par excellence. Le diagramme suivant illustre les étapes de cette méthode
Le point de départ d'une recherche scientifique est un problème ou une question qui est stimulée par des observations. Par induction, une hypothèse est avancée pour expliquer les observations. En utilisant la logique et en faisant des déductions, les implications de cette hypothèse sont développées en prédictions. Une expérience est alors planifiée pour tester ces prédictions. Les résultats de l’expérience sont analysés pour en tirer une conclusion. Si les conclusions supportent l’hypothèse, le problème peut être considéré comme résolu, et on peut passer à une autre problème. Si les conclusions expérimentales invalident l’hypothèse, l’hypothèse est modifiée ou remplacée par une autre hypothèse qui sera à son tour testée par une expérience. Le progrès dans un domaine scientifique est souvent relié à la vitesse à laquelle un cycle est complété.
Falsification d'hypothèsesLa Vérité, malheureusement, n'est pas à la portée de la Science. On doit toujours garder à l'esprit que même nos plus glorieux succès en science et nos explications les plus ingénieuses ne demeurent que des hypothèses à propos de la réalité. La méthode scientifique ne peut pas prouver qu'une hypothèse est vraie; elle ne peut que corroborer ou
Figure 1. Étapes de la démarche scientifique selon la méthode hypothético-déductive Hypothèse
Prédictions
ObservationsConclusions
Induction Déduction
Expérience
Inférence
Question

4 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
invalider (falsifier) des hypothèses. Une hypothèse qui a survécu à de nombreux et rigoureux tests est parfois considérée comme un fait, mais aucune hypothèse scientifique ne peut être vraiment considérée comme une vérité absolue. Démontrer qu'une hypothèse est fausse est quand même un pas dans la bonne direction puisque cela permet de raffiner l’hypothèse, et de réduire l'étendue du possible vers le probable.
Critères de qualité des hypothèses scientifiquesPuisque il est fort possible que toutes les hypothèses et théories scientifiques actuelles soit un jour invalidées, et parce qu'il y a couramment plusieurs hypothèses qui expliquent les mêmes faits, il est important d'avoir des critères objectifs permettant de juger de leur valeur relative. Ces critères ont été débattus par les philosophes des sciences depuis plusieurs décades si ce n'est des siècles. Ce qui suit n'est qu'un très bref sommaire des critères les plus importants:
Généralité.
La meilleure de deux hypothèses élimine plus de possibilités et peut être appliquée à plus de situations.
Exactitude.
Les prédictions d'une bonne hypothèse sont, en moyenne, correctes.
Précision.
La différence entre les valeurs observées et celles prédites par une bonne hypothèse est, en moyenne, petite.
Simplicité (le principe de parcimonie)
Une bonne hypothèse est simple et plus pratique ou économique à utiliser. Une bonne hypothèse est élégante
Dans bien des cas, ces critères sont rencontrés à divers degrés par les hypothèses en compétition pour expliquer les mêmes faits ou solutionner le même problème. Une hypothèse plus générale est souvent moins précise. Une hypothèse simple est souvent moins exacte. La coexistence de multiples hypothèses peut généralement être expliquée par l'absence d'une hypothèse supérieure aux autres à tous points de vue.

LE RÔLE DES STATISTIQUES DANS LA MÉTHODE SCIENTIFIQUE - 5
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Pourquoi les scientifiques utilisent-ils les statistiques?Les statistiques ont de multiples usages en science. Elles peuvent être utilisées comme un outil objectif pour évaluer la fiabilité des conclusions d'expériences ou pour résumer l'information contenue dans un ensemble de données. La connaissance des propriétés des tests statistiques peut également être mise à profit lors de la planification d'expérience et aider à maximiser la fiabilité des conclusions.
Se convaincre et convaincre les autres (statistiques inférentielles)
Les tests statistiques permettent d'estimer la probabilité que les résultats observés (par exemple la différence de rendement entre des plantes soumises à divers niveaux de radiation) soient causés par la chance ou des variations aléatoires. Nous savons tous que les entités biologiques (fussent-elles des enzymes ou des individus) sont variables et que leurs propriétés varient dans le temps. Compte-tenu de cette variabilité inhérente, les résultats d'expériences identiques effectuées sur des entités différentes doivent donc varier quelque peu. Sachant que la même expérience doit produire des résultats variables, comment juger si les différences observées pour divers traitements sont causées par les traitements ou simplement par les différences entre les entités mesurées? Comment se convaincre et convaincre les autres que les effets observés sont réels et non pas dûs à des variations aléatoires?
La procédure acceptée en science est de calculer la probabilité que les résultats observés aient pu être causés par la chance. Si cette probabilité est faible, il est alors raisonnable d'accepter que c'est la manipulation plutôt que la chance qui est responsable des différences observées entre les traitements. Les statistiques fournissent un ensemble de règles qui permettent d'estimer ces probabilités, et de tirer des conclusions objectives (faire des inférences).
Transmettre de l'information (statistiques descriptives)
Les statistiques peuvent également résumer l'information contenue dans un ensemble de données et ainsi faciliter sa transmission. Les revues scientifiques permettent rarement la publication de grands ensembles de données brutes. L'espace est limité, et la plupart des lecteurs ne sont pas intéressés par ces détails. Toutefois, pour pouvoir évaluer correctement les conclusions tirées d'une expérience, ils est souvent important de savoir certains détails à propos du matériel biologique utilisé (par exemple le nombre d'érables étudiés, leur âge, leur taille, etc.). Des descripteurs statistiques sont souvent employées

6 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
pour décrire la tendance centrale et la variabilité de variables biologiques. Il faut réaliser, toutefois, que ces descripteurs statistiques ne retiennent qu'une partie de l'information contenue dans les données brutes. La moyenne et l'écart-type d'une variable ne peuvent suffire (sauf dans de rares cas) à reproduire sa distribution empirique dans la population statistique.
Planifier des expériences
Si l'on connaît la variabilité naturelle des entités biologiques à l'étude, et si l'on s'attend à ce qu'une manipulation produise un effet d'une magnitude donnée, il est possible de déterminer à l'avance combien de fois une expérience devra être répétée pour obtenir des résultats convaincants. Ces considérations statistiques peuvent être d'une grande aide lors de la planification d'expériences ou d'études en indiquant combien de travail devra être réalisé avant d'obtenir une réponse valable, et parfois en nous indiquant qu'il y a peu d'espoir que nous puissions démontrer l'effet qui nous intéresse même en y travaillant pour le reste de notre vie.
Ce que les statistiques peuvent faire pour vousFournir des critères objectifs pour tester des hypothèses biologiques.
Une connaissance des statistiques permet de réaliser des travaux plus convaincants et de mieux évaluer le travail des autres. Dans le contexte scientifique, les statistiques jouent le rôle d'un juge impartial dont la fonction est de décider si vos découvertes sont dignes de mention ou si l'évidence que vous apportez est trop mince pour convaincre les autres.
Aider à optimiser vos efforts.
Personne n'aime perdre son temps. Pourtant, de nombreux scientifiques gaspillent un temps et des ressources précieuses à réaliser des expériences qui fournissent très peu d'information. Lorsque vous planifiez une expérience, vous ne devriez pas vous en tenir uniquement aux aspects techniques, mais également prévoir l'analyse statistique des résultats. Si vous effectuez votre expérience avant de penser à l'analyse des résultats, vous pourriez fort bien réaliser après coup que le design expérimental était inadéquat ou encore qu'il aurait été nécessaire de répéter l’expérience à de plus nombreuses reprises. Une connaissance pratique des statistiques peut réduire les chances que vous vous retrouviez dans cette fâcheuse position.

LE RÔLE DES STATISTIQUES DANS LA MÉTHODE SCIENTIFIQUE - 7
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Vous aider à évaluer critiquement des raisonnements
Tous le monde essaie de vous convaincre de quelque chose. Certains utilisent même des arguments “scientifiques” pour appuyer leurs dires. À mon avis, la plupart des gens (même les scientifiques) ne sont pas assez critiques face à ces arguments. Par exemple, j'ai entendu un débat entre deux politiciens sur les effets des programmes d’enregistrement des armes à feu sur les crimes violents. Un politicien citait une étude démontrant une réduction de 19% des crimes commis avec une arme à feu dans les régions où les armes devaient être enregistrées par rapport à celles où un tel enregistrement n’est pas obligatoire. Ce pourcentage cité était impressionnant, tel que voulu par le politicien. Toutefois, une lecture de l’étude en question révélait que, à cause de la grande variabilité entre les régions (avec ou sans programme d’enregistrement), cette réduction de 19% n’était pas statistiquement significative. Un auditeur statistiquement naïf pourrait avoir été convaincu par le politicien, mais pas vous après avoir suivi ce cours!
Ce que les statistiques ne peuvent faire pour vousLes statistiques ne peuvent remplacer la réflexion et le travail. Une des problèmes avec les statistiques est que les divers tests donnent toujours une réponse (spécialement lorsqu'effectués par ordinateur). Les logiciels n'indiquent presque jamais si un test statistique est mal employé ou si la réponse porte à confusion.
Dire la vérité
Même dans des conditions idéales, puisque l'improbable se produit de temps à autre, les statistiques vous induiront quelquefois à prendre la mauvaise décision. Il ne faut jamais confondre conclusion statistique et vérité absolue. Les statistiques ne peuvent dire la vérité; elles ne peuvent que permettre d'estimer la probabilité qu'un énoncé soit vrai, compte-tenu des données disponibles. C'est déjà beaucoup...
Compenser pour une mauvaise planification ou l'absence de contrôles.
Les résultats de l'analyse statistique ne peuvent être de meilleure qualité que les données qui sont à la source. Des manipulations statistiques poussées peuvent parfois cacher, mais jamais corriger, les lacunes d'une expérience. Si une expérience n'a pas de contrôle adéquat, les statistiques ne peuvent qu'indiquer si les chiffres diffèrent

8 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
entre le “contrôle” et le traitement, pas si la différence peut être attribuée au traitement. Par conséquent, il faut bien réfléchir avant de commencer une expérience.
Indiquer l'importance biologique.
Les tests statistiques permettent de déterminer la probabilité que le résultat observé soit dû uniquement à la chance. Si cette probabilité est faible, on dit que le résultat est significatif. Ce terme n'a rien à voir avec la signification biologique ou sociale d'un résultat. Dans ces contextes la signification est évaluée selon de critères différents et souvent moins impartiaux. La signification statistique n'implique pas la signification biologique. Par exemple, on pourrait trouver que la température a un effet statistiquement significatif sur le taux de reproduction des êtres humains. Toutefois, puisque d'autres facteurs (âge, milieu socio-économique) ont une influence beaucoup plus forte, certains seront portés à dire que l'effet de la température est biologiquement insignifiant comparé aux autres.
Critères de sélection des tests statistiquesLa nature du problème et les propriétés des données
Impressionnés par la grande variété de tests statistiques disponibles, certains ont l'impression qu'il est possible de choisir le test qui donnera la réponse voulue, supportant ainsi la parole célèbre de Benjamin D’Isreali: “There are three types of lies: lies, darn lies, and statistics...”. En fait, pour une hypothèse donnée, le nombre de tests statistiques qui peuvent s'appliquer est relativement restreint. Le choix d’un test statistique dépend du but visé, du design expérimental et du type de variables mesurées (continues, discontinues, rangs, fréquences, etc.).
La fiabilité.
Pour certains types d'hypothèses, plusieurs tests sont potentiellement applicables. Cependant la fiabilité de la majorité des tests repose sur certaines conditions d'application. Si ces conditions préalables ne sont pas respectées, le test peut ne pas être fiable. L’examen des conditions d’application des tests potentiels permet d'éliminer les tests les moins fiables.
La puissance.
Lorsque plusieurs tests fiables peuvent être utilisés, le choix est dicté par leur capacité relative à distinguer des effets de faible amplitude de la variation aléatoire. Dans une situation donné, le test le plus puissant

LE RÔLE DES STATISTIQUES DANS LA MÉTHODE SCIENTIFIQUE - 9
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
est celui qui a la plus petite limite de détection. Un test faible ne détectera pas un effet significatif qui serait détecté par un test plus puissant.

10 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

QUELQUES COMMENTAIRES SUR LES TESTS STATISTIQUES - 11
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Quelques commentaires sur les tests statistiques
Le sens de pLes tests statistiques sont bâtis à partir de plusieurs composantes: une hypothèse à tester (H0, l’hypothèse nulle), des observations à partir desquelles on peut calculer une statistique et des présomptions quant aux propriétés de cette statistique. Le résultat du test d’accepter ou de rejeter l’hypothèse nulle est basée sur p, la probabilité d’observer des résultats comme ceux qui ont été obtenus si l’hypothèse nulle est vraie.
P n'est pas la probabilité que l’hypothèse nulle soit vraie; quoique, pour simplifier les choses, on le conçoit souvent en pratique comme cela. Une définition plus exacte doit mentionner les conditions:
Si les données rencontrent les conditions d’application
et si H0 est vraie
alors, p est la probabilité d'observer une statistique aussi éloignée de la valeur prédite par l’hypothèse nulle. Cette probabilité est typiquement calculée en se basant sur des distributions théoriques.
Seuil de significationDit simplement (mais faussement!), les tests statistiques permettent d'estimer la probabilité qu'une hypothèse soit vraie. Si cette probabilité est faible, alors on rejette l'hypothèse. Le seuil de décision le plus souvent utilisé est 5%, et les hypothèses ayant moins de 5% des chances d'être correctes sont généralement rejetées. Il ne faut jamais oublier que ce seuil est arbitraire, et qu'il y a perte d’information lorsque seule la décision finale est rapportée sans la valeur de la probabilité. Il y a une grande différence entre un résultat significatif à 0.000001% et un autre à 4.9999%; alors qu'il n'y a que peu de différence entre un résultat non significatif à 5.01% et un résultat significatif à 4.99%.
Types d'erreur dans les tests statistiquesUne hypothèse vraie sera parfois rejetée, alors qu'une hypothèse fausse sera parfois acceptée. Ce sont les deux types d'erreurs qui peuvent être commises à la suite d'un test statistique. Le premier type d'erreur (rejeter une hypothèse vraie) est communément appelé erreur

12 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
du premier type, de type I, ou erreur α. Le second type d'erreur (accepter une hypothèse fausse) est appelé erreur du second type, erreur de type II, ou erreur β. La probabilité de commettre une erreur de type I est généralement connue: c'est le seuil de probabilité utilisé pour accepter ou rejeter l’hypothèse nulle. Par contre, on ne connaît généralement pas la probabilité de commettre une erreur de type II, quoique cette probabilité soit inversement reliée à la probabilité de commettre une erreur de type I. La seule façon de réduire les deux type d’erreurs est d’augmenter n, l’effectif de l’échantillon.
Dans certains cas, une information indirecte permet d’estimer la probabilité de commettre les deux types d’erreur. Par exemple, les premiers tests de dépistage des porteurs du Virus VIH permettaient de détecter 95% des porteurs. Des études ultérieures ont démontré que, dans environ 1% des cas, le test produisait de faux résultats positifs (i.e. le test disait qu’une personne était porteuse du VIH alors qu’elle ne l’était pas. Quelle horreur!). Dans ce cas, le niveau α est de 1% (dans 1% des cas, le test a infirmé l’hypothèse nulle que l’individu n’était pas porteur alors que cette hypothèse nulle était vraie) et le niveau β est de 5% (5% des individus porteurs du virus n’étaient pas détectés, et le médecin acceptait l’hypothèse nulle par erreur).
La pratique courante en biologie est de rapporter la probabilité associée au test d'hypothèse avec la conclusion d'accepter ou de rejeter l’hypothèse testée. Rarement voit-on une discussion ou un estimé de la probabilité de commettre une erreur de type II, même si c'est un élément d’information capital dans bien des cas. Considérez l'exemple suivant:
Une compagnie tente de développer un nouvel insecticide contre les mouches noires. Après d'importants investissements, un nouveau composé beaucoup plus efficace que ce qui est alors sur le marché est développé. Avant de le mettre en vente, la compagnie doit d'abord démontrer que le produit n'est pas dangereux pour les mammifères et les oiseaux. La compagnie se charge de faire des tests et rapporte que son produit n'a pas causé d'augmentation du taux de mortalité des cobayes exposés (p > 0.05). Seriez-vous prêt à autoriser la vente de ce produit?
La première question que vous devriez vous poser avant de rendre votre décision est: quelle est la probabilité que les tests effectués par la compagnie n'aient pu détecter un effet réel; i.e. quelle est la probabilité que la compagnie commette une erreur de type II et qu'en acceptant l’hypothèse selon laquelle son produit est sans danger elle accepte une hypothèse fausse. Puisque le taux de mortalité et l'espérance de vie des cobayes est variable, un moyen d'obtenir des résultats qui seraient avantageux (à court terme) pour la compagnie est d'utiliser un

QUELQUES COMMENTAIRES SUR LES TESTS STATISTIQUES - 13
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
échantillon petit et de faire une courte expérience. La probabilité de détecter un effet significatif serait alors très faible. La compagnie, pour vous convaincre, devrait donner une indication de la probabilité de détecter un effet de taille raisonnable, compte tenu du design expérimental utilisé. Par exemple, que compte tenu du nombre de cobayes utilisés, et de la durée des expériences, que le design expérimental aurait 95% des chances de détecter une augmentation de 2% du taux de mortalité des cobayes.
Notez que les probabilités α et β sont inversement reliées. Par exemple, en construisant un intervalle de confiance de la moyenne, si l'on réduit α, l'intervalle de confiance grandit. A la limite, si l'on pose α=0, alors l'intervalle de confiance est infini. β, qui dans ce cas correspondrait à la probabilité de faussement conclure qu'une observation fait partie de la même population, est alors 1 puisque toutes les valeurs possibles seront incluses dans l'intervalle de confiance.
Tests unilatéraux et bilatérauxPour la plupart des tests statistiques, il y a deux types d’hypothèses qui peuvent être éprouvées: si un paramètre est égal à une certaine valeur ou si un paramètre est plus petit ou égal (plus grand ou égal) à une certaine valeur. Dans les tests bilatéraux, l’hypothèse nulle est que le paramètre est égal à une certaine valeur théorique. Cette hypothèse sera acceptée si la valeur observée est près de la valeur théorique, et elle sera rejetée si elle est loin de la valeur théorique, peu importe si la valeur observée est plus grande ou plus petite que la valeur théorique. Si l’hypothèse nulle suppose que le paramètre est égal à 0, des valeurs observées très négatives ou très positives pourraient nous amener à rejeter l'hypothèse.
Dans les tests unilatéraux, l’hypothèse nulle est que le paramètre est plus grand (ou plus petit) ou égal à une valeur quelconque. Si l’hypothèse nulle suppose que le paramètre doit être plus petit que 0, seules des valeurs observées plus grandes que 0 pourraient nous amener à rejeter l'hypothèse.

14 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Il est donc important d'énoncer a priori l'hypothèse qui est testée comme étant une hypothèse bilatérale ou unilatérale. La conclusion statistique dépendra souvent du type d'hypothèse retenue. Par exemple, certaines différences entre les valeurs observées et les valeurs attendues pourraient ne pas être suffisamment grandes pour être “significatives” dans un test bilatéral mais l'être dans un test unilatéral. Cette propriété des tests unilatéraux peut être mise à profit par des chercheurs peu scrupuleux pour produire des résultats “significatifs”. Cette pratique aberrante a contribué à donner aux tests unilatéraux un petit air suspect qu’ils ne méritent pas. Les tests unilatéraux sont tout à fait appropriés lorsque l’hypothèse formulée à priori est unilatérale. Une exemple d’une telle situation serait un test d’un nouvel insecticide visant à démontrer qu’il est moins toxique que celui qui est présentement utilisé.
Figure 2. Zone d'acceptation et de rejet de l'hypothèse nulle pour un test bilatéral (A) et des tests unilatéraux (B et C). Notez que la partie ombrée (la zone de rejet) représente la même proportion dans les trois cas, mais les valeurs critiques diffèrent.
-3 -2 -1 0 1 2 3
-3 -2 -1 0 1 2 3
-3 -2 -1 0 1 2 3
"/2"/2
"
"
1-"
1-"
1-"
A
B
C
-3 -2 -1 0 1 2 3
-3 -2 -1 0 1 2 3
-3 -2 -1 0 1 2 3
α/2α/2
α
"
1-α
1-α
1-α
-3 -2 -1 0 1 2 3
-3 -2 -1 0 1 2 3
-3 -2 -1 0 1 2 3
"/2"/2
"
"
1-"
1-"
1-"
A
B
C
-3 -2 -1 0 1 2 3
-3 -2 -1 0 1 2 3
-3 -2 -1 0 1 2 3
α/2α/2
α
"
1-α
1-α
1-α

15 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

16 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

QUELQUES CONCEPTS FONDAMENTAUX: STATISTIQUES ET DISTRIBUTIONS - 17
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Quelques concepts fondamentaux: Statistiques et distributions
Cette section est une revue des techniques utilisées pour décrire la distribution des données dans un échantillon et pour calculer un intervalle de confiance autour d’une moyenne, de la médiane, et de la variance.
Les biologistes sont en général intéressés aux caractéristiques des populations (paramètres). Il est toutefois rare que l'on puisse travailler avec une population entière; la plupart du temps les données ne sont disponibles que pour un sous ensemble de cette population, un échantillon. C'est à partir de cet échantillon qu'on essaiera de décrire les paramètres de la population. Les estimés des paramètres obtenus à partir de l’échantillon sont appelés statistiques. Ces statistiques doivent idéalement être exactes, précises, et consistantes.
Exactitude. Une bonne statistique a, en moyenne, une valeur qui se rapproche de la vraie valeur du paramètre qu’elle estime. Une statistique exacte est donc non biaisée et une statistique inexacte est biaisée.
Précision. Une bonne statistique, lorsque calculée à partir de divers échantillons tirés de la même population, varie peu d’un échantillon à l’autre.
Consistance. Une bonne statistique tends de plus en plus vers la vraie valeur du paramètre qu’elle estime lorsque la taille de l’échantillon augmente.
Paramètres de positionLa mesure la plus utilisée pour décrire l'ordre de grandeur des valeurs et la valeur centrale autour de laquelle se groupent les observation est la moyenne arithmétique, calculée par:
où Xi dénote les valeurs observées et n est le nombre d'observation (l'effectif). Les moyennes ont plusieurs propriétés fort intéressantes: elles sont simple à calculer et leur distribution est souvent plus
(1)X
X
n
ii
n
= =∑
1

18 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
prévisible que celle des observations individuelles. En fait, si l'on estime à plusieurs reprise la moyenne d'une population à l'aide de grands échantillons (disons n >1000 pour être prudent) et que l'on construit un histogramme des moyennes calculées, la forme de cet histogramme sera toujours la même (celle d'une cloche, de la courbe normale) peu importe la forme de la distribution originale.
Toutefois, lorsque l’échantillon est petit, la moyenne peut être fortement influencée par une ou deux valeurs extrêmes. Donc, si votre échantillon contient une ou deux valeurs extrêmes, la moyenne de l’échantillon peut ne pas être un bon estimé de celle de la population. La même chose peut se produire si la distribution des données est très asymétrique. Dans ce cas, il est préférable de décrire la tendance centrale par une statistique qui est plus robuste (i.e moins sensible) à la présence de valeurs extrêmes, comme la médiane. La robustesse de la médiane est une propriété très désirable, et de nombreux tests statistiques utilisent la médiane plutôt que la moyenne.
Paramètres de dispersionL'étendue de la variation est conceptuellement la mesure la plus simple de dispersion. Ce n'est toutefois pas une bonne statistique car elle est généralement biaisée. Puisqu'il est improbable qu'un échantillon contienne la valeur minimale et la valeur maximale de la population, l'estimé obtenu à partir de l’échantillon sous-estime la valeur pour la population.
La somme des carrés (SC) est la somme des carrés des écarts à la moyenne:
où µ et sont respectivement la moyenne de la population et de l’échantillon et n et N l’effectif (le nombre d’observations) dans l’échantillon et la population.
(2)SC Xpopulation i
i
N
= −=∑ ( )µ 2
1
SC X Xéchantillon ii
n
= −=∑ ( )2
1
X

QUELQUES CONCEPTS FONDAMENTAUX: STATISTIQUES ET DISTRIBUTIONS - 19
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
La somme des carrés augmente avec l'effectif et doit donc être pondérée pour obtenir un estimé utile: la variance (σ2) pour la population, s2 pour l’échantillon:
Notez que la somme des carrés de l’échantillon est divisée par n - 1 plutôt que par n pour corriger une tendance à sous-estimer la variance de la population à partir de petits échantillons. Notez également que la formule utilisée par plusieurs chiffriers électroniques pour calculer la variance est la formule pour la population et non celle pour l'échantillon.
La variance de l’échantillon peut également être calculée par la formule suivante qui est plus pratique lorsque l'on utilise une calculatrice:
L'écart type (σ pour la population, s pour l’échantillon) représente la déviation moyenne des observations par rapport à la moyenne. Il est calculé par la racine carrée de la variance.
La distribution normaleLa distribution normale est l'une des distributions les plus utilisées en statistiques. Les raisons expliquant ce rôle central sont bien plus historiques et mathématiques que biologiques. En fait, il y a très peu de variables en biologie qui sont distribuées normalement. Cependant, la distribution des moyennes tend vers la normalité, et l'approximation normale devient souvent acceptable lorsque l'on travaille avec des moyennes.
(3)
(4)
σµ
2
2
1=−
=∑ ( )X
N
ii
N
sX X
n
ii
N
2
2
1
1=
−
−=∑ ( )
sX
Xn
n
ii
2
2
2
1=
−
−
∑∑d i

20 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
La distribution normale peut être décrite par deux paramètres: la moyenne de la distribution (µ), et la variance de la distribution (σ2):
Il y a une infinité de distributions normales, puisque la moyenne et la variance peuvent prendre une infinité de valeurs différentes. Pour simplifier les calculs et les tableaux des probabilités, les distributions normales sont généralement centrées et réduites de manière à produire une distribution normale avec une moyenne de 0 et une variance de 1: la distribution normale standard. La transformation pour standardiser la distribution est simple: il suffit de soustraire la moyenne (µ) et de diviser le résultat par la racine carrée de la variance (l'écart type, σ).
Intervalles de confiance pour observationsUn intervalle de confiance à x% pour les observation est un intervalle dans lequel on devrait retrouver x% des observations si on échantillonnait cette population. Si une population normale d'étudiants a une masse corporelle moyenne (µ) de 68 kg, 50% des étudiants seront plus légers que 68 kg. Pour calculer la proportion des étudiants qui sont plus lourds que 90 kg, on doit connaître σ, l'écart type de la population. Pour calculer cette proportion, on doit d'abord standardiser (ou normaliser) la masse corporelle (M) par:
ce qui équivaut, pour un individu de 90 kg dans une population dont la moyenne est de 68 kg et l'écart type est de 10 kg, à ((90-68)/10) = 2.2. La deuxième étape est de consulter un tableau des proportions de la distribution normale. Pour une valeur de Z de 2.2, cette proportion est de 0.0139 ou 1.39%, ce qui signifie qu'environ 1.4% des étudiants pèsent plus de 90 kg.
Lorsque la moyenne (µ) et la variance (σ2) d'une population sont connues, on peut calculer le limites d'un intervalle qui contient une proportion donnée de la population par:
(5)
(6)
(7)
f x ex
b gb g
=−
−12
2
22
σ π
µ
σ
Z M=
− µσ
µ σ± Z

QUELQUES CONCEPTS FONDAMENTAUX: STATISTIQUES ET DISTRIBUTIONS - 21
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
où Z est la valeur appropriée de l'abscisse de la distribution normale standard. Cet intervalle peut servir à déterminer si une nouvelle observation fait vraisemblablement partie de la même population.
Cette équation ne peut presque jamais être utilisée en pratique parce que les valeurs de µ et de σ ne sont rarement connues pour les populations étudiées. Une possibilité est de remplacer les valeurs de µ et de σ par les estimés de moyenne et d'écart type calculés à partir d'un échantillon, mais cette solution mène à de sérieux biais pour de petits échantillons. Ce biais peut être illustré à l'aide d'un programme de simulation statistique.
A partir d'une population ayant une moyenne µ et un écart type σ, tirer au hasard un échantillon de taille n. A partir des données de cet échantillon, calculer la moyenne et l'écart type (s) de l’échantillon, puis calculer un intervalle de confiance à 95% pour les observations comme la moyenne de l’échantillon ± 1.96s. Puisque dans ce cas les valeurs de µ et de σ sont connues, il est possible de calculer le pourcentage réel de la population dont les valeurs se situent à l'intérieur ou au dehors de l'intervalle calculé à partir de l'échantillon. Répéter toutes les étapes précédentes un grand nombre de fois et présenter les résultats sous forme d'histogramme.
La Fig. 3 illustre les résultats d'une telle simulation. Quoique les intervalles à 95% n'excluent pas toujours exactement 5% de la population lorsque calculés à partir de grands échantillons, en moyenne ils le font (ils sont exacts ou pas biaisés) et lorsqu'il ne le font pas ils ne sont jamais très loin du 5% (ils sont précis). Si le même exercice est répété, cette fois avec de petits échantillons (n = 3), on remarque que les intervalles de confiances basés sur la distribution normale sont biaisés (ils sont en moyenne trop petits et incluent seulement 76% de la population) et qu'ils sont terriblement imprécis (ils excluent de 1 à 99% de la population). Il y a un message important ici:
Figure 3. Pourcentage de la population à l'extérieur de l'intervalle de confiance à 95% incorrectement calculé à partir de la moyenne et de l'écart type de l’échantillon comme m ± 1.96 s. L'erreur est faible lorsque l'effectif de l’échantillon est grand (l'erreur moyenne pour un effectif de 1000 est de 5%), mais les intervalles de confiance à 95% calculés ainsi à partir de petits échantillons sont en moyenne trop petits (23.8% de la population se retrouve en moyenne en dehors de l'intervalle de confiance)
Proportion (%) de la population hors de l'intervalle de confiance à 95%
1000 simulationsEffectif=3
1000 simulationsEffectif=1000
0
50
100
150
0 20 40 60 80 1000
100
200
300
400
500
0 20 40 60 80 100

22 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Vous ne devriez jamais utiliser les valeurs Z pour calculer les intervalles de confiance de petits échantillons.
La distribution du t de StudentIl est possible, à l'aide de petits échantillons, de calculer des intervalles de confiance qui sont exacts, en remplaçant les valeurs de Z de la distribution normale par les valeurs de t de la distribution de Student. La distribution du t de Student ressemble en général à la distribution normale standard mais en diffère en ce que sa forme change en fonction du nombre de degrés de liberté (typiquement calculé comme le nombre d'observation moins le nombre de paramètres estimés). Lorsque l’échantillon est grand et donc que le nombre de degrés de liberté est élevé, la distribution de t tends vers la distribution normale. Lorsque le nombre de degrés de liberté est faible la distribution de t est plus pointue que la distribution normale standard, et les queues de la distribution sont plus longues.
Si on répète la simulation, cette fois en comparant les intervalles de confiance avec les valeurs critiques de Z et de t, on obtient les résultats illustrés à la Figure 4. L'emploi des valeurs de t pour calculer les intervalles de confiance à partir de petits échantillons permet d'obtenir des intervalles de confiance plus fiables. Notez cependant que c’est pour les très petits échantillons (n < 10) que la différence se fait le plus sentir, puisque les valeurs critiques de t convergent vers celles de Z pour les échantillons plus gros.
L’examen de la Fig. 4 révèle cependant que pour les échantillons très petits, les intervalles de confiance calculés à l'aide de t sont légèrement trop étroits. Ce biais s'explique par le fait que l'estimé de l'écart type obtenu à partir de petits échantillons est légèrement biaisé. La variance (s2) est un estimé non biaisé de la variance de la population, mais sa
Figure 4. Pourcentage de la population normale théorique inclus dans les intervalles de confiance calculés à partir des valeurs de Z ou de t en fonction de la taille de l'échantillon. Ces résultats sont basés sur une simulation par laquelle la population théorique a été échantillonnée 10,000 fois pour chaque valeur de l'effectif. Notez que les intervalles de confiance basés sur les valeurs de Z ne sont pas fiables lorsque l'effectif est petit et qu'ils sont en général trop petits.
Effectif de l'échantillon Effectif de l'échantillon
IC calculés avec Z IC calculés avec t
10 100 1000 1000010 100 1000 1000030
50
7080
90
95
9899
99.899.9
99% 99%
99.9%99.9%
95% 95%
90% 90%
75% 75%
50% 50%
30
50
7080
90
95
9899
99.899.9

QUELQUES CONCEPTS FONDAMENTAUX: STATISTIQUES ET DISTRIBUTIONS - 23
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
racine carrée (s) sous-estime σ, l'écart type de la population. Ce léger biais peut être corrigé, (c'est rarement fait) en multipliant s par le facteur de correction Cn:
où est la distribution gamma.
Le tableau 9 de Rohlf et Sokal (1981) donne les valeurs du facteur de correction pour des échantillons allant jusqu'à 30. Pour des échantillons plus gros, Cn peut être estimé par 1+1/4(n-1).
Intervalles de confiance pour la moyenneIntuitivement, nous savons tous que les moyennes varient moins que les observations individuelles. Par exemple, même si vous ne pouvez que prédire très grossièrement quelle sera votre note finale pour ce cours (une observation individuelle), vous pouvez sans doute prédire beaucoup plus précisément quelle sera la note moyenne pour le groupe.
Pour calculer un intervalle de confiance de la moyenne, il faut une mesure de la variabilité de la moyenne. Comme l'écart type (ou son carré, la variance) est un estimateur de la variabilité des observations individuelles, l'erreur type (ou écart type de la moyenne) est un estimé de l'incertitude de l'estimé de la moyenne de la population. Il existe deux façons d'estimer l'erreur type. La première, très rarement utilisée, consiste à échantillonner à répétition la même population (disons avec des échantillons de 10 observations), de calculer la moyenne pour chacun des échantillons, puis de calculer l'écart type des moyennes de tous les échantillons. La seconde, beaucoup plus simple et rapide, consiste simplement à diviser l'écart type des observations par la racine carrée de l'effectif. Le calcul de l'intervalle de confiance pour la moyenne est similaire à celui pour les valeurs individuelles sauf que l'erreur type est utilisée au lieu de l'écart type:
où est la moyenne de l’échantillon, s est l’erreur-type, n est l’effectif et tn-1, α/2 est la valeur critique de t avec n degrés de liberté au seuil α/2.
(8)
(9)
C nn
nn =−FHGIKJ
−FHGIKJ
FHGIKJ
12
12
2
12
Γ
Γ
Γ( )n
X t snn± −1 2, /α
X

24 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Effet de la taille de l’échantillon
Un coup d'oeil à l'équation pour l'intervalle de confiance d'une moyenne (Eq. 9) suffit pour déterminer que la taille de l’échantillon affecte la taille des intervalles de confiance. Avec un accroissement de l'effectif, la moyenne et l'écart type s'approchent des vraies valeurs. Toutefois, la valeur critique de t diminue vers la valeur de Z équivalente, ce qui réduit la taille de l'intervalle de confiance. Et comme l'intervalle de confiance est une fonction de l'inverse de la racine carrée de l'effectif, sa taille rétrécit lorsque l'effectif augmente.
Effort d'échantillonnage requis pour estimer la moyenneA partir d'une expérience préliminaire, on peut déterminer la taille de l’échantillon nécessaire pour obtenir un intervalle de confiance d'une largeur (W) donnée. Par exemple, supposons que vous vouliez estimer le nombre moyen de fourmis par appartement dans Sandy Hill. A partir de l’échantillon préliminaire, vous avez estimé cette moyenne à 100 fourmis, avec un écart type de 25. Vous aimeriez obtenir un intervalle de confiance de la moyenne qui ne dépasse pas 2 fourmis de large.
Pour ce faire, il suffit de réarranger l'équation pour les intervalles de confiance de la moyenne pour isoler n, l'effectif, étant donné l'écart type (s) et la largeur désirée de l'intervalle de confiance (W):
Le résultat est une équation avec 2 inconnues: n et t (qui est une fonction de n). Cette équation doit être résolue itérativement, jusqu’à convergence, en essayant une valeur pour n puis en calculant le résultat de l’équation 10 pour obtenir une nouvelle valeur de n. Cette nouvelle valeur est utilisée pour recalculer le résultat de l’équation 10 et ainsi de suite jusqu’à ce que n ne change plus d’une itération à l’autre. Dans notre exemple, cette procédure laborieuse mène éventuellement à n = 2404 appartements pour espérer obtenir un intervalle de confiance plus étroit que 2!
(10)
W t snn= −2 2 1α ,
W t snn
21 2
22
4= − ,α
n t sWn= −4 1 2
22
2,α

QUELQUES CONCEPTS FONDAMENTAUX: STATISTIQUES ET DISTRIBUTIONS - 25
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
En fait, 50% des intervalles de confiance calculés à partir d'échantillons de 2404 appartements seront plus étroits que 2 (les autres seront légèrement plus larges). Si on veut augmenter la probabilité que l'intervalle de confiance soit plus petit que la largeur désirée jusqu'à (1-β), on doit utiliser la formule suivante:
où est la valeur critique de la distribution de F, et n est le nombre de degrés de liberté pour l'estimé de la variance de la population dans l’expérience préliminaire. Cette équation doit également être solutionnée itérativement. Pour l'exemple des fourmis, pour que la probabilité soit de 0.95 que l'intervalle de confiance soit plus étroit que 2 fourmis (1-β=0.95, β=0.05), il faudrait échantillonner 6503 appartements.....
Intervalle de confiance pour la médianeLorsque la distribution d'une variable s'éloigne fortement de la normalité et spécialement si la distribution est fortement asymétrique, il est alors inapproprié de calculer un intervalle de confiance pour la moyenne en utilisant la distribution de t. Il y a trois solutions possibles: 1) augmenter l'effectif, 2) transformer les données pour les normaliser, et 3) utiliser la médiane comme mesure de la tendance centrale et calculer un intervalle de confiance pour la médiane.
La médiane, par définition, est la valeur au 50ième centile de la distribution cumulée; 50% des valeurs lui sont inférieures et 50% des valeurs lui sont supérieures. La probabilité qu'une observation soit plus grande que la médiane est donc de 0.5 (et de 0.5 également qu'elle soit inférieure à la médiane).
Les limites inférieure et supérieure d'un intervalle de confiance à 1-α sont obtenues par référence à la distribution binomiale avec n égal à l'effectif et p=q=0.5. La distribution binomiale est symétrique lorsque p=q. Les limites de l'intervalle de confiance peuvent être obtenues en répondant à la question: Si l'on effectue n mesures tirées d'une population dans laquelle nous nous attendons à ce que 0.5n des observations soient sous la médiane (et tout autant au-dessus), combien de ces observations se trouveront sous (au-dessus) de la médiane 1-α des fois où l’expérience serait répétée.
Par exemple, supposons qu’un chercheur aie mesuré la densité des larves de mouches noires sur des roches dans un des ruisseaux du Parc de la Gatineau. Il obtient les densités (ind m-2) suivantes:
(11)ns t F
Wn n= − −4 2
2 12
12
( , ) ( , , )α β ν
F n( , , )β ν−1

26 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
0, 0, 5, 7, 22, 733, 889, 1027, 2005, 7833
La médiane de ces 10 observations est calculée comme la moyenne des observations de rang 5 et 6: (22+733)/2= 377.5. Si l'on effectue 10 observations, et que chaque observation a une probabilité p = 0.5 d'être plus petite que la médiane, la probabilité d'obtenir 0 observations plus petites que la médiane dans un échantillon de 10 est de 0.0009766, celle de n'avoir qu'une observation sous la médiane est de 0.009766, et celle d'en avoir 2 est de 0.0439 (ces probabilités sont tirées de la distribution binomiale). La probabilité d'obtenir 0 ou 1 observation sous la médiane est donc de (0.0009766+0.009766= 0.0107) et celle d'en obtenir 2 ou moins seulement est de 0.0546. Comme les limites d'un intervalle de confiance bilatéral sont obtenues aux valeurs critiques correspondant à α/2 et 1-α/2, l'intervalle de confiance à 97.86% pour la médiane est obtenu par la 1ère et la 9ième valeur (0-2005), alors que l'intervalle de confiance à 89.08% est obtenu par les valeurs 2 et 8. La distribution binomiale étant une distribution discrète, il est généralement impossible de calculer un intervalle de confiance exactement à α=0.05 ou α=0.01.
Un test d’hypothèse sur la médiane peut être effectué en comparant la médiane présumée (hypothétique) à l’intervalle de confiance, ou en utilisant le test de “Wilcoxon signed-rank”.
Intervalle de confiance pour la varianceLes estimés de la variance de populations normales obtenus à partir d'un échantillon sont distribués comme khi-carré avec n-1 degrés de liberté. On peut donc référer à la distribution de χ2 pour calculer un intervalle de confiance. La distribution des estimés de la variance s'éloigne rapidement de la distribution de χ2 lorsque les données ne sont pas normales. Il faut donc considérer les intervalles de confiance pour la variance de données biologiques avec un grain de sel...
L'intervalle de confiance pour la variance peut être calculé par:
où s2 est la variance, n le nombre de degrés de liberté et χ2 la valeur critique de la distribution du khi-carré avec ν degrés de liberté. Notez que l'intervalle de confiance n'est pas symétrique puisque la distribution du khi-carré est étirée vers la droite.
(12)2 22
2 2/2, 1 /2,
s sν νσχ χα ν α ν
≤ ≤
−

QUELQUES CONCEPTS FONDAMENTAUX: STATISTIQUES ET DISTRIBUTIONS - 27
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
L'hypothèse que l’échantillon est tiré d'une population où la variance est égale à σ2 peut être testée en comparant
à la distribution de χ2 avec n-1 degrés de liberté.
(n-1) s2/σ2 (13)

28 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

TESTS D'AJUSTEMENT À UNE DISTRIBUTION THÉORIQUE - 29
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Tests d'ajustement à une distribution théorique
Une situation fréquente en analyse statistique est d’avoir à déterminer si une distribution empirique suit une distribution théorique donnée. Les test statistiques qui mesurent la distance entre la distribution théorique et celle qui est observées sont les test d’ajustement à une distribution théorique. Tous ces tests comparent les fréquences observées et attendues ou encore la distribution cumulée des données à la distribution cumulée théorique. Cette section traite du problème général de mesure de l'ajustement à une distribution théorique, en commençant par le cas le plus simple et en terminant par les tests de normalité.
Tests du Khi-carré et de GLe test de Khi-carré (ou Chi-carré) ne peut être utilisé que sur des données de fréquences par catégorie (échelle de variation nominale). Ce test permet d'estimer la probabilité que les données observées proviennent d'un population suivant une distribution théorique quelconque. La statistique du Khi-carré (X 2) se calcule généralement comme:
où fi est la fréquence observée pour la catégorie i, est la fréquence attendue pour la catégorie i, et k représente le nombre de total de catégories.
Cette statistique (X 2) est distribuée approximativement comme χ2 avec k-1 degrés de liberté lorsque le nombre total d'observations est élevé (n > 30) et que la fréquence attendue dans chaque catégorie est plus grande que 5. Notez que le X 2 ne peut être calculé que si la fréquence attendue est plus grande que zéro pour toutes les classes. Une catégorie pour laquelle la probabilité d’occurrence est nulle ne devrait pas apparaître dans un test de khi-carré.
(14)( )2ˆ2
ˆ1
f fk i iXfi i
−= ∑
=
f i

30 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Le test de G, appelé aussi test du rapport de vraisemblance, se calcule également à partir des fréquences observées et attendues:
La statistique G ainsi calculée est généralement très similaire à la statistique X 2 et est elle aussi distribuée comme χ2 avec k-1 degrés de liberté. Les catégories sans observations sont exclues du calcul de G dans l'équation ci-dessus, quoique le nombre de degrés de liberté ne soit pas affecté.
L’effectif de l’échantillon joue un rôle important ici. Les statistiques de X 2 et de G tendent à s’éloigner de la distribution de χ2 lorsque les échantillons sont petits, et les probabilités associées à ces statistiques deviennent alors moins fiables. La règle d’usage est que les fréquences attendues les plus faibles devraient être au moins de 5.
Facteurs de correction pour le test de khi-carré et de G lorsqu'il n'y a que deux catégoriesLes statistiques X 2 et G sont souvent distribuées comme χ2, ce qui permet donc de tester l'hypothèse que les données observées suivent la distribution supposée. Cependant, lorsqu'il n'y a que deux catégories, la distribution des 2 statistiques s'éloigne de celle de χ2, le test devient libéral, et la probabilité de rejeter l'hypothèse nulle augmente artificiellement au delà de α. Deux ajustements ont été suggérés pour contrer cet effet: l'ajustement pour continuité (appelée aussi l'ajustement de Yates), et l'ajustement de Williams. Les deux ajustements ont pour effet de réduire quelque peu la valeur calculée de la statistique du X 2 ou de G et donc le libéralisme du test lorsqu'il n'y a que deux catégories.
L'ajustement pour continuité consiste à réduire la valeur absolue de la différence entre la fréquence attendue et la fréquence observée dans chaque classe par 0.5:
(15)
(16)
G fffii
ii
k
=FHGIKJ=
∑21
ln
Xf f
f
i i
ii
k2
2
1
05=
− −
=∑
.e j

TESTS D'AJUSTEMENT À UNE DISTRIBUTION THÉORIQUE - 31
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
L'ajustement de Williams s'obtient en divisant la statistique X 2 ou G par un facteur q calculé comme:
L’ajustement de Williams peut être utilisé quand il y a deux classes (k = 2) et a été recommandé pour toutes les situations où l’effectif est inférieur à 200.
Les auteurs de manuels de statistique ont des positions qui diffèrent quant à la valeur relative de ces deux ajustements et quant aux conditions exactes qui dictent leur emploi. Néanmoins, tous mettent en garde contre l'emploi du test de Khi-carré (ou de G) lorsqu'il n'y a que deux classes, que l'effectif est faible (plus petit que 30), et que la fréquence attendue dans l'une des classe est plus petite que 5. Dans ces conditions, la probabilité obtenue sera vraisemblablement biaisée. Si un meilleur estimé de la probabilité est désiré (par exemple si la probabilité calculée est près du seuil de décision), il est préférable d'effectuer un test binomial.
Le test binomialLorsqu'il n'y a que deux catégories, la loi binomiale peut être utilisée pour calculer la probabilité que les données proviennent d'une population où les proportion dans les deux catégories sont connues. Par exemple, le test binomial pourrait être utilisé pour tester si le rapport des sexes dans une population est de 50:50. Si on dénote par p la probabilité d'appartenir à l'une catégorie, et par q la probabilité d'appartenir à l’autre catégorie, alors la probabilité que X observations parmi un total de n observations soient de la première catégorie (et donc n-X dans la seconde) peut être calculée par:
Notez que cette équation permet de calculer la probabilité qu'exactement X observations soient de la première catégorie. Si l'on veut tester si le nombre observé est vraisemblable compte tenu de p, alors on doit également considérer toutes les autres possibilités encore plus extrêmes. Un exemple permettra de clarifier ce point.
(17)
(18)
q kn k
= +−−
1 16 1
2
( )
P X nX n X
p qX n xb g b g=−
−!! !

32 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Vous avez récolté un échantillon de 10 castors au hasard dans le parc de la Gatineau. De ces 10 castors, 9 sont des mâles. Vous aimeriez calculer la probabilité d'observer un rapport des sexes si différent de 1:1 si les mâles correspondent à 50% de la population.
La première étape consiste à calculer la probabilité d'observer X (0, 1, 2,... ou 10) mâles dans un échantillon de taille (n) égale à 10, si la probabilité (p) d'être un mâle est de 0.5.
La probabilité d'observer 0 mâles dans un échantillon de 10 castors est:
De même, les probabilités d'observer 1, 2,... 10 mâles sont:
P(1)=0.009766P(2)=0.0439P(3)=0.117P(4)=0.205P(5)=0.246P(6)=0.205P(7)=0.117P(8)=0.0439P(9)=0.009766P(10)=0.0009766
Donc, si le rapport des sexes est de 1:1, la probabilité de capturer 10 castors du même sexe est de:
P(0)+P(10)= 0.0009766 + 0.0009766 = 0.001953
La probabilité de capturer 9 castors d'un sexe et 1 de l’autre est de:
P(1)+P(9)= 0.009767 + 0.009767 = 0.01954
La probabilité de capturer 9 ou plus de 9 castors du même sexe si le rapport des sexes dans la population est de 1:1 est donc de:
P(0)+P(1)+P(9)+P(10)= 0.02149
Donc la probabilité d’obtenir un échantillon qui dévie autant du rapport 1:1 attendu que le rapport 9:1 observé est de 2.15%, ce qui est statistiquement significatif. Ce résultat suggère que les pièges capturent préférentiellement les mâles.
(19)( ) ( )( )10 101010!0 0.5 0.5 0.009766
10! 10 10 !P −= =
−

TESTS D'AJUSTEMENT À UNE DISTRIBUTION THÉORIQUE - 33
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Pour de grands échantillons, ce calcul est très laborieux, surtout que l'équation ne peut être calculée par la plupart des ordinateurs (la factorielle de 170 est plus élevée que la valeur maximale qui peut être représentée avec 64 bits).
Tests de normalité à l'aide du Khi-carré ou de GOn peut calculer la probabilité que des données suivent la distribution normale par un test du khi-carré ou de G. Les données doivent d'abord être regroupées en k catégories ou classes comme pour bâtir un histogramme. La fréquence attendue dans chacune des catégories est calculée en se servant de 3 valeurs qui sont obtenues de l’échantillon: le nombre d'observation (n), la moyenne, et la l’écart type. Pour chaque catégorie, on doit d'abord calculer la valeur centrée et réduite des limites de la catégorie (Z), puis, en se référant à l'aire sous la courbe de la distribution normale standard, déterminer la proportion de la population se trouvant à l'intérieur de l'intervalle. Cette proportion, multipliée par l'effectif, donne la fréquence attendue pour la catégorie. Le calcul de la statistique de X 2 ou de G est alors facilement effectué, mais le nombre de degrés de liberté est de k-3 (le nombre de classes moins le nombre de paramètres estimés à partir de l’échantillon)
Comme le test de khi-carré (ou de G) n'est pas très fiable lorsque les fréquences attendues sont très faible, il est souvent préférable de regrouper plusieurs catégories dans les queues de la distribution. Watson (1957) recommande toutefois d'avoir au moins 10 catégories, ce qui implique que ces deux tests ne s'appliquent que lorsque l'effectif est plus grand que 50. Toutefois, puisqu'il y a perte d’information lorsque des données quantitatives sont regroupées en classes, les test de normalité de G et du Khi-carré ne sont pas les plus puissants. Les tests de Kolmogorov-Smirnov, Wilks-Shapiro et Lilliefors décrits plus loin permettent tous trois de détecter de plus faibles déviations de la normalité.
Le test de Kolmogorov-SmirnovLe test de Kolmogorov-Smirnov est souvent utilisé pour tester si des données suivent une distribution normale, mais ce test peut également être utilisé pour toute autre distribution continue. Dans ce test, il s'agit de comparer la distribution relative cumulée observée à la distribution théorique. La statistique du test, généralement dénotée Dmax correspond à la valeur absolue de la différence maximum entre les deux distributions cumulées. Pour obtenir Dmax il faut d'abord calculer

34 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
les fréquences cumulées relatives observées et attendues. Pour le données observées, trier les n observations en ordre croissant et calculer les fréquences relative cumulées (rel Fi) comme:
où i est l'ordre de chaque valeur dans la série des valeurs observées. La valeur attendue est calculée comme la proportion de la population qui serait plus petite ou égale à la valeur observée si la population suivait la distribution théorique.
Vous avez récolté un échantillon de 10 adultes de mouches noires dans le Parc de la Gatineau et vous avez mesuré la longueur de l'aile droite de chacune des mouches. Vous aimeriez déterminer si ces longueurs sont distribuées normalement. Les valeurs observées sont, en ordre croissant
4 4.5 4.9 5.0 5.0 5.1 5.5 5.5 5.6 5.7
Les fréquences relatives cumulées sont simplement:
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
Pour calculer les fréquences cumulées attendues, il faut d'abord centrer et réduire les données et se référer aux proportions d’une distribution normale:
puis consulter un tableau donnant les proportions sous la courbe normale standard.
Pour obtenir Dmax, il faut calculer le maximum de:
(20)
(21)
(22)
rel F ini =
ZX X
s=
−d i
D rel F rel Fi i i= −
D rel F rel Fi i i' = −−1

TESTS D'AJUSTEMENT À UNE DISTRIBUTION THÉORIQUE - 35
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Pour ces données cela donne:
avec un Dmax de 0.213. Cette valeur est ensuite comparée aux valeurs critiques de Dmax dans des tableaux de la statistique de Kolmogorov-Smirnov.
Graphiquement, cela ressemble à ça:
X rel Fi Z reli Di D'i
4 0.1 -2.027 0.022 0.0785 0
4.5 0.2 -1.088 0.138 0.0625 0.0375
4.9 0.3 -0.338 0.368 0.0681 0.1681
5 0.4 -0.150 0.440 0.0404 0.1404
5 0.5 -0.150 0.440 0.0596 0.0404
5.1 0.6 0.038 0.514 0.086 0.014
5.5 0.7 0.788 0.813 0.1129 0.2129
5.5 0.8 0.788 0.813 0.0129 0.1129
5.6 0.9 0.976 0.835 0.0651 0.0349
5.7 1 1.163 0.878 0.122 0.022
Figure 5. Représentation graphique de la statistique Dmax du test de Kolmogorov-Smirnov
ObservéThéorique
1.0
0.8
0.6
0.4
0.2
0.04.0 4.5 5.0 5.5
Dmax

36 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Le test de Kolmogorov-Smirnov s’applique à des données continues. Il peut également être appliqué à des données qui ont été regroupées par classe, mais il perd alors une partie de sa puissance.
Test de normalité de Wilks-ShapiroUne façon d’évaluer visuellement la normalité d’un ensemble de données est de faire un graphique de la distribution cumulée en utilisant une échelle de probabilité normale sur l’axe vertical (diagramme de probabilité). Sur un graphique avec cette échelle, une distribution normale apparaît comme une droite. W, la statistique de Wilks-Shapiro, mesure comment les données observées s’alignent sur une seule droite. (C’est en fait le carré du coefficient de corrélation entre les valeurs observées et leur équivalent Z basés sur leur fréquence cumulée relative). Si W est près de 1, on peut alors présumer de la normalité des données. Les valeurs critiques de la statistique peuvent être retrouvées dans des tableaux spéciaux.
Ce test est fastidieux à faire manuellement mais est considéré le meilleur pour les petits échantillons parce qu’il est très puissant. Heureusement, plusieurs logiciels statistiques calculent gaiement cette statistique et donnent la probabilité qui lui est associée.
Test de normalité de LillieforsLilliefors (1967) a démontré que le test de Kolmogorov-Smirnov est conservateur lorsqu’il est calculé en utilisant la moyenne et la variance estimée à l’aide des données de l’échantillon. Il a développé une modification qui est disponible dans de nombreux logiciels. C’est ce test qu’on devrait utiliser pour éprouver la normalité lorsque la moyenne et la variance ne sont pas connues à priori.
Commentaires sur les tests de normalitéDe nombreux tests statistiques sont paramétriques et présument que les données (ou les résidus de modèles ajustés) sont distribués normalement. Cependant, de nombreux travaux ont démontré que les méthodes paramétriques sont relativement insensibles aux déviations de la normalité lorsque les échantillons sont grands.
Tel qu’indiqué précédemment, il est possible d’éprouver la normalité avec des tests de qualité d’ajustement. Il y a cependant un paradoxe associé à l’utilisation de ces tests. Si les échantillons sont grands, et que la puissance de détection des déviations de la normalité est élevée, alors même des déviations infimes peuvent être détectées. On conclut

TESTS D'AJUSTEMENT À UNE DISTRIBUTION THÉORIQUE - 37
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
alors que les données ne sont pas distribuées selon la loi normale, et on est alors tenté d’utiliser des tests non-paramétriques même si les tests paramétriques sont robustes avec de grands échantillons.
D’un autre côté, lorsque les échantillons sont petits, la puissance est réduite et on ne peut détecter que de sévères déviations de la normalité. Donc, on accepte généralement l’hypothèse nulle que les données sont normalement distribuées et on passe aux tests paramétriques même si ces méthodes sont moins robustes avec de petits échantillons.
L’adhésion stricte à l’hypothèse implicite de normalité, justifiée par un test de qualité d’ajustement, peut donc mener à utiliser un test paramétrique quand un test non-paramétrique est peut-être plus approprié, et vice versa. C’est la raison pour laquelle il ne faut pas se fier uniquement aux tests de normalité pour décider de la méthode statistique à utiliser. D’autres considérations, dont la taille de l’échantillon, peuvent être plus importantes.

38 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

LE CONCEPT D'ERREUR TYPE ET LE PRINCIPE FONDAMENTAL DU TEST DE T - 39
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Le concept d'erreur type et le principe fondamental du test de t
Erreur type L'erreur type (la “standard error” des anglophones) est une mesure de l'incertitude autour d'une moyenne ou de l'estimé d'un paramètre d'une population. Cette mesure correspond, à peu de choses près, à la moyenne des déviations entre les valeurs qui seraient obtenues si l’expérience était répétée de nombreuses fois sur la même population, et ce avec le même effort d'échantillonnage. L'erreur type est donc une mesure de la précision d'un estimé.
Le principe du test de tLe principe du test de t est très simple, et c'est un principe que vous utilisez sans doute intuitivement plusieurs fois par jour.
Si la différence entre la valeur observée et la valeur attendue est beaucoup plus grande que la précision de la mesure, alors il y a quelque chose qui cloche.
Ou, si vous préférez des termes un peu plus précis et statistiques: si la différence entre la valeur observée et la valeur prédite par l'hypothèse nulle est “tant” de fois plus grande que l'erreur type, alors il faut rejeter l'hypothèse nulle. La valeur critique (“tant” dans la phrase précédente) est typiquement obtenue à partir de la distribution du t de Student et dépend du nombre de degrés de liberté. Ce principe peut être utilisé, par exemple, pour tester si la moyenne est égale à une valeur théorique µT quelconque en calculant
où est la moyenne de l’échantillon et est l’erreur type. Cette valeur peut ensuite être comparée aux valeurs critiques de la distribution du t de Student avec n-1 degrés de liberté.
Effet de violations de l'hypothèse implicite de normalitéLe test de t (Eq. 23) suppose que les données sont distribuées normalement. Si les données sont normales, alors les estimés de la moyenne seront également distribués normalement, et la statistique t
(23)tXss
T
X
=− µ
X sX

40 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
sera alors distribuée comme le t de Student avec n-1 degrés de liberté. Mais puisque les données biologiques ne sont presque jamais distribuées normalement, comment se fait-il que le test de t soit si fréquemment utilisé en biologie?
Quoique tous les tests statistiques reposent sur des hypothèses implicites, l’impact de violations de ces hypothèses sur la performance du test varie. Les test pour lesquels l’une ou plusieurs des hypothèses implicites peuvent être relaxées sans affecter considérablement la fiabilité du test sont dits robustes.
Heureusement, le test de t est robuste et est remarquablement fiable lorsque les données ne sont pas exactement normales. Une des raisons pour cette robustesse est qu'on le calcule à partir de moyennes qui tendent à être plus normales que les données brutes, surtout si l’échantillon est grand. Cependant, si la distribution des données est fortement asymétrique, la distribution des moyennes de ces données le sera également et les probabilités obtenues par le test de t ne seront pas fiables.
Cependant, avant de rejeter les conclusions tirées d’un test statistique, le gros bon sens suggère de tenir compte de la probabilité associée à la statistique. Si cette probabilité est beaucoup plus faible ou beaucoup plus forte que le seuil de décision α, alors la conclusion ne sera sans doute pas invalidée par un test statistique plus approprié. La probabilité du associée au test peut être biaisée si les données ne rencontrent pas l’hypothèse implicite de normalité, mais ce biais peut ne pas renverser la décision. Donc, pour des tests qui sont robustes, les inférences statistiques lorsque les conditions d’application ne sont pas rencontrées tendent à être qualitativement correctes lorsque la probabilité est très différente du seuil de décision. Cependant, lorsque les deux sont similaires, on peut tirer des conclusion erronées.
En bref, comme les données biologiques sont rarement normales, les probabilités associées aux tests de t doivent être considérées avec un grain de sel. Si l'effectif de l’échantillon est grand, alors la condition d’application du test (normalité) est rencontrée, peu importe la distribution des données brutes, et les probabilités sont fiables. Si l’échantillon est petit, l'ordre de grandeur de la probabilité est sans doute correct. Il est difficile de dire si le test devrait être fiable ou non à partir de petits échantillons car de grands échantillons sont généralement nécessaires pour déterminer si la distribution des données est normale ou non. Si la probabilité du test est près du seuil de décision et que le biologiste désire une conclusion fiable qui sera acceptée par la majorité de ses pairs il y a trois possibilités: 1)

LE CONCEPT D'ERREUR TYPE ET LE PRINCIPE FONDAMENTAL DU TEST DE T - 41
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
augmenter l'effectif, 2) transformer les données de manière à les rendre plus normales, ou 3) utiliser un test que ne suppose pas la normalité des données (on y reviendra plus loin).
Transformation des donnéesCertains types de données ne peuvent être distribuées normalement. Par exemple, les pourcentages car ils varient de 0 à 100% alors que des données normales varient de moins l'infini à plus l'infini. La densité de population est un autre exemple (puisqu'il n'y a pas de densité négative). L'application d'un test de t à ces données est donc une violation des conditions d’application du test. Dans plusieurs cas il est cependant possible de normaliser les données en utilisant une transformation mathématique. Le test est alors calculé à partir des données transformées, et la fiabilité de la conclusion est alors augmentée.
Le choix d'une transformation peut être empirique ou basé sur la théorie statistique. Si l'effectif est suffisant, on peut essayer plusieurs fonctions et tester si les données transformées sont normales (“Tests d'ajustement à une distribution théorique” à la page 27). Il existe même des algorithmes qui identifient la meilleure transformation à utiliser (Box and Cox 1964). L’approche générale est donc de vérifier la normalité avant de faire le test de t.
Malheureusement, cette approche empirique ne peut être utilisée pour de petits échantillons car la puissance des tests de normalité est faible pour les petits échantillons. Dans ces cas, une expérience préalable avec le même type de données ou des considérations théoriques peuvent suggérer une transformation appropriée. Mais la plupart du temps, la recherche d’une transformation est un lent processus d’essais et d’erreurs. Le temps investi à cette recherche peut souvent être plus judicieusement utilisé en passant à des tests non-paramétriques ou à des méthodes de simulation (discutées à la section “Permutation et Bootstrap” à la page 119).
Les transformations les plus utilisées sont la transformation arcsin (pour les pourcentages), logarithmique, racine carrée et inverse. Sokal and Rohlf (1995, pp. 409 - 422) passent en revue les transformation les plus fréquentes.

