
Introduction aux Réseaux et Bases de...
69
INSTITUT SUPERIEUR DE GESTION DE TUNIS Introduction aux Réseaux et Bases de Routage Kaouther Nouira 2011-2012
Transcript of Introduction aux Réseaux et Bases de...

INSTITUT SUPERIEUR DE GESTION DE TUNIS
Introduction aux Réseaux et Bases de Routage
Kaouther Nouira
2011-2012

2
Résumé
Ce cours a pour objectif de présenter les concepts et les technologies de base liés aux
réseaux.
Ce cours participe à la formation de nos étudiants de première année Licence Fondamentale
en Informatique de Gestion pour la Certification Cisco Networking Academy (CCNA). C’est
pour cette raison que le plan et la plupart des illustrations sont issus du cours en ligne CCNA
Exploration (module 1).
Les objectifs pédagogiques de ce cours sont :
Sensibiliser les étudiants sur l’importance des réseaux dans notre vie de tous les jours.
Comprendre la notion de communication.
Définir les modèles en couche (OSI et TCP/IP).
Définir le fonctionnement de chaque couche OSI.
Détailler les protocoles de la couche application et transport.
Ce cours s’étale sur le premier semestre de la première année Licence Fondamentale en
Informatique de Gestion à l’Institut Supérieur de Gestion de Tunis à raison de 1,5 heure de
cours par semaine.

3
Table des matières Chapitre 1: Introduction aux réseaux ....................................................... Erreur ! Signet non défini.
Introduction ................................................................................................................................. 7
Objectifs ....................................................................................................................................... 7
1.1 Communiquer dans un monde en réseau ............................................................................. 7
1.1.1 Adaptation des réseaux à notre mode de vie................................................................... 7
1.1.2 Exemples d’outils de communication .............................................................................. 9
1.1.3 Adaptation des réseaux à notre mode d’apprentissage .................................................. 10
1.1.4 Adaptation des réseaux à notre travail.......................................................................... 10
1.1.5 Adaptation des réseaux dans le monde de loisir ............................................................ 10
1.2 Communication ................................................................................................................. 11
1.2.1 Qu’est ce que la communication................................................................................... 11
1.2.2 Qualité des communications ........................................................................................ 11
1.3 Réseau en tant que plateforme.......................................................................................... 12
1.3.1 Eléments d’un réseau .................................................................................................. 12
1.3.2 Les réseaux multiples................................................................................................... 13
1.3.3 Réseaux convergents ................................................................................................... 13
1.4 Architecture réseau........................................................................................................... 14
1.4.1 La tolérance aux pannes............................................................................................... 14
1.4.2 L’évolutivité ................................................................................................................ 17
1.4.3 La qualité des services ................................................................................................. 17
1.4.4 La sécurité................................................................................................................... 18
Chapitre 2: Communication sur un réseau ................................................................................... 19
Introduction ............................................................................................................................... 19
Objectifs ..................................................................................................................................... 19
2.1 La plateforme pour la communication .................................................................................... 19
2.1.1 Les éléments de communication ...................................................................................... 19
2.1.2Communication des messages .......................................................................................... 20
2.1.3 Composants du réseau .................................................................................................... 21
2.1.4 Périphérique finaux et leur rôle sur le réseau.................................................................... 21
2.1.5 Périphériques intermédiaires et leur rôle sur le réseau...................................................... 22
2.1.6 Supports réseau .............................................................................................................. 22
2.2 Réseaux locaux, Réseaux étendus et Interréseaux ................................................................... 23
2.2.1 Réseaux locaux ............................................................................................................... 23

4
2.2.2 Réseaux étendus ............................................................................................................. 24
2.2.3 Interréseau (Internet, Réseau de réseaux) ........................................................................ 25
2.2.4 Représentation du réseau................................................................................................ 25
2.3 Les protocoles ....................................................................................................................... 26
2.3.1 Règles qui régissent les communications .......................................................................... 26
2.3.2 Protocoles réseau ........................................................................................................... 26
2.3.3 Suite de protocoles et normes de l’industrie ..................................................................... 26
2.3.4 Interaction de protocoles ................................................................................................ 26
2.3.5 Protocoles indépendants de la technologie....................................................................... 27
2.4 Utilisation des modèles en couche.......................................................................................... 28
2.4.1 Avantages de l’utilisation d’un modèle en couche ............................................................. 28
2.4.2 Modèles de protocoles et modèles de référence............................................................... 28
2.4.3 Modèle TCP/IP ................................................................................................................ 29
2.4.4 Processus de communication........................................................................................... 29
2.4.5 Unité de données de protocole et encapsulation .............................................................. 30
2.4.6 Processus d’envoi et de réception .................................................................................... 30
2.4.7 Le modèle OSI ................................................................................................................. 30
2.4.8 Comparaison des modèles OSI et TCP/IP .......................................................................... 31
2.5 Adressage de réseau .............................................................................................................. 32
2.5.1 Adressage dans le réseau................................................................................................. 32
2.5.2 Acheminement des données jusqu’au périphérique final................................................... 32
Chapitre 3: Fonctionnement et protocoles des couches applicatives ............................................ 34
Introduction ............................................................................................................................... 34
Objectifs ..................................................................................................................................... 34
3.1 Application : l’interaction entre les réseaux............................................................................. 35
3.1.1 Modèle OSI et TCP/IP ...................................................................................................... 35
3.1.2 Logiciels de la couche application..................................................................................... 37
3.1.3 Applications utilisateurs, services et protocoles de la couche application ........................... 37
3.1.4 Fonctions du protocole de couche application .................................................................. 38
3.2 Utilisation des applications et des services .............................................................................. 38
3.2.1 Modèle client serveur...................................................................................................... 38
3.2.2 Serveurs ......................................................................................................................... 39
3.2.3 Services et protocoles de la couche application ................................................................ 39
3.2.4 Réseau et applications peer to peer (P2P)......................................................................... 39

5
3.3 Exemples de services et protocoles de la couche application.................................................... 41
3.3.1 Services et protocoles DNS (Domain Name System) .......................................................... 41
3.3.2 Services WWW et HTTP ................................................................................................... 43
3.3.3 Services de messagerie et protocoles SMTP et POP ........................................................... 45
3.3.4 Services de téléchargement de fichiers et le protocole FTP ................................................ 48
3.3.5 Service DHCP .................................................................................................................. 48
3.3.6 Services pear to pear et protocole Gnutella ...................................................................... 50
Chapitre 4 : Couche transport OSI ............................................................................................... 51
Introduction ............................................................................................................................... 51
Objectifs pédagogiques ............................................................................................................... 51
4.1 Rôle de la couche transport.................................................................................................... 52
4.1.1 Objectifs de la couche transport ...................................................................................... 52
Suivi des conversations individuelles ..................................................................................... 52
Segmentation des données .................................................................................................. 52
Reconstitution des segments ................................................................................................ 52
Identification des applications .............................................................................................. 52
4.1.2 Contrôle des conversations.............................................................................................. 53
Établissement d’une session ................................................................................................. 53
Acheminement fiable ........................................................................................................... 54
Livraison dans un ordre défini............................................................................................... 54
Contrôle du flux ................................................................................................................... 54
4.1.3 Prise en charge des communications fiables ..................................................................... 54
Détermination du besoin de fiabilité ..................................................................................... 54
4.1.4 TCP/UDP......................................................................................................................... 55
Protocole UDP (User Datagram Protocol) .............................................................................. 55
Protocole TCP (Transmission Control Protocol) ...................................................................... 56
4.1.5 Adressage de ports.......................................................................................................... 56
Identification des conversations ........................................................................................... 56
Utilisation du protocole TCP et du protocole UDP .................................................................. 57
Liens ................................................................................................................................... 57
4.1.6 Segmentation et reconstitution : diviser et conquérir ........................................................ 57
Les protocoles TCP et UDP traitent différemment la segmentation. ........................................ 58
4.2 Protocole TCP : des communications fiables ............................................................................ 58
4.2.1 Fiabilisation des conversations......................................................................................... 58

6
4.2.2 Processus serveur TCP ..................................................................................................... 59
4.2.3 Etablissement et fermeture d’une connexion TCP ............................................................. 60
4.3 Gestion des sessions TCP........................................................................................................ 62
4.3.1 Réassemblage des segments TCP ..................................................................................... 62
4.3.2 Reçu TCP avec fenêtrage ................................................................................................. 63
4.3.3 Retransmission TCP ......................................................................................................... 64
4.3.4 Contrôle de l’encombrement sur TCP – Réduction de la perte de segments........................ 65
4.4 Protocole UDP : des communications avec peu de surcharge ................................................... 67
4.4.1 UDP : faible surcharge contre fiabilité .............................................................................. 67
4.4.2 Réassemblage des datagrammes UDP .............................................................................. 68
4.4.3 Processus et requêtes des serveurs UDP........................................................................... 69
4.4.4 Processus des clients UDP................................................................................................ 69

7
Chapitre 1
Introduction aux réseaux
Introduction Ce chapitre présente la plateforme de réseau de données dont nos relations sociales et
commerciales sont de plus en plus dépendantes.
Ce chapitre sert de base à l’étude des services, des technologies et des problèmes rencontrés par les
professionnels des réseaux lorsqu’ils reçoivent élaborent et assurent la maintenance des réseaux.
Objectifs • décrire l’impact des réseaux sur notre vie de tous les jours ;
• décrire le rôle des réseaux de données dans les relations humaines ;
• identifier les éléments clés de n’importe quel réseau de données ;
• identifier les opportunités et les défis posés par la convergence des réseaux ;
1.1 Communiquer dans un monde en réseau
1.1.1 Adaptation des réseaux à notre mode de vie
Parmi les éléments essentiels à l’existence humaine, le besoin de communiquer arrive juste
après le besoin de survie.
Les méthodes dont nous nous servons pour partager idées et informations changent et
évoluent sans cesse. Au début, la seule et unique méthode qui existait était la conversation
face à face. Aujourd’hui, les découvertes en matière de support étendent sans cesse la
portée de nos communications (voir tableau 1).
Tableau 1 : Exemples de communications, leurs portées et leurs supports :
Type de communication Portée Support
Journaux Ville Papier
Radio Ville Ondes
Télévision Ville Ondes
Réseau local Bâtiment Câble
Internet Globe terrestre Câble
Satellites Univers Ondes

8
Les premiers réseaux de données se limitaient à échanger des informations reposant sur des
caractères entre des systèmes informatiques. Les réseaux modernes ont évolué pour prendre
en charge l’audio, la vidéo, l’image et le texte entre des périphériques de types différents.
La nature instantanée des communications sur Internet encourage la formation de
communités internationales. Ces communités favorisent à leurs tours des interactions
sociales pour lesquelles géographie et fuseaux horaires n’ont aucune importance (voir
figure1).
Figure 1 : Internet encourage la formation de communités internationales
La technologie constitue aujourd’hui le principal vecteur de changement au monde car elle
contribue à créer un univers dans lequel les frontières nationales, les distances et les limites
physiques perdent de leurs importances.
Comme Internet connecte des individus et favorise des communications informelles, il
constitue la plateforme permettant de :
Travailler,
Informer,
Enseigner, …
Il permet aussi de:
Connaitre les conditions météorologiques.
Déterminer le trajet le moins embouteillé en visualisant les vidéos du trafic routier
transmises par les Webcams.
Consulter votre compte bancaire et payer vos factures.
Recevoir et envoyer des courriels et passer des appels téléphoniques via Internet.
Rechercher des informations médicales.
Etc… (voir figure 2).

9
Figure 2 : Les réseaux de données offrent des services qui font partie intégrante de notre
mode de vie
1.1.2 Exemples d’outils de communication dans un réseau de données
L’apparition puis l’adoption généralisée d’Internet ont entraîné la création de nouvelles
formes de communication (voir figure 3) :
La messagerie instantannée,
Les blog ou réseaux sociaux,
Le Podcast.
Figure 3 : outils de communication
Messagerie instantanée :
La messagerie instantanée est une forme de communication temps réel entre 2 personnes
ou plus basée sur la saisie du texte développé à partir de services de conversation IRC
(Internet Relay Chat). La messagerie instantanée incorpore des fonctionnalités telles que le
transfert de fichiers et les communications vocales et vidéo.
Blogs :
Les blogs sont des pages web qui sont faciles à mettre à jour et à modifier (ex. Twitter,
Facebook, …).
Podcast :
Le podcast est un support audio qui permet aux utilisateurs d’enregistrer des données audio,
de les convertir en fichiers informatiques et de les placer sur un site web à partir duquel des
tiers peuvent le télécharger.

10
1.1.3 Adaptation des réseaux de données à notre mode d’apprentissage
Les cours dispensés à l’aide d’un réseau ou de ressources Internet sont souvent appelés
formation en ligne ou e-learning.
Les cours en ligne peuvent contenir des données audio et vidéo et être à la disposition des
participants où et quand ils le veulent.
Les groupes et forums de discussion en ligne permettent aux participants de collaborer avec
leurs formateurs et les autres participants.
1.1.4 Adaptation des réseaux de données à notre travail
Au début, les entreprises exploitaient les réseaux de données pour enregistrer et
gérer en interne des informations et des données.
Ces réseaux d’entreprises ont ensuite évolué pour permettre le transfert de
nombreux types de services à savoir les courriels, la vidéo, la messagerie et la
téléphonie. Parmi ces réseaux nous citons :
Les Intranets :
Des réseaux privés exclusivement utilisés par l’entreprise permettant de
communiquer avec les employés partout dans le monde ainsi que les succursales.
Les extranets :
Partie de l’Intranet d’une entreprise accessible par des utilisateurs externes tels que
fournisseurs, clients, etc… via le réseau Internet.
Le Télétravail :
Les employés à distance, appelés télétravailleurs, ont recours à des services d’accès à
distance sécurisés à partir de leurs domiciles ou lors de leurs déplacements. Le
réseau de données leur permet de travailler comme s’ils étaient sur site. Il est
également possible d’organiser des réunions et conférences virtuelles auxquelles les
personnes éloignées peuvent participer.
1.1.5 Adaptation des réseaux de données dans le monde de loisir
Explorer virtuellement des lieux.
Ecouter des artistes.
Jouer en ligne.
Vendre et acheter en ligne.
Se regrouper avec une communité internationale sur un sujet particulier.

11
1.2 Communication
1.2.1 Qu’est ce que la communication
Avant de communiquer, nous établissons des règles appelées aussi conventions ou
protocoles qui régissent la conversation. Ces règles doivent être respectées pour que
le message soit correctement transmis et compris.
Parmi les protocoles qui régissent nos communications pour qu’elles se déroulent
correctement nous citons :
L’identification de l’expéditeur et du destinataire.
Le recours à une méthode de communication convenue (face à face,
téléphone, lettre, …).
L’utilisation d’une langue et d’une syntaxe communes.
La vitesse et le rythme d’élocution.
La demande de confirmation de réception si le message est important.
1.2.2 Qualité des communications
La communication entre individus est réussie lorsque le sens du message compris par
le destinataire est identique au sens que l’expéditeur a voulu lui donner.
Dans le cas de réseaux de données, certains critères de base servent à en déterminer
le succès. Lorsqu’un message se déplace sur un réseau, plusieurs facteurs peuvent
l’empêcher d’atteindre son destinataire ou déformer le sens initial. Ces facteurs
peuvent être externes ou internes.
Les facteurs externes :
Les facteurs externes qui affectent la communication sont liés à la complexité du
réseau et au nombre de périphériques par lesquels le message doit transiter avant
d’atteindre sa destination finale. Parmi les facteurs externes :
La qualité du chemin d’accès.
Le nombre de fois où le message doit changer de forme.
Le nombre de fois où le message doit être redirigé ou redressé.
La quantité d’autres messages transmis simultanément sur le réseau.
Le délai alloué à une communication réussie.
Les facteurs internes
Les facteurs internes gênant la communication réseau sont liés à la nature même du
message. Parmi les facteurs internes affectant la réussite d’une communication sur le
réseau, nous citons :
La taille du message (les messages volumineux peuvent être interrompus).
La complexité du message.

