
1 Module : Technologies des serveurs réseaux Présenter par : Mounir GRARI.

UNIVERSITE MOHAMMED PREMIER
FACULTE DES SCIENCES OUJDA
DEPARTEMENT DE MATHEMATIQUE & INFORMATIQUE
UFR : ANITS
Mémoire
Réalisé par:
Najlae KORIKACHE
En vue de l‟obtention de Diplôme des Etudes Supérieures Approfondies (DESA)
Discipline : Analyse Numérique, Informatique et Traitement du Signal (ANITS)
Spécialité : INFORMATIQUE - Bases de données
Création d’un opérateur OLAP de prédiction basé
sur une technique de fouille de données
Soutenue le Novembre 2007 devant le jury :
Mr. Mostafa AZIZI : Président du jury
Mme Amina YAHIA : Encadrant
Mr. El Miloud JAARA : Membre du jury
Année Universitaire : 2007/2008


-i-
Remerciements
Déjà deux ans depuis le tout début de ce DESA…
Tout d‟abord, je remercie Mr. Idriss SBIBIH, responsable de l‟UFR ANITS ainsi que
tous les enseignants qui ont été présent pendant ces deux années. Avec eux, j‟ai apprécié une
démarche organisée, une rigueur de travail et surtout un support scientifique inconditionné.
Je tiens à exprimer ma gratitude à mon encadrant de mémoire: Mme Amina YAHIA.
Je la remercie également pour la précieuse confiance qu‟elle m‟a donnée, pour la grande
liberté d‟idées et de travail qu‟elle m‟a accordée et pour le temps qu‟elle m‟a consacré. En
dehors de son apport scientifique, je n‟oublierai pas aussi de la remercier pour ses qualités
humaines et son soutien qui m‟a permis de mener à bien ce mémoire.
Je remercie les collègues du DESA ANITS. Je remercie aussi ceux que j‟ai côtoyés et
qui, de loin ou de près, ont apporté une plus-value à la qualité de mon travail par leurs
conseils, leurs remarques et leurs observations. Je tiens spécialement à remercier, en
particulier, Mounir GRARI, entant que frère, qui m‟a dirigé et m‟a encouragé pour s‟orienter
à l‟informatique.
Merci à mes parents, je leur suis reconnaissante pour les sacrifices qu‟ils ont dû faire
pendant mes années d‟études. À mon frère et ma sœur qui, malgré l‟éloignement, m‟ont
soutenu.
Merci à mes amis de toujours

-ii-
Résumé
L‟analyse en ligne OLAP (On Line Analytical Processing) est une solution qui a
largement fait ses preuves pour le résumé, l‟exploration et la navigation dans un entrepôt de
données numériques (Data Warehouse). Malheureusement, les opérateurs OLAP classiques
présentent un certain nombre de limites quand il s‟agit de les appliquer dans un entrepôt de
données complexes telles que des images, des documents XML ou des vidéos.
Nous cherchons à concevoir un cadre élargi d‟analyse pour pouvoir explorer,
expliquer et prédire les données complexes entreposées. Dans ce cadre nous proposons de
combiner les techniques d‟analyse en ligne (OLAP) et de fouille de données (DataMining).
Déjà de nouveaux opérateurs OLAP sont proposé, pour ; l‟agrégation des données complexes
basé sur une technique de classification automatique, opérateur OPAC, le réarrangement d‟un
cube par analyse factorielle (ACM), opérateur ORCA et l‟explication par recherche guidée de
règles d‟association dans un cube, opérateur AROX.
A l‟heure actuelle, nous souhaitons mettre en place un opérateur OLAP de prédiction
pour les données complexes.
Mots clés : entrepôt de données, cubes de données, analyse en ligne, fouille de données,
analyse des correspondances multiples, classification ascendante hiérarchique, extraction des
règles d‟association, données complexes, cadre formel général.

-1-
Chapitre1
Introduction générale
« On commence à vieillir quand on finit d'apprendre.. »
1.1 Contexte et problématique
Actuellement, les systèmes d'information sont principalement constitués par les bases
de données utilisées par les services de production tels que le processus de fabrication, la
gestion des approvisionnements, la gestion des ventes. L'exploitation directe des données des
bases de production s'avèrent souvent inadaptés à leurs besoins décisionnels en raison de
temps d'accès importants, de structures de données ésotériques, d'informations réparties dans
plusieurs sites. Face à ce problème, les industriels ont progressivement mis en place des
entrepôts de données, véritables interfaces entre les bases de données et les décideurs.
L'informatique décisionnelle a pour objectif d'élaborer des systèmes d'analyse de données
dédiés au soutien et à l'amélioration des processus décisionnels des organisations. Ces
systèmes OLAP (On- Line Analytic Processing) sont généralement constitués de bases de
données multidimensionnelles, communément appelées entrepôts (data warehouses) et/ou
magasins (data marts) de données. Ces dernières connaissent un important essor en raison de
leur adéquation dans la manipulation et l'exploitation rapide, efficace et performante des
données à des fins décisionnelles. En effet, les bases multidimensionnelles sont l'un des
nouveaux développements remarquables de la conception des bases de données qui étend de
faon considérable les possibilités d'analyse de grands ensembles de données
multidimensionnels.
Beaucoup sont les techniques liées à l'informatique décisionnelle, de l'entrepôt de
données qui définit un support au système d'information décisionnel, aux outils de fouille de
données permettant d'extraire de nouvelles connaissances, de nombreux moyens
informatiques sont aujourd'hui mis en œuvre pour aider les organes de décision des
entreprises.

Chapitre 1 : Introduction générale
-2-
Les volumes de données à traiter dans le cadre de l'apprentissage automatique et de la
fouille de données sont de plus en plus importants. L'étude des interactions possibles entre les
domaines des bases de données et de l'apprentissage est donc nécessaire pour pallier les
problèmes liés à la gestion de ces gros volumes de données. Apparus pour gérer de tels
volumes de données issues de sources hétérogènes, les entrepôts de données constituent l'outil
essentiel de collecte et de mise à disposition des données en vue de leur analyse. De ces
entrepôts de données peuvent être extraits des magasins de données, contenant des sous-
ensembles de données dédiés à une analyse particulière.
L'objectif est de collecter des données décrites de manière multidimensionnelle afin de
les mettre à disposition des décideurs à des fins d'analyse. Cette analyse fait appel à des
traitements OLAP (On-Line Analytical Processing), tâche majeure des systèmes de data
warehouse, analyse de données et décision, qui se distinguent des processus OLTP (On-Line
Transactional Processing), tâche majeure des BD relationnelles traditionnelles, opérations
quotidiennes enregistrées., principalement par leur complexité et par le nombre de données. Il
est apparu que le modèle relationnel, jusque là tout à fait adapté aux traitements OLTP, était
inadapté aux traitements OLAP.
Le modèle multidimensionnel a donc été proposé afin de permettre la mise en œuvre
de solutions OLAP. Ce modèle a été récemment étendu au traitement de données imparfaites
et de requêtes exibles. Il a également été utilisé dans le cadre de la fouille de données, dans
des systèmes visant à appliquer des méthodes de fouille de données à partir de bases de
données multidimensionnelles. On parle alors d'OLAP Mining.
L'utilisation des entrepôts de données et du modèle multidimensionnel a permis le
traitement de nombreuses problématiques. De nombreuses perspectives sont associées à ces
domaines de recherche, par exemple dans les domaines d'application émergeants tels que la
bio-informatique et le multimédia.
Outils
d’analyse
Magasins de
données
Entrepôt de
données
Système OLTP Système décisionnel OLAP
Données
décisionnelles
Schémas de
l‟entrepôt
Données
analysées
Schémas
utilisateurs
Données
opérationnelles
Schémas
des sources
Sources de
données
Fig. 1.1- Du système OLTP au système OLAP
Chapitre 1 : Introduction générale
-3-
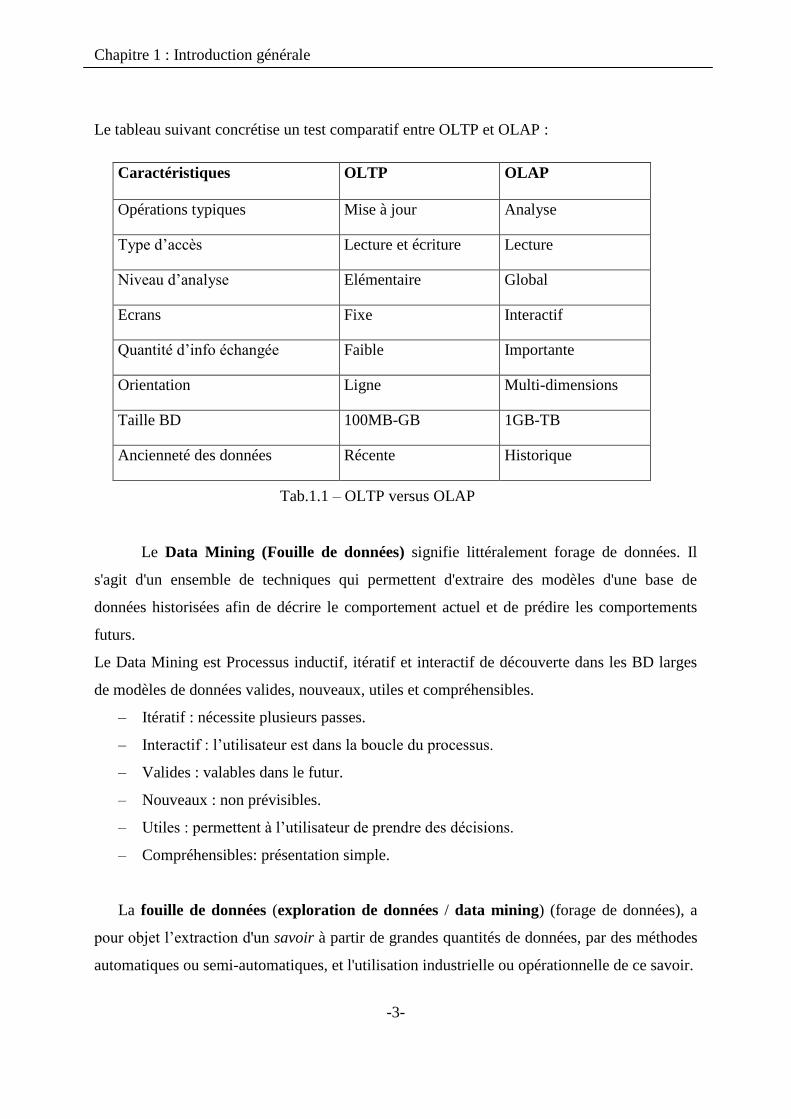
Le tableau suivant concrétise un test comparatif entre OLTP et OLAP :
Caractéristiques OLTP OLAP
Opérations typiques Mise à jour Analyse
Type d‟accès Lecture et écriture Lecture
Niveau d‟analyse Elémentaire Global
Ecrans Fixe Interactif
Quantité d‟info échangée Faible Importante
Orientation Ligne Multi-dimensions
Taille BD 100MB-GB 1GB-TB
Ancienneté des données Récente Historique
Le Data Mining (Fouille de données) signifie littéralement forage de données. Il
s'agit d'un ensemble de techniques qui permettent d'extraire des modèles d'une base de
données historisées afin de décrire le comportement actuel et de prédire les comportements
futurs.
Le Data Mining est Processus inductif, itératif et interactif de découverte dans les BD larges
de modèles de données valides, nouveaux, utiles et compréhensibles.
– Itératif : nécessite plusieurs passes.
– Interactif : l‟utilisateur est dans la boucle du processus.
– Valides : valables dans le futur.
– Nouveaux : non prévisibles.
– Utiles : permettent à l‟utilisateur de prendre des décisions.
– Compréhensibles: présentation simple.
La fouille de données (exploration de données / data mining) (forage de données), a
pour objet l‟extraction d'un savoir à partir de grandes quantités de données, par des méthodes
automatiques ou semi-automatiques, et l'utilisation industrielle ou opérationnelle de ce savoir.
Tab.1.1 – OLTP versus OLAP

Chapitre 1 : Introduction générale
-4-
Le Data Mining est en fait un terme générique englobant toute une famille d'outils facilitant
l'analyse des données contenues au sein d'une base décisionnelle de type Data Warehouse ou
DataMart. Certains considèrent cette technique comme "l'art" voire même la "science" de
l'extraction d'informations significatives de grandes quantités de données.
Le principe du Data Mining est de creuser une mine (le DW) pour rechercher un filon
(l‟information) et l‟évolution par rapport aux statistiques « classiques »
Ses objectifs sont la prédiction (What-if), la découverte de Règles Cachées (corrélations), la
confirmation d‟hypothèses.
En peu de mots, le Data Mining présente l'avantage de trouver des corrélations
informelles entre les données. Il permet de mieux comprendre les liens entre des phénomènes
en apparence distincts et d'anticiper des tendances encore peu discernables.
A contrario des méthodes classiques d'analyses statistiques, le Data Mining est
particulièrement adapté au traitement de grands volumes de données. Avec l'augmentation de
la capacité de stockage des supports informatiques, un maximum de renseignements seront
captés, ordonnés et rangés au sein du Data Warehouse. Comportement des acheteurs,
caractéristiques des produits, historisation de la production, désormais plus rien n'échappe à la
collecte. Avec le Data Mining, ces "tera-nesque" bases de données sont exploitables.
Les outils de data mining proposent différentes techniques à choisir en fonction de la nature
des données et du type d'étude que l'on souhaite entreprendre.
Il existe ainsi des méthodes utilisant les techniques de classification et de
segmentation.
Les méthodes utilisant des principes d'arbres de décision assez proches des techniques
de classification
Les méthodes fondées sur des principes et des règles d'associations ou d'analogies
Les méthodes exploitant les capacités d'apprentissage des réseaux de neurones
Et pour les études d'évolution de populations, les algorithmes génétiques
Processus de découverte des connaissances
– Data Mining : Cœur du KDD (Découverte de connaissances dans les données;
Knownledge Data Discovery)

Chapitre 1 : Introduction générale
-5-
Applications du Data Mining :
– L'analyse comportementale des consommateurs :
o ventes croisées, similarités de comportements, cartes de fidélité, ...
– La prédiction de réponse à un mailing ou à une opération de markting direct (pour en
optimiser les coûts)
– La prédiction de l'attrition des clients : quels sont les indices de comportement
permettant de détecter la probabilité qu'un client a de quitter son fournisseur
o sa banque, son opérateur de téléphonie mobile, ...
– La détection de comportements anormaux ou frauduleux
o transactions financières, escroquerie aux assurances, distribution d'énergie, ...
– La recherche des critères qui permettront d'établir ensuite un scoring pour repérer les
« bons » clients sans facteur de risque et leur proposer peut-être une tarification
adaptée
o par exemple pour une banque ou une compagnie d„assurance.
– La suggestion optimale en temps réel lors d'un appel à un call center.
OLAP - Data Mining:
OLAP= Le Quoi? Data Mining = Le Pour quoi?
Fig. 1.2- processus d‟extraction des connaissances à partir des données
Intégration de données
Connaissance
Evaluation
du modèle
Data
Mining
Données
pertinentes
Data
Warehouse
Data
Cleaning
Bases de
données
Sélection

Chapitre 1 : Introduction générale
-6-
1.2 Objectifs et contributions
Dans le cadre de ce mémoire, nous proposons de combiner l‟analyse en ligne et la
fouille de données afin de les intégrer dans un même processus d‟aide à la décision.
Le but de ce couplage est d‟enrichir les capacités de l‟analyse OLAP et de proposer aussi une
solution au problème de l‟analyse des données complexes.
L‟objectif de ce mémoire est de proposer une démarche pour intégrer l‟explication et
la prédiction de données complexes dans l‟analyse OLAP en s‟inspirant des méthodes
utilisées en fouille de données. Il s‟agit de faire une synthèse bibliographique sur les travaux
existants en matière d‟analyse des données complexes, du couplage entre fouille de données
et analyse en ligne et des méthodes de prédiction en fouille de données. Il s‟agit aussi de
proposer une formalisation théorique et une implémentation (sur une plateforme Web déjà
existante) d‟un opérateur OLAP de prédiction basé sur une méthode de fouille de données.
Une validation par expérimentations est aussi requise afin d‟évaluer l‟opérateur de prédiction
sur des cubes de données complexes.
1.3 Organisation du mémoire
La suite de ce rapport de mémoire est organisée de la manière suivante :
Le chapitre 2 introduit une étude bibliographique basée sur les travaux déjà existant en
matière d‟analyse des données complexes, du couplage entre fouille et l‟analyse en ligne et
des méthodes de prédiction en fouille de données. Le chapitre 3 présente les nouveaux
opérateurs OLAP existant. Le chapitre 3 spécifie une formalisation théorique d‟un opérateur
OLAP de prédiction basé sur une méthode de fouille de données en se basant sur les cubes de
prédiction. Le chapitre 4 présente quelques recherches en cours ; une plateforme
d‟entreposage XML de données. En fin nous conclurons et présentons quelques unes de
nombreuses perspectives associées à ce thème de recherche.

-7-
Etat d‟art
Résumé
Dans ce premier chapitre, nous présentons un état d‟art à partir d‟une synthèse d‟une
étude bibliographique dont nous explorons les travaux existants en matière d‟analyse des
données complexes, du couplage entre fouille et analyse en ligne et des méthodes de
prédiction en fouille de données.
Cette partie est scindée en 4 parties dont nous distinguons, d‟une manière générale le
contexte, les références, les travaux réalisés, les expositions scientifiques traitant cette
approche. Et on finira cette partie par une conclusion ou nous précisons le positionnement de
notre travail par rapport à l‟existant.
Sommaire
2.1 Introduction
2.2 Comparaison des propositions de couplage de l‟OLAP et de la fouille de données
selon la 1ére
approche : Adaptation des données multidimensionnelles
2.3 Comparaison des propositions de couplage de l‟OLAP et de la fouille de données
selon la 2éme
approche : Extension de l‟analyse OLAP et des langages de requêtes
2.4 Comparaison des propositions de couplage de l‟OLAP et de la fouille de données
selon la 3éme
approche : Adaptation des techniques de fouille de donnée
2.5 Conclusion

-8-
Chapitre2
Etat de l‟art
« L'histoire humaine est par essence l'histoire des idées.»
Herbert George Wells, Extrait de “The outline of history”
2.1 Introduction
Le problème de la représentation des données est un enjeu important dans le problème
du couplage entre l‟analyse en ligne et la fouille de données. En effet, d‟un côté, les
algorithmes de fouille ne peuvent opérer que sur des données présentées sous la forme
classique d‟un tableau attributs-valeurs (connu aussi sous le nom de tableau individus-
variables). De l‟autre côté, dans le contexte d‟un entrepôt de données, les données sont
organisées selon une structure multidimensionnelle adaptée à l‟analyse en ligne. Ainsi, la
divergence des espaces de représentation des données propres aux deux domaines fait de la
combinaison de l‟analyse en ligne et de la fouille de données une tâche particulièrement
délicate qui demande des adaptations préalables d‟un côté comme de l‟autre.
Imieliski et Mannila étaient les premiers qui se sont intéressés au problème général de
l‟intégration de l‟ECD dans les systèmes de gestion de bases de données (SGBDs). Dans
[IM96], les auteurs pensent déjà que la fouille dans les bases de données va aboutir à la
création de nouveaux concepts, de nouvelles stratégies d‟interrogation et de nouveaux
langages de requêtes. Les auteurs prévoient même la naissance d‟une seconde génération de
systèmes de gestion de bases de données. Ils imaginent deux scénarii pour la suite des
recherches dans ce domaine.
Le sujet de couplage entre la fouille de données et l‟analyse en ligne OLAP est tout
récent, peu sont les travaux réalisés dans ce contexte. Cependant trois grandes approches se
dégagent, la figure 2.1 s illustre ces approches :

Chapitre 2 : Etat de l‟art
9
1. La première approche : Adaptation des structures multidimensionnelles : Ce 1er
groupe d‟approche consiste à transformer les données multidimensionnelles en
données bidimensionnelles afin de les rendre exploitables par les algorithmes
classiques de fouille.
2. La deuxième approche : Extension de l’analyse OLAP et des langages de
requêtes : Ce groupe concerne des approches de type instrumental qui tirent partie des
spécificités et des outils offerts dans les systèmes de gestion de bases
multidimensionnelles (SGBDMs) ces approches consistent à étendre les opérateurs
OLAP ou le langage de requêtes SQL et à utiliser ces derniers comme instruments
pour extraire et transmettre les données nécessaires pour la construction d‟un modèle
d‟apprentissage.
3. La troisième approche : Adaptation des techniques de fouille de données : Ce 3éme
groupe comprend les approches qui ont pour but de faire évoluer les algorithmes de
fouille de données et de les adapter aux espaces de représentation
multidimensionnelles des données. Ainsi, selon ces approches, on peut appliquer des
algorithmes évolués directement dans les cubes de données.
Fig.2.1 - Les trois approches du couplage des techniques de fouille avec l‟analyse en ligne
SGBD
Technique de fouille
de données Opérateur OLAP
Adaptation des données
multidimensionnelles
Extension des opérateurs
OLAP

Chapitre 2 : Etat de l‟art
10
Nous détaillerons dans la suite les différents groupes d‟approches. Certes, s‟agissant
d‟un domaine de recherche en plein essor, nous essayons de présenter une liste la plus
exhaustive possible des références traitant du couplage de la fouille de données et de l‟analyse
en ligne. Néanmoins, nous présentons les travaux les plus intéressants et qui répondent au
mieux à la problématique étudiée.
Cette synthèse repose sur une organisation thématique qui croise les trois approches,
que nous avons détectées, avec les trois familles de techniques de fouille de technique de
fouilles de données, à savoir: (i) les techniques de visualisation et de description; (ii) les
techniques de structuration et de classification et (iii) les techniques d‟explication et de
prédiction.
Nous avons fait la différence entre les trois grands groupes d‟approches traitant le
problème du couplage de l‟analyse en ligne et de la fouille de données, afin de positionner nos
contributions nous exposons une synthèse des travaux existants.
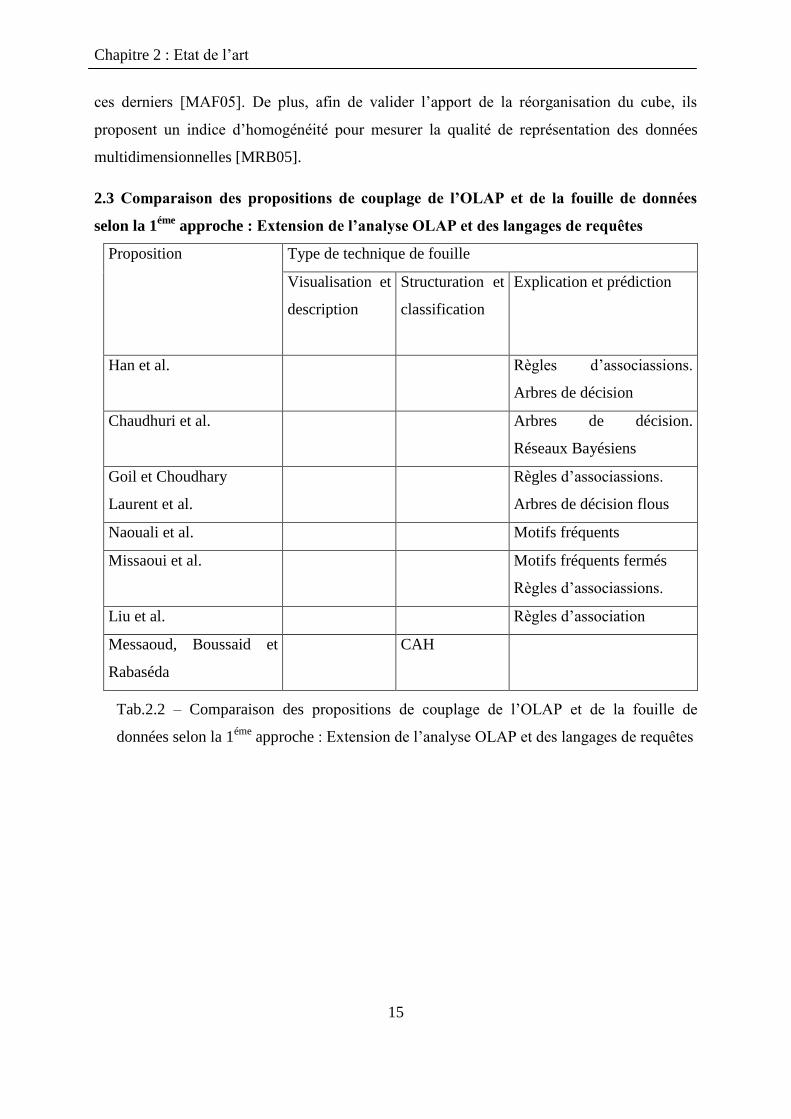
2.2 Comparaison des propositions de couplage de l’OLAP et de la fouille de données
selon la 1ére
approche : Adaptation des données multidimensionnelles
Proposition
Type de technique de fouille
Visualisation
et description
Structuration et
classification
Explication et
prédiction
Chen et al. Réseaux Bayésiens
Maedche et al. k-means
Goil et Choudhary Arbres de décision
Zaiane et al. Séries temporelles
Tjioe et Taniar
Fu
Règle d‟association
Arbres de décision
Messaoud,Bouddaid,Rabaséda ACM
Cette approche vise la création d‟un pont reliant les données multidimensionnelles et
les algorithmes classiques de fouille. Deux optiques sont envisageables dans ce sens. La
première consiste à utiliser les spécificités et les avantages des SGBDM (systèmes de gestion
des bases de données multidimensionnelles) pour aider l‟algorithme d‟apprentissage pendant
Tab 2.1 Comparaison des propositions de couplage de l‟OLAP et de la fouille de
données selon la 1ére
approche : Adaptation des données multidimensionnelles

Chapitre 2 : Etat de l‟art
11
la construction de son modèle de connaissances. La deuxième optique agit sur la structure
même des données cubiques afin de les transformer et de les rendre exploitables par
l‟apprentissage inductif.
Adaptation des SGBDM :
Dans l‟article [LGM00], ils proposent une coopération entre le SGBDM Oracle Express
avec un logiciel d‟arbres de décision flou (Salammbô), leur choix du SGBDM est provoqué
par sa capacité de calcul des agrégats complexes et son adaptation à la manipulation des
données. Permettant de transférer la gestion de la base d‟apprentissage, les contraintes de
stockage et de manipulation des données dans le SGBDM. Cependant pour réussir une telle
coopération, l‟algorithme d‟apprentissage et le SGBDM doivent être équipés par des
mécanismes de communication leur permettant d‟échanger automatiquement requêtes et
réponses (Figure 2.2).
Adaptation des données multidimensionnelles :
Ce groupe d‟approches consiste à faire un rapprochement entre les algorithmes classiques
de fouille et les données multidimensionnelles moyennant l‟adaptation de ces dernières.
Prétraitement des données multidimensionnelles avec l’OLAP :
Dans [CZC01], Chen et al. introduisent la plateforme IIMiner (Integrated Interactive
Data Miner) pour la fouille des données hétérogènes qui proviennent de sources différentes.
D‟une manière générale, avec le développement de la technologie des entrepôts de données,
les auteurs pensent qu‟il est naturel de voir une émergence de projets visant l‟intégration de la
fouille de données avec les outils OLAP dans les systèmes décisionnels. Dans la plateforme
proposée, les auteurs définissent un processus ECD selon lequel les entrepôts de données sont
le support des données et la technologie OLAP permet d‟effectuer des pré-traitements sur ces
données. Ainsi, un processus ECD est une succession d‟étapes prises en charge par
Fig. 2.2 – Coopération entre SGBDM et Algorithme d‟apprentissage
SGBDM
Module de
communication
Transfert de résultats
Transfert de requêtes Algorithme
d’apprentissage
Module de
communication

