
KEYRUS ACADEMY CATALOGUE DE FORMATIONS...
27
AGILITY I COLLABORATIVE INTELLIGENCE I INNOVATION I PERFORMANCE CONSULTING I TECHNOLOGY KEYRUS ACADEMY – CATALOGUE DE FORMATIONS 2015 / FORMATIONS STATISTIQUES ET DATA SCIENCE Janvier 2015 (Version 15.01_01)
Transcript of KEYRUS ACADEMY CATALOGUE DE FORMATIONS...

AGILITY I COLLABORATIVE INTELLIGENCE I INNOVATION I PERFORMANCE
CONSULTING I TECHNOLOGY
KEYRUS ACADEMY – CATALOGUE DE FORMATIONS 2015
/ FORMATIONS STATISTIQUES ET DATA SCIENCE
Janvier 2015 (Version 15.01_01)

2
©
Keyr
us –
Tous d
roits r
éserv
és
Informations clés
OFFRE DE FORMATION DE KEYRUS
/ Une offre de formation dédiée aux outils et méthodes du marché de la Business Intelligence, de
l’Analytique et la Data Science
/ Chiffres clés
/ 3 centres de formations en France (Paris, Lyon et Aix-en-Provence)
/ + de 15 ans d'expérience
/ Un catalogue de plus de 100 séminaires et stages de formation spécialisés
/ Un équipe de plus de 20 formateurs experts
/ + de 1 000 jours de formations dispensés en 2014
/ Nos atouts
/ Un centre de formation agréé par l’Etat (n°11 92 16285 92)
/ Une équipe de formateurs certifiés et collaborant aux projets de la Direction des Opérations de Keyrus
/ Une expertise technologique et pédagogique
/ Une démarche qualité rigoureuse
/ Une assistance pré et post-stage offerte
3
©
Keyr
us –
Tous d
roits r
éserv
és
Contacts pour les formations Statistiques et Data Science
OFFRE DE FORMATION DE KEYRUS
/ Vos contacts :
Ludovic BINETTE Business Analytics Sales Manager
Fixe : + 33 1 41 34 10 00
Mobile : +33 (0)6 99 36 03 14
Keyrus
155 rue Anatole France
92593 Levallois-Perret Cedex France
Nicolas MARIVIN Responsable de l’Agence Business Analytics
Fixe : + 33 1 41 34 10 00
Mobile: +33 6 98 67 29 58
Keyrus
155 rue Anatole France
92593 Levallois-Perret Cedex France

