
Réseaux de neurones, lissage de la fonction d'actualisation et prévision des OAT démembrées :...
15
RESEAUX DE NEURONES, LISSAGE DE LA FONCTION D’ACTUALISATION ET PREVISION DES OAT DEMEMBREES : UNE ETUDE EMPIRIQUE Saïd BOLGOT * et Jean-Christophe MEYFREDI ** Classification JEL : C4, C45, C1, C13, G, G12, Mots clefs : Réseaux de Neurones, Régularisation, prévision, Courbe des taux, Strip OAT Key words : Neural Networks, Regularization, Forcasting, Term Structure, Strip OAT * GREQAM, Groupement de Recherche en Economie Quantitative d’Aix-Marseille, Université de la Méditerranée. E-mail : [email protected] ** CETFI, Centre d’Etudes des Techniques Financières et d’Ingénierie, Faculté d’Economie Appliquée, Université d’Aix-Marseille III. E-mail : [email protected]
-
Upload
said-bolgot -
Category
Economy & Finance
-
view
33 -
download
1
Transcript of Réseaux de neurones, lissage de la fonction d'actualisation et prévision des OAT démembrées :...

RESEAUX DE NEURONES, LISSAGE DE LA FONCTIOND’ACTUALISATION ET PREVISION DES OAT
DEMEMBREES : UNE ETUDE EMPIRIQUE
Saïd BOLGOT* et Jean-Christophe MEYFREDI**
Classification JEL : C4, C45, C1, C13, G, G12,
Mots clefs : Réseaux de Neurones, Régularisation, prévision, Courbe des taux, Strip OAT
Key words : Neural Networks, Regularization, Forcasting, Term Structure, Strip OAT
* GREQAM, Groupement de Recherche en Economie Quantitative d’Aix-Marseille, Université de la Méditerranée.E-mail : [email protected]
** CETFI, Centre d’Etudes des Techniques Financières et d’Ingénierie, Faculté d’Economie Appliquée, Universitéd’Aix-Marseille III. E-mail : [email protected]

2
Résumé
La courbe de structure des taux d'intérêt est une des composantes fondamentales de la théorieéconomique et financière. Celle-ci, en établissant une relation entre les taux d'intérêt et les maturités,permet d’évaluer de nombreux actifs financiers. Or, les méthodes de révélation sont nombreuses maisn'offrent pas toutes des résultats satisfaisants et souffrent, parfois, de certaines limitations.
Dans cet article, nous proposons de tester certaines de ces méthodes sur des obligations d'étatdémembrées (strip). Nous montrerons que l'utilisation des réseaux de neurones artificiels peuts'avérer très satisfaisante et que cette méthode reste robuste quant à l'éventuelle existence de donnéesaberrantes.
Abstract
The term structure of interest rates is certainly one of the most important components ofeconomic and financial theory. In fact, by building a relationship between interest rates andmaturities, it permits to valuate numerous term structure derivatives. There exist several estimationmethods but they don't offer good results and sometimes, have some limits.
In this paper, we propose to perform an empirical comparison using french strip bond data.We’ll show that artificial neural networks can represent an interesting method, robust in presence ofoutliers.

3
1. Introduction
Les études relatives à la révélation de la structure par terme des taux d'intérêt sont peunombreuses sur le marché français. Cependant, de nombreux chercheurs ont tenté d'édifier une basede réflexion rigoureuse, en vue de l'estimation de la fonction d'actualisation qui serait à l'origine duprocessus de valorisation des actifs à revenu fixe négociés sur le marché obligataire.
En toute rigueur, la structure par terme des taux d'intérêt ne devrait être extraite qu'à partir desobligations zéro-coupon. En effet, l'utilisation, comme cela a souvent été le cas, de titres couponnésintroduit un facteur supplémentaire qui affecte le niveau des taux d'intérêt. Cependant, le manque detitres zéro-coupon sur le marché domestique a nécessité d'autres moyens d'obtention. Dès lors, il estnécessaire de recourir à l'utilisation du prix d'autres actifs financiers pouvant être considérés commesans risque, tels que le cours des OAT “classiques”1 (considérées comme un portefeuilled'obligations zéro-coupon) ou encore le cours des contrats de swaps des entreprises de premièrecatégorie.
La méthode la plus simple consistait à définir une courbe des taux zéro à partir des taux derendement actuariel (TRA) fournis par l'observation des obligations couponnées (DURAND[11],FISHER [14], MASERA [22]).
Les modèles qui ont succédé visaient à approcher une fonction d'actualisation en temps discret(CARLETON-COOPER [5]). AUGROS [1] a tenté d'adapter cette approche au marché obligatairefrançais. Cependant, il s'est heurté à un problème dû à la grande diversité des dates de détachementdes coupons. Pour y remédier, il lui a fallu caler les dates de versement des différents flux. Il a ainsiprocédé à un premier ajustement en utilisant les taux de rendement actuariel et une régressionmultiple; et en cas de non platitude, il réalise un second ajustement pour corriger le biais introduit parces derniers.
Afin de pallier la principale critique des modèles précédents, une nouvelle voie de recherche,consistant à mettre en place une fonction d'actualisation en temps continu, a été élaborée.MCCULLOCH [23] utilise une approximation par des splines polynômiaux2. SCHAEFFER [27] ajustela fonction d'actualisation par une série de polynômes de Bernstein. Mais l'application de cesméthodes au marché français par BONNEVILLE [4] ont révélé des valeurs aberrantes aux extrémitésde la courbe de structure des taux. En effet, les splines impliquent une fonction d'actualisation quidiverge au fur et à mesure de la croissance des maturités au lieu de converger vers 0 comme lesuppose la théorie.
Or, ces différentes méthodes sont limitées par le fait que les fonctions polynômiales onttendance à lisser la courbe de structure des taux d'une manière variable, en fonction des maturités.VASICEK et FONG [29], SHEA [28] ont pris en compte des fonctions d'actualisation de formeexponentielle ; CHAMBERS, CARLETON et WALDMAN [6] recourent quant à eux à des ajustementsnon linéaires et mettent en place une fonction d'actualisation qui est à la fois polynômiale etexponentielle. Enfin, on peut citer dans le même ordre d'idées le modèle de BERA et SIMONET [2]qui utilisent également une fonction d'actualisation de forme exponentielle, mais se limitant (aprèsestimation empirique) à un polynôme de degré 3.
