
Eviews 7
95
Formation Eviews 7 Introduction Jonathan Benchimol
-
Upload
nanien-pana-issouf-coulibaly -
Category
Education
-
view
5.001 -
download
1
Transcript of Eviews 7

Formation Eviews 7
Introduction
Jonathan Benchimol

Plan
Prise en main du logiciel
Utilisation
Création
Gestion
Analyse statistique
Représentations graphiques
Statistiques descriptives
Econométrie
Estimations
Tests
Méthodes
2 Jonathan Benchimol

Prise en main du logiciel
Jonathan Benchimol 3
Utilisation
Création
Gestion

Fenêtre initiale
Jonathan Benchimol 4

Fenêtre de commande
Jonathan Benchimol 5

Statuts et fenêtres
Jonathan Benchimol 6

Créer ou ouvrir un fichier
Jonathan Benchimol 7
Plusieurs manières d’accéder à des données:
Création d’un nouveau fichier de travail (Workfile)
File/New/Workfile puis suivre les indications
wfcreate(wf=annual, page=myproject) a 1950 2005
Ouvrir un fichier Eviews (.wf1)
File/Open/Workfile puis sélectionner le fichier à ouvrir
wfopen "c:\data files\data.wf1"
Ouvrir un fichier qui n’est pas en format Eviews
File/Open/Foreign Data as Workfile puis sélectionner le fichier à
ouvrir
wfopen "c:\data files\data.xls"

Création d’un nouveau workfile
Jonathan Benchimol 8
Création d’un nouveau
workfile:
File/New/Workfile
Choisir le type de structure
Choisir la fréquence
Choisir les bornes
Optionnel:
Donner un nom au workfile
Donner un nom à la page
du workfile

Saisie de données
Jonathan Benchimol 9
Première méthode: le copié/collé sur une nouvelle série.
Une fois le workfile créé, allez dans Excel et sélectionner une série sans son label.
Collez ensuite dans l’objet série la série sélectionnée (cf. ci après).
Si cela ne fonctionne pas, n’oubliez pas de déverrouiller le mode édition…

Création à partir d’Excel
Jonathan Benchimol 10

Fenêtre Workfile
Jonathan Benchimol 11
Repères
Nombre d’observations
Feuilles
Barre de boutons
Objets

Fenêtre Workfile
Jonathan Benchimol 12

Création et exécution d'un programme
Jonathan Benchimol 13
Deux façons d'éditer et d'exécuter un programme sous Eviews:
Interactive use Des commandes élémentaires peuvent tout d'abord être reportées une à une
dans la ligne de commande (située au-dessous de la barre de menu).
Les commandes seront alors exécutées immédiatement, mais ne seront pas enregistrées dans un fichier.
Batch use On ouvre une nouvelle fenêtre dans laquelle on va enregistrer une séquence de
commandes.
Pour ouvrir un programme existant:
File/Open/Program
Pour créer un programme
File/New/Program
program nom_du_programme
Ce mode permet d'exécuter un bloc de commandes et de les enregistrer dans un fichier. On pourra alors exécuter le programme de façon répétée et l'appliquer à d'autres bases de données.

Jonathan Benchimol 14
Alphanumérique Séries groupées Matrice symétrique
Vecteur de paramètres Vecteur colonne Système
Equation Echantillon d’observations Table
Facteur Scalaire Texte
Graphique Série temporelle Carte de valeurs
Groupe de séries
Max. de vraisemblance
Matrice
Modèle
VAR
Vecteur Représentation d'état
Etude transversale
Vecteur de chaînes de caractères
Chaînes de caractères

Les objets
Jonathan Benchimol 15
Ci-avant un récapitulatif de tous les types d’objets.
Deux moyens de déclaration:
Avec le menu:
Object/New Object
Avec la ligne de commande:
type_objet nom_objet
Types d’objets les plus utilisés:
Série temporelle:
series x
Groupe de séries:
group g x y
Equation:
equation eq01

Fenêtre Object
Jonathan Benchimol 16

Menu
Jonathan Benchimol 17
File: ouverture, fermeture, sauvegarde, impression…
Edit: copié, collé, retour en état précédent, rechercher…
Object: créer, gérer ou imprimer un type d’objet
View (lorsqu’un objet est sélectionné): voir, statistiques
sur l’objet, lien avec la base de données, ouvrir…
Proc: procédures globales ou particulières
Quick: estimation, statistiques groupées, tests statistiques,
VAR, générateur… bouton le plus utilisé !!!
Options, Add-in, Windows: facultatif
Help: à utiliser sans limite.

Analyse statistique
Jonathan Benchimol 18
Représentations graphiques
Statistiques descriptives

Introduction : Fenêtre Object
Jonathan Benchimol 19

Introduction : Fenêtre Série
Jonathan Benchimol 20
Manipulation de données
Afficher la série, etc…
Label
View/label
Sheet
View/Spreadsheet
Line
Views/Graph/Line
Stats
Views/Descriptive Statistics & tests

Introduction: Fenêtre Série
Jonathan Benchimol 21
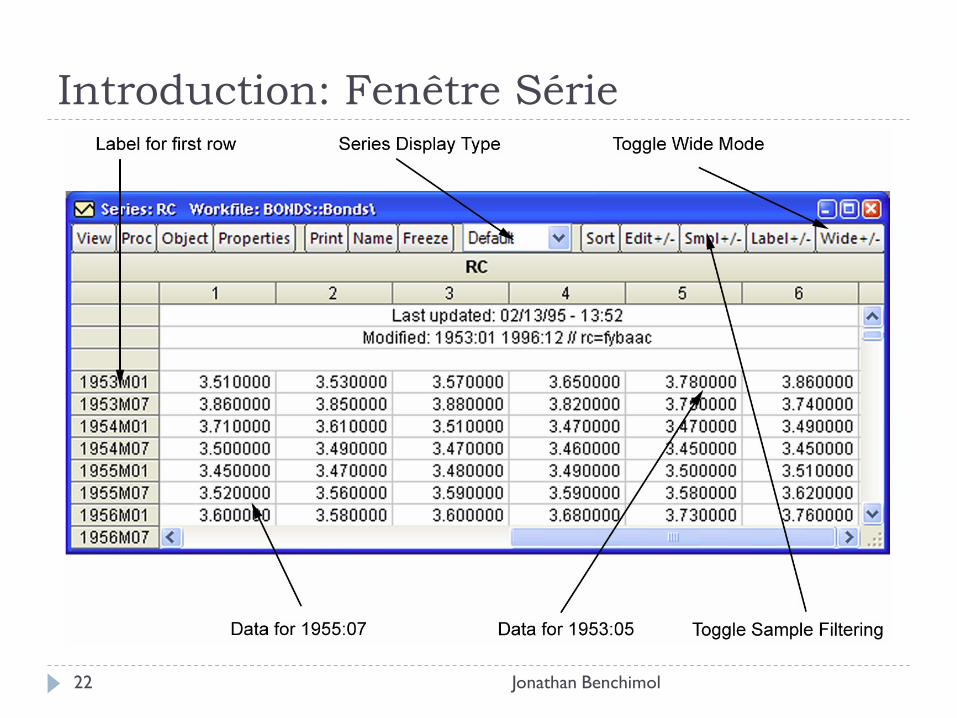
Introduction: Fenêtre Série
Jonathan Benchimol 22

