







Langages
Pages
Légal


Atelier SAS du Jeudi 4 Novembre 2004
Le Modèle multiniveau:Principes et applications
Marc LE VAILLANTCentre de recherche en Economie et Gestion Appliquées à la SantéINSERM U537- CNRS UPRESA 8052

Modèle multiniveau et modèle « classique »
Le modèle linéaire multiniveau est l’instrument de base permettant:
- prise en compte des effets de milieu dans l’analyse de la variabilité des comportements individuels.
- L’analyse de l’association entre caractéristiques individuelleset facteurs de niveau plus élevé.
- Le traitement des données corrélées.
Approche classique
- insuffisante du fait de la non indépendance des observations- Limitée : elle ne peut prendre en compte l’ensemble de la variabilité des phénomènes
Approche multiniveau
- Vise à mesurer et analyser la variance à chaque niveau- Contraste avec l’approche visant à ne voir dans les facteurs de niveau élevé que des facteurs de nuisance.
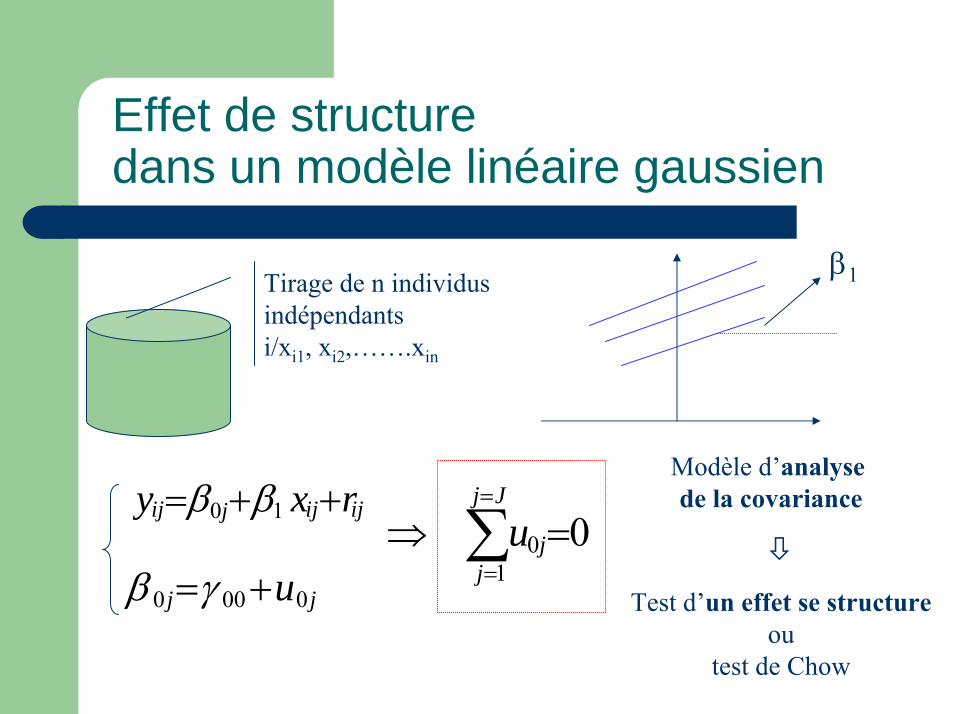
Effet de structure dans un modèle linéaire gaussien
Tirage de n individus indépendantsi/xi1, xi2,…….xin
ijijjij rxy ++= 10 ββ
jj u0000 +=γβ
β1
Modèle d’analyse de la covariance
0 1
0 =⇒ ∑=
=
Jj
jju
Test d’un effet se structureou
test de Chow
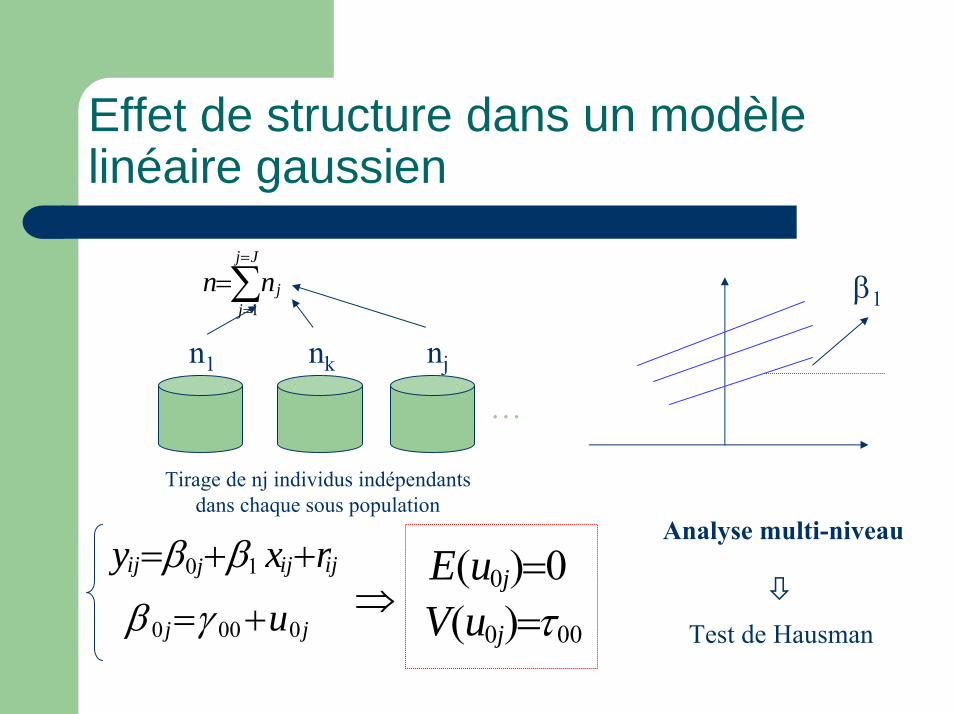
Effet de structure dans un modèle linéaire gaussien
ijijjij rxy ++= 10 ββ
jj u0000 +=γβ
β1
⇒0)( 0 =juE000 )( τ=juV
∑=
==
Jj
jjnn
1
…
n1 nk nj
Tirage de nj individus indépendants dans chaque sous population
Analyse multi-niveau
Test de Hausman
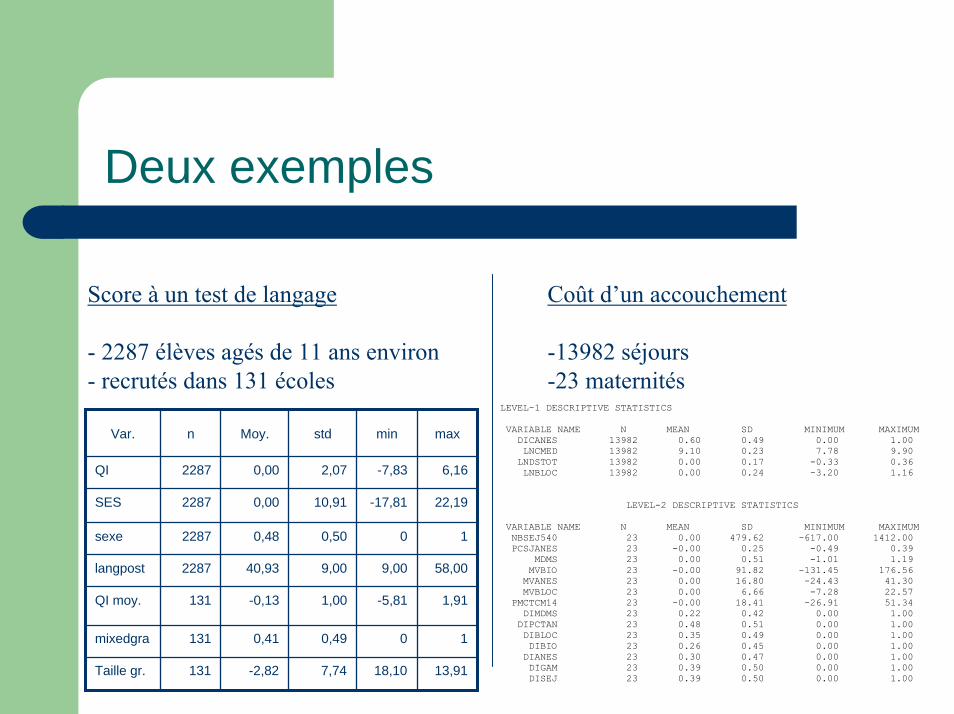
Deux exemples
Var. n Moy. std min max
QI 2287 0,00 2,07 -7,83 6,16
SES 2287 0,00 10,91 -17,81 22,19
sexe 2287 0,48 0,50 0 1
langpost 2287 40,93 9,00 9,00 58,00
QI moy. 131 -0,13 1,00 -5,81 1,91
mixedgra 131 0,41 0,49 0 1
Taille gr. 131 -2,82 7,74 18,10 13,91
Score à un test de langage Coût d’un accouchement
-13982 séjours-23 maternités
LEVEL-1 DESCRIPTIVE STATISTICS VARIABLE NAME N MEAN SD MINIMUM MAXIMUM DICANES 13982 0.60 0.49 0.00 1.00 LNCMED 13982 9.10 0.23 7.78 9.90 LNDSTOT 13982 0.00 0.17 -0.33 0.36 LNBLOC 13982 0.00 0.24 -3.20 1.16 LEVEL-2 DESCRIPTIVE STATISTICS VARIABLE NAME N MEAN SD MINIMUM MAXIMUM NBSEJ540 23 0.00 479.62 -617.00 1412.00 PCSJANES 23 -0.00 0.25 -0.49 0.39 MDMS 23 0.00 0.51 -1.01 1.19 MVBIO 23 -0.00 91.82 -131.45 176.56 MVANES 23 0.00 16.80 -24.43 41.30 MVBLOC 23 0.00 6.66 -7.28 22.57 PMCTCM14 23 -0.00 18.41 -26.91 51.34 DIMDMS 23 0.22 0.42 0.00 1.00 DIPCTAN 23 0.48 0.51 0.00 1.00 DIBLOC 23 0.35 0.49 0.00 1.00 DIBIO 23 0.26 0.45 0.00 1.00 DIANES 23 0.30 0.47 0.00 1.00 DIGAM 23 0.39 0.50 0.00 1.00 DISEJ 23 0.39 0.50 0.00 1.00
- 2287 élèves agés de 11 ans environ- recrutés dans 131 écoles

