
Modèle multidimensionnel et OLAP sur architecture de...
214
N° d'ordre 2009-ISAL-0002 Année 2009 Thèse Modèle multidimensionnel et OLAP sur architecture de grille Présentée devant L'institut National des Sciences Appliquées de Lyon Pour obtenir Le grade de docteur Spécialité Informatique École doctorale École doctorale Informatique et Information pour la Société Par Pascal Wehrle Jury MM. J. Darmont Professeur à l'Université Lyon 2 H. Kosch Professeur à l'Université de Passau (Rapporteur) N. Melab Professeur à l'Université Lille 1 M. Miquel Maître de Conférences HDR à l'INSA de Lyon (Directrice de thèse) F. Ravat Maître de Conférences HDR à l'Université de Toulouse 1 (Rapporteur) A. Tchounikine Maître de Conférences à l'INSA de Lyon (co-Directrice de thèse) LIRIS - Laboratoire d'InfoRmatique en Image et Systèmes d'information
Transcript of Modèle multidimensionnel et OLAP sur architecture de...

N° d'ordre 2009-ISAL-0002
Année 2009
Thèse
Modèle multidimensionnel et
OLAP sur architecture de grille
Présentée devant
L'institut National des Sciences Appliquées de Lyon
Pour obtenir
Le grade de docteur
Spécialité
Informatique
École doctorale
École doctorale Informatique et Information pour la Société
Par
Pascal Wehrle
Jury MM.
J. Darmont Professeur à l'Université Lyon 2
H. Kosch Professeur à l'Université de Passau (Rapporteur)
N. Melab Professeur à l'Université Lille 1
M. Miquel Maître de Conférences HDR à l'INSA de Lyon (Directrice de thèse)
F. Ravat Maître de Conférences HDR à l'Université de Toulouse 1 (Rapporteur)
A. Tchounikine Maître de Conférences à l'INSA de Lyon (co-Directrice de thèse)
LIRIS - Laboratoire d'InfoRmatique en Image et Systèmes d'information


Remerciements :
Tout d'abord je tiens à remercier sincèrement toutes les personnes qui m'ont
accompagné durant la réalisation de ce long mais passionnant travail de thèse.
Je souhaite remercier tous les membres du jury pour leurs l'intérêt qu'ils portent
à mon travail, en particulier Prof. Harald Kosch et Dr. Franck Ravat pour leurs
remarques constructives qui m'ont permis d'améliorer mon travail. Merci aussi à
Jérôme Darmont et Nouredine Melab d'avoir accepté de faire partie de mon
jury.
Merci à mes encadrantes et co-directrices de thèse Maryvonne Miquel et Anne
Tchounikine de m'avoir donné la chance d'entreprendre ce travail de thèse et de
s'être investi autant pour orienter et encourager le long processus de recherche
qui m'a permi d'explorer de nombreuses pistes scientifiques. Je leur suis très
reconnaissant d'avoir dirigé mes efforts de façon ciblée tout en me laissant une
grande autonomie jusqu'à l'aboutissement de ce projet. Merci également à
Robert Laurini d'avoir été mon directeur de thèse pendant les deux premières
années et d'avoir suivi et encouragé mon travail.
Merci à tous les participants du projet GGM pour des moments inoubliables de
travail, d'échanges fructueux et de détente tout au long du projet.
Merci également à tous les membres de mon équipe et tous ceux qui m'ont
entouré et accompagné au quotidien au laboratoire LIRIS et qui m'ont aidé par
leur présence et leur soutien, en particulier Jean-Sébastien, Ny Haingo, Sandro,
Julien, Romuald, Yonny, les stagiaires Damien et Michaël pour leur aide
précieuse dans la conception du prototype, Ruggero, Karla, Enzo, Yann,
Claudia, Sana, Frédéric et tous les autres.
Je remercie de tout cœur ma chère Estelle d'avoir cru en moi et de m'avoir
encouragé depuis le début, malgré les contraintes et à travers tous les passages
difficiles jusqu'à l'aboutissement de ce grand projet pour moi.
Enfin, je tiens à remercier toute ma famille pour leur soutien permanent, leurs
encouragements intarissables et leur confiance en moi.


Résumé :
Les entrepôts de données et les systèmes OLAP (OnLine Analytical Processing)
permettent un accès rapide et synthétique à de gros volumes de données à des
fins d'analyse. Afin d'améliorer encore les performances des systèmes
décisionnels, une solution consiste en la mise en œuvre d'entrepôts de données
sur des systèmes répartis toujours plus puissants. Les grilles de calcul en
particulier offrent d'importantes ressources de stockage et de traitement. Le
déploiement d'un entrepôt sur une infrastructure décentralisée de grille
nécessite cependant l'adaptation du modèle multidimensionnel et des processus
OLAP pour tenir compte de la répartition et de la réplication des données et de
leurs agrégats. Nous introduisons un modèle d'identification des données de
l'entrepôt réparti et une méthode d'indexation des données sous forme de blocs
multidimensionnels. Cette structure d'index s'appuie sur des index spatiaux en
X-tree et des treillis de cuboïdes, et permet la localisation des données
matérialisées ainsi que des agrégats calculables sur les différents nœuds de la
grille. Nous proposons une méthode de traitement de requêtes OLAP visant à
construire un plan d'exécution optimisé à partir de la liste des blocs candidats
contribuant au résultat de la requête. Enfin, nous définissons une architecture de
services de grille GIROLAP (Grid Infrastructure for Relational OLAP),
intégrée à l'intergiciel Globus, et déployée dans le cadre du projet GGM (Grille
Géno-Médicales) de l'ACI « Masse de Données ».
MOTS-CLÉS : entrepôt de données, grille de calcul, indexation
multidimensionnelle, requêtage OLAP, architecture de services


Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon ii
Sommaire
Table des matières
CHAPITRE 1 INTRODUCTION ............................................................. 1
1 Systèmes OLAP : des systèmes centralisés vers les systèmes distribués .............. 1 1.1 Motivations ..................................................................................................... 1 1.2 Eléments de la solution explorée ...................................................................... 2 1.3 Un exemple applicatif ...................................................................................... 3
2 Problématiques ................................................................................................ 4 2.1 Déployer des données multidimensionnelles sur une grille ................................ 5 2.2 Interroger un entrepôt sur grille ....................................................................... 5 2.3 Exécuter une requête ....................................................................................... 6 2.4 Définir des services de grille ............................................................................ 7
3 Contributions .................................................................................................. 7
4 Structure du document .................................................................................... 8
CHAPITRE 2 ÉTAT DE L'ART ........................................................... 11
1 Entrepôts de données et OLAP ........................................................................11 1.1 Fondements ................................................................................................... 11 1.2 Le modèle multidimensionnel ........................................................................ 12
1.2.1 Dimensions et hiérarchies de dimension................................................... 12 1.2.2 Faits, mesures et agrégats ........................................................................ 15 1.2.3 Représentation d'un modèle multidimensionnel ........................................ 16 1.2.4 Hypercube et treillis de cuboïdes ............................................................. 16
1.3 Architecture fonctionnelle d'un système OLAP ............................................... 18 1.3.1 Architecture trois tiers ............................................................................ 19
1.4 Modèles de stockage...................................................................................... 20 1.4.1 Stockage des données de l'entrepôt .......................................................... 20 1.4.2 Stockage des données de l'hypercube ....................................................... 22
2 Les grilles de calcul .........................................................................................24 2.1 Définition ..................................................................................................... 24 2.2 Infrastructure de grille ................................................................................... 24 2.3 Intégration de données ................................................................................... 26
2.3.1 L'approche médiation .............................................................................. 27 2.3.2 L'approche répartition et réplication ........................................................ 27 2.3.3 Bases de données sur grille ..................................................................... 28
3 Entrepôts de données en environnement distribué ...........................................28 3.1 Fragmentation d'un entrepôt ........................................................................... 29 3.2 Politiques de placement des fragments ........................................................... 30

Sommaire
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon ii
3.3 Entrepôts sur bases de données distribuées ..................................................... 31 3.4 Entrepôts sur infrastructures de grille ............................................................. 31
4 Discussion et conclusion ..................................................................................32
CHAPITRE 3 MODELISATION, IDENTIFICATION ET
INDEXATION DES DONNEES MULTIDIMENSIONNELLES
MATERIALISEES SUR GRILLE ........................................................ 35
1 Cas d'utilisation ..............................................................................................35
2 Un modèle conceptuel de données multidimensionnelles réparties ....................37 2.1 Schéma et instance de dimension ................................................................... 37 2.2 Faits et agrégats répartis ................................................................................ 40 2.3 Instances locales de dimension ....................................................................... 45 2.4 Ordonnancement des membres de dimension .................................................. 47
3 Identification de données multidimensionnelles ...............................................53 3.1 Définition et identification de « chunks » de données ...................................... 53 3.2 Construction de blocs de chunks .................................................................... 55
4 Indexation de données multidimensionnelles ....................................................58 4.1 Index T sur les différents niveaux d'agrégation ............................................... 58 4.2 Index X sur les blocs de chunks ..................................................................... 61 4.3 Opérations sur l'index TX .............................................................................. 64
4.3.1 Insertion dans l'index TX ........................................................................ 65 4.3.2 Suppression dans l'index TX ................................................................... 66
5 Conclusion ......................................................................................................67
CHAPITRE 4 INTEGRATION ET GESTION DES AGREGATS
CALCULABLES ..................................................................................... 71
1 Principes d'obtention des agrégats calculables .................................................71
2 Construction de blocs de chunks calculables ....................................................72 2.1 Fusion géométrique de blocs de chunks .......................................................... 72 2.2 Parties utiles pour l'obtention du bloc calculable ............................................. 76 2.3 Plans de calcul associés aux blocs calculables ................................................ 78
3 Indexation dynamique des agrégats calculables ...............................................81 3.1 Insertion des blocs calculables dans l'index TX .............................................. 81 3.2 Suppression des blocs calculables dans l'index TX .......................................... 85
4 Conclusion ......................................................................................................87
CHAPITRE 5 EXECUTION ET OPTIMISATION DE REQUETES
................................................................................................................... 89

Sommaire
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon iii
1 Cas d'utilisation ..............................................................................................89
2 Présentation générale des phases de traitement de requêtes .............................93
3 Réécriture de la requête client .........................................................................94
4 Localisation des données utiles pour la requête ................................................95 4.1 Principe général ............................................................................................ 95 4.2 Algorithme de localisation des données .......................................................... 96 4.3 Calcul de la contribution des blocs et mise à jour de la requête ........................ 98 4.4 Mise à jour des plans de calcul ..................................................................... 103
4.4.1 Création de plan de calcul pour blocs matérialisés .................................. 103 4.4.2 Mise à jour du plan de calcul des blocs calculables ................................ 105
5 Plan d'exécution et optimisation de l'exécution .............................................. 107 5.1 Calcul des estimations de coûts .................................................................... 108
5.1.1 Estimation des coûts pour les blocs matérialisés ..................................... 108 5.1.2 Estimation des coûts pour des blocs calculables ..................................... 110
5.2 Construction d'un plan d'exécution de requêtes optimisé ............................... 112 5.2.1 Mesure de la contribution au résultat pour les blocs candidats ................ 112 5.2.2 Algorithme glouton pour la construction du plan d'exécution .................. 113
6 Exécution parallèle et distribuée de requêtes ................................................. 115 6.1 Ordonnancement des tâches de transfert et de calcul ..................................... 116 6.2 Surveillance de l'exécution et assemblage du résultat .................................... 118
6.2.1 Surveillance et mise à jour du statut de l'exécution ................................. 118 6.2.2 Assemblage du résultat ......................................................................... 119
7 Conclusion .................................................................................................... 119
CHAPITRE 6 LE PROTOTYPE GIROLAP (GRID
INFRASTRUCTURE FOR RELATIONAL OLAP) ......................... 123
1 Présentation des services de grille GIROLAP pour l'entrepôt distribué .......... 123 1.1 Services d'accès aux données et de calcul fournis par le Globus Toolkit ......... 126 1.2 Service d'identification des données multidimensionnelles : « Dimension
Manager » (DM) ............................................................................................... 127 1.2.1 Fonctionnalités ..................................................................................... 127 1.2.2 Interaction avec les autres services ........................................................ 128
1.3 Service d'indexation locale : « Local Indexing Service » (LIS) ...................... 128 1.3.1 Fonctionnalités ..................................................................................... 128 1.3.2 Interaction avec les autres services ........................................................ 130
1.4 Service de recherche de chunks : « Chunk Resolution Service » (CRS) .......... 130 1.4.1 Fonctionnalités ..................................................................................... 130 1.4.2 Interaction avec les autres services ........................................................ 131
1.5 Service de catalogue des blocs de chunks : « Chunk Localization Array
Catalog » (CLAC) ............................................................................................. 132 1.5.1 Fonctionnalités ..................................................................................... 132 1.5.2 Interaction avec les autres services ........................................................ 132
1.6 Service de surveillance de la grille : « Network Distance Service » (NDS) ..... 132 1.6.1 Fonctionnalités ..................................................................................... 133

Sommaire
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon iv
1.6.2 Interaction avec les autres services ........................................................ 133 1.7 Service de gestion de l'exécution de requêtes : « Query Execution Management
Service » (QEMS) ............................................................................................. 134 1.7.1 Fonctionnalités ..................................................................................... 134 1.7.2 Interaction avec les autres services ........................................................ 135
1.8 Interface client OLAP .................................................................................. 135 1.8.1 Fonctionnalités ..................................................................................... 136 1.8.2 Interactions .......................................................................................... 136
2 Déploiement des services ............................................................................... 136 2.1 Nœud de stockage et de calcul GIROLAP ..................................................... 137 2.2 Nœuds pour services de catalogue et de surveillance ..................................... 138 2.3 Nœuds d'accès pour l'interrogation décentralisée de l'entrepôt ....................... 138
3 Déroulement du traitement de requête........................................................... 138 3.1 Réécriture ................................................................................................... 139 3.2 Recherche locale ......................................................................................... 139 3.3 Localisation au niveau de la grille ................................................................ 140 3.4 Optimisation et exécution distribuée ............................................................ 140
4 Conclusion .................................................................................................... 141
CHAPITRE 7 CONCLUSION ET PERSPECTIVES ....................... 143
1 Bilan et contributions .................................................................................... 143 1.1 Modèle formel d'identification et d'indexation des données multidimensionnelles
réparties ........................................................................................................... 143 1.2 Exécution et Optimisation de requêtes .......................................................... 145 1.3 L'architecture de services GIROLAP (Grid Infrastructure for Relational OLAP)
........................................................................................................................ 146
2 Limites et perspectives .................................................................................. 146 2.1 Gestion et maintenance des données de l'entrepôt réparti ............................... 146 2.2 Maintenance et adaptation des structures d'index TX en fonction de l'évolution
de l'entrepôt réparti ........................................................................................... 148 2.3 Evolution et optimisation de la méthode de traitement de requêtes ................ 149 2.4 Réalisation et intégration des méthodes par l'architecture de services de grille
GIROLAP ........................................................................................................ 150
ANNEXE A ALGORITHMES ............................................................ 155
ANNEXE B EXEMPLES DETAILLES ............................................. 165
ANNEXE C SCENARIO DE TEST SUR L'ENTREPOT GGM ..... 171
1 Scénario de test sur l'entrepôt GGM.............................................................. 171 1.1 Fragmentation du schéma en étoile centré patient ......................................... 171 1.2 Fragmentation et déploiement de la table de faits .......................................... 172 1.3 Matérialisation d'agrégats pré-calculés ......................................................... 173

Sommaire
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon v
1.4 Répartition et indexation des blocs matérialisés ............................................ 173 1.5 Catégories de requêtes distribuées ................................................................ 174
BIBLIOGRAPHIE ................................................................................ 179

Sommaire
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon vi
Liste des figures
Figure 1.1 : Schéma de l'architecture de services pour le projet GGM .............. 4
Figure 2.1 : Comparaison entre systèmes OLTP et OLAP (Kelly, 1997) ......... 12
Figure 2.2 : Schéma et instance de la dimension « lieu de naissance » ............ 14
Figure 2.3 : Schéma et instance non normalisée de la dimension « pathologie »
.................................................................................................................... 14
Figure 2.4 : Schéma et instance normalisée de la dimension « pathologie » .... 15
Figure 2.5 : Notation inspirée de MultiDimER pour la description des modèles
multidimensionnels d'entrepôts ..................................................................... 16
Figure 2.6 : Hypercube à trois dimensions..................................................... 17
Figure 2.7 : Treillis de cuboïdes OLAP pour 3 dimensions hiérarchisées ........ 18
Figure 2.8 : Architecture d'un système OLAP ................................................ 19
Figure 2.9 : Exemples de Clients OLAP ........................................................ 20
Figure 2.10 : Modèle MultiDimER d'une vue orientée « ventes » sur un entrepôt
.................................................................................................................... 20
Figure 2.11 : Schéma en étoile de l'entrepôt « ventes » .................................. 21
Figure 2.12 : Schéma en flocon de l'entrepôt « ventes » ................................. 21
Figure 2.13 : Schéma en constellation de l'entrepôt « ventes » ....................... 22
Figure 2.14 : Architecture de services en couches d'une grille........................ 25
Figure 2.15 : Architecture du service de médiation GDMS (Brezany et al.,
2003) ........................................................................................................... 27
Figure 3.1 : Schéma conceptuel de l'entrepôt centré Patient ........................... 36
Figure 3.2 : Interfaces client dans l'architecture d'entrepôt réparti sur grille ... 36
Figure 3.3: Schéma et extrait de l'instance de la dimension « lieu » ............... 39
Figure 3.4: Schéma et extrait de l'instance de la dimension « temps » ............ 39
Figure 3.5: Extrait de l'instance de la dimension « pathologie » ..................... 40
Figure 3.6 : Table de faits « patient » fragmentée pour être répartie sur 3 nœuds
de la grille selon les critères des 3 groupes d'utilisateurs associés à ces nœuds 42
Figure 3.7 : Exemple d'une table d'agrégat aux niveaux {région, année,
pathologie} .................................................................................................. 43
Figure 3.8 : Table d'agrégat « patient-région-année » fragmentée pour être
répartie sur les nœuds A et B de la grille ....................................................... 44
Figure 3.9 : Instances locales des dimensions « lieu » et « temps » pour le nœud
de grille A .................................................................................................... 46
Figure 3.10 : Intervalles de membres représentant des données équivalentes sur
différents niveaux hiérarchiques ................................................................... 50

Sommaire
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon vii
Figure 3.11 : Instance ordonnée de la dimension « lieu » ............................... 52
Figure 3.12 : Ordres propagés de l'instance ordonnée de la dimension
« pathologie » .............................................................................................. 52
Figure 3.13 : Lien entre un ensemble de chunks et un chunk agrégé en deux
dimensions ................................................................................................... 55
Figure 3.14 : Bloc de chunks contigus dans la table de faits « patient » .......... 57
Figure 3.15 : Index en treillis de blocs matérialisés ....................................... 61
Figure 3.16 : Index TX associant les sommets de l'index T en treillis et blocs de
chunks dans l'espace multidimensionnel........................................................ 62
Figure 3.17 : Représentation spatiale des blocs aux niveaux {ville,date,path-0}
.................................................................................................................... 63
Figure 3.18 : Structure du X-tree hébergeant les blocs indexés aux niveaux
{ville,date,path-0} ........................................................................................ 63
Figure 3.19 : Structure de l'index X spatial hébergeant les blocs au niveaux
{ville,date,path-0} ........................................................................................ 64
Figure 3.20 : Opération d'insertion sur l'index TX ......................................... 65
Figure 3.21 : Opération de suppression sur l'index T ..................................... 67
Figure 4.1 : Fusion de blocs de chunks adjacents dans la dimension « temps » 74
Figure 4.2 : Fusion de blocs de chunks dans les dimensions « temps » et « lieu »
.................................................................................................................... 75
Figure 4.3 : Blocs sources fusionnés dans la dimension « temps » pour créer un
bloc calculable aux niveaux {ville, mois, path-0} .......................................... 77
Figure 4.4 : Eléments sources d'un bloc calculable sur l'index X du nœud
LYON.......................................................................................................... 80
Figure 4.5 : Index TX après insertion d'un bloc matérialisé avant la mise à jour
des blocs calculables dans les dimensions « lieu » et « temps » ..................... 83
Figure 4.6 : Index TX après l'insertion des blocs calculables dépendants
uniquement de b8 .......................................................................................... 83
Figure 4.7 : Insertion d'un bloc calculable issu de la fusion de deux blocs source
dans l'index TX ............................................................................................ 84
Figure 4.8 : Mise à jour d'un bloc calculable suite à la suppression d'un bloc
matérialisé ................................................................................................... 86
Figure 5.1 : Identifiants de blocs matérialisés sur le nœud LYON .................. 90
Figure 5.2 : Identifiants de blocs matérialisés sur le nœud TOULOUSE ......... 91
Figure 5.3 : Identifiants de blocs matérialisés sur le nœud LILLE .................. 91
Figure 5.4 : Intersections dans l'espace de données entre une requête et deux
blocs de chunks matérialisés sur le nœud destination ..................................... 99

Sommaire
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon viii
Figure 5.5 : Calcul de la contribution du premier bloc à la requête et mise à jour
de l'ensemble des données manquantes ....................................................... 100
Figure 5.6 : Calcul de la contribution du deuxième bloc à la requête et
finalisation de l'ensemble des données manquantes ..................................... 100
Figure 5.7 : Découpage d'une requête portant sur les blocs indexés du nœud
LILLE ....................................................................................................... 102
Figure 5.8 : Eléments d'un plan de calcul créé pour un bloc candidat matérialisé
sur le nœud LYON ..................................................................................... 105
Figure 5.9 : Extraction partielle d'un plan de calcul d'un bloc calculable en
fonction d'une requête sur le nœud LYON ................................................... 106
Figure 5.10 : Bloc candidat matérialisé sur le nœud LILLE pour une requête
soumise au nœud TOULOUSE ................................................................... 109
Figure 5.11 : Recouvrement de la requête b*r sur le nœud LYON ................ 115
Figure 5.12 : Phases de lancement des différentes tâches du plan d'exécution
distribué..................................................................................................... 116
Figure 5.13 : Plan d'exécution distribué optimisé pour la requête b*r ........... 118
Figure 6.1 : Déploiement exemple des services de l'architecture GIROLAP . 126
Figure 6.2 : Représentation des identifiants de blocs et de leur intersection .. 127
Figure 6.3 : Visualisation en deux dimensions de la structure de l'index TX sur
un nœud ..................................................................................................... 129
Figure 6.4 : Phase de localisation de chunks exécutée par le service de
recherche de chunks ................................................................................... 131
Figure 6.5 : Client graphique Java du service NDS (Gossa et al., 2006) ....... 133
Figure 6.6 : Phase de localisation supervisée par le service de gestion de
l'exécution de requêtes ............................................................................... 134
Figure 6.7 : Interface graphique JPivot avec table de pivot montrant un
hypercube de l'entrepôt GGM ..................................................................... 135
Figure 6.8 : Types de nœuds au sein du déploiement exemple des services
GIROLAP .................................................................................................. 137
Figure 6.9 : Déroulement de la recherche locale de chunks sur un nœud ....... 139
Figure 6.10 : Localisation de blocs de chunks manquants sur la grille .......... 140
Figure 6.11 : Optimisation de la liste des blocs candidats et exécution distribuée
.................................................................................................................. 141
Figure B.1 : Recherche locale sur le nœud LYON suite à une requête b*r .... 167
Figure B.2 : Recherche sur le nœud TOULOUSE suite à la requête b*rm
..... 168
Figure B.3 : Recherche sur le nœud LILLE suite à la requête b*rm
............... 168
Figure C.1 : Vue centrée patient du schéma de l'entrepôt GGM ................... 171

Sommaire
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon ix
Liste des tableaux
Tableau 5.1 : Paramètres d'exploitation de la grille à la base des exemples du
chapitre ........................................................................................................ 92
Tableau 5.2 : Trace d'exécution de l'algorithme pour la construction de M .. 101
Tableau 6.1 : Nom et fonctionnalités mises à disposition par chaque service de
grille .......................................................................................................... 125
Tableau C.1 : Fragments de la table de faits « Patient » sous forme de blocs de
chunks ....................................................................................................... 172
Tableau C.2 : Blocs de chunks agrégés matérialisés en plus des chunks détaillés
.................................................................................................................. 173
Tableau C.3 : Requêtes portant sur les chunks matérialisés déployés sur la grille
GGM ......................................................................................................... 175
Tableau C.4 : Requêtes portant sur les chunks calculables sur la grille GGM 176
Tableau C.5 : Requêtes portant sur les chunks matérialisés et calculables sur la
grille GGM ................................................................................................ 178

Liste des définitions
Définition 3.1 : Schéma de dimension ........................................................... 38
Définition 3.2 : Instance de dimension .......................................................... 38
Définition 3.3 : Table de faits ....................................................................... 40
Définition 3.4 : Fragment de table de faits .................................................... 40
Définition 3.5 : Table d'agrégat .................................................................... 42
Définition 3.6 : Fragment de table d'agrégats ................................................ 43
Définition 3.7 : Instance locale de dimension ................................................ 45
Définition 3.8 : Relation d'ordre propagée descendante ................................. 49
Définition 3.9 : Relation d'ordre propagée ascendante ................................... 49
Définition 3.10 : Instance de dimension ordonnée ......................................... 50
Définition 3.11 : Chunk de données multidimensionnelles ............................. 53
Définition 3.12 : Bloc de chunks ................................................................... 56
Définition 3.13 : Index T en treillis de niveaux d'agrégation .......................... 59
Définition 3.14 : Index X des données multidimensionnelles ......................... 62
Définition 4.1 : Fusion de blocs de chunks .................................................... 73
Définition 4.2 : Plan de calcul associé à un bloc de chunks calculable ............ 78

Liste des exemples
Exemple 2.1 : Normalisation d'instances de dimension irrégulières ................ 13
Exemple 3.1 : Schémas et instances des dimensions de l 'entrepôt centré Patient
.................................................................................................................... 38
Exemple 3.2 : Fragmentation de la table de faits d'un entrepôt modélisé en
étoile ........................................................................................................... 41
Exemple 3.3 : Fragmentation d'une table d'agrégat ........................................ 43
Exemple 3.4 : Instance locale de dimension sur un nœud de la grille .............. 46
Exemple 3.5 : Ordonnancement d'instances de dimension .............................. 51
Exemple 3.6 : Identification d'un bloc de chunks ........................................... 56
Exemple 3.7 : Construction d'un index en treillis de niveaux d'agrégation ...... 59
Exemple 3.8 : Indexation spatiale au sein d'un sommet de l'index T ............... 63
Exemple 3.9 : Insertion d'un identifiant de bloc de chunks dans l'index TX .... 65
Exemple 3.10 : Suppression d'un identifiant de bloc de chunks dans l 'index TX
.................................................................................................................... 66
Exemple 4.1 : Fusion de blocs de chunks ...................................................... 74
Exemple 4.2 : Parties utiles de blocs sources associées à un bloc de chunks
calculable .................................................................................................... 76
Exemple 4.3 : Plan de calcul associé à un bloc calculable .............................. 79
Exemple 4.4 : Mise à jour de l'index TX suite à l'insertion d'un bloc matérialisé
.................................................................................................................... 82
Exemple 4.5 : Mise à jour d'un bloc calculable dans l'index TX suite à la
suppression d'un bloc matérialisé .................................................................. 86
Exemple 5.1 : Construction de requêtes portant sur les chunks recherchés ... 101
Exemple 5.2 : Création d'un plan de calcul pour blocs candidats matérialisés sur
nœuds distants............................................................................................ 104
Exemple 5.3 : Mise à jour du plan de calcul pour les blocs candidats calculables
.................................................................................................................. 106
Exemple 5.4 : Estimation des coûts pour bloc de chunks matérialisé ............ 109
Exemple 5.5 : Construction progressive d'un plan d'exécution optimisé ....... 113
Exemple 5.6 : Ordonnancement des tâches d'un plan d'exécution distribué
optimisé ..................................................................................................... 117


Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 1
Chapitre 1 Introduction
L'informatique décisionnelle constitue un domaine évoluant en permanence.
Depuis la définition du concept d'entrepôt de données par William H. Inmon
(Inmon, 1992), le marché des solutions décisionnelles basées sur les entrepôts
et outils OLAP (OnLine Analytical Processing) s'est fortement développé pour
atteindre un volume de 7 milliards de dollars en 2007 (Vesset et al., 2008). Les
secteurs de l'analyse en ligne OLAP et des analyses avancées de données du
type fouille de données connaissent une croissance particulièrement marquée.
L'informatique décisionnelle constitue une thématique majeure dans le monde
de l'industrie et de la recherche.
1 Systèmes OLAP : des systèmes centralisés vers les systèmes
distribués
1.1 Motivations
Avec le succès des solutions décisionnelles, vient l'augmentation des exigences
de service et d'usage. Ainsi, le volume de données à entreposer augmente en
même temps que les temps de réponse sont contraints de diminuer. De plus, la
diversification des domaines d'application exige des méthodes d'analyse de plus
en plus complexes, notamment pour les applications scientifiques comme par
exemple la bioinformatique. De nouveaux modèles et de nouvelles approches
technologiques doivent être développés pour s'adapter aux nouvelles exigences.
Il est naturel, pour des entreprises qui sont de plus en plus constituées de réseau
de petites ou moyennes structures réparties géographiquement, de s'adosser à
des Systèmes d'Information (SI) distribués. Pour des raisons de performance et
de disponibilité, les données sont généralement maintenues et gérées là où elles
sont produites, puis mises à disposition des entités distantes via des réseaux
étendus. La constitution d'un entrepôt de données, même dans le cas d'un SI
distribué, reste cependant avant tout un processus de centralisation : les
données pertinentes sont extraites des différents sites, puis homogénéisées et
agrégées dans un entrepôt puis dans un hypercube mono-site. Cependant, cette
solution pose d'une part des problèmes de scalabilité, en termes de volume et de
complexité des traitements, et d'autre part ne respecte pas la nature locale des
données, en termes de propriété, de confidentialité et de disponibilité. Enfin un
entrepôt centralisé ne favorise pas la gestion de toujours plus d'utilisateurs, se
connectant à distance, et ayant des besoins différents en matière de données et
d'outils d'analyse.

1 Introduction
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 2
1.2 Eléments de la solution explorée
Une des approches pour répartir la charge que représente le stockage d'un
entrepôt de données et les traitements associés consiste à s'appuyer sur les
solutions mises en œuvre dans le domaine des bases de données distribuées.
Notons que les traitements impliqués dans la chaîne décisionnelle concernent à
la fois le processus d'extraction et de transformation qui alimente l'entrepôt et
l'exécution de requêtes OLAP. Alors que l'alimentation survient généralement
de manière invisible à l'utilisateur lors de périodes de maintenances fixes,
l'interrogation de l'entrepôt par des outils OLAP demande une réactivité
importante. En effet, la navigation interactive à travers l'hypercube OLAP
engendre de nombreuses opérations d'agrégation sur des ensembles de données
choisies arbitrairement et dynamiquement par l'utilisateur. Afin d'assurer des
temps de réponse minimaux, le déploiement de l'entrepôt sur un système
distribué doit optimiser la répartition des données et la parallélisation des
traitements liés aux requêtes.
Les travaux existants mettent en œuvre des méthodes de partitionnement déjà
éprouvées dans le domaine des bases de données distribuées (Mehta et al.,
1997), (Poess et al., 2005). Les données de l'entrepôt sont réparties en parties
de taille égale et réparties uniformément sur les nœuds du système. Le contrôle
sur les ressources de stockage et la gestion des requêtes restent centralisées.
Cette solution présente des limites, en particulier liées au maintien de la gestion
centralisée de l'entrepôt. Un tel système ne fait essentiellement que déléguer le
stockage de l'entrepôt à une base de données distribuée, alors que les
métadonnées décrivant le modèle multidimensionnel de l'entrepôt sont
regroupées sur un nœud « maître ». L'ensemble des nœuds « esclaves » est
constitué de systèmes dédiés de capacité identique facilement accessibles et
gérables. Alors que cette configuration permet une bonne maîtrise des
processus de stockage et de traitements, elle limite cependant les possibilités de
passage à l'échelle et de réorganisation au sein de l'entrepôt. Le traitement
distribué de requêtes s'effectue selon le même principe, les nœuds « esclaves »
exécutant des parties d'opérations qui sont planifiées, déclenchées et gérées par
une instance unique. De plus, cette instance de contrôle centralisée constitue un
goulot d'étranglement par lequel doivent passer toutes les requêtes utilisateurs.
Ces limites sont de nature conceptuelle et nécessitent de nouvelles approches
pour les surmonter.
Une des voies les plus prometteuses dans ce contexte est l'utilisation de grilles
de calcul. En effet, une grille coordonne un ensemble de ressources hétérogènes
qui ne sont ni saisies ni contrôlées de manière centralisée. L'intergiciel de grille
organise l'utilisation de ces ressources mises à disposition à travers un réseau
étendu. Des ressources peuvent être ajoutées et supprimées à la grille de
manière dynamique, ce qui permet d'adapter les capacités de stockage et de
calcul en fonction des besoins et des disponibilités. Un entrepôt de données
déployé sur une grille reste ainsi modifiable et donc capable de répondre à des
exigences variables. De plus, la grille opère de manière entièrement
décentralisée, chaque nœud gérant lui-même l'utilisation et l'accès des
ressources dont il dispose. Dans un entrepôt réparti sur une grille, la répartition

1 Introduction
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 3
des données et des calculs peut donc être adaptée à la capacité mise à
disposition par chaque nœud. Il s'agit également de décentraliser la gestion des
métadonnées de l'entrepôt afin d'éviter de dépendre d'une instance unique du
modèle multidimensionnel. Ainsi, le traitement de requêtes OLAP peut
s'effectuer depuis n'importe quel nœud, chaque nœud ayant accès à
l'information et aux ressources nécessaires à la planification et à l'exécution de
requêtes. Une telle configuration est plus facilement capable d'assurer un
service accessible et fiable pour un grand nombre d'utilisateurs dans un
environnement hautement distribué.
1.3 Un exemple applicatif
Le contexte applicatif des travaux que nous présentons dans ce document est le
projet de recherche « Grille Géno-Médicale » (GGM), financé par l'ACI
« Masse de données ». Le projet GGM est une collaboration nationale incluant
l'équipe « Optimisation Parallèle Coopérative » de l'INRIA Dolphin à Lille,
l'équipe « Optimisation dynamique de requêtes réparties à grande échelle » de
l'IRIT à Toulouse et les équipes « Systèmes d'Information Spatio-Temporels et
Entreposage » et « Systèmes d'Information Pervasifs » du LIRIS à Lyon. Les
problématiques scientifiques et l'approche retenue sont détaillées par (Pierson et
al., 2005) et (Pierson et al., 2007).
La motivation à l'origine du projet est le manque de solutions permettant de
partager et d'exploiter efficacement les grands volumes de données produits par
des méthodes d'analyse protéomiques et génétiques dans le domaine médical
(Brunie et al., 2003). L'objectif est donc de proposer une architecture logicielle
pour la gestion et l'analyse de données géno-médicales complexes sur grille de
calcul. Les données traitées sont des données issues d'expériences mesurant
l'expression de gènes sur biopuces, associées aux dossiers médicaux
informatisés des patients concernés. Le concept d'entrepôt réparti sur cette
grille est essentiel pour apporter des capacités de gestion de ces données géno-
médicales hétérogènes et dynamiques, permettant ainsi l 'exécution distribuée de
traitements et d'analyses complexes sur ces données.
Le projet est divisé en plusieurs domaines qui traitent les problématiques
associées aux différentes unités fonctionnelles de l 'architecture. La figure 1.1
illustre l'architecture de services proposée dans le cadre du projet GGM. L'unité
fonctionnelle que représente l'entrepôt de données réparti a une place centrale
car il interagit directement avec le service de requêtes qui prend en charge
l'exécution des requêtes sur les données qui sont ensuite livrées au service de
fouille de données.

1 Introduction
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 4
GGM
Middleware de Grille
mandataire
BD patients BD publiques BD génétiques
Cache collaboratif
Exécution de Requêtes
Entrepôt de DonnéesRéparti
Fouille de Données
Interface Utilisateur
Monitoring
Figure 1.1 : Schéma de l'architecture de services pour le projet GGM
Le service de fouille de données est donc le client de l 'entrepôt de données
réparti. A partir de populations de patients sélectionnées dans l 'entrepôt par des
requêtes OLAP, une analyse approfondie par fouille de données est effectuée.
Cet aspect est l'objet du travail de l'équipe « Optimisation Parallèle
Coopérative » de l'INRIA Dolphin à Lille, présenté dans (Melab et al., 2006).
Les services de monitoring et de caches collaboratifs sont situés directement en
amont de l'intergiciel de grille et font partie du travail de l 'équipe « Systèmes
d'Information Pervasifs » du LIRIS à Lyon. Le service de cache collaboratif a
pour objectif d'optimiser et de gérer activement l 'utilisation des ressources de
stockage tout en fournissant un accès transparent aux données. Ce système est
détaillé dans (Cardenas et al., 2006). Un service de monitoring capable de
fournir des mesures détaillées sur l 'état de la grille délivre les informations
nécessaires à l'optimisation des requêtes a priori par l 'entrepôt de données et au
fil de l'exécution par le service de requêtes. Ce service est décrit dans (Gossa et
al., 2006). Enfin, le service de requêtes présenté par (Hussein et al., 2006) gère
l'exécution optimisée des requêtes faites d'opérations de sélection, projection et
de jointure (SPJ). Ce sont des agents mobiles autonomes qui optimisent
l'exécution en fonction des conditions de charge variables au sein d 'une grille.
Chaque agent dispose d'un plan d'exécution établi et optimisé avant exécution
par l'entrepôt de données réparti. Ces problématiques sont l'objet du travail de
l'équipe « Optimisation dynamique de requêtes réparties à grande échelle » de
l'IRIT à Toulouse.
2 Problématiques
Les problématiques associées aux solutions décisionnelles déployées sur grille
concernent d'une part la répartition des données multidimensionnelles sur
plusieurs nœuds autonomes, et d'autre part l'exécution de requêtes distribuées
sur ces données. Alors que le déploiement d'un entrepôt sur un système

1 Introduction
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 5
distribué maintient généralement l'aspect centralisé de la gestion de données et
du traitement de requêtes, l'absence de contrôle sur les systèmes constituant une
grille nécessite une approche décentralisée. Les problématiques à résoudre sont
détaillées ci-après.
2.1 Déployer des données multidimensionnelles sur une grille
Les ressources partagées par chaque système participant à la grille sont
hétérogènes en termes de capacité, d'accès et de disponibilité. De plus, l'accès
aux fonctionnalités de la grille par des applications clientes est possible depuis
un grand nombre de points d'accès. Avant de pouvoir déployer l'entrepôt sur
grille, celui-ci doit donc être fragmenté en fonction des besoins des utilisateurs
et de l'espace de stockage mis à disposition par les nœuds de grille. Il est
nécessaire d'établir une stratégie de placement qui peut prendre en compte des
critères comme la pertinence des fragments d'entrepôt, leur fréquence d'accès
reflétant leur usage, mais aussi la propriété et la confidentialité des données.
Les données ainsi réparties peuvent être également répliquées sur plusieurs
nœuds et déplacées en fonction de l'évolution de leur utilisation. Les données
de l'hypercube ne sont pas des données « traditionnelles ». Elles comportent
différents niveaux de détail ; elles peuvent être partiellement matérialisées, et
sont calculables à partir de données plus détaillées. Leur mode de stockage
physique présente des particularités qui doivent être maîtrisées pour une gestion
efficace : elles sont stockées sous forme d'un schéma en étoile dont la pièce
centrale est une table de faits qui référence un ensemble de tables de dimension
à l'aide de clés étrangères. La clé primaire de la table de fait est formée par la
composition des clés étrangères, reliant ainsi chaque fait à un ensemble de
membres de dimension faisant partie des métadonnées de l'entrepôt. Enfin, les
tables de dimension hébergeant les métadonnées décrivant la structure
hiérarchisée des dimensions de l'entrepôt sont dénormalisées.
Un entrepôt de données sur grille devra :
- être fragmenté sur plusieurs nœuds de la grille,
- intégrer des données détaillées, agrégées, matérialisées ou calculables,
- s'appuyer sur un modèle multidimensionnel,
- comporter des données répliquées,
- gérer le déplacement dynamique des données
2.2 Interroger un entrepôt sur grille
Afin de pouvoir interroger un entrepôt fragmenté et réparti sur les nœuds d'une
grille, la méthode de traitement de requêtes doit prendre en compte plusieurs
aspects spécifiques au fonctionnement de la grille. Tout d'abord, les données
utiles pour traiter une requête doivent être localisées parmi les nœuds de la
grille et peuvent être disponibles de manières différentes et combinables. Les
données recherchées peuvent être :
- partiellement ou entièrement matérialisées sur le nœud interrogé,
- matérialisées et répliquées sur un ou plusieurs autres nœuds de la grille,

1 Introduction
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 6
- calculables à partir de données matérialisées sur le nœud interrogé,
- calculables sur un ou plusieurs autres nœuds de la grille.
Pour assurer un accès rapide à ces informations, un index des données
disponibles est indispensable. Un index central serait pénalisé par le
fonctionnement décentralisé de la grille et difficile à maintenir à jour dans un
environnement dynamique. En effet, il ne s'agit pas d'indexer des clés simples,
mais les clés multidimensionnelles utilisées par le modèle de l'entrepôt. Ce
modèle impose en plus de l'indexation des données détaillées et de leurs
agrégats matérialisés, l'intégration des données calculables à partir de ceux-ci.
De plus l'index doit pouvoir être mis à jour en fonction des déplacements et
réplications fortement dynamiques au sein de la grille. Il est donc indispensable
de mettre en place l'indexation des données disponibles au niveau de chaque
nœud de grille. L'information sur les données disponibles sur chaque nœud doit
cependant rester consultable par les nœuds exécutants des requêtes.
Pour accéder aux données pertinentes pour répondre à une requête OLAP, il
faudra :
- indexer les données matérialisées ou calculables sur l 'ensemble des nœuds
de la grille,
- fournir les fonctionnalités nécessaires à la mise à jour de cet index pour
tenir compte de l'évolution de la matérialisation et du placement des
données sur la grille.
2.3 Exécuter une requête
Afin d'obtenir le résultat d'une requête, un nœud de grille doit pouvoir local iser
les parties utiles de l'entrepôt. Il est également nécessaire d'évaluer le coût des
opérations de chargement, de calcul et de transfert nécessaires pour chaque
partie du résultat. Au sein d'un entrepôt réparti, il existe souvent plusieurs
possibilités d'obtenir les données résultat. Il s'agit dans ces cas là de trouver la
solution la moins coûteuse parmi ces possibilités et de construire un plan
d'exécution optimisé prenant en compte l'ensemble des méthodes pour obtenir
les données depuis les sources identifiées. Une requête OLAP est une requête
complexe impliquant plusieurs opérations de sélection, de jointure ainsi que des
calculs d'agrégation. Les traitements sur une grille de calcul sont exécutés de
manière asynchrone, chaque nœud assurant lui-même l'ordonnancement des
tâches qui lui sont soumises. Afin de pouvoir bénéficier au maximum d'une
parallélisation des calculs et des transferts, le mécanisme qui traite le plan
d'exécution doit prendre en compte la nature des requêtes OLAP et l'autonomie
des nœuds exécutants pour ordonnancer les opérations en conséquence.
Le traitement d'une requête OLAP repose sur :
- le recensement des données disponibles sur la grille et des différentes
alternatives possibles,
- l'élaboration puis l'exécution d'un plan d'exécution optimisé.

1 Introduction
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 7
2.4 Définir des services de grille
Enfin, une solution d'entrepôt réparti dans une infrastructure de grille doit
fournir les fonctionnalités de gestion de l'entrepôt sous forme de services de
grille. En effet, l'architecture de grille est composée de services organisés en
différentes couches superposées (Foster et al., 2003). Standardisées par le
« Open Grid Services Architecture » (OGSA), les couches de services assurent
les fonctions d'accès, de communication, de coordination et de coopération.
Une solution pour l'exploitation d'un entrepôt doit s'intégrer à l'architecture en
couches établie en ajoutant des services spécifiques là où les mécanismes
existants ne permettent pas de fournir les fonctionnalités requises.
L'architecture logicielle d'un entrepôt sur grille devra :
- s'appuyer sur un ensemble de service de gestion,
- s'intégrer dans un intergiciel de grille existant, de type Globus Toolkit.
3 Contributions
Les travaux présentés dans ce document apportent des solutions aux
problématiques mentionnées. La base du déploiement d'un entrepôt est fournie
par la méthode de fragmentation horizontale de (Bellatreche et al., 1999) qui
fournit une répartition adaptée à la demande locale sur chaque nœud d'une grille
de calcul.
Sur cette base, nous proposons un modèle d'identification unique des données
de l'entrepôt reposant sur le schéma du modèle multidimensionnel associé à un
ordonnancement des membres de dimension à travers les hiérarchies. Les
identifiants logiques ainsi créés permettent de localiser tous les réplicas des
fragments de l'entrepôt réparties sur la grille. Chaque nœud de la grille recense
l'ensemble des données matérialisées et calculables dont il dispose en
construisant un index de ces données. La structure d'index appelé index TX que
nous proposons utilise les identifiants des données matérialisées pour les
indexer selon leur niveau d'agrégation et leur position dans l'espace de données
multidimensionnel. L'index TX est constitué d'un index T qui distingue les
niveaux d'agrégation par une structure de treillis et d'un index X spatial qui
décrit la position des données dans l'espace multidimensionnel créé à l'a ide du
modèle de l'entrepôt. Les données calculables à partir des fragments d'entrepôt
matérialisés sont intégrées à cet index. L'ensemble des index TX sur les nœuds
de la grille fournit ainsi les informations sur les données de l'entrepôt
disponibles et les met à disposition des autres nœuds.
A partir du modèle et des mécanismes d'indexation introduits, nous
développons une méthode d'exécution de requêtes adaptée à un d'entrepôt
réparti sur grille. La procédure d'exécution localise les données répondant à une
requête à l'aide des informations contenues dans les index locaux et calcule les
estimations de coûts dynamiques pour obtenir les données. Ces informations
sont utilisées pour sélectionner la solution de moindre coût. Les opérations du
plan d'exécution optimisé sont ordonnancées et exécutées en parallèle sur les

1 Introduction
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 8
nœuds source sélectionnés. Cette méthode permet d'assurer une exécution
distribuée tirant profit des capacités de stockage et de calcul distribués mises à
disposition par la grille.
L'intégration du modèle et des mécanismes conçus dans l'infrastructure de grille
est rendue possible par l'architecture de services de grille GIROLAP (Grid
Infrastructure for Relational OLAP), basée sur l'infrastructure fournie par
l'intergiciel Globus Toolkit. Nous introduisons des services dédiés pour
l'indexation locale des fragments de l'entrepôt, la publication et l'échange des
informations sur les données disponibles. La gestion de l'exécution de requêtes
requiert également un service spécifique qui assure la réécriture et
l'optimisation des requêtes client. L'ensemble de ces services assure le bon
fonctionnement d'un entrepôt de données issu du projet GGM et déployé sur
grille de calcul.
4 Structure du document
Ce document est structuré en 7 chapitres : Le chapitre suivant cette introduction
est l'état de l'art exposant les travaux existants dans les domaines des entrepôts
de données et de la gestion de données distribuées sur grilles. Le chapitre 3
détaille notre modèle multidimensionnel adapté à la gestion d'entrepôts répartis
sur grille ainsi que la structure d'indexation des données multidimensionnelles
matérialisées. L'index TX que nous proposons est étendu aux agrégats
calculables, ce qui fait l'objet du chapitre 4. Au chapitre 5, nous décrivons la
méthode d'exécution de requêtes distribuée basée sur le modèle introduit
précédemment. L'architecture de services GIROLAP qui réalise et intègre les
modèles et méthodes proposés est exposée au chapitre 6 et la conclusion
générale avec les perspectives pour de futurs travaux finalement fait l'objet du
chapitre 7. En annexe A, nous présentons les algorithmes développés, l'annexe
B contient certains exemples détaillés et l'annexe C expose un scénario de test
basé sur un cas d'utilisation du projet GGM.



Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 11
Chapitre 2 État de l'art
Les systèmes décisionnels requièrent des ressources de stockage et de
traitement de plus en plus performants. Les grilles de calcul apportent de
nouvelles solutions pour l'accès décentralisé à un grand nombre de ressources
partagées. Nous présentons dans ce chapitre les principes de construction et de
fonctionnement des entrepôts de données et des outils d'analyse associés, puis
l'architecture fonctionnelle des infrastructures de grille de calcul. Nous
décrivons ensuite les travaux relatifs à la répartition d'entrepôt au sein des bases
de données distribuées avant de présenter les diverses approches existantes pour
la mise en œuvre d'entrepôts de données distribués sur grilles.
1 Entrepôts de données et OLAP
Les systèmes d'aide à la décision se fondent généralement sur l 'analyse
statistique des données accumulées par les systèmes d 'information de
production. Cependant, ces grands volumes, gérés par des SGBDs classiques,
ne sont pas optimisés pour la lecture massive de données et leur modèle de
stockage reste peu propice au calcul rapide d'indicateurs synthétiques
représentatifs des connaissances recherchées. Les concepts d 'entrepôt de
données et d'analyse OLAP (OnLine Analytical Processing) sont ainsi nés de la
nécessité d'isoler et de tenir à disposition les données pertinentes pour une
analyse approfondie de données issues des systèmes d'information de
production.
1.1 Fondements
W.H. Inmon définit le concept d'entrepôt de données en 1992 comme « une
collection de données intégrées, non volatiles et historisées , support de la prise
de décisions » (Inmon, 1992). Un entrepôt de données doit permettre de gérer
d'importants volumes de données issues de systèmes d'information en
production, afin de les mettre à disposition d'outils d'aide à la décision.
Cet objectif nécessite de réorganiser les données par rapport à leur organisation
dans les bases de données classiques qui sont, elles, conçues pour traiter
efficacement les transactions d'ajout ou de mise à jour ainsi que les
consultations d'enregistrements au quotidien selon le paradigme OLTP (OnLine
Transaction Processing). Le chargement des données dans l 'entrepôt est effectué
par un processus complexe d'extraction, de transformation et de transfert (ETL -
Extract, Transform, Load) qui assure la qualité et la cohérence des données
extraites tout en les intégrant au schéma de l 'entrepôt. Il est généralement
effectué de façon périodique et incrémentielle, c'est-à-dire que les données
détaillées existantes dans l'entrepôt ne sont pas modifiées. L'analyse des
données est assurée par des outils d'analyse en ligne OLAP. Comme l'illustre le
tableau comparatif en figure 2.1, les caractéristiques des applications OLAP

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 12
sont fondamentalement différentes de celles des applications OLTP. De ce fait,
la modélisation des données pour les applications OLAP doit s'appuyer sur un
modèle spécifique. Ce modèle est appelé modèle multidimensionnel.
OLTP OLAP
Stockage de données principal pour
un système d'information de
production
Stockage consolidé, extrait
principalement des bases OLTP
Usage opérationnel pour le contrôle
et l'exécution de tâches au quotidien
Usage pour la planification, l'analyse
de projets et l'aide à la décision
Vue instantanée sur l'état du système
d'information
Vues historisées et adaptées selon les
critères d'analyse
Requêtes sur peu d'enregistrements,
mises à jour fréquentes et de petite
taille
Requêtes sur sous-ensembles
importants, mises à jour rares et
importantes
Partie en exploitation de taille
réduite, grands volumes uniquement
dans les archives
Grands volumes regroupant les
données historiques et leurs agrégats
consultables par clients
Structure en grand nombre de tables
normalisées
Structure en étoile, flocon ou
constellation de tables non
normalisées
Figure 2.1 : Comparaison entre systèmes OLTP et OLAP (Kelly, 1997)
1.2 Le modèle multidimensionnel
L'introduction de douze règles définissant les fonctionnalités des systèmes
OLAP par E. F. Codd en 1993 (Codd et al., 1993) marque le début du succès
des outils d'aide à la décision basés sur les entrepôts de données. Parmi les
exigences mises en avant, on note en particulier l 'interactivité et la liberté
offerte à l'analyste pour adapter la vue sur les données sans dégradation des
performances. Pour cela, un entrepôt de données est organisé selon un modèle
multidimensionnel de données. Celui-ci est défini par des axes d'analyse
nommés « dimensions » et par des objets d'analyse, nommés « faits » et
quantifiés par des « mesures ». Cette structure multidimensionnelle favorise
l'interrogation par un outil OLAP et offre à l 'utilisateur une navigation
interactive orientée selon les dimensions définies au sein de l 'entrepôt.
1.2.1 Dimensions et hiérarchies de dimension
Au niveau conceptuel, une dimension désigne un axe d'analyse qui oriente les
requêtes en leur donnant la possibilité d'obtenir une vue différenciée sur les
données de l'entrepôt suivant les critères d'analyse fournis par la dimension.
Dès la conception d'un entrepôt de données, le modèle multidimensionnel fixe
ainsi les possibilités de l'analyse en ligne.
Les dimensions d'un modèle multidimensionnel sont constituées de niveaux
hiérarchiques distincts. Les liens entre niveaux peuvent avoir des cardinalités

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 13
différentes qui caractérisent les relations entre leurs éléments, i.e. les
« membres » de dimension. Ces niveaux correspondent aux différents niveaux
de détail qu'il est possible d'obtenir à partir des données gérées par l'entrepôt.
Cette structure hiérarchisée forme la base de la navigation OLAP dans une
dimension et représente le « schéma de la dimension ». L'ensemble des
membres d'une dimension et des liens entre les membres forment « l'instance de
dimension ».
L'étude des différents types de hiérarchies et de leur gestion est le sujet de
nombreux travaux. Ainsi, (Pedersen et al., 1999) et (Malinowski et al., 2006)
définissent la classification suivante :
- Hiérarchies explicites : Ce type de hiérarchie est décrit explicitement par un
schéma de niveaux hiérarchiques.
- Hiérarchies multiples : Une hiérarchie multiple comporte plusieurs niveaux
alternatifs qui ne sont pas reliés par des liens de filiation directs, ce qui crée
plusieurs chemins au sein du schéma de la hiérarchie.
- Hiérarchies couvrantes : A chaque niveau de ce type de hiérarchie, les
membres couvrent l'ensemble des données de l'entrepôt. Il n'existe donc
aucun lien de filiation direct qui « saute » un niveau.
- Hiérarchies non-onto : Il existe dans la hiérarchie certains membres qui,
sans se trouver au niveau le plus détaillé de la hiérarchie, n'ont pas de
descendants.
- Hiérarchies strictes : Au sein d'une hiérarchie stricte, il ne peut pas exister
de relation de plusieurs à plusieurs entre les membres reliés par des liens de
filiation.
Cette classification des types de hiérarchies de dimension est basée aussi bien
sur la définition de la hiérarchie de dimension exprimée par son schéma que sur
l'instance de dimension composée des membres de cette dimension. Les classes
de hiérarchies introduites ne sont donc ni exhaustives, ni mutuellement
exclusives. Il s'agit de fournir des notions qui caractérisent les irrégularités
présentes au sein des hiérarchies de dimension. Les hiérarchies non couvrantes,
non-onto et/ou non strictes sont difficiles à gérer par les systèmes OLAP à
cause de leurs structures complexes. Il existe ainsi plusieurs méthodes de
« normalisation » qui permettent de transformer les hiérarchies irrégulières afin
de faciliter leur traitement. Un exemple de ces méthodes décrites par (Pedersen
et al., 1999) et (Malinowski et al., 2006) est présenté par l'exemple 2.1.
Exemple 2.1 : Normalisation d'instances de dimension irrégulières
La dimension « lieu » comporte une ville au niveau le plus détaillé, une région
et un pays aux niveaux plus élevés de la hiérarchie. La figure 2.2 représente son
schéma et une instance de cette dimension matérialisée par un entrepôt.

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 14
France
Rhône Alpes PACA Piémont
Bourg-en-Bresse GrenobleLyon St Etienne MarseilleNice Toulon Alexandrie NovareTurin
Italie
ALL
ville
région
pays
all
schéma instance
dimension « lieu »
Figure 2.2 : Schéma et instance de la dimension « lieu de naissance »
Le schéma est défini explicitement et ne comporte qu'un seul chemin, il s'agit
donc d'une hiérarchie non multiple. Au niveau de l'instance, chaque membre de
dimension n'est associé qu'à un seul père situé sur le niveau hiérarchique
directement supérieur. La hiérarchie est donc également stricte et comme le
montre la figure 2.2, elle est aussi couvrante et « onto ».
La dimension « pathologie », extraite de la classification internationale des
maladies (World Health Organization, 2008) nécessite quant à elle une
normalisation. En effet, l'instance de cette dimension présentée en figure 2.3 est
non-onto et non couvrante.
ALL
maladies du système nerveux maladies respiratoires
instance de la dimension « pathologie »
méningite
maladie d'A
lzheimer
maladie de P
arkinson
sclérose latérale amyot.
sclérose en plaques
épilepsie
pneumonie
grippe
BPCO
bronchite, emphysèm
e et asthme
bronchite et emphysèm
e
asthme
all
pathologie oufamille de path. 3
pathologie oufamille de path. 2
pathologie oufamille de path. 1
pathologie
schéma
Figure 2.3 : Schéma et instance non normalisée de la dimension « pathologie »
Sur les niveaux insuffisamment remplis pour former un arbre balancé, la
normalisation ajoute des membres médiateurs copies des membres des niveaux
inférieurs selon les recommandations faites par (Malinowski et al., 2006). La
normalisation de l'instance permet l'obtention d'une dimension onto et
couvrante, illustrée par la figure 2.4.