Ce sont ces trois derniers modèles qui font l'objet de l'étude menée conjointement par DE LA
1 Par opposition aux strips OAT que nous verrons ultérieurement.
2 Ce sont des fonctions qui doivent s'emboiter les unes aux autres afin de respecter une continuité dans leur jonctions.

4
BRUSLERIE et GELUSSEAU [10] sur un échantillon d'obligations du Trésor US et un second composéd'euro-obligations, toutes de maturité 1 à 15 ans (titres les plus nombreux et les plus liquides). Lesdeux auteurs écartent volontairement les obligations zéro-coupon pour lesquelles on obtientdirectement le taux comptant qui y est attaché. Ils parviennent à la conclusion que, compte tenu de laliaison entre les résidus et les variables explicatives (maturité, et dans une moindre mesure, le taux decoupon), les modèles testés sont significativement hétéroscédastiques, hormis peut-être pour lemodèle de VASICEK et FONG. Ce modèle semble le plus satisfaisant puisque la valeur du biais estfaible au long des différentes coupes. La difficulté majeure réside dans le fait que les résidus del'estimation sont très largement dispersés (2 points pour les T-bonds et 4 points pour les euro-obligations) ce qui empêche l'utilisation du modèle à des fins pratiques.
Depuis cette étude, de nouveaux modèles proposant des fonctions approchées notamment enterme de splines cubiques (FISHER, NYCHKA et ZERVOS [15]), des fonctions pas à pas (RONN [26]ainsi que COLEMAN et FISHER [8]), des fonctions linéaires par parties (FAMA et BLISS [12]) et desformes exponentielles (NELSON et SIEGEL [24]) ont été développés. BLISS [3] a testé 5 méthodesd'estimation de la courbe de structure des taux parmi lesquelles celle de MCCULLOCH , celle deFISHER et al. , celle de NELSON et SIEGEL, et enfin deux versions de la méthode de FAMA-BLISS
(une méthode lissée et une autre non lissée). Il teste ces différents modèles sur deux échantillons (unservant à l'extraction des paramètres du modèle et un second permettant de valider le modèle). Sonanalyse porte sur des données de fin de mois entre 1970 et 1996 (312 mois). Comme dans l'étudeprécédente, les obligations avec des clauses spéciales (telles que les obligations à clause deremboursement anticipé) et les titres pour lesquels il existait un problème de liquidité (titres inférieursà un mois), ont été écartés. Les différents tests qui ont été menés établissent, une nouvelle fois, quecertains facteurs ont été omis dans l'équation d'évaluation du cours des obligations et notammentpour les longues maturités.
L'objectif principal de cette étude est de déterminer, sur la base de données françaises (stripsOAT), la courbe de structure des taux d'intérêt, puis d'utiliser cette dernière pour évaluer desobligations. L'échantillon servant à la validation est composé de 13 OAT ordinaires n'ayant pas servià la détermination de la courbe des taux. Nous choisissons ainsi la démarche inverse de celle utiliséepar ROGER et ROSSIENSKY [25].
A titre de comparaison, nous avons choisi de confronter les résultats obtenus à l’aide desréseaux de neurones à ceux provenant de la méthode de VASICEK-FONG3 ainsi que d’un ajustementpolynômial4. Après avoir effectué des tests préliminaires, nous avons volontairement écarté laméthode des splines qui, si elle donne d’excellents résultats quant à l’estimation de la courbe destructure des taux, souffre de deux inconvénients. Le premier concerne son utilisation, puisque cetteméthode exige des maturités distinctes. Or, il est fréquent de rencontrer plusieurs taux pour desstrips de même maturité. Le second problème est que cette méthode n’est pas parcimonieuse.
L'article sera donc organisé de la façon suivante : dans une première section, nous décrirons lemodèle utilisé. Dans une seconde, nous présenterons brièvement les strips OAT qui ont servi desupport à l’obtention de la courbe de structure par terme des taux d’intérêt (CST). Dans unetroisième, nous rappellerons en quoi consiste la méthode des réseaux de neurones et de quellemanière ils peuvent s’appliquer à notre domaine d’étude. Enfin, après avoir décrit nos données dansune quatrième section, nous validerons notre approche par une étude empirique sur le marchéfrançais.
3 La fonction d’actualisation retenue par les auteurs est : ( ) ( ) ( ) ( )G t a a e a e a et t t= + + +− − −0 1 2
23
3α α α .
4 Aprés différents tests, nous retenons des polynômes d'ordre 3.

5
2. Le modèle
Nous supposerons au cours de notre étude que les marchés sont parfaits. Afin de pouvoirévaluer les taux au comptant, il convient de rappeler, tout d'abord, la formule d'actualisation de fluxcertains en l'absence de frictions (sans taxes, ni coûts de transaction) :
( ) ( )n
n
rn
t t
tt
r
V
r
CP
01 0 11 ++
+= ∑
=
(1)
où Pt désigne le prix d'une obligation hors risque de défaut à la maturité t, Ct la valeur du couponversé à l'année t, 0 rt le taux d'intérêt au comptant applicable à une obligation d'un an ne versant pasde coupon et Vr la valeur de remboursement.
Pour passer du cours de l'obligation zéro-coupon au taux d'intérêt au comptant correspondant,on utilise la relation suivante :
1100
1
0 −
=
t
tt P
r (2)
où 0 rt est le taux au comptant correspondant à la maturité t = T-t* avec T l'échéance du titre et t* ladate d'évaluation.
Lors de notre étude, nous nous servirons du cours des OAT démembrées afin d'obtenir lesdifférents taux au comptant associés, et ce à l'aide de la formule (2). Notre but est de pouvoir,ensuite, obtenir une fonction continue et lisse permettant d'ajuster au mieux la courbe observée et quipourra servir à la valorisation d'actifs contingents aux taux d'intérêt.
3. Les strips5
Les émissions de titres obligataires zéro-coupon sont extrêmement rares sur le marché françaiset ne pourraient, a fortiori, en aucun cas couvrir l'ensemble des échéances. Cependant, ce type detitres présente un double avantage. D’une part, ils permettent de supprimer l’incertitude liée auréinvestissement des coupons. D’autre part, s’il existait des obligations zéro-coupon couvrant tout lespectre des échéances, il deviendrait par la même trivial d’extraire les différents taux au comptantleur correspondant.
Voilà sans doute les raisons pour lesquelles, devant l'absence de ces titres si recherchés, il a étéchoisi de «démembrer » des obligations classiques en plusieurs obligations zéro-coupon. Ainsi, il serapossible, à partir d'un titre à taux fixe de maturité 10 ans de créer 11 titres zéro-coupon : dix,représentant chaque versement normal d'intérêt et un dernier représentant le capital. En France, lepremier démembrement d'OAT n'a été mené qu'en 19856, mais n'a pris son essor qu'en 1991 suite àun allégement des dispositions réglementaires et fiscales.
5 Pour avoir de plus amples renseignements sur le démembrement des OAT et leur réglementation le lecteur intéressépourra se reporter à l'ouvrage de FERRANDIER et KOEN [13] ou encore à celui de CLERMONT TONNERRE et LEVY [7].
6 Cette technique initiée aux Etats-Unis dès 1972, n'a connu un véritable succès qu'à partir de 1982, date à laquelle lesautorités américaines ont mis en place un cadre réglementaire pour le démembrement des titres ; on a alors parlé deprogramme strips (Separate Trading of Registred Interests and Principal of Securities).