1.- modélisation au niveau individu
Pour chaque unité j on écrit un modèlerigoureusement identique au modèle classique
ijijjj rQIlangpost ++= 10 ββ rij N(0,σ2)
E(β0j)=γ0 var (β0j)= τ00E(β1j)=γ1 var (β1j)= τ11
cov(β0j,β1j)= τ01
γ0 ordonnée à l ’origine dans la population des élèvesγ1 pente dans la population des élèvesτ00 dispersion des unités j autour de l ’ordonnée à l ’origineτ11 dispersion des unités j autour de la penteτ01 covariance entre les ordonnées à l ’origine et les pentes
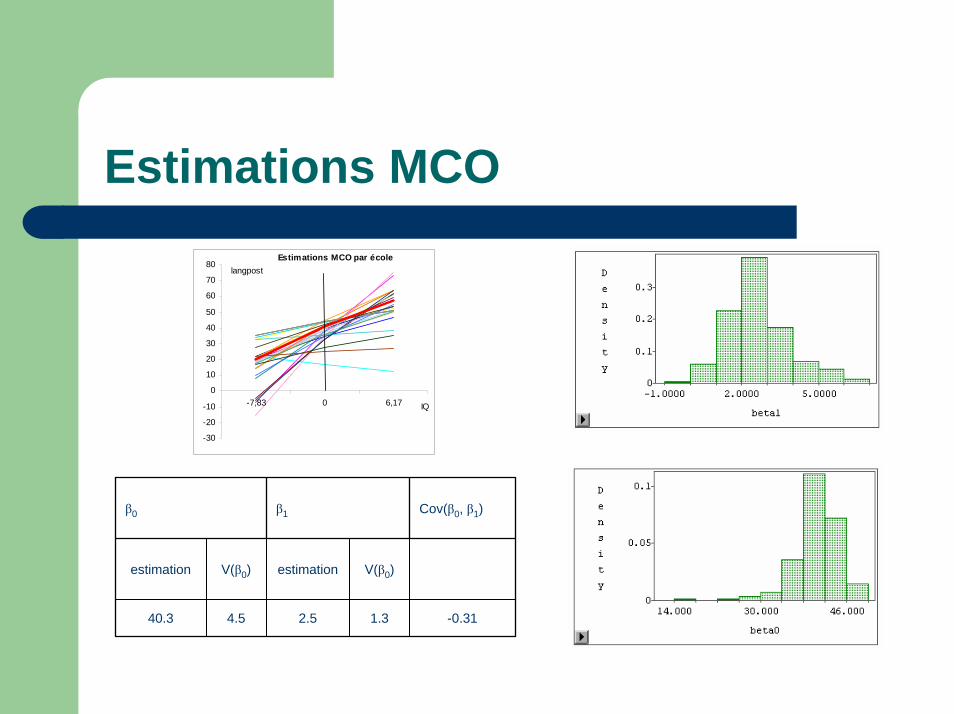
Estimations MCO
-30
-20
-10
0
10
20
30
40
50
60
70
80
-7,83 0 6,17
Estimations MCO par écolelangpost
IQ
β0 β1 Cov(β0, β1)
estimation V(β0) estimation V(β0)
40.3 4.5 2.5 1.3 -0.31

