
MODÉLISATION - emse.frpbreuil/capmes/conf mesuredoc2018.pdf · (pas d’hypothèse sur...
34
1 MESURE, INCERTITUDE & MODÉLISATION Philippe Breuil, janvier 2018 MODÉLISATION 2/62 Détermination à partir de données expérimentales d’une fonction mathématique mono ou multi-variables permettant de « reproduire » un phénomène
Transcript of MODÉLISATION - emse.frpbreuil/capmes/conf mesuredoc2018.pdf · (pas d’hypothèse sur...

1
MESURE, INCERTITUDE &
MODÉLISATION
Philippe Breuil, janvier 2018
MODÉLISATION
2/62
Détermination à partir de données
expérimentales d’une fonction
mathématique mono ou multi-variables
permettant de « reproduire » un phénomène
2
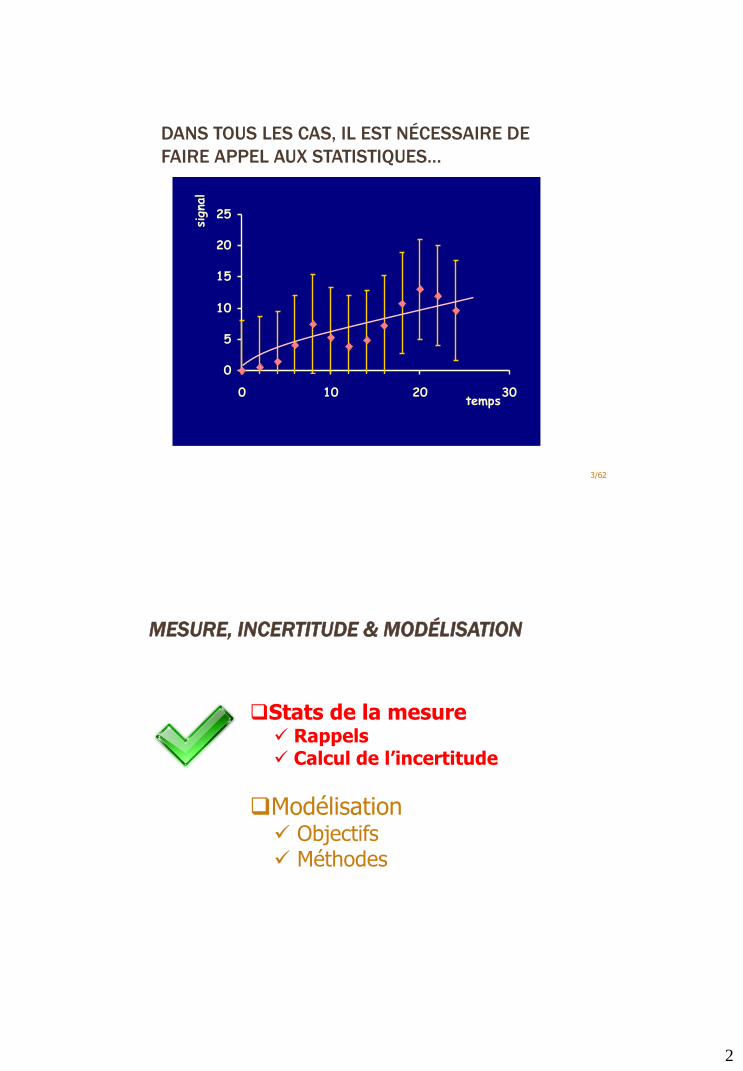
DANS TOUS LES CAS, IL EST NÉCESSAIRE DE
FAIRE APPEL AUX STATISTIQUES…
0
2
4
6
8
10
12
14
0 10 20 30temps
signa
l
3/62
0
2
4
6
8
10
12
14
16
0 10 20 30temps
signa
l
0
2
4
6
8
10
12
14
0 10 20 30temps
signa
l
0
2
4
6
8
10
12
14
16
0 10 20 30temps
signa
l
0
5
10
15
20
25
0 10 20 30temps
signa
l
MESURE, INCERTITUDE & MODÉLISATION
Stats de la mesure Rappels Calcul de l’incertitude
Modélisation Objectifs Méthodes
3
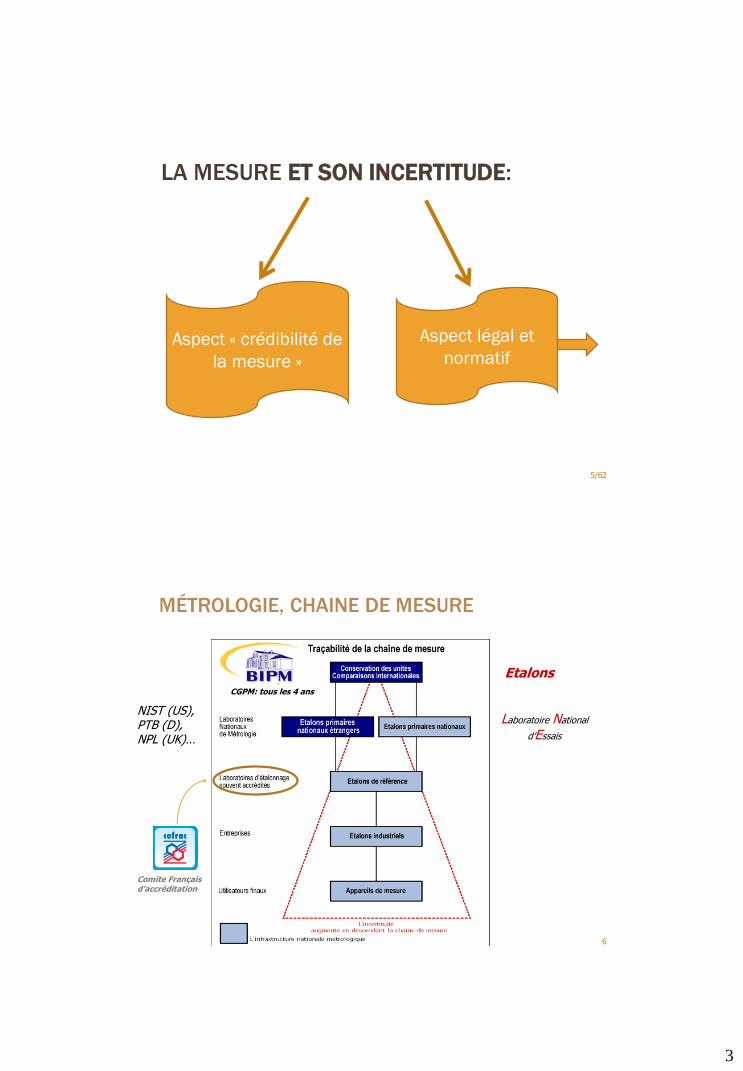
LA MESURE ET SON INCERTITUDE:
5/62
Aspect « crédibilité de
la mesure »
Aspect légal et
normatif
MÉTROLOGIE, CHAINE DE MESURE
6
Laboratoire National
d’Essais
NIST (US), PTB (D), NPL (UK)…
EtalonsCGPM: tous les 4 ans
Comite Français d’accréditation

4
QUELQUES RAPPELS SUR L'ERREUR ET L'INCERTITUDE…
Erreur systématique: eB
Systematic error
Erreur accidentelle ou aléatoire: eA
Random or accidental error
7
Mesure x d’une variable de valeur réelle xR:
ABRxx ee Erreur: variable e=xR-x
)(xExR (espérance de x)
Expectation
CARACTÉRISATION DE LA MESURE (ET DE L’ERREUR
ALÉATOIRE):
Moyenne estimée de n mesures d'une même valeur xR
8
n
ixn
x1
1
xR = valeur réelle
)()lim( xExR
n
x
(loi des grands nombres)
Estimated mean
Law of large numbers
(espérance de x)
Expectation
(Si erreur aléatoire)