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 15
ALL
maladies du système nerveux maladies respiratoires
méningite
maladie d'A
lzheimer
maladie de P
arkinson
sclérose latérale amyot.
sclérose en plaques
épilepsie
pneumonie
grippe
BPCO
bronchite, emphysèm
e et asthme
bronchite et emphysèm
e
asthme
méningite
maladie d'A
lzheimer
maladie de P
arkinson
sclérose latérale amyot.
sclérose en plaques
épilepsie
pneumonie
grippe
méningite
maladie d'A
lzheimer
maladie de P
arkinson
sclérose latérale amyot.
sclérose en plaques
épilepsie
pneumonie
grippe
all
niveau 3
niveau 2
niveau 1
niveau 0
schéma instance
dimension « pathologie »
Figure 2.4 : Schéma et instance normalisée de la dimension « pathologie »
La normalisation d'une hiérarchie de dimension améliore les performances des
requêtes OLAP sans pour autant modifier la table de faits du schéma en étoile.
1.2.2 Faits, mesures et agrégats
Le concept de fait désigne l'objet de l'analyse en ligne. Un fait est un concept
relevant du processus décisionnel, il modélise souvent un ensemble
d'événements d'une organisation. Un fait est constitué d'un ensemble de valeurs
associées aux différentes mesures disponibles. Les mesures sont le plus souvent
numériques et on leur assigne une fonction d'agrégation. Ces fonctions
permettent de calculer les mesures aux différents grains des hiérarchies de
dimension à partir des données détaillées. Par exemple, un fait dans un entrepôt
contenant des informations sur une chaîne de magasins peut regrouper des
mesures représentant le nombre d'unités vendues et le prix d'un produit vendu
dans un magasin et à une date donnée. Le nombre d'unités vendues pour une
région et/ou pour une année est agrégé par la fonction « SUM » qui fournit la
somme des ventes de tous les magasins de la région et/ou des mois de l'année.
Le prix est agrégé par la fonction « AVG » qui fournit la moyenne des prix.
Comme le précise (Blaschka et al., 1998), certaines mesures peuvent être
calculées à partir des mesures existantes. Ces mesures, nommées mesures
dérivées, sont définies sous forme de formules appliquées aux valeurs des
mesures contenues dans la table de faits. Par exemple, le chiffre d'affaires des
magasins pour un produit donné peut être calculé en multipliant le prix du
produit avec le nombre d'unités vendues.

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 16
1.2.3 Représentation d'un modèle multidimensionnel
Dans (Malinowski et al., 2006), les auteurs présentent une notation appelée
MultiDimER, inspirée par les travaux antécédents de (Tsois et al., 2001)
(Tryfona et al., 1999) et (Sapia et al., 1999), pour décrire un modèle
multidimensionnel. Nous utiliserons une notation inspirée de MultiDimER pour
les modèles multidimensionnels présentés dans ce document. Les principaux
éléments de la notation MultiDimER sont illustrés en figure 2.5.
Figure 2.5 : Notation inspirée de MultiDimER pour la description des modèles
multidimensionnels d'entrepôts
A l'aide de ces éléments de modélisation, il est possible de construire une
représentation graphique conceptuelle des modèles multidimensionnels.
1.2.4 Hypercube et treillis de cuboïdes
L'instance d'un modèle conceptuel multidimensionnel est un « hypercube ». Un
hypercube OLAP représente les mesures détaillées et agrégées dans un espace
multidimensionnel formé par les différentes dimensions du modèle.
L'hypercube de base se situe aux niveaux hiérarchiques les plus détaillés dans
les hiérarchies de dimension. La combinaison de membres des dimensions
sélectionnés forme un ensemble de coordonnées qui désigne une cellule de
l'hypercube. Chaque cellule contient les valeurs de mesures correspondant à la
combinaison de membres (figure 2.6).

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 17
55
22
4 7 14 7 1
mar 04
Lo
cali
sati
on
Temps
Produits
Micros
GS
Standa
Carebim
Alc54
Alc23
Asp 3
21
St 73
fev 04
jan 04
12 5 212 5 2Upim
50
400
67
135
54
468
23
200
50
400
67
135
54
468
23
200 …
7
50
15
150
25
140
7
45
14
48
12
9012
90
20
210
11
120
7
50
15
150
25
140
7
45
14
48
12
9012
90
20
210
11
120
28
200
35
150
8
120
12
80
…
…
…
…
…
…
…
…
…
…
Lyon
Paris
2004
Télép
hone
Ord
inat
eur
« Combien de
Alc 54 ont été
vendus par
Standa en Mars
2004 ? »
« Combien de produits ont été
vendus en Février 2004 ? »
« Combien de produits ont été
vendus au total ? »
Figure 2.6 : Hypercube à trois dimensions
L'algèbre OLAP, introduite par (Codd et al., 1993), définit les opérateurs
permettant la navigation à travers les cellules et entre les membres et les
niveaux des différentes dimensions. Les opérateurs standards sont :
- « slice », qui sélectionne un sous-ensemble de l'hypercube réduit à un
ensemble de membres sur une ou plusieurs dimensions,
- « dice », qui réduit l'hypercube d'une ou plusieurs dimensions,
- « roll-up », qui consiste à remonter d'un niveau dans une hiérarchie de
dimension vers un niveau plus agrégé,
- « drill-down », qui consiste à descendre dans une hiérarchie de dimension
vers un niveau plus détaillé.
On appelle cuboïde une vue définie par un niveau hiérarchique pour chaque
dimension. Les cuboïdes doivent être calculés et stockés à l'avance pour assurer
de bonnes performances. Les cuboïdes OLAP sont organisés en treillis, présenté
en figure 2.7, où ils sont représentés par des sommets reliés par des arêtes
indiquant le passage d'un niveau d'agrégation à un autre sur une dimension.
Introduit par (Harinarayan et al., 1996) et (Agarwal et al., 1996), le treillis
d'hypercubes représente l'ensemble des agrégats qu'il est possible d'obtenir à
partir d'un hypercube de base donné. (Harinarayan et al., 1996) définissent un
ordre partiel sur le treillis afin d'obtenir un graphe orienté acyclique. Ainsi, si
les données d'un cuboïde suffisent à répondre à une requête, alors les données
de ses ancêtres dans le treillis, qui représentent des données plus détaillées,
suffisent également à répondre à cette requête.

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 18
(pathologie, date, ville)
(pathologie, date, région)(pathologie, mois, ville)(famille, date, ville)
(famille, mois, ville) (famille, date, région) (pathologie, année, ville) (pathologie, mois, région) (pathologie, date, pays)
(famille, année, ville) (famille, mois, région) (famille, date, pays) (pathologie, année, région) (pathologie, mois, pays)
(famille, année, région) (famille, mois, pays) (pathologie, année, pays)
(famille, année, pays)
Figure 2.7 : Treillis de cuboïdes OLAP pour 3 dimensions hiérarchisées
Un grand nombre de travaux utilise les relations et dépendances entre les
agrégats représentés par le treillis des cuboïdes. En termes de stratégies de
matérialisation, (Kimball, 1996) privilégie le pré-calcul complet de tous les
cuboïdes. Une sélection devient cependant indispensable au-delà d'un certain
volume de données entreposées. (Ullman, 1996) donne un aperçu des
différentes méthodes visant à la sélection des cuboïdes à matérialiser.
(Harinarayan et al., 1996) introduisent un algorithme de type glouton qui
sélectionne les vues à matérialiser en tenant compte de leur bénéfice, c'est -à-
dire de leur potentiel à répondre aux requêtes portant sur leurs descendants dans
le treillis. (Shukla et al., 1998) et (Baralis et al., 1997) reprennent le principe de
la mesure de bénéfice pour développer des heuristiques basées sur la notion de
chemins dans le treillis sur lesquels se trouvent les vues à matérialiser. Le
problème fait toujours l'objet de nombreuses recherches, notamment en utilisant
des techniques de fouille de données pour déterminer les vues à matérialiser
(Aouiche et al., 2006).
1.3 Architecture fonctionnelle d'un système OLAP
Les ressources matérielles et logicielles pour l'exploitation d'un entrepôt sont
conçues en fonction de la structure des hypercubes, du nombre et de l'activité
des applications clientes qui soumettent des requêtes OLAP à l'entrepôt. Les
différents modèles pour bases de données OLAP sont décrites par (Vassiliadis
et al., 1999), les solutions architecturales sont recensées par (Chaudhuri et al.,
1997). L'architecture la plus répandue est une architecture trois tiers telle
qu'illustrée par la figure 2.8.

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 19
1.3.1 Architecture trois tiers
Les systèmes décisionnels s'appuient sur une architecture trois tiers telle
qu'illustrée par la figure 2.8. Le tier présentation représente l'interface client qui
assure la fonction d'entrée des requêtes client et de présentation du résultat de
ces requêtes. La logique de l'application est assurée par le moteur OLAP qui
gère la construction de l'hypercube et l'exécution des opérations OLAP.
Figure 2.8 : Architecture d'un système OLAP
Le premier tier est un SGBD. Les données pertinentes pour l'analyse sont
extraites des bases de données transactionnelles, nettoyées et transformées avec
les outils ETL et intégrées dans un entrepôt de données maintenu par le SGBD.
Le SGBD contient aussi un ensemble de métadonnées concernant les sources de
données, les mécanismes d'accès, les procédures de nettoyage et d'alimentation,
les utilisateurs, etc. Le deuxième niveau de l'architecture est un serveur OLAP,
tels que par exemple Mondrian, DB2 Olap Server, Oracle OLAP ou Microsoft
Analysis Services. Le serveur OLAP génère et maintient l'hypercube. Il fournit
une vue multidimensionnelle des données et implémente l'ensemble des
opérateurs OLAP (Roll-Up, Drill-Down, etc.) permettant de les analyser. Le
dernier niveau est un client OLAP, par exemple Microstrategy, Cognos, JPivot
etc. Le client offre une interface utilisateur composée d'outils de reporting,
d'analyse interactive, et parfois de fouille de données. Son rôle est de rendre
l'information multidimensionnelle « visible » (figure 2.9), en d'autres termes, de
permettre de découvrir des connaissances grâce à la seule visualisation et
interaction avec les données.

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 20
Figure 2.9 : Exemples de Clients OLAP
1.4 Modèles de stockage
Nous présentons ci-dessous les différents modes de stockage utilisés pour
maintenir les données entreposées (premier tier) et les données de l'hypercube
gérées et stockées par le serveur OLAP (deuxième tier).
1.4.1 Stockage des données de l'entrepôt
Nous illustrons le modèle de stockage à l'aide d'un entrepôt conçu pour analyser
les ventes d'une chaîne de magasins. Le modèle conceptuel MultiDimER de la
vue orientée « ventes » de l'entrepôt est illustré par la figure 2.10.
VENTES
Produit
Code_produit
Nom_produit
Montant : SUM
Volume : SUM
ProduitType de produit
Code_type
Nom_type
Jour
Date
Jour_semaine
Temps
Mois
Code_mois
Nom_mois
Année
Année
Magasin
Code_magasin
Nom_magasin
Adresse_magasin
LieuRégion
Code_région
Nom_région
Pays
Code_pays
Nom_pays
Figure 2.10 : Modèle MultiDimER d'une vue orientée « ventes » sur un entrepôt
Le modèle de stockage d'entrepôt dit « en étoile » (star schema) a été introduit
par Kimball (Kimball, 1996). Ce schéma comporte une seule relation centrale
qui relie l'ensemble des dimensions avec un ensemble de mesures unique. Cette
forme est considérée comme la forme de base sur laquelle sont fondées les

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 21
structures de modèles plus complexes. Le modèle en étoile est constitué d'une
table de faits centrale contenant les données les plus détaillées de l'entrepôt
correspondant à la table de fait VENTES dans la figure 2.11. Dans cette table,
les mesures associées au fait VENTE apparaissent comme attributs. Les tuples
de la table de faits sont liés via des clés étrangères à des tables de dimensions.
Dans la figure 2.11, les tables Temps, Localisation et Produit correspondent aux
trois dimensions du modèle. Contrairement aux bases de données OLTP où la
3ème
forme normale (3NF) est préconisée, les tables de dimension sont stockées
sous forme dénormalisée.
Figure 2.11 : Schéma en étoile de l'entrepôt « ventes »
Le modèle dit « en flocon » (snowflake schema) (Kimball, 1996) est illustré par
la figure 2.12 et représente une extension du schéma en étoile permettant de
mieux maîtriser la taille des tables de dimension. Les tables de dimension sont
normalisées et l'information devra être reconstituée par jointure.
Figure 2.12 : Schéma en flocon de l'entrepôt « ventes »

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 22
Le modèle dit « en constellation » (Kimball et al., 1998) est illustré en
figure 2.13, et permet de regrouper plusieurs tables de fait qui partagent toutes
ou une partie de leurs dimensions. Outre le fait de mutualiser les tables de
dimensions de l'entrepôt de données associées à différents faits, ce modèle met
également en évidence les liens entre les perspectives d 'analyse existantes pour
l'interrogation de l'entrepôt. Les constellations complexes, incluant notamment
des hiérarchies multiples associées à plusieurs perspectives, peuvent être gérées
par des modèles basés sur la définition de contraintes (Ghozzi et al., 2003).
Figure 2.13 : Schéma en constellation de l'entrepôt « ventes »
1.4.2 Stockage des données de l'hypercube
Il existe trois modes de stockage pour les données de l'hypercube. Le mode de
stockage le plus ancien qui a fortement influencé bon nombre de modèles
conceptuels est le « Relational OLAP », ou ROLAP. Il utilise un SGBD
relationnel et organise les données au sein de relations correspondant aux tables
du schéma de stockage en étoile. Ce modèle de stockage nécessite de
transformer les opérations sur les hypercubes vers des requêtes sur le schéma de
stockage en étoile. Ces requêtes ont une structure complexe pouvant notamment
inclure un grand nombre d'opérations de jointure. L'améliorer des performances
de ces requêtes dépend fortement de l'indexation des relations contenant les
données multidimensionnelles et des agrégats matérialisés. De nombreuses
solutions existent pour la problématique de l'indexation (Gupta et al., 1997).
Les index bitmap ont été utilisés dès les débuts (Chan et al., 1999), (O'Neil et
al., 1997), complétés par les index multidimensionnels tels les R-tree, UB-tree
et Cubetree (Kotidis et al., 1998), (Ramsak et al., 2001), (Sarawagi, 1997). Ces
approches ont depuis été développées pour inclure notamment la sélection
intelligente des index pertinents (Aouiche et al., 2005), (Qiu et al., 2001). Le
traitement des requêtes dites « Iceberg », nécessitant l'agrégation de grandes

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 23
parties de faits, a donné lieu à des travaux alliant la matérialisation d'agrégats à
l'indexation (Beyer et al., 1999), (Fang et al., 1998). Afin de s'affranchir
entièrement du modèle relationnel, pour le stockage des agrégats matérialisés
pour obtenir de meilleurs temps d'accès, de nombreuses approches ont
développé des structures de stockage multidimensionnelles.
Le stockage « Multidimensional OLAP » (MOLAP) (Vassiliadis et al., 1999)
matérialise les agrégats dans des structures multidimensionnelles à l 'image de
l'hypercube. Les solutions existantes sont basées sur des tableaux
multidimensionnels hébergeant les cellules des hypercubes dans des structures
spécialisés, parfois nommées SGBDs multidimensionnels (Agrawal et al.,
1997). Ce type de structure, réalisée par les Cubetree (Roussopoulos et al.,
1998), Dwarf (Sismanis et al., 2002), CubiST (Hammer et al., 2003) ou CUBE
File (Karayannidis et al., 2004), offrent de meilleures performances grâce à une
méthode de compression spécifique visant à ne stocker que les cellules non
vides des cuboïdes creux (« sparse cubes »). Ces approches visent également à
diminuer les coûts de mise en œuvre en limitant le nombre d'agrégats
matérialisés et la réorganisation de la structure en cas de mise à jour. Les
méthodes de mises à jour incrémentales des hypercubes MOLAP, notamment
celle présentée par (Lee et al., 2006), ont connu des progrès substantiels grâce à
l'optimisation de la gestion des mises à jour sur chaque cuboïde.
Le stockage « Hybride OLAP » (HOLAP) se veut une combinaison de la
puissance des SGBDs relationnels avec la rapidité des structures
multidimensionnelles. Selon (Moorman, 1999), il s'agit de garder les grands
volumes de données détaillées dans la partie ROLAP du système, car celle -ci
présente de meilleures performances pour la gestion des grands volumes et
intègre plus facilement les mises à jour incrémentales de l'entrepôt. La partie
MOLAP du système permet un accès plus rapide aux données fréquemment
consultées et stocke donc les cuboïdes contenant les agrégats matérialisés.
L'optimisation des performances HOLAP est étudiée par (Kaser et al., 2003),
qui proposent une optimisation du stockage de l'hypercube OLAP spécialement
adapté au stockage HOLAP et (Luk et al., 2004), qui introduisent une méthode
de pré-calcul d'agrégats respectant les contraintes d'espace de stockage
spécifiques au HOLAP.
Le principal défi de l'entreposage de données reste de garder rapidement
accessible et à jour un important volume de données détaillées ainsi que leurs
agrégats. Les différentes solutions structurelles et architecturales apportées à ce
problème ont permis des avancées considérables. Ces solutions font de plus en
plus souvent appel aux fonctionnalités offertes par des systèmes distribués,
capables de partager et de paralléliser le stockage et les divers traitements
nécessaires à l'exploitation d'un entrepôt. Parmi les systèmes distribués, le
concept récent des grilles de calcul est d'un intérêt particulier pour fournir des
ressources de stockage et de traitement à grande échelle.

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 24
2 Les grilles de calcul
Le développement des systèmes distribués est motivé par le besoin croissant
d'importantes capacités de traitement qui ne peuvent être obtenues par un
système unique centralisé. Les supercalculateurs récemment construits sont
quasiment sans exception des systèmes faits d'une multitude d'unités de calcul
identiques traitant de façon autonome une partie d'applications hautement
parallèles. Les unités de traitement peuvent être des PCs standard reliés à un
réseau local haut débit et contrôlés par une ou plusieurs unités centrales. Ces
systèmes nommés « grappes » ou « clusters » sont fréquemment employés pour
tous types de calculs distribués. L'approche de la grille de calcul est de rendre
accessibles les ressources de plusieurs de ces clusters, de PCs individuels ou
d'autres ressources hétérogènes via un réseau étendu.
2.1 Définition
Une infrastructure de grille de calcul est constituée de nœuds dispersés
géographiquement et reliés par un réseau étendu. Les ressources de stockage, de
transfert réseau et de capacité de calcul peuvent varier fortement d'un nœud à
l'autre et dans le temps. L'objectif d'une grille de calcul est donc l'utilisation
optimale des ressources disponibles au sein de réseaux informatiques
hétérogènes par une exploitation coopérative et contrôlée. Dans la première
édition de « The Grid: Blueprint for a New Computing Infrastructure » (Foster
et al., 1998), I. Foster et C. Kesselman définissent une grille comme « [..] une
infrastructure matérielle et logicielle qui fournit un accès fiable, consistant,
pervasif et peu coûteux à des capacités de traitement de haut niveau ». Suite à
de nombreuses interprétations du terme, (Foster, 2002) ajouta une liste de
points caractéristiques des « véritables » systèmes de grille. Ainsi, une grille :
- coordonne des ressources qui ne sont pas contrôlées d'une manière
centralisée et intègre ainsi des ressources de différentes organisations ou
institutions indépendantes comme par exemple les ordinateurs personnels
ou les ressources de traitement centralisées d'une entreprise,
- utilise des protocoles et interfaces standardisées, ouvertes et d'usage
universel,
- fournit une qualité de service « non triviale » aux applications clientes,
c'est-à-dire que les ressources partagées au sein d'une grille sont utilisées
d'une façon coordonnée pour fournir une qualité de service supérieure en
ajoutant par exemple des contraintes en terme de disponibilité et de
sécurité.
Ces propriétés mènent à la définition d'une architecture de services de référence
pour les infrastructures de grille.
2.2 Infrastructure de grille
L'infrastructure de grille est constituée de l'ensemble des ressources intégrées à
la grille ainsi que la partie intergiciel rendant accessible ces ressources aux
applications clientes. L'architecture caractéristique déployée sur cette

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 25
infrastructure est une architecture de services regroupés en couches superposées
(Foster et al., 2003), illustrée par la figure 2.14. Cette architecture reflète les
conventions à la base du premier effort de standardisation des infrastructures de
grilles par le « Open Grid Services Architecture » (OGSA), initiée par (Foster
et al., 2002). Les couches de l'infrastructure sont déterminées par les
caractéristiques des protocoles utilisés pour communiquer entre services de
grille. La couche de base, le « tissu » (« fabric ») de la grille met à disposition
les ressources physiques de stockage, de puissance de calcul et de capacité de
transfert. Les services de grille instaurent un accès partagé à ces ressources
pour les applications. Le partage de ces ressources par leurs « propriétaires »
représente le fondement qui assure le fonctionnement de la grille. Les services
mis à disposition par la couche de connectivité (« connectivity ») ajoutent à ce
fondement les fonctionnalités relatives au transport, routage et nommage
communes aux architectures de réseau, mais aussi des services spécifiques
d'authentification et de délégation intégrées aux solutions de sécurisation
locales. Les services de cette couche rendent ainsi accessible à distance les
ressources partagées de la grille depuis les autres systèmes intégrés à la grille et
depuis n'importe quel système client relié au réseau.
La gestion des ressources disponibles et leur surveillance est assurée par la
couche « ressources », qui représente donc une vue d'ensemble sur la grille.
Cette couche regroupe les services fournissant des protocoles d'information sur
la structure et l'état actuel des ressources et les protocoles de gestion et de
négociation d'accès. Afin de concilier les politiques de sécurité et de gestion
des ressources hétérogènes au sein d'une grille, les « nœuds » de la grille sont
répartis en organisations virtuelles (« virtual organisation », VO), présentées
par (Foster, 2001), dont la gestion est confiée aux services de la couche
« collective ». Les services de cette couche sont dédiés à la gestion de
l'exploitation des ressources partagées de la grille en faisant abstraction de leur
localisation physique et de leurs modalités de fonctionnement.
Figure 2.14 : Architecture de services en couches d'une grille

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 26
L'ensemble de ces services comprend les services d'annuaire, de surveillance et
de diagnostic des ressources, ainsi que les fonctionnalités d'allocation de
ressources et d'ordonnancement réparti. Cette couche gère également la
politique de sécurité commune à la VO, au même titre que tout autre service
relatif à la collaboration des composants de la VO, que ce soit la gestion de la
charge ou la réplication des données. A partir de cette architecture générale, les
infrastructures de grilles existantes ajoutent ou modifient des fonctionnalités
afin de s'adapter aux applications visées. Nous distinguons ici deux catégories
de travaux autour des grilles, les travaux orientés vers les applications et les
traitements, et les travaux orientés vers la gestion des données.
Les premiers travaux sur les infrastructures de grilles ont porté sur les aspects
traitement. La grille de calcul est née du constat que l'exploitation des
ressources mises en place dans le cadre de supercalculateurs souffrait de leur
isolement au sein de réseaux soumis à des politiques de sécurité et d'accès très
restrictives. L'intégration de ces grappes dans une infrastructure de grille
permet de bénéficier de leur puissance cumulée via une interface standardisée.
Ce type de mutualisation des ressources offre également un accès à distance et
une meilleure répartition des charges. De nombreuses infrastructures ont été
réalisées selon ces principes, notamment le projet national Grid5000 décrit par
(Cappello et al., 2005) et le projet nord-américain Teragrid présenté par (Reed,
2003). Ces approches mettent l'accent sur les calculs distribués, en contraste
avec les solutions centrées sur le stockage distribué des données.
Les infrastructures de grille qui l'intéressent la gestion des données et des
requêtes sont nommées « grilles de données » (data grids). Un exemple de ce
type de grille a été proposé dans le cadre du projet européen European DataGrid
(EU DataGrid, 2004), (Gagliardi et al., 2002), destiné à gérer les énormes
volumes de données produits par les expériences de physique des particules du
CERN (http://www.cern.ch). Les résultats obtenus par le projet DataGrid ont
été généralisés à de nouvelles applications, par exemple bioinformatiques, dans
le cadre du projet « Enabling Grids for E-sciencE » (EGEE project, 2008),
(Gagliardi, 2004). De nombreux travaux ont été effectués sur la gestion des
données au sein du projet EU DataGrid (Cameron et al., 2004), en particulier
sur la gestion des réplicas de fichiers stockés sur plusieurs nœuds de la grille.
Le transfert fiable et rapide de ces données fait également l'objet de travaux
approfondis, comme les mécanismes de transfert parallélisés présentés par
(Allcock et al., 2002). Les problématiques de gestion de données sur grille sont
également liées aux différentes façons d'intégrer des sources de données dans
l'infrastructure de grille.
2.3 Intégration de données
Une grille propose aux applications clientes une vue sur les ressources de calcul
à un niveau d'abstraction élevé par rapport aux mécanismes d'exécution mis en
place au niveau physique. La répartition des tâches de calcul soumises à la
grille nécessite un accès aux données sur lesquelles s'effectuent les calculs
depuis l'ensemble des nœuds impliqués. Comme les applications clientes
n'utilisent qu'une partie des données accessibles sur la grille, elles doivent

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 27
pouvoir localiser et sélectionner les données utiles. La façon dont les données
sont mises à disposition sur la grille dépend fortement des volumes de données
concernés, des ressources de stockage disponibles, du type d'accès et des
contraintes en termes de mise à jour et de sécurité. En fonction de ces
paramètres, deux approches différentes peuvent être appliquées : la médiation
qui offre un accès transparent à des données stockées en dehors de la grille et la
répartition combinée avec la réplication qui maintient une ou plusieurs copies
des données hébergées par les ressources de stockage intégrées à la grille.
2.3.1 L'approche médiation
La médiation consiste à introduire une couche d'abstraction au dessus de la
matérialisation des données sur le médium de stockage. Il s'agit de présenter
une interface indépendante du format ou de la localisation des données. Comme
le montre la figure 2.15, (Brezany et al., 2003) présentent une approche qui
introduit une structure de source de données virtuelle. Celle-ci est basée sur les
services d'abstraction de bases de données fournis par le système OGSA-DAI
(OGSA - Data Access and Integration), présentés par (Antonioletti et al., 2005).
Alors que l'architecture OGSA-DAI associe à chaque source de données une
instance du service « DataService », le médiateur offre l'accès à l'ensemble des
données via une instance unique d'un « Grid Data Mediation Service »
(GDMS). Les applications tirant profit de ce type de service sont en particulier
les applications de fouille de données comme celle introduite par (Brezany et
al., 2006), traitant d'importants volumes de données de diverses sources et
formats stockés le plus souvent par des bases de données externes à la grille.
Figure 2.15 : Architecture du service de médiation GDMS (Brezany et al., 2003)
2.3.2 L'approche répartition et réplication
La répartition combinée avec la réplication des données sur la grille n 'est pas
une approche opposée à la médiation. Elle est surtout utilisée dans le cadre de

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 28
grilles de données puisque la grille est d'abord utilisée comme une ressource de
stockage pour les données exploitées, les projets EDG et EGEE étant les
exemples les plus connus. Les données sont le plus souvent stockées sous forme
de fichiers qui sont transférés vers les nœuds effectuant les calculs. Afin
d'améliorer la disponibilité des données, la répartition des données parmi les
nœuds est adaptée par des mécanismes de réplication intégrés à l'infrastructure,
comme pour le projet EDG (Cameron et al., 2004). Les méthodes de répartition
des réplicas de fichiers ont été optimisées en fonction de la demande sur chaque
nœud de la grille grâce notamment à des modèles économiques comme celui
présenté par (Carman et al., 2002). Ce modèle intègre un mécanisme d'enchères
par lequel chaque nœud obtient les données auxquelles il attribue le plus grand
bénéfice. Pour le choix de réplicas lors de requêtes, (Weng et al., 2005)
appliquent la notion de bénéfice en fonction des données utiles. Afin de
permettre une gestion transparente des réplicas, les systèmes de cache
collaboratifs tels celui introduit par (Cardenas et al., 2006) contribuent à
optimiser l'utilisation des ressources de stockage tout en maintenant un accès
rapide et fiable pour les applications clientes.
2.3.3 Bases de données sur grille
Alors que les méthodes de médiation intègrent déjà les bases de données
relationnelles ou XML en tant que sources de données, celles-ci sont rarement
hébergées par la grille. Depuis de nombreuses années, les travaux comme le
projet Spitfire (Bell et al., 2002) et OGSA-DAI ont réalisé l'adaptation des
méthodes d'accès aux bases de données pour les rendre disponibles aux
applications de grille. L'objectif de ces approches reste la mise à disposition
d'un accès uniforme vers les données de bases hétérogènes. Les solutions pour
l'exécution distribuée de requêtes sur ces sources de données intégrées aux
grilles existent également, d'abord réalisées par les systèmes hébergeant les
métadonnées pour la découverte de services sur la grille (Hoschek, 2002). La
première application destinée à l'analyse de données bioinformatiques faisant
appel à l'exécution distribuée de requêtes sur des bases de données objet
hébergées sur une grille a été réalisée par le système Polar* (Smith et al.,
2002), dont les mécanismes ont été repris et développés par les services OGSA-
DQP (OGSA – Distributed Query Processing), présenté par (Alpdemir et al.,
2003). Ces travaux sont cependant toujours orientés vers l'inclusion d'un
maximum de sources hétérogènes pour les mettre à disposition des applications
sur la grille. Le déplacement ou la réplication active de ces données tel que
pratiqué pour les données sous forme de fichiers n'est pas directement
applicable à ces solutions.
3 Entrepôts de données en environnement distribué
Traditionnellement, tous les composants de stockage et de gestion de l'entrepôt
de données sont centralisés sur un serveur. Lorsque celui-ci atteint ses limites
de capacité, la solution consiste le plus souvent à dupliquer et déléguer les
fonctionnalités de stockage et de traitement. Cela se traduit par l 'emploi de
systèmes distribués qui implémentent la parallélisation des calculs et le
stockage distribué des données. Nous distinguons les approches qui appliquent

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 29
et développent les mécanismes établis dans les systèmes de bases de données
distribuées dédiés aux entrepôts de données et les approches qui visent à
construire et exploiter des entrepôts sur les infrastructures de grille partagées et
décentralisées. Les sections suivantes décrivent en premier l'aspect commun
aux deux approches qui est la fragmentation et la répartition d'un entrepôt sur
un système distribué, pour ensuite traiter les problématiques spécifiques à
chaque approche.
3.1 Fragmentation d'un entrepôt
La problématique commune aux approches pour la réalisation d'entrepôts sur
systèmes distribués classiques concerne la fragmentation et le placement des
données de l'entrepôt. Le placement a fait l'objet de travaux (Hua et al., 1990),
(Mehta et al., 1997) ayant pour objectif d'améliorer la disponibilité des données
en fonction de la charge et de la demande. En amont du processus de
placement, il est nécessaire de fragmenter les données de l'entrepôt pour
pouvoir les répartir parmi les unités de traitement du système.
Le premier objectif de la distribution du stockage d'un entrepôt de données de
grand volume est de tirer profit de l'espace de stockage mis à disposition par
une base de données distribuée, afin de répartir la charge imposée par le
traitement des requêtes, l'analyse des requêtes et les traitements d'agrégation. Il
est donc indispensable de considérer ces aspects dans le processus de
fragmentation de l'entrepôt de données précédant le déploiement de l'entrepôt
distribué.
Le partitionnement vertical consiste à diviser une table en plusieurs partitions
verticales qui regroupent chacune un ensemble d'attributs. Elle est étudiée
depuis de nombreuses années sur les tables de bases relationnelles (Navathe et
al., 1984). De nombreux travaux ont suivi portant sur le partitionnement
pertinent (Navathe et al., 1989), en particulier pour les bases de données
orientées objet (Ravat et al., 1997), (Ezeife et al., 1998) et face aux contraintes
sur le nombre de partitions générés (Son et al., 2004). A notre connaissance,
(Akinde et al., 2002) est la seule approche à employer ce type de
partitionnement à un entrepôt distribué. L'exécution de requêtes sur un tel
entrepôt engendre cependant un grand nombre d'opérations de jointure très
coûteuses.
Le second principe de découpage est celui du partitionnement horizontal. Cette
méthode consiste à diviser une table en partitions de plusieurs tuples complets.
La division est faite à partir d'un ensemble de requêtes associées à un groupe
d'utilisateurs. Lorsque le partitionnement introduit de la redondance et des
partitions de taille différentes, on parle plutôt de fragmentation horizontale.
L'objectif de la fragmentation des tables de l'entrepôt de données est d'isoler les
parties de l'entrepôt ayant des probabilités d'accès différentes. En effet, le fait
de regrouper les données correspondant à un ensemble de requêtes similaires
permet de limiter les temps de recherche et d'améliorer la gestion des mémoires
cache en fonction de la fréquence d'accès. Les fondations des méthodes de
fragmentation horizontale d'entrepôts de données sont le partitionnement

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 30
appliqué aux bases de données relationnelles, proposées par (Ceri et al., 1982)
et (Özsu et al., 1991). A partir de ces mécanismes, les travaux présentés par
(Bellatreche et al., 1999), (Bellatreche et al., 2000) et (Noaman et al., 1999)
introduisent la fragmentation des tables d'un schéma en étoile par fragmentation
horizontale dérivée sur la table de faits.
Chacune des méthodes de fragmentation prend en entrée un ensemble de
requêtes caractéristiques sur l'entrepôt de données cible associé à un groupe
d'utilisateurs. La fragmentation est déterminée à partir d'une fragmentation des
tables de dimensions sur lesquelles portent les prédicats de sélection des
requêtes. Pour fragmenter les tables de dimension, il est nécessaire d'extraire et
de séparer les prédicats de sélection utilisés par les requêtes sur chaque
dimension. L'algorithme COM_MIN présenté par (Özsu et al., 1991) limite ces
prédicats à un ensemble pertinent minimal et complet. Les prédicats retenus
sont ensuite transformés en mintermes dans toutes les combinaisons possibles
de leurs formes positives et négatives. Ces mintermes sont ensuite réduits pour
éliminer par exemple les contradictions et autres combinaisons de prédicats non
pertinents. L'approche la plus élaborée et la plus complexe dans ce domaine a
été développée pour les bases orientées objet par (Bellatreche et al., 2000).
L'étape suivante consiste à déduire la meilleure fragmentation possible pour la
table de faits. L'algorithme présenté par (Noaman et al., 1999) utilise les
prédicats de l'ensemble des tables de dimensions afin de créer un nouvel
ensemble de mintermes pour la fragmentation de la table de faits. L'approche
choisie par (Bellatreche et al., 2002) sélectionne une seule des fragmentations
opérées sur les tables de dimensions pour en déduire entièrement la
fragmentation de la table de faits. Ce choix d'une fragmentation pertinente a été
optimisé à l'aide d'un algorithme génétique par (Bellatreche et al., 2005).
3.2 Politiques de placement des fragments
Le placement de fragments au sein de systèmes de bases de données a fait
l'objet de nombreux travaux (Hua et al., 1990), (Zhou et al., 1997). L'objectif
des politiques de placement proposées est de répartir équitablement la charge
parmi un ensemble de nœuds identiques. La fragmentation est alors définie en
fonction des valeurs d'un seul attribut, ce qui permet à l'instance de contrôle
centrale de localiser facilement les données et de réorganiser leur répartition
pour rééquilibrer la charge. Le placement en fonction de la demande locale sur
un ensemble de nœuds non contrôlés par une instance centrale nécessite une
méthode plus différenciée de fragmentation utilisant plusieurs attributs. A partir
des fragments obtenus par ces méthodes, la politique de placement peut être
adaptée à l'architecture du système distribué. Ainsi, P. Furtado (Furtado, 2004a)
construit un « Node-Partitioned Data Warehouse » (NPDW) sur un ensemble de
nœuds autonomes en utilisant la « Multidimensional hierarchical fragmentation
method » (MDHF) introduite par (Stöhr et al., 2000). Sur ce NPDW, (de
Carvalho Costa et al., 2006) appliquent une politique de placement visant à
placer les données au plus proche des utilisateurs de façon à maximiser leur
disponibilité tout en équilibrant la charge.

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 31
3.3 Entrepôts sur bases de données distribuées
La plupart des travaux sur les entrepôts distribués est inspirée des solutions
existantes pour les bases de données distribuées. L'objectif principal de la
répartition du traitement des requêtes et du stockage des données est
l'amélioration des performances. Il s'agit donc dans un premier temps de
systèmes de type « grappe » ou « cluster », avec un grand nombre de nœuds
« esclaves » reliés par un réseau local haut débit et contrôlés par un système
« maître » central. Les principales problématiques dans ce domaine concernent
donc l'exécution parallèle de requêtes (Abdelguerfi et al., 1998), en particulier
des opérations de jointures (DeWitt et al., 1992), (Mehta et al., 1995), (O'Neil
et al., 1995). Les données de l'entrepôt sont le plus souvent réparties en parties
de taille égale (Furtado, 2004b), avec une gestion entièrement centralisée de
leur répartition ainsi que des requêtes. La seule démarche décentralisée se
trouve dans le domaine de mémoires cache des résultats (Deshpande et al.,
1998), (Kalnis et al., 2002), développées afin de limiter la charge causée par de
nombreux clients en particulier sur le système de contrôle central.
3.4 Entrepôts sur infrastructures de grille
Pour le déploiement d'entrepôts de données sur grilles, les quelques travaux
existants se concentrent sur l'accès aux données par médiation (Fiser et al.,
2004) ou par la recherche des données sur les serveurs OLAP existants
connectés à la grille (Lawrence et al., 2006), (Niemi et al., 2003). Le caractère
hétérogène et la dispersion géographique des nœuds de grille nécessitent
également la prise en compte d'une assurance de la qualité de service (de
Carvalho Costa et al., 2006) ainsi qu'une optimisation dynamique des requêtes
en cours d'exécution par des agents mobiles (Hameurlain et al., 2002). Ces
approches prennent bien en compte le rôle de la distribution des données dans
l'efficacité de l'exécution de requêtes. Cependant elles partent du fait qu'il s'agit
d'un ensemble de sources de données hétérogènes dont la somme représente
l'entrepôt, à l'opposé de la démarche pratiquée lors du déploiement d'entrepôts
centralisés sur des bases de données réparties. La répartition en partitions de
taille égale est uniquement pratiquée par (Poess et al., 2005), dans le contexte
d'un entrepôt déployé sur des nœuds de grille « esclaves », toujours contrôlés
de façon centralisée.
Ces systèmes favorisent généralement la centralisation de l'accès à l'entrepôt
avec un contrôle global de l'exécution de requêtes. Seul les systèmes de
mémoire cache de résultat côté client comme proposés par (Deshpande et al.,
1998) autorisent une gestion plus autonome des données de l'entrepôt distribué.
Cette approche est développée dans (Deshpande et al., 2000) par l'ajout du
calcul d'agrégats à partir du contenu du cache. Kalnis et al. (Kalnis et al., 2002)
introduisent un réseau pair-à-pair entre clients pour améliorer encore la
réutilisation des données résultat de requêtes.

2 Etat de l'art
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 32
4 Discussion et conclusion
Nous avons introduit les principes à la base de l'entreposage de données et de
l'analyse OLAP avec les problématiques associées à la matérialisation des
données et de leurs agrégats par les différents modèles de stockage. Les grilles
de calcul, par leur architecture de services de grille et les nombreux travaux
réalisés pour l'intégration et la gestion des données, sont une plateforme propice
au déploiement et à l'exploitation d'entrepôts de données répartis.
Il existe peu de travaux sur l'utilisation de grilles pour l'analyse OLAP de
données multidimensionnelles. Les approches existantes se limitent le plus
souvent à la définition d'architectures pour ajouter des fonctionnalités OLAP
sur des applications de data mining (Fiser et al., 2004) ou des applications
hautement spécialisées comme l'ingénierie moléculaire faisant appel à de
grands volumes de données répartis (Dubitsky et al., 2004). (Fiser et al., 2004)
notamment proposent un module OLAP central qui construit un cube virtuel sur
les sources de données mises à disposition par un service médiateur. Il s'agit
d'une vue multidimensionnelle sur ces données hétérogènes hébergées en
dehors de la grille. Les seuls travaux comportant l'extraction de données a priori
sont ceux présentés par (Niemi et al., 2003), qui se limitent cependant à la
construction de cubes faits de données XML. La seule proposition prenant en
compte l'importance de l'optimisation de la gestion de données pour une
exploitation d'un entrepôt réparti est décrite par (Lawrence et al., 2006). La
solution développée inclut l'indexation et le partage des données mises en
mémoire cache par les nœuds de grille, mais maintient les données source sur
des serveurs OLAP extérieurs rendus accessibles depuis la grille. La meilleure
possibilité d'obtenir les données pour une requête est déterminée au moment de
l'exécution par une recherche de données matérialisés ou calculables au niveau
des caches client et des serveurs source (Lawrence et al., 2007). Cette méthode
de recherche est inspirée par les travaux introduisant les mémoires cache client
adaptés aux données multidimensionnelles issues d'entrepôts centralisés
(Deshpande et al., 1998). Ces solutions permettent la réutilisation des résultats
pour le calcul d'agrégats (Deshpande et al., 2000) et proposent des réseaux pair-
à-pair pour l'échange et la réutilisation de résultats entre systèmes client (Kalnis
et al., 2002). Alors que cette approche décentralisée s'intègre bien dans le
fonctionnement d'une grille, il n'existe pas d'approche pour l'intégration
complète des données d'un entrepôt au sein d'une grille. Ainsi, les solutions
existantes ne tirent pas profit des méthodes de fragmentation avancées et des
capacités de gestion de données distribuée de la grille. Pour ce faire, il est
nécessaire de déployer entièrement un entrepôt centralisé sur une grille afin de
pouvoir exploiter pleinement les capacités de la grille en termes de ressources
de traitement et de stockage. L'architecture décentralisée de la grille ne
permettant pas l'application des mécanismes de gestion et de répartition
uniforme connus, il est donc nécessaire de trouver une approche alliant les
procédés de fragmentation et de répartition des entrepôts hébergés par les bases
de données réparties avec la structure décentralisée en absence d'instance
unique de contrôle que représente la grille.



Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 35
Chapitre 3 Modélisation, identification
et indexation des données
multidimensionnelles
matérialisées sur grille
Le fonctionnement décentralisé d'une grille nécessite d'adapter la gestion d'un
entrepôt de données. Il est nécessaire de gérer la distribution des données
multidimensionnelles matérialisées. Ces données matérialisées peuvent être des
données détaillées et/ou agrégées. Dans ce chapitre, nous proposons une
solution qui s'appuie sur :
- Un modèle multidimensionnel qui permet la construction de fragments pour
la table de faits, les tables d'agrégats et les tables de dimension.
- Un modèle d'identification des données de l'entrepôt. La construction
d'identifiants que nous proposons est basée sur des relations d'ordre total
appliquées aux ensembles des membres de dimensions. Ce mécanisme nous
permet d'identifier de façon unique et non ambigüe des blocs
multidimensionnels de données contiguës dans l'espace de données.
- Une méthode d'indexation locale au niveau des nœuds de la grille, utilisant
ces identifiants de données pour une interrogation entièrement décentralisée
de l'entrepôt. L'index référence l'ensemble des données matérialisées sur un
nœud de la grille. Cet index permet de connaître le niveau d'agrégation et la
position dans l'espace des dimensions des blocs de données matérialisés sur
chaque nœud de la grille.
Dans ce chapitre, après la présentation d'un cas d'utilisation issu du projet
GGM, nous développerons notre modèle multidimensionnel d'entrepôt réparti
sur grille.
1 Cas d'utilisation
Les données utilisées dans le cadre du projet GGM sont des ensembles de
résultats d'expériences géno-médicales sur biopuces associées aux dossiers
médicaux informatisés des patients concernés. Ces données permettent
notamment la sélection et l'étude de populations de patients. L'entrepôt de
données permet de gérer des données concernant des patients atteints par les
pathologies sur lesquelles portent les expériences. Les informations sur les
patients sont issues d'un dossier médical informatisé, le fait étudié est le
patient. Nous nous limitons à une version simplifiée à trois dimensions
d'analyse qui sont la pathologie, la date de naissance et le lieu de naissance. Le
modèle conceptuel de l'entrepôt selon le formalisme MultiDimER (Malinowski
et al., 2006) est présenté par la figure 3.1. L'entrepôt contient comme première
mesure l'évènement « décès » qui prend la valeur 0 ou 1 et qui est agrégée par
la fonction SUM. La seconde mesure que nous intégrons est l'identifiant unique
des patients, agrégé par la fonction LIST.

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 36
PATIENT
décès : SUM
id_patient : LIST
Temps
Date de naissance
date
Mois de naissance
mois
Année de naissance
année
Lieu
Ville de naissance
ville
population
Région de naissance
région
chef-lieu
Pays de naissance
pays
capitale
Pathologie
Pathologie
n° ICD
nom
famille de pathologies
Figure 3.1 : Schéma conceptuel de l'entrepôt centré Patient
Ainsi, l'entrepôt centré Patient permettra par exemple d'étudier la population de
patients atteints de la maladie d'Alzheimer par tranches d'âge. Un utilisateur de
cet entrepôt, par exemple un médecin ou un biologiste, doit pouvoir se
connecter à l'entrepôt depuis n'importe quel site via une interface cliente. Cette
interface OLAP classique (tableau de bord, table de pivot, graphiques…) doit
donner accès aux données de l'entrepôt réparti comme s'il était centralisé. La
figure 3.2 montre l'intégration de l'interface client dans l'architecture déployée
pour l'entrepôt de données réparti.
Figure 3.2 : Interfaces client dans l'architecture d'entrepôt réparti sur grille
Le client peut accéder à l'entrepôt par une interface web déployée sur les points
d'accès ou à l'aide de son propre client OLAP envoyant directement les requêtes
OLAP au point d'accès. Afin de pouvoir gérer efficacement les données

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 37
réparties de l'entrepôt parmi les nœuds d'une grille, nous introduisons un
modèle conceptuel pour les données décrivant le modèle multidimensionnel de
l'entrepôt réparti.
2 Un modèle conceptuel de données multidimensionnelles
réparties
Lors de la conception d'un entrepôt de données, les dimensions du modèle
multidimensionnel sont définies a priori comme des axes d 'analyse des données
qui sont présentées à l'utilisateur. Les possibilités de navigation réelles dans
une dimension sont ensuite déterminées par le modèle conceptuel de cet te
dimension et les données mises à disposition par l 'entrepôt. Ainsi, le contenu de
la table de faits représente les données détaillées disponibles et la structure
hiérarchisée des différentes tables de dimension donne accès aux agrégats de
ces données. L'accessibilité des données et de leurs agrégats est d 'autant plus
importante dans un contexte de stockage réparti comme celui d 'une grille, que
chaque nœud stocke un sous-ensemble des données de l'entrepôt. La
matérialisation du modèle multidimensionnel de l'entrepôt s'appuie dans ce cas-
là sur des fragments horizontaux de la table de faits ou des tables d 'agrégats
pré-calculées qui sont eux-mêmes liés à des fragments des tables de dimension.
L'objectif de la répartition est de distribuer les données de l 'entrepôt les plus
demandées par les différents groupes d'utilisateurs de l'entrepôt en les
matérialisant sur les nœuds de la grille les plus accessibles pour ces utilisateurs.
Pour cela, nous utilisons la méthode de fragmentation horizontale dérivée
exposée au chapitre 2 qui se base sur les profils de requêtes associés aux
utilisateurs de l'entrepôt. Le placement des fragments obtenus sur les nœuds de
la grille est optimisé pour fournir un accès rapide aux données en fonction de la
demande initiale. Pour améliorer les performances du traitement de requêtes
portant sur des agrégats, les agrégats les plus pertinents pour un groupe
d'utilisateurs peuvent être pré-calculés selon les méthodes décrites par (Shukla
et al., 1998) et (Ezeife, 2001). Le modèle d'entrepôt réparti doit donc également
prendre en compte des tables d'agrégats intégrées au schéma.
Nous développons par la suite les éléments du modèle décrivant les fragments
de la table de faits et des tables de dimension de l 'entrepôt matérialisés sur les
nœuds de la grille. Le modèle met également en relation les fragments avec le
modèle d'entrepôt complet tel qu'il est présenté à l'utilisateur.
2.1 Schéma et instance de dimension
Nous introduisons ici des définitions pour les concepts de schéma et d'instance
de dimensions largement inspirées des définitions classiques que l'on peut
trouver dans la littérature (Golfarelli et al., 1998), (Malinowski et al., 2006).

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 38
Définition 3.1 : Schéma de dimension
Le schéma d'une dimension est défini par un ensemble de niveaux
hiérarchiques reliés par des liens entre niveaux. Un lien représente le
passage d'un niveau plus détaillé vers un niveau immédiatement
supérieur.
Nous nous limitons par la suite aux schémas de dimension représentant des
hiérarchies dites « non-multiples », c'est-à-dire que chaque niveau possède au
plus un niveau père, comme présenté dans l'état de l'art. La plupart des outil s
OLAP introduisent pour chaque dimension un niveau hiérarchique fait d 'un seul
membre nommé « ALL » qui représente l'agrégat de toutes les données de
l'entrepôt selon cette dimension. Par la suite, nous allons inclure ce niveau dans
les représentations d'instances de dimension.
Définition 3.2 : Instance de dimension
L'instance ID de la dimension D est constituée de l'union des
ensembles de membres de tous les niveaux hiérarchiques et de l 'union
des ensembles de liens entre les membres de différents niveaux.
1
0 0
,k k
D i i
i i
I M L, où
- k est le nombre de niveaux hiérarchiques de D,
- Mi est l'ensemble des membres de chaque niveau hiérarchique i de
D,
- Li est l'ensemble des liens entre les membres du niveau i et les
membres du niveau i+1.
L'instance d'une dimension peut donc être représentée sous forme de graphe
dirigé dont les sommets sont les membres de la dimension. Les arêtes de ce
graphe sont l'expression des liens entre les membres de niveaux hiérarchiques
différents. L'exemple 3.1 illustre les notions de schéma et d'instance de
dimension créés pour l'entrepôt centré Patient issu du projet GGM.
Exemple 3.1 : Schémas et instances des dimensions de l'entrepôt centré Patient
La figure 3.3 présente le schéma de la dimension « lieu », et un extrait de
l'instance de dimension de l'entrepôt centré Patient. Cette dimension est
hiérarchisée avec l'ensemble des niveaux {ville, région, pays} et les liens
hiérarchiques entre les niveaux (ville, région) et (région, pays).

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 39
France
Rhône AlpesPACA Piémont
Bourg-en-Bresse Grenoble Lyon St EtienneMarseille Nice Toulon Alexandrie Novare Turin
Italie
ALL
ville (0)
région (1)
pays (2)
all (3)
schéma instance
dimension « lieu »
Figure 3.3: Schéma et extrait de l'instance de la dimension « lieu »
La dimension « temps » est décrit par une table contenant les dates au for-
mat AAAA-MM-JJ, regroupées par mois et par année. La hiérarchie corres-
pondante est définie par l'ensemble de niveaux {année, mois, date} et l'en-
semble de liens hiérarchiques entre les niveaux (date, mois)
et (mois, année). Un extrait du graphe associé est donné en figure 3.4.
1925
1925-01
1925-01-23
ALL
jour (0)
mois (1)
année (2)
all (3)
schéma instance
dimension « temps »
1925-12-01
1925-12
1939
1925-09
1925-09-211925-09-15 1939-12-10
1939-12
1926
1926-01-05
1926-01
1926-12-28
1926-12
1939-02-22
1939-02 ...
...
...
...
... ...
...
Figure 3.4: Schéma et extrait de l'instance de la dimension « temps »
Pour la dimension « pathologie », la hiérarchie comporte un nombre variable de
niveaux en fonction des liens de filiation entre les membres de chaque instance.
Il s'agit là d'une hiérarchie non-onto, non couvrante où les ascendants et
descendants sont représentés par des liens récursifs. Nous avons montré dans le
chapitre 2 comment ce type de hiérarchie pouvait être normalisée et un extrait
de l'instance de cette dimension est représentée par la figure 3.5.

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 40
ALL
maladies du système nerveux maladies respiratoires
méningite
maladie d'A
lzheimer
maladie de P
arkinson
sclérose latérale amyot.
sclérose en plaques
épilepsie
pneumonie
grippe
BPCO
bronchite, emphysèm
e et asthme
bronchite et emphysèm
e
asthme
Figure 3.5: Extrait de l'instance de la dimension « pathologie »
2.2 Faits et agrégats répartis
La table de faits d'un entrepôt modélisé en étoile contient des tuples qui
associent une combinaison de membres de dimension à un ensemble de mesures
nommé « fait ». Les faits constituent les données les plus détaillées de
l'entrepôt et servent de source pour le calcul de tous les agrégats disponibles à
l'utilisateur. Plus formellement, la table de faits peut être définie de la façon
suivante :
Définition 3.3 : Table de faits
Une table de faits F d'un entrepôt modélisé en étoile est une table dont
les tuples t = <m1,…,mn, f1,…,fp> sont constitués d'un membre mi de
dimension pour chacune des dimensions D1,…,Dn de l'entrepôt et d'un
ensemble de mesures f1,…,fp décrivant un fait. Chaque mi est une clé
étrangère vers la table de dimension correspondante.
La table de fait de l'entrepôt centralisé doit être répartie sur les différents nœuds
de la grille sous forme de fragments.
Définition 3.4 : Fragment de table de faits
Soit F une table de faits, soient S1,…,Sn des ensembles de membres
sélectionnés sur l'attribut qui référence la table de dimension pour
chacune des dimensions D1,…,Dn. Le fragment frag({S1,…,Sn},F) de F

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 41
correspondant aux sélections exprimées par S1,…,Sn est l'ensemble des
tuples de F pour lesquels 1, ,i im S i n .
Cette définition est conforme aux notions de fragmentation introduites par
(Özsu et al., 1991). L'exemple 3.2 illustre un cas simplifié de fragmentation
d'une table de faits. Les tuples de cette table initiale sont regroupés en fonction
de leur pertinence pour les différents groupes d'utilisateurs pour être stockés sur
les nœuds de la grille associés à ces utilisateurs. Les données isolées pour
chaque groupe d'utilisateurs sont sélectionnées grâce à un ensemble de
prédicats de sélection sur les membres de dimensions qui permet d 'identifier les
tuples pertinents de la table de faits.
Exemple 3.2 : Fragmentation de la table de faits d'un entrepôt modélisé en
étoile
Nous prenons comme exemple la fragmentation de la table de faits de l 'entrepôt
centré Patient. Supposons que la grille sur laquelle l 'entrepôt est réparti est
composée de trois nœuds A, B et C attribués à trois groupes d'utilisateurs.
Chaque groupe d'utilisateurs désigne ses données pertinentes par les prédicats
de sélection sur une ou plusieurs dimensions. Les prédicats de sélection portent
uniquement sur les dimensions « lieu » et « temps », ce qui indique l'inclusion
de tous les membres disponibles dans la dimension « pathologie ».
Groupe A :
Sélection des patients de toutes les villes françaises dans la dimension « lieu »
et de toutes les dates antérieures à 1927 dans la dimension « temps ».
Groupe B :
Sélection des patients de toutes les villes françaises dans la dimension « lieu »
et de toutes les dates postérieures à 1928 dans la dimension « temps ».
Groupe C :
Sélection des patients de toutes les villes disponibles nés en 1927 ou 1928 pour
la dimension « temps ».
La figure 3.6 montre les fragments désignés par les prédicats de sélection des
différents groupes d'utilisateurs. Notons que dans le cas présent ces fragments
sont disjoints. Nous verrons par la suite qu'un même tuple peut appartenir à
plusieurs fragments, ce qui correspond au cas où plusieurs groupes d'utilisateurs
ont des intérêts communs.

