
Outils et méthodes linguistiques pour l'annotation et … · 2016-04-18 · taper à la main...
35
Universität Stuttgart Achim Stein, Institut für Linguistik/ Romanistik Université de Paris IV 9 mars 2010 Achim Stein, Universität Stuttgart 1ère partie Présentation du Nouveau Corpus d'Amsterdam. Ressources et élaboration. 2e partie Annotation morphologique. Outils d'interrogation. 3e partie Annotation syntaxique. Problèmes de syntaxe diachrone. Outils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
-
Upload
truonghanh -
Category
Documents
-
view
212 -
download
0
Transcript of Outils et méthodes linguistiques pour l'annotation et … · 2016-04-18 · taper à la main...

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Université de Paris IV9 mars 2010
Achim Stein, Universität Stuttgart
1ère partiePrésentation du Nouveau Corpus d'Amsterdam. Ressources et élaboration.
2e partieAnnotation morphologique. Outils d'interrogation.
3e partieAnnotation syntaxique. Problèmes de syntaxe diachrone.
Outils et méthodes linguistiquespour l'annotation et l'exploitation
des textes médiévaux
Cette partie est obsolète!
Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
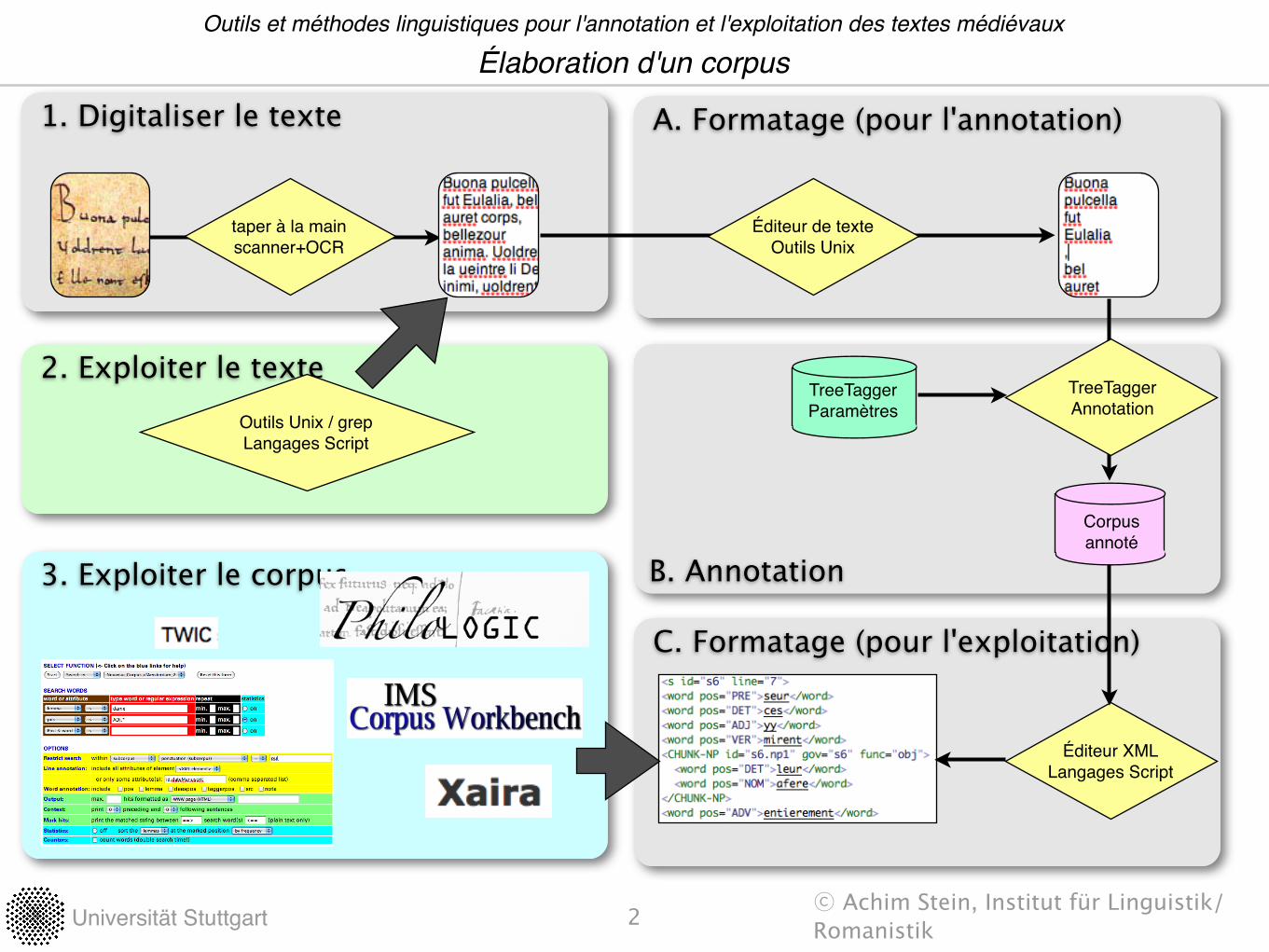
2. Exploiter le texte
C. Formatage (pour l'exploitation)
B. Annotation
1. Digitaliser le texte A. Formatage (pour l'annotation)
Élaboration d'un corpusOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
2
taper à la mainscanner+OCR
Éditeur de texteOutils Unix
Éditeur XMLLangages Script
3. Exploiter le corpus
Outils Unix / grepLangages Script
Corpusannoté
TreeTaggerParamètres
TreeTaggerAnnotation

Universität Stuttgart ������������������������������ �����������������
PlanOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
État actuel du corpus• Le texte brut, digitalisé• Les descripteurs bibliographiques• Balisage XML• Outils

Universität Stuttgart ������������������������������ �����������������
Le Corpus d'AmsterdamOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
4
Du texte digitalisé des années 1980...
La première saisie: le corpus d'Anthonij Dees (1987)
c6/ren2: or_311 me_412 *covient_513 tel_026 chose_006 dire_592c6/ren2: dont_341 je_411 vos_451 *puisse_521 faire_592 rire_592c6/ren2: car_331 je_411 *sai_511 bien_311 ce_341 *est_513 la_105 pure_025c6/ren2: que_600 de_301 sarmon_002 n_319 *avez_515 vos_451 cure_006c6/ren2: ne_600 de_301 corsaint_002 oir_592 la_106 vie_006c6/ren2: de_301 ce_341 ne_319 vos_451 *prant_513 nule_185 envie_005c6/ren2: mais_331 de_301 tel_026 chose_006 qui_600 vos_451 *plaise_523c6/ren2: or_311 *gart_523 chascuns_281 que_600 il_431 se_600 *taisse_523c6/ren2: que_600 de_301 2bien_002 dire_592 *sui_511 en_319 voie_006c6/ren2: et_331 toz_281 garniz_581 se_600 diex_001 me_412 *voie_523
Le roman de Renart, M.Roques, CFMA, Paris 1951 (B) BN fr 371

