
La modélisation par équations structurelles basée sur la ...
24
La modélisation par équations structurelles basée sur la méthode PLS : une approche intéressante pour la recherche en marketing Marie-Laure Mourre * Doctorante Université Paris-Est Créteil Enseignant-chercheur Institut Supérieur de Gestion * 147 avenue Victor Hugo 75116 Paris, [email protected] 06 61 39 02 71
Transcript of La modélisation par équations structurelles basée sur la ...

La modélisation par équations structurelles basée sur la méthode PLS : une
approche intéressante pour la recherche en marketing
Marie-Laure Mourre *
Doctorante
Université Paris-Est Créteil
Enseignant-chercheur
Institut Supérieur de Gestion
* 147 avenue Victor Hugo 75116 Paris, [email protected] 06 61 39 02 71

La modélisation par équations structurelles basée sur la méthode PLS :
une approche intéressante pour la recherche en marketing
Résumé
La modélisation par équations structurelles basée sur la méthode PLS diffère des méthodes
basées sur l’analyse de covariances telles que Lisrel par son caractère prédictif plutôt que
confirmatoire et sa plus grande souplesse notamment en ce qui concerne les conditions
préalables à son utilisation. Elle permet en outre de traiter l’hétérogénéité des données. Ainsi,
elle s’avère particulièrement intéressante pour les chercheurs en marketing. Après une
description de ses caractéristiques et avantages, nous proposons une illustration sur des
données réelles.
Mots-clés : équations structurelles, méthodologie, PLS
Abstract
Structural equation modeling based on the PLS method differs from covariance-based
methods such as Lisrel by its predictive nature rather than confirmatory and its greater
flexibility especially regarding the prerequisites to its use. In addition, it allows to address the
heterogeneity of the data. Thus, it is particularly interesting for researchers in marketing.
After a description of its features and benefits, we propose an illustration based on real data.
Keywords : SEM, methodology, PLS

La modélisation par équations structurelles basée sur la méthode PLS :
une approche intéressante pour la recherche en marketing
Introduction
La modélisation par équations structurelles est désormais couramment utilisée par les
chercheurs en marketing car elle permet de mettre à jour des liens de causalité entre plusieurs
variables, y compris modératrices et médiatrices, tout en incorporant les erreurs de mesure
(Bagozzi, 1980). Mais, il arrive que les prérequis à son utilisation ne soient pas parfaitement
respectés ; ainsi en est-il de la normalité des données qui est une condition à respecter de la
méthode basée sur l’analyse de covariances et le maximum de vraisemblance (Bentler et
Chou, 1987, Barnes et al., 2001). La violation de la normalité peut conduire à des résultats
erronés ou aberrants (Chin et al., 2001). Or, il existe une méthode d’estimation des paramètres
qui est moins exigeante dans ses conditions d’utilisation (pas de normalité, petits échantillons
acceptés), et qui par ailleurs, se trouve être plus adaptée aux recherches exploratoires et
prédictives tout en étant rigoureuse d’un point de vue statistique (Fernandes, 2012, Hair,
Ringle et Sarstedt, 2011). Il s’agit de la méthode PLS basée sur l’analyse de variance et la
méthode des moindre carrées partiels. Le fait qu’elle soit plus récente (Wold, 1982) et
disponible sur moins de logiciels statistiques explique probablement sa moindre utilisation
alors qu’elle nous semble présenter un grand intérêt pour les chercheurs en marketing.
Sans entrer dans le détail des soubassements théoriques et mathématiques de cette méthode1,
nous en présenterons les grands principes, nous exposerons les prérequis à son utilisation, ses
avantages et inconvénients en nous appuyant sur la littérature existante. Nous présenterons
également une méthode d’analyse multi-groupe qui en est issue qui permet de traiter
l’hétérogénéité des données en identifiant des sous-modèles. Nous proposerons enfin une
application sur des données réelles à titre d’illustration.
1. Rappel sur les équations structurelles à variables latentes
Les modèles d’équations structurelles à variables latentes (SEM) sont des modèles multivariés
utilisés pour modéliser les structures de causalité dans les données. L’intérêt de la
modélisation par équations structurelles réside essentiellement dans sa capacité à tester de
manière simultanée l’existence de relations causales entre plusieurs variables latentes. Une
variable latente est une variable qui n’est pas observable et ne peut être mesurée directement.
1 Pour une discussion plus fouillée sur ces aspects, on pourra se reporter à Valette-Florence (1993, 1998)

A l’inverse, pour une variable manifeste, on pourra recueillir une mesure de manière directe.
Les variables latentes peuvent être estimées à partir de variables manifestes en isolant leur
part de variance commune. Les modèles à équations structurelles consistent en un système
d’équations pouvant être représentées sous forme de graphe orienté, les nœuds représentent
les variables sous forme de carré pour les variables manifestes et sous forme de rond pour les
variables latentes, les arcs modélisent les liens de causalité. Chaque variable manifeste est
associée à une seule variable latente et les variables latentes peuvent être liées entre elles. Une
variable latente peut être de type réflexif : chaque variable manifeste reflète sa variable latente
et lui est reliée par une régression plus un terme d’erreur (c’est le cas de ξ1 et η1 de la Figure
1, on notera par exemple x11 = π11.η1+ε11 avec π11 le loading liant la variable manifeste x11 à la
variable latente 1). Elle peut être de type formatif : la variable latente est générée par ses
propres variables manifestes, c’est alors une fonction linéaire des variables manifestes plus un
terme résiduel (cas de η2 de la Figure 1, on notera par exemple η2 = π21x21+π22x22+π23x23+
π23x24+ ε avec πij le poids liant le variable manifeste xij à la variable latente η2). On parlera de
mode MIMIC lorsqu’une variable latente est de type mixte : une partie de ses variables
manifestes sont de type réflexif et les autres de type formatif. On qualifiera d’endogène une
variable dont les valeurs sont déterminées par le modèle et peut à son tour déterminer les
valeurs d’autres variables (η1 et η2 de la Figure 1). Une variable exogène pourra elle aussi
déterminer les valeurs d’autres variables du modèle mais sera elle-même déterminée par des
variables extérieures au modèle (ξ1 de la Figure 1). Enfin, on distinguera au sein du modèle
deux sous-modèles : le modèle de mesure ou modèle externe (outer model) liant les variables
manifestes aux variables latentes et le modèle structurel ou modèle interne (inner model) liant
les variables latentes entre elles. Le modèle structurel sera dit récursif si les liens entre
variables sont unidirectionnels. A l’inverse, un modèle non récursif pourra présenter des
boucles où deux variables endogènes seront réciproquement cause et conséquence l’une de
l’autre.
La modélisation par équations structurelles comporte quatre étapes :
- dans un premier temps, la spécification vise à développer un modèle conceptuel qui
pourra être traité par les logiciels statistiques,
- vient ensuite l’estimation des paramètres en fonction de l’algorithme choisi,
- puis l’évaluation du modèle qui se fera par le biais de différents indicateurs,
- et enfin, la modification du modèle en fonction des informations données par les indices
d’évaluation afin d’obtenir le meilleur modèle possible.