Opération sur les séries
Jonathan Benchimol 23
Créer une nouvelle série y:
series y
Créer la série y en fonction de x et z:
series y = 2*x + 3*z
Créer la série y log d’elle-même:
series y = log(y)
Créer la série y moyenne mobile d’ordre 6 de x:
series = @movav(x,6)

Opération sur les intervalles de temps
Jonathan Benchimol 24
Partie supérieure
Point initial et terminal
de l’intervalle
Partie inferieure
Zone conditionnelle

Exemple d’échantillon
Jonathan Benchimol 25
Partie supérieure: prendre en compte uniquement les
observations 50 à 100 et 200 à 250:
50 100 200 250
Partie inferieure: parmi ces observations, prendre en
compte uniquement celles où la variable x est comprise
entre 6 et 13 et la variable y est inferieure à sa moyenne:
(x>=6 and x<=13) or (y<@mean(y))

Définition d’échantillon
Jonathan Benchimol 26
La commande smpl permet de définir un échantillon de
données, avec ou sans condition:
Sélectionner uniquement un échantillon de 1970Q1 à 1999Q4:
smpl 1970Q1 1999Q4
Sélectionner uniquement , dans un échantillon de 1970Q1 à
1999Q4, les données où rates est supérieur à 1.8:
smpl 1970Q1 1999Q4 if rates>1.8
Sélectionner uniquement un échantillon de 1970Q1 à la
dernière valeur :
smpl 1970Q1 @last
Sauvegarder un échantillon de la première valeur à 1989Q2 :
Sample s1 @first 1989Q2
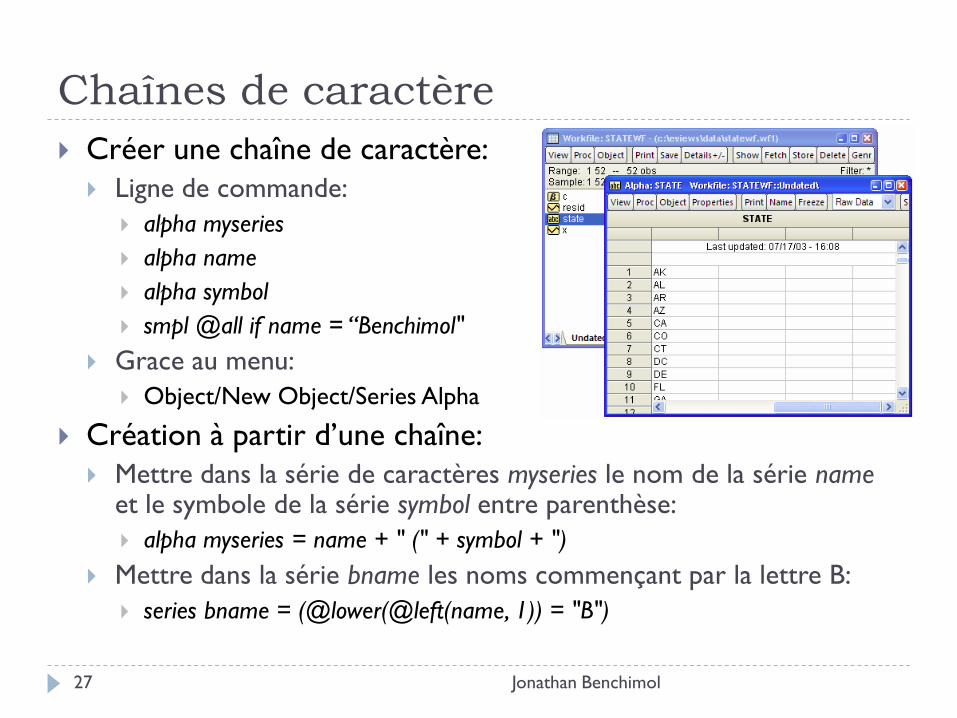
Chaînes de caractère
Jonathan Benchimol 27
Créer une chaîne de caractère:
Ligne de commande:
alpha myseries
alpha name
alpha symbol
smpl @all if name = “Benchimol"
Grace au menu:
Object/New Object/Series Alpha
Création à partir d’une chaîne:
Mettre dans la série de caractères myseries le nom de la série name et le symbole de la série symbol entre parenthèse:
alpha myseries = name + " (" + symbol + ")
Mettre dans la série bname les noms commençant par la lettre B:
series bname = (@lower(@left(name, 1)) = "B")

Attribution de labels
Jonathan Benchimol 28
Donner un label aux valeurs des variables: valmap
Object/New Object/ValMap
Utile uniquement lorsque la variable ne présente qu’un nombre restreint de valeurs.
Pour attribuer un label à une série, cliquer sur Properties dans le menu de celle-ci puis sur Value Map.

Attribution de labels
Jonathan Benchimol 29
Exemple d’attribution de labels:
valmap mymap
mymap.append 3 "trois"
mymap.append 99 "do not exist"

Groupe de séries
Jonathan Benchimol 30
Permet de visualiser et d’étudier plus d’une série, formant
ainsi un groupe de séries.
Créer simplement un groupe de séries en sélectionnant
plus d’une série du workfile (maintenir enfoncée la
touche Ctrl et cliquer sur les séries à sélectionner), puis
clic bouton droit, puis Open, puis as a Group.
Cet objet est très utile pour effectuer des tableaux
récapitulatifs, pour représenter l’évolution d’une série en
fonction d’une autre ou pour en représenter plusieurs
sur un même plan.