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 42
pathologie id_patient décès
Bourg-en-Bresse 1925-09-21 15099 0
Bourg-en-Bresse 1926-01-05 grippe 19936 1
... ... ... ... ...
Grenoble 1925-09-15 bronchite 17608 0
Grenoble 1926-09-19 bronchite 16975 1
Grenoble 1928-08-27 méningite 20702 0
Grenoble 1929-04-16 16813 1
Grenoble 1929-06-14 asthme 20417 0
Grenoble 1929-07-20 grippe 20980 0
... ... ... ... ...
Toulon 1925-12-01 asthme 16831 1
Toulon 1926-11-01 pneumonie 17322 0
Toulon 1926-12-28 asthme 18599 0
Toulon 1927-09-23 méningite 21598 0
Toulon 1927-11-22 bronchite 16097 1
Toulon 1928-02-06 grippe 17034 0
Toulon 1929-10-04 bronchite 22121 1
Toulon 1933-02-08 pneumonie 15526 1
... ... ... ... ...
1927-05-13 grippe 22363 1
1927-08-07 grippe 21341 1
1928-08-02 épilepsie 19986 1
1930-01-20 méningite 22380 1
1934-10-15 15445 1
... ... ... ... ...
Turin 1937-02-05 22375 0
Turin 1939-05-17 grippe 10716 1
lieu_naiss date_naiss
mal. d'Alzheimer
mal. d'Alzheimer
Novare
Novare
Novare
Novare
Novare mal. d'Alzheimer
mal. d'Alzheimer
groupe A :(lieu.pays = France) ET (temps.année < 1927)
groupe B :(lieu.pays = France) ET (temps.année > 1928)
groupe C :(temps.année = 1927) OU (temps.année = 1928)
fragment restant de la tableà déployer sur un autre nœud
sélection des données demandéespar les groupes d'utilisateurs
table de faits « patient » fragmentée selon les critères utilisateurs
Figure 3.6 : Table de faits « patient » fragmentée pour être répartie sur 3 nœuds de la
grille selon les critères des 3 groupes d'utilisateurs associés à ces nœuds
La structure des tables d'agrégats est identique à celle de la table de faits hormis
le fait que les membres de dimension qui décrivent les agrégats dans chaque
tuple appartiennent à des niveaux hiérarchiques plus élevés dans les tables de
dimension. Ainsi, si l'attribut « lieu_naiss » de la table de faits pour la
dimension « lieu » contient des valeurs de l'attribut « ville » dans la table de
dimension, une table d'agrégat contient des valeurs issues des attributs
« région » ou « pays » de cette même table de dimension.
Définition 3.5 : Table d'agrégat
Une table d'agrégat A est une table dont les tuples
t = <m1,…,mn, a1,…,ap> sont constitués d'un membre mi de dimension
pour chacune des dimensions D1,…,Dn de l'entrepôt avec au moins un
mi appartenant à un niveau d'agrégation supérieur à 0 et d'un ensemble
d'agrégats ai, i = 1,…,p obtenus par agrégation des mesures f1,…,fp.

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 43
L'intégration des tables d'agrégats dans une structure de schéma en étoile est
illustrée par la figure 3.7.
pays région ville
France Rhône Alpes Bourg-en-Bresse
France Rhône Alpes Grenoble
France Rhône Alpes Lyon
France Rhône Alpes St Etienne
France PACA Marseille
France PACA Nice
France PACA Toulon
Italie Piémont Alexandrie
Italie Piémont Novare
Italie Piémont Turin
date_naiss lieu_naiss pathologie id_patient décès
1928-01-14 Lyon épilepsie 17518 1
1928-08-02 Novare épilepsie 19986 1
... ... ... ... ...
1937-11-23 Bourg-en-Bresse méningite 17251 0
1938-02-08 Novare méningite 18228 0
1925-12-01 Toulon asthme 16831 1
1926-12-28 Toulon asthme 18599 0
... ... ... ... ...
1938-08-07 Toulon pneumonie 15638 1
1938-11-07 Alexandrie pneumonie 18370 0année mois date
1925 1925-01 1925-01-23
1925 1925-09 1925-09-15
1925 1925-09 1925-09-21
1925 1925-12 1925-12-01
... ... ...
1939 1939-03 1939-03-24
1939 1939-03 1939-03-30
1939 1939-05 1939-05-09
1939 1939-05 1939-05-18
1939 1939-12 1939-12-10
table de faits« patient »
table de dimension« lieu »table de dimension
« temps »
lien « clé étrangère »
1925 17608 0
1925 15099 0
... ... ... ... ...
1935 19060 0
1935 18902 0
1936 grippe 16665 1
1936 grippe 15238,18282 2
... ... ... ... ...
1938 18370 0
1939 19406 1
année région pathologie liste_id_patient somme_décès
Rhône Alpes bronchite
Rhône Alpes mal. d'Alzheimer
Rhône Alpes mal. de Parkinson
Rhône Alpes méningite
Rhône Alpes
Rhône Alpes
Piémont pneumonie
Piémont mal. de Parkinson
table d'agrégat« patient-région-année »
lien entre attributs de jointurepour calcul d'agrégats
Figure 3.7 : Exemple d'une table d'agrégat aux niveaux {région, année, pathologie}
Les tables d'agrégats sont fragmentées en utilisant les prédicats de sélection des
utilisateurs portant sur des agrégats. La définition d'un fragment de table
d'agrégats ne se distingue de la définition des fragments de tables de faits que
par leur relation avec les tables de dimension.
Définition 3.6 : Fragment de table d'agrégats
Soit A une table d'agrégats, soient S1,…,Sn des ensembles de membres
sélectionnés sur les attributs correspondants aux membres contenus
dans A pour chacune des dimensions D1,…,Dn. Alors le fragment
frag({S1,…,Sn},A) de A correspondant aux sélections exprimées par
S1,…,Sn est l'ensemble des tuples de A pour lesquels
1, ,i im S i n .
Exemple 3.3 : Fragmentation d'une table d'agrégat
Nous reprenons l'entrepôt centré Patient de l'exemple précédent avec la table
d'agrégat aux niveaux {région, année, pathologie} ajoutée au schéma de
l'entrepôt. Supposons que les groupes d'utilisateurs A et B aient besoin des
informations suivantes à un niveau agrégé :
Groupe A :
Sélection des régions Rhône Alpes et Piémont dans la dimension « lieu » et de
toutes les années postérieures à 1935 dans la dimension « temps ».

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 44
Groupe B :
Sélection des régions Rhône Alpes et PACA dans la dimension « lieu » et de
toutes les années antérieures à 1936 dans la dimension « temps ».
Les fragments de la table d'agrégats sont déterminés indépendamment des
fragments de la table de faits. Dans notre exemple, seuls les groupes
d'utilisateurs A et B consultent fréquemment des agrégats de données qui ne
sont qu'en partie matérialisées dans les fragments de la table de fa its associés à
chaque groupe. Par exemple, le groupe A consulte les agrégats portant sur la
région Piémont, alors que les faits au niveau le plus détaillé (ville) pour cette
région ne sont pas matérialisés pour ce groupe. La figure 3.8 présente la
fragmentation de la table d'agrégats selon les besoins des groupes A et B.
1925 17608 0
1925 15099 0
... ... ... ... ...
1935 19060 0
1935 18902 0
1936 grippe 16665 1
1936 grippe 15238,18282 2
... ... ... ... ...
1939 grippe 21781 1
1939 21397 1
PACA 1925 16831 1
PACA 1925 18468 0
... ... ... ... ...
PACA 1934 16563 0
PACA 1934 19696 0
PACA 1936 15149 1
PACA 1937 22297 1
... ... ... ... ...
PACA 1938 21417 0
PACA 1938 15638 1
1927 grippe 21341,22363 2
1928 19986 1
... ... ... ... ...
1935 grippe 16227 1
1935 20460 1
1936 19311 1
... ... ... ... ...
1938 18370 0
1939 19406 1
région année pathologie liste_id_patient somme_décès
Rhône Alpes bronchite
Rhône Alpes mal. d'Alzheimer
Rhône Alpes mal. de Parkinson
Rhône Alpes méningite
Rhône Alpes
Rhône Alpes
Rhône Alpes
Rhône Alpes mal. d'Alzheimer
asthme
mal. d'Alzheimer
mal. d'Alzheimer
pneumonie
pneumonie
épilepsie
mal. de Parkinson
pneumonie
Piémont
Piémont épilepsie
Piémont
Piémont mal. de Parkinson
Piémont pneumonie
Piémont pneumonie
Piémont mal. de Parkinson
table d'agrégats « patient » au niveau région-année fragmentée selon les critères utilisateurs
groupe A :(lieu.région IN {Rhône Alpes,Piémont}) ET (temps.année > 1935)
sélection des agrégats demandéspar les groupes d'utilisateurs
groupe B :(lieu.région IN {Rhône Alpes,PACA}) ET (temps.année < 1936)
Figure 3.8 : Table d'agrégat « patient-région-année » fragmentée pour être répartie
sur les nœuds A et B de la grille
Les fragments de table de faits et des tables d'agrégats créés par le processus de
répartition sont stockés sur les nœuds de la grille désignés pour servir les
différents groupes d'utilisateurs. Chacun de ces nœuds héberge donc un sous-
ensemble bien défini des données détaillées et agrégées de l'entrepôt. Afin de

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 45
rendre ces données disponibles à l'interrogation des utilisateurs, il est nécessaire
de répartir également les données concernant les dimensions, c 'est-à-dire le
contenu des tables de dimension.
2.3 Instances locales de dimension
Alors que la répartition de la table de faits et des tables d'agrégats vise
principalement à répartir la charge en termes de stockage et de calcul au sein de
la grille, la répartition des tables de dimensions a comme objectif de rendre
accessible localement les données détaillées et agrégées disponibles sur chaque
nœud. En effet, le traitement d 'une requête du type OLAP, même limitée aux
données localement présentes, nécessite les informations contenues dans les
tables de dimension pour identifier correctement le résultat demandé. Nous
nous intéressons ici à des tables de dimension modélisées en étoile, c 'est-à-dire
selon un modèle dénormalisé. Ces tables de dimension contiennent donc des
attributs représentant la hiérarchie et des attributs descriptifs. Par exemple, pour
la dimension « lieu », la hiérarchie est représentée par les attributs ville, région
et pays, et les attributs descriptifs pourraient être le nombre d 'habitants par ville
ou le nom de la préfecture d'une région.
Pour un nœud donné, nous construisons l'instance locale de dimension à partir
du contenu des fragments de table de faits ou d'agrégats matérialisés sur ce
nœud.
Définition 3.7 : Instance locale de dimension
Soit R l'ensemble des fragments de la table de faits et des tables
d'agrégats matérialisés sur un nœud de la grille.
Soit ID l'instance de dimension de l'entrepôt pour la dimension D.
Alors l'instance de dimension locale ID(R) est un sous-ensemble de ID
constitué des éléments suivants :
- l'ensemble M0 des membres du niveau 0 le plus détaillé de la
hiérarchie présents dans au moins un des tuples des fragments
de la table de faits matérialisés par R,
- l'union des ensembles Mj de membres des niveaux agrégés j,
j > 0 présents dans au moins un des tuples des fragments de
tables d'agrégat matérialisés par R,
- l'ensemble M' des membres contenus dans ID pour lesquels il
existe un lien de filiation avec les membres de M0 et/ou les
membres de l'union des Mj,
- l'ensemble L' des liens entre les membres des différents niveaux
présents dans l'union de M0, de tous les Mj et de M'.
L'instance locale ID(R) matérialise donc la partie de ID qui se limite
aux membres de l'union de M0, de tous les Mj et de M' avec l'ensemble
L' des liens hiérarchiques entre ces membres.

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 46
1
0
0 0
, ,k k
D i i
i i
I R M M M L L L
Autrement dit, nous matérialisons dans l'instance locale de dimension sur ce
nœud les membres contenus dans les fragments de table de faits ou d 'agrégats
ainsi que tous leurs ancêtres et descendants dans l 'instance de dimension.
Exemple 3.4 : Instance locale de dimension sur un nœud de la grille
Le nœud de grille A héberge un fragment de la table de faits « patient » ainsi
qu'un fragment de la table d'agrégats « patient-région-année ». Comme le
montre la figure 3.9, ces instances locales des dimensions « lieu » et « temps »
représentent les tuples des tables de dimension qui contiennent les membres
présents dans les fragments matérialisés sur le nœud.
pathologie id_patient décès
Bourg-en-Bresse 1925-09-21 15099 0
Bourg-en-Bresse 1926-01-05 grippe 19936 1
... ... ... ... ...
Grenoble 1925-09-15 bronchite 17608 0
Grenoble 1926-09-19 bronchite 16975 1
Toulon 1925-12-01 asthme 16831 1
Toulon 1926-11-01 pneumonie 17322 0
Toulon 1926-12-28 asthme 18599 0
lieu_naiss date_naiss
mal. d'Alzheimer
fragment de la table de faits « patient »pays région ville
France Rhône Alpes Bourg-en-Bresse
France Rhône Alpes Grenoble
France Rhône Alpes Lyon
France Rhône Alpes
France PACA Marseille
France PACA Nice
France PACA Toulon
Italie Piémont Alexandrie
Italie Piémont
Italie Piémont Turin
St Etienne
Novare
instance locale de la dimension « lieu »
fragment de la table d'agrégat « patient-région-année »instance local de la dimension « temps »
année mois date
1925 1925-01 1925-01-23
1925 1925-09 1925-09-15
... ... ...
1926 1926-11 1926-11-17
1926 1926-12 1926-12-28
1936 1936-01 1936-01-14
1936 1936-03 1936-03-18
... ... ...
1939 1939-05 1939-05-18
1939 1939-12 1939-12-10
1936 grippe 16665 1
1936 grippe 15238,18282 2
... ... ... ... ...
1939 grippe 21781 1
1939 21397 1
1936 19311 1
... ... ... ... ...
1938 18370 0
1939 19406 1
région année pathologie liste_id_patient somme_décès
Rhône Alpes
Rhône Alpes
Rhône Alpes
Rhône Alpes mal. d'Alzheimer
Piémont pneumonie
Piémont pneumonie
Piémont mal. de Parkinson
lien « clé étrangère »
lien entre attributs de jointurepour calcul d'agrégats
Figure 3.9 : Instances locales des dimensions « lieu » et « temps » pour le nœud de
grille A
Ainsi, il devient possible d'interroger les données présentes sur le nœud A en
ayant uniquement recours aux données matérialisées localement. Un utilisateur
peut demander par exemple le détail de tous les patients nés en 1925 pour
chaque ville en région PACA. L'entrepôt identifie alors à l'aide des
informations dans les instances locales de dimensions toutes les dates de
naissances disponibles pour l'année 1925 et les villes appartenant à la région

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 47
PACA, ce qui lui permet de sélectionner les tuples demandés dans le fragment
de table de faits matérialisé localement.
Grâce à la modélisation de fragments des tables de faits et d 'agrégats associée à
la création d'instances locales de dimensions, nous obtenons des parties
indépendantes de l'entrepôt réparties sur les différents nœuds.
Cette structure décentralisée donne une importante autonomie aux nœuds de la
grille en termes de gestion des données matérialisées. Par contre, dès qu 'il s'agit
de répondre à des requêtes portant sur des données non disponibles localement,
l'entrepôt de données réparti doit disposer d'un mécanisme d'identification des
données permettant de rechercher les données manquantes localement parmi les
nœuds de la grille.
2.4 Ordonnancement des membres de dimension
L'objectif de l'ordonnancement des membres d'une instance de dimension est de
faciliter le regroupement d'ensembles de données en les identifiant par leurs
limites inférieures et supérieures sur chaque dimension. Cet ordonnancement
permet ainsi d'obtenir des identifiants qui indiquent la position relative des
données qu'ils représentent dans le modèle multidimensionnel. Nous
introduisons pour cela certaines contraintes sur les instances de dimensions qui
permettront par la suite l'ordonnancement des membres de dimensions sur la
totalité de la structure hiérarchique de ces instances.
Les liens de filiation entre les membres de la table de dimension sont décrits
par la hiérarchie de dimension. Les hiérarchies possèdent certaines propriétés
en fonction de leur structure, explicitées par (Pedersen et al., 1999). Ces
propriétés permettent de déterminer si une instance peut être ordonnée selon la
méthode présentée ici. Pour que notre méthode d'ordonnancement soit
applicable, une hiérarchie de dimension doit être :
- explicite, définie par un schéma de hiérarchie,
- non-multiple, le schéma de hiérarchie ne comporte que des niveaux
hiérarchiques avec au plus un seul père et un seul fils,
- stricte, chaque membre a au maximum un père au niveau hiérarchique
supérieur (pas de relations n à n entre niveaux hiérarchiques),
- onto, c'est-à-dire représentée par un arbre balancé,
- couvrante, tous les liens père-fils sont établis entre un niveau donné et un
niveau immédiatement supérieur ou inférieur.
Nous partons de l'hypothèse que toutes les instances de dimension utilisées
respectent ces contraintes. Le chapitre 2 présente les méthodes de
« normalisation » existantes qui permettent de transformer les instances de
dimension ne respectant pas ces contraintes. C'est le cas de la dimension
« pathologie » de l'entrepôt centré Patient dont la normalisation est illustrée au
chapitre 2.

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 48
L'identification par ensembles contigus de données utilise une relation d'ordre
total i sur l'ensemble Mi des membres du niveau hiérarchique i appartenant à
une hiérarchie de dimension. Cette relation vérifie donc les propriétés
suivantes :
réflexive : i ix x x M
antisymétrique : ,i i ix y y x x y x y M
transitive : , ,i i i ix y y z x z x y z M
total : ,i i ix y y x x y M
L'ordre total ne peut s'appliquer qu'à un ensemble de membres appartenant au
même niveau hiérarchique, car la dernière condition exige que deux membres
de l'ensemble ordonné soient comparables. Cette contrainte est nécessaire pour
assurer que chaque sous-ensemble de Mi possède un maximum et un minimum
par rapport à la relation d'ordre. On peut ainsi créer des intervalles contigus de
membres. Nous avons également la possibilité d'ordonner les autres niveaux
hiérarchiques de la dimension à partir d'un ensemble de membres ordonné sur
un niveau inférieur ou supérieur. La relation d'ordre peut ainsi être propagée
aux autres niveaux ; nous introduisons ainsi la définition d'un « ordre propagé »
par rapport à un niveau ordonné de référence. Selon la position du niveau de
référence par rapport au niveau à ordonner, nous parlons de propagation
ascendante ou descendante. Les notions suivantes sont nécessaires à la
définition formelle de la propagation d'un ordre d'un niveau hiérarchique à
l'autre.
Soit :
,
, ,
i jg : M M
m j g m j
la fonction qui associe à chaque membre m de Mi du niveau i le membre ou
l'ensemble de membres de niveau j qui lui sont reliés par filiation. Par exemple,
dans la dimension de la figure 3.11, g(‘Nice',3) = {‘France'} et
g(‘PACA',1) = {‘Marseille', 'Nice', 'Toulon'}.
Soit j la relation d'ordre total sur l'ensemble Mj de membres au niveau j i
qui sert à induire un ordre total sur l'ensemble Mi de membres au niveau i. Nous
distinguons alors les deux cas suivants :
(1) Si i < j, alors l'ordre j doit être propagé de façon descendante vers le
niveau i. Compte tenu des propriétés des dimensions que nous avons
définies, deux membres arbitraires x et y du niveau i ont chacun un seul

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 49
ancêtre g(x,j) et g(y,j) au niveau j. En conséquence, x et y sont mis en
relation par la relation d
i directement déduite de j :
: , , d
j ii j g x j g y j x y
La relation d'ordre au niveau j ne permet cependant pas d'ordonner les
membres au niveau i dans le cas où , ,g x j = g y j . Par exemple, les deux
villes Nice et Toulon ne peuvent pas être comparées à l 'aide de leur ancêtre
commun au niveau région (PACA), il faut donc trouver un autre critère pour
créer un ordre total qui complète d
i . Les sous-ensembles aux ancêtres
communs sont alors ordonnés par une relation d'ordre total e
i . Cette
relation e
i peut être induite par une propriété de membre ou un autre
niveau k avec k i,k j . Par exemple, les villes d'une même région
peuvent être ordonnées à l'aide de leur population ou par ordre
alphabétique, comme l'illustre l'exemple 3.5.
Définition 3.8 : Relation d'ordre propagée descendante
Une relation d'ordre total propagée descendante i sur l'ensemble Mi
de membres au niveau i est définie comme suit à partir de l'ordre j ,
avec i < j :
, ,
, ,
d
i
i i e
i
x y si g x j g y jx, y M : x y
x y si g x j = g y j
(2) Si i > j, alors l'ordre j doit être propagé de façon ascendante vers le
niveau i. Comme les membres au niveau i peuvent avoir plusieurs
descendants au niveau j, il est nécessaire de sélectionner des représentants
parmi ces descendants. Ainsi, nous introduisons l 'ordre i en utilisant le
minimum des descendants selon j .
Définition 3.9 : Relation d'ordre propagée ascendante
Une relation d'ordre total propagée ascendante i sur l'ensemble Mi de
membres au niveau i est définie comme suit à partir de l'ordre j , avec
i > j :
, ,i i jx,y M : x y min g x j min g y j

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 50
Par exemple, en ordonnant le niveau pays (i = 2) à partir du niveau
région (j = 1) pour comparer les membres 'France' et 'Italie', on doit
sélectionner des représentants parmi les ensembles g('France',1) = {'PACA',
'Rhône Alpes'} et g('Italie',2) = {'Piémont'}. Nous supposons que le niveau
région est ordonné en ordre alphabétique, donc min(g('France',1)) = 'PACA'
et min(g('Italie',1)) = 'Piémont'. Nous obtenons donc l'équivalence
suivante :
'PACA' 1 'Piémont' 'France' 2 'Italie'
Note : Nous avons choisi ici d'utiliser le minimum pour le choix d'un
représentant parmi les descendants des membres du niveau i. Nous aurions
pu aussi bien choisir le maximum ou une autre fonction injective définie sur
les ensembles de descendants au niveau j.
L'objectif de l'ordonnancement propagé par un niveau hiérarchique est de
pouvoir déduire facilement les intervalles de membres représentant les mêmes
données à différents niveaux d'agrégation. Par exemple, si on souhaite obtenir
tous les agrégats associés aux membres entre 'PACA' et 'Rhône Alpes' au niveau
région, comme l'illustre la figure 3.10, l'ordre sur l'instance de dimension
permet de déterminer qu'il faut agréger pour cela l'ensemble des faits associés
aux membres entre 'Toulon' et 'Lyon' au niveau ville.
Rhône AlpesPACA
Bourg-en-Bresse Grenoble LyonSt EtienneMarseilleNiceToulon
intervalle de membres au niveau « ville »
intervalle de membres au niveau « région »
Figure 3.10 : Intervalles de membres représentant des données équivalentes sur
différents niveaux hiérarchiques
Afin d'assurer cette possibilité sur la totalité de l 'instance de dimension, nous
définissons une instance de dimension ordonnée.
Définition 3.10 : Instance de dimension ordonnée
Soit ID une instance d'une dimension dont le schéma comporte n
niveaux de 0 à n-1 et Mi l'ensemble de membres du niveau i ordonné
par la relation i . Alors ID est ordonnée si
10, , 1 , 1 , 1i i ii n , x,y M : x y g x i g y i

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 51
L'exemple 3.5 illustre la construction d'instances de dimension ordonnées par
l'usage de relations d'ordre propagées à travers leurs niveaux hiérarchiques.
Exemple 3.5 : Ordonnancement d'instances de dimension
Dans cet exemple, nous détaillons l 'ordonnancement des instances de
dimensions matérialisées pour l'entrepôt centré Patient.
L'instance de la dimension « temps » peut être ordonnée facilement à l 'aide de
l'ordre chronologique. En effet, celui-ci fournit un ordre total, peu importe le
niveau de la hiérarchie auquel il est appliqué. La figure 3.4 représente déjà
l'instance ordonnée, car indépendamment de la propagation choisie, on obtient
une instance entièrement ordonnée en utilisant l 'ordre chronologique.
L'ordonnancement de la dimension « lieu » s'avère plus complexe car la
sélection de membres représentant des unités géographiques ne se fait pas selon
un ordre prédéfini. Pour notre exemple, nous choisissons d'ordonner les
membres du niveau « pays » à l'aide la relation d'ordre alphabétique 2 . Les
régions sont ordonnées en fonction de leur pays parent par la relation d'ordre
1
d propagée depuis le niveau « pays » :
1
2
drégion1 région2
pays région1 pays région2 si pays région1 pays région2
Toutes les régions appartenant au même pays sont à leur tour triées par ordre
alphabétique par la relation 1
e. Enfin, les membres du niveau « ville » enfin
sont ordonnées en fonction de l'ordre défini sur les régions :
0 1
dville1 ville2 région ville1 région ville2
Finalement, les villes au sein d'une région sont ordonnées à l'aide de leur
propriété « population » qui définit la relation 0
e. Si deux villes d'une même
région ont la même population, il faudra introduire un nouveau critère, par
exemple l'ordre alphabétique. Le résultat est présenté par la figure 3.11.

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 52
France
Rhône AlpesPACA Piémont
Bourg-en-Bresse Grenoble LyonSt EtienneMarseilleNiceToulon Alexandrie Novare Turin
Italie
ALL
ville (0)
région (1)
pays (2)
all (3)
schéma instance
dimension « lieu »
relation d'ordre
Figure 3.11 : Instance ordonnée de la dimension « lieu »
Pour la dimension « pathologie », l'ordre numérique sur les numéros ICD
fournit un ordre total applicable à tous les niveaux hiérarchiques. Nous nous
basons ici sur la version « normalisée » de l'instance tel que décrite au chapitre
2. Issus du même ensemble de numéros ICD initial, les membres des différents
niveaux hiérarchiques peuvent être ordonnés sur chaque niveau par ce même
ordre numérique. Nous choisissons comme niveau de référence le niveau le plus
détaillé (niveau 0) de la hiérarchie. Ainsi, chaque membre mj d'un niveau
supérieur j avec j > 0 est comparé aux membres du même niveau à l 'aide de ses
descendants au niveau 0. Parmi ces descendants, le membre minimum est
choisi, c'est-à-dire celui avec le plus petit numéro ICD. Au niveau 3, l 'ordre est
alors obtenu grâce aux numéros ICD des membres du niveau 0. La figure 3.12
met en relation ces deux niveaux avec comme exemple les membres 'maladies
du système nerveux' et 'maladies respiratoires' au niveau 3.
0
3
54 73 ' ' ' '
' ' ' '
ICD ICD méningite pneumonie
maladies du système nerveux maladies respiratoires
ALL
maladies du système nerveux (ICD 53)
maladies respiratoires (ICD 72)
bronchite et emphysèm
e
(ICD 76)
asthme (IC
D 78)
méningite
(ICD 54)
maladie d'A
lzheimer
(ICD 55)
maladie de P
arkinson
(ICD 56)
sclérose latérale amyot.
(ICD 57)
sclérose en plaques
(ICD 58)
épilepsie
(ICD 59)
pneumonie
(ICD 73)
grippe (ICD
74)
all
path-3
path-0
schéma instance
dimension « pathologie »
Figure 3.12 : Ordres propagés de l'instance ordonnée de la dimension « pathologie »

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 53
Les minima de leurs descendants au niveau 0 sont les membres 'méningite'
(ICD 54) et 'pneumonie' (ICD 73). Nous sommes donc en mesure de mettre en
relation les membres 'maladies du système nerveux' et 'maladies respiratoires'
en partant des numéros ICD des membres au niveau 0.
La méthode d'ordonnancement présentée est appliquée à toutes les dimensions
de l'entrepôt de données. Sur cette base, nous introduisons un mécanisme
d'identification permettant de rechercher aussi bien les données détaillées que
les données agrégées disponibles parmi les nœuds de la grille.
3 Identification de données multidimensionnelles
La recherche des données disponibles dans un contexte d'entrepôt distribué et
décentralisé nécessite une identification non ambiguë des données de l'entrepôt.
Nous proposons une approche qui s'inspire de la façon dont les requêtes OLAP
référencent les données de l'entrepôt. En effet, une requête OLAP est constituée
d'une sélection de membres pour une ou plusieurs dimensions ainsi qu 'un choix
de mesures ou de leurs agrégats. Notre modèle d'identification s 'appuie sur les
membres des instances de dimensions. Ces identifiants sont utilisés par chaque
nœud de la grille pour indexer et publier les données qu 'ils hébergent. De façon
classique, l'index doit pouvoir identifier des ensembles de données. Nous allons
utiliser la méthode d'ordonnancement des instances de dimension afin de
comparer, regrouper et localiser les données de l'entrepôt.
3.1 Définition et identification de « chunks » de données
Les travaux concernant la gestion distribuée de données multidimensionnelles
s'appuient en grande partie sur une subdivision des données de l'entrepôt en
unités élémentaires auxquelles sont attribués des identifiants. Le terme le plus
souvent employé pour désigner ces unités est celui de « chunk », traduit par
« morceau », « tronçon » ou « unité naturelle ». La notion de « chunks » a été
utilisée dans le cadre de travaux portant sur l'optimisation du stockage de
données sur disque présentés par (Sarawagi et al., 1994) et la gestion de
mémoires cache client pour entrepôts de données distants décrite par
(Deshpande et al., 1998) et (Kalnis et al., 2002). Les « chunks » utilisés par ces
systèmes sont de taille variable en fonction des blocs gérés par les disques ou la
taille des résultats de requêtes stockées en mémoire cache. Afin de permettre un
accès au grain le plus fin, nous fixons la taille d'un chunk au sein de notre
méthode d'identification à un tuple d'une table de faits détaillés ou d'agrégats.
Définition 3.11 : Chunk de données multidimensionnelles
Soit T une table de faits détaillée ou une table d'agrégats, soit
{D1, .., Dn} l'ensemble des dimensions de l'entrepôt, un chunk C
correspond à un tuple donné de la table T. Ce tuple contient les clés

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 54
étrangères vers les membres de dimension et une ou plusieurs valeurs
de mesures ou d'agrégats.
L'identifiant unique c du chunk C est composé de la liste de ses
membres. Chaque membre est décrit par un label précisant le nom de
la dimension, le nom du niveau et le nom du membre :
L'identifiant c s'écrit donc
c = {nomDimension1.nomNiveau1.nomMembre1, …,
nomDimensionn.nomNiveaun.nomMembren}.
Nous introduisons une notation numérique équivalente qui substitue
aux labels le numéro de la dimension, le rang du niveau hiérarchique
et le rang du membre au sein de l'ordre défini sur le niveau de la
dimension.
Par exemple, l'identifiant de chunk c = {lieu.pays.France, temps.année.1937,
pathologie.path-0.asthme} identifie le tuple représentant le nombre de décès et
la liste des patients en France pour les patients nés en 1937 et la pathologie
asthme.
La notation numérique du label « temps.année.1937 » est « 2.2.13 », car :
- « temps » est la deuxième dimension,
- « année » est le troisième niveau hiérarchique de la dimension temps
(compté à partir du niveau 0 qui est le plus détaillé) et
- le membre « 1937 » est le treizième membre dans l'ordre du niveau.
L'espace de nommage créé par les identifiants de chunks va nous permettre de
référencer toutes les données matérialisées du modèle multidimensionnel, qu'il
s'agisse des données détaillées ou agrégées. Par la suite, nous désignons un
chunk de données par son identifiant, peu importe si celui-ci est matérialisé
dans l'entrepôt ou non. L'information sur la matérialisation d'un chunk est gérée
par les structures plus complexes que nous introduisons au cours des chapitres
suivants.
Ainsi construit, un identifiant de chunk désigne toutes les copies existantes d'un
même chunk sur la grille. Ceci présente une condition essentielle pour un
recensement et une localisation efficace des données distribuées à travers les
nœuds de stockage. En plus de référencer précisément un tuple d'une table de
faits ou d'agrégats, l'identifiant de chunk permet également d'établir
précisément les équivalences entre données détaillées et leurs agrégats. C'est à
travers les liens hiérarchiques existants entre membres de dimensions qu'il est
possible d'identifier les chunks d'un niveau d'agrégation inférieur nécessaires à
l'obtention d'un chunk agrégé. La figure 2.12 illustre le lien identifié à l'aide des
hiérarchies de dimension entre un ensemble de chunks définis dans deux
dimensions « dim A » et « dim B » aux niveaux i et j et le chunk représentant
l'agrégat de ces chunks aux niveaux hiérarchiques supérieurs i+1 et j+1.

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 55
dim
A
dim B
i+1
j+1
dim B
dim
A
i
j
i+1
j+1
agrégation
chunk
membre
Figure 3.13 : Lien entre un ensemble de chunks et un chunk agrégé en deux dimensions
En utilisant le rang dans l'ordre total sur ces niveaux hiérarchiques et la notion
d'intervalle introduite précédemment, il est également possible de calculer la
distance entre deux identifiants de chunk et ainsi d'évaluer le volume
multidimensionnel de données en nombre de chunks existantes entre deux
identifiants. Par exemple, le volume multidimensionnel volume(c1,c2) désigne le
maximum de chunks détaillés entre les deux chunks c1 et c2 :
Chunk 1 :
c1 = {lieu.ville.Toulon, temps.date.1935-01-17, pathologie.path-0.pneumonie}
(equ. {1.0.1, 2.0.61, 3.0.7})
Chunk 2 :
c2 = {lieu.ville.Turin, temps.date.1939-12-10, pathologie.path-0.pneumonie}
(equ. {1.0.10, 2.0.103, 3.0.10})
1 2, 1;10 * 61;103 * 7;10 10*43*4 1720volume c c .
L'étape suivante est de définir des structures regroupant des ensembles contigus
de chunks appelés blocs de chunks.
3.2 Construction de blocs de chunks
Pour faciliter la gestion de grandes quantités de données identifiées par chunks
au sein de l'entrepôt, nous définissons la notion de bloc de chunks. Celui -ci

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 56
représente un ensemble contigu de données dans un espace multidimensionnel
de données créé par les ensembles de membres ordonnés de dimension.
Définition 3.12 : Bloc de chunks
Un bloc de chunks B est un ensemble de chunks dont les membres au
sein d'une même dimension sont au même niveau hiérarchique. Un
bloc de chunks regroupe une section contiguë dans l 'espace
multidimensionnel de données formé par les ensembles ordonnés de
membres d'un niveau hiérarchique pour chaque dimension. Cette
section est délimitée par une limite inférieure et une limite supérieure
dans chaque dimension. Chaque limite correspond à un identifiant de
chunk.
L'identifiant unique b = <cinf , csup> d'un bloc de chunks est alors
composé des identifiants de chunk cinf pour la limite inférieure et csup
pour la limite supérieure du bloc.
Remarquons que nous notons B (en majuscule) le bloc de chunks et b (en
minuscule) son identifiant. Par exemple, le bloc de chunks qui regroupe tous les
chunks au niveau ville pour la dimension « lieu », année pour la dimension
« temps » et path-0 pour la dimension « pathologie » et dont les membres sont
compris entre 'Toulon' et 'Turin' pour la dimension « lieu », entre 1935 et 1939
pour la dimension « temps » et entre 'pneumonie' et 'asthme' pour la dimension
« pathologie », aura alors l'identifiant suivant :
<{lieu.ville.Toulon, temps.année.1935, pathologie.path-0.pneumonie},
{lieu.ville.Turin, temps.année.1939, pathologie.path-0.asthme}>
(equ. <{1.0.1, 2.2.11, 3.0.7},{1.0.10, 2.2.15, 3.0.10}>)
La forme numérique de l'identifiant, qui contient les numéros des dimensions et
des niveaux hiérarchiques et les rangs de membres dans leur ensemble de
membres ordonné, permet de comparer les membres sans accéder à la hiérarchie
de dimension et d'obtenir une estimation du volume de données contenu dans le
bloc. De plus, la relation d'ordre définie dans un niveau permet de vérifier
facilement l'appartenance d'un chunk à un bloc de chunks.
Exemple 3.6 : Identification d'un bloc de chunks
La figure 3.14 présente une section de la table de faits « patient » qui représente
un ensemble contigu de chunks.

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 57
id_patient
Toulon 1925-12-01 asthme 16831 1
Toulon 1926-11-01 pneumonie 17322 0
... ... ... ... ...
Marseille 1938-05-06 épilepsie 17609 1
Bourg-en-Bresse 1925-09-21 15099 0
Bourg-en-Bresse 1926-01-05 grippe 19936 1
Bourg-en-Bresse 1930-10-30 asthme 18650 0
Bourg-en-Bresse 1931-04-27 pneumonie 21261 0
Bourg-en-Bresse 1932-04-30 20905 1
Bourg-en-Bresse 1933-11-10 asthme 20407 1
Bourg-en-Bresse 1934-02-12 mal. de Parkinson 19131 1
Bourg-en-Bresse 1934-03-16 21352 0
Bourg-en-Bresse 1934-05-23 mal. de Parkinson 21871 1
Bourg-en-Bresse 1935-07-29 20835 0
Bourg-en-Bresse 1935-12-14 asthme 20039 1
Bourg-en-Bresse 1936-04-22 pneumonie 19768 0
Bourg-en-Bresse 1936-11-05 mal. de Parkinson 17250 1
... ... ... ... ...
1935-01-17 mal. de Parkinson 19060 0
1935-10-12 asthme 21283 1
1935-11-06 asthme 20513 0
1936-03-18 pneumonie 22267 1
1937-06-11 asthme 18067 1
... ... ... ... ...
Grenoble 1929-07-20 grippe 20980 0
Grenoble 1931-07-05 18232 0
Grenoble 1931-11-27 mal. de Parkinson 20731 0
Grenoble 1933-07-25 mal. de Parkinson 18302 1
Grenoble 1934-11-13 asthme 15012 1
Grenoble 1935-04-20 asthme 21762 0
Grenoble 1936-08-12 grippe 18282 1
... ... ... ... ...
Lyon 1933-08-03 méningite 16348 0
Lyon 1935-07-02 asthme 21742 0
Lyon 1935-09-07 méningite 18902 0
Lyon 1936-05-18 grippe 16665 1
Alexandrie 1929-11-11 mal. de Parkinson 20887 1
... ... ... ... ...
Turin 1937-02-05 22375 0
lieu_naiss date_naiss pathologie décès
mal. d'Alzheimer
bronchite et éphysème
bronchite et éphysème
mal. d'Alzheimer
St Etienne
St Etienne
St Etienne
St Etienne
St Etienne
bronchite et éphysème
mal. d'Alzheimer
Figure 3.14 : Bloc de chunks contigus dans la table de faits « patient »
Les parties encadrées en gras représente un bloc de chunks B dont l'identifiant b
est :
b = <{lieu.ville.Bourg-en-Bresse, temps.date.1930-10-30,
pathologie.path-0.pneumonie},
{lieu.ville.Lyon, temps.date.1936-05-18, pathologie.path-0.asthme}>
(equ. <{1.0.4, 2.0.32, 3.0.7},{1.0.7, 2.0.75, 3.0.10}>)
La table de faits étant triée par lieu de naissance, date de naissance et
pathologie, les chunks inclus dans le bloc ne sont pas contigus au niveau de la
table elle-même. Néanmoins, ces chunks sont contigus dans l 'espace
multidimensionnel. Les membres de la dimension « lieu » sont compris entre
'Bourg-en-Bresse' et 'Lyon', ceux de la dimension « temps » entre 1930-10-30 et
1936-05-18 et les membres de la dimension « pathologie » sont compris entre
'pneumonie' et 'asthme'.

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 58
Si on note c = {lieu.ville.X, temps.date.Y, pathologie.path-0.Z} (equ. {1.0.x,
2.0.y, 3.0.z}) l'identifiant d'un chunk C avec x,y,z les rangs des membres
respectifs dans l'ordre total défini pour chacune des dimensions « lieu »,
« temps » et « pathologie », alors, la condition nécessaire et suffisante pour que
c appartienne au bloc de chunks B est :
1930 10 30 1936 05 18
4 7 32 75 7 10
C B rang Bourg en Bresse x rang Lyon
rang y rang
rang pneumonie z rang asthme
x y z
Dans l'espace multidimensionnel, la notion de bloc représente un hyper-
rectangle dans l'espace formé par les ensembles de membres de dimension et
permet de gérer les fragments de l'entrepôt répartis sur les nœuds de la grille.
Nous détaillons par la suite la représentation des fragments de l'entrepôt de
données par ces blocs de chunks et leur déploiement sur la grille.
4 Indexation de données multidimensionnelles
La structure d'indexation que nous allons détailler associe une indexation pour
les différents niveaux d'agrégation, et, pour chaque niveau, une indexation
spatiale des données multidimensionnelles. En effet, il est nécessaire de
considérer ces deux modes d'indexation afin d'assurer la recherche des données
disponibles sur un nœud de la grille.
Le premier index, que nous appelons index T, est structuré en treillis et
distingue les données détaillées et les agrégats de différents niveaux sur le
nœud. Le deuxième index, que nous appelons index X, s'appuie sur une
indexation spatiale en X-tree du contenu des blocs de chunks. L'index TX, qui
permet d'indexer les données multidimensionnelles sur un nœud de la grille,
résulte de la combinaison de ces deux index. Des primitives pour la
maintenance (insertion, suppression) et la recherche au sein de la structure
d'index sont ensuite proposées.
4.1 Index T sur les différents niveaux d'agrégation
Classiquement, on définit un treillis de cuboïdes comme le graphe des agrégats
calculables à partir d'un cube de base (Harinarayan et al., 1996). Un sommet
représente un cuboïde à un niveau d'agrégation défini par la combinaison des
niveaux hiérarchiques de chaque dimension. Afin d'indexer les niveaux
d'agrégation présents sur chaque nœud de la grille, nous introduisons une
structure d'index T inspirée des treillis de cuboïdes. La structure de l 'index T

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 59
prend uniquement en compte le niveau d'agrégation des blocs disponibles sur le
nœud de la grille.
Définition 3.13 : Index T en treillis de niveaux d'agrégation
L'index T en treillis de niveaux d'agrégation est un graphe orienté
acyclique (V,E) constitué par un ensemble V de sommets et un
ensemble E d'arêtes, tels que :
- un sommet est créé dans V pour chaque niveau d'agrégation de
données disponibles sur le nœud
- une arête entre deux sommets est définie s'il existe au moins un
lien de filiation entre les niveaux hiérarchiques de ces sommets
Soit levels la fonction qui permet d'extraire à partir d'un identifiant de bloc la
liste de ses niveaux hiérarchiques.
Ainsi, pour b = <cinf , csup> avec
cinf = {nomDimension1.nomNiveau1.nomMembre1,…,
nomDimensionn.nomNiveaun.nomMembren} et
csup = {nomDimension1.nomNiveau1.nomMembre1',…,
nomDimensionn.nomNiveaun.nomMembren'}, on a :
levels(b) = {nomNiveau1,…,nomNiveaun}
Un sommet du treillis regroupe tous les blocs de chunks aux niveaux
hiérarchiques levels(b) identiques, donc du même niveau d'agrégation sur un
nœud de la grille. Les arêtes entre les sommets indiquent les opérations
d'agrégation nécessaires pour passer d'un niveau d'agrégation plus détaillé vers
un niveau plus agrégé pour chaque dimension.
Exemple 3.7 : Construction d'un index en treillis de niveaux d'agrégation
Prenons par exemple un nœud de la grille hébergeant cinq blocs détaillés bd, be,
bf, bg et bh ainsi qu'un ensemble de blocs agrégés bk, bl et bm contenant des
agrégats à des niveaux hiérarchiques supérieurs pour les dimensions « lieu » et
« temps » :
Les identifiants des blocs de chunks détaillés sont :
bd =
<{lieu.ville.Toulon, temps.date.1925-01-23, pathologie.path-0.méningite},
{lieu.ville.Grenoble, temps.date.1926-12-28,
pathologie.path-0.pneumonie}>
(equ. <{1.0.1, 2.0.1, 3.0.1},{1.0.6, 2.0.10, 3.0.7}>)
be =

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 60
<{lieu.ville.Toulon, temps.date.1929-01-12, pathologie.path-0.méningite},
{lieu.ville.Marseille, temps.date.1939-12-10, pathologie.path-0.épilepsie}>
(equ. <{1.0.1, 2.0.21, 3.0.1},{1.0.3, 2.0.103, 3.0.6}>)
bf =
<{lieu.ville.Toulon, temps.date.1927-01-13, pathologie.path-0.méningite},
{lieu.ville.St Etienne, temps.date.1928-12-27,
pathologie.path-0.sclérose en pl.}>
(equ. <{1.0.1, 2.0.11, 3.0.1},{1.0.5, 2.0.20, 3.0.5}>)
bg =
<{lieu.ville.Alexandrie, temps.date.1925-01-23, pathologie.path-0.grippe},
{lieu.ville.Turin, temps.date.1928-12-27, pathologie.path-0.asthme}>
(equ. <{1.0.8, 2.0.1, 3.0.8},{1.0.10, 2.0.20, 3.0.10}>)
bh =
<{lieu.ville.Lyon, temps.date.1929-01-12, pathologie.path-0.grippe},
{lieu.ville.Turin, temps.date.1939-12-10, pathologie.path-0.asthme}>
(equ. <{1.0.7, 2.0.21, 3.0.8},{1.0.10, 2.0.103, 3.0.10}>)
Les identifiants de blocs de chunks agrégés sont :
bk =
<{lieu.région.Rhône Alpes, temps.mois.1925-09,
pathologie.path-0.méningite},
{lieu.région.Piémont, temps.mois.1927-11, pathologie.path-0.asthme}>
(equ. <{1.1.2, 2.1.2, 3.0.1},{1.1.3, 2.1.13, 3.0.10}>)
bl =
<{lieu.ville.Bourg-en-Bresse, temps.année.1928,
pathologie.path-0.méningite},
{lieu.ville.Turin, temps.année.1939, pathologie.path-0.asthme}>
(equ. <{1.0.4, 2.2.4, 3.0.1},{1.0.10, 2.2.15, 3.0.10}>)
bm =
<{lieu.pays.Italie, temps.année.1925, pathologie.path-0.méningite},
{lieu.pays.Italie, temps.année.1928, pathologie.path-0.asthme}>
(equ. <{1.2.2, 2.2.1, 3.0.1},{1.2.2, 2.2.4, 3.0.10}>)
Le treillis construit à partir des identifiants de ces blocs comprend quatre
sommets v0,v1,v2 et v4 avec les niveaux hiérarchiques suivants :
- levels(v0) = {ville, date, path-0} (equ. {0,0,0})
- levels(v1) = {région, mois, path-0} (equ. {1,1,0})
- levels(v2) = {ville, année, path-0} (equ. {0,2,0})
- levels(v3) = {pays, année, path-0} (equ. {2,2,0})
Indépendamment de l'ordre d'insertion des blocs dans l'index, le treillis résultat
prend la forme illustrée par la figure 3.15.

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 61
v0
v1
v2
v3
répartition des identifiants de blocssur les sommets du treillis :v
0 (equ. {0,0,0}) : b
d, b
e, b
f, b
g, b
h
v1 (equ. {1,1,0}) : b
k
v2 (equ. {0,2,0}) : b
l
v3 (equ. {2,2,0}) : b
m
Figure 3.15 : Index en treillis de blocs matérialisés
Grâce à cette structure, chaque sommet peut être atteint depuis tous les
sommets ayant un niveau d'agrégation inférieur dans au moins une des
dimensions. La recherche d'un sommet dans le treillis est toujours effectuée à
partir du sommet racine qui indexe les données les plus détaillées.
Comme décrit précédemment, un bloc de chunks est associé selon son niveau
d'agrégation à un sommet de l'index T. Nous allons maintenant définir un index
spatial en X-tree pour indexer les blocs de chunks dans l'espace
multidimensionnel de données.
4.2 Index X sur les blocs de chunks
Le X-tree (Berchtold et al., 1996) est une extension du R*-tree (Beckmann et
al., 1990) qui minimise le nombre de zones indexées par plusieurs sous-arbres
afin d'offrir un temps de recherche constant. Par rapport au R*-tree, le X-tree
présente les caractéristiques suivantes :
- Il introduit une limite supérieure de tolérance pour le chevauchement relatif
de deux rectangles minimaux englobant caractérisant deux nœuds
intermédiaires.
- La division de nœuds intermédiaires est faite selon un algorithme basé sur
l'historique des divisions de tous les sous-arbres dépendants si l'algorithme
standard ne satisfait pas la contrainte de chevauchement maximum.
- Des nœuds intermédiaires de capacité variable permettent d'éviter les
fissions qui engendreraient un chevauchement au-delà du maximum toléré.
Ceci permet à l'arbre de grandir « en largeur », augmentant ainsi la
proportion de recherche séquentielle, préférable à la visite de plusieurs
sous-arbres superposés dans la zone recherchée.
Le X-tree reste équilibré en permanence et sa hauteur est limitée par rapport au
nombre d'objets indexés. Une recherche dans l'arbre se fait donc en O(log n)

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 62
avec n le nombre de blocs indexés. Ce mécanisme rend le X-tree
particulièrement bien adapté à l'indexation d'objets spatiaux ayant un grand
nombre de dimensions. Or, l'ensemble de blocs associés à un sommet de l'index
T peut être assimilé à un ensemble d'hyper-rectangles de l'espace
multidimensionnel construit à partir des ensembles de membres de chaque
dimension. La figure 3.16 présente l'association des sommets du treillis de
l'index T et des blocs dans l'espace multidimensionnel (limité ici à deux
dimensions) qui sont indexés par l'index X sur chaque sommet.
LIEU(ville)
ba
bb
bc
TEMPS(date)
v0
v1
v2
v3
LIEU(ville)
b'
b*
TEMPS(année)
Figure 3.16 : Index TX associant les sommets de l'index T en treillis et blocs de chunks
dans l'espace multidimensionnel
Soit i
i
lM l'ensemble ordonné de membres de la dimension Di au niveau
hiérarchique li. L'espace de données est alors décrit par le produit cartésien 1
1
n
l ln
M M . Les hyper-rectangles à indexer dans cet espace sont créés à
partir des coordonnées des limites inférieures et supérieures des identifiants de
blocs de chunks indexés par le sommet de l 'index T. Pour connaître les blocs de
chunks associés à chaque sommet de l'index T, nous introduisons un index, que
nous appelons index X.
Définition 3.14 : Index X des données multidimensionnelles
L'index X est un X-tree qui indexe le contenu des données
multidimensionnelles d'un ensemble de blocs associé à un sommet de
l'index T.
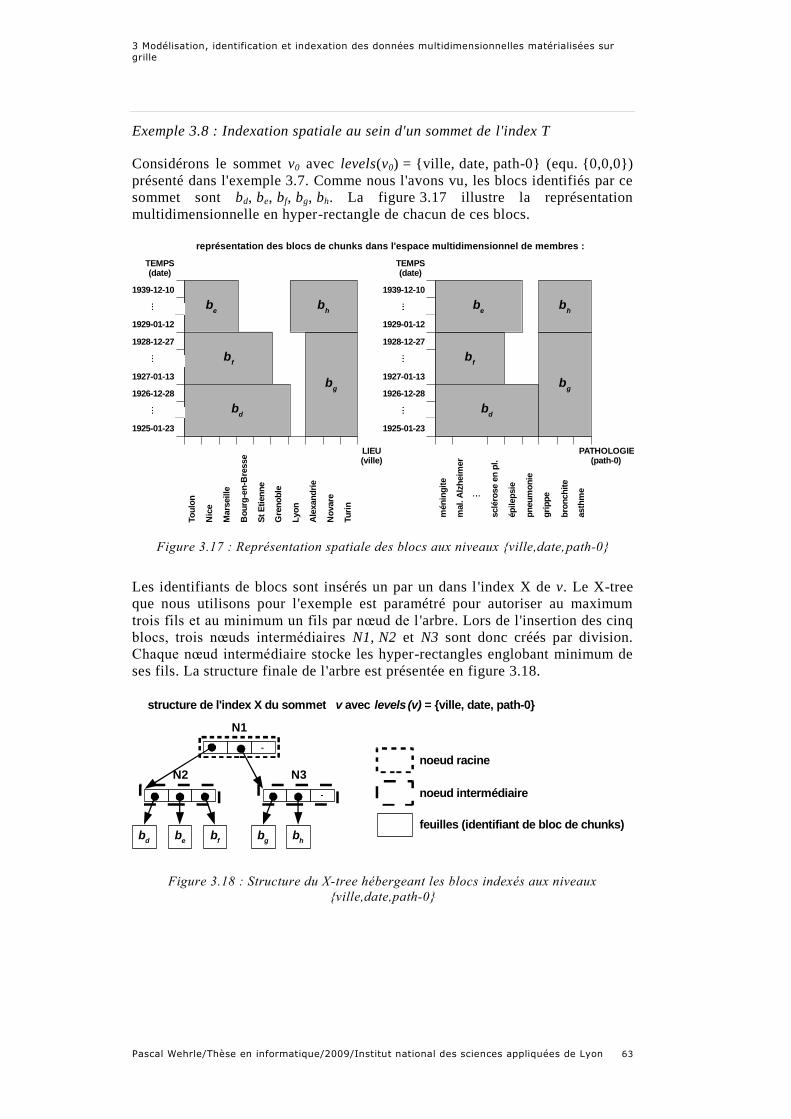
3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 63
Exemple 3.8 : Indexation spatiale au sein d'un sommet de l'index T
Considérons le sommet v0 avec levels(v0) = {ville, date, path-0} (equ. {0,0,0})
présenté dans l'exemple 3.7. Comme nous l'avons vu, les blocs identifiés par ce
sommet sont bd, be, bf, bg, bh. La figure 3.17 illustre la représentation
multidimensionnelle en hyper-rectangle de chacun de ces blocs.
bf
bd
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
be
bf
bd
bg
be
bh
bg
bh
représentation des blocs de chunks dans l'espace multidimensionnel de membres :
1925-01-23
TEMPS(date)
1927-01-13
1926-12-28
1928-12-27
1929-01-12
1939-12-10
1925-01-23
TEMPS(date)
1927-01-13
1926-12-28
1928-12-27
1929-01-12
1939-12-10
Figure 3.17 : Représentation spatiale des blocs aux niveaux {ville,date,path-0}
Les identifiants de blocs sont insérés un par un dans l 'index X de v. Le X-tree
que nous utilisons pour l'exemple est paramétré pour autoriser au maximum
trois fils et au minimum un fils par nœud de l 'arbre. Lors de l'insertion des cinq
blocs, trois nœuds intermédiaires N1, N2 et N3 sont donc créés par division.
Chaque nœud intermédiaire stocke les hyper-rectangles englobant minimum de
ses fils. La structure finale de l'arbre est présentée en figure 3.18.
bd
bg
bh
-
- -
be
N1
N2 N3
structure de l'index X du sommet v avec levels (v) = {ville, date, path-0}
noeud racine
noeud intermédiaire
feuilles (identifiant de bloc de chunks)b
f
Figure 3.18 : Structure du X-tree hébergeant les blocs indexés aux niveaux
{ville,date,path-0}
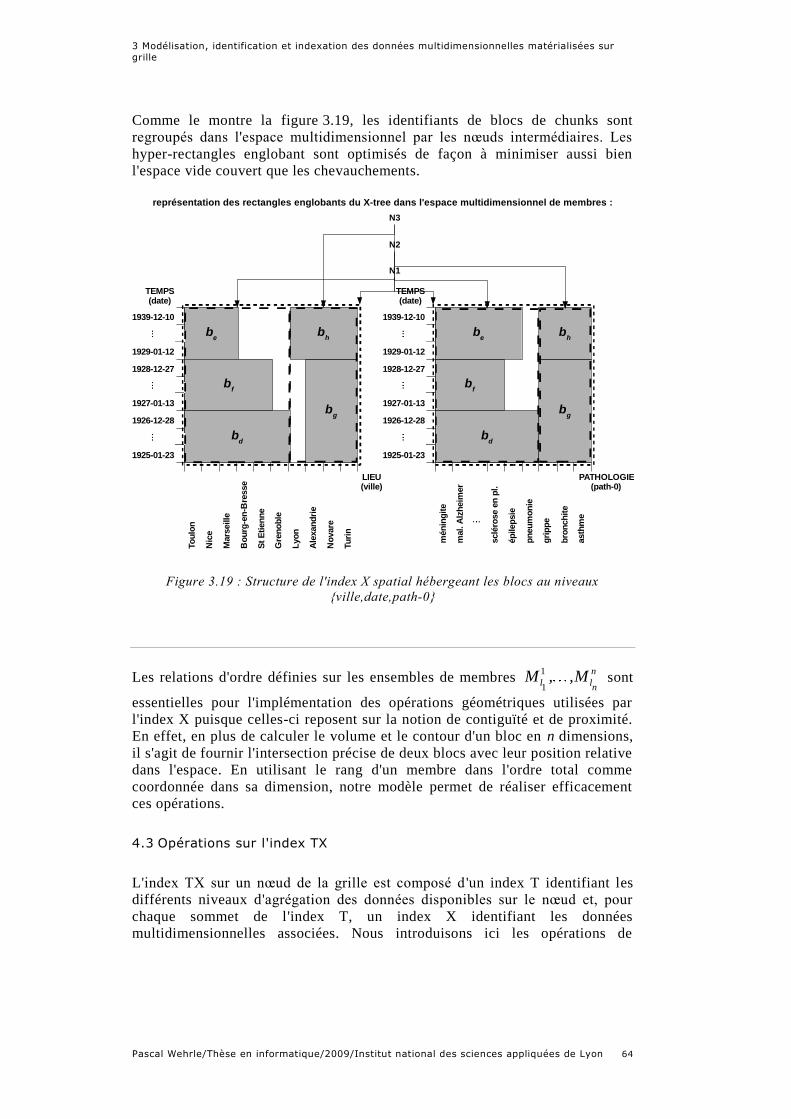
3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 64
Comme le montre la figure 3.19, les identifiants de blocs de chunks sont
regroupés dans l'espace multidimensionnel par les nœuds intermédiaires. Les
hyper-rectangles englobant sont optimisés de façon à minimiser aussi bien
l'espace vide couvert que les chevauchements.
bf
bd
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
be
bf
bd
bg
be
bh
bg
bh
représentation des rectangles englobants du X-tree dans l'espace multidimensionnel de membres :
1925-01-23
TEMPS(date)
1927-01-13
1926-12-28
1928-12-27
1929-01-12
1939-12-10
1925-01-23
TEMPS(date)
1927-01-13
1926-12-28
1928-12-27
1929-01-12
1939-12-10
N1
N2
N3
Figure 3.19 : Structure de l'index X spatial hébergeant les blocs au niveaux
{ville,date,path-0}
Les relations d'ordre définies sur les ensembles de membres 1
1
n
l ln
M , ,M sont
essentielles pour l'implémentation des opérations géométriques utilisées par
l'index X puisque celles-ci reposent sur la notion de contiguïté et de proximité.
En effet, en plus de calculer le volume et le contour d'un bloc en n dimensions,
il s'agit de fournir l'intersection précise de deux blocs avec leur position relative
dans l'espace. En utilisant le rang d'un membre dans l'ordre total comme
coordonnée dans sa dimension, notre modèle permet de réaliser efficacement
ces opérations.
4.3 Opérations sur l'index TX
L'index TX sur un nœud de la grille est composé d 'un index T identifiant les
différents niveaux d'agrégation des données disponibles sur le nœud et, pour
chaque sommet de l'index T, un index X identifiant les données
multidimensionnelles associées. Nous introduisons ici les opérations de

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 65
maintenance, c'est-à-dire l'insertion et la suppression de blocs au sein de la
structure d'index TX. L'index doit être mis à jour lorsque l 'entrepôt est rafraîchi
avec de nouvelles données et/ou lors du déplacement des données d 'un nœud de
la grille à l'autre.
4.3.1 Insertion dans l'index TX
L'index des données disponibles sur un nœud de la grille est construit par
insertions successives des identifiants de blocs matérialisés stockés sur ce
nœud. L'opération d'insertion débute par la recherche d'un sommet de l'index T
capable d'indexer le bloc à insérer. Le treillis est parcouru depuis sa racine vers
les sommets indexant les données agrégées. Si le sommet recherché n'existe pas
dans le treillis, il est créé à la position correspondante aux niveaux d'agrégation
du bloc à insérer. L'insertion du nouveau sommet dans le treillis est décrite en
détail par l'algorithme 3.1 présenté en annexe A. Une fois le bloc à insérer
associé à un sommet de l'index T, celui-ci est inséré dans l'index X hébergé par
ce sommet selon le mécanisme classique d'insertion dans les X-tree (Berchtold
et al., 1996).
Exemple 3.9 : Insertion d'un identifiant de bloc de chunks dans l'index TX
Le fonctionnement de l'insertion dans l 'index T est illustré à partir de
l'exemple 3.7. Supposons que l'index TX indexe les blocs bd, be, bf, bk et bl.
Nous insérons alors l'identifiant de bloc de chunks bm de la façon suivante :
bm =
<{lieu.pays.Italie, temps.année.1925, pathologie.path-0.méningite},
{lieu.pays.Italie, temps.année.1928, pathologie.path-0.asthme}>
(equ. <{1.2.2, 2.2.1, 3.0.1},{1.2.2, 2.2.4, 3.0.10}>)
v0
v1
v2
identifiants de blocs indexés :v
0 (equ. {0,0,0}) : b
d, b
e, b
f
v1 (equ. {1,1,0}) : b
k
v2 (equ. {0,2,0}) : b
l
v0
v1
v2
v3
● insertion de bm
● création du sommet v3 (equ. {2,2,0})
● ajout d'arêtes depuis v1 et v
2
bm
LIEU(pays)
Italie
Fra
nce
PATHOLOGIE(path-0)
mén
ing
ite
asth
me
bm
représentation de l'index X du sommet v3
dans l'espace multidimensionnel de membres :
1925
TEMPS(date)
1929
1928
1939
1925
TEMPS(date)
1929
1928
1939
noeud racine
insertion du bloc bm dans l'index T :
Figure 3.20 : Opération d'insertion sur l'index TX

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 66
L'insertion de bm engendre une recherche en profondeur sur l'index T qui
n'emploie que les chemins faits d'ancêtres du sommet v3 tels que
levels(v3) = {pays,année,path-0} (equ. {2,2,0}). Comme un tel sommet n'existe
pas dans l'index T, le sommet v3 est créé, comportant un index X vide. Ce
sommet est ensuite inséré dans le treillis de façon récursive afin d 'obtenir une
arête à l'extrémité de chaque chemin possible menant vers v3. L'identifiant de
bloc bm est ensuite inséré dans le X-tree de v3, comme le montre la figure 3.20.
4.3.2 Suppression dans l'index TX
Lors du déplacement de blocs de chunks parmi les nœuds de la grille et/ou
lorsqu'un bloc de chunks devient indisponible sur un nœud de la grille, l'index
TX est mis à jour par suppression de l'identifiant du bloc de chunks supprimé.
La procédure de suppression débute par la recherche du sommet associé aux
niveaux d'agrégation du bloc à supprimer dans l 'index T. Le bloc est ensuite
recherché et supprimé dans l'index X du sommet. Si le X-tree est vide suite à la
suppression du bloc, alors le sommet et les arêtes associées sont à leur tour
supprimés de l'index T. Si cette suppression crée un sommet isolé dans le
graphe, alors une arête est créée depuis son ancêtre le plus proche. La mise à
jour de l'index T est détaillée par l'algorithme 3.2 présenté en annexe A.
Exemple 3.10 : Suppression d'un identifiant de bloc de chunks dans l'index TX
Nous reprenons l'exemple 3.9 avec les blocs bd, be, bf, bk, bl et bm indexés sur
notre nœud de grille. Supposons que le bloc bk soit supprimé sur le nœud, nous
allons donc supprimer son identifiant de l'index TX :
bk =
<{lieu.région.Rhône Alpes, temps.mois.1925-09,
pathologie.path-0.méningite},
{lieu.région.Piémont, temps.mois.1927-11, pathologie.path-0.asthme}>
(equ. <{1.1.2, 2.1.2, 3.0.1},{1.1.3, 2.1.13, 3.0.10}>)
L'opération de suppression sur l'index T est illustrée par la figure 3.21. Le bloc
bk est recherché sur l'index T qui lui attribue le sommet v1 puis sur l'index X
associé à v1. La suppression du bloc bk dans l'index X entraîne une mise à jour
de l'index T. En effet, l'absence de blocs indexés par le X-tree du sommet v1
avec levels(v1) = {région,mois,path-0} déclenche la suppression de celui-ci dans
le treillis. Les arêtes (v0,v1) et (v1,v3) sont supprimées.