12
L’importance du message (message à faible priorité peut être abandonné en
cas de surcharge du réseau).
Il importe donc d’anticiper et de contrôler les facteurs internes et externes pour
assurer le succès des communications réseau.
1.3 Réseau en tant que plateforme
1.3.1 Eléments d’un réseau
La figure 4 montre les éléments constituant le plus souvent un réseau à savoir :
Les périphériques,
Les supports,
Les règles de communication,
Le message.
Figure 4 : Eléments d’un réseau
Pour qu’un réseau soit opérationnel, il faut que les périphériques soient connectés.
Les connexions peuvent être câblées ou sans fil.
Les câbles peuvent être en cuivre et transmettent des signaux électriques ou en
fibres optiques et transmettent la lumière.
Câbles à base de cuivre :
Câble téléphonique à paire torsadée.
Câble coaxial.
Câble à paires torsadées non blindées (UTP).
Les fibres optiques :
fin filament de verre ou de plastique qui véhicule des signaux lumineux.
Le réseau offre certains services aux applications informatiques présentes. Les
périphériques connectés les uns aux autres sont régis par des règles / protocoles
(voir tableau 1).

13
Tableau 1 : Pour chaque service il y a des protocoles
Les protocoles sont des règles utilisées par les périphériques en réseau pour
communiquer.
1.3.2 Les réseaux multiples
Les réseaux classiques de transfert de données téléphoniques, de radio, de télévision
ou informatiques intègrent tous leur propre version des quatre éléments de base
constituant les réseaux. Autrefois, chacun de ces services nécessitait une technologie
différente pour acheminer son signal de communication particulier. De plus, chaque
service utilisait son propre ensemble de règles et de normes pour assurer le succès
du transfert de son signal sur un support précis (voir figure 5).
Figure 5 : Les réseaux multiples
1.3.3 Réseaux convergents
Les progrès technologiques nous permettent aujourd’hui de réunir ces réseaux
disparates sur une même plateforme, une plateforme définie comme étant un réseau
convergent (voir figure 6).

14
Figure 6 : Le réseau convergent
Aujourd’hui, la norme en matière de réseau est un ensemble de protocoles appelés
TCP/IP (Transmission Control Protocol/ Internet Protocol). C’est en effet le protocole
TCP/IP qui définit les mécanismes de formatage, d’adressage et de routage utilisés.
1.4 Architecture réseau
L’architecture doit prendre en considération les caractéristiques suivantes :
La tolérance aux pannes.
L’évolutivité.
La qualité des services.
La sécurité.
1.4.1 La tolérance aux pannes
Comme des millions d’utilisateurs attendent d’Internet qu’il soit constamment disponible, il
faut une architecture réseau conçue et élaborée pour tolérer les pannes. Un réseau tolérant
aux pannes est un réseau qui limite l’impact des pannes du matériel et des logiciels et qui
peut être rétabli rapidement quand des pannes se produisent. De tels réseaux dépendent de
liaisons, ou chemins, redondantes entre la source et la destination d’un message. En cas de
défaillance d’une liaison (voir figure 7), les processus s’assurent que les messages sont
instantanément routés sur une autre liaison et ceci de manière totalement transparente
pour les utilisateurs aux deux extrémités. Aussi bien les infrastructures physiques que les
processus logiques qui dirigent les messages sur le réseau sont conçus pour prendre en
charge cette redondance. Il s’agit d’une caractéristique essentielle des réseaux actuels.

15
Figure 7 : La tolérance aux pannes
Les réseaux à commutation de circuit
De nombreux réseaux à commutation de circuit, tels que les réseaux téléphoniques, (voir
figure 8) donnent la priorité au maintien des connexions sur les circuits existants aux dépens
des requêtes de nouveaux circuits. Dans ce genre de réseaux orientés connexions, une fois
qu’un circuit a été établi, il demeure connecté même si aucune communication n’a lieu entre
les personnes à chaque extrémité de l’appel, et les ressources sont réservées jusqu’à ce que
l’une des parties mette fin à l’appel. Étant donné que la capacité à créer de nouveaux circuits
n’est pas illimitée, il est parfois possible de recevoir un message indiquant que tous les
circuits sont occupés et que l’appel ne peut être établi.
Figure 8 : Réseau téléphonique
Réseaux à commutation de paquets sans connexion
Dans leur quête d’un réseau capable de supporter la perte d’un nombre important de points
de transmission et de commutation, les premiers concepteurs d’Internet ont reconsidéré les
recherches préalables sur les réseaux à commutation de paquets. L’idée de base pour ce
type de réseaux est qu’un message peut être décomposé en de multiples blocs de message.
Les blocs individuels contenant des informations d’adressage indiquent le point d’origine
ainsi que la destination finale (voir Figure 9). Grâce à ces informations intégrées, les blocs de
message, appelés paquets, peuvent être envoyés sur le réseau en empruntant des chemins
variés avant d’être réassemblés pour recomposer le message d’origine une fois parvenus à
destination.

16
Figure 9 : Réseaux à commutation de paquets
Utilisation des paquets
Au sein du réseau même, les périphériques n’ont pas accès au contenu des paquets
individuels. Seule l’adresse de la destination finale et le prochain périphérique sur le chemin
vers cette destination leur sont indiqués. Aucun circuit réservé n’est établi entre l’expéditeur
et le destinataire. Chaque paquet est envoyé d’un emplacement de commutation à un autre
de façon indépendante. À chaque emplacement, une décision de routage est prise pour
déterminer le chemin qui sera emprunté pour transmettre le paquet vers sa destination
finale. Si un chemin précédemment utilisé n’est plus disponible, la fonction de routage peut
choisir dynamiquement le meilleur chemin suivant disponible. Comme les messages sont
fragmentés au lieu d’être envoyés sous forme de message unique complet, il est possible de
retransmettre sur un chemin différent les quelques paquets qui pourraient s’être perdus en
cas de défaillance. Dans bien des cas, le périphérique de destination ignore les défaillances
ou modifications de routages qui sont intervenues.
Réseaux à commutation de paquets sans connexion
Les chercheurs du DoD « American Department of Defence » ont compris qu’un réseau à
commutation de paquets sans connexion disposait des capacités requises pour prendre en
charge une architecture réseau résiliente et tolérante aux pannes. Dans ce type de réseau, il
est inutile de réserver un circuit unique de bout en bout. Chaque morceau du message peut
être envoyé sur le réseau par l’intermédiaire de n’importe quel chemin disponible. Des
paquets contenant des morceaux de messages provenant de sources différentes peuvent
emprunter simultanément le même réseau. Ceci résout le problème des circuits sous -utilisés
ou actifs car toutes les ressources disponibles peuvent être utilisées simultanément pour
livrer des paquets à leur destination finale. Parce qu’il permet d’utiliser dynamiquement les
chemins redondants sans intervention de l’utilisateur, Internet est devenu un moyen de
communication tolérant aux pannes et extensible.
Réseaux orientés connexions
Bien que les réseaux à commutation de paquets sans connexion répondent aux besoins du
DoD et continuent à constituer l’infrastructure de base d’Internet aujourd’hui, un système
orienté connexion comme le système téléphonique à commutation de circuit présente
quelques avantages. Étant donné que les ressources des divers emplacements de
commutation ont pour vocation de fournir un nombre précis de circuits, la qualité et la

17
cohérence des messages transmis sur un réseau orienté connexion peuvent être garanties.
En outre, le fournisseur du service peut facturer la période de temps pendant laquelle la
connexion est active aux utilisateurs du réseau, ce qui est un autre avantage. Pouvoir
facturer aux utilisateurs les connexions actives sur le réseau est un élément essentiel de
l’industrie des services de télécommunication.
1.4.2 L’évolutivité
Un réseau extensible est en mesure de s’étendre rapidement afin de prendre en charge de
nouveaux utilisateurs et applications sans que cec i n’affecte les performances du service
fourni aux utilisateurs existants (voir figure 10).
Figure 10 : Le réseau Internet est un réseau évolutif
Si Internet est capable de s’étendre au rythme que nous connaissons sans que ceci n’ait
d’impact sérieux sur ses performances au niveau des utilisateurs individuels, c’est grâce à la
conception des protocoles et des technologies sous-jacentes sur lesquels il repose. En fait,
Internet est un ensemble de réseaux privés et publics interconnectés disposant d’une
structure en couches hiérarchisées pour les services d’adressage, de désignation et de
connectivité (voir figure 11).
Figure 11 : L’évolutivité du réseau Internet
1.4.3 La qualité des services
Assurer le niveau de qualité de service requis en gérant les retards et les paramètres de
perte de paquets sur un réseau devient la clé du succès d’une solution destinée à garantir la

18
qualité d’une application de bout en bout. Garantir la qualité de service exige donc tout un
ensemble de techniques de gestion de l’utilisation des ressources réseau. Pour continuer à
assurer une haute qualité de service aux applications qui l’exigent, il convient de donner la
priorité aux types de paquets de données devant être livrés par préférence à d’autres types
de paquets pouvant être retardés ou abandonnés (voir figure 12).
Figure 12 : Qualité des services
1.4.5 La sécurité
Des mesures de sécurités prises sur un réseau doivent :
Empêcher la communication non autorisée ou le vol d’information.
Empêcher toute modification non autorisée des informations.
Prévenir les dénis (indisponibilité) des services.
Pour atteindre ces objectifs il faut :
Assurer la confidentialité.
Garantir l’intégrité des données.
Assurer la disponibilité.

19
Chapitre 2
Communication sur un réseau
Introduction De plus en plus, ce sont les réseaux qui nous relient. Les personnes communiquent en ligne depuis
n’importe où. Une technologie efficace et fiable permet au réseau d’être disponible n’importe quand
et n’importe où. Alors que notre réseau humain continue de s’étendre, la plateforme qui relie ce
réseau et le prend en charge doit également se développer.
Dans ce cours, l’accent sera mis sur la plateforme qui nous permet de communiquer de manière
rapide, fiable, sûre et économique.
Objectifs • expliquer les avantages que présente l’utilisation d’un modèle en couches pour décrire une
fonctionnalité réseau.
• décrire le rôle de chaque couche dans deux modèles de réseau reconnus : le modèle TCP/IP
et le modèle OSI.
• expliquer les avantages que présente l’utilisation d’un modèle en couches pour décrire une
fonctionnalité réseau.
• décrire le rôle de chaque couche dans deux modèles de réseau reconnus : le modèle TCP/IP
et le modèle OSI.
2.1 La plateforme pour la communication
2.1.1 Les éléments de communication La communication démarre avec un message, qui doit être envoyé d’un individu ou d’un
périphérique à un autre. Les personnes échangent des idées par de nombreuses méthodes de
communication différentes. Toutes ces méthodes ont en commun trois éléments. Le premier de ces
éléments est la source du message, ou l’expéditeur. Les sources d’un message sont les personnes, ou
les périphériques électroniques, qui doivent envoyer un message à d’autres individus ou
périphériques. Le deuxième élément de communication est la destination ou le destinataire du
message. La destination reçoit le message et l’interprète. Un troisième élément, appelé canal, est
constitué par le support qui fournit la voie par laquelle le message peut se déplacer depuis la source
vers la destination (voir figure 1).

20
Figure 1 : Les éléments de communication
2.1.2Communication des messages En théorie, une communication pourrait être transmise à travers un réseau depuis une source vers
une destination sous forme d’un flux continu et volumineux de bits.
Ce qui implique :
Un encombrement de la bande passante et aucun autre périphérique ne serait en mesure
d’envoyer ou de recevoir des messages au cours de ce temps.
Un retard de transmission.
En outre, si la transmission échoue, tout le message doit être retransmis.
En pratique, il existe une meilleure approche, qui consiste à diviser les données en petits blocs.
Cette division présente deux avantages principaux (voir figure 2) :
1. De nombreuses conversations différentes peuvent s’entremêler sur le réseau (le
multiplexage).
2. La segmentation peut augmenter la fiabilité des communications réseau. Les différentes
parties de chaque message n’ont pas besoin de parcourir le même chemin. Si un chemin
particulier devient encombré ou défaillant, les blocs du message peuvent être adressés à la
destination via un autre chemin.
Si une partie du message ne parvient pas à sa destination, seules les parties manquantes
doivent être transmises à nouveau.
Figure 2 : segmentation et multiplexage
Exemple de segmentation :
Si nous avons une lettre de 100 pages à envoyer en paquets de 1 page chacun. Nous aurons donc à
préparer 100 enveloppes sur lesquels nous mettons l‘adresse du destinataire ainsi que l’adresse
source. Les enveloppes peuvent parcourir des chemins différents. Le destinataire va recevoir et

21
ouvrir 100 enveloppes. Pour les rassembler, les lettres doivent être numérotées. De même pour les
segments, qui doivent être étiquetés (voir figure 3).
Exemple de multiplexage :
Le facteur ne distribue pas que les enveloppes de cette lettre mais peut avoir d’autres lettres à
distribuer.
Figure 3 : étiquetage des segments
2.1.3 Composants du réseau Les composants du réseau sont :
Périphériques,
Supports,
Services et processus.
Nous savons déjà que les périphériques et les supports représentent les composants physiques du
réseau.
Les services constituent le programme de communication appelés logiciels, qui sont exécutés sur les
périphériques réseau.
Exemple : service d’hébergement de messagerie, service d’hébergement Web, …
Les processus fournissent les fonctionnalités qui dirigent et déplacent les messages à travers le
réseau.
2.1.4 Périphérique finaux et leur rôle sur le réseau Les périphériques finaux forment l’interface entre le réseau humain et le réseau de communication.
Exemple :
PC.
PC portable.
Imprimente réseau.
Téléphone VoIP.
Caméra de surveillance.

22
Dans le réseau, les périphériques finaux sont appelés hôtes. Un périphérique hôte constitue soit la
source soit la destination d’un message.
Pour qu’il soit possible de distinguer entre les hôtes, chaque hôte situé sur un réseau est identifié par
une adresse. Dans les réseaux modernes, un hôte peut agir comme un client, un serveur, ou les deux.
Le logiciel installé sur l’hôte détermine son rôle sur le réseau.
Les serveurs sont des hôtes qui possèdent un logiciel installé leur permettant de fournir des
informations et des services (ex : courriel ou page Web) à d’autres hôtes sur le réseau.
Les clients sont des hôtes qui possèdent des logiciels installés leur permettant d’afficher les
informations obtenues à partir du serveur.
2.1.5 Périphériques intermédiaires et leur rôle sur le réseau Les périphériques intermédiaires fournissent la connectivité et travaillent en arrière plan afin de
garder le flux de données à travers le réseau.
Ces périphériques connectent soit les hôtes individuels au réseau, soit plusieurs réseaux afin de
former des interréseaux.
Parmi ces périphériques :
Périphériques d’accès au réseau (concentrateurs, commutateurs, points d’accès sans fil).
Périphériques interréseau (routeurs).
Périphériques de sécurité (pare feu).
Les processus qui s’exécutent sur les périphériques intermédiaires remplissent ces fonctions :
Régénérer et retransmettre des signaux de données.
Gérer les informations indiquant les chemins.
Indiquer aux autres périphériques les erreurs et les échecs de communication.
Diriger les données vers d’autres chemins en cas d’échec de liaison.
Classifier et diriger des messages en fonction des priorités.
Autoriser ou refuser le flux de données selon des paramètres de sécurité.
2.1.6 Supports réseau
Fil de cuivre.
Fibre optique de verre ou de plastique.
Transmission sans fil.
Le codage du signal qui doit se produire afin de transmettre le message diffère selon le type de
support.
Sur les fils métalliques les données sont codées en impulsions électriques.
Sue les fibres optiques les données sont codées en impulsions de lumière dans des plages de
lumière infrarouges ou visibles.

