
Indexation des Bases Vidéos à l’aide d’une...
6
Indexation des Bases Vidéos à l’aide d’une Modélisation du Flot Optique par Bases de Polynômes R. Negrel 1 V. Fernandes 2 P.H. Gosselin 1 M. Vieira 2 F. Precioso 3 1 ETIS, CNRS, ENSEA, Université Cergy-Pontoise F-95000 Cergy, France 2 Universidade Federal de Juiz de Fora, Brazil 3 Sophia-Antipolis, France Résumé La classification d’action dans les vidéos est un prob- lème courant dans la communauté de reconnaissance des formes. Nous proposons une méthode basée sur la mod- élisation du flot optique par une bases de polynômes et une représentation innovante des descripteurs en sac de tubes eux-mêmes décrits par des sacs de descripteurs de flot optique. Nous utilisons une classification par SVM et les bases vidéo KTH et Hollywood2 pour évaluer la per- formance de notre méthode sur la classification d’actions humaines dans les vidéos. Nos résultats démontrent que ces performances sont au moins comparables aux travaux les plus récents avec une approche plus simple et plus rapide. Mots Clef Indexation, sac de descripteurs de flot optique, reconnais- sance d’actions humaines. Abstract Action classification in videos is a current problem in the pattern recognition community. We propose a method based on optical flow modeling using polynomial basis and a new representation of bag of words descriptors, in their turn described by a bag of optical flow descriptors. We use a SVM classification with the KTH and Holly- wood2 databases for evaluating the performance of our method over human action classification on video. Our re- sults show that this performance is comparable to recent works with a much simpler and faster approach. Keywords Indexation, bag of optical flow descriptors, human action recognition. 1 Introduction La reconnaissance automatique des actions humaines dans les vidéos est une des problématiques les plus complexes de la vision par ordinateur. Avec l’accroissement de la taille des bases vidéos tant personnelles que professionnelles, ces méthodes deviennent des points clefs des applications d’in- dexation et de classification vidéo. La problématique de la reconnaissance d’action suscite l’intérêt depuis les premières bases vidéos et a énormément progressé ces dernières années. Les premiers travaux dans ce domaine consistaient à positionner, à la fois temporelle- ment et spatialement, les actions dans la vidéo, alors que de nos jours on recherche à identifier ces actions. Les méthodes récentes d’identification d’actions donnent de très bons résultats dans les bases vidéos d’actions en milieu contrôlé, par exemple dans la base KTH [8] et Weizman [3] . Mais pour le moment, aucune méthode n’a fourni de résultats réellement satisfaisants dans les bases de vidéos réelles (films, vidéo surveillance, ...), comme cela a été montré dans [1] et [4]. Il est donc essentiel d’éprou- ver les nouvelles méthodes développées sur des bases de vidéos réelles. Dans ce travail nous proposons un nouveau schéma d’in- dexation pour la reconnaissance d’action dans les vidéos. Pour la description du mouvement, nous proposons d’u- tiliser une modélisation du flot proposée par Druon dans [2]. Cette technique modélise le flot optique entre deux frames successives de la vidéo à l’aide d’une base de polynômes orthogonaux. Puis nous décrivons une méth- ode originale pour le calcul de signatures et de métriques compatibles avec la classification par SVM. Cette méthode s’appuie sur le formalisme des fonctions noyaux, et sur les méthodes basées sur le principe du "coding pooling". Enfin, nous utilisons la base vidéo KTH pour expérimenter de la méthode proposée sur des actions humaines en milieu contrôlé. Puis nous utilisons la base Hollywood2 [7] pour effectuer un test de la méthode proposée sur des actions humaines en milieu réel. 2 Description vectorielle du flot op- tique Dans cette section, nous présentons la méthode de descrip- tion vectorielle du flot optique proposée par Druon [2]. Cette méthode s’appuie tout d’abord sur une extraction du flot optique sous la forme d’un champ de vecteur. Cette ex- traction est effectuée par le biais de la methode de Lucas et Kanade [5]. Puis le champ de vecteur est modélisé à l’aide d’une projection sur une base de polynômes, dont les coef-
Transcript of Indexation des Bases Vidéos à l’aide d’une...

