
Niveau intermédiaire grammaire progressive du français livre + corrigés
Upload
dalibor-mladenovskiCategory
view
225download
4
Statpoint Technologies, Inc.
STATGRAPHICS® Centurion XVI
Manuel de l’Utilisateur

STATGRAPHICS® CENTURION XVI
MANUEL DE L’UTILISATEUR
2009 par StatPoint Technologies, Inc. www.STATGRAPHICS.com
Traduction par Christian R. CHARLES
www.STATGRAPHICS.fr Tous droits réservés. Aucune partie de ce document ne peut être reproduite, sous toute forme ou par tout moyen, sans l’accord écrit de StatPoint Technologies, Inc. Référencé comme : STATGRAPHICS® Centurion XVI - Manuel de l’Utilisateur STATGRAPHICS est une marque déposée de StatPoint Technologies, Inc. STATGRAPHICS Centurion XVI, StatPoint, StatFolio, StatGallery, StatReporter, StatPublish, StatWizard, StatLink et SnapStats sont des marques de StatPoint Technologies, Inc. Tous les produits et services mentionnés dans ce livre sont des marques ou services de leurs propriétaires respectifs.
Imprimé aux Etats-Unis d’Amérique.

iii / Table des matières
Table des matières
Table des matières ..................................................................................................... iii Préface ....................................................................................................................... ix Démarrer ..................................................................................................................... 1
1.1 Installer le logiciel .......................................................................................................... 1 1.2 Utiliser le logiciel ........................................................................................................... 8 1.3 Entrer des données ...................................................................................................... 14 1.4 Lire un fichier de données enregistré ............................................................................ 18 1.5 Analyser les données ................................................................................................... 20 1.6 Utiliser la barre d’outils d’analyse .................................................................................. 24 1.7 Diffuser les résultats .................................................................................................... 29 1.8 Enregistrer votre travail ............................................................................................... 29
Gestion des données .................................................................................................. 33 2.1 Le classeur .................................................................................................................. 34 2.2 Accéder aux données ................................................................................................... 36
2.2.1 Lire des données d’un fichier STATGRAPHICS Centurion XVI ............................. 37 2.2.2 Lire des données de fichiers Excel, ASCII, XML ou d’autres formats ....................... 38 2.2.3 Transférer des données par copier-coller ................................................................ 39 2.2.4 Faire une requête dans une base de données ODBC ................................................ 40
2.3 Manipuler les données ................................................................................................. 41 2.3.1 Copier et coller des données .................................................................................. 41 2.3.2 Créer de nouvelles variables à partir de colonnes existantes ..................................... 42 2.3.3 Transformer des données ....................................................................................... 45 2.3.4 Trier des données .................................................................................................. 48 2.3.5 Recoder des données ............................................................................................. 50 2.3.6 Combiner plusieurs colonnes ................................................................................. 51
2.4 Générer des données ................................................................................................... 53 2.4.1 Générer des données structurées ............................................................................ 54 2.4.2 Générer des nombres aléatoires .............................................................................. 56
2.5 Propriétés du classeur .................................................................................................. 57 2.6 Visualiseur de données ................................................................................................ 59
Mettre en œuvre des analyses statistiques ................................................................... 61 3.1 Boîtes de dialogue d’entrée des données ....................................................................... 63 3.2 Fenêtre d’analyse ......................................................................................................... 65

iv / Table des matières
3.2.1 Bouton Définition de l’analyse ................................................................................66 3.2.2 Bouton Options d’analyse .......................................................................................67 3.2.3 Bouton Tableaux et graphiques ...............................................................................68 3.2.4 Bouton Options pour la fenêtre ..............................................................................70 3.2.5 Bouton Enregistrer les résultats ...............................................................................72 3.2.6 Boutons pour les graphiques ...................................................................................73 3.2.7 Bouton Inclure / Exclure .......................................................................................74
3.3 Imprimer les résultats ...................................................................................................75 3.4 Publier les résultats .......................................................................................................77
Graphiques ................................................................................................................ 79 4.1 Modifier les graphiques ................................................................................................80
4.1.1 Options Apparence ................................................................................................81 4.1.2 Options Grille ........................................................................................................83 4.1.3 Options Lignes ......................................................................................................85 4.1.4 Options Points .......................................................................................................87 4.1.5 Options Titre principal ...........................................................................................89 4.1.6 Options Echelles des axes .......................................................................................91 4.1.7 Options Remplissages ............................................................................................93 4.1.8 Options Textes, Libellés et Légendes ......................................................................94 4.1.9 Ajouter un nouveau texte ........................................................................................94
4.2 Eparpiller un nuage de point .........................................................................................95 4.3 Brosser un nuage de points ...........................................................................................97 4.4 Lisser un nuage de points ........................................................................................... 100 4.5 Identifier des points ................................................................................................... 101 4.6 Copier des graphiques dans d’autres applications ......................................................... 105 4.7 Enregistrer des graphiques dans des fichiers ................................................................ 106
StatFolios ................................................................................................................. 107 5.1 Enregistrer votre session ............................................................................................ 107 5.2 Script de démarrage du StatFolio................................................................................. 108 5.3 Interroger les sources de données ............................................................................... 112 5.4 Publier les résultats au format HTML ......................................................................... 113
Utiliser la StatGallery .................................................................................................117 6.1 Configurer un page de la StatGallery ........................................................................... 117 6.2 Copier des graphiques dans la StatGallery .................................................................... 119 6.3 Superposer des graphiques .......................................................................................... 120 6.4 Modifier un graphique dans la StatGallery ................................................................... 121
6.4.1 Ajouter des éléments ............................................................................................ 121 6.4.2 Modifier des éléments........................................................................................... 122 6.4.3 Supprimer des éléments ........................................................................................ 122

v / Table des matières
6.5 Imprimer la StatGallery.............................................................................................. 123 Utiliser le StatReporter .............................................................................................. 125
7.1 La fenêtre StatReporter .............................................................................................. 125 7.2 Copier des résultats dans le StatReporter .................................................................... 126 7.3 Modifier les résultats dans le StatReporter .................................................................. 127 7.4 Enregistrer le StatReporter ......................................................................................... 127
Utiliser le StatWizard ................................................................................................ 129 8.1 Accéder à des données ou créer une nouvelle étude .................................................... 130 8.2 Sélectionner les analyses pour vos données ................................................................. 134 8.3 Rechercher les statistiques ou tests désirés .................................................................. 139
Préférences du logiciel .............................................................................................. 143 9.1 Préférences générales du logiciel................................................................................. 143 9.2 Impression ................................................................................................................ 146 9.3 Graphiques ............................................................................................................... 146
Didacticiel n° 1 : Analyser un unique échantillon ........................................................ 149 10.1 Mettre en oeuvre la procédure Analyse à une variable ................................................ 150 10.2 Statistiques résumés ................................................................................................. 153 10.3 Graphique en boîte à moustaches ............................................................................. 156 10.4 Tester la présence de points extrêmes ....................................................................... 158 10.5 Histogramme .......................................................................................................... 162 10.6 Graphique des quantiles et quantiles ......................................................................... 167 10.7 Intervalles de confiance............................................................................................ 168 10.8 Tests d’hypothèses ................................................................................................... 170 10.9 Limites des tolérances .............................................................................................. 172
Didacticiel n° 2 : Comparer deux échantillons ............................................................ 175 11.1 Mettre en oeuvre la procédure de comparaison des deux échantillons ........................ 176 11.2 Statistiques résumées ............................................................................................... 178 11.3 Double histogramme ............................................................................................... 179 11.4 Boîtes à moustaches................................................................................................. 179 11.5 Comparer les écarts-types ........................................................................................ 181 11.6 Comparer des moyennes .......................................................................................... 183 11.7 Comparer des médianes ........................................................................................... 184 11.8 Graphique des quantiles ........................................................................................... 185 11.9 Test de Kolmogorov-Smirnov pour deux échantillons ............................................... 186 11.10 Graphiques quantiles-quantiles ............................................................................... 187
Didacticiel n° 3 : Comparer plus de deux échantillons ................................................ 189 12.1 Mettre en oeuvre la procédure de comparaison de plusieurs échantillons .................... 190 12.2 Analyse de la variance .............................................................................................. 194 12.3 Comparer les moyennes ........................................................................................... 197

vi / Table des matières
12.4 Comparer des médianes ............................................................................................ 199 12.5 Comparer des écarts-types ........................................................................................ 201 12.6 Graphiques des résidus ............................................................................................. 202 12.7 Graphique de l’analyse des moyennes (ANOM) ......................................................... 203
Didacticiel n° 4 : Méthodes de régression .................................................................. 205 13.1 Analyse des corrélations ............................................................................................ 206 13.2 Régression simple ..................................................................................................... 210 13.3 Ajuster un modèle non linéaire .................................................................................. 213 13.4 Examiner les résidus ................................................................................................. 216 13.5 Régression multiple .................................................................................................. 217
Didacticiel n° 5 : Analyse de données qualitatives ...................................................... 227 14.1 Résumer des données qualitatives .............................................................................. 228 14.2 Analyse de Pareto ..................................................................................................... 229 14.3 Tri croisé ................................................................................................................. 232 14.4 Comparer deux échantillons ou plus .......................................................................... 239 14.5 Tableaux de contingence ........................................................................................... 243
Didacticiel n° 6 : Analyse d’aptitude d’un procédé ..................................................... 245 15.1 Visualiser graphiquement les données ........................................................................ 246 15.2 Procédure d’analyse d’aptitude .................................................................................. 248 15.3 Travailler avec des données non normales ................................................................. 252 15.4 Indices d’aptitude ..................................................................................................... 259 15.5 Calculatrice Six Sigma ............................................................................................... 263
Didacticiel n° 7 : Plans d’expériences ........................................................................ 267 16.1 Créer le plan ............................................................................................................. 268
Etape 1: Définir les réponses ........................................................................................ 269 Etape 2 : Définir les facteurs expérimentaux .................................................................. 270 Etape 3: Sélectionner le plan ......................................................................................... 270 Etape 4 : Préciser le modèle .......................................................................................... 276 Etape 5: Sélection des essais .......................................................................................... 278 Etape 6: Evaluer le plan ................................................................................................ 278 Etape 7: Enregistrer le plan d’expériences ...................................................................... 280
16.2 Analyser les résultats ................................................................................................. 281 Etape 8: Analyser les données ....................................................................................... 281 Etape 9: Optimiser les réponses .................................................................................... 294 Etape 10: Enregistrer les résultats .................................................................................. 297
16.3 Expériences complémentaires ................................................................................... 298 Etape 11 : Augmenter le plan ........................................................................................ 298 Etape 12 : Extrapoler.................................................................................................... 300
Livres suggérés ........................................................................................................ 303

vii / Table des matières
Fichiers des données ................................................................................................ 305 Index ....................................................................................................................... 307
viii / Table des matières

ix / Préface
Préface
Ce livre est conçu pour présenter, aux utilisateurs de STATGRAPHICS Centurion XVI, les opérations de base du logiciel et son utilisation pour analyser des données. Il donne un aperçu complet du logiciel : installation, gestion des données, mise en œuvre d’analyses statistiques, impression et publication des résultats. Comme ce livre a pour but de permettre aux utilisateurs d’utiliser le logiciel rapidement, il se concentre sur les fonctionnalités les plus importantes du logiciel plutôt que d’essayer de couvrir tous les détails. Le menu Aide dans STATGRAPHICS Centurion XVI donne accès à un grand nombre d’informations additionnelles avec un fichier PDF dédié pour chacune des 160 procédures statistiques.
Les neuf premiers chapitres de ce livre présentent l’utilisation de base du logiciel. Bien que vous puissiez probablement découvrir tout cela par vous-même en utilisant le logiciel, une lecture complète de ces chapitres vous aidera à prendre en main rapidement le logiciel et vous assurera que vous ne passez pas à côté d’importantes fonctionnalités.
Les sept derniers chapitres apportent des didacticiels qui ont pour but :
1. de vous présenter quelques-unes des analyses statistiques les plus courantes.
2. d’illustrer comment certaines des fonctionnalités uniques de STATGRAPHICS Centurion XVI vous facilitent la démarche d’analyse de vos données.
Il vous est recommandé d’explorer ces didacticiels car ils vous donneront une bonne idée sur la façon d’utiliser au mieux STATGRAPHICS Centurion XVI pour l’analyse de données réelles.
NOTE : une copie de ce manuel au format PDF est livrée avec le logiciel et peut être accédée par le menu Aide. Dans le document PDF, tous les graphiques sont en couleurs. Les fichiers de données et les StatFolios utilisés dans ce manuel sont également fournis avec le logiciel.
StatPoint Technologies, Inc. Décembre 2009
x / Préface

1 Démarrer
Démarrer
Installer STATGRAPHICS Centurion XVI, utiliser le logiciel et créer un fichier de données.
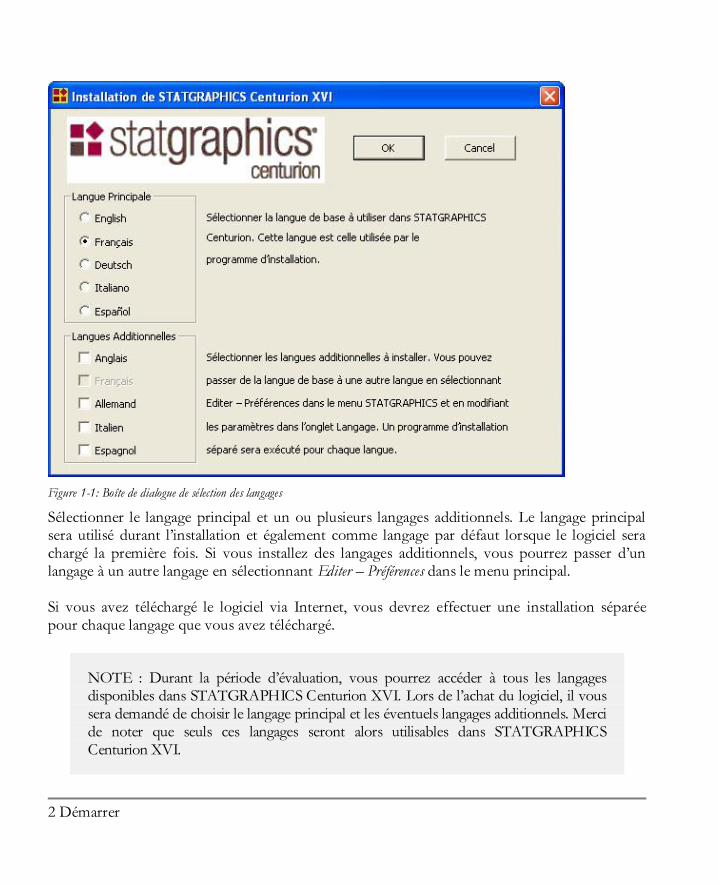
1.1 Installer le logiciel STATGRAPHICS Centurion XVI est livré de deux façons : via Internet sous la forme d’un unique fichier à télécharger sur votre ordinateur ou sous la forme d’un ensemble de fichiers sur un CD-ROM. Pour utiliser le logiciel, il doit préalablement être installé sur votre disque dur. Comme avec la plupart des logiciels sous Windows, l’installation est extrêmement simple : Etape 1 : Si vous avez reçu le logiciel sur un CD, insérez le CD dans votre lecteur de CD-ROM. Après quelques instants, le programme d’installation doit démarrer automatiquement. Si ce n’est pas le cas, ouvrir l’explorateur de Windows et exécuter le fichier sgcinstall.exe qui se trouve dans le répertoire principal du CD-ROM. Si vous avez téléchargé le logiciel via Internet, localisez le fichier téléchargé et double-cliquez sur son nom pour débuter le processus d’installation. Etape 2 : Plusieurs boîtes de dialogue vont ensuite s’afficher. Si vous installez le logiciel depuis un CD, la première boîte de dialogue qui s’affiche vous demande de préciser le langage ou les langages à installer :
Chapitre
1
2 Démarrer
Figure 1-1: Boîte de dialogue de sélection des langages
Sélectionner le langage principal et un ou plusieurs langages additionnels. Le langage principal sera utilisé durant l’installation et également comme langage par défaut lorsque le logiciel sera chargé la première fois. Si vous installez des langages additionnels, vous pourrez passer d’un langage à un autre langage en sélectionnant Editer – Préférences dans le menu principal. Si vous avez téléchargé le logiciel via Internet, vous devrez effectuer une installation séparée pour chaque langage que vous avez téléchargé.
NOTE : Durant la période d’évaluation, vous pourrez accéder à tous les langages disponibles dans STATGRAPHICS Centurion XVI. Lors de l’achat du logiciel, il vous sera demandé de choisir le langage principal et les éventuels langages additionnels. Merci de noter que seuls ces langages seront alors utilisables dans STATGRAPHICS Centurion XVI.
3 Démarrer
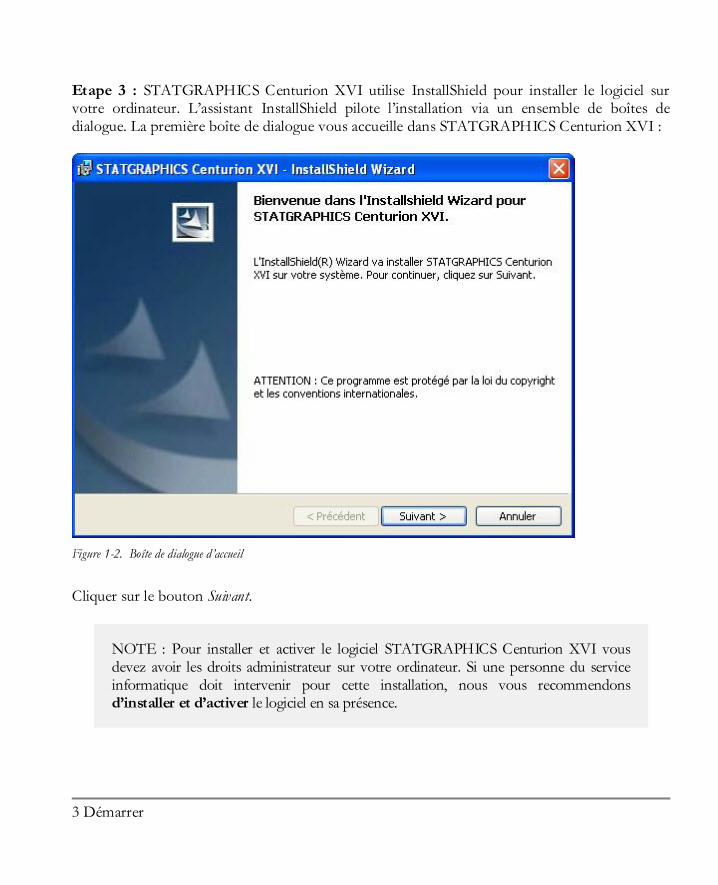
Etape 3 : STATGRAPHICS Centurion XVI utilise InstallShield pour installer le logiciel sur votre ordinateur. L’assistant InstallShield pilote l’installation via un ensemble de boîtes de dialogue. La première boîte de dialogue vous accueille dans STATGRAPHICS Centurion XVI :
Figure 1-2. Boîte de dialogue d’accueil
Cliquer sur le bouton Suivant.
NOTE : Pour installer et activer le logiciel STATGRAPHICS Centurion XVI vous devez avoir les droits administrateur sur votre ordinateur. Si une personne du service informatique doit intervenir pour cette installation, nous vous recommendons d’installer et d’activer le logiciel en sa présence.
4 Démarrer
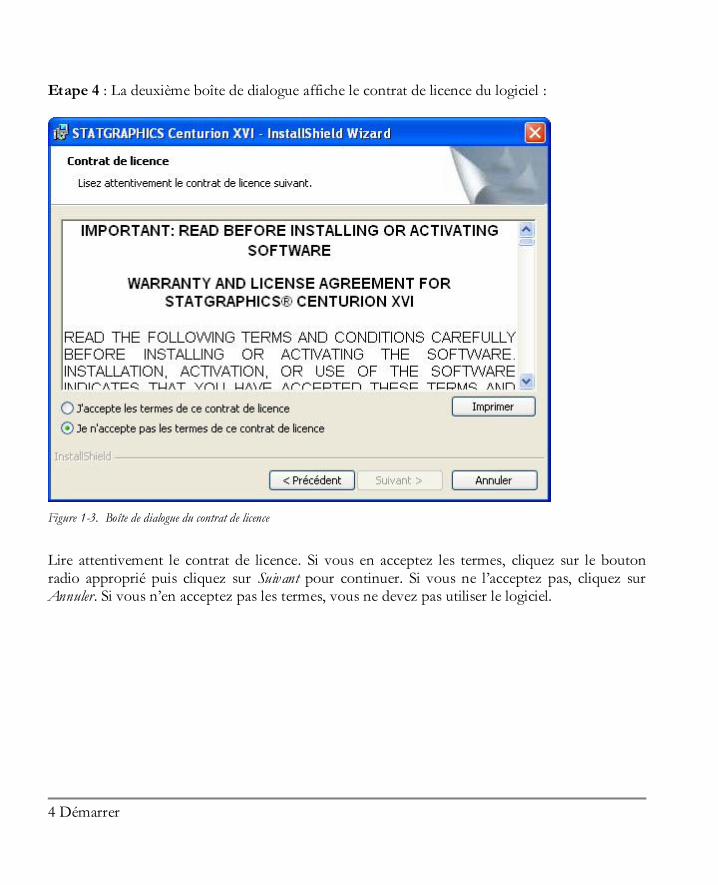
Etape 4 : La deuxième boîte de dialogue affiche le contrat de licence du logiciel :
Figure 1-3. Boîte de dialogue du contrat de licence
Lire attentivement le contrat de licence. Si vous en acceptez les termes, cliquez sur le bouton radio approprié puis cliquez sur Suivant pour continuer. Si vous ne l’acceptez pas, cliquez sur Annuler. Si vous n’en acceptez pas les termes, vous ne devez pas utiliser le logiciel.
5 Démarrer
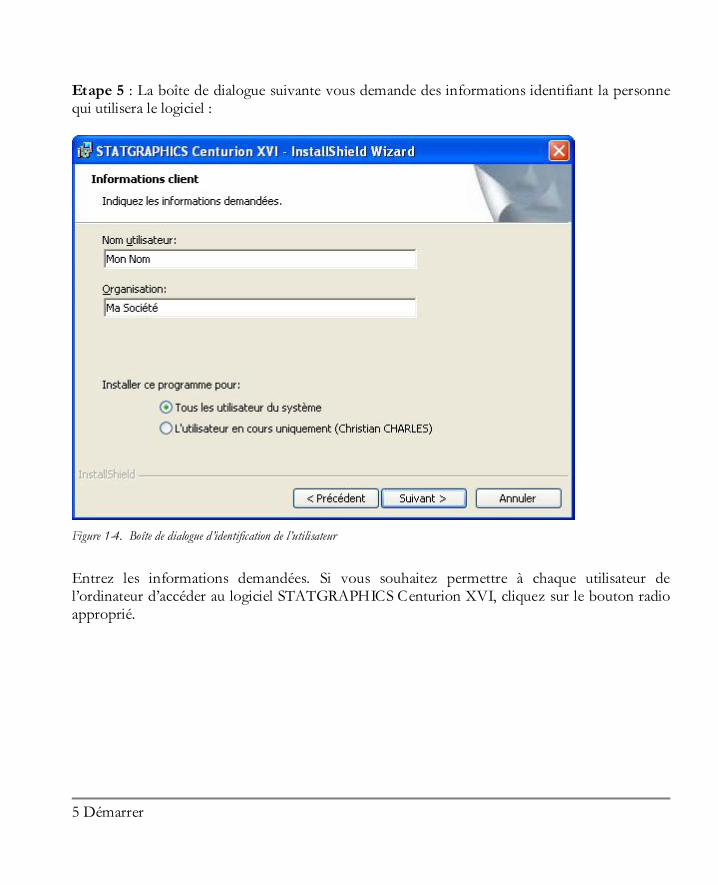
Etape 5 : La boîte de dialogue suivante vous demande des informations identifiant la personne qui utilisera le logiciel :
Figure 1-4. Boîte de dialogue d’identification de l’utilisateur
Entrez les informations demandées. Si vous souhaitez permettre à chaque utilisateur de l’ordinateur d’accéder au logiciel STATGRAPHICS Centurion XVI, cliquez sur le bouton radio approprié.
6 Démarrer
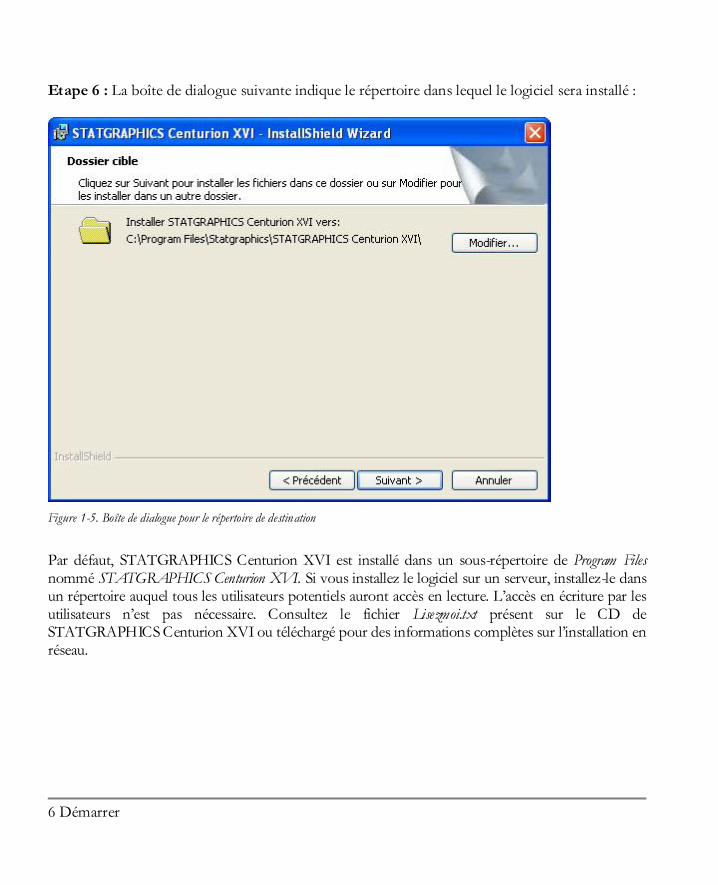
Etape 6 : La boîte de dialogue suivante indique le répertoire dans lequel le logiciel sera installé :
Figure 1-5. Boîte de dialogue pour le répertoire de destination
Par défaut, STATGRAPHICS Centurion XVI est installé dans un sous-répertoire de Program Files nommé STATGRAPHICS Centurion XVI. Si vous installez le logiciel sur un serveur, installez-le dans un répertoire auquel tous les utilisateurs potentiels auront accès en lecture. L’accès en écriture par les utilisateurs n’est pas nécessaire. Consultez le fichier Lisezmoi.txt présent sur le CD de STATGRAPHICS Centurion XVI ou téléchargé pour des informations complètes sur l’installation en réseau.
7 Démarrer
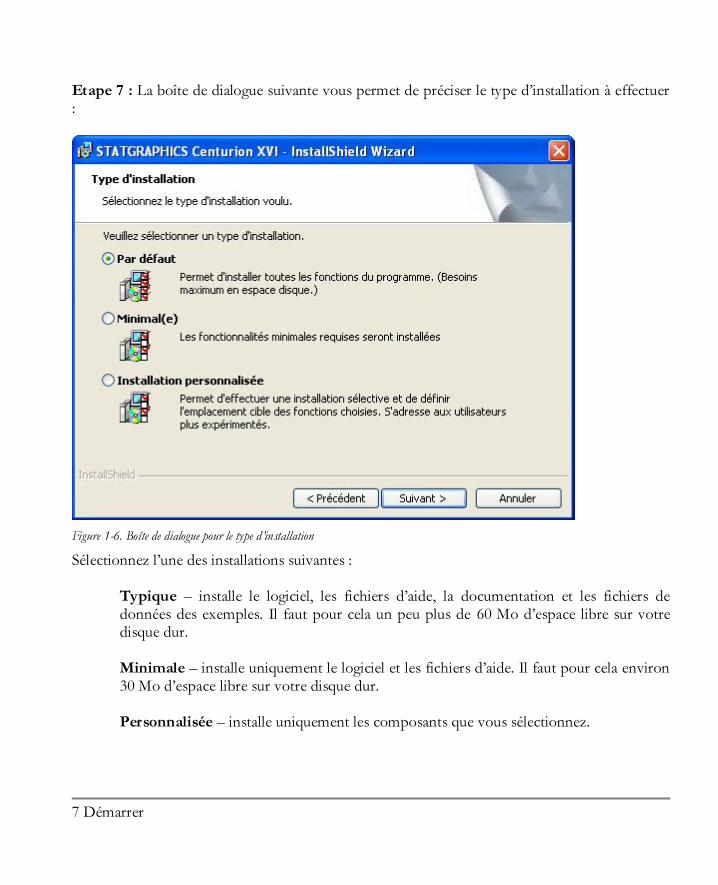
Etape 7 : La boîte de dialogue suivante vous permet de préciser le type d’installation à effectuer :
Figure 1-6. Boîte de dialogue pour le type d’installation
Sélectionnez l’une des installations suivantes :
Typique – installe le logiciel, les fichiers d’aide, la documentation et les fichiers de données des exemples. Il faut pour cela un peu plus de 60 Mo d’espace libre sur votre disque dur.
Minimale – installe uniquement le logiciel et les fichiers d’aide. Il faut pour cela environ 30 Mo d’espace libre sur votre disque dur.
Personnalisée – installe uniquement les composants que vous sélectionnez.
8 Démarrer
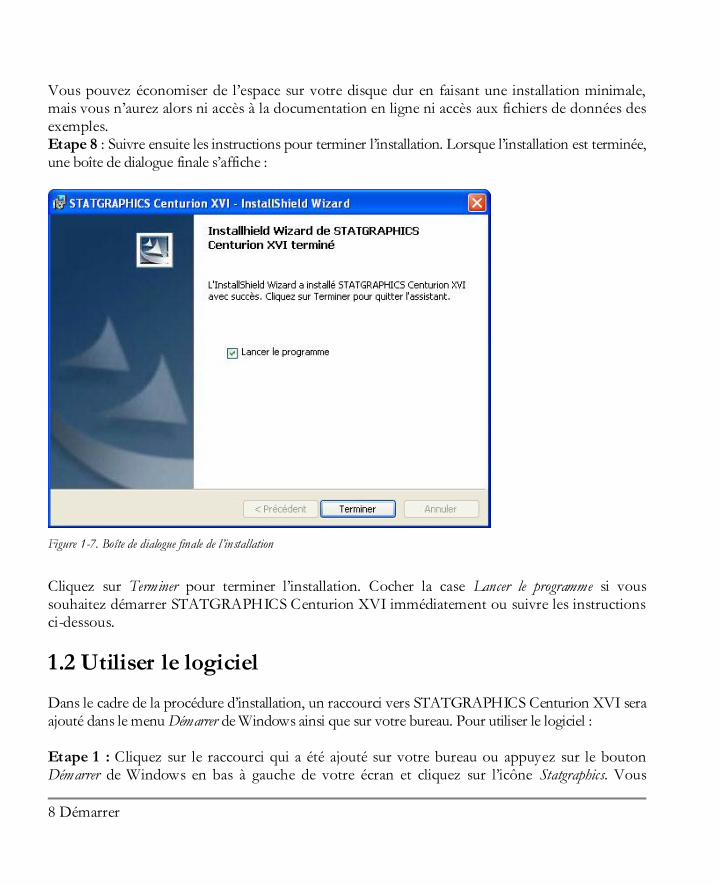
Vous pouvez économiser de l’espace sur votre disque dur en faisant une installation minimale, mais vous n’aurez alors ni accès à la documentation en ligne ni accès aux fichiers de données des exemples. Etape 8 : Suivre ensuite les instructions pour terminer l’installation. Lorsque l’installation est terminée, une boîte de dialogue finale s’affiche :
Figure 1-7. Boîte de dialogue finale de l’installation
Cliquez sur Terminer pour terminer l’installation. Cocher la case Lancer le programme si vous souhaitez démarrer STATGRAPHICS Centurion XVI immédiatement ou suivre les instructions ci-dessous.
1.2 Utiliser le logiciel Dans le cadre de la procédure d’installation, un raccourci vers STATGRAPHICS Centurion XVI sera ajouté dans le menu Démarrer de Windows ainsi que sur votre bureau. Pour utiliser le logiciel : Etape 1 : Cliquez sur le raccourci qui a été ajouté sur votre bureau ou appuyez sur le bouton Démarrer de Windows en bas à gauche de votre écran et cliquez sur l’icône Statgraphics. Vous
9 Démarrer
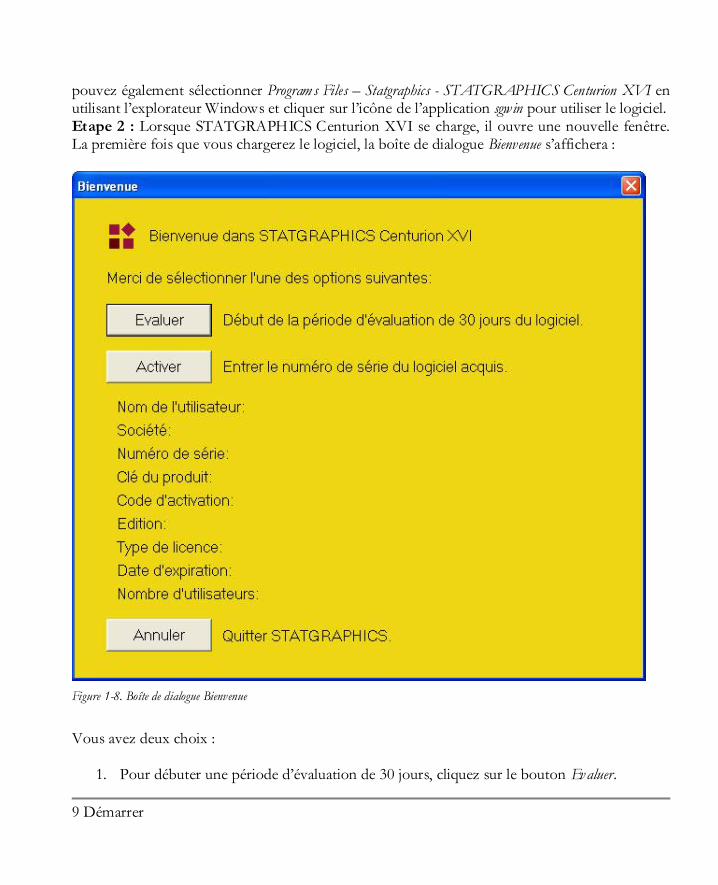
pouvez également sélectionner Program s Files – Statgraphics - STATGRAPHICS Centurion XVI en utilisant l’explorateur Windows et cliquer sur l’icône de l’application sgwin pour utiliser le logiciel. Etape 2 : Lorsque STATGRAPHICS Centurion XVI se charge, il ouvre une nouvelle fenêtre. La première fois que vous chargerez le logiciel, la boîte de dialogue Bienvenue s’affichera :
Figure 1-8. Boîte de dialogue Bienvenue
Vous avez deux choix :
1. Pour débuter une période d’évaluation de 30 jours, cliquez sur le bouton Evaluer.
10 Démarrer
2. Si vous avez déjà acquis le logiciel et avez reçu un numéro de série, cliquez sur le bouton
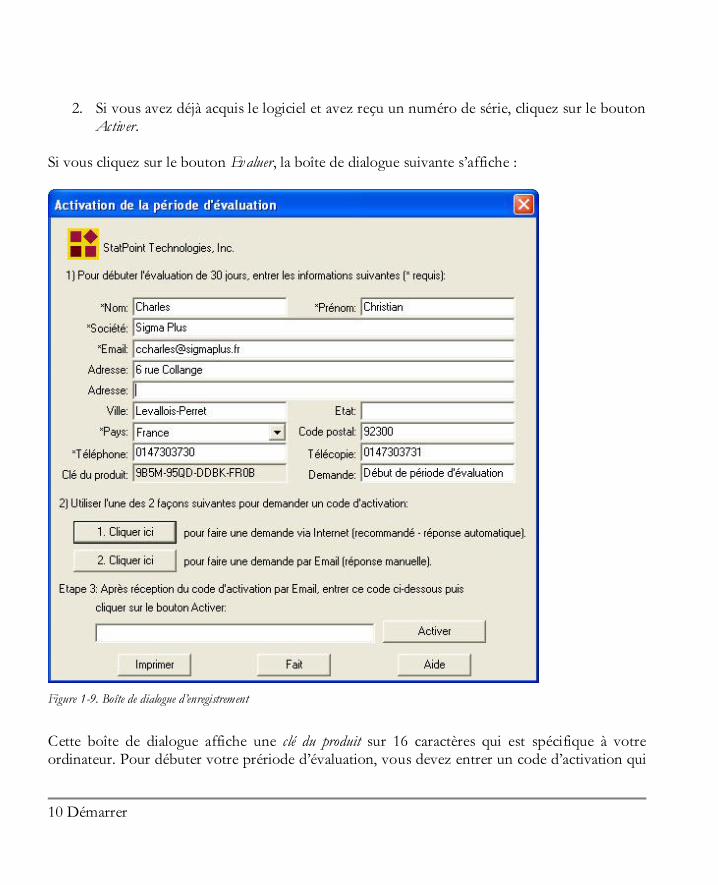
Activer. Si vous cliquez sur le bouton Evaluer, la boîte de dialogue suivante s’affiche :
Figure 1-9. Boîte de dialogue d’enregistrement
Cette boîte de dialogue affiche une clé du produit sur 16 caractères qui est spécifique à votre ordinateur. Pour débuter votre prériode d’évaluation, vous devez entrer un code d’activation qui

11 Démarrer
dépend de cette clé du produit. Pour recevoir ce code d’activation, cliquer sur l’un des deux boutons affichés en bas de la boîte de dialogue d’activation (étape 2) :
1. Le bouton « 1. Cliquer ici » permet d’envoyer automatiquement un message à StatPoint Technologies par Internet pour demander un code d’activation. Un service Web répond immédiatement à cette demande en envoyant le code d’activation à l’adresse de messagerie indiquée.
2. Le bouton « 2. Cliquer ici » accède à votre logiciel de messagerie par défaut et crée un message contenant les informations entrées pour envoi à StatPoint Technologies. Les demandes faites par messagerie sont traitées durant les heures de travail aux USA.
Pour éviter un délai, il est préférable d’utiliser la première méthode.
NOTE : Les utilisateurs activant un logiciel obtenu via un établissement d’enseignement possédant une licence de site doivent obligatoirement utiliser la première méthode. Le code d’activation sera uniquement envoyé à une adresse de messagerie de l’établissement. Le gestionnaire de la licence de site doit l’indiquer aux utilisateurs.
Etape 3 : Une fois la demande effectuée, un message vous sera envoyé indiquant le code d’activation. Entrez ce code dans le champ associé à l’étape 3) puis cliquez sur le bouton Activer. Si le code entré est bien associé à la clé du produit, le message suivant s’affiche :
Figure 1-10 : Message d’activation
Cliquez sur OK pour afficher la fenêtre principale du logiciel.
NOTE 1 : Si vous utilisez Microsoft Vista ou Windows 7 lorsque vous double-cliquez sur l’icône STATGRAPHICS pour démarrer le logiciel, il est possible que cela ne fonctionne pas. Dans ce cas, vous devez cliquer sur le bouton droit de la souris et sélectionner Exécuter en tant qu’administrateur dans la liste des options qui s’affiche.

12 Démarrer
NOTE 2 : Si vous installez plus tard STATGRAPHICS Centurion XVI sur un autre ordinateur, il faudra demander à nouveau un code d’activation car la clé du produit est spécifique à chaque ordinateur.
Etape 4 : La première fois que vous utiliserez le logiciel, il vous sera également demandé quel système de menus vous souhaitez utiliser. Vous avez le choix entre le classique menu STATGRAPHICS, qui organise les procédures statistiques en Graphique, Décrire, Comparer, Relier, Prévoir, MSP et Plans d’Expériences ou le menu Six Sigma qui organise les procédures en Définir, Mesurer, Analyser, Innover, Contrôler et Prévoir. Ces deux menus comportent les mêmes procédures. Seule l’organisation est différente. Vous pourrez modifier votre choix initial plus tard en sélectionnant Préférences dans le menu Editer du logiciel.
Figure 1-11 : Boîte de dialogue de choix du type de menus
13 Démarrer
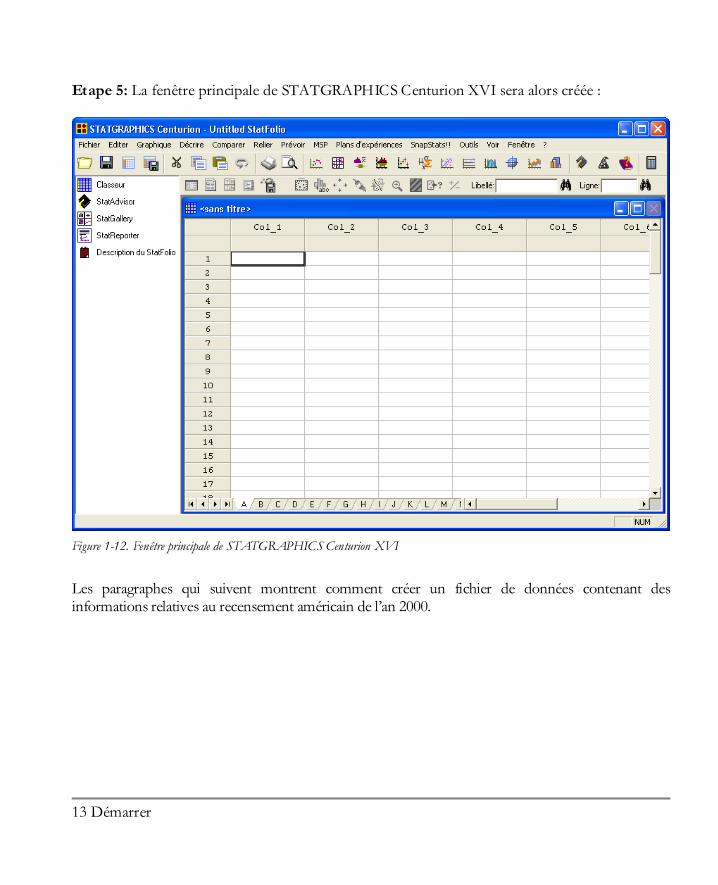
Etape 5: La fenêtre principale de STATGRAPHICS Centurion XVI sera alors créée :
Figure 1-12. Fenêtre principale de STATGRAPHICS Centurion XVI
Les paragraphes qui suivent montrent comment créer un fichier de données contenant des informations relatives au recensement américain de l’an 2000.
14 Démarrer
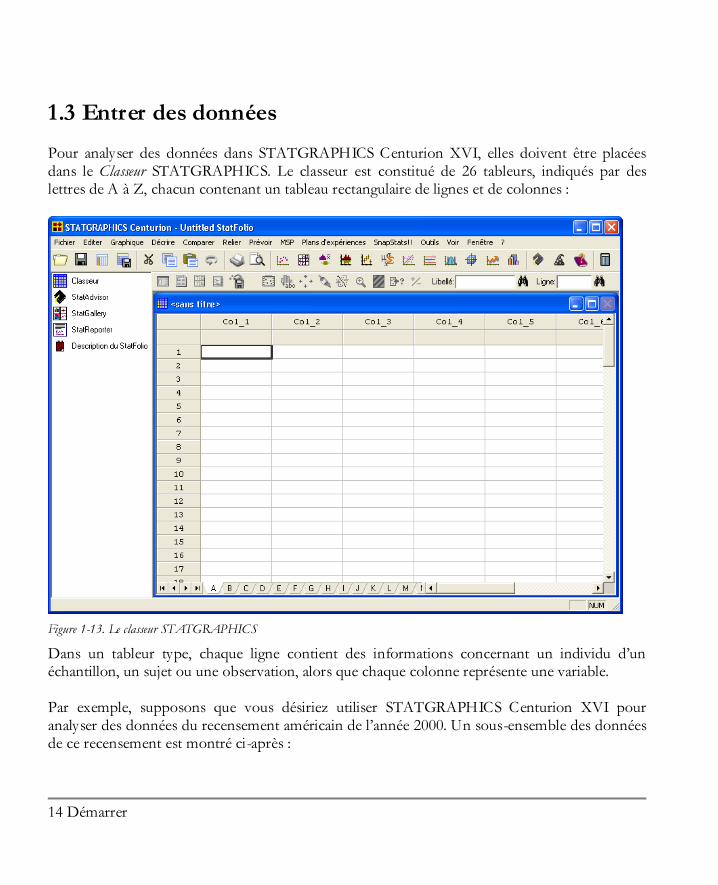
1.3 Entrer des données Pour analyser des données dans STATGRAPHICS Centurion XVI, elles doivent être placées dans le Classeur STATGRAPHICS. Le classeur est constitué de 26 tableurs, indiqués par des lettres de A à Z, chacun contenant un tableau rectangulaire de lignes et de colonnes :
Figure 1-13. Le classeur STATGRAPHICS
Dans un tableur type, chaque ligne contient des informations concernant un individu d’un échantillon, un sujet ou une observation, alors que chaque colonne représente une variable. Par exemple, supposons que vous désiriez utiliser STATGRAPHICS Centurion XVI pour analyser des données du recensement américain de l’année 2000. Un sous-ensemble des données de ce recensement est montré ci-après :
15 Démarrer
Etat Population Age médian % Femme Revenu par tête
Alabama 4447100 35,8 51,7 18819 $
Alaska 626932 32,4 48,3 22660 $
Arizona 5130632 34,2 50,1 20275 $
Arkansas 2673400 36,0 51,2 16904 $
California 33871648 33,3 50,2 22711 $
Colorado 4301261 34,3 49,6 24049 $
Figure 1-14. Données du recensement américain de l’année 2000
Lorsque vous entrez ces données dans le tableur de STATGRAPHICS Centurion XVI, les informations concernant chaque état doivent être placées dans une ligne différente. Cinq colonnes sont créées pour contenir les noms des états et les données du recensement. Pour entrer les données montrées ci-dessus dans STATGRAPHICS Centurion XVI, vous avez deux possibilités :
1. Entrer les données directement dans le tableur de STATGRAPHICS Centurion XVI.
2. Entrer les données dans un autre logiciel, comme par exemple Excel, puis les charger ou les copier dans le tableur de STATGRAPHICS Centurion XVI.
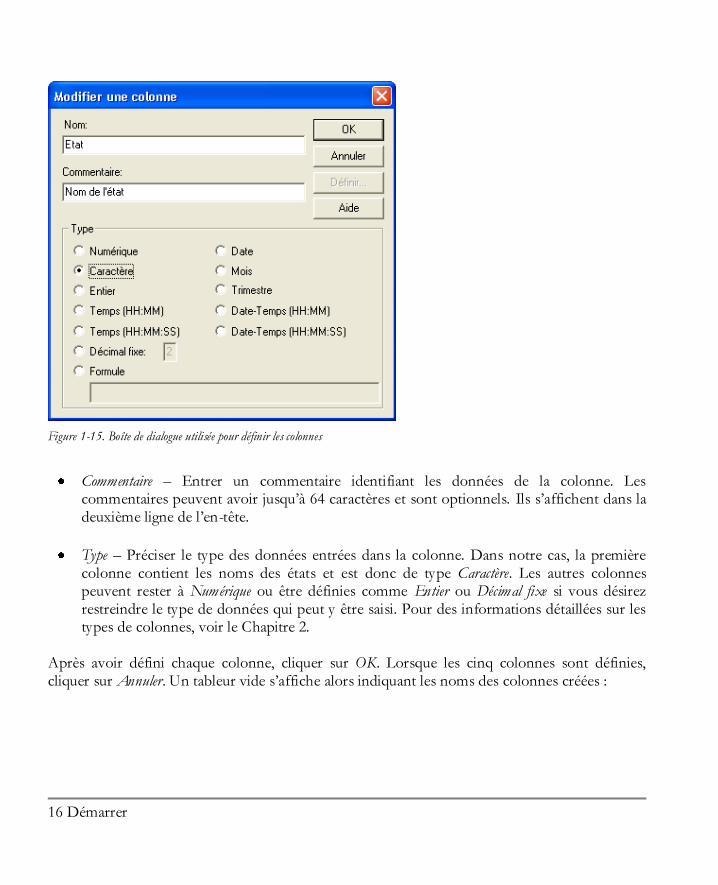
Dans ce paragraphe, nous choisirons la première approche. Pour débuter, double-cliquons sur l’entête de la première colonne dans laquelle le nom de la colonne est Col_1. Cela va afficher une boîte de dialogue que vous pourrez utiliser pour modifier d’importantes propriétés de cette colonne. Chaque colonne du tableur de STATGRAPHICS Centurion XVI est caractérisée par un nom, un commentaire et un type :
Nom – Donner un nom unique à chaque colonne, composé de 1 à 32 caractères. Les noms sont utilisés par le logiciel pour identifier les variables à analyser lorsqu’une analyse statistique est mise en oeuvre. Ils servent également de libellés par défaut dans la plupart des graphiques. Les noms peuvent être composés de tout caractère, ne distinguent pas les minuscules des majuscules et les espaces sont autorisés. Le logiciel affichera un message d’erreur si vous tentez d’utiliser le même nom pour plus d’une colonne dans un même tableur, même si des colonnes dans des tableurs différents peuvent porter le même nom.
16 Démarrer
Figure 1-15. Boîte de dialogue utilisée pour définir les colonnes
Commentaire – Entrer un commentaire identifiant les données de la colonne. Les commentaires peuvent avoir jusqu’à 64 caractères et sont optionnels. Ils s’affichent dans la deuxième ligne de l’en-tête.
Type – Préciser le type des données entrées dans la colonne. Dans notre cas, la première colonne contient les noms des états et est donc de type Caractère. Les autres colonnes peuvent rester à Numérique ou être définies comme Entier ou Décimal fixe si vous désirez restreindre le type de données qui peut y être saisi. Pour des informations détaillées sur les types de colonnes, voir le Chapitre 2.
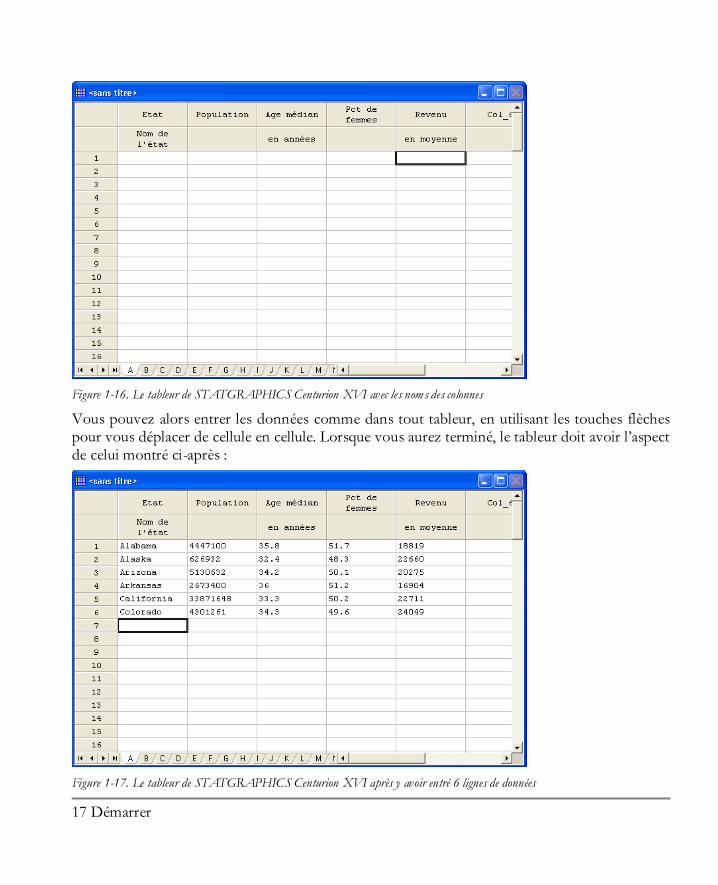
Après avoir défini chaque colonne, cliquer sur OK. Lorsque les cinq colonnes sont définies, cliquer sur Annuler. Un tableur vide s’affiche alors indiquant les noms des colonnes créées :
17 Démarrer
Figure 1-16. Le tableur de STATGRAPHICS Centurion XVI avec les noms des colonnes
Vous pouvez alors entrer les données comme dans tout tableur, en utilisant les touches flèches pour vous déplacer de cellule en cellule. Lorsque vous aurez terminé, le tableur doit avoir l’aspect de celui montré ci-après :
Figure 1-17. Le tableur de STATGRAPHICS Centurion XVI après y avoir entré 6 lignes de données
18 Démarrer
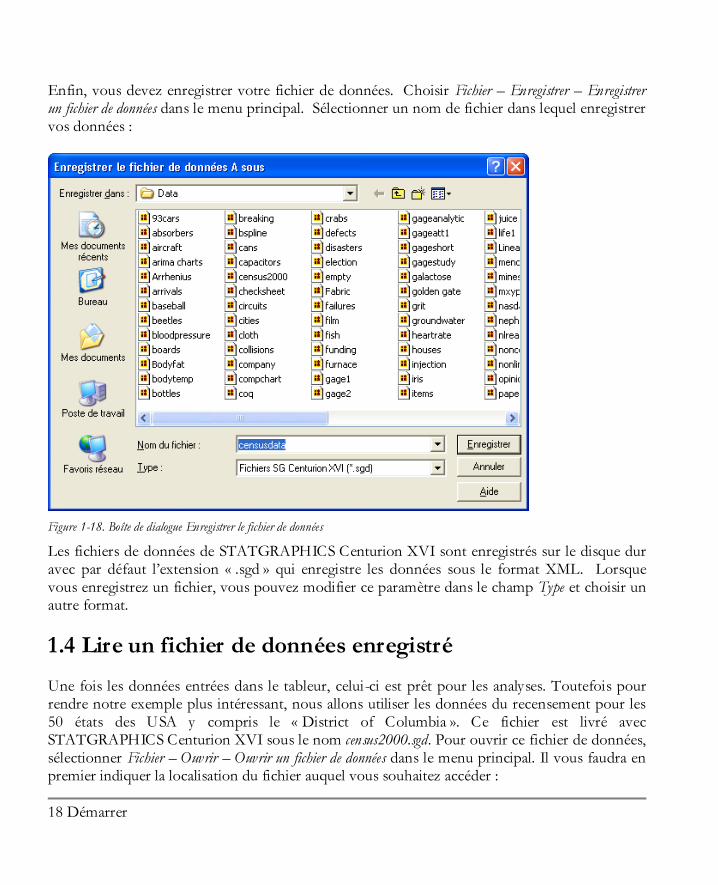
Enfin, vous devez enregistrer votre fichier de données. Choisir Fichier – Enregistrer – Enregistrer un fichier de données dans le menu principal. Sélectionner un nom de fichier dans lequel enregistrer vos données :
Figure 1-18. Boîte de dialogue Enregistrer le fichier de données
Les fichiers de données de STATGRAPHICS Centurion XVI sont enregistrés sur le disque dur avec par défaut l’extension « .sgd » qui enregistre les données sous le format XML. Lorsque vous enregistrez un fichier, vous pouvez modifier ce paramètre dans le champ Type et choisir un autre format.
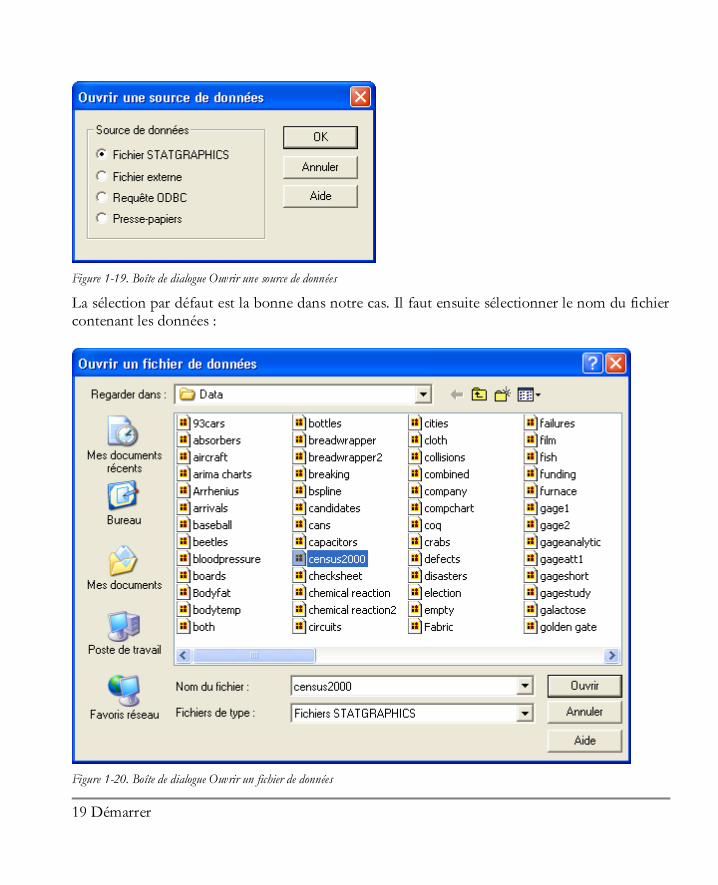
1.4 Lire un fichier de données enregistré Une fois les données entrées dans le tableur, celui-ci est prêt pour les analyses. Toutefois pour rendre notre exemple plus intéressant, nous allons utiliser les données du recensement pour les 50 états des USA y compris le « District of Columbia ». Ce fichier est livré avec STATGRAPHICS Centurion XVI sous le nom census2000.sgd. Pour ouvrir ce fichier de données, sélectionner Fichier – Ouvrir – Ouvrir un fichier de données dans le menu principal. Il vous faudra en premier indiquer la localisation du fichier auquel vous souhaitez accéder :
19 Démarrer
Figure 1-19. Boîte de dialogue Ouvrir une source de données
La sélection par défaut est la bonne dans notre cas. Il faut ensuite sélectionner le nom du fichier contenant les données :
Figure 1-20. Boîte de dialogue Ouvrir un fichier de données

20 Démarrer
Le fichier exemple est localisé dans le répertoire de données par défaut (habituellement c:\Program Files\Statgraphics\STATGRAPHICS Centurion XVI\Data). Ouvrir le fichier de données pour charger les 51 lignes de données dans le tableur :
Figure 1-21. Tableur affichant le contenu du fichier Census2000.sgd
1.5 Analyser les données Lorsque les données sont chargées dans le classeur de STATGRAPHICS Centurion XVI, chacune de ses 160 analyses statistiques peut être mise en oeuvre de différentes façons :
1. En sélectionnant la procédure désirée dans le menu principal.
2. En cliquant sur l’une des icônes de la barre d’outils.
3. En invoquant le StatWizard en cliquant sur son icône dans la barre d’outils.
21 Démarrer
Débutons en analysant la variabilité du revenu par tête dans les différents états. La meilleure procédure pour résumer une unique colonne de données numériques est l’Analyse à une variable. Cette procédure calcule des statistiques résumées comme la moyenne et l’écart-type d’un échantillon. Elle fournit également divers graphiques, dont un histogramme et une boîte à moustaches. La localisation de cette procédure d’Analyse à une variable dépend du système de menus utilisé :
1. Menu classique : Sélectionner Décrire – Données quantitatives – Analyse à une variable.
2. Menu Six-Sigma : Sélectionner Analyser – Données quantitatives – Analyse à une variable.
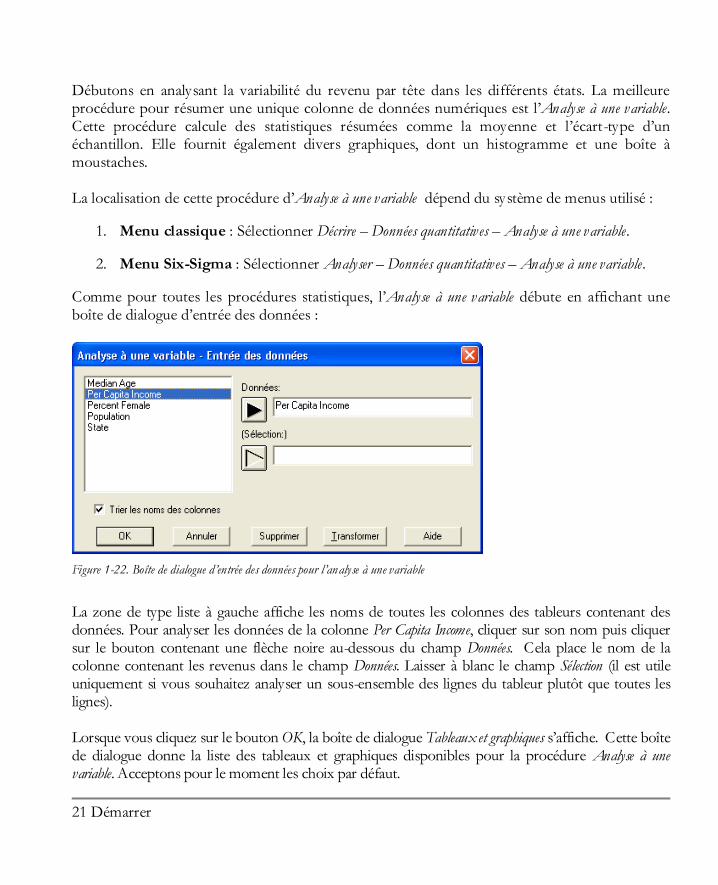
Comme pour toutes les procédures statistiques, l’Analyse à une variable débute en affichant une boîte de dialogue d’entrée des données :
Figure 1-22. Boîte de dialogue d’entrée des données pour l’analyse à une variable
La zone de type liste à gauche affiche les noms de toutes les colonnes des tableurs contenant des données. Pour analyser les données de la colonne Per Capita Income, cliquer sur son nom puis cliquer sur le bouton contenant une flèche noire au-dessous du champ Données. Cela place le nom de la colonne contenant les revenus dans le champ Données. Laisser à blanc le champ Sélection (il est utile uniquement si vous souhaitez analyser un sous-ensemble des lignes du tableur plutôt que toutes les lignes). Lorsque vous cliquez sur le bouton OK, la boîte de dialogue Tableaux et graphiques s’affiche. Cette boîte de dialogue donne la liste des tableaux et graphiques disponibles pour la procédure Analyse à une variable. Acceptons pour le moment les choix par défaut.

22 Démarrer
Figure 1-23 : Boîte de dialogue Tableaux et graphiques
En cliquant à nouveau sur le bouton OK, une nouvelle fenêtre d’analyse est créée :
Figure 1-24. Fenêtre de l’Analyse à une variable
La fenêtre contient quatre sous-fenêtres avec des barres déplaçables les séparant. Les deux sous-fenêtres de gauche contiennent des tableaux alors que les deux sous-fenêtres de droite contiennent des graphiques. Si vous double-cliquez dans la fenêtre en bas à gauche, le tableau des statistiques résumées est maximisé :

23 Démarrer
Figure 1-25. Fenêtre maximisée des statistiques résumées
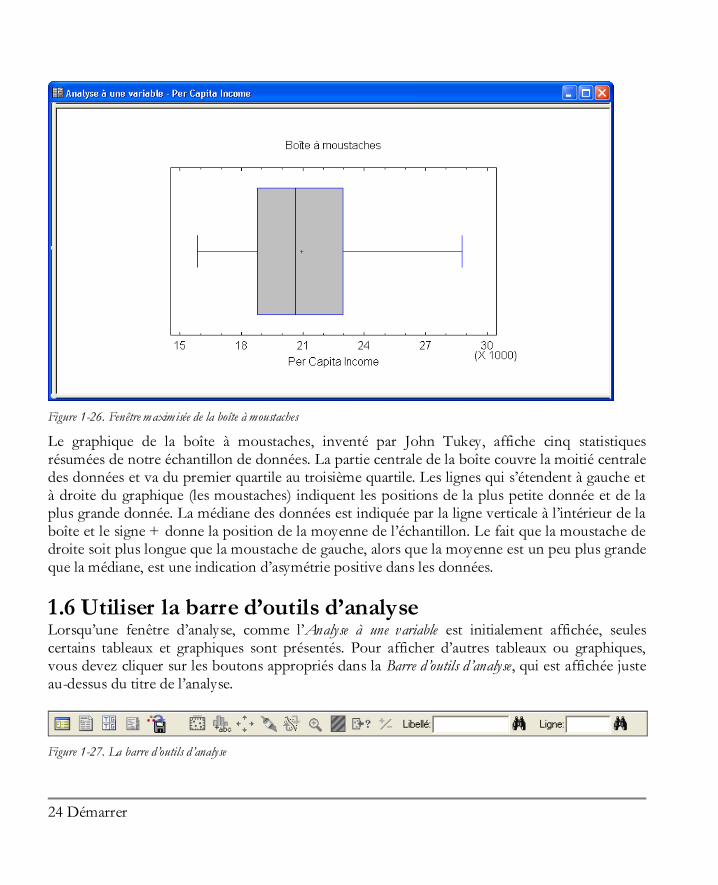
Plusieurs statistiques intéressantes sont données dans ce tableau. Dans les n = 51 états plus D.C., les revenus par tête varient entre 15.853$ et 28.766$. La moyenne des revenus par tête est de 20.934,47$. Au-dessous de tableau des résultats se trouve le StatAdvisor, qui vous donne une rapide interprétation des résultats. Dans notre cas, le StatAdvisor se concentre sur les deux statistiques affichées en rouge, qui mesurent l’asymétrie et l’aplatissement dans les données. Comme expliqué par le StatAdvisor, les données provenant d’une loi normale ou d’une distribution gaussienne doivent avoir une asymétrie standardisée et un aplatissement standardisé compris entre –2 et +2. Dans notre cas, les deux statistiques sont dans cette plage, ce qui indique qu’une loi normale en forme de cloche est un modèle raisonnable pour les observations, même si l’asymétrie standardisée est très près d’être statistiquement significative. Un double-clic dans le tableau des statistiques résumées nous permet de revenir à l’affichage d’origine en quatre sous-fenêtres. En double-cliquant dans la fenêtre en bas à droite, le graphique de la boîte à moustaches est maximisé :
24 Démarrer
Figure 1-26. Fenêtre maximisée de la boîte à moustaches
Le graphique de la boîte à moustaches, inventé par John Tukey, affiche cinq statistiques résumées de notre échantillon de données. La partie centrale de la boîte couvre la moitié centrale des données et va du premier quartile au troisième quartile. Les lignes qui s’étendent à gauche et à droite du graphique (les moustaches) indiquent les positions de la plus petite donnée et de la plus grande donnée. La médiane des données est indiquée par la ligne verticale à l’intérieur de la boîte et le signe + donne la position de la moyenne de l’échantillon. Le fait que la moustache de droite soit plus longue que la moustache de gauche, alors que la moyenne est un peu plus grande que la médiane, est une indication d’asymétrie positive dans les données.
1.6 Utiliser la barre d’outils d’analyse Lorsqu’une fenêtre d’analyse, comme l’Analyse à une variable est initialement affichée, seules certains tableaux et graphiques sont présentés. Pour afficher d’autres tableaux ou graphiques, vous devez cliquer sur les boutons appropriés dans la Barre d’outils d’analyse, qui est affichée juste au-dessus du titre de l’analyse.
Figure 1-27. La barre d’outils d’analyse

25 Démarrer
Les boutons de la barre d’outils d’analyse sont très importants. Les actions de ses sept premiers boutons sont décrites ci-après.
Nom Fonction
Définition de l’analyse Affiche la boîte de dialogue d’entrée des données et
permet de changer les colonnes de données à analyser.
Options d’analyse Permet de sélectionner les options qui s’appliquent à
tous les tableaux et graphiques de l’analyse en cours.
Tableaux et graphiques Affiche la liste des tableaux et des graphiques qui
peuvent être créés.
Options pour la fenêtre Sélectionne les options qui s’appliquent uniquement au
tableau ou au graphique maximisé.
Enregistrer des résultats Permet d’enregistrer des statistiques calculées dans des
colonnes du tableur.
Options graphiques Permet de modifier les titres, échelles et autres
caractéristiques du graphique maximisé.
Figure 1-28. Les boutons importants de la barre d’outils d’analyse
D’autres boutons à droite de ceux-ci permettent d’autres actions lorsqu’un graphique est maximisé, comme cela est expliqué dans le Chapitre 5. Par exemple, si vous cliquez sur le
bouton Tableaux et graphiques , une boîte de dialogue s’affichera listant tous les tableaux et graphiques disponibles pour l’Analyse à une variable :
Figure 1-29. Liste des graphiques disponibles
Cliquer dans la case à cocher à gauche de Histogramme d’effectifs puis cliquer sur OK ajoute un troisième graphique dans la partie droite de la fenêtre d’analyse :

26 Démarrer
Figure 1-30. La fenêtre de l’analyse à une variable après ajout de l’histogramme d’effectifs
Si vous double-cliquez dans l’histogramme pour le maximiser puis cliquez sur le bouton Options pour la fenêtre, une boîte de dialogue s’affiche avec des options spécifiques à l’histogramme :
27 Démarrer
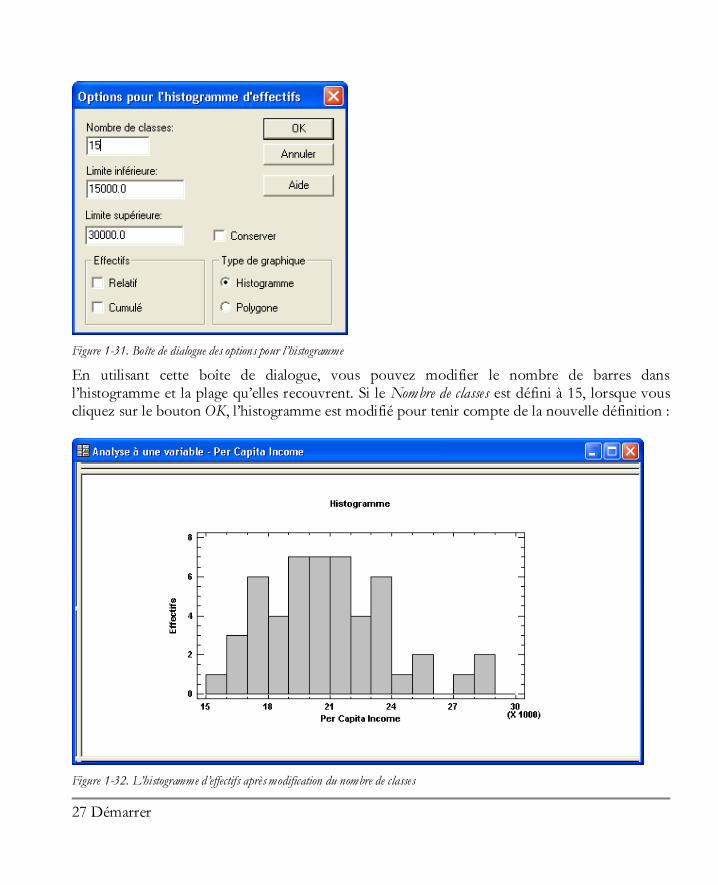
Figure 1-31. Boîte de dialogue des options pour l’histogramme
En utilisant cette boîte de dialogue, vous pouvez modifier le nombre de barres dans l’histogramme et la plage qu’elles recouvrent. Si le Nombre de classes est défini à 15, lorsque vous cliquez sur le bouton OK, l’histogramme est modifié pour tenir compte de la nouvelle définition :
Figure 1-32. L’histogramme d’effectifs après modification du nombre de classes

28 Démarrer
Vous pouvez également modifier le type de remplissage et la couleur des barres de l’histogramme en cliquant sur le bouton Options graphiques. Il s’affiche alors une boîte de dialogue à onglets qui vous permet de modifier la plupart des éléments du graphique. Si vous cliquez sur l’onglet Remplissages, la boîte de dialogue suivante s’affiche :
Figure 1-33. Boîte de dialogue à onglets des options graphiques
En cliquant sur le bouton radio n°1 puis en sélectionnant un nouveau Type de remplissages ou une nouvelle Couleur, la présentation des barres de l’histogramme sera modifiée. NOTE : Les opérations de nombreux boutons de la barre d’outils d’analyse peuvent également être effectuées en cliquant sur le bouton droit de la souris dans la sous-fenêtre contenant le tableau ou le graphique. Un menu popup s’affiche alors listant les opérations disponibles.

29 Démarrer
1.7 Diffuser les résultats Lorsqu’une analyse a été effectuée, les résultats peuvent être diffusés de diverses façons, dont :
Action Méthode
Imprimer les résultats. Cliquer sur le bouton Imprimante dans la barre d’outils principale pour imprimer tous les tableaux et tous les graphiques ou cliquer dans une sous-fenêtre sur le bouton droit de la souris et sélectionner Imprimer dans le menu popup pour imprimer un unique tableau ou un unique graphique.
Publier les résultats pour les visualiser via un navigateur sur le Web.
Sélectionner Publier les statistiques dans le menu Fichier. Une boîte de dialogue s’affiche pour vous demander de préciser la localisation des pages HTML.
Copier les résultats dans un autre logiciel.
Cliquer dans le tableau ou dans le graphique à copier et sélectionner Copier dans le menu Editer. Charger alors l’autre application et sélectionner Editer – Coller.
Enregistrer l’analyse dans un rapport.
Cliquer sur le bouton droit de la souris et sélectionner Copier l’analyse dans le StatReporter. Le StatReporter, décrit au Chapitre 7, peut être enregistré au format RTF pour importation dans d’autres logiciels comme Microsoft Word.
Enregistrer un graphique dans un fichier image.
Maximiser le graphique à enregistrer puis sélectionner Enregistrer un graphique dans le menu Fichier.
Figure 1-34. Méthodes pour diffuser les résultats de l’analyse
Chacune de ces actions est décrite dans les chapitres suivants.
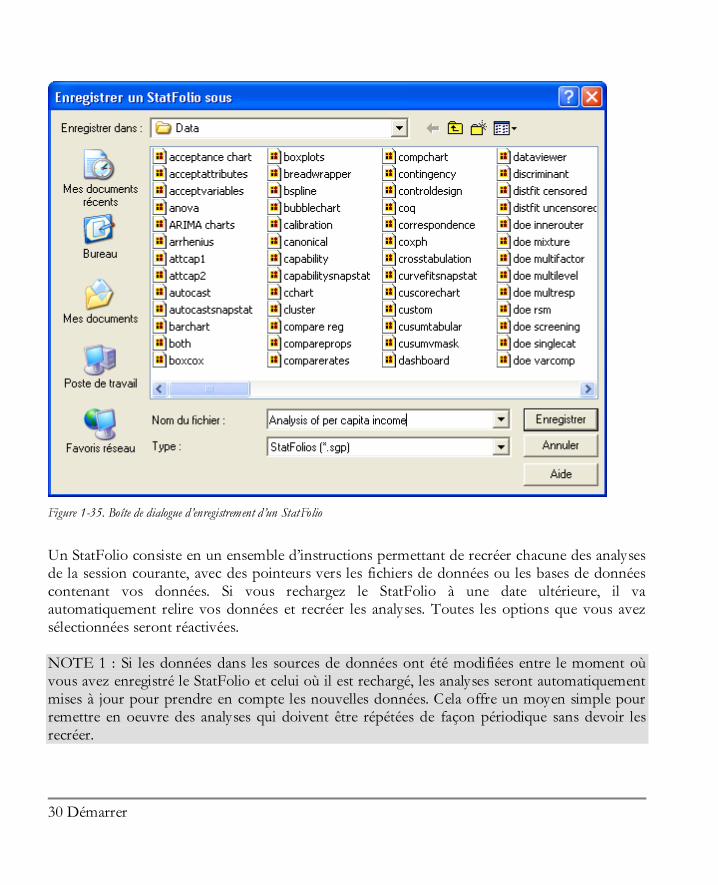
1.8 Enregistrer votre travail Vous pouvez enregistrer votre session courante STATGRAPHICS Centurion XVI à tout moment en sélectionnant Enregistrer un StatFolio dans le menu Fichier et en entrant un nom pour le fichier :
30 Démarrer
Figure 1-35. Boîte de dialogue d’enregistrement d’un StatFolio
Un StatFolio consiste en un ensemble d’instructions permettant de recréer chacune des analyses de la session courante, avec des pointeurs vers les fichiers de données ou les bases de données contenant vos données. Si vous rechargez le StatFolio à une date ultérieure, il va automatiquement relire vos données et recréer les analyses. Toutes les options que vous avez sélectionnées seront réactivées. NOTE 1 : Si les données dans les sources de données ont été modifiées entre le moment où vous avez enregistré le StatFolio et celui où il est rechargé, les analyses seront automatiquement mises à jour pour prendre en compte les nouvelles données. Cela offre un moyen simple pour remettre en oeuvre des analyses qui doivent être répétées de façon périodique sans devoir les recréer.

31 Démarrer
NOTE 2 : Les données et le StatFolio sont enregistrés dans des fichiers séparés. Si vous devez transférer un StatFolio sur un autre ordinateur, assurez-vous de transférer également le ou les fichiers de données.

