
PP16 Lec2 Intro2&Arch1
18
1.1 Parallel Processing sp2016 lec#2 Dr M Shamim Baig
-
Upload
rohfollower -
Category
Documents
-
view
228 -
download
0
Transcript of PP16 Lec2 Intro2&Arch1

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 1/18
1.1
Parallel Processingsp2016
lec#2
Dr M Shamim Baig

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 2/18
1.2
Why Use Parallel
Computing?• Limits to serial computing:
– Both physical & practical reasons pose
significant constraints to simply building
eer faster serial computers !"oors a$%
• imits to miniaturi'ation
• (ransmission speeds
• Po$er )issipation
• *nergy consumption
• *conomic limitations

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 3/18
1.+
Why Use Parallel Computing?• Save time and/or money:
• ,hile- Parallel clusters can be built from cheap-commodity components.
• But- (hro$ing more resources at a tas shortens
its time to completion
• /oling problems in shorter time results in saing
big "oney in many practical situations.

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 4/18
1.
Why Use Parallel Computing?• Provide concurrent Working environment:
– single compute resource can only do one thingat a time. "ultiple computing resources can do many
things simultaneously.
– or e3ample- ccess 4rid www.accessgrid.org proides
global collaboration net$or $here people around the$orld can meet & conduct $or 5irtually5

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 5/18
1.
Why Use Parallel Computing?• Integrating Remote Resources usage:
– 7sing compute resources on a $ide area net$or- oreen the 8nternet $hen local compute resources arescarce.
– or e3ample• /*(89home satiathome.berkeley.edu uses oer ++0-000
computers for a compute po$er oer 2: (era;P/• olding9home folding.stanforg.edu uses oer +0-000
computers for a compute po$er of .2 Peta;P/

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 6/18

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 7/181.?
*3ample 4rand @hallenge Problems
;nes that cannot be soled in a reasonableamount of time $ith todayAs computers.;biously- an e3ecution time of 10 years is
al$ays unreasonable e.g
• 4lobal $eather forecasting• "odeling motion of astronomical bodies.
• @ryptography *ncrypted code breaing

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 8/181.:
"odeling 4lobal ,eather orecast
• /uppose $hole global atmosphere diided into
cells of si'e 1 m × 1 m × 1 m to a height of10 m !10 cells high% about × 10: cells.
• /uppose each calculation re>uires 200 floatingpoint operations. 8n one time step- 1011 floating
point operations necessary.• (o forecast $eather oer ? days using 1minute
interals- a computer operating at 14flops !10C floating point operations<s% taes 106 seconds oroer 10 days.
• (o perform calculation in minutes re>uirescomputer operating at +. (flops !+. × 1012 floating point operations<sec%.

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 9/181.C
"odeling stronomical Bodies "otion
•*ach body attracted to each other body
by
graitationalforces. "oement of each body predicted by calculating
total force on each body.
• ,ith bodies- 1 forces to calculate for each body-
$e re>uire appro3. D2 calculations.
• fter determining ne$ positions of bodies-
calculations are repeated.
• gala3y might hae- say- 1011 stars.
•*en if each calculation is done in 1 ms !e3tremelyoptimistic figure%- it taes 10C years for one iteration
using D2 algorithm & almost 1 year for one iteration
using an efficient D log2D appro3imate algorithm
• @anAt do $ithout faster parallel processing
8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 10/181.10
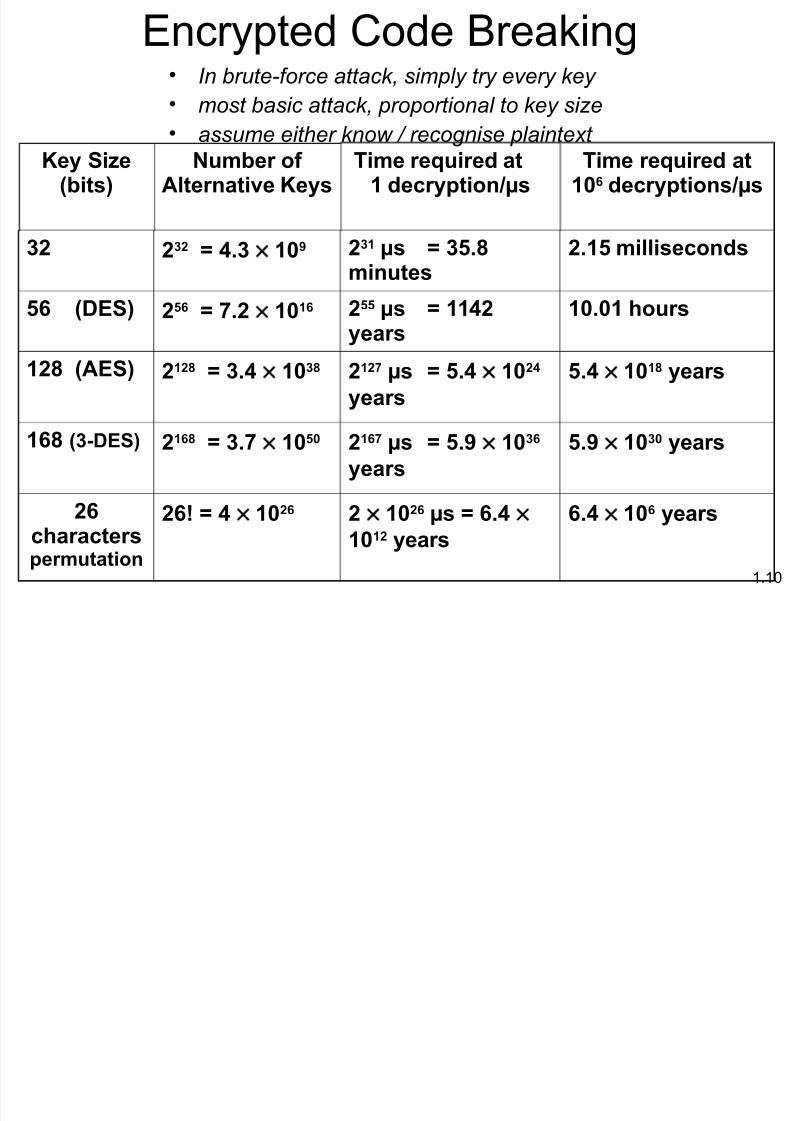
*ncrypted @ode Breaing• !n brute"force attack# simply try e$ery key
• most basic attack# proportional to key si%e
• assume either know / recognise plainte&t "ey Si#e
$its%&umer o'
(lternative "eys)ime re*uired at
+ decryption/,s)ime re*uired at
+-. decryptions/,s
0 00 1 23 +-4 0+ ,s 1 536
minutes
03+5 milliseconds
5. $78S% 05. 1 930 +-+. 055 ,s 1 ++20years
+-3-+ hours
+06 $(8S% 0+06 1 32 +-6 0+09 ,s 1 532 +-02
years
532 +-+6 years
+.6 $78S% 0+.6 1 39 +-5- 0+.9 ,s 1 534 +-.
years
534 +-- years
0.characterspermutation
0.; 1 2 +-0. 0 +-0. ,s 1 .32
+-+0 years
.32 +-. years

