
UNIVERSITÉ DU QUÉBEC EN OUTAOUAIS …w4.uqo.ca/dii/etudMaitrise/uploads/4.pdftechnique optimale...
83
UNIVERSITÉ DU QUÉBEC EN OUTAOUAIS DÉTECTION EFFICACE DE CONTOURS D’IMAGES MÉMOIRE PRÉSENTÉ COMME EXIGENCE PARTIELLE DE LA MAÎTRISE EN INFORMATIQUE PAR GUESDON VINCENT OCTOBRE 2004
Transcript of UNIVERSITÉ DU QUÉBEC EN OUTAOUAIS …w4.uqo.ca/dii/etudMaitrise/uploads/4.pdftechnique optimale...

UNIVERSITÉ DU QUÉBEC EN OUTAOUAIS
DÉTECTION EFFICACE DE CONTOURS D’IMAGES
MÉMOIRE
PRÉSENTÉ
COMME EXIGENCE PARTIELLE
DE LA MAÎTRISE EN INFORMATIQUE
PAR
GUESDON VINCENT
OCTOBRE 2004

UNIVERSITÉ DU QUÉBEC EN OUTAOUAIS
Département d’informatique et d’ingénierie
Ce mémoire intitulé :
DÉTECTION EFFICACE DE CONTOURS D’IMAGES
présenté par
Vincent Guesdon
pour l’obtention du grade de maître ès sciences (M.Sc.)
a été évalué par un jury composé des personnes suivantes :
Rokia Missaoui………….Directrice de recherche
Marek Zaremba………..………Président du jury
Nadia Baaziz………………..…..Membre du jury
Mémoire accepté le : 12 octobre 2004

ii
Remerciement
- Madame Rokia Missaoui pour son soutien et ses conseils tout au long
de ce mémoire.
- Mr Sarifuddin Madenda pour son aide dans le domaine du traitement
d’image
- Les musées du Québec pour les images qu’ils nous ont fournies
- Ganaël de l’équipe du laboratoire LARIM (Laboratoire de Recherche
en Information Multimédias) de l’UQO
- Céline, Guitta, Radhoine et Ghislaine du laboratoire LATECE de
l’UQAM
- Au Consortium CoRIMedia pour son soutien financier.

iii
Résumé
La détection des contours d’une image est une opération non triviale puisqu’il
existe un grand nombre de détecteurs et que chaque détecteur a des performances
différentes suivant les caractéristiques de l’image et les valeurs affectées aux paramètres
du détecteur. Les caractéristiques retenues dans cette étude sont le bruit, le flou,
l’homogénéité, les niveaux de détail et l’entropie.
Puisqu’une image peut comporter un ensemble de zones avec des caractéristiques
distinctes, ce mémoire de maîtrise propose une approche automatisée de détection de
contours qui décompose d’abord une image en zones homogènes, puis applique le
détecteur le plus approprié aux caractéristiques de chacune des zones identifiées. La
première étape fait appel aux arbres quaternaires et à des estimateurs des caractéristiques
de l’image pour la décomposition de l’image en zones homogènes. La deuxième étape est
rendue possible grâce à un travail préliminaire d’analyse et d’expérimentation d’une
sélection de détecteurs de contours et d’identification d’un ensemble de règles
heuristiques de détermination du détecteur le plus approprié aux caractéristiques de
l’image.
L’approche est validée sur un banc d’essai d’images et s’est avérée plus
performante que l’application d’un seul détecteur sur la totalité de l’image.

iv
Abstract
Edge detection in digital images is a non trivial operation because there are a lot
of detectors and each detector has different performances according to image
characteristics (noise, blur, homogeneity, levels of detail and entropy) and parameter
values of the selected detectors.
Since an image can contain a lot of regions with distinct characteristics, this
document proposes an automatic approach to edge detection, which decomposes a
picture into homogeneous zones and applies the best detector to the identified regions
based on the own characteristics. The first step of the approach makes use of quadtrees
and estimators of image characteristics to decompose images into homogeneous regions.
The second step is made possible due to a preliminary experimental study that aims to
construct a set of heuristic rules for the determination of the detectors that are more
appropriate to (and more performant according to) the characteristics of a given image.
The approach is validated on a image benchmark and proved to be more powerful
and efficient than the application of a unique detector on the whole image.

Table des matières
Table des figures………………………………...…………………………….………….vi
Chapitre 1............................................................................................................................ 1 Introduction......................................................................................................................... 1 Chapitre 2............................................................................................................................ 4 État de l’art.......................................................................................................................... 4
2.1 – Caractéristiques des images et des contours .......................................................... 4 2.2 – Détecteurs de contours ......................................................................................... 12 2.3 – La transformée en ondelettes ............................................................................... 19
Chapitre 3.......................................................................................................................... 22 Détection de contours ....................................................................................................... 22
3.1 – Le banc d’essai..................................................................................................... 22 3.2 – Estimation du bruit............................................................................................... 24 3.3 – Estimation du flou................................................................................................ 29 3.4 – Niveau de détail et entropie ................................................................................. 33 3.5 – Découpage d’une image en arbre quaternaire...................................................... 35 3.6 – Choix d’un détecteur............................................................................................ 40
Chapitre 4.......................................................................................................................... 45 Analyse expérimentale...................................................................................................... 45
4.1 – Analyse des résultats............................................................................................ 45 Chapitre 5.......................................................................................................................... 51 Conclusion ........................................................................................................................ 51 Bibliographies ................................................................................................................... 52 ANNEXE A ...................................................................................................................... 55 Résultats des détecteurs usuels ......................................................................................... 55 ANNEXE B ...................................................................................................................... 62 Tableaux d’analyse de détecteurs ..................................................................................... 62 ANNEXE C ...................................................................................................................... 73 Résultats DECAP.............................................................................................................. 73

vi
Table des figures
Figure 2.1 : Profil de contours : marche, rampe, toit, pic 7 Figure 2.2 : Triangle invisible pour un ordinateur 8 Figure 2.3 : Exemples d’erreur sur les contours 9 Figure 2.4 : Exemple d’un filtrage des hautes fréquences 12 Figure 2.6 : Schéma de filtrage pour les ondelettes 20 Figure 2.7 : ondelette de Haar 20 Figure 3.1 : Images du cameraman, du babouin et de Lena 23 Figure 3.2 : Résultats des images les plus connues 23 Figure 3.3 : Image Lena et image Lena bruitée 24 Figure 3.4 : Dérivation Image Lena et dérivation Lena bruitée 25 Figure 3.5 : Image Simple 26 Figure 3.6 :Image Hétérogène (Flou par endroit) 26 Figure 3.7 :Image avec beaucoup de détails 26 Figure 3.8 : Bruit de force 35 et bruit de force 85 27 Figure 3.9 :Estimation du bruit pour la figure 3.5 27 Figure 3.10 : Estimation du bruit pour la figure 3.6 28 Figure 3.11 : Estimation du bruit pour la figure 3.7 28 Figure 3.12 : Effet du flou sur une image 29 Figure 3.13, 3.14 et 3.15 : Graphes liés à l’image 3.12 30 Figure 3.16, 3.17 et 3.18 : Estimation du flou pour les figures 3.5, 3.6 et 3.7 32 Figure 3.19 : Représentation d’une image en arbres quaternaires 36 Figure 3.20 : Découpage de la figure 3.6 38 Figure 3.21 : Absence de découpage des figures 3.5 et 3.7 38 Figure 3.22 : Image dont la zone sud-Est est bruitée 39 Figure 3.23 : Arbre de l’image de la figure 3.22 39 Figure 3.24 : Arbre Quaternaire et indexation par points 40 Figure 3.25 : Image Lena et image Cellules 41 Figure 3.26 : Remarque sur le contour de type marche 42 Figure 3.27 : contours pour un contour de type impulsion 43 Figure 3.28 : Exemple de contour sur un dessin au crayon papier 43 Figure 4.1 : Contours marche, rampe, impulsion et rampe 45 Figure 4.2 : Tableau de résultats de notre détecteur 45 Figure 4.3 :Lena avec tache de bruit 47 Figure 4.4 : image avec zone sud ouest bruitée 47 Figure 4.5 : Détecteur Prewitt sur les figures 4.3 et 4.4 47 Figure 4.6 : Détecteur MIRA avec variance de 1.0 sur les figures 4.3 et 4.4 48 Figure 4.7 : Détecteur MIRA avec variance = 1.5 sur les figures 4.3 et 4.4 48 Figure 4.8 : Détecteur MIRA avec variance 2.5sur les figures 4.3 et 4.4 49 Figure 4.9 : découpage des images des figures 4.3 et 4.4 49 Figure 4.10 : résultats obtenu à partir du découpage des figures 4.3 et 4.4 50

Chapitre 1
Introduction
La détection de contours au sein d’une image est une caractéristique importante
du processus de recherche d’images selon le contenu. Face à un nombre important de
techniques et filtres de détection de contours, il peut être difficile de choisir l’approche la
plus adaptée à une collection spécifique d’images d’autant plus qu’il n’existe pas de
technique optimale pour tous les cas de figures. Par ailleurs, les techniques de détection
de contours analysent souvent une image dans sa globalité sans tenir compte des
spécificités des composantes de l’image.
Pour mener à bien cette opération de détection de contours et remédier à cet état
de fait, il est utile d’étudier dans un premier temps un ensemble de techniques et
d’analyser leur performance et adaptabilité selon les caractéristiques des images dans leur
globalité (image synthétique ou réelle, floue ou nette, bruitée) et selon leurs composantes
(zones de haute fréquence versus basse fréquence). Ensuite, une nouvelle approche de
détection de contours sera proposée et comparée avec l’ensemble de détecteurs retenus.

Introduction
2
Finalement, les résultats de l’analyse seront présentés sous forme de règles heuristiques
de sélection de détecteurs.
L’extraction des contours est utilisée, dans la majorité des cas, pour faciliter
l’étude des détails de l’image. L’application la plus simple est le rehaussement des
contours lorsque ceux-ci sont trop flous. Cependant, l’utilisation de ces techniques sert
aussi à la recherche d’image selon le contenu, au repérage d’objets spécifiques dans des
images ou encore à reconstruire des objets en trois dimensions. Pour ce genre
d’application, il est indispensable d’extraire les contours des objets présents afin de
pouvoir les reconnaître ou les reconstruire. Extraire les contours est donc souvent un
prétraitement indispensable de l’image avant la réalisation d’autres traitements.
Lorsque l’on souhaite extraire des contours, nous remarquons très rapidement que
le nombre de techniques existantes est très grand et que chaque détecteur possède ses
propres caractéristiques. Cela est d’autant plus contraignant que les performances de ces
détecteurs varient suivant les caractéristiques des contours de l’image et des paramètres
associés aux détecteurs. Il faut donc essayer d’identifier le détecteur le plus adéquat à une
image donnée. Pour cela, il est nécessaire de déterminer les caractéristiques de bruit, de
netteté ou encore de continuité des contours. Autant de paramètres qu’il peut paraître
subjectif de déterminer à l’œil nu. Ziou et Koukam [10] ont traité de ce problème en
proposant une approche permettant de choisir un détecteur et ses paramètres en fonction
des caractéristiques des contours présents dans l’image. Cependant, depuis cette époque,
les techniques en matière de détection de contours ont évolué, en particulier avec la
méthode des ondelettes [3,4] qui a permis le développement des « curvelets » [12,13] et
des « contourlets » [5,6,9].
Dans le présent document, nous présentons le problème et les avantages qui
découlent de la résolution de ce problème, ensuite nous abordons le sujet des
caractéristiques des images, en particulier les caractéristiques des contours. Enfin, nous
faisons un état de l’art des différents détecteurs que nous avons choisi pour faire nos
comparaisons. Finalement, le but de notre travail est de déterminer les caractéristiques

Introduction
3
des contours et le ou les détecteurs le(s) plus adapté(s) à une image donnée. Une étude
empirique complète le mémoire et sert de validation de l’approche proposée.

Chapitre 2
État de l’art
2.1 – Caractéristiques des images et des contours
Afin de pouvoir choisir au mieux un détecteur, il est important de bien connaître
le principe des images numériques et aussi la nature des contours dans ces mêmes
images. Pour cela, nous allons présenter dans cette partie les caractéristiques de bas
niveau des images, et des moyens pour les extraire. Dans notre travail nous nous
intéressons essentiellement aux caractéristiques suivantes :
- Le bruit blanc Gaussien
- Le flou Gaussien
- L’entropie
- L’homogénéité de l’image
- Le niveau de détail.

État de l’art
5
2.1.1 – Représentation d’une image
Elle peut s’effectuer selon diverses caractéristiques comme la couleur ou selon des
coefficients tels les coefficients de Fourier ou d’ondelette. En informatique, le plus petit
élément visuel représentable à l’écran se nomme pixel. Une image est donc représentée
comme un tableau de pixels de différentes couleurs ou niveaux de gris.
La couleur :
La façon la plus simple de représenter une image numérique est de considérer des
matrices où chaque case représente une composante de la couleur de l’image. Il existe
ensuite plusieurs manières de coder la couleur d’une image, la plus connue étant le
codage RVB (où les composantes rouge, vert et bleu de chaque pixel sont codées). Mais
il existe aussi les représentations CMY (Cyan, Magenta, Yellow), YCbCr (Luminance,
Chrominances) qui sont très utilisées en détection de contours, surtout pour la
composante qui représente l’intensité lumineuse du pixel. Chacun des éléments de la
matrice est codé sur un certains nombre de bits ce qui correspond à un certain nombre de
niveaux. Par exemple, pour un pixel en niveaux de gris codé sur 8 bits, on a 28 = 256
niveaux de gris différents, donc chaque élément du tableau est compris entre 0 et 255.
Le système de couleur RGB n’est pas un espace uniforme dans le sens où la
distance euclidienne entre deux couleurs RGB ne correspond pas à une différence de
couleur perceptible par un être humain. Pour cette raison, la Commission Internationale
de l’Éclairage (CIE) a défini deux espaces de couleur uniforme Lab et Luv. Nous allons
présenter ici l’espace Lab [26] (luminance, teinte, saturation) car ce système va être
utilisé dans le cadre de ce travail. Pour convertir une couleur de l’espace RGB vers Lab,
il faut passer par un espace intermédiaire défini par le CIE de la façon suivante :
BGRZBGRYBGRX
950227.0119193.0019334.0(1) 072169.0715160.0212671.0
180423.0357580.0412453.0
++=++=++=
On définit ensuite :

État de l’art
6
(4) )()(200
(3) )()(500
(2) 16)(116
⎥⎦
⎤⎢⎣
⎡−=
⎥⎦
⎤⎢⎣
⎡−=
−=
nn
nn
n
ZZf
YYfb
YYf
XXfa
YYfL
Où (5) sinon
11616787.7
0.008856q si )(
31
⎪⎩
⎪⎨
⎧
+
>=
q
qqf
nX , nY et nZ représentent un blanc de référence défini par la CIE et obtenu avec R = G =
B = 100.
Les coefficients de Fourier
La deuxième représentation la plus utilisée consiste à calculer les coefficients de
Fourier de l’image et à stocker ces coefficients dans une matrice. On obtient donc une
représentation fréquentielle de l’image. Cela revient aussi à considérer l’image comme un
signal 2D. Pour obtenir ces coefficients, on applique l’algorithme de la transformée de
Fourier directement aux pixels de l’image avec la formule suivante [8] :
(6) ),(),(0 0
)(2
∑∑= =
+−
=p
y
q
x
Nvyxui
eyxfvuFπ
Avec f un signal 2D, x et y les coordonnées dans l’espace, p et q les dimensions du
signal et N = p*q, et u,v les coordonnées dans l’espace de Fourier. Pour des raisons
d’efficacité, on utilisera l’algorithme de la transformée de Fourier rapide [8] qui n’est pas
expliqué dans ce document.
Les coefficients d’ondelette
La représentation par la transformée en ondelette devient de plus en plus un élément
important en traitement d’image. Elle permet une représentation fréquentielle d’un signal

État de l’art
7
mais permet de connaître éventuellement les variations temporelles des composantes
fréquentielles. De plus, il est possible d’appliquer la transformée en ondelette à la
résolution voulue.
C’est à partir de ces différentes représentations de l’image que nous allons essayer
par la suite de déterminer les contours d’une image.
2.1.2 – Les contours
Définition :
Dans une image, un contour peut être considéré de différentes manières. Nous
allons décrire ici trois principales manières de considérer un contour :
Premièrement, un contour peut être vu comme un changement brusque de l’intensité
de l’image [2,8]. Il existe plusieurs types de variations comme le montre la figure 2.1.
figure 2.1 : Profil de contours : marche, rampe, toit, pic
Deuxièmement, une façon très proche de celle citée ci-dessus est de considérer les
contours comme une différence sur la couleur.
Troisièmement, si on considère l’image comme étant un signal 2D, on peut passer
dans le domaine fréquentiel (par transformée de Fourier ou d’ondelette par exemple).
Dans ce cas, un contour peut être vu comme représentant les hautes fréquences du signal.
Cependant, ces représentations sont parfois insuffisantes pour représenter un
contour. À titre d’exemple, nous remarquons que parfois notre cerveau est capable de
repérer des contours invisibles sur l’image car il a la capacité d’utiliser ses connaissances
pour extraire des formes d’une image. Par exemple, le cerveau humain est capable de voir
le triangle dans l’image suivante.