32 Démarrer
33/ Gestion des données
Gestion des données
Accéder aux fichiers et bases de données, transformer les données, générer des données structurées.
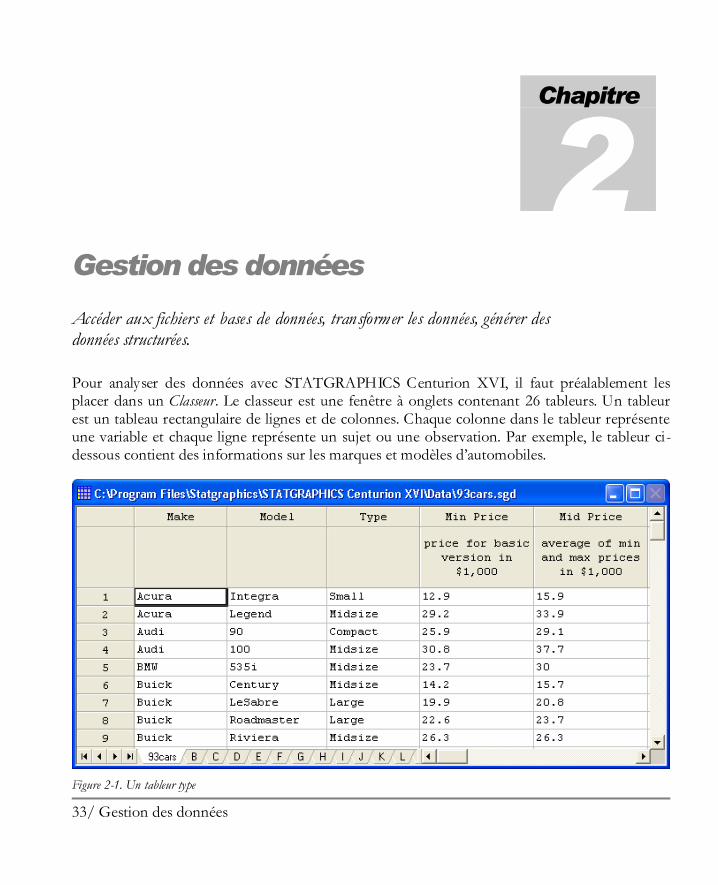
Pour analyser des données avec STATGRAPHICS Centurion XVI, il faut préalablement les placer dans un Classeur. Le classeur est une fenêtre à onglets contenant 26 tableurs. Un tableur est un tableau rectangulaire de lignes et de colonnes. Chaque colonne dans le tableur représente une variable et chaque ligne représente un sujet ou une observation. Par exemple, le tableur ci-dessous contient des informations sur les marques et modèles d’automobiles.
Figure 2-1. Un tableur type
Chapitre
2
34/ Gestion des données
Ce chapitre décrit tout ce que vous devez savoir sur les données avec STATGRAPHICS Centurion XVI, notamment comment y accéder, comment les manipuler et comment les utiliser dans les analyses statistiques.
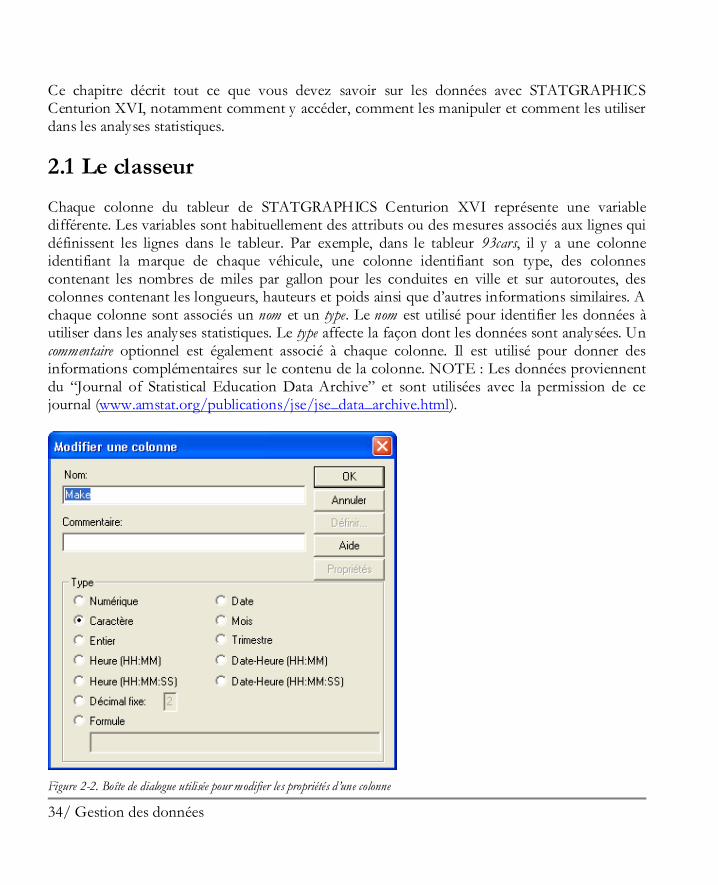
2.1 Le classeur Chaque colonne du tableur de STATGRAPHICS Centurion XVI représente une variable différente. Les variables sont habituellement des attributs ou des mesures associés aux lignes qui définissent les lignes dans le tableur. Par exemple, dans le tableur 93cars, il y a une colonne identifiant la marque de chaque véhicule, une colonne identifiant son type, des colonnes contenant les nombres de miles par gallon pour les conduites en ville et sur autoroutes, des colonnes contenant les longueurs, hauteurs et poids ainsi que d’autres informations similaires. A chaque colonne sont associés un nom et un type. Le nom est utilisé pour identifier les données à utiliser dans les analyses statistiques. Le type affecte la façon dont les données sont analysées. Un commentaire optionnel est également associé à chaque colonne. Il est utilisé pour donner des informations complémentaires sur le contenu de la colonne. NOTE : Les données proviennent du “Journal of Statistical Education Data Archive” et sont utilisées avec la permission de ce journal (www.amstat.org/publications/jse/jse_data_archive.html).
Figure 2-2. Boîte de dialogue utilisée pour modifier les propriétés d’une colonne

35/ Gestion des données
Pour afficher ou modifier les propriétés d’une colonne dans le tableur, double-cliquer sur le nom de la colonne pour afficher la boîte de dialogue Modifier une colonne.
Vous pouvez préciser :
1. Nom : de 1 à 32 caractères. Lorsque vous mettez en oeuvre des analyses statistiques, les colonnes sont identifiées par ces noms. Chaque colonne du tableur doit avoir un nom unique, mais des colonnes de différents tableurs peuvent avoir le même nom. Les noms peuvent inclure tout caractère y compris des espaces. Les noms ne doivent pas débuter par un chiffre, les espaces y sont autorisés et ils ne distinguent pas les minuscules des majuscules.
2. Commentaire : de 0 à 64 caractères, ils donnent des informations complémentaires sur le contenu de la colonne.
3. Type : le type de données autorisé dans la colonne. Les types suivants peuvent être définis :
Type Contenu Exemple
Numérique Tout nombre valide 3,14
Caractère Toute chaîne alphanumérique Chevrolet
Entier Un nombre entier 105
Date Jour, mois, année 19/02/06
Mois Mois, année 02/06
Trimestre Trimestre, année Q1/06
Heure (HH:MM) Heure, minute 3:15
Heure (HH:MM:SS) Heure, minute, seconde 3:15:53
Date-Heure (HH:MM) Jour, mois, année, heure, minute 19/02/06 3:15
Date-Heure (HH:MM:SS)
Jour, mois, année, heure, minute, seconde
19/02/06 3:15:53
Décimal fixe Nombre avec 1 à 9 décimales 34,10
Formule Calcul à partir d’autres colonnes MPG City/MPG Highway
Figure 2-3. Types des colonnes
Lorsque vous entrez des données dans le tableur, les données doivent être conformes aux types des colonnes dans lesquelles les données sont entrées. Par exemple, l’entrée d’un nom dans une colonne numérique sera rejetée. Lorsque vous entrez des données, le format des données doit également être en accord avec les paramètres de Windows. En particulier, STATGRAPHICS Centurion XVI utilise les paramètres de Windows suivants :

36/ Gestion des données
1. Séparateur décimal pour les valeurs numériques 2. Format heure et son séparateur 3. Format court des dates et son séparateur
Pour vérifier les paramètres de Windows sur votre ordinateur, il suffit d’accéder au Panneau de configuration de Windows. Lorsque vous entrez une date, vous devez utiliser le format indiqué dans la boîte de dialogue Editer - Préférences, soit 4 chiffres pour les années (par exemple 18/12/2009) soit 2 chiffres (par exemple 18/12/09). Si le format à 2 chiffres est utilisé pour les années, il est supposé que les années sont comprises entre 1950 et 2049. Plus d’informations sur les colonnes de type Formule peuvent être trouvées dans le paragraphe Manipuler des données plus loin dans ce chapitre.
2.2 Accéder aux données Le Chapitre 1 vous a montré comment entrer des données au clavier dans le tableur. Plus fréquemment, les utilisateurs accéderont à des données qui existent déjà dans d’autres fichiers ou logiciels. Il y a 3 façons simples pour charger des données déjà existantes dans le tableur de STATGRAPHICS Centurion XVI :
1. Lire un fichier déjà existant : Si les données ont déjà été saisies dans un fichier, vous pouvez les charger dans le tableur en sélectionnant Fichier – Ouvrir – Ouvrir une source de données. Cela permet de lire des données enregistrées sous divers formats, dont les fichiers Excel, les fichiers ASCII délimités, les fichiers XML, les fichiers STATGRAPHICS et les fichiers d’autres logiciels statistiques.
2. Copier et coller en utilisant le presse-papiers de Windows : Si vos données sont déjà
chargées dans un autre logiciel comme par exemple Excel, vous pouvez aisément les copier dans le presse-papiers de Windows et les coller dans STATGRAPHICS Centurion XVI en sélectionnant Editer – Coller.
3. Exécuter une requête SQL pour récupérer des données contenues dans une base
de données : Si vos données sont stockées dans une base de données compatible ODBC, comme par exemple Oracle ou Microsoft Access, elles peuvent être récupérées en sélectionnant Fichier – Ouvrir – Ouvrir une source de données puis en sélectionnant Requête ODBC.
37/ Gestion des données
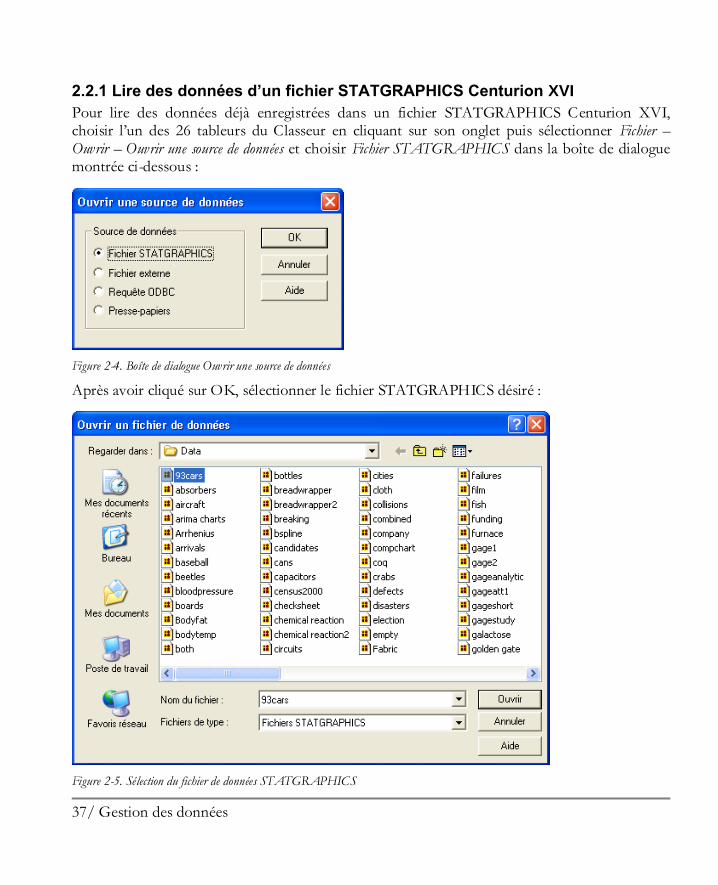
2.2.1 Lire des données d’un fichier STATGRAPHICS Centurion XVI
Pour lire des données déjà enregistrées dans un fichier STATGRAPHICS Centurion XVI, choisir l’un des 26 tableurs du Classeur en cliquant sur son onglet puis sélectionner Fichier – Ouvrir – Ouvrir une source de données et choisir Fichier STATGRAPHICS dans la boîte de dialogue montrée ci-dessous :
Figure 2-4. Boîte de dialogue Ouvrir une source de données
Après avoir cliqué sur OK, sélectionner le fichier STATGRAPHICS désiré :
Figure 2-5. Sélection du fichier de données STATGRAPHICS
38/ Gestion des données
Vous pouvez lire des fichiers de données de STATGRAPHICS Centurion XVI ou de toute version précédente de STATGRAPHICS dont STATGRAPHICS Plus. Les données du fichier remplaceront alors les données présentes dans le tableur sélectionné.
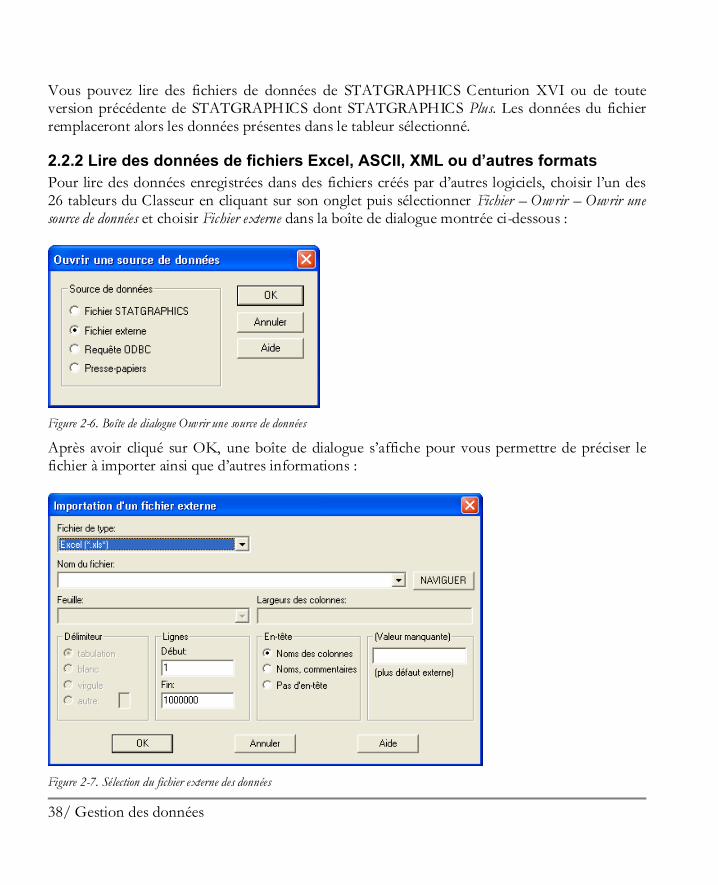
2.2.2 Lire des données de fichiers Excel, ASCII, XML ou d’autres formats
Pour lire des données enregistrées dans des fichiers créés par d’autres logiciels, choisir l’un des 26 tableurs du Classeur en cliquant sur son onglet puis sélectionner Fichier – Ouvrir – Ouvrir une source de données et choisir Fichier externe dans la boîte de dialogue montrée ci-dessous :
Figure 2-6. Boîte de dialogue Ouvrir une source de données
Après avoir cliqué sur OK, une boîte de dialogue s’affiche pour vous permettre de préciser le fichier à importer ainsi que d’autres informations :
Figure 2-7. Sélection du fichier externe des données

39/ Gestion des données
Les champs de cette boîte de dialogue sont :
1. Fichier de type – type du fichier à importer. STATGRAPHICS Centurion XVI peut importer des données depuis de nombreuses autres applications, dont Excel, Matlab, Minitab, JMP, SPSS, SAS et beaucoup d’autres logiciels statistiques.
2. Nom du fichier – nom du fichier à importer. Cliquer sur le bouton NAVIGUER pour
sélectionner le fichier désiré.
3. Feuille – nom de la feuille à importer (si utile). Seule une feuille peut être importée à la fois.
4. Largeurs des colonnes – les largeurs des colonnes, séparées par des virgules (pour les
fichiers ASCII formatés uniquement).
5. Délimiteur – délimiteur des colonnes (pour les fichiers ASCII délimités uniquement).
6. Lignes – la plage des lignes de la feuille qui sera lue. Cette plage inclut les noms des variables et les commentaires, s’il y en a.
7. En-tête - information continue dans les 2 premières lignes de la plage indiquée (pour les
tableurs comme Excel, par exemple). Les deux lignes immédiatement au-dessus des données à lire peuvent contenir des noms de colonnes et/ou des commentaires. Si les noms ne sont pas contenus dans le fichier, alors des noms par défaut seront générés.
8. Valeur manquante - tout symbole spécial utilisé dans le fichier externe pour indiquer
une valeur manquante, comme par exemple NA. Les cellules contenant le symbole indiqué seront converties en cellules vides lorsqu’elles seront placées dans le tableur de STATGRAPHICS Centurion XVI.
Lorsque vous cliquez sur OK, les données du fichier externe sont lues et chargées dans STATGRAPHICS Centurion XVI. Chaque colonne est inspectée et un type approprié lui est affecté. Les données sont alors prêtes pour les analyses.
2.2.3 Transférer des données par copier-coller
La façon la plus simple de transférer les données d’autres logiciels dans STATGRAPHICS Centurion XVI est fréquemment par le presse-papiers de Windows. Par exemple, si les données sont dans un fichier Excel, Excel peut être chargé et les données copiées dans le presse-papiers

40/ Gestion des données
en sélectionnant les données désirées dans Excel puis en choisissant Copier dans le menu Editer d’Excel. Une fois dans STATGRAPHICS, les données peuvent y être collées directement dans un tableur de STATGRAPHICS Centurion XVI en sélectionnant Coller dans le menu Editer de STATGRAPHICS. Lorsque les données sont collées dans une colonne du tableur, STATGRAPHICS Centurion XVI inspecte automatiquement les données et affecte le type approprié à la colonne. Lorsque vous copiez et collez des données, les noms des colonnes et les commentaires peuvent également être transférés. Il suffit d’inclure les noms des colonnes et les commentaires d’Excel lorsque vous copiez les données dans le presse-papiers. Dans STATGRAPHICS Centurion XVI, cliquez sur la ligne d’en-têtes du tableur avant de sélectionner Coller. Les informations du début du presse-papiers seront collées dans les lignes d’en-têtes.
2.2.4 Faire une requête dans une base de données ODBC
STATGRAPHICS Centurion XVI permet également de lire des données contenues dans des bases de données comme Oracle, Access ou toute base de données utilisant l’ODBC. Pour accéder à des données contenues dans une base de données, sélectionner Fichier – Ouvrir – Ouvrir une source de données puis Requête ODBC dans la boîte de dialogue initiale :
Figure 2-8. Boîte de dialogue Ouvrir une source de données
Une suite de boîtes de dialogue s’affichera dans lesquelles vous :
1. Sélectionnerez le nom de la base de données à lire.
2. Sélectionnerez les champs à transférer.
3. Définirez un filtre pour sélectionner les enregistrements à transférer.
4. Définirez la façon de trier les résultats.

41/ Gestion des données
Une requête SQL est alors construite et les résultats sont chargés dans le tableur actif de STATGRAPHICS Centurion XVI Des informations détaillées concernant la construction de requêtes ODBC peuvent être trouvées dans le document PDF intitulé Fichiers de données et StatLink.
2.3 Manipuler les données Une fois les données dans un tableur de STATGRAPHICS Centurion XVI, elles peuvent être manipulées de diverses façons :
1. Les données peuvent être copiées et collées dans d’autres emplacements.
2. De nouvelles colonnes peuvent être créées à partir de colonnes existantes.
3. Les données peuvent être transformées par des expressions algébriques ou des fonctions mathématiques.
4. Le tableur peut être trié en fonction d’une ou de plusieurs colonnes.
5. Les données peuvent être recodées pour créer des groupes ou pour d’autres besoins.
6. Les données de plusieurs colonnes peuvent être réorganisées en une unique colonne si cela est requis par une analyse statistique.
Ces importantes opérations sont décrites ci-après.
2.3.1 Copier et coller des données
Le tableur de STATGRAPHICS Centurion XVI permet de mettre en œuvre de nombreuses opérations usuelles proposées par les tableurs, dont couper, copier, coller, insérer et supprimer. Le fait important à retenir lorsque vous utilisez ces opérations est que chaque colonne a un type défini. Si par inadvertance, vous coller des données de type caractère dans une colonne de type numérique, STATGRAPHICS Centurion XVI va modifier le type de la colonne pour être en phase avec les nouvelles données. Si vous avez un doute sur le type d’une colonne, cliquez sur l’en-tête de la colonne pour afficher la boîte de dialogue Modifier une colonne. Vous pouvez modifier le type de la colonne en utilisant cette boîte de dialogue.
42/ Gestion des données
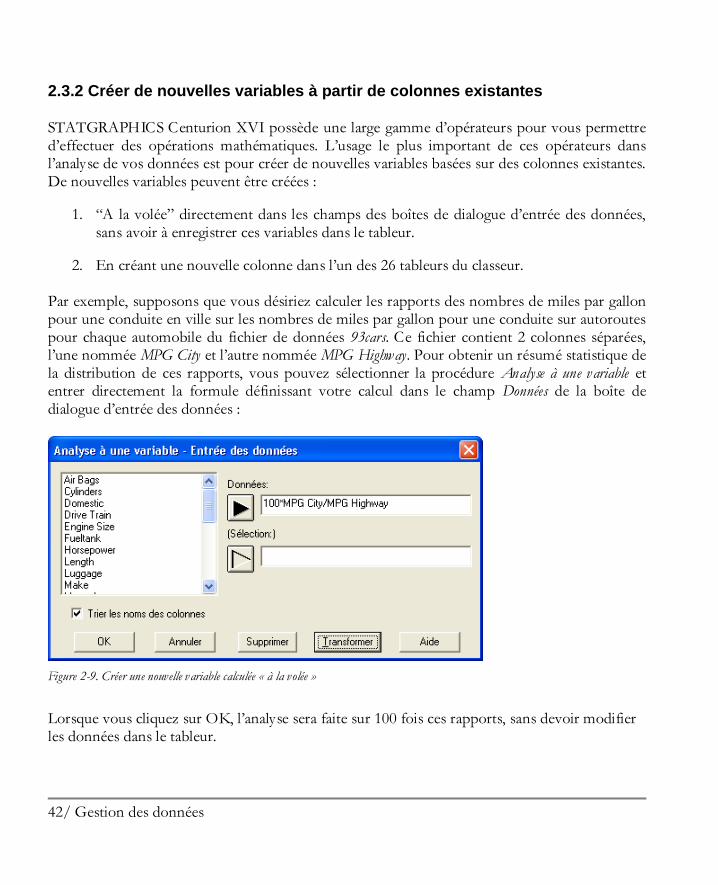
2.3.2 Créer de nouvelles variables à partir de colonnes existantes
STATGRAPHICS Centurion XVI possède une large gamme d’opérateurs pour vous permettre d’effectuer des opérations mathématiques. L’usage le plus important de ces opérateurs dans l’analyse de vos données est pour créer de nouvelles variables basées sur des colonnes existantes. De nouvelles variables peuvent être créées :
1. “A la volée” directement dans les champs des boîtes de dialogue d’entrée des données, sans avoir à enregistrer ces variables dans le tableur.
2. En créant une nouvelle colonne dans l’un des 26 tableurs du classeur. Par exemple, supposons que vous désiriez calculer les rapports des nombres de miles par gallon pour une conduite en ville sur les nombres de miles par gallon pour une conduite sur autoroutes pour chaque automobile du fichier de données 93cars. Ce fichier contient 2 colonnes séparées, l’une nommée MPG City et l’autre nommée MPG Highway. Pour obtenir un résumé statistique de la distribution de ces rapports, vous pouvez sélectionner la procédure Analyse à une variable et entrer directement la formule définissant votre calcul dans le champ Données de la boîte de dialogue d’entrée des données :
Figure 2-9. Créer une nouvelle variable calculée « à la volée »
Lorsque vous cliquez sur OK, l’analyse sera faite sur 100 fois ces rapports, sans devoir modifier les données dans le tableur.
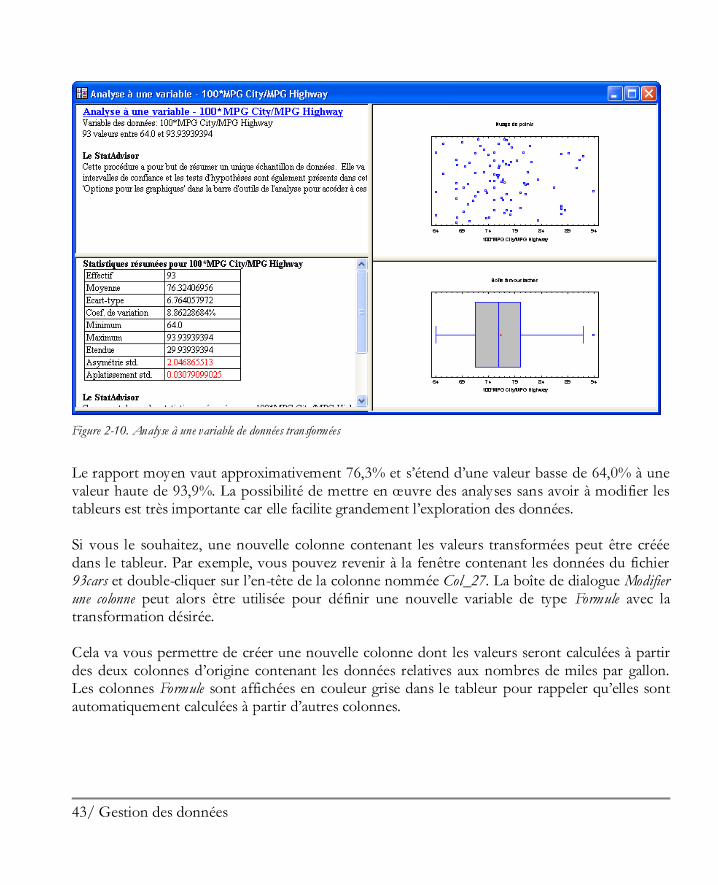
43/ Gestion des données
Figure 2-10. Analyse à une variable de données transformées
Le rapport moyen vaut approximativement 76,3% et s’étend d’une valeur basse de 64,0% à une valeur haute de 93,9%. La possibilité de mettre en œuvre des analyses sans avoir à modifier les tableurs est très importante car elle facilite grandement l’exploration des données. Si vous le souhaitez, une nouvelle colonne contenant les valeurs transformées peut être créée dans le tableur. Par exemple, vous pouvez revenir à la fenêtre contenant les données du fichier 93cars et double-cliquer sur l’en-tête de la colonne nommée Col_27. La boîte de dialogue Modifier une colonne peut alors être utilisée pour définir une nouvelle variable de type Formule avec la transformation désirée. Cela va vous permettre de créer une nouvelle colonne dont les valeurs seront calculées à partir des deux colonnes d’origine contenant les données relatives aux nombres de miles par gallon. Les colonnes Formule sont affichées en couleur grise dans le tableur pour rappeler qu’elles sont automatiquement calculées à partir d’autres colonnes.
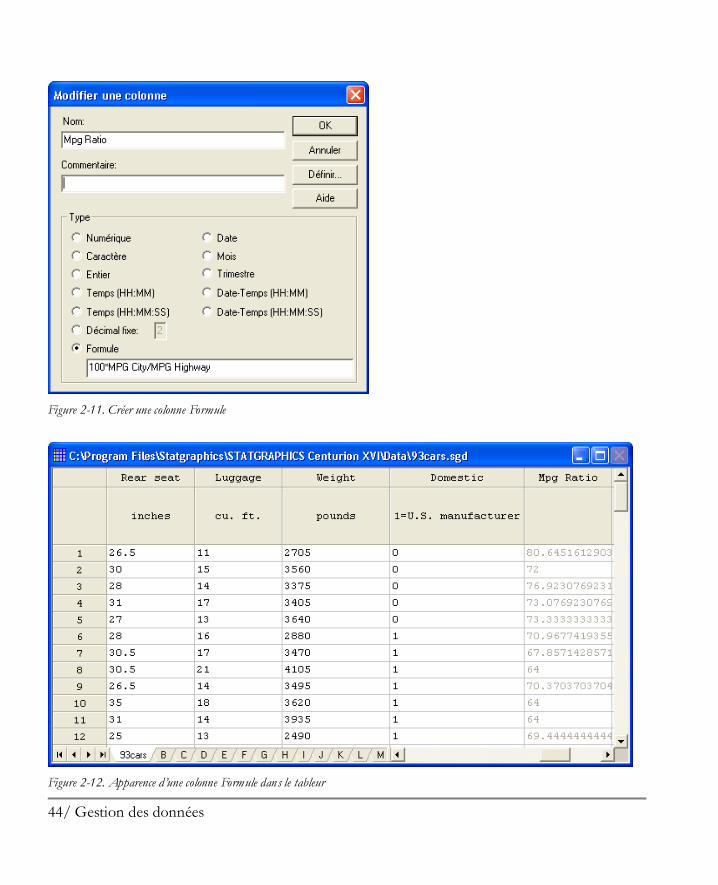
44/ Gestion des données
Figure 2-11. Créer une colonne Formule
Figure 2-12. Apparence d’une colonne Formule dans le tableur
45/ Gestion des données
Si les valeurs dans les colonnes MPG City ou MPG Highway sont modifiées, MPG Ratio sera automatiquement recalculée pour prendre en compte ces modifications.
NOTE : Le recalcul des colonnes de type Formule n’est pas effectué tant que ces colonnes ne sont pas nécessaires pour des calculs ou enregistrées ou imprimées. Vous pouvez forcer le recalcul immédiat de ces colonnes en sélectionnant Mettre à jour les formules dans le menu Editer.
2.3.3 Transformer des données
STATGRAPHICS Centurion XVI possède également un grand nombre de fonctions mathématiques qui peuvent être utilisées pour transformer des données existantes. Comme pour la création de nouvelles variables, les transformations peuvent être effectuées soit directement dans les champs de la boîte de dialogue d’entrée des données soit en créant de nouvelles colonnes dans le tableur. Par exemple, supposons que nous désirions tracer un graphique des nombres de miles par gallon pour nos automobiles par rapport au logarithme naturel des poids de ces véhicules. Sélectionnons la procédure Graphique X-Y dans le menu principal pour afficher la boîte de dialogue d’entrée des données :
Figure 2-13. Transformer des données dans une boîte de dialogue d’entrée des données
46/ Gestion des données
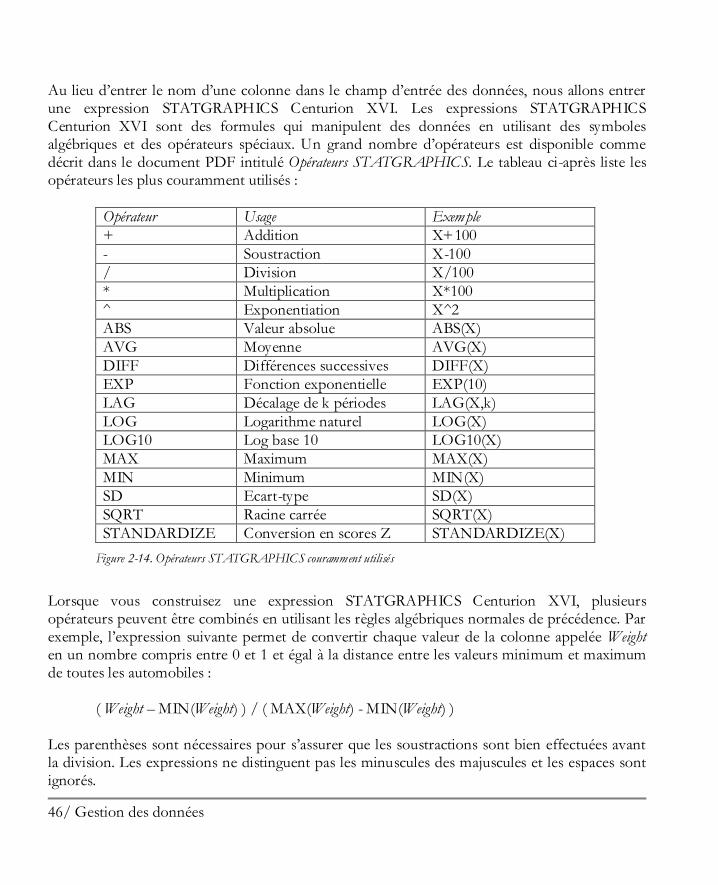
Au lieu d’entrer le nom d’une colonne dans le champ d’entrée des données, nous allons entrer une expression STATGRAPHICS Centurion XVI. Les expressions STATGRAPHICS Centurion XVI sont des formules qui manipulent des données en utilisant des symboles algébriques et des opérateurs spéciaux. Un grand nombre d’opérateurs est disponible comme décrit dans le document PDF intitulé Opérateurs STATGRAPHICS. Le tableau ci-après liste les opérateurs les plus couramment utilisés :
Opérateur Usage Exemple
+ Addition X+100
- Soustraction X-100
/ Division X/100
* Multiplication X*100
^ Exponentiation X^2
ABS Valeur absolue ABS(X)
AVG Moyenne AVG(X)
DIFF Différences successives DIFF(X)
EXP Fonction exponentielle EXP(10)
LAG Décalage de k périodes LAG(X,k)
LOG Logarithme naturel LOG(X)
LOG10 Log base 10 LOG10(X)
MAX Maximum MAX(X)
MIN Minimum MIN(X)
SD Ecart-type SD(X)
SQRT Racine carrée SQRT(X)
STANDARDIZE Conversion en scores Z STANDARDIZE(X)
Figure 2-14. Opérateurs STATGRAPHICS couramment utilisés
Lorsque vous construisez une expression STATGRAPHICS Centurion XVI, plusieurs opérateurs peuvent être combinés en utilisant les règles algébriques normales de précédence. Par exemple, l’expression suivante permet de convertir chaque valeur de la colonne appelée Weight en un nombre compris entre 0 et 1 et égal à la distance entre les valeurs minimum et maximum de toutes les automobiles : ( Weight – MIN(Weight) ) / ( MAX(Weight) - MIN(Weight) ) Les parenthèses sont nécessaires pour s’assurer que les soustractions sont bien effectuées avant la division. Les expressions ne distinguent pas les minuscules des majuscules et les espaces sont ignorés.
47/ Gestion des données
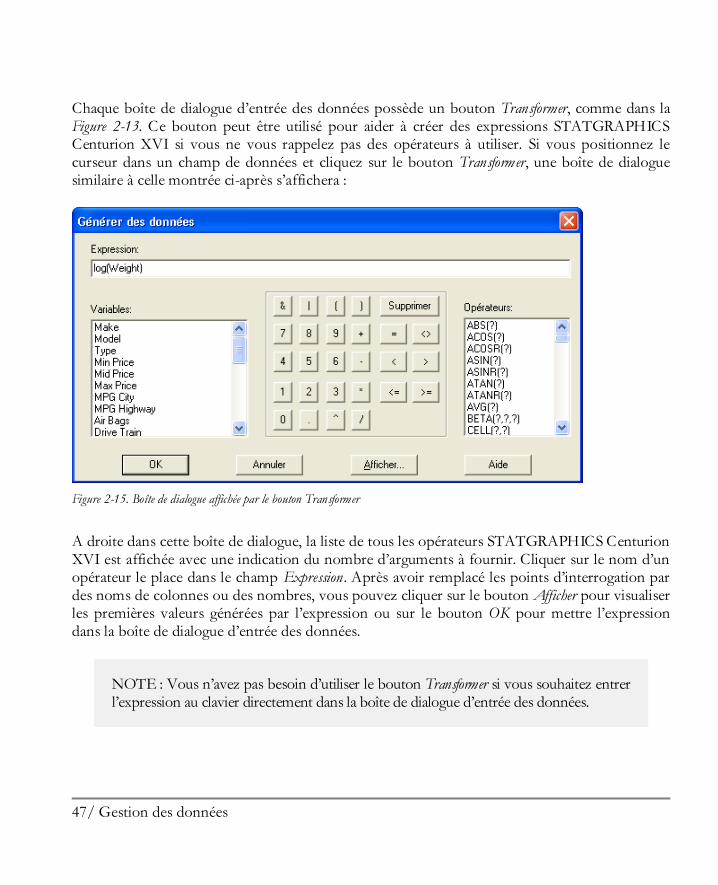
Chaque boîte de dialogue d’entrée des données possède un bouton Transformer, comme dans la Figure 2-13. Ce bouton peut être utilisé pour aider à créer des expressions STATGRAPHICS Centurion XVI si vous ne vous rappelez pas des opérateurs à utiliser. Si vous positionnez le curseur dans un champ de données et cliquez sur le bouton Transformer, une boîte de dialogue similaire à celle montrée ci-après s’affichera :
Figure 2-15. Boîte de dialogue affichée par le bouton Transformer
A droite dans cette boîte de dialogue, la liste de tous les opérateurs STATGRAPHICS Centurion XVI est affichée avec une indication du nombre d’arguments à fournir. Cliquer sur le nom d’un opérateur le place dans le champ Expression. Après avoir remplacé les points d’interrogation par des noms de colonnes ou des nombres, vous pouvez cliquer sur le bouton Afficher pour visualiser les premières valeurs générées par l’expression ou sur le bouton OK pour mettre l’expression dans la boîte de dialogue d’entrée des données.
NOTE : Vous n’avez pas besoin d’utiliser le bouton Transformer si vous souhaitez entrer l’expression au clavier directement dans la boîte de dialogue d’entrée des données.
48/ Gestion des données
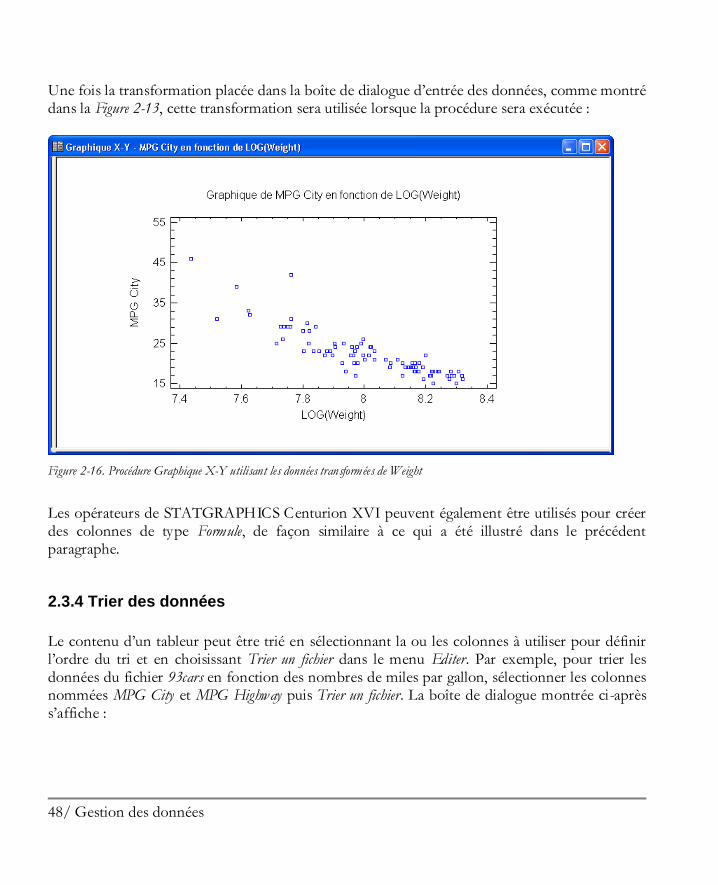
Une fois la transformation placée dans la boîte de dialogue d’entrée des données, comme montré dans la Figure 2-13, cette transformation sera utilisée lorsque la procédure sera exécutée :
Figure 2-16. Procédure Graphique X-Y utilisant les données transformées de Weight
Les opérateurs de STATGRAPHICS Centurion XVI peuvent également être utilisés pour créer des colonnes de type Formule, de façon similaire à ce qui a été illustré dans le précédent paragraphe.
2.3.4 Trier des données
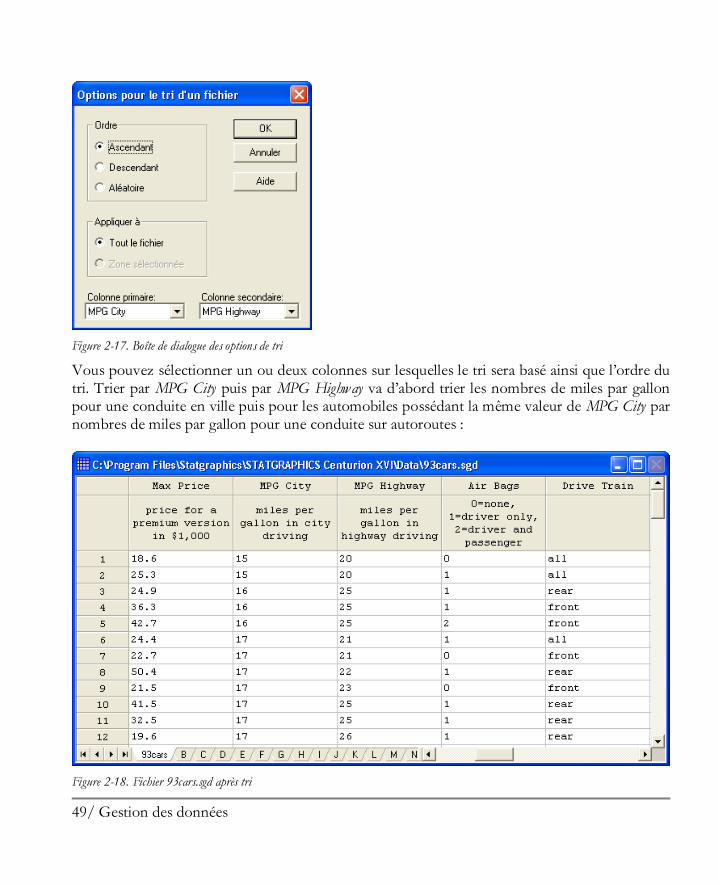
Le contenu d’un tableur peut être trié en sélectionnant la ou les colonnes à utiliser pour définir l’ordre du tri et en choisissant Trier un fichier dans le menu Editer. Par exemple, pour trier les données du fichier 93cars en fonction des nombres de miles par gallon, sélectionner les colonnes nommées MPG City et MPG Highway puis Trier un fichier. La boîte de dialogue montrée ci-après s’affiche :
49/ Gestion des données
Figure 2-17. Boîte de dialogue des options de tri
Vous pouvez sélectionner un ou deux colonnes sur lesquelles le tri sera basé ainsi que l’ordre du tri. Trier par MPG City puis par MPG Highway va d’abord trier les nombres de miles par gallon pour une conduite en ville puis pour les automobiles possédant la même valeur de MPG City par nombres de miles par gallon pour une conduite sur autoroutes :
Figure 2-18. Fichier 93cars.sgd après tri

50/ Gestion des données
NOTE : Les procédures statistiques ne vous demandent pas de trier les données avant de pouvoir les mettre en oeuvre car elles effectueront ce tri automatiquement si cela est nécessaire. De même, le fichier sur le disque n’est pas modifié lorsque vous effectuez un tri sauf si vous enregistrez à nouveau les données. Le tri n’affecte que l’ordre dans lequel les données sont affichées dans le tableur.
2.3.5 Recoder des données
Il est parfois utile de recoder des données, soit pour les regrouper en groupes similaires, soit pour affecter de nouveaux libellés. Pour recoder une colonne de données, cliquer en premier sur l’en-tête de la colonne à recoder puis sélectionner Recoder des données dans le menu Editer. La boîte de dialogue suivante s’affiche alors :
Figure 2-19. Boîte de dialogue pour recoder des données

51/ Gestion des données
Par exemple, la colonne nommée Domestic dans le fichier 93cars contient un 1 pour chaque automobile fabriquée par un constructeur américain et un 0 pour toutes les autres automobiles. Pour transformer les 0 dans la colonne en “Foreign” et tous les 1 en “U.S.”, la boîte de dialogue renseignée comme ci-dessus peut être utilisée. Jusqu’à 7 plages de valeurs peuvent être recodées à la fois. Le document PDF intitulé Menu Editer présente de façon détaillée deux exemples de recodifications.
2.3.6 Combiner plusieurs colonnes
De nombreuses procédures statistiques de STATGRAPHICS Centurion XVI supposent que les données à analyser sont dans une unique colonne. Parfois les données ne sont pas sous cette forme. Comme exemple simple, supposons que votre échantillon de 12 observations soit organisé en 4 colonnes comme montré ci-dessous :
Figure 2-20. Données de notre exemple organisées en plusieurs colonnes
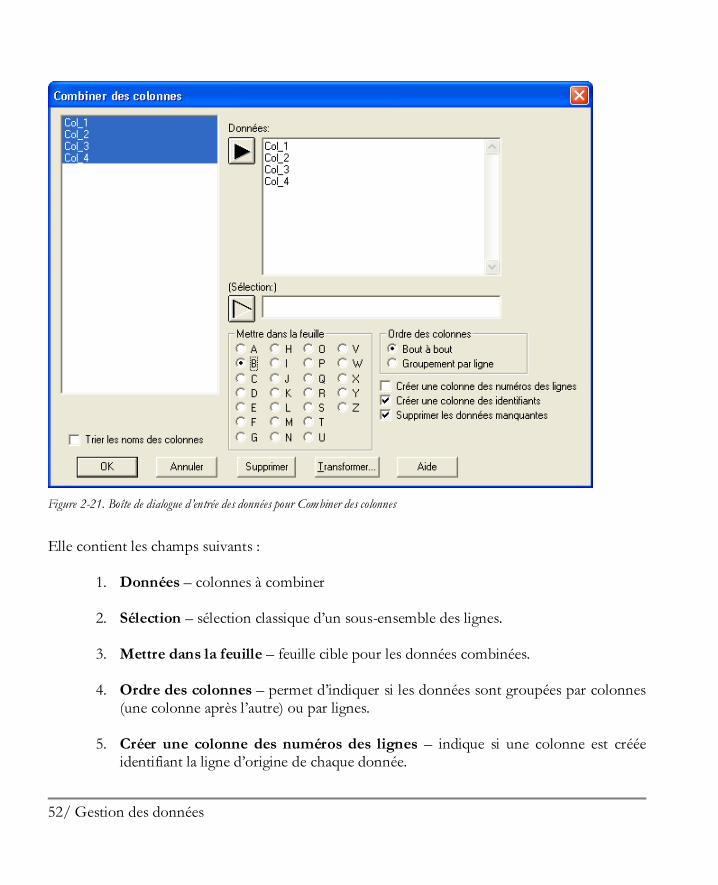
Pour organiser les données en une unique colonne, de nombreuses opérations copier et coller sont nécessaires. Une solution plus simple consiste à utiliser la procédure Combiner des colonnes qui se trouve dans le menu Editer. Cette procédure affiche une boîte de dialogue d’entrée des données qui demande les noms des colonnes contenant les données :
52/ Gestion des données
Figure 2-21. Boîte de dialogue d’entrée des données pour Combiner des colonnes
Elle contient les champs suivants :
1. Données – colonnes à combiner
2. Sélection – sélection classique d’un sous-ensemble des lignes.
3. Mettre dans la feuille – feuille cible pour les données combinées.
4. Ordre des colonnes – permet d’indiquer si les données sont groupées par colonnes (une colonne après l’autre) ou par lignes.
5. Créer une colonne des numéros des lignes – indique si une colonne est créée
identifiant la ligne d’origine de chaque donnée.

53/ Gestion des données
6. Créer une colonne des identifiants – indique si une colonne est créée identifiant la colonne d’origine de chaque donnée.
7. Supprimer les données manquantes – indique si les cellules vides sont supprimées
ou si elles son conservées. Après avoir cliqué sur OK, les données sont combinées dans une unique colonne comme montré ci-dessous:
Figure 2-22. Données combinées dans une unique colonne
2.4 Générer des données
STATGRAPHICS Centurion XVI donne la possibilité de créer des données et de les mettre dans des colonnes d’un tableur. Ce paragraphe décrit deux exemples importants :
1. Générer des données structurées. 2. Générer des nombres aléatoires.
54/ Gestion des données
2.4.1 Générer des données structurées
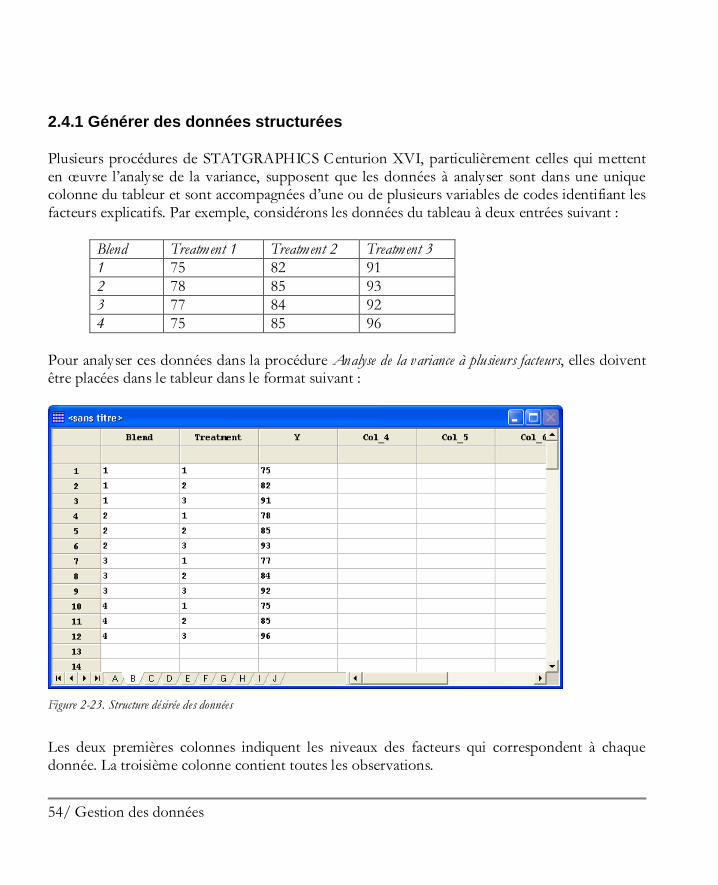
Plusieurs procédures de STATGRAPHICS Centurion XVI, particulièrement celles qui mettent en œuvre l’analyse de la variance, supposent que les données à analyser sont dans une unique colonne du tableur et sont accompagnées d’une ou de plusieurs variables de codes identifiant les facteurs explicatifs. Par exemple, considérons les données du tableau à deux entrées suivant :
Blend Treatment 1 Treatment 2 Treatment 3
1 75 82 91
2 78 85 93
3 77 84 92
4 75 85 96
Pour analyser ces données dans la procédure Analyse de la variance à plusieurs facteurs, elles doivent être placées dans le tableur dans le format suivant :
Figure 2-23. Structure désirée des données
Les deux premières colonnes indiquent les niveaux des facteurs qui correspondent à chaque donnée. La troisième colonne contient toutes les observations.
55/ Gestion des données
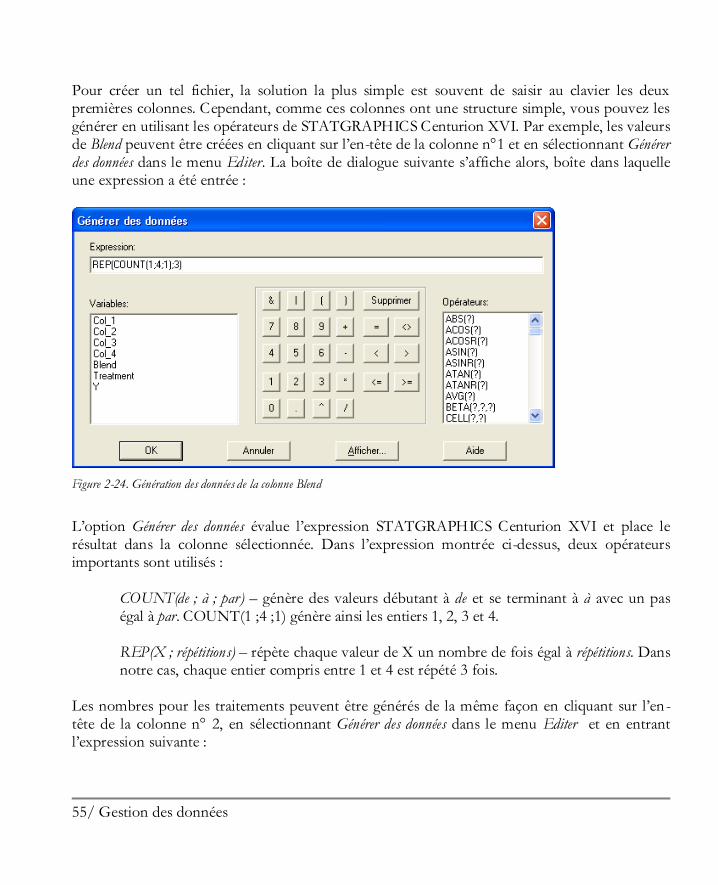
Pour créer un tel fichier, la solution la plus simple est souvent de saisir au clavier les deux premières colonnes. Cependant, comme ces colonnes ont une structure simple, vous pouvez les générer en utilisant les opérateurs de STATGRAPHICS Centurion XVI. Par exemple, les valeurs de Blend peuvent être créées en cliquant sur l’en-tête de la colonne n°1 et en sélectionnant Générer des données dans le menu Editer. La boîte de dialogue suivante s’affiche alors, boîte dans laquelle une expression a été entrée :
Figure 2-24. Génération des données de la colonne Blend
L’option Générer des données évalue l’expression STATGRAPHICS Centurion XVI et place le résultat dans la colonne sélectionnée. Dans l’expression montrée ci-dessus, deux opérateurs importants sont utilisés :
COUNT(de ; à ; par) – génère des valeurs débutant à de et se terminant à à avec un pas égal à par. COUNT(1 ;4 ;1) génère ainsi les entiers 1, 2, 3 et 4. REP(X ; répétitions) – répète chaque valeur de X un nombre de fois égal à répétitions. Dans notre cas, chaque entier compris entre 1 et 4 est répété 3 fois.
Les nombres pour les traitements peuvent être générés de la même façon en cliquant sur l’en -tête de la colonne n° 2, en sélectionnant Générer des données dans le menu Editer et en entrant l’expression suivante :
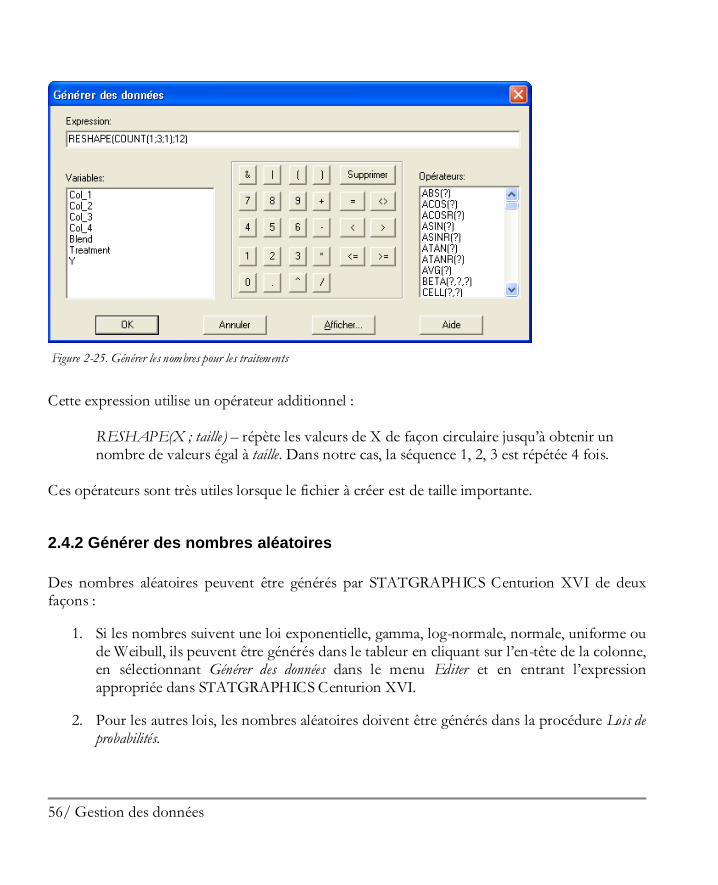
56/ Gestion des données
Figure 2-25. Générer les nombres pour les traitements
Cette expression utilise un opérateur additionnel :
RESHAPE(X ; taille) – répète les valeurs de X de façon circulaire jusqu’à obtenir un nombre de valeurs égal à taille. Dans notre cas, la séquence 1, 2, 3 est répétée 4 fois.
Ces opérateurs sont très utiles lorsque le fichier à créer est de taille importante.
2.4.2 Générer des nombres aléatoires
Des nombres aléatoires peuvent être générés par STATGRAPHICS Centurion XVI de deux façons :
1. Si les nombres suivent une loi exponentielle, gamma, log-normale, normale, uniforme ou de Weibull, ils peuvent être générés dans le tableur en cliquant sur l’en-tête de la colonne, en sélectionnant Générer des données dans le menu Editer et en entrant l’expression appropriée dans STATGRAPHICS Centurion XVI.
2. Pour les autres lois, les nombres aléatoires doivent être générés dans la procédure Lois de probabilités.
57/ Gestion des données
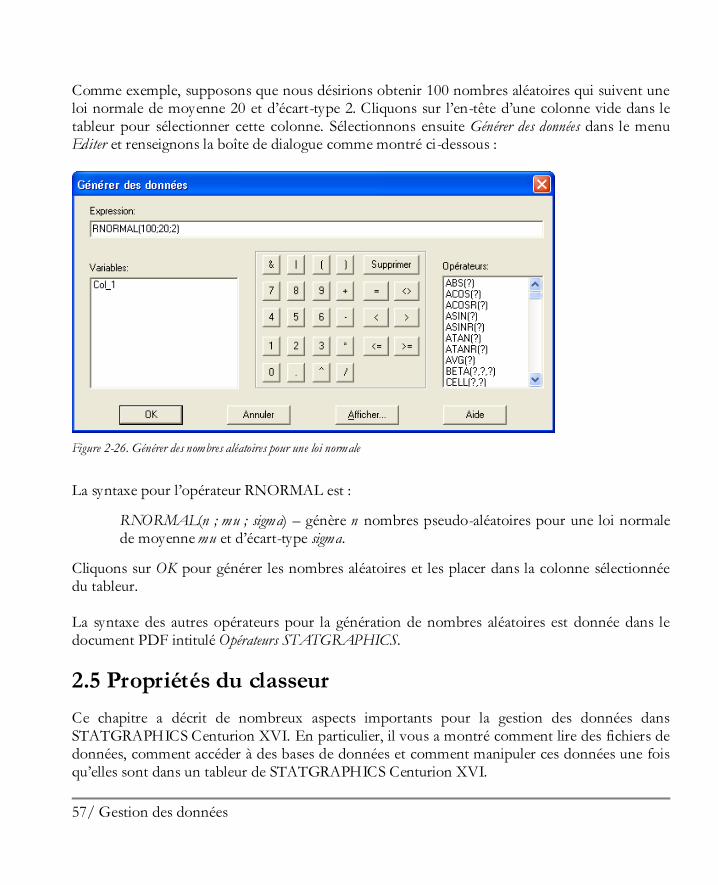
Comme exemple, supposons que nous désirions obtenir 100 nombres aléatoires qui suivent une loi normale de moyenne 20 et d’écart-type 2. Cliquons sur l’en-tête d’une colonne vide dans le tableur pour sélectionner cette colonne. Sélectionnons ensuite Générer des données dans le menu Editer et renseignons la boîte de dialogue comme montré ci-dessous :
Figure 2-26. Générer des nombres aléatoires pour une loi normale
La syntaxe pour l’opérateur RNORMAL est :
RNORMAL(n ; mu ; sigma) – génère n nombres pseudo-aléatoires pour une loi normale de moyenne mu et d’écart-type sigma.
Cliquons sur OK pour générer les nombres aléatoires et les placer dans la colonne sélectionnée du tableur. La syntaxe des autres opérateurs pour la génération de nombres aléatoires est donnée dans le document PDF intitulé Opérateurs STATGRAPHICS.
2.5 Propriétés du classeur
Ce chapitre a décrit de nombreux aspects importants pour la gestion des données dans STATGRAPHICS Centurion XVI. En particulier, il vous a montré comment lire des fichiers de données, comment accéder à des bases de données et comment manipuler ces données une fois qu’elles sont dans un tableur de STATGRAPHICS Centurion XVI.

58/ Gestion des données
A tout moment, le statut des tableurs peut être affiché en activant la fenêtre Classeur et en sélectionnant Propriétés du classeur dans le menu Editer ou en sélectionnant StatLink dans le menu Fichier :
Figure 2-27. Boîte de dialogue Propriétés du classeur
Cette boîte de dialogue affiche les sources des données pour les différents tableurs. Si vous le souhaitez, les tableurs peuvent être en lecture uniquement de façon à ne pas modifier par inadvertance les données. Il est également possible d’acquérir les données (les relire) à des intervalles réguliers de temps et d’automatiquement voir les analyses statistiques les utilisant mises à jour. Ces fonctionnalités importantes sont décrites au Chapitre 5.

59/ Gestion des données
2.6 Visualiseur de données Une nouvelle procédure a été ajoutée pour visualiser les fichiers de données dans STATGRAPHICS Centurion XVI. Cette procédure, accessible en sélectionnant Visualiseur de données dans le menu Outils, affiche un résumé indiquant le nombre de données non manquantes, le nombre de données uniques ainsi que le minimum et le maximum pour chaque variable sélectionnée :
Visualiseur de données Nombre de colonnes: 26 Nombre de lignes: 93 Nombre de sujets complets: 82
Nom de la Commentaire Type Nb valeurs Nb valeurs Minimum Maximum
colonne non manquantes uniques
Make Caractère 93 32
Model Caractère 93 93
Type Caractère 93 6
Min Price price for basic version in $1,000 Numérique 93 79 6.7 45.4
Mid Price average of min and max prices in $1,000 Numérique 93 81 7.4 61.9
Max Price price for a premium version in $1,000 Numérique 93 79 7.9 80.0
MPG City miles per gallon in city driving Numérique 93 21 15.0 46.0
MPG Highway miles per gallon in highway driving Numérique 93 22 20.0 50.0
Air Bags 0=none, 1=driver only, 2=driver and passenger Numérique 93 3 0 2.0
Drive Train Caractère 93 3
Cylinders Numérique 92 5 3.0 8.0
Engine Size liters Numérique 93 26 1.0 5.7
Horsepower maximum Numérique 93 57 55.0 300.0
RPM revs per minute at maximum horsepower Numérique 93 24 3800.0 6500.0
Revs per Mile revs per mile in highest gear Numérique 93 78 1320.0 3755.0
Manual 0=no, 1=yes Numérique 93 2 0 1.0
Fueltank gallons Numérique 93 38 9.2 27.0
Passengers persons Numérique 93 6 2.0 8.0
Length inches Numérique 93 51 141.0 219.0
Wheelbase inches Numérique 93 27 90.0 119.0
Width inches Numérique 93 16 60.0 78.0
U Turn Space feet Numérique 93 14 32.0 45.0
Rear seat inches Numérique 91 24 19.0 36.0
Luggage cu. ft. Numérique 82 16 6.0 22.0
Weight pounds Numérique 93 81 1695.0 4105.0
Domestic 1=U.S. manufacturer Numérique 93 2 0 1.0
Figure 2-28. Fenêtre Visualiseur de données

60/ Gestion des données

61/ Mettre en œuvre des analyses statistiques
Mettre en œuvre des analyses statistiques
Mettre en oeuvre une analyse, sélectionner des tableaux et des graphiques complémentaires, sélectionner des options, modifier les données en entrée et enregistrer des résultats.
Il y a plus de 160 procédures statistiques dans le menu principal de STATGRAPHICS Centurion XVI. Chaque sélection permet d’accéder à une procédure statistique différente. Toutefois toutes les procédures fonctionnent de la même façon :
1. Lorsqu’une analyse est sélectionnée par le menu, une boîte de dialogue d’entrée des données s’affiche. Les champs de cette boîte de dialogue sont utilisés pour préciser les variables à analyser.
2. Si la procédure sélectionnée possède des options qui affectent tous les tableaux et graphiques de cette procédure, une boîte de dialogue Options d’analyse est affichée pour choisir les paramètres désirés.
3. Si la procédure sélectionnée possède plus d’un tableau et plus d’un graphique, une boîte de dialogue Tableaux et graphiques s’affiche dans laquelle il est possible de choisir les tableaux et graphiques désirés.
4. Les données sont alors lues et analysées et une nouvelle fenêtre d’analyse est créée.
5. Les options sélectionnées peuvent être modifiées en utilisant le bouton Options d’analyse dans la barre d’outils d’analyse, suite à quoi tous les tableaux et tous les graphiques sont mis à jour.
6. Si désiré, des tableaux et des graphiques additionnels peuvent être demandés en cliquant sur le bouton Tableaux et graphiques dans la barre d’outils d’analyse.
Chapitre
3
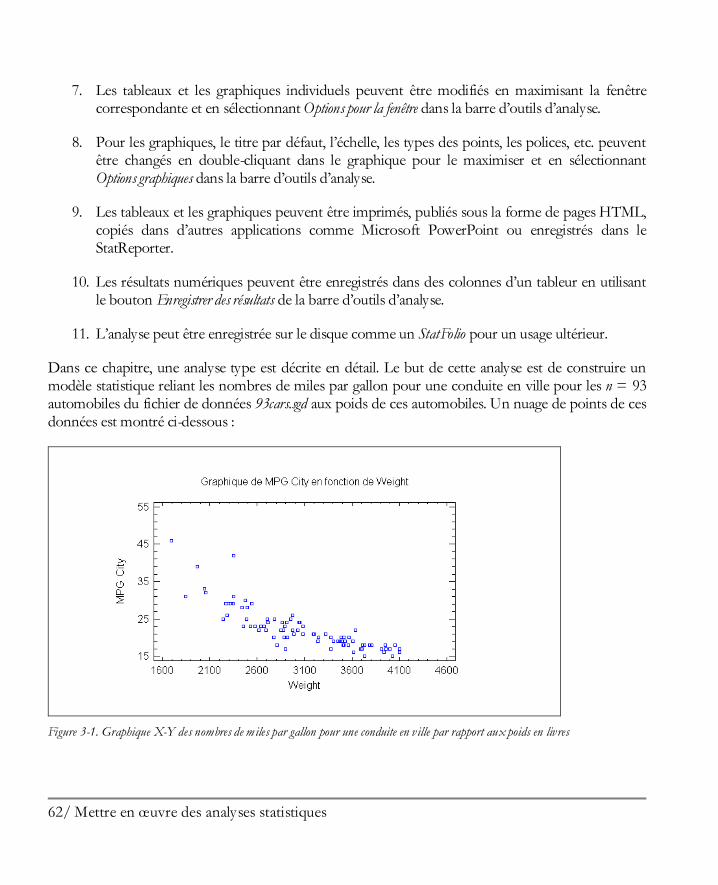
62/ Mettre en œuvre des analyses statistiques
7. Les tableaux et les graphiques individuels peuvent être modifiés en maximisant la fenêtre correspondante et en sélectionnant Options pour la fenêtre dans la barre d’outils d’analyse.
8. Pour les graphiques, le titre par défaut, l’échelle, les types des points, les polices, etc. peuvent être changés en double-cliquant dans le graphique pour le maximiser et en sélectionnant Options graphiques dans la barre d’outils d’analyse.
9. Les tableaux et les graphiques peuvent être imprimés, publiés sous la forme de pages HTML, copiés dans d’autres applications comme Microsoft PowerPoint ou enregistrés dans le StatReporter.
10. Les résultats numériques peuvent être enregistrés dans des colonnes d’un tableur en utilisant le bouton Enregistrer des résultats de la barre d’outils d’analyse.
11. L’analyse peut être enregistrée sur le disque comme un StatFolio pour un usage ultérieur.
Dans ce chapitre, une analyse type est décrite en détail. Le but de cette analyse est de construire un modèle statistique reliant les nombres de miles par gallon pour une conduite en ville pour les n = 93 automobiles du fichier de données 93cars.sgd aux poids de ces automobiles. Un nuage de points de ces données est montré ci-dessous :
Figure 3-1. Graphique X-Y des nombres de miles par gallon pour une conduite en v ille par rapport aux poids en livres
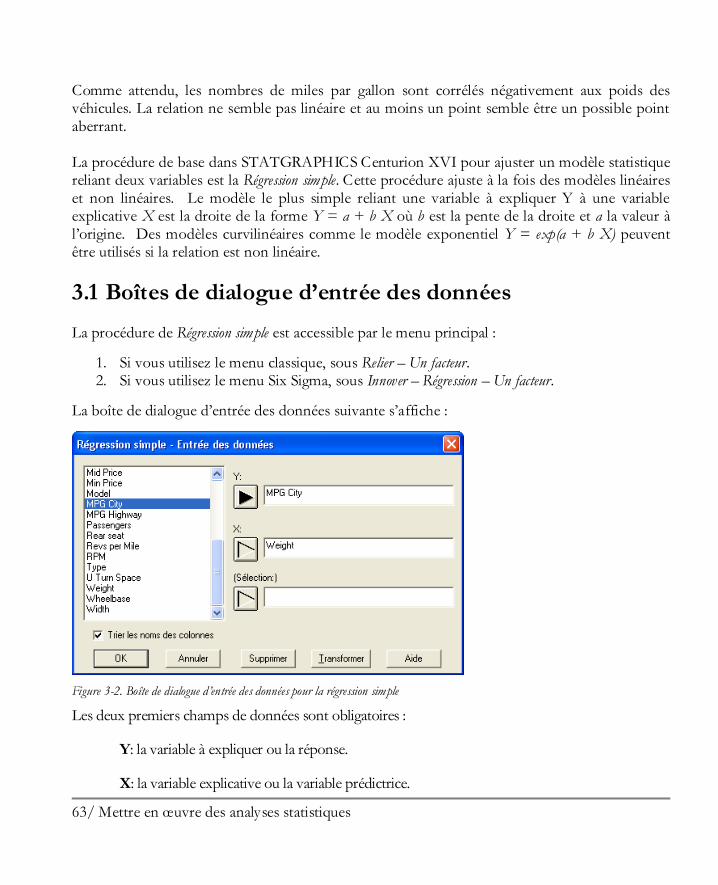
63/ Mettre en œuvre des analyses statistiques
Comme attendu, les nombres de miles par gallon sont corrélés négativement aux poids des véhicules. La relation ne semble pas linéaire et au moins un point semble être un possible point aberrant. La procédure de base dans STATGRAPHICS Centurion XVI pour ajuster un modèle statistique reliant deux variables est la Régression simple. Cette procédure ajuste à la fois des modèles linéaires et non linéaires. Le modèle le plus simple reliant une variable à expliquer Y à une variable explicative X est la droite de la forme Y = a + b X où b est la pente de la droite et a la valeur à l’origine. Des modèles curvilinéaires comme le modèle exponentiel Y = exp(a + b X) peuvent être utilisés si la relation est non linéaire.
3.1 Boîtes de dialogue d’entrée des données La procédure de Régression simple est accessible par le menu principal :
1. Si vous utilisez le menu classique, sous Relier – Un facteur. 2. Si vous utilisez le menu Six Sigma, sous Innover – Régression – Un facteur.
La boîte de dialogue d’entrée des données suivante s’affiche :
Figure 3-2. Boîte de dialogue d’entrée des données pour la régression simple
Les deux premiers champs de données sont obligatoires :
Y: la variable à expliquer ou la réponse.
X: la variable explicative ou la variable prédictrice.
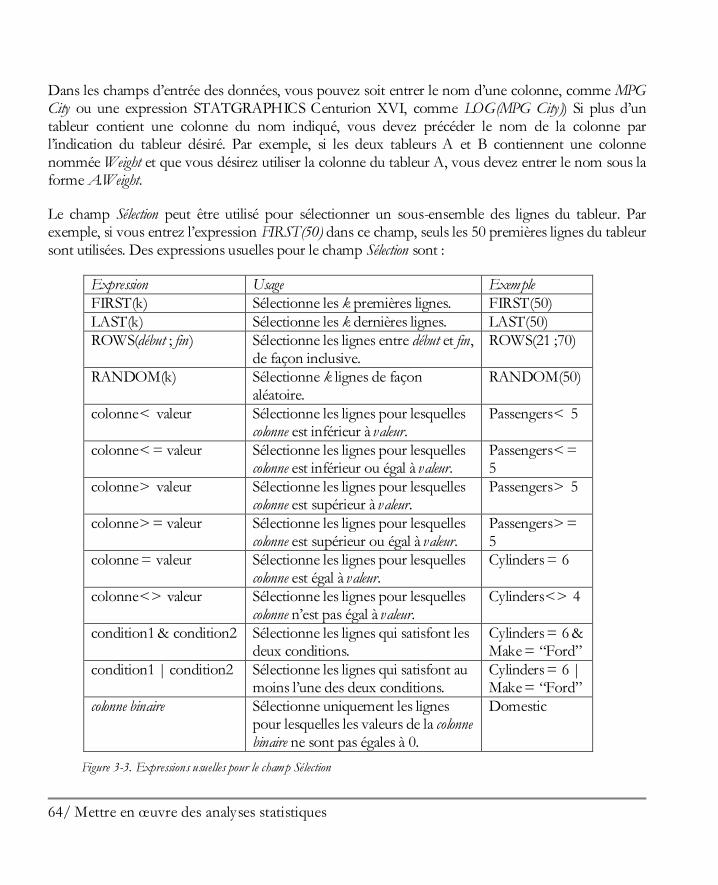
64/ Mettre en œuvre des analyses statistiques
Dans les champs d’entrée des données, vous pouvez soit entrer le nom d’une colonne, comme MPG City ou une expression STATGRAPHICS Centurion XVI, comme LOG(MPG City)) Si plus d’un tableur contient une colonne du nom indiqué, vous devez précéder le nom de la colonne par l’indication du tableur désiré. Par exemple, si les deux tableurs A et B contiennent une colonne nommée Weight et que vous désirez utiliser la colonne du tableur A, vous devez entrer le nom sous la forme A.Weight.
Le champ Sélection peut être utilisé pour sélectionner un sous-ensemble des lignes du tableur. Par exemple, si vous entrez l’expression FIRST(50) dans ce champ, seuls les 50 premières lignes du tableur sont utilisées. Des expressions usuelles pour le champ Sélection sont :
Expression Usage Exemple
FIRST(k) Sélectionne les k premières lignes. FIRST(50)
LAST(k) Sélectionne les k dernières lignes. LAST(50)
ROWS(début ; fin) Sélectionne les lignes entre début et fin, de façon inclusive.
ROWS(21 ;70)
RANDOM(k) Sélectionne k lignes de façon aléatoire.
RANDOM(50)
colonne < valeur Sélectionne les lignes pour lesquelles colonne est inférieur à valeur.
Passengers < 5
colonne < = valeur Sélectionne les lignes pour lesquelles colonne est inférieur ou égal à valeur.
Passengers < = 5
colonne > valeur Sélectionne les lignes pour lesquelles colonne est supérieur à valeur.
Passengers > 5
colonne > = valeur Sélectionne les lignes pour lesquelles colonne est supérieur ou égal à valeur.
Passengers > = 5
colonne = valeur Sélectionne les lignes pour lesquelles colonne est égal à valeur.
Cylinders = 6
colonne <> valeur Sélectionne les lignes pour lesquelles colonne n’est pas égal à valeur.
Cylinders <> 4
condition1 & condition2 Sélectionne les lignes qui satisfont les deux conditions.
Cylinders = 6 & Make = “Ford”
condition1 | condition2 Sélectionne les lignes qui satisfont au moins l’une des deux conditions.
Cylinders = 6 | Make = “Ford”
colonne binaire Sélectionne uniquement les lignes pour lesquelles les valeurs de la colonne binaire ne sont pas égales à 0.
Domestic
Figure 3-3. Expressions usuelles pour le champ Sélection
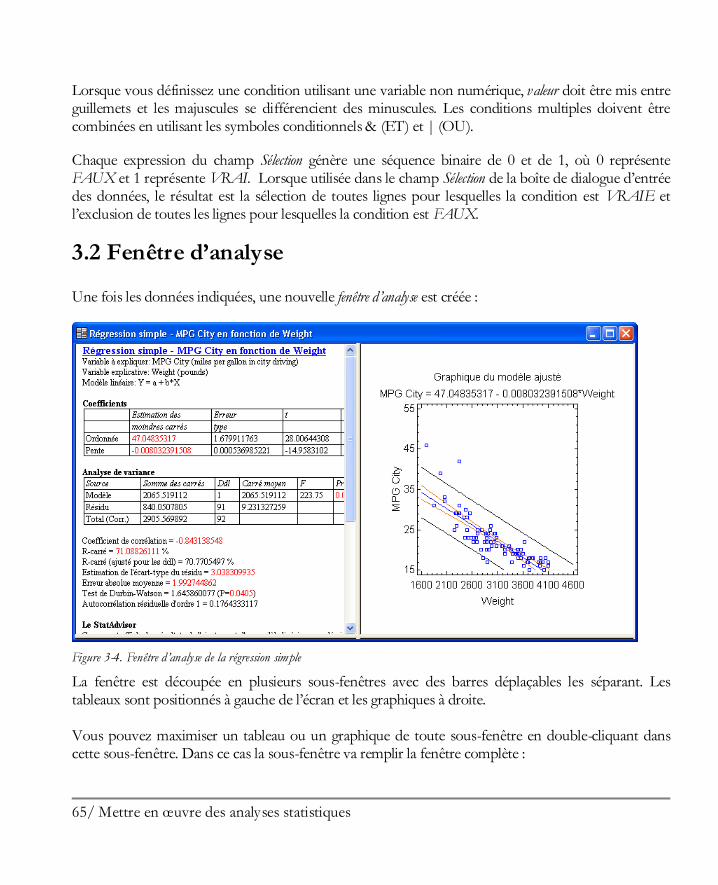
65/ Mettre en œuvre des analyses statistiques
Lorsque vous définissez une condition utilisant une variable non numérique, valeur doit être mis entre guillemets et les majuscules se différencient des minuscules. Les conditions multiples doivent être combinées en utilisant les symboles conditionnels & (ET) et | (OU).
Chaque expression du champ Sélection génère une séquence binaire de 0 et de 1, où 0 représente FAUX et 1 représente VRAI. Lorsque utilisée dans le champ Sélection de la boîte de dialogue d’entrée des données, le résultat est la sélection de toutes lignes pour lesquelles la condition est VRAIE et l’exclusion de toutes les lignes pour lesquelles la condition est FAUX.
3.2 Fenêtre d’analyse
Une fois les données indiquées, une nouvelle fenêtre d’analyse est créée :
Figure 3-4. Fenêtre d’analyse de la régression simple
La fenêtre est découpée en plusieurs sous-fenêtres avec des barres déplaçables les séparant. Les tableaux sont positionnés à gauche de l’écran et les graphiques à droite. Vous pouvez maximiser un tableau ou un graphique de toute sous-fenêtre en double-cliquant dans cette sous-fenêtre. Dans ce cas la sous-fenêtre va remplir la fenêtre complète :
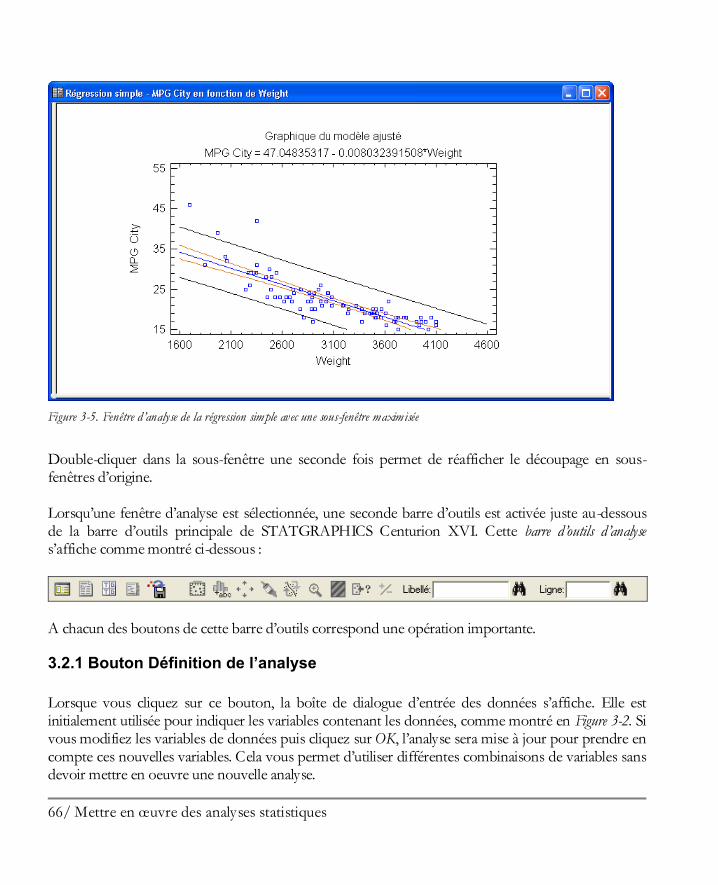
66/ Mettre en œuvre des analyses statistiques
Figure 3-5. Fenêtre d’analyse de la régression simple avec une sous-fenêtre maximisée
Double-cliquer dans la sous-fenêtre une seconde fois permet de réafficher le découpage en sous-fenêtres d’origine. Lorsqu’une fenêtre d’analyse est sélectionnée, une seconde barre d’outils est activée juste au-dessous de la barre d’outils principale de STATGRAPHICS Centurion XVI. Cette barre d’outils d’analyse s’affiche comme montré ci-dessous :
A chacun des boutons de cette barre d’outils correspond une opération importante.
3.2.1 Bouton Définition de l’analyse
Lorsque vous cliquez sur ce bouton, la boîte de dialogue d’entrée des données s’affiche. Elle est initialement utilisée pour indiquer les variables contenant les données, comme montré en Figure 3-2. Si vous modifiez les variables de données puis cliquez sur OK, l’analyse sera mise à jour pour prendre en compte ces nouvelles variables. Cela vous permet d’utiliser différentes combinaisons de variables sans devoir mettre en oeuvre une nouvelle analyse.

