
Hector 2 manuel principal 2011 - alain.dubus.r.et.d.free.fralain.dubus.r.et.d.free.fr/les manuels...
54
Mise à jour : 13/10/2011 Hector Manuel principal 1 Hector² Manuel principal révision 2011
Transcript of Hector 2 manuel principal 2011 - alain.dubus.r.et.d.free.fralain.dubus.r.et.d.free.fr/les manuels...

Mise à jour : 13/10/2011 Hector Manuel principal 1
Hector²
Manuel principal révision 2011

Mise à jour : 13/10/2011 Hector Manuel principal 2
PRESENTATION DU MANUEL
Organisation du document Quelques mots sur Hector Hector est un logiciel d’analyse de données statistiques orienté vers les besoins des chercheurs, des praticiens et des étudiants en Sciences Humaines, dans une acception étendue : Sociologie, Psychologie, Sciences de l'Education, et les champs professionnels de l'Education, du Travail Social et de l'Orthophonie. Le but recherché est l’autonomie de l’utilisateur dans le traitement de ses propres données. Hector correspond à un empan de connaissances statistiques qui s’étend jusqu’au Doctorat : les cas de chercheurs en Sciences Humaines qui auraient besoin de quelque chose qui n’est pas dans Hector sont rares, et relèvent de situations ou le chercheur développe volontiers lui-même ses outils statistiques. En même temps, grâce à sa simplicité d’emploi, Hector peut aisément être le support d’enseignements de statistique appliquée dès le premier cycle universitaire. Simplement, l’enseignant doit alors veiller à apporter en parallèle les connaissances statistiques nécessaires à l’usage heureux d’Hector, qui n’est pas en soi un didacticiel.
Les deux versions d’Hector D’un point de vue technique, Hector se compose d’un noyau riche et amplement suffisant pour les travaux statistiques en sciences humaines jusqu’aux frontières du doctorat, et d’extensions plus sophistiquées, développées selon les besoins et demandes des chercheurs confirmés. L’auteur est un ancien enseignant, toujours chercheur, et, nécessairement aussi un ingénieur logiciel ; mais ce n’est pas un commerçant ni le représentant d'une multinationale du logiciel. Aussi Hector fait-il l’objet d’un modèle économique spécifique :
• la version de base d’Hector est gratuite : elle se télécharge à une adresse indiquée dans la rubrique Mises à jour, ainsi que sa documentation et des corpus d’exemples. Les étudiants et les professionnels (à des fins d’autoformation) sont invités à visiter régulièrement ce site, car Hector est un logiciel vivant, dont les mises à jour sont fréquentes. L’usage professionnel de cette version gratuite est considéré comme déloyal. De plus, les utilisateurs de cette version ne peuvent prétendre à aucun soutien technique ou méthodologique direct de la part de l’auteur.
• la version professionnelle-recherche n’est pas non plus à vendre, mais elle peut être mise à disposition de laboratoires, d’équipes de recherche, d’UFR ou d’Instituts dans le cadre de conventions d’assistance méthodologique à la recherche ou à la formation. Ces conventions sont assorties d’une rémunération de l’auteur à des niveaux qui paraîtront bien modestes à quiconque a fait l’acquisition d’un des coûteux ensembles d’analyse de données disponibles sur le marché. L’assistance méthodologique s’exerce sous forme d’une hot-line en courrier électronique.
• de temps à autre, dans le cadre d’une campagne de recherche importante, ce qu’on appelle « un grand compte », c’est-à-dire un organisme de recherche doté de moyens substantiels, demande et finance un développement spécifique de nouvelles fonctionnalités, qui sont par la suite intégrées à la version professionnelle.

Mise à jour : 13/10/2011 Hector Manuel principal 3
Choix techniques Ce manuel est destiné au double usage de la lecture à l’écran et sur papier. Il constitue également le manuel de référence du logiciel. Ces multiples fonctions imposent des compromis d’organisation et de typographie. En particulier, le choix de la police de caractères et de sa taille est lié à la recherche de la meilleure lisibilité du fichier PDF sous Acrobat Reader© d’Adobe®, mais aussi à la possibilité pour l’usager d’imprimer ce manuel, y compris au format réduit de deux pages par feuille (4 en recto-verso) avec une imprimante possédant cette faculté, de manière à limiter le volume de papier nécessaire. Rappelons que le logiciel Acrobat Reader peut être téléchargé gratuitement sur le site www.adobe.com, dans la version appropriée au système d’exploitation employé . La solution la plus ergonomique consiste à imprimer la documentation en recto-verso sur des feuilles à perforer et à placer dans un classeur. Il est recommandé d’utiliser un papier de bonne qualité et d’un grammage supérieur à l’ordinaire, car l’expérience montre que le manuel est fort sollicité, surtout dans les premiers temps. Le caractère modulaire de la doc facilite les mises à jour partielles. Le logiciel Hector et sa documentation sont régulièrement remis à jour. Se reporter, en fin de ce manuel, à la rubrique « Téléchargement et versions », pour la méthode de téléchargement des mises à jour.
Structure modulaire Le noyau de cette documentation est constitué de sections de référence où les éléments du logiciel sont exposés de la manière la plus systématique et rigoureuse qui soit possible, et sans souci de redondance ni de didactisme. Dans certaines parties, des sections du genre « Comment faire ? », accompagnant pas à pas la démarche de l’usager débutant, sont d’ores et déjà présentes. Elles sont destinées à se multiplier et à se développer avec l’évolution du logiciel et de sa documentation. La version imprimée du manuel est destinée à la lecture systématique, chapitre par chapitre. La version électronique est plutôt destinée à la recherche rapide d’informations pertinentes, et exploite largement les signets et les liens pour y accéder. La documentation est découpée en plusieurs modules, qui ne sont pas indépendants au plan conceptuel, puisqu’ils font éventuellement référence les uns aux autres, mais qui le sont du point de vue de la fréquence des mises à jour, selon qu’ils relèvent d’aspects plus ou moins classiques ou plus ou moins expérimentaux d’Hector. Certains modules sont entièrement dévolus à des fonctions spécifiques à la version professionnelle-recherche, leur titre est ci-dessous en italique. On trouvera néanmoins dans certains modules relevant principalement de la version de base des fonctions réservées : elles seront signalées comme telles. Le découpage est le suivant : les quatre premiers manuels concernent la version de base, les suivants la version professionnelle.
• Le Manuel Principal est le document que vous êtes en train de lire. Il contient des renvois vers toutes les autres parties du logiciel. Il expose également les concepts généraux qui sous-tendent l’organisation du logiciel, les principes de gestion des données, leur saisie, édition et export et quelques aspects techniques et utilitaires généraux.
• Les Traitements de Base spécifient tout ce qui concerne les tris, croisements, graphiques, statistiques, traitements collectifs, plan de projection, ainsi que l’exploitation des résultats et leur transfert vers des logiciels de traitement de texte. Les besoins d’une statistique classique en sciences humaines, jusqu’au niveau du Master, y sont amplement couverts.
• Le Formulaire Statistique est un simple pense-bête rassemblant les formules utilisées dans les sections de traitements, et écartées de ces sections pour ne pas alourdir le texte.

Mise à jour : 13/10/2011 Hector Manuel principal 4
• Le manuel du Langage des Formules concerne la capacité unique d’Hector de modeler les données ad libitum, au moyen d’un langage de calcul un peu analogue aux langages de formules des tableurs, mais en beaucoup plus clair et en beaucoup plus développé. En particulier, le langage des formules d'Hector permet d’exploiter statistiquement des corpus hiérarchisés (bases de données relationnelles). Ce module comporte un exposé de la technique de formulation, la syntaxe détaillée du langage et des gammes d’exemples.
• Le Manuel des Approches Factorielles rassemble les techniques multi-dimensionnelles les plus populaires parmi les chercheurs : Analyse Factorielle des Correspondances Multiples, Analyse en Composantes Principales, Typologie par Classification Hiérarchique, Rotations, Régression multiple, Modèle d'Equations Structurales, et quelques intruments utiles qui les accompagnent. L’usage des ces techniques implique une bonne familiarité avec les éléments du module des Traitements.
• L’Analyse des Séquences est une technique originale, due à l’auteur d’Hector, d’étude d’éléments constitués de séries d’objets, de constructions typologiques sur ces objets et de réintégration de ces typologies dans des traitements classiques. Les champs d’application sont très variés : analyses longitudinales, études de biographie, analyses d’énoncés et de récit, classification de stratégies de résolution de problème. L’abord de cette technique nécessite évidemment un investissement intellectuel non négligeable, mais procure en retour des possibilités d’analyse difficilement accessibles autrement.
• Le Manuel des Spécialités rassemble des fonctions pas nécessairement orthodoxes, développées selon les besoins de recherche de l'auteur ou de ses partenaires. Ces fonctions sont en évolution constante, mais à l'heure de cette mise à jour de la documentation, on en compte six : les Dichotomies, les Collections parallèles, les Méta-Formules, la LPE-Consensus, la Connectivité et enfin l'étude et la représentation des Distances entre variables.

Mise à jour : 13/10/2011 Hector Manuel principal 5
CONCEPTS FONDAMENTAUX DANS HECTOR
Corpus, sujets, variables De manière générale en sciences humaines, le terme de corpus délimite l’ensemble des documents sur lesquels s’appuie une étude. Dans l’univers d’Hector, le mot de Corpus désigne un cas particulier de cette notion : un ensemble de données susceptibles d’être regroupées dans un unique fichier informatique porteur de l’extension .cn (Corpus-Nestor, du nom d'une version antérieure du logiciel, dont on a conservé la compatibilité de format). Du fait de cette unicité, on emploie le mot de corpus indifféremment pour désigner le fichier ou son contenu. Dans le langage usuel des systèmes de base de données, le corpus correspond à une Table.
Structure d’un corpus On peut se représenter un corpus comme une table, ou une matrice de données, telle qu’on pourrait la dresser sur du papier quadrillé ou la saisir dans un tableur :
Variable 1
Variable 2 …………… Variable j …………… Variable q
Sujet 1
Sujet 2
……………
Sujet i Valeur(i,j)
……………
Sujet p Chaque ligne de la table correspond à un sujet (et un seul). Chaque colonne correspond à une variable (et une seule). A l’intérieur de la table, dans une case on trouve la valeur que prend la variable de la colonne de cette case pour le sujet de la ligne de cette case. Par exemple, si la variable 2 code la couleur des yeux et que le sujet 3 correspond à notre ami Marcel, la case (3,2) peut contenir la valeur ‘bleu’, à supposer que Marcel ait les yeux bleus.
Qu’est-ce qu’un Sujet ? Peut-être à cause du terme utilisé, on a souvent tendance à penser à un sujet comme à une personne. Il est vrai que souvent en Sciences Humaines le sujet correspond à une personne : dans l’expérience de labo sur la mémoire, ou dans l’enquête par questionnaire, c’est le cas. Mais le sujet statistique, dans ces cas-là, ne fait que correspondre à la personne ; ce n’est pas la personne. En fait, le sujet statistique est simplement l’ensemble des observations, mesures ou caractéristiques dont on dispose à son propos, représenté ici par la ligne des valeurs du même sujet. De plus, dans de nombreux cas, le sujet ne correspond pas à une personne. Si j’étudie les différentes versions de la Cantilène de Sainte-Eulalie dans les Monastères Normands et Picards des Xème, XIème et XIIème siècles, le sujet statistique de base ne sera ni un moine copiste, ni un monastère, ni bien sûr Sainte-Eulalie, mais une copie du texte. Chaque copie répertoriée de la

Mise à jour : 13/10/2011 Hector Manuel principal 6
Cantilène sera l’un des sujets de mon corpus, pour lequel je pourrai relever des variables telles que l’identité du copiste, le Monastère où la copie a été réalisée, l’année présumée, et une quantité d’autres éléments qu’il faudrait être spécialiste de ce genre de choses pour préciser, mais qu’on peut imaginer, comme la fréquence de telle tournure stylistique, la présence ou l’absence de telle péripétie dans le récit, le niveau de dégradation du latin employé, mesuré par l’usage grandissant de prépositions, etc.
Qu’est-ce qu’une valeur ? C’est une propriété d’un sujet, représentable par une entité mathématique simple, telle qu’un nombre ou l’appartenance à une catégorie. Ce qui est le plus important de comprendre à propos des valeurs, c’est qu’un sujet donné ne peut avoir pour une variable donnée qu’une seule valeur au plus. Cela a des conséquences pour la détermination de ce qui, dans une étude, constituera le niveau des sujets, le niveau de l’observation élémentaire insécable, l’atome de recueil de données. Ainsi, si on étudie l’activité d’un centre de soins, les sujets statistiques ne peuvent être ni les personnels soignants, ni les patients, ni la maladie, puisque les clients peuvent revenir plusieurs fois pour des affections différentes, etc. En fait, le sujet le plus pertinent est ici la visite, qui a pour propriétés, décrites par des variables appropriées, l’identité du sujet, la maladie, le soignant qui intervient, le jour, l’heure… On a écrit « une seule valeur au plus ». C’est qu’en effet il peut ne pas y avoir de valeur. Une certaine variable peut ne pas avoir de valeur pour un sujet, pour les raisons les plus diverses : la variable n’a pas de signification pour ce sujet (date du décès pour des gens encore vivants), l’information n’est pas disponible… Il peut donc très bien y avoir une case vide dans le tableau. Dans Hector, on appelle cela une valeur absente, ou non-valeur.
Taille d’un corpus Si on décrit q variables pour p sujets, cela fait p×q valeurs, ce qui peut faire beaucoup. Jusqu’à combien, au juste ? En fait, les bornes d’Hector sont ainsi définies que les limites viendront plutôt de la capacité des disques durs et de la vitesse de traitement des processeurs que d’une limite théorique a priori. En effet, Hector admet en principe plus de 4 milliards (exactement 232) de sujets pour autant de variables, mais aucune machine de bureau actuelle ne supporterait de traiter de tels volumes dans des délais raisonnables. Un point de repère plus réaliste repose sur des tests effectivement appliqués : Hector, tournant à l'époque sur une machine cadencée à 800Mhz, ce qui est relativement modeste au regard des critères en vigueur à l’heure où l’on écrit ceci, effectuait et publiait le croisement de deux variables dotées de 10 positions différentes chacune (et générant donc un tableau croisé de 100 cases) en moins de 1/10ème de seconde pour 1 Million de sujets. En outre, la représentation interne des données dans Hector est optimisée en taille comme en vitesse de traitement, selon un format et des algorithmes propriété de l’auteur, et un corpus Hector occupe sur le disque environ 10 fois moins de place que son équivalent en format Texte, et 20 fois moins qu’en format DBF. En conclusion, Hector est construit dans la perspective d’un usage aisé pour des effectifs de l’ordre d’une ou deux centaines de milliers de sujets. Il est probable qu’au-delà, des traitements un peu complexes sur des ensembles de variables, comme les analyses factorielles, nécessiteraient des temps perceptibles, de l’ordre d’une ou quelques secondes, ce qui est assez désagréable. Bien sûr, la puissance des machines à venir peut faire reculer un tant soit peu ces contraintes. En ce qui concerne le nombre total de variables, ce n’est pas un problème pour Hector, qui ne lit en mémoire centrale que ce dont il a besoin à un instant donné ; la limite d’usage est plutôt du côté de l’opérateur : on travaille couramment sur quelques centaines de variables, mais cela demande un certain sens de l’organisation (et notamment l'usage du variArbre). Au delà du modèle de base, Hector autorise dès la version de base un modèle de données relationnelles, et, dans la version professionnelle, le modèle des Séquences.