42 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

COMPARAISONS DE DEUX MOYENNES, MÉDIANES, OU VARIANCES - 43
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Comparaisons de deux moyennes, médianes, ou variances
Cette section présente toute une batterie de tests utilisés pour comparer deux moyennes, médianes ou variances obtenues à partir d'échantillons. Tous ces tests ont une hypothèse nulle semblable: que les deux échantillons proviennent de la même populations ou de deux populations ayant les mêmes caractéristiques.
Différences entre moyennesPour deux échantillons distribués normalement ayant un effectif de n1 et n2 respectivement, des moyennes de et et des variances and , on peut calculer un test de t comme:
Notez que le dénominateur de la première équation, , est un estimé de l'erreur type de la différence entre les deux moyennes, et qu'il est calculé comme la racine carrée de la variance pondérée par l'effectif tel que montré dans la seconde équation. L’équation 24 peut être utilisée quand les deux échantillons suivent une distribution normale et que leur variance est égale. Ces deux conditions d’applications devraient être testées. Les tests de normalités sont retrouvés à la section “Tests d'ajustement à une distribution théorique” à la page 27. Les tests d’égalité des variances se retrouvent un peu plus bas (“Différences entre deux variances” à la page 44).
Des tests unilatéraux ou bilatéraux peuvent être effectués en comparant la valeur de t calculée à la valeur de critique de t avec (n1+n2-2) degrés de liberté. Les tests bilatéraux sont relativement robustes aux violations des conditions d’application du test (normalité et égalité des variances), spécialement si les effectifs sont grands et égaux. Les tests unilatéraux sont moins robustes
(24)
X1 X2 s12
s22
tX XsX X
=−
−
1 2
1 2
tX X
n s n s n nn n n n
=−
− + − +
+ −
1 2
1 12
2 22
1 2
1 2 1 2
1 12
b g b g b gb g
sX X1 2−

44 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Si les deux variables sont normales mais ont des variances inégales, un test de t corrigé (parfois appelé le test approximatif de Welch) peut être effectué en calculant:
et en comparant la valeur de t observés aux valeurs critiques du t de Student avec
degrés de liberté. Si le nombre de degrés de liberté calculé (ν) n'est pas un entier, utiliser le nombre entier immédiatement inférieur.
Différences entre deux variancesIl y a plusieurs méthodes différentes pour éprouver l’hypothèse d’homoscédasticité (égalité des variances). La plus simple est le test de F. Pour comparer deux estimés de variance et tester si ils proviennent de populations ayant une variance égale, calculer le plus grand de:
La valeur obtenue doit ensuite être comparée aux valeurs critiques de la distribution de F avec (n-1) degrés de liberté pour le numérateur et (n-1) degrés de liberté pour le dénominateur. Le test ci-dessus n'est pas très robuste aux déviations de l'hypothèse implicite de normalité
Les autres test d’égalité des variances (Bartlett's, Scheffé-Box, voir Sokal and Rohlf, 1995, pp. 396 - 406) sont légèrement plus robustes aux violations de l’hypothèse implicite de normalité. L’alternative la plus robuste est le test de Levene pour homogénéité des variances. Ce test est calculé comme un test de t sur les valeurs absolues des
(25)
(26)
(27)
tX X
sn
sn
=−
+
1 2
12
1
22
2
ν =+
FHG
IKJ
FHGIKJ
−+
FHGIKJ
−
sn
sn
snn
snn
12
1
22
2
2
12
1
2
1
22
2
2
21 1
Fss
ouss
= 12
22
22
12

COMPARAISONS DE DEUX MOYENNES, MÉDIANES, OU VARIANCES - 45
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
différences entre les observations dans chaque échantillon et la moyenne de l’échantillon. Il faut donc d'abord remplacer les i valeurs observées pour chaque traitement j (Xij) par:
puis calculer un test de t sur ces valeurs. Si le test de t mène à la conclusion que la variabilité moyenne diffère entre les échantillons, alors on peut conclure que la variance diffère entre les deux échantillons.
Différences entre deux médianesLe test de médianes peut être utilisé pour tester l'hypothèse nulle que deux échantillons proviennent de populations ayant la même médiane. Il s'agit de construire un tableau de contingence 2x2 où les colonnes représentent les deux échantillons, et les rangées la position des valeurs par rapport à la médiane de toutes les observations. Chaque case contient donc le nombre d'observation dans l’échantillon j qui sont au dessus (au dessous) de la médiane. Si l’échantillon est grand, ce tableau peut être analysé par un test de G ou de khi-carré tel que décrit à la section “Tests d'ajustement à une distribution théorique” à la page 27. Si les échantillons sont petits, alors le tableau devrait être analysé par le test de Fisher.
Autres tests nonparamétriques pour comparer la tendance centrale entre deux échantillonsLe test de médianes décrit ci-dessus est un test nonparamétrique que ne présume pas de la normalité ou de l'égalité des variances. Ce type de test devrait être utilisé lorsque les données violent les conditions d’application des tests paramétriques (comme le test de t) car il mène à des conclusions qui sont plus fiables et sont assez puissants. Toutefois, lorsque les données satisfont aux conditions d’application des tests paramétriques, les test nonparamétriques sont généralement moins puissants que les tests paramétriques. Par exemple, dans le cas d'un test de médianes qui serait utilisé avec des données qui satisfont aux conditions d’application du test de t (normalité, homoscedasticité), la puissance n'est que d'environ les 2/3 de celle du test de t. On devrait donc. tenter de transformer les données pour satisfaire à la condition de normalité des données avant de passer aux alternatives non-paramétriques.
(28)X X Xij ij j' = −

46 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Le test de Wilcoxon-Mann-Whitney est un autre test non-paramétrique, et il est plus puissant que le test des médianes. La statistique (U) est calculée à partir des données transformées en rangs et est comparée aux valeurs critiques provenant de tableaux spéciaux, ou en utilisant une approximation de la courbe normale lorsque les échantillons sont grands. Les calculs pour effectuer ce test sont décrits dans Sokal and Rohlf (1995, p. 427 - 431).
On est généralement intéressé à comparer la moyenne ou la variance de deux échantillons. Dans certains cas on peut vouloir comparer la forme générale de la distribution. On peut alors utiliser le test de Kolmogorov-Smirnov, décrit à la section “Le test de Kolmogorov-Smirnov” à la page 31. Généralement, si la moyenne ou la variance diffèrent, le test de Kolmogorov-Smirnov décèlera également une différence. D’un autre côté, le test de Kolmogorov-Smirnov peut détecter une différence entre deux échantillons dont la moyenne et la variance sont les mêmes si les autres moments (symétrie, kurtose) diffèrent.
Échantillons appariésIl arrive souvent que les observations d'un échantillons soient appariées à celles d'un autre échantillons, par exemple lorsque l'on compare une variable avant et après un traitement effectués sur une série d'individus. Dans ce cas, les données viennent par paires, et la variabilité observée dépend à la fois du traitement et de la variabilité entre individus.
Dans cette situation, les tests de l'hypothèse nulle que le traitement n'affecte pas la variable devront être effectués à partir de la différence entre les membres de chacune des paires. Si les différences sont distribuées normalement, alors on calculera:
(29)t DsD
=

COMPARAISONS DE DEUX MOYENNES, MÉDIANES, OU VARIANCES - 47
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
où est la moyenne des différences entre les paires d’observations et est l’erreur type de cette différence moyenne calculée comme
La statistique t calculée sera comparée aux valeurs critiques du t de Student avec (nombre de paires-1) degrés de liberté. Si les différences ne sont pas normalement distribuées, alors on utilisera le test des rangs de Wilcoxon (Wilcoxon signed ranked test).
Notez que si il y a une forte corrélation entre les valeurs pour les membres de chaque paire, alors le test apparié est beaucoup plus puissant que le test non apparié. Par contre, si il n'y a pas de corrélation ou si elle est faible, le test apparié est moins puissant car le nombre de degrés de liberté est plus faible.
(30)
DsD
ssnDD=
sD D
nDi
n
=−
−=∑d i2
1 1

48 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

ANALYSE DE VARIANCE (ANOVA) À UN CRITÈRE DE CLASSIFICATION - 49
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Analyse de variance (ANOVA) à un critère de classification
Il est souvent pertinent de vouloir comparer une variable entre plusieurs traitements. Par exemple, on peut vouloir estimer l'effet de différents types de fertilisants sur la croissance des plantes, ou encore comparer l'abondance des poissons dans plusieurs lacs. L'analyse de variance à un critère de classification (one way ANOVA) permet, en un seul test, de vérifier si toutes les moyennes sont égales.
Si il n'y a que deux traitements pour lesquelles les valeurs de la variable dépendante doivent être comparées, alors un test de t (décrit à la section “Différences entre moyennes” à la page 41) ou son équivalent non-paramétrique (“Autres tests nonparamétriques pour comparer la tendance centrale entre deux échantillons” à la page 43) suffit pour comparer les moyennes. Cependant, si il y a 3 catégories ou plus, alors on fait face à une difficulté. Il est tentant d'effectuer une batterie de tests de t comparant chaque paires possibles. Vous devez apprendre à résister à cette tentation car c'est une approche invalide. Le problème avec les comparaisons multiples est que, quoique chaque comparaison soit effectuée au niveau désiré, la probabilité de commettre une erreur du premier type (rejeter l'hypothèse nulle lorsqu'elle est vraie) parmi l'ensemble des comparaisons effectuées est de 1-(1-α)k, ou k est le nombre de comparaisons effectuées, typiquement m(m-1)/2 si il y a m moyennes à comparer. Par exemple, si il y a 4 moyennes, il y a 4(3)/2= 6 paires de moyennes à comparer, la probabilité d'accepter l'hypothèse nulle si elle est vraie est de 1-(0.95)6=1-0.735, et donc la probabilité de faire une erreur du premier type est de 0.265. Donc, si on effectue une série de test de t entre les 6 paires possibles de moyennes, et qu'en fait les 4 moyennes qui sont comparées sont égales, dans près de 27% des cas on détectera au moins une paire qui diffère “significativement”. Évidement la probabilité de commettre une erreur du premier type est trop élevée, et cette probabilité augmente si il y a plus de moyennes à comparer.
Lorsque l'on veut comparer plusieurs moyennes, il y a deux types d'hypothèses qui peuvent être testées: 1) si toutes les moyennes sont égales 2) si certaines paires de moyennes diffèrent. Le premier type d'hypothèses peut être testé par l'analyse de variance (ANOVA). Le second type d'hypothèses peut être éprouvé par une série de techniques regroupées sous le vocable de comparaisons multiples. La présente section traite de l'analyse de variance, la suivante des comparaisons multiples.

50 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Les trois types d’ANOVA (I, II et III)Il y a trois types d'ANOVA. Le type I est le modèle à effets fixes. Le but de ce type d'analyse est de détecter si le différents traitements affectent la variable dépendante. Dans les expériences qui sont analysées par une ANOVA de type I, les niveaux de chacun des traitements sont fixés par l'expérimentateur. Ce type d'analyse est similaire à une analyse de régression: le but est de quantifier l'effet de la variable indépendante. C'est le type le plus commun en biologie. Exemple: Rendement d'une variété de blé en fonction de l'ajout de fumier de différents animaux de ferme (mouton, vache, porc, poule). Dans ce type d’analyse on est intéressé à savoir si les moyennes diffèrent entre elles, et par les différences entres paires particulières de traitements.
Le type II est le modèle à effets aléatoires. Le but de ce type d'analyse est de partitionner la variabilité en ses différentes composantes. Dans les expériences analysées par une ANOVA de type II, les niveaux de chacun des traitements sont choisis au hasard. Ce type d'analyse est similaire à une analyse de corrélation: le but est de quantifier le pourcentage de variabilité qui peut être expliqué par la variable indépendante. Ce type d'analyse est particulièrement commun en génétique de populations, par exemple pour quantifier la proportion de la variabilité phénotypique due à des facteurs génétiques. Exemple: Taux de reproduction des femelles de différentes lignées de drosophiles. Dans ce type d'expérience, la valeur absolue des différences entre la fertilité des lignées a peu d'intérêt. Ce qui revêt de l'intérêt, c'est l'importance de la variabilité entre les lignées par rapport à la variabilité à l'intérieur d'une lignée.
Le troisième type d’ANOVA (type III) contient des effets fixes et des effets aléatoires. Évidemment, ce modèle est impossible pour une ANOVA à un seul critère de classification, mais il est très commun dans les design d’ANOVA à plusieurs critères de classification.
Les calculs d'ANOVA pour les analyses de type I et II sont les mêmes pour l'analyse à un seul critère de classification. La distinction devient toutefois très importante dans les analyses à plusieurs critères de classification car les calculs diffèrent alors. L'hypothèse nulle de chaque modèle est subtilement différente: pour le modèle de type I (effets fixes) c'est H0: toutes les moyennes sont égales; pour le modèle de type II (effets aléatoires) c'est H0: il n'y a pas de variabilité due au traitement.

ANALYSE DE VARIANCE (ANOVA) À UN CRITÈRE DE CLASSIFICATION - 51
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Les ANOVA de type I et II ne diffèrent pas seulement au niveau du design expérimental sous-jacent, mais également au niveau du modèle qui est ajusté. Dans une ANOVA de modèle I, on présume que les différences intergroupes entre les moyennes (si elles existent) sont dues aux traitements de l’expérimentateur. Le modèle général est:
où Yij est la valeur de l'observation j dans le traitement i, µ est la moyenne générale, αi est la différence entre la moyenne des valeurs de Y pour le traitement i et la moyenne de générale, et εij est la valeur résiduelle, distribuée normalement et ayant une moyenne de 0 et une variance de . Le modèle correspondant pour l’ANOVA de type II est
où l’effet fixe αi a été remplacé par l’effet aléatoire Ai.
La substitution de αi par Ai dans l’équation 32 peut sembler triviale, mais est en fait assez importante puisqu’elle reflète les objectifs de l’analyse. Lorsque l’on est intéressé à décomposer les sources de variation (analyse de type II), on ne veut pas vraiment comparer les moyennes.
Hypothèses implicites de l’ANOVAComme tous les autres tests statistiques, l’ANOVA repose sur des hypothèses implicites:
1. Les résidus (εij) sont distribués normalement et indépendants
2. La variance des résidus ne varie pas entre les traitements
Tests des conditions d’applicationComme les hypothèses implicites se réfèrent aux résidus, elles sont éprouvées a posteriori, quand l’ANOVA a été effectuée.
1. Normalité. Comme les tests de t, les tests de F sur lesquels L’ANOVA repose sont relativement robustes aux déviations de la normalité. Compte-tenu de cette relative robustesse, un examen visuel d’un diagramme de probabilité peut suffire. Si le diagramme
(31)
(32)
Yij i ij= + +µ α ε
sε2
Y Aij i ij= + +µ ε

52 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
forme une droite, alors les résidus sont approximativement distri-bués selon la loi normale. On peut également éprouver la norma-lité des erreurs résiduelles par les tests de normalité (Lilliefors, ou Wilks-Shapiro) décrits à la section “Test de normalité de Wilks-Shapiro” à la page 34 et “Test de normalité de Lilliefors” à la page 34.
2. Homoscedasticité. En général, l’ANOVA est plus sensible à hétéroscedasticité qu’aux violations de l’hypothèse de normalité. Un examen visuel des résidus en fonction des moyennes prédites pour chaque traitement est le meilleur point de départ pour éva-luer cette condition d’application. Si l’étendue des valeurs diffère considérablement entre traitements, il y a un problème potentiel. La règle d’usage veut que si on ne peut visuellement de différence de variance, alors les variances sont suffisamment homogènes pour ne pas affecter indûment l’ANOVA. Si vous percevez des différences à l’oeil, alors vous devriez effectuer un test statistique d’homogénéité des variances comme le test de Levene décrit en page 42. L’homoscedasticité des données peut être éprouvée à l'aide du test de Bartlett (Section 11.8 dans Zar). Il y a cependant un problème embêtant avec le test de Bartlett. Il est très sensible aux déviations de normalité, alors que l'ANOVA est relativement robuste à ces déviations, mais sensible à l'inégalité des variances. Par conséquent, des données non-normales mais homoscedasti-ques peuvent être analysées par ANOVA assez fiablement. Mal-heureusement, si les données ne sont pas normales mais que les variances sont égales, le test de Bartlett a tendance à incorrecte-ment indiquer que les variances sont inégales, et donc à indiquer que l'ANOVA ne devrait pas être utilisée alors qu'elle pourrait sans doute l'être...
3. Indépendance. D’une manière générale, cette condition d’appli-cation est plus sujette à être violée dans certains plans expérimen-taux dans lesquels les mêmes individus sont soumis à plusieurs traitements (comme dans les comparaisons avant-après), ou quand les réponses d’un individu sont influencées par les réponses du groupe (particulièrement commun dans les expériences compor-tementales d’animaux sociaux). Souvent les caractéristiques de l’expérience peuvent guider l’analyse visant à vérifier l’indépen-dance des données. Par exemple, si on a des mesures répétées sur les mêmes sujets, on peut faire un graphique des résidus “avant” en fonction des résidus “après”. On peut également estimer l’autocorrelation sérielle. Si les résidus sont indépendants, alors cette autocorrelation devrait être faible.

ANALYSE DE VARIANCE (ANOVA) À UN CRITÈRE DE CLASSIFICATION - 53
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Le tableau d'ANOVAIl peut paraître étrange qu'une épreuve d'hypothèse concernant l'égalité de plusieurs moyennes soit appelée Analyse de variance. Le nom reflète mieux le type de calcul effectués que le but du test. En ANOVA, la variabilité (variance) totale de la variable dépendante est décomposée en deux parties: 1) ce qui peut être attribué aux différences entre les traitements et 2) ce qui peut être attribué aux variations aléatoires. Si la portion attribuée aux différences entre les traitements est grande par rapport à la portion attribués aux variations aléatoires, il est alors peu probable que l'hypothèse nulle d'égalité des moyennes soit vraie.
Le mode de présentation le plus répandu des résultats de l'ANOVA est un tableau des sources de variabilité et des estimés de variance
où est la moyenne du groupe i, est la moyenne de toutes les observations, ni est l’effectif du groupe i, k est le nombre de groupes, et n est le nombre total d’observations. La somme des carrés totale (SCt) est égale à la somme des carrés des groupes (SCg) plus la somme des carrés associée au terme d’erreur (SCe),et les carrés moyens qui leur sont associés (CM) sont obtenus en divisant la somme des carrés par le nombre de degrés de liberté qui leur corresponds. La statistique F est le rapport du carré moyen des groupes sur le carré moyen de l’erreur, et peut être comparée aux valeurs critiques de la distribution de F au niveau α désiré avec k-1 et n-k degrés de liberté.
Source de variabilité
Somme des carrés (SC)
Degrés de liberté
(dl)
Carré moyen (CM)
F
Totale n-1 SC/dl
Groupes k-1 SC/dl
Erreur n-k SC/dl
Y Yijj
n
i
k i
−==
∑∑ d i211
n Y Yi ii
k
−=∑ c h2
1
CMGroupesCMErreur
---------------------------
Y Yij ij
n
i
k i
−==
∑∑ d i211
Yi Y

54 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
La loi de Taylor pour trouver la meilleure transformationSi les conditions d’applications (hypothèses implicites) ne sont pas rencontrées, une option est de transformer les données. La variance de données biologiques est souvent proportionnelle à la moyenne. Si cette tendance existe dans un ensemble de données, la loi de puissance de Taylor peut alors être utilisée pour identifier une transformation qui stabilisera la variance.
Pour trouver cette transformation, il faut d'abord calculer la moyenne et la variance pour chaque traitement, puis estimer par régression (voir “Régression linéaire simple” à la page 77) les coefficients du modèle:
Si cette équation de régression explique une proportion appréciable de la variabilité de log s2, alors souvent la transformation:
Alternative non-paramétriques à l’ANOVA: le test de Kruskall-WallisLorsqu'il n'est pas possible de transformer les données pour satisfaire aux conditions d’application de l'ANOVA, on peut alors utiliser le test de Kruskal-Wallis. Ce test possède environ 95% de la puissance de l'ANOVA lorsque les conditions d’application de cette dernières sont rencontrées.
Le test de Kruskal-Wallis est une ANOVA calculée sur les données transformées en rangs. La statistique du test, H, est obtenue en calculant:
ou N est le nombre total d'observations, k est le nombre de groupes, ni est l'effectif du traitement i, et Ri est la somme des rangs pour les observations dans le traitement i.
(33)
(34)
(35)
log logs a b X2 = +
′ = ≠′ = =
−Y Y bY Y b
b1 2 22
/
log( ) si
si
HN N
Rn
Ni
ii
k
=+
− +=∑12
13 1
1( )( )

ANALYSE DE VARIANCE (ANOVA) À UN CRITÈRE DE CLASSIFICATION - 55
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Lorsqu'il y a des égalités, la statistique H doit être ajustée en la divisant par:
où m est le nombre de groupes de valeurs à égalité et ti est le nombre de valeurs à égalité dans le groupe i.
Lorsqu'il y a moins de 6 traitements et que le nombre d'observations pour chaque traitement est faible, la statistique H doit être comparée aux valeurs critiques dans des tableaux pour cette statistique. Si les effectifs sont grands, ou si il y a de nombreux traitements qui sont comparés, alors la statistique H tend vers χ2 avec k-1 degrés de liberté (k est le nombre de traitements).
(36)C
t t
N N
i ii
m
= −−
−=∑
1
3
13

56 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

COMPARAISONS MULTIPLES - 57
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Comparaisons multiples
Comparaisons planifiées et non-planifiéesDans les plans expérimentaux du genre de l’ANOVA où il y a plus de deux niveaux par facteur, il y a deux situations possibles. Dans la première, on a a priori des raisons de s’attendre à ce que certains traitements diffèrent des autres (parce qu’une théorie fait cette prédiction). Par exemple, supposons que vous êtes intéressés par l’effet de la pression partielle de l’oxygène (PAO2) dans le sang sur le taux de production de catécholamines par des poissons stressés. Supposons de plus que vous avez une théorie qui suggère que cette relation n’est pas continue mais est caractérisée par un seuil de PAO2 (disons 30 torr) qui doit être atteint avant que les niveaux de cathecolamine augmentent au-delà des niveaux normaux. Si vous créez des traitement correspondant à divers niveaux de PAO2, vous savez déjà que les comparaisons les plus pertinentes et intéressantes se feront entre les traitements qui sont au-dessus et ceux qui sont en-dessous de 30 torr. Ce type de comparaisons est qualifié de planifiées ou d’a priori.
Dans la deuxième situation, suite à une analyse statistique ayant révélé des différences entre les traitements, on est intéressé à comparer les moyennes de ces traitements entre elles pour déterminer quelles sont celles qui diffèrent significativement les unes des autres. Dans ce cas, les comparaisons qui seront faites dépendent des résultats de l’analyse. Ces comparaisons sont qualifiées de non-planifiées ou a posteriori.
Les tests d’hypothèse pour les comparaison planifiées et non-planifiées sont très différents, et il est donc crucial de garder à l’esprit la distinction lorsque vous effectuez des analyses. Dans cette section, on ne traite que des comparaisons non-planifiées ou a posteriori. Pour un traitement des comparaisons planifiées, voir Sokal and Rohlf, 1995, pp. 229 - 240.
Des approches différentes aux comparaisons multiples non-planifiéesAprès avoir complété une ANOVA qui indique que les moyennes des groupes ne sont pas toutes les mêmes, la tâche suivante est généralement de déterminer quelles sont les paires de groupes qui diffèrent les uns des autres. Dans ces comparaisons multiples non-planifiées (a posteriori), il faut garder à l’esprit que la probabilité de faire une erreur de type I augmente avec le nombre de comparaisons. Il y a deux approches principales permettant de contrôler cette

58 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
probabilité de faire une erreur de type I: soit en réduisant le seuil de décision α, ou encore en utilisant une version modifiée de la statistique t. Les statisticiens ne s’entendent cependant pas quant à une solution universelle. Chaque méthode particulière à ses avantages et ses désavantages.
Méthode de Bonferroni et SidakCes deux méthodes contrôlent la probabilité de commettre une erreur de type I parmi toutes les comparaisons en ajustant α pour chaque comparaison de manière à ce que la probabilité d'obtenir un résultat significatif lorsque toutes les moyennes sont égales est égal à l'α désiré.
La méthode de Bonferroni consiste simplement à ajuster pour chacune des k comparaison faites par un test de t à α' = α/k. Cette méthode est conservatrice car α' est inférieur à la correction exacte pour le pire des cas et donc les valeurs de p obtenues sont un peu trop grandes.Cependant, cette méthode a l’avantage d’être simple à comprendre et d’être flexible quant au nombre de comparaisons qui sont faites. Par exemple, dans le cas d’une ANOVA à un critère de classification avec trois traitements (1,2,3), il y a trois comparaisons possibles (1,2), (1,3) et (2,3). Si on veut faire ces trois comparaisons alors on peut ajuster en utilisant k = 3. Par contre si la comparaison (2,3) n’a aucun intérêt, alors on peut utiliser k = 2.
La méthode de Sidak est similaire, sauf que α' est calculé par (1-α)1/k.
Ces deux méthodes sont simples, mais trop conservatrices pour être recommandées. Cependant, elles sont simples et ne requièrent pas de tableaux de probabilité spéciaux. Si les probabilités obtenues sont plus petites que α', on peut être relativement confiant de ces résultats. Cependant, si l'on ne peut détecter de différences significatives, alors il se peut que ce ne soit que le reflet du manque de puissance de ces méthodes.
Méthode de SchefféLe test de Scheffé est plus puissant que les deux méthodes précédentes. Il a également comme avantage d'être consistent avec l'ANOVA: il ne détectera jamais de différences significatives si

COMPARAISONS MULTIPLES - 59
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
l'ANOVA mène à la conclusion que toutes les moyennes sont égales. La statistique du test, souvent dénotée par S, est calculée comme la valeur absolue d'un test de t, et est calculée comme:
où s2 est la variance résiduelle, et A et B dénotent les groupes qui sont comparés. La valeur critique de la statistique au niveau a est obtenue par:
où k-1 et n-k sont le nombre de degrés de liberté pour le carré moyen des groupes et de l'erreur résiduelle.
Méthode de Tukey et GT2Pour ces deux tests, une statistique similaire au t (généralement dénotée par q) est calculée comme
La statistique calculée (q) est alors comparée aux valeurs critiques de la “studentized range distribution” pour le test de Tukey, et à celles du “studentized maximum modulus” pour le test GT2. Ces deux distributions dépendent du nombre de degrés de liberté associés à l'erreur résiduelle et du nombre de comparaisons effectuées. Une version plus raffinée du test de Tukey, appelée HSD (pour Tykey-Kramer Honest Significance Difference) est également disponible dans plusieurs logiciels statistiques.
(37)
(38)
(39)
SY Y
sn n
B A
B A
=−
+FHG
IKJ
2 1 1
S k F k n kα α= − − −( ) ( ), ,1 1 1
qY Y
sn n
B A
B A
=−
+FHG
IKJ
2 1 1

60 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Test de Student-Newman-Keuls (SNK) et de DuncanCes deux tests sont basés sur la statistique q des tests de Tukey et GT2, mais les valeurs critiques sont pour ces deux tests dépendent du nombre de moyennes contenues entre les deux moyennes qui sont comparées.
Le test SNK est le moins prisé des statisticiens. Il est puissant, mais trop libéral. Le test de Duncan est un peu plus fiable, mais encore trop libéral aux yeux de certains.
Le test de DunnettLe test de Dunnett diffère des tests précédents en ce qu'il ne permet que de comparer une moyenne (celle du témoin) à toutes les autres. La statistique, q, est calculée comme
doit être comparée aux valeurs critiques dans un tableau de probabilité particulier. Ces valeurs critiques dépendent de α, du nombre de degrés de liberté, et du nombre de moyennes dont la valeur se situe entre la moyenne du témoin et la moyenne du groupe qui est comparé.
Dans les expériences où l'on vise à comparer un contrôle à plusieurs traitements, il est désirable d'avoir plus d'observations dans le contrôle que dans le traitement. Pour un nombre total d'observation données, la puissance du test est maximisée lorsque l'effectif pour le contrôle est environ égale à la racine carrée du nombre de traitements fois l'effectif de chaque traitement.
Stratégies pour la sélection d’un test de comparaisons multiples a posterioriComme il y a plusieurs tests possibles pour les comparaisons multiples non-planifiées, le problème du choix d’un test se pose. Une approche possible est de ne pas choisir et de faire plusieurs tests pour voir si les conclusions sont les mêmes. Si oui, alors le choix d’un test devient secondaire. D’un autre côté, si les conclusions varient selon le test utilisé, c’est sans doute parce que (1) certains tests sont libéraux et d’autres conservateurs et (2) la puissance varie d’un test à l’autre. Selon les circonstances, on peut choisir le test le plus conservateur ou le plus
(40)q
Y Y
sn n
Témoin A
Témoin A
=−
+FHG
IKJ2 1 12

COMPARAISONS MULTIPLES - 61
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
libéral. Si le test de Bonferroni détecte une différence significative, alors les conclusions sont solides puisque c’est un test conservateur. D’un autre côté, si le test SNK ne détecte pas de différences entre deux moyennes, c’est encore une conclusion solide puisque c’est un test libéral. Dans tous les cas, si les conclusions varient entre les tests, il faut réfléchir avant de tirer des conclusions.
Comparaisons multiples non-paramétriquesLes comparaisons multiples non-paramétriques sont effectuées sur la somme des rangs dans chacun des groupes. L’équation 41 permet de calculer la statistique appropriée lorsqu’il n’y a pas d’égalités entre les rangs
où RA, RB sont les moyennes des rangs dans les groupes A et B et où nA, nB sont les effectifs des deux groupes. Cette statistique peut être comparée aux valeurs critiques fournies dans des tableaux spéciaux.
Intervalles de confiance pour les moyennes des groupesLe calcul des intervalles de confiance des moyennes de chaque groupes dans une ANOVA se fait similairement au calcul des intervalles de confiance d’une moyenne (voir “Intervalles de confiance pour la moyenne” à la page 21). Il y a trois manières de procéder. Si les variances sont homogènes entre les groupes, alors on doit utiliser le carré moyen de l’erreur (CME) du tableau d’ANOVA comme estimé de la variance de chaque groupe et le nombre total d’observations - 1 comme le nombre de degrés de liberté. Donc pour le groupe i avec un effectif de ni, on a
Si les variances ne sont pas homogènes (vous devriez alors reconsidérer l’utilisation de l’ANOVA...), on peut calculer l’intervalle de confiance de chaque groupe en utilisant la variance du groupe au lieu du carré moyen du terme d’erreur.
(41)
(42)
QR R
N Nn n
B A
A B
=−
++
FHG
IKJ
( )112
1 1
2, 1i
Ei n
i
CMX tnα −±

62 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Finalement, puisque la construction simultanée de plusieurs intervalles de confiance pose le même problème que les comparaisons multiples non-planifiées (voir “Comparaisons planifiées et non-planifiées” à la page 57), on peut ajuster le seuil α par la méthode de Bonferroni. La valeur critique du t correspondant à cet α ajusté est alors utilisée soit avec le carré moyen associé au terme d’erreur ou avec la variance de chaque groupe.
Quelques points à retenir1. Les tests de comparaison multiple peuvent mener à des résultats
contrintuitifs lorsque l'effectif varie beaucoup d'un traitement à l'autre.
2. Si l'hypothèse nulle est acceptée par l'ANOVA, ne perdez pas votre temps à effectuer des tests de comparaisons multiples. L'ANOVA est la plus puissante des méthodes fiables pour détecter des différences entre moyennes. Vous pourriez peut-être décou-vrir une paire de moyennes qui diffèrent “significativement” en utilisant un test libéral de comparaisons multiples lorsque l'ANOVA vous dit que toutes les moyennes sont égales: vous ne feriez que prêter le flanc à un réviseur pointilleux à propos des sta-tistiques.

ANALYSE DE VARIANCE À PLUSIEURS CRITÈRES DE CLASSIFICATION - 63
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Analyse de variance à plusieurs critères de classification
La présente section développe l'ANOVA à un critère de classification aux cas où les effets de plusieurs facteurs sont considérés simultanément. En fait, elle se limite aux cas où deux facteurs sont étudiés, mais l'extension à plus de deux facteurs est possible.
Il arrive fréquemment que l'effet de plusieurs facteurs intéresse le biologiste. L'ANOVA à un critère de classification lui permet d'analyser les résultats d'une série d'expériences visant à tester si ces facteurs influencent la variable d'intérêt. Par exemple, on peut vouloir étudier si la température de l'eau et son pH influencent le taux de mortalité de jeunes truites d'élevage. On pourrait planifier une expérience dans laquelle on ferait varier la température, et une autre où on ferait varier le pH. On pourrait ensuite analyser les résultats de ces expériences par deux ANOVA. Cette approche, fort logique et naturelle, a cependant une faiblesse: elle ne permettrait pas de dire si l'effet de la température sur la mortalité dépend du pH; ou si l'effet du pH sur la mortalité dépend de la température. Dans un cas comme celui-ci, un design expérimental d'ANOVA à deux critères de classification permettrait de répondre à cette question.
Comme pour les modèles log-linéaires (voir la section “Modèles log-linéaires” à la page 115), les modèles d’ANOVA à plusieurs facteurs de classification incluent des termes pour chaque facteur (effets principaux) et pour les interactions.
Distinction entre l'ANOVA factorielle à deux critères de classification et l'ANOVA hiérarchiqueSupposons que nous avons deux facteurs qui varient entre les traitements, A et B. Le facteur A varie entre deux niveaux (1 et 2) alors que le facteur B a cinq niveaux différents (I-V). Les données pourraient être regroupées de deux façons différentes .
B
A I II III IV V
1 ***** ***** ***** ***** *****
2 ***** ***** ***** ***** *****

64 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
La distinction est faite selon la nature des niveaux du facteur A. Si les niveaux 1 et 2 du facteur A sont les mêmes pour tous les niveaux du facteur B, alors il s'agit d'un design d'ANOVA factorielle à deux critères de classification. Par contre, si les niveaux du facteur A diffèrent entre les niveaux du facteur B, alors il s'agit d'une ANOVA hiérarchique à deux niveaux de classification. Par exemple, si un chercheur est intéressé à déterminer l'effet du sexe (facteur A) et de l’âge (facteur B) sur la taille des lézards, il s'agit d'un design à deux critères de classification. Par contre, si le même chercheur étudie l'effet de l'identité du technicien (facteur A) et de l'âge (facteur B) sur la taille des lézards et que chaque groupe d’âge de lézards (I à V) est mesuré par une paire différente de techniciens, il s'agit d'un design hiérarchique.
Donc, quoique l’ANOVA hiérarchique à deux niveaux de classification semble faire intervenir deux facteurs, ce n’est pas vraiment le cas puisque le deuxième facteur représente seulement une autre source de variabilité qui n’est pas particulièrement intéressante (du moins dans la plupart des cas). L’ANOVA hiérarchique à deux niveaux de classification s’apparente plutôt à l’ANOVA à un seul critère de classification.
Choisir entre l’ANOVA factorielle et l’ANOVA hiérarchiqueAu-delà des conditions classiques d’application de l’ANOVA (voir “Hypothèses implicites de l’ANOVA” à la page 49) un autre aspect est à considérer avant d’entreprendre l’analyse. Il faut choisir le modèle approprié, factoriel ou hiérarchique. Pour ce faire, considérez les points suivants:
1. Type d’ANOVA. Si tous les effets sont fixes et contrôlés par l’expérimentateur, alors c’est une ANOVA de type I. Si tous les effets sont aléatoires, c’est une ANOVA de type II. Et si il y a des effets fixes et des effets aléatoires, c’est une analyse de type III.
B
I II III IV V
A 1 2 1 2 1 2 1 2 1 2
*****
*****
*****
*****
*****
*****
*****
*****
*****
*****

ANALYSE DE VARIANCE À PLUSIEURS CRITÈRES DE CLASSIFICATION - 65
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Notez qu’une ANOVA hiérarchique a toujours un effet aléatoire pour au moins un facteur, i.e. l’effet du sous-groupe est toujours aléatoire.
2. Plan factoriel ou hiérarchique. Si tous les niveaux de tous les facteurs sont communs à tous les niveaux de tous les autres fac-teurs, alors c’est une ANOVA factorielle. Sinon, c’est une ANOVA hiérarchique.
3. Plan équilibré ou non-équilibré. Dans un plan équilibré, l’effec-tif est le même pour toutes les cellules (combinaisons de chaque niveau de chaque traitement). Dans les design non-équilibrés, l’effectif varie.
4. Plan avec ou sans réplication. Dans certaines expériences, il n’y a qu’une observation dans chaque cellule. L’ANOVA lorsqu’il n’y a pas de réplication est possible, mais est un cas spécial.
ANOVA hiérarchiqueModèle de l’ANOVA hiérarchique
Dans une ANOVA hiérarchique, il y a toujours un facteur qui est de type II (facteur aléatoire). Les autres facteurs peuvent être de type I ou II. Donc l’ANOVA hiérarchique est soit de type I (aléatoire) ou III (mixte). Pour une ANOVA hiérarchique à deux niveaux de classification de type II, le modèle est
où Yijk est la valeur de l’observation k dans le sous-groupe j du groupe i; Ai et Bj représentent l’effet (fixe) du groupe i du facteur A et l’effet (aléatoire) du sous-groupe j du facteur B et εijk est le terme d’erreur (résidu). Dans le cas d’un modèle mixte, on remplace Ai par αi.
(43)Y A Bijk i ij ijk= + + +µ ε

66 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Tableau d’ANOVA hiérarchique
Dans le tableau ci-dessus,
sont le nombre d’observations dans le groupe i et le nombre total d’observations respectivement.,
est la moyenne du groupe i,
est la moyenne du sous-groupe j du groupe i, bi est le nombre de sous-groupes dans le groupe i, nij est le nombre d’observations dans le sous-groupe j du groupe i et a est le nombre de groupes. Notez que l’effet des sous-groupes est éprouvé en faisant le rapport du carré moyen des sous-groupes sur le carré moyen du terme d’erreur, mais
Source de variabilité Somme des carrés (SC) dl CM F
Totale n-1 SCT /dl
Sous groupes SCS /dl CMS /CME
Entre les groupes a-1 SCG /dl CMG /CMS
Erreur SCE /dl
Y Yijkk
n
j
n
i
a iji
−===
∑∑∑ d i2111
n Y Yij ij ij
n
i
a i
−==
∑∑ d i211
b aii
a
−=∑
1
n Y Yi ii
a
−=∑ d i2
1
Y Yijk ijk
n
j
n
i
a iji
−===
∑∑∑ d i2111
n bii
a
−=∑
1
n n n ni ijj
b
ii
ai
= == =
∑ ∑1 1
Yn
Yii
ijkk
n
j
b iji
===
∑∑111
Yn
Yijij
ijkk
nij
==
∑11

ANALYSE DE VARIANCE À PLUSIEURS CRITÈRES DE CLASSIFICATION - 67
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
que l’effet des groupes est éprouvé en faisant le rapport du carré moyen du groupe sur le carré moyen des sous-groupes. Toutefois, dans certains cas le dénominateur du test de F éprouvant l’effet des groupes doit aussi inclure la variabilité attribuable à l’erreur. Sokal et Rohlf (1995, pp. 284 - 285) expliquent assez bien les règles qui devraient guider votre choix
ANOVA factorielle à deux facteurs de classificationLa meilleure façon d'illustrer une ANOVA à deux critères de classification est par un exemple. Une écologiste étudiant les lézards au Costa Rica est intéressé par l'effet du sexe et de l'âge sur la taille. Il y a deux classes d'âge: jeunes (< 1 an) et vieux (> 1 an); et deux sexes: mâle et femelle. Elle récolte 3 individus de chaque combinaison âge et sexe et mesure leur longueur totale (en mm). Les deux facteurs étudiés sont fixes; il s'agit donc d'un modèle de type I.
Ces données permettent de tester 3 hypothèses simultanément:
1. La taille ne varie pas entre les sexes (i.e. la taille moyenne des mâles est égale à celle des femelles)
2. La taille ne varie pas selon l'âge (i.e. la taille moyenne des jeunes est égale à celle des vieux)
3. Les effets de ces deux facteurs sont les mêmes peu importe l'âge ou le sexe (i.e. il n'y a pas d'interaction entre le sexe et l'âge sur la taille)
Ces trois hypothèses peuvent être testées en partitionnant la variabilité totale en 4 fractions: la variabilité due au sexe (premier facteur), la variabilité due à l'âge (deuxième facteur), la variabilité due à l'interaction de l'âge et du sexe, et la variabilité résiduelle (erreur).
Le modèle de l’ANOVA factorielle
Considérez une expérience au cours de laquelle on examine l’effet de deux facteurs, A et B. Si ces deux facteurs représentent des effets fixes, c’est alors un modèle I d’ANOVA. Dans ce cas, la valeur Yijk,, représentant l’observation k au niveau i du facteur A et j du facteur B peut être modélisée par
(44)Yijk i j ij ijk= + + + +µ α β αβ εb g

68 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
où µ la moyenne, αi et βj représentent les effets fixes du groupe i du facteur A et du groupe j du facteur B, (αβ)ij est l’effet de l’interaction pour la combinaison du niveau i du facteur A et du niveau j du facteur B, et εijk représente le terme d’erreur (résidu) de l’observation k dans le sous-groupe j. Si l’un des deux facteurs (ou les deux) sont aléatoires, on remplace α (β) par A (B) (voir “Les trois types d’ANOVA (I, II et III)” à la page 48). Toutes les conditions usuelles d’application de l’ANOVA doivent également être rencontrées (voir “Hypothèses implicites de l’ANOVA” à la page 49).
Tableau d’ANOVA factorielle
Dans ce tableau, a représente le nombre de niveaux du facteur A, b est le nombre de niveaux du facteur B, et n est le nombre d’observations par cellule.
Épreuves d’hypothèses en ANOVA factorielle
Le test approprié dépends du type d’ANOVA. Pour une ANOVA modèle I, le test est simple: toutes les sources de variabilité peuvent être éprouvées par un test de F sur le rapport du carré moyen de la source sur le carré moyen de l’erreur, tel qu’indiqué dans le tableau d’ANOVA.
Lorsque les deux facteurs sont aléatoires (modèle II) ou que l'un des facteurs est fixe et l’autre aléatoire (modèle mixte), le calcul est plus complexe. Il faut: (1) tester si l'interaction est significative par un test de F du carré moyen de l'interaction sur le carré moyen de l'erreur résiduelle (2) Si l'interaction est significative: tester l'effet de chaque facteur en comparant le carré moyen associé à chaque facteur à celui
Source de variabilité
Somme des carrés(SC) dl CM F
Totale abn-1 SCT /dl
Facteur A (colonnes) a-1 SCA /dl CMA /
CME
Facteur B (rangées) b-1 SCB /dl CMB /CME
Interaction (A x B) (a-1)(b-1) SCI /dl
i
Erreur ab(n-1) SCE/dl
Y Yijkk
n
j
b
i
a
−===
∑∑∑ d i2111
nb Y Yii
a
−=∑ d i2
1
na Y Yjj
b
−=
∑ d i21
n Y Y Y Yij i jj
b
i
a
− − +==
∑∑ d i211
Y Yijk ijk
n
j
b
i
a
−===
∑∑∑ d i2111

ANALYSE DE VARIANCE À PLUSIEURS CRITÈRES DE CLASSIFICATION - 69
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
de l'interaction (3) Si l'interaction n'est pas significative, il reste un problème épineux. Certains auteurs suggèrent de combiner les sommes des carrés de l'erreur et de l'interaction pour obtenir un meilleur estimé de la variance résiduelle et augmenter le nombre de degrés de liberté du dénominateur dans le test de F. Cependant, ce n’est pas toujours la meilleure stratégie, et il existe des règles complexes pour décide de la manière de procéder. (Sokal and Rohlf, 1995, pp. 284-285)
On peut remettre en question la pertinence des tests de l'effet des facteurs principaux lorsqu'il y a une interaction significative puisque dans ce cas l'assertion de l'effet principal a peu de sens.
Comparaisons multiplesLa procédure à suivre pour effectuer des comparaisons multiples est la suivante. (1) Si il y a des interactions significatives, il faut comparer les moyennes entre les niveaux d’un facteur pour chaque niveau de l’autre facteur. Donc, si il y a une interaction A x B et qu’il y a 3 niveaux pour chaque facteur (a = b = 3), il y a ab(ab-1)/2 (9 x 8 /2 = 36) comparaisons à faire au total entre les moyennes.
Si l’interaction n’est pas significative, alors on procède comme pour les comparaisons multiples dans le cas d’une ANOVA à un seul critère de classification tel que décrit à la section “Comparaisons multiples” à la page 55. On compare alors les moyennes de chaque niveau de A en utilisant regroupant les données de chaque niveau de B.
ANOVA à deux critères de classification sans réplicationDAns une ANOVA sans réplication il n’y a qu’une seule observation par cellule (intersection de tous les niveaux de tous les facteurs). Comme il n’y a pas plus d’une mesure, il est donc impossible d’estimer la variabilité à l’intérieur d’une cellule qui, lorsque l’on combine toutes les cellules, permet d’estimer la variabilité résiduelle du modèle. On doit alors utiliser le carré moyen de l’interaction comme estimé de la variabilité. Le prix à payer est donc de ne pas pouvoir tester l’hypothèse de l’existence de l’interaction et en plus, d’avoir une condition de validité supplémentaire: qu’il n’y a pas d’interaction entre les facteurs.

70 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Tableau d’ANOVA
Le tableau suivant correspond à l’ANOVA à deux critères de classification de modèle I sans réplication:
Notez que l’indice k a disparu du tableau puisqu’il n’y a qu’une observation par cellule.
Les tests d’hypothèse dans l’ANOVA sans réplication présupposent l’absence d’interaction. Si on soupçonne qu’il y a une interaction, alors il faut procéder avec des réserves: l’ANOVA tend alors à être trop libérale (i.e. a détecter des effets qui ne sont pas “réels”) pour les effets fixes d’un modèle I et pour l’effet aléatoire du modèle III.
Le plan sans réplication est répandu dans les expériences où un individu est mesuré à plusieurs reprises.
ANOVA à deux critères de classification non-paramétriqueL'ANOVA non-paramétrique à deux ou plusieurs critères de classification est une extension simple du test de Kruskal-Wallis (voir “Alternative non-paramétriques à l’ANOVA: le test de Kruskall-Wallis” à la page 52). La première étape consiste à ordonner les valeurs observées de la variable dépendante. Si il n'y a pas de valeurs égales, on peut simplement calculer une ANOVA paramétrique sur ces rangs. Cependant, contrairement au test de l'ANOVA paramétrique, la statistique utilisée (H) est calculée par le rapport de la somme des carrés due à chaque terme du modèle et de la variance totale. Cette
Source de variabilité Somme des carrés (SC) dl CM F
Totale ab-1 SCT /dl
Facteur A (colonnes) a-1 SCA /dl CMA /
CME
Facteur B (rangées) b-1 SCB dl CMB /
CME
Erreur (a-1)(b-1) SCE /dl
Y Yijj
b
i
a
−==
∑∑ d i211
b Y Yii
a
−=∑ d i2
1
a Y Yjj
b
−=
∑ d i21
Y Y Y Yij i ji
n
i
n
− − +==∑∑ d i2
11

ANALYSE DE VARIANCE À PLUSIEURS CRITÈRES DE CLASSIFICATION - 71
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
statistique est comparée à la distribution de Khi carré. Si il y a des égalités, alors un facteur de correction doit d'abord être appliqué à la statistique.
Effectifs inégaux (Plan non-balancé)Les formules abrégées de calcul des sommes des carrés données dans les manuels de statistique s'appliquent aux cas où les effectifs sont égaux à tous les niveaux de tous les facteurs. Les formules sont différentes (et cauchemardesques) lorsque les effectifs sont inégaux. Les bons logiciels statistiques permettent d'analyser les designs expérimentaux où les effectifs sont inégaux. Par exemple avec SAS, les procédures GLM permettent de le faire, alors que les procédures ANOVA ne fonctionnent qu'avec des effectifs égaux.

