
La vérité sur le budget de crawl - Philippe Yonnet - Petit déjeuner du 7-12-2017 - Paris
37
1 BIENVENUE #S4sight2017 @s4sight Auditorium Nexity, Paris Jeudi 7 décembre 2017 Petit Déjeuner SEOSEA Matinée Conférences SEO / SEA : le Search évolue, changez votre vision du Search Actualité SEO SEA, Mobile First Index, Gestion des Evénements saisonniers en SEO…
-
Upload
search-foresight -
Category
Internet
-
view
82 -
download
1
Transcript of La vérité sur le budget de crawl - Philippe Yonnet - Petit déjeuner du 7-12-2017 - Paris

SEO – Votre priorité 2018
optimiser les performances de votre site WebActualités SEO, Content marketing et E-commerce, Google Shopping, Crawl…
1
BIENVENUE#S4sight2017
@s4sight
Auditorium Nexity, ParisJeudi 7 décembre 2017
Petit Déjeuner SEOSEAMatinée Conférences
SEO / SEA : le Search évolue,
changez votre vision du SearchActualité SEO SEA, Mobile First Index, Gestion des Evénements saisonniers en SEO…

La vérité sur le budget de
crawl
07/12/2017
2

3
Le budget de crawl ?

Quelques phrases entendues ici ou là
Il faut supprimer ces pages pour économiser votre budget de crawl
Votre budget de crawl est fixe, donc il faut empêcher Google d’aller sur vos pages inutiles pour qu’il aille sur vos pages utiles
Votre budget de crawl est limité
Tout cela est fondamentalement faux.
La vérité est… ailleurs
4

Agence conseil en stratégie digitale | SEO • SEM • CRO • Inbound Marketing • Analytics
Le crawl pour les nuls
5

Le process de crawl et d’indexation
6

Le travail du crawler
Un crawler découvre des uls en téléchargeant des pages web et en en extrayant de nouvelles urls
Ces urls sont placées en file d’attente pour être ensuite téléchargées à leur tour
Et le process se poursuit jusqu’à épuisement des urls (ou pas)
7

Urls connues, crawlées, et … les autresLa notion de frontière de crawl
8

Un crawler se doit d’être poli avec les serveurs web
Le crawler doit éviter de demander trop de ressources trop souvent
Le crawler doit respecter les directives
Du robots.txtDe la meta robots ou de la x-robots-tagDes attributs nofollow
9

Le crawl « programmé »
C’était le fonctionnement de Google au début
Google crawlait tous les mois toutes les urlsde la file d’attente constituée le mois d’avant, de la première à la dernière
Combinait un « full crawl » (deep crawl) et un « incremental crawl » (fresh crawl) pour gagner en fraîcheur
Procédé simple, mais qui ne garantit pas la fraicheur, plus le volume
Parfois appelé crawl fini ou fermé
10

Le crawl infini ou continu
Le crawler ne s’arrête plus, il crawle et recrawle en permanence en fonction des priorités de crawl
C’est le fonctionnement actuel
L’ordonnanceur devient un outil sophistiqué
11

L’ordonnanceur (scheduler)
L’ordonnanceur décide de télécharger les urls selon un ordre de priorité
Le niveau de priorité est donné par une « note d’importance » de la page
12

Petite histoire des crawlers de Google
13
Phase 1 : crawl ferméGoogle crawle une liste d’urls finie chaque mois. Le crawl dure une dizaine de jours, puis crée ses index, calcule ses critères (dont le pagerank), puis déploie son nouvel index sur ses datacenters progressivement
Phase 2 : crawl ouvert -> 2004 ?Passage à un crawl « infini » : le crawler crawle indéfiniment, en suivant un ordre de priorité défini par l’ordonnanceur (été 2004 ?)
Phase 3 : infrastructure Bigdaddy (fin 2005 – début 2006)Plus grosse capacité à crawler et indexer, crawl en couches, exploitation de bigTable
Phase 4 : Fusion des botsChaque moteur vertical ou fonctionnalité avait abouti à la création d’un bot spécifique pour chaque utilisation => vers un bot unique qui sert tous les outils avec des user agents parfois différents
Phase 5 : Caffeine 2009Nouvelle architecture, fin du crawl par « couches », crawl prédictif et plus intellige
Phase 6 : HummingbirdExpansion de requêtes sémantiques

Agence conseil en stratégie digitale | SEO • SEM • CRO • Inbound Marketing • Analytics
La notion de budget de crawl
14

La définition de Google
Le budget de crawl correspond à ce que Google peut et veut crawler
Peut crawler : les ressources de Google et du serveur web sont limitées, et le temps aussiVeut crawler : Google crawle certaines urls en priorité et ignore les autres
https://webmasters.googleblog.com/2017/01/what-crawl-budget-means-for-googlebot.html