Chapitre 2 : Etat de l‟art
12
l‟entreposage de données, l‟analyse en ligne OLAP et la fouille de données. Dans la
plateforme IIMiner, Chen et al. cherchent des corrélations entre les données de l‟entrepôt.
Pour cela, ils utilisent des opérations OLAP pour mettre en forme les données, concernées par
l‟apprentissage, selon un tableau individus–variables. Les auteurs emploient ensuite la
méthode des réseaux bayésiens afin de découvrir et de représenter graphiquement les
causalités des données.
Dans [MHW00], Maedche et al. proposent également d‟utiliser l‟OLAP comme outil
de pré- traitement pour des données de télécommunication. Leur approche combine les bases
de données multidimensionnelles avec les systèmes classiques de fouille de données en
utilisant les outils OLAP comme interface (voir figure 3). D‟une manière générale, les auteurs
affirment que plus le volume des données est grand, plus leur compréhension et leur pré-
traitement deviennent difficiles. La vocation de l‟analyse en ligne est de gérer et d‟explorer
des grands volumes de données. En plus, l‟OLAP permet une bonne interaction entre
l‟utilisateur et la base de données. Dans le cadre de leur application, Maedche et al. proposent
donc de créer, à l‟aide d‟outils classiques de l‟analyse en ligne, un processus flexible pour
comprendre et nettoyer les grands volumes de données relatifs au domaine des
télécommunications. Ces données nettoyées sont mises en forme tabulaire et sont chargées
ensuite dans une composante de fouille de données. Dans [MHW00], les auteurs proposent
d‟utiliser la méthode des k-means pour classifier les abonnés du service téléphonique selon
leurs profils de consommation.
Fig. 2.3 – Pré-traitement des données avec les outils OLAP [MHW00]

Chapitre 2 : Etat de l‟art
13
Mise en forme des données multidimensionnelles avec l’OLAP
Dans [GC99], Goil et Choudhary affirment que les techniques de fouille de données
peuvent être appliquées en conjonction avec les outils de l‟analyse en ligne. Ils mentionnent
également qu‟une structure multidimensionnelle des données peut représenter une base
d‟apprentissage plus riche qu‟une structure classique. Dans le cadre d‟une plateforme
parallèle PARSIMONY dédiée à l‟analyse OLAP et la fouille de données, les auteurs
proposent un classement dans les données multidimensionnelles par arbres de décision
[GC99, GC01]. Cette approche consiste à utiliser les outils OLAP pour extraire, à partir d‟un
cube de données, une matrices de contingence pour chaque dimension et à chaque étape de la
construction de l‟arbre de décision. Ces matrices sont exploitées pour le calcul des indices de
Gini afin de déterminer la variable d‟éclatement de la prochaine itération.
Aplatissement et préparation des données d’un entrepôt :
En 2005, l‟article [TT05] et dans un contexte d‟extraction des règles d‟association à
partir des entrepôt de données, Tjioe et Taniar proposent des formalismes de pré-traitement
des données multidimensionnelles avant la phase de recherche des motifs fréquents. Ces
formalismes préparent les données à fouiller d‟une manière ciblée en vue de faciliter la
recherche des motifs les plus intéressants au sens de l‟analyse souhaitée par l‟utilisateur. Les
auteurs proposent quatre algorithmes de pré-traitement des données dans un cube : VAvg,
HAvg, WMAvg, et ModusFilter. L‟idée générale de ces algorithmes consiste à transformer les
données d‟un cube sous forme tabulaire dans un premier temps et d‟élaguer dans un second
temps les données inintéressantes ayant des valeurs inférieures à la moyenne par ligne ou par
colonne. Les tableaux de données obtenus (initialized tables) sont ensuite utilisés comme
entrée d‟un algorithme classique de recherche de motifs fréquents et d‟extraction de règles
d‟association.
Dans [Fu05], Fu pense que, dans un système d‟aide à la décision, l‟emploi d‟un
entrepôt de données et de l‟analyse en ligne est une solution simpliste qui ne répond pas aux
besoins de l‟extraction des connaissances. Par conséquent, l‟auteur propose une architecture
d‟un système intégré qui combine un SGBD pour les données multidimensionnelles, une
composante OLAP et une composante OLAM (Online Analytical Mining). Comme le montre
la figure6 ci dessus, selon cette architecture, les utilisateurs peuvent soumettre des requêtes
SQL, CQL ou DMQL (Data Mining Query Language) via une interface commune. La requête
de l‟utilisateur est ainsi analysée par un parseur qui va l‟acheminer vers les différentes

Chapitre 2 : Etat de l‟art
14
composantes du système. En cas d‟une incohérence syntaxique de la requête, le parseur
renvoie un message d‟erreur.
Dans le cadre de ce système, l‟auteur introduit aussi un classifieur, appelé CubeDT,
qui construit des arbres statistiques. Un arbre statistique est une structure multidimensionnelle
particulière inspirée des arbres de décision [FH00]. Cependant, l‟algorithme CubeDT
travaille sur des données extraites et aplaties par une composante de chargement (Loader) à
partir d‟un entrepôt de données via le serveur OLAP du système.
Réorganisation des cubes de données par une approche factorielle:
Dans [MRB05], les auteurs ont couplé l‟analyse en ligne avec une méthode factorielle
dédiée à la visualisation et à la description. Concrètement, ils ont utilisé l‟analyse de
correspondances multiples [ACM] dans le but d‟améliorer la présentation des faits dans un
cube de données [MBR06d, MBR06b].
Dans une phase préparatoire, les données du cube sont transformées en tableau disjonctif
complet selon un codage binaire approprié, l‟application de l‟ACM, sur ce dernier, fournit une
réorganisation des modalités dans les dimensions cube. Grace à cette réorganisation, ils ont
parvenu à fournir des points de vue intéressants qui homogénéisent au mieux le nuage des
faits dans le cube de données.
Ainsi, cette proposition permet de pallier le problème, souvent rencontré, de la
visualisation des données multidimensionnelles engendré par la volumétrie et l‟éparsité des
Fig. 2.4 – Architecture d‟un système intégrant SGBD, OLAP et MOLAP [Fu05]
Chapitre 2 : Etat de l‟art
15
ces derniers [MAF05]. De plus, afin de valider l‟apport de la réorganisation du cube, ils
proposent un indice d‟homogénéité pour mesurer la qualité de représentation des données
multidimensionnelles [MRB05].
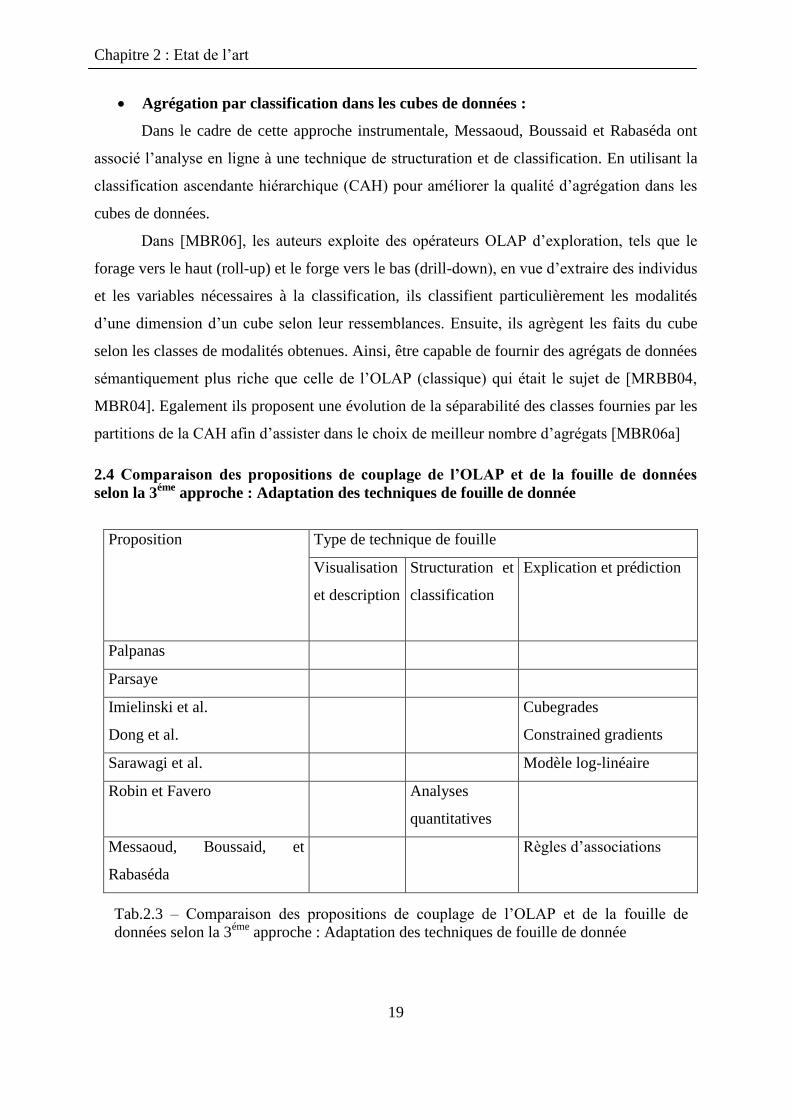
2.3 Comparaison des propositions de couplage de l’OLAP et de la fouille de données
selon la 1éme
approche : Extension de l’analyse OLAP et des langages de requêtes
Proposition
Type de technique de fouille
Visualisation et
description
Structuration et
classification
Explication et prédiction
Han et al. Règles d‟associassions.
Arbres de décision
Chaudhuri et al. Arbres de décision.
Réseaux Bayésiens
Goil et Choudhary
Laurent et al.
Règles d‟associassions.
Arbres de décision flous
Naouali et al. Motifs fréquents
Missaoui et al. Motifs fréquents fermés
Règles d‟associassions.
Liu et al. Règles d‟association
Messaoud, Boussaid et
Rabaséda
CAH
Tab.2.2 – Comparaison des propositions de couplage de l‟OLAP et de la fouille de
données selon la 1éme
approche : Extension de l‟analyse OLAP et des langages de requêtes

Chapitre 2 : Etat de l‟art
16
Les origines de ce deuxième groupe d‟approches de couplage entre l‟OLAP et la fouille
de données remontent aux propositions d‟implantation de la fouille dans les bases de données
relationnelles. En effet, nous estimons que l‟utilisation des outils des SGBDMs pour la fouille
des données multidimensionnelles s‟inscrit dans une logique de continuité avec les efforts
d‟intégration de la fouille dans les SGBDs relationnels. À titre d‟exemple, selon une approche
relationnelle, Meo et al. [MPC96] ont proposé un opérateur SQL pour la recherche de règles
d‟association dans les bases de données relationnelles. Cet opérateur consiste en une
extension de la syntaxe de SQL en y intégrant une nouvelle close MINE RULE. Dans
[STA98], Sarawagi et al. Ont largement étudié, moyennant une extension SQL, l‟intégration
de la découverte des règles d‟association dans les SGBDs. Afin d‟éviter des temps de
traitements important engendrés par les entrées-sorties dans une base relationnelle, d‟autres
travaux ont tenté d‟exploiter les outils propres aux SGBDs pour y intégrer la fouille. Par
exemple, Bentayeb et al. [BDU04, UBDB04] ont proposé d‟intégrer la fouille par arbre de
décision ID3 [Qui86] à l‟aide de procédures PL/SQL stockés dans Oracle.
Fouille de données en ligne
En 1997, Han a élaboré les premières recherches concernant le couplage de fouille de
données avec la l‟OLAP. Ces travaux ont abouti à la création d‟un système, baptisé DBMiner,
doté d‟outils de visualisation spatiale des cubes de données. Ce dernier est doté d‟outils
d‟exploration graphique et de visualisation spatiale des cubes de données. L‟objectif de ces
travaux est de réaliser de la fouille de données en ligne sur les grandes bases de données.
Fig.2.5- Exemple d‟une exploration d‟un cube à trois dimensions dans DBMiner [Han97]

Chapitre 2 : Etat de l‟art
17
Dans [Han97] [Han98], Han a défini la notion de l’OLAP Mining comme étant un
mécanisme qui intègre des taches de fouille de données dans des requêtes décisionnelles. Ce
mécanisme peut s‟appliquer à différents niveaux de granularité des données et à différentes
parties d‟un entrepôt de données (intégrer les opérateurs OLAP dans les techniques de fouille
de données et qui serait susceptible de s‟appliquer à différents niveaux hiérarchiques d‟une
dimension et à différentes portions d‟un entrepôt de données).
Dans [HCC98], on parle déjà de la terminologie On-Line Analytical Mining (OLAM)
pour un processus d‟analyse où les techniques de fouilles sont utilisées, comme des opérateurs
OLAP, pour extraire des connaissances. Une synthèse de la démarche OLAM est largement
évoquée dans [HCC98]. Avec le processus OLAM, Han et al. prévoient même que les
entrepôts de données feront, dans l‟avenir, une large plateforme pour l‟apprentissage
automatique.
Les travaux de Han sont motivés par les données multidimensionnelles qui sont déjà
nettoyées. Ceci les rend parfaitement appropriées pour une exploitation directe dans le
processus d‟extraction des connaissances sans trop avoir besoin de passer par les phases
habituelles de prétraitement et de nettoyage. D‟autre part, un entrepôt de données est doté
d‟un schéma conceptuel adapté à l‟analyse en ligne et offre de grandes potentialités de
navigation dans les données.
DBMiner, est fondé sur une instrumentation par les opérateurs OLAP en leur ajoutant
des extensions aptes à simuler diverses techniques de fouille de données telles que la
détection de règles d‟association, la caractérisation d‟attributs, la classification, la prédiction,
etc. Cependant, à nos yeux, les références relatives au système DBMiner, [Han97] [Han98]
[HCC98], décrivent plutôt le côté fonctionnel de ce dernier et manquent de précision sur les
procédés employés dans la réalisation de ce genre de brassage entre la fouille de données et
l‟analyse en ligne.
Dans la même optique instrumentale, le laboratoire HP a proposé un prototype, qui
génère des règles d‟association via l‟exploitation de la structure cubique par manipulation des
opérateurs OLAP [CDH99] [CDM00], de suivi des habitudes des consommateurs sur le web.
L‟architecture du prototype fait coopérer des serveurs OLAP et des bases
multidimensionnelles distribuées sur plusieurs sites géographiques.

Chapitre 2 : Etat de l‟art
18
Les serveurs OLAP jouent le rôle de moteurs de générations de règles d‟association
fonctionnelles à différentes portions et granularités des dimensions d‟un cube. Les règles
d‟association générées sont physiquement concrétisées par des cubes qui leur sont
spécifiques: Association rule cubes (Figure 2.6). La production de ces cubes se fait
périodiquement de façon incrémentale permettant ainsi la détection de l‟évolution des usages
de consommation.
Ces travaux rejoignent ceux de Han, où les opérateurs typiques de l‟OLAP sont
étendus dans leur langage de requête pour générer de nouvelles structures cubiques orientées
vers la simulation de la découverte des règles d‟association. Tout de même, il faut signaler la
distinction des travaux de [CDH99] [CDH00] qui incorporent cette stratégie dans le contexte
distribué des grandes bases de données.
Dans le contexte parallèle des bases de données, Goil et Choudhary [GoCh99]
[GoCh01], ont mené des recherches sur la question des apports potentiels de la structuration
cubique dans la découverte des connaissances, aussi ils signalent, dans [GoCh97] et
[GoCh98], que la structuration cubique a fait ses preuves avec les opérateurs OLAP en
apportant des solutions d‟interactivité et de performance dans l‟analyse en ligne. Ils suggèrent
que ces solutions peuvent être plus compétitives avec la mise en œuvre de la fouille de règles
d‟association. Leurs premiers travaux d‟instrumentation OLAP se sont focalisés dans la
détection des attributs ad hoc pour la génération des règles à différents niveaux d‟agrégation
des dimensions d‟un cube.
Fig. 2.6 – L‟architecture du moteur distribué de génération de règles d‟association
Cube de
profil Cubes de
règles
d’association
OLAP
Entrepôt de données
Station locale
OLAP
Entrepôt de données
Station locale OLAP
Entrepôt de données
Station globale
Chapitre 2 : Etat de l‟art
19
Agrégation par classification dans les cubes de données :
Dans le cadre de cette approche instrumentale, Messaoud, Boussaid et Rabaséda ont
associé l‟analyse en ligne à une technique de structuration et de classification. En utilisant la
classification ascendante hiérarchique (CAH) pour améliorer la qualité d‟agrégation dans les
cubes de données.
Dans [MBR06], les auteurs exploite des opérateurs OLAP d‟exploration, tels que le
forage vers le haut (roll-up) et le forge vers le bas (drill-down), en vue d‟extraire des individus
et les variables nécessaires à la classification, ils classifient particulièrement les modalités
d‟une dimension d‟un cube selon leur ressemblances. Ensuite, ils agrègent les faits du cube
selon les classes de modalités obtenues. Ainsi, être capable de fournir des agrégats de données
sémantiquement plus riche que celle de l‟OLAP (classique) qui était le sujet de [MRBB04,
MBR04]. Egalement ils proposent une évolution de la séparabilité des classes fournies par les
partitions de la CAH afin d‟assister dans le choix de meilleur nombre d‟agrégats [MBR06a]
2.4 Comparaison des propositions de couplage de l’OLAP et de la fouille de données
selon la 3éme
approche : Adaptation des techniques de fouille de donnée
Proposition
Type de technique de fouille
Visualisation
et description
Structuration et
classification
Explication et prédiction
Palpanas
Parsaye
Imielinski et al.
Dong et al.
Cubegrades
Constrained gradients
Sarawagi et al. Modèle log-linéaire
Robin et Favero Analyses
quantitatives
Messaoud, Boussaid, et
Rabaséda
Règles d‟associations
Tab.2.3 – Comparaison des propositions de couplage de l‟OLAP et de la fouille de
données selon la 3éme
approche : Adaptation des techniques de fouille de donnée

Chapitre 2 : Etat de l‟art
20
La troisième approche fait appel à un emploi direct des algorithmes d‟apprentissage
dans les données multidimensionnelles. Un travail d‟adaptation de ces algorithmes, dans ce
cas, est nécessaire pour établir la communication entre l‟algorithme et la nouvelle forme de
représentation des données. Peu de travaux ont abordé le couplage de la fouille avec les
données multidimensionnelles selon cette approche.
Palpanas explique ce fait par la nouveauté relative de la technologie OLAP et par la
focalisation des recherches sur le domaine de la fouille des données [Pal00]. Devant la
richesse des données multidimensionnelles, leur modélisation pour le domaine décisionnel et
l‟impuissance de la solution OLAP à satisfaire des besoins d‟analyses approfondies, une
analyse approfondie de ces données, basés sur la fouille de données entrainera des modèles de
connaissance plus valorisantes que le cas de la fouille classique [Pal00]. L‟auteur affirme
qu‟une analyse complète doit intégrer aussi bien des opérateurs OLAP que les techniques de
fouille dans un seul processus de découverte des connaissances. Dans ce processus, l‟OLAP
doit constituer un automate qui propose à l‟analyste des pistes pour le guider dans sa tâche
d‟exploration des données multidimensionnelles. Tout de même, Palpanas prévoit que la
structure multidimensionnelle peut servir de source pour l‟extraction de modèles de
connaissances plus riches et qui sont introuvables dans les données tabulaires, habituellement
inaccessibles avec la forme bidimensionnelle des données.
Palpanas prédit des horizons prometteurs pour la recherche de l‟intégration de la
fouille dans l‟environnement multidimensionnel. Il prévoit, également, une évolution des
algorithmes d‟apprentissage pour s‟adapter aussi bien aux opérateurs OLAP qu‟à la structure
hiérarchique des données. Ceci les rendra capables de produire des connaissances à différents
niveaux de granularité de l‟information [Pal00].
D‟une manière semblable, dans [Par97], l‟auteur propose un système théorique, appelé
OLAP Data Mining System, évoluant dans un espace hybride formé par des données et
agrégats. Ce système comprend trois composantes : une base de données relationnelle pour
l‟entreposage des données, un système MOLAP ou ROLAP pour la structuration et l‟accès
aux données et une composante de découverte de connaissances dans les données
multidimensionnelles (multidimensional discovery engine)
Actuellement, nous pensons que les travaux de Sarawagi et al. ([SAM98] [Sar99] et
[Sar01]) sont parmi les rares qui ont été concrètement réalisés selon cette approche.
Dans [SAM98], Sarawagi et al. proposent un outil d‟identification des régions
remarquables dans les cubes de données. Habituellement pour détecter des exceptions ou des

Chapitre 2 : Etat de l‟art
21
valeurs aberrantes dans les données multidimensionnelles (cubes), un utilisateur est amené à
naviguer dans un grand déluge de valeurs contenues dans un espace de dimensions étendues.
Ce qui rend ce travail assez pénible et coûteux en termes de temps et de traitements. Face à ce
problème, [SAM98] introduisent un nouveau modèle statistique intégré dans un serveur
OLAP (Discovery-driven) pour assister l‟utilisateur dans sa tâche d‟analyse et d‟exploration
dans les cubes de données (Figure 7). Le modèle a pour vocation de guider l‟utilisateur à
détecter les motifs des données remarquables à différents niveaux des dimensions d‟un cube ;
suivant plusieurs dimensions et à différents niveaux de granularité.
Le fondement du modèle se base essentiellement sur la comparaison des valeurs
prédites des cellules avec leurs contenus réels. Une combinaison avec les différentes
dimensions de ces cellules est envisagée pour la vérification de l‟aberrance du contenu.
Statistiquement, la prédiction de la valeur d‟une cellule est assurée par une régression
multidimensionnelle qui construit un modèle d‟équation expliquant la valeur prédite en
fonction des agrégats de ses dimensions.
Cependant, l‟implémentation de cette approche statistique n‟est pas évidente du
moment où elle doit tenir compte des différentes dimensions d‟un cube, ainsi que les
différents agrégats de chaque dimension et de l‟ensemble des combinaisons possibles de ces
dimensions. A ce propos, dans [SAM98], ils ont utilisé des méthodes d‟optimisation qui
réduisent les coûts de traitements et améliorent les performances d‟analyse par un facteur de
trois.
Une amélioration de ces travaux est réalisée par Sarawagi [Sar99] [Sar01], cet
approfondissement concerne une meilleure automatisation de l‟analyse par l‟emploi de la
programmation dynamique. Cette automatisation est garantie par le nouvel opérateur iDiff qui,
à la fois, détecte les régions remarquables et explore les raisons de présence de ces régions
dans un cube de données. Ces raisons sont exprimées, sous forme de tableaux sommaires, en
Fig. 2.7 – Architecture de l‟implémentation « Discovery-driven »
Interface de
visualisation
Procédure de détection
des régions
remarquables
Serveur
OLAP
Pilote ODBC
Réponse tabulée
Client
Serveur
Requête SQL
Résultat de la requête

Chapitre 2 : Etat de l‟art
22
fonction des valeurs d‟autres cellules du cube appartenant à des niveaux d‟agrégation plus fins
et en corrélation logique avec les cellules de départ. Un prototype est implémenté pour cet
opérateur sur le serveur DB2/OLAP d‟IBM. Des expérimentations sur ce prototype ont
démontré le bon niveau de performance de l‟algorithme en fonction du nombre de tuples, les
granularités choisies et la taille des réponses. Donc, Nous sommes en présence d‟une
implémentation faisant le lien entre une nouvelle forme de fouille et l‟analyse en ligne.
Des travaux similaires, de Favero et Robin qui ont adopté une approche semblable à
celle de Sarawagi. Dans [RF01], ils proposent le système HYSSOP (HYpertext Summary
System of On-line analytical Processing) pour générer automatiquement des statistiques
quantitative extraites à partir des cubes de données (données multidimensionnelles). Ces
statistiques sont examinées en langage naturel intégrant des liens hypertextes. Dans [FR00,
RF01], les auteurs pensent que l‟association entre la fouille de données et l‟analyse en ligne
peut réaliser des analyses quantitatives du contenu d‟un cube, ils proposent, ainsi, une
composante de fouille de données (Content Determination) intégrée dans HYSSOP, qui
concrétise cette approche en utilisant les hiérarchies du cube pour classifier les données. Les
résultats de ce module sont pris en charge par un générateur de langage naturel (Naturel
Language Generation) afin de donner des résumés textuels compréhensibles par l‟être
humain.
Généralisation des règles d’association aux données multidimensionnelles :
Imielinski et al. proposent une intégration des règles d‟association aux cubes de
donnés. Dans [IKA02], les auteurs introduisent une généralisation des cubes de données et des
règles d‟association; le concept des cubes de données différentielles nommé : Cubegrades. Ce
dernier est un formalisme qui calcule le différentiel des mesures agrégées d‟un cube de
données par passage d‟un cube source à un cube cible. Un tel passage peut correspondre à une
opération de spécification (drill-down), de généralisation (roll-up) ou de permutation d‟une
modalité dans une dimension (switch). (%Par exemple, un cubegrade permet de voir de
combien est la moyenne des âges de consommateurs de pain quand on spécialise la
population à celle des consommateurs de pain et de lait%). En d‟autres termes, un cubegrade
exprime de combien un agrégat d‟un cube de données peut varier lors de modification de
structure sur ce cube.
D‟après Imielinski et al. considèrent les cubegrades comme étant une nouvelle
formulation des connaissances hybrides combinant à la fois les règles d‟association et

Chapitre 2 : Etat de l‟art
23
l‟analyse en ligne, et aussi, sont des atomes de connaissances qui expliquent le comportement
des agrégats des différents segments d‟une base de données. Aussi, dans [IKA02], ils ont
introduit un langage de requête, appelé CGQL (CubeGrades Query Language), pour
interroger les cubegrades dans une base de données multidimensionnelles.
Après les travaux de Imielinski et al. , Dong et al. ont introduit un article [DHL+01]
dont ils ont proposé des améliorations dans le concept des cubegrades ou ils introduisent la
notion des constrained gradients qui respecte une contrainte de significativité. Cette contrainte
permet de contourner le problème de volumétrie des cubes de données à fouiller. Ainsi, la
recherche des cubegrades de limite à la partie significative du cube qui satisfait la contrainte.
Classiquement, la recherche des cubegrades consiste à comparer chaque cellule dans
un cube source avec les autres cellules dans le cube cible. Dong et al. mentionnent que, même
avec la contrainte de significativité, les cubegrades générés restent toujours nombreux. Par
conséquent, les auteurs proposent aussi de prendre en compte une deuxième contrainte
probabiliste permettant de restreindre la recherche des constrained gradients.
Les auteurs ajoutent que, dans une analyse OLAP, on ne s‟intéresse souvent qu‟à
certains niveaux de changements entre la cellule source et la cellule cible. Par exemple, un
utilisateur ne s‟intéresse qu‟aux cellules dont la moyenne augmente de plus de 40%. Les
auteurs, introduisent un seuil pour les mesures des cellules à choisir. Les paires de cellules
dont les mesures varient avec des taux supérieurs au seuil sont appelées cellules gradients
(gradient cells) et le seuil est appelé la contrainte du gradient (gradient constraint).
L‟algorithme LiveSet-Driven algorithm est également proposé dans [DHL+01] pour la
recherche des constrained gradients selon les trois contraintes développées.
Explication dans les cubes de données par règles d’association :
Messaoud, Boussaid et Rabaséda utilisent une méthode d‟explication dans les cubes de
données. Leur proposition consiste à adapter la recherche des règles d‟association aux
données multidimensionnelles. De ce fait, ils mettent en place un nouvel algorithme de type
Apriori, capable d‟extraire des règles d‟association directement à partir d‟une structure
multidimensionnelle sans avoir recours à une transformation tabulaire des données initiales.
Cet algorithme repose sur une fouille de données pilotée par les besoins de l‟utilisateur via la
définition d‟une méta-règle qui était traité dans [MRBM06]. Il se base sur une nouvelle
définition du support et de la confiance des règles d‟association adaptée au contexte de

Chapitre 2 : Etat de l‟art
24
l‟analyse en ligne [MBR06c]. Ils proposent aussi une visualisation graphique, basée sur la
sémiologie graphique afin de valoriser les connaissances véhiculées par les règles extraites.
2.5 Conclusion
Pour conclure, nous avons fait la différence entre les trois grandes groupes
d‟approches traitent le problème du couplage de l analyse en ligne et de la fouille de données.
Cette synthèse repose sur une organisation thématique qui croise les trois approches,
que nous avons détectées, avec les trois familles de techniques de fouille de technique de
fouilles de données, à savoir: (i) les techniques de visualisation et de description; (ii) les
techniques de structuration et de classification et (iii) les techniques d‟explication et de
prédiction.
Nous avons fait la différence entre les trois grands groupes d‟approches traitant le
problème du couplage de l‟analyse en ligne et de la fouille de données, afin de positionner nos
contributions nous exposons une synthèse des travaux existants.
La première approche (Adaptation des structures multidimensionnelles) de couplage
de l‟analyse en ligne et de la fouille de données regroupe les travaux préconisent la
transformation des données multidimensionnelles en données tabulaire. Cette approche bien
que simple et intuitive, permet tout de même d‟extraire des connaissances à partir de données
provenant de structures multidimensionnelles. Cependant, d‟une manière générale, la
transformation des données multidimensionnelles en données tabulaires présente le risque de
faire perdre à ces dernières leur aspect hiérarchique.
De plus mise à part la proposition de Maedche et al. [MHW00] ou les auteurs font de
la classification des consommateurs selon leur profits, toutes les autres propositions utilisent
des méthodes d‟explication et de prédiction telles que les réseaux bayésiens, les arbres de
décision et les règles d‟association.
Compte à Messaoud, Boussaid et Rabaséda, utilisent la méthode de visualisation et de
description, leur proposition permet d‟apporter une solution au problème de la visualisation
des données engendré par l‟éparsité des données. En se basant sur les résultats d‟une analyse
des correspondances multiples (ACM), ils tentent d‟atténuer l‟effet négatif de l‟éparsité en
réorganisant différemment les cellules d‟un cube de données. À travers ce couplage entre
l‟OLAP et l‟ACM, ils ont construit un espace de représentation se prêtant mieux à l‟analyse et
dans lequel les faits du cube sont regroupés le mieux possible.