État de l’art
8
figure 2.2 : Triangle invisible pour un ordinateur
Cependant, nous verrons que dans certains cas nous pouvons quand même
détecter le triangle grâce à des techniques spécifiques comme par exemple les
algorithmes de Hough [2] ou des algorithmes d’objets saillants [25].
Caractéristiques des contours
Au même titre que les caractéristiques visuelles de couleur et texture, les contours
ont également leurs particularités qu’il ne faut pas négliger. D’une part, il peuvent être de
différents types (cf. figure 2.1) et d’autre part, tous les détecteurs n’ont pas la même
performance face à chaque type de contour. Pour cela, nous allons définir une nouvelle
approche d’extraction des particularités des contours et de l’image afin de prévoir quel
détecteur sera le plus efficace.
Afin d’estimer l’efficacité des détecteurs, Ziou et Nguyen ont référencé six erreurs
[15] rencontrées lors de la détection de contours :
- Omission de certains pixels sur le contour à détecter. Elle se mesure en comptant
le nombre de pixels oubliés par rapport au nombre total de pixels du contour idéal
(cf. figure 2.3 b).
- Réponses multiples par la détection de plusieurs contours. Elle se mesure en
comptant le nombre de pixels ambigus par rapport à ceux qui ne le sont pas (cf.
figure 2.3 d).

État de l’art
9
- Localisation : cette erreur se produit quand un pixel d’un contour idéal non
ambigu n’est pas à la bonne place. Elle se mesure en comptant la distance totale
entre le contour détecté et le contour idéal. (cf. figure 2.3 c).
- Sensibilité : Cette erreur est souvent liée au bruit et correspond à de faux contours
détectés à proximité du contour idéal. Elle se mesure en comptant le nombre de
faux contours et le nombre total de contours détectés (cf. figure 2.3 e).
- Fausses suppressions de contours à la suite généralement d’un seuillage. Cette
erreur peut être évitée en s’assurant que l’intensité lumineuse d’un vrai contour
est plus forte que celle d’un faux contour.
- Orientation : Cette erreur survient quand l’orientation d’un contour n’est pas
correcte. Elle se mesure en calculant la différence entre l’orientation estimée et la
vraie orientation pour tous les vrais contours.
Les deux dernières erreurs sont difficiles à représenter.
Pour pouvoir connaître avec précision le contour idéal, Ziou et Nguyen [15] ont
utilisé des images synthétiques définies à partir de fonctions mathématiques. Ainsi, ils
peuvent choisir le type de contour (marche, rampe, toit, pic) et connaître sa position
exacte.
figure 2. 3 : Exemples d’erreur sur les contours, a: contour idéal, b: Omission, c:
délocalisation, d: réponses multiples, e: sensibilité.

État de l’art
10
Enfin, pour l’estimation des erreurs sur les contours, Zhu [24] a proposé une
évaluation des détecteurs sans connaître a priori les contours et a défini un ensemble de
règles. Ces dernières peuvent être estimées à partir des pixels voisins de ceux considérés
comme faisant partie d’un contour par le détecteur. Les règles retenues sont :
- Les contours ne doivent pas être trop épais et l’épaisseur sera préférablement de la
taille d’un pixel.
- Les contours doivent avoir une certaine continuité. Par exemple, la taille
minimum d’un contour correct doit être de deux pixels alors qu’un contour de
taille égal à un pixel représente du bruit dans l’image.
- La connexion entre les contours doit être assez importante. On propose que 90 %
des contours soient reliés à un autre contour, et que seulement 10 % aient des
bouts qui terminent le contour.
- La séparation des contours : les contours doivent être facilement identifiables les
uns par rapport aux autres, il ne faut pas que deux contours différents se touchent
de façon parallèle sur toute leur longueur. Ainsi, deux contours doivent être
séparés par au moins un pixel.
L’évaluation de Zhu des détecteurs se base ensuite sur l’image des contours détectés
et sur un ensemble de fenêtres de taille 3*3 qui permettent d’analyser chaque point
contour et ses voisins. Pour faire cette analyse, l’auteur détermine, sur la base des règles
précédemment décrites, quels cas sont viables pour un contour et quels cas ne le sont pas,
et ceci pour tous les cas possibles sur une fenêtre 3*3.
Pour le choix d’un bon détecteur, Ziou et Koukam [10] ont proposé une approche
utilisant principalement l’erreur de localisation, l’erreur d’omission, la continuité des
caractéristiques des points formant le contour ainsi que des caractéristiques du détecteur
comme le temps d’exécution et le rapport signal sur bruit (SNR). Ce dernier se calcule
sur la base de la formule ci-après en considérant une image dont les contours idéaux sont
connus :
∑∑
=
yx
rx
yxe
yxfSNR
,
2,
2
),(
),(
avec ),(),(),( yxfyxfyxe −′= (8)
)log(10 SNRSNRdB = (9)

État de l’art
11
où f représente l’image des contours idéaux, e l’erreur et f ′ l’image des contours
réels. Les variables x et y sont les coordonnées dans l’espace. Lorsque SNR tend vers
l’infini, la qualité de la détection est considérée parfaite, et quand 0=dBSNR (c’est à dire
SNR = 1) la qualité de la détection est mauvaise.
Dans ce travail, nous visons à identifier les détecteurs et les paramètres les plus
appropriés à divers cas de figures d’images. Pour cela, on s’intéresse à identifier des
caractéristiques de l’image par une estimation du flou et du bruit. Puis, par des
expérimentations sur une variété d’images et de détecteurs, on essaie d’établir des règles
de choix de détecteurs. La validation de l’approche se base sur les coefficients de Zhu et
sur les calculs d’erreurs sur les contours.
2.1.3 – Définition du filtrage
Afin de détecter les contours, nous allons, dans la majorité des algorithmes,
utiliser un filtrage linéaire afin d’appliquer les équations de détection à l’image [2,8]. Le
filtrage d’un signal consiste à éliminer certaines fréquences dans ce signal (cf. figure 4).
Il y a deux principales techniques pour appliquer un filtrage linéaire à une image :
La première consiste à faire une convolution de l’image avec le filtre. Si on
considère le filtre h de taille n*m et une image I de taille p*q, alors la convolution s’écrit :
∑ ∑−= −=
++=2/
2/
2/
2/),(),(),)(*(
n
nk
m
mllkhljkiIjihI (10)
Ou i varie dans [0,p-1] et j varie dans [0,q-1].
La deuxième technique consiste à passer par la transformée de Fourier. On peut
alors montrer que :
)()()*( hTFITFhITF = (11)
Dans la pratique, lorsque cela est possible, on essaie d’estimer le filtre dans ce
qu’on appelle un masque de convolution ce qui est équivalent à faire la convolution. Dans
le cas des images, il s’agit d’un tableau contenant les valeurs de h(k,l).

État de l’art
12
Figure 2.4 : Exemple d’un filtrage des hautes fréquences
2.1.4 – Résultats
En vue de valider les travaux qui seront effectués dans le cadre de ce mémoire,
nous utiliserons une collection d’image naturelles (fleurs, personnages, médicales,
paysages) et synthétiques (issues de fonctions mathématiques). Ainsi, il est possible de
définir les principales caractéristiques des détecteurs grâce aux images synthétiques dont
nous connaissons les propriétés et la localisation exacte des contours [15,10]. Nous
pourrons ensuite déterminer les performances sur des images réelles [24] ce qui nous
permettra d’estimer les performances suivant le type d’image (bruit, flou, peu de détails,
beaucoup de détails etc…). Cette étape nous permettra par la suite de choisir plus
facilement et de manière objective un détecteur par rapport à certaines propriétés de
l’image.
2.2 – Détecteurs de contours
Dans cette partie, nous présentons un aperçu des détecteurs les plus connus et les
plus représentatifs. La majorité des détecteurs sont basés sur des principes similaires et
proposent des convolutions de l’image avec des filtres de lissage et de dérivation. Nous
présenterons ici des détecteurs issus des techniques de dérivation des images (Robert,
Sobel, Prewitt, Kirsch. Canny et Dériche) en expliquant leurs différences au niveau des
filtres utilisés.

État de l’art
13
2.2.1 – Principe de la détection par dérivation
Lorsque l’on considère un contour comme une variation de l’intensité lumineuse,
on pense tout naturellement à la dérivation pour déterminer les variations de l’image.
Dans ce cas, on applique généralement la dérivation à la luminance de l’image. Cette
dérivation va donc annuler les zones de faibles variations (intensités uniformes) et
retourner de forts coefficients lors de variations importantes (contours) [2,8].
Tout d’abord, afin de pouvoir effectuer une dérivation à l’image, il va falloir
discrétiser les équations de dérivation car on ne peut appliquer une dérivation continue
sur une fonction discrète. L’élément minimal étant le pixel, les dérivées premières dans
les directions x et y s’écrivent :
),(),1(),( yxIyxIyxdxdI
−−= et ),()1,(),( yxIyxIyxdydI
−−= (12)
Nous allons présenter des filtres qui une fois appliqués à l’image selon le principe
de filtrage défini au paragraphe 2.1.3, donnent une image résultante correspondant à des
dérivées. Par exemple, les filtres correspondant aux dérivées partielles en x et en y
d’ordre 1 sont :
[ ]11 − et ⎥⎦
⎤⎢⎣
⎡−11
Les deux principales techniques de détection de contour utilisant les dérivations sont :
- L’approche du gradient qui consiste à extraire les zéros de la dérivée seconde dans
la direction du gradient.
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛=
dydI
dxdI
G (13)
- L’approche Laplacien qui revient à chercher les pixels où le Laplacien s’annule.
2
2
2
2
),(dy
Iddx
IdyxL += (14)

État de l’art
14
On peut calculer le Laplacien grâce aux filtres d’approximation suivants :
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−
−
010141
010 ou
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−−−−−−
111181111
Dans la suite, nous verrons plusieurs détecteurs basés sur la dérivation discrète
d’une image. Comme la manière de faire cette dérivation n’est pas unique, il existe un
grand nombre de filtres permettant d’approcher les résultats. Ce sont ces filtres que nous
présentons maintenant.
2.2.2 – Détecteur Robert
La technique de détection proposée par Robert [8] est une application directe du
calcul du gradient et consiste à utiliser deux filtres linéaires pour calculer les dérivées
dans les directions π/4 et 3π/4 :
⎥⎦
⎤⎢⎣
⎡−1001
et ⎥⎦
⎤⎢⎣
⎡− 01
10
Ce détecteur est malheureusement très localisé et donc très sensible au bruit, ce
qui nuit grandement à ses performances. Les autres sont moins sensibles au bruit et
offrent de meilleurs résultats.
2.2.3 – Détecteurs Sobel et Prewitt
Ces détecteurs [8] utilisent un filtre linéaire qui a l’avantage d’effectuer deux
opérations en même temps, soit un lissage de l’image et une dérivation. Ils restent
sensibles au bruit mais donnent de bons résultats sur des images non bruitées. Voici les
deux filtres impliquant un opérateur horizontal et un opérateur vertical.
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−− 1100011
α
α et
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−
1010
101αα

État de l’art
15
α = 1 pour Prewitt
α = 2 pour Sobel
Ces opérateurs calculent les variations dans seulement deux directions et ont
tendance à donner des contours légèrement épais, ce qui dans certains cas peut être
gênant. Cependant, il existe des détecteurs qui font des rotations sur les coefficients des
filtres pour inclure des dérivées dans d’autres directions. C’est ce que fait le détecteur
suivant.
2.2.4 – Détecteur de Kirsch
Lorsque plusieurs contours se rejoignent en un point, la détection sur seulement
deux directions peut être insuffisante. La détection de Kirsch utilise huit filtres calculant
les contours dans huit directions différentes. Cependant, les faibles résultats et la lourdeur
de ce détecteur font qu’il est peu utilisé.
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−−−
335305335
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−−−
333305355
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−−−
333303
555 …
Les autres filtres sont obtenus en continuant la rotation des coefficients.
Il est aussi possible d’utiliser les huit filtres dans ces mêmes directions pour les
dérivations de Sobel et Prewitt.
Les techniques suivantes utilisent des filtres différents pour calculer les contours. Plutôt
qu’une simple dérivation, on filtre l’image avant de la dériver.
2.2.5 – Méthode de Marr et Hildreth
Marr et Hildreth [1] ont développé une technique permettant de régler le problème
du bruit dans les images dont on veut détecter les contours. Ils ont fait une convolution de
l’image avec un Laplacien d’une gaussienne (LoG filter). Cela permet de supprimer du
bruit qui aurait été détecté par le Laplacien seul. Mais il faut cependant ajuster la variance

État de l’art
16
de la Gaussienne en fonction du type d’image à traiter. Un filtre de variance trop large
dégrade trop l’image (en la rendant trop floue et en éliminant les contours) et une
variance trop faible conduit à une détection de bruit trop importante.
Dans le cas continu, l’opérateur de Marr et Hildreth correspond à la convolution
de l’image de coordonnées x et y par l’opérateur dérivée seconde d’une Gaussienne de
varianceσ .
En deux dimensions, le filtre Gaussien s’écrit :
2
22
222
1),( σσ πσ
yx
eyxG+
−= (15)
2.2.6 – Filtre de Canny
Canny a proposé un filtre optimal pour la détection d’un contour idéal noyé dans
un bruit blanc Gaussien [18,19]. Le filtre proposé est optimal en localisation et maximise
le rapport signal sur bruit. Dans ce contexte, un contour idéal est représenté par une
fonction de Heaviside :
⎩⎨⎧
=10
)(tH sisi
00
≤>
tt
La solution à ce problème est la fonction suivante :
(16) )cos()sin()cos()sin()( 4321 cstewteawteawteawteatC tttt ++++= −− αααα
Canny a proposé des conditions qui permettent de trouver les coefficients de la solution.
Cependant cette solution étant difficile à mettre en œuvre, il l’a approchée par la fonction
dérivée première d’une Gaussienne.
Par la suite, Dériche [20,21] a repris les travaux de Canny et a proposé une solution
exacte au problème avec une qualité bien meilleure.
Filtre de dérivateur : t
D etCtF α−−= ..)( 1 (17)

