
Dynamique des systèmes cognitifs et des systèmes...
152
Université Lumière Lyon 2 Ecole Doctorale Informatique et Mathématiques Laboratoire LIRIS – Equipe COMBINING T HÈSE DE DOCTORAT EN I NFORMATIQUE Dynamique des systèmes cognitifs et des systèmes complexes Etude du rôle des délais de transmission de l’information Présentée par Régis MARTINEZ Dirigée par Hélène PAUGAM-MOISY, Professeur à l’Université Lumière Lyon 2 Soutenue publiquement le 26 septembre 2011 Devant le jury composé de : Frédéric ALEXANDRE Directeur de Recherche INRIA, Examinateur Hugue BERRY HDR, Chargé de Recherche INRIA Examinateur Philippe CAILLOU Maître de Conférence à l’Université Paris Sud XI / IUT de Sceaux Examinateur René DOURSAT HDR, Institut des Systèmes Complexes et CREA, Ecole Polytechnique/CNRS Rapporteur Nicolas FOURCAUD-TROCMÉ Chargé de Recherche CNRS Examinateur Hélène PAUGAM-MOIY Professeur à l’Université Lumière Lyon 2 Directeur de Thèse Phillipe TARROUX Professeur à l’Ecole Normale Supérieure Rapporteur
Transcript of Dynamique des systèmes cognitifs et des systèmes...

Université Lumière Lyon 2
Ecole Doctorale Informatique et Mathématiques
Laboratoire LIRIS – Equipe COMBINING
THÈSE DE DOCTORAT EN INFORMATIQUE
Dynamique des systèmes cognitifs etdes systèmes complexes
Etude du rôle des délaisde transmission de l’information
Présentée par Régis MARTINEZ
Dirigée par Hélène PAUGAM-MOISY, Professeur à l’Université Lumière Lyon 2
Soutenue publiquement le 26 septembre 2011
Devant le jury composé de :
Frédéric ALEXANDRE Directeur de Recherche INRIA, ExaminateurHugue BERRY HDR, Chargé de Recherche INRIA ExaminateurPhilippe CAILLOU Maître de Conférence à l’Université Paris Sud XI / IUT de Sceaux ExaminateurRené DOURSAT HDR, Institut des Systèmes Complexes et CREA, Ecole Polytechnique/CNRS RapporteurNicolas FOURCAUD-TROCMÉ Chargé de Recherche CNRS ExaminateurHélène PAUGAM-MOIY Professeur à l’Université Lumière Lyon 2 Directeur de ThèsePhillipe TARROUX Professeur à l’Ecole Normale Supérieure Rapporteur

Résumé
La représentation de l’information mnésique est toujours une question d’intérêt majeur enneurobiologie, mais également, du point de vue informatique, en apprentissage artificiel. Danscertains modèles de réseaux de neurones artificiels, nous sommes confrontés au dilemme dela récupération de l’information sachant, sur la base de la performance du modèle, que cetteinformation est effectivement stockée mais sous une forme inconnue ou trop complexe pourêtre facilement accessible. C’est le dilemme qui se pose pour les grands réseaux de neurones etauquel tente de répondre le paradigme du « reservoir computing ».
Le « reservoir computing » est un courant de modèles qui a émergé en même temps quele modèle que nous présentons ici. Il s’agit de décomposer un réseau de neurones en (1) unecouche d’entrée qui permet d’injecter les exemples d’apprentissage, (2) un « réservoir » com-posé de neurones connectés avec ou sans organisation particulière définie, et dans lequel ilpeut y avoir des mécanismes d’adaptation, (3) une couche de sortie, les « readout », sur laquelleun apprentissage supervisé est opéré. Nous apportons toutefois une particularité, qui est celled’utiliser les délais axonaux, temps de propagation d’une information d’un neurone à un autre.Leur mise en œuvre est un apport computationnel en même temps qu’un argument biologiquepour la représentation de l’information.
Nous montrons que notre modèle est capable d’un apprentissage artificiel efficace et pro-metteur même si encore perfectible. Sur la base de ce constat et dans le but d’améliorer lesperformances nous cherchons à comprendre les dynamiques internes du modèle. Plus précisé-ment nous étudions comment la topologie du réservoir peut influencer sa dynamique. Nousnous aidons pour cela de la théorie des groupes polychrones. Nous avons développé, pourl’occasion, des algorithmes permettant de détecter ces structures topologico-dynamiques dans unréseau, et dans l’activité d’un réseau de topologie donnée.
Si nous comprenons les liens entre topologie et dynamique, nous pourrons en tirer partipour créer des réservoirs adaptés aux besoins de l’apprentissage. Finalement, nous avons menéune étude exhaustive de l’expressivité d’un réseau en termes de groupes polychrones, en fonc-tion de différents types de topologies (aléatoire, régulière, petit-monde) et de nombreux pa-ramètres (nombre de neurones, connectivité, etc.). Nous pouvons enfin formuler un certainnombre de recommandations pour créer un réseau dont la topologie peut être un support richeen représentations possibles. Nous tentons également de faire le lien avec la théorie cogni-tive de la mémoire à traces multiples qui peut, en principe, être implémentée et étudiée par leprisme des groupes polychrones.
Mots clés : systèmes complexes, réseaux de neurones artificiels, délais axonaux, polychro-nisation, STDP, apprentissage artificiel
i

Abstract
How memory information is represented is still an open question in neurobiology, but also,from the computer science point of view, in machine learning. Some artificial neuron networksmodels have to face the problem of retrieving information, knowing that, in regard to the mo-del performance, this information is actually stored but in an unknown form or too complexto be easily accessible. This is one of the problems met in large neuron networks and which« reservoir computing » intends to answer.
« Reservoir computing » is a category of models that has emerged at the same period as,and has propoerties similar to the model we present here. It is composed of three parts thatare (1) an input layer that allows to inject learning examples, (2) a « reservoir » composed ofneurons connected with or without a particular predefined, and where there can be adaptationmecanisms, (3) an output layer, called « readout », on which a supervised learning if performed.We bring a particularity that consists in using axonal delays, the propagation time of informa-tion from one neuron to another through an axonal connexion. Using delays is a computationalimprovement in the light of machin learning but also a biological argument for informationrepresentation.
We show that our model is capable of a improvable but efficient and promising artificiallearning. Based on this observation and in the aim of improving performance we seek to un-derstand the internal dynamics of the model. More precisely we study how the topology ofthe reservoir can influence the dynamics. To do so, we make use of the theory of polychro-nous groups. We have developped complexe algorithms allowing us to detect those topologico-dynamic structures in a network, and in a network activity having a given topology.
If we succeed in understanding the links between topology and dynamics, we may take ad-vantage of it to be able to create reservoir with specific properties, suited for learning. Finally,we have conducted an exhaustive study of network expressivness in terms of polychronousgroups, based on various types of topologies (random, regular, small-world) and different pa-rameters (number of neurones, conectivity, etc.). We are able to formulate some recommanda-tions to create a network whose topology can be rich in terms of possible representations. Wepropose to link with the cognitive theory of multiple trace memory that can, in principle, beimplemented and studied in the light of polychronous groups.
Keywords : complex systems, artificial neuron networks, axonal delays, polychronization,STDP, machine learning
ii

Table des matières
1 Introduction 1
I Etat de l’art 4
2 Les réseaux de neurones artificiels 52.1 Contexte historique et introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.2 Les grandes familles de réseaux de neurones . . . . . . . . . . . . . . . . . . . . . 62.3 Les neurones impulsionnels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3.1 Les modèles de neurone impulsionnel . . . . . . . . . . . . . . . . . . . . . 82.3.2 Le Spike Response Model (SRM ) . . . . . . . . . . . . . . . . . . . . . . . 9
2.4 Codage temporel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3 Dynamiques neuronales et adaptations 123.1 Dynamique d’un neurone . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.1.1 Arguments neuro-physiologiques . . . . . . . . . . . . . . . . . . . . . . . 133.1.2 Précision temporelle du neurone et des signaux . . . . . . . . . . . . . . . 13
3.2 Dynamiques collectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.2.1 Paramètres d’influence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.2.2 Rôle des délais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173.2.3 Dynamiques remarquables . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4 Le réservoir computing 224.1 Définition générale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224.2 Modèles de référence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.2.1 Echo State Networks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244.2.2 Liquid State Machine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.3 Optimiser le réservoir . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254.3.1 Propriétés d’un réservoir . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254.3.2 Adapatation des paramètres du réservoir . . . . . . . . . . . . . . . . . . . 264.3.3 Apprentissage de la sortie . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.4 Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
5 Les réseaux complexes 295.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5.1.1 Les systèmes complexes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 295.1.2 La théorie des graphes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
5.2 La théorie des réseaux complexes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 315.2.1 Degré et distribution des degrés . . . . . . . . . . . . . . . . . . . . . . . . 315.2.2 Coefficient de clusterisation . . . . . . . . . . . . . . . . . . . . . . . . . . . 325.2.3 Efficacité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 325.2.4 Centralité d’intermédiarité . . . . . . . . . . . . . . . . . . . . . . . . . . . 335.2.5 Modularité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
5.3 Familles de réseaux et leurs propriétés . . . . . . . . . . . . . . . . . . . . . . . . . 355.3.1 Les réseaux réguliers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 355.3.2 Les réseaux aléatoires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36

5.3.3 Les réseaux petit-monde . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 365.3.4 Les réseaux invariants d’échelle . . . . . . . . . . . . . . . . . . . . . . . . 36
5.4 Dynamique et réseaux complexes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 375.4.1 L’influence de la topologie sur la dynamique . . . . . . . . . . . . . . . . . 385.4.2 Etude de la dynamique complexe . . . . . . . . . . . . . . . . . . . . . . . 38
5.5 Domaines d’application . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
II Modèle et résultats 40
6 Le simulateur 426.1 Aspects pour le contrôle des dynamiques neuronales . . . . . . . . . . . . . . . . 426.2 Aspects pour les architectures de réseaux complexes . . . . . . . . . . . . . . . . . 426.3 Aspects pour le Reservoir Computing . . . . . . . . . . . . . . . . . . . . . . . . . 436.4 Implémentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 436.5 Autres simulateurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
6.5.1 Simulateurs pour les réseaux de neurones impulsionnels . . . . . . . . . . 446.5.2 Logiciels pour les réseaux complexes . . . . . . . . . . . . . . . . . . . . . 45
7 Un modèle de classification supervisé 467.1 Le modèle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
7.1.1 Les paramètres du modèle . . . . . . . . . . . . . . . . . . . . . . . . . . . . 487.2 L’apprentissage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 497.3 Résultats préliminaires sur des motifs simples . . . . . . . . . . . . . . . . . . . . 51
7.3.1 Obervations et mesures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 517.3.2 Protocole de simulation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 527.3.3 Performances du modèle . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
7.4 Résultats en reconnaissance de caractères sur la base USPS . . . . . . . . . . . . . 56
8 Etude du réservoir et de son activité 608.1 Définition de la notion de groupe polychrone . . . . . . . . . . . . . . . . . . . . . 61
8.1.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 618.1.2 PG structuraux et PG dynamiques . . . . . . . . . . . . . . . . . . . . . . . 62
8.2 Recensement des groupes polychrones . . . . . . . . . . . . . . . . . . . . . . . . . 628.2.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
8.3 Algorithmes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 648.3.1 Algorithme 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 648.3.2 Algorithme 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 668.3.3 Algorithme 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
8.4 Etude de la complexité algorithmique . . . . . . . . . . . . . . . . . . . . . . . . . 688.5 Etude de la dynamique du réservoir . . . . . . . . . . . . . . . . . . . . . . . . . . 69
8.5.1 Sélection des groupes polychrones et spécialisation . . . . . . . . . . . . . 698.5.2 Vers une mémoire à traces multiples . . . . . . . . . . . . . . . . . . . . . . 728.5.3 Coloriage et interprétation des groupes spécialisés . . . . . . . . . . . . . . 75
9 Etude des propriétés des groupes polychrones 799.1 Etude préliminaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
9.1.1 Délais et apprentissage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 799.1.2 Liens entre PG et neurones . . . . . . . . . . . . . . . . . . . . . . . . . . . 80

9.2 Objet d’étude et objectifs de l’étude . . . . . . . . . . . . . . . . . . . . . . . . . . . 839.2.1 Paramètres contrôlés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 839.2.2 Quantités mesurées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
9.3 Etude paramétrique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 859.3.1 Nombre de PG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 859.3.2 Fréquence neuronale moyenne des PG . . . . . . . . . . . . . . . . . . . . 929.3.3 Durée et nombre de spikes des PG . . . . . . . . . . . . . . . . . . . . . . . 939.3.4 Population recrutée par les PG . . . . . . . . . . . . . . . . . . . . . . . . . 959.3.5 Proportion de PG tronqués (cycliques) . . . . . . . . . . . . . . . . . . . . . 97
10 Etude des distributions des groupes polychrones 9910.1 Distributions pour d = 10 = 1ms . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
10.1.1 Figure 10.2 - dtd = 0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10010.1.2 Figure 10.4 - dtd = 10 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10310.1.3 Figure 10.6 - dtd = 20 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10510.1.4 Synthèse : mesure d’entropie . . . . . . . . . . . . . . . . . . . . . . . . . . 107
10.2 Distributions pour d = 50 = 5ms . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10710.2.1 Figure 10.8 - dtd = 0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10710.2.2 Figure 10.10 - dtd = 10 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10910.2.3 Figure 10.11 - dtd = 20 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11110.2.4 Synthèse : mesure d’entropie . . . . . . . . . . . . . . . . . . . . . . . . . . 113
10.3 Entropie en fonction de d . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11310.4 Conclusion partielle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
11 Discussion et Perspectives 11611.1 Perspectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11711.2 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
III Annexes 119
A Distributions des PG 120A.1 Distributions pour dtd = 10 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120A.2 Distributions pour d = 10 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125A.3 Distributions pour d = 50 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
Bibliographie 135

1Introduction
Un des grands défis des sciences cognitives, depuis longtemps, est de comprendre les mystèresde la mémoire humaine. Il y a aujourd’hui un consensus sur le fait qu’une partie de la mé-moire à long terme est localisée dans des zones spécialisées du cortex associatif. Une questionouverte demeure celle de savoir comment les informations sont représentées et traitées par lecerveau. Dans le même temps les avancées en sciences cognitives ont permis d’apporter desidées nouvelles à l’ingénierie en s’inspirant des mécanismes biologiques. C’est par exemple lecas en apprentissage artificiel avec le premier modèle de neurone artificiel en 1943, qui fut suivipar la conception de nombreux modèles de réseaux de neurones artificiels essentiellement dansles années 80-90.
Emergence des aspects temporels
A la fin des années 90, l’élaboration de modèles de neurones artificiels tenant compte desinstants de décharge et des phénomènes internes aux neurones a permis aux modélisateurs des’intéresser à des questions plus bas niveau que jusqu’alors. L’émergence des neurones impul-sionnels suscite alors l’intérêt à la fois des communautés des neurosciences et de la cognition,mais aussi de celle de l’apprentissage artificiel (aussi communément appelé par son nom an-glais « machine learning »). Ces nouveaux modèles permettent d’étudier les aspects temporelsfins, c’est-à-dire à une ganularité temporelle en deça de la milliseconde. C’est pourquoi ils ontun intérêt d’une part pour les biologistes, à des fins de modélisation, et d’autre part pour l’ap-prentissage artificiel du fait de la plus grande puissance de calcul qu’ils représentent, compara-tivement aux générations de neurones précédentes. L’accroissement des capacités de calcul desordinateurs permettant désormais des simulations à grandes échelles, de nombreux travauxvoient le jour. Parmi ces nouveaux travaux basés sur les aspects temporels, poussés par desobservations en neurophysiologie (Swadlow, 1985), des études ont prouvé l’intérêt théoriquedes délais dans les réseaux de neurones impulsionnels (Maass & Schmitt, 1997). L’apport desdélais augmente notamment la capacité théorique d’apprentissage d’un réseau de neuronesimpulsionnels (Schmitt, 1999).
Vers une représentation de l’information mnésique
En 2006, Izhikevich, s’appuyant sur de précédents articles fondateurs tels que Edelman(1987); Fuji et al. (1996); Izhikevich et al. (2004), propose une hypothèse quant à la façon dontles assemblées neuronales tireraient parti des délais effectifs de transmission des informations.En effet, cette contrainte physique qu’est la vitesse de conduction des signaux électriques dansles fibres nerveuses, pourrait finalement être la brique de base de la mémorisation. Des motifstemporels pourraient ainsi être implicitement stockés dans la topologie. La combinaison deces structures pourrait alors former à l’infini des motifs plus complexes. L’auteur nomme ceprincipe la polychronisation.
1

Emergence du Reservoir Computing
Dans le même temps, du côté apprentissage artificiel, une nouvelle famille de modèles d’ap-prentissage fait son apparition sous le nom de Reservoir Computing (RC) (Schrauwen et al.,2007; Lukosevicius & Jaeger, 2009). Ces modèles ont la caractéristique d’avoir pour composantprincipal un réservoir. Il s’agit d’un système dans lequel a lieu une activité qui évolue avec letemps. Le temps peut être simulé ou être un simple recalcul de l’état du système à chaque cycle.Il s’agit donc d’un système dynamique, et la propagation de l’information y est sensible auxconditions initiales. La perturbation du système par un événement extérieur modifie la dyna-mique. Le principe est d’apprendre à reconnaître la dynamique en cours dans le réservoir pourpouvoir prédire l’évolution de celle-ci.
Vers un réservoir bio-inspiré
Dans nombre de modèles de RC, le réservoir est composé de neurones impulsionnels. Nousreprenons ce principe en introduisant la notion de délai. Nous souhaitons tirer parti des mé-canismes qu’ils permettent de simuler. Notamment nous espérons ainsi mettre en place unapprentissage basé sur l’activité temporelle du réservoir, celle-ci devant être sensible aux sti-mulations. Pour ce faire nous nous inspirons donc bien sûr des principes du RC, mais aussides théories de l’apprentissage artificiel que nous appliquons aux délais. Ainsi, nous utilisonsd’une part un réservoir composé de neurones impulsionnels soumis à un mécanisme d’adap-tation non-supervisé dépendant de l’activité, et d’autre par une couche de neurones de sor-tie qui reçoivent des connexions du réservoir, connexions sur lesquelles nous implémentonsun apprentissage supervisé des délais. Nous montrons que notre modèle d’apprentissage estfonctionnel.
Comprendre les mécanismes sous-jacents
Nous cherchons dès lors à comprendre précisément sur quelle base l’apprentissage fonc-tionne. Nous montrons que celui-ci arrive à se stabiliser. Nous nous interrogeons sur les basesneuronales (au sein du réservoir) du succès de l’apprentissage. Nous nous demandons où etsous quelle forme est stockée l’information qui s’avère pertinente pour l’apprentissage. Pour cefaire nous faisons appel à la notion de polychronisation qui nous permet d’étudier les micro-structures (appelées groupes polychrones) de la dynamique du réservoir. Nous observons queces micro-structures évoluent avec l’adaptation qui a lieu dans le réservoir, mais surtout nousremarquons que leur évolution dépend des stimulations appliquées au réservoir. Ces micro-structures se spécialisent pour certains types de stimulations. Notre conjecture est que plus leréseau sera riche de ces groupes polychrones, plus sa capacité d’apprentissage sera grande.Il semble alors pertinent de mieux étudier ces groupes polychrones afin de pouvoir en tirerparti en termes d’apprentissage artificiel mais aussi, de permettre, à terme, de proposer unemodélisation d’une théorie de la mémorisation appelée mémoire à traces multiples (Hintzman,1986).
Connaissance des groupes polychrones
Si les groupes polychrones sont effectivement une brique de base de la représentation del’information, donc de l’apprentissage et de la mémorisation, alors il est d’une importance ma-jeure de mieux les connaître. Nous réalisons une étude des propriétés des groupes polychroneset de leur évolution selon différentes structures de réseaux de neurones décrites par la théorie
2

des résaux complexes. Nous étudions alors le nombre de groupes polychrones, leur composi-tion, leurs caractéristiques en fonction de ces différents types de réseaux de neurones. Il s’avèrequ’il y a des différences très marquées d’un type de réseau à un autre, en termes de groupespolychrones.
Plan de la thèse
Nous avons découpé ce manuscrit en deux parties. La première partie présente princi-palement l’état des différents domaines auxquels nous avons fait appel dans nos travaux. Ladeuxème partie présente et explique les différents résultats que nous avons obtenus à ce jour.
Après avoir présenté les différents aspects de réseaux de neurones dans le chapitre 2, nousabordons la question des dynamiques neuronales et des critères qui les influencent dans lechapitre 3. Nous y abordons également un aspect étroitement lié aux dynamiques neuronales,à savoir les apprentissages qui peuvent être mis en œuvre dans les réseaux de neurones, tantbiologiques qu’artificiels impulsionnels. Dans le chapitre 4 nous présentons le paradigme duReservoir Computing et les différents apports théoriques qu’offrent ces modèles. Le chapitre 5présente l’état de l’art sur les réseaux complexes et leurs principales propriétés dont celles quenous utiliserons par la suite.
Avant de présenter nos travaux scientifiques, nous décrivons dans le chapitre 6 les aspectstechniques et néanmoins cruciaux du simulateur que nous avons développé. Ce simulateura été le support de l’ensemble des expériences que nous avons pu réaliser. Le modèle d’ap-prentissage à deux échelles que nous proposons est décrit en détail ainsi que les algorithmesd’apprentissage, dans le chapitre 7. Nous y étudions également les résultats préliminaires surles performances en classification. Nous cherchons ensuite à comprendre les bases du compor-tement de notre modèle en faisant appel à la notion de polychronisation dans le chapitre 8.De nouveaux résultats d’apprentissage convainquants y sont présentés. Nous abordons alorsl’étude exhaustive des groupes polychrones et de leurs propriétés en fonction de la topologiedu réseau, sous forme quantitative dans le chapitre 9 et sous forme de distributions dans lechapitre 10.
Nous avons adopté la convention d’écriture suivante :– en italique : les termes qui revêtent un sens particulier– en gras : les termes qui sont définis par la phrase qui les contient– « entre guillemets » : les termes en anglais
Exemple :“Nous souhaitons évaluer la cliquicité (en anglais « cliquishness »)”“Nous appellerons ce réseau principal, le sac de neurones ou réservoir.”
3

Première partie
Etat de l’art
4

2Les réseaux de neurones artificiels
Les neurones artificiels et réseaux de neurones artificiels sont le terreau, les fondations surlesquelles se basent nos travaux. Nous y consacrons ici un chapitre présentant les différentesarchitectures classiques et les modèles de neurones existants. Nous justifions ainsi notre choixdes neurones impulsionnels par deux de leurs avantages : un réalisme biologique suffisante etune complexité calculatoire satisfaisante.
2.1 Contexte historique et introduction
Les réseaux de neurones artificiels sont un domaine de l’informatique qui a émergé dansles années 40 et dont le composant atomique est le neurone artificiel. L’introduction du premierneurone artificiel et des premiers réseaux de neurones artificiels (McCulloch & Pitts, 1943; Ro-senblatt, 1958) a suscité un engouement de la part de la communauté scientifique. Le principefondamental de tout modèle de neurone artificiel est que l’état du neurone est sujet à des chan-gements au cours du temps, sous l’influence d’un événements extérieur i.e. d’une stimulation.Les premiers neurones artificiels étaient des modèles dont l’état était une métaphore du taux dedécharge d’un neurone biologique. Ces modèles sont communément appelés neurones à tauxde décharge. Dans cette génération de modèles, un neurone recevant la stimulation d’autresneurones recalcule son état, c’est-à-dire une valeur numérique représentant sa fréquence dedécharge, en fonction de la force des stimulations reçues. Ainsi, un ensemble de neurones arti-ficiels dépendant les uns des autres (quelles que soient la nature et la forme de ces dépendances)est appelé réseau de neurones artificiels (RNA).
En 1969 Minsky & Papert (1969) publient un argumentaire mettant en évidence les fai-blesses des RNA, à savoir leur incapacité à résoudre des problèmes non-linéaires, tels que lamodélisation de la fonction logique XOR. Il s’en est suivi une diminution substentielle desfonds affectés à la recherche dans ce domaine, qui resta donc au point mort. Puis il connu unregain d’intérêt au tout début des années 80, avec l’émergence de modèles qui proposent desavancées outrepassant les faiblesses des RNA. Cette période voit l’apparition du mécanismed’apprentissage dit de rétro-propagation (Rumelhart et al., 1986), mais également de nouvellesarchitectures telles que les cartes auto-organisatrices (Kohonen, 1982) et les réseaux récurrents(Hopfield, 1982; Elman, 1990; Jordan, 1986).
Ainsi les premiers neurones artificiels étaient des modèles simulant le taux de décharge(i.e. la fréquence) moyen d’un neurone biologique. Dans les années 90, avec la croissance dela puissance de calcul des ordinateurs, et les avancées en biologie, une nouvelle génération deneurones nommés neurones impulsionnels (en anglais « spiking neurons ») apparaît dans lemonde des science de l’informatique (Watts, 1994; Maass, 1997a,b; Maass & Natschläger, 1997;Gerstner & Kistler, 2002). Ces modèles ne simulent plus la fréquence de décharge, mais s’in-téressent aux émissions individuelles de potentiels d’action. Pour traiter de la génération desneurones à taux de décharge, nous parlerons des neurones artificiels classiques. Voir Haykin
5

(1999) pour une revue des RNA classiques et Paugam-Moisy & Bothe (2011) pour une revuedes réseaux de neurones impulsionnels.
2.2 Les grandes familles de réseaux de neurones
Nous présentons ici les grandes familles de RNA organisées en fonction de leur dynamique,indépendamment des modèles de neurones artificiels, dont nous parlerons dans la section 2.3.
Les réseaux « feed forward » Ce sont des réseaux dont la structure suit une logique de traite-ment de l’information au travers de couches de neurones successives, de l’entrée vers la sortie,sans retour de l’information en amont (voir figure 2.1). C’est par exemple le cas des percep-trons et perceptrons multi-couches (Rosenblatt, 1958; Rumelhart et al., 1986). Ces architecturesrestent souvent utilisées. Dans ces réseaux la dynamique est dirigée par la présentation desexemples d’entrée. Les activations se propagent en sens unique, de la couche d’entrée à lacouche de sortie.
FIGURE 2.1 – Exemple de réseau de neurones artificiel
Les réseaux auto-organisés Les cartes auto-organisatrices (Fukushima, 1975; Grossberg, 1976a;Kohonen, 1982; Rumelhart & Zipser, 1985) sont inspirées de la structure du cortex, notammentvisuel, dans lequel on peut observer une connectivité locale. En d’autres termes, chaque neu-rone est connecté aux entrées et à ses voisins. Ce concept permet le traitement par un RNAd’informations dont on sait qu’elles portent des relations spatiales en elles, telles les pixelsd’une image.
Les réseaux récurrents Il s’agit de réseaux dont la structure, représentée sous forme de graphe,peut comporter des boucles (voir section 5.1.2 p.30 sur les notions de graphe et de boucle). Cesboucles peuvent changer radicalement la dynamique qui pourra s’instaurer dans un RNA, etl’amener à s’auto-entretenir. La notion de réseau récurrent est étudiée et mise en applicationpar Hopfield (1982), dans une mémoire auto-associative, i.e. un réseau constitué d’une seulecouche de neurones qui sont à la fois entrée et sortie. La récurrence se trouve dans le fait que
6

les neurones sont tous interconnectés. Cette idée de récurrence sera reprise dans le contexte desperceptrons multicouches, avec le réseau de Jordan (1986) et le réseau de Elman (1990). Dansces deux modèles, l’activation de la couche de sortie (dans le cas Jordan) ou de la couche cachée(dans le cas de Elman) est dupliquée en retour dans la couche d’entrée. La propriété de récur-rence est présente dans un grand nombre de modèles. Les modèles de « reservoir computing »(voir chapitre 4) se basent sur des architectures de ce type.
Les réseaux à résonance Ces réseaux sont structurés de telle manière que l’activité de tousles neurones est envoyée à tous les autres neurones, provoquant ainsi des phénomènes de ré-sonance et d’oscillation dans la dynamique du réseau. Parmi les représentants de cette famille,le modèle ART pour « Adaptive Resonance Theory » (Grossberg, 1976a,b). Les réseaux de Hop-field (1982) présentés dans les réseaux récurrents peuvent également avoir un fonctionnementen résonance. Ce principe est par exemple utilisé dans les modèles de mémoires associativetels que les « Bidirectional Associative Memory » (Kosko, 1988) et les « Boltzman Machines »(Ackley et al., 1985).
2.3 Les neurones impulsionnels
Avant de décrire les principaux modèles de neurone impulsionnel, nous rappelons briève-ment les grandes lignes du fonctionnement d’un neurone réel. Comme le montre la figure 2.2,nous considérons ici deux neurones : l’un chronologiquement placé avant la synapse (neu-rone pré-synaptique), l’autre placé après la synapse (neurone post-synaptique). Le neuronepré-synaptique émet une impulsion électrique appelée potentiel d’action (ou spike, ou encorepulse), symbolisée sur la figure par une flèche le long de l’axone. En traversant une synapse(l’encadré sur la figure), ce spike induit un potentiel électrique dans la membrane du neuronepost-synaptique.
FIGURE 2.2 – Exemple d’une connexion entre deux neurones biologiques
Ce potentiel est appelé potentiel post-synaptique (abrégé par PPS, en anglais « Post Sy-naptic Potential » abrégé PSP). Celui-ci se propage le long de la membrane du neurone post-synaptique (sur la figure 2.2 : flèches de petite taille sur les dendrites, symbolisant chacune la
7

propagation d’un PPS). En arrivant au soma, si les PPS sont suffisants en nombre et en am-plitude, et suffisament synchronisés pour que le potentiel de membrane dépasse un certainseuil, alors un nouveau potentiel d’action est créé : le neurone post-synaptique émet à sontour un spike. Notons qu’un PPS peut être excitateur (le potentiel de membrane du neuronepost-synaptique se rapprochera du seuil de déclenchement sous son influence) ou inhibiteur(le potentiel de membrane du neurone post-synaptique s’éloignera du seuil de déclenchementsous son influence), selon que le neurone pré-synaptique est lui-même excitateur ou inhibiteur.
2.3.1 Les modèles de neurone impulsionnel
Les modèles computationnels de neurone impulsionnel ont l’avantage de proposer une in-tégration temporelle de l’information. La réponse du neurone à une stimulation n’est plus unevaleur représentant le taux de décharge (principe du neurone à seuil ou sigmoïdal), mais letemps d’émission du prochain spike. L’information transmise n’est plus cadencée par la pré-sentation d’un stimulus. Un spike est émis à l’instant où l’excitation du neurone dépasse leseuil. Il est donc nécessaire d’adopter une horloge virtuelle permettant, au sein d’un RNA, detemporiser les émissions de spikes des neurones, qui peuvent alors être considérées commedes événements datés. Les modèles de neurone impulsionnel possèdent la propriété de détec-ter la corrélation temporelle des potentiels d’action afférents, surpassant en cela les modèles deneurone classiques. Les modèles de neurone impulsionnel proposés dans la littérature peuventêtre regroupés en quatre grandes familles :
1. Le modèle de Hodgkin & Huxley (HH) (Hodgkin & Huxley, 1952b,a) : ce modèle mathé-matique décrit la dynamique temporelle du neurone par les variations de concentrationsioniques (K+, Ca2+) dans différents compartiments et reproduit les principaux "modes"de fonctionnement du neurone biologique. Une activation peut se traduire par l’émissiond’un potentiel d’action unique, ou de quelques potentiels d’action à très haute fréquence("burst"), ou par une activité périodique soutenue. Le modèle est défini par quatre équa-tions différentielles inter-dépendantes.
2. Le modèle Integrate & Fire (IF) et ses dérivés : proposé par Lapicque en 1907 (Lapicque,1907) (article traduit en l’anglais par Brunel & van Rossum (2007)) se place à un niveaude détail de modélisation moins précis que le modèle de Hodgkin & Huxley. Le neu-rone est modélisé tel un circuit électrique composé d’un condensateur et d’une résistanceélectrique (dipôle RC). Ainsi, la dynamique du neurone est décrite par son potentiel demembrane et par l’intensité qui le traverse. Le modèle est décrit, mathématiquement, parune seule équation différentielle. Ce modèle ne rend pas compte des variations du poten-tiel de membrane mais seulement des émissions de spikes.
Le modèle Leaky Integrate & Fire (LIF) : dans le modèle IF précédent, le fait que le po-tentiel de membrane reste constant jusqu’à une prochaine stimulation est une carence parrapport à la réalité biologique. Aussi est-il possible d’adapter ce modèle afin que le po-tentiel de membrane tende à revenir à sa valeur de repos, en l’absence de stimulation.Le modèle IF avec cette propriété supplémentaire de potentiel de membrane à fuite estappelé « Leaky Integrate and Fire ».
Le modèle Quadratic Inegrate & Fire (QIF) (Ermentrout & Kopell, 1986; Fourcaud-Trocméet al., 2003, plus récemment) : il s’agit d’une variante du modèle QIF. En remplaçant
8