Mise à jour : 13/10/2011 Hector Manuel principal 7
Modèles de données relationnels et hiérarchiques Si le modèle de données « à plat », avec une seule matrice de données définies dans une table rectangulaire sujets×variables est celui qui convient à la définition des calculs statistiques et correspond pour cette raison au fichier-corpus chez Hector, ce n’est pas la seule façon d’organiser des informations. Par exemple, en reprenant le cas de l’étude sur l’activité du centre de soins, on peut certes considérer la visite comme le sujet de base, avec comme variables le patient et le praticien, mais le patient lui-même présente des caractéristiques qui ne sont pas sans intérêt dans l’étude des visites. Une solution pour rester dans le modèle de la matrice de données est de coder les caractéristiques du patient comme des variables de la visite. Cela fonctionne, mais c’est assez lourd, puisque pour chaque visite du même patient, les mêmes informations doivent être dupliquées ; il en va de même, bien sûr, des caractéristiques du praticien. Une autre solution réside dans le principe des bases de données relationnelles, qui étend la notion de corpus, ou d’ensemble cohérent de données, à plusieurs tables qui entretiennent entre elles des liens hiérarchiques. Ainsi, dans notre exemple, on aurait trois tables :
• La table des visites, qui comporterait, entre autres variables, une variable de liaison contenant le numéro de dossier d’un patient, et une autre variable de liaison contenant le numéro d’identification d’un praticien.
• La table des dossiers des patients
• La table des praticiens Cette façon de concevoir une base de données relationnelles est rustique mais robuste : elle se résume ainsi : un corpus, dit corpus-fils, possède une variable, dite variable-clef, qui pour chaque sujet-fils contient le numéro d’un sujet-père dans un autre corpus dit corpus-père. La métaphore du fils et du père est liée à l’unicité du père dans son corpus (puisqu’il est repéré par un numéro de sujet, unique par essence) et à la multiplicité possible des fils du même père dans le corpus-fils. Ainsi la table des visites sera, au sens d’Hector, un corpus-fils de la table des dossiers des patients, considérée comme le corpus père. La table des praticiens est aussi un corpus-père de la table des visites. C’est une méthode de filiation assez singulière, qui permet à un même sujet d’avoir plusieurs pères ; mais on voit bien que ce n’est qu’une métaphore, et qu’il peut y avoir un père biologique, un père spirituel, un père artistique, etc. Pour exprimer cette relation dans le langage usuel des bases de données, on dira que les patients sont avec les visites dans une relation 1-n, c’est-à-dire qu’à chaque patient peuvent correspondre plusieurs visites. C’est la même chose avec les praticiens, qui sont dans un rapport 1-m (pour ne pas répéter n) avec les visites. Comme ces relations peuvent être récursives, que le fils d’un point de vue peut être père à son tour, ce mécanisme rustique permet d’exprimer n’importe quelle structure de données, au prix parfois d’un léger effort d’analyse. On trouvera dans la littérature relative aux bases de données la notion de relation n-m (par exemple entre les praticiens et les patients), dont la représentation naturelle ne serait pas une liste, mais tableau croisant les deux types d’entité. En fait, on montre aisément que cette structure se laisse toujours décomposer en deux relations 1-n ; il faut seulement trouver quelle sorte d’entité réunit un élément côté n à un élément côté m. Dans notre exemple, c’est précisément le rôle de la visite. Hector ne crée pas de superstructure au dessus de ses corpus pour en manifester les relations. En effet, cela s’accompagnerait de contraintes complexes sur la présence simultanée des tables concernées, l’intégrité de leurs liens, etc. Au contraire, les relations entre corpus s’exercent de manière dynamique, au moyen du langage des formules. Le but de l’opération est de permettre, au niveau d’un corpus-fils, des opérations statistiques mettant en jeu le corpus-père : « Parmi les visites de cette semaine, combien concernaient des

Mise à jour : 13/10/2011 Hector Manuel principal 8
hommes de moins de 30 ans ? », et vice versa : « quelle est la proportion de pathologies psychosomatiques pour chaque praticien ? ». On le pressent, ce procédé peut s’avérer extrêmement puissant, même s’il nécessite de bien comprendre ce qu’on fait.
Variété des variables On a jusqu’ici évoqué les variables sans trop s’appesantir sur ce qu’elles sont, combien de sorte y en a-t-il, d’où viennent-elles. Hector fait un usage systématique de la notion de type des variables, au point que la plupart du temps, le type des variables impliquées dans une action statistique gouverne le genre et la forme du résultat, ainsi que l’éventail des options autorisées. Cette contrainte très forte est l’une des dimensions des préoccupations didactiques et d’ergonomie cognitive dans Hector : une des meilleures méthodes pour éviter l’erreur de manœuvre est de ne pas permettre qu’elle se produise. Ainsi, si une certaine statistique n’a pas de sens avec un certain type de variable, Hector refuse simplement de la produire. On évoque ensuite l’origine et la destinée des variables, avec la saisie, la dérivation et le calcul de variables.
Le type des variables Le type des variables est en relation avec le genre de caractéristiques qu’elles s’emploient à coder. L’opposition fondamentale est entre les variables quantitatives, souvent codées par un nombre parce qu’elles renvoient d’une manière ou d’une autre à une mesure ou à un comptage, et les variables qualitatives, qui sont codées par des noms arbitraires parce qu’elles renvoient uniquement à l’appartenance à l’une ou l’autre catégorie. Ainsi, la taille d’un individu est une variable quantitative, et sa nationalité est une variable qualitative. Avec le quantitatif, on peut faire diverses opérations arithmétiques telles qu’addition, multiplication, moyenne. Avec le qualitatif, on ne peut rien faire de tout cela ; la seule comparaison qu’on peut faire entre deux sujets est de savoir s’ils appartiennent ou non à la même catégorie. Il est parfois difficile et troublant de déterminer le type d’une entité, notamment parce que l’informatique ancienne utilisait des nombres pour coder n’importe quoi, et qu’il en reste des traces dans les usages quotidiens. Il suffit pour s’en convaincre de réfléchir sur un numéro d’identification INSEE tel que 1460662119030. La plupart des gens savent qu’il se décompose en plusieurs tronçons : 1 46 06 62 119 030, mais peuvent-ils sans se tromper identifier le type de donnée de chaque tronçon ? 1 correspond à une variable qualitative, le sexe (on dit genre si on veut rester politically correct). Le lien 1-hommes 2-femmes est arbitraire. 46 correspond à une variable quantitative, les deux dernières années du millésime, qui est lui même le compte des années écoulées depuis la date choisie comme début de l’ère. Cette variable n’est d’ailleurs pas exempte de défauts techniques, puisqu’elle est cyclique : 46 code actuellement 1946, mais codera aussi 2046. 06 correspond à une variable quantitative, le numéro du mois de naissance dans l’année 62 correspond à une variable qualitative, le code du département de naissance. Il s’agit initialement d’une variable quantitative, le numéro d’ordre du département dans une liste alphabétique. Mais cette liste s’est fossilisée et les numéros, qui ne sont pas remis à jour, sont maintenant arbitraires. 119 correspond à une variable qualitative, le code arbitraire d’une commune dans le département, qui n’a jamais correspondu à un ordre quelconque. 030 correspond à une variable quantitative, le numéro d’ordre de la naissance dans le jour considéré, ou plus précisément le nombre d’enfants enregistrés avant celui-là ce mois-là, plus un.

Mise à jour : 13/10/2011 Hector Manuel principal 9
On le voit, tout ce qui s’écrit avec des chiffres n’est pas un nombre. A partir de cette opposition fondamentale entre qualitatif et quantitatif, Hector formule des nuances jusqu’à proposer six types distincts :
• Le type texte-libre, qui contient des textes de longueur quelconque, ne permet aucune opération statistique régulière mais sert de support au codage des séquences, ou plus prosaïquement au stockage d'informations individuelles non utiles au calcul.
• Le type nominal, qui code des systèmes de catégories où ranger les sujets, avec la seule exigence que le système soit complet et exclusif, c’est-à-dire qu’il y ait pour chaque sujet une valeur (sauf cas de non-valeur), et qu’il n’y en ait qu’une. Une variable nominale typique est la couleur des yeux, ou la première nationalité (pas la nationalité en général, à cause des doubles-nationalités qui ne peuvent pas être codées avec une seule variable). Dans une variable nominale, l’ordre dans lequel sont rangées et présentées les catégories est arbitraire et peut être changé sans dommage.
• Le type ordinal, qui code aussi des systèmes de catégories comparables à celles du type nominal, à ceci près que l’ordre des catégories est défini et significatif : il y a un avant et un après. Une variable ordinale typique est le système scolaire des mentions : Passable, Assez Bien, Bien, Très Bien. L’ordre des catégories ne peut être modifié sans altérer la signification de la variable.
• Le type logique, qui code les systèmes binaires Vrai/Faux, Oui/Non, tout ce qui ne prendre que l’une de deux valeurs antagonistes (sauf le sexe, qui traditionnellement se code en nominal, parce que sinon la variable ne serait pas « Sexe : homme ou femme ? », mais « Homme : vrai ou faux ? », ou encore « Femme : vrai ou faux ?», et alors comment choisir entre les deux formules sans se faire des ennemi(e)s ?). Ce type, par sa simplicité même, possède simultanément la puissance du quantitatif et les vertus du qualitatif. Selon les besoins, on peut le regarder comme une variable nominale de deux catégories (mais avec seulement deux catégories elle est aussi forcément ordinale) ou comme un nombre 0 ou 1, voire comme le cas limite d’une probabilité. Ce type est aussi d’une très grande utilité concrète à cause de la possibilité de l’utiliser dans une arithmétique booléenne (ou logique propositionnelle).
• Le type numérique, qui code des nombres positifs ou négatifs, entiers ou réels. Ce type code tout ce qui se compte, se mesure, s’additionne, se divise, et sur quoi l’on peut calculer des moyennes, des écarts-types, etc.
• Le type calendaire, qui est en fait une variante du précédent, puisqu’il compte les jours écoulés depuis une certaine date prise comme début du comput. Il est intrinsèquement numérique, entier, et doit son existence spécifique comme type au fait qu’il requiert une modalité de représentation particulière (jj/mm/aaaa, et non pas un nombre de jours).
Ces différents types de variables obéissent à diverses conventions quant à leur implémentation dans Hector.
Intitulé de variable En premier lieu, toutes les variables possèdent un intitulé, qui est un texte d’une longueur maximale de 35 caractères, tous les caractères, majuscules, minuscules, accentuées, ponctuation étant autorisés, à l’exception du caractère _ (souligné), sert précisément, dans le langage des formules , à représenter l'espace à l'intérieur d'un texte, tandis que l'espace lui-même sert à séparer les mots dans une formule. Le choix des intitulés des variables est crucial, et ce pour deux raisons distinctes : Les résultats d’Hector font usage des noms (ou intitulés) de variables et il ne sert à rien de donner des intitulés abstrus composés avec des abréviations sans voyelles, et pis encore des codes arbitraires. Le nom de variable permet aussi à l’usager de repérer la variable qu’il souhaite

Mise à jour : 13/10/2011 Hector Manuel principal 10
examiner dans une liste parfois longue. Trente-cinq caractères permettent une certaine souplesse d’expression. En cas de nécessité d’abréger, l’usager est invité à se doter d’un système d’abréviation régulier et univoque, de sorte que son lecteur éventuel accepte de se l’approprier avant de jeter, d’exaspération, le rapport, la thèse ou le mémoire à la poubelle. Dans certaines circonstances, Hector est amené à résumer un intitulé de variable sur neuf ou dix caractères pour des raisons d’encombrement. Il le fait de la manière suivante : il considère les mots de l’intitulé (séparés par un espace ou un signe de ponctuation) et leur accorde une fraction de l’espace final dépendant du nombre de mots, en séparant les débuts de mots par des majuscules internes. Ainsi « Fréquentation du club de sports » devient, condensé sur neuf caractères, devient « FrDuClDeS ». On voit qu’il eût été préférable d’éviter les articles dans l’intitulé, car « Fréquentation club sports », tout aussi intelligible pour le lecteur, devient en résumé « FréCluSpo », où on a encore une petite chance de reconnaître l’original. L’intitulé d’une variable doit être unique dans le corpus. Les majuscules et minuscules sont pertinentes, et « Fréquentation club sports » n’est pas la même chose que « fréquentation club Sports ». Il est cependant très déconseillé de se servir de nuances aussi discrètes pour différencier des variables. Attention ! Dans un intitulé de variable ou une étiquette, l’espace compte pour un caractère. Au-delà de l’intitulé, chaque type de variable possède ses conventions et ses contraintes.
Type nominal C’est le type de variable qui code les catégories entre lesquelles il n’existe pas d’ordre intrinsèque. Il existe toujours un ordre de présentation pour ces catégories, mais il ne possède pas de signification particulière et on peut le changer sans inconvénient. Les valeurs, ou positions possibles des variables nominales, sont représentées par des étiquettes, c’est-à-dire des textes de dix caractères au maximum, tout caractère étant autorisé dans ces textes, à l’exception du caractère _. Dans les étiquettes, les différences entre majuscule et minuscule, entre caractère accentué et son équivalent sans accent, sont significatives : « Marine » n’est pas la même chose que « marine », « flèche » n’est pas la même chose que « fleche ». Les étiquettes sont arbitraires, c’est-à-dire qu’elles sont librement choisies par l’utilisateur lors de la construction du corpus, et ne sont nullement interprétées par le logiciel, lequel est aussi dépourvu de capacités sémantiques que d’humour. Comme les intitulés des variables, les étiquettes ont donc un système de communication entre l’usager et ses lecteurs, à commencer par lui-même. La clarté de ces petits textes constitue donc un enjeu important. La limitation des étiquettes à dix caractères est une nécessité technique pour le contrôle de la taille des tableaux de résultats. Ce n’est pas sans poser des problèmes aux utilisateurs, qui sont souvent contraints à faire usage d’abréviations parce que dix caractères ne suffisent pas à exprimer en clair le contenu d’une catégorie. Le choix de bonnes abréviations est tout un art, parce que de la qualité du résultat dépend la facilité de lecture des tableaux. On veillera à employer des systèmes d’abréviation réguliers, au sens où un même mot sera toujours abrégé de la même manière ; on utilisera la majuscule interne pour éviter de gaspiller de la place pour un espace ou un séparateur : ainsi, pour « Ouvrier qualifié de l’industrie », on préférera « OuvQualInd » à « Ou.Qua.Ind » qui a pourtant la même longueur. En divers contextes dans Hector, comme dans cette documentation elle-même, un symbole distinct est associé à chaque type de variable. Pour le type nominal, ce symbole est le caractère $. De même, les noms de variables sont affichés dans une couleur correspondant à leur type. Pour le type nominal, ces noms sont écrits en vert. Le choix du caractère $ vient de ce que dans le très ancien langage de programmation Basic, c’était le suffixe des variables de type texte, et il se prononçait « string », au sens de « chaîne » (de caractères). Quoique l’utilisateur n’ait pas en général à se préoccuper de la manière dont Hector gère les données de manière interne, cela peut l’intéresser de savoir que les étiquettes des variables nominales ne sont pas « collées » sur chaque sujet, et donc reproduites autant de fois qu’elles sont

Mise à jour : 13/10/2011 Hector Manuel principal 11
portées, comme dans une base de données classiques, mais conservées à part dans une liste où elles n’apparaissent qu’une fois, tandis que le sujet ne retient que le numéro de son étiquette dans la liste, numéro codé de telle sorte qu’il n’occupe que le nombre minimum de « bits » nécessaires, au maximum le logarithme en base 2 du nombre d’étiquettes différentes, et souvent bien moins grâce aux méthodes de compression. Ce choix technique explique la taille étonnamment réduite des corpus Hector au regard de leur encombrement dans d’autres formats.
Type ordinal Le type ordinal est proche du type nominal : comme lui, il possède un système de valeurs, ou catégories, codé par des étiquettes arbitraires. L’unique mais très importante différence est que les étiquettes d’une variable ordinale possèdent un ordre en soi, qui ne peut être modifié sans défigurer la variable. L’existence de cet ordre présente un grand intérêt du point de vue statistique. En effet, sans qu’il s’agisse réellement d’une mesure, dès qu’il y a un ordre sur les catégories il peut y avoir un rang pour les sujets, et ce rang est lui-même une mesure. Ce qui manque à une variable ordinale pour être semblable à une mesure est l’égalité des intervalles, qui permettrait de calculer des moyennes : on sait que « à la folie » est plus fort que « passionnément », lui même plus fort que « beaucoup », qui l’emporte sur « un peu », lequel est supérieur à « pas du tout », mais rien ne permet de comparer la différence entre « passionnément » et « à la folie » à la différence entre « beaucoup » et « un peu ». Le symbole associé au type ordinal est le caractère §, et la couleur dans laquelle sont affichés les noms des variables ordinales est un jaune foncé, ou brun-doré. Le choix du caractère § est dû au fait qu’il ressemble assez à $ tout en étant nettement différent, et qu’il connote l’alinéa, et donc l’ordre de succession des paragraphes dans un texte. La représentation interne des variables ordinales est la même que celle des variables ordinales, et ne consomme pas davantage de mémoire.
Type logique Le type logique n’a pas besoin d’une définition explicite de ses valeurs possibles, puisque par construction, il ne peut en prendre que deux : Vrai et Faux. Concrètement, dans les tableaux et les graphiques de résultats, les deux valeurs d’une variable logique sont représentées par une étiquette de synthèse, fabriquée par Hector en condensant le nom de la variable sur neuf caractères au plus, et en ajoutant – ou + selon qu’il s’agit du Faux ou du Vrai. Ainsi, une variable « Première inscription ? » génère les deux étiquettes PremInsc?- et PremInsc ?+. Le symbole associé au type logique est le caractère £, et la couleur dans laquelle sont affichés les noms des variables logiques est le bleu. Le choix du caractère £ provient de l’analogie avec $ comme symbole monétaire, et du fait qu’il contient un L comme logique. La représentation interne des variables logiques est idéalement la plus économique, puisqu’en principe un seul bit est nécessaire. En fait un autre bit est utilisé pour coder la pertinence de la variable pour le sujet, c’est-à-dire le fait que le sujet possède effectivement une valeur pour cette variable, et pas une non-valeur. C’est également le cas pour les autres types de variables. Il n’en reste pas moins que le type logique est le plus puissant en termes de rapidité de calculs, ce qui n’est pas étonnant, puisque c’est en quelque sorte la « langue maternelle » des ordinateurs.
Type numérique C’est le type dans lequel on code les nombres, positifs ou négatifs, entiers ou réels. Il n’y a pas de limite théorique à l’étendue des nombres qui peuvent être codés ainsi, mais des limites pratiques. En effet, de manière interne, les valeurs numériques sont toujours codées comme des entiers positifs : pour une série de nombres compris entre un minimum de 1,84 et un maximum de 2,56, avec deux décimales, le codage est le suivant : Facteur de décalage décimal : 2 (nombre de chiffres après la virgule) Valeur minimale 184 (minimum après correction décimale)