Chapitre 2 : Etat de l‟art
25
La deuxième approche (Extension de l‟analyse OLAP et des langages de requêtes) est
instrumentale et consiste à exploiter ou à étendre des outils existants à des taches de fouille de
données. Cette extension porter sur les SGBDMs, les langages de requêtes SQL ou les
opérateurs OLAP.
Cette approche est intéressante car elle permet d‟intégrer la fouille de données dans un
SGBDMs [Cha98] Ou dans des modules d‟analyse annexes [CFB97, CFB98]. Elle permet
aussi d‟établir une coopération entre un SGBDM et un logiciel externe pour la fouille de
données [LGM00, LBMD+00]. Le langage de requêtes SQL est donc utilisé afin d‟assurer la
communication entre la source de données et l‟algorithme de fouille. Profitant de sa capacité
d‟interroger de grandes bases de données nécessaire à chaque étape de construction des
modèles d‟apprentissage. Par exemple, dans [CFB97, CFB98] pour chaque nœud d‟un arbre
de décision, une requête SQL est formulée à la volée.
Selon cette approche. La technologie OLAP peut être exploité pour extraire de
données nécessaires à la recherche des règles d‟association dans les cubes de données
[GC98a, GC98b] les opérateurs OLAP peuvent aussi faire l‟objet d‟une extension à une
fouille en ligne [Han97, Han 98, HCC98]. De plus, avec ses capacités classiques
d‟exploration et de navigation, l‟OLAP peut devenir un instrument utile pour la validation des
connaissances extraites à partir des données multidimensionnelles [TNBP00, NNQ04,
MJN06, LZBX06].
Tous les travaux qui abordent le problème de couplage selon cette approche, se
limitent à des techniques d‟explication et de prédiction tel que les arbres de décision, les
réseaux bayésiens, les motifs fréquents ou les règles d‟association.
Cependant, dans [MBR06], les auteurs ont associé l analyse en ligne à une technique
de structuration et de classification des données multidimensionnelles. Ils ont adopté
l‟approche du couplage entre l‟analyse en ligne et la fouille de données qui exploite les outils
OLAP afin d‟extraire les données nécessaires à la construction de l‟algorithme de fouille.
Cette proposition fait l‟objet d‟une nouvelle agrégation des faits d‟un cube en se basant sur la
classification ascendante hiérarchique (CAH). Celle-ci permet d‟obtenir de nouveaux agrégats
sémantiquement plus riches que ceux fournis par les opérateurs OLAP classiques.
La troisième approche (Adaptation des techniques de fouille de données) se base sur
l‟adaptation des algorithmes de fouille aux données multidimensionnelles. Bien que récente
et ayant peu d‟application concrètes, cette approche est aussi intéressante car elle permet
d‟extraire des connaissances directement à partir des cubes de données, ce qui permet de

Chapitre 2 : Etat de l‟art
26
prendre en compte l‟aspect multidimensionnelles et hiérarchiques des données dans la
construction d‟un modèle d‟apprentissage. Dans l‟avenir cette approche est capable de créer
une nouvelle génération de technique de fouille de données multidimensionnelles.
Dans le cadre de cette approche, il n‟y a pas beaucoup de travaux qui ont concrétisé cet aspect
de couplage sauf quelques propositions purement théorique de Palpanas [Pal 00] et de Parsaye
[Par97] les cubegrades de Imielinski et al. [IKA02], les constrained gradients de Dong et al
[DHL+02] et l‟opérateur iDiff de Sarawagi [Sar 99, Sar01] sont les seules qui tentent
véritablement d‟adapter la fouille aux données multidimensionnelles.
Messaoud, Boussaid et Rabaséda proposent un algorithme de fouille afin d‟extraire
des connaissances directement à partir de la structure multidimensionnelle des données. Leur
proposition s‟inscrit dans une démarche explicative dans les cubes de données en se basant
sur les règles d‟association. Ils mettent en place un nouvel algorithme, de type Apriori, pour
une recherche guidée des règles d‟association dans les cubes de données. Une visualisation
graphique des règles d‟association extraites est également proposée afin de mieux valoriser
les connaissances qu‟elles véhiculent.

27
Opérateurs de couplage entre OLAP et DM
Résumé
L‟idée de combiner l‟analyse en ligne et la fouille de données est une solution
prometteuse pour renforcer le processus d‟aide à la décision, notamment dans le cas des
données complexes.
En effet, il s‟agit de deux domaines qui peuvent se compléter dans le cadre d‟un
processus d‟analyse unifié. L‟objectif de cette partie est de présenter les nouvelles approches
d‟aide à la décision qui reposent sur le couplage de l‟analyse en ligne et de la fouille de
données.
Sommaire
3.1 Introduction
3.2 Réarrangement d‟un cube par analyse factorielle (ACM): Opérateur ORCA
3.3 Agrégation par classification dans les cubes de données (CAH) : Opérateur OPAC
3.4 Explication par recherche guidée de règles d‟association dans un cube: Opérateur
AROX
3.5 Conclusion

28
Chapitre 3
Opérateurs de couplage entre OLAP et DM
« Savoir ce que tout le monde sait, c’est ne rien savoir. Le savoir
commence là ou commence ce que le monde ignore. »
Remy de Gourmont, “Promenades philosophiques”
3.1 Introduction
Pour l‟analyse des données complexes, un nouveau cadre d‟analyse est nécessaire
Double constat :
o Opérateurs OLAP classiques pas forcément adaptés aux données complexes
o Possibilités d‟analyse du DM beaucoup plus riches que celles de l‟OLAP :
extraction de connaissances sous forme de modèles compréhensibles et validés
(exploration, structuration ou prédiction)
Fig 3.1 – Objectifs du couplage OLAP & DM

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
29
Par conséquent :
Besoin d‟une analyse en ligne plus élaborée et adaptée aux données complexes.
Couplage OLAP et DM pour une analyse plus élaborée des données complexes.
Certes, il y a des problèmes posés par le couplage :
Couplage analyse en ligne et fouille de données
o Utilisation conjointe des techniques d‟analyse OLAP et de fouille sur des
mêmes données entreposées ?
o Peut-on associer fouille de données et analyse OLAP pour une même analyse ?
Vocation
o des opérateurs OLAP : navigation et visualisation, agrégation dans le cube
o de la fouille : exploration, classification et structuration, explication et
prédiction
Comment appliquer des algorithmes de fouille
Comment appliquer les algorithmes de fouille de données sur des données
multidimensionnelles ?
Dans l‟analyse multidimensionnelle, comment étendre les opérateurs OLAP à de
nouveaux opérateurs basés sur des techniques de fouille de données ?
Fusionner les vocations de l‟OLAP et de la fouille de données en proposant des opérateurs
d‟exploration, d‟agrégation et d‟explication des données complexes.
Différentes approches de couplage :
Comme nous avons mentionné dans le second chapitre, il existe trois groupes d‟approche de
couplage : Adaptation des structures multidimensionnelles, Extension des opérateurs OLAP et
Adaptation des algorithmes de fouille de données
Adaptation des structures multidimensionnelles :
Adaptation de la structure multidimensionnelle des données pour les rendre exploitables par
des techniques de fouille
Pinto et al. (Motifs fréquents multidimensionnels)
Goil et Choudhary (Arbre de décision à partir d’un cube de données)
Chen et al. (IIMiner : OLAP = Outil de prétraitement des données)

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
30
Extension des opérateurs OLAP :
Techniques d'apprentissage utilisées comme des opérateurs OLAP dans l'analyse en ligne,
simulation par les opérateurs OLAP de techniques de fouille (règles d'association,
caractérisation d'attributs, classification, prédiction, …) et s'appliquant à différents niveaux
hiérarchiques d'une dimension
OLAM - OLAP Mining (Han, 1997) et le système DBMiner
Règles d‟association à partir des cubes (Goil et Choudhary, 1999)
Association rule cubes (Chen, Dayal )
Adaptation des algorithmes de fouille de données :
Application de la fouille au cœur des données multidimensionnelles
Palpanas (Visions théoriques : processus d‟analyse élaborée)
Sarawagi et al. (Discovery-driven : détection des valeurs remarquables)
Favero et Robin (HYSSOP : rapports statistiques en langage naturel)
Mais aucune des ces trois approches n‟emploie le couplage entre la fouille de données et
l‟analyse en ligne en vue d‟étendre les fonctionnalités d‟OLAP pour une analyse plus élaborée
des données complexes. Cependant, trois opérateurs de couplage ont été proposés :
Réarrangement d‟un cube par analyse factorielle (ACM)
o Opérateur ORCA
Agrégation par classification (CAH)
o Opérateur OPAC
Explication par recherche guidée de règles d‟association dans un cube
o Opérateur AROX

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
31
3.2 Réarrangement d’un cube par analyse factorielle (ACM) :
o Opérateur ORCA
3.2.1 Introduction :
Les opérateurs OLAP classiques permettent de: naviguer, explorer et résumer un cube
et détecter des régions intéressantes dans le cube. Mais, dans des cubes épars et de grande
taille il aura une navigation et exploration difficile ainsi qu‟un manque d‟outils automatiques.
Par exemple, observer les niveaux de ventes en fonction des produits, des périmètres
commerciaux (localisation géographique..) et de période d‟achat. De cette visualisation
dépend la qualité de l‟exportation des données. Plusieurs facteurs peuvent dégrader cette
visualisation ; représentation multidimensionnelle engendre une éparsité car à l‟intersection
de différentes modalités de dimension, il n‟existe pas forcement de faits correspondants :
l‟éparsité peut être accentuée par la présence d‟un grand nombre de dimensions (et/ou grand
nombre) de modalités dans chacune de dimensions.
En outres, les modalités des dimensions sont représentées selon un ordonnancement
lexical pré-établi qui correspond souvent à un ordre naturel (ordre chronologique pour les
dates et alphabétique pour les libellés par exemple.) Par conséquent, les points associés aux
faits observés (les cellules pleines) sont éparpillés dans l‟espace des dimensions d‟un cube de
données.
Pour améliorer la visualisation des données dans les cubes, ils ont proposé une
méthode qui consiste à coupler l‟analyse en ligne avec l‟analyse des correspondances
multiples (ACM) [Ben 73].
Cette proposition adapte la première approche du coulage basant sur la transformation
des données multidimensionnelles en données tabulaire afin de les exploiter par des
algorithmes de fouille.

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
32
Le Principe du réarrangement par analyse factorielle est illustré dans le schéma
suivant :
La 1ére
étape consiste à transformer les données initiales d‟un cube en tableau
individus- variables selon un codage binaire spécifique à l‟ACM. Dans la 2éme
étape, ils
appliquent l‟ACM aux données transformées afin d‟obtenir des axes factoriel représentant aux
mieux les faits OLAP et traduisant des relations avec les modalités des dimensions du cube,
chaque axe factoriel (ou facteur) est caractérisé par une valeur propre indiquant l‟inertie
(dispersion) des individus dans la direction définie par cet axe [LMP00].
D‟où l‟intérêt d‟une méthode de réorganisation des données multidimensionnelles pour
réduire l‟effet de leur éparsité, dans cette méthode, ils utilisent l‟ACM comme étant un outil
d‟aide à la construction de cubes de données ayant de meilleures caractéristiques pour la
visualisation.
L‟objectif de cette proposition est d‟atténuer l‟effet négatif de l‟éparsité des cubes sur
la visualisation pas de diminuer l‟éparsité des cubes [NNT03]. Pour ce fait, ils regroupent les
cellules pleines et les séparent le mieux possible des cellules vides dans l‟espace de
représentation d‟un cube de données (arranger l‟ordre des modalités dans chaque dimension
Fig.3.2 – étapes de la réorganisation d‟un cube de données par approche factorielle
Chapitre 3 : Opérateurs de couplage entre OLAP et DM
33
du cube étudié étant donné que leur ordres initiaux n‟engendrent pas forcement une bonne
visualisation.)
Dans [MRB05], ils ont débuté une réflexion sur l‟usage de l‟analyse factorielle dans
un contexte OLAP où ils ont montré que l‟ACM construit des axes factoriels qui offrent de
meilleurs points de vue du nuage de points des faits d‟un cube. Dans [MAF05], ils arrangent
les modalités selon leur projection sur les axes factoriels mais dans [MBR05, MBR06d,
MBR06], ils les arrangent selon leurs valeurs-test.
Le but de l‟OLAP est de fournir à l‟utilisateur un outil visuel pour explorer et naviguer
dans les données d‟un cube afin d‟y découvrir des informations pertinentes. Certes, dans le
cas de données volumineuses, telles que les données bancaires ou les données
démographiques considérées dans notre étude, l‟analyse en ligne n‟est pas une tâche facile
pour l‟utilisateur. En effet, un cube à forte dimensionnalité comportant un grand nombre de
modalités, présente souvent une structure éparse difficile à exploiter visuellement. De plus,
l‟éparsité, souvent répartie de façon aléatoire dans le cube, altère davantage la qualité de la
visualisation et de la navigation dans les données.
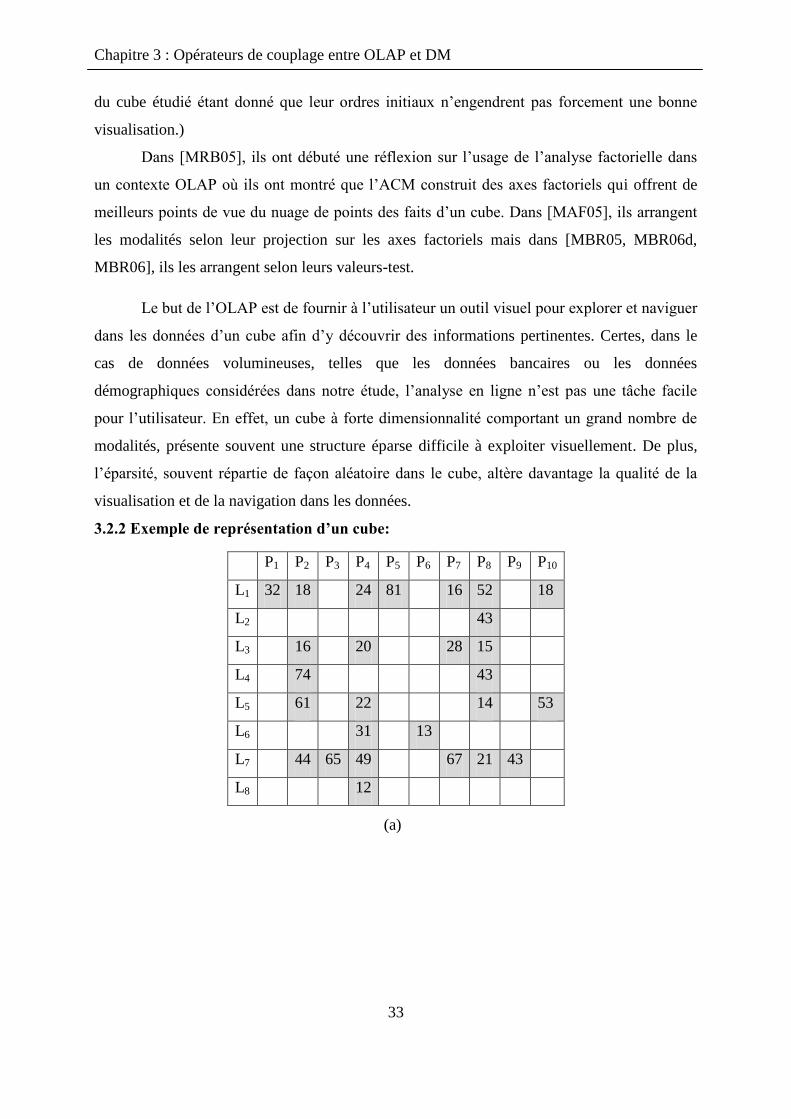
3.2.2 Exemple de représentation d’un cube:
(a)
P1 P2 P3 P4 P5 P6 P7 P8 P9 P10
L1 32 18 24 81 16 52 18
L2 43
L3 16 20 28 15
L4 74 43
L5 61 22 14 53
L6 31 13
L7 44 65 49 67 21 43
L8 12

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
34
(b)
Dans cet exemple, les deux tableaux présentent un cube de données à deux
dimensions: les localités géographiques d‟agences bancaires (L1, . . ., L8) et les produits de la
banque (P1, . . ., P10). Les cellules grisées sur la figure 3.3 sont pleines et représentent la
mesure des faits existants (chiffres d‟affaires, par exemple) alors que les cellules blanches
sont vides et correspondent à des faits inexistants. La répartition des cellules pleines dans la
représentation (a) ne se prête pas facilement à l‟interprétation. En effet, visuellement,
l‟information est éparpillée dans l‟espace de représentation des données. En revanche, dans la
représentation (b), les cellules pleines sont concentrées dans une zone centrale du cube. Cette
représentation offre des possibilités de comparaison et d‟analyse des valeurs des cellules
pleines (les mesures des faits) plus aisées et plus rapides pour l‟utilisateur.
La représentation (b) est obtenue après une simple permutation de lignes et de
colonnes de (a).
Cette méthode permet à l‟utilisateur d‟améliorer automatiquement la qualité de la
représentation des données (appelé nuage des faits, cellules pleines), cette réorganisation
consiste à rassembler les cellules pleines dans l‟espace de représentation des données.
En résumé, le but de cette méthode est de réorganiser le cube de manière à atténuer l‟impact
négatif sur la visualisation que l‟éparsité engendre.
Pour des raisons de complexité de traitements, ils excluent la recherche d‟un optimum
global, voire même local, de l‟indice de qualité selon une exploration exhaustive des
configurations possibles du cube ; c‟est à dire, toutes les combinaisons des arrangements
possibles des modalités des dimensions du cube.
P1 P3 P5 P7 P8 P4 P2 P10 P9 P6
L2 43
L6 31 13
L3 28 15 20 16
L1 32 81 16 52 24 18 18
L7 65 67 21 44 44 43
L5 14 22 61 53
L4 43 74
L8 12
Fig. 3.3- cube de données à deux dimensions

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
35
3.2.3 Notations générales
Considérons les notations générales relatives à la structure d‟un cube de données. Pour
faciliter la compréhension des formalismes des différentes propositions.
On utilise également le même exemple du cube de données des ventes de la figure 3.4.
Soit donc C un cube de données ayant les propriétés suivantes :
– C est constitué d‟un ensemble non vide de d dimensions D = Di (1≤i≤d) ;
– C contient un ensemble non vide de m mesures M= Mq(1≤q≤m) ;
– Chaque dimension Di ∈ D contient un ensemble non vide de ni niveaux hiérarchiques. Nous
considérons que Hji est le j
ième niveau hiérarchique de la dimension Di.
Par exemple, dans la figure 3.4, la dimension Lieu (D1) contient deux niveaux (n1 = 2):
Continent et Pays. Le niveau Continent est noté H11 et le niveau Pays est noté H
12 ;
– Le niveau d‟agrégation totale All dans une dimension correspond au niveau hiérarchique
zéro.
Par exemple, dans la dimension D1 ce niveau est noté H01 ;
– Hi = Hij(0≤j≤ni) représente l‟ensemble des niveaux hiérarchiques de la dimension Di,
Par exemple, dans figure 3.4, l‟ensemble des niveaux hiérarchiques de D2 est:
H2 = H2
0 ,H2
1 ,H2
2 = All, Famille de produits, Produit ;
– Chaque niveau hiérarchique Hij ∈ Hi consiste en un ensemble non vide de lij modalités.
Nous considérons que aij
t est la tième
modalité du niveau Hij .
Fig.3.4- exemple d‟un cube de données de ventes

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
36
Par exemple, dans le cube de figure 3.4, le niveau Famille de produits (H2
1) de la dimension
Produit (D2) contient trois modalités (l21 = 3) : PC, notée a121
, PC por, notée a221
et MP3,
notée a321
;
– Aij = atij (1≤t≤lij ) représente l‟ensemble des modalités du niveau hiérarchique Hj
i de la
dimension Di. Par exemple, dans la figure 3.4, l‟ensemble des modalités du niveau Produit de
D2 est A22 =iTwin, iPower, DV-400, EN-700, aStar, aDream ;
– Pour le niveau d‟agrégation total d‟une dimension, nous considérons que All est la seule
modalité de ce niveau. Ainsi, pour une dimension Di, on note que a1i0
= All et Ai0 = All.
Dans la suite, considérons un cube C à d dimensions (D1, . . . ,Di, . . . ,Dd) et n faits
OLAP observés selon la mesure quantitative Mq.
Pour alléger les notations, on associe une dimension Di à son niveau hiérarchique Hji
(0 < j ≤ ni) sélectionné par l‟utilisateur.
Ainsi, on note que chaque dimension Di contient li modalités catégorielles au lieux de lij .
Soit donc a1i, . . . , at
i, . . . , ali
i l‟ensemble des modalités de la dimension Dt.
On note aussi que 𝑙 = 𝑙𝑖𝑑𝑖=1 est le nombre total de toutes les modalités de C.
On considère également qu‟une cellule A dans un cube C est pleine (respectivement,
vide) si elle contient une mesure d‟un fait existant (respectivement, ne contient pas de faits).
3.2.4 Etape 1 : Construction du tableau disjonctif complet Z
Une analyse de correspondance multiple (ACM) ne peut opérer que sur des données
catégorielles codées en binaire selon un tableau disjonctif complet. Ainsi, afin d‟appliquer
l‟ACM sur un cube C, on est amené à transformer ce dernier et à le représenter sous forme
d‟un tableau disjonctif complet.
Pour chaque dimension Di (i ∈ 1, . . . , d), soit une matrice Zi à n lignes et li colonnes.
Zi est telle que sa kiéme
ligne contenant (li − 1) fois la valeur 0 et une fois la valeur 1 dans la
colonne correspondant à la modalité que prend le fait fk (k ∈ 1, . . . , n).
Zi est un sous-tableau disjonctif qui décrit la partition des n faits induite par les modalités de
la dimension Di. Le terme général de la matrice Zi s‟écrit :
0
1i
ktz
Si le fait fk prend la modalité ati de la dimension Di
Sinon

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
37
En juxtaposant les d matrices Zi, nous construisons la matrice Z à n lignes et l colonnes.
Z = [Z1, Z2, . . . , Zi, . . . , Zd] est un tableau disjonctif complet qui décrit les d positions des n
faits du cube C par un codage binaire.
Id D1 D2 D3 M1
1
2
3
4
L1 T2 P1
L2 T2 P3
L2 T1 P2
L1 T1 P3
9
5
6
7
3.2.5 Etape 2 : Diagonalisation du tableau de Burt B (Tableau de contingence)
A partir du tableau disjonctif complet Z, nous construisons le tableau symétrique B =
Z′Z, ou Z′ désigne la transposée de Z. B est une matrice d‟ordre (l, l) qui rassemble les
croisements deux à deux de toutes les dimensions du cube C. B est appelé tableau de
contingence de Burt associé à Z. La matrice B contient en diagonale d sous-matrices
diagonales correspondant chacune à une dimension. Chacune de ces sous-matrices contient en
diagonale les effectifs marginaux de chaque modalité de la dimension en question. En dehors
de ces sous-matrices, la matrice B contient tous les croisements possibles des effectifs des
modalités des d dimensions du cube de données C.
Par exemple, la figure (b) représente le tableau de contingence de Burt obtenu à partir
du tableau disjonctif complet Z de la figure (a).
𝑍 =
1 0 0 1 1 0 00 1 0 1 0 0 1 0 1 1 0 0 1 01 0 1 0 0 0 1
𝐵 = 𝑍𝑡𝑍 =
2 0 1 1 1 0 10 2 1 1 0 1 11 1 2 0 0 1 11 1 0 2 1 0 11 0 0 1 1 0 00 1 1 0 0 1 01 1 1 1 0 0 2
Cette étape permet : l‟extraction des valeurs propres, la détermination des vecteurs
propres associés et la construction des axes factoriels
Z
Z1 Z2 Z3
Id L1 L2 T1 T2 P1 P2 P3
1
2
3
4
1 0
0 1
0 1
1 0
0 1
0 1
1 0
1 0
1 0 0
0 0 1
0 1 0
0 0 1
Tab 3.1. Exemple de transformation d‟un cube de données en tableau disjonctif complet
Fig.3.5 – Exemple de transformation d‟un tableau disjonctif complet en tableau de contingence
de Burt
(a) (b)

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
38
3.2.6 Etape 3 : Tri croissant des modalités de chaque dimension Di selon :
Leurs projections : cet arrangement de modalités consiste à associer à chaque
dimension initiale Di le meilleur axe factoriel Fα possible donc ;
o Nouvelles coordonnées dans l‟axe factoriel Fα
o Fα est l‟axe le mieux expliqué par les modalités de Di
Leurs valeurs-test
o Nombre d‟écart-types entre une modalité ati de Di (le centre de gravité des nt
i)
et le centre de gravité d‟un axe factoriel Fα
Ainsi, la position d‟une modalité est intéressante dans la direction d‟un axe factoriel Fα si le
sous-nuage qu‟elle constitue occupe une zone étroite dans cette direction et si cette zone est
éloignée du centre de l‟axe Fα. La valeur-test est un critère qui permet d‟apprécier si une
modalité a une position significative sur un axe factoriel.
o Premiers axes factoriels Fα les plus importants
Une valeur-test d‟une modalité est plus importante lorsqu‟elle indique la position de cette
dernière sur un axe factoriel important (ayant une grande valeur propre).
Pour cela, ils proposent de trier les modalités d‟une dimension selon l‟ordre croissant de leurs
valeurs-test sur le premier axe factoriel F1, puis sur le deuxième axe factoriel F2, jusqu‟au tri
des valeurs-test sur le sième
axe factoriel Fs…
3.2.7 Etape 4 : Evaluation de la pertinence de la réorganisation
Mesure la qualité d‟une représentation d‟un cube de données : l‟indice d‟homogénéité
[MBR05].
Grâce à cet indice, on peut évaluer le gain induit par l‟arrangement des modalités des
dimensions.
Indice d‟homogénéité basé sur :
o Le voisinage géométrique des cellules (plus les cellules pleines (ou bien vides)
sont concentrées, plus le cube est dit “homogène”.)
o La similarité entre les cellules

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
39
Le voisinage géométrique des cellules :
La similarité entre les cellules A et B : notée δ(A,B), est un scalaire dans IR défini comme
suit:
Où ||A| − |B|| est la valeur absolue de la différence des mesures contenues dans A et B.
max(C) (respectivement, min(C)) est la valeur maximale (respectivement, la valeur minimale)
de la mesure dans C, avec min(C) ≠ max(C).
Dans le cube de la figure 3.6, où les cellules grises sont pleines et les cellules blanches
sont vides, la mesure maximale du cube correspond à la cellule S (max(C) =7) et la mesure
minimale correspond à la cellule K (min(C) = 1, 5). Par conséquent, la similarité des cellules
A et B de la figure 3.5 est : δ (A, B) = 1 − ( |5,7−4,5|/(7−1,5) ) ≃ 0, 78.
En revanche, la similarité des cellules A et Y est nulle vue que la cellule Y est vide. Il
est à noter que cette définition de la similarité de deux cellules n‟est pas applicable dans le cas
où les cellules du cube C comportent la même valeur de la mesure. Ceci explique la condition
min(C) ≠max(C).
Similarité au voisinage: Soit une cellule A d‟un cube de données C. La similarité de A à son
voisinage, notée ¢(), est un scalaire dans R défini comme suit :
∆ 𝐴 = 𝛿(𝐴, 𝐵)
𝐵∈𝛾(𝐴)
Fig.3.6– Exemple en 2 dimensions de la notion de voisinage des cellules d‟un cube de données

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
40
∆ 𝐴 correspond à la somme des similarités de la cellule A avec toutes ses cellules voisines
dans le cube de données. Par exemple, la similarité au voisinage de la cellule A de la figure
3.5 se calcule selon :
Soit un cube de données C. L‟indice d‟homogénéité du cube C, noté IH(C), est défini comme
suit :
L‟indice d‟homogénéité d‟un cube C représente le rapport de l‟indice d‟homogénéité brut de
ce dernier par son indice d‟homogénéité maximale 𝐼𝐻𝐵max 𝐶 = 1𝐵∈𝛾(𝐴)𝐴∈𝐶
Avec l‟indice d‟homogénéité brut est donnée par :
Par exemple, l‟indice d‟homogénéité brut du cube de la figure 3.5 se calcule selon :
𝐼𝐻𝐵 𝐶 = ∆ 𝐹 + ∆ 𝐾 + ∆ 𝐴 + ∆ 𝑆 + ∆ 𝐵 + ∆ 𝐸 ≅ 6,67 sachant que l‟indice
d‟homogénéité brut maximum de cube C de la figure 3.5 est IHBmax(C) = 84, l‟indice
d‟homogénéité est dans ce cas égal à : IH(C) = 6,67/84 ≃ 0, 08.