Utilisation de l’aide
Jonathan Benchimol 31
IMPORTANT: dès que vous avez une question, cliquez sur
Help, puis sur Quick Help Reference, puis sur l’un des
type correspondant à votre interrogation:
Question sur un Objet ?
Question sur une Commande ?
Question sur une Fonction ?
Question sur les Matrices ?
Question sur la Programmation ?
Une fois que vous avez ouvert le champ correspondant à
votre question, tapez-y un mot clés de votre
IMPORTANT: utilisez le plus souvent possible l’aide.
Jonathan Benchimol 32

Créer un graphique
Jonathan Benchimol 33
Lorsque vous avez
ouvert une série,
cliquer sur
View/Graph…
Un écran apparait
(cf. ci-contre).
Configurer votre
graphique puis
cliquer sur OK
pour l’afficher.

Créer un graphique de plusieurs séries
Jonathan Benchimol 34
Créer un groupe de séries
Ouvrir le groupe puis allez
dans View/Graph… puis OK
Si vous voulez obtenir
plusieurs graphiques sur une
seule fenêtre, cliquer sur
Options, puis dans Multiple
Series, cliquer sur Multiple
Graphs
Pour changer de Template,
cliquer aussi sur Options (ou
double-clic sur le graphique),
puis Template & Objects puis
laissez-vous guider.

Présentation du graphique
Jonathan Benchimol 35
Possibilités: ajouter du texte, modifier l’échelle des axes,
modifier l’apparence (template), sauvegarder son propre
template, afin de le réutiliser, etc…
Ces agréments esthétiques sont très pratiques lorsque
les graphiques doivent répondre à une même charte
graphique par exemple.
Mettons en pratique par plusieurs exemple ces
possibilités.

Figer ou pas Figer ?
Jonathan Benchimol 36
Le graphique généré à partir d’une série par Eviews peut
être soit connecté aux données, soit déconnecté des
données à partir desquelles il a été construit:
Si l’on change quelque chose dans les données, cela modifiera
l’aspect du graphique: Freeze
Si l’on change quelque chose dans les données, ou si on passe à
une autre visualisation, cela ne modifiera pas l’aspect du
graphique: Freeze
« Freezer » un objet crée un autre objet qui devient
indépendant de l’objet originel. Il n’y a plus d’actualisation
possible.
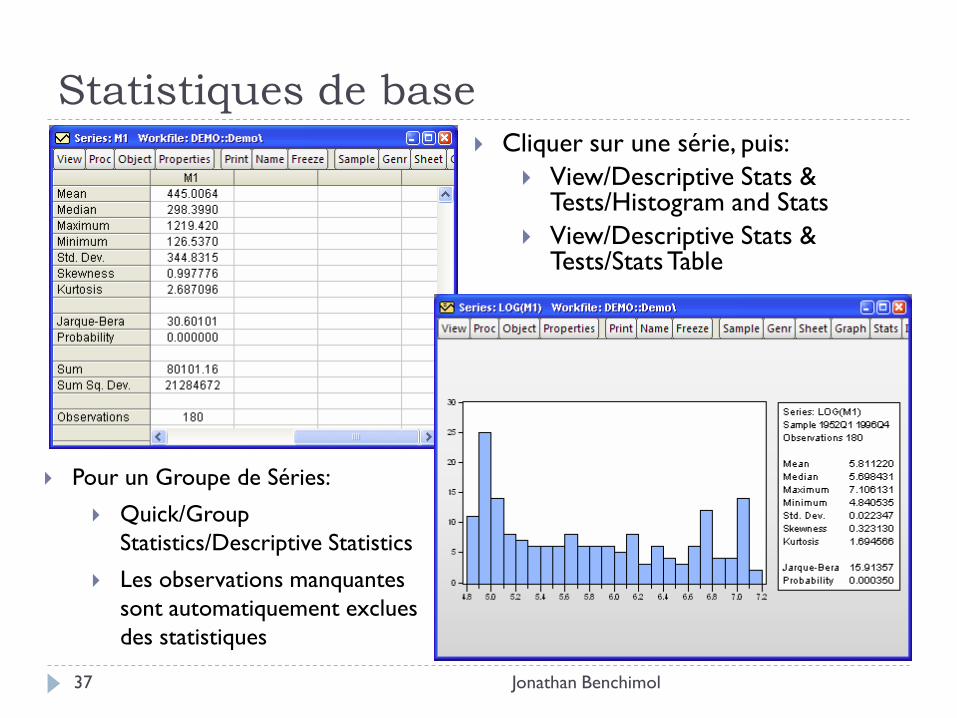
Statistiques de base
Jonathan Benchimol 37
Cliquer sur une série, puis:
View/Descriptive Stats & Tests/Histogram and Stats
View/Descriptive Stats & Tests/Stats Table
Pour un Groupe de Séries:
Quick/Group
Statistics/Descriptive Statistics
Les observations manquantes
sont automatiquement exclues
des statistiques

Econométrie
Jonathan Benchimol 38
Estimations
Tests
Méthodes

Qu’est-ce que l’économétrie
Jonathan Benchimol 39
Ensemble des techniques destinées à mesurer des
grandeurs économiques.
Mesure de grandeurs préalablement définies par l'économie
(emploi, croissance, valeur ajoutée, etc.);
Vérification empirique de relations entre ces grandeurs
prédites par des modèles issus de l'économie mathématique ;
Etude a priori de relations entre grandeurs mathématiques
indépendamment d'un modèle économique sous-jacent.

Objectifs
Jonathan Benchimol 40
Utiliser Eviews pour
Expliquer ces mesures.
Exploiter des données.
Etablir et tester des relations robustes entre elles.
Exposer et présenter ses résultats.
Quantifier des paramètres d’un modèle.
Tester des hypothèses ou des prévisions.
Confronter des modèles concurrents.
Simuler des évolutions passées ou à venir.
Etudier des interactions entre variables.
Rapprocher la théorie à la réalité.

