
29/06/17 Matinale Python
55
© Soft Computing – www.softcomputing.com Utilisez Python pour votre projet Big Data et Data Sciences 29/06/17
-
Upload
soft-computing -
Category
Technology
-
view
1.472 -
download
1
Transcript of 29/06/17 Matinale Python

© Soft Computing – www.softcomputing.com
Utilisez Python pour votre projet Big Data et Data
Sciences
29/06/17

© 2
Comment utiliser Python pour votre projet Big Data et Data Science ?
Matinale Technologique Python le 29 juin 2017
Avec Python, langage des Data Ingenieurs et des Data Scientists, découvrez comment mener à bien vos projets dans votre environnement Big Data.
Avec le développement du Big Data, Python devient un outil incontournable pour les Data Ingenieurs et les
Data Scientists car il cumule de nombreux avantages : libre de droit, simple d’utilisation, de larges capacités
pour le traitement des données, les statistiques et le Machine Learning. Systématiquement associé à
l’installation d’une plate-forme Big Data, il peut être utilisé en local ou en serveur de manière transparente
pour l’utilisateur, utilisé par l’ensemble de la communauté internationale des Data Ingenieurs et
Data Scientists et accès aux procédures les plus innovantes.
A propos
Soft Computing est le spécialiste du marketing digital data-driven. Ses 400 consultants, experts en sciences de la donnée, en marketing digital et en
technologies big data, aident au quotidien plus de 150 entreprises à travers le monde à exploiter tout le potentiel de la donnée pour améliorer l’expérience
de leurs clients et le ROI de leur marketing digital. Soft Computing est côté à Paris sur NYSE Euronext (ISIN : FR0000075517, Symbole : SFT). Cet événement est réservé aux clients et prospects Soft Computing. Pour tout autre profil, l'inscription sera soumise à validation.
Soft Computing |55 quai de Grenelle|75015 Paris|01 73 00 55 00 | www.softcomputing.com
Agenda : 08h45 – 11h30
▪ Python dans le monde Big Data / Data Science
▪ Pyspark – Des données au Machine Learning
▪ Python – focus sur deux incontournables
▪ Retours d’expérience et bonnes pratiques
Pré requis :
Ces démonstrations pratiques sont ouvertes à des développeurs ayant déjà pratiqué la manipulation de données sous SAS ainsi que des Chefs de
Projet désireux d'avoir un aperçu des possibilités de Reporting sous SAS.
Modalités :
Ce séminaire aura lieu dans les
locaux de Soft Computing.
Ou via notre site:
www.softcomputing.com

© 3
Carte d’identité

© 4
Exploiter tout le potentiel de la data
Créer des expériences Client sans couture
Démultiplier la performance du marketing digital
Mission
Marketing Intelligence
Big Data Driven
Digital Experience

© 5
Compétences : un mix unique de compétences pointues
Digital
Marketing
Data
Science
Project
Management
Information
Technologies

© 6
A la carte
Think Build Run
Délégation Projet Centre de services
Digital-Marketing IT AMOA
Offre
Delivery
Clients

© 7
Extraits de références
Digital Marketing Big Data
Valorisation des données Web Analytics
via l’analyse des parcours de
conversion.
Cadrage des uses cases et mise en
œuvre opérationnelle d'un POC DMP.
Programme relationnel multi-devices et
remarketing. Déploiement
international.
DMP, CRM, orchestration omnicanal, et
déploiement des usages Data-driven
Marketing.
Mise en œuvre et exploitation
opérationnelle d'une DMP.
Refonte de la stratégie de fidélisation
omnicanale multi-marques.
Centre de Services gestion des
campagnes marketing multicanal, mise
en place du Web Analytics.
Mesure de l'impact des parcours
multicanaux sur le NPS et
recommandations d'améliorations.
Déploiement d’une plate-forme CRM
multi-marques multi-pays.
Centre de Services gestion des
campagnes marketing et connaissance
clients.
Accompagnement Data Science à la
valorisation des données Big Data.
Stratégie de sécurité et construction
d'une plate-forme d’industrialisation
des flux Big Data.
Formation aux méthodes et outils en
Data Science, France et international.
Définition de la gouvernance d’un
Référentiel client multi-activités et
international.
Mise en œuvre et intégration des flux
Big Data pour optimiser l'animation des
parcours clients.

© 8
Experts reconnus
Informer Ecrire Enseigner
blog.softcomputing.com/
fr.slideshare.net/softcomputing
twitter.com/softcomputing
linkedin.com/company/soft-computing
facebook.com/softcomputing
softcomputing.com/news/
© 9
Recruteur de talents
Datascience Projet
Technologies Digital
Marketing
CRM
Big Data
100 CDI à pourvoir cette année
Contact : [email protected] –
http://www.softcomputing.com/offres-d-emploi

© 10
1. Python dans le monde Big Data / Data Science
2. Pyspark – Des données au Machine Learning
3. Python – focus
A.Python multicore
B. Machine Learning – Scikit-learn
C. Gitlab
4. Retours d’expérience et bonnes pratiques
5. Q&A

