
MLAD Modèles de langage et Dialogue -...
70
Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007 Traitements linguistiques et reconnaissance automatique de la parole : utilisation de modèles numériques et d'apprentissage automatique sur corpus dans le cadre du dialogue oral homme-machine et de la fouille de données audio Frédéric Béchet LIA, Université d’Avignon
Transcript of MLAD Modèles de langage et Dialogue -...

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Traitements linguistiques et reconnaissance automatique de la parole :
utilisation de modèles numériques et d'apprentissage automatique sur corpus
dans le cadre du dialogue oral homme-machine et de la fouille de données audio
Frédéric BéchetLIA, Université d’Avignon
Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
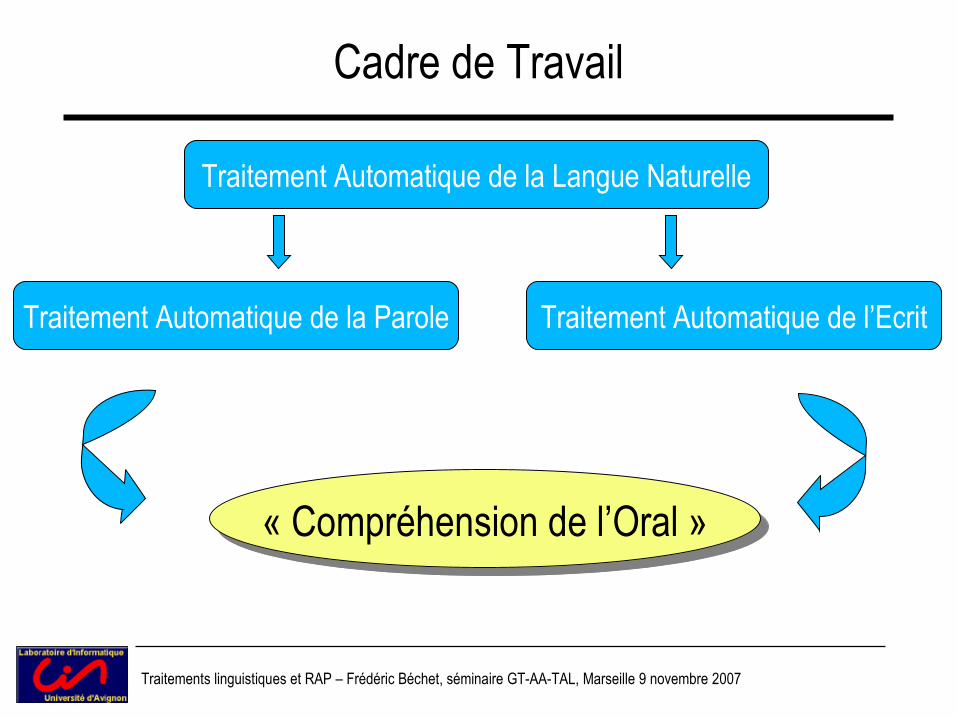
Cadre de Travail
Traitement Automatique de la Langue Naturelle
Traitement Automatique de la Parole Traitement Automatique de l’Ecrit
« Compréhension de l’Oral »
Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
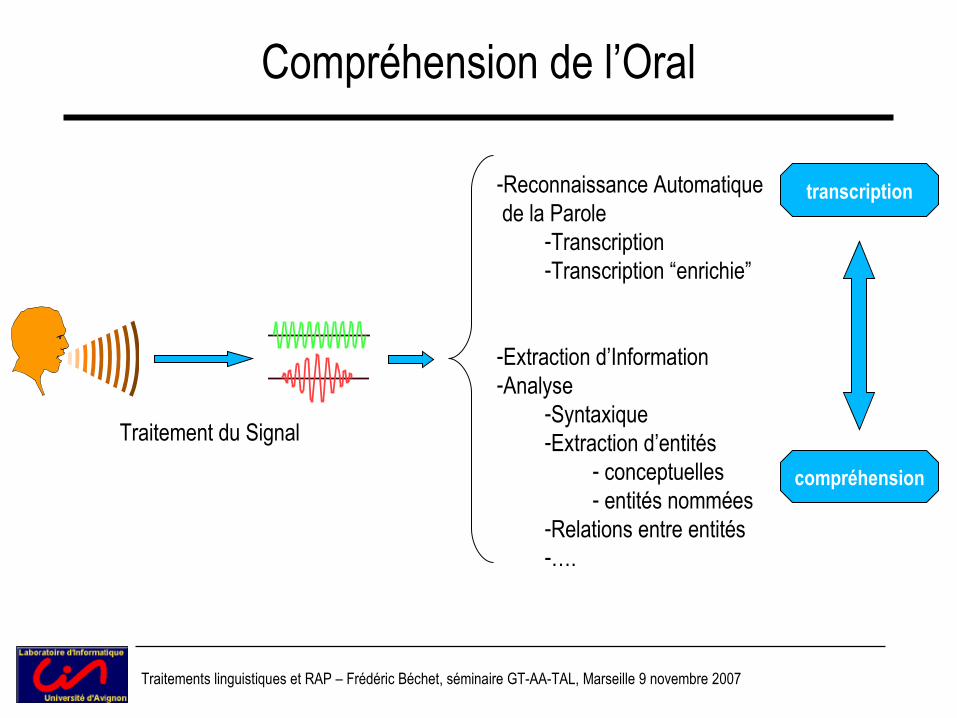
Compréhension de l’Oral
compréhension
Traitement du Signal
-Reconnaissance Automatique de la Parole
-Transcription-Transcription “enrichie”
-Extraction d’Information-Analyse
-Syntaxique-Extraction d’entités
- conceptuelles- entités nommées
-Relations entre entités-….
transcription

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Reconnaissance Automatique de la Parole (RAP)
à quoi ça sert ?

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Classes d'application
• Deux grands contextes d'application– langage = outils de communication
• applications dans les domaines des interfaces • contrainte importante d'application = traitement en temps réel
– langage = formalisme de représentation des connaissances• applications dans le domaine de la recherche d'information• Performances encore faibles => compenser par la capacité à traiter des
volumes importants de données (pour compenser la faible performance)

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
• Application aux interfaces homme-machine– Langage de commande et de contrôle– Saisie vocale d’informations (via téléphone)– Conversation
• Kiosks d’information (accès à des bases de données)• Processus de transaction (ex: commerce)• Agents Intelligents
Langage = Outils de communication

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
• Accès à des informations– Indexation et recherche de documents audio (ex : INA)– Sous-titrage automatique
• Dictée vocale– Documents (lettres, rapports, …)– Messagerie vocale
Langage = Formalisme de représentation de connaissances

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Reconnaissance Automatique de la Parole (RAP)
Pourquoi c’est difficile ?