Méthodologie
Jonathan Benchimol 41
Spécifier du modèle
Choisir les variables explicatives
Choisir la forme fonctionnelle
Prendre en compte les chocs
Confronter le modèle aux données
Estimer le modèle
Evaluer et analyser les résultats
Tester de la robustesse de l’estimation
Utiliser le model
Prévoir
Envisager des variantes
Cas extrêmes

Nomenclature
Jonathan Benchimol 42
Relation entre une variable expliquée (Yt) et des variables
explicatives (Xt,k) pondérées par des paramètres (ak), une
constante (paramètre a0) et une perturbation (choc ut,i):
Yt = a0 + a1Xt,1 + a2Xt,2 + … + aiXt,i + ut,i
On cherche à estimer les paramètres, inconnus du
modèle.
ut,i peut être perçu comme un choc, une perturbation,
une erreur ou un aléa.
Il s’agit ici d’an modèle linéaire avec un terme constant.

Objectifs spécifiques
Jonathan Benchimol 43
A l’aide d’observations des variables (données), on
cherche à:
Estimer les paramètres du modèle.
Evaluer la précision des estimations.
Montrer le pouvoir explicatif du modèle.
Savoir si la liaison globale entre Yt et Xt,k est significative.
Savoir si l’apport marginal de chaque variable est significatif.
Evaluer la capacité prédictive du modèle.
Envisager des aspect particuliers.

MCO: Tests
Jonathan Benchimol 44
Pour toute l’estimation
R² ajusté
Mean dependent var
S.D. dependent var
S.E. of regression
Akaike info criterion
Sum squared resid
Schwarz criterion
Log likelihood
Hannan-Quinn criter.
F-statistic
Durbin-Watson stat
Prob(F-statistic)
Pour chaque paramètre:
Student (p-value)
Std. Error

Estimation d’un équation par les MCO
Jonathan Benchimol 45
Créer un workfile regroupant les données à analyser
Estimer les coefficients de la régression:
Quick/Estimate Equation… ou Object/Equation
Ecrire la relation sous forme d’une équation: VExpliquée=c(1)*VExplicative1+c(2)*VExplicative2+C(3)
ou
LS Vexpliquée C Vexplicatives séparées par un espace
Les variables suivies de (-1), (-2) … sont des variables retardées.
L’estimation se fait en ajustant l’échantillon de façon à ne pas tenir compte des données manquantes.

Fenêtre Equation Estimation
Jonathan Benchimol 46
Eviews donne le choix
entre plusieurs
techniques d’estimation,
et une personnalisation
de l’échantillon au
moment de l’estimation.
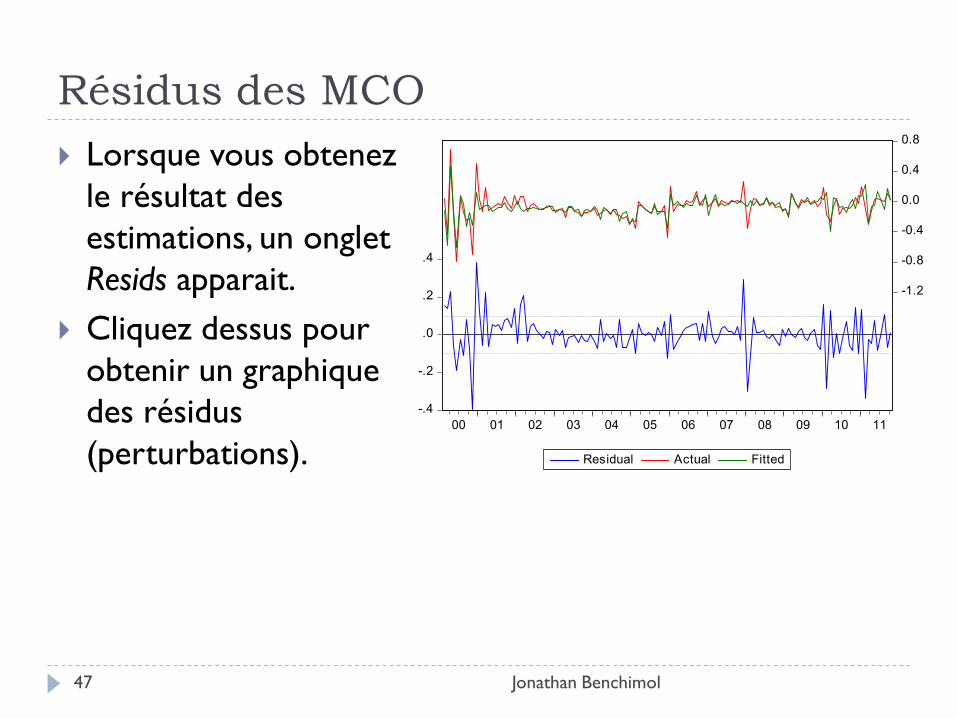
Résidus des MCO
Jonathan Benchimol 47
Lorsque vous obtenez
le résultat des
estimations, un onglet
Resids apparait.
Cliquez dessus pour
obtenir un graphique
des résidus
(perturbations).
-.4
-.2
.0
.2
.4
-1.2
-0.8
-0.4
0.0
0.4
0.8
00 01 02 03 04 05 06 07 08 09 10 11
Residual Actual Fitted

Travailler avec les résultats statistiques
Jonathan Benchimol 48
Fonctions retournant
un scalaire:

Travailler avec les résultats statistiques
Jonathan Benchimol 49
Fonctions retournant
un vecteur ou une
matrice d’objets:
Fonctions retournant
des caractères:

Travailler avec la régression
Jonathan Benchimol 50
Cliquez sur View pour voir:
Les représentations
Les sorties
La structure ARMA
Les résidus
Gradients, dérivés
Matrice des covariances
Tests sur les coefficients
Tests sur les résidus
Tests de stabilité
Etc…

Travailler avec la régression
Jonathan Benchimol 51
Cliquez sur Proc pour
effectuer:
Des prévisions
Un modèle
Des dérivées de la fonction
de régression par rapport
aux paramètres
Un groupe des régresseurs

En ligne de commande
Jonathan Benchimol 52
Estimer une équation par les moindres carrés (MCO):
eq1.ls(options) y c x1 x2
eq1.ls(options) y = c(1) + c(2)*x1 + c(3)*x2
Stocker dans un vecteur l’estimation d’une équation par
les moindres carrés (MCO):
coef(3) myvector
eq1.ls(options) y = myvector(1) + myvector(2)*x1 + myvector(3)*x2
Afficher le spécification de l’équation estimée:
show eq1.spec
Afficher les résultats d’une équation estimée:
show eq1.results