72 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

CORRÉLATION - 73
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
CorrélationLa corrélation est une mesure de l'association linéaire entre deux variables. Le coefficient de corrélation de Pearson entre deux variables (X et Y) avec n paires d’observations calculée par:
où x et y dénotent les déviations de X et Y par rapport à leur moyenne respective. Le coefficient de corrélation peut varier de -1 (corrélation négative parfaite) à +1 (corrélation positive parfaite).
Le carré du coefficient de corrélation, r2, est appelé le coefficient de détermination. Il correspond à la proportion de la variabilité d’une variable qui peut être “expliquée” par l’autre. Le r2 varie donc entre 0 et 1.
Hypothèses implicites1. Normalité: Pour chaque X, les valeurs de Y sont normalement
distribuées; et pour chaque Y, les valeurs de X sont normalement distribuées
(45)rxy
x y
i
n
i
n
i
n= =
= =
∑
∑ ∑1
2
1
2
1
Figure 6. Corrélation entre X1 et X2
X1
X2
X2
X2
r = 0.9
r = 0.5
r = 0 r = 0
r = -0.5
r = -0.9

74 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
1. Homoscedasticité: La variance de X est indépendante de celle de Y, et vice-versa. Les variances de X et de Y ne sont pas néces-sairement égales.
2. Linéarité: La relation entre X et Y est linéaire.
Test de significationLa signification statistique des corrélations dépend de leur grandeur et de la taille de l'échantillon. Les estimés de corrélation ne sont généralement pas normalement distribués, sauf lorsque la corrélation de la population est 0. Dans ce dernier cas, la probabilité que l’échantillon provienne d'une population où la corrélation est égale à 0 peut être calculée par un test de t:
où
et n est le nombre d’observations. Cette valeur de t est alors comparée aux valeurs critiques de la distribution du t de Student avec n-2 degrés de liberté au seuil de probabilité α/2.
Si l'hypothèse nulle est que la corrélation de la population est une valeur différente de 0, il est alors nécessaire de transformer les valeurs théoriques et observées pour compenser pour la non-normalité de la distribution des coefficients de corrélation. La valeur observée (r) et la valeur théorique (ρ) doivent d'abord être transformées en z et ζ par:
(46)
(47)
(48)
t rsr
=
s rnr =−−
12
2
z rr
=+−LNMOQP
=+−LNMOQP
05 11
0 5 11
. ln
. lnζ ρρ

CORRÉLATION - 75
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Puis, on doit calculer la valeur de la variable Z (qui sera approximativement distribuée normalement) par:
où
La statistique Z obtenue peut alors être comparée aux valeurs critiques de la distribution normale standard.
Intervalles de confianceLes intervalles de confiances pour les corrélations doivent d'abord être calculés à partir des valeurs transformées (z), puis être reconvertis en unités standards.
L'intervalle de confiance de la corrélation transformée (z) est calculé par:
où
Les limites de l'intervalle de confiance des corrélations transformées peuvent alors être retransformées en unités standards par:
ou en se référant à un tableau de conversion approprié.
(49)
(50)
(51)
(52)
(53)
Z z
Z
=− ς
σ
σ Z n=
−1
3
z t z± ∞α σ2b g,
σ z n=
−1
3
r ee
X
X=−+
2
2
11

76 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Comparaison de deux corrélationsPour comparer deux coefficients de corrélation (r1 et r2, transformés en z1 et z2 selon l’équation 48) et tester si les échantillons ayant servi à leur calcul proviennent de populations qui ont la même corrélation, on calcule:
et on compare la statistique Z obtenue aux valeurs critiques de la distribution normale standard.
Corrélation de rangLorsque les données sont tirées de populations qui s'éloignent de la distribution binormale, la corrélation calculée ne peut être aisément utilisée pour un test d'hypothèse ou pour calculer un intervalle de confiance. Il est alors préférable de calculer une statistique de rang. Une statistique simple, quoique rarement utilisée en biologie, est la corrélation calculée en remplaçant les valeurs originales de X et de Y par leur rangs respectifs. Sa signification et son intervalle de confiance sont calculés comme pour la corrélation ordinaire.
La corrélation de rang de Spearman est une statistique très similaire à la corrélation simple de rang, mais elle est calculée à partir de la somme du carré de la différence de rang de X (RX) et du rang de Y (RY):
Des tableaux spéciaux doivent être consultés pour déterminer la probabilité associée à rs. Lorsqu'il y a des égalités, il faut alors ajuster les statistiques pour ces égalités, comme illustré à la section 18.9 dans Zar (1996), section 19.9 dans Zar (1999).
Une autre statistique souvent calculée est le tau de Kendall. Ce coefficient de corrélation de rang mène presque toujours à la même conclusion statistique que le coefficient de Spearman. Ces deux tests ont une puissance similaire, mais les tests basés sur le coefficient de Spearman sont, parait-il, plus puissants lorsque l'effectif est grand.
(54)
(55)
Z z z
n n
=−
−+
−
1 2
1 2
13
13
rR R
n ns
Xi Yii
n
= −−
−=∑
16 2
13
b g

CORRÉLATION - 77
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa

78 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

RÉGRESSION LINÉAIRE SIMPLE - 79
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Régression linéaire simpleLa régression permet de détecter et de quantifier l'effet d'une variable indépendante sur une variable dépendante. Lorsque l'on applique une analyse de régressions, l'on assume que la variable indépendante est responsable d'une partie de la variation de la variable dépendante, mais que la variable dépendante n'affecte pas la variable indépendante.
Les régressions sont couramment utilisées en biologie. Non seulement elles permettent d'effectuer des tests d'hypothèse quant à l'effet d'une variable sur une autre, mais elles permettent également de prédire les valeurs de la variable dépendante dans certaines conditions et donc de quantifier l'effet de la variable indépendante. De plus, les régressions peuvent être utilisées pour corriger les biais potentiels lorsque des contrôles appropriés ne sont pas possibles, ou d'estimer les valeurs d'une variable à partir de mesure indirectes beaucoup plus facile à effectuer.
Régression vs CorrélationLes analyse de régression et de corrélation sont proches parentes. Plusieurs des calculs sont les mêmes, ainsi que plusieurs des statistiques qui sont calculées. Il existe toutefois des différences très importantes et ces deux analyses ne doivent pas être confondues. La corrélation mesure le degré d'association entre deux variables. La régression mesure l'intensité de l'effet d'une variable sur une autre. En régression il y a une cause et un effet implicite, et le but est de prédire la valeur de la variable dépendante. En corrélation il n'y a pas de cause et d'effet présumé, et le but est de quantifier le degré d'association entre deux variables. Le type d'échantillonnage requis pour une analyse de corrélation et pour la régression sont différents, et il est rarement possible d'effectuer une analyse de corrélation et de régression sur les mêmes données.
Le modèle général et les hypothèses implicitesLa régression linéaire simple consiste à estimer la valeur des coefficients du modèle suivant:
(56)Y bXi i i= + +α ε

80 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
où Xi et Yi sont les valeurs de X et Y pour l’observation i, α est l’ordonnée à l’origine, β est la pente et εi est la valeur résiduelle de l’observation i.
Hypothèses implicites1. Les valeurs résiduelles (εi) sont distribuées normalement
2. La variance des résidus est stable, i.e. elle est égale pour toutes les valeurs de X
3. La relation entre X et Y est linéaire
4. Il n'y a pas d'erreur de mesure sur X
Épreuves d’hypothèsesIl y a deux tests équivalents pour éprouver l’hypothèse que la pente (β) de la régression est égale à 0. Le premier est un test de t sur l’estimé de la pente divisé par son erreur-type. Le second test est un test de F comparant le carré moyen de la variabilité expliquée par le modèle à la variance résiduelle.
Test des hypothèses implicitesLes tests concernant les hypothèses implicites de l'analyse de régression ne peuvent généralement être effectués qu'après que la régression ait été calculée (analyse post-mortem...). Le seul postulat qui peut être facilement testé est celui concernant l'absence d'erreur de mesure sur la variable indépendante. Ce postulat n'est pas testé statistiquement, mais par référence à ce que l'on sait de la variable indépendante et de nos méthodes de mesure. En pratique, puisqu'il y a toujours une certaine quantité d'erreur de mesure, il faut que cette
Figure 7. Régression linéaire simple. Le but de la régression est de tracer une droite au travers du nuage de points observés. Cette droite est caractérisée par deux paramètres: l'ordonnée à l'origine et la pente. Les valeurs de ces deux paramètres sont calculées de manière à minimiser la variabilité résiduelle autour de la droite.
X
YVariabilitétotale
Variabilitérésiduelle
Ordonnéeà l’origine
Pente

RÉGRESSION LINÉAIRE SIMPLE - 81
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
erreur de mesure soit petite par rapport à l'étendue des valeurs de la variable indépendante. Des erreurs de mesures qui dépassent quelques pourcentages de l'étendue des valeurs de la variable indépendante biaisent les régressions (valeurs absolues de pentes calculées sous-estiment les valeurs absolues des pentes réelles).
Le postulat de normalité des résidus peut être testé en appliquant un des tests de normalité (Kolmogorov- Smirnov, Wilks-Shapiro, Lilliefors ou Khi carré) aux résidus.
Pour tester les deux autres postulats: homoscedasticité et linéarité, il est souvent utile d'examiner le graphique des résidus en fonction de la variable indépendante. L’examen de ce graphique permet souvent de détecter visuellement les violations de ces conditions implicites.
Lorsqu'il y a plusieurs mesures de la variable dépendante pour chaque valeur de la variable indépendante, il est possible de calculer un test statistique de linéarité (voir “Régression avec réplication” à la page 84) et d'homoscedasticité comme le test de Levene (voir “Différences entre deux variances” à la page 42).Il faut cependant garder à l’esprit que la puissance de ces tests est assez faible lorsque l’effectif est faible à chaque niveau de la variable indépendante.
Erreur type de la penteL’erreur type de la pente est un estimé de la déviation moyenne qui serait observée si la régression était recalculée sur d'autres ensembles de données similaires, obtenus de la même façon, avec le même effectif, et aux mêmes valeurs de X.
La variance de la pente est calculée comme l’indique l’équation 57 où le numérateur est la variance résiduelle, et le dénominateur est la somme du carré des écarts de la variable indépendante. L'erreur type de la pente est simplement la racine carrée de cette variance
L’examen de l'équation 57 révèle comment l'on peut réduire l'erreur type d'un estimé de pente. Le numérateur est hors de notre contrôle puisqu’il représente la variabilité qui n’est pas expliquée par la variable indépendante. Cependant, on peut facilement augmenter le dénominateur en mesurant les deux variables à des valeurs extrêmes de la variable indépendante. Plus l'étendue des valeurs de X sera
(57)ssxbYX22
2=∑

82 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
grand, plus petite sera l'erreur type de la pente, et donc plus grande sera la capacité à détecter une pente qui diffère significativement de 0 (la puissance sera plus grande).
Intervalles de confiance en régressionL'intervalle de confiance à 100 (1-α)% pour la pente peut être obtenu par:
où sb est l'erreur type de la pente
L'intervalle de confiance pour la valeur moyenne de Y à une valeur de X donnée est:
Cette équation devrait vous rappeler celle pour l'intervalle de confiance pour une moyenne. Le meilleur estimé de la moyenne de Y pour une valeur de X donnée est la valeur prédite par la régression. L'intervalle de confiance est calculé en multipliant la valeur critique de t (avec n-2 degrés de liberté car 2 paramètres on été estimés: l'ordonnée à l'origine et la pente), par l'erreur type de la moyenne (le terme sous le signe de la racine carrée).
Cette erreur type de la moyenne est calculée à partir de la variance résiduelle, du nombre d'observations, et d'un facteur de correction qui dépend de la distance entre le point pour lequel on prédit la valeur de Y et le centroïde des observations ayant servi à calculer la régression.
(58)
(59)
b t sn b± −α 2 2b g b g,
,Y t sn
X X
xn YX± +−L
NMM
O
QPP− ∑α 2 2
2
2
2
1b g b g
d i

RÉGRESSION LINÉAIRE SIMPLE - 83
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Les intervalles de confiance pour la moyenne sont typiquement représentés graphiquement par deux courbes, une de chaque coté de la droite de régression, formant ainsi une bande de confiance.
Les intervalles de confiances pour les valeurs individuelles de Y à une valeur de X donnée sont calculés par:
Ces deux équations (Eq. 59 et 60) pour les intervalles de confiances nous indiquent comment planifier des expériences qui mènent à de petits intervalles de confiances: 1) augmenter l'effectif, 2) augmenter l'étendue des valeurs de la variable indépendante.
Prédiction inverséeLes courbes de calibration sont un cas typique d’application de prédictions inversées. Par exemple, la mesure de la concentration de substances en solution est couramment effectuée à l'aide d'un spectrophotomètre. Les mesures d'absorbance ou de densité optique obtenues à l'aide du spectrophotomètre sont alors converties en concentrations à l'aide d'une courbe de calibration obtenue à partir d'échantillons ayant des concentrations connues. La courbe de calibration est typiquement obtenue en reliant la lecture obtenue par le spectrophotomètre (Y), à la concentration de la substance (X).
Figure 8. Intervalles de confiance pour les valeurs moyennes prédites et pour les valeurs individuelles de la variable dépendante (Y).
Y
X
Y
Moyennes
Observations
(60),Y t s
n
X X
xi n YX± + +−L
NMM
O
QPP− ∑α 2 2
2
2
21 1b g b g
d i

84 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
L'équation obtenue est ensuite manipulée algébriquement pour obtenir une équation donnant la concentration en fonction de la lecture obtenue.
Il semblerait plus direct et plus simple de régresser la concentration sur la valeur de lecture. Cette approche n'est pas désirable, toutefois, car on violerait alors la supposition d'absence d'erreur de mesure sur la variable indépendante.
Les calculs pour la prédiction inversée sont illustrés à la section 16.5 dans Zar (1996), section 17.5 dans Zar (1999) et dans Sokal and Rohlf (1995), Section 14.7. Graphiquement, les intervalles de confiance, peuvent être obtenu comme les valeurs de X où les limites des intervalles de confiance sur la lecture ont la même valeur que la valeur lue. La figure suivante (Fig. 9) illustre cette gymnastique.
Régression avec réplicationLorsqu'il y a plusieurs observations à chaque valeur de la variable indépendante, on peut effectuer un test de linéarité afin de vérifier l'un des postulats de l'analyse de régression. Les calculs sont présentés en détail par Zar (1996) à la section 16.7, Zar (1999) à la section 17.7 et dans Sokal et Rohlf (1995) à la section 14.5. La méthode consiste à partitionner la variabilité entre les observations à chaque valeur de X en deux: la variabilité qui peut être expliquée par la régression, et la variabilité due aux déviations à la linéarité; puis à comparer la déviation à la linéarité à la variation intragroupe. Si la relation entre X et Y est linéaire, alors la valeur de Y moyenne observée à chaque valeur de X va s'approcher de la valeur prédite par la régression lorsque l’échantillon est grand. Dans ce cas, la différence entre les
Figure 9. Méthode graphique pour le calcul de l'intervalle de confiance pour une prédiction inversée.
Lecture
Limiteinférieure
Limitesupérieure
Prédiction

RÉGRESSION LINÉAIRE SIMPLE - 85
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
valeurs moyennes de Y observées et les valeurs prédites seront dues uniquement à l'erreur d'échantillonnage. La probabilité associée au test de linéarité est la probabilité d'observée des moyennes de Y qui dévient autant des valeurs prédites que les valeurs moyennes observées si la relation est linéaire.
Certains auteurs appellent ce test un test de “manque d'ajustement” (lack of fit) parce que la méthode ne permet pas uniquement de tester si la relation est linéaire, mais également si le modèle est adéquat. En effet, la même approche peut être utilisée pour déterminer si la relation entre X et Y dévie d'une relation non-linéaire donnée. De plus, même si la relation entre X et Y est linéaire, le test pourrait nous amener à rejeter l'hypothèse de linéarité entre X et Y si un autre facteur affecte les valeur de Y à certaines valeurs de X. Un manque d'ajustement significatif ne signifie donc pas nécessairement que la relation n'est pas linéaire, mais indique toujours que le modèle n'est pas approprié et qu'il ne s'ajuste pas bien aux données.
La linéarité est une condition d’application très importante en régression si on veut effectuer des prédictions qui ne sont pas biaisées. Le test de linéarité ou de manque d'ajustement devrait donc être effectué à chaque fois que les données le permettent. Il est donc désirable d'avoir plusieurs mesures de la variable dépendante pour chaque valeur de la variable indépendante, et de distribuer également les valeurs de X dans la fenêtre d'observation. Même si les estimés les plus précis de la pente et des valeurs prédites sont obtenus en n'effectuant des mesures qu'aux valeurs extrêmes de X, il n'est généralement pas recommandé de planifier une expérience de cette façon car on ne peut alors tester la linéarité de la relation.
Transformation des donnéesLes données biologiques doivent très souvent être transformées avant d'être analysées par régression. Ces transformations visent à corriger les violations des postulats de l'analyse de régression: normalité, linéarité, homoscedasticité.
Les transformations de la variable indépendante (X) sont effectuées uniquement pour linéariser la relation entre X et Y. Les transformations sur la variable dépendante (Y) visent soit à linéariser la relation, ou à stabiliser la variance, ou les deux. Si l’examen du diagramme de dispersion suggère que la variance des résidus augmente avec des valeurs croissantes de Y, la transformation logarithmique ou racine carrée de Y va souvent corriger cette hétéroscedasticité. Si la variance des résidus diminue lorsque Y augmente (c'est plus rare), alors une transformation exponentielle (carré, cube, etc.) est suggérée.
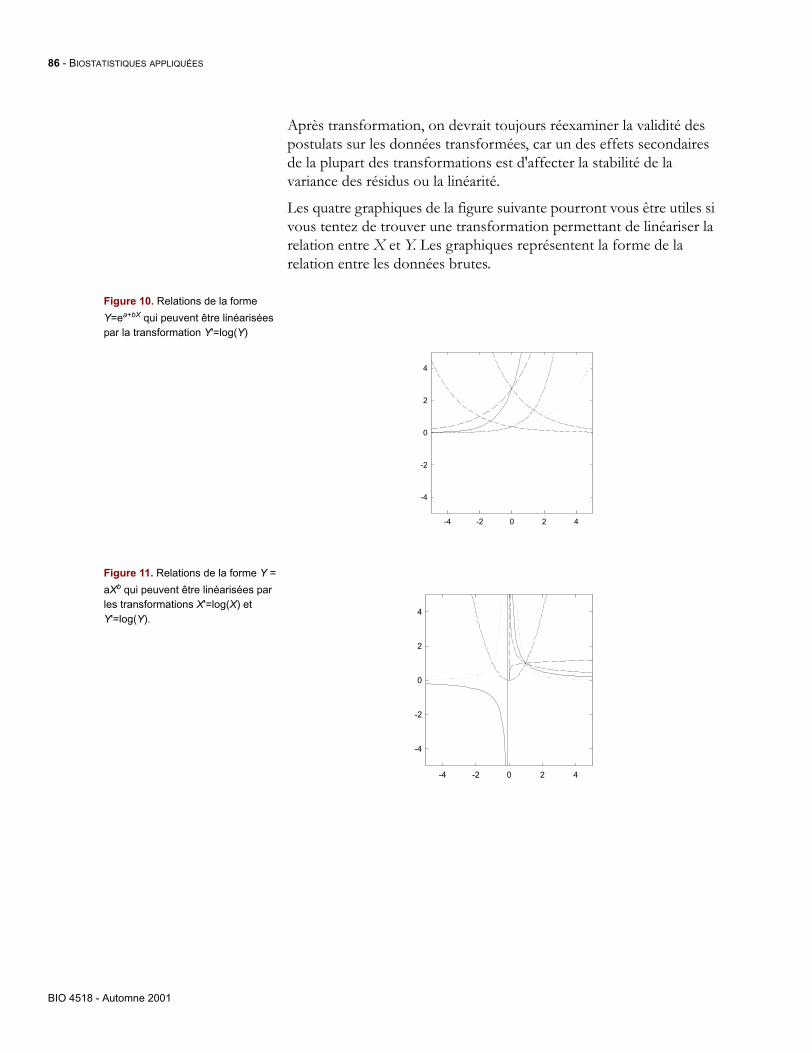
86 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Après transformation, on devrait toujours réexaminer la validité des postulats sur les données transformées, car un des effets secondaires de la plupart des transformations est d'affecter la stabilité de la variance des résidus ou la linéarité.
Les quatre graphiques de la figure suivante pourront vous être utiles si vous tentez de trouver une transformation permettant de linéariser la relation entre X et Y. Les graphiques représentent la forme de la relation entre les données brutes.
Figure 10. Relations de la forme Y=ea+bX qui peuvent être linéarisées par la transformation Y'=log(Y)
Figure 11. Relations de la forme Y = aXb qui peuvent être linéarisées par les transformations X'=log(X) et Y'=log(Y).
-4 -2 0 2 4
-4
-2
0
2
4
-4 -2 0 2 4
-4
-2
0
2
4

RÉGRESSION LINÉAIRE SIMPLE - 87
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
L’influence des valeurs extrêmes en régressionIl arrive fréquemment qu’on obtienne des valeurs extrêmes qui semblent être très différentes du reste des données récoltées au cours d’une expérience. Ces valeurs extrêmes peuvent être dûes à des erreurs de mesure ou de retranscription, mais peuvent aussi représenter des valeurs réelles. Il y a donc deux aspects importants lors de l’analyse des valeurs extrêmes: (1) comment détecter ces valeurs extrêmes, et (2) est-ce que ces valeurs extrêmes changent significativement les résultats de l’analyse.
Il y a plusieurs méthodes permettant de détecter les valeurs extrêmes. Si les valeurs sont normalement distribuées, on peut calculer la probabilité qu’une observation donnée fasse partie de la même population que le reste de l’échantillon. Les routines permettant de tracer des “box plots” font exactement cela et identifient les valeurs extrêmes qui ont une probabilité inférieure à un seuil donné (généralement 5%) de faire partie de la même population (présumée
Figure 12. Relations de la forme Y= a+b/X qui peuvent être linéarisées par la transformation X'=1/X
Figure 13. Relations de la forme 1/Y= a+bX qui peuvent être linéarisées par la transformation Y'=1/Y.
-4 -2 0 2 4
-4
-2
0
2
4
-4 -2 0 2 4
-4
-2
0
2
4

88 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
normale) que le reste de l’échantillon. Mais comme les données ne sont pas toujours tirées de populations normales, cette approche ne peut servir qu’à attirer notre attention et ne suffit pas pour poser un diagnostic.
On peut également examiner les résidus normalisés (“Studentized residuals”). Les observations qui ont des résidus normalisés élevés contribuent fortement à la variance résiduelle autour de la régression, mais peuvent ne pas affecter beaucoup la droite de régression. Le “leverage” mesure directement l’influence potentielle d’un point sur la droite, en fait il dépends uniquement de la distance entre la valeur de ce point et la moyenne de l’axe des X. Les points qui sont près de la moyenne on un faible potentiel d’influence sur la pente, ceux qui s’en éloignent on un fort potentiel d’influence (et donc un “leverage” élevé). Cependant, un point qui s’éloigne de la moyenne des X (et qui a un “leverage” élevé) peut avoir une influence minime sur la droite de régression si il tombe près de la droite qui serait estimée sans ce point. Le “leverage” ne mesure donc que le potentiel d’influence. Finalement, la distance de Cook combine les caractéristiques des deux mesures précédents (“leverage” et résidu normalisé) et mesure donc l’influence réelle qu’exerce un point sur la droite de régression.
Les observations qui ont un résidu normalisé, un “leverage” et une distance de Cook élevés sont donc à considérer avec attention en analyse de régression. La règle d’usage veut que des résidus normalisés ayant une valeur plus grande que 2.5 ou 3, des “leverages” plus élevés que 4/n où n est le nombre d’observations et des distances de Cook plus élevées que 1.0 méritent une attention particulière.
Si vous avez identifié certaines observations comme étant extrêmes, que faire ensuite? La question est de savoir si ces observations affectent significativement les résultats de l’analyse de régression. Pour y répondre, il suffit de refaire l’analyse sans ces valeurs extrêmes et de comparer les résultats à ceux obtenus avec toutes les observations. Si la pente et l’ordonnée à l’origine du sous-ensemble restent à l’intérieur des intervalles de confiance original, l’élimination des valeurs extrêmes a deux effets: (1) elle réduit l’effectif pour l’analyse, et (2) elle augmente la précision. Comme ces deux effets on un impact inverse sur la puissance, l’élimination des valeurs extrêmes peut augmenter ou diminuer la puissance des tests. Cependant, si l’effectif de départ est faible, l’élimination de une ou deux valeurs peut entraîner une perte considérable de puissance.
Si l’élimination des valeurs extrêmes a un effet significatif, alors il faut faire preuve de jugement. Si il y a une bonne raison de croire que ces valeurs sont réellement aberrantes, alors il convient de les éliminer. Sinon, on a trois choix: les inclure et ne présenter que ces résultats sur

RÉGRESSION LINÉAIRE SIMPLE - 89
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
l’ensemble complet, présenter les résultats de l’analyse sur l’ensemble complet et sur l’ensemble moins les valeurs extrêmes ou, enfin, récolter des données supplémentaires.
Régression pondéréeDans le modèle standard de régression, toutes les observations ont le même poids. Cela signifie que (du moins implicitement) l’on croit que l’erreur associée à chaque observation est la même. Cependant, si la variable dépendante est une moyenne, et que l’effectif varie d’une observation à l’autre, il semblerait plus juste de donner plus de poids aux moyennes de gros échantillons et moins de poids à celles provenant de petits échantillons. La régression pondérée permet de faire varier le poids de chaque observation. Lorsque la variable dépendante est une moyenne, on utilise généralement l’effectif des différentes moyennes comme poids dans l’analyse, ou encore l’inverse de la variance. Comme cela, les moyennes qui sont basées sur de gros échantillons, ou qui ont une variance faible, ont plus de poids dans l’analyse.
Quelques points à retenir• Une forte relation entre deux variables n'est pas suffisante pour
établir une relation de cause à effet. Si il y a une relation causale, on s'attend à une relation significative entre X et Y, mais une forte relation entre X et Y pourrait être causée par une autre variable affectant X et Y à la fois.
• N'oubliez pas que des régressions “significatives” seront obtenues par chance même si il n'existe pas de relation entre X et Y (envi-ron 5% du temps si les conditions d’application de la régression sont remplies, souvent plus si on viole certain des postulats).
• Attention aux grands échantillons. Lorsque l’effectif est élevé, la puissance de détection est grande, et il arrive souvent qu’on détecte une régression significative, mais avec une pente si faible qu’elle est biologiquement insignifiante.
• Attention aux petits échantillons. Il est facile d'obtenir des régres-sions très précises qui ne peuvent être répétées.
• Attention aux extrapolations. Si l'étendue des valeurs de X n’est pas bien représentée par l’échantillon, il est possible que la relation ne soit pas linéaire. L'extrapolation des prédictions au dehors de l'étendue des valeurs échantillonnée ne vaut souvent pas grand chose, et l’interpolation entre des groupes d’observations est par-semée d’éceuils elle aussi.

90 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

ANALYSE DE COVARIANCE (ANCOVA) - 91
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Analyse de covariance (ANCOVA)L'ANOVA à plusieurs critères de classification permet d'analyser les résultats d'expériences au cours desquelles plusieurs facteurs (décrits par des variables discontinues) sont manipulés simultanément. La régression multiple, présentée à la section suivante, permet une analyse similaire lorsque les variables indépendantes sont continues. Cependant, dans plusieurs cas les variables indépendantes forment un mélange de variables continues (nécessitant un traitement par régression) et discontinues (nécessitant un traitement par ANOVA). Par exemple, on pourrait vouloir tester si la masse (variable continue) et le sexe (variable discontinue) affectent la vitesse de vol de différentes espèces d'oiseaux. Ou encore simplement vouloir tester si la vitesse de vol des mâles et des femelles, corrigée pour des différences de taille, est la même. L'analyse de covariance (ANCOVA) permet d'analyser ce type de données.
Le modèle d’ANCOVALe cas le plus simple d'analyse de covariance est lorsqu'il n'y a qu'une seule variable continue et que deux catégories de la variable discontinue. Le modèle est alors:
où i est l'indice des catégories de la variable discontinue, j est l'indice des observations dans chaque catégorie, µ est la moyenne générale, αi est la différence entre la moyenne du groupe i et la moyenne générale, β est la pente de la relation entre la variable dépendante et la variable indépendante continue, et est la moyenne de la variable indépendante continue pour la catégorie i.
Hypothèses implicitesLes hypothèses implicites lorsque l'on effectue une ANCOVA sont les mêmes que pour l'ANOVA et la régression:
1. Les résidus sont indépendants et distribués normalement.
2. Homoscedasticité. La variance des résidus est constante peu importe la valeur de X ou de la variable représentant les catégo-ries.
(61)Y X Xij i ij i ij= + + − +µ α β εd i
Xi

92 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
3. Absence d'erreur de mesure sur les variables indépendantes.
4. La relation entre Y et la variable indépendante continue est linéaire.
En plus, l’ANCOVA postule que:
5. La pente de Y sur X est la même pour tous les groupes.
L’ajustement des modèles en ANCOVADans le cas où il y a une variable indépendante continue (X1) et une variable indépendante discontinue X2 qui a plus d’un niveau, la question qui se pose est de savoir si la régression de Y sur X1 est la même peu importe le niveau de X2. Puisque la droite de régression est définie par deux paramètres, l’ordonnée à l’origine et la pente), cela revient à se demander si les pentes et/ou les ordonnées à l’origine sont les mêmes à tous les niveaux de X2.
L’analyse se fait par étapes, en ajustant une série de modèles débutant par le plus complexe. La signification statistique des termes inclus dans un modèle est évaluée en comparant la variabilité résiduelle du modèle à celle d’un modèle plus simple où le terme en question a été éliminé. La différence de variabilité résiduelle de ces deux modèles peut être attribuée au terme manipulé. On peut ainsi simplifier le modèle complexe en éliminant les termes qui n’expliquent pas une quantité significative de variabilité.
Pour une modèle contenant deux variables indépendantes, l’une continue et l’autre discontinue, le modèle complet est:
Notez que, contrairement au modèle d’ANCOVA (Eq. 61), l’équation du modèle complet (Eq. 62) ajuste une pente différente pour chaque niveau de la variable discontinue. En d’autres mots, ce modèle permet d’ajuster des régressions séparées pour chaque groupe. Le résultat de cet ajustement sur des données de vitesse de vol d’oiseaux mâles et femelles est illustré à la figure 14. Deux éléments sont retenus de
(62)Y X Xij i i ij i ij= + + − +µ α β εd i

ANALYSE DE COVARIANCE (ANCOVA) - 93
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
l’ajustement du modèle complet: la somme des carrés des écarts des résidus et le nombre de degrés de libertés qui lui est associée (n-2k-1), où k est le nombre de niveaux (groupes)
Le modèle complet est le plus complexe, mais cette complexité est-elle nécessaire? Pour répondre à cette question, on ajuste ensuite le modèle d’ANCOVA de l’équation 61. Ce modèle diffère du modèle complet (Eq. 62) en ce que la pente est la même pour tous les groupes. La différence de qualité d’ajustement entre le modèle complet et le modèle d’ANCOVA permet d’éprouver l’hypothèse que tous les groupes ont la même pentes. Il est évident que le modèle d’ANCOVA ne va pas ajuster les données aussi bien que le modèle complet puisque au moins une petite partie de la variabilité peut être attribuable aux différences de pente. Cependant, la question est de savoir si cette variabilité est statistiquement significative.
Graphiquement, le modèle d’ANCOVA pour l’exemple des vitesses de vol est illustré à la figure 15. La différence entre la somme des carrés des résidus du modèle complet et celle du modèle d’ANCOVA, divisée par son nombre de degrés de liberté (k-1), donne un carré moyen qui peut être comparé au carré moyen des résidus du modèle complet pour éprouver l’hypothèse nulle que toutes les pentes sont égales. Si cette hypothèse est rejetée, l’analyse s’arrête généralement ici et des régressions différentes sont ajustées pour chaque groupe. Si
Figure 14. Le modèle complet. Notez que deux régressions différentes sont ajustées, l’une pour les mâles et l’autre pour les femelles.
Intercepts et pentes différents
0 40 80 120Masse corporelle (g)
0
5
10
15
Vite
sse
de v
ol (m
/s)
MâlesFemelles

94 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
l’hypothèse nulle est acceptée, alors les données rencontrent la condition d’égalité des pentes et l’analyse du modèle d’ANCOVA se poursuit.
L’hypothèse que tous les groupes ont la même ordonnée à l’origine peut ensuite être éprouvée en ajustant le modèle le plus simple, une régression simple entre la variable dépendante et la variable indépendante continue. L’ajustement de ce modèle est illustré à la figure 16.
Figure 15. Le modèle d’ANCOVA. Ici la régression de la vitesse de vol sur la masse corporelle a une ordonnée à l’origine (intercept) différent pour chaque sexe, mais les pentes sont les mêmes.
Intercepts différents et pente commune
0 40 80 120Masse corporelle (g)
0
5
10
15
Vite
sse
de v
ol (m
/s)
MâlesFemelles
Intercepts différents et pente commune
0 40 80 120Masse corporelle (g)
0
5
10
15
Vite
sse
de v
ol (m
/s)
MâlesFemelles
Figure 16. Le modèle de régression simple, dans lequel les mâles et femelles sont considérés appartenir à la même population statistique.
Régression commune
0 40 80 120Masse corporelle (g)
0
5
10
15
Vite
sse
de v
ol (m
/s)
MâlesFemelles
Régression commune
0 40 80 120Masse corporelle (g)
0
5
10
15
Vite
sse
de v
ol (m
/s)
MâlesFemelles

ANALYSE DE COVARIANCE (ANCOVA) - 95
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
La somme des carrés des écarts des résidus de cette régression est alors calculée. La différence entre cette somme et celle du modèle d’ANCOVA mesure la variabilité qui est attribuable aux différences d’ordonnées à l’origine. Cette somme des carrés, divisée par le nombre de degrés de libertés (k-1) est alors comparée au carré moyen des résidus du modèle complet. Si l’hypothèse nulle d’égalité des ordonnées à l’origine est rejetée, alors on peut utiliser les procédures de comparaisons multiples pour identifier quels groupes diffèrent les uns des autres. Si l’hypothèse nulle est acceptée, on rapporte alors généralement la régression simple puisque ni la pente, ni l’ordonnée à l’origine ne diffère significativement entre les groupes.

96 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

RÉGRESSION MULTIPLE - 97
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Régression multipleLa régression multiple est une méthode qui permet d'estimer les coefficients de modèles qui décrivent ou de prédisent la valeur d'une variable dépendante en fonction de plusieurs variables indépendantes continues. Elle permet également de tester des hypothèses concernant les coefficients de chacun des termes du modèle qui est ajusté aux données. Le principe général et les conditions d’application sont les mêmes que pour la régression simple. Toutefois, l'inclusion de plusieurs facteurs permet de construire des modèles qui sont plus réalistes et généraux que ceux qui peuvent être construit à partir d'une seule variable.
Le modèle généralLe modèle général pour la régression multiple avec k variables indépendantes est:
où α est l’ordonnée à l’origine du modèle, βj est le coefficient de régression partielle de la variable dépendante sur la variable indépendante j, Xj est la valeur de la variable indépendante j et εi est le résidu de l’observation i. Dans cette équation (Eq. 63), le coefficient de régression partielle est égal à la pente de le régression linéaire de Y su la variable indépendante j lorsque toutes les autre variables sont maintenues constantes.
Lorsque l’on veut comparer l’effet relatif de chaque variable indépendante sur la variable dépendante, on a besoin de la version normalisée de l’équation de régression. Pour obtenir cette version normalisée, les variables sont d’abord normalisées en soustrayant leur moyenne puis en divisant par l’erreur-type:
où Yi l’observation i de la variable dépendante Y, Xij est l’observation i de la variable indépendante j, et sont leur moyennes, et sY et
sont leur écart-type. En utilisant le modèle de l’équation 63 sur les
(63)
(64)
Y Xi j ijj
k
i= + +=
∑α β ε1
Y Y Ys
XX Xsi
i
Yij
ij j
X j
* *;=−
=−
Xj YsXj

98 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
données normalisées, on obtient les coefficients normalisés de régression partielle qui sont reliés aux coefficients de régression partielle non-normalisés (βj) de l’équation (63) par
Ces coefficients normalisés de régression partielle donnent le taux de changement de Y (en unités d’écart-type) par écart-type de Xj lorsque toutes les autres variables sont maintenues constantes. Comme l’effet des différentes échelles de mesures est éliminé, les coefficient normalisés de régression partielle donne un indice de l’impact relatif de chaque variable indépendante sur la variable dépendante.
Hypothèses implicitesLes hypothèse implicites sont les mêmes que pour la régression linéaire simple:
1. Les résidus sont indépendants et distribués normalement.
2. Homoscedasticité des résidus
3. Linéarité des relations entre Y et tous les X.
4. Pas d’erreur de mesure sur les variables indépendantes.
5. L’effet de chaque variable indépendante est additif (i.e. il n’y a pas d’interactions)
Les conséquences des violations des conditions d’application sont généralement les mêmes que pour la régression linéaire simple.
Épreuves d'hypothèsesLa signification statistique du modèle complet peut être éprouvée par un test de F comparant le carré moyen de la régression à la variance résiduelle. Ce test permet de dire si au moins un des coefficients de régression partielle est différent de zéro.
Cependant, une régression multiple significative n’implique pas nécessairement que toutes les variable aient des coefficients de régression partielle différents de zéro.
(65)
βj'
β βj jX
Y
s
sj' =

RÉGRESSION MULTIPLE - 99
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
La signification statistique des coefficients de régression est généralement éprouvée par des tests de t. Toutefois, cette signification peut être également éprouvée par une approche faisant intervenir la somme des carrés supplémentaire expliquée par chacun des termes du modèle.
MulticolinéaritéUn des problèmes les plus courants en régression multiple est celui de la multicolinéarité, la corrélation entre les variables indépendantes. Idéalement, les variables indépendantes utilisées dans une régression multiple devraient être orthogonales, c'est-à-dire qu'il ne devrait exister aucune corrélation entre elles. Dans cette situation idéale, les estimés de coefficients de régression partielle pourraient être obtenus à partir de régressions simples. Par exemple, si il n'y a aucune corrélation entre les deux variables indépendantes (X1 et X2) dans un modèle à deux variables, alors on pourrait obtenir les estimés de tous les coefficients par 2 régressions simples: la première étant la régression de Y sur X1, et la deuxième étant la régression des résidus de la première sur la seconde variable indépendante (X2) tel que dans l’équation 66.
Les coefficients du modèle de régression multiple pourraient alors être obtenu en remplaçant dans la première équation de régression par la partie de droite de la deuxième équation de régression comme à l’équation 67.
En pratique, les données biologiques s'approchent rarement de cette situation idéale et il y a toujours une certaine quantité de corrélation entre les variables indépendantes qui fait que cette méthode simple du calcul des coefficients et de l'ordonnée à l'origine donne des estimés incorrects.
Dans les cas extrêmes, où les 2 variables indépendantes sont parfaitement corrélées, il est impossible d'obtenir les coefficients de régression partielle par des régression simples.
(66)
(67)
Y a b X
a b XYX
YX YX X
= + +
= + +1 1 1
2 2 2
1
1 1 2
ε
ε ε
Y a b X a b X
Y a a b X b XYX X
YX X
= + + + +
= + + + +1 1 1 2 2 2
1 2 1 1 2 2
1 2
1 2
ε
εb g

100 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Dans cette situation, si on estime l'équation de régression simple entre Y et X1, on inclue implicitement l'effet de X2, et la pente calculée est biaisée. Si on procédait par la suite à la régression simple entre les résidus et la deuxième variable indépendante, on conclurait que X2 n'a pas d'effet sur Y. Si on avait commencé par estimer l'effet de X2, on aurait obtenu la conclusion contraire. Ce cas extrême ne se produit pas souvent, et fait joyeusement planter les programmes de régression multiple.
Les données réelles se situent la plupart du temps quelque part entre ces deux extrêmes: aucune corrélation ou corrélation parfaite entre les variables indépendantes. Le long de ce gradient, une augmentation de la corrélation entre les variables indépendantes va faire augmenter les estimés d'erreur standard et diminuer la puissance.
La multicolinéarité est souvent un problème de plan expérimental, et les messages d’erreur que les programmes statistiques donnent ne devraient pas être pris à la légère. Imaginez une expérience dans laquelle les connaissances en statistiques des étudiants de Carleton et de l’Université d’Ottawa serait comparée, mais où les étudiants de Carleton de l’échantillons seraient en première année, et ceux d’ici seraient de cette classe. La différence observée (enfin, j’espère qu’il y en aurait une!) entre les deux groupes pourrait être attribuée soit aux différences entre universités ou encore aux différences entre les cours suivis par les étudiants, ou aux deux. Mais cette expérience ne pourrait trancher entre ces hypothèses.
En pratique, les conséquences de ce problème sont: 1) une inflation de l'estimé de l'erreur standard des coefficients et 2) une grande sensibilité des coefficients estimés et des erreurs standards à de petits changements dans les données. Cependant, les estimés des coefficients de régression partielle ne sont pas biaisés.
Détection de la multicolinéaritéLa multicolinéarité est un problème pratique, ce n'est pas une violation des conditions d’application de la régression. Ce problème pratique diminue la précision des estimés. Il n'est donc pas nécessaire de tester la multicolinéarité, mais il est souvent informatif d'avoir une mesure de son importance dans un cas particulier.
Plusieurs indices peuvent aider à détecter la présence d'un problème de multicolinéarité:

RÉGRESSION MULTIPLE - 101
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Un R2 élevé mais peu de variables significatives. Un signe fiable: le test de F sur le modèle complet rejette l'hypothèse nulle que tous les coefficients de régression sont égaux à zéro, mais les tests de t sur les variables du modèles donnent une indication contraire.
Fortes corrélations entre les variables indépendantes. La matrice de corrélation des variables indépendantes permet souvent d'identifier les paires de variables qui sont fortement corrélées.
Fortes corrélations partielles entre les variables indépendantes.
Si l'une des variables indépendante est une fonction linéaire de plusieurs autres, les corrélations partielles seront alors élevées.
Valeurs propres, indice de condition, et facteur d'inflation de la variance. La plupart des logiciels de régression multiple permettent de calculer l'un de ces indices de multicolinéarité. Les calculs de ces indice sont complexes et apparentés aux calculs utilisés en analyse des composantes principales. Les valeurs propres sont proportionnelles aux dimensions orthogonales de l'enveloppe à k dimensions dans l'espace multidimensionnel des k variables indépendantes. Lorsqu'il n'y a pas de corrélations entre les variables indépendantes, cette enveloppe est une sphère multidimensionnelle et les valeurs propres sont égales. Lorsqu'il y a des corrélations, l'enveloppe est allongée le long de certains des axes et les valeurs propres varient. L'indice de condition est calculé à partir des valeurs propres en calculant la racine carrée du rapport de la plus grande valeur propre sur la plus petite. Le facteur d'inflation de la variance est aussi calculé à partir des valeurs propres.
Solutions au problème de multicolinéarité
Récolter des données supplémentaires
La meilleure solution, mais aussi la moins pratique. Lorsque l'on a identifié quelles variables sont fortement corrélées, il est alors possible de récolter des données supplémentaires qui réduiront la corrélation entre les variables indépendantes.
Éliminer certaines des variables indépendantes
La solution la plus simple. Si certaines des variables indépendantes sont colinéaires, alors l'ensemble des données est inadéquat pour tester le modèle complet. Par contre, l'élimination d'une variable qui

102 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
influence vraiment la variable dépendante risque de mener à des coefficients biaisés pour les variables restantes. Le remède peut donc être pire que le mal dans certains cas.
Régression sur les composantes principales ou “Ridge régression”
Ces deux techniques avancées proposent des solutions de compromis. Elles mènent à des estimés des coefficients qui sont biaisés, mais qui ont des erreurs types plus petites que les coefficients de régression multiple. Draper et Smith (1981) donnent un exposé assez clair et abordable de ces deux techniques.
Sélection des variables indépendantesA partir d'un ensemble de variables indépendantes qui potentiellement affectent la variable dépendante, on veut souvent extraire un modèle qui permet de bien prédire la variable dépendante. Il y a plusieurs approches possibles pour trouver le “meilleur” modèle; cependant ces diverses approches ne donnent pas toujours le même résultat.
Une partie du problème vient du fait qu'il y a plusieurs définition du “meilleur” modèle. Ce peut être celui qui a le coefficient de détermination multiple (R*2) le plus élevé, celui qui a la variance résiduelle la plus petite, celui qui a le R2 le plus élevé pour un nombre donné de variables indépendantes, celui qui a le R2 le plus élevé mais qui ne contient que des termes significatifs, etc.
Un deuxième aspect du problème est qu’il n’y a pas d’accord unanime ni de recette infaillible pour trouver le modèle qui réponds le mieux à une série de critères. Si le nombre de variables indépendantes est petit, il est possible d’estimer tous les modèles possibles et d’appliquer les critères de sélection adoptés. Mais dès qu’il y a plus d’une demi-douzaine de variables, le nombre de modèles à ajuster devient rapidement astronomique. Il faut alors recourir à une procédure quelconque pour réduire le nombre de modèles à ajuster.
Il y a deux approches communes. Dans la première, on commence avec une seule variable indépendante, et on en ajoute d’autres, une à la fois, jusqu’à ce que le coefficient de détermination n’augmente plus. C’est l’approche par sélection progressive (forward selection). Dans la seconde, on commence avec toutes les variables et on élimine graduellement celles qui ne contribuent pas significativement à réduire la variance résiduelle. C’est l’élimination rétrograde (backward elimination).
L’approche par sélection progressive a une faiblesse. Une variable qui est dans le modèle y reste, même si elle a une contribution insignifiante lorsque d’autres variables indépendantes sont ajoutées.

RÉGRESSION MULTIPLE - 103
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
L’élimination rétrograde a une faiblesse équivalente: lorsqu’une variable a été éliminée, elle ne peut plus être réadmise dans le modèle, même si elle est une bonne variable prédictrice lorsque d’autres variables ont été éliminées.
Pour résoudre ce problème, les régressions pas-à-pas (stepwise forward ou stepwise backward) peuvent être utilisées. Dans ces algorithmes de sélection de variables indépendantes, à chaque étape, les variables qui restent sont évaluées pour inclusion ou exclusion.
Les algorithmes de sélection des variables les plus utilisés sont les suivants:
Toutes les régressions
A partir de k variables indépendantes, calculer tous les modèles possibles qui incluent 1, 2,..., k variables. Choisir le meilleur modèle à partir des critères établis au préalable.
Désavantages: Le nombre de régressions à calculer est 2k-1 (1023 régressions avec 10 variables indépendantes). Cette méthode coûte cher en temps d'ordinateur (et en papier). Le problème de la définition du “meilleur” modèle reste entier.
Avantages: Si le “meilleur” modèle existe il sera trouvé.
Sélection progressive
A chaque pas, évaluer toutes les variables qui ne sont pas encore dans le modèle, et inclure celle qui est la plus significative. Arrêter lorsqu'il ne reste plus de variables significatives. Le critère utilisé pour évaluer la signification est un test de F qui mesure si la variabilité additionnelle qui pourrait être expliquée par cette variable est significative. Le processus arrête lorsque toutes les variables qui restent n’atteignent pas le seuil critique de probabilité pour entrer dans le modèle (p to enter).
Désavantages: Si il y a multicolinéarité, peut ne pas trouver le “meilleur” modèle. Peut calculer jusqu'à 2k-1 régressions. Certaines variables qui étaient significatives peuvent devenir non-significatives plus tard lors de l'inclusion de nouvelles variables dans le modèle.
Avantages: En général, cette procédure estime seulement une fraction de tous les modèles possibles.

104 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Élimination rétrograde
Commencer avec le modèle complet qui inclue les k variables indépendantes. A chaque pas, éliminer la variable qui est la moins significative du modèle jusqu'à ce que toutes les variables restantes soient significatives. Le critère utilisé est ici aussi un test de F au seuil déterminé par l’usager (p to remove).
Désavantages: Si il y a multicolinéarité, cet algorithme peut ne pas trouver le “meilleur” modèle.
Avantages: C'est rapide, au plus k régressions seront calculées,
Régression pas à pas
Évaluer toutes les variables pour trouver le meilleur modèle avec une variable indépendante. Ensuite, à chaque pas ajouter la variable qui est la plus significative dans les variables qui restent, puis éliminer les variables qui sont dans le modèle et qui sont devenues non-significatives lors de l'inclusion de la dernière variable. On doit spécifier les seuils de probabilités critique pour l’inclusion et l’exclusion des variables (p to enter et p to remove)
Désavantages: Pour empêcher l'algorithme d'entrer dans une boucle sans fin, le niveau alpha pour l'inclusion de nouvelles variables doit différer du niveau pour l'exclusion des variables dans le modèle. Si il y a multicolinéarité, alors peut ne pas trouver le “meilleur” modèle.
Régression curvilinéaire (polynomiale)Les relations entre variables biologiques sont rarement linéaires, ce qui rend l'analyse de régression (simple ou multiple) peu appropriée pour l'analyse de ces données. Deux solutions s'offrent lorsqu'il n'est pas possible de linéariser la relation par une transformation: l'emploi d'une méthode de régression non-linéaire, ou l'ajustement d'une régression multiple avec des termes de degrés croissants de la variable indépendante. Le choix entre ces deux options devrait être dicté par la théorie ou par la forme de la relation entre les deux variables.
En régression polynomiale, on considère des modèles dans lesquels la variable dépendante est une fonction polynomiale d’une variable indépendante:
(68)Y X X Xi i i i i= + − + +α β β β ε1 22
33 ...

RÉGRESSION MULTIPLE - 105
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Il est important de réaliser que les régressions polynomiales sont presque toujours des ajustements empiriques, et que la signification biologique des termes X 2, X 3, etc peut être inconnue; ils ne sont utilisés que pour améliorer l’ajustement. La procédure habituelle implique d’ajuster d’abord un modèle linéaire, puis d’ajouter un terme quadratique pour évaluer si il permet un ajustement significativement supérieur. Si c’est le cas, ce terme quadratique est retenu et on répète les étapes pour l’inclusion d’un terme cubique.
Par exemple, examinez le diagramme suivant illustrant la biomasse des larves de mouches noires sur des roches dans un ruisseau en fonction de la vitesse du courant au-dessus des roches:
Ce graphique suggère que la biomasse des larves augmente avec la vitesse du courant jusqu'à 80 cm/s, puis se stabilise. On pourrait ajuster une régression simple à ces données
0 40 80 120Vitesse du courant (cm/s)
10
100
1000
Biom
ass e
des
larv
e s (m
g/m
-2)
0 40 80 120Vitesse du courant (cm/s)
10
100
1000
Biom
ass e
des
larv
e s (m
g/m
-2)

106 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Les résidus de cette régression suggèrent toutefois que la relation n'est pas linéaire. On devrait alors tenter d'ajuster un modèle curvilinéaire de la forme:
log Bi = a + β1v + β2v2 +εi
qui donnerait un bien meilleur ajustement:
La signification du terme de deuxième degré est évaluée comme pour n'importe quelle variable en régression multiple. Par définition, les termes d'ordre supérieur seront fortement corrélés entre eux et le problème de multicolinéarité sera toujours présent en régression curvilinéaire (ou polynomiale). Cette forte multicolinéarité ne devrait pas vous empêcher d’utiliser la régression polynomiale lorsque nécessaire puisque, malgré les grandes erreurs-types des coefficients, l’effet de la variable indépendante sur la variable dépendante sera bien décrit par le polynôme.
L'extrapolation de modèles de régression est toujours dangereuse. L'extrapolation de régressions curvilinéaires est presque toujours ridicule. Les coefficients des termes d'ordre supérieur (2, 3, 4,...) sont toujours estimés avec peu de précision, et de petites modifications aux données changent souvent les coefficients considérablement. Quoique les prédictions de l'abondance des larves des modèles d'ordre 2, 3, ou 4 sont semblables dans les conditions échantillonnées, elles diffèrent dramatiquement en dehors de ces conditions.
Variables indicatricesL'utilisation de variables indicatrices (dummy variables) est une alternative à l'ANCOVA qui permet d'inclure des variables discontinues dans un modèle de régression multiple.
0 40 80 120Vitesse du courant (cm/s)
10
100
1000
Biom
ass e
des
larv
e s (m
g/m
-2)

RÉGRESSION MULTIPLE - 107
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
En revenant à l'exemple de la vitesse de vol des mâles et des femelles d'oiseaux de différentes tailles utilisé pour illustrer l'ANCOVA, on pourrait réécrire le modèle d'ANCOVA complet par:
où Zi est une variable indicatrice qui prend la valeur de 0 lorsque l'oiseau est un mâle, et la valeur de 1 lorsque l'oiseau est une femelle.
Ce modèle ajuste en fait deux régression séparées, la première pour les mâles (Z=0):
et la seconde pour les femelles (Z=1):
Le test d'égalité des pentes entre les deux sexes peut être fait à partir de la somme des carrés supplémentaires calculée par différence comme en ANCOVA, ou plus simplement par un test de t sur l'estimé du coefficient γ2.
En général, on peut tenir compte de r groupes en introduisant (r-1) variables indicatrices.
(69)
(70)
(71)
Y X Z ZXi i i i i= + + + +α β γ γ ε2
Y Xi i i= + +α β ε
Y Xi i i= + + + +α γ β γ ε1 2b g b g

108 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

RÉGRESSION PONDÉRÉE, PROBIT, NORMIT, LOGIT ET NON-LINÉAIRE - 109
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Régression pondérée, probit, normit, logit et non-linéaire
Cette section introduit plusieurs sujets avancés en régression. Une brève description de chacune des méthodes et de leur utilité est donnée. Des informations complémentaires pourront être obtenues dans Draper et Smith (1981), McCullagh et Nelder (1983) ou Finney (1978).
Régression pondéréeIl arrive souvent que, dans un ensemble de données analysées par régression, certaines des observations soient “meilleures” que d'autres. Par exemple, si plusieurs méthodes différentes sont utilisées, il est probable que certaines des méthodes donnent des résultats plus précis. On devrait alors donner une plus grande influence à ces données obtenues par les méthodes les plus précises. De plus, si la précision diffère entre les méthodes, la variance des résidus ne sera pas constante entre les méthodes. Les données violeront alors l'une des conditions d’application de l'analyse de régression.
La solution consiste à transformer les données brutes de manière à stabiliser la variance. Cette transformation diffère de toutes celles vues jusqu'à présent en ce qu'elle ne peut être une fonction directe des valeurs de X et de Y, mais doit plutôt être une fonction de la variance des observations. Comme il n'est pas possible de transformer les données facilement de cette façon pour solutionner le problème, on pondérera plutôt les valeurs lors du calcul de la régression.
Les poids donnés aux observations sont en général proportionnels à l'inverse de leur variance. On doit donc d'abord obtenir un estimé de la variance pour chacune des observations utilisées pour la régression. Par exemple, ce peut être un estimé pour chacune des méthodes de mesure utilisées. Dans les cas où l'on utilise des moyennes, ce serait la variance de ces moyennes qui devrait être utilisée.
Régression probit, normit et logitCes trois types de régression (en fait seulement deux puisque probit et normit sont à toutes fin utiles la même chose) sont utilisées typiquement pour des bioessais ou encore pour prédire le pourcentage de réponses en fonction d'une variable continue.

110 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Par exemple, supposons que vous aimeriez décrire la toxicité d'un composé pour les organismes aquatiques de manière à pouvoir établir une norme acceptable pour les émissions de ce composé dans l'environnement. La méthode établie et de faire un bioessai au cours duquel vous exposerez des organismes à des diverses concentrations (doses) et mesurerez la mortalité. Idéalement, vous obtiendrez un histogramme de la dose létale pour plusieurs individus qui permettrait de décrire la sensibilité des organismes à ce composé. A partir de ces données, il serait alors aisé de déterminer une concentration acceptable, c'est-à-dire une concentration à laquelle très peu d’individus seraient affectés.
Malheureusement cette mesure directe de la concentration létale n'est pas facile à obtenir. Elle implique une exposition répétée du même individu à des concentrations croissantes du composé jusqu'à ce que mort s'en suive. C'est long et le nombre élevé de manipulations augmente les possibilités d'erreur. Une alternative est d'exposer des groupes différents d’individus à des doses différentes et de mesurer leur pourcentage de mortalité. Il s'agit ensuite d’estimer une fonction qui décrira ce pourcentage de mortalité en rapport avec la dose.
Fréq
uenc
e
0
5
10
15
20
25
4 6 8 10Dose

RÉGRESSION PONDÉRÉE, PROBIT, NORMIT, LOGIT ET NON-LINÉAIRE - 111
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Il y a deux problèmes lorsque l'on tente de calculer la régression entre le pourcentage de mortalité et la dose. Le premier est que cette relation n'est généralement pas linéaire:
Il faut donc transformer ces pourcentages de manière à linéariser la relation. Il y a trois transformations qui sont couramment utilisées: normit, probit, et logit. La transformation normit traduit les pourcentages en équivalents d'écart type d'une distribution normale standard. La transformation probit est une survivante d'avant l'avènement des ordinateurs. Il s'agit de la transformation normit à laquelle on a ajouté 5 de manière à éliminer les valeurs négatives (et réduire les erreur de calcul manuel). La transformation logit est:
où p est la proportion de mortalité.
Figure 17. Relation typique entre la dose et la mortalité.
4 6 8
0
20
40
60
80
100
120
Dose
Pour
cent
age
de m
orta
lité
(72)′ =−FHGIKJY pp
ln1

112 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Dans la plupart des cas, ces trois transformations vont linéariser convenablement la relation entre la dose et le pourcentage de réponses. Le choix de la transformation est alors une question d'habitude ou de disponibilité.
Le deuxième problème avec des données de ce type et que la variance du pourcentage de mortalité (même transformé) n'est pas constante. La variance de cette valeur est une fonction de la taille de l’échantillon (le nombre d'organismes testés à cette dose) et du pourcentage de mortalité de la population. Ce dernier point pose une difficulté supplémentaire puisque les valeurs pour la population sont rarement connues. La solution implique de d'abord régresser les données transformées sur la dose, de prédire le pourcentage de mortalité de la population à partir de cette régression ordinaire, puis de calculer la variance des observations à partir de l'estimé de cette régression. On fait alors une deuxième régression, pondérée cette fois par l'inverse de la variance calculée à la première étape. Ce cycle est ensuite répété jusqu'à convergence des estimés. Les coefficients obtenus sont ceux reliant le pourcentage de mortalité transformé (logit ou normit) à la dose. Le calcul d'une dose acceptable est alors un cas de prédiction inversée.
Figure 18. Relation typique entre la dose et la mortalité qui a été linéarisée en appliquant la transformation normit ou logit.
Prob
it ou
logi
t
Dose
-5
-4
-3
-2
-1
0
1
2
3
4
5
4 6 8

RÉGRESSION PONDÉRÉE, PROBIT, NORMIT, LOGIT ET NON-LINÉAIRE - 113
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Régression non-linéairePlusieurs modèles en biologie ne peuvent être linéarisés par une transformation. Par exemple le modèle écologique de la croissance logistique:
où r est le taux intrinsèque de croissance de la population et k est la capacité limite de l'environnement. L'intégrale de ce modèle est:
où N0 est le nombre initial d’individus dans la population.
A partir de données historique de l'abondance d'une population, on peut vouloir estimer r et k. Malheureusement on ne peut utiliser la régression simple car l'équation ci-dessus ne peut être linéarisée par une transformation.
Les technique de régression non-linéaire permettent d'estimer les paramètres et leur erreur type. Il existe plusieurs approches différentes mais elles partagent la même stratégie. En partant d'estimés initiaux pour les paramètres désirés, explorer d'autres valeurs possibles pour ces paramètres de manière à améliorer l'ajustement. Pour certains de ces algorithmes, c'est l'utilisateur qui décide du critère de qualité d'ajustement. (ce peut être de minimiser la somme des carrés des écarts comme en régression, mais ce pourrait être autre chose). La plupart des programmes permettent également d'estimer les erreurs types. Ces estimes seront généralement corrects assymptotiquement, mais leur distribution n'est pas nécessairement normale. Par conséquent, les tests de t qui peuvent être effectués ne sont qu'approximatifs.
Une mise en garde.
Les algorithmes ont des forces et des faiblesses. Dans bien des cas, les algorithmes donnent tous une réponse semblable et qui est sensée. Dans d'autres cas tous les algorithmes s'écrasent misérablement. Il est de bon ton de comparer les résultats obtenus par plus d'une méthode
(73)
(74)
dNdt
rN k Nk
=−b g
N kN et rt=
+1 0

114 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
et de comparer les résultats obtenus à partir de divers estimés initiaux. Le comportement pathologique de ces algorithmes est trop commun pour croire les réponses obtenues sans en vérifier le réalisme.

TABLEAUX DE CONTINGENCE ET MODÈLES LOG-LINÉAIRES - 115
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Tableaux de contingence et modèles log-linéaires
Les tableaux de contingences sont utilisés pour éprouver l’indépendance des fréquences d’observations dans 2 catégories ou plus entre 2 groupes (ou plus). Les statistiques calculées sont le khi-carré (X 2) ou le G couvertes à la section “Tests d'ajustement à une distribution théorique” à la page 27. Les tableaux de contingence pourraient être utilisés, par exemple, pour comparer l’efficacité de deux fongicides pour contrôler la tavelure de la pomme. On éprouverait alors l’hypothèse d’indépendance du nombre de pommiers infectés (vs non-infectés) en fonction du type de fongicide. L’hypothèse nulle serait alors l’indépendance des fréquences d’infection en rapport avec le type de fongicide.
X 2 et test de GConsidérons l’exemple suivant. On pense que l’habitat des canards eider mâles et femelles de l’Est de la Baie d’Hudson n’est pas la même après l’éclosion des oeufs: les femelles resteraient avec leur couvée dans les lagons interdidaux alors que les mâles se déplaceraient vers les bancs d’algues et la haute mer. Au cours de l’été 1994, les données de fréquence suivantes ont été obtenues près de Churchill au Manitoba
Pour calculer le X 2 ou G pour ce tableau de contingence, ont doit avoir un estimé de la fréquence attendue de mâles et de femelles dans chaque habitat si l’hypothèse nulle est vraie, i.e. si le rapport des sexe est indépendant de l’habitat. Dans ce cas, la probabilité qu’un canard pris au hasard soit observé dans un lagon est égale à la fraction des observations qui ont été faites dans cet habitat, soit 64/160 = 0.4. La probabilité que n’importe quel canard soit un mâle est égale à la proportion de mâles dans l’échantillon, soit 97/160 = 0.60625. Donc, si le rapport des sexe est indépendant de l’habitat, la probabilité qu’un canard soit (a) un mâle et (b) dans un lagon est simplement le produit
Habitat Mâles Femelles Total
Lagons 30 34 64
Bancs d’algues 55 25 80
Haute mer 12 4 16
Total 97 63 160

116 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
des deux probabilités: (0.4)(0.60625) = 0.2425. Donc, si les mâles et les femelles utilisent les mêmes habitats, on s’attend à 160(0.2425) = 38.8 canards mâles dans les lagons.
La fréquence attendue, dans l’habitat i des canards du sexe j, peut être calculée par l’équation suivante, où Ri est le nombre total de canards dans l’habitat i, Cj est le nombre total de canards du sexe j observés et N est le nombre total de canards observés
Les statistiques X 2 et G peuvent être calculées par:
Les valeurs obtenues pour ces deux statistiques sont ensuite comparées à la distribution du χ2 avec (n-1)(m-1) degrés de liberté pour éprouver l’hypothèse nulle, où n est le nombre de rangées et m le nombre de colonnes du tableau de contingence.
Dans l’exemple précédent, les valeurs calculées pour le khi-carré et G sont 8.67 et 8.69 respectivement. Ces valeurs sont comparées aux valeurs critiques de χ2 avec (3-1)(2-1) = 2degrés de liberté, ce qui donne une probabilité d’environ 1% d’observer ces fréquences si le rapport des sexes ne change pas entre les habitats.
Les tests de khi-carré et de G pour éprouver des hypothèses d’indépendance dans des tableaux de contingence sont sujets aux même contraintes que les tests d’ajustement à une distribution théorique. Les échantillons doivent être raisonnablement grands et les fréquences attendues ne devraient pas être inférieures à 5.
Lorsqu’il y a seulement 4 cellules (un tableau 2x2), il est possible d’utiliser un test qui est plus fiable pour les petits échantillons, le test exact de Fisher (vois Sokal et Rohlf (1995), p. 730-736). L’ajustement
(75)
(76)
(77)
f ij
fR CNiji j=
Xf f
fij ij
ijj
m
i
n2
2
11
=−
==∑∑e j
G f f R R C C N Nij ij i i j jj
m
i
n
j
m
i
n
= − − +LNM
OQP====
∑∑∑∑21111
ln ln ln ln

TABLEAUX DE CONTINGENCE ET MODÈLES LOG-LINÉAIRES - 117
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
pour continuité (Section “Facteurs de correction pour le test de khi-carré et de G lorsqu'il n'y a que deux catégories” à la page 28) peut être utilisé pour obtenir un test plus conservateur.
Subdivision d’un tableau de contingence
Lorsque l’on rejette l’hypothèse d’indépendance, il est souvent utile d’identifier quel “traitement” est responsable de la dépendance. Dans l’exemple précédent sur les canards eider, un examen sommaire du tableau de contingence suggère que la plus grosse différence se situe entre le lagon et les deux autres milieux puisque dans les bancs d’algues et en haute mer il y a beaucoup plus de mâles que de femelles. L’approche générale est de trouver l’ensemble des plus grands sous-tableaux homogènes, c’est à dire les sections du tableau de contingence où on ne peut rejeter l’hypothèse nulle d’indépendance. On commence donc avec la plus petite section possible (un tableau 2x2), et on ajoute des colonnes ou des rangées jusqu’à ce que l’on rejette l’hypothèse d’indépendance. Le résultat final est un ensemble des sous-tableaux de taille maximale qui sont homogènes, mais qui diffèrent significativement les uns des autres. Dans notre exemple, la procédure est assez simple puisqu’il n’y a que trois sous-tableaux possibles (lagon-bancs d’algues, lagon-haute mer, et banc d’algues-haute mer), mais pour des tableaux de contingence avec plusieurs rangées et colonnes cela peut être extrêmement laborieux.
Un erreur fréquente
Les statistiques de khi-carré et de G doivent toujours être calculées à partir des fréquences observées et attendues, jamais les proportions ou les pourcentages.
Modèles log-linéairesLe concept de dépendance ou d’interaction peut être étendu aux tableaux de contingence à plusieurs critères de classification dans lesquels on examine l’effet de plus d’un facteur. Supposons qu’on veuille tester l’effet de la température (haute ou basse) et de l’humidité (haute ou basse) sur le nombre de plantes infectées par un pathogène. Dans ce cas on aurait besoin d’un tableau de contingence à trois critères de classification: État de la plante (infectée, non-infectée), Température (haute, basse) et Humidité (haute, basse).