5
ECART-TYPE DE L'ERREUR ALÉATOIRE:
9
n
i xxn
s1
2)(1
1Ecart-type estimé de
l'erreur aléatoire
Variance (de l’erreur aléatoire) :
xr
Ecart type
relatif :
n
ii xExn
xEx1
22))((
1)(
Valeur réelle,
À priori inconnue…
Standard deviation of random error
Variance (of random error)
Ecart-type de
l'erreur aléatoire V
et s ont même espérance…
2RxxV
QUELQUES CALCULS, JUSTIFICATION DU TERME (N-1)
10
Soit la grandeur: 2222 1)( xxxx
nxxxv
i
i
2222)( xExExxEvE
)()()()()( 22 xVxExVxEvE
)(1
)(1
)()()()( 22 xVn
nxV
nxExVxEvE
i
i xxn
xvn
n 2
1
1)(
1Donc le terme a pour espérance V(x)…
22222)()()()(2)()( xExExExxExExExExV
)()()( 22 xVxExE
)()( xExE
théorème de la moyenne, démo + loin, propag erreur
n
xVxV
)()(
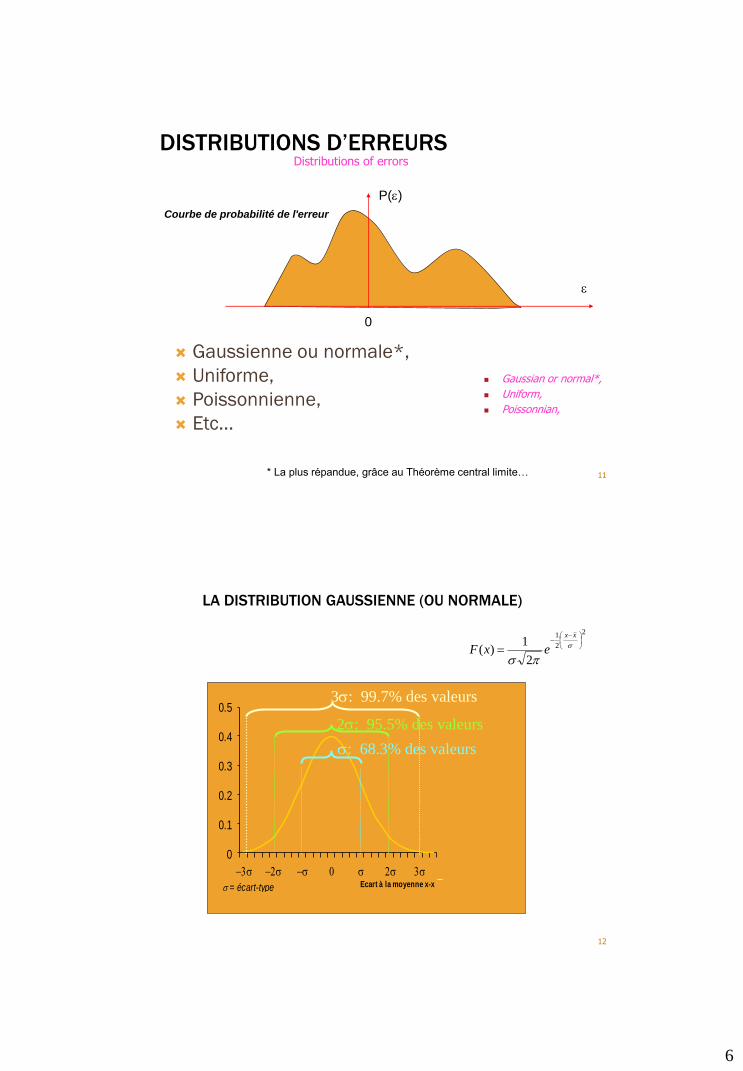
6
DISTRIBUTIONS D’ERREURS
Gaussienne ou normale*,
Uniforme,
Poissonnienne,
Etc…
11* La plus répandue, grâce au Théorème central limite…
e
0
P(e)
Courbe de probabilité de l'erreur
Distributions of errors
Gaussian or normal*,
Uniform,
Poissonnian,
LA DISTRIBUTION GAUSSIENNE (OU NORMALE)
12
0
0.1
0.2
0.3
0.4
0.5
3 2 0 2 3Ecart à la moyenne x-x = écart-type
: 68.3% des valeurs
2: 95.5% des valeurs
3: 99.7% des valeurs
2
2
1
2
1)(
xx
exF

7
THÉORÈME CENTRAL LIMITE
Si une variable est la résultante d'un grand nombre de causes, petites, àeffet additif, cette variable tend vers une loi normale.
C'est à cause de cette interprétation que la loi normale est très souventemployée comme modèle (malheureusement pas toujours à raison).
13Demo
Central Limit Theorem
TP1
DISTRIBUTION DE POISSON
Ex: comptage d’évènements aléatoires non
simultanés (désintégration radioactive,
queue…)
14
Moyenne: m
Variance: m
demo

8
LES TESTS D’HYPOTHÈSE
15
Significance tests
Tests d’une hypothèse (« null hypothesis », ex: 2 échantillons ont même
moyenne) à partir d’un nombre fini d’échantillons, entachés d’erreur aléatoire.Le résultat du test n’est pas absolu mais est une probabilité qui est une aide à la validation ou non de l’hypothèse initiale, il ne constitue donc jamais une preuve.
Tests paramétriques(hypothèse sur distribution + ou – nécessaire)
1-sample T-test Comp. Échantillon à valeur de référence, intervalle de confiance
2-samples T-test Comparaison de 2 échantillons
F-Test Comparaison de la variance de 2 échantillons
ANOVA Analyse de variance: analyse des variances de K échantillons, comparaison
des moyennes (n≥2)
Chi-Square test Utilisation notamment pour vérifier une hypothèse de distribution
Grubbs’ test Détection des valeurs aberrantes (« outliers »)
Tests non paramétriques(pas d’hypothèse sur distribution)
Test Wilcoxon.M.W Comparaison de 2 échantillons, méthode de rang
En rouge: tests décrits + loin, sinon voir biblio ou google
ONE-SAMPLE T-TEST « SIMPLIFIÉ »
16
95%
1.96s
Comparaison de la mesure X d’un échantillon à une valeur de référence R, on suppose que la distribution est normale.
Hypothèses:• « X est différent de R »?• « X est significativement différent de R »?
Cette hypothèse de différence H1 est retenue si sa probabilité est supérieure à 95% (par exemple) (ou si la probabilité d’égalité est inférieure à 5% (H2)
1 mesure: X, écart-type estimé de la mesure: s, distr. gaussienne
X R
-3s -2s –s 0 s 2s 3s
Hypothèse retenue si:
stRX .
si s est calculable « précisément *»:
(t=coef de Student)
H1: 95% (ou
H2: 5%)
H1: 99% (ou H2:
1%)
H1: 99.9% (ou
H2: 0.1%)
t 1.96 2.56 3.28
Oui, quasiment toujours, à cause de l’erreur aléatoire…
• « La différence entre X et R n’est pas due qu’à l’erreur aléatoire »
*n>20, sinon, tableau des coefs de Student…
X

9
17
TABLEAU DES COEFFICIENTS « t » DE STUDENT
P N=5 N=10 N=20 N> 100
50 % 0,73·σ 0,70·σ 0,69·σ 0,67·σ
68 % 1·σ
70 % 1,16·σ 1,09·σ 1,06·σ 1,04·σ
87 % 1,5·σ
90 % 2,02·σ 1,81·σ 1,73·σ 1,65·σ
95 % 2,57·σ 2,23·σ 2,09·σ 1,96·σ
99 % 4,03·σ 3,17·σ 2,85·σ 2,56·σ
99,7 % 3·σ
99,9 % 6,87·σ 4,59·σ 3,85·σ 3,28·σ
99,999 999 8 % 6·σ
.tXXprobaP R
=1-LOI.STUDENT.BILATERALE(t;N)
• N = nb degré de liberté (nb
échantillons utilisés pour le
calcul de -1)
• P = probabilité
Utilisation lorsque l’écart-type est calculé à partir d’un nombre faible (<20) d’échantillons
Sinon, t~2, 95%...
=LOI.STUDENT.INVERSE.BILATERALE(P, N)
CALCUL PROBABILITÉ:
ONE-SAMPLE T-TEST « OFFICIEL »
18
95%
Comparaison de la moyenne d’un échantillon à une valeur de référence R, on suppose que la distribution est normale*.Hypothèse: « la différence entre la moyenne de n mesures et une valeur de référence n’est pas due qu’aux erreurs aléatoires »
Cette hypothèse est retenue si sa probabilité est supérieure à 95% (par exemple)
n mesures: moyenne m, écart-type estimé de chaque mesure: s
On montre (+ loin…) que l’écart-type estimé de la moyenne est: n
ss '
m R
-4s’ -3s’ -2s’ –s’ 0 s’ 2s’ 3s’ 4s’
Hypothèse retenue si:
n
stR m
si s est calculable « précisément »:
(t=coef de Student)
H1: 95% (ou
H2: 5%)
H1: 99% (ou H2:
1%)
H1: 99.9% (ou
H2: 0.1%)
t 1.96 2.56 3.28
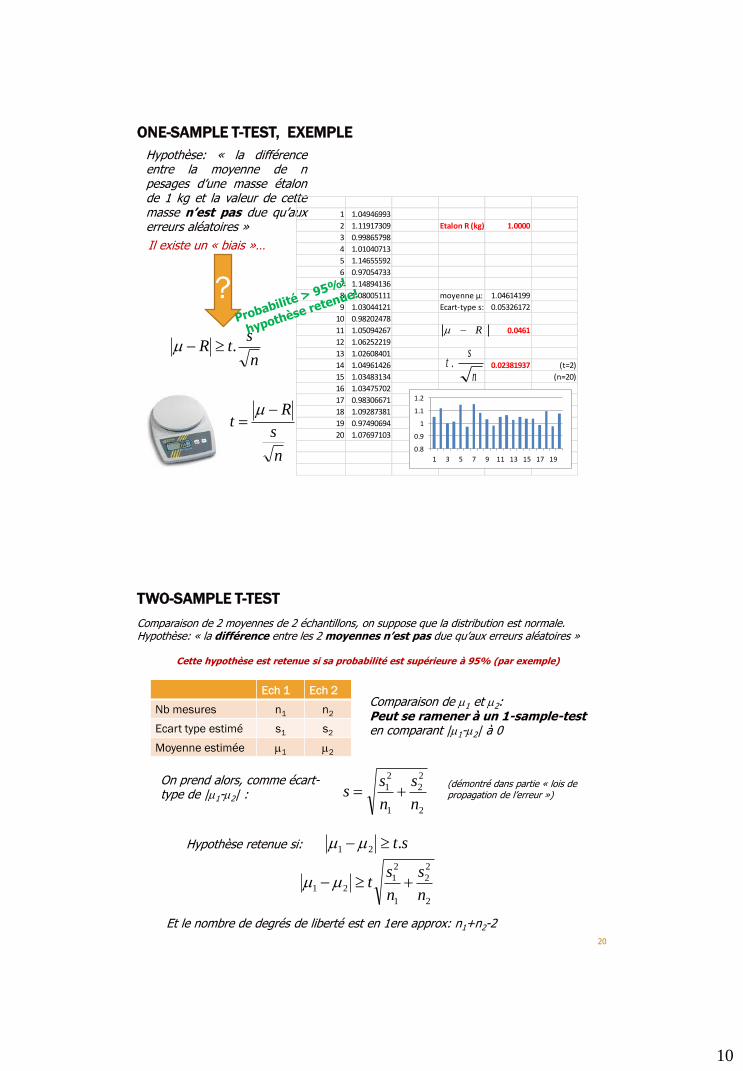
10
ONE-SAMPLE T-TEST, EXEMPLE
Hypothèse: « la différenceentre la moyenne de npesages d’une masse étalonde 1 kg et la valeur de cettemasse n’est pas due qu’auxerreurs aléatoires »
n
stR .m
?
n
s
Rt
m
1 1.04946993
2 1.11917309 Etalon R (kg) 1.0000
3 0.99865798
4 1.01040713
5 1.14655592
6 0.97054733
7 1.14894136
8 1.08005111 moyenne µ: 1.04614199
9 1.03044121 Ecart-type s: 0.05326172
10 0.98202478
11 1.05094267 0.0461
12 1.06252219
13 1.02608401
14 1.04961426 0.02381937 (t=2)
15 1.03483134 (n=20)
16 1.03475702
17 0.98306671
18 1.09287381
19 0.97490694
20 1.07697103
0.8
0.9
1
1.1
1.2
1 3 5 7 9 11 13 15 17 19
Rm
n
st .
Il existe un « biais »…
TWO-SAMPLE T-TEST
20
Comparaison de 2 moyennes de 2 échantillons, on suppose que la distribution est normale.Hypothèse: « la différence entre les 2 moyennes n’est pas due qu’aux erreurs aléatoires »
Ech 1 Ech 2
Nb mesures n1 n2
Ecart type estimé s1 s2
Moyenne estimée m1 m2
Comparaison de m1 et m2:Peut se ramener à un 1-sample-test en comparant |m1-m2| à 0
On prend alors, comme écart-type de |m1-m2| :
2
2
2
1
2
1
n
s
n
ss
(démontré dans partie « lois de propagation de l’erreur »)
Et le nombre de degrés de liberté est en 1ere approx: n1+n2-2
st.21 mmHypothèse retenue si:
Cette hypothèse est retenue si sa probabilité est supérieure à 95% (par exemple)
2
2
2
1
2
121
n
s
n
st mm