En ligne de commande
Jonathan Benchimol 53
Stocker les résidus d’une équation estimée dans une série
nom_residus:
eq1.makeresids nom_residus
Afficher les résidus estimés:
eq1.resids(options)
g pour une représentation graphique
t pour une représentation sous forme de tableau
show eq1.resids
Créer un modèle à partir de l’équation estimée:
makemodel

Signification des tests
Jonathan Benchimol 54
Student: test de significativité d’un paramètre
Fisher: test de significativité global
Test de normalité des erreurs
Durbin Watson: Test d’autocorrélation
White: Test d’hétéroscédasticité
Show: Test de stabilité
Test de colinéarité

Autres tests
Jonathan Benchimol 55
Après avoir effectué votre régression, les test Student, de
Fisher et de Durbin-Watson figurent directement dans la
fenêtre équation générée.
Pour calculer d’autres tests statistiques, cliquez sur le bouton View de la fenêtre Equation, et sélectionnez soit un des trois type de diagnostic: Coefficient, Residuals ou Stability.
Pour revenir aux résultats de la régression, cliquez sur le bouton Stats.

Spécification d’un modèle
Jonathan Benchimol 56
Considérations importantes au moment du choix d’un
modèle
Conséquences du choix d’un mauvais modèle
Assurer la validité d’un modèle
Critères de choix
Erreurs de spécification
Remèdes
Evaluation des performances de modèles

Spécification d’un modèle
Jonathan Benchimol 57
Types d’erreurs de spécification:
Omission d’une variable pertinente
Inclusion d’une variable superflue
Forme fonctionnelle erronée
Erreurs de mesure
Erreurs de spécification du terme stochastique
Détection de variables non-pertinentes:
Test de Student (pour une variable)
Test de Fisher (pour plusieurs variables)
Détection de variables omises:
Examen des résidus
Analyse de l’autocorrélation ou de l’hétéroscédasticité

Autocorrélation des résidus
Jonathan Benchimol 58
Après avoir effectué votre régression, cliquez sur View de
la fenêtre équation puis cliquez sur Residuals Diagnostics,
puis sur Correlegram Q Statistics…
Vous devez ensuite choisir l’ordre maximal
d’autocorrélation des résidus que vous désirez obtenir.
Remarque
Un processus AR(1) est fréquemment postulé, car il traduit
l’idée qu’un choc exogène à un moment donné a un effet
persistant mais décroissant exponentiellement avec le temps.

Analyse des résidus
Jonathan Benchimol 59
Examen visuel des résidus
L’analyse graphique des résidus permet le plus souvent de
détecter une autocorrélation des erreurs lorsque :
Les résidus sont pendant plusieurs périodes consécutives, soit positifs,
soit négatifs : corrélation positive
Les résidus sont alternés : corrélation négative.
Cependant, le plus souvent, l’analyse graphique est
délicate à interpréter.
Il faut faire des tests d’autocorrélation:
Statistique de DW
View/Residual Diagnostics/Correlogram-Q-statistics
View/Residual Diagnostics/Serial Correlation LM Test…

Test de Durbin et Watson
Jonathan Benchimol 60
Le test de Durbin Watson (DW) teste seulement
l’autocorrélation du premier ordre.
Il existe un plage de valeurs pour lesquelles on ne peut
conclure.
Dans un modèle auto régressif, le test de DW est biaisé
en faveur de l’acceptation de l’hypothèse nulle:
En effet, prenons le modèle AR suivant
Yt = a0 + a1 Yt-1 + a2Xt + ut
La variable expliquée Yt dépend de ses valeurs passées.

Test de Breusch-Pagan-Godfrey
Jonathan Benchimol 61
Si les erreurs suivant un
AR(p), alors il faut tester
l’égalité à zéro de tous
les coefficients de cet
AR(p).
Dans la fenêtre équation,
aller dans View, puis
Residuals Diagnostics, puis
dans Heteroskedasticity
Tests…

Test de Breusch-Pagan-Godfrey
Jonathan Benchimol 62
Les régresseurs du modèle peuvent comprendre des
valeurs décalées de la variable dépendante (ce qui tranche
avec les restrictions du test de DW).
Ce test est également applicable lorsque les erreurs
suivant un MA(q).
Si l’on ne considère qu’un AR(1), le test BG est connu
sous le nom de test M de Durbin.
La valeur p, longueur du décalage, ne peut être précisée à
priori. Il est inévitable de procéder à quelques
expérimentations. On peut alors utiliser les critères AIC,
HQC et SC pour choisir le bonne longueur du décalage.

En présence d’autocorrélation
Jonathan Benchimol 63
Trouver si l’autocorrélation est une pure autocorrélation
et non le résultat d’une mauvaise spécification du modèle.
Les résidus peuvent être dus à une mauvaise spécification
du modèle ou à une forme fonctionnelle incorrecte.
Est-ce que les variables prises en compte présentent des
tendances, auquel cas il faut intégrer dans le modèle le
temps (@trend). Si en changeant la spécification, la
statistique de DW reste anormalement faible alors on
peut effectivement conclure la présence
d’autocorrélation.
Si il s’agit d’autocorrélation pure MCQG

Exemple: Nombre d’oeufs
Jonathan Benchimol 64
-600
-400
-200
0
200
400
600
2,000
2,400
2,800
3,200
3,600
4,000
00 01 02 03 04 05 06 07 08 09 10 11
Residual Actual Fitted
2,200
2,400
2,600
2,800
3,000
3,200
3,400
3,600
3,800
4,000
00 01 02 03 04 05 06 07 08 09 10 11 12
Nombre d'oeufs
2,200
2,400
2,600
2,800
3,000
3,200
3,400
3,600
3,800
4,000
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
Means by Season
Nombre d'oeufs par saison

Test de la stabilité des paramètres
Jonathan Benchimol 65
Lorsqu’on utilise un modèle sur des séries temporelles, des changements structurels peuvent se produire entre la variable à expliquer et les variables explicatives: les paramètres ne restent globalement pas identiques sur toute la période.
Comment détecter un changement structurel ?
Représentation graphique
Test de Chow
Le test de Chow estime deux modèles: en utilisant l’ensemble des données et un autre utilisant une période restreinte. Si la différence entre les deux modèles est significative, on peut douter de la stabilité de la relation sur l’ensemble de la période.