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Difficultés principales de la RAP
• Du signal jusqu’aux paramètres acoustiques– Parole / non-Parole– Bruit (rapport Signal sur Bruit)
• Des paramètres acoustiques jusqu’aux unités de parole– Phénomènes de co-articulation– Débit de parole– Déformations

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
• Des unités de parole vers les mots– Variations dialectales– Locuteurs non-natifs– Contraintes phonologiques– Mots hors-vocabulaire
• Des mots vers les phrases– Disfluence– Niveau de langage
Difficultés principales de la RAP
Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
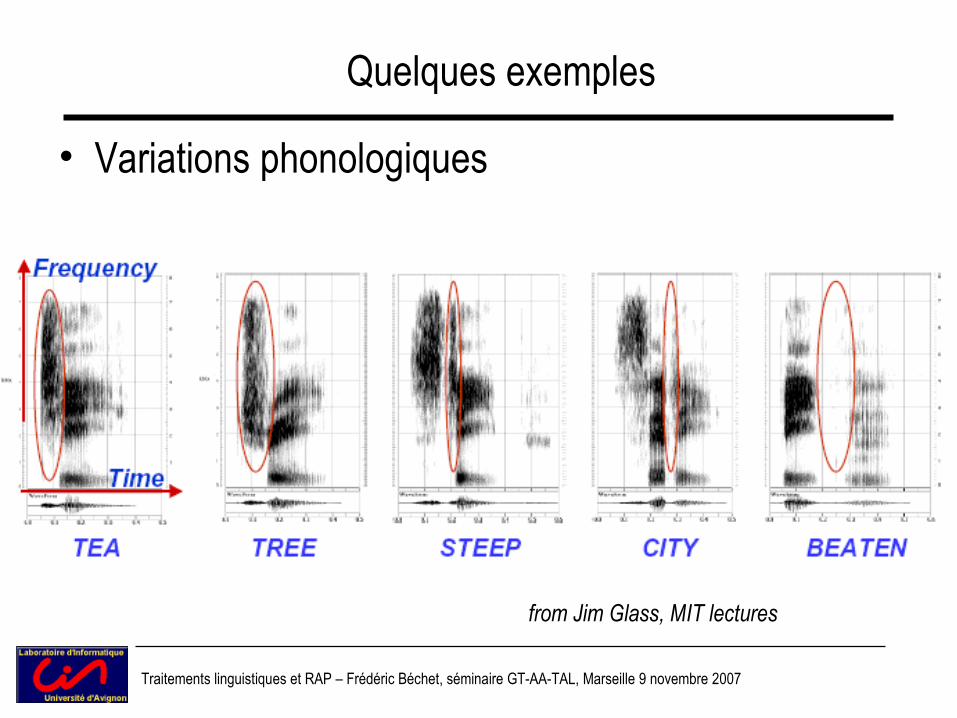
Quelques exemples
• Variations phonologiques
from Jim Glass, MIT lectures

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Quelques exemples• Des phonèmes vers les mots
– 1 lexique de 64K mots– 1 chaîne de phonèmes : « Ceci est un test » = s φ s i e t ũ t ε s t– Plus de 100K alignements possibles !!
se six est un test ceci est un testentceci est un testsceci est un testceux ci est un testceux ci est un testentceux ci est un tests
ceux ci uns testentceux ci ait uns testsceux ci uns testsceux ci ait Un testceux ci ait Un testentceci ait uns testentceci ait uns tests
ceux ci ait un testentceux ci ait un testsceci est un t STceux ci est un th estse sit est un testsceci est un tes STceux ci ait uns test
Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
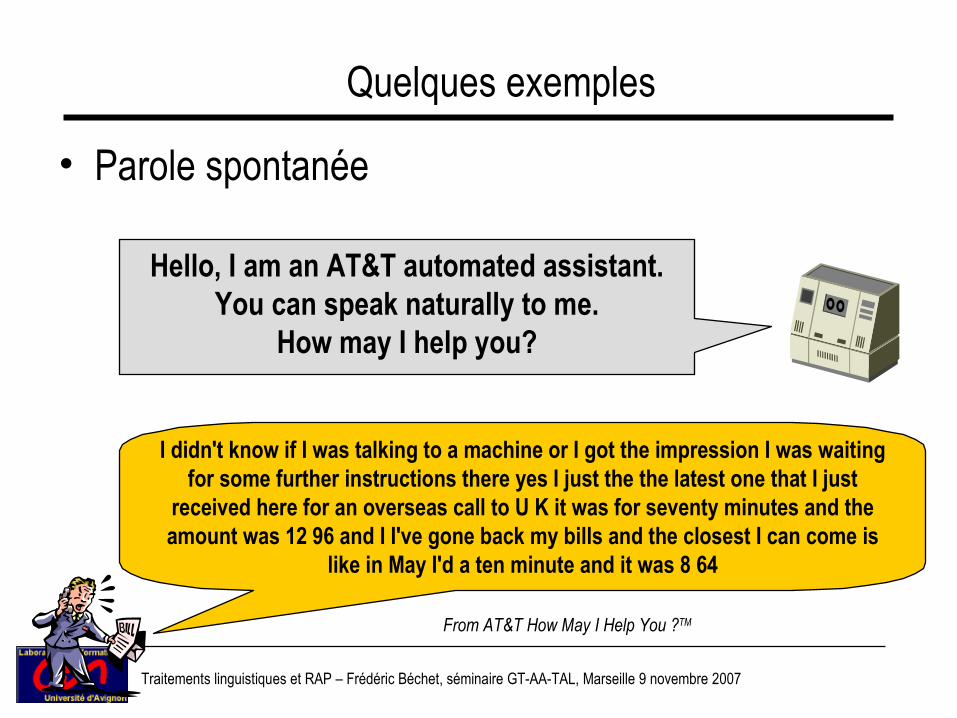
Hello, I am an AT&T automated assistant. You can speak naturally to me.
How may I help you?
I didn't know if I was talking to a machine or I got the impression I was waiting for some further instructions there yes I just the the latest one that I just
received here for an overseas call to U K it was for seventy minutes and the amount was 12 96 and I I've gone back my bills and the closest I can come is
like in May I'd a ten minute and it was 8 64
Quelques exemples
• Parole spontanée
From AT&T How May I Help You ?TM