© 11
Le Datalab Data Science
➢Développer et industrialiser les projets de Data Science, dans un
environnement centralisé, partagé et sécurisé,
➢ Permettre des traitements de données performants, y compris sur des
volumétries massives
OBDA
Data
lake
Ready
© 12
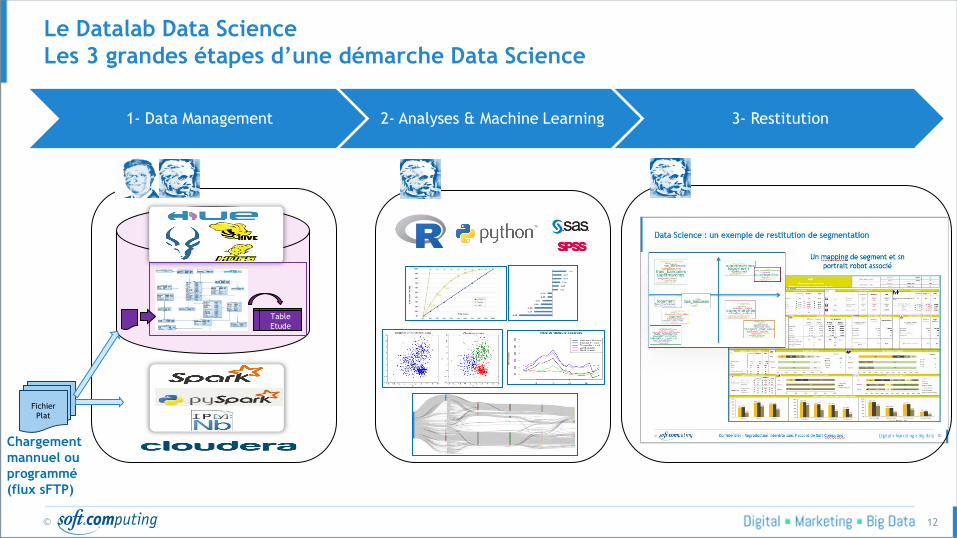
Le Datalab Data Science
Les 3 grandes étapes d’une démarche Data Science
1- Data Management 2- Analyses & Machine Learning 3- Restitution
Fichier
Plat
Chargement
mannuel ou
programmé
(flux sFTP)
Table
Etude