Nous ne rentrerons pas dans le détail des procédures d’estimation des paramètres mais nous
en rappellerons les grands principes dans les lignes qui suivent.
L’estimation des paramètres du modèle se fait aujourd’hui en recourant à différents types
d’algorithme :
- la méthode Lisrel (Linear Structural Relationships) qui repose sur l’analyse de la
structure de covariance et utilise l’approche du maximum de vraisemblance ; elle
requiert la multinormalité des données,
- la méthode GLS (Generalized Least Squares) est moins sensible à la non normalité
mais demeure très sensible à la complexité du modèle,
- les méthodes ADF (Asymptotic Distribution Free) et WLS (Weighted Least Squares)
ne requièrent pas la multinormalité mais exigent des échantillons de plus de 2 500
observations,
- la méthode PLS (Partial Least Square) qui repose sur l’analyse de la variance et
utilise l’approche des moindre carrés partiels.
Nous aborderons uniquement Lisrel qui est la plus utilisée et PLS qui est le sujet de cette
communication.
Figure 1 : Exemple de modèle structurel à variables latentes

2. La méthode Lisrel
Lisrel permet de spécifier, estimer comparer et évaluer des modèles afin de confirmer une
théorie. Lisrel est donc une méthode confirmatoire (ou « a priori ») qui nécessite un fort
substrat théorique afin de penser en terme de modèles et d’hypothèses. La spécification du
modèle est donc une phase cruciale dans le travail de modélisation.
A partir du modèle théorique construit a priori, on obtient une matrice de covariance
théorique Σ comportant les coefficients de corrélation attendus. A partir des données réelles,
on construit la matrice de covariance observée (ou empirique) S qui comporte les coefficients
de corrélation de la relation entre deux variables. Les paramètres du modèle seront estimés de
manière itérative de sorte à minimiser la différence entre les deux matrices S et Σ.
Si on prend l’exemple du modèle de la figure 1, on a donc les deux équations structurelles
suivantes :
η2 = β1ξ1 + β2η1 + ε2
η1 = β3ξ1 + ε1
avec β le coefficient de régression et ε l’erreur résiduelle.
La matrice de variance-covariance correspondant au modèle de la Figure 1 pourra s’écrire de
la façon suivante :
(
( ) ( ) ( )
) = Σ = (
)
Ainsi, la covariance entre η1 et η2 pourra s’écrire :
σ23 = cov(β1ξ1 + β2η1 + ε2, η1) = β1σ12 + β2σ22
On peut donc exprimer la matrice Σ sous forme d’une série d’équations où apparaissent les
paramètres du modèle. Il s’agit des coefficients de régression β, des variances des variables
indépendantes σ2 y compris la variance des erreurs qu’on notera ψ et les covariances entre
variables indépendantes σ. On notera les paramètres sous forme de vecteur nommé ϴ.
Dans notre exemple :
ϴ = (β1, β2, β3, σ12, ψ1, ψ2)
Le principe de la modélisation par équations structurelles consiste à estimer ϴ en minimisant
les résidus entre les matrices S et Σ (on écrira F(S, Σ(ϴ)) ou simplement F).
La méthode Lisrel consiste à rendre la matrice de covariance théorique Σ la plus proche
possible de la matrice empirique S en utilisant l’approche du maximum de vraisemblance
(Maximum Likelihood ou plus simplement ML). Il s’agit de trouver le maximum de la

fonction de vraisemblance, qui est une fonction de probabilités conditionnelles qui décrit les
valeurs d’une loi statistique en fonction des paramètres supposés connus :
FML () = log|)| + tr{S)–1} – log|S| – q
avec tr la trace c’est-à-dire la somme des coefficients diagonaux de la matrice et q le nombre
de variables observées.
L’évaluation de la qualité d’ajustement du modèle aux données est faite au moyen de
différents indicateurs2 dont les plus utilisés sont :
- le test du χ2 : si le modèle étudié est exact alors (n-1)F= χ
2(DF) avec DF le degré de
liberté égal au nombre de covariances moins le nombre de paramètres. Le modèle est
considéré comme bon si χ2/DF<=3 et p-valeur<=0.05,
- GFI (Goodness of Fit Index) : cet indice donne la proportion d’information expliquée par
la matrice S ; une valeur supérieure ou égale à 0.9 indique une bonne qualité du modèle,
- RMSEA (Root Mean Square Error of Approximation) : cet indice calcule la différence
entre la matrice de covariances obtenue et celle de la population globale. On acceptera le
modèle pour un RMSEA inférieur ou égal à 0.08.
- NNFI ou indice de Tucker-Lewis : il permet de mesurer l’augmentation de la qualité
d’ajustement quand on passe du modèle de référence (null model) au modèle étudié. On
acceptera le modèle pour une valeur supérieure ou égale à 0.95
- CFI (Comparative Fit Index) : cet indice permet de comparer le modèle étudié au modèle
d’indépendance complète. On acceptera le modèle pour une valeur supérieure ou égale à
0.9.
L’utilisation de cette méthode suppose :
- la linéarité du modèle,
- l’indépendance des observations,
- la normalité multivariée des données,
- l’unidimensionalité des blocs de variables,
- un nombre d’observations minimum de 5 par paramètre à estimer ; en pratique, 200
observations minimum sont recommandées (Roussel et al., 2002).
Les deux conditions les plus difficiles à respecter sont généralement la normalité des données
et la taille de l’échantillon. En effet, dans le domaine des sciences sociales, plusieurs
recherches ont mis en évidence que, dans la plupart des cas, les données ne suivent pas une
distribution normale (Bentler et Chou, 1987, Barnes et al., 2001), ce qui conduisit Wold
2 Pour une présentation détaillée, on pourra se reporter à Hoyle (1995)

(1982) à considérer les conditions requises par la méthode Lisrel peu réalistes pour les
recherches empiriques. L’impact du non-respect de la normalité des données a été évalué dans
un certain nombre d’approches. Dans le cas du maximum de vraisemblance, peu de
changements ont été constatés (Diamantopoulos et al., 2000, Bollen, 1989, Reinartz et al.,
2009). Par ailleurs, l’utilisation du ré-échantillonnage selon la méthode du bootstrap permet
de contourner en partie les problèmes de normalité et du nombre d’observations (Preacher et
Hayes, 2004). Ainsi, nombre de recherches utilisent des méthodes de modélisation basées sur
la covariance bien que les données initiales s’y prêtent peu. Il n’en reste pas moins que la
violation du prérequis de normalité reste un pis-aller car les résultats sont biaisés (Chin et
Newsted, 1999) et ne peut s’envisager que pour des écarts modérés à la distribution normale.
En effet, Lei et Lomax (2005) indiquent que la violation de la normalité :
- biaise les estimations des paramètres surtout quand les échantillons sont de petite taille
(100 observations)
- a un effet significatif sur l’estimation des loadings et des coefficients structurels
- a un rôle plus important que la taille de l’échantillon et la méthode d’estimation
choisie
- a un effet significatif sur le test du χ2.
Ainsi, quand les données s’éloignent fortement de la normalité, l’utilisation de Lisrel est
déconseillée et d’autres méthodes, telles que la méthode PLS, doivent être employées (Hair et
al. 2012).
3. La méthode PLS
Elle tire son nom de l’utilisation des techniques de régression en moindre carrés pour estimer
les modèles. L’objectif de la modélisation PLS est de maximiser la variance expliquée de la
variable latente dépendante alors que celui des méthodes basées sur la covariance est de
reproduire la matrice théorique de covariances. L’estimation des paramètres est itérative,
c’est-à-dire que l’on va estimer les variables latentes successivement par le modèle externe
(via les variables manifestes) puis par le modèle interne (via les autres variables latentes
auxquelles elle est liée) jusqu’à convergence. Plus précisément, il y a 4 étapes :
1) on commence par estimer la valeur des variables latentes sur la base des scores des
variables manifestes et des poids du modèle externe (issu de l’étape 4 ou fixés
arbitrairement pour initialiser l’itération),
2) puis, on estime les liens structurels entre variables latentes (modèle interne),