l’une des équations différentielles par un terme quadratique (du second degré), le mo-dèle garde une capacité de modéliser des comportements biologiques pertinents, tout enperdant en complexité.
Les modèles à conductance Integrate & Fire (gIF) (Rudolph & Destexhe, 2006) : il s’agitd’une classe de modèles qui apporte une amélioration au modèle LIF en basant les cal-culs de la dynamique interne du neurone sur sa conductance membranaire. Ce modèleest ainsi sujet à l’expérimentation de mécanismes d’adaptation, supervisée ou non super-visée.
3. Le Spike Response Model (SRM) (Gerstner & Kistler, 2002) : il s’agit d’une modélisa-tion phénoménologique du neurone, au sens où l’on ne considère pas les mécanismes sous-jacents, mais seulement le comportement du neurone. La formalisation de ce modèle secompose d’une fonction noyau donnant la dynamique du potentiel de membrane du neu-rone, et d’une fonction calculant la sommation des potentiels post-synaptiques (PPS). Saformulation mathématique provient d’une intégration des équations différentielles sous-jacentes, ce qui la rend plus proche de celle des neurones classiques, même si elle restebasée sur le temps. Nous détaillerons ce modèle dans la section suivante.
4. Le modèle d’Izhikevich (Izhikevich, 2003) fait intervenir deux équations différentiellescouplées, afin de modéliser les flux d’ions et les dynamiques de potentiel du neurone. Ilpermet de reproduire une vingtaine de comportements dynamiques différents, ce qui lerend précieux pour les modélisateurs qui souhaitent que leurs modèles restent prochesdes observations biologiques.
Nous décrivons ci-après les détails du modèle SRM0 car c’est celui qui a retenu notre atten-tion et que nous avons utilisé pour les travaux décrits dans cette thèse.
2.3.2 Le Spike Response Model (SRM )
SRM0 est une variante du SRM ne tenant compte, dans le calcul de la période réfractaire,que du dernier spike émis par le neurone. Nous utilisons ce modèle car il permet de modéli-ser une propriété essentielle qui est la détection de synchronie. En effet, le modèle SRM0 pro-posé par Gerstner et Kistler (Gerstner & Kistler, 2002), permet de reproduire en simulation lecomportement du neurone de Hodgkin & Huxley avec une bonne précision temporelle, et descalculs moins coûteux. Dans le modèle SRM0, le potentiel de membrane uj du neurone Nj estdécrit comme résultant, à l’instant t, de l’impact des PPS induits par les dernières émissions tfides neurones pré-synaptiques Ni :
uj(t) = η(t− tfj ) +∑
i
wijε(t− tfi − dij)
où tfj est l’instant d’émission du dernier spike du neurone Nj , ainsi t − tfj est le temps écoulédepuis cette émission. De façon similaire, t − tfi est le temps écoulé depuis le dernier spikedu neurone amont Ni. La fonction η(t − tfj ) décrit le décours temporel du potentiel de mem-brane du neuroneNj et permet la simulation d’une période réfractaire. Quant à elle, la fonctionε(t− tfi − dij) décrit le décours temporel d’un PPS en fonction du dernier spike du neurone Ni.Il faut noter que, dans ce modèle, le seuil du neurone a une valeur fixée ϑ, qui ne varie pas au
9
cours du temps. Le prochain spike tf+1j est déclenché dès que uj(t) dépasse le seuil : uj(t) ≥ ϑ
avec u′j(t) > 0.
Pour résumer, uj est donc la somme du potentiel de membrane et des PPS du dernier spikede chaque neurone amontNi reçu après un délai axonal dij , et pondéré par un poids synaptiquewij .
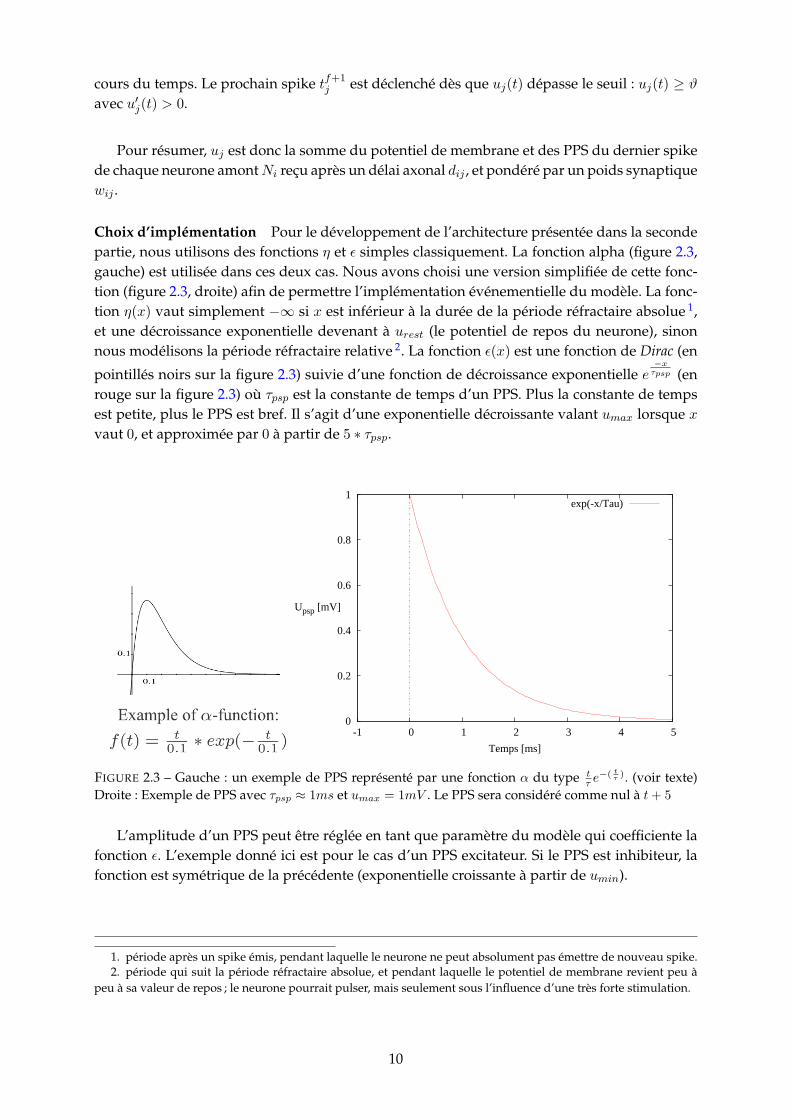
Choix d’implémentation Pour le développement de l’architecture présentée dans la secondepartie, nous utilisons des fonctions η et ε simples classiquement. La fonction alpha (figure 2.3,gauche) est utilisée dans ces deux cas. Nous avons choisi une version simplifiée de cette fonc-tion (figure 2.3, droite) afin de permettre l’implémentation événementielle du modèle. La fonc-tion η(x) vaut simplement −∞ si x est inférieur à la durée de la période réfractaire absolue 1,et une décroissance exponentielle devenant à urest (le potentiel de repos du neurone), sinonnous modélisons la période réfractaire relative 2. La fonction ε(x) est une fonction de Dirac (en
pointillés noirs sur la figure 2.3) suivie d’une fonction de décroissance exponentielle e−xτpsp (en
rouge sur la figure 2.3) où τpsp est la constante de temps d’un PPS. Plus la constante de tempsest petite, plus le PPS est bref. Il s’agit d’une exponentielle décroissante valant umax lorsque xvaut 0, et approximée par 0 à partir de 5 ∗ τpsp.
0
0.2
0.4
0.6
0.8
1
-1 0 1 2 3 4 5
Temps [ms]
Upsp [mV]
exp(-x/Tau)
FIGURE 2.3 – Gauche : un exemple de PPS représenté par une fonction α du type tτ e
−( tτ ). (voir texte)Droite : Exemple de PPS avec τpsp ≈ 1ms et umax = 1mV . Le PPS sera considéré comme nul à t+ 5
L’amplitude d’un PPS peut être réglée en tant que paramètre du modèle qui coefficiente lafonction ε. L’exemple donné ici est pour le cas d’un PPS excitateur. Si le PPS est inhibiteur, lafonction est symétrique de la précédente (exponentielle croissante à partir de umin).
1. période après un spike émis, pendant laquelle le neurone ne peut absolument pas émettre de nouveau spike.2. période qui suit la période réfractaire absolue, et pendant laquelle le potentiel de membrane revient peu à
peu à sa valeur de repos ; le neurone pourrait pulser, mais seulement sous l’influence d’une très forte stimulation.
10

2.4 Codage temporel
Dans la mesure où les réseaux de neurones impulsionnels utilisent des informations tem-porelles, il faut une règle de transcription permettant de convertir sous forme d’informationstemporelles des entrées habituellement codées en intensité sous forme de vecteurs numériques.Pour cela, nous utilisons un codage temporel (Hopfield et al., 1998). Par ce codage, un vecteurd’entrée numérique contenant différentes valeurs d’intensité est traduit par différents instantsd’émission de spikes par un neurone (voir figure 2.4).
cd
ba a
bc
d
tt−1
Neurones
Temps
Codage temporel
Composantes du vecteur
Codage en intensité
Vecteur numérique
Intensité
Vague de spikes dans un intervallede codage temporel
FIGURE 2.4 – Conversion d’un vecteur numérique en codage temporel
Plus la valeur à transmettre est élevée, plus l’émission du neurone d’entrée qui doit la trans-mettre sera précoce. Inversement, plus la valeur est faible, plus le neurone émettra tardivement.Comme le montre la figure inspirée de Kempter et al. (1996), les valeurs analogiques d’un vec-teur sont ainsi traduites dans un codage temporel, par rapport à un temps de référence t.
Nous avons présenté les RNA et les différents modèles de neurones. Une autre questiontout aussi essentielle est celle de l’information transmise par un neurone. La donnée est unspike. Mais que représente un ensemble de spikes et quelles peuvent être les propriétés decette représentation ? Puis, à l’échelle du réseau de neurones, comment se traduit cette repré-sentation de l’information ? Enfin, nous savons qu’il existe dans le cerveau des mécanismes quiremodèlent en permanence certaines zones, permettant l’apprentissage et l’adaptation. Com-ment ces aspects sont-ils liés et comment peuvent-ils nous aider à comprendre et à élaborer unmodèle d’apprentissage artificiel.
11

3Dynamiques neuronales et adaptations
Du fait de la grande diversité de types de neurones qui existent du point vue neurophysiolo-gique, on peut distinguer une multitude de comportements différents et modélisables. Izhike-vich (2004) reprend les comportements caractéristiques de certains types de neurones et pro-pose une nomenclature des modèles de neurones artificiels adaptés aux comportements quel’on souhaite modéliser. A la vue de ces comportements possibles on se demande quelle infor-mation est utilisée par les neurones. Nous nous intéressons donc ici à la question essentielle del’encodage de l’information par les neurones au sens général.
Représentation de l’information
La représentation de l’information et l’encodage neuronal sont deux notions que nous sou-haitons distinguer, mais qui pourtant sont intrinsèquement liées. A notre sens, la représentationde l’information se rapporte au stockage à long terme. La question de la représentation mentaled’un concept ou d’un objet, sa remémoration, se rapporte en premier lieu aux théories cogni-tives de la mémoire. Ces aspects haut niveau de la fonction mnésique peuvent nous donner desindices sur l’implémentation plus bas niveau. Ainsi par exemple, un modèle de mémoire quinous intéresse particulièrement est celui de la mémoire à traces multiples, proposé initialementpar Hintzman (1986). Ce modèle postule que chaque expérience vécue par l’individu laisseune trace mnésique. Cette trace est une empreinte des informations reçues lors de l’expérience,telles que les informations sensorielles, l’émotion, etc. Si l’individu vit une autre expériencesimilaire, la trace mnésique précédente va être réactivée (remémorée) et renforcée. C’est biensûr un mécanisme multimodal (lié à différentes modalités cognitives, telles que les sens), voireamodal (lié indifférement à différentes entrées qui sont toutes traitées de la même manière)(Versace et al., 2009).
Cette question de la représentation de l’information, de la mémorisation, doit permettre deréduire le champ d’investigation de la question de l’encodage bas niveau de cette information.L’encodage se rapporte à la manière dont cette information est extraite dynamiquement et aucode neuronal utilisé. Cette notion nous amène à des aspects tels que le « binding problem » –comment est faite l’intégration d’informations distribuées – et les oscillations (Singer & Gray,1995) : quel est le code neuronal mis en œuvre ?
3.1 Dynamique d’un neurone
Abeles (1982) évoque deux modes de fonctionnement du neurone qui s’opposent. D’unepart le comportement en détecteur de coïncidence caractérise un neurone qui sera sensibleà des stimulations rapprochées, d’autre part le comportement en intégrateur caractérise unneurone sensible à des stimulations plus étalées dans le temps, donc capable de tenir comptede spikes moins rapprochés. Ces deux modes de fonctionnement sont illustrés par la figure 3.1.
12

Threshold
Potential (mV)
Membrane Potential
Time (ms)
output spikes
input spikes
Potential (mV)
Membrane Potential
Threshold
Time (ms)
output spikes
input spikes
Intégrateur Détecteur de coïcidence
FIGURE 3.1 – Deux comportements différents selon la fuite d’un PPS. Gauche : comportement d’un neu-rone intégrateur. Droite : comportement d’un neurone détecteur de coïncidence. Figure d’après Paugam-Moisy (2006)
Paramètres d’influence
Typiquement, ces comportements peuvent être contrôlés par la constante de temps mem-branaire du neurone. Celle-ci, rappelons-le, représente la vitesse avec laquelle le potentiel demembrane du neurone revient à sa valeur de repos. D’un point de vue computationnel, dansle neurone impulsionnel SRM0, le réglage du paramètre τ permet de modifier la capacité d’unneurone à détecter la coïncidence des stimulations, ou plutôt à accumuler les stimulations pourles intégrer.
3.1.1 Arguments neuro-physiologiques
Softky & Koch (1993) ont mis en évidence que l’activité corticale est caractérisée par uneforte irréguarité de l’intervalle inter spikes (ISI). Une telle variabilité semble aléatoire et selonShadlen & Newsome (1994), peut être provoquée :• soit par le fait que les neurones sont des intégrateurs et qu’un équilibre entre excitation
et inhibition maintient le potentiel de membrane en fluctuation aléatoire, auquel cas l’in-formation transmise n’est pas un motif temporel précis, mais bien aléatoire,• soit par le fait que les neurones sont des détecteurs de coïncidence avec une constante
de temps très courte. Les observations alors vont à l’encontre d’une constante de tempscourte.
Néanmoins, König et al. (1996) pour l’aspect neurophysiologique et Watanabe & Aihara(1997) pour l’aspect computationnel, soutiennent qu’il est possible que les neurones corticauxutilisent effectivement une constante de temps courte. Kempter et al. (1998) montrent que laconstante de temps membranaire n’est pas le seul paramètre capable d’influencer le compor-tement du neurone, et suggèrent que la variation du seuil de déclenchement pourrait être unmécanisme d’adaptation dynamique du comportement du neurone.
3.1.2 Précision temporelle du neurone et des signaux
Il semble que la précision temporelle du neurone soit de l’ordre de la milliseconde (Crooket al., 1998), avec une distinction pouvant aller jusqu’au dixième de milliseconde (Mainen &Sejnowski, 1995; Cessac et al., 2009), mais pas davantage.
13

3.2 Dynamiques collectives
La dynamique individuelle des neurones est la brique de base de l’activité des populationsneuronales. Fuji et al. (1996) évoquent la notion d’assemblées neuronales dynamiques. Il s’agitd’ensembles de neurones dont l’activité est concertée. Plusieurs assemblées peuvent se mettreen interaction (par exemple par un mécanisme d’oscillations). Nous soutenons ici que l’activitéd’une population particulière est conditionnée par les stimulations qu’elle reçoit. En effet, àl’échelle de la population de neurones, l’activité globale est conditionnée par de nombreuxfacteurs, dont notamment :• la distribution des poids,• le comportement du neurone,• l’équilibre entre excitation et inhibition,• la structure du réseau de neurones,• la densité des connexions,• la distribution des latences (délais) axonales.
Il est évident, du point de vue physiologique, que bien d’autres paramètres influencentl’activité neuronale, mais il s’agit là de quelques-uns des plus importants et auxquels nouslimitons notre travail. Nous allons aborder chacun de ces points un à un et voir comment ilsinfluencent les dynamiques neuronales.
3.2.1 Paramètres d’influence
Distribution des poids
Les poids des connexions synaptiques modulent l’impact d’un PPS sur un neurone. La mo-dification de ces poids peut conditionner radicalement la dynamique du réseau. Gerstner et al.(1997) postulent l’idée d’un mécanisme d’adaptation des poids synaptiques basé sur une plas-ticité dépendante de l’activité synaptique. Ce mécanisme a été observé biologiquement (Mar-kram et al., 1997; Bi & Poo, 1998) et est connu sous le nom de Spike Time Dependent Plasticity(STDP). En biologie, il s’agit d’un mécanisme de plasticité au niveau synaptique où, selon l’ac-tivité de la synapse définie en termes de spikes, l’influence de la synapse se voit renforcée(Long Term Potentiation, LTP) ou dépréciée (Long Term Depression, LTD). Lorsqu’un poten-tiel d’action pré-synaptique atteint un neurone dans un court laps de temps avant que celui-cine décharge (potentiel d’action post-synaptique), la synapse reliant l’émetteur et le récepteurdu spike se voit renforcée. Inversement, lorsqu’un potentiel atteint un neurone peu de tempsaprès que ce dernier ait déchargé, la synapse se voit dépréciée. La quantité de modification seréduit quand l’écart temporel entre le potentiel d’action pré-synaptique et le potentiel d’actionpost-synaptique augmente, jusqu’à s’annuler au-delà de 20ms ou en-deça de −20ms. La fonc-tion qui relie la modification du poids de la synapse au décalage temporel entre les spikes pré-et post-synaptiques se lit sur une fenêtre de STDP (voir figure 3.2). La STDP, s’inspirant duprincipe d’apprentissage hebbien, est parfois également applée règle de Hebb temporelle.
Lorsque le mécanisme de STDP est mis en action dans un réseau de neurones impulsion-nels, il favorise les connexions qui sont pertinentes pour un neurone. Ces connexions sont cellesdont la majorité des potentiels d’action pré-synaptiques sont causalement corrélés avec (i.e. in-terviennent avant) l’émission d’un spike par le neurone post-synaptique. De telles synapses
14

1.0
−1.0
20 mstpost − tpre [ms]
−20 ms
décalage temporel de la synapse (tpost − tpre)
augmentation du poids
Delta W
FIGURE 3.2 – Exemple de fenêtre STDP
sont donc sélectionnées, puisque leur poids est augmenté, les autres tendent à être ignoréespuisque dépréciées.
Implémentation de la STDP Dans l’architecture neuronale que nous proposons, nous utili-sons une STDP multiplicative (Rubin et al., 2001) et non additive, afin de limiter une adaptationqui aboutirait à une distribution des poids qui serait saturée aux valeurs extrêmes. Dans le casde la STDP additive, la quantité ajoutée ou enlevée serait directement celle extraite de la fe-nêtre STDP. Dans notre cas, lors d’une modification des poids, la quantité de modification estproportionnelle à la distance entre la valeur du poids et la borne concernée (borne minimalewmin si c’est une diminution, borne maximale wmax si c’est une augmentation du poids). Nousutilisons donc les formules suivantes, où α est le taux d’apprentissage, un paramètre réglable :
Si ∆W ≤ 0, le poids est augmenté :
wij ← wij + α ∗ (wij − wmin) ∗∆W (3.1)
Si ∆W ≥ 0, le poids est diminué :
wij ← wij + α ∗ (wmax − wij) ∗∆W (3.2)
Dans nos travaux, nous avons utilisé la valeur α = 0.1. Généralement, et particulièrementdans nos simulations, les poids sont bornés avec des valeurs wmin = 0 et wmax = 1, que lasynapse soit excitatrice ou inhibitrice. La distinction entre synapse excitatrice ou inhibitrice estfaite au moment du calcul de l’impact du PPS. La fonction qui donne le ∆W est différente selonque la synapse est excitatrice ou inhibitrice, comme le montrent les fenêtres de STDP que nousavons utilisées (figure 3.3) selon les recommandations de Meunier (2007). Cette fonction donnela quantité de modification ∆W en fonction de la quantité ∆t = tpost − tpre = t− (tfi + dij).
Plasticité intrinsèque du neurone
Un mécanisme de plasticité peut avoir lieu à l’intérieur même du neurone, modifiant soncomportement. L’existence de ce mécanisme de plasticité appelé plasticité intrinsèque, a étémontré physiologiquement (Zhang & Linden, 2003). A la différence de la plasticité synaptique,ce mécanisme opére au sein du neurone. Cette plasticité pourrait influencer les dynamiquesinternes du neurone de plusieurs manières, dont entre autres :
15

1.0
POTENTIATION
DEPRESSION −0.5
t
W
10ms 20ms
100ms
1.0
t
W
20ms−20ms
−0.25
DEPRESSION DEPRESSION
POTENTIATION
+infini−infini
FIGURE 3.3 – Fenêtre STDP excitatrice (gauche) et inhibitrice (droite), tirées de Meunier & Paugam-Moisy (2005)
• en modifiant sa capacité d’intégration des entrées,• en modifiant son excitabilité,• en modifiant la rétro-propagation des spikes.
Comme le notent Kempter et al. (1998), un tel mécanisme peut influencer le comportementen intégrateur ou en détecteur de coïncidence. Plusieurs modèles de plasticité intrinsèque ontdéjà été proposés en modélisation, tels que Triesch (2005a) pour les neurones classiques à tauxde décharge, Joshi & Triesch (2009); Naudé et al. (2008) pour les neurones impulsionnels. Nousn’avons pas implémenté ce mécanisme d’adptation dans notre modèle de neurone, bien quenous modélisions la notion de seuil de déclenchement. Il serait néanmoins très simple à mettreen place en permettant la modulation de la constante de temps du potentiel de membrane τpsp
(capacité d’intégration), du seuil ϑ de déclenchement (excitabilité) et du taux d’apprentissageα de la STDP (rétro-propagation) .
Equilibre excitation/inhibition
Plusieurs études ont montré que l’implication des neurones inhibiteurs dans un réseau ap-porte de la richesse aux comportements possibles à l’échelle globale. Notamment Brunel (2000)montre que plusieurs régimes sont possibles dès lors que des neurones inhibiteurs sont utili-sés. van Vreeswijk & Sompolinsky (1996) ont également mis en évidence une activité chaotiquedans un réseau composé d’une population d’inhibiteurs et d’une population d’excitateurs. En-fin, il semble que la propotion corticale soit de 80% d’excitateurs pour 20% d’inhibiteurs.
Topologies neuronales
Nous aborderons dans le chapitre 5 la question des structures de réseau indépendammentdu domaine des réseaux de neurones. Néanmoins les réseaux de neurones n’échappent pas àl’intérêt porté aux réseaux complexes. Tout d’abord il semble que les propriétés petit-mondedes réseaux tendent à favoriser les phénomènes de synchronization et d’oscillation (Lago-Fernández et al., 2000; Barahona & Pecora, 2002). De plus, aspect intéressant, la STDP pourraitdonner au réseau de neurones des propriétés petit-monde (Kato et al., 2009; Suzuki & Ikeguchi,2008).
Connectivité
La densité de connexions, aussi appelée connectivité, conditionne le niveau d’activité d’unréseau de neurones. En effet plus le nombre de connexions est élevé, plus chaque spike émis
16

impactera de neurones, augmentant ainsi la probabilité que d’autre neurones soient à leur tourdéclenchés.
Distribution des délais axonaux
Abeles (1982) aborde la question du comportement d’intégrateur ou de détecteur de coïn-cidence des neurones dans le cortex, mais ne tient pas compte des délais axonaux qui influentsur les durées de transmission des spikes. Par ailleurs, les observations de Swadlow (1985)donnent la preuve de la diversité des délais, in vivo, généralement autour de 10ms, mais pou-vant aller de 0.1 à 44ms. Vibert et al. (1998) mettent également en évidence l’importance desdélais de transmission dans les réseaux de neurones artificiels, montrant que des délais diffé-rents induisent des comportements différents à l’échelle du réseau. Pour l’aspect algorithmiqueet computationnel, Maass & Schmitt (1997) montrent que les délais de transmission confèrentaux réseaux de neurones artificiels une meilleure capacité calculatoire en termes de fonctionsqu’ils sont capable de modéliser. En revanche les délais augmentent également la complexitéde l’apprentissage. Schmitt (1999) montre que les capacités de calcul et d’apprentissage desneurones et des réseaux sont accrus avec des délais de transmission adaptables. Néanmoins ilnote également que le problème de l’apprentissage des poids et des délais dans un réseau deneurones impulsionnels, afin de résoudre un problème de classification, est NP-complet.
3.2.2 Rôle des délais
Nous allons considérer plusieurs aspects des délais axonaux. Nous parlerons tout d’abordde la notion de sélection des délais synaptiques, qui est une conséquence de la STDP. Puis nousaborderons différentes méthodes proposées pour l’adaptation des délais. Nous évoquerons laplausibilité biologique de ces méthodes.
Sélection de délais
La STDP telle que décrite précédemment, est un mécanisme d’adaptation des poids des sy-napses. La STDP ne tient pas explicitement compte des délais de celles-ci. Le critère d’adapta-tion des poids est la différence des instants d’émission de spikes de deux neurones connectés.Cependant, il est physiologiquement démontré que ces délais existent. Du fait que le critèred’adaptation est de nature temporelle, la dépréciation et la potentiation des poids tient implici-tement compte des délais axonaux. En effet, comme le montrent Gerstner et al. (1997), la STDPa pour effet de ne conserver que les synapses dont les délais induisent des PPS qui coïncidentavec l’émission d’un spike par le neurone post-synaptique, en maximisant leur poids. Dansleur exemple, les poids des synapses atteignent les bornes de poids maximales (synapses po-tentiées) et minimales (synapses dépréciées). Les synapses potentiées sont celles dont le délaiaxonal est un multiple de T , où T étant la période de la stimulation imposée en entrée du ré-seau. Au final, les auteurs observent une forte synchronisation de phase (phase-locking) entreentrée et sortie : le réseau est devenu sensible à une organisation temporelle particulière desstimulations qu’on lui présente.
Adaptation des délais
L’adaptation des délais axonaux est un mécanisme principalement computationel. Les mé-thodes proposées ci-après sont donc plutôt à considérer comme des outils d’apprentissage ar-
17

tificiel et non comme une modélisation de mécanismes biologiques. Il semble néanmoins quecertains mécanismes puissent moduler légèrement le délai de transmission d’un neurone à unautre (Senn et al., 2002). Notamment, il semble que lorsqu’un poids synaptique est plus fort, latransmission de cette synapse est plus rapide, ce qui modifie légèrement (de l’ordre de 0.1ms)le délai de transmission.
Plusieurs techniques d’adaptation des délais ont été proposées. Ce sont des mécanismes quidépendent de l’activité synaptique. Tout d’abord Hüning et al. (1998) suggèrent qu’une adap-tation du délai peut être réalisée lorsque le potentiel de membrane du neurone post-synaptiquedépasse un certain seuil ϑ. Dans ce cas, la modification du délai de chaque synapse est l’inté-grale, sur l’intervalle où le seuil est dépassé, du PPS pondéré par une fonction d’apprentissagecalée sur l’intervalle de temps du PPS (Hüning et al., 1998, figure 2, pour plus de détails). No-tons toutefois que le seuil ϑ doit être fixé à la main, et que nous n’avons pas réellement d’infor-mation pour régler ce paramètre. Ce mécanisme est néanmoins intéressant car il donne lieu àune modification traduisant la contribution de la synapse à la dépolarisation post-synaptique.Cependant ce mécanisme risque être computationnellement lourd à gérer du fait de la préci-sion temporelle qu’il impose.
Un autre mécanisme a été avancé dans Eurich et al. (1999, 2000). Il s’inspire de la STDPpuisqu’il dépend de l’activité synaptique, et plus particulièrement des instants d’impact desspikes afférents et des instants d’émission du neurone post-synaptique (voir figure 3.4 gauche).Le délai est raccourci lorsque l’ordre de l’impact pré- et de l’émission post-synaptique est cau-sal (tpost − tpre > 0). Il est rallongé dans le cas contraire (tpost − tpre < 0). Cette adaptation nonsupervisée des délais axonaux est accompagnée d’une STDP sur les poids dont la fonction esten forme de chapeau mexicain (voir figure 3.4 droite). Notons que cette fenêtre STDP n’est pascohérente avec les observations biologiques qui montrent une rupture nette entre le cas causalet le cas non causal. Ce mécanisme est intéressant car, en concurrence avec la STDP, il rend leneurone de sortie sensible à un motif temporel particulier.
FIGURE 3.4 – Fenêtre temporelle pour l’adaptation des délais (gauche) et des poids (droite), tiré de Eurichet al. (2000)
3.2.3 Dynamiques remarquables
Depuis que les réseaux de neurones sont utilisés comme outils de modélisation en neu-rosciences, de nombreuses recherches ont été menées pour proposer différentes hypothèses ausujet des mécanismes qui pourraient sous-tendre les processus cognitifs de haut niveau. Ainsides concepts tels que la synchronisation d’assemblées, ou les synfire chains ont été développés.
18

Synchronisation
L’idée de synchronisation décrit le fait que des neurones fortement connectés entre euxforment une assemblée de neurones qui peut être distribuée dans l’ensemble du système ner-veux. Une assemblée synchronisée est alors un groupe de neurones qui travaillent en rythme enémettant des spikes dans un intervalle de temps commun. Il est postulé, que, dans le cerveau,une assemblée de neurones est activée par l’intervention d’un stimulus particulier. Lorsqu’ellecommence à être activée, une assemblée tend à activer tous les neurones qui la composent.Ainsi, la présence d’un stimulus particulier serait traduite par l’activation d’assemblées parti-culières, et par la réverbération synchrone de l’activité entre ces assemblées, créant des fluctua-tions électriques qui génèreraient des oscillations (Singer & Gray, 1995).
Synfire chain
Il semble admis que le système nerveux est le siège de phénomènes temporels très précis,non dictés par le hasard. Par exemple il a été observé (Abeles, 1991) dans les cellules corti-cales du singe, le motif suivant, déclenché par un stimulus donné : lorsqu’un neurone initialA, émet, un second neurone B emet 151ms plus tard, suivi par un troisième neurone C 289msplus tard, le tout avec une précision de 1ms sur l’ensemble des essais. Comme nous l’avonsnoté précédemment, les délais axonaux varient entre 0.1 et 44ms, la transmission entre A et Cimplique donc plusieurs neurones intermédiaires autres que le neurone B. Cela signifie que lesystème est capable de reproduire des motifs temporels précis et identiques dans le temps. Cephénomène est appelé synfire chain.
Polychronisation
Izhikevich (2006) propose la notion de polychronisation, inspirée des hypothèses précé-dentes. Les seules notions de synfire chain et de synchronie sont restrictives quant à la topo-logie du réseau, imposant une certaine structure des délais et de la connectivité. Izhikevichpostule l’existence de groupes polychrones (en anglais « polychronous groups », notés PG)dans le cortex cérébal, et les modèlise dans des réseaux de neurones impulsionnels avec desdélais de transmission axonaux.
Un groupe polychrone peut être décrit comme un motif temporel d’émissions de spikes.C’est un motif qui apparaît plus souvent que par chance dans l’activité, car il est lié à la struc-ture du réseau. Le principe du groupe polychrone se base sur la notion de propagation desspikes illustrée dans la figure 3.5. Le déclenchement de s premiers neurones, avec un motiftemporel donné, suffit à activer d’autres neurones du réseau selon un certain motif temporel.Ce motif temporel sera toujours le même si les s premiers neurones sont à nouveau déclenchésavec le même motif de départ. Ces groupes sont directement dépendants de la topologie duréseau, c’est-à-dire de la connectivité et des valeurs des délais axonaux.
19

(a)
N3
15 msN1
N4
N2
7 ms
N3
N1
N4
Time [ms]
N2
15 ms
7 ms
(b)
N3
15 msN1
N4
N2
7 ms
9 ms
17 ms N3
N1
N4
Time [ms]
N2
17 ms
15 ms
7 ms
9 ms
(c)
N3
15 msN1
N4
N2
3 ms
8 ms
10 ms N3
N1
N4
Time [ms]
N2
10 ms
15 ms
8 ms 3 ms
FIGURE 3.5 – gauche : exemple de topologie entre 4 neurones ; droite : exemple d’émissions de spikes(a) Les neurones N1 et N2 émettent un spike respectivement aux instants t et t + 8 et déclenchent N3t+ 15 ;(b) Les neurones N1 et N2 émettent aux mêmes instants que (a) et déclenchent N3 et N4 respectivementaux instants t+ 15 et t+ 17 ;(c) La topologie est telle que deux timing de spikes différents pour N1 et N2 déclenchent deux neuronesdifférents : t et t+ 12 déclenchent N3 ; t et t+ 2 déclenchent N4.
Tous les groupes polychrones possibles dans un réseau ne sont pas nécessairement tousactivés au cours d’une simulation. En effet, les stimulations injectées dans le réseau ne pro-duiront l’activation que d’un sous-ensemble des groupes supportés par la topologie. La STDPaura vraissemblablement une influence sur ces groupes, en sélectionnant les sous-graphes duréseau qui sont sensibles aux stimulations. Ceci réduira le nombre de groupes polychrones àceux qui seront également sensibles à la stimulation.
Notons que n’importe quel neurone peut être activé au sein du réseau, laissant la possibi-lité à plusieurs groupes polychrones d’être activés simultanément. Cette considération laissepenser que d’importantes capacités de mémoire sont sous-tendues par ces groupes. Izhikevichpostule en effet que le nombre de groupes possibles pour une topologie donnée, est plus grandque le nombre de neurones. Notons que ces groupes ne sont pas des ensembles disjoints deneurones, mais qu’ils peuvent posséder des neurones en commun.
20

Pour donner une image nous pouvons comparer les PG à des extraits d’une musique. Lors-qu’on entend une mélodie, on peut reconnaître certains ensembles de notes récurrents. Ces en-sembles de notes sont contraints par les règles de la musique, par les notes que les instrumentssont capables de produire, les mouvements que le musicien est capable de faire. La mélodie estune phrase qui respecte une grammaire. De même un PG est un extrait d’activité qui respectela topologie du réseau.
La polychronisation est compatible avec la théorie des oscillations. En effet, avec une dis-tribution des délais gaussienne, les spikes peuvent, sous certaines conditions, être temporelle-ment rapprochés et ainsi se propager par vagues.
Régime chaotique
Une activité chaotique est caractérisée par l’imprédictibilité. Une activité chaotique est uneactivité dans laquelle aucun motif n’est reproductible autrement que par le hazard. Plusieursarticles abordent la notion de régime chaotique. van Vreeswijk & Sompolinsky (1996) observentun régime chaotique lorsque l’activité est équilibrée entre inhibition et excitation. Watanabe &Aihara (1997) observent également une activité chaotique lorsque les neurones fontionnent endétecteurs de coïncidence. L’activité chaotique pourrait être considérée comme l’activité defond d’un réseau, pouvant être interpréter comme “je ne sais pas”, et devenant oscillatoire oudu moins non chaotique lorsqu’une stimulation est reçue.
Nous avons compris que les dynamiques neuronales peuvent être extrêmement complexes,mais qu’elles sont conditionnées par un certain nombre de paramètres identifiables et contrô-lables. Nous allons à présent aborder le sujet du Reservoir Computing. Les modèles de ce cou-rant utilisent, pour certains d’entre eux, un réseau de neurones artificiels doté de propriétéstemporelles, permettant un apprentissage qui s’appuie sur les dynamiques neuronales et lesmécanismes d’adaptation hebbiens. Nous utiliserons ce paradigme dans nos travaux.
21

