Spark Streaming
34
Présentation Société Mars 2013 @ Paris Stanislas BOCQUET CEO +33(0)1 43 12 89 42 [email protected] SPARK STREAMING, LES DONNÉES QUI VOUS PARLENT EN TEMPS RÉEL 30 SEPTEMBRE 2015 @Paris Nadhem LAMTI Architecte Technique chez PALO IT Saâd-Eddine MALTI Expert BDD chez Voyages SNCF &
-
Upload
palo-it -
Category
Technology
-
view
580 -
download
5
Transcript of Spark Streaming

Présentation Société
Mars 2013 @ Paris
Stanislas BOCQUETCEO+33(0)1 43 12 89 [email protected]
SPARK STREAMING, LES DONNÉES QUI VOUS PARLENT EN TEMPS RÉEL
30 SEPTEMBRE 2015 @Paris
Nadhem LAMTIArchitecte Technique chez PALO ITSaâd-Eddine MALTIExpert BDD chez Voyages SNCF
&

2
Au programme
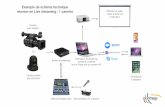
Streaming et Architecture Big Data
Introduction to Spark Streaming : Word Count
Intégration de Flume à Spark Streaming
Use case « logs applicatifs »
Architecture générale : driver / workers / receivers
Monitoring
Fail over : reliable / unreliable sources, checkpoint, recoverTuning et performance

Streaming et architecture
BigData

4
RAPPELS
Juin 2015
HDFS : système de fichiers distribués
MAPREDUCE : traitement distribué
PIG HIVESCRIPTING SEQUENTIEL
SQL LIKE
JAVAPlumbing
• In Memory• RDD• Scala/Java/
Python

5
ARCHITECTURE BIG DATA
Plus familièrement : architecture LAMBDASTOCKENT : en vue d’un REPORTING mensuel par exEt TRAITENT en temps réel la donnée : en vue d’un MONITORING par ex
Savent gérer la donnée à la fois comme :
UN STOCKUN FLUX
Cas d’utilisation :Systèmes de recommandationsStatistiques en temps réel : ex taux d’erreurPub en ligne : nombre de clics/transformations par campagne

6
ARCHITECTURE BIG DATA
Batch LAYER Stocker l’ensemble de donnéesItération pouvant prendre plusieurs heures
Speed LAYER : « temps réel »Traite que les données récentes et compense la latence élevée de la couche BatchCalculées de manière incrémentale en s’appuyant sur des systèmes de traitement de flux et des bases de données en lectures/écritures aléatoires.
Serving LAYER:Charger et Exposer les vues des couches batch et temps réel

7
SPARK STREAMING

88
SPARK STREAMING
Etend l’API de Spark Core
Scalable, haut débit, tolérance au panne
Traitement au fil de l’eau des données temps réelles

99
SPARK STREAMING
Plusieurs sources possibles
Processing utilisant des algorithmes complexes mais des APIs simples : map, reduce, join, window, …
Les données traitées peuvent être poussées vers des systèmes de stockage, Dashboards, …
Haut niveau d’abstraction : Discritized Stream (DStream) Séquence de RDDs

1010
WORD COUNT

1111
WORD COUNT

12
Intégration avec Flume

1313
DATASOURCE FLUME
Système distribué, fiable, à haute disponibilité Solution de collecte et d’agrégation de gros volumes données depuis plusieurs sources Pusher vers un entrepôt de données centralisé (HDFS, ELS …)AgentsSource, Channel, Sink

1414
DATASOURCE FLUME
Configuration Type

1515
DATASOURCE FLUME
Spark Streaming + Flume Integration Guide
Approche 1 : Push-based approach :Spark Streaming, essentiellement, initialise un “receiver” agissant comme un agent Avro pour Flume, dans lequel ce dernier peut pousser ses donnéesConfiguration de Flume :
Linking : Package spark-streaming-flume_2.10Programming :

1616
DATASOURCE FLUME
Spark Streaming + Flume Integration Guide
Approche 2 : Pull-based approach :Flume pousse les données dans le sink, et ces dernières restent en mémoire tampon.Spark Streaming utilize un reliable Flume receiver de manière transactionnelle pour récupérer les données du sink. Une transaction est considérée OK seulement après acquittement et replication de la donnée par Spark StreamingConfiguration Flume :
Sink Jars : spark-streaming-flume-sink_2.10, scala-library Config file Linking : Package spark-streaming-flume_2.10Programming :

17
DEMO : USE CASE LOG APPLICATIF

1818
DEMO : USE CASE LOG APPLICATIF
Operations :Transformations : lazy
Stateless : map, reduce, filter, join, combineByKeyStateful : utilise les données et les résultat du batch précédent. Nécessite un checkpoint.
» window / silde :exemple : reduceByKeyAndWindow
» Statut à travers le temps : updateByState
Actions : output des operations. Sert pour évaluer le contenu d’un Dstream et démarrer un contexteexemple : myDStream.saveAsTextFiles(“mydir”,”.txt”)foreachRDD() : generic output operation