Mise à jour : 13/10/2011 Hector Manuel principal 12
Toute valeur x dans cet intervalle est codée comme 100×(x-1,84) Ainsi, 1,84 est codé 0, 1,85 est codé 1 … 2,56 est codé 72 Du « point de vue » d’Hector, la variable est un jeu d’entiers de 0 à 72, qui se code sur environ 7 bits. Le reste constitue des « ornements » restitués dans les résultats, mais qui n’influent pas sur le cœur des calculs. Cela pourrait tout aussi bien représenter des nombres compris entre –72000 et 0, avec trois chiffres avant la virgule, ou si l’on préfère un décalage décimal de –3. Toute valeur x serait alors codée (x+72000)/1000. Bien sûr toutes les valeurs possibles ont trois zéros. La notion qui est ici en jeu est celle de dynamique de la variable (assez analogue à la capacité d’un canal, ou à la bande passante d’un dispositif électronique). Cette notion, dont l’usager n’a que faire en règle générale, peut avoir son importance s’il s’agit de traiter rapidement de très grands volumes de données. La dynamique d’une variable numérique se définit ici comme l’étendue d’entiers à laquelle elle est réduite par le décalage décimal et la soustraction du minimum. Il faut savoir que le temps de traitement est grosso modo proportionnel au nombre de sujets concernés et au logarithme (en base 2) de la dynamique des variables impliquées. Cela veut dire que la précision des nombres a un coût direct en temps de calcul. Une décimale de plus multiplie par 3,32 le temps de traitement, deux décimales de plus le multiplient par 11. Cela n’a aucune importance si le temps de traitement est de l’ordre du millième de seconde, ça peut commencer à en avoir s’il flirte avec le dixième de seconde (avec un million de sujets, par exemple) ; pour un utilisateur habitué à l’instantanéité des traitements informatiques, une seconde c’est très long, voire franchement agaçant. On peut donc être amené à rechercher des compromis précision/vitesse, et renoncer parfois à des longues suites de décimales illusoires. Dans cet esprit, Hector limite le nombre de chiffres significatifs (avant comme après la virgule) à 9. La dynamique réellement autorisée est donc, après réduction, de 0 à 999999999. L’expérience montre que c’est plus que très suffisant pour les données des Sciences Humaines. Hector n’a en effet pas l’ambition de satisfaire tous les besoins de calcul, de la biologie moléculaire à l’astronomie. Le symbole associé au type numérique est le caractère #, et les noms des variables numériques s’écrivent en rouge. Le caractère # est utilisé comme abréviation de nombre ou numéro en anglais.
Type calendaire C’est une variante du type numérique. Le type calendaire ne comporte en interne que des entiers représentant le nombre de jours écoulés depuis le 30/12/1899, avec des valeurs négatives pour des dates antérieures. Il offre surtout l’intérêt de permettre un format d’affichage spécifique pour les résultats. Sa dynamique est fonction de l’étendue des dates codées. Le symbole associé au type calendaire est le caractère µ (purement arbitraire), et les noms de variables calendaires s’écrivent en violet.
Type texte-libre On a laissé de côté le type texte-libre, qui ne permet pas de calculs statistiques. Son symbole est ¤, et ses intitulés de variables s'écrivent en noir.
Conversions de type Le type d’une variable est, on l’a vu, une caractéristique forte et fondamentale. Pourtant il arrive qu’une variable ne soit pas initialement disponible dans le type le plus approprié, notamment quand on travaille avec des données récupérées depuis un autre système de traitement. Ainsi dans certaines bases, la notion de variable logique n’existe pas en soi, et on utilise les chiffres 0 et 1 pour coder Faux et Vrai. L’usager souhaitera vraisemblablement convertir cette variable apparemment numérique en ce qu’elle est vraiment, une variable logique. Autre exemple : on importe des données qui contiennent une variable codant le département de résidence des sujets. Cette variable utilise les codes des plaques d’immatriculation, et les fonctions

Mise à jour : 13/10/2011 Hector Manuel principal 13
d’importation décèlent une variable numérique. Cependant, la véritable nature de ces données est nominale, et il y a donc besoin d’une conversion. Ces conversions, également nommées transtypages, peuvent être appliquées à une variable de manière définitive, si l’on est certain de ne pas se tromper (parce qu’il peut y avoir une perte d’information). C’est alors une opération ordinaire de gestion des variables. En cas de doute, on préférera souvent créer une nouvelle variable du type souhaité, dérivée de la variable initiale au moyen d’une formule de dérivation et sans altérer la variable d’origine. C’est alors une opération de création de variable par dérivation. Dans les deux cas, les méthodes de conversion reposent sur des principes communs. On ne distingue pas ici les nominales des ordinales, qui se comportent de la même façon dans cette circonstance. Dans tous les cas, les non-valeurs sont converties en non-valeurs.
• Conversion de nominale ou ordinale vers logique : tout repose sur la première lettre de l’étiquette. Si elle appartient à l’ensemble de lettres {oOvVtT1}, la valeur résultante est Vrai (cf. oui, true …). Si elle appartient à l’ensemble de lettres {nNfF0}, la valeur résultante est Faux. Dans les autres cas, la conversion donne une non-valeur.
• Conversion de nominale ou ordinale vers numérique : le logiciel tente d’interpréter l’étiquette comme un nombre, éventuellement avec point ou virgule décimal, éventuellement avec un signe moins initial. S’il n’y parvient pas, le résultat est une non-valeur.
• Conversion de nominale ou ordinale vers calendaire : le logiciel tente d’interpréter l’étiquette comme une date correcte au format jj/mm/aaaa. Le format court jj/mm/aa est également supporté, mais pose le problème de l’ambiguïté du siècle.
• Conversion de logique vers nominale ou ordinale : les valeurs vraies produisent une étiquette « oui », les valeurs fausses une étiquette « non ».
• Conversion de logique vers numérique : les valeurs vraies deviennent des 1, les valeurs fausses des 0
• Conversion de logique vers calendaire : impossible et sans intérêt
• Conversion de numérique vers nominale ou ordinale : le nombre est transcrit avec le nombre de décimales correct, dans la limite de 9 chiffres significatifs en tout
• Conversion de numérique vers logique : les 0 engendrent des valeurs fausses, toutes les autres valeurs engendrent des valeurs vraies.
• Conversion de numérique vers calendaire : le nombre est interprété comme un nombre de jours écoulés depuis le 30/12/1899. Les éventuelles décimales sont ignorées.
• Conversion de calendaire vers ordinale ou nominale : les étiquettes générées sont des transcriptions de dates au format jj/mm/aaaa.
• Conversion de calendaire vers logique : impossible et sans intérêt.
• Conversion de calendaire vers numérique : fournit un nombre entier qui mesure les jours écoulés depuis le 30/12/1899
Collections Les variables peuvent être regroupées en collections. Cette opération, qui est explicitement sous le contrôle de l’usager, s’effectue dans la page de gestion des variables et des collections. L’utilité des collections est précisément de permettre des opérations collectives, c’est-à-dire des actions dont les effets s’appliquent simultanément à toutes les variables qui forment la collection. Une caractéristique importante des collections est qu’elles sont monotypes, c’est-à-dire que toutes les variables d’une collection sont nécessairement du même type, faute de quoi les mêmes règles

Mise à jour : 13/10/2011 Hector Manuel principal 14
ne pourraient s’appliquer à toutes. De ce fait, une variable appartenant à une collection ne peut pas être transtypée (modifiée quant au type) ni être supprimée. Les applications des collections sont nombreuses dans les opérations statistiques de base, mais aussi dans les traitements avancés et dans la définition de formules de dérivation.
D’où viennent les variables ? Hector distingue les variables d’origine, les variables formulées et les variables calculées.
Variables d’origine Ce sont d’une certaine manière celles où Hector n’est pour rien, celles qui viennent du monde extérieur, soit qu’elles aient été explicitement créées, décrites et saisies par l’utilisateur, soient qu’elles se déduisent des intitulés et du contenu des colonnes lors d’une importation de données externes.
Variables formulées Ces variables sont fabriquées par Hector, à partir de variables existant déjà, d’origine ou elles-mêmes formulées, au moyen de formules rédigées par l’utilisateur dans le langage des formules d’Hector. Une fois la formule rédigée et testée, elle est exécutée en une seule fois pour tous les sujets, un peu comme les formules de cellule dans un tableur, mais avec une souplesse très supérieure. Une caractéristique très intéressante des variables formulées est qu'elles gardent le souvenir de leur formule, ce qui permet de les rejouer. Ainsi les modifications apportées aux variables d’origine par correction des erreurs, par exemple, sont répercutées aux variables formulées quand les formules sont exécutées à nouveau. De même, il est tout à fait possible de saisir quelques données pour quelques sujets, puis de décrire des variables formulées. Après avoir saisi ultérieurement les données de nouveaux sujets, les valeurs des variables formulées peuvent être établies automatiquement. Ceci illustre l’un des principes d’Hector : un corpus est, dès qu’il existe, dans un état pleinement fonctionnel, même s’il ne comporte encore aucune donnée. En d’autres termes, Hector ne connaît pas la notion de corpus inachevé, et il est toujours possible de venir ajouter des variables, des sujets et leurs données. Dans les listes de variables, les noms des variables formulées sont écrits en italique. Une variable formulée peut aussi changer de statut : on peut l’affranchir, c’est-à-dire en faire une variable libre, l’égale d’une variable d’origine. L‘inconvénient est évidemment qu’elle perd alors le souvenir de sa formule, et ne peut plus être rejouée. Aussi cette manœuvre est-elle à réserver à des corpus ou à des copies de corpus dont on estime qu’ils disposent de toutes leurs données et qu’ils sont désormais figés.
Variables calculées Les variables calculées sont elles aussi fabriquées par Hector, à travers des opérations telles que l’analyse factorielle, la typologie ou L'analyse des séquences, mais, contrairement aux variables dérivées, elles sont si dépendantes de nombreux paramètres en vigueur au moment de leur calcul qu’il n’est pas possible pour elles de conserver le souvenir de leurs variables d’origine : il faut explicitement les recalculer quand leur source a changé.

Mise à jour : 13/10/2011 Hector Manuel principal 15
GESTION D’UN CORPUS, DE VARIABLES ET DE COLLECTIONS
Organisation générale du logiciel A l’ouverture du logiciel Hector, l’aspect général de l’écran ressemble vraisemblablement à ceci, à quelques détails près :
Cet écran peut être analysé en quatre zones distinctes.
• Une bande bleue en haut, classique sous Windows : elle contient le numéro de licence (quand on en détient une), le numéro de version d'Hector et l'adresse du corpus actuellement ouvert. On en reparlera.
• Un panneau plein de boutons à gauche, couramment appelé panneau de commande.
• Une vaste zone à droite, actuellement occupée par un motif décoratif, mais sera surtout une zone de travail.
• Un bandeau en bas, la zone des Onglets de Page. Cliquer sur l’un de ces onglets mène à une autre page du logiciel, dédiée à un type spécifique d’activités.
La zone des onglets Vue de plus près, elle se présente ainsi :
Outre la page intitulée CORPUS, qui est la présente page d’accueil, les pages accessibles sont :
• La page VARIABLES, où se gèrent les variables et les collections. C’est cette page qui fait l’objet principal du présent chapitre.
• La page TRAITEMENTS, qui est celle où l’on procède à des calculs, où l’on produit des tableaux, des statistiques, des graphiques. Elle fait l’objet du manuel séparé Traitements.

Mise à jour : 13/10/2011 Hector Manuel principal 16
• La page FORMULES est celle où l’on définit et exécute les formules qui engendrent les nouvelles variables. Elle fait l'objet du manuel séparé Variables Formulées
Ceci étant le jeu de pages accessibles dans la version de base. Avec la version professionnelle, on aurait également :
• La page FACTORIELLES est dédiée aux analyses factorielles et typologiques et possède son manuel propre.
• La page SPECIALITES concerne des traitements statistiques avancés, qui réclament de l’utilisateur une connaissance approfondie de la chose. Elle possède aussi son manuel.
• La page SEQUENCES concerne l’analyse des données en forme de séquences. Elle dispose pour elle toute seule d'un épais manuel avec des exemples.
La raison du choix de munir ces pages d’un moyen rapide pour passer de l’une à l’autre (les onglets de page) est qu’elles rassemblent les opérations les plus fréquentes dans une campagne d’analyse des données, et qu’il est indispensable d’y accéder très aisément, et non à travers un dédale de menus.
Le panneau de commande
La différence entre les commandes de cette zone et les fonctions contenues dans les autres pages est que ces commandes auxquelles on accède par un bouton sont utilisées nettement moins souvent dans une session de travail, voire pas du tout, qu’elles donnent éventuellement accès à des actions techniques optionnelles qui ne sont pas la priorité pour le débutant, et qu’elles auraient inutilement encombré la série des onglets et des pages si on les avait placées là.
Entrées et sorties de données Il s’agit d’entrées et de sorties de données (les informations brutes de base), et non des sorties de résultats, qui concernent la page TRAITEMENTS.

Mise à jour : 13/10/2011 Hector Manuel principal 17
Les données d’un corpus Hector sont rangées dans un fichier possédant l’extension .cn. Il en existe normalement déjà un dans l’environnement immédiat du logiciel, aux fins de découverte et d’exercice.
Ouverture d’un corpus Si aucun corpus n’a été ouvert, Hector, qui exècre le vide, en contient quand même un, qui a pour commentaire « Corpus anonyme ». Ce corpus a la particularité de ne posséder encore aucune variable, aucun sujet, aucun fichier .cn ; bref, un fantôme de corpus, mais qui a tout pour prendre corps. C’est la condition dans laquelle on doit se trouver quand il s’agit de créer un nouveau corpus. Si un corpus est déjà ouvert, on se place dans cette condition en cliquant le bouton de commande [créer un nouveau corpus vide]. On notera qu’il y a une distinction entre le commentaire d’un corpus et le nom du fichier qui le contient ; ils sont affichés à la suite dans le bandeau bleu du haut. Le commentaire du corpus est un texte libre d’une longueur maximale de 35 caractères : on peut donc y stocker un intitulé en clair. Le nom du fichier .cn est plutôt à déterminer selon les règles usuelles d’abréviation propres aux noms de fichiers informatiques. Pour modifier le commentaire d’un corpus, on tape son nouveau commentaire dans la zone d’édition de texte placée sous le bouton [associer au corpus ce commentaire], et on clique ce dernier. Pour charger un corpus existant, on clique le bouton [charger un corpus depuis un fichier], qui donne accès au système de navigation/exploration du système d’exploitation (cela ne dépend pas d’Hector) : on parcourt ainsi les dossiers ou répertoires jusqu’à trouver le fichier .cn souhaité, qu’on sélectionne et dont on valide le choix.
Modifications et sauvegardes Il est assez courant qu’un corpus soit modifié au cours d’une session de traitement, soit qu’on y ajoute des données sur de nouveaux sujets ou de nouvelles variables, ou qu’on y corrige des erreurs, ou qu’on crée de nouvelles variables par formulation ou calcul, soit encore qu’on fasse évoluer la structure des collections. Il est important (et relativement rassurant) de savoir que, tant qu’on n’en n’a pas donné l’ordre explicite en demandant l’enregistrement (la sauvegarde), le fichier original n’est pas modifié. Les changements sont stockés dans des fichiers temporaires qui sont assemblés au dernier moment de l’enregistrement pour former le nouveau fichier de corpus. Si un incident intervient pendant le traitement (coupure de courant, blocage de l’ordinateur…), le fichier d’origine sera intact ; on trouvera éventuellement trace des fichiers temporaires (à l'extension .TMP), qui n’auront pas été supprimés comme il le faudrait. Aucune importance : ils le seront dès le prochain lancement d’Hector. Il ne faut en aucun cas essayer d’ouvrir un fichier .cn avec un autre logiciel que Hector. Cela ne donnerait rien d’intelligible, et la structure du fichier pourrait être irrémédiablement endommagée. De même, les fichiers temporaires ne contiennent rien d’utilisable par un autre logiciel. L’enregistrement d’une version modifiée du corpus intervient
• sur demande explicite de l’usager avec [enregistrer le corpus dans son fichier], qui conserve le nom et le chemin du fichier initial pour stocker la copie, ou avec le bouton [enregistrer dans un nouveau fichier], qui ouvre un dialogue de désignation d’un nouveau fichier (ou d’un nouvel emplacement) pour stocker le corpus modifié.
• sur confirmation de l’usager à une question du logiciel, qui apparaît quand on veut quitter le logiciel, charger un autre corpus ou initier un corpus vide alors que le corpus courant a été modifié.
On rappelle ici que le même nom de fichier dans deux emplacements (chemins) différents constitue deux fichiers distincts et sans lien entre eux. La question de savoir s’il faut enregistrer

Mise à jour : 13/10/2011 Hector Manuel principal 18
un corpus sous le même nom que précédemment ou sous un nouveau nom est une affaire de gestion d’archives et de versions de corpus : avant de procéder à des modifications lourdes ou destructives dans un corpus, il peut être utile d’en sauvegarder une copie, par exemple dans un répertoire dont le nom évoque la date d’archivage.
Répertoire compagnon Les données du variArbre, quand on l'utilise, ou encore la sauvegarde demandée de formules de calcul, sont stockées dans un répertoire compagnon, qui a le même nom que le fichier .cn du corpus, mais avec l'extension .co, et qui est placé dans le même répertoire que le corpus. Ce répertoire n'est créé qu'en cas de nécessité. Il est donc tous à fait possible de ne jamais en apercevoir un.
Mécanismes avancés de sauvegarde Le mécanisme des sauvegardes datées, exposé ci-dessous, n'est disponible que dans la version professionnelle. Au lancement d’Hector, deux cas sont possibles : • si on n’avait pas, lors d’une utilisation précédente, en passant par le bouton Option de configuration et Habitudes, coché la case Toujours ouvrir le dernier corpus, Hector s’ouvre sur un corpus vide et anonyme : il va falloir explicitement Charger un corpus depuis un fichier. • Si on avait coché cette case, Hector réouvre directement le corpus le plus récemment traité, en proposant au passage une Sauvegarde datée, avant même d’afficher sa page d’accueil, ce qui peut être assez troublant. Dans le premier cas, la proposition de sauvegarde datée est faite quand on demande de Charger un corpus depuis un fichier. Dans le nouveau système, il est conseillé de ne pas cocher la case Toujours ouvrir le dernier corpus. A chaque lancement d’Hector après un premier usage, la manœuvre de Chargement d’un corpus ouvrira toujours le dialogue de choix du fichier à charger dans le répertoire permanent : On vient d’ouvrir Hector :
on clique le bouton Charger un corpus depuis un fichier. S’ouvre le dialogue Windows d’ouverture de fichier :
On double-clique, par exemple, Cèdre Bleu CONTACT.cn. Hector lance la proposition de sauvegarde datée :