© 13
Architecture

© 14
Python quel version ?
packages BDA
Edge
© 15
PySpark
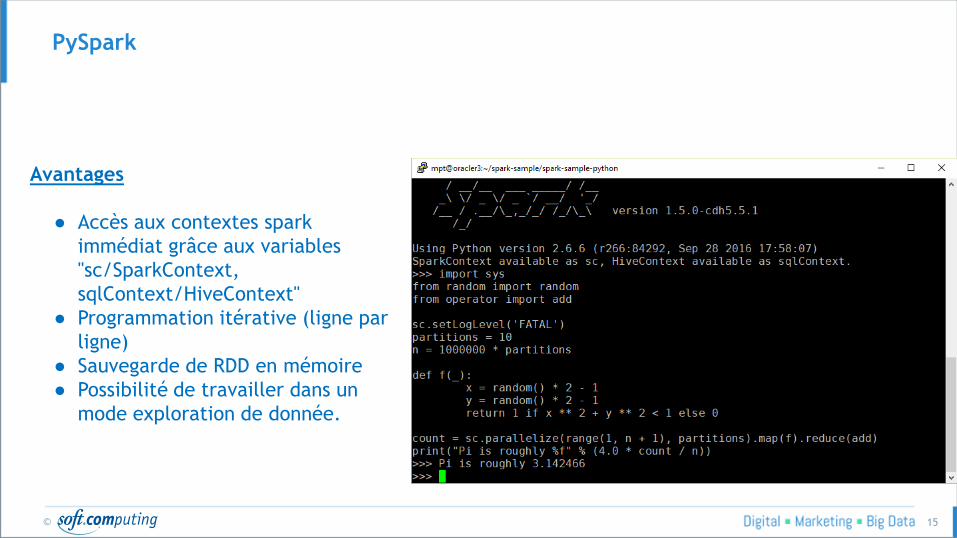
Avantages
● Accès aux contextes spark
immédiat grâce aux variables
"sc/SparkContext,
sqlContext/HiveContext"
● Programmation itérative (ligne par
ligne)
● Sauvegarde de RDD en mémoire
● Possibilité de travailler dans un
mode exploration de donnée.
© 16
PySpark
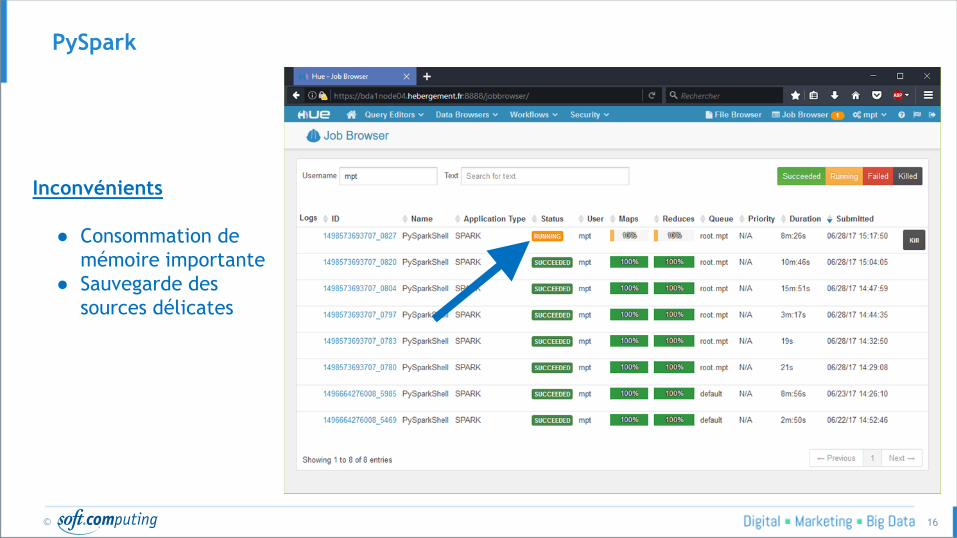
Inconvénients
● Consommation de
mémoire importante
● Sauvegarde des
sources délicates
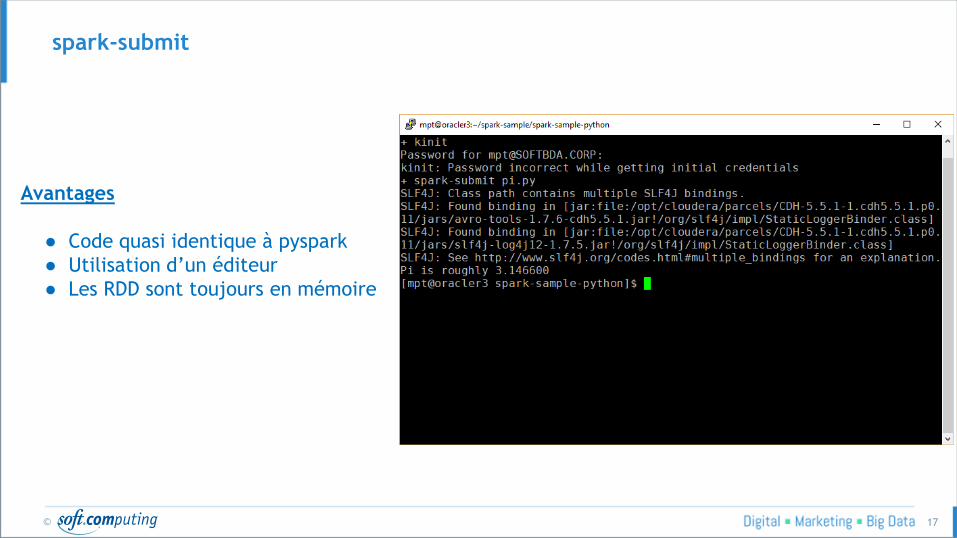
© 17
spark-submit
Avantages
● Code quasi identique à pyspark
● Utilisation d’un éditeur
● Les RDD sont toujours en mémoire
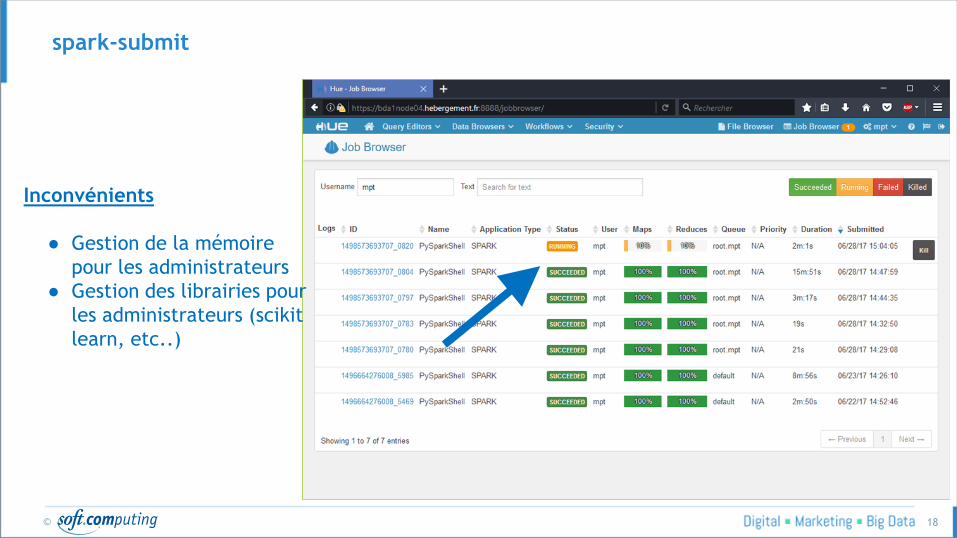
© 18
spark-submit
Inconvénients
● Gestion de la mémoire
pour les administrateurs
● Gestion des librairies pour
les administrateurs (scikit
learn, etc..)
© 19
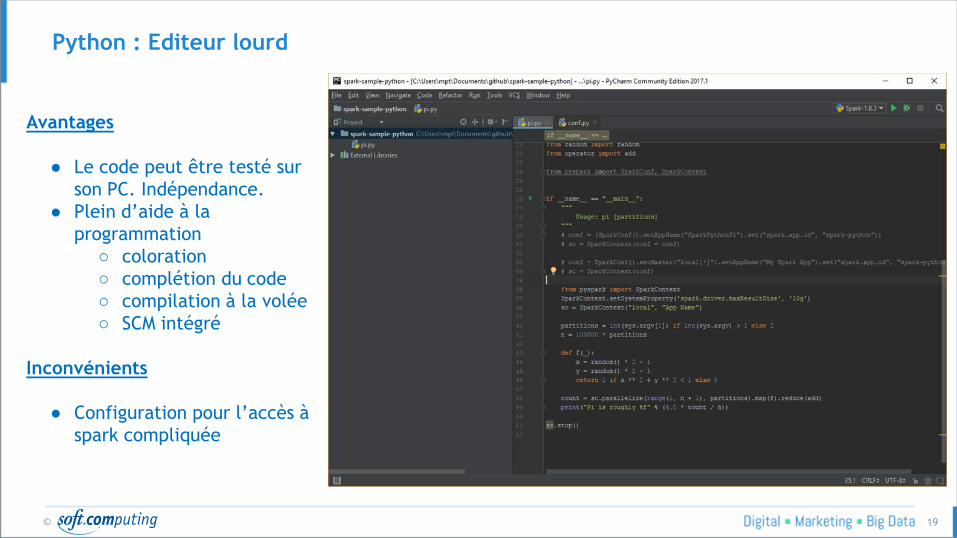
Python : Editeur lourd
Avantages
● Le code peut être testé sur
son PC. Indépendance.
● Plein d’aide à la
programmation
○ coloration
○ complétion du code
○ compilation à la volée
○ SCM intégré
Inconvénients
● Configuration pour l’accès à
spark compliquée