67/ Mettre en œuvre des analyses statistiques
3.2.2 Bouton Options d’analyse
La plupart des analyses ont de nombreuses options. Lorsqu’une analyse est mise en œuvre la première fois, des valeurs par défaut sont sélectionnées pour ces options. Elles sont souvent suffisantes. Cependant, en cliquant sur le bouton Options d’analyse dans toute procédure, il est possible de modifier ces valeurs par défaut. Pour la Régression simple, la boîte de dialogue Options d’analyse permet de préciser le type de modèle à ajuster et la méthode d’estimation des coefficients inconnus du modèle :
Figure 3-6. Boîte de dialogue des Options d’analyse pour la régression simple
Si vous examinez le contenu de la Figure 3-9 ci-après, il peut y être noté que dans le tableau de comparaison des modèles alternatifs plusieurs modèle curvilinéaires ont un R-carré plus élevé que le modèle linéaire. En haut de la liste se trouve le modèle Courbe en S. Si vous sélectionnez ce modèle dans la boîte de dialogue des Options d’analyse puis cliquez sur le bouton OK, toute l’analyse prendra en compte ce nouveau modèle. Comme cela peut être vu en regardant le graphique du modèle ajusté, une courbe en S permet de capturer assez bien la courbure dans les données :
68/ Mettre en œuvre des analyses statistiques
Figure 3-7. Modèle ajusté Courbe en S
3.2.3 Bouton Tableaux et graphiques
Ce bouton affiche la liste des tableaux et graphiques qui peuvent être ajoutés à la fenêtre d’analyse. Pour la régression simple, les tableaux et graphiques disponibles sont :
Figure 3-8. Boîte de dialogue Tableaux et graphiques pour la régression simple
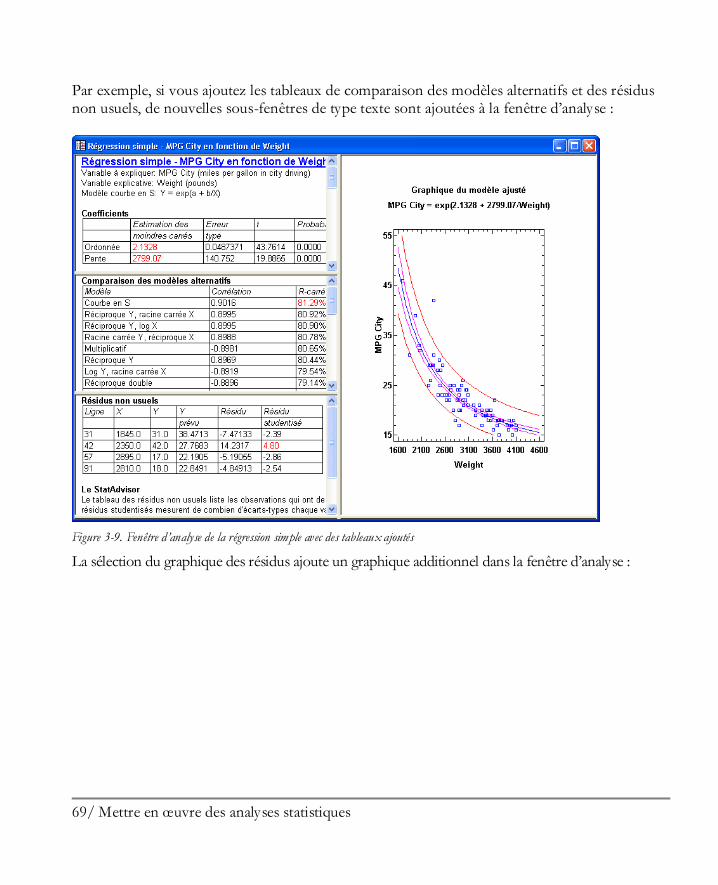
69/ Mettre en œuvre des analyses statistiques
Par exemple, si vous ajoutez les tableaux de comparaison des modèles alternatifs et des résidus non usuels, de nouvelles sous-fenêtres de type texte sont ajoutées à la fenêtre d’analyse :
Figure 3-9. Fenêtre d’analyse de la régression simple avec des tableaux ajoutés
La sélection du graphique des résidus ajoute un graphique additionnel dans la fenêtre d’analyse :
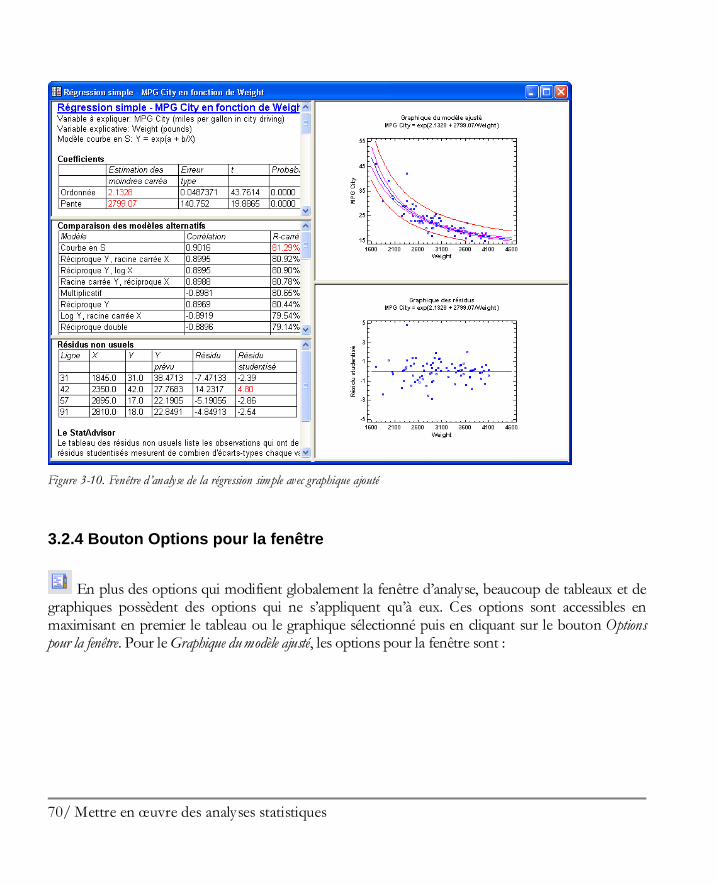
70/ Mettre en œuvre des analyses statistiques
Figure 3-10. Fenêtre d’analyse de la régression simple avec graphique ajouté
3.2.4 Bouton Options pour la fenêtre
En plus des options qui modifient globalement la fenêtre d’analyse, beaucoup de tableaux et de graphiques possèdent des options qui ne s’appliquent qu’à eux. Ces options sont accessibles en maximisant en premier le tableau ou le graphique sélectionné puis en cliquant sur le bouton Options pour la fenêtre. Pour le Graphique du modèle ajusté, les options pour la fenêtre sont :
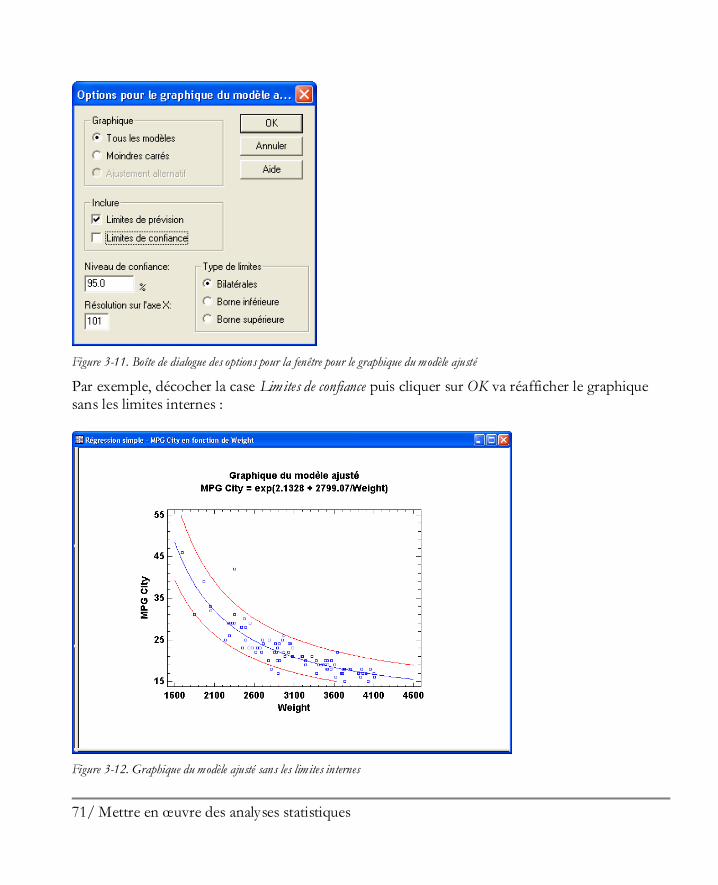
71/ Mettre en œuvre des analyses statistiques
Figure 3-11. Boîte de dialogue des options pour la fenêtre pour le graphique du modèle ajusté
Par exemple, décocher la case Limites de confiance puis cliquer sur OK va réafficher le graphique sans les limites internes :
Figure 3-12. Graphique du modèle ajusté sans les limites internes

72/ Mettre en œuvre des analyses statistiques
3.2.5 Bouton Enregistrer les résultats
Ce bouton vous permet d’enregistrer des résultats numériques calculés par l’analyse statistique dans des colonnes d’un tableur. Pour la Régression simple, il affiche les choix suivants :
Figure 3-13. Boîte de dialogue d’enregistrement des résultats pour la régression simple
Pour enregistrer des informations, cocher les éléments à enregistrer dans le champ Enregistrer. Pour chaque élément à enregistrer, donner un nom de colonne dans le champ Variables cibles et indiquer le feuille souhaitée. Si vous souhaitez enregistrer un commentaire avec les données, cocher Enregistrer les commentaires.
La case à cocher Enregistrement automatique est utilisée pour enregistrer à nouveau l’élément sélectionné à chaque fois que l’analyse est mise en oeuvre. Cela est utile si vous souhaitez enregistrer les analyses dans un StatFolio car les analyses sont remises en oeuvre lorsque les StatFolios sont chargés. En cochant la case Enregistrement automatique, vous pouvez créer un StatFolio qui calcule et enregistre automatiquement les statistiques désirées. Lorsque vous combinez cet enregistrement automatique avec les possibilités des scripts décrites au Chapitre 5, cela vous permet de mettre en place des procédures automatisées.

73/ Mettre en œuvre des analyses statistiques
3.2.6 Boutons pour les graphiques
Lorsqu’un graphique est maximisé dans une fenêtre d’analyse, plusieurs boutons complémentaires sont activés. Ces boutons sont les suivants :
Options graphiques – affiche une boîte de dialogue permettant de modifier les couleurs, libellés, échelles des axes et autres paramètres similaires.
Ajouter un texte – utile pour ajouter un texte dans le graphique.
Eparpiller – utile pour ajouter de petites valeurs aléatoires aux coordonnées horizontales et verticales des points pour éviter la superposition de ces points.
Brosser – permet de colorer les points d’un nuage de points en fonction des valeurs d’une variable sélectionnée.
Lissage/Rotation – lissage d’un graphique à deux dimensions ou rotation d’un graphique à trois dimensions.
Panoramique ou zoom – permet de faire un panoramique ou un zoom dans un graphique par rapport à une direction X, Y ou Z.
Explorer – explore de façon dynamique une surface de réponse ou un graphique de contours.
Identifier – affiche un libellé identifiant le point lorsqu’on clique sur ce point avec la souris.
Localiser par un libellé – éclaire en rouge tous les points dont les valeurs sont égales à celle entrée dans le champ Libellé (à utiliser avec le bouton Identifier).
Localiser par une ligne – éclaire en rouge tous les points qui correspondent au numéro de ligne entré dans le champ Ligne. Chacun de ces boutons est décrit de façon détaillée au Chapitre 4.
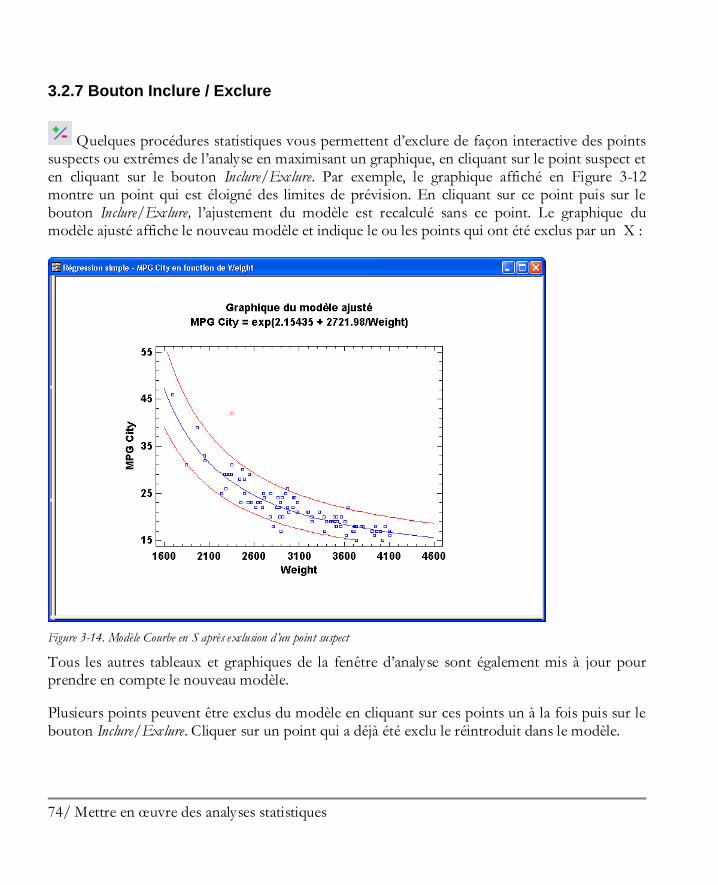
74/ Mettre en œuvre des analyses statistiques
3.2.7 Bouton Inclure / Exclure
Quelques procédures statistiques vous permettent d’exclure de façon interactive des points suspects ou extrêmes de l’analyse en maximisant un graphique, en cliquant sur le point suspect et en cliquant sur le bouton Inclure/Exclure. Par exemple, le graphique affiché en Figure 3-12 montre un point qui est éloigné des limites de prévision. En cliquant sur ce point puis sur le bouton Inclure/Exclure, l’ajustement du modèle est recalculé sans ce point. Le graphique du modèle ajusté affiche le nouveau modèle et indique le ou les points qui ont été exclus par un X :
Figure 3-14. Modèle Courbe en S après exclusion d’un point suspect
Tous les autres tableaux et graphiques de la fenêtre d’analyse sont également mis à jour pour prendre en compte le nouveau modèle.
Plusieurs points peuvent être exclus du modèle en cliquant sur ces points un à la fois puis sur le bouton Inclure/Exclure. Cliquer sur un point qui a déjà été exclu le réintroduit dans le modèle.

75/ Mettre en œuvre des analyses statistiques
3.3 Imprimer les résultats
Pour imprimer les résultats de l’analyse statistique, deux options sont disponibles :
1. Pour imprimer tous les tableaux et graphiques de la fenêtre d’analyse, cliquer sur le bouton Imprimer de la barre d’outils d’analyse ou sélectionner Imprimer dans le menu Fichier.
2. Pour imprimer un unique tableau ou graphique, cliquer dans cette sous-fenêtre sur le bouton droit de la souris et sélectionner Imprimer dans le menu popup qui s’affiche.
Lorsque vous imprimez toute l’analyse, la boîte de dialogue suivante s’affiche :
Figure 3-15. Boîte de dialogue pour imprimer une analyse
Dans la partie Etendue d’impression, il faut préciser les sous-fenêtres à imprimer. Vous pouvez de façon simultanée imprimer les fenêtres d’autres analyses en cochant Toutes les analyses. D’autres options utilisées lors de l’impression sont proposées dans la boîte de dialogue Mise en page du menu Fichier :
76/ Mettre en œuvre des analyses statistiques
Figure 3-16. Boîte de dialogue Mise en page
Dans cette boîte de dialogue, vous pouvez :
1. Préciser les marges pour les pages imprimées.
2. Définir un en -tête qui sera imprimé en haut de chaque page.
3. Indiquer si chaque sous-fenêtre (tableau ou graphique) doit être imprimée sur une page séparée ou si plusieurs sous-fenêtres doivent être imprimées sur une même page si cela est possible.
4. Préciser la taille relative des graphiques en pourcentage des dimensions de la page.
5. Décider si vous imprimez en noir et blanc, même si votre imprimante peut imprimer en
couleurs.
6. Imprimer la couleur du fond (s’il y en a une) de vos graphiques.
7. Imprimer des lignes épaisses utilisant deux pixels au lieu d’un. Cette option est utile dans le cas d’imprimantes ayant de hautes résolutions.

77/ Mettre en œuvre des analyses statistiques
D’autres options, comme par exemple imprimer en mode portrait ou paysage, sont définies en sélectionnant Configuration de l’impression dans le menu Fichier, qui donne accès à la boîte de dialogue spécifique à votre pilote d’imprimante.
3.4 Publier les résultats Les résultats d’une analyse statistique peuvent être publiés au format HTML pour les visualiser avec un navigateur Web en sélectionnant StatPublish dans le menu Fichier. Cela vous permet de rendre vos résultats accessibles à toutes les personnes de votre entreprise même si STATGRAPHICS Centurion XVI n’est pas installé sur leurs ordinateurs. Publier est décrit au Chapitre 5. Vous pouvez également copier les analyses dans le StatReporter, ce qui vous permet de les annoter et d’enregistrer les résultats au format RTF (rich text format), qui peut être lu par d’autres logiciels comme par exemple Microsoft Word. L’utilisation du StatReporter est décrite au Chapitre 6.

78/ Mettre en œuvre des analyses statistiques

79/ Graphiques
Graphiques
Modifier les graphiques, enregistrer les profils graphiques, interagir avec les graphiques, enregistrer les graphiques dans des fichiers et copier les graphiques dans d’autres applications.
Les 160 procédures statistiques de STATGRAPHICS Centurion XVI permettent de créer des centaines de graphiques différents. Pour faciliter le processus d’analyse de vos données, des titres par défaut, des échelles et d’autres attributs par défaut sont sélectionnés automatiquement lorsqu’un nouveau graphique est créé. Pour les besoins d’analyse, ces valeurs par défaut sont généralement suffisantes. Mais lorsque vous souhaitez publier vos résultats définitifs, créer un graphique de qualité publiable devient important.
Ce chapitre décrit tout ce que vous devez savoir pour travailler avec des graphiques dans STATGRAPHICS Centurion XVI. Il vous indique comment les mettre en forme pour la publication, comment les copier dans d’autres applications comme par exemple Microsoft Word et PowerPoint. Il vous indique également comment interagir avec les graphiques. Par exemple, lorsque vous repérez un point intéressant et voulez en savoir plus sur ce point ou lorsque vous souhaitez mettre un graphique 3D en rotation pour visualiser les éventuelles relations présentes entre les variables X, Y et Z définissant les axes.
Comme exemple, nous utiliserons à nouveau le fichier de données 93cars.sgd. Pour débuter, le graphique du modèle ajusté reliant les nombres de miles par gallon pour une conduite en ville aux poids des véhicules sera utilisé pour illustrer quelques-unes des opérations importantes avec les graphiques.
Chapitre
4
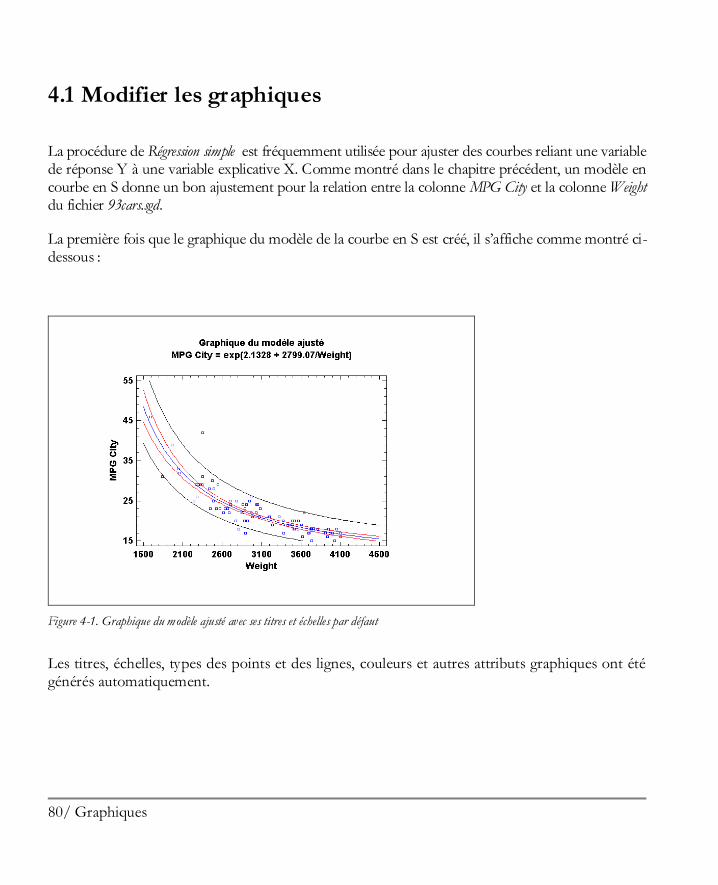
80/ Graphiques
4.1 Modifier les graphiques
La procédure de Régression simple est fréquemment utilisée pour ajuster des courbes reliant une variable de réponse Y à une variable explicative X. Comme montré dans le chapitre précédent, un modèle en courbe en S donne un bon ajustement pour la relation entre la colonne MPG City et la colonne Weight du fichier 93cars.sgd.
La première fois que le graphique du modèle de la courbe en S est créé, il s’affiche comme montré ci-dessous :
Figure 4-1. Graphique du modèle ajusté avec ses titres et échelles par défaut
Les titres, échelles, types des points et des lignes, couleurs et autres attributs graphiques ont été générés automatiquement.
81/ Graphiques
4.1.1 Options Apparence
Pour modifier un graphique une fois qu’il est créé, il faut d’abord double-cliquer dans le graphique pour le maximiser à la taille de la fenêtre d’analyse puis il faut cliquer sur le bouton
Options graphiques de la barre d’outils d’analyse. Une boîte de dialogue à onglets s’affiche avec des onglets pour les différents éléments du graphique. L’onglet Apparence de la boîte de dialogue des Options graphiques est utile pour modifier des caractéristiques de base du graphique :
Figure 4-2. Onglet Apparence de la boîte de dialogue des options graphiques
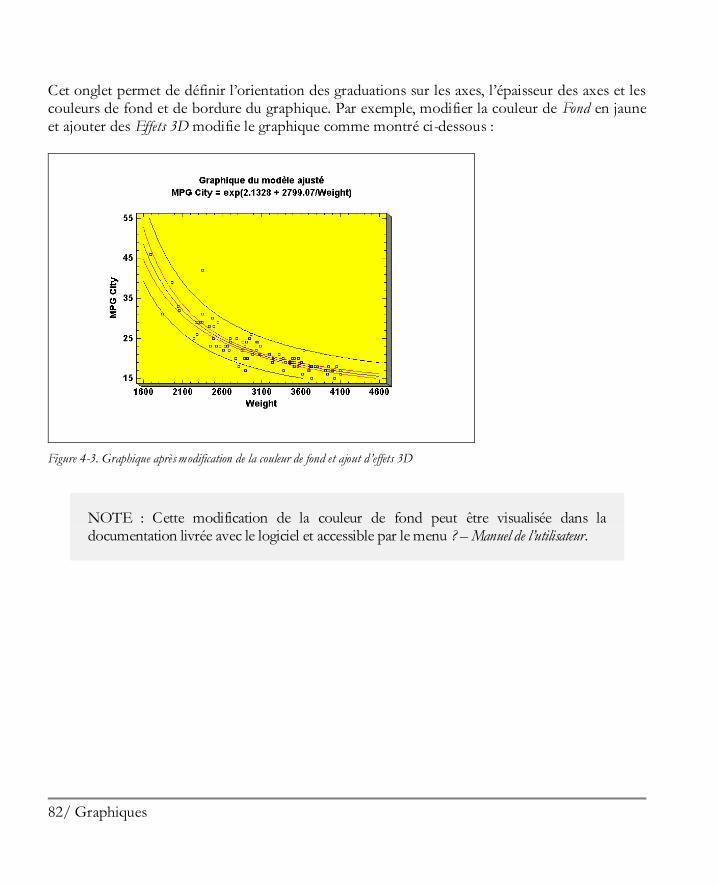
82/ Graphiques
Cet onglet permet de définir l’orientation des graduations sur les axes, l’épaisseur des axes et les couleurs de fond et de bordure du graphique. Par exemple, modifier la couleur de Fond en jaune et ajouter des Effets 3D modifie le graphique comme montré ci-dessous :
Figure 4-3. Graphique après modification de la couleur de fond et ajout d’effets 3D
NOTE : Cette modification de la couleur de fond peut être visualisée dans la documentation livrée avec le logiciel et accessible par le menu ? – Manuel de l’utilisateur.
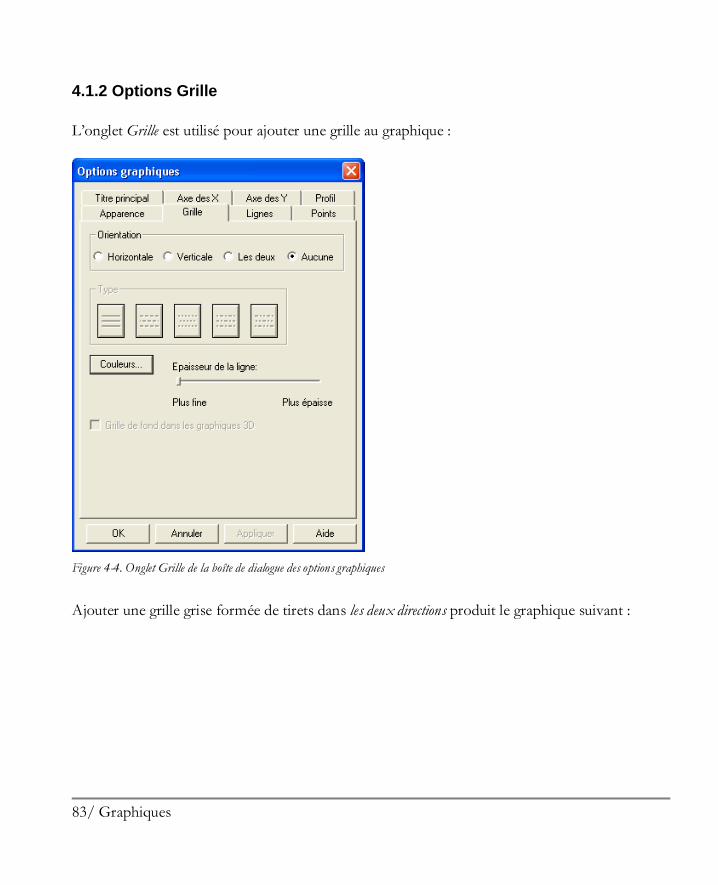
83/ Graphiques
4.1.2 Options Grille
L’onglet Grille est utilisé pour ajouter une grille au graphique :
Figure 4-4. Onglet Grille de la boîte de dialogue des options graphiques
Ajouter une grille grise formée de tirets dans les deux directions produit le graphique suivant :
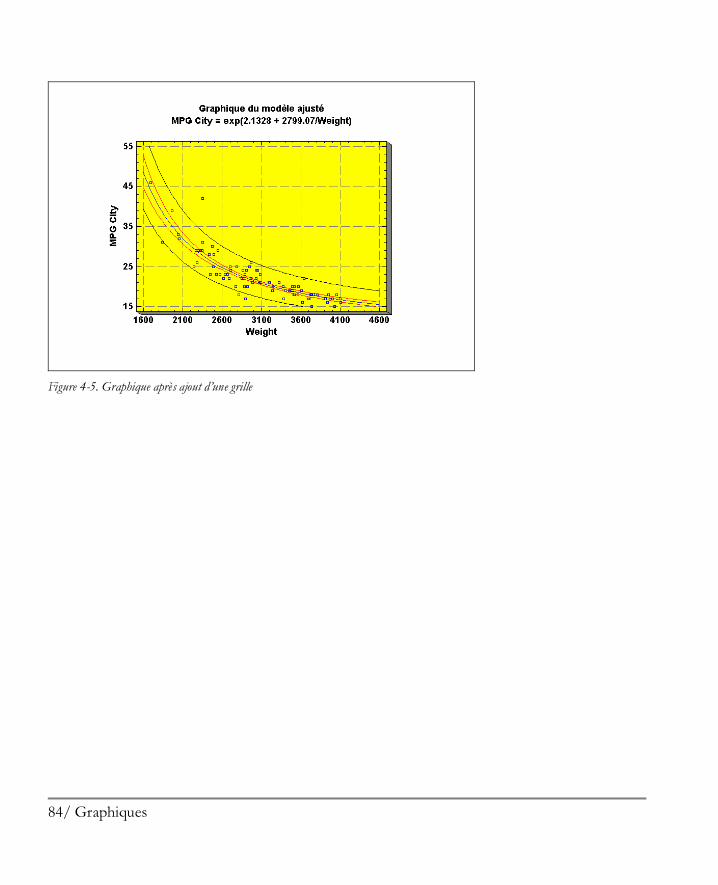
84/ Graphiques
Figure 4-5. Graphique après ajout d’une grille
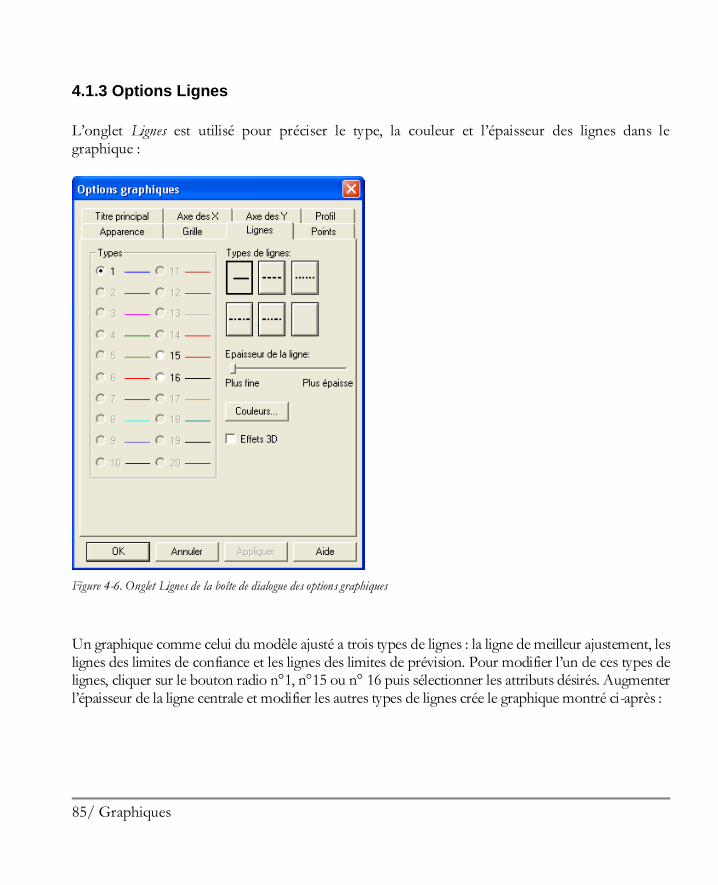
85/ Graphiques
4.1.3 Options Lignes
L’onglet Lignes est utilisé pour préciser le type, la couleur et l’épaisseur des lignes dans le graphique :
Figure 4-6. Onglet Lignes de la boîte de dialogue des options graphiques
Un graphique comme celui du modèle ajusté a trois types de lignes : la ligne de meilleur ajustement, les lignes des limites de confiance et les lignes des limites de prévision. Pour modifier l’un de ces types de lignes, cliquer sur le bouton radio n°1, n°15 ou n° 16 puis sélectionner les attributs désirés. Augmenter l’épaisseur de la ligne centrale et modifier les autres types de lignes crée le graphique montré ci-après :
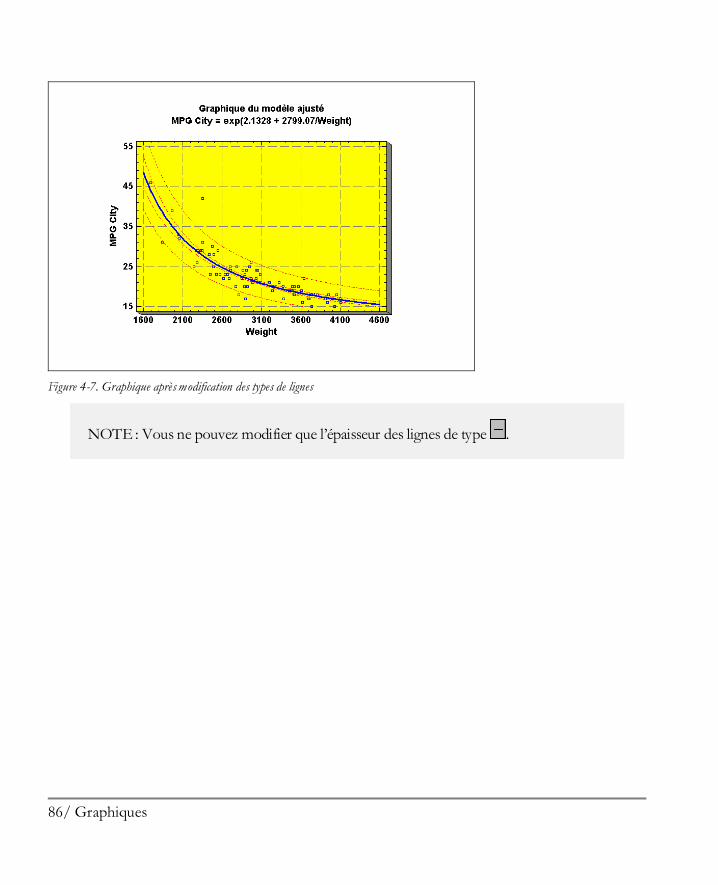
86/ Graphiques
Figure 4-7. Graphique après modification des types de lignes
NOTE : Vous ne pouvez modifier que l’épaisseur des lignes de type .
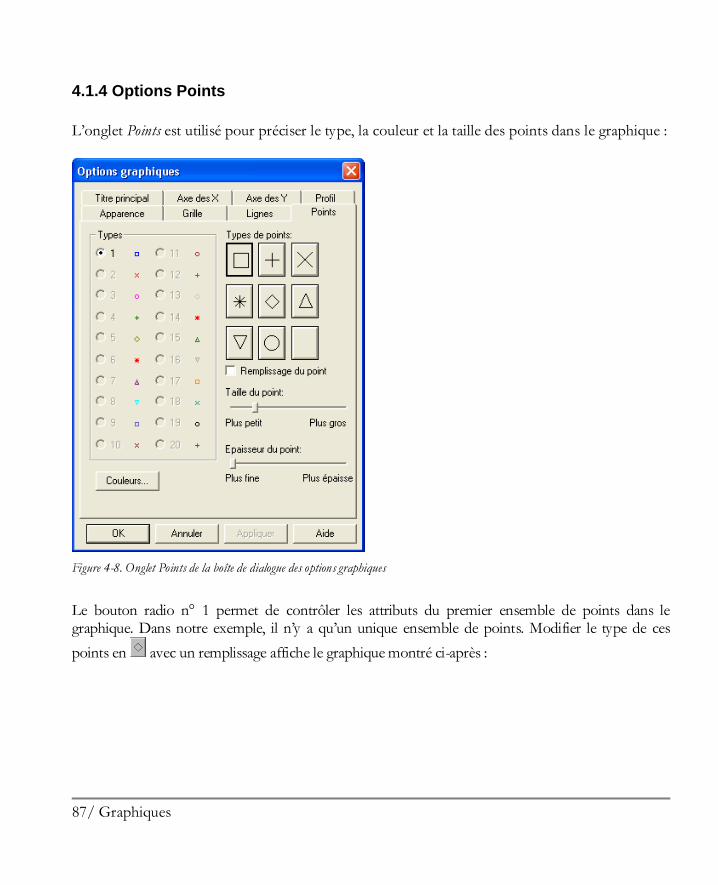
87/ Graphiques
4.1.4 Options Points
L’onglet Points est utilisé pour préciser le type, la couleur et la taille des points dans le graphique :
Figure 4-8. Onglet Points de la boîte de dialogue des options graphiques
Le bouton radio n° 1 permet de contrôler les attributs du premier ensemble de points dans le graphique. Dans notre exemple, il n’y a qu’un unique ensemble de points. Modifier le type de ces
points en avec un remplissage affiche le graphique montré ci-après :
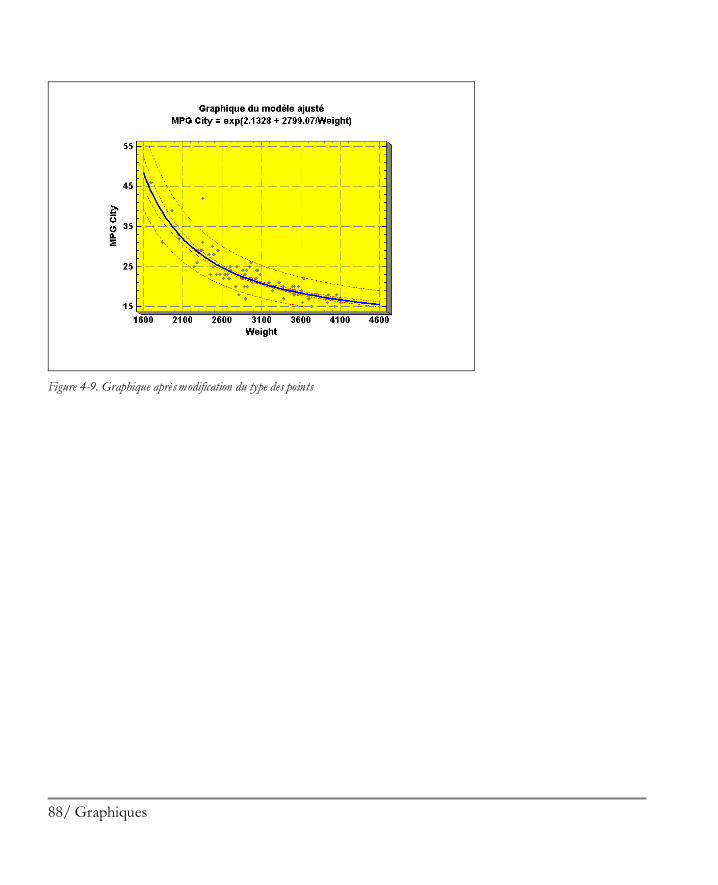
88/ Graphiques
Figure 4-9. Graphique après modification du type des points
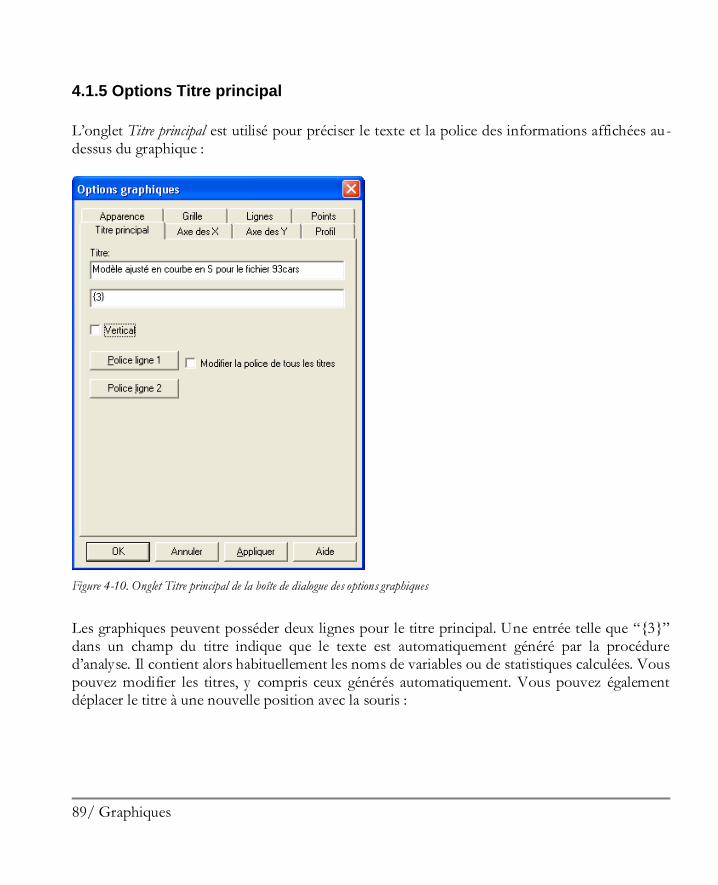
89/ Graphiques
4.1.5 Options Titre principal
L’onglet Titre principal est utilisé pour préciser le texte et la police des informations affichées au-dessus du graphique :
Figure 4-10. Onglet Titre principal de la boîte de dialogue des options graphiques
Les graphiques peuvent posséder deux lignes pour le titre principal. Une entrée telle que “{3}” dans un champ du titre indique que le texte est automatiquement généré par la procédure d’analyse. Il contient alors habituellement les noms de variables ou de statistiques calculées. Vous pouvez modifier les titres, y compris ceux générés automatiquement. Vous pouvez également déplacer le titre à une nouvelle position avec la souris :
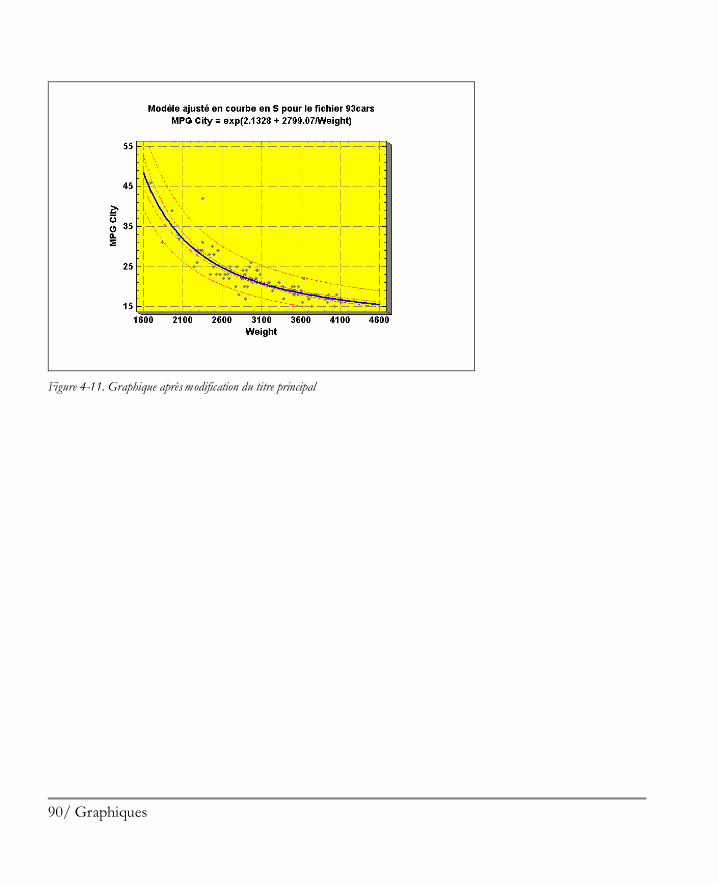
90/ Graphiques
Figure 4-11. Graphique après modification du titre principal
91/ Graphiques
4.1.6 Options Echelles des axes
La boîte de dialogue des Options graphiques contient également des onglets qui vous permettent de modifier les titres et les échelles des axes :
Figure 4-12. Onglet Axe des X de la boîte de dialogue des options graphiques
Il y a plusieurs champs importants dans cette boîte de dialogue :
1. Titre : le titre affiché le long de l’axe.
2. De, A, Par et Sauter : permet de définir l’échelle des graduations. La valeur dans Sauter est utilisée pour éviter que des graduations se chevauchent. Par exemple, une valeur de 1 dans le champ Sauter permet de n’afficher qu’une graduation sur deux.
3. Rotation des libellés : permet d’afficher verticalement les libellés des graduations.
92/ Graphiques
4. Pas de puissance : n’affiche pas les petits ou les grands nombres avec des libellés comportant une puissance comme (X 1000).
5. Echelle : trace l’axe en utilisant différents type d’échelles.
6. Si modification des données : permet de préciser si l’échelle est constante ou se modifie avec les
données.
7. Polices : cliquer sur ces boutons pour modifier la couleur, la taille ou le type de la police pour le titre ou les graduations.
Le graphique créé suite aux modifications apportées dans la boîte de dialogue est affiché ci-dessous :
Figure 4-13. Graphique après modifications des titres des axes et des échelles
93/ Graphiques
4.1.7 Options Remplissages
Certains graphiques, comme les histogrammes, possèdent des zones avec remplissages. L’onglet Remplissages de la boîte de dialogue Options graphiques permet de préciser la couleur et le type de bâtons, polygones et parts d’un diagramme circulaire :
Figure 4-14. Onglet Remplissages de la boîte de dialogue des options graphiques
Le bouton radio n° 1 contrôle le premier type de remplissage dans le graphique. Dans un histogramme, toutes les barres utilisent ce premier type. Dans certains graphiques, comme les diagrammes circulaires, plus d’un type est utilisé. Dans ces cas, les boutons n° 2 à 20 contrôlent les autres types de remplissages. Pour des graphiques comme les histogrammes, définir un type de remplissage hachuré est souvent un bon choix lorsque vous imprimez les résultats en noir et blanc :
94/ Graphiques
Figure 4-15. Histogrammes avec un type de remplissage modifié
4.1.8 Options Textes, Libellés et Légendes
Pour les graphiques contenant des légendes ou des libellés additionnels, des onglets spéciaux sont proposés dans la boîte de dialogue des Options graphiques. Ils vous permettent de modifier les textes et les polices.
4.1.9 Ajouter un nouveau texte
Des textes additionnels peuvent également être ajoutés dans tout graphique en cliquant sur le
bouton Ajouter un texte dans la barre d’outils d’analyse. Une boîte de dialogue s’affiche dans laquelle vous pouvez entrer le texte à ajouter :
Figure 4-16. Boîte de dialogue pour ajouter un nouveau texte
95/ Graphiques
Le texte sera initialement positionné sous le titre principal. Il peut être déplacé à la souris à tout endroit du graphique :
Figure 4-17. Graphique après ajout d’un nouveau texte
Après avoir ajouté un texte, cliquer sur ce texte puis sur le bouton des Options graphiques pour y apporter des modifications.
4.2 Eparpiller un nuage de point Lorsqu’une ou les deux variables d’un nuage de points sont discrètes, il est assez probable que plusieurs points possèdent les mêmes valeurs et que de ce fait ils soient superposés. La barre d’outils d’analyse propose un bouton Eparpiller qui permet de résoudre ce problème en ajoutant une petite quantité aléatoire aux valeurs définissant la position horizontale et la position verticale dans le graphique. Par exemple, considérons le graphique suivant des données du fichier 93cars.sgd :
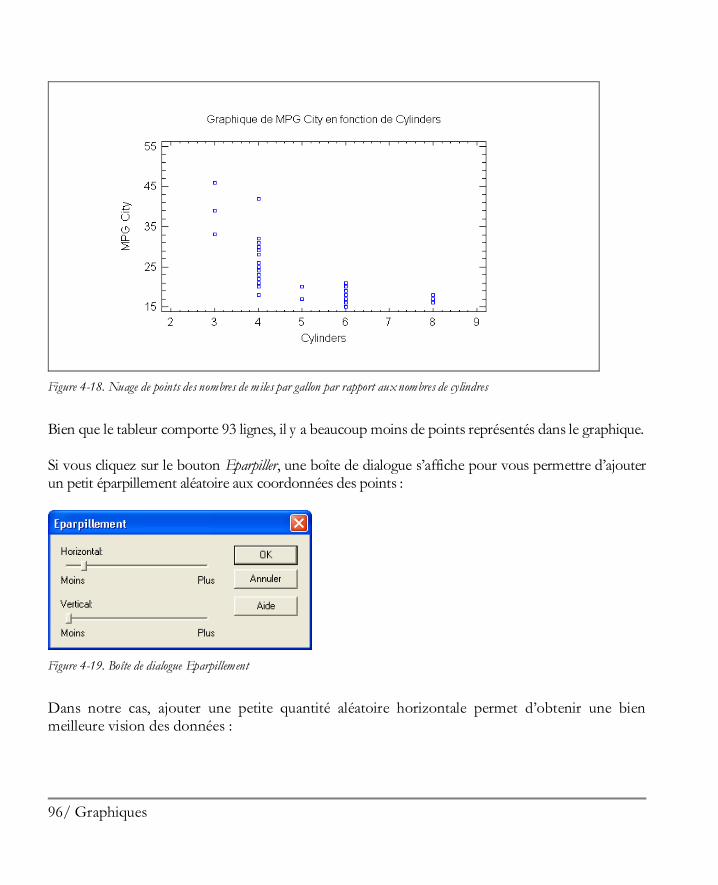
96/ Graphiques
Figure 4-18. Nuage de points des nombres de miles par gallon par rapport aux nombres de cylindres
Bien que le tableur comporte 93 lignes, il y a beaucoup moins de points représentés dans le graphique. Si vous cliquez sur le bouton Eparpiller, une boîte de dialogue s’affiche pour vous permettre d’ajouter un petit éparpillement aléatoire aux coordonnées des points :
Figure 4-19. Boîte de dialogue Eparpillement
Dans notre cas, ajouter une petite quantité aléatoire horizontale permet d’obtenir une bien meilleure vision des données :
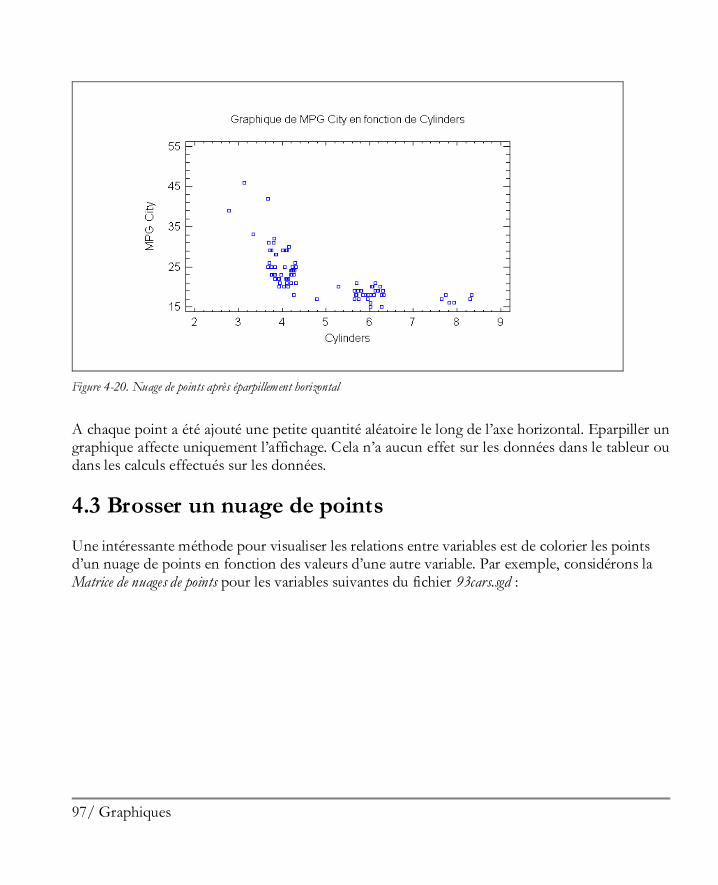
97/ Graphiques
Figure 4-20. Nuage de points après éparpillement horizontal
A chaque point a été ajouté une petite quantité aléatoire le long de l’axe horizontal. Eparpiller un graphique affecte uniquement l’affichage. Cela n’a aucun effet sur les données dans le tableur ou dans les calculs effectués sur les données.
4.3 Brosser un nuage de points Une intéressante méthode pour visualiser les relations entre variables est de colorier les points d’un nuage de points en fonction des valeurs d’une autre variable. Par exemple, considérons la Matrice de nuages de points pour les variables suivantes du fichier 93cars.sgd :
98/ Graphiques
Figure 4-21. Matrice de nuages de points pour des variables du fichier 93cars
Le nuage de points dans chaque cellule de la matrice de nuages de points affiche les valeurs des variables qui correspondent aux identifiants de la ligne et de la colonne caractérisant cette cellule.
Supposons que nous désirions visualiser comment la puissance des automobiles est reliée aux
cinq variables affichées. Si vous cliquez sur le bouton Brosser dans la barre d’outils d’analyse, la boîte de dialogue suivante s’affiche :
Figure 4-22. Boîte de dialogue de sélection de la variable de brossage
99/ Graphiques
Sélectionnons la variable quantitative à utiliser pour coder les points. Après sélection de la variable de brossage, une boîte de dialogue flottante s’affiche :
Figure 4-23. Boîte de dialogue flottante pour définir l’intervalle de brossage
Les deux réglettes sont utilisées pour définir les limites basse et haute pour la variable. Tous les points compris dans l’intervalle sont colorés en rouge. Par exemple, dans le graphique ci -dessous, toutes les automobiles dont la puissance est comprise entre 55,0 et 121,15 sont colorées en rouge :
Figure 4-24. Matrice de nuages de points après brossage
Il est clair à partir du graphique ci-dessus que la puissance Horsepower est fortement corrélée à d’autres variables.

100/ Graphiques
4.4 Lisser un nuage de points Pour aider à visualiser les relations entre les variables d’un nuage de points, un lissage peut y être
ajouté. Pour lisser un nuage de points, cliquer sur le bouton Lissage/Rotation dans la barre d’outils d’analyse. La boîte de dialogue suivante s’affiche alors :
Figure 4-25. Boîte de dialogue de lissage d’un nuage de points
Lisser un nuage de points se fait en définissant un ensemble de positions sur l’axe des X et en affichant à chacune de ces positions une moyenne pondérée de la fraction des points qui sont proches de cette position. Une des meilleures méthodes de lissage est appelée LOWESS (LOcally WEighted Scatterplot Smoothing) et utilise habituellement une fraction de lissage comprise entre 40% et 60%. Le résultat de ce lissage sur la Matrice de nuages de points des données de nos automobile est affiché ci-dessous :

101/ Graphiques
Figure 4-26. Matrice de nuages de points après lissage Lowess avec une fraction de lissage de 50%
Le lissage aide à visualiser les types de relations entre les variables.
4.5 Identifier des points Pour afficher le numéro de la ligne d’un point du graphique et ses coordonnées, il suffit de cliquer sur ce point dans le graphique. Une petite boîte s’affiche alors dans le coin supérieur droit du graphique indiquant le numéro de la ligne et les coordonnées du point :
102/ Graphiques
Figure 4-27. Afficher des informations concernant un point sélectionné
Simultanément, le numéro de la ligne du point s’affiche dans le champ Ligne de la barre d’outils d’analyse :
Figure 4-28. Barre d’outils d’analyse affichant le numéro de la ligne du point sélectionné
D’autres informations concernant le point sélectionné peuvent être obtenues en cliquant sur le
bouton Identifier et en sélectionnant une colonne du Classeur :
103/ Graphiques
Figure 4-29. Boîte de dialogue d’identification d’un point
Après avoir sélectionné une variable, cliquer sur un point quelconque affiche la valeur de la variable sélectionnée dans le champ Libellé de la barre d’outils d’analyse :
Figure 4-30. Barre d’outils d’analyse affichant la marque du point sélectionné
Les boutons de localisation à droite des champs Libellé et Ligne peuvent être utilisés pour localiser des points dans le graphique. Si vous entrez une valeur dans l’un de ces champs puis cliquez sur le bouton de localisation correspondant, tous les points du graphique qui possèdent la valeur entrée s’afficheront dans une couleur différente. Par exemple, dans le graphique ci -après, les points qui correspondent à des automobiles de marque Honda sont affichés en rouge :
104/ Graphiques
Figure 4-31. Graphique mettant en évidence les automobiles de marque Honda
Cette technique est également utile pour la Matrice de nuages de points. Dans l’affichage suivant, tous les points qui correspondent à la ligne 42 ont été mis en évidence :
Figure 4-32. Matrice de nuages de points mettant en évidence la ligne 42

105/ Graphiques
Localiser un point dans une Matrice de nuages de points peut vous aider à identifier si ce point est ou n’est pas un point extrême par rapport à une ou plusieurs variables.
NOTE : La couleur utilisée pour mettre en évidence les points peut être définie dans l’onglet Graphiques de la boîte de dialogue Préférences accessible par le menu Editer.
4.6 Copier des graphiques dans d’autres applications Une fois qu’un graphique a été créé dans STATGRAPHICS Centurion XVI, il peut être aisément copié dans d’autres applications comme Microsoft Word ou PowerPoint en :
1. Maximisant la sous-fenêtre contenant le graphique. 2. Sélectionnant Copier dans le menu Editer de STATGRAPHICS Centurion XVI.
3. Sélectionnant Coller dans l’autre application.
Par défaut, les graphiques sont collés dans le format “Image” qui correspond au format métafichier de Windows. Dans de rares occasions lorsque vous désirez coller le graphique dans un autre format, vous pouvez utiliser Collage spécial au lieu du simple Coller. Pour copier une analyse complète dans une autre application, incluant les tableaux et les graphiques, il faut en premier copier l’analyse dans le StatReporter en utilisant le menu qui s’affiche en cliquant sur le bouton droit de la souris, puis copier le StatReporter dans l’autre application. Cette technique est décrite dans le Chapitre 7. Pour copier le graphique et la fenêtre l’entourant, un logiciel de capture d’écran est recommandé. Pour produire ce manuel, le logiciel SnagIt a été utilisé. Il peut être obtenu à www.techsmith.com . Si vous utilisez SnagIt, nous vous recommandons de définir l’Input à “Window” et l’Output à “Clipboard”. Vous pourrez alors copier vos images directement dans tout document.
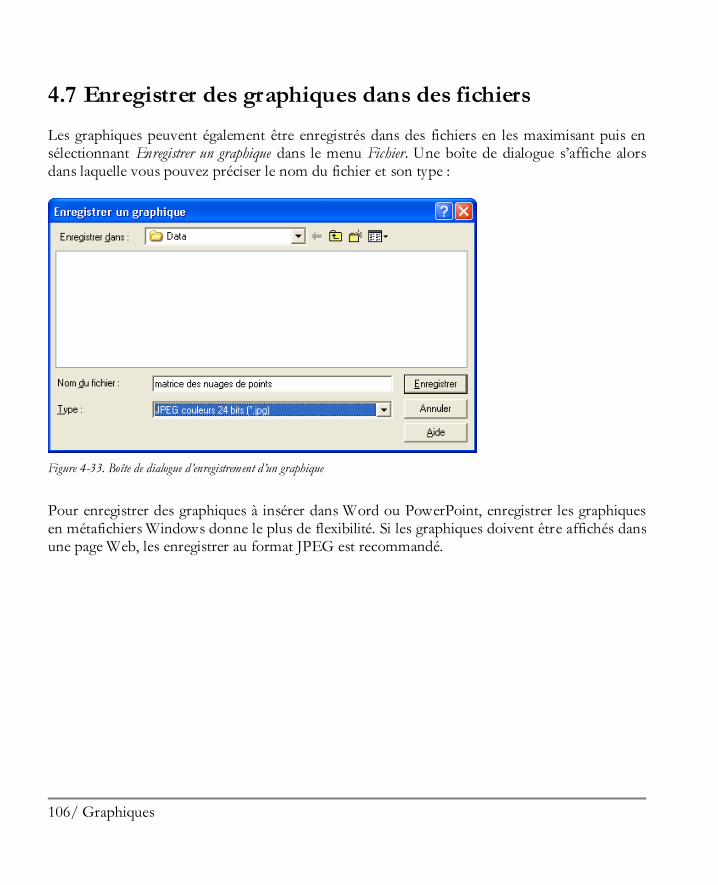
106/ Graphiques
4.7 Enregistrer des graphiques dans des fichiers Les graphiques peuvent également être enregistrés dans des fichiers en les maximisant puis en sélectionnant Enregistrer un graphique dans le menu Fichier. Une boîte de dialogue s’affiche alors dans laquelle vous pouvez préciser le nom du fichier et son type :
Figure 4-33. Boîte de dialogue d’enregistrement d’un graphique
Pour enregistrer des graphiques à insérer dans Word ou PowerPoint, enregistrer les graphiques en métafichiers Windows donne le plus de flexibilité. Si les graphiques doivent être affichés dans une page Web, les enregistrer au format JPEG est recommandé.

107/ StatFolios
StatFolios
Enregistrer votre session, publier vos résultats au format HTML et automatiser les analyses en utilisant des scripts de démarrage.
A chaque fois que vous sélectionnez une analyse statistique dans le menu de STATGRAPHICS Centurion XVI, une nouvelle fenêtre d’analyse est créée. Vous pouvez enregistrer toutes les fenêtres des analyses en créant un StatFolio. Un StatFolio est un fichier contenant la définition de toutes les analyses statistiques qui ont été mises en oeuvre avec des pointeurs vers les données qu’elles ont utilisées. En enregistrant un StatFolio et en le rouvrant plus tard, vous enregistrez et rechargez votre session de travail STATGRAPHICS Centurion XVI. Lorsqu’une session est enregistrée dans un StatFolio, c’est la définition des analyses qui est enregistrée, pas les résultats. Lorsque vous rouvrez un StatFolio, les données des sources de données sont relues et les analyses sont recalculées. Le StatFolio apporte ainsi un moyen simple de répéter des analyses plus tard sur d’autres jeux de données. Vous pouvez également y associer un script qui est exécuté lorsque le StatFolio est chargé. Des détails sur le script et d’autres fonctionnalités du StatFolio sont donnés plus loin dans ce chapitre.
5.1 Enregistrer votre session Pour enregistrer votre session STATGRAPHICS Centurion XVI en cours, sélectionnez Fichier – Enregistrer – Enregistrer un StatFolio dans le menu principal et entrez un nom pour le StatFolio dans la boîte de dialogue montrée ci-après :
Chapitre
5
108/ StatFolios
Figure 5-1. Boîte de dialogue d’entrée d’un nom pour l’enregistrement du StatFolio
Les StatFolios sont enregistrés dans des fichiers dont l’extension est .sgp. Ils contiennent :
1. Une définition de toutes les analyses qui ont été mises en oeuvre, dont les noms des variables, les tableaux et les graphiques, les paramètres de toutes les options, les modifications faites aux graphiques, etc. Lorsqu’un StatFolio est rouvert, les analyses sont remises en oeuvre et tous les tableaux et graphiques sont mis à jour.
2. Les liens aux sources de données définis dans le Classeur. Si les données ont été
modifiées entre le moment où le StatFolio a été enregistré et le moment où il est rouvert, les fenêtres des analyses prendront en compte ces modifications.
3. Les liens aux fichiers de la StatGallery et du StatReporter, si des éléments ont été placés
dans ces fichiers avant que le StatFolio ne soit enregistré. Le logiciel vous demandera des noms pour ces fichiers StatGallery et StatReporter lorsque le StatFolio sera enregistré.
5.2 Script de démarrage du StatFolio Lorsqu’un StatFolio est chargé, toutes les fenêtres des analyses sont d’abord recréées. STATGRAPHICS Centurion XVI vérifie ensuite si un script de démarrage a été enregistré avec le StatFolio et, s’il y en a un, l’exécute. Un script peut être créé en sélectionnant Script de démarrage du StatFolio dans le menu Editer. Une boîte de dialogue s’affiche contenant des champs permettant de définir une séquence d’actions à exécuter :
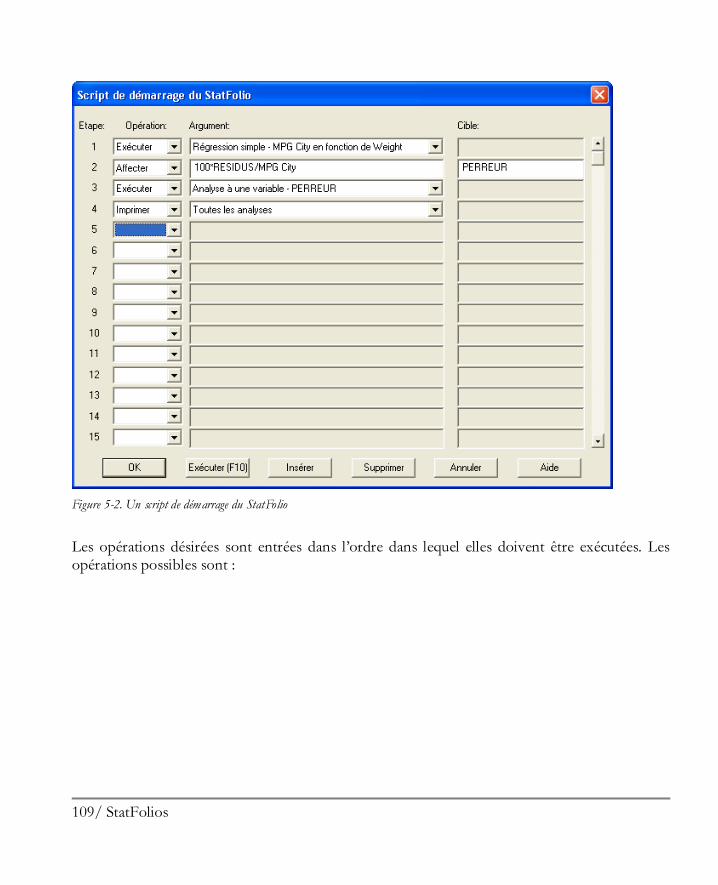
109/ StatFolios
Figure 5-2. Un script de démarrage du StatFolio
Les opérations désirées sont entrées dans l’ordre dans lequel elles doivent être exécutées. Les opérations possibles sont :
110/ StatFolios
Opération Argument Cible Description
Exécuter Titre de l’analyse Met à jour l’analyse indiquée.
Affecter Expression STATGRAPHICS Centurion XVI
Nom de colonne
Evalue l’expression et affecte le résultat dans la colonne indiquée.
Imprimer Fenêtre(s) à imprimer Imprime le contenu des fenêtres indiquées.
Publier Exécute le StatPublish pour publier le contenu du StatFolio au format HTML.
Commande Commande Windows à exécuter
Argument de la commande
Demande à Windows d’exécuter la commande.
Délai Nombre de secondes Effectue une pause du temps indiqué.
Charger Nom du StatFolio Indique le StatFolio à charger après l’exécution du script. Cela permet d’exécuter des StatFolios de façon enchaînée.
Quitter Quitte STATGRAPHICS Centurion XVI.
Figure 5-3. Opérations pour le script de démarrage
Dans l’exemple montré en Figure 5-2, une Régression simple est mise en oeuvre. Dans cette analyse, on suppose que l’option Enregistrement des résultats a été activée pour automatiquement enregistrer les résidus du modèle ajusté dans une colonne nommée RESIDUS. Les résidus sont alors divisés par les valeurs des données d’origine et multipliés par 100 pour créer des pourcentages d’erreurs qui sont affectés à une nouvelle variable nommée PERREUR. Des calculs de statistiques descriptives sont alors effectués sur les valeurs de PERREUR en utilisant la procédure Analyse à une variable puis les résultats de ces deux analyses sont imprimés. NOTE : Les StatFolios peuvent être enchaînés en utilisant l’opération CHARGER dans un script pour charger et démarrer le script d’un autre StatFolio. Vous pouvez également quitter automatiquement STATGRAPHICS Centurion XVI en utilisant l’opération QUITTER. NOTE : Vous pouvez désactiver l’exécution des scripts en sélectionnant Désactiver les scripts dans l’onglet Général de la boîte de dialogue Préférences accessible par le menu Editer :
111/ StatFolios
Figure 5-4. Désactiver les scripts de démarrage des StatFolios

112/ StatFolios
5.3 Interroger les sources de données Une fois qu’un StatFolio contenant diverses analyses a été créé, les données des sources de données peuvent être relues à des intervalles de temps fixes et les analyses mises à jour automatiquement. Cela est réalisé en utilisant la boîte de dialogue Propriétés du classeur dans le menu Editer ou en sélectionnant StatLink dans le menu Fichier :
Figure 5-5. Boîte de dialogue des propriétés du classeur pour l’interrogation des sources de données
Pour interroger les sources de données de façon répétitive :
1. Cocher la case Acquérir pour chacune des sources de données à relire.
2. Sélectionner le bouton radio Oui dans le champ Acquisition par le StatLink.
3. Préciser la fréquence d’interrogation des sources de données.
113/ StatFolios
4. Cocher Exécuter le script si vous désirez exécuter le script de démarrage du StatFolio à chaque fois que les données sont lues.
En incluant l’étape Publier dans chaque script de démarrage, vous pouvez demander à STATGRAPHICS Centurion XVI de charger automatiquement les résultats des analyses sur un serveur du réseau.
5.4 Publier les résultats au format HTML Les résultats d’un StatFolio peuvent être publiés sous un format visualisable en utilisant un simple navigateur Internet en sélectionnant Publier les statistiques dans le menu Fichier. Une boîte de dialogue s’affiche alors pour préciser les résultats à publier et où ils sont publiés :
Figure 5-6. Boîte de dialogue StatPublish pour créer un rapport au format HTML
Les champs de cette boîte de dialogue sont utilisés pour préciser :

114/ StatFolios
Fichier HTML dans le répertoire local : C’est le nom du fichier HTML qui contient la table des matières pour le StatFolio. Il liste le contenu du StatFolio et contient des liens vers d’autres fichiers HTML qui correspondent à chacune des fenêtres dans le StatFolio. Par défaut, il est placé dans le même répertoire que le StatFolio et porte le même nom que le StatFolio mais avec une extension .htm au lieu de .sgp. Pour visualiser un StatFolio publié, un navigateur Internet est appelé pour ouvrir ce fichier.
URL du site FTP : Tous les résultats publiés sont d’abord placés dans le répertoire local indiqué ci-dessus. Cela inclut les fichiers HTML, les fichiers contenant les graphiques et d’autres fichiers. Si vous avez renseigné le champ URL du site FTP, tous les fichiers sont également chargés à l’endroit indiqué par l’URL. C’est classiquement un répertoire sur un serveur. A noter que vous devez avoir un droit d’écriture en mode FTP dans l’URL indiqué, ce qui doit être paramétré par l’administrateur du réseau.
Utilisateur FTP : Nom de l’utilisateur pour l’accès en mode FTP à l’URL indiqué.
Mot de passe FTP : Mot de passe pour accéder en mode FTP à l’URL indiqué.
Inclure : Cocher toutes les fenêtres du StatFolio qui doivent être publiées.
Largeur et hauteur des graphiques : La taille des graphiques en pixels lorsqu’ils sont insérés dans les pages HTML.
Format des images : Les graphiques peuvent être insérés dans les fichiers HTML sous trois formats :
1. JPEG – images statiques enregistrées au format JPEG. Les fichiers sont créés avec des
noms comme pubexemple_analyse1_graph1.jpg.
2. PNG – images statiques enregistrées au format PNG. Les fichiers sont créés avec des noms comme pubexemple_analyse1_graph1.png.
3. Applet Java – résultats publiés et visualisés de façon dynamique dans le navigateur
Internet. Dans le navigateur Internet, les graphiques sont mis à jour en fonction de l’intervalle de temps défini, en lisant un fichier auxiliaire portant un nom comme pubexemple_analysis1_graph1.sgz.

115/ StatFolios
Cette option est conçue pour être utilisée en conjonction avec l’acquisition en temps réel utilisant le StatLink, comme décrit dans le document PDF intitulé Gestion et analyse dynamique des données. NOTE : tous les graphiques ne seront pas publiés correctement par cette option. Si un ou plusieurs graphiques ne sont pas publiés correctement, choisir une option différente.
Interactivité des applets : Pour les graphiques publiés sous la forme d’applets, la sélection de cette fonctionnalité permet d’afficher des informations concernant les données en cliquant sur un point avec la souris depuis le navigateur Internet.
Après avoir renseigné ces champs, cliquer sur OK pour publier le StatFolio. Pour visualiser un StatFolio publié, démarrer le navigateur Internet et utiliser son menu Fichier pour ouvrir le fichier indiqué dans le premier champ de la Figure 5-6. Vous pouvez également visualiser les résultats en sélectionnant Voir les statistiques publiées dans le menu Fichier de STATGRAPHICS Centurion XVI.
NOTE : Les tableaux et les graphiques sont insérés dans les fichiers HTML avec des noms créés automatiquement par le StatPublish. Depuis le navigateur Internet, vous pouvez afficher le code source et aisément déterminer les noms de ces fichiers. Ces fichiers peuvent alors être insérés dans vos propres pages Web si vous le désirez.

116/ StatFolios

117/ Utiliser la StatGallery
Utiliser la StatGallery
Juxtaposer et superposer des graphiques.
La StatGallery est une fenêtre spéciale de STATGRAPHICS Centurion XVI dans laquelle les graphiques créés par d’autres procédures peuvent être juxtaposés ou superposés. Juxtaposer les graphiques est un puissant outil pour comparer deux jeux de données, deux modèles statistiques ou deux niveaux d’un graphique d’iso-contours. Superposer des graphiques permet de créer de nouveaux graphiques non proposés par le logiciel.
La StatGallery est enregistrée dans un fichier de suffixe .sgg. Si vous copiez des éléments dans la StatGallery, un pointeur vers le fichier de la StatGallery est enregistré dans le StatFolio courant. Lorsque le StatFolio est rouvert, il charge automatiquement la StatGallery associée.
6.1 Configurer un page de la StatGallery La StatGallery est contenue dans une fenêtre séparée qui est créée lorsque STATGRAPHICS Centurion XVI est chargé. Elle est constituée d’une ou de plusieurs pages, chacune pouvant contenir jusqu’à 9 graphiques. Par défaut, chaque page de la galerie contient 4 graphiques, comme montré ci-après :
Chapitre
6

118/ Utiliser la StatGallery
Figure 6-1. La fenêtre StatGallery
Les boutons en haut de la fenêtre vous permettent de vous déplacer vers les autres pages de la galerie. Si vous désirez modifier le nombre de graphiques affichés dans une page, cliquez sur le bouton droit de la souris et sélectionnez Arranger les fenêtres. Des arrangements contenant jusqu’à 9 graphiques peuvent être sélectionnés pour chaque page :
Figure 6-2. Configurations possibles de la page de la StatGallery
Les sept configurations de gauche correspondent à des arrangements rectangulaires de lignes et de colonnes. L’option Par colonnes vous permet de créer des arrangements comportant des nombres différents de lignes pour chacune des 3 colonnes.