1919
DEMO : USE CASE LOG APPLICATIF
Déploiement Inclure les dépendances Spark et celles des sources Générer un package avec Maven Assembly
Exécution./bin/spark-submit -- class … -- master …-- jars [jar_1,jar_2,…,jar_n]-- conf p1=v1….<app-jar>[app-arguments]
ConfigurationSparkConf.set(“p1”,”v1”)Dynamique :-- conf p1=v1-- conf p2=v2
Config Chargée depuis conf/spark-defaults.conf : Les propriétés peuvent être consultées depuis la webUI(http://<driver>:4040) # TAB “Environment”

ARCHITECTURE

21
ARCHITECTURE
Cluster Manager : Standalone, MESOS, YARN et local( dev/test/debug)
WorkerNode : Receives + Processes
Driver : programme principale contenant « sparkContext »

22
MONITORING
webUI : http://<driver>:4040Streaming \ tab
Running Receivers : ActiveNumber of records receivedReceiver error
Batches : Processing TimeTimesQueing delays
Environment \tab …

TOLERANCE AUX PANNES

24
TOLERANCE AUX PANNES
3 étapes pour traiter les données
Recevoir les données
Traiter/transformer les données
Pusher les données vers l’éxterieur

25
TOLERANCE AUX PANNES
Réception des données :
Reliable : acquittement après avoir s’assurer que la donnée reçue est répliquée : cas de « PollingFlume »Unreliable : à partir de « Spark 1.2 », « WriteAheadLog » (spark.streaming.receiver.writeAheadLog.enabled -> true)
Attention aux performances : utiliser plus qu’un Receiver en // et désactiver la réplication

26
TOLERANCE AUX PANNES
Traiter/Transformer les données :
CHECKPOINT : Sauvegarder le statut périodiquement dans un système de fichier fiable :
Data : RDD intermédiaires sur les opération de transformation Statefull
Metadata : Recover from Driver :
Utiliser “getOrCreate” : recréer sparkStreamingContext depuis checkpoint Data dans le répertoire checkpoint
-- supervise : redémarrage en cas d’échec du Driver (seulement on standalone mode)
-- deploy-mode cluster : lancer sur un cluster distant

27
TOLERANCE AUX PANNES
Push des données vers l’éxterieur:
Mise à jour transactionnelle
Doit avoir un identifiant de transaction
Du moment ou ça concerne un système externe, c’est de la responsabilité du système d’assurer la cohérence des données

28
TOLERANCE AUX PANNESMode Normal

29
TOLERANCE AUX PANNESMode « Recover »

Tunning et performance

31
Tunning et performance
Important : Le temps totale d’exécution d’un batch (scheduling delay + processing time) < batchIntervalSuivi via Spark UI Monitoring
Data Receiving :Setter le bon « BatchInterval » : tester la limite en jouant sur le débitAugmenter le nombre de Receivers :
Attention : un « Receiver » = un « Worker » ou un « Core » Merge des Dstream de chaque receiver
Alternative au multiple Dstream : « inputStream.repartition () » distribue les données reçues sur des machines du « Cluster » avant « processing »« spark.streaming.backpressure.enabled » : gestion dynamique de la conf « spark.streaming.receiver.maxRate »

32
Tunning et performance
Data Processing :Niveau du parallélisme
Spark.core.max - nbr consommateurs Ajouter la conf « spark.default.parallelism » selon le type du cluster Manager Réduire le nombre de partitions pour réduire le temps de Processing :
Chaque block de données généré par le « Receiver » produit une partition « spark.streaming.blockInterval » : les données reçu se transforment en un block de données Partitions = « consumers » * « bactchInterval » / « blockInterval » « spark.streaming.blockInterval » nbr Partitions mais « batchInterval » mod
« blockInterval » = 0 Recommandé par Spark : nb Partition = 2x-3x nombre de « Cores » disponibles « spark.streaming.blockInterval » = « consumers » * « bactchInterval » / 2 ou 3 * « nb
Cores »Eviter les log de parcours des « Dstream » logs mode verbeux et silencieuxKryo pour une sérialisation plus efficace : « spark.serializer org.apache.spark.serializer.KryoSerializer »

33
Tunning et performance
Setting the right batch interval : >=500 msTraite la donnée dès sa réception
Memory tuning and GC behavior :Taille de la Window
Mémoire requise de la taille de donnée dans chaque “executor” Set spark.default.parallelism
Large pause causée par JVM GC non désirable : Utiliser plus d’éxécuteurs avec une taille mémoire plus petite
CMS GC : diminuer les pauses In Driver : --driver-java-options In Executor : spark.executor.extraJavaOptions
Contrôler l’éviction des données si pas besoin Peut se faire explicitement pour les vieilles données au delà de “spark.cleaner.ttl” (peut
réduire la pression de l’activité GC)

Présentation Société
Mars 2013 @ Paris
Stanislas BOCQUETCEO+33(0)1 43 12 89 [email protected]
MERCI DE VOTRE
ATTENTION !