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Élaboration du corpusOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
Le format d'origine
5
Extrait de texte du corpus d'Anthonij Dees'(Dees 1987)
c6/ren2: or_311 me_412 *covient_513 tel_026 chose_006 dire_592c6/ren2: dont_341 je_411 vos_451 *puisse_521 faire_592 rire_592c6/ren2: car_331 je_411 *sai_511 bien_311 ce_341 *est_513 la_105 pure_025c6/ren2: que_600 de_301 sarmon_002 n_319 *avez_515 vos_451 cure_006c6/ren2: ne_600 de_301 corsaint_002 oir_592 la_106 vie_006c6/ren2: de_301 ce_341 ne_319 vos_451 *prant_513 nule_185 envie_005c6/ren2: mais_331 de_301 tel_026 chose_006 qui_600 vos_451 *plaise_523c6/ren2: or_311 *gart_523 chascuns_281 que_600 il_431 se_600 *taisse_523c6/ren2: que_600 de_301 2bien_002 dire_592 *sui_511 en_319 voie_006c6/ren2: et_331 toz_281 garniz_581 se_600 diex_001 me_412 *voie_523
Le roman de Renart, M.Roques, CFMA, Paris 1951 (B) BN fr 371
Extrait de la bibliographie du corpus d'Anthonij Dees'(Dees 1987)
... amad Amadas et Ydoine, v.1-2316 J.R. Reinhard, CFMA,Paris 1974 (P) BN ffr 375 1288 378102 amile Ami et Amile, v.1-808 P.F. Dembowski, CFMA,Paris 1969 BN f.fr. 860 2e moitie2 13e s 618001 amou Le bestiaire d'amour rim], v.1-2658 A. Thordstein,Lund-Copenhague 1941 BN 1951 fin 13e, de2but 14e s 328901 amo L'art d'amors und li remedes d'Amors von Jacquesd'Amiens G. Koerting, Leipzig 1868 (0) Kon.oeffentl.Bibl.Dresden,64 fin 13e, de2but 14e s 407801...

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Élaboration du corpusOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
Nouveaux descripteurs bibliographiques
‣ dateComposition / dateManuscript (fast vollständig)‣ auteur: un tiers des textes sont anonymes‣ genre: classification en voie d'élaboration (cf. CCFM)‣ vers ou prose: (vers=oui/non)‣ localisation‣ codes introduits par Dees: aabbcc‣ aa = région, bb = index de conformité, cc = différentiation
‣ qualité du manuscrit / de l'édition‣ code: 1=bonne, 2=acceptable, 3=criticable‣ Liens vers la bibliographie DEAF (www.deaf-page.de) ‣ Dictionnaire étymologique de l'ancien français
6

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
@id=poitdeaf=Turpin_1A*titreDees=Der sogenannte poitevinische Pseudo-Turpin, p. 262,1-294,22editionDees=éd. Th. Auracher, ZfRP I (1877), p. 259-336manuscritDees=Codex 5714regionDees=VENDEE, DEUX-SEVREScoefficientRegionDees=78 (Vendée)dateMoyenneDees=1250*codeRegional=04coefficientRegional=78vers=nonponctuation=nonmots=26116lignes=4256passage=intégralité des fol. 41 à 85, partie intitulée 'turpin interpolé'commentairePhilologique=éd. T. AURACHER, ms. BN fr. 5714 (ZrPh 1, 1877, 259-336)qualite=ms1sourceQualite=XG (éd.)commentaireForme=parchemin, 19,5x14 cm, 86 feuillets, 2 col./page, 24 l./col.auteur=PSEUDO-TURPINdateComposition=1200cadateManuscrit=1213pm8lieuComposition=OISElieuManuscrit=SUD-OUEST, poit. ? (entre Dordogne et Loire); Saint DEAFsourceDateComposition=DEAFsourceDateManuscrit=éd.sourceLieuComposition=DEAFsourceLieuManuscrit=éd.genre=chronique en prose (relatant les événements de l'époque carolingienne)traditionTextuelle=traductionanalyses=pour l'histoire, DLF 292-295; IS III, 314-315; DEAF 391
Descripteurs bibliographiques (format brut, extrait)Outils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
7
Informations en format "libre"
Informations codées pour faciliter les requêtes
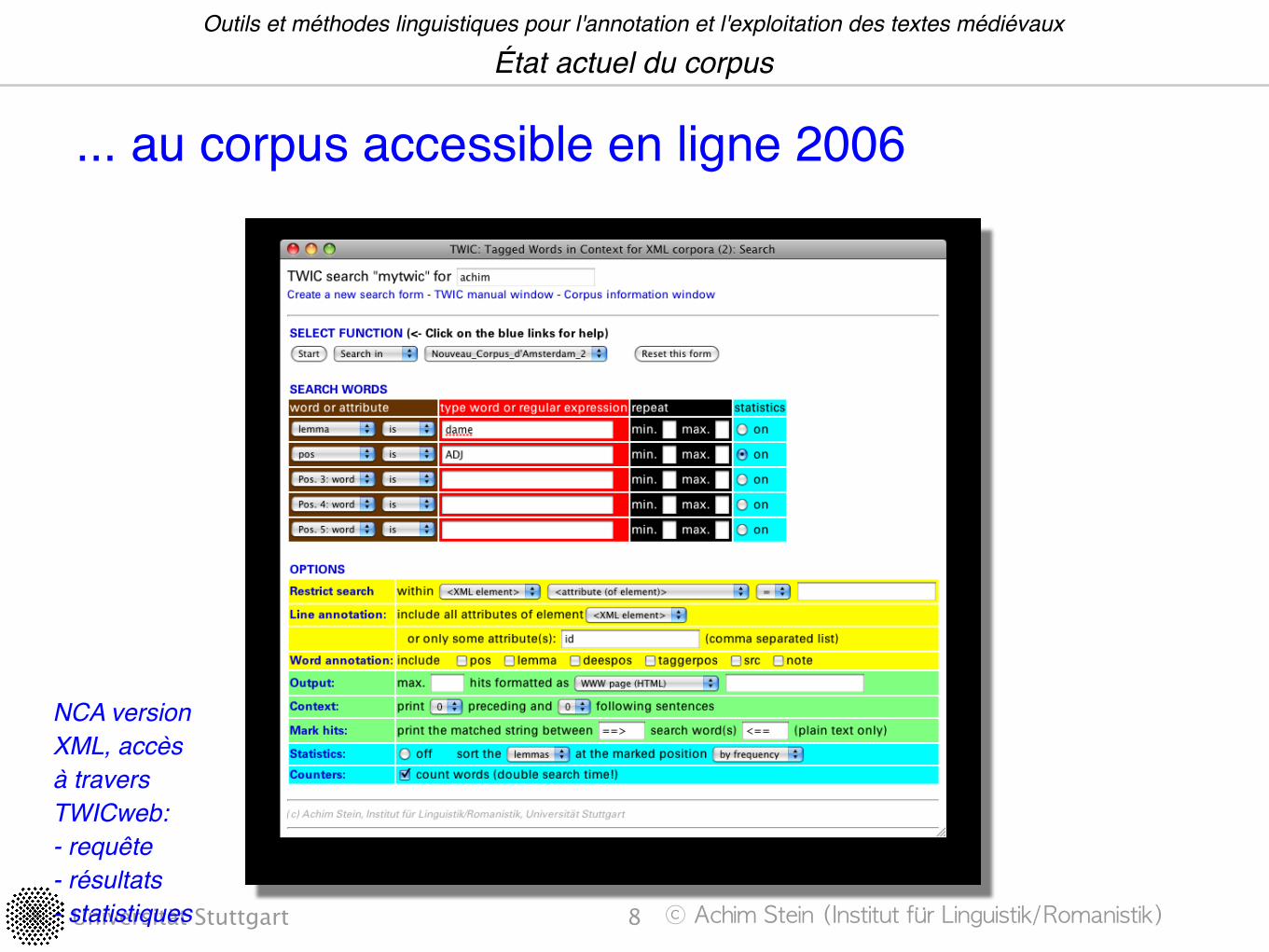
Universität Stuttgart ������������������������������ �����������������
État actuel du corpusOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
8
... au corpus accessible en ligne 2006
NCA version XML, accès à travers TWICweb:- requête- résultats- statistiques