Mise à jour : 13/10/2011 Hector Manuel principal 19
On peut répondre Non, ça n’empêche pas de travailler, mais il est conseillé de répondre Oui de temps à autre. Si c’est le cas, tout se passe ensuite normalement, mais si par la suite on va regarder (sous Windows) dans le dossier Sauvegardes, on y trouve ceci :
C’est-à-dire la Sauvegarde du corpus Cèdre Bleu CONTACT effectuée le 31 Mars 2011 à 10h42. A quoi servent les sauvegardes ? La plupart du temps, à rien, heureusement. On a besoin si on veut repartir d’un état antérieur de la base, soit qu’on pense qu’on a saisi des données erronées, soit qu’on a fait une manœuvre malheureuse conduisant à effacer des données ou des variables utiles, soit (c’est rarissime, mais même gagner au loto, ça arrive) qu’Hector a crashé et que le corpus est endommagé. C’est pour faire face à toutes les possibilités que la sauvegarde datée est proposée avant qu’on travaille sur le corpus. Si on veut récupérer une sauvegarde et la mettre à la place du corpus dans le répertoire permanent, il faut (sous Windows pour que ça ne soit pas trop facile et donc susceptible d’être fait accidentellement ou par erreur) : • Aller dans le dossier Sauvegardes et prendre une copie de la sauvegarde choisie (ctrl-C) • Remonter dans le dossier permanent de données et y coller la sauvegarde (ctrl-V) • Détruire l’ancien fichier corpus • Renommer la sauvegarde avec le nom de l’ancien fichier corpus. De manière générale, si on fait attention ça ne devrait pas se produire. Cette manière de travailler avec les sauvegardes permet d’avoir toujours affaire au mêmes fichiers placés au même endroit. Au bout de quelques temps, on peut aller dans le dossier Sauvegardes détruire les sauvegardes les plus anciennes, pour désencombrer le dossier. Le format des noms des sauvegardes fait que l’ordre alphabétique est aussi l’ordre chronologique. De plus, pour la mise en relation des tables pour les opérations de base de donnée relationnelle (avec les formules appropriées), il est beaucoup plus simple que toutes les tables actives soient toujours ensemble dans le même dossier.
Entrée de données Plusieurs approches sont possibles quant à l’incorporation de données dans un corpus Hector.
• S’il s’agit de données qu’on a recueilli soi-même, on trouvera probablement plus commode d’employer l’éditeur de données intégré à Hector, qui offre le confort du contrôle d’erreur et la possibilité de « cueillir » les valeurs textuelles dans des listes préétablies plutôt que les taper intégralement.
• S’il s’agit de données déjà constituées en tables sous un autre système, on emploiera l’importation de données. Le bouton [importer des données au format texte] donne accès à cette fonctionnalité, qui est documentée en détail dans un autre chapitre. Indiquons cependant que le « format texte » consiste simplement en un fichier de texte dont la première ligne contient (facultativement) les intitulés des variables, séparés par des tabulations, et dont chaque ligne ordinaire contient (facultativement) un numéro de sujet, puis les valeurs des différentes variables pour le sujet concerné par la ligne, séparées par des tabulations. Ce format très élémentaire a été choisi précisément pour sa rusticité, et le fait qu’il ne dépende d’aucun logiciel en particulier. En revanche, la plupart des logiciels de gestion de données admettent des sorties de ce genre.
Les deux approches peuvent être employées alternativement avec le même corpus. En effet, tout corpus dans Hector peut être indéfiniment étendu : il n’y a pas de notion de corpus terminé. Un
Mise à jour : 13/10/2011 Hector Manuel principal 20
corpus vide est déjà un corpus, mais dès qu’il contient des données, il peut faire l’objet d’un traitement.
Gérer variables et collections Ces opérations s’effectuent dans la page VARIABLES. Les différents aspects des variables (et éventuellement des collections) qui peuvent faire l’objet d’opérations de gestion sont :
• L’existence
• Le type et les paramètres
• La structure
• La visibilité L’écran de la page VARIABLES comporte, comme les autres pages à l'exception de la page d'accueil CORPUS, le panneau des variables et des collections à droite. Le haut de l'écran concerne les variables, le bas, les collections.
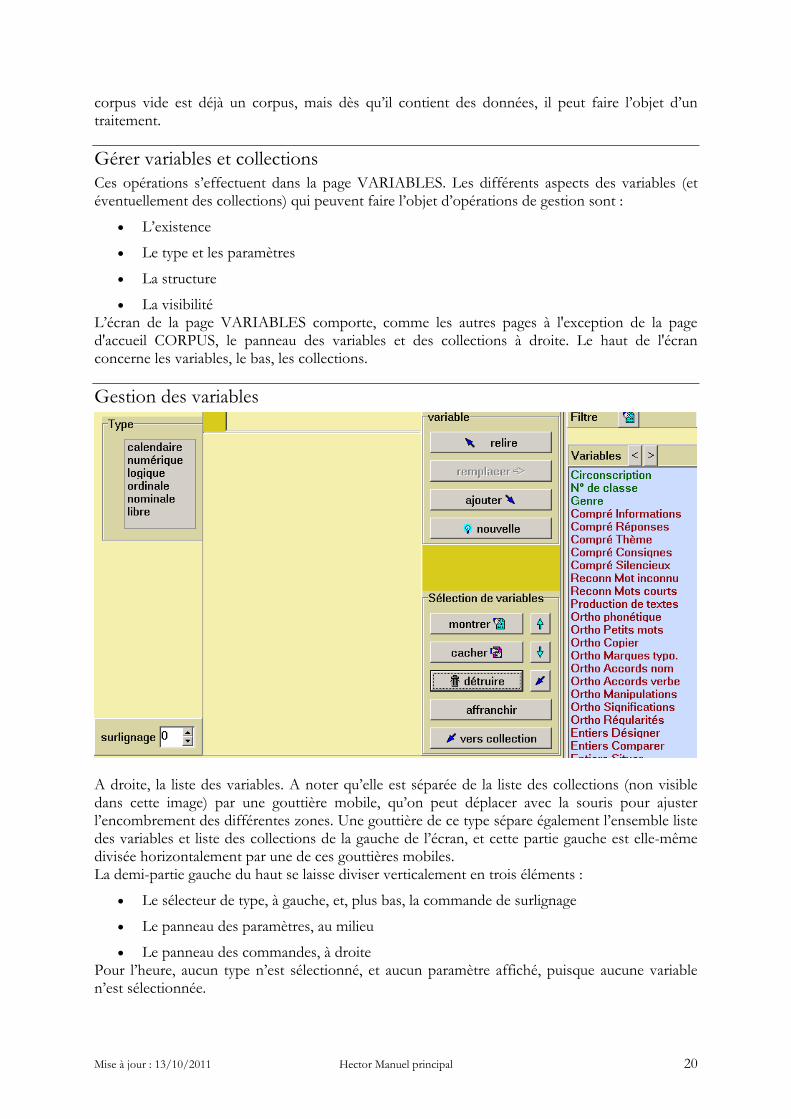
Gestion des variables
A droite, la liste des variables. A noter qu’elle est séparée de la liste des collections (non visible dans cette image) par une gouttière mobile, qu’on peut déplacer avec la souris pour ajuster l’encombrement des différentes zones. Une gouttière de ce type sépare également l’ensemble liste des variables et liste des collections de la gauche de l’écran, et cette partie gauche est elle-même divisée horizontalement par une de ces gouttières mobiles. La demi-partie gauche du haut se laisse diviser verticalement en trois éléments :
• Le sélecteur de type, à gauche, et, plus bas, la commande de surlignage
• Le panneau des paramètres, au milieu
• Le panneau des commandes, à droite Pour l’heure, aucun type n’est sélectionné, et aucun paramètre affiché, puisque aucune variable n’est sélectionnée.

Mise à jour : 13/10/2011 Hector Manuel principal 21
Si l’on étudie le panneau des commandes, on constate qu’il se laisse à son tour diviser en deux sous ensembles distincts :
• En haut, le cadre [variable]. Ce qui s’y passe ne concerne qu’une variable à la fois, et si plusieurs sont sélectionnées, seule la dernière est prise en compte.
• En bas, le cadre [sélection de variables]. Si plusieurs variables sont sélectionnées (ce qui est possible en cliquant-traînant, ou encore avec shift-clic ou ctrl-clic), les opérations de ce cadre les concernent toutes à la fois.
Commandes du cadre Variable Le bouton [nouvelle] sert à remettre le système dans l’état initial, avec aucune variable sélectionnée. Le bouton [relire] affiche les paramètres de la variable actuellement sélectionnée, s’il y en a une, et si ce n’est pas une variable dérivée (son nom serait alors écrit en italiques). Double-cliquer sur une variable équivaut à la sélectionner, puis à cliquer [relire]. Ce qui apparaît alors dépend étroitement du type de la variable relue :
Ci-dessus, une variable calendaire, « date de naissance ». Dans la liste, elle était affichée en violet. Le symbole à côté de son nom est le µ caractéristique des calendaires. Son type est mis en relief dans le sélecteur. Aucun paramètre n’est affiché, parce que les paramètres des variables calendaires sont implicites : il s’agit de dates exprimées dans un seul et unique format (18/06/1946, par exemple).
Ci-dessus, une variable numérique, « moyenne en maths ». Elle était affichée en rouge dans la liste des variables, et son symbole est #. Cette fois, le panneau affiche trois paramètres : le minimum, le maximum et le nombre de décimales, c’est-à-dire le nombre de chiffres significatifs après la virgule. Ce nombre de décimales s’applique aussi au minimum et au maximum. Ici, ce jeu de paramètres signifie que la variable « moyenne en maths » prend ses valeurs entre 0 et 100, avec deux chiffres significatifs, ou, si l’on préfère, entre 0,00 et 100,00 par pas de 0,01. La détermination judicieuse du nombre de décimales (assez précis, mais pas de précision illusoire) est cruciale pour l’organisation du stockage des données et donc pour l’efficacité des traitements. Le nombre de décimales peut être nul : il s’agit alors d’une variable numérique à valeurs entières. Il peut être négatif : il s’agit alors du nombre de zéros avant la virgule. Ainsi les paramètres 25,65,-2 désigneraient ils une étendue de 2500 à 6500 par pas de 100.
Beaucoup plus simple, « position maths » est une variable de type logique, et son symbole est £. Son nom apparaissait en bleu dans la liste des variables. Elle n’affiche pas de paramètres, parce que les siens sont implicites : elle peut valoir Vrai ou Faux, c’est tout.

Mise à jour : 13/10/2011 Hector Manuel principal 22
Ci-dessus, une variable de type ordinal, « niveau calcul mental ». Son symbole est §, et elle était affichée en brun doré. Un variable de type nominal aurait eu pour symbole $ et pour couleur le vert, mais pas d’autres différences à ce niveau avec la variable ordinale. Le type libre a pour symbole le ¤ et pour couleur le noir, mais pas de paramètres. Avec les nominales et les ordinales, le panneau des paramètres est ici au maximum de sa complexité : il porte à droite la liste actuelle des étiquettes de cette variables, c’est-à-dire la série exclusive des valeurs qu’elle peut prendre. Sur la gauche, des instruments de création/manipulation/édition de ces étiquettes, qui jouent un rôle fondamental dans la création et la modification des variables ordinales et nominales. Avant d’aborder cet aspect, finissons-en avec les deux autres boutons du cadre Variable.
Ajouter et remplacer une variable Le bouton [ajouter] sert à créer une nouvelle variable, après qu’on ait saisi son nom et ses paramètres si son type en réclame. C’est la façon de procéder normale quand on prépare un corpus en vue d’une saisie manuelle des données à l’aide de l’éditeur intégré de données. La variables est créée vide, c’est-à-dire que si le corpus possède déjà des sujets, la nouvelle variable a initialement des non-valeurs pour tous ces sujets. La seule contrainte est que le nom de la variable ne doit pas déjà exister, ni pour une variable, ni pour une collection. Attention ! Les intitulés de variables et de collections sont case sensitive, ce qui veut dire qu’un intitulé ne différant d’un autre que par une simple majuscule (ou un accent, ou un espace en plus) est un intitulé différent. Toutefois, si l’on veut garder la maîtrise de son corpus, il est peu conseillé de créer de tels quasi-homonymes. Le bouton [remplacer] du cadre variable est très important. Dans l’image du début de rubrique, il est grisé et inopérant, parce qu’aucune variable n’a été relue. Il ne prend son aspect normal que quand il peut être utilisé. L’idée de base du remplacement d’une variable est que la variable actuellement sélectionnée va être remplacée par celle qui est décrite dans le tableau des paramètres, quelle que soit la nature des modifications. Il peut s’agir simplement d’une modification de l’intitulé, qu’on a édité dans l’éditeur de texte où il est affiché. Le nouvel intitulé ne doit pas déjà exister. Cette modification, comme toutes les autres, est impossible pour une variable qui est prise dans un réseau de dépendances, telles que l’appartenance à une collection ou l’évocation comme variable-source dans une formule de dérivation. Il peut également s’agir d’une conversion, ou transtypage (voir les règles de conversion dans le chapitre Concepts fondamentaux…). Cette opération est normale et aisée quand on en est au stade de la définition préalable des variables d’un corpus, et qu’on s’est trompé. Elle peut intervenir aussi pour rectifier des types inappropriés après une importation au format texte. Dans tous les autres cas, elle est à employer avec précautions, parce que le changement de type peut entraîner dans certains cas des pertes d’information. La modification la plus fréquente est le changement de paramètres. Dans le cas des variables numériques, on peut souhaiter modifier le nombre de décimales, ou élargir minimum et maximum parce qu’on s’aperçoit en cours de saisie qu’on a prévu trop court.

Mise à jour : 13/10/2011 Hector Manuel principal 23
Attention : dans le cas où on réduit le nombre de décimales d’une variable numérique qui a déjà des données, l’éventuelle perte de précision est irréversible. Dans le cas des variables nominales et ordinales, le changement de paramètres concerne la liste des étiquettes et leur ordre. Rappelons que l’ordre des étiquettes, s’il ne gouverne que l’ordre d’affichage pour les variables nominales, est supposé pour les variables ordinales correspondre à une signification intrinsèquement ordonnée de ces étiquettes.
Édition des étiquettes Parmi les instruments d’édition des étiquettes, la zone d’édition [étiquette] permet des modifications de texte, avec la souris et le clavier. Le bouton [relire] recopie dans la zone d’édition l’étiquette actuellement sélectionnée. Le bouton [ajouter] fait du contenu de la zone d’édition une nouvelle étiquette qui vient initialement se placer en queue de liste. Le bouton [remplacer] substitue le contenu de la zone d’édition à l’étiquette sélectionnée. Plusieurs cas de figure peuvent se présenter :
• L’étiquette de remplacement n’existe pas dans la liste : elle y rentre, à la place de celle qu’elle remplace.
• L’étiquette de remplacement existe déjà dans la liste : elle y demeure, à sa place, mais celle qu’elle remplace disparaît de la liste. Les sujets porteurs de l’ancienne valeur seront assimilés à la nouvelle.
• L’étiquette de remplacement est nulle : la zone d’édition est vide. Après confirmation que la manœuvre est bien intentionnelle, l’étiquette à remplacer disparaît. Il faut savoir que les sujets porteurs de l’ancienne valeur auront en fin d’opérations des non-valeurs.
On le voit, les modifications sont éventuellement périlleuses. Heureusement, elles n’ont réellement lieu qu’au moment où l’on utilise la commande [remplacer] du cadre Variable. On dispose donc d’une brève possibilité de remords. Les autres commandes d’édition des étiquettes concernent l’ensemble des étiquettes simultanément sélectionnées dans la liste (ensemble qui peut se réduire à une seule). Les deux petites flèches bleu clair permettent de faire monter ou descendre la sélection par rapport aux étiquettes non-sélectionnées, et donc de modifier l’ordre des étiquettes. Le bouton [enlever], orné d’une poubelle, sert à supprimer d’un seul coup toute la sélection d’étiquettes, après confirmation bien sûr.
Les commandes du cadre Sélection de variables On reconnaît deux petites flèches bleu clair dont la fonction est de faire monter ou descendre toute une sélection de variables (même discontinue grâce au ctrl-clic) dans la liste des variables. Près d’elles, les boutons de gestion de la visibilité des variables : [montrer] et [cacher]. Leur action consiste à rendre visible ou invisible toute la sélection de variables. Une variable rendue invisible l’est toujours quand la page VARIABLES est active. Son nom est simplement barré dans la liste, mais on la voit encore ; autrement, comment la retrouver ? En revanche elle ne sera plus visible dès qu’on passera dans une autre page. L’utilité de cette fonction est de ne garder visibles que les variables sur lesquelles on est effectivement en train de travailler : en effet, le nombre de variables dans un corpus peut devenir très important, surtout si on utilise généreusement, comme c’est l’usage, la création par dérivation. Si toutes les variables sont visibles en même temps, aller chercher l’une des dernières de la liste devient une manœuvre pénible et répétitive. En revanche, il est rare que dans une phase particulière du traitement on s’intéresse simultanément à plus d’une trentaine de variables. Il suffit donc de ne montrer temporairement que celles-là. Le bouton [détruire], orné d’une poubelle, propose après confirmation la suppression définitive des variables actuellement sélectionnées dans la liste. Les variables impliquées dans un réseau de dépendances (collections, dérivations) ne peuvent être détruites tant que ce réseau n’a pas été démonté (dans l’ordre inverse de sa construction).