3) ensuite, on estime les variables latentes par le modèle interne, c’est-à-dire grâce aux
valeurs des variables latentes calculées à l’étape 1 et aux liens calculés à l’étape 2,
4) et enfin, on estime les poids du modèle externe grâce aux valeurs des variables
latentes issues de l’étape 3 et on revient à la première étape du processus.
On répète cette boucle jusqu’à convergence de sorte que la différence entre les sommes des
paramètres issus de deux boucles consécutives soit minime, en pratique inférieure à 10-5
.
Ensuite, on procède à l’estimation finale des paramètres (poids internes, poids externes et
liens structurels) en utilisant la méthode des moindres carrés pour chacune des régressions du
modèle.
Notons qu’il existe deux modes d’estimation des poids externes selon que les variables sont
de type réflexif ou formatif. De même, pour les poids internes, on pourra choisir entre 3
schémas d’estimation : centroïde (le plus utilisé), factoriel ou structurel3. L’algorithme PLS
est donc très sensible à la qualité du modèle de mesure à la différence de la méthode Lisrel
qui utilise les observations (matrice S) et le modèle théorique (matrice Σ). Il convient donc de
s’assurer que les échelles choisies pour mesurer les variables latentes sont de bonne qualité en
termes de validité et de fiabilité.
A la différence de l’approche Lisrel, l’approche PLS ne nécessite pas la multinormalité des
variables et peut convenir aux variables continues, métriques et nominales. Elle est également
utilisable avec des variables réflexives et formatives. Elle nécessite moins d’observations.
Enfin, PLS est plus appropriée dans le cadre du test de modèles non encore établis par la
théorie. En effet, pour Jöreskog et Wold (1982), « la méthode du maximum de vraisemblance
est orientée vers la théorie et met l’accent sur la transition entre l’analyse exploratoire et
confirmatoire. PLS a comme premier objectif l’analyse causale et prédictive dans le cadre de
modèles complexes mais développés sur une base théorique limitée4. » La méthode PLS
apparaît plus souple que la méthode Lisrel. Néanmoins, les prérequis suivants doivent être
respectés :
- le modèle doit être linéaire,
- le modèle doit être récursif,
- les observations doivent être indépendantes les unes des autres,
- les variables réflexives doivent être unidimensionnelles,
3 Pour une présentation de ces trois modes, on pourra se reporter Esposito-Vinzi, Trinchera et Amato
(2010). 4 Traduction personnelle

- le nombre d’observations minimum doit être égal à 10 fois le nombre de relations
émanant du construit central du modèle (Chin, 1998). Autrement dit, on multipliera
par 10 le nombre de variables manifestes liées à la variable latente qui est liée avec le
plus de variables (exemple : si la variable latente qui est liée au plus de variables
possède 5 variables manifestes, l’échantillon devra comporter au moins 50
observations).
Dans le cadre d’équations structurelles selon la méthode PLS, il convient de suivre une
procédure en quatre étapes pour évaluer le modèle de mesure (Esposito-Vinzi, Trinchera et
Amato, 2010, Tenenhaus et Esposito-Vinzi, 2005)
1. Evaluation de la fiabilité : on utilise les alpha de Crombach et le rho de Dillon-Goldstein
qui doivent être supérieurs ou égaux à 0.7
2. Vérification de l’unidimensionnalité : on utilise les valeurs propres issues de l’analyse en
composantes principales, la première doit être supérieure à 1 et les suivantes inférieures à
1. On vérifie également que les variables manifestes sont davantage corrélées avec la
variable latente qu’elles sont censés mesurer qu’avec les autres.
3. Evaluation de la validité convergente : examen des corrélations (loading factors) des
items avec leur variable latente qui doivent être supérieures à 0.7
4. Evaluation de la validité discriminante : chaque variable latente doit être liée plus
fortement à ses indicateurs qu’aux autres variables latentes du modèle. Cela est le cas
lorsque la corrélation au carré entre 2 variables latentes est inférieure aux index AVE
(variance extraite moyenne) de chaque variable latente aussi appelée communalité
moyenne (Tenhenhaus et al., 2005). Chin (1998) préconise que l’AVE ait une valeur
supérieure ou égale à 0.5
Puis on peut procéder à l’évaluation du modèle structurel :
1. Pertinence prédictive du modèle : elle est indiquée par les pourcentages de variance
expliquée pour chaque régression du modèle. Croutsche (2002) indique que le modèle est
significatif si le R2 est supérieur à 0.1. Chin (1998) précise que des R
2 de 0.67, 0.33 et
0.19 peuvent être considérés respectivement comme substantiel, modéré et faible. La
qualité de chaque équation structurelle peut aussi être évaluée par le coefficient Q2 de
Stone-Geisser qui doit être supérieur à 0. « Il s’agit d’un test de R² en validation croisée
entre les variables manifestes d’une variable latente endogène et toutes les variables
manifestes associées aux variables latentes expliquant la variable latente endogène, en
utilisant le modèle structurel estimé. » (Fernandes, 2012).