4Le réservoir computing
Nous présenterons ici les fondements d’une branche des réseaux de neurones qui a émergédepuis le début des années 2000. Deux modèles, l’Echo State Network et la Liquid State Ma-chine, proposés indépendamment en 2001 et 2002 ont marqué cette émergence, révélant le po-tentiel de ce nouveau paradigme désormais nommé reservoir computing. Nous donnons toutd’abord une définition générale, puis présentons les deux modèles fondateurs de ce paradigme.Nous abordons ensuite la question de l’optimisation du modèle dans le cas général avant dedécrire les mécanismes d’apprentissage supervisé et non supervisé couramment utilisés. Enfinnous présenterons quelques applications du reservoir computing.
4.1 Définition générale
Le reservoir computing (RC) définit une catégorie de modèles de réseaux de neurones quis’appuient sur des réseaux récurrents (voir section 2.2 p.6). En effet ces derniers présententun intérêt computationel indéniable de part la richesse de la dynamique qu’ils peuvent avoir.Néanmoins ils s’avèrent difficiles à entrainer. Les modèles de RC ont une architecture similaireet s’appuient sur les mêmes mécanismes fondamentaux, afin d’accomplir une tâche d’appren-tissage. Voir Schrauwen et al. (2007); Paugam-Moisy & Bothe (2011) pour une revue concise,Lukosevicius & Jaeger (2009) pour une revue plus extensive.
Dans le paradigme du RC, il s’agit de décomposer le modèle en trois ingrédients : (1) unecouche d’entrée qui permet d’injecter les exemples d’apprentissage, (2) un réservoir composéde neurones connectés sans organisation particulière définie, et dans lequel il peut y avoir desmécanismes d’adaptation, (3) une couche de sortie, les « readout », sur laquelle un apprentis-sage supervisé est opéré. Un tel modèle est généralement soumis à un signal d’entrée par lebiais de la couche d’entrée, qui entretient l’activité du réservoir et qui conditionne donc sonétat. La sortie du réseau est une combinaison linéaire ou non-linéaire de l’état du réservoir,dont on cherche, par apprentissage, à ce qu’elle s’approche de la sortie désirée. Nous pouvonsdécrire ce paradigme de façon formelle (voir figure 4.1). En admettant que n ∈ [1, T ] est le pasde temps de la simulation, nous pouvons définir un modèle de RC comme étant composé deséléments suivants :
• une couche d’entrée dont le signal u(n) de taille Nu est présenté au pas de temps n. Cesignal est transformé en un signal x(n) de dimension supérieure Nx par le plongementde connexions pondérées sur le réservoir (voir ci-dessous). Les poids de ces connexionssont regroupés dans une matrice Win de dimension Nu ×Nx.• une couche cachée appelée réservoir dynamique, dont le signal x(n) est de dimensionNx (généralement Nx > Nu) :
x(n) = x(u(n)) = Winu(n)) (4.1)
x() est appelé la fonction d’expansion. Le réservoir est donc un réseau de neurones ré-
22

current au sein duquel s’instaure une dynamique maintenue et influencée par le signald’entrée. Les poids des connexions de ce réservoir sont stockés dans la matrice des poidsdu réservoir W de dimension Nx ×Nx.• une couche de sortie communément appelée « readout » y(n) est de dimension Ny :
y(n) = fout(Woutx(n)) = fout(Woutx[u(n)]) (4.2)
Le réservoir est connecté à la sortie via la matrice des poids Wout de dimension Nx×Ny.• le signal de sortie désiré ytarget(n) est de dimensionNy. Il permet de calculer l’erreur entre
la sortie effective du réseau et la sortie désirée. Nous notons cette erreurE(y(n),ytarget(n))
Win, W et Wout sont donc respectivement la projection linéaire (i.e. les poids) de u(n) surx(n), de x(n) sur lui-même , et de x(n) sur y(n). L’objectif est alors de trouver les fonctions x()et y() afin de minimiser l’erreur E entre y(n) et ytarget(n).
FIGURE 4.1 – Paradigme du reservoir computing
L’intérêt principal du réservoir est qu’il s’agit d’un système dynamique, c’est-à-dire un sys-tème dont l’état change au cours du temps. Le RC prend donc tout son sens lorsque le signald’entrée est une séquence temporelle et qu’il existe une relation entre les signaux u(n − 1) etu(n). Dans ce cas, la formalisation du paradigme peut être adaptée en donnant au réservoirune influence des n− 1 entrées précédentes :
x(n) = x(x(n− 1),u(n)) (4.3)
Plus particulièrement, en faisant intervenir les matrices de poids,
x(n) = f(Winu(n) + Wx(n− 1) + Wofby(n− 1)) (4.4)
où Wofb est un retour (optionnel) de la sortie au pas de temps précédent sur l’état actuel duréservoir, et f() n’est autre que la fonction d’activation des neurones.
4.2 Modèles de référence
Les deux modèles de référence qui ont donné naissance au RC sont l’Echo State Networket la Liquid State Machine (nous garderons les noms originaux, en anglais).
23

4.2.1 Echo State Networks
En 2001, Jeager propose le modèle Echo State Network (ESN) dans le contexte de l’appren-tissage artificiel (Jaeger, 2001a). Voir Jaeger (2007) pour une revue récente. L’auteur part duconstat qu’un réseau de neurones récurrent aléatoire possède des propriétés algébriques pourcréer et adapter une sortie linéaire de ce réseau, ce qui est souvent suffisant pour résoudreune tâche d’apprentissage. Ainsi, l’ESN s’inscrit dans le paradigme du RC (voir figure 4.2a),les neurones sont habituellement des neurones classiques à taux de décharge, dont la fonc-tion d’activation peut être une fonction logistique (sigmoïde, entre 0 et 1) ou une fonction tanh(entre -1 et 1). Les sorties utilisent l’équation 4.2 et ont généralement l’identité pour fonctiond’activation fout. Wout, la matrice des poids de sortie est l’objet de l’apprentissage, par regres-sion linéaire.
FIGURE 4.2 – (a) Modèle de l’Echo State Network (b) Modèle de la Liquid State Machine – Figure d’aprèsPaugam-Moisy & Bothe (2010)
4.2.2 Liquid State Machine
En 2002, Maass, Natschläger et Markram proposent indépendamment de l’ESN, un modèlenommé Liquid State Machine (LSM) (Maass et al., 2002) qui n’a pas vocation à fournir un mo-dèle d’apprentissage artificiel. Ce modèle est issu des neurosciences computationelles et veutavant tout étudier les propriétés des circuits neuronaux biologiques. Il est le deuxième modèlereconnu comme un des pionniers du RC. L’ambition originale de ce modèle est d’expliquercomment un flot continu d’entrées changeant rapidement au cours du temps, peut être traitépar un réseau de neurones récurrent. L’inspiration biologique fait que des neurones impulsion-nels de type intègre et tire sont souvent utilisés dans ces modèles.
La LSM veut donc recevoir une fonction du temps u(.) en entrée et donner une fonctiondu temps y(.) en sortie (voir figure 4.2b). La fonction y(.) peut être vue comme une analysede la fonction d’entrée en temps réel. LM le filtre liquide (en anglais « liquid filter ») est unsystème dynamique qui réalise la transformation de la série temporelle en entrée u(.) en unétat xM (t) à l’instant t. Il reste alors à transformer cet état en une sortie y(t) par une fonctionassociative fM (Maass, 2007). y(.) constitue la réponse du modèle aux entrées des pas de tempsprécédents s < t. Le filtre liquide est à l’image de la surface d’un fluide qui, perturbé par un si-gnal (pénétration d’un objet, vibrations sonores, souffle du vent, etc) créé une dynamique (desondulations) qui se propage en s’estompant peu à peu.
24

4.3 Optimiser le réservoir
Les modèles de RC utilisent tous un réservoir dont l’état et la dynamique jouent le rôle demémoire des expériences passées, et dont on souhaite extraire les informations pertinentes parle biais de la sortie. Le paradigme du RC tel qu’il est défini habituellement utilise un réseaude neurones récurrent comme réservoir dynamique. Il est toutefois possible de remplacer leréservoir par un autre système doté de la capacité de mémoire qui s’atténue (en anglais « fadingmemory »). Il s’agit de la capacité de conserver dans la dynamique une trace des expériencespassées et récentes. Nous présentons tout d’abord les critères structuraux reconnus commeétant ceux d’un bon réservoir, puis nous explorerons les différents mécanismes d’apprentissage,supervisés et non supervisés, dans le réservoir et sur les sorties.
4.3.1 Propriétés d’un réservoir
On considère qu’on a un bon réservoir lorsque celui-ci conserve la mémoire des entrées lesplus récentes mais est néanmoins capable d’oubli à long terme (« fading memory »). On attendégalement qu’il soit capable de produire un ensemble varié de dynamiques différentes. Nousdécrivons ici les principales propriétés d’un bon réservoir.
La propriété de séparation est la capacité de différentier les états internes liés à des entréesdistinctes, il s’agit de faire une séparation linéaire entre les différents états x(n) supportés parle réservoir. Une mesure de cette propriété est le rang de X, la matrice composée de l’ensembledes vecteurs x(n) concaténés.
La propriété d’approximation est la capacité des readouts à recoder les états internes en unesortie donnée, cible de l’apprentissage.
La propriété d’état-écho (en anglais « echo state property ») est la capacité qu’a l’état du ré-servoir à garder la mémoire (l’écho) des entrées passées (Jaeger, 2001a). Jaeger affirme qu’enpratique le rayon spectral 1 (en anglais « spectral radius ») de la matrice des poids du réservoirρ(W) < 1 assure généralement d’avoir la propriété d’état-écho. Néanmoins, il souligne que cettecondition ne vaut que dans le cas de neurones du réservoir à fonction d’activation tanh(), sanssignal d’entrée, et qu’elle n’est pas toujours suffisante ni nécessaire. De plus, comme nous l’ex-pliquons plus loin, Jiang et al. (2008) ont trouvé que fixer la matrice des poids de sorte que lerayon spectral soit à une valeur précédemment optimisée ne semble pas être un critère d’amé-lioration significative des performances.
L’étendue de l’ensemble des valeurs propres (« eigenvalue spread ») est le rapport de lavaleur propre maximale sur la valeur propre minimale de la matrice d’auto-corrélation desétats x(n). C’est une valeur que l’on cherche à minimiser.
La topologie du réservoir a un rôle important dans la performance du modèle final. Uneétude exhaustive de Liebald (2004) n’a pas montré de différence significative ni dans la qualitédu réseau (en termes de diffusion de la valeur propre) ni dans le taux d’erreurE avec différentsréservoirs de topologies diverses, notamment petit-monde, invariantes d’échelles, aléatoires(voir section 5.3 p.35 pour une définition de ces classes de topologies). Cependant la topologie
1. rayon spectral d’une matrice : valeur propre de magnitude maximale
25

joue un rôle mais celui-ci n’est pas clair à ce jour. Comme l’ont constaté Jiang et al. (2008),les performances démontrées par un ESN peuvent grandement varier d’un tirage aléatoire àl’autre des connexions et des poids du réservoir.
La dynamique est l’essence des modèles de RC, aussi, comme nous l’avons dit précédem-ment, le réservoir doit être capable de démontrer un ensemble de dynamiques variées. Dans cecontexte, il a été proposé que le réservoir devrait être paramétré pour fonctionner au limite duchaos (« at the edge of chaos ») au sens des systèmes dynamiques car cela donne au système unplus grand panel d’expression (Legenstein & Maass, 2007).
4.3.2 Adapatation des paramètres du réservoir
Dans le paradigme du RC, l’apprentissage se fait essentiellement sur les readout, mais il estpossible également d’avoir des mécanismes d’adaptation opérant à l’intérieur le réservoir.
La plasticité synaptique est un mécanisme d’adaptation des poids synaptiques. Elle est im-plémentée par la STDP qui est un mécanisme hebbien, d’inspiration biologique, d’adaptationlocale des poids basée sur la corrélation temporelle de deux extrêmités de la connexion (voirsection 3.2.1 p.14 pour une présentation de ce mécanisme). Elle est souvent utilisée dans lesréseaux de neurones.
La plasticité intrinsèque (IP) est un mécanisme hebbien d’adaptation locale, non supervisé,inspiré de la biologie. Cet apprentissage opère sur la dynamique interne (intrinsèque) du neu-rone en modifiant son excitabilité. Ce mécanisme a été formalisé pour les réseaux de neuronesartificiels à taux de décharge (Triesch, 2005b,a). Pour un neurone dont la somme des entréesest x et sa propre activation est y, Triesch définit la fonction d’activation du neurone par unesigmoïde (voir section 3.2.1 p.15).La linéarité de la fonction dépend de paramètres qui, d’aprèsl’auteur, doivent être considérés comme un contrôle de l’importance relative entre (1) maximi-ser l’entropie versus (2) minimiser la moyenne. Le but est que la distribution de x soit exponen-tielle ce qui maximise son entropie. Ainsi l’information transmise par le neurone est maximale.
La BackPropagation-DeCorrelation (BPDC) s’inspire de la méthode d’apprentissage d’Atiya-Parlos (APRL pour « Atiya-Parlos Recurrent Learning » (Atiya & Parlos, 2000)) qui s’appliquedans le contexte général des réseaux de neurones récurrents. Celle-ci évalue le gradient d’ap-prentissage des poids en fonction du ratio erreur-activation de chaque neurone et en déduitune modification de tous les poids (Wout, W, Win et éventuellement Wofb). Ce mécanismed’apprentissage supervisé converge plus rapidement que nombre d’autres mécanismes dansles réseaux récurrents comme la Backpropagation Through Time (Werbos, 1990), les filtres deKalman étendus (Puskorius & Feldkamp, 1994) ou l’algorithme de maximisation de la prédic-tion (Ma & Ji, 1998) (en anglais « Expectation-Maximisation »). Le mécanisme de BPDC (Steil,2004, 2006, 2007) est une simplification de l’APRL, avec un apprentissage uniquement sur lespoids de la sortie Wout, en faisant une méthode adaptée au RC.
Il apparaît que les performances sont améliorées en appliquant le mécanisme de plasticitéintrinsèque couplé avec un apprentissage supervisé BPDC (Steil, 2007). Avec ces mêmes mé-canismes, Schrauwen et al. (2008) montrent qu’un ESN peut également reconnaitre plusieursmotifs qui s’expriment simultanément.
26

L’optimisation par algorithme évolutionaire peut être utilisée afin de générer des réservoirscorrespondant aux critères d’optimalité précédemment cités. Par exemple Jiang et al. (2008)améliorent les performances d’un ESN en optimisant le rayon spectral du réservoir, tel queρ(W) < 1 tout en adaptant les poids du réseau. Toutefois les auteurs testent également lemodèle en fixant ρ(W) à la valeur trouvée après apprentissage. Il s’avère que les performancesne sont que très légèrement améliorées. Il est possible qu’au lieu d’être un critère d’optimisationà part entière, le rayon spectral soit seulement un indice mis à profit par l’algorithme génétique.
4.3.3 Apprentissage de la sortie
L’algorithme d’apprentissage le plus répandu est celui originellement utilisé par Jeager (Jae-ger, 2001a) dans l’ESN, à savoir la méthode de régression linéaire des moindre carrés (« LeastMean Square », LMS), qui revient à trouver la solution du système d’équations linéaires :
WoutX = Ytarget (4.5)
soit :Wout = YtargetX+ (4.6)
où X+ est la matrice pseudo-inverse de la matrice X composée de l’ensemble des vecteursx(n). Ytarget est la matrice composée de l’ensemble des vecteurs ytarget(n) correspondant auxentrées u(n). Le calcul de la matrice pseudo-inverse requiert une grande quantité de mémoire,aussi une réécriture de cette équation est en générale adoptée :
Wout = YtargetXT (XXT + α2I)−1 (4.7)
I étant l’identité, et α étant un facteur de régularisation.Dans nos travaux nous utilisons un réservoir à l’intérieur duquel la STDP est active. Nous
ne nous sommes pas préoccupés du rayon spectral.
4.4 Applications
Plusieurs applications du RC ont été décrites dans la littérature notamment pour la classi-fiation de motifs dynamiques (Jaeger, 2001b) ou le calcul de fonctions non-linéaires sur la basede la fréquence de décharge des neurones (Maass et al., 2004). Les modèles de RC sont égale-ment particulièrement adaptés au traitement de séries temporelles en temps réel, telles que lareconnaissance vocale (Verstraeten et al., 2005).
Pour démontrer la pertinence de la métaphore des LSM, Fernando & Sojakka (2003) ont réa-lisé un modèle de RC en remplaçant le réservoir habituel par un bassin rempli d’eau. Le signald’entrée est produit par des moteurs produisant des vibrations à la surface de l’eau, cette sur-face étant importée dans le système par une caméra vidéo. Cet exemple est anecdotique maisreprésentatif des concepts du RC. Voir Schrauwen et al. (2007) pour plus d’exemples d’appli-cations.
Un certain nombre d’outils ont été développés par une communauté scientifique très active.La Reservoir Computing ToolBox est un simulateur générique pour le RC développé au Reser-voir Lab et décrit par Verstraeten et al. (2007). On pourra se référer au cite web dédié au RC et
27

maintenu par la communauté http ://www.reservoir-computing.org, et à la page personnellede Jaeger http ://minds.jacobs-university.de/esn_research.
Le RC est donc un paradigme largement reconnu et étudié, bien qu’il n’ait émergé que ré-cemment. Une question essentielle, et difficile à résoudre pour ce genre de modèle, est de savoirsi une architecture particulière pour le réservoir pourrait améliorer la performance. C’est dansce sens que des propriétés telles que le rayon spectral sont étudiées, néanmoins sans résultatconcluant. Habituellement le réservoir est une structure aléatoire, éventuellement soumise àun mécanisme d’adaptation. Notre point de vue est qu’il pourrait être intéressant d’explorerles propriétés du réservoir pour d’autres structures. Aussi nous nous intéressons à la théo-rie des réseaux complexes qui nous donneront les outils nécessaires pour explorer ces aspectsstructuraux.
28

5Les réseaux complexes
Nous abordons dans ce chapitre la théorie des réseaux complexes, un outil puissant pourétudier, autant que pour créer artificiellement, une structure particulière de réseaux. Aprèsavoir introduit le concept de système complexe, nous présentons quelques notions de la théo-rie des graphes, indispensables à la compréhension des réseaux complexes. Nous abordonsensuite les propriétés des réseaux complexes. Enfin nous passons en revue les quatre grandesfamilles de réseaux complexes et les méthodes permettant de les générer artificiellement.
5.1 Introduction
De prime abord, il est difficile d’établir un parallèle entre le système métabolique d’un êtrevivant et le Web que l’on consulte quotidiennement, ou entre un réseau de distribution d’élec-tricité et un écosystème. Il y a une vingtaine d’années la réponse à cette interrogation auraitété mince ou nulle. Pourtant de nombreux systèmes tels que ceux-ci ont des propriétés simi-laires, ou du moins comparables, que l’on peut mesurer, et analyser. Qu’ils soient biologiques,technologiques, sociaux ou autres, ces systèmes peuvent être représentés et analysés à la lu-mière de différents outils, que sont l’étude de la dynamique non linéaire (théorie des systèmesdynamiques), la physique statistique, et la théorie des réseaux complexes (Amaral & Ottino,2004).
5.1.1 Les systèmes complexes
Nous pouvons considérer un système composé de nombreuses pièces et dont le fonctionne-ment est pourtant parfaitement maîtrisé ; un ordinateur par exemple. Un tel système comportenombre de pièces dont chacune à un rôle clairement défini : une carte son, une carte vidéo, etc.Si la carte vidéo vient à défaillir, ni la carte son ni aucun autre système de l’ordinateur ne pourraen aucune manière la suppléer, n’étant pas conçu pour cela. A moins de posséder une deuxièmecarte vidéo, c’est tout l’ordinateur qui devient inutilisable, bien que tout le reste du systèmesoit parfaitement fonctionnel. Si une de ses pièces tombe en panne, l’ordinateur ne pourra plusfonctionner. Nous le qualifions de système compliqué. Dans ce genre de système la seule paradeà la panne est la redondance. C’est la solution adoptée, par exemple, lorsque les données d’undisque dur ne doivent pas être perdues : on utilise un second disque dur (voire plusieurs dansle cas de données vitales) dont le contenu est systématiquement maintenu identique à l’origi-nal.
A la différence de ces systèmes, les systèmes complexes sont composés d’un grand nombrede composants fondamentaux n’ayant pas de rôle spécifique prédéfini et qui sont susceptiblesd’avoir un comportement différent selon le contexte. Les caractéristiques de ces systèmes sontdifficiles à résumer en quelques phrases du fait de la diversité de leurs natures. Ces systèmesont comme composants fondamentaux de nombreux éléments non nécessairement similairesdont chacun est d’une manière ou d’une autre en interaction avec tout ou partie du reste du
29

système. Par exemple les individus dans une communauté, les espèces dans un écosystème,les routeurs (les équipements réseaux plus généralement) dans InterNet, les neurones dans lecerveau. Les interactions qu’entretiennent les composants, considérées sur une ligne tempo-relle, forgent la dynamique de ce système. Celui-ci peut alors être étudié à plusieurs échelles etdans plusieurs dimensions : à l’échelle globale du système dans son ensemble (échelle macro-scopique), à l’échelle locale du composant seul (échelle microscopique), ou avec son voisinage(échelle mésoscopique), et tout cela pendant un ou plusieurs instants différents.
La capacité d’adaptation tant à l’échelle du composant qu’à l’échelle du système, est unedes caractéristiques des systèmes complexes. Cette capacité va de paire avec la capacité d’auto-organisation. Cela signifie d’une part qu’un système complexe s’organise de façon étrangèreà toute intervention artificielle ou supervisée, cette organisation émergeant simplement de sonfonctionnement et de son interaction avec l’environnement. Cela signifie d’autre part que lapanne d’un des composants n’empêchera pas le système de fonctionner dans sa globalité, ladéfaillance de l’élément provoquant plutôt une adaptation et une ré-organisation du système.
Ce qui rend ces systèmes complexes, c’est le fait qu’il est difficile, voire même impossible, deprédire le comportement qu’aura l’ensemble, même si l’on connait les règles de fonctionnementet d’interaction de chaque composant. Ce phénomène est connu sous le nom d’émergence : lefait qu’une organisation s’instaure dans ce système, de paire avec la dynamique, le fait que letout est bien plus que la somme de ses composants (Amaral & Ottino, 2004).
Trois grandes catégories d’outils se sont développées pour l’étude des systèmes complexes :la théorie des systèmes dynamiques, la physique statistique et plus récemment la théorie desréseaux complexes. La théorie des réseaux complexes est un domaine d’étude particulier dessystèmes complexes qui s’intéresse à la structure des interactions dans ces systèmes. Cette théo-rie dérive de la théorie des graphes.
5.1.2 La théorie des graphes
La notion de réseau s’appuie sur celle de graphe et lui emprunte donc une partie de sesconcepts, quoique certains soient exprimés différemment selon le domaine d’étude. Nous rap-pelons les termes suivants de la théorie des graphes.
• Le sommet est l’élément fondamental d’un graphe, aussi dénommé nœud en informa-tique, ou acteur en sociologie, neurone ou unité dans les réseaux de neurones, site enphysique, etc.• Une arête (non orientée) ou un arc (orienté) sont un lien entre deux sommets. L’arête et
l’arc sont des notions similaires, la nuance se place sur la distinction du sens du lien. Unlien non orienté entre deux sommets est une arête, un lien orienté est un arc.• Chaîne (non orientée) ou chemin (orienté) : une chaîne est une suite finie de sommets
reliés entre eux par des arêtes. Un chemin est une suite finie de sommets reliés entres euxpar des arcs orientés dans le sens du cheminement, de l’origine (premier sommet) versl’extrémité (dernier sommet).• Cycle (non orienté) ou circuit (orienté) : un cycle est une chaîne dont l’origine et l’extré-
mité sont confondues. Un circuit est un chemin dont l’origine et l’extrémité sont confon-dues.
30

• Une Clique est un ensemble de sommets deux-à-deux adjacents, c’est-à-dire formant unsous-graphe complet.• Une composante connexe est un ensemble de sommets dont chacun peut atteindre tous
les autres sommets de la composante, via au moins une chaîne. Une composante forte-ment connexe est un ensemble de sommets dont chacun peut atteindre et être atteint partous les autres sommets de la composante, via au moins un chemin.• La connectivité ou densité d’un graphe est le rapport du nombre d’arêtes/arcs existant
effectivement dans le graphe sur le nombre total d’arêtes/arcs qu’il pourrait avoir enétant complètement connecté (cas où chaque sommet est lié à tous les autres).• Le plus court chemin entre deux sommets est le chemin, reliant ces deux sommets, dont
le nombre d’arêtes ou d’arcs est minimal. Il peut exister plusieurs plus courts cheminsentre deux sommets.Le plus court chemin moyen est la longueur moyenne (en nombre d’arêtes ou d’arcs) desplus courts chemins entre toutes les paires de sommets du graphe.Le diamètre d’un graphe est la longueur du plus long chemin parmi tous les plus courtschemins du graphe.
• Un graphe biparti est un graphe dans lequel il existe une partition de son ensemble desommets en deux sous-ensembles U et V telle que chaque arête ait une extrémité dansU et l’autre dans V . Un graphe biparti permet notamment de représenter une relationbinaire.
Pour qualifier les éléments d’un réseau, nous dénommerons un sommet par le terme denœud, une arête par le terme de lien, un arc par le terme de lien orienté, ou connexion dans lecontexte particulier des réseaux de neurones.
Les réseaux complexes sont une classe de réseaux qui présentent des propriétés communes.La théorie des réseaux complexes définit ces propriétés et la façon de les mesurer. Les réseauxcomplexes ont donc vocation à représenter le support des interactions locales entre les nom-breux éléments d’un système complexe.
5.2 La théorie des réseaux complexes
Afin de caractériser un système complexe, nous pouvons représenter ses acteurs sous formede nœuds et leurs interactions sous forme de liens. Il est alors possible d’étudier un tel réseau.Certaines mesures sont communément utilisées. Elle se basent toutes sur la comptabilisationdes nœuds et des liens. Voir Albert & Barabasi (2002); Newman (2003); Amaral & Ottino (2004)pour une revue du domaine des réseaux complexes.
5.2.1 Degré et distribution des degrés
Le degré d’un nœud est le nombre de liens qu’il comporte. Dans le cas de liens orientés,nous distinguons le degré entrant, nombre de liens arrivant au nœud, du degré sortant, nombrede liens partant du nœud. Généralement, le degré d’un nœud i est noté d(i), din(i) le degré en-trant, dout(i) le degré sortant. Dans un réseau orienté, d(i) = din(i) + dout(i).
31

La distribution des degrés d’un réseau peut être observée en discrétisant l’intervalle desdegrés en sous-intervalles puis en comptant pour chaque sous-intervalle de degrés possible,le nombre de nœuds du réseau qui ont un degré inclus dans cette plage de valeurs (voir fi-gure 5.1).
5.2.2 Coefficient de clusterisation
La mesure du coefficient de clusterisation évalue la transitivité d’un réseau G. Plus préci-sément, il s’agit de la probabilité, lorsqu’un nœud i est lié à un nœud j et à un nœud k, queles nœuds j et k soient également liés entre eux. C’est l’image des relations d’amitié : quelleest la probabilité pour que les amis de mes amis soient également mes amis ? Considérons Gi
le sous-graphe de G contenant uniquement les li voisins de i. Ce sous-graphe peut comporterau plus li(li − 1)/2 liens (non orientés). Nous pouvons définir Ci l’indice de clusterisation dunœud i :
Ci =Nombre de liens effectivement présents dans Gi
li(li − 1)/2(5.1)
L’indice de clusterisation C est alors l’indice de clusterisation moyen sur tous les nœuds(Watts & Strogatz, 1998). Cet indice permet d’évaluer la cliquicité (en anglais « cliquishness »)du réseau, la densité de cliques présentes dans le graphe du réseau.
L’équation 5.1 est définie pour un contexte non-orienté. Dans un contexte orienté, l’arc ai,j
est distinct de l’arc aj,i. Le nombre de liens possibles dans le sous-graphe Gi est li(li − 1), et lecoefficient de clusterisation du nœud i peut être redéfini ainsi :
Ci =Nombre de liens orientés effectivement présents dans Gi
li(li − 1)(5.2)
Plusieurs généralisations du coefficient de clusterisation ont été proposées par Saramäkiet al. (2007) pour le cas des réseaux pondérés (dont les liens portent des valeurs pondérées) ;Ces définitions utilisent la moyenne des poids émanant du nœud i.
5.2.3 Efficacité
Latora & Marchiori (2001) relèvent le fait que les mesures définies par Watts & Strogatz(1998), telles que le coefficient de clusterisation, ne tiennent pas compte du fait que le graphedu réseau peut ne pas être connexe. Ils définissent tout d’abord dij la longueur, en nombre deliens, du plus court chemin entre les sommets i et j. L’efficacité εij de la communication entrei et j peut alors être vue comme inversement proportionnelle à leur distance : εij = 1/dij . Parconvention, si i et j sont dans des composantes connexes distinctes, dij vaut +∞ et εij = 0.L’efficacité E(G) dans un graphe G à N sommets vaut alors la moyenne des l’efficacités entretous nœuds i et j :
E(G) =
∑i,j∈G|i 6=j εij
N(N − 1)(5.3)
(5.4)
32

Efficacités globale et locale Afin de normaliser la valeur de l’efficacité, il faut diviser E(G)par l’efficacité maximale possible, c’est-à-dire dans le cas du grapheGcomplet composé des som-mets de G et complètement connecté. Ceci justifie l’équation 5.5 qui défini l’efficacité globale.En effet elle décrit la rapidité de propagation dans le graphe G.
Eglob =E(G)
E(Gcomplet)(5.5)
L’efficacité Eglob(G) est ainsi comprise entre 0 et 1. Nous pouvons définir, pour tout i appar-tenant à G, une mesure similaire sur le graphe Gi restreint aux sommets voisins de i, i /∈ Gi.Ceci nous permet de définir l’efficacité locale de G, qui est la moyenne des E(Gi). Nous écri-rons alors :
Eloc =1N
∑i∈G
E(Gi) (5.6)
Cette valeur évalue la tolérance du système en cas de défaillance du sommet i. En effet, iétant par définition exclu du graphe Gi, E(Gi) révèle l’efficacité du graphe des voisins privésde i.
5.2.4 Centralité d’intermédiarité
La notion de centralité d’intermédiarité de nœud ou intermédiarité de nœud a été définiepar Freeman (Freeman, 1977) et généralisée à la centralité d’intermédiarité de lien ou intermé-diarité de lien par Newman et Girvan (Girvan & Newman, 2002; Newman & Girvan, 2004).L’intermédiarité donne une estimation de la force du nœud ou du lien, au sens de la massed’information qui transite par son intermédiaire. Cette propriété s’appuie sur le comptage desplus courts chemins qui traversent ce nœud ou ce lien. L’équation 5.7, la centralité d’intermé-diarité de nœud, l’équation 5.8 définit la centralité d’intermédiarité de lien.
CI(k) =∑i 6=j
σij(k)σij
(5.7)
CI(ak,k′) =∑i 6=j
σij(ak,k′)σij
(5.8)
où σij(X) est le nombre de plus courts chemins entre i et j passant pas le lien ou le nœud X , etσij est le nombre de plus courts chemins entre i et j.
5.2.5 Modularité
La modularité dénote le concept de communauté en sciences sociales, comparable à la no-tion de « cluster » dans les réseaux technologiques ou de module dans les réseaux biologiques,et que nous dénommerons module. Il s’agit d’un ensemble de nœuds qui interagissent, com-muniquent, partagent davantage avec les nœuds du même module qu’avec les nœuds desautres modules. La modularité est donc une mesure qui veut évaluer la pertinence d’une par-tition d’un graphe en plusieurs modules contenant des nœuds plus connectés mutuellementqu’avec les nœuds des autres modules. La modularité s’écrit comme la somme des rapports du
33

nombre de liens à l’intérieur de chaque module, sur le nombre de liens qu’il y aurait si ceux-ciétaient distribués aléatoirement (Guimerà & Amaral, 2005b) :
M(P ) =NM∑s=1
[lsL−(ds
2L
)2]
(5.9)
où NM est le nombre de modules, L le nombre total de liens dans le réseau, ls le nombre deliens entre les nœuds du module s, et ds est la somme des degrés des nœuds du module s.Nous pouvons traduire cette définition par la phrase : une bonne partition en modules d’un ré-seau doit comprendre beaucoup de liens intra-module, et aussi peu de liens inter-modules quepossible. De plus, si les nœuds sont répartis aléatoirement dans les modules, ou s’ils sont tousdans le même module,M vaudra 0. Ainsi l’objectif de la recherche d’une partition optimale,en termes de modules, consistera en la maximisation de la quantitéM.
Détection des modules. Une des méthodes les plus fiables pour détecter les modules est l’al-gorithme de Newman et Girvan (NG), qui fonctionne en deux phases. La première phase sup-prime itérativement des liens du réseau, par ordre d’intermédiarité de lien décroissante. Elleest décrite dans Girvan & Newman (2002). Les auteurs complètent cette phase dans Newman& Girvan (2004), par une deuxième phase qui rétablit un à un les liens du réseau, dans l’ordreinverse de leur suppression. Le but de cette seconde phase est de déterminer la partition quimaximise la modularité du réseau. La méthode complète peut donc être détaillée comme suit.
1. Première phase : suppression des liens1. Calculer la centralité d’intermédirarité de lien (voir eq. 5.8) pour chaque lien du réseau2. Trouver le lien de plus forte valeur et le supprimer du réseau3. Recalculer la centralité d’intermédiarité de lien pour tous les liens restants4. Tant qu’il reste des liens, répéter à partir de [2.]
2. Deuxième phase : reconstruction des liens1. Calculer la modularité du réseau initial.2. Rajouter le dernier lien retiré.3. Recalculer la modularité du réseau ainsi modifié, mémoriser la partition et sa modu-
larité.4. Tant qu’il reste des liens à rajouter, répéter à partir de [2.]5. La partition P pour laquelleM(P ) est maximale est la meilleure partition modulaire.
Plusieurs implémentations ont été proposées (Danon et al., 2005). Deux optimisations dansl’implémentation de l’algorithme de NG permettent de diminuer la complexité de O(n2m) àO(nlog2n) (Newman, 2004; Clauset et al., 2004). Notamment l’utilisation d’un algorithme glou-ton permet de passer directement à la deuxième phase. L’utilisation de la méthode de recuitsimulé (Kirkpatrick et al., 1983), permet d’obtenir une grande précision dans la détection desmodules, mais au prix d’une complexité plus élevée (Guimerà et al., 2004; Guimerà & Amaral,2005a).
L’algorithme de NG a été défini dans le cas de réseaux non-orientés. Une version adap-tée au cas des réseaux orientés est proposée par Meunier & Paugam-Moisy (2008). La secondephase diffère. Lors de la reconstruction, à l’ajout d’un lien orienté de i vers j, si celui-ci reliedeux modules distincts, cela ne provoque la fusion des modules que s’il existe par ailleurs unchemin quelconque qui relie également j vers i.
34

Des variantes de cette méthode ont déjà été proposées dans le contexte des réseaux bipartis(Guimerà et al., 2007; Barber, 2008) ou celui des réseaux orientés (Guimerà et al., 2007; Leicht& Newman, 2008). En effet, il est possible de convertir un réseau orienté en réseau non orienté,et un réseau biparti en réseau unipartite, mais ces conversions sont intrinsèquement sourcesd’une perte d’information et peuvent mener à des partitions incorrectes. Les solutions de Leicht& Newman (2008) et Barber (2008) sont des méthodes spectrales, la méthode de Guimerà et al.(2007) est une adaption de l’algorithme deNG. Bien que n’ayant pas fait l’objet d’un comparatifà notre connaissance, ces méthodes sembles équivalentes en termes de précision, ainsi qu’entermes de complexité.
5.3 Familles de réseaux et leurs propriétés
Nous présentons ici les grandes familles de réseaux communément étudiées par le biais dela théorie des réseaux complexes. Les extrêmes, qui sont les réseaux réguliers et les réseauxaléatoires, bornent le domaine d’intérêt. Entre ces deux limites se situent deux autres classesque sont les réseaux aux propriétés petit-monde, et une famille encore différente, que sont lesréseaux invariants d’échelle.
a. b. c. d.
e.
0
100
200
300
400
500
600
0 5 10 15 20 25 30
Nb
of n
euro
ns
Degree
degrees
f.
0
100
200
300
400
500
600
0 5 10 15 20 25 30
Nb
of n
euro
ns
Degree
degrees
g.
0
100
200
300
400
500
600
0 5 10 15 20 25 30
Nb
of n
euro
ns
Degree
degrees
h.
0
100
200
300
400
500
600
0 5 10 15 20 25 30
Nb
of n
euro
ns
Degree
degrees
FIGURE 5.1 – Exemples de réseaux a. régulier, b. petit-monde, c. aléatoire, d. invariant d’échelle. Distri-bution des degrés typique correspondant à un réseau e. régulier (k = 4, p = 0), f. petit-monde (k = 4,p = 0.05), g. aléatoire (k = 4, p = 1), h. invariant d’échelle (m = 4). Les distributions ont été calculéessur un réseau de 1000 nœuds et de connectivité égale pour chaque type de réseau. Dans e., le pic desdegrés est tronqué à 600 au lieu de 1000 par souci d’échelle de comparaison avec les autres réseaux.
5.3.1 Les réseaux réguliers
On définit un réseau régulier, ou lattice, en organisant les nœuds spatialement, de façonordonnée et homogène, sur un anneau (voir figure 5.1a.), et en restreignant le nombre de voisinsde chaque nœud. Il s’agit d’établir une connectivité locale régulière.
Méthode de construction Le paramètre k permet de contrôler la connectivité d’un réseaurégulier. Il définit le nombre de voisins avec lesquels chaque nœud est lié. k doit être pair, carchaque nœud i est lié aux k/2 nœuds précédents et aux k/2 nœuds suivants sur l’anneau. Ledegré de tous les nœuds est identique (voir figure 5.1e.).
35