Indexation des Bases Vidéos à l’aide d’une Modélisation du Flot Optique parBases de Polynômes
R. Negrel1 V. Fernandes2 P.H. Gosselin1 M. Vieira2 F. Precioso3
1 ETIS, CNRS, ENSEA, Université Cergy-Pontoise F-95000 Cergy, France2 Universidade Federal de Juiz de Fora, Brazil
3 Sophia-Antipolis, France
RésuméLa classification d’action dans les vidéos est un prob-lème courant dans la communauté de reconnaissance desformes. Nous proposons une méthode basée sur la mod-élisation du flot optique par une bases de polynômes etune représentation innovante des descripteurs en sac detubes eux-mêmes décrits par des sacs de descripteurs deflot optique. Nous utilisons une classification par SVM etles bases vidéo KTH et Hollywood2 pour évaluer la per-formance de notre méthode sur la classification d’actionshumaines dans les vidéos. Nos résultats démontrent que cesperformances sont au moins comparables aux travaux lesplus récents avec une approche plus simple et plus rapide.
Mots ClefIndexation, sac de descripteurs de flot optique, reconnais-sance d’actions humaines.
AbstractAction classification in videos is a current problem inthe pattern recognition community. We propose a methodbased on optical flow modeling using polynomial basisand a new representation of bag of words descriptors, intheir turn described by a bag of optical flow descriptors.We use a SVM classification with the KTH and Holly-wood2 databases for evaluating the performance of ourmethod over human action classification on video. Our re-sults show that this performance is comparable to recentworks with a much simpler and faster approach.
KeywordsIndexation, bag of optical flow descriptors, human actionrecognition.
1 IntroductionLa reconnaissance automatique des actions humaines dansles vidéos est une des problématiques les plus complexesde la vision par ordinateur. Avec l’accroissement de la tailledes bases vidéos tant personnelles que professionnelles, cesméthodes deviennent des points clefs des applications d’in-dexation et de classification vidéo.
La problématique de la reconnaissance d’action suscitel’intérêt depuis les premières bases vidéos et a énormémentprogressé ces dernières années. Les premiers travaux dansce domaine consistaient à positionner, à la fois temporelle-ment et spatialement, les actions dans la vidéo, alors quede nos jours on recherche à identifier ces actions.Les méthodes récentes d’identification d’actions donnentde très bons résultats dans les bases vidéos d’actions enmilieu contrôlé, par exemple dans la base KTH [8] etWeizman [3] . Mais pour le moment, aucune méthode n’afourni de résultats réellement satisfaisants dans les bases devidéos réelles (films, vidéo surveillance, ...), comme cela aété montré dans [1] et [4]. Il est donc essentiel d’éprou-ver les nouvelles méthodes développées sur des bases devidéos réelles.Dans ce travail nous proposons un nouveau schéma d’in-dexation pour la reconnaissance d’action dans les vidéos.Pour la description du mouvement, nous proposons d’u-tiliser une modélisation du flot proposée par Druon dans[2]. Cette technique modélise le flot optique entre deuxframes successives de la vidéo à l’aide d’une base depolynômes orthogonaux. Puis nous décrivons une méth-ode originale pour le calcul de signatures et de métriquescompatibles avec la classification par SVM. Cette méthodes’appuie sur le formalisme des fonctions noyaux, et sur lesméthodes basées sur le principe du "coding pooling".Enfin, nous utilisons la base vidéo KTH pour expérimenterde la méthode proposée sur des actions humaines en milieucontrôlé. Puis nous utilisons la base Hollywood2 [7] poureffectuer un test de la méthode proposée sur des actionshumaines en milieu réel.
2 Description vectorielle du flot op-tique
Dans cette section, nous présentons la méthode de descrip-tion vectorielle du flot optique proposée par Druon [2].Cette méthode s’appuie tout d’abord sur une extraction duflot optique sous la forme d’un champ de vecteur. Cette ex-traction est effectuée par le biais de la methode de Lucas etKanade [5]. Puis le champ de vecteur est modélisé à l’aided’une projection sur une base de polynômes, dont les coef-

ficients forment la description vectorielle du flot entre deuxframes successives.