2. Test de la significativité des coefficients de régression : étant donné la nature non
paramétrique de la modélisation PLS, cela est réalisé par le moyen de techniques de ré-
échantillonnage (bootstrap ou jacknife) qui donnent des intervalles de confiance.
L’évaluation globale de la prédictivité du modèle est donnée par l’index de Goodness of Fit
(GoF) qui est la moyenne géométrique entre la communalité moyenne (qui mesure la
performance du modèle externe) et le R2 moyen (qui mesure la performance du modèle
interne), ainsi il évalue la performance d’ensemble du modèle (Tenenhaus et al., 2005) . Les
valeurs absolues et relatives du GoF sont comprises entre 0 et 1. La valeur absolue permet de
comparer des modèles ou des groupes d’individus entre eux. La valeur relative est plus utile
pour interpréter un modèle. Elle permet de mesurer la performance du modèle par rapport à sa
meilleure performance possible (c'est-à-dire la performance de l’Analyse en composante
principale sur chaque bloc et de l’analyse canonique pour chaque équation structurelle) en
prenant en compte la spécification du modèle. Le GoF est un index descriptif, il n’existe pas
de seuil empirique pour l’évaluer. On peut néanmoins considérer qu’un GoF supérieur ou égal
à 0.9 atteste d’une bonne qualité d’ajustement du modèle aux données.
4. Avantages de PLS pour la recherche en marketing
Les méthodes basées sur l’analyse de covariance restent prédominantes en recherche
marketing. Une simple requête sur le moteur de recherche Ebsco dans les bases Academic
Search Premier et Business Source Complete avec les 3 entrées « SEM », « marketing » et
« Lisrel » donne un résultat de 1 332 occurrences entre 1979 et 2012 dans les revues
académiques à comité de lecture contre 562 pour PLS. Mais la méthode PLS gagne en
popularité. Selon Eggert (2007), une vingtaine de recherches utilisant la méthode PLS ont été
publiées dans cinq des revues du premier tiers des revues scientifiques de marketing. Plus
récemment, Fernandes (2012) compte 51 articles en management publiés de 1985 à 2008 dans
des revues classées par le CNRS, l’AERES ou l’ESSEC avec 70% des articles publiés après
l’année 2000. Hair et al. (2012) recensent pas moins de 204 articles de recherche en marketing
s’appuyant sur cette méthode. Enfin, des articles récents tels que ceux de Hair, Ringle et
Sarstedt (2011) ou Picot-Coupey (2009) viennent souligner l’intérêt de l’approche PLS en
modélisation marketing.
En pratique, l’utilisation de PLS sera recommandée dans les cas suivants (Chin et Newsted,
1999) :
a) l’objectif de la recherche est de nature davantage exploratoire que confirmatoire,
b) le modèle est nouveau ou changeant, le modèle de mesure et/ou structurel ne sont pas
fermement établis,
c) le modèle est complexe avec un grand nombre de variables,
d) la distribution normale n’est pas respectée,
e) le nombre d’observations est faible.
Il n’est pas rare que les recherches en marketing présentent les quatre premières
caractéristiques5. La méthode PLS permet donc de traiter des données peu propices à
l’exploitation avec la méthode Lisrel. Certains inconvénients sont néanmoins à signaler. On
citera notamment l’impossibilité de tester des modèles non récursifs qui sont quelquefois plus
réalistes et rendent mieux compte de la réalité des influences entre variables que les modèles
récursifs. Une comparaison des deux méthodes souligne le fait que PLS a tendance à
surestimer les laodings alors que Lisrel les sous-estime et que PLS sous-estime les
coefficients structurels alors que Lisrel les surestime (Vilares et al. 2007). L’absence
d’indicateur global d’évaluation des modèles a également été vue comme un inconvénient de
la méthode PLS mais la proposition de l’indice GoF par Tenenhaus et Esposito-Vinzi (2005) a
partiellement résolu ce problème même si l’on peut regretter qu’aucun seuil ne puisse être
fixé. PLS reste néanmoins très attractif pour la recherche en marketing d’autant plus qu’elle
permet de mener des analyses multi-groupes afin d’isoler des sous-modèles, ce qui peut
s’avérer particulièrement intéressant pour saisir la diversité des comportements de
consommation.
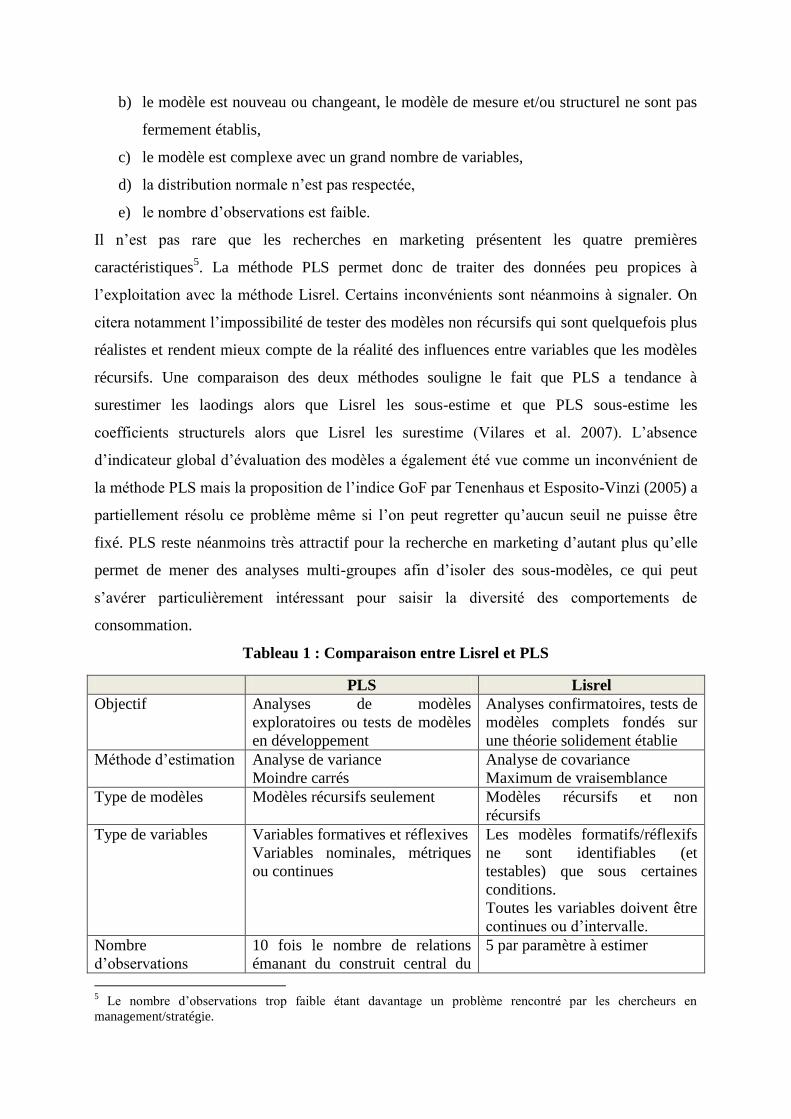
Tableau 1 : Comparaison entre Lisrel et PLS
PLS Lisrel
Objectif Analyses de modèles
exploratoires ou tests de modèles
en développement
Analyses confirmatoires, tests de
modèles complets fondés sur
une théorie solidement établie
Méthode d’estimation Analyse de variance
Moindre carrés
Analyse de covariance
Maximum de vraisemblance
Type de modèles Modèles récursifs seulement
Modèles récursifs et non
récursifs
Type de variables Variables formatives et réflexives
Variables nominales, métriques
ou continues
Les modèles formatifs/réflexifs
ne sont identifiables (et
testables) que sous certaines
conditions.
Toutes les variables doivent être
continues ou d’intervalle.
Nombre
d’observations
10 fois le nombre de relations
émanant du construit central du
5 par paramètre à estimer
5 Le nombre d’observations trop faible étant davantage un problème rencontré par les chercheurs en
management/stratégie.

modèle
Distribution Pas de normalité exigée
Multinormalité exigée
Processus
d’estimation
Modèle de mesure et modèle
structurel sont estimés
simultanément.
L’estimation et la validation du
modèle de mesure sont
indépendantes de celle du
modèle structurel.
Evaluation du modèle Modèle de mesure : communalité
Modèle structurel : R2, Q
2
Modèle total : GoF
χ2
GFI RMSEA NNFI CFI
5. Le traitement de l’hétérogénéité des données
La modélisation par équations structurelles suppose l’homogénéité des données. On entend
par homogénéité le fait que toutes les observations sont bien représentées par un modèle
unique. Or, il peut arriver qu’un certain nombre d’observations ne soient pas très bien
reflétées par le modèle. Ainsi, des sous-modèles (ou modèles locaux) avec des coefficients
différents du modèle initial (ou modèle global) - aussi bien dans le modèle structurel que dans
le modèle de mesure - peuvent permettre de mieux rendre compte de la diversité des données.
On parlera d’hétérogénéité observée lorsqu’on a connaît a priori le nombre de classes
d’observations et leurs caractéristiques et d’hétérogénéité non observée quand on ne connaît
ni le nombre de classes ni leurs compositions. Traditionnellement, on procédait par clustering
en assignant les observations à différentes classes dont on estimait et évaluait les paramètres
dans un second temps. Or, les techniques de clustering supposent l’indépendance des
variables alors que, par définition, les variables sont liées entre elles dans un modèle
structurel. Il y a donc un problème théorique à utiliser les techniques de clustering
conjointement aux équations structurelles. Dans le cadre de la modélisation par la méthode
PLS, on peut utiliser les techniques d’analyse multigroupe pour traiter l’hétérogénéité
observée (Esposito-Vinzi et al., 2008). Pour ce qui est de l’hétérogénéité non observée,
différentes techniques existent au nombre desquelles la technique REBUS (Trinchera, 2007)
qui est désormais intégrée au logiciel xlstat PLS-PM). REBUS cherche à identifier les sources
d’hétérogénéité au sein des variables observées, latentes, endogènes et exogènes. Pour cela,
on calcule la distance entre chaque observation et le modèle en prenant en compte la
performance du modèle quant aux résidus des modèles interne et externe pour toutes les
variables latentes (Esposito-Vinzi et al., 2008). Cette mesure de proximité est définie par
rapport à l’index GoF qui est la moyenne géométrique entre la communalité (performance du
modèle externe) et le R2 (performance du modèle interne). L’algorithme REBUS est itératif. Il
faut d’abord estimer le modèle global selon la procédure PLS décrite plus haut, puis calculer