Universität Stuttgart ������������������������������ �����������������
État actuel du corpusOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
Le projet "Nouveau Corpus d'Amsterdam"
‣ Projet Transcoop Stuttgart/Ottawa‣ financé par la Fondation Alexander von Humboldt, 2003-2006‣ Objectifs:‣ Annotation, lemmatisation et publication du corpus‣ Outils et ressources pour l'ancien français (lexiques, étiqueteur)‣ Partenaires et domaines‣ Pierre Kunstmann (Ottawa)‣ Éditions, lexique, lemmatisation
‣ Achim Stein (Stuttgart)‣ Lemmatisation, programmes de requête et d'analyse
‣ Martin-Dietrich Gleßgen (Zürich)‣ Bibliographie et évaluation critique
9

Universität Stuttgart ������������������������������ �����������������
Annotation syntaxiqueOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
Le Nouveau Corpus d'Amsterdam (2006, 2008)
10
‣ Ressources lexicales:‣ Lexique des formes (250.000 graphies)‣ avec information morphologique et lemme(s)
‣ Outils:‣ TreeTagger pour l'ancien français (fichier de paramètres)‣ librement accessible, étiquetage et lemmatisation de textes bruts
‣ Nouveau Corpus d'Amsterdam (Stein et al. 2006)‣ 3.183.226 mots, étiquetés, lemmatisés‣ format XML, information méta-textuelle (bibliographie, descripteurs)‣ Licence de recherche (gratuite):‣ http://www.uni-stuttgart.de/lingrom/stein/corpus/‣ Version 2 (2008): accessible en ligne

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Élaboration du corpusOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
Principes d'élaboration
‣ Fidélité:‣ conserver les données d'origine (projet Anthonij Dees)‣ utiliser des méthodes transparentes pour créer la nouvelle version‣ Réutilisabilité:‣ utiliser des formats de texte standardisés‣ utiliser des logiciels librement accessibles‣ Qualité:‣ évaluer la qualité des textes‣ Disponibilité:‣ accès libre aux chercheurs
11

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Élaboration du corpusOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
Le Nouveau Corpus d'Amsterdam (NCA)
‣ Balisage XML‣ DTD provisoire et ouverte à l'intégration de nouveaux attributs‣ Sousdivision en <subcorpus>‣ Informations metatextuelles‣ cf. infra pour une description plus détaillée
‣ Sousdivision en phrases ou vers (= unité d'analyse)‣ éditions en prose: en suivant la ponctuation‣ éditions en vers: découpage en vers
12

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Élaboration du corpusOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
Le format d'origine
‣ Köln 1999: transfert des fichiers de textes saisis dans le projet d'Anthonij Dees (Université libre d'Amsterdam).‣ Contexte: digitalisation du Dictionnaire d'ancien français de Tobler/
Lommatzsch.‣ Contenu:‣ 296 fichiers‣ transcriptions de manuscrits et éditions
‣ plus de trois millions de mots‣ sans ponctuation, parfois ommission de noms propres
‣ annotation morphologique manuelle (225 étiquettes)‣ p.ex.: 566 => verbe, futur, 3e personne, pluriel
‣ catégories "poubelle" (sans différenciation)‣ p.ex. 600 => pronoms, conjonctions
13

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
PlanOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
Du texte au corpus• Étapes de l'élaboration
Annotation lexicale (part of speech tagging)• Utilisation des ressources lexicales• L'étiqueteur: TreeTagger• Limitations de l'annotation automatique• Du texte au corpus

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Annotation lexicaleOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
28
catégorie lemmeforme
Corpus d'Amsterdam
(Dees/van Reenen)
Graphiesverbales(R. Martin)
GraphiesGodefroy
(P. Kunstmann)
variantes de lemme
Tobler-Lommatzsch
(Blumenthal/Stein)
Éditions électroniques
(LFA, Ottawa)
Lexique des formes fléchiesforme catégorie lemme|variante1|...
Ressources lexicales et textuelles
These are the lexical resources that were used to build the Old French lexicon. The TreeTagger uses the form-tag-lemma triplets contained in the lexicon during the training process.(cf. slide #30)