2.1 Extraction du mouvement apparentL’estimation du mouvement consiste à mesurer la projec-tion 2D dans le plan de l’image d’un mouvement réel 3D.Le mouvement 2D est aussi appelé flot optique, il peut êtredéfini comme le champ de vitesse décrivant le mouvementapparent des motifs d’intensité de l’image sous l’hypothèsed’illumination constante :
∂I
∂x1vx1 +
∂I
∂x2vx2 +
∂I
∂t= 0
avec (vx1, vx2
) ∈ R2 les composantes horizontal et verticaldu flot optique et
I : V ⊂ R3 → [0, 1](x1, x2, t)→ I(x1, x2, t)
la fonction de luminance de la vidéo.La méthode de Lucas et Kanade [5] est une approche lo-cale différentielle pour l’extraction du flot optique. Elle faitl’hypothèse que le flot optique est localement constant surun voisinage spatial. Alors, cette méthode détermine le dé-placement d’un pixel x = (x1, x2, t) ∈ V à partir de l’in-formation des pixels voisins dans une fenêtre W (x) ⊂ V(Eq. (1)). Le flot ~v(x) est obtenu avec la minimisation decette énergie :
min~v(x)
∫W (x)
~v(x)>(∇I(x′))(∇I(x′))>~v(x)dx′. (1)
Au lieu d’avoir un simple moyennage du voisinage de x, ilest possible de pondérer l’équation par une fonction h(x)qui est, généralement, un noyau gaussien de moyenne nulleet d’écart type sx
h(x) =1
2πs2x
e− x>x
2s2x . (2)
Si nous supposons que :
〈f〉 (x) =
∫W (x)
h(x− x′)f(x′, t)dx′ (3)
et queS =
⟨(∇I)(∇I)>
⟩(4)
est la définition du tenseur de structure, alors, le problèmede l’Eq. (1) peut être réécrit comme :
min~v=(vx1
,vx2,1)~v>S~v. (5)
La minimisation de l’énergie est un problème de moindrescarrés pondérés et la solution revient à considérer le sys-tème d’equations suivant :
A
(vx1
vx2
)= b (6)
où A =
( ⟨I2x1
⟩〈Ix1
Ix2〉
〈Ix1Ix2〉
⟨I2x2
⟩ ) et b =
(〈Ix1
It〉〈Ix2
It〉
).
La méthode de Lucas et Kanade permet de corriger locale-ment les problèmes d’ouvertures, mais il peuvent persistersi des parties de la vidéo (plus grande que le voisinsW (x))ont une structure linéaire.
2.2 Modélisation par polynôme de LegendreL’idée de la modélisation par polynômes orthogonaux estd’approximer des fonctions réelles par des combinaisonslinéaires de fonctions polynomiales [2]. Nous souhaitonsainsi approximer le flot optique par des polynômes d’unebase orthogonale, par exemple celle de Legendre. On peutdéfinir le flot optique F à un instant t de la vidéo commesuit :
~v :It → R2
(x1, x2)→ (V 1(x1, x2), V 2(x1, x2))(7)
oú It = (x1, x2, tV) ∈ V | tV = t et, V 1(x1, x2) etV 2(x1, x2) sont deux applications correspondant respec-tivement aux déplacements horizontaux et verticaux aupoint de coordonnées (x1, x2).Alors, nous utilisons des polynômes définis dans R2 de lafaçon suivante :
P (x1, x2)K,L =
K∑k=0
L∑l=0
ck,l(x1)k(x2)l (8)
avec K ∈ N+ le degré maximal de x1, L ∈ N+ le degrémaximal de x2 et ck,l l’ensemble des coefficients réels dupolynôme. Le dégre du polynôme est alors K + L [2]. Leproduit scalaire dans les bases de polynômes bidimension-nelles est définie par :
〈f |g〉 =
∫∫Ω
f(x1, x2)g(x1, x2)ω(x1, x2) dx1 dx2
avec ω(x1, x2) la fonction de poids du produit scalaire.