119/ Utiliser la StatGallery
Vous pouvez également utiliser les barres déplaçables de la fenêtre de la StatGallery pour créer tout arrangement désiré.
6.2 Copier des graphiques dans la StatGallery Pour ajouter un graphique dans la StatGallery , vous devez d’abord le copier dans le presse-papiers de Windows depuis la fenêtre d’analyse dans laquelle il a été créé. Par exemple, supposons que vous désiriez visualiser des graphiques d’iso-contours créés par la procédure de plans d’expériences Analyser un plan pour deux niveaux différents d’un facteur expérimental sélectionné. Les étapes à suivre sont les suivantes :
1. Configurer la page sélectionnée de la StatGallery pour y afficher un graphique à gauche et un graphique à droite.
2. Générer un graphique d’iso-contours dans la procédure Analyser un plan pour un niveau
du facteur expérimental et le copier dans le presse-papiers de Windows.
3. Activer la fenêtre StatGallery. Cliquer sur le bouton droit de la souris dans la sous-fenêtre de gauche et sélectionner Coller dans le menu popup pour placer le graphique d’iso-contours dans la StatGallery.
4. Revenir à la fenêtre Analyser un plan et générer le deuxième graphique d’iso-contours
pour un autre niveau du facteur expérimental. Le copier dans le presse-papiers de Windows.
5. Revenir à la fenêtre StatGallery. Cliquer sur le bouton droit de la souris dans la sous-
fenêtre de droite et sélectionner Coller dans le menu popup. Cela place le second graphique dans la StatGallery à droite du premier.
Le résultat obtenu est similaire à celui montré ci-après :
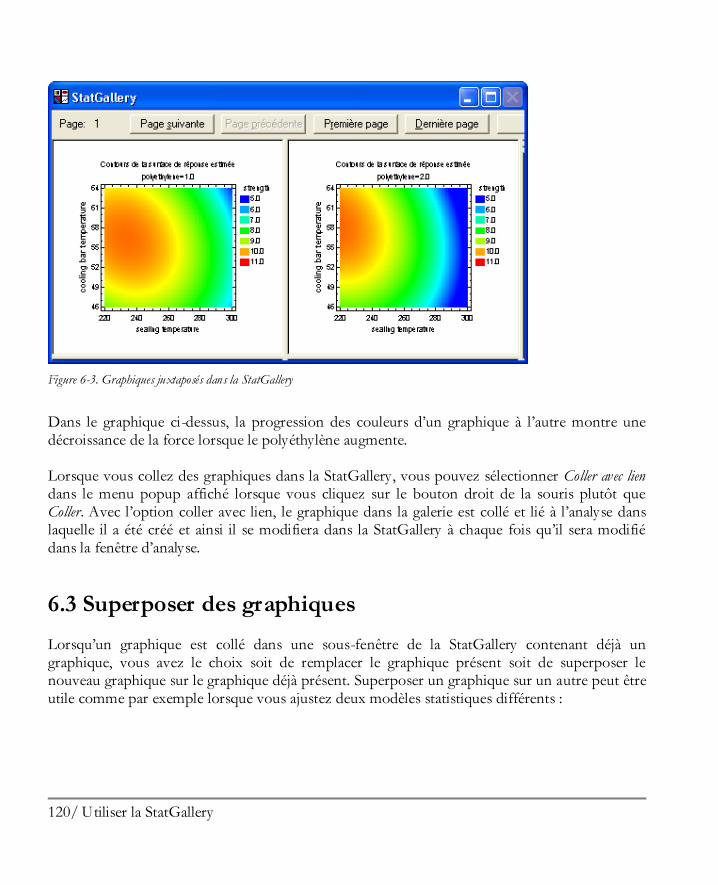
120/ Utiliser la StatGallery
Figure 6-3. Graphiques juxtaposés dans la StatGallery
Dans le graphique ci-dessus, la progression des couleurs d’un graphique à l’autre montre une décroissance de la force lorsque le polyéthylène augmente. Lorsque vous collez des graphiques dans la StatGallery, vous pouvez sélectionner Coller avec lien dans le menu popup affiché lorsque vous cliquez sur le bouton droit de la souris plutôt que Coller. Avec l’option coller avec lien, le graphique dans la galerie est collé et lié à l’analyse dans laquelle il a été créé et ainsi il se modifiera dans la StatGallery à chaque fois qu’il sera modifié dans la fenêtre d’analyse.
6.3 Superposer des graphiques Lorsqu’un graphique est collé dans une sous-fenêtre de la StatGallery contenant déjà un graphique, vous avez le choix soit de remplacer le graphique présent soit de superposer le nouveau graphique sur le graphique déjà présent. Superposer un graphique sur un autre peut être utile comme par exemple lorsque vous ajustez deux modèles statistiques différents :
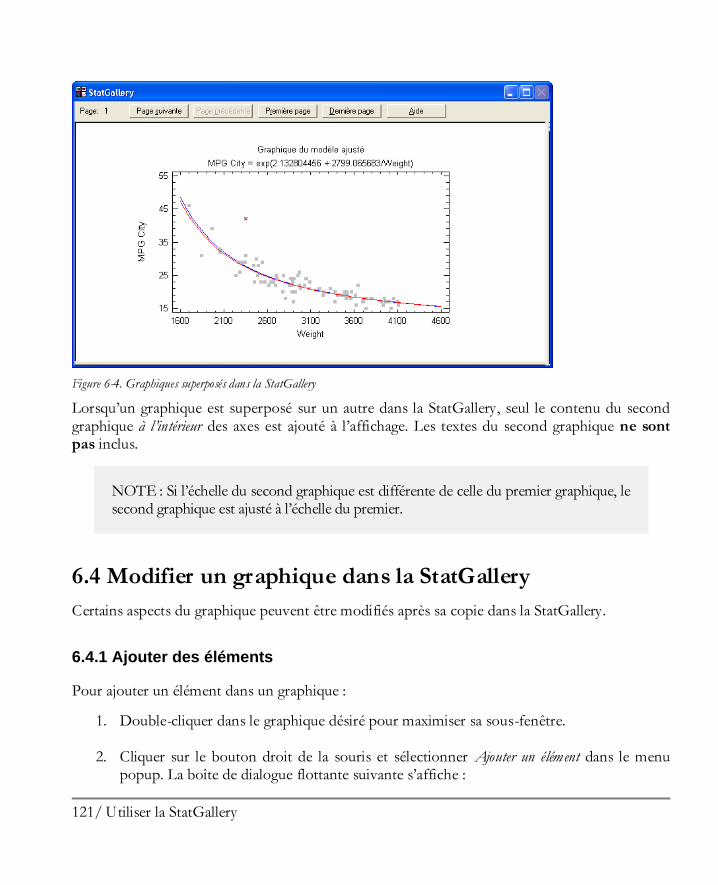
121/ Utiliser la StatGallery
Figure 6-4. Graphiques superposés dans la StatGallery
Lorsqu’un graphique est superposé sur un autre dans la StatGallery, seul le contenu du second graphique à l’intérieur des axes est ajouté à l’affichage. Les textes du second graphique ne sont pas inclus.
NOTE : Si l’échelle du second graphique est différente de celle du premier graphique, le second graphique est ajusté à l’échelle du premier.
6.4 Modifier un graphique dans la StatGallery
Certains aspects du graphique peuvent être modifiés après sa copie dans la StatGallery.
6.4.1 Ajouter des éléments
Pour ajouter un élément dans un graphique :
1. Double-cliquer dans le graphique désiré pour maximiser sa sous-fenêtre.
2. Cliquer sur le bouton droit de la souris et sélectionner Ajouter un élément dans le menu popup. La boîte de dialogue flottante suivante s’affiche :

122/ Utiliser la StatGallery
Figure 6-5. Boîte de dialogue Ajouter un élément
3. Sélectionner le type d’élément à ajouter dans le graphique. Les cinq premiers boutons de la boîte de dialogue montrée en Figure 6-5 s’utilisent en maintenant appuyé le bouton de la souris et en se déplaçant jusqu’à ce que la ligne ou la figure possède la forme désirée. Le dernier bouton active le mode texte. Au prochain clic dans le graphique, une boîte de dialogue permettant d’entrer le texte s’affichera. Le texte ajouté peut être déplacé à la position souhaitée.
6.4.2 Modifier des éléments
Pour modifier un élément de la StatGallery :
1. Double-cliquer dans le graphique désiré pour maximiser sa sous-fenêtre.
2. Cliquer sur l’élément à modifier avec la souris pour le sélectionner. Des petits carrés s’affichent aux extrémités de l’élément qui a été sélectionné.
3. Cliquer sur le bouton droit de la souris et sélectionner Modifier un élément dans le menu popup.
Une boîte de dialogue correspondant au type de l’élément sélectionné s’affiche dans laquelle vous pouvez faire les modifications souhaitées.
6.4.3 Supprimer des éléments
Pour supprimer un élément de la StatGallery :
1. Double-cliquer dans le graphique désiré pour maximiser sa sous-fenêtre.
2. Cliquer sur l’élément à supprimer avec la souris pour le sélectionner.
3. Cliquer sur le bouton droit de la souris et sélectionner Supprimer un élément dans le menu popup.

123/ Utiliser la StatGallery
6.5 Imprimer la StatGallery Pour imprimer les éléments de la StatGallery :
1. Activer la fenêtre StatGallery en cliquant dans cette fenêtre avec la souris.
2. Cliquer sur l’icône Imprimer de la barre d’outils principale ou cliquer sur le bouton droit de la souris et sélectionner Imprimer dans le menu popup.
Vous pouvez imprimer toutes les pages ou les pages sélectionnées.

124/ Utiliser la StatGallery

125/ Utiliser le StatReporter
Utiliser le StatReporter
Copier des analyses dans le StatReporter, annoter les résultats et les enregistrer dans un fichier RTF pour importation dans Microsoft Word.
Le StatReporter est une fenêtre dans laquelle les résultats de différentes analyses statistiques peuvent être intégrés pour former un rapport. C’est une version de WordPad fonctionnant dans STATGRAPHICS Centurion XVI. Le StatReporter vous permet :
1. De créer un rapport complet dans STATGRAPHICS sans devoir utiliser un autre logiciel.
2. D’enregistrer le contenu du StatReporter dans un fichier RTF (Rich Text Format), qui
peut être lu directement dans d’autres logiciels comme Microsoft Word.
7.1 La fenêtre StatReporter Le StatReporter est une fenêtre séparée de STATGRAPHICS Centurion XVI créée automatiquement lorsque le logiciel est chargé. Elle consiste en un unique contrôle « rich-edit » et en une barre d’outils :
Chapitre
7
126/ Utiliser le StatReporter
Figure 7-1. La fenêtre StatReporter
Vous pouvez saisir tout texte dans la fenêtre et y copier des résultats créés dans les analyses de STATGRAPHICS.
7.2 Copier des résultats dans le StatReporter
STATGRAPHICS Centurion XVI offre 3 méthodes pour copier des résultats dans le StatReporter :
1. Pour copier un unique tableau ou graphique dans le StatReporter, le copier d’abord dans le presse-papiers de Windows en maximisant la sous-fenêtre et en sélectionnant Copier dans le menu Editer. Se placer ensuite dans la fenêtre du StatReporter, mettre le curseur à l’emplacement désiré et sélectionner Editer – Coller.
2. Maximiser la sous-fenêtre contenant le tableau ou le graphique à copier en double-
cliquant dans cette fenêtre. Cliquer ensuite sur le bouton droit de la souris et sélectionner Copier la fenêtre dans le StatReporter dans le menu popup. Cela permet de copier automatiquement le tableau ou le graphique dans le StatReporter à l’emplacement où est positionné le curseur.

127/ Utiliser le StatReporter
3. Pour copier tous les résultats de la fenêtre d’analyse, cliquer sur le bouton droit de la souris et sélectionner Copier l’analyse dans le StatReporter dans le menu popup. Tous les tableaux et tous les graphiques de l’analyse sont copiés dans le StatReporter.
Chacune des opérations ci-dessus effectue un collage statique (les résultats dans le StatReporter ne seront jamais mis à jour). Vous pouvez lier un tableau ou un graphique à sa source en utilisant la méthode n°1 ci-dessus et en sélectionnant Copier avec lien au lieu de Coller. Le tableau ou le graphique collé sera lié et mis à jour automatiquement lorsque la source des résultats sera modifiée.
7.3 Modifier les résultats dans le StatReporter La barre d’outils du StatReporter vous permet de modifier les résultats placés dans la fenêtre. Pour modifier du texte, sélectionner le texte à modifier et cliquer sur un des boutons de la barre d’outils du StatReporter. Vous pouvez également insérer la date et l’heure en cliquant sur le bouton Date/Heure.
7.4 Enregistrer le StatReporter Pour enregistrer le contenu du StatReporter, sélectionner Fichier – Enregistrer – Enregistrer un StatReporter dans le menu principal et donner un nom au fichier à enregistrer. Le contenu du StatReporter est enregistré dans un fichier de type .rtf qui peut être lu directement dans d’autres logiciels comme Microsoft Word. Lorsqu’un StatFolio est ouvert, il charge automatiquement le StatReporter qui était présent lorsque le StatFolio a été enregistré. Vous pouvez également ouvrir un StatReporter de façon indépendante en utilisant le menu Fichier – Ouvrir.

128/ Utiliser le StatReporter

129/ Utiliser le StatWizard
Utiliser le StatWizard
Sélectionner l’analyse statistique adaptée, rechercher les statistiques et tests désirés et créer de multiples fenêtres pour différents niveaux d’un facteur.
Le StatWizard est une fonctionnalité unique de STATGRAPHICS Centurion XVI conçue pour vous assister de différentes façons :
1. Il peut vous aider à créer un nouveau tableur de données ou à lire une source de données.
2. Il peut suggérer les analyses à mettre en oeuvre en se basant sur les types des données à
analyser.
3. Il peut rechercher les statistiques ou les tests que vous désirez utiliser et vous proposer les analyses qui les calculent.
4. Il peut vous aider à définir des transformations de vos données ou à sélectionner des
sous-ensembles de vos données.
5. Il peut répéter les analyses désirées pour chaque valeur unique d’une colonne de données.
Le StatWizard peut être appelé à tout moment en cliquant sur le bouton de la barre d’outils principale.
Chapitre
8
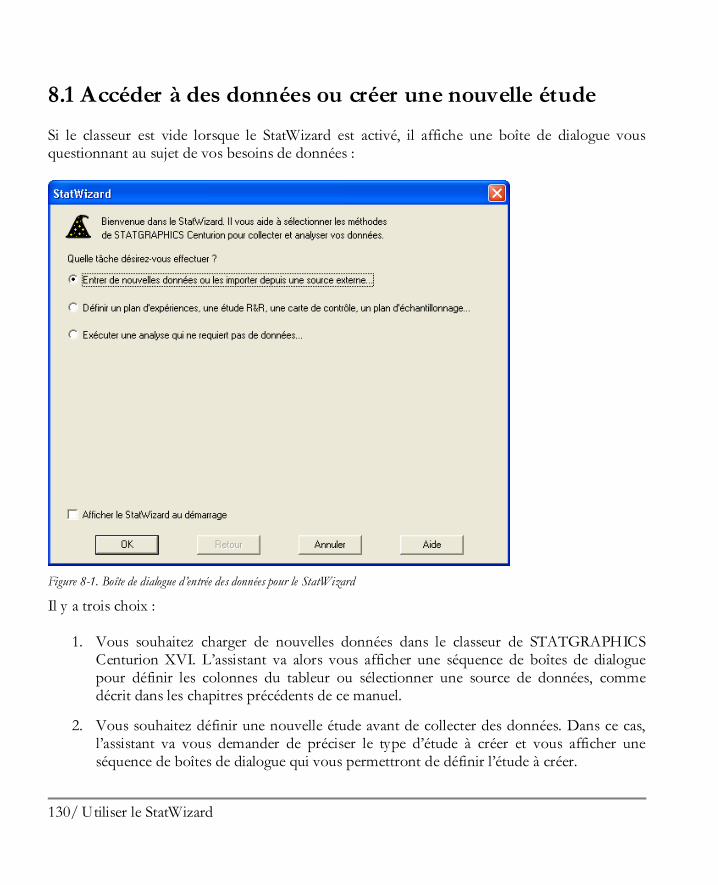
130/ Utiliser le StatWizard
8.1 Accéder à des données ou créer une nouvelle étude Si le classeur est vide lorsque le StatWizard est activé, il affiche une boîte de dialogue vous questionnant au sujet de vos besoins de données :
Figure 8-1. Boîte de dialogue d’entrée des données pour le StatWizard
Il y a trois choix :
1. Vous souhaitez charger de nouvelles données dans le classeur de STATGRAPHICS Centurion XVI. L’assistant va alors vous afficher une séquence de boîtes de dialogue pour définir les colonnes du tableur ou sélectionner une source de données, comme décrit dans les chapitres précédents de ce manuel.
2. Vous souhaitez définir une nouvelle étude avant de collecter des données. Dans ce cas, l’assistant va vous demander de préciser le type d’étude à créer et vous afficher une séquence de boîtes de dialogue qui vous permettront de définir l’étude à créer.
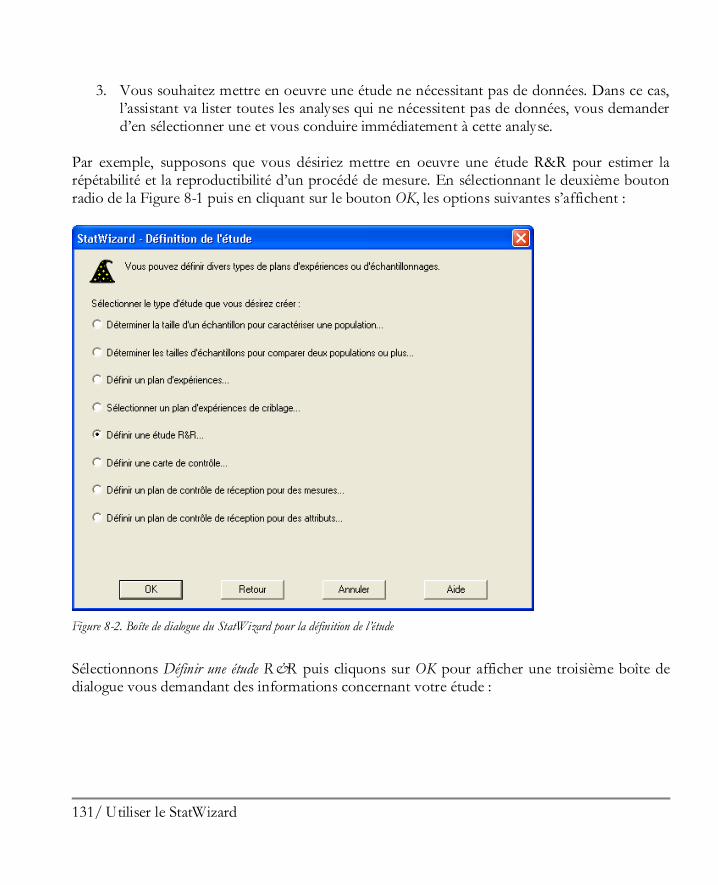
131/ Utiliser le StatWizard
3. Vous souhaitez mettre en oeuvre une étude ne nécessitant pas de données. Dans ce cas, l’assistant va lister toutes les analyses qui ne nécessitent pas de données, vous demander d’en sélectionner une et vous conduire immédiatement à cette analyse.
Par exemple, supposons que vous désiriez mettre en oeuvre une étude R&R pour estimer la répétabilité et la reproductibilité d’un procédé de mesure. En sélectionnant le deuxième bouton radio de la Figure 8-1 puis en cliquant sur le bouton OK, les options suivantes s’affichent :
Figure 8-2. Boîte de dialogue du StatWizard pour la définition de l’étude
Sélectionnons Définir une étude R &R puis cliquons sur OK pour afficher une troisième boîte de dialogue vous demandant des informations concernant votre étude :
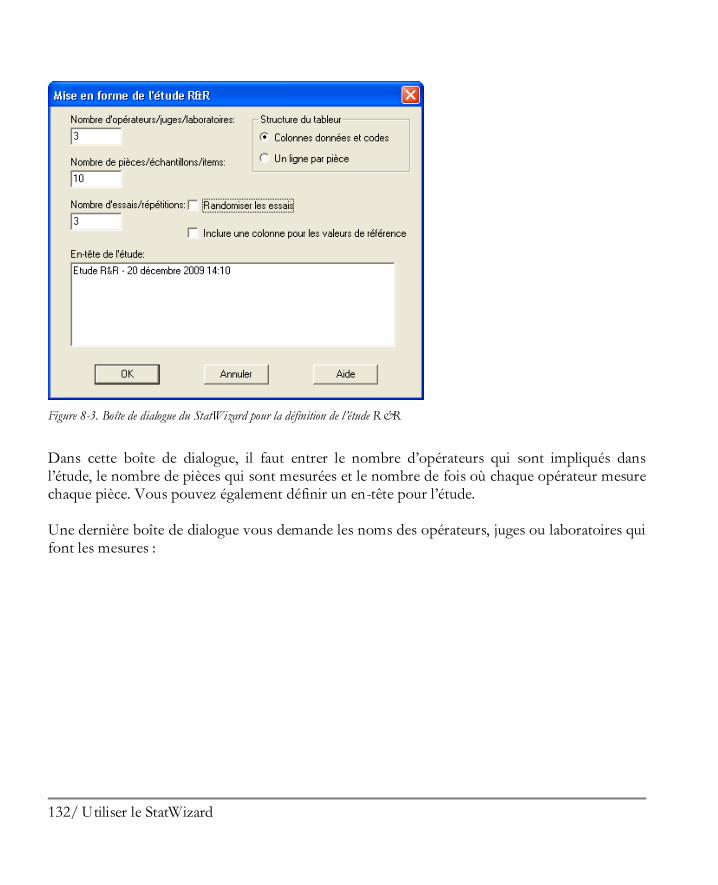
132/ Utiliser le StatWizard
Figure 8-3. Boîte de dialogue du StatWizard pour la définition de l’étude R &R
Dans cette boîte de dialogue, il faut entrer le nombre d’opérateurs qui sont impliqués dans l’étude, le nombre de pièces qui sont mesurées et le nombre de fois où chaque opérateur mesure chaque pièce. Vous pouvez également définir un en-tête pour l’étude. Une dernière boîte de dialogue vous demande les noms des opérateurs, juges ou laboratoires qui font les mesures :
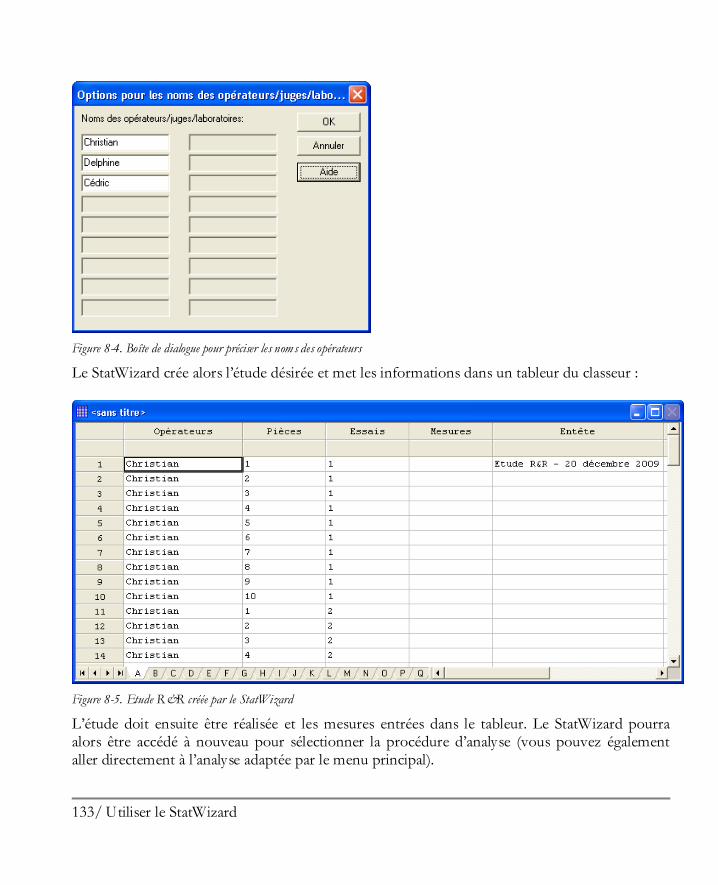
133/ Utiliser le StatWizard
Figure 8-4. Boîte de dialogue pour préciser les noms des opérateurs
Le StatWizard crée alors l’étude désirée et met les informations dans un tableur du classeur :
Figure 8-5. Etude R &R créée par le StatWizard
L’étude doit ensuite être réalisée et les mesures entrées dans le tableur. Le StatWizard pourra alors être accédé à nouveau pour sélectionner la procédure d’analyse (vous pouvez également aller directement à l’analyse adaptée par le menu principal).
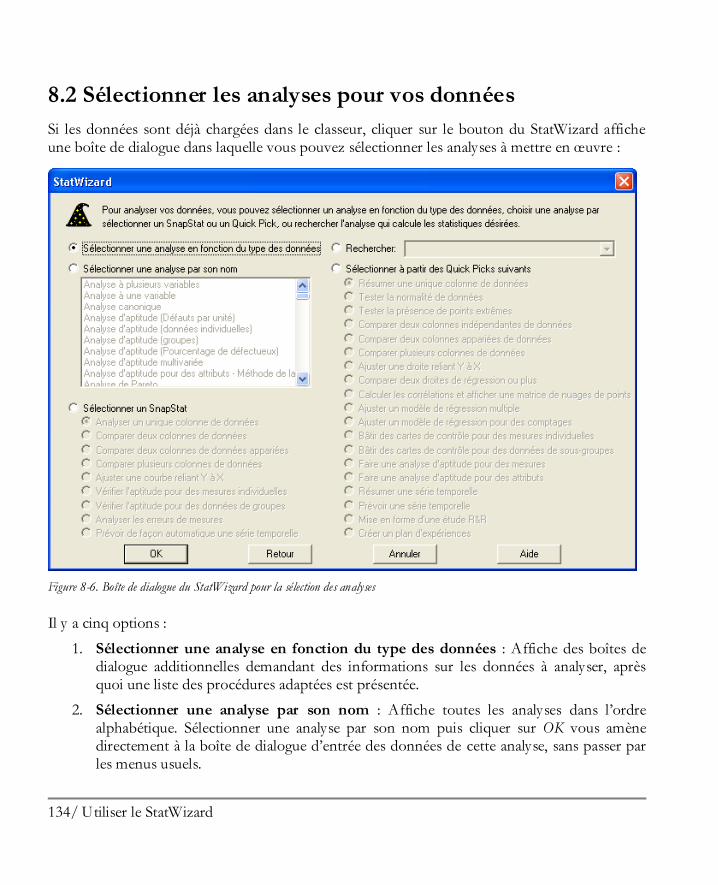
134/ Utiliser le StatWizard
8.2 Sélectionner les analyses pour vos données
Si les données sont déjà chargées dans le classeur, cliquer sur le bouton du StatWizard affiche une boîte de dialogue dans laquelle vous pouvez sélectionner les analyses à mettre en œuvre :
Figure 8-6. Boîte de dialogue du StatWizard pour la sélection des analyses
Il y a cinq options :
1. Sélectionner une analyse en fonction du type des données : Affiche des boîtes de dialogue additionnelles demandant des informations sur les données à analyser, après quoi une liste des procédures adaptées est présentée.
2. Sélectionner une analyse par son nom : Affiche toutes les analyses dans l’ordre alphabétique. Sélectionner une analyse par son nom puis cliquer sur OK vous amène directement à la boîte de dialogue d’entrée des données de cette analyse, sans passer par les menus usuels.
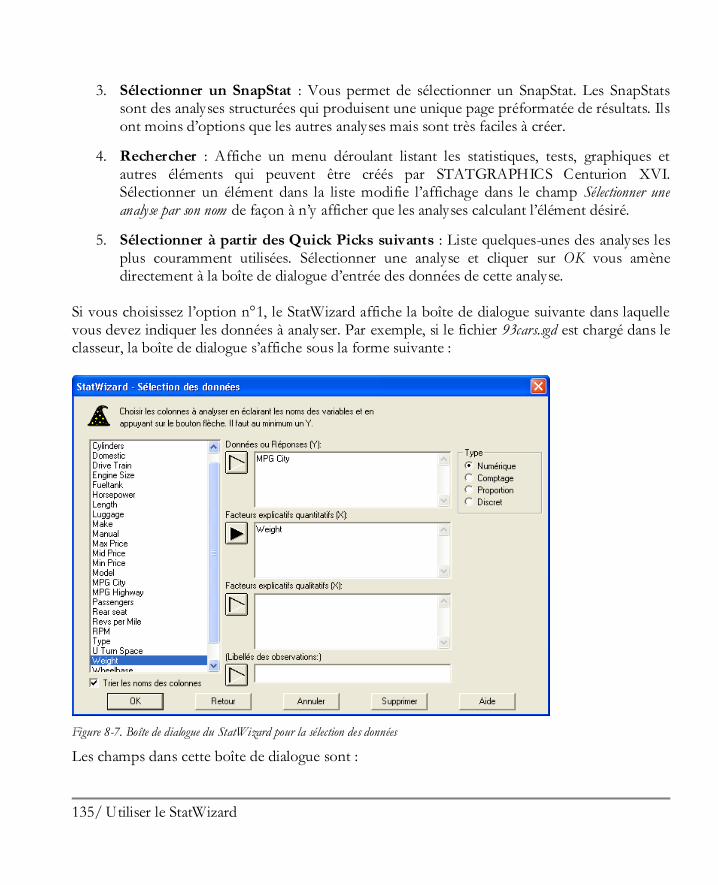
135/ Utiliser le StatWizard
3. Sélectionner un SnapStat : Vous permet de sélectionner un SnapStat. Les SnapStats sont des analyses structurées qui produisent une unique page préformatée de résultats. Ils ont moins d’options que les autres analyses mais sont très faciles à créer.
4. Rechercher : Affiche un menu déroulant listant les statistiques, tests, graphiques et autres éléments qui peuvent être créés par STATGRAPHICS Centurion XVI. Sélectionner un élément dans la liste modifie l’affichage dans le champ Sélectionner une analyse par son nom de façon à n’y afficher que les analyses calculant l’élément désiré.
5. Sélectionner à partir des Quick Picks suivants : Liste quelques-unes des analyses les plus couramment utilisées. Sélectionner une analyse et cliquer sur OK vous amène directement à la boîte de dialogue d’entrée des données de cette analyse.
Si vous choisissez l’option n°1, le StatWizard affiche la boîte de dialogue suivante dans laquelle vous devez indiquer les données à analyser. Par exemple, si le fichier 93cars.sgd est chargé dans le classeur, la boîte de dialogue s’affiche sous la forme suivante :
Figure 8-7. Boîte de dialogue du StatWizard pour la sélection des données
Les champs dans cette boîte de dialogue sont :

136/ Utiliser le StatWizard
Données ou Réponses (Y) : une ou plusieurs variables Y contenant les données à analyser. Si une unique colonne contient les données à analyser, elle doit être entrée ici.
Type : le type des données contenues dans les variables Y. Les analyses affichées dans les boîtes de dialogue suivantes dépendent de ce choix.
Facteurs explicatifs quantitatifs (X) : tous les facteurs quantitatifs qui doivent être utilisés pour modéliser les variables Y. Pour une régression, les variables explicatives sont à entrer ici.
Facteurs explicatifs qualitatifs (X) : tous les facteurs non quantitatifs qui doivent être utilisés pour modéliser les variables Y. Pour une ANOVA, les facteurs explicatifs sont à entrer ici.
Libellés des observations : une colonne contenant les libellés pour chacune des observations (lignes).
Les procédures proposées dans les boîtes de dialogue suivantes dépendent des réponses données dans la Figure 8-7. La prochaine boîte de dialogue vous demande de préciser les lignes du fichier à analyser :
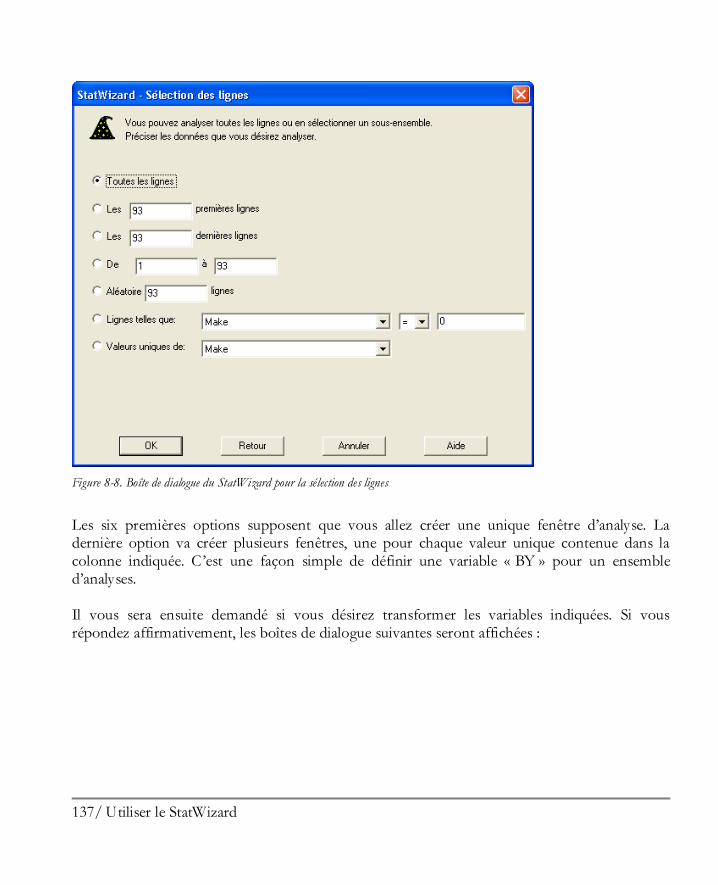
137/ Utiliser le StatWizard
Figure 8-8. Boîte de dialogue du StatWizard pour la sélection des lignes
Les six premières options supposent que vous allez créer une unique fenêtre d’analyse. La dernière option va créer plusieurs fenêtres, une pour chaque valeur unique contenue dans la colonne indiquée. C’est une façon simple de définir une variable « BY » pour un ensemble d’analyses. Il vous sera ensuite demandé si vous désirez transformer les variables indiquées. Si vous répondez affirmativement, les boîtes de dialogue suivantes seront affichées :
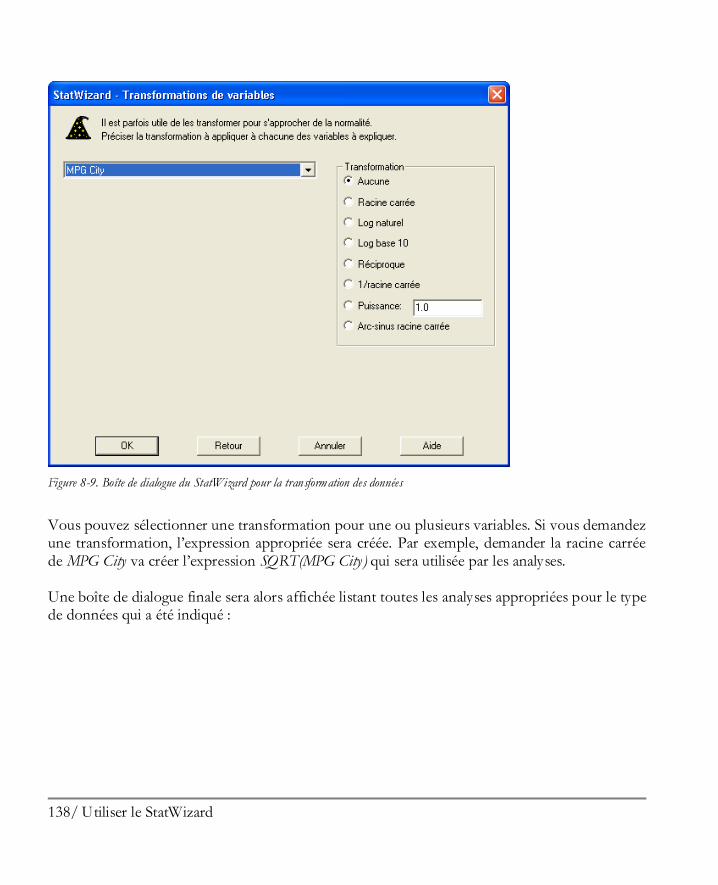
138/ Utiliser le StatWizard
Figure 8-9. Boîte de dialogue du StatWizard pour la transformation des données
Vous pouvez sélectionner une transformation pour une ou plusieurs variables. Si vous demandez une transformation, l’expression appropriée sera créée. Par exemple, demander la racine carrée de MPG City va créer l’expression SQRT(MPG City) qui sera utilisée par les analyses. Une boîte de dialogue finale sera alors affichée listant toutes les analyses appropriées pour le type de données qui a été indiqué :
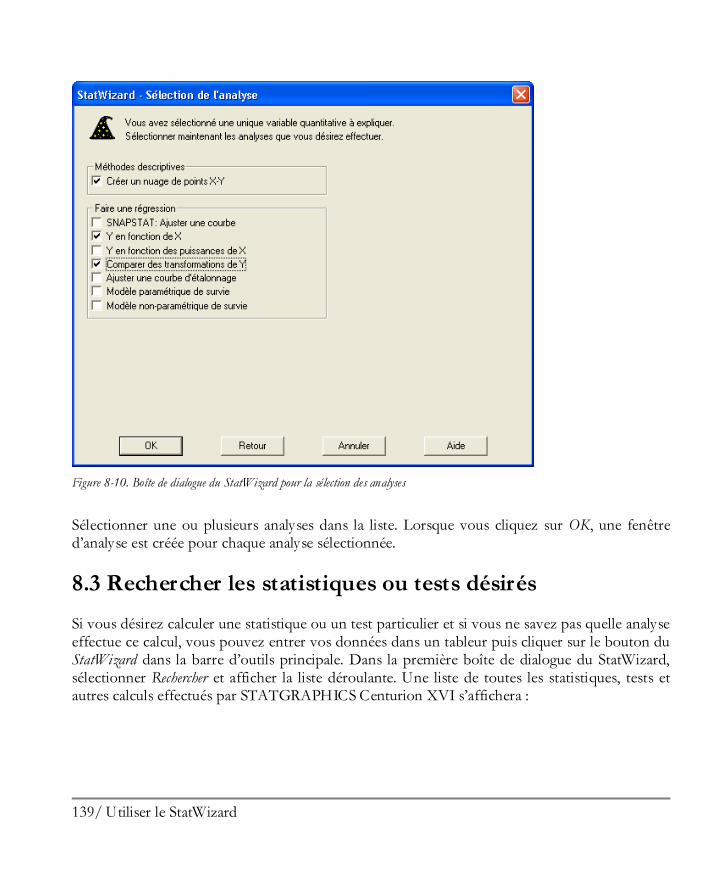
139/ Utiliser le StatWizard
Figure 8-10. Boîte de dialogue du StatWizard pour la sélection des analyses
Sélectionner une ou plusieurs analyses dans la liste. Lorsque vous cliquez sur OK, une fenêtre d’analyse est créée pour chaque analyse sélectionnée.
8.3 Rechercher les statistiques ou tests désirés Si vous désirez calculer une statistique ou un test particulier et si vous ne savez pas quelle analyse effectue ce calcul, vous pouvez entrer vos données dans un tableur puis cliquer sur le bouton du StatWizard dans la barre d’outils principale. Dans la première boîte de dialogue du StatWizard, sélectionner Rechercher et afficher la liste déroulante. Une liste de toutes les statistiques, tests et autres calculs effectués par STATGRAPHICS Centurion XVI s’affichera :
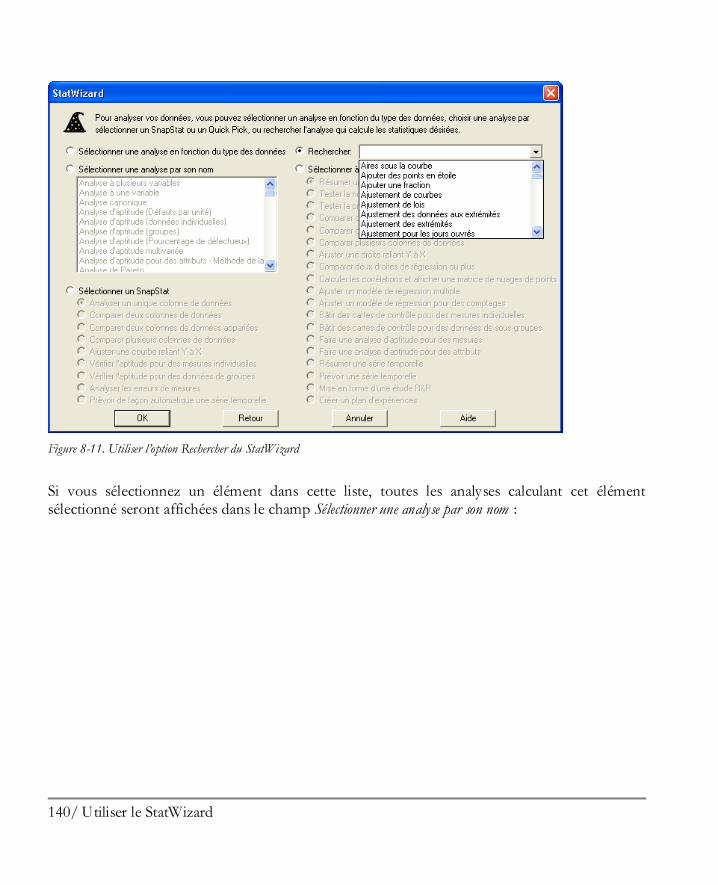
140/ Utiliser le StatWizard
Figure 8-11. Utiliser l’option Rechercher du StatWizard
Si vous sélectionnez un élément dans cette liste, toutes les analyses calculant cet élément sélectionné seront affichées dans le champ Sélectionner une analyse par son nom :
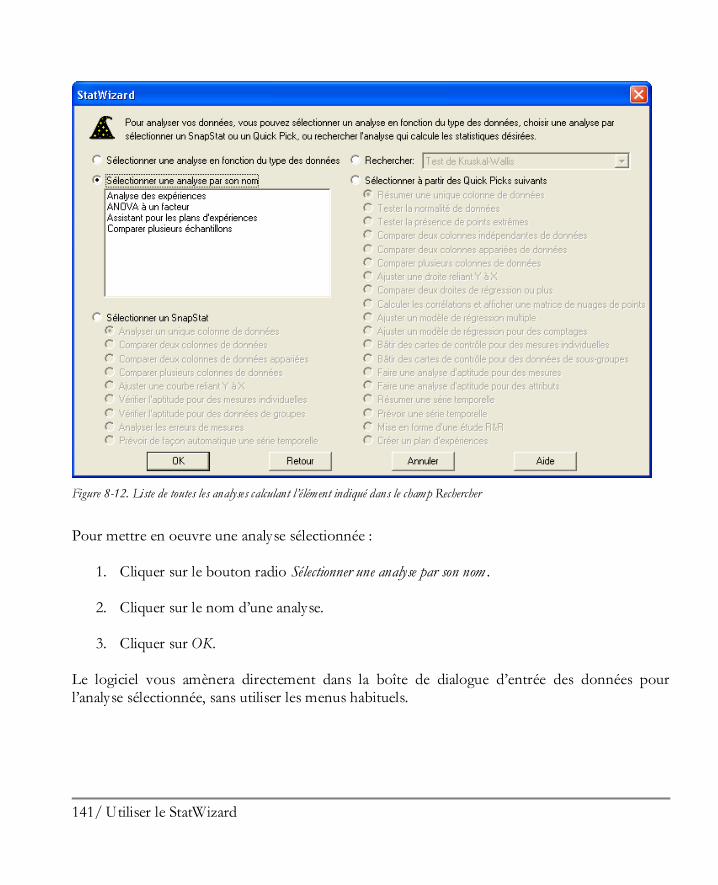
141/ Utiliser le StatWizard
Figure 8-12. Liste de toutes les analyses calculant l’élément indiqué dans le champ Rechercher
Pour mettre en oeuvre une analyse sélectionnée :
1. Cliquer sur le bouton radio Sélectionner une analyse par son nom .
2. Cliquer sur le nom d’une analyse.
3. Cliquer sur OK. Le logiciel vous amènera directement dans la boîte de dialogue d’entrée des données pour l’analyse sélectionnée, sans utiliser les menus habituels.

142/ Utiliser le StatWizard

143/ Préférences du logiciel
Préférences du logiciel
Définir les préférences pour l’utilisation du logiciel.
STATGRAPHICS Centurion XVI contient des centaines d’options, chacune d’elles ayant une valeur par défaut définie pour satisfaire la plupart des utilisateurs. Si vous le souhaitez, vous pouvez définir de nouvelles valeurs par défaut pour beaucoup de ces options. Il y a trois endroits principaux dans le logiciel où vous pouvez le faire :
1. Préférences générales du logiciel : définies dans la boîte de dialogue Préférences accessible par le menu Editer.
2. Options pour l’impression : définies dans la boîte de dialogue Mise en page accessible
par le menu Fichier.
3. Graphiques : définies en sélectionnant Options graphiques lorsqu’un graphique est affiché. L’onglet Profil de la boîte de dialogue Options graphiques vous permet d’enregistrer plusieurs ensembles d’attributs graphiques.
9.1 Préférences générales du logiciel Les valeurs par défaut pour les préférences générales du logiciel et quelques procédures statistiques sélectionnées peuvent être modifiées en sélectionnant Préférences dans le menu Editer. Une boîte de dialogue à onglets s’affiche alors avec un onglet Général pour les préférences globales du logiciel et d’autres onglets pour les valeurs par défaut des analyses statistiques :
Chapitre
9
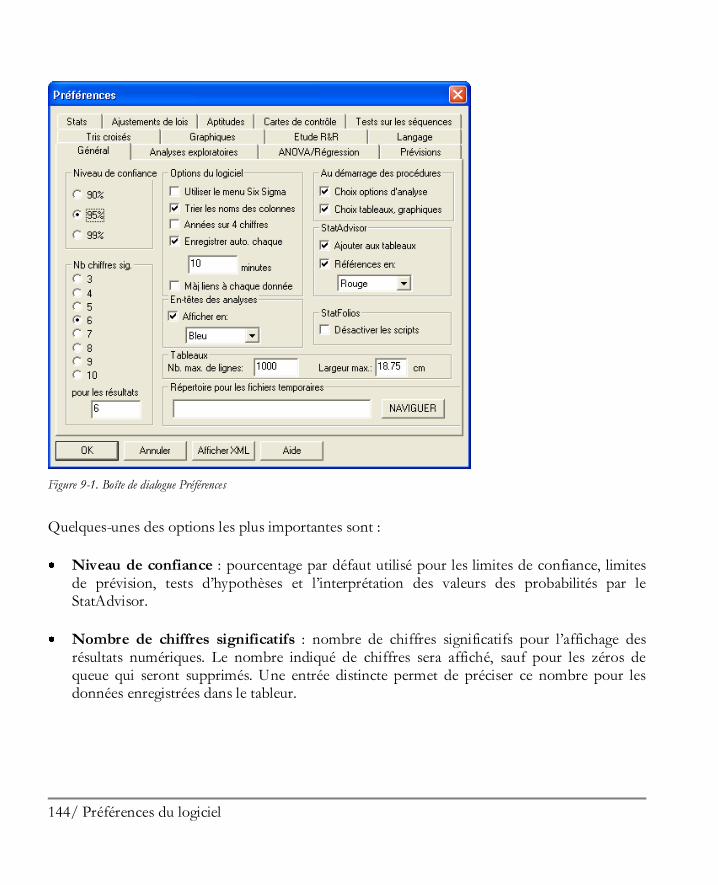
144/ Préférences du logiciel
Figure 9-1. Boîte de dialogue Préférences
Quelques-unes des options les plus importantes sont :
Niveau de confiance : pourcentage par défaut utilisé pour les limites de confiance, limites de prévision, tests d’hypothèses et l’interprétation des valeurs des probabilités par le StatAdvisor.
Nombre de chiffres significatifs : nombre de chiffres significatifs pour l’affichage des résultats numériques. Le nombre indiqué de chiffres sera affiché, sauf pour les zéros de queue qui seront supprimés. Une entrée distincte permet de préciser ce nombre pour les données enregistrées dans le tableur.

145/ Préférences du logiciel
Options du logiciel : options qui s’appliquent à tout le logiciel.
o Utiliser le menu Six Sigma : organise les analyses dans des menus qui correspondent à la démarche DMAIC du Six Sigma (Définir, Mesurer, Analyser, Innover, Contrôler). Les mêmes analyses que dans le menu classique sont disponibles, sauf qu’elles sont accessibles dans des menus différents.
o Trier les noms des colonnes : permet de lister les noms des colonnes dans l’ordre
alphabétique dans les boîtes de dialogue d’entrée des données. Sinon, les noms des colonnes sont listés dans l’ordre des colonnes dans les tableurs.
o Années sur 4 chiffres : indique si les années pour les dates doivent être affichées avec 4
chiffres ou avec 2 chiffres. Par défaut, les années sont sur 2 chiffres comme par exemple 2/1/05 et sont supposées représenter des dates entre 1950 et 2049. Modifier cette option ne prendra effet qu’après avoir rechargé le logiciel.
o Enregistrement automatique : permet d’enregistrer le StatFolio courant et les fichiers
de données de façon automatique en tâche de fond et de préciser la durée entre deux enregistrements. Si cette option est activée et si vous avez un problème avec le logiciel ou votre ordinateur, le logiciel vous proposera de recharger votre StatFolio et les fichiers de données à l’ouverture de sa prochaine session.
o Mise à jour des liens à chaque donnée : permet de recalculer toutes les statistiques
dès qu’une donnée est modifiée dans un des tableurs. Normalement, les statistiques ne sont pas recalculées avant qu’une analyse n’en reçoive l’ordre, soit imprimée, publiée ou que le StatFolio ne soit enregistré.
StatAdvisor: permet de définir les options par défaut pour le StatAdvisor.
o Ajouter aux tableaux : indique si le texte du StatAdvisor doit être automatiquement ajouté en pied des fenêtres de type texte. Le texte du StatAdvisor est toujours accessible
en cliquant sur le bouton de la barre d’outils principale. o Références en : indique si les éléments référencés dans le StatAdvisor doivent être
affichés en couleur dans les fenêtres de type texte.
En-têtes des analyses : indique si le titre de l’analyse doit être affiché en couleur en haut de la sous-fenêtre Résumé de l’analyse.

146/ Préférences du logiciel
StatFolios: cocher Désactiver les scripts pour éviter d’exécuter les scripts de démarrage lorsque les StatFolios sont chargés.
Répertoire pour les fichiers temporaires : Si un répertoire est indiqué, les StatFolios, fichiers de données et autres fichiers seront d’abord enregistrés dans ce répertoire avant d’être copiés dans le répertoire final de destination. En indiquant un disque local, cela peut réduire de façon importante le temps nécessaire pour l’enregistrement d’un fichier sur un réseau, car cela diminue le nombre de requêtes d’accès au réseau.
Pour une description des options des autres onglets, voir le fichier PDF intitulé Préférences.
9.2 Impression Deux options dans le menu Fichier permettent de contrôler les impressions :
1. Configuration de l’impression : accède à la boîte de dialogue usuelle des options pour l’imprimante. Cette boîte de dialogue permet notamment de choisir la taille du papier et l’orientation paysage ou portrait pour les impressions.
2. Mise en page : une boîte de dialogue de STATGRAPHICS Centurion XVI permettant de
définir les marges, l’en-tête et d’autres options. Cette boîte de dialogue a été présentée au paragraphe 3.3.
9.3 Graphiques Maximiser une sous-fenêtre contenant un graphique dans toute fenêtre d’analyse active le bouton Options graphiques dans la barre d’outils d’analyse. Ce bouton affiche une boîte de dialogue à onglets qui permet de modifier l’apparence d’un graphique, comme décrit en détails dans le Chapitre 4. Cette boîte de dialogue inclut également un onglet Profil qui vous permet d’enregistrer des ensembles de paramètres graphiques dans des profils d’utilisateurs et de modifier le profil par défaut utilisé lorsqu’un nouveau graphique est créé :
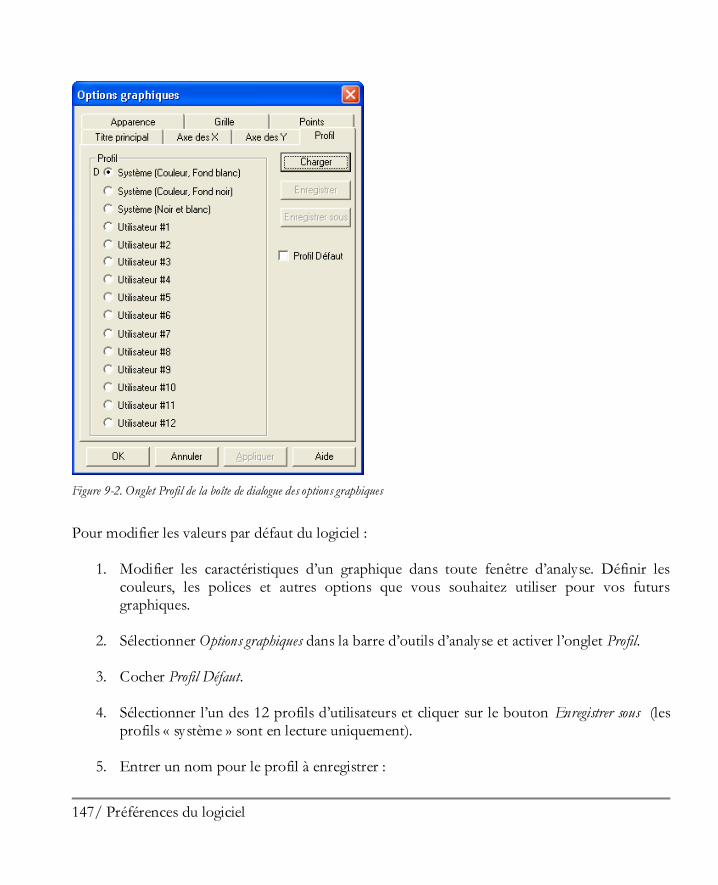
147/ Préférences du logiciel
Figure 9-2. Onglet Profil de la boîte de dialogue des options graphiques
Pour modifier les valeurs par défaut du logiciel :
1. Modifier les caractéristiques d’un graphique dans toute fenêtre d’analyse. Définir les couleurs, les polices et autres options que vous souhaitez utiliser pour vos futurs graphiques.
2. Sélectionner Options graphiques dans la barre d’outils d’analyse et activer l’onglet Profil.
3. Cocher Profil Défaut.
4. Sélectionner l’un des 12 profils d’utilisateurs et cliquer sur le bouton Enregistrer sous (les
profils « système » sont en lecture uniquement).
5. Entrer un nom pour le profil à enregistrer :

148/ Préférences du logiciel
Figure 9-3. Boîte de dialogue d’enregistrement d’un profil
6. Cliquer sur OK pour enregistrer l’ensemble des paramètres graphiques (couleurs, polices,
types des points et des lignes, etc.) dans le nouveau profil. Le prochain graphique utilisera le nouveau profil enregistré. Vous pouvez également utiliser d’autres profils enregistrés pour un nouveau graphique en créant le graphique avec les paramètres par défaut puis :
1. En sélectionnant Options graphiques dans la barre d’outils d’analyse et en choisissant l’onglet Profil.
2. En sélectionnant l’un des 15 profils et en cliquant sur le bouton Charger.
Le graphique en cours sera immédiatement mis à jour et utilisera les paramètres graphiques du profil sélectionné.

149/ Analyse d’un échantillon
Didacticiel n° 1 : Analyser un
unique échantillon
Statistiques résumées, histogramme, boîte à moustaches, intervalles de confiance et tests d’hypothèses.
Un problème fréquent en statistique est l’analyse d’un échantillon de n observations issues d’une unique population. Par exemple, considérons les températures corporelles relevées sur n = 130 individus :
98.4 98.4 98.2 97.8 98 97.9 99 98.5 98.8 98
97.4 98.8 99.5 98 100.8 97.1 98 98.7 98.9 99
98.6 97.7 96.7 98.8 98.2 97.5 97.2 97.4 97.1 96.7
99.2 97.9 98.8 97.6 98.6 98.8 98.5 98.7 97.5 97.9
97.1 98.4 97.4 98.6 97.8 98.2 98 98 98.3 98.6
98.8 98.7 98.8 98.1 96.4 98.8 98.7 97.9 98.6 99.2
98.6 98 99.1 97.8 97.2 98.2 98.7 98.4 98.2 97.7
98.3 98.7 96.8 98 97.2 97.9 96.9 98.3 97.8 97
98.6 98.4 98.2 98 98 98.2 97.8 99 98.1 97.7
97.4 98.8 99.3 98.9 96.3 97.8 99.9 98.4 99.4 98.7
98.4 98.2 99.3 98.5 98.3 99 99.2 97.6 99.1 97.6
98.4 97.6 98.4 98 98.8 97.3 98.7 98.6 99.4 100
98.6 98.3 98.6 97.4 98.1 97.8 98.2 99 99.1 98.2
Ces données proviennent du “Journal of Statistical Education Data Archive” (www.amstat.org/publications/jse/jse_data_archive.html) et sont utilisées avec sa permission.
Chapitre
10
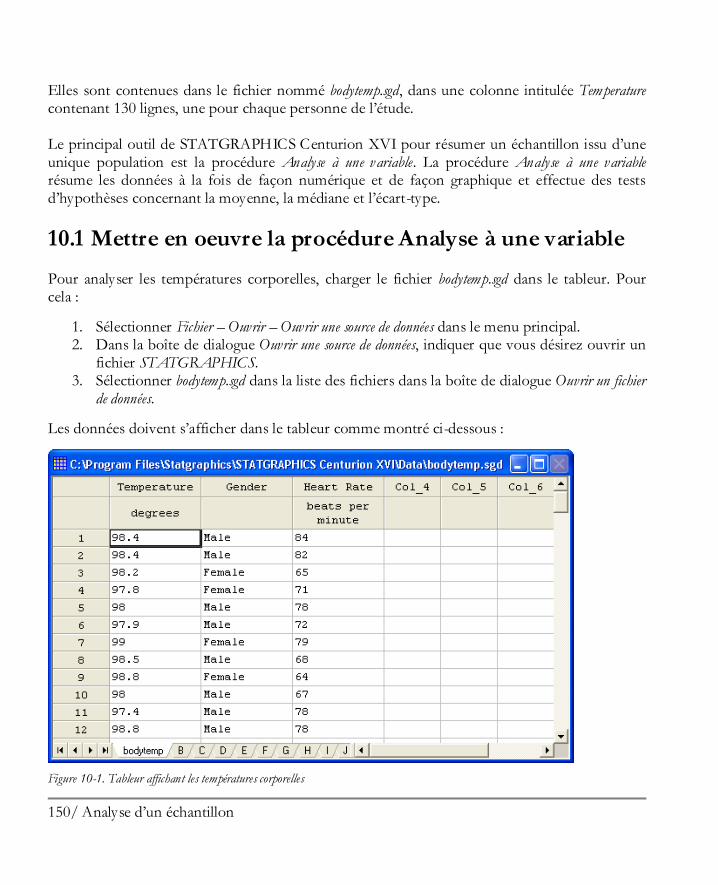
150/ Analyse d’un échantillon
Elles sont contenues dans le fichier nommé bodytemp.sgd, dans une colonne intitulée Temperature contenant 130 lignes, une pour chaque personne de l’étude. Le principal outil de STATGRAPHICS Centurion XVI pour résumer un échantillon issu d’une unique population est la procédure Analyse à une variable. La procédure Analyse à une variable résume les données à la fois de façon numérique et de façon graphique et effectue des tests d’hypothèses concernant la moyenne, la médiane et l’écart-type.
10.1 Mettre en oeuvre la procédure Analyse à une variable Pour analyser les températures corporelles, charger le fichier bodytemp.sgd dans le tableur. Pour cela :
1. Sélectionner Fichier – Ouvrir – Ouvrir une source de données dans le menu principal. 2. Dans la boîte de dialogue Ouvrir une source de données, indiquer que vous désirez ouvrir un
fichier STATGRAPHICS. 3. Sélectionner bodytemp.sgd dans la liste des fichiers dans la boîte de dialogue Ouvrir un fichier
de données.
Les données doivent s’afficher dans le tableur comme montré ci-dessous :
Figure 10-1. Tableur affichant les températures corporelles
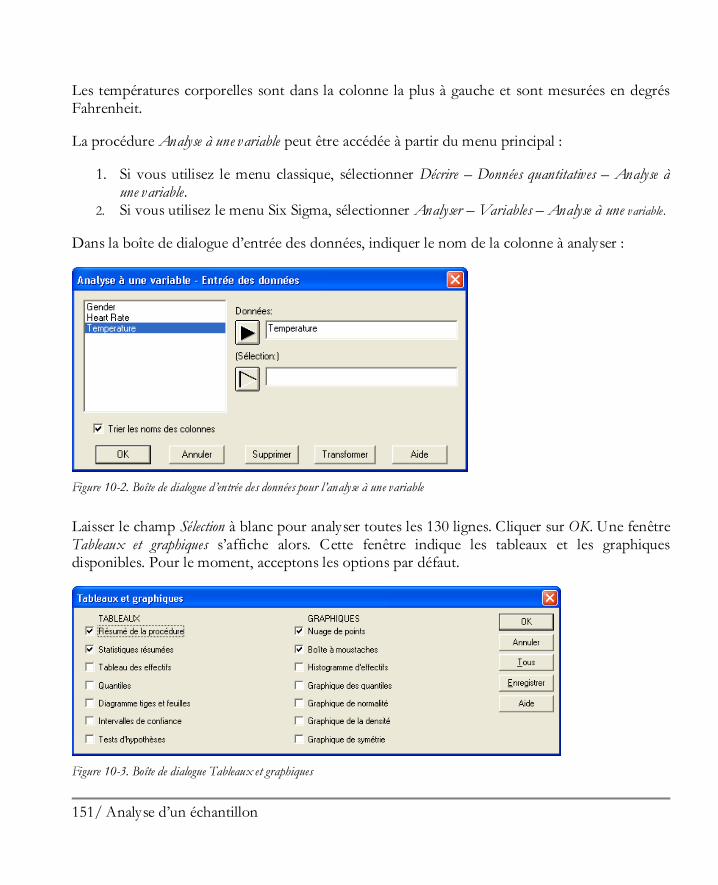
151/ Analyse d’un échantillon
Les températures corporelles sont dans la colonne la plus à gauche et sont mesurées en degrés Fahrenheit.
La procédure Analyse à une variable peut être accédée à partir du menu principal :
1. Si vous utilisez le menu classique, sélectionner Décrire – Données quantitatives – Analyse à une variable.
2. Si vous utilisez le menu Six Sigma, sélectionner Analyser – Variables – Analyse à une variable.
Dans la boîte de dialogue d’entrée des données, indiquer le nom de la colonne à analyser :
Figure 10-2. Boîte de dialogue d’entrée des données pour l’analyse à une variable
Laisser le champ Sélection à blanc pour analyser toutes les 130 lignes. Cliquer sur OK. Une fenêtre Tableaux et graphiques s’affiche alors. Cette fenêtre indique les tableaux et les graphiques disponibles. Pour le moment, acceptons les options par défaut.
Figure 10-3. Boîte de dialogue Tableaux et graphiques

152/ Analyse d’un échantillon
Une fenêtre d’analyse s’affiche contenant quatre sous-fenêtres :
Figure 10-4. Fenêtre de l’analyse à une variable
La sous-fenêtre en haut à gauche indique que l’échantillon possède n = 130 valeurs comprises entre 96,3 et 100,8 degrés. La sous-fenêtre en haut à droite affiche un nuage de points des données, avec les points éparpillés de façon aléatoire le long de l’axe vertical. A noter que la densité de points est plus forte entre 98 et 99 degrés et moins forte ailleurs et des deux côtés. Cela est typique d’un échantillon issu d’une population dont la distribution possède un pic central. Les sous-fenêtres d’en bas affichent des statistiques résumées des données et une boîte à moustaches et sont décrites dans les prochains paragraphes.

153/ Analyse d’un échantillon
10.2 Statistiques résumés Le tableau dans la sous-fenêtre d’en bas affiche plusieurs statistiques concernant l’échantillon. D’autres statistiques peuvent y être ajoutées en maximisant cette sous-fenêtre (en double-cliquant dans cette sous-fenêtre) et en sélectionnant Options pour la fenêtre :
Figure 10-5. Boîte de dialogue des options pour les statistiques résumées
L’ajout de la médiane de l’échantillon, des quartiles et de l’étendue inter -quartiles affiche le nouveau tableau suivant :
Statistiques résumées pour Temperature
Effectif 130
Moyenne 98.2492
Médiane 98.3
Ecart-type 0.733183
Coef. de variation 0.746248%
Minimum 96.3
Maximum 100.8
Etendue 4.5
1er quartile 97.8
3ème quartile 98.7
Etendue inter-quartiles 0.9
Asymétrie std. -0.0205699
Aplatissement std. 1.81642
Figure 10-6. Tableau des statistiques résumées

154/ Analyse d’un échantillon
Une hypothèse courante pour des mesures est que les données proviennent d’une population qui suit une loi gaussienne, c’est-à-dire qu’elles s’affichent sous la forme d’une courbe en cloche. Les données qui suivent une loi normale sont complètement décrites par deux statistiques :
1. La moyenne de l’échantillon 1 98,25
n
i
i
x
xn
, qui estime la valeur centrale de la loi.
2. L’écart-type de l’échantillon
2
1 0,7331
n
i
i
x x
sn
, qui donne une information sur
l’étendue de la loi.
Pour une loi normale, approximativement 68% des données sont à moins d’un écart-type de la moyenne de la population, approximativement 95% sont à moins de deux écarts-types et approximativement 99,73% à moins de trois écarts-types.
La moyenne et l’écart-type de l’échantillon décrivent complètement l’échantillon uniquement si celui-ci suit une loi normale. Deux statistiques peuvent être utilisées pour vérifier cette hypothèse. Ce sont les asymétrie et aplatissement standardisés. Ces statistiques sont des mesures de la forme :
1. L’asymétrie mesure la symétrie ou le manque de symétrie. Une loi symétrique comme la loi normale a une asymétrie nulle. Des lois qui ont des valeurs plutôt au-dessus du pic qu’au-dessous ont une asymétrie positive. Des lois qui ont des valeurs plutôt au-dessous du pic qu’au-dessus ont une asymétrie négative.
2. L’aplatissement mesure la forme d’une loi symétrique. Une loi normale ou en forme de cloche a un aplatissement nul. Une loi plus pointue que la loi normale a un aplatissement positif. Une loi plus plate que la loi normale a un aplatissement négatif.
Si les données suivent une loi normale, les asymétrie et aplatissement standardisés doivent être compris entre -2 et +2. Dans ce cas, la loi normale est un modèle raisonnable pour les données.
Une autre façon de résumer les données est fournie par cinq valeurs choisies par John Tukey :
Minimum (plus petite valeur des données) = 96,3 Premier quartile (25ème centile) = 97,8 Médiane (50ème centile) = 98,3 Troisième quartile (75ème centile) = 98,7 Maximum (plus grande valeur des données) = 100,8

155/ Analyse d’un échantillon
Ces cinq nombres divisent l’échantillon des données en quatre zones et sont à la base du graphique en boîte à moustaches, décrit dans le prochain paragraphe.
NOTE : Sélectionner d’autres statistiques en utilisant Options pour la fenêtre modifie la sélection pour cette analyse en cours uniquement. Pour modifier les statistiques par défaut pour les futures analyses, aller dans le menu Editer et sélectionner Préférences. L’onglet Stats dans la boîte de dialogue vous permet de modifier les statistiques calculées par défaut lorsque l’Analyse à une variable est mise en oeuvre (ainsi que dans d’autres analyses affichant des statistiques résumées) :
Figure 10-7. Boîte de dialogue Préférences utilisée pour sélectionner les statistiques par défaut
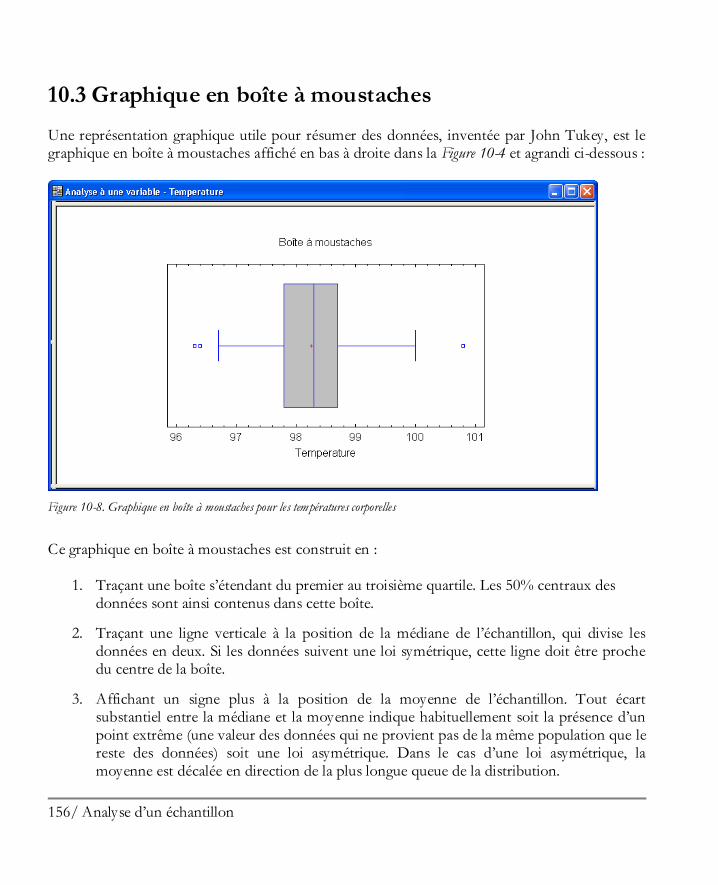
156/ Analyse d’un échantillon
10.3 Graphique en boîte à moustaches Une représentation graphique utile pour résumer des données, inventée par John Tukey, est le graphique en boîte à moustaches affiché en bas à droite dans la Figure 10-4 et agrandi ci-dessous :
Figure 10-8. Graphique en boîte à moustaches pour les températures corporelles
Ce graphique en boîte à moustaches est construit en :
1. Traçant une boîte s’étendant du premier au troisième quartile. Les 50% centraux des données sont ainsi contenus dans cette boîte.
2. Traçant une ligne verticale à la position de la médiane de l’échantillon, qui divise les données en deux. Si les données suivent une loi symétrique, cette ligne doit être proche du centre de la boîte.
3. Affichant un signe plus à la position de la moyenne de l’échantillon. Tout écart substantiel entre la médiane et la moyenne indique habituellement soit la présence d’un point extrême (une valeur des données qui ne provient pas de la même population que le reste des données) soit une loi asymétrique. Dans le cas d’une loi asymétrique, la moyenne est décalée en direction de la plus longue queue de la distribution.

157/ Analyse d’un échantillon
4. Affichant des moustaches qui s’étendent des quartiles aux plus petite et plus grande
valeurs des données de l’échantillon, à moins que des valeurs soient suffisamment éloignées de la boîte pour être classées non usuelles. Dans ce cas, les moustaches s’étendent jusqu’aux points les plus distants non classés éloignés. STATGRAPHICS Centurion XVI suit les règles définies par Tukey en distinguant deux types de points non usuels :
a. « Points très éloignés » – points à plus de 3 fois l’étendue inter-quartiles au-dessus
ou au-dessous des limites de la boîte. (NOTE : l’étendue inter-quartiles est la distance entre les quartiles et est égale à la largeur de la boîte.) Les points très éloignés sont marqués par un symbole de point (habituellement un petit carré) avec un signe plus ajouté à l’intérieur. Si les données suivent une loi normale, la probabilité pour q’un point soit suffisamment éloigné pour être classé comme point très éloigné est de 1 sur 300 dans un échantillon de cette taille. A moins que l’échantillon ne soit constitué de milliers de points, des points très éloignés indiquent la présence de points extrêmes (ou d’une loi non normale).
b. « Points éloignés » - points à plus d’1,5 fois l’étendue inter-quartiles au-dessus ou
au-dessous des limites de la boîte. Les points éloignés sont marqués par un symbole de point mais sans signe plus ajouté. Même lorsque les données suivent une loi normale, la probabilité d’observer 1 ou 2 points éloignés dans un échantillon de n = 100 observations est d’environ 50% et n’indique pas nécessairement la présence de vrais points suspects. Ces points doivent uniquement vous inciter à faire plus d’investigations.
Le graphique de la boîte à moustaches de la Figure 10-8 est raisonnablement symétrique. Les moustaches sont à peu près de mêmes longueurs et la moyenne et la médiane de l’échantillon sont proches et près du centre de la boîte. Trois points sont marqués, mais il n’y a pas de points extrêmes. En cliquant sur le point le plus à droite, le logiciel indique qu’il correspond à la ligne n° 15 du fichier. Si vous sélectionnez les Options pour la fenêtre dans la barre des outils d’analyse, vous pouvez ajouter une encoche sur la médiane dans le graphique :
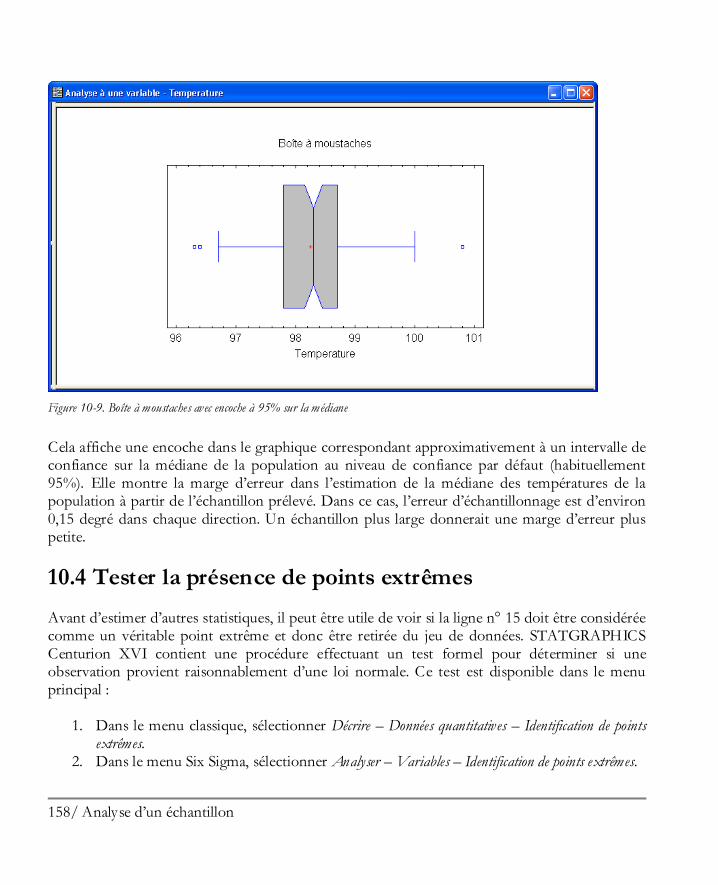
158/ Analyse d’un échantillon
Figure 10-9. Boîte à moustaches avec encoche à 95% sur la médiane
Cela affiche une encoche dans le graphique correspondant approximativement à un intervalle de confiance sur la médiane de la population au niveau de confiance par défaut (habituellement 95%). Elle montre la marge d’erreur dans l’estimation de la médiane des températures de la population à partir de l’échantillon prélevé. Dans ce cas, l’erreur d’échantillonnage est d’environ 0,15 degré dans chaque direction. Un échantillon plus large donnerait une marge d’erreur plus petite.
10.4 Tester la présence de points extrêmes Avant d’estimer d’autres statistiques, il peut être utile de voir si la ligne n° 15 doit être considérée comme un véritable point extrême et donc être retirée du jeu de données. STATGRAPHICS Centurion XVI contient une procédure effectuant un test formel pour déterminer si une observation provient raisonnablement d’une loi normale. Ce test est disponible dans le menu principal :
1. Dans le menu classique, sélectionner Décrire – Données quantitatives – Identification de points extrêmes.
2. Dans le menu Six Sigma, sélectionner Analyser – Variables – Identification de points extrêmes.