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 11/181.11
(he uture
• )uring the past 20 years- the trends
indicated by eer
faster net$ors- distributed systems- &
multiprocessor computer architectures
'e$en at the desktop le$el( clearly show that
parallelism is the future of computing

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 12/18
Implicitly Parallel Processorarchitectures 'or ILP
1.12

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 13/181.1+
/cope of Parallelism
• @onentional architectures coarselycomprise of processor - memory & datapath
• *ach of these components present
significant performance bottlenecs.• 8t is important to understand each of
these performance bottlenecs
• Parallelism addresses each of thesecomponents in significant $ays..
• ,e start ne3t $ith the processor leel
parallel architectures.

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 14/181.1
8mplicit Parallelism (rends in
"icroprocessor rchitectures
• "icroprocessor cloc speeds hae postedimpressie gains oer the past t$o decades
!t$o to three orders of magnitude%.
• Eigher leels of deice integration hae made
aailable a large number of transistors.• (he >uestion of ho$ best to utili'e these
resources effectiely is an important one.
• @urrent processors use these resources by
e3ecuting multiple instructions in the samecycle using multiple pipelines < functional units
• (he precise manner in $hich these instructions
are selected and e3ecuted proides impressie
diersity in architectures.

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 15/181.1
8mplicit Parallel rchitectures
8P "icroprocessors
• Pipelined Processors
• /uperscalar Processor
• F8, Processor

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 16/181.16
Pipelining
• (his is ain to an assembly line formanufacture of cars
• Pipelining oerlaps arious stages ofactiity !instruction e3ecution orarithmetic operation% to achiee theperformance gain.
• or e3ample- in instruction pipeline aninstruction can be e3ecuted $hile thene3t one is being decoded & the ne3tone is being fetched.

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 17/181.1?
Pipeline Performance
• 8nstruction & rithmeticunit Pipeline
• 8deal pipeline /peedup calculation & imits
• @hained Pipeline Performance
• )he speed"up of a pipeline is e$entually limited by thenumber of stages * time of slowest stage.
• +or this reason# con$entional processors rely on $erydeep"pipeline ',- stage pipeline is an e&le of deep pipeline compared to normal pipeline of " stages(

8/16/2019 PP16 Lec2 Intro2&Arch1
http://slidepdf.com/reader/full/pp16-lec2-intro2arch1 18/181 1:
Pipeline Performance Bottlenecs
• Pipeline has follo$ing performance bottlenecs
Gesource @onstraint
)ata )ependency
Branch Prediction
• 0ppro& e$ery 1"th instruction is a conditional 2ump3
)his re4uires $ery accurate branch prediction.• )he penalty of a prediction error grows with the depthof the pipeline# since a larger number of instructionswill ha$e to be flushed .
• Eence need for better architecturesHHHH







![Lec2 Idea Gen[1]](https://static.fdocuments.fr/doc/165x107/577d36c91a28ab3a6b940390/lec2-idea-gen1.jpg)