5.3.2 Les réseaux aléatoires
Un réseau aléatoire est défini par le modèle de graphe aléatoire de Erdos & Rényi (1959).Les liens créés entre les nœuds du réseau sont choisis aléatoirement, de manière équiprobable(figure 5.1c.). Il en résulte que tous les nœuds n’ont pas nécessairement le même degré, maiscelui-ci est néanmoins proche d’une valeur caractéristique : la distribution des degrés est unegaussienne (voir figure 5.1f.).
5.3.3 Les réseaux petit-monde
L’effet petit-monde (en anglais small-world) est le fait que la plupart des paires de nœudssont reliées par un chemin relativement court à travers le réseau. Ce phénomène a été mis enévidence pour la première fois par Milgram (Milgram, 1967), sociologue américain, en 1967.Dans cette célèbre expérience, les sujets choisis au hasard à travers les Etats-Unis étaient char-gés de faire parvenir un document à une personne cible, en le transmettant à une personnequ’il connaissait par son prénom, qui devrait à son tour transmettre le document de la mêmemanière. Le choix de l’intermédiaire devant être fait avec l’idée d’atteindre le destinataire oude se rapprocher de lui. Peu de documents sont finalement arrivés à destination, mais ceux quisont arrivés n’ont traversé en moyenne que 6 intermédiaires. Le principe de tels réseaux est quele diamètre est fortement réduit par la présence de liens faisant office de raccourcis à travers leréseau (voir figure 5.1c.).
Un réseau petit-monde est caractérisé par une décorrélation entre le plus court cheminmoyen et le coefficient de clusterisation (figure 5.2). L’information se propage rapidement dansle réseau, tout en maintenant une connectivité localisée dans l’ensemble du réseau : la majoritédes nœuds sont liés à leurs voisins proches, mais néanmoins quelques nœuds sont égalementliés à des nœuds beaucoup plus éloignés.
Méthode de construction La procédure proposée par Watts & Strogatz (1998) consiste, enpartant d’un réseau régulier, à recâbler ou non, chaque lien du réseau de façon aléatoire. Ladécision de recâbler un lien particulier est prise selon le paramètre p, la probabilité de recâblage.Ainsi, en faisant varier p de 0 à 1, divers réseaux peuvent être générés, du réseau régulier(p = 0), jusqu’au réseau aléatoire (p = 1), en passant par le réseau petit-monde (0 < p << 1,sachant que de faibles valeurs de p rendent le réseau petit-monde (Amaral & Ottino, 2004)).
5.3.4 Les réseaux invariants d’échelle
Les réseaux invariants d’échelle (en anglais « scale-free »), ou réseaux fractals, ont la carac-téristique d’avoir une distribution des degrés de leurs nœuds qui suit une loi de puissance.(voir figure 5.1d. et h.). Cela signifie que la plupart des nœuds ont un degré plutôt faible alorsque peu de nœuds ont un degré plutôt élevé. Ces derniers, véritables relais de la transmis-sion, sont appelés hubs. Il s’avère que de nombreux réseaux du monde réel ont une structureinvariante d’échelle. C’est par exemple le cas des citations scientifiques (de Solla Price, 1965),du web (Amaral & Ottino, 2004), de certains réseaux métaboliques. Price (de Solla Price, 1976)tente d’expliquer ce phénomène par ce qu’il appelle les processus d’avantages cumulés, pluscouramment nommés attachement préférentiel (Barabasi & Albert, 1999). Cette hypothèse pro-pose que plus un nœud a un degré élevé, plus la probabilité est grande pour qu’il soit choisicomme extrémité d’un lien nouvellement créé.
36

FIGURE 5.2 – Zone petit-monde : décorrélation du plus court chemin moyen (l) et du coefficient declusterisation (C), en fonction de p - figure d’après Newman (2003)
Méthode de construction Le modèle de de Solla Price (1976), repris par Barabasi & Albert(1999) propose la procédure itérative suivante :
1. Créer un réseau aléatoire de m0 nœuds.
2. Ajouter un nœud.
3. Ajouter m (≤ m0) liens entre ce dernier nœud et un autre nœud i choisi avec une proba-bilité P (i) dépendant de son degré deg(i).
4. Répéter t fois à partir du 2. (ainsi le réseau comporte m0 + t nœuds).
On peut écrire P (i) la probabilité de choisir un nœud i de degré deg(i) comme extrémité :
P (i) =deg(i)∑j deg(j)
(5.10)
Pennock et al. (2002) proposent de raffiner P (i) afin de donner à tout nœud une probabilitéminimale. Nous proposons d’adapter cette méthode au contexte des réseaux orientés.
A l’étape 3. de l’algorithme précédent, nous ajoutons autant de liens entrants que de lienssortants. Nous avons élaboré la probabilité Poriente(i) de choisir un nœud i, de degré entrantdegentrant(i) et de degré sortant degsortant(i), comme extrémité d’une nouvelle connexion. Nousimposons que les valeurs des coefficients α, β et γ soient telles que α+ β + γ = 1
Poriente(i) = αdegentrant(i)nombre de liens
+ βdegsortant(i)nombre de liens
+ γ1
nombre de nœuds(5.11)
5.4 Dynamique et réseaux complexes
Deux objets d’étude peuvent être couverts par le terme dynamique. Le premier est l’ensembledes interactions qui ont lieu entre les nœuds, au sein du réseau et au cours du temps, aussiappelé activité du réseau. Cette activité est conditionnée par la structure du réseau. Le secondobjet pouvant être dénommé par le terme de dynamique est l’ensemble des modifications de la
37

structure du réseau (ajout, destruction, pondération de nœuds ou de liens), au cours du temps.Une telle dynamique est souvent conditionnée par l’activité (exemple : apprentissage dans lesréseaux de neurones : les poids des connexions sont modifiés sous l’influence de l’activité).Cet objet peut être étudié par le biais de la théorie des graphes dynamiques (Harary & Gupta,1997), mais il reste à explorer précisément les liens entre structure et dynamique.
Ici, et dans le reste de ce document, le terme dynamique dénotera l’activité du réseau.
5.4.1 L’influence de la topologie sur la dynamique
La propagation d’une épidémie Les propriétés de la dynamique du réseau sont condition-nées par celles de la structure du réseau. Par exemple dans les réseaux épidémiologiques, ila été montré qu’un certain nombre de paramètres influencent la propagation de la maladie.Ainsi la caractérisation d’un seuil épidémiologique permet de déterminer si la dyamique seranon-épidémique ou endémique. Parmi les variables du seuil se trouve les caractéristiques dela maladie (probabilité de transmission, durée d’incubation), mais également le degré moyendes nœuds. Ainsi, dans un réseau aléatoire, un moyen efficace d’arrêter la propagation de lamaladie consiste à immuniser un maximum d’individus, afin de réduire le degré moyen. Enrevanche si le réseau social de propagation de la maladie est un réseau invariant d’échelle,il faut immuniser en priorité les nœuds de degré élevé, les hubs qui sont en fait les vecteursprivilégiés de la propagation (Pastor-Satorras & Vespignani, 2002).
La fiabilité d’un réseau Une panne, en termes de réseau, est la suppression d’un nœud et deses liens. Si l’on considère la robustesse comme étant la capacité d’un réseau à rester connexe,les réseaux invariants d’échelle et petit-monde sont plus tolérants aux pannes (Albert et al.,2000) car l’activité peut se redistribuer rapidement dans le reste du réseau. En revanche ils sontplus vulnérables aux attaques ciblées du fait du caractère localement centralisé de leur struc-ture. La panne d’un hub peut provoquer la redistribution d’une trop grande charge d’activitéet déclencher des pannes en chaîne sur d’autres nœuds. C’est par exemple ce qui s’est passélors des grandes pannes électriques dans l’Ohio en août 2003 (Amaral & Ottino, 2004).
Synchronisation neuronale Plusieurs travaux ont montré que les synchronisations d’assem-blées de neurones sont favorisées dans les réseaux de structure petit-monde (Lago-Fernándezet al., 2000; Barahona & Pecora, 2002), permettant même l’émergence d’états épileptiques, c’est-à-dire des états dans lesquels l’activité s’emballe et s’auto-entretient (Ponten et al., 2007).
5.4.2 Etude de la dynamique complexe
Dans le contexte particulier des réseaux de neurones, des outils ont été proposés dans Sethet al. (2006), pour mesurer la complexité de la dynamique neuronale. Il s’agit de la propriétéd’une partie de l’activité à être à la fois séparée (certains nœuds se comportent de façon indé-pendante les uns des autres) et d’une autre partie de l’activité à être intégrée (l’activité de cer-tains nœuds est corrélée avec celle des autres). Ces outils ont été utilisés par Shanahan (2008),montrant que les réseaux petit-monde ne sont capables d’avoir une activité auto-entretenue etcomplexe que pour un petit intervalle de valeurs de la probabilité de recâblage p.
38

5.5 Domaines d’application
Newman (2003) distingue quatre grandes familles historiques de systèmes complexes réelsdont les réseaux ont été étudiés par le biais de la théorie des réseaux complexes : les réseauxsociaux, les réseaux technologiques, les réseaux d’information, les réseaux biologiques.
Les réseaux sociaux Dans cette catégorie de réseaux, chaque nœud est un individu et les liensreprésentent les relations sociales entre les individus. Les exemples les plus courants sont lesréseaux d’acteurs, (Watts & Strogatz, 1998; Wasserman & Faust, 1994), les réseaux de contactssexuels, et les réseaux épidémiologiques.
Les réseaux technologiques Cette famille de réseaux englobe les réseaux de nature techno-logique. Cette catégorie comprend des réseaux aussi divers que les réseaux de distributiond’énergie électrique (Amaral et al., 2000; Watts & Strogatz, 1998), les réseaux d’aéroports (Ama-ral et al., 2000), ou le réseau de communication InterNet (Pastor-Satorras & Vespignani, 2003).
Les réseaux d’information Cette famille comprend des réseaux représentant le partage etla transmission de l’information entre plusieurs entités. On citera comme exemples les réseauxde pages web (Barabasi & Albert, 1999) et les réseaux de collaborations scientifiques (Newman,2001).
Les réseaux biologiques Dans cette famille, les réseaux représentent des entités biologiquestelles que des cellules ou populations de cellules (telles que les neurones), ou des protéines.Dans les réseaux d’interactions protéiniques chaque nœud est une protéine, et les liens carac-térisent les relations d’influence entre ces protéines. Les réseaux cérébraux fonctionnels modé-lisent des zones d’activité dont la corrélation temporelle est représentée par des liens (Eguiluzet al., 2005; Guimerà & Amaral, 2005b; Meunier, 2007). Il semble que les réseaux cérébrauxfonctionnels aient une structure petit-monde (Bullmore et al., 2009; Sporns, 2006). Dans les ré-seaux neuronaux, les nœuds sont des neurones et les liens sont les connexions axonales (doncorientées) entre les neurones, comme par exemple dans la modélisation du système nerveuxdu ver C. Elegans (Watts & Strogatz, 1998). Dans des travaux récents, Meunier et al. (2009b,a)ont étudié l’évolution des réseaux d’interation cérébrales avec le vieillissement.
Les réseaux complexes sont donc un outil utilisé dans de nombreux domaines, pour étudierdes structures de réseaux aussi divers que nombreux. Dans nos travaux, nous faisons appelà ces outils pour créer des architectures de réseaux de neurones ayant certaines propriétés.Ces outils nous permettent également d’analyser les résultats que nous obtenons en ayant unevision claire des propriétés des réseaux utilisés.
39

Deuxième partie
Modèle et résultats
40

Transition
Les réseaux de neurones artificiels utilisant des modèles de neurones temporels peuventpermettre de mieux comprendre le fonctionnement des dynamiques tant au niveau microsco-pique (neurone) qu’au niveau macroscopique (réseau). Nous comprenons que ces dynamiquespeuvent évoluer sous l’influence des mécanismes de plasticité ayant cours dans le réseau, auniveau des synapses ou dans les neurones eux-mêmes. La mise en œuvre de ces aspects dansun modèle computationnel peut être complexe. Nous avons développé un simulateur spéci-fique implémentant à la fois des réseaux de neurones impulsionnels, des structures de réseauxcomplexes et des outils permettant d’analyser les résultats des simulations. Nous souhaitonstout particulièrement étudier l’influence des délais de transmission au sein des réseaux de neu-rones. Pour ce faire nous proposons un modèle d’apprentissage qui s’inscrit dans le courantdu Reservoir Computing. Nous allons plus loin en cherchant à comprendre la structuration dela dynamique du réservoir, à l’aide de la notion de polychronisation. Les résultats de nos ob-servations nous permettent de faire une hypothèse forte quant au support de la mémorisationdans le réservoir. Nous menons alors une étude exhaustive des groupes polychrones au seind’un réseau dont nous contrôlons la structure complexe.
41

6Le simulateur
Le simulateur que nous avons développé, ainsi que tous les outils d’analyse qui l’accom-pagnent, constituent un résultat à part entière de ce travail de thèse, que nous souhaitons mettreen valeur et diffuser. En effet, le simulateur implémente nombre de fonctionnalités permettantde manipuler tous les aspects que nous avons évoqués dans les chapitres précédents, dont no-tamment : les paramètres contrôlant les dynamiques neuronales, les méthodes de ReservoirComputing, les outils de réseaux complexes. Nous sommes donc capables de jouer sur tous cesparamètres d’influence et nous allons présenter brièvement les fonctionnalités du simulateur.
6.1 Aspects pour le contrôle des dynamiques neuronales
Paramètres du neurone : les paramètres de constante membranaire et de seuil sont modifiables.Notre modèle de neurone est un SRM0. Un développement futur devrait permettre d’implé-menter d’autres modèles dont le modèle d’Izhikevich (2003).Distribution des poids : nous pouvons spécifier la valeur moyenne et l’écart-type de la gau-sienne de distribution des poids.Distribution des délais : le simulateur tient compte des délais axonaux et nous pouvons spé-cifier la valeur moyenne et l’écart-type de la gausienne de distribution des délais.Connectivité (densité de connexion) : dans tous les types de réseau, nous pouvons définir ladensité des connexions, c’est-à-dire la probabilité qu’un lien entre deux neurones existe.
Adaptation des poids par STDP : les mécanismes de STDP, multiplicative et additive, sont im-plémentés et peuvent être activés ou non. La fonction de STDP est facilement modifiable.Adaptation des délais par plasticité synaptique : un mécanisme identique à la STDP est implé-menté pour être appliqué aux délais. Cette STDP de délai peut être activée ou non. La fonctionde plasticité est modifiable.
Précision temporelle : elle est modifiable et est fixée par défaut au dixième de milliseconde.Equilibre excitation / inhibition : un neurone peut être défini comme inhibiteur ou excita-teur, ses synapses étant alors toutes de même type. Un neurone inhibiteur n’a que des synapesinhibitrices et ses impacts post-synaptiques sont d’amplitude négative.
6.2 Aspects pour les architectures de réseaux complexes
Comme nous l’avons présenté dans le chapitre 5, la théorie des réseaux complexes définitplusieurs familles de réseaux. Des méthodes prédéfinies dans notre simulateur permettent decréer de tels réseaux, puis de les analyser.Structure du réseau : il est possible de construire un réseau structuré en assemblées de neu-rones, et de définir les faisceaux de connexions (projections) allant d’une assemblée à une autre.
42

Topologie régulière, petit-monde, aléatoire : construction de réseau de degré moyen 2 ∗ k, etrecâblage selon la probabilité p.Topologie invariante d’échelle : construction de réseau par attachement préférentiel en fonc-tion des degrés entrant 2 ∗ kin et sortant 2 ∗ kout des neurones.Analyse des propriétés complexes du réseau : distribution des longueurs, distribution desdegrés, degré sortant moyen, degré entrant moyen, plus court chemin moyen, coefficient declusterisation (voir chapitre 5), à l’aide de la bibliothèque de réseau complexes igraph. Desspikes raster plot peuvent être générés et nombre d’autres figures peuvent être tracées aisé-ment à l’aide de scripts produisant des familles de graphique en fonction d’un ou plusieursparamètres.
6.3 Aspects pour le Reservoir Computing
Protocoles de simulation : il est possible d’écrire des scripts de simulation incluant des phases,pouvant être récursives (une phase peut en contenir une autre). Chaque phase contient desévénements, incluant des évènements prédéfinis tels que des mécanismes d’adaptation, la pré-sentation d’exemples d’entrée. Ces scripts sont simples et facilement modifiables.Apprentissage supervisé des readouts : le mécanisme d’apprentissage supervisé des délais,présenté dans le chapitre 7, est implémenté.Exemples d’entrée : un module du simulateur gère la transformation d’exemples d’entrée (sousforme de vecteurs numériques, telle qu’une image) en instants de spikes, via le codage tempo-rel présenté dans le chapitre 2, figure 2.4.Outils d’analyse : Détections des groupes polychrones (voir chapitre 8) ; Analyse des groupespolychrones (voir chapitres de résultats 9 et 10) ;Calculs optimisés : de nombreux aspects du simulateur et des outils d’analyse ont été optimi-sés afin de réduire le temps de calcul tout en garantissant l’exactitude.
6.4 Implémentation
Un des atoûts essentiels du simulateur est qu’il a été conçu entièrement avec une approcheévénementielle, ou encore « event-driven ». Le fonctionnement événementiel permet un coûtcomputationel minimal, puisqu’au contraire des modèles « clock-driven » (aussi appelés « time-driven »), nous ne recalculons pas l’état de l’ensemble des neurones à chaque instant virtuel.Nous recalculons uniquement l’état des neurones pour lesquels il se passe quelque chose, etuniquement lorsqu’un événement arrive. Ainsi, pour prendre un exemple caricatural maisconcret, s’il y a seulement un événement au temps 0 et un autre au temps 1000000, la simu-lation sera quasi-instantanée, ne traitant que ces deux événements, et non tous les instants del’intervalle.
Nous avons développé le simulateur en C++ pour des plateformes de type Unix/Linux, enutilisant des threads pour le moteur de simulation. Le langage de script Lua permet le char-gement des paramètres et la génération d’architectures de réseau. La nomre XML est utiliséepour le stockage des architectures de réseau générées. Le code source est distribué sous licence
43

GNU/GPL, avec une documentation synthétique en anglais, disponible à partir de la page webde l’auteur http://regis.martinez3.free.fr.
Toutes les expériences qui sont présentées dans ce manuscrit sont des simulations qui ontété éxécutées soit sur une machine de bureau (Dell Optiplex) ou un portable (Dell Inspiron9400), soit, pour les plus lourdes d’entre elles, sur la grille de calcul du centre de calcul del’IN2P3.
6.5 Autres simulateurs
6.5.1 Simulateurs pour les réseaux de neurones impulsionnels
Il existe plusieurs simulateurs de réseaux de neurones impulsionnels. Pour un comparatifdétaillé, on pourra se reporté à la review Brette et al. (2007). Chaque simulateur a son fonc-tionnement propre et ses fonctionnalités spécifiques. Parmi les aspects les plus courants surlesquels les simlateurs se différencient, nous trouvons :• le mode de simulation event-driven versus clock-driven• le(s) modèle(s) de neurone simulable(s)• la méthode de définition des protocoles simulations• les mécanismes d’apprentissage ou de plasticité implémentés• les types de données générées (diagrammes de spikes, structure du réseau, etc.)• les post-traitement proposés (analyse du réseau après apprentissage, analyse de fréquences,
etc.)
Voici quelques uns des simulateurs :• GENESIS (Bower & Beeman, 1998)• SpikeNet (Delorme et al., 1999)• NEURON (Hines & Carnevale, 2001)• NEST (Diesmann & oliver Gewaltig, 2002)• BRIAN (Goodman & Brette, 2008)• DAMNED (Mouraud & Puzenat, 2009)
Nous avons utilisé notre propre simulateur principalement pour des raisons historiques.En effet la première version de notre simulateur a été développée au cours de notre stage deMaster. La question pourrait rester pertinente si ce n’est que, à notre sens, l’objectif d’un stagede Master est de se former, de comprendre et même de s’approprier les concepts et les prin-cipes de son domaine de recherche. En cela le développement d’un nouveau simulateur peutêtre vu comme un bac à sable, un outil pédagogique d’autoformation.
D’autre part, lorsqu’on travaille sur un sujet de recherche précis, comme c’est tout le tempsle cas en recherche, nous avons souvent des besoins spécifiques en termes de fonctionnalités,d’outils de post-traitement des données. Faire de tels développement sur un simulateur donton ne maîtrise pas le code source peut être coûteux en temps, alors que l’ajout d’une fonc-tionnalité dans un simulateur qu’on connait bien est un moyen de maîtriser le résultat obtenu,
44

connaissant le détail des calculs internes au simulateur. Ayant alors un simulateur opération-nel dont nous maîtrisions le code de A à Z, nous avons préféré continuer à l’améliorer et à yapporter de nouvelles foncitonnalités, au lieu de se réapproprier un autre simulateur.
6.5.2 Logiciels pour les réseaux complexes
Il existe de nombreux logiciels existant pour l’analyse et la construction de réseaux com-plexes. Parmi ceux-là nous pouvons citer Gephi 1, Pajek 2, Cytoscape 3, NetworkX 4, GraphViz 5.Nous avons utilisé la librairie igraph 6 développée par Gábor Csárdi (2006), pour nos analyse deréseaux complexes. Un moteur de recherche très complet permet de trouver des logiciels de vi-sualisation et d’analyse existants : http ://gvsr.polytech.univ-nantes.fr/GVSR/task ?action=browse#
Mis à part igraph, nous avons brièvement utilisé Pajek afin de valider nos outils de construc-tion de réseaux complexes. Nous n’avons pas eut bensoin, dans l’état d’avancement actuel denos travaux, de faire appel à des logiciels de visualisation ou d’analyse complexe.
1. http ://gephi.org2. http ://vlado.fmf.uni-lj.si/pub/networks/pajek/3. http ://www.cytoscape.org4. http ://networkx.lanl.gov5. http ://www.graphviz.org6. http ://igraph.sourceforge.net
45

7Un modèle de classification supervisé
Travail publié dans Meunier et al. (2006); Paugam-Moisy et al. (2007, 2008)
Nous pensons que les délais de transmission jouent un rôle important dans les dynamiquesneuronales. Souhaitant tirer parti de ces aspects, nous réalisons une étude exploratoire s’ap-puyant sur un modèle d’apprentissage artificiel. Le but visé est de montrer que l’intégrationdu temps de latence axonale dans les réseaux de neurones impulsionnels doit être considérécomme une richesse supplémentaire du modèle, autant pour la performance en termes d’ap-prentissage artificiel que de pertinence biologique. Nous présentons ici le modèle computation-nel utilisé dans nos travaux, et justifions certains choix d’implémentation.
7.1 Le modèle
Dans un travail préliminaire (Martinez, 2005) nous avons remarqué l’utilité des délais axo-naux, dans un modèle de classifieur par réseau de neurones artificiels. La traduction en instantsde spikes des exemples d’entrée – qui étaient de nature binaire – ne permettait pas de faire unapprentissage efficace. Dans chaque diagramme de la figure 7.1, chaque point rouge représenteun spike émis par le neurone indiqué en ordonnées, à l’instant indiqué en abscisses. Les 400premiers neurones sont la couche d’entrée, les suivants sont la couche de sortie. La couched’entrée est connecté à la sortie par des connexions utilisant un délai. Les deux diagrammesmontrent une stimulation des entrée avec un exemple d’apprentissage dont les composantesvalent 0 (spike tardif) ou 1 (spike précoce), à gauche avec des délais axonaux tous égaux, àdroite avec des délais axonaux aléatoires. Avec les délais aléatoires (droite), la réponse des neu-rones de sortie est moins stéréotypée.
0
100
200
300
400
500
600
0 20 40
Neu
rone
s
Temps
Diagramme de Pulses
0
100
200
300
400
500
600
0 20 40
Neu
rone
s
Temps
Diagramme de Pulses
FIGURE 7.1 – En ordonnées les indices des neurones (entrées : #0 à #399, sorties : #400 à #549), en abscissesle temps, un point rouge est l’émission d’un spike. à gauche : les délais axonaux entre couche d’entréeet couche de sortie sont tous de 20 ms ; à droite : les délais axonaux entre entrée et sortie sont aléatoires
D’inspiration biologique, l’introduction de délais axonaux, menant à un bruitage des ins-tants de spike a permis de résoudre le problème d’apprentissage qui découlait de cette repré-sentation binaire. Nous avons dès lors porté notre attention sur l’influence des délais axonaux,
46

tant pour l’aspect neurophysiologique que pour l’aspect computationnel.
Nous proposons un modèle de réseau de neurones impulsionnels utilisant des délais axo-naux. Ce modèle conserve une inspiration biologique, mais est conçu pour la classification ausens classique de l’apprentissage artificiel. L’architecture de notre réseau s’inscrit dans le cou-rant des modèles du « reservoir computing » (RC, voir chapitre 4 p.22) bien que ne s’en étantpas explicitement inspiré, mais ayant émergé en même temps.
.
.
.
classe 2
classe 1
L cellules de sortie (ici L = 2)K cellules d’entrée
Réservoir
N cellules internes
connexions entrantes
connexions internes
connexion sortantesavec délai adaptable
FIGURE 7.2 – Architecture tri-partite proposée : une assemblée de K neurones d’entrée, une assembléede N neurones du réservoir, une assemblée de L neurones de sortie
Le modèle que nous proposons (figure 7.2) se compose d’un réseau principal deN neuronesinternes, d’une assemblée de K neurones d’entrée, et d’une assemblée de sortie composée deL neurones. Le réseau principal n’a pas d’organisation préconçue, et sa connectivité interne estpartielle. Nous appellerons ce réseau principal, le sac de neurones ou réservoir, reflétant ainsil’absence d’une structure prédéfinie. La seule donnée imposée est la proportion de neurones ex-citateurs et inhibiteurs. Pour respecter les observations biologiques et obtenir un équilibre dansl’activité, nous imposerons généralement 80% de neurones excitateurs pour 20% de neuronesinhibiteurs. Chaque connexion synaptique, d’un neurone i vers un neurone j, est caractériséepar un poids wij et un délai axonal dij . La topologie interne est basée sur une organisation aléa-toire et éparse, avec une probabilité Crsv qu’il y ait une connexion de i vers j, pour tout couple(i, j) ∈ {1, ..., N}2.
L’assemblée d’entrée permet la stimulation du réservoir : ces neurones d’entrée sont lesémetteur d’impulsions forcées qui impacteront immédiatement (délai nul) le réservoir. Le rôlede ces neurones est donc d’injecter une stimulation dans le réservoir. L’assemblée d’entrée estconnectée au réservoir avec une connectivité faible et des poids forts Win, afin que chaqueimpulsion de l’entrée déclenche de façon certaine un spike par les neurones impactés dans leréservoir. La probabilité de connexion ou connectivité entre cette assemblée et le réservoir estCin.
Le réservoir présente une organisation aléatoire dont la connectivité est fixée à Crsv. Géné-ralement cette connectivité est faible (ex : 10%), ce qui confère au réservoir un caractère clair-semé (en anglais « sparse »).
L’assemblée de sortie reçoit, pour chacun de ses neurones, des connexions venant de tous
47

les neurones du réservoir (la connectivité entre réservoir et assemblée de sortie est Cout = 1),avec des délais aléatoires et modifiables, et des poids fixés Wout.
Nous utilisons une version événementielle du modèle SRM0, comme décrit p.9.
7.1.1 Les paramètres du modèle
Paramètres architecturaux :Paramètre Description Valeur par défautK Nombre de neurones d’entrée 10N Nombre de neurones du réservoir 100Ninh Nombre de neurones inhibiteurs du réservoir 20% de NNexcit Nombre de neurones excitateurs du réservoir 80% de NL Nombre de neurones de sortie 2Cin Connectivité de de la couche d’entrée vers le réservoir 0.1Crsv Connectivité du réservoir 0.3Cout Connectivité du réservoir vers la couche de sortie 1Win Poids des connexions de la couche d’entrée vers le réservoir 3Wrsv Poids des connexions internes au réservoir 0.5Wout Poids des connexions du réservoir vers la couche de sortie 0.5wmin Valeur minimum pour le poids d’une connexion 0wmax Valeur maximum pour le poids d’une connexion 1dmin Délai minimal d’une connexion 0.1 msdmax Délai maximal d’une connexion 20 ms
A ces paramètres architecturaux s’ajoutent les paramètres dynamiques régissant le compor-tement des neurones.
Paramètres dynamiques :
Paramètre Descriptionumax L’amplitude d’un PPSτpsp La constante de temps de l’exponentielle décroissante du potentiel de membraneϑ Le seuil de déclenchement du neuroneurest Le potentiel de repos du neuroneτrefract La constante de temps de l’exponentielle décroissante du potentiel réfractaire relatiftrefract Durée de la période réfractaire absolueurefract L’amplitude du potentiel de réfractaire absolu
Justification des choix• Pourquoi 80% et 20% ? Nous cherchons à garder une certaine cohérence avec l’article
d’Izhikevich (2006). Celui-ci justifie ce choix par la plausibilité biologique. Il semble eneffet établi que la proportion de neurones excitateur et inhibiteur avoisine ces valeursdans le cortex.• Pourquoi des délais axonaux entre 1 et 20ms ? Cette plage de valeurs des délais est moins
importante que celle observée biologiquement par Swadlow (1985), quoique ces résultatsrestent controversés, néanmoins la majeure partie des délais est distribuée dans cet inter-valle. Izhikevich utilise le même intervalle.• Pourquoi un poids initial de 0.5 ? Le choix de cette valeur de départ est simplement le
choix d’une valeur médiane, pour le démarrage de la simulation, la STDP opérant destransformations en continu, entre les valeurs wmin = 0 et wmax = 1
48

• Pourquoi un poids de 3 pour les connexions de l’entrée vers le sac de neurones ? Cepoids est choisi de façon à donner une influence prédominante à la stimulation d’entréepar rapport à l’activité interne du réservoir.
L’idée sous-jacente à ce modèle est d’arriver à adapter les délais des connexions entre le ré-servoir et les neurones de sortie, de sorte que chacun des neurones de sortie devienne sensibleà une famille d’entrées (classe) particulière. La proposition d’Izhikevich (voir chapitre 8 p.60),est pertinente dans ce contexte puisqu’elle soutient qu’un réseau non structuré avec des délaisvariés et un mécanisme de plasticité synaptique de type STDP permet l’émergence de groupesde neurones sensibles à des motifs temporels particuliers. Nous appliquerons, à l’intérieur duréservoir, le mécanisme de STDP décrit dans le chapitre 3.
Nous expliquons à présent le fonctionnement de ce mécanisme d’apprentissage à deuxéchelles de temps.
7.2 L’apprentissage
Deux mécanismes d’apprentissage concurrents sont mis en place dans le modèle :• D’une part, un apprentissage non supervisé des poids, par STDP, opére dans le réser-
voir, à l’échelle de la milliseconde, à chaque nouvel impact pré-synaptique ou à chaqueémission post-synaptique.• D’autre part, un apprentissage supervisé opère sur les délais de sortie, après chaque pré-
sentation d’une entrée, à l’échelle de la centaine de millisecondes. Ce second mécanismed’apprentissage est basé sur un critère à marge, souvent utilisé en apprentissage artificiel,par exemple pour les SVM 1, mais nous considérons ici une notion de marge temporelle.
Nous imposons aux neurones de sortie une période réfractaire absolue de sorte que ceux-ci pulsent une fois et une seule, dans la fenêtre temporelle dédiée à chaque présentation d’unexemple d’entrée. L’objectif du mécanisme d’apprentissage supervisé que nous proposons iciest de modifier les délais entre les neurones activés dans le réservoir et les neurones de sorties,de telle façon que le neurone de sortie correspondant à la classe cible émette un spike avantcelui correspondant à la classe non-cible. De plus, comme le montre la littérature, la maximi-sation d’une marge entre une classe positive et une classe négative conduit à l’améliorationdes performances en généralisation (Vapnik, 1995). De façon plus formelle, nous cherchons àminimiser le critère suivant :
C =∑
p∈classe1
|tf1(p)− tf2(p) + ε|+ +∑
p∈classe2
|tf2(p)− tf1(p) + ε|+ (7.1)
où tfi (p) représente l’instant d’émission du neurone de sortie i répondant au motif d’entréep, ε représente la marge minimum que nous voulons imposer au délai entre les émissions desdeux neurones de sortie, avec la notation |z|+ = max(0, z). Donc, pour une entrée appartenantà la classe 1, nous voulons que le neurone de sortie 1 spike au moins ε ms avant le neurone desortie 2. Afin de minimiser ce critère, nous adoptons une approche stochastique en itérant laboucle suivante :
1. SVM = Support Vector Machines (Vapnik, 1995)
49