159/ Analyse d’un échantillon
En entrant Temperature dans le champ Données, les fenêtres des Options puis des Tableaux et graphiques s’affichent. Après sélection des options désirées, un tableau de statistiques est affiché dans la moitié inférieure de la sous-fenêtre de gauche. La partie particulièrement intéressante de ce tableau est celle affichant les 5 plus petites et les 5 plus grandes valeurs des données de l’échantillon :
Données triées
Valeurs studentisées Valeurs studentisées Scores Z MAD
Ligne Valeur sans suppression avec suppression modifiés
95 96.3 -2.65859 -2.74567 -2.698
55 96.4 -2.52219 -2.59723 -2.5631
23 96.7 -2.11302 -2.15912 -2.1584
30 96.7 -2.11302 -2.15912 -2.1584
73 96.8 -1.97663 -2.01521 -2.0235
...
99 99.4 1.56955 1.59096 1.4839
13 99.5 1.70594 1.7323 1.6188
97 99.9 2.25151 2.30628 2.1584
120 100.0 2.3879 2.45231 2.2933
15 100.8 3.47903 3.67021 3.3725
Test de Grubbs (suppose la normalité)
Valeur de la statistique = 3.47903
Probabilité = 0.0484379
Figure 10-10. Partie sélectionnée du tableau des résultats pour l’identification des points extrêmes
La valeur la moins usuelle des données est celle de la ligne n° 15 qui est affichée en rouge. Elle a une valeur studentisée sans suppression de 3,479. Les valeurs studentisées sont calculées à partir de :
s
xxz i
i
Une valeur de 3,479 indique que l’observation est à 3,479 écarts-types au-dessus de la moyenne de l’échantillon lorsque cette observation est incluse dans le calcul de x et de s. La valeur studentisée avec suppression indique de combien d’écarts-types chaque observation est éloignée de la moyenne de l’échantillon lorsque cette observation n’est pas utilisée dans les calculs. Si la ligne n° 15 n’est pas incluse dans les calculs, elle est alors à 3,67 écarts-types de la moyenne. Des observations à plus de 3 écarts-types de la moyenne sont des données non usuelles, à moins que la taille n de l’échantillon ne soit grande ou que la loi ne soit pas normale. Un test d’hypothèses formel peut être effectué :
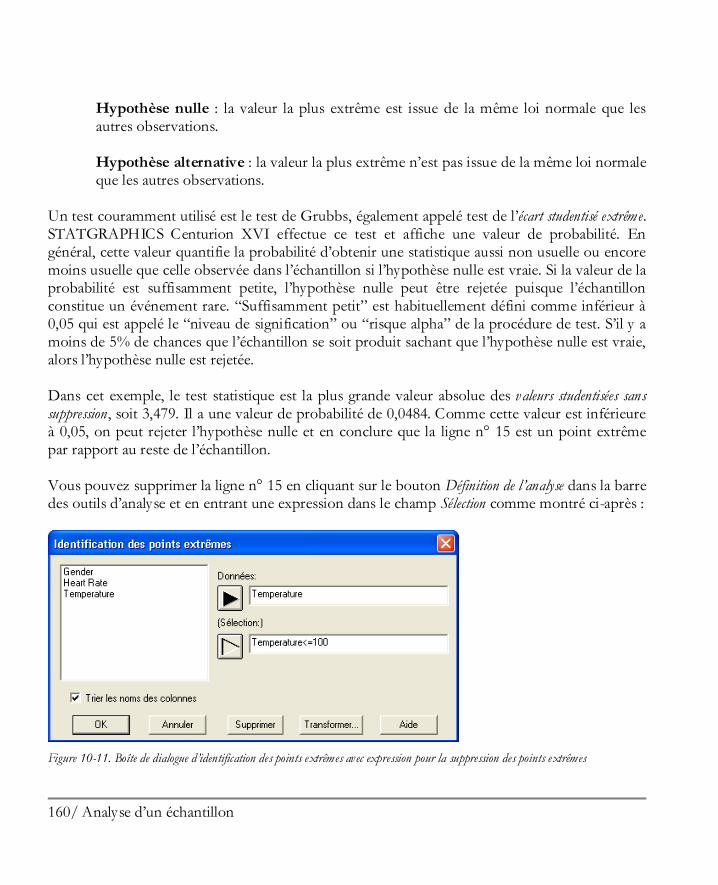
160/ Analyse d’un échantillon
Hypothèse nulle : la valeur la plus extrême est issue de la même loi normale que les autres observations.
Hypothèse alternative : la valeur la plus extrême n’est pas issue de la même loi normale que les autres observations.
Un test couramment utilisé est le test de Grubbs, également appelé test de l’écart studentisé extrême. STATGRAPHICS Centurion XVI effectue ce test et affiche une valeur de probabilité. En général, cette valeur quantifie la probabilité d’obtenir une statistique aussi non usuelle ou encore moins usuelle que celle observée dans l’échantillon si l’hypothèse nulle est vraie. Si la valeur de la probabilité est suffisamment petite, l’hypothèse nulle peut être rejetée puisque l’échantillon constitue un événement rare. “Suffisamment petit” est habituellement défini comme inférieur à 0,05 qui est appelé le “niveau de signification” ou “risque alpha” de la procédure de test. S’il y a moins de 5% de chances que l’échantillon se soit produit sachant que l’hypothèse nulle est vraie, alors l’hypothèse nulle est rejetée. Dans cet exemple, le test statistique est la plus grande valeur absolue des valeurs studentisées sans suppression, soit 3,479. Il a une valeur de probabilité de 0,0484. Comme cette valeur est inférieure à 0,05, on peut rejeter l’hypothèse nulle et en conclure que la ligne n° 15 est un point extrême par rapport au reste de l’échantillon. Vous pouvez supprimer la ligne n° 15 en cliquant sur le bouton Définition de l’analyse dans la barre des outils d’analyse et en entrant une expression dans le champ Sélection comme montré ci-après :
Figure 10-11. Boîte de dialogue d’identification des points extrêmes avec expression pour la suppression des points extrêmes
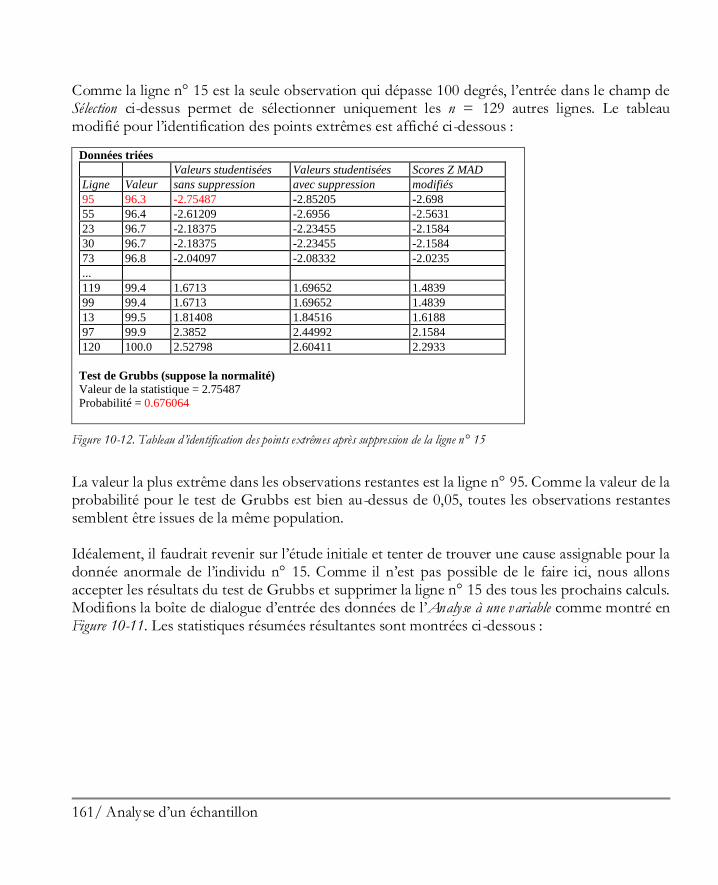
161/ Analyse d’un échantillon
Comme la ligne n° 15 est la seule observation qui dépasse 100 degrés, l’entrée dans le champ de Sélection ci-dessus permet de sélectionner uniquement les n = 129 autres lignes. Le tableau modifié pour l’identification des points extrêmes est affiché ci-dessous :
Données triées
Valeurs studentisées Valeurs studentisées Scores Z MAD
Ligne Valeur sans suppression avec suppression modifiés
95 96.3 -2.75487 -2.85205 -2.698
55 96.4 -2.61209 -2.6956 -2.5631
23 96.7 -2.18375 -2.23455 -2.1584
30 96.7 -2.18375 -2.23455 -2.1584
73 96.8 -2.04097 -2.08332 -2.0235
...
119 99.4 1.6713 1.69652 1.4839
99 99.4 1.6713 1.69652 1.4839
13 99.5 1.81408 1.84516 1.6188
97 99.9 2.3852 2.44992 2.1584
120 100.0 2.52798 2.60411 2.2933
Test de Grubbs (suppose la normalité)
Valeur de la statistique = 2.75487
Probabilité = 0.676064
Figure 10-12. Tableau d’identification des points extrêmes après suppression de la ligne n° 15
La valeur la plus extrême dans les observations restantes est la ligne n° 95. Comme la valeur de la probabilité pour le test de Grubbs est bien au-dessus de 0,05, toutes les observations restantes semblent être issues de la même population. Idéalement, il faudrait revenir sur l’étude initiale et tenter de trouver une cause assignable pour la donnée anormale de l’individu n° 15. Comme il n’est pas possible de le faire ici, nous allons accepter les résultats du test de Grubbs et supprimer la ligne n° 15 des tous les prochains calculs. Modifions la boîte de dialogue d’entrée des données de l’Analyse à une variable comme montré en Figure 10-11. Les statistiques résumées résultantes sont montrées ci-dessous :

162/ Analyse d’un échantillon
Statistiques résumées pour Temperature
Effectif 129
Moyenne 98.2295
Médiane 98.3
Ecart-type 0.70038
Coef. de variation 0.713004%
Minimum 96.3
Maximum 100.0
Etendue 3.7
1er quartile 97.8
3ème quartile 98.7
Etendue inter-quartiles 0.9
Asymétrie std. -1.40217
Aplatissement std. 0.257075
Figure 10-13. Statistiques résumées après suppression de la ligne n° 15
10.5 Histogramme Un autre affichage graphique classique illustrant un échantillon de mesures est l’histogramme d’effectifs. En revenant à l’Analyse à une variable, un histogramme peut être créé en cliquant sur le
bouton Tableaux et graphiques de la barre des outils d’analyse et en sélectionnant Histogramme d’effectifs. L’histogramme par défaut est montré ci-après. La hauteur de chaque barre de l’histogramme représente le nombre d’observations qui appartiennent à l’intervalle des températures défini par la barre. Le nombre de barres et la largeur des barres sont définis par défaut en se basant sur la taille n de l’échantillon et en utilisant la règle choisie dans l’onglet Analyses exploratoires de la boîte de dialogue Editer - Préférences.
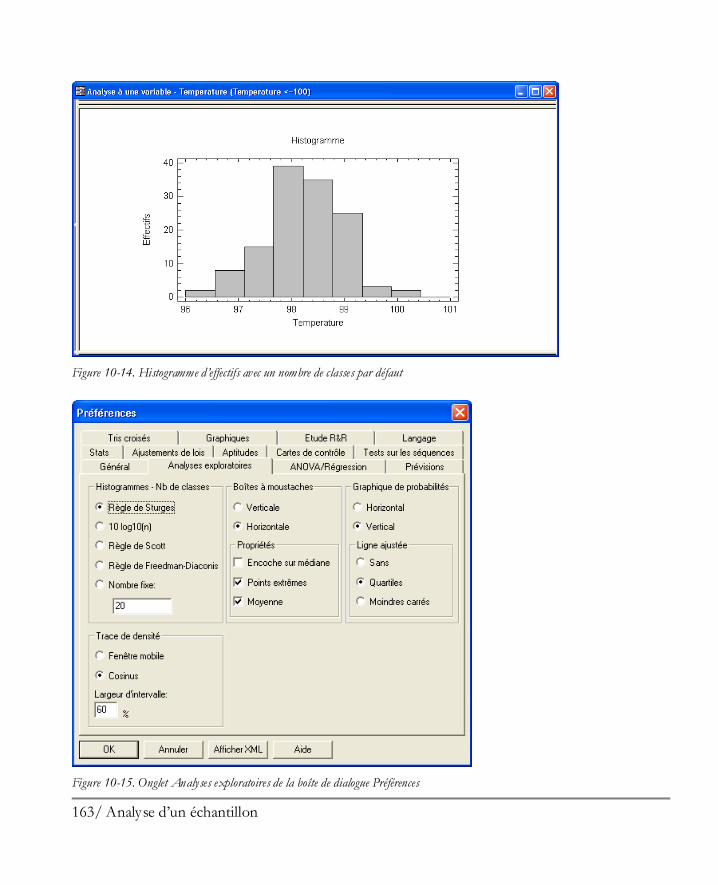
163/ Analyse d’un échantillon
Figure 10-14. Histogramme d’effectifs avec un nombre de classes par défaut
Figure 10-15. Onglet Analyses exploratoires de la boîte de dialogue Préférences

164/ Analyse d’un échantillon
En utilisant la règle de Sturges, le nombre de barres est défini comme le plus petit entier n’étant pas inférieur à (1+3,322log10(n )). D’autres règles, comme la règle 10log10(n), tendent à produire plus de barres par défaut et peuvent être préférables si vous travaillez avec de grands jeux de données. Une modification temporaire de ce nombre de barres pour un histogramme déjà créé est possible en double-cliquant dans l’histogramme pour maximiser sa sous-fenêtre et en sélectionnant les Options pour la fenêtre :
Figure 10-16. Boîte de dialogue des options pour la fenêtre pour l’histogramme d’effectifs
Lors de la définition des classes, le nombre de chiffres significatifs des données doit être pris en compte. Par exemple, les températures corporelles sont mesurées à 0,1 degré près. La largeur des intervalles pour les barres doit donc être définie comme un entier multiple de 0,1. De cette façon, chaque barre représentera le même nombre de mesures possibles. Le graphique ci -après affiche 25 intervalles compris entre 96 et 101 degrés, chacun couvrant un intervalle de 0,2 degré.
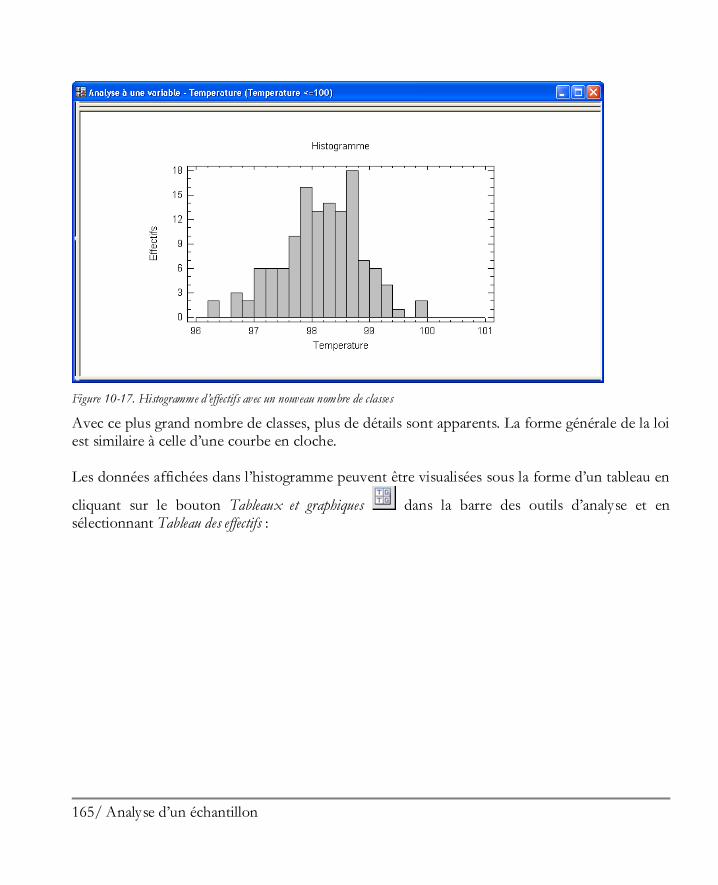
165/ Analyse d’un échantillon
Figure 10-17. Histogramme d’effectifs avec un nouveau nombre de classes
Avec ce plus grand nombre de classes, plus de détails sont apparents. La forme générale de la loi est similaire à celle d’une courbe en cloche. Les données affichées dans l’histogramme peuvent être visualisées sous la forme d’un tableau en
cliquant sur le bouton Tableaux et graphiques dans la barre des outils d’analyse et en sélectionnant Tableau des effectifs :
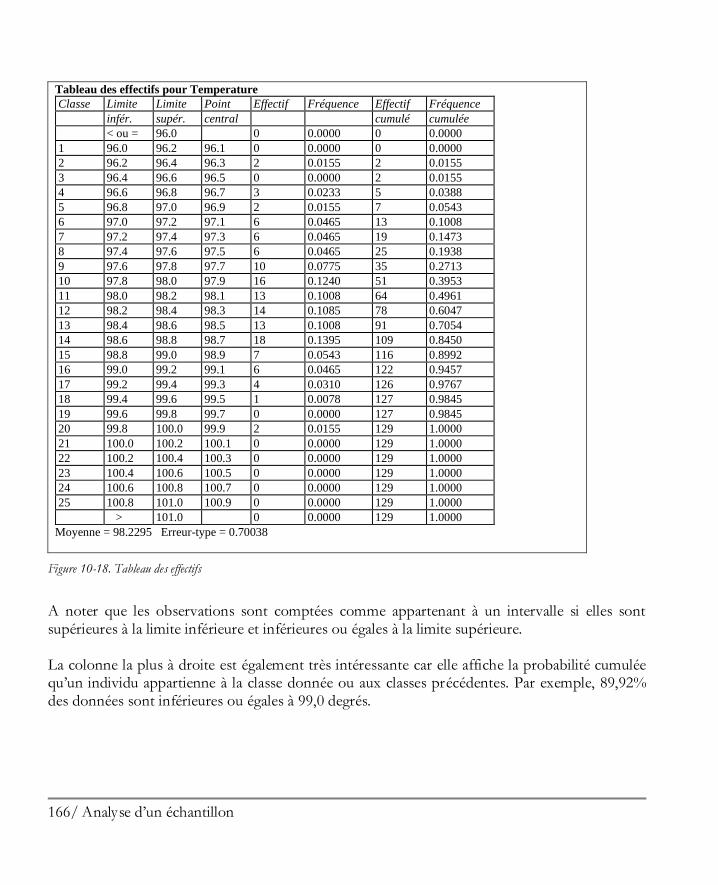
166/ Analyse d’un échantillon
Tableau des effectifs pour Temperature
Classe Limite Limite Point Effectif Fréquence Effectif Fréquence
infér. supér. central cumulé cumulée
< ou = 96.0 0 0.0000 0 0.0000
1 96.0 96.2 96.1 0 0.0000 0 0.0000
2 96.2 96.4 96.3 2 0.0155 2 0.0155
3 96.4 96.6 96.5 0 0.0000 2 0.0155
4 96.6 96.8 96.7 3 0.0233 5 0.0388
5 96.8 97.0 96.9 2 0.0155 7 0.0543
6 97.0 97.2 97.1 6 0.0465 13 0.1008
7 97.2 97.4 97.3 6 0.0465 19 0.1473
8 97.4 97.6 97.5 6 0.0465 25 0.1938
9 97.6 97.8 97.7 10 0.0775 35 0.2713
10 97.8 98.0 97.9 16 0.1240 51 0.3953
11 98.0 98.2 98.1 13 0.1008 64 0.4961
12 98.2 98.4 98.3 14 0.1085 78 0.6047
13 98.4 98.6 98.5 13 0.1008 91 0.7054
14 98.6 98.8 98.7 18 0.1395 109 0.8450
15 98.8 99.0 98.9 7 0.0543 116 0.8992
16 99.0 99.2 99.1 6 0.0465 122 0.9457
17 99.2 99.4 99.3 4 0.0310 126 0.9767
18 99.4 99.6 99.5 1 0.0078 127 0.9845
19 99.6 99.8 99.7 0 0.0000 127 0.9845
20 99.8 100.0 99.9 2 0.0155 129 1.0000
21 100.0 100.2 100.1 0 0.0000 129 1.0000
22 100.2 100.4 100.3 0 0.0000 129 1.0000
23 100.4 100.6 100.5 0 0.0000 129 1.0000
24 100.6 100.8 100.7 0 0.0000 129 1.0000
25 100.8 101.0 100.9 0 0.0000 129 1.0000
> 101.0 0 0.0000 129 1.0000
Moyenne = 98.2295 Erreur-type = 0.70038
Figure 10-18. Tableau des effectifs
A noter que les observations sont comptées comme appartenant à un intervalle si elles sont supérieures à la limite inférieure et inférieures ou égales à la limite supérieure. La colonne la plus à droite est également très intéressante car elle affiche la probabilité cumulée qu’un individu appartienne à la classe donnée ou aux classes précédentes. Par exemple, 89,92% des données sont inférieures ou égales à 99,0 degrés.
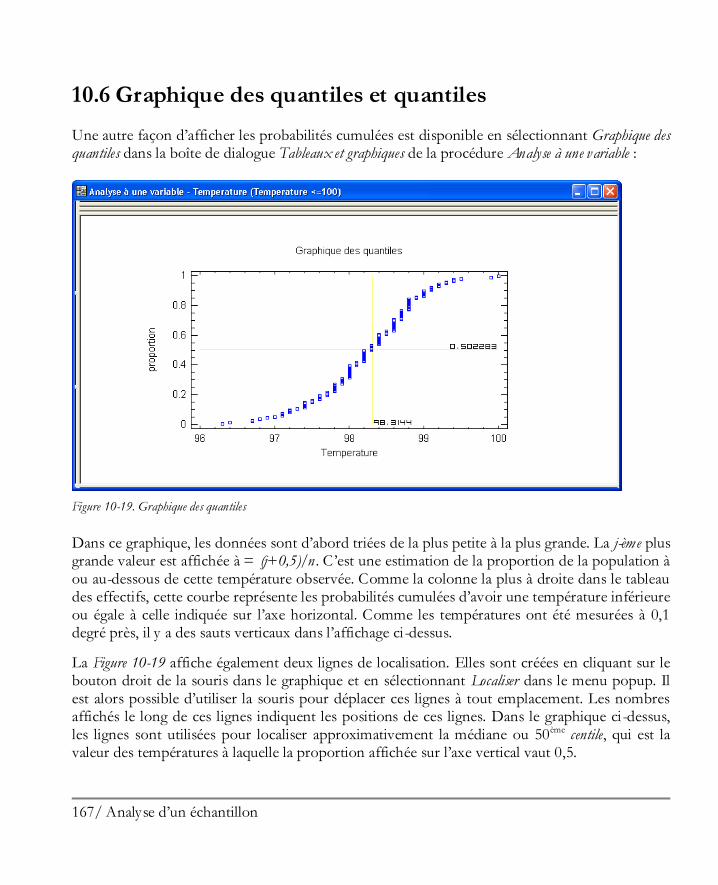
167/ Analyse d’un échantillon
10.6 Graphique des quantiles et quantiles Une autre façon d’afficher les probabilités cumulées est disponible en sélectionnant Graphique des quantiles dans la boîte de dialogue Tableaux et graphiques de la procédure Analyse à une variable :
Figure 10-19. Graphique des quantiles
Dans ce graphique, les données sont d’abord triées de la plus petite à la plus grande. La j-ème plus grande valeur est affichée à = (j+0,5)/n . C’est une estimation de la proportion de la population à ou au-dessous de cette température observée. Comme la colonne la plus à droite dans le tableau des effectifs, cette courbe représente les probabilités cumulées d’avoir une température inférieure ou égale à celle indiquée sur l’axe horizontal. Comme les températures ont été mesurées à 0,1 degré près, il y a des sauts verticaux dans l’affichage ci-dessus.
La Figure 10-19 affiche également deux lignes de localisation. Elles sont créées en cliquant sur le bouton droit de la souris dans le graphique et en sélectionnant Localiser dans le menu popup. Il est alors possible d’utiliser la souris pour déplacer ces lignes à tout emplacement. Les nombres affichés le long de ces lignes indiquent les positions de ces lignes. Dans le graphique ci -dessus, les lignes sont utilisées pour localiser approximativement la médiane ou 50ème centile, qui est la valeur des températures à laquelle la proportion affichée sur l’axe vertical vaut 0,5.

168/ Analyse d’un échantillon
Un tableau des quantiles peut aussi être créé en sélectionnant Quantiles dans la liste des tableaux :
Quantiles pour Temperature
Quantiles Limite inférieure Limite supérieure
1.0% 96.4 96.34 96.811
5.0% 97.0 96.8727 97.2473
10.0% 97.2 97.1538 97.4829
25.0% 97.8 97.6152 97.8846
50.0% 98.3 98.1082 98.3508
75.0% 98.7 98.5743 98.8437
90.0% 99.1 98.9761 99.3051
95.0% 99.3 99.2116 99.5862
99.0% 99.9 99.6479 100.119
Le rapport affiche les limites normales bilatérales de confiance à 95.0%.
Figure 10-20. Tableau des quantiles
Le p-ème quantile estime la valeur des températures au-dessous de laquelle est p % de la population. Les Options pour la fenêtre ont été utilisées pour ajouter des intervalles de confiance à 95% aux quantiles, en se basant sur l’hypothèse que l’échantillon est issu d’une loi normale. Par exemple, le 90ème quantile est une valeur des températures dépassée uniquement par 10% des individus de la population. La meilleure estimation de ce quantile sur les données de notre échantillon est de 99,1 degrés. Cependant, compte tenu de la taille limitée de notre échantillon, le 90ème quantile est en fait compris entre 98,98 et 99,31 degrés, avec un niveau de confiance de 95%.
10.7 Intervalles de confiance Après avoir retiré le point extrême de notre échantillon, il est possible de calculer des estimations des paramètres de la loi dont les données sont issues. Sélectionner Intervalles de confiance dans la boîte de dialogue Tableaux et graphiques :
Intervalles de confiance pour Temperature
Intervalle de confiance à 95.0% pour la moyenne: 98.2295 +/- 0.122015
[98.1074;98.3515]
Intervalle de confiance à 95.0% pour l'écart-type: [0.624081;0.798114]
Figure 10-21. Intervalles de confiance à 95% pour la moyenne et l’écart-type

169/ Analyse d’un échantillon
Les intervalles de confiance fournissent une borne de l’erreur potentielle d’estimation de la moyenne et de l’écart-type de la population. A partir des n = 129 observations restantes, on peut déclarer avec un niveau de confiance de 95% que la température moyenne de la population est comprise entre 98,11 degrés et 98,35 degrés. De même, l’écart-type de la population est compris entre 0,624 degré et 0,798 degré. En sélectionnant les Options pour la fenêtre, des intervalles de confiance additionnels peuvent être demandés en utilisant la méthode « bootstrap » :
Figure 10-22. Boîte de dialogue des options pour les intervalles de confiance
Les intervalles “bootstrap”, à la différence des intervalles de la Figure 10-21, ne supposent pas que la population suit une loi normale. Au lieu de cela, des échantillons aléatoires de n = 129 observations sont prélevés dans les données par un échantillonnage avec remise (la même observation peut être sélectionnée plusieurs fois). Ceci est répété 500 fois, des statistiques des échantillons sont calculées et les 95% centraux de ces résultats sont utilisés pour évaluer les intervalles de confiance. Le tableau ci-après affiche les intervalles « bootstrap” pour la moyenne, l’écart-type et la médiane de la population :
Intervalles de confiance pour Temperature
Intervalle de confiance à 95.0% pour la moyenne: 98.2295 +/- 0.122015 [98.1074;98.3515]
Intervalle de confiance à 95.0% pour l'écart-type: [0.624081;0.798114]
Intervalles de validation croisée
Moyenne: [98.1147;98.3543]
Ecart-type: [0.61717;0.781741]
Médiane: [98.1;98.4]
Figure 10-23. Intervalles de confiance « Bootstrap » à 95%
NOTE : Vos résultats peuvent être différents de ceux affichés ci-dessus.
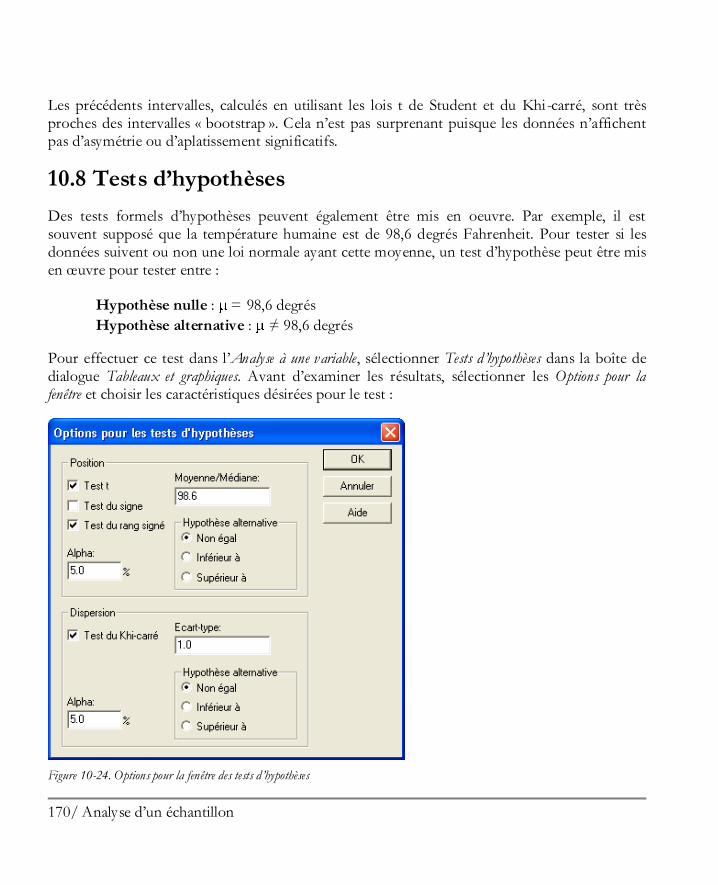
170/ Analyse d’un échantillon
Les précédents intervalles, calculés en utilisant les lois t de Student et du Khi-carré, sont très proches des intervalles « bootstrap ». Cela n’est pas surprenant puisque les données n’affichent pas d’asymétrie ou d’aplatissement significatifs.
10.8 Tests d’hypothèses
Des tests formels d’hypothèses peuvent également être mis en oeuvre. Par exemple, il est souvent supposé que la température humaine est de 98,6 degrés Fahrenheit. Pour tester si les données suivent ou non une loi normale ayant cette moyenne, un test d’hypothèse peut être mis en œuvre pour tester entre :
Hypothèse nulle : = 98,6 degrés
Hypothèse alternative : ≠ 98,6 degrés
Pour effectuer ce test dans l’Analyse à une variable, sélectionner Tests d’hypothèses dans la boîte de dialogue Tableaux et graphiques. Avant d’examiner les résultats, sélectionner les Options pour la fenêtre et choisir les caractéristiques désirées pour le test :
Figure 10-24. Options pour la fenêtre des tests d’hypothèses

171/ Analyse d’un échantillon
La valeur entrée pour la Moyenne représente l’hypothèse nulle. Dans Hypothèse alternative, vous pouvez sélectionner l’une des trois hypothèses alternatives suivantes :
1. Non égal : ≠ 98.6
2. Inférieur à : < 98.6
3. Supérieur à : > 98.6 Même si l’échantillon suggère une température moyenne inférieure, un test bilatéral alternatif a
été sélectionné. Choisir un test unilatéral avec une hypothèse alternative de < 98,6 degrés n’est pas correct à ce point car l’hypothèse est formulée après avoir déjà regardé les données. Les résultats du test sont montrés ci-dessous :
Tests d'hypothèses pour Temperature
Moyenne de l'échantillon = 98.2295
Médiane de l'échantillon = 98.3
test t
Hypothèse nulle: moyenne = 98.6
Alternative: non égal
Statistique t calculée = -6.00896
Proba. = 1.81264E-8
Rejet de l'hypothèse nulle pour alpha = 0.05.
test du signe
Hypothèse nulle: médiane = 98.6
Alternative: non égal
Nombre de valeurs au-dessous de la médiane hypothétique: 81
Nombre de valeurs au-dessus de la médiane hypothétique: 38
Test statistique sur large échantillon = 3.85013 (correction de continuité appliquée)
Proba. = 0.000118096
Rejet de l'hypothèse nulle pour alpha = 0.05.
test du rang signé
Hypothèse nulle: médiane = 98.6
Alternative: non égal
Rang moyen des valeurs au-dessous de la médiane hypothétique: 67.7099
Rang moyen des valeurs au-dessus de la médiane hypothétique: 43.5658
Test statistique sur large échantillon = 5.07771 (correction de continuité appliquée)
Proba. = 3.82663E-7
Rejet de l'hypothèse nulle pour alpha = 0.05.
Figure 10-25. Résultats des tests d’hypothèses

172/ Analyse d’un échantillon
Les résultats des deux tests sont donnés :
1. Un test t classique, qui suppose que les données sont issues d’une loi normale (même si ce test n’est pas trop sensible à cette hypothèse).
2. Un test non paramétrique des rangs signés, basé sur les rangs de la distance de chaque
observation à la médiane hypothétique. Ce test ne suppose pas la normalité et est moins sensible aux points extrêmes que le test t.
Dans les deux cas, la valeur de la probabilité est bien au-dessous de 0,05, rejetant l’hypothèse que l’échantillon est issu d’une population suivant une loi normale de moyenne 98,6 degrés.
NOTE : la notation E-8 après un nombre indique que ce nombre doit être multiplié par 10-8. La valeur de la probabilité affichée comme 1.81264E-8 est donc égale à 0.0000000181264.
Il faut noter que l’intervalle de confiance pour la moyenne, donné au paragraphe 10.8, n’inclut pas la valeur 98,6. Toute valeur non comprise dans l’intervalle de confiance aurait été rejetée par le test t utilisé ici. Vous pouvez donc considérer les intervalles de confiance comme des intervalles contenant toutes les valeurs possibles pour la population et qui sont tolérables par l’échantillon de données.
10.9 Limites des tolérances Une analyse additionnelle est utile pour nos températures corporelles. Elle calcule des limites de tolérances normales qui sont des limites à l’intérieur desquelles un pourcentage donné de la population doit appartenir à un niveau de confiance indiqué. Les limites statistiques de tolérances sont disponibles dans le menu principal :
1. Pour le menu classique, sélectionner Décrire – Données quantitatives – Limites statistiques de tolérances
2. Pour le menu Six Sigma, sélectionner Analyser – Variables – Analyse d’aptitude – Limites statistiques de tolérances
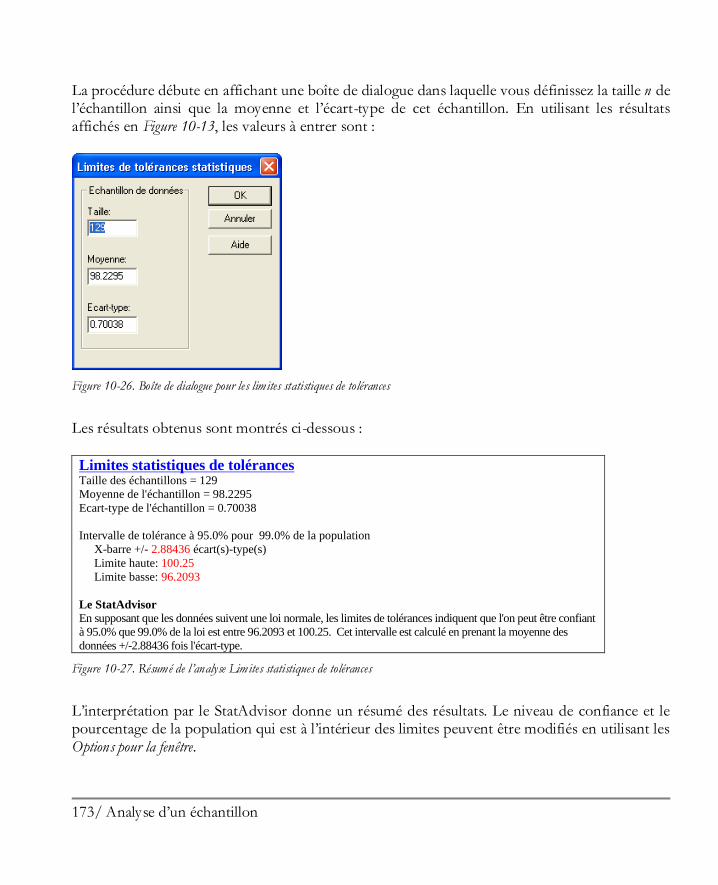
173/ Analyse d’un échantillon
La procédure débute en affichant une boîte de dialogue dans laquelle vous définissez la taille n de l’échantillon ainsi que la moyenne et l’écart-type de cet échantillon. En utilisant les résultats affichés en Figure 10-13, les valeurs à entrer sont :
Figure 10-26. Boîte de dialogue pour les limites statistiques de tolérances
Les résultats obtenus sont montrés ci-dessous :
Limites statistiques de tolérances Taille des échantillons = 129
Moyenne de l'échantillon = 98.2295
Ecart-type de l'échantillon = 0.70038
Intervalle de tolérance à 95.0% pour 99.0% de la population
X-barre +/- 2.88436 écart(s)-type(s)
Limite haute: 100.25
Limite basse: 96.2093
Le StatAdvisor
En supposant que les données suivent une loi normale, les limites de tolérances indiquent que l'on peut être confiant
à 95.0% que 99.0% de la loi est entre 96.2093 et 100.25. Cet intervalle est calculé en prenant la moyenne des
données +/-2.88436 fois l'écart-type.
Figure 10-27. Résumé de l’analyse Limites statistiques de tolérances
L’interprétation par le StatAdvisor donne un résumé des résultats. Le niveau de confiance et le pourcentage de la population qui est à l’intérieur des limites peuvent être modifiés en utilisant les Options pour la fenêtre.
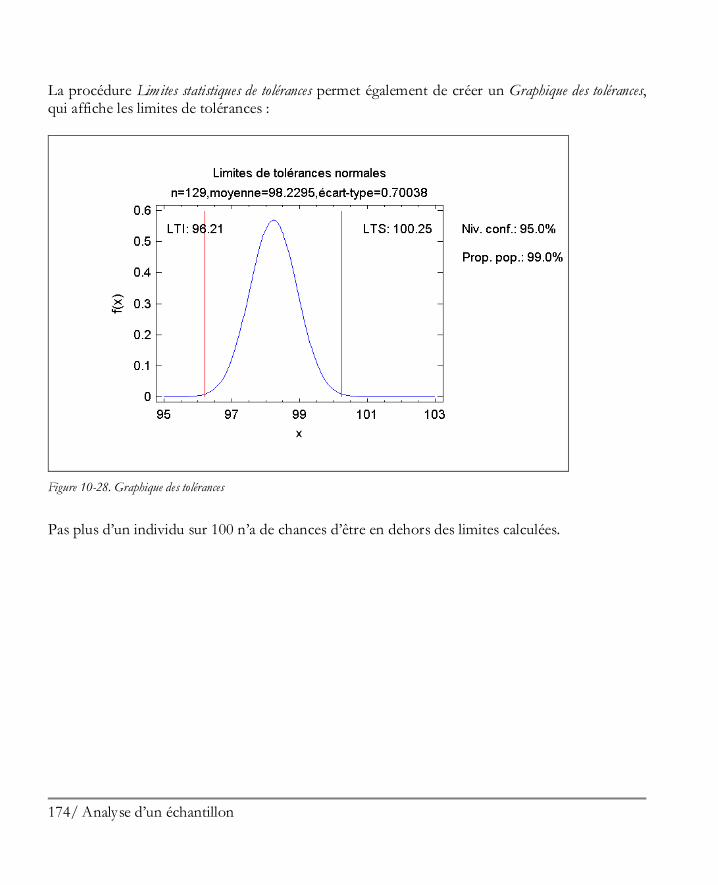
174/ Analyse d’un échantillon
La procédure Limites statistiques de tolérances permet également de créer un Graphique des tolérances, qui affiche les limites de tolérances :
Figure 10-28. Graphique des tolérances
Pas plus d’un individu sur 100 n’a de chances d’être en dehors des limites calculées.

175/ Comparer deux échantillons
Didacticiel n° 2 : Comparer deux
échantillons
Comparaisons graphiques et tests d’hypothèses.
Souvent, les données à analyser sont constituées de deux échantillons éventuellement issus de populations différentes. Dans de tels cas, il est utile de :
1. Afficher les données de telle façon que des comparaisons visuelles soient possibles.
2. Tester des hypothèses pour déterminer s’il y a ou non une différence statistiquement significative entre les deux échantillons.
Le didacticiel n° 1 du chapitre précédent a étudié un jeu de données constitué de températures corporelles mesurées sur 130 individus. Parmi ces individus, 65 sont des femmes et 65 sont des hommes. Dans ce didacticiel, nous allons comparer les données des femmes à celles des hommes. Pour analyser les températures corporelles, ouvrir le fichier de données bodytemp.sgd en utilisant Ouvrir une source de données dans le menu Fichier – Ouvrir.
Chapitre
11
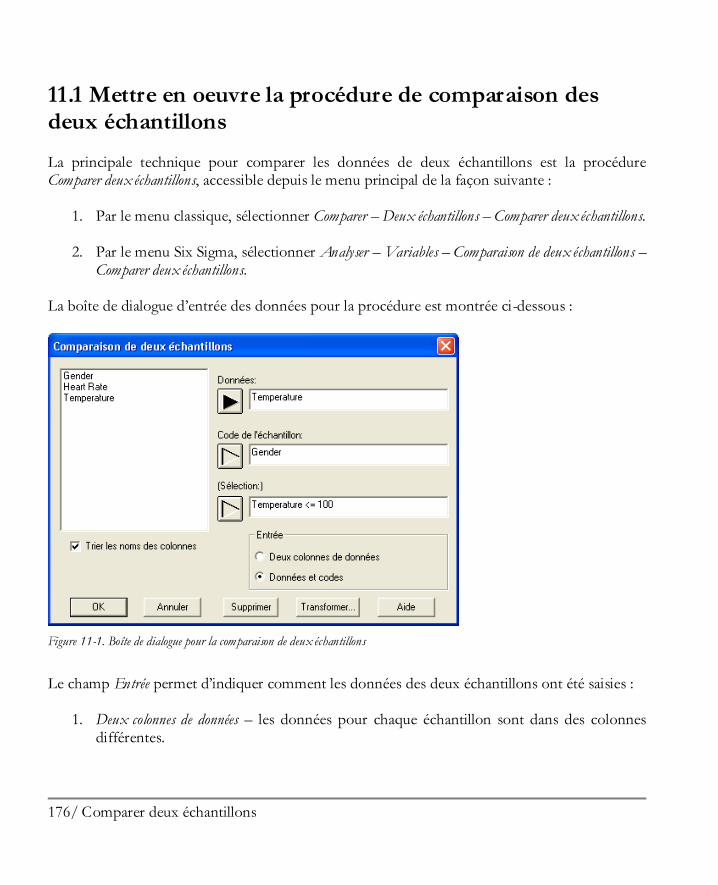
176/ Comparer deux échantillons
11.1 Mettre en oeuvre la procédure de comparaison des deux échantillons La principale technique pour comparer les données de deux échantillons est la procédure Comparer deux échantillons, accessible depuis le menu principal de la façon suivante :
1. Par le menu classique, sélectionner Comparer – Deux échantillons – Comparer deux échantillons.
2. Par le menu Six Sigma, sélectionner Analyser – Variables – Comparaison de deux échantillons – Comparer deux échantillons.
La boîte de dialogue d’entrée des données pour la procédure est montrée ci-dessous :
Figure 11-1. Boîte de dialogue pour la comparaison de deux échantillons
Le champ Entrée permet d’indiquer comment les données des deux échantillons ont été saisies :
1. Deux colonnes de données – les données pour chaque échantillon sont dans des colonnes différentes.
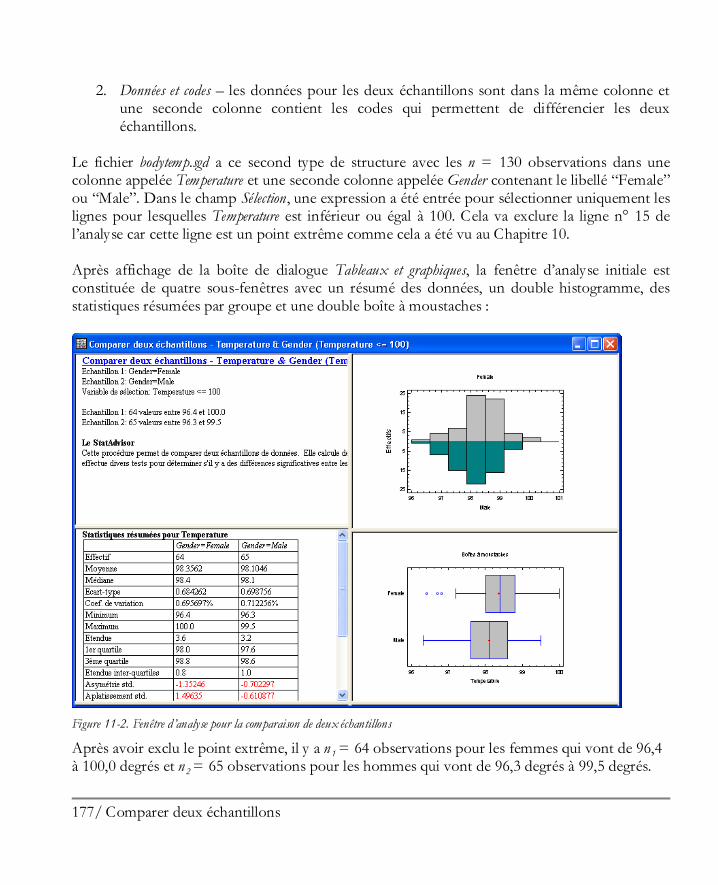
177/ Comparer deux échantillons
2. Données et codes – les données pour les deux échantillons sont dans la même colonne et une seconde colonne contient les codes qui permettent de différencier les deux échantillons.
Le fichier bodytemp.sgd a ce second type de structure avec les n = 130 observations dans une colonne appelée Temperature et une seconde colonne appelée Gender contenant le libellé “Female” ou “Male”. Dans le champ Sélection, une expression a été entrée pour sélectionner uniquement les lignes pour lesquelles Temperature est inférieur ou égal à 100. Cela va exclure la ligne n° 15 de l’analyse car cette ligne est un point extrême comme cela a été vu au Chapitre 10. Après affichage de la boîte de dialogue Tableaux et graphiques, la fenêtre d’analyse initiale est constituée de quatre sous-fenêtres avec un résumé des données, un double histogramme, des statistiques résumées par groupe et une double boîte à moustaches :
Figure 11-2. Fenêtre d’analyse pour la comparaison de deux échantillons
Après avoir exclu le point extrême, il y a n 1 = 64 observations pour les femmes qui vont de 96,4 à 100,0 degrés et n 2 = 65 observations pour les hommes qui vont de 96,3 degrés à 99,5 degrés.

178/ Comparer deux échantillons
11.2 Statistiques résumées Le tableau Statistiques résumées affiche diverses statistiques calculées sur chacun des échantillons :
Statistiques résumées pour Temperature
Gender=Female Gender=Male
Effectif 64 65
Moyenne 98.3562 98.1046
Médiane 98.4 98.1
Ecart-type 0.684262 0.698756
Coef. de variation 0.695697% 0.712256%
Minimum 96.4 96.3
Maximum 100.0 99.5
Etendue 3.6 3.2
1er quartile 98.0 97.6
3ème quartile 98.8 98.6
Etendue inter-quartiles 0.8 1.0
Asymétrie std. -1.35246 -0.702297
Aplatissement std. 1.49635 -0.610877
Figure 11-3. Statistiques résumées par échantillon
Plusieurs éléments de ce tableau sont particulièrement intéressants :
1. La température moyenne des femmes est d’environ 0,25 degré plus élevée que celle des hommes. La différence entre les médianes est de 0,30 degré.
2. L’écart-type pour les femmes est relativement plus faible que celui pour les hommes, ce
qui indique que les températures corporelles des femmes sont moins variables que celles des hommes.
3. Les deux échantillons ont des asymétries standardisées et des aplatissements standardisés
compris entre -2 et +2. Comme expliqué dans le Chapitre 10, des valeurs dans cette plage confirment l’hypothèse que les données sont issues de lois normales.
Il reste à déterminer si la différence apparente entre les femmes et les hommes est statistiquement significative.
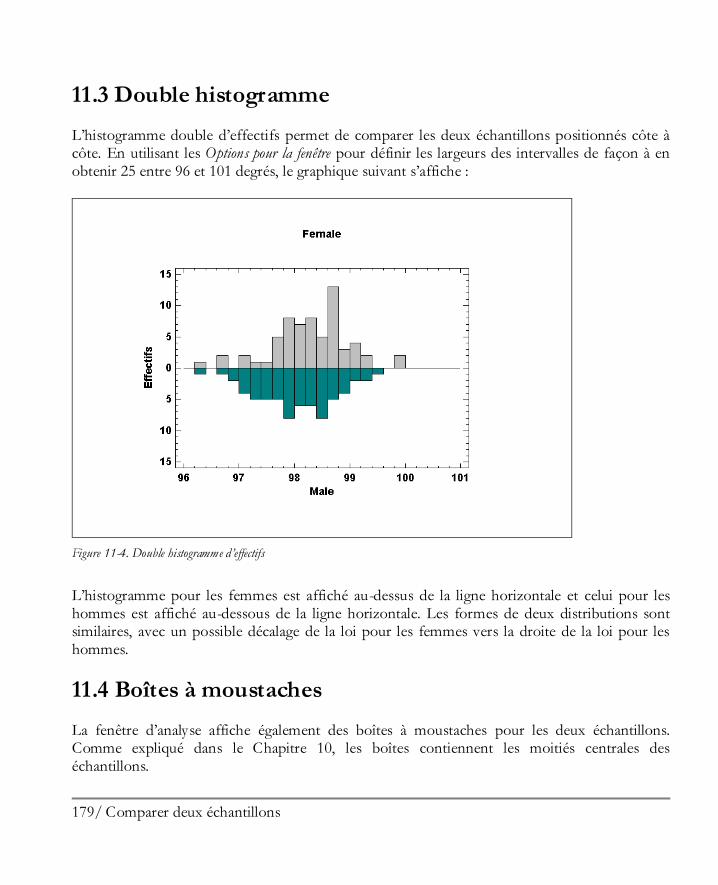
179/ Comparer deux échantillons
11.3 Double histogramme L’histogramme double d’effectifs permet de comparer les deux échantillons positionnés côte à côte. En utilisant les Options pour la fenêtre pour définir les largeurs des intervalles de façon à en obtenir 25 entre 96 et 101 degrés, le graphique suivant s’affiche :
Figure 11-4. Double histogramme d’effectifs
L’histogramme pour les femmes est affiché au-dessus de la ligne horizontale et celui pour les hommes est affiché au-dessous de la ligne horizontale. Les formes de deux distributions sont similaires, avec un possible décalage de la loi pour les femmes vers la droite de la loi pour les hommes.
11.4 Boîtes à moustaches La fenêtre d’analyse affiche également des boîtes à moustaches pour les deux échantillons. Comme expliqué dans le Chapitre 10, les boîtes contiennent les moitiés centrales des échantillons.
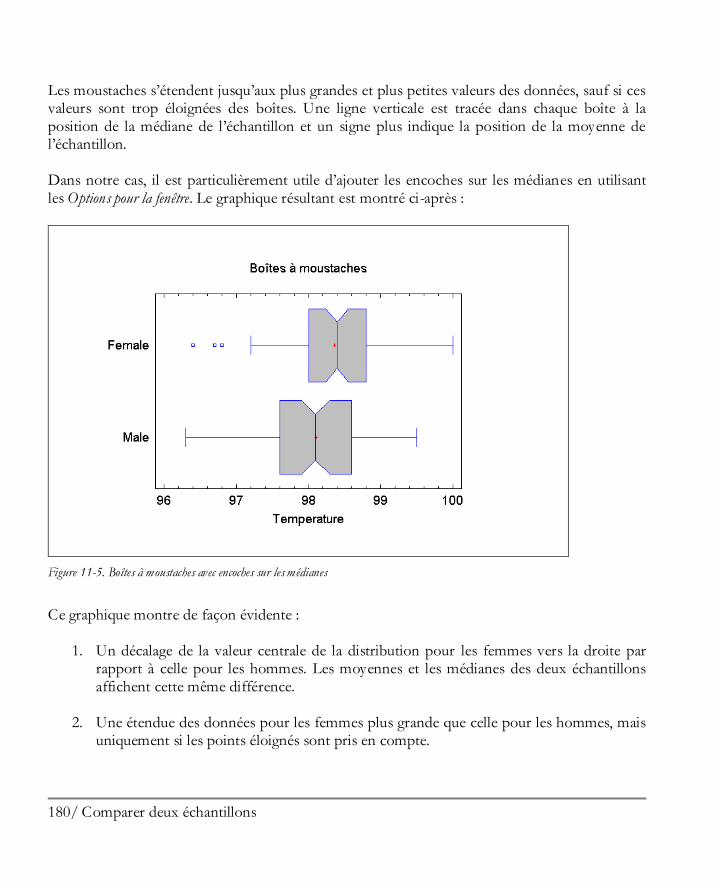
180/ Comparer deux échantillons
Les moustaches s’étendent jusqu’aux plus grandes et plus petites valeurs des données, sauf si ces valeurs sont trop éloignées des boîtes. Une ligne verticale est tracée dans chaque boîte à la position de la médiane de l’échantillon et un signe plus indique la position de la moyenne de l’échantillon. Dans notre cas, il est particulièrement utile d’ajouter les encoches sur les médianes en utilisant les Options pour la fenêtre. Le graphique résultant est montré ci-après :
Figure 11-5. Boîtes à moustaches avec encoches sur les médianes
Ce graphique montre de façon évidente :
1. Un décalage de la valeur centrale de la distribution pour les femmes vers la droite par rapport à celle pour les hommes. Les moyennes et les médianes des deux échantillons affichent cette même différence.
2. Une étendue des données pour les femmes plus grande que celle pour les hommes, mais
uniquement si les points éloignés sont pris en compte.

181/ Comparer deux échantillons
3. Une encoche sur la médiane pour les femmes qui chevauche celle pour les hommes. Les encoches sont tracées de telle façon que si deux encoches ne se chevauchent pas, il est alors possible de déclarer que les deux médianes ne sont pas significativement différentes au niveau de signification défini par défaut dans le logiciel (ici 5%). Une comparaison plus formelle est décrite dans un prochain paragraphe.
En se basant sur ce graphique, il apparaît qu’il y a une différence entre les valeurs centrales de ceux deux échantillons, même si la signification statistique de cette différence n’est pas encore confirmée.
11.5 Comparer les écarts-types La première comparaison formelle entre les deux échantillons consiste à tester l’hypothèse que
les écarts-types ( ) des populations dont les données proviennent sont égaux par rapport à l’hypothèse qu’ils ne le sont pas :
Hypothèse nulle : 1 = 2
Hypothèse alternative : 1 ≠ 2
Cela nous permettra de déterminer si la différence apparente entre la variabilité des hommes et celle des femmes est statistiquement significative ou si elle est de l’ordre de celle habituelle pour des échantillons de ces tailles.
Pour mettre en oeuvre ce test, cliquer sur bouton Tableaux et graphiques dans la barre des outils d’analyse et sélectionner Comparaison des écarts-types. Les résultats les plus importants dans ce tableau sont affichés en rouge :
1. Rapport des variances : affiche un intervalle de confiance à 95% pour le rapport des
variances de la population des femmes, 12, divisé par la variance de la population des
hommes, 22. La variance est une mesure de la variabilité calculée en prenant le carré de
l’écart-type. (NOTE : les comparaisons des variabilités de plusieurs échantillons sont classiquement basées sur les variances, plutôt que sur les écarts-types, car elles possèdent
des propriétés mathématiques intéressantes.). L’intervalle pour 12 / 2
2 s’étend de 0,58 à 1,58.

182/ Comparer deux échantillons
Cela indique que la variance des femmes est comprise entre 58% et 158% de la variance des hommes. Ce manque de précision est typique lorsqu’on compare les variabilités de relativement petits échantillons.
Comparaison des écarts-types pour Temperature
Gender=Female Gender=Male
Ecart-type 0.684262 0.698756
Variance 0.468214 0.48826
Ddl 63 64
Rapport des variances = 0.958945
Intervalles de confiance à 95.0%
Ecart-type de Gender=Female: [0.582853;0.828723]
Ecart-type de Gender=Male: [0.595887;0.844885]
Rapport des variances: [0.584028;1.57609]
Test F de comparaison des écarts-types
Hypothèse nulle: sigma1 = sigma2
(1) Hypothèse Alt.: sigma1 NE sigma2
F = 0.958945 Probabilité = 0.8684
Ne pas rejeter l'hypothèse nulle pour alpha = 0.05.
Figure 11-6. Comparaison des écarts-types de deux échantillons
2. La valeur de la probabilité associée au test F des hypothèses définies ci-dessus. Une
probabilité inférieure à 0,05 indiquerait une différence statistiquement significative entre les variances des femmes et des hommes au niveau de signification de 5%. Comme la valeur de la probabilité est bien supérieure à 0,05, il n’y a pas de raison de rejeter l’hypothèse d’égalité des variances et donc d’égalité des écarts-types.
Il n’y a donc pas de raison de conclure à une variabilité différente des températures corporelles de femmes par rapport à celles des hommes. Il doit être noté que ce test est assez sensible à l’hypothèse que les échantillons sont issus de populations distribuées selon des lois normales, une hypothèse qui est raisonnable si l’on se base sur les valeurs des coefficients d’asymétrie standardisée et d’aplatissement standardisé.

183/ Comparer deux échantillons
11.6 Comparer des moyennes
La deuxième comparaison entre nos deux échantillons teste l’hypothèse que les moy ennes ( ) des deux populations sont égales :
Hypothèse nulle : 1 = 2
Hypothèse alternative : 1 ≠ 2
Pour effectuer ce test, cliquer à nouveau sur le bouton Tableaux et graphiques et sélectionner Comparaison des moyennes. Les résultats obtenus sont :
Comparaison des moyennes pour Temperature
Intervalle de confiance à 95.0% pour la moyenne de Gender=Female: 98.3562 +/- 0.170924
[98.1853;98.5272]
Intervalle de confiance à 95.0% pour la moyenne de Gender=Male: 98.1046 +/- 0.173144
[97.9315;98.2778]
Intervalle de confiance à 95.0% pour la différence entre les moyennes :
en supposant l'égalité des variances: 0.251635 +/- 0.240998 [0.0106371;0.492632]
Test t de comparaison des moyennes
Hypothèse nulle: moy1 = moy2
(1) Hypothèse Alt.: moy1 NE moy2
en supposant l'égalité des variances: t = 2.06616 Probabilité = 0.040846
Rejet de l'hypothèse nulle pour alpha = 0.05.
Figure 11-7. Comparaison des moyennes de deux échantillons
Les parties les plus importantes du tableau des résultats sont à nouveau affichées en rouge :
1. Différence entre les moyennes (en supposant l’égalité des variances) : affiche un intervalle de confiance à 95% pour la moyenne de la population des femmes moins la moyenne de la
population des hommes. L’intervalle pour 1 - 2 s’étend de 0,01 à 0,49, indiquant que la température moyenne des femmes est de 0,01 degré à 0,49 degré supérieure à la température moyenne des hommes.
2. La valeur de la probabilité associée au test t des hypothèses définies ci-dessus. Comme la
valeur de la probabilité est inférieure à 0,05, il est possible de rejeter l’hypothèse d’égalité des moyennes et donc de déclarer que les moyennes des deux populations sont significativement différentes au niveau de signification de 5%.

184/ Comparer deux échantillons
A noter que ce test a été effectué en supposant que les variances des deux populations sont égales, ce qui a été validé par le test F dans le précédent paragraphe. Si les variances avaient été significativement différentes, un test t approximé aurait pu être calculé en demandant les Options pour la fenêtre et en décochant la case intitulée Egalité des écarts-types. Il apparaît ainsi que les femmes sont issues d’une population dont la moyenne des températures est supérieure à celle des hommes.
11.7 Comparer des médianes S’il est suspecté que les données puissent contenir des valeurs extrêmes, un test non paramétrique peut être mis en œuvre pour comparer les médianes plutôt que les moyennes. Les tests non paramétriques ne supposent pas que les données sont issues de lois normales et sont moins sensibles à la présence de points extrêmes.
Sélectionner Comparaison des médianes dans la boîte de dialogue Tableaux et graphiques pour calculer un test W de Mann-Whitney (Wilcoxon). Dans ce test, les deux échantillons sont d’abord combinés. Les données combinées sont triées de 1 à n 1+n2 et les valeurs d’origine sont remplacées par leurs rangs respectifs. Un test statistique W est alors calculé en comparant les rangs moyens des observations des deux échantillons :
Comparaison des médianes pour Temperature
Médiane de l'échantillon 1: 98.4
Médiane de l'échantillon 2: 98.1
Test W de Mann-Whitney (Wilcoxon) de comparaison
des médianes
Hypothèse nulle: médiane1 = médiane2
(1) Hypothèse Alt.: médiane1 NE médiane2
Rang moyen de l'échantillon 1: 71.9219
Rang moyen de l'échantillon 2: 58.1846
W = -443.0 Probabilité = 0.0368312
Rejet de l'hypothèse nulle pour alpha = 0.05.
Figure 11-8. Comparaison des médians de deux échantillons
L’interprétation du test de Mann-Whitney (Wilcoxon) est similaire à celle du test t décrit dans le paragraphe précédent, avec une petite valeur de probabilité indiquant que les médianes des deux populations sont significativement différentes.
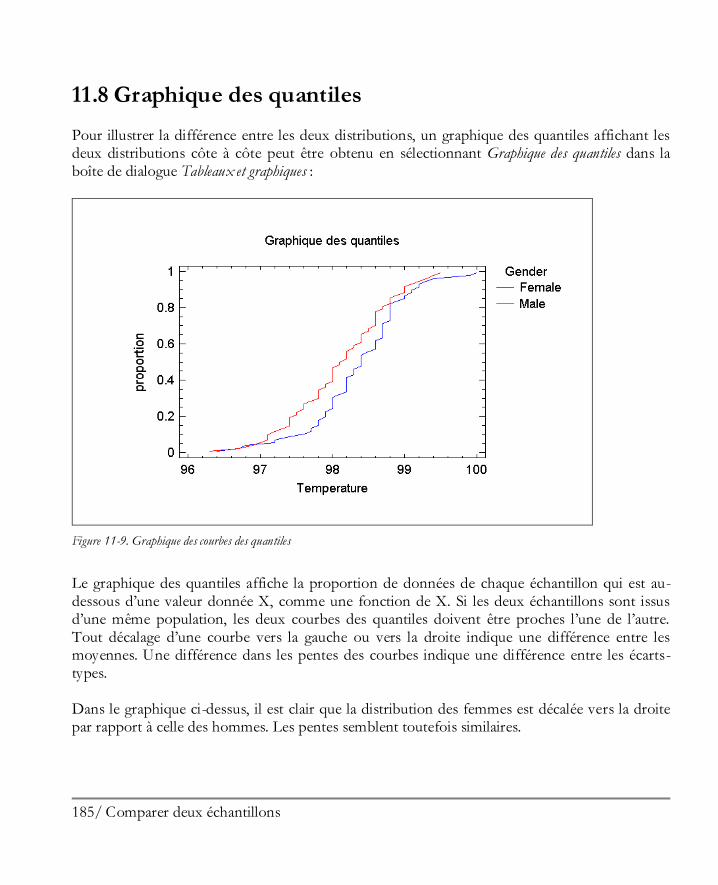
185/ Comparer deux échantillons
11.8 Graphique des quantiles Pour illustrer la différence entre les deux distributions, un graphique des quantiles affichant les deux distributions côte à côte peut être obtenu en sélectionnant Graphique des quantiles dans la boîte de dialogue Tableaux et graphiques :
Figure 11-9. Graphique des courbes des quantiles
Le graphique des quantiles affiche la proportion de données de chaque échantillon qui est au-dessous d’une valeur donnée X, comme une fonction de X. Si les deux échantillons sont issus d’une même population, les deux courbes des quantiles doivent être proches l’une de l’autre. Tout décalage d’une courbe vers la gauche ou vers la droite indique une différence entre les moyennes. Une différence dans les pentes des courbes indique une différence entre les écarts-types. Dans le graphique ci-dessus, il est clair que la distribution des femmes est décalée vers la droite par rapport à celle des hommes. Les pentes semblent toutefois similaires.

186/ Comparer deux échantillons
11.9 Test de Kolmogorov-Smirnov pour deux échantillons Un test non paramétrique supplémentaire peut être effectué si l’hypothèse de distributions normales ne peut pas être retenue. C’est le test de Kolmogorov-Smirnov pour deux échantillons. Ce test est basé sur le calcul de la distance verticale maximale entre les fonctions de répartition des deux échantillons, qui est approximativement la distance maximale entre les courbes des quantiles dans le graphique de la Figure 11-9. Si la distance maximale est suffisamment grande, il est possible de déclarer que les deux échantillons proviennent de populations significativement différentes. Sélectionner Test de Kolmogorov -Smirnov dans la boîte de dialogue Tableaux et graphiques affiche les résultats suivants :
Test de Kolmogorov-Smirnov pour Temperature
Statistique DN globale estimée = 0.242548
Statistique K-S bilatérale pour larges échantillons =
1.37737
Probabilité approximée = 0.0449985
Figure 11-10. Résultats du test de Kolmogorov -Smirnov
La distance verticale maximale, notée DN, est approximativement égale à 0,24 pour nos températures corporelles. La valeur de la probabilité est utilisée pour déterminer si les distributions sont significativement différentes l’une de l’autre ou non. Une petite valeur de la probabilité indique qu’il y a une différence significative. Comme la valeur de la probabilité pour nos données est inférieure à 0,05, il y a une différence significative entre les distributions des femmes et des hommes au niveau de signification de 5%.
Attention : Si les données sont fortement arrondies, ce test peut ne pas être fiable car la fonction de répartition empirique peut afficher de grands sauts. Lorsque cela est possible, il est alors préférable de comparer les paramètres des distributions, comme les moyennes, écarts-types et médianes.
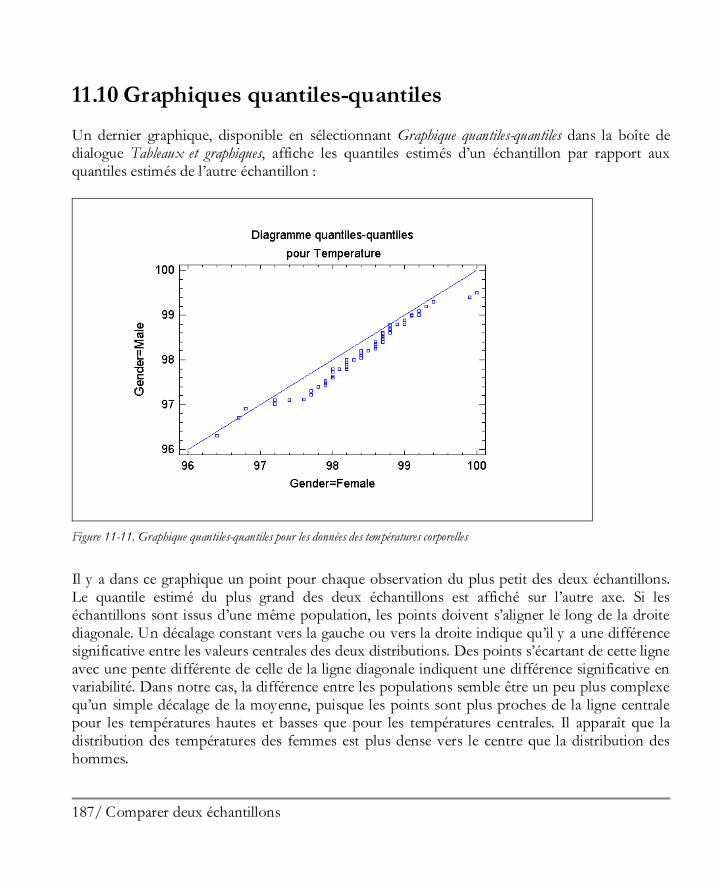
187/ Comparer deux échantillons
11.10 Graphiques quantiles-quantiles Un dernier graphique, disponible en sélectionnant Graphique quantiles-quantiles dans la boîte de dialogue Tableaux et graphiques, affiche les quantiles estimés d’un échantillon par rapport aux quantiles estimés de l’autre échantillon :
Figure 11-11. Graphique quantiles-quantiles pour les données des températures corporelles
Il y a dans ce graphique un point pour chaque observation du plus petit des deux échantillons. Le quantile estimé du plus grand des deux échantillons est affiché sur l’autre axe. Si les échantillons sont issus d’une même population, les points doivent s’aligner le long de la droite diagonale. Un décalage constant vers la gauche ou vers la droite indique qu’il y a une différence significative entre les valeurs centrales des deux distributions. Des points s’écartant de cette ligne avec une pente différente de celle de la ligne diagonale indiquent une différence significative en variabilité. Dans notre cas, la différence entre les populations semble être un peu plus complexe qu’un simple décalage de la moyenne, puisque les points sont plus proches de la ligne centrale pour les températures hautes et basses que pour les températures centrales. Il apparaît que la distribution des températures des femmes est plus dense vers le centre que la distribution des hommes.

188/ Comparer deux échantillons

189/ Comparer plus de deux échantillons
Didacticiel n° 3 : Comparer plus
de deux échantillons
Comparer des moyennes et des écarts-types, ANOVA à un facteur, ANOM et méthodes graphiques.
Lorsque les données sont dans plus de deux groupes, un ensemble différent de techniques, par rapport à celles présentées dans le précédent chapitre, doit être utilisé. Par exemple, supposons que l’on souhaite comparer la solidité de pièces fabriquées à partir de quatre matériaux différents. Une expérimentation typique consiste à fabriquer des pièces (ici 12) dans chacun des 4 matériaux de façon à les comparer Les données ci-dessous représentent les résultats de l’expérimentation :
Matériau A Matériau B Matériau C Matériau D
64.7 60.4 58.3 60.8
64.8 61.8 62.1 60.2
66.8 63.3 62.4 59.8
67.0 61.6 60.3 58.3
64.9 61.0 60.6 56.4
63.7 63.8 60.0 61.6
61.8 60.9 60.3 59.5
64.3 65.1 62.4 62.0
64.3 61.5 61.9 61.4
65.9 60.0 63.1 58.6
63.6 62.9 60.2 59.5
64.6 60.6 58.6 60.0
Chapitre
12

190/ Comparer plus de deux échantillons
Il est très intéressant de pouvoir déterminer le matériau qui donne la plus grande solidité aux pièces, ainsi que de savoir quels sont les matériaux qui sont statistiquement différents de façon significative des autres. Il y a deux façons d’entrer les données de multiples échantillons dans le tableur :
1. Utiliser une colonne séparée pour chaque échantillon.
2. Utiliser une colonne unique pour les données et créer une seconde colonne contenant des codes permettant d’identifier l’échantillon d’origine de chaque donnée.
Dans cet exemple, la première approche est utilisée. Les données pour les pièces sont placées dans les quatre colonnes du fichier widgets.sgd que vous pouvez ouvrir en sélectionnant Ouvrir – Ouvrir une source de données dans le menu Fichier.
12.1 Mettre en oeuvre la procédure de comparaison de plusieurs échantillons La procédure Comparaison de plusieurs échantillons est disponible dans le menu principal :
1. Dans le menu classique, sélectionner : Comparer – Plusieurs échantillons – Comparer plusieurs échantillons.
2. Dans le menu Six Sigma, sélectionner : Analyser – Variables – Comparaisons de plusieurs
échantillons – Comparer plusieurs échantillons. La boîte de dialogue initiale permet d’indiquer comment les données ont été entrées dans le tableur :
Figure 12-1. Boîte de dialogue initiale pour la comparaison de plusieurs échantillons
191/ Comparer plus de deux échantillons
Dans notre cas, les données ont été structurées en plusieurs colonnes dans le tableur. La deuxième boîte de dialogue vous demande les noms des colonnes contenant les données :
Figure 12-2. Boîte de dialogue d’entrée des données pour la comparaison de plusieurs échantillons
Dans le fichier de données de notre exemple, les observations sont dans quatre colonnes nommées A, B, C et D. Après avoir cliqué sur OK, la boîte de dialogue Tableaux et graphiques s’affiche. Les options par défaut sont conservées pour ce didacticiel. Lorsque la fenêtre d’analyse s’ouvre, elle contient quatre sous-fenêtres :
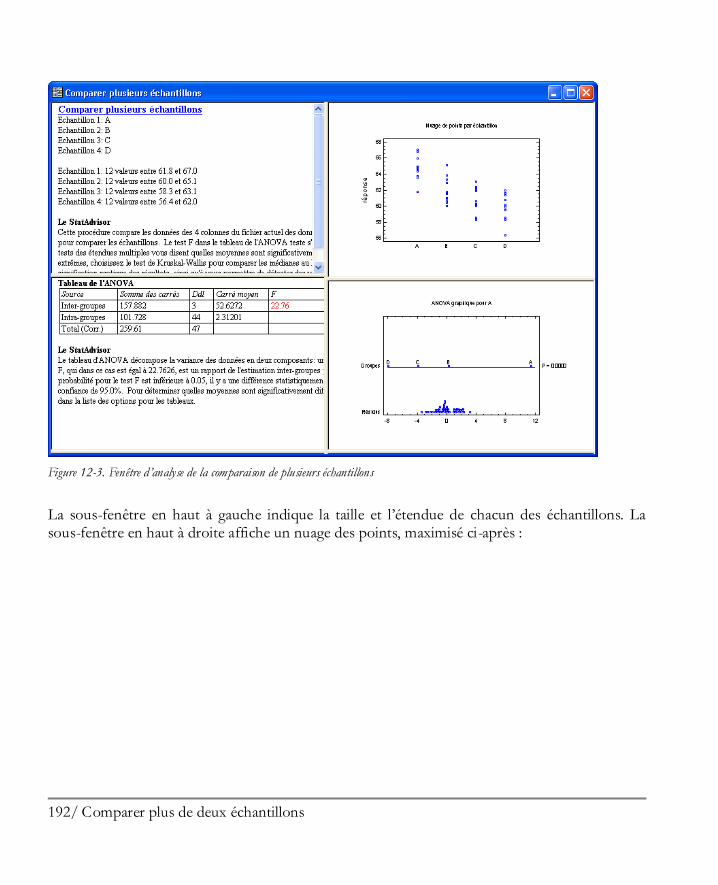
192/ Comparer plus de deux échantillons
Figure 12-3. Fenêtre d’analyse de la comparaison de plusieurs échantillons
La sous-fenêtre en haut à gauche indique la taille et l’étendue de chacun des échantillons. La sous-fenêtre en haut à droite affiche un nuage des points, maximisé ci-après :
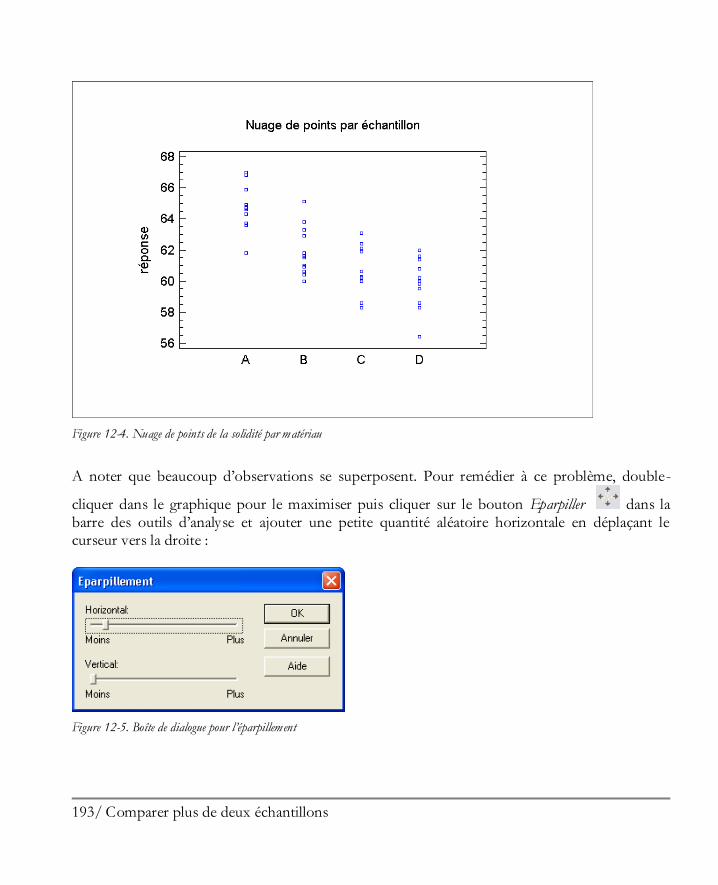
193/ Comparer plus de deux échantillons
Figure 12-4. Nuage de points de la solidité par matériau
A noter que beaucoup d’observations se superposent. Pour remédier à ce problème, double-
cliquer dans le graphique pour le maximiser puis cliquer sur le bouton Eparpiller dans la barre des outils d’analyse et ajouter une petite quantité aléatoire horizontale en déplaçant le curseur vers la droite :
Figure 12-5. Boîte de dialogue pour l’éparpillement
194/ Comparer plus de deux échantillons
Cela décale de façon aléatoire chaque point d’une petite quantité par rapport à l’axe horizontal, rendant la vision des points individuels plus facile :
Figure 12-6. Nuage de points après éparpillement
L’éparpillement n’affecte que l’affichage, pas les données ni les calculs effectués à partir de ces données.
12.2 Analyse de la variance La première étape lorsque vous comparez plusieurs échantillons est classiquement de faire une analyse de la variance à un facteur (ANOVA). L’ANOVA est utilisée pour tester l’hypothèse d’égalité des moyennes des populations en choisissant entre les deux hypothèses suivantes :
Hypothèse nulle : A = B = C = D
Hypothèse alternative : les moyennes ne sont pas toutes égales

195/ Comparer plus de deux échantillons
où j représente la moyenne de la population dont l’échantillon j provient. Le rejet de l’hypothèse nulle indique que les échantillons sont issus de populations dont les moyennes ne sont pas toutes égales.
Les résultats de l’ANOVA sont contenus dans le tableau de l’ANOVA affiché dans la sous-fenêtre en haut à gauche de la fenêtre d’analyse :
Tableau de l'ANOVA
Source Somme des carrés Ddl Carré moyen F Probabilité
Inter-groupes 157.882 3 52.6272 22.76 0.0000
Intra-groupes 101.728 44 2.31201
Total (Corr.) 259.61 47
Figure 12-7. Tableau de l’analyse de la variance
L’analyse de la variance décompose la variabilité des données observées en deux composants : un composant inter-groupes, quantifiant les différences entre les pièces fabriquées dans différents matériaux, et un composant intra-groupe, quantifiant les différences entre les pièces fabriquées avec le même matériau. Si la variabilité estimée entre les groupes est significativement plus grande que la variabilité estimée dans les groupes, il est alors évident que les moyennes des groupes ne sont pas toutes les mêmes.
La valeur clé dans la Figure 12-7 est la valeur de la probabilité. De petites valeurs de cette probabilité (inférieures à 0,05 pour un niveau de signification de 5%) conduisent à rejeter l’hypothèse que toutes les moyennes sont égales. Dans cet exemple, il est clair que les moyennes sont significativement différentes.
Dans la récente édition de Statistics for Experimenters de Box, Hunter et Hunter (John Wiley and Sons, 2005), les auteurs présentent un nouveau graphique illustrant les résultats d’une ANOVA. L’ANO VA graphique est affichée par défaut dans la sous-fenêtre en bas à droite de la fenêtre d’analyse :
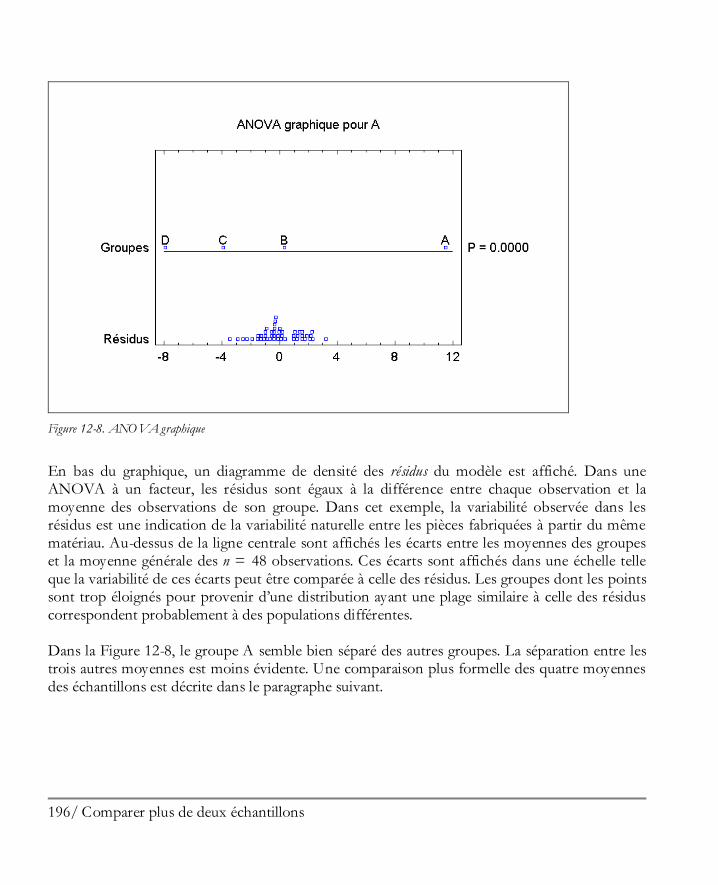
196/ Comparer plus de deux échantillons
Figure 12-8. ANO VA graphique
En bas du graphique, un diagramme de densité des résidus du modèle est affiché. Dans une ANOVA à un facteur, les résidus sont égaux à la différence entre chaque observation et la moyenne des observations de son groupe. Dans cet exemple, la variabilité observée dans les résidus est une indication de la variabilité naturelle entre les pièces fabriquées à partir du même matériau. Au-dessus de la ligne centrale sont affichés les écarts entre les moyennes des groupes et la moyenne générale des n = 48 observations. Ces écarts sont affichés dans une échelle telle que la variabilité de ces écarts peut être comparée à celle des résidus. Les groupes dont les points sont trop éloignés pour provenir d’une distribution ayant une plage similaire à celle des résidus correspondent probablement à des populations différentes. Dans la Figure 12-8, le groupe A semble bien séparé des autres groupes. La séparation entre les trois autres moyennes est moins évidente. Une comparaison plus formelle des quatre moyennes des échantillons est décrite dans le paragraphe suivant.
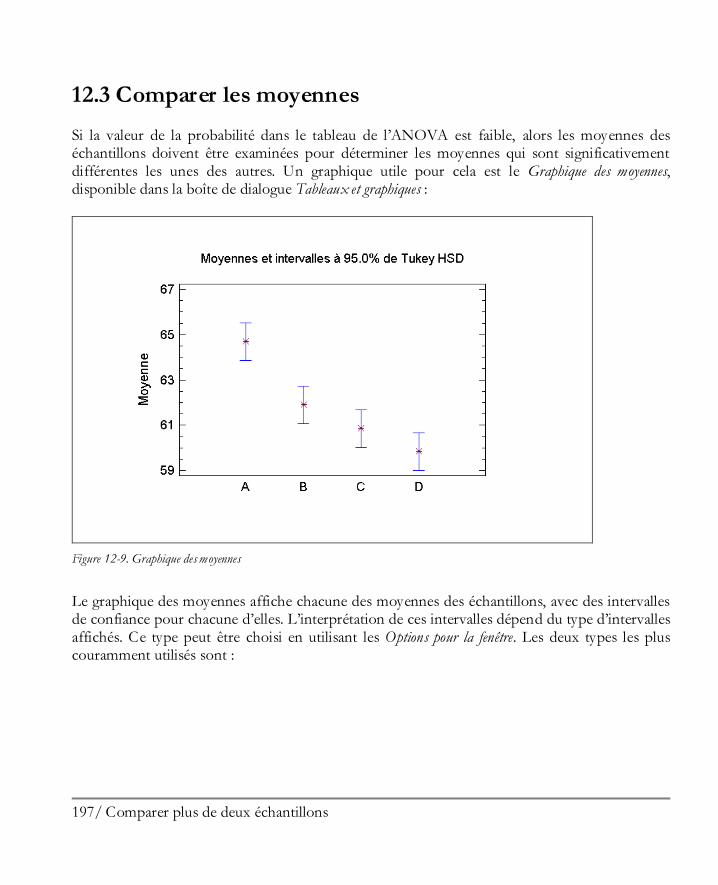
197/ Comparer plus de deux échantillons
12.3 Comparer les moyennes Si la valeur de la probabilité dans le tableau de l’ANOVA est faible, alors les moyennes des échantillons doivent être examinées pour déterminer les moyennes qui sont significativement différentes les unes des autres. Un graphique utile pour cela est le Graphique des moyennes, disponible dans la boîte de dialogue Tableaux et graphiques :
Figure 12-9. Graphique des moyennes
Le graphique des moyennes affiche chacune des moyennes des échantillons, avec des intervalles de confiance pour chacune d’elles. L’interprétation de ces intervalles dépend du type d’intervalles affichés. Ce type peut être choisi en utilisant les Options pour la fenêtre. Les deux types les plus couramment utilisés sont :
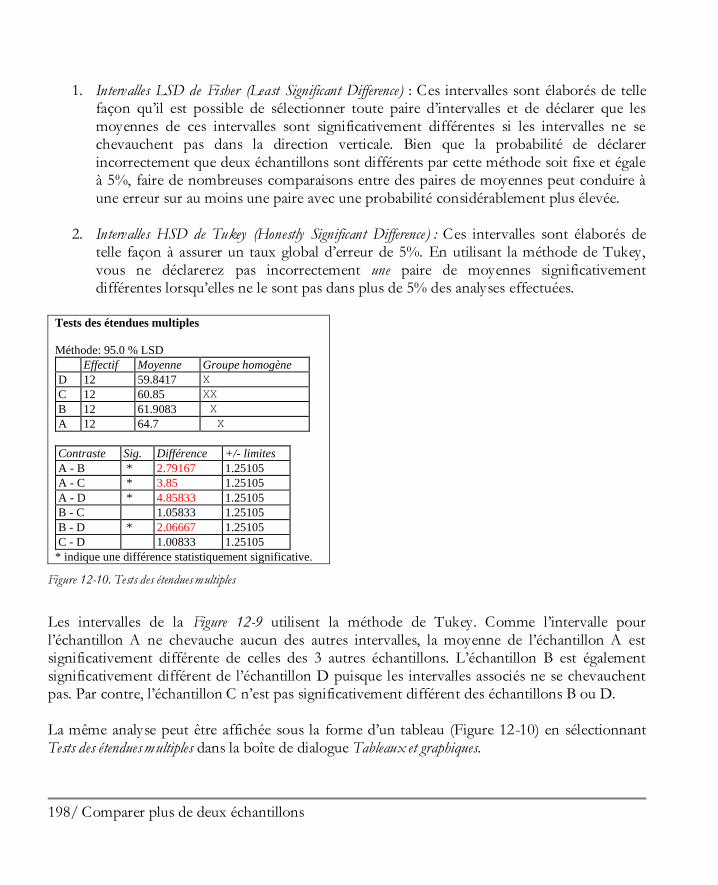
198/ Comparer plus de deux échantillons
1. Intervalles LSD de Fisher (Least Significant Difference) : Ces intervalles sont élaborés de telle façon qu’il est possible de sélectionner toute paire d’intervalles et de déclarer que les moyennes de ces intervalles sont significativement différentes si les intervalles ne se chevauchent pas dans la direction verticale. Bien que la probabilité de déclarer incorrectement que deux échantillons sont différents par cette méthode soit fixe et égale à 5%, faire de nombreuses comparaisons entre des paires de moyennes peut conduire à une erreur sur au moins une paire avec une probabilité considérablement plus élevée.
2. Intervalles HSD de Tukey (Honestly Significant Difference) : Ces intervalles sont élaborés de
telle façon à assurer un taux global d’erreur de 5%. En utilisant la méthode de Tukey, vous ne déclarerez pas incorrectement une paire de moyennes significativement différentes lorsqu’elles ne le sont pas dans plus de 5% des analyses effectuées.
Tests des étendues multiples
Méthode: 95.0 % LSD
Effectif Moyenne Groupe homogène
D 12 59.8417 X
C 12 60.85 XX
B 12 61.9083 X
A 12 64.7 X
Contraste Sig. Différence +/- limites
A - B * 2.79167 1.25105
A - C * 3.85 1.25105
A - D * 4.85833 1.25105
B - C 1.05833 1.25105
B - D * 2.06667 1.25105
C - D 1.00833 1.25105
* indique une différence statistiquement significative.
Figure 12-10. Tests des étendues multiples
Les intervalles de la Figure 12-9 utilisent la méthode de Tukey. Comme l’intervalle pour l’échantillon A ne chevauche aucun des autres intervalles, la moyenne de l’échantillon A est significativement différente de celles des 3 autres échantillons. L’échantillon B est également significativement différent de l’échantillon D puisque les intervalles associés ne se chevauchent pas. Par contre, l’échantillon C n’est pas significativement différent des échantillons B ou D. La même analyse peut être affichée sous la forme d’un tableau (Figure 12-10) en sélectionnant Tests des étendues multiples dans la boîte de dialogue Tableaux et graphiques.