© 20
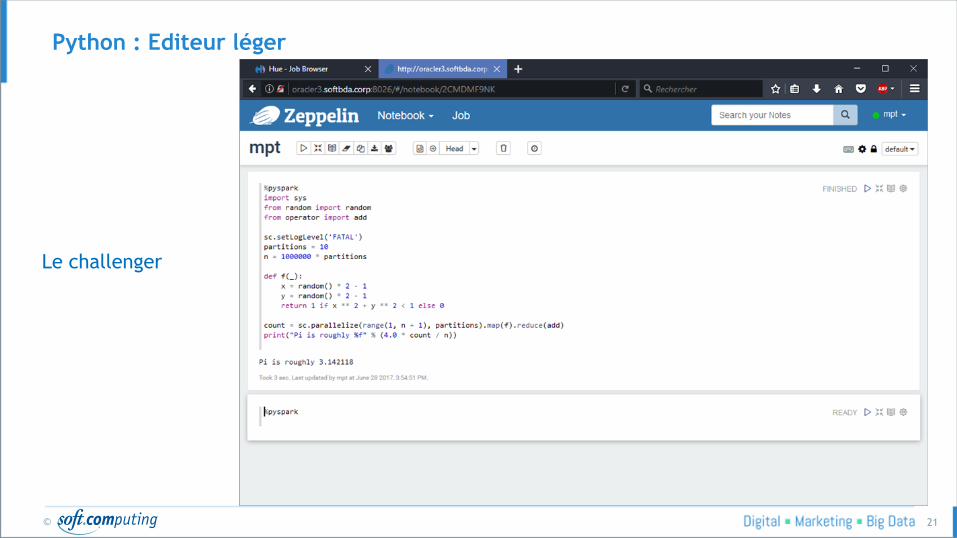
Python : Editeur léger
Avantages
● Le code peut être testé sur
un serveur puissant.
● Configuration d’accès à
spark facile
● Multi-interpréteur
Inconvénients
● Dépendance vis des autres
développeurs (CPU, RAM)
● Absence d’aide à la
programmation
© 21
Python : Editeur léger
Le challenger

© 22
1. Python dans le monde Big Data / Data Science
2. Pyspark – Des données au Machine Learning
3. Python – focus
A. Python multicore
B. Machine Learning – Scikit-learn
C. Gitlab
4. Retours d’expérience et bonnes pratiques
5. Q&A

© 23
Démo - Atelier 1
✓ Import des données
✓ Cleaning et retraitement
✓ Future engineering
✓ Machine Learning : score

© 24
RETOUR D’EXPERIENCE
Construction d’un prototype pour automatiser la réalisation des
segmentations et des scores
Distribution ✓ Efficacité dans la construction des segmentations et scores
✓ Garantir le choix du meilleur modèle enjeux secteur
Démarche
▪ Moteur d’import des données ➔ tables HIVE
▪ Rapport d’audit : complétude, fiabilité des données (tendance
centrale et dispersion des données)
▪ Future engineering : transformation des données, agrégats
clients et indicateurs
▪ Machine Learning : pipeline (fiting, tunning des paramètres par
cross validation et évaluation)
▪ Restitution : fiche de présentation et modèle
réalisation
Dém
o
Démo
Spark ML