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
41
L‟indicateur de la qualité d‟une représentation multidimensionnelle est plus important
quand les cellules pleines et similaires sont voisines. Avec cet indice, on peut mesurer
l‟apport d‟une réorganisation de la même représentation d‟un cube de données en évaluant le
gain de la qualité induit par cette réorganisation.
Pour mesurer l‟apport de l‟arrangement des modalités sur la représentation d‟un cube
de données C, nous calculons le gain d‟homogénéité, noté g, selon la formule :
Où IH(Cini) est l‟indice d‟homogénéité de la représentation du cube initial et IH(Carr) est celui
de la représentation réorganisée selon la méthode considérée. A noter que, pour le même type
d‟arrangement des modalités (selon les projections ou selon les valeurs- test), quelle que soit
la représentation initiale du cube, on obtient toujours la même réorganisation par notre
méthode. En effet, l‟ACM est une méthode déterministe qui n‟est pas sensible à l‟ordre des
variables en entrée.
Exemple :
Soit l‟étude de cas dédiée à un cube de données démographiques. Ce dernier fait
l‟objet d‟une réorganisation selon les valeurs-test de ses modalités [MBR06d, MBR06b].
Soit un cube à 5 dimensions dont les données sont extraites à partir de la base Census-
Income Database1 concernant un recensement sur les revenus de la population des États-Unis
d‟Amérique entre 1994 et 1995. Le cube étudié contient n = 199 523 faits OLAP où chaque
fait représente un profil d‟une sous-population d‟employés mesuré par le salaire par heure
(M1). Le tableau 3.2 détaille la description des cinq dimensions prises en compte pour
observer ces faits.
Dimension li
D1 : niveau d‟éducation l1=17
D2 : catégorie socioprofessionnelle l2=22
D3 : état de résidence l3=51
D4 : situation du ménage l4=38
D5 : pays de naissance l5=42
Tab.3.2. Description des dimensions du cube des données démographique
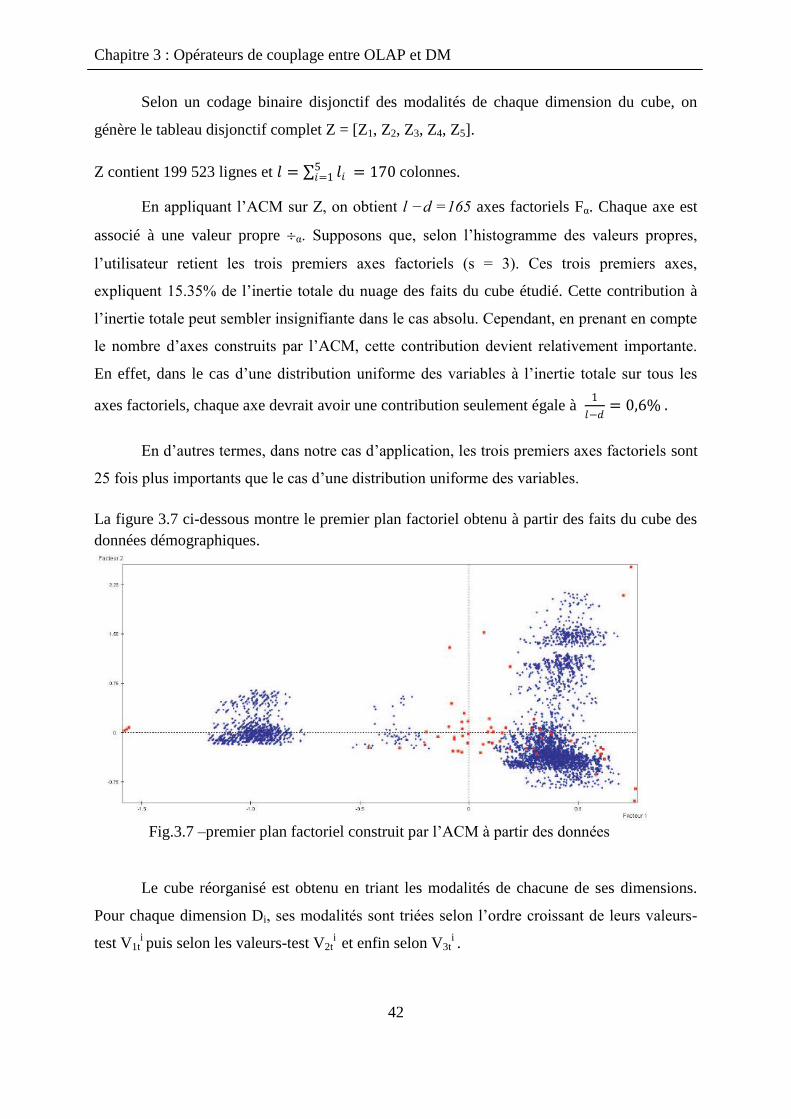
Chapitre 3 : Opérateurs de couplage entre OLAP et DM
42
Selon un codage binaire disjonctif des modalités de chaque dimension du cube, on
génère le tableau disjonctif complet Z = [Z1, Z2, Z3, Z4, Z5].
Z contient 199 523 lignes et 𝑙 = 𝑙𝑖 = 170 5𝑖=1 colonnes.
En appliquant l‟ACM sur Z, on obtient l −d =165 axes factoriels Fα. Chaque axe est
associé à une valeur propre α. Supposons que, selon l‟histogramme des valeurs propres,
l‟utilisateur retient les trois premiers axes factoriels (s = 3). Ces trois premiers axes,
expliquent 15.35% de l‟inertie totale du nuage des faits du cube étudié. Cette contribution à
l‟inertie totale peut sembler insignifiante dans le cas absolu. Cependant, en prenant en compte
le nombre d‟axes construits par l‟ACM, cette contribution devient relativement importante.
En effet, dans le cas d‟une distribution uniforme des variables à l‟inertie totale sur tous les
axes factoriels, chaque axe devrait avoir une contribution seulement égale à 1
𝑙−𝑑= 0,6% .
En d‟autres termes, dans notre cas d‟application, les trois premiers axes factoriels sont
25 fois plus importants que le cas d‟une distribution uniforme des variables.
La figure 3.7 ci-dessous montre le premier plan factoriel obtenu à partir des faits du cube des
données démographiques.
Le cube réorganisé est obtenu en triant les modalités de chacune de ses dimensions.
Pour chaque dimension Di, ses modalités sont triées selon l‟ordre croissant de leurs valeurs-
test V1ti puis selon les valeurs-test V2t
i et enfin selon V3t
i .
Fig.3.7 –premier plan factoriel construit par l‟ACM à partir des données
démographiques

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
43
Par exemple, le tableau 3.3 montre le nouvel ordre des modalités de la dimension “catégorie
socio- professionnelle” (D2). Notons que, d‟après ce tableau, t est l‟indice de l‟ordre
alphabétique des noms des modalités initialement établi.
Les figures 3.8 et 3.9 montre l‟effet visuel que produit l‟arrangement des modalités sur
la représentation d‟une vue partielle du cube des données démographiques. Cette vue résulte
du croisement de la dimension “catégorie socioprofessionnelle” (D2) en colonnes avec la
dimension “pays de naissance” (D5) en lignes. Dans la figure10 : l‟éparsité = 63% et
HI(Cini) = 14% et dans la figure 11 : Eparsité = 63% , HI(Carr) = 17% et Gain = 24 %
Tab.3.3- Nouvel ordre des modalités de la dimension D2 du cube des données
démographiques
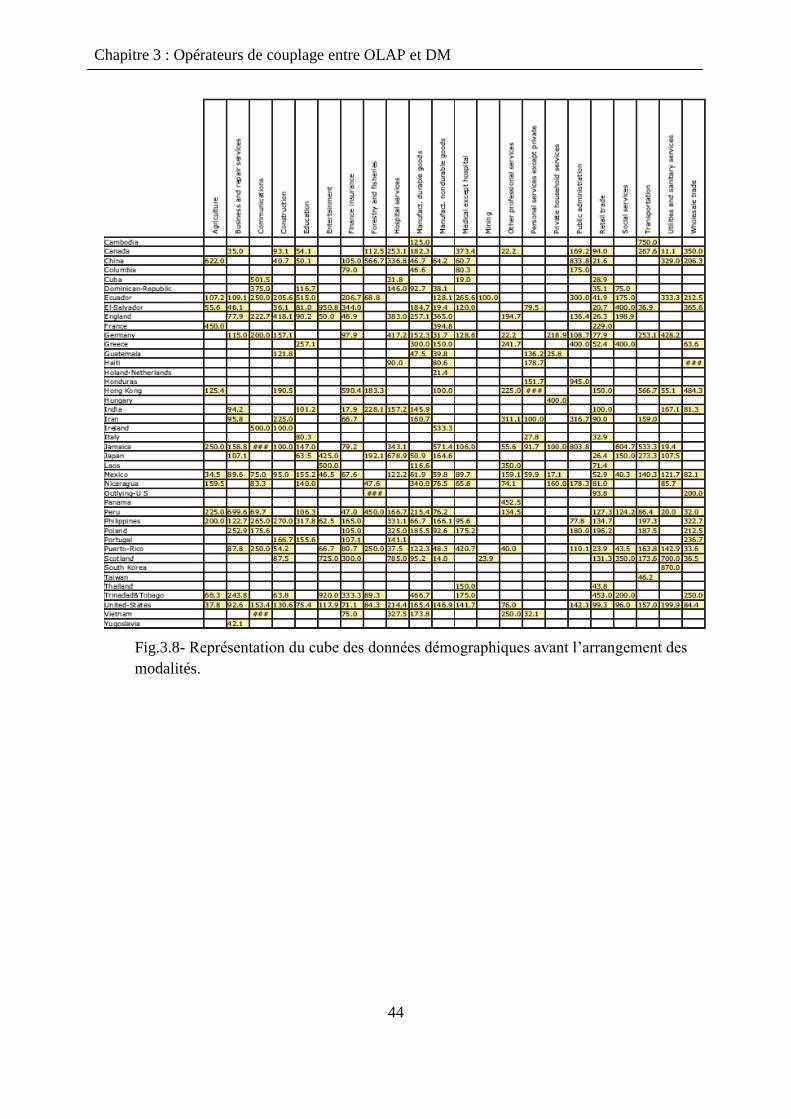
Chapitre 3 : Opérateurs de couplage entre OLAP et DM
44
Fig.3.8- Représentation du cube des données démographiques avant l‟arrangement des
modalités.

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
45
Fig.3.9- Représentation du cube des données démographiques après l‟arrangement des
modalités

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
46
Remarquons que plus le cube est éparse, plus on a une meilleure marge de manœuvre
pour concentrer les données et les regrouper ensemble autour des axes factoriels de l‟ACM.
Notons aussi que le gain en homogénéité, pour les fortes éparsités, peut fléchir localement.
Ceci est inhérent à la structure des données. C‟est-à-dire, si les données du cube initial sont
déjà dans une représentation homogène, l‟application de notre méthode n‟apportera pas de
gain considérable. En effet, dans ce cas, la méthode n‟aura qu‟un effet de translation du nuage
des faits vers les zones centrales des axes factoriels.
3.2.8 Conclusion et perspectives :
Cette méthode est une approche factorielle apportant une solution au problème de la
visualisation des données dans un cube éparse. Sans réduire l‟éparsité, ils cherchent à
réorganiser l‟espace multidimensionnel des données en regroupant géométriquement les
cellules pleines dans un cube. La recherche d‟un arrangement optimal du cube est un
problème complexe et coûteux en temps de calcul. Donc, ils ont choisi d‟utiliser les résultats
de l‟ACM comme heuristique pour réduire cette complexité.
On pense que plusieurs perspectives sont à prévoir. Tout d‟abord, étudier la
complexité de cette méthode. Cette étude doit prendre en compte aussi bien les propriétés du
cube (taille, éparsité, cardinalités, etc..) que l‟impact de l‟évolution des données
(rafraîchissement de l‟entrepôt de données). Ensuite, à ce stade les travaux existants, pour
appliquer l‟ACM, tiennent seulement compte de la présence ou de l‟absence des faits du cube
dans la construction des axes factoriels. Alors introduire la valeur de la mesure comme
pondération des faits (poids des individus de l‟ACM). Ceci permettra de construire des axes
factoriels qui traduisent mieux la représentation des faits du cube selon leur ordre de grandeur.
Dans ce cas, il serait également intéressant d‟introduire la notion de distance entre cellules
voisines en fonction des valeurs de la mesure qu‟elles contiennent.
Dans le même ordre d‟idées, utiliser les résultats de l‟ACM afin de faire émerger des
régions intéressantes pour l‟analyse à partir d‟un cube de données initial. En effet, l‟ACM
permet de concentrer dans les zones centrales des axes factoriels les individus ayant un
comportement moyen, et d‟éloigner ceux ayant des comportements atypiques vers les zones
extrêmes. On peut déjà exploiter les résultats de l‟arrangement des modalités du cube dans le
cadre de la distinction de régions correspondant à ces comportements caractéristiques.

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
47
Cette approche peut être considérée comme une extension d‟une méthode proposée
dans [CR98], (L‟objectif de cette méthode est de proposer une visualisation optimisée d‟un
tableau de contingence. Cependant, elle se limite à des tableaux à deux dimensions sans
données manquantes et ne peut pas s‟appliquer à des cubes de forte dimensionnalité.),
concernant la dimensionnalité du cube et l‟éparsité de ses données.
Par ailleurs, la matérialisation des cubes de données permet le pré-calcul et le stockage
des agrégats multidimensionnels de manière à rendre l‟analyse OLAP plus performante. Cela
requiert un temps de calcul important et génère un volume de données élevé lorsque le cube
matérialisé est à forte dimensionnalité. Au lieu de calculer la totalité du cube, il serait
judicieux de calculer et de matérialiser que les parties intéressantes du cube (fragments
contenant l‟information utile). Comme l‟information réside dans les cellules pleines, le cube
arrangé obtenu par l‟application de l‟ACM serait un point de départ pour déterminer ces
fragments. Ainsi, comme dans [BS97], chaque fragment donnera lieu à un cube local. Les
liens entre ces cubes permettront de reconstruire le cube initial.

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
48
3.3 Agrégation par classification dans les cubes de données (CAH)
o Opérateur OpAC
3.3.1 Introduction :
Cette approche consiste à créer un opérateur d'analyse en ligne, baptisé OpAC
(Opérateur d'Agrégation par Classification). OpAC consiste en l'agrégation sémantique des
données complexes en se basant sur la technique de la classification ascendante hiérarchique
(CAH) [LaWi67]. est dédiée pour la structuration et la classification des données
multidimensionnelles, c‟est une agrégation des faits d‟un cube de données selon leur ordre de
proximité et non selon l‟ordre d‟appartenance hiérarchique de leurs modalités dans les
dimensions.
Dans [MBR04], ils utilisent la classification ascendante hiérarchique (CAH) en vue
de construire des classes correspondant à de nouveaux agrégats dans le cube. Ainsi, la
classification est perçue comme une technique d‟agrégation sémantique dans les cubes de
données. Dans cette approche, la mise en œuvre de la classification dans les données
multidimensionnelles se base sur la deuxième approche « la structuration et la
classification » de couplage entre l‟analyse en ligne et la fouille de données. Comme le
montre la figure 3.10, des opérations OLAP sont utilisés afin d‟extraire les données,
notamment les individus et les variables, nécessaires à la classification.
Fig.3.10- Etapes de l‟agrégation par classification dans les cubes de données

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
49
Dans [MRBB04, MBR04], ils ont introduit une première formalisation de cette
approche de classification dans les cubes de données. Dans [MBR06a], ils ont amélioré et
appliqué l‟approche à un cas de données complexes. Ce cas d‟application concerne des
données de mammographies relatives à des dossiers de patientes atteintes du cancer du sein.
3.3.2 Objectifs de l’opérateur OpAC :
La construction d‟un cube de données cible un problème d‟analyse précis. Le choix
des dimensions et des mesures dépend des besoins de l‟analyse. D‟une manière générale, une
dimension est organisée sur plusieurs hiérarchies traduisant différents niveaux de granularité.
Chaque hiérarchie comporte un ensemble de modalités, et chaque modalité d‟une hiérarchie
regroupe des modalités de la hiérarchie immédiatement inférieure selon un ordre
d‟appartenance logique.
Par exemple, une dimension temporelle peut être structurée en quatre niveaux hiérarchiques :
jours, mois, trimestres et années.
Toutefois, la granularité d‟une dimension est fortement dépendante du niveau de
précision exigé par l‟analyse. Par exemple, si l‟analyse exclut les mesures quotidiennes, on
peut limiter la dimension temporelle aux niveaux : mois, trimestre et années. En revanche,
l‟organisation des modalités d‟une dimension est toujours régie par un ordre d‟appartenance
logique dicté par l‟usage naturel des objets ou des concepts du monde réel. Par exemple, il est
naturel de dire que la modalité « 1er
trimestre » de la dimension temporelle contient les mois
« Janvier », « Février » et « Mars ».
Le cube de la figure 3.11 est constitué de trois dimensions : Localité géographique, Temps et
Produit. La dimension temporelle est organisée selon deux niveaux hiérarchique : celui des
mois et celui des trimestres.
Fig.3.11 Agrégation (a) classique dans le contexte OLAP et (b) agrégation par classification

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
50
L‟idée de base de l‟opérateur OpAC consiste à exploiter les mesures contenues dans
un cube de données afin d‟agréger les modalités d‟une de ses dimensions. Si on veut agir sur
la dimension Temps, les mois sont vus comme des individus qu‟on peut décrire par des
mesures significatives provenant du cube. Comme le montre la figure 3.11, on peut considérer
« Les ventes des Parfums » et « Les ventes à Paris » comme des descripteurs des individus.
Par exemple, le mois « Juin » est caractérisé par 17unités de ventes de Parfums et 26 unités de
ventes à Paris. En adoptons une technique de classification, on agrège les mois les plus proche
au sens des deux descripteurs cités ci-dessus.
Contrairement à l‟agrégation au sens OLAP classique, basée sur le sens de
l‟appartenance logique des modalités, cette approche constitue une forme d‟agrégation
sémantique qui tient compte des faits réels contenus dans un cube de données. Le but de
l‟opérateur OpAC est de pouvoir agréger les modalités selon leurs liens sémantiques et pas
selon leurs liens logiques. Par exemple, dans la figure 3.11, les mois de « Janvier »,
« février »et « Mars » forment un agrégat puisqu‟ils appartiennent tous au premier trimestre
de l‟année. Alors que, dans la 2éme figure, l‟agrégation sémantique permet de constater que
« Janvier » et « Juin » forment un agrégat plus significatif du point de vue de l‟utilisateur
puisqu‟ils représentent des périodes particulières (niveaux de ventes semblables) concernant
les ventes de Parfums à Paris.
3.3.3 Le choix de la classification ascendante hiérarchique :
Contrairement aux modalités d‟une dimension, qui sont organisées selon un ordre
prédéfini, OpAC fournit des agrégats mettant en évidence les liens sémantiques entre les faits
contenus dans les données. Cette forme d‟agrégation permet de véhiculer des informations
plus riches que celles fournies par l‟agrégation classique d‟OLAP. En tenant compte ces
objectifs, le choix s‟est porté sur la classification ascendante hiérarchique (CAH) et cela est
justifié par :
Classification ascendante hiérarchique (Lance et William 1967)
1. Aspect hiérarchique : Analogie pertinente entre la CAH, la structuration d‟une
dimension et les résultats prévus pour l‟opérateur
2. CAH vs CDH (la Classification Descendante Hiérarchique):
a. La CAH inclut la partition la plus fine dans l‟éventail de ses résultats
b. La stratégie ascendante est plus rapide que la stratégie descendante

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
51
3. Compatibilité avec l‟esprit de l‟analyse en ligne: navigation entre les niveaux de la
classification par division ou par agrégation.
3.3.4 Formalisation théorique de l’opérateur OpAC:
Des contraintes sont imposées afin d‟assurer la validité statistique et logique des
données extraites. On définit des individus et des variables de la classification à partir d‟un
cube de données.
Soient Ω l‟ensemble des individus et 𝑙′𝑒𝑛𝑠𝑒𝑚𝑏𝑙𝑒 des variables de la classification à
définir.
Soit un cube de données C ayant d dimensions et m mesures. Considérons D1,….., Di,….,Dd
les dimensions de C et M1,…, Mq,…,Mm ses mesures.
Fig.3.12- Choix de la technique de classification
Fig.3.13- Formalisation théorique de l‟opérateur OpAC

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
52
On suppose que :
Pour tout 𝑖 ∈ 1, 𝑑 la dimension Di comprend ni niveaux hiérarchiques, hij le niveau
hiérarchique j de Di avec 𝑗 ∈ 1, 𝑛𝑖 ;
Pour tout 𝑗 ∈ 1, 𝑛𝑖 le niveau hiérarchique hij comprend lij modalités, gijt la modalité t de hij
avec 𝑡 ∈ 1, 𝑙𝑖𝑗 ;
𝐺(ℎ𝑖𝑗 ) l‟ensemble des modalités de hij.
Supposons que nous cherchons à agir sur la hiérarchie hij. Statistiquement, 𝐺(ℎ𝑖𝑗 ) représente
la population des individus du problème de la classification.
(Le choix de hij dépend des besoins de l‟analyse et des objectifs de l‟utilisation de l‟opérateur
d‟agrégation.)
Soit : Ω = 𝐺 ℎ𝑖𝑗 = 𝑔𝑖𝑗 1, 𝑔𝑖𝑗 2, … , 𝑔𝑖𝑗𝑡 , … , 𝑔𝑖𝑗 𝑙𝑖𝑗
On considère les notations suivantes :
* Un méta-symbole désignant l‟agrégat total d‟une dimension ;
G l‟ensemble des n-uplets des modalités des hiérarchique du cube C y compris les
agrégats totaux des dimensions.
On définit aussi, pour tout 𝑞 ∈ 1, 𝑚 la mesure Mq en tant qu‟une fonction de l‟ensemble G
des réels IR. 𝑀𝑞 : 𝐺 𝐼𝑅
Soit l‟exemple du cube de la figure 3.12 composé de trois dimensions D1 (la
dimension temporelle), D2 (la dimension géographique), D3 (la dimension des produits) et
d‟une mesure (les niveaux de ventes d‟une chaine de magasins).
Dans ce cas :
M1 (Février 1999, Lyon, *) désigne la mesure du niveau des ventes de tous les
produits au mois de Février de l‟année 1999 dans la ville de Lyon ;
M1 (Février 1999, *, Produits laitiers) désigne la mesure du niveau des ventes de
Produits laitiers dans toutes les localités géographiques au mois Février de l‟année
1999.

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
53
En tenant compte de l‟information contenue dans les données d‟un cube. Ils considèrent
les mesures du cube comme des variables quantitatives décrivant la population des individus
[]. Il faut aussi respecter certaines contraintes logiques et statistiques fondamentales dans le
choix de ces variables :
Première contrainte: Aucun niveau hiérarchique de la dimension retenue pour les
individus ne doit être générateur des variables de la classification. En effet, décrire un
individu par une variable exprimant une propriété qui le contient, ou qui l‟agrège, n‟aura
aucun sens logique. Il serait insensé de vouloir décrire, par exemple, l‟année 1999 par le
niveau des ventes du mois de Janvier 1999 ou le niveau des ventes en France par celui de
Lyon. Inversement, une variable qui spécifie des propriétés d‟appartenance à un individu ne
peut servir que pour la description de cet individu particulier. Par exemple, le niveau des
ventes du mois Janvier 1999 ne peut servir de descripteur que pour l‟année 1999 et sera
inutilisé pour la description des niveaux de ventes des autres années.
Seconde contrainte: Par dimension, on ne peut choisir qu‟un seul niveau hiérarchique
pour générer les variables. Cette contrainte est essentielle pour assurer l‟indépendance des
variables de la classification. En effet, la valeur d‟une modalité peut s‟obtenir par
combinaison linéaire des valeurs des modalités qui lui appartiennent dans la hiérarchie
inférieure. Par exemple, la somme des valeurs des ventes pour chaque mois d‟une année
correspond bien à la valeur totale des ventes de l‟année en question.
En conclusion, ils supposent queΩ = 𝐺 ℎ𝑖𝑗 , les variables de la classification de
l‟opérateur appartiennent à l‟ensemble suivant :
∁ 𝑋 /∀𝑡 ∈ 1, 𝑙𝑖𝑗 , 𝑋 𝑔𝑖𝑗𝑡 = 𝑀𝑞(∗, … ,∗, 𝑔𝑖𝑗𝑡 ,∗, … , 𝑔𝑠𝑟𝑣 ,∗, … ,∗)
𝑎𝑣𝑒𝑐 𝑠 ≠ 𝑖 , 𝑟 ∈ 1, 𝑛𝑠 𝑒𝑠𝑡 𝑢𝑛𝑖𝑞𝑢𝑒 𝑝𝑜𝑢𝑟 𝑐ℎ𝑎𝑞𝑢𝑒 𝑠, 𝑣 ∈ 1, 𝑙𝑠𝑟 𝑒𝑡 𝑞 ∈ 1, 𝑚
Reprenons l‟exemple de la figure 3.12 du cube, on suppose que, pour des choix
d‟analyse, on souhaite classer les mois de l‟année selon les niveaux des ventes par régions
et/ou par produit. Dans ce cas, on retient les modalités du niveau des mois de la dimension D1
comme individus statistiques. On aura donc :
Ω= Janvier, Février, Mars, Avril, Mai, Juin

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
54
Pour satisfaire à la première, on ne peut plus réutiliser la dimension D1 pour la
génération des variables. Aussi pour la seconde contrainte, on ne peut choisir qu‟un seul
niveau hiérarchique de D2 et/ou de D3 comme générateur de variables. Par exemple, si on
choisit des villes de la dimension D2 pour générer les variables, on fait des agrégations totales
Roll-up sur toutes les autres dimensions du cube outre la dimension D1, retenue pour les
individus, et D2 retenue pour les variables. Dans cet exemple, on fait une agrégation totale sur
D3 de la figure 3.12. On obtient, un tableau de contingence exprimant les valeurs des ventes
pour les modalités de D1 croisées avec celles de D2, c'est-à-dire les valeurs des ventes par ville
pour chaque mois. De la même manière, on peut générer des variables à partir de D3 en faisant
une agrégation totale sur D2.
Comme le montre la figure 3.12, „Le niveau des ventes à Marseille‟, „Le niveau des ventes à
Nantes‟, „Le niveau des ventes à Toulouse‟, „Le niveau des ventes à Paris‟, „Le niveau des
ventes à Lorient‟ et „Le niveau des ventes à Lyon‟ est un ensemble de variables possibles
pour le problème de classification.