État de l’art
17
Filtre de lissage : t
D etKtH αα −+= |)|1()( (17a)
Dériche a ensuite proposé une implémentation de cette solution sous forme
récursive en implémentant un lissage de l’image puis une dérivation avec les équations
suivantes :
Lissage :
MmmymymiMmmyemyemxemxeKmy
MmmyemyemxemxKmy
,..,1 )()()(1,.., ),2()1(2 )]2()1()1([)(
,..,1 ),2()1(2)]1()1()([)(22
2
=+=
=−−−++−++=
=−−−+−−+=
−+
+−+−−−−
+−+−−+
αααα
ααα
α
α
(18)
Dérivateur :
Mmmymymi
MmmyemyemxCmy
MmmyemyemxCmy
,..,1 )()()(
1,.., )2()1(2)1()(
,..,1 )2()1(2)1()(2
1
21
=+=
=+−+++=
=−−−+−=
−+
−−−−−
+−+−+
αα
αα
(19)
où αα
α
α 2
2
21)1(
−−
−
−+−
=ee
eK et ααα 21 211
−− −+=
eeC
Avec x une ligne ou une colonne de l’image, y+ et y- des signaux
intermédiaires pour les calculs et i est la ligne ou la colonne résultante.
2.2.7 – Le détecteur MIRA
Le détecteur MIRA (Multimedia Information Retrieval Application) a été
développé dans le laboratoire LARIM de l’Université du Québec en Outaouais (UQO)
[29]. Ce détecteur utilise comme Canny le filtre Gaussien et sa dérivée première,
cependant il propose une détection directionnelle plus élaborée qui permet une meilleure
identification des contours en forme de ligne directionnelle, en coin et de forme
circulaire. On rappelle les formules de la Gaussienne et de sa dérivée :

État de l’art
18
2
2
2
2
23
2
2)('
21)( σσ
πσπσ
xx
exxfetexf−− −
== (20)
Où σ représente la variance et x représente les coordonnées d’un signal à une dimension.
Afin de détecter les contours dans une image (2D), le détecteur MIRA définit plusieurs
filtres bidimensionnels de la façon suivante :
22
22
22
22
..)().('),(
..)(').(),(
22
11
σ
σ
yx
yx
exCyfxfyxF
eyCyfxfyxF+
+
−
−
−==
−==(21)
Où x et y représentent les coordonnées d’un pixel de l’image, F1 représente le filtre dans
la direction x et F2 le filtre dans la direction y. Enfin, pour détecter les contours en
forme de ligne directionnelle, en coin ou en forme circulaire, il suffit d’introduire une
rotation dans les coordonnées des filtres pour obtenir des filtres circulaires :
22
22
22
22
)cos.sin..()','(
).sin.cos..()','(
11
22
σ
σ
θθ
θθyx
yx
eyxCyxF
eyxCyxF+
+
−
−
+−−=
+−=(22)
θ représente un angle entre 0 et 90 degrés, et C1 et C2 sont des constantes de
normalisation des filtres. Ainsi, nous pouvons maintenant appliquer les filtres dans toutes
les directions souhaitées afin de détecter au mieux les contours.
2.2.8 – Affinage des contours
Tous les détecteurs cités précédemment offrent des contours épais qui ne
correspondent pas aux critères de Zhu de bons contours. Puisque nous avons décidé
d’utiliser les critères de Zhu pour mesurer l’efficacité des détecteurs, nous allons utiliser
sur tous nos détecteurs un algorithme d’affinage des contours développé dans le
laboratoire LARIM de l’UQO [29]. Cet affinage s’effectue suivant la direction de
détection des contours sur chacun des filtres d’un détecteur. Ainsi, la formule suivante
donne l’affinage des contours détectés par le filtre dans la direction θ :

État de l’art
19
( )( ) )23(
)(),(),(),()(),(),(0
),(⎪⎩
⎪⎨⎧
++>
++≤=
byaxEyxEsiyxEbyaxEyxEsi
yxEϕϕϕ
ϕϕϕ
et
( )( )⎪⎩
⎪⎨⎧
−−>
−−≤=
)(),(),(),()(),(),(0
),(111111
111111 byaxEyxEsiyxE
byaxEyxEsiyxE
ϕϕϕ
ϕϕϕ (24)
Avec ., 11 yhyetxwx −=−= Les paramètres w et h sont respectivement la largeur et
la hauteur d’image,ϕ représente la direction du contour, ϕE est l’image avec les
contours de cette direction. Les valeurs a et b sont déterminées selon la direction de
contours comme suit : - contours horizontaux a = 0 et b = 1,
- contours verticaux a = 1 et b = 0,
- contours diagonaux 450 a = -1 et b = 1
- contours diagonaux 1350 a = 1 et b = 1
2.3 – La transformée en ondelettes
Dans cette partie, nous n’allons pas nous intéresser directement à des détecteurs
de contours. Nous aborderons une technique récente d’analyse du signal nommée
transformée en ondelette qui permet de représenter les hautes fréquences de l’image à
différentes résolutions. Puisque les contours d’une image peuvent être considérés comme
les hautes fréquences, la transformée en ondelette peut alors permettre d’afficher les
contours. Nous n’aborderons par la théorie au complet mais seulement la manière
d’utiliser ces ondelettes.
2.3.4 - L’analyse multi résolution
De même qu’il existe une implémentation efficace de la transformée de Fourier
dans le domaine discret, il existe une implémentation discrète de la transformée en
ondelette. Son avantage, en plus de donner une représentation temps – fréquences est
d’avoir une complexité en O(N), où N est le nombre d’échantillons du signal [ 3, 4, 7].

État de l’art
20
L’analyse multi-résolution consiste à utiliser deux filtres complémentaires h
(passe haut) et g (passe bas) calculés à partir des fonctions d’échelle (pour réduire ou
augmenter la résolution d’étude du signal) et d’ondelette (pour calculer les coefficients
d’ondelette). On applique ensuite le filtrage suivant le schéma ci-après :
Figure 2.6 : Schéma de filtrage pour les ondelettes
La figure 2.7 montre le résultat de l’application de la transformée en ondelette de
Haar à une image et identifie les groupes de fréquence (BB, HB, BH et HH) obtenus à
chacune des deux premières résolutions. BB représente les basses fréquences du filtrage
des lignes et des colonnes alors que HB exprime les hautes fréquences des lignes et les
basses fréquences des colonnes. BH délimite les hautes fréquences des colonnes et les
basses fréquences des lignes alors que HH représente les hautes fréquences du filtrage des
lignes et des colonnes.
Figure 2.7 : deux premiers niveaux de résolutions d’une ondelette de Haar

État de l’art
21
Les ondelettes de Mallat qui seront utilisées dans notre travail utilisent les filtres h
et g discrets suivant :
}265571.468858,0.0.265571,0{}0.2655710.531142,--0.265571,{
==
hg
(25)
Cette analyse du signal va nous permettre d’extraire des contours par les
ondelettes. En effet, nous remarquons que la zone HB correspond aux contours verticaux,
BH aux contours horizontaux et HH aux contours diagonaux. Par la suite, la détection des
contours par ondelette reviendra essentiellement à choisir une ondelette appropriée ainsi
que la bonne résolution. Afin de conserver au mieux les contours, nous n’effectuerons pas
de sous-échantillonnage lors des filtrages.

Chapitre 3
Détection de contours
Nous allons dans cette partie expliquer les algorithmes et techniques que nous
avons utilisé pour extraire les caractéristiques des images comme le bruit, le flou
l’homogénéité, le niveau de détail et l’entropie. Ensuite nous décrirons la structure de
données employée pour stocker nos images et leurs caractéristiques et présenterons la
méthode de sélection d’un détecteur en fonction de ces caractéristiques.
3.1 – Le banc d’essai
Afin de tester notre application de manière efficace, nous avons conçu un banc
d’essai contenant 123 images qui ont été sélectionnées suivant les critères suivants :
- Les images contiennent des objets de domaines très différents (vie courante,
paysages, dessins, radiographies, images de musée, images synthétiques …)
- Certaines images contiennent du flou ou des zones floues
- Certaines images contiennent du bruit ou des zones bruitées.
Détection de contours
23
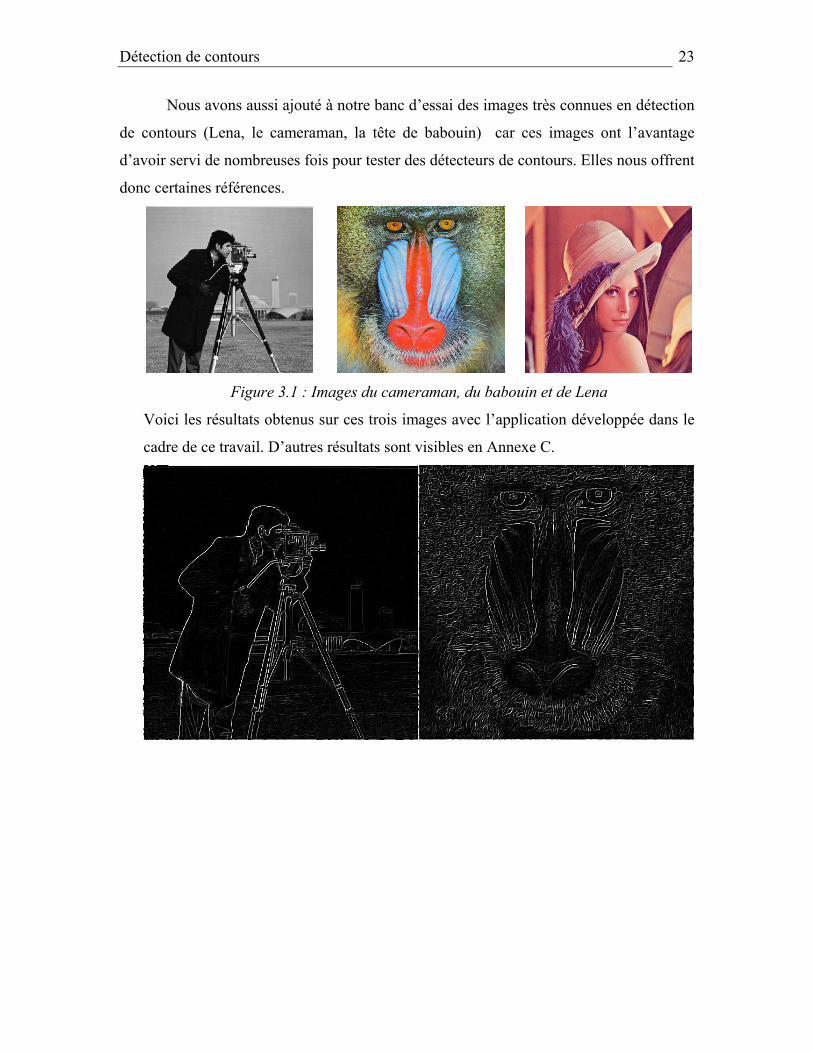
Nous avons aussi ajouté à notre banc d’essai des images très connues en détection
de contours (Lena, le cameraman, la tête de babouin) car ces images ont l’avantage
d’avoir servi de nombreuses fois pour tester des détecteurs de contours. Elles nous offrent
donc certaines références.
Figure 3.1 : Images du cameraman, du babouin et de Lena
Voici les résultats obtenus sur ces trois images avec l’application développée dans le
cadre de ce travail. D’autres résultats sont visibles en Annexe C.

Détection de contours
24
Figure 3.2 : Résultats des images les plus connues
3.2 – Estimation du bruit Il sera essentiel dans notre travail d’avoir une certaine estimation du bruit. Cela
nous permettra, entre autres, de choisir la variance la plus appropriée à l’élimination du
bruit dans l’image. Le bruit étant dans les hautes fréquences de l’image, nous allons
utiliser un filtre passe haut afin de laisser passer uniquement les hautes fréquences, c'est-
à-dire le bruit et les contours. Le filtre le plus simple qui permet de laisser passer les
hautes fréquences est la dérivation. Nous allons donc dériver notre image puis essayer
d’en extraire une information utile.
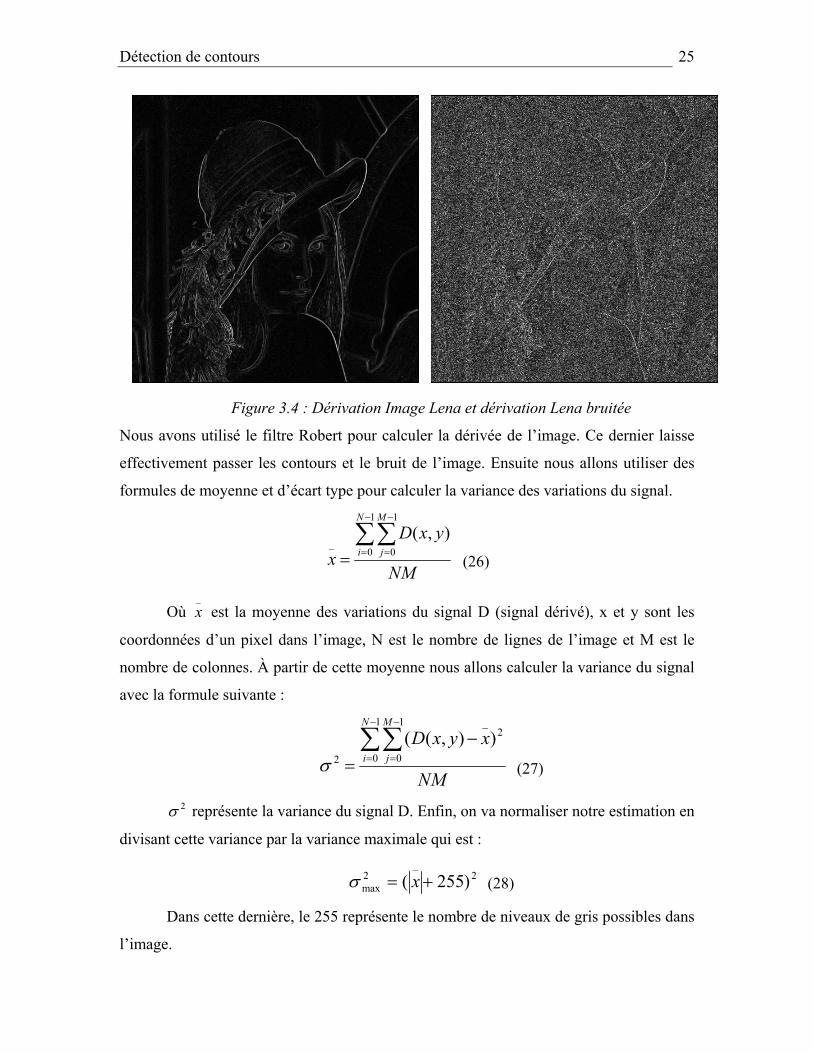
Figure 3.3 : Image Lena et image Lena bruitée
Le bruit analysé est un bruit blanc Gaussien additif. Maintenant regardons le résultat de la
dérivation de chacune de ces images.
Détection de contours
25
Figure 3.4 : Dérivation Image Lena et dérivation Lena bruitée
Nous avons utilisé le filtre Robert pour calculer la dérivée de l’image. Ce dernier laisse
effectivement passer les contours et le bruit de l’image. Ensuite nous allons utiliser des
formules de moyenne et d’écart type pour calculer la variance des variations du signal.
NM
yxDx
N
i
M
j∑∑−
=
−
==
1
0
1
0_
),( (26)
Où _x est la moyenne des variations du signal D (signal dérivé), x et y sont les
coordonnées d’un pixel dans l’image, N est le nombre de lignes de l’image et M est le
nombre de colonnes. À partir de cette moyenne nous allons calculer la variance du signal
avec la formule suivante :
NM
xyxDN
i
M
j∑∑−
=
−
=
−=
1
0
1
0
2_
2
)),(( σ (27)
2σ représente la variance du signal D. Enfin, on va normaliser notre estimation en
divisant cette variance par la variance maximale qui est :
2_
2max )255( += xσ (28)
Dans cette dernière, le 255 représente le nombre de niveaux de gris possibles dans
l’image.