Mise à jour : 13/10/2011 Hector Manuel principal 24
Le bouton [affranchir] joue un rôle très particulier, en relation avec les variables dérivées. Des variables dérivées sont en quelque sorte esclaves de leurs variables-source : si on modifie celles-ci, par exemple en saisissant de nouvelles données, les modifications se répercutent aux dérivées en vertu du lien dynamique (voir le chapitre Concepts fondamentaux..). Affranchir une variable dérivée, c’est lui faire perdre ce statut de dépendance et la rendre autonome. En même temps, elle perd jusqu’au souvenir de sa formule de dérivation, et ne répercute plus les modifications des ses sources perdues ; en revanche, elle peut maintenant être saisie directement. En certaines circonstances particulières, cela peut s’avérer intéressant, mais il faut savoir ce que l’on fait. Le dernier bouton, [vers collection], sert à constituer ou à compléter la collection courante de variables au moyen des variables sélectionnées. Les collections sont des ensembles de variables qui sont toutes du même type. Plusieurs situations peuvent se présenter :
• La collection est actuellement vide, et les variables sélectionnées sont toutes du même type : elles vont ensemble dans la liste de variables de la collection.
• La collection est vide, mais les variables sélectionnées ne sont pas toute du même type : un message du logiciel donne le choix entre intégrer à la collection la première variable de la sélection et celles qui sont du même type, ou renoncer.
• La collection n’est pas vide ; elle a donc déjà un type. Si toutes les variables sélectionnées sont de ce type, l’intégration se fait sans problèmes.
• La collection n’est pas vide ; mais toutes les variables sélectionnées ne sont pas du bon type (ou aucune ne l’est) : seules les variables compatibles en type pourront rejoindre la collection.
Cette dernière commande, placée près de la frontière des deux demi-panneaux, fournit très logiquement la transition vers ce qui suit.
Gestion des collections Voici les organes de gestion des collections :
Pour arriver à cette image, on a très exactement fait ceci : Dans la liste des variables, sélectionner (d’un clic, garde le bouton enfoncé, traîne la souris et relâche le bouton quand la liste est complète) les cinq variables numériques ci-dessus En bas du demi-panneau de gestion des variables, cliquer le bouton [vers collection] : les noms des variables s’inscrivent dans la liste de variables de la collection courante. La case à symbole, à

Mise à jour : 13/10/2011 Hector Manuel principal 25
côté de la zone d’édition du nom de la collection, arbore le signe # car il s’agit de numériques. La collection n’a pas encore de nom On a saisi le nom « Compréhension » dans la zone d’édition, et on a cliqué le bouton [valider] du cadre Collection. La collection notes rejoint la liste des collections, les différents espaces d’édition de la collection sont vidés. Ici, on a fait d'autres collections ensuite. On sélectionne la collection « Compréhension » dans la liste, et on clique le bouton [relire] du cadre Collection (ou bien ou double clique le nom de la collection, ce qui revient au même). La collection s’affiche à nouveau en détail. Par analogie avec les organes d’édition des variables, la compréhension des différents organes devrait être aisée.
Le cadre Sélection A gauche de la liste des variables de la collection, il comporte deux boutons à flèche bleu clair, qui servent à faire monter ou descendre dans l’ordre des variables la ou les variables sélectionnées dans la liste d’à côté. L’ordre des variables dans une collection n’a pas beaucoup d’importance, parce qu’aucune fonctionnalité d’Hector de distingue parmi les variables d’une même collection selon leur rang : les collections sont des ensembles non structurés. Le seul intérêt est de conserver une certaine régularité dans la présentation des résultats : il s’agit d’un ordre d’exposition et non d’un ordre sémantique. Le bouton [enlever], orné d’une poubelle, enlève de la collection la ou les variables sélectionnées. Cette manœuvre ne comporte aucun danger : les modifications n’auront lieu que quand et si on clique le bouton [valider] du cadre Collection. On peut donc enlever des variables, changer d’avis et aller les rechercher dans la liste générale des variables, avec le bouton [vers collection], changer leur ordre… rien de tout cela n’a d’effet tant qu’on ne valide pas.
Le cadre Sélection de collections Il concerne la ou les collections sélectionnées dans la liste générale des collections. Il gère l’ordre des collections dans cette liste, avec les flèches bleu clair. L’ordre a peu d’importance, et sert seulement à faciliter le travail de l’usager en rapprochant ce qui a un rapport. Les boutons [montrer] et [cacher] concernent la visibilité, mais contrairement à la visibilité des variables, qui était individuelle, agir sur la visibilité d’une collection a des effets sur la collection et sur toutes les variables qui la composent : si on la cache, toutes ses variables sont cachées, et inversement. Il est cependant toujours possible, après avoir agi globalement sur la visibilité d’une collection et de ses variables, d’aller modifier individuellement la visibilité de l’une ou l’autre variable. Rappelons que les variables et collections cachées sont cachées partout, sauf quand la page VARIABLES est affichée : alors le fait qu’un élément soit caché se manifeste par le fait que son nom est barré. Le bouton [détruire], orné d’une poubelle, a pour effet, après confirmation de l’usager, de supprimer la collection (ce n’est pas possible si elle est évoquée dans des dérivations). Cette suppression que concerne que l’entité collection en tant qu’elle regroupe des variables, nullement les variables qui la constituent : la dissolution du club n’implique pas l’assassinat de ses membres. Dans le même ordre d’esprit, l’appartenance d’une variable à une collection n’a rien d’exclusif : elle peut appartenir à autant de collections différentes que l’on voudra. Les collections ne sont qu’un emballage, un moyen commode de réaliser d’un seul coup un traitement sur plusieurs variables à la fois.
Le cadre Collection On a déjà évoqué le bouton [relire], qui ré-affiche le contenu de la collection sélectionnée. Le bouton [valider] propose l’installation dans la liste générale des collections de la collection en cours d’édition. Plusieurs cas de figure peuvent se présenter :

Mise à jour : 13/10/2011 Hector Manuel principal 26
• Il n’existe aucune collection (ni variable) de ce nom : la collection est acceptée sans conditions.
• Il existe une collection de ce nom, : après confirmation par l’usager, la nouvelle définition de la collection remplace l’ancienne. Les modifications concernent généralement la liste des variables, mais peuvent aussi concerner le type de la collection, si on l’a vidée et reconstituée avec des variables d’un autre type que l’initial.
De manière générale, l’usager est encouragé à user abondamment des collections. Elles donnent accès à des fonctionnalités qui autrement ne seraient possible qu’au prix de lourdes manipulations ; elles n’ont qu’un très faible coût d’encombrement informatique puisque ce sont de simples listes de références vers des variables. Elles n’encombrent pas non plus le champ visuel ou cognitif de l’opérateur, puisqu’il est aisé de les cacher.
Éléments avancés en Gestion de variables Le surlignage Le panneau de Gestion des variables comporte un organe un peu sybillin :
Un nom de variable peut-être surligné : c’est seulement une question de présentation, mais cela permet de séparer visuellement diverses rubriques du plan de codage. Le surlignage apparaît partout où apparaissent les noms de variables, y compris dans la saisie et l’édition des données, où il est bien utile. En épaisseur, il va de 1 à 6 pour manifester si besoin est des hiérarchies de rubriques. Un surlignage de zéro est une absence de surlignage. Le surlignage peut être indiqué lors de la création de la variable, mais on peut aussi changer le surlignage d’une variable en la relisant, en informant l’épaisseur souhaitée et en cliquant le bouton [Remplacer] des variables.
Le multi-colonnage Dans le cas de corpus dotés de très nombreuses variables, le travail sur celles-ci peut être rendu très fastidieux par la nécessité d’user sans cesse de l’ascenseur. Certes, pour le traitement, il est loisible et conseillé de cacher les variables dont on ne sert pas pour le moment. Cependant, quand on travaille sur la définition des variables elles-mêmes, ce dispositif est sans intérêt. Il est donc possible de rendre la liste générale des variables multi-colonnes (et celle des collections suit le mouvement). Il suffit de cliquer avec le bouton de droite de la souris dans le panneau intitulé Variables pour augmenter le nombre de colonnes, et de cliquer avec le bouton de droite pour le réduire. Pour que cela présente un intérêt, il faut également se servir de la cloison mobile qui borde le panneau afin de l’élargir.

Mise à jour : 13/10/2011 Hector Manuel principal 27
Création automatique de collections On se propose par exemple de rassembler dans une collection appelée « comp. D1_C3 » toutes les variables dont l’intitulé commence (on sélectionne donc [au début] ) par ce qui est écrit dans la case [comportant : ], en l’occurrence D1_C3. L’appui sur le bouton [Créer] fabrique automatiquement la collection souhaitée, sous les conditions usuelles : les variables doivent être du même type, le nom de collection ne doit pas être déjà utilisé. A titre de variante, on peut également exploiter la présence d’un élément n’importe où dans les intitulés ([dedans]) ou en fin d’intitulé ([à la fin]). Ce dispositif très commode en gain de temps suppose évidemment qu’on ait choisi dès le départ des noms de variables qui s’y prêtent.
Le clonage Un nom un peu pompeux pour une technique simple. Assez souvent, lors de la création des variables d’un corpus, une série de variables à créer ressemble comme deux gouttes d’eau à une autre, à un détail près. Ainsi, dans une enquête approfondie sur les origines familiales des sujets, à une série de variables concernant le Père succède une série similaire concernant la Mère. On peut sélectionner et relire les variables une par une, y corriger Père en Mère et faire à chaque fois [Remplacer]. Long et sujet à l’erreur. On peut aussi cloner les variables, au moyen de l'organe suivant, qui n'est accessible que dans la version professionnelle :
Il comporte deux champs éditables : en haut le champ « avant », en bas le champ « après ». Après avoir informé ces deux champs, on peut cliquer une variable deux fois, une fois à gauche pour la sélectionner et une fois à droite pour la cloner : cela provoque la création d’une nouvelle variable dotée des mêmes paramètres, avec un intitulé presque semblable, sauf que si par exemple elle s’appelait « Profession du père » et que les champs de clonage étaient respectivement informés de « du père » et « de la mère », la nouvelle variable s’appelle « Profession de la mère ». On peut ainsi cloner en série mais une par une toute une suite de variables. Si le champ « avant » ne contient rien, le contenu du champ « après » est supposé s’insérer devant l’ancien intitulé. Si le champ « après » est vide, il ne se passe rien, pour éviter tout risque de variable sans nom.
Structuration des variables avec le vari-Arbre Cette fonctionnalité n'est disponible que dans la version professionnelle.
Définitions, portée et restrictions L’arbre des variables, ou variArbre est une superstructure arborescente adossée au système de variables d’Hector et interférant avec lui juste ce qui est nécessaire pour conserver les fonctionnalités antérieurement définies. Son utilité est d’organiser les variables en dossiers et sous-dossiers ; son usage se présente ainsi comme une alternative à la gestion de l’encombrement de la liste des variables par la notion de visibilité ; toutefois, comme il ne s’agit que d’une superstructure, il est subordonné à cette notion. Le variArbre apparaît, quand il est visible, dans un composant visuel du genre TreeView superposé à la liste des variables partout où celle-ci est affichée (Pages VARIABLES, TRAITEMENTS, FACTORIELLES, SPECIALITES, FORMULES). Toutes les fonctionnalités exposées ci-dessous sont valables dans toutes ces pages, sauf dans la page FORMULES où certaines combinaisons de clics et touches de contrôle sont déjà utilisées à d’autres fins. On peut

Mise à jour : 13/10/2011 Hector Manuel principal 28
donc organiser ses variables de manière arborescente partout, sauf dans la page FORMULES. Toutefois, dans cette dernière, la structuration effectuée dans une autre page reste valide. Le variArbre est visible quand la case [arb] est cochée dans l’en-tête du panneau des variables :
Cette case à cocher n’est visible que dans la version professionnelle.
Aspect et composants
Voici un aspect typique du variArbre : c’est une arborescence typique, où les nœuds portent des + ou des – selon qu’ils sont ou non développés. Cliquer sur un nœud développé le referme, et vice versa. Les nœuds portent des icônes :
• Le nœud descriptives porte une icône de classeur, parce que c’est un groupe
• Le nœud année naissance porte une icône de bloc-notes vert parce que c’est une variable nominale (c’est le cas dans ce corpus pas encore bien nettoyé)
• Le nœud age porte une icône de calculatrice rouge parce que c’est une variable numérique
• Le nœud ZEP/REP porte une icône d’ampoule bleue parce que c’est une variable logique On pourrait trouver aussi une icône de calepin jaune pour les variables ordinales, et de calendrier violet pour les variables calendaires. Le nœud Vrac ne porte pas d’icône, parce qu’il est actuellement sélectionné. Les nœuds sélectionnés sont en inversion vidéo et ne portent pas d’icône tant qu’ils sont sélectionnés. Comme D1_C1 et D1_C2, Vrac est un groupe, c’est-à-dire toute structure d’un rang plus élevé que la variable de base. On veillera à ne pas confondre groupe et collection, c’est tout autre chose et ça n’a pas la même utilité. Notamment, une variable peut appartenir simultanément à plusieurs groupes, mais à un seul groupe.
Le groupe Vrac Ce groupe a d’autres spécificités : Il ne peut contenir que des variables, alors que les autres groupes peuvent contenir des variables, mais aussi d’autres groupes Il contient toutes les variables visibles qui ne sont pas dans d’autres groupes. (Le variArbre ne déroge pas aux lois de visibilité des variables gérées dans la page VARIABLES). C’est la réserve de variables visibles non rangées, d’où son nom.
• Il est toujours présent comme premier élément du variArbre, même s’il est vide.
• Il ne peut pas être pris comme élément d’un autre groupe
• On ne peut pas changer son nom
• Bref, faut pas embêter le groupe Vrac.

Mise à jour : 13/10/2011 Hector Manuel principal 29
Monter et démonter des groupes Partout sauf dans la page FORMULES, on peut travailler la structure : on sélectionne et/ou co-sélectionne (avec Ctrl-clic et Shift-clic) des variables et/ou des groupes :
Si on fait la première sélection avec in Clic simple, ça marche, mais ça fait aussi ce que fait le clic simple dans la Page actuellement ouverte. Faire plutôt avec un Ctrl-clic ou un Shift-clic. Les trois éléments inversés et sans icône constituent la sélection. Si on n’est pas content de la sélection, on peut déselectionner un par un avec Ctrl-clic, ou d’un seul coup avec Clic-droit, qui annule toujours la sélection. On procède alors, n’importe où dans le variArbre, à un Alt-clic.
Les éléments qui étaient sélectionnés ont quitté leur emplacement précédent pour se retrouver dans un nouveau groupe provisoirement nommé groupe anonyme. On clique le groupe anonyme, on le re-clique après un bref délai pour éviter le double-clic :
On peut éditer l’intitulé du groupe, c’est-à-dire changer son nom, tout de suite ou plus tard. On peut changer les noms de tous les groupes (sauf Vrac), on ne peut pas changer le nom des variables. On a évidemment intérêt à donner immédiatement un nom significatif à tout nouveau groupe. Les noms des groupes n’interfèrent pas avec les noms de variables, mais il pourrait y avoir un problème au cas où un groupe viendrait à se vider et pourrait être pris par erreur pour une variable ; de toutes manières, ce serait vraiment très bête d’utiliser des noms de variables pour les groupes. Incidemment, si on veut créer une jolie pagaille, on peut toujours donner à une variable le nom de Vrac.
Quand on a fini d’éditer le nom du groupe, on tape la touche Entrée. Le groupe reste sélectionné, mais un simple clic-droit met un terme à cet état.
Démonter un groupe On sélectionne le groupe (un seul à la fois) qu’on veut démonter, et on exécute un Alt-clic-droit.

Mise à jour : 13/10/2011 Hector Manuel principal 30
Le groupe machin a été démonté. Parmi ses éléments, ce qui était du genre groupe (D1_C1) est devenu un adhérent direct de la marge gauche, ce qui était variable (sexe et diplôme) est retourné dans le Vrac, en queue de celui-ci (aucune variable ne peut être libre).
Déplacer des éléments dans le variArbre L’emplacement des éléments, et notamment des variables, dans le variArbre, est totalement indépendante de leur emplacement dans la liste des variables. On peut faire monter ou descendre des éléments sélectionnés dans le variArbre : noter que les éléments sélectionnés ne sont pas nécessairement de même niveau
après un Ctrl+Alt-clic (pour monter), on obtient ceci :
D1_C2 est passé avant descriptives, et age avant année_naissance. Si on fait un Ctrl+Alt-clic-droit (pour descendre), on se retrouve dans la situation précédente. On pourrait même faire monter et descendre simultanément un groupe et un des éléments qui le composent. Cet ascenseur connaît cependant des limitations :
• Dans le mouvement de montée ou de descente, les éléments ne peuvent pas franchir les frontières du groupe auquel ils appartiennent.
• De ce fait, si on fait monter ou descendre ou monter répétitivement plusieurs éléments d’un même groupe, ils finiront par s’agglutiner à une extrémité où à l’autre du groupe, et son continue à essayer de les faire monter/descendre, ils se livreront peut-être à quelques fantaisies de permutations circulaires selon le bon plaisir de l’algorithme employé (qui est assez tordu).
• Aucun groupe ne peut, en montant, passer avant le Vrac.
Couper et coller des éléments dans le variArbre Supposons qu’à un moment donné on ait une situation de ce genre :

Mise à jour : 13/10/2011 Hector Manuel principal 31
On a créé un groupe D1 dans lequel il y a logiquement D1_C1, mais on voudrait y mettre aussi D1_C2. Monter et descendre ne permettent pas de franchir les frontières de groupe. Alors on sélectionne D1_C2, puis on fait Shift+Alt-clic-droit (Couper) :
Ca ne semble pas avoir d’effet immédiat, sauf que D1_C2 porte maintenant une icône de ciseaux : ce groupe est désigné pour être coupé, mais il ne l’est pas encore. Il ne le sera qu’au moment où on saura où il faut le coller (il n’y a rien qui ressemble à un presse-papier pour les groupes). On sélectionne D1, et on fait Shift+Alt-clic (Coller) :
Et le tour est joué. Le Couper observe quelques règles :
• Si on essaye de re-couper le nœud déjà désigné, cela annule la désignation
• Si on essaye de désigner un autre nœud à couper, cela annule la désignation précédente
• On peut couper indifféremment un groupe ou une variable
• On ne peut pas couper le Vrac Le Coller a aussi les siennes
• On ne peut pas coller si rien n’a été désigné pour être coupé
• Dans le Vrac, on ne peut coller que des variables, pas des groupes
• On ne peut rien coller dans une variable (une variable n’a pas de « dans »)
• Si on essaye de coller dans un élément désigné pour être coupé (faut être malade), cela annule la désignation.
Les usages du variArbre dans les différentes pages Dans la page VARIABLES Cliquer une variable dans le variArbre équivaut à la double-cliquer, et donc à la [relire] La variable reste alors sélectionnée dans la liste sous-jacente des variables. Si, après modification des paramètres, on clique le [remplacer] des variables, les modifications sont correctement répercutées. L’usage le plus intéressant du variArbre dans cette page est la constitution de collections. On peut sélectionner un ou plusieurs éléments, variables ou groupes, et cliquer [vers collection]. Hector essaiera d’envoyer dans la liste des variables constituant la collection à construire toutes les variables contenues dans la sélection, à quelque profondeur que ce soit. Cependant, il respectera la règle de l’unitypicité de la collection : les variables d’un type différent de la première installée ne pourront être admise dans la collection, et l’usager aura un message lui demandant de choisir entre l’abandon et une liste réduite aux variables compatibles. De même, le bouton [affranchir] fonctionne avec le variArbre. Les commandes [ajouter], [cacher], [détruire], fonctionnent aussi, mais nécessitent un rafraîchissement (sauvegarde/réentrée) du variArbre qui peut ralentir les opérations dans une série prolongée.