23
Dans la transmission sans fil, des modèles d’ondes électromagnétiques illustrent les différentes
valeurs de bits.
Tous les supports réseau ne possèdent pas les mêmes caractéristiques et ne conviennent pas pour le
même objectif (voir tableau 1).
Paires torsadées Câble coaxial Fibre optique Sans fil
Sensible aux
interférences
électromagnétiques
protection aux
interférences
électromagnétiques
satisfaisante
Insensible aux
interférences
électromagnétiques
Sensible aux interférences
électromagnétiques
Pas chère Pas chère Trop chère Modérément chère
Débit de 10 à 100 MB/s
avec une longueur de
100 mètres
Débit 100MB/s si distance
<1Km
Sur plusieurs centaines de
kilomètres les vitesses
sont de l’ordre de
100kbits/s
Peut atteindre 160
Gbit/s sur une
liaison en fibre
optique de
4 000 Km
Débit >11 Mb/s
Amplification après
plusieurs dizaines de
kilomètres
Amplification chaque 2 ou
9 kilomètres
Pas d’amplification Amplification
généralement après une
vingtaine ou une
cinquantaine de mètres
dans des lieux fermés à
plusieurs centaines de
mètres en environnement
ouvert.
Tableau 1 : caractéristiques des supports réseau
Les critères de chois d’un support réseau sont :
La distance sur laquelle les supports peuvent transporter correctement un signal.
L’environnement dans lequel les supports doivent être installés.
La quantité de données et le débit de la transmission.
Le coût des supports de l’installation.
La fibre optique est utilisée dans le câblage sous-marin pour relier les continents.
2.2 Réseaux locaux, Réseaux étendus et Interréseaux
2.2.1 Réseaux locaux Les infrastructures réseau peuvent considérablement varier selon :
24
La taille de la zone couverte.
Le nombre d’utilisateurs connectés.
Le nombre de types de services disponibles.
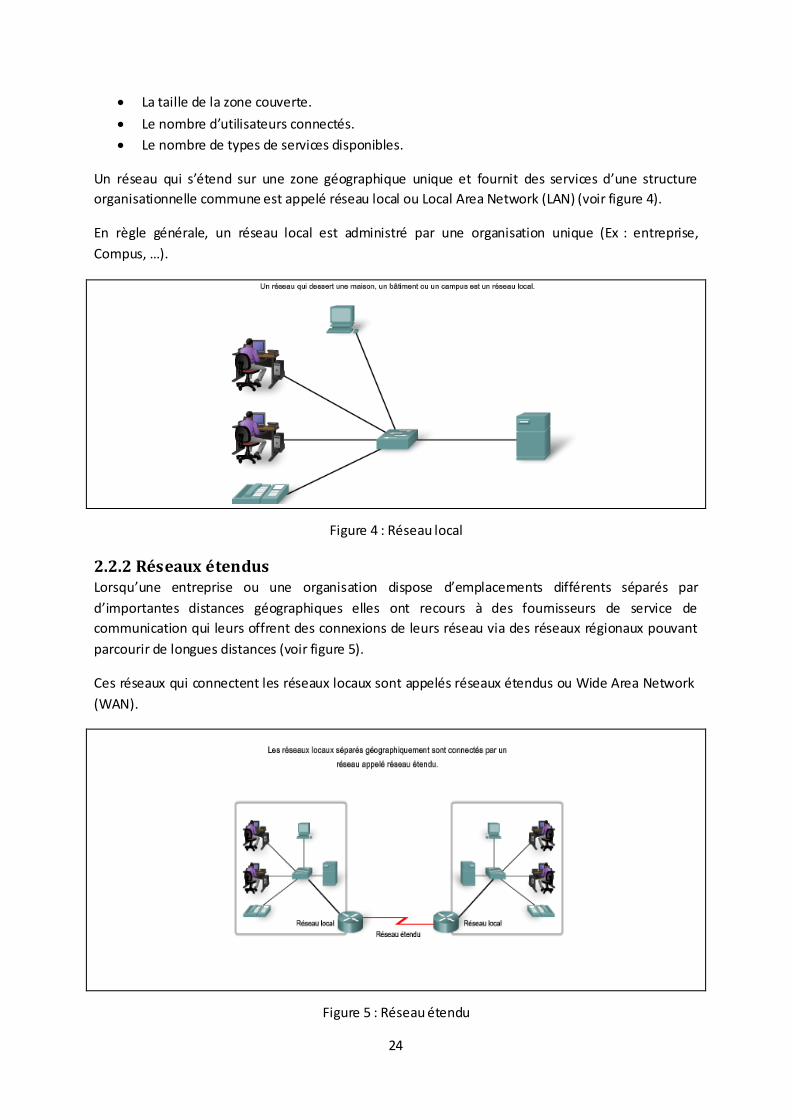
Un réseau qui s’étend sur une zone géographique unique et fournit des services d’une structure
organisationnelle commune est appelé réseau local ou Local Area Network (LAN) (voir figure 4).
En règle générale, un réseau local est administré par une organisation unique (Ex : entreprise,
Compus, …).
Figure 4 : Réseau local
2.2.2 Réseaux étendus Lorsqu’une entreprise ou une organisation dispose d’emplacements différents séparés par
d’importantes distances géographiques elles ont recours à des fournisseurs de service de
communication qui leurs offrent des connexions de leurs réseau via des réseaux régionaux pouvant
parcourir de longues distances (voir figure 5).
Ces réseaux qui connectent les réseaux locaux sont appelés réseaux étendus ou Wide Area Network
(WAN).
Figure 5 : Réseau étendu

25
2.2.3 Interréseau (Internet, Réseau de réseaux) De plus des LAN et des WAN qui ont des avantages au sein des entreprises, le réseau Internet
propose d’autres types de communication :
L’envoi d’un courriel à un ami se trouvant dans un autre pays.
L’accès à des informations ou à des produits se trouvant sur un site Web.
La messagerie instantanée avec une connaissance qui se trouve dans une autre ville.
Le réseau Internet est un maillage international de réseaux interconnectés (voir figure 6).
La garantie d’une communication efficace à travers es divers infrastructures du réseau nécessite
l’application de technologie et de protocoles cohérents.
Figure 6 : Interréseau
2.2.4 Représentation du réseau Comme tout autre langage, le langage propre au réseau utilise un ensemble de symboles pour
représenter les différents périphériques finaux, périphériques réseau et supports (voir figure 7).
Figure 7 : Représentations du réseau
En plus de ces représentations, il ya des termes importants qu’il faut retenir :
La carte réseau : C’est un adaptateur de réseau local fournit la connexion physique entre un hôte et
un périphérique réseau.

26
Port physique : Connecteur ou prise sur un périphérique réseau.
Interface : Ports spécialisés sur un périphérique réseau qui se connectent à des réseaux individuels.
Les ports sur un routeur sont appelés interfaces réseau.
2.3 Les protocoles
2.3.1 Règles qui régissent les communications Toutes les communications face à face ou à travers un réseau sont régies par des règles appelées
protocoles.
Ces protocoles sont spécifiques aux caractéristiques de la conversation.
Dans nos conversations quotidiennes, les règles que nous utilisons pour communiquer face à face ou
à travers un appel téléphonique ou des lettres ne sont pas nécessairement identiques.
De même pour la communication sur un réseau vu l’ensemble des applications et des services qui
veulent communiquer.
Donc la nécessité d’une communication entre différents hôtes nécessite l’interaction de nombreux
protocoles. Ce groupe de protocole est appelé suite de protocoles. Cette suite est implémentée sur
chaque hôte et périphérique réseau.
2.3.2 Protocoles réseau La suite des protocoles réseau décrivent des processus tels que :
Le format ou la structure du message.
La méthode selon laquelle des périphériques réseau partagent des informations sur des
chemins avec d’autres réseaux.
Comment et à quel moment des messages d’erreur et systèmes sont transférés entre des
périphériques.
La configuration et l’arrêt des sessions de transfert de données.
2.3.3 Suite de protocoles et normes de l’industrie L’utilisation de normes dans l’enveloppement et l’implémentation de protocoles garantit que les
produits provenant de différents fabricants peuvent fonctionner ensemble pour créer des
communications efficaces.
2.3.4 Interaction de protocoles L’interaction entre un serveur Web et un navigateur Web constitue un exemple de l’utilisation d’une
suite de protocoles dans des communications réseau (voir figure 8). Cette interaction utilise plusieurs
protocoles dans le processus d’échange d’informations :
Protocole d’application (HTTP).
Protocole de transfert (TCP).
Protocole interréseau (IP).
Protocole d’accès au réseau.

27
Figure 8 : Interaction de protocoles
HTTP : est un protocole qui régit la manière selon laquelle un serveur Web et un navigateur Web
(Client Web) interagissent. Le protocole HTTP décrit le contenu et la mise en forme des requêtes et
des réponses échangées entre le client Web et le serveur Web.
TCP : représente le protocole de transport qui gère les conversations individuelles entre le serveur
Web et le client Web. Le protocole TCP divise les messages HTTP en parties de plus petites tailles,
appelées segments, pour les envoyer à l’hôte de destination.
IP : est responsable de la récupération des segments formatés à partir du protocole TCP, de leur
encapsulation en paquets, de l’affectation des adresses appropriées et de la sélection du meilleur
chemin vers l’hôte de destination.
Les protocoles d’accès réseau : décrivent deux fonctions principales :
1. La gestion de liaisons de données.
2. La transmission physique des données sur les supports.
Les protocoles de gestion de liaisons de données prennent les paquets depuis le protocole IP et les
formatent pour les transmettre à travers les supports.
Les normes et les protocoles des supports physiques régissent la manière dont les signaux sont
envoyés à travers les supports.
2.3.5 Protocoles indépendants de la technologie En général, les protocoles n’indiquent pas comment remplir une fonction particulière. En indiquant
uniquement quelles fonctions sont requises pour une règle de communication spécifique mais pas
comment ces fonctions doivent être exécutées, l’implémentation d’un protocole particulier peut être
indépendante de la technologie.
Cela signifie qu’un ordinateur et tout autre périphérique (par exemple, des téléphones portables ou
des assistants numériques personnels) peut accéder à une page Web stockée sur n’importe quel type
de serveur Web qui utilise n’importe quel système d’exploitation, n’importe où sur Internet (voir
Figure 9).

28
Figure 9 : De nombreux types de périphériques peuvent communiquer ensemble en utilisant le
même protocole
2.4 Utilisation des modèles en couche
2.4.1 Avantages de l’utilisation d’un modèle en couche L’utilisation d’un modèle en couches :
Aide à la conception d’un protocole, car des protocoles qui fonctionnent à une couche
spécifique disposent d’informations définies à partir desquelles ils agissent, ainsi que d’une
interface définie par rapport aux couches supérieures et inférieures.
Il favorise la concurrence car des produits de différents fournisseurs peuvent fonctionner
ensemble.
Empêche que la modification de la technologie ou des fonctionnalités au niveau d’une
couche affecte des couches supérieure et inférieure.
Fournit un langage commun pour décrire des fonctions et des fonctionnalités réseau.
2.4.2 Modèles de protocoles et modèles de référence Il existe deux types de modèles de réseau de base (voir figure 10):
Les modèles de protocoles.
Les modèles de référence.
Figure 10 : Modèles de protocoles (TCP/IP) et modèles de référence (OSI)

29
Un modèle de protocole fournit un modèle qui correspond étroitement à la structure d’une suite de
protocoles particulière. Le modèle TCP/IP est un modèle de protocole car il décrit les fonctions qui
interviennent à chaque couche au sein de la suite TP/IP.
Un modèle de référence fournit une référence commune. Pour maintenir la cohérence dans tous les
types de protocoles et de services réseau. Un modèle de référence n’est pas destiné à être une
spécification d’implémentation. Le principal objectif d’un modèle de référence est d’aider à obtenir
une compréhension plus claire des fonctions et des processus impliqués.
Le modèle OSI constitue le modèle de référence le plus répandu. Il est utilisé par la conception de
réseaux de données.
2.4.3 Modèle TCP/IP Le premier modèle de protocole en couches pour les communications interréseau fut créé au début
des années 70 et est appelé modèle Internet. Il définit quatre catégories de fonctions qui doivent
s’exécuter pour que les communications réussissent. L’architecture de la suite de protocoles TCP/IP
suit la structure de ce modèle (voir figure 11). Pour cette raison, le modèle Internet est généralement
appelé modèle TCP/IP.
Figure 11 : Modèle TCP/IP
2.4.4 Processus de communication Le modèle TCP/IP décrit la fonctionnalité des protocoles qui constituent la suite de protocoles
TCP/IP.
Ces protocoles qui sont implémentés sur des hôtes émetteurs et récepteurs, interagissent pour
fournir une livraison de bout en bout sur un réseau.
Un processus de communication de données comprend ces étapes :
1. Création de données sur la couche application de l’hôte émetteur.
2. Segmentation et encapsulation des données lorsqu’elles descendent la pile de protocoles de
l’hôte émetteur.
3. Génération de données sur les supports au niveau de la couche d’accès au réseau de la pile.
4. Transport des données via l’interréseau.
5. Réception des données au niveau de la couche d’accès au réseau de l’hôte récepteur.

30
6. Décapsulation et assemblage des données lorsqu’elles remontent la pile de protocoles de
l’hôte récepteur.
7. Transmission de ces données à l’application de destination.
2.4.5 Unité de données de protocole et encapsulation Lorsque les données d’application descendent la pile de protocoles en vue de leur transmission sur le
support réseau, différent protocoles ajoutent des informations à chaque niveau. Il s’agit du processus
d’encapsulation (voir figure 12).
La forme qu’emprunte une donnée sur n’importe quelle couche est appelée unité de données de
protocoles.
Figure 12 : Unité de données de protocole et encapsulation
Au cours de l’encapsulation chaque couche suivante encapsule l’unité de donnée de protocole
qu’elle reçoit de la couche supérieure. A chaque étape du processus, une unité de données de
protocole possède un nom :
Données : unité de données de protocole au niveau de la couche application.
Segment : unité de données de protocole au niveau de la couche transport.
Paquet : unité de données de protocole au niveau de la couche interréseau.
Trame : unité de données de protocole au niveau de la couche accès au réseau.
Bits : unité de données de protocole utilisée lors de la transmission physique de données à travers le
support.
2.4.6 Processus d’envoi et de réception
2.4.7 Le modèle OSI En tant que modèle de référence, le modèle OSI (voir figure 13) fournit une liste exhaustive de
fonctions et de services qui peuvent intervenir à chaque couche. Il décrit également l’interaction de
chaque couche avec la couche directement supérieure ou inférieure.