Détection de contours
26
Résultats de cet estimateur
Nous avons testé l’estimateur sur trois images différentes pour avoir un premier aperçu
avant de l’utiliser sur notre benchmark.
Figure 3.5 : image simple Figure 3.6 : Image hétérogène (Flou par endroit)
Figure 3.7 : Image avec beaucoup de détail.
Afin de tester notre estimateur, nous avons appliqué à l’image originale un bruit blanc
Gaussien additif de plus en plus fort suivant la formule suivante :
Pour chaque pixel (x,y) de l’image :
- On utilise un générateur pseudo-aléatoire pour obtenir un nombre aléatoire à
partir d’une distribution de probabilité Gaussienne
- On multiplie cette valeur par le poids que l’on souhaite pour notre bruit (un
nombre entre 1 et 100 valable pour toute l’image).

Détection de contours
27
- On ajoute le résultat au pixel courant.
Figure 3.8 : Bruit de force 35 et bruit de force 85
Maintenant nous allons appliquer le bruit avec une force de plus en plus élevée allant de
1 à 100 pour tracer la courbe de notre estimateur de bruit.
Estimation/bruit
0
0,05
0,1
0,15
0,2
0,25
0 20 40 60 80 100 120
bruit
estim
atio
n
Series1
Figure 3.9 : Estimation du bruit pour l’image de la figure 3.5
Détection de contours
28
Estimation/bruit
00,050,1
0,150,2
0,250,3
0,350,4
0 20 40 60 80 100 120
bruit
Estim
atio
n
Series1
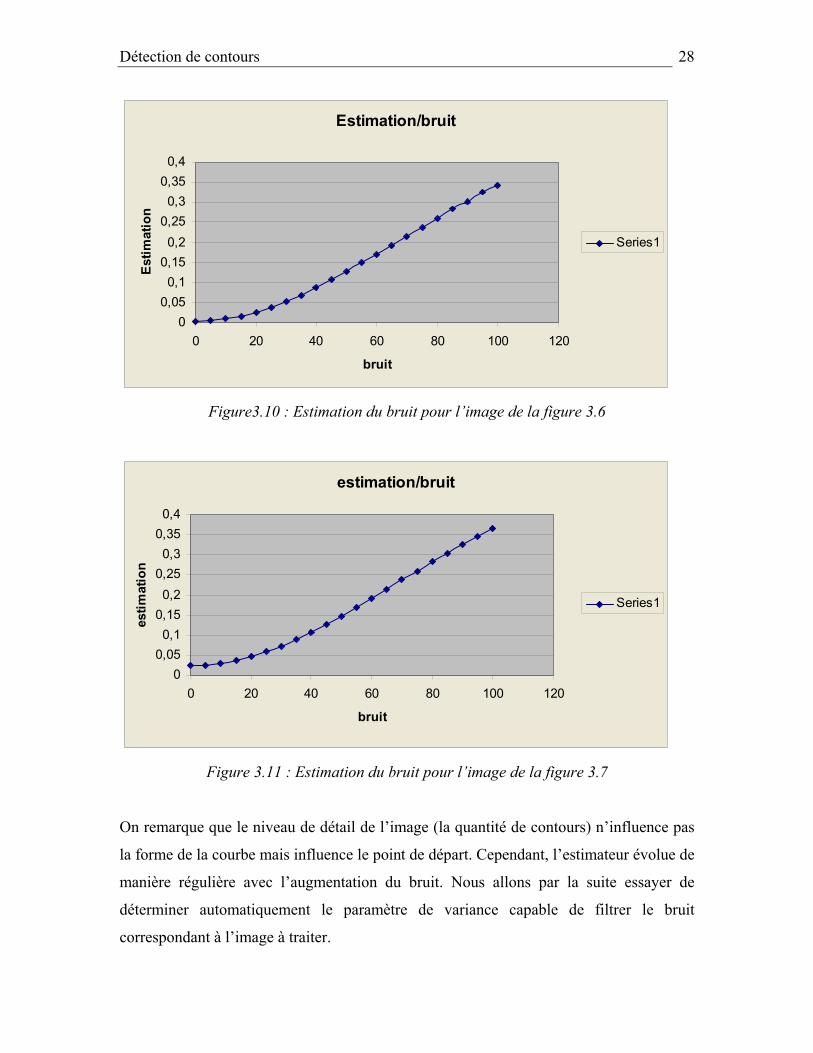
Figure3.10 : Estimation du bruit pour l’image de la figure 3.6
estimation/bruit
00,050,1
0,150,2
0,250,3
0,350,4
0 20 40 60 80 100 120
bruit
estim
atio
n
Series1
Figure 3.11 : Estimation du bruit pour l’image de la figure 3.7
On remarque que le niveau de détail de l’image (la quantité de contours) n’influence pas
la forme de la courbe mais influence le point de départ. Cependant, l’estimateur évolue de
manière régulière avec l’augmentation du bruit. Nous allons par la suite essayer de
déterminer automatiquement le paramètre de variance capable de filtrer le bruit
correspondant à l’image à traiter.

Détection de contours
29
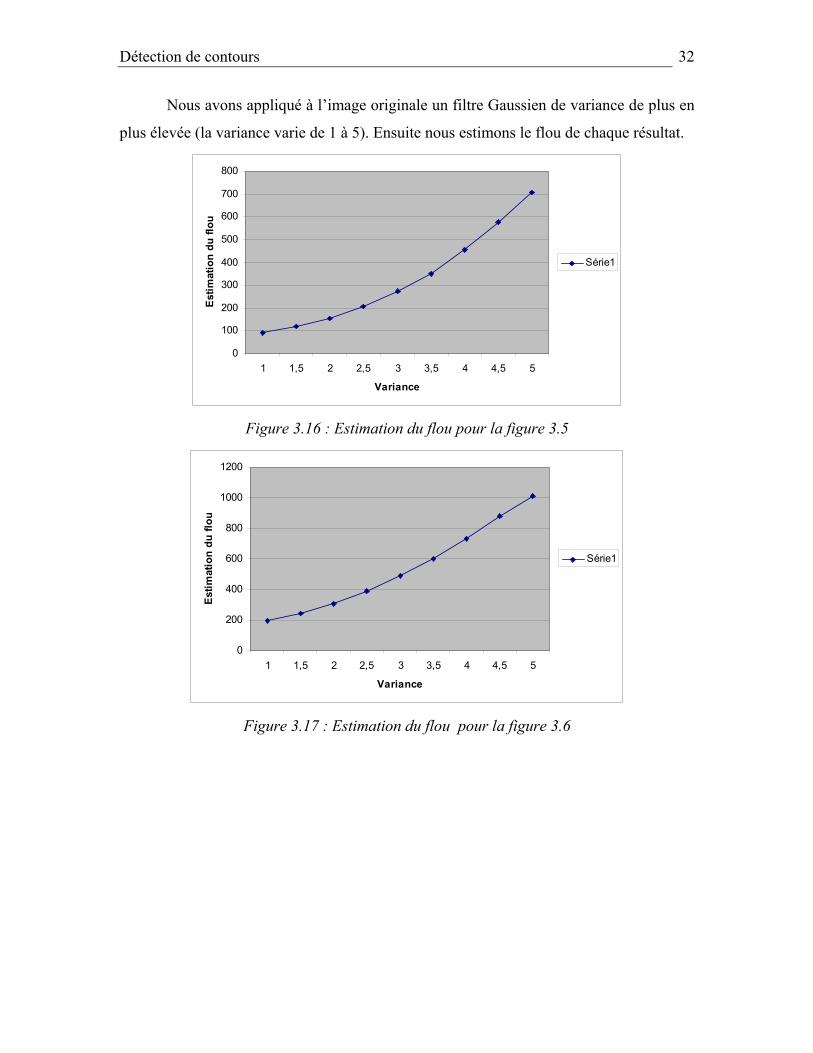
3.3 – Estimation du flou Afin d’obtenir une estimation globale du flou dans une image, il nous a fallu
élaborer une formule. Dans la majorité des cas, lorsque l’on souhaite quantifier du flou, il
est nécessaire de connaître les paramètres de prise de vue de l’image (focal de la lentille,
distances) [27]. Cependant, lorsque nous avons affaire à des images dont les paramètres
ne sont pas connus, il faut trouver une autre solution. L’estimation que nous allons
utiliser se base sur une remarque très simple et permet d’estimer globalement la quantité
de flou gaussien dans une image.
Le principe que nous allons utiliser est le suivant : Plus une image est floue, moins
elle sera affectée par un filtre gaussien. Ou encore, plus un signal est lisse moins le
lissage aura d’effet sur lui.
Figure 3.12 : (a) – image originale, (b) – image (a) après un filtrage gaussien de
variance 2, (c) - même image que (b) , (d) – image (c) après une filtrage Gaussien de 2.
Gaussienne Variance = 2
Gaussienne Variance =
a a b
c a d

Détection de contours
30
Regardons maintenant les graphes des variations des niveaux de gris de la ligne centrale
de ces images.
Figure 3.13 : graphe image (a)
Figure 3.14 : Graphes images (b) et (c)
Figure 3.15 : Graphe image (d)

Détection de contours
31
On remarque que la différence entre les images (a) et (b) est plus importante que
celle entre les images (c) et (d) alors que le filtrage est le même. Ceci est dû uniquement
au fait que (c) est plus floue que (a).
Pour observer cette différence de manière plus concrète nous procèderons avec la logique
suivante : supposons f(x,y) représentant l’image originale, f’(x,y) représente l’image
filtrée par une gaussienne et e(x,y) est la différence entre f et f’. Nous calculons ensuite le
rapport entre l’image originale f(x,y) et l’effet d’une gaussienne e(x,y) comme suit :
∑∑
=
yx
rxff yxe
yxfdiff
,
2,
2
', ),(
),(
avec ),(),(),( yxfyxfyxe −′= (29)
Nous rappelons que plus les images sont similaires, plus le e(x,y) tendra vers zéro et donc
EF sera grand. Ici nous avons :
18.50, =badiff
43.143, =dcdiff (plus de flou)
Enfin plutôt que d’estimer le flou directement sur l’image originale, nous avons préféré
estimer l’évolution du flou de l’image entre deux variances, ceci pour mesurer l’évolution
de l’effet de la gaussienne par rapport aux mêmes références quelque soit l’image à
analyser. Ainsi pour estimer le flou d’une image I, nous allons la filtrer par une
gaussienne de variance 1 ce qui donnera une image I1, puis nous filtrerons I par une
gaussienne de variance 4 qui donnera l’image I2. Notre estimateur de flou est alors
calculé par :
Estimation du flou EF = 2,1 IIdiff (30)
Résultats de cet estimateur
Nous avons effectué un test préliminaire de l’estimateur de flou sur trois images
différentes (cf. figures 3.5, 3.6 et 3.7) avant de l’utiliser sur notre banc d’essai.
Détection de contours
32
Nous avons appliqué à l’image originale un filtre Gaussien de variance de plus en
plus élevée (la variance varie de 1 à 5). Ensuite nous estimons le flou de chaque résultat.
0
100
200
300
400
500
600
700
800
1 1,5 2 2,5 3 3,5 4 4,5 5
Variance
Est
imat
ion
du fl
ou
Série1
Figure 3.16 : Estimation du flou pour la figure 3.5
0
200
400
600
800
1000
1200
1 1,5 2 2,5 3 3,5 4 4,5 5
Variance
Estim
atio
n du
flou
Série1
Figure 3.17 : Estimation du flou pour la figure 3.6

Détection de contours
33
0
50
100
150
200
250
300
350
400
450
500
1 1,5 2 2,5 3 3,5 4 4,5 5
Variance
Estim
atio
n du
flou
Série1
Figure 3.18 : Estimation du flou pour la figure 3.7
Il est important de retenir que cet estimateur est global et ne permet pas de savoir
où se situent les zones floues. Il permet juste de savoir si l’image dans sa globalité
contient du flou. L’estimation peut donc donner des résultats difficiles à analyser dans le
cas où l’image contient des zones très nettes et des zones très floues.
3.4 – Niveau de détail et entropie Il est important lorsque nous allons étudier nos images de pouvoir savoir si elles
contiennent beaucoup ou peu de détails. Une image contenant beaucoup de détails sera
traitée différemment d’une image très homogène. Pour cela nous allons calculer deux
coefficients, l’entropie et le niveau de détail.
L’entropie
L’entropie est très utilisée en compression de données. Elle permet de quantifier
la quantité d’information contenue dans une donnée. Si on prend une image de N pixels
où chaque pixel varie entre 0 et 255 niveaux de gris, on appelle in le nombre de pixels
pour le niveau de gris i. Alors la probabilité qu’un pixel x soit de la couleur i est :

Détection de contours
34
Nn
ixP i=∈ )( (31)
On définit l’entropie de l’image par la formule suivante :
∑=
∈∈−=255
0
))(log(*)()Image(i
ixPixPH (32)
Prenons maintenant quelques images et analysons leur entropie. Nous appelons I1
l’image de la figure 3.6, I2 l’image de la figure 3.5 et I3 l’image de la figure 3.7.
On trouve comme résultats : H(I1) = 5.16 , H(I2) = 1.51 et H(I3) = 5.31
On en déduit donc facilement que l’image I2 contient beaucoup moins
d’information que les images I1 et I3. Ceci nous servira dans le choix des détecteurs de
contours, puisque lorsqu’une image contient très peu d’information, il suffira d’utiliser un
détecteur de contour très simple (comme Robert par exemple).
Niveau de détails
Le niveau de détails de l’image est une donnée supplémentaire que nous utilisons
pour estimer la quantité de contours présents dans l’image. Pour cela, nous examinons
l’histogramme des niveaux de gris de l’image. Plus l’image contient de niveaux de gris
différents plus le niveau de détail va être important. On calcule donc cette valeur avec la
formule suivante :
gris deniveau de Nombre imagel' de ehistogramml' dans nulsnon gris deniveaux de Nombre)Image( =D (33)
On obtient les résultats suivants sur les trois images précédentes :
D(I1) = 0.65 , D(I2) = 0.003 et D(I3) = 0.88.
Homogénéité
L’homogénéité de l’image est une donnée qui va nous permettre de savoir si les
niveaux de gris présents dans l’image sont très dispersés dans l’image ou s’ils forment
des zones de couleur homogène. Pour cela, on va analyser chaque pixel avec ses 8 plus
proches voisins. S’il existe une différence de niveau de gris supérieure à un seuil entre le
pixel et l’un des ses voisins, alors on incrémente le résultat de 1. On divise le résultat
final par le nombre de pixels afin d’obtenir un coefficient entre 0 et 1.