Quelques exemples
euh bonjour donc c' est XX à l' appareil je sais pas si vous savez très bien qui je suis euhdonc par rapport au à la niveau de la satisfaction de ma satisfaction personnelle par rapportà votre service euh je dirai que dans l' ensemble je suis euh plutôt satisfait euh vous avez untrès bon service clientèle qui sait écouter qui euh non qui j' ai pas grand chose à dire c' estc' est très très bien sinon ben juste par rapport au à ce que vous avez mis en place euh toutde suite justement c' est une très bonne idée justement d' une façon à ce qu' y ait un taux deréponse euh assez important maintenant c' est vrai qu' on est obligé de rappeler plusieurs foiset encore quand on prend le temps de rappeler pour euh pour euh pour euh pour répondre parceque quand on nous dit euh vous allez nous donner vous allez donner euh votre euh vos idéeseuh vos vos suggestions et ben on n' a rien en tête donc c' est pour ça que j' ai été obligé deraccrocher et de réfléchir à ce que je vais vous dire on ça c' est pas je pense euh que ça c' estle point collectif ou c' est le point négatif et sinon dans l' ensemble je suis très satisfait sinony a une chose que j' ai annoter euh j' ai deux comptes chez vous euh je trouve ça un peuembêtant de pouvoir euh de pas pouvoir accéder euh aux deux par la même personne quandj' appelle mon service clientèle donc ça je trouve ça un peu dommage que je sois obligé dedépenser en plus parce que faut que je c' est pas le même type euh c' est pas la même personnequi s' occupe de mon dossier donc ce qui aurait été bien c' est quand même regrouper les deuxdossiers sous euh euh sous un seul quoi de façon à ce que quand on appelle on puisse accéderaux deux dossiers séparément bien sûr mais les deux dossiers donc voilà euh sinon ben je vousremercie en tous cas pour euh pour votre gentillesse et votre amabilité vos conseillers clientèlesont très très gentils et très à l' écoute et donc je vous en remercie au revoir bonne journée bonne soirée
• Transcrire ?

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
mais …. principale difficulté :
Transcrire = ComprendreTranscrire = Comprendreet
nous traitons de la Langue NaturelleLangue Naturelle

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Reconnaissance Automatique de la Parole (RAP)
Etat de l’art des performances ?
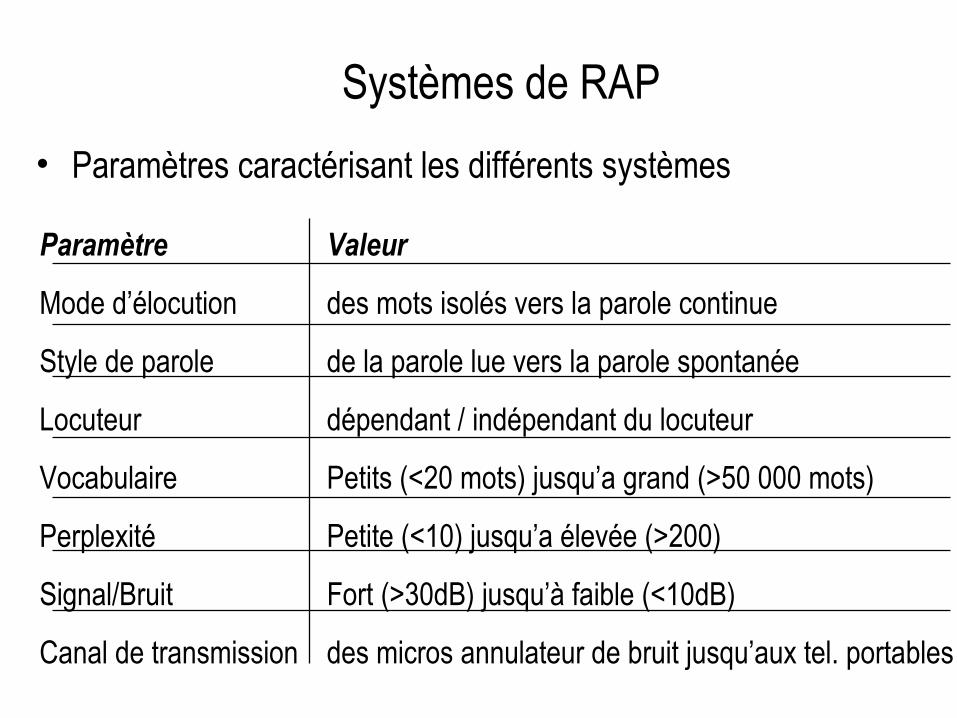
Systèmes de RAP• Paramètres caractérisant les différents systèmes
Paramètre Valeur
Mode d’élocution des mots isolés vers la parole continue
Style de parole de la parole lue vers la parole spontanée
Locuteur dépendant / indépendant du locuteur
Vocabulaire Petits (<20 mots) jusqu’a grand (>50 000 mots)
Perplexité Petite (<10) jusqu’a élevée (>200)
Signal/Bruit Fort (>30dB) jusqu’à faible (<10dB)
Canal de transmission des micros annulateur de bruit jusqu’aux tel. portables
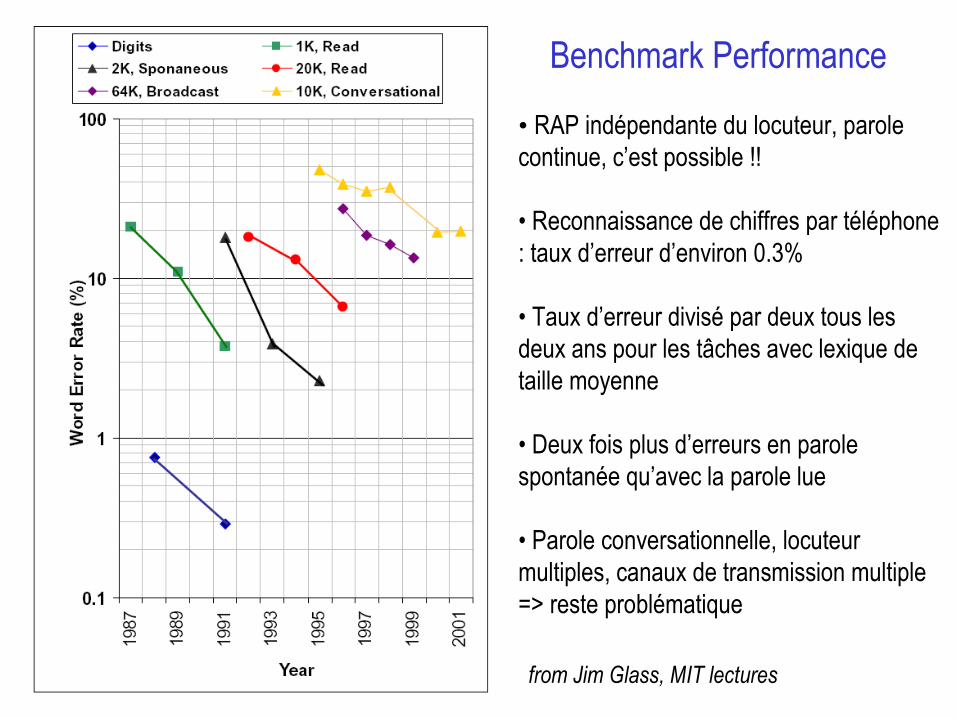
Benchmark Performance
from Jim Glass, MIT lectures
• RAP indépendante du locuteur, parole continue, c’est possible !!
• Reconnaissance de chiffres par téléphone : taux d’erreur d’environ 0.3%
• Taux d’erreur divisé par deux tous les deux ans pour les tâches avec lexique de taille moyenne
• Deux fois plus d’erreurs en parole spontanée qu’avec la parole lue
• Parole conversationnelle, locuteur multiples, canaux de transmission multiple => reste problématique