Les principaux critères pris en compte
Fraicheur
Qualité (du point de vue de l’expérience de recherche)
Popularité
Rappel (volume)
Le crawl est priorisé en fonction des critères qui maximisent la qualité de l’index collecté
16
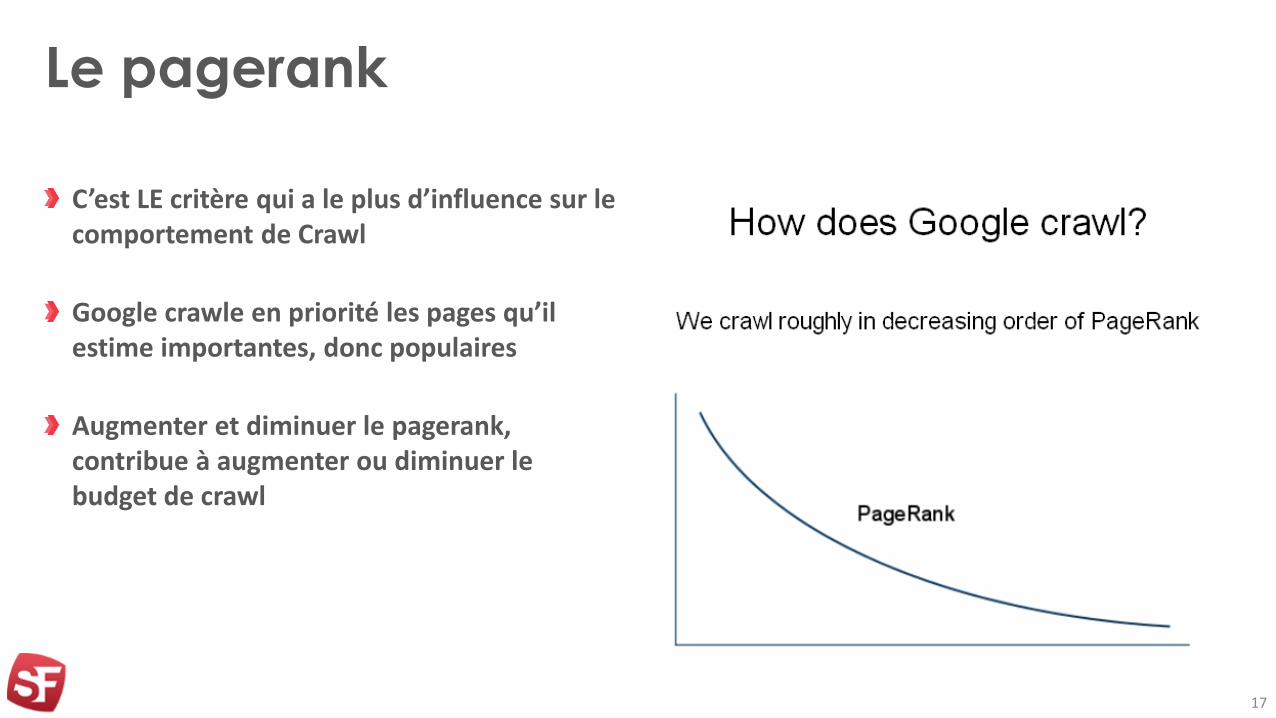
Le pagerank
C’est LE critère qui a le plus d’influence sur le comportement de Crawl
Google crawle en priorité les pages qu’il estime importantes, donc populaires
Augmenter et diminuer le pagerank, contribue à augmenter ou diminuer le budget de crawl
17

La profondeur a un impact négatif
Plus une page est profonde, plus son pagerank interne est faible
Une page dont le pagerank est faible a moins de chances d’être crawlée, ou est crawlée moins fréquemment
Conclusion, plus une page est profonde, moins elle est crawlée
Cela se vérifie quasi systématiquement
18
0
20000
40000
60000
80000
100000
120000
140000
Prof0
Prof1
Prof2
Prof3
Prof4
Prof5
Prof6
Prof7
Prof8
nb urlscrawlables noncrawlées
nb urlscrawlées

La notion de fraicheur
Google cherche à maximiser la fraicheur de son index
La « fraicheur » n’a rien à voir avec l’âge de la page. Si on considère une seule page :
Soit l’index correspond à l’état de la page sur le site -> la page en index est « fraiche »Soit la version indexée est obsolète -> la page n’est plus fraiche
La fraicheur de l’index mesure la proportion de pages dans l’index qui ne sont pas obsolètes
Dans le même temps, maintenir un agemoyen des pages bas augmente la fraicheur
19