2.-Modélisation au niveau unité
- Les coefficient β0j et β1j sont les variables dépendantes- les variables explicatives (wj )caractérisent les unités j
1jj11101j umγγβ ++= ixedgra0jj01000j uγγβ ++= mixedgra
γ00 ordonnée à l ’origine pour l ’ensemble des écoles de composition homogène γ01 différence d ’ordonnée à l ’origine entre les écoles selon leur compositionu0j effet propre de l’école. j sur l ’ordonnée à l ’origine sachant mixedgrajγ10, γ11 , u1j idem relativement à la pente.
u0j aléatoire tel que E(u0j)=0 et Var(u0j)=τ00u1j aléatoire tel que E(u1j)=0 et Var(u1j)=τ11cov(u0j,u1j)=τ01
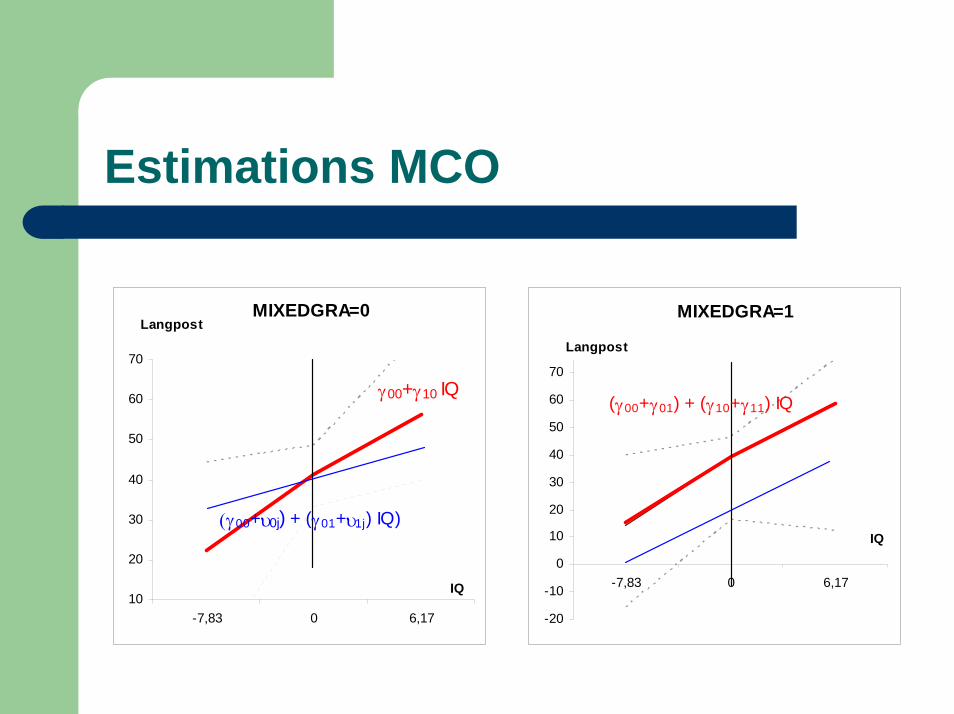
Estimations MCO
MIXEDGRA=0
10
20
30
40
50
60
70
-7,83 0 6,17
Langpost
IQ
γ00+γ10 IQ
(γ00+υ0j) + (γ01+υ1j) IQ)
MIXEDGRA=1
-20
-10
0
10
20
30
40
50
60
70
-7,83 0 6,17
Langpost
IQ
(γ00+γ01) + (γ10+γ11) IQ

Estimations MCO
MIXEDGRA=1
-20
-10
0
10
20
30
40
50
60
70
-7,83 0 6,17
Langpost
IQ
MIXEDGRA=1
-20
-10
0
10
20
30
40
50
60
70
-7,83 0 6,17
Langpost
IQ
(γ00+γ01) + (γ10+γ11) IQ

Estimation ML
Model Information
Data Set EX1.SCORMATHDependent Variable langpostCovariance Structure UnstructuredSubject Effect idschoolEstimation Method MLResidual Variance Method ProfileFixed Effects SE Method Model-BasedDegrees of Freedom Method Containment
Dimensions
Covariance Parameters 4Columns in X 4Columns in Z Per Subject 2Subjects 131Max Obs Per Subject 35Observations Used 2287Observations Not Used 0Total Observations 2287
Iteration History
Iteration Evaluations -2 Log Like Criterion
0 1 15427.807711391 2 15211.23580569 0.000008192 1 15211.18935758 0.000000023 1 15211.18925831 0.00000000
Convergence criteria met.
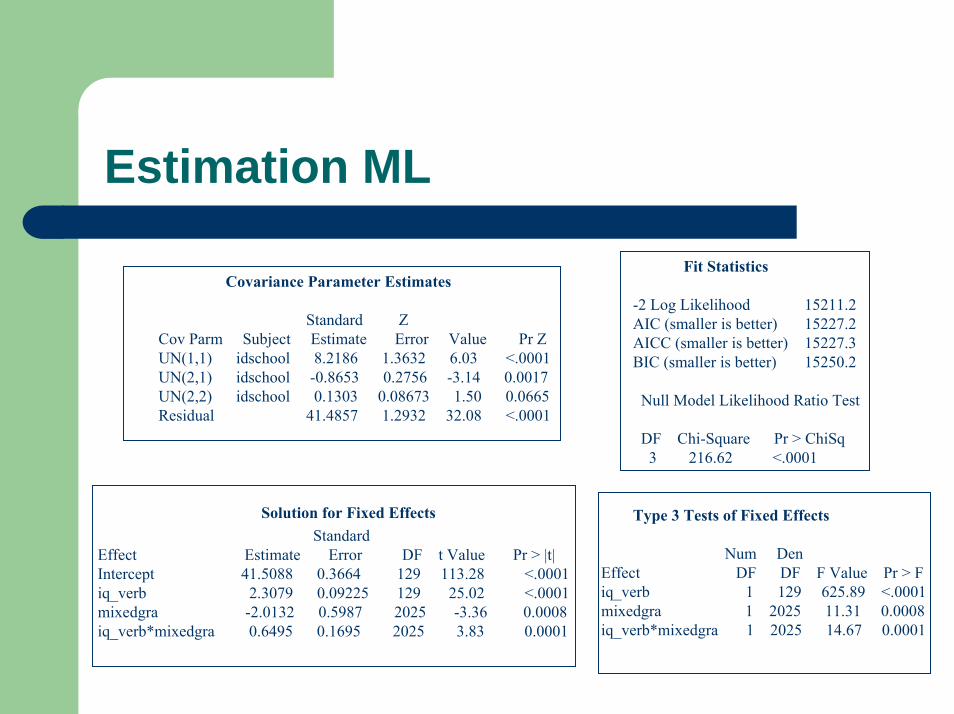
Estimation ML
Covariance Parameter Estimates
Standard ZCov Parm Subject Estimate Error Value Pr ZUN(1,1) idschool 8.2186 1.3632 6.03 <.0001UN(2,1) idschool -0.8653 0.2756 -3.14 0.0017UN(2,2) idschool 0.1303 0.08673 1.50 0.0665Residual 41.4857 1.2932 32.08 <.0001
Solution for Fixed EffectsStandard
Effect Estimate Error DF t Value Pr > |t|Intercept 41.5088 0.3664 129 113.28 <.0001iq_verb 2.3079 0.09225 129 25.02 <.0001mixedgra -2.0132 0.5987 2025 -3.36 0.0008iq_verb*mixedgra 0.6495 0.1695 2025 3.83 0.0001
Fit Statistics
-2 Log Likelihood 15211.2AIC (smaller is better) 15227.2AICC (smaller is better) 15227.3BIC (smaller is better) 15250.2
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq3 216.62 <.0001
Type 3 Tests of Fixed Effects
Num DenEffect DF DF F Value Pr > Fiq_verb 1 129 625.89 <.0001mixedgra 1 2025 11.31 0.0008iq_verb*mixedgra 1 2025 14.67 0.0001

Conduire une analyse multiniveau
- Méthodes d’estimation- Le modèle vide et la décomposition de la variance- Mesure globale de la variance expliquée- Centrage des variables explicatives- Déviance et comparaison de modèles- Test d’hypothèses- Adéquation du modèle aux données