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Du coté des applications
• Application aux interfaces homme-machine– Langage de commande et de contrôle OK OK – Saisie vocale d’informations (via téléphone) OK OK – Conversation
• Kiosks d’information OK with restrictionOK with restriction• Processus de transaction OK OK / / NONO• Agents Intelligents OK OK / / NONO

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Du coté des applications
• Accès à des informations– Indexation et recherche de doc. Audio OKOK– Sous-titrage automatique NONO
• Dictée vocale– Documents (lettres, rapports, …) OK OK / / NONO– Messagerie vocale OK OK / / NONO

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Reconnaissance Automatique de la Parole (RAP)
Comment ça marche ?
Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
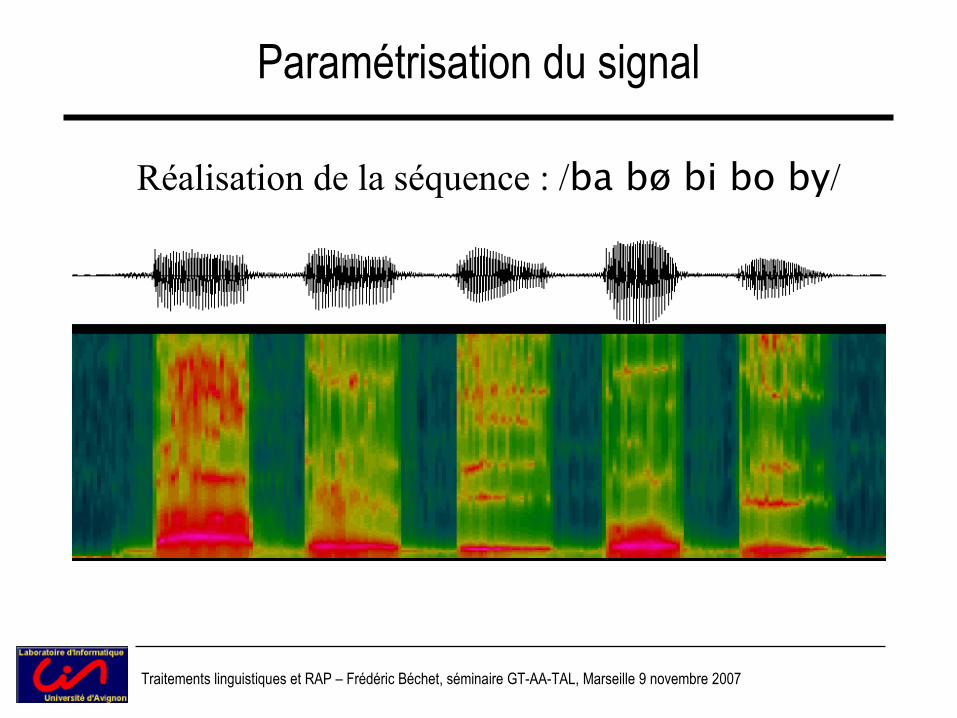
Paramétrisation du signal
Réalisation de la séquence : /ba bø bi bo by/

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Principes de la RAP• (petit) Historique
– Approche à base de connaissance• systèmes experts, reconnaissance de formes• « je sais ce qu’est un /a/ »
– Alignement dynamique• Dynamic Time Warping (DTW)• « je peux enregistrer un /a/ et le comparer à d’autres échantillons de /a/ »
– Modélisation probabiliste• Hidden Markov Model• « je sais pas ce qu’est un /a/ mais je peux modéliser son comportement de
manière probabiliste à partir d’un corpus d’exemples de /a/»– Modèles discriminants
• Classifieurs (Réseaux de neurones, Support Vector Machine, etc)• « je peux modéliser ce qui différencie un /a/ d’un /e/ »

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Principes de la RAP• Approche « gagnante »
– Modélisation probabiliste– Approche à base d’apprentissage sur corpus– Paradigme de la communication à travers un canal bruité (Shannon)
• Validation des modèles– pas liée à leur capacité explicative du fonctionnement de la langue– évaluation de l'amélioration des performances par rapport à une classe
d’application• Quelques citations caractéristiques :
– “There’s no data like more data” (Bob Mercer, 1985)– “More data is more important than better algorithms” (Eric Brill)– “Whenever I fire a linguist our system performance improves” (Fred Jelinek, 1988)
Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
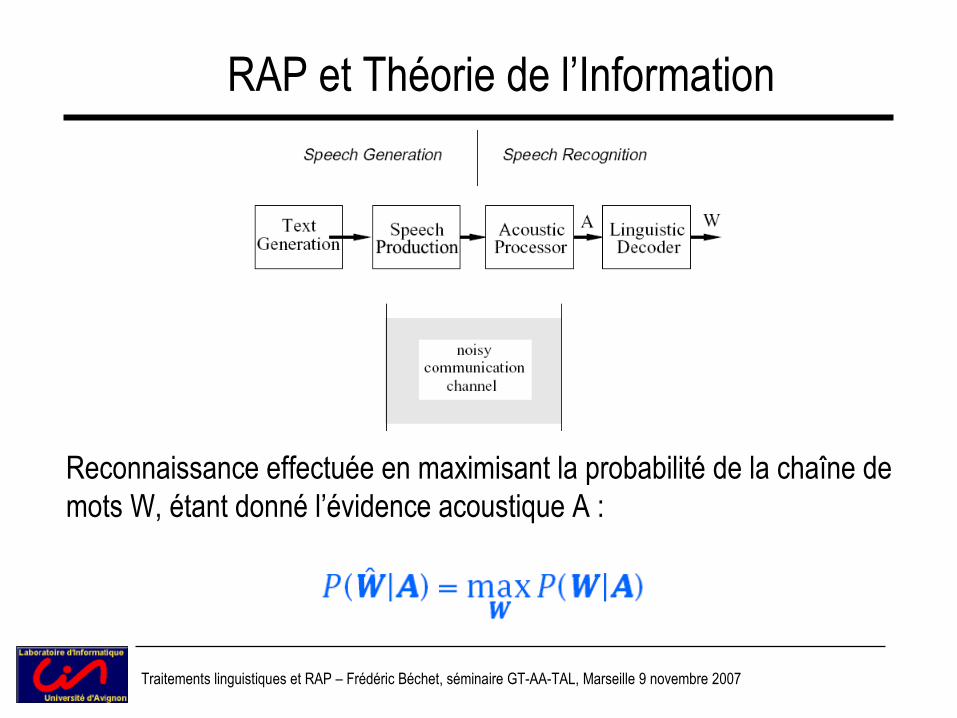
RAP et Théorie de l’Information
Reconnaissance effectuée en maximisant la probabilité de la chaîne de mots W, étant donné l’évidence acoustique A :