31
Figure 13 : Le modèle OSI
Bien que le contenu de ce cours est structuré autour du modèle OSI, la discussion traitera
essentiellement les protocoles identifiés dans la pile du protocole TCP/IP.
2.4.8 Comparaison des modèles OSI et TCP/IP Les protocoles qui constituent la suite de protocoles TCP/IP peuvent être décrits selon les termes d u
modèle de référence OSI. Dans le modèle OSI, la couche d’accès réseau et la couche application du
modèle TCP/IP sont encore divisées pour décrire des fonctions discrètes qui doivent intervenir au
niveau de ces couches (voir figure 14).
Figure 14 : Comparaison entre les modèles OSI et TCP/IP
Les principaux parallèles entre les deux modèles de réseau se situent aux couches 3 et 4 du modèle
OSI. La couche 3 du modèle OSI, la couche réseau, est utilisée presque partout dans le monde afin de
traiter et de documenter l’éventail des processus qui interviennent dans tous les réseaux de données
pour adresser et acheminer des messages à travers un interréseau. Le protocole IP est le protocole
de la suite TCP/IP qui contient la fonctionnalité décrite à la couche 3.

32
La couche 4, la couche transport du modèle OSI, sert souvent à décrire des services ou des fonctions
générales qui gèrent des conversations individuelles entre des hôtes source et de destination. Au
niveau de cette couche, les protocoles TCP/IP Transmision Control Protocol (TCP) et User Datagram
Protocol (UDP) fournissent les fonctionnalités nécessaires.
La couche application TCP/IP inclut plusieurs protocoles qui fournissent des fonctionnalités
spécifiques à plusieurs applications d’utilisateur final. Les couches 5, 6 et 7 du modèle OSI sont
utilisées en tant que références pour les développeurs et les éditeurs de logiciels d’application, afin
de créer des produits qui doivent accéder aux réseaux pour des communications.
2.5 Adressage de réseau
2.5.1 Adressage dans le réseau Le modèle OSI décrit des processus de codage, de mise en forme, de segmentation et
d’encapsulation de données pour la transmission sur le réseau. Un flux de données envoyé depuis
une source vers une destination peut être divisé en parties et entrelacé avec des messages transmis
depuis d’autres hôtes vers d’autres destinations. À n’importe quel moment, des milliards de ces
parties d’informations se déplacent sur un réseau. Il est essentiel que chaque donnée contienne les
informations d’identification suffisantes afin d’arriver à bonne destination.
Il existe plusieurs types d’adresses qui doivent être incluses pour livrer correctement les données
depuis une application source exécutée sur un hôte à l’application de destination correcte exécutée
sur un autre. En utilisant le modèle OSI comme guide, nous apercevons les différents identificateurs
et adresses nécessaires à chaque couche.
2.5.2 Acheminement des données jusqu’au périphérique final Au cours du processus d’encapsulation, des identificateurs d’adresse sont ajoutés aux données
lorsque celles-ci descendent la pile de protocoles sur l’hôte source. Tout comme il existe plusieurs
couches de protocoles qui préparent les données à la transmission vers leur destination, il existe
plusieurs couches d’adressage pour garantir leur livraison (voir figure 15):
Couche transport (Couche 4).
Couche réseau (Couche 3).
Couche liaison de données (Couche 2).
Au niveau de la couche 4, les informations contenues dans l’en-tête d’unité de données de protocole
identifient le processus ou le service spécifique s’exécutant sur le périphérique hôte de destination
qui doit intervenir sur les données en cours de livraison.
Chaque application ou service est représenté(e) au niveau de la couche 4 par un numéro de port. Un
dialogue unique entre des périphériques est identifié par une paire de numéros de port source et de
destination de la couche 4, qui représentent les deux applications qui communiquent. Lors de la
réception des données sur l’hôte, le numéro de port est examiné pour déterminer quel processus ou
application constitue la destination correcte des données.
Les protocoles de la couche 3 ont été principalement conçus pour déplacer des données depuis un
réseau local vers un autre réseau local au sein d’un interréseau. Tandis que les adresses de la

33
couche 2 sont uniquement utilisées pour communiquer entre des périphériques sur un réseau local
unique, les adresses de la couche 3 doivent inclure des identificateurs qui permettent aux
périphériques réseau intermédiaires de localiser des hôtes sur différents réseaux. Dans la suite de
protocoles TCP/IP, chaque adresse hôte IP contient des informations sur le réseau où se trouve
l’hôte.
À la limite de chaque réseau local, un périphérique réseau intermédiaire, généralement un routeur,
décapsule la trame pour lire l’adresse hôte de destination contenue dans l’en-tête du paquet, l’unité
de données de protocole de la couche 3. Les routeurs utilisent la partie d’identificateur de réseau de
cette adresse pour déterminer le chemin à utiliser afin d’atteindre l’hôte de destination. Une fois le
chemin déterminé, le routeur encapsule le paquet dans une nouvelle trame et l’envoie vers le
périphérique final de destination. Lorsque la trame atteint sa destination finale, les en-têtes de trame
et de paquet sont supprimés et les données sont transmises à la couche 4 supérieure.
L’adresse physique de l’hôte, est contenu dans l’en-tête de l’unité de données de protocole de la
couche 2, appelée trame. La couche 2 est chargée de la livraison des messages sur un réseau local
unique. L’adresse de couche 2 est unique sur le réseau local et représente l’adresse du périphérique
final sur le support physique. Dans un réseau local qui utilise Ethernet, cette adresse est appelée
adresse MAC (Media Access Control). Lorsque deux périphériques finaux communiquent sur le
réseau Ethernet local, les trames échangées entre eux contiennent les adresses MAC de destination
et source. Une fois qu’une trame a été correctement reçue par l’hôte de destination, les informations
sur l’adresse de couche 2 sont supprimées lors de la décapsulation des données et de leur
déplacement vers le haut de la pile de protocoles, à la couche 3.
Figure 15 : phénomène d’adressage par couche

34
Chapitre 3 :
Fonctionnement et protocoles des couches
applicatives
Introduction La plupart d’entre nous utilisons Internet via le Web, les services de messagerie et les programmes
de partage de fichiers. Ces applications, ainsi que de nombreuses autres, constituent l’interface
humaine entre l’utilisateur et le réseau sous-jacent et nous permettent d’envoyer et de recevoir des
informations avec une relative facilité. Un professionnel des réseaux doit savoir dans quelle mesure
une application est capable de formater, de transmettre et d’interpréter les messages envoyés et
reçus via le réseau.
Le modèle Open System Interconnection (OSI) permet de visualiser plus facilement les mécanismes
sous-jacents de la communication via le réseau (voir figure 1). Ce chapitre porte sur le rôle d’une
couche, la couche application, et de ses composants :
1. applications,
2. services,
3. protocoles.
Nous examinerons comment ces trois éléments permettent une communication robuste via le
réseau d’informations.
Figure 1 : La couche applicative du modèle OSI
Objectifs Dans ce chapitre, vous apprendrez à :
décrire comment les fonctions des trois couches supérieures du modèle OSI fournissent des
services de réseau aux applications destinées à l’utilisateur final ;
décrire comment les protocoles de la couche application TCP/IP fournissent les services
spécifiés par les couches supérieures du modèle OSI ;

35
définir comment les utilisateurs se servent de la couche application pour communiquer via le
réseau d’informations ;
décrire le fonctionnement d’applications TCP/IP très courantes, telles que le Web et le
courrier électronique et les services associés;
expliquer comment, grâce aux protocoles, les services exécutés sur un type de périphérique
peuvent envoyer des données vers de nombreux périphériques réseau différents et recevoir
des données de ces périphériques ;
3.1 Application : l’interaction entre les réseaux
3.1.1 Modèle OSI et TCP/IP Le modèle de référence OSI est une représentation abstraite en couches servant de guide à la
conception des protocoles réseau. Il divise le processus de réseau en sept couches logiques, chacune
comportant des fonctionnalités uniques et se voyant attribuer des services et des protocoles
spécifiques.
Dans ce modèle, les informations sont transmises d’une couche à l’autre, en commençant au niveau
de la couche application sur l’hôte émetteur (voir figure 2), puis en descendant dans la hiérarchie
jusqu’à la couche physique, pour ensuite transiter sur le canal de communication vers l’hôte de
destination, où les informations remontent la hiérarchie jusqu’à la couche application.
Figure 2 : Transmission de l’information d’une couche à l’autre selon le modèle OSI
La couche application (couche 7) est la couche supérieure des modèles OSI et TCP/IP. Elle est la
couche qui sert d’interface entre les applications que nous utilisons pour communiquer et le réseau
sous-jacent via lequel nos messages sont transmis. Les protocoles de couche application sont utilisés
pour échanger des données entre les programmes s’exécutant sur les hôtes source et de destination.
Il existe de nombreux protocoles de couche application et de nouveaux protocoles sont
constamment en cours de développement.
Bien que la suite de protocoles TCP/IP ait été développée avant la définition du modèle OSI, les
fonctionnalités des protocoles de couche application TCP/IP s’intègrent à la structure des trois
couches supérieures du modèle OSI (voir figure 3):
La couche application,

36
La couche présentation,
La couche session.
Figure 3 : Correspondance entre modèle OSI et TCP/IP
La couche présentation
La couche présentation remplit trois fonctions principales :
1. codage et conversion des données de la couche application afin que les données issues du
périphérique source puissent être interprétées par l’application appropriée sur le
périphérique de destination ;
2. compression des données de sorte que celles-ci puissent être décompressées par le
périphérique de destination ;
3. chiffrement des données en vue de leur transmission et déchiffrement des données reçues
par le périphérique de destination.
Couche session
Comme l’implique le nom de la couche session, les fonctions s’exécutant au niveau de cette couche
permettent un dialogue entre les applications source et de destination. La couche session traite
l’échange des informations pour initier et maintenir un dialogue et pour redémarrer les sessions
interrompues ou inactives pendant une longue période.
Les protocoles de couche application TCP/IP les plus connus sont ceux permettant l’échange
d’informations entre les utilisateurs. Ces protocoles spécifient les informations de format et de
contrôle nécessaires à un grand nombre de fonctions courantes de communication via Internet. Voici
certains de ces protocoles TCP/IP :
Le protocole DNS (Domain Name Service) est utilisé pour traduire les adresses Internet en
adresses IP.
Le protocole HTTP (Hypertext Transfer Protocol) est utilisé pour transférer les fichiers qui
constituent les pages du Web.
Le protocole SMTP (Simple Mail Transfer Protocol) est utilisé pour transférer les courriels et
les pièces jointes.

37
Le protocole Telnet, protocole d’émulation de terminal, est utilisé pour permettre un accès
distant aux serveurs et aux périphériques réseau.
Le protocole FTP (File Transfer Protocol) est utilisé pour le transfert interactif de fichiers
entre les systèmes.
3.1.2 Logiciels de la couche application Les fonctions associées aux protocoles de couche application permettent au réseau des utilisateurs
de faire une interface avec le réseau de données sous-jacent. Lorsque l’utilisateur ouvre un
navigateur Web ou une fenêtre de messagerie instantanée, une application est lancée et le
programme est placé dans la mémoire du périphérique, où il est exécuté. Chaque programme en
cours d’exécution chargé sur un périphérique est nommé processus.
La couche application comprend deux formes de programmes ou processus logiciels permettant
d’accéder au réseau : les applications et les services.
Applications orientées réseau
Les applications sont les programmes logiciels qui permettent aux utilisateurs de communiquer sur le
réseau. Certaines applications destinées à l’utilisateur final sont orientées réseau, à savoir qu’elles
implémentent les protocoles de couche application et sont capables de communiquer directement
avec les couches inférieures de la pile de protocoles. Les clients de messagerie et les navigateurs
Web sont des exemples de ces types d’applications.
Services de couche application
D’autres programmes peuvent nécessiter l’assistance des services de couche application (par
exemple, le transfert de fichiers ou la mise en file d’attente de tâches d’impression réseau). Bien que
transparents pour l’utilisateur, ces services constituent les programmes qui établissent l’interface
avec le réseau et préparent les données à transférer.
Chaque application ou service réseau utilise des protocoles qui définissent les normes et les formats
de données à utiliser. Sans protocoles, le réseau de données ne disposerait d’aucune méthode
commune pour formater et transmettre les données.
3.1.3 Applications utilisateurs, services et protocoles de la couche
application Comme mentionné précédemment, la couche application utilise des protocoles implémentés au sein
d’applications et de services. Alors que les applications permettent aux utilisateurs de créer des
messages et que les services de couche application établissent une interface avec le réseau, les
protocoles fournissent les règles et les formats qui régissent la manière dont les données sont
traitées. Ces trois composants peuvent être utilisés par le même programme exécutable et peuvent
même porter le même nom. Par exemple, « Telnet » peut faire référence à l’application, au service
ou au protocole.
Dans le modèle OSI, les applications qui interagissent directement avec les utilisateurs sont
considérées comme étant au sommet de la pile. De même que toutes les couches au sein du modèle
OSI, la couche application fait appel aux fonctions des couches inférieures pour terminer le processus
de communication. Au sein de la couche application, les protocoles indiquent quels messages sont

38
échangés entre les hôtes source et de destination, la syntaxe des commandes de contrôle, le type et
le format des données transmises et les méthodes appropriées de notification et de correction des
erreurs.
3.1.4 Fonctions du protocole de couche application Les protocoles de couche application sont utilisés par les périphériques source et de destination
pendant une session de communication. Pour que les communications aboutissent, les protocoles de
couche application implémentés sur les hôtes source et de destination doivent correspondre (voir
figure 4).
Figure 4 : Correspondance des protocoles de la couche application
Les protocoles établissent des règles cohérentes pour échanger des données entre les applications et
les services chargés sur les périphériques concernés.
Ils indiquent la manière dont les données figurant dans les messages sont structurées et le type des
messages envoyés entre les hôtes source et de destination. Ces messages peuvent être des requêtes
de services, des reçus, des messages de données, des messages d’état ou des messages d’erreur. Les
protocoles définissent également les dialogues au niveau des messages et assurent qu’un message
envoyé reçoit la réponse prévue et que les services appropriés sont invoqués lorsque se produit un
transfert de données.
3.2 Utilisation des applications et des services
3.2.1 Modèle client serveur Lorsque l’utilisateur tente d’accéder aux informations situées sur son périphérique, qu’il s’agisse d’un
PC, d’un ordinateur portable, d’un assistant numérique personnel, d’un téléphone portable ou autre
périphérique connecté au réseau, les données peuvent ne pas être stockées sur ce périphérique.
Dans ce cas, une requête d’accès aux informations doit être adressée au niveau du périphérique sur
lequel résident les données.
Dans le modèle client/serveur, le périphérique demandant les informations est nommé client et celui
répondant à la demande est nommé serveur. Les processus client et serveur sont considérés comme
faisant partie de la couche application. Le client commence l’échange en demandant des données au
serveur, qui répond en envoyant un ou plusieurs flux de données au client. Les protocoles de couche
application décrivent le format des requêtes et des réponses entre clients et serveurs. Outre le
transfert de données effectif, cet échange peut également nécessiter des informations de contrôle,
telles que l’authentification de l’utilisateur et l’identification d’un fichier de données à transférer.