6
Cependant, l'utilisation des strips n'est elle-même pas exempte de toute critique puisqu'il estpossible de trouver pour une même maturité des taux au comptant différents (coupon et principalarrivant à échéance au même moment), ce qui va à l'encontre de l'hypothèse d'un prix unique pour unmême actif.
4. Les réseaux de neurones
Une manière courante et commode de présenter un réseau neuronal est de le décrire sousforme de schéma ou d’un graphe. En ce qui nous concerne, nous nous intéressons à un type deréseaux dit multi-couches ou feedforward composé d’une couche d’entrée, d’une couche de sortie etd’une ou plusieurs couches intermédiaires appelées couches cachées7. Chacune de ces différentescouches est composée d’un certain nombre d’unités appelées neurones et qui sont munies defonctions d’activation (fonctions de transfert).
Fig-1 : Réseau
Multi-Couches
Nous désignons par ),( βα=wl’ensemble des paramètres du modèle, parq le nombre d’unités dans la couchecachée, par F(x) la fonction d’activationdes unités de la couche de sortie, par
)(xϕ celle des unités de la couche cachée,par p le nombre de variables explicativeset par s le nombre de variables expliquées. La couche d’entrée envoie des signaux ),...,,1(~
1 ′= pxxx
qui en termes économétriques correspondent aux variables exogènes augmentées de la constanteappelée aussi biais ou threshold. Ces variables sont ensuite pondérées par des poids de connexion αet transformées par les fonctions d’activation ϕ. On obtient alors de nouvelles variables inobservables
)(1
0 ∑=
+=p
iiijjj xh ααϕ où p est le nombre de variables explicatives. Ces nouvelles variables sont à
leur tour pondérées par des poids de connexion β et transformées par les fonctions d’activation de lacouche de sortie F. Chaque neurone k de la couche de sortie produit alors :
skxFyq
j
p
iiijjjkkk ,...,1 ))((ˆ
1 100 =++= ∑ ∑
= =
ααϕββ (3)
Les kj 00 et βα sont des constantes (biais) et le choix des fonctions ϕ et F est arbitraire,
généralement des fonctions sigmoïdales de forme générale :
∈++−
= ,, 1
1)( kbab
e
eax
kx
kx
ϕ IR et a, k > 0 (4)
7 Nous nous limiterons à une seule couche cachée pour trois raisons. La première est d‘ordre numérique, car leserreurs de précision et d‘arrondis de la machine peuvent s‘accumuler rapidement. La deuxième concerne le temps decalcul qui peut devenir prohibitif. La troisième raison est théorique : les principaux résultats ont été démontrés pourun réseau à une couche cachée.

7
Dans la pratique, le plus souvent, )exp(1
1)(
xx
−+=ϕ (fonction logistique) ou encore
)tanh()( xx =ϕ (tangente hyperbolique) ; et F(x) = x (fonction identité). L’équation 3 devient
∑ ∑= =
++=q
j
p
iiijjjkkk xy
1 100 )(ˆ ααϕββ (5)
jk
q
jjkkk xwxfy βαϕβ ∑
=
′+==1
0 )~(),(ˆˆ (6)
Nous nous situons donc dans le cadre d’un modèle de régression non linéaire multivariée d’une
forme particulière. Disposant d’un échantillon ( )[ ]N
tttN yxZ 1, == contenant N paires de vecteurs
),( tt xy avec ),...,( 1 ′= tptt xxx et ),...,( 1 ′= tstt yyy notre but est de construire, à partir de NZ , un
estimateur )ˆ,...,ˆ(ˆ1 sfff = de la fonction multivariée f. Pour cela, nous estimons l’ensemble des
paramètres w de manière à minimiser une fonction objective basée, par exemple, sur la somme descarrés des résidus :
∑=
−
∈−=
N
ttt
Ww
wxfyNw1
21 )],(ˆ[minargˆ (7)
HORNIK, STINCHOMBE et WHITE [19] et [20], GALLANT et WHITE [17] démontrent dansl’espace de Sobolev (espace des fonctions continues et dérivables) que l’équation 6 est très riche etpeut approcher une très grande classe de fonctions ainsi que leurs dérivées avec autant de précisionqu’on le souhaite à condition d’avoir suffisamment d’unités dans la couche cachée et que lescoefficients soient « proprement » estimés. Nous pouvons retrouver des résultats similaires dansCYBENCO [9], FUNAHASHI [16] et HECHT-NIELSEN [18].
Pour éviter certains problèmes de sur-apprentissage8 liés principalement à une abondance deparamètres (q grand), autrement dit, pour que la courbe estimée soit lisse, ce qui nous intéresseparticulièrement en ce qui concerne l’estimation de la courbe des taux d’intérêt, on minimise lasomme des carrés des résidus pénalisée (ou régularisée)
∑=
− Ψ+−N
ttt wxfyN
1
21 )],(ˆ[ λ (8)
Le deuxième terme de cette expression permet, à travers le coefficient λ de contrôler le degréde lissage de la fonction f. Ψ est un stabilisateur (régulateur) qui pénalise le degré de courbure de la
fonction recherchée. En général ∫ ′′=Ψ dttf 2)]([ . Mais il peut prendre bien d’autres formes dont la
plus simple est ∑=Ψ 2iw (Weight Decay). La valeur de λ est optimisée par la méthode de
validation croisée.
Les paramètres d’intérêt w peuvent être estimés de différentes manières. La méthode la plusutilisée est celle de la descente du gradient :
)),(ˆ(ˆˆ 1 wxfyZww ttii −+=+ η (9)
où η est le pas d’estimation qui peut être constant ou variable et wfZ ∂∂= / (jacobien).
8 Dans le jargon connexioniste, le terme apprentissage désigne l‘estimation des paramètres. Le sur-apprentissageconsiste à ce que les réseaux réalisent un ajustement parfait, au détriment de l’obtention d’une courbe lisse.

8
A cet algorithme nous avons préféré celui de LEVENBERG-MARQUARDT car celui-ci estbeaucoup plus rapide et plus robuste. Il s’exprime comme suit :
)),(ˆ()(ˆˆ 11 wxfyZIZZww ttii −′+′−= −
+ µ (10)
Le paramètre µ permet de rendre la matrice ZZ ′ inversible lorsque celle-ci est mal conditionnée. Cetalgorithme constitue un compromis entre l’algorithme de Gauss-Newton (lorsque µ → 0) et celui dela descente du gradient (cas ou µ → ∞).
Pour estimer la courbe des taux, nous avons utilisé un réseau à une couche cachée contenanttrois neurones. Le modèle reçoit en entée les différentes maturités et fournit en sortie les tauxd’intérêt correspondants.