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
– Règle de Bayes :
– P(A|W) est la probabilité acoustique a-priori étant donné les modèles acoustiques
– P(W) est la probabilité de la chaîne de mots W donné par le Modèle de Langage
RAP et Théorie de l’Information

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Modèles Probabilistes• Modèles de Markov
– Approche à base de corpus– Représentation des connaissances : homogène et simple– Acquisition des connaissance: automatique– Très peu de connaissances a priori requises– Mais beaucoup de données nécessaires pour apprendre
les modèles

Modèles de Markov Cachés Discrets
Description
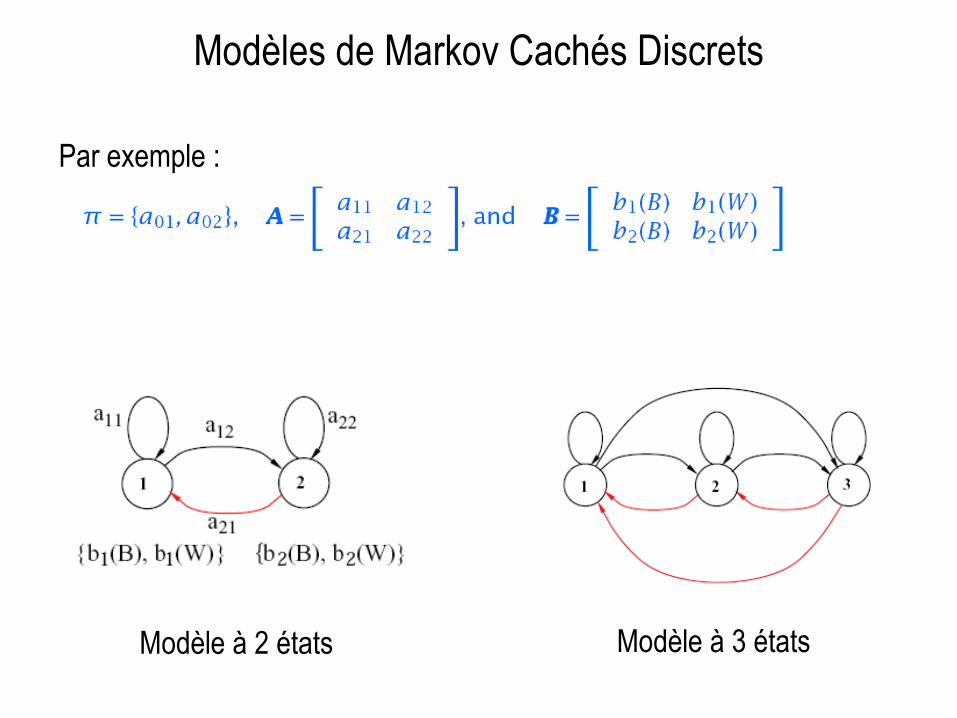
Modèles de Markov Cachés Discrets
Par exemple :
Modèle à 2 états Modèle à 3 états

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Modèles acoustiques• Modèles de Markov cachés
• Observables– Vecteurs de coefficients cepstraux– 1 vecteur par trame de signal
• États– Plusieurs états par modèle phonétique– En général, 3 états par phonèmes
• Probabilités– Continuous density HMM– Mixture de gaussiennes
• Algorithmes• Forward Backward, Viterbi, Baum-Welch, …

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Modèles de Langage
– Calcul de P(W) avec W=w1w2w3w4…wn
• Grammaire– P(W) équiprobable pour toute chaîne acceptée
• Grammaire stochastique– P(W) dépend des probabilités d’application des règles
• Modèles n-grammes– Chaînes de Markov– Accepte toute chaîne de mots– Donne une probabilité à chacune

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Modèles n-grammes– Probabilité d’un mot étant donné un historique
– Définition de classes d’historique• Ex: 2-gram models
– Probabilités estimées sur les comptes des mots sur un corpus
P(Hello World)=P(Hello).P(World|Hello)

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Différents types de Modèles n-grammes– Les modèles diffèrent selon
• leurs portées (en général n=3)• leurs méthodes de repli (lorsque C(w)=0)
– Interpolation avec des modèles d’ordre inférieur– Calcul d’un facteur de repli
– Beaucoup de variantes• Intégration de classes de mots (automatiques ou syntaxiques)• Modèles à portée variables (modèles syntagmes)• Modèles hybride : n-grammes + grammaires régulières• Modèles n-grammes avec des arbres syntaxiques (Structured Language Model)
– Mais …• Amélioration marginale par rapport à un modèle 3-gramme bien appris !!

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Modèles n-grammes : pour
– Pourquoi les modèles n-grammes marchent-ils si bien ?• Probabilités basées sur des corpus relatifs à l’application visée• Paramètres appris automatiquement à partir de ces corpus• Incorpore directement des contraintes locales
– Syntaxiques, sémantiques et pragmatiques
• Beaucoup de langage ont une tendance forte à garder un ordre local régulier sur les mots
• Facile à intégrer dans un processus de décodage (algorithme Viterbi ou A*)