118 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
L’analyse de tableaux de contingence est en fait une procédure d’ajustement de modèles. Pour un tableau de contingence à deux critères de classification, on a le modèle
où est le logarithme naturel de la fréquence attendue dans la rangée i et la colonne j du tableau, représentent les effets des catégories i et j des facteurs A et B respectivement et est un terme d’interaction représentant la dépendance de la catégorie i du facteur A sur la catégorie j du facteur B. L’hypothèse nulle qui est éprouvée avec une statistique X 2 ou G, est que est zéro. Pour un tableau avec trois facteurs (A, B et C), l’équation équivalente est
Notez que dans ce cas il y a trois interactions du deuxième degré et une interaction du troisième degré.
L’analyse de tableaux de contingences à plusieurs facteurs de classification procède de façon hiérarchique en éprouvant une série de modèles débutant par le plus complexe. Dans le cas d’un tableau à trois facteurs, on commence par éprouver l’hypothèse nulle que
= 0, ce qui peut se faire en ajustant un modèle qui ne contient pas ce terme:
Pour un tableau à trois facteurs avec a catégories du facteur A, b du facteur B et c du facteur C, la statistique G pour l’interaction ABC est obtenue en calculant
Notez que dans presque toutes les analyses statistiques visant à éprouver des hypothèses sur l’existence d’interactions (tableaux de contingence, ANOVA, ANCOVA, régression multiple) les tests sont
(78)
(79)
(80)
(81)
ln f ijk i j ij= + + +µ α β αβb g
ln f ijkα βi jet
αβb gij
αβb gij
ln f ijk i j k ij ik jk ijk= + + + + + + +µ α β γ αβ αγ βγ αβγb g b g b g b g
αβγb gijk
ln f ijk i j k ij ik jk= + + + + + +µ α β γ αβ αγ βγb g b g b g
G ff
fABC ijkijk
ijkk
c
j
b
i
a
=FHGIKJ===
∑∑∑2111
ln

TABLEAUX DE CONTINGENCE ET MODÈLES LOG-LINÉAIRES - 119
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
effectués en ajustant deux modèles: l’un avec le terme d’interaction et l’autre sans. Dans le cas d’un tableau avec trois facteurs, la statistique obtenue par l’équation 81 est simplement une mesure de la réduction de la qualité d’ajustement lorsque l’on exclue le terme représentant l’interaction du troisième degré. Si cette réduction n’est pas significative, alors cela signifie que l’interaction n’est pas significative. Si ce terme est significatif, cela veut dire que l’interaction entre les facteurs A et B (ou B et C, ou A et C) dépend du niveau facteur C (ou A ou B). Dans ce cas, on devrait faire des tests séparés d’indépendance pour chaque niveau de l’un des facteurs.
D’un autre côté, si le terme d’interaction du troisième degré n’est pas significatif, on peut l’éliminer et essayer d’ajuster un modèle plus simple. Pour un tableau avec trois facteurs, il y a trois modèles à éprouver, chacun excluant l’interaction du troisième degré et l’une des interactions du deuxième degré dans l’équation 81. Les interactions qui sont significatives (dont l’exclusion entraîne une dégradation significative de la qualité d’ajustement) sont conservées, les autres sont éliminées. Cependant, puisque l’on éprouve l’hypothèse d’une interaction en présence des deux autres (on compare un modèle avec deux interactions du deuxième degré à un modèle qui en contient 3), on ne peut conclure que parce que les deux interactions AB et AC ne sont pas significatives, alors que le modèle
donne un ajustement approprié. Cette inférence n’est justifiée que si l’on éprouve la signification de l’interaction BC en l’absence des deux autres interactions.
Le résultat final de cette procédure hiérarchique d’ajustement de modèle est le modèle le plus parcimonieux qui s’ajuste convenablement aux données, un modèle dont tous les termes d’interactions sont significatifs. C’est à partir de ce modèle que les conclusions sont tirées.
Tous les logiciels qui permettent d’estimer des modèles log-linéaires estiment les fréquences attendues selon le modèle ajusté et produisent des mesures des résidus, les déviations entre les fréquences attendues et observées. Si le modèle est bon, alors les résidus sont relativement petits et il n’y a pas de pattern évident des signes des résidus dans le tableau. Si il y en a, alors on devrait considérer une analyse plus approfondie du tableau. La valeur critique d’un résidu est difficile à établir d’une façon générale, mais pour un tableau avec trois facteurs
(82)ln f ijk i j k jk= + + + +µ α β γ βγb g

120 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
(A, B et C), ayant a, b et c niveaux respectivement, un résidu d’un modèle avec ν degrés de libertés ne devrait pas avoir une valeur absolue plus grande que
où est la valeur de khi-carré avec un degré de liberté et α = 0.05.
(83)νχ . ,05 12
abc
χ . ,05 12

PERMUTATION ET BOOTSTRAP - 121
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Permutation et BootstrapMalgré tous vos efforts, il arrivera que vos données s'éloigneront trop des conditions d’application des statistiques paramétriques que vous aimeriez utiliser et que vous ne trouverez pas d'alternative non paramétrique. La tentation sera alors grande de ne pas faire de statistiques et de simplement décrire les résultats. Vous devrez résister à cette tentation si vous désirez convaincre vos collègues. Il existe une alternative, mais elle implique généralement l’écriture de programmes d'ordinateur. Deux approches sont ici décrites brièvement.
Tests de permutationCette catégorie de tests ne s'applique qu'aux épreuves d'hypothèses. L'idée générale implique trois étapes:
1. Considérez l’échantillon obtenu comme l'un des échantillons pos-sibles d'événements, échantillons ayant tous la même probabilité d'existence
2. Énumérez toutes ces possibilités
3. En examinant la distribution de toutes ces possibilités, évaluez si l’échantillon obtenu est suffisamment improbable pour rejeter l'hypothèse nulle.
Par exemple, supposons que vous désirez tester si deux échantillons suivants de deux observations proviennent de deux populations ayant la même moyenne
Échantillon 1 10, 20 Échantillon 2 21, 25
Étape 1 . Calculez la moyenne pour chaque échantillon (15 et 23).Calculez la valeur absolue de la différence entre les moyennes (8).
Étape 2 . Générez toutes les paires possibles d'échantillons de deux observations et calculez la valeur absolue de la différence entre les deux moyennes:
10, 20 vs 21, 25 (8)10, 21 vs 20, 25 (7)10, 25 vs 20, 21 (3)20, 25 vs 10, 21 (7)20, 21 vs 10, 25 (3)21, 25 vs 10, 20 (8)

122 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Étape 3. Comparer la valeur observés aux valeurs possibles.
Il y a 6 valeurs possibles pour la valeur absolue de la différence entre les deux moyennes. De ces six valeurs, 2 (33%) sont égales ou plus élevées que la valeur de 8 observée. Il est donc probable que ces deux moyennes viennent de la même population
Cet exemple est trivial, mais le principe peut facilement être étendu à des situations plus complexes. Avec de grands échantillons il est souvent peu pratique de calculer toutes les combinaisons possibles. Dans ce cas, on prendra un échantillon aléatoire de ces possibilités.Cet échantillon devra être grand (idéalement plus de quelques centaines), et servira à comparer la valeur observée à la distribution de la statistique lors des permutations.
BootstrapCette approche permet de tester des hypothèses et de calculer des intervalles de confiance. Elle est appropriée lorsque les échantillons ne sont pas trop petits.
Le principe général implique deux étapes:
1. Échantillonner, avec remplacement, l’échantillon original et calcu-ler la statistique désirée. Répéter cette étape un grand nombre de fois (200-500)
2. A partir de la distribution des estimés bootstrap, déterminer les limites d'un intervalle de confiance au niveau de signification désiré.
Par exemple, supposons que vous désirez calculer un intervalle de confiance de la pente d'une régression calculée avec 10 observations.
Étape 1. Choisir au hasard, avec remplacement, 10 observations dans l’échantillon de 10.
Étape 2. Calculer la régression, garder la valeur de la pente.
Étape 3. Répéter 500 fois les étapes 1 et 2.
Étape 4. Mettre en ordre croissant les 500 pentes obtenues. Calculer les limites de l'intervalle de confiance à 95% comme la valeur de la 12ième et 487ième observation.
Pour tester l'hypothèse nulle, comparer la valeur prédite par l’hypothèse nulle à l'intervalle de confiance.Si la valeur prédite est incluse dans l’intervalle de confiance, accepter l’hypothèse nulle.

PERMUTATION ET BOOTSTRAP - 123
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
CommentairesCes deux approches peuvent être utilisées dans tous les cas que vous pouvez imaginer. Comme les données biologiques violent généralement les conditions d’application des tests paramétriques, ces deux approches peuvent leur être préférables. Cependant, elles requièrent de nombreux calculs qui ne peuvent être effectués qu'à l'aide d'ordinateurs en rédigeant des programmes spécifiques. Les tests non-paramétriques standards sont aussi puissants que les tests de permutation et le bootstrap, mais requièrent beaucoup moins de calculs.

124 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

EXERCICES DE LABORATOIRE - 125
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Exercices de laboratoireLes exercices de laboratoire que vous retrouverez dans les pages qui suivent sont conçus de manière à vous permettre de développer une expérience pratique en analyse de données à l'aide d'un logiciel (SYSTAT 7.0). SYSTAT est un logiciel très puissant et relativement convivial mais, comme tous les logiciels, il a des limites. En particulier il ne peut réfléchir à votre place, vous dire si l'analyse que vous tentez d'effectuer est appropriée ou sensée, ou interpréter biologiquement les résultats.
Quelques points importants à retenir
• Avant de commencer une analyse statistique, il faut d'abord vous familiariser son fonctionnement. Cela ne veut pas dire que vous devez connaître les outils mathématiques qui la sous-tende, mais vous devriez au moins comprendre les principes utilisés lors de cette analyse. Avant de faire un exercice de laboratoire, lisez donc la section correspondante dans les notes de cours. Sans cette lec-ture préalable, il est très probable que les résultats produits par le logiciel, même si l'analyse a été effectuée correctement, seront indéchiffrables.
• SYSTAT peut être utilisé de deux façons : (1) avec des lignes de commandes (command mode) et (2) en utilisant les menus. En mode menu, toutes les analyses sont réalisées en faisant des choix et en remplissant les formulaires des diverses fenêtres de SYSTAT. En mode commande, il faut taper les commandes désirées dans la fenêtre de commandes ou dans un fichier de commander pour indiquer à SYSTAT quoi faire. Notez que la plupart des exercices de laboratoire indiquent seulement comment effectuer les analyses en mode menu.. Vous devriez cependant savoir que le mode com-mande est beaucoup plus flexible et qu'il permet de faire certaines choses plus efficacement que le mode menu. Pour cette raison, les utilisateurs expérimentés de SYSTAT préfèrent le mode com-mande et utilisent que rarement les menus.
• Les laboratoires sont conçus pour compléter les cours théoriques et vice versa. À cause des contraintes d'horaires, il se pourrait que le cours et le laboratoire ne soient pas parfaitement synchronisés. N'hésitez donc pas à poser des questions sur le labo en classe ou des questions théoriques au laboratoire.
• Travaillez sur les exercices de laboratoire à votre propre rythme. Certains exercices prennent beaucoup moins de temps que d'autres et il n'est pas nécessaire de compléter un exercice par

126 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
séance de laboratoire. En fait deux séances de laboratoire sont prévues pour certains des exercices. Mêmes si vous n'êtes pas notés sur les exercices de laboratoire, soyez conscient que ces exercices sont essentiels. Si vous ne les faites pas, il est très peu probable que vous serez capable de compléter les devoirs et l'exa-men final. Prenez donc ces exercices de laboratoire au sérieux !

LABO- INTRODUCTION À SYSTAT - 127
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Labo- Introduction à SYSTATAprès avoir complété cet exercice de laboratoire, vous devriez pouvoir utiliser les menus de SYSTAT pour :
• Ouvrir des fichiers de données SYSTAT
• Faire des diagrammes de dispersion
• Calculer des statistiques descriptives
• Importer et exporter des fichiers
• Manipuler des données dans le chiffrier
• Trouver des cas
• Sélectionner des cas
• Transformer des données
• Trier des données
• Produire des graphiques
• Sauvegarder et imprimer les fichiers de sortie, les graphiques et les lignes de commande
Notez que les exercices qui suivent ne font qu'effleurer l'ensemble des fonctions disponibles dans SYSTAT. Lorsque vous serez familiarisés avec cet environnement, vous devriez explorer par vous-même les autres fonctions. Les manuels, disponibles au laboratoire vous seront d'un grand secours. Les fichiers d'aide ne sont pas à dédaigner non plus !
Pour chaque séance de laboratoire, vous devriez avoir en main une disquette. Elle vous servira à sauvegarder votre travail.
Le cahier de bord, une habitude à prendreJe vous recommande de garder des notes détaillées sur vos analyses avec SYSTAT. Une méthode des plus simpleest de d'abord ouvrir un document dans le traitement de texte de votre choix, par exemple Word ou WordPerfect. Les résultats apparaissant dans les fenêtres de SYSTAT peuvent alors être simplement copiés-collés en utilisant la commande Cut/Copy du menu Edit de SYSTAT. Les graphiques peuvent aussi être copiés de SYSTAT à votre traitement de texte.
Quelques points à considérer. Premièrement, pour éviter d'avoir à recommencer du début si (lorsque…) le serveur tombe en panne, vous devriez sauvegarder votre travail à intervalles rapprochés.

128 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Deuxièmement, la fenêtre principale de SYSTAT où apparaissent les résultats ne peut contenir qu'une quantité limitée de texte. Si vos fichiers de sortie sont très longs ou que vous faites plusieurs analyses à la queue l'une de l'autre, il est fort possible que vous perdiez les premières pages de résultats. Troisièmement, lorsque vous produisez un résultat que vous aimeriez garder, ajoutez-y une courte note décrivant ce que vous avez fait, pourquoi vous avez fait cette analyse et quelle est la conclusion que vous en faites. Nous savons par expérience qu'il est très difficile d'essayer de se souvenir de ce que l'on a fait et pourquoi seulement à partir des fichiers de sortie SYSTAT…
Ouvrir un fichier de données SYSTATPour ouvrir un fichier de données dans SYSTAT, choisir File-Open au menu de la fenêtre principale de SYSTAT, puis Data au menu suivant et finalement choisir ou taper le nom du fichier à ouvrir dans la fenêtre de dialogue qui apparaît.
Ouvrez le fichier TUTDAT.SYS. Ce fichier contient des données sur des marais de la région d'Ottawa, en particulier leur superficie, le nombre d'espèces d'oiseaux, de mammifères et de plantes qui y sont retrou-vées, etc.
Lorsque vous ouvrez ce fichier, le message suivant devrait apparaître dans la fenêtre principale de sortie SYSTAT (Output organiser) (les premières lignes peuvent ne pas être visibles à l’écran)
SYSTAT Rectangular file F:\data\usr\amorin\BIO4518\1998\Labo\data\Tutdat.sys,
created Fri Jul 11, 1997 at 07:12:06, contains variables:
NAME SURV LAT LONG AREA(1) SWAMP
BUILD1 BDENS(1) PLANT BIRD MAMMAL HERPTILE
TSPECIES HRS LOGPL LOGAREA LOGHERP LOGBIRDS
LOGMAM CHT3 CHT3DEN THTDEN
pendant que les données apparaissent dans le chiffrier (fenêtre SYSTAT Data) qui s'ouvre automatiquement. Vous pouvez passer d'une fenêtre à l'autre en pesant simultanément sur Alt-Tab. La dimension des fenêtres peut être changée en cliquant-pressant sur un coin ou une bordure et ensuite en déplaçant la souris.
Création de diagrammes de dispersion
La première étape de toute analyse statistique est d'examiner les don-nées. Pour créer un diagramme de dispersion, choisir Graph-Plots-Scatterplot à la barre du menu principal. Sélectionnez la variable cor-respondant au nombre d'espèces de plantes (PLANT) en cliquant des-

LABO- INTRODUCTION À SYSTAT - 129
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
sus, puis cliquez sur Add pour en faire la variable de l'ordonnée (Y-variable). Ensuite cliquez sur la variable correspondant à la superficie du marais (AREA(1)) pour la sélectionner et cliquez sur Add pour en faire la variable de l'abscisse (X-variable). Cliquez ensuite sur OK.
Un graphique de PLANT vs AREA(1) apparaîtra alors. Si vous double cliquez sur le graphique, une nouvelle fenêtre apparaîtra. Le menu et les boutons au haut de cette fenêtre vous permettent de modifier les axes, ajouter une légende ou un titre, ajouter une ligne ou du texte, etc. À la barre de menu principal, allez à Graph-Layout ou Graph-Appear-ance et expérimentez un peu en changeant la taille et l'apparence de votre graphique. Vous pouvez accéder à encore plus de fonctions à partir de la fenêtre de dialogue principale pour le diagramme de dis-persion qui est accessible à partir de la fenêtre principale (Main win-dow) à Graph-Plots-Scatterplot en cliquant sur les boutons Options, Axes, Layout et Appearance.
SYSTAT 7 a un très grand répertoire de types de graphiques. Vous pouvez faire des diagrammes de dispersion, des histogrammes, et même des graphiques en 3 dimensions. Essayons un graphique en trois dimensions.
Allez à la fenêtre principale (Main window), cliquez sur Graph-Plots-Scatterplot et entrez PLANT, AREA(1) et HRS comme variables Z, X et Y respectivement. Cliquez sur Axes-All axes. Dans la boîte Axes to display, allez à 3-D et choisissez Box et cliquez sur Continue. Puis
0 500 1000 1500 2000AREA(1)
0
100
200
300
PLAN
T

130 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
allez à Axes- X-Axis, entrez 800 comme valeur maximum dans la boîte Scale range, et cliquez sur Continue. Puis allez à Options-Plot Options et cliquez sur Vertical spikes to Y et ensuite Continue. Finale-ment cliquez sur OK pour produire le graphique. Expérimentez avec les menus Options et Layout pour changer l'apparence de votre graphique.
Si vous désirez examiner les relations entre plusieurs paires de variables dans vos données, vous pouvez utiliser la procédure ScatterPlot matrix (SPLOM) accessible de la fenêtre principale à Graph-Multivariate Displays sur la barre de menu. Dans la fenêtre de dialogue qui apparaît, ajoutez PLANT, AREA(1) et HRS aux Row variables et cliquez sur OK.
PLANT
PLAN
T
AREA(1) HRS
PLANT
ARE A
(1) AR
EA(1)
PLANT
HR
S
AREA(1) HRS
HR
S

LABO- INTRODUCTION À SYSTAT - 131
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Calculer des statistiques descriptives
Pour calculer des statistiques descriptives, allez à la fenêtre principale (Main window) et, à la barre de menu principal, cliquez sur Statistics-Descriptive statistics-Basic statistics. Une fenêtre de dialogue s'ouvrira pour vous permettre de choisir les variables à décrire et quelles sont les statistiques à calculer. Choisissez plusieurs variables et générez les statistiques descriptives. Les résultats pour le nombre d'espèces de plantes (PLANT), d'oiseaux (BIRD) et la superficie des marais (AREA(1)) sont reproduits ci-dessous :
PLANT BIRD AREA(1)
N of cases 58 58 58
Minimum 27.000 5.000 3.500
Maximum 248.000 112.000 1641.700
Mean 131.241 37.052 277.447
Standard Dev 55.628 19.397 348.906
Importer/Exporter des fichiersLe chiffrier de SYSTAT (la fenêtre SYSTAT Data) n'est pas un véritable chiffrier et n'est pas particulièrement convivial pour entrer des données. La majorité des utilisateurs utilisent donc d'autres programmes pour entrer leurs données, par exemple Quattro ou Excel, et importent ensuite leurs données dans SYSTAT.
L'importation des données dans SYSTAT peut être problématique. En particulier, les cellules vides des chiffriers sont parfois simplement éliminées. De plus, certains formats ne peuvent être importés parce que la version de SYSTAT que vous utilisez n'a pas le filtre approprié. Par exemple, un fichier Excel 97 ne peut être importé directement dans SYSTAT 7. Pour importer ces données il faut d'abord sauvegarder le fichier Excel en une version antérieure, avant de les importer. Vérifiiez donc toujours le fichier de données SYSTAT que vous créez en important des données pour vous assurer qu’il contient toute l'information du fichier original.
Pour importer un fichier de données, il suffit de l'ouvrir : à la fenêtre principale (Main window), choisir File-Open-Data, spécifiez le type de fichier (dans la liste déroulante List files of type), choisissez le fichier, puis cliquez OK. Les données devraient maintenant se trouver dans le chiffrier SYSTAT (s'il n'est pas visible, cliquez sur Window-Data). S'il y a un gros accrochage à l'importation un message d'erreur apparaîtra. Mais ne présumez pas que tout a été importé correctement s'il n'y a pas de message d'erreur et que SYSTAT réponds : "IMPORT SUCCESSFULLY COMPLETED.". Vérifiez !

132 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Pour exporter un fichier, assurez-vous d'abord que le fichier désiré se trouve dans le chiffrier SYSTAT, puis sélectionnez File-Save as et sélectionnez le répertoire où vous voulez sauvegarder le fichier, un format (par exemple.xls) et un nom de fichier.
Essayez d'importer le fichier AGE.XLS pour créer un fichier SYSTAT, puis exportez-le sous un autre format.
Manipulation de données dans le chiffrier
Ouvrez le fichier TUTDAT.SYS dans SYSTAT et essayez de faire les opérations suivantes :
Effacer une valeur.
Pour effacer une valeur, cliquez dans la cellule du chiffrier qui la contient et appuyez sur Delete.
Effacer une rangée (cas).
Cliquez sur le numéro de rangée (la première colonne ombrée dans le chiffrier) de la rangée que vous voulez effacer pour la sélectionner. Sélectionnez ensuite Delete au menu Edit.
Effacer une colonne (variable).
Cliquez sur le nom de la variable (la première rangée ombrée dans le chiffrier) pour sélectionner toute la colonne. Sélectionnez ensuite Delete au menu Edit.
Effacer un bloc de données.
Sélectionnez le bloc de valeur à effacer en cliquant d'abord dans la cellule formant le coin gauche supérieur puis, en pressant sur le bouton de la souris, glissez le pointeur jusqu'à la cellule formant le coin droit inférieur. Relâchez le bouton de la souris quand le bloc désiré est entièrement sélectionné puis sélectionnez Delete au menu Edit. Notez que cette opération n'efface pas les rangées ni les colonnes, seulement le contenu des cellules sélectionnées.
Changer une valeur.
Cliquez dans la cellule contenant la valeur à changer, inscrivez la nouvelle valeur et appuyez sur Tab sur le clavier. La valeur sera changée et le curseur se déplacera dans la cellule suivante dans la rangée.

LABO- INTRODUCTION À SYSTAT - 133
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Ajouter une nouvelle variable.
Déplacez le curseur dans la rangée contenant le nom des variables (la première rangée du fichier), juste après la dernière variable. Double-cliquez sur cette cellule, inscrivez le nom de la nouvelle variable et choisissez le type de variable désiré. Puis cliquez sur OK. Si la nouvelle variable doit contenir une chaîne de caractères (par opposition à des chiffres), le nom doit se terminer par $ (par exemple VARIABLE1$). Si vous essayez de changer le type de variable de numérique à caractère, SYSTAT retournera un message d'erreur !
Ajouter un nouveau cas.
Déplacez le curseur au bas du tableau jusqu'à la première cellule libre. Inscrivez la valeur désirée et appuyez sur Tab pour passer à la colonne (variable) suivante.
Insérer une colonne
Cliquez sur la première ligne du chiffrier dans la colonne qui doit suivre celle de la nouvelle variable. Toute la colonne sera surligneé. Cliquez avec le bouton de droite, et choisissez Insert variable.
Trouver des casPour trouver un cas, à partir de la fenêtre Data, déplacez le curseur dans la colonne contenant la valeur que vous cherchez puis sélectionnez, l'option Edit-Find in column. Une fenêtre de dialogue s'ouvrira et vous permettra d'identifier le ou les cas que vous recherchez en spécifiant un critère de recherche.
Sélectionner des casIl arrive fréquemment qu'une analyse se concentre sur un sous-ensemble des observations contenues dans un fichier de données. Pour sélectionner un sous-ensemble, cliquez sur Data-Select cases à partir du chiffrier, puis inscrivez votre critère de sélection dans la fenêtre de dialogue qui apparaît. Par exemple, pour sélectionner tous les cas du fichier TUTDAT.SYS qui ont été répertoriés par le chercheur #1, inscrire "SURV=1" puis cliquer sur OK. Une étoile apparaîtra dans la colonne des numéros de cas pour tous les cas ainsi sélectionnés. Pour revenir à l'ensemble des données en entier, cliquer sur Turn select off dans la boîte de dialogue Select cases.
Attention ! Vos sélections restent en vigueur jusqu'à ce que vous ouvriez un autre fichier, sortiez de SYSTAT ou reveniez à l'ensemble entier en cliquant sur Turn select off. Donc, après avoir sélectionné un

134 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
sous-ensemble, toutes les analyses ne sont faites que sur ce sous-ensemble. Si vous voulez analyser l'ensemble entier, n'oubliez pas d'effacer vos sélections.
Comme exercice, essayez de faire un diagramme de dispersion de logpl vs logarea pour le sous-ensemble de cas où SURV=1 et HRS>0.
Dans certains cas, par exemple avec de très grands ensembles de données, vous voudrez créer des fichiers séparés pour les différents sous-ensembles. Pour ce faire, sélectionnez d'abord les cas qui vous intéressent, puis cliquez sur Extract file au menu Data. Une fenêtre de dialogue apparaîtra pour vous permettre d'indiquer le nom du fichier à sauvegarder.
Transformer des donnéesCréer de nouvelles variables qui sont une fonction mathématique d'autres variables
Il est très souvent nécessaire de créer de nouvelles variables à partir de variables existantes. Par exemple, la densité des souris dans un champ est le nombre de souris dénombrées (N) divisé par la superficie du champ (A). Si votre fichier de données contient les valeurs de N et de A pour chaque site, vous pouvez calculer la densité en sélectionnant Transform-Let du menu Data, et en inscrivant D dans la boîte de gauche et N/A dans la boîte de droite. Cette action va créer une nouvelle variable (colonne) contenant la densité (D) pour chaque cas. S'il y a des données manquantes de A ou de N, D sera aussi manquant.
1.0 1.5 2.0 2.5 3.0LOGAREA
1.7
1.8
1.9
2.0
2.1
2.2
2.3
2.4
LOG
P L

LABO- INTRODUCTION À SYSTAT - 135
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
En utilisant TUTDAT.SYS, créez une nouvelle variable VERT=BIRD+HERP-TILE+MAMMAL et ensuite un graphique de dispersion VERT vs LOGAREA.
SYSTAT contient tout un répertoire de fonctions mathématiques standard : LOG (logarithme naturel), L10 (logarithme base 10), ABS (valeur absolue), etc.
Il est également possible de faire des transformations différentes pour divers sous-ensembles de cas. Par exemple, supposons que nous sachions que le chercheur #1 répertorie un habitat deux fois moins vite que le chercheur #2 et que ce dernier répertorie 3 hectares de marais à l'heure. On pourrait calculer la couverture effectuée pour chaque cas comme : COVERAGE=HRS*3 IF SURV=2 et COVERAGE=HRS*3*0.5 IF SURV=1. Essayez !
Créer de nouvelles variables qui sont des fonctions logiques ou relationnelles d'autres variables
Il est parfois nécessaire de créer des variables qui représentent des groupes de cas. Par exemple, supposons qu'on doive regrouper tous les marais de l'échantillon en trois catégories : petit (<50 ha), moyen (50 - 100 ha) et grand (> 100 ha). Pour ce faire, on pourrait procéder comme suit : au menu Data du chiffrier, sélectionner Transform-Let et définir une nouvelle VARIABLE SIZE_CLASS=CUT(AREA(1), 50,100). Cette opération va créer la variable SIZE_CLASS qui va contenir les valeurs 1.0, 2.0 ou 3.0 selon que la surface du marais (AREA(1)) est plus petite ou égale à 50 ha, entre 50 et 100 ha ou plus grande que 100 ha. On peut ensuite créer des étiquettes (Labels) en sélectionnant Data-Label, sélectionnant SIZE_CLASS et inscrivant 1 comme Value(s) et SMALL comme Label dans la première rangée, 2 comme Value(e) et Medium comme Label dans la deuxième rangée, etc. Finalement, on
1.0 1.5 2.0 2.5 3.0LOGAREA
0
50
100
150
VER
T

136 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
utilise Transform-Let pour créer une autre nouvelle variable (de type caractère) SIZE_CLASS$=LAB$(SIZE_CLASS) qui contiendra la valeur de l'étiquette (par exemple Small) correspondant à une valeur de SIZE_CLASS. Essayez !
Calculer les rangs
De nombreuses statistiques non-paramétriques sont calculées sur les rangs des données plutôt que sur les valeurs brutes. Pour transformer la valeur d'une variable en son rang, sélectionnez Data-Rank au menu du chiffrier, puis choisissez la variable que vous désirez ordonner. ATTENTION ! À moins que vous ne cliquiez sur la boîte Save file, vous données originales seront remplacées par leur rang. Si vous désirez garder une copie des données originales, cliquez sur Save file et inscrivez le nom du fichier contenant les rangs à sauvegarder.
Essayez de calculer les rangs pour la variable représentant l'aire des marais (AREA(1)) dans TUTDAT.SYS.
Normaliser des données
Plusieurs tests statistiques sont effectués sur des données normalisées plutôt que sur les données brutes. L'une des normalisations les plus fréquemment employée, la transformation Z, est effectuée en soustrayant la moyenne de toutes les observations de chaque observation originale, puis en divisant le résultat par l'erreur-type de l'échantillon. Cette transformation produit des valeurs normalisées ayant une moyenne de 0 et une erreur-type de 1. Une autre normalisation commune consiste à soustraire de chaque valeur la valeur minimale, puis de diviser le résultat par l'étendue. Ceci produit des valeurs normalisées variant de 0 à 1. Pour effectuer ces deux normalisations, sélectionner Data-Standardize à la fenêtre du chiffrier, puis sélectionnez la variable à transformer et le type de normalisation désirée : SD pour la transformation Z, Range pour normaliser entre 0 et 1. ATTENTION, comme pour le calcul des rangs, la normalisation des données efface les valeurs originales. Vous pouvez cependant sauvegarder les données normalisées dans un autre fichier en cliquant sur a boîte Save file.
Normalisez les données de superficie des marais (AREA(1)) dans TUT-DAT.SYS.

LABO- INTRODUCTION À SYSTAT - 137
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Trier des donnéesPour trier des données, sélectionnez Sort au menu Data, et choisissez la ou les variables par lesquelles vous voulez trier les cas. Vous pouvez trier en ordre croissant ou décroissant.
Triez les marais de TUTDAT.SYS en ordre croissant de densité d'espèces de vertébrés (VERTDEN), calculée comme le nombre d'espèces de vertébrés (BIRD + MAMMAL + HERPTILE) divisé par la superficie du mar-ias (AREA(1)).
Produire des graphiquesEn plus des diagrammes de dispersion, SYSTAT permet de faire plusieurs autres graphiques. Les plus communs sont décrits ici, mais soyez conscients que SYSTAT offre beaucoup plus de possibilités que ce qui est décrit ici.
Histogramme
La routine Histogram, accessible au menu Graph-Density Displays de la fenêtre principale de SYSTAT (Main Window) génère des histogrammes. SYSTAT produit les histogrammes en comptant le nombre de cas dans chaque catégorie de la variable désignée, par exemple le nombre de marais dans TUTDAT.SYS qui sont petits, moyens ou grands. Pour produire un histogramme, choisir Graph-Density Displays-Histogram. Une fenêtre de dialogue apparaîtra pour vous permettre de choisir la variable à utiliser. Notez qu'il y a plusieurs types d'histogrammes disponibles. Le type d'ordonnée (Y variable) par défaut est la densité (density). Sélectionnez PLANT comme variable pour l'axe des X (X variable) et cliquez sur OK. SYSTAT produira alors un histogramme du nombre d'espèces de plantes dans les marais. Pour changer l'apparence du graphique, allez à Options, Axes, Layout ou Appearance et modifiez les paramètres jusqu'à ce que vous soyez satisfait du résultat.
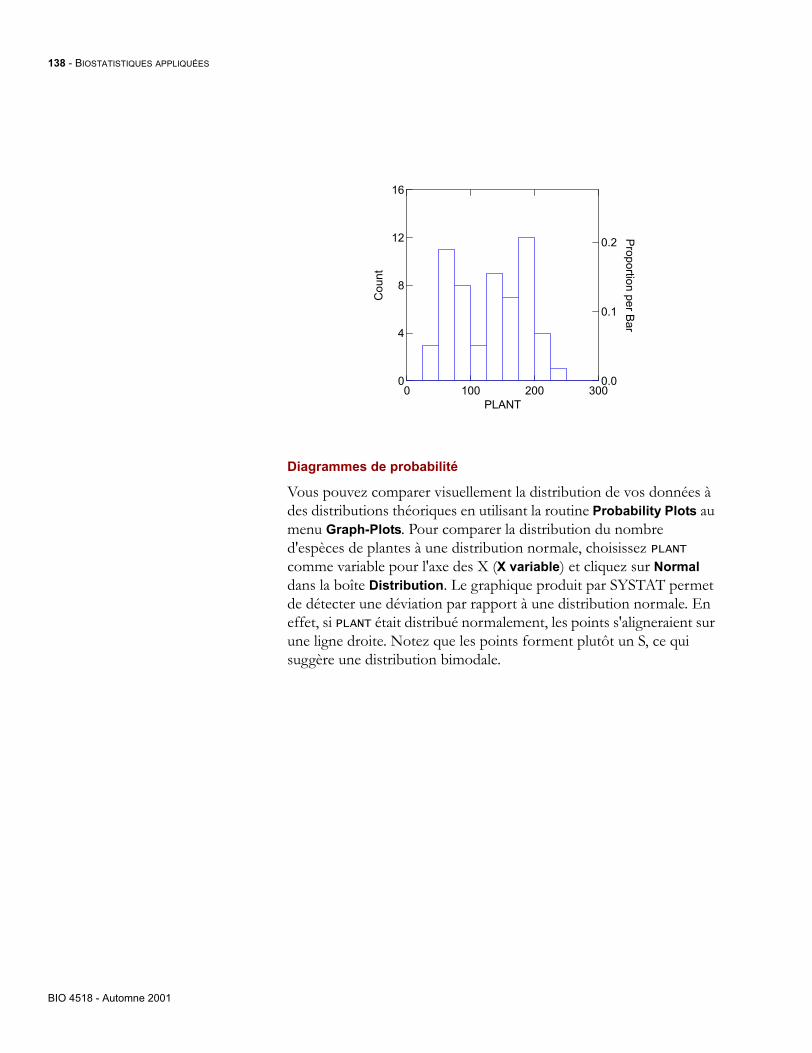
138 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Diagrammes de probabilité
Vous pouvez comparer visuellement la distribution de vos données à des distributions théoriques en utilisant la routine Probability Plots au menu Graph-Plots. Pour comparer la distribution du nombre d'espèces de plantes à une distribution normale, choisissez PLANT comme variable pour l'axe des X (X variable) et cliquez sur Normal dans la boîte Distribution. Le graphique produit par SYSTAT permet de détecter une déviation par rapport à une distribution normale. En effet, si PLANT était distribué normalement, les points s'aligneraient sur une ligne droite. Notez que les points forment plutôt un S, ce qui suggère une distribution bimodale.
0 100 200 300PLANT
0
4
8
12
16
Cou
nt0.0
0.1
0.2 Proportion per Bar

LABO- INTRODUCTION À SYSTAT - 139
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Box plots
Les Box plots permettent de comparer visuellement différents groupes. Par exemple, supposons que vous vouliez comparer la taille des mâles et des femelles, un box plot illustrerait comment la distribution des tailles diffère entre les deux. Pour faire un Box plot, sélectionnez Graph-Density Displays-Box Plot, puis la variable dont vous voulez comparer la distribution, et ensuite la variable représentant les groupes à comparer (dans l'exemple, ce serait la taille et le sexe respectivement).
Pour essayer, sélectionnez PLANT comme variable Y (Y-variable) et SIZE_CLASS$ comme X variable. Le graphique qui en résulte décrit comment la distribution de la richesse spécifique varie selon les trois catégories de marais. Dans un box plot, la ligne près du centre de la boîte représente la valeur médiane, les extrémités de la boîte (les charnières) représentent le premier et troisième quartile. L'étendue représentée par la boîte contient donc 50% des valeurs. Les valeurs extrêmes (outliers) sont représentées par des astérisques ou des cercles. (Pour des explications plus détaillées sur les box plots, consultez le manuel SYSTAT Graphics, p. 106).
0 100 200 300PLANT
-3
-2
-1
0
1
2
3
Expe
cted
Val
ue fo
r Nor
mal
Dis
tribu
ti on

140 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Sauvegarder et imprimer les fichiers de sortieSYSTAT produit trois types de sorties : ce qui apparaît dans la fenêtre principale (SYSTAT Output Organizer), ce qui apparaît dans la fenêtre du chiffrier (SYSTAT Data), et les graphiques apparaissant dans la fenêtre graphique (SYSTAT Graph). Ces produits peuvent être imprimés ou sauvegardés dans des fichiers.
Fenêtre principale (SYSTAT Output Organizer)
Les résultats de vos analyses apparaissent à la fenêtre principale. Il est avantageux d'annoter les résultats au fur et à mesure en les y inscrivant. Pour sauvegarder le tout dans un fichier, sélectionnez File-Save as et inscrivez un nom de fichier.
Pour imprimer les résultats, sélectionnez File-Print. Si vous ne désirez imprimer qu'une partie du contenu de la fenêtre, sélectionnez les lignes qui vous intéressent en cliquant au début de la première ligne, puis en déplaçant la souris jusqu'à la dernière ligne tout en pressant sur le bouton de gauche. Ensuite allez à File-Print et cliquez sur Selection.
Fenêtre des graphiques (SYSTAT Graph)
Pour sauvegarder vos graphiques dans un fichier, cliquez sur File-Save as, et inscrivez le nom du fichier et le répertoire désiré dans la fenêtre de dialogue qui apparaîtra. Par défaut, les graphiques sont sauvegardés en format Windows Metafile (.wmf).
Large Medium SmallSIZE_CLASS$
0
100
200
300
PLAN
T

LABO- INTRODUCTION À SYSTAT - 141
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Vous pouvez aussi imprimer votre graphique en sélectionnant File-Print lorsque vous êtes dans la fenêtre SYSTAT Graph.
Fenêtre du chiffrier (SYSTAT Data)
Dans la fenêtre du chiffrier, sélectionnez File-Save (pour sauvegarder tous les changements depuis la dernière sauvegarde en remplaçant le fichier original) ou File-Save as en spécifiant une destination et un format si vous désirez exporter les données.
Pour imprimer votre chiffrier, cliquez sur File-Print et entrez l'information appropriée dans la fenêtre de dialogue.
Essayez d'imprimer et de sauvegarder les fichiers de sortie créés lors des exercices précédents.

142 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

LABO- COMPARAISON DE DEUX ÉCHANTILLONS - 143
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Labo- Comparaison de deux échantillonsAprès avoir complété cet exercice de laboratoire, vous devriez pouvoir :
• Utiliser SYSTAT pour éprouver l'hypothèse de normalité
• Utiliser SYSTAT pour comparer les moyennes de deux échan-tillons distribués normalement
• Utiliser SYSTAT pour comparer les moyennes de deux échan-tillons qui ne sont pas normalement distribués
• Utiliser SYSTAT pour comparer les moyennes de deux échan-tillons appareillés
• Utiliser SYSTAT pour comparer les médianes et les variances de deux échantillons
• Utiliser SYSTAT pour comparer les distributions de deux échan-tillons
Éprouver l'hypothèse de normalitéUne des conditions d'application commune à de nombreuses épreuves d'hypothèse est que les données suivent une distribution normale. La robustesse des tests face à la non-normalité varie et certains sont peu affectés, mais il est recommandé de jeter un coup d'œil à la distribution des données avant de commencer l'analyse.
Supposons que l'on veuille comparer la distribution en taille des esturgeons de The Pas et Cumberland House. La variable FKLNGTH dans le fichier STURGDAT.SYS représente la longueur (en cm) à la fourche de chaque poisson mesurée de l'extrémité de la tête à la base de la fourche de la nageoire caudale. Pour commencer, examinons si cette variable est normalement distribuée.
Une excellente façon de comparer visuellement une distribution à la distribution normale est de superposer un histogramme des données observées à une courbe normale. Avec SYSTAT, cela implique la création de deux graphiques qui doivent apparaître sur la même page. Pour ce faire, il faut procéder en trois étapes : 1) indiquer à SYSTAT que nous voulons mettre plus d'un graphique par page, 2) spécifier les graphiques à superposer et 3) donner la commande de produire les graphiques.

144 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
En utilisant les données du fichier STURGDAT.SYS, générez les histo-grammes et les distributions normales ajustées aux données de FKL-NGTH à The Pas et Cumberland House.
Aller à Graph-Begin Single Page Mode au menu de la fenêtre princi-pale de SYSTAT pour indiquer que les graphiques doivent être super-posés. Notez que jusqu'à ce que cette option soit désactivée, les graphiques n'apparaîtront pas immédiatement dans la fenêtre graphique.
Ensuite, pour créer l'histogramme des données, cliquez sur Graph-Density Displays-Histogram, inscrivez FKLNGTH comme X-variable, laissez Density comme Y-variable, sélectionnez LOCATION$ comme groupe (grouping variable). Cela créera 2 graphiques, un par site. À Options-Histogram options, indiquez un intervalle pour chaque bâton (Width of bar) de 2 cm. Cliquez sur Continue pour refermer la fenêtre de dialogue. Le graphique n'apparaîtra pas (les commandes sont mémorisées jusqu'à ce que le mode single page soit désactivé à la prochaine étape). Spécifier ensuite le deuxième graphique en allant à Graph-Density Displays-Density function. Inscrire FKLNGTH comme X-variable, Density comme Y-variable, LOCATION$ comme variable indiquant le groupe et vérifiez que le Type of Graph est bien Normal. Ensuite allez à Axes-All axes et indiquez que les axes ne doivent pas être imprimés en sélectionnant None pour Axes to Display et Scales to Display. Cliquez ensuite sur Continue et OK.
Pour faire apparaître les graphiques à l'écran, il ne reste plus qu'à cliquer sur Graph-End single page mode. Visuellement, ces deux échantillons sont-ils normalement distribués d'après vous ?
Programme SYSTAT pour générer les histogrammes et les distributions normales superposées.USE 'C:\DATA\AMORIN\BIO4518\1998\LABO\DATA\STURGDAT.SYS'
BEGIN
DENSITY FKLNGTH/ GROUP=LOCATION$ HIST BWIDTH=2
DENSITY FKLNGTH/ GROUP=LOCATION$ NORMAL AXES=NONE SCALE=NONE
END

LABO- COMPARAISON DE DEUX ÉCHANTILLONS - 145
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Le graphique pour Cumberland House suggère que les données se rapprochent de la normalité, mais que les données de The Pas ne suivent pas très bien la distribution normale
En utilisant la routine Plots-Probability plot au menu Graph, faites des graphiques de probabilité pour chaque site. Cette autre façon de représenter les données vous porte-t-elle à changer votre conclusion sur la normalité des données?
L’inspection visuelle de ces graphiques suggère que cette variable est distribuée approximativement suivant la loi normale dans chaque échantillon, quoiqu’il y ait une certaine leptokurtose (distribution trop haute et serrée) à The Pas et que les données de Cumberland s’approchent plus d’une distribution normale.
Éprouvez la normalité de chaque échantillon à l'aide du test de Kol-mogorov-Smirnov et celui de Lilliefors. Allez à Statistics-Nonpara-metric tests-One-sample KS. Pour faire le test KS, inscrivez FKLNGHT comme variable, sélectionnez Normal à Options et indiquez la moy-enne et l'écart-type dans les boîtes. (Vous pouvez les calculer avec SYSTAT en allant à Statistics-Descriptive statistics-Basic statistics).
Cumberland
20 30 40 50 60 70FKLNGTH
0
5
10
15
20
25
Cou
nt
0.0
0.1
0.2
Proportion per Bar
The_Pas
20 30 40 50 60 70FKLNGTH
0
5
10
15
20
Cou
nt
0.00.020.040.060.080.100.120.140.160.18
Proportion per BarCumberland The_Pas
Commande SYSTAT pour produire les graphiques de probabilitéPPLOT FKLNGTH/ GROUP=LOCATION$ NORMAL
Cumberland
20 30 40 50 60 70FKLNGTH
-3
-2
-1
0
1
2
3
Expe
cted
Val
ue fo
r Nor
mal
Dis
tribu
tion
The_Pas
20 30 40 50 60 70FKLNGTH
-3
-2
-1
0
1
2
3
Expe
cted
Val
ue fo
r Nor
mal
Dis
tribu
tion

146 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Pour faire le test de Lilliefors, sélectionnez Lillefors à Options. Que concluez-vous ? Pourquoi ?
The Pas
Kolmogorov-Smirnov One Sample Test using Normal(43.37,6.44) distribution
Variable N-of-Cases MaxDif Probability (2-tail)
FKLNGTH 101.000 0.078 0.569
Kolmogorov-Smirnov One Sample Test using Normal(0.00,1.00) distribution
Variable N-of-Cases MaxDif Lilliefors Probability (2-tail)
FKLNGTH 101.000 0.078 0.127
Cumberland
Kolmogorov-Smirnov One Sample Test using Normal(45.04,3.98) distribution
Variable N-of-Cases MaxDif Probability (2-tail)
FKLNGTH 84.000 0.089 0.513
Kolmogorov-Smirnov One Sample Test using Normal(0.00,1.00) distribution
Variable N-of-Cases MaxDif Lilliefors Probability (2-tail)
FKLNGTH 84.000 0.089 0.094
Ici les deux tests nous incitent à accepter l’hypothèse nulle que les deux distributions sont normales. Notez cependant que la probabilité associée au test de KS est plus grande que celle associée au test de Lilliefors : ceci reflète le fait que lorsque l’hypothèse est intrinsèque (comme dans ce cas-ci), le test de KS est plus conservateur.
Commandes SYSTAT pour les tests de normalité de Kolmogorov-Smirnov et Lilliefors pour les longueurs à la fourche aux deux sites npar
Note 'The Pas'
select location$='The_Pas'
KS FKLNGTH / NORMAL=43.37,6.435
KS FKLNGTH / LILLIEFORS
Note 'Cumberland'
select location$='Cumberland'
KS FKLNGTH / NORMAL=45.038,3.981
KS FKLNGTH / LILLIEFORS

LABO- COMPARAISON DE DEUX ÉCHANTILLONS - 147
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
On conclue donc que FKLENGTH est approximativement normalement distribué et qu’on peut utiliser une analyse paramétrique. Les déviations de la normalité sont petites et, lorsque l’effectif est grand (comme c’est le cas ici), les analyses paramétriques sont assez robustes aux déviations de normalité.
Comparer les moyennes de deux échantillons indépendants : comparaisons paramétriques et non paramétriques
Pour éprouver l'hypothèse nulle d'égalité de la longueur à la fourche à The Pas et Cumberland House, allez à Statistics-T-test-Two Groups. Inscrivez FKLNGTH comme variable et LOCATION$ comme groupe. Que concluez-vous?
Éprouvez la même hypothèse nulle en allant à Statistics-Nonparamet-ric tests-Kruskall-Wallis. À partir des résultats des analyses paramétrique et non-paramétrique, que concluez-vous ? Pourquoi ?
Two-sample t test on FKLNGTH grouped by LOCATION$
Group N Mean SD
Cumberland 84 45.038 3.981
The_Pas 101 43.370 6.435
Separate Variance t = 2.156 df = 169.9 Prob = 0.033
Difference in Means = 1.668 95.00% CI = 0.141 to 3.195
Commandes SYSTAT pour le test de t et de Kruskall-WallisTEST FKLNGTH * LOCATION$
NPAR
KRUSKAL FKLNGTH * LOCATION$
CumberlandThe_Pas
LOCATION$
20
30
40
50
60
70
FKLN
GTH
0102030405060Count
0 10 20 30 40 50 60Count

148 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Pooled Variance t = 2.068 df = 183 Prob = 0.040
Difference in Means = 1.668 95.00% CI = 0.077 to 3.259
Categorical values encountered during processing are:
LOCATION$ (2 levels)
Cumberland, The_Pas
Kruskal-Wallis One-Way Analysis of Variance for 185 cases
Dependent variable is FKLNGTH
Grouping variable is LOCATION$
Group Count Rank Sum
Cumberland 84 8457.000
The_Pas 101 8748.000
Mann-Whitney U test statistic = 4887.000
Probability is 0.075
Chi-square approximation = 3.165 with 1 df
En se fiant au test de t, on rejette donc l’hypothèse nulle. Il y a une différence significative (mais pas hautement significative) entre les deux moyennes des longueurs à la fourche. Notez que SYSTAT donne deux statistiques: l’une pour le cas où les deux variances sont égales ("Pooled variance") et l’autre pour le cas où les variances sont inégales ("Separate variance").
Le graphique automatique (Quickgraph) contient les box plots et les distributions. Ce graphique suggère que les variances diffèrent entre les deux échantillons.
Notez que si l’on se fie au test de Kruskal-Wallis, il faut accepter l’hypothèse nulle. Les deux tests mènent donc à des conclusions contradictoires. La différence significative obtenue par le lets de t peut provenir en partie d’une violation des conditions d’application du test (normalité et homoscedasticité). D’un autre coté, l’absence de différence significative selon le test de Kruskal-Wallis pourrait être dûe au fait que, pour un effectif donné, la puissance du test non-paramétrique est inférieure à celle du test paramétrique correspondant. Compte-tenu 1) des valeurs de p obtenues pour les deux tests, et 2) le fait que pour des grands échantillons (des effectifs de 84 et 101 sont considérés grands) le test de t est considéré robuste, il est raisonable de rejeter l’hypothèse nulle.
Comparer les moyennes de deux échantillons appareillésDans certaines expériences les mêmes individus sont mesurés deux fois, par exemple avant et après un traitement ou encore à deux moments au cours de leur développement. Les mesures obtenues lors de ces deux événements ne sont pas indépendantes, et des comparaisons de ces mesures appariées doivent être faites.

LABO- COMPARAISON DE DEUX ÉCHANTILLONS - 149
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Le fichier SKULLDAT.SYS contient des mesures de la partie inférieure du visage de jeunes filles d'Amérique du Nord prises à 5 ans, puis à 6 ans (données de Newman and Meredith, 1956)
Utilisez Statistics-T-test-Two Groups pour éprouver l'hypothèse que la figure à 5 ans et à 6 ans a la même largeur en assumant que les mesures viennent d'échantillons indépendants. Pour ce faire utiliser WIDTH comme variable dépendante et AGE comme variable de groupe (grouping variable). Que concluez-vous ?
Utilisez Statistics-T-test-Paired pour éprouver l'hypothèse que la largeur du visage ne change pas entre age 5 et age 6. Pour ce faire, uti-lisez deux variables dépendantes (WIDTH5 et WIDTH6) et pas de variable pour le groupe. C'est comme cela que SYSTAT distingue les com-paraisons d'échantillons appariés de ceux qui se font sur des échantil-lons indépendants. Quelle est votre conclusion ? Comparez aux résultats précédents et expliquez les différences
Two-sample t test on WIDTH grouped by AGE
Group N Mean SD
5 15 7.461 0.300
6 15 7.661 0.315
Separate Variance t = -1.781 df = 27.9 Prob = 0.086
Difference in Means = -0.200 95.00% CI = -0.430 to 0.030
Commandes SYSTAT pour les tests de t ordinaire et appariéUSE 'C:\DATA\AMORIN\BIO4518\1998\LABO\DATA\SKULLDAT.SYS'
TTEST
TEST WIDTH * AGE
TEST WIDTH5 WIDTH6
56
AGE
6.5
7.0
7.5
8.0
8.5
WID
TH
024681012Count
0 2 4 6 8 10 12Count
1

150 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Pooled Variance t = -1.781 df = 28 Prob = 0.086
Difference in Means = -0.200 95.00% CI = -0.430 to 0.030
Paired samples t test on WIDTH5 vs WIDTH6 with 15 cases
Mean WIDTH5 = 7.459
Mean WIDTH6 = 7.661
Mean Difference = -0.202 95.00% CI = -0.224 to -0.180
SD Difference = 0.040 t = -19.541
df = 14 Prob = 0.000
Les deux tableau de résultats qui précèdent donnent:
les résultats de l’analyse lorsque l’on considère que les mesures faites à 5 ans et 6 ans sont indépendantes, et
les résultats de l’analyse qui tient compte que chaque fillette a été mesurées deux fois et donc que les mesures sont appariées.
Notez que, dans le premier cas, on accepte l’hypothèse nulle, mais que le test apparié rejette l’hypothèse nulle. Donc, le test qui est approprié (le test apparié) indique un effet très significatif de l’âge, mais le test inapproprié sugg‘re que l’âge n’importe pas. C’est parce qu’il y a une très forte corrélation entre la largeur du visage à 5 et 6 ans:
avec r = 0.993. En présence d’une si forte corrélation, l’erreur-type de la différence appariée de largeur du visage entre 5 et 6 ans est beaucoup plus petit que l’erreur-type de la différence entre la largeur
WIDTH6 WIDTH5Index of Case
6.5
7.0
7.5
8.0
8.5
Valu
e2
1
2
6.5 7.0 7.5 8.0WIDTH5
7.0
7.5
8.0
8.5
WID
T H6

LABO- COMPARAISON DE DEUX ÉCHANTILLONS - 151
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
moyenne à 5 ans et la largeur moyenne à 6 ans. Par conséquent, la statistique t associée est beaucoup plus élevée pour le test apparié, la puissance du test est plus grande, et la valeur de p plus petite.
Répétez l'analyse en utilisant Statistics-Nonparametric tests-Wilcoxon. Que concluez-vous ?
Wilcoxon Signed Ranks Test Results
Counts of differences (row variable greater than column)
WIDTH5 WIDTH6
WIDTH5 0 0
WIDTH6 15 0
Z = (Sum of signed ranks)/square root(sum of squared ranks)
WIDTH5 WIDTH6
WIDTH5 0.0
WIDTH6 3.416 0.0
Two-sided probabilities using normal approximation
WIDTH5 WIDTH6
WIDTH5 1.000
WIDTH6 0.001 1.000
Donc on tire la même conclusion qu’avec le test de t apparié.
Comparer la médiane et la variance de deux échantillonsBUMPDAT.SYS est un ensemble de données célèbres récoltées par Hermon Bumpus, biologiste à Brown University à la fin du XIXe siècle. Juste après une forte tempête le 1er février 1898, Bumpus ramassa 49 moineaux moribonds sur le campus. La moitié environ d'entre eux moururent, et Bumpus vit la possibilité d'étudier la sélection naturelle avec ces oiseaux. Il prit 8 mesures de chaque oiseaux et en mesura également la masse. BUMDAT.SYS contient 5 mesures morphologiques : TOTLNGTH la longueur totale, ALAR la longueur des ailes, HEAD la longueur de la tête et du bec, HUMERUS la longueur de l'humérus et STERNUM la longueur du sternum. Toutes les mesures sont en mm. Le fichier contient aussi la variable SURVIVAL$ qui indique si l'oiseau a survécu ou non (Bumpus 1898).
À l'aide des données de Bumpus, éprouvez l'hypothèse que la longueur totale médiane (TOTLNGTH) des oiseaux qui ont survécu est la même
Commandes SYSTAT pour le test de Wilcoxon NPAR
WILCOXON WIDTH5 WIDTH6

152 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
que celle de ceux qui sont morts. Pour ce faire calculez d'abord la médiane pour tout l'échantillon des 49 oiseaux. Puis allez à Data-Transform-Let… pour créer une nouvelle variable TEMP = TOTLNGTH - (la valeur de la médiane). Puis utilisez Transform encore pour créer une autre variable CLASS$ qui sera ‘above’ si temp > 0 et ‘below’ si temp < 0. Finalement, utilisez la routine Statistics-Crosstabs-Two-way et faites un test d'indépendance (utilisez l'option Statistics-Likeli-hood ratio chi-square pour faire un test G). Que concluez-vous ?
Frequencies
CLASS$ (rows) by SURVIVAL$ (columns)
no yes Total
+-------------+
above | 16 6 | 22
below | 12 12 | 24
+-------------+
Total 28 18 46
Test statistic Value df Prob
Pearson Chi-square 2.489 1.000 0.115
Likelihood ratio Chi-square 2.525 1.000 0.112
Donc on accepte l’hypothèse nulle que les médianes ne diffèrent pas entre le groupe des survivants et des non survivants.
Éprouvez l'hypothèse que la variance de la longueur de l'humérus des survivants est plus petite que celle de ceux qui n'ont pas survécu en faisant le test de Levene d'égalité des variances. Pour ce faire, calculez d'abord la moyenne de l'ensemble des valeurs, puis utilisez Data-Transform-Let pour créer une nouvelle variable HUMERDIV = ABS (HUMERUS - la moyenne des longueurs de l'humerus) qui représente la valeur absolue de la déviation à la moyenne. Comparez ensuite la moy-enne de cette nouvelle variable entre les deux échantillons. Que con-cluez-vous ?
Commandes SYSTAT pour comparer les médianesUSE 'C:\DATA\AMORIN\BIO4518\1998\LABO\DATA\BUMPDAT.SYS'
STATS
STATS TOTLNGTH / Median
LET TEMP = TOTLNGTH-158
IF (TEMP>0) THEN LET CLASS$='above'
IF (TEMP<0) THEN LET CLASS$='below'
XTAB
PRINT NONE/ FREQ CHISQ LRCHI
TABULATE CLASS$ * SURVIVAL$

LABO- COMPARAISON DE DEUX ÉCHANTILLONS - 153
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Two-sample t test on HUMERDIV grouped by SURVIVAL$
Group N Mean SD
no 28 0.515 0.400
yes 21 0.314 0.269
Separate Variance t = 2.094 df = 46.5 Prob = 0.042
Difference in Means = 0.200 95.00% CI = 0.008 to 0.393
Pooled Variance t = 1.982 df = 47 Prob = 0.053
Difference in Means = 0.200 95.00% CI = -0.003 to 0.404
Notez que les probabilités données sont pour un test bilatéral, alors que l’hypothèse biologique suggère un test unilatéral. avec des survivants moins variables que les non-survivants. La probabilité associée au test unilatéral est simplement p/2 puisque le l’hypothèse bilatérale a deux régions de rejets, une dans chaque queue de la distribution.
Comparer la distribution de deux échantillonsDans certains cas on veut comparer non seulement les moyennes et les variances, mais également la forme de la distribution toute entière. Par exemple, certains traitements peuvent ne pas affecter la moyenne ou la variance mais changer certains autres moments comme la kurtose ou la symétrie.
Éprouvez l'hypothèse que la longueur de la tête est la même pour les survivants et les non-survivants. Utilisez Statistics-Nonparametric Test- Two sample KS et utilisez TOTLNGTH comme variable dépendante et SURVIVAL$ comme variable de groupe. Que concluez-vous ?
Commandes SYSTAT pour le test de LeveneBY SURVIVAL$
STATS
STATS HUMERUS / Mean
by
IF (SURVIVAL$='yes') THEN LET humerdiv=abs(humerus-18.5)
IF (SURVIVAL$='no') THEN LET humerdiv=abs(humerus-18.446)
TEST HUMERDIV * SURVIVAL$

154 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Categorical values encountered during processing are:
SURVIVAL$ (2 levels)
no, yes
Kolmogorov-Smirnov Two Sample Test results
Maximum differences for pairs of groups
no yes
no 0.000
yes 0.286 0.000
Two-sided probabilities
no yes
no .
yes 0.232 .
On accepte donc l’hypothèse nulle que les deux distributions sont similaires. Cette analyse révèle donc qu’on a pas de raison de rejeter l’hypothèse nulle que les distributions sont les mêmes alors que l’analyse précédente a démontré que les variances diffèrent. Cette apparente contradiction eput être expliquées par le fait que le test de Kolmogorov-Smirnov compare tous les moments des deux distributions, alors que le test de Levene ne compare que le deuxième moment (la variance). Le test de Levene est donc plus puissant.
RéférencesBumpus, H.C. (1898) The elimination of the unfit as illustrated by
the introduced sparrow, Passer domesticus. Biological Lectures, Woods Hole Biology Laboratory, Woods Hole, 11 th Lecture: 209 - 226.
Newman, K.J. and H.V. Meredith. (1956) Individual growth in skele-tal bigonial diameter during the childhood period from 5 to 11 years of age. Amer. J. Anat. 99: 157 - 187.
Commandes SYSTAT pour le test de comparaison de deux échantillons de Kolmogorov-SmirnovNPAR
KS TOTLNGTH * SURVIVAL$

LABO- ANOVA À UN CRITÈRE DE CLASSIFICATION - 155
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Labo- ANOVA à un critère de classificationAprès avoir complété cet exercice de laboratoire, vous devriez être capable de :
• Utiliser SYSTAT pour effectuer une analyse de variance paramé-trique à un critère de classification, suivie de comparaisons multi-ples
• Utiliser SYSTAT pour vérifier si les conditions d'application de l'ANOVA paramétrique sont rencontrées
• Utiliser SYSTAT pour faire une ANOVA à un critère de classifica-tion non-paramétrique
• Utiliser SYSTAT pour transformer des données de manière à mieux rencontrer les conditions d'application de l'ANOVA para-métrique.
ANOVA à un critère de classification et comparaisons multiplesL'ANOVA à un critère de classification est l'analogue du test de t pour des comparaisons de moyennes de plus de deux échantillons. Les conditions d'application du test sont essentiellement les mêmes, et lorsque appliqué à deux échantillons ce test est mathématiquement équivalent au test de t.
En 1961-1962, le barrage Grand Rapids était construit sur la rivière Saskatchewan en amont de Cumberland House. On croit que, durant la construction, plusieurs gros esturgeons restèrent prisonniers dans des sections peu profondes et moururent. Des inventaires de la population d'esturgeons furent faits en 1954, 1958, 1965 et 1966. Au cours de ces inventaires, la longueur à la fourche (FRKLNGTH) et la masse (RNDWGHT) furent mesurées (pas nécessairement sur chaque poisson cependant). Ces données sont dans le fichier DAM10DAT.SYS.
À partir des données du fichier DAM10DAT.SYS, faites une ANOVA sur frklngth en allant à Statistics-Analysis of Variance-Estimate, et en inscrivant FKLNGTH comme variable dépendante (Dependent variable) et l'année (YEAR) comme variable indépendante (Factor). Que con-cluez-vous ?