Tests de stationnarité
Jonathan Benchimol 66
Un exemple avec le test de Dickey-Fuller Augmenté (ADF). Ce test se base
sur l’hypothèse de corrélation des résidus et sur l’estimation par les MCO
des 3 modèles suivants :
sachant que les résidus sont iid.

Exemple
Jonathan Benchimol 67
Test de stationnarité de la
série CATTLE_NB: modèle
avec tendance et constante
« en niveau », on commence
toujours par ce choix.
Le test est plus grand que
les seuils d’erreurs à 1%, 5%
et 10%: on rejette donc
l’hypothèse de stationnarité.
Remarque: il peut exister un
lien entre CATTLE_NB et
CATTLE_NB (-12).

Exemple
Jonathan Benchimol 68
Test de stationnarité de la
série des CATTLE_NB:
modèle avec constante «
en niveau »: mêmes
remarques que
précédemment.

Exemple
Jonathan Benchimol 69
Ici, on test la série
D(CATTLE_NB_SA) i.e. la
série CATTLE_NB vue
précédemment mais
ajustée des variations
purement saisonnières.
cattle_nb.x12(mode=a)
On utilise le mode additif
car notre série contient des
valeurs négatives !
Il y a stationnarité en
différence première.

Test RESET de Ramsey
Jonathan Benchimol 70
Ce test de spécification utilise des modèles artificiels non
linéaires afin de les confronter au modèle estimé.
Ces modèles artificiels sont composés du modèle estimé
plus une composante de deuxième et/ou de troisième
ordre multipliée par un coefficient.
Si ces coefficients sont nuls, le modèle initial est adéquat.
Deux moyens d’effectuer ce test:
View/Stability Diagnostics/Ramsey RESET Test
eq1.ramsey(options)

Programmation
Jonathan Benchimol 71
Un programme peut être enregistré et/ou être utilisé
et/ou modifié à l’infini.
En automatisant un processus, et en écrivant cela dans un
programme, vous gagnerez énormément de temps.
Exemple:
Ecrire un programme qui permet de désaisonnaliser la série
cattle_nb par la méthode x12 additive
Puis qui effectue la différence première du résultat par deux
méthodes (différence et log différence).
Avant de commencer à écrire ce programme, faite cette
procédure uniquement avec votre souris…

Un programme pour aller plus vite ?
Jonathan Benchimol 72
cattle_nb.x12(mode=a)
genr cattle_nb_sa_d1=D(cattle_nb_sa)
genr cattle_nb_sa_d2=log(cattle_nb_sa/cattle_nb_sa(-1))
cow_nb.x12(mode=a)
genr cow_nb_sa_d1=D(cow_nb_sa)
genr cow_nb_sa_d2=log(cow_nb_sa/cow_nb_sa(-1))
meat_nb.x12(mode=a)
genr meat_nb_sa_d1=D(meat_nb_sa)
genr meat_nb_sa_d2=log(meat_nb_sa/meat_nb_sa(-1))
Etc…
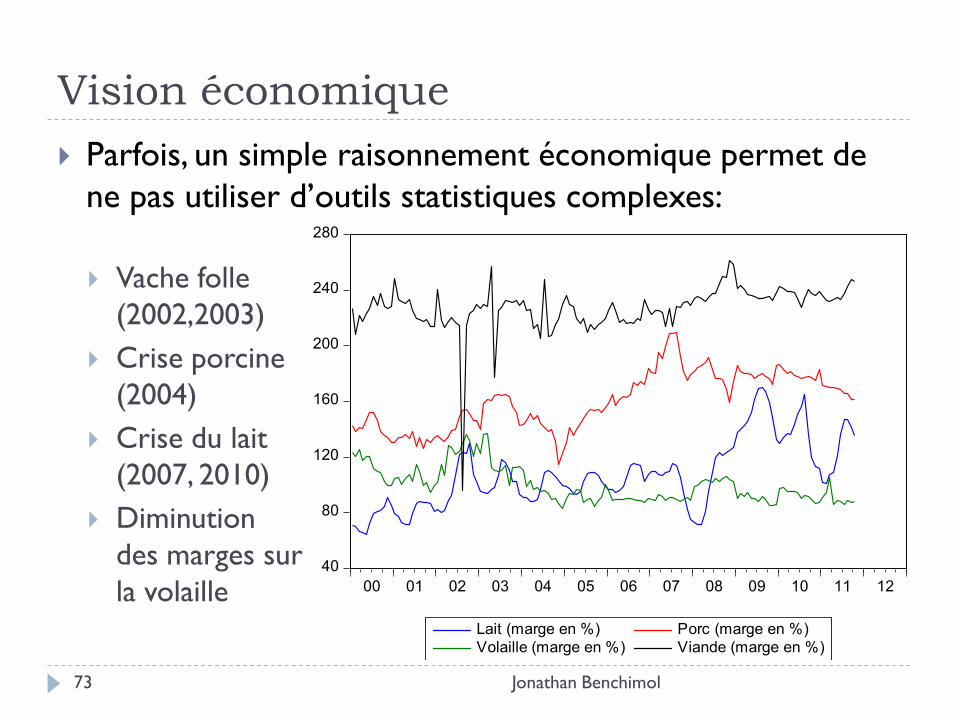
Vision économique
Jonathan Benchimol 73
Parfois, un simple raisonnement économique permet de
ne pas utiliser d’outils statistiques complexes:
40
80
120
160
200
240
280
00 01 02 03 04 05 06 07 08 09 10 11 12
Lait (marge en %) Porc (marge en %)
Volaille (marge en %) Viande (marge en %)
Vache folle
(2002,2003)
Crise porcine
(2004)
Crise du lait
(2007, 2010)
Diminution
des marges sur
la volaille

Analyse en composantes principales
Jonathan Benchimol 74
L'ACP permet de transformer des variables corrélées en
nouvelles variables décorrélées les unes des autres.
Objectif:
Réduire l'information en un nombre de composantes
principales plus limité que le nombre initial de variables.
Approche
Géométrique: représentation des variables dans un nouvel
espace géométrique selon des directions d'inertie maximale
Statistique: recherche d'axes indépendants expliquant au mieux
la variance des données

ACP: un exemple
Jonathan Benchimol 75
PC1 explique 98% de la variance totale.
PC1 est une combinaison linéaire de l'ensemble des cinq prix.
PC1 peut-être interprété comme un indice des prix.