11
TWO-SAMPLE T-TEST: EXEMPLE
2
2
2
1
2
121 .
n
s
n
st mm
op1 op2 op1 op2
3.59385514 3.49673556 moyenne µ 3.54463973 3.55551443
3.58810682 3.50481358 écart-type s 0.04510027 0.04809217
3.53371004 3.47201328
3.52760094 3.553306 |µ1-µ2| 0.01087473.44867115 3.57512954
3.51024893 3.55717682
3.60880932 3.62969549
3.53927667 3.66487781 0.01393613.55719746 3.54702026
3.52552333 3.54598904 n: 43 t=2
3.49798625 3.48741103
3.49706929 3.56409401 s.t: 0.02787228
3.56771949 3.56622487
3.59781434 3.54564972
3.54032574 3.50388551
3.57799787 3.65577103
3.49003712 3.55839436
3.57276739 3.53637213
3.61263276 3.57229694
3.50544464 3.56392763
3.60261554
3.52637678
3.5652033
3.58384532
3.50903522
3.3
3.35
3.4
3.45
3.5
3.55
3.6
3.65
3.7
1 3 5 7 9 11 13 15 17 19 21 23 25
2
2
2
1
2
1
n
s
n
ss
Hypothèse: « la différence entre les moyennes de pesages d’une même masse par 2 opérateurs n’est pas due qu’aux erreurs aléatoires »
?
1 2
Il existe un « biais entre les 2 opérateurs»…
TP2
INTERVALLE DE CONFIANCE
22
L'intervalle de confiance à p (95%) d’une mesure x est un intervalle de valeurs qui a une probabilité centrée p (95%) de contenir la vraie valeur xR du paramètre estimé.
xx ,
La calcul de et en fonction de la probabilité P (généralement 95%) dépend de la loi de
distribution de l'erreur
0
et = incertitude à p (95%)
Distribution symétrique:
• =
•Valeur moyenne de la mesure
= la plus probable0
Confidence interval
2/1)()( pxxPxxP RR
Distribution normale

12
INTERVALLE DE CONFIANCE, CAS DE LA DISTRIBUTION NORMALE:
23
L'intervalle de confiance à p (95%) d’une mesure x est un intervalle de valeurs qui a une probabilité centrée p (95%) de contenir la vraie valeur xR du paramètre estimé.
stxstx .,.
• Choix de la probabilité: 95% usage…
• Choix de t: si distrib. Normale et s calculé « confortablement » (n>20), t~2
ÉCRITURE D’UNE MESURE (DISTRIBUTION NORMALE)
24
Loi normale:
95%
Le résultat d’une mesure doit comporter 4 éléments :Ex : CNO = 125.3 ppb 1.7 ppb (à 95% ou t=2)
1 2 3 41 : Valeur numérique avec un nombre correct de décimales2 : Unité3 : Incertitude élargie = t.4 : Le coefficient d’élargissement t utilisé
Probabilité en % pour que la mesure
soit dans l’intervalle tsxtsx ,
1 : Numerical value with a correct number of decimals2 : Unit3 : expanded uncertainty = t.s4 : Coverage factor t
Si pas précisé:t=2 et 95%

13
ÉVALUATION DE L’INCERTITUDE :
Évaluation par analyse statistique de séries de mesures (« type A »)
(généralement mesure, mais aussi simulation)
25
Évaluation par calcul de l’effet sur l’incertitude finale des différentes
sources d’incertitude (« type B »: « par tout autre moyen »!), elles même
évaluées :
par une méthode de type A,
par des données constructeur, d’étalonnage etc…
Il est alors nécessaire de connaître les lois de propagation de
l’erreur…
QUELLE EST LA PESÉE LA PLUS PRÉCISE?
(les erreurs sont aléatoires)

14
LOIS DE PROPAGATION DES INCERTITUDES DES ERREURS ALÉATOIRES
INDÉPENDANTES (1)
27
Exemple de la somme: s=a+b
es
eb
ea
es=ea+ebRappel: les erreurs s’ajoutent algébriquement:
Et leur écart-type?
combined standard uncertainty for random & independant errors
a b a+b2.82 1.51 4.33
2.61 1.71 4.32
2.64 1.68 4.32
3.45 2.02 5.48
3.32 1.90 5.23
2.79 2.08 4.88
3.17 1.55 4.72
2.70 2.09 4.79
3.10 1.86 4.96
3.40 1.56 4.95
moyenne 3.00 1.80 4.80 4.80 somme moyennes
variance 0.11 0.05 0.16 0.16 somme variances
ecartype 0.33 0.23 0.39 0.55 somme écart-types
0.00
1.00
2.00
3.00
4.00
5.00
6.00
1 2 3 4 5 6 7 8 9 10
a
b
a+b
LOIS DE PROPAGATION DES INCERTITUDES DES ERREURS ALÉATOIRES
INDÉPENDANTES (2)
28
Exemple de la somme: s=a+b
Erreur aléatoire:
)()()( bas
combined standard uncertainty for random & independant errors
)()()( bVaraVarbaVar
Les écart-types (et donc les incertitudes) ne s’ajoutent pas!!
Mais les variances si!!*
22baba 222
baba
Les écart-types s’ajoutent quadratiquement*
*si les erreurs sont indépendantes et aléatoires

15
QUELLE EST LA PESÉE LA PLUS PRÉCISE?
ÉCART TYPE DE L'ERREUR ALÉATOIRE DE LA SOMME DE
VARIABLES
30
Exemple de la somme: s=a+b (suite)
Variance: 2
1
1)(
aa
naVar i
21
1)(
bb
nbVar i
21
1)(
bbaan
sVar ii
bbaabbaan
iiii 21
1 22
)()( aVarbaVar
Somme quadratique des écart-types
22baba
=0 si erreurs indépendantes
)(bVar ),(2 baCov
Les variances s’ajoutent,
Et les écarts-types?