Algorithme 1 (deux-classes) :répéter
Pour chaque exemple X = (p, classe) de la base d’apprentissage
{ présenter le motif d’entrée p;
définir le neurone de sortie cible selon la classe;
si ( le neurone de sortie cible émet moins de µ ms
avant le neurone non-cible, ou émet après )
alors
{ sélectionner aléatoirement une des connexions ayant déclenché
le neurone cible et décrémenter son délai de (−1 ms),
sauf si dmin est déjà atteint;
sélectionner aléatoirement une connexion ayant déclenché
le neurone de sortie non-cible et incrémenter son délai de (+1 ms),
sauf si dmax est déjà atteint;
}
}
jusqu’à ce que une limite de temps d’apprentissage donnée soit écoulée.
Ainsi, à chaque itération de l’algorithme, nous diminuons la probabilité d’erreur du réseaudans sa réponse à la prochaine présentation d’une entrée similaire. Ce mécanisme est compu-tationnellement intéressant car le calcul réalisé à chaque itération est peu coûteux en temps etdemande très peu de ressource informatique. Pour que ce principe soit efficace, il faut que lesmotifs présentés en entrée activent des motifs temporels précis dans le réservoir, qui provoque-ront l’activation d’un des deux neurones de sortie préférentiellement à l’autre.
Nous proposons ensuite une généralisation de ce modèle biclasse, vers un modèle à plu-sieurs classes. Au lieu de deux neurones de sortie, nous utilisons autant de neurones de sortiequ’il y a de classes à discriminer. Le mécanisme d’apprentissage non supervisé par STDP resteinchangé, mais l’algorithme d’adaptation des délais doit être adapté :
Algorithme 2 (multi-classes) :répéter
Pour chaque exemple X = (p, classe) de la base d’apprentissage
{ présenter le motif d’entrée p;
définir le neurone de sortie cible selon la classe;
si ( le neurone de sortie cible émet moins de µ ms
avant la seconde émission parmi les neurones non-cible,
ou bien émet plus tard que un ou plusieurs neurones non-cible )
alors
{ sélectionner aléatoirement une des connexions ayant déclenché
le neurone cible et décrémenter son délai de (−1 ms),
sauf si dmin est déjà atteint;
sélectionner aléatoirement un neurone parmi les non-cible
ayant émit en premier;
pour ce neurone, sélectionner aléatoirement une des connexions l’ayant
déclenché
et incrémenter son delai de (+1 ms),
sauf si dmax est déjà atteint;
}
}
jusqu’à ce que une limite de temps d’apprentissage donné soit écoulée.
Nous présentons à présent une série de trois expérimentations dont l’objectif est de com-prendre comment la dynamique des réseaux de neurones est influencée par l’introduction de
50

délais de conduction axonaux. Le premier groupe d’expérimentations s’appuie sur des motifsd’entrée simples tandis que les expérimentations suivantes utilisent des motifs d’entrée issusd’une base de chiffres manuscrits fréquemment étudiés en tant que benchmark en apprentis-sage artificiel. L’objectif est de valider la capacité du modèle à opérer sur un grand nombre dedonnées réelles, difficiles à discriminer.
7.3 Résultats préliminaires sur des motifs simples
Les premiers résultats obtenus sur ce modèle (Martinez, 2006) portent sur deux classes destimulus simples inspirés de la figure 12 de Izhikevich (2006) :
FIGURE 7.3 – Motifs utilisés par Izhikevich (2006) et groupes polychrones identifiés par l’auteur
7.3.1 Obervations et mesures
Un premier élément d’observation est le « spike raster plot ». En français diagramme despikes, il présente tous les instants d’émission de tous les neurones : le temps exprimé en msest en abscisses et les numéros des neurones sont en ordonnées. Par exemple en figure 7.4 (bas)les K = 10 neurones de l’assemblée d’entrée sont visibles en bas du diagramme (# 0 à 9), suivisdesN = 100 neurones du réservoir (10 à 89 pour les neurones excitateurs, 90 à 109 pour les neu-rones inhibiteurs). Les spikes des deux neurones de sortie sont isolés en haut du diagramme.
L’autre élément d’appréciation que nous présentons ici sont les performances de classifica-tion du modèle, en apprentissage puis en généralisation.
51
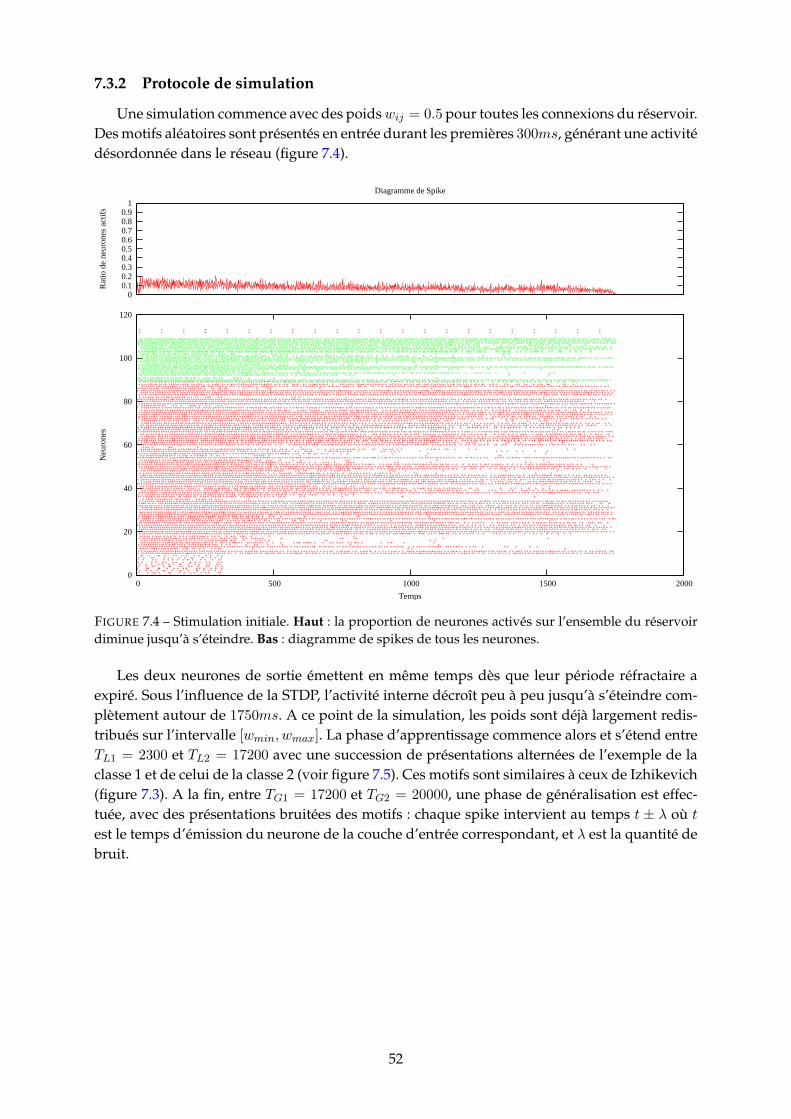
7.3.2 Protocole de simulation
Une simulation commence avec des poidswij = 0.5 pour toutes les connexions du réservoir.Des motifs aléatoires sont présentés en entrée durant les premières 300ms, générant une activitédésordonnée dans le réseau (figure 7.4).
0
20
40
60
80
100
120
0 500 1000 1500 2000
Neu
rone
s
Temps
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
1
Rat
io d
e ne
uron
es a
ctif
s
Diagramme de Spike
FIGURE 7.4 – Stimulation initiale. Haut : la proportion de neurones activés sur l’ensemble du réservoirdiminue jusqu’à s’éteindre. Bas : diagramme de spikes de tous les neurones.
Les deux neurones de sortie émettent en même temps dès que leur période réfractaire aexpiré. Sous l’influence de la STDP, l’activité interne décroît peu à peu jusqu’à s’éteindre com-plètement autour de 1750ms. A ce point de la simulation, les poids sont déjà largement redis-tribués sur l’intervalle [wmin, wmax]. La phase d’apprentissage commence alors et s’étend entreTL1 = 2300 et TL2 = 17200 avec une succession de présentations alternées de l’exemple de laclasse 1 et de celui de la classe 2 (voir figure 7.5). Ces motifs sont similaires à ceux de Izhikevich(figure 7.3). A la fin, entre TG1 = 17200 et TG2 = 20000, une phase de généralisation est effec-tuée, avec des présentations bruitées des motifs : chaque spike intervient au temps t ± λ où t
est le temps d’émission du neurone de la couche d’entrée correspondant, et λ est la quantité debruit.
52

Pour cette simulation, les paramètres sont les suivants :
Paramètre de l’architecture du réseau :Paramètre ValeurK 10N 100Nexcit 80Ninhib 20L 2Cin 0.1Crsv 0.3Cout 1dmin 1 msdmax 20 msWin 3Wrsv 0.5Wout 0.5
Paramètre dynamiques (modèle de neurone impulsionnel) :
Paramètre Valeurumax 8 mVτm 3 msϑ -50 mVτabs 7 msurest -65 mV
Paramètres d’apprentissage :
Paramètre Valeurtrefract 80 ms pour la période réfractaire des neurones de sortieµ 5 pour la marge constante
Pour cette implémentation, nous utilisons un temps discret, avec une résolution temporellede 1 ms.
7.3.3 Performances du modèle
Phase d’apprentissage Dans ces expérimentations préliminaires, le paramètre µ (voir algo-rithme 1) est fixé à 5. Comme nous pouvons le voir sur la figure 7.5, l’activité du réservoirdécroit rapidement et se stabilise sur deux motifs alternés différents, un pour chaque classe.Chacun dure un peu plus longtemps que le temps de présentation de l’entrée.
L’évolution du temps d’émission des deux neurones de sortie reflète l’application de l’algo-rithme d’apprentissage. Commençant par des spikes simultanés, leurs réponses se dissocientpeu à peu en correspondance avec la classe, d’une présentation à l’autre (figure 7.5 : haut dudiagramme de gauche). Dans le diagramme de droite de la figure, l’intervalle de temps sé-parant les deux spikes de sortie devient plus grand du fait de l’adaptation des délais et ilreste stable car le critère de marge ε est atteint. L’activité interne est invariante à l’exceptionde quelques rares modifications dues à la STDP, toujours active.
53
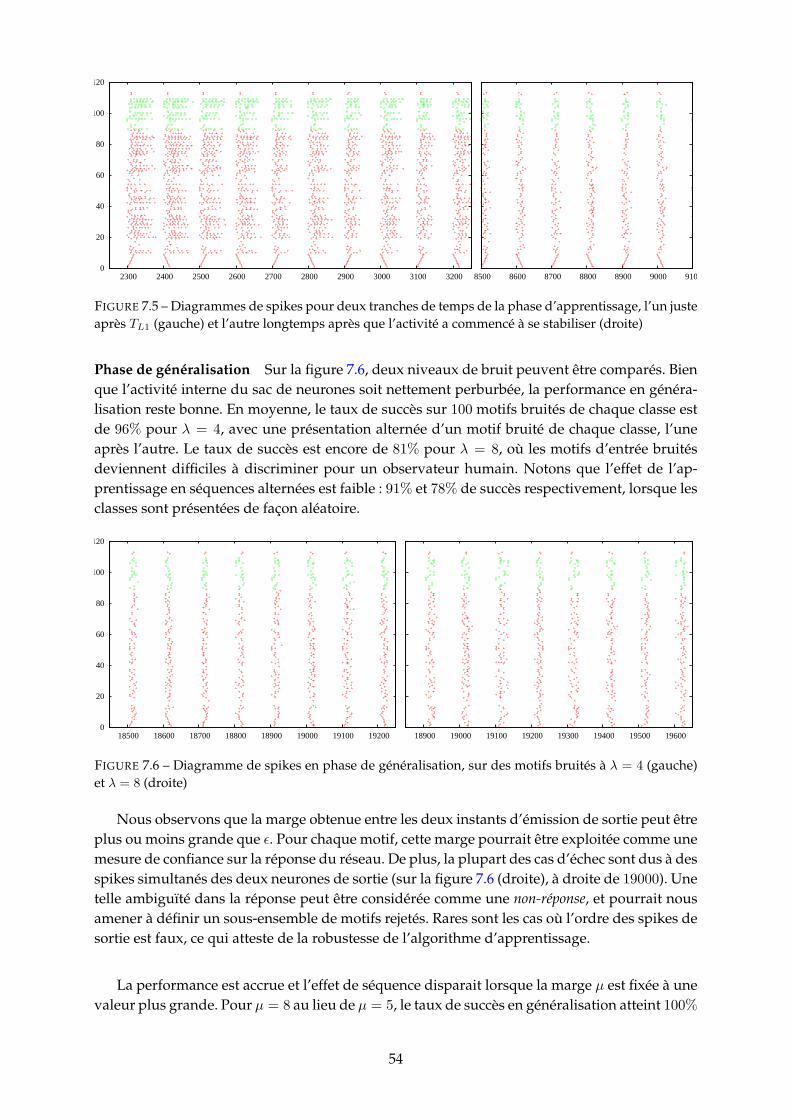
0
20
40
60
80
100
120
2300 2400 2500 2600 2700 2800 2900 3000 3100 3200 8500 8600 8700 8800 8900 9000 9100
FIGURE 7.5 – Diagrammes de spikes pour deux tranches de temps de la phase d’apprentissage, l’un justeaprès TL1 (gauche) et l’autre longtemps après que l’activité a commencé à se stabiliser (droite)
Phase de généralisation Sur la figure 7.6, deux niveaux de bruit peuvent être comparés. Bienque l’activité interne du sac de neurones soit nettement perburbée, la performance en généra-lisation reste bonne. En moyenne, le taux de succès sur 100 motifs bruités de chaque classe estde 96% pour λ = 4, avec une présentation alternée d’un motif bruité de chaque classe, l’uneaprès l’autre. Le taux de succès est encore de 81% pour λ = 8, où les motifs d’entrée bruitésdeviennent difficiles à discriminer pour un observateur humain. Notons que l’effet de l’ap-prentissage en séquences alternées est faible : 91% et 78% de succès respectivement, lorsque lesclasses sont présentées de façon aléatoire.
0
20
40
60
80
100
120
18500 18600 18700 18800 18900 19000 19100 19200 18900 19000 19100 19200 19300 19400 19500 19600
FIGURE 7.6 – Diagramme de spikes en phase de généralisation, sur des motifs bruités à λ = 4 (gauche)et λ = 8 (droite)
Nous observons que la marge obtenue entre les deux instants d’émission de sortie peut êtreplus ou moins grande que ε. Pour chaque motif, cette marge pourrait être exploitée comme unemesure de confiance sur la réponse du réseau. De plus, la plupart des cas d’échec sont dus à desspikes simultanés des deux neurones de sortie (sur la figure 7.6 (droite), à droite de 19000). Unetelle ambiguïté dans la réponse peut être considérée comme une non-réponse, et pourrait nousamener à définir un sous-ensemble de motifs rejetés. Rares sont les cas où l’ordre des spikes desortie est faux, ce qui atteste de la robustesse de l’algorithme d’apprentissage.
La performance est accrue et l’effet de séquence disparait lorsque la marge µ est fixée à unevaleur plus grande. Pour µ = 8 au lieu de µ = 5, le taux de succès en généralisation atteint 100%
54
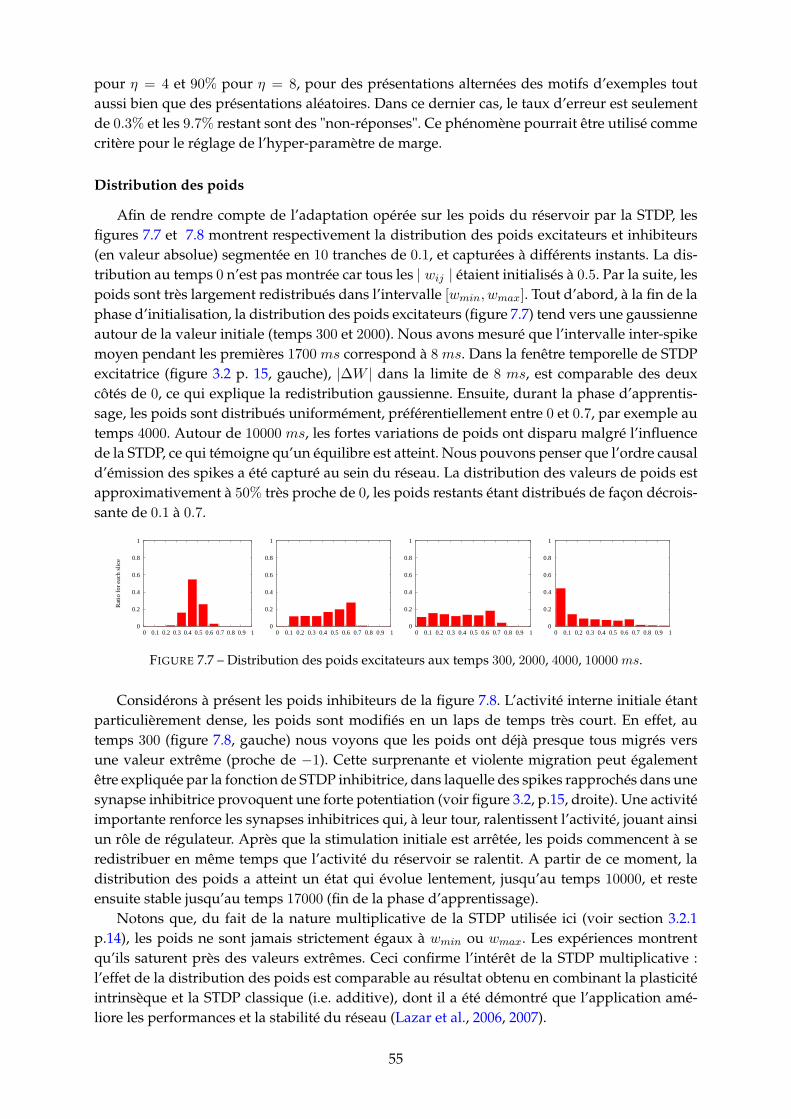
pour η = 4 et 90% pour η = 8, pour des présentations alternées des motifs d’exemples toutaussi bien que des présentations aléatoires. Dans ce dernier cas, le taux d’erreur est seulementde 0.3% et les 9.7% restant sont des "non-réponses". Ce phénomène pourrait être utilisé commecritère pour le réglage de l’hyper-paramètre de marge.
Distribution des poids
Afin de rendre compte de l’adaptation opérée sur les poids du réservoir par la STDP, lesfigures 7.7 et 7.8 montrent respectivement la distribution des poids excitateurs et inhibiteurs(en valeur absolue) segmentée en 10 tranches de 0.1, et capturées à différents instants. La dis-tribution au temps 0 n’est pas montrée car tous les | wij | étaient initialisés à 0.5. Par la suite, lespoids sont très largement redistribués dans l’intervalle [wmin, wmax]. Tout d’abord, à la fin de laphase d’initialisation, la distribution des poids excitateurs (figure 7.7) tend vers une gaussienneautour de la valeur initiale (temps 300 et 2000). Nous avons mesuré que l’intervalle inter-spikemoyen pendant les premières 1700 ms correspond à 8 ms. Dans la fenêtre temporelle de STDPexcitatrice (figure 3.2 p. 15, gauche), |∆W | dans la limite de 8 ms, est comparable des deuxcôtés de 0, ce qui explique la redistribution gaussienne. Ensuite, durant la phase d’apprentis-sage, les poids sont distribués uniformément, préférentiellement entre 0 et 0.7, par exemple autemps 4000. Autour de 10000 ms, les fortes variations de poids ont disparu malgré l’influencede la STDP, ce qui témoigne qu’un équilibre est atteint. Nous pouvons penser que l’ordre causald’émission des spikes a été capturé au sein du réseau. La distribution des valeurs de poids estapproximativement à 50% très proche de 0, les poids restants étant distribués de façon décrois-sante de 0.1 à 0.7.
0
0.2
0.4
0.6
0.8
1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Rat
io f
or e
ach
slic
e
0
0.2
0.4
0.6
0.8
1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0
0.2
0.4
0.6
0.8
1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0
0.2
0.4
0.6
0.8
1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
FIGURE 7.7 – Distribution des poids excitateurs aux temps 300, 2000, 4000, 10000 ms.
Considérons à présent les poids inhibiteurs de la figure 7.8. L’activité interne initiale étantparticulièrement dense, les poids sont modifiés en un laps de temps très court. En effet, autemps 300 (figure 7.8, gauche) nous voyons que les poids ont déjà presque tous migrés versune valeur extrême (proche de −1). Cette surprenante et violente migration peut égalementêtre expliquée par la fonction de STDP inhibitrice, dans laquelle des spikes rapprochés dans unesynapse inhibitrice provoquent une forte potentiation (voir figure 3.2, p.15, droite). Une activitéimportante renforce les synapses inhibitrices qui, à leur tour, ralentissent l’activité, jouant ainsiun rôle de régulateur. Après que la stimulation initiale est arrêtée, les poids commencent à seredistribuer en même temps que l’activité du réservoir se ralentit. A partir de ce moment, ladistribution des poids a atteint un état qui évolue lentement, jusqu’au temps 10000, et resteensuite stable jusqu’au temps 17000 (fin de la phase d’apprentissage).
Notons que, du fait de la nature multiplicative de la STDP utilisée ici (voir section 3.2.1p.14), les poids ne sont jamais strictement égaux à wmin ou wmax. Les expériences montrentqu’ils saturent près des valeurs extrêmes. Ceci confirme l’intérêt de la STDP multiplicative :l’effet de la distribution des poids est comparable au résultat obtenu en combinant la plasticitéintrinsèque et la STDP classique (i.e. additive), dont il a été démontré que l’application amé-liore les performances et la stabilité du réseau (Lazar et al., 2006, 2007).
55

0
0.2
0.4
0.6
0.8
1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Rat
io f
or e
ach
slic
e
0
0.2
0.4
0.6
0.8
1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0
0.2
0.4
0.6
0.8
1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0
0.2
0.4
0.6
0.8
1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
FIGURE 7.8 – Distribution de | wij | pour les poids inhibiteurs aux temps 300, 2000, 4000, 10000 ms.
Jaeger (2001a) suggère que le rayon spectral de la matrice des poids du réservoir soit in-férieur à 1. Nous avons déjà discuté ce point dans le chapitre 4. D’après certaines études surla dynamique du réservoir, il semblerait qu’un rayon spectral de 1 soit une valeur optimale.Néanmoins Verstraeten et al. (2007) prétendent que ce paramètre n’a aucune influence pour lesneurones impulsionnels. Steil (2007) montre qu’une règle d’apprentissage basée sur la plasti-cité intrinsèque a pour effet d’éloigner les valeurs propres du centre du disque unitaire. Surun nombre restreint de mesures nous avons observé un effet de la règle d’apprentissage sur lerayon spectral : par exemple prenant une valeur supérieure à 1, e.g. λ = 8.7 pour la matricede poids initiale, et λ = 2.3 après la phase d’apprentissage de 20000 ms. La valeur de λ di-minue maie reste supérieur à 1, même à la fin d’un apprentissage conduisant à d’excellentesperformances.
7.4 Résultats en reconnaissance de caractères sur la base USPS
Les motifs de la base d’exemples USPS 2(Hastie et al., 2001) consistent en vecteurs de di-mensions 256, composés de nombres réels entre 0 et 2, correspondant aux niveaux de gris des16 × 16 pixels d’images de chiffres manuscrits en niveaux de gris (exemples sur la figure 7.9).Ils sont présentés au réseau sous forme de codage temporel : plus la valeur numérique estgrande, plus le pixel est sombre, plus tôt le neurone d’entrée correspondant émettra, dans unefenêtre temporelle T = 20 ms. Ainsi, la partie significative du motif (i.e. l’emplacement despixels noirs) est présentée en premier au réseau, ce qui est avantageux comparé aux méthodesconventionnelles qui balayent la matrice des pixels de l’image ligne par ligne.
FIGURE 7.9 – Exemples de motifs USPS : chiffres 1, 5, 8, 9
Pour cette tâche, les constantes du modèle de neurone, et les hyper-paramètres sont lessuivants :
2. http ://www-stat-class.stanford.edu/∼tibs/ElemStatLearn/data.html
56

Paramètre de l’architecture du réseau :Paramètre ValeurK 256Cin 0.01
Tous les autres paramètres sont les mêmes que pour les expériences préliminaires.
Classification à deux classes
Nous testons tout d’abord la capacité du modèle à discriminer deux classes USPS choisiesarbitrairement, où chaque classse correspond à un chiffre spécifique. Nous avons donc légè-rement modifié le protocole de stimulation. En effet, au lieu de présenter alternativement lesdeux classes, tous les motifs d’apprentissage des deux classes sont présentés dans un ordrealéatoire. Plusieurs époques 3 sont itérées. Finalement, afin d’évaluer la performance en clas-sification, tous les mécanismes d’apprentissage sont stoppés, et deux époques sont exécutées.La première porte sur les exemples de la base d’apprentissage utilisée, la seconde porte surles exemples dits de test, jamais présentés jusqu’alors. Cette seconde époque permet d’évaluerl’erreur en généralisation. La performance en généralisation dépend de manière drastique desdeux classes choisies. La partie gauche des tableaux 7.1 et 7.2 montre les résultats pour deuxcouples de classes représentatifs, avec un réservoir de 100 neurones. Peu de cas ont de mauvaistaux de reconnaissance. Par exemple, 5 versus 8 (tableau 7.2) parvient à un taux d’erreur prochede 12% en généralisation. Pour améliorer ces cas, nous avons augmenté la taille du réservoirjusqu’à 2000 neurones ce qui améliore en effet légèrement les taux de succès, comme montrédans la partie droite des tableaux 7.1 et 7.2. En particulier, 5 versus 8 atteint 4.6% d’erreur, maisle taux de motifs rejetés (cas où les neurones de sortie émettent strictement simultanément)augmente également.
Apprentissage Généralisation Apprentissage Généralisation
Taux d’erreur 0.42% 2.72% 0.36% 1.81%Taux de succès 99.2% 96.8% 99.4% 97.3%Taux de rejet 0.36% 0.45% 0.24% 0.91%
TABLE 7.1 – Meilleur cas pour la discrimination à deux classes sur les chiffres USPS : les taux de la classe1 contre 9 avec 100 neurones (gauche) et 2000 neurones (droite) dans le réservoir.
Apprentissage Généralisation Apprentissage Généralisation
Taux d’erreur 10.7% 12.3% 3.10% 4.60%Taux de succès 85.4% 80.7% 90.4% 84.4%Taux de rejet 3.92% 7.06% 6.47% 11.0%
TABLE 7.2 – Pire cas pour la discrimination à deux classes sur les chiffres USPS : les taux de la classe 5contre 8 avec 100 neurones (gauche) et 2000 neurones (droite) dans le réservoir.
La dimension des motifs USPS étant environ 13 fois supérieure à celle des motifs utilisésdans les expériences préliminaires, nous nous attendions à plus de difficultés pour atteindredes performances raisonnables sans changer les hyper-paramètres. Bien qu’il s’agisse d’unetâche de classification à deux classes, le fait que nous obtenions des taux d’erreur assez faibles
3. Une époque correspond à une présentation de l’ensemble des exemples d’apprentissage (i.e. plusieurs cen-taines de motifs, le nombre exact dépendant du nombre de classe utilisées).
57

avec un réservoir de seulement 100 neurones est un résultat encourageant, surtout lorsque l’onpense à la dimension de motifs d’entrée (256) et au fait que la base USPS est réputée difficile enapprentissage artificiel. Ces résultats ont pu être améliorés avec un réservoir de 2000 neurones,ce qui est une taille communément rencontrée dans la littérature du RC.
Classification multi-classes
Nous avons mené de nouvelles simulations sur l’ensemble des 10 classes de la base USPS.Plusieurs réglages expérimentaux des hyper-paramètres nous ont mené aux valeurs suivantes :
Paramètre de l’architecture du réseau :Paramètre ValeurK 256N = Ninhbi +Nexcit 2000 = 400 + 1600L 10Cin 0.01Crsv 0.0145dmax 100 ms, uniquement pour les connexions du réservoir vers les sortiesWout 0.02
Paramètre dynamiques (modèle de neurone impulsionnel) :
Paramètre Valeurτm 20 ms
Tous les autres paramètres sont les mêmes que dans les expériences précédentes.Nous simulons 20 époques avant d’évaluer les taux sur les bases d’apprentissage et de
test. Nous obtenons un taux d’erreur de 8.8% sur la base d’apprentissage, taux qui passe à13.6% sur la base de test (tableau 7.3). Bien que les performances ne soient pas comparablesavec les meilleurs modèles d’apprentissage artificiel qui atteignent à peine 2% en taux d’erreursur la base de test (voir Keysers et al. (2002) pour revue des performance sur la base USPS),la règle d’apprentissage multi-échelle se comporte correctement sur des données réelles. Letaux d’erreur a été atteint après des réglages dépendants de la taille et de la complexité de labase. Tout d’abord, l’augmentation de la taille du réservoir de 100 à 2000 neurones amélioreles performances. Notons qu’une valeur plus grande pour τm (i.e. 20, au lieu de 3, voir lesparamètres du modèle), dans les neurones de sortie induit seulement une décroissance pluslente de leur potentiel de membrane. Les neurones sont alors réglés pour se comporter commedes neurones intégrateurs (voir chapitre 3).
Apprentissage Généralisation
Taux d’erreur 8.87% 13.6%Taux de succès 85.0% 79.1%Taux de rejet 6.13% 7.32%
TABLE 7.3 – Taux sur les 10 classes de la base USPS
Un autre point clé ici, a été de choisir une plus grande plage de valeurs possibles pour lesdélais du réservoir vers les sorties, permettant aux connexions d’être réglées dans l’intervalle[1, 100] au lieu de [1, 20]. Ceci a également amélioré le taux de succès, tout en réduisant le tauxde rejet. Ceci laisse à penser que la discrétisation des délais était trop faible pour permettre une
58

bonne discrimination et éviter la coïncidence des spikes de sortie. Afin de vérifier cette hypo-thèse, nous avons réalisé un test en utilisant un pas de temps plus fin que celui utilisé jusquelà : 0.1 ms au lieu de 1 ms, sur un réservoir de 200 neurones. Le résultat a été une améliorationde 7% du taux de succès sur la base de test, provenant principalement d’une diminution dutaux de rejet de 5.5%.
Les performances de notre modèle restent en deça de celles des meilleurs modèles clas-siques (MLP, SVM, etc.) ayant subi des adaptations spécifiques pour traiter efficacement desbases de caractères manuscrits. Néanmoins nous pouvons considérer que les résultats obte-nus sont suffisamment honorables pour constituer une preuve de principe pour l’utilisationde notre modèle de RC en classification. Notons au passage qu’il n’y a aucune performanceconnue pour d’autres modèles de RC appliqués aux bases benchmarks de caractères manus-crits USPS ou MNIST.
Les réglages des hyper-paramètres (notamment la taille du réservoir et la connectivité)doivent être améliorés, en restant cohérents avec les paramètres dynamiques afin de conser-ver un niveau d’activité suffisant pour permettre la trasmission de l’information jusqu’auxsorties, mais également en interdisant l’existence d’une activité persistante dans le réservoir.Une meilleur compréhension de l’activité et de l’influence de la connectivité pourra nous don-ner des indices pour améliorer les performances. C’est dans ce sens que nous nous attacheronsdans les chapitres suivants, à étudier la structure du réservoir et de son activité sous différentesconditions, et à en faire le lien avec les mécanismes d’apprentissage. Nous allons en particuliernous appuyer sur la théorie des groupes polychrones avancée par Izhikevich (2006).
59

8Etude du réservoir et de son activité
Travail publié dans Martinez & Paugam-Moisy (2008a) ; Martinez & Paugam-Moisy (2008b)
Martinez & Paugam-Moisy (2009)
L’observation de l’activité du réservoir n’est pas suffisante pour avoir une piste quant à lamanière dont celui-ci représente l’information. La figure 8.1 est un diagramme de spikes quiprésente l’activation du réseau en réponse à 125 motifs de chiffres manuscrits présentés unefois chacun, 6 ou 9 aléatoirement. On observe que quasiment tous les neurones du réservoir(entre 257 et 457) sont activés, indépendamment de la catégorie. Ce ne sont donc pas des sous-ensembles distincts de neurones qui permettent de discriminer les motifs. Cette observation vaà l’encontre de la théorie des assemblées de neurones spatiales.
0
50
100
150
200
250
300
350
400
450
500
80 82 84 86 88 90
# ne
uron
s
Temps [s]
Spike raster plot
FIGURE 8.1 – Diagramme de spikes pendant la phase de généralisation d’une simulation à deux classes(6 versus 9) avec les exemples USPS
Nous allons nous intéresser à des expériences menées après la phase d’apprentissage etportant sur l’étude de l’activité interne du réservoir. L’objectif est de comprendre commentle réseau a mémorisé les motifs appris. Nous recherchons une représentation qui prenne encompte non seulement les aspects spatiaux de la connectivité et de l’architecture du réseau,mais aussi certains aspects temporels liés à sa dynamique. Nous proposons d’adopter la théorie
60
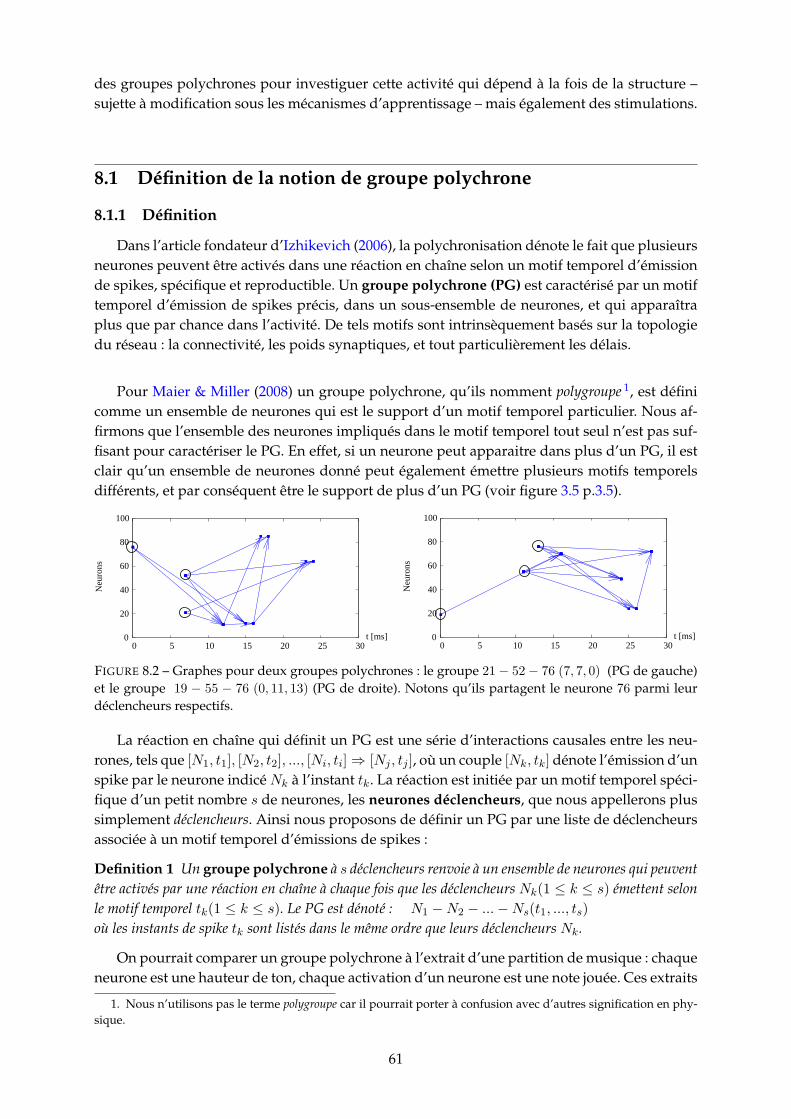
des groupes polychrones pour investiguer cette activité qui dépend à la fois de la structure –sujette à modification sous les mécanismes d’apprentissage – mais également des stimulations.
8.1 Définition de la notion de groupe polychrone
8.1.1 Définition
Dans l’article fondateur d’Izhikevich (2006), la polychronisation dénote le fait que plusieursneurones peuvent être activés dans une réaction en chaîne selon un motif temporel d’émissionde spikes, spécifique et reproductible. Un groupe polychrone (PG) est caractérisé par un motiftemporel d’émission de spikes précis, dans un sous-ensemble de neurones, et qui apparaîtraplus que par chance dans l’activité. De tels motifs sont intrinsèquement basés sur la topologiedu réseau : la connectivité, les poids synaptiques, et tout particulièrement les délais.
Pour Maier & Miller (2008) un groupe polychrone, qu’ils nomment polygroupe 1, est définicomme un ensemble de neurones qui est le support d’un motif temporel particulier. Nous af-firmons que l’ensemble des neurones impliqués dans le motif temporel tout seul n’est pas suf-fisant pour caractériser le PG. En effet, si un neurone peut apparaitre dans plus d’un PG, il estclair qu’un ensemble de neurones donné peut également émettre plusieurs motifs temporelsdifférents, et par conséquent être le support de plus d’un PG (voir figure 3.5 p.3.5).
0 0
20 20
40 40
60 60
80 80
100 100
0 0 5 5 10 10 15 15 20 20 25 25 30 30
Neu
rons
Neu
rons
t [ms] t [ms]
FIGURE 8.2 – Graphes pour deux groupes polychrones : le groupe 21− 52− 76 (7, 7, 0) (PG de gauche)et le groupe 19 − 55 − 76 (0, 11, 13) (PG de droite). Notons qu’ils partagent le neurone 76 parmi leurdéclencheurs respectifs.
La réaction en chaîne qui définit un PG est une série d’interactions causales entre les neu-rones, tels que [N1, t1], [N2, t2], ..., [Ni, ti]⇒ [Nj , tj ], où un couple [Nk, tk] dénote l’émission d’unspike par le neurone indicé Nk à l’instant tk. La réaction est initiée par un motif temporel spéci-fique d’un petit nombre s de neurones, les neurones déclencheurs, que nous appellerons plussimplement déclencheurs. Ainsi nous proposons de définir un PG par une liste de déclencheursassociée à un motif temporel d’émissions de spikes :
Definition 1 Un groupe polychrone à s déclencheurs renvoie à un ensemble de neurones qui peuventêtre activés par une réaction en chaîne à chaque fois que les déclencheurs Nk(1 ≤ k ≤ s) émettent selonle motif temporel tk(1 ≤ k ≤ s). Le PG est dénoté : N1 −N2 − ...−Ns(t1, ..., ts)où les instants de spike tk sont listés dans le même ordre que leurs déclencheurs Nk.
On pourrait comparer un groupe polychrone à l’extrait d’une partition de musique : chaqueneurone est une hauteur de ton, chaque activation d’un neurone est une note jouée. Ces extraits
1. Nous n’utilisons pas le terme polygroupe car il pourrait porter à confusion avec d’autres signification en phy-sique.
61