4
©
Keyr
us –
Tous d
roits r
éserv
és
L’offre de formations Statistiques et Data Science
CATALOGUE DE FORMATIONS
/ MÉTHODOLOGIES STATISTIQUES
/ OUTILS D'ANALYSE STATISTIQUE
/ DATA SCIENCE
5
©
Keyr
us –
Tous d
roits r
éserv
és
Méthodologies statistiques
FORMATIONS STATISTIQUES ET DATA SCIENCE
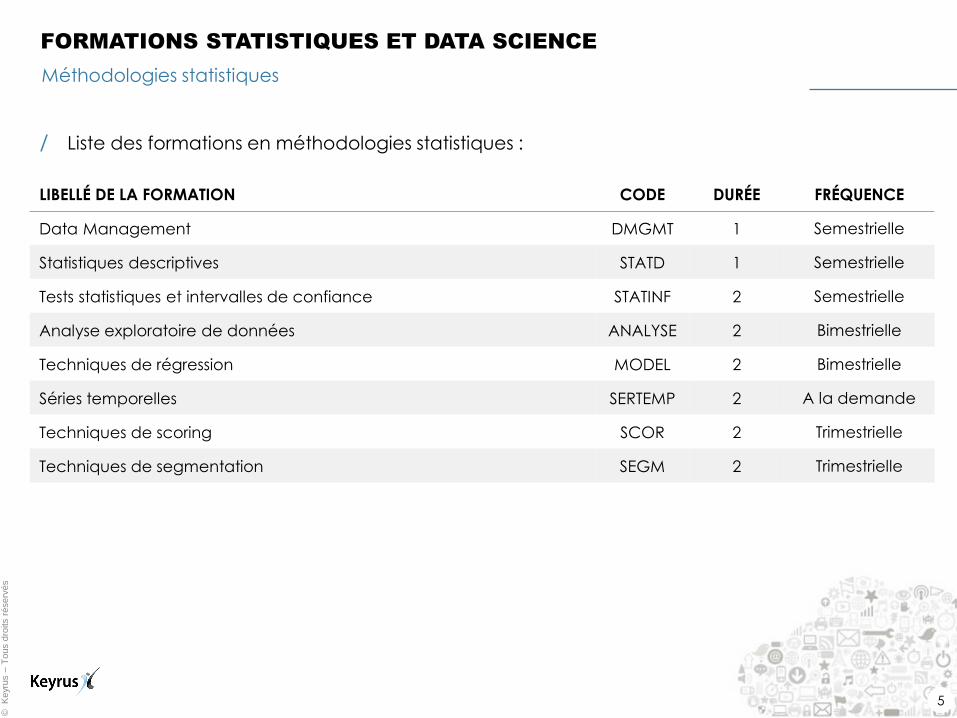
/ Liste des formations en méthodologies statistiques :
LIBELLÉ DE LA FORMATION CODE DURÉE FRÉQUENCE
Data Management DMGMT 1 Semestrielle
Statistiques descriptives STATD 1 Semestrielle
Tests statistiques et intervalles de confiance STATINF 2 Semestrielle
Analyse exploratoire de données ANALYSE 2 Bimestrielle
Techniques de régression MODEL 2 Bimestrielle
Séries temporelles SERTEMP 2 A la demande
Techniques de scoring SCOR 2 Trimestrielle
Techniques de segmentation SEGM 2 Trimestrielle
6
©
Keyr
us –
Tous d
roits r
éserv
és
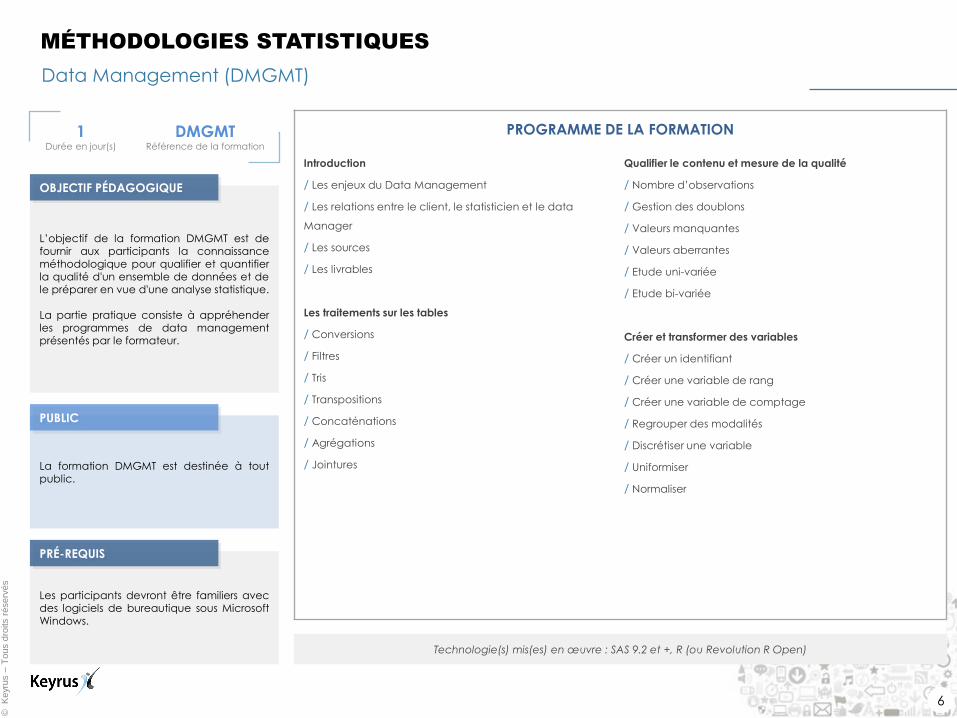
Data Management (DMGMT)
MÉTHODOLOGIES STATISTIQUES
1 Durée en jour(s)
DMGMT Référence de la formation
L’objectif de la formation DMGMT est de fournir aux participants la connaissance méthodologique pour qualifier et quantifier la qualité d'un ensemble de données et de le préparer en vue d'une analyse statistique.
La partie pratique consiste à appréhender les programmes de data management présentés par le formateur.
La formation DMGMT est destinée à tout public.
Les participants devront être familiers avec des logiciels de bureautique sous Microsoft Windows.
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : SAS 9.2 et +, R (ou Revolution R Open)
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/ Les enjeux du Data Management
/ Les relations entre le client, le statisticien et le data
Manager
/ Les sources
/ Les livrables
Les traitements sur les tables
/ Conversions
/ Filtres
/ Tris
/ Transpositions
/ Concaténations
/ Agrégations
/ Jointures
Qualifier le contenu et mesure de la qualité
/ Nombre d’observations
/ Gestion des doublons
/ Valeurs manquantes
/ Valeurs aberrantes
/ Etude uni-variée
/ Etude bi-variée
Créer et transformer des variables
/ Créer un identifiant
/ Créer une variable de rang
/ Créer une variable de comptage
/ Regrouper des modalités
/ Discrétiser une variable
/ Uniformiser
/ Normaliser
7
©
Keyr
us –
Tous d
roits r
éserv
és
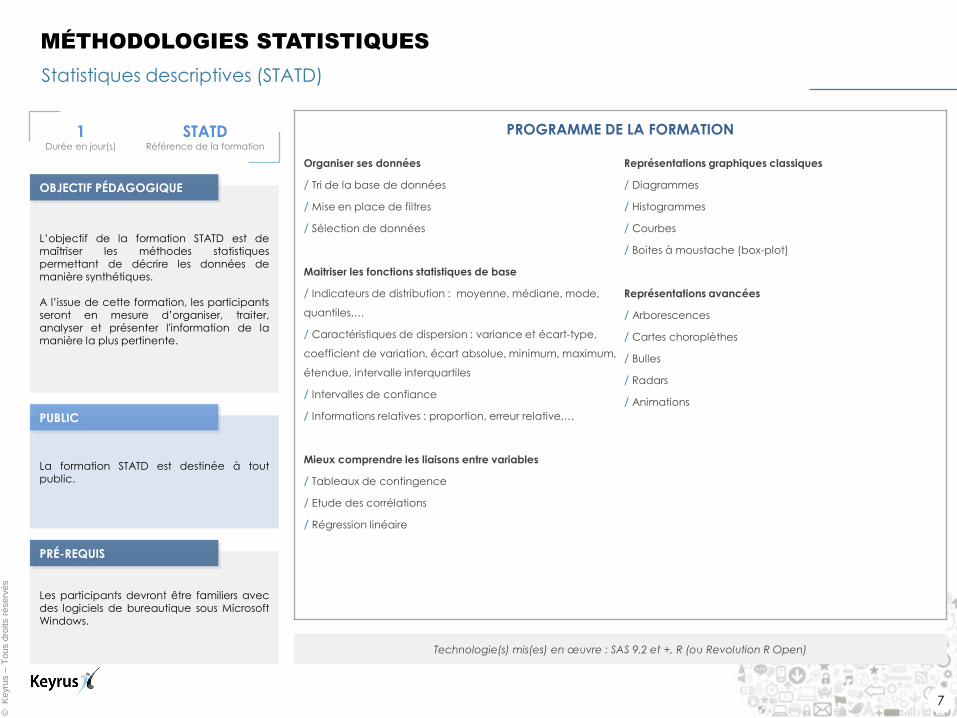
Statistiques descriptives (STATD)
MÉTHODOLOGIES STATISTIQUES
1 Durée en jour(s)
STATD Référence de la formation
L’objectif de la formation STATD est de maîtriser les méthodes statistiques permettant de décrire les données de manière synthétiques. A l’issue de cette formation, les participants
seront en mesure d’organiser, traiter, analyser et présenter l'information de la manière la plus pertinente.
La formation STATD est destinée à tout public.
Les participants devront être familiers avec des logiciels de bureautique sous Microsoft Windows.
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : SAS 9.2 et +, R (ou Revolution R Open)
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Organiser ses données
/ Tri de la base de données
/ Mise en place de filtres
/ Sélection de données
Maitriser les fonctions statistiques de base
/ Indicateurs de distribution : moyenne, médiane, mode,
quantiles,…
/ Caractéristiques de dispersion : variance et écart-type,
coefficient de variation, écart absolue, minimum, maximum,
étendue, intervalle interquartiles
/ Intervalles de confiance
/ Informations relatives : proportion, erreur relative,…
Mieux comprendre les liaisons entre variables
/ Tableaux de contingence
/ Etude des corrélations
/ Régression linéaire
Représentations graphiques classiques
/ Diagrammes
/ Histogrammes
/ Courbes
/ Boites à moustache (box-plot)
Représentations avancées
/ Arborescences
/ Cartes choroplèthes
/ Bulles
/ Radars
/ Animations