Mise à jour : 13/10/2011 Hector Manuel principal 32
Les petites flèches bleues monter/descendre n’ont pas d’effet visible sur le variArbre, même si elles agissent effectivement sur les variables sous-jacentes, car l’ordre dans le variArbre est indifférent à l’ordre sous-jacent. Les masquages/révélations massifs opérées via les collections provoquent également un rafraîchissement. Dans la page TRAITEMENTS Cliquer sur une variable dans le variArbre équivaut à la double-cliquer dans la liste des variables, et donc à l’installer dans la boîte à tri. La cliquer une seconde fois déclenche le tri, de même que cliquer une variable déjà installée déclenche le croisement quand il y en a plusieurs. Dans la page FORMULES Contrairement aux autres pages, les manœuvres de groupement/dégroupement, monter/descendre, couper/coller ne sont pas possible dans la page FORMULES, parce que les combinaisons de touches qu’elles réclament sont utilisées en partie. Le clic simple évoque la variable dans la formule. Le Ctrl-clic révèle les étiquettes d’une variable nominale ou ordinale. Le clic-droit (après un premier clic de sélection) relit une variable formulée.
Sauvegarde et relecture du variArbre Simple superstructure au dessus des variables, le variArbre n’est pas stocké dans le corpus (dont il eu fallu modifier le format, ce qu’on n’envisage pas sans frémir), mais dans un fichier auxiliaire portant le même nom que le corpus, mais avec l’extension .avh (Arbre des Variables chez Hector) et dans le même répertoire. La relecture a lieu quand on coche la case arb dans l’en-tête des variables. Elle consiste dans les opérations suivantes :
• Réinstallation des structures préalablement sauvées, en éliminant au passage les variables qui n’existeraient plus ou qui seraient devenues invisibles.
• Re-création du groupe Vrac en première place, garni de toutes les variables visibles non déjà prises en compte dans les autres groupes.
La sauvegarde a lieu quand on dé-coche la même case, et consiste dans les opérations suivantes :
• Suppression du groupe Vrac
• Sauvegarde des autres groupes dans le fichier .avh On remarque que le Vrac ne fait pas partie de la sauvegarde : c’est en effet inutile puisqu’il ne contient par définition que ce qui n’est pas structuré. Petit effet collatéral : les variables du Vrac retrouvent après relecture l’ordre qui est le leur dans le corpus. Le rafraîchissement, sauvegarde immédiatement suivi d’une relecture, est opéré automatiquement par les manœuvres qui modifient l’existence et la visibilité des variables. Une sauvegarde de l’arbre est proposée quand on quitte le logiciel ou qu’on ouvre un nouveau corpus. Un fichier .avh est en fait un fichier de texte. Ainsi, ce variArbre :
est sauvegardé sous la forme suivante :
descriptives discipline

Mise à jour : 13/10/2011 Hector Manuel principal 33
age année_naissance site D1 D1_C1 D1_C1_français D1_C1_math D1_C1_eps D1_C1_science D1_C1_histoir_geo D1_C1_arts D1_C1_mac D1_C1_music D1_C1_langue D1_C1_ADPP D1_C1_ARP D1_C1_Dominante D1_C1_FGP D1_C1_memoire D1_C1_C2I D1_C1_visite D1_C1_stage_PA D1_C1_stage_resp D1_C1_stage_filé D1_C2 D1_C2_français D1_C2_math D1_C2_eps D1_C2_science D1_C2_histoir_geo D1_C2_arts D1_C2_mac D1_C2_music D1_C2_langue D1_C2_ADPP D1_C2_ARP D1_C2_Dominante D1_C2_FGP D1_C2_memoire D1_C2_C2I

Mise à jour : 13/10/2011 Hector Manuel principal 34
D1_C2_visite D1_C2_stage_PA D1_C2_stage_resp D1_C2_stage_filé
où les incréments sont de simples tabulations. De ce fait, on peut tout à fait éditer ce fichier via un traitement de texte : ça ne présente aucun danger, puisqu’à la relecture seules des variables existantes peuvent être prises en compte, et que le vrac n’est pas sauvegardé. On peut ainsi corriger d’éventuelles erreurs ; on peut même envisager des traitements externes organisant automatiquement la structure du corpus.
Récapitulatif des commandes du variArbre
nu Shift Ctrl Alt Ctrl Alt Shift Alt
Clic gauche sélection Sélection série cosélection on/off grouper monter coller
Clic droit désélection dégrouper descendre couper Rappel : les effets des combinaisons de touches sont différents dans la Page FORMULES.

Mise à jour : 13/10/2011 Hector Manuel principal 35
SAISIE, EDITION ET IMPORT-EXPORT DES DONNEES
Même si elles peuvent ensuite faire l’objet de Formulations ou de calculs Factoriels et Typologiques, les données doivent au départ venir de quelque part. On examine dans ce chapitre deux principaux cas de figure :
• Les données sont importées depuis un fichier au format texte tabulé.
• Les données sont saisies ou modifiées au moyen de l’éditeur intégré à Hector
Importation au format texte Cette technique permet :
• soit de créer ex nihilo un nouveau corpus,
• soit d’ajouter des données à un corpus déjà existant. On se place d’abord ici dans la première hypothèse, on s’est d’ailleurs assuré au préalable de la vacuité du corpus en cliquant le bouton [créer un nouveau corpus vide]. On accède à la fonction d’importation depuis la page CORPUS, en cliquant le bouton [importer des données au format texte] du cadre [entrées/sorties]. Un dialogue système permet alors à l’usager de sélectionner, en naviguant dans les répertoires ou dossiers, un fichier au format texte (porteur de l’extension .txt). Hector affiche alors un écran qui se divise en trois parties :
• A gauche, la grille de sélection et d’ajustement des variables à importer
• Au milieu, un panneau de compte-rendu
• A droite un panneau de commandes Au départ, la grille de sélection et le panneau de compte-rendu sont vides. Le panneau de commandes offre par défaut (si on n’a pas changé les paramètres depuis le lancement du programme) :
La situation change quand on clique le bouton [Analyses préalables]. Après un temps plus ou moins long selon la taille du fichier (temps matérialisé par un indicateur vertical de progression), la grille de sélection affiche quelque chose de ce genre :

Mise à jour : 13/10/2011 Hector Manuel principal 36
L’analyse du fichier texte a fourni à Hector le nom des variables (colonne nom d’origine) et de quoi poser des hypothèses sérieuses sur leur type et leurs paramètres (bornes). La colonne [ok] indique que tout va bien. La colonne [nom dans le corpus] ne contient rien, car on est parti d’un corpus vide, il n’y a donc pas de noms à reconnaître?
Les noms des variables Ce que Hector a placé dans la colonne [Nom d’origine], il ne l’a pas deviné. En fait les options sélectionnées au moment de cliquer le bouton [Analyses préalables] lui ont indiqué que la première ligne du fichier (L1) devait comporter les intitulés des variables. C’est ce que signifie la case à cocher [variables nommées (L1)] dans le panneau de commandes. Muni de cette information, le logiciel a pu analyser correctement le fichier et fournir un premier compte-rendu :
Ce compte-rendu ne dit rien des numéros de sujets. En effet, la case à cocher [Numéros explicites (C1)] n’étant pas cochée, ces numéros sont implicites. S’ils étaient explicites, ces numéros devraient figurer dans la première colonne du fichier (C1). Si les variables n’avaient pas été nommées, le logiciel aurait cherché des données dès la première ligne, et aurait écrit dans la première colonne de la grille de sélection, en lieu et place des intitulés de variables, des noms provisoires fabriqués sur le modèle Colonne1, Colonne2, etc. En résumé, selon l’état des deux cases à cocher, quatre variantes de format du fichier sont attendues :
Ni noms de variable, ni numéros de sujets Le contenu fichier importé aurait la structure suivante :
x1,1 → x1,2 → x1,3 … x1,j … x2,1 → x2,2 → x2,3 … x2,j … x3,1 → x3,2 → x3,3 … x3,j … … xi,1 → xi,2 → xi,3 … xi,j … …
Il s’agit de texte tabulé, autrement dit d’un fichier texte dont les composanst sont séparés par des tabulations, ici représentées par des signes →. L’élément xi,j désigne la valeur de la jème colonne pour le ième sujet. Les tabulations peuvent avoir été placées explicitement par l’usager dans un traitement de texte, mais il a alors intérêt à activer l’option qui rend visible les caractères de mise en page (souvent un bouton ¶), car il est très difficile de gérer ces choses-là à l’aveuglette, et le format doit être strictement observé : .le nombre de tabulations doit être le même pour toutes les lignes, puisqu’il équivaut aux séparateurs de colonnes d’un tableau, et les cases vides, toujours possibles, sont représentées par deux tabulations consécutives, autrement dit rien entre les deux tabulations

Mise à jour : 13/10/2011 Hector Manuel principal 37
Elles peuvent également provenir de la sortie [enregistrer sous], format [texte tabulé] d’un tableur.
Pas de noms de variable, mais des numéros de sujets explicites n1 → x1,1 → x1,2 → x1,3 … x1,j … n2 → x2,1 → x2,2 → x2,3 … x2,j … n3 → x3,1 → x3,2 → x3,3 … x3,j … … ni → xi,1 → xi,2 → xi,3 … xi,j … …
L’élément ni désigne le numéro de sujet pour la ligne. Ces numéros n’ont pas besoin d’être consécutifs, ni même dans l’ordre. Si plusieurs sujets ont le même numéro, tant pis ! C’est le dernier à fournir une valeur qui l’emporte.
Des noms de variables, mais pas de numéros de sujets V1 → V2 → V3 … Vj … x1,1 → x1,2 → x1,3 … x1,j … x2,1 → x2,2 → x2,3 … x2,j … x3,1 → x3,2 → x3,3 … x3,j … … xi,1 → xi,2 → xi,3 … xi,j … …
L’élément Vj désigne l’intitulé de la jème variable. Cet intitulé peut comporter n’importe quel caractère, sauf des accolades. Sa longueur utile ne pourra dépasser 35 caractères.
Des noms de variables et des numéros de sujets explicites → V1 → V2 → V3 … Vj … n1 → x1,1 → x1,2 → x1,3 … x1,j … n2 → x2,1 → x2,2 → x2,3 … x2,j … n3 → x3,1 → x3,2 → x3,3 … x3,j … … ni → xi,1 → xi,2 → xi,3 … xi,j … …
C’est le format le plus détaillé. Noter que la première ligne commence dans ce cas par une tabulation, pour respecter la structure en tableau de l’ensemble, ou les tabulations représentent des lignes verticales. De la même, une non valeur, ou valeur vide, est représentée par absolument rien, même pas un espace, en début ou fin de ligne ou entre deux tabulations. Si on génère le fichier texte au moyen d’un autre logiciel, s’assurer qu’il ne compacte pas les tabulations, c’est-à-dire qu’il ne remplace pas une série de plusieurs tabulations par une seule (certains le font). En l’absence d’informations générales sur la structure du fichier, Hector ne pourra s’y retrouver, et protestera que le nombre de tabulations n’est pas le même dans toutes les lignes, ce qui est rédhibitoire.
Le type des variables Le logiciel commence par analyser les données proposées, en essayant de repérer le type le plus exigeant qui se puisse appliquer à chaque variable :
• On essaye d’abord le type calendaire, qui doit correspondre à un format jj/mm/aaaa : deux chiffres pour le jour, une barre oblique, deux chiffres pour le mois, une barre oblique, quatre chiffres pour l’année. Le format court jj/mm/aa est accepté, mais l’ambiguïté séculaire sera levée par le logiciel selon des consignes propres au système d’exploitation lui-même (notion de pivot à 50), qui ne seront pas nécessairement garanties

Mise à jour : 13/10/2011 Hector Manuel principal 38
dans les versions suivantes. De plus, la date doit être une date plausible : 29/02/2002 n’est pas acceptable, parce que 2002 n’est pas bissextile.
• En cas d’échec, on essaye le type numérique, entier ou réel, positif ou négatif. Le séparateur décimal peut être le point ou la virgule, mais pas les deux dans la même valeur. En cas de succès, Hector identifie le minimum, le maximum et le nombre de chiffres après la virgule. Dans notre exemple, il a ainsi repéré que la variable dont le nom d’origine est Age prend ses valeurs entre 20 et 56, avec 0 chiffre après la virgule.
• En cas d’échec, on considère qu’on a affaire à du texte, mais qui peut être représente des valeurs logiques. Le logiciel suppute que c’est le cas si tous les textes de cette variable commencent par l’un des caractères suivants {OYTVNF} en majuscules ou minuscules, correspondant au mots Oui, Yes, True, Vrai, Non, No, False, Faux, ou par un 0 ou un 1.
• En cas d’échec, il s’agit décidément d’une variable texte. Le logiciel n’a pas, à ce stade des opérations, de moyen de discerner entre nominale et ordinale.
Préparation de l’import Un certain nombre de tâches sont à accomplir avant de procéder à l’import. Dans la grille de sélection, toutes les variables présentes dans le fichier texte sont marquées, dans la colonne [ok], d’un X qui signifie qu’il faut les inclure dans l’import. Cliquer sur la case enlève ou remet cette marque de sélection. Le « nom dans le corpus » est le nom que portera la variable après l’import ; il n’est pas nécessairement celui de l’origine. Si le corpus était vide et que les noms d’origine sont satisfaisants, on peut laisser les choses en l’état : les noms d’origine seront adoptés dans le corpus. Si ces noms ne conviennent pas, on peut en saisir d’autres dans chaque case de la colonne « nom dans le corpus ». Si enfin le corpus comporte déjà des variables, et que l’importation a pour objet d’apporter des valeurs à ces variables pour de nouveaux sujets ou de corriger des valeurs existantes, il faut saisir dans la colonne « nom dans le corpus », en face de chaque variable à importer, le nom de la variable existante à laquelle on désire l’associer. Pour ne pas risquer de se tromper dans la graphie de ces variables, il suffit de droite-cliquer dans la case d’édition : une liste des variables existantes d’un type compatible apparaît, dans laquelle il suffit alors de cliquer pour récupérer le bon intitulé. Après avoir demandé et obtenu les [Analyses préalables], préparé le choix des variables à importer et éventuellement fait le nécessaire pour les intitulés, il ne faut plus modifier les cases à cocher [Variables nommées (L1)] et [Numéros explicites (C1)], puisqu’elles gouvernent la structure présumée du fichier à importer. A moins, bien sûr, qu’on se soit trompé sur ce point. Si par exemple on voit une première variable dont le nom est vide, qui est numérique et qui va de 1 à n, il y a de fortes chances qu’on a pris pour une variable une première colonne de numéros explicites de sujets. Si toutes les variables s’appellent Colonne_x et sont de type texte, il est fort possible qu’une première ligne d’intitulés ait été interprétée comme les données d’un premier sujet, et ait donc conféré à toutes les variables le type le moins contraignant. Quand les numéros sont explicites, il n’y a pas de souci à se faire sur l’endroit où iront les valeurs : à leur place. Si les lignes ne commencent pas par des numéros, ceux-ci sont implicites et consécutifs : par défaut, ils sont supposés aller de 1 à n, mais on peut aussi leur imposer un décalage, ou, en cliquant [à la queue des sujets actuels], faire en sorte que le décalage corresponde exactement au nombre de sujets déjà connus dans le corpus.