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
55
3.3.5 Conclusion et perspectives :
Cet opérateur est une première réponse à l‟analyse en ligne des données complexes
aussi cette démarche a permis de profiter de la validité de la fouille dans les données
complexes et la flexibilité de la structuration multidimensionnelle.
Le choix de la CAH n‟exclut pas l‟utilisation d‟autres techniques de classification mais
l‟utilisation d‟autres techniques de fouille pour établir de nouveaux modèles d‟apprentissage
en ligne sur les données complexes.
Des améliorations possibles sont à prévoir pour cette approche. En dehors de sa
vocation de structuration et de classification, il est possible aussi d‟exploiter cette méthode
d‟agrégation en vue d‟améliorer l‟organisation des faits OLAP selon leur ordre de
ressemblance dans l‟espace de représentation d‟un cube de données. En effet, en classifiant
les modalités de chaque dimension d‟un cube, on réorganise implicitement les faits dans
l‟espace de représentation du cube. Ceci permet potentiellement de faire émerger des régions
intéressantes dans le cube de données, ou les faits OLAP sont décrits par des modalités qui
sont les plus semblables possible au sens de la classification.
Dans le cadre d‟une plateforme générale pour l‟analyse et la fouille dans les cubes de
données, il est prévu une implémentation qui concrétise cette approche d‟agrégation par
classification. Dans cette implémentation, les outils d‟analyse en ligne OLAP sont exploités
afin d‟interagir avec l‟algorithme de la CAH et d‟extraire, à partir du cube de données étudié,
les données nécessaires pour la construction des agrégats. Une extension de cette agrégation
par classification aux données complexes est aussi possible. Cette perspective sous-entend la
définition au préalable d‟une méthodologie d‟entreposage et de construction de cubes de
données complexes. Elle sous-entend également, sur un plan technique, l‟adaptation d‟une
implémentation à ce nouveau modèle de données.

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
56
3.4 Explication par recherche guidée de règles d’association dans un cube
o Opérateur AROX
3.4.1 Introduction
Différemment aux deux premiers opérateurs, cette méthode adapte un algorithme de
fouille afin d‟extraire des connaissances directement à partir de la structure
multidimensionnelle des données.
Cette proposition s‟inscrit dans une démarche explicative dans les cubes de données en
se basant sur les règles d‟association. Dans [MRBM06, MBR06c], les auteurs mettent en
place un nouvel algorithme, de type Apriori, pour une recherche guidée des règles
d‟association dans les cubes de données. Une visualisation graphique des règles d‟association
extraites est également proposée afin de mieux valoriser les connaissances qu‟elles
véhiculent.
La technologie OLAP se limite à des tâches exploratoires et ne fournit pas d‟outils
automatiques pour expliquer les relations et les associations potentiellement existantes entre
les données d‟un cube.
Par exemple, un utilisateur peut noter, à partir d‟un cube de données de ventes, que le
niveau de vente des sacs de couchage est particulièrement élevé dans une ville donnée. En
revanche, cette exploration ne permet par d‟expliquer automatiquement les raisons de ce fait
particulier. En effet, pour arriver à expliquer l‟ordre de certains faits OLAP ou des
phénomènes particuliers, un utilisateur est habituellement supposé explorer manuellement et
observer l‟ensemble des données selon plusieurs axes d‟analyse. Par exemple, le niveau élevé
des ventes des sacs de couchage peut s‟expliquer par son association à une saison estivale et à
une clientèle relativement jeune.
Beaucoup d‟études ont abordé le problème de l‟extraction des règles d‟association à
partir des cubes de données.
Cette proposition de couplage entre l‟analyse en ligne et la fouille de données se base
sur une approche qui adapte plutôt l‟algorithme de la fouille aux données
multidimensionnelles. Ainsi, ils introduisent un nouvel algorithme pour la recherche des
règles d‟association directement à partir des cubes de données sans transformation préalable
de ce dernier.

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
57
En effet, comme le montre l‟aperçu de cette méthode dans la figure 3.13, la recherche
des règles d‟association se fait directement à partir du cube étudié et ne requiert pas de
traitement sur les données de ce dernier.
Dans le cadre général pour la recherche de règles d‟association à partir des cubes de
données. Ils utilisent le concept des méta-règles inter dimensionnelles afin d‟offrir à
l‟utilisateur la possibilité de guider le processus de fouille vers des contextes d‟analyse ciblés
qui répondent à ses besoins d‟explication et à partir desquels seront extraites les règles
d‟association.
3.4.2 Historique des règles d’association :
Le concept des règles d‟association a été introduit la première fois par Agrawal et al.
[AIS93]. Motivés par le problème de l‟analyse du panier de la ménagère, les auteurs ont établi
les premières bases d‟un processus d‟extraction de règles d‟association. Ils sont aussi à
l‟origine de l‟algorithme Apriori qui se base essentiellement sur la propriété d‟anti-
monotonie, selon laquelle tout motif comprenant un sous-motif non fréquent est non fréquent.
Depuis, les algorithmes d‟extraction des règles d‟association ont connu plusieurs évolutions.
Ces évolutions couvrent divers aspects.
La première génération des règles d‟association d‟Agrawal et al. [AIS93] concernait
des données booléennes de transactions, ou chaque produit (item) est codé selon sa présence
ou son absence dans une transaction de vente. L‟idée de base d‟un algorithme d‟extraction de
règles, notamment Apriori, consiste à découvrir des relations intéressantes entre les produits
qui s‟achètent le plus souvent ensemble. Certaines références dans le domaine de la fouille de
données parlent carrément de règles d‟association booléennes. Un grand nombre de variantes
de l‟algorithme Apriori, travaillant toujours sur des données booléennes, ont été largement
étudiées dans la littérature [AS94, MTV94, PCY95, SON95, Toi96].
Fig.3.14 - Etapes de l‟explication dans les cubes de données par règle d‟association

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
58
L‟extension des règles aux données quantitatives a été proposée pour la première fois
par Srikant et Agrawal dans [SA96]. L‟objectif de cette proposition consistait à extraire une
nouvelle génération de règles d‟association quantitatives à partir des tables d‟une base de
données relationnelle. Pour cela, les auteurs proposent une phase de pré-traitement qui
discrétise les données quantitatives en variables qualitatives et les transforme ensuite en
données booléennes selon un codage binaire. Suite à cette extension, beaucoup de travaux se
sont basés sur les règles d‟association quantitatives afin de les exploiter et de les étendre
davantage pour couvrir des données de différentes natures liées à des domaines d‟application
spécifiques. On cite par exemple, l‟étude des effets de causalité dans les données [BMS97,
SBMU98], l‟étude de phénomènes cycliques [ORS98, RMS98] ou de périodicités partielles
[HDY99] dans des données temporelles. Pour un exposé plus complet sur les différents types
de règles d‟association quantitatives, on renvoie le lecteur à [Zhu98].
Toutes ces approches de règles d‟association traitent des données se présentant selon
des structures tabulaires. Kamber et al. [KHC97] sont les premiers à faire de la fouille de
règles d‟association dans les structures multi- dimensionnelles des cubes de données.
3.4.3 Règles d’association dans les structures multidimensionnelles
o Fouille guidée des règles d’association
Dans [KHC97], Kamber et al. ont introduit la fouille guidée des règles d‟association
dans les bases de données multidimensionnelles (metarule-guided mining). Cette proposition
consiste à utiliser une méta-règle qui va piloter le processus d‟extraction pour la découverte
de règles intéressantes répondant aux besoins d‟analyse de l‟utilisateur. Une méta-règle est un
modèle général qui définit le contenu des règles d‟association recherchées à partir d‟un cube
de données. Les auteurs définissent une méta-règle générale selon la forme :
P1 ∧ P2 ∧ ・ ・ ・ ∧ Pm ⇒ Q1 ∧ Q2 ∧ ・ ・ ・ ∧ Ql
Où Pi (i = 1, . . ., m) et Qj (j = 1, . . ., l) sont des prédicats ou des instances de prédicats définit
par l‟utilisateur à partir des modalités du cube de données. Les auteurs affirment que la fouille
guidée réduit l‟espace de recherche dans le cube et permet de focaliser le processus
d‟extraction sur des régions de données ciblées par l‟utilisateur. Ainsi, les règles d‟association
extraites répondent mieux aux attentes d‟analyse de l‟utilisateur. Quant à la structure
multidimensionnelle des données, Kamber et al. confirment que la structuration des données
dans un entrepôt et les agrégats pré-calculés d‟un cube se prêtent au processus d‟extraction de
règles d‟association.

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
59
Les auteurs proposent deux familles d‟algorithmes d‟extraction de règles à partir des
cubes de données :
(1) des algorithmes pour les cubes de données MOLAP matérialisés dont les agrégats sont
tous pré-calculés (multi-D-slicing et n-D cube search) ;
(2) des algorithmes pour les cubes de données ROLAP non matérialisés et dont les agrégats
ne sont pas pré-calculés (abridged n-D cube construction et abridged multi-p-D cube
construction).
Tous ces algorithmes se basent sur la propriété d‟anti- monotonie d‟Apriori.
o Analyse en ligne des règles d’association
Zhu distingue dans [Zhu98] trois types de règles d‟association qui peuvent être
extraites à partir d‟un cube de données : les règles inter-dimensionnelles, les règles intra-
dimensionnelles et les règles hybrides. À la différence de l‟approche de Kamber et al.
[KHC97] – ou les règles sont extraites directement de la structure multidimensionnelle des
données – Zhu aplatit le cube et le transforme selon une forme tabulaire appropriée, recherche
les motifs fréquents en utilisant Apriori et génère ensuite les règles d‟association.
Par exemple, supposons qu‟un utilisateur souhaite découvrir des règles d‟association
inter-dimensionnelles dans un cube de ventes selon trois dimensions : Lieu, Produit et Temps.
Dans ce cas, les faits du cube sont aplatis en fonction de ces trois dimensions comme le
montre l‟exemple du tableau 3.3 ci dessous.
Lieu Produit Temps COUNT
Canada
Canada
Canada
iTwin
iTwin
aStar
2002
2003
2002
30
10
30
France
France
France
France
France
iPower
DV-400
DV-400
EN-700
EN-700
2005
2005
2004
2006
2003
20
85
25
25
20
USA
USA
USA
USA
DV-400
iTwin
iTwin
aStar
2002
2005
2002
2004
100
20
40
25
Japon
Japon
Japon
DV-400
iTwin
EN-700
2006
2004
2006
10
20
20
Tab.3.4- Aplatissement d‟un cube de données pour l‟extraction de règles inter
dimensionnelles [Zhu98]

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
60
Un motif inter-dimensionnel consiste en une conjonction de plusieurs modalités ou
chaque modalité provient d‟une dimension distincte. Par exemple USA, DV-400, 2002 est
un motif (3-itemset) inter-dimensionnel dans le tableau 3.4.
Pour calculer le support de ce motif, Zhu prend en considération le nombre
d‟occurrences de ce dernier fourni par l‟agrégation COUNT. Si le motif est fréquent (son
support est supérieur au support minimum), il peut ainsi générer les règles d‟association inter-
dimensionnelles suivantes :
USA ∧ DV-400 ⇒ 2002 confiance = 1/1 = 100%
USA ∧ 2002 ⇒ DV-400 confiance = 1/2 = 50%
DV-400 ∧ 2002 ⇒ USA confiance = 1/1 = 100%
Un motif intra-dimensionnel est une conjonction de plusieurs modalités provenant
d‟une même dimension. Zhu considère qu‟un processus d‟extraction de règles d‟association
intra-dimensionnelles fait intervenir deux dimensions du cube : une première pour générer les
modalités de la règle et une deuxième de regroupement, appelée dimension de transaction,
dont les modalités sont considérées comme des identifiants de transactions. Dans le cube des
ventes, on peut considérer par exemple la dimension Produit pour les éléments (items) des
transactions regroupés selon les modalités de la dimension Lieu. Ainsi, l‟auteur construit une
table de transactions selon l‟exemple du tableau 3.5 et cherche ensuite les motifs fréquents et
les règles d‟association intra- dimensionnelles à partir de cette table.
ID transaction (Lieu) Produit
Canada
France
USA
Japon
iTwin, aStar
iPower, DV-400,EN-700
DV-400, iTwin, aStar
DV-400, iTwin, EN-700
Supposons que dans cet exemple, le motif DV-400, iTwin, aStar est un 3-itemset
fréquent. À partir de ce motif, on peut obtenir les règles d‟association intra-dimensionnelles
suivantes : DV-400 ∧ iTwin ⇒ aStar confiance = 2/2 = 100%
DV-400 ∧ aStar ⇒ iTwin confiance = 2/2 = 100%
iTwin ∧ aStar ⇒ DV-400 confiance = 2/3 = 67%
Tab .3.5 – Aplatissement d‟un cube de données pour l‟extraction de règles intra
dimensionnelles [Zhu98]

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
61
Les règles d‟association hybrides sont des combinaisons de règles inter et intra-
dimensionnelles. Ainsi, une règle hybride consiste en un ensemble de modalités à la fois
répétitives et provenantes de plusieurs dimensions. Dans ce cadre, un motif candidat L peut
s‟écrire d‟une manière générale sous la forme d‟une conjonction L = Linter ∧ Lintra, ou
Linter est un motif inter-dimensionnel et Lintra est un motif intra- dimensionnel. Pour trouver
les motifs hybrides fréquents, l‟auteur propose de chercher les motifs fréquents inter et intra-
dimensionnels séparément, puis de fusionner les deux.
o Cubes de données différentielles
Imielinski et al. proposent, dans un contexte OLAP, une approche de généralisation des règles
d‟association appelée Cubegrades [IKA02]. Un cubegrade est un formalisme qui calcule le
différentiel d‟une mesure agrégée d‟un cube de données suite à des opérations de
spécialisation (drill-down), de généralisation (roll-up) ou de changement de modalité dans une
dimension (switch). Les auteurs reprochent aux règles d‟association classiques de n‟exploiter
que les comptages – correspondant à la mesure COUNT dans un contexte OLAP – dans
l‟évaluation de l‟implication existante entre l‟antécédent et le conséquent d‟une règle. Ils
proposent d‟exploiter dans les cubegrades d‟autres agrégations de mesures. Formellement, un
cubegrade est défini selon une implication de la forme générale :
Cube source ⇒ Cube cible [Mesures, Valeurs, Delta-valeurs]
Cube source et le Cube cible représentent deux configurations de données du même
cube ou la deuxième configuration est obtenue à partir de la première suite à une des
opérations suscitées.
Fig.3.15– Opérations possibles dans un cubegrade [IKA02]

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
62
Par exemple, comme le montre la figure3.15, à partir d‟une configuration source (A = a1, B =
b1, C = c1), le cube peut changer par :
(i) généralisation par agrégation de toute la dimension C ; on obtient alors le cube
cible (A = a1, B = b1) ;
(ii) spécialisation par rajout d‟une nouvelle dimension D qui prend une modalité d1 ;
on obtient alors le cube cible (A = a1, B = b1, C = c1, D = d1) ; ou par
(iii) mutation par changement de la modalité c1 par c2 dans la dimension C ; on obtient
alors le cube cible (A = a1, B = b1, C = c2).
Mesures correspondent à un ensemble d‟une ou de plusieurs mesure agrégées selon les
fonctions SUM, AVG, MAX et MIN. Par exemple, à partir d‟un cube de ventes,
AVG(Bénéfice) permet d‟agréger la mesure Bénéfice en calculant sa moyenne. Valeurs
correspondent à l‟ensemble des valeurs que prennent les mesures agrégées dans la
configuration du cube source. Delta-valeurs mesurent les différentiels des valeurs des
mesures agrégées entre le cube cible et le cube source.
Pour résumer cette approche, considérons l‟exemple du cubegrade suivant :
(Lieu=France) ⇒ (Lieu=France, Temps=2005)
[AVG(Bénéfice), AVG(Bénéfice) = $ 40 000, DeltaAVG(Bénéfice) = 80%]
Cet exemple signifie que la moyenne des bénéfices générés par les ventes en France,
évalués à $ 40 000, enregistrent une baisse de 20% pendant l‟année 2005.
Imielinski et al. affirment que les cubegrades sont une généralisation des règles
d‟association et des cubes de données. Cette approche généralise le concept d‟une règle
d‟association et fait un rapprochement avec les cubes de données. Mais, elle ne généralise
nullement le processus d‟extraction des règles d‟association à partir d‟un cube de données. En
effet, les auteurs ne proposent pas des algorithmes pour la découverte des cubegrades dans
une base multidimensionnelle. Ils ne définissent pas non plus le calcul du support et de la
confiance d‟un cubegrade.
o Règles inter-dimensionnelles basées sur les quantités
Guenzel et al. proposent un processus d‟extraction de règles inter-dimensionnelles avec des
prédicats non répétitifs à partir d‟un environnement multidimensionnel des données [GAL99].
Cette approche construit une règle d‟association à partir d‟un ensemble de modalités, appelé
éléments dimensionnels, provenant de dimensions distinctes du cube. Chaque élément
dimensionnel d‟une règle d‟association est pris à partir d‟un seul niveau hiérarchique d‟une

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
63
dimension. Les auteurs identifient chaque motif candidat d‟une règle par une cellule ou un
sous-cube dans le cube étudié. Le support et la confiance d‟une règle sont ensuite exprimés en
fonction des fréquences contenues dans ces cellules ou dans ces sous- cubes.
Par exemple, soit la règle inter dimensionnelle suivante :
Produit(iTwin) ⇒ Lieu(France) ∧ Temps(2004)
Le support de cette règle s‟exprime selon la quantité du produit iTwin vendu en France
pendant l‟année 2004. Par exemple, le support de cette règle peut être égal à 1200 unités
vendues. La confiance de cette règle est calculée en divisant la quantité d‟unités du produit
iTwin, vendu en France pendant l‟année 2004, par la quantité d‟unités totales vendues pour le
produit iTwin. Cette approche de calcul du support et de la confiance rejoint le cas classique
qui se base sur le comptage des faits supportés par la règle selon la mesure COUNT.
o Règles intra-dimensionnelles contextualisées
Dans [CDH99, CDH00], Chen et al. proposent une plateforme OLAP pour la fouille dans les
transactions relatives au commerce électronique (distributed OLAP based infrastructure).
Selon les auteurs, cette plateforme inclut des outils d‟entreposage, d‟analyse en ligne et des
techniques de fouille de données. Chen et al. Introduisent dans cette plateforme un processus
d‟extraction de règles d‟association intra- dimensionnelles. Une règle intra-dimensionnelle
contient des modalités provenant du même niveau hiérarchique d‟une même dimension,
appelée dimension de base. Elle s‟exprime selon un contexte de données en fonction d‟autres
dimensions du cube. Par exemple, considérons la règle suivante :
[x ∈ Client : achète produit(x, A) ⇒ achète produit(x, B)]
Lieu = France, Temps = 2005
Dans cet exemple, Client est la dimension de base, les produits sont les éléments
(item) de la règle et Lieu et Temps sont les dimensions selon lesquelles l‟utilisateur définit le
contexte du cube d‟o`u la règle est extraite. Selon Chen et al., le contexte d‟une règle intra-
dimensionnelle peut-être défini de différentes manières selon le niveau de granularité souhaité
par l‟utilisateur. Par exemple, la règle précédente peut également être exprimée dans des
contextes différents : [x ∈ Client : achète produit(x, A) ⇒ achète produit(x, B)]
Lieu = Lyon, Temps = 2005
[x ∈ Client : achète produit(x, A) ⇒ achète produit(x, B)]
Lieu = France, Temps = janvier 2005

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
64
o Règles d’association étendues
Dans [NJ03], Nestorov et Jukic introduisent un processus d‟extraction de règles
d‟association étendues (extended association rules) à partir des entrepôts de données. Cette
approche consiste à exploiter le langage de requête SQL fourni dans les systèmes de gestion
des bases de données multidimensionnelles sans faire recours à des composantes extérieures
de fouille de données. Une règle d‟association étendue est une règle intra-dimensionnelle avec
prédicats répétitifs. Elle exprime une association entre les modalités d‟une seule dimension
(item dimension) et qui satisfont des conditions fixées par l‟utilisateur dans d‟autres
dimensions (non-item dimensions).
Cependant, cette approche s‟inscrit dans le problème d‟analyse du panier de la
ménagère. En effet, les éléments d‟une règle d‟association étendue désignent exclusivement
des produits de ventes. Si un utilisateur cherche à découvrir les associations des produits
vendus dans le sud de la France pendant la saison estivale, un exemple d‟une règle
d‟association étendu peut-être:
Dans le Sud et pendant l‟Eté : Tente ⇒ Sac de couchage (Support = 1%, Confiance = 50%)
Pour obtenir une telle règle, l‟utilisateur doit tout d‟abord choisir la modalité Sud dans
la dimension Lieu et la modalité ´ Eté dans la dimension Temps. L‟utilisateur doit également
fixer les seuils minimums du support et de la confiance. Le processus d‟extraction des règles
étendues utilise une séquence dynamique de requêtes SQL.
o Règles d’association à partir d’un entrepôt de données
Tjioe et Taniar proposent une approche pour extraire des règles d‟association inter-
dimensionnelles à partir d‟un entrepôt de données [TT05]. Cette approche consiste en un
ensemble de procédures de pré-traitement des données afin de les préparer pour la phase de
fouille. Ces procédures partent des dimensions choisies par l‟utilisateur pour le processus de
fouille. Les pré-traitements effectués ensuite sur les données de ces dimensions se basent
essentiellement sur la fonction d‟agrégation de la moyenne (AVG).
En effet, les auteurs proposent quatre algorithmes de pré-traitement : VAvg, HAvg,
WMAvg et ModusFilter. Les trois premiers algorithmes consistent à calculer, dans un premier
temps, la valeur moyenne d‟une mesure, sélectionnée par l‟utilisateur. ModusFilter calcule le
mode de la mesure, c‟est-à-dire la valeur la plus fréquente de la mesure. Dans un second
temps, ces algorithmes élaguent les faits OLAP ayant une mesure inférieure à la valeur
moyenne. Les auteurs considèrent que les faits dont la mesure est en dessous de la valeur

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
65
moyenne sont inintéressants pour le processus de fouille parce qu‟ils ne peuvent pas générer
de règles d‟association.
L‟algorithme VAvg calcule la moyenne verticale d‟une mesure selon les dimensions
choisies, alors que HAvg calcule plutôt la moyenne horizontale. WMAvg calcule la moyenne
mobile pondérée verticalement dans les dimensions choisies. Par exemple, en partant du
croisement des dimensions Temps et Produit, l‟algorithme VAvg calcule la moyenne générale
des bénéfices de chaque produit sur toutes les années. Ensuite, comme le résume le
tableau3.5, l‟algorithme élimine pour chaque produit les faits dont les bénéfices annuels sont
au-dessous de la moyenne générale. WMAvg fonctionne de la même manière que VAvg dans
la phase d‟élagage. En revanche, au lieu de calculer une simple moyenne d‟un produit,
WMAvg calcule plutôt une moyenne mobile pondérée par les quantités annuelles de ce
produit.
L‟algorithme ModusFilter calcule pour chaque produit le mode, c‟est-à-dire la valeur
des bénéfices la plus fréquente dans le temps. Ensuite, pour chaque produit, il ne garde que les
faits ayant une mesure égale au mode.
Temps iTwin Bénéfices) ……. aDream (Bénéfices
2000
2001
2002
2003
2004
2005
2006
100
120
300
200
250
270
280
250
125
80
110
100
150
180
Vavg 217.14 142 ,14
Avec le même exemple de dimensions, l‟algorithme HAvg calcule plutôt la moyenne
générale des bénéfices de chaque année pour tout les produits. Comme le résume le tableau
3.6 (Exemple de fonctionnement de l‟algorithme Havg [TT05]), pour chaque année,
l‟algorithme élimine ensuite les faits dont les bénéfices d‟un produit sont en dessous de la
moyenne générale.
Tab.3.6– Exemple de fonctionnement de l‟algorithme Vavg [TT05]

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
66
Temps iTwin DV-400 aStar aDream Havg
2000 100 200 150 125 143
2001 135 160 90 145 132
.
2006 125 50 175 150 125
Ces algorithmes de pré-traitement suivent tous une démarche relationnelle et
emploient des requêtes SQL pour élaguer, dans la table des faits, les données jugées inutiles
pour le processus de fouille. Les données filtrées sont aplaties selon un format tabulaire
(initialized table). Les auteurs proposent ensuite trois algorithmes, de type Apriori,
d‟extraction de règles d‟association inter-dimensionnelles à partir de ces données filtrées :
l‟algorithme GenNLI pour les règles à prédicats non répétitifs et les algorithmes ComDims et
GenHLI pour les règles à prédicats répétitifs.
3.4.4 Formalisation de l’opérateur AROX :
Définition (Sous-cube de données)
On considère D′ ⊆ D un sous-ensemble non vide de p dimensions D1, . . . ,Dp du cube de
données C (p ≤ d).
Le p-uplet (£1, . . . ,£p) est un sous-cube de données dans C selon D′ si et seulement si
∀i ∈ 1, . . . , p, £i ≠ ∅ et il existe un indice unique j ≥ 0 tels que £i ⊆ Aij .
Un sous-cube de données selon un ensemble de dimensions D′ correspond à une
portion du cube de données original C. Il s‟agit de fixer un niveau hiérarchique Hji dans
chaque dimension de Di ∈ D′ et de sélectionner dans ce niveau un sous-ensemble £i non vide
de modalités appartenant à l‟ensemble de toutes les modalités Aij de Hji.
Tab.3.7– Exemple de fonctionnement de l‟algorithme Havg [TT05]
Fig.3.16– Exemple d‟un sous-cube de données dans le cube des ventes

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
67
Par exemple, considérons le sous-ensemble des dimensions D′ = D1,D2 du cube C de
la figure 3.16. Soient le sous-ensemble des modalités £1=Europe du niveau H11
(Continent)
de la dimension D1 (Lieu) et le sous-ensemble des modalités £2=EN- 700, aStar, aDream du
niveau H22 (Produit) de la dimension D2 (Produit).
Dans ce cas, (£1, £2) = (Europe, EN-700, aStar, aDream) correspond au sous- cube
grisé dans la figure 3.16 dans le cube C selon les dimensions D′ = D1,D2. Il est à noter que,
selon cette définition, un même sous-cube de données peut-être désigné par différentes
notations :
-En changeant le nombre des dimensions selon lesquelles est défini le sous-cube et en
fixant à All les dimensions restantes. Par exemple, la portion grisée de la figure 3.16 peut
aussi se définir comme le sous-cube de données (Europe, EN-700, aStar, aDream, All )
selon l‟ensemble des dimensions D = D1,D2,D3 ;
– En changeant, si possible, de niveau hiérarchique d‟une des dimensions selon lesquelles est
défini le sous-cube. Par exemple, la portion grisée de la figure 3.16 peut aussi se définir
comme le sous-cube de données (France, Italie, Espagne, EN-700, aStar, aDream) selon
l‟ensemble des dimensions D = D1, D2 ;
– En changeant, si possible, le nombre de dimensions selon lesquelles est défini le sous-cube
et leurs niveaux hiérarchiques. Par exemple, la portion grisée de la figure 3.16 peut aussi se
définir comme le sous-cube de données (France, Italie, Espagne, EN-700, aStar, aDream,
All ) selon l‟ensemble des dimensions D = D1,D2,D3.
On note aussi qu‟une cellule d‟un cube de données C correspond au cas particulier d‟un sous-
cube de données défini selon l‟ensemble entier des dimensions D = D1, . . . , Dd et tel que
∀i ∈ 1, . . . , d, £i est un singleton contenant une seule modalité appartenant au niveau
hiérarchique le plus fin de la dimension Di. Par exemple, la cellule noire dans le cube de la
figure 3.16 est exprimée selon le sous-cube (Japon, iTwin, 2002) selon l‟ensemble des
dimensions D = D1, D2, D3.
o Agrégation SUM d’un sous-cube de données
Chaque cellule du cube de données C représente un fait OLAP qui s‟évalue dans IR
selon une mesure M ∈M. Dans cette proposition, ils évaluent un sous-cube de données selon
l‟agrégation SUM de la mesure M. Cette dernière est définie comme suit :
Définition (Agrégation SUM d‟un sous-cube de données)
Soient (£1, . . . , £p) un sous-cube de données dans C selon un sous-ensemble de dimensions