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Modèles n-grammes : contre
– Pourquoi les modèles n-grammes ne suffisent ils pas ?• Impossible de représenter des contraintes de longue distance
– Les cours de la bourse s’effondre
• Modèles peu dynamiques– Difficile d’ajouter des mots nouveaux– Ne s’adapte pas aux changements dynamiques– Malgré de nombreuses méthodes : mauvaise gestion des replis
• Ne contient aucune information relative au sens– D’un flux audio à un flux de mots– Pas de ponctuation, pas de « phrases », des successions de n-grammes
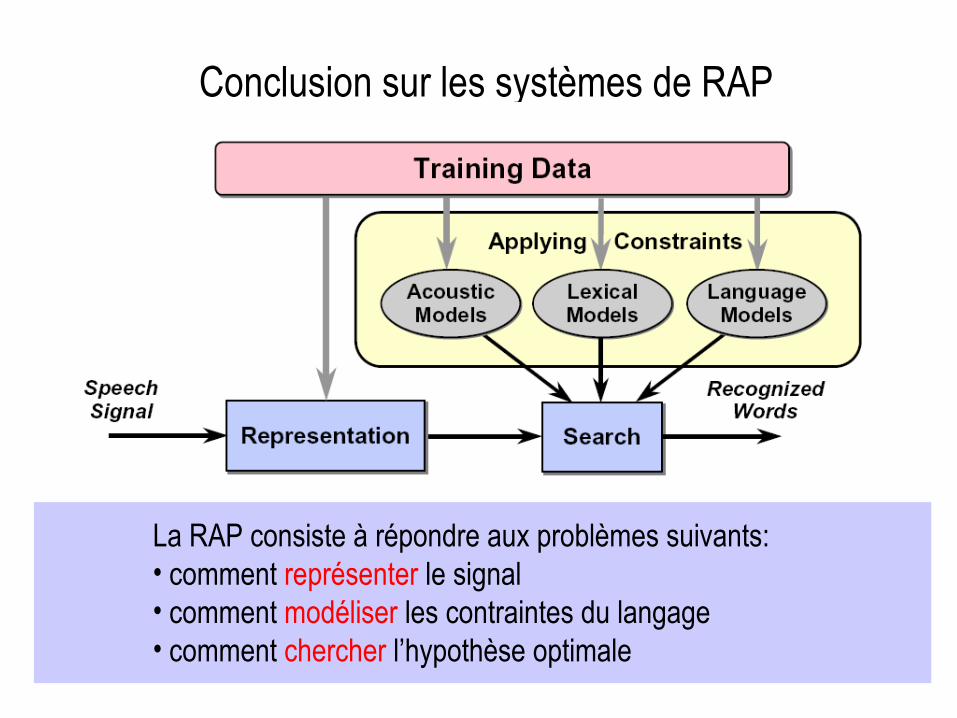
Conclusion sur les systèmes de RAP
La RAP consiste à répondre aux problèmes suivants:• comment représenter le signal• comment modéliser les contraintes du langage• comment chercher l’hypothèse optimale

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
DEMO 1• Décodeur SPEERAL (LIA)
• Apprentissage : corpus : ESTER (Technolangue)
• Emissions radiophoniques
• Multi locuteur / grands vocabulaire (64M mots)

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
DEMO 2• Projet Européen LUNA
• Application France Télécom 3000
• Renseignement et achat de services téléphoniques
• Mis en service depuis 2005
• Demo de projection de graphes de mots vers des graphes de concepts puis d’interprétations (LunaViz)
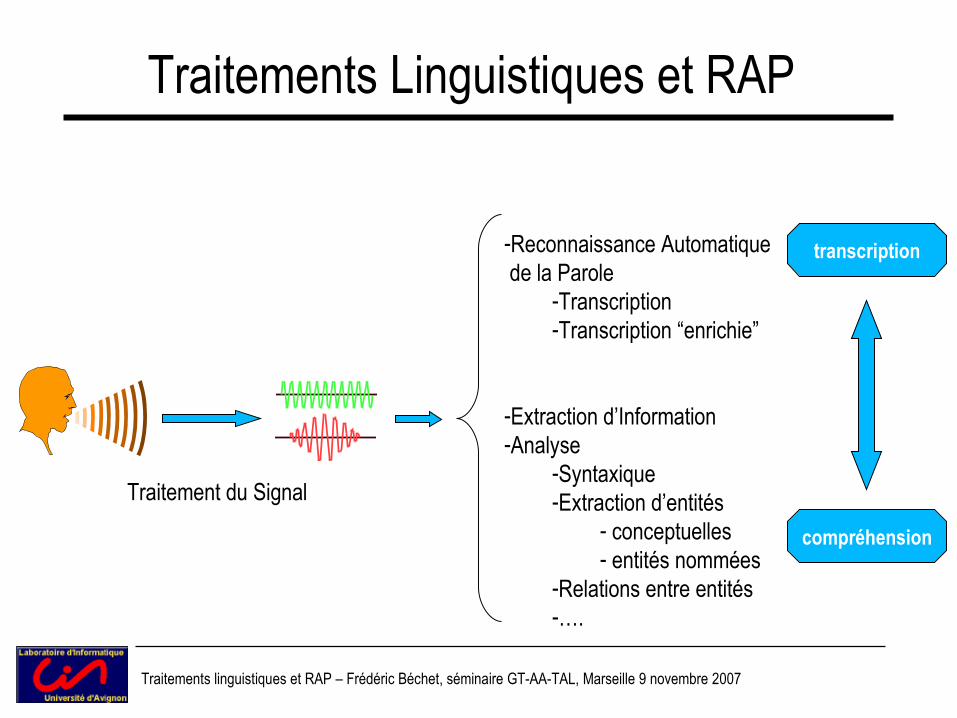
Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Traitements Linguistiques et RAP
compréhension
Traitement du Signal
-Reconnaissance Automatique de la Parole
-Transcription-Transcription “enrichie”
-Extraction d’Information-Analyse
-Syntaxique-Extraction d’entités
- conceptuelles- entités nommées
-Relations entre entités-….
transcription
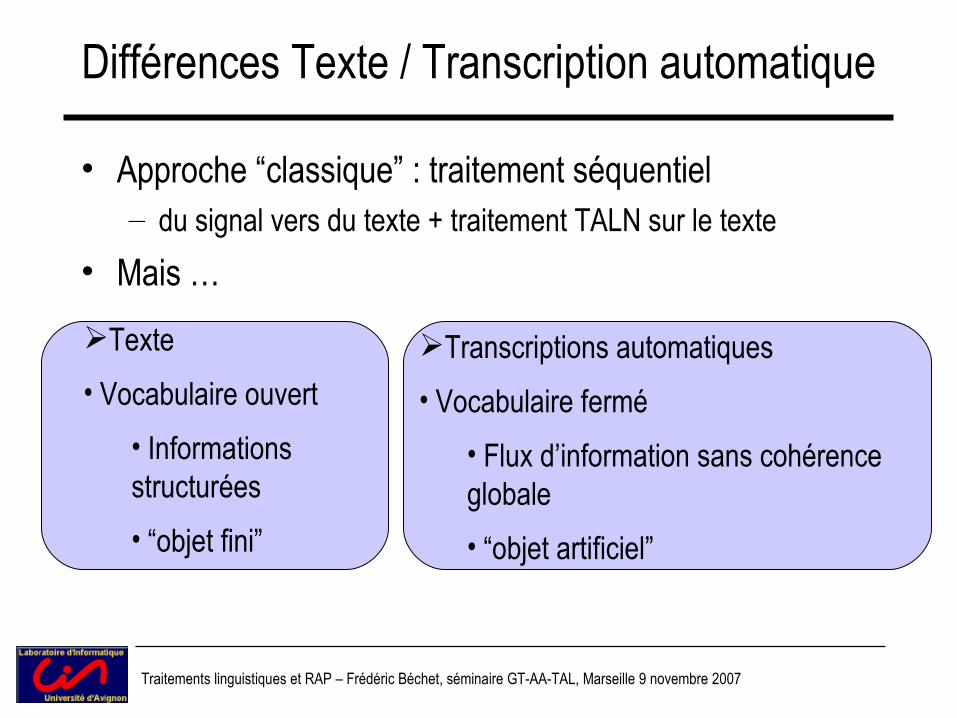
Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Différences Texte / Transcription automatique
• Approche “classique” : traitement séquentiel– du signal vers du texte + traitement TALN sur le texte
• Mais …Texte• Vocabulaire ouvert
• Informations structurées• “objet fini”
Transcriptions automatiques• Vocabulaire fermé
• Flux d’information sans cohérence globale• “objet artificiel”