8
©
Keyr
us –
Tous d
roits r
éserv
és
Tests statistiques et intervalles de confiance (STATINF)
MÉTHODOLOGIES STATISTIQUES
2 Durée en jour(s)
STATINF Référence de la formation
L’objectif de la formation STATINF est de fournir aux participants la connaissance nécessaire pour établir la significativité statistique de tests d’hypothèse et encadrer
des estimations au moyen d’intervalles de confiance.
La formation STATINF est destinée à tout public souhaitant établir la validité d’une hypothèse, et aux analystes ou chercheurs désirant publier des mesures de significativité.
Les participants devront être familiers avec des logiciels de bureautique sous Microsoft Windows et disposer de connaissances élémentaires en mathématique (moyenne, proportion).
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : SAS 9.2 et +, R (ou Revolution R Open)
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/ Définitions
/ Probabilités élémentaires
/ Statistique paramétrique et non-paramétrique
/ Le théorème central-limite
/ Lois usuelles de convergence
Méthodologie de test
/ Interprétation
/ Choix de l’hypothèse
/ Risque de première et seconde espèce
/ Puissance de test
Comparaison d’échantillons indépendants
/ Tests d’égalité de moyennes
/ Tests d’égalité de variance
/ Cas particulier d’une proportion pour un grand échantillon
Comparaison d’échantillons appariés
/ Tests d’égalité de moyennes
/ Tests d’égalité de variance
Tests d’adéquation
/ Test d’ajustement du Khi -deux
/ Test d’ajustement de Kolmogorov-Smirnov
Les intervalles de confiance
/ Interprétation
/ Estimation paramétrique
/ Estimation non-paramétrique
Déterminer le nombre d’individus à échantillonner
/ Influence du nombre d’individus sur la région de
confiance
/ Formules donnant le nombre d’individus

9
©
Keyr
us –
Tous d
roits r
éserv
és
Analyse exploratoire de données (ANALYSE)
MÉTHODOLOGIES STATISTIQUES
2 Durée en jour(s)
ANALYSE Référence de la formation
L’objectif de la formation ANALYSE est de rendre opérationnelle toute personne rencontrant dans son métier le besoin de comprendre les relations entre un nombre
important de variables.
La formation ANALYSE est destinée à tout public.
Les participants devront au minimum avoir suivi la formation STATDESC ou justifier d’un niveau de connaissance équivalent à cette formation.
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : SAS 9.2 et +, R (ou Revolution R Open)
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/ Contexte et présentation des objectifs
/ Qualification des données (préparation)
Analyse en Composantes Principales (ACP)
/ Données utilisées
/ Construction des axes
/ Choix du nombre d’axes
/ Interprétation des axes
/ Cercle des corrélations
/ Représentation des individus dans l’espace factoriel
/ Projection des individus et variables supplémentaires
Analyse Factorielle des Correspondances (AFC)
/ Tableau de contingence
/ Métrique du Chi-deux
/ Choix du nombre d’axes
/ Interprétation des axes
Analyse des Correspondances Multiples (ACM)
/ Tableau disjonctif complet
/ Tableau de Burt
/ AFC du tableau de Burt
/ Interprétation des axes
/ Représentations graphiques associées
Méthode de classification
/ Arbre de décision
Synthèse et extensions
/ ACP avec rotation
/ Analyse en Composantes Indépendantes (uniquement
sous R)

10
©
Keyr
us –
Tous d
roits r
éserv
és
Techniques de régression (MODEL)
MÉTHODOLOGIES STATISTIQUES
2 Durée en jour(s)
MODEL Référence de la formation
L’objectif de la formation MODEL est de fournir aux participants la connaissance suffisante des techniques de modélisation afin de pouvoir répondre à des problèmes
concrets (explication, prévision de différents phénomènes,…).
La formation MODEL s’adresse à toute personne souhaitant construire un modèle permettant de répondre à un problème concret.
Les participants devront au minimum avoir suivi la formation STATDESC ou justifier d’un niveau de connaissance équivalent à cette formation.
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : SAS 9.2 et +, R (ou Revolution R Open)
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/ Expliquer ou prévoir
/ Choix du modèle en fonction de données
La régression simple
/ La méthode des moindres carrées
/ Validation du modèle
/ Tests de significativité
/ Analyse des résidus
La régression multiple
/ Visualisation des individus et des variables
/ Modélisation : estimation des paramètres, tests, qualité du
modèle
/ Sélection des variables : méthode de régression pas à pas,
choix du « meilleur modèle
Analyse de la variance
/ Tests de comparaison
/ Notion d’interaction
/ Variables quantitatives et qualitatives
Les autres régressions
/ Régression linéaire généralisé
/ Régression logistique

11
©
Keyr
us –
Tous d
roits r
éserv
és
Séries temporelles (SERTEMP)
MÉTHODOLOGIES STATISTIQUES
2 Durée en jour(s)
SERTEMP Référence de la formation
L’objectif de la formation SERTEMP est de fournir aux participants la connaissance nécessaire pour analyser des données temporelles et se servir de leurs régularités à
des fins d’interpolation et de prévision.
La formation SERTEMP s’adresse à toute personne souhaitant étudier l’évolution passée de grandeurs numériques au cours du temps afin d’en prévoir le comportement futur.
Les participants devront au minimum avoir suivi la formation STATDESC ou justifier d’un niveau de connaissance équivalent à cette formation.
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : SAS 9.2 et +, R (ou Revolution R Open)
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/ Présentation des séries temporelles
/ Représentation graphique
/ La méthodologie SEMMA
/ Points forts / Points faibles
Modèles de composition
/ Modèle additif
/ Modèle multiplicatif
/ Lissage par moyennes mobiles
/ Lissage exponentiel
/ Méthode de Holt-Winters
/ Calcul des variations saisonnières
/ Série corrigée des variations saisonnières
Fondamentaux d’analyse stochastique
/ Processus stochastique
/ Auto-corrélation, auto-covariance
/ Stationnarité
/ Hétéroscédasticité
Méthode de Box et Jenkins
/ Processus Auto-régressif (AR)
/ Processus Moyenne Mobile (MA)
/ Identification d’un modèle ARMA par étude des
corrélogrammes
/ Estimation des paramètres ARMA
Traitement des cas non-stationnaires
/ Par différenciation : ARIMA, SARIMA
/ Traitement de l’hétéroscédasticité : processus ARCH,
GARCH

12
©
Keyr
us –
Tous d
roits r
éserv
és
Techniques de scoring (SCOR)
MÉTHODOLOGIES STATISTIQUES
2 Durée en jour(s)
SCOR Référence de la formation
L’objectif de la formation SCOR est de fournir aux participants la connaissance nécessaire pour concevoir et implémenter des modèles statistiques de classification
aboutissant à la création d’un score.
La formation SCOR est destinée aux statisticiens et aux dataminers.
Les participants devront être familiers avec des logiciels de bureautique sous Microsoft Windows et disposer de connaissances élémentaires en mathématique (moyenne, proportion).
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : SAS 9.2 et +, R (ou Revolution R Open)
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/ Types de score : octroi, appétence, churn
/ Finalité : la carte de score
/ Interprétation probabiliste
Préparation des données
/ Définition du périmètre et choix des données
/ Identifier les variables discriminantes
/ Faut-il discrétiser ? Si oui, comment ?
/ Traitement des valeurs manquantes
/ Echantillon d’apprentissage/test
Création du score
/ Analyse discriminante
/ Régression logistique
/ Arbres de décision
/ Combinaison de modèles
Evaluation de la performance
/ Matrice de confusion
/ Courbes de lift, ROC
/ Robustesse
/ Suivi du modèle : structure de la population, stabilité par
variable de score
Communication des résultats
/ Importance des variables dans le score
/ Création d’une grille de score
/ Mise en production
Cas particuliers courants
/ Cas où l’événement à prédire est rare
/ Cas où l’événement à prédire possède plusieurs modalités
/ Cas où les coûts de mauvaise affectation ne sont pas
symétriques