199/ Comparer plus de deux échantillons
Le bas du tableau affiche chacune des paires de moyennes. La colonne Différence affiche la moyenne de l’échantillon dans le premier groupe moins la moyenne de l’échantillon dans le second groupe. La colonne +/- limites donne l’intervalle d’incertitude pour la différence. Chaque paire pour laquelle la valeur absolue de la différence excède la limite est statistiquement significative au niveau de confiance choisi et est marquée par une * dans la colonne Sig. Dans notre exemple, quatre des six paires de moyennes affichent des différences significatives. Le haut du tableau présente les échantillons en groupes homogènes affichés sous la forme de colonnes de X. Un groupe homogène est un groupe dans lequel il n’y a pas de différences significatives. Dans notre cas, l’échantillon A constitue un groupe à lui seul car il est statistiquement différent de tous les autres échantillons. L’échantillon C appartient à deux groupes, un avec B et un autre avec D. Plus de données seraient nécessaires pour savoir à quel groupe l’échantillon C appartient effectivement.
12.4 Comparer des médianes Si la présence de points extrêmes est suspectée, une procédure non paramétrique peut être utilisée comme alternative à l’analyse de la variance standard en sélectionnant Tests de Kruskal-Wallis et de Friedman dans la boîte de dialogue Tableaux et graphiques. Ces tests comparent les médianes des échantillons plutôt que les moyennes :
Hypothèse nulle : les médianes sont toutes égales
Hypothèse alternative : les médianes ne sont pas toutes égales Le type du test peut être sélectionné en utilisant les Options pour la fenêtre. Deux types sont disponibles :
1. Test de Kruskal-Wallis – approprié lorsque chaque colonne contient un échantillon aléatoire de sa population. Dans un tel cas, les lignes n’ont pas de significations particulières.
2. Test de Friedman – approprié lorsque chaque ligne représente un bloc, c’est-à-dire le
niveau d’une quelconque autre variable. De telles variables définissant des blocs sont par exemple les jours de la semaine, les équipes, les implantations d’usines.
Dans notre exemple, les lignes n’ont pas de significations et donc le test de Kruskal -Wallis est approprié :
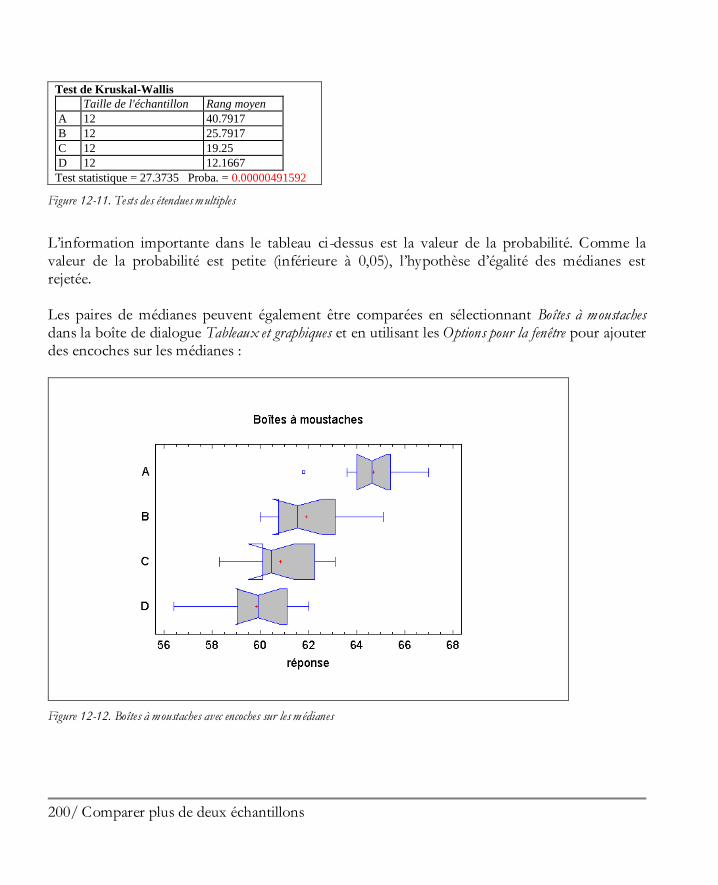
200/ Comparer plus de deux échantillons
Test de Kruskal-Wallis
Taille de l'échantillon Rang moyen
A 12 40.7917
B 12 25.7917
C 12 19.25
D 12 12.1667
Test statistique = 27.3735 Proba. = 0.00000491592
Figure 12-11. Tests des étendues multiples
L’information importante dans le tableau ci-dessus est la valeur de la probabilité. Comme la valeur de la probabilité est petite (inférieure à 0,05), l’hypothèse d’égalité des médianes est rejetée. Les paires de médianes peuvent également être comparées en sélectionnant Boîtes à moustaches dans la boîte de dialogue Tableaux et graphiques et en utilisant les Options pour la fenêtre pour ajouter des encoches sur les médianes :
Figure 12-12. Boîtes à moustaches avec encoches sur les médianes

201/ Comparer plus de deux échantillons
La plage couverte par chaque encoche montre l’incertitude associée à l’estimation de la médiane du groupe. Les encoches sont élaborées de telle façon que si les encoches de deux échantillons ne se chevauchent pas, il est alors possible de déclarer que les médianes de ces deux échantillons sont significativement différentes au niveau de signification par défaut du logiciel (habituellement 5%). Dans le graphique ci-dessus, les encoches pour les échantillons B, C et D se chevauchent, mais la médiane pour l’échantillon A est significativement plus grande que celles des trois autres échantillons.
NOTE : le repliement des encoches observé en Figure 12-12 survient lorsqu’une encoche s’étend au-delà du bord de la boîte.
12.5 Comparer des écarts-types Il est également possible de tester l’hypothèse d’égalité des écarts-types :
Hypothèse nulle : A = B = C = D Hypothèse alternative : les écarts-types ne sont pas tous égaux
Cela est fait en sélectionnant Test des variances dans la boîte de dialogue Tableaux et graphiques :
Tests des variances
Test Probabilité
Test de Levene 0.143286 0.933432
Figure 12-13. Comparaison des variances des échantillons
Un des quatre tests s’affichera en fonction des paramètres des Options pour la fenêtre. Trois des tests disponibles, dont le test de Levene, donnent des valeurs de probabilités. Une valeur de probabilité inférieure à 0,05 conduit au rejet de l’hypothèse d’égalité des écarts-types au niveau de signification de 5%. Dans notre cas, les écarts-types ne sont pas significativement différents les uns des autres, puisque la valeur de la probabilité est bien plus grande que 0,05. En résumé, il apparaît que la solidité moyenne varie avec les différents matériaux. Cependant, la variabilité entre les pièces fabriquées avec ces matériaux est à peu près la même pour tous les matériaux.
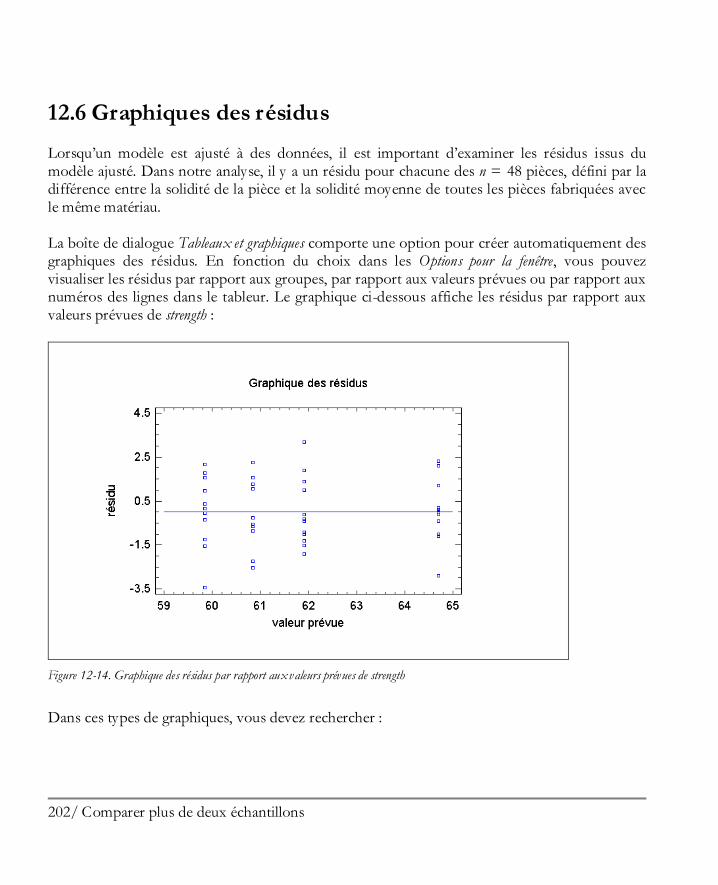
202/ Comparer plus de deux échantillons
12.6 Graphiques des résidus Lorsqu’un modèle est ajusté à des données, il est important d’examiner les résidus issus du modèle ajusté. Dans notre analyse, il y a un résidu pour chacune des n = 48 pièces, défini par la différence entre la solidité de la pièce et la solidité moyenne de toutes les pièces fabriquées avec le même matériau. La boîte de dialogue Tableaux et graphiques comporte une option pour créer automatiquement des graphiques des résidus. En fonction du choix dans les Options pour la fenêtre, vous pouvez visualiser les résidus par rapport aux groupes, par rapport aux valeurs prévues ou par rapport aux numéros des lignes dans le tableur. Le graphique ci-dessous affiche les résidus par rapport aux valeurs prévues de strength :
Figure 12-14. Graphique des résidus par rapport aux valeurs prévues de strength
Dans ces types de graphiques, vous devez rechercher :
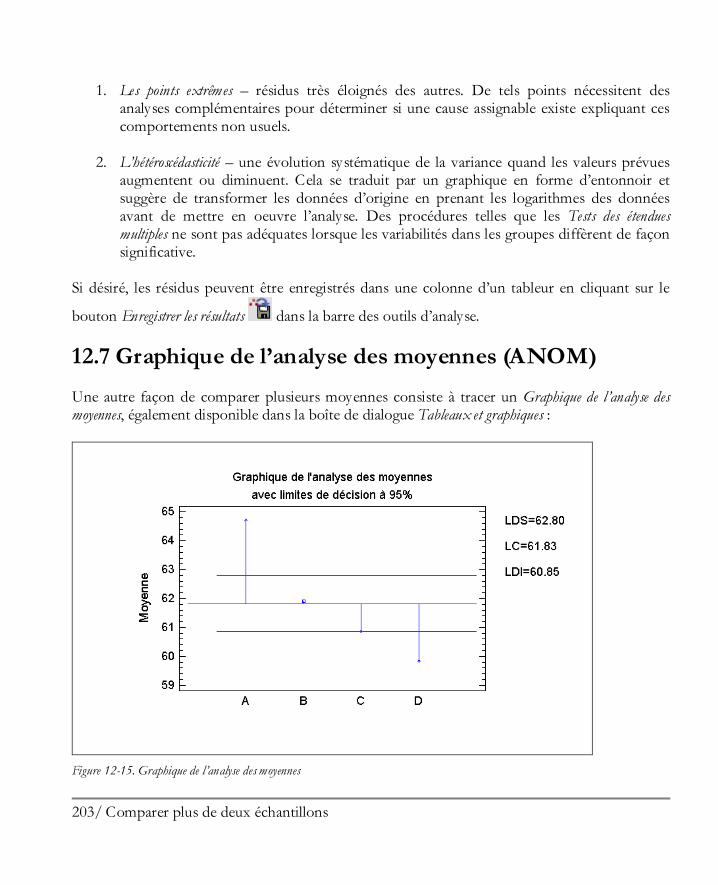
203/ Comparer plus de deux échantillons
1. Les points extrêmes – résidus très éloignés des autres. De tels points nécessitent des analyses complémentaires pour déterminer si une cause assignable existe expliquant ces comportements non usuels.
2. L’hétéroscédasticité – une évolution systématique de la variance quand les valeurs prévues
augmentent ou diminuent. Cela se traduit par un graphique en forme d’entonnoir et suggère de transformer les données d’origine en prenant les logarithmes des données avant de mettre en oeuvre l’analyse. Des procédures telles que les Tests des étendues multiples ne sont pas adéquates lorsque les variabilités dans les groupes diffèrent de façon significative.
Si désiré, les résidus peuvent être enregistrés dans une colonne d’un tableur en cliquant sur le
bouton Enregistrer les résultats dans la barre des outils d’analyse.
12.7 Graphique de l’analyse des moyennes (ANOM) Une autre façon de comparer plusieurs moyennes consiste à tracer un Graphique de l’analyse des moyennes, également disponible dans la boîte de dialogue Tableaux et graphiques :
Figure 12-15. Graphique de l’analyse des moyennes

204/ Comparer plus de deux échantillons
Conçu pour être similaire à une carte de contrôle, ce graphique affiche les moyennes des échantillons avec une ligne verticale tracée à la moyenne générale des observations. Des limites de décision sont ajoutées au-dessus et au-dessous de la moyenne générale. Toute moyenne d’un échantillon qui est en dehors de ces limites peut être déclarée significativement différente de la moyenne générale. Dans notre cas, l’interprétation est que les pièces de l’échantillon A sont significativement plus solides que la moyenne, alors que les pièces des échantillons C et D sont significativement moins solides que la moyenne. Ce type d’interprétation peut parfois être très utile.

205/ Méthodes de régression
Didacticiel n° 4 : Méthodes de
régression
Ajuster des modèles de régression linéaire et non linéaire, sélectionner le meilleur modèle, faire un graphique des résidus et afficher les résultats.
Une des parties les plus utilisées de STATGRAPHICS Centurion XVI est celle relative à la modélisation statistique par méthodes de régression. Dans un modèle de régression, une variable de réponse Y est exprimée comme une fonction d’une ou de plusieurs variables prédictrices X plus un bruit. Dans beaucoup de cas, mais pas tous, la forme de la fonction est linéaire par rapport aux coefficients inconnus, si bien que le modèle peut être exprimé sous la forme :
Yi = 0 + 1X1,i + 2x2,i + 3X3,i + … + kXk,i + i
où l’indice i représente la i-ème observation dans l’échantillon des données, les sont les
coefficients inconnus du modèle et est un écart aléatoire habituellement supposé suivre une loi
normale de moyenne 0 et d’écart-type . A partir d’un jeu de données contenant une variable de réponse Y et une ou plusieurs variables prédictrices, le but de l’analyse de régression est de construire un modèle qui :
1. Décrit la relation entre les variables de façon à permettre de bien prévoir Y à partir de valeurs connues des X.
2. Ne contient pas plus de variables X que nécessaire pour obtenir une bonne prévision.
Chapitre
13
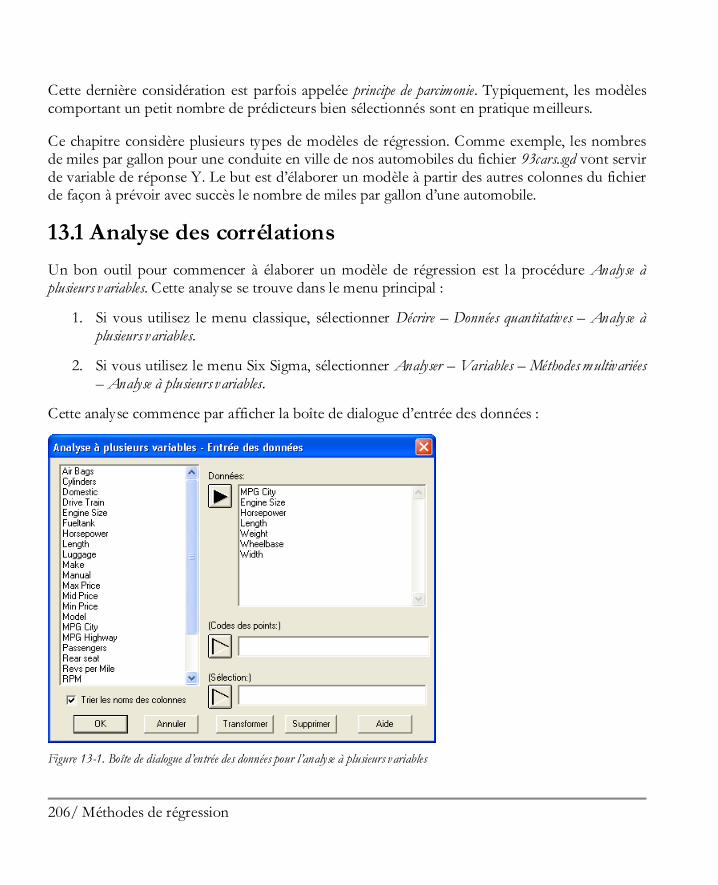
206/ Méthodes de régression
Cette dernière considération est parfois appelée principe de parcimonie. Typiquement, les modèles comportant un petit nombre de prédicteurs bien sélectionnés sont en pratique meilleurs.
Ce chapitre considère plusieurs types de modèles de régression. Comme exemple, les nombres de miles par gallon pour une conduite en ville de nos automobiles du fichier 93cars.sgd vont servir de variable de réponse Y. Le but est d’élaborer un modèle à partir des autres colonnes du fichier de façon à prévoir avec succès le nombre de miles par gallon d’une automobile.
13.1 Analyse des corrélations
Un bon outil pour commencer à élaborer un modèle de régression est la procédure Analyse à plusieurs variables. Cette analyse se trouve dans le menu principal :
1. Si vous utilisez le menu classique, sélectionner Décrire – Données quantitatives – Analyse à plusieurs variables.
2. Si vous utilisez le menu Six Sigma, sélectionner Analyser – Variables – Méthodes multivariées – Analyse à plusieurs variables.
Cette analyse commence par afficher la boîte de dialogue d’entrée des données :
Figure 13-1. Boîte de dialogue d’entrée des données pour l’analyse à plusieurs variables
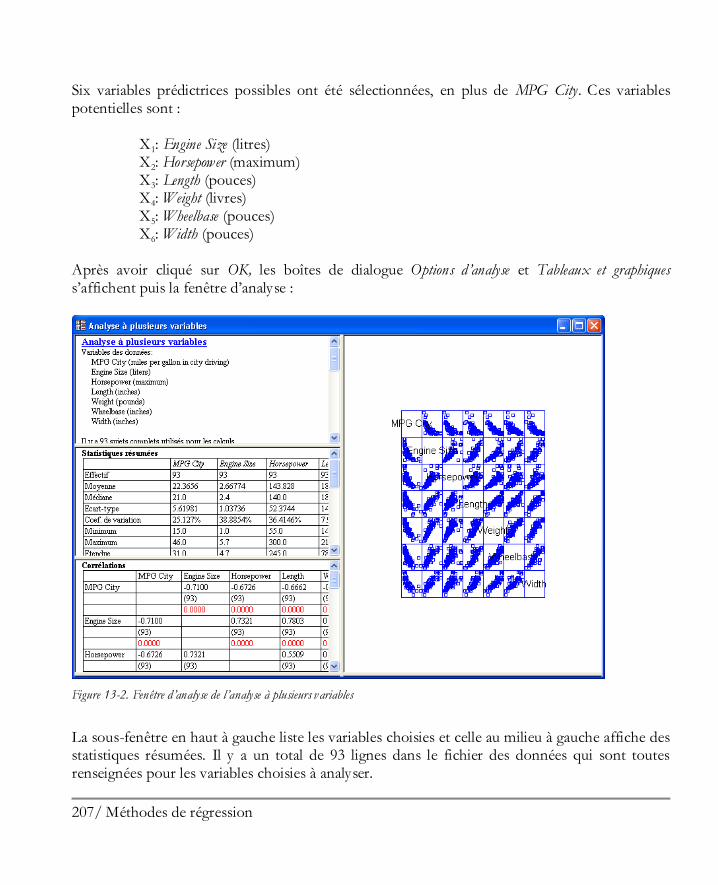
207/ Méthodes de régression
Six variables prédictrices possibles ont été sélectionnées, en plus de MPG City. Ces variables potentielles sont :
X1: Engine Size (litres) X2: Horsepower (maximum) X3: Length (pouces) X4: Weight (livres) X5: Wheelbase (pouces) X6: Width (pouces)
Après avoir cliqué sur OK, les boîtes de dialogue Options d’analyse et Tableaux et graphiques s’affichent puis la fenêtre d’analyse :
Figure 13-2. Fenêtre d’analyse de l’analyse à plusieurs variables
La sous-fenêtre en haut à gauche liste les variables choisies et celle au milieu à gauche affiche des statistiques résumées. Il y a un total de 93 lignes dans le fichier des données qui sont toutes renseignées pour les variables choisies à analyser.

208/ Méthodes de régression
La matrice de nuages de points à droite affiche des graphiques X-Y pour chaque paire de variables :
Figure 13-3. Matrice de nuages de points avec ajout d’un lissage
Pour interpréter ce graphique, choisir une variable, par exemple MPG City. La variable choisie est affichée sur l’axe vertical de chaque graphique de cette ligne et sur l’axe horizontal de chaque graphique de cette colonne. Chaque paire de variables est donc affichée deux fois, une fois au-dessus de la diagonale et une fois au-dessous de la diagonale. Des lisseurs robustes LOWESS ont été ajoutés dans la figure ci-dessus en maximisant la sous-fenêtre et en sélectionnant le bouton Lissage/Rotation dans la barre des outils d’analyse. La première ligne est particulièrement intéressante. Elle affiche MPG City par rapport à chacune des 6 variables prédictrices potentielles. Toutes les variables sont clairement corrélées avec les nombres de miles par gallon, quelques-unes de façon non linéaire. Il y a également une importante multicolinéarité entre les variables (corrélation entre les variables prédictrices), ce qui laisse présager que de nombreuses différentes combinaisons des variables peuvent être intéressantes pour prévoir Y.
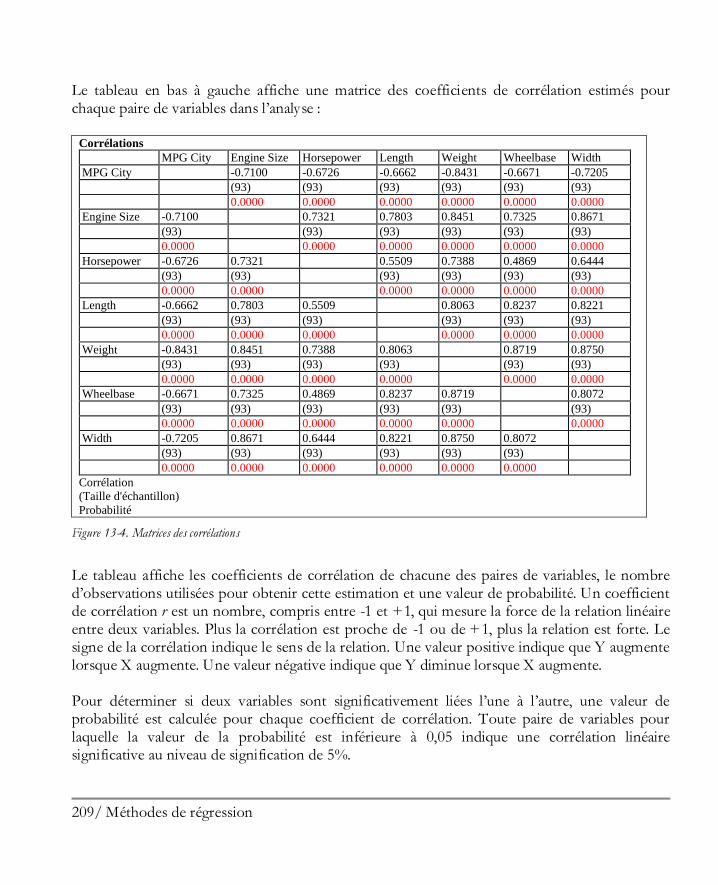
209/ Méthodes de régression
Le tableau en bas à gauche affiche une matrice des coefficients de corrélation estimés pour chaque paire de variables dans l’analyse :
Corrélations
MPG City Engine Size Horsepower Length Weight Wheelbase Width
MPG City -0.7100 -0.6726 -0.6662 -0.8431 -0.6671 -0.7205
(93) (93) (93) (93) (93) (93)
0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
Engine Size -0.7100 0.7321 0.7803 0.8451 0.7325 0.8671
(93) (93) (93) (93) (93) (93)
0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
Horsepower -0.6726 0.7321 0.5509 0.7388 0.4869 0.6444
(93) (93) (93) (93) (93) (93)
0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
Length -0.6662 0.7803 0.5509 0.8063 0.8237 0.8221
(93) (93) (93) (93) (93) (93)
0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
Weight -0.8431 0.8451 0.7388 0.8063 0.8719 0.8750
(93) (93) (93) (93) (93) (93)
0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
Wheelbase -0.6671 0.7325 0.4869 0.8237 0.8719 0.8072
(93) (93) (93) (93) (93) (93)
0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
Width -0.7205 0.8671 0.6444 0.8221 0.8750 0.8072
(93) (93) (93) (93) (93) (93)
0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
Corrélation
(Taille d'échantillon)
Probabilité
Figure 13-4. Matrices des corrélations
Le tableau affiche les coefficients de corrélation de chacune des paires de variables, le nombre d’observations utilisées pour obtenir cette estimation et une valeur de probabilité. Un coefficient de corrélation r est un nombre, compris entre -1 et +1, qui mesure la force de la relation linéaire entre deux variables. Plus la corrélation est proche de -1 ou de +1, plus la relation est forte. Le signe de la corrélation indique le sens de la relation. Une valeur positive indique que Y augmente lorsque X augmente. Une valeur négative indique que Y diminue lorsque X augmente. Pour déterminer si deux variables sont significativement liées l’une à l’autre, une valeur de probabilité est calculée pour chaque coefficient de corrélation. Toute paire de variables pour laquelle la valeur de la probabilité est inférieure à 0,05 indique une corrélation linéaire significative au niveau de signification de 5%.
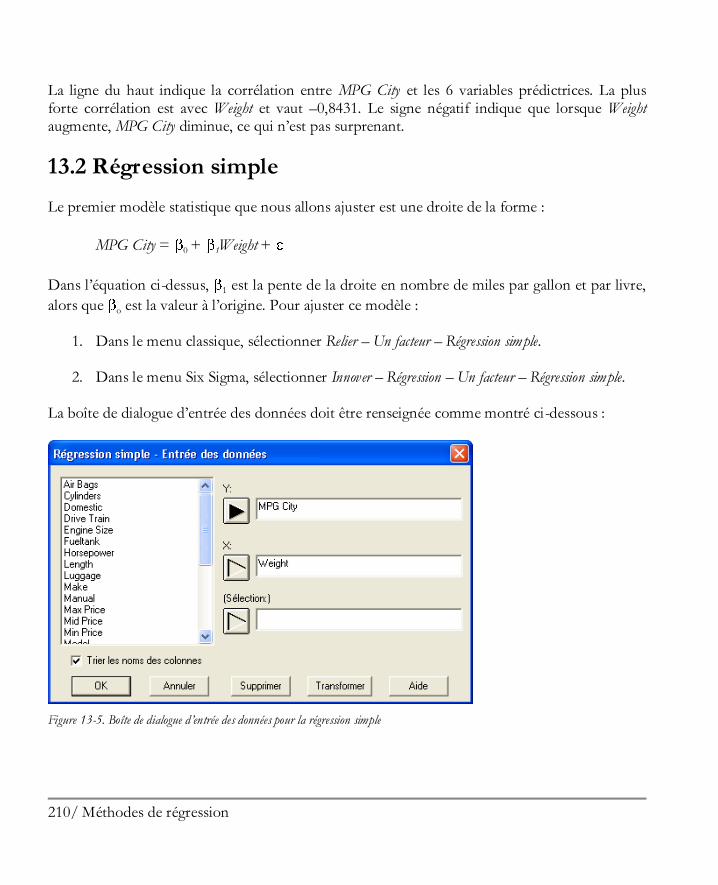
210/ Méthodes de régression
La ligne du haut indique la corrélation entre MPG City et les 6 variables prédictrices. La plus forte corrélation est avec Weight et vaut –0,8431. Le signe négatif indique que lorsque Weight augmente, MPG City diminue, ce qui n’est pas surprenant.
13.2 Régression simple Le premier modèle statistique que nous allons ajuster est une droite de la forme :
MPG City = 0 + 1Weight +
Dans l’équation ci-dessus, 1 est la pente de la droite en nombre de miles par gallon et par livre,
alors que o est la valeur à l’origine. Pour ajuster ce modèle :
1. Dans le menu classique, sélectionner Relier – Un facteur – Régression simple.
2. Dans le menu Six Sigma, sélectionner Innover – Régression – Un facteur – Régression simple. La boîte de dialogue d’entrée des données doit être renseignée comme montré ci-dessous :
Figure 13-5. Boîte de dialogue d’entrée des données pour la régression simple
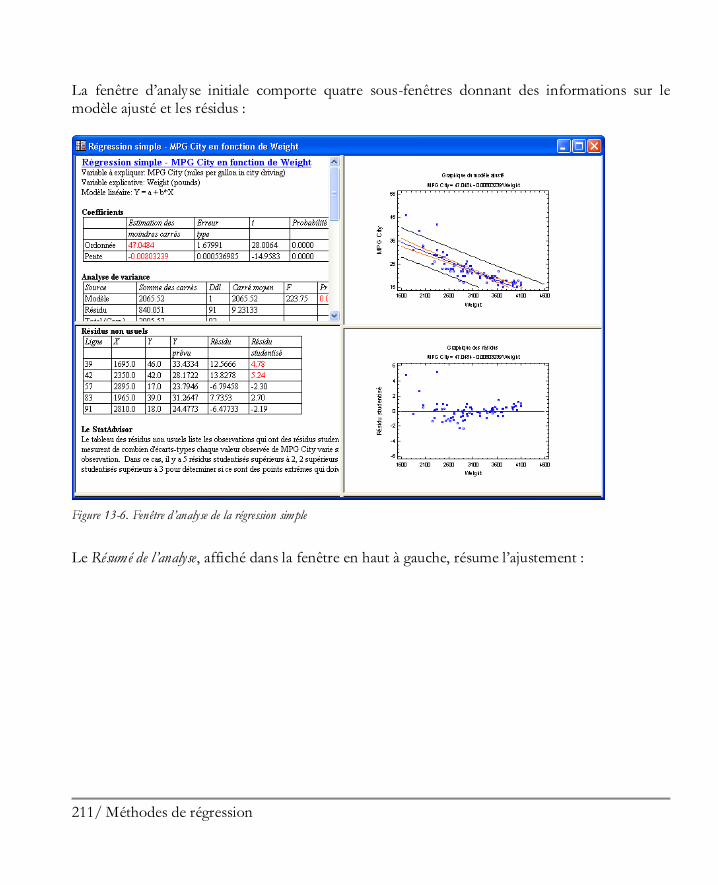
211/ Méthodes de régression
La fenêtre d’analyse initiale comporte quatre sous-fenêtres donnant des informations sur le modèle ajusté et les résidus :
Figure 13-6. Fenêtre d’analyse de la régression simple
Le Résumé de l’analyse, affiché dans la fenêtre en haut à gauche, résume l’ajustement :

212/ Méthodes de régression
Régression simple - MPG City en fonction de Weight Variable à expliquer: MPG City (miles per gallon in city driving)
Variable explicative: Weight (pounds)
Modèle linéaire: Y = a + b*X
Coefficients
Estimation des Erreur t Probabilité
moindres carrés type
Ordonnée 47.0484 1.67991 28.0064 0.0000
Pente -0.00803239 0.000536985 -14.9583 0.0000
Analyse de variance
Source Somme des carrés Ddl Carré moyen F Probabilité
Modèle 2065.52 1 2065.52 223.75 0.0000
Résidu 840.051 91 9.23133
Total (Corr.) 2905.57 92
Coefficient de corrélation = -0.843139
R-carré = 71.0883 %
R-carré (ajusté pour les ddl) = 70.7705 %
Estimation de l'écart-type du résidu = 3.03831
Erreur absolue moyenne = 1.99274
Test de Durbin-Watson = 1.64586 (P=0.0405)
Autocorrélation résiduelle d'ordre 1 = 0.176433
Figure 13-7. Résumé de l’analyse de régression simple
Parmi les nombreuses statistiques dans ce tableau, les statistiques suivantes sont les plus importantes :
1. Coefficients : les coefficients estimés du modèle. Le modèle ajusté qui peut être utilisé pour faire des prévisions est :
MPG City = 47,0484 – 0,00803239Weight
2. R-carré : le pourcentage de la variabilité de Y qui a été expliquée par le modèle. Dans
notre cas, une régression linéaire par rapport à Weight explique environ 71,1% de la variabilité de MPG City.
3. Valeur de la probabilité : teste l’hypothèse nulle que le modèle ajusté n’est pas meilleur
qu’un modèle n’incluant pas Weight. Une valeur de probabilité inférieure à 0,05, comme dans cet exemple, indique que Weight est une variable prédictrice utile pour MPG City.
Le graphique en haut à droite de la fenêtre d’analyse affiche le modèle ajusté :
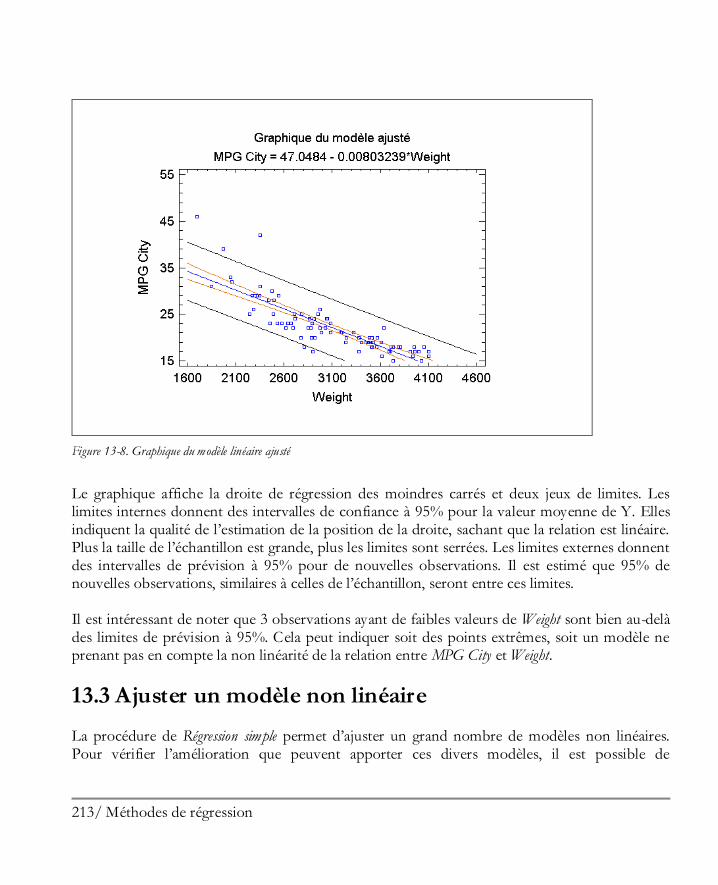
213/ Méthodes de régression
Figure 13-8. Graphique du modèle linéaire ajusté
Le graphique affiche la droite de régression des moindres carrés et deux jeux de limites. Les limites internes donnent des intervalles de confiance à 95% pour la valeur moyenne de Y. Elles indiquent la qualité de l’estimation de la position de la droite, sachant que la relation est linéaire. Plus la taille de l’échantillon est grande, plus les limites sont serrées. Les limites externes donnent des intervalles de prévision à 95% pour de nouvelles observations. Il est estimé que 95% de nouvelles observations, similaires à celles de l’échantillon, seront entre ces limites. Il est intéressant de noter que 3 observations ayant de faibles valeurs de Weight sont bien au-delà des limites de prévision à 95%. Cela peut indiquer soit des points extrêmes, soit un modèle ne prenant pas en compte la non linéarité de la relation entre MPG City et Weight.
13.3 Ajuster un modèle non linéaire La procédure de Régression simple permet d’ajuster un grand nombre de modèles non linéaires. Pour vérifier l’amélioration que peuvent apporter ces divers modèles, il est possible de
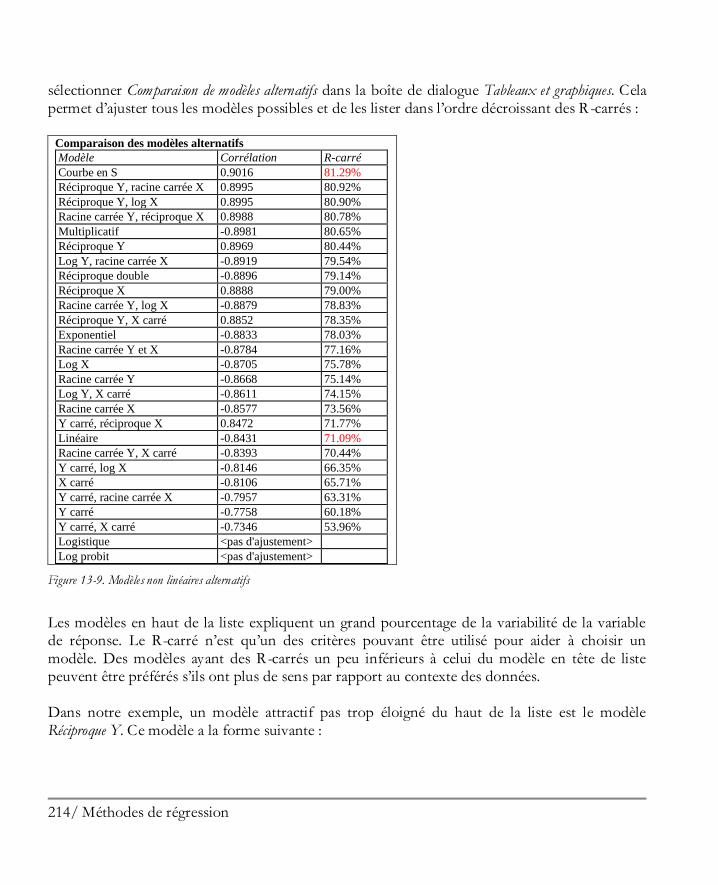
214/ Méthodes de régression
sélectionner Comparaison de modèles alternatifs dans la boîte de dialogue Tableaux et graphiques. Cela permet d’ajuster tous les modèles possibles et de les lister dans l’ordre décroissant des R -carrés :
Comparaison des modèles alternatifs
Modèle Corrélation R-carré
Courbe en S 0.9016 81.29%
Réciproque Y, racine carrée X 0.8995 80.92%
Réciproque Y, log X 0.8995 80.90%
Racine carrée Y, réciproque X 0.8988 80.78%
Multiplicatif -0.8981 80.65%
Réciproque Y 0.8969 80.44%
Log Y, racine carrée X -0.8919 79.54%
Réciproque double -0.8896 79.14%
Réciproque X 0.8888 79.00%
Racine carrée Y, log X -0.8879 78.83%
Réciproque Y, X carré 0.8852 78.35%
Exponentiel -0.8833 78.03%
Racine carrée Y et X -0.8784 77.16%
Log X -0.8705 75.78%
Racine carrée Y -0.8668 75.14%
Log Y, X carré -0.8611 74.15%
Racine carrée X -0.8577 73.56%
Y carré, réciproque X 0.8472 71.77%
Linéaire -0.8431 71.09%
Racine carrée Y, X carré -0.8393 70.44%
Y carré, log X -0.8146 66.35%
X carré -0.8106 65.71%
Y carré, racine carrée X -0.7957 63.31%
Y carré -0.7758 60.18%
Y carré, X carré -0.7346 53.96%
Logistique <pas d'ajustement>
Log probit <pas d'ajustement>
Figure 13-9. Modèles non linéaires alternatifs
Les modèles en haut de la liste expliquent un grand pourcentage de la variabilité de la variable de réponse. Le R-carré n’est qu’un des critères pouvant être utilisé pour aider à choisir un modèle. Des modèles ayant des R-carrés un peu inférieurs à celui du modèle en tête de liste peuvent être préférés s’ils ont plus de sens par rapport au contexte des données. Dans notre exemple, un modèle attractif pas trop éloigné du haut de la liste est le modèle Réciproque Y. Ce modèle a la forme suivante :
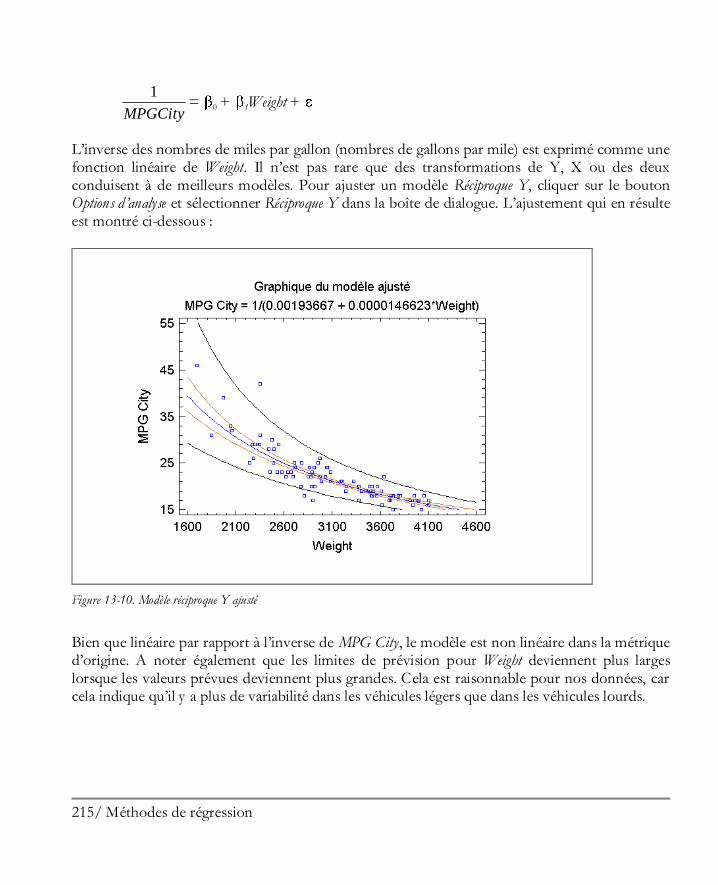
215/ Méthodes de régression
CityMPG
1= 0 + 1Weight +
L’inverse des nombres de miles par gallon (nombres de gallons par mile) est exprimé comme une fonction linéaire de Weight. Il n’est pas rare que des transformations de Y, X ou des deux conduisent à de meilleurs modèles. Pour ajuster un modèle Réciproque Y, cliquer sur le bouton Options d’analyse et sélectionner Réciproque Y dans la boîte de dialogue. L’ajustement qui en résulte est montré ci-dessous :
Figure 13-10. Modèle réciproque Y ajusté
Bien que linéaire par rapport à l’inverse de MPG City, le modèle est non linéaire dans la métrique d’origine. A noter également que les limites de prévision pour Weight deviennent plus larges lorsque les valeurs prévues deviennent plus grandes. Cela est raisonnable pour nos données, car cela indique qu’il y a plus de variabilité dans les véhicules légers que dans les véhicules lourds.
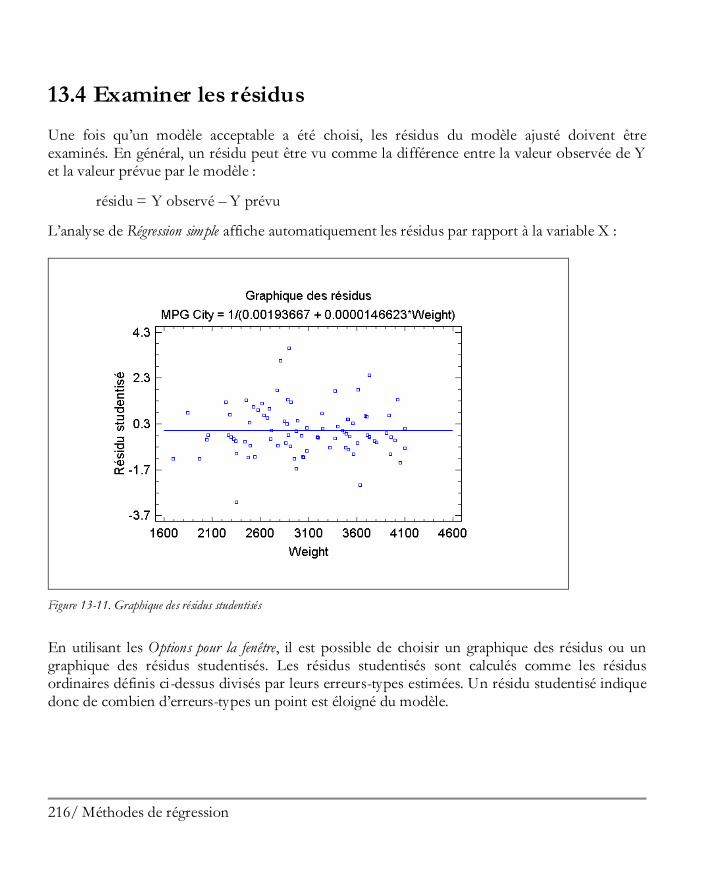
216/ Méthodes de régression
13.4 Examiner les résidus Une fois qu’un modèle acceptable a été choisi, les résidus du modèle ajusté doivent être examinés. En général, un résidu peut être vu comme la différence entre la valeur observée de Y et la valeur prévue par le modèle :
résidu = Y observé – Y prévu
L’analyse de Régression simple affiche automatiquement les résidus par rapport à la variable X :
Figure 13-11. Graphique des résidus studentisés
En utilisant les Options pour la fenêtre, il est possible de choisir un graphique des résidus ou un graphique des résidus studentisés. Les résidus studentisés sont calculés comme les résidus ordinaires définis ci-dessus divisés par leurs erreurs-types estimées. Un résidu studentisé indique donc de combien d’erreurs-types un point est éloigné du modèle.

217/ Méthodes de régression
STATGRAPHICS Centurion XVI calcule les résidus studentisés après suppression. Ces résidus sont calculés en retirant une observation à la fois, en réajustant le modèle et en déterminant de combien d’erreurs-types le point retiré est du nouveau modèle ajusté. Cela permet de diminuer l’impact d’un point extrême sur le modèle lorsque son résidu est calculé. L’option Résidus non usuels dans la boîte de dialogue Tableaux et graphiques affiche les résidus studentisés qui sont supérieurs à 2 en valeurs absolues :
Résidus non usuels
Ligne X Y Y Résidu Résidu
prévu studentisé
5 3640.0 22.0 18.0808 3.91924 -2.38
36 3735.0 15.0 17.6366 -2.63658 2.41
42 2350.0 42.0 27.4778 14.5222 -3.11
57 2895.0 17.0 22.5306 -5.53064 3.60
91 2810.0 18.0 23.1816 -5.18157 3.04
Figure 13-12. Tableau des résidus non usuels
Les résidus studentisés supérieurs à 3, comme par exemple celui de la ligne n° 57, sont de potentiels points extrêmes qui semblent ne pas appartenir au reste des données. La ligne n° 57 correspond au véhicule Mazda RX-7 qui ne fait que 17 miles par gallon pour une conduite en ville alors que le modèle en prévoit 22,5. Comme le prochain paragraphe ajoute des variables supplémentaires au modèle qui peuvent améliorer sa capacité de prévision pour des telles voitures sportives, la ligne n° 57 ne sera pas exclue de l’ajustement même si elle demande une attention particulière.
13.5 Régression multiple Pour améliorer le modèle, d’autres variables prédictrices doivent être ajoutées. Cela peut être fait aisément par l’analyse de Régression multiple qui se trouve dans le menu principal sous :
1. Pour le menu classique, sélectionner Relier – Plusieurs facteurs – Régression multiple.
2. Pour le menu Six Sigma, sélectionner Innover – Régression –Plusieurs facteurs – Régression multiple.
Voici la boîte de dialogue d’entrée des données de cette analyse :
218/ Méthodes de régression
Figure 13-13. Boîte de dialogue d’entrée des données pour la régression multiple
Pour débuter, les 6 variables prédictrices considérées dans la procédure Analyse à plusieurs variables discutée précédemment sont entrées dans le modèle comme variables explicatives. La variable à expliquer est l’inverse de MPG City, c’est-à-dire le nombre de gallons par mile. La boîte de dialogue des Options d’analyse s’affiche alors puis celle des Tableaux et graphiques. Le résumé de cette analyse est affiché ci-dessous :
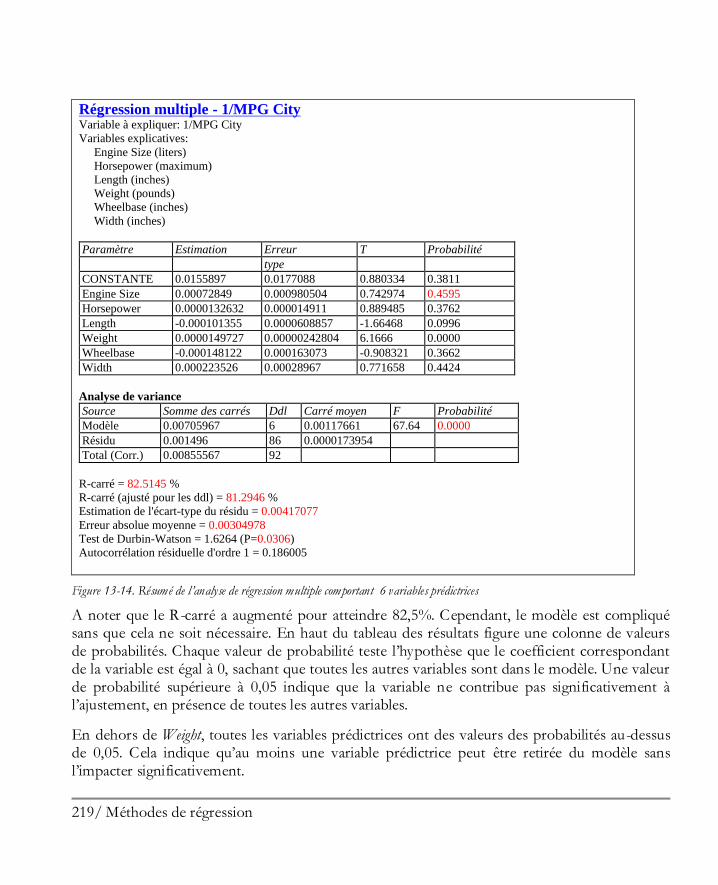
219/ Méthodes de régression
Régression multiple - 1/MPG City Variable à expliquer: 1/MPG City
Variables explicatives:
Engine Size (liters)
Horsepower (maximum)
Length (inches)
Weight (pounds)
Wheelbase (inches)
Width (inches)
Paramètre Estimation Erreur T Probabilité
type
CONSTANTE 0.0155897 0.0177088 0.880334 0.3811
Engine Size 0.00072849 0.000980504 0.742974 0.4595
Horsepower 0.0000132632 0.000014911 0.889485 0.3762
Length -0.000101355 0.0000608857 -1.66468 0.0996
Weight 0.0000149727 0.00000242804 6.1666 0.0000
Wheelbase -0.000148122 0.000163073 -0.908321 0.3662
Width 0.000223526 0.00028967 0.771658 0.4424
Analyse de variance
Source Somme des carrés Ddl Carré moyen F Probabilité
Modèle 0.00705967 6 0.00117661 67.64 0.0000
Résidu 0.001496 86 0.0000173954
Total (Corr.) 0.00855567 92
R-carré = 82.5145 %
R-carré (ajusté pour les ddl) = 81.2946 %
Estimation de l'écart-type du résidu = 0.00417077
Erreur absolue moyenne = 0.00304978
Test de Durbin-Watson = 1.6264 (P=0.0306)
Autocorrélation résiduelle d'ordre 1 = 0.186005
Figure 13-14. Résumé de l’analyse de régression multiple comportant 6 variables prédictrices
A noter que le R-carré a augmenté pour atteindre 82,5%. Cependant, le modèle est compliqué sans que cela ne soit nécessaire. En haut du tableau des résultats figure une colonne de valeurs de probabilités. Chaque valeur de probabilité teste l’hypothèse que le coefficient correspondant de la variable est égal à 0, sachant que toutes les autres variables sont dans le modèle. Une valeur de probabilité supérieure à 0,05 indique que la variable ne contribue pas significativement à l’ajustement, en présence de toutes les autres variables.
En dehors de Weight, toutes les variables prédictrices ont des valeurs des probabilités au-dessus de 0,05. Cela indique qu’au moins une variable prédictrice peut être retirée du modèle sans l’impacter significativement.
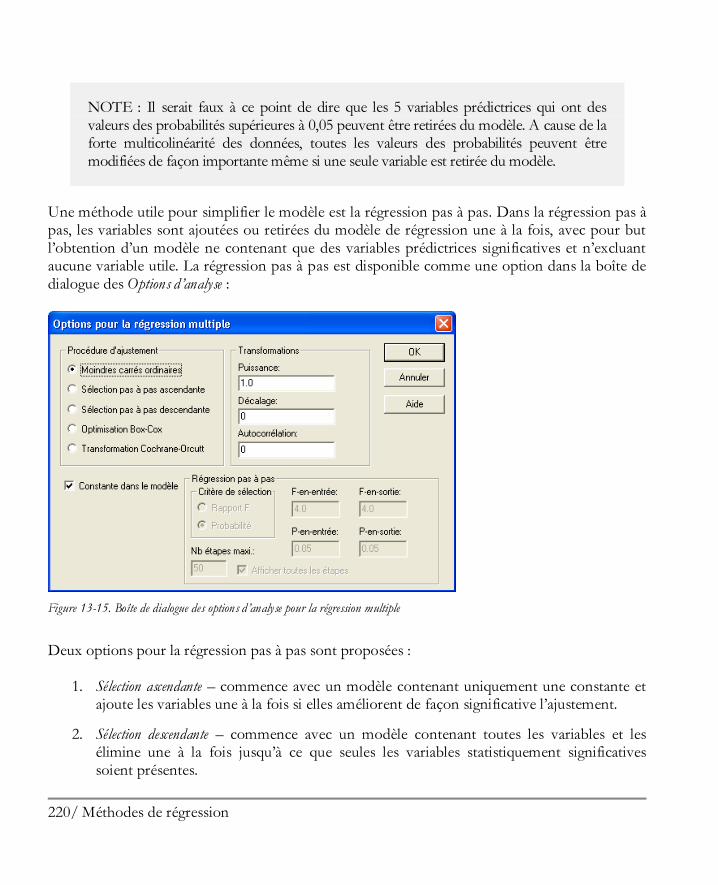
220/ Méthodes de régression
NOTE : Il serait faux à ce point de dire que les 5 variables prédictrices qui ont des valeurs des probabilités supérieures à 0,05 peuvent être retirées du modèle. A cause de la forte multicolinéarité des données, toutes les valeurs des probabilités peuvent être modifiées de façon importante même si une seule variable est retirée du modèle.
Une méthode utile pour simplifier le modèle est la régression pas à pas. Dans la régression pas à pas, les variables sont ajoutées ou retirées du modèle de régression une à la fois, avec pour but l’obtention d’un modèle ne contenant que des variables prédictrices significatives et n’excluant aucune variable utile. La régression pas à pas est disponible comme une option dans la boîte de dialogue des Options d’analyse :
Figure 13-15. Boîte de dialogue des options d’analyse pour la régression multiple
Deux options pour la régression pas à pas sont proposées :
1. Sélection ascendante – commence avec un modèle contenant uniquement une constante et ajoute les variables une à la fois si elles améliorent de façon significative l’ajustement.
2. Sélection descendante – commence avec un modèle contenant toutes les variables et les élimine une à la fois jusqu’à ce que seules les variables statistiquement significatives soient présentes.
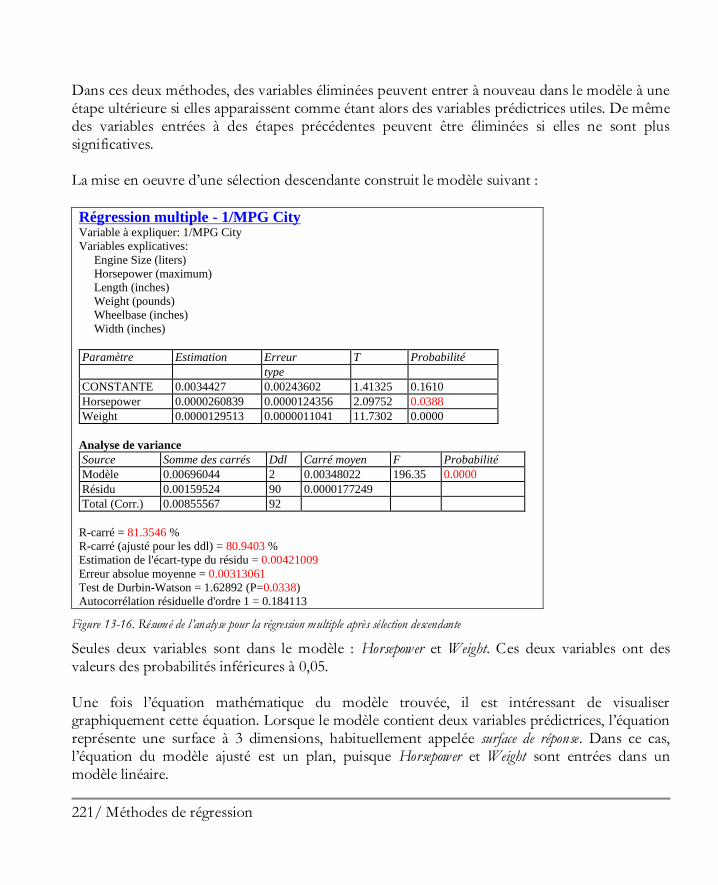
221/ Méthodes de régression
Dans ces deux méthodes, des variables éliminées peuvent entrer à nouveau dans le modèle à une étape ultérieure si elles apparaissent comme étant alors des variables prédictrices utiles. De même des variables entrées à des étapes précédentes peuvent être éliminées si elles ne sont plus significatives. La mise en oeuvre d’une sélection descendante construit le modèle suivant :
Régression multiple - 1/MPG City Variable à expliquer: 1/MPG City
Variables explicatives:
Engine Size (liters)
Horsepower (maximum)
Length (inches)
Weight (pounds)
Wheelbase (inches)
Width (inches)
Paramètre Estimation Erreur T Probabilité
type
CONSTANTE 0.0034427 0.00243602 1.41325 0.1610
Horsepower 0.0000260839 0.0000124356 2.09752 0.0388
Weight 0.0000129513 0.0000011041 11.7302 0.0000
Analyse de variance
Source Somme des carrés Ddl Carré moyen F Probabilité
Modèle 0.00696044 2 0.00348022 196.35 0.0000
Résidu 0.00159524 90 0.0000177249
Total (Corr.) 0.00855567 92
R-carré = 81.3546 %
R-carré (ajusté pour les ddl) = 80.9403 %
Estimation de l'écart-type du résidu = 0.00421009
Erreur absolue moyenne = 0.00313061
Test de Durbin-Watson = 1.62892 (P=0.0338)
Autocorrélation résiduelle d'ordre 1 = 0.184113
Figure 13-16. Résumé de l’analyse pour la régression multiple après sélection descendante
Seules deux variables sont dans le modèle : Horsepower et Weight. Ces deux variables ont des valeurs des probabilités inférieures à 0,05. Une fois l’équation mathématique du modèle trouvée, il est intéressant de visualiser graphiquement cette équation. Lorsque le modèle contient deux variables prédictrices, l’équation représente une surface à 3 dimensions, habituellement appelée surface de réponse. Dans ce cas, l’équation du modèle ajusté est un plan, puisque Horsepower et Weight sont entrées dans un modèle linéaire.
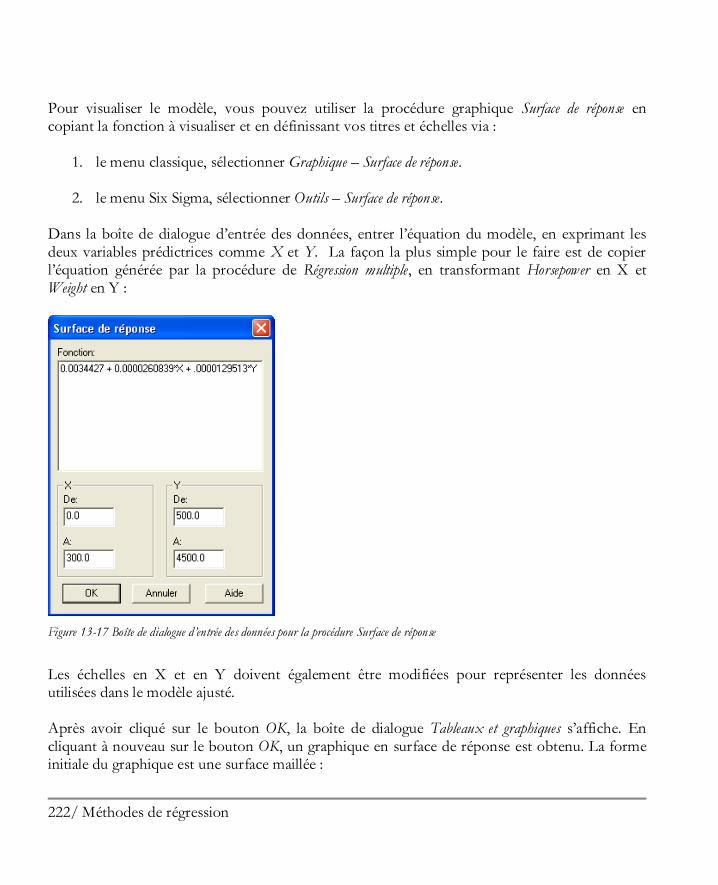
222/ Méthodes de régression
Pour visualiser le modèle, vous pouvez utiliser la procédure graphique Surface de réponse en copiant la fonction à visualiser et en définissant vos titres et échelles via :
1. le menu classique, sélectionner Graphique – Surface de réponse.
2. le menu Six Sigma, sélectionner Outils – Surface de réponse. Dans la boîte de dialogue d’entrée des données, entrer l’équation du modèle, en exprimant les deux variables prédictrices comme X et Y. La façon la plus simple pour le faire est de copier l’équation générée par la procédure de Régression multiple, en transformant Horsepower en X et Weight en Y :
Figure 13-17 Boîte de dialogue d’entrée des données pour la procédure Surface de réponse
Les échelles en X et en Y doivent également être modifiées pour représenter les données utilisées dans le modèle ajusté. Après avoir cliqué sur le bouton OK, la boîte de dialogue Tableaux et graphiques s’affiche. En cliquant à nouveau sur le bouton OK, un graphique en surface de réponse est obtenu. La forme initiale du graphique est une surface maillée :
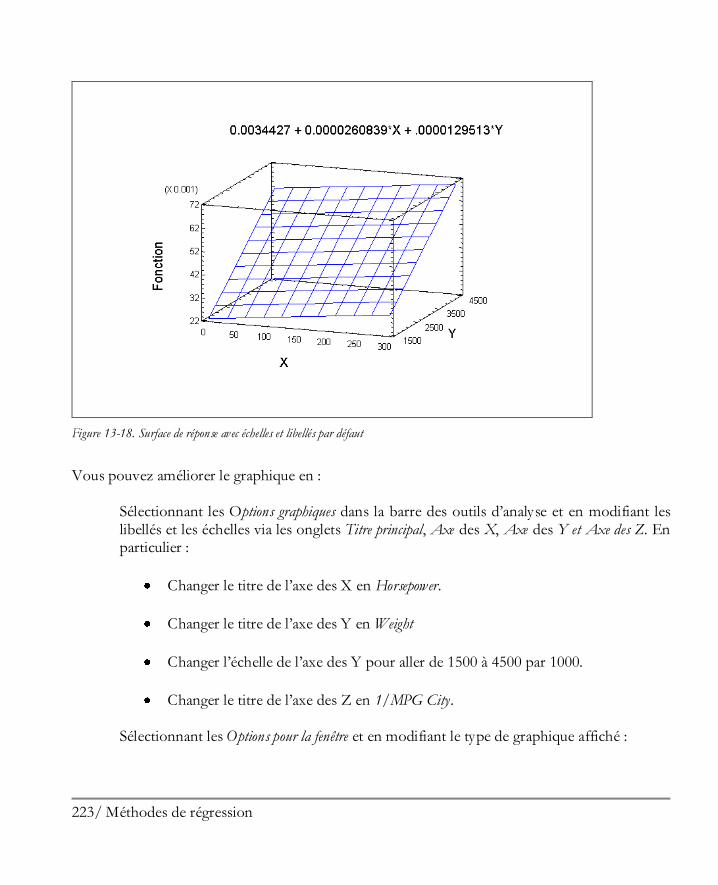
223/ Méthodes de régression
Figure 13-18. Surface de réponse avec échelles et libellés par défaut
Vous pouvez améliorer le graphique en :
Sélectionnant les Options graphiques dans la barre des outils d’analyse et en modifiant les libellés et les échelles via les onglets Titre principal, Axe des X, Axe des Y et Axe des Z. En particulier :
Changer le titre de l’axe des X en Horsepower.
Changer le titre de l’axe des Y en Weight
Changer l’échelle de l’axe des Y pour aller de 1500 à 4500 par 1000.
Changer le titre de l’axe des Z en 1/MPG City.
Sélectionnant les Options pour la fenêtre et en modifiant le type de graphique affiché :
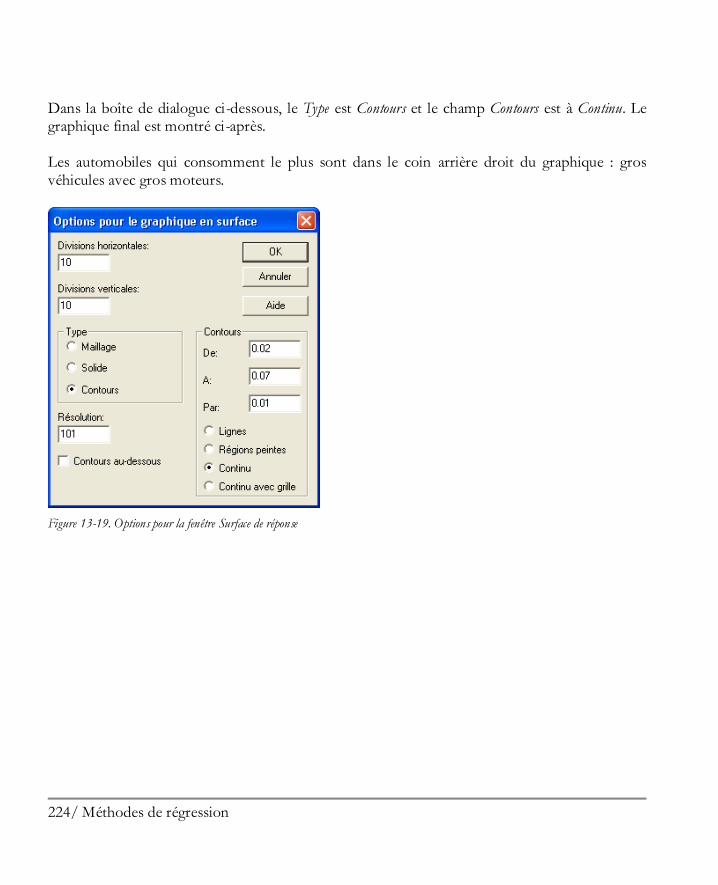
224/ Méthodes de régression
Dans la boîte de dialogue ci-dessous, le Type est Contours et le champ Contours est à Continu. Le graphique final est montré ci-après. Les automobiles qui consomment le plus sont dans le coin arrière droit du graphique : gros véhicules avec gros moteurs.
Figure 13-19. Options pour la fenêtre Surface de réponse
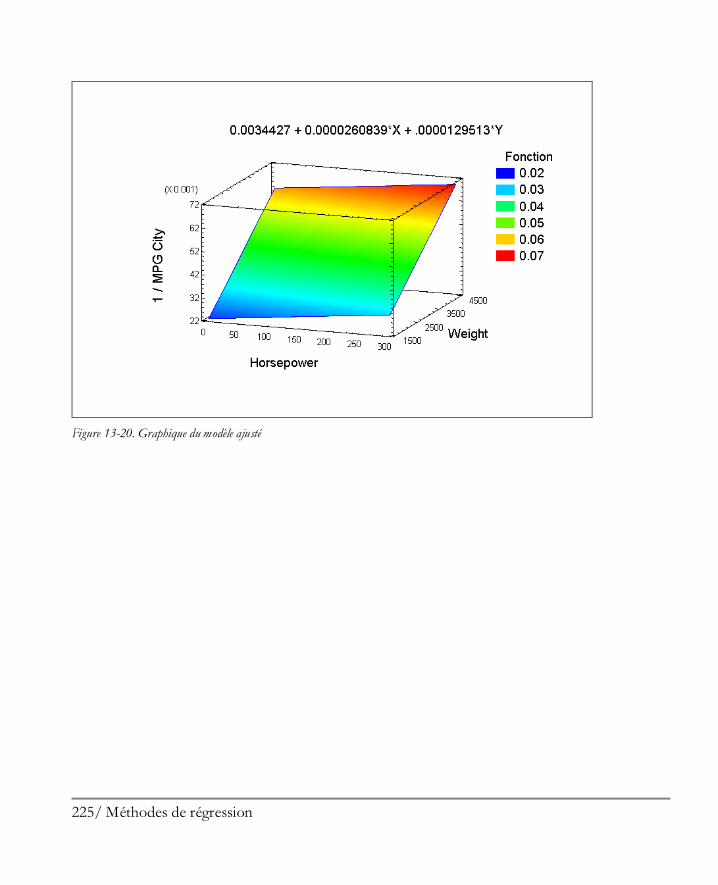
225/ Méthodes de régression
Figure 13-20. Graphique du modèle ajusté

226/ Méthodes de régression

227/ Analyse de données qualitatives
Didacticiel n° 5 : Analyse de
données qualitatives
Tri à plat, tableau de contingence et analyse de Pareto.
Chacun des quatre premiers didacticiels a utilisé des données quantitatives avec des observations représentées par des nombres mesurés sur des échelles continues. Ce didacticiel examine un jeu de données qualitatives, dans lequel chaque observation est une modalité ou catégorie d’une variable de type attribut, plutôt que des mesures. Comme exemple, considérons les données contenues dans le fichier defects.sgd. Une partie de ce fichier est montrée ci-dessous :
Defect Facility
Misaligned Virginia
Contaminated Texas
Contaminated Virginia
Contaminated Texas
Missing parts Texas
Misaligned Virginia
Contaminated Texas
Leaking Texas
Damaged Virginia
Contaminated Texas
Chapitre
14
228/ Analyse de données qualitatives
Les données sont constituées de n = 120 lignes, chacune correspondant à un défaut observé sur une pièce manufacturée. Le fichier indique également le type de défaut et l’usine qui a produit la pièce.
14.1 Résumer des données qualitatives En ignorant pour l’instant l’usine qui a fabriqué chaque pièce, les données des types de défauts peuvent être résumées :
1. En utilisant le menu classique, sélectionner Décrire – Données qualitatives – Tri à plat. 2. En utilisant le menu Six Sigma, sélectionner Analyser – Attributs – Un facteur – Tri à plat.
La boîte de dialogue d’entrée des données demande le nom de l’unique colonne contenant les données de type attribut :
Figure 14-1. Boîte de dialogue d’entrée des données pour le tri à plat
Cette procédure analyse la colonne et identifie chaque valeur unique. La boîte de dialogue Tableaux et graphiques s’affiche puis une fenêtre d’analyse similaire à celle montrée ci-après :

229/ Analyse de données qualitatives
Figure 14-2. Fenêtre d’analyse du tri à plat
La fenêtre en haut à gauche indique que 9 valeurs uniques ont été trouvées dans les n = 120 lignes. Le diagramme en bâtons et le diagramme circulaire à droite donnent les effectifs de chaque type de défaut, effectifs également affichés dans le tableau en bas à gauche. Le type de défaut le plus courant est « Contaminated », qui représente environ 44% de tous les défauts.
14.2 Analyse de Pareto La procédure de Tri à plat ordonne les types de défauts dans l’ordre alphabétique. Pour ordonner ces types du plus fréquent au moins fréquent, il faut utiliser l’Analyse de Pareto. Cette analyse se trouve :
1. Si vous utilisez le menu classique, sélectionner MSP – Evaluation de la qualité – Analyse de Pareto.
2. Si vous utilisez le menu Six Sigma, sélectionner Analyser – Attributs – Un facteur – Analyse de Pareto.
230/ Analyse de données qualitatives
La boîte de dialogue d’entrée des données doit être renseignée comme montré ci-dessous :
Figure 14-3. Boîte de dialogue d’entrée des données pour l’analyse de Pareto
L’Analyse de Pareto accepte des données sous deux formats :
1. Données non tabulées qui doivent être comptées, comme dans notre exemple.
2. Données tabulées, c’est-à-dire des comptages par type de défaut. Cela est applicable si vous avez deux colonnes, une identifiant les types des défauts et une contenant les nombres de fois où chaque défaut est apparu.
La fenêtre d’analyse affiche un tableau résumé et un diagramme de Pareto :