16
RAPPEL: LOI DE PROPAGATION D’UNE « PETITE » ERREUR
31
n
i
i
xx
fy
1
)(
,..),..( 1 ixxfy Fonction quelconque:
)(xfy xdx
dfxfxxf .)()(
xdx
dfy .
Cas particulier, produit:2/1
3..
d
cbay
d
d
c
c
b
b
a
a
y
y
2/13
LOIS DE PROPAGATION DES INCERTITUDES, CAS GÉNÉRAL
32
)()(1
2
2
2
i
n
i
xx
fy
,..),..( 1 ixxfy Fonction quelconque:
Ecart-type:Si erreurs indépendantes…
Donc si les lois de distribution sont connues, on peut en déduire la loi de propagation des incertitudes:
Exemple, distr. Gaussienne et I=2:
)()(1
2
2
2
i
n
i
xx
fy II

17
LOIS DE PROPAGATION DES INCERTITUDES DES ERREURS ALÉATOIRES
INDÉPENDANTES (4)
33
Ex: somme ou différence:
cbay
222 )()()()( cbay
i
ii xay i
ii xay 22 ))(()( Combinaison linéaire:
Application fondamentale en instrumentation: La moyenne
LOIS DE PROPAGATION DES INCERTITUDES DES ERREURS ALÉATOIRES
INDÉPENDANTES (5)
34
n
ixn
x1
1
n
xx
nx
n )()(
1)(
1
2
Application fondamentale en instrumentation: La moyenne
DemoLoi "des grands nombres"
Théorème de la moyenne:Si une série de mesures a une erreur aléatoire et indépendante d’écart-type , alors la moyenne de n de ces mesures a une erreur aléatoire dont l’écart-type est divisé par racine carrée de n.
Theorem of the mean
18
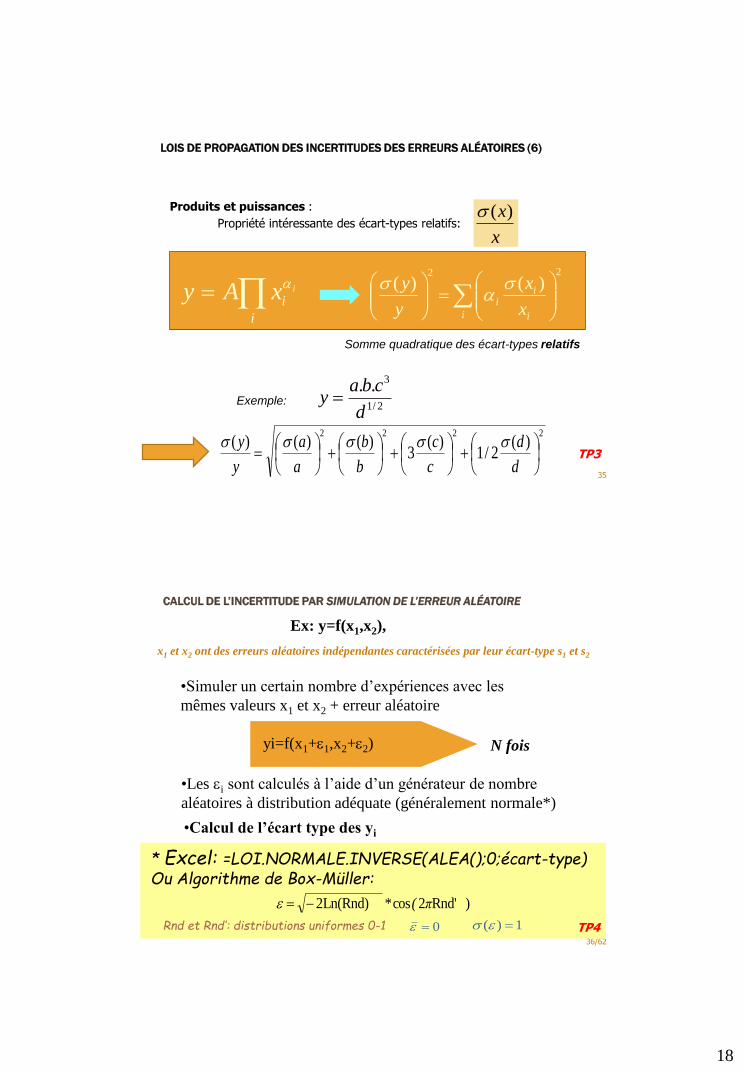
LOIS DE PROPAGATION DES INCERTITUDES DES ERREURS ALÉATOIRES (6)
35
Produits et puissances :
i
iixAy
i i
ii
x
x
y
y22
)()(
Somme quadratique des écart-types relatifs
x
x)(Propriété intéressante des écart-types relatifs:
2/1
3..
d
cbay
2222)(
2/1)(
3)()()(
d
d
c
c
b
b
a
a
y
y
Exemple:
TP3
CALCUL DE L’INCERTITUDE PAR SIMULATION DE L’ERREUR ALÉATOIRE
36/62
Ex: y=f(x1,x2),
x1 et x2 ont des erreurs aléatoires indépendantes caractérisées par leur écart-type s1 et s2
•Simuler un certain nombre d’expériences avec les
mêmes valeurs x1 et x2 + erreur aléatoire
yi=f(x1+e1,x2+e2) N fois
•Calcul de l’écart type des yi
•Les ei sont calculés à l’aide d’un générateur de nombre
aléatoires à distribution adéquate (généralement normale*)
) Rnd'2cos* Ln(Rnd)2 π(e
* Excel: =LOI.NORMALE.INVERSE(ALEA();0;écart-type)Ou Algorithme de Box-Müller:
0e 1)( eRnd et Rnd’: distributions uniformes 0-1 TP4
19
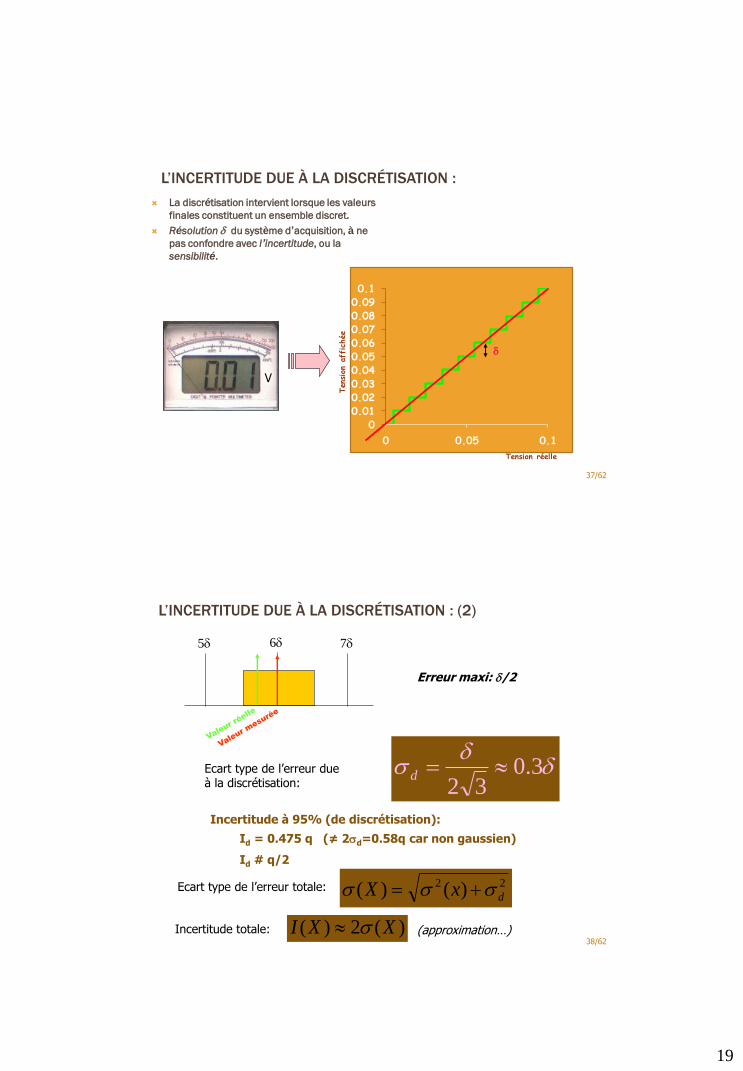
L’INCERTITUDE DUE À LA DISCRÉTISATION :
La discrétisation intervient lorsque les valeurs
finales constituent un ensemble discret.
Résolution d du système d’acquisition, à ne
pas confondre avec l’incertitude, ou la
sensibilité.
00.010.020.030.040.050.060.070.080.090.1
0 0.05 0.1
Ten
sion
aff
ichée
Tension réelle
37/62
d
V
L’INCERTITUDE DUE À LA DISCRÉTISATION : (2)
38/62
dd
3.032d
Ecart type de l’erreur due à la discrétisation:
22 )()( dxX Ecart type de l’erreur totale:
5d 6d 7d
Erreur maxi: d/2
Incertitude à 95% (de discrétisation):
Id = 0.475 q (≠ 2d=0.58q car non gaussien)
Id # q/2
Incertitude totale: )(2)( XXI (approximation…)