5. Les données
Elles se composent des cours de clôture journaliers des strips OAT issus de la base de donnéesDatastream entre le 1er janvier 1996 et le 31 octobre de cette même année. Nous avons écarté denotre échantillon les OAT démembrées émises en écu pour lesquelles il existait une prime de risqueplus élevée, ce qui risquait d'entraîner d'importants écarts entre le cours tel qu'il est observé sur lemarché et le cours théorique obtenu, ainsi que les strips représentant le capital. Au total 61 strips ontété utilisées.
Notre base de données comporte, aussi, un échantillon de validation composé de 13 OATordinaires.
6. Les résultats
Comme nous l'avons déjà souligné, ce travail s'effectue en deux étapes : la première consiste àestimer la courbe des taux, puis dans une seconde étape on procède à l'utilisation de cette dernièrepour l'évaluation des 13 OAT de validation.
Lors de l’estimation des paramètres de VASICEK-FONG, par la méthode Gauss-Newton, nousavons été confrontés à de larges problèmes d’instabilité du modèle. Sur les 219 dates, l’algorithmen’a convergé que très rarement et lorsqu’il y avait convergence, les paramètres étaient touslargement non significatifs. Ces difficultés sont dues au fait que la matrice hessienne est malconditionnée (singulière), ce qui explique le niveau élevé des écart-types d’estimation (et donc deleur significativité). Nous avons donc choisi d’avoir recours à l’algoritme de Marquardt.
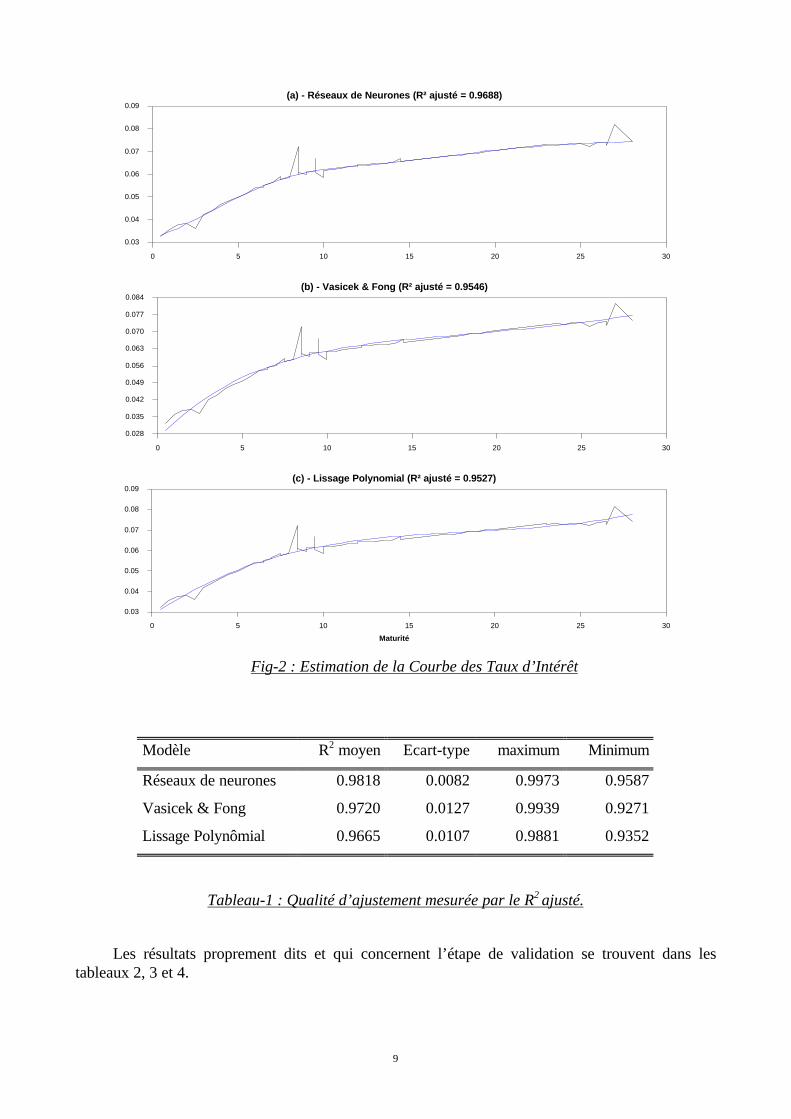
La figure-2, représente l'estimation de la courbe des taux via les trois méthodes retenuesau 31/10/96. Cette étape a nécessité l'estimation de 219 × 3 modèles correspondant au nombre dejours de la période considérée. Les réseaux utilisés sont régularisés9 et entraînés à l'aide del'algorithme de Levenberg-Marquardt. Le tableau-1 résume les résultats de cette étape.
9 La notion de régularisation est essentielle, car l'objectif n'est pas, seulement, d'avoir un R2 élevé mais surtout d'avoirune courbe lisse et d'éviter les problèmes de sur-apprentissage.
9
(a) - Réseaux de Neurones (R² ajusté = 0.9688)
0 5 10 15 20 25 30
0.03
0.04
0.05
0.06
0.07
0.08
0.09
(b) - Vasicek & Fong (R² ajusté = 0.9546)
0 5 10 15 20 25 30
0.028
0.035
0.042
0.049
0.056
0.063
0.070
0.077
0.084
(c) - Lissage Polynomial (R² ajusté = 0.9527)
Maturité
0 5 10 15 20 25 30
0.03
0.04
0.05
0.06
0.07
0.08
0.09
Fig-2 : Estimation de la Courbe des Taux d’Intérêt
Modèle R2 moyen Ecart-type maximum Minimum
Réseaux de neurones 0.9818 0.0082 0.9973 0.9587
Vasicek & Fong 0.9720 0.0127 0.9939 0.9271
Lissage Polynômial 0.9665 0.0107 0.9881 0.9352
Tableau-1 : Qualité d’ajustement mesurée par le R2 ajusté.