Polynôme de Legendre. Les polynômes de Legendresont des solutions de l’équation différentielle de Legendre,et constituent un exemple de base de polynômes orthogo-naux.Ils peuvent être construits par la formule de récurrencesuivante :
P−1,j = 0Pi,−1 = 0P0,0 = 1Pi+1,j = 2i+1
i+1 x1Pi,j − ii+1Pi−1,j
Pi,j+1 = 2j+1j+1 x2Pi,j − j
j+1Pi,j−1
. (9)
Alors, une base bidimensionnelle de degré d peut être com-posée par les polynômes de Legendre Pi,j avec i+j ≤ d.Le nombre de polynômes qui composent la base de degréd est :
nd =(d+ 1)(d+ 2)
2. (10)

Le domaine d’orthogonalité des polynômes de Legendrebidimensionnels est Ω ∈ [−1, 1]2. Il est important deremarquer que la fonction de poids du produit scalaireω(x1, x2) vaut 1. Cela rend le calcul du produit scalairebeaucoup plus simple.
Projection dans la base. La modélisation du flot op-tique est générée à partir de la projection de V 1(x1, x2)et V 2(x1, x2) sur chaque polynôme Pi,j de la base or-thogonale de degré d. Alors, l’approximation du flot op-tique v = (V 1(x1, x2), V 2(x1, x2)), peut être expriméecomme :
V 1(x1, x2) =∑di=0
∑d−1j=0 v
1i,jPi,j
V 2(x1, x2) =∑di=0
∑d−1j=0 v
2i,jPi,j
(11)
avec v1i,j =
⟨V 1|Pi,j
⟩v2i,j =
⟨V 2|Pi,j
⟩ . (12)
Ce processus de modélisation nous permet de décrirechaque paire r de frames successives de chaque vidéo ssous la forme d’un vecteur brs ∈ R2nd . Ce vecteur brscontient l’ensemble des coefficients v1
i,j et v2i,j issus de la
projection du champ de vecteurs sur la base polynomialechoisie.
3 Reconnaissance d’action3.1 Approche proposéeNous proposons d’utiliser le descripteur présenté dans lasection précédente pour la classification d’actions dans lesvidéos. Notre méthode se base sur des tubes vidéos, où untube vidéo est un sous-ensemble d’une vidéo (de forme par-allélépipédique rectangle dans notre cas). Chaque tube i estdécrit par un sacBi ∈ B de descripteurs bri, où chaque de-scripteur correspond à une paire r de frames successives.Puis, nous proposons de munir l’espace B avec unemétrique compatible avec les méthodes de classificationpar hyperplan telles que les séparateurs à vaste marge(SVM) [9].Pour ce faire, les données à classifier doivent être décritesdans un espace hilbertien H. Dans le but de créer cet es-pace, nous avons alors choisi d’utiliser la méthode parnoyau. Cette méthode propose de transformer l’espace ini-tial B via une fonction φ : B → H, puis travaille sur lamétrique dans l’espaceH, appelée fonction noyau :
k(Bi, Bj) = 〈φ(Bi)|φ(Bj)〉.
Dans notre cas particulier où l’espace initial est un ensem-ble de sac, nous avons besoin d’utiliser une fonction noyaudite sur sacs. Parmi celles-ci, nous avons basé notre modèlesur la fonction proposée par Lyu [6], avec p ≥ 1 et k(., .)une fonction noyau entre vecteurs :
K(Bi, Bj) =∑r
∑s
k(bri,bsj)p.
Et pour p = 2 et k(·, ·) = 〈·|·〉, on peut expliciter φ :
K(Bi, Bj) =∑r
∑s 〈bri|bsj〉
2
=∑r
∑s(b>ribsj)
2
= trace(∑
r
∑s(brib
>ri)>bsjb
>sj
)= vect
(∑r brib
>ri
)>vect
(∑s bsjb
>sj
)avec vect(·) une fonction qui déplie une matrice en vecteur.Nous proposons donc d’expliciter φ par :
φ(Bi) = vect
(∑r
brib>ri
).
Finalement, nous proposons de représenter un tube i sousla forme d’un vecteur ti = φ(Bi)
‖φ(Bi)‖ ∈ H.