20
LE « DITHERING »
39/62
La présence d’erreur aléatoire permet ici d’améliorer la « précision » de la mesure !!!
Pas de « bruit », pas de moyennage Pas de « bruit », moyenne 50
signaux
« bruit », pas de moyennage « bruit », moyenne 50 signaux
La méthode du moyennage peut réduire aussi l’erreur de discrétisation (= quantification):
On peut gagner 1 bit de résolution chaque fois que l’on multiplie par 4 la fréquence d’échantillonnage…
… à condition que le signal avant numérisation contienne un bruit (aléatoire et indépendant) de valeur efficace supérieure à la résolution initiale…
demo
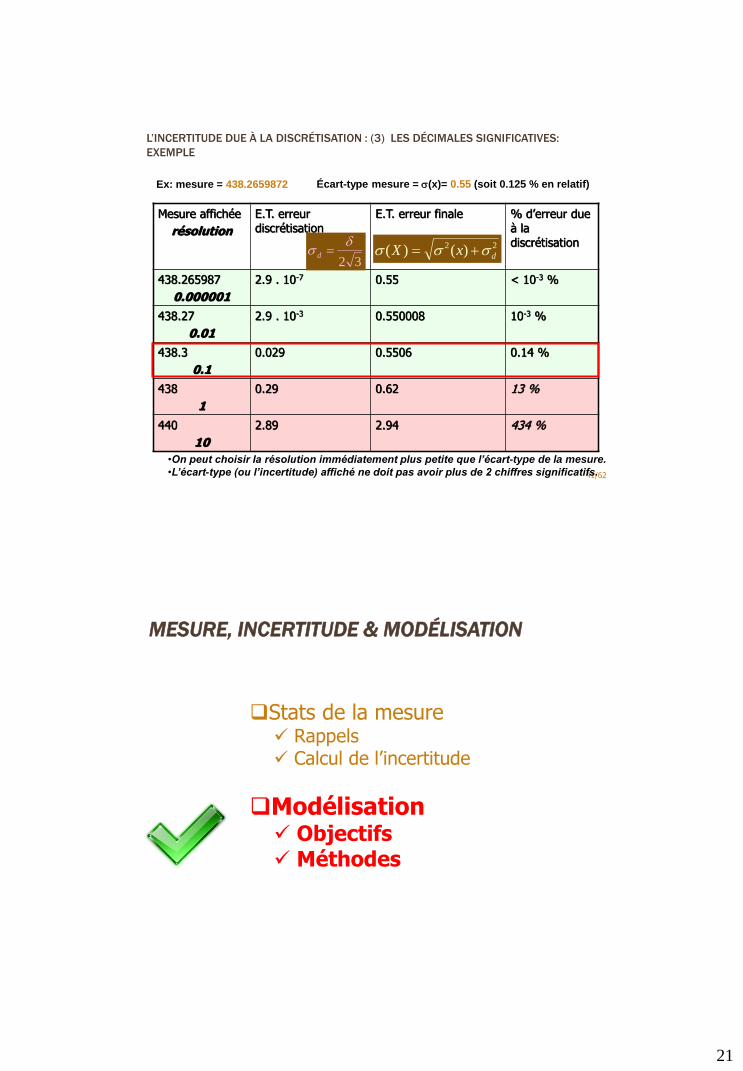
L’INCERTITUDE DUE À LA DISCRÉTISATION : (3) LES DÉCIMALES
SIGNIFICATIVES
40/62
Ecriture d’un nombre avec un nombre de chiffres fini Erreur de discrétisation
Pour une mesure, l’écart type de l’erreur introduite doit être petit devant celui
de l’erreur de mesure initiale
Ex: mesure = 438.2659872 Écart-type mesure = 0.55 (soit 0.125 % en relatif)
Doit-on écrire:
438.2659872 ?
438.265 ?
438 ?
Mais les systèmes numériques peuvent donner beaucoup de chiffres significatifs…
21
L’INCERTITUDE DUE À LA DISCRÉTISATION : (3) LES DÉCIMALES SIGNIFICATIVES:
EXEMPLE
Mesure affichée
résolution
E.T. erreur discrétisation
E.T. erreur finale % d’erreur due à la discrétisation
438.265987
0.000001
2.9 . 10-7 0.55 < 10-3 %
438.27
0.01
2.9 . 10-3 0.550008 10-3 %
438.3
0.1
0.029 0.5506 0.14 %
438
1
0.29 0.62 13 %
440
10
2.89 2.94 434 %
41/62
32
d d
22 )()( dxX
Ex: mesure = 438.2659872 Écart-type mesure = (x)= 0.55 (soit 0.125 % en relatif)
•On peut choisir la résolution immédiatement plus petite que l’écart-type de la mesure.
•L’écart-type (ou l’incertitude) affiché ne doit pas avoir plus de 2 chiffres significatifs.
MESURE, INCERTITUDE & MODÉLISATION
Stats de la mesure Rappels Calcul de l’incertitude
Modélisation Objectifs Méthodes