les résidus de toutes les observations par rapport au modèle global. Ensuite, on réalise une
classification hiérarchique des résidus sous forme de dendrogramme, puis on réalise une
partition en G classes. On assigne alors chaque observation à une classe en fonction de
l’analyse en cluster, et on estime les G modèles locaux (un pour chaque classe). On calcule
ensuite la mesure de proximité de chaque observation par rapport à son modèle local et on
réassigne si nécessaire les observations en fonction de cette mesure aux différentes classes.
Quand il n’y a plus de changement de classes et que la stabilité est atteinte, on peut procéder à
la description des classes en fonction des différences entre les modèles locaux obtenus sinon,
on reprend le processus au niveau de l’estimation des modèles locaux après réassignation des
observations.
6. Application
Si PLS n’est pas une méthode de modélisation confirmatoire, elle nécessite néanmoins la
construction d’un modèle reposant sur des bases théoriques établies.
Dans cette application, nous utiliserons une modélisation de la résistance à la persuasion
établie dans le cadre d’une publicité de lutte contre le tabac. Dans un premier temps, nous
décrirons les bases théoriques sur lesquelles nous avons construit le modèle ; puis, nous
exposerons brièvement les conditions de l’expérimentation avant de faire part des résultats
issus de l’analyse selon la méthode PLS. Grâce à l’analyse multigroupe permettant de gérer
l’hétérogénéité des observations, nous avons pu faire émerger deux modèles locaux distincts.
a. Présentation du modèle conceptuel
Si l’étude des mécanismes de persuasion a fait l’objet d’une intense recherche au cours des
soixante dernières années, la résistance à la persuasion a moins concentré l’attention du
monde académique, même si des chercheurs de premier plan tel McGuire avec la théorie de
l’inoculation s’y sont intéressés dès les années 1960. Pourtant, les appels à
l’approfondissement de la compréhension de la résistance à la persuasion n’ont pas manqué
(Eagly et Chaiken, 1993, Knowles et Linn, 2004). Néanmoins, l’ouvrage coordonné par
Knowles et Linn (2004) rassemble des contributions qui ont permis des avancées
significatives. Cependant, l’intégration des résultats de ces recherches en un modèle unifié n’a
pas été réalisée. Constatant ce vide dans la littérature, nous avons entrepris avec cette
recherche de proposer un modèle intégrateur de la résistance à la persuasion.
Pour cela, nous nous sommes basée sur la littérature sur la persuasion et le changement
comportemental et sur les résultats des recherches sur la résistance à la persuasion. Nous
avons également utilisé des travaux sur la résistance du consommateur en général afin d’avoir

un regard aussi large que possible sur la nature de la résistance à la persuasion. Ainsi, nous
avons retenu plusieurs cadres théoriques pour modéliser la résistance à la persuasion. Tout
d’abord, nous nous sommes appuyés sur le modèles duaux de la persuasion dont l’Elaboration
Likelihood Model (Petty et Cacioppo, 1986) pour identifier les variables et mécanismes
régissant le processus persuasif et notamment le changement d’attitudes suite à une
communication persuasive. Nous avons également retenu du Persuasion Knowledge Model
(Friestadt et Wright, 1994) que la connaissance des techniques persuasives permettait au
consommateur de gérer les épisodes persuasifs en fonction de ses propres objectifs. Notre
étude des facettes de la résistance à la persuasion ayant mis en évidence sa nature
multidimensionnelle et notamment ses composantes attitudinales, intentionnelles et
comportementales (Roux, 2007), nous avons souhaité élargir la perspective de notre recherche
au niveau comportemental et non pas simplement attitudinal. Cela constitue un apport au
regard des recherches qui se concentrent essentiellement sur la résistance attitudinale sans
nécessairement investiguer les relations avec l’intention comportementale et le comportement
effectif. Or, de nombreuses communications persuasives ont un objectif de changement
comportemental. Ainsi, étudier la résistance à la persuasion en allant au-delà de l’attitude
nous a paru essentiel pour contribuer à une meilleure connaissance de ce phénomène. Pour ce
faire, les travaux de Fisbein et Ajzen et plus particulièrement la Théorie du comportement
planifiée (Ajzen, 1985) nous ont permis de retenir des variables telles que les normes sociales
subjectives ou le sentiment de contrôle comportemental pour expliquer la formation
d’intentions comportementales et la réalisation de comportements effectifs. Nous nous
sommes également intéressés aux travaux Higgins, Shah et Friedman (1997) qui introduisent
avec l’orientation régulatrice une variable psychologique motivationnelle susceptible de
rendre compte des choix comportementaux des individus.
Notre intention étant de proposer une modélisation causale de la résistance à la persuasion,
nous avons choisi de tester empiriquement notre modèle. Pour cela, nous avons dû choisir un
terrain d’expérimentation. La faculté de résister à la persuasion étant une condition de la
liberté individuelle, et à ce titre une qualité désirable à nos yeux, nous avons décidé d’étudier
la résistance à la persuasion quand celle-ci peut s’avérer néfaste pour le sujet. Pour éviter de
rentrer dans des considérations morales et de longs débats sur ce qui est bon ou mauvais pour
les individus, nous avons pensé judicieux de choisir la santé comme thématique. En effet, la
médecine se donne notamment pour objet de déterminer de manière objective et scientifique
ce qui est bon ou mauvais pour la santé. Résister à une publicité de prévention de la santé peut
donc s’avérer néfaste. Nous avons ensuite cherché des thématiques de communication