Le modèle développé
ijijj1j0ijj11ij10j0100ij rxuuxwxwy +++γ+γ+γ+γ=
Rij
Dans ce modèle l ’expression du terme aléatoire résiduel (Rij) permet de faire apparaître les deux caractéristiques potentiellement possédées par les résidus du modèle HLM:
1- Hétéroscédasticité: Pour chaque individu la variance résiduelle est variable:elle est dépendante de Xij.
2- autocorrélation: Au sein d’une école les résidus de deux élèves sont corrélés: ils dépendent à la fois de u0j et u1j qui varient d’un établissementà l’autre

Méthodes d’estimation: première approche: MCO et MCG
Les estimations MCO sont sans biais mais les écarts types sont généralement sous-évalués.
Les estimations MCG permettent d’obtenir des estimations efficaces desécarts types mais elle suppose de connaître la matrice de covariance des erreurs.
La procédure d’estimation par les MCG est itérative: MCGI
Estimation d’une matrice de
covariance de départ en utilisantLes MCO sur le
Modèle développé
Procédure MCGUtilisant la matrice
Estimée dans le modèle MCO
Nouvelle estimationde la matrice de
covariance des erreurs

Méthodes d’estimation: seconde approche: ML et REML
La Différence entre les deux méthodes vient du fait que l’estimation ML des composantes de variance est effectuée en supposant que les coefficients fixes ne sont pas estimés.
Exemple: [ ] V(X)0,N i110 →++= ∑ −− εεββ ippi Xy
β vrais β estimés
1ˆ2
2
+−= ∑
pniεσε
ni∑=2
2 εσε
Estimation ML Estimation REML

L’algorithme REML
Estimation des coefficients fixes γ par les MCO ou les MCG
Estimation des résidus.
sous les hypothèses usuelles écriture de la fonction de vraisemblance Ld’observer les résidus.
Maximisation de la fonction L pour obtenir les composantes de variance
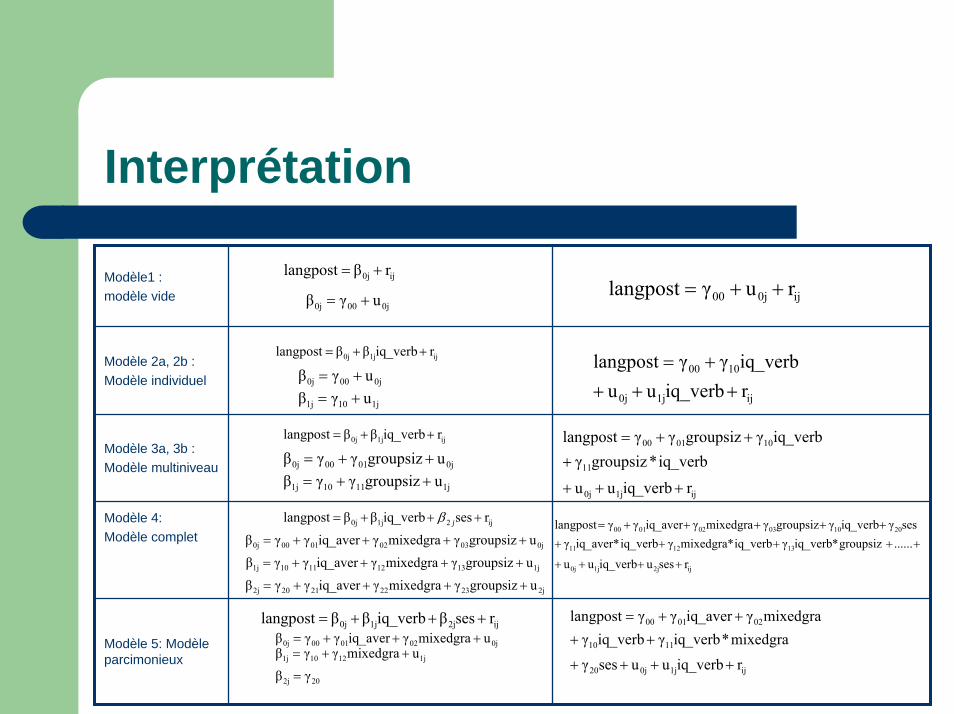
Interprétation
Modèle1 : modèle vide
Modèle 2a, 2b :Modèle individuel
Modèle 3a, 3b : Modèle multiniveau
Modèle 4: Modèle complet
Modèle 5: Modèleparcimonieux
ij0j rβlangpost +=
0j000j uγβ += ij0j00 ruγlangpost ++=
ij1j0j riq_verbββlangpost ++=
0j000j uγβ +=
1j101j uγβ += ij1j0j
1000
riq_verbuuiq_verbγγlangpost
++++=
ij1j0j
11
100100
riq_verbuu
iq_verb*groupsizγiq_verbγgroupsizγγlangpost
+++
+++=
0j01000j ugroupsizγγβ ++=
1j11101j ugroupsizγγβ ++=
ij2j1j0j
131211
201003020100
rsesuiq_verbuu
...... groupsiz*iq_verbγ iq_verb*mixedgraγiq_verb *iq_averγsesγiq_verbγgroupsizγ mixedgraγiq_averγγlangpost
++++
++++++++++=
0j030201000j ugroupsizγmixedgraγiq_averγγβ ++++=
ij1j0j riq_verbββlangpost ++=
ij21j0j rsesiq_verbββlangpost +++= jβ
1j131211101j ugroupsizγmixedgraγiq_averγγβ ++++=
2j232221202j ugroupsizγmixedgraγiq_averγγβ ++++=
ij1j0j20
1110
020100
riq_verbuusesγ
mixedgra*iq_verbγiq_verbγmixedgraγiq_averγγlangpost
++++
++++=
ij2j1j0j rsesβiq_verbββlangpost +++=0j0201000j umixedgraγiq_averγγβ +++=
1j12101j umixedgraγγβ ++=
202j γβ =

Modèle vide
ijj0ij ry +β=
j000j0 u+γ=β
rij N(0,σ2)
u0j N(0,τ00)ijj000ij ruy ++γ=
β0j est la moyenne « class specific »γ00 est la moyenne générale
- Chaque donnée individuelle s’éloigne de la moyenne de classeDe la quantité rij
-Chaque moyenne ‘class specific’ s’éloigne de la moyenne générale de la quantité u0j
jj
2
.j Vn)r(var =σ=j.j0j. ry +β=
j.j000j. ruy ++γ= jj00.j v)y(var ∆=+τ=

Le coefficient de corrélation intra-classe
002
00
τ+στ
=ρσ2 estime la variance intra-classeτ00 estime la variance interclasse
Le coefficient de corrélation intra-classe mesure:
Le rapport entre la variance inter-classe et la variance totale
le coefficient de corrélation liant deux individus observés dans la même classe

Matrice de variance covariance
200
200
0000
20000
002
00
000000
00000000000
σ+τσ+τττ
σ+τττσ+τ
2
2
2
2
2
00000000000000000000
σσ
σσ
σ
- la variance d ’un individu est σ2 + τ00- la covariance de deux individus dans une même unité est τ00- la covariance de deux individus dans deux unités différentes est 0

Décomposition de la variance
The outcome variable is LANGPOST
Final estimation of fixed effects (with robust standard errors)Standard Approx.
Fixed Effect Coefficient Error T-ratio d.f. P-value------------------------------------------------------------------------------------------------------------------INTRCPT2, G00 40.364049 0.426363 94.671 130 0.000
Final estimation of variance components:Random Effect Standard Variance df Chi-square P-value
Deviation Component------------------------------------------------------------------------------------------------------------------INTRCPT1, U0 4.40800 19.43043 130 733.95978 0.000level-1, R 8.03540 64.56761
Statistics for current covariance components model------------------------------------------------------------------------------------------------------------------Deviance = 16251.380618 Number of estimated parameters = 3