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 67
identifiants de blocs indexés :v
0 (equ. {0,0,0}) : b
d, b
e, b
f
v1 (equ. {1,1,0}) : b
k
v2 (equ. {0,2,0}) : b
l
v3 (equ. {2,2,0}) : b
m
v0
v2
v3
● suppression de bk
● suppression du sommet v1 (equ. {1,1,0})
et des arêtes depuis v0 et vers v
3
suppression du bloc bk dans l'index TX :
v0
v1
v2
v3
Figure 3.21 : Opération de suppression sur l'index T
A l'aide des opérations d'insertion et de suppression, l'index TX peut fournir et
maintenir à jour l'information sur les fragments d'entrepôt matérialisés sur un
nœud. L'index T permet d'accéder rapidement aux niveaux d'agrégation
disponibles et l'index X fournit l'information sur les positions dans l'espace
multidimensionnel de données.
5 Conclusion
Nous avons introduit dans ce chapitre un modèle multidimensionnel adapté aux
exigences d'un entrepôt de données décentralisé réparti sur les nœuds d'une
grille. L'ordonnancement des membres de dimension à travers les hiérarchies de
dimension permet de créer des identifiants uniques pour l'ensemble des données
matérialisées décrites par le modèle multidimensionnel. Il est ainsi possible
d'identifier tous les réplicas disponibles d'une donnée entreposée parmi les
nœuds de la grille. La méthode d'identification par chunks et blocs de chunks
contigus que nous avons proposée permet de localiser rapidement l'ensemble
des fragments d'entrepôt répondant à une requête. L'avantage par rapport à une
solution basée sur la médiation est que ces identifiants référencent directement
les fragments matérialisés sans nécessiter de transformation vers les schémas et
formats spécifiques aux sources de données hétérogènes. Pour faciliter l'accès
aux informations sur les blocs disponibles sur un nœud, nous avons conçu un
mécanisme d'indexation utilisant les identifiants introduits. L'index TX
regroupe les données de mêmes niveaux d'agrégation et indexe les composantes
spatiales des blocs de chunks dans l'espace multidimensionnel de données. Au
lieu de centraliser la gestion de la répartition des fragments, l'entrepôt réparti

3 Modélisation, identification et indexation des données multidimensionnelles matérialisées sur
grille
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 68
publie l'information sur la disponibilité par blocs de données de façon
entièrement décentralisée à l'aide des index TX déployés sur chaque nœud. Les
nœuds de la grille peuvent donc gérer les données multidimensionnelles qu'ils
hébergent de façon autonome et répartissent ainsi la charge sans coordination
centrale. De plus, l'information sur le modèle multidimensionnel ainsi répartie
permet de déduire l'ensemble des agrégats calculables sur chaque nœud. Il nous
faut intégrer cette information au mécanisme d'indexation de l'index TX. Cet
aspect est développé par le chapitre suivant.



Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 71
Chapitre 4 Intégration et gestion des
agrégats calculables
Une grande partie des requêtes traitées par un entrepôt de données portent sur
des agrégats, tels la somme ou la moyenne des mesures à différents niveaux de
détail des dimensions. Ces requêtes nécessitent des calculs parfois coûteux sur
les données détaillées. Il est classique qu'une partie de ces agrégats
fréquemment utilisés peut être matérialisée par avance grâce aux capacités de
stockage et de calcul mises à disposition par la grille. Comme nous l'avons vu
au chapitre 3, les données détaillées et les agrégats matérialisés sont distribués
et parfois répliqués sur les différents nœuds de la grille. Les agrégats
manquants sont calculés à la volée au moment du requêtage. Il existe ainsi
plusieurs stratégies pour l'obtention d'un agrégat. Ainsi, compte tenu de
l'évolution de l'accessibilité des nœuds et des coûts de transfert, il est parfois
plus judicieux de calculer un agrégat à partir des données existantes que de le
transférer depuis un nœud distant.
Pour sélectionner la meilleure stratégie, il est nécessaire de répertorier a priori
les possibilités d'obtention des agrégats à partir des données détaillées ou
d'autres agrégats de niveaux inférieurs. L'indexation des blocs de chunks que
nous avons présenté au chapitre 3 recense l'ensemble des données détaillées et
agrégats matérialisés sur un nœud de la grille. C 'est pourquoi nous proposons
d'étendre notre structure d'indexation à l'ensemble des données calculables à
partir des données matérialisées.
Pour cela, il nous faut :
- déduire les données calculables à partir de données détaillées ou agrégats
matérialisés sur un nœud,
- recueillir les informations nécessaires à l'obtention de l'agrégat calculable,
- étendre l'index TX à ces agrégats.
1 Principes d'obtention des agrégats calculables
Les blocs de chunks matérialisés sur les nœuds de la grille sont représentés par
leurs identifiants, comme introduits au chapitre 3. Ces identifiants sont indexés
au niveau local sous forme d'hyper-rectangles dans l'espace de données
multidimensionnel de chaque niveau d'agrégation existant sur le nœud. Les
parties de cet espace recouvert par un ou plusieurs blocs représentent les
données utilisables pour le calcul d'agrégats. La combinaison de blocs de
données nécessaires à l'obtention d'un agrégat s'effectue dans l'espace
multidimensionnel décrit par les schémas hiérarchiques et les instances locales
des dimensions (voir chapitre 3). Nous appelons « blocs sources » les blocs
utilisés pour le calcul des agrégats et « partie utile d'un bloc source » la partie
réellement utilisée pour fournir l'agrégat. Afin de maximiser la taille des

4 Intégration et gestion des agrégats calculables
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 72
agrégats, il est nécessaire dans un premier temps de détecter des volumes de
données contigus parmi les données matérialisées. Ainsi, certains blocs de
chunks matérialisés pourront être « fusionnés » dans la dimension d'agrégation.
Cette fusion doit avoir la forme de bloc de chunks pour pouvoir servir de base
pour la construction d'un bloc calculable au niveau agrégé. A leur tour, les
blocs calculables pourront être utilisés pour calculer de nouveaux agrégats de
niveaux supérieurs.
L'information sur les blocs sources et les parties à en extraire doit être associée
à l'agrégat calculable. Ces informations seront utiles lors de l'exécution de
requêtes. De plus, s'il existe plusieurs stratégies d'obtention d'un agrégat
calculable, l'estimation du coût d'extraction de la partie utile de chaque bloc
source sera utilisée. Ainsi, la liste de blocs sources nécessaires pour obtenir un
bloc calculable est intégrée dans une structure de plan de calcul associé au bloc
calculable. Pour chaque bloc source, le plan contient également le bloc
désignant la partie utile du bloc source et l'estimation de coût pour son
extraction.
2 Construction de blocs de chunks calculables
Un bloc de chunks calculable est un bloc de chunks au sens de la définition
introduite au chapitre 3. Ses chunks ne sont pas matérialisés sur le nœud, mais
peuvent être obtenus à partir de l 'agrégation de chunks matérialisés sur ce
nœud. Le bloc de chunks calculable est décrit par un identifiant de bloc, associé
à un plan de calcul référençant les blocs sources, les parties extraites de ceux -ci
et le coût estimé de cette extraction.
A partir d'un bloc source, on peut obtenir un nouveau bloc calculable contenant
un chunk pour le membre m si le bloc source contient des chunks pour tous les
membres fils de m. Suite à la fragmentation et au comportement dynamique de
l'entrepôt, il se peut que les fils nécessaires au calcul d'une agrégation ne soient
pas dans le même bloc de chunks mais dans plusieurs blocs sur le même nœud.
Dans ce cas, il est intéressant de construire des assemblages de blocs du nœud
afin de constituer un bloc source contenant tous les fils nécessaires. Cet
assemblage est réalisé en fusionnant géométriquement les blocs sources dans
l'espace multidimensionnel.
2.1 Fusion géométrique de blocs de chunks
L'intérêt de regrouper les blocs de chunks disponibles par une opération de
fusion géométrique réside dans la possibilité d'obtenir des chunks agrégés dont
les descendants sont initialement répartis sur plusieurs blocs sources. Prenons
par exemple un bloc de chunks, identifié par bx, contenant des chunks pour tous
les membres au niveau mois entre janvier et septembre 1925 dans la dimension
« temps » et by contenant des chunks pour tous les membres d'octobre 1925 à
juin 1926. bx et by permettent de calculer un bloc d'agrégats au niveau « année »
pour le membre 1925 si les membres associés aux chunks de bx et by dans les
autres dimensions sont identiques. Ainsi, un chunk associé par exemple à la

4 Intégration et gestion des agrégats calculables
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 73
ville de Nice dans la dimension « lieu » ne peut être utilisé avec un chunk
associé à Lyon pour calculer le chunk agrégé contenant les agrégats pour
l'année 1925 sur la ville de Lyon. Il est nécessaire de déterminer comment les
positions relatives de plusieurs blocs dans l 'espace multidimensionnel peuvent
permettre leur fusion en vue de l'obtention d'un bloc calculable.
Soient b et b' deux blocs de chunks tels que :
- b et b' sont adjacents ou bien b et b' ont une intersection non nulle sur la
dimension Di au niveau j,
- et b et b' ont une intersection non vide sur toutes les autres dimensions,
alors on peut extraire le bloc de chunk maximum noté fusion(b,b',Di) contenu
dans l'union des blocs de chunks b et b'. Ce bloc de chunks correspond à
l'hyper-rectangle contenu dans l'union géométrique des hyper-rectangles
représentant b et b' couvrant le maximum de membres dans la dimension Di et
correspondant à l'intersection de b et b' dans les autres dimensions.
Notons 1 2,m m l'intervalle des membres du bloc b dans la dimension Di au
niveau j et 1 2,m m l'intervalle des membres du bloc b' dans la dimension Di au
niveau j, alors l'adjacence de b et b' est vérifiée si :
2 1 2 1 2 1 2 1, ,m m m m m m m m
L'intersection de b et b' est vérifiée si :
1 2 1 2, ,m m m m
Lorsque deux blocs sont ainsi adjacents ou ont une intersection non nulle sans
être entièrement superposés dans la dimension Di, leur inclusion dans un bloc
calculable agrégé dans cette dimension est pertinente. En effet, les chunks de
données complémentaires inclus dans le bloc calculable permettent l'obtention
d'un ensemble d'agrégats maximum dans la dimension Di. Nous formalisons
cette combinaison des blocs sources et définissons ainsi la fusion de blocs de
chunks.
Définition 4.1 : Fusion de blocs de chunks
La fusion dans la dimension Di de deux identifiants de blocs de chunks
b et b' adjacents ou ayant une intersection non vide, notée
fusion(b,b',Di) est le plus grand hyper-rectangle contenu dans l'union
géométrique de b et b'. L'identifiant de fusion(b,b',Di) est composé des
membres de l'intersection de b et b' dans toutes les dimensions Dj
avec 1,..., ,j n j i et les membres de l'union de b et b' dans la
dimension Di.

4 Intégration et gestion des agrégats calculables
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 74
L'exemple qui suit illustre les possibilités de fusion de deux blocs de chunks en
vue d'une création d'un bloc de chunks regroupant les données sources pour un
bloc calculable. Nous détaillons le cas où les blocs sont adjacents dans
plusieurs dimensions et le cas où les blocs sont en partie superposés.
Exemple 4.1 : Fusion de blocs de chunks
Le cas particulier des blocs de chunks adjacents dans une dimension est illustré
par la figure 4.1. Cet exemple utilise les deux blocs de chunks b1 et b2 aux
niveaux levels(b1) = levels(b2) = {ville, date, path-0}, qui ont une intersection
vide.
b2
1925-01-23
TEMPS(date)
1931-07-05
⋮
1931-06-27
⋮
1934-12-28
1935-01-17
⋮
1939-12-10
b1
1925-01-23
TEMPS(date)
1931-07-05
⋮
1931-06-27
⋮
1934-12-28
1935-01-17
⋮
1939-12-10
b1
b2
positions de blocs de chunks adjacents sans intersection et de leur fusion dans la dimension « temps » :
fusion dans la dimension « temps »
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
Figure 4.1 : Fusion de blocs de chunks adjacents dans la dimension « temps »
Pour la dimension « temps » D2, l'intersection entre b1 et b2 est vide. Bien que
les intersections dans les autres dimensions soient toutes non nulles,
l'intersection dans l'espace multidimensionnel est également vide. Il est
néanmoins possible de créer un intervalle contigu de membres, car les
intervalles de membres en D2 se touchent :
'1931 06 27', '1931 07 05' '1931 06 27' '1931 07 05'
Les blocs b1 et b2 peuvent donc être fusionnés, mais uniquement dans la
dimension « temps ». Le résultat de la fusion sera le nouveau bloc ayant pour
identifiant :
fusion(b1,b2,D2) =
<{lieu.ville.Toulon, temps.date.1925-01-23, pathologie.path-0.méningite},

4 Intégration et gestion des agrégats calculables
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 75
{lieu.ville.Bourg-en-Bresse, temps.date.1934-12-28,
pathologie.path-0.épilepsie}>
(equ. <{1.0.1, 2.0.1, 3.0.1},{1.0.4, 2.0.60, 3.0.6}>)
Le deuxième cas illustré dans cet exemple est basée sur deux blocs identifiés
par b3 et b4 aux niveaux levels(b3) = levels(b4) = {ville, date, path-0}, dont les
positions relatives sont présentées en figure 4.2.
Nous obtenons une intersection non nulle entre les deux identifiants de blocs :
3 4b b =
<{lieu.ville.Bourg-en-Bresse, temps.date.1931-07-05,
pathologie.path-0.méningite},
{lieu.ville.Lyon, temps.date.1934-12-28, pathologie.path-0.épilepsie}>
(equ. <{1.0.4, 2.0.37, 3.0.1},{1.0.7, 2.0.60, 3.0.6}>)
positions de blocs de chunks et de leur fusion dans les dimensions « temps » et « lieu » :
fusion dans la dimension « lieu »fusion dans la dimension « temps »
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
1925-01-23
TEMPS(date)
1927-01-13
1926-12-28
1928-12-27
1929-01-12
1939-12-10
1925-01-23
TEMPS(date)
1927-01-13
1926-12-28
1928-12-27
1929-01-12
1939-12-10
b3
b4
b3
b4
Figure 4.2 : Fusion de blocs de chunks dans les dimensions « temps » et « lieu »
En conséquence, la fusion de b3 et b4 est possible dans toutes les dimensions.
Pour les dimensions « lieu » D1 et « temps » D2, les blocs fusionnés sont
illustrés en figure 4.2. Pour la dimension « pathologie » D3, la fusion est égale à
l'intersection, donc plus petite qu'au moins l'un des deux blocs. Elle n'est donc
pas intéressante pour un bloc calculable dans la dimension D3 regroupant b3 et
b4.

4 Intégration et gestion des agrégats calculables
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 76
L'opération de fusion permet de faire émerger des hyper-rectangles maximum
au niveau i d'une dimension qui seront utilisés pour le calcul d'agrégats au
niveau i+1.
2.2 Parties utiles pour l'obtention du bloc calculable
La fusion d'un ou plusieurs blocs sources au niveau i sert de base à la
construction d'un bloc calculable sur le niveau i+1 de la dimension
sélectionnée. A partir des identifiants de blocs fusionnés et des instances
locales des dimensions, il est possible de construire les identifiants de blocs
calculables au niveau i+1. Les blocs de chunks étant composés de chunks
ordonnés et contigus, il suffit d'utiliser les limites inférieures et supérieures du
bloc fusionné au niveau i et le schéma hiérarchique de la dimension pour en
déduire l'ensemble des chunks calculables au niveau i+1. L'algorithme pour la
construction du bloc de chunks calculable transpose au niveau i+1 l'intervalle
que représente la fusion au niveau i, en éliminant les membres au niveau i+1
pour lesquelles tous les descendants ne sont pas représentés dans la fusion des
blocs sources. Il construit ainsi des intervalles aux extrémités du bloc fusion qui
ne sont pas utilisables pour le calcul de l'agrégat au niveau supérieur. Pour
déterminer les parties utiles de chaque bloc source, ces intervalles « inutiles »
sont enlevés dans la partie que chaque bloc source contribue à la fusion. Lors
de cette opération, les parties utiles bp des blocs sources bs, c'est-à-dire les
chunks réellement utilisés pour le calcul de l'agrégat, sont identifiés.
Par exemple, en prenant les blocs bx et by, avec bx contenant des chunks pour
tous les membres au niveau mois entre janvier et septembre 1925 dans la
dimension « temps » et by contenant des chunks pour tous les membres
d'octobre 1925 à juin 1926. La fusion des deux blocs dans la dimension
« temps » contient donc les membres de janvier 1925 à juin 1926 inclus. La
transposition de la fusion vers le niveau année contient uniquement le membre
1925, car tous les mois de 1926 ne sont pas couverts par la fusion. Pour
constituer l'agrégat pour l'année 1925, il nous faut utiliser tous les chunks de bx
et une partie des chunks de by. La partie utile dans la dimension « temps » du
bloc source bx est donc constituée de l'intervalle allant de janvier à juin 1925,
celle du bloc source by de l'intervalle allant de juillet à décembre 1925.
L'exemple qui suit illustre la procédure pour le cas multidimensionnel.
Exemple 4.2 : Parties utiles de blocs sources associées à un bloc de chunks
calculable
Nous prenons comme exemple la construction du bloc calculable bc1 à partir de
la fusion de deux blocs source matérialisés b5 et b6. La figure 4.3 présente les
positions dans l'espace multidimensionnel de ces blocs. Pour chacun des blocs
sources, nous sélectionnons la partie utile du bloc pour le calcul de bc1. Comme
le montre la figure 4.3, l'intégralité des chunks du bloc b5 est utilisée pour le
calcul de bc1. Nous obtenons donc un identifiant de partie utile bp5 = b5. Parmi
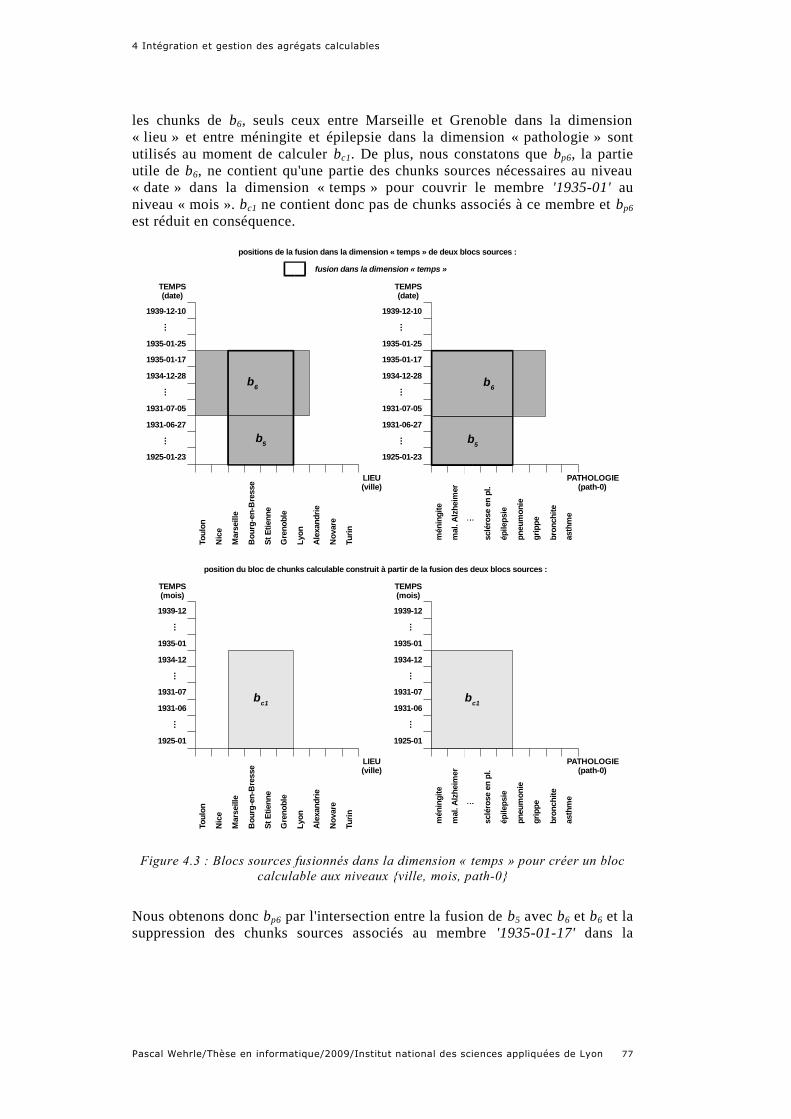
4 Intégration et gestion des agrégats calculables
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 77
les chunks de b6, seuls ceux entre Marseille et Grenoble dans la dimension
« lieu » et entre méningite et épilepsie dans la dimension « pathologie » sont
utilisés au moment de calculer bc1. De plus, nous constatons que bp6, la partie
utile de b6, ne contient qu'une partie des chunks sources nécessaires au niveau
« date » dans la dimension « temps » pour couvrir le membre '1935-01' au
niveau « mois ». bc1 ne contient donc pas de chunks associés à ce membre et bp6
est réduit en conséquence.
positions de la fusion dans la dimension « temps » de deux blocs sources :
fusion dans la dimension « temps »
b5
1925-01-23
TEMPS(date)
1931-07-05
⋮
1931-06-27
⋮
1934-12-28
1935-01-17
⋮
1939-12-10
1935-01-25
b6
b6
b5
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
1925-01-23
TEMPS(date)
1931-07-05
⋮
1931-06-27
⋮
1934-12-28
1935-01-17
⋮
1939-12-10
1935-01-25
1925-01
TEMPS(mois)
1931-07
⋮
1931-06
⋮
1934-12
1935-01
⋮
1939-12
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
1925-01
TEMPS(mois)
1931-07
⋮
1931-06
⋮
1934-12
1935-01
⋮
1939-12
bc1
bc1
position du bloc de chunks calculable construit à partir de la fusion des deux blocs sources :
Figure 4.3 : Blocs sources fusionnés dans la dimension « temps » pour créer un bloc
calculable aux niveaux {ville, mois, path-0}
Nous obtenons donc bp6 par l'intersection entre la fusion de b5 avec b6 et b6 et la
suppression des chunks sources associés au membre '1935-01-17' dans la

4 Intégration et gestion des agrégats calculables
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 78
dimension « temps ». Pour le bloc calculable bc1, nous obtenons donc la liste de
blocs sources Lc(bc1) = {<bp5, b5>, <bp6, b6>}, où :
bp5 = b5,
bp6 =
<{lieu.ville.Marseille, temps.date.1931-07-05, pathologie.path-0.méningite},
{lieu.ville.Grenoble, temps.date.1934-12-28, pathologie.path-0.épilepsie}>
(equ. <{1.0.3, 2.0.37, 3.0.1},{1.0.6, 2.0.60, 3.0.6}>)
2.3 Plans de calcul associés aux blocs calculables
L'objectif du plan de calcul que nous construisons et associons à chaque bloc
calculable est de faciliter l'exécution de requêtes en permettant d'accéder à
l'ensemble de l'information sur les blocs sources utilisés par le bloc calculable.
Les éléments du plan de calcul d'un bloc calculable sont les blocs de chunks
sources, leurs parties utiles pour l'obtention du bloc calculable et une estimation
de coût pour l'extraction des parties utiles. Nous définissons ce plan de calcul
de la façon suivante :
Définition 4.2 : Plan de calcul associé à un bloc de chunks calculable
Un plan de calcul Pc associé à un bloc de chunks calculable bc est un
ensemble de tuples {<bp1, S1, coutExtraction(bp1, S1)>, …, <bpn, Sn,
coutExtraction(bpn, Sn)>} où :
- bpi est l'identifiant de la partie utile de Si qui contribue au calcul
de bc,
- Si est l'identifiant du bloc source utilisé pour l'obtention de bpi. Si
est soit un bloc matérialisé, soit un bloc calculable,
- coutExtraction(bpi, Si) représente le coût estimé pour extraire la
partie utile bpi à partir de Si.
Le calcul de coût d'extraction de bp à partir d'un bloc source S dépend si S est
matérialisé ou non. Le coût d'extraction de bp à partir d'un bloc matérialisé S est
fonction du nombre de chunks de bp, du nombre de chunks de S et des coûts de
lecture sur le système de fichiers. Le nombre de chunks de bp est lié au nombre
de chunks de la source S ayant pour identifiant bs. Afin de pouvoir estimer le
coût d'extraction, nous prenons en compte le nombre de chunks nbChunks(bs)
matérialisés de chaque bloc source bs. La proportion de ces chunks qu'il faut
extraire pour obtenir la partie utile est estimée à l'aide du ratio entre les
volumes volume(bp) de la partie utile bp par rapport au bloc source entier dans
l'espace multidimensionnel de données.
*p
p s
s
volume bnbChunks b nbChunks b
volume b

4 Intégration et gestion des agrégats calculables
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 79
Si on note chunksparPage le nombre de chunks stockés sur une page disque et
tempsAccesPage le temps moyen pour accéder à une page disque, alors le coût
d'extraction pour la partie utile bp d'un bloc matérialisé bs est calculé comme
suit :
, *p
p s
nbChunks bcoutExtraction b b tempsAccesPage
chunksParPage
Si bp est obtenu à partir du bloc calculable S, alors S est associé à un plan de
calcul Ps avec Ps = {<b'p1, S'1, coutExtraction(b'p1,S'1)>,…, <b'pm, S'm,
coutExtraction(b'pm,S'm)>. Le coût d'extraction de bp selon le plan de calcul
associé à S est la somme des coûts d'extraction des blocs de Ps. Nous obtenons
donc :
1
, ,m
p pj j
j
coutExtraction b S coutExtraction b S
Chaque S'j peut lui-même être un bloc matérialisé ou calculable. Ce processus
de calcul des coûts est un procès itératif qui s'arrête lorsque tous les blocs
intervenants dans les plans de calcul sont matérialisés.
Exemple 4.3 : Plan de calcul associé à un bloc calculable
Nous allons illustrer la structure de plan de calcul à l'aide d'un bloc calculable
bc1 aux niveaux d'agrégation {ville, mois, path-0} (equ. {0,1,0}), comme
introduit par l'exemple 4.2.
Comme le montre la figure 4.4, le bloc calculable bc1 est obtenu à l'aide des
parties utiles des deux blocs sources b5 et b6 aux niveaux
{ville, date, path-0} (equ. {0,0,0}). Le plan de calcul Pc1 associé à bc1 comporte
donc les deux tuples <bp5, b5, coutExtraction(bp5, b5)> et <bp6, b6,
coutExtraction(bp6, b6)>.
Nous obtenons les valeurs suivantes pour le nombre de chunks à extraire
nbChunks(bp) :
5
5 5
5
*
3;4 * 1;36 * 1;6 864648 * 648 *
8643;4 * 1;36 * 1;6
648
p
p
volume bnbChunks b nbChunks b
volume b
chunks chunks
chunks
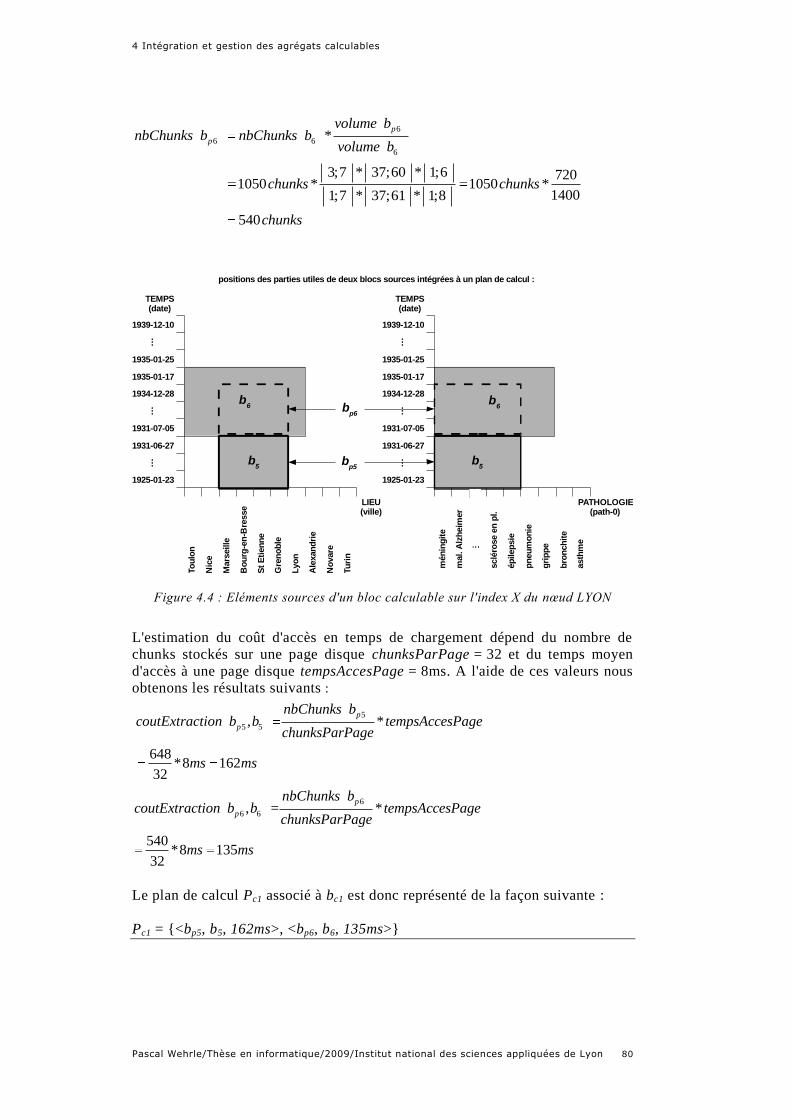
4 Intégration et gestion des agrégats calculables
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 80
6
6 6
6
*
3;7 * 37;60 * 1;6 7201050 * 1050 *
14001;7 * 37;61 * 1;8
540
p
p
volume bnbChunks b nbChunks b
volume b
chunks chunks
chunks
positions des parties utiles de deux blocs sources intégrées à un plan de calcul :
b5
1925-01-23
TEMPS(date)
1931-07-05
⋮
1931-06-27
⋮
1934-12-28
1935-01-17
⋮
1939-12-10
1935-01-25
b6
b6
b5
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
1925-01-23
TEMPS(date)
1931-07-05
⋮
1931-06-27
⋮
1934-12-28
1935-01-17
⋮
1939-12-10
1935-01-25
bp6
bp5
Figure 4.4 : Eléments sources d'un bloc calculable sur l'index X du nœud LYON
L'estimation du coût d'accès en temps de chargement dépend du nombre de
chunks stockés sur une page disque chunksParPage = 32 et du temps moyen
d'accès à une page disque tempsAccesPage = 8ms. A l'aide de ces valeurs nous
obtenons les résultats suivants :
5
5 5, *
648*8 162
32
p
p
nbChunks bcoutExtraction b b tempsAccesPage
chunksParPage
ms ms
6
6 6, *
540*8 135
32
p
p
nbChunks bcoutExtraction b b = tempsAccesPage
chunksParPage
ms ms
Le plan de calcul Pc1 associé à bc1 est donc représenté de la façon suivante :
Pc1 = {<bp5, b5, 162ms>, <bp6, b6, 135ms>}

4 Intégration et gestion des agrégats calculables
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 81
Nous avons vu comment on pouvait identifier des blocs de chunks calculables
et élaborer les plans de calcul associés. Le processus de mise en évidence des
blocs de chunks calculables doit être déclenché à chaque fois que les données
matérialisées évoluent sur le nœud de la grille, c'est-à-dire à chaque fois qu'un
bloc matérialisé est inséré ou supprimé du nœud. Ce processus est donc intégré
aux opérations de mise à jour dynamique de l'index. Ainsi, lors de la recherche
de données répondant à une requête, nous connaîtrons pour chaque nœud la
totalité des données qui sont disponibles sur ce nœud, matérialisées et/ou
calculables.
3 Indexation dynamique des agrégats calculables
Lorsqu'un bloc de chunks est matérialisé ou supprimé sur un nœud de la grille,
l'index TX est mis à jour. Cette procédure s'applique aussi bien lors du
déploiement initial des fragments de l'entrepôt de données sur la grille que pour
les mouvements de blocs matérialisés en phase d'exploitation. Dans les deux
cas, l'ensemble des blocs calculables dans l 'index qui dépendent du bloc
matérialisé inséré ou supprimé doivent être mis à jour afin d'assurer la
cohérence des informations de l'index concernant la disponibilité des données
sur un nœud. Nous commençons par le mécanisme d 'insertion d'un nouveau
bloc de chunks matérialisé conduisant à l'insertion d'un ou plusieurs blocs
calculables.
3.1 Insertion des blocs calculables dans l'index TX
L'insertion d'un identifiant de bloc matérialisé bm dans l'index TX, comme
décrit au chapitre 3, déclenche une mise à jour récursive qui crée ou modifie les
blocs calculables à partir de bm. Si le bloc bm est inséré au sein d'un sommet v
de l'index T aux niveaux hiérarchiques levels(v) = {l1, .., ln}, alors nous pouvons
déterminer la partie du treillis de l 'index T susceptible d'indexer des blocs
calculables utilisant bm comme source. Soient a1,…,an les niveaux « all », i.e.
les plus agrégés des hiérarchies, pour les dimensions D1,…,Dn. La partie du
treillis à mettre à jour contient tous les sommets v' du treillis avec
levels(v') = {l'1, .., l'n} pour lesquels 1, ,i i il l a i n . Par exemple, si le
bloc bm est indexé aux niveaux levels(v) = {région, mois, path-0}
(equ. {1,1,0}), alors les sommets concernés pas la mise à jour sont tous ceux
avec un niveau entre pays(2) et « all »(3) dans la dimension « lieu », un niveau
entre année(2) et « all »(3) dans la dimension « temps » et un niveau entre
path-1(1) et « all »(4) dans la dimension « pathologie ».
Notre méthode se distingue de l'approche de la « Virtual Count Based
Method » (VCM), présentée par (Deshpande et al., 2000), qui maintient pour
chaque agrégat calculable un compteur représentant le nombre de « chemins » à
travers le treillis à l'aide desquels cet agrégat peut être obtenu. Alors que cette
approche nécessite une recherche sur tous les ancêtres d'un sommet dans le
treillis pour retrouver les données sources, notre approche met en relation les
blocs indexés sur un sommet de l'index T avec les niveaux d'agrégation

4 Intégration et gestion des agrégats calculables
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 82
directement supérieurs dans chacune des dimensions. Ainsi, pour chaque
sommet, nous prenons en compte les positions relatives des blocs au sein de son
index X pour créer des blocs calculables qui sont insérés sur les sommets qui
sont ses successeurs directs dans le treillis. Notre sommet exemple v avec
levels(v) = {région, mois, path-0} (equ. {1,1,0}) va donc générer des blocs
calculables pour les niveaux {pays, mois, path-0} (equ. {2,1,0}), {région,
année, path-0} (equ. {1,2,0}) et {région, mois, path-1} (equ. {1,1,1}).
Les blocs calculables pertinents sont déterminés en utilisant l'index X du
sommet v. L'identifiant de bloc bm qui vient d'être inséré est l'élément
déclencheur de la construction de blocs calculables utilisant bm et les autres
blocs indexés par l'index X. Pour chaque dimension Di où le niveau « all » n'est
pas encore atteint, l'ensemble des blocs qu'il est possible de fusionner avec bm
est recensé. Les fusions possibles de bm avec ces blocs sont ensuite évaluées par
un algorithme de programmation dynamique présenté en annexe A (algorithme
4.1). Le ou les blocs calculables qui en résultent sont finalement insérés dans
l'index X du sommet v' aux niveaux levels(v') = {l1,…,li+1,…,ln}, ce qui
déclenche à son tour la mise à jour des successeurs de v'.
Exemple 4.4 : Mise à jour de l'index TX suite à l'insertion d'un bloc matérialisé
Cet exemple illustre la mise à jour d'un index TX à l'aide des opérations
d'insertion de deux blocs de chunks agrégés matérialisés b7 et b8 aux niveaux
levels(b7) = levels(b8) = {région, mois, all} (equ. {1,1,4}). Nous supposons
qu'au départ il n'y a pas de bloc indexé à ce niveau d'agrégation. Les blocs b7 et
b8 sont insérés l'un après l'autre dans l'index TX.
L'insertion de b7 engendre la création du sommet v4 avec levels(v4) = {région,
mois, all} (equ. {1,1,4}). Nous commençons par déterminer la partie du treillis
de l'index T concernée par la mise à jour des blocs calculables. La dimension
« pathologie » ne peut être plus agrégée, donc la partie du treillis mise à jour
suite à l'insertion de b7 et b8 comprend les sommets des niveaux pays et « all »
dans la dimension « lieu » et année et « all » dans la dimension « temps ». La
mise à jour récursive déclenchée par l'insertion de b7 produit un seul bloc
calculable bc7 inséré sur le sommet v5, levels(v5) = {région, année, all}
(equ. {1,2,4}), avec comme seul bloc source b7. La recherche d'autres blocs
calculables à partir de b7 aux niveaux « all » dans la dimension « temps » et aux
niveaux pays et « all » dans la dimension « lieu » ne donne aucun résultat.
Nous insérons donc le bloc matérialisé b8. La figure 4.5 montre la situation de
la partie de l'index TX concernée après l'insertion de b8.

4 Intégration et gestion des agrégats calculables
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 83
positions de blocs de chunks matérialisés et d'un bloc calculable sur plusieurs sommets :
1925-01
TEMPS(mois)
1931-07
⋮
1931-06
⋮
1934-12
1935-01
⋮
1939-12
b8
b7
LIEU(région)
Pié
mo
nt
Rh
ôn
e A
lpes
PA
CA
1925
TEMPS(année)
1932
⋮
1931
1934
1935
⋮
1939
1930
1933
bc7
LIEU(région)
Pié
mo
nt
Rh
ôn
e A
lpes
PA
CA
v4
v5
Figure 4.5 : Index TX après insertion d'un bloc matérialisé avant la mise à jour des
blocs calculables dans les dimensions « lieu » et « temps »
La mise à jour des blocs calculables suite à l'insertion de b8 commence par
rechercher les possibles agrégats dans la dimension « lieu ». La figure 4.6
montre qu'aux niveaux {pays, mois, all}, il est possible de calculer l'agrégat
pour la France à partir de b8. Nous insérons donc un sommet v6 avec
levels(v6) = {pays, mois, all} (equ. {2,1,4}) pour indexer le bloc calculable bc8.
positions de blocs de chunks calculables dépendants sur plusieurs sommets :
1925-01
TEMPS(mois)
1931-07
⋮
1931-06
⋮
1934-12
1935-01
⋮
1939-12
LIEU(région)
Pié
mo
nt
Rh
ôn
e A
lpes
PA
CA
bc8
LIEU(pays)
Italie
Fra
nce
v4
v6
1925-01
TEMPS(mois)
1931-07
⋮
1931-06
⋮
1934-12
1935-01
⋮
1939-12
v7
b'c8
LIEU(pays)
Italie
Fra
nce
1925
TEMPS(année)
1932
⋮
1931
1934
1935
⋮
1939
1930
1933
b8
b7
Figure 4.6 : Index TX après l'insertion des blocs calculables dépendants uniquement
de b8

4 Intégration et gestion des agrégats calculables
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 84
L'insertion de ce bloc sur v6 déclenche à son tour la création d'un sommet v7
avec levels(v7) = {pays, année, all} (equ. {2,2,4}) pour indexer un deuxième
bloc calculable b'c8, toujours basé sur b8. Comme le montre la figure 4.6, les
chunks agrégés pour l'année 1931 ne sont pas disponibles car b8 ne couvre que
les 6 derniers mois de cette année-là.
Pour créer un bloc calculable optimal en agrégeant la dimension « temps » à
partir du sommet v4, les blocs b7 et b8 sont fusionnés dans cette dimension.
Comme le montre la figure 4.7, cette fusion permet d'indexer aux niveaux
{région, année, all} un bloc calculable bc78 inséré sur le sommet v5. Pour l'année
1931, b8 fournit les chunks pour les 6 derniers mois, ce qui permet d'inclure les
chunks agrégés pour cette année dans bc78. La partie de b8 non couverte par la
fusion est utilisée pour créer un deuxième bloc calculable b*c8. Nous constatons
également que bc7, le bloc précédemment inséré sur v5, est entièrement couvert
par bc78 et peut être supprimé.
position du bloc de chunks calculable mis à jour suite à une insertion :
bc78
1925-01
TEMPS(mois)
1931-07
⋮
1931-06
⋮
1934-12
1935-01
⋮
1939-12
b8
b7
LIEU(région)
Pié
mo
nt
Rh
ôn
e A
lpes
PA
CA
1925
TEMPS(année)
1932
⋮
1931
1934
1935
⋮
1939
1930
1933 b*c8
LIEU(région)
Pié
mo
nt
Rh
ôn
e A
lpes
PA
CA
v4
v5
fusion dans la dimension « temps »
Figure 4.7 : Insertion d'un bloc calculable issu de la fusion de deux blocs source dans
l'index TX
La recherche de blocs calculables sur l'index X de v5 suite à cette insertion ne
fournit aucun nouveau bloc calculable pertinent pour l'agrégation dans la
dimension « lieu ».
L'indexation récursive des blocs calculables à travers l'index TX permet de
recenser tous les agrégats qu'il est possible d'obtenir grâce aux blocs
matérialisés hébergés par un nœud de grille. En fonction des niveaux
d'agrégation de bloc matérialisé inséré dans l'index, la mise à jour peut être

4 Intégration et gestion des agrégats calculables
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 85
coûteuse. Néanmoins, l'étendue de la mise à jour de l'index est limitée par deux
facteurs.
Le premier facteur est le phénomène d'épuisement des chunks disponibles au fil
des agrégations. Comme le démontre l'exemple ci-dessus, cet effet intervient au
moment où les chunks présents à un niveau hiérarchique i ne sont plus
suffisants pour constituer un chunk agrégé au niveau i+1 car on ne dispose pas
de tous les fils nécessaires.
Le deuxième facteur intervient lorsqu'un nouveau bloc calculable est déjà
entièrement inclus dans les blocs indexés par l'index X sur un sommet v. Si le
nouveau bloc calculable ne présente pas un avantage au niveau des coûts
d'extraction estimés par rapport aux blocs existants, il n'est pas inséré dans
l'index et la mise à jour ne va pas au-delà de v.
Comme l'insertion de nouveaux blocs, la suppression d'un bloc provoque une
mise à jour récursive à travers la partie de l'index T susceptible d'indexer des
blocs calculables dépendants du bloc supprimé.
3.2 Suppression des blocs calculables dans l'index TX
La mise à jour de l'index TX après la suppression d'un identifiant de bloc
matérialisé bm concerne uniquement les blocs calculables indexés dépendant de
bm. Soit v le sommet de l'index T aux niveaux hiérarchiques
levels(v) = {l1, .., ln}. Une fois bm supprimé dans l'index X de v, comme décrit
au chapitre 3, les blocs calculables touchés par cette suppression sont
recherchés et modifiés. La partie de l'index T susceptible de contenir ces blocs
est identique à celle identifiée pour la mise à jour après une insertion sur v.
L'ordre dans lequel cette partie est parcourue reste également inchangé, la
principale différence avec la procédure d'insertion réside dans l'adaptation des
blocs de chunks touchés par la suppression de bm. En effet, lorsque l'identifiant
de bloc calculable bc dépendant de bm doit être modifié, notre méthode prévoit
plusieurs étapes afin de limiter l'impact de la suppression sur la disponibilité
des données.
Soit v' le sommet de l'index T sur lequel est indexé bc et v le sommet ancêtre sur
lequel bm a été supprimé. La première étape consiste à évaluer l'impact de la
suppression sur le bloc calculable en déterminant l'identifiant de bloc m cb b
qui correspond à la partie calculée à partir de bm que contribue bm à bc. Ensuite,
les sommets ancêtres *v v de v' sont consultés pour vérifier s'il existe un bm*
indexé sur v* qui peut remplacer bm pour fournir b'm. Par exemple, si
levels(v) = {région, année, path-0} (equ. {1,2,0}) et levels(v') = {pays, année,
path-0} (equ. {2,2,0}), alors les sommets v* peuvent avoir les niveaux {pays,
mois, path-0} (equ. {2,1,0}) ou {pays, date, path-0} (equ. {2,0,0}).
Si un remplaçant pour b'm est trouvé, celui-ci va être intégré dans bc. Par contre,
s'il n'existe aucun remplacement, le bloc calculable doit être modifié ou
reconstruit à partir des blocs sources restants. Dans le cas où bc peut être
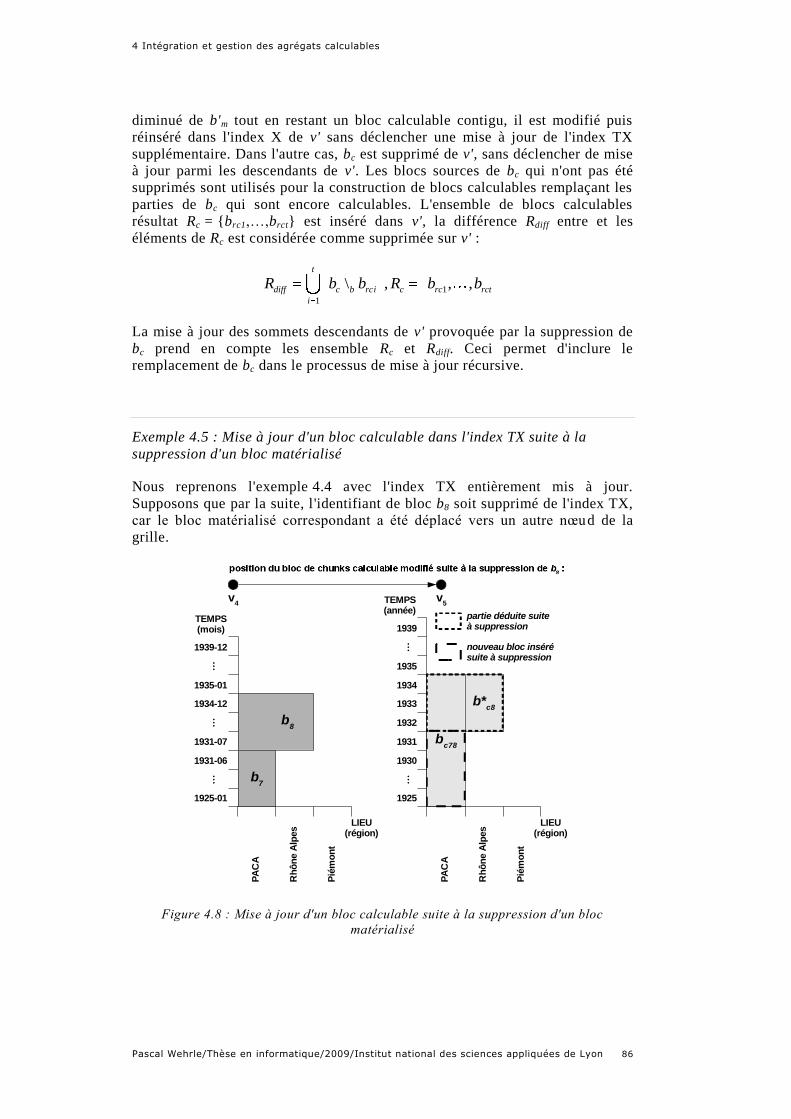
4 Intégration et gestion des agrégats calculables
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 86
diminué de b'm tout en restant un bloc calculable contigu, il est modifié puis
réinséré dans l'index X de v' sans déclencher une mise à jour de l'index TX
supplémentaire. Dans l'autre cas, bc est supprimé de v', sans déclencher de mise
à jour parmi les descendants de v'. Les blocs sources de bc qui n'ont pas été
supprimés sont utilisés pour la construction de blocs calculables remplaçant les
parties de bc qui sont encore calculables. L'ensemble de blocs calculables
résultat Rc = {brc1,…,brct} est inséré dans v', la différence Rdiff entre et les
éléments de Rc est considérée comme supprimée sur v' :
1
1
\ , , ,t
diff c b rci c rc rct
i
R b b R b b
La mise à jour des sommets descendants de v' provoquée par la suppression de
bc prend en compte les ensemble Rc et Rdiff. Ceci permet d'inclure le
remplacement de bc dans le processus de mise à jour récursive.
Exemple 4.5 : Mise à jour d'un bloc calculable dans l'index TX suite à la
suppression d'un bloc matérialisé
Nous reprenons l'exemple 4.4 avec l'index TX entièrement mis à jour.
Supposons que par la suite, l'identifiant de bloc b8 soit supprimé de l'index TX,
car le bloc matérialisé correspondant a été déplacé vers un autre nœud de la
grille.
bc78
1925-01
TEMPS(mois)
1931-07
⋮
1931-06
⋮
1934-12
1935-01
⋮
1939-12
LIEU(région)
Pié
mo
nt
Rh
ôn
e A
lpes
PA
CA
1925
TEMPS(année)
1932
⋮
1931
1934
1935
⋮
1939
1930
1933 b*c8
LIEU(région)
Pié
mo
nt
Rh
ôn
e A
lpes
PA
CA
v4
v5
partie déduite suiteà suppression
nouveau bloc insérésuite à suppression
b8
b7
Figure 4.8 : Mise à jour d'un bloc calculable suite à la suppression d'un bloc
matérialisé

4 Intégration et gestion des agrégats calculables
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 87
C'est sur le sommet v4 avec levels(v4) = {région, mois, all} (equ. {1,1,4}) que b8
est retrouvé et supprimé dans l'index X. La recherche de blocs calculables
dépendants de b8 commence sur le sommet v5 avec levels(v5) = {région, année,
all} (equ. {1,2,4}). Le bloc calculable bc78 doit être modifié pour prendre en
compte la suppression des chunks contenus dans la partie contribuée par b8.
Comme le montre la figure 4.8, bc78 peut être diminué sans perdre sa structure
de bloc calculable. En conséquence, il ne reste que b8 comme seul bloc source
pour le calcul de bc78. La suite de la mise à jour supprime les blocs calculables
bc8 sur le sommet v6 et b'c8 sur le sommet v7. Comme les sommets v6 et v7 n'ont
plus de blocs indexés sur leur index X, ces sommets sont supprimés de
l'index T.
Les opérations d'insertion et de suppression de blocs de chunks matérialisés
dans l'index TX d'un nœud de la grille permettent ainsi de maintenir à jour les
informations détaillées sur l'ensemble des données que peut fournir chaque
nœud.
4 Conclusion
L'intégration des agrégats calculables dans notre méthode d'indexation s'appuie
sur le modèle multidimensionnel adapté que nous avons introduit au chapitre 3.
Les index locaux permettent de connaître l'ensemble des données matérialisées
sur chaque nœud, mais aussi l'ensemble des agrégats qui peuvent être calculés à
la volée à partir de ces données matérialisées. La consultation des données
calculables est aussi rapide que pour les données matérialisées car l'index X
spatial chargé de recenser les composantes spatiales des blocs de données
indexe les blocs calculables de façon entièrement transparente. Lors de la
construction de blocs calculables, toute l'information nécessaire à leur calcul est
stockée dans un plan de calcul associé. Ce plan est conçu pour être directement
exploitable pour le traitement de requêtes et comporte déjà les es timations de
coûts statiques indispensables pour une optimisation de l'exécution de requêtes.
La construction du plan de calcul pour chaque bloc calculable évite en
conséquence les longues recherches de données répondant à une requête. Toutes
les opérations complexes d'optimisation de la construction des blocs calculables
sont effectuées lors de la mise à jour de l'index TX. Au moment de la recherche
de données répondant à une requête, l'index fournit les blocs matérialisés et
calculables disponibles sans traitement préalable.


Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 89
Chapitre 5 Exécution et optimisation de
requêtes
L'utilisateur va accéder à l'entrepôt et effectuer ses requêtes sur le nœud de la
grille sur lequel il est connecté au travers d'une interface client. Cette interface
client doit lui permettre de requêter l 'entrepôt dont la répartition doit rester
transparente. L'utilisateur aura ainsi accès à un entrepôt que nous appelons
entrepôt virtuel comme si celui-ci était centralisé. Compte tenu de la puissance
de stockage et de calcul fournie par la grille, l 'utilisateur doit recevoir
rapidement les données qu'il recherche ainsi que les agrégats les plus complexes
sur ces données.
Pour répondre à ces exigences, le système d'entrepôt réparti doit être associé à
un mécanisme de traitement de requêtes OLAP optimisé pour minimiser le
temps de réponse à une requête utilisateur. L'environnement de grille est
généralement hautement dynamique et varie en fonction de la disponibilité des
ressources (données, nœuds, réseau). La solution que nous proposons est la
suivante : Dans un premier temps, le processus d'exécution de requêtes doit
disposer des informations sur la disponibilité des données demandées sur la
grille. Il recense ensuite les différents choix possibles pour l 'obtention du
résultat de la requête. Ce résultat peut être obtenu par des données directement
stockées sur un ou plusieurs nœuds de la grille ou à partir de données détaillées
qui devront être agrégées à la volée. La solution correspondant au temps de
réponse estimé minimal est ensuite choisie. Il s 'agit enfin d'ordonnancer les
opérations de transfert et de calcul distribuées qui produisent le résultat final.
Dans ce chapitre, nous définissons les différentes phases du traitement de
requêtes au sein de l'entrepôt réparti sur la grille. Les mécanismes et procédés
spécifiques à notre approche sur chacune de ces phases d'exécution sont
présentés en détail. Ces mécanismes sont illustrés sur le cas d 'utilisation que
nous présentons ci-dessous.
1 Cas d'utilisation
Le scénario d'utilisation que nous introduisons se base sur une grille
expérimentale établie sur les trois sites des équipes participantes au projet
GGM, à savoir Toulouse, Lille et Lyon.
Les données utilisées sont celles introduites au chapitre 3. Nous supposons dans
l'exemple que la grille expérimentale est composée d 'un nœud sur chacun des
trois sites de Lyon, Lille et Toulouse. L'ensemble des blocs de chunks
matérialisés de l'entrepôt est réparti sur ces nœuds. Lors de la phase de
déploiement, l'index TX de chaque nœud intègre les agrégats calculables à
partir des blocs matérialisés localement. Nous supposons que le réseau déployé
entre les différents nœuds fournit un débit constant pour tous les transferts de

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 90
données et une latence fixe pour la transmission des messages. Pour l'exemple,
les différents nœuds ont tous la même capacité de calcul. Nous présentons par
la suite la répartition des blocs de chunks matérialisés sur les nœuds de la grille.
Par souci de lisibilité, les figures se limitent à la représentation des blocs
matérialisés dans l'espace multidimensionnel de membres avec les sommets de
l'index T associés. La structure des index X ainsi que les blocs calculables
seront introduits au fur et à mesure de leur utilisation lors des exemples de ce
chapitre.
La figure 5.1 représente l'ensemble des blocs matérialisés sur le nœud LYON.
L'index T, pour ces blocs matérialisés, comporte deux sommets vLY1 et vLY2
respectivement aux niveaux levels(vLY1) = {ville, date, path-0} (equ. {0,0,0}) et
levels(vLY2) = {région, année, path-0} (equ. {1,2,0}). Par exemple, l'index X du
sommet vLY1 comprend le bloc suivant :
bLY1 =
<{lieu.ville.Toulon, temps.date.1925-01-23, pathologie.path-0.grippe},
{lieu.ville.Bourg-en-Bresse, temps.date.1929-12-11,
pathologie.path-0.asthme}>
(equ. <{1.0.1, 2.0.1, 3.0.8},{1.0.4, 2.0.27, 3.0.10}>)
Nous représentons ce bloc multidimensionnel sur la figure 5.1 dans le plan lieu-
temps et dans le plan pathologie-temps.
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
bLY2
bLY1
bLY1
bLY2
1925-01-23
TEMPS(date)
1930-01-20
1929-12-11
1934-06-27
1934-07-19
1939-12-10
⋮
⋮
⋮
1925-01-23
TEMPS(date)
1930-01-20
1929-12-11
1934-06-27
1934-07-19
1939-12-10
⋮
⋮
⋮
bLY5
LIEU(région)
Pié
mo
nt
Rh
ôn
e A
lpes
PA
CA
1925
TEMPS(année)
⋮
1937
⋮
1939
1936
vLY1
vLY2
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
1925
TEMPS(année)
⋮
1937
⋮
1939
1936
bLY5
bLY4
bLY4
bLY3
bLY3
Figure 5.1 : Identifiants de blocs matérialisés sur le nœud LYON

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 91
De même, la figure 5.2 représente les blocs matérialisés sur le nœud de
Toulouse et la figure 5.3 ceux du nœud de Lille. On trouvera en annexe B
(exemple 5.a) le détail des identifiants de blocs présents sur ces trois nœuds.
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
bTO1
bTO1
1925-01-23
TEMPS(date)
1930-01-20
1929-12-11
1934-06-27
1934-07-19
1939-12-10
⋮
⋮
⋮
1925-01-23
TEMPS(date)
1930-01-20
1929-12-11
1934-06-27
1934-07-19
1939-12-10
⋮
⋮
⋮
vTO1
bTO2
bTO2
Figure 5.2 : Identifiants de blocs matérialisés sur le nœud TOULOUSE
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
bLI1
bLI1
1925-01-23
TEMPS(date)
1930-01-20
1929-12-11
1934-06-27
1934-07-19
1939-12-10
⋮
⋮
⋮
1925-01-23
TEMPS(date)
1930-01-20
1929-12-11
1934-06-27
1934-07-19
1939-12-10
⋮
⋮
⋮
bLI3
1925
TEMPS(année)
⋮
1937
⋮
1939
1936
vLI1
vLI2
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
1925
TEMPS(année)
⋮
1937
⋮
1939
1936
bLI3
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
bLI2
bLI2
Figure 5.3 : Identifiants de blocs matérialisés sur le nœud LILLE

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 92
Note : La notation employée dans ce chapitre pour les identifiants de blocs est
basée sur une numérotation continue des blocs matérialisés de chaque nœud,
par exemple bLY1, bLY2,…,bLYn. Les blocs calculables à partir de ces blocs
matérialisés sont notés b' et portent en indice les index de leurs nœuds sources
accolés, par exemple b'LY12 désigne le bloc calculable issu des blocs source bLY1
et bLY2.
Dans ce chapitre, nous utiliserons pour les exemples un ensemble de paramètres
qui caractérisent les conditions d'exploitation de la grille. Ces paramètres
décrivent un état momentané de la grille. L'ensemble des paramètres est
répertorié dans le tableau 5.1.
description du paramètre Valeur
Nombre moyen de chunks
matérialisés dans un bloc b par
rapport au volume multi-
dimensionnel de son identifiant, i.e.
le taux de remplissage des blocs
matérialisés
nbChunks(b)/volume(b) = 0,75
Nombre de chunks par page disque
du medium de stockage sur chaque
nœud de la grille (voir chapitre 4,
section 2.3)
chunksParPage = 20 chunks
temps de lecture d'une page disque
depuis le medium de stockage
tempsAccesPage = 4ms
taille d'un chunk d'un bloc b
matérialisé
tailleChunk(b) = 1,6 Ko
débit disponible sur le réseau reliant
les nœuds
lien LYON vers LILLE : 260 Ko/s
lien LYON vers TOULOUSE : 200 Ko/s
lien TOULOUSE vers LYON : 400 Ko/s
lien TOULOUSE vers LILLE : 280 Ko/s
lien LILLE vers LYON : 240 Ko/s
lien LILLE vers TOULOUSE : 320 Ko/s
capacité de calcul disponible sur les
nœuds de la grille, en opérations par
seconde
nœud LYON : 500 ops/s
nœud TOULOUSE : 900 ops/s
nœud LILLE : 800 ops/s
Tableau 5.1 : Paramètres d'exploitation de la grille à la base des exemples du chapitre
A l'aide de cet entrepôt réparti, nous allons présenter la procédure d'exécution
de requêtes. Dans notre déploiement, que nous présentons ci -après, les requêtes

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 93
peuvent être soumises à tous les nœuds de la grille et sont traitées en plusieurs
phases.
2 Présentation générale des phases de traitement de requêtes
Les différentes étapes de traitement d'une requête OLAP sont décrites
succinctement ci-dessous. Nous les détaillerons dans les paragraphes suivants.
(1) Réécriture de la requête client :
Les requêtes soumises à l'entrepôt distribué portent sur l'entrepôt virtuel et
sont exprimées sous forme de requêtes OLAP classiques. La requête OLAP
est traduite sous forme d'identifiants de blocs de chunks afin de pouvoir
localiser les données demandées via l'interrogation des index TX sur les
différents nœuds de la grille. La réécriture d'une requête OLAP,
initialement exprimée en SQL, vers la représentation en identifiants de
blocs de chunks s'appuie d'une part sur le modèle multidimensionnel de
l'entrepôt et d'autre part sur l'ordre que nous avons défini sur les instances
de dimension.
(2) Localisation des données utiles pour la requête :
Il s'agit lors de cette phase de localisation d'identifier les données
contribuant au résultat d'une requête et de les localiser parmi les données
disponibles sur l'ensemble des nœuds de la grille sous forme de blocs de
chunks matérialisés ou calculables. Le résultat de cette localisation est le
recensement des différentes sources permettant d'obtenir les données utiles
pour une requête ainsi que les informations nécessaires à l'évaluation de
leurs coûts d'obtention.
(3) Construction du plan d'exécution optimisé :
Afin de pouvoir répartir et exécuter efficacement les tâches qui extraient et
calculent les données demandées par une requête, le processus
d'optimisation que nous mettons en place sélectionne les meilleures sources
ainsi que le meilleur ordonnancement des transferts et calculs. La phase
d'optimisation consiste à estimer le coût total pour l'obtention de chaque
bloc de chunks source localisé. Le coût total prend en compte le coût de
chargement des données (i.e. la lecture des chunks) et si nécessaire le coût
de calcul d'agrégation et le coût de transfert des données depuis le nœud
source. Pour déterminer le plan d'exécution optimisé en termes de temps
d'exécution, les différents blocs de chunks source doivent être sélectionnés
en fonction de ce coût estimé. Finalement, pour la requête traitée, nous
construisons le plan d'exécution distribuée optimisé à partir des blocs
sources choisis pour fournir les données demandées. Le processus de
création du plan d'exécution doit prendre en compte les possibilités de
calcul à la volée d'agrégats et favorise l'implication d'un maximum de
sources en parallèle.

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 94
(4) Exécution parallèle et distribuée de la requête :
La phase d'exécution proprement dite regroupe l'ordonnancement, le
lancement et la surveillance des tâches du plan d'exécution distribuée pour
une requête. Ce plan d'exécution se décompose en tâches de calcul et de
transfert attribués aux différents nœuds sources de données. Ces tâches sont
ordonnancées en fonction de leurs besoins en capacité de calcul et en bande
passante pour minimiser l'accès concurrent aux ressources et ainsi permettre
un maximum d'exécutions en parallèle. Il s'agit en particulier de répartir au
mieux la charge sur les ressources du nœud destination sur lequel le résultat
final est matérialisé (i.e. celui sur lequel a été émise la requête). Par
exemple, si un bloc de chunks détaillés doit être transféré du nœud
TOULOUSE vers le nœud LYON où il sert de source pour un calcul de
chunks agrégés, alors le transfert de ce bloc est prioritaire par rapport au
transfert de blocs agrégés matérialisés qui n'ont plus besoin de subir de
calculs avant de pouvoir être ajoutés au résultat de la requête. Le lancement
des tâches dans l'ordre préconisé est associé à une surveillance de leur
exécution afin de minimiser les délais imprévus, tels la déconnexion d 'un
nœud ou un retard exceptionnel suite à une charge plus haute que prévue sur
un nœud. Finalement, le résultat de la requête est matérialisé sur le nœud
destination au fur et à mesure de l 'aboutissement de chaque tâche.
Nous détaillons par la suite les quatre grandes phases identifiées pour le
traitement des requêtes.
3 Réécriture de la requête client
Nous introduisons ici la méthode de réécriture d'une requête posée via
l'interface client de l'entrepôt réparti. Cette requête s'appuie sur le schéma de
l'entrepôt virtuel présenté à l'utilisateur et doit donc être réécrite sous forme
d'identifiants de blocs pour pouvoir être traitée par l'entrepôt réparti. La
réécriture de la requête client consiste à extraire de la requête OLAP les
éléments capables d'identifier les données recherchées et à construire
l'identifiant de bloc correspondant.
Une requête OLAP classique s'exprime sous forme d'une requête SQL
comportant les éléments suivants :
- La clause « SELECT » désigne les attributs correspondants aux niveaux
hiérarchiques sélectionnés sur les différentes dimensions ainsi que les
agrégats demandés.
- La clause « FROM » contient la source des données demandées, qui est
pour une requête OLAP l'hypercube lui-même, i.e. la jointure entre les
tables de dimension et la table de faits.
- La clause « WHERE » comporte les prédicats de sélection des membres de
dimension pour chaque dimension.
- La clause « GROUP BY » précise les niveaux d'agrégation demandés sur
les dimensions.

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 95
Nous allons exploiter ces éléments de la requête pour identifier les blocs de
chunks qui représentent les données demandées. Les clauses « SELECT » et
« GROUP BY » donnent l'information sur les niveaux d'agrégation demandés
par la requête. Les parties contiguës dans l'espace multidimensionnel de
membres sont déterminées à l'aide des prédicats de la clause « WHERE ».
Prenons par exemple la requête OLAP suivante :
SELECT lieu.ville, temps.mois, pathologie.path-0, list(id_patient), sum(décès)
FROM faits, lieu, temps, pathologie
WHERE (ville BETWEEN 'Toulon' AND 'Lyon') AND (mois BETWEEN
'1925-01' AND '1934-12') AND (path-0 BETWEEN 'épilepsie' AND 'grippe')
GROUP BY lieu.ville, temps.mois, pathologie.path-0
Cette requête recherche des données des niveaux
{ville, mois, path-0} (equ. {0,1,0}) et définit pour chaque dimension des
membres limite inférieure et limite supérieure qui délimitent le bloc de chunks
br, représentation multidimensionnelle du résultat recherché.
br =
<{lieu.ville.Toulon, temps.mois.1925-01, pathologie.path-0.épilepsie},
{lieu.ville.Lyon, temps.mois.1934-12, pathologie.path-0.grippe}>
(equ. <{1.0.1, 2.1.1, 3.0.6},{1.0.7, 2.1.51, 3.0.8}>)
L'origine des données telle qu'elle est décrite dans la clause « FROM » n'est pas
prise en compte car elle fait référence au schéma virtuel de l'entrepôt tel qu'il
est présenté à l'utilisateur. Au sein de l'entrepôt réparti, les chunks de données
sont extraits des fragments de la table de faits ou des tables d'agrégats à l'aide
des instances locales de dimensions sur chaque nœud. Comme nous allons le
montrer en section 6, ces sous-requêtes transparentes pour l'utilisateur ont la
même structure que des requêtes OLAP.
4 Localisation des données utiles pour la requête
Une requête OLAP est soumise par un utilisateur sur un nœud de la grille. Cette
requête OLAP correspond à un bloc de chunks recherchés. Ces chunks
recherchés existent, éventuellement en plusieurs exemplaires, sur la grille sous
leur forme matérialisée et/ou calculable. Ils sont contenus dans des blocs
indexés sur un ou plusieurs nœuds. Le processus de localisation de données
utiles pour la requête consiste alors à rechercher, parmi tous les nœuds de la
grille, l'ensemble des blocs qui contribuent à la requête.
4.1 Principe général
L'utilisateur est connecté à un nœud DST sur lequel il émet sa requête OLAP,
réécrite sous forme d'un bloc de chunk br. L'index TX de ce nœud est interrogé
en premier afin de déterminer si la requête peut être satisfaite à partir des blocs

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 96
de chunks disponibles localement. Ces blocs, s'ils sont matérialisés, sont
retenus comme éléments de réponse à la requête dans un ensemble noté R. Si
R suffit pour répondre à la requête, alors le processus de localisation est
terminé. Dans le cas où les données matérialisées localement ne permettent pas
de répondre à l'intégralité de la requête, alors les données manquantes M doivent être recherchées dans les blocs calculables localement et également
dans les blocs matérialisés et/ou calculables sur les autres nœuds de la grille. En
effet, pour des raisons de performance, il peut être plus efficace d'aller chercher
des données matérialisées, voire même de les calculer et de les transférer,
depuis un nœud distant plutôt que de les calculer sur le nœud d'émission de la
requête. Ces possibilités sont recueillies dans un ensemble de blocs candidats
noté C.
4.2 Algorithme de localisation des données
Nous explicitons ci-dessous l'algorithme de localisation sur le nœud local DST
et l'algorithme de localisation sur les nœuds distants SRC.
Algorithme 1 : localisation sur le nœud DST
Entrées :
- le bloc recherché br
Sorties :
- l'ensemble R des blocs matérialisés localement
- l'ensemble C0 des blocs candidats
- l'ensemble M des blocs recherchés
1 début
2 M = {br} // au départ M représente la requête elle-même
3 construire les ensembles B1 et B2 de blocs bi indexés dans TX tels que
ib rb // B1 contient les blocs matérialisés et B2 contient les blocs
calculables
4 pour chaque bloc bi de B1 faire
5 R = ibR
6 pour chaque bQj de M faire
7 calculer la contribution de bi à bQj
8 mettre bQj dans l'ensemble des requêtes à supprimer Ms
9 calculer l'ensemble de requêtes Ma = parties manquantes de
bQj après soustraction de la contribution de bi
10 finpour
11 mettre à jour M en enlevant la contribution de bi , i.e. en rempla-
çant dans M les éléments de Ms par les éléments de Ma

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 97
12 finpour
13 pour chaque bloc bi de B2 faire
14 si i Qjb b alors
15 pour chaque bQj de M faire
16 ib0 0C C
17 mettre à jour le plan de calcul de bi en limitant à la par-
tie utile i Qjb b
18 finpour
19 finsi
20 finpour
21 fin
Algorithme 2 : localisation des données manquantes sur un nœud SRC
Entrées :
- l'ensemble des blocs recherchés M
Sorties :
- l'ensemble CSRC des blocs candidats
1 début
2 pour chaque bQj de M faire
3 construire les ensembles B1 et B2 de blocs bi indexés dans TX tels
que i Qjb b // B1 contient les blocs matérialisés et B2 contient
les blocs calculables
4 pour chaque bloc bi de B1 faire
5 SRC SRC ibC C
6 créer un plan de calcul pour l'obtention de bi avec la partie
utile i Qjb b
7 finpour
8 pour chaque bloc bi de B2 faire
9 SRC SRC ibC C
10 mettre à jour le plan de calcul de bi en limitant à la partie
utile i Qjb b
11 finpour
12 finpour
13 fin

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 98
L'algorithme 1 commence par lancer la requête sur l'index TX du nœud DST.
Celui-ci fournit l'ensemble des blocs indexés qui contribuent au résultat de la
requête. Les éléments du résultat sont divisés en un ensemble de blocs
matérialisés B1 et un ensemble de blocs calculables localement B2. Les blocs
matérialisés sont considérés comme éléments certains pour le calcul du résultat.
Ces blocs matérialisés sont donc ajoutés à l'ensemble R des blocs sources à
partir de la ligne 6 . Au fur et à mesure que ces blocs sont sélectionnés, leur
contribution au résultat est enlevée de l'ensemble M décrivant les données
manquantes. Ce mécanisme est décrit en détail par la section 4.3. Une fois que
M est mis à jour et représente les données demandées non matérialisées sur
DST, la contribution des blocs calculables localement est analysée (ligne 13 ).
Pour chaque bloc calculable localement qui contribue à une partie de M, on
construit un plan de calcul adapté pour fournir la partie utile identifiée. Cette
méthode est illustrée en section 4.4.2. Ces blocs sont ajoutés à l'ensemble des
candidats CO pour fournir les données manquantes afin de les mettre en
concurrence avec les blocs matérialisés ou calculables qui seront trouvés par l a
suite sur les autre nœuds SRC de la grille.
L'algorithme 2 effectue la recherche des données manquantes sur un nœud
distant SRC. Ces données manquantes sont issues de l'algorithme 1 : il s'agit de
l'ensemble M, ensemble de blocs recherchés. L'index TX est interrogé pour
fournir l'ensemble B1 des blocs matérialisés et l'ensemble B2 des blocs
calculables sur SRC correspondants aux données manquantes recherchées. Les
blocs matérialisés de B1 sont ajoutés à C (ligne 6 ) et nous créons un plan de
calcul pour extraire la partie utile de chaque bloc. Les blocs calculables sont
également ajoutés à C en adaptant leur plan de calcul en fonction de la partie
utile qu'ils fournissent pour la construction du résultat (ligne 10 ).
A la fin du processus, R représente les blocs matérialisés sur le nœud DST
contribuant à la requête. L'union C de C0 et des ensembles CSRC pour chaque
nœud, représente les blocs candidats pour fournir les données manquantes.
4.3 Calcul de la contribution des blocs et mise à jour de la requête
Nous introduisons ici la méthode de construction progressive de l'ensemble M
des identifiants de blocs décrivant les données manquantes sur un nœud
exécutant une requête.
Lorsqu'une requête br est soumise à l'index TX, celui-ci fournit l'ensemble des
blocs matérialisés localement qui contribuent à br. Chacun de ces blocs
matérialisés bi est inséré dans l'ensemble R en calculant sa partie utile pour la
construction du résultat de br. Au fur et à mesure que les parties utiles des blocs
sont déterminées, notre méthode calcule les éléments de l'ensemble M des
données encore manquantes pour répondre à la requête. Pour constituer
l'ensemble M, notre méthode créé à chaque itération un ensemble Ms de blocs

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 99
à supprimer de M et un ensemble Ma de blocs à ajouter à M. Les blocs à
supprimer de Ms sont ceux qui ont une intersection non nulle avec la requête et
dont la contribution doit être supprimée de M. Leurs identifiants sont
remplacés dans M par les blocs de Ma, l'ensemble de blocs représentant la
différence géométrique entre les données manquantes et le bloc matérialisé
localement.
Nous allons illustrer le fonctionnement de l'algorithme à l'aide d'un exemple
comportant une requête br pour laquelle la recherche sur l'index TX a identifié
deux blocs matérialisés b1 et b2 qui ont une intersection non nulle. La partie de
br considérée comme manquante est obtenu grâce à une opération de différence
géométrique notée « \b » qui permet d'enlever progressivement la contribution
des blocs matérialisés. L'opérateur de différence géométrique « \b » prend en
paramètre un bloc représentant une requête et calcule l'intersection avec un
second bloc donné. La différence est représentée par un ensemble de blocs
couvrant les chunks du premier bloc non couverts par le second. Pour construire
cet ensemble, nous commençons par rechercher les intervalles de membres de la
requête non couverts par un bloc matérialisé dans toutes les dimensions et
construisons les volumes manquants à partir de ceux-ci. La construction des
volumes manquants utilise les intervalles non couverts en ordre décroissant
pour maximiser le volume des blocs recherchés. Le détail de ces opérations est
décrit par l'algorithme 5.1 en annexe A.
La figure 5.4 illustre la situation de départ, c'est-à-dire les blocs b1 et b2 qui
contribuent chacun une partie des chunks demandés. M est initialisé avec un
unique élément br, tous les chunks de b
r étant considérés comme manquants
avant la prise en compte des contributions de b1 et b2 dans l'ensemble R.
b2
b1
br
bloc matérialisé
requête d'origine
blocs de chunks matérialisés b1 et b
2 ayant une intersection non nulle avec la requête br
Figure 5.4 : Intersections dans l'espace de données entre une requête et deux blocs de
chunks matérialisés sur le nœud destination
Le résultat de la première itération de l'algorithme est présenté en figure 5.5. La
contribution de b1 est prise en compte par l'ajout de b1 à R. L'opération de
différence géométrique br \b b1 engendre la création de trois blocs b
r11, b
r12 et
br13
pour décrire les parties manquantes de la requête après la suppression de la

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 100
contribution de b1. Ces nouveaux blocs sont ajoutés à l'ensemble Ma alors que
br est ajouté à Ms.
br13
b2
b1
br12
br11
bloc matérialisé
requête sur chunksmanquants
division de la requête d'origine pour supprimer la contribution du bloc de chunks matérialisés b1
Figure 5.5 : Calcul de la contribution du premier bloc à la requête et mise à jour de
l'ensemble des données manquantes
A la fin de la première itération, les éléments de Ms, à savoir br, sont
supprimés dans M et remplacés par les éléments de Ma, br11, b
r12 et b
r13. La
deuxième itération de l'algorithme est illustrée par la figure 5.6. Pour chaque
élément de M, la contribution de b2 est soustraite et le résultat ajouté à Ma.
Comme b2 n'a qu'une intersection avec br11
et br12
, ces deux blocs sont marqués
pour être supprimés dans Ms, tandis que les ensembles br11
\b b2 = {br21
, br22
} et
br12
\b b2 = {br23
} sont ajoutés à Ma.
br13
b2
b1
br23
br22
br21
bloc matérialisé
requête sur chunksmanquants
division des requêtes pour supprimer la contribution du bloc de chunks matérialisés b2
Figure 5.6 : Calcul de la contribution du deuxième bloc à la requête et finalisation de
l'ensemble des données manquantes
Suite à cette dernière itération nous obtenons un ensemble M contenant les
quatre blocs recouvrant les chunks de br qui ne sont ni fournis par b1, ni par b2.
La trace d'exécution complète de cet exemple est détaillée par le tableau 5.2.

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 101
Itération R M Ma Ms
1 br
1 b1 br b
r
1 b1 br b
r11, b
r12, b
r13 b
r
1 b1 br11
, br12
, br13
2 b1, b2 br11
, br12
, br13
br11
2 b1, b2 br11
, br12
, br13
br21
, br22
br11
2 b1, b2 br11
, br12
, br13
br21
, br22
br11
, br12
2 b1, b2 br11
, br12
, br13
br21
, br22
, br23
br11
, br12
2 b1, b2 br21
, br22
, br13
Tableau 5.2 : Trace d'exécution de l'algorithme pour la construction de M
L'exemple suivant illustre la procédure décrite dans le cadre du traitement d'une
requête sur le nœud LILLE.
Exemple 5.1 : Construction de requêtes portant sur les chunks recherchés
Soit une requête soumise au nœud LILLE, réécrite sous forme d'identifiant de
bloc b'r. Elle porte sur les chunks des niveaux
{ville, année, path-0} (equ. {0,2,0}) où sont indexés le bloc matérialisé bLI3 et

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 102
le bloc calculable b'LI12, issu de la fusion des blocs bLI1 et bLI2 dans la dimension
« temps ».
b'r =
<{lieu.ville.Marseille, temps.année.1930, pathologie.path-0.pneumonie},
{lieu.ville.Lyon, temps.année.1939, pathologie.path-0.grippe}>
(equ. <{1.0.3, 2.2.6, 3.0.7},{1.0.7, 2.2.15, 3.0.8}>)
La figure 5.7 montre l'intersection de b'r avec le bloc matérialisé bLI3 et fait
apparaître les parties identifiées par notre méthode comme manquantes (zones
blanches de la figure). Le regroupement des chunks manquants aboutit à une
répartition en deux blocs b'rm1
et b'rm2
représentés dans la figure 5.7. b'rm1
est
créé en premier pour occuper un volume maximum dans la dimension
« temps », tout en gardant les mêmes coordonnées que b'r dans les autres
dimensions. b'rm2
occupe ensuite le restant de l'espace contenu dans b'r non
rempli par bLI3.
bLI3
1934
TEMPS(année)
1937
⋮
1939
1936
1930
⋮
1935
1925
⋮
1929
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
bLI3
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
1934
TEMPS(année)
1937
⋮
1939
1936
1930
⋮
1935
1925
⋮
1929 b'LI12
b'LI12
contour du bloc requête b'r
b'rm2
b'rm1
Figure 5.7 : Découpage d'une requête portant sur les blocs indexés du nœud LILLE
Nous obtenons ainsi deux requêtes exprimées sous forme de blocs de chunks à
rechercher sur les autres nœuds de la grille.
b'rm1
=
<{lieu.ville.Marseille, temps.année.1930, pathologie.path-0.pneumonie},
{lieu.ville.Lyon, temps.année.1936, pathologie.path-0.grippe}>
(equ. <{1.0.3, 2.2.6, 3.0.7},{1.0.7, 2.2.12, 3.0.8}>)

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 103
b'rm2
=
<{lieu.ville.Grenoble, temps.année.1937, pathologie.path-0.pneumonie},
{lieu.ville.Lyon, temps.année.1939, pathologie.path-0.grippe}>
(equ. <{1.0.5, 2.2.13, 3.0.7},{1.0.7, 2.2.15, 3.0.8}>)
Grâce à cette méthode les parties non matérialisés localement du résultat de la
requête sont identifiées et peuvent être recherchées parmi les blocs calculables
localement ou disponibles sur d'autres nœuds de la grille. Pour ces blocs non
matérialisés localement, il est nécessaire de créer ou d'adapter les plans de
calcul utiles pour leur obtention.
4.4 Mise à jour des plans de calcul
L'ensemble des chunks manquants sont recherchés parmi les blocs calculables
localement et les blocs matérialisés et/ou calculables sur les autres nœuds de la
grille. Afin de pouvoir évaluer les différentes possibilités d'obtenir ces chunks,
il est nécessaire de déterminer la partie utile de chacun de ces blocs et d'ajouter
son coût d'obtention estimé. La partie utile ainsi que les coûts associés à chaque
bloc source sont répertoriés par des plans de calcul réunis dans un ensemble de
blocs candidats.
L'ensemble de blocs candidats CSRC associée à l'ensemble de chunks manquants
M sur le nœud DST est constitué des identifiants des blocs sources qui
fournissent les chunks utiles à la requête et pour chaque bloc source un plan de
calcul qui décrit les opérations nécessaires pour obtenir la partie utile à partir
du bloc source. Les plans de calcul comprennent l'estimation de coûts pour
l'obtention de la partie utile à partir du bloc source. Pour un bloc source
matérialisé sur un nœud distant il est nécessaire de créer ce plan de calcul. Pour
les blocs sources calculables, le plan de calcul existant est mis à jour afin de
fournir uniquement la partie utile contribuant à la requête.
4.4.1 Création de plan de calcul pour blocs matérialisés
Soit M = {brm1
, …, brmk
} l'ensemble des blocs recherchés pour répondre à la
requête br. Soit bm un bloc de chunks matérialisé sur un nœud distant pour
lequel il existe au moins un brmi
tels que , 1, ,mb i krmib . Le bloc
bm offre donc une possibilité d'obtenir une partie du résultat de br par extraction
et transfert de chunks matérialisés. Pour prendre en compte l'ensemble des
chunks que peut fournir bm pour la construction du résultat nous créons un plan
de calcul Pm associé à bm, composé d'un ou plusieurs éléments de la forme
suivante :
Pm = {< bpm1, bm, coutExtraction(bpm1, bm)>, …, < bpmu, bm, coutExtraction(bpmu,
bm)>}, 1 u k

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 104
La partie utile bpmj de bm est obtenu par l'intersection du bloc de chunks
manquants brmi
et bm :
, 1, , , 1, ,pmj mb b i k j lrmib
Ainsi, un plan de calcul est créé pour chaque bloc bm matérialisé sur un nœud
SRC ayant une intersection non nulle avec un ou plusieurs des blocs de M.
Comme chaque partie utile bpmj est disjointe des autres parties utiles, les coûts
d'extraction sont calculés de la même manière que si les différentes bpmj
provenaient de sources différentes. L'élément ajouté à CSRC est l'identifiant de
bloc bm et son plan de calcul associé Pm.
Exemple 5.2 : Création d'un plan de calcul pour blocs candidats matérialisés
sur nœuds distants
Pour cet exemple nous utilisons l'ensemble M = {brm1
, brm2
} comportant deux
blocs requêtes aux niveaux {région, année, path-0} (equ. {1,2,0}). Comme le
montre la figure 5.8, ce deux requêtes sont soumises au nœud distant LYON.
brm1
=
<{lieu.région.Rhône Alpes, temps.année.1934, pathologie.path-0.pneumonie},
{lieu.région.Rhône Alpes, temps.année.1935, pathologie.path-0.asthme}>
(equ. <{1.1.2, 2.2.10, 3.0.7},{1.1.2, 2.2.11, 3.0.10}>)
brm2
=
<{lieu.région.PACA, temps.année.1925, pathologie.path-0.épilepsie},
{lieu.région.Rhône Alpes, temps.année.1933, pathologie.path-0.bronchite}>
(equ. <{1.1.1, 2.2.1, 3.0.6},{1.1.2, 2.2.9, 3.0.9}>)
Le bloc de chunks matérialisé bLY5 a une intersection non nulle avec les deux
requêtes posées. Ce bloc est ainsi considéré comme bloc candidat et un plan de
calcul PLY5 est créé avec les intersections comme parties utiles :
PLY5 = {< 5LYbrm1b , bLY5, coutExtraction( 5LYbrm1b , bLY5)>, < 5LYbrm2b ,
bLY5, coutExtraction( 5LYbrm2b , bLY5)>}
Le bloc bLY5 associé à son plan de calcul PLY5 est donc ajouté à la l'ensemble C
des candidats pour fournir les chunks recherchés par M.

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 105
bLY5
LIEU(région)
Pié
mo
nt
Rh
ôn
e A
lpes
PA
CA
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
1925
TEMPS(année)
⋮
1936
⋮
1939
1935
1934
1933
bLY5
b'LY12
b'LY12
1925
TEMPS(année)
⋮
1936
⋮
1939
1935
1934
1933
brm2
brm1
Figure 5.8 : Eléments d'un plan de calcul créé pour un bloc candidat matérialisé sur le
nœud LYON
4.4.2 Mise à jour du plan de calcul des blocs calculables
Soit M = {brm1
, …, brmk
} l'ensemble des blocs recherchés pour répondre à la
requête br. Soit bc un bloc de chunks calculable localement qui fournit une
partie des chunks couverts par au moins un brmi
, i.e. , , ,cb i 1 krmib .
Soit Pc le plan de calcul associé à bc, tel que :
Pc = {<bp1, S1, coutExtraction(bp1, S1)>, …, <bpn, Sn, coutExtraction(bpn, Sn)>}
Il existe alors un plan de calcul P'c extrait du plan de calcul Pc qui fournit les
chunks du bloc calculable contenus dans les intersections cbrmib , i = 1,…,k.
P'c est défini par {<b'p1, S1, coutExtraction(b'p1, S1)>, …, <b'pn, Sn,
coutExtraction(b'pn, Sn)>}, n > 0, où :
- b'pj est l'identifiant de la partie utile de Sj qui contribue au calcul
d'une intersection , , ,cb i 1 krmib ,
- Sj est l'identifiant du bloc source utilisé pour l'obtention de b'pj.
- coutExtraction(b'pj, Sj) représente le coût estimé pour extraire la
partie utile b'pj à partir de Sj.
La construction du plan P'c permet d'adapter l'estimation des coûts pour
l'extraction des données source à la seule partie utile. Le nouveau coût tiendra
compte de la réduction du volume des données.

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 106
Exemple 5.3 : Mise à jour du plan de calcul pour les blocs candidats
calculables
L'exemple qui suit poursuit l'exemple 5.2 avec l'ensemble M = {brm1
, brm2
}
soumis au nœud distant LYON. Ces requêtes sont recherchés au sein de
l'index TX, qui fournit pour la requête brm2
le bloc calculable b'LY12 en résultat.
Le plan de calcul de ce bloc (cf. chapitre 4) utilise les blocs bp1 et bp2.
bLY5
LIEU(région)
Pié
mo
nt
Rh
ôn
e A
lpes
PA
CA
vLY1
vLY2
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
1925
TEMPS(année)
⋮
1936
⋮
1939
1935
1934
1933
bLY5
b'LY12
b'LY12
1925
TEMPS(année)
⋮
1936
⋮
1939
1935
1934
1933
brm2
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
bLY2
bLY1
bLY1
bLY2
1925-01-23
TEMPS(date)
1930-01-20
1929-12-11
1934-06-27
⋮
⋮
1934-01-12
1933-12-24
⋮
1925-01-23
TEMPS(date)
1930-01-20
1929-12-11
1934-06-27
⋮
⋮
1934-01-12
1933-12-24
⋮
b'p2
b'p1
brm1
Figure 5.9 : Extraction partielle d'un plan de calcul d'un bloc calculable en fonction
d'une requête sur le nœud LYON
Comme le montre la figure 5.9, nous calculons l'intersection de ces deux blocs
avec la requête pour obtenir les deux parties utiles b'p1 et b'p2 :
b'p1 = 1pb rm2b =
<{lieu.ville.Toulon, temps.date.1925-01-23, pathologie.path-0.grippe},

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 107
{lieu.ville.Marseille, temps.date.1929-12-11, pathologie.path-0.bronchite}>
(equ. <{1.0.1, 2.0.1, 3.0.8},{1.0.3, 2.0.27, 3.0.9}>)
b'p2 = 2pb rm2b =
<{lieu.ville.Toulon, temps.date.1930-01-20, pathologie.path-0.grippe},
{lieu.ville.Marseille, temps.date.1933-12-24, pathologie.path-0.bronchite}>
(equ. <{1.0.1, 2.0.28, 3.0.8},{1.0.3, 2.0.51, 3.0.9}>)
Dans le plan de calcul mis à jour, b'p1 et b'p2 remplacent les blocs bp1 et bp2 dans
les tuples du plan initial. Nous construisons ainsi un nouveau plan de calcul
P'LY12 qui nous permettra d'extraire les parties utiles du bloc calculable :
P'LY12 = {<b'p1, bLY1, coutExtraction(b'p1,bLY1)>,
<b'p2, bLY2, coutExtraction (b'p2,bLY2)>}
Les valeurs pour les estimations de coûts d'extraction sont également mises à
jour en fonction des parties utiles identifiées. Le bloc b'LY12 est donc ajouté à
l'ensemble CSRC, associé à son plan de calcul mis à jour P'LY12.
Les ensembles CSRC obtenus sur les différents nœuds distants sont transmis au
nœud DST où ils sont intégrés avec l'ensemble des blocs calculables localement
C0 dans l'ensemble de blocs candidats global C.
On trouvera en annexe B (exemple 5.b) un exemple de la constitution des
ensembles des blocs candidats CSRC sur plusieurs nœuds distants pour une
requête donnée. A la fin de la phase de localisation, l'ensemble R des blocs
matérialisés localement et l'ensemble C des blocs candidats distants ou locaux
est constituée sur le nœud destination DST. A l'aide de cette information DST
va pouvoir sélectionner les possibilités les plus avantageuses pour obtenir les
chunks non matérialisés localement.
5 Plan d'exécution et optimisation de l'exécution
Cette phase a pour objectif de construire un plan d'exécution distribué pour la
requête en choisissant parmi les solutions possibles celle qui minimise le temps
d'exécution. Le critère utilisé pour effectuer le choix des blocs candidats est
l'estimation d'un coût total qui inclut l'extraction depuis les blocs sources
matérialisés, le calcul d'agrégation pour les blocs calculables et le transfert par
le réseau vers le nœud destination pour les blocs distants. Les coûts d'extraction
depuis les blocs source matérialisés sont statiques, comme décrit au chapitre 4.
Les autres coûts sont fonction de caractéristiques dynamiques de la grille telles
que la bande passante disponible, la latence, la capacité de calcul de chaque
nœud. Pour chaque bloc candidat identifié lors de la phase de localisation les
coûts dynamiques doivent être calculés à la volée en fonction des nœuds source
et destination. Ces coûts vont en particulier permettre de choisir entre le nœud

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 108
source et nœud destination le meilleur site pour effectuer le calcul d'agrégation.
La construction du plan d'exécution final emploie un algorithme de type
glouton pour sélectionner les sources de chunks en minimisant le temps
d'exécution estimé.
5.1 Calcul des estimations de coûts
Le coût total d'obtention d'un bloc sur le nœud destination est fonction du coût
d'extraction coutExtraction(bp,bs) de la partie utile bp du bloc source bs
disponibles sur le nœud et de coûts dynamiques. Ces coûts dynamiques
concernent les coûts de transfert des chunks matérialisés distants , la
combinaison entre les coûts de calcul pour les chunks calculables et le transfert
soit des chunks à agréger, soit des chunks résultats du calcul d'agrégation. Ci -
après nous détaillons le calcul des coûts pour les blocs matérialisés, puis pour
les blocs calculables.
5.1.1 Estimation des coûts pour les blocs matérialisés
Le coût d'obtention coutTotal(bp, SRC, DST) d'une partie bp du bloc matérialisé
bm sur le nœud SRC, est la somme de son coût d'extraction
coutExtraction(bp,bm) et de son coût de transfert vers le nœud DST.
Pour estimer le coût de transfert d'un bloc de chunks bp extrait d'un bloc
matérialisé bm, nous supposons que l'infrastructure de surveillance de la grille
nous permet de connaître la bande passante bandePass(SRC,DST) disponible
entre le nœud source et le nœud destination. La taille totale de données à
transférer est calculée à partir du nombre estimé de chunks nbChunks(bp) à
transférer et la taille tailleChunk(bp) d'un chunk du bloc source. Le temps de
transfert total transf(bp,SRC,DST) est calculé selon le « Raw BandWidth
model » (RBW) utilisé par (Faerman et al., 1999) pour les transferts de données
sur grille :
,
0
p p
p
nbChunks b tailleChunk bsi SRC DST
transf b ,SRC DST = bandePass SRC,DST
sinon
Cette fonction renvoie le temps estimé à l'aide des données de surveillance les
plus récentes disponibles sur la grille. Le nœud destination peut mettre à jour
ces données au moment de l'interrogation des nœuds sources pendant la phase
de localisation. Le coût total pour la partie utile bp est alors :
, , , ,p p m pcoutTotal b SRC DST coutExtraction b b transf b ,SRC DST
Le coût total pour l'obtention de la partie utile d'un bloc candidat matérialisé bm
est associé à ce bloc dans l'ensemble des candidats C. Dans le cas où la partie

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 109
utile est représentée par plusieurs blocs bp1,…,bpn, le coût total est calculé
comme la somme des coûts totaux de chaque bpi, i = 1,…,n :
1..
, ,m pi
i n
coutTotal b SRC coutTotal b SRC
Exemple 5.4 : Estimation des coûts pour bloc de chunks matérialisé
Nous prenons comme exemple un ensemble de requêtes sur chunks manquants
M' = {b*rm
}, dont l'unique élément est recherché sur le nœud source LILLE
pour une requête dont le résultat doit être matérialisé sur le nœud destination
TOULOUSE. L'intersection avec les blocs indexés sur le nœud LILLE est
illustré en figure 5.10.
b*rm =
<{lieu.ville.Marseille, temps.année.1936, pathologie.path-0.pneumonie},
{lieu.ville.Lyon, temps.année.1939, pathologie.path-0.grippe}>
(equ. <{1.0.3, 2.2.12, 3.0.7},{1.0.7, 2.2.15, 3.0.8}>)
bLI3
1934
TEMPS(année)
1937
⋮
1939
1936
1930
⋮
1935
1925
⋮
1929
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
bLI3
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
1934
TEMPS(année)
1937
⋮
1939
1936
1930
⋮
1935
1925
⋮
1929 b'LI12
b'LI12
b*rm
Figure 5.10 : Bloc candidat matérialisé sur le nœud LILLE pour une requête soumise
au nœud TOULOUSE
Le bloc candidat matérialisé bLI3, dont la partie utile correspond au bloc bcLI3,
est ajouté à la liste des candidats CLILLE et renvoyé au nœud TOULOUSE qui
calcule l'estimation de coûts de transfert pour la partie utile.
bcLI3 =
<{lieu.ville.Marseille, temps.année.1937, pathologie.path-0.pneumonie},
{lieu.ville.St Etienne, temps.année.1939, pathologie.path-0.grippe}>

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 110
(equ. <{1.0.3, 2.2.13, 3.0.7},{1.0.5, 2.2.15, 3.0.8}>)
Le lien réseau du nœud LILLE vers le nœud TOULOUSE dispose d'une bande
passante de 320Ko/s, qui sont entièrement utilisés pour transférer les 18 chunks
de bcLI3.
3 3
3 ,,
18*1,60,09
320 /
cLI cLI
cLI
nbChunks b tailleChunk btransf b ,LYON TOULOUSE =
bandePass LYON TOULOUSE
Kos
Ko s
En somme nous obtenons un coût total suivant pour la partie utile du bloc
candidat matérialisé bLI3 :
3
3 3 3
, ,
, ,
0,128 0,09 0,137
LI
cLI LI cLI
coutTotal b LYON TOULOUSE
coutExtraction b b transf b ,LYON TOULOUSE
s s s
5.1.2 Estimation des coûts pour des blocs calculables
Le coût d'obtention coutTotal(bc, SRC, DST) d'un bloc calculable bc disponible
sur le nœud SRC et le transfert des données vers le nœud DST dépend du nœud
où est effectué le calcul. Nous distinguons trois cas de figure.
- Cas 1 : le bloc calculable est déjà sur le nœud destination.
- Cas 2 : le bloc calculable est sur un nœud source distant et le calcul de
l'agrégat est effectué sur ce nœud source.
- Cas 3 : le bloc calculable est sur un nœud source distant et le calcul de
l'agrégat est effectué sur le nœud destination.
Dans le cas 1, pour un bloc calculable qui est déjà sur le nœud destination, le
coût d'obtention coutTotal(bc,DST,DST) est la somme du coût d'extraction des
parties utiles de bc à partir du plan de calcul Pc et du coût de calcul des agrégats
sur le nœud destination à partir de bc. Le coût de calcul coutCalcul(bc,DST)
dépend du temps de calcul d'une opération élémentaire calcElem(DST) sur le
nœud et du nombre de chunks matérialisés à traiter pour fournir l'agrégation.
Soit le plan de calcul Pc = {<bp1, S1, coutExtraction(bp1 , S1)>,…, <bpm, Sm,
coutExtraction(bpm , Sm)>}, alors le coût de calcul est estimé de la façon
suivante :
1..
, *c pi
i m
coutCalcul b DST nbChunks b calcElem DST

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 111
Le coût total est alors fourni par :
, , ,c c c ccoutTotal b DST DST coutExtraction b P coutCalcul b ,DST
Dans le cas 2, le bloc calculable est sur un nœud source distant SRC et le calcul
d'agrégat est effectué sur ce même nœud source. Le coût de calcul de l'agrégat
est donc fonction des caractéristiques du nœud source.
Soit le plan de calcul Pc = {<bp1, S1, coutExtraction(bp1 , S1)>,…, <bpm, Sm,
coutExtraction(bpm , Sm)>}, le coût de calcul est donc estimé de la façon
suivante :
1..
, *c pi
i m
coutCalcul b SRC nbChunks b calcElem SRC
Le coût de transfert de l'agrégat depuis la source SRC jusqu'à la destination DST
est transf(bc,SRC,DST). Le coût total est alors fourni par :
1..
, ,
, , ,
c
pi i c c
i m
coutTotal b SRC DST
coutExtraction b S coutCalcul b ,SRC transf b SRC DST
Dans le cas 3, le bloc calculable bc est sur un nœud source distant SRC et le
calcul d'agrégat est effectué sur le nœud destination DST. Le coût total sera
donc la somme :
- du coût d'extraction sur la source SRC des parties utiles bpi des blocs
sources éléments du plan de calcul de bc,
- du transfert des bpi depuis SRC à DST,
- du calcul de l'agrégat sur le nœud destination DST.
Soit le plan de calcul Pc = {<bp1, S1, coutExtraction(bp1 , S1)>,…, <bpm, Sm,
coutExtraction(bpm , Sm)>}, alors
1..
, ,
, , , ,
c
pi i pi c
i m
coutTotal b SRC DST
coutExtraction b S transf b SRC DST coutCalcul b DST
L'avantage du calcul sur le nœud source consiste à réduire le volume de
données à transférer par la suite, car s'agissant d'un agrégat, le résultat du calcul
est bien moins volumineux. En revanche, le calcul sur le nœud destination peut
s'avérer plus rapide si le nœud destination dispose d'une capacité de calcul
disponible plus importante et que la bande passante du lien entre les nœuds ne
pénalise pas le transfert des blocs source. Lors de la phase d'exécution et
d'optimisation de la requête, la solution la moins coûteuse sera retenue. Le coût
total incluant les coûts dynamiques est ajouté à chaque élément ba de l'ensemble
de blocs candidats C établi lors de la phase de localisation.

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 112
En utilisant les estimations de coûts calculées pour chacun des blocs candidats,
nous introduisons maintenant une méthode pour la construction d'un plan
d'exécution de requêtes distribué optimisé.
5.2 Construction d'un plan d'exécution de requêtes optimisé
Nous disposons maintenant de l'ensemble C de blocs candidats pour contribuer
au résultat d'une requête, associés à leurs plans d'exécution et à une estimation
de leurs coûts d'obtention. Le mécanisme de construction du plan d'exécution
optimisé est basé sur un mécanisme de sélection de réplicas spécifique aux
grilles de calcul, introduit par (Weng et al., 2005). Nous reprenons en
particulier la mesure de bénéfice de cette méthode pour sélectionner les
candidats à intégrer au plan d'exécution.
5.2.1 Mesure de la contribution au résultat pour les blocs candidats
La contribution d'un bloc candidat ab C à l'ensemble de chunks manquants M
est facilement mesurable en utilisant le nombre de chunks nbChunks(ba) du bloc
candidat. Si l'identifiant de bloc ba représente toujours une partie d'un ou
plusieurs éléments de M, certains des chunks de ba peuvent cependant être
fournis par d'autres blocs candidats. Afin de pouvoir mettre à jour la
contribution réellement fournie par chaque bloc candidat au cours de la
démarche d'optimisation, nous normalisons le coût total à l'aide du nombre de
chunks maximum fournis par un bloc candidat ba. Nous obtenons ainsi le coût
d'obtention moyen coutChunk(ba) d'un chunk du bloc candidat :
, ,a
a
a
coutTotal b SRC DSTcoutChunk b
nbChunks b
Le nombre de chunks nbChunksContr(ba, M) de ba retenus pour contribuer à la
construction du résultat représenté par M permet de calculer le bénéfice
g(ba,M), appelé « goodness » par (Weng et al., 2005).
,,
a
a
a
nbChunksContr bg b =
coutChunk b
MM
La normalisation de la valeur du coût « par chunk » rend les différents blocs
candidats comparables, car il inclut l'ensemble des coûts, de l'extraction depuis
les blocs matérialisés au calcul d'agrégat. Le bénéfice est calculé pour
l'ensemble des blocs candidats à la construction des blocs résultat représentés
par M. Le mécanisme de sélection des meilleurs candidats que nous présentons
par la suite se sert de cette valeur pour inclure progressivement les candidats
retenus dans le plan d'exécution distribué.

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 113
5.2.2 Algorithme glouton pour la construction du plan d'exécution
L'algorithme que nous proposons pour la construction progressive du plan
d'exécution de requête est orienté vers la minimisation locale du temps de
réponse. Il s'agit d'un algorithme de type glouton opérant sur l'ensemble C de
blocs candidats triée par leur valeur de bénéfice. Ces blocs doivent être utilisés
pour recouvrir un ensemble M d'identifiants de blocs qui représentent la
différence géométrique entre la requête initiale br et les parties déjà couvertes
par des blocs matérialisés localement. L'objectif est de trouver le meilleur
recouvrement de ces blocs par une itération basée sur la sélection successive
des blocs candidats. A chaque itération, l'algorithme met à jour les identifiants
des blocs candidats restants afin de prendre en compte les changements
occasionnés par l'ajout progressif de blocs candidats au plan d'exécution. On
calcule ainsi la partie utile de chaque bloc, c'est-à-dire la partie non couverte
par les blocs déjà sélectionnés. Le détail de ces opérations est décrit par
l'algorithme 5.2 en annexe A.
Lorsque l'algorithme choisit le bloc candidat b*a avec le plus grand bénéfice
g(b*a,M) dans l'ensemble C des candidats, le reste des blocs dans C doit être
mis à jour selon les règles suivantes :
- Le nombre de chunks utiles nbChunksContr(ba,M) des blocs restants dans
C est diminué si ceux-ci contribuent au résultat avec les mêmes chunks que
b*a. Cela entraîne notamment la suppression des blocs entièrement couverts
par b*a.
- Les blocs qui proviennent du même nœud source que b*a sont pénalisés, en
réduisant leur bénéfice, pour tenir compte de l'occupation de ressources de
ce nœud engendrée par la sélection de b*a. Cette mesure privilégie en même
temps la parallélisation en favorisant l'implication d'un grand nombre de
nœuds sources dans l'exécution de la requête.
Le résultat que rend l'algorithme est un plan d'exécution qui permet l'exécution
des sous-requêtes pour chaque bloc de M. Les opérations incluses dans ce plan
d'exécution sont d'abord celles nécessaires à l'extraction des parties de blocs
matérialisés. Les calculs d'agrégation sur le nœud source sont inclus dans ces
requêtes générées à partir des identifiants de blocs. Pour compléter la
description de l'exécution, il est nécessaire d'introduire des opérations de
transfert par le réseau, que ce soit les blocs matérialisés source ou les résultats
de calculs d'agrégation. L'opération d'union est également incluse afin de
décrire l'assemblage des chunks des parties du résultat.
Exemple 5.5 : Construction progressive d'un plan d'exécution optimisé
Nous prenons l'exemple simplifié d'une requête b*r soumise au nœud LYON
aux niveaux levels(b*r) = {ville, année, path-0} (equ. {0,2,0}).