© 25
Démo Big Data
➢ Le choix de plateforme et des outils est un pilier important quand on
développe et industrialise des projets Data Science.
© 26
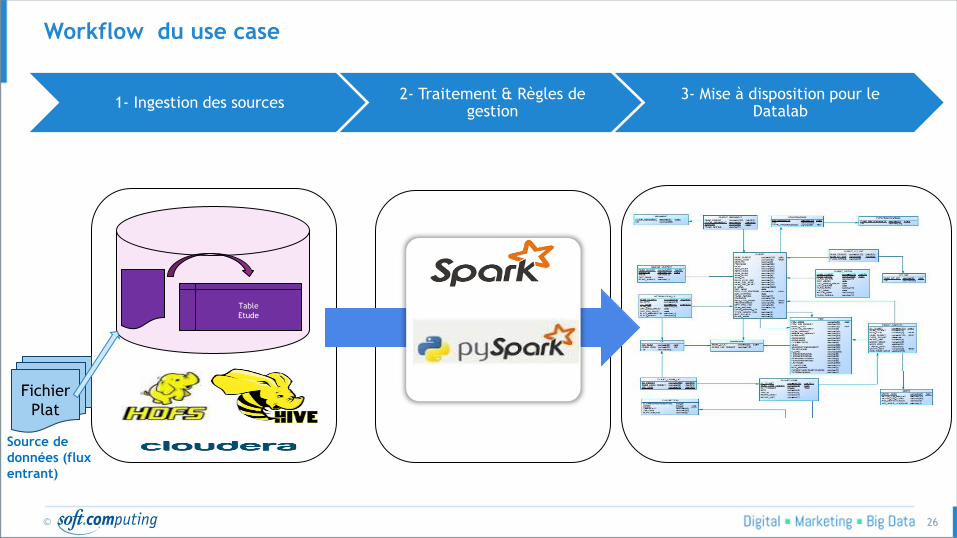
Workflow du use case
1- Ingestion des sources 2- Traitement & Règles de
gestion 3- Mise à disposition pour le
Datalab
Fichier
Plat
Source de
données (flux
entrant)
Table
Etude
© 27
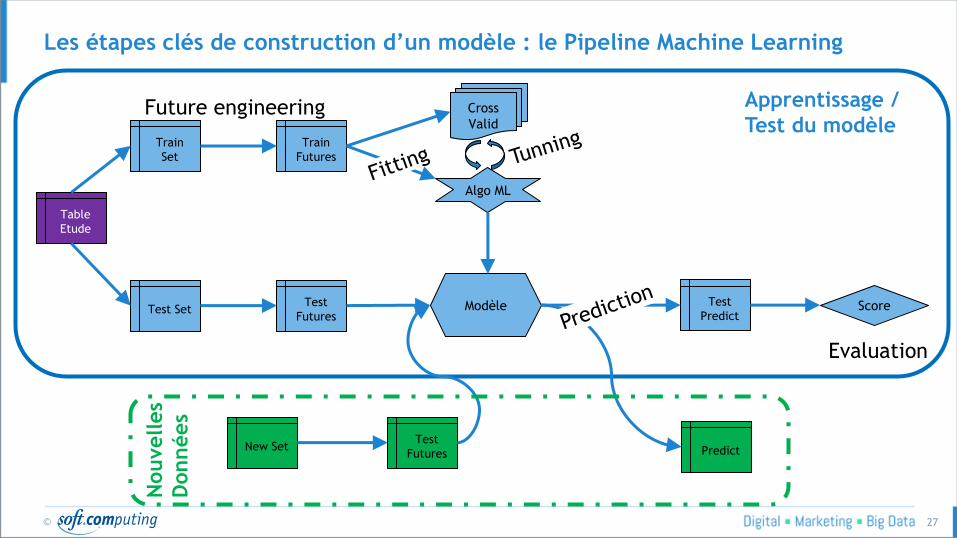
Les étapes clés de construction d’un modèle : le Pipeline Machine Learning
Table
Etude
Train
Set
Test Set
Train
Futures
Algo ML
Cross
Valid
Modèle Test
Futures
Test
Predict Score
Future engineering
New Set
Evaluation
Test
Futures Predict
Nouvelles
Données
Apprentissage /
Test du modèle

© 28
RETOUR D’EXPERIENCE
Des exemples de livrables
Segmentation Persona Segmentation Comportement d’achat – Les Portraits Robots
Score - Restitution
© 29
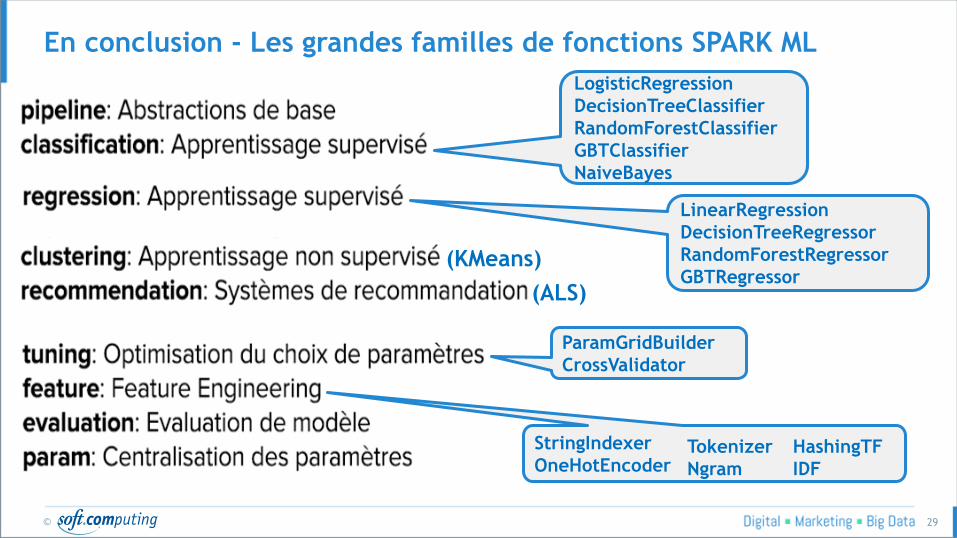
En conclusion - Les grandes familles de fonctions SPARK ML
LogisticRegression
DecisionTreeClassifier
RandomForestClassifier
GBTClassifier
NaiveBayes
LinearRegression
DecisionTreeRegressor
RandomForestRegressor
GBTRegressor
ParamGridBuilder
CrossValidator
StringIndexer
OneHotEncoder Tokenizer
Ngram
HashingTF
IDF
(ALS)
(KMeans)

© 30
1. Python dans le monde Big Data / Data Science
2. Pyspark – Des données au Machine Learning
3. Python – focus
A. Python multicore
B. Machine Learning – Scikit-learn
C. Gitlab
4. Retours d’expérience et bonnes pratiques
5. Q&A