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
68
D′ ⊆ D et une mesure M ∈ M. L‟agrégation SUM de la mesure M du sous-cube (£1, . . . , £p) ,
notée SUMM(£1, . . . , £p), est la somme de toutes les valeurs de la mesure M des faits présents
dans le sous-cube.
Par exemple, le bénéfice des ventes du sous-cube de données grisé dans la figure 3.16
peut être évalué selon l‟agrégation SUMBénéfice(Europe, EN-700, aStar, aDream) qui
représente la somme des valeurs des bénéfices présentes dans toutes les cellules du sous-cube
en question, c‟est à dire les cellules grisées dans le cube des ventes.
o Prédicat dimensionnel
Définition (Prédicat dimensionnel)
Soit Di une dimension d‟un cube de données C. Un prédicat dimensionnel dans Di, noté αi, est
un prédicat de la forme <a ∈ Aij>.
Un prédicat dimensionnel est un prédicat qui prend la valeur d‟une modalité de la
dimension dans laquelle il est défini. Par exemple, dans la dimension D1 de la figure 5.3, un
prédicat dimensionnel possible peut prendre la forme α1 =<a ∈ A11>=<a ∈ Amérique,
Europe, Asie>.
o Prédicat inter-dimensionnels
Définition (Prédicat inter-dimensionnels) Soit D′ ⊆ D un sous-ensemble non vide de p
dimensions D1, . . . ,Dp du cube de données C (2 ≤ p ≤ d). (α1 ∧・ ・ ・∧ αp) est un
prédicat inter-dimensionnels dans D′ si et seulement si ∀i ∈ 1, . . . , p, αi est un prédicat
dimensionnel dans Di.
Par exemple, soit D′ = D1,D2 un sous-ensemble de dimensions du cube de données de la
figure 3.15. Un prédicat inter-dimensionnels possible dans D′ peut prendre la forme (<a1 ∈
A11> ∧ <a2 ∈ A21>). Un prédicat inter-dimensionnel est une conjonction de prédicats
dimensionnels non répétitifs. C‟est-à-dire, chaque dimension de D′ a un prédicat dimensionnel
distinct dans l‟expression du prédicat inter-dimensionnel.
o Méta-règle inter-dimensionnelles
En s‟inspirant du formalisme fourni par Plantevit et al. [PCL+05], ils ont établit une
partition dans les dimensions D du cube de données C selon trois sous-ensembles DC,DA et DI
tels que:
– DC est un sous-ensemble de p dimensions de contexte. Un sous-cube de données dans C
selon DC est défini afin d‟établir le contexte d‟analyse à partir duquel les règles d‟association
seront extraites ;

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
69
– DA est un sous-ensemble de (s+r) dimensions d‟analyse à partir desquelles les prédicats
d‟une méta-règle inter-dimensionnelles sont choisis ;
– DI est le sous-ensemble des dimensions restantes. Ces dimensions sont fixées à l‟agrégat
total All. Il s‟agit des dimensions inutilisées qui sont totalement agrégées et qui, par
conséquent, n‟interviennent ni dans la définition du contexte du processus d‟extraction des
règles d‟association, ni dans la définition de la méta-règle.
Une méta-règle inter-dimensionnelles est un modèle de règles d‟association défini par
l‟utilisateur selon un schéma général de la forme :
Dans le contexte (£1, . . . ,£p)
(α1 ∧ …. ∧ αs) ⇒ (β1 ∧ …. ∧ βr)
où (£1, . . . ,£p) est un sous-cube de C défini selon le sous-ensemble des dimensions DC.
Ce sous-cube désigne la portion du cube de données dans laquelle sera conduit le
processus d‟extraction des règles d‟association. à la différence du schéma de la méta- règle
proposé par Kamber et al. dans [KHC97], notre méta-règle permet de cibler un contexte
d‟analyse précis dans le cube en définissant la population des faits qui se trouvent dans le
sous-cube de données (£1, . . . ,£p). Il est à remarquer que le cas ou le sous-ensemble des
dimensions de contexte est vide (DC = ∅), correspond à un contexte d‟analyse général qui
couvre tous les faits du cube de données C.
Il est à noter que ∀k ∈ 1, . . ., s (respectivement ∀k ∈ 1, . . ., r), αk (respectivement
βk) est un prédicat dimensionnel dans une dimension distincte de DA. Par conséquent, la
conjonction des prédicats (α1 ∧ …. ∧ αs) ⇒ (β1 ∧ …. ∧ βr) est un prédicat inter-dimensionnels
dans DA. Le nombre de prédicats (s + r) dans la méta-règle est égal au nombre de dimensions
dans DA. Ainsi, notre méta-règle est un modèle qui définit des règles d‟association inter-
dimensionnelles avec des prédicats non répétitifs.
Par exemple, en plus des trois dimensions représentées dans la figure 3.16, supposons
que le cube des ventes contient quatre autres dimensions : Profil du consommateur (D4),
Profession du consommateur (D5), Sexe (D6) et Promotion (D7). Considérons alors la partition
suivante des dimensions du cube des ventes :
– DC = D5, D6 = Profession du consommateur, Sexe ;
– DA = D1, D2, D3 = Lieu, Produit, Temps ;
– DI = D4, D7 = Profil du consommateur, Promotion.
R

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
70
Selon cette partition, un utilisateur peut souhaiter extraire des règles d‟association répondant
au modèle de la méta-règle inter-dimensionnelles suivante :
Dans le contexte (Etudiant, Femme)
<a1 ∈ Continent> ∧ <a3 ∈ Année> ⇒ <a2 ∈ Produit>
Selon cette méta-règle, les règles d‟association inter-dimensionnelles sont extraites à
partir du sous-cube de données (Etudiant, Femme) qui couvre les ventes concernant seulement
la population des étudiantes. Les dimensions inutilisées (Profil du consommateur, Promotion)
sont totalement agrégées et n‟interviennent pas dans le processus d‟extraction des règles
d‟association. En revanche, les dimensions d‟analyse interviennent dans la découverte des
règles. En effet, les prédicats des règles extraites proviennent des dimensions de DA. Deux
prédicats dimensionnels dans D1 et D3 sont prévus dans l‟antécédent des règles, alors qu‟un
seul prédicat dimensionnel est prévu dans le conséquent des règles. Le premier prédicat
dimensionnel de l‟antécédent est fixé au niveau Continent de D1. Le deuxième prédicat
dimensionnel de l‟antécédent est fixé au niveau Année de D3. Quant au prédicat dimensionnel
du conséquent, il est fixé au niveau Produit de D2.

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
71
Algorithme Apriori : Algorithme d‟Extraction des règles d‟association inter-dimensionnelles à partir
d‟un cube de données
Entrée C,DC,DA,DU,R,M,minsupp,minconf
Sortie : X ⇒ Y, Supp,Conf, Lift, Loev
1: C(1) ← ∅
2: pour k ← 1 à (s + r) faire
3: C(k) ← C(k) ∪ Akj
4: fin pour
5: k ← 1
6: tant que C(k) ≠ ∅ et k ≤ (s + r) faire
7: F(k) ← ∅
8: pour tout A ∈ C(k) faire
9: si A est un prédicat inter-dimensionnels alors
10: Supp ← CalculSupport(A,M)
11: si Supp ≥ minsupp alors
12: F(k) ← F(k) ∪ A
13: fin si
14: fin si
15: fin pour
16: pour tout A ∈ F(k) faire
17: pour tout B ≠ ∅ et B ∈ A faire
18: si A\B ⇒ B répond à R alors
19: Conf ← CalculConfidence(A\B,B,M)
20: si Conf ≥ minconf alors
21: X ← A\B
22: Y ← B
23: Lift ← CalculLift(X, Y,M)
24: Loev ← CalculLoevinger(X, Y,M)
25: retourner (X ⇒ Y, Supp,Conf, Lift, Loev)
26: fin si
27: fin si
28: fin pour
29: fin pour
30: C(k + 1) ← ∅
31: pour tout A ∈ F(k) faire
32: pour tout B ∈ F(k) qui partage k − 1 items avec A faire
33: si Tout Z ⊂ A ∪ B ayant k items est un prédicat inter-dimensionnels et est fréquent
alors
34: C(k + 1) ← C(k + 1) ∪ A ∪ B 35: fin si
36: fin pour
37: fin pour
38: k ← k + 1
39: fin tant que

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
72
3.4.5 Conclusion et perspectives
Cette méthode établi un cadre général pour l‟extraction des règles d‟association inter-
dimensionnelles pour l‟explication dans les cubes de données. Cette approche couple les
règles d‟association avec la technologie OLAP en adaptant l‟algorithme de recherche des
règles au contexte des données multidimensionnelles. Selon cette approche, aucun pré-
traitement préalable est nécessaire sur les cubes de données. L‟algorithme proposé est une
adaptation d‟Apriori aux données multidimensionnelles. Il repose sur une recherche
ascendante des motifs fréquents qui exploite la propriété d‟anti-monotonie particulièrement
adaptée aux données éparses.
Ils ont employé les méta-règles inter-dimensionnelles afin de piloter le processus de
recherche des règles dans un cube de données. Ainsi, un utilisateur peut cibler un contexte
d‟analyse spécifique défini par une portion particulière dans le cube étudié. Également, ils ont
revisité les principes classiques du support et de la confiance d‟une règle d‟association.
Ils proposent un formalisme qui redéfinit ces derniers en offrant la possibilité de les calculer
en fonction des unités de masse d‟une mesure choisie par l‟utilisateur. Ils ont montré que cette
nouvelle façon d‟évaluer une règle d‟association est plus pertinente au sens d‟une analyse en
ligne. En général, le support et la confiance entraînent la génération d‟un grand nombre de
règles d‟association qui sont inexploitables dans la plupart des cas. Pour cela, nous proposons
de filtrer les règles extraites en ne gardant que celles les plus intéressantes aux sens du critère
du Lift et de l‟indice de Loevinger.
Afin de valoriser les règles d‟association extraites, ils ont proposé un codage
graphique de ses dernières selon la sémiologie graphique de Bertin [Ber67]. Ce codage prend
en compte l‟ordre d‟importance de chaque règle en fonction des valeurs de ses critères
d‟évaluation. ils utilisent également ce codage dans le cadre d‟une nouvelle approche de
visualisation des règles d‟association dans un espace de représentation du cube de données
étudié.
Suite à ce travail, des améliorations possibles et de nouvelles pistes de recherche
méritent d‟être étudiées. Tout d‟abord, il est aussi intéressant d‟intégrer la valeur de la mesure
dans l‟expression de la règle inter-dimensionnelle. La mesure peut aussi faire l‟objet d‟un
codage graphique intégré dans celui de la règle. Ainsi, offrir à l‟utilisateur une visualisation
complète de l‟espace de représentation du cube de données incluant les mesures des faits
OLAP et les liens entre ces faits par les règles d‟association.

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
73
Vu le grand nombre de travaux sur les règles d‟association dans les cubes de données,
il est nécessaire d‟élaborer une étude comparative afin de positionner notre approche, en
terme de performance, par rapport aux approches existantes.
Enfin, une autre amélioration possible de cette approche consisterait à mieux profiter de
l‟aspect hiérarchique des dimensions du cube de données étudié afin d‟en extraire des règles
d‟association avec des prédicats appartenant à plusieurs niveaux de granularité.

Chapitre 3 : Opérateurs de couplage entre OLAP et DM
74
3.5 Conclusion
Dans cette partie, nous avons essayé d‟apporter des solutions au problème de
l‟analyse des données complexes. Nous nous sommes basés sur le couplage entre l‟analyse en
ligne et la fouille de données. Nous avons énoncé les deux domaines sont complémentaires et
peuvent évoluer dans le cadre d‟un processus décisionnel unique. Leur association est capable
d‟enrichir et de rehausser le processus décisionnel. De plus, la fouille a déjà avancé des
solutions pour l‟extraction des connaissances à partir des données complexes. Par conséquent,
la fouille de données est capable d‟étendre les capacités de l‟OLAP pour analyser les données
complexes.
A partir de la fin des années 90, le couplage de l‟analyse en ligne et de la fouille
de données a suscité beaucoup d‟intérêts. Plusieurs travaux ont abordé le sujet en proposant
des approches variées selon différents types de motivations. Néanmoins, nous avons distingué
trois grandes approches ou chacune se caractérise par une manière d‟opérer le couplage entre
les deux domaines. La première consiste à transformer les données multidimensionnelles en
données tabulaires exploitables par les algorithmes classiques de fouille. La deuxième
approche repose sur une extension des outils OLAP et des langages de requêtes des SGBDMs
aux techniques de fouille. Enfin, la troisième approche adapte les techniques classiques de
fouille au contexte des données multidimensionnelles.
Cependant nous avons mis le point sur les trois opérateurs de couplage entre OLAP et
DM à savoir : le réarrangement d‟un cube par analyse factorielle (ACM): Opérateur ORCA,
l‟agrégation par classification dans les cubes de données (CAH) : Opérateur OPAC et
l‟explication par recherche guidée de règles d‟association dans un cube: Opérateur AROX.

75
Cubes de prédiction
Résumé
Nous présentons une nouvelle famille des outils pour l'analyse de données
exploratoire, appelés cubes de prédiction. Comme dans la norme OLAP des cubes de
données, chaque cellule dans un cube de prédiction contient une valeur qui résume les
données appartenant à cette cellule, et la granularité des cellules peut être changée via des
opérations telles que le roll-up et -down.
Contrairement aux cubes de données, dans lesquelles chaque valeur de cellules est
calculée par une fonction d‟agrégation, par exemple, SUM ou AVG, chaque valeur de cellules
dans un cube de prédiction résume un modèle prédictif formé sur les données correspondant à
cette cellule, et caractérise son comportement ou prédit la décision. Nous proposons et
motivons la prédiction dans les cubes, et nous montrons qu'ils peuvent être efficacement
calculés en exploitant l'idée d'un modèle de décomposition.
Sommaire
4.1 Introduction
4.2 Contributions et futures directions
4.3 Exemple de motivation
4.4 Modèles prédictifs
4.5 Les cubes de prédiction
4.6 Conclusion et perspective

76
Chapitre4
Cubes de prédiction
« Les prédictions d'événements inattendus sont toujours plus précises si
on ne les a pas rédigées auparavant »
Carl Sagan, Extrait de Contact
4.1 Introduction
Il est souvent dit que l'analyse de données exploratoire est un processus itératif, et que
la partie du temps est passée sur l'arrangement de la structure et les modèles sont suggérés en
appliquant un ou plusieurs algorithmes de fouille de données sur différents sous-ensembles ou
différente condition sur les versions des données.
Cependant, presque toute la recherche s'est concentrée sur améliorer la qualité et l'efficacité
des algorithmes de fouille, et a ignoré le rétrécissement de l'humain dans la boucle. Nous
adressons, ainsi, directement la question de la façon dont nous pouvons aider l'analyste en
identifiant des sous-ensembles de données qui sont aussi bien - intéressant à la lumière d'un
modèle prédictif donné- l'idée fondamentale peut être généralisée pour soutenir d'autres
genres d'arrangements exploratoires d'analyse.
Notre proposition de base est simple pourtant puissante, OLAP est maintenant un outil
bien compris et puissant pour explorer systématiquement des questions d'agrégation à travers
des sous-ensembles de données.
4.2 Contributions et futures directions
En cette partie, nous : (1) présentons la cubes de prédiction, (2) développons une
technique informatique générale, appelée la décomposition de marquage de fonction, pour
améliorer l'efficacité de les cubes de prédiction, (3) comment s'appliquer la technique
proposée à la construction de cubes de prédiction pour plusieurs algorithmes utilisés
généralement d'étude de machine, et finalement (4) présentons par série d'expériences qui
évaluent empiriquement l'exactitude et l'efficacité de la construction de cube.

Chapitre 4 : Cubes de prédiction
-77-
Cette partie est une première étape, et ouvre un certain nombre de directions
intéressantes pour la future recherche. Au delà des améliorations possibles aux algorithmes,
en construisant les cubes de prédiction pour d'autres modèles prédictifs est un défi important.
Si nous regardons des paramètres des algorithmes d‟étude comme dimensions du cube, ceci
ouvre la porte à une utilisation plus générale de cubes de prédiction ; en accordant
l'algorithme d‟étude (par exemple, pour divers choix - les seuils magiques, le calcul efficace
de cube pour ces généralisations est grand ouvert.
4.3 Exemple de motivation
Considérons une banque dans tout le pays dont les directeurs veulent analyser le
processus de reconnaissance du prêt de la banque en ce qui concerne deux dimensions,
Location et Time (illustrés en figure1). Ils sont intéressés par les questions comme :
1. Etant donné un ensemble d'attributs (par exemple, race et sexe), y a-t-il des endroits et les
périodes pendant lesquels les approbations ont dépendu fortement de ces attributs ?
2. Y a-t-il des endroits et les périodes où la prise de décision était semblable à celle en 1950?
Quand les modèles prédictifs sont construit par un chemin de fer tel que l'algorithme,
ils sont employés pour aider à des décisions de reconnaissance, les questions essentiellement
doivent être faites avec façon prévisible de certains attributs et ressemblance des modèles
qualifiés sur différents sous-ensembles de données. Les sociologues ont soulevé des
inquiétudes que l'utilisation de l'exploitation de données présente le risque de discrimination.
Ces questions sont également compliquées par le fait que les réponses de candidat sont
des sous-ensembles de données, divisés par des valeurs d'endroit et de temps ; clairement, il y
a un grand nombre de candidats. Bien que les hiérarchies d'endroit et de Temps soient
connues, le niveau juste (granularité) pour l'analyse est peu clair ; par exemple, exécutant
l'analyse qui emploie l'État-Mois mieux qu'en utilisant la Ville-Année ? Ainsi, il est
Fig. 4.1: Exemple de dimension hiérarchique
All
MA WI MN
Madison, WI Green Bay, WI
Z1(3)
= All
Z1(2)
= State
Z1(1)
= City
Z1 = Location
All
8
5
8
6
0
4
Jan.8
6
Dec.8
6
Z2(3)
= All
Z2(2)
= Year
Z2(1)
=
Month
Z2 = Time

Chapitre 4 : Cubes de prédiction
-78-
souhaitable d'avoir un outil qui permet aux analystes de la banque de se diriger par différents
niveaux hiérarchique par rolling-up ou/et drill-down. Nous proposons ainsi, un nouveau genre
d'outil de fouille des données, appelé cubes de prédiction, pour soutenir une telle analyse.
Le figure 4.3 (a) et (b) montre un exemple à deux dimensions un cube de prédiction pour
répondre à la première question. Sur le figure 4.3 (c), chaque cellule est classée par paire [état,
année]. Chaque valeur de cellules est l‟attribut prévisible, calculé en évaluant deux modèles
formé sur le sous-ensemble de données de cette cellule. (Dans la section suivante, nous
discutons comment mesurer le prévisible) nous appelons cette sorte de cube de prédiction ; un
cube prévisible. La prédiction est la navigation de cubes par l'intermédiaire du roll-up (par
exemple, de [état, année] [état, tout]) et drill-down (par exemple, de [état, année] [état, mois]).
4.4. Modèles prédictifs
Les modèles prédictifs sont les objets centraux dans les cubes de prédiction. Nous
présentons d'abord les concepts de base et les notations, et nous décrivons ensuite des
techniques standard d'étude pour mesurer l'exactitude de mode, la ressemblance entre les
modèles, et l'attribut prévisible.
4.4.1 Fondations
Soit D une table de données du schéma [X, Y], où X = X1,…, Xm est un ensemble
d'attributs de facteur prédictif et Y est l'étiquette (c.-à-d., l'attribut dépendant).
Chaque ligne dans D s'appelle un exemple. Un modèle prédictif h(X ; D) est un modèle
qualifié sur D en utilisant l'algorithme de h qui prévoit l'étiquette d'un nouvel exemple X.
Pour faciliter l'expression, si l'ensemble de données n'est pas important ou peut être impliqué
du contexte, nous employons juste h (X) pour noter un modèle prédictif.
En outre, nous employons h(x ; D) pour noter la fonction qui produit la prédiction de
h(X ; D) sur l'entrée X.
Par exemple, D est une table des données d'application de prêt, avec le schéma [Age, Gender,
Race, Approval], où X= Age, Gender, Race note les attributs de facteur prédictif et
Y=Approval est l'étiquette.
Fig.4.3 : Exemple de différents niveaux de cube
(a) Le cube de niveau [1,1] (b) Le cube de niveau [1,2] (c) Le cube de niveau [2,2]

Chapitre 4 : Cubes de prédiction
-79-
Le modèle prédictif decision_tree(X ; D) est l'arbre de décision déterminé dans D, pour
prévoir si une application de prêt d‟une personne serait approuvée se basant sur son Age,
Gender et Race.
Dans l'étude et les statistiques, on assume que D est un échantillon aléatoire tiré
indépendamment d'une distribution fondamentale de probabilité p*(X, Y).
Puisque les différents ensembles de données viennent de différentes distributions, nous
employons p* (X, Y | D) pour noter la distribution de l'ensemble de données D.
Etant donner cette distribution, l'étiquette pour l'entrée x est l'étiquette qui maximise la
probabilité conditionnelle p*(Y=y | X=x, D), pour toute la classe y ; c.-à-d.,
best_class (x | D) = argmaxy p*(Y=y | X=x, D).
De ce point de vue probabiliste, un modèle prédictif h (X ; D) est optimal si pour n'importe
quelle entrée x, h (x ; D) produit toujours la meilleure étiquette de x ; c.-à-d.,
h (x ; D) = argmaxy p*(Y=y | X=x, D)
Ainsi, h (X ; D) peut être considéré comme l‟approximation de p*(Y | X, D).
De plus, il est intuitif pour imaginer cela, h (X ; D) construit une distribution interne de
probabilité ph (Y | X, D) qui approxime p*(Y | X, D).
Ainsi, la prédiction de h (X ; D) en x est l'étiquette de classe qui maximise ph(Y=y | X=x, D),
pour tout y ; c.-à-d.,
h (x ; D) = argmaxy ph (Y=y | X=x, D).
En fait, beaucoup d'algorithmes d'étude ont de telles distributions de probabilité, ou
ont quelques composants de marquage qui ont une signification probabiliste semblable, bien
que les points ne soient pas réellement des probabilités.
4.4.2 L’exactitude du Modèle
Théoriquement, l'exactitude de h (X ; D) est défini par combien de fois nous nous
attendons à qu'il soit correct : Ex,y[I (h (x ; D) = y )],
où (x, y) est tiré de p*(X, Y | D),
et I est la fonction indicatrice. Si ¥est vrai, I (¥) = 1, sinon I (¥) = 0.
Donc, p*(X, Y | D) est une distribution inconnue

Chapitre 4 : Cubes de prédiction
-80-
Définition 1 : Test-set accuracy. (Exactitude de l‟ensemble test)
Soit ∆ un schéma de test de [X, Y], Test-set accuracy (l‟exactitude de l‟ensemble test) de h
(X ; D) est :
1
∆ 𝐼 ℎ 𝑥; 𝐷 = 𝑦
(𝑥 ,𝑦)∈∆
où ∆ est la taille de ∆.
Notons que si nous n'avons pas un ensemble mis de côté de test, une méthode générale
est utilisée. Nous divisons d'abord aléatoirement D en n-recouvrement D1,…, Dn.
Puis, pour i = 1 à n, nous employons ∪ 𝑗 ≠ 𝐼 (𝐷 j) comme données pour établir un modèle, et
puis employer Di comme des tests pour mesurer le modèle Test-set accuracy (Exactitude de
l‟ensemble test). Puis, l'exactitude de vérification est la moyenne des exactitudes ci-dessus de
n. Un choix commun de n est 10.
4.4.3 Ressemblance du modèle
La notion de la ressemblance (ou de la différence) entre les modèles est importante
dans la prédiction.
Considérons h1(x) et h2(x) deux modèles prédictifs. Une méthode simple de mesurer la
ressemblance entre h1(x) et h2(x) est d'examiner si ces deux modèles prévoient les mêmes
classes d‟étiquettes pour la plupart des exemples d‟ensemble de test.
Définition 2: Prediction similarity and distance (ressemblance prévisible et distance).
La ressemblance prévisible (test-set-based) entre deux modèles, h1(x) et h2 (x), sur l'ensemble
de test est :
Nous utilisons la différence (h1(x), h2 (x)) pour noter la ressemblance modèle entre h1(x) et
h2(x). La prédiction de distance entre h1 (x) et h
2(x) est 1-similarity (h
1(x), h
2(x)).
Notons que l'ensemble de test utilisé n'ayez pas besoin d'avoir des classes
d‟étiquettes. Il est employé pour fournir la distribution désirée du X. Habituellement, est
produit selon la véritable distribution fondamentale p ∗ (x). Cependant, nous pouvons
également commander les tests ; c.-à-d., en employant le test à différent place, on peut
comparer des modèles basés sur différentes régions de l'espace de dispositif. Par exemple, en
employant un ensemble de test d'informations sur les personnes riches, nous pouvons
concentrer la comparaison sur la façon dont deux modèles traitent les personnes riches.

Chapitre 4 : Cubes de prédiction
-81-
Du point de vue probabiliste, les modèles h1(x) et h2(x) peut également estimer les
classe de probabilités conditionnelles, c.-à-d., 𝑝ℎ1 𝑌 𝑋 et 𝑝ℎ2
𝑌 𝑋 , alors nous pouvons
mesurer la ressemblance entre h1(x) et h2(x) plus avec précision en employant la divergence
de Kullback-Leibler (KL) entre 𝑝ℎ1 𝑌 𝑋 et 𝑝ℎ2
𝑌 𝑋 .
Définition 3 : KL-distance [KL14]. La test-set-based KL entre les modèles, h1(x) et h2(x),
sur l'ensemble de test ∆ est :
1
∆ 𝑝ℎ1
𝑦 𝑥 log𝑝ℎ1
𝑦 𝑥
𝑝ℎ2 𝑦 𝑥
𝑦𝑥∈∆
Nous employons KL_distance (h1 (x), h 2(x)) pour noter la KL-distance entre h1(x) et h2(x).
Notons qu‟en général, 𝐾𝐿_𝑑𝑖𝑠𝑡𝑎𝑛𝑐𝑒 (ℎ1, ℎ2) ≠ 𝐾𝐿_𝑑𝑖𝑠𝑡𝑎𝑛𝑐𝑒 (ℎ2, ℎ1).
4.4.4 Attribut prévisible :
Des modèles prédictifs peuvent être employés pour mesurer si un ensemble d'attributs
𝑉 ⊆ 𝑋 est prédictif avec Y est dans un ensemble de données D. L'intuition est que V n'est pas
prédictif si et seulement si V est indépendant de Y et d‟autre attribut X-V ; c.-à-d., 𝑝 ∗
𝑌 𝑋 − 𝑉, 𝐷) = 𝑝 ∗ (𝑌 | 𝑋, 𝐷).
Ainsi, la ressemblance entre ces deux probabilités est une bonne mesure du prévisible
de V. Par suite p ∗ est inconnu dans la pratique, nous employons la différence (prédiction ou
KL-distance) entre ℎ (𝑋 ; 𝐷) et ℎ (𝑋 − 𝑉 ; 𝐷) comme mesure du prévisible.
Notons qu'il y a une autre manière de mesurer le prévisible de V, basé sur l'intuition
que V est prédictif si et seulement si le modèle employant V est plus précis que le modèle
n'employant pas V ; c.-à-d., h (X ; D) est plus précis que ℎ (𝑋 − 𝑉 ; 𝐷). La validation peut
être employée pour estimer les exactitudes de ℎ (𝑋 ; 𝐷) et ℎ (𝑋 − 𝑉 ; 𝐷). Dans l'intérêt de
l'espace, nous ne discutons pas de cette alternative plus d'avantage.
4.5. Les cubes de prédiction
Dans cette section, nous définissons formellement les cubes de prédiction. Nous
présentons d'abord les genres d'analyse pour lesquels les cubes de prédiction est conçu, et puis
nous définissons les cubes de prédiction ainsi considérer leur réalisation.