156 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
YEAR (4 levels)
1954, 1958, 1965, 1966
Dep Var: FKLNGTH N: 118 Multiple R: 0.368 Squared multiple R: 0.136
-1
Estimates of effects B = (X'X) X'Y
FKLNGTH
CONSTANT 45.866
YEAR 1954 2.158
YEAR 1958 2.345
YEAR 1965 -3.349
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
YEAR 485.264 3 161.755 5.957 0.001
Error 3095.295 114 27.152
--------------------------------------------------------------------------
Least squares means. LS Mean SE N
YEAR =1954 48.024 0.857 37
YEAR =1958 48.212 1.022 26
YEAR =1965 42.517 1.504 12
YEAR =1966 44.712 0.795 43
--------------------------------------------------------------------------
--------------------------------------------------------------------------
*** WARNING ***
Case 59 is an outlier (Studentized Residual = 5.992)
Durbin-Watson D Statistic 1.787
First Order Autocorrelation 0.103
Programme SYSTAT pour l’ANOVA à un critère de classificationUSE 'C:\DATA\AMORIN\BIO4518\1998\LABO\DATA\DAM10DAT.SYS'
PRINT LONG
ANOVA
CATEGORY YEAR
COVAR
DEPEND FKLNGTH
ESTIMATE
1
2
3
4

LABO- ANOVA À UN CRITÈRE DE CLASSIFICATION - 157
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Le nombre d'observations de la variable indépendante et le coefficient de détermination du modèle d'ANOVA ajusté (Square multiple R)
Tableau des coefficients estimés pour les termes inclus dans le modèle d'ANOVA.
Le tableau d'ANOVA indiquant les sources de variation et la probabilité que toutes les moyennes sont égales.
Les moyennes de chaque groupe. Ces dernières sont d'ailleurs présentées sous forme graphique automatiquement si l'option Edit-Options-Output-Statistical quickgraphs est en vigueur.
On rejette donc l’hypothèse nulle : il y a une évidence très forte de différence de longueurs à la fourche entre les années. Il faut cependant noter que, même si la statistique de Durbin-Watson (une mesure d’autocorrélation) est rassurante (une valeur de 2 indique qu’il n’y a pas d’autocorrélation), il y a une valeur extrême qui pourrait influencer grandement ces résultats.
Répétez la même procédure, mais cette fois en faisant des comparai-sons de moyennes par trois méthodes différentes : Tukey, Scheffé et Bonferroni en cliquant sur Post-hoc tests et en sélectionnant les options correspondantes. Que concluez-vous de ces analyses ?
1
2
3
4
Least Squares Means
1954 1958 1965 1966YEAR$
35.0
38.8
42.6
46.4
50.2
54.0
FKLN
GT H

158 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
COL/
ROW YEAR
1 1954
2 1958
3 1965
4 1966
Using least squares means.
Post Hoc test of FKLNGTH
--------------------------------------------------------------------------
Using model MSE of 27.152 with 114 df.
Matrix of pairwise mean differences:
1 2 3 4
1 0.0
2 0.187 0.0
3 -5.508 -5.695 0.0
4 -3.313 -3.500 2.195 0.0
Scheffe Test.
Matrix of pairwise comparison probabilities:
1 2 3 4
1 1.000
2 0.999 1.000
3 0.021 0.024 1.000
4 0.050 0.068 0.646 1.000
--------------------------------------------------------------------------
ROW YEAR
1 1954
2 1958
3 1965
4 1966
Using least squares means.
Post Hoc test of FKLNGTH
--------------------------------------------------------------------------
Using model MSE of 27.152 with 114 df.
Matrix of pairwise mean differences:
1 2 3 4
1 0.0
2 0.187 0.0
3 -5.508 -5.695 0.0
4 -3.313 -3.500 2.195 0.0
Commandes SYSTAT pour l’ANOVA à un critère de classification avec tests post-hocsANOVA
CATEGORY YEAR
COVAR
DEPEND FKLNGTH / SCHEFFE
ESTIMATE
DEPEND FKLNGTH / BONF
ESTIMATE
DEPEND FKLNGTH / TUKEY
ESTIMATE
1
2
3

LABO- ANOVA À UN CRITÈRE DE CLASSIFICATION - 159
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Bonferroni Adjustment.
Matrix of pairwise comparison probabilities:
1 2 3 4
1 1.000
2 1.000 1.000
3 0.011 0.013 1.000
4 0.033 0.047 1.000 1.000
--------------------------------------------------------------------------
COL/
ROW YEAR
1 1954
2 1958
3 1965
4 1966
Using least squares means.
Post Hoc test of FKLNGTH
--------------------------------------------------------------------------
Using model MSE of 27.152 with 114 df.
Matrix of pairwise mean differences:
1 2 3 4
1 0.0
2 0.187 0.0
3 -5.508 -5.695 0.0
4 -3.313 -3.500 2.195 0.0
Tukey HSD Multiple Comparisons.
Matrix of pairwise comparison probabilities:
1 2 3 4
1 1.000
2 0.999 1.000
3 0.010 0.012 1.000
4 0.027 0.039 0.571 1.000
--------------------------------------------------------------------------
SYSTAT imprime d'abord la légende qui permet de relier les années (niveaux du facteur) aux codes employés dans les deux tableaux qui suivent
Ce tableau représente la matrice des différences entre les moyennes pour chaque niveau du facteur étudié. Par exemple, la différence entre la longueur moyenne à la fourche (FKLNGTH) en 1965 et en 1954 est à l'intersection de la ligne avec le code 3 (pour l'année 1965) et la colonne avec le code 1 (pour 1954) et est égale à -5.508.
Le tableau des probabilités associées à l'hypothèse nulle qu'il n'y ait pas de différence entre les deux moyennes, obtenues dans ce cas-ci par le test de Scheffé.
Les trois tests post-hoc mènent à la même conclusion. FKLNGTH varie d’une année à l’autre. Les différences significatives sont entre 2 groupes: 1954/58 et 1965/66 puisque toutes les comparaisons indiquent des différences significatives entre 1-3, 1-4, 2-3 et 2-4 et pas de différences significatives entre les autres paires d’années.
1
2
3

160 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Répétez ces deux analyses en utilisant RDWGHT au lieu de FRKLNGTH. Que concluez-vous ? Vos analyses supportent-elles l'hypothèse que la con-struction du barrage a causé une réduction du nombre de vieux et gros esturgeons ?
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
YEAR (4 levels)
1954, 1958, 1965, 1966
34 case(s) deleted due to missing data.
Dep Var: RDWGHT N: 84 Multiple R: 0.374 Squared multiple R: 0.140
-1
Estimates of effects B = (X'X) X'Y
RDWGHT
CONSTANT 26.164
YEAR 1954 6.736
YEAR 1958 1.016
YEAR 1965 -6.351
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
YEAR 1733.183 3 577.728 4.330 0.007
Error 10673.373 80 133.417
--------------------------------------------------------------------------
Least squares means.
LS Mean SE N
YEAR =1954 32.900 1.899 37
YEAR =1958 27.180 3.653 10
YEAR =1965 19.812 4.084 8
YEAR =1966 24.762 2.145 29
--------------------------------------------------------------------------
--------------------------------------------------------------------------
*** WARNING ***
Case 23 is an outlier (Studentized Residual = 4.887)
Case 59 is an outlier (Studentized Residual = 3.603)
Durbin-Watson D Statistic 1.503
First Order Autocorrelation 0.245
Notez que l’autocorrélation est pire que pour FKLNGTH et qu’il y a maintenant deux valeurs extrêmes.
Si on refait les comparaisons a posteriori avec RDWGHT au lieu de FKLNGTH, on observe que, peu importe la méthode utilisée, on rejette l’hypothèse nulle d’absence de différence seulement entre 1-3 et 1-4. Par exemple, en utilisant la méthode de Bonferroni, on obtient:

LABO- ANOVA À UN CRITÈRE DE CLASSIFICATION - 161
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
COL/
ROW YEAR
1 1954
2 1958
3 1965
4 1966
Using least squares means.
Post Hoc test of RDWGHT
--------------------------------------------------------------------------
Using model MSE of 133.417 with 80 df.
Matrix of pairwise mean differences:
1 2 3 4
1 0.0
2 -5.720 0.0
3 -13.087 -7.368 0.0
4 -8.138 -2.418 4.950 0.0
Bonferroni Adjustment.
Matrix of pairwise comparison probabilities:
1 2 3 4
1 1.000
2 1.000 1.000
3 0.028 1.000 1.000
4 0.034 1.000 1.000 1.000
--------------------------------------------------------------------------
Donc, pour cette variable, il n’y a pas d’évidence que les esturgeons capturés en 1958 étaient différents de ceux capturés en 1965 ou 1966. La différence d’avec l’analyse précédente peut s’expliquer en partie par le faible effectif et la forte variance (pour RDWGHT) en 1958 et 1965; la puissance du test est donc plus faible que dans l’analyse avec FKLNGTH.
Dans l’ensemble, ces analyses supportent l’hypothèse que la construction du barrage E. B. Campbell a entraîné une perte de gros esturgeons âgés.
Vérifier si les conditions d'application de l'ANOVA paramétrique sont rencontréesL'ANOVA paramétrique a trois conditions principales d'application : 1) les résidus sont normalement distribués, 2) la variance des résidus est égale dans tous les traitements (homoscedasticité) et 3) les résidus sont indépendants les uns des autres. Dans l'analyse précédente, nous avons présumé que toutes ces conditions étaient remplies. Il faut cependant faire une analyse post-mortem pour vérifier si c'est bien le cas.
SYSTAT peut produire toute l'information requise pour cette analyse des résidus. En utilisant le fichier DAM10DAT.SYS, refaites l'ANOVA sur FRKLNGTH, mais cette fois en sélectionnant l'option Save file et Residuals/Data.

162 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
SYSTAT vous demandera si vous voulez sauvegarder le tout dans un fichier appelé ANOVA.SYD par défaut. Ce nom convient très bien. Le résultat de cette option sera la création d'un fichier contenant les données originales, plus les résidus (RESIDUALS), les valeurs prédites (PREDICTED) et d'autres valeurs diagnostiques.
Éprouver la normalité des résidus
Ouvrez le fichier ANOVA.SYD et faite un graphique de probabilité de RESIDUAL (Graph-Probability Plots). Éprouvez la normalité des rési-dus à l'aide du test de Lilliefors. Allez à Statistics-Nonparametric tests-One-sample KS et sélectionnez Lilliefors à Options.
Commandes SYSTAT pour effectuer l’ANOVA et sauvegarder les résidus et autres valeurs diagnostiquesANOVA
SAVE 'C:\DATA\AMORIN\BIO4518\1998\LABO\DATA\ANOVA.SYD' / RESIDU-
ALS,
DATA
CATEGORY YEAR
COVAR
DEPEND FKLNGTH
ESTIMATE
Commandes SYSTAT pour éprouver la normalité des résidusUSE 'C:\DATA\AMORIN\BIO4518\1998\LABO\DATA\ANOVA.SYD'
PPLOT RESIDUAL/ NORMAL
NPAR
KS RESIDUAL / LILLIEFORS
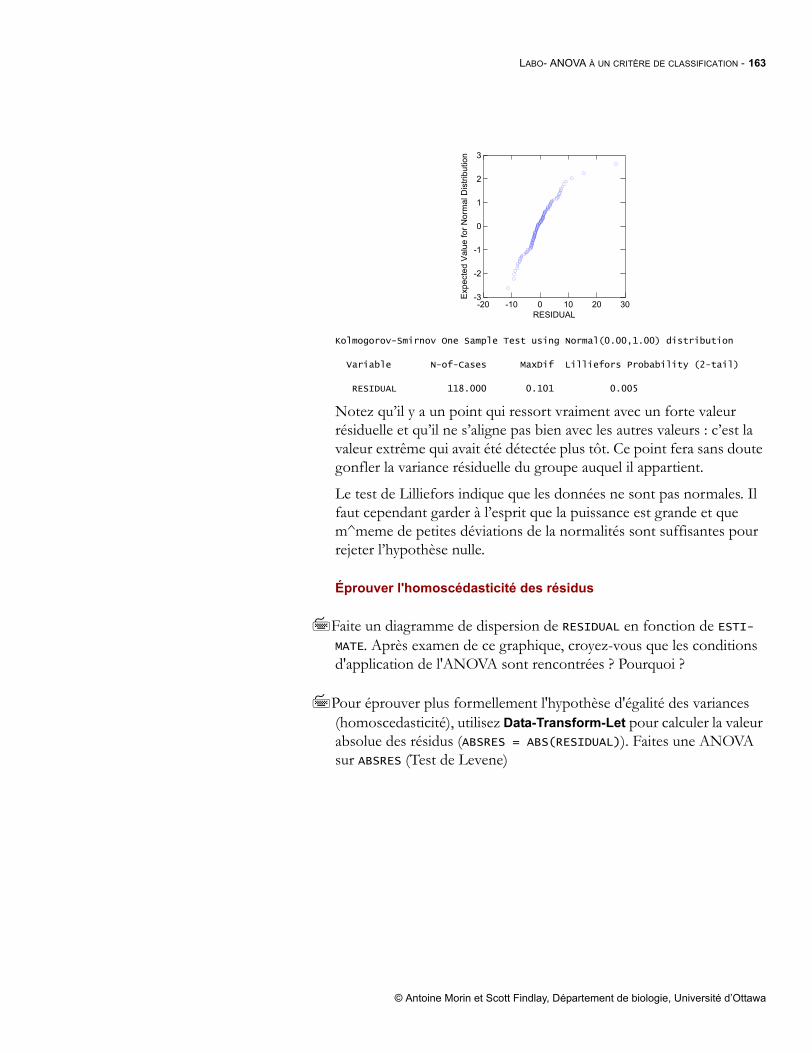
LABO- ANOVA À UN CRITÈRE DE CLASSIFICATION - 163
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Kolmogorov-Smirnov One Sample Test using Normal(0.00,1.00) distribution
Variable N-of-Cases MaxDif Lilliefors Probability (2-tail)
RESIDUAL 118.000 0.101 0.005
Notez qu’il y a un point qui ressort vraiment avec un forte valeur résiduelle et qu’il ne s’aligne pas bien avec les autres valeurs : c’est la valeur extrême qui avait été détectée plus tôt. Ce point fera sans doute gonfler la variance résiduelle du groupe auquel il appartient.
Le test de Lilliefors indique que les données ne sont pas normales. Il faut cependant garder à l’esprit que la puissance est grande et que m^meme de petites déviations de la normalités sont suffisantes pour rejeter l’hypothèse nulle.
Éprouver l'homoscédasticité des résidus
Faite un diagramme de dispersion de RESIDUAL en fonction de ESTI-MATE. Après examen de ce graphique, croyez-vous que les conditions d'application de l'ANOVA sont rencontrées ? Pourquoi ?
Pour éprouver plus formellement l'hypothèse d'égalité des variances (homoscedasticité), utilisez Data-Transform-Let pour calculer la valeur absolue des résidus (ABSRES = ABS(RESIDUAL)). Faites une ANOVA sur ABSRES (Test de Levene)
-20 -10 0 10 20 30RESIDUAL
-3
-2
-1
0
1
2
3
Expe
cte d
Val
ue fo
r Nor
mal
Dis
tr ibu
tion

164 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
YEAR (4 levels)
1, 2, 3, 4
Commandes SYSTAT pour éprouver l’homoscédasticité des résidusPLOT RESIDUAL*ESTIMATE
LET ABSRES=ABS(RESIDUAL)
ANOVA
CATEGORY YEAR
COVAR
DEPEND ABSRES
ESTIMATE
42 43 44 45 46 47 48 49ESTIMATE
-20
-10
0
10
20
30
RES
IDU
AL
Least Squares Means
1 2 3 4YEAR$
0
2
4
6
ABSR
ES

LABO- ANOVA À UN CRITÈRE DE CLASSIFICATION - 165
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Dep Var: ABSRES N: 118 Multiple R: 0.267 Squared multiple R: 0.071
-1
Estimates of effects B = (X'X) X'Y
ABSRES
CONSTANT 3.687
YEAR 1 1.047
YEAR 2 0.463
YEAR 3 -0.321
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
YEAR 108.083 3 36.028 2.905 0.038
Error 1413.692 114 12.401
--------------------------------------------------------------------------
Least squares means.
LS Mean SE N
YEAR =1 4.734 0.579 37
YEAR =2 4.151 0.691 26
YEAR =3 3.367 1.017 12
YEAR =4 2.498 0.537 43
--------------------------------------------------------------------------
Donc on rejette l’hypothèse nulle parce qu’il est évident que la variability varie entre les groupes. En fait, si on se fie au graphique, on voit que la variabilité des résidus diminue dans le temps (au fur et à mesure que les poissons rapetissent).
Examen des valeurs extrêmes
Vous devriez avoir remarqué au cours des analyses précédentes que SYSTAT a identifié plusieurs valeurs extrêmes (outliers). Refaites les analyses sans ces valeurs. Les conclusions changent-elles ?
Si on refait l’ANOVA sans la valeur extrême, SYSTAT identifie alors une seconde valeur extrême (cas 23). Si on enlève ces deux valeurs, on obtient:Dep Var: FKLNGTH N: 116 Multiple R: 0.373 Squared multiple R: 0.139
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
YEAR 339.889 3 113.296 6.034 0.001
Error 2102.820 112 18.775
--------------------------------------------------------------------------

166 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Least squares means.
LS Mean SE N
YEAR =1 47.594 0.722 36
YEAR =2 47.140 0.867 25
YEAR =3 42.517 1.251 12
YEAR =4 44.712 0.661 43
--------------------------------------------------------------------------
--------------------------------------------------------------------------
Durbin-Watson D Statistic 1.687
First Order Autocorrelation 0.152
Ce qui est essentiellement le résultat obtenu précédemment, sauf que les valeurs extrêmes ont disparu. Si on refait le test de Lilliefors sur les résidus, on obtient:
Kolmogorov-Smirnov One Sample Test using Normal (0.00,1.00) distribution
Variable N-of-Cases MaxDif Lilliefors Probability (2-
tail)
RESIDUAL 116.000 0.076 0.094
C’est donc un peu mieux et on peut accepter l’hypothèse nulle de normalité des données. Cependant, si on refait le test de Levene, on obtient:
Dep Var: ABSRES N: 116 Multiple R: 0.297 Squared multiple R: 0.088
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
YEAR 73.968 3 24.656 3.623
0.015
Error 762.154 112 6.805
--------------------------------------------------------------------------
Least squares means.
LS Mean SE N
YEAR =1 4.436 0.435 36
YEAR =2 3.245 0.522 25
YEAR =3 3.367 0.753 12
YEAR =4 2.498 0.398 43
--------------------------------------------------------------------------
--------------------------------------------------------------------------
*** WARNING ***
Case 85 is an outlier (Studentized Residual = 3.586)
Case 114 is an outlier (Studentized Residual = 3.551)
Ce qui n’est pas terrible.
L’élimination des valeurs extrêmes améliore un peu les choses, mais ce n’est pas parfait. Un transformation des données, le log peut-être, serait peut-être nécessaire.

LABO- ANOVA À UN CRITÈRE DE CLASSIFICATION - 167
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Transformations de données et ANOVA non-paramétriqueSi les données ne rencontrent pas les conditions de l'ANOVA paramétrique, il y a 3 options : 1) Ne rien faire. Si les effectifs dans chaque groupe sont grands, on peut relaxer les conditions d'application car l'ANOVA est alors assez robuste aux violations de normalité (mais moins aux violations d'homoscedasticité), 2) on peut transformer les données, ou 3) on peut faire une analyse non-paramétrique.
Refaites l'ANOVA de la section précédente après avoir transformé FKLNGTH en faisant le logarithme. Avec les données transformées, est-ce que les problèmes qui avaient été identifiés disparaissent ?
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
YEAR (4 levels)
1954, 1958, 1965, 1966
Dep Var: LFKL N: 118 Multiple R: 0.377 Squared multiple R: 0.142
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
YEAR 0.040 3 0.013 6.281
0.001
Error 0.243 114 0.002
Least squares means.
LS Mean SE N
YEAR =1954 1.678 0.008 37
YEAR =1958 1.679 0.009 26
YEAR =1965 1.626 0.013 12
YEAR =1966 1.649 0.007 43
--------------------------------------------------------------------------
--------------------------------------------------------------------------
*** WARNING ***
Case 59 is an outlier (Studentized Residual = 4.702)
Durbin-Watson D Statistic 1.750
First Order Autocorrelation 0.121
Residuals have been saved.
--------------------------------------------------------------------------
Si on refait l’analyse sans le cas 59, on obtient:
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
YEAR (4 levels)
1954, 1958, 1965, 1966
Dep Var: LFKL N: 117 Multiple R: 0.381 Squared multiple R: 0.145

168 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
YEAR 0.034 3 0.011 6.378
0.000
Error 0.203 113 0.002
--------------------------------------------------------------------------
Least squares means.
LS Mean SE N
YEAR =1954 1.678 0.007 37
YEAR =1958 1.671 0.008 25
YEAR =1965 1.626 0.012 12
YEAR =1966 1.649 0.006 43
--------------------------------------------------------------------------
--------------------------------------------------------------------------
Durbin-Watson D Statistic 1.571
First Order Autocorrelation 0.210
Tout semble bien aller. Si on regarde les résidus:
Les choses semblent un peu mieux aussi. Cependant, si on fait le test de Lilliefors et celui de Levene sur les résidus, on obtient:Kolmogorov-Smirnov One Sample Test using Normal(0.00,1.00) distribution
Variable N-of-Cases MaxDif Lilliefors Probability (2-tail)
RESIDUAL 117.000 0.087 0.031
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
YEAR (4 levels)
1, 2, 3, 4
Dep Var: ABSRES N: 117 Multiple R: 0.296 Squared multiple R: 0.087
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
-0.2 -0.1 0.0 0.1 0.2RESIDUAL
-3
-2
-1
0
1
2
3
Expe
c ted
Val
ue f o
r Nor
mal
Dis
tribu
tion

LABO- ANOVA À UN CRITÈRE DE CLASSIFICATION - 169
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
YEAR 0.007 3 0.002 3.605
0.016
Error 0.075 113 0.001
--------------------------------------------------------------------------
Least squares means.
LS Mean SE N
YEAR =1 0.043 0.004 37
YEAR =2 0.030 0.005 25
YEAR =3 0.035 0.007 12
YEAR =4 0.024 0.004 43
--------------------------------------------------------------------------
--------------------------------------------------------------------------
*** WARNING ***
Case 115 is an outlier (Studentized Residual = 4.218)
Durbin-Watson D Statistic 1.836
First Order Autocorrelation 0.079
On semble donc encore avoir des problèmes avec l’homoscédasticité et la normalité des résidus.
L'analogue non-paramétrique de l'ANOVA à un critère de classifica-tion le plus employé est le test de Kruskall-Wallis. Faites ce test (Sta-tistics- Nonparametric tests-Kruskall-Wallis) sur FKLNGTH et comparez les résultats à ceux de l'analyse paramétrique. Que concluez-vous?
Categorical values encountered during processing are:
YEAR (4 levels)
1, 2, 3, 4
Kruskal-Wallis One-Way Analysis of Variance for 118 cases
Dependent variable is FKLNGTH
Grouping variable is YEAR
Group Count Rank Sum
1 37 2570.500
2 26 1877.000
3 12 437.500
4 43 2136.000
Kruskal-Wallis Test Statistic = 15.731
Probability is 0.001 assuming Chi-square distribution with 3 df
Commandes SYSTAT pour l’ANOVA non-paramétrique (test de Kruskal-Wallis)NPAR
KRUSKAL FKLNGTH * YEAR

170 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
La conclusion est donc la même qu’avec l’ANOVA paramétrique: on rejette l’hypothèse nulle que le rang moyen est le même pour chaque année. Donc, même si les conditions d’application de l’analyse paramétrique n’étaient pas parfaitement rencontrées, les conclusions sont les mêmes, ce qui illustre la robustesse de l’ANOVA paramétrique.

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 171
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Labo- ANOVA à critères multiples : plans factoriels et hiérarchiques
Après avoir complété cet exercice de laboratoire, vous devriez être capable de :
• Utiliser SYSTAT pour faire une ANOVA paramétrique d'un plan hiérarchique avec réplication
• Utiliser SYSTAT pour faire une ANOVA paramétrique d'un plan factoriel avec deux facteurs de classification et réplication
• Utiliser SYSTAT pour faire une ANOVA paramétrique d'un plan factoriel avec deux facteurs de classification sans réplication
• Utiliser SYSTAT pour faire une ANOVA avec mesures répétées
• Utiliser SYSTAT pour faire une ANOVA non paramétrique avec deux facteurs de classification
• Utiliser SYSTAT pour faire des comparaisons multiples
Il existe une très grande variété de plans (designs) d'ANOVA que SYSTAT peut analyser. Cet exercice n'est qu'une introduction aux plans les plus communs. Vous trouverez plus d'explications sur les autres plans au Chapitre 6 de SYSTAT 7 Statistics.
Plans hiérarchiquesUn design expérimental fréquent implique la division de chaque groupe du facteur majeur en sous-groupes aléatoires. Par exemple, une généticienne intéressée par l'effet du génotype sur la résistance à la dessiccation chez la drosophile effectue une expérience. Pour chaque génotype (facteur principal) elle prépare trois chambres de croissances (sous-groupes) avec une température et humidité contrôlées. Dans chaque chambre de croissance, elle place cinq larves, puis mesure le nombre d'heures pendant lesquelles chaque larve survit.
Le fichier NESTDAT.SYS contient les résultats d'une expérience sem-blable. Il contient trois variables : GENOTYPE$, CHAMBER et SURVIVAL. Effectuez une ANOVA hiérarchique en allant à Statistics-General Linear Model (GLM)-Estimate. Inscrivez SURVIVAL comme variable dépendante et GENOTYPE et CHAMBER(GENOTYPE$) comme variables indépendantes. (Pour créer le dernier terme, ajoutez d'abord GENO-TYPE$ puis sélectionnez CHAMBER et cliquez sur Nest).

172 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Attention ! Si vous cliquez sur OK maintenant, SYSTAT va essayer de faire une analyse et produire un message d'erreur. En effet, le facteur chamber est représenté par un chiffre allant de 1 à 9. Pour que SYS-TAT considère ce facteur comme une variable discontinue représen-tant des catégories, il faut aller à Categories et ajouter CHAMBER comme Categorical variable. (Les variables contenant du texte sont toujours considérées être des catégories par SYSTAT).
Que concluez-vous de cette analyse ? Que devrait être la prochaine étape ? (Indice : si l'effet de GENOTYPE$(CHAMBER) n'est pas significatif, vous pouvez augmenter la puissance des comparaisons entre géno-types en regroupant les chambres de chaque génotype.). Faites-le ! N'oubliez pas de vérifier les conditions d'applications de l'ANOVA !
Programme SYSTAT pour l’ANOVA hiérarchique à deux critères de classificationUSE 'C:\DATA\AMORIN\BIO4518\1998\LABO\DATA\NESTDAT.SYS'
MGLH
CATEGORY CHAMBER / EFFECT
MODEL SURVIVAL = CONSTANT + GENOTYPE$+CHAMBER(GENOTYPE$)
ESTIMATE

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 173
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
CHAMBER (9 levels)
1, 2, 3, 4, 5, 6, 7,
8, 9
GENOTYPE$ (3 levels)
AA, Aa, aa
Dep Var: SURVIVAL N: 45 Multiple R: 0.971 Squared multiple R: 0.943
-1
Estimates of effects B = (X'X) X'Y
SURVIVAL
CONSTANT 47.364
GENOTYPE$ AA 9.902
GENOTYPE$ Aa 0.036
CHAMBER 1
GENOTYPE$ AA -0.067
CHAMBER 2
GENOTYPE$ AA 1.633
CHAMBER 4
GENOTYPE$ Aa -0.300
CHAMBER 5
GENOTYPE$ Aa -0.700
CHAMBER 7
GENOTYPE$ aa 0.973
CHAMBER 8
GENOTYPE$ aa -0.447
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
GENOTYPE$ 2952.220 2 1476.110 292.608 0.000
CHAMBER(GENOTYPE$) 40.655 6 6.776 1.343 0.264
Error 181.608 36 5.045
--------------------------------------------------------------------------
Least squares means.
LS Mean SE N
GENOTYPE$ =AA 57.267 0.580 15
GENOTYPE$ =Aa 47.400 0.580 15
GENOTYPE$ =aa 37.427 0.580 15
--------------------------------------------------------------------------
CHAMBER =1
GENOTYPE$ =AA 57.200 1.004 5
CHAMBER =2
GENOTYPE$ =AA 58.900 1.004 5
CHAMBER =3
GENOTYPE$ =AA 55.700 1.004 5
CHAMBER =4
GENOTYPE$ =Aa 47.100 1.004 5
CHAMBER =5

174 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
GENOTYPE$ =Aa 46.700 1.004 5
CHAMBER =6
GENOTYPE$ =Aa 48.400 1.004 5
CHAMBER =7
GENOTYPE$ =aa 38.400 1.004 5
CHAMBER =8
GENOTYPE$ =aa 36.980 1.004 5
CHAMBER =9
GENOTYPE$ =aa 36.900 1.004 5
--------------------------------------------------------------------------
--------------------------------------------------------------------------
Durbin-Watson D Statistic 1.686
First Order Autocorrelation 0.145
On conclue de cette analyse que la variation entre les chambres de croissance n’est pas significative, mais qu’on doit rejeter l’hypothèse nulle que tous les génotypes ont la même résistance à la dessiccation.
Comme l’effet hiérarchique CHAMBER(GENOTYPE$) n’est pas significatif, on peut regrouper les observations pour augmenter le nombre de degrés de liberté:MGLH
CATEGORY GENOTYPE$ / EFFECT
MODEL SURVIVAL = CONSTANT + GENOTYPE$
ESTIMATE
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
GENOTYPE$ (3 levels)
AA, Aa, aa
Dep Var: SURVIVAL N: 45 Multiple R: 0.964 Squared multiple R: 0.930
-1
Estimates of effects B = (X'X) X'Y
SURVIVAL
CONSTANT 47.364
GENOTYPE$ AA 9.902
GENOTYPE$ Aa 0.036
Least Squares Means
AA Aa aaGENOTYPE$
31
39
47
55
63
SUR
VIV A
L

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 175
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
GENOTYPE$ 2952.220 2 1476.110 278.934 0.000
Error 222.263 42 5.292
--------------------------------------------------------------------------
Least squares means.
LS Mean SE N
GENOTYPE$ =AA 57.267 0.594 15
GENOTYPE$ =Aa 47.400 0.594 15
GENOTYPE$ =aa 37.427 0.594 15
--------------------------------------------------------------------------
--------------------------------------------------------------------------
Durbin-Watson D Statistic 1.420
First Order Autocorrelation 0.284
Donc on conclue qu’il y a une variation significative de résistance à la dessiccation entre les trois génotypes.
Le graphique suggère que la résistance à la dessiccation varie entre chaque génotype.
Lorsque vous aurez complété ce qui précède, faites des comparaisons multiples pour déterminer quels génotypes diffèrent significativement les uns des autres. Que concluez-vous ?
COL/
ROW GENOTYPE$
1 AA
2 Aa
3 aa
Using least squares means.
Post Hoc test of SURVIVAL
--------------------------------------------------------------------------
Using model MSE of 5.292 with 42 df.
Matrix of pairwise mean differences:
1 2 3
1 0.0
2 -9.867 0.0
3 -19.840 -9.973 0.0
Bonferroni Adjustment.
Matrix of pairwise comparison probabilities:
1 2 3
Commandes SYSTAT pour le test a posteriori de BonferroniHYPOTHESIS
POST GENOTYPE$/ BONF

176 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
1 1.000
2 0.000 1.000
3 0.000 0.000 1.000
--------------------------------------------------------------------------
On conclue donc que la résistance à la dessiccation (R), telle que mesurée par la survie dans des conditions chaudes et sèches, varie significativement entre les trois génotypes avec R(AA) > R(Aa) > R(aa).
Cependant, avant d’accepter cette conclusion, il faut éprouver les conditions d’application du test. Voici les diagnostics des résidus pour l’ANOVA à un critère de classification (non hiérarchique):
Kolmogorov-Smirnov One Sample Test using Normal(0.00,1.00) distribution
Variable N-of-Cases MaxDif Lilliefors Probability (2-tail)
RESIDUAL 45.000 0.083 0.595
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
GENOTYPE$ (3 levels)
AA, Aa, aa
Dep Var: ABSRES N: 45 Multiple R: 0.070 Squared multiple R: 0.005
-1
Estimates of effects B = (X'X) X'Y
ABSRES
CONSTANT 1.794
GENOTYPE$ AA 0.126
GENOTYPE$ Aa -0.087
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
GENOTYPE$ 0.376 2 0.188 0.102 0.903
Error 77.093 42 1.836
-5 -4 -3 -2 -1 0 1 2 3 4 5RESIDUAL
-3
-2
-1
0
1
2
3
Expe
cted
Val
ue fo
r Nor
mal
Dis
tr ibu
tion

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 177
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
--------------------------------------------------------------------------
Least squares means.
LS Mean SE N
GENOTYPE$ =AA 1.920 0.350 15
GENOTYPE$ =Aa 1.707 0.350 15
GENOTYPE$ =aa 1.755 0.350 15
--------------------------------------------------------------------------
--------------------------------------------------------------------------
Donc, toutes les conditions d’application semblent être rencontrées, et on peut donc accepter les conclusions. Notez que si l’on compare le coefficient de détermination (R2) de l’ANOVA hiérarchique et de l’ANOVA à un critère de classification, ils sont presque identiques. Cela n’est pas surprenant compte tenu de la faible variabilité associée aux chambres de croissance pour chaque génotype.
Plan factoriel à deux facteurs de classification et réplicationIl est fréquent de vouloir analyser l'effet de plusieurs facteurs simultanément. L'ANOVA factorielle à deux critères de classification permet d'examiner deux facteurs à la fois, mais la même approche peut être utilisée pour 3, 4 ou même 5 facteurs quoique l'interprétation des résultats devienne beaucoup plus complexe.
Supposons que vous êtes intéressés par l'effet de deux facteurs : site (LOCATION$, Cumberland House ou The Pas) et sexe (SEX$, mâle ou femelle) sur la taille des esturgeons. Comme le premier facteur est un effet aléatoire (random effect) et que le second est fixe, il s'agit donc d'un modèle mixte (Modèle III) d'ANOVA. (Jetez un coup d'œil aux notes de cours pour vous rafraîchir la mémoire si nécessaire). De plus, comme l'effectif n'est pas le même pour tous les groupes, c'est un plan qui n'est pas balancé.
À l'aide du fichier STU2WDAT.SYS, faites une ANOVA factorielle à deux critères de classification en allant à Statistics-Generalized Linear Model (GLM)-Estimate Model et en inscrivant RNDWGHT comme vari-able dépendante, et SEX$ , LOCATION$ et SEX$*LOCATION$ comme vari-ables indépendantes. Que concluez-vous ?

178 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
SEX$ (2 levels)
female, male
LOCATION$ (2 levels)
Cumberland, The_Pas
4 case(s) deleted due to missing data.
Dep Var: RDWGHT N: 182 Multiple R: 0.312 Squared multiple R: 0.097
-1
Estimates of effects B = (X'X) X'Y
RDWGHT
CONSTANT 24.535
SEX$ female 3.141
LOCATION$ Cumberland 0.223
SEX$ female
LOCATION$ Cumberland -0.525
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
SEX$ 1745.358 1 1745.358 17.722 0.000
LOCATION$ 8.778 1 8.778 0.089 0.766
SEX$*LOCATION$ 48.692 1 48.692 0.494 0.483
Error 17530.360 178 98.485
Commandes SYSTAT pour l’ANOVA factorielle à deux critères de classificationUSE 'C:\DATA\AMORIN\BIO4518\1998\LABO\DATA\STU2WDAT.SYS'
MGLH
MODEL RDWGHT = CONSTANT + SEX$+LOCATION$+SEX$*LOCATION$
ESTIMATE

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 179
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
--------------------------------------------------------------------------
Least squares means.
LS Mean SE N
SEX$ =female 27.675 0.983 102
SEX$ =male 21.394 1.122 80
--------------------------------------------------------------------------
LOCATION$ =Cumberland 24.757 1.108 83
LOCATION$ =The_Pas 24.312 1.000 99
--------------------------------------------------------------------------
SEX$ =female
LOCATION$ =Cumberland 27.373 1.418 49
SEX$ =female
LOCATION$ =The_Pas 27.977 1.363 53
SEX$ =male
LOCATION$ =Cumberland 22.141 1.702 34
SEX$ =male
LOCATION$ =The_Pas 20.647 1.463 46
--------------------------------------------------------------------------
--------------------------------------------------------------------------
*** WARNING ***
Case 101 is an outlier (Studentized Residual = 7.708)
Durbin-Watson D Statistic 1.933
First Order Autocorrelation 0.032
Les graphiques montrent clairement qu’aux deux sites les femelles sont plus grandes que les mâles, mais que les tailles ne varient pas beaucoup d’un site à l’autre. Suite à l’ANOVA, on accepte deux hypothèses nulles: (1) que l’effet du sexe ne varie pas entre les sites (pas d’interaction significative) et (2) qu’il n’y a pas de différence de tailels des esturgeons (peu importe le sexe) entre les deux sites. D’un autre coté, on rejette l’hypothèse nulle qu’il n’y a pas de différence de taille entre les esturgeons mâles et les femelles, tel que suggéré par les graphiques.
Least Squares Means
Cumberland
female maleSEX$
15.0
18.4
21.8
25.2
28.6
32.0
RD
WG
HT
The_Pas
female maleSEX$
15.0
18.4
21.8
25.2
28.6
32.0
RD
WG
HT

180 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Cependant, on ne peut se fier à ces résultats sans vérifier si les conditions d’application de l’ANOVA étaient rencontrées. La statistique de Durbin-Watson est près de 2, et l’autocorrélation de premier ordre est très faible; il semble donc que la condition implicite d’indépendance des résidus soit rencontrée. D’un autre coté, il y a au moins une valeur extrême. De plus, si on éprouve la normalité, on obtient:Kolmogorov-Smirnov One Sample Test using Normal(0.00,1.00) distribution
Variable N-of-Cases MaxDif Lilliefors Probability (2-tail)
RESIDUAL 182.000 0.084 0.003
Et le test de Levene donne:Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
SEX$ (2 levels)
female, male
LOCATION$ (2 levels)
Cumberland, The_Pas
4 case(s) deleted due to missing data.
Dep Var: ABSRES N: 182 Multiple R: 0.242 Squared multiple R: 0.059
-1
Estimates of effects B = (X'X) X'Y
ABSRES
CONSTANT 6.613
SEX$ female 1.138
LOCATION$ Cumberland -1.313
SEX$ female
LOCATION$ Cumberland 0.608
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
SEX$ 229.246 1 229.246 4.879 0.028
LOCATION$ 305.167 1 305.167 6.495 0.012
SEX$*LOCATION$ 65.356 1 65.356 1.391 0.240
Error 8363.054 178 46.983
--------------------------------------------------------------------------
Si les résidus étaient homoscédastiques, on accepterait l’hypothèse nulle que le ABSRES moyen ne varie pas entre les sexes, les sites, ni entre aucune des combinaisons sexe-site. Le tableau d’ANOVA ci-dessus montre que deux de ces hypothèses sont rejetées. Il y a donc évidence d’hétéroscédasticité. En bref, nous avons donc plusieurs

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 181
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
conditions d’application qui ne sont pas respectées. La question qui reste est: ces violations sont-elles suffisantes pour invalider nos conclusions ?
Répétez la même analyse avec les données du fichier STU2MDAT.SYS. Que concluez-vous ? Supposons que vous vouliez comparer la taille des mâles et des femelles. Comment cette comparaison diffère entre les deux ensembles de données ?
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
SEX$ (2 levels)
female, male
LOCATION$ (2 levels)
Cumberland, The_Pas
4 case(s) deleted due to missing data.
Dep Var: RDWGHT N: 182 Multiple R: 0.312 Squared multiple R: 0.097
-1
Estimates of effects B = (X'X) X'Y
RDWGHT
CONSTANT 24.535
SEX$ female -0.525
LOCATION$ Cumberland 0.223
SEX$ female
LOCATION$ Cumberland 3.141
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
SEX$ 48.692 1 48.692 0.494 0.483
LOCATION$ 8.778 1 8.778 0.089 0.766
SEX$*LOCATION$ 1745.358 1 1745.358 17.722 0.000
Error 17530.360 178 98.485
--------------------------------------------------------------------------
Least squares means.
LS Mean SE N
SEX$ =female 24.010 1.019 95
SEX$ =male 25.059 1.090 87
--------------------------------------------------------------------------
LOCATION$ =Cumberland 24.757 1.108 83
LOCATION$ =The_Pas 24.312 1.000 99
--------------------------------------------------------------------------
SEX$ =female
LOCATION$ =Cumberland 27.373 1.418 49
SEX$ =female
LOCATION$ =The_Pas 20.647 1.463 46
SEX$ =male
LOCATION$ =Cumberland 22.141 1.702 34

182 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
SEX$ =male
LOCATION$ =The_Pas 27.977 1.363 53
--------------------------------------------------------------------------
--------------------------------------------------------------------------
*** WARNING ***
Case 101 is an outlier (Studentized Residual = 7.708)
Durbin-Watson D Statistic 1.933
First Order Autocorrelation 0.032
Notez que cette fois les femelles sont plus grandes que les mâles à Cumberland House, mais que c’est le contraire à The Pas. C’est ce qui cause l’intéraction significative (SEX$*LOCATION$) dans l’ANOVA.
Il y a une différence importante entre les résultats obtenus avec STU2WDAT.SYS et STU2MDAT.SYS. Dans le premier cas, puisqu’il n’y a pas d’intéraction, on peut regrouper les données des deux niveaux d’un facteur (le sexe, par exemple) pour éprouver l’hypothèse d’un effet de l’autre facteur (le site). En fait, si on fait cela et calculons une ANOVA à un critère de classification (SEX$), on obtient:Dep Var: RDWGHT N: 182 Multiple R: 0.308 Squared multiple R: 0.095
-1
Estimates of effects B = (X'X) X'Y
RDWGHT
CONSTANT 24.484
SEX$ female 3.203
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
SEX$ 1839.553 1 1839.553 18.831 0.000
Error 17583.314 180 97.685
Least Squares Means
Cumberland
female maleSEX$
15.0
18.4
21.8
25.2
28.6
32.0
RD
WG
HT
The_Pas
female maleSEX$
15.0
18.4
21.8
25.2
28.6
32.0
RD
WG
HT

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 183
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
--------------------------------------------------------------------------
Notez que le R2 ici (0.095) est presque égal au R2 du modèle complet (0.097) de l’ANOVA factorielle à deux facteurs. C’est parce que dans cette anova factorielle, le terme d’intéraction et le terme représentant l’effet du site n’expliquent qu’une partie infime de la variabilité.
D’un autre coté, si on essaie le même truc avec STU2MDAT, on obtient:Dep Var: RDWGHT N: 182 Multiple R: 0.076 Squared multiple R: 0.006
-1
Estimates of effects B = (X'X) X'Y
RDWGHT
CONSTANT 24.906
SEX$ female -0.790
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
SEX$ 113.399 1 113.399 1.057 0.305
Error 19309.467 180 107.275
--------------------------------------------------------------------------
Ici le R2 (0.006) est beaucoup plus petit que celui de l’ANOVA factorielle (0.097) parce qu’une partie importante de la variabilité expliquée par le modèle est associée à l’interaction. Notez que si on n’avait fait que cette analyse, on concluerait que les esturgeons mâles et femelles ont la même taille. Mais en fait leur taille diffère; seulement la différence est à l’avantage des mâles à un site et à l’avantage des femelles à l’autre. Il est donc délicat d’interpréter l’effet principal (sexe) en présence d’une intéraction significative...
Notez que par défaut, SYSTAT présume que c'est une ANOVA de Modèle I et que les effets des facteurs principaux et de l'interaction sont éprouvés en les comparant au carré moyen associé avec le terme d'erreur (Error Mean-Square). Toutefois, pur une ANOVA de modèle III, les effets des termes principaux doivent être comparés au carré moyen associé à l'interaction (ou la somme du terme d'interaction et d'erreur selon certains statisticiens).
La procédure GLM de SYSTAT permet d'éprouver des hypothèses particulières et permet donc de faire des analyses d'ANOVA de modèle II ou III. Refaites l'analyse sur STU2WDAT.SYS. Puis allez à Sta-tistics-General Linear Model-Hypothesis Test et inscrivez SEX$ dans la boîte Effects. Sélectionnez Between Subject(s) Effect(s) dans la

184 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
boîte Error Term et inscrivez SEX$*LOCATION$ comme terme d'erreur. Cliquez sur OK. En procédant de cette façon, on indique à SYSTAT d'utiliser le carré moyen de l'interaction plutôt que celui de l'erreur pour éprouver l'effet des termes principaux.
Refaites ensuite les mêmes opérations avec LOCATION$ dans la boîte Effect(s).
Test for effect called: SEX$
Null hypothesis contrast AB
3.141
-1
Inverse contrast A(X'X) A'
0.006
Commandes SYSTAT pour les épreuves d’hypothèses utilisant l’interaction comme terme d’erreur.USE 'C:\DATA\AMORIN\BIO4518\1998\LABO\DATA\STU2WDAT.SYS'
MGLH
MODEL RDWGHT = CONSTANT + SEX$+LOCATION$+SEX$*LOCATION$
ESTIMATE
HYPOTHESIS
EFFECT=sex$
ERROR=sex$*location$
STANDARDIZE=WITHIN
TEST
HYPOTHESIS
EFFECT=location$
ERROR=sex$*location$
STANDARDIZE=WITHIN
TEST

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 185
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Test of Hypothesis
Source SS df MS F P
Hypothesis 1745.358 1 1745.358 35.845 0.105
Error 48.692 1 48.692
--------------------------------------------------------------------------
Notez que la somme des carrés de l’hypothèse (Hypothesis SS) est identique à la somme des carrés associée à SEX$ dans l’ANOVA originale alors que la somme des carrés de l’erreur est maintenant égale à celle associée à l’interaction SEX$*LOCATION$ dans l’ANOVA originale. Cependant, notez que maintenant la valeur de p n’est plus significative. C’est parce que le carré moyen de l’erreur est beaucoup plus petit que celui associé à l’interaction.
Plan factoriel à deux facteurs de classification sans réplication Dans certains plans d'expérience il n'y a pas de réplicats pour chaque combinaison de facteurs, par exemple parce qu'il serait trop coûteux de faire plus d'une observation. L'ANOVA à deux critères de classification est quand même possible dans ces circonstances, mais il y a une limitation importante.
Comme il n'y a pas de réplicats, on ne peut estimer la variance du terme d'erreur. En effet on ne peut qu'estimer la somme des carrés associés à chacun des facteurs principaux, et la quantité de variabilité qui reste (Remainder Mean Square) représente la somme de la variabilité attribuable à l'interaction et au terme d'erreur. Cela a une implication importante : s'il y a une interaction, seul un modèle II d'ANOVA peut être entièrement testé et dans un modèle III d'ANOVA, seul l'effet fixe peut être testé (il est éprouvé en les comparant au carré moyen associé avec le remainder MS). Dans le cas d'un modèle I ou pour l'effet aléatoire d'un modèle III on ne peut tester les effets principaux que si on est sur qu'il n'y a pas d'interaction.
Un limnologiste qui étudie Round Lake dans le Parc Algonquin prend une seule mesure de température (TEMP) à 10 profondeurs différentes (DEPTH, en m) à quatre dates (DATE$) au cours de l'été. Ses données sont au fichier 2WNRDAT.SYS.
À l'aide de la routine General Linear Model, effectuez une ANOVA à deux critères de classification en utilisant TEMP comme variable dépen-dante et DATE$ et DEPTH comme variables indépendantes. Si on sup-pose que c'est un modèle III d'ANOVA (DATE$ aléatoire, DEPTH fixe), que concluez-vous ? (Indice : faites 4 graphiques de la température en

186 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
fonction de la profondeur, un pour chaque date, pour voir ce qui se passe).
Le tableau d’ANOVA donne:Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
DATE$ 591.147 3 197.049 16.364 0.000
DEPTH 1082.820 9 120.313 9.992 0.000
Error 325.121 27 12.042
--------------------------------------------------------------------------
Least squares means
LS Mean SE N
DATE$ =aug1 15.610 1.097 10
DATE$ =july1 15.200 1.097 10
DATE$ =june1 10.580 1.097 10
DATE$ =may1 6.180 1.097 10
--------------------------------------------------------------------------
DEPTH =0 18.450 1.735 4
DEPTH =1 17.750 1.735 4
SYSTAT commands for two-way ANOVA without replicationGLM
CATEGORY DATE$ DEPTH / EFFECT
MODEL TEMP = CONSTANT + DATE$+DEPTH
ESTIMATE
Least Squares Means
aug1 july1 june1 may1DATE
2
6
10
14
18
TEM
P

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 187
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
DEPTH =2 17.150 1.735 4
DEPTH =3 16.400 1.735 4
DEPTH =4 14.250 1.735 4
DEPTH =5 10.200 1.735 4
DEPTH =6 8.350 1.735 4
DEPTH =9 5.850 1.735 4
DEPTH =12 5.400 1.735 4
DEPTH =15 5.125 1.735 4
--------------------------------------------------------------------------
--------------------------------------------------------------------------
Durbin-Watson D Statistic 0.466
First Order Autocorrelation 0.710
La température diminue significativement en profondeur. Pour tester l’effet du mois (le facteur aléatoire), on doit présumer qu’il n’y a pas d’interaction entre la profondeur et le mois (donc que l’effet de la profondeur sur la température est le même à chaque mois). C’est peu probable: si vous faites un graphique de la température en fonction de la profondeur pour chaque mois, vous observerez que le profil de température change au fur et à mesure du développement de la thermocline. Bref, comme le profil change au cours de l’été, ce modèle ne fait pas de très bonnes prédictions.
Least Squares Means
0 1 2 3 4 5 6 9 12 15DEPTH
1
8
15
22
TEM
P

188 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Notez la faible valeur de la statistique Durbin-Watson et la relativement forte autocorrelation de premier-ordre. Pour la normalité:
Le test de Lilliefors sur les résidus donne Maxdif = .120, p = .147, donc l’hypothèse de normalité ne semble pas être en doute. Pour l’égalité des variances, on peut seulement comparer entre les mois en utilisant les profondeurs comme réplicats (ou l’inverse). En utilisant les profondeurs commes réplicats, on obtient:Dep Var: ABSRES N: 40 Multiple R: 0.823 Squared multiple R: 0.677
-1
Estimates of effects B = (X'X) X'Y
ABSRES
CONSTANT 2.413
DATE$ aug1 0.510
Commandes pour produire les profils de température par moisPLOT DEPTH*TEMP / OVERLAY GROUP=DATE$ LINE YREV
0 10 20 30TEMP
01234569
1215
DEP
TH
may1june1july1aug1
DATE
-10 -5 0 5 10RESIDUAL
-3
-2
-1
0
1
2
3
Expe
cted
Val
ue fo
r Nor
mal
Dis
tr ibu
tion

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 189
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
DATE$ july1 -0.462
DATE$ june1 -1.723
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
DATE$ 62.457 3 20.819 25.143 0.000
Error 29.809 36 0.828
Il y a donc un problème d’hétéroscédasticité, en plus de celui d’indépendance des résidus. Cette analyse n’est donc pas très satisfaisante: il y a des violations des conditions d’application et il semble y avoir une interaction entre DEPTH et DATE$ qui pourrait invalider l’analyseé
ANOVA avec mesures répétéesIl est fréquent de réaliser une expérience au cours de laquelle des mesures répétées des individus ou parcelles sont effectuées. Par exemple, pour comparer la croissance, on mesure généralement la taille des individus formant un échantillon à plusieurs moments. En médecine clinique, ces études sont qualifiées de longitudinales.
Il est tentant de considérer ce plan expérimental comme un plan à un critère de classification. Ce serait incorrect puisque ce plan ne rencontre pas l'une des conditions d'application de l'ANOVA à un critère de classification. En effet les observations répétées sur un même individu sont en général corrélées, et donc non indépendantes. Le problème est contourné en considérant ce plan comme un cas spécial de l'ANOVA modèle III à deux critères de classification, où l'effet fixe est le temps et l'effet aléatoire est l'individu qui sert de réplicat à l'intérieur des blocs temps.
Les plans d'ANOVA à mesures répétées peuvent avoir des designs très complexes, et les fichiers de sortie de SYSTAT incluent beaucoup de statistiques dont on ne parlera pas ici. L'exercice présenté ici est à peu près le plus simple possible, mais sert néanmoins à illustrer plusieurs concepts importants.
Le fichier REPDAT.SYS contient des mesures de la largeur du visage d'un échantillon de 15 jeunes filles à l'âge de 5, 6 et 7 and (WIDTH5, WIDTH6 et WIDTH7 respectivement). Éprouvez l'hypothèse que la largeur du visage ne varie pas avec l'âge en sélectionnant Statistics-Analysis of Variance- Estimate Model et en inscrivant WIDTH5, WIDTH6 et WIDTH7 comme variables dépendantes. Cliquez sur le bouton Repeated….

190 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Sélectionnez Perform repeated measures analysis dans la fenêtre de dialogue qui s'ouvrira. Inscrivez Age dans la boîte de la colonne intit-ulée Name à la ligne First, et 3 à Levels (correspond aux trois classes d'âge). N'inscrivez rien dans la boîte Metric. Cliquez sur OK, et encore sur OK pour produire le fichier de sortie suivant (En mode medium à Edit-Option-Output results-Length) :
Number of cases processed: 15
Dependent variable means
WIDTH5 WIDTH6 WIDTH7
7.461 7.661 7.880
--------------------------------------------------------------------------
Univariate and Multivariate Repeated Measures Analysis
Within Subjects
---------------
Source SS df MS F P G-G H-F
Age 1.315 2 0.658 437.292 0.000 0.000 0.000
Error 0.042 28 0.002
Greenhouse-Geisser Epsilon: 0.6502
Huynh-Feldt Epsilon : 0.6892
--------------------------------------------------------------------------
Single Degree of Freedom Polynomial Contrasts
---------------------------------------------
Polynomial Test of Order 1 (Linear)
Source SS df MS F P
Age 1.315 1 1.315 508.601 0.000
Error 0.036 14 0.003
Polynomial Test of Order 2 (Quadratic)
Source SS df MS F P
Age 0.001 1 0.001 2.057 0.173
Error 0.006 14 0.000
1
2
3

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 191
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
--------------------------------------------------------------------------
Multivariate Repeated Measures Analysis
Test of: Age Hypoth. df Error df F P
Wilks' Lambda= 0.026 2 13 241.606 0.000
Pillai Trace = 0.974 2 13 241.606 0.000
H-L Trace = 37.170 2 13 241.606 0.000
Le tableau d'ANOVA univariée : il indique clairement qu'il y a un effet significatif de l'âge. Cela n'est pas surprenant puisque les moyennes des groupes (Dependent variable means) augmentent avec l'âge.
Pour que les résultats des tests univariés de l'ANOVA à mesure répétées soient valides, il faut que, en plus des conditions d'application standard de l'ANOVA, les données rencontrent la condition dite "compound symmetry" qui veut dire que si l'on considère WIDTH5, WIDTH6 et WIDTH7 comme trois variables différentes, leur matrice de covariance devrait avoir une valeur constante sur la diagonale, et que toutes les autres valeurs devraient être égales entre elles. (Vous pouvez évaluer cela en allant à Statistics-Simple Correlation, sélectionnant les 3 variables et sélectionner l'option Covariance dans la fenêtre de texte Continuous data).
Si la condition de "compound symmetry" n'est pas remplie, vous devez alors utiliser les statistiques G-G (Greenhouse-Geiser) et H-F (Huynh-Feldt). Si les probabilités associées à ces statistiques sont très différentes de celle associée à la valeur de F vous avez alors un indice que la condition de "compound symmetry" n'est pas rencontrée.
La deuxième partie du fichier de sortie contraste les groupes. Le test de premier ordre (linéaire) permet de détecter un effet croissant ou décroissant. Le test de second ordre (quadratique) permet de détecter un effet quadratique passant par un maximum ou un minimum. Dans ce cas-ci, il y a une tendance linéaire significative et pas d’effet quadratique (p=0.173).
La dernière partie du fichier de sortie est l'ANOVA multivariée dans laquelle WIDTH5, WIDTH6 et WIDTH7 sont considérées comme des variables séparées. On ne traitera pas de cela dans ce cours-ci.
Que concluez-vous ?
Pour faire des comparaisons post-hoc entre les âges, allez à Statistics-Analysis of Variance-Hypothesis test et inscrivez Age dans la boîte Within.
4
1
2
3
4

192 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Cliquez sur Contrast et sélectionnez Difference.
Cliquez sur Continue pour produire le fichier de sortie suivant :
Hypothesis.
C Matrix
1 2 3
1 1.000 -1.000 0.0
2 0.0 1.000 -1.000
Univariate F Tests
Effect SS df MS F P
1 0.600 1 0.600 388.889 0.000
Error 0.022 14 0.002
2 0.717 1 0.717 310.168 0.000
Error 0.032 14 0.002
Multivariate Test Statistics
Wilks' Lambda = 0.026
F-Statistic = 241.606 df = 2, 13 Prob = 0.000
Pillai Trace = 0.974
F-Statistic = 241.606 df = 2, 13 Prob = 0.000
Hotelling-Lawley Trace = 37.170
F-Statistic = 241.606 df = 2, 13 Prob = 0.000
1
2
3

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 193
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Les -1.000 dans la matrice C produite par SYSTAT indiquent quelles sont les comparaisons qui sont faites. Dans ce cas entre âge 5 et 6, et entre âge 6 et 7.
Les comparaisons post-hoc indiquent qu'il y a une augmentation significative de la taille entre 5 et 6 ans (effect 1), et entre 6 et 7 ans (effetc2).
Suite à ces comparaisons, quelle est votre conclusion ?
ANOVA non paramétrique avec deux facteurs de classificationL'ANOVA non paramétrique à deux critères de classification est une extension de celle à un critère de classification vue précédemment. Elle débute par une ANOVA faite sur les données transformées en rangs. Elle peut se faire sur des données avec ou sans réplicats.
À partir du fichier STU2WDAT.SYS, effectuez une ANOVA non paramétrique à deux facteurs de classification pour examiner l'effet de SEX$ et LOCATION$ sur RNDWGHT. Pour ce faire, utilisez d'abord la sour-outine Rank accessible à Data. Ensuite, faites une ANOVA à deux critères de classification sur les rangs.
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
SEX$ (2 levels)
female, male
LOCATION$ (2 levels)
Cumberland, The_Pas
4 case(s) deleted due to missing data.
Dep Var: RDWGHT N: 182 Multiple R: 0.326 Squared multiple R: 0.106
-1
Estimates of effects B = (X'X) X'Y
RDWGHT
CONSTANT 89.832
SEX$ female 16.539
1
2
3
SYSTAT programUSE "F:\data\usr\amorin\BIO4518\1998\Labo\data\Stu2wdat.sys"
REM -- Following commands were produced by the RANK dialog:
RANK RDWGHTCATEGORY SEX$ LOCATION$
COVAR
DEPEND RDWGHT
ESTIMATE

194 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
LOCATION$ Cumberland 2.425
SEX$ female
LOCATION$ Cumberland -2.694
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
SEX$ 48402.191 1 48402.191 19.193 0.000
LOCATION$ 1040.161 1 1040.161 0.412 0.522
SEX$*LOCATION$ 1284.469 1 1284.469 0.509 0.476
Error 448884.022 178 2521.820
--------------------------------------------------------------------------
Least squares means
LS Mean SE N
SEX$ =female 106.372 4.976 102
SEX$ =male 73.293 5.679 80
--------------------------------------------------------------------------
LOCATION$ =Cumberland 92.257 5.604 83
LOCATION$ =The_Pas 87.408 5.060 99
--------------------------------------------------------------------------
Least Squares Means
female maleSEX
57
73
89
105
121
RD
WG
HT

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 195
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
SEX$ =female
LOCATION$ =Cumberland 106.102 7.174 49
SEX$ =female
LOCATION$ =The_Pas 106.642 6.898 53
SEX$ =male
LOCATION$ =Cumberland 78.412 8.612 34
SEX$ =male
LOCATION$ =The_Pas 68.174 7.404 46
--------------------------------------------------------------------------
--------------------------------------------------------------------------
Durbin-Watson D Statistic 1.712
First Order Autocorrelation 0.142
Least Squares Means
Cumberland The_PasLOCATION
72
79
86
93
100
107
RD
WG
HT
Least Squares Means
Cumberland
female maleSEX
51
75
99
123
RD
WG
HT
The_Pas
female maleSEX
51
75
99
123
RD
WG
HT

196 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
L'extension du test de Kruskall-Wallis de Schreirer-Ray-Hare se fait ensuite à la main. Il faut d'abord calculer la statistique H égale au rapport de la somme des carrées de l'effet testé, divisée par le carré moyen total. Le carré moyen total peut être obtenu en additionnant toutes les sommes des carrés du tableau d'ANOVA (incluant celle associée au terme d'erreur) et en divisant par l'effectif moins 1.
Testez l'effet de SEX$ et LOCATION$ sur RDWGHT. Que concluez-vous ? Comment ce résultat se compare-t-il à celui obtenu en faisant l'ANOVA paramétrique faite précédemment ?
On calcule la statistique H pouc chacun des termes:
Hsex$ = 48402.191/2760.28 = 17.5 (p < .0001)
Hlocation$ = 1040.16/2760.28 = 0.38 (p >> .05)
Hsex$*location$ = 1284.5/2760.28 = 0.47 (p >> .05)
Ces résultats sont semblables aux résultats de l’ANOVA non-paramétrique à deux critères de classification. Malgré la puissance réduite, il y a encore un effet significatif du sexe, mais ni interation ni effet du site.
Il y a toutefois une différence importante. Rappelez-vous que l’ANOVA paramétrique il y avait un effet significatif de SEX$ en considérant le problème comme un modèle I d’ANOVA. Cependant, si on traite le problème comme un modèle III, l’effet significatif de SEX$ pourrait disparaître parce que le nombre de dl associés au CM de l’intéraction est plus élevé que le nombre de dl du CM de l’erreur du modèle I. Dans ce cas ci, cependant, le CM de l’intéraction est environ la moitié deu CM de l’erreur. Par conséquent, l’effet significatif de SEX$ pourrait devenir encore plus significatif si le problème est analysé (comme il se doit) comme une ANOVA de modèle III. Encor eune fois on peut voir l’importance de spécifier le modèle adéquat en ANOVA.
Comparaisons multiplesLes épreuves d'hypothèses subséquentes en ANOVA à plus d'un critère de classification dépendent des résultats initiaux de l'ANOVA. Si vous êtes intéressés à comparer des effets moyens d'un facteur pour tous les niveaux d'un autre facteur (par exemple l'effet du sexe sur la taille des esturgeons peu importe d'où ils viennent), alors vous pouvez procéder exactement tel que décrit dans la section sur les comparaisons multiples suivant l'ANOVA à un critère de classification. Pour comparer les moyennes de s cellules entre elles, il faut spécifier l'interaction comme variable qui représente le groupe.