13
©
Keyr
us –
Tous d
roits r
éserv
és
Techniques de segmentation (SEGM)
MÉTHODOLOGIES STATISTIQUES
2 Durée en jour(s)
SEGM Référence de la formation
L’objectif de la formation SEGM est de fournir aux participants la connaissance nécessaire pour segmenter des individus en segments optimisant des critères
d’homogénéité et de différenciation.
La formation SEGM est destinée aux statisticiens et aux dataminers.
Les participants devront être familiers avec des logiciels de bureautique sous Microsoft Windows et disposer de connaissances élémentaires en mathématique (moyenne, proportion).
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : SAS 9.2 et +, R (ou Revolution R Open)
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/ Méthodologie de mise en œuvre
/ Vocabulaire usuel
Définir le périmètre
/ Quels individus ?
/ Définir la similarité entre individus
/ Quelles variables intégrer ?
/ Quelles transformations réaliser avant la segmentation ?
Réaliser le regroupement
/ Stratégie hiérarchique vs partitionnement
/ Classification ascendante hiérarchique
/ K-moyennes
/ Choix du nombre de segments
Caractériser les segments obtenus
/ Qualité globale d’une segmentation
/ Interpréter les segments
/ Communiquer les résultats
Affecter les nouveaux individus
/ Si les données utilisées pour la segmentation sont
disponibles
/ Si les données utilisées pour la segmentation ne sont pas
disponibles
/ Mettre en production une segmentation
Cas pratiques usuels
/ Segmentation client basée sur récence, fréquence et
montant
/ Segmentation client basée sur le comportement de
consommation
/ Intégrer une dimension temporelle dans une segmentation
/ Intégrer des données textuelles dans une segmentations

14
©
Keyr
us –
Tous d
roits r
éserv
és
Outils d'analyse statistique
FORMATIONS STATISTIQUES ET DATA SCIENCE
/ Liste des formations sur les outils d'analyse statistique :
Remarque : Les formations SAS proposées par Keyrus Academy sont disponibles dans un catalogue dédié aux outils et solutions SAS.
LIBELLÉ DE LA FORMATION CODE DURÉE FRÉQUENCE
JMP – Initiation JMP 2 A la demande
Logiciel R – Découverte RINIT 2 Trimestrielle
Logiciel R – Etudes et modélisation statistiques RSTAT 2 Trimestrielle
Logiciel R – Programmation avancée RPROG 2 Trimestrielle
Logiciel R – Data Management NOUVEAU RDM 2 Trimestrielle
Logiciel R – Data Viz avec Shiny NOUVEAU RDVIZ 2 Trimestrielle
IBM SPSS Statistics – Initiation SPSSSTAT 2 A la demande
IBM SPSS Modeler – Initiation SPSSMOD 2 A la demande

15
©
Keyr
us –
Tous d
roits r
éserv
és
JMP – Initiation (JMP)
OUTILS D'ANALYSE STATISTIQUE
2 Durée en jour(s)
JMP Référence de la formation
L’objectif de la formation JMP est de fournir aux participants la connaissance nécessaire pour accéder, analyser et visualiser des
données sous JMP.
La formation JMP est destinée aux programmeurs SAS, aux créateurs de rapports et aux statisticiens.
Les participants devront être familiers avec des logiciels de bureautique sous Microsoft Windows. Aucune connaissance particulière statistique n'est requise.
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : JMP 9 et +
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Découverte de JMP
/ Introduction
/ JMP starter
/ Fenêtre d’accueil JMP
/ Didacticiels
/ Indices statistiques
Chargement des données
/ Ouverture d’une base MS Excel
/ Ouverture d’une base TXT
/ Présentation base JMP
Manipulation sur les colonnes et les lignes
/ Actions possibles sur colonnes et/ou sur lignes
/ Actions spécifiques aux lignes
/ Manipulations de base sur graphiques
Manipulation sur les tables et tableaux
/ Tri
/ Extraction
/ Jointure
/ Statistiques descriptives
/ Tableaux croisés dynamiques
Exploration graphique des données
/ Diagrammes
/ Nuages de points
/ Outils graphiques
/ Graphiques en bulles
/ Mosaïques
/ Arbres de décision
Sauvegarde des résultats
/ Journal
/ Projet

16
©
Keyr
us –
Tous d
roits r
éserv
és
Logiciel R – Découverte (RINIT)
OUTILS D'ANALYSE STATISTIQUE
2 Durée en jour(s)
RINIT Référence de la formation
L’objectif de la formation RINIT est de fournir aux participants la connaissance des principes fondamentaux du langage R et des fonctions usuelles pour importer,
manipuler, analyser et visualiser des données.
La formation RINIT s’adresse à tout public souhaitant réaliser des traitements de données sous R.
Les participants devront être familiers avec des logiciels de bureautique sous Microsoft Windows. Aucune connaissance particulière statistique n'est requise.
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : R (ou Revolution R Open)
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/ Présentation générale
/ Concepts fondamentaux
/ Points forts et points faibles
Prise en main
/ Présentation de l’interface
/ Première prise en main
/ Installer et charger des packages
/ Intégration des données
/ Manipulation des vecteurs/matrices
Objets de R
/ Tableaux
/ Data.frames
Gestion des données
/ Extraction de sous-tables
/ Fusion, tri
/ Gestion des doublons
/ Gestion des caractères et des dates
Graphiques
/ Graphiques usuels : Nuage de points, histogrammes,
diagrammes
/ Options graphiques
Statistiques
/ Statistiques univariées
/ Tableaux croisés
Programmation
/ Fonctions
/ Structures logiques
Présentation des résultats/sorties
/ Création de tables
/ Reporting
Extensions
/ Quelques packages usuels et comment les utiliser
/ Améliorer sa productivité grâce aux interfaces de
développement

17
©
Keyr
us –
Tous d
roits r
éserv
és
Logiciel R – Etude et modélisation statistiques (RSTAT)
OUTILS D'ANALYSE STATISTIQUE
2 Durée en jour(s)
RSTAT Référence de la formation
L’objectif de la formation RSTAT est de fournir aux participants la connaissance pratique des fonctions et packages R utilisés dans la réalisation d’études ou de modèles
statistiques.
La formation RSTAT s’adresse aux chargés d’études et statisticiens.
Les participants devront avoir un niveau sous R équivalent à celui de la formation RINIT, ainsi qu’une connaissance des principes généraux des méthodes de modélisation statistique.
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : R (ou Revolution R Open)
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/Rappel des fondamentaux de R
Analyses exploratoires
/Statistiques univariées
/Statistiques bivariées
/Analyses factorielles (ACM, AFC, ACM)
Tests et intervalles de confiance
/Echantillons indépendants
/Echantillons appariés
/Tests d’adéquation
Modélisation statistique
/Régression linéaire / ANOVA
/Régression logistique
/Sélection automatique de variables
/Méthodes de régularisation : PLS, Lasso
/Arbres de décision
/Forêts aléatoires
/SVM
Techniques de segmentation
/K-moyennes
/Classification ascendante hiérarchique
/Cartes de Kohonen
Simulation
/Echantillonnage
/Boostrapping
/Méthode de Monte Carlo par chaînes de Markov