Détection de contours
35
Les résultats obtenus sur les trois images sont :
Homog(I1) = 0.27, Homog(I2) = 0.89 et Homog(I3) = 0.03.
Le premier avantage de ces calculs est de pouvoir déterminer approximativement
le type d’image à laquelle nous avons affaire. Ainsi, nous pouvons à partir de ces valeurs
déterminer que l’image I2 contient peu de détails et des zones très homogènes tandis que
l’image I3 contient beaucoup de détails et peu de zones homogènes (donc un grand
nombre de contours ou beaucoup de bruit). Maintenant que nous avons extrait les
caractéristiques, il va falloir utiliser une structure adaptée pour découper nos images et
conserver l’information.
3.5 – Découpage d’une image en arbre quaternaire
Puisqu’une image peut comporter un ensemble de régions avec des propriétés
distinctes au niveau des caractéristiques, il serait intéressant de procéder à un découpage
automatique de l’image.
Pour cela, nous nous baserons sur une structure d’arbre quaternaire. Il s’agit d’un
arbre où chaque nœud possède 4 fils au plus. C’est une structure de données hiérarchique
qui trouve son application dans plusieurs domaines tels que l’infographie, le traitement
d’images, les systèmes d’information géographiques…
Une telle structure utilise la décomposition récursive pour délimiter des régions
d’un objet (ex. images) telle que les régions d’une image. Les arbres quaternaires peuvent
être différenciés selon :
- le type de données représentées
- le critère de décomposition
- la résolution (le nombre de décompositions à réaliser) : variable ou non
Implantation hiérarchique :
L’un des types d’arbres quaternaires les plus connus est celui basé sur les régions. Selon
le critère de décomposition qui peut être l’homogénéité de la couleur ou de la texture
d’une région d’une image, cette dernière est récursivement décomposée jusqu'à

Détection de contours
36
l’obtention de zones homogènes. Par exemple, chaque région va être décomposée en
quatre quadrants (carrés) identiques. Chaque quadrant est représenté par un nœud qui
aura quatre nœuds fils correspondant aux quatre sous-quadrants (NO :Nord-Ouest,
NE :Nord-Est, SO :Sud-Ouest et SE :Sud-est) du quadrant initial si ce dernier est
décomposé. La racine de l’arbre quaternaire représente l’image initiale.
Pour savoir à quelle partie de l’image correspond un nœud de l’arbre, on a besoin d’une
fonction d’identification des nœuds. Un façon de faire est de numéroter les nœuds par des
séquences de numéros compris entre 0 et 3 : 0 correspond au quadrant NO, 1 au NE, 2 au
SO et 3 au SE. Le nœud racine est identifié par 0. Ses 4 fils sont identifiés respectivement
par 00, 01, 02 et 03. La figure 3.19 illustre ce qui précède.
Figure 3.19 : Représentation d’une image en arbres quaternaires

Détection de contours
37
Avec cette structure, on a la possibilité d’effectuer des opérations rapidement comme par
exemple, un zoom sur une région, en stockant dans les nœuds internes le niveau de gris
représentant la moyenne des couleurs des nœuds fils.
Dans le cadre de ce travail nous allons utiliser l’arbre quaternaire pour
décomposer les images suivant la quantité de floue et de bruit de chaque quadrant.
Algorithme de découpage
Afin de découper notre image, nous allons procéder comme suit :
- L’image entière est la racine de l’arbre
- On découpe l’image du nœud courant en quatre images égales qui représentent
les quatre fils du nœud.
- On analyse les caractéristiques de chaque fils (bruit, flou, entropie, niveau de
détails, niveau d’homogénéité)
- On compare les caractéristiques des fils. Si une différence notable1 apparaît
entre deux fils, alors on découpe la racine en ces quatre fils. Sinon, on ne
découpe pas le nœud
- On agit récursivement de la même manière sur chacun des fils.
L’algorithme s’arrête quand toutes les feuilles sont homogènes en caractéristiques ou
quand la taille de l’image du nœud devient trop petite (inférieure à 16 pixels).
Seuils de découpage
Nous allons ici définir ce que représente pour nous une différence notable dans les
caractéristiques des zones de l’image. Une fois l’image découpée, nous souhaitons utiliser
différents détecteurs de contours sur chacune des zones. Il va donc falloir différencier les
zones qui utiliseront des détecteurs différents.
Pour cela, nous avons procédé de deux manières : empirique et graphique. La
façon empirique consiste à choisir approximativement les seuils de différences à respecter
en fonction des résultats visibles. Voici les seuils obtenus par cette méthode sur les trois
images utilisées précédemment:
- Seuil pour le flou : 27.0
- Seuil pour le bruit : 0.02
1 Nous préciserons plus tard ce que signifie notable pour chaque caractéristique

Détection de contours
38
La deuxième méthode est basée sur les graphiques obtenus pour les estimateurs de
bruit et de flou. Pour ce faire, nous avons calculé la pente des estimateurs entre chaque
point de contrôle2 et fait une moyenne de cette pente, la valeur obtenue est notre seuil de
différence. Nous obtenons alors les résultats suivants sur les mêmes trois images
précédentes.
- Seuil pour le flou : 31.45
- Seuil pour le bruit : 0.015
Voici maintenant les résultats du découpage de quelques images avec notre algorithme.
Figure 3.20 : Découpage de la figure 3.6
Figure 3.21 : Absence de découpage des figures 3.5 et 3.7
2 Un écart entre les points de contrôles de 5 pour la force du bruit et de 0.15 sur la variance du flou Gaussien

Détection de contours
39
On remarque que les images ayant des caractéristiques homogènes ne sont pas découpées
quelque soit le niveau de détail de l’image. Le même détecteur sera alors utilisé pour
toute l’image. Tel est le cas de la figure 3.21.
Maintenant, observons le découpage d’une image comportant une zone bruitée.
Figure 3.22 : Image dont la zone sud-Est est bruitée
Figure 3.23 : Arbre de l’image de la figure 3.22

Détection de contours
40
La zone bruitée a été considérée comme ayant des caractéristiques homogènes et
n’a pas été découpée. Il faudra probablement utiliser un détecteur de contour résistant au
bruit et choisir judicieusement les paramètres des filtres pour détecter correctement les
contours de chaque zone découpée.
L’arbre quaternaire non régulier
Il existe une structure d’arbre quaternaire où les fils n’ont pas forcement tous les
mêmes dimensions. Il s’agit en effet de découper les quadrants en fonctions d’un point de
l’image plutôt que de découper toujours au centre comme le montre la figure 3.24.
Figure 3.24 : Arbre quaternaire et indexation par points
Cette structure est plus adaptée à notre travail puisqu’elle permettrait de découper
les zones de caractéristiques encore plus précisément. Cependant, le calcul du point de
découpage est particulièrement difficile et coûteux en temps de calcul ce qui rend nos
algorithmes inefficaces. Pour cette raison, nous avons préféré conserver la structure
d’arbre avec découpage régulier.
3.6 – Choix d’un détecteur Une fois le découpage de l’image effectué, il va falloir choisir un détecteur et ses
paramètres en fonction des caractéristiques de la zone. Pour cela, nous allons tout d’abord

Détection de contours
41
effectuer une série de tests sur un banc d’essai d’images de divers types afin de repérer
les principaux avantages de chaque détecteur. Le banc d’essai comporte 123 images dont
des images synthétiques contenant des contours de type marche, pic, rampe et impulsion
ainsi que des image fréquemment utilisé en détection de contours (Lena, singe et
cameraman).
Figure 3.25 : Image Lena et image Cellules
Nous allons soumettre ces images à tous les détecteurs implémentés dans le cadre
de notre travail : Robert, Sobel, Prewitt, Kirsch, Canny, Dériche, ondelettes de Mallat,
ondelettes de Haar et MIRA [29].
Avant d’être soumises aux détecteurs, les images seront traitées de plusieurs
façons, par l’ajout de bruit et de flou.
Enfin nous allons traiter les résultats avec les mesures d’erreur de localisation,
l’erreur d’omission, le calcul du rapport signal sur bruit (SNR) et les mesures d’efficacité
de Zhu.
Nous obtenons donc un tableau récapitulatif des performances des détecteurs suivant
différents cas de figure (cf. résultats en Annexe B). Les résultats empiriques permettent
d’émettre les observations suivantes :
1. L’erreur de localisation présente un problème majeur puisque dans le cas d’un contour
de type marche, il faut décider arbitrairement où se trouve le contour puisque dans

Détection de contours
42
l’absolu il se trouve entre les deux pixels ayant des couleurs différentes comme le montre
la figure 45.
Figure 3.26 : image a : Un contour de type marche, image b : premier contour possible,
image c : Deuxième contour possible.
Il se trouve que certains détecteurs utilisent le schéma 3.26.b alors que d’autres utilisent
le schéma 3.26.c. Lorsque nous calculons l’erreur de localisation, nous utilisons un
contour idéal selon le schéma 3.26.b. Cela signifie que certains détecteurs indiquent une
erreur de localisation alors qu’en fait il s’agit juste d’une différence de positionnement du
contour.
2. En analysant les résultats en fonction de la remarque précédente, on constate que
certains détecteurs sont plus efficaces quel que soit le cas. Par exemple, dans le cas des
images nettes, le détecteur Prewitt3 est toujours meilleur que Robert, Sobel ou Kirsch.
Ceci va en partie simplifier le choix du détecteur par la suite. De même, dans le cas des
images bruitées, le détecteur MIRA se comporte mieux que celui de Canny et Dériche et
sera donc préféré à ces deux détecteurs. Les détecteurs de Shen, ainsi que ceux issus des
ondelettes de Haar et Mallat seront utilisés dans des cas très précis.
3. Les contours de type impulsion et pic doivent-ils être considérés comme étant un seul
contours ? Ce problème vient essentiellement du fait que le pixel possède une épaisseur et
donc un contour de chaque côté comme le montre la figure 3.27.
3 Il s’agit d’une implémentation performante du détecteur Prewitt.
a b c

Détection de contours
43
Figure 3.27 : contours pour un contour de type impulsion
Ce problème du contour de type impulsion est surtout gênant lorsque l’on souhaite
obtenir les contours d’un dessin comme dans le cas de la figure 3.28.
Figure 3.28 : Exemple de contour sur un dessin au crayon papier.
À partir de ces constatations, nous allons maintenant sélectionner nos détecteurs et
leurs paramètres de la façon suivante :
Choix de la variance :
Pour choisir la variance, nous allons analyser les résultats de l’estimateur de bruit.
Pour un bruit quasi nul, nous utiliserons une variance de 1.5. Si le bruit atteint ou
dépasse une valeur de 0.3 (valeur moyenne pour le bruit de force 100) alors nous

Détection de contours
44
utiliserons une variance de 4. Au delà de 4, la variance devient trop forte et les contours
sont très délocalisés. De plus, un bruit supérieur à cette valeur suppose que l’image est
trop bruitée pour permettre une détection de contour efficace. Enfin, pour les estimations
de bruit intermédiaire, nous ferons une interpolation linéaire entre ces valeurs.
Le flou peut aussi venir influencer la variance. Les détecteurs Canny, Dériche et
MIRA offrent des résultats souvent plus performants quand les contours sont légèrement
flous. C’est pour cette raison qu’une image sans bruit et sans flou donnera de bons
résultats avec une variance de 1.5 plutôt que 1.0. Cependant, lorsque l’image est floue, il
faut diminuer la variance pour éviter de perdre des contours lors du lissage. Pour cela,
nous diminuons la variance selon des paliers de flou choisis en fonction des graphiques
de l’estimateur sur le banc d’essai.
Règles de sélection du détecteur :
D’après les remarques précédentes et en nous référant à l’Annexe B relative aux
résultats expérimentaux, nous avons établi les règles heuristiques de sélection suivantes :
- Si l’homogénéité est supérieure à 90% et le niveau de détail inférieur à 1% alors
nous utilisons le détecteur issu des ondelettes de Mallat
- Si l’image contient peu de bruit (estimateur inférieur à 0.02) et une homogénéité
moyenne (supérieure à 50%) alors nous utilisons le détecteur de Prewitt.
- Sinon, nous utilisons le détecteur MIRA en calculant la variance suivant la
formule d’interpolation décrite précédemment.
Variance = 1.5+8.58*Estimation Bruit (34)
Nous avons seulement utilisé les détecteurs Mallat, Prewitt et MIRA car ils
offrent chacun les meilleurs résultats. MIRA a été préféré à Canny ou Dériche car son
efficacité sur les contours en forme de ligne directionnelle, en coin et de forme circulaire
est meilleure. Maintenant, nous allons montrer et analyser les résultats pour expliquer en
quoi notre démarche offre de meilleurs résultats et pourquoi.