© 31
Démo - Atelier 2
✓Python multi core
✓Scikit-learn
✓Gitlab
© 32
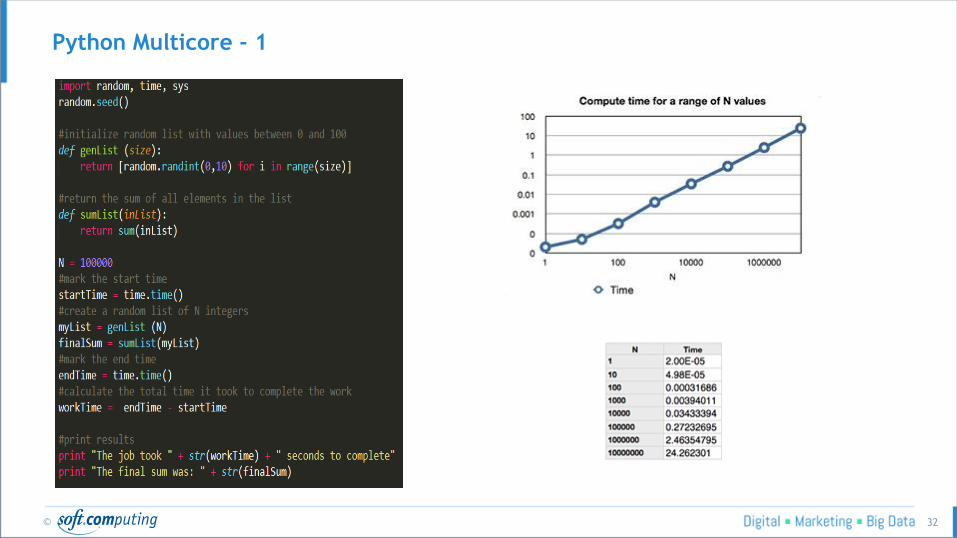
Python Multicore - 1
© 33
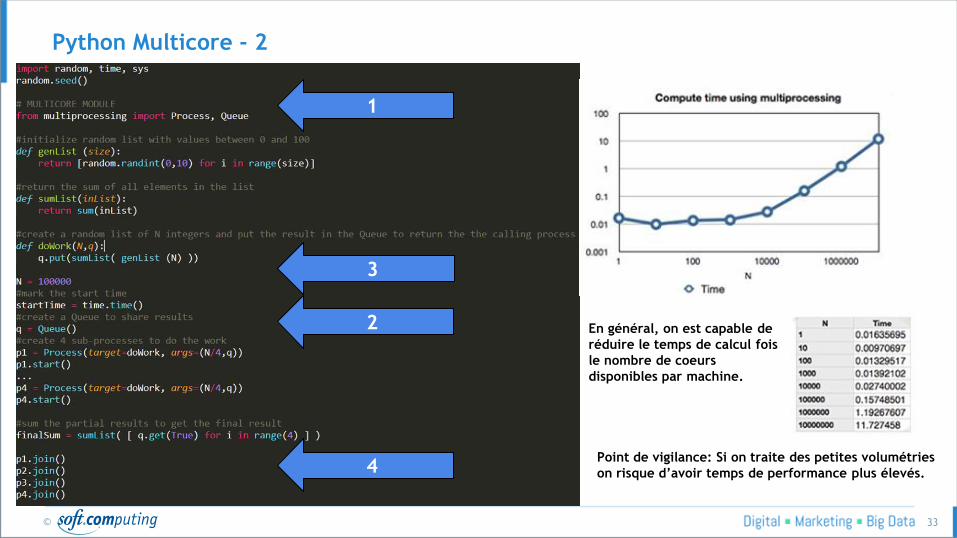
Python Multicore - 2
1
2
3
4 Point de vigilance: Si on traite des petites volumétries
on risque d’avoir temps de performance plus élevés.
En général, on est capable de
réduire le temps de calcul fois
le nombre de coeurs
disponibles par machine.

© 34
Python Multicore - 3
1
2
Le temps de réponse sont
équivalents à l’approche
précédant mais avec des
avantages:
● Lisibilité du code
● Maintenance du code
● Parametrization
dynamique possible

© 35
Démo - Atelier 2
© 36
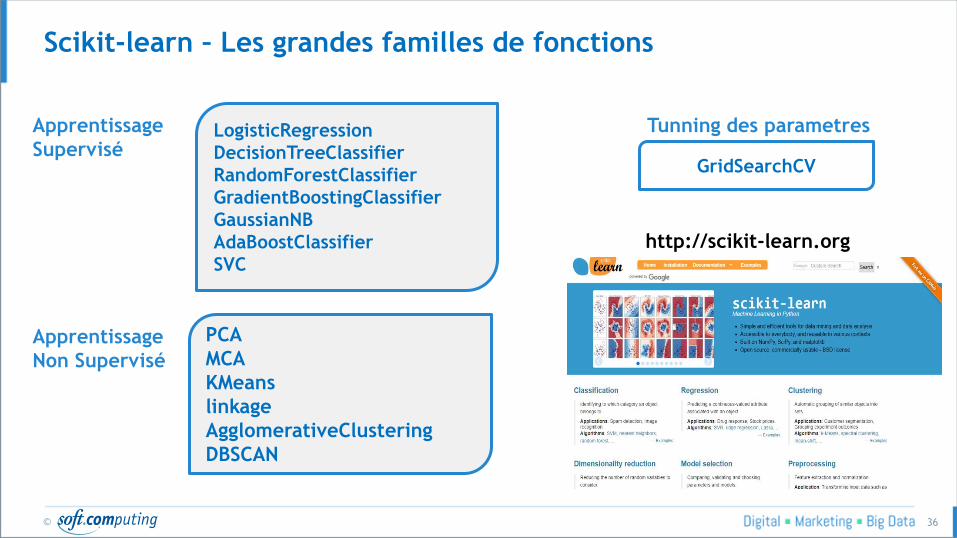
Scikit-learn – Les grandes familles de fonctions
LogisticRegression
DecisionTreeClassifier
RandomForestClassifier
GradientBoostingClassifier
GaussianNB
AdaBoostClassifier
SVC
GridSearchCV
PCA
MCA
KMeans
linkage
AgglomerativeClustering
DBSCAN
Apprentissage
Non Supervisé
Apprentissage
Supervisé
Tunning des parametres
http://scikit-learn.org