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 114
b*r =
<{lieu.ville.Nice, temps.année.1932, pathologie.path-0.grippe},
{lieu.ville.St Etienne, temps.année.1939, pathologie.path-0.bronchite}>
(equ. <{1.0.2, 2.2.8, 3.0.8},{1.0.5, 2.2.15, 3.0.9}>)
Les blocs indexés sur les différents nœuds répondant en partie à la requête sont
les suivants :
Nœud LYON :
b*LY12 =
<{lieu.ville.Toulon, temps.année.1925, pathologie.path-0.grippe},
{lieu.ville.Marseille, temps.année.1933, pathologie.path-0.bronchite}>
(equ. <{1.0.1, 2.2.1, 3.0.8},{1.0.3, 2.2.9, 3.0.9}>)
Nœud TOULOUSE :
b'TO2 =
<{lieu.ville.Toulon, temps.année.1930, pathologie.path-0.pneumonie},
{lieu.ville.St Etienne, temps.année.1939, pathologie.path-0.asthme}>
(equ. <{1.0.1, 2.2.6, 3.0.7},{1.0.5, 2.2.15, 3.0.10}>)
Nœud LILLE :
bLI3 =
<{lieu.ville.Marseille, temps.année.1937, pathologie.path-0.pneumonie},
{lieu.ville.St Etienne, temps.année.1939, pathologie.path-0.asthme}>
(equ. <{1.0.3, 2.2.13, 3.0.7},{1.0.5, 2.2.15, 3.0.10}>)
La figure 5.11 illustre les positions des différents blocs dans l'espace
multidimensionnel de membres et leurs chevauchements respectifs. Nous
commençons par calculer les valeurs de bénéfice pour chaque bloc candidat :
g(bcLI3,b*r) = nbChunksContr(bcLI3,b*
r) / coutChunk(bcLI3)
= 18 / 0,112s = 160,71s-1
g(b'cTO2,b*r) = nbChunksContr(b'cTO2,b*
r) / coutChunk(b'cTO2)
= 48 / 0,185s = 259,46s-1
g(bcLY12,b*r) = nbChunksContr(bcLY12,b*
r) / coutChunk(bcLY12)
= 8 / 0,32s = 25s-1
Avant de pouvoir lancer l'algorithme glouton de sélection des blocs candidats,
l'ensemble C est trié selon le bénéfice :
C = {(b'cTO2;259,46s-1
),(bcLI3;160,71s-1
),(bcLY12;25s-1
)}

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 115
b'TO2
bLI3
b'TO2
bLI3
b*LY12
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
b*LY12
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
1925
TEMPS(année)
⋮
⋮
1939
1932
1931
1937
1936
⋮
1933
1930
b*r
1925
TEMPS(année)
⋮
⋮
1939
1932
1931
1937
1936
⋮
1933
1930
Figure 5.11 : Recouvrement de la requête b*r sur le nœud LYON
A partir de cet ensemble, la première itération de l'algorithme sélectionne le
bloc candidat b'cTO2 avec le bénéfice maximum. La mise à jour des blocs
candidats restants dans C élimine aussi bien bcLI3 que bcLY12, car ceux-ci sont
entièrement contenus dans b'cTO2. L'identifiant b'cTO2 sert à construire le plan
d'exécution sous forme de requête OLAP sur le nœud TOULOUSE. Le transfert
vers le nœud LYON et l'assemblage du résultat sont ajoutés pour donner le plan
d'exécution final.
L'ensemble des opérations nécessaires associées à un bloc source qui fournit
une partie du résultat avant cet assemblage final sont regroupées au sein d'une
« tâche », ou « job » dans le vocabulaire usuel des grilles de calcul. Afin de
compléter le plan d'exécution, pour chaque élément de l'ensemble R des blocs
source matérialisés localement une tâche est construite et ajoutée au plan
d'exécution. A partir du plan d'exécution ainsi construit, le nœud des tination va
procéder à l'ordonnancement des différentes tâches décrites par ce plan. Le
lancement de ces tâches sur les différents nœuds de la grille entraîne une phase
d'exécution parallèle des sous-requêtes associées aux blocs sources
sélectionnés. Nous présentons ce processus plus en détail dans la section
suivante.
6 Exécution parallèle et distribuée de requêtes
L'exécution proprement dite du plan d'exécution distribué se divise en une
phase préparatoire, qui comprend un ordonnancement rapide des différentes

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 116
tâches qui peuvent être parallélisées et une phase de lancement et de
surveillance qui aboutit avec l'assemblage du résultat et sa transmission à
l'application client. Dans un premier temps, nous considérons que le plan
d'exécution construit est constitué de tâches indépendantes attribuées à
différents nœuds source. Ces tâches ont pour seul point commun la
matérialisation de leur résultat sur le nœud destination, ce qui les rend
entièrement indépendantes les unes des autres. Dans un deuxième temps, il nous
faudra prendre en compte la compétition qui existe entre les différentes tâches
pour les ressources en rapport avec le nœud destination sur lequel le résultat
doit être matérialisé.
6.1 Ordonnancement des tâches de transfert et de calcul
Le nœud destination procède à un ordonnancement par catégories de tâches. Cet
ordonnancement se fait selon un ensemble de règles heuristiques visant à
prendre en compte les conflits de ressources potentiels dus au fait que
l'ensemble des chunks résultat doit aboutir sur un seul nœud destination.
La procédure d'ordonnancement attribue à chaque tâche une priorité pour le
lancement de son exécution. Comme le montre la figure 5.12, nous obtenons
ainsi plusieurs phases en fonction du type et de la complexité de chaque tâche,
c'est-à-dire selon si elle est constituée uniquement d'une opération d'extraction,
d'opérations de transfert voire d'opérations de calcul sur les nœuds sources ou
nœuds destination.
TEMPS
calcul distant
transfert résultat
union parties
transfert sources
calcul local
calcul local
transfert source
extraction distante
extraction locale
extraction distante
extraction distante
extraction locale
phase 1
phase 2
phase 3
phase 4
phase 5
Figure 5.12 : Phases de lancement des différentes tâches du plan d'exécution distribué
Le nœud source regroupe donc les tâches du plan d'exécution en cinq phases de
lancement distinctes :

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 117
1. Les tâches comportant le transfert de blocs matérialisés depuis un nœud
source suivi d'un calcul d'agrégation sur le nœud destination sont
lancées en premier. Pour ce type de tâche, le calcul d'agrégation dépend
de l'aboutissement du transfert des données source vers le nœud
destination. L'anticipation de ce transfert augmente les possibilités
d'ordonnancement des calculs sur le nœud destination.
2. Les tâches constituées d'opérations de calcul d'agrégation à partir de
blocs matérialisés sur le nœud destination sont lancées ensuite. Ceci
permet d'utiliser au mieux la capacité de calcul du nœud destination en
attendant l'aboutissement des transferts lancés précédemment.
3. Les tâches comportant des calculs d'agrégation sur le nœud source avant
le transfert des chunks résultat sont ensuite soumises aux nœuds sources
concernés. Il s'agit ici d'anticiper le transfert des résultats qui dépend
essentiellement de l'aboutissement du calcul d'agrégation.
4. Les dernières tâches dépendant de nœuds sources distants, à savoir les
simples tâches de transfert de blocs matérialisés sont lancées par la
suite. Elles sont indépendantes des capacités de calcul disponibles des
différents nœuds et occupent la bande passante du lien réseau en
attendant l'aboutissement des calculs lancées en phase 3.
5. Les tâches qui ne consistent qu'à extraire des chunks matérialisés sur le
nœud destination sont lancées en dernier. Leur aboutissement rapide
permet d'assembler immédiatement une partie du résultat qui peut déjà
être transférée à l'utilisateur ou peut lui indiquer la progression de
l'exécution.
Exemple 5.6 : Ordonnancement des tâches d'un plan d'exécution distribué
optimisé
Le plan d'exécution construit dans le cadre de l'exemple 5.5 est illustré par la
figure 5.13. Ce plan comprend une tâche qui extrait et transfère la partie bcLI3 du
bloc matérialisé bLI3 du nœud LILLE vers le nœud LYON. La seconde tâche
extrait et agrège les parties b'cTO2-1 et b'cTO2-2 du bloc calculable b'TO2 sur le
nœud TOULOUSE avant de transférer le résultat vers le nœud LYON.
La première tâche appartient donc à la phase de lancement 4 (transfert de bloc
matérialisé) et doit être lancée juste après la deuxième tâche qui appartien t,
elle, à la phase de lancement 3 (calcul sur nœud source, puis transfert).

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 118
Figure 5.13 : Plan d'exécution distribué optimisé pour la requête b*r
Une fois le lancement de l'ensemble des tâches effectué, le nœud destination
met en place une surveillance de l'exécution et réceptionne les chunks résultat
dans une structure dédiée.
6.2 Surveillance de l'exécution et assemblage du résultat
Les fonctions de surveillance de l'exécution des différentes tâches sont fournies
par l'infrastructure de grille. L'objectif de la surveillance est de prévenir les
délais supplémentaires dus à la surcharge ou l'indisponibilité soudaine d'un
nœud source, un phénomène connu dans un environnement dynamique et
partagé comme la grille.
6.2.1 Surveillance et mise à jour du statut de l'exécution
La surveillance concerne uniquement les nœuds sources sur lesquels sont
exécutés des tâches sur plan d'exécution distribué. En fonction de la durée
estimée de l'exécution, le nœud destination sollicite à intervalles réguliers les
nœuds source. Ce mode de communication appelé « polling » permet de mettre
à jour régulièrement le statut d'avancement de l'exécution de la requête. Le
nœud destination peut ainsi transmettre en continu l'information sur la
progression de la requête à l'application client.

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 119
De plus, cela permet de détecter au plus tôt l'indisponibilité d'un nœud source et
de prendre des mesures adaptées pour compenser cette défaillance. Le nœud
destination garde en mémoire le temps estimé pour l'exécution de chaque tâche
et la compare au temps réellement utilisé. Dès que ce temps est dépassé et/ou si
un nœud source tarde à répondre à la sollicitation du nœud destination, celui -ci
peut déclencher une opération de remplacement pour la partie bp des chunks
résultat qui aurait due être fournie par le nœud source. Le remplacement
consiste essentiellement à relancer la procédure de choix optimisé d'un bloc
candidat ba décrite en section 5.2.2, mais cette fois-ci limité à la requête bp. Si
un recouvrement de bp est trouvé, le nœud source peut alors créer une ou
plusieurs tâches qui vont fournir les chunks demandés.
6.2.2 Assemblage du résultat
Les blocs de chunks représentant les différentes parties du résultat sont
matérialisés au fur et à mesure de l'aboutissement des tâches du plan
d'exécution sur le nœud destination. Il reste alors une opération d'union à
effectuer pour chacun de ces résultats partiels afin d'obtenir le bloc représentant
le résultat. Comme ces parties sont toutes complémentaires, il n'y a aucune
détection de doublons à effectuer. Grâce à l'ordonnancement des membres dans
les différentes dimensions le nœud destination peut facilement assembler les
chunks dans l'ordre dans lequel ils seront transmis à l'application client.
7 Conclusion
La méthode d'optimisation et d'exécution des requêtes sur l'entrepôt réparti sur
grille que nous avons présenté dans ce chapitre tire pleinement profit de nos
structures d'indexation des données disponibles déployées sur la grille. Cette
infrastructure basée sur le modèle d'identification unique des chunks de
données multidimensionnelles introduit au chapitre 3 facilite le recensement des
différentes possibilités pour obtenir les chunks qui satisfont la requête. Ainsi, à
partir d'une requête OLAP utilisateur classique, nous avons développé les
différentes phases de traitement, de la recherche des chunks disponibles jusqu'à
une démarche d'optimisation pour minimiser le temps de réponse à la requête.
L'optimisation se base sur un calcul de coût qui inclut aussi bien les estimations
de coût d'extraction calculées lors de l'indexation des blocs que les estimations
de coût de calcul et de transfert par le réseau qui sont calculées dynamiquement
grâce aux données fournies par le système de surveillance de la grille. La phase
d'optimisation produit un plan d'exécution distribué dont les opérations sont
regroupées en tâches exécutables en parallèle. Ces tâches subissent une dernière
sélection pour favoriser un ordonnancement adapté aux contraintes du
traitement sur la grille avant d'être lancées sur les différents nœuds. La phase
finale comporte la surveillance de l'exécution et l'assemblage progressif du
résultat qui est finalement transmis à l'application client. L'ensemble du
traitement des requêtes est transparent aux yeux de l'utilisateur qui s'adresse à
un seul nœud interface interagissant avec les autres nœuds de la grille pour
répondre à la requête. Nous détaillons au chapitre suivant l'architecture de
services de grille qui implémente la structure d'indexation et l'ensemble des

5 Exécution et optimisation de requêtes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 120
services pour la recherche des chunks de données sur la grille et l'exécution
optimisée des requêtes.



Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 123
Chapitre 6 Le prototype GIROLAP (Grid
Infrastructure for Relational
OLAP)
Dans ce chapitre, nous présentons l'architecture de services de grille conçue
pour implémenter les modèles et les méthodes pour l'identification, l'indexation
et l'interrogation des données multidimensionnelles de l'entrepôt réparti sur
grille. Les services que nous avons réalisés pour l'exploitation de l'entrepôt
distribué s'appuient sur les services existants dans l'infrastructure de grille.
Après l'organisation fonctionnelle des services, nous introduisons un schéma de
répartition des services de grille parmi les différents nœuds de grille. En
fonction de la structure d'une organisation virtuelle sur la grille, nous
définissons une politique de déploiement de ces fonctionnalités. La démarche
est illustrée par la description du traitement de requêtes sur l'entrepôt de
données réalisé dans le cadre du projet GGM.
1 Présentation des services de grille GIROLAP pour l'entrepôt
distribué
Les services de grille qui constituent l'infrastructure de grille proprement dite
sont encadrés par l'intergiciel de grille Globus Toolkit 4.0 (Foster, 2005)
conforme au standard OGSA (Open Grid Services Architecture). Une
application utilisant la grille dispose des fonctionnalités d'un ensemble de
services déjà fournis par l'infrastructure de grille. Sur cette base, nous avons
conçu et implémenté l'architecture de services de grille GIROLAP (Grid
Infrastructure for Relational OLAP) qui s'appuie sur l'infrastructure de grille
initiale. GIROLAP ajoute à l'infrastructure des services spécifiques à la gestion
et à l'interrogation des données multidimensionnelles d'un entrepôt réparti sur la
grille. Les nœuds de la grille qui participent à l'exploitation de l'entrepôt de
données distribué fournissent un ensemble de services prenant en charge
l'indexation, la communication et le catalogage des données présentes sur la
grille.
Le tableau 6.1 présente le nom de chaque service et la forme sous laquelle il est
implémenté, avec les fonctionnalités mises à disposition par chacun des
services. Les services en italique sont les services fournis par l'infrastructure de
grille Globus Toolkit ou réalisés par d'autres équipes du projet GGM, les autres
étant ceux que nous avons développés.

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 124
Nom Type
d'implémentation
Fonctionnalités
GridFTP(intégré à Globus)
application
client/server
- Transfert de fichiers entre
nœuds de grille
Grid Resource Allocation
and Management service
(GRAM, intégré à Globus)
service de grille - Exécution de tâches de
calcul sur un nœud
- Suivi de la progression de
l'exécution de tâche
Dimension Manager (DM) bibliothèque
logicielle
- Mise à disposition
d'identifiants de chunks
multidimensionnels
- Calculs géométriques sur
les identifiants de chunks
Local Index Service (LIS) Service de grille - Indexation des chunks
matérialisés sur un nœud
de grille
- Calcul et mise à jour des
chunks calculables à
partir des chunks
matérialisés
Chunks Resolution Service
(CRS)
Service de grille - Localisation de chunks au
niveau de la grille entière
- Evaluation des coûts de
calcul et de transfert
Chunk Localization Array
Catalog (CLAC)
Service de grille - Recensement des blocs
disponibles sur la grille
- Localisation des nœuds
possédant certains blocs
Network Weather Service
(NWS, intégré à Globus)
Application
client/server
- Mesure de bande
passante, capacité CPU
etc.
- Transfert et stockage des
mesures recueillies

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 125
Network Distance Service
(NDS)
Service de grille - Mise à disposition des
informations sur les
conditions de transfert et
de calcul
- Calcul d'indicateurs de
performances
Query Execution
Management Service
(QEMS)
Service de grille - Réécriture de requêtes
OLAP client
- Construction de plans
d'exécution optimisés à
partir du résultat de la
localisation
- Lancement et gestion de
l'exécution distribuée de
la requête
IHM client OLAP
JPivot+Mondrian
Application web
client
- Client OLAP
- Construction de requêtes
OLAP en SQL
- Présentation interactive
des résultats (tableau
Pivot, présentation
graphique)
Tableau 6.1 : Nom et fonctionnalités mises à disposition par chaque service de grille
Un exemple de l'architecture GIROLAP déployée sur une grille est illustré par
la figure 6.1. On notera qu'un service peut être déployé sur plusieurs nœuds de
la grille, par exemple le service LIS qui prend en charge l'indexation des
données locales sera implémenté sur les nœuds qui hébergent des données de
l'entrepôt.

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 126
Figure 6.1 : Déploiement exemple des services de l'architecture GIROLAP
Nous détaillons par la suite les fonctionnalités de chaque service ainsi que les
interfaces et interactions de ces services entre eux. Afin de garantir une
démarche cohérente, nous commençons par les services fournis par
l'infrastructure de grille que nous utilisons.
1.1 Services d'accès aux données et de calcul fournis par le Globus
Toolkit
L'infrastructure de grille basée sur l'intergiciel « Globus Toolkit 4.0 » comprend
un choix de services de base nécessaires pour effectuer les tâches inhérentes à
une grille de calcul, à savoir l'exécution de calculs sur des données stockées sur
les différents nœuds de la grille. Chaque nœud donne accès aux données qu'il
héberge en activant une instance du service GridFTP (Allcock et al., 2002). Ce
service opère au niveau de fichiers pour en extraire des lignes selon plusieurs
critères de sélection. Les blocs de chunks étant stockées sous forme de fichiers,
c'est donc ce service que nous utilisons pour effectuer l'extraction des chunks
suite à une requête. Pour le calcul des agrégats, un nœud met sa capacité de
calcul à disposition de la grille via le service d'allocation et de gestion des
ressources qui prend en charge et ordonnance les tâches de calcul à exécuter sur
ce nœud. Ce service, nommé « Grid Resource Allocation and Management
service » (GRAM), permet de calculer à la volée des agrégats sur chaque nœud.
Ces services fonctionnent localement sur chaque nœud de grille. Leurs
fonctionnalités se limitent aux données matérialisées sur les supports physiques
du nœud et ne prennent pas en compte le modèle multidimensionnel de
l'entrepôt de données réparti. L'accès par les identifiants basés sur le modèle
multidimensionnel est géré par le service d'identification des données
multidimensionnelles.

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 127
1.2 Service d'identification des données multidimensionnelles :
« Dimension Manager » (DM)
Comme nous l'avons décrit au chapitre 3, les identifiants de chunks et de blocs
de chunks sont construits à partir des ensembles de membres ordonnés pour
chacune des dimensions du modèle. L'ordonnancement des hiérarchies de
membres de dimension et la gestion des identifiants sont pris en charge par le
service d'identification des données multidimensionnelles, implémenté par le
« Dimension Manager » (DM).
1.2.1 Fonctionnalités
Pour disposer des hiérarchies de membres ordonnées, le DM s'appuie sur les
instances locales des dimensions matérialisées sur chaque nœud. Le DM
construit des identifiants de chunks à partir de ces membres ordonnés. En
utilisant les identifiants de chunks, le DM définit les identifiants de blocs de
chunks matérialisés ou calculables, i.e. il détermine les ensembles de chunks
contigus selon l'ordre introduit.
Figure 6.2 : Représentation des identifiants de blocs et de leur intersection

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 128
Le DM définit également le plan de calcul associé aux identifiants de blocs de
chunks calculables. Il réalise les opérateurs géométriques tels que l'intersection
ou la différence sur l'ensemble des identifiants de chunks. Ces opérateurs sont
essentiels pour l'indexation et la localisation des chunks ainsi que le traitement
de requêtes. La figure 6.2 montre plusieurs identifiants de blocs indexés sur le
nœud LYON. Par exemple, le bloc encadré A est décrit par les informations
décrivant la forme sous laquelle est matérialisé le bloc ainsi que le coût estimé
pour le chargement du bloc entier (A.1). Cette information est associée à
l'identifiant du bloc décrivant sa position dans l'espace multidimensionnel de
membres (A.2).
1.2.2 Interaction avec les autres services
Les fonctionnalités mises à disposition par le Dimension Manager sont utilisées
par la majorité des services du système GIROLAP. En effet, en mettant à
disposition les fonctionnalités de création et de modification des identifiants de
chunks et de blocs de chunks, le DM fournit les opérations de base pour le
fonctionnement des mécanismes d'indexation et de localisation au sein de
l'entrepôt réparti. Compte tenu du nombre d'appels que cela représente, le DM
n'est pas réalisé comme un service de grille, mais comme une bibliothèque
logicielle. Cette bibliothèque est intégrée à chaque service faisant appel aux
fonctions d'identification et de calculs sur ces identifiants. Le service
d'indexation locale notamment intègre le DM pour construire l'index TX des
blocs disponibles sur un nœud.
1.3 Service d'indexation locale : « Local Indexing Service » (LIS)
Pour pouvoir localiser les données de l'entrepôt réparti sur la grille, chaque
nœud hébergeant des données matérialisées de l'entrepôt déploie une instance
du service d'indexation locale, le « Local Indexing Service » (LIS).
1.3.1 Fonctionnalités
Ce service construit et maintient l'index TX des blocs de chunks localement
disponibles, tel que décrit au chapitre 3 pour les données matérialisées et au
chapitre 4 pour les agrégats calculables. Cet index permet de rendre rapidement
accessible l'ensemble des blocs de chunks disponibles sur le nœud sur lequel il
est déployé, soit par extraction depuis un bloc matérialisé, soit par calcul à la
volée suite à une requête portant sur des agrégats non matérialisés. Le LIS
fournit ainsi l'information nécessaire à la localisation des chunks disponibles
pour répondre à une requête. La figure 6.3 illustre la structure de l'index TX
avec un sommet de treillis et un index X spatial associé à chaque niveau
d'agrégation. Dans l'exemple présenté, les blocs calculables b'1 et b'2 sont
indexés sur le sommet v' du treillis.

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 129
Figure 6.3 : Visualisation en deux dimensions de la structure de l'index TX sur un
nœud
Le service LIS offre également les fonctionnalités de mise à jour et de
recherche dans l'index TX. La construction ou la modification de l'index TX
intervient lors du déploiement ou de la mise à jour de l'entrepôt. L'index doit
être mis à jour en fonction des ajouts ou suppressions de blocs matérialisés sur
le nœud de grille. Le LIS permet donc d'insérer dans l'index un bloc matérialisé
décrit par son identifiant associé à un ensemble de propriétés nécessaires à
l'accès aux données et à l'estimation des coûts d'extraction de chunks à partir de
ce bloc (voir chapitres 3 et 4). Seuls les identifiants de blocs matérialisés sont
explicitement insérés car l'ensemble des blocs calculables est automatiquement
créé et mis à jour au sein de l'index en fonction des blocs matérialisés indexés.
Lors de l'appel de l'opération de suppression d'un bloc matérialisé dans l'index
TX, le LIS effectue la mise à jour des blocs calculables dépendants. Pour
chaque insertion ou suppression d'un bloc indexé, le LIS implémente un
mécanisme de notification. Celui-ci permet de faire remonter les informations
sur les blocs disponibles pour une publication au sein de la grille vers le service
de catalogue des blocs de chunks (voir section 1.5).
Contrairement aux opérations d'insertion et de suppression, la consultation de
l'index TX n'entraîne aucune mise à jour ou notification. L'opération de requête
est donc conçue pour renvoyer en un délai minimum toute l'information
pertinente sur les possibilités d'obtenir les chunks de données décrits par la
requête. Pour cette opération, le LIS prend en argument un identifiant de bloc
de chunks recherchés. Le résultat est une liste d'identifiants de blocs

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 130
matérialisés ou calculables indexés qui peuvent fournir au moins une partie des
chunks demandés. Comme nous l'avons décrit au chapitre 5, les plans de calcul
pour ces blocs calculables sont adaptés et les mesures de coût estimé pour
l'obtention des chunks résultat sont également recalculées en fonction de la
requête.
1.3.2 Interaction avec les autres services
Les fonctionnalités du service LIS sont sollicitées par le service de recherche de
chunks (voir section 1.4) lors de la phase de localisation des données, aussi bien
lors de la recherche locale que pendant la recherche parmi l'ensemble des
nœuds de la grille. Pour orienter la recherche sur l'ensemble de la grille, le LIS
publie à l'avance l'information sur les blocs disponibles. Cette publication se
fait via le service de catalogue de chunks (CLAC) qui stocke l'ensemble de
l'information sur la disponibilité de blocs de chunks sur chaque nœud. Il est
donc nécessaire de mettre à jour les informations publiées suite à toute
opération de maintenance sur le LIS. Le déclenchement de cette mise à jour
passe par un système de notification auquel est abonné le CLAC, qui est ainsi
averti de tout changement dans l'index TX d'un nœud. La fraîcheur des
informations ainsi recueillies par le CLAC est importante pour un bon
déroulement de la phase de localisation de chunks qu'effectue le service de
recherche de chunks.
1.4 Service de recherche de chunks : « Chunk Resolution Service » (CRS)
Le service de recherche de chunks, nommé « Chunk Resolution
Service » (CRS), permet de localiser les blocs matérialisés ou calculables
disponibles sur la grille correspondant à une requête donnée.
1.4.1 Fonctionnalités
La fonction de recherche de chunks mise à disposition par le CRS prend comme
argument une requête exprimée sous forme d'identifiant de bloc. Le résultat
qu'il renvoie est constitué de la liste des blocs candidats introduite au
chapitre 5, c'est-à-dire l'ensemble des identifiants de blocs calculables qui
répondent au moins partiellement à la requête. Avec ces identifiants de blocs
candidats, le CRS fournit également le plan de calcul associé à chaque bloc
candidat ainsi que les mesures de débit réseau et de capacité de calcul des
nœuds source et destination. La figure 6.4 montre le déroulement de la
recherche avec l'interrogation successive des nœuds source. Ainsi on voit la
phase de localisation d'une requête exécutée sur le nœud « TOULOUSE ».
Aucun bloc indexé sur ce nœud ne peut contribuer au résultat, donc le CRS
soumet la même requête aux autres nœuds (après avoir consulté le catalogue) et
reçoit une réponse positive de la part du nœud LYON.

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 131
Figure 6.4 : Phase de localisation de chunks exécutée par le service de recherche de
chunks
1.4.2 Interaction avec les autres services
L'opération de localisation des chunks parmi l'ensemble des nœuds de la grille
s'appuie sur l'opération de recherche locale dans l'index TX construit sur un
nœud via l'interface du LIS. Le CRS interroge en premier le catalogue des blocs
disponibles au sein de la grille entière mis à disposition par le CLAC. Une fois
orienté par la liste de nœuds fournie par le CLAC, le CRS interroge les
instances du LIS de la liste de façon ciblée. Les informations sur les conditions
de transfert et de calcul sur les nœuds source et destination sont obtenues à
partir d'une interrogation du service de surveillance NDS (voir section 1.6).

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 132
1.5 Service de catalogue des blocs de chunks : « Chunk Localization
Array Catalog » (CLAC)
Afin d'orienter les recherches de chunks effectuées par le CRS sur la grille les
identifiants des blocs de chunks disponibles sur chaque nœud sont publiés par
le service de catalogue, nommé « Chunk Localization Array Catalog » (CLAC).
Ce service regroupe les identifiants des blocs indexés sur l'ensemble des nœuds.
1.5.1 Fonctionnalités
Chaque index local signale à une instance du CLAC sa capacité à fournir des
chunks de l'entrepôt. Cet index transmet tous les identifiants de blocs en
spécifiant s'ils sont matérialisés ou calculables. Le CLAC stocke les identifiants
recensés en les associant aux adresses des nœuds qui les hébergent. Le
catalogue ne sauvegarde que les identifiants, ce qui permet de détecter les
intersections avec les requêtes soumises sans gérer les dépendances entre les
blocs matérialisés et calculables. Les données associées sur les lieux de
stockage physiques des blocs sources ainsi que les plans de calculs ne sont
fournis que par les nœuds sources eux-mêmes. Le catalogue est stocké dans une
base de données relationnelle capable de traiter un grand nombre de requêtes
simples. La structure du déploiement du service de catalogue par rapport aux
instances de LIS et de CRS est décrite en section 2.2.
1.5.2 Interaction avec les autres services
Le CLAC met à disposition l'opération de recherche de nœuds utilisée par les
différentes instances du CRS. Les interactions avec les services d'indexation
locale (LIS) sur lequel s'appuie le CLAC sont les suivantes :
- Une instance du LIS nouvellement déployée signale sa présence,
- le CLAC s'abonne à cette nouvelle instance,
- le LIS signale par notification les changements dans son index TX.
Le catalogue dispose ainsi de données à jour à propos de la disponibilité des
blocs de chunks sur les nœuds de la grille. Pour enrichir encore cette
information, les données de surveillance de la grille sont fournies par un service
spécialisé.
1.6 Service de surveillance de la grille : « Network Distance
Service » (NDS)
Comme nous l'avons présenté au chapitre 5, au moment de la dernière étape de
la phase de localisation, les mesures de capacité de transfert et de calcul pour
chaque nœud source potentiel sont recensées. Ces données sont fournies par le
service de surveillance de l'état de la grille, le « Network Distance
Service » (NDS).

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 133
1.6.1 Fonctionnalités
Le NDS a été développé par une des équipes partenaires du projet GGM (Gossa
et al., 2006). Il s'appuie notamment sur le « Network Weather Service » (NWS)
(Wolski, 1997), intégré à l'infrastructure de grille qui mesure en continu la
vitesse et la latence des liens entre nœuds à l'aide d'un réseau de senseurs sur
l'ensemble des nœuds de la grille. Le NDS permet d'obtenir des valeurs brutes
sur l'état de la grille ainsi que des valeurs calculées à partir des métriques de
base. La figure 6.5 montre un client graphique qui expose les fonctionnalités du
service, avec en 1) la sélection des sources et destination des transferts à
mesurer, 2) le choix des métriques disponibles, 3) la définition des fonctions
dérivées des valeurs de base et en 4) le graphe des nœuds objets de la mesure.
Figure 6.5 : Client graphique Java du service NDS (Gossa et al., 2006)
1.6.2 Interaction avec les autres services
Le NDS utilise les données obtenues par le réseau de senseurs du NWS. Le
NDS est invoqué par le CRS au cours de la phase de localisation. Les données
collectées sont intégrées au résultat de la localisation et transmises au service
de gestion de l'exécution des requêtes, que nous allons présenter dans la section
suivante.

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 134
1.7 Service de gestion de l'exécution de requêtes : « Query Execution
Management Service » (QEMS)
Le service de gestion de l'exécution de requête a pour but de coordonner
l'ensemble des opérations nécessaires à l'interrogation de l'entrepôt réparti
GIROLAP. Ce service, baptisé « Query Execution Management
Service » (QEMS), délègue la recherche des chunks demandés au CRS mais
gère lui-même l'optimisation, l'ordonnancement et la surveillance de l'exécution
d'une requête. Il prend en charge la communication avec l'application client et
gère l'exécution distribuée des requêtes en interne de l'entrepôt.
1.7.1 Fonctionnalités
Le QEMS assure la fonction de réécriture de la requête client soumise en
format SQL. Cette réécriture vers le format bloc de chunks, comme décrite au
chapitre 5, permet de transmettre la requête au CRS chargé le la localisation des
données. La gestion de l'exécution assurée par le QEMS implique également la
construction d'un plan d'exécution optimisé pour l'obtention des chunks non
matérialisés sur le nœud destination. Cette fonction prend en entrée la liste des
blocs candidats avec les estimations de coûts fournies pas le CRS suite à la
phase de localisation. L'exécution du plan établi est ordonnancée, lancée et
supervisée par le QEMS qui assemble ensuite les résultats partiels avant de les
transférer au client. La figure 6.6 montre l'interface de gestion conçue pour
lancer manuellement les opérations de la démarche implémentée par le QEMS.
Figure 6.6 : Phase de localisation supervisée par le service de gestion de l'exécution
de requêtes

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 135
Une fois que le chargement et l'indexation des blocs matérialisés et des blocs
calculables à partir de ceux-ci est achevé, cette interface permet de charger des
requêtes exprimées sous forme de blocs de chunks et de les exécuter sur un des
nœuds, en obtenant en retour la trace de l'exécution de la requête.
1.7.2 Interaction avec les autres services
Après avoir reçu et réécrit la requête de l'application cliente, le QEMS lance la
localisation des chunks recherchés en invoquant le CRS. L'interaction avec le
CRS se limite à la transmission de la requête et la récupération des ensembles
de blocs qui peuvent contribuer à la requête localisés. Le QEMS maintient
également la connexion avec l'application client et lui attribue un identifiant de
session à l'aide duquel le contexte d'interrogation est sauvegardé. L'application
client est informée du statut de l'exécution de la requête via des notifications
émises par le QEMS au cours de l'exécution. En cas de perte de connexion
l'exécution de la dernière requête soumise est menée à bien et les données de la
session maintenues pendant un délai fixe. Chaque requête soumise au QEMS
est ainsi exécutée dans son contexte indépendant. Après avoir construit un plan
d'exécution distribué pour la requête le QEMS va lancer et gérer son exécution.
Le QEMS sollicite alors directement les services d'accès aux données et de
calcul et les surveille à l'aide des mécanismes de notification ou de surveillance
de l'intergiciel de grille. L'interaction du QEMS avec ces services nécessite une
certaine orchestration des services de grille. Nous allons dans la section 2
exposer les constellations de services de l'architecture GIROLAP pertinentes
pour le déploiement d'un entrepôt de données réparti.
1.8 Interface client OLAP
L'interrogation de l'entrepôt réparti fourni par l'architecture GIROLAP
nécessite une interface client interactive. La solution que nous employons pour
la navigation à travers les hypercubes est constituée de l'application web JPivot
(JPivot, 2008) qui présente une vue dite de « table de pivot », permettant à
l'utilisateur de visualiser et de naviguer à travers plusieurs dimensions à l'aide
d'une simple table.
Figure 6.7 : Interface graphique JPivot avec table de pivot montrant un hypercube de
l'entrepôt GGM

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 136
Le module Mondrian (Mondrian, 2008) fournit la transformation du modèle
multidimensionnel vers des requêtes SQL. La figure 6.7 présente un exemple de
résultat de requête via l'interface OLAP. Ce résultat est restitué sous forme de
table de pivot.
1.8.1 Fonctionnalités
La solution d'interface client que nous avons déployée fonctionne d'abord en
tant que client OLAP, c'est-à-dire qu'il permet à l'utilisateur d'effectuer des
opérations OLAP sur un ou plusieurs cubes OLAP. L'interface émet des
requêtes SQL à l'entrepôt en fonction des actions de l'utilisateur. La
présentation des résultats de ces actions est prise en charge par la table de pivot
standard présentée à l'utilisateur sous forme de page web. Il est également
possible de visualiser les données sous forme de graphes et de diagrammes.
1.8.2 Interactions
En dehors de l'interaction avec l'utilisateur de l'entrepôt, l'interface
JPivot+Mondrian interagit uniquement avec l'instance du QEMS déployée sur
le nœud qui sert de point d'accès à la grille. En plus de lui transmettre les
requêtes SQL, l'interface obtient du QEMS le statut d 'exécution de ses requêtes
en cours. Le résultat est transmis en entier à la fin de l'exécution. L'interface
client possède un point d'accès attribué, qui est lui-même un nœud hébergeant
des fragments de l'entrepôt et sur lequel est déployée une combinaison de
services de grille caractéristique de son rôle de point d'accès.
Nous présentons par la suite les différents rôles que peuvent prendre les nœuds
participants à l'infrastructure GIROLAP et leur intégration dans l'architecture
de services associée.
2 Déploiement des services
Nous avons précédemment introduit les différents services de l'architecture
GIROLAP en précisant les interactions entre les différents services. Le
prototype réalisé qui implémente les fonctionnalités d'indexation est basé sur
des services de grille faisant partie de l'intergiciel de grille Globus Toolkit 4.0.
Nous déployons sur chaque nœud de la grille l'ensemble des services de base
qui constituent l'infrastructure. Sur cette base viennent se greffer les services de
l'architecture GIROLAP. Il nous faut maintenant définir une politique de
déploiement de ces services sur la grille. Cette politique s'appuie sur une
typologie des nœuds de la grille. Nous distinguons les nœuds de stockage et de
calcul pour les blocs de chunks, les nœuds dédiés pour les services de catalogue
et de surveillance (CLAC et NDS) et les nœuds d'accès pour l'interrogation de
l'entrepôt.
Un déploiement exemple est illustré par la figure 6.8 sur une grille comportant
trois sites A, B, et C regroupant six nœuds répartis géographiquement et reliés
par un réseau étendu partagé.

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 137
Figure 6.8 : Types de nœuds au sein du déploiement exemple des services GIROLAP
2.1 Nœud de stockage et de calcul GIROLAP
Un nœud de grille sur lequel est installée la distribution du « Globus Toolkit »
standard en version 4.0 comporte le service GridFTP pour assurer un accès
direct aux données sous forme de fichiers et le service GRAM pour la gestion
de tâches de calcul locales. Ainsi équipé, chaque nœud de stockage et de calcul
dispose des moyens de stocker des données et de les mettre à disposition du
reste de la grille mais aussi d'effectuer des traitements sur ces données. Les
services spécifiques à l'architecture GIROLAP sont ensuite déployés.
Dans l'exemple de la figure 6.8, les nœuds 1 à 4 sont des nœuds de stockage et
de calcul. Ils gèrent le stockage, l'indexation et l'interrogation d'un ensemble de
blocs de chunks. Chaque nœud héberge un ensemble de blocs de chunks de
l'entrepôt.
L'extraction et le transfert de chunks à partir des blocs matérialisés dans le
cadre de l'exécution distribuée sont réalisés via le service GridFTP. Le second
service d'infrastructure étroitement lié à la gestion de ressources que nous
ajoutons est une instance du service NWS qui déploie les senseurs nécessaires à
la surveillance de la grille. Enfin, le service d'indexation local LIS est déployé
sur chaque nœud de stockage afin de répertorier et publier les blocs disponibles
sur le nœud. Sa fonction s'appuie sur le DM qui implémente le modèle
multidimensionnel de l'entrepôt. Un nœud de stockage peut être ajouté ou
supprimé sans arrêter l'exploitation de l'entrepôt réparti. Ainsi, le nombre et le
contenu de nœuds de stockage est adaptable aux conditions changeantes de la
grille, notamment par la réplication et le déplacement des blocs matérialisés en
fonction des conditions de transfert et de calcul sur la grille.

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 138
2.2 Nœuds pour services de catalogue et de surveillance
Pour un entrepôt distribué, nous déployons une seule instance du CLAC sur un
nœud relié par un lien réseau de faible latence avec le restant de la grille, de
façon à garantir son accessibilité par les instances du LIS et du CRS déployées.
Pour des raisons d'optimisation, il est préférable que les nœuds de stockage et
de calcul soient distincts des nœuds pour services de catalogue et de
surveillance. Dans l'exemple illustré en figure 6.8, ces nœuds sont regroupés
sur le site C. Ainsi, le nœud 5 en figure 6.8 n'est pas utilisé comme nœud de
stockage pour l'entrepôt réparti, ses ressources restent disponibles pour
l'exploitation du catalogue de blocs. Nous appliquons la même politique de
déploiement pour le service NDS. Son instance unique sur le nœud 6 donne
accès aux données de surveillance collectées par l'ensemble des senseurs
déployés sur les nœuds de stockage.
2.3 Nœuds d'accès pour l'interrogation décentralisée de l'entrepôt
Lors de la conception de l'entrepôt réparti, il est nécessaire de définir des points
d'accès, c'est-à-dire un ensemble de nœuds auxquels les applications client se
connectent pour soumettre les requêtes OLAP utilisateur. Le choix de ces
nœuds est déterminé par la topologie du réseau et la structure de l'organisation
virtuelle sur la grille. En effet, les mécanismes introduits au chapitre 3 sont
conçus pour associer à chaque nœud un ensemble de fragments de l'entrepôt
consulté par un groupe d'utilisateurs particulier. Au sein d'une organisation
virtuelle, les fonctions de stockage et d'exécution peuvent être par exemple
partagées entre plusieurs nœuds d'un site. Comme l'illustre la figure 6.8, les
nœuds 1 et 2 sur le site A et les nœuds 3 et 4 sur le site B sont des nœuds de
stockages déployés sur le réseau local d'un site. Les nœuds 1 et 4 hébergent en
plus des services nécessaires au stockage de blocs les services CRS et QEMS.
Ce nœud représente donc le point d'accès à l'entrepôt GIROLAP pour les
applications clientes sur leurs sites respectifs. Chacun de ces nœuds servant
d'interface client prend en charge la gestion de l'exécution de requêtes à l'aide
du QEMS ainsi que la localisation des chunks à l'aide du CRS. L'architecture
GIROLAP permet ainsi de déployer des mécanismes de traitement de requêtes
décentralisés sur n'importe quel nœud de stockage. Comme pour les nœuds de
stockage simples, le nombre et l'emplacement de nœuds interface client peut
être adapté dynamiquement en fonction de leur charge et des conditions
d'exploitation de l'entrepôt réparti.
Pour illustrer le fonctionnement et les possibilités de l'architecture GIROLAP
nous décrivons par la suite le déroulement du traitement d'une requête par
l'architecture de services décrite.
3 Déroulement du traitement de requête
Le client OLAP JPivot+Mondrian, utilisée pour consulter l'entrepôt réparti
GIROLAP, se connecte au QEMS d 'un nœud défini comme point d'accès à

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 139
l'entrepôt. Le QEMS forme l'interface client et gère les différentes étapes du
traitement de la requête, à commencer par la réécriture de la requête.
3.1 Réécriture
La réécriture de la requête OLAP par l'application client est nécessaire pour
obtenir la représentation en identifiants de blocs de chunks utilisés pour la
localisation et l'exécution de la requête. En partant de la représentation SQL, la
méthode de réécriture entièrement prise en charge par le QEMS produit un
ensemble d'identifiants de blocs représentant les données demandées par la
requête. Cette représentation de la requête permet au QEMS de consulter le
CRS déployé sur le même nœud pour localiser les données demandées.
3.2 Recherche locale
Le CRS prend en charge l'intégralité de la localisation des chunks recherchés.
Comme le montre la figure 6.9, la recherche débute toujours par l'interrogation
du LIS sur le nœud même. Le LIS renvoie la liste des blocs disponibles indexés
capables de fournir au moins une partie des chunks demandés. Si certains
chunks recherchés ne sont pas matérialisés sur le nœud, le CRS calcule les
identifiants des blocs de chunks regroupant les chunks manquants, selon la
méthode décrite au chapitre 5. Ces chunks manquants doivent être ensuite
localisés parmi l'ensemble des nœuds de la grille.
Figure 6.9 : Déroulement de la recherche locale de chunks sur un nœud

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 140
3.3 Localisation au niveau de la grille
Le CRS du nœud sur lequel la requête a été transmise gère la phase de
localisation, illustrée en figure 6.10. En premier lieu, il lance une recherche sur
le catalogue de blocs de chunks disponibles entretenu par le service CLAC afin
d'identifier les nœuds de la grille susceptibles d'héberger les par ties manquantes
du résultat de la requête. Les résultats obtenus sont ensuite utilisés par le CRS
pour envoyer des requêtes spécifiques aux instances du LIS désignées par le
catalogue. Ces requêtes permettent d'acquérir et de vérifier toutes les
informations sur la disponibilité des chunks recherchés, les références vers
leurs lieux de stockage physiques ou le plan d'exécution pour leur calcul.
Figure 6.10 : Localisation de blocs de chunks manquants sur la grille
Avant de renvoyer le résultat de la localisation au QEMS, le CRS ajoute les
données provenant du NDS concernant les transferts et le calcul des chunks
résultat vers le nœud destination.
3.4 Optimisation et exécution distribuée
Une fois le résultat de la localisation des chunks demandés, à savoir la liste des
blocs candidats disponibles, le QEMS prend en charge la construction du plan
d'exécution optimisé et le lancement de l'exécution distribuée de celui -ci. La
figure 6.11 illustre les étapes correspondantes.
Le procédé d'optimisation de calcul et de choix des blocs candidats pour fournir
le résultat d'une requête est décrit en détail au chapitre 5. A l 'aide des
informations fournies par la requête de localisation, le QEMS élabore un plan
de requête distribué optimisé pour réduire au maximum le temps de réponse à la
requête. Les blocs de chunks candidats localisés sont évalués selon leur coût
d'obtention estimé incluant le transfert et le calcul d'agrégats. Pour obtenir le
recouvrement des blocs du résultat ayant le moindre coût, les blocs localisés
sont ensuite sélectionnés progressivement par un algorithme glouton.

6 Le prototype GIROLAP (Grid Infrastructure for Relational OLAP)
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 141
Figure 6.11 : Optimisation de la liste des blocs candidats et exécution distribuée
Chaque bloc de chunks sélectionné pour contribuer au résultat se voit attribuer
une tâche de traitement dans le plan d'exécution de requête final. La
construction du plan d'exécution final est effectué par le nœud destination qui a
la charge de répartir les traitements en parallélisant les différentes tâches du
plan. Les tâches de traitement sont attribuées aux différents nœuds sources. Ces
tâches peuvent être entièrement parallélisées car elles fournissent des parties
complémentaires du résultat final. Le module d'ordonnancement du QEMS
lance les différentes tâches du plan d'exécution dans un ordre défini en fonction
de leurs caractéristiques (voir chapitre 5). Le statut des différentes tâches est
surveillé en continu et peut être communiqué à l'application client. Au fur et à
mesure de la matérialisation du résultat sur le nœud destination, le QEMS gère
l'assemblage des résultats partiels et le transfert vers l'application client.
4 Conclusion
Nous avons présenté l'architecture GIROLAP qui implémente les méthodes et
mécanismes introduits au cours des chapitres 3, 4 et 5. Il s'agit d'une
architecture de services de grille qui fournit les fonctionnalités nécessaires pour
l'identification, l'indexation et l'interrogation des données multidimensionnelles
de l'entrepôt réparti sur grille. En accord avec ces fonctionnalités, les services
sont organisés créant ainsi plusieurs types de nœuds. Nous avons illustré les
différentes possibilités de déploiement des services en fonction de la structure
de la grille employée. Pour finir nous avons détaillé le déroulement d'une
requête traitée par le système GIROLAP. Un scénario de test illustrant le
fonctionnement à l'aide de différentes catégories de requêtes est présenté en
annexe C.


Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 143
Chapitre 7 Conclusion et perspectives
1 Bilan et contributions
Les travaux que nous avons présentés dans ce mémoire constituent une
démarche de construction progressive composée des éléments suivants :
- L'adaptation du modèle multidimensionnel aux données
multidimensionnelles fragmentées et réparties sur une grille,
- La construction d'un modèle d'identification des données
multidimensionnelles réparties sur les nœuds d'une grille,
- L'introduction d'une méthode d'indexation locale basée sur le modèle
d'identification qui recense l'ensemble des données matérialisées et
calculables sur chaque nœud,
- La proposition d'un mécanisme d'exécution de requêtes distribuée tirant
profit de la répartition des données rendues accessibles par l'indexation et la
parallélisation des calculs,
- La conception d'une architecture de services de grille basée sur les modèles
et méthodes introduites pour la gestion d'un entrepôt de données sur grille.
Nous présentons par la suite les apports des différents points dans la réalisation
de notre solution pour les entrepôts répartis sur grille.
1.1 Modèle formel d'identification et d'indexation des données
multidimensionnelles réparties
Le modèle multidimensionnel que nous avons adapté pour gérer les données
réparties (Wehrle et al., 2005a) est essentiel pour pouvoir rechercher et
échanger les données de l'entrepôt parmi les nœuds de la grille. L'organisation
des dimensions de l'entrepôt offre la possibilité de décrire les fragments de
façon compacte et de distribuer cette description sur les nœuds de la grille avec
les fragments de l'entrepôt. L'ordonnancement des membres de dimension à
travers l'ensemble des hiérarchies de dimension permet de représenter les
données par intervalles dans les différentes dimensions. Grâce à ces intervalles,
il est possible de détecter les recouvrements dans les différentes dimensions
entre les données de requêtes ou des fragments de données. L'ordonnancement
des hiérarchies de dimension permet également de déterminer les ensembles de
membres représentant les mêmes données à différents niveaux hiérarchiques et
ainsi de déduire les agrégats calculables à partir d'un ensemble de données ou
d'agrégats existants. Les fragments obtenus par fragmentation horizontale aussi
bien au niveau détaillé qu'aux niveaux agrégés peuvent ainsi être construits et
identifiés par les intervalles de membres.
Le modèle multidimensionnel conçu à l'aide de ces hiérarchies de dimension
ordonnées produit des identifiants uniques pour l'ensemble des données de

7 Conclusion et Perspectives
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 144
l'entrepôt, aussi bien les faits détaillés que les agrégats de tous niveaux, qu'ils
soient matérialisés ou non. Ainsi, chaque nœud peut offrir une vue sur
l'intégralité du modèle multidimensionnel aux utilisateurs et exécuter des
requêtes sur l'ensemble de l'entrepôt (Wehrle et al., 2005b). Les identifiants que
nous avons introduits rendent possible cette interrogation en référençant les
données entreposées au grain le plus fin sous forme de chunks, eux-mêmes
regroupés en blocs de chunks contigus. La représentation des blocs par des
hyper-rectangles dans l'espace multidimensionnel de membres transforme les
opérations complexes d'évaluation de prédicats de sélection en simples
opérations géométriques qui permettent le calcul rapide des volumes de blocs et
d'intersections entre requêtes et blocs de chunks. De plus, la représentation sous
forme d'identifiants de chunks offre la possibilité de construire rapidement des
requêtes utilisables pour l'extraction et/ou le calcul de données sur chacun des
nœuds de la grille.
Nous avons présenté une méthode d'indexation en index TX qui met à profit les
propriétés du modèle d'identification adapté à la gestion décentralisé de
données multidimensionnelles. A l'aide de ce modèle d'identification, chaque
nœud de la grille est capable de construire un index local regroupant aussi bien
les données détaillées que leurs agrégats. La structure d'index TX proposée
distingue les niveaux d'agrégation par l'utilisation d'un treillis et intègre une
structure d'index spatial pour situer les données dans l'espace de données
multidimensionnel. Cette distinction entre les deux propriétés déterminantes des
données indexées permet des recherches ciblées et rapides sur l'index, en
déterminant avec précision la disponibilité de données à différents niveaux
d'agrégation et en chiffrant précisément les contributions des blocs trouvés à
une requête donnée. Les agrégats calculables à la volée à partir des blocs
matérialisés sont intégrés à l'index TX pour offrir une vue complète des
données disponibles sur chaque nœud de la grille. Le principal avantage de
l'indexation de ces données est de rendre accessible l'information sur les
agrégats non matérialisés, mais disponibles par calcul à la volée, aussi
rapidement que l'information sur les blocs matérialisés. Ce mécanisme met à
profit les liens entre données détaillées et agrégats de différents niveaux
recensés par les métadonnées réparties de l'entrepôt. Ces liens contenus dans les
hiérarchies de dimension permettent de sauvegarder et de mettre à jour
l'information sur les sources de données et les opérations nécessaires à
l'obtention d'un agrégat avant que celle-ci ne soit utilisée dans le cadre du
traitement d'une requête. L'index limite ainsi les délais liés au nombre et à la
complexité des opérations de recherche de données sur les nœuds de la grille.
De plus, les identifiants de blocs de chunks matérialisés ou calculables
disponibles sur chaque nœud peuvent être publiés et partagés sur la grille afin
d'accélérer la localisation des données utiles pour une requête.
Une fois les index TX locaux établis avec l'ensemble de l'information sur les
agrégats calculables, la mise à jour de l'entrepôt en phase d'exploitation tire
profit des mécanismes d'organisation des instances de dimension et
d'identification des fragments d'entrepôt. Un entrepôt stocke des données
historisées, c'est-à-dire que chaque fait stocké est situé à un instant dans le
temps, comme par exemple le nombre de ventes d'un produit dans un magasin

7 Conclusion et Perspectives
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 145
pour une journée. Pour cette raison, la plupart des entrepôts de données sont
régulièrement alimentés de façon incrémentielle par des données récentes qui
viennent compléter l'historique. Ce type de mise à jour reste facilement gérable
au sein de l'entrepôt réparti car ni les données ajoutées ni les métadonnées
correspondantes n'entrent en conflit avec les données entreposées. L'approche
que nous avons proposée pour la gestion de l'entrepôt est particulièrement
favorable aux mises à jour incrémentielles. Les structures d'index et la méthode
de traitement de requêtes décentralisées permettent l'intégration des mises à
jour sans interruption de l'exploitation normale, comme c'est le cas pour bon
nombre d'entrepôts.
1.2 Exécution et Optimisation de requêtes
L'entrepôt réparti offre un mécanisme de traitement de requêtes OLAP optimisé
pour un temps de réponse minimum aux requêtes. Ce mécanisme s 'appuie sur le
modèle d'identification et les index locaux mis en place sur les nœuds de la
grille. Le processus de traitement de requêtes réalise la localisation des données
demandées, à partir d'un nœud hébergeant des fragments de l'entrepôt. A l'aide
des opérations géométriques sur les identifiants de blocs, les blocs matérialisés
localement sont exclus de la recherche sur les nœuds distants de la gril le. Cette
méthode exploite donc au maximum des données matérialisées sur chaque nœud
et limite ainsi la communication et les transferts inutiles entre nœuds distants de
la grille. Pour assurer l'accès transparent aux données matérialisées sur les
nœuds distants ainsi qu'aux agrégats calculables, nous avons introduit une
méthode efficiente pour leur localisation à travers les index TX locaux qui
inclut d'une part l'adaptation de leur plan de calcul et d'autre part l'estimation
des coûts impliqués pour obtenir ces données. Nous avons également conçu un
mécanisme d'optimisation de l'exécution qui prend en compte les différentes
options pour obtenir chaque partie du résultat d'une requête afin d'utiliser au
mieux les ressources partagées par les nœuds de la gril le tout en minimisant les
temps de réponse. Ce mécanisme adapte les choix des options en fonction des
estimations de coûts pré-calculées en combinaison avec des estimations de
coûts de transfert et de calcul obtenues au moment de l'exécution. Le processus
d'optimisation utilise ainsi les informations pré-calculées des index TX et les
informations dynamiques sur l'état de la grille. L'option qui promet un temps de
réponse estimé minimal est choisie et intégrée à un plan d'exécution distribué.
L'ordonnancement des tâches parallélisables du plan d'exécution limite les
effets de l'absence de contrôle centralisé et du partage des ressources avec
d'autres applications au sein de la grille. Le processus d'exécution et
d'optimisation des requêtes met ainsi en œuvre les fonctionnalités établies pour
l'identification des données entreposées ainsi que la consultation et l'échange
d'informations pour leur localisation afin de mettre en place un accès
décentralisé rapide et transparent à l'entrepôt réparti.

7 Conclusion et Perspectives
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 146
1.3 L'architecture de services GIROLAP (Grid Infrastructure for Relational
OLAP)
Nous avons proposé une architecture de services de grille GIROLAP (Wehrle et
al., 2007a) établie à partir du cadre fonctionnel fourni par l'intergiciel Globus
Toolkit. Les fonctionnalités introduites par l'architecture GIROLAP s'intègrent
à l'architecture en couches existante au niveau des services spécifiques aux
applications. Les services proposés sont adaptés à la communication
asynchrone entre nœuds de la grille en regroupant les différentes fonctionnalités
de l'entrepôt de données réparti au sein de modules et services assurant
l'identification, l'indexation, la communication et la gestion de l'exécution de
requêtes. Les fonctionnalités existantes de gestion de données et de surveillance
de la grille sont intégrées et mises à profit pour l'exploitation de l'entrepôt. Le
système de gestion distribué de l'entrepôt que nous avons introduit (Wehrle et
al., 2007b) se conforme aux paradigmes de fonctionnement des applications sur
grille, en particulier la décentralisation des fonctionnalités essentielles pour
assurer un fonctionnement autonome de chaque nœud de la grille. Des solutions
éprouvées au sein d'infrastructures de grille comme le service de catalogue pour
les réplicas de données ont été adaptées à la gestion de données
multidimensionnelles. Les fonctionnalités et les interactions des différents
services engendrent la définition de plusieurs types de nœuds au sein de
l'entrepôt réparti. Ces nœuds spécialisés permettent la construction modulaire,
flexible et scalable de solutions spécifiques pour de multiples scénarios
d'utilisation.
2 Limites et perspectives
Les perspectives pour de futurs travaux basés sur notre approche visent à lever
les limites et à étendre les travaux dans les domaines suivants :
- La gestion et la maintenance des données de l'entrepôt à l'aide du modèle
multidimensionnel adapté pour les données réparties,
- La maintenance et l'adaptation des structures d'indexation en fonction de
l'évolution du placement de données au sein de l'entrepôt réparti,
- L'évolution et l'optimisation de la méthode de traitement de requêtes,
- La réalisation et l'intégration par l'architecture de services GIROLAP des
méthodes introduites.
Certaines des problématiques associées à ces domaines bénéficient du modèle
d'identification que nous avons introduit en tant que base pour de nouvelles
solutions. En effet, l'identification et l'indexation des données disponibles sur la
grille forme un point de départ pour de nombreuses évolutions possibles.
2.1 Gestion et maintenance des données de l'entrepôt réparti
Le modèle multidimensionnel adapté à la gestion d'un entrepôt réparti parmi les
nœuds d'une grille que nous proposons impose de fortes restrictions sur les

7 Conclusion et Perspectives
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 147
hiérarchies de dimensions. Ainsi, les conditions pour pouvoir ordonner les
instances de certains types de dimensions ne peuvent être remplies que suite à
d'importantes opérations de normalisation (voir chapitre 2). De plus, ces
opérations doivent impérativement être effectuées avant le déploiement de
l'entrepôt, pour maintenir la cohérence des données réparties et répliquées. La
nécessité d'ordonner l'ensemble des niveaux hiérarchiques impose entre autre de
trouver des relations d'ordre total, soit pour l'ensemble des membres d'un
niveau, soit pour des sous-ensembles de membres aux ancêtres communs dans
la hiérarchie. Ces relations peuvent être complexes et nécessiter un pré-calcul
des rangs des différents membres dans l'ordre total, ce qui rend plus difficile les
modifications a posteriori.
Ces difficultés rencontrées principalement lors de la conception de l'entrepôt
réparti, en particulier concernant l'ordonnancement des hiérarchies de
dimension ne peuvent être facilement levées. Les approches existantes pour la
normalisation des hiérarchies de dimension (Malinowski et al., 2006) doivent
être étendues pour produire des instances de dimension ordonnées. La
problématique visant à déterminer un ordre total sur une hiérarchie est résolue
provisoirement par l'emploi de relations d'ordre simples comme l'ordre
alphabétique. En effet, un tel ordre peut être trouvé dans tous les cas, car les
membres doivent se distinguer par leur valeur ou par leurs ancêtres dans la
hiérarchie. Le pré-calcul des rangs des membres dans l'ordre total est nécessaire
pour effectuer les opérations géométriques sur les identifiants. Ce calcul doit
être répété lors de mises à jour qui ajoutent ou modifient les instances de
dimension de l'entrepôt. Il est donc nécessaire de mettre en place une méthode
de mise à jour de l'entrepôt réparti qui tient compte de la complexité des
opérations impliquées tout en assurant la cohérence des données. Nous
distinguons dans ce cadre les mises à jour d'insertion qui sont incrémentielles et
les mises à jour modifiant les fragments et/ou le schéma des dimensions
réparties.
La mise à jour incrémentielle consiste à introduire des faits ou agrégats pré -
calculés dans l'entrepôt qui sont soit référencés par des membres de dimension
existants ou par des membres de dimension ajoutés à une ou plusieurs
dimensions. Si les membres de dimension associés aux nouveaux faits existent
déjà dans les tables de dimensions, les données supplémentaires peuvent être
matérialisées en tant que nouveaux fragments sans influence sur le reste des
données entreposées. Ces fragments peuvent être créés de la même manière que
les fragments existants à partir des profils de groupes d'utilisateurs. Leur
déploiement sur les nœuds choisis nécessite éventuellement des ajouts de
membres dans les instances locales de dimensions. Le mécanisme de gestion de
données doit être adapté à des mises à jour incrémentielles des tables de
dimensions, c'est-à-dire des ajouts de membres non existants qui ne modifient
pas le rang des membres dans l'ordre total introduit sur chaque niveau
hiérarchique. Par exemple, l'ajout de nouveaux membres pour les jours du mois
précédant en chaque début de mois sur un niveau « jour » ordonné par ordre
chronologique ne crée aucun conflit avec l'ordre sur les membres existants. En
plus des nœuds hébergeant les nouveaux fragments, les ajouts sont
obligatoirement déployés sur l'ensemble des nœuds servant de point d'accès, i.e.