18
©
Keyr
us –
Tous d
roits r
éserv
és
Logiciel R – Programmation avancée (RPROG)
OUTILS D'ANALYSE STATISTIQUE
2 Durée en jour(s)
RPROG Référence de la formation
L’objectif de la formation RPROG est de fournir aux participants la compétence de développement R.
La formation RPROG s’adresse aux personnes amenées à développer de manière régulière sous R ou chargées d’administrer des scripts R en production.
Les participants devront avoir un niveau sous R équivalent à celui de la formation RINIT.
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : R (ou Revolution R Open)
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/ Présentation générale
/ Concepts fondamentaux
/ Points forts et points faibles
Typage des données
/ Types de base
/ Programmation objet
Développer ses propres fonctions
/ Structure d’une fonction
/ Arguments
/ Valeur retour
/ Scoping
/ Opérateurs de fonctions
Ecrire un code performant et maintenable
/ Conventions de nommage
/ Vectoriser
/ Factoriser
/ Sauvegarder et rediriger les logs
Surveiller l’usage des ressources
/ Monitorer l’usage mémoire
/ Profiling et benchmarking
Entrées/sorties
/ Les devices graphiques
/ Générer des rapports
/ Lire et écrire dans un SGBD
/ Lire et écrire dans un fichier propriétaire (Excel, SAS,
SPSS…)
Automatiser R
/Séquencer des scripts
/Utiliser R en mode batch
Construire son propre package
/ Création
/ Documentation
/ Automatisation des tests
/ Déploiement

19
©
Keyr
us –
Tous d
roits r
éserv
és
Logiciel R – Data Management (RDM) NOUVEAU
OUTILS D'ANALYSE STATISTIQUE
2 Durée en jour(s)
RDM Référence de la formation
Acquérir les compétences fondamentales en programmation R dans le domaine de la gestion de données. Savoir manipuler et exploiter des données digitales structurées et semi-structurées.
Connaitre les standards technologiques d’échange de données digitales tels que JSON.
La formation RDM est destiné aux statisticiens et aux informaticiens souhaitant acquérir les compétences requises pour la gestion de données digitales.
Connaissance de la programmation R (avoir déjà programmé en mode projet ou avoir suivi récemment une formation d’introduction à R).
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : R (ou Revolution R Open)
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/ Rappel des enjeux et des concepts fondamentaux de la
gestion de données
/ Focus sur les spécificités des données digitales
Intégration des données]
/ Lecture/écriture de fichiers (CSV, XML,…)
/ Connexion à des bases de données relationnelles (Oracle,
MySQL, PostgreSQL,…)
/ Manipulation de données JSON
/ Interrogation de données digitales structurées avec
Google Analytics API
Mise en qualité des données
/ Mesure de la qualité de données : statistiques descriptives,
détection des doublons, des valeurs
manquantes/atypiques,…
/ Nettoyage de données : redressement, traitement des
données manquantes/atypiques,…
Traitement et manipulation des données
/ Manipulation des données : sélection de lignes/colonnes,
gestion de variables (conversion de types,
transformation,…), tris, agrégation,…
/ Concaténation et fusion de données
/ Transposition/rotation des données
Travaux pratiques
/ Production d’indicateurs statistiques (Top 10 par mois,…)
sur le téléchargement de packages R à partir des logs
structurées disponibles sur le site Web du CRAN
/ Constitution d’une base de données d’informations
météorologiques à partir des données JSON disponibles via
le site OpenWeatherMap
/ Réalisation d’analyse d’audience de sites Web via
l’intégration de données Google Analytics

20
©
Keyr
us –
Tous d
roits r
éserv
és
Logiciel R – Data Visualization avec Shiny (RDVIZ) NOUVEAU
OUTILS D'ANALYSE STATISTIQUE
2 Durée en jour(s)
RDVIZ Référence de la formation
Appréhender les concepts fondamentaux, les bonnes pratiques et les représentations innovantes de visualisation de données. Maitriser le développement d’applications Web avec l’environnement de développement R et le package Shiny.
Disposer d’une connaissance avancée des bibliothèques graphiques majeures et savoir les intégrer au sein d’applications Web orientées visualisation de données.
La formation RDVIZ est destinée aux statisticiens et aux informaticiens souhaitant découvrir et maitriser les méthodes et techniques de visualisation de données.
Connaissance de la programmation R (avoir déjà programmé en mode projet ou avoir suivi récemment une formation d’introduction à R).
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : R (ou Revolution R Open) et bibliothèques Javascript (D3.js, Chart.js,…)
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/ Présentation des concepts fondamentaux de la
visualisation de données
/ Panorama des modes de visualisation de données
/ Focus sur les formes de représentations spécialisées et/ou
innovantes : diagramme de Sankey,,…
/ Présentation du « Data Journalisme » ou comment
transformer les données en une visualisation graphique
attractive pour le lecteur
Premier pas avec le package Shiny (langage R)
/ Présentation du package R et des concepts
fondamentaux associés
/ Focus sur les interfaces graphiques (UI.r)
/ Gestion des interactions entre interface et moteur de
traitements R
/ Fonctionnalités de deboggage
Développement d'une application Web avec Shiny
/ Présentation de l'application Web à développer
/ Construction de l'interface graphique de base
/ Mise en œuvre d'un tableau de restitution des données
/ Enrichissement de l'interface avec plusieurs restitutions sous
forme d'onglet
/ Mise en œuvre de restitutions graphiques avec ggplot2
Data Visualization avec Shiny
/ Techniques d’Intégration de bibliothèques Javascript au
sein d’une application Shiny
/ Mise en œuvre d’outils de visualisation de données via
l’intégration de bibliothèques graphiques (D3.js, googleVis,
Chart.js,…)
Travaux pratiques
/ Mise en œuvre d’un baromètre visuel de données
d’informations et de critiques de films
/ Représentation de parcours clients sur un site Web via un
diagramme de Sankey
21
©
Keyr
us –
Tous d
roits r
éserv
és
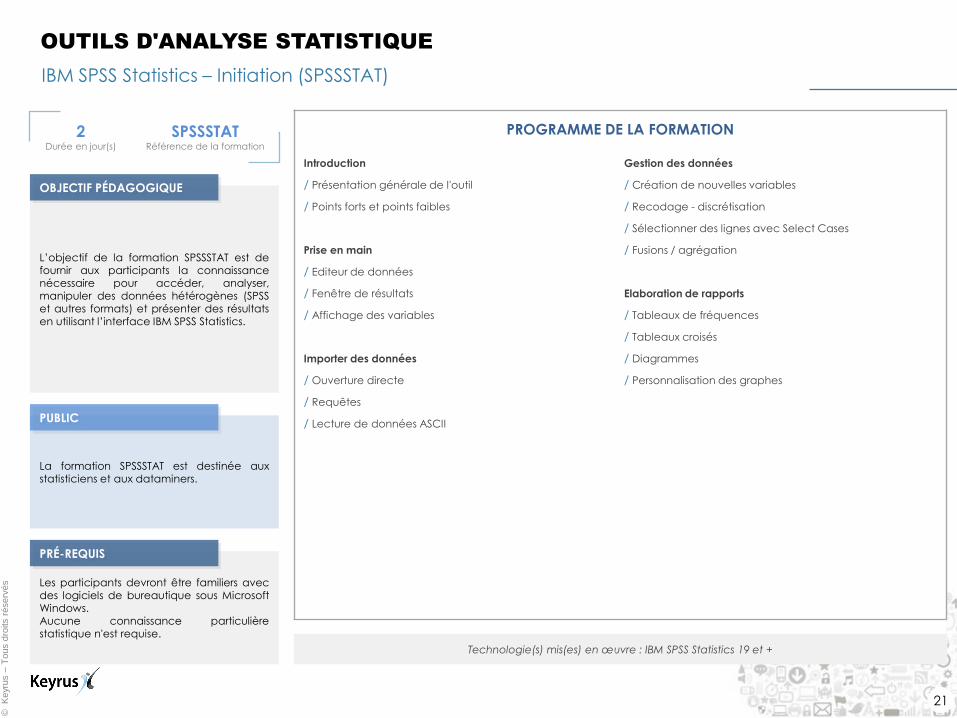
IBM SPSS Statistics – Initiation (SPSSSTAT)
OUTILS D'ANALYSE STATISTIQUE
2 Durée en jour(s)
SPSSSTAT Référence de la formation
L’objectif de la formation SPSSSTAT est de fournir aux participants la connaissance nécessaire pour accéder, analyser, manipuler des données hétérogènes (SPSS
et autres formats) et présenter des résultats en utilisant l’interface IBM SPSS Statistics.
La formation SPSSSTAT est destinée aux statisticiens et aux dataminers.
Les participants devront être familiers avec des logiciels de bureautique sous Microsoft Windows. Aucune connaissance particulière statistique n'est requise.
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : IBM SPSS Statistics 19 et +
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/ Présentation générale de l'outil
/ Points forts et points faibles
Prise en main
/ Editeur de données
/ Fenêtre de résultats
/ Affichage des variables
Importer des données
/ Ouverture directe
/ Requêtes
/ Lecture de données ASCII
Gestion des données
/ Création de nouvelles variables
/ Recodage - discrétisation
/ Sélectionner des lignes avec Select Cases
/ Fusions / agrégation
Elaboration de rapports
/ Tableaux de fréquences
/ Tableaux croisés
/ Diagrammes
/ Personnalisation des graphes