Chapitre 4
Analyse expérimentale
4.1 – Analyse des résultats
En premier lieu, nous allons chercher à savoir si les contours détectés grâce à
notre méthode donnent de meilleurs coefficients et des erreurs plus faibles que si on avait
appliqué un détecteur seul sur toute l’image. Notre détecteur se nomme DECAP pour
Détection Efficace des Contours Avec Prétraitement.
Les quatre images de contours synthétiques utilisées sont les suivantes :
Figure 4.1 : Contours marche, rampe, impulsion et rampe
DÉTECTEUR IMAGE TRAITÉE BRUIT SNR LOCALISATION OMISSION
ZHU
TOTAL COMMENTAIRES
DECAP
Contour
MARCHE 0
0,5
ou
53.5
0,58 ou 0.0 si
on tiens compte
de la première 0 0,71
MIRA variance 1 pour toute
l'image
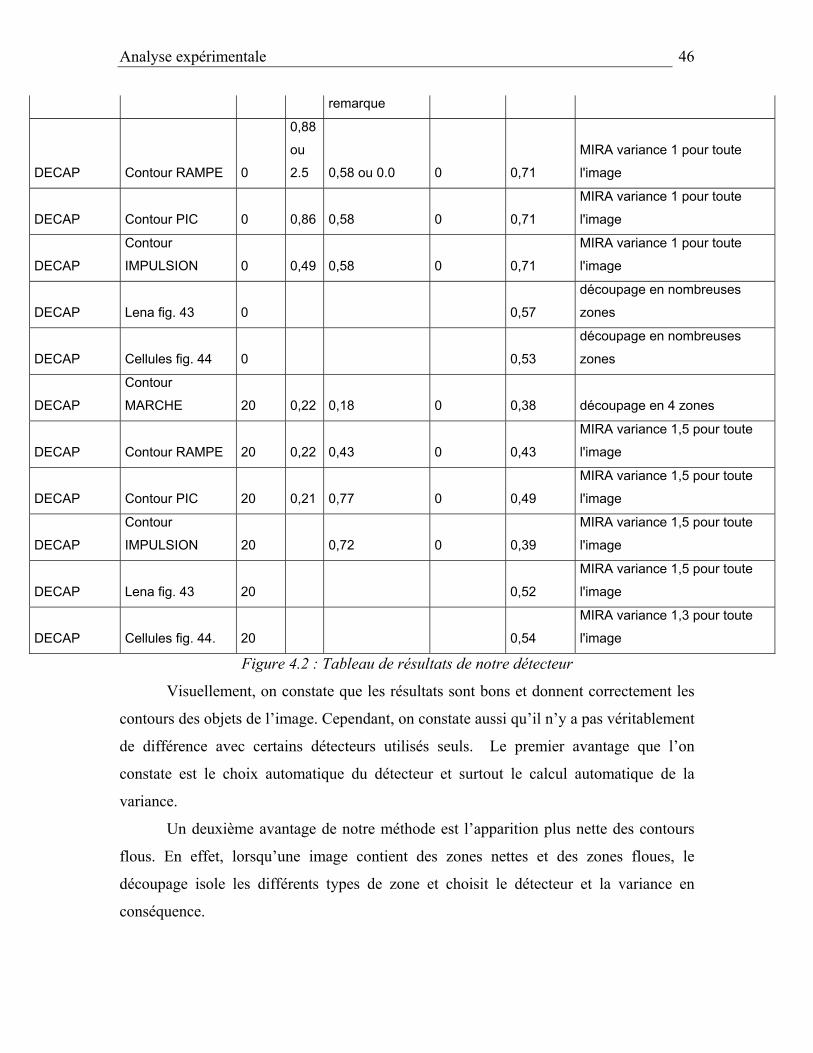
Analyse expérimentale
46
remarque
DECAP Contour RAMPE 0
0,88
ou
2.5 0,58 ou 0.0 0 0,71
MIRA variance 1 pour toute
l'image
DECAP Contour PIC 0 0,86 0,58 0 0,71
MIRA variance 1 pour toute
l'image
DECAP
Contour
IMPULSION 0 0,49 0,58 0 0,71
MIRA variance 1 pour toute
l'image
DECAP Lena fig. 43 0 0,57
découpage en nombreuses
zones
DECAP Cellules fig. 44 0 0,53
découpage en nombreuses
zones
DECAP
Contour
MARCHE 20 0,22 0,18 0 0,38 découpage en 4 zones
DECAP Contour RAMPE 20 0,22 0,43 0 0,43
MIRA variance 1,5 pour toute
l'image
DECAP Contour PIC 20 0,21 0,77 0 0,49
MIRA variance 1,5 pour toute
l'image
DECAP
Contour
IMPULSION 20 0,72 0 0,39
MIRA variance 1,5 pour toute
l'image
DECAP Lena fig. 43 20 0,52
MIRA variance 1,5 pour toute
l'image
DECAP Cellules fig. 44. 20 0,54
MIRA variance 1,3 pour toute
l'image
Figure 4.2 : Tableau de résultats de notre détecteur
Visuellement, on constate que les résultats sont bons et donnent correctement les
contours des objets de l’image. Cependant, on constate aussi qu’il n’y a pas véritablement
de différence avec certains détecteurs utilisés seuls. Le premier avantage que l’on
constate est le choix automatique du détecteur et surtout le calcul automatique de la
variance.
Un deuxième avantage de notre méthode est l’apparition plus nette des contours
flous. En effet, lorsqu’une image contient des zones nettes et des zones floues, le
découpage isole les différents types de zone et choisit le détecteur et la variance en
conséquence.

Analyse expérimentale
47
Cependant le gain est plus significatif lorsque les images présentent des
caractéristiques hétérogènes comme sur les images des figures 4.3 et 4.4.
Figure 4.3 :Lena avec tache de bruit figure 4.4 : image avec zone sud ouest bruitée
En effet ces images contiennent des zones très floues, des zones très nettes, des zones
bruitées, des zones avec beaucoup de détails et des zones plus homogènes. Il est d’abord
intéressant de regarder les résultats d’un détecteur utilisé seul sur l’ensemble de l’image.
On peut voir sur la figure 4.5 le résultat d’un détecteur Prewitt et sur les figures 4.6 et 4.7
le détecteur MIRA avec plusieurs variances différentes.
Figure 4.5 : Détecteur Prewitt sur les figures 4.3 et 4.4

Analyse expérimentale
48
Figure 4.6 : Détecteur MIRA avec variance de 1.0 sur les figures 4.3 et 4.4
Figure 4.7 : Détecteur MIRA avec variance = 1.5 sur les figures 4.3 et 4.4

Analyse expérimentale
49
Figure 4.8 : Détecteur MIRA avec variance 2.5sur les figures 4.3 et 4.4
Des résultats corrects sont obtenus avec le détecteur MIRA à partir d’une variance
de 1.5. Cependant, le bruit est totalement éliminé avec une variance de 2.5 ce qui
introduit malheureusement une délocalisation des contours situés dans des zones n’ayant
pas de bruit.
Regardons maintenant le résultat obtenu grâce au découpage (cf. figure 4.9 et
4.10). D’abord, nous constatons que lors du découpage en arbre quaternaire, l’application
propose un grand nombre de zones différentes donc des caractéristiques très hétérogènes
comme le montre la figure 4.9.
Figure 4.9 : découpage des images des figures 4.3 et 4.4

Analyse expérimentale
50
Le but de ce découpage est surtout d’appliquer un filtre très résistant au bruit sur
les zones bruitées et un filtre plus simple sur les zones non bruitées afin de conserver au
mieux les contours. Nous obtenons alors les résultats de la figure 4.10.
Figure 4.10 : résultats obtenu à partir du découpage des figures 4.3 et 4.4
On constate que sans aucune intervention de l’utilisateur, nous obtenons un résultat où
tous les contours essentiels apparaissent et où l’intensité des contours est bonne. De plus,
le bruit a été en grande partie éliminé sans avoir à choisir une variance et les zones non
bruitées offrent moins de délocalisation que si on avait appliqué la même variance4 sur
toute l’image. Les résultats de notre application sur quelques images de notre banc
d’essai sont visibles en Annexe C.
4 La variance est élevée à cause de la présence de bruit

Chapitre 5
Conclusion
A l’issue de ce travail, nous avons réussi à développer une application capable de
découper automatiquement des images suivant des zones homogènes au niveau de
quelques caractéristiques et de choisir automatiquement les détecteurs de contours les
plus adéquats et les plus efficaces pour les caractéristiques de chacune des zones. Les
caractéristiques utilisées sont le bruit blanc, le flou Gaussien, le niveau de détails,
l’homogénéité et l’entropie. Cependant, il est possible d’améliorer encore les résultats en
étudiant des caractéristiques plus spécifiques ou en développant de meilleurs détecteurs
de contours ou de meilleurs estimateurs.
Nous pourrions aussi envisager d’utiliser certaines techniques spécifiques et
récentes pour traiter les zones avant de détecter les contours, comme par exemple
effectuer un débruitage à l’aide de l’outil Contourlet. Cependant, ces techniques
nécessitent un travail à part entière et n’ont donc pas pu être traitées dans ce document.
Finalement, notre travail présente des avantages certains en détection de contours
mais les possibilités d’extension sont encore très vastes, que ce soit au niveau des
caractéristiques ou au niveau des détecteurs de contours.

52
Bibliographies
[1] David Marr et E. Hildreth : “Theory of Edge Detection”, Proc. R. Soc. London, B
207, pp :187-217, 1980
[2] Radu Horaud et Olivier Monga – « Vision par Ordinateur » - Deuxième édition –
édition Hermes, 1995.
[3] Stéphane G Mallat – « A theory for multiresolution signal decomposition : The
wavelet representation » - IEEE transactions on pattern analysis and machine
intelligence VOL II. No 7 11(7):674-693 Juillet 1989.
[4] Albert Cohen et Jelena Kolacevic – « Wavelets : the mathematical background » -
Proceedings of the IEEE, 8(4):514—522 , octobre 1996.
[5] Duncan D-Y Po et Minh N. Do. - « Directionnel multiscale modeling of images
using the contourlet » - Coordinated Science Lab and Beckman Institute, University
of Illinois at Urbana-Champaign - Urbana IL 61801 , 2003.
[6] M. N. Do et M. Vetterli, “The contourlet transform: an efficient directional
multiresolution image representation”. IEEE Transactions Image Processing, 2003.
[7] Geert Uytterhoeven, Dirk Roose et Adhemar Bultheel – « Wavelet Transforms
Using the lifting scheme » - Report ITA – Wavelet-WP1.1 (Revised version) Avril
1997. site web : http://www.cs.kuleuven.ac.be/~wavelets/ dernier accès le 20 janvier
2004
[8] R. C. Gonzales et R. E. Woods “Digital Image Processing” Second edition.
Prentice Hall 2002
[9] M. N. Do et M. Vetterli, « Contourlets ». Beyond Wavelets, G. V. Welland ed.,
Academic Press, 2003.
[10] D. Ziou et A. Koukam. “ Knowledge-based assistant for the selection of edge
detectors”, Pattern Recognition (31)5, pp. 587-596, 1998.
[11] D. Ziou et S. Tabbone. « Edge detection techniques - An overview » Technical
Report AI Memo 833, Massachusette Institute of Technology, Artifical Intelligence
Laboratory, 1997.

53
[12] D. L. Donoho et M. R. Duncan. « Digital curvelet transform : Strategy,
Implementation and experiments » . Proc Aerosense 2000, Wavelet applications VII,
SPIE 2000, vol. 4056, pp. 1229.
[13] E. J. Candes et D. L. Donoho. « Curvelets – A surprisingly effective
nonadaptive representation for objects with edges » Curves and surfaces IV ed P.-J.
Laurent. 1999
[14] M. N. Do et M. Vetterli. « The finite ridgelet transform for image
representation » IEEE transaction on image processing., 2002.
[15] D. Ziou et T. B. Nguyen, “Contextual and non-contextual performance
evaluation of edge detectors Pattern” Recognition Letters 21(9), 2000.
[16] J. H. Elder et S. W. Zucker, « Local scale control for edge detection and blur
estimation » IEEE transaction on pattern analysis and machine intelligence Vol 20 No
7, Juillet 1998.
[17] F. Matùs et J. Flusser, « Image representation via the finite radon transform » ,
IEEE transaction on pattern analysis and machine intelligence Vol 15 No 10, Octobre
1993.
[18] J. F. Canny, “finding edges and lines in image” technical report No 720 , 1983
[19] J. F. Canny, “A computational approach to edge detection” , IEEE transaction on
pattern analysis and machine intelligence, Novembre 1986
[20] R. Dériche, “using Canny’s criteria to derive a recursive implemented optimal
edge detector”, The international journal of computer science, 1987
[21] R. Dériche, “Optimal edge detection using recursive filtering”, Proceedings of
the first international conference in computer vision, 1987.
[22] P. J. Burt et E. H. Adelson , “The Laplacian Pyramid as a Compact Image Code”
IEEE Transactions on Communications, 1983.
[23] R. H. Bamberger et M. J. T. Smith. « A filter bank for the directional
decomposition of images: Theory and design”. IEEE Trans. Signal Proc., pp 882 –
893, Avril 1992.
[24] Q. Zhu, « Improving edge detection by an objective edge evaluation » , 1992
ACM/SIGAPP Symposium on Applied Computing, Kansas City, MO. pp. 459-468.

54
[25] Roman M. Palenichka, Rokia Missaoui & Marek B. Zaremba. Extraction of
Salient Features for Image Retrieval Using Multi-scale Image Relevance Function.
Poster Paper In Proceedings of the International Conference on Image and Video
Retrieval (CIVR), Dublin, Ireland, July 2004.
[26] George Paschos – “ Perceptually Uniform Color Spaces for Color Texture
Analysis: An Empirical Evaluation ” – IEEE Transaction on image processing, VOL
10, NO 6, Juin 2001
[27] Djemel Ziou et Francois Deschenes – “Depth From Defocus Estimation in
Spatial Domain” - Computer Vision and Image Understanding 81, pp. 143--165, 2001
[28] Yitzhak Yitzhaky et Eli Peli – “A Method for Objective Edge Detection
Evaluation and Detector Parameter Selection” – IEEE transactions on pattern analysis
ans machine intelligence, vol. 25 No 8 - Août 2003
[29] Rokia Missaoui, M. Sarifuddin, N. Baaziz et V. Guesdon – “Détection de
contours par décomposition de l’image en régions homogènes” – Rapport technique,
UQO, novembre 2004.

ANNEXE A
Résultats des détecteurs usuels
Les figures contenues dans cette annexe fournissent le résultat de l’application d’un seul
détecteur sur l’ensemble de l’image. Tous les détecteurs utilisés sont présentés ici.
Figure A-1 : Contours Robert

ANNEXE A
56
Figure A-2 : Contours Sobel
Figure A-3 : Contours Prewitt

ANNEXE A
57
Figure A-4 : Contours Marr et Hildreth σ = 4
Figure A-5 : Contours Canny σ = 1 , seuil = 0.7

ANNEXE A
58
Figure A-6 : Contours par ondelette, Coefficients de Mallat - résolution 2
Figure A-7 : Contour par ondelette, Coefficients de Haar – résolution 2

ANNEXE A
59
Figure A-8 : Contours par filtre de Dériche, 3.1=α avec seuillage
Figure A-9 : Contours par filtre du système MIRA5, 2=σ , avec affinage par recherche
des maxima
5 Il s’agit d’un filtre développé par notre équipe de recherche et intégré dans le prototype MIRA.