7 Conclusion et Perspectives
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 148
hébergeant le service de gestion de l'exécution de requêtes introduit au chapitre
5, afin de permettre aux clients de soumettre des requêtes incluant les nouveaux
membres. Cette approche ne nécessite a priori pas de mécanisme de gestion de
cohérence dédié, car les modifications ne touchent pas les données de l'entrepôt
existant.
Une mise à jour modifiant les données existantes peut consister en des
modifications plus profondes affectant aussi bien les faits ou agrégats, i.e. les
données objets de l'analyse, que les données décrivant le modèle
multidimensionnel de l'entrepôt. Ce type de maintenance est rare et requiert
généralement un arrêt complet de l'exploitation de l'entrepôt. Au sein du
système que nous avons proposé, un tel arrêt pourrait être mis en place pour
l'ensemble des nœuds hébergeant tout ou une partie des blocs concernés par la
mise à jour, évitant ainsi l'interruption de service. Les nœuds servant de point
d'accès aux clients OLAP doivent dans ce cas limiter les requêtes aux parties de
l'entrepôt non concernés par la mise à jour. Les ressources de calcul des nœuds
concernés seraient disponibles pour les traitements à effectuer dans le cadre de
la mise à jour. Lorsqu'il s'agit de modifier des fragments existants ainsi que la
structure et l'ordre des instances de dimension, la gestion de la cohérence par un
mécanisme de mise à jour distribué devient indispensable. De nombreuses
approches existent dans les domaines des entrepôts sur systèmes distribués,
notamment l'utilisation de graphes de dépendances de vues (view dependency
graph) (Zhuge et al., 1997), employés par (Stanoi et al., 1999) pour un entrepôt
distribué. Dans notre approche, chaque fragment de l'entrepôt correspond à une
vue matérialisée sur une partie de l'entrepôt. Les mécanismes de maintenance
établis sont donc applicables aux fragments matérialisés sur la grille. La
principale difficulté consiste alors à mettre à jour l'ensemble des réplicas d'un
fragment ainsi que l'ensemble des agrégats dépendant du fragment mis à jour.
Les travaux existants sur les entrepôts distribués emploient une notion de
cohérence « faible » (Stanoi et al., 1998) qui réduit les contraintes sur l'état
cohérent par rapport à un entrepôt centralisé. Une telle approche mise en œuvre
pour l'entrepôt réparti sur grille peut tirer profit des mécanismes de localisation
des fragments à travers les index locaux pour déterminer le nombre et les
emplacements des fragments matérialisés concernés par une mise à jour. Les
index TX peuvent entre autre servir à limiter temporairement la consultation
des données concernées par la mise à jour.
2.2 Maintenance et adaptation des structures d'index TX en fonction de
l'évolution de l'entrepôt réparti
L'indexation locale des données de l'entrepôt disponibles sur chaque nœud
nécessite la mise en place d'une structure volumineuse d'index pour gérer aussi
bien les différents niveaux d'agrégation que la position des blocs de données
dans l'espace multidimensionnel de membres. L'intégration des agrégats
calculables à la volée à partir d'autres agrégats reste limitée à certaines
fonctions d'agrégation distributives et/ou algébriques. La construction et la
maintenance de cette structure engendrent de nombreux traitements complexes,
en particulier pour la mise à jour en cascade des blocs calculables en fonction

7 Conclusion et Perspectives
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 149
des blocs matérialisés sur le nœud. La maintenance et le rafraîchissement de
l'entrepôt réparti peut donc entraîner d'importantes modifications sur les
différents niveaux d'agrégation de l'index T et les index X associés. Il faut
également répercuter ces changements par la publication sur la grille des
informations sur les blocs de chunks disponibles, ce qui engendre des
traitements et délais supplémentaires lors de la mise à jour.
La maîtrise des opérations complexes liées à la maintenance des structures
d'index des blocs disponibles demande une méthode de gestion des fragments
avancée qui limite le nombre et l'étendue des mises à jour. Il s'agit en
particulier de maintenir une forte corrélation entre les fragments matérialisés
sur un nœud et les requêtes fréquentes soumises à ce nœud par les utilisateurs.
L'évolution de la répartition des données pendant l'exploitation de l'entrepôt
consiste à modifier la définition des fragments conformément au comportement
des utilisateurs. Initialement, les fragments sont définis de manière statique
pour chaque groupe d'utilisateurs en fonction de leurs requêtes fréquentes a
priori. Les fragments de l'entrepôt correspondants sont ensuite matérialisés sur
tous les nœuds associés aux utilisateurs concernés. Cet ensemble de fragments
évolue seulement lorsqu'il s'agit de déplacer des fragments entiers ou de créer
de nouveaux fragments à partir de résultats de requêtes. Le but d'une gestion de
la fragmentation avancée serait de faire évoluer le profil de requêtes de chaque
groupe d'utilisateurs en fonction du comportement de ses membres et de
redéfinir la fragmentation en fonction de ces évolutions. Les critères de
sélection décrivant les profils de requêtes peuvent être exprimés selon le
modèle d'identification que nous avons introduit. En associant ces identifiants à
leurs fréquences parmi les requêtes qui définissent le profil, il est possible de
stocker le profil des groupes d'utilisateurs de façon accessible et modifiable sur
la grille. En enregistrant les fréquences d'accès au niveau des chunks contenus
dans les fragments matérialisés et en recensant les requêtes les plus fréquentes
soumises par le groupe d'utilisateurs associé durant l'exploitation, l'entrepôt
serait capable de détecter les changements du comportement des utilisateurs. En
s'orientant sur un seuil minimum fixé pour la fréquence d'accès, les fragments
matérialisés pourraient être redéfinis en supprimant les données dont la
fréquence d'accès est inférieure et en matérialisant les données non matérialisés
dont la demande dépasse le seuil. Ainsi, en adaptant les fragments aux requêtes
fréquentes soumises à chaque nœud, les traitements complexes engendrés par la
localisation et l'optimisation de l'exécution de requêtes seraient tenues à un
minimum.
2.3 Evolution et optimisation de la méthode de traitement de requêtes
Les limites de la méthode d'exécution et d'optimisation de requêtes OLAP sur
l'entrepôt réparti que nous avons introduite sont en particulier liées aux
contraintes de la grille. Ainsi, la localisation des données non matérialisées sur
le nœud destination nécessite la consultation des index TX de tous les nœuds
sources potentiels afin d'obtenir des informations détaillées sur la façon
d'obtenir les données demandées. L'adaptation des plans de calcul pour les
blocs sources calculables peut s'avérer coûteuse dans le cas où les identifiants et
les estimations de coûts de nombreux éléments du plan doivent être modifiés.

7 Conclusion et Perspectives
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 150
Les estimations de coûts pour l'extraction, le calcul et le transfert que nous
avons introduits constituent encore une approche simpliste du problème. A
partir de ces modèles simples (Faerman et al., 1999), l'évolution des
estimations de coût devra intégrer les avancées spécifiques au traitement de
requêtes OLAP en systèmes distribués (Akinde et al., 2002), (Poess et al.,
2005) et de l'interrogation de sources de données au sein d'infrastructures de
grille (Alpdemir et al., 2003). La construction du plan d'exécution optimisé
comprend également des traitements importants qui dépendent de valeurs
fournies par le système de surveillance de la grille, ce qui peut introduire des
délais supplémentaires dans le traitement de requêtes. De plus, l'algorithme
d'optimisation de type glouton ne garantit pas de trouver la solution au coût
estimé minimal, mais seulement un minimum local. La démarche de
construction du plan d'exécution ne peut donc être considérée que comme une
première solution à développer. Le principal défi dans ce développement
consiste à anticiper les conditions d'exécution des tâches exécutées par les
nœuds source dans le plan d'exécution et dans l'ordonnancement des tâches.
Alors qu'une telle anticipation impliquerait l'usage d'heuristiques complexes, la
possibilité de réagir aux conditions changeantes au sein de la grille pendant
l'exécution de requêtes est plus prometteuse. Ceci est valable en particulier pour
les mesures de surveillance utilisées pour le choix des sources de données, qui
peuvent être rendues obsolètes suite aux variations de disponibilité des
ressources de calcul et de transfert partagées. Afin de corriger les éventuelles
erreurs d'estimation, le mécanisme d'exécution de requêtes doit être capable de
modifier certains choix faits au moment de la construction du plan d'exécution.
Une approche d'optimisation en cours d'exécution qui utilise des agents mobiles
autonomes a été développée dans le cadre du projet GGM (Pierson et al., 2007).
L'exécution de requêtes simples selon un plan d'exécution spécifique aux
requêtes OLAP est possible à l'aide des opérations de l'algèbre relationnelle
implémentées par les agents mobiles. L'intégration des multiples choix
possibles pour obtenir les données dans le fonctionnement des agents cependant
nécessiterait le développement d'agents spécialisés qui s'appuieraient sur les
services de l'architecture GIROLAP pour orienter leurs choix. L'agent devrait
ainsi pouvoir recalculer le temps de réponse estimé pour plusieurs solutions
possibles en se déplaçant d'un nœud à l'autre.
2.4 Réalisation et intégration des méthodes par l'architecture de services
de grille GIROLAP
L'architecture de services de grille GIROLAP que nous avons conçue pour
implémenter les fonctionnalités d'entrepôt de données réparti sur grille
constitue une première solution pour l'adaptation des mécanismes de gestion de
données multidimensionnelles décentralisés que nous avons proposés.
L'environnement dynamique et partagé de la grille conditionne la nécessité de
maintenir un couplage fort entre certaines fonctionnalités dans la définition des
services. Par exemple, le service de gestion de l'exécution de requêtes (QEMS)
regroupe l'ensemble des fonctionnalités essentielles à l'exécution de requêtes,
ce qui revient à introduire une forme de centralisation qui augmente la
dépendance vis-à-vis de ce service. De plus, l'instauration d'un service

7 Conclusion et Perspectives
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 151
centralisé pour le maintient d'un catalogue des blocs disponibles sur la grille
(CLAC) représente un compromis concernant la centralisation de
fonctionnalités, inspiré des solutions existantes pour la gestion des réplicas de
fichiers sur grilles. La forte intégration avec les services existants de la grille
présente un avantage pour l'architecture GIROLAP, mais introduit également
une dépendance du bon fonctionnement de cette infrastructure sous-jacente. En
particulier, la structure partiellement centralisée du service de surveillance de la
grille (NDS) rend le fonctionnement des mécanismes d'optimisation vulnérables
vis-à-vis de la disponibilité du nœud servant de point d'accès à ce service.
L'anticipation de ces risques ainsi que le dimensionnement et le placement des
ressources employées pour l'exploitation de l'entrepôt réparti sur grille demeure
une problématique pour laquelle l'architecture GIROLAP ne fournit que les
composants sous forme de types de nœuds spécialisés.
Les évolutions possibles de l'architecture proposée concernent en particulier
une amélioration de l'interaction entre les services de grille existants et les
services de l'entrepôt réparti afin d'augmenter la qualité de service offerte aux
clients. Il s'agit notamment de développer des mécanismes plus sophistiqués
pour la gestion des données réparties sur la grille, en faisant évoluer le
placement des fragments de l'entrepôt de manière dynamique. Dans notre
proposition nous utilisons la fragmentation horizontale du schéma en étoile,
établie à l'aide de profils de requêtes statiques. Le placement initial des
fragments obtenus suit la localisation des groupes d'utilisateurs associés à ces
profils de requêtes. L'évolution du placement des fragments matérialisés sur les
nœuds peut être prise en charge par des mécanismes de réplication existants
pour les fichiers (Cameron et al., 2004). Ce genre de gestion ne prend
cependant pas en compte le modèle multidimensionnel de l'entrepôt qui décrit
entre autres des dépendances entre faits détaillés et agrégats de différents
niveaux. Afin d'éviter par exemple de matérialiser des données redondantes sur
un même nœud ou de supprimer des données sur un nœud qui peuvent servir à
calculer des agrégats demandés, ces liens entre membres de différents niveaux
doivent être pris en compte.
Les systèmes existants se fient principalement au nombre d'accès à un fichier
depuis un nœud de grille (Carman et al., 2002) pour juger de l'utilité d'une
donnée sur un nœud. Un système adapté à un entrepôt déployé sur la grille doit
compter les accès à une donnée en fonction de sa position dans l'espace
multidimensionnel de données, des redondances avec d'autres données
disponibles et des possibilités d'obtenir des agrégats à partir de cette donnée. Le
système de cache collaboratif développé dans le cadre du projet GGM
(Cardenas et al., 2006) est capable de prendre des décisions pour le stockage
d'un fichier en fonction de différents paramètres, comme la demande locale sur
un nœud et l'espace de stockage disponible. L'intégration d'un tel système de
cache nécessiterait la définition d'une interface qui permet de communiquer les
décisions de déplacements de fichiers faits par le cache vers les services
chargés de la gestion de l'entrepôt réparti. En retour, les services de l'entrepôt
pourraient communiquer l'information sur les liens entre les éléments du
modèle multidimensionnel au système de cache pour influencer ses décisions de
placement des données. Les fonctions qu'utilise le cache distribué pour calculer

7 Conclusion et Perspectives
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 152
le bénéfice de chaque fichier pour un nœud particulier pourraient être adaptées
pour prendre en compte l'intérêt attribué à chaque bloc du point de vue du
modèle multidimensionnel de l'entrepôt réparti. Un tel système de cache
collaboratif décentralisé peut être utilisé pour créer des schémas de déploiement
levant en partie les contraintes de centralisation de l'architecture GIROLAP,
notamment celle appliquée au catalogue des réplicas des blocs disponibles sur
la grille. En effet, il serait imaginable de répliquer de manière ciblée les blocs
parmi les nœuds de la grille de façon à proposer des vues partielles sur
l'entrepôt spécifiques à certains groupes d'utilisateurs. Ces vues seraient alors
représentées par des instances du service de catalogue limitées à un sous -
ensemble des fragments de l'entrepôt.
Dans le cadre d'une démarche de coopération avec des services fournis par
l'infrastructure de grille pouvant améliorer le fonctionnement de l'entrepôt
réparti, l'intégration des sources de données externes à la grille par des
mécanismes de médiation offre la possibilité d'ajouter à l'entrepôt des données
dont l'accès et la mobilité sont restreinte. Par exemple, pour des raisons de
confidentialités et de sécurité l'accès aux données médicales détaillées peut être
limité par une interface externe à la grille qui ne fournit les données qu'à la
demande aux parties autorisées. Une telle source de données ne peut être
accessible depuis la grille qu'à l'aide d'une interface de médiation. Cela
nécessite une adaptation de notre approche pour la gestion de données qui se
base initialement sur les fragments d'un entrepôt centralisé qui est ensuite
déployé sur les ressources de stockage intégrées et contrôlées par la grille. Les
solutions que nous avons proposées ne tirent donc a priori pas profit des
possibilités qu'offre l'intégration de sources de données par médiation dans les
infrastructures de grille. Comme nous l'avons évoqué au chapitre 2, la
médiation permet en particulier de rendre accessible des données externes à la
grille par une interface standard. Cette interface est utilisable de manière
transparente, donc indépendante de la nature ou des modalités d'accès
inhérentes à chaque source de données. Cependant, les données ne sont
extraites de ces sources qu'au moment où elles font l'objet d'une requête. Alors
que l'aspect d'extraction à la demande a été exploré dans le cadre des entrepôts
de données, les délais engendrés par l'extraction et la transformation des
données source ainsi que la disponibilité incertaine des sources externes
pénalisent les performances et la fiabilité de l'entrepôt. Dans une démarche
visant à résoudre ces problèmes, il faudrait introduire une méthode pour inclure
des fragments d'entrepôt issus de sources externes accessibles par médiation, à
condition d'obtenir une estimation sur le coût d'extraction des données
concernées. L'optimisation de l'exécution de requêtes sur l'entrepôt réparti
dépend de ces estimations statiques, ainsi que des mesures de surveillance qui
servent à estimer les temps de transfert et de calcul nécessaires pour l'ob tention
d'un résultat partiel. Il s'agirait donc de concevoir un type de médiateur capable
de fournir ces informations pour une source externe afin de l'intégrer à
l'entrepôt réparti.

7 Conclusion et Perspectives
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 153
La modélisation et le déploiement d'entrepôts de données sur infrastructures de
grille pour l'interrogation à l'aide d'outils OLAP ouvre de nombreuses
possibilités pour l'informatique décisionnelle en environnement distribué.
L'exploitation et la consultation décentralisée d'un entrepôt réparti sur grille
nécessitent de repenser les modèles et les méthodes de gestion des données
objet de l'analyse, de leurs agrégats ainsi que les dimensions associées. La
transition vers un fonctionnement entièrement décentralisé impose des
changements importants dans la manière de traiter des requêtes OLAP sur
l'entrepôt, de gérer la distribution de données au sein d'une infrastructure de
grille et de faire évoluer l'entrepôt au fil de son existence. Notre travail s'inscrit
dans cette démarche qui présente encore de nombreux défis à résoudre au cours
de travaux futurs.


Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 155
Annexe A Algorithmes
Algorithme 3.1 : Insertion d'un sommet dans l'index T
Entrée(s) : index T en treillis (V,E), sommet vi à insérer
5
Sortie(s) : index T en treillis \i r aV v , E E E , avec Er l'ensemble des
arêtes enlevées et Ea l'ensemble des arêtes ajoutées suite à l'insertion de vi
// point de départ pour parcours récursif du treillis
r = racine(V,E); 10
insertion(r, vi);
// fonction, renvoie vrai si v' doit être un successeur de v dans le treillis
fonction succ(v, v') {
si 1,, ,i i i nlevel v D level v' D D D ,D alors 15
renvoie vrai;
sinon
renvoie faux;
finsi
} 20
// fonction récursive insérant v' dans le sous-arbre dont v est la racine
fonction insertion(v, v') {
inséré = faux;
25
// vérification si sommet n'est pas déjà été inséré
si (v égal v') alors
renvoie vrai;
finsi
30
// itération à travers l'ensemble des successeurs directs de v
|s d sS = v ,v E v = v ;
pour chaque (v, vd) dans S faire
// insertion dans le sous-graphe avec origine vd
inséré = inséré OU insertion(vd,v'); 35
// cas d'insertion de v' entre v et son successeur vd
si (succ(v,v') ET succ(v',vd)) alors
\ dE = E v,v
; 40
inséré = vrai;

A Algorithmes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 156
finsi
// cas d'insertion d'un successeur de v'
si ((succ(v,v') égal faux) ET succ(v',vd)) alors
dE = E v',v ; 5
finsi
finpour
// cas où v' est successeur de v, mais d'aucun de ses descendants
si ((inséré égal faux) ET succ(v,v')) alors 10
E= E v,v' ;
inséré = vrai;
finsi
renvoie inséré;
} 15
Algorithme 3.2 : Suppression d'un sommet dans l'index T
Entrée(s) : index T en treillis (V,E), sommet vs à supprimer
20
Sortie(s) : index T en treillis \ \i r aV v , E E E , avec Er l'ensemble des
arêtes enlevées et Ea l'ensemble des arêtes ajoutées suite à la suppression de vs
// point de départ pour parcours récursif
r = racine(V,E); 25
si (existe(r, vs)) alors
suppression(r,vs);
finsi
// fonction, renvoie vrai si v' doit être un successeur de v dans le treillis 30
fonction succ(v, v') {
si 1,, ,i i i nlevel v D level v' D D D ,D alors
renvoie vrai;
sinon
renvoie faux; 35
finsi
}
// fonction récursive de recherche d'un sommet dans le treillis
fonction existe(v,v') { 40
|s d sS = v ,v E v = v ;

A Algorithmes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 157
trouvé = faux;
// itération à travers les successeurs directs de v
pour chaque (v, vd) dans S faire
si (vd égal v') alors
renvoie vrai; 5
finsi
// appel récursif si vd est un prédécesseur de v'
si (succ(vd,v')) alors
trouvé = existe(vd,v');
finsi 10
si (trouvé) alors
renvoie vrai;
finsi
finpour
renvoie trouvé; 15
}
// fonction récursive supprimant v' dans le sous-arbre dont v est la racine
fonction suppression (v,v') {
|s d sS = v ,v E v = v ; 20
// itération à travers les successeurs directs de v
pour chaque (v, vd) dans S faire
si (vd égal v') alors
// v' trouvé, suppression de l'arête menant à v'
\ dE = E v,v ; 25
// suppression de v' même
\V =V v' ;
// réinsertion des successeurs de v'
|s e sS' = v ,v E v = v' ;
pour chaque (v', ve) dans S faire 30
insertion(v,ve);
finpour
sinon
suppression(vd,v');
finsi 35
finpour
}
Algorithme 4.1 : Calcul des fusions possibles dans une dimension au
sein d'un index X après insertion d'un bloc de chunks
40
Entrée(s) : bloc b inséré dans l'index X du sommet v de l'index T,

A Algorithmes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 158
dimension Di
Sortie(s) : ensemble de blocs de chunks calculables à indexer sur le sommet v'
d'un niveau d'agrégation supérieur à v dans la dimension Di
5
// fonction, renvoie l'intervalle de membres pour le bloc b dans la dimension Di
fonction intervalle(b, Di) {
// extraction des chunks limites inf et sup
chunk chinf = chunk limite inférieure de b;
chunk chsup = chunk limite supérieure de b; 10
// extraction des membres pour la dimension D i
membre minf = membre du chunk chinf dans la dimension Di;
membre msup = membre du chunk chsup dimension Di;
renvoie [minf; msup];
} 15
// fonction, renvoie la fusion des blocs b et b' dans la dimension Di
fonction fusion(b,b',Di) {
bloc bf = {};
intervalle inti = intervalle , intervalle ,i ib D b D ; 20
bf = inti;
pour chaque dimension Dj avec j i faire
intervalle intj = intervalle , intervalle ,j jb D b D ;
bf = f jb int ;
finpour 25
renvoie bf;
}
/* recherche de toutes les fusions possibles entre les blocs indexés et b grâce à
un bloc de recherche augmenté be */ 30
membre mlie = prédécesseur dans l'ensemble de membres ordonné du membre
limite inférieure de intervalle(b, Di);
membre mlse = successeur dans l'ensemble de membres ordonné du membre
limite supérieure de intervalle(b, Di);
bloc be = 1intervalle intervallelie mse nb,D m ;m b,D ; 35
// recherche des blocs en intersection ou adjacents dans la dimension D i
ensemble de blocs Br = résultat de requête be sur l'index X de v;
// ensemble de blocs pour accueillir toutes les fusions
Bf = {}; 40
pour chaque bloc b' dans Br faire
// élimination des blocs sans fusion avec b ou inclus dans b parmi B r
si intervalle intervallei ib',D b,D alors
supprime b' dans Br;
finsi 45
// calcul de la fusion
f = fusion(b,b',Di);

A Algorithmes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 159
// ajout de la fusion au résultat
f fB = B f ;
finpour
// ensemble pour fusions défini en tant que résultats intermédiaires 5
Bn = Bf;
// boucle programmation dynamique, fusion de fusions
tant que nB faire
pour chaque b* dans Bn faire 10
pour chaque b' dans f rB B faire
f' = fusion(b*,b',Di);
// ajout de la fusion si plus de membres dans D i
taillemax = max(|intervalle(b*,Di)|,|intervalle(b',Di)|)
si |intervalle(f',Di)| taillemax alors 15
n nB = B f' ;
finsi
finpour
si * fb B alors
*f fB = B b ; 20
finsi
\ *n nB = B b ;
finpour
fintant
25
renvoie Bf ;

Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 160
Algorithme 5.1 : calcul optimisé de la différence entre deux identifiants
de blocs de chunks
Entrée(s) : identifiant de bloc de départ bm, identifiant de bloc à soustraire bs
Sortie(s) : ensemble de q identifiants de blocs S = {bd1,…,bdq} avec 2nq pour
n dimensions
// recensement et tri par volume des différences dans les n dimension
tableau de tuples (dimension dim; entier val_diff; interval interv_inf; interval
interv_sup) diff[n] = {};
// extraction des chunks limites inf et sup
chunk ch_minf = chunk limite inférieure de bm;
chunk ch_msup = chunk limite supérieure de bm;
chunk ch_sinf = chunk limite inférieure de bs;
chunk ch_ssup = chunk limite supérieure de bs;
pour chaque dimension 1,i nD D ,D faire
// extraction des membres pour la dimension D i
membre memb_minf = membre_chunk_dim(ch_minf,Di);
membre memb_msup = membre_chunk_dim(ch_msup,Di);
membre memb_sinf = membre_chunk_dim(ch_sinf,Di);
membre memb_ssup = membre_chunk_dim(ch_ssup,Di);
// construction et sauvegarde des intervalles différence
diff[i] = (Di; |[memb_minf; memb_sinf[|+|]memb_ssup; memb_msup]|;
[memb_minf; memb_sinf[; ]memb_ssup; memb_msup])
finpour
// tri par ordre décroissant de la valeur de la différence
trie les éléments de diff[] par ordre décroissant de la taille de la différence
val_diff;
// construction de l'ensemble des blocs différence dimension par dimension
ensemble d'identifiants de blocs résultat S = {bm};
// itération sur toutes les dimensions, application des intervalles trouvés
pour chaque entier i de 1 à n faire
// l'on applique à chaque bloc le(s) intervalle(s) différence
pour chaque b dans S faire
booléen duplication = faux;
// si interval différence inférieur non vide
si (diff[i].interv_inf ) alors
assigne l'interval diff[i].interv_inf (i.e.
[memb_minf;memb_sinf[) au bloc b dans la dimension
Di;
duplication = vrai;

A Algorithmes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 161
finsi
// si interval différence supérieur non vide
si (diff[i].interv_sup = ]memb_ssup; memb_msup] ) alors
identifiant de bloc b';
// ajout d'un deuxième bloc si nécessaire
si (duplication égal vrai) alors
b' = copie(b);
S S b ;
sinon
b' = b;
finsi
assigne l'interval diff[i].interv_sup (i.e. ]memb_ssup;
memb_msup]) au bloc b' dans la dimension Di;
finsi
finpour
finpour
renvoie S;
Algorithme 5.2 : construction d'un plan d'exécution de requête
distribué optimisé
Entrée(s) : ensemble M d'identifiants de blocs représentant les chunks
manquants ou calculables sur le nœud destination DST, ensemble C de blocs
candidats, trié par bénéfice g(ba,M) décroissant
Sortie(s) : plan d'exécution PE constitué d'une tâche T pour chaque bloc
candidat retenu
plan d'exécution PE = {};
// itération tant que la requête n'a pas été entièrement recouverte et tant qu'il
// reste des blocs candidats
tant que M ET C faire
// sélection du bloc candidat au plus grand bénéfice
identifiant de bloc candidat ba = C[0];
supprimer l'élément ba dans C;
tâche T;
nœud SRC = nœud source où est indexé ba;
// création d'une tâche extraction+transfert pour les blocs matérialisés
si (ba est matérialisé) alors

A Algorithmes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 162
opération ext = opération d'extraction des données de ba sur
le nœud SRC;
ajoute ext à tâche T;
opération trf = opération de transfert des données de ba du
nœud SRC vers DST
ajoute trf à tâche T;
finsi
// création d'une tâche combinant extraction, calcul et transfert pour
// blocs calculables
si (ba est calculable) alors
// extraction de tous les blocs sources
pour chaque identifiant bloc source bs de ba faire
opération ext = opération d'extraction de la partie
utile de bs sur le nœud SRC;
ajoute ext à tâche T;
finpour
// calcul sur le nœud source
si (lieu de calcul d'agrégation de ba égal SRC) alors
opération cal = opération de calcul d'agrégation de
ba sur le nœud SRC;
ajoute cal à tâche T;
opération trf = opération de transfert du résultat du
calcul de ba du nœud SRC vers DST
ajoute trf à tâche T;
finsi
// calcul sur le nœud destination
si (lieu de calcul d'agrégation de ba égal DST) alors
opération trf = opération de transfert des parties
utiles des blocs source de ba de SRC vers DST
ajoute trf à tâche T;
opération cal = opération de calcul d'agrégation de
ba sur le nœud DST;
ajoute cal à tâche T;
finsi
finsi
ajouter tâche T au plan d'exécution PE;
// mise à jour des blocs de M non couverts
pour chaque bloc br de M faire
// supprime parties couvertes par ba
si abrb alors
\ rM M b
;
finsi
finpour

A Algorithmes
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 163
// mise à jour des blocs candidats restants dans la liste
pour chaque bloc bi de C faire
// pénalité pour les blocs du même nœud source
si (nœud source de bi égal SRC) alors
g(bi,M) = g(bi,M) - g(ba,M);
finsi
pour chaque partie utile bix que bi contribue à M faire
pour chaque partie utile bax de ba faire
si ax ixb b alors
remplace bix par bix \b bax;
finsi
finpour
finpour
si parties utiles de bi alors
C = C \ {bi};
finsi
finpour
// tri par bénéfice décroissant de la liste des candidats
trier les éléments bi de C par ordre décroissant de bénéfice g(bi,M);
fintant
renvoie plan d'exécution PE;


Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 165
Annexe B Exemples détaillés
Exemple 5.a : Identifiants des blocs matérialisés sur les différents nœuds de la
grille exemple
Nœud LYON :
Blocs de chunks matérialisés aux niveaux {ville, date, path-0} (equ. {0,0,0}) :
bLY1 =
<{lieu.ville.Toulon, temps.date.1925-01-23, pathologie.path-0.grippe},
{lieu.ville.Bourg-en-Bresse,
temps.date.1929-12-11, pathologie.path-0.asthme}>
(equ. <{1.0.1, 2.0.1, 3.0.8},{1.0.4, 2.0.27, 3.0.10}>)
bLY2 =
<{lieu.ville.Toulon, temps.date.1930-01-20, pathologie.path-0.pneumonie},
{lieu.ville.Marseille, temps.date.1934-06-27, pathologie.path-0.asthme}>
(equ. <{1.0.1, 2.0.28, 3.0.7},{1.0.3, 2.0.56, 3.0.10}>)
bLY3 =
<{lieu.ville.Grenoble, temps.date.1930-01-20, pathologie.path-0.méningite},
{lieu.ville.Lyon, temps.date.1934-06-27, pathologie.path-0.épilepsie}>
(equ. <{1.0.6, 2.0.28, 3.0.1},{1.0.7, 2.0.56, 3.0.6}>)
bLY4 =
<{lieu.ville.Bourg-en-Bresse, temps.date.1934-07-19,
pathologie.path-0.méningite},
{lieu.ville.Lyon, temps.date.1939-12-10, pathologie.path-0.épilepsie}>
(equ. <{1.0.4, 2.0.57, 3.0.1},{1.0.7, 2.0.103, 3.0.6}>)
Blocs de chunks matérialisés aux niveaux {région, année, path-0}
(equ. {1,2,0}) :
bLY5 =
<{lieu.région.Rhône Alpes, temps.année.1925,
pathologie.path-0.sclérose en pl.},
{lieu.région.Rhône Alpes, temps.année.1936, pathologie.path-0.asthme}>
(equ. <{1.1.2, 2.2.1, 3.0.5},{1.1.2, 2.2.12, 3.0.10}>)
Nœud TOULOUSE :
Blocs de chunks matérialisés aux niveaux {ville, date, path-0} (equ. {0,0,0}) :
bTO1 =
<{lieu.ville.Alexandrie, temps.date.1925-01-23, pathologie.path-0.méningite},
{lieu.ville.Turin, temps.date.1934-06-27, pathologie.path-0.épilepsie}>
(equ. <{1.0.8, 2.0.1, 3.0.1},{1.0.10, 2.0.56, 3.0.6}>)

B Exemples détaillés
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 166
bTO2 =
<{lieu.ville.Toulon, temps.date.1930-01-20, pathologie.path-0.pneumonie},
{lieu.ville.St Etienne, temps.date.1939-12-10, pathologie.path-0.asthme}>
(equ. <{1.0.1, 2.0.28, 3.0.7},{1.0.5, 2.0.103, 3.0.10}>)
Nœud LILLE :
Blocs de chunks matérialisés aux niveaux {ville, date, path-0} (equ. {0,0,0}) :
bLI1 =
<{lieu.ville.Marseille, temps.date.1925-01-23, pathologie.path-0.épilepsie},
{lieu.ville.Turin, temps.date.1929-12-11, pathologie.path-0.asthme}>
(equ. <{1.0.3, 2.0.1, 3.0.6},{1.0.10, 2.0.27, 3.0.10}>)
bLI2 =
<{lieu.ville.Toulon, temps.date.1930-01-20, pathologie.path-0.méningite},
{lieu.ville.Lyon, temps.date.1934-06-27, pathologie.path-0.grippe}>
(equ. <{1.0.1, 2.0.28, 3.0.1},{1.0.7, 2.0.56, 3.0.8}>)
Blocs de chunks matérialisés aux niveaux {ville, année, path-0} (equ. {0,2,0}) :
bLI3 =
<{lieu.ville.Marseille, temps.année.1937, pathologie.path-0.pneumonie},
{lieu.ville.St Etienne, temps.année.1939, pathologie.path-0.asthme}>
(equ. <{1.0.3, 2.2.13, 3.0.7},{1.0.5, 2.2.15, 3.0.10}>)
Exemple 5.b : Calculs préliminaires à la construction d'un plan d'exécution
optimisé
Pour cet exemple, nous prenons une requête b*r soumise au nœud LYON aux
niveaux levels(b*r) = {ville, année, path-0} (equ. {0,2,0}). Comme le montre la
figure b.1, la recherche sur l'index TX local fournit un bloc candidat calculable
bcLY12 qui est une partie du bloc calculable b*LY12, lui-même calculé à partir des
blocs sources bLY1 et bLY2 aux niveaux {ville, date, path-0} (equ. {0,0,0}).
b*r =
<{lieu.ville.Nice, temps.année.1932, pathologie.path-0.grippe},
{lieu.ville.St Etienne, temps.année.1939, pathologie.path-0.bronchite}>
(equ. <{1.0.2, 2.2.8, 3.0.8},{1.0.5, 2.2.15, 3.0.9}>)
b*LY12 =
<{lieu.ville.Toulon, temps.année.1925, pathologie.path-0.grippe},
{lieu.ville.Marseille, temps.année.1933, pathologie.path-0.bronchite}>

B Exemples détaillés
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 167
(equ. <{1.0.1, 2.2.1, 3.0.8},{1.0.3, 2.2.9, 3.0.9}>)
bcLY12 = 12*LYbrb* =
<{lieu.ville.Nice, temps.année.1932, pathologie.path-0.grippe},
{lieu.ville.Marseille, temps.année.1933, pathologie.path-0.bronchite}>
(equ. <{1.0.2, 2.2.8, 3.0.8},{1.0.3, 2.2.9, 3.0.9}>)
Nous supposons ici que le bloc candidat bcLY12 fournit 8 chunks agrégés à un
coût estimé de 0,32s par chunk.
b*LY12
vLY3
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
b*LY12
requête b*r sur un bloc de chunks calculable sur le n œud LYON aux niveaux levels(v
LY3) = {ville,année,path-0} :
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
1925
TEMPS(année)
⋮
⋮
1939
1933
1932
1931
1925
TEMPS(année)
⋮
⋮
1939
1933
1932
1931
b*r
Figure B.1 : Recherche locale sur le nœud LYON suite à une requête b*r
A partir du résultat de la recherche locale sur le nœud LYON, nous construisons
l'ensemble M de blocs désignant les chunks manquants à rechercher sur le les
autres nœuds de la grille. Comme le seul bloc candidat disponible sur le nœud
LYON est indexé comme calculable, l'identifiant b*rm
= b*r est le seul élément
de M.
La recherche sur le nœud TOULOUSE renvoie un bloc candidat b'cTO2
calculable issu du bloc calculable indexé b'TO2, comme l'illustre la figure b.2.
b'TO2 =
<{lieu.ville.Toulon, temps.année.1930, pathologie.path-0.pneumonie},
{lieu.ville.St Etienne, temps.année.1939, pathologie.path-0.asthme}>
(equ. <{1.0.1, 2.2.6, 3.0.7},{1.0.5, 2.2.15, 3.0.10}>)
b'cTO2 = 2TObrmb* =
<{lieu.ville.Nice, temps.année.1932, pathologie.path-0.grippe},
{lieu.ville.St Etienne, temps.année.1939, pathologie.path-0.bronchite}>
(equ. <{1.0.2, 2.2.8, 3.0.8},{1.0.5, 2.2.15, 3.0.9}>)
Nous supposons que le bloc candidat b'cTO2 fournit 48 chunks agrégés à un coût
estimé de 0,185s par chunk pour un calcul sur le nœud source avant transfert du
résultat.

B Exemples détaillés
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 168
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
1925
TEMPS(année)
⋮
⋮
1939
1932
1931
1930
b'TO2
b'TO2
b*rm
1925
TEMPS(année)
⋮
⋮
1939
1932
1931
1930
vTO2
requête b*rm
sur un bloc de chunks calculable sur le n œud TOULOUSE aux niveaux levels(vTO2
) = {ville,année,path-0} :
Figure B.2 : Recherche sur le nœud TOULOUSE suite à la requête b*rm
La recherche sur le nœud LILLE renvoie un bloc candidat bcLI3 matérialisé
provenant du bloc indexé bLI3, comme l'illustre la figure b.3.
bLI3
vLI2
PATHOLOGIE(path-0)
ép
ilep
sie
mal. A
lzh
eim
er
mén
ing
ite
asth
me
bro
nch
ite
pn
eu
mo
nie
gri
pp
e
sclé
rose e
n p
l.
1925
TEMPS(année)
⋮
1937
⋮
1939
1936
1932
⋮
bLI3
requête b*rm
sur un bloc de chunks matérialisé sur le n œud LILLE aux niveaux levels(vLI2
) = {ville,année,path-0} :
LIEU(ville)
Bo
urg
-en
-Bre
sse
Gre
no
ble
Lyo
n
St
Eti
en
ne
Mars
eille
Nic
e
To
ulo
n
Ale
xan
dri
e
No
vare
Tu
rin
b*rm
1925
TEMPS(année)
⋮
1937
⋮
1939
1936
1932
⋮
Figure B.3 : Recherche sur le nœud LILLE suite à la requête b*rm
bLI3 =
<{lieu.ville.Marseille, temps.année.1937, pathologie.path-0.pneumonie},
{lieu.ville.St Etienne, temps.année.1939, pathologie.path-0.asthme}>
(equ. <{1.0.3, 2.2.13, 3.0.7},{1.0.5, 2.2.15, 3.0.10}>)

B Exemples détaillés
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 169
bcLI3 = 3LIbrmb* =
<{lieu.ville.Marseille, temps.année.1937, pathologie.path-0.grippe},
{lieu.ville.St Etienne, temps.année.1939, pathologie.path-0.bronchite}>
(equ. <{1.0.3, 2.2.13, 3.0.8},{1.0.5, 2.2.15, 3.0.9}>)
Nous supposons que le bloc candidat bcLI3 fournit 18 chunks agrégés à un coût
estimé de 0,112s par chunk.


C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 171
Annexe C Scénario de test sur
l'entrepôt GGM
1 Scénario de test sur l'entrepôt GGM
L'entrepôt de données développé dans le cadre du projet GGM fournit un cas
d'utilisation basé sur la vue « Patient » de l'entrepôt. Nous avons réalisé un
scénario d'utilisation sous forme d'un déploiement exemple sur les trois sites
LYON, LILLE et TOULOUSE de la grille expérimentale du projet. Pour ce
scénario, chaque site héberge un nœud de stockage unique qui est également
chargé de la gestion de l'exécution de requêtes. Suite à la description de la
répartition des fragments du schéma en étoile sur ces nœuds de stockage, nous
introduisons plusieurs catégories de requêtes permettant de valider le
fonctionnement de l'infrastructure GIROLAP.
1.1 Fragmentation du schéma en étoile centré patient
La partie de l'entrepôt de données GGM utilisée pour ce scénario d'utilisation
est limité à la vue « Patient », présentée en figure c.1. Cette vue est matérialisée
par une table de faits centrale associée à trois tables de dimension
« date_naissance », « lieu_naissance » et « pathologie ». La vue de l'entrepôt
présentée à l'utilisateur lui permet donc de sélectionner des membres sur ces
trois dimensions pour obtenir en tant que mesure la liste des identifiants des
patients et le nombre de décès. La table de faits contient 60000 lignes de
données simulées.
patient
ID_patient : integer
pathologie : text
date_naiss : date
date_naissance
date_naiss : date
mois : char(7)
annee : char(4)
pathologie
ICD_pathologie : integer
ICD_famille_path : integer
nom_pathologie : text lieu_naiss : text
lieu_naissance
region : text
ville : text
deces : integer
pays : text
Figure C.1 : Vue centrée patient du schéma de l'entrepôt GGM
Nous définissons trois profils de requêtes pour chacun des sites géographiques
qui permettent de fragmenter la table de faits en trois ensembles de blocs à
déployer.

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 172
1.2 Fragmentation et déploiement de la table de faits
La table « patient » est divisée en huit blocs matérialisés de différentes tailles et
en partie redondants, détaillés par le tableau c.1. Chaque bloc est déployé sur
un des nœuds de stockage et inséré dans l'index TX de ce nœud. Le service
d'indexation LIS en déduit l'ensemble des nœuds calculables à partir de ces
blocs issus de la table de faits.
ID
fragment
identifiant de bloc matérialisé volume
(lignes)
A <{lieu_naiss.ville.Ville000, date_naiss.date.1900-01-01,
pathologie.path-0.0},
{lieu_naiss.ville.Ville049, date_naiss.date.1929-12-31,
pathologie.path-0.52}>
3887
B <{lieu_naiss.ville.Ville000, date_naiss.date.1900-01-01,
pathologie.path-0.53},
{lieu_naiss.ville.Ville049, date_naiss.date.1929-12-31,
pathologie.path-0.119}>
5005
C <{lieu_naiss.ville.Ville050, date_naiss.date.1900-01-01,
pathologie.path-0.0},
{lieu_naiss.ville.Ville099, date_naiss.date.1929-12-31,
pathologie.path-0.119}>
9087
D <{lieu_naiss.ville.Ville030, date_naiss.date.1930-01-01,
pathologie.path-0.30},
{lieu_naiss.ville.Ville099, date_naiss.date.1959-12-31,
pathologie.path-0.119}>
9509
E <{lieu_naiss.ville.Ville030, date_naiss.date.1930-01-01,
pathologie.path-0.0},
{lieu_naiss.ville.Ville099, date_naiss.date.1959-12-31,
pathologie.path-0.29}>
3081
F <{lieu_naiss.ville.Ville000, date_naiss.date.1930-01-01,
pathologie.path-0.0},
{lieu_naiss.ville.Ville029, date_naiss.date.1959-12-31,
pathologie.path-0.119}>
5403
G <{lieu_naiss.ville.Ville000, date_naiss.date.1940-01-01,
pathologie.path-0.0},
{lieu_naiss.ville.Ville089, date_naiss.date.1999-12-31,
pathologie.path-0.119}>
32355
H <{lieu_naiss.ville.Ville090, date_naiss.date.1940-01-01,
pathologie.path-0.0},
{lieu_naiss.ville.Ville099, date_naiss.date.1999-12-31,
pathologie.path-0.119}>
3653
Tableau C.1 : Fragments de la table de faits « Patient » sous forme de blocs de chunks
En plus des blocs de chunks détaillés, nous matérialisons un ensemble de blocs
constitués de chunks agrégés pré-calculés.
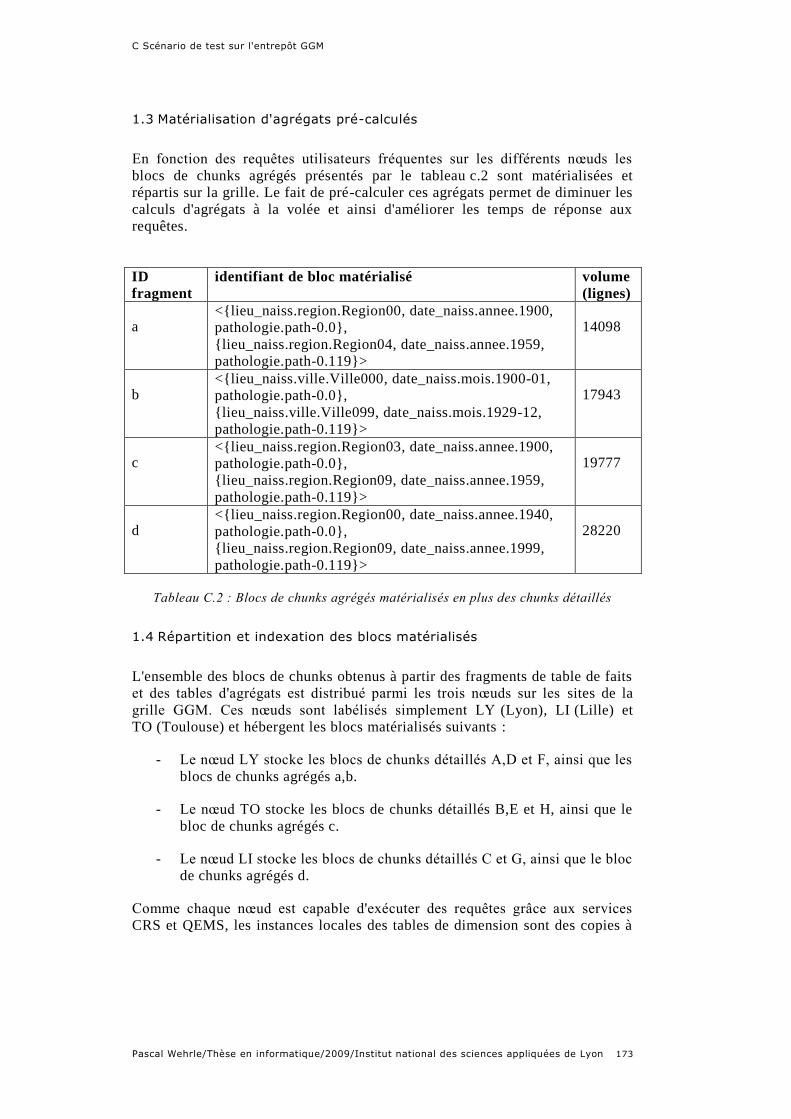
C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 173
1.3 Matérialisation d'agrégats pré-calculés
En fonction des requêtes utilisateurs fréquentes sur les différents nœuds les
blocs de chunks agrégés présentés par le tableau c.2 sont matérialisées et
répartis sur la grille. Le fait de pré-calculer ces agrégats permet de diminuer les
calculs d'agrégats à la volée et ainsi d'améliorer les temps de réponse aux
requêtes.
ID
fragment
identifiant de bloc matérialisé volume
(lignes)
a <{lieu_naiss.region.Region00, date_naiss.annee.1900,
pathologie.path-0.0},
{lieu_naiss.region.Region04, date_naiss.annee.1959,
pathologie.path-0.119}>
14098
b <{lieu_naiss.ville.Ville000, date_naiss.mois.1900-01,
pathologie.path-0.0},
{lieu_naiss.ville.Ville099, date_naiss.mois.1929-12,
pathologie.path-0.119}>
17943
c <{lieu_naiss.region.Region03, date_naiss.annee.1900,
pathologie.path-0.0},
{lieu_naiss.region.Region09, date_naiss.annee.1959,
pathologie.path-0.119}>
19777
d <{lieu_naiss.region.Region00, date_naiss.annee.1940,
pathologie.path-0.0},
{lieu_naiss.region.Region09, date_naiss.annee.1999,
pathologie.path-0.119}>
28220
Tableau C.2 : Blocs de chunks agrégés matérialisés en plus des chunks détaillés
1.4 Répartition et indexation des blocs matérialisés
L'ensemble des blocs de chunks obtenus à partir des fragments de table de faits
et des tables d'agrégats est distribué parmi les trois nœuds sur les sites de la
grille GGM. Ces nœuds sont labélisés simplement LY (Lyon), LI (Lille) et
TO (Toulouse) et hébergent les blocs matérialisés suivants :
- Le nœud LY stocke les blocs de chunks détaillés A,D et F, ainsi que les
blocs de chunks agrégés a,b.
- Le nœud TO stocke les blocs de chunks détaillés B,E et H, ainsi que le
bloc de chunks agrégés c.
- Le nœud LI stocke les blocs de chunks détaillés C et G, ainsi que le bloc
de chunks agrégés d.
Comme chaque nœud est capable d'exécuter des requêtes grâce aux services
CRS et QEMS, les instances locales des tables de dimension sont des copies à

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 174
l'identique des tables de dimensions de l'entrepôt centralisé. Nous introduisons
par la suite les différentes catégories de requêtes utilisées pour tester les
fonctionnalités de l'architecture GIROLAP.
1.5 Catégories de requêtes distribuées
Pour effectuer des tests, nous avons défini plusieurs classes de requêtes selon
les critères suivants :
Les requêtes posées à l'entrepôt sont réparties en catégories selon plusieurs
critères qui donnent lieu à une classification en plusieurs étapes. Le nœud
d'origine de la requête, qui est en même temps la destination du résultat joue un
rôle prépondérant car il détermine le déroulement de la requête. En effet, la
disponibilité locale des données demandées influence fortement la stratégie
d'exécution.
Le premier critère déterminant la classification est constitué par le fait qu'une
requête est satisfaite uniquement par des données matérialisées, par des données
calculées à la volée ou par une combinaison des deux. Le second critère de
classification dépend des fragments de l'entrepôt matérialisés et calculables sur
chaque nœud. Selon ce critère une requête est caractérisée par le fait qu'elle
porte soit sur de donnée disponibles localement, dite « intra-nœud », soit sur
des données non disponibles localement, mais disponibles sur d'autres nœuds de
la grille, donc « extra-nœud », soit combinant les deux, donc « inter-nœuds ». A
l'aide du second critère nous subdivisons les requêtes test en trois ensembles
qui couvrent tous les cas de figure possibles selon les critères mentionnés.
1. Les requêtes portant sur des chunks matérialisés ne nécessitent aucun
calcul à la volée car elles peuvent être satisfaites à moindre coût par les
chunks matérialisés sur un des nœuds de stockage. Le tableau c.3
présente le nœud destination, la représentation de la requête sous forme
de blocs de chunks, la catégorie de la requête selon le premier critère et
la description des solutions possibles pour obtenir les données résultat.
ID r
eq
uête
nœ
ud
dest
.
bloc de chunks décrivant la
requête
intr
a-n
œu
d
ex
tra
-nœ
ud
inte
r-n
œu
ds
solutions possibles
M1 LI <{lieu_naiss.ville.Ville070,
date_naiss.date.1960-01-01,
pathologie.path-0.0},
{lieu_naiss.ville.Ville089,
date_naiss.date.1979-12-31,
pathologie.path-0.119}>
X G (matérialisé sur LI)

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 175
M2 LY <{lieu_naiss.ville.Ville040,
date_naiss.date.1920-01-01,
pathologie.path-0.40},
{lieu_naiss.ville.Ville040,
date_naiss.date.1939-12-31,
pathologie.path-0.50}>
X A (matérialisé sur LY)
et
D (matérialisé sur LY)
M3 LI <{lieu_naiss.ville.Ville020,
date_naiss.mois.1920-01,
pathologie.path-0.20},
{lieu_naiss.ville.Ville089,
date_naiss.mois.1924-12,
pathologie.path-0.30}>
X b (matérialisé sur LY)
M4 TO <{lieu_naiss.ville.Ville060,
date_naiss.date.1925-01-01,
pathologie.path-0.40},
{lieu_naiss.ville.Ville079,
date_naiss.date.1934-12-31,
pathologie.path-0.90}>
X C (matérialisé sur LI)
et
D (matérialisé sur LY)
M5 LI <{lieu_naiss.region.Region03,
date_naiss.annee.1930,
pathologie.path-0.50},
{lieu_naiss.region.Region03,
date_naiss.annee.1979,
pathologie.path-0.50}>
X d (matérialisé sur LI)
ou
a (matérialisé sur LY)
ou
c (matérialisé sur TO)
M6 LY <{lieu_naiss.ville.Ville010,
date_naiss.date.1920-01-01,
pathologie.path-0.30},
{lieu_naiss.ville.Ville069,
date_naiss.date.1929-12-31,
pathologie.path-0.60}>
X A (matérialisé sur LY)
et
B (matérialisé sur TO)
et
C (matérialisé sur LI)
Tableau C.3 : Requêtes portant sur les chunks matérialisés déployés sur la grille GGM
2. Les requêtes nécessitant uniquement des calculs à la volée portent
toutes sur de blocs de chunks calculables indexé sur un ou plusieurs des
nœuds de stockage. Le tableau c.4 présente les mêmes caractéristiques
que le tableau c.3 pour les requêtes portant sur les chunks matérialisés,
avec en tant que les combinaisons de blocs sources utilisables pour le
calcul du résultat.