ACP: un exemple
Jonathan Benchimol 76
PC2 dépend négativement des prix de la viande rouge
(porc, bœuf et viande) et positivement des prix de la
viande de volaille (chair de poulet et volaille).
0
1
2
3
4
5
1 2 3 4 5
Scree Plot (Ordered Eigenvalues)
Le graphique ci-contre
montre la forte baisse
entre la première et la
deuxième valeur propre.

Prévision
Jonathan Benchimol 77
Après avoir effectué une régression, cliquez sur le bouton
Forecast du menu de la fenêtre équation et choisissez la
méthode adéquate.
Prévision dynamique: pour
chaque période, la valeur
prévue à la date t-1 est
utilisée pour calculer la
prévision à la date t.
Prévision statique: pour une
période au delà de la période
d’observation, cette prévision
est plus précise.

Traitement des prévisions
Jonathan Benchimol 78
Pour construire des prévisions statiques (lorsque
l’équation estimée contient comme régresseur la variable
expliquée retardée), les valeurs observées sont utilisées.
do eq1.fit yhat yse
Stock dans yhat et yse la série ajustée et les écart types
associés.
Pour construire des prévisions dynamiques (lorsque
l’équation estimée contient comme régresseur la variable
expliquée retardée), les valeurs prévues sont utilisées
lorsque l’horizon de prévision est supérieur à 1.
smpl 1 100, do eq1.ls y c x, smpl 101 105, do eq1.forecast yhat yse.

Dessaisonalisation
Jonathan Benchimol 79
Dessaisonalisations de base:
Xsat = log(Xt/Xt-12)
Xsat = (Xt-Xt-12)/Xt-12
Autres types de dessaisonalisation:
X11
X12
TRAMO
Moyenne mobile

Exemple: TRAMO et données aériennes
Jonathan Benchimol 80

Exemple: TRAMO et données aériennes
Jonathan Benchimol 81
0
100
200
300
400
500
600
700
800
49 50 51 52 53 54 55 56 57 58 59 60 61 62
X Forecast of series
0
100
200
300
400
500
600
700
49 50 51 52 53 54 55 56 57 58 59 60
Actual series Linearized series

Autres exemple utilisant TRAMO
Jonathan Benchimol 82
40
60
80
100
120
1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998
X Forecast of series Linearized series

Analyse graphique de saisonnalités
Jonathan Benchimol 83
Exemple: quantité
d’œufs
Une saisonnalité peut
être dans les données.
La connaissance de la
variable nous indique
une saisonnalité.
2,200
2,400
2,600
2,800
3,000
3,200
3,400
3,600
3,800
4,000
00 01 02 03 04 05 06 07 08 09 10 11 12
EGGS_NB
View/Graph…/Seasonal Graph/Paneled lines and means

Analyse graphique de saisonnalités
Jonathan Benchimol 84
On obtient un graphique ventilant les informations:
Une moyenne par mois
Une série mensuelle
2,200
2,400
2,600
2,800
3,000
3,200
3,400
3,600
3,800
4,000
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
Means by Season
EGGS_NB by Season
Juin est la période où le nombre d’œufs produits est maximal.
Février est la période basse.
La production est en croissance en moyenne sur l’échantillon.

Analyse graphique de saisonnalités
Jonathan Benchimol 85
A partir d’un groupe de séries temporelles, on obtient:
14
16
18
20
22
24
26
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
Russia: Total Sheep & Goats number, mln heads by Season
13
14
15
16
17
18
19
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
Russia: Total Pig Number, mln heads by Season
8
9
10
11
12
13
14
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
Russia: Total Cow Number, mln heads by Season
18
20
22
24
26
28
30
32
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
Means by Season
Russia: Total Cattle Number, mln heads by Season

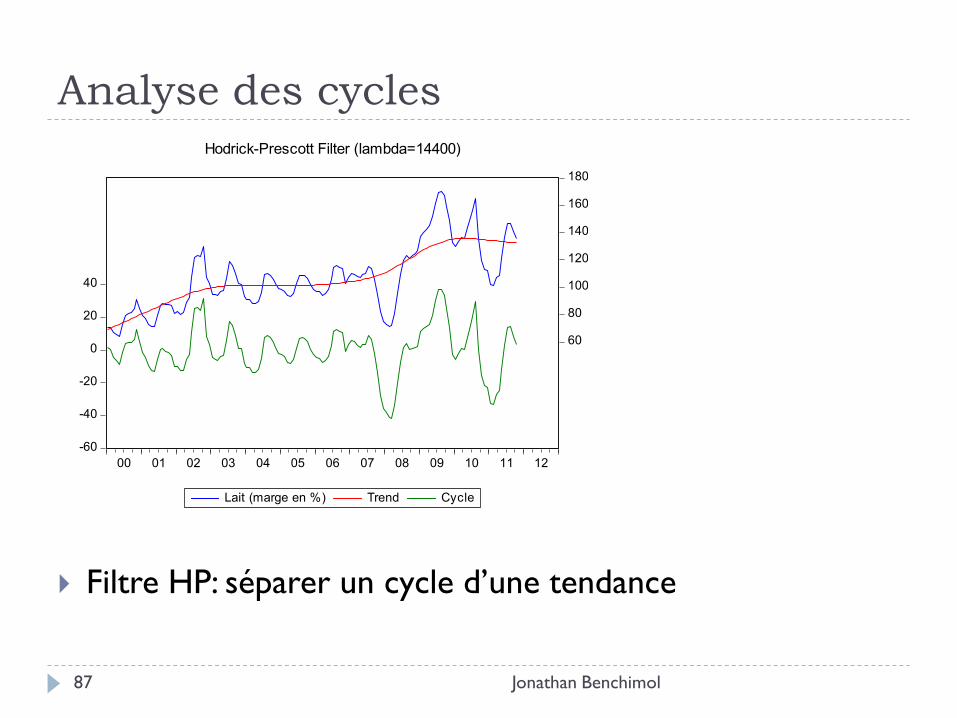
Analyse des cycles
Jonathan Benchimol 86
Filtre de fréquence: séparer une dynamique issue d’un cycle de celle qui n’est pas engendrée par un cycle.
Aller dans Proc sur le menu de la fenêtre de la série, puis dans Frequency Filter…
-40
-20
0
20
40
80
120
160
200
2000 2002 2004 2006 2008 2010 2012
Lait (marge en %)
Non-cyclical
Cycle
Fixed Length Symmetric (Baxter-King) Filter
-0.2
0.0
0.2
0.4
0.6
0.8
1.0
1.2
.0 .1 .2 .3 .4 .5
Actual Ideal
Frequency Response Function
cycles/period
Analyse des cycles
Jonathan Benchimol 87
-60
-40
-20
0
20
40
60
80
100
120
140
160
180
00 01 02 03 04 05 06 07 08 09 10 11 12
Lait (marge en %) Trend Cycle
Hodrick-Prescott Filter (lambda=14400)
Filtre HP: séparer un cycle d’une tendance