231/ Analyse de données qualitatives
Figure 14-4. Fenêtre de l’analyse de Pareto
Le diagramme de Pareto affiché à droite est particulièrement intéressant. Il affiche les effectifs de chaque type de défaut dans l’ordre du plus fréquent au moins fréquent. Initialement les libellés des barres se superposent à cause du nombre et de la longueur des libellés. Cela peut être corrigé en :
1. Double-cliquant dans le graphique pour maximiser la sous-fenêtre dans la fenêtre d’analyse.
2. Choisissant les Options graphiques dans la barre des outils d’analyse, en cliquant sur l’onglet Axe des X et en cochant la case Rotation des libellés.
3. Après avoir quitté la boîte de dialogue des Options graphiques, les libellés peuvent ne pas s’afficher complètement à l’écran. Si c’est le cas, vous pouvez les déplacer en cliquant et en maintenant le bouton de la souris appuyé, ou vous pouvez déplacer vers le haut l’axe des X pour réduire la taille de l’axe vertical.
Lorsque vous avez terminé, le diagramme de Pareto doit ressembler à celui montré ci-après :
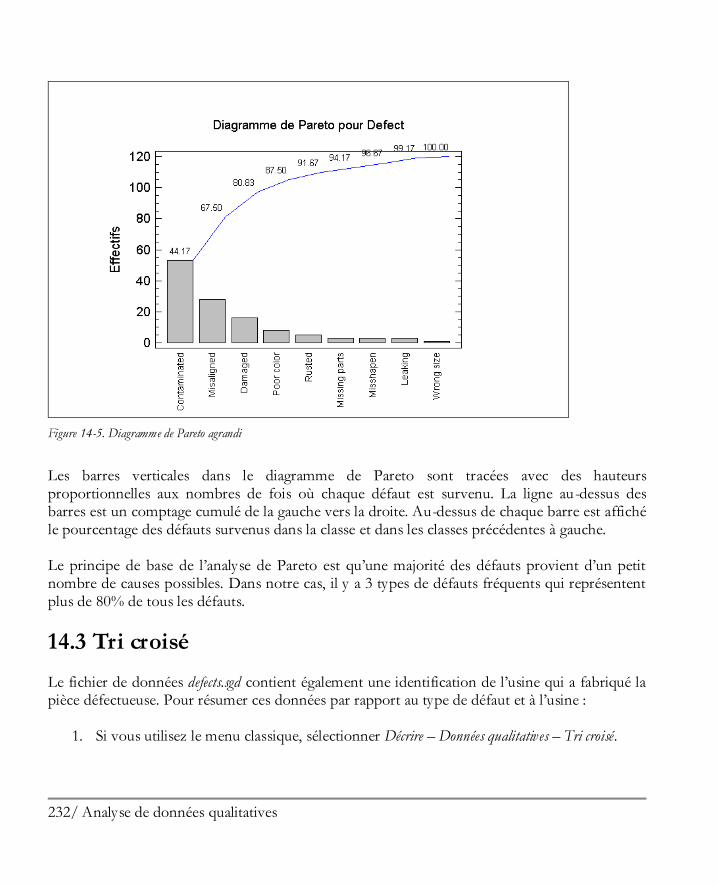
232/ Analyse de données qualitatives
Figure 14-5. Diagramme de Pareto agrandi
Les barres verticales dans le diagramme de Pareto sont tracées avec des hauteurs proportionnelles aux nombres de fois où chaque défaut est survenu. La ligne au-dessus des barres est un comptage cumulé de la gauche vers la droite. Au-dessus de chaque barre est affiché le pourcentage des défauts survenus dans la classe et dans les classes précédentes à gauche. Le principe de base de l’analyse de Pareto est qu’une majorité des défauts provient d’un petit nombre de causes possibles. Dans notre cas, il y a 3 types de défauts fréquents qui représentent plus de 80% de tous les défauts.
14.3 Tri croisé Le fichier de données defects.sgd contient également une identification de l’usine qui a fabriqué la pièce défectueuse. Pour résumer ces données par rapport au type de défaut et à l’usine :
1. Si vous utilisez le menu classique, sélectionner Décrire – Données qualitatives – Tri croisé.
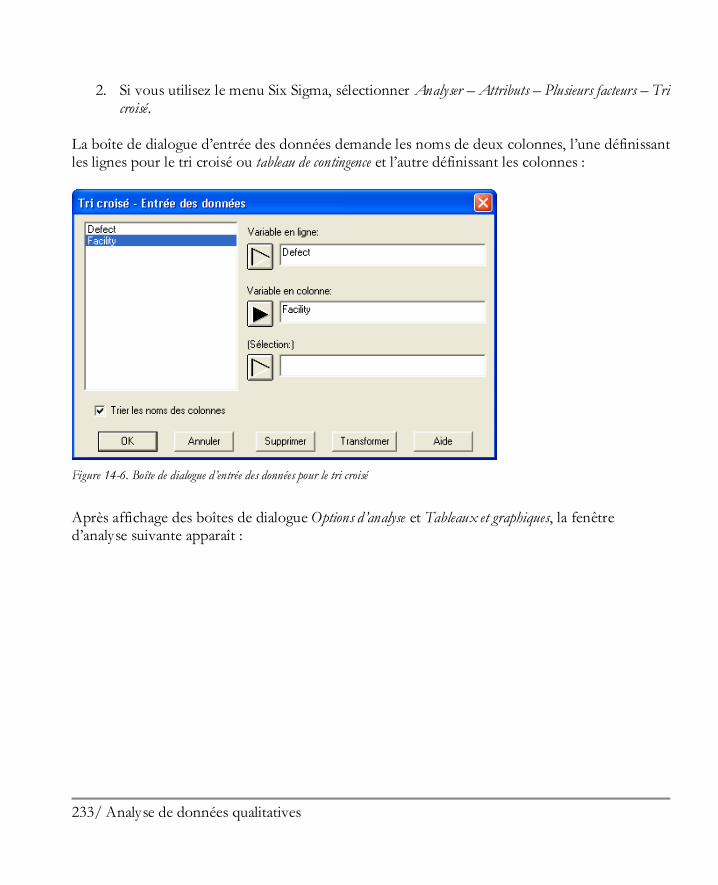
233/ Analyse de données qualitatives
2. Si vous utilisez le menu Six Sigma, sélectionner Analyser – Attributs – Plusieurs facteurs – Tri croisé.
La boîte de dialogue d’entrée des données demande les noms de deux colonnes, l’une définissant les lignes pour le tri croisé ou tableau de contingence et l’autre définissant les colonnes :
Figure 14-6. Boîte de dialogue d’entrée des données pour le tri croisé
Après affichage des boîtes de dialogue Options d’analyse et Tableaux et graphiques, la fenêtre d’analyse suivante apparaît :

234/ Analyse de données qualitatives
Figure 14-7. Fenêtre d’analyse du tri croisé
Le tableau en bas à gauche affiche les comptages par type de défaut et par usine :
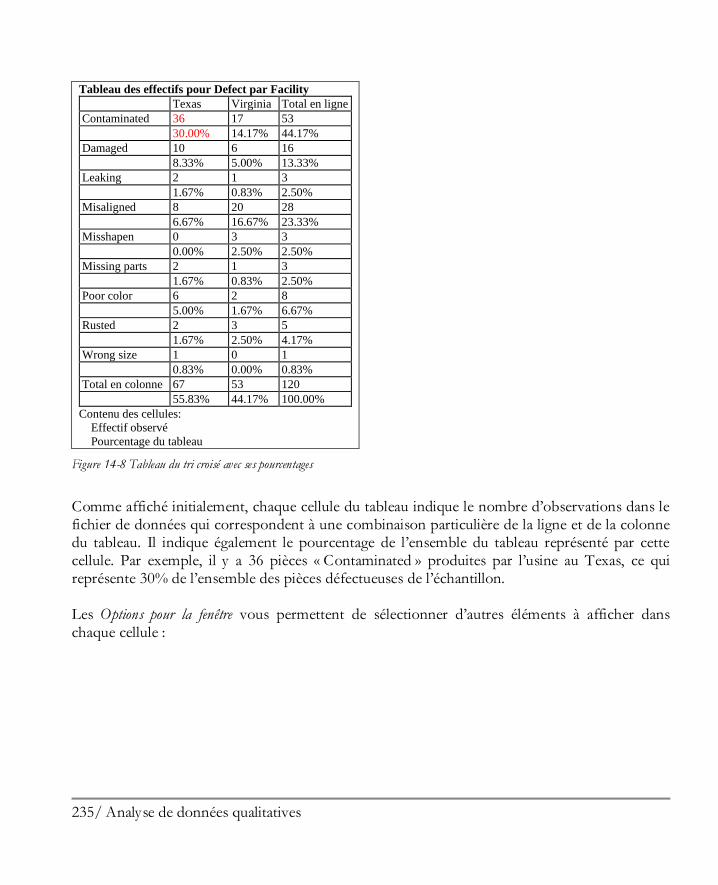
235/ Analyse de données qualitatives
Tableau des effectifs pour Defect par Facility
Texas Virginia Total en ligne
Contaminated 36 17 53
30.00% 14.17% 44.17%
Damaged 10 6 16
8.33% 5.00% 13.33%
Leaking 2 1 3
1.67% 0.83% 2.50%
Misaligned 8 20 28
6.67% 16.67% 23.33%
Misshapen 0 3 3
0.00% 2.50% 2.50%
Missing parts 2 1 3
1.67% 0.83% 2.50%
Poor color 6 2 8
5.00% 1.67% 6.67%
Rusted 2 3 5
1.67% 2.50% 4.17%
Wrong size 1 0 1
0.83% 0.00% 0.83%
Total en colonne 67 53 120
55.83% 44.17% 100.00%
Contenu des cellules:
Effectif observé
Pourcentage du tableau
Figure 14-8 Tableau du tri croisé avec ses pourcentages
Comme affiché initialement, chaque cellule du tableau indique le nombre d’observations dans le fichier de données qui correspondent à une combinaison particulière de la ligne et de la colonne du tableau. Il indique également le pourcentage de l’ensemble du tableau représenté par cette cellule. Par exemple, il y a 36 pièces « Contaminated » produites par l’usine au Texas, ce qui représente 30% de l’ensemble des pièces défectueuses de l’échantillon. Les Options pour la fenêtre vous permettent de sélectionner d’autres éléments à afficher dans chaque cellule :
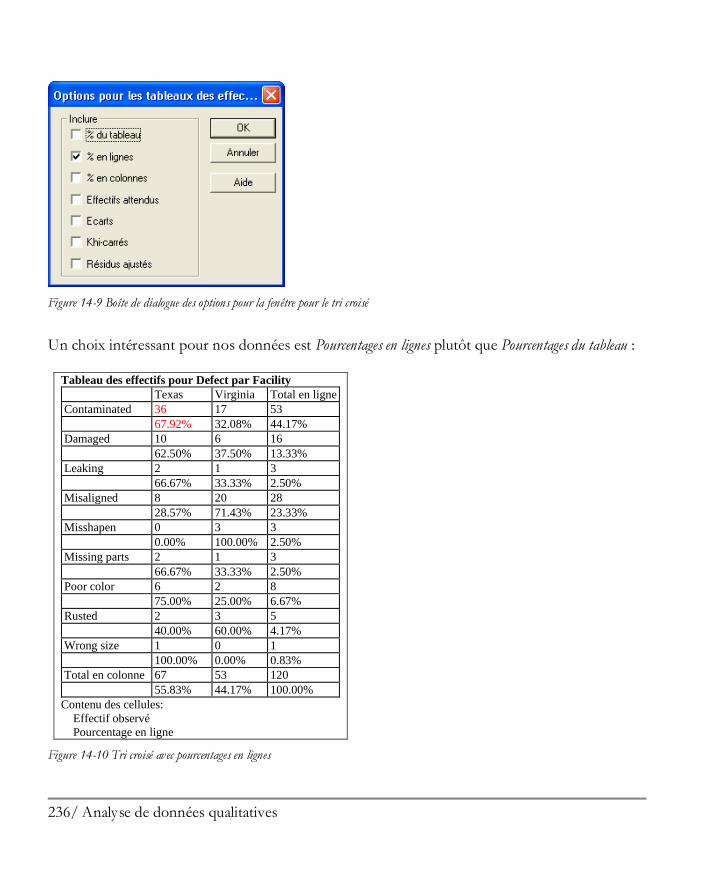
236/ Analyse de données qualitatives
Figure 14-9 Boîte de dialogue des options pour la fenêtre pour le tri croisé
Un choix intéressant pour nos données est Pourcentages en lignes plutôt que Pourcentages du tableau :
Tableau des effectifs pour Defect par Facility
Texas Virginia Total en ligne
Contaminated 36 17 53
67.92% 32.08% 44.17%
Damaged 10 6 16
62.50% 37.50% 13.33%
Leaking 2 1 3
66.67% 33.33% 2.50%
Misaligned 8 20 28
28.57% 71.43% 23.33%
Misshapen 0 3 3
0.00% 100.00% 2.50%
Missing parts 2 1 3
66.67% 33.33% 2.50%
Poor color 6 2 8
75.00% 25.00% 6.67%
Rusted 2 3 5
40.00% 60.00% 4.17%
Wrong size 1 0 1
100.00% 0.00% 0.83%
Total en colonne 67 53 120
55.83% 44.17% 100.00%
Contenu des cellules:
Effectif observé
Pourcentage en ligne
Figure 14-10 Tri croisé avec pourcentages en lignes
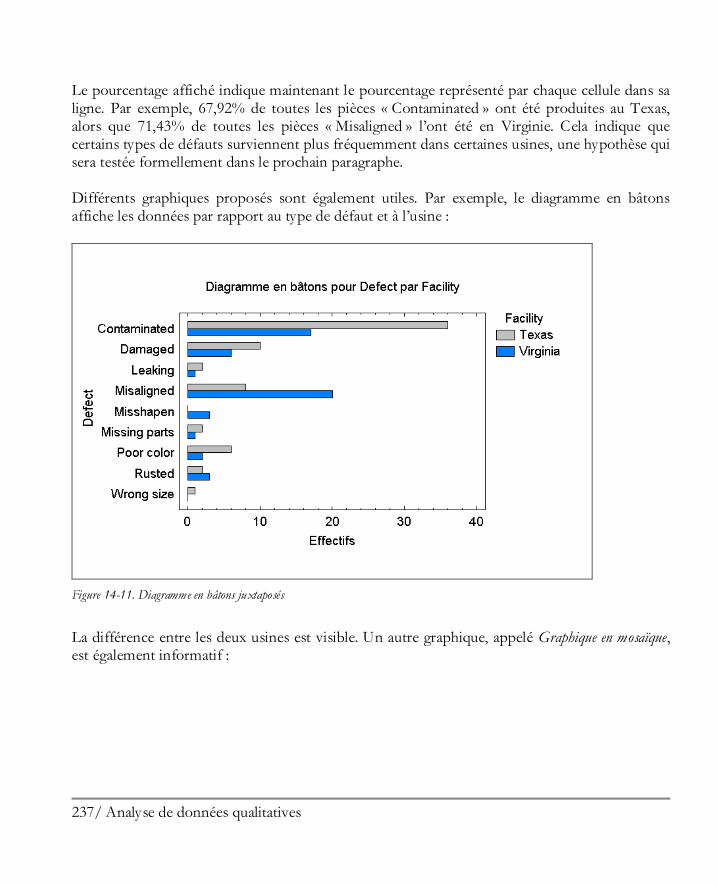
237/ Analyse de données qualitatives
Le pourcentage affiché indique maintenant le pourcentage représenté par chaque cellule dans sa ligne. Par exemple, 67,92% de toutes les pièces « Contaminated » ont été produites au Texas, alors que 71,43% de toutes les pièces « Misaligned » l’ont été en Virginie. Cela indique que certains types de défauts surviennent plus fréquemment dans certaines usines, une hypothèse qui sera testée formellement dans le prochain paragraphe. Différents graphiques proposés sont également utiles. Par exemple, le diagramme en bâtons affiche les données par rapport au type de défaut et à l’usine :
Figure 14-11. Diagramme en bâtons juxtaposés
La différence entre les deux usines est visible. Un autre graphique, appelé Graphique en mosaïque, est également informatif :
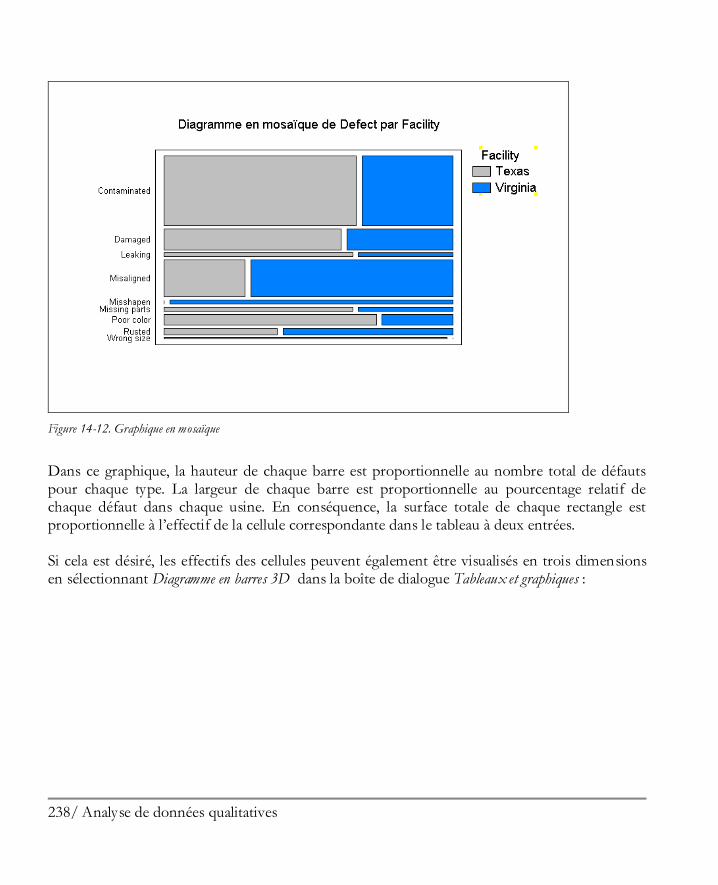
238/ Analyse de données qualitatives
Figure 14-12. Graphique en mosaïque
Dans ce graphique, la hauteur de chaque barre est proportionnelle au nombre total de défauts pour chaque type. La largeur de chaque barre est proportionnelle au pourcentage relatif de chaque défaut dans chaque usine. En conséquence, la surface totale de chaque rectangle est proportionnelle à l’effectif de la cellule correspondante dans le tableau à deux entrées. Si cela est désiré, les effectifs des cellules peuvent également être visualisés en trois dimensions en sélectionnant Diagramme en barres 3D dans la boîte de dialogue Tableaux et graphiques :
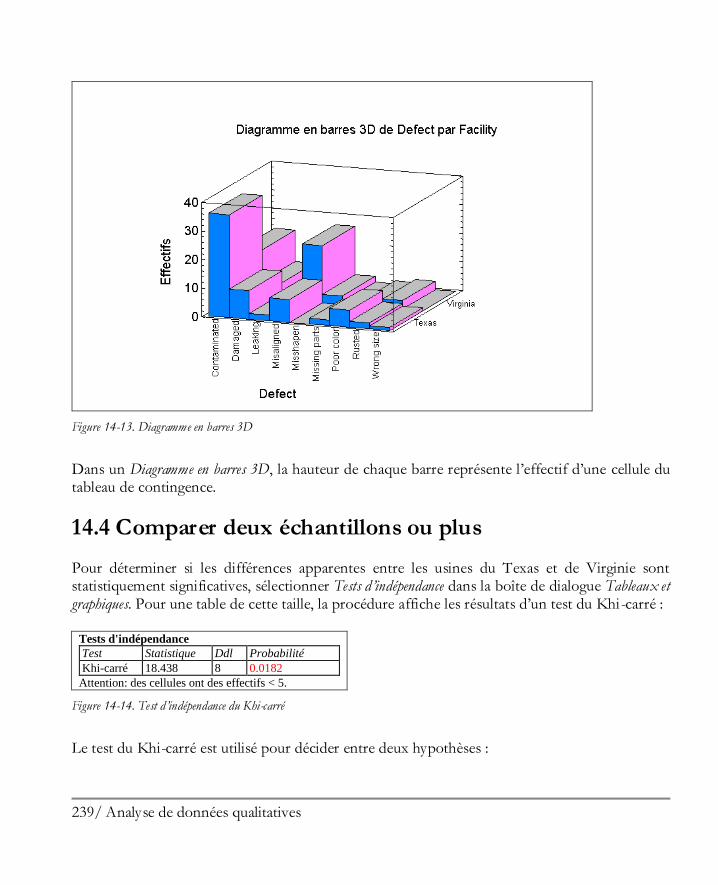
239/ Analyse de données qualitatives
Figure 14-13. Diagramme en barres 3D
Dans un Diagramme en barres 3D, la hauteur de chaque barre représente l’effectif d’une cellule du tableau de contingence.
14.4 Comparer deux échantillons ou plus Pour déterminer si les différences apparentes entre les usines du Texas et de Virginie sont statistiquement significatives, sélectionner Tests d’indépendance dans la boîte de dialogue Tableaux et graphiques. Pour une table de cette taille, la procédure affiche les résultats d’un test du Khi -carré :
Tests d'indépendance
Test Statistique Ddl Probabilité
Khi-carré 18.438 8 0.0182
Attention: des cellules ont des effectifs < 5.
Figure 14-14. Test d’indépendance du Khi-carré
Le test du Khi-carré est utilisé pour décider entre deux hypothèses :

240/ Analyse de données qualitatives
Hypothèse nulle : les lignes et les colonnes sont indépendantes. Hypothèse alternative : les lignes et les colonnes ne sont pas indépendantes. L’indépendance implique que le type de défaut trouvé sur une pièce n’a rien à voir avec l’usine qui a fabriqué la pièce. Pour le test du Khi-carré, une petite valeur de probabilité indique que les lignes et les colonnes ne sont pas indépendantes. Dans notre cas, la valeur de la probabilité est inférieure à 0,05, indiquant qu’au niveau de signification de 5% la distribution des types de défauts pour l’usine du Texas est différente de celle pour l’usine de Virginie. Une mise en garde est toutefois affichée, car certaines cellules dans le tableau à deux entrées ont des comptages inférieurs à 5. (Techniquement cette mise en garde s’affiche si le comptage attendu dans une cellule quelconque est inférieur à 5 en supposant que l’hypothèse nulle est vraie). Avec de petits comptages dans certaines cellules, la valeur de la probabilité n’est pas fiable. Une solution à ce problème consiste à regrouper les types de défauts peu fréquents dans une unique catégorie puis à refaire le test. Cela est fait aisément dans STATGRAPHICS Centurion XVI de la façon suivante :
1. Revenir dans le tableur et cliquer sur l’en-tête de la colonne Defects pour la sélectionner. 2. Cliquer sur le bouton droit de la souris et sélectionner Recoder des données dans le menu
popup.
3. Renseigner la boîte de dialogue Recoder des données comme montré ci-après pour combiner les types de défauts les moins fréquents dans une catégorie appelée « Other »:
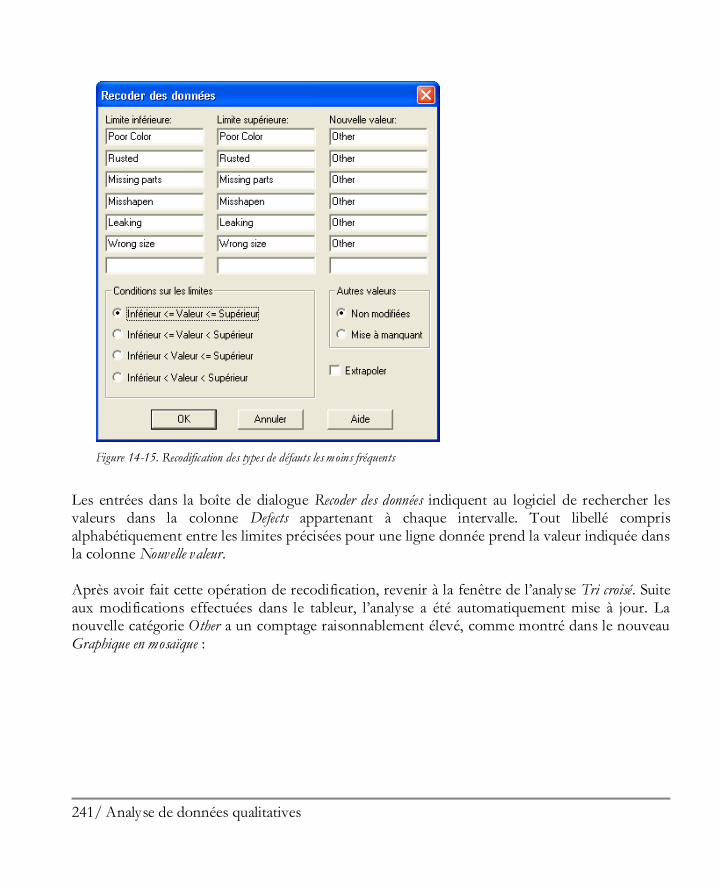
241/ Analyse de données qualitatives
Figure 14-15. Recodification des types de défauts les moins fréquents
Les entrées dans la boîte de dialogue Recoder des données indiquent au logiciel de rechercher les valeurs dans la colonne Defects appartenant à chaque intervalle. Tout libellé compris alphabétiquement entre les limites précisées pour une ligne donnée prend la valeur indiquée dans la colonne Nouvelle valeur. Après avoir fait cette opération de recodification, revenir à la fenêtre de l’analyse Tri croisé. Suite aux modifications effectuées dans le tableur, l’analyse a été automatiquement mise à jour. La nouvelle catégorie Other a un comptage raisonnablement élevé, comme montré dans le nouveau Graphique en mosaïque :
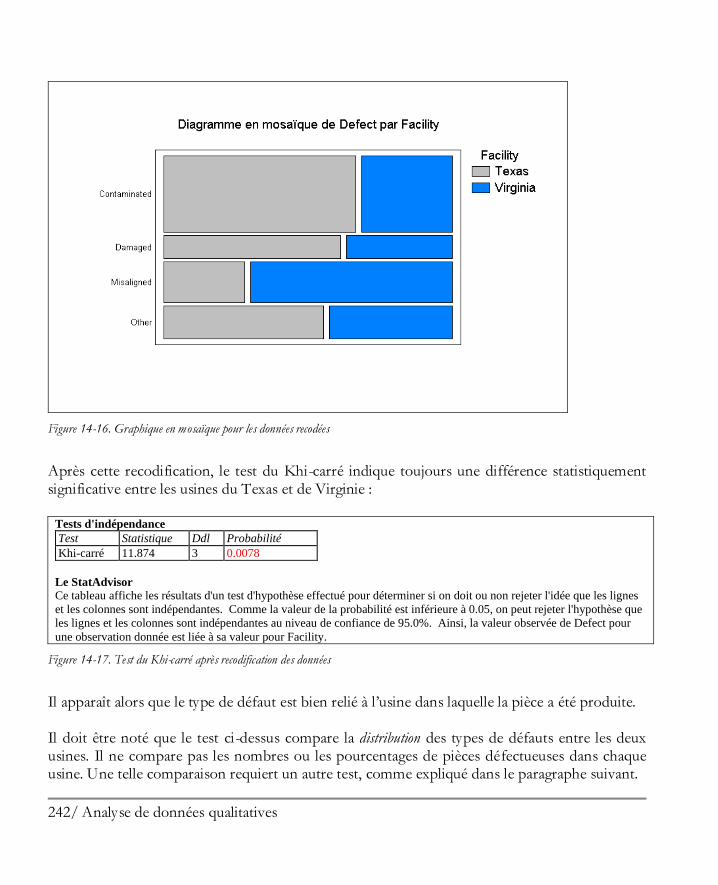
242/ Analyse de données qualitatives
Figure 14-16. Graphique en mosaïque pour les données recodées
Après cette recodification, le test du Khi-carré indique toujours une différence statistiquement significative entre les usines du Texas et de Virginie :
Tests d'indépendance
Test Statistique Ddl Probabilité
Khi-carré 11.874 3 0.0078
Le StatAdvisor
Ce tableau affiche les résultats d'un test d'hypothèse effectué pour déterminer si on doit ou non rejeter l'idée que les lignes
et les colonnes sont indépendantes. Comme la valeur de la probabilité est inférieure à 0.05, on peut rejeter l'hypothèse que
les lignes et les colonnes sont indépendantes au niveau de confiance de 95.0%. Ainsi, la valeur observée de Defect pour
une observation donnée est liée à sa valeur pour Facility.
Figure 14-17. Test du Khi-carré après recodification des données
Il apparaît alors que le type de défaut est bien relié à l’usine dans laquelle la pièce a été produite. Il doit être noté que le test ci-dessus compare la distribution des types de défauts entre les deux usines. Il ne compare pas les nombres ou les pourcentages de pièces défectueuses dans chaque usine. Une telle comparaison requiert un autre test, comme expliqué dans le paragraphe suivant.

243/ Analyse de données qualitatives
14.5 Tableaux de contingence Pour déterminer si une usine produit plus de pièces défectueuses qu’une autre, il faut connaître la production totale de chaque usine. Supposons que le tableau ci -dessous corresponde à un mois de production :
Usine Nombre de défauts
Nombre de pièces fabriquées
Texas 67 6237
Virginia 53 7343
Soit 1 la proportion de pièces défectueuses produites au Texas et 2 la proportion de pièces défectueuses produites en Virginie. Les proportions estimées sont données par :
1
67ˆ 0,01076237
2
53ˆ 0,00727343
En se basant sur ces données, il apparaît que le pourcentage de pièces défectueuses fabriquées au Texas est supérieur au pourcentage de pièces défectueuses fabriquées en Virginie. Pour déterminer si cette différence apparente est statistiquement significative, créons un tableur comme montré ci-dessous :
Figure 14-18. Tableur pour comparer deux proportions
Les lignes contiennent les comptages des pièces défectueuses et non défectueuses. Sélectionnons Tableau de contingence dans le même menu que Tri croisé. Renseignons la boîte de dialogue comme montré ci-après :
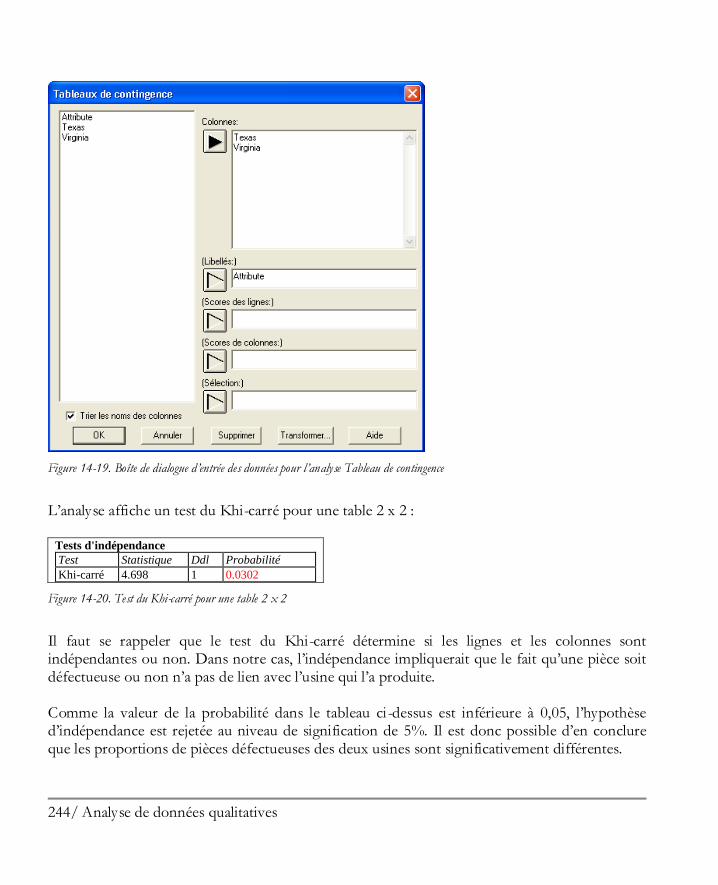
244/ Analyse de données qualitatives
Figure 14-19. Boîte de dialogue d’entrée des données pour l’analyse Tableau de contingence
L’analyse affiche un test du Khi-carré pour une table 2 x 2 :
Tests d'indépendance
Test Statistique Ddl Probabilité
Khi-carré 4.698 1 0.0302
Figure 14-20. Test du Khi-carré pour une table 2 x 2
Il faut se rappeler que le test du Khi-carré détermine si les lignes et les colonnes sont indépendantes ou non. Dans notre cas, l’indépendance impliquerait que le fait qu’une pièce soit défectueuse ou non n’a pas de lien avec l’usine qui l’a produite. Comme la valeur de la probabilité dans le tableau ci -dessus est inférieure à 0,05, l’hypothèse d’indépendance est rejetée au niveau de signification de 5%. Il est donc possible d’en conclure que les proportions de pièces défectueuses des deux usines sont significativement différentes.

245/ Analyse d’aptitude d’un procédé
Didacticiel n° 6 : Analyse
d’aptitude d’un procédé
Calculer le DPM ou le pourcentage au-delà des limites des spécifications.
STATGRAPHICS Centurion XVI est largement utilisé par des personnes dont le métier est de s’assurer que les produits ou les services qu’ils fournissent est de la plus haute qualité. Un travail courant dans ce cadre est la collecte de données issues du procédé et la comparaison à des limites de spécifications établies. Le résultat de ce type d’analyse d’aptitude est une estimation de la capacité du procédé à satisfaire ces spécifications. Le Six Sigma, méthodologie très utilisée pour atteindre un niveau de qualité de classe mondiale, cible un taux de défauts de 3,4 défauts par million d’opportunités.
Comme exemple, considérons un produit dont la solidité requise est comprise entre 190 et 230 psi (pound force per square inch). Supposons que n = 100 échantillons soient prélevés durant la fabrication et que les forces soient mesurées, comme montré dans le tableau ci-dessous :
213.5 203.3 191.3 197.1 205.7 215.6 193.7 201.7 201.5 207.1
207.0 200.4 197.2 202.4 205.2 211.0 214.5 201.5 200.9 206.8
205.8 200.3 196.1 205.9 195.1 203.9 192.9 199.0 195.5 203.1
197.4 194.8 201.0 202.5 199.0 200.7 197.6 198.5 205.3 197.1
202.8 201.6 197.4 200.9 203.3 209.4 201.4 199.5 207.8 204.9
205.5 203.0 208.1 200.2 218.2 202.0 209.3 201.2 200.4 201.0
195.7 229.5 199.9 208.1 210.3 202.0 202.6 213.6 198.0 197.8
196.7 216.0 211.6 208.7 199.4 200.8 201.1 195.3 206.8 211.3
201.5 200.0 211.8 195.6 201.9 199.0 200.3 197.8 200.8 194.8
199.5 195.5 201.0 206.0 215.3 202.6 199.9 200.6 197.6 207.4
Chapitre
15

246/ Analyse d’aptitude d’un procédé
Ce chapitre décrit comment mettre en oeuvre une analyse d’aptitude pour ce type de données mesurées.
15.1 Visualiser graphiquement les données La première étape lors de l’étude d’un nouveau jeu de données consiste à visualiser graphiquement les données. Pour un jeu de données comme celui de notre exemple, l’Analyse à une variable décrite dans le Chapitre 10 apporte plusieurs outils utiles. Pour analyser ces données :
1. Ouvrir le fichier de données appelé item s.sgd.
2. Exécuter la procédure Analyse à une variable en utilisant la colonne nommée Strength. La fenêtre d’analyse initiale est montrée ci-après :
Figure 15-1. Fenêtre initiale de l’analyse à une variable
Plusieurs résultats intéressants sont immédiatement visibles :
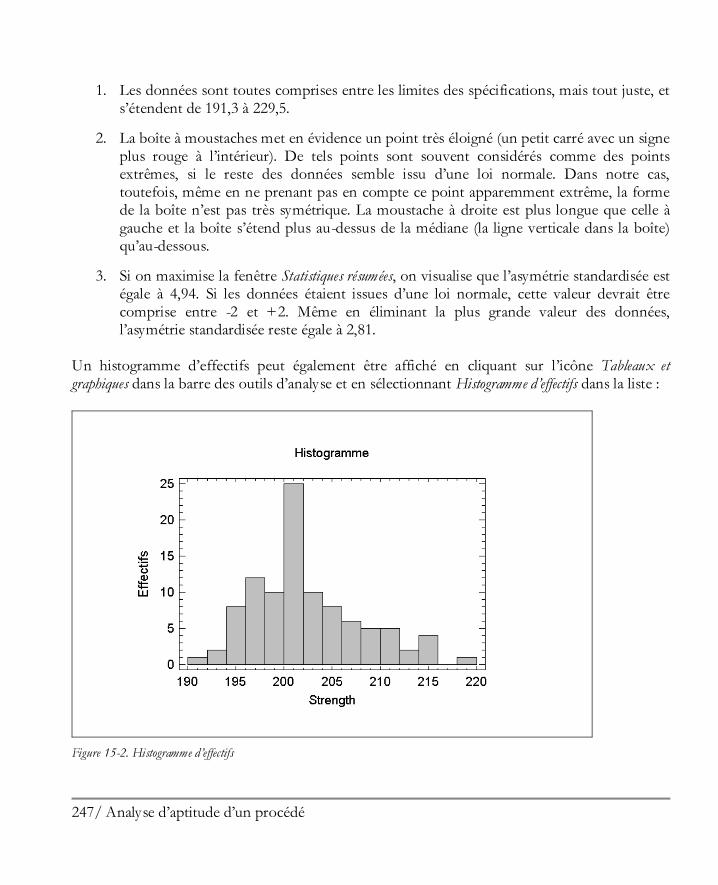
247/ Analyse d’aptitude d’un procédé
1. Les données sont toutes comprises entre les limites des spécifications, mais tout juste, et s’étendent de 191,3 à 229,5.
2. La boîte à moustaches met en évidence un point très éloigné (un petit carré avec un signe plus rouge à l’intérieur). De tels points sont souvent considérés comme des points extrêmes, si le reste des données semble issu d’une loi normale. Dans notre cas, toutefois, même en ne prenant pas en compte ce point apparemment extrême, la forme de la boîte n’est pas très symétrique. La moustache à droite est plus longue que celle à gauche et la boîte s’étend plus au-dessus de la médiane (la ligne verticale dans la boîte) qu’au-dessous.
3. Si on maximise la fenêtre Statistiques résumées, on visualise que l’asymétrie standardisée est égale à 4,94. Si les données étaient issues d’une loi normale, cette valeur devrait être comprise entre -2 et +2. Même en éliminant la plus grande valeur des données, l’asymétrie standardisée reste égale à 2,81.
Un histogramme d’effectifs peut également être affiché en cliquant sur l’icône Tableaux et graphiques dans la barre des outils d’analyse et en sélectionnant Histogramme d’effectifs dans la liste :
Figure 15-2. Histogramme d’effectifs

248/ Analyse d’aptitude d’un procédé
Les données affichent clairement une asymétrie positive, s’étendant plus loin à droite du pic qu’à gauche du pic. Des données non normales comme celles de notre exemple sont fréquemment rencontrées. Une approche classique pour travailler avec de telles données consiste souvant à ignorer la non normalité et à calculer des indices comme le Cpk en utilisant des formules pour des données issues d’une loi normale. Comme cela sera vu dans ce didacticiel, ignorer la non normalité peut conduire à des résultats faux qui surestiment ou sous-estiment de façon significative le pourcentage de produits au-delà des limites des spécifications.
15.2 Procédure d’analyse d’aptitude STATGRAPHICS contient des procédures pour mettre en oeuvre l’analyse d’aptitude sur des données collectées soit une par une (données individuelles) soit par sous-groupes (comme par exemple 5 observations chaque heure). En supposant que l’échantillon soit constitué de données individuelles, une analyse d’aptitude du procédé peut être mise en œuvre :
1. Par le menu classique, en sélectionnant MSP – Analyse d’aptitude – Variables – Données individuelles.
2. Par le menu Six Sigma, en sélectionnant Analyser – Variables – Analyse d’aptitude – Données
individuelles. La boîte de dialogue d’entrée des données demande le nom d’une unique colonne contenant les données. Les données de l’échantillon sont dans la colonne nommée Strength dans le fichier appelé item s.sgd :
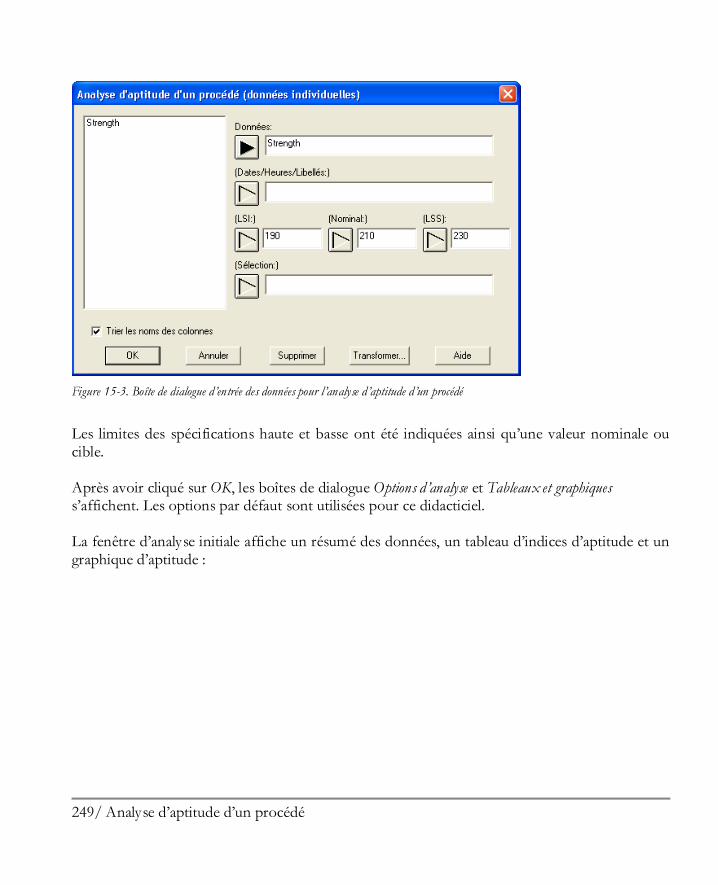
249/ Analyse d’aptitude d’un procédé
Figure 15-3. Boîte de dialogue d’entrée des données pour l’analyse d’aptitude d’un procédé
Les limites des spécifications haute et basse ont été indiquées ainsi qu’une valeur nominale ou cible. Après avoir cliqué sur OK, les boîtes de dialogue Options d’analyse et Tableaux et graphiques s’affichent. Les options par défaut sont utilisées pour ce didacticiel. La fenêtre d’analyse initiale affiche un résumé des données, un tableau d’indices d’aptitude et un graphique d’aptitude :

250/ Analyse d’aptitude d’un procédé
Figure 15-4. Fenêtre d’analyse de l’analyse d’aptitude d’un procédé
Lorsque l’analyse d’aptitude est mise en oeuvre la première fois, une loi normale est ajustée aux données. Le Graphique d’aptitude affiche un histogramme des données ainsi que la courbe du meilleur ajustement par une loi normale :
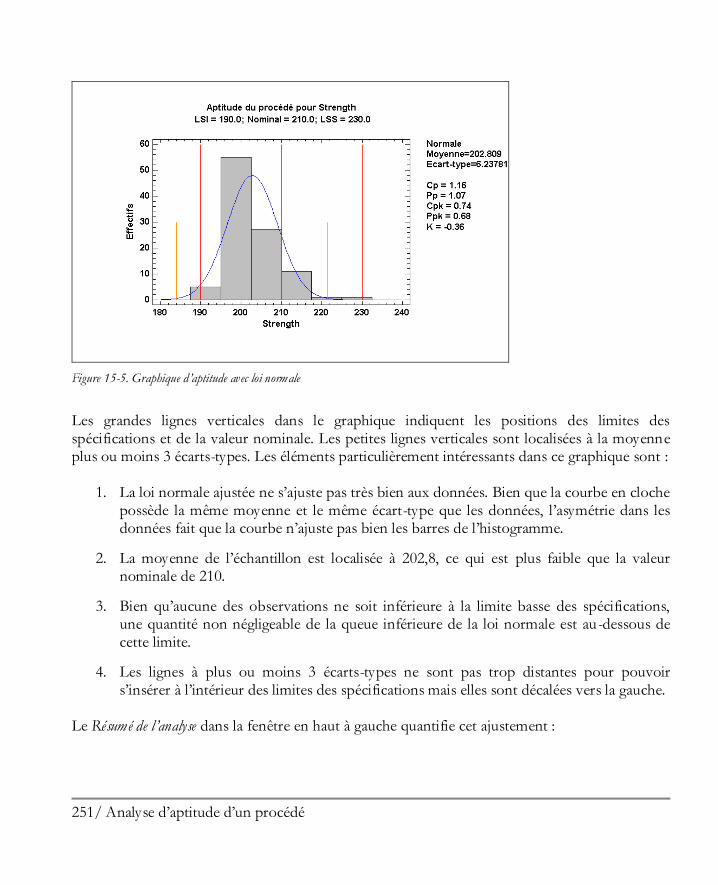
251/ Analyse d’aptitude d’un procédé
Figure 15-5. Graphique d’aptitude avec loi normale
Les grandes lignes verticales dans le graphique indiquent les positions des limites des spécifications et de la valeur nominale. Les petites lignes verticales sont localisées à la moyenne plus ou moins 3 écarts-types. Les éléments particulièrement intéressants dans ce graphique sont :
1. La loi normale ajustée ne s’ajuste pas très bien aux données. Bien que la courbe en cloche possède la même moyenne et le même écart-type que les données, l’asymétrie dans les données fait que la courbe n’ajuste pas bien les barres de l’histogramme.
2. La moyenne de l’échantillon est localisée à 202,8, ce qui est plus faible que la valeur nominale de 210.
3. Bien qu’aucune des observations ne soit inférieure à la limite basse des spécifications, une quantité non négligeable de la queue inférieure de la loi normale est au-dessous de cette limite.
4. Les lignes à plus ou moins 3 écarts-types ne sont pas trop distantes pour pouvoir s’insérer à l’intérieur des limites des spécifications mais elles sont décalées vers la gauche.
Le Résumé de l’analyse dans la fenêtre en haut à gauche quantifie cet ajustement :

252/ Analyse d’aptitude d’un procédé
Analyse d'aptitude (données individuelles) - Strength Variable des données: Strength (specs are 190-230)
Transformation: sans
Distribution: Normale
Taille de l'échantillon = 100
moyenne = 202.809
ecart-type = 6.23781
6.0 écarts-types pour les limites
+3.0 écarts-types = 221.522
moyenne = 202.809
-3.0 écarts-types = 184.096
Observé Estimé Défauts
Spécifications au-delà spéc Score Z au-delà spéc par million
LSS = 230.0 0.000000% 4.36 0.000654% 6.54
Nominal = 210.0 1.15
LSI = 190.0 0.000000% -2.05 2.001465% 20014.65
Total 0.000000% 2.002119% 20021.19
Figure 15-6. Résumé de l’analyse d’aptitude
La partie basse du tableau est particulièrement intéressante car elle estime le pourcentage des produits qui sont en dehors des spécifications. En se basant sur la loi normale ajustée, le pourcentage estimé de produits en dehors des spécifications est d’environ 2%, ce qui correspond à 20.021 défauts par million (DPM).
15.3 Travailler avec des données non normales Le DPM estimé calculé ci-dessus est fortement basé sur l’hypothèse que les données sont issues d’une loi normale. Un test formel de cette hypothèse peut être effectué en sélectionnant Tests de normalité dans la boîte de dialogue Tableaux et graphiques :
Tests de normalité pour Strength
Test Statistique Probabilité
W de Shapiro-Wilks 0.931784 0.0000321356
Figure 15-7. Tests de normalité
En fonction des préférences définies dans votre logiciel, un ou plusieurs tests de normalité s’affichent. Chacun des tests disponibles est basé sur les hypothèses suivantes :

253/ Analyse d’aptitude d’un procédé
Hypothèse nulle : les données sont issues d’une loi normale. Hypothèse alternative : les données ne sont pas issues d’une loi normale. Une valeur de probabilité en dessous de 0,05 conduit au rejet de l’hypothèse de normalité au niveau de signification de 5%. Dans le tableau ci-dessus, le test de Shapiro-Wilks permet de rejeter l’hypothèse que les données sont issues d’une loi normale. Ainsi, toutes les valeurs estimées du DPM ou des indices d’aptitude basées sur cette hypothèse de normalité sont erronées. Lorsque les données ne sont pas normales, deux approches sont possibles :
1. Sélectionner une autre loi que la loi normale pour faire l’analyse.
2. Transformer les données pour que les données transformées suivent une loi normale. Pour aider à sélectionner une autre loi, STATGRAPHICS Centurion XVI possède une option appelée Comparaison des lois alternatives dans la boîte de dialogue Tableaux et graphiques. Cette option ajuste plusieurs autres lois et liste ces lois dans l’ordre de qualité d’ajustement. En utilisant la sélection par défaut des lois, le tableau suivant s’affiche :
Comparaison des lois alternatives
Loi Nb. paramètres
estimés
KS D A^2
Plus grande valeur
extrême
2 0.0675422 0.372613
Log-logistique 2 0.0913779 1.15081
Logistique 2 0.0941708 1.27599
Log-normale 2 0.13213 1.66564
Laplace 2 0.0920985 1.68399
Gamma 2 0.134136 1.73401
Normale 2 0.138628 1.90094
Weibull 2 0.177886 5.67166
Plus petite valeur
extrême
2 0.189989 6.28546
Exponentielle 1 0.61064 43.3327
Pareto 1 0.628084 45.3859
Figure 15-8. Lois ajustées affichées dans l’ordre de qualité d’ajustement

254/ Analyse d’aptitude d’un procédé
Les lois ont été listées en fonction des valeurs de la statistique de qualité d’ajustement de Kolmogorov-Smirnov, qui mesure la distance maximale entre la fonction de répartition des données et celle de la loi ajustée. Dans notre cas, la loi donnant le meilleur ajustement est la loi de la Plus grande valeur extrême. Vous pouvez choisir cette loi en accédant aux Options d’analyse :
Figure 15-9. Boîte de dialogue des options d’analyse pour l’analyse d’aptitude d’un procédé
L’ajustement qui en résulte est montré ci-après :
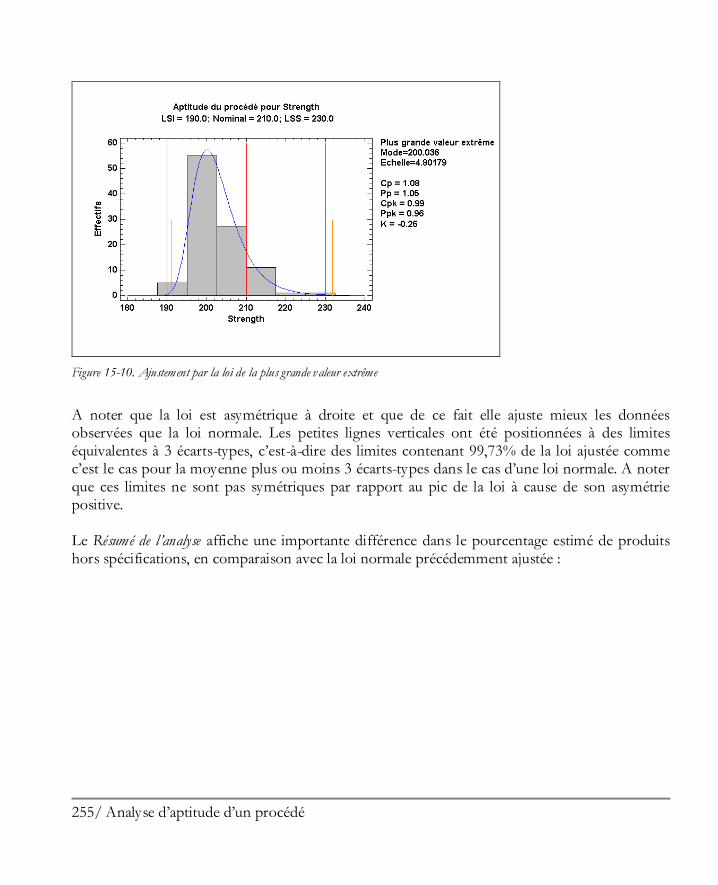
255/ Analyse d’aptitude d’un procédé
Figure 15-10. Ajustement par la loi de la plus grande valeur extrême
A noter que la loi est asymétrique à droite et que de ce fait elle ajuste mieux les données observées que la loi normale. Les petites lignes verticales ont été positionnées à des limites équivalentes à 3 écarts-types, c’est-à-dire des limites contenant 99,73% de la loi ajustée comme c’est le cas pour la moyenne plus ou moins 3 écarts-types dans le cas d’une loi normale. A noter que ces limites ne sont pas symétriques par rapport au pic de la loi à cause de son asymétrie positive. Le Résumé de l’analyse affiche une importante différence dans le pourcentage estimé de produits hors spécifications, en comparaison avec la loi normale précédemment ajustée :
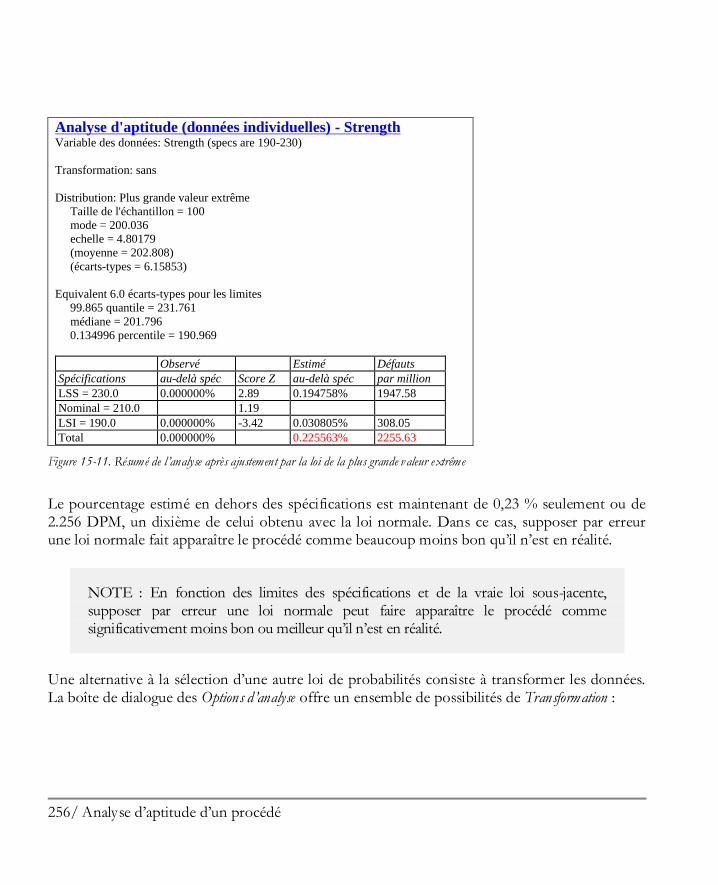
256/ Analyse d’aptitude d’un procédé
Analyse d'aptitude (données individuelles) - Strength Variable des données: Strength (specs are 190-230)
Transformation: sans
Distribution: Plus grande valeur extrême
Taille de l'échantillon = 100
mode = 200.036
echelle = 4.80179
(moyenne = 202.808)
(écarts-types = 6.15853)
Equivalent 6.0 écarts-types pour les limites
99.865 quantile = 231.761
médiane = 201.796
0.134996 percentile = 190.969
Observé Estimé Défauts
Spécifications au-delà spéc Score Z au-delà spéc par million
LSS = 230.0 0.000000% 2.89 0.194758% 1947.58
Nominal = 210.0 1.19
LSI = 190.0 0.000000% -3.42 0.030805% 308.05
Total 0.000000% 0.225563% 2255.63
Figure 15-11. Résumé de l’analyse après ajustement par la loi de la plus grande valeur extrême
Le pourcentage estimé en dehors des spécifications est maintenant de 0,23 % seulement ou de 2.256 DPM, un dixième de celui obtenu avec la loi normale. Dans ce cas, supposer par erreur une loi normale fait apparaître le procédé comme beaucoup moins bon qu’il n’est en réalité.
NOTE : En fonction des limites des spécifications et de la vraie loi sous-jacente, supposer par erreur une loi normale peut faire apparaître le procédé comme significativement moins bon ou meilleur qu’il n’est en réalité.
Une alternative à la sélection d’une autre loi de probabilités consiste à transformer les données. La boîte de dialogue des Options d’analyse offre un ensemble de possibilités de Transformation :

257/ Analyse d’aptitude d’un procédé
Figure 15-12. Boîte de dialogue des options d’analyse pour sélectionner une transformation
Parmi les choix proposés, on trouve le logarithme naturel, l’élévation de chaque valeur à une puissance donnée ou la sélection d’une transformation par les méthodes de Box et Cox. Cette dernière approche considère un ensemble de transformations de la forme Yp en utilisant les méthodes de Box et Cox et sélectionne une valeur optimale pour p. Si une transformation est sélectionnée, une loi normale est ajustée aux données transformées. Le graphique ci-après affiche les résultats de l’approche Box-Cox :
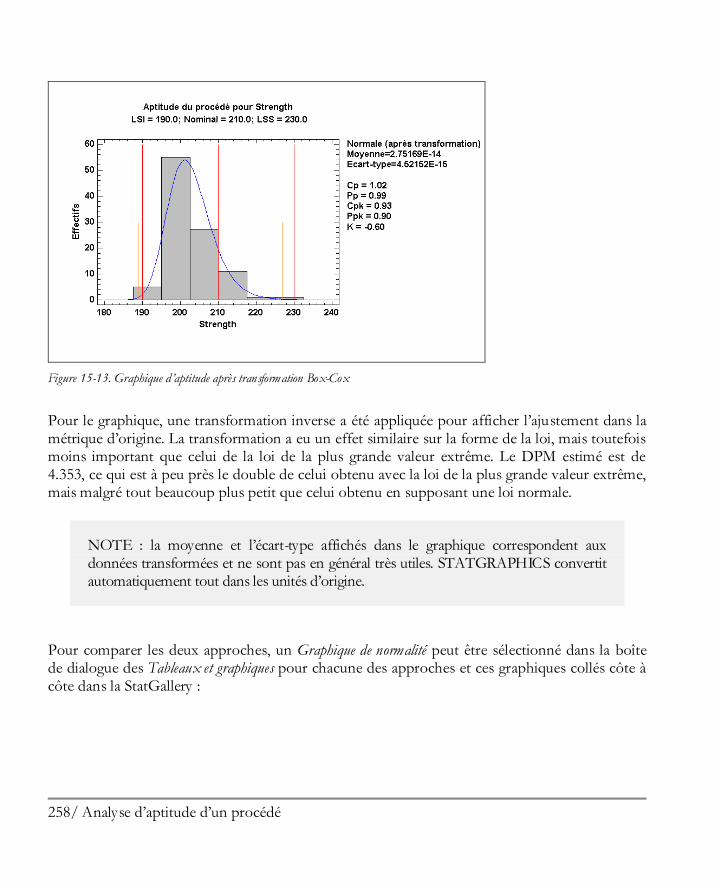
258/ Analyse d’aptitude d’un procédé
Figure 15-13. Graphique d’aptitude après transformation Box-Cox
Pour le graphique, une transformation inverse a été appliquée pour afficher l’ajustement dans la métrique d’origine. La transformation a eu un effet similaire sur la forme de la loi, mais toutefois moins important que celui de la loi de la plus grande valeur extrême. Le DPM estimé est de 4.353, ce qui est à peu près le double de celui obtenu avec la loi de la plus grande valeur extrême, mais malgré tout beaucoup plus petit que celui obtenu en supposant une loi normale.
NOTE : la moyenne et l’écart-type affichés dans le graphique correspondent aux données transformées et ne sont pas en général très utiles. STATGRAPHICS convertit automatiquement tout dans les unités d’origine.
Pour comparer les deux approches, un Graphique de normalité peut être sélectionné dans la boîte de dialogue des Tableaux et graphiques pour chacune des approches et ces graphiques collés côte à côte dans la StatGallery :
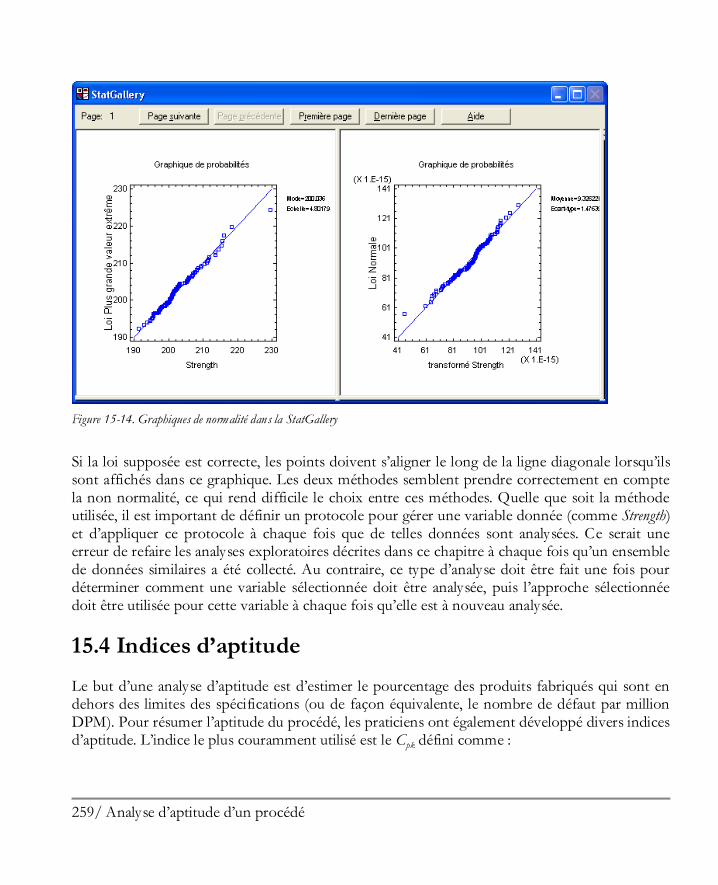
259/ Analyse d’aptitude d’un procédé
Figure 15-14. Graphiques de normalité dans la StatGallery
Si la loi supposée est correcte, les points doivent s’aligner le long de la ligne diagonale lorsqu’ils sont affichés dans ce graphique. Les deux méthodes semblent prendre correctement en compte la non normalité, ce qui rend difficile le choix entre ces méthodes. Quelle que soit la méthode utilisée, il est important de définir un protocole pour gérer une variable donnée (comme Strength) et d’appliquer ce protocole à chaque fois que de telles données sont analysées. Ce serait une erreur de refaire les analyses exploratoires décrites dans ce chapitre à chaque fois qu’un ensemble de données similaires a été collecté. Au contraire, ce type d’analyse doit être fait une fois pour déterminer comment une variable sélectionnée doit être analysée, puis l’approche sélectionnée doit être utilisée pour cette variable à chaque fois qu’elle est à nouveau analysée.
15.4 Indices d’aptitude Le but d’une analyse d’aptitude est d’estimer le pourcentage des produits fabriqués qui sont en dehors des limites des spécifications (ou de façon équivalente, le nombre de défaut par million DPM). Pour résumer l’aptitude du procédé, les praticiens ont également développé divers indices d’aptitude. L’indice le plus couramment utilisé est le Cpk défini comme :
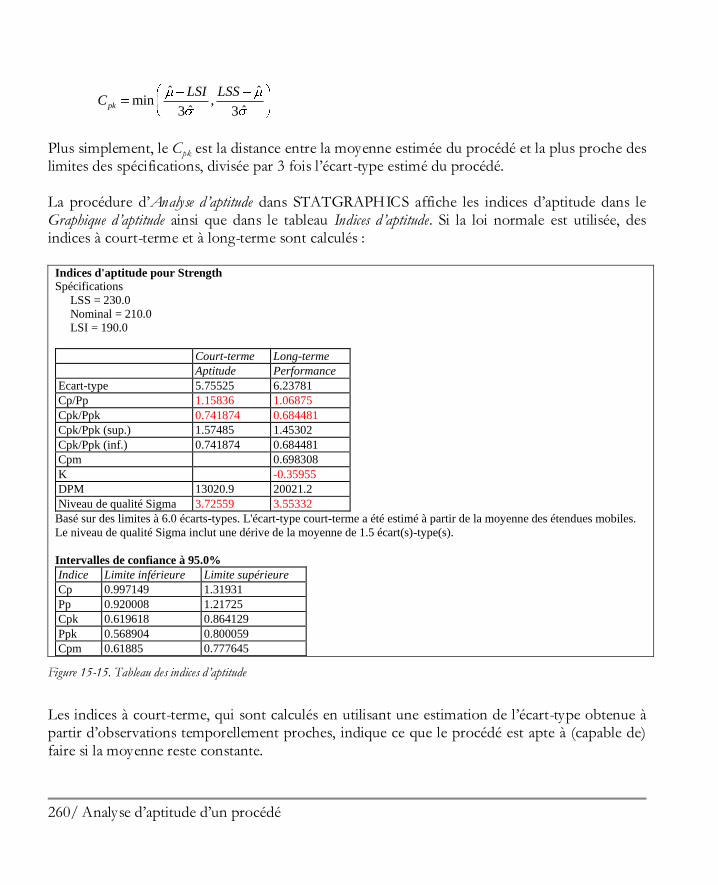
260/ Analyse d’aptitude d’un procédé
ˆ ˆmin ,
ˆ ˆ3 3pk
LSI LSSC
Plus simplement, le Cpk est la distance entre la moyenne estimée du procédé et la plus proche des limites des spécifications, divisée par 3 fois l’écart-type estimé du procédé. La procédure d’Analyse d’aptitude dans STATGRAPHICS affiche les indices d’aptitude dans le Graphique d’aptitude ainsi que dans le tableau Indices d’aptitude. Si la loi normale est utilisée, des indices à court-terme et à long-terme sont calculés :
Indices d'aptitude pour Strength
Spécifications
LSS = 230.0
Nominal = 210.0
LSI = 190.0
Court-terme Long-terme
Aptitude Performance
Ecart-type 5.75525 6.23781
Cp/Pp 1.15836 1.06875
Cpk/Ppk 0.741874 0.684481
Cpk/Ppk (sup.) 1.57485 1.45302
Cpk/Ppk (inf.) 0.741874 0.684481
Cpm 0.698308
K -0.35955
DPM 13020.9 20021.2
Niveau de qualité Sigma 3.72559 3.55332
Basé sur des limites à 6.0 écarts-types. L'écart-type court-terme a été estimé à partir de la moyenne des étendues mobiles.
Le niveau de qualité Sigma inclut une dérive de la moyenne de 1.5 écart(s)-type(s).
Intervalles de confiance à 95.0%
Indice Limite inférieure Limite supérieure
Cp 0.997149 1.31931
Pp 0.920008 1.21725
Cpk 0.619618 0.864129
Ppk 0.568904 0.800059
Cpm 0.61885 0.777645
Figure 15-15. Tableau des indices d’aptitude
Les indices à court-terme, qui sont calculés en utilisant une estimation de l’écart-type obtenue à partir d’observations temporellement proches, indique ce que le procédé est apte à (capable de) faire si la moyenne reste constante.

261/ Analyse d’aptitude d’un procédé
Les indices à long-terme, qui sont calculés en utilisant une estimation de l’écart-type obtenue à partir de la variabilité totale des observations sur toute la période d’échantillonnage, indique ce qu’a été la performance du procédé. Un procédé hors contrôle dont la moyenne est fortement instable durant la période de collecte des données peut afficher une performance beaucoup moins bonne que celle qu’il serait apte à réaliser si le procédé était sous contrôle. Par défaut, STATGRAPHICS Centurion XVI donne des libellés aux indices d’aptitude commençant par la lettre « C » et aux indices de performance des libellés commençant par la lettre « P ». L’onglet Aptitudes de la boîte de dialogue Préférences, accessible par Editer dans le menu principal de STATGRAPHICS, permet de préciser les indices à calculer par défaut, ainsi que d’autres importantes options :
Figure 15-16. Préférences du logiciel pour les indices d’aptitude
La partie gauche de la boîte de dialogue liste les indices qui peuvent être calculés. En plus du Cpk, les indices disponibles sont :

262/ Analyse d’aptitude d’un procédé
1. Cp – un indice bilatéral d’aptitude calculé de la façon suivante :
ˆ6p
LSS LSIC
Cet indice calcule le rapport de la distance entre les limites des spécifications sur la distance représentée par six écarts-types. Cp est toujours supérieur ou égal à Cpk. Une différence sensible entre ces deux indices apparaît lorsque le procédé n’est pas bien centré.
2. K – une mesure du décentrage du procédé. K est calculé de la façon suivante :
ˆ
( ) / 2
NOMK
LSS LSI
où NOM est la valeur nominale ou cible. Une valeur de K proche de 0 indique un procédé bien centré.
3. Niveau de Qualité Sigma – un indice utilisé pour le Six Sigma pour indiquer le niveau de
qualité associé à un procédé. Un Niveau de Qualité Sigma de 6 est habituellement associé à un taux de défauts de 3,4 par million.
La boîte de dialogue Préférences permet également de définir les indices affichés dans le Graphique d’aptitude ainsi que les libellés de ces indices. Une discussion détaillée de ces divers indices est disponible dans le document PDF intitulé Analyse d’aptitude (Variables). En plus des indices d’aptitude, le tableau de la Figure 15.15 inclut des intervalles de confiance indiquant la marge d’erreur dans l’estimation de ces indices. Par exemple, le tableau indique une valeur du Cpk égale à 0,74. L’intervalle de confiance à 95% s’étend de 0,62 à 0,86. Cela indique que la vraie valeur du Cpk du procédé dont les données échantillonnées proviennent est comprise entre 0,62 et 0,86. Lorsque les données ne suivent pas une loi normale, les indices d’aptitude doivent être modifiés. L’option par défaut dans la boîte de dialogue Préférences calcule des indices non normaux en évaluant en premier des scores Z équivalents pour la loi non normale ajustée. Pour une loi normale, le score Z mesure le nombre d’écarts-types entre la moyenne du procédé et une limite des spécifications et est directement relié à la probabilité qu’une observation soit au -delà de cette limite.

263/ Analyse d’aptitude d’un procédé
Pour une loi non normale, un score Z équivalent est en premier calculé en déterminant la probabilité de dépasser cette limite et en trouvant le score Z qui vaut cette probabilité. Après avoir calculé des scores Z équivalents pour la limite base et la limite haute des spécifications, le Cpk peut être calculé à partir de :
min ,pk lss lsiC Z Z /3
NOTE : Bien que la boîte de dialogue des Préférences offre l’option de calcul des indices d’aptitude à partir des quantiles plutôt que des scores Z équivalents, le faire ne permet plus d’avoir la relation usuelle entre indices d’aptitude et DPM.
15.5 Calculatrice Six Sigma En tant qu’indice, Cpk est un résumé utile de l’aptitude du procédé. S’il est bien calculé, il peut être relié au DPM. Le menu Outils de STATGRAPHICS Centurion XVI contient une procédure Calculatrice Six Sigma permettant de convertir Cpk en DPM, sous réserve que :
1. Les données suivent une loi normale.
2. Les scores Z équivalents soient utilisés pour calculer les indices. La boîte de dialogue d’entrée des données de la procédure Calculatrice Six Sigma est montrée ci-après :
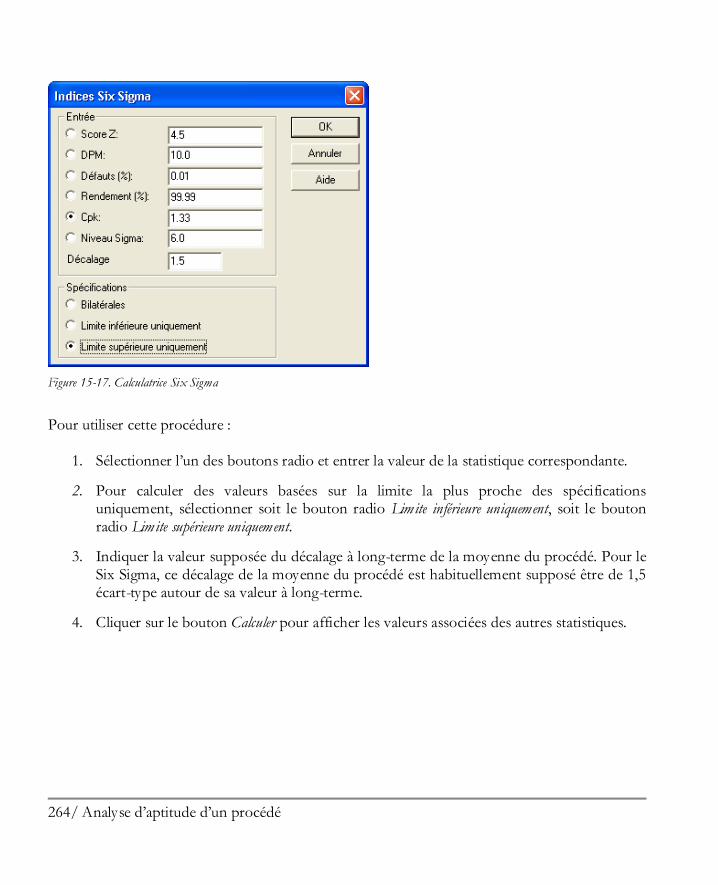
264/ Analyse d’aptitude d’un procédé
Figure 15-17. Calculatrice Six Sigma
Pour utiliser cette procédure :
1. Sélectionner l’un des boutons radio et entrer la valeur de la statistique correspondante.
2. Pour calculer des valeurs basées sur la limite la plus proche des spécifications uniquement, sélectionner soit le bouton radio Limite inférieure uniquement, soit le bouton radio Limite supérieure uniquement.
3. Indiquer la valeur supposée du décalage à long-terme de la moyenne du procédé. Pour le Six Sigma, ce décalage de la moyenne du procédé est habituellement supposé être de 1,5 écart-type autour de sa valeur à long-terme.
4. Cliquer sur le bouton Calculer pour afficher les valeurs associées des autres statistiques.

265/ Analyse d’aptitude d’un procédé
Figure 15-18. Valeurs équivalentes des indices de qualité
En supposant que la moyenne du procédé ne se décale pas, un Cpk de 1,33 est équivalent à environ 33 défauts par million au-delà de la limite la plus proche des spécifications.