3.2 SignaturesSignatures mono-tube. Nous pouvons classifier les ac-tions en utilisant directement la vidéo comme un tubevidéo. En effet, étant donné que chaque tube i est décritpar un représentant ti dans un espace Hilbertien, on peututiliser directement toutes les méthodes compatibles avecces espaces, dans notre cas les SVM.
Signatures multi-tubes. Nous proposons de définir pourchaque vidéo un ensemble de tubes vidéos. Chaque vidéosera donc décrite par un sac de descripteurs de tube :
Si = · · · , tri, · · · ∈ S
avec tri ∈ H.Nous présentons une approche pour extraire des tubes dansla partie 4.2.Au même titre qu’avec les sacsB de paires de frames, noussouhaitons utiliser des classifieurs par hyperplan. Nousproposons aussi d’effectuer un changement d’espace, cettefois-ci par le biais d’une fonction ψ : S → C. Cepen-dant, dans ce cas nous avons choisi d’utiliser une approchepar codage [10]. Notons que nous aurions aussi pu utiliserl’approche par fonction noyau, cependant dans ce cas pré-cis nous aurions eu des problèmes en terme de complexitécalculatoire.L’indexation par codage se déroulent en deux étapes :– Une première étape, le coding, qui consiste en la trans-
formation des descripteurs t ∈ H en codes c(t) dans unespace C.
– Une deuxième étape, le pooling, qui consiste à rassem-bler tous les codes c(tri)r d’un même sac Si en unseul code c(Si).
J. Wang propose une méthode originale de coding, leLocality-Constrained Linear Coding (LLC) [10] qui utilisela contrainte suivante :
minC
∑t
‖t−Dc(t)‖2 + λ‖d(t, D) c(t)‖2
s.t. ∀t 1>c(t) = 1
où D = (dj)j∈[1..M ] est un dictionnaire visuel, C =c(t)t l’ensemble des codes, le produit de Hadamard

et d(t, D) le vecteur de similarité entre le descripteur t etles vecteurs de la base D :
d(t, D) = exp
(dist(t, D)
σ
)avec dist(t, D) = [dist(t,d1), · · · ,dist(t,dM )]> etdist(t,dj) la distance euclidienne entre t et dj .L’article [10] propose également une méthode approximéedu LLC pour l’encodage rapide, cette méthode consisteà effectuer la projection d’un descripteur t sur un sousdictionnaire D(t) spécifique à chaque descripteur t. Cesous-dictionnaireD(t) est uniquement composé des n plusproches descripteurs du dictionnaire D de t (typiquementn = 5). On résout pour cela le problème suivant :
minC
∑t
‖t−D(t)c(t)‖2
s.t. ∀t 1>c(t) = 1.
Le dictionnaire de descripteurs D est obtenu par l’appli-cation d’un algorithme de type K-Means sur l’ensembledes descripteurs de tube extraits de l’ensemble des vidéos.Par construction, chaque descripteur du dictionnaire est unbarycentre d’un ensemble de descripteurs de tubes c’estpourquoi chaque descripteur du dictionnaire di peut êtreinterprété comme le descripteur d’un tube type. Le nombrede barycentre du dictionnaire définit la taille du codage etdonc la dimension du descripteur de sac que l’on obtientpar cette méthode.Il existe plusieurs méthodes pour effectuer l’opération de"pooling", par exemple :– somme pooling : c(Si) =
∑t∈Si
c(t)– max pooling : c(Si) = maxt∈Si
c(t) .Les méthodes de "coding pooling" permettent de définir unsac de descripteur par un unique descripteur, tout en effec-tuant une forte compression des données et également defournir une aussi grande importance à chaque types de de-scripteurs du sac quelque soit leur nombres d’occurrences.
4 Expériences4.1 Base KTHPour tester le descripteur global nous utilisons la base devidéos KTH [8]. Cette base contient six types d’actionshumaines : walking, jogging, running, boxing, hand wav-ing et hand clapping (Figure 1). Ces actions sont faites par25 sujets différents dans quatre scénarios : dehors, dehorsavec variation d’échelle, dehors avec différents vêtements,à l’intérieur.Toutes les séquences sont en noir et blanc avec un fond ho-mogène et une caméra statique de 25 images par seconde,elles ont une résolution de 160x120 et durent environ 4 sec-ondes.