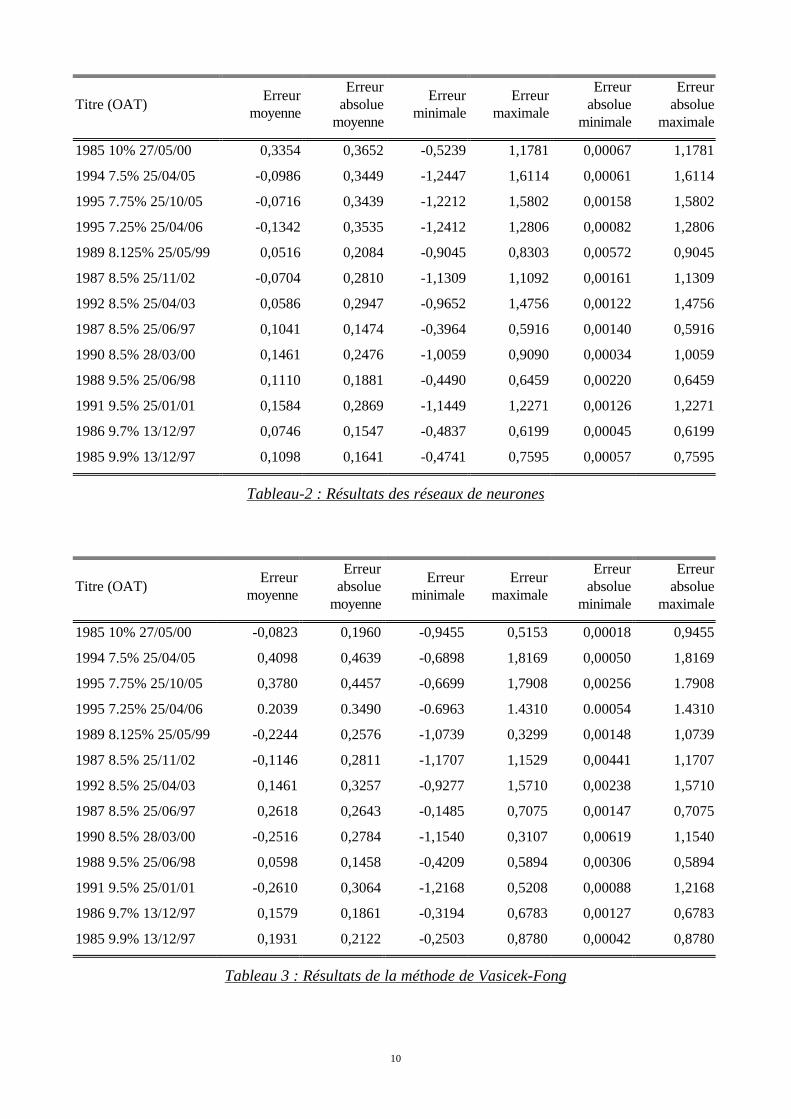
Les résultats proprement dits et qui concernent l’étape de validation se trouvent dans lestableaux 2, 3 et 4.
10
Titre (OAT)Erreur
moyenne
Erreurabsolue
moyenne
Erreurminimale
Erreurmaximale
Erreurabsolue
minimale
Erreurabsolue
maximale
1985 10% 27/05/00 0,3354 0,3652 -0,5239 1,1781 0,00067 1,1781
1994 7.5% 25/04/05 -0,0986 0,3449 -1,2447 1,6114 0,00061 1,6114
1995 7.75% 25/10/05 -0,0716 0,3439 -1,2212 1,5802 0,00158 1,5802
1995 7.25% 25/04/06 -0,1342 0,3535 -1,2412 1,2806 0,00082 1,2806
1989 8.125% 25/05/99 0,0516 0,2084 -0,9045 0,8303 0,00572 0,9045
1987 8.5% 25/11/02 -0,0704 0,2810 -1,1309 1,1092 0,00161 1,1309
1992 8.5% 25/04/03 0,0586 0,2947 -0,9652 1,4756 0,00122 1,4756
1987 8.5% 25/06/97 0,1041 0,1474 -0,3964 0,5916 0,00140 0,5916
1990 8.5% 28/03/00 0,1461 0,2476 -1,0059 0,9090 0,00034 1,0059
1988 9.5% 25/06/98 0,1110 0,1881 -0,4490 0,6459 0,00220 0,6459
1991 9.5% 25/01/01 0,1584 0,2869 -1,1449 1,2271 0,00126 1,2271
1986 9.7% 13/12/97 0,0746 0,1547 -0,4837 0,6199 0,00045 0,6199
1985 9.9% 13/12/97 0,1098 0,1641 -0,4741 0,7595 0,00057 0,7595
Tableau-2 : Résultats des réseaux de neurones
Titre (OAT)Erreur
moyenne
Erreurabsolue
moyenne
Erreurminimale
Erreurmaximale
Erreurabsolue
minimale
Erreurabsolue
maximale
1985 10% 27/05/00 -0,0823 0,1960 -0,9455 0,5153 0,00018 0,9455
1994 7.5% 25/04/05 0,4098 0,4639 -0,6898 1,8169 0,00050 1,8169
1995 7.75% 25/10/05 0,3780 0,4457 -0,6699 1,7908 0,00256 1.7908
1995 7.25% 25/04/06 0.2039 0.3490 -0.6963 1.4310 0.00054 1.4310
1989 8.125% 25/05/99 -0,2244 0,2576 -1,0739 0,3299 0,00148 1,0739
1987 8.5% 25/11/02 -0,1146 0,2811 -1,1707 1,1529 0,00441 1,1707
1992 8.5% 25/04/03 0,1461 0,3257 -0,9277 1,5710 0,00238 1,5710
1987 8.5% 25/06/97 0,2618 0,2643 -0,1485 0,7075 0,00147 0,7075
1990 8.5% 28/03/00 -0,2516 0,2784 -1,1540 0,3107 0,00619 1,1540
1988 9.5% 25/06/98 0,0598 0,1458 -0,4209 0,5894 0,00306 0,5894
1991 9.5% 25/01/01 -0,2610 0,3064 -1,2168 0,5208 0,00088 1,2168
1986 9.7% 13/12/97 0,1579 0,1861 -0,3194 0,6783 0,00127 0,6783
1985 9.9% 13/12/97 0,1931 0,2122 -0,2503 0,8780 0,00042 0,8780
Tableau 3 : Résultats de la méthode de Vasicek-Fong
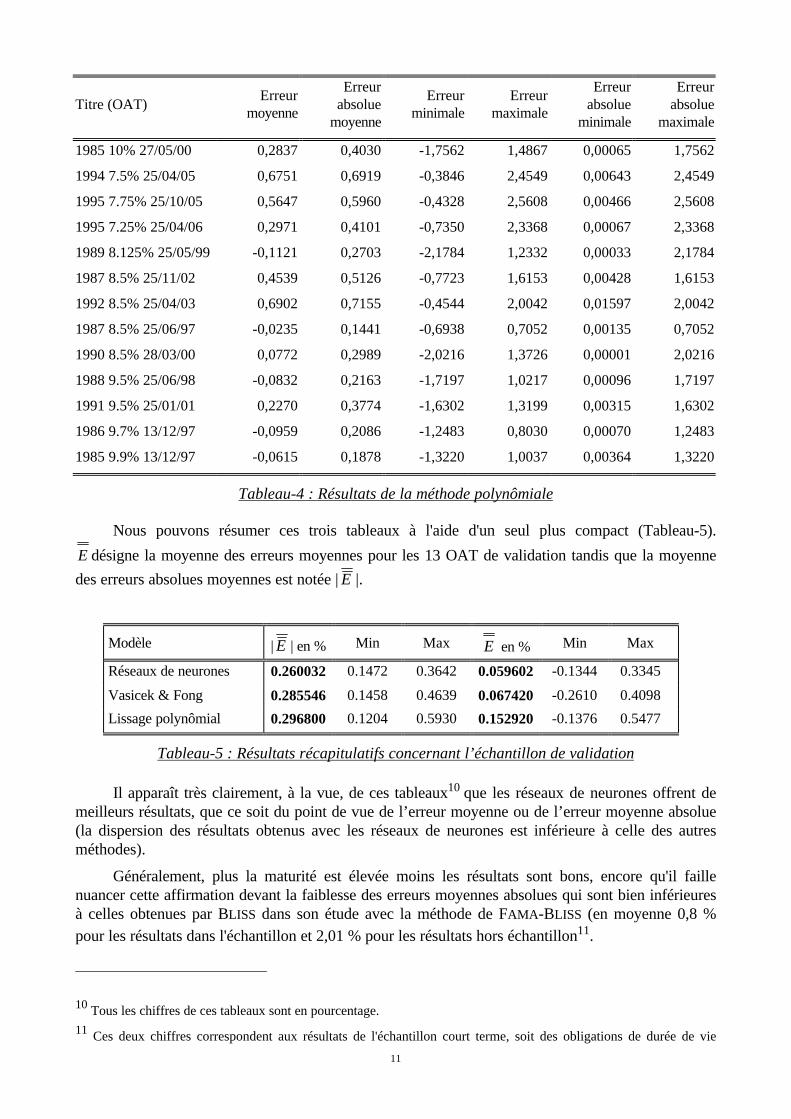
11
Titre (OAT)Erreur
moyenne
Erreurabsolue
moyenne
Erreurminimale
Erreurmaximale
Erreurabsolue
minimale
Erreurabsolue
maximale
1985 10% 27/05/00 0,2837 0,4030 -1,7562 1,4867 0,00065 1,7562
1994 7.5% 25/04/05 0,6751 0,6919 -0,3846 2,4549 0,00643 2,4549
1995 7.75% 25/10/05 0,5647 0,5960 -0,4328 2,5608 0,00466 2,5608