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Spécificités transcription automatique
• Sorties imparfaites– Nécessité d’intégrer cette imprécision
• Sorties multiples : listes de n-meilleurs solutions, treillis de solutions
• Pas de structure• Vocabulaire fermé• Nécessité de disposer de corpus
d’apprentissage liés à la tâche
Utilisation deconnaissancessur l’applicationvisée

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Traitements Linguistiques et cadres applicatifs
• Deux cadres applicatifs
– Dialogue oral Homme-Machine
– Fouille de données audio
• transcription en mots• extraction d’entités• classification• analyse de surface• analyse profonde• résolution référence• etc.

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Traitements Linguistiques
• Analyse de surface “shallow parsing”– syntaxique / sémantique– Obtention d’une structure “à plat”– Dialogue
• compréhension = extraction de concepts• compréhension = classification de messages
– Fouille de données• Indexation
– Mots clés / thèmes / entités• Recherche de relations entre entités

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
From Walter Daelemans, CNTS, University of Antwerp, BelgiumILK, Tilburg University, Netherlands
Exemple d’analyse de surface
« shallow parsing »
Fouille de données / Dialogue oral



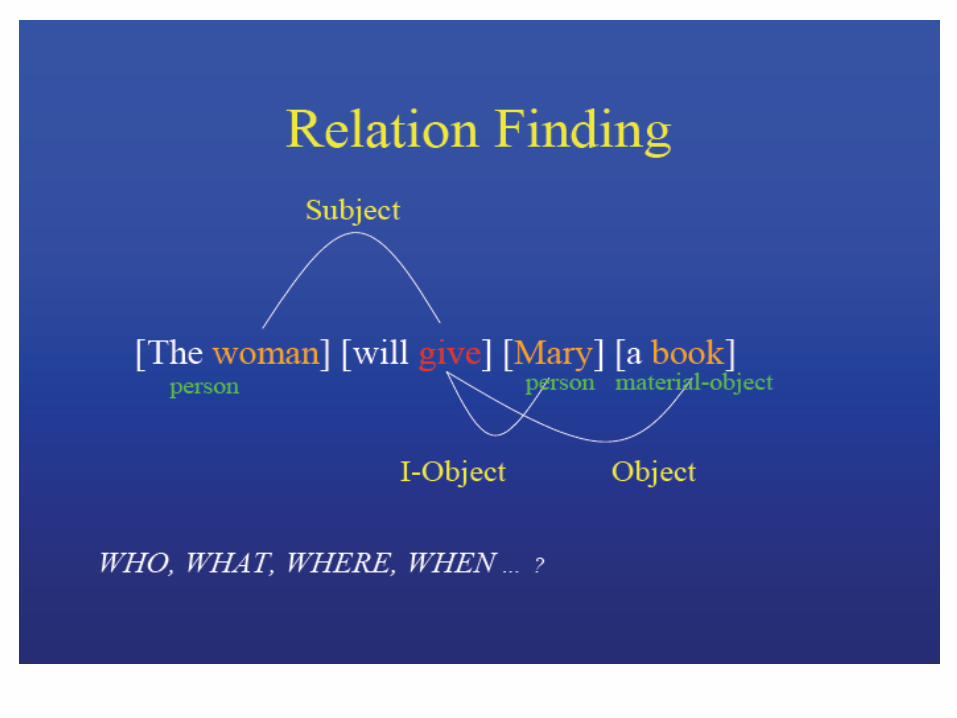

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Exemple d’analyse profonde pour le dialogue
Fouille de données / Dialogue oral
Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
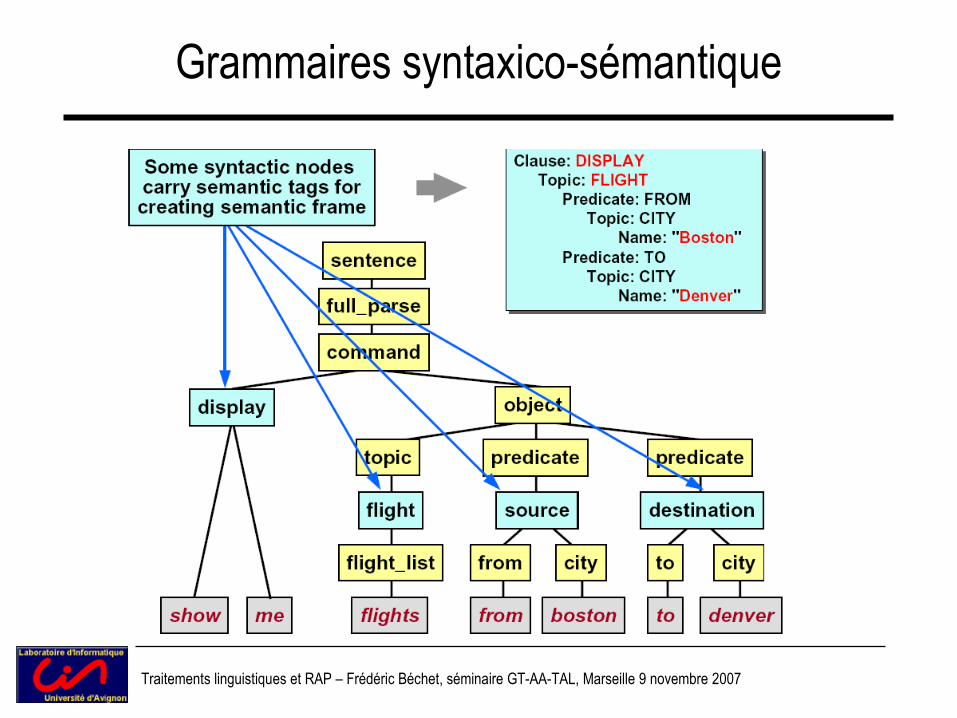
Grammaires syntaxico-sémantique
Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
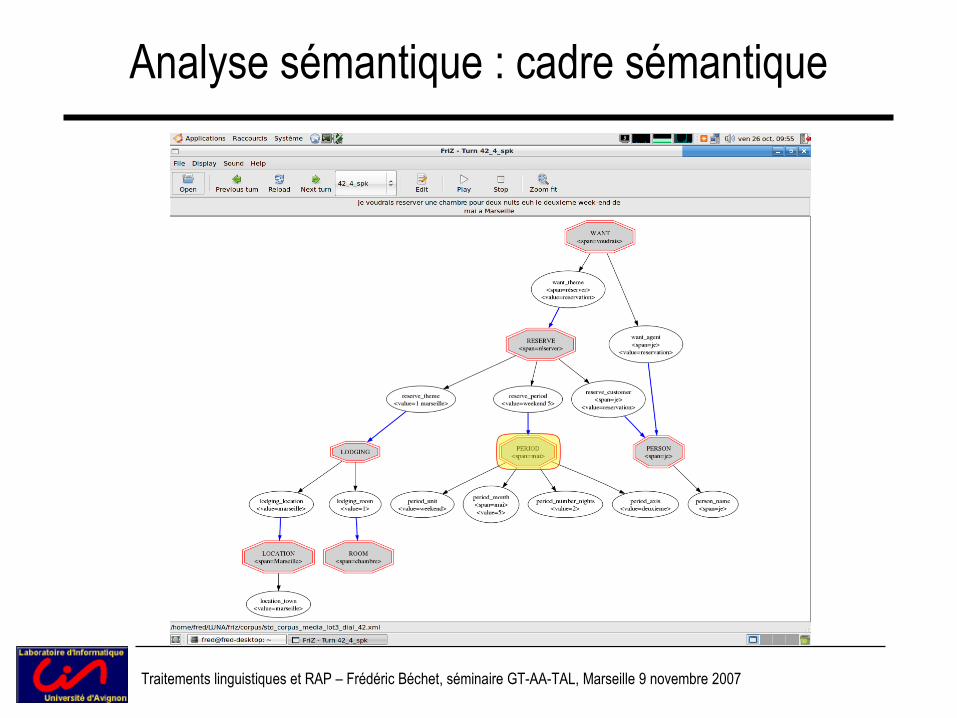
Analyse sémantique : cadre sémantique

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Traitements Linguistiques
• Quels modèles et quels algorithmes ?– Méthodes basées sur l’analyse
• Modèles = grammaires ou modèles de langage
• Algorithmes = analyseurs (CHART), automates, viterbi
– Méthodes d’étiquetage / classification
• Compréhension = “traduire” une séquence d’observations (mots, paramètres acoustiques) en une séquence d’objets sémantiques
• Algorithmes
– Hidden Markov Model, MaxEnt, Conditional Random Fields
– Support Vector Machines, Boosting, Arbres de décision, réseaux de neurones, etc.

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Quelques exemples
• Etiquetage de séquence
• Classification d’appels
• Analyse sémantique de surface

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Traitements Linguistiques
• Quels corpus ?– Trois types de corpus
• Corpus “écologiques”– Données radiodiffusées
» Ex : ESTER– Données collectées dans les centres d’appel
» Ex : SCOrange• Corpus de laboratoire
– Collectés pour le développement de systèmes– Protocoles de collectes : Magicien d’Oz
» Ex: MEDIA• Corpus collectés auprès d’applications déployées
– Systèmes de dialogue existant – collecte des fichiers “logs”» Ex : How May I Help You? (USA)» France Télécom 3000 (France)

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Exemple de corpus / d’annotations
Corpus ESTER – Entitées Nommées

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Exemple de corpus / d’annotations