ANNEXE A
60
figure A-10 : Contour Kirsch
Figure A-11 : Contours Kirsch avec affinage

ANNEXE A
61
Figure A-12 : Contours Kirsch avec affinage et seuillage

ANNEXE B
Tableaux d’analyse de détecteurs
Cette annexe présente les résultats des calculs d’erreur de localisation et d’omission ainsi que les coefficients de Zhu pour quatre
images synthétiques (figure 4.1) et deux images réelles (Figure 3.25). Ce tableau tient aussi compte de l’affinage des contours et de la
quantité de bruit introduit dans l’image. On y voit aussi les paramètres des détecteurs utilisés.
DÉTECTEUR IMAGE TRAITÉE AFFINAGE BRUIT VARIANCE RÉSOLUTION SNR LOCALISATION OMISSION
ZHU TOTAL COMMENTAIRES
ROBERT Contour MARCHE NON 0 AUCUNE AUCUNE 1,01 0,99 0,99 0
intensité extrêmement faible
ROBERT Contour MARCHE NON 0 AUCUNE AUCUNE 256 0 0 0,71
avec le seuillage automatique
ROBERT Contour RAMPE NON 0 AUCUNE AUCUNE 1,69 0 0 0,71
ROBERT Contour PIC NON 0 AUCUNE AUCUNE 1,51 0 0 0,36
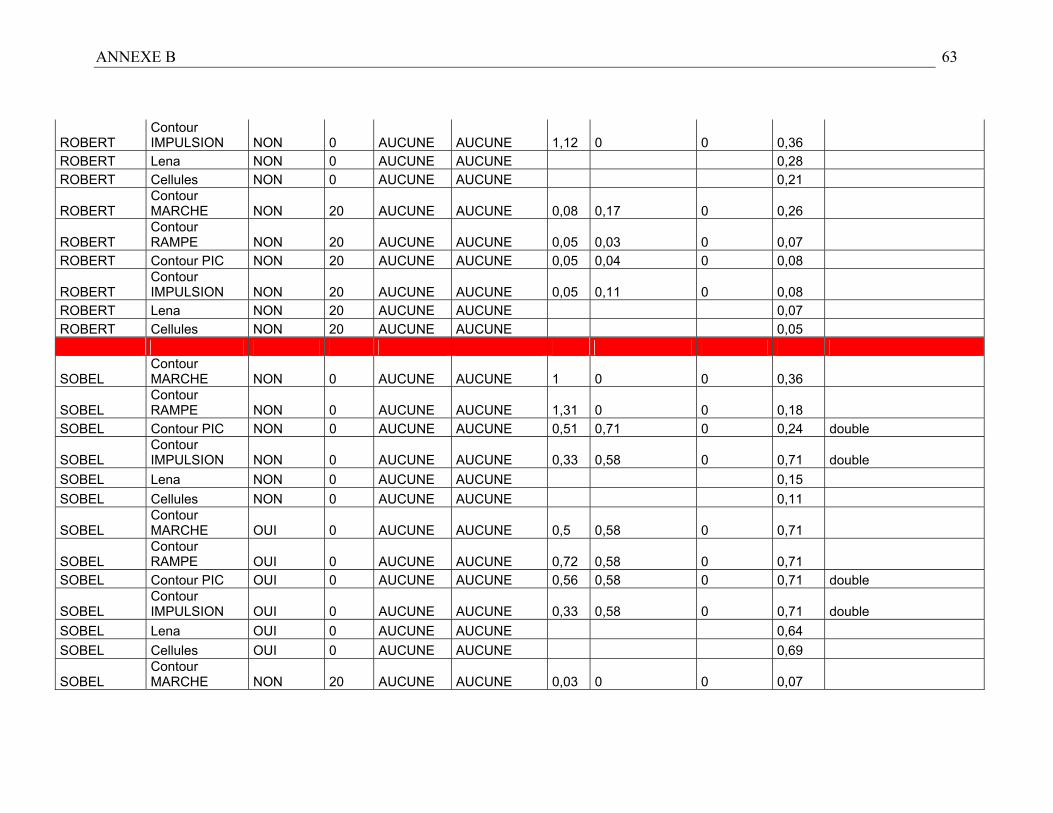
ANNEXE B
63
ROBERT Contour IMPULSION NON 0 AUCUNE AUCUNE 1,12 0 0 0,36
ROBERT Lena NON 0 AUCUNE AUCUNE 0,28 ROBERT Cellules NON 0 AUCUNE AUCUNE 0,21
ROBERT Contour MARCHE NON 20 AUCUNE AUCUNE 0,08 0,17 0 0,26
ROBERT Contour RAMPE NON 20 AUCUNE AUCUNE 0,05 0,03 0 0,07
ROBERT Contour PIC NON 20 AUCUNE AUCUNE 0,05 0,04 0 0,08
ROBERT Contour IMPULSION NON 20 AUCUNE AUCUNE 0,05 0,11 0 0,08
ROBERT Lena NON 20 AUCUNE AUCUNE 0,07 ROBERT Cellules NON 20 AUCUNE AUCUNE 0,05
SOBEL Contour MARCHE NON 0 AUCUNE AUCUNE 1 0 0 0,36
SOBEL Contour RAMPE NON 0 AUCUNE AUCUNE 1,31 0 0 0,18
SOBEL Contour PIC NON 0 AUCUNE AUCUNE 0,51 0,71 0 0,24 double
SOBEL Contour IMPULSION NON 0 AUCUNE AUCUNE 0,33 0,58 0 0,71 double
SOBEL Lena NON 0 AUCUNE AUCUNE 0,15 SOBEL Cellules NON 0 AUCUNE AUCUNE 0,11
SOBEL Contour MARCHE OUI 0 AUCUNE AUCUNE 0,5 0,58 0 0,71
SOBEL Contour RAMPE OUI 0 AUCUNE AUCUNE 0,72 0,58 0 0,71
SOBEL Contour PIC OUI 0 AUCUNE AUCUNE 0,56 0,58 0 0,71 double
SOBEL Contour IMPULSION OUI 0 AUCUNE AUCUNE 0,33 0,58 0 0,71 double
SOBEL Lena OUI 0 AUCUNE AUCUNE 0,64 SOBEL Cellules OUI 0 AUCUNE AUCUNE 0,69
SOBEL Contour MARCHE NON 20 AUCUNE AUCUNE 0,03 0 0 0,07
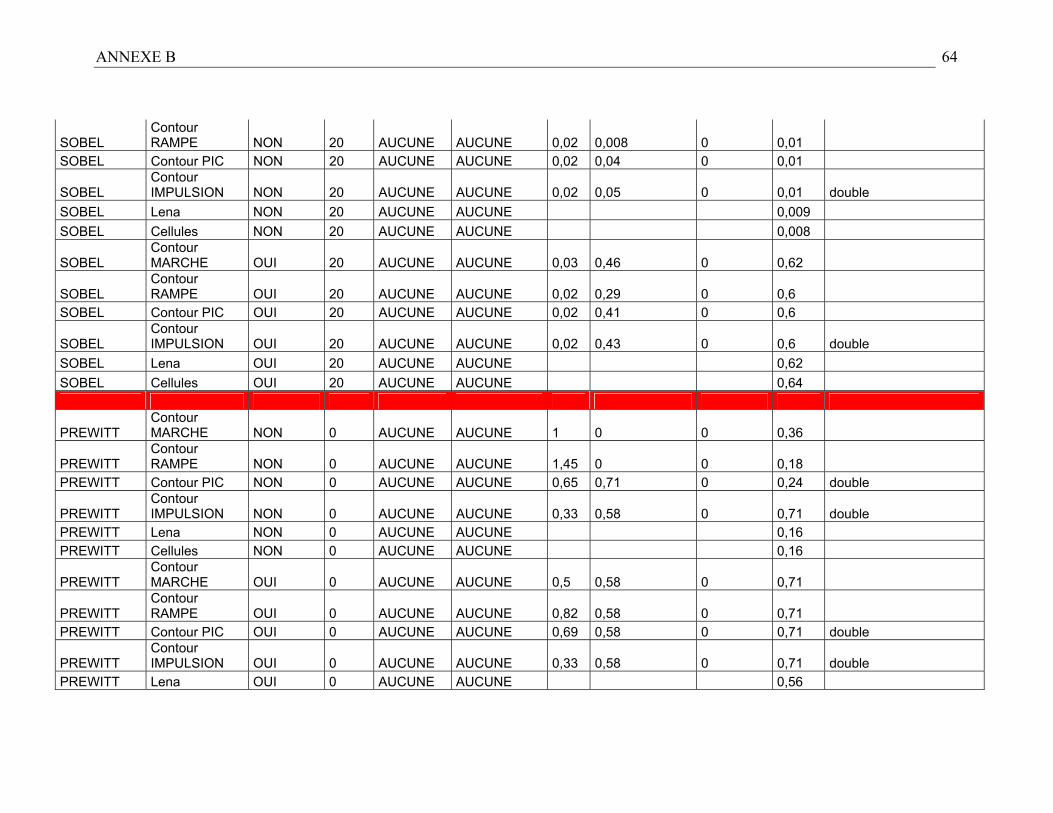
ANNEXE B
64
SOBEL Contour RAMPE NON 20 AUCUNE AUCUNE 0,02 0,008 0 0,01
SOBEL Contour PIC NON 20 AUCUNE AUCUNE 0,02 0,04 0 0,01
SOBEL Contour IMPULSION NON 20 AUCUNE AUCUNE 0,02 0,05 0 0,01 double
SOBEL Lena NON 20 AUCUNE AUCUNE 0,009 SOBEL Cellules NON 20 AUCUNE AUCUNE 0,008
SOBEL Contour MARCHE OUI 20 AUCUNE AUCUNE 0,03 0,46 0 0,62
SOBEL Contour RAMPE OUI 20 AUCUNE AUCUNE 0,02 0,29 0 0,6
SOBEL Contour PIC OUI 20 AUCUNE AUCUNE 0,02 0,41 0 0,6
SOBEL Contour IMPULSION OUI 20 AUCUNE AUCUNE 0,02 0,43 0 0,6 double
SOBEL Lena OUI 20 AUCUNE AUCUNE 0,62 SOBEL Cellules OUI 20 AUCUNE AUCUNE 0,64
PREWITT Contour MARCHE NON 0 AUCUNE AUCUNE 1 0 0 0,36
PREWITT Contour RAMPE NON 0 AUCUNE AUCUNE 1,45 0 0 0,18
PREWITT Contour PIC NON 0 AUCUNE AUCUNE 0,65 0,71 0 0,24 double
PREWITT Contour IMPULSION NON 0 AUCUNE AUCUNE 0,33 0,58 0 0,71 double
PREWITT Lena NON 0 AUCUNE AUCUNE 0,16 PREWITT Cellules NON 0 AUCUNE AUCUNE 0,16
PREWITT Contour MARCHE OUI 0 AUCUNE AUCUNE 0,5 0,58 0 0,71
PREWITT Contour RAMPE OUI 0 AUCUNE AUCUNE 0,82 0,58 0 0,71
PREWITT Contour PIC OUI 0 AUCUNE AUCUNE 0,69 0,58 0 0,71 double
PREWITT Contour IMPULSION OUI 0 AUCUNE AUCUNE 0,33 0,58 0 0,71 double
PREWITT Lena OUI 0 AUCUNE AUCUNE 0,56

ANNEXE B
65
PREWITT Cellules OUI 0 AUCUNE AUCUNE 0,56
PREWITT Contour MARCHE NON 20 AUCUNE AUCUNE 0,05 0 0 0,13
PREWITT Contour RAMPE NON 20 AUCUNE AUCUNE 0,03 0,01 0 0,02
PREWITT Contour PIC NON 20 AUCUNE AUCUNE 0,03 0,06 0 0,02
PREWITT Contour IMPULSION NON 20 AUCUNE AUCUNE 0,03 0,05 0 0,02 double
PREWITT Lena NON 20 AUCUNE AUCUNE 0,02 PREWITT Cellules NON 20 AUCUNE AUCUNE 0,01
PREWITT Contour MARCHE OUI 20 AUCUNE AUCUNE 0,06 0,2 0 0,53
PREWITT Contour RAMPE OUI 20 AUCUNE AUCUNE 0,03 0,25 0 0,48
PREWITT Contour PIC OUI 20 AUCUNE AUCUNE 0,04 0,57 0 0,48
PREWITT Contour IMPULSION OUI 20 AUCUNE AUCUNE 0,04 0,58 0 0,48 double
PREWITT Lena OUI 20 AUCUNE AUCUNE 0,48 PREWITT Cellules OUI 20 AUCUNE AUCUNE 0,47
KIRSCH Contour MARCHE NON 0 AUCUNE AUCUNE 1 0 0 0,36
KIRSCH Contour MARCHE OUI 0 AUCUNE AUCUNE 0,5 0,58 0 0,71
KIRSCH Contour RAMPE NON 0 AUCUNE AUCUNE 0,54 0 0 0,14
KIRSCH Contour RAMPE OUI 0 AUCUNE AUCUNE 0,5 0,58 0 0,71
KIRSCH Contour PIC NON 0 AUCUNE AUCUNE 0,27 0 0 0,08 KIRSCH Contour PIC OUI 0 AUCUNE AUCUNE 0,33 0,58 0 0,71 double
KIRSCH Contour IMPULSION NON 0 AUCUNE AUCUNE 0,5 0 0 0,24
KIRSCH Contour IMPULSION OUI 0 AUCUNE AUCUNE 0,33 0,58 0 0,71 double

ANNEXE B
66
KIRSCH Lena NON 0 AUCUNE AUCUNE 0,02 KIRSCH Lena OUI 0 AUCUNE AUCUNE 0,35 KIRSCH Cellules NON 0 AUCUNE AUCUNE 0,004 KIRSCH Cellules OUI 0 AUCUNE AUCUNE 0,33
KIRSCH Contour MARCHE NON 20 AUCUNE AUCUNE 0,003 0 0 0,004
KIRSCH Contour MARCHE OUI 20 AUCUNE AUCUNE 0,004 0,72 0 0,24
KIRSCH Contour RAMPE NON 20 AUCUNE AUCUNE 0,002 0 0 0,003
KIRSCH Contour RAMPE OUI 20 AUCUNE AUCUNE 0,003 0,29 0 0,2
KIRSCH Contour PIC NON 20 AUCUNE AUCUNE 0,002 0 0 0,002 KIRSCH Contour PIC OUI 20 AUCUNE AUCUNE 0,003 0,45 0 0,2
KIRSCH Contour IMPULSION NON 20 AUCUNE AUCUNE 0,02 0 0 0,003
KIRSCH Contour IMPULSION OUI 20 AUCUNE AUCUNE 0,003 0,63 0 0,2
KIRSCH Lena NON 20 AUCUNE AUCUNE 0,002 KIRSCH Lena OUI 20 AUCUNE AUCUNE 0,23 KIRSCH Cellules NON 20 AUCUNE AUCUNE 0,002 KIRSCH Cellules OUI 20 AUCUNE AUCUNE 0,27
CANNY Contour MARCHE NON 0 1 AUCUNE 0,77 0,003 0 0,24
CANNY Contour MARCHE OUI 0 1 AUCUNE 0,82 0,85 0 0,71
CANNY Contour MARCHE OUI 0 1,5 AUCUNE 0,81 0,85 0 0,71
CANNY Contour RAMPE NON 0 1 AUCUNE 0,81 0,71 0 0,24
CANNY Contour RAMPE OUI 0 1 AUCUNE 0,96 0,85 0 0,71
CANNY Contour OUI 0 1,5 AUCUNE 0,97 0,85 0 0,71
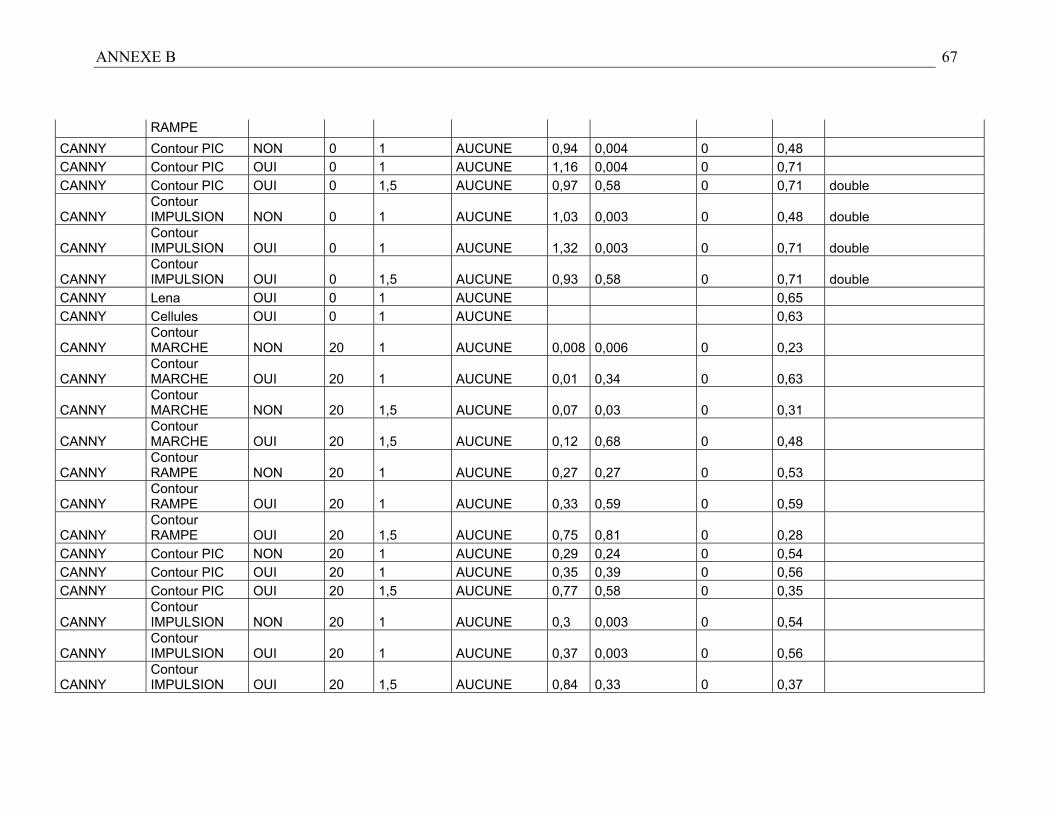
ANNEXE B
67
RAMPE CANNY Contour PIC NON 0 1 AUCUNE 0,94 0,004 0 0,48 CANNY Contour PIC OUI 0 1 AUCUNE 1,16 0,004 0 0,71 CANNY Contour PIC OUI 0 1,5 AUCUNE 0,97 0,58 0 0,71 double
CANNY Contour IMPULSION NON 0 1 AUCUNE 1,03 0,003 0 0,48 double
CANNY Contour IMPULSION OUI 0 1 AUCUNE 1,32 0,003 0 0,71 double
CANNY Contour IMPULSION OUI 0 1,5 AUCUNE 0,93 0,58 0 0,71 double
CANNY Lena OUI 0 1 AUCUNE 0,65 CANNY Cellules OUI 0 1 AUCUNE 0,63
CANNY Contour MARCHE NON 20 1 AUCUNE 0,008 0,006 0 0,23
CANNY Contour MARCHE OUI 20 1 AUCUNE 0,01 0,34 0 0,63
CANNY Contour MARCHE NON 20 1,5 AUCUNE 0,07 0,03 0 0,31
CANNY Contour MARCHE OUI 20 1,5 AUCUNE 0,12 0,68 0 0,48
CANNY Contour RAMPE NON 20 1 AUCUNE 0,27 0,27 0 0,53
CANNY Contour RAMPE OUI 20 1 AUCUNE 0,33 0,59 0 0,59
CANNY Contour RAMPE OUI 20 1,5 AUCUNE 0,75 0,81 0 0,28
CANNY Contour PIC NON 20 1 AUCUNE 0,29 0,24 0 0,54 CANNY Contour PIC OUI 20 1 AUCUNE 0,35 0,39 0 0,56 CANNY Contour PIC OUI 20 1,5 AUCUNE 0,77 0,58 0 0,35
CANNY Contour IMPULSION NON 20 1 AUCUNE 0,3 0,003 0 0,54
CANNY Contour IMPULSION OUI 20 1 AUCUNE 0,37 0,003 0 0,56
CANNY Contour IMPULSION OUI 20 1,5 AUCUNE 0,84 0,33 0 0,37