39
3.2.2 Serveurs Dans un contexte général de réseau, un périphérique qui répond à des requêtes émanant
d’applications clientes opère en tant que serveur. Un serveur est généralement un ordinateur qui
contient des informations à partager avec de nombreux systèmes clients. Par exemple, les pages
Web, les documents, les bases de données, les images, les fichiers vidéo et les fichiers audio peuvent
tous être stockés sur un serveur et transmis à des clients demandeurs.
Dans un réseau client/serveur, le serveur exécute un service, ou processus, parfois nommé démon de
serveur (voir figure 5).
3.2.3 Services et protocoles de la couche application Les serveurs comportent généralement plusieurs clients demandant des informations en même
temps. Par exemple, un serveur peut comporter de nombreux clients demandant à se connecter à ce
serveur (voir figure 5). Ces requêtes de client individuelles doivent être traitées simultanément et
séparément pour que le réseau fonctionne correctement. Les processus et les services de la couche
application sont assistés par les fonctions des couches inférieures pour gérer correctement les
conversations multiples.
Figure 5: Plusieurs clients se connectent au même serveur
3.2.4 Réseau et applications peer to peer (P2P)
Modèle Peer to Peer
Outre le modèle de réseau client/serveur, il existe également un modèle Peer to Peer. Le réseau Peer
to Peer implique deux formes différentes : la conception de réseau Peer to Peer et les applications
Peer to Peer (P2P). Les deux formes comportent des caractéristiques similaires mais, dans les faits,
fonctionnent très différemment.
Réseaux Peer to Peer
40
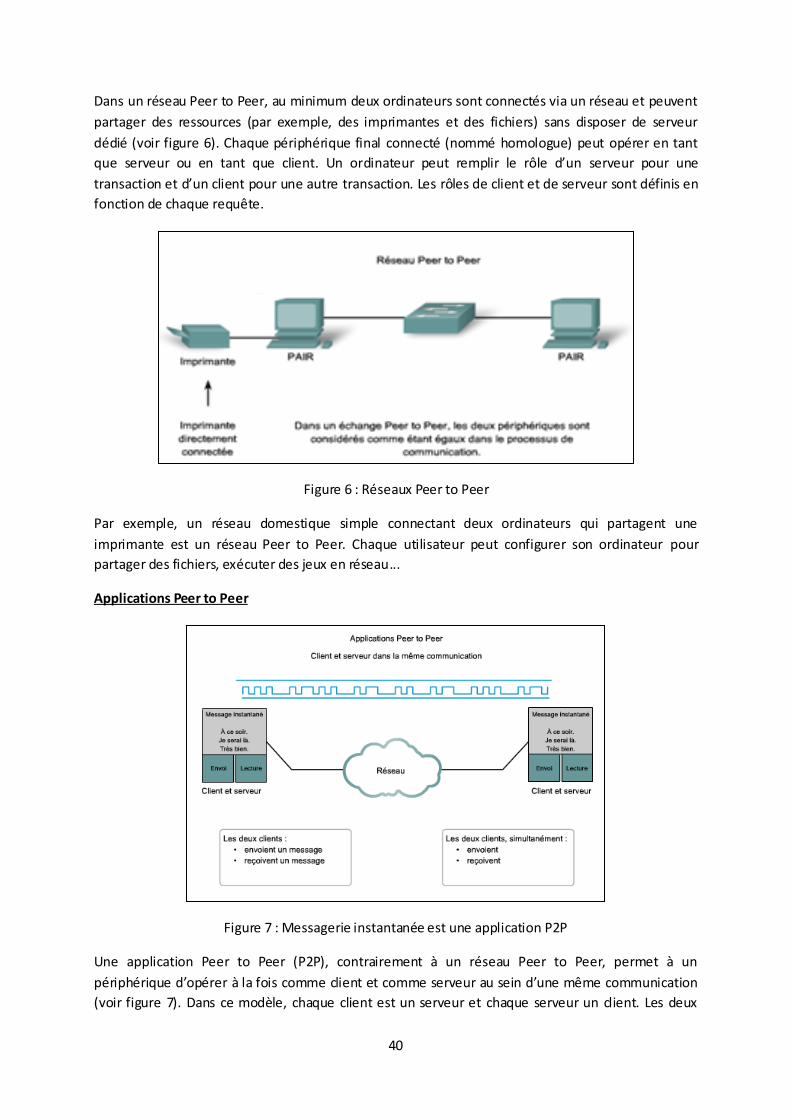
Dans un réseau Peer to Peer, au minimum deux ordinateurs sont connectés via un réseau et peuvent
partager des ressources (par exemple, des imprimantes et des fichiers) sans disposer de serveur
dédié (voir figure 6). Chaque périphérique final connecté (nommé homologue) peut opérer en tant
que serveur ou en tant que client. Un ordinateur peut remplir le rôle d’un serveur pour une
transaction et d’un client pour une autre transaction. Les rôles de client et de serveur sont définis en
fonction de chaque requête.
Figure 6 : Réseaux Peer to Peer
Par exemple, un réseau domestique simple connectant deux ordinateurs qui partagent une
imprimante est un réseau Peer to Peer. Chaque utilisateur peut configurer son ordinateur pour
partager des fichiers, exécuter des jeux en réseau...
Applications Peer to Peer
Figure 7 : Messagerie instantanée est une application P2P
Une application Peer to Peer (P2P), contrairement à un réseau Peer to Peer, permet à un
périphérique d’opérer à la fois comme client et comme serveur au sein d’une même communication
(voir figure 7). Dans ce modèle, chaque client est un serveur et chaque serveur un client. Les deux

41
peuvent lancer une communication et sont considérés comme égaux dans le processus de
communication. Cependant, les applications P2P nécessitent que chaque périphérique final fournisse
une interface utilisateur et exécute un service en tâche de fond. Lorsque vous lancez une application
P2P spécifique, elle invoque l’interface utilisateur et les services en tâche de fond requis. Les
périphériques peuvent ensuite communiquer directement.
Les applications P2P peuvent être utilisées sur des réseaux Peer to Peer, des réseaux client/serveur
et via Internet.
3.3 Exemples de services et protocoles de la couche application
3.3.1 Services et protocoles DNS (Domain Name System) À présent que nous savons mieux comment les applications fournissent une interface à l’utilisateur
et permettent d’accéder au réseau, nous allons examiner certains protocoles spécifiques courants.
Comme nous allons le voir par la suite dans ce cours, la couche transport utilise un modèle
d’adressage nommé numéro de port. Les numéros de port identifient les applications et les services
de la couche application qui constituent la source et la destination des données. Les programmes
serveur utilisent généralement des numéros de port prédéfinis connus des clients. En examinant les
différents protocoles et services de couche application TCP/IP, nous nous référerons aux numéros de
port TCP et UDP normalement associés à ces services. Certains de ces services sont les suivants :
DNS (Système de noms de domaine) - Port TCP/UDP 53
HTTP (Hypertext Transfer Protocol) - Port TCP 80
SMTP (Simple Mail Transfer Protocol) - Port TCP 25
POP (Post Office Protocol) - Port UDP 110
Telnet - Port TCP 23
DHCP (Dynamic Host Configuration Protocol) - Port UDP 67
FTP (File Transfer Protocol) - Ports TCP 20 et 21
DNS
Sur les réseaux de données, les périphériques sont étiquetés par des adresses IP numériques, ce qui
leur permet de participer à l’envoi et à la réception de messages via le réseau. Cependant, la plupart
des utilisateurs mémorisent très difficilement ces adresses numériques. Pour cette raison, des noms
de domaine ont été créés pour convertir les adresses numériques en noms simples et explicites.
Sur Internet, ces noms de domaine (par exemple, www.cisco.com) sont beaucoup plus faciles à
mémoriser que leurs équivalents numériques (par exemple, 198.133.219.25, l’adresse numérique du
serveur de Cisco). De plus, si Cisco décide de changer d’adresse numérique, ce changement est
transparent pour l’utilisateur car le nom de domaine demeure www.cisco.com.

42
Figure 8 : Fonctionnement du protocole DNS
Le protocole DNS a été créé afin de permettre la résolution de nom pour ces réseaux. Le protocole
DNS utilise un ensemble distribué de serveurs pour convertir les noms associés à ces adresses en
numéros.
Le protocole DNS est un service client/serveur. Cependant, il diffère des autres services
client/serveur examinés dans ce cours. Les autres services utilisent un client qui constitue une
application (par exemple, un navigateur Web ou un client de messagerie) tandis que le client DNS
s’exécute en tant que service lui-même. Le client DNS, parfois nommé résolveur DNS, prend en
charge la résolution de noms pour nos autres applications réseau et pour les autres services qui en
ont besoin.
Un serveur DNS effectue la résolution des noms à l’aide du démon de nom, souvent appelé named
(name daemon).
Lorsqu’un client effectue une demande, le processus de démon de nom du serveur examine d’abord
ses propres enregistrements pour voir s’il peut résoudre le nom (voir figure 8). S’il ne peut pas
résoudre le nom à l’aide de ses enregistrements stockés, il contacte d’autres serve urs pour résoudre
le nom (voir figure 9).
La requête peut être transmise à plusieurs serveurs, ce qui peut nécessiter un délai supplémentaire
et consommer de la bande passante. Lorsqu’une correspondance est trouvée et retournée au
serveur demandeur d’origine, le serveur stocke temporairement dans le cache l’adresse numérique
correspondant au nom.
Si ce même nom est de nouveau demandé, le premier serveur peut retourner l’adresse en utilisant la
valeur stockée dans son cache de noms. La mise en cache réduit le trafic réseau de données de

43
demandes DNS et les charges de travail des serveurs situés aux niveaux supérieurs dans la hiérarchie.
Le service client DNS sur les PC Windows optimise les performances de la résolution de noms DNS en
stockant également en mémoire les noms déjà résolus.
Le protocole DNS utilise un système hiérarchique pour créer une base de données afin d’assurer la
résolution de noms. La hiérarchie ressemble à une arborescence inversée dont la racine se situe au
sommet et les branches en dessous (Figure 9).
Figure 9 : Hiérarchie des serveurs DNS
Les différents domaines de premier niveau représentent le type d’organisation ou le pays d’origine.
Voici des exemples de domaines de premier niveau :
.au : Australie
.co : Colombie
.com : entreprise ou industrie
.jp : Japon
.org : organisme à but non lucratif
3.3.2 Services WWW et HTTP Lorsqu’une adresse Web (ou URL Uniform Resource Locator) est tapée dans un navigateur Web, ce
dernier établit une connexion au service Web s’exécutant sur le serveur à l’aide du protocole HTTP.
Les URL sont les noms que la plupart des utilisateurs associent aux adresses Web.

44
Figure 10 : Fonctionnement du protocole HTTP
Par exemple, http://www.cisco.com/index.html est une adresse URL qui se réfère à une ressource
spécifique : une page Web nommée index.html située sur le serveur cisco.com (voir figure 10).
Les navigateurs Web sont les applications clientes que les ordinateurs utilisent pour se connecter au
Web et accéder aux ressources stockées sur un serveur Web. Comme avec la plupart des processus
serveur, le serveur Web s’exécute en tant que service en tâche de fond et met différents types de
fichiers à la disposition de l’utilisateur.
Pour accéder au contenu Web, les clients Web établissent des connexions au serveur et demandent
les ressources voulues. Le serveur retourne les ressources et, à la réception de ces ressources, le
navigateur interprète les données et les présente à l’utilisateur.
Les navigateurs peuvent interpréter et présenter de nombreux types de données, tels que des
données en texte clair ou HTML (Hypertext Markup Language), langage dans lequel sont conçues les
pages Web.
Pour mieux comprendre l’interaction entre le navigateur Web et le client Web, voyons comment une
page Web s’ouvre dans un navigateur. Cet exemple utilise l’adresse URL suivante :
http://www.cisco.com/index.html.
Le navigateur commence par interpréter les trois parties de l’adresse URL :
1. http (protocole ou modèle)
2. www.cisco.com (nom du serveur)
3. index.html (nom du fichier demandé).

45
Le navigateur fait ensuite appel à un serveur DNS pour convertir l’adresse www.cisco.com en une
adresse numérique, qu’il utilise pour se connecter au serveur. À l’aide des caractéristiques du
protocole HTTP, le navigateur envoie une requête GET au serveur et demande le fichier index.html.
En réponse, le serveur envoie le code HTML de cette page Web au navigateur. Enfin, le navigateur
déchiffre le code HTML et formate la page en fonction de sa fenêtre.
Le protocole HTTP constitue un protocole de requête/réponse. Lorsqu’un client (généralement un
navigateur Web) envoie une requête à un serveur, le protocole HTTP définit les types de messages
que le client utilise pour demander la page Web, ainsi que les types de messages que le serveur
utilise pour répondre. Les trois types de messages courants sont GET, POST et PUT.
GET est une requête cliente pour obtenir des données. Un navigateur Web envoie le message GET
pour demander des pages à un serveur Web.
Les requêtes POST et PUT sont utilisées pour envoyer des messages qui téléchargent des données
vers le serveur Web. Par exemple, lorsque l’utilisateur entre des données dans un formulaire
incorporé à une page Web, la requête POST comprend les données dans le message envoyé au
serveur.
Bien qu’il soit remarquablement flexible, le protocole HTTP n’est pas un protocole sécurisé. Les
messages POST téléchargent des informations vers le serveur dans un format de texte clair pouvant
être intercepté et lu. De même, les réponses du serveur (généralement, des pages HTML) ne sont pas
chiffrées.
Pour une communication sécurisée via Internet, le protocole HTTPS (HTTP Secure) est utilisé lors de
l’accès aux informations du serveur Web ou de leur publication. Le protocole HTTPS peut procéder à
l’authentification et au chiffrement pour sécuriser les données pendant qu’elles circulent entre le
client et le serveur.
3.3.3 Services de messagerie et protocoles SMTP et POP La messagerie électronique, le service de réseau le plus répandu, par sa simplicité et sa vitesse
d’exécution, a révolutionné la manière dont nous communiquons. Mais pour s’exécuter sur un
ordinateur ou autre périphérique final, une messagerie nécessite plusieurs applications et services.
Les protocoles POP (Post Office Protocol) et SMTP (Simple Mail Transfer Protocol), illustrés dans la
figure 11, sont deux exemples de protocoles de couche application. Tout comme le protocole HTTP,
ces protocoles définissent des processus client/serveur.

46
Figure 11 : Protocoles SMTP et POP
Lorsque l’utilisateur rédige un courriel, il fait généralement appel à une application connue sous le
nom d'agent de messagerie (MUA), ou client de messagerie. L’agent de messagerie permet l’envoi
des messages et place les messages reçus dans la boîte aux lettres du client, ces deux processus étant
des processus distincts.
Pour recevoir le courriel d’un serveur de messagerie, le client de messagerie peut utiliser le protocole
POP. L’envoi de courriel à partir d’un client ou d’un serveur implique l’utilisation de commandes et
de formats de messages définis par le protocole SMTP. Un client de messagerie fournit généralement
les fonctionnalités des deux protocoles au sein d’une application.
Processus de serveur de messagerie : MTA et MDA
Le serveur de messagerie opère deux processus distincts :
1. Agent de transfert des messages (MTA).
2. Agent de remise des messages (MDA).
Le processus MTA est utilisé pour transférer le courriel. Comme l’illustre la figure 12, l’agent de
transfert des messages reçoit des messages de l’agent de messagerie ou d’un autre agent de
transfert des messages sur un autre serveur de messagerie. En fonction de l’en-tête du message, il
détermine la manière dont un message doit être transmis pour arriver à destination. Si le message
est adressé à un utilisateur dont la boîte aux lettres réside sur le serveur local, le message est
transmis à l’agent de remise des messages (MDA). Si le message est adressé à un utilisateur ne se
situant pas sur le serveur local, l’agent de transfert des messages l’achemine vers l’agent de transfert
des messages du serveur approprié.
Dans la figure 12, l’agent de remise des messages (MDA) accepte un courriel d’un agent de transfert
des messages (MTA) et procède à la remise effective du courriel. L’agent de remise des messages
reçoit tous les messages entrants de l’agent de transfert des messages et les place dans la boîte aux
lettres des utilisateurs appropriés. Il peut également traiter les derniers aspects liés à la remise, tels
que l’analyse antivirus, le filtrage du courrier indésirable et la gestion des reçus. La plupart des
communications par courriel utilisent les applications MUA, MTA et MDA.