1995 7.25% 25/04/06 0,2971 0,4101 -0,7350 2,3368 0,00067 2,3368
1989 8.125% 25/05/99 -0,1121 0,2703 -2,1784 1,2332 0,00033 2,1784
1987 8.5% 25/11/02 0,4539 0,5126 -0,7723 1,6153 0,00428 1,6153
1992 8.5% 25/04/03 0,6902 0,7155 -0,4544 2,0042 0,01597 2,0042
1987 8.5% 25/06/97 -0,0235 0,1441 -0,6938 0,7052 0,00135 0,7052
1990 8.5% 28/03/00 0,0772 0,2989 -2,0216 1,3726 0,00001 2,0216
1988 9.5% 25/06/98 -0,0832 0,2163 -1,7197 1,0217 0,00096 1,7197
1991 9.5% 25/01/01 0,2270 0,3774 -1,6302 1,3199 0,00315 1,6302
1986 9.7% 13/12/97 -0,0959 0,2086 -1,2483 0,8030 0,00070 1,2483
1985 9.9% 13/12/97 -0,0615 0,1878 -1,3220 1,0037 0,00364 1,3220
Tableau-4 : Résultats de la méthode polynômiale
Nous pouvons résumer ces trois tableaux à l'aide d'un seul plus compact (Tableau-5).
E désigne la moyenne des erreurs moyennes pour les 13 OAT de validation tandis que la moyenne
des erreurs absolues moyennes est notée | E |.
Modèle | E | en % Min Max E en % Min Max
Réseaux de neurones 0.260032 0.1472 0.3642 0.059602 -0.1344 0.3345
Vasicek & Fong 0.285546 0.1458 0.4639 0.067420 -0.2610 0.4098
Lissage polynômial 0.296800 0.1204 0.5930 0.152920 -0.1376 0.5477
Tableau-5 : Résultats récapitulatifs concernant l’échantillon de validation
Il apparaît très clairement, à la vue, de ces tableaux10 que les réseaux de neurones offrent de
meilleurs résultats, que ce soit du point de vue de l’erreur moyenne ou de l’erreur moyenne absolue(la dispersion des résultats obtenus avec les réseaux de neurones est inférieure à celle des autresméthodes).
Généralement, plus la maturité est élevée moins les résultats sont bons, encore qu'il faillenuancer cette affirmation devant la faiblesse des erreurs moyennes absolues qui sont bien inférieuresà celles obtenues par BLISS dans son étude avec la méthode de FAMA-BLISS (en moyenne 0,8 %pour les résultats dans l'échantillon et 2,01 % pour les résultats hors échantillon11.
10 Tous les chiffres de ces tableaux sont en pourcentage.
11 Ces deux chiffres correspondent aux résultats de l'échantillon court terme, soit des obligations de durée de vie
12
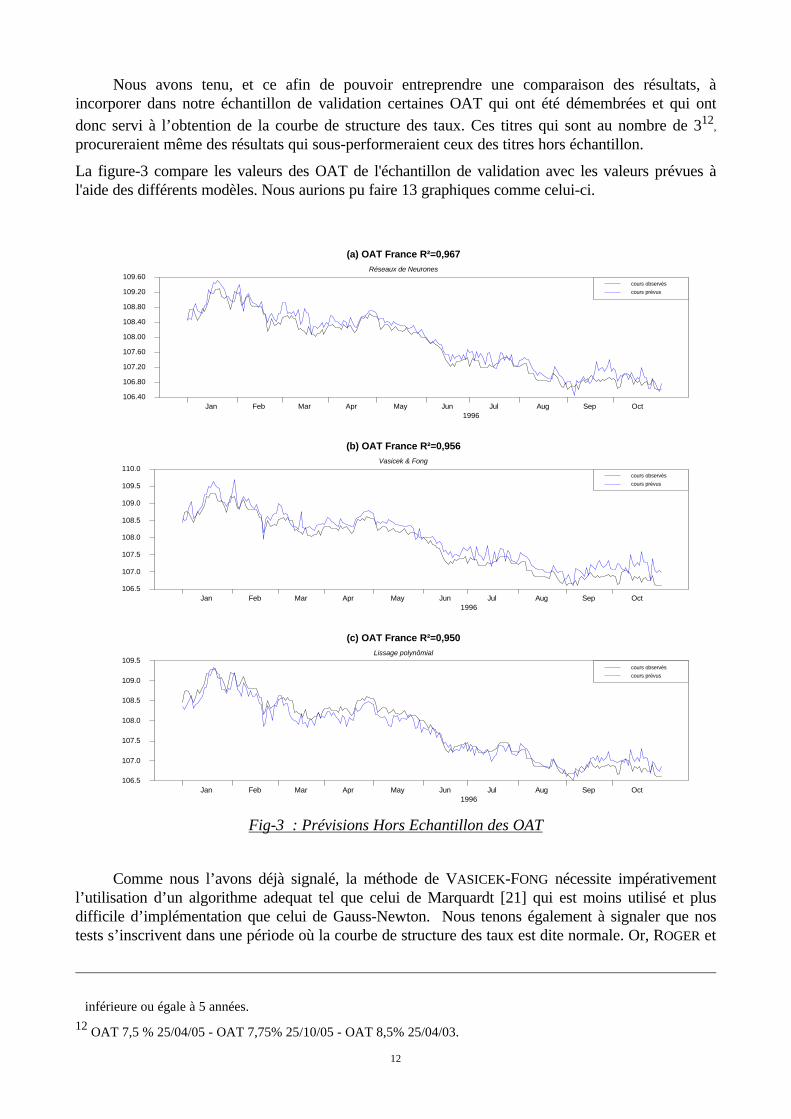
Nous avons tenu, et ce afin de pouvoir entreprendre une comparaison des résultats, àincorporer dans notre échantillon de validation certaines OAT qui ont été démembrées et qui ontdonc servi à l’obtention de la courbe de structure des taux. Ces titres qui sont au nombre de 312
,
procureraient même des résultats qui sous-performeraient ceux des titres hors échantillon.