Chapitre 4 : Cubes de prédiction
-82-
4.5.1 Model_based Subset Analysis
Nous sommes intéressé par l'analyse des données de modèle basé (ou modèle fondé). Plus
spécifiquement, donné une table de données D au schéma [X, Y], nous voulons comprendre
le rapport entre X et Y (c.-à-d., 𝑝 ∗ (𝑌 | 𝑋, 𝐷)) en établissant un modèle (c.-à-d., ℎ (𝑋 ; 𝐷)).
Des sous-ensembles 𝜎(𝐷) sont définis par des sélections relationnelles, et nous employons les
modèles ℎ (𝑋 ; 𝜎(𝐷)) pour approximer les vraies distributions 𝑝 ∗ (𝑌 | 𝑋, 𝜎(𝐷)). Les
caractéristiques du modèle que nous sommes intéressés sont :
Test-set behavior (conduite de l‟ensemble de test): étant donné un ensemble de test
du schéma [X, Y], nous voulons savoir si les modèles établis sur différent sous
ensembles de D se comportent comme la distribution fondamentale qui produit ∆. Par
exemple, peut être une liste d'applications de prêt qui ont été injustement traitées.
Ceci peut être estimé en employant Test-set accuracy (Exactitude de l‟ensemble test).
Model-based data similarity (Modèle basé sur la ressemblance des données): Etant
donné un ensemble de données D0, qui peut être un sous-ensemble de D, nous voulons
savoir si le semblable D0 est différent au sous-ensemble de D. Cette comparaison peut
être faite en mesurant la ressemblance ou la distance entre le modèle établi sur D0et les
modèles établis sur différents sous-ensembles de D.
Attribute predictiveness (Attribut prévisible): Etant donné un ensemble V ⊆ X
d'attributs, par exemple, attributs comme race et le sexe, nous voulons savoir si V est
prédictif en ce qui concerne Y sur différents sous-ensembles de D. C'est la notion de
prévisible définie dans la section suivante.
Tant que les exactitudes des modèles prédictifs sont raisonnablement hautes, cette
prétention est courante dans l'étude et les statistiques. Dans la pratique, nous pouvons essayer
différents algorithmes d‟étude, et nous obtenons un bon sens au sujet de la prédiction ou les
caractéristiques de décision. Cependant, le nombre de tous les sous-ensembles possibles de D
est trop grand. Ainsi, nous empruntons l'idée des données multidimensionnelles et
hiérarchiques groupant à OLAP, et contraignez les sous-ensembles que nous considérons à
ceux définis par des groupements hiérarchiques multidimensionnels valides.
4.5.2 De cubes en données aux cubes de prédiction
OLAP est un environnement qui soutient l'analyse de données multidimensionnelle et
hiérarchique. Ces données sont stockées dans une table D de fait avec un ensemble

Chapitre 4 : Cubes de prédiction
-83-
𝑍 = 𝑍1, … , 𝑍𝑑 des attributs de dimension et d'un attribut Y de mesure, où chaque
dimension 𝑍𝐼a un domaine hiérarchique, par exemple, le figure1. Un cube de données est une
rangée de dimension d où la valeur en chaque cellule est une valeur globale, par exemple, la
somme ou la moyenne, qui récapitulent le sous-ensemble de données situant dans cette
cellule. Le figure3 (c) est un exemple. Formellement, la valeur dans la cellule classée près
[𝑧1, … , 𝑧𝑑 ] est définie par une question de la forme suivante.
agg (Y) Z1
z1 AND … Z
d=z
d;
où zi sont des valeurs dans les hiérarchies et agg() est une fonction globale, par exemple,
somme ou moyenne. Par exemple, sur le figure3 (c), la cellule indexée par [WI, 86] est 0.9.
Tandis que le cube de données est un moyen utile pour comprendre les traits autour de
sous-ensemble des données, ils fournissent un savoir caractéristique de prédiction ou de
décisions. Ainsi, nous prolongeons le concept d'un cube de données comme suit :
Utiliser le mécanisme OLAP pour diviser des données en sous-ensembles et utiliser
l'interface utilisateur OLAP pour choisir des sous-ensembles à vérifier, par exemple, le
roll-up et drill-down.
Introduire de nouveaux genres de fonctions globales qui capturent la prédiction ou la
décision des données. Au lieu de l'agrégation simple, par exemple, la somme et la
moyenne, la valeur dans chaque cellule est calculé en évaluant un modèle basé sur le
sous ensemble de données associé à la cellule.
Nous appelons ce nouveau genre de cube ; les cubes de prédiction.
La complexité de calcul de manipulation des cubes de prédiction est plus haute qu'aux cubes
de données.

Chapitre 4 : Cubes de prédiction
-84-
4.5.3 Dimensions et hiérarchies :
D'abord, nous redéfinissons le schéma D pour qu‟il soit [Z, X, Y], où 𝑍 = 𝑍1, … , 𝑍𝑑
est un ensemble de dimension d'attributs, d est le nombre de dimensions, X est un ensemble
d'attributs de facteur prédictif et Y est la classe d'étiquette.
Dans l'exemple de motivation, Z = Location, Time. Le long de chaque dimension𝑍𝑖 ,
il y a une hiérarchie. Pour la simplicité de l'exposition, nous assumons que la hiérarchie de 𝑍𝑖
est linéaire : <Zi
(1),…, Z
i
(k)>, pour un certain k, où Z
i
(t) est un domaine plus général que Z
i
(t-1).
Ainsi, Zi
(t) est appelé le domaine le moins général, et le Z
i
(k) s'appelle le domaine le plus
général. Nous disons que Zi
(a) est plus général que Z
i
(b) si chaque valeur dans le domaine Z
i
(b) est
exactement un fils d‟une valeur dans le domaine Zi
(a) dans la hiérarchie. Nous appelons Z
i
(t) le
domaine au niveau t.
Par exemple, suivant les indications du figure1, la hiérarchie de domaine de Location
est < City, State, All >, où la City est au niveau 1 et c‟est le domaine le moins général ; All est
au niveau 3 et c‟est le domaine le plus général.
Dans cette hiérarchie, chaque ville (City) est exactement un fils d‟un état (State), et chaque
état (State) est un fils de All dans la hiérarchie Location.
Nous utilisons 𝑣 ∈ 𝑍𝑖(𝑡)
pour noter qu'une valeur est du domaine Zi
(t).
Sans perte de généralité, nous assumons cela pour n'importe quelle dimension Zi, les
domaines Zi
(1),…, Z
i
(k) ont des différents ensembles de valeurs ;
c.-à-d., il n'y a aucune valeur 𝑣 tels que 𝑣 ∈ 𝑍𝑖(𝑎)
et 𝑣 ∈ 𝑍𝑖(𝑏)
, pour tout i, a et b.
Par exemple, il y a différentes valeurs du domaine mois pour le même mois de différentes
années.
Semblable à la table de fait dans OLAP, nous supposons que les valeurs dans les
attributs de dimension de la table D de données viennent des moindres domaines généraux, c.-
à-d., le 𝑍𝑖(𝑙)
𝑠.
Le sous-ensemble hiérarchique multidimensionnel au niveau 𝑙1, … , 𝑙𝑑 , est noté par
𝜎 𝑣1 ,…,𝑣𝑑 (𝐷) où 𝑣𝑖 ∈ 𝑍𝑖(𝑙𝑖)
, est défini par:
où desc (vi) représente
l'ensemble de valeurs qui sont les descendants de vi dans la hiérarchie de Zi et vi .

Chapitre 4 : Cubes de prédiction
-85-
Par exemple, 𝜎[𝑊𝐼 ,86] (𝐷) est le sous-ensemble de données avec l'endroit dans WI et le
temps dans 86. Notons que le niveau de ce sous-ensemble est [2.2].
Nous pouvons visualiser un sous-ensemble hiérarchique multidimensionnel en traçant
chaque exemplaire de D comme point dans un espace d -dimensionnel basé sur leurs valeurs
des attributs.
Puis, le sous-ensemble hiérarchique multidimensionnel 𝜎 𝑣1 ,…,𝑣𝑑 (𝐷) est l'ensemble
d'exemples (points de données) tombant dans la boîte définie par 𝑣1, … , 𝑣𝑑 .
Par exemple, 𝜎[𝑊𝐼 ,86] (𝐷) est l'ensemble d'exemples situés dans le rectangle du le
figure 4.2.
Un cube au niveau 𝑙1, … , 𝑙𝑑 est une rangée de dimension d, où chaque cellule est indexé par
[𝑣1, … , 𝑣𝑑 ] , 𝑣1𝑖 ∈ 𝑍𝑖(𝑙𝑖)
, et la valeur dans la cellule est un nombre qui récapitule
𝜎 𝑣1 ,…,𝑣𝑑 (𝐷).
Nous disons que 𝜎 𝑣1 ,…,𝑣𝑑 (𝐷) est le sous-ensemble défini par la cellule 𝑣1, … , 𝑣𝑑 .
Le figure 4.3 montre un exemple d'un cube à différents niveaux. Par exemple, dans le cube du
niveau [2, 2] chaque cellule de la rangée est indexée par une Location et une année. La valeur
dans la cellule [𝑊𝐼, 86] est un nombre qui récapitulent 𝜎[𝑊𝐼 ,86] (𝐷) (nous définirons la
signification des valeurs dans les cubes de prédiction plus tard). Le Roll-up est l'opérateur qui
change le cube de prédiction du niveau [𝑙1, … , 𝑙𝑖 , … , 𝑙𝑑 ] au niveau [𝑙1, … , 𝑙𝑖∗, … , 𝑙𝑑] , où 𝑙𝑖
∗ > 𝑙𝑖 ,
pour une certaine dimension i. Drill-down est l'opérateur qui change le cube de prédiction du
niveau [𝑙1, … , 𝑙𝑖 , … , 𝑙𝑑 ] au niveau [𝑙1, … , 𝑙𝑖∗, … , 𝑙𝑑], où 𝑙𝑖
∗ < 𝑙𝑖 , pour une certaine dimension i.
Fig. 4.2 - visualisation du 𝜎 𝑊𝐼, 86 𝐷

Chapitre 4 : Cubes de prédiction
-86-
4.5.4 Cubes de prédiction
Nous définissons maintenant trois types de test-set based (TS) des cubes de
prédiction, et expliquons comment les employer pour exécuter le modèle d'analyse basée de
sous ensemble. Pour tous TS les cubes de prédiction, l'utilisateur indique : (1) les données de
la table D, du schéma [Z, X, Y], ainsi que les hiérarchies liées à Z, (2) un algorithme d‟étude
h, et (3) un ensemble de données de test du schéma [X, Y] (pour des cubes de prédiction
TS; mais [X] pour les deux autres types de cubes).
Notons que l'ensemble de test est un paramètre personnalisé par l'utilisateur. Cela signifie
que l'utilisateur peut choisir l'ensemble de test basé sur sa distribution désirée de données.
Définition 4 : TS cube d’exactitude.
TS- cube d‟exactitude au niveau [𝑙1, … , 𝑙𝑑] est une rangée de dimension d, dans laquelle la
valeur de chaque cellule est l'exactitude test-set de ℎ (𝑋 ; 𝜎(𝐷)) basé sur l'ensemble de test
, où σ(D) est le sous-ensemble défini par cette cellule.
Définition 5 : Cube en Modèle-ressemblance (ou distance) Model-similary (or distance).
Etant donné un autre modèle personnalisé par l'utilisateur h0(X), la ressemblance des cubes de
prédiction (ou cube KL-distance) au niveau [𝑙1, … , 𝑙𝑑] est une rangée d-dimensionnelle, dans
laquelle la valeur en chaque cellule est la ressemblance de prédiction (ou KL-distance) entre
h0(x) et h (X ; σ(D)) basé sur l'ensemble non étiqueté de test , où σ(D) est le sous-ensemble
défini par cette cellule.
Définition 6 : Cube de façon prévisible.
Etant donné un ensemble 𝑉 ⊆ 𝑋 d'attributs, le PD (ou KL-) cube prévisible au niveau
[𝑙1, … , 𝑙𝑑] est une rangée d-dimensionnelle, dans laquelle la valeur en chaque cellule est la
distance prédite (ou KL) entre ℎ (𝑋 − 𝑉 ; 𝜎(𝐷)) 𝑒𝑡 ℎ (𝑋 ; 𝜎(𝐷)) mesuré par l'ensemble non
étiqueté de test , où 𝜎(𝐷) est le sous-ensemble défini par cette cellule.
Notons que les opérateurs des cubes de prédiction sont les mêmes pour le cube de données,
par exemple, roll-up et drill-down le bas.
Dans le suivant, nous expliquons comment employer les cubes de prédiction pour
exécuter un model-based subset analysis.
Test-set behavior (conduite de l‟ensemble de test): Nous pouvons employer le TS -
cube d‟exactitude pour analyser le test-set (∆)sur différents sous-ensembles

Chapitre 4 : Cubes de prédiction
-87-
Model-based data similarity (Modèle basé sur la ressemblance des données): Etant
donné un ensemble de données D0 , qui peut être un sous-ensemble de D, nous
pouvons d'abord établir un modèle h0 sur D0 , et mesurer le model-based similary de
D0 à différents sous-ensembles de D en utilisant les cubes model-similary (ou
distance) en supposons que h0 est un des paramètres d'entrée.
Attribute predictiveness (attribut prévisible): Etant donné un ensemble 𝑉 ⊆ 𝑋
d'attributs, nous pouvons vérifier le prévisible de V w.r.t. Y sur différents sous-
ensembles en utilisant les cubes de façon prévisible.
Généralisons des cubes ci-dessus, si l'utilisateur fournit une fonction d'évaluation
Eval (ℎ, 𝜎(𝐷) | ∆, 𝜃) dont il évalue le comportement du modèle 𝜎(𝐷) en utilisant l'algorithme
d‟étude h basé sur l'ensemble de test et quelques paramètres facultatifs 𝜃, puis les TS-cube
de prédiction (general test-set-based prediction cube) peut être défini comme suit.
Définition 7 : le général TS-cube de prédiction.
Etant donné une fonction d'évaluation Eval et un ensemble de paramètre facultatif 𝜃, le
général TS-cube de prédiction au niveau [𝑙1, … , 𝑙𝑑 ] est une rangée d-dimensionnelle, où la
valeur en chaque cellule est Eval (ℎ, 𝜎(𝐷) | ∆, 𝜃), et 𝜎(𝐷) est le sous-ensemble défini par
cette cellule.
Notons que pour TS-accuracy cubes, Eval (h, σ(D) | ∆, θ) est Test-set accuracy
(Exactitude de l‟ensemble test) de h (X ; σ(D) ) en utilisant avec étant vide. Pour des
cubes en modèle-ressemblance (ou distance), est h0 et Eval (h, σ(D) | ∆, θ)est la
ressemblance (ou la distance) entre h (X ; σ(D) ) et h0 (X) basé dans . Pour des cubes de
façon prévisible, Eval (h, σ(D) | ∆, θ ) est la ressemblance (ou la distance) entre h (X ; σ(D) )
et h (X − V ; σ(D) ) basé dans avec étant V.
En outre, notons que nous pouvons définir les cubes de prédiction basés sur la contre-
vérification. Cependant, dans l'intérêt de l'espace, nous ne discutons pas cette variation.
4.5.5 Réalisation de cubes de prédiction
Bien que le concept de cubes de prédiction est intuitif, la navigation de cube de
prédiction est informatique très coûteuse. Ainsi, il est généralement nécessaire de réaliser des
réponses interactives acceptables, matérialisant les valeurs de cellules à différents niveaux.

Chapitre 4 : Cubes de prédiction
-88-
Pour la simplicité, nous considérons seulement la pleine réalisation, c.-à-d., réalisation de
toutes valeurs de cellules pour tous les niveaux possibles.
La réalisation partielle avec des contraintes peut être faite en prolongeant les
techniques de réalisation développée ici en utilisant les techniques partielles de réalisation
développées pour des cubes des données, par exemple, développer dans [HRH96].
Définition 8 : La réalisation de la table pleine.
La réalisation de la table pleine du cube de prédiction est une table du schéma [Z1,…, Zd, M]
qui contient toutes valeurs de cellules du cube à tous les niveaux possibles. C'est-à-dire, la
table contient un couple [v1,…, vd, m(v1,…, vd)], où m(v1,…, vd)est la valeur dans la cellule
de cube [v1,…, vd], pour chaque 𝑣𝑖 ∈ 𝑧𝑖(𝑙)
, pour tout i et l.
Notons que les valeurs de Zi dans la table de donnée D sont du domaine 𝑧𝑖(𝑙)
, le
domaine le moins général. Cependant, les valeurs de l'attribut Zj dans la réalisation de la table
pleine sont l'union de tous les domaines de cette dimension, c.-à-d. 𝑍𝑖(𝑙)
𝑙
Une manière de produire la réalisation de la table pleine pour un cube de prédiction
est d'établir exhaustivement un modèle et de l'évaluer pour chaque cellule et pour chaque
niveau.
Cela signifie que nous devons construire 𝑍1(𝑙)
× … ×𝑙 𝑍𝑑(𝑙)
𝑙 modèles.
Nous appelons cette méthode la méthode exhaustive. Notons que les tailles de données
pour ces modèles sont différentes.
À une extrémité, nous considérons les cellules dans le cube au plus bas niveau [1,…,
1]. La taille des données situées dans chacune de telles cellules est petite. Cela signifie qu'en
établissant un modèle pour une telle cellule est relativement moins cher. À une autre
extrémité, considérons la cellule dans le cube au plus général niveau. Dans ce cas-ci, les
données pour cette cellule sont l'ensemble de données entier de D. Cela signifie qu‟en
établissant un modèle pour cette cellule exige les ressources extrêmement grandes. De plus, il
est très probable qu'établir le modèle simple de la plus générale cellule soit beaucoup plus
cher qu'en établissant les modèles pour toutes cellules au plus bas niveau. Cette observation
précise un grand défi informatique dans la réalisation des cubes de prédiction. Si nous
n'adaptons pas des algorithmes d'étude pour des cubes de données, une construction du
modèle pour 𝑍1(𝑙)
× … ×𝑙 𝑍𝑑(𝑙)
𝑙 semble inévitables, et les grandes conditions de

Chapitre 4 : Cubes de prédiction
-89-
ressource pour des cellules aux niveaux élevés rendent la situation encore plus mauvaise.
Ainsi, d‟arranger les modèles plutôt que d'obtenir zéro à plusieurs reprises
4.6 Conclusion et perspective
Les cubes de prédiction et leurs défis informatiques associés sont de nouveaux
problèmes dans l'exploitation de données. Dans cette partie, nous avons motivé ces problèmes
et nous avons présenté quelques résultats préliminaires. Nos futures directions incluent : (1)
développer un mécanisme pour manipuler le cas où quelques sous-ensembles n'ont pas des
données suffisantes pour établir un bon modèle, (2) dérivant le marquage décomposable
fonctionnant pour d'autres modèles prédictifs, (3) étudiant le problème de la façon à faire les
modèles interprétable dans les cubes de prédiction, et (4) prolonger la définition des
dimensions pour inclure des paramètres des algorithmes d‟étude.
Dans un travail relatif, les cubes de données ont été prolongés en utilisant des règles
d'association dans [IKA02], mais les règles l'association sont tout à fait différentes que les
modèles prédictifs décrits dans cette partie et les méthodes particulières proposées dans
[IKA02] ne peuvent pas être appliquées aux cubes de prédiction.
Trouver un couple dans les environs des cellules ayant la particularité d'être associer avec un
grand changement dans un cube de données étudié dans [DHL+01].
Cependant, la ressemblance définie dedans [DHL+01] est très différente de la ressemblance
définie entre le comportement du modèle prédictif. Établir des modèles dans OLAP a été
également étudié dans [BW01, MFT01].
Dans [BW01], ils ont considéré les modèles statistiques log-linéaires pour approximer des
régions denses dans un cube de données, alors que dans [MFT01], ils ont considéré à établir le
réseau bayésiens (BN) sur le cube de données pour répondre approximativement à des
questions de compte. Cependant, leur but était d'employer des modèles pour condenser des
cubes de données, plutôt que model-based data analysis proposée en cette partie. Notons que
l'algorithme BN proposé dedans [MFT01] peut être adaptée de sorte qu‟il soit un exemple de
notre méthode décomposable. Dans l'étude de machine, la méthode [Die00] est une technique
employée couramment pour amplifier l'exactitude des algorithmes d‟étude instables.
Cependant, un ensemble se compose typiquement d'un ensemble de classificateurs bas,
chacun qualifié sur une grande partie d‟ensemble de données plein; notre utilisation
d'ensemble n'a pas cette propriété et n'a pas été soigneusement étudiée.

Chapitre 5 : Conclusion générale
-90-
Chapitre 5
Conclusion générale
« C’est là en effet un des grands et merveilleux caractères des beaux
livres que pour l’auteur ils pourraient s’appeler ‘Conclusions’ et pour le
lecteur ‘Incitations’. »
Marcel Proust, “Sur la lecture”
6.1 Bilan et contributions
Dans le cadre de ce mémoire, nous avons essayé d‟apporter des solutions au
problème de l‟analyse des données complexes. Pour y parvenir, nous nous sommes basés sur
le couplage entre l‟analyse en ligne et la fouille de données. Nous avons énoncé les deux
domaines sont complémentaires et peuvent évoluer dans le cadre d‟un processus décisionnel
unique. Leur association est capable d‟enrichir et de rehausser le processus décisionnel. De
plus, la fouille a déjà avancé des solutions pour l‟extraction des connaissances à partir des
données complexes. Par conséquent, la fouille de données est capable d‟étendre les capacités
de l‟OLAP pour analyser les données complexes.
A partir de la fin des années 90, le couplage de l‟analyse en ligne et de la fouille de données a
suscité beaucoup d‟intérêts. Plusieurs travaux ont abordé le sujet en proposant des approches
variées selon différents types de motivations. Néanmoins, nous avons distingué trois grandes
approches ou chacune se caractérise par une manière d‟opérer le couplage entre les deux
domaines. La première consiste à transformer les données multidimensionnelles en données
tabulaires exploitables par les algorithmes classiques de fouille. La deuxième approche repose
sur une extension des outils OLAP et des langages de requêtes des SGBDMs aux techniques
de fouille. Enfin, la troisième approche adapte les techniques classiques de fouille au contexte
des données multidimensionnelles.
Cependant nous avons mis le point sur les trois opérateurs de couplage entre OLAP et
DM à savoir : le réarrangement d‟un cube par analyse factorielle (ACM): Opérateur ORCA,
l‟agrégation par classification dans les cubes de données (CAH) : Opérateur OPAC et
l‟explication par recherche guidée de règles d‟association dans un cube: Opérateur AROX.

Chapitre 5 : Conclusion générale
-91-
6.2 Perspectives de recherche
Les travaux réalisés dans ce domaine ouvrent diverses perspectives de recherche.
Tout d‟abord, nous continuons à croire que le couplage de l‟analyse en ligne et de la fouille de
données est une solution adéquate pour l‟analyse des données complexes. Nous projetons la
généralisation des cas d‟application aux données complexes de différentes propositions basées
sur le couplage. Nous pensons que, par analogie à l‟agrégation par classification, la
réorganisation par l‟ACM et l‟explication par les règles d‟association peuvent aussi fournir
des connaissances pertinentes dans les données de mammographies, en particulier, et dans les
données complexes, en général. Nous croyons aussi que XML est une solution adaptée à la
modélisation multidimensionnelle des données complexes. Au vu des divers efforts dans le
domaine des entrepôts de données XML, nous pensons que, dans un avenir proche, XML sera
un nouveau standard pour un processus d‟entreposage particulièrement adapté aux données
complexes. Cette évolution, va naturellement engendrer une redéfinition des mécanismes
d‟interrogation des données au niveau de l‟analyse en ligne. Parallèlement, l‟extension de
l‟analyse en ligne à la fouille doit aussi tenir compte de cette nouvelle représentation des
données complexes. D‟une manière similaire aux données multidimensionnelles, nous
pensons que nous serons amenés à réfléchir à un nouveau type de couplage entre l‟analyse en
ligne et la fouille de données qui adapterait les algorithmes de fouille aux données XML.
Dans des travaux réalisés, ils ont exploité le couplage de l‟analyse en ligne et de la fouille de
données afin d‟étendre les capacités de l‟OLAP. Ces capacités ont porté principalement sur la
description et la visualisation, la classification et l‟explication. Cependant, il est encore
important d‟étendre l‟analyse en ligne à des capacités de prédiction. En effet, dans un
processus décisionnel, un utilisateur observe les faits OLAP dans un cube afin d‟extraire des
informations intéressantes au regard du contexte d‟analyse. Ces informations permettent à
l‟utilisateur de comprendre des relations ou des phénomènes existants dans les données. Ils
permettent aussi à l‟utilisateur d‟anticiper, intuitivement, la réalisation de phénomènes futurs
selon un certains nombre de conditions. Nous pensons que, avec une technique de prédiction
appropriée au contexte des données multidimensionnelles, il est possible d‟assister
l‟utilisateur dans cette tâche. La combinaison de l‟analyse en ligne avec une technique de
prédiction est capable de fournir, par exemple, des estimations des valeurs des mesures d‟un
fait inexistant ou d‟un fait qui va se réaliser dans l‟avenir.

Chapitre 5 : Conclusion générale
-92-
Enfin, la nécessité de la mise en place d‟un cadre formel général pour le couplage de
l‟analyse en ligne et de la fouille de données. Ils ont déjà mis en place une première base
théorique à cet effet. Nous projetons une formalisation complète de ce cadre afin de fournir
une algèbre générale incluant à la fois les opérateurs classiques de l‟OLAP et la nouvelle
génération des opérateurs de fouille de données en ligne.
A l‟image de nos réalisations existantes et futures, notre objectif est d‟étendre le noyau
minimal de notre algèbre actuelle à un nouveau noyau dédié, non seulement à la structuration
et la navigation dans les données multidimensionnelles, mais aussi à la description, la
classification, l‟explication et la prédiction dans les données complexes.

-93-
Bibliographie
[AIS93] Agrawal R., Imielinski T., Swami A., « Mining Association Rules between
Sets of Items in Large Databases », in Proceedings of the ACM SIGMOD
International Conference on Management of Data (SIGMOD‟1993), pp. 207–
216, Washington, D.C., USA : ACM Press. May 1993.
[ACS03] ACS Public Use Microdata Sample (PUMS) 2003
< http://factfinder.census gov/home/en/acs_pums_2003.html>
[AS94] Agrawal R., Srikant R., « Fast Algorithms for Mining Association Rules », in
Proceedings of the 20th International Conference on Very Large Data Bases
(VLDB‟1994), pp. 487–499, Santiago, Chile : Morgan Kaufmann. September
1994.
[BB03] X. Baril, Z. Bellahsène, "Designing and Managing an XML Warehouse", ln
XML Data Management: Native XML and XML-enabled Database Systems,
Addison Wesley, 2003, 455-473.
[BBL06] R. Ben Messaoud, O. Boussaïd, S. Loudcher, "A Data Mining-Based OLAP
Aggregation of Complex Data: Application on XML Documents",
International Journal of Data Warehousing and Mining, to appear, 2006.
[BCCOP04] K.S. Beyer, R.J. Cochrane, L.S. Colby, F. Ozcan, H. Pirahesh, "XQuery for
Analytics: Challenges and Requirements", lst International Workshop on
XQuery Implementations, Experiments and Perspectives (XIME-P 04), Paris,
France, 2004, 3-8.
[BDU04] Bentayeb F., Darmont J., Udréa C., « Efficient Integration of Data Mining
Techniques in Database Management Systems », in Proceedings of the 8th
International Database Engineering and Applications Symposium
(IDEAS‟2004), pp. 59–67, Coimbra, Portugal : IEEE Computer Society. July
2004.
[Ben73] Benzécri J.P., L‟analyse des correspondances, Paris : Dunold. 1973.
[Ber67] Bertin J., Sémiologie Graphique, Paris : Gauthier-Villars. 1967.