Modèle individuel
Final estimation of fixed effects (with robust standard errors)----------------------------------------------------------------------------
Standard Approx.Fixed Effect Coefficient Error T-ratio d.f. P-value
----------------------------------------------------------------------------INTRCPT (γ00) -9.851451 1.761932 -5.591 130 0.000IQ_VERB (γ10) 2.526530 0.081444 31.022 130 0.000
----------------------------------------------------------------------------
Final estimation of variance components:-----------------------------------------------------------------------------------------------------------------------------------------Random Effect Standard Variance df Chi-square P-value
Deviation Component------------------------------------------------------------------------------intercept(u0j) 12.01598 144.38379 130 202.36344 0.000IQ_VERB (u1j) 0.45902 0.21070 130 183.21965 0.000Niveau 1 (Rij) 6.44023 41.47655------------------------------------------------------------------------------
Deviance =15228.939296Nombre de paramètres estimés=6

Centrage des variables explicatives
centrage par rapport à la moyenne générale ( )- la constante est égale à la moyenne de y ajustée sur les caractéristiques de l’individu moyen
- la variance V(β0) est la variance de cette moyenne ajustée entre les groupes.
centrage par rapport aux moyennes de groupe ( )- la constante est égale à la moyenne de y ajustée sur les
caractéristiques de l’individu moyen du groupe j- la variance V(β0) est la variance des moyennes de groupe.
XXx ijij −=
jijij XXx −=

Modèle individuel centré
Final estimation of fixed effects (with robust standard errors)----------------------------------------------------------------------------
Standard Approx.Fixed Effect Coefficient Error T-ratio d.f. P-value
----------------------------------------------------------------------------INTRCPT (γ00) 40.709449 0.304257 133.800 130 0.000IQ_VERB (γ10) 2.526530 0.081444 31.022 130 0.000
----------------------------------------------------------------------------
Final estimation of variance components:-----------------------------------------------------------------------------------------------------------------------------------------Random Effect Standard Variance df Chi-square P-value
Deviation Component------------------------------------------------------------------------------intercept(u0j) 3.05871 9.35568 130 586.63062 0.000IQ_VERB (u1j) 0.45902 0.21070 130 183.21965 0.000Niveau 1 (Rij) 6.44023 41.47655------------------------------------------------------------------------------
Deviance =15228.939296Nombre de paramètres estimés=6

Modèle multiniveau
Final estimation of fixed effects (with robust standard errors)----------------------------------------------------------------------------
Standard Approx.Fixed Effect Coefficient Error T-ratio d.f. P-value
----------------------------------------------------------------------------INTERCPT
INTRCPT (γ00) 40.954023 0.304264 134.600 129 0.000GROUPSIZ (γ01) 0.097798 0.039055 2.504 129 0.013
IQ_AVERINTRCPT (γ10) 2.492426 0.079355 31.408 129 0.000GROUPSIZ (γ11) -0.031149 0.011154 -2.793 129 0.000
----------------------------------------------------------------------------
Final estimation of variance components:-----------------------------------------------------------------------------------------------------------------------------------------Random Effect Standard Variance df Chi-square P-value
Deviation Component------------------------------------------------------------------------------intercept(u0j) 2.94841 8.69311 129 569.30574 0.000IQ_VERB (u1j) 0.41575 0.17285 129 178.31577 0.003Niveau 1 (Rij) 6.43766 41.44350------------------------------------------------------------------------------
Deviance =15217.675640Nombre de paramètres estimés=8

Modèle multiniveau: modèle centré
Final estimation of fixed effects (with robust standard errors)----------------------------------------------------------------------------
Standard Approx.Fixed Effect Coefficient Error T-ratio d.f. P-value
----------------------------------------------------------------------------INTERCPT
INTRCPT (γ00) 40.678472 0.296808 137.053 129 0.000GROUPSIZ (γ01) 0.097798 0.039055 2.504 129 0.013
IQ_AVERINTRCPT (γ10) 2.580191 0.086121 29.960 129 0.000GROUPSIZ (γ11) -0.031149 0.011154 -2.793 129 0.006
----------------------------------------------------------------------------
Final estimation of variance components:-----------------------------------------------------------------------------------------------------------------------------------------Random Effect Standard Variance df Chi-square P-value
Deviation Component------------------------------------------------------------------------------intercept(u0j) 2.94841 8.69311 129 569.30574 0.000IQ_VERB (u1j) 0.41575 0.17285 129 178.31577 0.003Niveau 1 (Rij) 6.43766 41.44350------------------------------------------------------------------------------
Deviance =15217.675640Nombre de paramètres estimés=8

Modèle completFinal estimation of fixed effects (with robust standard errors)----------------------------------------------------------------------------
Standard Approx.Fixed Effect Coefficient Error T-ratio d.f. P-value
----------------------------------------------------------------------------INTERCPT
INTRCPT (γ00) 41.641317 0.387795 107.380 127 0.000IQ_AVER (γ01) 0.775061 0.316425 2.449 127 0.015MIXEDGRA (γ01) -2.107717 0.768740 -2.742 127 0.007GROUPSIZ (γ01) -0.045334 0.044796 -1.012 129 0.312
IQ_VERBINTRCPT (γ10) 2.079745 0.111938 18.579 127 0.000
IQ_AVER (γ11) -0.036521 0.103958 -0.351 127 0.725MIXEDGRA (γ12) 0.505909 0.221445 2.285 127 0.022GROUPSIZ (γ13) 0.003867 0.013672 0.283 127 0.777
SESINTRCPT (γ20) 0.172187 0.022847 7.536 127 0.000
IQ8AVER (γ21) -0.021731 0.018670 -1.164 127 0.245MIXEDGRA (γ22) -0.003665 0.043692 -0.084 127 0.934GROUPSIZ (γ23) -0.002599 0.002600 -1.000 127 0.318
----------------------------------------------------------------------------
Final estimation of variance components:-----------------------------------------------------------------------------------------------------------------------------------------Random Effect Standard Variance df Chi-square P-value
Deviation Component------------------------------------------------------------------------------intercept(u0j) 2.70530 7.31867 126 439.54615 0.000IQ_VERB (u1j) 0.41328 0.17080 126 172.46377 0.004IQ_VERB (u2j) 0.04531 0.00205 126 130.40529 0.376Niveau 1 (Rij) 6.24658 39.01971------------------------------------------------------------------------------
Deviance =15079.580057Nombre de paramètres estimés=19

Modèle parcimonieuxFinal estimation of fixed effects (with robust standard errors)----------------------------------------------------------------------------
Standard Approx.Fixed Effect Coefficient Error T-ratio d.f. P-value
----------------------------------------------------------------------------INTERCPT
INTRCPT (γ00) 41.347286 0.334096 123.759 128 0.000IQ_AVER (γ01) 0.832863 0.327860 2.540 128 0.011MIXEDGRA (γ01) -1.714362 0.614266 -2.791 128 0.006
IQ_VERBINTRCPT (γ10) 2.079294 0.092197 23.053 129 0.000MIXEDGRA (γ12) 0.541890 0.179483 3.019 129 0.003
SESINTRCPT (γ20) 0.156155 0.014466 10.795 2281 0.000
----------------------------------------------------------------------------
Final estimation of variance components:-----------------------------------------------------------------------------------------------------------------------------------------Random Effect Standard Variance df Chi-square P-value
Deviation Component------------------------------------------------------------------------------intercept(u0j) 2.74198 7.51844 128 534.34469 0.000IQ_VERB (u1j) 0.34339 0.11792 129 164.70872 0.018Niveau 1 (Rij) 6.26746 39.28102------------------------------------------------------------------------------
Deviance =15086.328162Nombre de paramètres estimés=10