47
Figure 12 : Applications MUA, MTA et MDA
Un client peut être connecté à un système de messagerie d’entreprise, tel que Lotus Notes d’IBM,
Groupwise de Novell ou Exchange de Microsoft. Ces systèmes disposent souvent de leur propre
format de messagerie interne et leurs clients communiquent généralement avec le serveur de
messagerie à l’aide d’un protocole propriétaire.
Autre alternative : les ordinateurs ne disposant pas d’un agent de messagerie peuvent encore se
connecter à un service de messagerie sur un navigateur Web pour récupérer et envoyer des
messages de cette manière.
Comme indiqué précédemment, le courriel peut utiliser les protocoles POP et SMTP. Les protocoles
POP et POP3 (Post Office Protocol, version 3) sont des protocoles de remise du courrier entrant et
constituent des protocoles client/serveur standard. Ils transmettent le courriel du serveur de
messagerie au client de messagerie. L’agent de remise des messages (MDA) procède à une écoute
pour détecter le moment où un client se connecte à un serveur. Une fois qu’une connexion est
établie, le serveur peut remettre le courriel au client.
Par ailleurs, le protocole SMTP (Simple Mail Transfer Protocol) régit le transfert du courriel sortant du
client expéditeur au serveur de messagerie (MDA), ainsi que le transport du courriel entre les
serveurs de messagerie (MTA). Le protocole SMTP permet le transport du courriel sur des réseaux de
données entre différents types de logiciels serveur et client, ainsi que l’échange de courriel via
Internet.
Le format de message du protocole SMTP utilise un ensemble rigide de commandes et de réponses.
Ces commandes prennent en charge les procédures du protocole SMTP, telles que l’ouverture de
session, la transaction du courriel, le transfert du courriel, la vérification des noms de boîte aux
lettres, le développement des listes de diffusion et les échanges de début et de fin.
Certaines des commandes spécifiées dans le protocole SMTP sont les suivantes :
HELO : identifie le processus client SMTP pour le processus serveur SMTP.

48
MAIL FROM : identifie l’expéditeur.
RCPT TO : identifie le destinataire.
DATA : identifie le corps du message.
3.3.4 Services de téléchargement de fichiers et le protocole FTP Le protocole FTP (File Transfer Protocol) est un autre protocole de couche application couramment
utilisé. Il a été développé pour permettre le transfert de fichiers entre un client et un serveur. Un
client FTP est une application s’exécutant sur un ordinateur et utilisée pour extraire des fichiers d’un
serveur exécutant le démon FTP (FTPd).
Figure 13 : Fonctionnement du protocole FTP
Pour transférer les fichiers correctement, le protocole FTP nécessite que deux connexions s oient
établies entre le client et le serveur : une connexion pour les commandes et les réponses et une
autre pour le transfert même des fichiers (voir figure 13).
Le client établit la première connexion au serveur sur le port TCP 21. Cette connexion est utilisée
pour le trafic de contrôle et se compose de commandes clientes et de réponses serveur.
Le client établit la seconde connexion au serveur via le port TCP 20. Cette connexion est destinée au
transfert même des fichiers et est établie à chaque transfert de fichiers.
Le transfert de fichiers peut s’effectuer dans l’une des deux directions. Le client peut télécharger un
fichier à partir du serveur ou en direction du serveur.
3.3.5 Service DHCP Le service DHCP (Dynamic Host Configuration Protocol) permet aux périphériques d’un réseau
d’obtenir d’un serveur DHCP des adresses IP et autres informations. Il permet à un hôte d’obtenir
une adresse IP dynamiquement lorsqu’il se connecte au réseau. Le serveur DHCP est contacté et une
adresse est demandée. Le serveur DHCP choisit une adresse dans une plage d’adresses configurée
(nommée pool) et affecte cette adresse à l’hôte pour une durée définie.
Sur les réseaux locaux ou sur les réseaux dont les utilisateurs changent fréquemment, le protocole
DHCP est préférable. De nouveaux utilisateurs peuvent se présenter travaillant sur des ordinateurs
portables et nécessitant une connexion. D’autres peuvent disposer de nouvelles stations de travail

49
devant être connectées. Plutôt que de faire attribuer des adresses IP par l ’administrateur réseau à
chaque station de travail, il est plus efficace que les adresses IP soient attribuées automatiquement à
l’aide du protocole DHCP.
Le protocole DHCP vous permet d’accéder à Internet via des points d’accès sans fil dans des
aéroports ou des cafés. Lorsque vous pénétrez dans la zone, le client DHCP de votre ordinateur
portable contacte le serveur DHCP local via une connexion sans fil. Le serveur DHCP attribue une
adresse IP à votre ordinateur portable.
Les adresses attribuées via le protocole DHCP ne sont pas affectées aux hôtes définitivement mais
uniquement pour une durée spécifique. Si l’hôte est mis hors tension ou retiré du réseau, l’adresse
est retournée au pool pour être réutilisée.
Comme l’illustre la figure 14, dans la plupart des réseaux de taille moyenne à grande, le serveur
DHCP est généralement un serveur local dédié basé sur un PC.
Dans le cas des réseaux domestiques, il est généralement situé au niveau du fournisseur de services
Internet et un hôte sur le réseau domestique reçoit directement sa configuration IP du fournisseur de
services Internet.
Figure 14 : Position des serveurs DHCP dans le réseau
Sans le protocole DHCP, les utilisateurs doivent manuellement entrer l’adresse IP. Les adresses IP
étant des adresses dynamiques (temporairement attribuées) et non pas des adresses statiques
(définitivement attribuées), les adresses qui ne sont plus utilisées sont automatiquement retournées
au pool pour être réattribuées. Lorsqu’un périphérique configuré pour le protocole DHCP est mis
sous tension ou se connecte au réseau, le client diffuse un paquet DHCP DISCOVER pour identifier les
serveurs DHCP disponibles du réseau. Un serveur DHCP répond avec un paquet DHCP OFFER, à savoir
un message d’offre de bail qui indique une adresse IP attribuée, et autres informations.
Le serveur DHCP s’assure que toutes les adresses IP sont uniques (une adresse IP ne peut pas être
attribuée à deux périphériques réseaux différents en même temps). Le protocole DHCP permet aux
administrateurs réseau de reconfigurer aisément les adresses IP des clients sans devoir apporter de
modifications manuelles aux clients. La plupart des fournisseurs Internet utilisent un protocole DHCP
pour attribuer des adresses à leurs clients ne nécessitant pas d’adresse statique.

50
3.3.6 Services pear to pear et protocole Gnutella Vous avez appris que le protocole FTP constitue une méthode permettant d’obtenir des fichiers.
Voici maintenant un autre protocole d’application. Partager des fichiers via Internet est devenu très
courant. Avec les applications Peer to Peer basées sur le protocole Gnutella, les utilisateurs peuvent
mettre les fichiers situés sur leur disque dur à la disposition des autres utilisateurs pour que ces
derniers les téléchargent. Les logiciels clients compatibles avec le protocole Gnutella permettent aux
utilisateurs de se connecter aux services Gnutella via Internet et de localiser des ressources
partagées par d’autres homologues Gnutella pour y accéder.
De nombreuses applications clientes sont disponibles pour permettre aux utilisateurs d’accéder au
réseau Gnutella, parmi lesquelles : BearShare, Gnucleus, LimeWire, Morpheus, WinMX et XoloX
(reportez-vous à la capture d’écran de LimeWire présentée dans la figure 15).
Figure 15 : Capture d’écran de LimeWire
De nombreuses applications Peer to Peer n’utilisent pas de base de données centrale pour
enregistrer tous les fichiers disponibles sur les homologues. À la place, chaque périphérique du
réseau, lorsqu’il est interrogé, indique aux autres périphériques quels fichiers sont disponibles et
utilise le protocole et les services Gnutella pour prendre en charge la localisation des ressources.
Reportez-vous à la figure 16.
Figure 16 : Interrogation et réponse des homologues

51
Chapitre 4 :
Couche transport OSI
Introduction Les réseaux de données et Internet étayent le réseau humain en permettant aux individus de
communiquer de façon transparente et fiable, aussi bien à l’échelon local qu’au niveau international.
Nous pouvons, sur un même périphérique, utiliser des services aussi divers que les messageries
électroniques, le Web ou les messageries instantanées pour envoyer des messages et recevoir des
informations. Grâce aux applications de clients de messagerie, de navigateurs Internet et de clients
de messagerie instantanée, nous sommes en mesure d’envoyer et de recevoir des messages et des
informations par le biais d’ordinateurs et de réseaux.
Dans chacun de ces types d’applications, les données sont empaquetées, transportées et livrées au
démon du serveur approprié ou à l’application voulue sur le périphérique de destination. Le
processus décrit dans la couche transport OSI accepte des données provenant de la couche
application et les prépare pour les adresser à la couche réseau. La couche transport est globalement
responsable du transfert de bout en bout des données d’application.
Ce chapitre est consacré à l’étude du rôle de la couche transport dans le processus d’encapsulation
des données d’application en vue de leur utilisation par la couche réseau. La couche transport
remplit également d’autres fonctions :
elle permet à de nombreuses applications de communiquer sur le réseau au même moment,
sur un même périphérique ;
elle vérifie, si cela est nécessaire, que toutes les données sont reçues de façon fiable et dans
l’ordre par l’application voulue ;
elle utilise des mécanismes de gestion des erreurs.
Objectifs pédagogiques À l’issue de ce chapitre, vous serez en mesure d’effectuer les tâches suivantes :
Expliquer l’utilité de la couche transport.
Définir le rôle de la couche transport en matière de transfert, de bout en bout, de données
entre applications.
Décrire le rôle de deux protocoles utilisés par la couche transport TCP/IP, à savoir les
protocoles TCP et UDP.
Citer les principales fonctions de la couche transport, y compris en matière de fiabilité,
d’adressage de ports et de segmentation.
Expliquer comment les protocoles TCP et UDP gèrent, chacun, des fonctions clés.
Reconnaître les situations où l’utilisation des protocoles TCP ou UDP s’impose et fournir des
exemples d’applications utilisant chacun de ces protocoles.

52
4.1 Rôle de la couche transport
4.1.1 Objectifs de la couche transport Au niveau de la couche transport, chaque ensemble de blocs transitant entre une application source
et une application de destination est appelé une conversation.
La couche transport segmente les données et se charge du contrôle nécessaire au réassemblage de
ces blocs de données dans les divers flux de communication. Pour ce faire, il doit :
effectuer un suivi des communications individuelles entre les applications résidant sur les
hôtes source et de destination ;
segmenter les données et gérer chaque bloc individuel ;
réassembler les segments en flux de données d’application ;
identifier les différentes applications.
Suivi des conversations individuelles
Tout hôte peut héberger plusieurs applications qui communiquent sur le réseau. Chacune de ces
applications communique avec une ou plusieurs applications hébergées sur des hôtes distants. Il
incombe à la couche transport de gérer les nombreux flux de communication entre ces applications
(voir figure 1).
Segmentation des données
Chaque application crée un flux de données à envoyer vers une application distante ; ces données
doivent donc être préparées pour être expédiées sur le support sous forme de blocs faciles à gérer.
Reconstitution des segments
L’hôte recevant les blocs de données peut les diriger vers l’application appropriée. Il faut en outre
que ces blocs de données individuels puissent être réassemblés dans un flux de données complet
utile à la couche application.
Identification des applications
Pour que les flux de données atteignent les applications auxquelles ils sont destinés, la couche
transport doit identifier l’application cible. Pour cela, la couche transport affecte un identificateur à
chaque application. Les protocoles TCP/IP appellent cet identificateur un numéro de port. Chaque
processus logiciel ayant besoin d’accéder au réseau se voit affecter un numéro de port unique sur
son hôte. Ce numéro de port est inclus dans l’en-tête de transport afin de préciser à quelle
application ce bloc de données est associé.
En outre, les couches inférieures ignorent que plusieurs applications envoient des données sur le
réseau. Leur responsabilité se limite à livrer les données au périphérique approprié. La couche
transport trie ensuite ces blocs avant de les acheminer vers l’application voulue.

53
Figure 1 : Suivi de conversations
4.1.2 Contrôle des conversations Tous les protocoles de la couche transport ont des fonctions essentielles communes :
Segmentation et reconstitution. La plupart des réseaux limitent la quantité de données
pouvant être incluses dans une même unité de données de protocole. La couche transport
divise les données d’application en blocs de données d’une taille adéquate. Une fois ces
blocs parvenus à destination, la couche transport réassemble les données avant de les
envoyer vers l’application ou le service de destination.
Multiplexage de conversations. De nombreux services ou applications peuvent s’exécuter
sur chaque hôte sur le réseau. Une adresse, appelée port, est affectée à chacun de ces
services ou applications afin que la couche transport puisse déterminer à quel service ou
application les données se rapportent.
Dans le cadre des fonctions essentielles que sont la segmentation et la reconstitution des données, la
couche transport fournit, en plus des informations contenues dans les en-têtes :
des conversations avec connexion ;
un acheminement fiable ;
une reconstitution ordonnée des données ;
un contrôle du flux.
Établissement d’une session
La couche transport est en mesure d’orienter la connexion en créant des sessions entre les
applications. Ces connexions préparent les applications à communiquer entre elles avant le transfert
des données. Dans ces sessions, il est possible de gérer avec précision les données d’une
communication entre deux applications.