réunis forment une mélodie, de même que plusieurs groupes polychrones réunis forment l’ac-tivité d’un réseau.
Pour décider si un neurone pourrait être activé selon le nombre de spikes qu’il a reçu si-multanément, nous suivons Izhikevich (2006) en étendant la notion d’impact simultané à unintervalle de temps dénoté jitter. Une représentation graphique d’un PG peut être réalisée surun diagramme de spike de l’activité du réseau, en ne portant attention qu’au sous-ensemblede neurones du groupe, et en traçant des liens additionnels pour représenter les interactionscausales (voir figure 8.2). Une telle représentation est un sous-graphe de l’activité neuronale,où chaque sommet est un couple [Nk, tk], et chaque lien dirigé est une influence causale d’unneurone pré-synaptique vers un neurone post-synaptique.
8.1.2 PG structuraux et PG dynamiques
La définition 1 nous permet d’inventorier tous les PG de s déclencheurs possibles supportéspar un réseau de neurones impulsionnels donné ayant une connectivité connue et des délaisaxonaux, sans se préoccuper des valeurs des poids. Puisque de tels PG ne dépendent que del’architecture du réseau, ils sont structuraux et nous les appelons des PG supportés.
Néanmoins, les poids synaptiques sont souvent soumis à une règle d’apprentissage et leursvaleurs changent au cours du temps, ce qui peut influencer la décision qu’un neurone émetteun spike ou non, selon le nombre d’impacts simultanés reçus. Nous définissons alors la notionde PG adapté en tenant compte dans la définition 1 de la dynamique du potentiel de membranedes neurones, et des valeurs des poids synaptiques. Les PG adaptés ne tenant pas compte del’activité en elle-même, mais seulement de la structure du réseau à un instant t, nous considé-rons qu’il s’agit également de PG structuraux. Les PG adaptés peuvent alors être considéréscomme des PG structuraux qui tiennent compte des modifications survenues dans la topolo-gie, du fait de la dynamique. Il est donc envisageable de répertorier les PG adaptés à différentsmoments d’une simulation, afin de photographier le paysage des PG adaptés, et possiblementd’en étudier l’évolution.
Une autre question est de trouver quels PG apparaissent effectivement dans l’activité duréseau de neurones pendant une fenêtre de temps donnée. Ces PG sont un sous-ensemble desPG structuraux et nous les appelons les PG activés. Contrairement aux PG structuraux qui nedépendent que de la structure du réseau, les PG activés sont considérés comme des PG dyna-miques puisqu’ils dépendent de l’activité du réseau, sous l’influence de stimuli présentés enentrée.
Nous proposons ici trois algorithmes qui permettent de recenser ces trois types de PG quesont les PG supportés, les PG adaptés et les PG activés.
8.2 Recensement des groupes polychrones
Les algorithmes 1 et 2 sont conçus pour rechercher les PG structuraux, à savoir, respective-ment, les PG supportés et les PG adaptés. Ils sont basés sur une topologie de réseau donnée,
62

avec une connectivité connue, des délais axonaux et des poids synaptiques. L’algorithme 3 estconçu pour rechercher les PG dynamiques, i.e. ceux qui sont activés par un stimulus.
Dans l’algorithme 1, toutes les combinaisons de s neurones sont testées comme des jeuxde déclencheurs possibles, avec pour hypothèse que NbSpikesNeeded sont nécessaires pourgénérer une interaction causale faisant émettre un spike au neurone Nj (s et NbSpikesNeededsont des paramètres parmi d’autres, présentés plus loin de manière exhaustive). Les potentielspost-synaptiques (PPSs) ne sont pas pris en compte dans l’algorithme 1 alors que dans l’al-gorithme 2, la décision de laisser un neurone Nj émettre un spike requiert le calcul des PPSspondérés par les poids afférents à Nj . Dans l’algorithme 2, la quantité de spikes entrants peutdifférer de NbSpikesNeeded, un paramètre qui n’est alors plus utile (s est toujours nécessairequant à lui, et est choisi par l’utilisateur).
L’algorithme 3 est conçu pour rechercher les apparitions effectives dans l’activité du réseaudes PG structuraux (i.e. supportés ou adaptés) précédemment répertoriés, ce dans un intervallede temps donné de la simulation.
Les trois algorithmes sont utilisables pour n’importe quel modèle de neurone pouvant fonc-tionner en mode événementiel. L’algorithme 2 utilise l’équation du modèle de neurone pourdécider qu’il y a émission de spike ou non, sur la base de l’historique récent des PPSs. Cettecontrainte peut être omise pour l’algorithme 1 qui peut être directement adapté quelque soit lemodèle de neurone. En effet, il est basé sur les événements de spikes, et ne tient pas compte dela dynamique interne du neurone.
Le modèle de neurone que nous utilisons, rappellons-le, est le modèle SRM0 (voir sec-tion 2.3.2 p.9). Nous utilisons une discrétisation du temps à 0.1 ms de précision. Les variablesde chaque neurone sont mises à jour à chaque arrivée d’un nouveau spike (programmationévénementielle). Nous définissons ci-après les paramètres utilisés dans nos algorithmes.
8.2.1 Définitions
NotationsN : nombre de neurones dans le réseauNi : neurone d’indice iNTk : neurone déclencheur numéroté Tk, avec k entre 1 et st : instant actuel (temps virtuel, dans les simulations)dij : délai de conduction de la connexion de Ni à Njwij : poids synaptiques de Ni à Nj , égal à 0 si la connexion n’existe pas
Structures de donnéesPotentiel Post-Synaptique (en anglais « Post Synaptic Potential », PSP). Un PPS est dénotéPSPtpsp,Nl,Nm :
Potentiel Post-Synaptique évoqué à l’instant tpsp par le neurone pré-synaptique Nl sur un neu-rone post-synaptique Nm.
File des événements. La file EventQueue est une structure pour le traitement des événementsde simulation (PPS évoqués). Elle contient les événements futurs ordonnés chronologiquement.
Liste des PPS, stockée dans les neurones. Pour les besoins de l’algorithme, nous devons stocker,pour chaque neurone, la liste des spikes reçus pendant un laps de temps écoulé donné, le Jitter
63

(voir Section 1). Cette liste est appelée PSPListi, pour le neurone Ni.Structure de données pour un PG. Quand un PG est calculé, des informations doivent être
stockées :– les instants tT1 , ..., tTs des déclencheurs NT1 à NTs ;– pour chaque PPS, PSPtpsp,Nl,Nm , l’indice de Nm et de ses instants d’émissions de spikes,
l’indice de Nl et l’instant d’évocation du PPS.
VariablesNbTriggeringConnectionsi : nombre de connexions provenant des déclencheurs, reçues par NiMaxPotentiali : valeur maximum du potentiel de membrane que le neurone Ni peut atteindre sousl’action des déclencheurstLastSpikei : instant de l’émission du spike le plus récent du neuroneNi, initialisé à−RefractoryPeriode,de sorte que les spikes précédents soient hors de la période réfractaire
Parameterss : nombre de déclencheurs, fixé pour tous les groupes polychronesNbSpikesNeeded : nombre de spikes impactants simultanés nécessaires pour déclencher un nouveauspike dans un neuroneJitter : laps de temps dans lequel deux spikes sont considérés comme simultanésNbSpikesMax : nombre maximum de spikes dans un groupe polychrone avant d’être tronquéNbSpikeMin : nombre minimum de spikes dans un groupe polychrone pour être enregistréMaxTimeSpan : durée maximum d’un groupe polychrone, en temps virtuel, avant d’être tronquéMinTimeSpan : durée minimum d’un groupe polychrone, en temps virtuel pour être enregistréPSPStrength : amplitude d’un PPSRestingPotential : le potentiel de membrane de repos d’un neurone (potentiel de membrane en absencede stimulation)Threshold : valeur du potentiel de membrane au-delà duquel un spike est émis par le neuroneRefractoryPeriode : durée après l’émission d’un spike, pendant laquelle le neurone ne peut plus ré-émettre
8.3 Algorithmes
8.3.1 Algorithme 1
Afin de lister les PG supportés, nous regardons toutes les combinaisons d’un nombre s deneurones (les déclencheurs). Pour chaque combinaison, nous chercons si elle peut déclencherun spike dans un ou plusieurs autres neurones, par l’impact d’au moinsNbSpikesNeeded des sspikes initiaux de cette combinaison. Si de tels neurones (potentiellement déclenchés) existent,alors cette combinaison devient un ensemble de déclencheurs dont nous simulons l’émission despikes avec le bon timing, et enregistrons la propagation de l’activité à travers le réseau, jusqu’àce que celle-ci s’éteigne ou atteigne une borne maximale de temps (paramètre MaxTimeSpan)ou un nombre maximal de spikes émis (paramètreNbSpikesMax). Ces limites sont nécessairesafin de tronquer les éventuels PG cycliques, i.e. qui ont une activité qui s’auto-entretient pério-diquement.
Dans cet algorithme, la propagation de l’activité est basée sur le nombre de spikes reçus parchaque neurone dans une fenêtre de temps. Par exemple, les neurones peuvent être paramétrésafin qu’ils émettent un spike à chaque fois qu’ils sont impactés par au moins trois spikes en0.5 ms. Nous déroulons ci-dessous le détail de l’algorithme.
64

1: // Lines starting with // are comments.
2: for all combination of s neurons out of n neurons of the network do3: // Look for PG triggered by this combination
4: for all i from 1 to n do5: NbTriggeringConnectionsi = 06: end for
7: // Count connections comming from triggers, to find common triggers output neurons8: for all p from 1 to s do9: for all i with wiTp 6= 0 do
10: NbTriggeringConnectionsi = NbTriggeringConnectionsi + 111: end for12: end for
13: for all p from 1 to s do14: for all i with wiTp 6= 0 do15: NbPSPi = 0 // Reset count of PSP evoked in Ni in the last Jitter ms
16: if NbTriggeringConnectionsi > NbSpikesNeeded then17: // Reset NbTriggeringConnectionsi18: NbTriggeringConnectionsi = 0
19: // A spike from Ni is triggered.20: We will calculate the PG with trigger neurons {NT1 , NT2 , ... , NTs } firing at Ni21: firing with timing {dmax − dT1i, dmax − dT2i, ... , dmax − dTsi}22: with dmax = max(dT1i, dT2i, ..., dTsi)23: thus triggering neuron Ni.
24: Add triggering spikes to PG. // Store triggering spikes to the PG data structure25: PGSpikeCount = s // Count of spikes in this PG26: t = 0 // Initialise clock
27: // Enqueue PSPs from triggers starting at t = 0.28: for all neuron Nh recieving a connection from NTk , ∀k from 1 to s do29: Enqueue the new upcoming PSP evoked in Nh at time t + (dmax − dTki) + dTkh by the
spike from NTk30: end for
31: while (PGSpikeCount < NbSpikesMax) and (PSP queue not empty) and (t < MaxTimeSpan)do
32: Consider next upcoming PSP PSPtpsp,Nl,Nm evoked at time tpsp with33: Nl : firing pre-synaptic neuron of the spike that evoked PSPtpsp,Nl,Nm34: Nm : post-synaptic neuron in which the PSP is evoked
35: t = tpsp36: NbPSPm = NbPSPm + 137: for all PSPtpsp,No,Nm with t− tpsp > Jitter do38: Erase PSP // Erase PSPs evoked in Nm older than t− Jitter ms.39: end for
40: if (t− tLastSpikem > RefractoryPeriode) and (NbPSPm > NbSpikesNeeded) then41: // Nm fires a spike42: tLastSpikem = t
43: Add a spike from Nm at time t, to PG44: PGSpikeCount = PGSpikeCount+ 1
65

45: for all neuron Nm recieving a connection from Nl do46: Enqueue an upcoming PSP evoked in Nm at time t+ dlm by the spike from Nl47: end for48: end if49: end while
50: if PGSpikeCount > NbSpikeMin then51: Save the PG52: end if53: end if54: end for55: end for56: end for
8.3.2 Algorithme 2
Le principe l’algorithme 2 est très similaire au précédent, à l’exception du fait que la déci-sion d’émettre un spike ou non est basée sur le niveau du potentiel de membrane du neurone,qui lui-même dépend :
(a) des poids de ses connexions entrantes qui modulent ainsi le potentiel de membrane etdonc la probabilité de générer un spike,
(b) le temps écoulé depuis les PPS précédents.Comme dans l’algorithme 1, nous regardons toutes les combinaisons de s déclencheurs. La
seule différence est que l’activité des neurones est calculée à partir de son potentiel de mem-brane pour savoir si elle dépasse ou non le seuil du neurone. Dans cet algorithme, la propa-gation de l’activité est basée sur le fait que le potentiel de membrane dépasse le seuil. Nousdéroulons ci-dessous le détail de l’algorithme.
N.B. : Les sections de code en rouge mettent en valeur les lignes qui diffèrent de l’algo-rithme 1.
66

1: for all combination of s neurons out of n neurons of the network do2: // Look for PG triggered by this combination
3: for all Neuron Ni, output of a triggering neuron do4: NbPSPi = 0 // Count of PSP evoked in Ni in the last Jitter ms5: Potentiali = RestingPotential // Set initial membrane potential for Ni6: MaxPotentiali = Potentiali +
∑TjwTjiPSPStrength
7: if MaxPotentiali > Threshold then8: // A spike from Ni is triggered.9: We will calculate PG with trigger neurons {NT1 , NT2 , ... , NTs } firing at Ni
10: firing with timing {dmax − dT1i, dmax − dT2i, ... , dmax − dTsi}11: with dmax = max(dT1i, dT2i, ..., dTsi)12: thus triggering neuron Ni.
13: Add triggering spikes to PG. // Store triggering spikes to PG data structure14: PGSpikeCount = 0 // Count of spikes in this PG15: t = 0
16: // Enqueue PSPs from triggers17: for all neuron Nh recieving a connection from NTk , ∀k from 1 to s do18: Enqueue the new upcoming PSP evoked in Nh at time t+ (dmax−dTki) +dTkh by the spike
from NTk19: end for
20: while (PGSpikeCount < NbSpikesMax) and (PSP queue not empty) and (t < MaxTimeSpan)do
21: Consider next upcoming PSP PSPtpsp,Nl,Nm evoked at time tpsp with22: Nl : firing pre-synaptic neuron of the spike that evoked PSPtpsp,Nl,Nm23: Nm : post-synaptic neuron in which the PSP is evoked
24: t = tpsp
25: for all PSPtpsp,No,Nm with t− tpsp > Jitter do26: Erase PSP // Erase PSPs evoked in Nm older than t− Jitter ms.27: end for
28: // Re-evaluate decreasing membrane potential, with regard to last spike recieved tf
29: Potentialm = η(Potentiall, tf )30: Potentialm = Potentialm + wlm × PSPStrength
31: if (Potentialm > Threshold) then32: // Nm fires a spike33: Add a spike to from Nm at time t, to PG34: PGSpikeCount = PGSpikeCount+ 135: for all neuron Nm recieving a connection from Nl do36: Enqueue an upcoming PSP evoked in Nm at time t+ dlm by the spike from Nl37: end for38: end if39: end while
40: if PGSpikeCount > NbSpikeMin then41: Save the PG42: end if43: end if44: end for45: end for
67

8.3.3 Algorithme 3
L’algorithme 3 est écrit pour rechercher l’occurrence de PG connus (préalablement détec-tés par l’algorithme 1 ou 2) dans l’activité enregistrée d’une simulation, dans un intervalle detemps donné.
Afin de détecter l’activation d’un PG dans une fenêtre temporelle particulière de l’activitéenregistrée d’une simulation, il serait idéal de vérifier si chaque groupe polychrone préalable-ment recensé est entièrement activé (i.e. que tous ses spikes sont présents dans l’activité, avecle bon timing). Pour des raisons d’économie computationnelle, nous ne recherchons que lesspikes des déclencheurs du PG, avec le bon motif temporel à une précision temporelle Jitter msprès. Nous basons cette simplification algorithmique sur l’hypothèse que l’activation des dé-clencheurs activera également la queue du PG avec peu de changement (Izhikevich, 2006).Ainsi si les déclencheurs sont détectés dans l’activité, il est presque sûr que le reste du PG soitégalement activé avec peu de variation. Cette hypothèse est en effet raisonnable avec les PGadaptés, elle peut être plus risquée avec les PG supportés.
1: // We look for the actual activation of known PG in a temporal range [Start;End]. For each neuronNi, the list of spikes fired by this neuron between times Start and End is stored already (i.e. weassume that the spike raster has been recorded).
2: Let Spikemi be the mth spike of the list of spikes fired by Ni, at time tSpikemi
3: for all PG triggered by {NT1 , NT2 , ... , NTs } with timing {tT1 , tT2 , ... , tTs } do4: ∀SpikemT1 at time tSpikemT1
5: if ∀k ∈ [T2;Ts], ∃ SpikemTk at time tSpikemT1+ (tTk − tT1) then
6: Save activation of PG at time tSpikemT1− tT1
7: end if8: end for
8.4 Etude de la complexité algorithmique
Nous développons tout d’abord l’estimation de la complexité pour l’algorithme 1. Puisnous abordons la complexité des algorithmes 2 et 3.
Soit C la connectivité d’un réseau, i.e. la probabilité qu’un neurone projette une connexionsur un autre neurone. Soit AC = (n− 1)×C le nombre moyen de connexions reçues par n’im-porte quel neurone du réseau. Rappelons-nous que s est le nombre de déclencheurs.
Le nombre de combinaisons à passer en revue est CsN = N !
s!(N−s)! . Pour chaque combinai-son, nous cherchons le nombre de neurones qui reçoivent des connexions concurrentes desdéclencheurs, et nous comptons le nombre de ces connexions. Cette étape est effectuée avecune complexité O(n+ s×AC).
La probabilité qu’un neurone reçoive k = NbSpikesNeeded connexions d’un autre neurone,avec k ≤ s, est Ck. Nous regardons quels neurones ont assez de connexions entrantes prove-nant des déclencheurs pour émettre un spike. Pour chaque neurone excité, nous initialisons lecalcul du PG correspondant et ajoutons les événements de spikes à une file d’attente c’est-à-
68

dire s×AC opérations.
Le bloc while est plus difficile à évaluer du fait des différents paramètres qu’il inclut. Dansle pire des cas, les N neurones reçoivent tous NbSpikesNeeded spikes, et émettent à leur tour.Alors il y aurait N × k événements à traiter, et N ×AC nouveau PPS à mettre en file d’attente.Les neurones émettraient alors à nouveau aussitôt sortis de leur période réfractaire. Il y auraitau plusM/R×n×AC événements à traiter dans l’ensemble du calcul, oùM = MaxTimeSpan
et R = RefractoryPeriode.
Ainsi, la complexité globale Xalgo1 de l’algorithme 1, dans le pire des cas, est :
Csn︸︷︷︸
combin.
×[ (N + s×AC)︸ ︷︷ ︸recherche declencheurs
+ (s×AC)× (Ck)︸ ︷︷ ︸nb declencheurs
×( s×AC︸ ︷︷ ︸init. spikes
+ M/R× n×AC)︸ ︷︷ ︸evt dans le pire des cas
]
Puisque s � N , le nombre de combinaisons CsN peut être approximé par
(Ns
)s et AC =(N − 1)× C remplacé par C ×N , ce qui conduit à une borne supérieure pour Xalgo1 :
Xalgo1 ≤1 + s× C
ssN s+1 +
Ck+2
ss−2N s+2 +
M
R× Ck+2
ss−1N s+3 (8.1)
Il en résulte que la complexitéXalgo1 est de l’ordreO(N s+3) dans le pire des cas. En pratique,les réseaux de neurones impulsionnels ont habituellement une connectivité éparse. Fixer lagrandeur de la connectivité C à 1/
√N semble une estimation réaliste, à la fois pour les réseaux
artificiels (e.g. C = 0.1 dans une réseau de 100 neurones) et les réseaux biologiques (environ105 connexions par neurone entre 1011 neurones dans le cerveau humain). Remplacer C parN−1/2 dans l’équation (8.1) nous donne :
Xalgo1 ≤1ssN s+1 +
1ss−1
N s+1/2 +1
ss+2N s +
M
R× 1ss−1
N s+1 car k ≥ 2 (8.2)
Enfin, en pratique, la complexité de l’algorithme 1 est d’ordre O(N s+1).
La complexité Xalgo2 de l’algorithme 2 est similaire à Xalgo1 car les deux algorithmes ont lamême structure de contrôle. Néanmoins, exécuter l’algorithme 2 devrait être plus consomma-teur de temps si le modèle de neurone est complexe.
La complexité Xalgo3 de l’algorithme 3 est de d’ordre O(P ∗ S/N), où P est le nombre degroupes polychrones connus (trouvés par l’algorithme 1 ou 2), et S le nombre total de spikesdans l’intervalle de temps choisi pour la recherche dans l’activité du réseau.
8.5 Etude de la dynamique du réservoir
8.5.1 Sélection des groupes polychrones et spécialisation
Un neurone peut être activé dans plusieurs PG, à des instants différents (e.g. le neurone 76dans la figure 8.2). Par conséquent le nombre de PG coexistants dans un réseau peut être bienplus élevé que le nombre de ses neurones, ouvrant la possibilité d’une immense capacité demémorisation. Dans le réservoir utilisé pour les expériences sur les motifs d’Izhikevich (voir
69

section 7.3 p.51), nous avons répertorié tous les PG possibles inhérents à la topologie du réseau,avec s = 3 déclencheurs (voir figure 8.2 par exemple). Nous avons ainsi pu détecter 104 PG po-tentiellement activables dans le réservoir deN = 100 neurones. Dans des conditions similaires,le nombre de PG dépasse déjà 3000 dans un réseau de N = 200 neurones.
0 5
10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95
100 105
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000 11000 12000 13000 14000 15000 16000 17000 18000 19000 20000
Poly
chro
nous
gro
ups
t [ms]
Initial stimulation Training Testing
FIGURE 8.3 – Evolution de l’activation des groupes polychrones au cours des phases d’initialisation,d’apprentissage et de généralisation des expériences décrites dans la section 7.3, avec une présentationalternée des classes d’exemples. Attention : dans cette figure, l’axe des ordonnées montre les indices desPG, et non plus les indices des neurones comme c’était le cas dans les diagrammes de spikes.
Nous observons sur la figure 8.3 que beaucoup de PG sont fréquement activés pendant laphase d’initialisation aléatoire. En effet celle-ci génère une activité dense et désordonnée dansle réservoir (avant 2000 ms). Au début de la phase d’apprentissage (qui s’étend de 2000 msà 17000 ms), de nombreux groupes sont encore activés. Puis, environ à partir de 5000 ms, lepaysage d’activation devient plus stable. Comme nous pouvions nous y attendre, seulementquelques groupes polychrones continuent à être activés. Un petit sous-ensemble des PG peutêtre associé à chaque classe : les groupes 3, 41, 74, 75 et 83 (qui laisse sa place à 85), s’allumentpour la classe 1, alors que les groupes 12, 36, 95, parfois 99, et 49 (qui s’éteint au profit de 67),s’allument pour la classe 2. Pendant la phase de généralisation (après 17000ms), les principauxgroupes, et les plus activés, sont ceux identifiés pendant la phase d’apprentissage. Cette ob-servation supporte l’hypothèse que les groupes polychrones deviennent représentatifs d’uneclasse, sous l’influence des mécanismes d’apprentissage.
Plusieurs observations intéressantes peuvent être faites. Comme Izhikevich l’a remarqué, ilexiste des groupes qui commencent à être activés seulement après un grand nombre de stimu-lations (par exemple 41, 49, 67 et 85), alors que d’autres groupes s’éteignent après un moment(e.g. 5 et quelques autres actifs jusqu’à 4000/5000ms seulement, 49, 70, 83 et 99 plus tard). Nouspouvons également observer que les groupes polychrones se spécialisent pour une classe par-ticulière (après 8000ms) au lieu de répondre aux deux classes comme ils le font au début. C’estnotamment clairement le cas entre 2000 et 5000 ms.
Une représentation sous forme d’histogramme d’un sous-ensemble des 104 PG (figure 8.4)montre clairement ce phénomène. Un cas très intéressant ici, est celui du groupe 95 qui est ini-tialement activé pour les deux classes, puis (autour de 7500 ms) s’arrête de répondre à la classe
70

0
20
40
60
80
100
60 65 70 75 80 85 90 95 100
Perc
ent o
f ac
tivat
ion
# polychronous groups
activations in response to class 1activations in response to class 2
0
20
40
60
80
100
60 65 70 75 80 85 90 95 100
Perc
ent o
f ac
tivat
ion
# polychronous groups
activations in response to class 1activations in response to class 2
FIGURE 8.4 – Proportion d’activation des PG pour chacune des deux classes, de 2000 à 5000 ms, et de8000 à 11000ms. Pour chaque stimulation nous montrons deux barres d’histogramme côte à côte : Classe1 en noir, classe 2 en bleu clair.
1, se spécialisant ainsi pour la classe 2. Un tel phénomène soutient que la plasticité synaptiquefournit au réseau une adaptation pertinente et souligne bien l’importance des deux aspects denotre algorithme d’apprentissage, la STDP et l’optimisation des délais.
10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90
17000 10000 2000 0
Neu
rons
t [ms]
Initial stimulation Training Testing
FIGURE 8.5 – Les 80 neurones excitateurs du réservoir ont été marqués par un « + » rouge (en niveaux degris) pour la classe 1 ou par un « x » bleu (gris clair en noir et blanc) pour la classe 2 à chaque fois qu’ilsjouent le rôle de neurone pré-synaptique responsable d’une modification du délai axonal de sortie parl’algorithme d’apprentissage supervisé.
L’influence des PG activés sur le processus d’apprentissage peut être observé par le biaisde la figure 8.5. Sur cette figure nous avons répertorié les indices des neurones pré-synaptiquesresponsables de l’application de la règle de mise à jour des délais de sortie, à chaque itéra-tion où un exemple n’a pas été classifié correctement (cf. algorithme 1 de la section 7.2 p.49).Par exemple, le neurone 42, qui est répétitivement responsable de l’adaptation du délai, estun des neurones déclencheurs du groupe polychrone 12, activé pour la classe 2 pendant laphase d’apprentissage. Nous pouvons noter que l’adaptation des délais s’arrête avant que laphase d’apprentissage ne soit terminée, ce qui signifie que le processus d’apprentissage est déjàefficace autour de 10000 ms. Un tel contrôle pourrait être implémenté dans l’algorithme d’ap-prentissage comme une heuristique, afin de déterminer quand arrêter l’apprentissage (au lieude l’actuel « jusqu’à ce que une limite de temps d’apprentissage donnée soit écoulée »).
71
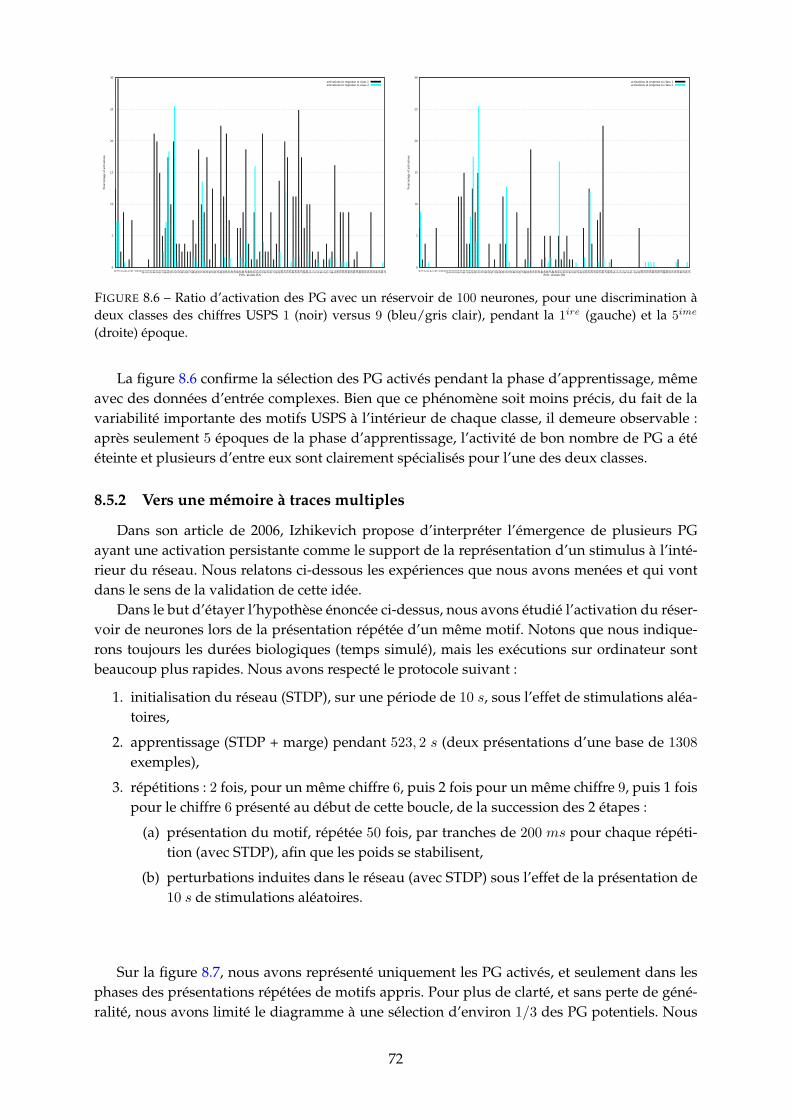
0
5
10
15
20
25
30
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97
Pour
cent
age
of a
ctiv
atio
ns
Poly. groups IDs
activations in response to class 1activations in response to class 2
0
5
10
15
20
25
30
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97
Pour
cent
age
of a
ctiv
atio
ns
Poly. groups IDs
activations in response to class 1activations in response to class 2
FIGURE 8.6 – Ratio d’activation des PG avec un réservoir de 100 neurones, pour une discrimination àdeux classes des chiffres USPS 1 (noir) versus 9 (bleu/gris clair), pendant la 1ire (gauche) et la 5ime
(droite) époque.
La figure 8.6 confirme la sélection des PG activés pendant la phase d’apprentissage, mêmeavec des données d’entrée complexes. Bien que ce phénomène soit moins précis, du fait de lavariabilité importante des motifs USPS à l’intérieur de chaque classe, il demeure observable :après seulement 5 époques de la phase d’apprentissage, l’activité de bon nombre de PG a étééteinte et plusieurs d’entre eux sont clairement spécialisés pour l’une des deux classes.
8.5.2 Vers une mémoire à traces multiples
Dans son article de 2006, Izhikevich propose d’interpréter l’émergence de plusieurs PGayant une activation persistante comme le support de la représentation d’un stimulus à l’inté-rieur du réseau. Nous relatons ci-dessous les expériences que nous avons menées et qui vontdans le sens de la validation de cette idée.
Dans le but d’étayer l’hypothèse énoncée ci-dessus, nous avons étudié l’activation du réser-voir de neurones lors de la présentation répétée d’un même motif. Notons que nous indique-rons toujours les durées biologiques (temps simulé), mais les exécutions sur ordinateur sontbeaucoup plus rapides. Nous avons respecté le protocole suivant :
1. initialisation du réseau (STDP), sur une période de 10 s, sous l’effet de stimulations aléa-toires,
2. apprentissage (STDP + marge) pendant 523, 2 s (deux présentations d’une base de 1308exemples),
3. répétitions : 2 fois, pour un même chiffre 6, puis 2 fois pour un même chiffre 9, puis 1 foispour le chiffre 6 présenté au début de cette boucle, de la succession des 2 étapes :
(a) présentation du motif, répétée 50 fois, par tranches de 200 ms pour chaque répéti-tion (avec STDP), afin que les poids se stabilisent,
(b) perturbations induites dans le réseau (avec STDP) sous l’effet de la présentation de10 s de stimulations aléatoires.
Sur la figure 8.7, nous avons représenté uniquement les PG activés, et seulement dans lesphases des présentations répétées de motifs appris. Pour plus de clarté, et sans perte de géné-ralité, nous avons limité le diagramme à une sélection d’environ 1/3 des PG potentiels. Nous
72

3400
3600
3800
4000
4200
4400
4600
4800
5000
820 830 840 850 860 870 880 890 900 910
# PG
Temps [s]
6 6 9 9 6
FIGURE 8.7 – Sur ce diagramme, chaque point représente, en fonction du temps (en abscisse), l’activationd’un groupe polychrone [une sélection, pour plus de clarté], et non plus d’un neurone – ce n’est pas undiagramme de spikes – , pendant des tranches de présentations répétées d’un 6 et d’un 9 (voir texte pourles détails du protocole), séparées par des phases de perturbations du réservoir (les PG activés pendantces phases-là ne sont pas représentés).
constatons (au sein de chacune des cinq colonnes de points) une bonne persistance des PGactivés par la dynamique du réservoir, surtout après une petite vingtaine de répétitions dumotif. Nous observons d’autre part une excellente stabilité de la représentation du motif : pourle chiffre 6, les diagrammes des deux premières colonnes et de la dernière sont très similairesentre eux ; pour le chiffre 9, les deux diagrammes situés entre 860 s et 890 s de temps simulésont très semblables entre eux. Nous pouvons enfin remarquer une forte disparité entre lesdiagrammes obtenus pour le “6” et ceux obtenus pour le “9”.
Par ailleurs, nous avons vérifié que la phase de perturbations aléatoires (b) avait réellementun fort impact sur la dynamique du réseau : la figure 8.8 présente la distribution des poidssynaptiques, à la fin de plusieurs phases successives du protocole et met en évidence de trèsfortes variations des forces de connexions, sous l’effet de la STDP. Ainsi, lorsque les PG sontréactivés lors de la présentation d’un motif déjà vu (par exemple : deuxième colonne de lafigure 8.7), le réseau se trouve, au début de cette phase de répétition, dans un état très différentde celui dans lequel il était à la fin de la phase précédente. Cette observation nous permetuniquement d’affirmer que les poids varient fortement d’une phase à l’autre. Nous n’avons pasanalysé les variations locales des connexions. Pour conclure sur cette expérience, nous dironsque, contrairement au diagramme de spikes (figure 8.1), l’espace des PG (figure 8.7) permetd’obtenir une représentation plus parcimonieuse (de nombreux PG ne sont pas activés) et devisualiser certains invariants de la dynamique du réseau.
73