Mesure de la variance expliquée
Mesure globale de la part de variance expliquée:
2YY,
2 RR pseudo =
Mesures basées sur les composantes de variance:
(m.vide)σ(var x)σ(m.vide)σR Pseudo 2
ε
2ε
2ε2
ε−
=Au niveau 1
vide)(m.σ(var w)σ vide)(m.σR Pseudo 2
ε
2ε
2ε2
S−
=Au niveau 2

La déviance
[ ]),(log),( θµ iYii yfyl =
modèle saturé:Modèle dans lequel il y a autant de paramètres à estimer que d’observations
⎥⎦⎤
⎢⎣⎡−=
saturé modèledu ncevraisembla testémodèledu ncevraisembla 2logRV
( ) )],( ),([2, yylylyD −−= µµ ),( ii yylLog-vraisemblance
),( ii yl µLog-vraisemblance

Utilisation de la déviance pour la comparaison des modèles
- Comparaison de deux modèles emboîtés:
21 DDD −=∆⎥⎦⎤
⎢⎣⎡−=
saturé modèledu ncevraisembla testémodèledu ncevraisembla 2log1D
⎥⎦⎤
⎢⎣⎡−=
saturé modèledu ncevraisembla testémodèledu ncevraisembla 2log2D
21 MM ⊂ Sous H0 :2
21 ppD −→∆ χ
- test de la significativité d’un coefficient
Sous H0 :⎥⎦⎤
⎢⎣⎡−=
variablela avec modèledu ncevraisembla variablela sans modèledu ncevraisembla 2logD
21 χ→∆D

Conditions de validité pour l’utilisation de la déviance
Chaque modèle doit être estimé avec les mêmes données.
Les modèles doivent être emboîtés: un des modèles doit être obtenus en fixant des contraintes dans l’autre modèle.
La méthode d’estimation utilisée doit être le ML et non les REML
- les ML maximise la vraisemblance ⇒ maximisation de l’ensemble des paramètres : (γ,σ)
-Les REML maximise les résidus⇒ maximisation des σ seuls

Comparer des modèles non emboîtés: AIC et BIC
AIC: Akaike Information CriterionBIC: Bayesian Information Criterion
Mesures basées sur la pénalisation de la fonction LL
AIC (Nb paramètres) BIC (Nb observations)
[ ]param. Nb1LL2AIC ×−−= param. Nb2logndévianceBIC ×+=
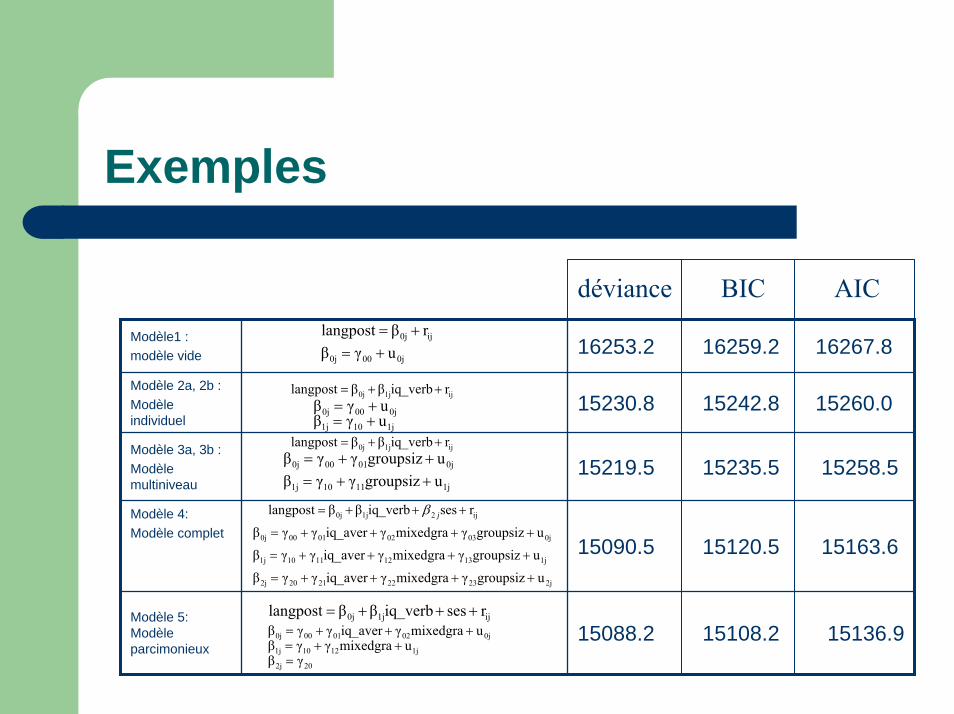
Exemples
Modèle1 : modèle vide 16253.2 16259.2 16267.8
Modèle 2a, 2b :Modèle individuel
15230.8 15242.8 15260.0
Modèle 3a, 3b : Modèle multiniveau
15219.5 15235.5 15258.5
Modèle 4: Modèle complet
15090.5 15120.5 15163.6
Modèle 5: Modèleparcimonieux
15088.2 15108.2 15136.9
ij0j rβlangpost +=
0j000j uγβ +=
ij1j0j riq_verbββlangpost ++=
0j000j uγβ +=1j101j uγβ +=
0j01000j ugroupsizγγβ ++=
1j11101j ugroupsizγγβ ++=
0j030201000j ugroupsizγmixedgraγiq_averγγβ ++++=
ij1j0j rsesiq_verbββlangpost +++=0j0201000j umixedgraγiq_averγγβ +++=
1j131211101j ugroupsizγmixedgraγiq_averγγβ ++++=
2j232221202j ugroupsizγmixedgraγiq_averγγβ ++++=
1j12101j umixedgraγγβ ++=202j γβ =
ij1j0j riq_verbββlangpost ++=
ij21j0j rsesiq_verbββlangpost +++= jβ
déviance BIC AIC

Tests d’hypothèses
uw :2N
) N(0, r , rxy :N1
qjsjqs0qqj
2ijijqijqjj0ij
+γ+γ=β
σ→+β+β=
∑∑
uqj suit une loi normale multivariée telle que:V(uqj )=τqq et cov(uqj , uqj )= τqq ’
On peut alors formuler des hypothèses simples ou multiples sur
les coefficients fixes γles coefficients aléatoires βles composantes de variance σ, T

Tests d’hypothèses simples
( ) 2/1
ˆ
qsv
z qs
γ
γ=
( ) 2/1ˆ
ˆ
qqj
qj
vz
β=
test de nullité d ’un coefficient fixe
0 :1H
0 :H0
qs
qs
≠γ
=γ
test de nullité d ’un coefficient aléatoire
0 :1H
0 :H0
qj
qj
≠β
=β
test de nullité d ’une composante de variance
0 :1H
0 :H0
≠τ
=τ ( )qqj
jsjqsqqj
v
ws
ˆ
ˆˆˆ0∑ ∑−−
=γγβ