Protocole expérimental. Nous utilisons un classifieurSVM avec une fonction noyau triangulaire de σ = 1 avecune distance euclidienne. Le flot optique est estimé à l’aidede la méthode de Lucas-Kanade avec une fenêtre de taille5.
Boxing HandClapping HandWaving
Jogging Running Walking
FIGURE 1 – Exemple de vidéo de la base KTH
Degré de la base Taux de reconnaissance1 0,6382 0,6753 0,7094 0,7375 0,7549 0,787
13 0,79015 0,776
TABLE 1 – Taux de reconnaissance pour différents degrésde la base de polynômes.
Résultats. Le Tableau 1 présente les taux de reconnais-sance pour plusieurs degré de la base de polynômes.Il est intéressant de remarquer que plus le degré de la baseest grand, plus le descripteur est performant. Cela montreque même si le modèle de Legendre commence à être tropprécis et à prendre en compte le bruit du flot optique, leclassifieur SVM arrive à séparer le bruit des données dansle descripteur.Le meilleur résultat obtenu a été 79.04% avec une base dedegré 13. La matrice de confusion pour ce résultat est don-née dans le Tableau 2. Nous pouvons voir que les pires casde confusion sont entre l’ensemble de mouvements run-ning, jogging et walking. En fait, le mouvement joggingest un mouvement au milieu de walking et running, donc, siune personne marche plus vite, son jogging sera plus rapideet il peut être confondu avec le mouvement running. Demême, si une personne marche plus lentement, son joggingsera plus lent et il peut être confondu avec le mouvementwalking.
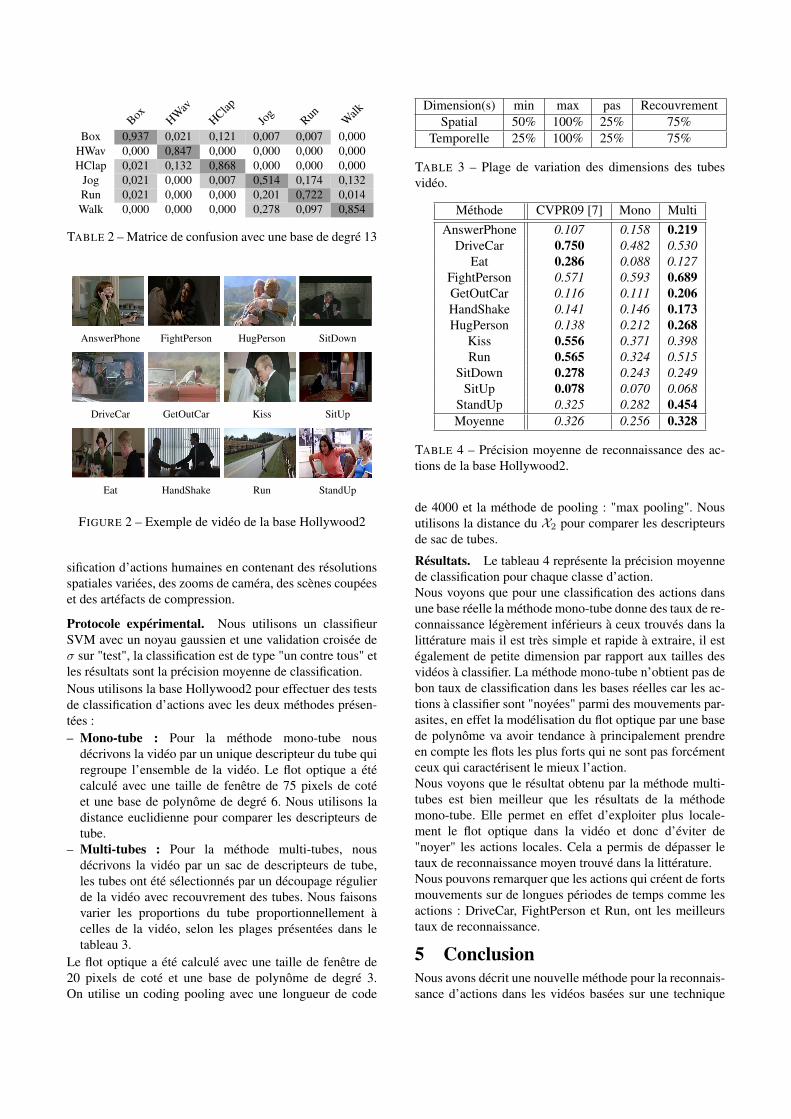
4.2 Base Hollywood2La base de test Hollywood2 [7] est constituée d’une col-lection de clips vidéo extraits de 69 films et classifiés dans12 classes d’actions humaines (Figure 2). Elle totalise ap-proximativement 20,1 heures de vidéo et contient approxi-mativement 150 échantillons vidéo par actions. Elle permetd’offrir une évaluation plus réaliste des méthodes de clas-
Box HWav
HClapJo
gRun W
alk
Box 0,937 0,021 0,121 0,007 0,007 0,000HWav 0,000 0,847 0,000 0,000 0,000 0,000HClap 0,021 0,132 0,868 0,000 0,000 0,000
Jog 0,021 0,000 0,007 0,514 0,174 0,132Run 0,021 0,000 0,000 0,201 0,722 0,014Walk 0,000 0,000 0,000 0,278 0,097 0,854
TABLE 2 – Matrice de confusion avec une base de degré 13