54
Acheminement fiable
Bien des circonstances peuvent entraîner la corruption ou la perte d’un bloc de données lors de son
transfert sur le réseau. La couche transport veille à ce que tous les blocs atteignent leur destination
en demandant au périphérique source de retransmettre les données qui ont pu se perdre.
Livraison dans un ordre défini
Étant donné que les réseaux fournissent une multitude de routes dont les délais de transmission
varient, il se peut que les données arrivent dans le désordre. En numérotant et en ordonnant les
segments, la couche transport s’assure que ces segments sont réassemblés dans le bon ordre.
Contrôle du flux
Les hôtes du réseau disposent de ressources limitées, par exemple en ce qui concerne la mémoire ou
la bande passante. Quand la couche transport détermine que ces ressources sont surexploitées,
certains protocoles peuvent demander à l’application qui envoie les données d’en réduire le flux. Le
contrôle du flux contribue à prévenir la perte de segments sur le réseau et à rendre inutiles les
retransmissions.
4.1.3 Prise en charge des communications fiables Souvenez-vous que la fonction première de la couche transport est de gérer les données
d’application des conversations entre hôtes. Cependant, des applications différentes ont des
exigences différentes pour leurs données, de sorte que des protocoles de transport différents ont été
développés afin de satisfaire ces exigences.
Un protocole de couche transport est en mesure d’assurer l’acheminement fiable des données. Dans
le contexte des réseaux, la fiabilité consiste à veiller à ce que chaque bloc de données envoyé par la
source parvienne à destination. Au niveau de la couche transport, les trois opérations de base en
matière de fiabilité consistent à :
effectuer le suivi des données transmises ;
accuser réception des données ;
retransmettre toute donnée n’ayant pas fait l’objet d’un reçu.
Ces processus assurant la fiabilité augmentent la surcharge des ressources du réseau du fait des
opérations de reçu, de suivi et de retransmission.
Il s’établit ainsi un compromis entre la valeur accordée à la fiabilité et la charge qu’elle représente
sur le réseau. Les développeurs d’appl ications doivent déterminer quel type de protocole de
transport est approprié en fonction des exigences de leurs applications. Au niveau de la couche
transport, il existe des protocoles qui précisent des méthodes choisies pour leur fiabilité (protocole
TCP) ou leur acheminement au mieux (protocole UDP). Dans le contexte des réseaux,
l’acheminement au mieux est considéré comme n’étant pas fiable car aucun reçu ne confirme que les
données sont arrivées à destination (voir figure 2).
Détermination du besoin de fiabilité
Certaines applications, comme les bases de données, les pages Web et les courriels, ont besoin que
toutes les données envoyées arrivent à destination dans leur état d’origine afin que ces données
soient utiles. Toute donnée manquante risque de corrompre la communication en la rendant
incomplète ou illisible. Cependant, ces applications sont conçues pour utiliser un protocole de

55
couche transport qui implémente la fiabilité. On considère que cette surcharge supplémentaire pour
le réseau est indispensable pour ces applications.
D’autres applications tolèrent mieux la perte de petites quantités de données. Si, par exemple, un ou
deux segments d’une lecture vidéo n’arrivent pas, cela ne fera que créer une interruption
momentanée du flux. Ceci pourra se traduire par une distorsion de l’image que l’utilisateur ne
remarquera peut-être même pas.
Imposer une surcharge pour garantir la fiabilité de cette application risquerait de réduire l’utilité de
l’application. L’image produite par une lecture vidéo en continu serait fortement dégradée si le
périphérique de destination devait rendre compte des données perdues et retarder la lecture en
continu le temps qu‘elles arrivent. Mieux vaut assurer un rendu aussi bon que possible de l’image à
l’aide des segments qui arrivent et renoncer à la fiabilité.
Figure 2 : Propriétés des protocoles
4.1.4 TCP/UDP Les deux protocoles de la suite de protocoles TCP/IP les plus couramment employés sont le protocole
TCP (Transmission Control Protocol) et le protocole UDP (User Datagram Protocol). Ces deux
protocoles gèrent les communications de nombreuses applications. Ce sont les fonctions spécifiques
implémentées par chaque protocole qui les différencient.
Protocole UDP (User Datagram Protocol)
Le protocole UDP est un protocole simple. Il présente l’avantage d’imposer peu de surcharge pour
l’acheminement des données. Les blocs de communications utilisés dans le protocole UDP sont
appelés des datagrammes. Ces datagrammes sont envoyés « au mieux » par ce protocole de couche
transport.
Le protocole UDP est notamment utilisé par des applications de :
Système de noms de domaine (DNS)
Lecture vidéo en continu
Voix sur IP (VoIP)

56
Protocole TCP (Transmission Control Protocol)
Le protocole TCP impose une surcharge pour accroître les fonctionnalités. Le protocole TCP spécifie
d’autres fonctions, à savoir la livraison dans l’ordre, l’acheminement fiable et le contrôle du flux.
Chaque segment du protocole TCP utilise 20 octets de surcharge dans l’en-tête pour encapsuler les
données de la couche application alors que chaque segment du protocole UDP n’ajoute sur 8 octets
de surcharge. Examinez le tableau comparatif à la figure 3.
Le protocole TCP est utilisé par des applications de :
Navigateurs Web
Courriel
Transfert de fichiers
Figure 3 : Entête TCP/UDP
4.1.5 Adressage de ports
Identification des conversations
Reprenons l’exemple précédent d’un ordinateur envoyant et recevant simultanément des courriels,
des messages instantanés, des pages Web et un appel de voix sur IP.
Pour différencier les segments et les datagrammes de chaque application, les protocoles TCP et UDP
utilisent chacun des champs d’en-tête identifiant ces applications de façon unique. Ces
identificateurs uniques sont les numéros de port.
Lorsqu’une application cliente envoie une requête à une application serveur, le port de destination
inclus dans l’en-tête est le numéro de port affecté au démon du service s’exécutant sur l’hôte
distant. Le logiciel client doit savoir quel numéro de port est associé au processus serveur sur l ’hôte
distant. Ce numéro de port de destination est configuré par défaut ou manuellement. Ainsi, quand
une application de navigateur Web envoie une requête à un serveur Web, le navigateur utilise le
protocole TCP et le port numéro 80. Ceci est dû au fait que le port 80 du protocole TCP est le port
affecté par défaut aux applications de service Web. De nombreuses applications courantes ont des
ports qui leur sont affectés par défaut.

57
Le port source d’un en-tête de segment ou de datagramme d’une requête de client est généré de
façon aléatoire. Du moment que le numéro de port n’entre pas en conflit avec d’autres ports utilisés
par le système, le client peut choisir n’importe quel numéro de port. Le numéro de port fait office
d’adresse de retour pour l’application envoyant la requête. La couche transport effectue le suivi du
port et de l’application à l’origine de la requête afin que la réponse, quand elle sera envoyée, soit
transmise à l’application appropriée. Le numéro de port de l’application envoyant la requête sert de
numéro de port de destination dans la réponse renvoyée depuis le serveur.
L'Internet Assigned Numbers Authority (IANA) attribue les numéros de ports. L’IANA est une agence
de normalisation responsable de l’affectation de diverses normes d’adressage.
Il existe différents types de numéros de ports :
Ports réservés (numéros 0 à 1023). Ces numéros sont réservés à des services et applications.
Ils sont généralement réservés à des applications de type HTTP (serveur Web), POP3/SMTP
(serveur de messagerie) et Telnet.
Ports inscrits (numéros 1024 à 49151). Ces numéros de ports sont affectés à des processus
ou applications d’utilisateurs. Ces processus sont essentiellement des applications
particulières qu’un utilisateur a choisi d’installer plutôt que des applications courantes qui
recevraient un port réservé.
Utilisation du protocole TCP et du protocole UDP
Certaines applications utilisent le protocole TCP et le protocole UDP. En effet, la faible surcharge du
protocole UDP permet au service DNS de gérer très rapidement de nombreuses requêtes de clients.
Parfois, cependant, l’envoi des informations demandées exige la fiabilité du protocole TCP. Dans ce
cas, le port réservé 53 est utilisé par les deux protocoles en association avec ce service.
Liens
Vous trouverez une liste des numéros de ports actuels sur le site :
http://www.iana.org/assignments/port-numbers
4.1.6 Segmentation et reconstitution : diviser et conquérir Dans un chapitre précédent, nous vous avons expliqué que les unités de données de protocole sont
élaborées en faisant transiter les données d’une application par divers protocoles afin de créer des
unités de données de protocole qui sont ensuite transmises sur le support. Une fois les données
parvenues sur l’hôte de destination, le processus est inversé jusqu’à ce que les données puissent être
communiquées à l’application.
Certaines applications transmettent de très importants volumes de données pouvant parfois
atteindre plusieurs gigaoctets. Transmettre l’ensemble de ces données en un envoi massif serait peu
pratique car aucun autre trafic ne pourrait être transmis sur le réseau pendant l’envoi de ces
données. De plus, l’envoi d’une grosse quantité de données peut prendre de plusieu rs minutes à
plusieurs heures. En outre, si une erreur se produisait, l’ensemble du fichier de données serait perdu
ou devrait être réexpédié. La mémoire tampon des périphériques réseau ne serait pas suffisante
pour stocker autant de données pendant leur transmission ou leur réception. La limite varie selon la
technologie réseau employée et le support physique particulier qui est utilisé.

58
Diviser les données d’application en blocs permet de s’assurer que les données sont transmises en
tenant compte des limites du support et que les données provenant d’applications différentes
peuvent faire l’objet d’un multiplexage sur le support.
Les protocoles TCP et UDP traitent différemment la segmentation.
Avec le protocole TCP, chaque en-tête de segment contient un numéro d’ordre. Ce numéro d’ordre
permet aux fonctions de la couche transport, au niveau de l’hôte de destination, de réassembler les
segments dans l’ordre de leur envoi. L’application de destination peut ainsi disposer des données
sous la forme exacte voulue par l’expéditeur.
Bien que les services utilisant le protocole UDP effectuent également un suivi des conversations
entre les applications, ils ne prêtent pas attention à l’ordre dans lequel les informations ont été
transmises ni au maintien de la connexion. Un en-tête UDP ne contient pas de numéro d’ordre. La
conception du protocole UDP est plus simple et produit moins de surcharge que le protocole TCP, de
sorte que le transfert de données est plus rapide.
Il se peut que les informations arrivent dans un ordre différent de celui dans lequel elles ont été
transmises car les différents paquets peuvent emprunter plusieurs chemins sur le réseau. Les
applications qui utilisent le protocole UDP doivent tolérer le fait que les données peuvent arriver
dans un ordre différent de celui dans lequel elles ont été envoyées.
4.2 Protocole TCP : des communications fiables
4.2.1 Fiabilisation des conversations La fiabilité est le principal élément différentiateur entre les protocoles TCP et UDP. La fiabilité des
communications TCP est assurée à l’aide de sessions avec connexion. Avant qu’un hôte utilisant le
protocole TCP n’envoie de données à un autre hôte, la couche transport initie un processus destiné à
établir une connexion avec la destination. Cette connexion rend possible le suivi d’une session, ou
d’un flux de communication, entre les hôtes. Ce processus veille à ce que chaque hôte soit notifié de
la communication et qu’il y soit prêt. Une conversation TCP complète exige l’établissement d’une
session entre les hôtes dans les deux directions.
Lorsqu’une session a été établie, la destination envoie des reçus à la source pour les segments qu’elle
reçoit. Ces reçus constituent l’élément de base de la fiabilité dans la session TCP. Quand la source
reçoit un reçu, elle sait que les données ont bien été livrées et qu’elle peut cesser d’en effectuer le
suivi. Si la source ne reçoit pas de reçu dans un délai prédéterminé, elle retransmet ces données vers
la destination.
La surcharge provoquée par l’utilisation du protocole TCP provient en partie du trafic réseau généré
par les reçus et les retransmissions. L’établissement des sessions crée une surcharge prenant la
forme d’un échange supplémentaire de segments. Une surcharge supplémentaire provoquée par la
nécessité d’effectuer un suivi des segments pour lesquels on attend un reçu et par le processus de
retransmission pèse également sur les hôtes individuels.
La fiabilité est assurée par le recours à des champs du segment TCP qui ont, chacun, une fonction
précise ainsi que l’illustre la figure 4.

59
Figure 4 : Les champs de l’entête TCP
Le numéro de port source (16 bits) contient le numéro de port de l’application source.
Le numéro de port destination (16 bits) contient le numéro de port de l’application
destination.
Le numéro d’ordre (32 bits) contient le nombre des bits envoyés plus 1.
Le numéro de reçu (32 bits) peut importe son contenu si le segment est un segment de
données. Et il contient le numéro du prochain bit à recevoir si le segment est un accuse de
réception.
Longueur d’E-T (4 bits) contient la longueur exacte de l’entête TCP du segment envoyé.
Indicateurs ou bits de code ou bits de contrôle (6 bits) est une séquence de bits indiquant le
type du segment envoyé.
Taille de fenêtre (16 bits) indique le nombre de segment à recevoir avant d’envoyer un
accusé de réception.
La somme de contrôle (16 bits) contient la somme de tous les octets de segments ce qui
permet de vérifier à la réception s’il ya eu erreur de transmission (c’est-à-dire changement
de bits).
4.2.2 Processus serveur TCP Chaque processus applicatif qui s’exécute sur le serveur est configuré par défaut, ou manuellement
par un administrateur système, pour utiliser un numéro de port. Deux services ne peuvent pas être
affectés au même numéro de port d’un serveur particulier au sein des mêmes services de la couche
transport. Il est impossible qu’une application de serveur Web et une application de transfert de
fichiers s’exécutant sur un hôte soient toutes deux configurées pour utiliser le même port. Quand
une application de serveur active est affectée à un port spécifique, on considère que ce port est
« ouvert » sur le serveur. Ceci signifie que la couche transport accepte et traite les segments adressés
à ce port. Toute demande entrante d’un client qui est adressée à l’interface de connexion correcte
est acceptée et les données sont transmises à l’application de serveur. De nombreux ports peuvent
être ouverts simultanément sur un serveur, chacun étant destiné à une application de serveur active.

60
Il est courant qu’un serveur fournisse plusieurs services simultanément, par exemple en tant que
serveur Web et en tant que serveur Messagerie.
Limiter l’accès au serveur aux seuls ports associés aux services et applications devant être accessibles
aux demandeurs autorisés est un moyen d’améliorer la sécurité sur le serveur.
La figure 5 illustre l’affectation typique de ports source et de destination dans des opérations
clients/serveurs TCP.
Figure 5 : affectation de ports source et destination
4.2.3 Etablissement et fermeture d’une connexion TCP Lorsque deux hôtes communiquent à l’aide de TCP, une connexion est établie avant que les données
ne puissent être échangées. Une fois la communication terminée, les sessions sont fermées et il est
mis fin à la connexion. Les mécanismes de connexion et de sessions permettent la fonction de
fiabilité de TCP.
L’hôte effectue un suivi de chaque segment de données au sein d’une session et échange des
informations sur les données reçues par chaque hôte grâce aux informations contenues dans l’en-
tête TCP.
Chaque connexion représente deux flux de communications, ou sessions, unidirectionnels. Pour
établir la connexion, l’hôte effectue une connexion en trois étapes. Les bits de contrôle de l’en -tête
TCP indiquent la progression et l’état de la connexion.
Dans les connexions TCP, l’hôte client initie la session auprès du serveur. Les trois étapes de
l’établissement d’une connexion TCP sont les suivantes (voir figure 6) :
1. Le client envoie au serveur un segment contenant un numéro d’ordre initial (SEQ) sous forme
de requête afin de commencer une session de communication.
2. Le serveur répond par un segment contenant un numéro de reçu (ACK) égal au numéro
d’ordre reçu plus 1, ainsi que son propre numéro d’ordre de synchronisation. Le numéro de
reçu permet au client de relier la réponse au segment d’origine envoyé au serveur.
3. Le client initiant la session répond par un numéro de reçu égal au numéro d’ordre reçu plus
un. Ceci achève le processus d’établissement de la connexion.

61
Pour comprendre le processus de connexion en trois étapes, il convient d’examiner les différentes
valeurs échangées par les deux hôtes. Dans l’en-tête du segment TCP se trouvent six champs de 1 bit
contenant des informations de contrôle (appelés bits de contrôle dans la figure 3 et indicateurs dans
la figure 4) qui servent à gérer les processus TCP. Il s’agit des champs :
URG : pointeur de données urgentes valide
ACK : champ de reçu valide
PSH : fonction de livraison des données sans attendre le remplissage des tampons (Push)
RST : réinitialisation de la connexion
SYN : synchronisation des numéros d’ordre
FIN : plus d’envoi de données par l’expéditeur
Ces champs sont appelés des indicateurs car la valeur de chaque champ n’est que de 1 bit et que,
donc, ils ne peuvent prendre que deux valeurs, à savoir 1 ou 0. Quand une valeur de bit est définie
sur 1, ceci indique le type d’informations de contrôle contenues dans le segment.
Exemples :
La séquence 010000 indique que ce segment est un accusé de réception (ACK).
La séquence 000010 indique que ce segment est une requête de synchronisation (SYN).
La séquence 010010 indique que ce segment est une requête de synchronisation (SYN) + est
un accusé de réception (ACK).
La séquence 000001 indique que ce segment est une requête de fin de session (FIN).
Figure 6 : Etablissement d’une connexion
Un processus en quatre étapes permet d’échanger les indicateurs pour mettre fin à une connexion
TCP (voir figure 7).