Tests d’hypothèses multiples
γCˆCγH 1C
' ′= −v
CvC'V γc =
H0 : C’γ = 0
H1: C’γ ≠ 0
ij1j0j20
1110
020100
riq_verbuusesγ
mixedgra*iq_verbγiq_verbγmixedgraγiq_averγγlangpost
++++
++++=
Mixedgra=0Iq_aver=0 essγiq_verbγγlangpost 201000 ++=
2CH χ→
Results of General Linear Hypothesis Testing---------------------------------------------------------------------------
Coefficients Contrast---------------------------------------------------------------------------For INTRCPT1, B0
INTRCPT2, G00 41.347286 0.000 0.000IQ_AVER, G01 0.832863 0.000 0.000
MIXEDGRA, G02 -1.714362 0.000 0.000For IQ_VERB slope, B1
INTRCPT2, G10 2.079294 1.000 0.000MIXEDGRA, G11 0.541890 0.000 0.000
For SES slope, B2INTRCPT2, G20 0.156155 0.000 1.000
Chi-square statistic = 759.211984Degrees of freedom = 2P-value = 0.000000
⎥⎦
⎤⎢⎣
⎡=
100000001000
C
[ ]201110020100 γγγγγγγ =
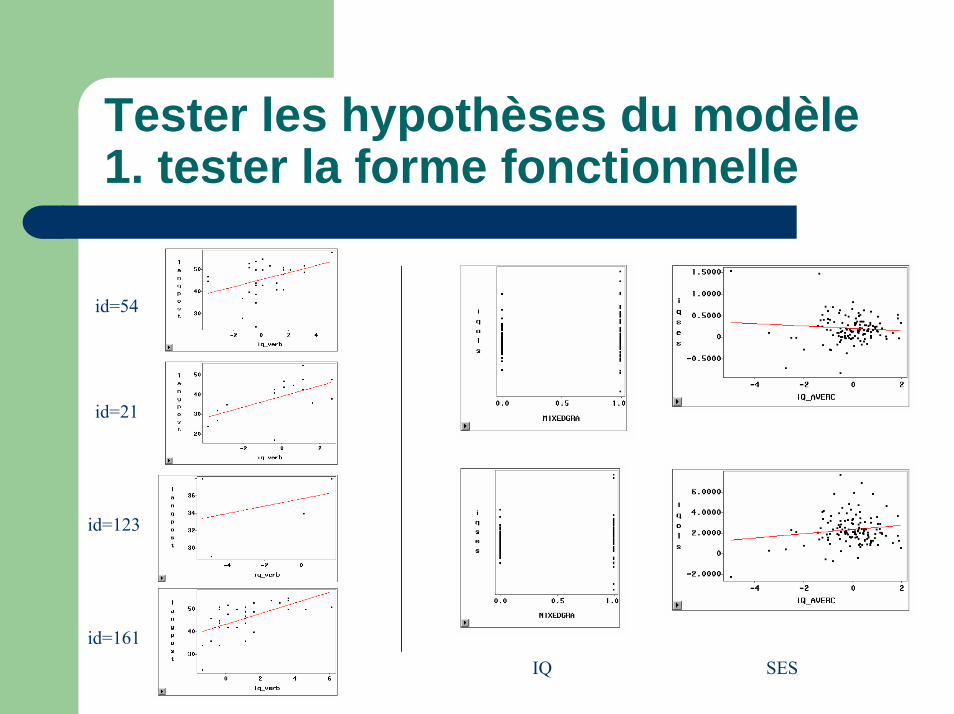
Tester les hypothèses du modèle1. tester la forme fonctionnelle
id=54
id=21
id=123
id=161IQ SES
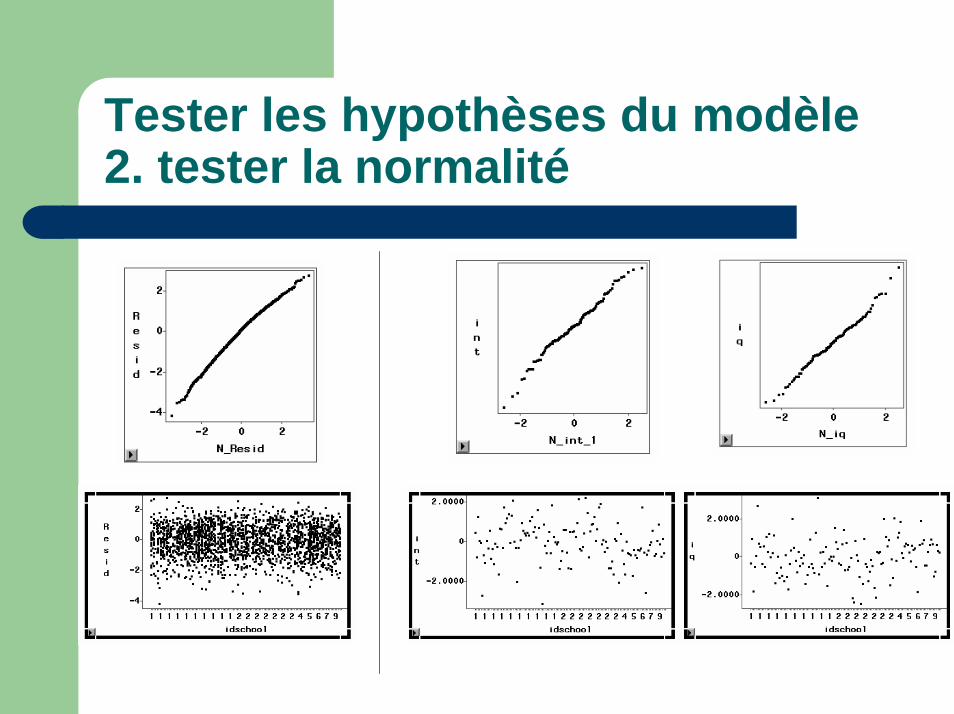
Tester les hypothèses du modèle2. tester la normalité
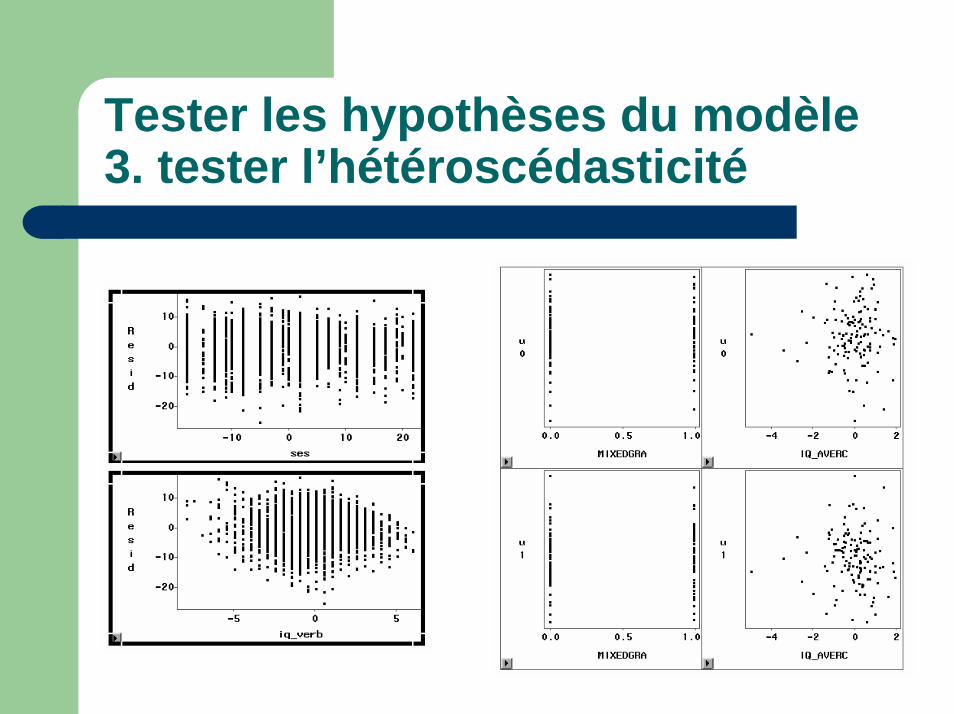
Tester les hypothèses du modèle3. tester l’hétéroscédasticité