AnswerPhone FightPerson HugPerson SitDown
DriveCar GetOutCar Kiss SitUp
Eat HandShake Run StandUp
FIGURE 2 – Exemple de vidéo de la base Hollywood2
sification d’actions humaines en contenant des résolutionsspatiales variées, des zooms de caméra, des scènes coupéeset des artéfacts de compression.
Protocole expérimental. Nous utilisons un classifieurSVM avec un noyau gaussien et une validation croisée deσ sur "test", la classification est de type "un contre tous" etles résultats sont la précision moyenne de classification.Nous utilisons la base Hollywood2 pour effectuer des testsde classification d’actions avec les deux méthodes présen-tées :– Mono-tube : Pour la méthode mono-tube nous
décrivons la vidéo par un unique descripteur du tube quiregroupe l’ensemble de la vidéo. Le flot optique a étécalculé avec une taille de fenêtre de 75 pixels de cotéet une base de polynôme de degré 6. Nous utilisons ladistance euclidienne pour comparer les descripteurs detube.
– Multi-tubes : Pour la méthode multi-tubes, nousdécrivons la vidéo par un sac de descripteurs de tube,les tubes ont été sélectionnés par un découpage régulierde la vidéo avec recouvrement des tubes. Nous faisonsvarier les proportions du tube proportionnellement àcelles de la vidéo, selon les plages présentées dans letableau 3.
Le flot optique a été calculé avec une taille de fenêtre de20 pixels de coté et une base de polynôme de degré 3.On utilise un coding pooling avec une longueur de code
Dimension(s) min max pas RecouvrementSpatial 50% 100% 25% 75%
Temporelle 25% 100% 25% 75%
TABLE 3 – Plage de variation des dimensions des tubesvidéo.
Méthode CVPR09 [7] Mono MultiAnswerPhone 0.107 0.158 0.219
DriveCar 0.750 0.482 0.530Eat 0.286 0.088 0.127
FightPerson 0.571 0.593 0.689GetOutCar 0.116 0.111 0.206HandShake 0.141 0.146 0.173HugPerson 0.138 0.212 0.268
Kiss 0.556 0.371 0.398Run 0.565 0.324 0.515
SitDown 0.278 0.243 0.249SitUp 0.078 0.070 0.068
StandUp 0.325 0.282 0.454Moyenne 0.326 0.256 0.328
TABLE 4 – Précision moyenne de reconnaissance des ac-tions de la base Hollywood2.
de 4000 et la méthode de pooling : "max pooling". Nousutilisons la distance du X2 pour comparer les descripteursde sac de tubes.