266/ Analyse d’aptitude d’un procédé

267/ Plans d’expériences
Didacticiel n° 7 : Plans
d’expériences
Planifier des expériences pour aider à améliorer un procédé.
Toutes les données n’ont pas la même valeur. Souvent, une petite étude bien planifiée fournit plus d’informations qu’une importante étude mal élaborée. Ce dernier didacticiel examine quelques-unes des possibilités de STATGRAPHICS Centurion XVI pour créer et analyser des plans d’expériences.
Considérons le cas d’un ingénieur souhaitant déterminer les variables de son procédé qui ont le plus grand impact sur le produit final. Il envisage d’étudier l’impact lié aux variations de 5 facteurs : température, écoulement, concentration, agitation et catalyseur. En pratique, ce problème peut être traité de plusieurs façons, dont :
1. Essai et erreur : sélection arbitraire d’une combinaison des facteurs à chaque fois qu’une expérience est effectuée. Une telle approche donne rarement des résultats intéressants.
2. Un facteur à la fois : maintien de tous les facteurs sauf un à des niveaux constants pour déterminer l’effet d’un facteur. Cette approche est particulièrement inefficace et peut être trompeuse s’il existe des interactions entre les facteurs.
3. Utiliser un plan d’expériences conçu statistiquement : définition d’une séquence d’expériences à mettre en oeuvre permettant d’obtenir le plus d’informations possibles sur les facteurs et leurs interactions tout en réalisant le plus petit nombre possible d’expériences.
Ce didacticiel décrit comment bâtir un plan d’expériences en utilisant la troisième approche et comment les données résultantes sont analysées.
Chapitre
16

268/ Plans d’expériences
16.1 Créer le plan
STATGRAPHICS Centurion XVI possède un Assistant pour les plans d’expériences qui guide les utilisateurs dans la construction et l’analyse d’un plan d’expériences. Pour accéder à cet assistant :
1. Par le menu classique, sélectionner Plans d’expériences – Assistant pour les plans d’expériences.
2. Par le menu Six Sigma, sélectionner Innover –Assistant pour les plans d’expériences.
Une nouvelle fenêtre est créée contenant une barre d’outils qui vous guidera au travers d’une séquence de 12 étapes :
Figure 16-1. Fenêtre principale de l’assistant pour les plans d’expériences avec sa barre d’outils à 12 étapes
Les 7 premières étapes permettent d’élaborer le plan d’expériences et sont mises en oeuvre avant que les expériences ne soient faites. Les 5 dernières étapes sont mises en oeuvre une fois les expériences réalisées et permettent d’analyser les résultats collectés.
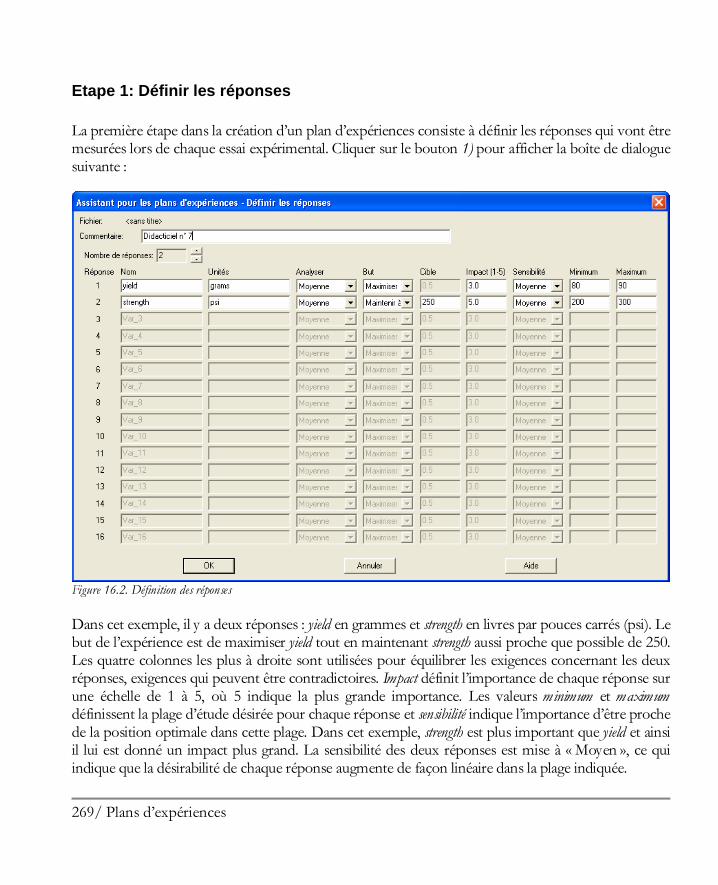
269/ Plans d’expériences
Etape 1: Définir les réponses
La première étape dans la création d’un plan d’expériences consiste à définir les réponses qui vont être mesurées lors de chaque essai expérimental. Cliquer sur le bouton 1) pour afficher la boîte de dialogue suivante :
Figure 16.2. Définition des réponses
Dans cet exemple, il y a deux réponses : yield en grammes et strength en livres par pouces carrés (psi). Le but de l’expérience est de maximiser yield tout en maintenant strength aussi proche que possible de 250. Les quatre colonnes les plus à droite sont utilisées pour équilibrer les exigences concernant les deux réponses, exigences qui peuvent être contradictoires. Impact définit l’importance de chaque réponse sur une échelle de 1 à 5, où 5 indique la plus grande importance. Les valeurs minimum et maximum définissent la plage d’étude désirée pour chaque réponse et sensibilité indique l’importance d’être proche de la position optimale dans cette plage. Dans cet exemple, strength est plus important que yield et ainsi il lui est donné un impact plus grand. La sensibilité des deux réponses est mise à « Moyen », ce qui indique que la désirabilité de chaque réponse augmente de façon linéaire dans la plage indiquée.
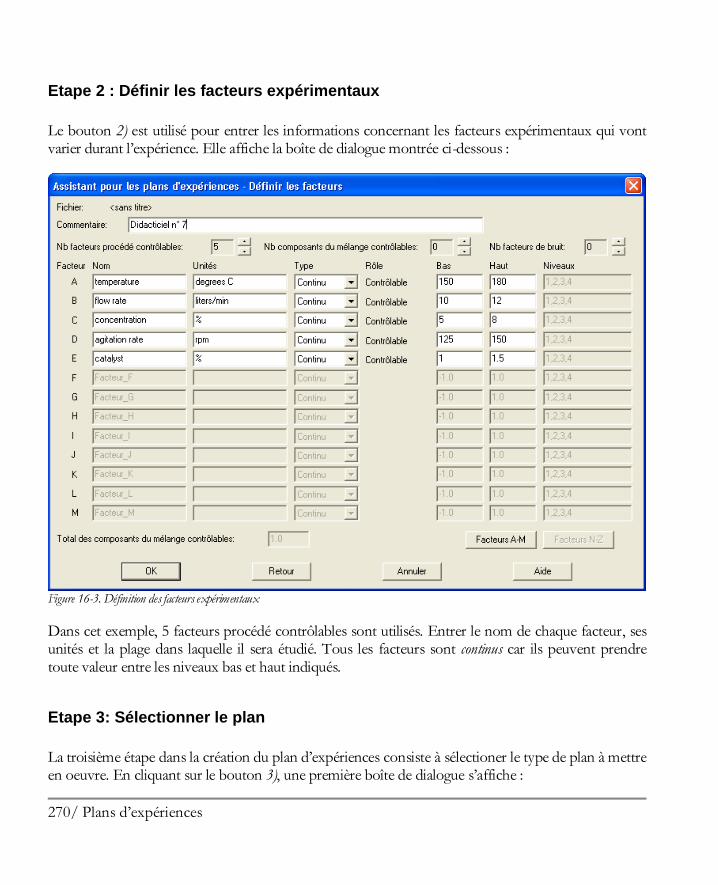
270/ Plans d’expériences
Etape 2 : Définir les facteurs expérimentaux
Le bouton 2) est utilisé pour entrer les informations concernant les facteurs expérimentaux qui vont varier durant l’expérience. Elle affiche la boîte de dialogue montrée ci-dessous :
Figure 16-3. Définition des facteurs expérimentaux
Dans cet exemple, 5 facteurs procédé contrôlables sont utilisés. Entrer le nom de chaque facteur, ses unités et la plage dans laquelle il sera étudié. Tous les facteurs sont continus car ils peuvent prendre toute valeur entre les niveaux bas et haut indiqués.
Etape 3: Sélectionner le plan
La troisième étape dans la création du plan d’expériences consiste à sélectioner le type de plan à mettre en oeuvre. En cliquant sur le bouton 3), une première boîte de dialogue s’affiche :
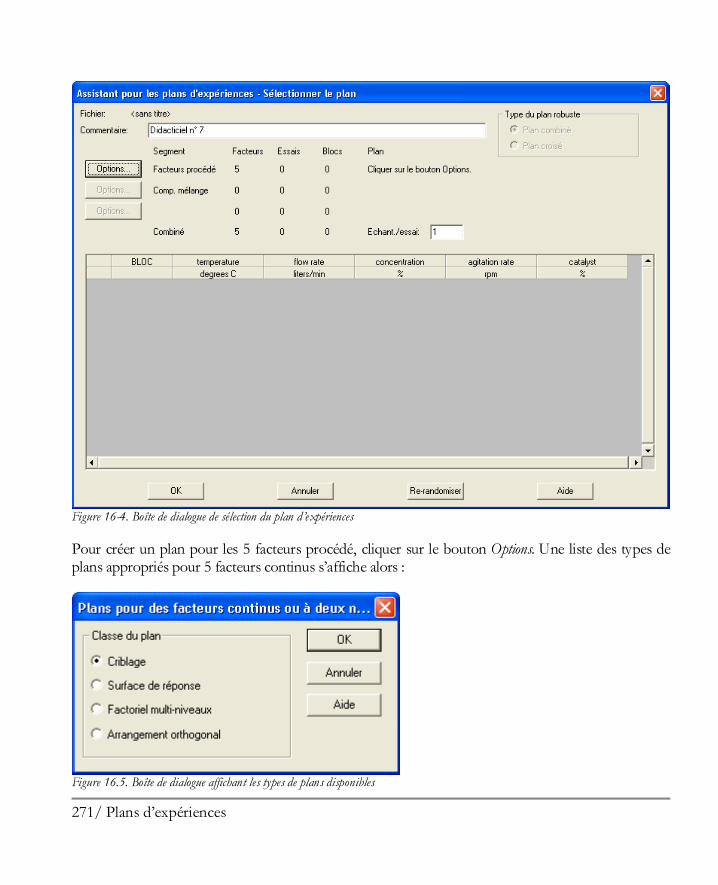
271/ Plans d’expériences
Figure 16-4. Boîte de dialogue de sélection du plan d’expériences
Pour créer un plan pour les 5 facteurs procédé, cliquer sur le bouton Options. Une liste des types de plans appropriés pour 5 facteurs continus s’affiche alors :
Figure 16.5. Boîte de dialogue affichant les types de plans disponibles
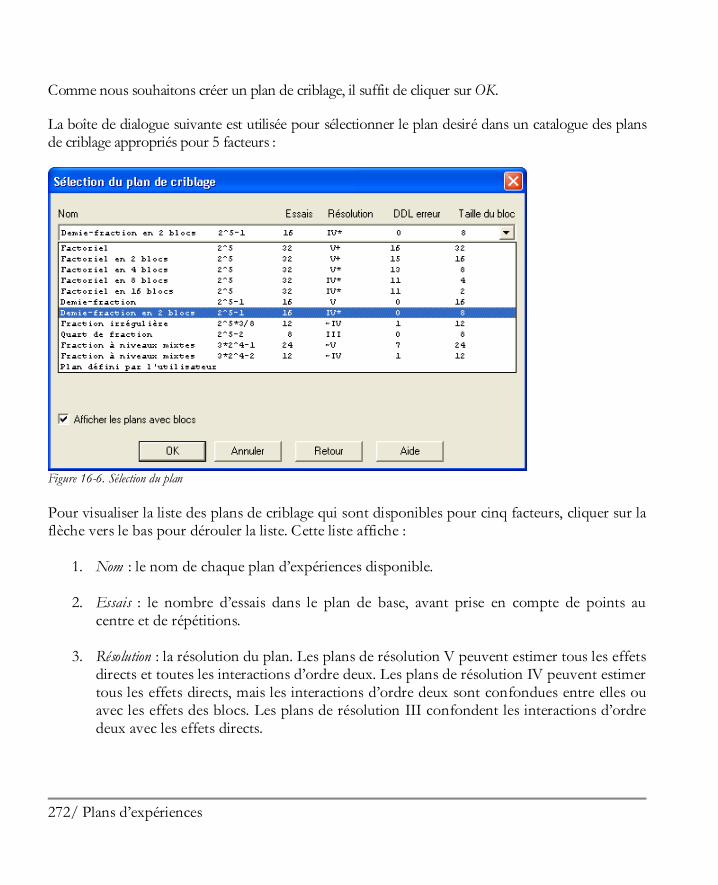
272/ Plans d’expériences
Comme nous souhaitons créer un plan de criblage, il suffit de cliquer sur OK.
La boîte de dialogue suivante est utilisée pour sélectionner le plan desiré dans un catalogue des plans de criblage appropriés pour 5 facteurs :
Figure 16-6. Sélection du plan
Pour visualiser la liste des plans de criblage qui sont disponibles pour cinq facteurs, cliquer sur la flèche vers le bas pour dérouler la liste. Cette liste affiche :
1. Nom : le nom de chaque plan d’expériences disponible.
2. Essais : le nombre d’essais dans le plan de base, avant prise en compte de points au centre et de répétitions.
3. Résolution : la résolution du plan. Les plans de résolution V peuvent estimer tous les effets
directs et toutes les interactions d’ordre deux. Les plans de résolution IV peuvent estimer tous les effets directs, mais les interactions d’ordre deux sont confondues entre elles ou avec les effets des blocs. Les plans de résolution III confondent les interactions d’ordre deux avec les effets directs.

273/ Plans d’expériences
4. DDL erreur : le nombre de degrés de liberté disponibles pour estimer l’erreur expérimentale. La puissance des tests statistiques est liée à ce nombre de degrés de liberté, ainsi qu’au nombre total d’essais dans le plan d’expériences. Normalement, au moins 3 degrés de liberté doivent être disponibles, même si plus est préférable.
5. Taille du bloc : le nombre d’essais dans le plus grand bloc.
Dans notre cas, l’ingénieur a sélectionné un plan en demie-fraction comportant deux blocs de 8 essais chacun. La boîte de dialogue finale est utilisée pour ajouter des points au centre ou des réplications d’essais :
Figure 16-7. Boîte de dialogue des options pour le plan de criblage avec blocs
Les champs à renseigner sont :
1. Points au centre : le nombre d’essais à effectuer au centre du domaine expérimental. Ajouter des points au centre est une bonne façon d’ajouter des degrés de liberté pour l’erreur expérimentale.
2. Emplacement : l’emplacement des points au centre. Les choix les plus fréquents sont Aléatoire, (répartition aléatoire des points au centre parmi les autres essais) et Espacé (espacement régulier des points au centre parmi les autres essais).

274/ Plans d’expériences
3. Réplication du plan : le nombre de fois supplémentaires où chaque expérience est remise en oeuvre. La réplication de l’ensemble du plan de cette façon peut augmenter le nombre des essais à réaliser très rapidement.
4. Randomisation : indique si les essais doivent être listés dans un ordre aléatoire. La randomisation doit être effectuée à chaque fois que cela est possible pour éviter les effets perturbateurs de variables externes (comme des modifications dans le procédé au cours du temps) qui peuvent biaiser les résultats.
Pour notre expérimentation, quatre points au centre sont demandés, portant le nombre d’essais à 20 pour notre plan final. Il est également demandé de faire les expériences dans un ordre aléatoire, ce qui veut dire que l’ordre des 10 essais dans chaque bloc sera généré aléatoirement.
Après cette boîte de dialogue finale, la fenêtre Sélectionner le plan indique les essais expériementaux à réaliser :
Figure 16-8. Fenêtre de sélection du plan indiquant les essais à réaliser
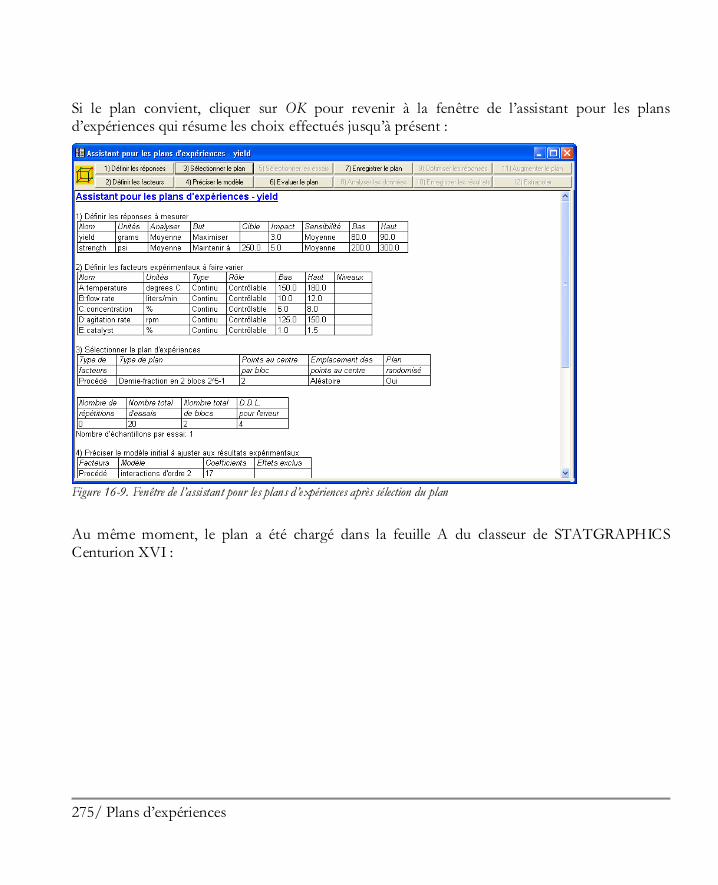
275/ Plans d’expériences
Si le plan convient, cliquer sur OK pour revenir à la fenêtre de l’assistant pour les plans d’expériences qui résume les choix effectués jusqu’à présent :
Figure 16-9. Fenêtre de l’assistant pour les plans d’expériences après sélection du plan
Au même moment, le plan a été chargé dans la feuille A du classeur de STATGRAPHICS Centurion XVI :
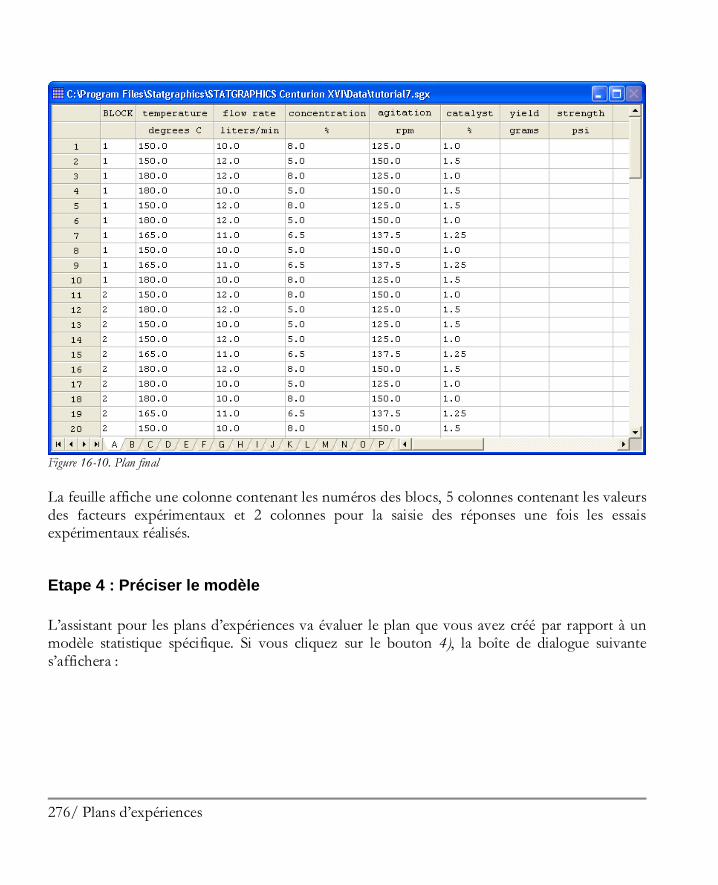
276/ Plans d’expériences
Figure 16-10. Plan final
La feuille affiche une colonne contenant les numéros des blocs, 5 colonnes contenant les valeurs des facteurs expérimentaux et 2 colonnes pour la saisie des réponses une fois les essais expérimentaux réalisés.
Etape 4 : Préciser le modèle
L’assistant pour les plans d’expériences va évaluer le plan que vous avez créé par rapport à un modèle statistique spécifique. Si vous cliquez sur le bouton 4), la boîte de dialogue suivante s’affichera :
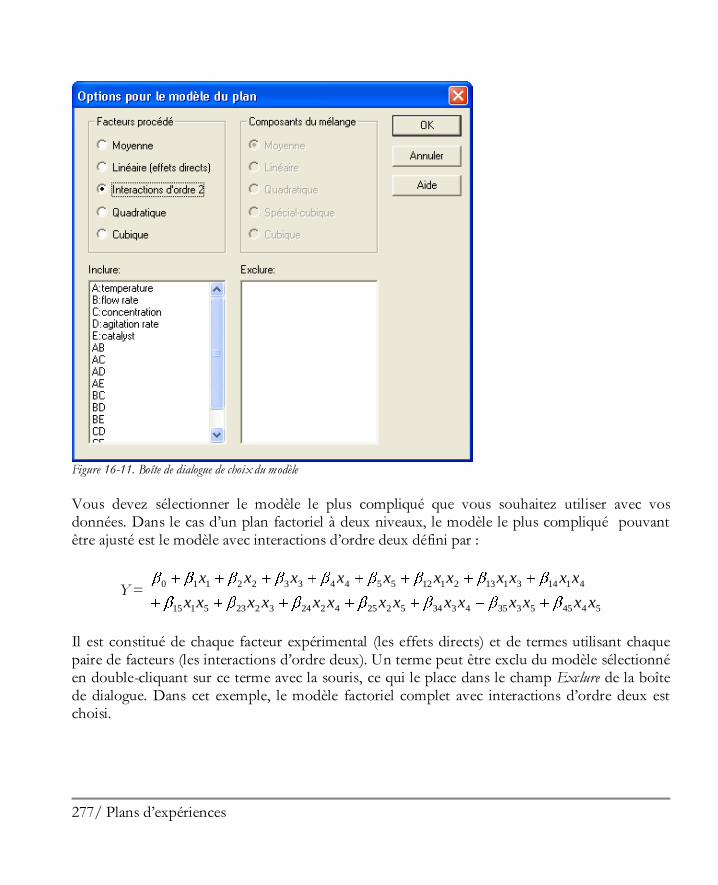
277/ Plans d’expériences
Figure 16-11. Boîte de dialogue de choix du modèle
Vous devez sélectionner le modèle le plus compliqué que vous souhaitez utiliser avec vos données. Dans le cas d’un plan factoriel à deux niveaux, le modèle le plus compliqué pouvant être ajusté est le modèle avec interactions d’ordre deux défini par :
Y = 5445533543345225422432235115
41143113211255443322110
xxxxxxxxxxxxxx
xxxxxxxxxxx
Il est constitué de chaque facteur expérimental (les effets directs) et de termes utilisant chaque paire de facteurs (les interactions d’ordre deux). Un terme peut être exclu du modèle sélectionné en double-cliquant sur ce terme avec la souris, ce qui le place dans le champ Exclure de la boîte de dialogue. Dans cet exemple, le modèle factoriel complet avec interactions d’ordre deux est choisi.

278/ Plans d’expériences
Etape 5 : Sélection des essais
Pour des plans plus compliqués, il peut être souhaitable de ne réaliser qu’un sous-ensemble des essais créés à l’étape 3. En cliquant sur le bouton 5), un algorithme de sélection des essais peut être utilisé pour créer un sous-ensemble des essais qui est D-optimal. Dans cet exemple, tous les essais seront réalisés, ainsi l’étape 5 est omise.
Etape 6 : Evaluer le plan
En cliquant sur le bouton 6), une boîte de dialogue s’affiche listant tous les tableaux et graphiques pouvant être ajoutés à la fenêtre de l’assistant pour les plans d’expériences :
Figure 16-12. Tableaux et graphiques pour l’évaluation du plan expérimental sélectionné
Une option utile pour les plans de criblage est Matrice des corrélations, qui indique s’il y a des confusions entre les termes du modèle qui va être ajusté :
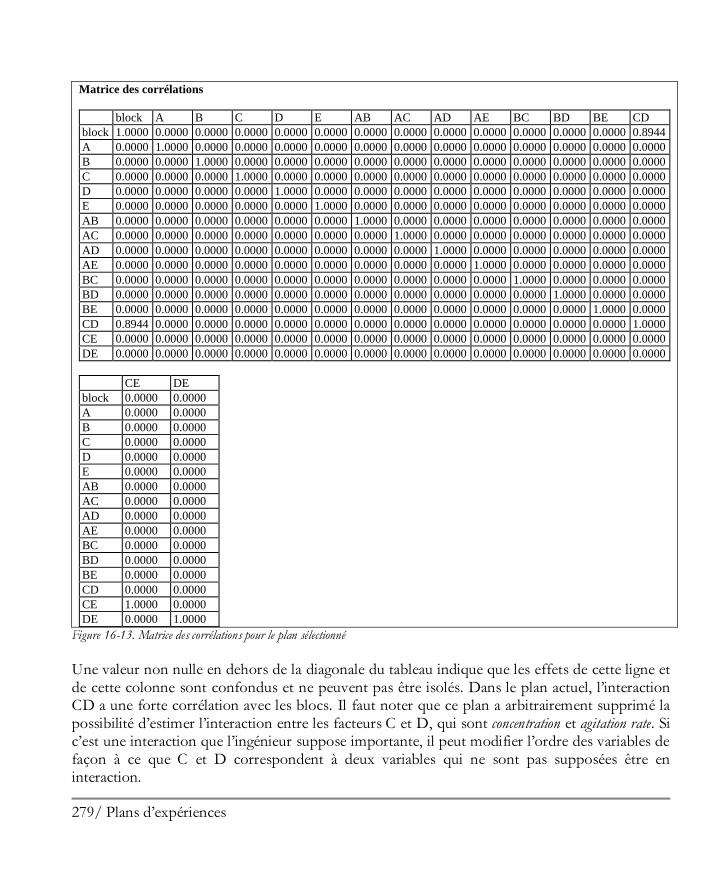
279/ Plans d’expériences
Matrice des corrélations
block A B C D E AB AC AD AE BC BD BE CD
block 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.8944
A 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
B 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
C 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
D 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
E 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
AB 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
AC 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
AD 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000
AE 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000
BC 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000
BD 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000
BE 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000
CD 0.8944 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000
CE 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
DE 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
CE DE
block 0.0000 0.0000
A 0.0000 0.0000
B 0.0000 0.0000
C 0.0000 0.0000
D 0.0000 0.0000
E 0.0000 0.0000
AB 0.0000 0.0000
AC 0.0000 0.0000
AD 0.0000 0.0000
AE 0.0000 0.0000
BC 0.0000 0.0000
BD 0.0000 0.0000
BE 0.0000 0.0000
CD 0.0000 0.0000
CE 1.0000 0.0000
DE 0.0000 1.0000
Figure 16-13. Matrice des corrélations pour le plan sélectionné
Une valeur non nulle en dehors de la diagonale du tableau indique que les effets de cette ligne et de cette colonne sont confondus et ne peuvent pas être isolés. Dans le plan actuel, l’interaction CD a une forte corrélation avec les blocs. Il faut noter que ce plan a arbitrairement supprimé la possibilité d’estimer l’interaction entre les facteurs C et D, qui sont concentration et agitation rate. Si c’est une interaction que l’ingénieur suppose importante, il peut modifier l’ordre des variables de façon à ce que C et D correspondent à deux variables qui ne sont pas supposées être en interaction.
280/ Plans d’expériences
Etape 7 : Enregistrer le plan d’expériences
En cliquant sur le bouton 7), il est possible d’enregistrer le plan d’expériences dans un fichier. La boîte de dialogue suivante s’affiche :
Figure 16-14. Boîte de dialogue pour enregistrer le plan d’expériences
Les plans d’expériences créés par l’assistant pour les plans d’expériences sont enregistrés dans des fichiers ayant le suffixe .sgx. Ils sont similaires à des fichiers de données classiques, à l’exception qu’ils contiennent des informations additionnelles concernant le plan expérimental et le modèle statistique sélectionné.

281/ Plans d’expériences
16.2 Analyser les résultats Après avoir défini le plan d’expériences, l’ingénieur doit réaliser les 20 essais indiqués. Le logiciel est ensuite redémarré, le fichier du plan d’expériences rouvert et les valeurs mesurées de yield et de strength entrées dans le tableur du plan d’expériences. Pour remettre en œuvre son analyse, vous pouvez charger le fichier tutorial7.sgx de la même façon que tout fichier de données STATGRAPHICS en sélectionnant Ouvrir une source de données dans le menu Fichier. L’ouverture d’un fichier de plan d’expériences affiche automatiquement la fenêtre de l’assistant pour les plans d’expériences.
Etape 8: Analyser les données
Pour analyser les données expérimentales, cliquer sur le bouton 8). L’analyse débute en affichant la boîte de dialogue suivante :
Figure 16-15. Boîte de dialogue Analyser les données
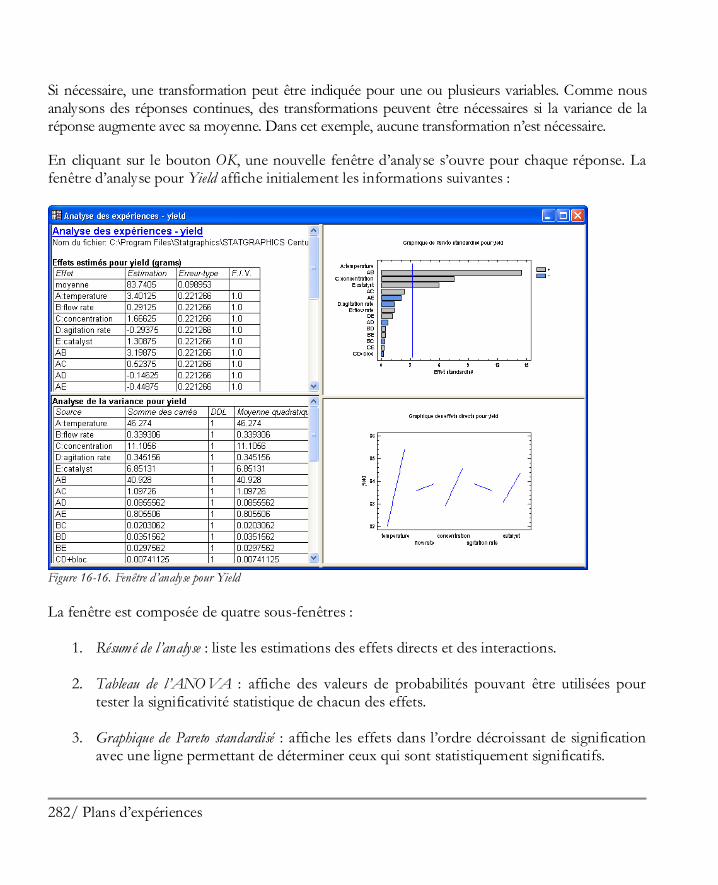
282/ Plans d’expériences
Si nécessaire, une transformation peut être indiquée pour une ou plusieurs variables. Comme nous analysons des réponses continues, des transformations peuvent être nécessaires si la variance de la réponse augmente avec sa moyenne. Dans cet exemple, aucune transformation n’est nécessaire.
En cliquant sur le bouton OK, une nouvelle fenêtre d’analyse s’ouvre pour chaque réponse. La fenêtre d’analyse pour Yield affiche initialement les informations suivantes :
Figure 16-16. Fenêtre d’analyse pour Yield
La fenêtre est composée de quatre sous-fenêtres :
1. Résumé de l’analyse : liste les estimations des effets directs et des interactions.
2. Tableau de l’ANO VA : affiche des valeurs de probabilités pouvant être utilisées pour tester la significativité statistique de chacun des effets.
3. Graphique de Pareto standardisé : affiche les effets dans l’ordre décroissant de signification
avec une ligne permettant de déterminer ceux qui sont statistiquement significatifs.
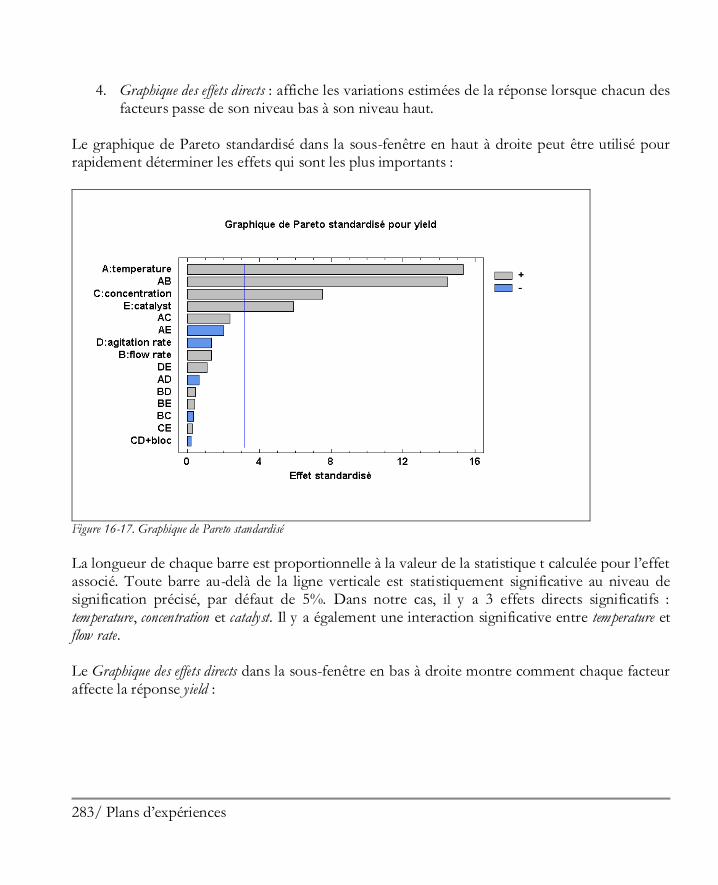
283/ Plans d’expériences
4. Graphique des effets directs : affiche les variations estimées de la réponse lorsque chacun des facteurs passe de son niveau bas à son niveau haut.
Le graphique de Pareto standardisé dans la sous-fenêtre en haut à droite peut être utilisé pour rapidement déterminer les effets qui sont les plus importants :
Figure 16-17. Graphique de Pareto standardisé
La longueur de chaque barre est proportionnelle à la valeur de la statistique t calculée pour l’effet associé. Toute barre au-delà de la ligne verticale est statistiquement significative au niveau de signification précisé, par défaut de 5%. Dans notre cas, il y a 3 effets directs significatifs : temperature, concentration et catalyst. Il y a également une interaction significative entre temperature et flow rate. Le Graphique des effets directs dans la sous-fenêtre en bas à droite montre comment chaque facteur affecte la réponse yield :
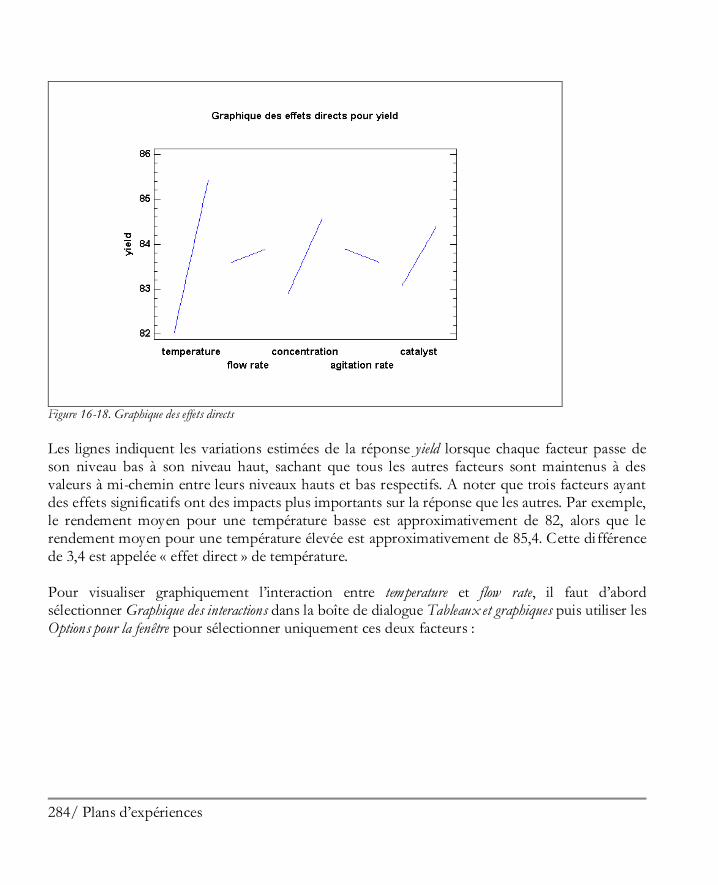
284/ Plans d’expériences
Figure 16-18. Graphique des effets directs
Les lignes indiquent les variations estimées de la réponse yield lorsque chaque facteur passe de son niveau bas à son niveau haut, sachant que tous les autres facteurs sont maintenus à des valeurs à mi-chemin entre leurs niveaux hauts et bas respectifs. A noter que trois facteurs ayant des effets significatifs ont des impacts plus importants sur la réponse que les autres. Par exemple, le rendement moyen pour une température basse est approximativement de 82, alors que le rendement moyen pour une température élevée est approximativement de 85,4. Cette différence de 3,4 est appelée « effet direct » de température. Pour visualiser graphiquement l’interaction entre temperature et flow rate, il faut d’abord sélectionner Graphique des interactions dans la boîte de dialogue Tableaux et graphiques puis utiliser les Options pour la fenêtre pour sélectionner uniquement ces deux facteurs :
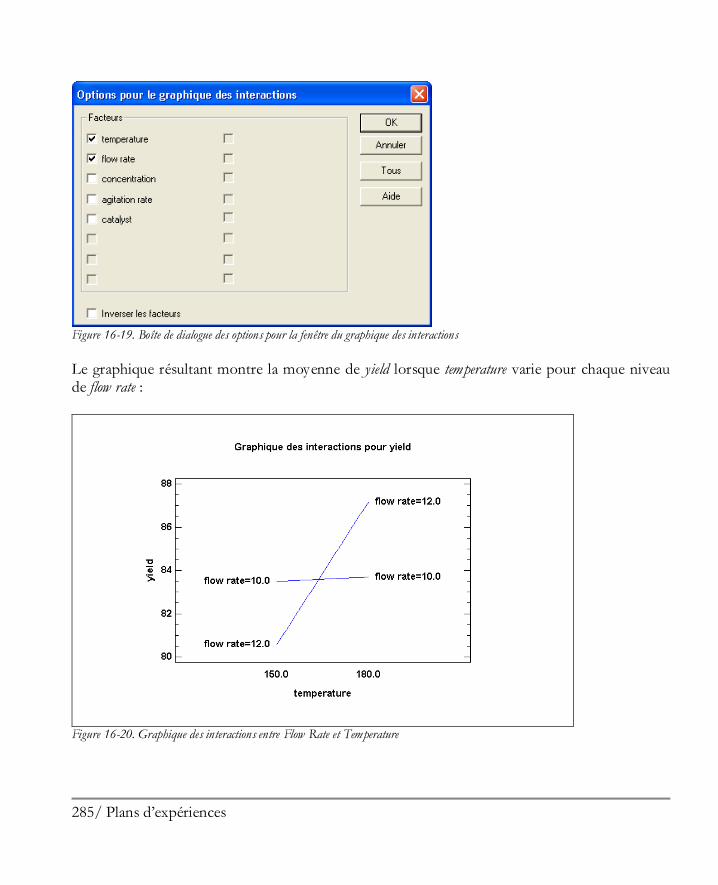
285/ Plans d’expériences
Figure 16-19. Boîte de dialogue des options pour la fenêtre du graphique des interactions
Le graphique résultant montre la moyenne de yield lorsque temperature varie pour chaque niveau de flow rate :
Figure 16-20. Graphique des interactions entre Flow Rate et Temperature

286/ Plans d’expériences
A noter que si flow rate est à son niveau bas, temperature a un faible effet sur le rendement. Par contre si flow rate est à son niveau haut, temperature est un facteur important. Avant d’utiliser un modèle statistique dans cette analyse, il est important de retirer les effets non significatifs. Pour retirer ces effets :
1. Cliquer sur le bouton Options d’analyse dans la barre des outils d’analyse.
2. Cliquer sur le bouton Exclure dans la boîte de dialogue des options pour l’estimation des effets.
3. Dans la boîte de dialogue Options pour l’exclusion d’effets, double-cliquer sur chacun des
effets que vous souhaitez exclure, ce qui le déplace de la colonne Inclure vers la colonne Exclure :
Figure 16-21. Boîte de dialogue pour l’exclusion d’effets
La règle à suivre lors de l’exclusion d’effets est la suivante :
1. Exclure toutes les interactions entre deux facteurs non significatives.
2. Exclure tous les effets directs non significatifs et qui ne sont pas présents dans des interactions significatives.
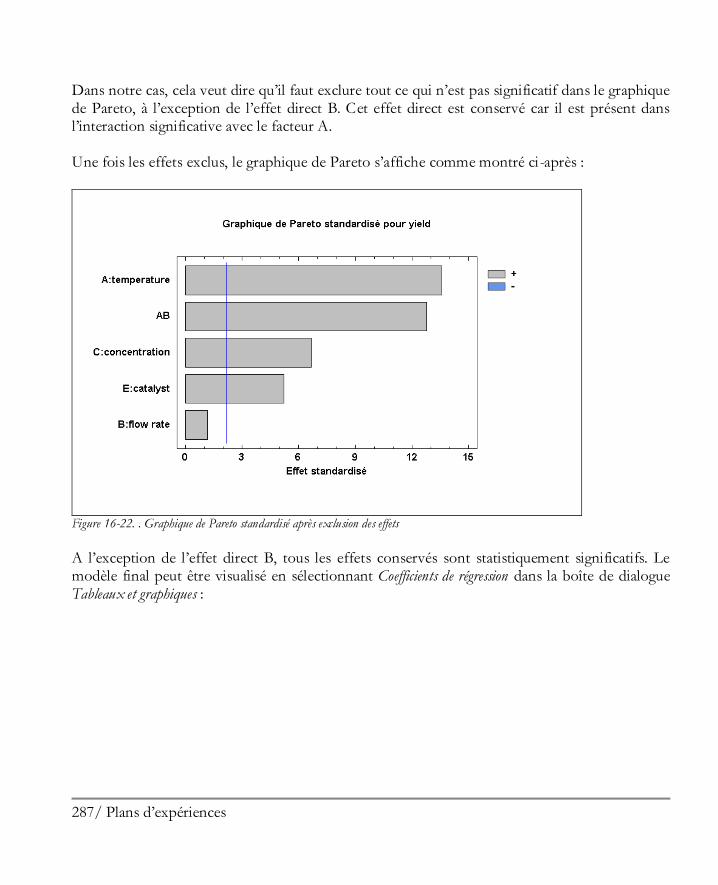
287/ Plans d’expériences
Dans notre cas, cela veut dire qu’il faut exclure tout ce qui n’est pas significatif dans le graphique de Pareto, à l’exception de l’effet direct B. Cet effet direct est conservé car il est présent dans l’interaction significative avec le facteur A. Une fois les effets exclus, le graphique de Pareto s’affiche comme montré ci-après :
Figure 16-22. . Graphique de Pareto standardisé après exclusion des effets
A l’exception de l’effet direct B, tous les effets conservés sont statistiquement significatifs. Le modèle final peut être visualisé en sélectionnant Coefficients de régression dans la boîte de dialogue Tableaux et graphiques :
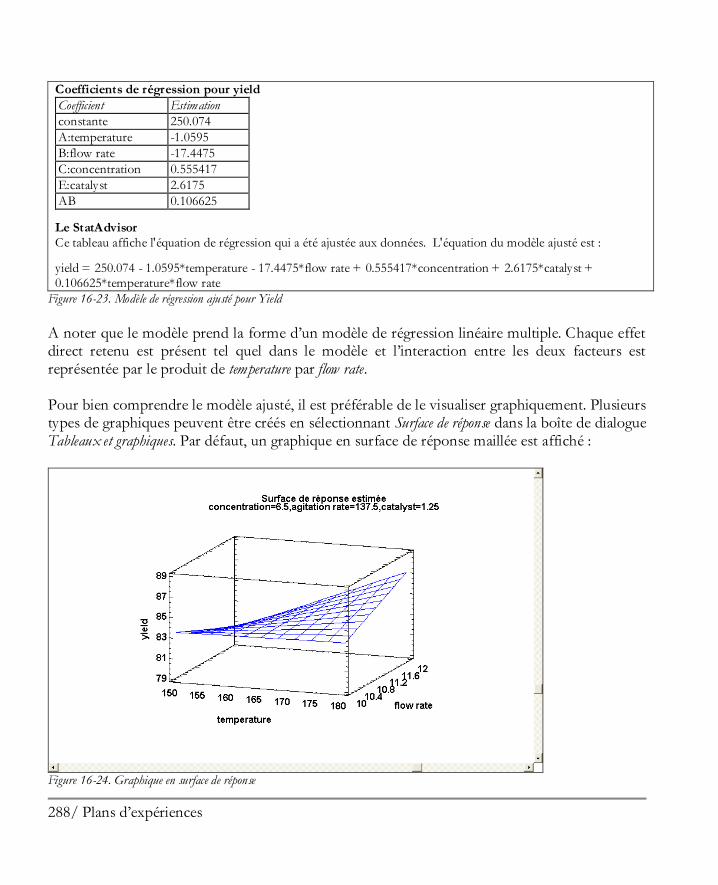
288/ Plans d’expériences
Coefficients de régression pour yield
Coefficient Estimation
constante 250.074
A:temperature -1.0595
B:flow rate -17.4475
C:concentration 0.555417
E:catalyst 2.6175
AB 0.106625
Le StatAdvisor Ce tableau affiche l'équation de régression qui a été ajustée aux données. L'équation du modèle ajusté est :
yield = 250.074 - 1.0595*temperature - 17.4475*flow rate + 0.555417*concentration + 2.6175*catalyst + 0.106625*temperature*flow rate
Figure 16-23. Modèle de régression ajusté pour Yield
A noter que le modèle prend la forme d’un modèle de régression linéaire multiple. Chaque effet direct retenu est présent tel quel dans le modèle et l’interaction entre les deux facteurs est représentée par le produit de temperature par flow rate. Pour bien comprendre le modèle ajusté, il est préférable de le visualiser graphiquement. Plusieurs types de graphiques peuvent être créés en sélectionnant Surface de réponse dans la boîte de dialogue Tableaux et graphiques. Par défaut, un graphique en surface de réponse maillée est affiché :
Figure 16-24. Graphique en surface de réponse

289/ Plans d’expériences
Dans ce graphique, la hauteur de la surface représente la valeur prévue de yield dans les plages affichées de temperature et de flow rate, avec les trois autres facteurs maintenus fixés aux valeurs moyennes respectives. Les plus grands rendements sont obtenus pour une température élevée et un écoulement élevé. Le type du graphique et les facteurs utilisés pour afficher la réponse peuvent être modifiés en utilisant les Options pour la fenêtre :
Figure 16-25. Options pour la fenêtre pour le graphique en surface de réponse
Les types de graphiques qui peuvent être créés sont :
1. Surface : affiche l’équation ajustée sous la forme d’une surface 3D par rapport à deux facteurs expérimentaux quelconques. La surface peut être maillée, unie ou contourée. L’option Contours au-dessous ajoute les iso-contours en pied du graphique.

290/ Plans d’expériences
2. Contour : crée un graphique 2D des iso-contours par rapport à deux facteurs expérimentaux quelconques. Les contours peuvent être affichés comme des lignes, à l’identique d’une carte topographique, comme des régions peintes ou en utilisant une coloration continue.
3. Carré : affiche la région expérimentale par rapport à deux facteurs expérimentaux
quelconques et indique les valeurs prévues de la réponse en chaque sommet du carré.
4. Cube : affiche la région expérimentale par rapport à trois facteurs expérimentaux quelconques et indique les valeurs prévues de la réponse en chaque sommet du cube. Pour créer ce graphique, il faut préalablement cliquer sur le bouton Facteurs et sélectionner un troisième facteur.
5. Contours 3-D : affiche des contours pour la réponse par rapport à 3 facteurs
expérimentaux simultanément.
6. Maillage 3-D : crée un graphique maillé affichant la valeur de la réponse dans une région expérimentale à 3 dimensions.
Le bouton Facteurs est utilisé pour sélectionner les facteurs qui définissent les axes des graphiques et les valeurs auxquelles les autres facteurs sont maintenus :
291/ Plans d’expériences
Figure 16-26. Boîte de dialogue des options pour le choix des facteurs
Pour créer le graphique ci-après, le champ Contours a été positionné à Régions peintes, la Surface à Unie avec des Contours au-dessous et la plage pour les contours définie de 81 à 86 par pas de 1 :
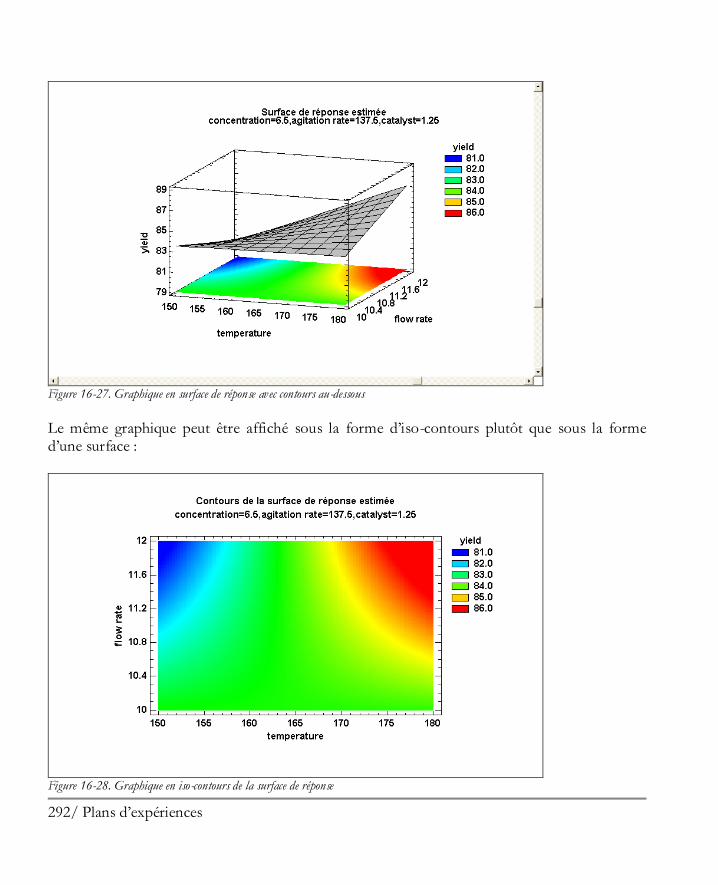
292/ Plans d’expériences
Figure 16-27. Graphique en surface de réponse avec contours au-dessous
Le même graphique peut être affiché sous la forme d’iso-contours plutôt que sous la forme d’une surface :
Figure 16-28. Graphique en iso-contours de la surface de réponse
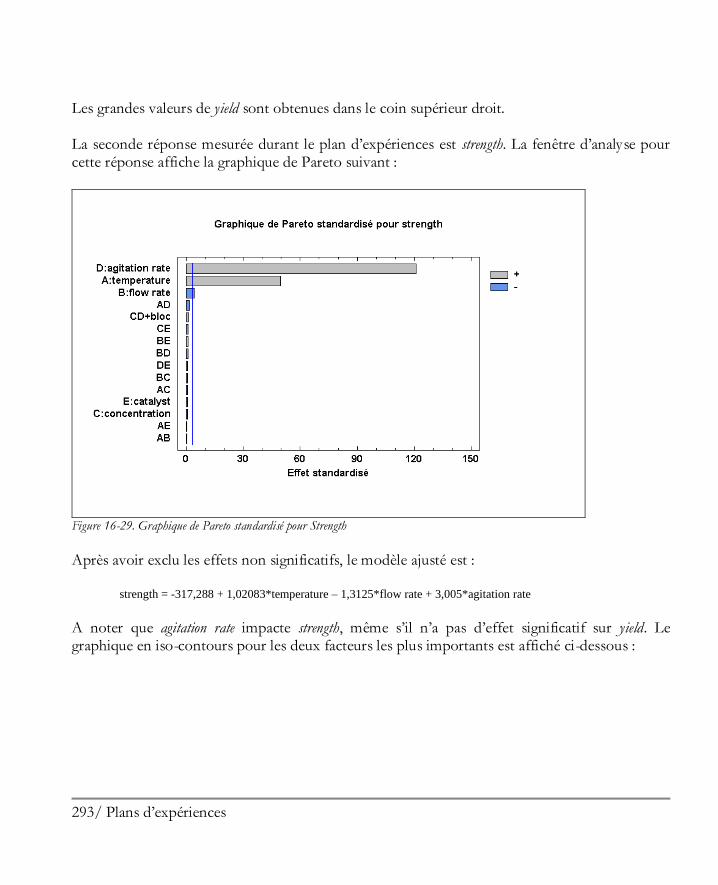
293/ Plans d’expériences
Les grandes valeurs de yield sont obtenues dans le coin supérieur droit. La seconde réponse mesurée durant le plan d’expériences est strength. La fenêtre d’analyse pour cette réponse affiche la graphique de Pareto suivant :
Figure 16-29. Graphique de Pareto standardisé pour Strength
Après avoir exclu les effets non significatifs, le modèle ajusté est :
strength = -317,288 + 1,02083*temperature – 1,3125*flow rate + 3,005*agitation rate
A noter que agitation rate impacte strength, même s’il n’a pas d’effet significatif sur yield. Le graphique en iso-contours pour les deux facteurs les plus importants est affiché ci-dessous :
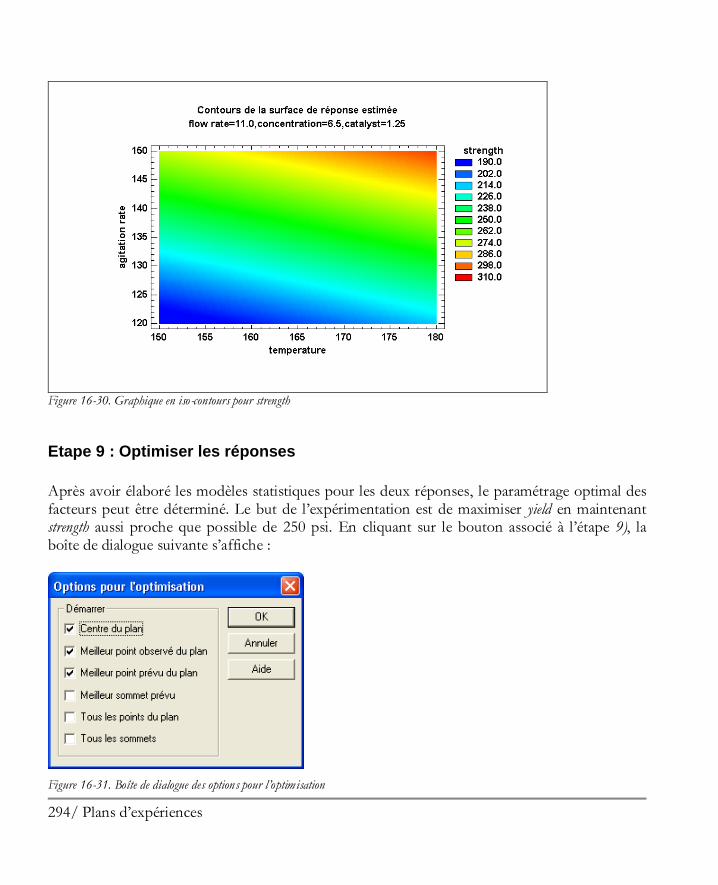
294/ Plans d’expériences
Figure 16-30. Graphique en iso-contours pour strength
Etape 9 : Optimiser les réponses
Après avoir élaboré les modèles statistiques pour les deux réponses, le paramétrage optimal des facteurs peut être déterminé. Le but de l’expérimentation est de maximiser yield en maintenant strength aussi proche que possible de 250 psi. En cliquant sur le bouton associé à l’étape 9), la boîte de dialogue suivante s’affiche :
Figure 16-31. Boîte de dialogue des options pour l’optimisation

295/ Plans d’expériences
Puisque le logiciel effectuera une recherche numérique de la meilleure position dans la région expérimentale, il est bon de démarrer cette recherche à partir de plusieurs points de façon à éviter de trouver un optimum local. Cliquer sur OK pour démarrer la recherche. Après quelques instants, le message suivant s’affichera :
Figure 16-32. Message affiché lorsque l’optimisation est terminée
Au même moment, le tableau ci-dessous est ajouté dans la fenêtre principale de l’assistant pour les plans d’expériences :
9) Optimiser les réponses Réponse Valeurs à l'optimum
Réponse Prévision Limite inférieure à 95.0% Limite supérieure à 95.0% Désirabilité
yield 88.6734 78.5661 98.7808 0.867344
strength 250.0 187.505 312.495 1.0
Désirabilité globale = 0.948029 Valeurs des facteurs à l'optimum
Facteur Valeur
temperature 180.0
flow rate 12.0
concentration 8.0
agitation rate 132.946
catalyst 1.49998
Figure 16-33. Résumé de l’optimisation ajouté à la fenêtre de l’assistant pour les plans d ’expériences
Pour le paramétrage indiqué des facteurs, il est estimé que yield est égal à 88,67 grammes et strength à 250 psi. La désirabilité de yield est de 0,867, car distant de 86,7% dans la plage s’étendant de 80 à 90 grammes. Strength a une désirabilité de 1, car exactement sur la cible. La désirabilité globale est égale à 0,948 et est calculée à partir de la désirabilité de chaque réponse, en l’élevant à la puissance indiquée comme impact, en multipliant les résultats ensemble et en élevant le produit a une puissance égale à 1 divisé par la somme des impacts. Le résultat est un nombre compris entre 0 et 1, avec un poids plus grand donné à la réponse ayant le plus fort impact.
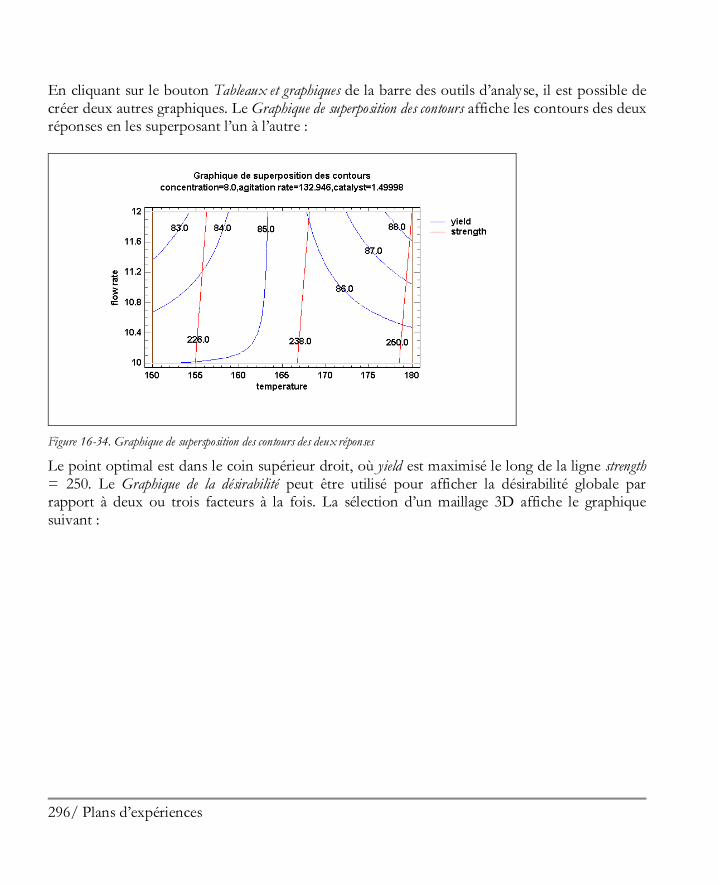
296/ Plans d’expériences
En cliquant sur le bouton Tableaux et graphiques de la barre des outils d’analyse, il est possible de créer deux autres graphiques. Le Graphique de superposition des contours affiche les contours des deux réponses en les superposant l’un à l’autre :
Figure 16-34. Graphique de supersposition des contours des deux réponses
Le point optimal est dans le coin supérieur droit, où yield est maximisé le long de la ligne strength = 250. Le Graphique de la désirabilité peut être utilisé pour afficher la désirabilité globale par rapport à deux ou trois facteurs à la fois. La sélection d’un maillage 3D affiche le graphique suivant :
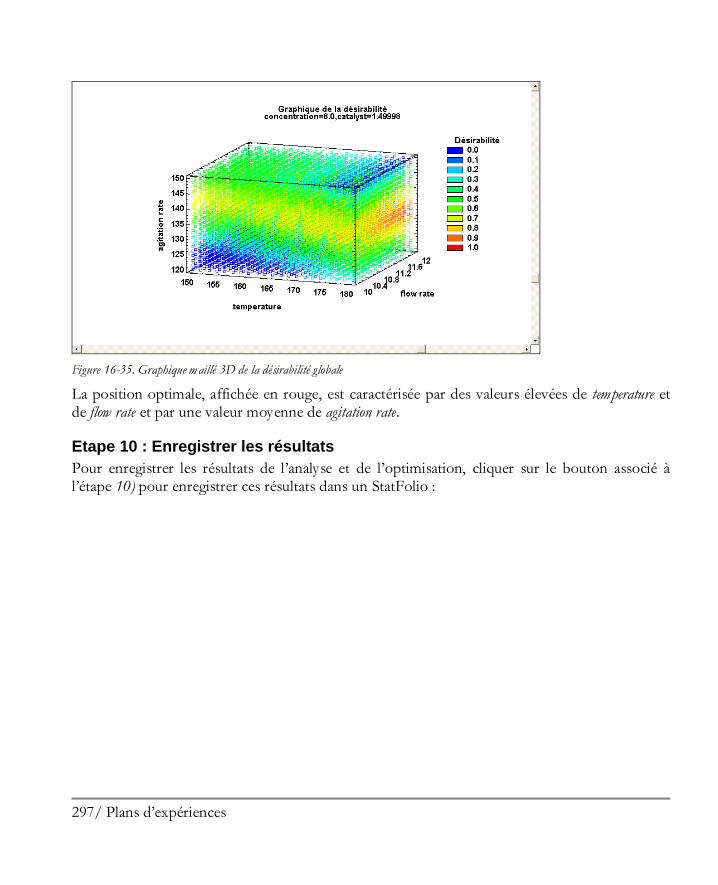
297/ Plans d’expériences
Figure 16-35. Graphique maillé 3D de la désirabilité globale
La position optimale, affichée en rouge, est caractérisée par des valeurs élevées de temperature et de flow rate et par une valeur moyenne de agitation rate.
Etape 10 : Enregistrer les résultats
Pour enregistrer les résultats de l’analyse et de l’optimisation, cliquer sur le bouton associé à l’étape 10) pour enregistrer ces résultats dans un StatFolio :
298/ Plans d’expériences
Figure 16-36. Boîte de dialogue d’enregistrement des résultats
16.3 Expériences complémentaires Si des expériences complémentaires sont souhaitées, STATGRAPHICS Centurion XVI peut vous aider en augmentant le plan existant ou en générant des points le long du chemin de la plus grande pente.
Etape 11 : Augmenter le plan
En cliquant sur le bouton associé à l’étape 11), il est possible d’ajouter des essais additionnels au plan courant. La boîte de dialogue montrée ci-dessous s’affiche alors :
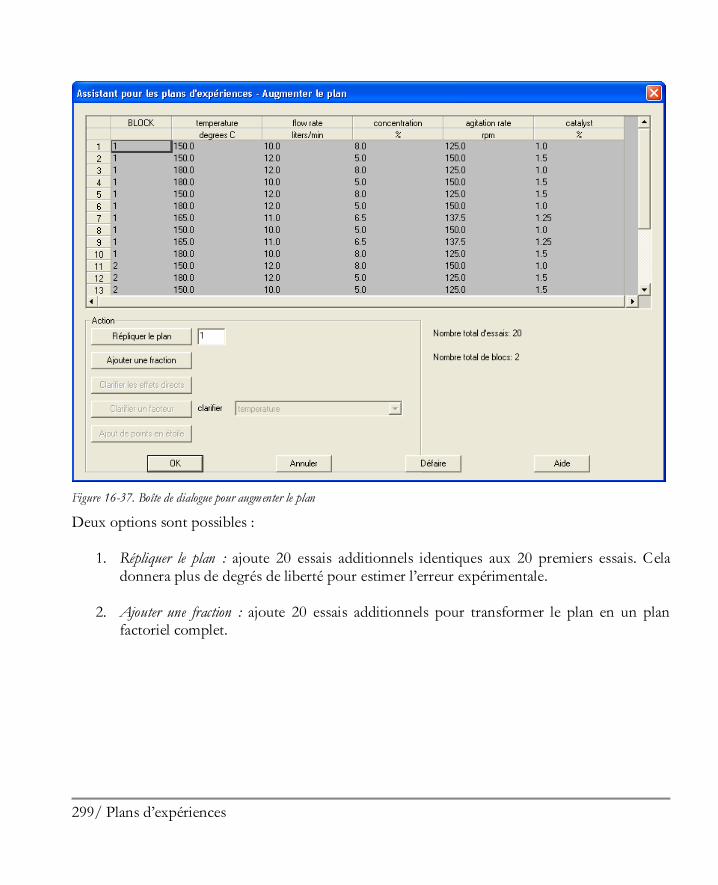
299/ Plans d’expériences
Figure 16-37. Boîte de dialogue pour augmenter le plan
Deux options sont possibles :
1. Répliquer le plan : ajoute 20 essais additionnels identiques aux 20 premiers essais. Cela donnera plus de degrés de liberté pour estimer l’erreur expérimentale.
2. Ajouter une fraction : ajoute 20 essais additionnels pour transformer le plan en un plan
factoriel complet.

300/ Plans d’expériences
Etape 12 : Extrapoler
Il est possible de générer des points le long du chemin de la plus grande pente, dans le but de se déplacer rapidement dans des régions où le rendement est plus élevé, à partir d’un point donné de la région expérimentale et en se déplaçant dans la direction de plus forte variation de la réponse estimée pour les plus faibles modifications des facteurs expérimentaux. Suivre ce chemin peut être très utile pour obtenir des améliorations importantes très rapidement. En cliquant sur le bouton associé à l’étape 12), la boîte de dialogue suivante s’affiche :
Figure 16-38. Boîte de dialogue des options d’extrapolation
Les informations entrées dans la boîte de dialogue ci -dessus indiquent au logiciel de démarrer à l’optimum calculé et de faire varier 5 facteurs entre des bornes basses et hautes qui doublent la largeur de la région expérimentale dans chaque dimension. Il est demandé d’afficher les
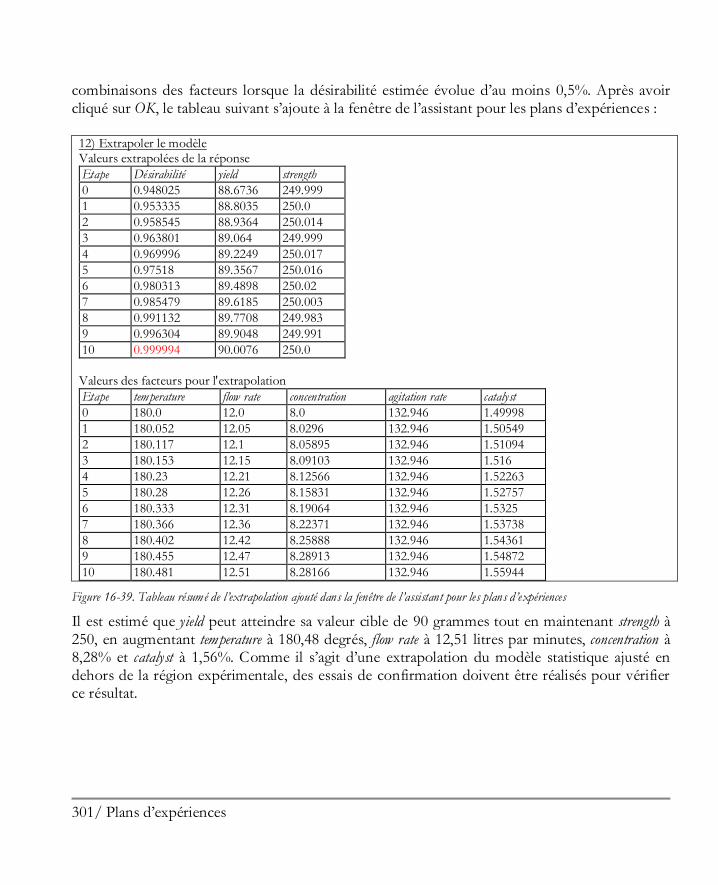
301/ Plans d’expériences
combinaisons des facteurs lorsque la désirabilité estimée évolue d’au moins 0,5%. Après avoir cliqué sur OK, le tableau suivant s’ajoute à la fenêtre de l’assistant pour les plans d’expériences :
12) Extrapoler le modèle Valeurs extrapolées de la réponse
Etape Désirabilité yield strength
0 0.948025 88.6736 249.999
1 0.953335 88.8035 250.0
2 0.958545 88.9364 250.014
3 0.963801 89.064 249.999
4 0.969996 89.2249 250.017
5 0.97518 89.3567 250.016
6 0.980313 89.4898 250.02
7 0.985479 89.6185 250.003
8 0.991132 89.7708 249.983
9 0.996304 89.9048 249.991
10 0.999994 90.0076 250.0
Valeurs des facteurs pour l'extrapolation
Etape temperature flow rate concentration agitation rate catalyst
0 180.0 12.0 8.0 132.946 1.49998
1 180.052 12.05 8.0296 132.946 1.50549
2 180.117 12.1 8.05895 132.946 1.51094
3 180.153 12.15 8.09103 132.946 1.516
4 180.23 12.21 8.12566 132.946 1.52263
5 180.28 12.26 8.15831 132.946 1.52757
6 180.333 12.31 8.19064 132.946 1.5325
7 180.366 12.36 8.22371 132.946 1.53738
8 180.402 12.42 8.25888 132.946 1.54361
9 180.455 12.47 8.28913 132.946 1.54872
10 180.481 12.51 8.28166 132.946 1.55944
Figure 16-39. Tableau résumé de l’extrapolation ajouté dans la fenêtre de l’assistant pour les plans d’expériences
Il est estimé que yield peut atteindre sa valeur cible de 90 grammes tout en maintenant strength à 250, en augmentant temperature à 180,48 degrés, flow rate à 12,51 litres par minutes, concentration à 8,28% et catalyst à 1,56%. Comme il s’agit d’une extrapolation du modèle statistique ajusté en dehors de la région expérimentale, des essais de confirmation doivent être réalisés pour vérifier ce résultat.

302/ Plans d’expériences

303/Livres suggérés
Livres suggérés
Les livres suivants sont d’excellentes sources d’informations sur les techniques statistiques décrites dans ce manuel :
Statistiques de base : Applied Statistics and Probability for Engineers, 4ème édition par Douglas C. Montgomery et George C. Runger (2006). John Wiley and Sons, New York.
Analyse de la variance : Applied Linear Statistical Models, 5ème édition par Michael H. Kutner, Christopher J. Nachtsheim et John Neter (2004). McGraw Hill.
Méthodes de régression : Applied Linear Regression, 3ème édition par Sanford Weisberg (2005). John Wiley and Sons, New York.
Maîtrise statistique des procédés : Introduction to Statistical Quality Control, 6ème édition par Douglas C. Montgomery (2008). John Wiley and Sons, New York.
Plans d’expériences : Statistics for Experimenters: Design, Innovation and Discovery, 2ème édition par George E. P. Box, William G. Hunter et J. Stuart Hunter (2005). John Wiley and Sons, New York.

304/Livres suggérés

305/Fichiers des données
Fichiers des données
93cars.sgd
Ces données ont été téléchargées depuis le site Web du « Journal of Statistical Education ». Elles ont été réunies par Robin Lock du département mathématique de l’Université St. Lawrence et sont utilisées avec sa permission. Un article, associé à ce jeu de données, est paru dans le Journal of Statistics Education, volume 1, numéro 1 (juillet 1993).
bodytemp.sgd
Ces données ont également été téléchargées depuis le site Web du « Journal of Statistical Education ». Elles ont été réunies par Allen Shoemaker du département de psychologie du « Calvin College » et sont utilisées avec sa permission. Ces données sont issues d’un article paru dans le Journal of the American Medical Association (1992, vol. 268, pp. 1578-1580) intitulé « A Critical Appraisal of 98.6 Degrees F, the Upper Limit of the Normal Body Temperature, and Other Legacies of Carl Reinhold August Wunderlich » par P. A. Mackowiak, S. S. Wasserman et M. M. Levine. Un article associé au jeu de données est paru dans le Journal of Statistics Education , volume 4, numéro 2 (juillet 1996).
Site Web des données du Journal of Statistical Education (JSE) :
http://www.amstat.org/publications/jse/jse_data_archive.html

306/Fichiers des données

307/Index
Index
ABS ............................................................ 47 Analyse à une variable ........................ 22, 152, 249 Analyse d’aptitude .......................................... 251 analyse d’aptitude d’un procédé ................... 248 analyse de la variance .................................. 197 Analyse de Pareto ........................................... 232 analyse de régression ................................... 208 analyse des corrélations ............................... 209 analyse des moyennes .................................. 207 ANOM ...................................................... 207 ANOVA .................................................... 197 ANOVA graphique..................................... 198 aplatissement .............................................. 156 asymétrie .................................................... 156 augmenter le plan........................................ 301 AVG ........................................................... 47 barre d’outils d’analyse ............................ 25, 68 boîte de dialogue d’entrée des données ..... 65, 68 boîtes à moustaches ............................ 182, 203 brosser un nuage de points ........................... 99 Calculatrice Six Sigma .................................... 266 centiles ....................................................... 156 champs de sélection ..................................... 66 chemin de la plus grande pente .................... 303 Classeur ................................................. 14, 34 coefficients de régression ............................ 290 colonne de données
commentaire ................................. 16, 36 nom.............................................. 15, 36 type .............................................. 16, 36
Comparaison de deux échantillons ....................... 179 Comparaison de plusieurs échantillons .................. 193 Configuration de l’impression ............................. 148 contrat de licence ........................................... 4 COUNT ..................................................... 57
Cp ............................................................. 265 Cpk ............................................................. 262 dates .......................................................... 147 diagramme circulaire ................................... 232 diagramme en barres 3D .................................. 241 diagramme en bâtons ........................... 232, 240 DIFF ........................................................... 47 données
accès .................................................. 37 coller ................................................. 42 combiner plusieurs colonnes ............... 53 copier ................................................ 42 couper ............................................... 42 entrée ................................................ 14 fichiers ............................................... 19 générer .............................................. 55 insérer................................................ 42 nouvelles variables .............................. 43 recodage .......................................... 243 recoder .............................................. 52 structurées ......................................... 56 supprimer .......................................... 42 tableur ............................................... 14 transformations .................................. 46 trier ................................................... 50
données qualitatives .................................... 230 DPM .................................................. 259, 262 écart-type ................................................... 156 encoche sur la médiane ............................... 159 Enregistrement automatique ......................... 74, 147 Enregistrer les résultats ...................................... 74 en-têtes des analyses ................................... 148 éparpiller un nuage de points .................. 97, 196

308/ Index
ET .............................................................. 67 études R&R ............................................... 133 exclusion d’effets ....................................... 289 EXP ............................................................ 47 extrapoler .................................................. 303 fenêtre d’analyse .......................................... 23 fichiers ASCII .............................................. 39 fichiers de données
acquérir .............................................. 60 lecture ................................................ 38 lecture uniquement ............................. 60
fichiers Excel .......................................... 39, 41 fichiers HTML ........................................... 116 fichiers XML ............................................... 39 FIRST ......................................................... 66 formules
conversion en scores Z ....................... 48 décalage de k périodes ......................... 47 différences successives ........................ 47 écart-type ........................................... 48 fonction exponentielle ......................... 47 log base 10.......................................... 48 logarithme naturel ............................... 47 maximum ........................................... 48 minimum ............................................ 48 moyenne ............................................ 47 racine carrée ....................................... 48 valeur absolue ..................................... 47
FTP .......................................................... 116 Générer des données ..................................... 49, 57 graphique d’aptitude ............................ 253, 263 graphique de la boîte à moustaches ............... 25 graphique de normalité ............................... 261 graphique de Pareto ................................... 286 graphique de Pareto standardisé ......................... 285 graphique de superposition des contours ..... 299 graphique des effets directs ......................... 286 graphique des interactions .......................... 287 graphique des moyennes ............................. 200 graphique des quantiles ....................... 169, 188 graphique des résidus ................................. 219
graphique des tolérances ............................. 176 graphique en boîte à moustaches ................. 158 graphique en carré ...................................... 292 graphique en cube ....................................... 292 graphique en mosaïque................................ 240 graphique en surface ................................... 292 graphique maillé 3D .................................... 300 graphique quantiles-quantiles ....................... 190 graphiques
ajouter un texte ...................................96 boutons de la barre d’outils ..................75 copier dans d’autres applications ........ 107 échelle log ...........................................94 effets 3D ............................................84 enregistrer des fichiers graphiques ...... 108 exclure des points ...............................76 fond ...................................................84 identifier des points ........................... 103 modifier..............................................82 modifier l’apparence par défaut .......... 148 polices ................................................94 rotation ............................................ 102 rotation des libellés des axes ................93 titres des axes ......................................93
graphiques
échelles des axes..................................93 graphiques des résidus................................. 205 hétéroscédasticité ........................................ 206 histogramme d’effectifs ................ 164, 182, 250 imprimer
analyses ..............................................77 en-tête ................................................78 fond ...................................................78 lignes épaisses .....................................78 marges ................................................78
Inclure/Exclure ...............................................76 indices d’aptitude ........................................ 263 installation ..................................................... 1 intervalles bootstrap .................................... 171 intervalles de confiance
écart-type .......................................... 170

309/ Index
médiane ............................................ 171 moyenne ........................................... 170
intervalles HSD .......................................... 201 intervalles LSD ........................................... 201 iso-contours ............................................... 292 K 265 LAG ........................................................... 47 LAST .......................................................... 66 limites statistiques de tolérances ................... 175 lissage Lowess ............................................ 102 lisser un nuage de points ............................. 102 LOG ........................................................... 47 LOG10 ....................................................... 48 loi cumulée ................................................. 168 loi de la plus grande valeur extrême .............. 257 loi normale ......................................... 156, 254 LOWESS ................................................... 211 matrice de nuages de points ................. 106, 211 matrice des corrélations ....................... 212, 281 MAX .......................................................... 48 maximum ................................................... 157 médiane ..................................................... 156 menu Six Sigma .................................... 12, 147 méthodes non paramétriques
test de Friedman ............................... 202 test de Kolmogorov-Smirnov .... 189, 257 test de Kruskal-Wallis ........................ 202 test de Mann-Whitney (Wilcoxon) ...... 187 test des rangs signés .......................... 172
Mettre à jour les formules ................................... 46 MIN ........................................................... 48 minimum ................................................... 156 mise à jour des liens .................................... 147 Mise en page .................................................. 77 modèle linéaire de régression ....................... 216 modèle non linéaire de régression ................ 217 Modifier une colonne ......................................... 36 moyenne .................................................... 156 niveau de confiance
valeur par défaut ............................... 146 Niveau de Qualité Sigma ................................. 265 nombre de chiffres significatifs
valeur par défaut .............................. 146 nombres aléatoires ........................................ 58 opérateurs algébriques
addition ............................................. 47 division .............................................. 47 exponentiation ................................... 47 multiplication ..................................... 47 soustraction ....................................... 47
optimisation ............................................... 297 Options d’analyse ............................................. 69 Options graphiques ........................................... 29
grille ....................................................... 85 axes ................................................... 93 lignes ................................................... 87 onglet remplissages .................................. 95 points .................................................. 89 profils .............................................. 148 texte, libellés et légendes............................ 96 titre principal ........................................ 91
Options graphiques
apparence ............................................. 83 Options pour la fenêtre................................. 27, 72 OU .............................................................. 67 parcimonie ................................................. 209 plans d’expériences ..................................... 270 plans de criblage ......................................... 275 points au centre .......................................... 276 points extrêmes ................................... 160, 206 points très éloignés ..................................... 159 Préférences ............................................. 112, 145
onglet Analyses exploratoires ............ 164 onglet Aptitudes ............................... 264 onglet Stats ......................................... 157
Propriétés du classeur ........................................ 60 qualité d’ajustement .................................... 257 quantiles .................................................... 170 quartiles ..................................................... 156 RANDOM .................................................. 66 randomisation ............................................ 277 R-carré ................................................ 215, 217 rechercher les statistiques ou tests désirés..... 141

310/ Index
Recoder des données .......................................... 52 références .................................................. 306 règle de Sturges .......................................... 166 Régression multiple ......................................... 220 régression pas à pas .................................... 223 Régression simple ...................................... 65, 213 REP ............................................................ 57 répertoire pour les fichiers temporaires ........ 148 requêtes ODBC ........................................... 41 RESHAPE .................................................. 58 résidus ................................................ 205, 219 résidus studentisés ...................................... 219 RNORMAL ................................................ 59 ROWS ........................................................ 66 scores Z .................................................... 266 SD .............................................................. 48 sélection des analyses ................................. 136 séquences binaires ........................................ 67 sgcinstall.exe .................................................. 1 Six Sigma ................................................... 248 sources de données
interrogation ..................................... 114 sous-fenêtres ............................................... 67 SQRT.......................................................... 48 STANDARDIZE ........................................ 48 StatAdvisor
défauts ............................................. 147 StatFolios
enregistrer .................................. 30, 109 publier .............................................. 115 script de démarrage ............ 110, 115, 148
StatGallery ................................................. 261
configurer ......................................... 119 imprimer .......................................... 125 modifier les graphiques ..................... 123 superposer des graphiques ................. 122 y copier des graphiques ..................... 121
Statistics for Experimenters ........................ 198 Statistiques résumées .................... 24, 155, 181, 250 StatLink ................................................ 60, 114 StatPublish .................................................. 115 StatReporter .............................................. 127
enregistrer......................................... 129 modifier............................................ 129 y copier des résultats ......................... 128
StatWizard ................................................. 131 surface de réponse .................................... 225, 292 système de menus .........................................12 tableau de contingence ................................ 236 Tableau de l’ANO VA .................................. 285 Tableau des effectifs ......................................... 167 Tableaux .......................................................70 tableaux à deux entrées ............................... 238 tableaux de contingence .............................. 246 test de Friedman ......................................... 202 test de Grubbs ............................................ 162 test de Kolmogorov-Smirnov ............... 189, 257 test de Kruskal-Wallis ................................. 202 test de l’écart studentisé extrême .................. 162 test de Levene ............................................ 205 test de Mann-Whitney (Wilcoxon) ............... 187 test de Shapiro-Wilks .................................. 255 test des rangs signés .................................... 172 test du Khi-carré .................................. 242, 247 test F ......................................................... 184 test t ................................................... 172, 186 tests d’hypothèses
coefficient de corrélation ................... 212 comparer des distributions................. 189 comparer des écarts-types .................. 184 comparer des médianes ..................... 187 comparer des moyennes .................... 186 comparer des proportions ................. 247 comparer plusieurs écarts-types ......... 205 comparer plusieurs médianes ............. 202 comparer plusieurs moyennes ............ 197 médiane ............................................ 172 moyenne ........................................... 172 normalité .......................................... 255 points extrêmes ................................. 162 régression ......................................... 215 tableau à deux entrées ....................... 242
tests des étendues multiples ......................... 202

311/ Index
Transformation Box-Cox ............................ 260 transformations .......................................... 140 Tri à plat ..................................................... 231 Tri croisé ...................................................... 235 trier les noms des colonnes .......................... 147
Trier un fichier ................................................ 50 utiliser le logiciel .............................................8 valeurs de probabilités ................................ 162 valeurs studentisées .................................... 161 variables BY ............................................... 139


