0
20
40
60
80
100
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 (a) 0
20
40
60
80
100
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 (b) 0
20
40
60
80
100
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 (c)
0
20
40
60
80
100
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 (d) 0
20
40
60
80
100
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 (e)
FIGURE 8.8 – Evolution de la répartition des valeurs prises par les poids synaptiques (en valeurs abso-lues), à la fin de chacune des phases indiquées sous les histogrammes. Pendant les stimulations aléa-toires, le réseau subit de fortes perturbations, mais il retrouve des configurations de poids semblables,d’une phase de répétition à l’autre. – (a) initialisation (b) apprentissage (c) 1re répétition (d) perturba-tions (e) 2nd répétition
Représentation dans l’espace des groupes polychrones Afin de démontrer le caractère gé-nérique des observations qui viennent d’être présentées sur des motifs isolés, nous avons réa-lisé une autre étude, plus systématique. Le nouveau protocole d’expérience se déroule commesuit : successivement, pour chacun des motifs pris dans une base d’exemples constituée de 163chiffres 6 et 140 chiffres 9, on exécute les phases suivantes :
1. initialisation du réseau (STDP) sur une période de 10 s, sous l’effet de stimulations aléa-toires,
2. apprentissage (STDP + marge) pendant 121, 2 s (deux présentations de la base réduite à303 exemples),
3. répétition, 4 fois, pour un même motif, de la succession des deux étapes ci-dessous :
(a) présentation du motif, répétée 50 fois, par tranches de 200 ms pour chaque répéti-tion (avec STDP),
(b) perturbations induites dans le réseau (avec STDP) sous l’effet de la présentation de10 s de stimulations aléatoires,
4. retour en 3, avec un autre motif.
Pour chaque motif X et pour chacune des quatre répétitions de la phase 3, nous enregis-trons un vecteur Xr (1 ≤ r ≤ 4) dont la dimension est le nombre de PG potentiels dans leréservoir, et dont chaque composante k contient le nombre de fois où le PG numéro k a étéactivé pendant la phase a), normalisé par le nombre de répétitions (ici : 50). Nous obtenonsainsi une représentation de la dynamique du réseau dans l’espace des PG. On observe que lescomposantes de ces vecteurs Xr sont essentiellement proches de 0 (un PG non actif) ou de 1(un PG activé de manière répétitive), ce qui confirme la persistance observée sur la figure 8.7.Pour chaque motif X , on vérifie que les distances qui séparent les vecteurs Xr sont faibles ettrès inférieures à celles les séparant de vecteurs Yr associés à d’autres motifs Y . Ces mesures
74

confirment la stabilité des PG qui sont réactivés lors de plusieurs séries de présentations d’unmême motif X , même lorsque le réseau a été fortement perturbé entre temps. En revanche, ladisparité que l’on pouvait observer sur la figure 8.7 entre les activations provoquées par le 6 etpar le 9 se retrouve aussi, à force à peu près égale, entre plusieurs instances de 6 (ou de 9). Leréseau n’a donc pas su construire une représentation générique du chiffre présenté en entrée.Contrairement aux deux précédents, ce résultat est un peu décevant, bien qu’il soit facilementexplicable par la forte variabilité des caractères de la base USPS.
8.5.3 Coloriage et interprétation des groupes spécialisés
Notre modèle nous a permis d’apprendre à distinguer des chiffres manuscrits extraits descodes postaux américains, avec des performances raisonnables. Ces chiffres sont des motifsvisuels très réalistes : certains d’entre eux sont difficilement identifiables par un sujet humainet, pour chaque chiffre, la base de données présente une très grande variabilité. Lorsque l’onprésente les chiffres après apprentissage, on constate qu’ils sont bien reconnus par le modèle,mais lorsque l’on regarde les activités neuronales à l’intérieur du réservoir, on a du mal à dis-tinguer les raisons de cette bonne identification. Les diagrammes de spikes permettent d’affir-mer que ce sont des assemblées de neurones temporelles, et non pas seulement spatiales quisemblent véhiculer l’information significative. En effet, lorsque le modèle a appris à distinguerun chiffre 6 d’un chiffre 9 (figure 8.1), on constate que la plupart des neurones sont activés à lafois pour les deux chiffres. Ce ne sont donc pas des sous-ensembles de neurones distincts quiles représentent en mémoire. Cependant ces diagrammes sont denses et présentent de fortesvariations : ils sont difficilement exploitables pour capturer les différences inter-classes et lessimilarités intra-classes. Nous pourrions peut-être tirer une information de ces diagrammes enleur appliquant des mesures de distance entre trains de spikes, telles que celles proposées parVictor & Purpura (1996), mais nous avons poursuivi une autre piste.
Notre idée est de chercher à capturer les spikes les plus significatifs, un peu dans le mêmeesprit que le calcul des « support vectors » dans le modèle SVM de Vapnik (1998). Dans cetesprit, nous pensons que les neurones qui pourraient jouer un tel rôle sont ceux qui (parmiles neurones activés lors de la présentation d’un exemple d’entrée) sont des neurones déclen-cheurs pour des groupes polychrones. En effet, leur activation engendre une bonne partie del’activation des autres neurones observable sur les diagrammes de spikes, mais la connaissancedes neurones déclencheurs est suffisante et elle procure une information plus synthétique.
Nous avons donc effectué un changement d’espace de représentation en visualisant l’ac-tivité du réseau par les groupes polychrones activés, et non plus par les neurones activés. Lafigure 8.9 présente, sous forme d’histogramme, un sous-ensemble de tous les groupes poly-chrones possibles (plusieurs dizaines de milliers, même pour un réservoir de quelques cen-taines de neurones). En abscisse sont présentés les numéros des PG ; un trait vertical représentele nombre de fois où le groupe concerné a été activé lors de la présentation de tous les chiffresde la base USPS (de l’ordre de 600 motifs, pour chaque classe), en rouge s’il s’agit d’un 6 et ennoir s’il s’agit d’un 9. La figure ne représente que les PG dont l’activité est reproduite au moins20 fois sur tous les chiffres d’une classe donnée. On observe une spécialisation des PG activés,selon qu’il s’agit d’un 6 ou d’un 9, lorsqu’on présente les chiffres en test (STDP désactivée)après une phase d’apprentissage de 3645s de temps biologique simulé, soit 14 passes de la based’exemples.
75
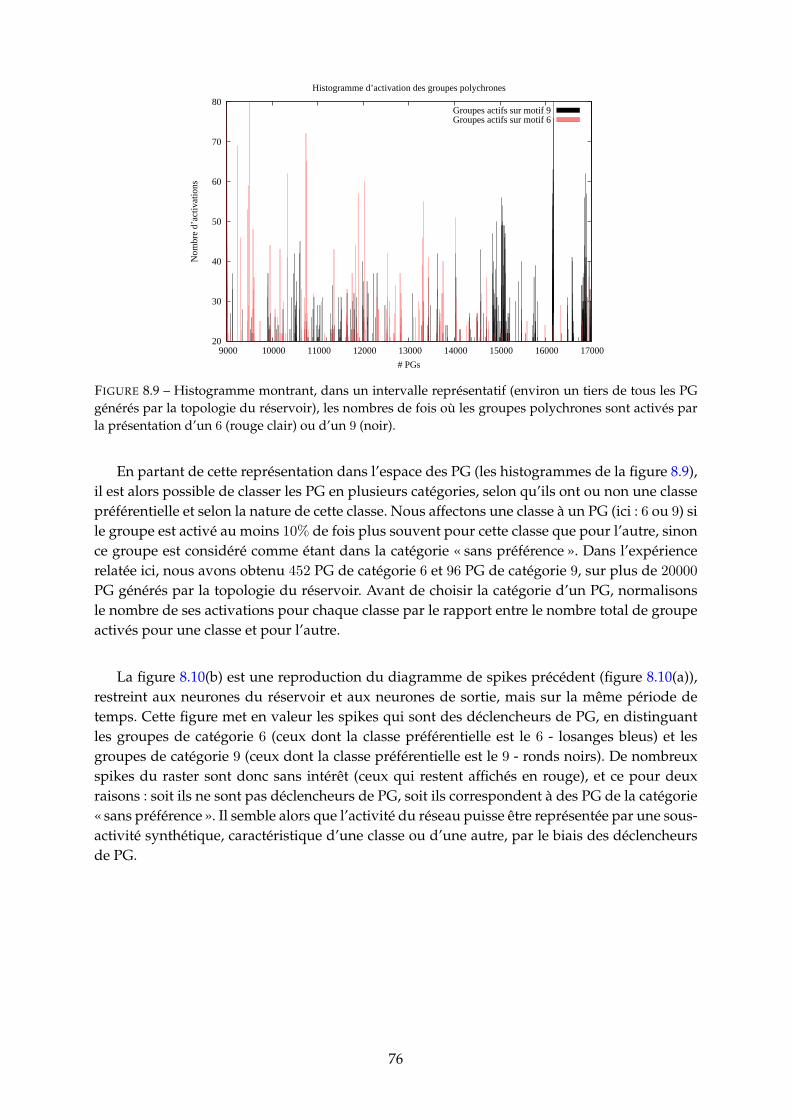
20
30
40
50
60
70
80
9000 10000 11000 12000 13000 14000 15000 16000 17000
Nom
bre
d’ac
tivat
ions
# PGs
Histogramme d’activation des groupes polychrones
Groupes actifs sur motif 9Groupes actifs sur motif 6
FIGURE 8.9 – Histogramme montrant, dans un intervalle représentatif (environ un tiers de tous les PGgénérés par la topologie du réservoir), les nombres de fois où les groupes polychrones sont activés parla présentation d’un 6 (rouge clair) ou d’un 9 (noir).
En partant de cette représentation dans l’espace des PG (les histogrammes de la figure 8.9),il est alors possible de classer les PG en plusieurs catégories, selon qu’ils ont ou non une classepréférentielle et selon la nature de cette classe. Nous affectons une classe à un PG (ici : 6 ou 9) sile groupe est activé au moins 10% de fois plus souvent pour cette classe que pour l’autre, sinonce groupe est considéré comme étant dans la catégorie « sans préférence ». Dans l’expériencerelatée ici, nous avons obtenu 452 PG de catégorie 6 et 96 PG de catégorie 9, sur plus de 20000PG générés par la topologie du réservoir. Avant de choisir la catégorie d’un PG, normalisonsle nombre de ses activations pour chaque classe par le rapport entre le nombre total de groupeactivés pour une classe et pour l’autre.
La figure 8.10(b) est une reproduction du diagramme de spikes précédent (figure 8.10(a)),restreint aux neurones du réservoir et aux neurones de sortie, mais sur la même période detemps. Cette figure met en valeur les spikes qui sont des déclencheurs de PG, en distinguantles groupes de catégorie 6 (ceux dont la classe préférentielle est le 6 - losanges bleus) et lesgroupes de catégorie 9 (ceux dont la classe préférentielle est le 9 - ronds noirs). De nombreuxspikes du raster sont donc sans intérêt (ceux qui restent affichés en rouge), et ce pour deuxraisons : soit ils ne sont pas déclencheurs de PG, soit ils correspondent à des PG de la catégorie« sans préférence ». Il semble alors que l’activité du réseau puisse être représentée par une sous-activité synthétique, caractéristique d’une classe ou d’une autre, par le biais des déclencheursde PG.
76

0
50
100
150
200
250
300
350
400
450
500
3667 3667.5 3668 3668.5
# ne
uron
es
Temp [s]
Diagramme de spikes
9 6 9 9 6 6 9 9 9 9
(a)
300
350
400
450
3667 3667.5 3668 3668.5
# ne
uron
es
time (ms)
9 6 9 9 6 6 9 9 9 9
(b)
0
50
100
150
200
250
300
350
400
450
3667 3667.5 3668 3668.5
Nom
bre
de P
G a
ctiv
es
Temps [s]
Nb de PG afillies a la classe 6Nb de PG affilies a la classe 9
(c)
FIGURE 8.10 – (a) Exemples de diagramme de spikes pour la présentation (les 256 neurones du bas) destimuli pour les chiffres 6 et 9 (classe précisée tout en haut), et activité neuronale dans le réservoir (neu-rones 257 à 417 excitateurs et neurones 418 à 457 inhibiteurs). (b) Même diagramme de spikes que (a),montrant les déclencheurs des groupes polychrones activés. On distingue les spikes déclencheurs desPG de catégorie 6 (losanges bleus) de ceux de catégorie 9 (ronds noirs). (c) Histogrammes des groupespolychrones activés, en correspondance avec les stimulations testées sur (a) et (b)

Pour plus de rigueur, nous quantifions cette activité par rapport à chaque classe : nouscomptons, pour chaque stimulation, le nombre de PG affiliés à chacune des deux classes. Nouspouvons ainsi générer, pour chaque stimulation, un histogramme représentant la balance desgroupes des deux affiliations différentes (figure 8.10(c)). L’histogramme nous permet de confir-mer que, dans la réponse à une stimulation, la proportion de PG activés la plus importante estcelle correspondant à la classe de la stimulation. Dans certains cas, qui restent rares (non pré-sentés) la tendance est inversée. Ceci s’explique par l’observation de la réponse des neuronesde sortie qui montre que ce motif est peu clairement discriminé (la marge temporelle n’est pasatteinte) par le réseau. Dans un souci de clarté, nous avons présenté les résultats pour seule-ment dix stimulations, mais les mesures réalisées sur d’autres intervalles de temps conduisentà des résultats analogues.
Nous avons mis en évidence, par nos modélisations, que l’hypothèse selon laquelle les PGjoueraient un rôle prépondérant dans la représentation de l’information est tout à fait perti-nente. A minima, les PG sont un bon moyen de comprendre les changements qui s’opèrentdans le réseau. Nous souhaitons donc analyser de façon exhaustive les caractéristiques desgroupes polychrones selon différents types d’architecture de réseau.
78

9Etude des propriétés des groupes polychrones
Nous avons montré précédemment que l’apprentissage a une influence importante sur les PGactivés. Nous nous interrogeons sur l’impact qu’a eu l’apprentissage sur le réseau, notammentpar rapport aux délais. Nous présentons dans un premier temps un résultat intéressant obtenuen collaboration avec Berry sur l’influence de l’apprentissage sur les délais dans notre réser-voir (travail non publié). Sur la base de ces travaux, nous cherchons à éclaircir le lien entre lesneurones et les PG. Dans un second temps nous présentons une étude exhaustive des PG enfonction de différents types d’architectures.
9.1 Etude préliminaire
9.1.1 Délais et apprentissage
Nous remercion H. Berry pour l’analyse qu’il a faite sur les données que nous avions four-nies. Cette partie 9.1.1 reprend les conclusions qu’il nous a transmises.
Nous avons observé que les distributions des poids varient fortement entre l’initialisationdu réseau et les stimulations. Nous avons repris l’architecture du réseau de 100 neurones utilisépour la classification de motifs simples dans le chapitre 7, dans la section 7.3. Nous avons extraitde ce réseau la matrice des poids d’une part et des délais d’autre part, ce avant apprentissage etaprès apprentissage. Berry a étudié ces matrices avec les outils d’analyse des réseaux complexesqu’il avait alors développés (en 2008). En utilisant un seuillage des poids afin de n’étudier queles connexions de poids forts, on peut observer l’effet de l’apprentissage sur la structure duréseau, considérant que les connexions de poids inférieur au seuil sont négligeables. L’analysea montré que l’apprentissage ne modifiait pas significativement les propriétés du réseau, quireste de l’ordre du réseau aléatoire en termes de plus courts chemins moyens et de coefficientsde clustrerisation.
FIGURE 9.1 – A gauche : Délai en fonction du poids pour chaque lien après apprentissage. Trait bleu :liens excitateurs ; Pointillés rouges : liens inhibiteurs. A droite : Délai moyen par lien versus poids moyenpar lien pour chaque neurone après apprentissage (excitateurs et inhibiteurs). (Figures de Berry)
79

Cependant, un autre aspect de l’analyse de Berry est très intéressant. L’observation des dé-lais des connexions après apprentissage, en fonction de leur poids, conduit à remarquer quela STDP favorise les connexions rapides, dont le délai est faible. La figure 9.1 (gauche) montrecette tendance.
Cette tendance se retrouve au niveau des neurones. Pour le montrer, on peut évaluer pourchaque neurone, d’une part le poids moyen des connexions entrantes et sortantes, et d’autrepart le délai moyen des connexions entrantes et sortantes. Comme on peut le voir sur la fi-gure 9.1 (droite), majoritairement les neurones de poids forts sont aussi les neurones de délaisfaibles. Nous observons quelques exceptions dont les indices sont indiqués sur la figure. Berrynote que ces neurones sont très peu connectés (5 fois moins que la moyenne) ce qui expliqueleur excentricité.
Pour chaque plus court chemin, on peut calculer la somme des poids et la somme des délaisde ces connexions. Comme le montre la figure 9.2, la STDP diminue les poids de toutes lesconnexions, mais affecte moins les connexions des chemins dont le délai est court.
FIGURE 9.2 – Chemins de moindres délais. Moyenne de la somme des poids le long des chemins demoindres délais (en noir) et poids moyen sur tout le réseau (en blanc) avant et après apprentissage. Leschiffres indiquent la valeur moyenne et l’écart-type (barre d’erreur) correspondants. (Figure de Berry)
Enfin, Berry a noté que certains chemins ont des poids très élevés par rapport à la moyennedu réseau, notamment trois chemins remarquables. Ces chemins ont des poids cumulés plusforts que la moyenne (≈ 4.0, soit > 4.7 fois le poids moyen dans le reste du réseau), et desdélais cumulés courts (≈ 7 ou 8 ms, soit 1 ou 2 ms pas connexion).
49→ 64→ 32→ 12→ 89→ 95→ 57→ 76; delai = 7
90→ 82→ 75→ 45→ 89→ 95→ 57→ 76; delai = 7
87→ 24→ 36→ 62→ 59→ 20→ 73→ 37; delai = 8
9.1.2 Liens entre PG et neurones
Les observations de Berry nous montrent qu’un certain nombre de neurones font partie dechemins forts. En nous basant sur les groupes polychrones supportés que nous avons pu dé-tecter dans le réseau utilisé ci-dessus (104 PG), nous cherchons la relation entre les chemins
80
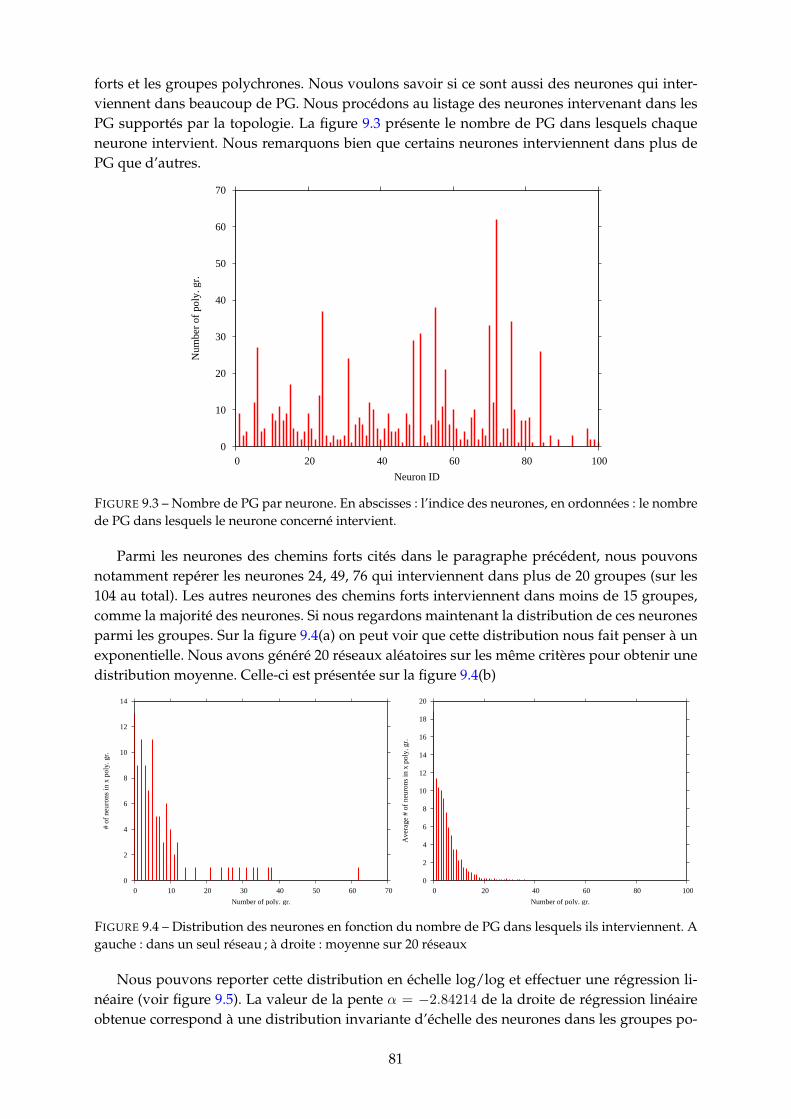
forts et les groupes polychrones. Nous voulons savoir si ce sont aussi des neurones qui inter-viennent dans beaucoup de PG. Nous procédons au listage des neurones intervenant dans lesPG supportés par la topologie. La figure 9.3 présente le nombre de PG dans lesquels chaqueneurone intervient. Nous remarquons bien que certains neurones interviennent dans plus dePG que d’autres.
0
10
20
30
40
50
60
70
0 20 40 60 80 100
Num
ber
of p
oly.
gr.
Neuron ID
FIGURE 9.3 – Nombre de PG par neurone. En abscisses : l’indice des neurones, en ordonnées : le nombrede PG dans lesquels le neurone concerné intervient.
Parmi les neurones des chemins forts cités dans le paragraphe précédent, nous pouvonsnotamment repérer les neurones 24, 49, 76 qui interviennent dans plus de 20 groupes (sur les104 au total). Les autres neurones des chemins forts interviennent dans moins de 15 groupes,comme la majorité des neurones. Si nous regardons maintenant la distribution de ces neuronesparmi les groupes. Sur la figure 9.4(a) on peut voir que cette distribution nous fait penser à unexponentielle. Nous avons généré 20 réseaux aléatoires sur les même critères pour obtenir unedistribution moyenne. Celle-ci est présentée sur la figure 9.4(b)
0
2
4
6
8
10
12
14
0 10 20 30 40 50 60 70
# of
neu
rons
in x
pol
y. g
r.
Number of poly. gr.
0
2
4
6
8
10
12
14
16
18
20
0 20 40 60 80 100
Ave
rage
# o
f ne
uron
s in
x p
oly.
gr.
Number of poly. gr.
FIGURE 9.4 – Distribution des neurones en fonction du nombre de PG dans lesquels ils interviennent. Agauche : dans un seul réseau ; à droite : moyenne sur 20 réseaux
Nous pouvons reporter cette distribution en échelle log/log et effectuer une régression li-néaire (voir figure 9.5). La valeur de la pente α = −2.84214 de la droite de régression linéaireobtenue correspond à une distribution invariante d’échelle des neurones dans les groupes po-
81

lychrones. En d’autres termes, la plupart des neurones interviennent dans seulement quelquesPG, mais quelques neurones participent à beaucoup de PG.
-6
-4
-2
0
2
4
6
8
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5
Ave
rage
num
ber
of n
euro
ns in
x p
oly.
gr.
Number of poly. gr.
FIGURE 9.5 – La pente α de la droite de régression linéaire est −2.84214
Nous souhaiterions approfondir ce résultat en examinant les communautés de PG au sensdes neurones. Ce que nous entendons par là est qu’il serait intéressant de savoir s’il exite desclusters de PG qui partagent des neurones. Pour cela l’algorithme de détection de cluster pré-senté dans le chapitre 5 pourra être utilisé. Un problème se pose pour réaliser une telle étude,qui est la façon de représenter un graphe comportant à la fois des PG et des neurones.
Piste envisagée Il est possible de faire appel à une famille de graphes s’appelant les graphesbipartis comme dans la figure 9.6. Ces graphes ont la particularité d’avoir deux types de nœudset chaque nœud ne peut être lié qu’à des nœuds de type différent de lui-même. Comme précisédans le chapitre 5, des variantes de la mesure de modularité (mesure utilisée dans l’algorithmede détection de clusters) ont été proposées (Guimerà et al., 2007; Barber, 2008). Nous pourrionsalors chercher les communautés de PG liés par les neurones qu’ils partagent.
Une autre approche est envisageable. Comme le suggèrent Albert & Barabasi (2002)(p.67),il est possible de convertir le graphe biparti en un graphe classique. Pour notre cas, nous pour-rions générer le graphe où chaque nœud est un PG, et où les liens entre PG traduisent le faitqu’ils partagent un ou plusieurs neurones en commun, le poids du lien étant le nombre de PGen commun. Il serait alors possible de rechercher des communauté de PG avec l’algorithmeclassique de détection de clusters.
Cette piste de recherche nous semble fort intéressante. Néanmoins il nous semble priori-taire de chercher à comprendre avant tout comment les groupes polychrones évoluent avec latopologie du réseau. Nous avons donc laissé cette recherche en pause pour réaliser une étudeexhaustive sur les PG dans les réseaux complexes.
82
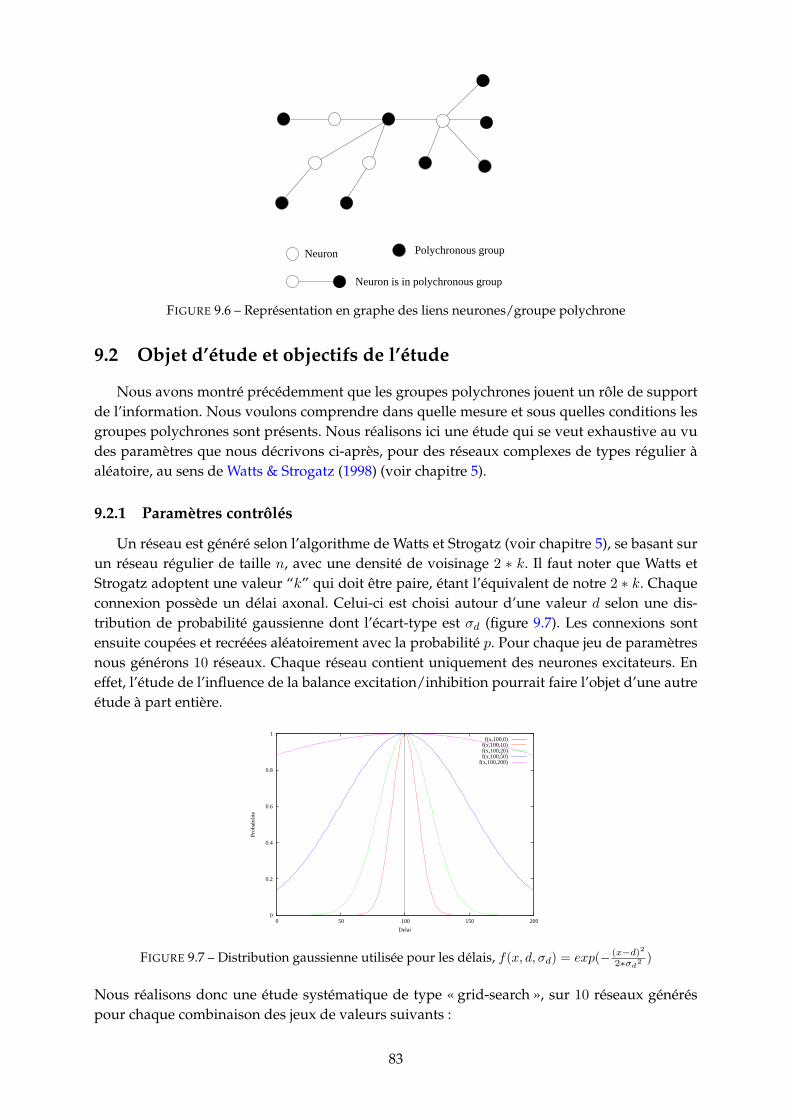
Polychronous groupNeuron
Neuron is in polychronous group
FIGURE 9.6 – Représentation en graphe des liens neurones/groupe polychrone
9.2 Objet d’étude et objectifs de l’étude
Nous avons montré précédemment que les groupes polychrones jouent un rôle de supportde l’information. Nous voulons comprendre dans quelle mesure et sous quelles conditions lesgroupes polychrones sont présents. Nous réalisons ici une étude qui se veut exhaustive au vudes paramètres que nous décrivons ci-après, pour des réseaux complexes de types régulier àaléatoire, au sens de Watts & Strogatz (1998) (voir chapitre 5).
9.2.1 Paramètres contrôlés
Un réseau est généré selon l’algorithme de Watts et Strogatz (voir chapitre 5), se basant surun réseau régulier de taille n, avec une densité de voisinage 2 ∗ k. Il faut noter que Watts etStrogatz adoptent une valeur “k” qui doit être paire, étant l’équivalent de notre 2 ∗ k. Chaqueconnexion possède un délai axonal. Celui-ci est choisi autour d’une valeur d selon une dis-tribution de probabilité gaussienne dont l’écart-type est σd (figure 9.7). Les connexions sontensuite coupées et recréées aléatoirement avec la probabilité p. Pour chaque jeu de paramètresnous générons 10 réseaux. Chaque réseau contient uniquement des neurones excitateurs. Eneffet, l’étude de l’influence de la balance excitation/inhibition pourrait faire l’objet d’une autreétude à part entière.
0
0.2
0.4
0.6
0.8
1
0 50 100 150 200
Prob
abili
te
Delai
f(x,100,0)f(x,100,10)f(x,100,20)f(x,100,50)
f(x,100,200)
FIGURE 9.7 – Distribution gaussienne utilisée pour les délais, f(x, d, σd) = exp(− (x−d)22∗σd2 )
Nous réalisons donc une étude systématique de type « grid-search », sur 10 réseaux généréspour chaque combinaison des jeux de valeurs suivants :
83

• le nombre de neurones n ∈ {100; 200; 400; 600; 800; 1000} (6 valeurs)• le rayon du voisinage de chaque neurone : k ∈ {2; 4; 6; 8} (4 valeurs)• la probabilité de recâblage : p ∈ {0; 0.1; 0.15; 0.2; 0.25; 0.3; 0.5; 0.8; 1} (9 valeurs)• le délai moyen, en dixièmes de ms : d ∈ {10; 50; 100; 150; 200} (5 valeurs)• l’écart-type des délais, en dixièmes de ms : dtd ∈ {0; 5; 10; 20; 50; 100; 200} (7 valeurs)
soit au total 6 ∗ 4 ∗ 9 ∗ 5 ∗ 7 = 7560 combinaisons, soit 75600 réseaux générés et analysés, princi-palement grâce aux ressources informatiques de l’IN2P3.
L’hypothèse première s’appuie sur la probabilité de recâblage p utilisée dans la procédurede construction d’un réseau selon Watts et Strogatz. Sur la base des résultats précédents noussupposons que des caractéristiques changent en fonction de ce paramètre et seront observablespar le biais des PG. On sait notamment déjà, comme l’ont observé Maier & Miller (2008) qu’il ya une progression linéaire du nombre de PG avec la taille du réseau pour un k donné (nombrede neurones voisins auxquels chaque neurone est connecté), dans le cas des réseaux réguliers(p = 0). Nous contrôlons également certains paramètres de structure des réseaux, notammentla valeur moyenne des délais axonaux et leur distribution (étalement de la gaussienne autourde la valeur moyenne).
9.2.2 Quantités mesurées
Nous avons restreint cette étude aux groupes polychrones supportés, en effet la combi-natoire des jeux de paramètres implique autant de cas à étudier en réalisant la détection desgroupes pour chaque jeu de paramètres, sur dix réseaux distincts afin d’obtenir des chiffressignificatifs. Les PG détectés sont soumis aux caractéristiques suivantes (voir section 8.2 p. 8.2pour un rappel des paramètres) :• nombre de déclencheurs : s = 3• nombre de spikes nécessaires pour déclencher un nouveau spike : NbSpikesNeeded = 2,• durée minimum d’un PG : MinTimeSpan = 5ms• durée maximum d’un PG : MaxTimeSpan = 150ms• nombre minimum de spikes : NbSpikeMin = 5, dont les s = 3 spikes déclencheurs• nombre minimum de spikes : NbSpikeMax = 1000, dont les s = 3 spikes déclencheurs• laps de temps dans lequel deux spikes sont considérés comme simultanés : Jitter = 1ms• période réfractaire des neurones : RefractoryPeriode = 5ms
Nous disposons de plusieurs caractéristiques mesurables que sont :• le nombre de PG,• la taille des PG en nombre de spikes,• la durée ded PG en ms (timespan),• la population recrutée par chaque PG,• la fréquence neuronale moyenne des PG.
Parmi tous les PG resencés nous distinguons les PG qui dépassent la limite de calcul im-posée en nombre de spikes et en temps virtuel (MinTimeSpan, MaxTimeSpan, NbSpikeMin,NbSpikeMax). Les PG qui dépassent une de ces limites de calcul sont tronqués dans l’étatoù ce dépassement intervient. En règle générale, un PG qui dépasse ces limites est un PG cy-clique, c’est-à-dire dont l’activité se répète et s’auto-entretient indéfiniment. Nous pouvonsalors compter le nombre de PG probablement cycliques et leur proportion sur le nombre total
84

de PG.
9.3 Etude paramétrique
9.3.1 Nombre de PG
Influence de la probabilité de recâblage p
La figure 9.8 présente le nombre de PG en fonction de la taille du réseau et de la probabilitéde recâblage p, pour k = 4 (à gauche), et pour k = 8 (à droite). Pour une valeur de p donnée,et toutes choses étant égales par ailleurs, on observe que le nombre de PG augmente linéaire-ment avec la taille du réseau, mais avec une pente différente selon p. Le nombre de groupescroît exponentiellement avec la décroissance de p. Nous cherchons s’il est possible de réaliserun modèle empirique de ces données. Notons que les échelles verticales sont graduées diffé-remment (maximum à 14000 pour k = 4 versus maximum à 250000 pour k = 8), nénmoins leprofil des variations, en fonction du nombre de neurones et de p est identique pour les deuxvaleurs de k. Le profil de la surface est le même pour k = 2 et k = 6, où le maximum vautrespectivement 14 et 80000.
Number of PG/p for different Number of neurons | k=4.0
0 0.2
0.4 0.6
0.8 1
p 0 200
400 600
800 1000
Number of neurons 0
2000
4000
6000
8000
10000
12000
14000
Num
ber
of P
G
Number of PG/p for different Number of neurons | k=8.0
0 0.2
0.4 0.6
0.8 1
p 0 200
400 600
800 1000
Number of neurons 0
50000
100000
150000
200000
250000
Num
ber
of P
G
FIGURE 9.8 – Nombre de PG en fonction de la taille du réseau et de la probabilité de recâblage, pourk ∈ {4, 8}
Nous avons trouvé qu’une bonne approximation du nombre de PG en fonction de p étaitréalisée par un polynôme de degré 5 d’équation f(x) = a.x5 + b.x4 + c.x3 + d.x2 + e.x + f ,où x représente p. Nous utilisons l’algorithme d’approximation non-linéaire par moindre car-rés de Marquardt-Levenberg (Levenberg, 1944; Marquardt, 1963), implémenté dans le logicielGnuplot. Dans le cas k = 6, nous avons obtenu les coefficients suivants a, b, c, d, e, f pourdifférentes valeurs de n, la taille du réseau :
f(x) = 14970.01x5 +−49442.77x4 + 45472.99x3 + 3460.06x2 +−21539.96x + 7925.41 pour n=100
f(x) = 76817.89x5 +−213377.06x4 + 184073.47x3 +−18168.31x2 +−44753.13x + 15857.51 pour n=200
f(x) = 222014.53x5 +−596306.36x4 + 509814.32x3 +−78849.71x2 +−88115.77x + 31671.44 pour n=400
f(x) = 345297.38x5 +−921545.98x4 + 781138.38x3 +−117709.59x2 +−134591.50x + 47561.51 pour n=600
f(x) = 493925.40x5 +−1310938.63x4 + 1108918.98x3 +−176573.83x2 +−178585.49x + 63367.99 pour n=800
f(x) = 636745.45x5 +−1688569.64x4 + 1430881.15x3 +−236602.07x2 +−221492.78x + 79129.20 pour n=1000
La figure 9.9 montre ces approximations (lignes tracées) et les données empiriques (points).
85