Mise à jour : 13/10/2011 Hector Manuel principal 39
La boîte à options [textes trop longs] guide l’attitude du logiciel devant des valeurs texte qui excèdent les 10 caractères dévolus aux étiquettes :
• Tronquer, c’est-à-dire couper strictement, et ne conserver que les 10 premiers caractères.
• Abréger, c’est-à-dire appliquer un algorithme qui prend le début des mots et compose un résumé du texte en 10 caractères avec des Majuscules internes comme délimiteur. Ainsi « Cadres moyens et supérieurs » sera abrégé en « CadMoyEtSu ».
• Texte libre, c’est-à-dire renoncer au type nominal pour les variables contenant des textes trop longs, et leur conférer le type Texte libre. Dans ce cas, il faut re-cliquer [analyses préalables] pour que ce choix soit pris en compte.
Le choix dépend du genre de données dont il s’agit : tronquer peut créer des homonymes non désirés, abréger peut engendrer des monstruosités. Dans certains cas, il n’y a pas de solution satisfaisante à ce niveau, et il vaut mieux retourner intervenir sur le fichier texte dans une traitement de texte ou dans un tableur, pour choisir soi-même ses versions raccourcies des textes et les remplacer au moyen de commandes du type « remplacer partout ». La case à cocher [priorité aux vides] doit être utilisée avec précautions. Cochée, elle a pour effet qu’importer une non-valeur (rien entre deux tabulations) pour un sujet existant et une variable existante provoque l’effacement d’une éventuelle valeur existante, et son remplacement par une non valeur. Par défaut, elle n’est pas cochée, et les valeurs existantes ne peuvent être remplacées que par de nouvelles valeurs et non pas effacées. Ceci permet d’apporter de nouvelles informations de manière partielle et incrémentale, sans prendre le risque d’effacer des données déjà acquises. La case [0/1 -> logique], si elle est cochée, a pour effet que les variables numériques de minimum 0, de maximum 1 et de précision 0 (pas de décimales) sont plutôt interprétées comme des logiques que comme des numériques, ceci pour s’adapter aux données provenant de logiciels qui notent 0/1 les logiques. La case [rejouer les dérivations] est obsolète et ne figure que pour la compatibilité ascendante avec d’anciens corpus.
Importer Toutes ces préparatifs une fois effectués, il reste une avant-dernière étape de contrôle : on clique le bouton [Vérifier avant import]. Si quelque chose ne va pas, l’import n’aura pas lieu, et un commentaire est affiché dans le panneau de compte-rendu. Parmi ce qui peut ne pas aller, l’un des cas les plus fréquents apparaît quand on importe une variable texte, qu’on a associée à une variable nominale ou ordinale existante, mais que cette

Mise à jour : 13/10/2011 Hector Manuel principal 40
variable texte à importer comporte des étiquettes que la variable-hôte ne connaît pas. Un panneau de dialogue apparaît pour signaler le problème, et propose trois issues :
• Abandonner l’importation des données : on peut alors aller définir l’étiquette manquante dans la variable-hôte (page VARIABLES) avant de procéder à nouveau à l’import. C’est ce qu’il faut faire si l’étiquette incriminée correspond à quelque chose d’important qu’il ne faut pas perdre.
• Ignorer cette valeur d’étiquette : tous les sujets initialement porteurs de cette étiquette auront une non-valeur pour la variable en question. C’est ce qu’on peut faire si l’étiquette incriminée est sans intérêt.
• Substituer à l’étiquette inconnue une étiquette existante pour la variable en question, prélevée dans la liste d’étiquette qui est affichée. C’est le cas le plus fréquent, quand les différences d’étiquettes ne sont que des variantes orthographiques, voire de majuscules ou d’accents.
Un autre cas intervient quand on importe une variable numérique, qu’on a associée à une variable numérique existante, et que la variable numérique à importer contient des valeurs qui sortent des bornes actuellement définies pour la variable-hôte : il faut au préalable modifier ces bornes dans la page VARIABLES. On le voit, ces règles de précaution reposent sur le principe que l’importation ne peut imposer des modifications structurelles des variables d’accueil sans l’accord de l’opérateur. Si tout va bien, un message apparaît, qui dit en substance « Tout va bien, on peut y aller ». Il reste à l’usager à confirmer son intention, et l’import s’effectue. Selon la taille des données, cela peut prendre un certain temps, matérialisé par un indicateur visuel de progression. Enfin un message rend compte du bon déroulement des opérations, et offre à l’usager le choix de procéder à d’autres imports à partir du même fichier, ou de revenir à la page CORPUS.
Utilisation de l’éditeur intégré On y accède depuis la page [CORPUS], par le bouton [saisie et édition manuelle des données] du cadre [entrées-sorties]. S’il s’agit d’un corpus nouvellement créé et vide, l’accès à l’édition est refusé, car la définition des variables est un préalable absolu à toute saisie de données. L’organe principal de l’éditeur intégré est la grille de saisie. Chaque ligne de cette grille correspond à une variable désignée par son intitulé, et chaque colonne à un sujet, désigné par son numéro d’ordre, qui est implicite : il n’y a pas besoin d’une variable pour le définir. La case placée à l’intersection de la ligne d’une variable et de la colonne d’un sujet contient donc la valeur de cette variable pour ce sujet. Si la case est vide, c’est que la donnée n’existe pas, autrement dit que le sujet possède une non-valeur pour cette variable. Les variables et les valeurs obéissent au même code de couleur correspondant au type de variable.
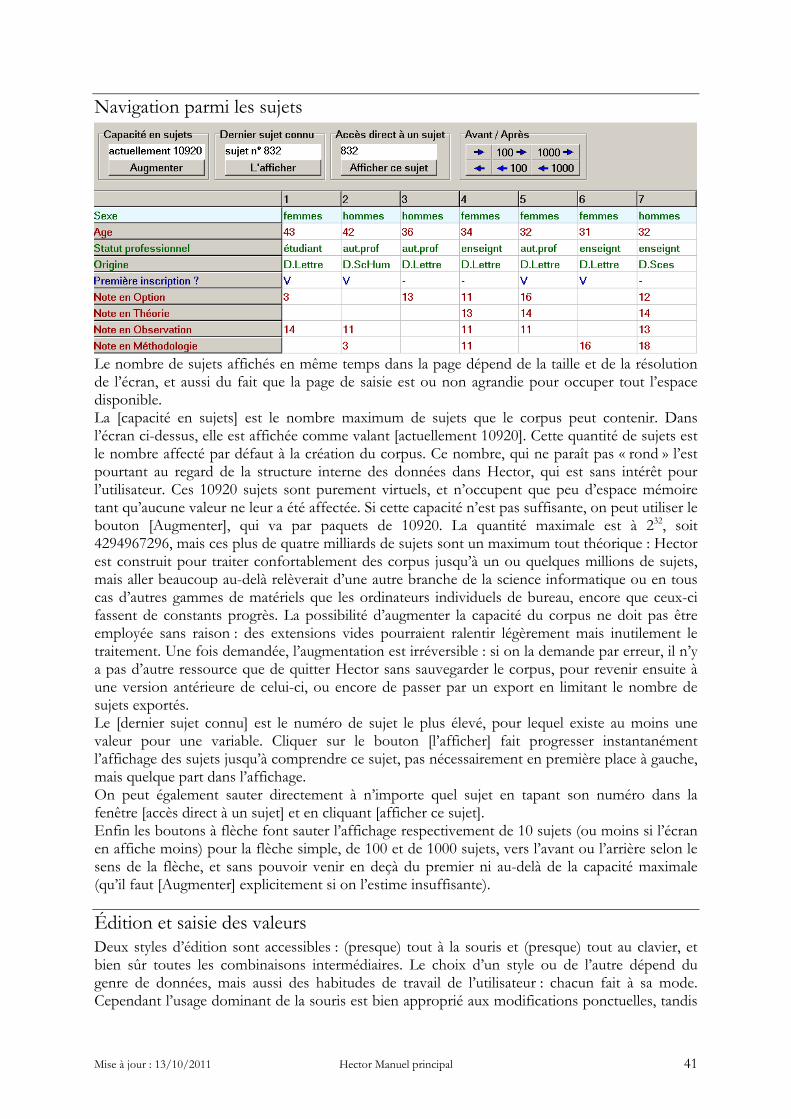
Mise à jour : 13/10/2011 Hector Manuel principal 41
Navigation parmi les sujets
Le nombre de sujets affichés en même temps dans la page dépend de la taille et de la résolution de l’écran, et aussi du fait que la page de saisie est ou non agrandie pour occuper tout l’espace disponible. La [capacité en sujets] est le nombre maximum de sujets que le corpus peut contenir. Dans l’écran ci-dessus, elle est affichée comme valant [actuellement 10920]. Cette quantité de sujets est le nombre affecté par défaut à la création du corpus. Ce nombre, qui ne paraît pas « rond » l’est pourtant au regard de la structure interne des données dans Hector, qui est sans intérêt pour l’utilisateur. Ces 10920 sujets sont purement virtuels, et n’occupent que peu d’espace mémoire tant qu’aucune valeur ne leur a été affectée. Si cette capacité n’est pas suffisante, on peut utiliser le bouton [Augmenter], qui va par paquets de 10920. La quantité maximale est à 232, soit 4294967296, mais ces plus de quatre milliards de sujets sont un maximum tout théorique : Hector est construit pour traiter confortablement des corpus jusqu’à un ou quelques millions de sujets, mais aller beaucoup au-delà relèverait d’une autre branche de la science informatique ou en tous cas d’autres gammes de matériels que les ordinateurs individuels de bureau, encore que ceux-ci fassent de constants progrès. La possibilité d’augmenter la capacité du corpus ne doit pas être employée sans raison : des extensions vides pourraient ralentir légèrement mais inutilement le traitement. Une fois demandée, l’augmentation est irréversible : si on la demande par erreur, il n’y a pas d’autre ressource que de quitter Hector sans sauvegarder le corpus, pour revenir ensuite à une version antérieure de celui-ci, ou encore de passer par un export en limitant le nombre de sujets exportés. Le [dernier sujet connu] est le numéro de sujet le plus élevé, pour lequel existe au moins une valeur pour une variable. Cliquer sur le bouton [l’afficher] fait progresser instantanément l’affichage des sujets jusqu’à comprendre ce sujet, pas nécessairement en première place à gauche, mais quelque part dans l’affichage. On peut également sauter directement à n’importe quel sujet en tapant son numéro dans la fenêtre [accès direct à un sujet] et en cliquant [afficher ce sujet]. Enfin les boutons à flèche font sauter l’affichage respectivement de 10 sujets (ou moins si l’écran en affiche moins) pour la flèche simple, de 100 et de 1000 sujets, vers l’avant ou l’arrière selon le sens de la flèche, et sans pouvoir venir en deçà du premier ni au-delà de la capacité maximale (qu’il faut [Augmenter] explicitement si on l’estime insuffisante).
Édition et saisie des valeurs Deux styles d’édition sont accessibles : (presque) tout à la souris et (presque) tout au clavier, et bien sûr toutes les combinaisons intermédiaires. Le choix d’un style ou de l’autre dépend du genre de données, mais aussi des habitudes de travail de l’utilisateur : chacun fait à sa mode. Cependant l’usage dominant de la souris est bien approprié aux modifications ponctuelles, tandis

Mise à jour : 13/10/2011 Hector Manuel principal 42
que pour les saisies systématiques et en volume important le style clavier dominant est plus ergonomique et permet d’atteindre de bonnes vitesses de saisie.
À la souris On clique la case à éditer (saisir ou modifier). Le résultat dépend du type de la variable. Ci-dessous, le cas d’une variable à texte (nominale ou ordinale ou logique) : une liste apparaît avec les valeurs possibles pour cette variable. La bande de sélection horizontale sert à rappeler quelle variable est concernée par l’édition : elle sert de ligne de rappel. En effet, on ne peut totalement se fier à la position de la liste, parce qu’elle peut apparaître plutôt vers le haut ou plutôt vers le bas selon la position de la ligne dans la page.
Cette liste n’est pas modifiable à la saisie : s’il manque une valeur, il faut quitter la page de saisie-édition et aller compléter le jeu d’étiquettes dans la page VARIABLES, en tous cas pour les nominales et les ordinales, pas pour les logiques dont les deux étiquettes sont implicites. On peut alors cliquer la valeur souhaitée ; la liste se referme et la nouvelle valeur est affectée. La modification est immédiate et n’est pas réversible, sauf à quitter Hector sans sauvegarder, pour retrouver un état antérieur du corpus : c’est en effet à la sauvegarde que le fichier est réécrit et que les modifications deviennent réellement irréversibles, encore qu’on puisse très bien conserver dans un autre dossier et/ou sous un autre nom une version antérieure du corpus. Cette pratique peut s’avérer très utile, mais doit s’accompagner de la tenue d’un cahier de travail où est consignée la date et la nature de chaque version, si on veut pouvoir s’y retrouver en cas de besoin. Une bonne pratique est au moins de procéder à une sauvegarde avant d’entamer une campagne de saisie-édition, et de sauvegarder à intervalles réguliers, à des phases où on est sûr de la validité de ce qu’on a fait, par exemple tous les 10 sujets saisis et vérifiés. La dernière des choses à faire est de saisir pendant des heures sans jamais sauvegarder : c’est le meilleur moyen de devenir enragé(e) parce qu’on a perdu son ouvrage à la première coupure inopinée de courant. Une autre issue est de droite-cliquer la liste : cela a pour effet d’imposer une non-valeur à cette case. On peut enfin renoncer à faire quoi que ce soit, en utilisant la touche [Echap] ou [Esc] du clavier, qui ferme la liste sans modifier la valeur de la case. Il ne sert à rien cependant d’utiliser la touche [Echap] après la fermeture de la liste : il est trop tard pour ressusciter la valeur antérieure. Si la variable concernée est une variable à nombre (calendaire ou numérique), ce qui apparaît est une zone d’édition, où la valeur antérieure est pré-sélectionnée :
On ne peut pas dans ce cas se passer totalement du clavier, puisqu’il faut bien saisir les chiffres. Si on tape tout de suite quelque chose, cela va remplacer la sélection. Si on veut la conserver pour ne la modifier que partiellement, il faut d’abord cliquer dans la zone pour « désarmer » la sélection, ou déplacer le curseur de la zone avec la touche flèche à droite. Le séparateur numérique est indifféremment la virgule ou le point. On valide la saisie avec la touche [fin] (ou [end]). La vérification de la qualité de la saisie intervient seulement à ce moment-là. Deux types d’erreurs peuvent se produire :
• On n’a pas respecté le format souhaité : caractères inappropriés (lettres dans un nombre, voyelles I et O au lieu des chiffres 1 et 0), format de date incorrect.
• On a proposé pour une variable numérique une valeur inférieure au minimum ou supérieure au maximum défini pour cette variable, et modifiable seulement dans la page VARIABLES.
Dans les deux cas, un message offre de retourner à l’édition de la case, ou de renoncer.

Mise à jour : 13/10/2011 Hector Manuel principal 43
Le format approprié aux variables calendaires est jj/mm/aaaa, soit 18/06/1946 pour le Dix-huit Juin 1946. La version abrégée 18/06/46 est également supportée, mais sa conversion au format complet suppose que le logiciel fasse une hypothèse sur le siècle, au moyen d’une valeur pivot : actuellement 51 fait 2051, mais 52 fait 1952. Or cette valeur pivot, et même son caractère absolu ou relatif à l’année en cours, n’est pas gérée par Hector mais par le système d’exploitation sous-jacent, et on ne peut garantir ni prédire son comportement dans des versions ultérieures de ces systèmes. On ne saurait donc trop recommander de taper des dates complètes. Entiers ou fractionnaires, les nombres dans Hector ne peuvent dépasser 9 chiffres significatifs. De plus la précision (nombre de chiffres après la virgule) est définie avec les extrema de la variable : il est inutile de saisir des chiffres au-delà de la précision, ils seront ignorés, et le sens de l’arrondi ne peut être garanti. Le texte des variables de type texte libre est à taper in extenso, l’éventuelle ancienne valeur étant initialement sélectionnée. Comme avec les variables à valeur texte, droite-cliquer impose une non-valeur et la touche [Echap] renonce à la modification.
Au clavier Il faut quand même commencer par un clic de souris pour sélectionner la case où l’on commence. Ensuite tout peut se faire au clavier. Dans une case correspondant à une valeur texte, les touches fléchées simples vers le haut ou vers le bas déplacent la sélection dans la liste, et ce, de manière cyclique : arrivé en bas ça repart en haut et vice versa. Si on tape au clavier une lettre, la sélection se déplace vers la première étiquette commençant par cette lettre. Les variables logiques se comportent comme des valeurs texte, avec ‘V’ pour Vrai et ‘-’ pour faux, de manière à obtenir un contraste visuel maximal. La façon normale de valider la valeur souhaitée est d’utiliser la touche [Entrée] ou [Return] du clavier (indifféremment celle de la zone lettres ou celle du pavé numérique). Cette touche [Entrée] a pour effet de valider la valeur sélectionnée, puis de passer à la case suivante et de l’ouvrir, ce qui réduit considérablement le nombre de manipulations nécessaires dans une saisie en masse. La touche [Suppr] ou [Del] du clavier impose une non-valeur et passe à la case suivante. On peut aussi valider avec la touche [Fin], mais dans ce cas la case suivante n’est pas ouverte : c’est ainsi qu’on met fin à une série de saisie au clavier. La touche [Echap] met également fin à la série de saisie au clavier, mais sans valider la dernière modification. Le comportement de la zone d’édition des valeurs chiffrées est le même en ce qui concerne les touches du clavier. En fait les modalités de saisie sont optimisées pour une utilisation exclusive du pavé numérique (verrouillé en mode numérique) et des touches placées dans sont environnement immédiat, sauf [Echap] qui correspond à une manœuvre rare. Passer à la case suivante assure l’affichage de cette case suivante, même si elle n’était pas encore visible. Éventuellement, la case suivante est la première de la colonne suivante, et si la colonne suivante était initialement hors de l’écran, l’affichage se décale pour l’afficher.
Copier-coller et fonctions annexes Droite-cliquer dans la colonne d’un sujet affiche un menu flottant comportant une série de fonctionnalités concernant ce sujet (celui dans la colonne duquel était le pointeur de la souris quand on a droite-cliqué) :
Copier les valeurs de ce sujet dans un sujet modèle Le sujet modèle est une colonne invisible qui sert pour le copier-coller de toutes les valeurs (y compris les non-valeurs) d’un sujet. L’intérêt de la manœuvre apparaît quand dans un corpus il est possible de repérer, au moins pour une série de sujets, des valeurs qui sont presque les mêmes

Mise à jour : 13/10/2011 Hector Manuel principal 44
pour tous les sujets, à quelques différences individuelles près : on les appelle des valeurs par défaut. On fabrique un sujet qui possède ces valeurs par défaut, et on le copie dans le sujet modèle, avant de le coller dans d’autres colonnes :
Coller dans ce sujet toutes les valeurs du modèle Ayant collé le sujet modèle, qui possède les caractéristiques presque communes à tous les sujets, il suffit d’aller éditer les différences, c’est-à-dire changer seulement ce qui diffère pour le sujet en particulier. Si le sujet dans lequel on veut coller possède déjà des valeurs, Hector demande confirmation avant de coller, pour éviter d’écraser accidentellement des valeurs. Si en revanche toutes las cases du sujet destinataire sont vides, le collage est immédiatement effectué.
Coller seulement dans les cases vides Dans cette variante du collage précédent, seules les cases vides se voient imposer une valeur venant de la case correspondante dans le sujet modèle, et aucune confirmation n’est demandée.
Supprimer toutes les valeurs de ce sujet Le sujet concerné est entièrement mis à blanc, après confirmation compte-tenu du caractère plutôt radical de la manœuvre.
Insérer un sujet vide devant celui-ci Un nouveau sujet vide est créé à la place du sujet concerné, qui est décalé vers les numéros supérieurs ainsi que tous les sujets qui le suivent. Ceci est utile quand on a sauté par erreur un sujet dans la saisie, et qu’on attache de l’importance à la conservation de l’ordre des numéros. Si cette insertion doit augmenter le nombre de sujets au delà de la capacité du corpus, il faut au préalable augmenter celle-ci.
Supprimer ce sujet et décaler les suivants Cette manœuvre, qui nécessite confirmation, écrase les valeurs du sujet par celles de son voisin de droite, et ainsi de suite jusqu’au dernier sujet. On notera que la combinaison de ces différentes manœuvres permet aussi de réordonner les sujets comme on l’entend. Toutefois l’utilisation la plus fréquente est l’imposition du sujet modèle pour accélérer une saisie monotone, comme par exemple dans un cas où on listerait les défauts possibles de véhicules, avec des séries de variables logiques du genre « Mauvaise tenue au vent latéral », « Consommation exagérée », etc. Comme peu de véhicules ont tous les défauts, et même que la plupart des véhicules n’en ont que quelques-uns, le plus sage est de créer un sujet modèle, qui, c’est le cas de le dire, n’aurait aucun défaut, et donc des valeurs « Faux » pour toutes ces variables. Ensuite on colle ce sujet modèle sur chaque nouveau sujet, avant de juste modifier ce qui doit être modifié. Le sujet modèle est conservé dans le corpus : il est donc disponible d’une session de saisie à l’autre.
Relation avec les variables formulées Deux cases à cocher peuvent intriguer l’utilisateur, en haut et à droite de l’écran.
Rejouer les variables formulées en quittant Les variables dérivées ont avec leurs variables d’origine un lien dynamique, qui fait que si on modifie des valeurs de ces dernières, ou si on saisit de nouveaux sujets, les modifications se répercutent aux variables formulées par la ré-exécution de leurs formules.
Afficher aussi les variables formulées Les variables formulées, qui dépendent des variables d’origine par des formules, ne peuvent pas être modifiées manuellement, puisqu’on créerait ainsi des exceptions aux règles. Alors pourquoi les afficher dans l’écran de saisie ? Précisément pour permettre de vérifier les effets d’une formule