susceptibles de rencontrer une résistance de la part du public ciblé. Parmi les sujets possibles
(prévention des maladies sexuellement transmissibles, campagnes de vaccination contre la
grippe, campagnes de dépistage des cancers du sein ou des cancers colorectaux etc…), la lutte
contre le tabagisme a été retenue pour plusieurs raisons :
- c’est un sujet qui provoque facilement de la résistance chez les fumeurs,
- c’est un enjeu de santé publique puisqu’on considère que le tabagisme est responsable
de 60 000 morts prématurées en France ;
- c’est également un sujet d’actualité car la prévalence tabagique quotidienne en France
a augmenté entre 2005 et 2010 malgré une réglementation de plus en plus restrictive ;
- c’est ensuite un sujet de santé qui rentre de manière limitée dans la sphère de l’intime
et se prête donc plus aisément à une expérimentation que des sujets gênants ou
sensibles ;
- enfin, le tabagisme est un phénomène complexe mêlant des facteurs psychologiques
individuels et sociaux en plus de facteurs physico-chimiques qui devrait donc
permettre d’explorer la richesse des mécanismes de résistance.
Afin d’affiner notre modèle et de l’adapter au terrain de recherche, nous avons exploré la
littérature en matière de communication persuasive dans le domaine de la santé. Nous avons
donc mobilisé les recherches en marketing social portant sur les modèles de changement
comportemental en matière de santé (Armirtage et Conner, 2000) et l’efficacité de techniques
persuasives telles que la peur dans les publicités de prévention. Cela nous a conduits à
confirmer la pertinence de la Théorie du comportement planifié et à introduire dans notre
modèle la variable de peur ressentie face à la publicité (Girandola, 2000, Gallopel-Morvan,
2006).
Les variables retenues au terme de cette exploration de la littérature sont présentées Tableau
2. Le modèle faisant apparaître les relations causales entre les variables apparaît en figure 2.
Tableau 2 : Variables et instruments de mesures retenus
Variable Définition Mesure
Attitude envers les effets
négatifs de la cigarette
Degré d’accord avec les
conséquences négatives de la
consommation de
Etter et al. (2000)
Intention d’arrêter de fumer
Probabilité d’arrêter de fumer à
semaines/à 6 mois
Mesure directe
Voie de traitement empruntée Style de traitement de l’information
en fonction du niveau d’élaboration
cognitive. On distinguera les
traitements systématique, heuristique
et experiential (Meyers-Levy et
Oculométrie
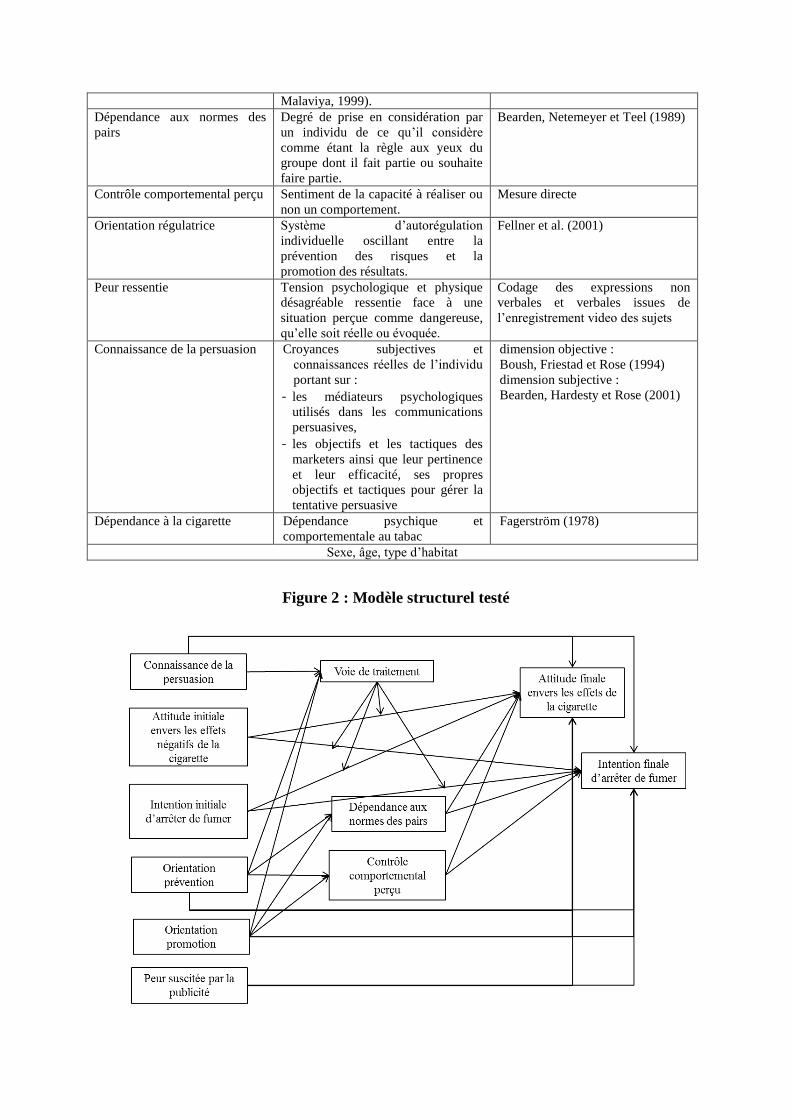
Malaviya, 1999).
Dépendance aux normes des
pairs
Degré de prise en considération par
un individu de ce qu’il considère
comme étant la règle aux yeux du
groupe dont il fait partie ou souhaite
faire partie.
Bearden, Netemeyer et Teel (1989)
Contrôle comportemental perçu Sentiment de la capacité à réaliser ou
non un comportement.
Mesure directe
Orientation régulatrice Système d’autorégulation
individuelle oscillant entre la
prévention des risques et la
promotion des résultats.
Fellner et al. (2001)
Peur ressentie Tension psychologique et physique
désagréable ressentie face à une
situation perçue comme dangereuse,
qu’elle soit réelle ou évoquée.
Codage des expressions non
verbales et verbales issues de
l’enregistrement video des sujets
Connaissance de la persuasion Croyances subjectives et
connaissances réelles de l’individu
portant sur :
- les médiateurs psychologiques
utilisés dans les communications
persuasives,
- les objectifs et les tactiques des
marketers ainsi que leur pertinence
et leur efficacité, ses propres
objectifs et tactiques pour gérer la
tentative persuasive
dimension objective :
Boush, Friestad et Rose (1994)
dimension subjective :
Bearden, Hardesty et Rose (2001)
Dépendance à la cigarette Dépendance psychique et
comportementale au tabac
Fagerström (1978)
Sexe, âge, type d’habitat
Figure 2 : Modèle structurel testé