-94-
[BFR98] Bradley P.S., Fayyad U.M. and Reina C.A., Scaling EM (Expectation-
Maximization) Clustering to Large Databases. ICML 1998.
[BF01] Breiman L., Random Forests. Machine Learning, 2001.
[BMS97] Brin S., Motwani R., Silverstein C., « Beyond Market Baskets: Generalizing
Association Rules to Correlations », in Proceedings of the ACM SIGMOD
International Conference on Management of Data (SIGMOD‟1997), pp. 265–
276, Tucson, Arizona, USA: ACM Press. May 1997.
[BS97] Barbara D., Sullivan M., « Quasi-Cubes : Exploiting Approximations in
Multidimensional Databases », SIGMOD Record, 26(3) :12–17. 1997.
[BW01] Barbara D. and Wu X.. Loglinear-Based Quasi Cubes. J. Intelligent
Information System, 2001.
[CDH99] Chen Q., Dayal U., Hsu M., « A Distributed OLAP Infrastructure for E-
Commerce », in Proceedings of the 4th IECIS International Conference on
Cooperative Information Systems (COOPIS‟1999), pp. 209–220, Edinburgh,
Scotland: IEEE Computer Society. September 1999.
[CDH00] Chen Q., Dayal U., Hsu M., « An OLAP-based Scalable Web Access Analysis
Engine », in Proceedings of the 2nd International Conference on Data
Warehousing and Knowledge Discovery (DaWaK‟2000), Lecture Notes in
Computer Science, pp. 210–223, London, UK : Springer-Verlag. September
2000.
[CDRBB03] F. Clerc, A. Duffoux, C. Rose, F. Bentayeb, O. Boussaïd, "SMAIDoC : Un
Système Multi-Agents pour l'Intégration des Données Complexes", Revue des
Nouvelles Technologies de l'Information, No. l, 2003, 13-24.
[CFB97] Chaudhuri S., Fayyad U., Bernhardt J., « Scalable Classification over SQL
Databases », Technical Report MSR-TR-97-35, Microsoft Research, Redmond,
WA, USA. 1997.

-95-
[CFB99] Chaudhuri S., Fayyad U., Bernhardt J., « Scalable Classification over SQL
Databases », in Proceedings of the 15th International Conference on Data
Engineering (ICDE‟1999), pp. 470–479, Sydney, Australia. March 1999.
[Cha98] Chaudhuri S., « Data Mining and Database Systems: Where is the
Intersection?», Bulletin of the IEEE Computer Society Technical Committee
on Data Engineering, 21(1):4–8. March 1998.
[CH92] Cooper G.F., Herskovits E.. A Bayesian Method for the Induction of
Probabilistic Networks from Data, Machine Learning, 1992.
[CZC01] Chen M., Zhu Q., Chen Z., « An Integrated Interactive Environment for
Knowledge Discovery from Heterogeneous Data Resources », Information and
Software Technology, 43(8): 487–496. July 2001.
[DBRA05] J. Darmont, O. Boussaïd, J.C. Ralaivao, K. Aouiche, "An Architecture
Framework for Complex Data Warehouses", 7th International Conference on
Enterprise Information Systems (ICEIS 05), Miami, USA, May 2005,370-373.
[DG02] A.Danna, O.Gandy. All the Glitters is not Gold: Digging Beneath the Surface
of Data Mining. J. Business Ethics, 2002.
[DHL+01] Dong G., Han J., Lam J., Pei J., Wang K., « Mining Multi-Dimensional
Constrained Gradients in Data Cubes », in Proceedings of the 27th
International Conference on Very Large Data Bases (VLDB‟2001), pp. 321–
330, Roma, Italy : Morgan Kaufmann. September 2001.
[Die00] T.G. Dietterich. Ensemble Methods in Machine Learning Int. Workshop on
Multiple Classifier Systems (MCS), 2000.
[FBB06] C. Favre, F. Bentayeb, O. Boussaïd, "A Rule-based Data Warehouse Model",
23rd British National Conference on Databases (BNCOD 06), Belfast,
Northern 1re land, July 2006; to appear in LNCS.

-96-
[FH00] Fu L., Hammer J., «CUBIST: a New Algorithm for Improving the Performance
of Ad-hoc OLAP Queries », in Proceedings of the 3rd ACM International
Workshop on Data warehousing and OLAP (DOLAP‟2000), pp. 72–79,
Washington, D.C., USA : ACM Press. November 2000.
[FR00] Favero E., Robin J., « Using OLAP and Data Mining for Content Planning in
Natural Language Generation », in Proceedings of the 5th International
Conference on Applications of Natural Language to Information Systems
(NLDB‟2000), pp. 164–175, Versailles, France : Lecture Notes in Computer
Science. June 2000.
[Fu05] Fu L., « Novel Efficient Classifiers Based on Data Cube », International
Journal of Data Warehousing and Mining, 1(3) :15–27. 2005.
[GC98a] Goil S., Choudhary A., « High Performance Data Mining Using Data Cubes on
Parallel Computers », in Proceedings of the 12th International Parallel
Processing Symposium (IPPS‟1998), pp. 548–555, Orlando, Florida, USA.
April 1998.
[GC98b] Goil S., Choudhary A., « High Performance Multidimensional Analysis and
Data Mining », in Proceedings of the 10th High Performance Networking and
Computing Conference (SC‟1998), Orlando, Florida, USA. November 1998.
[GC99] Goil S., Choudhary A.N., « A parallel Scalable Infrastructure for OLAP and
Data Mining », in Proceedings of the 3rd International Database Engineering
and Applications Symposium (IDEAS‟1999), pp. 178–186, Montreal, Canada :
IEEE Computer Society. August 1999.
[GC01] Goil S., Choudhary A.N., « PARSIMONY: An Infrastructure for Parallel
Multidimensional Analysis and Data Mining », Journal of Parallel and
Distributed Computing, 61(3) :285–321. March 2001.
[GCB+97] J.Gray, S.Chaudhuri , A.Bosworth, A. Layman, D.Riechart and M.Venkatrao.
Data Cube: A Relational Aggregate Operator Generalizing Group-By, Cross-
Tab, and Sub-Tables. J.Data Mining and Knowledge Discovery, 1997.

-97-
[GGR99] V.Ganti, J.Gehrke and R.Ramakrishnan. CACTUS-Clustering Categorical Data
Using Summaries. KDD 1999.
[GoCh97] S. Goil, A. Choudhary. High Performance Data Mining Using Data Cubes on
Parallel Computer. Journal of Data Mining and Knowledge Discovery, 1997,
Vol 1, N°.4, pp 391-417.
[GoCh98] S. Goil, A. Choudhary. High Performance Multidimensional Analysis and Data
Mining. In : High Performance Networking and Computing Conference
(SC‟98), novembre 1998, Orlando.
[GoCh99] S. Goil, A. Choudhary. A parallel Scalable Infrastructure for OLAP and Data
Mining, In: International Data Engineering and Applications Symposium
(IDEAS‟99), 2-4 août 1999, Montreal, Canada, pp 178.
[GoCh01] S. Goil, A. Choudhary. PARSIMONY: An Infrastructure for parallel
Multidimensional Analysis and Data Mining. Journal of parallel and distributed
computing, 2001, Vol 61, N°3, pp 285-321.
[HAH03] W. Hümmer, H. Andreas, B.G. Harde, "XCube: XML for Data Warehouses",
6th ACM International Workshop on Data warehousing and OLAP (DOLAP
03), New Orleans, USA, 2003, 33-40.
[Han97] J. Han. OLAP Mining: An Integration of OLAP with Data Mining. In:
Proceedings of the IFIP Conference on Data Semantics, octobre.1997, Leysin,
Switzerland, pp 1-11.
[Han98] J. Han. Toward On-line Analytical Mining in Large Databases. In : SIGMOD
Record, 1998, 27(1):97-107, 1998.
[HCC98] Han J., Chee S.H., Chiang J.Y., « Issues for On-Line Analytical Mining of
Data Warehouses », in Proceedings of the 1998 SIGMOD Workshop on
Research Issues on Data Mining and Knowledge Discovery (DMKD‟1998), pp.
2 :1–2 :5, Seattle, Washington, USA. June 1998.

-98-
[HDY99] Han J., Dong G., Yin Y., « Efficient Mining of Partial Periodic Patterns in
Time Series Database », in Proceedings of the 15th
International Conference on
Data Engineering (ICDE‟1999), pp. 106– 115, Sydney, Australia : IEEE
Computer Society. April 1999.
[HRH96] V. Harinarayan, A.Rajaraman and J.D? Ullman. Implementing Data Cubes
Efficiently. SIGMOD 1996.
[HT96] T. Hastie and R. Tibshirani. Discriminant Analysis by Gaussian Mixtures. J.
Royal Statical Societ, 1996.
[IKA02] Imielinski T., Khachiyan L., Abdulghani A., « Cubegrades: Generalizing
Association Rules », Data Mining and Knowledge Discovery, 6(3):219–258,
ISSN 1384-5810. 2002.
[Inm02] W.H. Inmon, "Building the Data Warehouse", Troisième edition, John Wiley
& Sons, 2002.
[Inm96] Inmon W.H., Building the Data Warehouse, John Wiley & Sons. 1996.
[Kim96] Kimball R., The Data Warehouse Toolkit , John Wiley & Sons. 1996.
[KHC97] Kamber M., Han J., Chiang J., « Metarule-Guided Mining of Multi-
Dimensional Association Rules Using Data Cubes », in Proceedings of the 3rd
International Conference on Knowledge Discovery and Data Mining
(KDD‟1997), pp. 207–210, Newport Beach, CA, USA : The AAAI Press.
August 1997.
[KL51] S. Kullback and R.A. Leibler. On information and sufficiency. Ann. Math.
Stat., 22:79-86, 1951.
[LBMD+00] Laurent A., Bouchon-Meunier B., Doucet A., Ganc¸arski S., Marsala C., «
Fuzzy Data Mining from Multidimensional Databases », in Proceedings of the
International Symposium on Computational Intelligence (ISCI‟2000), pp. 278–
283, Kosice, Slovakia. 2000.

-99-
[LGM00] Laurent A., Gancarski S., Marsala C., « Coopération entre un système
d‟extraction de connaissances floues et un système de gestion de bases de
données multidimensionnelles », in Rencontres Francophones sur la Logique
Floues et ses Applications (LFA‟2000), La Rochelle, France. 2000.
[LMP00] Lebart L., Morineau A., Piron M., Statistique exploratoire multidimensionnelle,
Paris : Dunold, 3e édition, édition. 2000.
[LR03] Q. Li and J. Racine. Nomparametic Estimation of Distributions with Categorical
and Continuous Data. J. Multivariate Analysis, 2003.
[LZBX06] Liu B., Zhao K., Benkler J., Xiao W., « Rule Interestingness Analysis Using
OLAP Operations », in Proceedings of the 12th ACM SIGKDD International
Conference on Knowledge Discovery and Data Mining (KDD‟2006), pp. 297–
306, Philadelphia, PA, USA : ACM Press. August 2006.
[MAD06] H. Mahboubi, K. Aouiche, J. Darmont, "Materialized View Selection by Query
Clustering in XML Data Warehouses", 4th International Multiconference on
Computer Science and Information Technology (CSIT 06), Amman, Jordan,
April 2006.
[MAF05] Messaoud R.B., Aouiche K., Favre C., « Une approche de construction
d‟espaces de représentation multidimensionnels dédiés à la visualisation », in
1ère journée francophone sur les Entrepôts de Données et l‟Analyse en ligne
(EDA‟2005), Revue des Nouvelles Technologies de l‟Information, pp. 34–50,
Lyon, France: Cépaduès Editions. Juin 2005.
[MBR04] Messaoud R.B., Boussaid O., Rabaséda S., « A New OLAP Aggregation Based
on the AHC Technique », in Proceedings of the 7th ACM International
Workshop on Data Warehousing and OLAP (DOLAP‟2004), pp. 65–72,
Washington D.C., VA, USA : ACM Press. November 2004.

-100-
[MBR05] Messaoud R.B., Boussaid O., Rabaséda S.L., « Evaluation of a MCA-Based
Approach to Organize Data Cubes », in Proceedings of the 14th ACM
International Conference on Information and Knowledge Management
(CIKM‟2005), pp. 341–342, Bremen, Germany : ACM Press. October –
November 2005.
[MBR06a] Messaoud R.B., Boussaid O., Rabaséda S.L., « A Data Mining- Based OLAP
Aggregation of Complex Data: Application on XML Documents »,
International Journal of Data Warehousing and Mining, 2(4) :1–26. 2006.
[MBR06b] Messaoud R.B., Boussaid O., Rabaséda S.L., « Efficient Mul-tidimensional
Data Representation Based on Multiple Correspondence Analysis », in
Proceedings of the 12th ACM SIGKDD International Conference on
Knowledge Discovery and Data Mining (KDD‟2006), pp. 662–667,
Philadelphia, PA, USA : ACM Press. August 2006.
[MBR06c] Messaoud R.B., Boussaid O., Rabaséda S.L., « Mining Association Rules in
OLAP Cubes », in Proceedings of the 1st International Conference on
Innovations in Information Technology (IIT‟2006), Dubai, UAE : IEEE
Communications Society. November 2006.
[MBR06d] Messaoud R.B., Boussaid O., Rabaséda S.L., « Using a Factorial Approach for
Efficient Representation of Relevant OLAP Facts », in Proceedings of the 7th
International Baltic Conference on Databases and Information Systems
(DB&IS‟2006), pp. 98–105, Vilnius, Lithuania: IEEE Communications
Society. July 2006.
[MFT01] D. Margaritis, C. Faloutsos and S.Thrun. NetCube: A Scalable Tool for Fast
Data Mining and Compression. VLDB, 2001.
[Mit97] T. Mitchell. Machine Learning, McGraw Hill, 1997.

-101-
[MRBB04] Messaoud R.B., Rabaséda S., Boussaid O., Bentayeb F., « OpAC : Opérateur
d‟analyse en ligne bas´e sur une technique de fouille de données », in 4èmes
Journées francophones d‟Extraction et de Gestion des Connaissances
(EGC‟2004), volume 2 de Revue des Nouvelles Technologies de l‟Information,
pp. 35–46, Clermont-Ferrand, France. Janvier 2004.
[MRBM06] Messaoud R.B., Rabas´eda S.L., Boussaid O., Missaoui R., « Enhanced Mining
of Association Rules from Data Cubes », in Proceedings of the 9th ACM
International Workshop on Data Warehousing and OLAP (DOLAP‟2006), pp.
11–18, Arlington, VA, USA : ACM Press. November 2006.
[MHW00] Maedche A., Hotho A., Wiese M., « Enhancing Preprocessing in Data-
Intensive Domains using Online-Analytical Processing », in Proceedings of the
2nd International Conference on Data Warehousing and Knowledge Discovery
(DaWaK‟2000), pp. 258–264, London, UK : Springer. September 2000.
[MJBN06] Missaoui R., Jatteau G., Boujenoui A., Naouali S., Data Warehouses and
OLAP : Concepts, Architectures and Solutions, chapitre Towards Integrating
Data Warehousing with Data Mining Techniques, Idea Group Inc. February
2006.
[MPC96] Meo R., Psaila G., Ceri S., « A New SQL-like Operator for Mining Association
Rules », in Proceedings of the 22nd International Conference on Very Large
Data Bases (VLDB‟1996), pp. 122–133, Bombay, India : Morgan Kaufmann.
September 1996.
[MRB05] Messaoud R.B., Rabaséda S., Boussaid O., « L‟analyse factorielle pour la
construction de cubes de données complexes », in 2ème atelier Fouille de
Données Complexes (FDC‟2005), pp. 53–56, Paris, France. Janvier 2005.
[MRBB04] Messaoud R.B., Rabaséda S., Boussaid O., Bentayeb F., « OpAC : Opérateur
d‟analyse en ligne bas´e sur une technique de fouille de données », in 4èmes
Journées francophones d‟Extraction et de Gestion des Connaissances
(EGC‟2004), volume 2 de Revue des Nouvelles Technologies de l‟Information,
pp. 35–46, Clermont-Ferrand, France. Janvier 2004.

-102-
[MRBM06] Messaoud R.B., Rabaséda S.L., Boussaid O., Missaoui R., « Enhanced Mining
of Association Rules from Data Cubes », in Proceedings of the 9th ACM
International Workshop on Data Warehousing and OLAP (DOLAP‟2006), pp.
11–18, Arlington, VA, USA : ACM Press. November 2006.
[MTV94] Mannila H., Toivonen H., Verkamo I., « Efficient Algorithm for Discovering
Association Rules », in Proceedings of the AAAI Workshop on Knowledge
Discovery in Databases (KDD‟1994), pp. 181–192, Seattle, Washington, USA:
AAAI Press. July 1994.
[NNQ04] Naouali S., Nachouki G., Quafafou M., « Mining OLAP Cubes: Semantic
Links Based on Frequent Itemsets », in Proceedings of the 1st International
Conference on Information & Communication Technologies: from Theory to
Applications (ICTTA‟2004), pp. 447–449, Damascus, Syria : IEEE Section
France. April 2004.
[NNT03] Niemi T., Nummenmaa J., Thanisch P., « Normalising OLAP Cubes for
Controlling Sparsity », Data & Knowledge Engineering , 46(3) :317–343.
2003.
[NRDR05] V. Nassis, R. Rajagopalapillai, T.S. Dillon, W. Rahayu, "Conceptual and
Systematic Design Approach for XML Document Warehouses", International
Journal of Data Warehousing and Mining, 1(3),2005,63-87.
[ORS98] Ozden B., Ramaswamy S., Silberschatz A., « Cyclic Association Rules », in
Proceedings of the 14th International Conference on Data Engineering
(ICDE‟1998), pp. 412–421, Orlando, Florida, USA : IEEE Computer Society.
February 1998.
[Pal00] Palpanas T., « Knowledge Discovery in Data Warehouses », SIGMOD Record
– ACM Special Interest Group on Management of Data, 29(3): 88–100. 2000.
[Par97] Parsaye K., « OLAP and Data Mining: Bridging the Gap », Database
Programming and Design, 10: 30–37. 1997.

-103-
[PCY95] Park J.S., Chen M.S., Yu P.S., « An Effective Hash-Based Algorithm for
Mining Association Rules », SIGMOD Record, 24(2): 175– 186, ISSN 0163-
5808. 1995.
[PHS05] B.K. Park, H. Han, I.Y. Song, "XML-OLAP: A Multidimensional Analysis
Framework for XML Warehouses", 7th International Conference on Data
Warehousing and Knowledge Discovery (DaWaK 05), Copenhagen, Denmark,
32-42.
[Pok01] J. Pokorny, "Modelling Stars Using XML", 4th ACM Internatio
nal Workshop on Data Warehousing and OLAP (DOLAP 01), Atlanta, USA,
24-31.
[Qui86] Quinlan J.R., « Induction of Decision Trees », Machine Learning, 1 :81–106.
1986.
[Qui86] Quinlan J.R., C4.5: Programs for Machine Learning, Morgan Kaufmann, 1993.
[RF01] Robin J., Favero E., « HYSSOP: Natural Language Generation Meets
Knowledge Discovery in Databases », in Proceedings of the 3rd
International
Conference on Information Integration and Web-based Applications and
Services (iiWAS‟2001), pp. 243–256, Linz, Austria: Austrian Computer
Society. September 2001.
[RMS98] Ramaswamy S., Mahajan S., Silberschatz A., « On the Discovery of Interesting
Patterns in Association Rules », in Proceedings of the 24th
International
Conference on Very Large Data Bases (VLDB‟1998), pp. 368–379, New York
City, NY, USA : Morgan Kaufmann. August 1998.
[RRT05] L.I. Rusu, J.W. Rahayu, D. Taniar, "A Methodology for Building XML Data
Warehou ses", International Journal of Data Warehousing and Mining, 1 (2),
2005, 23-48.

-104-
[SA96] Srikant R., Agrawal R., « Mining Quantitative Association Rules in Large
Relational Tables », in Proceedings of the ACM SIGMOD International
Conference on Management of Data (SIGMOD‟1996), pp. 1–12, Montreal,
Quebec, Canada : ACM Press. June 1996.
[SAM98] Sarawagi S., Agrawal R., Megiddo N., « Discovery-driven Exploration of
OLAP Data Cubes », in Proceedings of the 6th International Conference on
Extending Database Technology (EDBT‟1998), pp. 168– 182, Valencia, Spain:
Springer. Mars 1998.
[Sar99] Sarawagi S., « Explaining Differences in Multidimensional Aggregates », in
Proceedings of the 25th International Conference on Very Large Data Bases
(VLDB‟1999), pp. 42–53, Edinburgh, Scotland, UK: Morgan Kaufmann.
September 1999.
[Sar01] Sarawagi S., «iDiff: Informative Summarization of Differences in
Multidimensional Aggregates », Data Mining and Knowledge Discovery, 5(4):
255–276(22). October 2001.
[SBMU98] Silverstein C., Brin S., Motwani R., Ullman J., « Scalable Techniques for
Mining Causal Structures », Data Min. Knowl. Discov., 4(2-3) :163–192, ISSN
1384-5810. 1998.
[SDRK02] Sismanis Y., Deligiannakis A., Roussopoulos N., Kotidis Y., « Dwarf :
Shrinking the PetaCube », in Proceedings of the ACM SIGMOD International
Conference on Management of Data (SIGMOD‟2002), pp. 464–475, Madison,
Wisconsin, USA : ACM Press. 2002.
[SON95] Savasere A., Omiecinski E., Navathe S.B., « An Efficient Algorithm for
Mining Association Rules in Large Databases », in Proceedings of the 21st
International Conference on Very Large Data Bases (VLDB‟1995), pp. 432–
444, Zurich, Switzerland : Morgan Kaufmann. September 1995.
[STA98] Sarawagi S., Thomas S., Agrawal R., « Integrating Association Rule Mining
with Relational Database Systems: Alternatives and Implications », in

-105-
Proceedings of the 1998 ACM SIGMOD International Conference on
Management of Data (SIGMOD‟1998), pp. 343–354, Seattle, Washington,
USA: ACM Press. 1998.
[TNBP00] Teusan T., Nachouki G., Briand H., Philippe J., « Discovering Association
Rules in Large, Dense Databases », in Proceedings of the 4th European
Conference on Principles of Data Mining and Knowledge Discovery
(PKDD‟2000), pp. 638–645, Lyon, France: Springer. September 2000.
[Toi96] Toivonen H., « Sampling Large Databases for Association Rules », in
Proceedings of the 22nd International Conference on Very Large Data Bases
(VLDB‟1996), pp. 134–145, Mumbai (Bombay), India : Morgan Kaufmann.
September 1996.
[TT05] Tjioe H.C., Taniar D., « Mining Association Rules in Data Warehouses »,
International Journal of Data Warehousing and Mining, 1(3): 28–62. 2005.
[UBDB04] Udréa C., Bentayeb F., Darmont J., Boussaid O., « Intégration efficace de
méthodes de fouille de données dans les SGBD », in 4èmes Journées
Francophones d‟Extraction et de Gestion des Connaissances (EGC‟2004),
Clermont-Ferrand, France. Janvier 2004.
[VW99] Vitter J.S., Wang M., « Approximate Computation of Multidimensional
Aggregates of Sparse Data Using Wavelets », in Proceedings of the ACM
SIGMOD International Conference on Management of Data (SIGMOD‟1999),
pp. 193–204, Philadelphia, PA, USA : ACM Press. June 1999.
[WF00] I.H. Witten and E. Frank. Data Mining: Practical Machine Learning Tools with
Java Implementations, Morgan Kaufmann, 2000.
[Zhu98] Zhu H., On-Line Analytical Mining of Association Rules, Master‟s thesis,
Simon Fraser University, Burnaby, British Columbia, Canada. December 1998.
[ZRL99] Zhang T., Ramakrishnan R. and Livny M., Fast density estimation using CF-
kernel for large databases. KDD 1999.

-106-
Liste des figures
1.1 Du système OLTP au système OLAP
1.2 Processus d‟extraction des connaissances à partir des données
2.1 Les trois approches du couplage des techniques de fouille avec l‟analyse en ligne
2.2 Coopération entre SGBDM et Algorithme d‟apprentissage
2.3 Pré-traitement des données avec les outils OLAP [MHW00]
2.4 Architecture d‟un système intégrant SGBD, OLAP et MOLAP [Fu05]
2.5 Exemple d‟une exploration d‟un cube à trois dimensions dans DBMiner [Han97]
2.6 L‟architecture du moteur distribué de génération de règles d‟association
2.7 Architecture de l‟implémentation « Discovery-driven »
3.1 Objectifs du couplage OLAP & DM
3.2 Étapes de la réorganisation d‟un cube de données par approche factorielle
3.3 Cube de données à deux dimensions
3.4 Exemple d‟un cube de données de ventes
3.5 Exemple de transformation d‟un tableau disjonctif complet en tableau de contingence
de Burt
3.6 Exemple en 2 dimensions de la notion de voisinage des cellules d‟un cube de données
3.7 Premier plan factoriel construit par l‟ACM à partir des données démographiques
3.8 Représentation du cube des données démographiques avant l‟arrangement des
modalités
3.9 Représentation du cube des données démographiques après l‟arrangement des
modalités
3.10 Etapes de l‟agrégation par classification dans les cubes de données
3.11 Agrégation (a) classique dans le contexte OLAP et (b) agrégation par classification
3.12 Choix de la technique de classification
3.13 Formalisation théorique de l‟opérateur OpAC
3.14 Etapes de l‟explication dans les cubes de données par règle d‟association

-107-
3.15 Opérations possibles dans un cubegrade [IKA02]
3.16 Exemple d‟un sous-cube de données dans le cube des ventes
4.1 Exemple de dimension hiérarchique
4.2 Visualisation du 𝜎 𝑊𝐼, 86 𝐷
4.3 Exemple de différents niveaux de cube

-108-
Liste des tableaux
1.1 OLTP versus OLAP
2.1 Comparaison des propositions de couplage de l‟OLAP et de la fouille de données
selon la 1ére
approche : Adaptation des données multidimensionnelles.
2.2 Comparaison des propositions de couplage de l‟OLAP et de la fouille de données
selon la 1éme
approche : Extension de l‟analyse OLAP et des langages de requêtes
2.3 Comparaison des propositions de couplage de l‟OLAP et de la fouille de données
selon la 3éme
approche : Adaptation des techniques de fouille de donnée
3.1 Exemple de transformation d‟un cube de données en tableau disjonctif complet
3.2 Description des dimensions du cube des données démographique
3.3 Nouvel ordre des modalités de la dimension D2 du cube des données démographiques
3.4 Aplatissement d‟un cube de données pour l‟extraction de règles inter dimensionnelles
[Zhu98]
3.5 Aplatissement d‟un cube de données pour l‟extraction de règles intra dimensionnelles
[Zhu98]
3.6 Exemple de fonctionnement de l‟algorithme Vavg [TT05]
3.7 Exemple de fonctionnement de l‟algorithme Havg [TT05]

-109-
Tables de matière
Remerciements
Résumé
Introduction générale
Etat d‟art
2.1 Introduction
2.2 Comparaison des propositions de couplage de l‟OLAP et de la fouille de
données selon la 1ére
approche : Adaptation des données
multidimensionnelles
2.3 Comparaison des propositions de couplage de l‟OLAP et de la fouille de
données selon la 2éme
approche : Extension de l‟analyse OLAP et des
langages de requêtes
2.4 Comparaison des propositions de couplage de l‟OLAP et de la fouille de
données selon la 3éme
approche : Adaptation des techniques de fouille de
donnée
2.5 Conclusion
Opérateurs de couplage entre OLAP et DM
3.1 Introduction
3.2 Réarrangement d‟un cube par analyse factorielle (ACM):
Opérateur ORCA
3.3 Agrégation par classification dans les cubes de données (CAH) :
Opérateur OPAC
3.4 Explication par recherche guidée de règles d‟association dans un cube:
Opérateur AROX
3.5 Conclusion
Cubes de prédiction
4.1 Introduction
4.2 Contributions et futures directions
1
8
10
7
15
19
24
31
28
27
48
74
56
76
76
75
i
ii

-110-
4.3 Exemple de motivation
4.4 Modèles prédictifs
4.5 Les cubes de prédiction
4.6 Conclusion et perspective
Conclusion générale
5.1 Bilan et contributions
5.2 Perspectives de recherche
Bibliographie
Liste des figures
Liste des tableaux
Tables de matière
77
78
81
89
90
90
91
106
108
109
93


