62
1. Le client envoie au serveur un segment contenant un numéro d’ordre (SEQ) sous forme de
demandant de fin de session.
2. Le serveur répond par un segment contenant un numéro de reçu (ACK) égal au numéro
d’ordre reçu plus 1 en attendant qu’il termine la réception des segments.
3. Une fois touts les segments sont reçus, le serveur envoie à son tour une demande de fin de
session.
4. Le client répond par un numéro de reçu égal au numéro d’ordre reçu plus un. Ceci achève le
processus de fin de connexion.
Figure 7 : Fermeture d’une connexion
4.3 Gestion des sessions TCP
4.3.1 Réassemblage des segments TCP
Réordonnancement des segments dans l’ordre de leur transmission
Quand des services envoient des données à l’aide du protocole TCP, il arrive que les segments
parviennent à destination dans le désordre. Pour que le destinataire puisse comprendre le message
d’origine, il faut que les données contenues dans ces segments soient réagencées dans leur ordre
d’origine. Pour cela, des numéros d’ordre sont affectés à l’en-tête de chaque paquet.
Lors de la configuration de la session, un numéro d’ordre initial, ou ISN, est défini. Ce numéro d’ordre
initial représente la valeur de départ des octets de cette session qui seront transmis à l’application
réceptrice. Lors de la transmission des données pendant la session, le numéro d’ordre est incrémenté
du nombre d’octets ayant été transmis. Ce suivi des octets de données permet d’identifier chaque
segment et d’en accuser réception individuellement. Il est ainsi possible d’identifier les segments
manquants.
Les numéros d’ordre des segments permettent la fiabilité en indiquant comment réassembler et
réordonnancer les segments reçus, ainsi que l’illustre la figure 8.
Le processus TCP récepteur place les données d’un segment dans une mémoire tampon de
réception. Les segments sont remis dans l’ordre correct et sont transmis à la couche application une

63
fois qu’ils ont été réassemblés. Tous les segments reçus dont les numéros d’ordre ne sont pas
contigus sont conservés en vue d’un traitement ultérieur. Puis ces segments sont traités quand les
segments contenant les octets manquants sont reçus.
Figure 8 : Réorganisation des segments TCP
4.3.2 Reçu TCP avec fenêtrage
Confirmation de la réception des segments
L’une des fonctions de TCP est de veiller à ce que chaque segment atteigne sa destination. Les
services TCP sur l’hôte de destination accusent réception des données reçues à l’application source.
Le numéro d’ordre et le numéro de reçu de l’en-tête du segment sont utilisés ensemble pour
confirmer la réception des octets de données contenus dans les segments. Le numéro d’ordre est le
nombre relatif d’octets qui ont été transmis dans cette session plus 1 (qui est le numéro du premier
octet de données dans le segment actuel). TCP utilise le numéro de reçu des segments renvoyés à la
source pour indiquer l’octet suivant de cette session que le récepteur s’attend à recevoir. C’est ce
que l’on appelle un reçu prévisionnel.
La source est informée que la destination a reçu tous les octets de ce flux de données jusqu’à l’octet
indiqué par le numéro de reçu, mais sans inclure ce dernier. L’hôte expéditeur est censé envoyer un
segment qui utilise un numéro d’ordre égal au numéro de reçu.
Souvenez-vous qu’en fait chaque connexion est composée de deux sessions unidirectionnelles. Les
numéros d’ordre et les numéros de reçu sont échangés dans les deux sens.
Dans l’exemple de la figure 9, l’hôte de gauche envoie des données à l’hôte de droite. Il envoie un
segment contenant 10 octets de données pour cette session et un numéro d’ordre égal à 1 dans l’en-
tête.

64
Figure 9 : échange des numéros d’ordre et des numéros de reçu
L’hôte récepteur sur la droite reçoit le segment au niveau de la couche 4 et détermine que le numéro
d’ordre est 1 et qu’il y a 10 octets de données. L’hôte renvoie alors un segment à l’hôte de gauche
pour accuser réception de ces données. Dans ce segment, l’hôte définit le numéro de reçu à 11 pour
indiquer que le prochain octet de données qu’il s’attend à recevoir dans cette session est l’octet
numéro 11.
Quand l’hôte émetteur sur la gauche reçoit ce reçu, il peut envoyer le segment suivant contenant des
données pour cette session commençant par l’octet numéro 11.
Dans notre exemple, si l’hôte émetteur devait attendre un reçu pour chaque ensemble de 10 octets
reçu, le réseau subirait une forte surcharge. Pour réduire la surcharge de ces reçus, plusieurs
segments de données peuvent être envoyés à l’avance et faire l’objet d’un reçu par un unique
message TCP en retour. Ce reçu contient un numéro de reçu basé sur le nombre total d’octets reçus
dans la session.
Prenons l’exemple d’un numéro d’ordre de début égal à 2001. Si 10 segments de 1000 octets chacun
étaient reçus, un numéro de reçu de 12001 serait renvoyé à la source.
La quantité de données qu’une source peut transmettre avant de devoir recevoir un reçu est appelée
la taille de fenêtre. La taille de fenêtre est un champ de l’en-tête TCP qui permet de gérer les
données perdues et le contrôle du flux.
4.3.3 Retransmission TCP
Traitement des pertes de segments
Tous les réseaux, même les mieux conçus, connaissent parfois des pertes de données. Le protocole
TCP fournit donc des méthodes de traitement de ces pertes de segments. Parmi elles se trouve un
mécanisme de retransmission des segments contenant des données sans reçu.

65
En général, un service sur l’hôte de destination utilisant le protocole TCP ne génère de reçu que pour
les séquences contiguës d’octets. Si un ou plusieurs segments sont manquants, seules les données
des segments qui complètent le flux donnent lieu à l’émission de reçus.
Par exemple, en cas de réception des segments dont les numéros d’ordre vont de 2001 à 4000 et de
6001 à 12000, le numéro du reçu sera 4001. Ceci s’explique par le fait que certains segments n’ont
pas été reçus entre les numéros d’ordre 4001 et 12000.
Quand le protocole TCP sur l’hôte source n’a pas reçu de reçu après un délai prédéterminé, il revient
au dernier numéro de reçu et retransmet les données depuis ce point.
Dans une implémentation TCP classique, un hôte peut transmettre un segment, placer une copie du
segment dans une file d’attente de retransmission et lancer un minuteur. Quand le reçu des données
est reçu, le segment est supprimé de la file d’attente. Si le reçu n’est pas reçu avant l’écoulement du
délai prévu, le segment est retransmis.
4.3.4 Contrôle de l’encombrement sur TCP – Réduction de la perte de
segments
Contrôle de flux
Le protocole TCP inclut également des mécanismes de contrôle de flux. Le contrôle de flux contribue
à la fiabilité des transmissions TCP en réglant le taux effectif de flux de données entre les deux
services de la session. Quand la source est informée que la quantité de données spécifiée dans les
segments a été reçue, elle peut continuer à envoyer plus de données pour cette session.
Ce champ Taille de fenêtre dans l’en-tête TCP précise la quantité de données pouvant être transmise
avant qu’il ne soit nécessaire de recevoir un reçu. La taille de fenêtre initiale est déterminée lors du
démarrage de la session.
Le mécanisme de retour d’information TCP règle le taux de transmission effectif des données sur le
flux maximum que le réseau et le périphérique de destination peuvent prendre en charge sans perte.
Le TCP s’efforce de gérer le taux de retransmission de façon à ce que toutes les données soient
reçues et que les retransmissions soient limitées au maximum.
La figure 10 présente une représentation simplifiée de la taille de fenêtre et des reçus. Dans cet
exemple, la taille de fenêtre initiale d’une session TCP représentée est définie à 3000 octets. Lorsque
l’expéditeur a transmis 3000 octets, il attend le reçu de ces octets avant de transmettre d’autres
segments de cette session.
Une fois que l’expéditeur a reçu le reçu du destinataire, il peut transmettre 3000 octets
supplémentaires.
Pendant le délai d’attente de réception du reçu, l’expéditeur n’enverra pas de segment
supplémentaire pour cette session. Quand le réseau est encombré ou que les ressources de l’hôte
récepteur subissent une forte pression, le délai peut augmenter. Plus ce délai s’allonge, plus le taux
de transmission effectif des données de cette session diminue. La diminution du taux de transfert des
données contribue à réduire les conflits d’utilisation des ressources.

66
Figure 10 : Taille des fenêtres et reçus
Réduction de la taille de fenêtre
L’utilisation de tailles de fenêtres dynamiques permet également de contrôler le flux de données.
Quand les ressources réseau sont soumises à de fortes contraintes, le protocole TCP peut réduire la
taille de fenêtre afin d’imposer l’envoi plus fréquent de reçus pour les segments reçus. Ceci a pour
effet de ralentir le taux de transmission car la source attend des reçus des données plus fréquents.
L’hôte TCP destinataire envoie la valeur de la taille de fenêtre à l’expéditeur TCP afin de lui indiquer
le nombre d’octets qu’il est préparé à recevoir dans le cadre de cette session. Si la destination doit
ralentir le taux de communication parce que la mémoire tampon est limitée, elle peut envoyer une
valeur de taille de fenêtre plus petite à la source en l’intégrant à un reçu.
Comme l’illustre la figure 11, si un hôte récepteur subit un encombrement, il peut répondre à l’hôte
expéditeur avec un segment dont la taille de fenêtre est réduite. Ce graphique montre que l’un des
segments a été perdu. Dans cette conversation, le destinataire a changé le champ de fenêtre dans
l’en-tête TCP des segments renvoyés en le ramenant de 3000 à 1500. L’expéditeur a donc été obligé
de réduire la taille de fenêtre à 1500.
Quand un certain temps se sera écoulé sans perte de données ni contraintes excessives sur les
ressources, le destinataire pourra recommencer à augmenter la taille de fenêtre. Ceci réduit la
surcharge du réseau car un moins grand nombre de reçus doit être envoyé. La taille de fenêtre
continuera à augmenter jusqu’à ce que des données soient à nouveau perdues, ce qui entraînera une
réduction de la taille de fenêtre.
Ces augmentations et réductions dynamiques de la taille de fenêtre constituent un processus continu
dans le protocole TCP, processus qui détermine la taille de fenêtre optimale pour chaque session
TCP. Dans les réseaux très efficaces, les tailles de fenêtres peuvent augmenter beaucoup car les
données ne sont pas perdues. Sur les réseaux dont l’infrastructure sous-jacente est soumise à
beaucoup de contraintes, la taille de la fenêtre demeurera probablement réduite.

67
Liens
Vous pourrez trouver des informations détaillées sur les différentes fonctions de gestion de
l’encombrement du protocole TCP dans le document RFC 2581.
http://www.ietf.org/rfc/rfc2581.txt
Figure 11 : Réduction de la taille de fenêtre
4.4 Protocole UDP : des communications avec peu de surcharge
4.4.1 UDP : faible surcharge contre fiabilité Le protocole UDP est un protocole simple offrant des fonctions de couche transport de base. Il crée
beaucoup moins de surcharge que le protocole TCP car il est sans connexion et ne propose pas de
mécanismes sophistiqués de retransmission, de séquençage et de contrôle de flux.
Mais cela ne signifie pas que les applications utilisant le protocole UDP manquent toujours de
fiabilité. Cela signifie simplement que ces fonctions ne sont pas fournies par le protocole de la
couche transport et qu’elles doivent être implémentées à un autre niveau, le cas échéant.
Bien que le volume total de trafic UDP trouvé sur un réseau typique soit relativement faible, des
protocoles importants de la couche application utilisent le protocole UDP, notamment :
DNS (Domain Name System)
SNMP (Simple Network Management Protocol)
DHCP (Dynamic Host Configuration Protocol)
RIP (Routing Information Protocol)
TFTP (Trivial File Transfer Protocol)
Jeux en ligne
Certaines applications, comme les jeux en ligne ou la voix sur IP, peuvent tolérer la perte d’une
certaine quantité de données. Si ces applications utilisaient le protocole TCP, elles risqueraient d’être
confrontées à de longs délais pendant que le protocole TCP détecterait les pertes de données et

68
retransmettrait les données. Ces délais seraient plus préjudiciables à l’application que la perte d’une
petite quantité de données. Certaines applications, comme le système DNS, se contentent
simplement de répéter leur requête si elles ne reçoivent pas de réponse. Elles n’ont donc pas besoin
du protocole TCP pour garantir la livraison du message.
La faible surcharge qu’engendre le protocole UDP rend celui-ci très intéressant pour de telles
applications.
4.4.2 Réassemblage des datagrammes UDP Comme le protocole UDP n’utilise pas de connexion, les sessions ne sont pas établies avant que la
communication n’ait lieu comme c’est le cas avec le protocole TCP. Le protocole UDP est connu pour
être un protocole basé sur les transactions. En d’autres termes, quand une application doit envoyer
des données, elle les envoie tout simplement.
De nombreuses applications utilisant le protocole UDP envoient de petites quantités de données
pouvant tenir dans un seul segment. Cependant, certaines applications envoient des volumes de
données plus importants qui doivent être découpés en plusieurs segments. L’unité de données de
protocole UDP est appelée un datagramme, bien que les termes segment et datagramme soie nt
souvent utilisés l’un pour l’autre pour décrire une unité de données de protocole de la couche
transport.
Quand plusieurs datagrammes sont envoyés vers une destination, ils peuvent emprunter des
chemins différents et arriver dans le désordre. Le protocole UDP n’effectue pas de suivi des numéros
d’ordre comme le fait le protocole TCP. Il n’a en effet aucun moyen de réordonnancer les
datagrammes pour leur faire retrouver leur ordre de transmission d’origine. Consultez la figure 12.
Le protocole UDP se contente donc de réassembler les données dans l’ordre dans lequel elles ont été
reçues, puis de les transmettre à l’application. Si l’application attache une grande importance à
l’ordre des données, elle devra identifier l’ordre correct des données et déterminer leur mode de
traitement.
Figure 12 : Le protocole UDP n’effectue pas de suivi des numéros d’ordre

69
4.4.3 Processus et requêtes des serveurs UDP Comme c’est le cas avec des applications basées sur le protocole TCP, des numéros de ports réservés
sont affectés aux applications serveur basées sur le protocole UDP. Quand ces applications ou
processus s’exécutent, ils ou elles acceptent les données correspondant au numéro de port attribué.
Quand le protocole UDP reçoit un datagramme destiné à l’un de ces ports, il transmet les données
applicatives à l’application appropriée d’après son numéro de port.
4.4.4 Processus des clients UDP Comme c’est le cas avec le protocole TCP, la communication entre le client et le serveur est initiée
par une application cliente qui demande des données à un processus serveur. Le processus client
UDP sélectionne un numéro de port aléatoire dans une plage dynamique de numéros de ports et il
l’utilise comme port source pour la conversation. Le port de destination est généralement le numéro
de port réservé affecté au processus serveur.
Le choix aléatoire des numéros de ports source présente également un avantage en matière de
sécurité. Quand il existe un modèle prévisible de sélection du port de destination, il est plus facile
pour un intrus de simuler un accès à un client en tentant de se connecter au numéro de port le plus
susceptible d’être ouvert.
Étant donné que le protocole UDP ne crée pas de session, dès que les données sont prêtes à être
envoyées et que les ports sont identifiés, il peut créer le datagramme et le soumettre à la couche
réseau pour son adressage et son envoi sur le réseau.
Souvenez-vous qu’une fois qu’un client a choisi le port source et le port de destination, la même
paire de port est utilisée dans l’en-tête de tous les datagrammes utilisés dans la transaction. Quand
des données sont renvoyées du serveur vers le client, les numéros de port source et de port de
destination sont inversés dans l’en-tête du datagramme.


