© 37
Au-delà de Scikit-Learn
Visualisation des données : pandas & seaborn
Deep Learning

© 38
Démo - Atelier 2

© 39
Présentation d’un SCM : GitLab

© 40
Gitlab : Création d’un nouveau projet
Git global setup
git config --global user.name "Mickael Patron"
git config --global user.email "[email protected]"
Create a new repository
git clone [email protected]:mpt/myproject.git
cd myproject
touch README.md
git add README.md
git commit -m "add README"
git push -u origin master
Existing folder
cd existing_folder
git init
git remote add origin [email protected]:mpt/myproject.git
git add .
git commit -m "Initial commit"
git push -u origin master
Existing Git repository
cd existing_repo
git remote add origin [email protected]:mpt/myproject.git
git push -u origin --all
git push -u origin --tags

© 41
Gitlab : Repository

© 42
Gitlab : Commit

© 43
Gitlab : Versioning

© 44
Gitlab : Le wiki

© 45
Gitlab : Deployment automatique

© 46
Gitlab : Éditeurs multi-environnement

© 47
1. Python dans le monde Big Data / Data Science
2. Pyspark – Des données au Machine Learning
3. Python – focus sur deux incontournables
A. Python multicore
B. Machine Learning – Scikit-learn
C. Gitlab
4. Retours d’expérience et bonnes pratiques
5. Q&A

© 48
RETOUR D’EXPERIENCE
Accompagnement dans la réalisation d’un moteur de recommandation
Site Web ✓ Construction d’un moteur de recommandation personnalisée
✓ Montée en compétence des ressources internes enjeux secteur
▪ Cadrage : Définition de la vision cible (ergonomie du site, algorithme de
recommandation, architecture).
➢ Entretiens avec le métier et l'IT pour définir les besoins
➢ Benchmarch ergonomie du site
réalisation ▪ Accompagnement au quotidien des équipes Data Science et IT
➢ Formation des équipes à Python (programmation et Machine Learning)
➢ Algorithmes de recommandation (recommandation personnalisée, en fonction de la demande de
l’internaute et de sa navigation sur le site) : feuille de route et plan de recette
➢ Architecture : accompagnement environnement et Web Services.
DEMARCHE EN 2 ETAPES

© 49
RETOUR D’EXPERIENCE
Mises en place de Scores de Churn & Prospection et Segmentation client
Re-Assurance
B2B
✓ Refonte de la segmentation actuelle vers une segmentation
lifecycle
✓ Elaboration et mise en production de multiples scores pour les
équipes Marketing de différents pays : Churn, Prospection enjeux secteur
▪ Segmentation :
➢ Réunions de cadrage et définition du scope avec les équipes métiers
➢ Proposition de 3 types de segmentations aux équipes métiers (valeur, naturelle, lifecycle) : méthodologie DEEP +
programmation Python avec utilisation ScikitLearn
▪ Scores sur des BU internationales :
➢ Réunions de cadrage et définition du scope avec les équipes métiers
➢ Construction des matrices de travail sous Python : croisement de plusieurs sources – Sales Force, IRP, CRM
➢ Machine Learning en Python sur machine Amazon Web Services (EC2)
➢ Data Visualisation en Python pour améliorer les outils internes des équipes directement en relation avec le client
➢ Mise en production avec automatisation des flux
réalisation
© 50
RETOUR D’EXPERIENCE
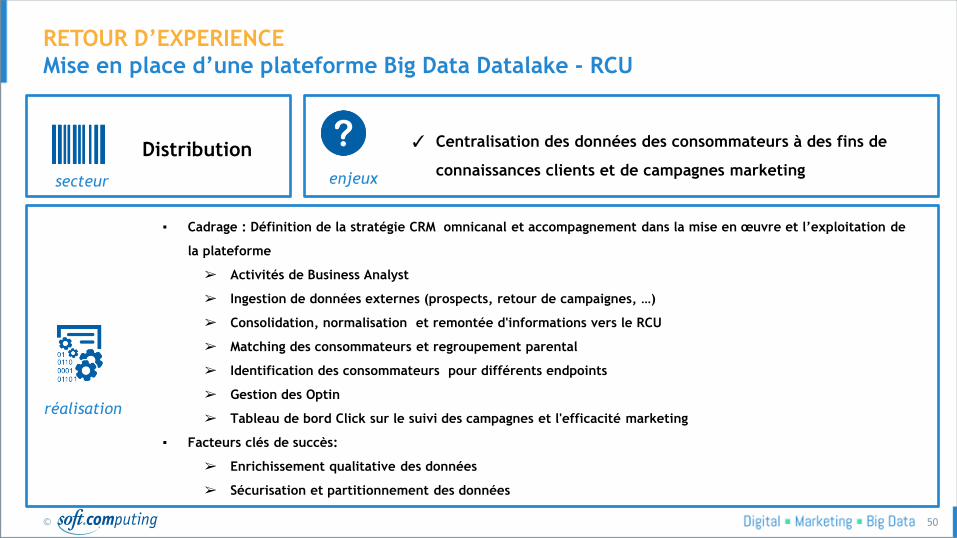
Mise en place d’une plateforme Big Data Datalake - RCU
Distribution ✓ Centralisation des données des consommateurs à des fins de
connaissances clients et de campagnes marketing enjeux secteur
▪ Cadrage : Définition de la stratégie CRM omnicanal et accompagnement dans la mise en œuvre et l’exploitation de
la plateforme
➢ Activités de Business Analyst
➢ Ingestion de données externes (prospects, retour de campaignes, …)
➢ Consolidation, normalisation et remontée d'informations vers le RCU
➢ Matching des consommateurs et regroupement parental
➢ Identification des consommateurs pour différents endpoints
➢ Gestion des Optin
➢ Tableau de bord Click sur le suivi des campagnes et l'efficacité marketing
▪ Facteurs clés de succès:
➢ Enrichissement qualitative des données
➢ Sécurisation et partitionnement des données
réalisation