22
©
Keyr
us –
Tous d
roits r
éserv
és
IBM SPSS Modeler – Initiation (SPSSMOD)
OUTILS D'ANALYSE STATISTIQUE
2 Durée en jour(s)
SPSSMOD Référence de la formation
L’objectif de la formation SPSSMOD est de fournir aux participants la connaissance nécessaire pour accéder, analyser, manipuler des données hétérogènes (SPSS
et autres formats) et présenter des résultats en utilisant l’interface IBM SPSS Modeler.
La formation SPSSMOD est destinée aux statisticiens et aux dataminers.
Les participants devront être familiers avec des logiciels de bureautique sous Microsoft Windows. Aucune connaissance particulière statistique n'est requise.
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : IBM SPSS Modeler 14 et +
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/ Présentation générale de l'outil
/ Introduction au Datamining
/ La méthodologie CRISP DM
/ Points forts et points faibles
Prise en main
/ Présentation de l’interface
/ Sources de données
/ Typage
/ Filtre et échantillon
Audit et qualité des données
/ Audit
/ Remplacement des données manquantes
/ Restitution graphique
Gestion des données
/ Création d’indicateurs
/ Valeurs globales
/ Langage de manipulation des données
/ Fusion, concaténation et agrégation
Segmentation
/ Le nœud k-means
/ Le nœud Two Step
/ Le nœud Kohonen
Modélisation
/ Les nœuds de modélisation
/ Arbres de décision
/ Régression
/ Comparaison de modèles
Exportation de données
23
©
Keyr
us –
Tous d
roits r
éserv
és
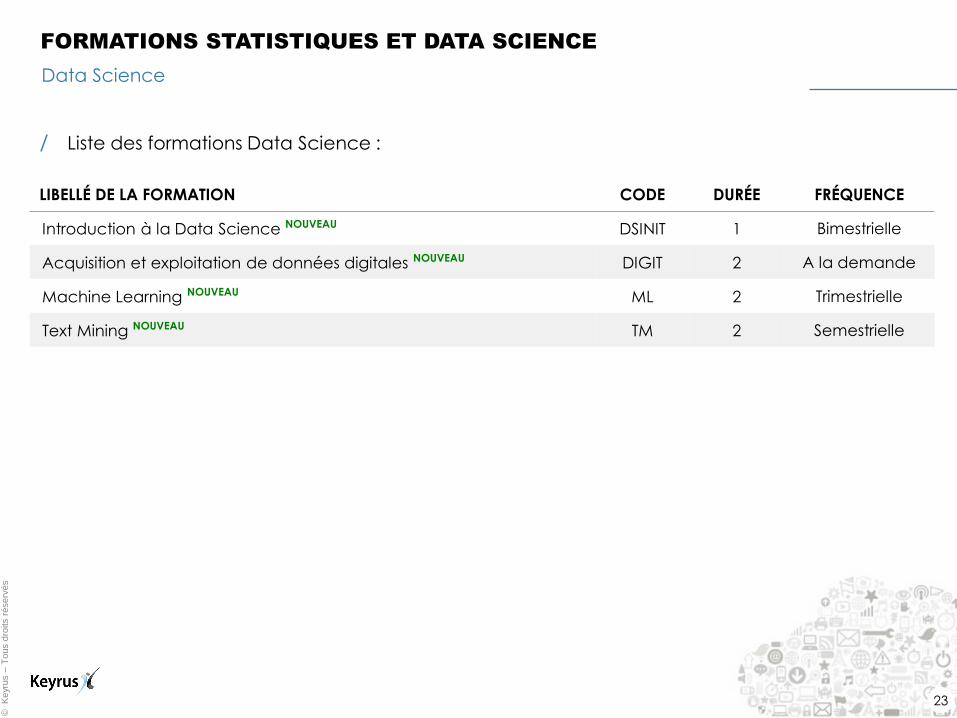
Data Science
FORMATIONS STATISTIQUES ET DATA SCIENCE
/ Liste des formations Data Science :
LIBELLÉ DE LA FORMATION CODE DURÉE FRÉQUENCE
Introduction à la Data Science NOUVEAU DSINIT 1 Bimestrielle
Acquisition et exploitation de données digitales NOUVEAU DIGIT 2 A la demande
Machine Learning NOUVEAU ML 2 Trimestrielle
Text Mining NOUVEAU TM 2 Semestrielle
24
©
Keyr
us –
Tous d
roits r
éserv
és
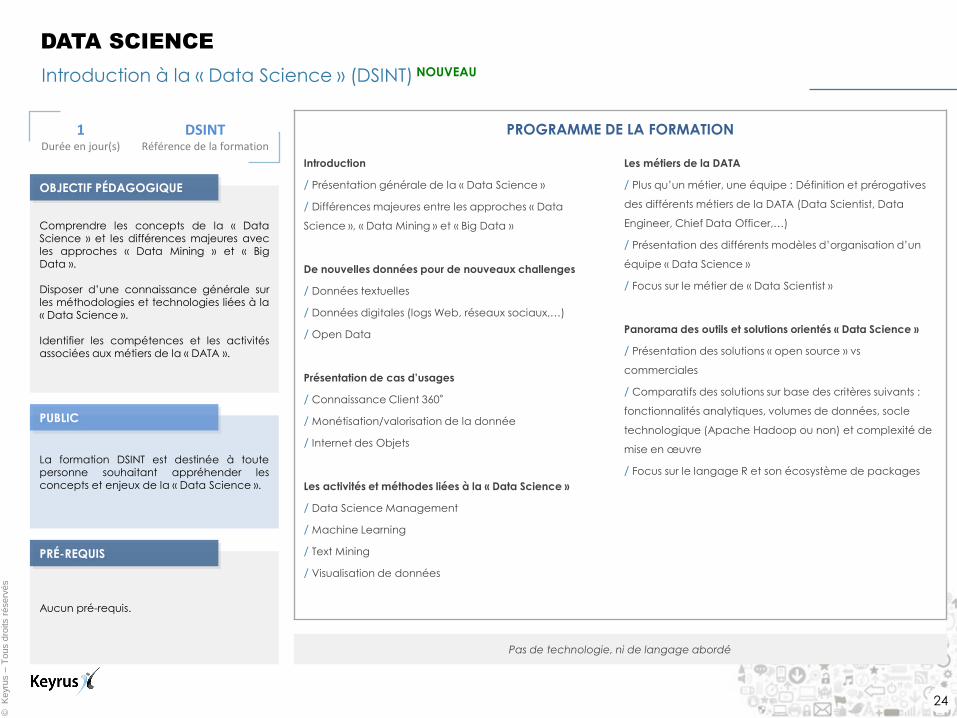
Introduction à la « Data Science » (DSINT) NOUVEAU
DATA SCIENCE
1 Durée en jour(s)
DSINT Référence de la formation
Comprendre les concepts de la « Data Science » et les différences majeures avec les approches « Data Mining » et « Big Data ». Disposer d’une connaissance générale sur les méthodologies et technologies liées à la
« Data Science ». Identifier les compétences et les activités associées aux métiers de la « DATA ».
La formation DSINT est destinée à toute personne souhaitant appréhender les concepts et enjeux de la « Data Science ».
Aucun pré-requis.
PROGRAMME DE LA FORMATION
Pas de technologie, ni de langage abordé
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/ Présentation générale de la « Data Science »
/ Différences majeures entre les approches « Data
Science », « Data Mining » et « Big Data »
De nouvelles données pour de nouveaux challenges
/ Données textuelles
/ Données digitales (logs Web, réseaux sociaux,…)
/ Open Data
Présentation de cas d’usages
/ Connaissance Client 360°
/ Monétisation/valorisation de la donnée
/ Internet des Objets
Les activités et méthodes liées à la « Data Science »
/ Data Science Management
/ Machine Learning
/ Text Mining
/ Visualisation de données
Les métiers de la DATA
/ Plus qu’un métier, une équipe : Définition et prérogatives
des différents métiers de la DATA (Data Scientist, Data
Engineer, Chief Data Officer,…)
/ Présentation des différents modèles d’organisation d’un
équipe « Data Science »
/ Focus sur le métier de « Data Scientist »
Panorama des outils et solutions orientés « Data Science »
/ Présentation des solutions « open source » vs
commerciales
/ Comparatifs des solutions sur base des critères suivants :
fonctionnalités analytiques, volumes de données, socle
technologique (Apache Hadoop ou non) et complexité de
mise en œuvre
/ Focus sur le langage R et son écosystème de packages