La figure-3 compare les valeurs des OAT de l'échantillon de validation avec les valeurs prévues àl'aide des différents modèles. Nous aurions pu faire 13 graphiques comme celui-ci.
Fig-3 : Prévisions Hors Echantillon des OAT
Comme nous l’avons déjà signalé, la méthode de VASICEK-FONG nécessite impérativementl’utilisation d’un algorithme adequat tel que celui de Marquardt [21] qui est moins utilisé et plusdifficile d’implémentation que celui de Gauss-Newton. Nous tenons également à signaler que nostests s’inscrivent dans une période où la courbe de structure des taux est dite normale. Or, ROGER et
inférieure ou égale à 5 années.
12 OAT 7,5 % 25/04/05 - OAT 7,75% 25/10/05 - OAT 8,5% 25/04/03.
(a) OAT France R²=0,967Réseaux de Neurones
Jan Feb Mar Apr May Jun Jul Aug Sep Oct1996
106.40
106.80
107.20
107.60
108.00
108.40
108.80
109.20
109.60cours observés
cours prévus
(b) OAT France R²=0,956Vasicek & Fong
Jan Feb Mar Apr May Jun Jul Aug Sep Oct1996
106.5
107.0
107.5
108.0
108.5
109.0
109.5
110.0cours observés
cours prévus
(c) OAT France R²=0,950Lissage polynômial
Jan Feb Mar Apr May Jun Jul Aug Sep Oct1996
106.5
107.0
107.5
108.0
108.5
109.0
109.5cours observés
cours prévus
13
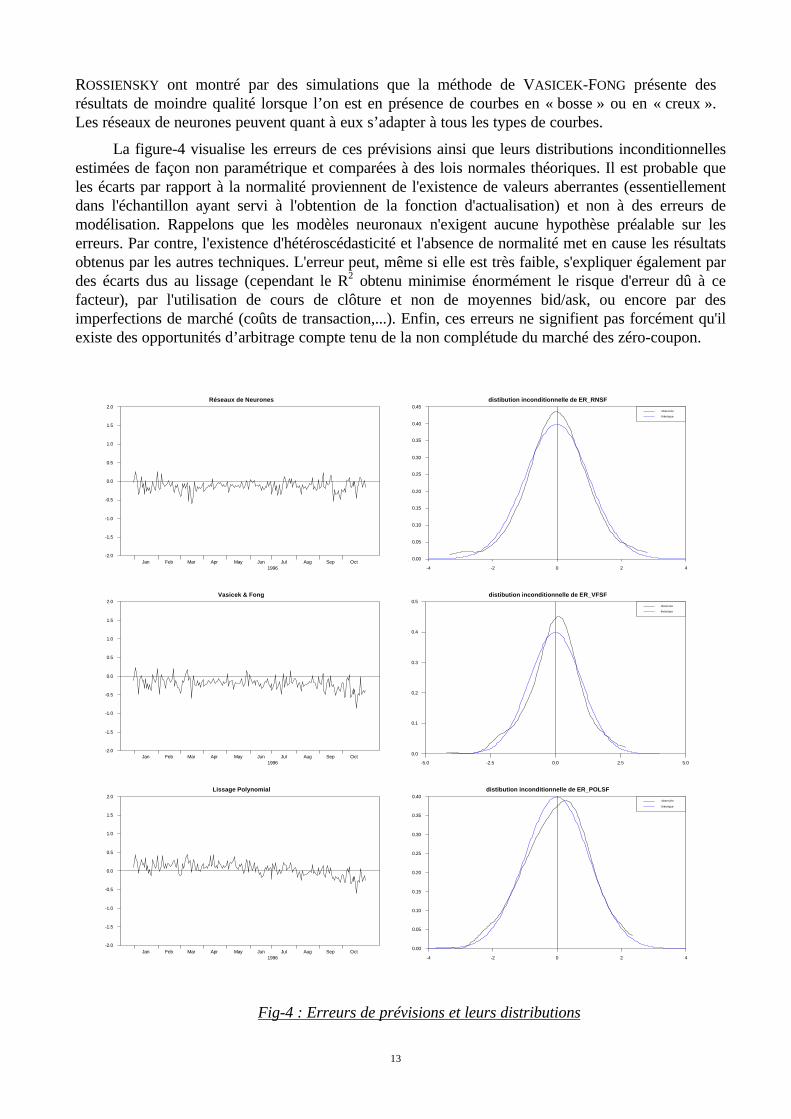
ROSSIENSKY ont montré par des simulations que la méthode de VASICEK-FONG présente desrésultats de moindre qualité lorsque l’on est en présence de courbes en « bosse » ou en « creux ».Les réseaux de neurones peuvent quant à eux s’adapter à tous les types de courbes.
La figure-4 visualise les erreurs de ces prévisions ainsi que leurs distributions inconditionnellesestimées de façon non paramétrique et comparées à des lois normales théoriques. Il est probable queles écarts par rapport à la normalité proviennent de l'existence de valeurs aberrantes (essentiellementdans l'échantillon ayant servi à l'obtention de la fonction d'actualisation) et non à des erreurs demodélisation. Rappelons que les modèles neuronaux n'exigent aucune hypothèse préalable sur leserreurs. Par contre, l'existence d'hétéroscédasticité et l'absence de normalité met en cause les résultatsobtenus par les autres techniques. L'erreur peut, même si elle est très faible, s'expliquer également pardes écarts dus au lissage (cependant le R2 obtenu minimise énormément le risque d'erreur dû à cefacteur), par l'utilisation de cours de clôture et non de moyennes bid/ask, ou encore par desimperfections de marché (coûts de transaction,...). Enfin, ces erreurs ne signifient pas forcément qu'ilexiste des opportunités d’arbitrage compte tenu de la non complétude du marché des zéro-coupon.