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Annotation lexicaleOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
29
Lemmatisation
‣ Lemmatisation manuelle dans différents projets:‣ v.a. Robert Martin (verbes), Pierre Kunstmann (lexiques)‣ Fusion des ressources lexicales‣ Définition d'une ressource "d'autorité"‣ "Tobler/Lommatzsch": Altfranzösisches Wörterbuch‣ Vérification des lemmes dans le Tobler/Lommatzsch
‣ Application des règles au formes non lemmatisées:‣ 70 règles orthographiques rattachent les formes non lemmatisées à
celles qui sont lemmatisées, par exemple:‣ règles générales: nm/mm, an/en, -eur/-eor etc.‣ règles contextuelles (début du mot, entre voyelles etc.)
‣ Résultat: environ 30.000 formes lemmatisées ajoutées.
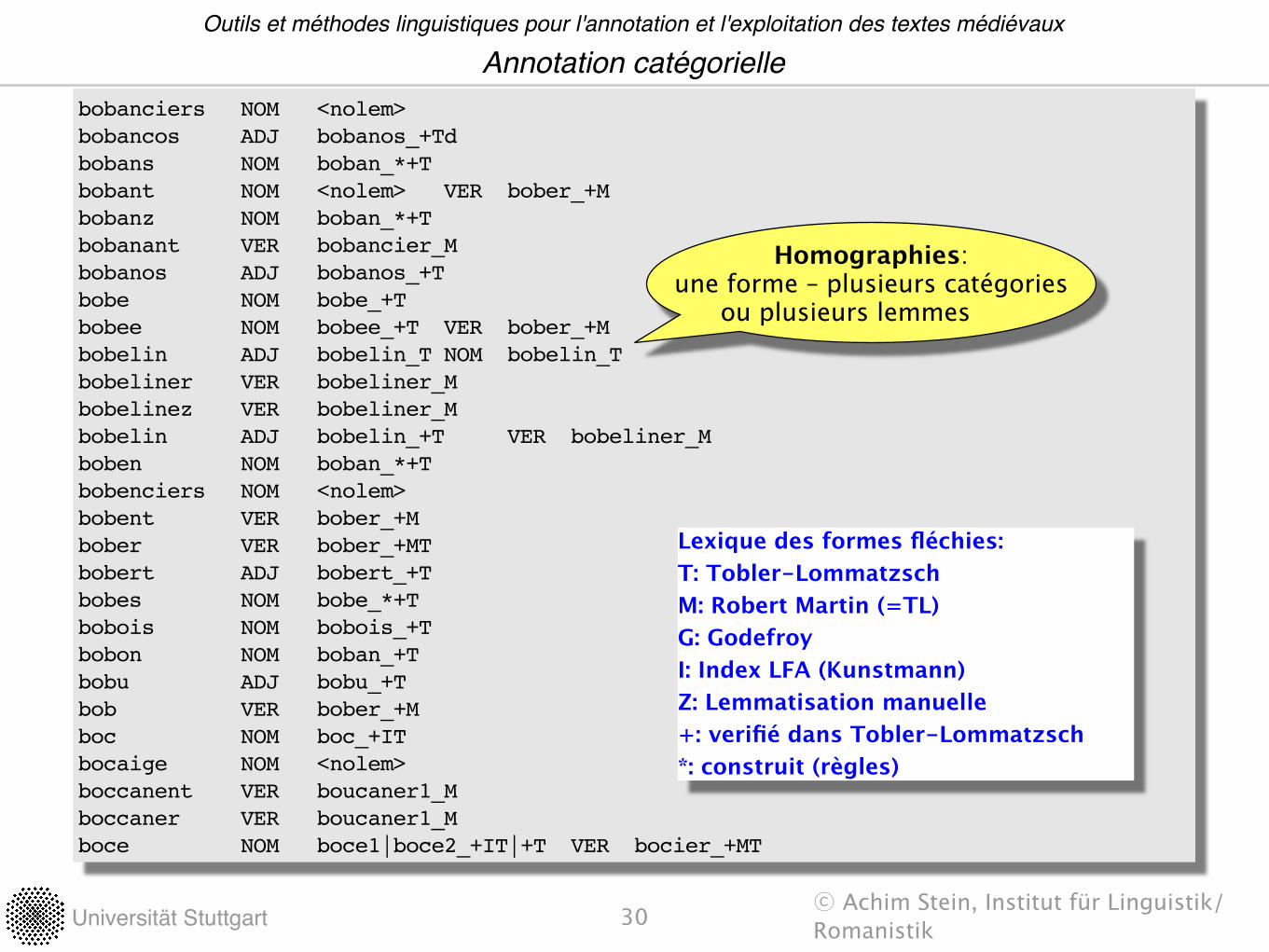
Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
bobanciers! NOM! <nolem>bobancos! ADJ! bobanos_+Tdbobans! NOM! boban_*+Tbobant! NOM! <nolem>! VER! bober_+Mbobanz! NOM! boban_*+Tbobanant! VER! bobancier_Mbobanos! ADJ! bobanos_+Tbobe! NOM! bobe_+Tbobee! NOM! bobee_+T! VER! bober_+Mbobelin! ADJ! bobelin_T!NOM! bobelin_Tbobeliner! VER! bobeliner_Mbobelinez! VER! bobeliner_Mbobelin! ADJ! bobelin_+T! VER! bobeliner_Mboben! NOM! boban_*+Tbobenciers! NOM! <nolem>bobent! VER! bober_+Mbober! VER! bober_+MTbobert! ADJ! bobert_+Tbobes! NOM! bobe_*+Tbobois! NOM! bobois_+Tbobon! NOM! boban_+Tbobu! ADJ! bobu_+Tbob!! VER! bober_+Mboc!! NOM! boc_+ITbocaige! NOM! <nolem>boccanent! VER! boucaner1_Mboccaner! VER! boucaner1_Mboce! NOM! boce1|boce2_+IT|+T! VER! bocier_+MT
Annotation catégorielleOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
30