L’estimateur empirique de Bayes
deux estimateurs de β0j
j.j0j. ry +β=
j000j0 u+γ=β
⇒ y.j est un estimateur sans biais de β0j (niveau 1)
⇒ γ00 est un estimateur commun de β0j (niveau 2)
( ) 00.*0 1 γλλβ ⋅−+⋅= jjjj y
Le meilleur estimateur: L ’estimateur empirique de Bayes
( )( ) )(
varvar
00
00
.
0
jj
jj Vy +
==ττβλavec
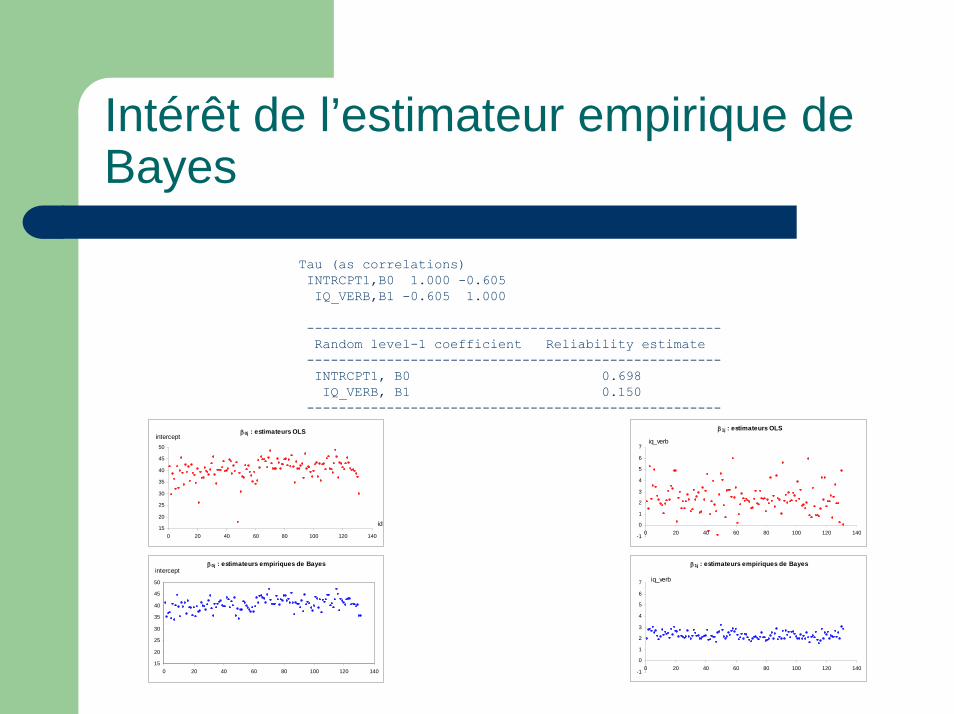
Intérêt de l’estimateur empirique de Bayes
intercept
15
20
25
30
35
40
45
50
0 20 40 60 80 100 120 140
id
β0j : estimateurs OLS
β0j : estimateurs empiriques de Bayes
15
20
25
30
35
40
45
50
0 20 40 60 80 100 120 140
intercept
β1j : estimateurs OLS
-1
0
1
2
3
4
5
6
7
0 20 40 60 80 100 120 140
iq_verb
Tau (as correlations)INTRCPT1,B0 1.000 -0.605IQ_VERB,B1 -0.605 1.000
----------------------------------------------------Random level-1 coefficient Reliability estimate----------------------------------------------------INTRCPT1, B0 0.698IQ_VERB, B1 0.150
----------------------------------------------------
β1j : estimateurs empiriques de Bayes
-1
0
1
2
3
4
5
6
7
0 20 40 60 80 100 120 140
iq_verb
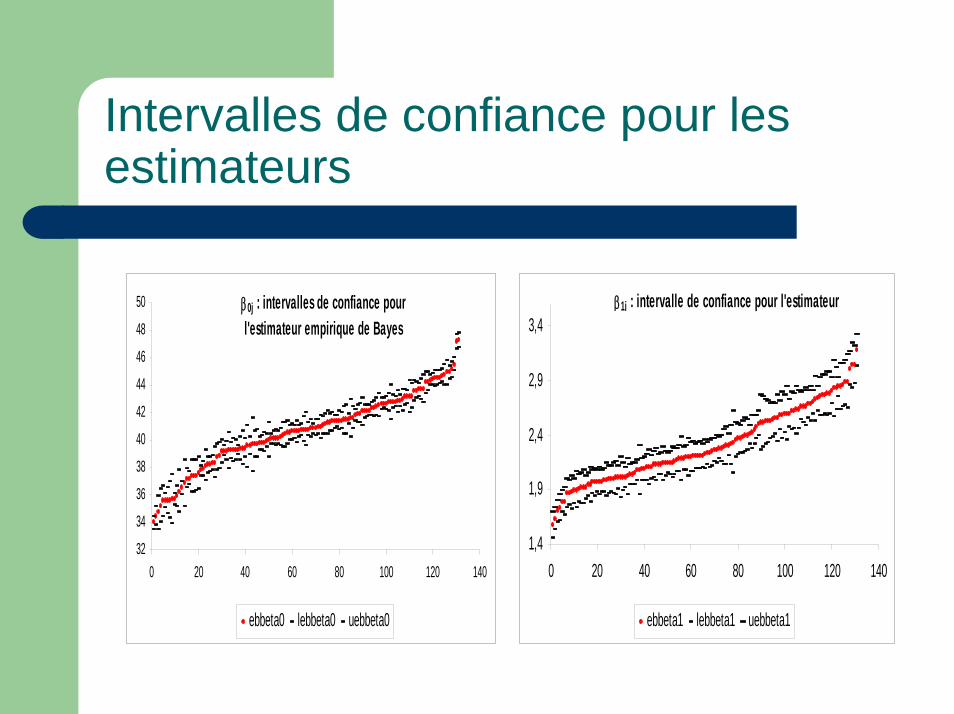
Intervalles de confiance pour les estimateurs
32
34
36
38
40
42
44
46
48
50
0 20 40 60 80 100 120 140
ebbeta0 lebbeta0 uebbeta0
β0j : intervalles de confiance pour l'estimateur empirique de Bayes
1,4
1,9
2,4
2,9
3,4
0 20 40 60 80 100 120 140
ebbeta1 lebbeta1 uebbeta1
β1j : intervalle de confiance pour l'estimateur
Top Related