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 197
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Le fichier 2WMCDAT.SYS contient des mesures de consommation d'oxygène (O2CONS) de deux espèces (SPECIES$) d'un mollusque (une patelle) à trois concentrations différentes d'eau de mer (CONC) (ces données sont présentées à la p. 332 de Sokal et Rohlf 1995). Le fichier 2WMC2DAT.SYS est une version modifiée de ces mêmes données.
Effectuez une ANOVA factorielle à deux critères de classification sur ces données en utilisant 02CONS comme variable dépendante et SPE-CIES$ et CONC comme les facteurs. Que concluez-vous ?
Comme l’effectif dans chaque cellule est relativement petit, il faudrait idéalement refaire cette analyse avec une ANOVA non-paramétrique. Pour le moment, contentons nous de la version paramétrique.Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
SPECIES$ (2 levels)
A, B
CONC (3 levels)
50, 75, 100
Dep Var: O2CONS N: 48 Multiple R: 0.581 Squared multiple R: 0.338
-1
Estimates of effects B = (X'X) X'Y
O2CONS
CONSTANT 8.682
SPECIES$ A -0.349
CONC 50 0.755
CONC 75 -1.068
SPECIES$ A
CONC 50 -2.540
SYSTAT ProgramUSE "F:\data\usr\amorin\BIO4518\1998\Labo\data\2wmc2dat.sys"
SAVE 'F:\data\usr\amorin\BIO4518\1998\Labo\data\ANOVA.SYD' /
RESIDUALS,DATA
CATEGORY SPECIES$ CONC
COVAR
DEPEND O2CONS
ESTIMATE
USE "F:\data\usr\amorin\BIO4518\1998\Labo\data\ANOVA.SYD"
LET absres = abs(residual)
CATEGORY CONC SPECIES$
COVAR
DEPEND ABSRES
ESTIMATE

198 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
SPECIES$ A
CONC 75 0.625
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
SPECIES$ 5.838 1 5.838 0.616 0.437
CONC 28.959 2 14.479 1.528 0.229
SPECIES$*CONC 168.151 2 84.076 8.874 0.001
Error 397.914 42 9.474
--------------------------------------------------------------------------
Least squares means
LS Mean SE N
SPECIES$ =A 8.333 0.628 24
SPECIES$ =B 9.031 0.628 24
--------------------------------------------------------------------------
CONC =50 9.438 0.770 16
CONC =75 7.614 0.770 16
CONC =100 8.995 0.770 16
--------------------------------------------------------------------------
Least Squares Means
A BSPECIES
5
7
9
11
O2C
ON
S

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 199
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
SPECIES$ =A
CONC =50 6.549 1.088 8
SPECIES$ =A
CONC =75 7.890 1.088 8
SPECIES$ =A
CONC =100 10.561 1.088 8
SPECIES$ =B
CONC =50 12.326 1.088 8
SPECIES$ =B
CONC =75 7.338 1.088 8
SPECIES$ =B
CONC =100 7.429 1.088 8
--------------------------------------------------------------------------
Least Squares Means
50 75 100CONC
4
6
8
10
12
O2C
ON
S

200 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
--------------------------------------------------------------------------
Durbin-Watson D Statistic 2.211
First Order Autocorrelation -0.120
Le test d’homogénéité des variances donne::Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
CONC (3 levels)
50, 75, 100
SPECIES$ (2 levels)
A, B
Dep Var: ABSRES N: 48 Multiple R: 0.202 Squared multiple R: 0.041
-1
Estimates of effects B = (X'X) X'Y
ABSRES
CONSTANT 2.489
CONC 50 0.023
CONC 75 -0.251
SPECIES$ A -0.019
CONC 50
SPECIES$ A -0.167
CONC 75
Least Squares Means
50
A BSPECIES
3
7
11
15
O2C
ON
S
75
A BSPECIES
3
7
11
15
O2C
ON
S
100
A BSPECIES
3
7
11
15
O2C
ON
S

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 201
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
SPECIES$ A -0.139
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
CONC 1.839 2 0.920 0.401 0.672
SPECIES$ 0.017 1 0.017 0.008 0.931
CONC*SPECIES$ 2.266 2 1.133 0.494 0.614
Error 96.435 42 2.296
Les variances semblent donc égales. Le test de Lilliefors donne Maxdif= .179, p=.001. Il y a donc évidence de non-normalité, mais à part ça tout semble aller. Comme l’ANOVA est relativement robuste à la non-normalité, on va regarder de l’autre coté. (Si vous voulez être plus saints que le pape, vous pouvez tourner une ANOVA non paramétrique. Vous arriverez aux mêmes conclusions.)
À la suite des résultats que vous venez d'obtenir, quelles moyennes voudriez-vous comparer ? Pourquoi? Effectuez ces comparaisons en allant à Statistics-General Linear Model-Pairwise comparisons et en entrant la variable appropriée dans la boîte Group. Que concluez-vous ?
On conclue donc qu’il n’y a pas de différence entre les espèces et que l’effet de la concentration ne dépends pas de l’espèce (il n’y a pas d’intéraction). Par conséquent, les seules comparaisons justifiables sont entre les concentrations:
COL/
ROW CONC
1 50
2 75
3 100
Using least squares means.
Post Hoc test of O2CONS
--------------------------------------------------------------------------
Commandes SYSTATUSE "F:\data\usr\amorin\BIO4518\1998\Labo\data\2wmc2dat.sys"
CATEGORY SPECIES$ CONC
COVAR
DEPEND O2CONS
ESTIMATE
HYPOTHESIS
POST conc/ BONF
TEST

202 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Using model MSE of 9.474 with 42 df.
Matrix of pairwise mean differences:
1 2 3
1 0.000
2 -1.824 0.000
3 -0.442 1.381 0.000
Bonferroni Adjustment.
Matrix of pairwise comparison probabilities:
1 2 3
1 1.000
2 0.304 1.000
3 1.000 0.634 1.000
Il y a donc une différence de consommation d’oxygène significative lorsque la salinité est réduite de 50%, mais pas à 25% de réduction.
Pour éprouver l’hypothèse que la consommation d’oxygène ne vaire pas entre les espèces à chaque concentration, effectuez une ANOVA non-paramétrique pour chaque concentration:
The following results are for:
CONC = 100.000
Categorical values encountered during processing are:
SPECIES$ (2 levels)
A, B
Kruskal-Wallis One-Way Analysis of Variance for 16 cases
Dependent variable is O2CONS
Grouping variable is SPECIES$
Group Count Rank Sum
A 8 85.000
B 8 51.000
Mann-Whitney U test statistic = 49.000
Probability is 0.074
Chi-square approximation = 3.192 with 1 df
The following results are for:
CONC = 75.000
Categorical values encountered during processing are:
SPECIES$ (2 levels)
A, B
Kruskal-Wallis One-Way Analysis of Variance for 16 cases
Dependent variable is O2CONS
Grouping variable is SPECIES$
Group Count Rank Sum
SYSTAT commandsBY CONC
NPAR
KRUSKAL O2CONS * SPECIES$

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 203
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
A 8 74.000
B 8 62.000
Mann-Whitney U test statistic = 38.000
Probability is 0.528
Chi-square approximation = 0.399 with 1 df
The following results are for:
CONC = 50.000
Categorical values encountered during processing are:
SPECIES$ (2 levels)
A, B
Kruskal-Wallis One-Way Analysis of Variance for 16 cases
Dependent variable is O2CONS
Grouping variable is SPECIES$
Group Count Rank Sum
A 8 41.000
B 8 95.000
Mann-Whitney U test statistic = 5.000
Probability is 0.005
Chi-square approximation = 8.064 with 1 df
Notez que cette analyse suggère une différence presque significative à une CONC=100 entre les deux espèces alors que l’ANOVA à deux critères de classification indique qu’il n’y a pas d’effet de SPECIES$ ni de l’intéraction SPECIES$CONC. Rappelez-vous qu’il est possible d’observer des différences entre des paires de moyennes même lorsque l’ANOVA indique qu’il n’y a pas de différences entre toutes les moyennes. C’est ce qui se passe ici. Il n’est pas justifié de comparer ces moyennes entre les espèces puisque l’ABNOVA à deux critères de classification indique qu’on devrait accepter l’hypothèse nulle que les moyennes ne diffèrent pas entre SPECIES$.
Répétez les deux analyses précédentes sur les données du fichier 2WMC2DAT.SYS. Comment les résultats se comparent-ils à ceux obte-nus précédemment ?
En utilisant 2WMC2DAT.SYS, on obtient:Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
SPECIES$ (2 levels)
A, B
CONC (3 levels)
50, 75, 100
Dep Var: O2CONS N: 48 Multiple R: 0.581 Squared multiple R: 0.338
-1
Estimates of effects B = (X'X) X'Y
O2CONS
CONSTANT 8.682
SPECIES$ A -0.349
CONC 50 0.755

204 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
CONC 75 -1.068
SPECIES$ A
CONC 50 -2.540
SPECIES$ A
CONC 75 0.625
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
SPECIES$ 5.838 1 5.838 0.616 0.437
CONC 28.959 2 14.479 1.528 0.229
SPECIES$*CONC 168.151 2 84.076 8.874 0.001
Error 397.914 42 9.474
Dans ce cas ci, il y a une interaction significative, et il n’est par conséquent pas approprié de comparer les moyennes regroupées par espèce ou concentration. On compare donc chacune des 6 moyennes les unes avec les autres, avec l’ajustement de Bonferonni. COL/
ROW SPECIES$ CONC
1 A 50
2 A 75
3 A 100
4 B 50
5 B 75
6 B 100
Using least squares means.
Post Hoc test of O2CONS
--------------------------------------------------------------------------
Using model MSE of 9.474 with 42 df.
Matrix of pairwise mean differences:
1 2 3 4 5
1 0.000
2 1.341 0.000
3 4.013 2.671 0.000
4 5.777 4.436 1.765 0.000
5 0.789 -0.553 -3.224 -4.989 0.000
6 0.880 -0.461 -3.133 -4.897 0.091
6
6 0.000
Bonferroni Adjustment.
Matrix of pairwise comparison probabilities:
1 2 3 4 5
1 1.000
2 1.000 1.000
3 0.189 1.000 1.000
4 0.008 0.093 1.000 1.000
5 1.000 1.000 0.634 0.035 1.000
6 1.000 1.000 0.722 0.041 1.000
6
6 1.000

LABO- ANOVA À CRITÈRES MULTIPLES : PLANS FACTORIELS ET HIÉRARCHIQUES - 205
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Dans cette analyse on a utilisé le CM = 9.474 du modèle d’ANOVA pour comparer les moyennes. En ce faisant, on présume qu’il s’agit d’une situation d’ANOVA de modèle I, ce qui n’est peut-être pas le cas (CONC est certainement fixe, mais SPECIES$ peut être fixe ou aléatoire).
Cette analyse indique que la différence principale est entre le groupse 4 et tous les autres sauf le groupe 3. L’interprétation n’est pas évidente, mais il est clair qu’il y a quelque chose de différent pour le groupe 4 (qui correspond à SPECIES$ = B, CONC = 50).
Quelques conseils
• Pour spécifier un dénominateur autre que le carré moyen associé au terme d'erreur du modèle pour éprouver un effet particulier (par exemple pour les ANOVA de modèle III), utilisez GLM (Gen-eral Linear Model).
• Vérifiez toujours les conditions d'application : indépendance (Durbin-Watson statistics et/ou graphiques d'autocorrélation), normalité (graphique de probabilité, Lilliefors), homogénéité des variances (test de Levene). Gardez cependant à l'esprit que ces tests sont peu puissants lorsque les effectifs sont faibles. Si les effectifs de chaque cellule sont plus petits que 10, considérez les alternatives non paramétriques.
• Lorsque le nombre d'hypothèses à éprouver est grand, contrôlez pour le taux d'erreur de l'ensemble (experiment-wise error rate) en utilisant la correction de Bonferroni.
• Ne faites pas de tests post-hocs à moins qu'ils vous soient suggé-rés par l'ANOVA initiale.

206 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

LABO- CORRÉLATION LINÉAIRE ET RÉGRESSION LINÉAIRE SIMPLE - 207
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Labo- Corrélation linéaire et régression linéaire simple
Après avoir complété cet exercice de laboratoire, vous devriez être en mesure de :
• Utiliser SYSTAT pour produire un diagramme de dispersion pour illustrer la relation entre deux variables
• Utiliser SYSTAT pour faire des transformations simples
• Utiliser SYSTAT pour calculer le coefficient de corrélation de Pearson entre deux variables et en évaluer sa signification statisti-que.
• Utiliser SYSTAT pour calculer la corrélation de rang entre des pai-res de variables avec le r de Spearman et le tau de Kendall.
• Utiliser SYSTAT pour évaluer la signification de corrélations dans une matrice de corrélation en utilisant les probabilités ajustées par la méthode de Bonferroni.
• Utiliser SYSTAT pour faire une régression linéaire simple.
• Utiliser SYSTAT pour évaluer si un ensemble de données rencon-tre les conditions d'application d'une analyse de régression simple.
Diagrammes de dispersionLes analyses de corrélation et de régressions devraient toujours commencer par un examen des données. C'est une étape critique qui sert à évaluer si ce type d'analyse est approprié pour un ensemble de données.
Supposons que nous sommes intéressés à évaluer si la longueur d'esturgeons mâles dans la région de The Pas covarie avec leur poids. Pour répondre à cette question, regardons d'abord la corrélation entre FKLNGTH et RNDWGTH.
Souvenez-vous qu'une des conditions d'application de l'analyse de corrélation est que la relation entre les deux variables est linéaire. Pour évaluer cela, commençons par un diagramme de dispersion :
En utilisant le fichier STURGDAT.SYS, sélectionnez les données sur les mâles. Puis allez à Graph-Plots-Scatterplot pour faire un diagramme de dispersion de FKLNGTH en fonction de RNDWGHT. Ajustez une corube LOWESS à ces données en sélectionnant Options-Smoother-LOW-

208 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
ESS. Est-ce que la dispersion des points suggère une bonne corréla-tion entre les deux variables ? La relation apparaît-elle linéaire ?
Ce graphique suggère une tendance plus curvilinéaire que linéaire. Malgré tout il semble y avoir une forte corrélation entre les deux variables.
Transformez chaque variable en son logarithme base 10 en allant à Data-Transform-Let. Créez deux variables : LFKL et LRDWGHT. Ensuite, créez deux autres variables (SQRDWT et SQFKL) qui contiendront la racine carrée des variables originales (i.e. SQRDWT = SQR(RDWGHT)). Faites un diagramme de dispersion pour chacune des deux paires de variables et comparez-les au graphique des variables non trans-formées. D'après vous, quelle est la paire de variable la plus appropriée pour une analyse de corrélation ?
Pour les données transformées, on obtient des relations plus linéaire. Pour les données log, cela donne:
ce qui est nettement plus linéaire. La transformation par la racine carrée linéarise un peu, mais moins bien que la transformation log.
0 10 20 30 40 50 60 70 80 90 100RDWGHT
20
30
40
50
60
70
FKLN
GTH
1.3 1.4 1.5 1.6 1.7 1.8 1.9LFKL
0.5
1.0
1.5
2.0
LRD
WG
HT

LABO- CORRÉLATION LINÉAIRE ET RÉGRESSION LINÉAIRE SIMPLE - 209
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Comme l’analyse de corrélation présuppose une relation linéaire entre les variables, on devrait donc privilégier l’analyse sur les données log-transformées.
Transformations et le coefficient de corrélationUne autre condition préalable à l'analyse de corrélation est que les deux variables concernées suivent une distribution normale bidimensionnelle. Malheureusement, il n'est pas évident de vérifier l'ajustement à une distribution normale bidimensionnelle, et SYSTAT ne peut le faire. Cependant on peut aisément vérifier l'ajustement à une distribution normale de chacune des 2 variables séparément tel que décrit dans l'exercice de laboratoire sur les comparaisons de deux échantillons. Si les deux variables sont normalement distribuées, on présume généralement qu'elles suivent une distribution normale bidimensionnelle lorsque analysées simultanément (notez que ce n'est pas toujours le cas cependant).
Générez des diagrammes de probabilité pour les six variables (les deux variables originales et les variables transformées). Que concluez-vous de l'inspection visuelle de ces graphiques ?
Les figures ci-dessous sont les diagrammes de probablilité (obtenus en passant par Graph-Plots-Probability Plots puis en sélectionnant les six variables):
4 5 6 7 8 9SQFKL
2
3
4
5
6
7
8
9
10
SQR
DW
T

210 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Il n’y a pas grand chose à redire: aucune des distribution n’est parfaitement normale, mais les déviations semblent mineures.
Éprouvez la normalité de chaque variable en utilisant le test de Lillie-fors. Que concluez-vous ? Pourquoi ?
Le test de Lilliefors donne:Kolmogorov-Smirnov One Sample Test using Normal(0.00,1.00) distribution
Variable N-of-Cases MaxDif Lilliefors Probability (2-tail)
FKLNGTH 185.000 0.060 0.106
RDWGHT 182.000 0.089 0.001
LFKL 185.000 0.080 0.006
LRDWGHT 182.000 0.056 0.164
SQRDWT 182.000 0.051 0.281
SQFKL 185.000 0.066 0.046
Donc aucune des variables (sauf SQRDWT) n’est distribuée normalement. La belle affaire ! Puisque l’effectif est relativement grand, la puissance du test est assez élevée et permet de détecter comme significatives des légères déviations à la normalité.
20 30 40 50 60 70FKLNGTH
-3
-2
-1
0
1
2
3
Exp
ecte
d Va
lue
for N
orm
al D
istri
butio
n
0 10 20 30 40 50 60 70 80 90 100RDWGHT
-3
-2
-1
0
1
2
3
Exp
ecte
d Va
lue
for N
orm
al D
istri
butio
n
1.3 1.4 1.5 1.6 1.7 1.8 1.9LFKL
-3
-2
-1
0
1
2
3
Exp
ecte
d Va
lue
for N
orm
al D
istri
butio
n
0.5 1.0 1.5 2.0LRDWGHT
-3
-2
-1
0
1
2
3
Expe
cted
Val
ue fo
r Nor
mal
Dis
tribu
tion
2 3 4 5 6 7 8 9 10SQRDWT
-3
-2
-1
0
1
2
3
Expe
cted
Va l
ue fo
r Nor
mal
Dis
tribu
tion
4 5 6 7 8 9SQFKL
-3
-2
-1
0
1
2
3
Expe
cted
Val
ue fo
r Nor
mal
Dis
tribu
tion

LABO- CORRÉLATION LINÉAIRE ET RÉGRESSION LINÉAIRE SIMPLE - 211
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Présumons pour l'instant que chaque paire de variable suit une distri-bution normale bidimensionnelle. Calculez le coefficient de corréla-tion de Pearson et la probabilité qui lui est associée entre chaque paire (variables originales, logtransformées et transformées en leur racine carrée) en utilisant Stats-Correlation-Simple et en ajoutant les six vari-ables dans la Variables boîte de texte, en sélectionnant Continuous data et Pearson. Que concluez-vous ? Pourquoi la corrélation entre les variables originales est-elle la plus faible des trois ?
Le graphique SPLOM donne
Fréquemment, il y a des données manquantes dans un échantillon. SYSTAT peut procéder de deux façons pour en tenir compte. Soit qu'il élimine toutes les lignes du fichier pour lesquelles les variables ne sont pas toutes mesurées (Listwise), ou encore il n'élimine une observation que lorsqu'un des deux membres de la paire a une valeur manquante (Pairwise). Dans le premier cas, toutes les corrélations seront calculées avec le même nombre de cas, alors que dans le second, si les données manquantes pour différentes variables se retrouvent dans un groupe différent d'observation, les corrélations ne seront pas nécessairement calculées sur le même nombre de cas ni sur le même sous-ensemble de cas. En général, vous devriez utiliser l'option Listwise à moins que vous ayez un très grand nombre de données manquantes et que cette façon de procéder élimine la plus grande partie de vos observations.Means
FKLNGTH RDWGHT LFKL LRDWGHT SQRDWT
44.045 24.872 1.640 1.361 4.891
FKLN
GTH
RD
WG
HT
LFKL
LRD
WG
HT
SQR
DW
T
FKLNGTH
SQFK
L
RDWGHT LFKL LRDWGHT SQRDWT SQFKL

212 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
SQFKL
6.623
Pearson correlation matrix
FKLNGTH RDWGHT LFKL LRDWGHT SQRDWT
FKLNGTH 1.000
RDWGHT 0.918 1.000
LFKL 0.992 0.876 1.000
LRDWGHT 0.965 0.927 0.967 1.000
SQRDWT 0.958 0.981 0.937 0.981 1.000
SQFKL 0.998 0.898 0.998 0.968 0.949
SQFKL
SQFKL 1.000
Plusieurs choses à noter ici. Premièrement, la corrélation entre la longueur à la fourche et le poids rond est élevée, peu importe la transformation: les poissons pesants ont tendance à être longs. Deuxièmement, la corrélation est plus forte pour les données transformées que pour les données brutes. Pourquoi? Parce que le coefficient de corrélation est inversement proportionnel au bruit autour de la relation linéaire. Si la relation est curvilinéaire (comme dans le cas des données non-transformées), le bruit est plus grand que si la relation est parfaitement linéaire. Par conséquent la corrélation est plus faible.
Les esturgeons de cet échantillon ont été capturés à l'aide de filets et d'hameçons d'une taille fixe. Quel impact cette méthode de capture peut-elle avoir eu sur la forme de la distribution de FKLNGTH et RDWGHT ? Compte tenu de ces circonstances, l'analyse de corrélation est-elle appropriée ?
Rappelez vous que l’analyse de corréaltion présume aussi que chaque variable est échantillonnée aléatoirement. Dans le cas de nos esturgeons ce n’est pas le cas: les hameçons apatés et les filets ne capturent pas de petits esturgeons (et c’est pourquoi il n’y en a pas dans l’échantillon). Il faut donc réaliser que les coefficients de corrélation obtenus dans cette analyse ne reflètent as nécessairment ceux de la population totale des esturgeons.
Corrélations non paramétriques : r de Spearman et tau de KendallL'analyse faite à la section précédente suggère que l'une des conditions préalables à l'analyse de corrélation, soit la distribution normale bidimensionnelle de données, pourrait ne pas être rencontrée pour FKLNGTH et RDWGHT, ni pour les paires de variables transformées. La recherche d'une transformation appropriée peut parfois être difficile.

LABO- CORRÉLATION LINÉAIRE ET RÉGRESSION LINÉAIRE SIMPLE - 213
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Pire encore, pour certaines distributions il n'existe pas de transformation qui va normaliser les données. Dans ces cas-là, la meilleure option est de faire une analyse non paramétrique qui ne présume ni de la normalité ni de la linéarité. Ces analyses sont basées sur les rangs. Les deux plus communes sont le coefficient de rang de Spearman et le tau de Kendall.
Allez à Stats-Correlations-Simple, sélectionnez l'option Rank et Spearman dans la boîte associée pour calculer le coefficient de cor-rélation de rang de Spearman entre les trois paires de variables. Com-parer les résultats de cette analyse à l'analyse paramétrique. Pourquoi y-a-t'il une différence ?
Spearman correlation matrix
FKLNGTH RDWGHT LFKL LRDWGHT SQRDWT
FKLNGTH 1.000
RDWGHT 0.952 1.000
LFKL 1.000 0.952 1.000
LRDWGHT 0.952 1.000 0.952 1.000
SQRDWT 0.952 1.000 0.952 1.000 1.000
SQFKL 1.000 0.952 1.000 0.952 0.952
SQFKL
SQFKL 1.000
Note that here the correlations are identical. This is because we are using the ranks, rather than the raw data.
Répétez les mêmes étapes en sélectionnant le tau de Kendall. Com-parez aux résultats du r de Spearman. Pourquoi y-a-t'il une différence ?
Pour le tau de Kendall, on obtient:Kendall Tau-B coefficients matrix
FKLNGTH RDWGHT LFKL LRDWGHT SQRDWT
FKLNGTH 1.000
RDWGHT 0.821 1.000

214 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
LFKL 1.000 0.821 1.000
LRDWGHT 0.821 1.000 0.821 1.000
SQRDWT 0.821 1.000 0.821 1.000 1.000
SQFKL 1.000 0.821 1.000 0.821 0.821
SQFKL
SQFKL 1.000
Qualitativement le même résultat. Notez cependant que les corrélations obtenues avec le tau de Kendall sont plus faibles que celles du coefficient de Spearman. Le tau pondère un peu plus les grandes différences entre les rangs alors que le coefficient de Spearman donne le même poids à chaque paire d’observation. En général, on préfère le tau de Kendall lorsqu’il y a plus d’incertitude quant aux rangs qui sont près les uns des autres.
Matrices de corrélations et correction de BonferroniUne pratique courante est d'examiner une matrice de corrélation à la recherche des associations significatives. Si cette matrice contient un grand nombre de corrélations, il n'est pas surprenant d'en trouver au moins une qui soit "significative". En effet, on s'attend à en trouver 5% en moyenne lorsqu'il n'y a en fait aucune corrélation entre les paires de moyennes. Une façon d'éliminer ces résultats fautifs est d'ajuster le niveau α auquel on attribue une signification statistique en divisant α par le nombre k de corrélations qui sont examinées : α' = α/k (ajustement de Bonferroni). Si initialement α = 0.05 et qu'il y a 5 corrélations qui sont examinées, alors α'= 0.01.
En utilisant les données du fichier BUMPDAT.SYS, calculez la matrice de corrélations de Pearson pour les cinq variables TOTLNGTH, HEAD, ALAR, HUMERUS et STERNUM en utilisant Correlation, Simple, et en sélection-nant les options Pearson et Listwise. Refaites la même chose en sélectionnant l'option Bonferroni (accessible dans la fenêtre qui s'ouvre lorsque l'on clique sur le bouton Options). Comparez les résultats et expliquez les différences.

LABO- CORRÉLATION LINÉAIRE ET RÉGRESSION LINÉAIRE SIMPLE - 215
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Voici la matrice de corrélation:Means
TOTLNGTH ALAR HEAD HUMERUS STERNUM
157.980 241.327 31.455 18.469 20.829
Pearson correlation matrix
TOTLNGTH ALAR HEAD HUMERUS STERNUM
TOTLNGTH 1.000
ALAR 0.735 1.000
HEAD 0.666 0.673 1.000
HUMERUS 0.645 0.769 0.757 1.000
STERNUM 0.592 0.516 0.515 0.600 1.000
Les probabilités (non corrigées):Matrix of Probabilities
TOTLNGTH ALAR HEAD HUMERUS STERNUM
TOTLNGTH 0.000
ALAR 0.000 0.000
HEAD 0.000 0.000 0.000
HUMERUS 0.000 0.000 0.000 0.000
STERNUM 0.000 0.000 0.000 0.000 0.000
Number of observations: 49
TOTL
NG
THAL
ARH
EAD
HU
ME R
US
TOTLNGTH
STER
NU
M
ALAR HEAD HUMERUS STERNUM

216 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
et les probabilités corrigées par l’ajustement de Bonferonni:Bartlett Chi-square statistic: 148.538 df=10 Prob= 0.000
Matrix of Bonferroni Probabilities
TOTLNGTH ALAR HEAD HUMERUS STERNUM
TOTLNGTH 0.000
ALAR 0.000 0.000
HEAD 0.000 0.000 0.000
HUMERUS 0.000 0.000 0.000 0.000
STERNUM 0.000 0.001 0.002 0.000 0.000
Number of observations: 49
Dans ce cas-ci, l’ajustement de Bonferonni ne fait aucune différence (du moins quant aux conclusions)
En biologie de la conservation des espèces, une des questions intéressante et importante est de déterminer s'il existe des points chauds de diversité, c'est à dire des sites où la biodiversité de groupes taxonomiques différents est sont toutes élevées. Si tel est le cas, alors on s'attend à ce qu'un échantillon de divers sites posséderait des corrélations positives entre la richesse spécifique (le nombre d'espèces différentes) de différents groupes.
Le fichier WETDAT.SYS contient des données sur des marais de la région d'Ottawa, en particulier le nombre d'espèces de plantes (PLANT), d'oiseaux (BIRD), de mammifères (MAMMAL) et d'amphibiens et de rep-tiles (HERPS) dans chaque marais, ainsi que le log de ces variables (LGPLANTS, etc.). Étudiez la matrice de corrélation des variables log transformées et comparez les probabilités brutes et les probabilités corrigées par l'ajustement de Bonferroni. Existe-t-il une différence ? Pourquoi ?
Means
LGPL
ANTS
LGBI
RD
SLG
HER
PS
LGPLANTS
LGM
AMS
LGBIRDS LGHERPS LGMAMS

LABO- CORRÉLATION LINÉAIRE ET RÉGRESSION LINÉAIRE SIMPLE - 217
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
LGPLANTS LGBIRDS LGHERPS LGMAMS
2.148 1.545 0.739 0.778
Pearson correlation matrix
LGPLANTS LGBIRDS LGHERPS LGMAMS
LGPLANTS 1.000
LGBIRDS 0.645 1.000
LGHERPS 0.715 0.733 1.000
LGMAMS 0.351 0.601 0.515 1.000
Bartlett Chi-square statistic: 52.683 df=6 Prob= 0.000
Matrix of Probabilities
LGPLANTS LGBIRDS LGHERPS LGMAMS
LGPLANTS 0.000
LGBIRDS 0.000 0.000
LGHERPS 0.000 0.000 0.000
LGMAMS 0.062 0.001 0.004 0.000
Number of observations: 29
Bartlett Chi-square statistic: 52.683 df=6 Prob= 0.000
Matrix of Bonferroni Probabilities
LGPLANTS LGBIRDS LGHERPS LGMAMS
LGPLANTS 0.000
LGBIRDS 0.001 0.000
LGHERPS 0.000 0.000 0.000
LGMAMS 0.372 0.003 0.026 0.000
Number of observations: 29
Cette fois, l’ajustement de Bonferonni fait une différence: si on utilise les probabilités non-ajustées, on peut presque rejeter l’hypothèse nulle que la corrélation entre LGPLANTS et LGMAMS est nulle. Avec les probabilités ajustées, on accepte sans hésitation l’hypothèse nulle.

218 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Programme SYSTAT pour exercice de corrélationREM *****************************************************
USE "F:\data\usr\amorin\BIO4518\1998\Labo\data\Sturgdat.sys"
REM -- select only males
SELECT (SEX$= "male")
REM -- plot with lowess smooth:
PLOT FKLNGTH*RDWGHT / SMOOTH=LOWESS TENSION =0.500
REM -- transform data
LET lfkl = l10(FKLNGTH)
LET sqrdwt = SQR(rdwght)
LET lrdwght = l10(RDWGHT)
LET sqfkl = sqr(FKLNGTH)
REM -- plot transformed data
PLOT LRDWGHT*LFKL / SMOOTH=LOWESS TENSION =0.500
PLOT SQRDWT*SQFKL / SMOOTH=LOWESS TENSION =0.500
REM -- Make normal probability plots for all 6 variables
PPLOT FKLNGTH RDWGHT LFKL LRDWGHT SQRDWT SQFKL/ NORMAL
REM -- Run Lilliefors test on all 6 variables
NPAR
KS FKLNGTH RDWGHT LFKL LRDWGHT SQRDWT SQFKL / LILLIEFORS
REM -- Calculate correlations
CORR
PEARSON FKLNGTH RDWGHT LFKL LRDWGHT SQRDWT SQFKL
SPEARMAN FKLNGTH RDWGHT LFKL LRDWGHT SQRDWT SQFKL
TAU FKLNGTH RDWGHT LFKL LRDWGHT SQRDWT SQFKL
REM *****************************************************
REM -- Correlations on Bumpus data
USE "F:\data\usr\amorin\BIO4518\1998\Labo\data\Bumpdat.sys"
REM -- Pearson correlations (on all variables)
PEARSON
REM -- Probablilties of Pearson correlations
PEARSON / PROB
REM -- Bonferonni corrected probabilities
PEARSON / BONF
REM *****************************************************
REM -- Wetland data
USE "F:\data\usr\amorin\BIO4518\1998\Labo\data\wetdat.sys"
REM -- Pearson correlations
PEARSON LGPLANTS LGBIRDS LGHERPS LGMAMS
REM -- Probabilities of Pearson correlations
PEARSON LGPLANTS LGBIRDS LGHERPS LGMAMS / PROB
REM -- Bonferonni corrected probabilities of Pearson correlations
PEARSON LGPLANTS LGBIRDS LGHERPS LGMAMS / BONF
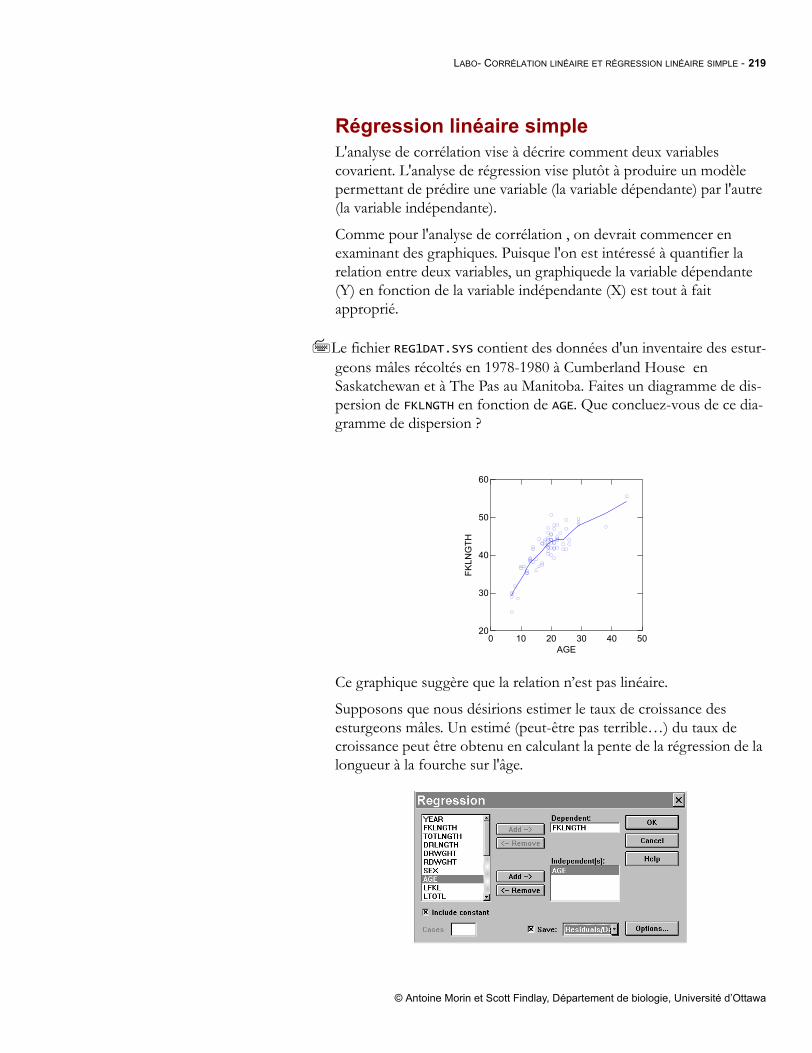
LABO- CORRÉLATION LINÉAIRE ET RÉGRESSION LINÉAIRE SIMPLE - 219
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Régression linéaire simpleL'analyse de corrélation vise à décrire comment deux variables covarient. L'analyse de régression vise plutôt à produire un modèle permettant de prédire une variable (la variable dépendante) par l'autre (la variable indépendante).
Comme pour l'analyse de corrélation , on devrait commencer en examinant des graphiques. Puisque l'on est intéressé à quantifier la relation entre deux variables, un graphiquede la variable dépendante (Y) en fonction de la variable indépendante (X) est tout à fait approprié.
Le fichier REG1DAT.SYS contient des données d'un inventaire des estur-geons mâles récoltés en 1978-1980 à Cumberland House en Saskatchewan et à The Pas au Manitoba. Faites un diagramme de dis-persion de FKLNGTH en fonction de AGE. Que concluez-vous de ce dia-gramme de dispersion ?
Ce graphique suggère que la relation n’est pas linéaire.
Supposons que nous désirions estimer le taux de croissance des esturgeons mâles. Un estimé (peut-être pas terrible…) du taux de croissance peut être obtenu en calculant la pente de la régression de la longueur à la fourche sur l'âge.
0 10 20 30 40 50AGE
20
30
40
50
60FK
LNG
TH

220 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Utilisez Stats-Regression-Linear et inscrivez FKLNGTH comme variable dépendante et AGE comme variable indépendante. Ce faisant, assurez-vous que Include constant et Save Residuals/Data sont sélectionnés. Le nom par défaut pour le fichier à sauvegarder (REGRESS.SYD) convi-ent très bien. Que concluez-vous ? Quelle est l'équation de régression ?
L’analyse de régression donne:Dep Var: FKLNGTH N: 75 Multiple R: 0.829 Squared multiple R: 0.687
Adjusted squared multiple R: 0.683 Standard error of estimate: 3.050
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 28.742 1.078 0.000 . 26.661 0.000
AGE 0.687 0.054 0.829 1.000 12.657 0.000
L’équation de la droite de régression estimée est donc:
Fklngth = 28.742 + 0.687*age
Le tableau ci-dessus donne donc les coefficients de la droite de régression, leur erreur-type, les coefficients standardisés, les statistiques de t et leur probablilité associée aux deux hypothèses nulles (que la constante =0 et que la pente = 0). La tolérance est une mesure de multicolinéarité qui ne s’applique pas en régression linéaire simple.Effect Coefficient Lower 95% Upper 95%
CONSTANT 28.742 26.593 30.890
AGE 0.687 0.579 0.796
Ce tableau donne les coefficients et leur intervalle de confiance à 95%.Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 1490.320 1 1490.320 160.203 0.000
Residual 679.098 73 9.303
Et ce dernier tableau est celui de l’analyse de variance. On rejette donc l’hypothèse nulle qu’il n’y a pas de raltion entre la taille et l’âge.*** WARNING ***
Case 37 has large leverage (Leverage = 0.232)
Durbin-Watson D Statistic 2.009
First Order Autocorrelation -0.005
Residuals and data have been saved.

LABO- CORRÉLATION LINÉAIRE ET RÉGRESSION LINÉAIRE SIMPLE - 221
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Le “Leverage” est une mesure de l’influence de chaque point sur la position de la droite de régression. On voit que le cas 37 a une grande influence. On s’attend donc à ce que la régression change si on refait l’analyse en enlevant ce point.
Vérifier les conditions d'application de la régressionLa régression simple de modèle I a quatre conditions préalables :
1. il n'y a pas d'erreur de mesure sur la variable indépendante (X),
2. la relation entre Y et X est linéaire,
3. les résidus sont normalement distribués et
4. la variance des résidus constante pour toutes les valeurs de la variable indépendante.
Procédons maintenant à l'examen post-mortem. La première condition est rarement remplie avec des données biologiques ; il y presque toujours de l'erreur sur X et sur Y. Cela veut dire qu'en général les pentes estimées sont biaisées, mais que les valeurs prédites ne le sont pas (voir Sokal et Rohlf 1995, p. 543-544 pour plus d'information). Toutefois, si l'erreur de mesure sur X est petite par rapport à l'étendue des valeurs de X, le résultat de l'analyse n'est pas dramatiquement influencé. Par contre, si l'erreur de mesure est relativement grande (toujours par rapport à l'étendue des valeurs de X), la droite de régression obtenue par la régression de modèle I est un piètre estimé de la relation fonctionnelle entre X et Y. Dans ce cas, il est préférable de passer à la régression de modèle II, malheureusement au-delà du contenu de ce cours.
Les autres conditions préalables à l'analyse de régression de modèle I peuvent cependant être vérifiées.
Inspectez le diagramme de dispersion obtenu à la section précédente. La relation vous semble-t-elle linéaire ?
L’examen du graphique suggère que la relation n’est pas linéaire.
À l'aide du fichier REGRESS.SYD créé précédemment, faites un dia-gramme de probabilité des résidus. À l'examen de ce diagramme, con-cluez-vous que les résidus suivent une distribution normale ?
Le diagramme de probabilité ressemble à:

222 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
ce qui est plutôt joli.
Faites un diagramme des résidus normalisés (studentized residuals, STUDENT) en fonction des valeurs prédites (ESTIMATE). Que concluez-vous de ce diagramme ?
Le graphique des résidus normalisés donne:
Il ne semble donc pas y avoir de problème d’hétéroscédasticité, mais il y a une tendance avec les résidus: ceux des extrémités sont négatifs alors que ceux du milieu sont positifs. C’est typique des cas ou on trace une droite au travers d’un nuage de points courbe.
La présomption d'indépendance peut être éprouvée à l'aide de la statistique de Durbin Watson (D-W) qui mesure la corrélation de l'erreur. Cette statistique peut varier entre 0 et 4 ; les valeurs près de 0 indiquent une très forte corrélation négative et celle près de 4 une forte corrélation positive. Les valeurs près de 2 suggèrent une absence de corrélation.
Interprétez la statistique associée à votre régression.
-10 -5 0 5 10RESIDUAL
-3
-2
-1
0
1
2
3
Expe
cted
Val
ue fo
r Nor
mal
Dis
tr ibu
tion
30 40 50 60ESTIMATE
-4
-3
-2
-1
0
1
2
3
STU
DEN
T

LABO- CORRÉLATION LINÉAIRE ET RÉGRESSION LINÉAIRE SIMPLE - 223
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
La statistique de D-W est d’environ 2 et l’autocorrélation de premier ordre est très faible. Il ne semble donc pas y avoir de problèmes de ce coté.
La routine ACF (accessible sous Stats-Time Series) permet aussi de faire un diagramme d'autocorrélation des résidus. Qu'est-ce que ce graphique vous suggère à propos de l'indépendance des résidus ?
Il semble donc que la présomption de normalité et d’indépendance soit valide, mais on a des doutes quant à la linéarité.
Transformation des données en régressionLes analyses précédentes devraient vous avoir conduit à conclure qu'au moins une des conditions préalables à l'analyse de régression n'est pas remplie (Laquelle ? Lesquelles ?). Si on veut pouvoir faire une analyse de régression, une transformation des données s'impose :
Effectuez une transformation logarithmique et répétez l'analyse de régression et l'examen post-mortem des résidus. Comparez aux résul-tats obtenus à partir des données brutes. Quelle est votre conclusion ?
L’analyse des données log-transformées donne:Dep Var: LFKL N: 75 Multiple R: 0.887 Squared multiple R: 0.787
Adjusted squared multiple R: 0.784 Standard error of estimate: 0.028
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 1.199 0.026 0.000 . 46.872 0.000
LAGE 0.334 0.020 0.887 1.000 16.413 0.000
Effect Coefficient Lower 95% Upper 95%
CONSTANT 1.199 1.148 1.250
LAGE 0.334 0.294 0.375
Autocorrelation Plot
0 10 20 30 40 50 60Lag
-1.0
-0.5
0.0
0.5
1.0
Cor
rela
tion

224 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Correlation matrix of regression coefficients
CONSTANT LAGE
CONSTANT 1.000
LAGE -0.992 1.000
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.216 1 0.216 269.381 0.000
Residual 0.059 73 0.001
--------------------------------------------------------------------------
*** WARNING ***
Case 4 is an outlier (Studentized Residual = -3.342)
Durbin-Watson D Statistic 2.041
First Order Autocorrelation -0.025
L’analyse des données transformées permet d’expliquer 10% de plus de l avariation de la variable dépendante (from .687 to .787). D’un autre côté, on a une valeur extrême.
Si one examine les données pour évaluer si les conditions d’application de la régression sont rencontrées, on obtient:
La relation est plus linéaire. Le test de Lilliefors donne Maxdif = .077, p = .298, donc les résidus sont normaux. La statistique de D-W et l’autocorrélation de premier ordre suggèrent qu’on a pas à trop s’inquiéter de l’indépendance. Le graphique des résidus normalisés donne:
0.5 1.0 1.5 2.0LAGE
1.3
1.4
1.5
1.6
1.7
1.8
LFKL

LABO- CORRÉLATION LINÉAIRE ET RÉGRESSION LINÉAIRE SIMPLE - 225
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Il y a donc du progrès, mais ce n’est pas encore idéal.
Si on refait l’analyse en enlevant la valeur extrême, on obtient:Dep Var: LFKL N: 74 Multiple R: 0.881 Squared multiple R: 0.776
Adjusted squared multiple R: 0.773 Standard error of estimate: 0.027
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 1.224 0.025 0.000 . 48.712 0.000
LAGE 0.315 0.020 0.881 1.000 15.797 0.000
Effect Coefficient Lower 95% Upper 95%
CONSTANT 1.224 1.174 1.274
LAGE 0.315 0.275 0.355
Correlation matrix of regression coefficients
CONSTANT LAGE
CONSTANT 1.000
LAGE -0.992 1.000
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.176 1 0.176 249.532 0.000
Residual 0.051 72 0.001
--------------------------------------------------------------------------
Durbin-Watson D Statistic 1.971
First Order Autocorrelation 0.011
Il n’y a pas de grand changement. Les coefficients tombent à l’intérieur des intervalles de confiance à 95% calculés précédemment. Bref, l’analyse des données transformées est nettement plus satisfaisante que celle des données brutes.
Plot of Residuals against Predicted Values
1.4 1.5 1.6 1.7 1.8ESTIMATE
-0.10
-0.05
0.00
0.05
0.10
RES
IDU
AL

226 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Programme SYSTAT pour l’exercice de régressionREM *****************************************************
REM -- Regression example data
USE "F:\data\usr\amorin\BIO4518\1998\Labo\data\Reg1dat.sys"
REM -- Firs plot data with LOWESS smooth
PLOT FKLNGTH*AGE / SMOOTH=LOWESS TENSION =0.500
REM -- Fit regression and save residuals/data
REGRESS
SAVE 'F:\data\usr\amorin\BIO4518\1998\Labo\data\REGRESS.SYD' /
RESIDUALS,DATA
MODEL FKLNGTH = CONSTANT+AGE
ESTIMATE
REM -- Open residuals/data file
USE "F:\data\usr\amorin\BIO4518\1998\Labo\data\REGRESS.SYD"
REM -- Probability plot for residuals
PPLOT RESIDUAL/ NORMAL
REM -- Plot of studentized residuals
PLOT STUDENT*ESTIMATE / SMOOTH=QUAD
REM -- Plot ACF
SERIES
ACF RESIDUAL
REM -- Plot, then fit regression on log transformed data
PLOT LFKL*LAGE / SMOOTH=LOWESS TENSION =0.500
REGRESS
MODEL LFKL = CONSTANT+LAGE
ESTIMATE
REM -- Eliminate outlier by selecting all cases but #4, then refit
regression
SELECT (case<> 4)
MODEL LFKL = CONSTANT+LAGE
ESTIMATE

LABO- ANCOVA - 227
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Labo- ANCOVAAprès avoir complété cet exercice de laboratoire, vous devriez pouvoir :
• Utiliser SYSTAT pour éprouver l'hypothèse d'égalité des pentes de plusieurs régressions linéaires simples
• Utiliser SYSTAT pour faire une analyse de covariance (ANCOVA)
• Utiliser SYSTAT pour vérifier les conditions préalables à l'ANCOCA
Homogénéité des pentesPour répondre à de nombreuses questions biologiques il est nécessaire de déterminer si deux (ou plus de deux) régressions diffèrent significativement. Par exemple, pour comparer l'efficacité de deux insecticides on doit comparer la relation entre leur dose et la mortalité. Ou encore, pour comparer le taux de croissance des mâles et des femelles on doit comparer la relation entre la taille et l'âge des mâles et des femelles. Comme chaque régression linéaire est décrite par deux paramètres, la pente et l'ordonnée à l'origine, on doit considérer les deux dans la comparaison. Le modèle d'ANCOVA, à strictement parler, n'éprouve que l'hypothèse d'égalité des ordonnées à l'origine. Cependant, avant d'ajuster ce modèle, il faut éprouver l'hypothèse d'égalité des pentes (homogénéité des pentes).
En utilisant les données du fichier ANC1DAT.SYS, éprouvez l'hypothèse que le taux de croissance des esturgeons mâles et femelles de The Pas est le même (données de 1978-1980). Pour les besoins de cet exercice, nous utiliserons la pente de la relation entre le logarithme base 10 de la longueur à la fourche (LFKL) et le logarithme de l'âge (LAGE). Allez à Stats-General Linear Model-Estimate model, inscrivez LFKL comme variable dépendante et LAGE, SEX$ et LAGE*SEX$ comme variables indépendantes. Assurez-vous de sauvegarder les résidus en cliquant sur l'option Save file : Residuals/Data. Que concluez-vous ?

228 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
SEX$ (2 levels)
female, male
Dep Var: LFKL N: 92 Multiple R: 0.835 Squared multiple R: 0.697
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
LAGE 0.143 1 0.143 176.650 0.000
SEX$ 0.000 1 0.000 0.504 0.479
SEX$*LAGE 0.000 1 0.000 0.337 0.563
Error 0.071 88 0.001
--------------------------------------------------------------------------
Adjusted least squares means.
Adj. LS Mean SE N
SEX$ =female 1.649 0.004 54
SEX$ =male 1.641 0.005 38
--------------------------------------------------------------------------
--------------------------------------------------------------------------
*** WARNING ***
Case 49 is an outlier (Studentized Residual = -3.534)
Durbin-Watson D Statistic 2.330
First Order Autocorrelation -0.175
Coefficient de détermination du modèle estimé : LFKL=CONTSTANT+LAGE+SEX$+LAGE*SEX$
Probabilité que le terme LAGE*SEX$ n'affecte pas la longueur à la fourche (i.e. que la pente ne diffère pas entre les sexes ou, vice-versa, que la différence entre les sexes (si elle existe) de change pas avec l'âge)
À la suite de cette analyse, on conclue donc (1) que la pente de la régression du log de la longueur à la fourche sur le log de l’âge est la même pour les mâles et les femelles, et (2) que les ordonnées à
1
2
1
2

LABO- ANCOVA - 229
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
l’origine sont les mêmes pour les deux sexes. Mais, avant d’accepter ces conclusions, il faut éprouver les conditions d’application de la manière habituelle.
En ce qui concerna la normalité, ça a l’air d’aller quoiqu’il y a quelques points, en haut à droite, qui dévient de la droite. Si on effectue le test de Lilliefors, on obtient une probabilité de 0.535, ce qui confirme que les résidus sont distribués normalement. Il n’y a pas de tendance évidente dans les résidus normalisés non plus. Cependant, il faut vérifier aussi que les variances sont homogènes entre les niveaux de la variable discontinue (ici SEX$). Un graphique des résidus en fonction des valeurs prédites pour chaque sexe donne:
Les variances ont l’air similaire sur ces graphiques. Pour s’en assurer on peut aussi faire le test de Levene:Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
SEX$ (2 levels)
female, male
Dep Var: ABSRES N: 92 Multiple R: 0.122 Squared multiple R: 0.015
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
SEX$ 0.000 1 0.000 1.369 0.245
Error 0.025 90 0.000
-0.10 -0.05 0.0 0.05 0.10RESIDUAL
-3
-2
-1
0
1
2
3
Expe
cted
Val
u e fo
r Nor
mal
Dis
tr ibu
tion
1.5 1.6 1.7 1.8ESTIMATE
-4
-3
-2
-1
0
1
2
3
STU
DEN
T
female
1.5 1.6 1.7 1.8ESTIMATE
-4
-3
-2
-1
0
1
2
3
STU
DEN
T
male
1.5 1.6 1.7 1.8ESTIMATE
-4
-3
-2
-1
0
1
2
3
STU
DE N
T

230 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
--------------------------------------------------------------------------
*** WARNING ***
Case 19 is an outlier (Studentized Residual = 3.832)
Case 49 is an outlier (Studentized Residual = 4.656)
Case 50 is an outlier (Studentized Residual = 3.503)
Durbin-Watson D Statistic 1.625
First Order Autocorrelation 0.184
Pour éprouver l’indépendance, on fait le graphique d’autocorrélation. Encore une fois, tout a l’air parfait. (Rappelez-vous que la statistique de Durbin-Watson ne mesure la corrélation qu’avec un pas (lag) de 1. Pour vérifier les autres décalages, il vaut mieux faire le graphique d’autocorrélation.
La dernière condition d’application est que la variable continue indépendante (LAGE) est mesurée sans erreur. On ne peut vérifier cela par un test. Pour vérifier cela il faudrait avoir plusieurs estimés de l’âge de chaque poissons (par exemple des estimés obtenus par différentes méthodes ou des chercheurs différents).
Vous noterez qu'il y a une observation qui a un résidu normalisé (stu-dentized residual) qui est élevé, i.e. une valeur extrême. Éliminez-la de l'ensemble de données et refaites l'analyse. Vos conclusions changent-elles ?
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
SEX$ (2 levels)
female, male
Dep Var: LFKL N: 91 Multiple R: 0.854 Squared multiple R: 0.729
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
LAGE 0.144 1 0.144 201.273 0.000
SEX$ 0.000 1 0.000 0.527 0.470
SEX$*LAGE 0.000 1 0.000 0.313 0.577
Error 0.062 87 0.001
--------------------------------------------------------------------------
Durbin-Watson D Statistic 2.156
First Order Autocorrelation -0.088
La conclusion ne change pas après avoir enlevé la valeur extrême. Le coefficient de détermination (R2) augmente de .697 à .729 comme on pourrait s’y attendre. Comme on a pas de bonne raison d’éliminer

LABO- ANCOVA - 231
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
cette valeur, il est probablement mieux de la conserver. Un examen des conditions d’application après avoir enlevé cette valeur révèle qu’elles sont toutes rencontrées.
Le fichier ANC3DAT.SYS contient des données sur des esturgeons mâles de deux sites (LOCATE$) : Lake of the Woods dans le Nord-Ouest de l'Ontario et Chruchill River dans le Nord du Manitoba. En utilisant la même procédure, éprouvez l'hypothèse que la pente de la régression de LFKL sur LAGE est la même aux deux sites. Que concluez-vous ?
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
LOCATE$ (2 levels)
LofW, Nelson
Dep Var: LFKL N: 92 Multiple R: 0.805 Squared multiple R: 0.649
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
LAGE 0.078 1 0.078 133.566 0.000
LOCATE$ 0.010 1 0.010 16.591 0.000
LOCATE$*LAGE 0.009 1 0.009 15.575 0.000
Error 0.051 88 0.001
Durbin-Watson D Statistic 2.132
First Order Autocorrelation -0.075
Residuals have been saved.
--------------------------------------------------------------------------
ici, on rejette les hypothèses nulels (1) que les pentes sont les mêmes dans les deux sites et (2) que les ordonnées à l’origine sont égales, En d’autres mots, si on veut orédire la longueur ‘ala fourche d’un esturgeon à un âge donné précisément, il faut savoir de quel site il provient. Puisque les pentes diffèrent, il faut estimer des régressions séparées.
Si on examine les résidus, on voit qu’il n’y a pas de problème de linéarité, no d’autocorrélation, ni de normalité (Maxdif = .084, p = .103). Cependant, le test de Levene sugg‘re la présence d’hétéroscédasticité (F = 3.14, p = .08). Cela est encore plus évident lorsque l’on estime des régresisons séparées:
The following results are for:
LOCATE$ = Nelson
Dep Var: LFKL N: 38 Multiple R: 0.687 Squared multiple R: 0.472
Adjusted squared multiple R: 0.457 Standard error of estimate: 0.022

232 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 1.449 0.035 0.0 . 40.820 0.000
LAGE 0.160 0.028 0.687 1.000 5.673 0.000
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.015 1 0.015 32.181 0.000
Residual 0.017 36 0.000
--------------------------------------------------------------------------
*** WARNING ***
Case 65 has large leverage (Leverage = 0.289)
Durbin-Watson D Statistic 2.483
First Order Autocorrelation -0.245
The following results are for:
LOCATE$ = LofW
Dep Var: LFKL N: 54 Multiple R: 0.834 Squared multiple R: 0.695
Adjusted squared multiple R: 0.689 Standard error of estimate: 0.026
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 1.228 0.040 0.0 . 30.968 0.000
LAGE 0.325 0.030 0.834 1.000 10.882 0.000
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.078 1 0.078 118.416 0.000
Residual 0.034 52 0.001
--------------------------------------------------------------------------
*** WARNING ***
Case 92 has large leverage (Leverage = 0.257)
Durbin-Watson D Statistic 2.170
First Order Autocorrelation -0.106
La pente pour Lake of the Woods est près du double de celle pour la rivière Nelson, et l’ordonnée à l’origine est beaucoup plus petite. Notez que l’IC à 95% pour les pentes et les ordonnées à l’origines ne se chevauchent pas. La conclusion qualitative obtenue à l’examen du modèle compelt est donc supportée: Les esturgeons grandissent plus vite dans Lake of the Woods que dans la rivière Neslson..