Lexique des formes fléchies:T: Tobler-LommatzschM: Robert Martin (=TL)G: GodefroyI: Index LFA (Kunstmann)Z: Lemmatisation manuelle+: verifié dans Tobler-Lommatzsch*: construit (règles)
Homographies:une forme – plusieurs catégories
ou plusieurs lemmes
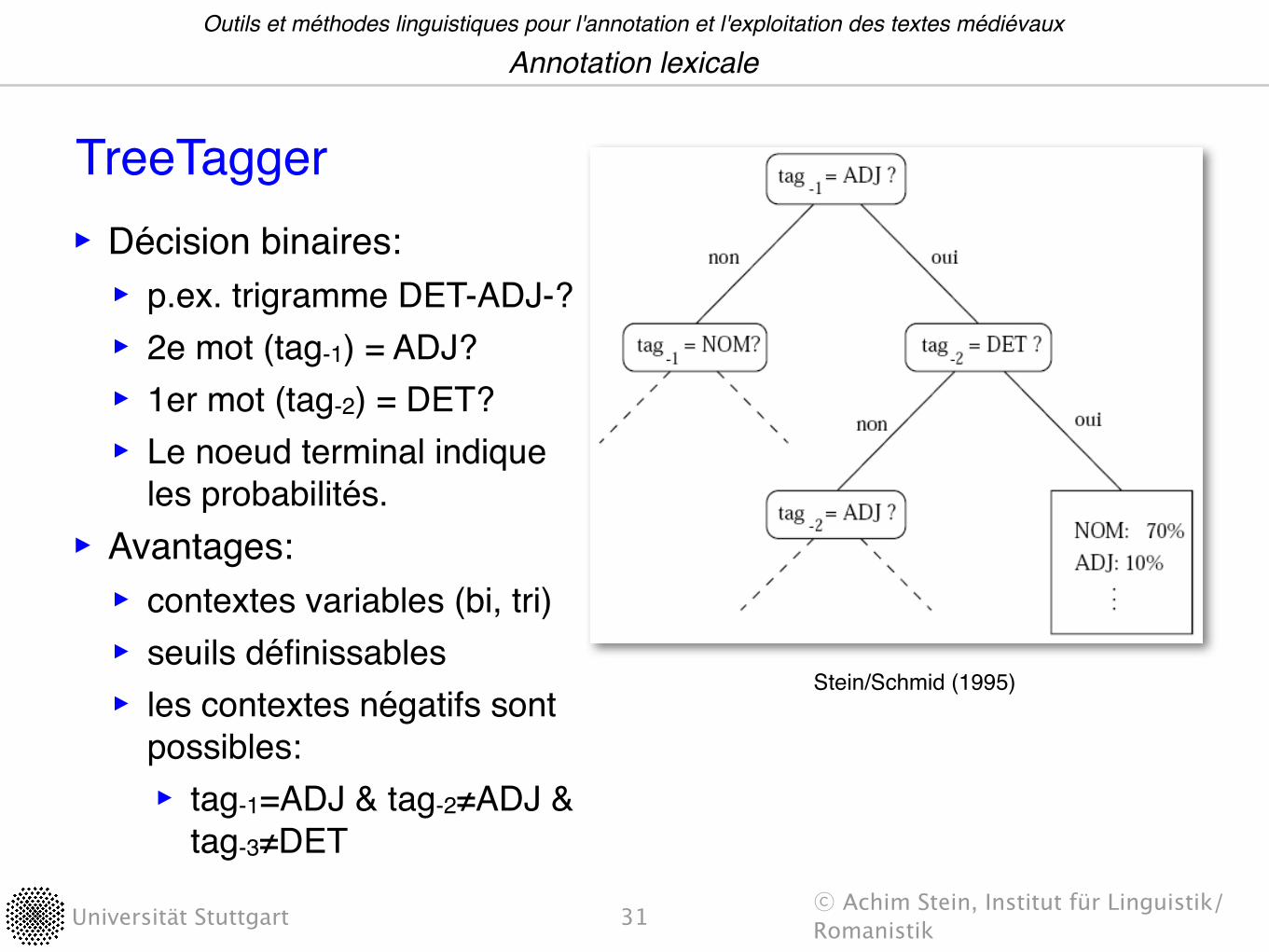
Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Stein/Schmid (1995)
Annotation lexicaleOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
TreeTagger‣ Décision binaires:‣ p.ex. trigramme DET-ADJ-?‣ 2e mot (tag-1) = ADJ?‣ 1er mot (tag-2) = DET?‣ Le noeud terminal indique
les probabilités.‣ Avantages:‣ contextes variables (bi, tri)‣ seuils définissables‣ les contextes négatifs sont
possibles:‣ tag-1=ADJ & tag-2≠ADJ &
tag-3≠DET
31
Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Stein/Schmid (1995)
Annotation lexicaleOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
TreeTagger
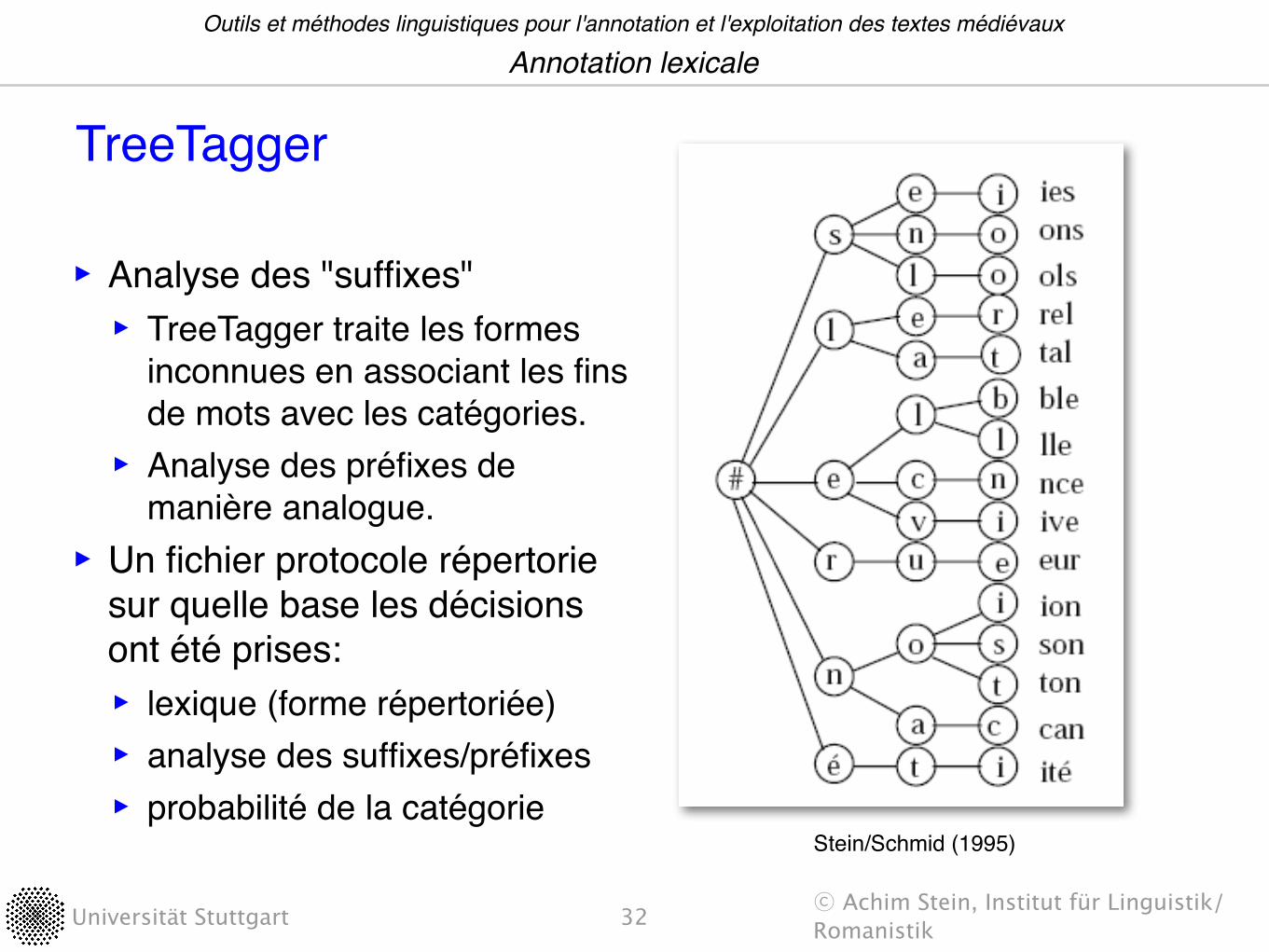
‣ Analyse des "suffixes"‣ TreeTagger traite les formes
inconnues en associant les fins de mots avec les catégories.‣ Analyse des préfixes de
manière analogue.‣ Un fichier protocole répertorie
sur quelle base les décisions ont été prises:‣ lexique (forme répertoriée)‣ analyse des suffixes/préfixes‣ probabilité de la catégorie
32
Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Annotation lexicaleOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
33
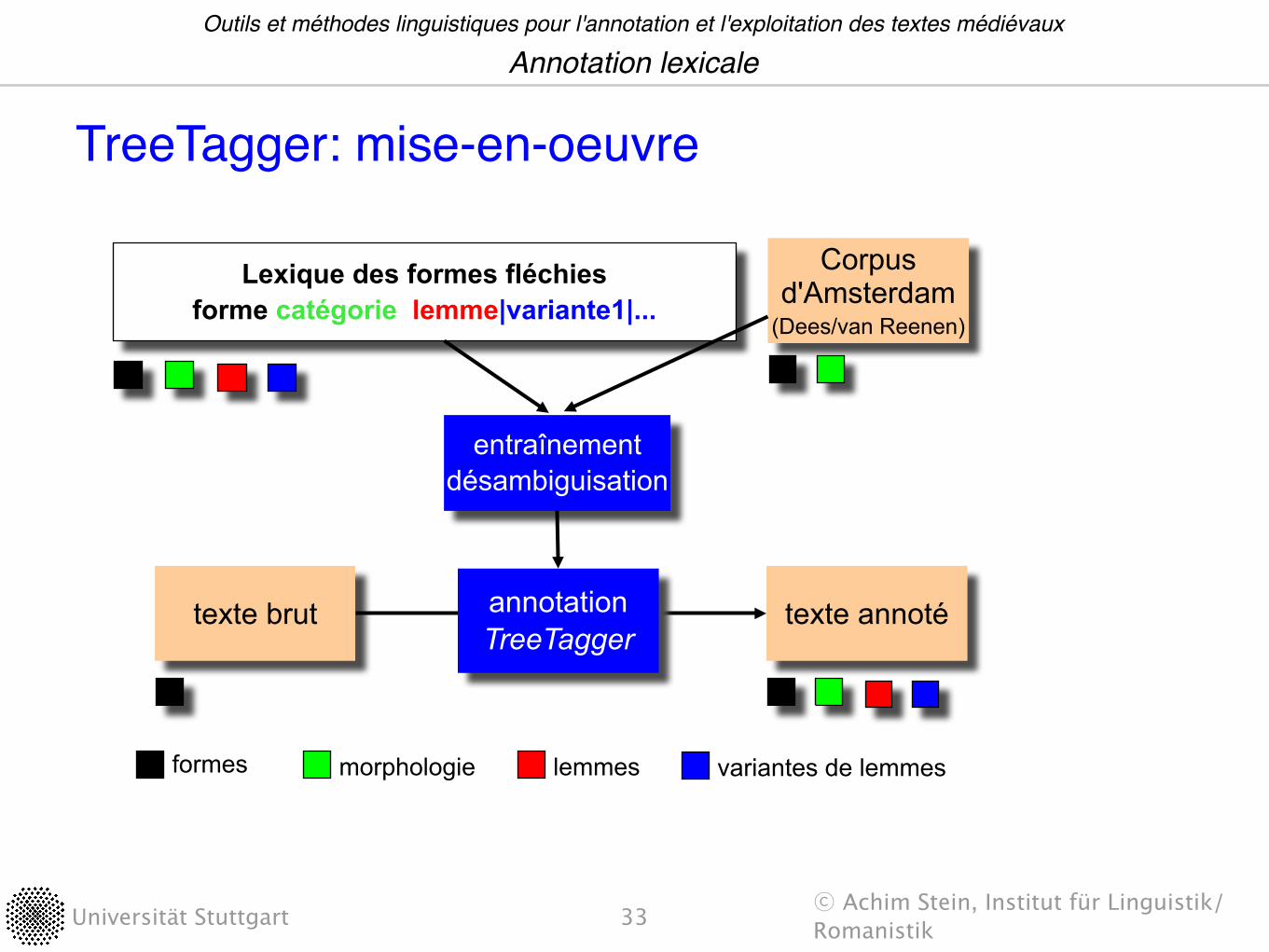
morphologie lemmesformes variantes de lemmes
Corpus d'Amsterdam
(Dees/van Reenen)
Lexique des formes fléchiesforme catégorie lemme|variante1|...
texte annotétexte brut
entraînementdésambiguisation
annotationTreeTagger
TreeTagger: mise-en-oeuvre