25
©
Keyr
us –
Tous d
roits r
éserv
és
Acquisition et exploitation des données digitales (DIGIT) NOUVEAU
DATA SCIENCE
2 Durée en jour(s)
DIGIT Référence de la formation
Maitriser les principes et concepts fondamentaux d’acquisition et d’exploitation de données digitales. Disposer de connaissances fondamentales en programmation Python, langage de référence pour les activités de Web Crawling/Scraping.
Maitriser les techniques de Web Crawling/Scraping et de récupération via les API Web de données provenant des réseaux sociaux.
La formation DIGIT est destiné aux profils ayant des connaissances avancées en programmation souhaitant acquérir les compétences requises pour l’acquisition et l’exploitation de données digitales.
Connaissance de la programmation R (avoir déjà programmé en mode projet ou avoir suivi récemment une formation d’introduction à R). Avoir des notions en langage HTML/XML.
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : Python et R (ou Revolution R Open)
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Principe d’acquisition des données digitales
/ Présentation des concepts fondamentaux d’acquisition
de données digitales : Web Crawling (exploration de sites
Web), Web Scraping (extraction de contenu Web) et
données de réseaux sociaux
Programmation Python
/ Présentation générale du langage Python
/ Installation de Python et présentation de l’environnement
de développement IDLE
/ Bases syntaxiques : syntaxe, conventions de codage,
règles de nommage, affectation, commentaires,…
/ Présentation/manipulation des types de données
/ Contrôle du flux d'exécution : structure
conditionnelle (if/elif/else), opérateurs logiques et de
comparaison, boucles while/for, instructions
break/continue,…
/ Importation et utilisation des modules les plus courants
(math, sys, calendar,…)
/ Expressions régulières (module « re ») et parsing de chaînes
de caractères
/ Gestion d’accès aux données
Manipulation de données digitales avec Python
/ Mise en œuvre des techniques de Web Crawling/Scraping
avec le langage Python et la bibliothèque « Beautiful Soup »
/ Présentation et mise en œuvre de Scrapy, framework
Open Source dédié aux activités de crawling et scraping
de sites Web
/ Extraction de données depuis des logs Web
Acquisition de données via des API Web
/ Acquisition de données via les API des réseaux sociaux
(Twitter, Facebook,…)
/ Focus et démonstration des packages R dédiés aux
réseaux sociaux : twitteR, Rfacebook,…
Travaux pratiques
/ Récupération de la liste de membres d’un groupe donnée
sur la plateforme « Meetup.com »
/ Enrichissement de la connaissance des membres d’un
groupe Meetup avec les informations disponibles sur les
réseaux sociaux
26
©
Keyr
us –
Tous d
roits r
éserv
és
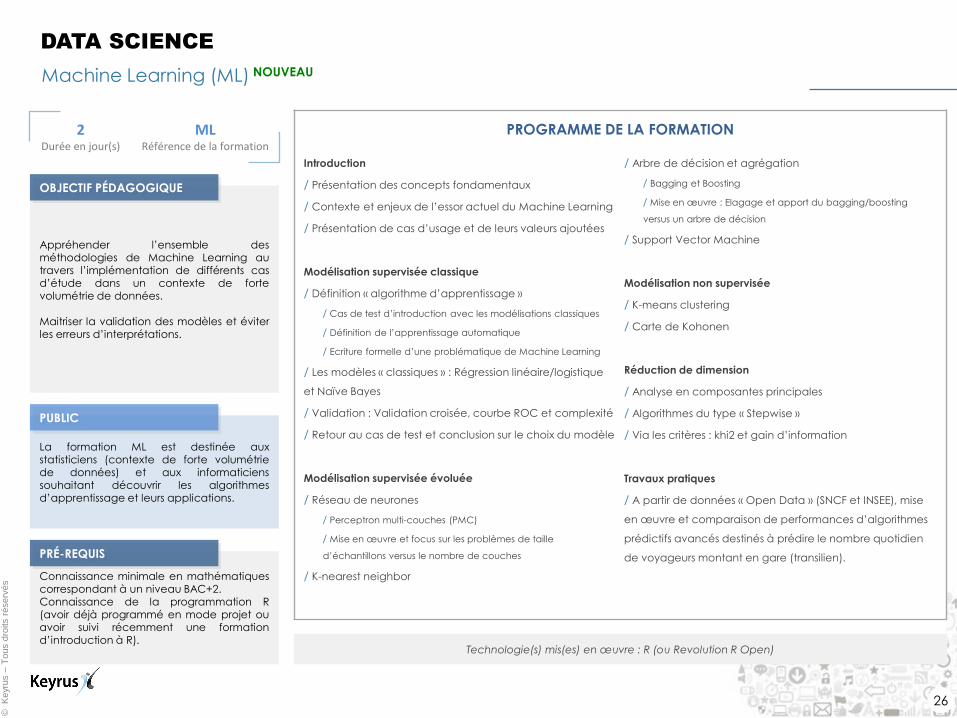
Machine Learning (ML) NOUVEAU
DATA SCIENCE
2 Durée en jour(s)
ML Référence de la formation
Appréhender l’ensemble des méthodologies de Machine Learning au travers l’implémentation de différents cas d’étude dans un contexte de forte volumétrie de données.
Maitriser la validation des modèles et éviter les erreurs d’interprétations.
La formation ML est destinée aux statisticiens (contexte de forte volumétrie de données) et aux informaticiens souhaitant découvrir les algorithmes d’apprentissage et leurs applications.
Connaissance minimale en mathématiques correspondant à un niveau BAC+2. Connaissance de la programmation R (avoir déjà programmé en mode projet ou avoir suivi récemment une formation d’introduction à R).
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : R (ou Revolution R Open)
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/ Présentation des concepts fondamentaux
/ Contexte et enjeux de l’essor actuel du Machine Learning
/ Présentation de cas d’usage et de leurs valeurs ajoutées
Modélisation supervisée classique
/ Définition « algorithme d’apprentissage »
/ Cas de test d’introduction avec les modélisations classiques
/ Définition de l’apprentissage automatique
/ Ecriture formelle d’une problématique de Machine Learning
/ Les modèles « classiques » : Régression linéaire/logistique
et Naïve Bayes
/ Validation : Validation croisée, courbe ROC et complexité
/ Retour au cas de test et conclusion sur le choix du modèle
Modélisation supervisée évoluée
/ Réseau de neurones
/ Perceptron multi-couches (PMC)
/ Mise en œuvre et focus sur les problèmes de taille
d’échantillons versus le nombre de couches
/ K-nearest neighbor
/ Arbre de décision et agrégation
/ Bagging et Boosting
/ Mise en œuvre : Elagage et apport du bagging/boosting
versus un arbre de décision
/ Support Vector Machine
Modélisation non supervisée
/ K-means clustering
/ Carte de Kohonen
Réduction de dimension
/ Analyse en composantes principales
/ Algorithmes du type « Stepwise »
/ Via les critères : khi2 et gain d’information
Travaux pratiques
/ A partir de données « Open Data » (SNCF et INSEE), mise
en œuvre et comparaison de performances d’algorithmes
prédictifs avancés destinés à prédire le nombre quotidien
de voyageurs montant en gare (transilien).