LABO- ANCOVA - 233
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Notez cependant la différence du carré moyen des résidus entre les deux sites: .017 vs .001, un facteur de 17! Ceci confirme la tendance suggérée par le test de Levene (p=.08). Il semble donc que les esturgeons grandissent plus vite à lake of the Woods, mais aussi qu’il y a plus de variabilité de taille entre les individus du même âge qu’à la rivière Nelson.. Pourquoi? Pensez-y maintenant. La réponse n’est pas écologique mais allométrique !
Le modèle d'ANCOVASi le test d'homogénéité des pentes indique qu'elles diffèrent, alors on devrait estimer des régressions individuelles pour chaque niveau des variables discontinues. Cependant, si on accepte l'hypothèse d'égalité des pentes, l'étape suivante est de comparer les ordonnées à l'origine.
En utilisant les données du fichier ANC1DAT.SYS, éprouvez l'hypothèse d'égalité des ordonnées à l'origine entre les mâles et les femelles en allant à Stats-General Linear Model-Estimate et en inscrivant LFKL comme variable dépendante et LAGE et SEX$ comme variables indépendantes. Sélectionnez l'option pour sauvegarder les données et les résidus (Save, Residuals/data) et cliquez sur OK. Que concluez-vous ?
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
SEX$ (2 levels)
female, male
Dep Var: LFKL N: 92 Multiple R: 0.834 Squared multiple R: 0.696
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
LAGE 0.143 1 0.143 178.163 0.000
SEX$ 0.001 1 0.001 1.851 0.177
LofW
1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8LAGE
1.5
1.6
1.7
1.8
1.9
LFKL
Nelson
1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8LAGE
1.5
1.6
1.7
1.8
1.9
LFKL

234 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Error 0.072 89 0.001
--------------------------------------------------------------------------
*** WARNING ***
Case 49 is an outlier (Studentized Residual = -3.557)
Durbin-Watson D Statistic 2.345
First Order Autocorrelation -0.180
On accepte l’hypothèse nulle que les ordonnées à l’origine sont les mêmes pour les deux sexes. Comme pour le modèle complet, il y a une valeur extrême (cas 49). Notez que le R2 est presque le même que pour le modèle complet, ce qui est normal pusique l’interaction n’expliquait presque pas de variabilité. Si on examine les résidus, on voit qu’il n’y a pas de problème de linéarité, d’indépendance, d’homogénéité des variances (F = 1.49, p = .23), ni de normalité (Maxdif = .53, p = .73).
En examinant le fichier de sortie, vous noterez que même si SYSTAT n'identifie qu'une seule valeur extrême, il y a trois observations dont la valeur absolue du résidu normalisé (studentized residual) est plus grande que 3. Ces observations pourraient avoir un effet dispropor-tionné sur les résultats de l'analyse. Éliminez-les et refaites l'analyse. Les conclusions changent-elles ?
Effects coding used for categorical variables in model.
Categorical values encountered during processing are:
SEX$ (2 levels)
female, male
Dep Var: LFKL N: 89 Multiple R: 0.878 Squared multiple R: 0.771
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
LAGE 0.140 1 0.140 243.095 0.000
SEX$ 0.002 1 0.002 4.037 0.048
Error 0.050 86 0.001
--------------------------------------------------------------------------
Durbin-Watson D Statistic 0.010
Ouch! Les résultats changent. Il faudrait donc rejeter l’hypothèse nulle et conclure que les ordonnées à l’origine diffèrent! Une conclusion qualitativement différente de celle obtenue en considérant toutes les données. Pourquoi? Il y a deux raisons possibles : (1) les valeurs extrêmes influencent beaucoup les régressions ou (2) l’exclusion des

LABO- ANCOVA - 235
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
valeur extrêmes permet d’augmenter la puissance de détection d’une différence. La première explication est moins plausible parce que les valeurs extrêmes n’avaient pas une grande influence (leverage faible).
En utilisant Stats-Regression-Linear, ajustez une régression simple entre LFKL et LAGE pour l'ensemble complet de données et aussi pour le sous-ensemble sans les 3 valeurs déviantes. Comparez ces modèles avec les modèles d'ANCOVA ajustés précédemment. Que concluez-vous ? Quel modèle, d'après vous, a le meilleur ajustement aux don-nées ? Pourquoi ?
Dep Var: LFKL N: 89 Multiple R: 0.872 Squared multiple R: 0.760
Adjusted squared multiple R: 0.757 Standard error of estimate: 0.024
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 1.204 0.027 0.0 . 45.089 0.000
LAGE 0.341 0.021 0.872 1.000 16.590 0.000
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.164 1 0.164 275.230 0.000
Residual 0.052 87 0.001
--------------------------------------------------------------------------
*** WARNING ***
Case 89 has large leverage (Leverage = 0.152)
Durbin-Watson D Statistic 0.066
First Order Autocorrelation 0.918
Deux chose à noter ici. D’abord, il y a une nouvelle valeur extrême, cette fois avec une forte influence (leverage). Ensuite, il n’y a pas une grosse différence de R2 entre la régression simple et le modèle ANCOVA (.76 vs.77). Ceci suggère que le bénéfice (1%) de la variabilité ne vaut pas le coût (une augmentation de 50% du nombre de termes dans le modèle).
Si on ajuste une régresison simple sur toutes les données, on obtient:
Dep Var: LFKL N: 92 Multiple R: 0.830 Squared multiple R: 0.690
Adjusted squared multiple R: 0.686 Standard error of estimate: 0.029
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 1.211 0.031 0.0 . 39.191 0.000
LAGE 0.336 0.024 0.830 1.000 14.144 0.000
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P

236 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Regression 0.163 1 0.163 200.051 0.000
Residual 0.073 90 0.001
--------------------------------------------------------------------------
*** WARNING ***
Case 1 is an outlier (Studentized Residual = -3.392)
Case 82 has large leverage (Leverage = 0.149)
Durbin-Watson D Statistic 0.088
First Order Autocorrelation 0.861
Encore une fois, le R2 de la régression simple et de l’ANCOVA sont similaires.
Donc, dans les deux cas (avec ou sans les valeurs extrêmes), l’addition d’un terme supplémentaire pour le sexe n’ajoute pas grand chose. Il semble donc que le meilleur modèle soit celui de la régression simple. Un estimé raisonablement précis de la taille des esturgeons peut être obtenu de le régression commune sur l’ensemble des résultats.
Note: Il est fréquent que l’élimination de valeurs extrêmes en fait apparaître d’autres. C’est parce que ces valeurs extrêmes dépendent de la variabilité résiduelle. Si on élimine les valeurs les plus déviantes, la variabilité résiduelle diminue, et certaines observation qui n.étaient pas si déviantes que cela deviennent proportionnellement plus déviantes. Notez aussi qu’en éliminant des valeurs extrêmes, l’effectif diminue et que la puissance décroît. Il faut donc être prudent.
Programme SYSTATUSE 'F:\DATA\USR\AMORIN\BIO4518\1998\LABO\DATA\ANC1DAT.SYS'
EDIT
MGLH
SAVE 'F:\DATA\USR\AMORIN\BIO4518\1998\LABO\DATA\GLM.SYD' / RESIDUALS,DATA
MODEL LFKL = CONSTANT + LAGE+SEX$+LAGE*SEX$
ESTIMATE
USE 'F:\DATA\USR\AMORIN\BIO4518\1998\LABO\DATA\GLM.SYD'
PLOT STUDENT*ESTIMATE / GROUP=SEX$
let absres=abs(residual)
CATEGORY SEX$
COVAR
DEPEND ABSRES
ESTIMATE
select case<>49
MODEL LFKL = CONSTANT + LAGE+SEX$+LAGE*SEX$
ESTIMATE
USE 'F:\DATA\USR\AMORIN\BIO4518\1998\LABO\DATA\ANC3DAT.SYS'
SAVE 'F:\DATA\USR\AMORIN\BIO4518\1998\LABO\DATA\GLM.SYD' / RESIDUALS,
DATA
MODEL LFKL = CONSTANT + LAGE+LOCATE$+LAGE*LOCATE$
ESTIMATE
by locate$
REGRESS
MODEL LFKL = CONSTANT+LAGE
ESTIMATE

LABO- ANCOVA - 237
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
by
PLOT LFKL*LAGE / GROUP=LOCATE$ SMOOTH=LINEAR
USE 'F:\DATA\USR\AMORIN\BIO4518\1998\LABO\DATA\ANC1DAT.SYS'
MGLH
SAVE 'F:\DATA\USR\AMORIN\BIO4518\1998\LABO\DATA\GLM.SYD' / RESIDUALS,DATA
MODEL LFKL = CONSTANT + LAGE+SEX$
ESTIMATE
USE 'F:\DATA\USR\AMORIN\BIO4518\1998\LABO\DATA\GLM.SYD'
select abs(student)<3
MODEL LFKL = CONSTANT + LAGE+SEX$
ESTIMATE
MODEL LFKL = CONSTANT + LAGE+
estimate
select
estimate

238 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

LABO- RÉGRESSION MULTIPLE - 239
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Labo- Régression multipleAprès avoir complété cet exercice de laboratoire, vous devriez pouvoir :
• Utiliser SYSTAT pour faire une régression multiple et utiliser les algorithmes de sélection pas à pas rétrograde (backward stepwise) et agglomérative (forward stepwise) de sélection des variables indépendantes pour sélectionner le “meilleur” modèle.
• Utiliser SYSTAT pour éprouver des hypothèses sur l'effet des variables indépendantes sur la variable dépendante.
• Utiliser SYSTAT pour évaluer la multicolinéarité entre les varia-bles indépendantes et en évaluer ses effets.
• Utiliser SYSTAT pour effectuer une régression curvilinéaire (poly-nomiale).
Conseils générauxLes variables qui intéressent les biologistes sont généralement influencées par plusieurs facteurs, et une description exacte ou une prédiction de la variable dépendante requiert que plus d'une variable soit incluse dans le modèle. La régression multiple permet de quantifier l'effet de plusieurs variables continues sur la variable dépendante.
Il est important de réaliser que la maîtrise de la régression multiple ne s'acquiert pas instantanément et que c'est un art autant qu'une science. Les débutants doivent garder à l'esprit plusieurs points importants :
1. Un modèle de régression multiple peut être hautement significatif même si aucun des termes pris isolément ne l'est,
2. Un modèle peut ne pas être significatif alors que l'un ou plusieurs des termes l'est et
3. À moins que les variables indépendantes soient parfaitement orthogonales (c'est-à-dire qu'il n'y ait aucune corrélation entre elles) les diverses approches de sélection des variables indépen-dantes peuvent mener à des modèles différents.
Sélection des variables indépendantesCommençons par le cas le plus simple : une variable dépendante et 2 variables indépendantes.

240 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Le fichier MREGDAT.SYS contient des données de richesse spécifique de quatre groupes d'organismes dans 30 marais de la région Ottawa-Cornwall-Kingston. Les variables sont la richesse spécifique des oiseaux (BIRD, et son logarithme base 10 LOGBIRD), ces mammifères (MAMMAL, LOGMAM), des amphibiens et reptiles (HERPTILE, LOGHERP) et celle des vertébrés (TOTSP, LOGTOT) ; les coordonnées des sites (LAT, LONG) ; la superficie du marais (LOGAREA), le pourcentage du marais inondé toute l'année (SWAMP) le pourcentage des terres couvertes par des forêts dans un rayon de 1km du marais (CPFOR2) et la densité des routes pavées (en m/ha) dans un rayon de 1km du marais (THTDEN).
En utilisant les données de ce fichier, faites la régression simple de LOGHERP sur LOGAREA en allant à Stats-Regression-Linear et en inscriv-ant LOGHERP comme la variable dépendante et LOGAREA comme la vari-able indépendante. Sauvegardez les résidus et les données (Save: Residual/Data) dans REGRESS.SYD. Que concluez-vous à partir de cette analyse?
Dep Var: LOGHERP N: 28 Multiple R: 0.596 Squared multiple R: 0.355
Adjusted squared multiple R: 0.330 Standard error of estimate: 0.186
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 0.185 0.157 0.0 . 1.177 0.250
LOGAREA 0.247 0.065 0.596 1.000 3.784 0.001
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.494 1 0.494 14.321 0.001
Residual 0.896 26 0.034
*** WARNING ***
Case 20 is an outlier (Studentized Residual = 3.034)
Durbin-Watson D Statistic 2.005
First Order Autocorrelation -0.025

LABO- RÉGRESSION MULTIPLE - 241
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Il semble donc y avoir une relation positive entre la richesse spécifique des reptiles et des amphibiens et la surface des marais. La régression n’explique cependant qu’environ le tiers de la variabilité (R2=.355). L’analyse des résidus indique qu’il n’y a pas de problème avec la normalité (Lillefors, p=.707), l’homoscédasticité, ni l’indépendance. Il y a une valeur extrême. Si on refait l’analyse sans cette valeur, le R2 fait un bond à .491. Cependant, les coefficients de la régression ne changent pas significativement.
+Faites ensuite la régression de LOGHERP sur CPFOR2. Désactivez l'option de sauvegarde des résidus. Que concluez-vous?
Dep Var: LOGHERP N: 28 Multiple R: 0.305 Squared multiple R: 0.093
Adjusted squared multiple R: 0.058 Standard error of estimate: 0.220
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 0.609 0.104 0.0 . 5.845 0.000
CPFOR2 0.003 0.002 0.305 1.000 1.632 0.115
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.129 1 0.129 2.662 0.115
Residual 1.260 26 0.048
--------------------------------------------------------------------------
Durbin-Watson D Statistic 1.780
First Order Autocorrelation 0.082
Ici, on doit accepter l’hypothèse nulle et conclure qu’il n’y a pas de relation entre la richesse spécifique dans les marais et la proportion de forêts sur les terres adjacentes.
Toutefois, on sait qu’une partie de la variabilité de LOGHERP peut être expliquée par la surface des marais. En faisant une régression de LOGHERP sur CPFOR2 seulement, on ne prend pas en compte cette relation. Il est possible que cette variabilité dûe à la surface des marais cache la relation entre LOGHERP et CPFOR2. Pour éliminer cette explication, il faut d’abord corriger les valeurs observées pour l’effet de la taille du marais.
Ouvrez le fichier REGRESS.SYD et faite une régression de RESIDUALS (de la régression LOGHERP-LOGAREA) sur CPFOR2. Que concluez-vous? Pourquoi ces résultats diffèrent-ils de ceux obtenus en régressant LOGHERP sur CPFOR2?
Dep Var: RESIDUAL N: 28 Multiple R: 0.382 Squared multiple R: 0.146

242 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Adjusted squared multiple R: 0.113 Standard error of estimate: 0.172
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT -0.157 0.081 0.0 . -1.933 0.064
CPFOR2 0.003 0.001 0.382 1.000 2.108 0.045
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.131 1 0.131 4.444 0.045
Residual 0.765 26 0.029
--------------------------------------------------------------------------
Durbin-Watson D Statistic 2.251
First Order Autocorrelation -0.158
On voit donc que, si on corrige la richesse spécifique pour la taille des marais en utilisant les résidus de la régression LOGHERP-LOGAREA comme variable dépendante, on détecte un effet positif et significatif de CPFOR2.
Dans l'analyse qui précède, nous avons corrigé pour l'effet de LOGAREA sur LOGHERP, mais sans tenir compte de la possibilité que LOGAREA et CPFOR2 soient corrélés. Pour mesurer l'effet “réel” de CPFOR2 sur LOGHERP il faudrait “corriger” CPFOR2 pour enlever l'effet de sa corrélation avec LOGAREA en calculant les résidus de la régression CPFOR2-LOGAREA.
Faites la régression de CPFOR2 sur LOGAREA et sauvegardez les résidus et les données au fichier REGRESS1.SYD. Ensuite ouvrez le fichier REGRESS.SYD et créez une nouvelle variable R2. Ouvrez maintenant le fichier REGRESS1.SYD et copiez les résidus de la régression CPFOR2-LOGAREA dans la colonne R2 du fichier REGRESS.SYD. Enfin, régressez RESIDUAL (i.e. le résidu de la régression LOGHERP-LOGAREA) sur R2. Que concluez-vous?
Dep Var: RESIDUAL N: 28 Multiple R: 0.381 Squared multiple R: 0.145
Adjusted squared multiple R: 0.112 Standard error of estimate: 0.172
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT -0.008 0.033 0.0 . -0.234 0.816
R2 0.003 0.001 0.381 1.000 2.100 0.046
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.130 1 0.130 4.408 0.046
Residual 0.766 26 0.029
--------------------------------------------------------------------------

LABO- RÉGRESSION MULTIPLE - 243
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Durbin-Watson D Statistic 2.229
First Order Autocorrelation -0.147
Notez que ces résultats sont presque identiques à ceux obtenue par régression de RESIDUAL sur CPFOR2. Ceci suggère que la corrélation entre CPFOR2 et LOGAREA doit être faible. En effet, elle n’est que de 0.076.
À partir du fichier original (MREGDAT.SYS) faites la régression de LOGH-ERP sur LOGAREA et CPFOR2 en allant à Stats-Regression-Linear et en inscrivant LOGHERP comme variable dépendante et LOGAREA et CPFOR2 comme variables indépendantes. Que concluez-vous?
Dep Var: LOGHERP N: 28 Multiple R: 0.670 Squared multiple R: 0.449
Adjusted squared multiple R: 0.405 Standard error of estimate: 0.175
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 0.027 0.167 0.0 . 0.162 0.872
LOGAREA 0.248 0.062 0.597 1.000 4.022 0.000
CPFOR2 0.003 0.001 0.307 1.000 2.067 0.049
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.624 2 0.312 10.198 0.001
Residual 0.765 25 0.031
--------------------------------------------------------------------------
Durbin-Watson D Statistic 2.252
First Order Autocorrelation -0.159
Plusieurs choses sont à noter ici. (1) On rejette les deux hypothèses nulles de l’absence d’effet de LOGAREA et de CPFOR2 sur LOGHERP. (2) Le R2 du modèle a augmenté jusqu’à 0.449. environ la somme de la proportion de variance expliquée par la régression de LOGHERP sur LOGAREA (.355) plus celle expliquée par la régression du résidu de LOGHERP-LOGAREA sur celle du résidu de CPFOR2-LOGAREA (.145) moins le carré de la corrélation entre CPFOR2 et LOGAREA (.076). (3) Les tolérances pour CPFOR2 et LOGAREA sont 1, reflétant la faible corrélation entre ces deux variables. (4) La valeur extrême originale a disparue parce que, si ce cas avait un gros résidus lorsque seule la taille du marais était considérée, le résidus semble pouvoir être expliqué par la valeur de CPFOR2 pour ce cas.

244 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Répétez les cinq étapes précédentes, cette fois en remplaçant CPFOR2 par THTDEN. Que concluez-vous?
Dep Var: LOGHERP N: 28 Multiple R: 0.496 Squared multiple R: 0.246
Adjusted squared multiple R: 0.217 Standard error of estimate: 0.201
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 0.926 0.067 0.0 . 13.824 0.000
THTDEN -0.049 0.017 -0.496 1.000 -2.916 0.007
Effect Coefficient Lower < 95%> Upper
CONSTANT 0.926 0.788 1.064
THTDEN -0.049 -0.083 -0.014
Correlation matrix of regression coefficients
CONSTANT THTDEN
CONSTANT 1.000
THTDEN -0.824 1.000
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.342 1 0.342 8.502 0.007
Residual 1.047 26 0.040
--------------------------------------------------------------------------
Durbin-Watson D Statistic 1.534
First Order Autocorrelation 0.201
On rejette donc l’hypothèse nulle que la richesse spécifique des amphibiens et reptiles ne change pas avec la densité des routes sur les terres adjacentes. Si on effectue maintenant la régression des résidus de la relation LOGHERP-LOGAREA sur les résidus de la régression de THTDEN-LOGAREA, on obtient:
Dep Var: RESIDUAL N: 28 Multiple R: 0.528 Squared multiple R: 0.278
Adjusted squared multiple R: 0.251 Standard error of estimate: 0.158
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT -0.007 0.030 0.0 . -0.239 0.813
R2 -0.042 0.013 -0.528 1.000 -3.168 0.004
Effect Coefficient Lower < 95%> Upper
CONSTANT -0.007 -0.069 0.054
R2 -0.042 -0.069 -0.015
Correlation matrix of regression coefficients
CONSTANT R2
CONSTANT 1.000

LABO- RÉGRESSION MULTIPLE - 245
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
R2 0.076 1.000
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.249 1 0.249 10.034 0.004
Residual 0.647 26 0.025
--------------------------------------------------------------------------
Durbin-Watson D Statistic 1.931
First Order Autocorrelation 0.008
Comme dans le cas de CPFOR2, si on corrige pour la taille du marais, il y a encore une relation négative significative entre la richesse spécifique des amphibiens et reptiles et la densité des routes sur les terres adjacentes. Si on inclue ces deux facteurs dans un modèle de régression multiple, on obtient:
Dep Var: LOGHERP N: 28 Multiple R: 0.732 Squared multiple R: 0.536
Adjusted squared multiple R: 0.499 Standard error of estimate: 0.161
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 0.376 0.149 0.0 . 2.521 0.018
LOGAREA 0.225 0.057 0.542 0.984 3.947 0.001
THTDEN -0.042 0.013 -0.428 0.984 -3.118 0.005
Effect Coefficient Lower < 95%> Upper
CONSTANT 0.376 0.069 0.684
LOGAREA 0.225 0.108 0.342
THTDEN -0.042 -0.070 -0.014
Correlation matrix of regression coefficients
CONSTANT LOGAREA THTDEN
CONSTANT 1.000
LOGAREA -0.933 1.000
THTDEN -0.411 0.126 1.000
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.744 2 0.372 14.426 0.000
Residual 0.645 25 0.026
--------------------------------------------------------------------------
Durbin-Watson D Statistic 1.965
First Order Autocorrelation -0.009
On rejette donc l’hypothèse nulle que la richesse spécifique n’est pas influencée par la taille des marais ni par la densité des routes.

246 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Calculez les corrélations entre LOGAREA, CPFOR2 et THTDEN. En vous basant sur tous les résultats à date, quelle est votre conclusion? Pour-quoi?
Estimez un modèle de régression avec LOGHERP comme variable dépendante et LOGAREA, CPFOR2 et THTDEN comme variables indépen-dantes. Que concluez-vous? Comment expliquez-vous que CPFOR2 a un coefficient qui n'est pas significativement différent de 0 dans ce modèle alors vous avez observé une régression significative entre les résidus de LOGHERP-LOGAREA sur les résidus de CPFOR2-LOGAREA?
Jusqu’à présent, il semble que la richesse spécifique des amphibiens et reptiles (LOGHERP) soit reliée à la surface des marais (LOGAREA), au couvert forestier sur les terres adjacents (CPFOR2) et à la densité des routes (THTDEN). Est-ce que cela implique que dans une régression multiple ces trois variables vont être significatives? Non, parce qu’il est possible que CPFOR2 et THTDEN soient corrélés. Si, par exemple, ces deux variables étaient parfaitement corrélées, alors l’effet de THTDEN pourrait être en fait attribuable à CPFOR2 (et vice-versa), et lorsqu’on inclurait l’une de ces deux variables dans le modèle de régression, il ne resterait plus rien à expliquer par la variable restante.
De fait, la corrélation entre CPFOR2 et THTDEN est significative : r = -.559, p = .001. Ces deux variables sont négativement reliées : plus il y a de routes, moins il reste de forêt.
Cette corrélation suggère qu’une partie de l’effet attribué à THTDEN peut être en fait le reflet de l’effet de CPFOR2, et vice-versa. Donc, on peut s’attendre à ce que dans un modèle de régression multiple contenant les trois variables indépendantes, une des deux variables ne sera pas significative. On peut même s’attendre à ce que ce soit CPFOR2 puisque la relation entre LOGHERP et CPFOR2, corrigée pour logarea est plus faible (R2 = .146) que celle entre LOGHERP et THTDEN (R2= .246).
Le modèle de régression multiple avec les trois variables donne:
Dep Var: LOGHERP N: 28 Multiple R: 0.740 Squared multiple R: 0.547
Adjusted squared multiple R: 0.490 Standard error of estimate: 0.162
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 0.285 0.191 0.0 . 1.488 0.150
LOGAREA 0.228 0.058 0.551 0.978 3.964 0.001
THTDEN -0.036 0.016 -0.365 0.732 -2.276 0.032
CPFOR2 0.001 0.001 0.123 0.744 0.774
0.447
Effect Coefficient Lower < 95%> Upper
2
3
1

LABO- RÉGRESSION MULTIPLE - 247
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
CONSTANT 0.285 -0.110 0.680
LOGAREA 0.228 0.110 0.347
THTDEN -0.036 -0.068 -0.003
CPFOR2 0.001 -0.002 0.004
Correlation matrix of regression coefficients
CONSTANT LOGAREA THTDEN CPFOR2
CONSTANT 1.000
LOGAREA -0.779 1.000
THTDEN -0.592 0.147 1.000
CPFOR2 -0.618 0.077 0.506 1.000
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.760 3 0.253 9.662 0.000
Residual 0.629 24 0.026
--------------------------------------------------------------------------
Durbin-Watson D Statistic 2.076
First Order Autocorrelation -0.069
Plusieurs choses à noter ici :
Tel que prédit, le coefficient de régression pour cpfor2 n’est plus significativement différent de 0. Une fois que la variabilité attribuable à logarea et thtden est enlevée, il ne reste qu’une fraction non-significative de la variabilité attribuable à cpfor2.
Le R2 pour ce modèle(.547) n’est que légèrement supérieur au R2 du modèle avec seulement LOGAREA et THTDEN (.536), ce qui confirme que CPFOR2 n’explique pas grand chose de plus.
Les tolérances pour THTDEN et CPFOR2 sont plus faibles que pour LOGAREA, ce qui indique que ces deux variables sont plus corrélées avec les autres variables indépendantes que is LOGAREA.
Notez que même si le coefficient de régression pour THTDEN n’a pas beaucoup changé par rapport à ce qui avait été estimé lorsque seul THTDEN et LOGAREA étaient dans le modèle (-.036 vs -.042), l’IC à 95% pour l’estimé du coefficient est plus grand et ce modèle plus complexe mène à un estimé moins précis. Si la corrélation entre THTDEN et CPFOR2 était plus forte, la décroissance de la précision serait encore plus grande.
À la suite de cette analyse, on doit conclure que :
1. Le meilleur modèle est celui incluant THTDEN et LOGAREA.
2. Il y a une relation négative entre la richesse spécifique des amphi-biens et reptiles et la densité des routes sur les terres adjacentes.
4
1
2
3
4

248 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
3. Il y a une relation positive entre la richesse spécifique et la taille des marais.
4. L’importance de la densité des routes et de la taille des marais est similaire puisque les coefficients de régression normalisés sont à peu près les mêmes (.428 et .54)
Notez que le “meilleur” modèle n’est pas nécessairement le modèle parfait, seulement le meilleur n’utilisant que ces trois variables indépendantes. Il est évident qu’il y a d’autres facteurs qui contrôlent la richesse spécifique dans les marais puisque, même le “meilleur” modèle n’explique que la moitié de la variabilité.
Refaite la régression précédente (LOGHERP vs LOGAREA CPFOR2 et THT-DEN), mais cette fois en activant l'option Regression, Linear, Options…, Stepwise-Backward. Utilisez une valeur de 0.15 comme Probability-Enter et 0.15 pour Probability- Remove. Comment le résultat se compare-t-il à ce qui avait été obtenu précédemment? Répétez la procédure en utilisant Stepwise-Forward. Vos conclusions changent-elles? Il est généralement recommandé d'essayer plus d'une méthode (Forward, Backward, etc.) et de comparer les résultats. Si les résultats diffèrent, le meilleur modèle n'est pas nécessairement évident et vous devrez être prudent en faisant vos inférences.
2 case(s) deleted due to missing data.
Step # 0 R = 0.740 R-Square = 0.547
Effect Coefficient Std Error Std Coef Tol. df F 'P'
In
___
1 Constant
2 CPFOR2 0.001 0.001 0.123 0.74380 1 0.599 0.447
3 THTDEN -0.036 0.016 -0.365 0.73208 1 5.180 0.032
4 LOGAREA 0.228 0.058 0.551 0.97835 1 15.710 0.001
Out Part. Corr.

LABO- RÉGRESSION MULTIPLE - 249
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
___
none
--------------------------------------------------------------------------
>STEP /AUTO
Dependent Variable LOGHERP
Minimum tolerance for entry into model = 0.000000
Backward stepwise with Alpha-to-Enter=0.150 and Alpha-to-Remove=0.150
Step # 1 R = 0.732 R-Square = 0.536
Term removed: CPFOR2
Effect Coefficient Std Error Std Coef Tol. df F 'P'
In
___
1 Constant
3 THTDEN -0.042 0.013 -0.428 0.98424 1 9.725 0.005
4 LOGAREA 0.225 0.057 0.542 0.98424 1 15.581 0.001
Out Part. Corr.
___
2 CPFOR2 0.156 . . 0.74380 1 0.599 0.447
--------------------------------------------------------------------------
Au premier pas, CPFOR2 est enlevé puisque le coefficient associé à cette variable n’est pas statistiquement différent de 0. Au deuxième pas, rien n’est enlevé puisque toutes les variables sont significatives.
L’algorithme de sélection progressive (Forward) donne :
Step # 0 R = 0.000 R-Square = 0.000
Effect Coefficient Std Error Std Coef Tol. df F 'P'
In
___
1 Constant
Out Part. Corr.
___
2 CPFOR2 0.305 . . 1.00000 1 2.662 0.115
3 THTDEN -0.496 . . 1.00000 1 8.502 0.007
4 LOGAREA 0.596 . . 1.00000 1 14.321 0.001
--------------------------------------------------------------------------
>STEP /AUTO
Dependent Variable LOGHERP
Minimum tolerance for entry into model = 0.000000
Forward stepwise with Alpha-to-Enter=0.150 and Alpha-to-Remove=0.150
Step # 1 R = 0.596 R-Square = 0.355
Term entered: LOGAREA
Effect Coefficient Std Error Std Coef Tol. df F 'P'
In
___
1 Constant
4 LOGAREA 0.247 0.065 0.596 1.00000 1 14.321 0.001
Out Part. Corr.
___
2 CPFOR2 0.382 . . 0.99999 1 4.273 0.049
3 THTDEN -0.529 . . 0.98424 1 9.725 0.005

250 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
--------------------------------------------------------------------------
Step # 2 R = 0.732 R-Square = 0.536
Term entered: THTDEN
Effect Coefficient Std Error Std Coef Tol. df F 'P'
In
___
1 Constant
3 THTDEN -0.042 0.013 -0.428 0.98424 1 9.725 0.005
4 LOGAREA 0.225 0.057 0.542 0.98424 1 15.581 0.001
Out Part. Corr.
___
2 CPFOR2 0.156 . . 0.74380 1 0.599 0.447
--------------------------------------------------------------------------
----------------------------------------------------------------------
Donc, peu importe l’algorithme utilisé, dans ce cas-ci, on arrive au même modèle.
Pour conclure cette section, quelques conseils concernant les méthodes automatisées de sélection des variables indépendantes:
1. Les différentes méthodes de sélection des variables indépendantes peuvent mener à des modèles différents. Il est souvent utile d’essayer plus d’une méthode et de comparer les résultats. Si les résultats diffèrent, c’est presque toujours à cause de multicollinéa-rité entre les variables indépendantes.
2. Attention à la régression pas à pas. Les auteurs de SYSTATen disent: “Stepwise regression is probably the most abused compu-terized statistical technique ever devised. If you think you need automated stepwise regression to solve a particular problem, you probably don't. Professional statisticians rarely use automated stepwise regression because it does not necessarily find the "best" fitting model, the "real" model, or alternative "plausible" models. Furthermore, the order in which variables enter or leave a stepwise program is usually of no theoretical signficance. You are always better off thinking about why a model could generate your data and then testing that model.” En bref, on abuse trop souvent de cette technique.
3. Les résultats peuvent varier si on change les valeurs du seuil pour l’inclusion ou l’exclusion des variables indépendantes dans le modèle. Si les variables indépendantes ne sont pas trop corrélées entre elles, les valeurs de 0.15 pour alpha-to-enter et alpha-to-remove sont généralement bonnes. Si il y a une forte multicolli-néarité, il vaut mieux réduire ces valeurs à moins de 0.05
4. Il faut toujours garder à l’esprit que l’existence d’une régression significative n’est pas suffisante pour prouver une relation causale.

LABO- RÉGRESSION MULTIPLE - 251
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Détecter la multicolinéaritéSYSTAT produit plusieurs indices de multicollinéarité. L'approche la plus évidente est de scruter la matrice de corrélation des variables indépendantes comme vous l'avez fait plus haut. Cependant, cela n'est pas suffisant parce que des corrélations entre groupes de variables peuvent ne pas être évidentes dans la matrice de corrélation.
La tolérance est une mesure diagnostique qui permet d'aller plus loin que l'examen de la matrice de corrélation. La tolérance est définie comme le coefficient d'indétermination (1-R2) de la régression de la variable indépendante d'intérêt sur toutes les autres variables indépendantes. Une tolérance de près de 0 veut dire que cette variable est presque une combinaison linéaire parfaite des autres variables. En pratique les tolérances de moins de 0.1 indiquent un problème potentiel. L'inclusion de telles variables indépendantes dans un modèle de régression multiple ajoute peu à la qualité d'ajustement mais contribue à augmenter les erreurs types des autres coefficients de régression.
Deux autres mesures diagnostiques sont l'indice de condition (Condition index) et la proportion de variance (Variance proportion) qui toutes deux mesurent d'une certaine façon comment la variance d'une variable indépendante peut être expliquée par la variance des autres variables. En général, un indice de condition entre 10 et 30 commence à indiquer un problème, à plus de 30 c'est un sérieux problème. Quant à la "variance proportion", une valeur supérieure à 0.5, associée à une forte valeur de l'indice de condition indiquent une multicollinéarité assez importante pour affecter les résultats.
Refaites la régression multiple de LOGHERP vs LOGAREA CPFOR2 et THT-DEN, mais cette fois faites imprimer la version longue des résultats (allez à Edit-Options-Output results-Length et sélectionnez Long). Examinez la tolérance pour chacune des variables indépendantes. Que concluez-vous?
Examinez le fichier de sortie de SYSTAT. En vous fiant aux indices de condition et aux "variance proportions", que concluez-vous?
Pour le modèle incluant les trois variables, on avait obtenu :Dep Var: LOGHERP N: 28 Multiple R: 0.740 Squared multiple R: 0.547
Adjusted squared multiple R: 0.490 Standard error of estimate: 0.162
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 0.285 0.191 0.0 . 1.488 0.150
CPFOR2 0.001 0.001 0.123 0.744 0.774 0.447
THTDEN -0.036 0.016 -0.365 0.732 -2.276 0.032

252 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
LOGAREA 0.228 0.058 0.551 0.978 3.964 0.001
Notez que les tolérances pour CPFOR2 et THTDEN sont plus basses que pour LOGAREA, quoique les tolérances ne soient pas particulièrement faibles. Ceci suggère que LOGAREA est indépendant des deux autres variables, mais que CPFOR2 et THTDEN sont corrélés. Si on examine les autres indices de multicollinéarité, on a :
Eigenvalues of unit scaled X'X
1 2 3 4
3.530 0.372 0.081 0.018
Pour bien comprendre ce tableau des valeur propre il faut comprendre l’algèbre matricielle. Pour l’interpréter, il suffit de savoir que dans un ensemble de variables indépendantes fortement corrélées les unes avec les autres, la plupart des valeurs propres (eigenvalues) seront près de 0. Ici, une seule (la quatrième) est petite. ceci suggère un petit problème potentiel de multicollinéarité.
Condition indices
1 2 3 4
1.000 3.080 6.610 14.185
L’indice de condition (condition index) est la racine carrée du rapport de la valeur propre sur la première valeur propre. Ici, comme l’une des valeurs est >10, il y a peut-être un petit problème.
Variance proportions
1 2 3 4
CONSTANT 0.002 0.000 0.013 0.985
CPFOR2 0.008 0.098 0.596 0.297
THTDEN 0.014 0.423 0.284 0.279
LOGAREA 0.004 0.002 0.275 0.720
Les proportions de variance correspondent à la fraction de la variabilité de la variable indépendante expliquée par chacune des composantes principales des variables indépendantes. Cela ne vous dit probablement pas grand chose, et ce qui compte, c’est que vous devriez commencer à vous inquiéter lorsque une composante ayant un fort indice de condition a des valeurs de plus de 0.5 pour plus d’une variable. Ici, cela ne se produit que pour la quatrième composante.
Tout compte fait, il n’y a pas de forte multicollinéarité ici.
Souvenez-vous que l’absence de multicollinéarité n’est pas une condition préalable à l’emploi de la régression multiple. L’effet de la multicollinéarité est d’augmenter les erreurs-types des coefficients, et par conséquent de réduire les statistiques F et t associées aux épreuves d’hypothèses sur ces coefficients et donc augmenter les valeur de p.

LABO- RÉGRESSION MULTIPLE - 253
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Donc la multicollinéarité réduit la puissance et peut faire en sorte que des facteurs importants ne soient pas inclus dans le modèle final retenu.
Régression polynomialeLa régression requiert la linéarité de la relation entre les variables dépendante et indépendante(s). Lorsque la relation n'est pas linéaire, il est parfois possible de linéariser la relation en effectuant une transformation sur une ou plusieurs variables. Cependant, dans bien des cas il est impossible de transformer les axes pour rendre la relation linéaire. On doit alors utiliser une forme ou l'autre de régression non-linéaire.
La forme la plus simple de régression non-linéaire est la régression polynomiale dans laquelle les variables indépendantes sont à une puissance plus grande que 1 (Ex : X2 ou X3)
Faites un diagramme de dispersion des résidus (RESIDUAL) de la régres-sion LOGHERP-LOGAREA en fonction de SWAMP.
L'examen de ce graphique suggère qu'il y a une forte relation entre les deux variables, mais qu'elle n'est pas linéaire. Essayez de faire une régression de RESIDUAL sur SWAMP. Quelle est votre conclusion?
Dep Var: RESIDUAL N: 28 Multiple R: 0.158 Squared multiple R: 0.025
Adjusted squared multiple R: 0.0 Standard error of estimate: 0.183
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 0.085 0.109 0.0 . 0.774 0.446
10 20 30 40 50 60 70 80 90 100110SWAMP
-0.4
-0.3
-0.2
-0.1
0.0
0.1
0.2
0.3
0.4
0.5
RES
IDU
AL

254 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
SWAMP -0.001 0.001 -0.158 1.000 -0.816 0.422
Effect Coefficient Lower < 95%> Upper
CONSTANT 0.085 -0.140 0.309
SWAMP -0.001 -0.004 0.002
En deux mots, l’ajustement est épouvantable! Malgré le fait que le graphique suggère une relation très forte entre les deux variables. Cependant, cette relation n’est pas linéaire... (ce qui est également apparent si vous examinez les résidus du modèle linéaire).
Créez une nouvelle variable SWAMP2= SWAMP*SWAMP (Data, Transform, Let). Ensuite faite une régression multiple des résidus de la régression LOGHERP-LOGAREA comme variable dépendante et SWAMP et SWAMP2 comme les variables indépendantes. Que concluez-vous? Qu'est-ce que l'examen des résidus de cette régression multiple révèle?
DEP VAR: CHERP N: 28 MULTIPLE R: 0.783 SQUARED MULTIPLE R: 0.613
ADJUSTED SQUARED MULTIPLE R: .582 STANDARD ERROR OF ESTIMATE:
0.118
VARIABLE COEFFICIENT STD ERROR STD COEF TOLERANCE T P(2 TAIL)
CONSTANT -0.780 0.157 0.000 . -4.975 0.000
SWAMP 0.034 0.006 4.690 0.024 5.892 0.000
SWAMP2 -0.000 0.000 -4.908 0.024 -6.166 0.000
ANALYSIS OF VARIANCE
SOURCE SUM-OF-SQUARES DF MEAN-SQUARE F-RATIO P
REGRESSION 0.549 2 0.275 19.817 0.000
RESIDUAL 0.347 25 0.014
WARNING: CASE 11 HAS LARGE LEVERAGE (LEVERAGE = .466)
DURBIN-WATSON D STATISTIC 1.962
FIRST ORDER AUTOCORRELATION -.076
Il devient évident que si on corrige la richesse spécifique pour la taille des marais, une fraction importante de la variabilité résiduelle peut être associée à SWAMP, selon une relation quadratique. Si vous examinez les résidus, vous observerez que l’ajustement est nettement meilleur qu’avec le modèle linéaire.
Notez que comme SWAMP2 est simplement le carré de SWAMP, ces deux variables sont très corrélées, tel qu’indiqué par les valeurs de tolérance.
En vous basant sur les résultats de la dernière analyse, comment sug-gérez-vous de modifier le modèle de régression multiple? Quel est, d'après vous, le meilleur modèle? Pourquoi? Ordonnez les différents
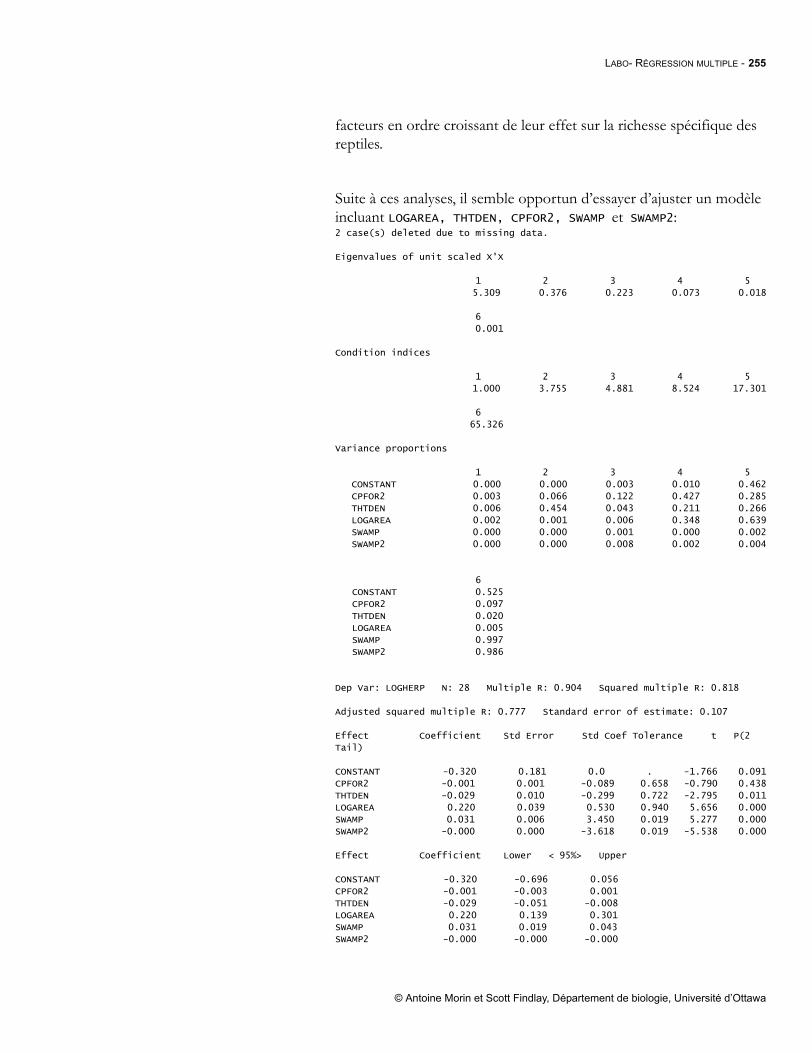
LABO- RÉGRESSION MULTIPLE - 255
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
facteurs en ordre croissant de leur effet sur la richesse spécifique des reptiles.
Suite à ces analyses, il semble opportun d’essayer d’ajuster un modèle incluant LOGAREA, THTDEN, CPFOR2, SWAMP et SWAMP2:2 case(s) deleted due to missing data.
Eigenvalues of unit scaled X'X
1 2 3 4 5
5.309 0.376 0.223 0.073 0.018
6
0.001
Condition indices
1 2 3 4 5
1.000 3.755 4.881 8.524 17.301
6
65.326
Variance proportions
1 2 3 4 5
CONSTANT 0.000 0.000 0.003 0.010 0.462
CPFOR2 0.003 0.066 0.122 0.427 0.285
THTDEN 0.006 0.454 0.043 0.211 0.266
LOGAREA 0.002 0.001 0.006 0.348 0.639
SWAMP 0.000 0.000 0.001 0.000 0.002
SWAMP2 0.000 0.000 0.008 0.002 0.004
6
CONSTANT 0.525
CPFOR2 0.097
THTDEN 0.020
LOGAREA 0.005
SWAMP 0.997
SWAMP2 0.986
Dep Var: LOGHERP N: 28 Multiple R: 0.904 Squared multiple R: 0.818
Adjusted squared multiple R: 0.777 Standard error of estimate: 0.107
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT -0.320 0.181 0.0 . -1.766 0.091
CPFOR2 -0.001 0.001 -0.089 0.658 -0.790 0.438
THTDEN -0.029 0.010 -0.299 0.722 -2.795 0.011
LOGAREA 0.220 0.039 0.530 0.940 5.656 0.000
SWAMP 0.031 0.006 3.450 0.019 5.277 0.000
SWAMP2 -0.000 0.000 -3.618 0.019 -5.538 0.000
Effect Coefficient Lower < 95%> Upper
CONSTANT -0.320 -0.696 0.056
CPFOR2 -0.001 -0.003 0.001
THTDEN -0.029 -0.051 -0.008
LOGAREA 0.220 0.139 0.301
SWAMP 0.031 0.019 0.043
SWAMP2 -0.000 -0.000 -0.000

256 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Correlation matrix of regression coefficients
CONSTANT CPFOR2 THTDEN LOGAREA SWAMP
CONSTANT 1.000
CPFOR2 -0.180 1.000
THTDEN -0.490 0.434 1.000
LOGAREA -0.432 0.099 0.132 1.000
SWAMP -0.698 -0.336 0.115 -0.110 1.000
SWAMP2 0.669 0.340 -0.114 0.085 -0.990
SWAMP2
SWAMP2 1.000
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 1.137 5 0.227 19.783 0.000
Residual 0.253 22 0.011
--------------------------------------------------------------------------
*** WARNING ***
Case 11 has large leverage (Leverage = 0.694)
Durbin-Watson D Statistic 1.761
First Order Autocorrelation 0.012
Les résultats de cette analyse suggèrent qu’on devrait probablement exclure CPFOR2 du modèle:
Eigenvalues of unit scaled X'X
1 2 3 4 5
4.511 0.318 0.146 0.024 0.001
Condition indices
1 2 3 4 5
1.000 3.766 5.552 13.774 57.334
Variance proportions
1 2 3 4 5
CONSTANT 0.001 0.000 0.018 0.275 0.706
THTDEN 0.010 0.685 0.124 0.072 0.108
LOGAREA 0.002 0.002 0.108 0.887 0.001
SWAMP 0.000 0.001 0.001 0.002 0.996
SWAMP2 0.000 0.002 0.010 0.004 0.984
Dep Var: LOGHERP N: 28 Multiple R: 0.902 Squared multiple R: 0.813
Adjusted squared multiple R: 0.780 Standard error of estimate: 0.106
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT -0.346 0.177 0.0 . -1.957 0.063
THTDEN -0.026 0.009 -0.262 0.890 -2.744 0.012
LOGAREA 0.223 0.038 0.538 0.949 5.810 0.000
SWAMP 0.030 0.006 3.276 0.022 5.365 0.000
SWAMP2 -0.000 0.000 -3.443 0.022 -5.649 0.000
Effect Coefficient Lower < 95%> Upper
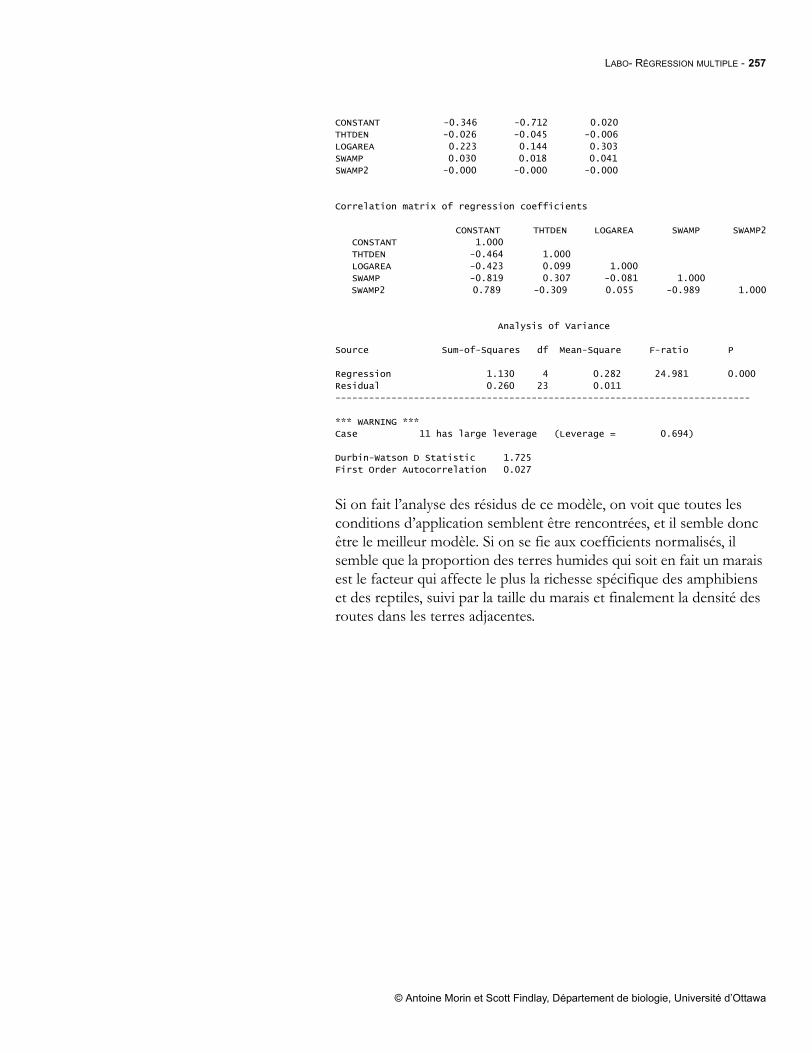
LABO- RÉGRESSION MULTIPLE - 257
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
CONSTANT -0.346 -0.712 0.020
THTDEN -0.026 -0.045 -0.006
LOGAREA 0.223 0.144 0.303
SWAMP 0.030 0.018 0.041
SWAMP2 -0.000 -0.000 -0.000
Correlation matrix of regression coefficients
CONSTANT THTDEN LOGAREA SWAMP SWAMP2
CONSTANT 1.000
THTDEN -0.464 1.000
LOGAREA -0.423 0.099 1.000
SWAMP -0.819 0.307 -0.081 1.000
SWAMP2 0.789 -0.309 0.055 -0.989 1.000
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 1.130 4 0.282 24.981 0.000
Residual 0.260 23 0.011
--------------------------------------------------------------------------
*** WARNING ***
Case 11 has large leverage (Leverage = 0.694)
Durbin-Watson D Statistic 1.725
First Order Autocorrelation 0.027
Si on fait l’analyse des résidus de ce modèle, on voit que toutes les conditions d’application semblent être rencontrées, et il semble donc être le meilleur modèle. Si on se fie aux coefficients normalisés, il semble que la proportion des terres humides qui soit en fait un marais est le facteur qui affecte le plus la richesse spécifique des amphibiens et des reptiles, suivi par la taille du marais et finalement la densité des routes dans les terres adjacentes.

258 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

LABO- TABLEAUX DE CONTINGENCE ET MODÈLES LOG-LINÉAIRES. - 259
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Labo- Tableaux de contingence et modèles log-linéaires.
Après avoir complété cet exercice de laboratoire, vous devriez pouvoir :
• Créer des fichiers SYSTAT pour analyser des données de fréquen-ces
• Utiliser SYSTAT pour éprouver une hypothèse extrinsèque à pro-pos d'une population à partir de données de fréquences
• Utiliser SYSTAT pour éprouver l'hypothèse d'indépendance dans un tableau de fréquences à deux critères de classification
• Utiliser SYSTAT pour ajuster un modèle log-linéaire à des don-nées d'un tableau de fréquences à plus de deux dimensions
Création du fichier de donnéesPlusieurs expériences en biologie génèrent des données de fréquence, comme, par exemple, le nombre de plantes infectées par un pathogène lorsque soumises à différents niveaux d'exposition, ou le nombre de mâles et de femelles qui éclosent lorsque des œufs de tortue sont incubés à diverses températures (chez les tortues, la détermination du sexe est affectée par la température !), etc. Généralement, la question statistique revient à déterminer si la proportion des observations dans les diverses catégories (infecté vs non infecté, mâle vs femelle) diffère significativement entre les traitements. Pour répondre à cette question, il faut créer un fichier de données qui contient le nombre d'individus dans chaque catégorie.