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
POS types (vedettes) tokens (mots occurrents)ADJ 2129/2774= 76.75% 24009/24795= 96.83%ADV 1012/1285= 78.75% 36514/36923= 98.89%CON 136/ 136=100.00% 26497/26497=100.00%DET 264/ 264=100.00% 49427/49427=100.00%GDF 8/ 8=100.00% 16/ 16=100.00%INT 16/ 28= 57.14% 190/ 251= 75.70%NOM 6915/9483= 72.92% 76113/80050= 95.08%NPR 657/2185= 30.07% 6206/ 8800= 70.52%PON 11/ 11=100.00% 14212/14212=100.00%PRE 177/ 177=100.00% 42914/42914=100.00%PREDET 29/ 29=100.00% 6838/ 6838=100.00%PRO 438/ 438=100.00% 79774/79774=100.00%PROCON 18/ 18=100.00% 21832/21832=100.00%VER 14336/7282= 82.95% 104439/07652= 97.02%
Annotation lexicaleOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
TreeTagger: Resultat
34
‣ Résultats des paramètres actuels pour l'ancien français‣ Annotation de la catégorie: précision 92,7%‣ Lemmatisation: 76,6% des types (vedettes), 97,8% des tokens.

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Annotation lexicale: format XMLOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
35
Annotation des ambiguités
Informations méta-textuelles
Conservation de l'annotation d'origine (A. Dees)
Référencement des ressources lexicales
catégorie "lisibles"

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik36
Format des balises XML:<élément attribut="valeur">
Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
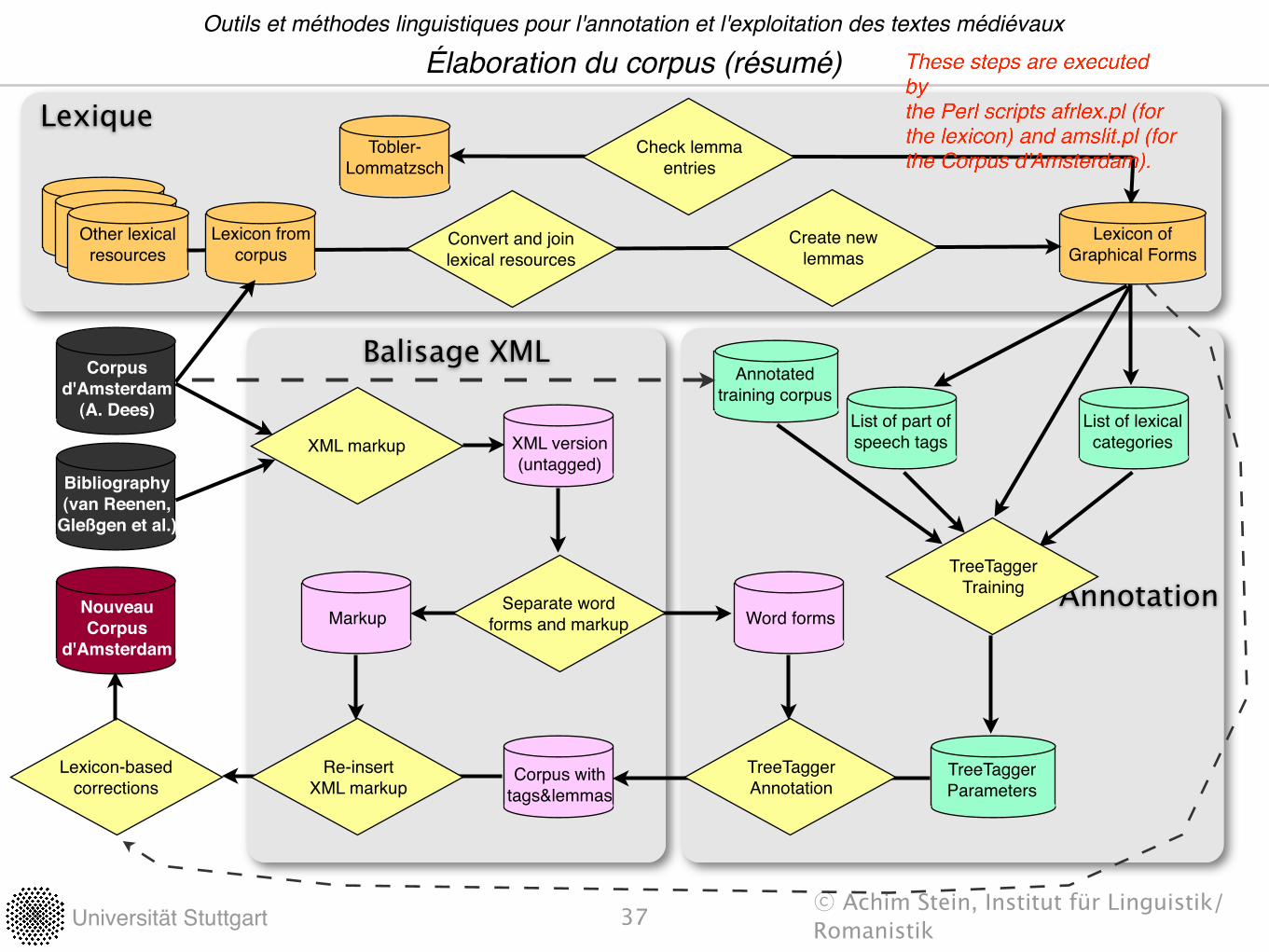
Lexique
Balisage XML
Annotation
Élaboration du corpus (résumé)Outils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
37
Other lexicalresources
Tobler-Lommatzsch
Check lemma entries
Lexicon of Graphical Forms
Convert and join lexical resources
Create new lemmas
Korpus-Lexikon
List of lexicalcategories
List of part ofspeech tags
Corpusd'Amsterdam
(A. Dees)
Bibliography(van Reenen,
Gleßgen et al.)
Annotatedtraining corpus
Word formsMarkupSeparate word
forms and markup
TreeTaggerParameters
TreeTaggerTraining
XML version(untagged)
XML markup
Corpus withtags&lemmas
TreeTaggerAnnotation
Lexicon from corpus
Lexicon-basedcorrections
NouveauCorpus
d'Amsterdam
Re-insert XML markup
These steps are executed by the Perl scripts afrlex.pl (for the lexicon) and amslit.pl (for the Corpus d'Amsterdam).