Fig-4 : Erreurs de prévisions et leurs distributions
Réseaux de Neurones
Jan Feb Mar Apr May Jun Jul Aug Sep Oct1996
-2.0
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
2.0
Vasicek & Fong
Jan Feb Mar Apr May Jun Jul Aug Sep Oct1996
-2.0
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
2.0
Lissage Polynomial
Jan Feb Mar Apr May Jun Jul Aug Sep Oct1996
-2.0
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
2.0
distibution inconditionnelle de ER_RNSF
-4 -2 0 2 4
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0.45observée
théorique
distibution inconditionnelle de ER_VFSF
-5.0 -2.5 0.0 2.5 5.0
0.0
0.1
0.2
0.3
0.4
0.5observée
théorique
distibution inconditionnelle de ER_POLSF
-4 -2 0 2 4
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40observée
théorique

14
7. Conclusion et développements futurs
Nous avons, au cours de cet article, présenté et testé une approche de lissage de la courbe destructure des taux permettant d'aborder sous un nouvel angle les difficultés d'interpolation entre lesdifférentes valeurs composant la structure par terme des taux d'intérêt. La méthode que nouspréconisons, et pour laquelle nous obtenons des résultats significatifs, permet d'obtenir avec un degréde précision élevé, les prix cotés des obligations assimilables du Trésor sur la période s'étalant du 1erJanvier au 31 Octobre 1996. La fonction obtenue, lisse et continue, répond ainsi aux deux principalesqualités requises par la courbe de structure des taux.
Il serait intéressant de reprendre, dans le cadre de recherches ultérieures, l'approche préconiséedans cet article et de la comparer avec d ’autres approches économétriques et sur des périodes ou lacourbe de structure des taux est inversée, en creux ou en bosse, ou encore de prendre un échantillonde titres couponnés comme échantillon d’évaluation. Chaque titre sera vu comme un portefeuilled'obligations zéro-coupon ; on obtiendrait alors un système de t équations à n inconnues (t étant lenombre d'obligations utilisées dans l'échantillon et n le nombre de coupons).
Bibliographie
[1] AUGROS J.C., Etude de la structure des taux d’intérêt des obligations du secteur privé :Application à l’extraction des taux au comptant, Analyse Financière, 1er Trimestre 1983.
[2] BERA M. et M. SIMONET, Quelques outils d’analyse du marché obligataire, Document detravail, Séminaire HEC, Juin 1985.
[3] BLISS R., Testing Term Structure Estimation Methods, Document de travail, Federal ReserveBank of Atlanta, Octobre 1996.
[4] BONNEVILLE E., Les structures des taux d’intérêt spot, Finance , 2, Juin-Octobre 1981.
[5] CARLETON W. et I. COOPER, Estimation and Uses of the Term Structure of Interest Rates,The Journal of Finance, 31(4), 1976.
[6] CHAMBERS D., W.CARLETON ET WALDMAN, A New Approach to the Estimation of theTerm Structure of Interest Rate, Journal of Financial and Quantitative Analysis, Vol 19(3),1984.
[7] CLERMONT-TONNERRE (DE) A. et M.A. LEVY, Les Obligations à Coupon Zéro, Economica,1992.
[8] COLEMAN T. Et E. FISHER, Estimating Forward Interest Rates and Yield Curves fromGovernment Bond Prices : Methodologie and Selected Results, Rapport Technique, RutgersUniversity, June 1987.
[9] CYBENKO G., Approximations by Superpositions of a Sigmoidal Fonction, Mathematics ofControl, Signal and Systems, 2, 1989.
[10] DE LA BRULERIE H. ET L. GELUSSEAU, La mise en évidence empirique de la structure parterme des taux d’intérêt, Finance, 8, Janvier 1987.
[11] DURAND D., Basic Yields of Corporate Bonds 1900-1942, Rapport Technique, NationalBureau of Economic Research, New-York, 3, 1942.
[12] FAMA E. et R. BLISS, The Information in Long-Maturity Forward Rates, American EconomicReview, 77(4), September 1987

15
[13] FERRANDIER et KOEN, Marchés de Capitaux et Techniques Financières, Economica.
[14] FISHER D., Expectations, the Term Structure of Interest Rates and Recent British Experience,Economica, Novembre 1964.
[15] FISHER M., D. NYCHKA et D. ZERVOS, Fitting the Term Structure of Interest Rates withSmoothing Splines, Document de Travail, Federal Resrve Board, Janvier 1995.
[16] FUNAHASHI K., On the Approximate Realization of Continuous Mappings by NeuralNetworks, Neural Networks, 2, 1989.
[17] GALLANT A.R. et H WHITE, On Learning Derivatives of an Unknown Mapping withMultilayer Feedforward Networks, Neural Networks, 4, 1991.
[18] HECHT-NIELSEN R, Theory of the Back-Propagation Neural Network, Proceedings of theInternational Joints Conference on Neural Networks, Washington D.C. New-York, IEEEPress, 1989.
[19] HORNIK K., M. STINCHOMBE et H. WHITE, Multilayer Feedforward Networks are UniversalApproximators, Neural Networks, 2, 1989.
[20] HORNIK K., M. STINCHOMBE et H. WHITE, Universal Approximation of an UnknownMapping and its Derivatives Using Multilayer Feedforward Neural Networks, NeuralNetworks, 3, 1990.
[21] MARQUARDT D., An Algorithm for Least-Squares Estimation of Non-Linear Parameters,SIAM, J. Of Appl. Math., 11, 1963.
[22] MASERA, The Term Structure of Interest Rate, Clarendon Press, Oxford, 1972.
[23] MC CULLOCH J.H., The Tax-adjusted Yield Curve, Journal of Finance, 30, Juin 1975.
[24] NELSON C.R. et A. SIEGEL, Parsimonious Modelling of Yield Curves, Journal of Business,60(4), Octobre 1987.
[25] ROGER P. et N. ROSSIENSKY, Estimation de la Structure des Taux par le Simplexe et leLissage des Taux Forward, Finance, 16(1), 1995.
[26] RONN E.I., A New Linear Programming Approach to Bond Portfolio Management, Journal ofFinancial and Quantitative Analysis, 22, Décembre 1987.
[27] SCHAEFFER S, On Measuring the Term Structure of Interest Rates, Document de Travail,London Business School of Finance and Accounting, 1973.
[28] SHEA G., Pitfalls in Smoothing Interest Rate Term Structure Data : Equilibrium Models andSplines Approximation, Journal of Financial and Quantitative Analysis, 19, 1984.
[29] VASICEK O. et H. FONG, Term Structure Modelling Exponential Splines, Journal of finance,37(2), 1981.
[30] WHITE H., Learning in Artificial Neural Networks : A Statistical Perpective, NeuralComputation, 1, 1989.


