b. Méthodologie expérimentale
Afin de tester note modèle, nous avons conçu un plan expérimental de type « avant-après exposition
avec groupe de contrôle » afin de mesurer les effets de l’exposition à une publicité anti-tabac sur la
résistance et le rôle des variables retenues. L’échantillon de départ était constitué de 450 étudiants en
école de commerce (fumeurs et non-fumeurs), ce choix ayant été dicté à la fois par la prévalence
tabagique élevée des 20-25 ans qui fait des jeunes une des cibles privilégiées des campagnes de
prévention tabagique et par la facilité d’accès aux étudiants pour une expérimentation en deux temps.
Nous avons choisi comme stimulus une publicité presse développée par l’Organisation Mondiale de la
Santé ciblant les jeunes fumeurs et les incitant à arrêter de fumer. La publicité représente une jeune
femme séduisante présentant une trachéotomie et n’a pas été utilisée en France. Au final, nous
disposons de 74 observations exploitables provenant uniquement de fumeurs.
c. Evaluation du modèle de mesure
Comme indiqué précédemment, la méthode PLS repose sur le modèle de mesure, il faut donc
s’assurer de la bonne validité et fiabilité des instruments de mesure. Pour cela, on a procédé
au préalable à une épuration des échelles par analyse factorielle exploratoire en composantes
principale suivie d’une analyse factorielle confirmatoire.
Puis, on a procédé à l’examen des indicateurs concernant le modèle externe. Les échelles
présentent des alpha de Cronbach et des rho supérieurs à la valeur seuil de 0.7, on en conclut
la bonne validité des échelles de mesure. L’unidimensionnalité est également vérifiée : toutes
les premières valeurs propres sont supérieures à 1 et les suivantes inférieures à 1. L’examen
du tableau de cross-loadings permet de vérifier que les variables manifestes loadent plus sur
leur variable latente associée que sur les autres variables latentes avec des loadings supérieurs
à 0.7. On a donc une bonne validité convergente. La validité discriminante est également
vérifiée : les AVE sont supérieures aux carrés des covariances.
Le modèle de mesure présente donc une bonne qualité.
d. Evaluation du modèle structurel
L’analyse multi-groupe réalisée à partir du modèle structurel global a permis de dégager deux
modèles locaux différents selon que les individus résistent ou non à la publicité anti-tabac du
test (figures 3 et 4). Avec 0,811, l’indice GoF relatif du modèle résistant n’atteint pas le seuil
préconisé de 0.9 mais reste satisfaisant. En outre, grâce à l’indice GoF relatif permettant de comparer
des modèles locaux entre eux, on constate que le modèle résistant affiche une meilleure prédictivité
globale que le modèle non résistant avec un GoF relatif de 0,811 contre 0,767 (tableau 3).
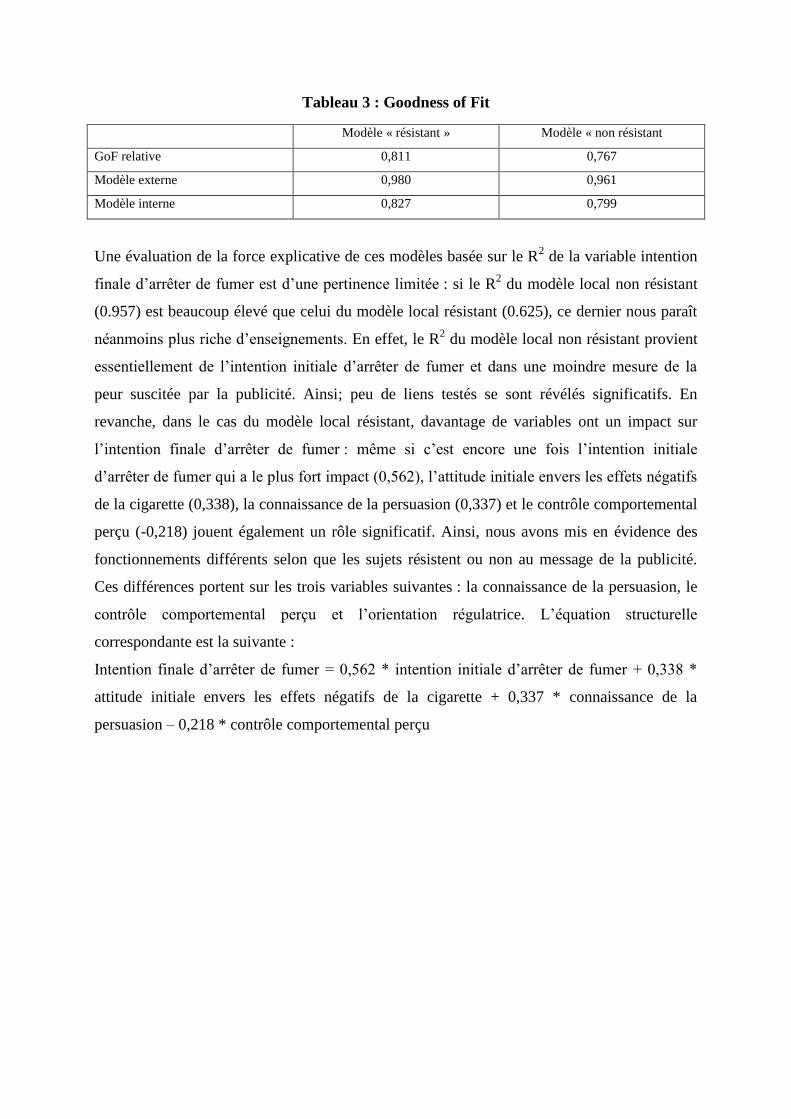
Tableau 3 : Goodness of Fit
Modèle « résistant » Modèle « non résistant
GoF relative 0,811 0,767
Modèle externe 0,980 0,961
Modèle interne 0,827 0,799
Une évaluation de la force explicative de ces modèles basée sur le R2 de la variable intention
finale d’arrêter de fumer est d’une pertinence limitée : si le R2 du modèle local non résistant
(0.957) est beaucoup élevé que celui du modèle local résistant (0.625), ce dernier nous paraît
néanmoins plus riche d’enseignements. En effet, le R2 du modèle local non résistant provient
essentiellement de l’intention initiale d’arrêter de fumer et dans une moindre mesure de la
peur suscitée par la publicité. Ainsi; peu de liens testés se sont révélés significatifs. En
revanche, dans le cas du modèle local résistant, davantage de variables ont un impact sur
l’intention finale d’arrêter de fumer : même si c’est encore une fois l’intention initiale
d’arrêter de fumer qui a le plus fort impact (0,562), l’attitude initiale envers les effets négatifs
de la cigarette (0,338), la connaissance de la persuasion (0,337) et le contrôle comportemental
perçu (-0,218) jouent également un rôle significatif. Ainsi, nous avons mis en évidence des
fonctionnements différents selon que les sujets résistent ou non au message de la publicité.
Ces différences portent sur les trois variables suivantes : la connaissance de la persuasion, le
contrôle comportemental perçu et l’orientation régulatrice. L’équation structurelle
correspondante est la suivante :
Intention finale d’arrêter de fumer = 0,562 * intention initiale d’arrêter de fumer + 0,338 *
attitude initiale envers les effets négatifs de la cigarette + 0,337 * connaissance de la
persuasion – 0,218 * contrôle comportemental perçu
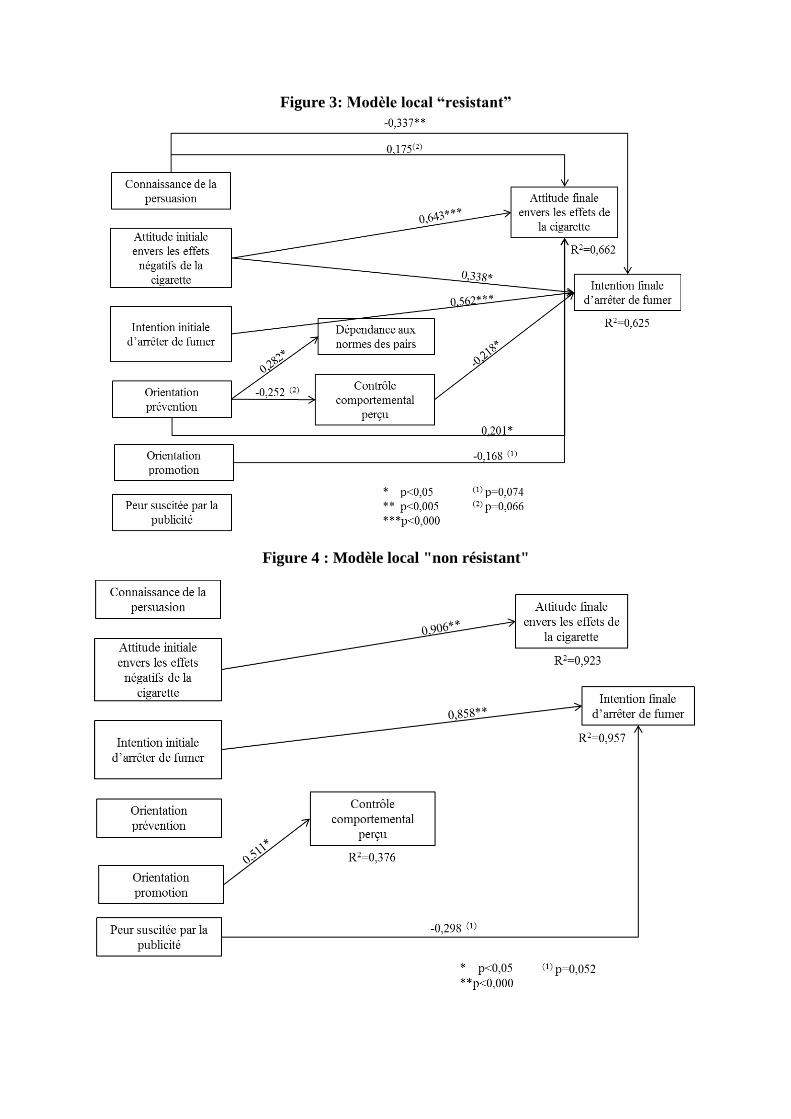
Figure 3: Modèle local “resistant”
Figure 4 : Modèle local "non résistant"

Conclusion
L’utilisation de la méthode PLS pour la modélisation par équations structurelles est
intéressante pour les chercheurs en marketing car elle peut être plus adaptée que les méthodes
basées sur la covariance à la fois dans ses objectifs et ses contraintes d’utilisation. En effet,
elle permet de tester des modèles en développement, de prendre en compte des données non-
normales, de fonctionner sur des échantillons comportant un nombre limité d’observations et
d’identifier les sources d’hétérogénéité au sein des données afin de faire émerger d’éventuels
modèles locaux. Dans notre application au modèle de résistance à la persuasion, l’analyse
multi-groupe a permis de mettre au jour deux modèles locaux distincts selon que les individus
résistent ou non à la publicité testée. Mais plutôt que d’opposer les méthodes Lisrel et PLS, à
l’instar de Wold (1982) ou Vilares, Almeida et Coelho (2007), on peut les considérer
complémentaires l’une de l’autre : PLS, par sa nature prédictive peut s’utiliser dans le cadre
d’analyse visant à développer un modèle et Lisrel, plus orienté vers la confirmation basée sur
la théorie, peut server à valider ce modèle.
Bibliographie
- Ajzen, I. (1985), From intentions to actions: A theory of planned behavior, in J. Kuhl & J.
Beckman (Eds.), Action-control: From cognition to behavior, 11-39, Heidelberg: Springer.
- Armitage C.J. et Conner M. (2000), Social Cognition Models and Health Behaviour: a
Structured Review, Psychology and Health, 15, 173-189.
- Bagozzi R. P. (1980), Causal Models in Marketing, New York: Wiley.
- Barnes J., Cote J., Cudeck R. et Malthouse E. (2001), Checking Assumptions of Normality
before Conducting Factor Analyses, Journal of Consumer Psychology, 10,1/2, 79-81.
- Bearden W.O., Netemeyer R.G. et Teel J.E. (1989), Measurement of Susceptibility to
Interpersonal Influence, Journal of Consumer Research, 15, 473-481.
- Bentler P.M. et Chou C.-P. (1987), Practical issues in structural modeling, Sociological
Methods & Research, 16, 78-117.
- Bollen K. A. (1989), Structural equations with latent variables, Wiley New York.
- Chin W.W. (1998), The partial least squares approach to structural equation modeling, in
G. A. Marcoulides (Ed.), Modern Methods for Business Research, 295–358, Mahwah, NJ:
Lawrence Erlbaum Associates.
- Chin W.W. et Newsted P.R. (1999), Structural equation modeling analysis with small
samples using partial least squares, in Statistical strategies for small sample research ed.
R.H.Hoyle, 307–342 Thousand Oaks, CA: Sage.