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Élaboration du corpusOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
Le NCA lors de sa publication (2006)
38
‣ Conclusion du projet Transcoop à Lauterbad (2006)‣ Publication de la première édition du corpus‣ Ressources lexicales:‣ Lexique des formes (250.000 graphies)‣ ajoutés: catégories et lemmes
‣ Outils:‣ TreeTagger: paramètre pour l'ancien français‣ librement disponibles pour l'annotation automatique
‣ Nouveau Corpus d'Amsterdam (Stein et al. 2006)‣ L'un des deux plus grands corpus d'ancien français‣ à côté de la Banque du français médiéval (C. Marchello-Nizia)
‣ 3.183.226 mots, annotés, lemmaisés‣ Format XML, information méta-textuelle exhaustive.

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Élaboration du corpusOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
NCA: projets
‣ Perfection de la bibliographie (en cours: M.-D. Glessgen, Zürich)‣ Amélioration du format XML‣ Descripteurs standardisés‣ éventuellement en-tête TEI (Text Encoding Initiative)‣ Annotation syntaxique‣ Syntactic Reference Corpus of Medieval French (SRCMF)‣ Projet franco-allemand ANR/DFG, 2009-2012
‣ Coopération: Lattice (Paris) + ENS (Lyon) – ILR (Stuttgart)
39

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
PlanOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
Analyse syntaxiqueMéthodes d'annotation syntaxiqueParseursLe projet SRCFM (Syntactic Reference Corpus of Medieval French)
This part is obsolete.For more information, see the SRCMF documentation on http://srcmf.org

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
‣ Responsables: Sophie Prévost, Achim Stein‣ Durée: 3 ans (1.3.2009 - 29.2.2012)‣ Financement: ANR et DFG
Annotation syntaxique (SRCMF)Outils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
Syntactic Reference Corpus of Medieval French
‣ Coopération‣ Paris: UMR 8094-LaTTiCe (CNRS/ENS): Sophie Prévost‣ Lyon: ENS/LSH‣ Céline Guillot, Serge Heiden, Alexei Lavrentiev, Christiane
Marchello-Nizia (professeur émérite)‣ Stuttgart: Institut für Linguistik/Romanistik (ILR)‣ Achim Stein, Beatrice Bischof, Nicolas Mazziotta
‣ Montréal (UQAM): Fernande Dupuis‣ Experts: Richard Ingham (Birmingham), Bernard Victorri (LaTTiCe)
41

Universität Stuttgart ������������������������������ �����������������
Annotation syntaxique (SRCMF)Outils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
Syntactic Reference Corpus of Medieval French
‣ Objectifs‣ Améliorer les deux plus grandes bases textuelles pour le français
médiéval (environ 3 millions de mots chacune)‣ BFM: Base de Français médiéval (ENS-LSH Lyon)‣ NCA: Nouveau Corpus d'Amsterdam (ILR, Stuttgart)
‣ Attribuer une couche d'annotation commune à ces deux corpus‣ L'annotation syntaxique sera a priori indépendante des couches
d'annotation existantes (p.ex. morphologique)
42

Universität Stuttgart ������������������������������ �����������������
Banque de Français Médiéval (BFM)
• ENS-LSH Lyon (C. Guillot)• Le corpus• environ 3 million de mots• Ancien et Moyen français• Textes entiers
• Annotation morphosyntaxique partielle• Annotation manuelle de 5 textes• Développement d'un jeu d'étiquettes
(CATTEX)• Publication en ligne• Outils de recherche• Weblex, IMS Corpus Workbench• Utilisation et développement d'outils
d'étiquetage:• SATO, Brill
Nouveau Corpus d'Amsterdam (NCA)
• Kunstmann, Gleßgen, Stein (2006)• Le corpus
• 296 textes (entiers ou extraits)• couvrant les variétés dialectale (Dees
1987)• 3.183.226 mots, étiquetés,
lemmatisés• format XML, information méta-
textuelle (bibliographie, descripteurs)• Licence de recherche (gratuite):
• Version 2 (2008): accessible en ligne• Outil de recherche: TWIC
• Ressources lexicales:• Lexique des formes (250.000
graphies), avec catégorie et lemme• Outils
• TreeTagger pour l'ancien français
Annotation syntaxiqueOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
Syntactic Reference Corpus of Medieval French
43

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Notabene
Annotation syntaxiqueOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
44
‣ Nicolas Mazziotta (Stuttgart/Liège, projet SRCMF)‣ Outil pour
l'annotation et la correction syntaxique manuelle‣ constituants et
dépendances
NotaBene