22
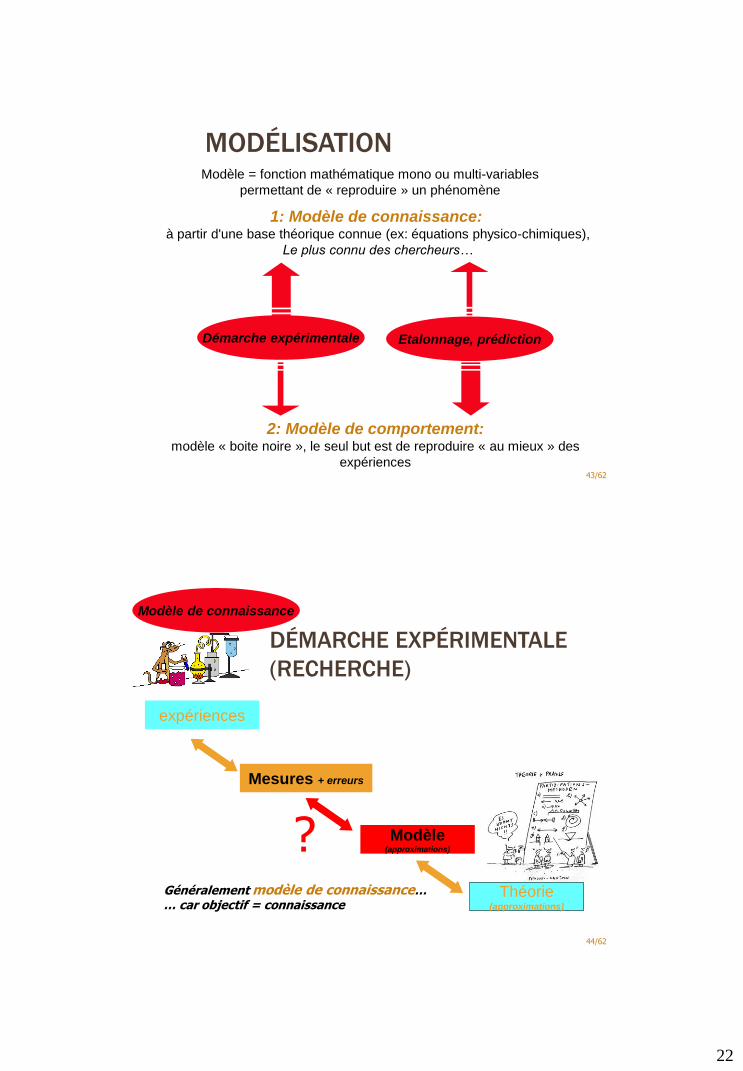
MODÉLISATION
43/62
Modèle = fonction mathématique mono ou multi-variables
permettant de « reproduire » un phénomène
1: Modèle de connaissance:à partir d'une base théorique connue (ex: équations physico-chimiques),
Le plus connu des chercheurs…
2: Modèle de comportement: modèle « boite noire », le seul but est de reproduire « au mieux » des
expériences
Démarche expérimentale Etalonnage, prédiction
DÉMARCHE EXPÉRIMENTALE
(RECHERCHE)
44/62
expériences
Théorie(approximations)
Modèle(approximations)
Mesures + erreurs
?Généralement modèle de connaissance…… car objectif = connaissance
Modèle de connaissance
23
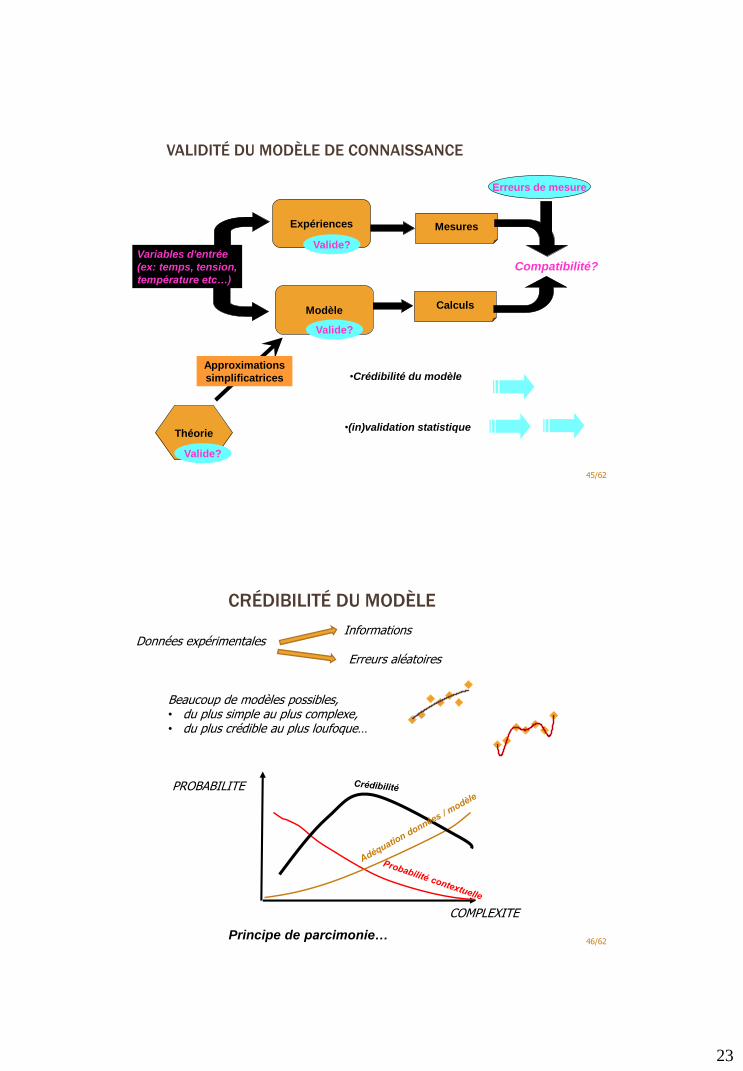
VALIDITÉ DU MODÈLE DE CONNAISSANCE
45/62
Mesures
Calculs
Erreurs de mesure
Théorie
Valide?
•Crédibilité du modèle
Modèle
Valide?
Approximations
simplificatrices
Compatibilité?
•(in)validation statistique
Expériences
Variables d'entrée
(ex: temps, tension,
température etc…)
Valide?
CRÉDIBILITÉ DU MODÈLE
46/62Principe de parcimonie…
COMPLEXITE
PROBABILITE
Données expérimentalesInformations
Erreurs aléatoires
Beaucoup de modèles possibles, • du plus simple au plus complexe, • du plus crédible au plus loufoque…
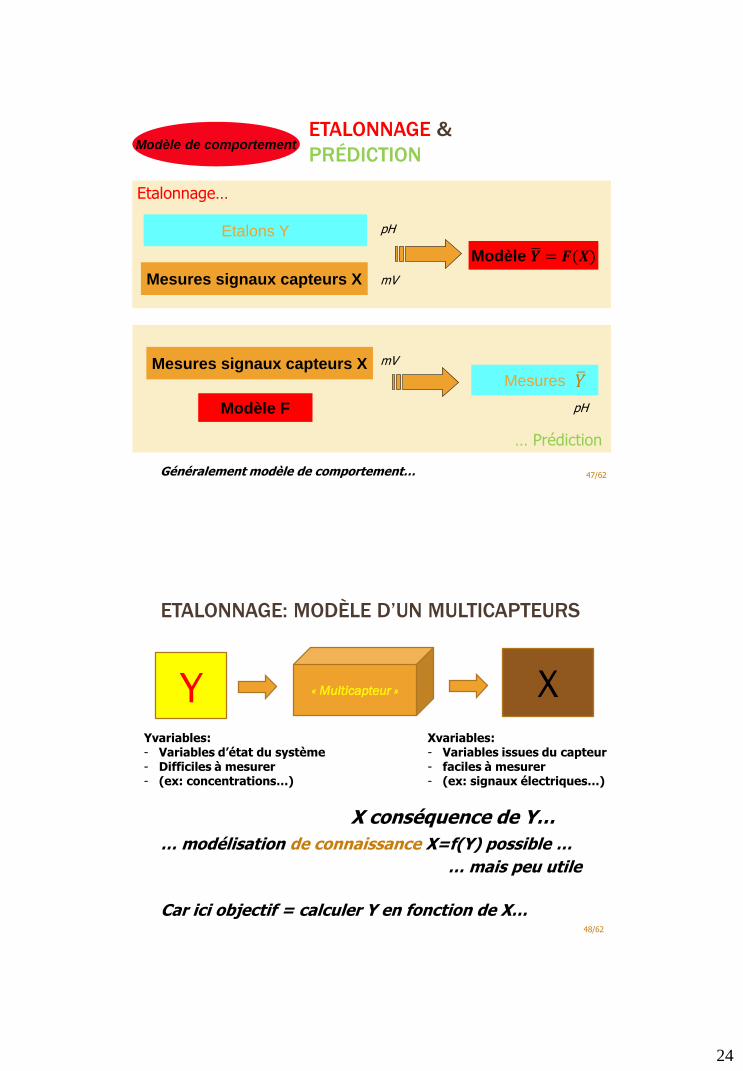
24
ETALONNAGE &
PRÉDICTION
47/62
Etalons Y
Mesures signaux capteurs X
Modèle ഥ𝒀 = 𝑭(𝑿)
Modèle F
Mesures signaux capteurs XMesures
pH
mV
mV
pH
Etalonnage…
… Prédiction
Généralement modèle de comportement…
ത𝑌
Modèle de comportement
ETALONNAGE: MODÈLE D’UN MULTICAPTEURS
48/62
XYYvariables:- Variables d’état du système- Difficiles à mesurer- (ex: concentrations…)
« Multicapteur »
Xvariables:- Variables issues du capteur- faciles à mesurer- (ex: signaux électriques…)
X conséquence de Y…
… modélisation de connaissance X=f(Y) possible …
… mais peu utile
Car ici objectif = calculer Y en fonction de X…