Message pour les utilisateurs - SCOrange
Exemple de message avec annotation des opinions

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Exemple de corpus / d’annotations

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Exemple de corpus / d’annotations
exemple

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Exemple de corpus / d’annotations

Exemple de corpus / d’annotations

Exemple de corpus / d’annotations

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Traitements Linguistiques
• Comment évaluer ?– Évaluation de séquences
• N = nb de symboles de réference, N’ = nb de symboles hypothèses• i = nb insertion ; s = nb substitution ; d = nb de supression

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Traitements Linguistiques
- Évaluation globale

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Conclusions et perspectives

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Problèmes ouverts liant AA et TAP
• Problèmes liés à l’apprentissage– Manque de données d’apprentissage
• Coût et complexité de l’annotation• Manque de corpus
– Dialogue = problème de « la poule et de l’œuf »
– Bruits dans les données• Erreurs d’annotation / ambiguïtés
– Distribution non homogène des étiquettes• Difficultés de modéliser des phénomènes peu
fréquents

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Problèmes ouverts liant AA et TAP
• Incertitude des observations– Sorties imparfaites du décodeur de RAP– Intégration des mesures de confiance dans les
observations• Adaptation
– Adaptation statique• Comment projeter un modèle appris pour une application
X vers une application Y ?
– Adaptation dynamique• Comment détecter un changement ?• Comment modifier dynamiquement un modèle pour
prendre en compte un nouveau phénomène ?

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Proposition d’étude
• Un des sujets “chauds” du moment …– Comment diminuer l’effort d’annotation manuel de
corpus ?• Apprentissage non ou faiblement supervisé• Bootstrap et généralisation d’annotations• Par exemple :
– Active learning» Gokhan Tur, Dilek Hakkani-Tür, Robert E. Schapire. Combining
Active and Semi-Supervised Learning for Spoken Language Understanding. Journal of Speech Communication. Vol: 45, No: 2, pp: 171-186. 2005
– Co-training» Umit Guz, Sebastien Cuendet, Dilek Hakkani-Tür and Gokhan Tur.
Co-Training Using Prosodic and Lexical Information for Sentence Segmentation. In the Proceedings of International Conference on Spoken Language Processing (Interspeech 2007). Antwerp, Belgium. 2007.

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Proposition d’étude
• Par exemple dans :
Conclusion

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007
Proposition d’étude
• Possibilité pour un projet ANR– Déficit criant de ressources linguistiques annotées
pour le Français• Entités nommées, Tree bank, semantic role, etc.
– Etude d’algorithmes permettant de limiter l’effort d’annotation
• Choix de corpus et de niveaux d’annotation• Apprentissage actif, non ou semi supervisé, mesures de
confiance, etc.
– Résultats doubles• Algorithme = AA• Corpus = TAL

Traitements linguistiques et RAP – Frédéric Béchet, séminaire GT-AA-TAL, Marseille 9 novembre 2007


