Comment maximiser la fraicheur ?
20

La qualité de la « search experience »
21

Le rappel : crawler plus de pages
22

L’impact des performances sur le crawl
Baisser le temps de téléchargement du code peut améliorer sensiblement le taux de pages crawlées et la fréquence de recrawl
Attention, les chiffres fournis par Google sont très difficiles à interpréter
Pas de distinction crawl unique / recrawlTemps de téléchargement moyens !
Et le recrawl
23

Agence conseil en stratégie digitale | SEO • SEM • CRO • Inbound Marketing • Analytics
Idées reçues et vraies solutions
24

Mon budget de crawl est limité …
Pas vraiment : si le score de priorité de vos pages augmente, Google les crawlera plus souvent et plus systématiquement
L’inverse est vrai aussi
Si j’empêche Google de crawler des pages « inutiles », il n’ira pas forcément crawler les pages « utiles »
LA BONNE APPROCHE :
Si je trouve que Google ne crawle pas tout mon contenu, ou pas au bon rythme
Il faut augmenter les scores de prioritéNe surtout pas essayer le bot herding

Ces urls consomment mon budget de crawl…
En fait ce n’est pas toujours vraiQuelques cas où c’est vrai :Si des urls pointent vers des doublons, les éliminer augmentera le score de priorité des autres pages (note de qualité)Si des pages listings (facettes) sont trop nombreuses, les bloquer renforcera le taux de pages produits crawlés (augmentation du pagerank)
Les cas où ce n’est pas vraiSupprimer les pages inactives sur un site web
Le pagerank interne diminue fortement localement et globalement, ce qui diminuera le budget de crawl
Supprimer les pages de paginationEn général, cela gêne le crawl, cela ne le facilite pas. Il faut garder ces pages et optimiser l’arborescence
26

Modifier les pages régulièrement augmente le rythme de recrawl…
En général, nonC’est efficace uniquement si Google pense que crawler ces pages plus souvent améliore la fraicheur de son index, les modifications artificielles ont peu d’impact visible sur le comportement du botIl faut se demander si la page répond ou non à des requêtes QDF (Query DeservesFreshness)Requêtes liés à l’actualitéRequêtes appelant des pages dont le contenu doit être récent
Requêtes sur les prix, les promosRequêtes sur des infos à faible durée de vie (sites d’annonces)
27

Agence conseil en stratégie digitale | SEO • SEM • CRO • Inbound Marketing • Analytics
Contrôler le rythme de recrawl
28

Ce qui ne marche pas
Le paramètre « crawl delay » dans le robots.txt
Google n’en tient pas compte, surtout si vous voulez accélérer le crawl
La meta « revisit-after »
Les balises <priority> dans les sitemaps

Le contrôle via la search console
Paramètre disponible dans les paramètres de site (la roue crénelée en haut à droite)
Ne pas diminuer la vitesse sauf si le serveur est surchargé
Si vous diminuez la vitesse d’exploration, pensez à remettre le paramètre à la normale après !
Si vous augmentez la vitesse d’exploration, Google augmentera le rythme de crawl… ou pas
Cela ne fonctionne vraiment pas à tous les coups (il faut que vos pages aient de bons scores d’importance)
30

La gestion des paramètres dans la GSC
Peut remplacer le blocage dans le robots.txt pour les doublons qui peuvent consommer le budget de crawl
Mais cela ne marche que pour les paramètres …
Une fonctionnalité souvent oubliée
31

« Pinger » Google
Il est possible de « pinger » Google pour accélérer la découverte des pages
Le plus efficace semble de se servir du service PubHubSub et des Feeds RSS pour les urls
Marche évidemment pour les sitemaps au format RSS
32

La gestion des 304
On peut faciliter de façon impressionnante le crawl de Google en supportant les requêtes conditionnelles pour « if-modified-since »
Avec la même bande passante, un crawler pourra mettre à jour votre site beaucoup plus rapidement
Le gain n’est observable que pour des très gros sites (à partir de dizaines, voire de centaines de milliers d’urls et +)
33

Agence conseil en stratégie digitale | SEO • SEM • CRO • Inbound Marketing • Analytics
Conclusion
34

On peut augmenter son budget de crawl !
Pour exprimer tout le potentiel du site, il faut que 100% des urls utiles soient crawlables et crawlées
La meilleure façon d’augmenter le taux de pages utiles crawlées, c’est d’augmenter les notes de priorité des pages
Au total, cela se traduira par un budget de crawl augmenté
Le budget de crawl n’est pas une quantité figée, il reflète un comportement complexe qui résulte de la prise en compte :
De contraintes techniques : politeness, bande passante, performances du site etc.De l’intérêt des pages pour l’index : fraicheur, qualité, intérêt pour l’expérience de recherche (pertinence)

Merci !
Et maintenant, à vos questions
36

Restons en contact
Philippe YONNET | CEO
+33 1 74 18 29 40
Slideshare.net/S4sight
@S4sight | @Cariboo_seo
www.search-foresight.com
37


