25
ETALONNAGE = MODÈLE DIT « INVERSE »
49/62
X=F(Y): F fonction univoque, calculable par modèle de connaissance (physico-chimie)
Mais, utilisation du multicapteur (« prédiction ») = Calcul de Y à partir de X
X Y« Modèle de
prédiction »
Donc modèle généralement comportemental (boite noire) dont l’obtention est alors obtenue à partir d’expériences et à l’aide des statistiques…
Problème dit du « modèle inverse », plus complexe (inverse à relation cause – effet, relation éventuellement multivoque)
49
MODÈLE DE COMPORTEMENT -1-
Modélisation de type « boite noire »
But = prédire une variable
Approche 100% statistique
Modélisation = étalonnage
Les expériences d'étalonnage doivent comprendre tous les cas possibles
(extrapolation risquée…)
50/62
?

26
EXEMPLE: LA PRÉVISION MÉTÉOROLOGIQUE:
OBJECTIF = PRÉDICTION
Approche "connaissance" Approche "comportement"
51/62
qq k
m
espace
sol
Échanges:
•Énergie
•Matière
•Qtité mouvement
Mise en équation…
Acquisition conditions
initiales…
Calculs colossaux…
Modélisation des données
météo et de leur évolution à
partir de statistiques
"Telle situation va statistiquement
aboutir à telle prévision"
Il faudrait des centaines
d'années de données fiables
et fines pour pouvoir prévoir
tous les cas, notamment
les extrêmes.
Mesures
météorologiques
J-5 à J
prévisions
météorologiques
J+1 à J+10
Modèle
Découpage atmosphère en briques élémentaires:
SUR ET SOUS MODÉLISATION
52/62
Sous-modélisation: modèle trop simple par rapport aux expériences et à la
réalité
Sur-modélisation: modèle correct avec les expériences mais trop complexe par
rapport à la réalité, on a modélisé des particularités des expériences (erreur
aléatoire) alors que le modèle doit être universel
Demo
Excel
Adaptation de la complexité du modèle à la réalité du phénomène…
Modèle: fonction paramétrée Y=F(X, A)
•Y=mesures "Yvariables"
•X=variables d'entrée "Xvariables"
•A= paramètres d'ajustement
F
A
X YEx: Y=a0+a1.X1+a2.X2
Le problème est qu’on ne connait pas forcement la réalité…
Principe de parcimonie!
Modèle de comportement
& connaissance
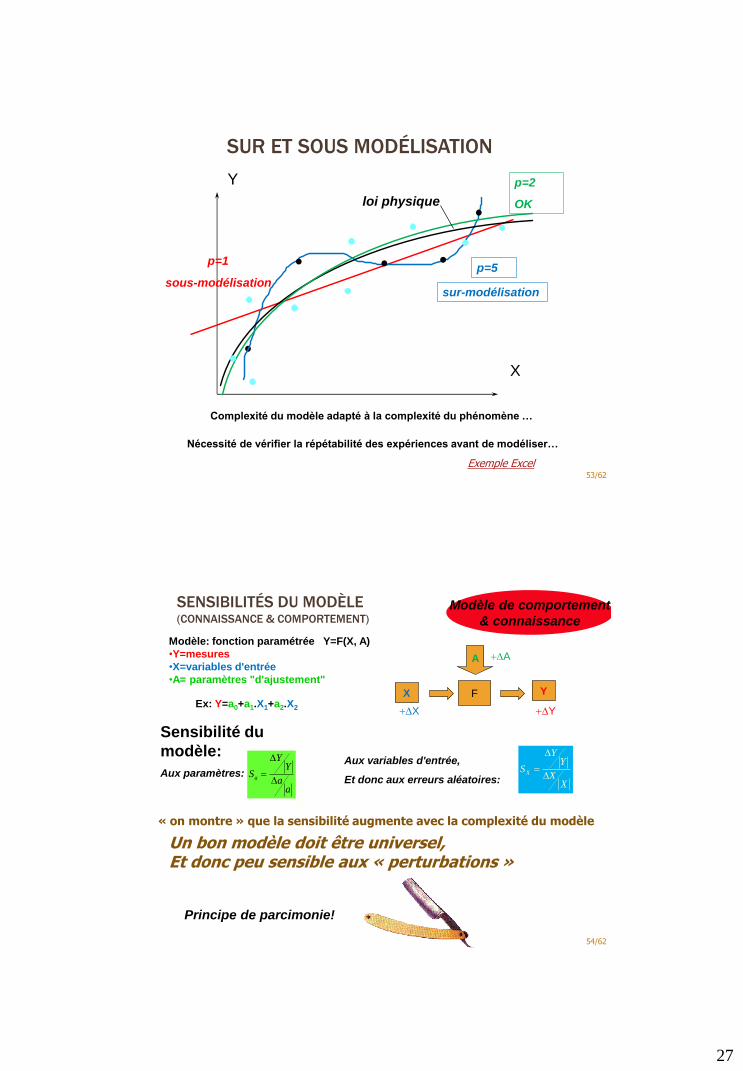
27
SUR ET SOUS MODÉLISATION
53/62
Y
X
loi physique
p=1
sous-modélisation
p=5
sur-modélisation
p=2
OK
Complexité du modèle adapté à la complexité du phénomène …
Nécessité de vérifier la répétabilité des expériences avant de modéliser…
Exemple Excel
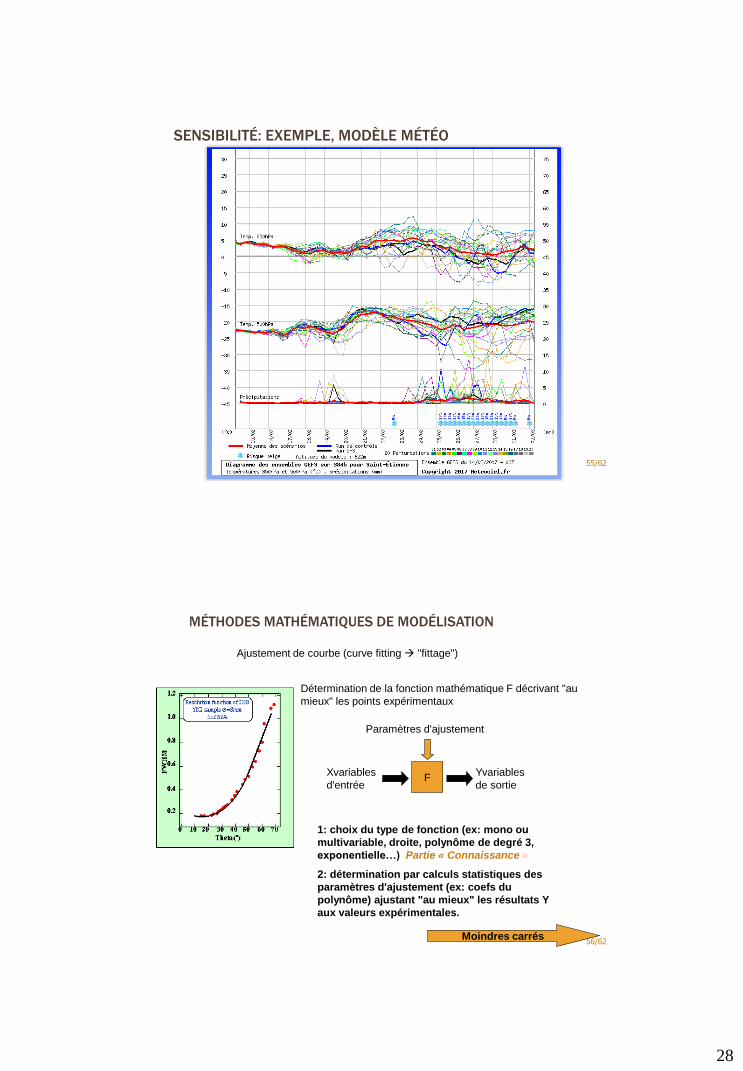
SENSIBILITÉS DU MODÈLE(CONNAISSANCE & COMPORTEMENT)
AA
YY
S p
54/62
Modèle: fonction paramétrée Y=F(X, A)
•Y=mesures
•X=variables d'entrée
•A= paramètres "d'ajustement"
F
A
X Y
Sensibilité du
modèle:
Aux paramètres:
X
A
Y
XX
YY
SX
Ex: Y=a0+a1.X1+a2.X2
Aux variables d'entrée,
Et donc aux erreurs aléatoires:
Un bon modèle doit être universel,Et donc peu sensible aux « perturbations »
« on montre » que la sensibilité augmente avec la complexité du modèle
aa
YY
Sa
Principe de parcimonie!
Modèle de comportement
& connaissance
28
SENSIBILITÉ: EXEMPLE, MODÈLE MÉTÉO
55/62
MÉTHODES MATHÉMATIQUES DE MODÉLISATION
56/62
Ajustement de courbe (curve fitting "fittage")
Détermination de la fonction mathématique F décrivant "au
mieux" les points expérimentaux
FXvariables
d'entrée
Yvariables
de sortie
Paramètres d'ajustement
1: choix du type de fonction (ex: mono ou
multivariable, droite, polynôme de degré 3,
exponentielle…) Partie « Connaissance »
2: détermination par calculs statistiques des
paramètres d'ajustement (ex: coefs du
polynôme) ajustant "au mieux" les résultats Y
aux valeurs expérimentales.
Moindres carrés