- Croutsche J.J. (2002), Etude des relations de causalité : utilisation des modèles d’équations
structurelles, La revue des sciences de gestion, 198, 81-97.
- Diamantopoulos A., Siguaw J. et Siguaw J. A. (2000), Introducing LISREL: A guide for
the uninitiated, Sage Publications.
- Eagly A.H. et Chaiken S. (1993), The psychology of attitudes, Fort Worth, Harcourt,
Brace, Jovanovich.
- Eggert A. (2007), Getting your PLS research published: A personal and interpersonal
perspective, Proceedings of the academy of marketing science world marketing congress,
Verona, Italy.
- Esposito-Vinzi V., Trinchera L. et Amato S. (2010), PLS Path Modeling: From
Foundations to Recent Developments and Open Issues for Model Assessment and
Improvement, in: Handbook of Partial Least Squares: Concepts, Methods and
Applications, Heidelberg (Germany) : Springer, 47-82.
- Esposito-Vinzi V., Trinchera L., Squillacciotti S. et Tenenhaus M. (2008), REBUS-PLS: A
response-based procedure for detecting unit segments in PLS path modeling, Applied
Stochastic Models in Business and Industry, 24 (5), 439‑458.
- Etter J.-F., Humair J.-P., Bergman M.M. et Perneger, T.V. (2000), Development and
validation of the Attitude Towards Smoking Scale (ATS-18), Addiction, 95, 4, 613-625.
- Fellner B., Holler M., Kirchler E. et Schabmann A. (2007), Regulatory focus scale (rfs):
development of a scale to record dispositional regulatory focus, Swiss Journal of
Psychology, 66, 2, 109-116.
- Fernandes V. (2012), En quoi l’approche PLS est-elle une méthode à (re)-découvrir pour
les chercheurs en management? M@n@gement, 15,1, 101-123.
- Fishbein M.A. et Ajzen I. (1975), Belief, attitude, intention and behavior: an introduction
to theory and research, Reading, MA, Addison Wesley.
- Friestad M. et Wright P. (1994), The Persuasion Knowledge Model: How People Cope
with Persuasion Attempts, Journal of Consumer Research, 21 ,1, 1-31.
- Gallopel-Morvan K. (2006), L'utilisation de la peur dans un contexte de marketing social :
état de l'art, limites et voies de recherche, Recherche et Applications en Marketing, 21, 4,
41-59.
- Girandola F. (2000), Peur et persuasion : présentations des recherches (1953-1998) et
d’une nouvelle lecture, L’année psychologique, 100, 333-376.
- Hair J.F., Ringle C.M. et Sarstedt M. (2011), PLS-SEM: Indeed a Silver Bullet, Journal of
Marketing Theory and Practice, 19, 2, 139–151.

- Hair J.F., Sarstedt M., Ringle C.M. et Mena J.A. (2012), An assessment of the use of
partial least squares structural equation modeling in marketing research, Journal of the
Academy of Marketing Science, 40, 414–433.
- Higgins E.T., Shah J. et Friedman R. (1997), Emotional Responses to Goal Attainment:
Strength of Regulatory Focus as Moderator, Journal of Personality & Social Psychology,
72 (3) 515-525.
- Hoyle R.H. (1995), Structural Equation Modeling: Concepts, Issues, and Applications, ed.
Sage Publications.
- Jöreskog K.G. et Wold H. (1982), The ML and PLS techniques for modeling with latent
variables: Historical and comparative aspects, in K.G. Jöreskog et H. Wold (coord.),
Systems under indirect observation: Part I, 263-270, Amsterdam: North-Holland.
- E. S. Knowles E.S. et Linn J.A. (2004)), Resistance and Persuasion, Mahwah, Erlbaum.
- Lei M. et Lomax R. G. (2005), The effect of varying degrees of nonnormality in structural
equation modeling, Structural Equation Modeling, 12(1), 1-27.
- Petty R.E. et Cacioppo J.T. (1986), The Elaboration Likelihood Model of Persuasion,
Advances in Experimental Social Psychology, 19, 123-205.
- Preacher K.J. et Hayes A.F. (2004), SPSS and SAS procedures for estimating indirect
effects in simple mediation models, Behavior Research Methods, Instruments, &
Computer, 36, 4, 717-731.
- Reinartz W., Haenlein M. et Henseler J. (2009), An empirical comparison of the efficacy
of covariance-based and variance-based SEM, International Journal of Research in
Marketing, 26, 332-344.
- Richmond R.L, Kehoe L.A. et Webster I.W. (1993), Multivariate models for predicting
abstention following intervention to stop smoking by general practitioners, Addiction, 88,
1127-1135.
- Roux D. (2007), La résistance du consommateur : proposition d’un cadre d’analyse,
Recherche et Applications en Marketing, 22, 4, 59-80.
- Sheppard B.H., Hartwick J. et Warshaw P.R. (1988), The theory of reasoned action: A
meta-analysis of past research with recommendations for modifications and future
research, Journal of Consumer Research, 15, 3, 325-343.
- Tenenhaus M., Esposito-Vinzi V., Chatelin Y.M. et Lauro C. (2005), PLS path modeling,
Computational Statistics and Data Analysis, 48, 1, 159–205.

- Tenenhaus M. et Esposito-Vinzi V. (2005), PLS Regression, PLS Path Modeling and
Generalized Procrustean Analysis: A Combined Approach for Multiblock Analysis,
Journal of Chemometrics, 19, 145‑153.
- Trinchera L. (2007), Unobserved Heterogeneity in Structural Equation Models: a new
approach in latent class detection in PLS Path Modeling, Thèse de doctorat, Département
de mathématiques et de statistiques, Université de Naples Federico II.
- Valette-Florence P (1993), Dix Années de Modèles d'Equations Structurelles: un Etat de
l'Art, Actes du 20ème Séminaire International de Recherche en Marketing, La Londe des
maures, juin, 423-442.
- Valette-Florence P. (1998), Apports des analyses hiérarchiques multiniveaux et des
modèles de mélange aux techniques de modélisation selon les équation structurelles vers
une troisième génération d'analyse multivariée, Actes du 14ème congrès de l'Association
Française de Marketing, mai, Bordeaux, pp. 695-712.
- Vilares M., Almeida M. et Coelho P. (2007), Sample size effect on the comparison of
likelihood and PLS estimators for structural equation modeling: a simulation with
customer satisfaction data, Proceedings of PLS’07 International Symposium, Aas,
Norvège, 39-41.
- Wold H. (1982), Soft Modeling: Intermediate between Traditional Model Building and
Data Analysis, Mathematical Statistics, 6, 333-346.


