ANNEXE B
68
CANNY Lena OUI 20 1 AUCUNE 0,64 CANNY Cellules OUI 20 1 AUCUNE 0,68
DERICHE Contour MARCHE NON 0 1 AUCUNE 0,17 0 0 0,12
DERICHE Contour RAMPE NON 0 1 AUCUNE 0,36 0 0 0,13
DERICHE Contour PIC NON 0 1 AUCUNE 0,47 0.71 0 0,23
DERICHE Contour IMPULSION NON 0 1 AUCUNE 0,51 0 0 0,15
DERICHE Lena NON 0 1 AUCUNE 0,15 DERICHE Cellules NON 0 1 AUCUNE 0,09
DERICHE Contour MARCHE OUI 0 1 AUCUNE 0,21 0,58 0 0,47
DERICHE Contour RAMPE OUI 0 1 AUCUNE 0,41 0,58 0 0,48
DERICHE Contour PIC OUI 0 1 AUCUNE 0,52 0,72 0 0,53 double DERICHE Contour PIC OUI 0 1,5 AUCUNE 0,52 0,58 0 0,47
DERICHE Contour IMPULSION OUI 0 1 AUCUNE 0,52 0,58 0 0,48
DERICHE Lena OUI 0 1 AUCUNE 0,64 DERICHE Cellules OUI 0 1 AUCUNE 0,68
DERICHE Contour MARCHE NON 20 1 AUCUNE 0,17 0 0 0,12
DERICHE Contour RAMPE NON 20 1 AUCUNE 0,31 0,29 0 0,15
DERICHE Contour PIC NON 20 1 AUCUNE 0,39 0,57 0 0,20
DERICHE Contour IMPULSION NON 20 1 AUCUNE 0,42 0 0 0,15
DERICHE Lena NON 20 1 AUCUNE 0,17 DERICHE Cellules NON 20 1 AUCUNE 0,10
DERICHE Contour MARCHE OUI 20 1 AUCUNE 0,21 0,58 0 0,45
DERICHE Contour OUI 20 1 AUCUNE 0,37 0,63 0 0,4

ANNEXE B
69
RAMPE
DERICHE Contour RAMPE OUI 20 0,5 AUCUNE 0,41 0,64 0 0,47
DERICHE Contour PIC OUI 20 1 AUCUNE 0,46 0,54 0 0,45
DERICHE Contour IMPULSION OUI 20 1 AUCUNE 0,49 0,31 0 0,4
DERICHE Lena OUI 20 1 AUCUNE 0,58 DERICHE Cellules OUI 20 1 AUCUNE 0,66
SHEN Contour MARCHE NON 0 1 AUCUNE 0,19 0 0 0,16
SHEN Contour RAMPE NON 0 1 AUCUNE 0,29 0,71 0 0,23
SHEN Contour PIC NON 0 1 AUCUNE 0,43 0 0 0,26
SHEN Contour IMPULSION NON 0 1 AUCUNE 0,48 0 0 0,26
SHEN Lena NON 0 1 AUCUNE 0,19 SHEN Cellules NON 0 1 AUCUNE 0,12
SHEN Contour MARCHE OUI 0 1 AUCUNE 0,2 0,58 0 0,47
SHEN Contour RAMPE OUI 0 1 AUCUNE 0,3 0,58 0 0,48
SHEN Contour PIC OUI 0 1 AUCUNE 0,41 0,58 0 0,47
SHEN Contour IMPULSION OUI 0 1 AUCUNE 0,39 0,58 0 0,47
SHEN Lena OUI 0 1 AUCUNE 0,58 SHEN Cellules OUI 0 1 AUCUNE 0,64
SHEN Contour MARCHE NON 20 1 AUCUNE 0,15 0 0 0,37
SHEN Contour RAMPE NON 20 1 AUCUNE 0,18 0,29 0 0,45
SHEN Contour PIC NON 20 1 AUCUNE 0,22 0,11 0 0,45
SHEN Contour IMPULSION NON 20 1 AUCUNE 0,23 0 0 0,45

ANNEXE B
70
SHEN Lena NON 20 1 AUCUNE 0,32 SHEN Cellules NON 20 1 AUCUNE 0,21
SHEN Contour MARCHE OUI 20 1 AUCUNE 0,18 0,59 0 0,23
SHEN Contour RAMPE OUI 20 1 AUCUNE 0,22 0,6 0 0,25
SHEN Contour RAMPE OUI 20 0,5 AUCUNE 0,32 0,62 0 0,32
SHEN Contour PIC OUI 20 1 AUCUNE 0,27 0,38 0 0,26
SHEN Contour IMPULSION OUI 20 1 AUCUNE 0,29 0,23 0 0,26
SHEN Lena OUI 20 1 AUCUNE 0,42 SHEN Cellules OUI 20 1 AUCUNE 0,52
MIRA Contour MARCHE NON 0 1 AUCUNE 0,77 0,008 0 0,18
MIRA Contour RAMPE NON 0 1 AUCUNE 1,39 0,008 0 0,15
MIRA Contour PIC NON 0 1 AUCUNE 0,77 0,71 0 0,24 double
MIRA Contour IMPULSION NON 0 1 AUCUNE 0,44 0,71 0 0,36 double
MIRA Lena NON 0 1 AUCUNE 0,12 MIRA Cellules NON 0 1 AUCUNE 0,1
MIRA Contour MARCHE OUI 0 1 AUCUNE 0,5 0,58 0 0,71
MIRA Contour RAMPE OUI 0 1 AUCUNE 0,88 0,58 0 0,71
MIRA Contour PIC OUI 0 1 AUCUNE 0,86 0,58 0 0,71 double
MIRA Contour IMPULSION OUI 0 1 AUCUNE 0,49 0,58 0 0,71 double
MIRA Lena OUI 0 1 AUCUNE 0,6 MIRA Cellules OUI 0 1 AUCUNE 0,52
MIRA Contour MARCHE NON 20 1 AUCUNE 0,14 0,008 0 0,33
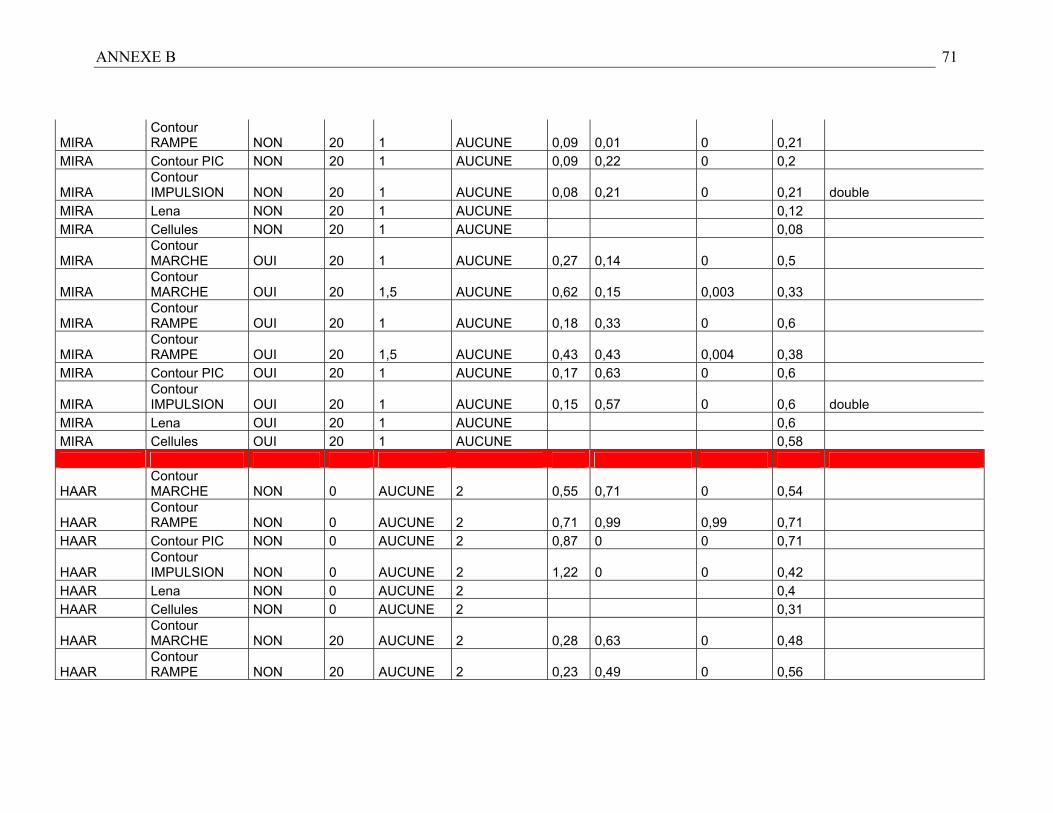
ANNEXE B
71
MIRA Contour RAMPE NON 20 1 AUCUNE 0,09 0,01 0 0,21
MIRA Contour PIC NON 20 1 AUCUNE 0,09 0,22 0 0,2
MIRA Contour IMPULSION NON 20 1 AUCUNE 0,08 0,21 0 0,21 double
MIRA Lena NON 20 1 AUCUNE 0,12 MIRA Cellules NON 20 1 AUCUNE 0,08
MIRA Contour MARCHE OUI 20 1 AUCUNE 0,27 0,14 0 0,5
MIRA Contour MARCHE OUI 20 1,5 AUCUNE 0,62 0,15 0,003 0,33
MIRA Contour RAMPE OUI 20 1 AUCUNE 0,18 0,33 0 0,6
MIRA Contour RAMPE OUI 20 1,5 AUCUNE 0,43 0,43 0,004 0,38
MIRA Contour PIC OUI 20 1 AUCUNE 0,17 0,63 0 0,6
MIRA Contour IMPULSION OUI 20 1 AUCUNE 0,15 0,57 0 0,6 double
MIRA Lena OUI 20 1 AUCUNE 0,6 MIRA Cellules OUI 20 1 AUCUNE 0,58
HAAR Contour MARCHE NON 0 AUCUNE 2 0,55 0,71 0 0,54
HAAR Contour RAMPE NON 0 AUCUNE 2 0,71 0,99 0,99 0,71
HAAR Contour PIC NON 0 AUCUNE 2 0,87 0 0 0,71
HAAR Contour IMPULSION NON 0 AUCUNE 2 1,22 0 0 0,42
HAAR Lena NON 0 AUCUNE 2 0,4 HAAR Cellules NON 0 AUCUNE 2 0,31
HAAR Contour MARCHE NON 20 AUCUNE 2 0,28 0,63 0 0,48
HAAR Contour RAMPE NON 20 AUCUNE 2 0,23 0,49 0 0,56

ANNEXE B
72
HAAR Contour PIC NON 20 AUCUNE 2 0,24 0,22 0 0,55
HAAR Contour IMPULSION NON 20 AUCUNE 2 0,26 0 0 0,55
HAAR Lena NON 20 AUCUNE 2 0,54 HAAR Cellules NON 20 AUCUNE 2 0,46
MALLAT Contour MARCHE NON 0 AUCUNE 2 46,5 0,004 0 0,71
MALLAT Contour RAMPE NON 0 AUCUNE 2 1 0,99 0,99 0
MALLAT Contour PIC NON 0 AUCUNE 2 1 0,99 0,99 0
MALLAT Contour IMPULSION NON 0 AUCUNE 2 0,2 0,76 0 0,36 double
MALLAT Lena NON 0 AUCUNE 2 0,5 Il manque beaucoup de contours
MALLAT Cellules NON 0 AUCUNE 2 0,55
MALLAT Contour MARCHE NON 20 AUCUNE 2 0,006 0,014 0 0,58
MALLAT Contour RAMPE NON 20 AUCUNE 2 0,004 0,38 0 0,56
MALLAT Contour PIC NON 20 AUCUNE 2 0,004 0,55 0 0,56
MALLAT Contour IMPULSION NON 20 AUCUNE 2 0,005 0,5 0 0,56
MALLAT Lena NON 20 AUCUNE 2 0,56 MALLAT Cellules NON 20 AUCUNE 2 0,57

ANNEXE C
Résultats DECAP Résultat du détecteur DECAP sur quelques images du banc d’essai.
Figure A.13 : Image 90 du benchmark

ANNEXE C
74
Figure A.14 : image 86 du benchmark

ANNEXE C
75
Figure A.15 : Image73 du benchmark
Figure A.16 : Image 69 du benchmark

ANNEXE C
76
Figure A.17 : Image 109 du benchmark
![[Fr] mythes & réalité des médias sociaux - Dii](https://static.fdocuments.fr/doc/165x107/546e174daf79590b198b5838/fr-mythes-realite-des-medias-sociaux-dii.jpg)

