29
LES MOINDRES CARRÉS (1)
57/62
Modélisation de données expérimentales à l’aide d’une fonction mathématique:
Y
X
Détermination d’un fonction représentant « au mieux » les points expérimentaux
•Choix du type de fonction (ex: polynôme de degré 3)
•Détermination des paramètres (ex: coefficients du polynôme)
« au mieux »:•Tenir compte du principe de parcimonie•Tenir compte des connaissances•Choix d’une distance
LES MOINDRES CARRÉS (2)
58/62
),,..,(),( 1 ipi xaafyXAFYE
On veut modéliser: Y = f(X), en fait, généralement la courbe ne
passe pas par tous les points, on a donc:
Y = f(X) + E où E = « résidu » ou erreur à « minimiser »
),,..,(2
1 i
ipj xaafy
On utilise généralement la distance Euclidienne, on minimisera donc son carré:
« minimale »
Y=(y1…yn)
X=(x1…xn)A=(a1…ap)
N points
expérimentaux
P paramètres
de la fonction f
Trouver les a1..ap tels que:
TP5
30
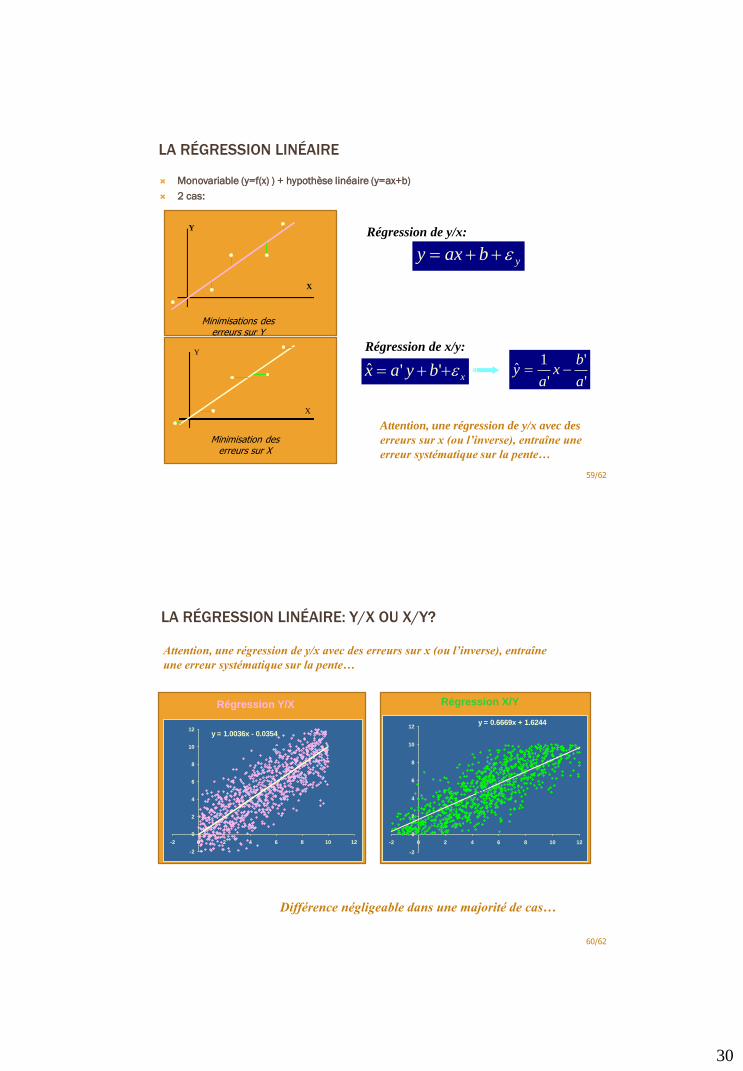
LA RÉGRESSION LINÉAIRE
Monovariable (y=f(x) ) + hypothèse linéaire (y=ax+b)
2 cas:
59/62
X
Minimisations des erreurs sur Y
Régression de y/x:
ybaxy e
Régression de x/y:
xbyax e ''ˆ'
'
'
1ˆ
a
bx
ay
Attention, une régression de y/x avec des
erreurs sur x (ou l’inverse), entraîne une
erreur systématique sur la pente…
Y
Minimisation des erreurs sur X
X
Y
LA RÉGRESSION LINÉAIRE: Y/X OU X/Y?
60/62
Attention, une régression de y/x avec des erreurs sur x (ou l’inverse), entraîne
une erreur systématique sur la pente…
Différence négligeable dans une majorité de cas…
y = 1.0036x - 0.0354
-2
0
2
4
6
8
10
12
-2 0 2 4 6 8 10 12
y = 0.6669x + 1.6244
-2
0
2
4
6
8
10
12
-2 0 2 4 6 8 10 12
Régression Y/X Régression X/Y
31
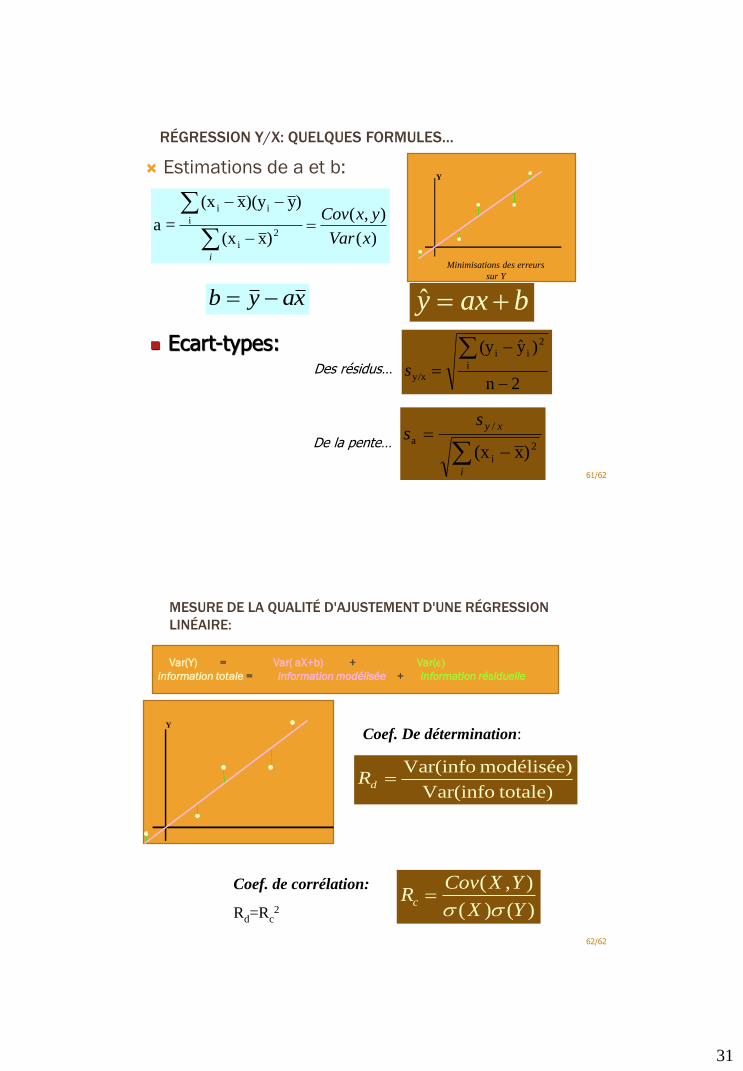
RÉGRESSION Y/X: QUELQUES FORMULES…
Estimations de a et b:
61/62
)(
),(
)x(x
)y)(yx(x
=a2
i
i
ii
xVar
yxCov
i
xayb
Minimisations des erreurs
sur Y
baxy ˆ
Y
Ecart-types:
2n
)y(yi
2
ii
y/x
s
i
xyss
2
i
/
a
)x(x
Des résidus…
De la pente…
MESURE DE LA QUALITÉ D'AJUSTEMENT D'UNE RÉGRESSION
LINÉAIRE:
Var(Y) = Var( aX+b) + Var(e
information totale = information modélisée + information résiduelle
62/62
Coef. De détermination:
totale)Var(info
modélisée) Var(infodR
)()(
),(
YX
YXCovRc
Coef. de corrélation:
Rd=Rc2
Y
32
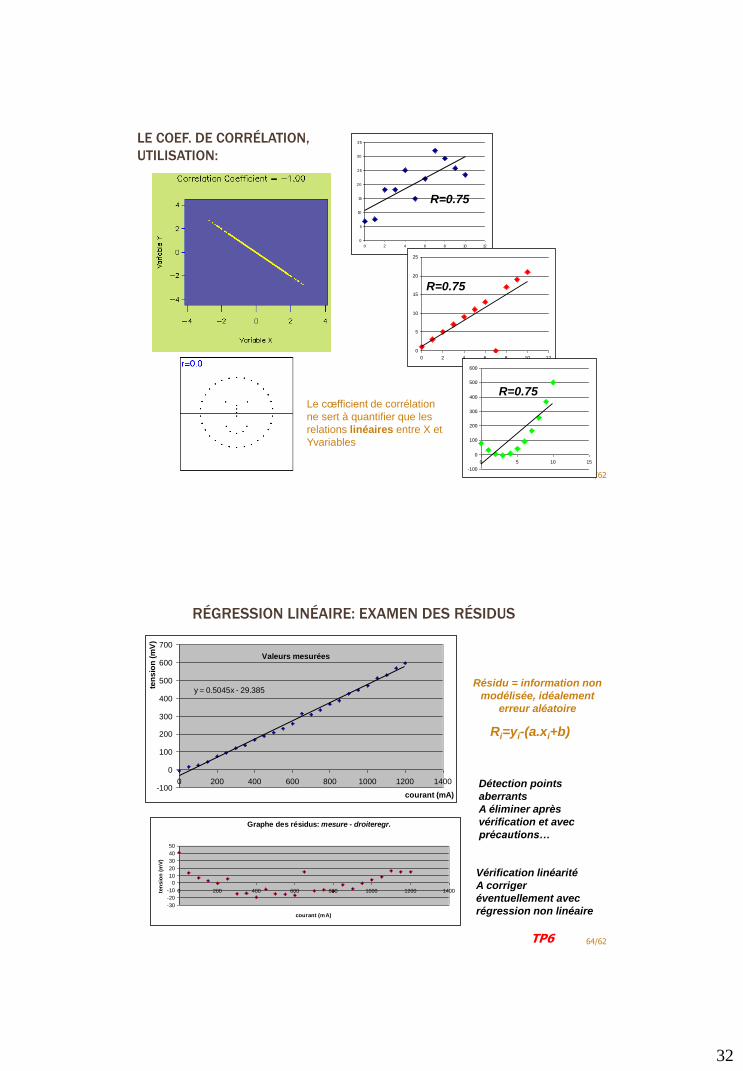
LE COEF. DE CORRÉLATION,
UTILISATION:
63/62
0
5
10
15
20
25
30
35
0 2 4 6 8 10 12
R=0.75
0
5
10
15
20
25
0 2 4 6 8 10 12
R=0.75
-100
0
100
200
300
400
500
600
0 5 10 15
R=0.75Le cœfficient de corrélation
ne sert à quantifier que les
relations linéaires entre X et
Yvariables
RÉGRESSION LINÉAIRE: EXAMEN DES RÉSIDUS
Graphe des résidus: mesure - droiteregr.
-30
-20
-10
0
10
20
30
40
50
0 200 400 600 800 1000 1200 1400
courant (mA)
ten
sio
n (
mV
)
64/62
Vérification linéarité
A corriger
éventuellement avec
régression non linéaire
Détection points
aberrants
A éliminer après
vérification et avec
précautions…
Valeurs mesurées
y = 0.5045x - 29.385
-100
0
100
200
300
400
500
600
700
0 200 400 600 800 1000 1200 1400
courant (mA)
ten
sio
n (
mV
)
Ri=yi-(a.xi+b)
Résidu = information non
modélisée, idéalement
erreur aléatoire
TP6

33
RÉGRESSION MULTIVARIABLES LINÉAIRE (MLR):
n Xvariables, p expériences
pnnpp
nn
xaxay
xaxay
,,11
1,1,111
...
...
65/62
p<n: pas de solution…
A=Y.XT.(X.XT)-1
p>n: X non carrée…Mais peut-être quand même une solution au sens des moindres carrés!
XT.(X.XT)-1 est appelée "pseudo-inverse de X
Y= A.X+eyÉcriture matricielle pour les p expériences: À minimiser
•Utiliser fonction "DROITEREG" d'Excel
p=n: peut-être une solution: A= Y.X-1 Résidu ey nul…
(Ex: 2 points pour déterminer 1 droite…)
Demo
Excel TP7
BIBLIO & LIENS UTILES
66/62
Bouquins:
"Statistics for analytical Chemistry" 3 rd ed. J.C. Miller and J.N. Miller John Wiley & Sons, 1998.
"Multivariate Statistical Methods, A Primer" B.F.J. Monley, Chapman & Hall 1986.
"Modélisation et estimation des erreurs de mesure", M Neuilly, CETAMA, Lavoisier, Paris 1993.
Sites WWW: (la plupart en anglais…)
http://www.emse.fr/%7Epbreuil/capmes/index.html: Ce document + exercices sous Excel
http://physics.nist.gov/cuu/Uncertainty/index.html: excellent site simple et succinct mais de référence
sur la calcul des incertitudes, ce document s'en est beaucoup inspiré. Un cours plus complet de
statistiques est disponible à : http://www.itl.nist.gov/div898/handbook/
http://www.agro-montpellier.fr/cnam-lr/statnet/cours.htm: Cours en Français sur les techniques de la
statistique
https://www.predictiveanalyticstoday.com/top-free-statistical-software/: Freewares sur les stats
http://www.deltamu.com/fr/Publications : Deltamu PME de métrologie offrant de nombreuses
ressources
http://www.asqualab.com/documents/qualite/metrologie/19-unites_pifometriques.pdf: Norme pifométrique…

34
LA NORME AFNOR LA PLUS UTILISÉE:
67/62http://www.qualiteonline.com/norme_afnor_pifometrique.pdf


