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 176
ID r
eq
uête
nœ
ud
dest
.
bloc de chunks décrivant la
requête
intr
a-n
œu
d
ex
tra
-nœ
ud
inte
r-n
œu
ds
solutions possibles
C1 TO <{lieu_naiss.ville.Ville090,
date_naiss.mois.1950-01,
pathologie.path-0.40},
{lieu_naiss.ville.Ville099,
date_naiss.mois.1965-12,
pathologie.path-0.60}>
X calculable à partir de
H (matérialisé sur TO)
C2 LY <{lieu_naiss.region.Region02,
date_naiss.mois.1935-01,
pathologie.path-0.40},
{lieu_naiss.region.Region04,
date_naiss.mois.1955-01,
pathologie.path-0.70}>
X calculable à partir de
D (matérialisé sur LY)
et de
F (matérialisé sur LY)
C3 TO <{lieu_naiss.region.Region00,
date_naiss.mois.1905-01,
pathologie.path-0.20},
{lieu_naiss.region.Region04,
date_naiss.mois.1915-01,
pathologie.path-0.50}>
X calculable à partir de
b (matérialisé sur LY)
ou à partir de
A (matérialisé sur LY)
C4 LI <{lieu_naiss.ville.Ville045,
date_naiss.annee.1930,
pathologie.path-0.10},
{lieu_naiss.ville.Ville075,
date_naiss.annee.1939,
pathologie.path-0.50}>
X calculable à partir de
D (matérialisé sur LY)
et de
E (matérialisé sur TO)
C5 LI <{lieu_naiss.ville.Ville070,
date_naiss.mois.1975-01,
pathologie.path-0.80},
{lieu_naiss.ville.Ville099,
date_naiss.mois.1984-12,
pathologie.path-0.100}>
X calculable à partir de
G (matérialisé sur LI)
et de
H (matérialisé sur TO)
C6 LY <{lieu_naiss.ville.Ville060,
date_naiss.annee.1915,
pathologie.path-0.10},
{lieu_naiss.ville.Ville085,
date_naiss.annee.1965,
pathologie.path-0.20}>
X calculable à partir de
b (matérialisé sur LY)
et de
E (matérialisé sur TO)
et de
G (matérialisé sur LI)
Tableau C.4 : Requêtes portant sur les chunks calculables sur la grille GGM

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 177
3. Les requêtes hétérogènes combinent l'extraction de chunks depuis les
blocs matérialisés et des calculs à la volée. Le tableau c.5 enfin présente
comme le tableau c.3 les chunks matérialisés servant de sources, avec
en plus la partie calculable avec ses blocs sources.
ID r
eq
uête
nœ
ud
dest
.
bloc de chunks décrivant la
requête
intr
a-n
œu
d
ex
tra
-nœ
ud
inte
r-n
œu
ds
solutions possibles
H1 TO <{lieu_naiss.region.Region01,
date_naiss.annee.1920,
pathologie.path-0.70},
{lieu_naiss.region.Region03,
date_naiss.annee.1929,
pathologie.path-0.80}>
X partie matérialisée
extraite de
c (matérialisé sur TO)
et partie calculable à
partir de
B (matérialisé sur TO)
H2 LI <{lieu_naiss.ville.Ville012,
date_naiss.mois.1915-01,
pathologie.path-0.90},
{lieu_naiss.ville.Ville022,
date_naiss.mois.1934-12,
pathologie.path-0.119}>
X partie matérialisée
extraite de
b (matérialisé sur LY)
et partie calculable à
partir de
F (matérialisé sur LY)
ou calculable à partir
de
B (matérialisé sur TO)
H3 LY <{lieu_naiss.region.Region09,
date_naiss.annee.1931,
pathologie.path-0.80},
{lieu_naiss.region.Region09,
date_naiss.annee.1961,
pathologie.path-0.110}>
X partie matérialisée
extraite de
d (matérialisé sur LI)
et partie calculable à
partir de
H (matérialisé sur TO)
H4 LI <{lieu_naiss.region.Region00,
date_naiss.annee.1931,
pathologie.path-0.10},
{lieu_naiss.region.Region02,
date_naiss.annee.1942,
pathologie.path-0.40}>
X partie matérialisée
extraite de
d (matérialisé sur LI)
et partie calculable à
partir de
F (matérialisé sur LY)
H5 LY <{lieu_naiss.region.Region01,
date_naiss.annee.1925,
pathologie.path-0.30},
{lieu_naiss.region.Region05,
date_naiss.annee.1972,
pathologie.path-0.50}>
X partie matérialisée
extraite de
c (matérialisé sur TO)
et de
d (matérialisé sur LI)
et partie calculable à
partir de
A (matérialisé sur LY)

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 178
H6 LY <{lieu_naiss.ville.Ville040,
date_naiss.mois.1927-01,
pathologie.path-0.20},
{lieu_naiss.ville.Ville060,
date_naiss.mois.1974-12,
pathologie.path-0.20}>
X partie matérialisée
extraite de
b (matérialisé sur LY)
et partie calculable à
partir de
E (matérialisé sur TO)
et à partir de
G (matérialisé sur LI)
H7 TO <{lieu_naiss.region.Region03,
date_naiss.annee.1935,
pathologie.path-0.10},
{lieu_naiss.region.Region06,
date_naiss.annee.1982,
pathologie.path-0.10}>
X partie matérialisée
extraite de
a (matérialisé sur LY)
et partie calculable à
partir de
E (matérialisé sur TO)
et à partir de
G (matérialisé sur LI)
Tableau C.5 : Requêtes portant sur les chunks matérialisés et calculables sur la grille
GGM

Bibliographie
(Abdelguerfi et al., 1998) ABDELGUERFI Mahdi, WONG K. Parallel
Database Techniques. New York, NY, USA : Wiley-IEEE Computer Society
Press, 1998, 230 p.
ISBN 978-0-8186-8398-5
(Agarwal et al., 1996) AGARWAL Sameet, AGRAWAL Rakesh,
DESHPANDE Prasad, GUPTA Ashish, NAUGHTON Jeffrey F.,
RAMAKRISHNAN Raghu, SARAWAGI Sunita. On the Computation of
Multidimensional Aggregates. In : VIJAYARAMAN T.M., BUCHMANN A.P.,
MOHAN C., SARDA N.L. (Eds.). VLDB'96, Proceedings of 22th International
Conference on Very Large Data Bases, September 3-6, 1996, Mumbai
(Bombay), India. San Francisco, CA, USA : Morgan Kaufmann, 1996, pp. 506-
521.
ISBN 1-55860-382-4
(Agrawal et al., 1997) AGRAWAL Rakesh, GUPTA Ashish, SARAWAGI
Sunita. Modeling Multidimensional Databases. In : GRAY W.A., LARSON P.
(Eds.). Proceedings of the Thirteenth International Conference on Data
Engineering, April 7-11, 1997, Birmingham, UK. Los Alamitos, CA, USA :
IEEE Computer Society Press, 1997, pp. 232-243.
ISBN 0-8186-7807-0
(Akinde et al., 2002) AKINDE Michael O., BÖHLEN Michael H., JOHNSON
Theodore, LAKSHMANAN Laks V. S., SRIVASTAVA Divesh. Efficient
OLAP Query Processing in Distributed Data Warehouses. In : JENSEN C.S.,
JEFFERY K.G., POKORNÝ J., SALTENIS S., BERTINO E., BÖHM K.,
JARKE M. (Eds.). Proceedings of the 8th International Conference on
Extending Database Technology (EDBT 2002), March 25-27 2002, Prague,
Czech Republic. Berlin/Heidelberg, Allemagne : Springer-Verlag, 2002, pp.
336-353. (Lecture Notes in Computer Science, 2287)
ISBN 3-540-43324-4
(Allcock et al., 2002) ALLCOCK William E, BESTER J., BRESNAHAN J.,
CHERVENAK A.L., FOSTER I.T., KESSELMAN C., MEDER S.,
NEFEDOVA V., QUESNEL D., TUECKE S. Data management and transfer in
high-performance computational grid environments. Parallel Computing, 2002,
vol. 28, n°5, pp. 749-771.
ISSN 0167-8191
(Alpdemir et al., 2003) ALPDEMIR M Nedim, MUKHERJEE Arijit, PATON
Norman W, WATSON Paul, FERNANDES Alvaro A A, GOUNARIS
Anastasios, SMITH Jim. Service-Based Distributed Querying on the Grid. In :
ORLOWSKA M.E., WEERAWARANA S., PAPAZOGLOU M.P., YANG J.
(Eds.). Proceedings of Service-Oriented Computing - ICSOC 2003, First
International Conference, Trento, Italy, December 15-18, 2003.

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 180
Berlin/Heidelberg, Allemagne : Springer-Verlag, 2003, pp. 467-482. (Lecture
Notes in Computer Science, 2910)
ISBN 3-540-20681-7
(Antonioletti et al., 2005) ANTONIOLETTI Mario, KRAUSE Amy, PATON
Norman W. An Outline of the Global Grid Forum Data Access and Integration
Service Specifications. In : PIERSON J. (Ed.). Revised Selected Papers of Data
Management in Grids: First VLDB Workshop (DMG 2005), September 2-3
2005, Trondheim,Norway. Berlin/Heidelberg, Allemagne : Springer-Verlag,
2005, pp. 71 - 84. (Lecture Notes in Computer Science, 3836)
ISBN 3-540-31212-9
(Aouiche et al., 2005) AOUICHE Kamel, DARMONT Jérôme, BOUSSAID
Omar, BENTAYEB Fadila. Automatic Selection of Bitmap Join Indexes in Data
Warehouses. In : TJOA A.M., TRUJILLO J. (Eds.). Proceedings of Data
Warehousing and Knowledge Discovery, 7th International Conference, DaWaK
2005, Copenhagen, Denmark, August 22-26, 2005. Berlin/Heidelberg,
Allemagne : Springer-Verlag, 2005, pp. 64-73. (Lecture Notes in Computer
Science, 3589)
ISBN 3-540-28558-X
(Aouiche et al., 2006) AOUICHE Kamel, JOUVE Pierre-Emmanuel,
DARMONT Jérôme. Clustering-Based Materialized View Selection in Data
Warehouses. In : MANOLOPOULOS Y., POKORNỲ J., SELLIS T.K. (Eds.).
Proceedings of Advances in Databases and Information Systems, 10th East
European Conference, ADBIS 2006, September 3-7, 2006, Thessaloniki,
Greece. Berlin/Heidelberg, Allemagne : Springer-Verlag, 2006, pp. 81-95.
(Lecture Notes in Computer Science, 4152)
ISBN 3-540-37899-5
(Baralis et al., 1997) BARALIS Elena, PARABOSCHI Stefano, TENIENTE
Ernest. Materialized Views Selection in a Multidimensional Database. In :
JARKE M., CAREY M.J., DITTRICH K.R., LOCHOVSKY F.H.,
LOUCOPOULOS P., JEUSFELD M.A. (Eds.). VLDB'97, Proceedings of 23rd
International Conference on Very Large Data Bases, August 25-29, 1997,
Athens, Greece. San Francisco, CA, USA : Morgan Kaufmann, 1997, pp. 156-
165.
ISBN 1-55860-470-7
(Beckmann et al., 1990) BECKMANN Norbert, KRIEGEL Hans-Peter,
SCHNEIDER Ralf, SEEGER Bernhard. The R*-Tree: An Efficient and Robust
Access Method for Points and Rectangles. In : GARCIA-MOLINA H.,
JAGADISH H.V. (Eds.). Proceedings of the 1990 ACM SIGMOD International
Conference on Management of Data, May 23-25 1990, Atlantic City, NJ, USA.
New York, NY, USA : ACM Press, 1990, pp. 322-331.
(Bell et al., 2002) BELL William H., BOSIO D., HOSCHEK W., KUNSZT P.,
MCCANCE G., SILANDER M. Project Spitfire - Towards Grid Web Service
Databases [en ligne]. Disponible sur : http://www.gridpp.ac.uk/papers/ggf5-
spitfire.pdf. (consulté le 30/09/2008).

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 181
(Bellatreche et al., 1999) BELLATRECHE Ladjel, KARLAPALEM Kamalakar,
MOHANIA Mukesh K. OLAP Query Processing for Partitioned Data
Warehouses. In : KAMBAYASHI Y., TAKAKURA H. (Eds.). 1999
International Symposium on Database Applications in Non-Traditional
Environments (DANTE '99), November 28-30, 1999, Kyoto, Japan. Los
Alamitos, CA, USA : IEEE Computer Society Press, 1999, pp. 35-42.
ISBN 0-7695-0496-5
(Bellatreche et al., 2000) BELLATRECHE Ladjel, KARLAPALEM K.,
SIMONET A. Algorithms and Support for Horizontal Class Partitioning in
Object-Oriented Databases. Distributed and Parallel Databases, 2000, vol. 8,
n°2, pp. 155-179.
ISSN 0926-8782
(Bellatreche et al., 2002) BELLATRECHE Ladjel, SCHNEIDER Michel,
MOHANIA Mukesh K, BHARGAVA Bharat K. PartJoin: An Efficient Storage
and Query Execution for Data Warehouses. In : KAMBAYASHI Y.,
WINIWARTER W., ARIKAWA M. (Eds.). Proceedings of Data Warehousing
and Knowledge Discovery, 4th International Conference, DaWaK 2002,
September 4-6, 2002, Aix-en-Provence, France. Berlin/Heidelberg, Allemagne :
Springer-Verlag, 2002, pp. 296-306. (Lecture Notes in Computer Science,
2454)
ISBN 3-540-44123-9
(Bellatreche et al., 2005) BELLATRECHE Ladjel, BOUKHALFA Kamel. An
Evolutionary Approach to Schema Partitioning Selection in a Data Warehouse.
In : TJOA A.M., TRUJILLO J. (Eds.). Proceedings of Data Warehousing and
Knowledge Discovery, 7th International Conference, DaWaK 2005,
Copenhagen, Denmark, August 22-26, 2005. Berlin/Heidelberg, Allemagne :
Springer-Verlag, 2005, pp. 115-125. (Lecture Notes in Computer Science,
3589)
ISBN 3-540-28558-X
(Berchtold et al., 1996) BERCHTOLD Stefan, KEIM Daniel A., KRIEGEL
Hans-Peter. The X-tree : An Index Structure for High-Dimensional Data. In :
VIJAYARAMAN T.M., BUCHMANN A.P., MOHAN C., SARDA N.L. (Eds.).
VLDB'96, Proceedings of 22th International Conference on Very Large Data
Bases, September 3-6, 1996, Mumbai (Bombay), India. San Francisco, CA,
USA : Morgan Kaufmann, 1996, pp. 28-39.
ISBN 1-55860-382-4
(Beyer et al., 1999) BEYER Kevin S, RAMAKRISHNAN Raghu. Bottom-Up
Computation of Sparse and Iceberg CUBEs. In : DELIS A., FALOUTSOS C.,
GHANDEHARIZADEH S. (Eds.). SIGMOD 1999, Proceedings ACM
SIGMOD International Conference on Management of Data, June 1-3, 1999,
Philadelphia, Pennsylvania, USA. New York, NY, USA : ACM Press, 1999, pp.
359-370.
ISBN 1-58113-084-8

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 182
(Blaschka et al., 1998) BLASCHKA Markus, SAPIA Carsten, HÖFLING
Gabriele, DINTER Barbara. Finding Your Way through Multidimensional Data
Models. In : WAGNER R. (Ed.). Proceedings of Data Warehouse Design and
OLAP Technology (DWDOT'98), Ninth International Workshop on Database
and Expert Systems Applications (DEXA '98), Vienna, Austria, August 24-28,
1998. Los Alamitos, CA, USA : IEEE Computer Society Press, 1998, pp. 198-
203.
ISBN 8186-8353-8
(Brezany et al., 2003) BREZANY Peter, TJOA A Min, WANEK Helmut,
WÖHRER Alexander. Mediators in the Architecture of Grid Information
Systems. In : WYRZYKOWSKI R., DONGARRA J., PAPRZYCKI M.,
WASNIEWSKI J. (Eds.). Revised Papers of Parallel Processing and Applied
Mathematics, 5th International Conference, PPAM 2003, Czestochowa, Poland,
September 7-10, 2003. Berlin/Heidelberg, Allemagne : Springer-Verlag, 2003, .
(Lecture Notes in Computer Science, 3019)
ISBN 3-540-21946-3
(Brezany et al., 2006) BREZANY Peter, JANCIAK Ivan, BREZANYOVA
Jarmila, TJOA A Min. GridMiner: An Advanced Grid-Based Support for Brain
Informatics Data Mining Tasks. In : ZHONG N., LIU J., YAO Y., WU J., LU
S., LI K. (Eds.). Revised Selected and Invited Papers of Web Intelligence Meets
Brain Informatics, First WICI International Workshop, WImBI 2006, December
15-16, 2006, Beijing, China. Berlin/Heidelberg, Allemagne : Springer-Verlag,
2006, pp. 353-366. (Lecture Notes in Computer Science, 4845)
ISBN 978-3-540-77027-5
(Brunie et al., 2003) BRUNIE Lionel, MIQUEL Maryvonne, PIERSON Jean-
Marc, TCHOUNIKINE Anne, DHAENENS Clarisse, MELAB Nouredine,
TALBI El-Ghazali, HAMEURLAIN Abdelkader, MORVAN Franck.
Information grids: managing and mining semantic data in a grid infrastructure;
open issues and application to geno-medical data. In : 14th International
Workshop on Database and Expert Systems Applications (DEXA'03),
September 1-5 2003, Prague, Czech Republic. Los Alamitos, CA, USA : IEEE
Computer Society Press, 2003, pp. 509-516.
(Cameron et al., 2004) CAMERON David G, CASEY J., GUY L., KUNSZT
P.Z., LEMAITRE S., MCCANCE G., STOCKINGER H., STOCKINGER K.,
ANDRONICO G., BELL W.H., BEN-AKIVA I., BOSIO D., CHYTRACEK R.,
DOMENICI A., DONNO F., HOSCHEK W., LAURE E., LUCIO L., MILLAR
A.P., SALCONI L., SEGAL B., SILANDER M. Replica Management in the
European DataGrid Project. Grid Computing, 2004, vol. 2, n°4, pp. 341-351.
ISSN 1570-7873
(Cappello et al., 2005) CAPPELLO Franck, CARON Eddy, DAYDÉ Michel J.,
DESPREZ Frédéric, JÉGOU Yvon, VICAT-BLANC PRIMET Pascale,
JEANNOT Emmanuel, LANTERI Stéphane, LEDUC Julien, MELAB
Nouredine, MORNET Guillaume, NAMYST Raymond, QUÉTIER Benjamin,
RICHARD Olivier. Grid'5000: a large scale and highly reconfigurable grid

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 183
experimental testbed. In : Proceedings of The 6th IEEE/ACM International
Conference on Grid Computing (GRID 2005), November 13-14, 2005, Seattle,
Washington, USA. Los Alamitos, CA, USA : IEEE Computer Society Press,
2005, pp. 99-106.
ISBN 0-7803-9493-3
(Cardenas et al., 2006) CARDENAS Yonny, PIERSON Jean-Marc, BRUNIE
Lionel. Temporal storage space for grids. In : GERNDT M.,
KRANZLMÜLLER D. (Eds.). The 2006 International Conference on High
Performance Computing and Communications (HPCC-06), September 13-15,
Munich, Germany. Berlin/Heidelberg, Allemagne : Springer-Verlag, 2006, pp.
803-812. (Lecture Notes in Computer Science, 4208)
ISBN 978-3-540-39368-9
(Carman et al., 2002) CARMAN Mark, ZINI Floriano, SERAFINI Luciano,
STOCKINGER Kurt. Towards an Economy-Based Optimisation of File Access
and Replication on a Data Grid. In : RANA O. (Ed.). 2nd IEEE International
Symposium on Cluster Computing and the Grid (CCGrid 2002), 22-24 May
2002, Berlin, Germany. Los Alamitos, CA, USA : IEEE Computer Society
Press, 2002, pp. 340-345.
ISBN 0-7695-1582-7
(Ceri et al., 1982) CERI Stefano, NEGRI Mauro, PELAGATTI Giuseppe.
Horizontal Data Partitioning in Database Design. In : SCHKOLNICK M. (Ed.).
Proceedings of the 1982 ACM SIGMOD International Conference on
Management of Data, June 2-4, 1982, Orlando, Florida. New York, NY, USA :
ACM Press, 1982, pp. 128-136.
(Chan et al., 1999) CHAN Chee Yong, IOANNIDIS Yannis E. An Efficient
Bitmap Encoding Scheme for Selection Queries. In : DELIS A., FALOUTSOS
C., GHANDEHARIZADEH S. (Eds.). SIGMOD 1999, Proceedings ACM
SIGMOD International Conference on Management of Data, June 1-3, 1999,
Philadelphia, Pennsylvania, USA. New York, NY, USA : ACM Press, 1999, pp.
215-226.
ISBN 1-58113-084-8
(Chaudhuri et al., 1997) CHAUDHURI Surajit, DAYAL U. An overview of
data warehousing and OLAP technology. ACM SIGMOD Record, 1997, vol.
26, n°1, pp. 65-74.
ISSN 0163-5808
(Codd et al., 1993) CODD Edgar F., CODD S.B., SALLEY C.T. Providing
OLAP to User-Analysts: An IT Mandate. Santa Clara, CA, USA : Hyperion
Solutions Corporation, 1993, 24 p.
(de Carvalho Costa et al., 2006) DE CARVALHO COSTA Rogério Luís,
FURTADO Pedro. Data Warehouses in Grids with High QoS. In : TJOA A.M.,
TRUJILLO J. (Eds.). Proceedings of Data Warehousing and Knowledge
Discovery, 8th International Conference, DaWaK 2006, Krakow, Poland,
September 4-8, 2006. Berlin/Heidelberg, Allemagne : Springer-Verlag, 2006,

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 184
pp. 207-217. (Lecture Notes in Computer Science, 4081)
ISBN 3-540-37736-0
(Deshpande et al., 1998) DESHPANDE Prasad, RAMASAMY Karthikeyan,
SHUKLA Amit, NAUGHTON Jeffrey F. Caching multidimensional queries
using chunks. In : HAAS L.M., TIWARY A. (Eds.). Proceedings of SIGMOD
1998, ACM SIGMOD International Conference on Management of Data, June
2-4 1998, Seattle, Washington, USA. New York, NY, USA : ACM Press, 1998,
pp. 259-270.
ISBN 0-89791-995-5
(Deshpande et al., 2000) DESHPANDE Prasad, NAUGHTON Jeffrey F.
Aggregate Aware Caching for Multi-Dimensional Queries. In : ZANIOLO C.,
LOCKEMANN P.C., SCHOLL M.H., GRUST T. (Eds.). Proceedings of the 7th
International Conference on Extending Database Technology (EDBT 2000),
March 27-31 2000, Konstanz, Germany. Berlin/Heidelberg, Allemagne :
Springer-Verlag, 2000, pp. 167-182. (Lecture Notes in Computer Science,
1777)
ISBN 3-540-67227-3
(Dewitt et al., 1992) DEWITT David J, NAUGHTON Jeffrey F, SCHNEIDER
Donovan A, SESHADRI S. Practical Skew Handling in Parallel Joins. In :
YUAN L. (Ed.). Proceedings of the 18th International Conference on Very
Large Data Bases (VLDB'92), August 23-27, 1992, Vancouver, Canada. San
Francisco, CA, USA : Morgan Kaufmann, 1992, pp. 27-40.
ISBN 1-55860-151-1
(Dubitsky et al., 2004) DUBITSKY Werner, MCCOURT D., GALUSHKA M.,
ROMBERG M., SCHULLER B. Grid-enabled data warehousing for molecular
engineering. Parallel Computing, 2004, vol. 30, n°9-10, pp. 1019-1035.
ISSN 0167-8191
(EGEE project, 2008) EGEE PROJECT. EGEE project, Enabling Grids for E-
sciencE [en ligne]. Disponible sur : http://www.eu-egee.org. (consulté le
30/09/2008).
(EU DataGrid, 2004) EU DATAGRID. The EU DataGrid project [en ligne].
Disponible sur : http://eu-datagrid.web.cern.ch. (consulté le 30/09/2008).
(Ezeife, 2001) EZEIFE Christie I. Selecting and materializing horizontally
partitioned warehouse views. Data & Knowledge Engineering, 2001, vol. 36,
n°2, pp. 185-210.
ISSN 0169-023X
(Ezeife et al., 1998) EZEIFE Christie I., BARKER K. Distributed Object Based
Design: Vertical Fragmentation of Classes. Distributed and Parallel Databases,
1998, vol. 6, n°4, pp. 317-350.
ISSN 0926-8782

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 185
(Faerman et al., 1999) FAERMAN Marcio, SU Alan, WOLSKI Richard,
BERMAN Francine. Adaptive Performance Prediction for Distributed Data-
Intensive Applications. In : ACM/IEEE SC99 Conference on High Performance
Networking and Computing, November 14 - 19, 1999, Portland, OR, USA. Los
Alamitos, CA, USA : IEEE Computer Society, 1999, .
ISBN 1-58113-091-0
(Fang et al., 1998) FANG Min, SHIVAKUMAR Narayanan, GARCIA-
MOLINA Hector, MOTWANI Rajeev, ULLMAN Jeffrey D. Computing Iceberg
Queries Efficiently. In : GUPTA A., SHMUELI O., WIDOM J. (Eds.).
VLDB'98, Proceedings of 24rd International Conference on Very Large Data
Bases, August 24-27, 1998, New York City, New York, USA. San Francisco,
CA, USA : Morgan Kaufmann, 1998, pp. 299-310.
ISBN 1-55860-566-5
(Fiser et al., 2004) FISER Bernhard, ONAN Umut, ELSAYED Ibrahim,
BREZANY Peter, TJOA A Min. On-Line Analytical Processing on Large
Databases Managed by Computational Grids. In : 15th International Workshop
on Database and Expert Systems Applications (DEXA 2004), 30 August - 3
September 2004, Zaragoza, Spain. Los Alamitos, CA, USA : IEEE Computer
Society Press, 2004, pp. 556-560.
ISBN 0-7695-2195-9
(Foster, 2001) FOSTER Ian T. The Anatomy of the Grid: Enabling Scalable
Virtual Organizations. In : ROE P. (Ed.). First IEEE International Symposium
on Cluster Computing and the Grid (CCGrid 2001), May 15-18, 2001, Brisbane,
Australia. Los Alamitos, CA, USA : IEEE Computer Society Press, 2001, pp. 6-
7.
(Foster, 2002) FOSTER Ian T. What is the Grid? A Three Point Checklist [en
ligne]. Disponible sur :
http://www-fp.mcs.anl.gov/~foster/Articles/WhatIsTheGrid.pdf. (consulté le
30/09/2008).
(Foster, 2005) FOSTER Ian T. Globus Toolkit Version 4: Software for Service-
Oriented Systems. In : IFIP International Conference on Network and Parallel
Computing, NPC 2005, November 30 - December 3, 2005, Beijing, China.
Berlin/Heidelberg, Allemagne : Springer-Verlag, 2005, pp. 2-13. (Lecture
Notes in Computer Science, 3779)
ISBN 3-540-29810-X
(Foster et al., 1998) FOSTER Ian, KESSELMAN C. The Grid: Blueprint for a
New Computing Infrastructure. San Francisco, CA, USA : Morgan Kaufmann,
1998, 701 p.
ISBN 978-1558604759
(Foster et al., 2002) FOSTER Ian T., KESSELMAN C., NICK J.M., TUECKE
S. Grid Services for Distributed System Integration. Computer, 2002, vol. 35,
n°6, pp. 37-46.
ISSN 0018-9162

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 186
(Foster et al., 2003) FOSTER Ian T., KESSELMAN C. The Grid 2: Blueprint
for a New Computing Infrastructure. San Francisco, CA, USA : Morgan
Kaufmann, 2003, 748 p.
ISBN 1-55860-933-4
(Furtado, 2004a) FURTADO Pedro. Workload-based Placement and Join
Processing in Node-Partitioned Data Warehouses. In : KAMBAYASHI Y.,
MOHANIA M.K., WÖß W. (Eds.). Proceedings of Data Warehousing and
Knowledge Discovery, 6th International Conference, DaWaK 2004, September
1-3, 2004, Zaragoza, Spain. Berlin/Heidelberg, Allemagne : Springer-Verlag,
2004, . (Lecture Notes in Computer Science, 3181)
ISBN 3-540-22937-X
(Furtado, 2004b) FURTADO Pedro. Experimental evidence on partitioning in
parallel data warehouses. In : SONG I., DAVIS K.C. (Eds.). Proceedings of
DOLAP 2004, ACM Seventh International Workshop on Data Warehousing and
OLAP, November 12-13, 2004, Washington, DC, USA. New York, NY, USA :
ACM Press, 2004, pp. 23-30.
ISBN 1-58113-977-2
(Gagliardi, 2004) GAGLIARDI Fabrizio. The EGEE European Grid
Infrastructure Project. In : DAYDÉ M.J., DONGARRA J., HERNÁNDEZ V.,
PALMA J.M.L.M. (Eds.). Revised Selected and Invited Papers of High
Performance Computing for Computational Science - VECPAR 2004, 6th
International Conference, June 28-30, 2004, Valencia, Spain.
Berlin/Heidelberg, Allemagne : Springer-Verlag, 2004, pp. 194-203. (Lecture
Notes in Computer Science, 3402)
ISBN 3-540-25424-2
(Gagliardi et al., 2002) GAGLIARDI Fabrizio, JONES B., REALE M., BURKE
S. European DataGrid Project: Experiences of Deploying a Large Scale Testbed
for E-science Applications. Lecture Notes in Computer Science, 2002, vol.
2459, n°1, pp. 255-264.
ISSN 0302-9743
(Ghozzi et al., 2003) GHOZZI Faïza, RAVAT Franck, TESTE Olivier,
ZURFLUH Gilles. Constraints and Multidimensional Databases. In : .
Proceedings of the 5th International Conference on Enterprise Information
Systems 'ICEIS 2003), April 22-26, 2003, Angers, France . pp. 104-111.
(Golfarelli et al., 1998) GOLFARELLI Matteo, RIZZI Stefano. A
Methodological Framework for Data Warehouse Design. In : SONG I.,
TEOREY T.J. (Eds.). Proceedings of DOLAP '98, ACM First International
Workshop on Data Warehousing and OLAP, November 2-7, 1998, Bethesda,
MD, USA, . New York, NY, USA : ACM Press, 1998, pp. 3-9.
ISBN 1-58113-120-8
(Gossa et al., 2006) GOSSA Julien, PIERSON Jean-Marc, BRUNIE Lionel.
Evaluation of network distances properties by NDS, the Network Distance
Service. In : Proceedings of 3rd International Conference on Broadband

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 187
Communications, Networks and Systems, 2006. BROADNETS 2006, October
1-5, 2006, San Jose, CA, USA. Los Alamitos, CA, USA : IEEE Computer
Society Press, 2006, .
ISBN 978-1-4244-0425-4
(Gupta et al., 1997) GUPTA Himanshu, HARINARAYAN Venky,
RAJARAMAN Anand, ULLMAN Jeffrey D. Index Selection for OLAP. In :
GRAY W.A., LARSON P. (Eds.). Proceedings of the Thirteenth International
Conference on Data Engineering, April 7-11, 1997, Birmingham, UK. Los
Alamitos, CA, USA : IEEE Computer Society Press, 1997, pp. 208-219.
ISBN 0-8186-7807-0
(Hameurlain et al., 2002) HAMEURLAIN Abdelkader, MORVAN Franck,
TOMSICH Philipp, BRUCKNER Robert M, KOSCH Harald, BREZANY Peter.
Mobile Query Optimization Based on Agent-Technology for Distributed Data
Warehouse and OLAP Applications. In : 13th International Workshop on
Database and Expert Systems Applications (DEXA 2002), September 2-6,
2002, Aix-en-Provence, France. Los Alamitos, CA, USA : IEEE Computer
Society Press, 2002, pp. 795-799.
ISBN 0-7695-1668-8
(Hammer et al., 2003) HAMMER Joachim, FU L. CubiST++: Evaluating Ad-
Hoc CUBE Queries Using Statistics Trees. Distributed and Parallel Databases,
2003, vol. 14, n°, pp. 221-254.
ISSN 0926-8782
(Harinarayan et al., 1996) HARINARAYAN Venky, RAJARAMAN Anand,
ULLMAN Jeffrey D. Implementing Data Cubes Efficiently. In : JAGADISH
H.V., MUMICK I.S. (Eds.). Proceedings of the 1996 ACM SIGMOD
International Conference on Management of Data, June 4-6, 1996, Montreal,
Quebec, Canada. New York, NY, USA : ACM Press, 1996, pp. 205-216.
(SIGMOD Record, 25(2))
(Hoschek, 2002) HOSCHEK Wolfgang. A Unified Peer-to-Peer Database
Framework for Scalable Service and Resource Discovery. In : PARASHAR M.
(Ed.). Proceedings of Grid Computing - GRID 2002, Third International
Workshop, November 18 2002, Baltimore, MD, USA. Berlin/Heidelberg,
Allemagne : Springer-Verlag, 2002, pp. 126-144. (Lecture Notes in Computer
Science, 2536)
ISBN 3-540-00133-6
(Hua et al., 1990) HUA Kien A, LEE Chiang. An Adaptive Data Placement
Scheme for Parallel Database Computer Systems. In : MCLEOD D., SACKS-
DAVIS R., SCHEK H. (Eds.). Proceedings of the 16th International Conference
on Very Large Data Bases, August 13-16, 1990, Brisbane, Queensland,
Australia. San Francisco, CA, USA : Morgan Kaufmann, 1990, pp. 493-506.
ISBN 1-55860-149-X
(Hussein et al., 2006) HUSSEIN Mohammad, MORVAN Franck,
HAMEURLAIN Abdelkader. Dynamic Query Optimization: from Centralized

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 188
to Decentralized. In : PETERSON G.D. (Ed.). Proceedings of the ISCA 19th
International Conference on Parallel and Distributed Computing Systems,
September 11-20, 2006, San Francisco, California, USA. : ISCA, 2006, pp.
273-279.
ISBN 978-1-880843-60-4
(Inmon, 1992) INMON William H. Building the Data Warehouse. New York,
NY, USA : John Wiley & Sons, 1992, 272 p.
ISBN 0-47156-960-7
(JPivot, 2008) JPIVOT. JPivot - JSP custom tag library that renders an OLAP
table and chart [en ligne]. Disponible sur : http://jpivot.sourceforge.net/.
(consulté le 30/09/2008).
(Kalnis et al., 2002) KALNIS Panos, NG Wee Siong, OOI Beng Chin,
PAPADIAS Dimitris, TAN Kian-Lee. An adaptive peer-to-peer network for
distributed caching of OLAP results. In : FRANKLIN M.J., MOON B.,
AILAMAKI A. (Eds.). Proceedings of the 2002 ACM SIGMOD International
Conference on Management of Data, June 3-6 2002, Madison, Wisconsin. New
York, NY, USA : ACM Press, 2002, pp. 25-36.
ISBN 1-58113-497-5
(Karayannidis et al., 2004) KARAYANNIDIS Nikos, SELLIS Timos K,
KOUVARAS Yannis. CUBE File: A File Structure for Hierarchically Clustered
OLAP Cubes. In : BERTINO E., CHRISTODOULAKIS S., PLEXOUSAKIS
D., CHRISTOPHIDES V., KOUBARAKIS M., BÖHM K., FERRARI E. (Eds.).
Proceedings of Advances in Database Technology - EDBT 2004, 9th
International Conference on Extending Database Technology, March 14-18,
2004, Heraklion, Crete, Greece. Berlin/Heidelberg, Allemagne : Springer-
Verlag, 2004, pp. 621-638. (Lecture Notes in Computer Science, 2992)
ISBN 3-540-21200-0
(Kaser et al., 2003) KASER Owen, LEMIRE Daniel. Attribute value reordering
for efficient hybrid OLAP. In : SONG I., RIZZI S. (Eds.). Proceedings of
DOLAP 2003, ACM Sixth International Workshop on Data Warehousing and
OLAP, November 7, 2003, New Orleans, Louisiana, USA. New York, NY,
USA : ACM Press, 2003, pp. 1-8.
ISBN 978-1581137279
(Kelly, 1997) KELLY Sean. Data Warehousing in Action. New York, NY,
USA : John Wiley & Sons, 1997, 334 p.
ISBN 978-0471966401
(Kimball, 1996) KIMBALL Ralph. The Data Warehouse Toolkit. New York,
NY, USA : John Wiley & Sons, 1996, 464 p.
ISBN 0-47115-337-0
(Kimball et al., 1998) KIMBALL Ralph, REEVES L., ROSS M., et al. The
Data Warehouse Lifecycle Toolkit : Expert Methods for Designing,
Developing, and Deploying Data Warehouses. New York, NY, USA : John

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 189
Wiley & Sons, 1998, 800 p.
ISBN 978-0471255475
(Kotidis et al., 1998) KOTIDIS Yannis, ROUSSOPOULOS Nick. An
Alternative Storage Organization for ROLAP Aggregate Views Based on
Cubetrees. In : HAAS L.M., TIWARY A. (Eds.). SIGMOD 1998, Proceedings
ACM SIGMOD International Conference on Management of Data, June 2-4,
1998, Seattle, Washington, USA. New York, NY, USA : ACM Press, 1998, pp.
249-258.
ISBN 0-89791-995-5
(Lawrence et al., 2007) LAWRENCE Michael, DEHNE Frank, RAU-CHAPLIN
Andrew. Implementing OLAP Query Fragment Aggregation and Recombination
for the OLAP Enabled Grid. In : IEEE CS (Ed.). Parallel and Distributed
Processing Symposium (IPDPS 2007), March 26-30, 2007, Long Beach, CA,
USA. Los Alamitos, CA, USA : IEEE Computer Society Press, 2007, pp. 1-8.
ISBN 1-4244-0910-1
(Lawrence et al., 2006) LAWRENCE Michael, RAU-CHAPLIN Andrew. The
OLAP-Enabled Grid: Model and Query Processing Algorithms. In : 20th
Annual International Symposium on High Performance Computing Systems and
Applications (HPCS 2006), May 14-17, 2006, St. John's, Newfoundland,
Canada. Los Alamitos, CA, USA : IEEE Computer Society Press, 2006, p. 4.
(Lee et al., 2006) LEE Ki Yong, KIM Myoung-Ho. Efficient Incremental
Maintenance of Data Cubes. In : DAYAL U., WHANG K., LOMET D.B.,
ALONSO G., LOHMAN G.M., KERSTEN M.L., CHA S.K., KIM Y. (Eds.).
Proceedings of the 32nd International Conference on Very Large Data Bases,
September 12-15, 2006, Seoul, Korea. New York, NY, USA : ACM Press,
2006, pp. 823-833.
ISBN 1-59593-385-9
(Luk et al., 2004) LUK Wo-Shun, LI Chao. A Partial Pre-aggregation Scheme
for HOLAP Engines. In : KAMBAYASHI Y., MOHANIA M.K., WÖß W.
(Eds.). Proceedings of Data Warehousing and Knowledge Discovery, 6th
International Conference, DaWaK 2004, September 1-3, 2004, Zaragoza, Spain.
Berlin/Heidelberg, Allemagne : Springer-Verlag, 2004, pp. 129-137. (Lecture
Notes in Computer Science, 3181)
ISBN 3-540-22937-X
(Malinowski et al., 2006) MALINOWSKI Elzbieta, ZIMÁNYI E. Hierarchies
in a multidimensional model: From conceptual modeling to logical
representation. Data & Knowledge Engineering, 2006, vol. 59, n°2, pp. 348-
377.
ISSN 0169-023X
(Mehta et al., 1995) MEHTA Manish, DEWITT David J. Managing Intra-
operator Parallelism in Parallel Database Systems. In : DAYAL U., GRAY
P.M.D., NISHIO S. (Eds.). VLDB'95, Proceedings of 21th International
Conference on Very Large Data Bases, September 11-15, 1995, Zurich,

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 190
Switzerland. San Francisco, CA, USA : Morgan Kaufmann, 1995, pp. 382-394.
ISBN 1-55860-379-4
(Mehta et al., 1997) MEHTA Manish, DEWITT D.J. Data Placement in Shared-
Nothing Parallel Database Systems. VLDB Journal, 1997, vol. 6, n°1, pp. 53-
72.
ISSN 1066-8888
(Melab et al., 2006) MELAB Nouredine, CAHON S., TALBI E. Grid
computing for parallel bioinspired algorithms. Journal of Parallel Distributed
Computing, 2006, vol. 66, n°8, pp. 1052-1061. ISSN 0167-739X
(Mondrian, 2008) MONDRIAN. Mondrian - an OLAP server written in Java
[en ligne]. Disponible sur : http://mondrian.pentaho.org/. (consulté le
30/09/2008).
(Moorman, 1999) MOORMAN Mark. The Art of Designing HOLAP Databases.
In : Proceeding of the Twenty-Fourth Annual SAS Users Group International
Conference, April 11-14, 1999, Miami Beach, Florida, USA. Cary, NC, USA :
SAS Institute Inc., 1999, pp. 139-143.
(Navathe et al., 1984) NAVATHE Shamkant, CERI S., WIEDERHOLD G.,
DOU J. Vertical partitioning algorithms for database design. ACM Transactions
on Database Systems (TODS), 1984, vol. 9, n°4, pp. 680-710.
ISSN 0362-5915
(Navathe et al., 1989) NAVATHE Shamkant B., RA Minyoung. Vertical
Partitioning for Database Design: A Graphical Algorithm. In : CLIFFORD J.,
LINDSAY B.G., MAIER D. (Eds.). Proceedings of the 1989 ACM SIGMOD
International Conference on Management of Data, May 31 - June 2, 1989,
Portland, Oregon, USA. New York, NY, USA : ACM Press, 1989, pp. 440-450.
(SIGMOD Record, 17(3))
(Niemi et al., 2003) NIEMI Tapio, NIINIMÄKI Marko, NUMMENMAA Jyrki,
THANISCH Peter. Applying Grid Technologies to XML Based OLAP Cube
Construction. In : LENZ H., VASSILIADIS P., JEUSFELD M.A., STAUDT M.
(Eds.). Proceedings of the 5th Intl. Workshop Design and Management of Data
Warehouses 2003 (DMDW'2003), September 8, 2003, Berlin, Germany,. :
CEUR-WS.org, 2003, . (CEUR Workshop Proceedings, 77)
(Noaman et al., 1999) NOAMAN Amin Y., BARKER Ken. A Horizontal
Fragmentation Algorithm for the Fact Relation in a Distributed Data
Warehouse. In : Proceedings of the 1999 ACM CIKM International Conference
on Information and Knowledge Management, November 2-6, 1999, Kansas
City, Missouri, USA. New York, NY, USA : ACM Press, 1999, pp. 162-169.
ISBN 1-58113-146-1
(O'Neil et al., 1995) O'NEIL Patrick E., GRAEFE G. Multi-Table Joins
Through Bitmapped Join Indices. ACM SIGMOD Record, 1995, vol. 24, n°3,

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 191
pp. 8-11.
ISSN 0163-5808
(O'Neil et al., 1997) O'NEIL Patrick E, QUASS Dallan. Improved Query
Performance with Variant Indexes. In : PECKHAM J. (Ed.). SIGMOD 1997,
Proceedings ACM SIGMOD International Conference on Management of Data,
May 13-15, 1997, Tucson, Arizona, USA. New York, NY, USA : ACM Press,
1997, pp. 38-49. (SIGMOD Record, 26(2))
(Pedersen et al., 1999) PEDERSEN Torben Bach, JENSEN Christian S.
Multidimensional Data Modeling for Complex Data. In : KITSUREGAWA M.,
MACIASZEK L., PAPAZOGLOU M., PU C. (Eds.). Proceedings of the 15th
International Conference on Data Engineering, 23-26 March 1999, Sydney,
Australia. Los Alamitos, CA, USA : IEEE Computer Society Press, 1999, pp.
336-345.
ISBN 978-0769500713
(Pierson et al., 2005) PIERSON Jean-Marc, BRUNIE Lionel, DHAENENS
Clarisse, HAMEURLAIN Abdelkader, MELAB Nordine, MIQUEL Maryvonne,
MORVAN Franck, TALBI El-Ghazali, TCHOUNIKINE Anne. Grid for Geno-
Medicine: a glimpse on the GGM project. In : RANA O. (Ed.). 5th
International Symposium on Cluster Computing and the Grid (CCGrid 2005), 9-
12 May, 2005, Cardiff, UK. Los Alamitos, CA, USA : IEEE Computer Society
Press, 2005, pp. 527-528.
(Pierson et al., 2007) PIERSON Jean-Marc, GOSSA J., WEHRLE P.,
CARDENAS Y., EL SAMAD M., CAHON S., BRUNIE L., DHAENENS C.,
HAMEURLAIN A., MELAB N., MIQUEL M., MORVAN F., TALBI E.,
TCHOUNIKINE A. GGM Efficient Navigation and Mining in Distributed
Geno-Medical Data. Transactions on NanoBioscience, 2007, vol. 6, n°2, pp.
110-116.
ISSN 1536-1241
(Poess et al., 2005) POESS Meikel, OTHAYOTH Raghunath. Large Scale Data
Warehouses on Grid: Oracle Database 10g and HP ProLiant Systems. In :
BÖHM K., JENSEN C.S., HAAS L.M., KERSTEN M.L., LARSON P., OOI
B.C. (Eds.). Proceedings of the 31st International Conference on Very Large
Data Bases, August 30 - September 2 2005, Trondheim, Norway. New York,
NY, USA : ACM Press, 2005, pp. 1055-1066.
ISBN 1-59593-154-6, 1-59593-177-5
(Qiu et al., 2001) QIU Shi Guang, LING Tok Wang. Index Filtering and View
Materialization in ROLAP Environment. In : Proceedings of the 2001 ACM
CIKM International Conference on Information and Knowledge Management,
November 5-10, 2001, Atlanta, Georgia, USA. New York, NY, USA : ACM
Press, 2001, pp. 334-340.
ISBN 1-58113-436-3
(Ramsak et al., 2001) RAMSAK Frank, MARKL Volker, FENK Robert,
BAYER Rudolf, RUF Thomas. Interactive ROLAP on Large Datasets: A Case

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 192
Study with UB-Trees. In : ADIBA M.E., COLLET C., DESAI B.C. (Eds.).
Proceedings of the International Database Engineering & Applications
Symposium, IDEAS '01, July 16-18, 2001, Grenoble, France. Los Alamitos,
CA, USA : IEEE Computer Society Press, 2001, pp. 167-176.
ISBN 0-7695-1140-6
(Ravat et al., 1997) RAVAT Franck, DE MICHIEL Marianne, ZURFLUH
Gilles. Distributed Object Oriented Databases: An Allocation Method. In :
HAMEURLAIN A., TJOA A.M (Eds.). Proceedings of Database and Expert
Systems Applications, 8th International Conference, DEXA '97, September 1-5,
1997, Toulouse, France. Berlin/Heidelberg, Allemagne : Springer-Verlag, 1997,
pp. 367-376. (Lecture Notes in Computer Science, 1308)
ISBN 3-540-63478-9
(Reed, 2003) REED Daniel A. Grids, the TeraGrid, and Beyond. Computer,
2003, vol. 36, n°1, pp. 62-68.
ISSN 0018-9162
(Roussopoulos et al., 1998) ROUSSOPOULOS Nick, KOTIDIS Yannis. The
Cubetree Storage Organization. In : GUPTA A., SHMUELI O., WIDOM J.
(Eds.). VLDB'98, Proceedings of 24rd International Conference on Very Large
Data Bases, August 24-27, 1998, New York City, New York, USA. San
Francisco, CA, USA : Morgan Kaufmann, 1998, p. 700.
ISBN 1-55860-566-5
(Sapia et al., 1999) SAPIA Carsten, BLASCHKA Markus, HÖFLING Gabriele,
DINTER Barbara. Extending the E/R Model for the Multidimensional
Paradigm. In : Proceedings of Advances in Database Technologies, ER '98
Workshops on Data Warehousing and Data Mining, Mobile Data Access, and
Collaborative Work Support and Spatio-Temporal Data Management,
Singapore, November 19-20, 1998. Berlin/Heidelberg, Allemagne : Springer-
Verlag, 1999, pp. 105-116. (Lecture Notes in Computer Science, 1552)
ISBN 3-540-65690-1
(Sarawagi, 1997) SARAWAGI Sunita. Indexing OLAP Data. IEEE Data
Engineering Bulletin, 1997, vol. 20, n°1, pp. 36-43.
(Sarawagi et al., 1994) SARAWAGI Sunita, STONEBRAKER Michael.
Efficient Organization of Large Multidimensional Arrays. In : Proceedings of
the Tenth International Conference on Data Engineering, February 14-18, 1994,
Houston, Texas, USA. Los Alamitos, CA, USA : IEEE Computer Society Press,
1994, pp. 328-336.
ISBN 0-8186-5400-7
(Shukla et al., 1998) SHUKLA Amit, DESHPANDE Prasad, NAUGHTON
Jeffrey F. Materialized View Selection for Multidimensional Datasets. In :
GUPTA A., SHMUELI O., WIDOM J. (Eds.). VLDB'98, Proceedings of 24rd
International Conference on Very Large Data Bases, August 24-27, 1998, New
York City, New York, USA. San Francisco, CA, USA : Morgan Kaufmann,

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 193
1998, pp. 488-499.
ISBN 1-55860-566-5
(Sismanis et al., 2002) SISMANIS Yannis, DELIGIANNAKIS Antonios,
ROUSSOPOULOS Nick, KOTIDIS Yannis. Dwarf: shrinking the PetaCube.
In : FRANKLIN M.J., MOON B., AILAMAKI A. (Eds.). Proceedings of the
2002 ACM SIGMOD International Conference on Management of Data, June 3-
6, 2002, Madison, Wisconsin, USA. New York, NY, USA : ACM Press, 2002,
pp. 464-475.
ISBN 1-58113-497-5
(Smith et al., 2002) SMITH Jim, GOUNARIS Anastasios, WATSON Paul,
PATON Norman W., FERNANDES Alvaro A. A., SAKELLARIOU Rizos.
Distributed Query Processing on the Grid. In : PARASHAR M. (Ed.).
Proceedings of Grid Computing - GRID 2002, Third International Workshop,
November 18 2002, Baltimore, MD, USA. Berlin/Heidelberg, Allemagne :
Springer-Verlag, 2002, pp. 279-290. (Lecture Notes in Computer Science,
2536)
ISBN 3-540-00133-6
(Son et al., 2004) SON Jin Hyun, KIM M.H. An adaptable vertical partitioning
method in distributed systems. Journal of Systems and Software, 2004, vol. 73,
n°3, pp. 551-561.
ISSN 0164-1212
(Stanoi et al., 1998) STANOI Ioana, AGRAWAL Divyakant, EL ABBADI
Amr. Weak Consistency in Distributed Data Warehouses. In : TANAKA K.,
GHANDEHARIZADEH S., KAMBAYASHI Y. (Eds.). The 5th International
Conference of Foundations of Data Organization (FODO'98), November 12-13,
1998, Kobe, Japan. Dordrecht, Pays-Bas : Kluwer Academic Publishers, 1998,
pp. 107-116.
ISBN 0-7923-7954-3
(Stanoi et al., 1999) STANOI Ioana, AGRAWAL Divyakant, EL ABBADI
Amr. Modeling and Maintaining Multi-View Data Warehouses. In : AKOKA J.,
BOUZEGHOUB M., COMYN-WATTIAU I., MÉTAIS E. (Eds.). Proceedings
of Conceptual Modeling - ER '99, 18th International Conference on Conceptual
Modeling, Paris, France, November, 15-18, 1999. Berlin/Heidelberg,
Allemagne : Springer-Verlag, 1999, pp. 161-175. (Lecture Notes in Computer
Science, 1728)
ISBN 3-540-66686-9
(Stöhr et al., 2000) STÖHR Thomas, MERTENS Holger, RAHM Erhard. Multi-
Dimensional Database Allocation for Parallel Warehouses. In : EL ABBADI
A., BRODIE M.L., CHAKRAVARTHY S., DAYAL U., KAMEL N.,
SCHLAGETER G., WHANG K. (Eds.). Proceedings of 26th International
Conference on Very Large Data Bases, September 10-14, 2000, Cairo, Egypt.
San Francisco, CA, USA : Morgan Kaufmann, 2000, pp. 273-284.
ISBN 1-55860-715-3

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 194
(Tryfona et al., 1999) TRYFONA Nectaria, BUSBORG Frank, BORCH
CHRISTIANSEN Jens G. starER: A Conceptual Model for Data Warehouse
Design. In : SONG I., TEOREY T.J. (Eds.). DOLAP '99, ACM Second
International Workshop on Data Warehousing and OLAP, November 6, 1999,
Kansas City, Missouri, USA. New York, NY, USA : ACM Press, 1999, pp. 3-8.
(Tsois et al., 2001) TSOIS Aris, KARAYANNIDIS Nikos, SELLIS Timos K.
MAC: Conceptual data modeling for OLAP. In : THEODORATOS, DIMITRI:
HAMMER, JOACHIM, JEUSFELD M.A., STAUDT M. (Eds.). Proceedings of
the 3rd Intl. Workshop on Design and Management of Data Warehouses,
DMDW'2001, June 4, 2001, Interlaken, Switzerland. : CEUR-WS.org, 2001, p.
5. (CEUR Workshop Proceedings, 39)
(Ullman, 1996) ULLMAN Jeffrey D. Efficient Implementation of Data Cubes
Via Materialized Views. In : SIMOUDIS E., HAN J., FAYYAD U.M. (Eds.).
Proceedings of the Second International Conference on Knowledge Discovery
and Data Mining (KDD-96).Portland, Oregon, USA, 1996 . Menlo Park, CA,
USA : AAAI Press, 1996, pp. 386-388.
ISBN 1-57735-004-9
(Vassiliadis et al., 1999) VASSILIADIS Panos, SELLIS T. A survey of logical
models for OLAP databases. ACM SIGMOD Record, 1999, vol. 28, n°4, pp.
64-69.
ISSN 0163-5808
(Vesset et al., 2008) VESSET Dan, MCDONOUGH B. Worldwide Business
Intelligence Tools 2007 Vendor Shares: Query, Reporting, and Analysis, and
Advanced Analytics Markets Stable in the Face of Economic Turmoil.
Framingham, MA, USA : IDC Research, 2008, 20 p.
(Wehrle et al., 2005a) WEHRLE Pascal, MIQUEL Maryvonne,
TCHOUNIKINE Anne. A Model for Distributing and Querying a Data
Warehouse on a Computing Grid. In : BAROLLI L. (Ed.). 11th International
Conference on Parallel and Distributed Systems (ICPADS 2005), 20-22 July
2005, Fukuoka, Japan. Los Alamitos, CA, USA : IEEE Computer Society Press,
2005, pp. 203-209.
ISBN 0-7695-2281-5
(Wehrle et al., 2005b) WEHRLE Pascal, MIQUEL M., TCHOUNIKINE A.
Entrepôts de données sur grilles de calcul. Revue des Nouvelles Technologies
de l'Information, 2005, vol. RNTI-E-5, n°, pp. 195-198.
ISSN 2.85428.707.X
(Wehrle et al., 2007a) WEHRLE Pascal, MIQUEL Maryvonne,
TCHOUNIKINE Anne. A Grid Services-Oriented Architecture for Efficient
Operation of Distributed Data Warehouses on Globus. In : The 21st
International Conference on Advanced Information Networking and
Applications (AINA 2007), May 21-23, 2007, Niagara Falls, Canada. Los
Alamitos, CA, USA : IEEE Computer Society Press, 2007, pp. 994-999.
ISBN 1550-455X

C Scénario de test sur l'entrepôt GGM
Pascal Wehrle/Thèse en informatique/2009/Institut national des sciences appliquées de Lyon 195
(Wehrle et al., 2007b) WEHRLE Pascal, TCHOUNIKINE Anne, MIQUEL
Maryvonne. Grid Services for Efficient Decentralized Indexation and Query
Execution on Distributed Data Warehouses. In : EDER J., TOMASSEN S.L.,
OPDAHL A.L., SINDRE G. (Eds.). CAiSE'07 Forum, Proceedings of the
CAiSE'07 Forum at the 19th International Conference on Advanced Information
Systems Engineering, Trondheim, Norway, 11-15 June 2007. CEUR-WS.org,
2007, pp. 13-16. (CEUR Workshop Proceedings, 247)
ISBN 1503-416X
(Weng et al., 2005) WENG Li, ÇATALYÜREK Ümit V., KURÇ Tahsin M.,
AGRAWAL Gagan, SALTZ Joel H. Servicing range queries on
multidimensional datasets with partial replicas. In : RANA O. (Ed.). 5th
International Symposium on Cluster Computing and the Grid (CCGrid 2005),
May 9-12, 2005, Cardiff, UK. Los Alamitos, CA, USA : IEEE Computer
Society Press, 2005, pp. 726-733.
(Wolski, 1997) WOLSKI Richard. Forecasting Network Performance to
Support Dynamic Scheduling using the Network Weather Service. In :
Proceedings of The 6th International Symposium on High Performance
Distributed Computing (HPDC '97), August 5-8, 1997, Portland, OR, USA. Los
Alamitos, CA, USA : IEEE Computer Society Press, 1997, pp. 316-325.
(World Health Organization, 2008) WORLD HEALTH ORGANIZATION.
International Classification of Diseases (ICD) [en ligne]. Disponible sur :
http://www.who.int/classifications/icd/en/. (consulté le 30/09/2008).
(Zhou et al., 1997) ZHOU Shaoyu, WILLIAMS M.H. Data placement in paralle
database systems. In : ABDELGUERFI Mahdi, WONG K. Parallel Database
Techniques. New York, NY, USA : Wiley-IEEE Computer Society Press, 1997,
pp. 203-218
ISBN 978-0-8186-8398-5
(Zhuge et al., 1997) ZHUGE Yue, GARCIA-MOLINA Hector, WIENER Janet
L. Multiple View Consistency for Data Warehousing. In : GRAY W.A.,
LARSON P. (Eds.). Proceedings of the Thirteenth International Conference on
Data Engineering, April 7-11, 1997, Birmingham, UK. Los Alamitos, CA,
USA : IEEE Computer Society Press, 1997, pp. 289-300.
ISBN 0-8186-7807-0
(Özsu et al., 1991) ÖZSU M. Tamer, VALDURIEZ P. Principles of distributed
database systems. Englewood Cliffs, NJ, USA : Prentice Hall, 1991, 540 p.
ISBN 0-13-715681-2



