Résultats. Le tableau 4 représente la précision moyennede classification pour chaque classe d’action.Nous voyons que pour une classification des actions dansune base réelle la méthode mono-tube donne des taux de re-connaissance légèrement inférieurs à ceux trouvés dans lalittérature mais il est très simple et rapide à extraire, il estégalement de petite dimension par rapport aux tailles desvidéos à classifier. La méthode mono-tube n’obtient pas debon taux de classification dans les bases réelles car les ac-tions à classifier sont "noyées" parmi des mouvements par-asites, en effet la modélisation du flot optique par une basede polynôme va avoir tendance à principalement prendreen compte les flots les plus forts qui ne sont pas forcémentceux qui caractérisent le mieux l’action.Nous voyons que le résultat obtenu par la méthode multi-tubes est bien meilleur que les résultats de la méthodemono-tube. Elle permet en effet d’exploiter plus locale-ment le flot optique dans la vidéo et donc d’éviter de"noyer" les actions locales. Cela a permis de dépasser letaux de reconnaissance moyen trouvé dans la littérature.Nous pouvons remarquer que les actions qui créent de fortsmouvements sur de longues périodes de temps comme lesactions : DriveCar, FightPerson et Run, ont les meilleurstaux de reconnaissance.
5 ConclusionNous avons décrit une nouvelle méthode pour la reconnais-sance d’actions dans les vidéos basées sur une technique

qui modélise le flot optique entre deux frames successivesde la vidéo à l’aide d’une base de polynômes orthogonaux.Puis nous avons utilisé une méthode originale pour le cal-cul de signatures et de métriques compatibles avec la clas-sification par SVM. Nous avons évalué cette méthode surles bases vidéo KTH et Hollywood2. Nous avons obtenudes résultats au moins aussi bon que ce que l’on trouvedans la littérature avec notre méthode qui est plus simple etrapide que les méthodes exposées dans la littérature. Pourle moment, cette méthode a été testée avec un grand nom-bre de paramètres fixés arbitrairement. Une étude plus ap-profondie de ces paramètres permettrait d’améliorer cetteméthode de classification. Il existe également de nom-breuses pistes qui permettront d’améliorer cette méthode.
Références[1] Mert Dikmen, Huazhong Ning, Dennis J. Lin, Lian-
gliang Cao, Vuong Le, Shen-Fu Tsai, Kai-Hsiang Lin,Zhen Li, Jianchao Yang, Thomas S. Huang, FengjunLv, Wei Xu, Ming Yang, Kai Yu, Guangyu Zhu,and Yihong Gong. Surveillance event detection. InTRECVID, 2008.
[2] Martin Druon. Modélisation du mouvement parpolynômes orthogonaux : application à l’étude d’é-coulements fluides. PhD thesis, Université de Poitiers,2009.
[3] Lena Gorelick, Moshe Blank, Eli Shechtman, MichalIrani, and Ronen Basri. Actions as space-time shapes.In The Tenth IEEE International Conference on Com-puter Vision, pages 1395–1402, 2005.
[4] Ivan Laptev, Marcin Marszałek, Cordelia Schmid,and Benjamin Rozenfeld. Learning realistic humanactions from movies. In Conference on Computer Vi-sion & Pattern Recognition, jun 2008.
[5] Bruce D. Lucas and Takeo Kanade. An iterativeimage registration technique with an application tostereo vision (ijcai). In Proceedings of the 7th In-ternational Joint Conference on Artificial Intelligence(IJCAI 81), pages 674–679, April 1981.
[6] S. Lyu. Mercer kernels for object recognition withlocal features. In IEEE International Conferenceon Computer Vision and Pattern Recognition, pages223–229, San Diego, CA, 2005.
[7] Marcin Marszalek, Ivan Laptev, and CordeliaSchmid. Actions in context. In IEEE Conferenceon Computer Vision and Pattern Recognition, pages2929–2936, 2009.
[8] Christian Schüldt, Ivan Laptev, and Barbara Caputo.Recognizing human actions : A local svm approach.In In Proc. ICPR, pages 32–36, 2004.
[9] V.N. Vapnik. Statistical Learning Theory. Wiley-Interscience, New York, 1998.
[10] Jingjun Wang, Jianchao Yang, Kai Yu, FengjunLv, Thomas Huang, and Yihong Gong. Locality-constrained linear coding for image classification. In
IAPR International Conference on Pattern Recogni-tion, pages 3360–3367, 2010.


