260 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Le tableau ci-dessous contient les résultats d'un recensement fait en 1980 dans une petite ville du centre des États Unis ::
Créez un fichier SYSTAT à partir de ces données. Pour ce faire, ouvrez un nouveau chiffrier et crées trois variables : AGE_CLASS$, SEX$ et COUNT. Le fichier complet devrait avoir 3 colonnes et 18 rangées.
Classe d’âge (années)
Femelles Mâles
0-9 17619 17538
10-19 17947 18207
20-29 21344 21401
30-39 19138 18837
40-49 13135 12568
50-59 11617 10661
60-69 11053 9374
70-79 7712 5348
80+ 4114 1926
Programme SYSTAT pour créer le fichier de données MYFILE contenant les données du recencementBASIC
NEW
SAVE MYFILE
INPUT age_class$, sex$ count
RUN
0-9 male 17619
10-19 male 17947
20-29 male 21344
30-39 male 19138
40-49 male 13135
50-59 male 11617
60-69 male 11053
70-79 male 7712
80+ male 4114
0-9 female 17538
10-19 female 18207
20-29 female 21401
30-39 female 18837
40-49 female 12568
50-59 female 10661
60-69 female 9374
70-79 female 5348
80+ female 1926
~

LABO- TABLEAUX DE CONTINGENCE ET MODÈLES LOG-LINÉAIRES. - 261
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Ensuite, toujours à la fenêtre du chiffrier, cliquez sur Data-Frequency et inscrivez COUNT comme variable représentant les fréquences. Passez à la fenêtre principale (SYSTAT Main, et cliquez sur Stats-Crosstabs-Two-way). Inscrivez AGE_CLASS$ comme variable représentant les rangées du tableau (Row variable) et SEX$ pour les colonnes (Column variable), vérifiez que Frequencies est sélectionné et enfin cliquez sur OK. Assurez-vous que le tableau qui apparaîtra correspond aux don-nées ci-dessus.
Le tableau de fréquences devrait ressembler à:female male TOTAL
---------------------
0-9 | 17619 17538 | 35157
| |
10-19 | 17947 18207 | 36154
| |
20-29 | 21344 21401 | 42745
| |
30-39 | 19138 18837 | 37975
| |
40-49 | 13135 12568 | 25703
| |
50-59 | 11617 10661 | 22278
| |
60-69 | 11053 9374 | 20427
| |
70-79 | 7712 5348 | 13060
| |
80+ | 4114 1926 | 6040
---------------------
TOTAL 123679 115860 239539
SYSTAT peut générer des tableaux de fréquences à partir de fichier de données de deux façons. Si vous aviez entré chaque observation sur une ligne séparée correspondant à un individu (votre fichier de données aurait alors 239,539 rangées…), vous auriez pu créer le même tableau en suivant les même directives, sauf l'étape Data-Frequency. Sans cette étape, SYSTAT considère chaque rangée du fichier de données comme une observation.
Si vous oubliez l’étape Data, Frequency (ou la commande FREQUENCY COUNT), vous obtenez le tableau suivant puisque SYSTAT considère alors chaque ligne du fichier comme une seule observation !Frequencies
AGECLASS$ (rows) by SEX$ (columns)
female male Total
Commandes SYSTAT pour produire le tableau de fréquenceFREQUENCY COUNT
XTAB
PRINT / FREQ
TABULATE AGE_CLASS$ * SEX$

262 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
+---------------+
0-9 | 1 1 | 2
10-19 | 1 1 | 2
20-29 | 1 1 | 2
30-39 | 1 1 | 2
40-49 | 1 1 | 2
50-59 | 1 1 | 2
60-69 | 1 1 | 2
70-79 | 1 1 | 2
80+ | 1 1 | 2
+---------------+
Total 9 9 18
Éprouver une hypothèse extrinsèqueCertaines hypothèses biologiques reposent sur la fréquence relative de différentes classes dans une population. Par exemple, l'hypothèse que le taux de mortalité aux États Unis est plus élevé chez les hommes que chez les femmes mène à la prédiction que la proportion des mâles devrait aller en décroissant au fur et à mesure qu'ils vieillissent.
En utilisant les données pour la classe d'âge 0-9 ans, éprouvez l'hypothèse que la proportion des mâles et des femelles à la naissance est égale en créant un fichier de données avec deux rangées (Observed et Expected) et deux colonnes (male et female), puis en utilisant Stats-Crosstabs-Two way. Que concluez-vous ? Croyez-vous que ces don-nées sont appropriées pour tester cette hypothèse?
Pour éprouver l’hypothèse extrinsèque que la proportion des mâles et des femelles est égale à la naissance, il faut construire un tableau de contingence 2x2 des fréquences attendues et observées. Les fréquences attendues sont obtenues en faisant la somme des fréquences des mâles et des femelles et en divisant par 2.Frequencies
SAMPLE$ (rows) by SEX$ (columns)
female male Total
+-------------------+
expected | 17578 17578 | 35156
observed | 17619 17538 | 35157
+-------------------+
Total 35197 35116 70313
Test statistic Value df Prob
Pearson Chi-square 0.093 1.000 0.760
Likelihood ratio Chi-square 0.093 1.000 0.760
Yates corrected Chi-square 0.089 1.000 0.766
Pour obtenir ce fichier de sortie, allez à Crosstabs>Two-way> Statistics, et activez les options Yates Corrected et Likelihood-ratio Chi-square (G). Notez que dans ce cas-ci, les valeurs de G et du khi-carré sont identiques. Notez aussi que puisque c’est un tableau 2x2, on

LABO- TABLEAUX DE CONTINGENCE ET MODÈLES LOG-LINÉAIRES. - 263
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
devrait utiliser une correction, soit celle de Yates ou de Fisher. Cette analyse nous amène à la conclusion que le rapport des sexes est de 1:1 à la naissance.
Ces observations ne sont pas particulièrement utiles pour évaluer si le rapport des sexes à la naissance est de 1:1 parce que la première classe d’âge est trop grande. Il est tout à fait possible qu’à la naissance la proportion des mâles et des femelles diffère mais qu’un taux de mortalité différent entre les sexes viennent compenser (ex: il y a plus de mâles à la naissance, mais leur taux de mortalité est plus élevé au cours des 9 premières années de vie). Dans ce cas, le rapport des sexes à la naissance n’est pas de 1:1, mais nous acceptons néanmoins l’hypothèse nulle en se basant sur la classe d’âge 0-9.
En utilisant les données pour la classe d'âge 80+, éprouvez l'hypothèse nulle que la proportion des mâles et des femelles est la même dans cette classe d'âge. Que concluez-vous ?
Pour la classe 80+, on procède de la même manière que précédemment pour obtenir:female male Total
+-------------------+
expected | 3020 3020 | 6040
observed | 4114 1926 | 6040
+-------------------+
Total 7134 4946 12080
Test statistic Value df Prob
Pearson Chi-square 409.746 1.000 0.000
Likelihood ratio Chi-square 412.422 1.000 0.000
Yates corrected Chi-square 408.997 1.000 0.000
Et on rejette donc l’hypothèse nulle. Il y a significativement plus de femelles que de mâles dans la classe d’âge 80+.
Programme SYSTAT pour analyser un tableau 2x2BASIC
NEW
SAVE MYFILE
INPUT sample$, sex$ count
RUN
expected female 17578
expected male 17578
observed female 17619
observed male 17538
~
FREQUENCY COUNT
XTAB
PRINT / FREQ CHISQ YATES LRCHI
TABULATE sample$ * SEX$

264 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Épreuve d'indépendance pour tableau à deux critères de classificationUne utilisation fréquente des tableaux de contingence est de répondre à des questions sur comment la proportion de différentes catégories d'observations diffère entre traitements. Une différence statistiquement significative entre les traitements signifie que les proportions dépendent des traitements, c'est-à-dire qu'il y a une interaction entre le traitement et la proportion des observations dans une catégorie.
Le fichier STURGDAT.SYS contient des données sur des échantillons d'esturgeons récoltés près de The Pas au Manitoba et Cumberland House en Saskatchewan entre 1978 et 1980. Parmi les variables mesurées il y a le sexe (SEX$), l'année (YEAR$) et le nom du site (LOCATION$). À partir de ces données :
Éprouvez l'hypothèse nulle que, à The Pas, la proportion des mâles et des femelles était la même en 1978, 1979 et 1979. Quelle est votre conclusion ?
D’abord, on doit sélectionner les cas pour lesquels LOCATION$ = The_Pas pour obtenir:FREQUENCIES
1978 1979 1980 TOTAL
-------------------------------
female | 5 12 38 | 55
| |
male | 16 12 18 | 46
-------------------------------
TOTAL 21 24 56 101
TEST STATISTIC VALUE DF PROB
PEARSON CHI-SQUARE 12.200 2 0.002
LIKELIHOOD RATIO CHI-SQUARE 12.559 2 0.002
On rejette donc l’hypothèse nulle. Le rapport des sexes des esturgeons a varié au cours de la période 1978-1980, passant d’une dominance de mâles en 1978 à une dominance de femelles en 1980.
Commandes SYSTAT: tableau de contingence 2x2SELECT (LOCATION$= "The_Pas")
PRINT NONE/ FREQ CHISQ LRCHI
TABULATE SEX$ * YEAR$

LABO- TABLEAUX DE CONTINGENCE ET MODÈLES LOG-LINÉAIRES. - 265
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Éprouvez l'hypothèse nulle que le rapport des sexes, toutes années confondues, était le même à The Pas et Cumberland House. Quelle est votre conclusion?
Pour éprouver l’hypothèse nulle que le sex ratio ne varie pas entre les sites, on doit générer le tableau suivant:
Cumberland The_Pas TOTAL
---------------------
female | 51 55 | 106
| |
male | 34 46 | 80
---------------------
TOTAL 85 101 186
TEST STATISTIC VALUE DF PROB
PEARSON CHI-SQUARE 0.579 1 0.447
LIKELIHOOD RATIO CHI-SQUARE 0.580 1 0.446
YATES CORRECTED CHI-SQUARE 0.375 1 0.540
FISHER EXACT TEST (TWO-TAIL) 0.461
Comme c’est un tableau 2x2, on devrait utiliser une correction (Yates ou Fisher). Notez que les valeurs de p après correction de Yates et Fisher sont plus élevées que celles associées à la statistique G et au khi-carré: ceci illustre le fait que dans les tableaux 2x2, G et khi-carré sont trop libéraux. Mais ici, peu importe, puisque toutes les probabilités sont beaucoup plus grandes que 0.05. On accepte donc l’hypothèse nulle que la proportion des deux sexes est la même aux deux sites.
Notez que cette analyse n’éprouve PAS l’hypothèse nulle que le rapport des sexes est 1:1 aux deux sites, seulement qu’il est le même à The Pas et Cumberland (1:1 ou quelque chose d’autre).
Modèles log-linéaires et tableaux de contingence à critères de classification multiples.Le concept d'interaction peut être étendu à des tableaux de contingences à plus de deux critères de classification, c'est-à-dire à des tableaux qui ont 3 dimensions ou plus, correspondant chacune à un critère utilisé pour classifier les observations. Par exemple, supposez que nous désirions examiner l'effet de la température (deux niveaux :
Commandes SYSTAT: tableau de contingence 2x2SELECT
PRINT NONE/ FREQ CHISQ YATES FISHER LRCHI
TABULATE SEX$ * LOCATION$

266 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
basse et élevée) et de la lumière (deux niveaux : lumière basse et lumière intense) sur le nombre de plantes infectées par un pathogène (deux niveaux d'infestations : infectée et non-infectée). Dans ce cas nous aurions besoin d'un tableau de contingence à trois critères de classification.
Tel que décrit dans les notes de cours, l'ajustement de modèles log-linéaires à des données de fréquences est un processus séquentiel par lequel une série de modèles, commençant par le modèle complet, sont tour à tour ajustés aux données. À chaque étape, un terme d'interaction d'intérêt est mis de côté, et la réduction de l'ajustement du modèle est évaluée : si la réduction de l'ajustement n'est pas significative, le terme est éliminé du modèle ; par contre, si le modèle réduit correspond significativement moins bien aux observations alors le terme est retenu. Comme pour les tableaux à deux critères de classification, les seuls termes intéressants sont les termes d'interaction puisque l'on tente d'éprouver l'indépendance des différents facteurs.
Comment spécifier un modèle log-linéaire avec SYSTAT
Le fichier LOGLIN.SYD contient les fréquences (FREQUENCY) de plantes infectées ou non infectées (INFECTED$) dans les traitements à basse et haute température (TEMPERATURE$) et à basse et haute luminosité (LIGHT$). Pour analyser ces fréquences de manière à déterminer si l'infection est indépendante de la lumière et de la température, on peut construire un modèle log-linéaire.
Ouvrez le fichier LOGLIN.SYD, et indiquez à SYSTAT que les fréquences pour chaque catégorie ont déjà été compilées en allant à Data-Frequency, et en inscrivant FREQUENCY comme Variable. Ensuite, allez à Stats-Loglinear Model- Estimate Model. La fenêtre de dialogue suivante apparaîtra alors :

LABO- TABLEAUX DE CONTINGENCE ET MODÈLES LOG-LINÉAIRES. - 267
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Pour spécifier le modèle à ajuster, vous devez inscrire les termes à inclure dans le modèle (Model Terms) et définir le tableau de contingence qui sera modélisé (Define Table). Pour ajuster le modèle complet, entrez les termes :
LIGHT$TEMPERATURE$INFECTED$LIGHT*TEMPERATURE$LIGHT$*INFECTED$TEMPERATURE$*INFECTED$LIGHT$*TEMPERATURE$*INFECTED$
et définissez le tableau de contingence comme étant:
LIGHT$*TEMPERATURE$*INFECTED$
(Pour inscrire les termes d'interaction, comme par exemple LIGHT$*TEMPERATURE$, cliquer sur la première variable dans la liste apparaissant à gauche, puis sur Add, puis cliquer sur la deuxième variable et enfin sur Cross.)
Interprétation du fichier de sortie de SYSTAT
Après avoir spécifié le tableau à analyser et les termes à inclure, SYSTAT va produire les résultats suivants dont la signification est brièvement décrite à la fin.Case frequencies determined by value of variable FREQUENCY.
Observed Frequencies
====================
INFECTED$ LIGHT$ | TEMPERATURE$
| High Low
---------+---------+-------------------------
No High | 50.000 85.000
Low | 20.000 70.000
+
Yes High | 50.000 15.000
Low | 80.000 30.000
-------------------+-------------------------
Commandes SYSTAT: modèle log-linéaire.USE 'C:\DATA\AMORIN\BIO4518\1998\LABO\DATA\LOGLIN.SYD'
FREQUENCY FREQUENCY
LOGLIN
MODEL INFECTED$*TEMPERATURE$*LIGHT$ = LIGHT$+TEMPERA-
TURE$+INFECTED$,
+TEMPERATURE$*LIGHT$+INFECTED$*LIGHT$+INFECTED$*TEMPERATURE$,
+INFECTED$*TEMPERATURE$*LIGHT$
PRINT NONE/ CHISQ RATIO MLE ELAMBDA TERM HTERM OBSFREQ EXPECT
STAND
ESTIMATE
1

268 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Pearson ChiSquare 0.0000 df 0 Probability .
LR ChiSquare 0.0000 df 0 Probability .
Raftery's BIC 0.0000
Dissimilarity 0.0000
Expected Values
===============
INFECTED$ LIGHT$ | TEMPERATURE$
| High Low
---------+---------+-------------------------
No High | 50.000 85.000
Low | 20.000 70.000
+
Yes High | 50.000 15.000
Low | 80.000 30.000
-------------------+-------------------------
Standardized Deviates = (Obs-Exp)/sqrt(Exp)
===========================================
INFECTED$ LIGHT$ | TEMPERATURE$
| High Low
---------+---------+-------------------------
No High | -0.000 0.000
Low | -0.000 0.000
+
Yes High | 0.000 -0.000
Low | 0.000 0.000
-------------------+-------------------------
Lambda / SE(Lambda)
===================
THETA
-------------
3.750
-------------
TEMPERATURE$
High Low
-------------------------
0.840 -0.840
-------------------------
LIGHT$
High Low
-------------------------
-0.110 0.110
-------------------------
INFECTED$
No Yes
-------------------------
2.501 -2.501
-------------------------
LIGHT$ | TEMPERATURE$
| High Low
---------+-------------------------
High | 1.977 -1.977
Low | -1.977 1.977
---------+-------------------------
INFECTED$| TEMPERATURE$
| High Low
---------+-------------------------
No | -8.300 8.300
Yes | 8.300 -8.300
---------+-------------------------
2
3
4

LABO- TABLEAUX DE CONTINGENCE ET MODÈLES LOG-LINÉAIRES. - 269
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
INFECTED$| LIGHT$
| High Low
---------+-------------------------
No | 4.756 -4.756
Yes | -4.756 4.756
---------+-------------------------
INFECTED$ LIGHT$ | TEMPERATURE$
| High Low
---------+---------+-------------------------
No High | 1.044 -1.044
Low | -1.044 1.044
+
Yes High | -1.044 1.044
Low | 1.044 -1.044
-------------------+-------------------------
Multiplicative Effects = exp(Lambda)
====================================
THETA
-------------
42.533
-------------
TEMPERATURE$
High Low
-------------------------
1.051 0.951
-------------------------
LIGHT$
High Low
-------------------------
0.993 1.007
-------------------------
INFECTED$
No Yes
-------------------------
1.161 0.861
-------------------------
LIGHT$ | TEMPERATURE$
| High Low
---------+-------------------------
High | 1.125 0.889
Low | 0.889 1.125
---------+-------------------------
INFECTED$| TEMPERATURE$
| High Low
---------+-------------------------
No | 0.609 1.642
Yes | 1.642 0.609
---------+-------------------------
INFECTED$| LIGHT$
| High Low
---------+-------------------------
No | 1.329 0.753
Yes | 0.753 1.329
---------+-------------------------
INFECTED$ LIGHT$ | TEMPERATURE$
| High Low
---------+---------+-------------------------
No High | 1.064 0.940
Low | 0.940 1.064

270 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
+
Yes High | 0.940 1.064
Low | 1.064 0.940
-------------------+-------------------------
Model ln(MLE): -22.372
Term tested The model without the term Removal of term from
model
ln(MLE) Chi-Sq df p-value Chi-Sq df p-value
--------------- --------- -------- ---- -------- -------- ---- --------
TEMPERATURE$ . -22.726 0.71 1 0.3999 0.71 1 0.3999
LIGHT$ . . . . -22.378 0.01 1 0.9122 0.01 1 0.9122
INFECTED$. . . -25.540 6.34 1 0.0118 6.34 1 0.0118
LIGHT$
* TEMPERATURE$ -24.379 4.01 1 0.0451 4.01 1 0.0451
INFECTED$
* TEMPERATURE$ -62.197 79.65 1 0.0000 79.65 1 0.0000
INFECTED$
* LIGHT$ . . . -34.379 24.01 1 0.0000 24.01 1 0.0000
INFECTED$
* LIGHT$
* TEMPERATURE$ -22.914 1.08 1 0.2978 1.08 1 0.2978
Term tested The model without the term Removal of term from
model
hierarchically ln(MLE) Chi-Sq df p-value Chi-Sq df p-value
--------------- --------- -------- ---- -------- -------- ---- --------
TEMPERATURE$ . -63.403 82.06 4 0.0000 82.06 4 0.0000
LIGHT$ . . . . -35.781 26.82 4 0.0000 26.82 4 0.0000
Did not converge after 10 iterations. At the last iteration
the relative change in the log-likelihood was 0.0000000
the largest relative change of parameters was 0.0000000
INFECTED$. . . -76.918 109.09 4 0.0000 109.09 4 0.0000
LIGHT$
* TEMPERATURE$ -25.400 6.06 2 0.0484 6.06 2 0.0484
INFECTED$
* TEMPERATURE$ -63.403 82.06 2 0.0000 82.06 2 0.0000
INFECTED$
* LIGHT$ . . . -35.781 26.82 2 0.0000 26.82 2 0.0000
SYSTAT imprime d'abord le tableau de contingence avec les fréquences observées. C'est une bonne idée d'y jeter un coup d'œil pour vérifier que les données du fichier ont été interprétées correctement et que SYSTAT a bel et bien compris que les données avaient déjà été compilées par catégorie.
Ensuite, SYSTAT imprime la probabilité que le modèle spécifié prédise adéquatement les observations. Dans ce cas-ci, comme le modèle complet a été spécifié, l'ajustement est parfait et la probabilité est de 1 (que SYSTAT imprime comme un point). Aux étapes subséquentes, lorsque des termes seront éliminés, la probabilité associée à la valeur de khi-carré pour le log du rapport de vraisemblance (LR ChiSquare) est généralement celle qui nous intéresse. Si cette probabilité est plus faible que 0.05, cela indique que le modèle ajusté ne contient pas tous les termes importants.
Les valeurs prédites (attendues) pour chacune des cellules du tableau de contingence sont imprimées.
5
6
7
8
1
2
3

LABO- TABLEAUX DE CONTINGENCE ET MODÈLES LOG-LINÉAIRES. - 271
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Les valeurs estimées pour chacun des coefficients du modèle, normalisées en divisant par l'estimé de leur erreur-type. On peut examiner ces valeurs pour mieux comprendre les relations entre les facteurs considérés dans le modèle. Ces valeurs tendent à être distribuées normalement pour de grands échantillons, et donc celles dont la valeur absolue est nettement plus élevée que 3 indiquent un effet probablement significatif. Par exemple, la valeur de 8.3 pour l'interaction TEMPERATURE$*INFECTED suggère que la température affecte significativement la probabilité qu'une plante soit infectée ou non.
Le logarithme naturel de la valeur de l'estimé du maximum de vraisemblance (MLE, Maximum Likelihood Estimate). Dans ce cas-ci, c'est pour le modèle complet et la valeur servira donc de référence pour les autres modèles qui contiendront moins de termes.
Cette dernière section est la plus utile pour suggérer la prochaine étape. La partie de gauche du tableau représente la probabilité qu'un modèle n'incluant pas le terme de cette ligne prédise correctement les données observées. Si cette probabilité est plus petite que 0.05, cela suggère que ce terme doive être conservé. Par contre, si cette probabilité est nettement plus élevée que 0.05, il est probable qu'un modèle n'incluant pas ce terme (plus simple, parcimonieux et donc préférable) serait approprié.
La partie de droite du tableau est en fait un test d'hypothèse sur l'effet de ce terme. Si la probabilité est plus petite que 0.05, cela indique que ce terme est probablement requis dans le modèle. Dans ce cas-ci, parce que le modèle complet est ajusté, les parties gauche et droite sont identiques. Cela n'est pas le cas pour des modèles réduits.
Cette dernière section est similaire au tableau précédent, sauf que les modèles réduits examinés ne sont pas les mêmes. Pour chaque ligne du tableau, tous les termes du modèle spécifié qui contiennent le terme de cette ligne ainsi que les interactions qui contiennent ce terme, sont enlevés simultanément. Par exemple, pour la ligne TEMPERATURE$, le modèle qui est comparé ne contient ni TEMPERATURE$, ni TEMPERATURE$*INFECTED,ni TEMPERATURE$*LIGHT, ni TEMPERATURE$*LIGHT*INFECTED.
Exercice
Ouvrez le fichier STURGDAT.SYS, puis utilisez Stats, Loglinear Model, Estimate pour ajuster le meilleur modèle possible aux observations. Comment interprétez-vous le modèle auquel vous arrivez ? (Consultez le manuel SYSTAT Statistics pour les explications mécanique et
4
5
6
7
8

272 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
l'interprétation des fichiers de sortie). Vous devriez tester en premier lieu l'interaction du troisième degré (LOCATION$*YEAR$*SEX$), puis ensuite chacune des interactions du deuxième degré
Pour chaque modèle, examinez les résidus normalisés (standardized residuals) pour détecter les anomalies. Cet examen vous indique t-il un manque d'ajustement systématique ?
On doit analyser un tableau de contingence à trois critères de classification: SEX$, LOCATION$ et YEAR$. Le modèle complet inclue donc 7 termes: les trois effets principaux (SEX$, LOCATION$ et YEAR$), les trois intéractions du deuxième degré (SEX$*YEAR$, SEX$*LOCATION$ and LOCATION$*YEAR$) et le terme d’interaction du troisième degré (SEX$*LOCATION$*YEAR$). Pour commencer on éprouve l’hypothèse qu’il n’y a pas d’intéraction du troisième degré (que SEX$*LOCATION$*YEAR$ = 0). Choisissez Stats>Log-linear>Estimate et spécifiez six termes dans le modèle: les 3 termes pour les effets principaux et les 3 termes d’intéraction du deuxième degré. Pour le tableau à analyser, inscrivez SEX$*LOCATION$*YEAR$.
SYSTAT produira le fichier de sortie suivant:Observed Frequencies
====================
LOCATION$ SEX$ | YEAR$
| 1978 1979 1980
---------+---------+-------------------------------------
Cumberlan female | 10.000 30.000 11.000
male | 14.000 14.000 6.000
+
The_Pas female | 5.000 12.000 38.000
male | 16.000 12.000 18.000
-------------------+-------------------------------------
Pearson ChiSquare 1.7330 df 2 Probability 0.42042
LR ChiSquare 1.6677 df 2 Probability 0.43437
Raftery's BIC -8.7838
Dissimilarity 3.7920
La valeur d’intérêt ici est la statistique de khi-carré associée au log du rapport de vraisemblance (LR ChiSquare). Cette statistique permet d’évaluer si le modèle s’ajuste adéquatement aux observations. Comme le modèle spécifié n’inclue pas SEX$*LOCATION$*YEAR$, on
Commandes SYSTAT: modèle log-linéaireUSE 'C:\DATA\AMORIN\BIO4518\1998\LABO\DATA\STURGDAT.SYS'
PRINT MEDIUM
MODEL YEAR$*LOCATION$*SEX$ = SEX$+LOCATION$+YEAR$+,
LOCATION$*SEX$+YEAR$*SEX$+YEAR$*LOCATION$
PRINT NONE/ CHISQ RATIO MLE ELAMBDA TERM HTERM OBSFREQ EXPECT
STAND
ESTIMATE
1
1

LABO- TABLEAUX DE CONTINGENCE ET MODÈLES LOG-LINÉAIRES. - 273
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
éprouve l’hypothèse que SEX$*LOCATION$*YEAR$ = 0. En se fiant sur le LR ChiSquare, on accepte H0. Le modèle qui s’ajuste le mieux n’inclue pas l’interaction du troisième degré.
Qu’est-ce que cela signifie? Cela signifie que si il y a des intéractions significatives du deuxième degré, elles ne varient pas selon le niveau de la troisième variable. Par exemple, dans cet exercice cela veut dire que si le rapport des sexes varie d’une année à l’autre (une interaction SEX$*YEAR$), cette variation temporelle est la même aux deux sites. Cette absence d’intéraction du troisième degré signifie également que l’aggrégation (pooling) des données est justifiée et préférable. Par exemple, si on veut éprouver l’intéraction SEX$*LOCATION$, on peut regrouper les données de toutes les années, pour produire un tableau de contingence 2x2 dont les fréquences dans chaque cellule est le nombre total d’esturgeon d’un sexe et d’un site donné capturé entre 1978 et 1980. En augmentant la fréquence dans chaque cellule, on accroît la puissance, ce qui est évidemment désirable.
Voici le reste du fichier de sortie. Pour une description plus détaillée, consultez le fichier d’aide de SYSTAT.Expected Values
===============
LOCATION$ SEX$ | YEAR$
| 1978 1979 1980
---------+---------+-------------------------------------
Cumberlan female | 9.221 29.016 12.763
male | 14.779 14.984 4.237
+
The_Pas female | 5.779 12.984 36.237
male | 15.221 11.016 19.763
-------------------+-------------------------------------
Standardized Deviates = (Obs-Exp)/sqrt(Exp)
===========================================
LOCATION$ SEX$ | YEAR$
| 1978 1979 1980
---------+---------+-------------------------------------
Cumberlan female | 0.257 0.183 -0.494
male | -0.203 -0.254 0.857
+
The_Pas female | -0.324 -0.273 0.293
male | 0.200 0.296 -0.397
-------------------+-------------------------------------
Ces résidus normalisés semblent corrects: ils sont assez petits et il n’y a pas de tendance évidente, c’est-à-dire pas de sousgroupe formé de valeurs positives ou négatives seulement.
Lambda / SE(Lambda)
===================
THETA
-------------
2.583
-------------
SEX$
female male

274 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
-------------------------
1.145 -1.145
-------------------------
LOCATION$
Cumberland The_Pas
-------------------------
-1.066 1.066
-------------------------
YEAR$
1978 1979 1980
-------------------------------------
-1.887 1.564 0.484
-------------------------------------
SEX$ | YEAR$
| 1978 1979 1980
---------+-------------------------------------
female | -3.672 1.039 2.884
male | 3.672 -1.039 -2.884
---------+-------------------------------------
LOCATION$| SEX$
| female male
---------+-------------------------
Cumberlan| 1.462 -1.462
The_Pas | -1.462 1.462
---------+-------------------------
LOCATION$| YEAR$
| 1978 1979 1980
---------+-------------------------------------
Cumberlan| 1.573 3.329 -4.747
The_Pas | -1.573 -3.329 4.747
---------+-------------------------------------
Multiplicative Effects = exp(Lambda)
====================================
THETA
-------------
13.234
-------------
SEX$
female male
-------------------------
1.095 0.913
-------------------------
LOCATION$
Cumberland The_Pas
-------------------------
0.917 1.090
-------------------------
YEAR$
1978 1979 1980
-------------------------------------
0.791 1.193 1.060
-------------------------------------
SEX$ | YEAR$
| 1978 1979 1980
---------+-------------------------------------
female | 0.637 1.122 1.399
male | 1.570 0.891 0.715
---------+-------------------------------------

LABO- TABLEAUX DE CONTINGENCE ET MODÈLES LOG-LINÉAIRES. - 275
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
LOCATION$| SEX$
| female male
---------+-------------------------
Cumberlan| 1.132 0.883
The_Pas | 0.883 1.132
---------+-------------------------
LOCATION$| YEAR$
| 1978 1979 1980
---------+-------------------------------------
Cumberlan| 1.216 1.439 0.571
The_Pas | 0.822 0.695 1.750
---------+-------------------------------------
Model ln(MLE): -27.474
Il semble donc que le modèle avec les trois facteurs principaux et les trois intéractions du second degré décrit adquatement les données. Mais, est-ce le modèle le plus simple? Peut-on éliminer certains des termes du modèles sans réduire substanciellement la qualité d’ajustement? Si un modèle ne contenant que 2 des trois intéractions du second degrés s’ajuste aussi bien, alors on devrait le choisir de préférence au modèle avec les trois intéractions parce qu’il est plus simple.
Les résultats suivants, obtenus en mode medium, permettent de répondre à cette question. Pour chaque terme du modèle, le tableau indique (1) un test de qualité d’ajustement pour un modèle qui inclut tous les termes sauf le terme en question et (2) un test de la réduction de la qualité d’ajustement lorsque l’on élimine ce terme. Par exemple, selon le tableau, si l’on exclut le terme SEX$*YEAR$, on obtient un khi-carré de 17.25 (4 dl, p=0.0017) comme mesure de la qualité d’ajustement. Le modèle avec les trois termes d’intéractions (voir plus haut) avait une valeur correspondante de 1.6677 (2 dl, p=0.434). La différence (17.25-1.67=15.58, avec 4-2=2 dl) de qualité d’ajustement est assez grande (avec une p associée de 0.0004). Donc l’omission de ce terme dans le modèle résulte en une décroissance significative de la qualité d’ajustement. On doit donc garder ce terme dans le modèle.
Term tested The model without the term Removal of term from model
ln(MLE) Chi-Sq df p-value Chi-Sq df p-value
--------------- --------- -------- ---- -------- -------- ---- --------
SEX$ . . . . . -28.126 2.97 3 0.3959 1.30 1 0.2533
LOCATION$. . . -28.044 2.81 3 0.4221 1.14 1 0.2854
YEAR$. . . . . -29.608 5.94 4 0.2039 4.27 2 0.1183
SEX$
* YEAR$. . . . -35.266 17.25 4 0.0017 15.58 2 0.0004
LOCATION$
* SEX$ . . . . -28.562 3.84 3 0.2788 2.18 1 0.1402
LOCATION$
* YEAR$. . . . -41.649 30.02 4 0.0000 28.35 2 0.0000
Term tested The model without the term Removal of term from model
hierarchically ln(MLE) Chi-Sq df p-value Chi-Sq df p-value
1
2
3

276 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
--------------- --------- -------- ---- -------- -------- ---- --------
SEX$ . . . . . -37.379 21.48 6 0.0015 19.81 4 0.0005
LOCATION$. . . -42.628 31.98 6 0.0000 30.31 4 0.0000
YEAR$. . . . . -52.426 51.57 8 0.0000 49.90 6 0.0000
En suivant la même logique, on peut conclure que seule l’intéraction LOCATION$*SEX$ peut être omise sans réduire significativement la qualité d’ajustement (quoique, avec p=0.14, on s’approche du seuil de décision). On ajuste alors un modèle avec les cinq autres termes pour obtenir:
Observed Frequencies
====================
LOCATION$ SEX$ | YEAR$
| 1978 1979 1980
---------+---------+-------------------------------------
Cumberlan female | 10.000 30.000 11.000
male | 14.000 14.000 6.000
+
The_Pas female | 5.000 12.000 38.000
male | 16.000 12.000 18.000
-------------------+-------------------------------------
Pearson ChiSquare 3.8397 df 3 Probability 0.27931
LR ChiSquare 3.8440 df 3 Probability 0.27881
Raftery's BIC -11.8333
Dissimilarity 5.6285
Notez que la statistique de khi-carré associée au log du rapport de vraisemblance (LR-Chi-Square) est la même ue ce qui est donné au tableau précédent pour le modèle sans le terme SEX$*LOCATION$.Expected Values
===============
LOCATION$ SEX$ | YEAR$
| 1978 1979 1980
---------+---------+-------------------------------------
Cumberlan female | 8.000 27.176 11.411
male | 16.000 16.824 5.589
+
The_Pas female | 7.000 14.824 37.589
male | 14.000 9.176 18.411
-------------------+-------------------------------------
Standardized Deviates = (Obs-Exp)/sqrt(Exp)
===========================================
LOCATION$ SEX$ | YEAR$
| 1978 1979 1980
---------+---------+-------------------------------------
Cumberlan female | 0.707 0.542 -0.122
male | -0.500 -0.688 0.174
+
The_Pas female | -0.756 -0.733 0.067
male | 0.535 0.932 -0.096
-------------------+-------------------------------------
Lambda / SE(Lambda)
===================
THETA
-------------
2.598
-------------

LABO- TABLEAUX DE CONTINGENCE ET MODÈLES LOG-LINÉAIRES. - 277
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
SEX$
female male
-------------------------
1.056 -1.056
-------------------------
LOCATION$
Cumberland The_Pas
-------------------------
-0.943 0.943
-------------------------
YEAR$
1978 1979 1980
-------------------------------------
-1.922 1.440 0.644
-------------------------------------
SEX$ | YEAR$
| 1978 1979 1980
---------+-------------------------------------
female | -3.562 1.464 2.561
male | 3.562 -1.464 -2.561
---------+-------------------------------------
LOCATION$| YEAR$
| 1978 1979 1980
---------+-------------------------------------
Cumberlan| 1.209 3.489 -4.604
The_Pas | -1.209 -3.489 4.604
---------+-------------------------------------
Multiplicative Effects = exp(Lambda)
====================================
THETA
-------------
13.430
-------------
SEX$
female male
-------------------------
1.087 0.920
-------------------------
LOCATION$
Cumberland The_Pas
-------------------------
0.927 1.078
-------------------------
YEAR$
1978 1979 1980
-------------------------------------
0.788 1.176 1.079
-------------------------------------
SEX$ | YEAR$
| 1978 1979 1980
---------+-------------------------------------
female | 0.651 1.169 1.315
male | 1.537 0.855 0.761
---------+-------------------------------------
LOCATION$| YEAR$
| 1978 1979 1980
---------+-------------------------------------
Cumberlan| 1.153 1.460 0.594
The_Pas | 0.867 0.685 1.683

278 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
---------+-------------------------------------
Model ln(MLE): -28.562
Term tested The model without the term Removal of term from model
ln(MLE) Chi-Sq df p-value Chi-Sq df p-value
--------------- --------- -------- ---- -------- -------- ---- --------
SEX$ . . . . . -29.117 4.95 4 0.2921 1.11 1 0.2923
LOCATION$. . . -29.007 4.74 4 0.3156 0.89 1 0.3452
YEAR$. . . . . -30.655 8.03 5 0.1546 4.19 2 0.1233
SEX$
* YEAR$. . . . -35.556 17.83 5 0.0032 13.99 2 0.0009
LOCATION$
* YEAR$. . . . -41.939 30.60 5 0.0000 26.75 2 0.0000
Term tested The model without the term Removal of term from model
hierarchically ln(MLE) Chi-Sq df p-value Chi-Sq df p-value
--------------- --------- -------- ---- -------- -------- ---- --------
SEX$ . . . . . -37.379 21.48 6 0.0015 17.63 3 0.0005
LOCATION$. . . -42.628 31.98 6 0.0000 28.13 3 0.0000
YEAR$. . . . . -52.716 52.15 9 0.0000 48.31 6 0.0000
L’examen du tableau ci-haut révèle que l’omission de l’un ou l’autre des termes d’intéraction du second degré entraîne une diminution significative de la qualité d’ajustement. On conclue donc, en se fiant sur cette analyse, que le modèle le plus approprié est:
ln[f(ijk)] = µ + location$ + sex$ + year$ + sex$*year$ + location$*year$
Quelle est l’interprétation biologique de tout cela? Rappelez-vous que, comme dans les tests d’indépendance, on n’est pas vraiment intéressé par les effets principaux, seulement par les intéractions significatives. Par exemple, l’existence de l’effet principal location$ implique que le nombre total d’esturgeons capturés (des deux sexes au cours de la période 1978-1980) n’est pas le même au deux sites. Cela n’est ni surprenant, ni intéressant. Cependant, l’intéraction SEX$*YEAR$ révèle que le rapport des sexes a varié d’une année à l’autre (et comme l’intéraction SEX$*YEAR$*LOCATION$ n’est pas significative, que cette variation était la même dans les deux sites). L’intéraction indique que le nombre d’esturgeons récoltés a non seulement varié d’une année à l’autre, mais que ce changement n’était pas le même aux deux sites. Ceci est moins surprenant, et peut probablement s’expliquer par des différences d’effort d’échantillonnage entre les deux sites.

LABO- RÉGRESSION PONDÉRÉE, LOGISTIQUE ET NON-LINÉAIRE - 279
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Labo- Régression pondérée, logistique et non-linéaire
Après avoir complété cet exercice de laboratoire, vous devriez pouvoir :
• Utiliser SYSTAT pour faire une régression pondérée
• Utiliser SYSTAT pour faire une régression logistique
• Utiliser SYSTAT pour faire une régression non linéaire
Régression pondéréeDans tous les modèles de régression et d'analyse de variance considérés jusqu'ici, toutes les observations étaient considérées être de la même qualité et avaient le même poids dans l'analyse. Cela veut dire, implicitement que nous considérions que l'erreur associée à chaque mesure était la même. Cependant, dans certaines situations tel n'est pas le cas. Par exemple, considérez une expérience visant à examiner l'effet de la densité des plantes sur la densité d'un pathogène. Un plan expérimental simple serait d'avoir 5 champs (réplicats) à chaque niveau de densité de plante et de dénombrer le nombre de plantes infectées dans chaque champ. La variable dépendante dans une analyse de régression (ou une ANOVA) pourrait être le nombre moyen de plantes infectées par champ. Si, comme c'est souvent le cas, la variance entre les réplicats varie aux différentes densités alors : 1) les moyennes des traitements ayant une faible variances sont de meilleurs estimés du niveau d'infection et 2) la condition préalable d'homoscédasticité est invalide.
Dans un cas comme celui-là, l'analyse par régression (ou ANOVA) pondérée est l'approche appropriée. En régression pondérée, un poids est attribué à chaque observation. Lorsque la variable dépendante est une moyenne, ce poids est souvent le nombre d'observation ou encore l'inverse de la variance, ce qui fait que les moyennes de plus grands nombres d'observations (ou celles qui ont les plus petites variances) ont plus de poids que les autres dans l'analyse.
Le fichier WREG3DAT.SYS contient la moyenne du log de la longueur moyenne à la fourche pour chaque classe d'âge (LAVFKL), le log de l'âge (LAGE), le nombre d'individus utilisé pour obtenir ces moyennes (N) et la variance du log de la longueur moyenne à la fourche (VAR) pour un échantillon d' esturgeons de la rivière Sakatchewan.

280 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Faites d'abord une régression (Regression, Linear) de LAVFKL sur LAGE. Ensuite, allez à Data-Weight et inscrivez N comme variable pondérale. Refaites ensuite la régression. Comment les résultats de la régression pondérée diffèrent-ils de ceux de la régression simple ? Pourquoi ?
Créez une nouvelle variable (INVVAR) calculée comme 1/VAR (Data, Transform, Let) . Utilisez cette variable pour calculer une autre régres-sion pondérée. Les résultats changent-ils ? Pourquoi ?
Les résultats de la régression de LAVFKL sur LAGE donnent:Dep Var: LAVFKL N: 15 Multiple R: 0.885 Squared multiple R: 0.784
Adjusted squared multiple R: 0.767 Standard error of estimate: 0.017
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 1.279 0.050 0.000 . 25.352 0.000
LAGE 0.271 0.039 0.885 1.000 6.865 0.000
Effect Coefficient Lower 95% Upper 95%
CONSTANT 1.279 1.170 1.388
LAGE 0.271 0.186 0.356
Correlation matrix of regression coefficients
CONSTANT LAGE
CONSTANT 1.000
LAGE -0.996 1.000
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.014 1 0.014 47.123 0.000
Residual 0.004 13 0.000
Les résultats lorsque les données sont pondérées par l’effectif sont:Dep Var: LAVFKL N: 15 Multiple R: 0.899 Squared multiple R: 0.807
Adjusted squared multiple R: 0.793 Standard error of estimate: 0.029
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 1.269 0.049 0.000 . 25.714 0.000
LAGE 0.282 0.038 0.899 1.000 7.381 0.000
Effect Coefficient Lower 95% Upper 95%
CONSTANT 1.269 1.162 1.376
LAGE 0.282 0.199 0.364
Correlation matrix of regression coefficients
CONSTANT LAGE
CONSTANT 1.000
LAGE -0.989 1.000

LABO- RÉGRESSION PONDÉRÉE, LOGISTIQUE ET NON-LINÉAIRE - 281
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.045 1 0.045 54.481 0.000
Residual 0.011 13 0.001
En calculant la pondération comme= INVAR = 1/VAR, puis en refaisant la régression de LAVFKL sur LAGE on obtient:Dep Var: LAVFKL N: 15 Multiple R: 0.841 Squared multiple R: 0.707
Adjusted squared multiple R: 0.685 Standard error of estimate: 0.045
Effect Coefficient Std Error Std Coef Tolerance t P(2
Tail)
CONSTANT 1.309 0.059 0.000 . 22.199 0.000
LAGE 0.251 0.045 0.841 1.000 5.606 0.000
Effect Coefficient Lower 95% Upper 95%
CONSTANT 1.309 1.181 1.436
LAGE 0.251 0.155 0.348
Correlation matrix of regression coefficients
CONSTANT LAGE
CONSTANT 1.000
LAGE -0.980 1.000
Analysis of Variance
Source Sum-of-Squares df Mean-Square F-ratio P
Regression 0.065 1 0.065 31.428 0.000
Residual 0.027 13 0.002
Le R2 de la régression pondérée est un peu plus petit que celui de la régression simple. Mais les coefficients reflètent vraisemblablement mieux les données quand même puisque la régression tient compte du poids relatif de chaque observation. Notez toutefois que si les données sont fortement hétéroscedastiques vous ne pouvez vous fier aux probabilitées imprimées automatiquement. Dans ce cas, vous devrez faire une analyse sur les données transformées pour faire des inférences..
Régression logistiqueJusqu'à présent, nous avons considéré des modèles de régression dans les quelles les variables dépendantes et indépendantes sont continues (comme la longueur à la fourche des esturgeons) ou presque (comme le nombre d'espèces dans un marais). Cependant certaines variables ne peuvent prendre que quelques valeurs, par exemple le sexe ou la présence ou absence d'une espèce particulière dans un marais. Si on

282 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
désire modéliser ces variables discontinues en fonction de une ou plusieurs variables continues et/ou discontinues, on ne peut utiliser les méthodes habituelles de régression ou d'ANOVA.
Comme une variable dépendante qui ne peut prendre que quelques valeurs suit une distribution multinomiale (binomiale dans le cas d'une variable qui ne peut prendre que deux valeurs, mort ou vivant par exemple), l'analyse procède par la méthode du maximum de vraisemblance plutôt que par celle des moindres carrés. L'estimé d'un paramètre obtenu par la méthode du maximum de vraisemblance est celui qui a la plus grande probabilité de générer les valeurs observées. En fait, toutes les régressions sont ajustées par le maximum de vraisemblance, c'est seulement parce que, pour des variables distribuées normalement, la méthode du maximum de vraisemblance est mathématiquement équivalente à celle des moindres carrés. Mais lorsque la variable dépendant ne suit pas une distribution normale, les deux méthodes peuvent mener à des résultats très différents.
Le fichier HEART.SYD contient des données sur le niveau d'une enzyme, la creatinine kinase (CK) chez des patients qui ont eu (HEART=1) ou pas (HEART=0) d'attaque cardiaque. FREQ est le nombre de patients dans chaque niveau de CK.
Ouvrez le fichier HEART.SYD et pendant que vous êtes dans le chiffrier, allez à Data-Frequency et ajoutez FREQ à la liste des variables. Puis allez à la fenêtre principale et choisissez Regression, Logit, Estimate Model et inscrivez HEART comme variable dépendante et CK comme variable indépendante.
Case frequencies determined by value of variable FREQ.
Categorical values encountered during processing are:
HEART (2 levels)
0, 1
Categorical variables are effects coded with the highest value as reference.
***WARNING***
Different categorical coding strategies (e.g., effects vs. dummy) can
produce different results. Use CATEGORY <varlist> / EFFECTS for
effect coding and CATEGORY <varlist> / DUMMY for dummy coding.
Cases having zero weights processed as missing.
Binary LOGIT Analysis.
Dependent variable: HEART
Analysis is weighted by FREQ
Sum of weights = 325.000
Input records: 26
Records for analysis: 19
Records deleted for missing data: 7
Sample split
Weighted
Category Count Count
REF 12 195.000
1
2

LABO- RÉGRESSION PONDÉRÉE, LOGISTIQUE ET NON-LINÉAIRE - 283
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
RESP 7 130.000
Total : 19 325.000
L-L at iteration 1 is -225.273
L-L at iteration 2 is -132.037
L-L at iteration 3 is -106.801
L-L at iteration 4 is -96.270
L-L at iteration 5 is -94.005
L-L at iteration 6 is -93.887
L-L at iteration 7 is -93.886
L-L at iteration 8 is -93.886
Log Likelihood: -93.886
Parameter Estimate S.E. t-ratio p-value
1 CONSTANT -3.730 0.439 -8.490 0.000
2 CK 0.035 0.004 8.601 0.000
95.0 % bounds
Parameter Odds Ratio Upper Lower
2 CK 1.036 1.044 1.027
Log Likelihood of constants only model = LL(0) = -218.729
2*[LL(N)-LL(0)] = 249.685 with 1 df Chi-sq p-value = 0.000
McFadden's Rho-Squared = 0.571
Covariance Matrix
1 2
1 0.193
2 -0.002 0.000
Correlation Matrix
1 2
1 1.000 -0.907
2 -0.907 1.000
Indication que le nombre d'observations est donné par la variable freq
REF est le nombre de cas pour lesquels heart=0, i.e. qui n'ont pas eu d'attaque cardiaque, RESP est le nombre de cas qui ont eu une attaque.
Le processus itératif d'estimation par maximum de vraisemblance. Dans ce cas, la convergence a été atteinte après 8 itérations lorsqu'il n'y avait plus d'amélioration.
Ce tableau est similaire à celui d'une régression ordinaire et est interprété de la même façon. L'interprétation des coefficients est cependant différente. Le coefficient pour CK indique de combien le logit augmente par unité d'augmentation de CK, mais comme le logit est calculé comme ln(p/(1-p)), où p est la probabilité d’une attaque cardiaque, la probabilité n'augmente pas linéairement avec le CK.
Le "odds ratio" est p/(1-p) où p est la probabilité d'une réponse (dans cet cas, une attaque cardaique). Ce rapport représente le facteur multiplicatif par lequel le risque change lorsque la variable
3
4
5
6
7
1
2
3
4
5

284 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
indépendante augmente d'une unité. Donc un odds ratio de 1 indique qu'il n'y a pas d'effet, donc si l'intervalle de confiance à 95% incluse 1, il n'y a pas de raison de rejeter l'hypothèse nulle
Ceci est essentiellement une statistique G qui compare l'ajustement d'un modèle avec CK et une constante (ordonnée à l'origine) à celui d'un modèle avec seulement une constante. Si CK est un prédicteur important, alors cette différence devrait être grande et la probabilité correspondante faible.
Cette statistique est analogue au R2 en régression standard. Cependant, en géneral, MCFADDENS RHO-SQUARED est moins élevé que le R2 en régression standard : une valeur de 0.3 ou 0.4 est considerée élevée.
Régression non-linéaireSi la régression multiple s'apparente à un art, la régression non-linéaire s'y apparente encore plus. En effet, comme il n'y a pas vraiment de contraintes quant à la forme du modèle, il faut absolument débuter par un modèle spécifique. Cela implique 1) soit qu'on possède une théorie qui prédit une forme quantitative particulière pour la relation entre la variable dépendante et la ou les variables indépendantes ou 2) qu'on connaisse suffisamment bien les formes fonctionnelles pour être capable de dire, pour une tendance empirique quelconque, "Ceci me semble une relation exponentielle négative (ou quelque chose du genre)" et commencer par ajuster ce type de modèle.
Si vous devez effectuer ce type d'analyse vous devriez toujours garder à l'esprit les deux points suivants :
• La plupart des algorithmes de régression non-linéaire requièrent des valeurs initiales pour les paramètres du modèle. Même si cela n'est pas toujours indispensable, il est préférable de les fournir. En effet, l'un des problèmes avec presque tous les algorithmes de régression non-linéaire est que, dépendant des coordonnées initia-les, la recherche de la solution la plus vraisemblable peut s'enliser près d'un minimum local. Donc, lorsque l'on fait des régressions non-linéaires, il est important d'ajuster le modèle en utilisant plu-sieurs ensembles de valeurs initiales très différents, et même d'employer plus d'un algorithme. Si toutes vos tentatives conver-gent vers la même solution, alors vous pouvez être raisonnable-ment confiant que c'est la bonne.
• Le fait d'obtenir un très bon ajustement avec un modèle donné ne garantit pas que le modèle soit correct.
6
7

LABO- RÉGRESSION PONDÉRÉE, LOGISTIQUE ET NON-LINÉAIRE - 285
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
L'exemple qui suit est très simple et a été choisi pour vous introduire aux rudiments de l'analyse de régression non-linéaire avec SYSTAT.
Le fichier BOD.SYD contient des mesures de demande biologique en oxygène (BOD) d'une série d'échantillons d'eau provenant d'un ruisseau. Les échantillons ont étés inoculés avec des micro-organismes, scellés, incubés, puis récoltés à différents moments (TIME) pour analyser la concentration d'oxygène dissout. Allez à Stats-Regression-Nonlinear-Model/loss, et inscrivez BOD = THETA_1*(1-THETA_2^TIME) dans la boîte de texte Expression.
Iteration
No. Loss THETA_1 THETA_2
0 .22280D+03 .1010D+02 .1021D-01
1 .21850D+03 .1114D+02 .5325D+00
2 .29485D+02 .1515D+02 .5188D+00
3 .37516D+01 .1714D+02 .4550D+00
4 .96702D+00 .1734D+02 .5109D+00
5 .60673D+00 .1768D+02 .5451D+00
6 .54975D+00 .1771D+02 .5406D+00
7 .54630D+00 .1775D+02 .5419D+00
8 .54626D+00 .1775D+02 .5421D+00
9 .54626D+00 .1776D+02 .5422D+00
Dependent variable is BOD
Source Sum-of-Squares df Mean-Square
Regression 1601.574 2 800.787
Residual 0.546 5 0.109
Total 1602.120 7
Mean corrected 68.840 6
Raw R-square (1-Residual/Total) = 1.000
Mean corrected R-square (1-Residual/Corrected) = 0.992
R(observed vs predicted) square = 0.992
Wald Confidence Interval
Parameter Estimate A.S.E. Param/ASE Lower < 95%>
Upper
THETA_1 17.755 0.241 73.583 17.135 18.375
THETA_2 0.542 0.016 33.700 0.501 0.584
BOD BOD
Case Observed Predicted Residual
1 8.300 8.164 0.136
2 12.300 12.575 -0.275
3 15.300 14.957 0.343
4 16.000 16.243 -0.243
5 16.500 16.939 -0.439
6 17.400 17.314 0.086
7 17.800 17.517 0.283
Asymptotic Correlation Matrix of Parameters
THETA_1 THETA_2
THETA_1 1.000
THETA_2 0.794 1.000
Le tableau d'ANOVA standard. Son interprétation n'a plus de secrets pour vous.
1
2
1

286 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
Les estimés pour les paramètres du modèle, avec leurs erreurs type asymptotiques (A.S.E). La colonne PARAM/ ASE est approximativement équivalente à une statistique t. Les intervalles de confiance de Wald (WALD CONFIDENCE INTERVAL)sont obtenus par l'estimé du coefficient (ESTIMATE) ± t X A.S.E. où t est la valeur critique de la distribution de t avec (n - nombre de paramètres) degrés de liberté.
2

RÉFÉRENCES - 287
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
RéférencesBox, G. E. P., et D. R. Cox. 1964. An analysis of transformations. Jour-
nal of the Royal Statistical Association. B17: 1-34.Daniel, C., and F. S. Wood. 1980. Fitting Equations to Data, Second
Edition, Wiley, Ney York, NY, 427p.Draper, N. et H. Smith. 1981. Applied Regression Analysis, Second
Edition, Wiley, New York, NY, 709p.Finney, D. J. 1978. Statistical method in biological assay. Oxford Uni-
versity Press, New York, NY. 508p.Gujarati, D. N. 1988. Basic Econometrics. 2nd Ed. McGraw-Hill.
New York. 705p.Koteja, P. 1991. On the relation between basal and field metabolic
rates in birds and mammals. Functional Ecology 5: 56-64.McCullagh, P., et J. A. Nelder. 1983. Generalized linear models. Mono-
graphs on Statistics and Applied Probability, Chapman and Hall, New York, NY.
Rohlf, F. J., and R. R. Sokal. 1981. Statistical tables. W. H. Freeman and Company. San Francisco. 219p.
Scherrer, B. 1984. Biostatistique. Gaëtan Morin, Boucherville, 850p.Sokal, R. R. and F.J Rohlf. 1995. Biometry, 3rd edition. W.H. Freeman
and Co. San Francisco. 219p.Van Valen, L. 1978. The statistics of variation. Evol. Theory 4: 33-43.Watson, G. S. 1957. The χ2 goodness of fit test for normal distribu-
tions. Biometrika 44: 336-348.Zar, J.H. 1996. Biostatistical Analysis, 3rd edition. Prentice-Hall,
Englewood Cliffs, NJ, 718 pp.Zar, J.H. 1999. Biostatistical Analysis, 4rthedition. Prentice-Hall,
Englewood Cliffs, NJ, 663 pp

288 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001

GLOSSAIRE - 289
© Antoine Morin et Scott Findlay, Département de biologie, Université d’Ottawa
Glossaire
BiaisTerme s’appliquant généralement aux statistiques de l’échantillon. Une statistique n’est pas biaisée si un échantillonnage répété d’une population ayant un paramètre connu (ex: la moyenne de la population) produit des statistiques de l’échantillon (ex: moyenne de l’échantillon) qui, en moyenne, tendent vers la valeur du paramètre (ex: la moyenne de toutes les moyennes des échantillons est égale à la moyenne de la population). Une statistique qui ne possède pas cette propriété est qualifiée de biaisée.
ConservateurDans un test conservateur, le niveau d’erreur de type I est plus petit que le niveau nominal d’erreur de type I. Cela implique que l’on accepte l’hypothèse nulle plus souvent qu’on le devrait.
Erreur αL’erreur associée au rejet d’une hypothèse nulle lorsqu’elle est vraie (appelée aussi erreur de type I). Dans la plupart des tests statistiques le seuil critique α est fixé par convention à 0.05. Il y a donc 5% des chances qu’une hypothèse nulle vraie soit rejetée par erreur.
Erreur β
L’erreur associée à l’acceptation de l’hypothèse nulle lorsqu’elle est fausse (aussi appelée erreur de type II). Pour calculer cette erreur, on doit spécifier une hypothèse nulle alternative. Lorsqu’il y a une hypothèse alternative spécifiée, le taux d’erreur de type II diminue lorsque le taux d’erreur de type I augmente.
ExactitudeUne mesure de la distance entre la valeur mesurée ou estimée et la valeur réelle.
LibéralDans un test libéral, le taux d’erreur de type I est plus grand que le taux nominal d’erreur de type I. Cela implique que l’on rejette l’hypothèse nulle plus souvent qu’on le devrait.

290 - BIOSTATISTIQUES APPLIQUÉES
BIO 4518 - Automne 2001
ParamètreEn statistiques, un paramètre représente une caractéristique de la population (ex: la moyenne) et la statistique de l’échantillon (ex: moyenne de l’échantillon) est utilisée comme estimé de ce paramètre.
Puissance1-β, donc la probabilité de rejeter l’hypothèse nulle lorsqu’elle est fausse et qu’une hypothèse alternative est correcte. Pour les tests statistiques, la puissance détermine de combien les observations doivent différer de l’hypothèse nulle pour pouvoir la rejeter. Les tests puissants peuvent détecter de petites différences, les tests qui ne sont pas puissants ne peuvent détecter que de grandes différences.
PrécisionLa précision mesure la distance entre des mesures répétées (ou des estimés) de la même quantité (ou paramètre). Pour des estimée de paramètres, la précision est mesurée par l’erreur-type. Plus l’erreur-type est petit, plus grande est la précision.
RobustesseUn test statistique est robuste aux violations de l’une ou de plusieurs de ses conditions d’application (hypothèse implicites) si ces violations ne changent pas significativement la différence entre le taux d’erreur de type I et le taux nominal d’erreur de type I.
SensibilitéCe terme a deux significations. La sensibilité d’un test peut être une mesure de la différence entre le taux d’erreur de type I et le taux nominal d’erreur de type I lorsque les condition d’application (hypothèses implicites) ne sont pas rencontrées. Donc un test sensible n’est pas robuste et un test insensible est robuste. La sensibilité peut également décrire la capacité d’un test à détecter de petites différences entre les observations et l’hypothèse nulle. Un test sensible est donc puissant.

291
IndexAAjustement
continuité 30de Williams 30Yates 30
Ajustement à une distribution théoriquetest 29
Analyse de covariance 91Voir ANCOVA
ANCOVA 91ajustement des modèles 92Hypothèses implicites 91modèle 91modèle complet 92modèle d’ANCOVA 93modèle de régression simple 94with SYSTAT 227
ANOVAà plusieurs critères de classification 63à un critère de classification 49alternative non-paramétrique 54avec SYSTAT 171choix de l’ANOVA factorielle ou
hiérarchique 64Comparaisons multiples 69comparaisons multiples 57distinction entre ANOVA factorielle et
hiérarchique 63effectifs inégaux (plan non-balancé) 71factorielle
avec SYSTAT 171Épreuves d’hypothèses 68non-paramétrique 70
factorielle à deux facteurs 67hiérarchique 65
avec SYSTAT 171Hypothèses implicites 51Intervalles de confiance pour les
moyennes des groupes 61mesures répétées
avec SYSTAT 189modèle
factoriel 67hiérarchique 65
non paramétriqueavec SYSTAT 193
sans réplication 69tableau
à un critère de classification 53
factorielle 68hiérarchique 66sans réplication 70
Tests des conditions d’application 51transformation 54
BBiais 289biaisée 17Binomial
test 31Bioessai 110Bonferroni 214Bootstrap 122Box plot 139
CCoefficient normalisé de régression partielle 98Comparaisons multiples 57
Bonferroni 58Duncan 60Dunnett 60GT2 59non-paramétriques 61Scheffé 58Sidak 58stratégies pour la sélection d’un test 60Student-Newman-Keuls (SNK) 60Tukey 59
Conservateur 289Consistance 17Cook,distance de 88Corrélation 73
avec SYSTAT 207coefficient 73comparaison de deux 76de rang 76hypothèses implicites 73intervalles de confiance 75non paramétrique
avec SYSTAT 212test de signification 74
DDiagramme de dispersion
SYSTAT 128

292 INDEX
Diagrammes de dispersionavec SYSTAT 207
Diagrammes de probabilité 138Différences
entre moyennesComparaisons
de deux moyennes 43Distribution normale 19
équation 20Distribution normale standard 20Dmax 33
EÉcart type 19Erreur
relation entre type I et type II 13type I ou alpha 11, 289type II ou beta 12, 289types d’erreur statistiques 11
Erreur type 23, 39Étendue 18Exactitude 17, 289extrapolations 89
FFalsification d'hypothèses 3Fiabilité
d’un test statistique 8Fréquence attendue 116
GG 115
test de 29
HHistogramme 137Hypothèse
critères de qualité 4exactitude 4généralité 4précision 4simplicité 4
IIintervalle de confiance
effet de la taille de l’échantillon 24interpolation 89Intervalle de confiance
médiane 25
Intervalles de confiancepour la moyenne 23pour observations 22
moyenne et variance connue 20variance 26
Intervalles de confiancespour observations
facteur de correction (Cn) 23
KKhi-carré 115
test 29Kolmogorov-Smirnov
AjustementKolmogorov-Smirnov 33
Kruskall-Wallis 54
Lleverage 88Libéral 289Logit 109Log-linéaire
modèle, analyse avec SYSTAT 259
MMédiane
intervalle de confiance 25Méthode hypothetico-déductive 3Méthode scientifique 3Modèle
log-linéaire 117régression 79
Modèles log-linéaires 115Moyenne
arithmétique 17effort requis pour estimer la 24équation 17
Multicolinéarité 99détection avec SYSTAT 251
Nnon biaisée 17Normale
distribution 19Normalité
effets des violations 39test de
G 33Khi-carré 33
Lilliefors 36

293
Kolmogorov-Smirnov 33Wilks-Shapiro 36
Normit 109
Pp
définition 11définition incorrecte 11sens de 11
Paramètre 290Pearson
coefficient de corrélation de 73Pente
erreur type 81Position
paramètre de 17Précision 17, 290Probit 109Puissance 290
d’un test statistique 8des tests de normalité 36
RRang
corrélation de 76Regression
variables indicatrices 106Régression
avec réplication 84avec SYSTAT 207, 219curvilinéaire (polynomiale) 104hypothèses implicites 79
éprouver avec SYSTAT 221influence des valeurs extrêmes 87intervalles de confiance 82logistique
avec SYSTAT 281logit 109modèle 79multiple 97
avec SYSTAT 239détection de la multicolinéarité 100élimination rétrograde 104épreuves d’hypothèses 98hypothèses implicites 98modèle 97multicolinéarité 99régression pas à pas 104sélection des variables avec
SYSTAT 239sélection des variables
indépendantes 102
sélection progressive 103solutions au problème de
multicolinéarité 101non-linéaire 113
avec SYSTAT 284normit 109polynomiale
avec SYSTAT 253pondérée 89, 109
avec SYSTAT 279prédiction inversée 83probit 109transformations 85
Résidu normalisé 88Robustesse 290
SSC 18Sensibilité 290Signification
biologique 8statistique 11
Somme des carrés 18équation 18
Spearmancorrélation de rang 76
SYSTATbox plot 139diagramme de probabilité 138diagrammes de dispersion 128graphiques 137histogramme 137imprimer les fichiers de sortie 140Introduction à 127manipulation de données
ajouter un nouveau cas 133Ajouter une nouvelle variable 133changer une valeur 132effacer un bloc de données. 132effacer une colonne (variable) 132effacer une rangée (cas) 132insérer une colonne 133transformer des données 134trouver des cas 133
Ouvrir un fichier de données 128sauvegarde du fichier de sortie 127sauvegarder les fichiers de sortie 140statistiques descriptive 131trier des données 137
Tt

294 INDEX
de Student 22équation 43statistique 43test approximatif de Welch 44test de
principe 39Tableau de contingence 115
analyse avec SYSTAT 259subdivision 117
tau de Kendall 76Taylor
loi de 54Test
unilatéral 13Test binomial 31Test des hypothèses implicites 80Tests
de permutation 121Théorème de la limite centrale 18Transformation 41
avec SYSTAT 134choix de la 41normit, probit, et logit 111régression 85
VVariabilité
paramètres de 18Variance 19
analyse de 49Voir ANOVA
équation 19
WWelch 44


