27
©
Keyr
us –
Tous d
roits r
éserv
és
Text Mining (TM) NOUVEAU
DATA SCIENCE
2 Durée en jour(s)
TM Référence de la formation
Appréhender l’ensemble des méthodes de valorisation des données non structurées. Maitriser les techniques de préparation et de visualisation des données textuelles.
Maitriser les différentes techniques d’analyses (analyse descriptive, analyse exploratoire et classification) de données textuelles.
La formation TM est destinée aux statisticiens et aux informaticiens souhaitant découvrir et maitriser les méthodes de valorisation des données non structurées.
Connaissance minimale en mathématiques correspondant à un niveau BAC+2. Connaissance de la programmation R (avoir déjà programmé en mode projet ou avoir suivi récemment une formation d’introduction à R).
PROGRAMME DE LA FORMATION
Technologie(s) mis(es) en œuvre : R (ou Revolution R Open) et R.TeMiS
PUBLIC
OBJECTIF PÉDAGOGIQUE
PRÉ-REQUIS
Introduction
/ Origine et développement des méthodes de Text mining
/ Apport du Text mining et intérêt par rapport à des logiciels
d’aide à la lecture de texte ou à la recherche par mot clés
/ Différents types de corpus de texte
/ Comparaison approche linguistique (traitement du
langage naturel) vs approche statistique (« sac de mots »)
Pre-processing des textes
/ Intérêt du preprocessing
/ Filtrage des « mots-outils » (« stopwords »)
/ Lemmatisation versus racinisation
/ Pré-traitements de mise en forme
/ Représentations du texte : sacs de mots, bigrammes,,…
/ Filtrage des termes peu fréquents
Analyse descriptive du corpus
/ Analyse à plat : termes les plus fréquents, hapax, nuage
de mots,…
/ Analyse croisée : spécificités lexicales, nuage de mots
avec discrimination,…
/ Termes co-occurrents
Analyse exploratoire des textes
/ Analyse des correspondances et analyse sémantique
latente (avec pondération des termes)
/ Interprétation des résultats : lecture des graphiques,
interprétation des axes,…
/ Clustering : calcul de distances et CAH
/ Description des classes obtenues : termes discriminants,
textes représentatifs,…
Classification de textes
/ Objectif de la classification
/ Choix des prédicteurs : sélection des termes vis à vis d'un
critère (score du khi2, TF-IDF) et utilisation de la fréquence
des termes vs coordonnées de l'analyse
sémantique/analyse des correspondances
/ Modèles de classification : SVM, classification bayésienne,
arbre et random forest
/ Indicateurs de qualité du modèle
Travaux pratiques
/ Notation de la qualité et de la satisfaction de restaurants
via l’analyse textuelle d’avis clients


