Mise à jour : 13/10/2011 Hector Manuel principal 45
dans des cas difficiles ou incertains, en comparant les valeurs des variables d’origine avec les valeurs des variables formulées pour les sujets qui posent problème, et qu’on a par exemple repérés au moyen de filtres.
Exporter des données au format texte Cette fonction est le symétrique de la fonction d’importation. On y accède depuis la page CORPUS, en cliquant le bouton [exporter des données au format texte].
La totalité des variables est affichée dans le panneau, en plusieurs colonnes si nécessaire (le nombre de colonnes est contrôlé par le compteur en bas à droite. Comme dans la page VARIABLES, les variables actuellement cachées sont quand même affichées, mais leur intitulé est barré. Le panneau de droite contient les éléments qui permettent de définir le contenu de l’export. On n’utilise le bouton [Procéder à l’exportation] qu’après que tout a été préparé. L’exportation ne porte pas nécessairement sur la totalité du corpus. A l’affichage de la page, l’intervalle des numéros de sujets à exporter est initialisé comme « de 1 à n », où n est le numéro maximal de sujet dans le corpus. Il est possible de modifier ces valeurs, soit en éditant explicitement les numéros, soit en utilisant les petites flèches d’augmentation/diminution. Si la valeur du dernier numéro devient inférieure à celle du premier, un message en avertira l’utilisateur lors de l’export, et lui proposera d’échanger ces valeurs ou de renoncer. Une autre manière de ne pas exporter les valeurs de tous les sujets est de demander que le filtre, s’il y en a un de défini (cf. « Manuel des traitements »), soit appliqué ; dans ce cas, les sujets qui ne satisfont pas au critère du filtre sont sautés lors de l’export. S’il n’y a pas de filtre, la case à cocher [Appliquer le filtre] est inactive. Le format de sortie texte est strictement similaire au format d’entrée texte : chaque ligne représente les données d’un sujet, les valeurs des données étant séparées par une tabulation. Si la

Mise à jour : 13/10/2011 Hector Manuel principal 46
case [Numéros explicites] est cochée, chaque ligne commencera par le numéro du sujet ; sinon, chaque ligne commence directement avec les données. Une valeur absente est codée par rien, même pas un espace : après la tabulation qui précède, on passe immédiatement à celle qui suit. La question de savoir s’il faut ou non fournir les numéros de sujet dépend du destin ultérieur des données exportées. Il n’est pas non plus nécessaire d’exporter toutes les variables. Si c’est ce qu’on souhaite, le bouton [Tout sélectionner] sélectionne effectivement toutes les variables du corpus, cachées ou non, d’origine ou dérivées. On peut aussi mettre au point la sélection avec la souris : l’usage du contrôle-clic (cliquer, la touche Ctrl du clavier étant maintenue enfoncée) est particulièrement précieux, puisqu’il permet d’ajouter/enlever un par un des éléments à la sélection, sans défaire ce qui est déjà fait. Le bouton [Inverser la sélection] a pour effet de sélectionner ce qui ne l’était pas, et vice versa. Il peut trouver son utilité si on veut procéder à deux exports complémentaires, l’un d’une série de variables, l’autre du reste des variables. La case [Noms en première ligne], quand elle est cochée, a pour effet que la première ligne du fichier texte sera constituée des noms des variables exportées, séparées par des tabulations. Cette ligne commence elle-même par une tabulation si la case [Numéros explicites] est également cochée, puisque la ligne des noms de variables n’a pas de numéro. La question de savoir s’il faut fournir les noms de variables dépend de ce qu’on veut en faire. Si l’export est destiné à créer un tableau pour impression, ou encore à créer un corpus dans un logiciel qui comme Hector accepte des noms de variables de 35 caractères quelconques, il est utile de fournir ces noms de variables. Si en revanche on s’oriente vers un de ces logiciels de base de données qui imposent de sévères restrictions en nombre et type de caractères aux noms de variables, c’est inutile, car les noms seront trop abîmés pour que cela vaille la peine. Quand tous les paramètres de l’exportation sont corrects, on clique enfin le bouton [Procéder à l’exportation]. Un dialogue de choix du nom et de l’emplacement du fichier texte qui contiendra l’export s’ensuit. Après un temps qui peut n’être pas négligeable si le volume de données est important, l’utilisateur a de nouveau la main, et peut procéder à un autre export ou fermer la page pour retourner à la page CORPUS.

Mise à jour : 13/10/2011 Hector Manuel principal 47
LE CADRE GENERALITES
Le bouton « A propos d’Hector » provoque l’affichage d’une présentation rapide du logiciel, dans le style des messages d’Hector (sur fond vert pâle), nettement distinct des messages du système d’exploitation. Le bouton « Comment obtenir de l’aide ? » lance effectivement l’aide d’Hector, avec une première rubrique qui explique comment fonctionne l’aide. Il s’agit d’un système hypertexte basique et rugueux, mais efficace, et surtout d’un système d’aide contextuel : n’importe où dans Hector, l’appui sur la touche F1 du clavier provoque l’affichage de l’aide, avec une rubrique qui correspond à l’élément qui était sous le curseur de la souris. Si cet élément ne possède pas de rubrique en propre, on est renvoyé à la rubrique de l’élément qui le contient, etc. Ceci ne fonctionne que si, dans le même répertoire que le logiciel Hector.exe, on a téléchargé le fichier aide_hector.zip, qu’il ne faut en aucun cas décomprimer. La mise en place de l’aide est un processus évolutif, inachevé à l’heure où nous écrivons ceci, mais en constant progrès. Il est donc judicieux d’aller régulièrement télécharger des mises à jour.
Configuration et habitudes L’écran de réglage des configurations et habitudes comporte divers organes qui règlent les comportements généraux d’Hector. Le cadre [Habitudes] comporte
• la case à cocher [toujours réouvrir le dernier corpus]. Cette option, commode pour le chercheur (mais non pour le Hector installé dans une salle de formation), conserve dans le fichier d’habitudes le souvenir du dernier corpus ouvert, et le réouvre à la session suivante.
• la case à cocher [enregistrer les options de traitement]. Si elle est cochée, les options de présentation des tableaux, graphiques et statistiques de la page TRAITEMENTS sont sauvegardées et restituées à la session suivante.
Le cadre [Paramètres du document de sortie] règle les options du fichier document d’échange, et notamment l’éventuelle mise en forme des tableaux. Ces aspects sont discutés dans le chapitre « Exploitation des documents » du « Manuel des traitements ». C’est dans le même chapitre qu’on trouvera les détails relatifs à la configuration de l’imprimante, dans le cadre [Envoi direct à l’imprimante]. Le bouton [Installer une version professionnelle] n’est disponible que dans le version de base. Voir la rubrique « Téléchargement et versions ».

Mise à jour : 13/10/2011 Hector Manuel principal 48
LE CADRE ELEMENTS TECHNIQUES AVANCES
Ces éléments ne sont accessibles que dans la version professionnelle-recherhe.
Le détail du plan de codage Le bouton [Information détaillée et plan de codage] donne accès à un écran spécialisé qui présente l’aspect suivant :
L’usage de cet écran est toujours technique, mais varié :
• il a joué un rôle important dans la mise au point du logiciel
• il permet de produire rapidement un document « Plan de codage » plus ou moins détaillé
• il permet de démêler certaines situations de dépendances compliquées entre variables Le bouton [compte-rendu] provoque l’affichage des informations, selon le jeu d’options sélectionné au dessus :
• la case à cocher [jeux d’étiquettes] gouverne l’affichage détaillé des étiquettes des variables nominales et ordinales
• la case à cocher [collections] gouverne l’affichage des collections.
• la case à cocher [formulées et dérivées] gouverne l’affichage des formulées et des dérivées avec leur formule.

Mise à jour : 13/10/2011 Hector Manuel principal 49
• quand la case [informations techniques] est cochée, le compte-rendu comprend, pour toutes les variables, la liste de leurs adhésions (à des collections) et leurs liens mère-fille dans les dérivations.
Le bouton [vers un fichier] ouvre un dialogue standard de désignation de fichier texte pour y envoyer le compte-rendu. Le bouton [vers l’imprimante] envoie à l’imprimante courante.
Reprendre tableau au format texte Il s’agit de récupérer des données déjà présentées en tableaux pour en faire une analyse secondaire. La démarche consiste à fabriquer un nouveau corpus, et ce en deux temps :
• La fonction Reprendre tableau… lit un fichier texte spécial d’import secondaire et en extrait un fichier d’import texte
• Le fichier d’import texte est utilisé pour créer un nouveau corpus une fiche de dialogue apparaît, avec les boutons suivants :
Le bouton [ouvrir un fichier …] déclenche un classique dialogue d’ouverture de fichier. Il faut désigner un fichier texte présentant la structure suivante :
Machin → truc 12 → a → p 14 → a → q 9 → b → q
où le caractère → représente une tabulation, normalement invisible. La première ligne contient les noms de variables (35caractères max), les lignes suivantes, autant de lignes de données que le tableau initial recense de cas de figure distincts. Une ligne de donnée commence par un effectif, suivi der la série de valeur. Ainsi, la ligne
12 → a → p signifie qu’il y a dans le tableau 12 sujets qui ont la valeur a pour la variable Machin et p pour la variable truc. Il doit y avoir autant de valeurs que de variables à chaque ligne. Le fichier choisi est affiché pour qu’on puisse vérifier qu’on a pris le bon (mais les tabulations y sont représentées par des carrés) :
On clique alors le bouton [générer le fichier texte pour l’import], et on obtient un dialogue de choix de fichier texte, en écriture cette fois. Ensuite on quitte cette fiche pour procéder à l’import proprement dit, dans la page CORPUS. Si un corpus était ouvert, on commence par utiliser
puis, on clique

Mise à jour : 13/10/2011 Hector Manuel principal 50
pour obtenir la page d’importation, non sans devoir sélectionner au passage le fichier à importer, qui n’est pas le fichier original, mais celui qu’on a créé à l’étape juste précédente. On procède aux manœuvres habituelles d’importation, en s’assurant d’abord que les paramètres d’import ont bien la configuration suivante :
On procédera ensuite aux [Analyses préalables], puis à [Vérifier avant import]. En principe tout doit bien se passer. Quand on quitte la fiche d’import, on dispose d’un corpus avec les deux variables indiquées, qu’on peut utiliser comme un corpus quelconque, et notamment croiser les variables et obtenir les graphiques et tests souhaités. Dans notre exemple, on n’a utilisé que deux variables. En fait on peut en mettre autant que l’on veut, mais il faut que le nombre de valeurs dans chaque ligne corresponde au nombre de variables dans la première ligne.
Exporter comme corpus-fils Ce bouton placé comme le précédent dans le groupe [éléments techniques avancés] donne accès une fiche spéciale :
La démarche consiste à choisir le position de coupure (si on souhaite utiliser cette fonctionnalité), puis à sélectionner une collection et à [installer la collection sélectionnée].
Chaque intitulé de variable de la collection est décomposé en deux parties selon le point de coupure choisi ; dans l’exemple fourni, on exploite évidemment la structure régulière des intitulés. Quand on fera [exécuter l’export en format texte], un fichier texte sera créé, susceptible de servir à créer un nouveau corpus, qui comportera quatre variables :
• Une variable {Sujet} numérique, qui contient le numéro de sujet dans le corpus de départ
• Une variable {V1} nominale, qui contient la première partie de l’intitulé de la variable initiale
• Une variable {V2} nominale, qui contient la seconde partie de l’intitulé de la variable initiale
• Une variable {Valeur} dont le type est le même que celui de la collection de départ, et qui contient la valeur de la variable
Si on n’utilise par la coupure (en décochant la case), il n’y a que trois variables, et la seconde contient les dix premiers caractères du nom de la variable de départ. A quoi ça sert ? Dans l’exemple utilisé, chaque variable du style D1_C1_FPD désigne une valeur portée par un enquêté dans une case d’un tableau, la partie D1_C1 renvoyant à une ligne et FPD à une colonne, à moins que ce ne soit l’inverse. Dans le corpus de départ, le sujet statistique est l’enquêté. Dans le nouveau corpus qu’on va créer, le sujet statistique est une croix dans une case d’un tableau, et le numéro du sujet qui l’a

Mise à jour : 13/10/2011 Hector Manuel principal 51
tracée est un de ses attributs (une de ses variables). Cela va permettre d’étudier les relations statistiques entre lignes et colonnes du tableau. On parle de corpus-fils parce que la présence dans le nouveau corpus (dit corpus-fils) d’une variable {Sujet} qui renvoie effectivement au numéro de sujet dans le corpus-père permet d’utiliser les fonctionnalités de base de données relationnelle hiérarchisée, telles qu’elles sont décrites dans le langage des formules.
Mise à jour : 13/10/2011 Hector Manuel principal 52
TELECHARGEMENT ET VERSIONS
Les mises à jour d’Hector, liées à la correction des éventuels bogues et à l’ajout de fonctionnalités que l’usage montrera nécessaire, sont gratuites et s’opèrent par téléchargement à l’adresse : http://alain.dubus.r.et.d.free.fr .
On trouve à cette adresse le logiciel Hector et son fichier d’aide en ligne hector_aide.zip, mais aussi la totalité de la documentation pour les versions de base et professionnelle, ainsi que des corpus-exemples, dont la collection peut s’enrichir. Les mises à jour du logiciel et/ou de la documentation (au format PDF) peuvent être attendues à une fréquence approximativement trimestrielle (éventuellement plus rapide en cas de découverte de bogues très gênantes). La mise à jour d’hector.exe concerne indifféremment la version de base ou la version professionnelle, car physiquement il s’agit du même logiciel, mais logiquement l’accès à la version professionnelle est contrôlé par un numéro de licence assortie d’une clé d’activation. Aussi le bouton suivant est-il disponible dans le cadre Généralités de la version de base :
Il provoque l’affichage du panneau suivant :
Numéro de licence et clé d’activation peuvent être obtenues après signature d’une convention avec l’auteur. Pour toute information complémentaire, s’adresser à [email protected] . Le champ « numéro de licence » doit être entièrement rempli par le numéro (sans trace des ‘_’ initiaux). De même pour la clef d’activation. Une licence est généralement délivrée pour une durée fixée par convention. A l’issue de cette durée, et après rappel, le logiciel repasse en version de base, ce qui permet de continuer à exploiter les données, mais sans les fonctions professionnelles. Les conditions de renouvellement de la licence sont généralement prévues par la convention, et passent par un message à l’adresse ci-dessus.

Mise à jour : 13/10/2011 Hector Manuel principal 53
SOMMAIRE
Présentation du manuel ...............................................................................................................................2 Organisation du document.....................................................................................................................2
Choix techniques .................................................................................................................................3
Concepts fondamentaux dans Hector.......................................................................................................5 Corpus, sujets, variables..........................................................................................................................5
Structure d’un corpus .........................................................................................................................5 Modèles de données relationnels et hiérarchiques .........................................................................7
Variété des variables ................................................................................................................................8 Le type des variables ...........................................................................................................................8 Conversions de type..........................................................................................................................12 Collections..........................................................................................................................................13 D’où viennent les variables ? ...........................................................................................................14
Gestion d’un corpus, de variables et de collections ..............................................................................15 Organisation générale du logiciel.........................................................................................................15
La zone des onglets...........................................................................................................................15 Le panneau de commande ...............................................................................................................16
Entrées et sorties de données...............................................................................................................16 Ouverture d’un corpus .....................................................................................................................17 Modifications et sauvegardes...........................................................................................................17 Entrée de données.............................................................................................................................19 Gérer variables et collections...........................................................................................................20 Gestion des variables ........................................................................................................................20 Gestion des collections.....................................................................................................................24 Éléments avancés en Gestion de variables ....................................................................................26 Structuration des variables avec le vari-Arbre...............................................................................27
Saisie, édition et import-export des données .........................................................................................35 Importation au format texte.................................................................................................................35
Les noms des variables .....................................................................................................................36 Le type des variables .........................................................................................................................37 Préparation de l’import.....................................................................................................................38

Mise à jour : 13/10/2011 Hector Manuel principal 54
Importer..............................................................................................................................................39 Utilisation de l’éditeur intégré ..............................................................................................................40
Navigation parmi les sujets ..............................................................................................................41 Édition et saisie des valeurs .............................................................................................................41 Copier-coller et fonctions annexes .................................................................................................43 Relation avec les variables formulées .............................................................................................44
Exporter des données au format texte ...............................................................................................45
Le cadre Généralités...................................................................................................................................47 Configuration et habitudes...............................................................................................................47
Le cadre éléments techniques avancés ....................................................................................................48 Le détail du plan de codage ..................................................................................................................48 Reprendre tableau au format texte ......................................................................................................49 Exporter comme corpus-fils ................................................................................................................50
Téléchargement et versions ......................................................................................................................52
Sommaire.....................................................................................................................................................53


