© 51
Conclusion : OPEN SOURCE - S’orienter selon son besoin
Identifier l’environnement, le besoin pour choisir les outils en adéquation
Datalab
Volumétrie Volumétrie
OUI NON
Industrialisation
© 52
Coaching et formation
Sélection des cas d’usages
Sélection de l’outillage
Modélisation/ Machine Learning
Optimisation
Intégration informatique
Consolidation Datalab
Exploitation
On peut aider ?

© 53
Soft Computing, vivier de compétences Python, vous propose une formation
Python dispensée par ses experts
Formation Python
■ 1 800 € HT/ personne en
inter-entreprise
■ 9h – 17h30
■ Déjeuners compris dans
le coût de la formation
■ Dans les locaux de Soft
Computing Paris
Nous consulter pour une
version intra entreprise
Public concerné Présentation de Python Modalités
■ Data Scientist / DataMiner
■ Débutant en Python
■ Statisticien
■ Marketer spécialiste de la data
■ Utilisateur de bases de données
intéressé par l’analyse
Pré-requis
Agrément
■ Connaissances en statistiques
■ Connaissances d’un autre langage
de programmation
SAS/SPSS/VBA/MatLab/R/C
Objectifs de la formation
Apprendre à programmer en Python dans le but de :
• Faire son data management sous Python
• Explorer ses données sous Python
• Utiliser les principaux algorithmes de modélisation du datamining sous Python
■ Numéro d’agrément de
formation :
11 75 43610 75
Soft Computing ▪ 55 Quai de Grenelle-75015 Paris ▪ Tél. +33 (0)1 73 00 55 00 ▪ www.softcomputing.com
▪ Siret : 330 076 159 00079 ▪ DA : 11 75 43610 75
■ Libre de droit et simple
d’installation
■ Systématiquement associé à
l’installation d’une plate-
forme Big Data, peut être
utilisé en local ou en
serveur de manière
transparente pour
l’utilisateur
Python est un langage et un environnement pour la manipulation de
données, les calculs statistiques et leurs représentations graphiques.
Cet outil devient incontournable pour les Data Scientists car il cumule
nombre d’avantages :
■ Utilisé par la communauté
internationale des Data
Ingenieur, Data Miners et
des Data Scientists
■ Donne accès aux procédures
les plus innovantes
2, 3 & 4 octobre 2017 :

© 54
Jour 2
Segmenter Construire une classification et
les portraits-robots
■ analyse factorielle sous
Python
■ algorithmes non supervisés
sous Python
Jour 1
Les fondamentaux Créer une base de travail et l’explorer :
■ débuter un programme sous Python, les bonnes pratiques
■ importer des données, auditer et faire le data management
■ faire l’analyse exploratoire des données
Formation Python
Programme de formation Extrait de références
Soft Computing, principal vivier de compétences Python en France vous
propose une formation Python dispensée par ses experts
Prochaines sessions
■ 2-3-4 Octobre 2017
(sous réserve d’un minimum de 4
inscrits)
Inscriptions
Les + SC University
©
■ Télécharger et retourner le bulletin d’inscription dûment
complété à [email protected]
■ Les formateurs sont des chefs
de projets qui utilisent Python
dans le cadre des missions
effectuées auprès de nos
clients
■ Supervision académique des
contenus de la formation
■ Possibilité de personnaliser la
formation
■ Repartez de la formation avec
vos codes prêts à l’emploi
travaillant sur votre
ordinateur dans votre
environnement
Jour 3
Scorer Créer un modèle de score et
le réappliquer
■ algorithmes supervisés
sous Python
■ Retourner un exemplaire de la convention qui vous sera envoyée
dûment complétée et signée
■ Conditions générales de vente téléchargeables sur notre site

© 55
- www.softcomputing.com -
@softcomputing @softcomputing @softcomputing
Merci !
Des questions
[email protected] – Tél. : +33 (0)1 73 00 55 00
















![[French] Matinale du Big Data Talend](https://static.fdocuments.fr/doc/165x107/5577f170d8b42a24198b4a9b/french-matinale-du-big-data-talend.jpg)