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Annotation syntaxiqueOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
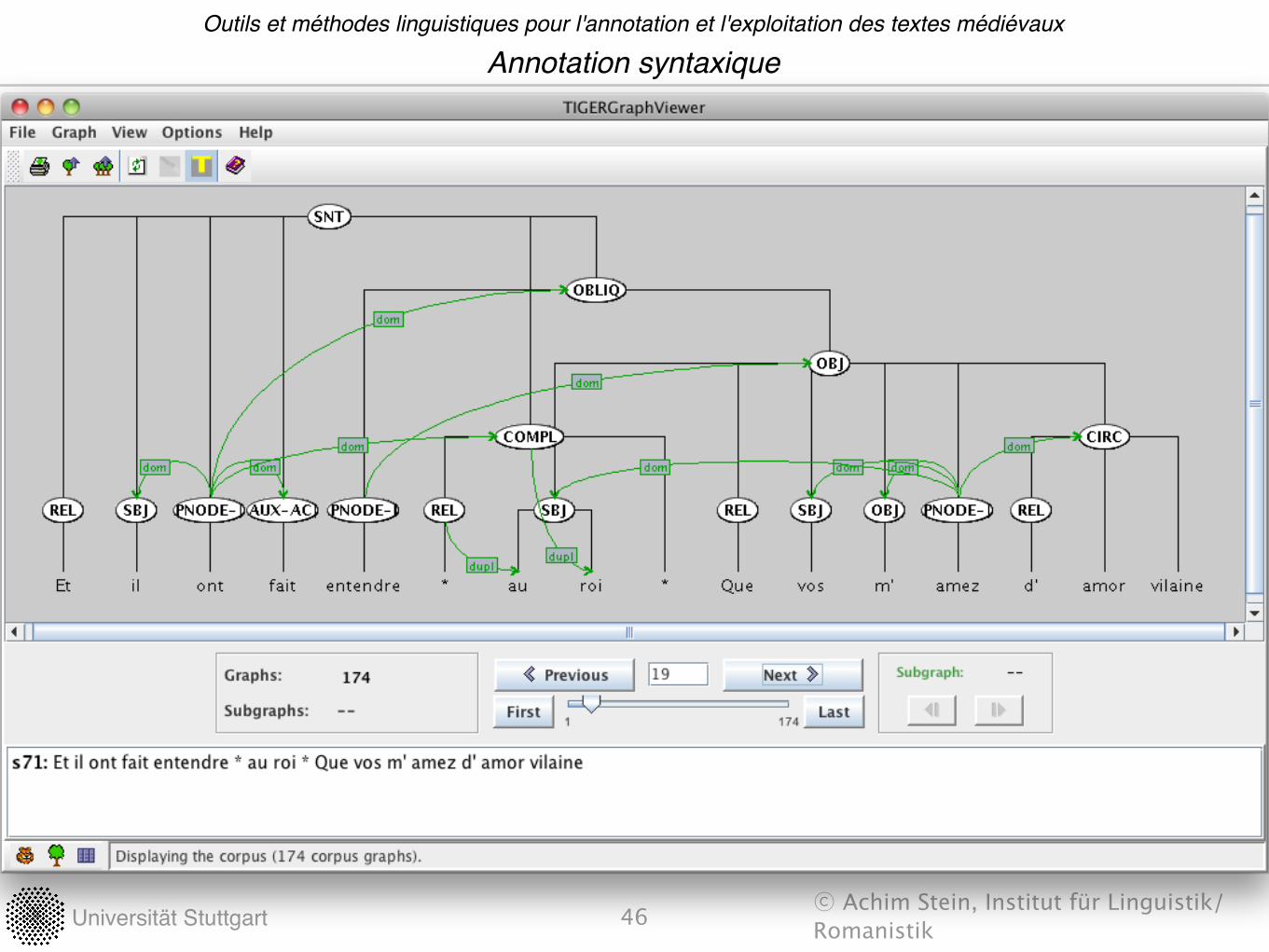
Requêtes syntaxiques: TigerSearch
45
‣ Tiger Search (IMS, Stuttgart; Lezius 2002, 2006):‣ Aspects techniques:‣ Implémenté en Java (pour Unix, Windows, Mac, …)‣ Interface graphique‣ Propriétés:‣ format Tiger-XML‣ importe les formats "treebank" courants‣ Format de requête et de description‣ pour les graphes syntaxiques (orientés, acycliques)‣ plus‣ les arcs peuvent être étiquetés‣ les arcs peuvent se croiser
Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Annotation syntaxiqueOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
46

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
Outils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
Pour conclure
47
‣ Annotation linguistique‣ définir les unités lexicales‣ annoter les unités lexicales‣ partie de discours, lemme
‣ annoter les structures: syntaxe‣ déterminer les fonctions grammaticales
‣ Outils: génériques ou académiques, non commercialisés‣ Annotation meta-linguistique‣ différencier entre les types de fonctions (actants)‣ agent, patient etc.: qui agit? qui subit l'action?
‣ attacher des ressources encyclopédiques (aux lemmes)‣ utiliser des hiérarchies sémantiques (WordNet)

Universität Stuttgart ��Achim Stein, Institut für Linguistik/Romanistik
•Bourigault, D.; Fabre, C.; Frérot, C.; Jacques, M.-P.; Ozdowska, S. (2005): Syntex, analyseur syntaxique de corpus. Actes des 12èmes journées sur le Traitement Automatique des Langues Naturelles, Dourdan, France.
•Dees, Anthonij (1980): Atlas des formes et des constructions des chartes françaises du 13e siècle, Tübingen: Niemeyer.•Dees, Anthonij (1987): Atlas des formes linguistiques des textes littéraires de l'ancien français, Tübingen: Niemeyer.•Gleßgen, M.D./Gouvert, X./Muller, C.: "La base textuelle du Nouveau Corpus d'Amsterdam: objectifs, résultats, perspectives"
- in: Kunstmann/Stein (to appear).•Kunstmann, Pierre et. al. (ed.) (2003): Ancien et moyen français sur le Web: Enjeux méthodologiques et analyse du discours,
Ottawa: Les Éditions David.•Kunstmann, Pierre & Stein, Achim (ed.) (to appear): Le Nouveau Corpus d'Amsterdam. Actes de l'atelier de Lauterbad, 23-26
février 2006, Stuttgart: Steiner.•Lezius, Wolfgang (2002): Ein Suchwerkzeug für syntaktisch annotierte Textkorpora (German). Stuttgart: Institut für
Maschinelle Sprachverarbeitung (IMS).•Le Nouveau Corpus d'Amsterdam (2006): Le corpus d'Amsterdam des textes littéraires de l'ancien français, compilé par A.
Dees, edité par Pierre Kunstmann et Achim Stein, Stuttgart: Institut für Linguistik/Romanistik.•Schmid, Helmut (1997): "Probabilistic Part-of-Speech Tagging Using Decision Trees" - Jones, Daniel & Somers, Harold (ed.):
New Methods in Language Processing, London, GB: UCL Press, 154-164.•Stein, Achim (2003): "Étiquetage morphologique et lemmatisation de textes d'ancien français" - in Kunstmann (2003),
273-284.•Stein, Achim & Schmid, Helmut (1995): "Etiquetage morphologique de textes français avec un arbre de décisions" -
traitement automatique des langues, Volume 36, Numéro 1-2: Traitements probabilistes et corpus, 23-35
BibliographieOutils et méthodes linguistiques pour l'annotation et l'exploitation des textes médiévaux
48








![Grammaire Francaise Dussouchet Ocr[1]](https://static.fdocuments.fr/doc/165x107/5572000649795991699ea4bf/grammaire-francaise-dussouchet-ocr1.jpg)