Filtre Hodrick-Prescott (HP)
Jonathan Benchimol 88
Objectif: dissocier les cycles de court terme et de long terme.
Tolérances: inflexions lentes de la tendance, en imposant que cet écart à la tendance ne dépasse pas une certaine valeur représentant les évolutions de la partie conjoncturelle.
Atout: Représentation non linéaire de la tendance.
Lambda = 100*(nombre de période dans l’année)²
Données annuelles = 100*1² = 100
Données trimestrielles = 100*4² = 1 600
Données mensuelles = 100*12² = 14 400
Données hebdomadaires = 100*52² = 270 400

ANOVA
Jonathan Benchimol 89
L'analyse de la variance (ANalysis Of VAriance) permet
de vérifier que plusieurs échantillons sont issus d'une
même population.
Ce test s'applique lorsque l'on mesure une ou plusieurs
variables explicatives catégorielles (facteurs de variabilité,
de différentes modalités ou niveaux) qui ont de l'influence
sur la distribution d'une variable continue à expliquer.
On parle d'analyse à un facteur, lorsque l'analyse porte
sur un modèle décrit par un facteur de variabilité,
d'analyse à deux facteurs ou d'analyse multifactorielle
sinon.

Tests de causalité
Jonathan Benchimol 90
Après avoir validé la
stationnarité des
données, on peut
tester un lien de
causalité entre des
séries temporelles.
Ci-contre, on montre
que:
MEAT MILK
CATTLE MEAT
COW MEAT
CATTLE COW*

Quelques repères
Jonathan Benchimol 91
@R2 R²
@RBAR2 R² ajusté
@SE Ecart type de la régression
@SSR Somme des carrés des résidus
@DW Durbin–Watson
@F F–statistic
@LOGL Valeur de la fonction de vraisemblance
@REGOBS Nombre d’observation de la régression
@AIC Critère d’information d’Akaike
@SC Critère de Schwartz
@MEANDEP Moyenne de la variable dépendante
@SDDEP Ecart type de la variable dépendante
@NCOEF Nombre total de coefficients estimés
@COVARIANCE(i,j) Covariance des coefficients i et j
@RESIDCOVA(i,j) Covariance des résidus de l’équation i avec ceux de l’équation j dans un VAR ou un objet système. @RESIDCOVA doit être précédé du nom de l’objet.

Quelques repères
Jonathan Benchimol 92
+ Addition
– Soustraction
* Multiplication
/ Division
^ Puissance
> Supérieur; X>Y vaut 1 si X est supérieur à Y et vaut 0 sinon. Idem avec =, <, <>, <=, >=.
D(X) Différence première de X, X – X(–1)
D(X,n) Différence du nième ordre de X
D(X,n,s) Différence du nième ordre de X et différence saisonnière d’ordre s.

Quelques repères
Jonathan Benchimol 93
LOG(X) Logarithme naturel
DLOG(X) Différence première de logarithme naturel: LOG(X)– LOG(X(–1))
DLOG(X,n) Différence du nième ordre du logarithme de X: LOG(X)– LOG(X(–n))
DLOG(X,n,s) Différence du nième ordre du logarithme de X et différence saisonnière d’ordre s.
EXP(X) Fonction exponentielle
ABS(X) Fonction valeur absolue
SQR(X) Fonction racine carrée
SIN(X) Fonction sinus
COS(X) Fonction cosinus
@ASIN(X) Fonction arc sinus
@ACOS(X) Fonction arc cosinus

Quelques repères
Jonathan Benchimol 94
RND Nombre aléatoire uniformément distribué entre zéro et un.
NRND Nombre aléatoire normalement distribué N(0;1)
@PCH(X) Pourcentage de variation: (X–X(–1))/X(–1)
@INV(X) Inverse ou réciproque: 1/X
@DNORM(X) Densité normale standard
@CNORM(X) Distribution normale cumulative
@LOGIT(X) Logit de X
@SUM(X) Somme des X
@MEAN(X) Moyenne des X
@VAR(X) Variance des X
@SUMSQ(X) Somme des carrés de X
@OBS(X) Nombre d’observations de X valides
@COV(X,Y) Covariance entre X et Y

Quelques repères
Jonathan Benchimol 95
@COR(X,Y) Corrélation entre X et Y
@CROSS(X,Y) Produit croisé entre X et Y
@MOVAV(X,n) Moyenne mobile sur n périodes de X, où n entier naturel
@MOVSUM(X,n) Somme mobile sur n périodes de X, où n entier naturel
@TREND(d) Tendance normalisée à zéro en période d où d est une date ou un numéro d’observation.
@SEAS(d) Variable dummy saisonnière égale à un lorsque le trimestre ou le mois vaut d, et zéro sinon.
@DNORM(X) Fonction standard de densité normale de X
@CNORM(X) @DNORM(X) cumulative de X
@TDIST(X, d) Probabilité que le test de Student dépasse X avec d degrés de liberté.
@FDIST(X, n, d) Probabilité que le test de Fisher dépasse X avec n degrés de liberté au numérateur et d degrés de liberté au dénominateur.
@CHISQ(X, d) Probabilité que le test du Chi² dépasse X avec d degrés de liberté.


