-10000
0
10000
20000
30000
40000
50000
60000
70000
80000
0 0.2 0.4 0.6 0.8 1
Num
ber
of P
G
p
Number of PG / p for different n | k=6.0
experimental data for n=100.0experimental data for n=200.0experimental data for n=400.0experimental data for n=600.0experimental data for n=800.0
experimental data for n=1000.0
FIGURE 9.9 – Approximation du nombre de PG en fonction de la probabilité de recâblage p, pour k = 6
La progression du nombre de PG en fonction de la taille du réseau peut être approximée dela même manière par une droite d’équation g(x) = a.x+ b où x représente n :
g(x) = 79.21x + 23.34 pour p=0
g(x) = 55.22x + 299.44 pour p=0.1
g(x) = 44.28x + 437.66 pour p=0.15
g(x) = 33.99x + 634.00 pour p=0.2
g(x) = 24.69x + 746.36 pour p=0.25
g(x) = 16.54x + 910.12 pour p=0.3
g(x) = 1.71x + 752.01 pour p=0.5
g(x) = −0.67x + 673.08 pour p=0.8
g(x) = −0.71x + 680.56 pour p=1
La figure 9.10 présente ces approximations (lignes tracées) et les échantillons expérimentaux(points). Nous souhaitons alors proposer un modèle empirique à partir de ces observations.
-10000
0
10000
20000
30000
40000
50000
60000
70000
80000
0 200 400 600 800 1000
Num
ber
of P
G
Number of neurons
Number of PG / Number of neurons for different p | k=6.0
experimental data for p=0.0experimental data for p=0.1
experimental data for p=0.15experimental data for p=0.2
experimental data for p=0.25experimental data for p=0.3experimental data for p=0.5experimental data for p=0.8experimental data for p=1.0
FIGURE 9.10 – Approximation du nombre de PG en fonction de la taille du réseau pour k = 6
86

A partir de ces approximations, nous extrapolons un modèle en 3 dimensions du nombrede PG en fonction de la taille du réseau et de la probabilité de recâblage p. L’erreur la plusfaible est constatée pour f(p) lorsque n = 600 et pour g(n) lorsque p = 0.2. En se basant sur lesapproximations fn=600(p) et gp=0.2(n) nous proposons le modèle extrapolé suivant :
h(x, y) = f(x) ∗ gp=0.2(y)g(600)
, pour k=6
La figure 9.11, (a) montre à la fois le modèle (surface bleue hachurée) et les données expé-rimentales (surface rouge). Les deux surfaces sont visuellement proches. Pour nous en assurer,nous nous intéressons à l’erreur du modèle.
Number of PG / p for different Number of neurons | k=6.0
Experimental dataExperimental model
0 0.2
0.4 0.6
0.8 1
p 0 200
400 600
800 1000
Number of neurons-10000
0 10000 20000 30000 40000 50000 60000 70000 80000
Num
ber
of P
G
(a)
0 0.2
0.4 0.6
0.8 1 0
200 400
600 800
1000
-1500
-1000
-500
0
500
1000
Diff
eren
ce E
rror
of N
umbe
r of
PG
Number of PG / p for different Number of neurons | k=6.0 - Difference Error
p
Number of neurons
Diff
eren
ce E
rror
of N
umbe
r of
PG
-1500
-1000
-500
0
500
1000
(b)
0 0.2
0.4 0.6
0.8 1 0
200 400
600 800
1000
-20
0
20
40
60
80
100
% E
rror
of N
umbe
r of
PG
Number of PG / p for different Number of neurons | k=6.0 - % Error
p
Number of neurons
% E
rror
of N
umbe
r of
PG
-20 0 20 40 60 80 100
(c)
FIGURE 9.11 – (a) : Modèle extrapolé pour le nombre de PG en fonction de la taille du réseau et de laprobabilité de recâblage p. En bleu : surface du modèle, en rouge : surface des données expérimentales(b) : différence entre les valeurs expérimentales et le modèle(c) : pourcentage d’erreur du modèle par rapport aux valeurs expérimentales
La différence entre le modèle et les données expérimentales est représentée dans la fi-
87
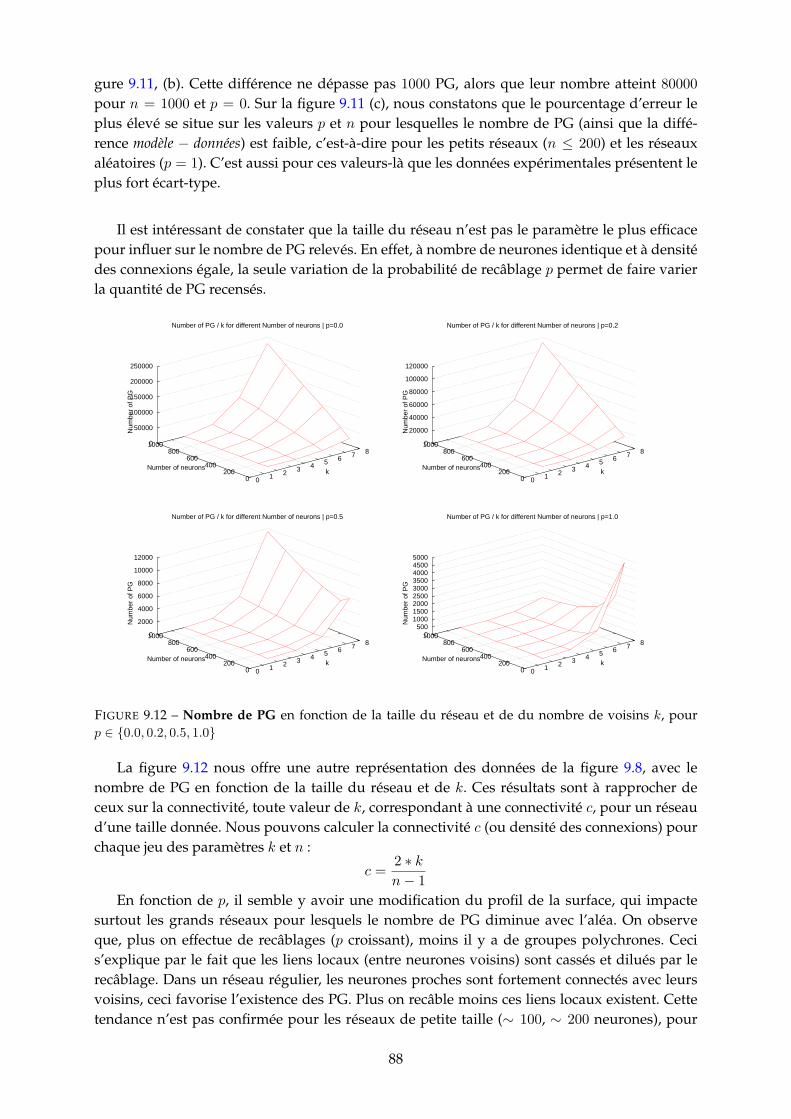
gure 9.11, (b). Cette différence ne dépasse pas 1000 PG, alors que leur nombre atteint 80000pour n = 1000 et p = 0. Sur la figure 9.11 (c), nous constatons que le pourcentage d’erreur leplus élevé se situe sur les valeurs p et n pour lesquelles le nombre de PG (ainsi que la diffé-rence modèle − données) est faible, c’est-à-dire pour les petits réseaux (n ≤ 200) et les réseauxaléatoires (p = 1). C’est aussi pour ces valeurs-là que les données expérimentales présentent leplus fort écart-type.
Il est intéressant de constater que la taille du réseau n’est pas le paramètre le plus efficacepour influer sur le nombre de PG relevés. En effet, à nombre de neurones identique et à densitédes connexions égale, la seule variation de la probabilité de recâblage p permet de faire varierla quantité de PG recensés.
Number of PG / k for different Number of neurons | p=0.0
0 1 2 3 4 5 6 7 8
k 0
200 400
600 800
1000
Number of neurons
0
50000
100000
150000
200000
250000
Num
ber
of P
G
Number of PG / k for different Number of neurons | p=0.2
0 1 2 3 4 5 6 7 8
k 0
200 400
600 800
1000
Number of neurons
0
20000
40000
60000
80000
100000
120000
Num
ber
of P
G
Number of PG / k for different Number of neurons | p=0.5
0 1 2 3 4 5 6 7 8
k 0
200 400
600 800
1000
Number of neurons
0
2000
4000
6000
8000
10000
12000
Num
ber
of P
G
Number of PG / k for different Number of neurons | p=1.0
0 1 2 3 4 5 6 7 8
k 0
200 400
600 800
1000
Number of neurons
0 500
1000 1500 2000 2500 3000 3500 4000 4500 5000
Num
ber
of P
G
FIGURE 9.12 – Nombre de PG en fonction de la taille du réseau et de du nombre de voisins k, pourp ∈ {0.0, 0.2, 0.5, 1.0}
La figure 9.12 nous offre une autre représentation des données de la figure 9.8, avec lenombre de PG en fonction de la taille du réseau et de k. Ces résultats sont à rapprocher deceux sur la connectivité, toute valeur de k, correspondant à une connectivité c, pour un réseaud’une taille donnée. Nous pouvons calculer la connectivité c (ou densité des connexions) pourchaque jeu des paramètres k et n :
c =2 ∗ kn− 1
En fonction de p, il semble y avoir une modification du profil de la surface, qui impactesurtout les grands réseaux pour lesquels le nombre de PG diminue avec l’aléa. On observeque, plus on effectue de recâblages (p croissant), moins il y a de groupes polychrones. Cecis’explique par le fait que les liens locaux (entre neurones voisins) sont cassés et dilués par lerecâblage. Dans un réseau régulier, les neurones proches sont fortement connectés avec leursvoisins, ceci favorise l’existence des PG. Plus on recâble moins ces liens locaux existent. Cettetendance n’est pas confirmée pour les réseaux de petite taille (∼ 100, ∼ 200 neurones), pour
88

lesquels les neurones sont toujours relativement proches les uns des autres, du fait de la petitetaille du réseau. Nous montrons l’équivalent de ces figures en fonction de la connectivité aulieu de k, dans la figure 9.13.
Influence de la connectivité c / voisinage k
Number of PG
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18
Connectivity 0 200
400 600
800 1000
Number of neurons
0
50000
100000
150000
200000
250000
NbP
Gs
Number of PG
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18
Connectivity 0 200
400 600
800 1000
Number of neurons
0
20000
40000
60000
80000
100000
120000
NbP
Gs
Number of PG
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18
Connectivity 0 200
400 600
800 1000
Number of neurons
0
2000
4000
6000
8000
10000
12000
NbP
Gs
Number of PG
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18
Connectivity 0 200
400 600
800 1000
Number of neurons
0 500
1000 1500 2000 2500 3000 3500 4000 4500 5000
NbP
Gs
FIGURE 9.13 – Nombre de PG en fonction de la taille du réseau et de la connectivité, pour p ∈{0.0, 0.2, 0.5, 1.0}
Il y a un lien entre le nombre de connexions et le nombre de groupes polychrones. Plus laconnectivité augmente plus nous avons de groupes, et ce lien est renforcé avec une probabilitéde recâblage p petite. Cette double influence est très clairement mise en évidence dans la fi-gure 9.14, dans laquelle le maximum est atteint pour la plus petite valeur de p et la plus grandevaleur de c.
Number of PG / Connectivity for different p | Number of neurons=200.0
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08
Connectivity 0
0.2 0.4
0.6 0.8
1
p
0 5000
10000 15000 20000 25000 30000 35000 40000 45000 50000
Num
ber
of P
G
Number of PG / Connectivity for different p | Number of neurons=800.0
0 0.005
0.01 0.015
0.02
Connectivity 0
0.2 0.4
0.6 0.8
1
p
0 20000 40000 60000 80000
100000 120000 140000 160000 180000 200000
Num
ber
of P
G
FIGURE 9.14 – Nombre de PG en fonction de la taille du réseau et de la probabilité de recâblage, pourn ∈ {200, 800}
89

Influence de la longueur des délais d et de l’écart-type des délais dtd
Number of PG/dtd for different Number of neurons | k=4.0 and delay=10
0 50
100 150
200dtd 0
200 400
600 800
1000
Number of neurons 0
1000 2000 3000 4000 5000 6000 7000 8000
Num
ber
of P
GNumber of PG/dtd for different Number of neurons | k=8.0 and delay=10
0 50
100 150
200dtd 0
200 400
600 800
1000
Number of neurons 0
50000
100000
150000
200000
250000
300000
350000
Num
ber
of P
G
Number of PG/dtd for different Number of neurons | k=4.0 and delay=50
0 50
100 150
200dtd 0
200 400
600 800
1000
Number of neurons 0
1000 2000 3000 4000 5000 6000 7000 8000 9000
10000
Num
ber
of P
G
Number of PG/dtd for different Number of neurons | k=8.0 and delay=50
0 50
100 150
200dtd 0
200 400
600 800
1000
Number of neurons 0
20000 40000 60000 80000
100000 120000 140000 160000 180000
Num
ber
of P
G
Number of PG/dtd for different Number of neurons | k=4.0 and delay=150
0 50
100 150
200dtd 0
200 400
600 800
1000
Number of neurons 0
1000 2000 3000 4000 5000 6000 7000 8000 9000
10000
Num
ber
of P
G
Number of PG/dtd for different Number of neurons | k=8.0 and delay=150
0 50
100 150
200dtd 0
200 400
600 800
1000
Number of neurons 0
20000 40000 60000 80000
100000 120000 140000 160000 180000
Num
ber
of P
G
FIGURE 9.15 – Nombre de PG en fonction de la taille du réseau et de l’écart-type des délais, avec desconnexions d’un délai moyen d ∈ {10, 50, 150} correspondant aux 3 lignes, et pour k ∈ {2, 8} correspon-dant aux 2 colonnes
Le pic visible sur les graphiques de la figure 9.15 se manifeste pour la valeur dtd = 5, lenombre de PG retombant significativement pour des valeurs de dtd voisines. Il semble doncqu’une variabilité des délais contrarie la présence de groupes polychrones. Il serait intéressantde vérifier expérimentalement les performances de tels réseaux avec le paradigme de classifi-cation présenté dans le chapitre 8. Nous remarquons également que pour des délais très courts(d = 10, première ligne) le nombre de PG resencés est presque le double (du moins au niveaudu pic) de celui obtenu pour les autres valeurs de d. Un constat similaire peut être fait avecles délais, dans la figure 9.16. Ces figures mettent en évidence le fait que des délais courts ap-portent un grand nombre de PG.
Dans la détection des PG supportés, nous considérons qu’un neurone émet un spike s’il re-çoit suffisament de spikes dans le laps de temps nommé jitter. Celui-ci est de 1ms, soit 10 uni-
90

Number of PG/d for different Number of neurons | k=6.0 and deltadelay=0
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
5000 10000 15000 20000 25000 30000 35000 40000 45000 50000
Num
ber
of P
G
Number of PG/d for different Number of neurons | k=8.0 and deltadelay=0
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
20000 40000 60000 80000
100000 120000 140000 160000
Num
ber
of P
G
Number of PG/d for different Number of neurons | k=6.0 and deltadelay=5
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
20000
40000
60000
80000
100000
120000
Num
ber
of P
G
Number of PG/d for different Number of neurons | k=8.0 and deltadelay=5
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
50000
100000
150000
200000
250000
300000
350000
Num
ber
of P
G
Number of PG/d for different Number of neurons | k=6.0 and deltadelay=50
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
5000
10000
15000
20000
25000
30000
Num
ber
of P
G
Number of PG/d for different Number of neurons | k=8.0 and deltadelay=50
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
10000 20000 30000 40000 50000 60000 70000 80000 90000
100000
Num
ber
of P
G
FIGURE 9.16 – Nombre de PG en fonction du délai moyen des connexions, pour un écart-type dtd ∈{0, 5, 50}, et pour k ∈ {6, 8}
tés de temps. Ainsi, systématiquement, lorsque le délai moyen des connexions devient faible,plusieurs spikes ont plus de chances d’arriver dans un même laps de temps. Le nombre de PGaugmente alors, les connexions du réseau étant plus favorables à la coïncidence des spikes.
91
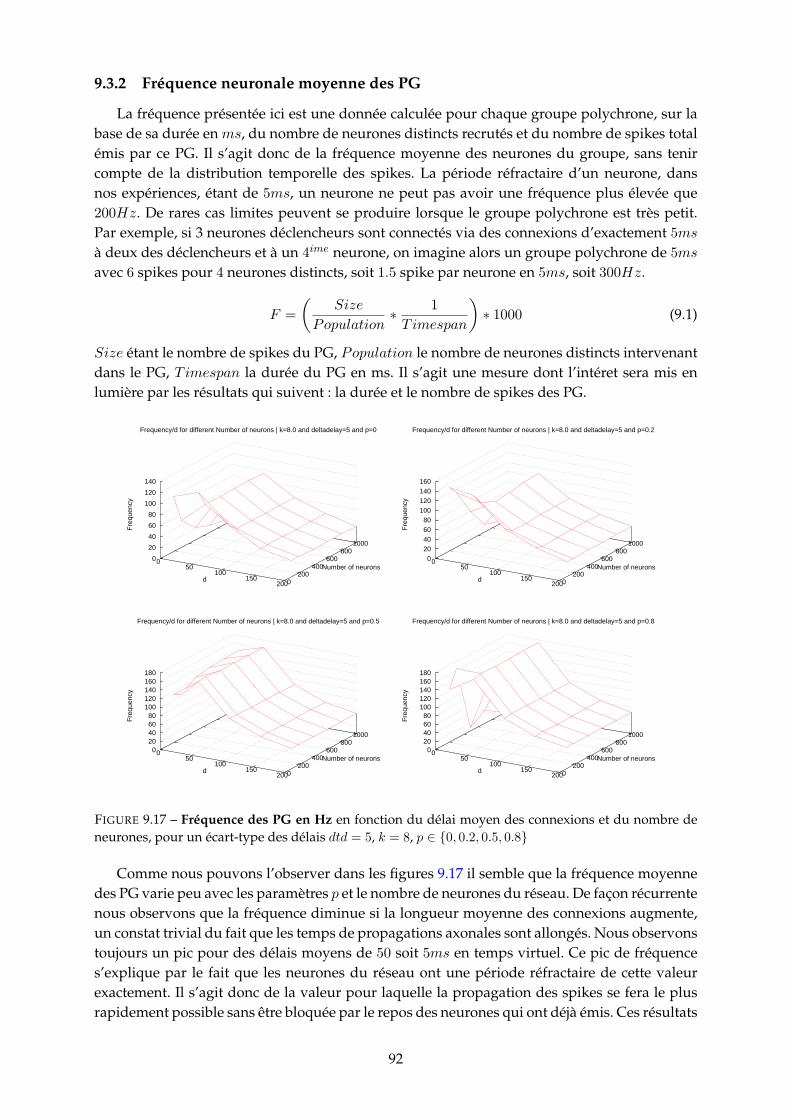
9.3.2 Fréquence neuronale moyenne des PG
La fréquence présentée ici est une donnée calculée pour chaque groupe polychrone, sur labase de sa durée en ms, du nombre de neurones distincts recrutés et du nombre de spikes totalémis par ce PG. Il s’agit donc de la fréquence moyenne des neurones du groupe, sans tenircompte de la distribution temporelle des spikes. La période réfractaire d’un neurone, dansnos expériences, étant de 5ms, un neurone ne peut pas avoir une fréquence plus élevée que200Hz. De rares cas limites peuvent se produire lorsque le groupe polychrone est très petit.Par exemple, si 3 neurones déclencheurs sont connectés via des connexions d’exactement 5msà deux des déclencheurs et à un 4ime neurone, on imagine alors un groupe polychrone de 5msavec 6 spikes pour 4 neurones distincts, soit 1.5 spike par neurone en 5ms, soit 300Hz.
F =(
Size
Population∗ 1Timespan
)∗ 1000 (9.1)
Size étant le nombre de spikes du PG, Population le nombre de neurones distincts intervenantdans le PG, Timespan la durée du PG en ms. Il s’agit une mesure dont l’intéret sera mis enlumière par les résultats qui suivent : la durée et le nombre de spikes des PG.
Frequency/d for different Number of neurons | k=8.0 and deltadelay=5 and p=0
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
20
40
60
80
100
120
140
Fre
quen
cy
Frequency/d for different Number of neurons | k=8.0 and deltadelay=5 and p=0.2
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
20 40 60 80
100 120 140 160
Fre
quen
cy
Frequency/d for different Number of neurons | k=8.0 and deltadelay=5 and p=0.5
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
20 40 60 80
100 120 140 160 180
Fre
quen
cy
Frequency/d for different Number of neurons | k=8.0 and deltadelay=5 and p=0.8
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
20 40 60 80
100 120 140 160 180
Fre
quen
cy
FIGURE 9.17 – Fréquence des PG en Hz en fonction du délai moyen des connexions et du nombre deneurones, pour un écart-type des délais dtd = 5, k = 8, p ∈ {0, 0.2, 0.5, 0.8}
Comme nous pouvons l’observer dans les figures 9.17 il semble que la fréquence moyennedes PG varie peu avec les paramètres p et le nombre de neurones du réseau. De façon récurrentenous observons que la fréquence diminue si la longueur moyenne des connexions augmente,un constat trivial du fait que les temps de propagations axonales sont allongés. Nous observonstoujours un pic pour des délais moyens de 50 soit 5ms en temps virtuel. Ce pic de fréquences’explique par le fait que les neurones du réseau ont une période réfractaire de cette valeurexactement. Il s’agit donc de la valeur pour laquelle la propagation des spikes se fera le plusrapidement possible sans être bloquée par le repos des neurones qui ont déjà émis. Ces résultats
92
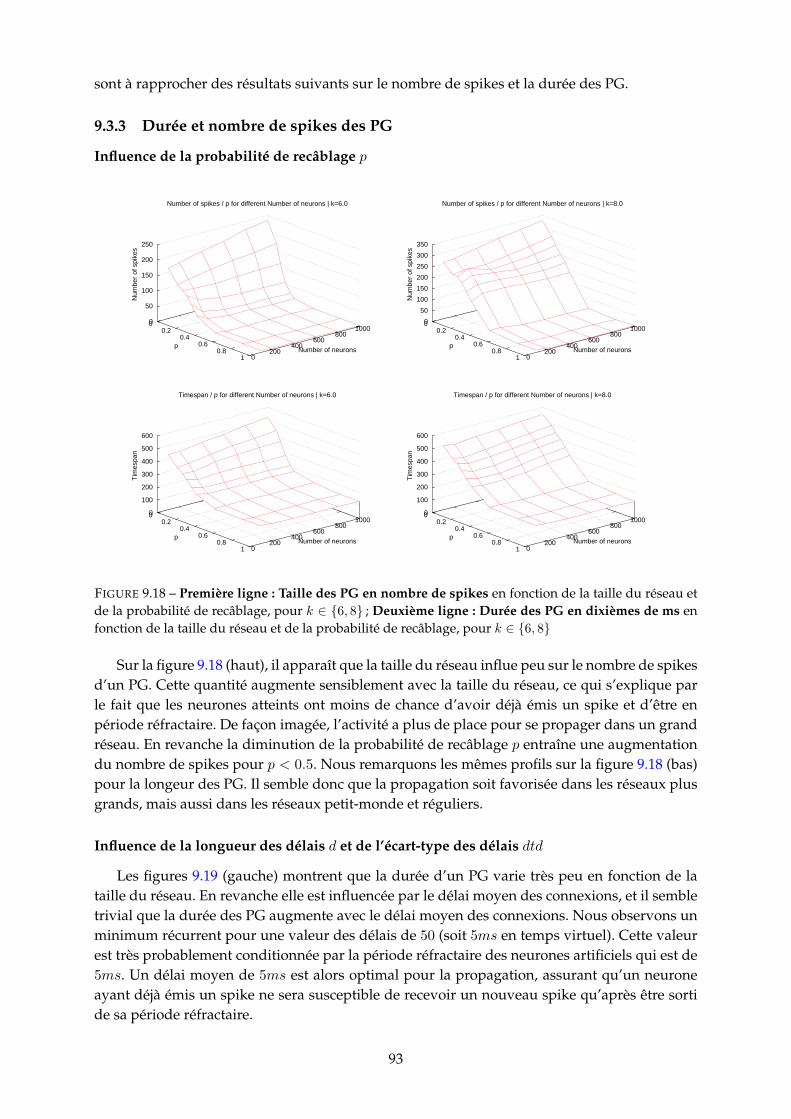
sont à rapprocher des résultats suivants sur le nombre de spikes et la durée des PG.
9.3.3 Durée et nombre de spikes des PG
Influence de la probabilité de recâblage p
Number of spikes / p for different Number of neurons | k=6.0
0 0.2
0.4 0.6
0.8 1
p
0 200
400 600
800 1000
Number of neurons
0
50
100
150
200
250
Num
ber
of s
pike
s
Number of spikes / p for different Number of neurons | k=8.0
0 0.2
0.4 0.6
0.8 1
p
0 200
400 600
800 1000
Number of neurons
0
50
100
150
200
250
300
350
Num
ber
of s
pike
s
Timespan / p for different Number of neurons | k=6.0
0 0.2
0.4 0.6
0.8 1
p
0 200
400 600
800 1000
Number of neurons
0
100
200
300
400
500
600
Tim
espa
n
Timespan / p for different Number of neurons | k=8.0
0 0.2
0.4 0.6
0.8 1
p
0 200
400 600
800 1000
Number of neurons
0
100
200
300
400
500
600
Tim
espa
n
FIGURE 9.18 – Première ligne : Taille des PG en nombre de spikes en fonction de la taille du réseau etde la probabilité de recâblage, pour k ∈ {6, 8} ; Deuxième ligne : Durée des PG en dixièmes de ms enfonction de la taille du réseau et de la probabilité de recâblage, pour k ∈ {6, 8}
Sur la figure 9.18 (haut), il apparaît que la taille du réseau influe peu sur le nombre de spikesd’un PG. Cette quantité augmente sensiblement avec la taille du réseau, ce qui s’explique parle fait que les neurones atteints ont moins de chance d’avoir déjà émis un spike et d’être enpériode réfractaire. De façon imagée, l’activité a plus de place pour se propager dans un grandréseau. En revanche la diminution de la probabilité de recâblage p entraîne une augmentationdu nombre de spikes pour p < 0.5. Nous remarquons les mêmes profils sur la figure 9.18 (bas)pour la longeur des PG. Il semble donc que la propagation soit favorisée dans les réseaux plusgrands, mais aussi dans les réseaux petit-monde et réguliers.
Influence de la longueur des délais d et de l’écart-type des délais dtd
Les figures 9.19 (gauche) montrent que la durée d’un PG varie très peu en fonction de lataille du réseau. En revanche elle est influencée par le délai moyen des connexions, et il sembletrivial que la durée des PG augmente avec le délai moyen des connexions. Nous observons unminimum récurrent pour une valeur des délais de 50 (soit 5ms en temps virtuel). Cette valeurest très probablement conditionnée par la période réfractaire des neurones artificiels qui est de5ms. Un délai moyen de 5ms est alors optimal pour la propagation, assurant qu’un neuroneayant déjà émis un spike ne sera susceptible de recevoir un nouveau spike qu’après être sortide sa période réfractaire.
93

Timespan/d for different Number of neurons | k=8.0 and deltadelay=5 and p=0
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
200
400
600
800
1000
1200
1400
Tim
espa
n
Number of spikes/d for different Number of neurons | k=8.0 and deltadelay=5 and p=0
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
200
400
600
800
1000
Num
ber
of s
pike
s
Timespan/d for different Number of neurons | k=8.0 and deltadelay=5 and p=0.2
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
100 200 300 400 500 600 700 800 900
1000
Tim
espa
n
Number of spikes/d for different Number of neurons | k=8.0 and deltadelay=5 and p=0.2
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
100 200 300 400 500 600 700 800 900
1000
Num
ber
of s
pike
s
Timespan/d for different Number of neurons | k=8.0 and deltadelay=5 and p=0.5
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
50
100
150
200
250
Tim
espa
n
Number of spikes/d for different Number of neurons | k=8.0 and deltadelay=5 and p=0.5
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
20 40 60 80
100 120 140 160
Num
ber
of s
pike
s
Timespan/d for different Number of neurons | k=8.0 and deltadelay=5 and p=0.8
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
50
100
150
200
250
Tim
espa
n
Number of spikes/d for different Number of neurons | k=8.0 and deltadelay=5 and p=0.8
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
10 20 30 40 50 60 70 80 90
Num
ber
of s
pike
s
FIGURE 9.19 – Gauche : Durée des PG en dixièmes ms, Droite : Taille des PG en nombre de spikes, enfonction du délai moyen des connexions et du nombre de neurones, pour un écart-type dtd = 5, k = 8,p ∈ {0, 0.2, 0.5, 0.8}
Les figures 9.19 (droite) présentent le nombre de spikes des PG en fonction des délaismoyens des connexions, chaque figure pour une valeur de p différente. Le nombre de spikesne varie pas avec la taille du réseau, à l’exception de la condition d = 10, où les délais des
94
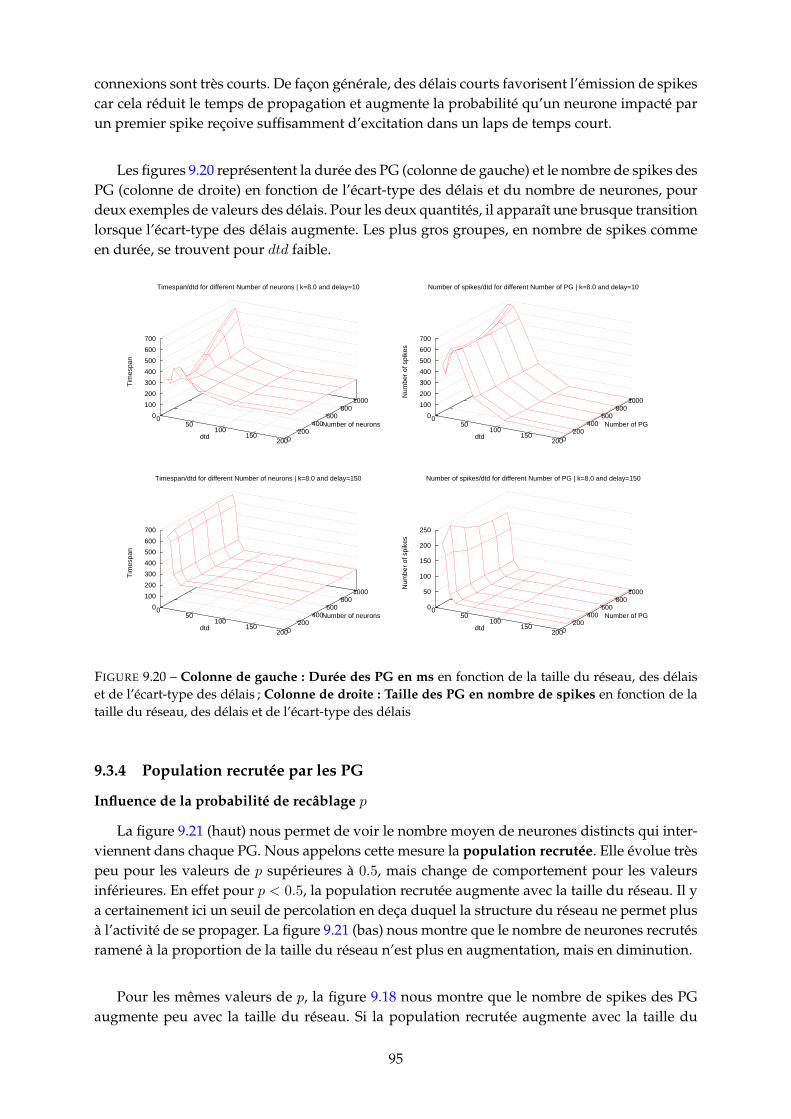
connexions sont très courts. De façon générale, des délais courts favorisent l’émission de spikescar cela réduit le temps de propagation et augmente la probabilité qu’un neurone impacté parun premier spike reçoive suffisamment d’excitation dans un laps de temps court.
Les figures 9.20 représentent la durée des PG (colonne de gauche) et le nombre de spikes desPG (colonne de droite) en fonction de l’écart-type des délais et du nombre de neurones, pourdeux exemples de valeurs des délais. Pour les deux quantités, il apparaît une brusque transitionlorsque l’écart-type des délais augmente. Les plus gros groupes, en nombre de spikes commeen durée, se trouvent pour dtd faible.
Timespan/dtd for different Number of neurons | k=8.0 and delay=10
0 50
100 150
200dtd 0
200 400
600 800
1000
Number of neurons 0
100
200
300
400
500
600
700
Tim
espa
n
Number of spikes/dtd for different Number of PG | k=8.0 and delay=10
0 50
100 150
200dtd 0
200 400
600 800
1000
Number of PG 0
100
200
300
400
500
600
700
Num
ber
of s
pike
s
Timespan/dtd for different Number of neurons | k=8.0 and delay=150
0 50
100 150
200dtd 0
200 400
600 800
1000
Number of neurons 0
100
200
300
400
500
600
700
Tim
espa
n
Number of spikes/dtd for different Number of PG | k=8.0 and delay=150
0 50
100 150
200dtd 0
200 400
600 800
1000
Number of PG 0
50
100
150
200
250
Num
ber
of s
pike
s
FIGURE 9.20 – Colonne de gauche : Durée des PG en ms en fonction de la taille du réseau, des délaiset de l’écart-type des délais ; Colonne de droite : Taille des PG en nombre de spikes en fonction de lataille du réseau, des délais et de l’écart-type des délais
9.3.4 Population recrutée par les PG
Influence de la probabilité de recâblage p
La figure 9.21 (haut) nous permet de voir le nombre moyen de neurones distincts qui inter-viennent dans chaque PG. Nous appelons cette mesure la population recrutée. Elle évolue trèspeu pour les valeurs de p supérieures à 0.5, mais change de comportement pour les valeursinférieures. En effet pour p < 0.5, la population recrutée augmente avec la taille du réseau. Il ya certainement ici un seuil de percolation en deça duquel la structure du réseau ne permet plusà l’activité de se propager. La figure 9.21 (bas) nous montre que le nombre de neurones recrutésramené à la proportion de la taille du réseau n’est plus en augmentation, mais en diminution.
Pour les mêmes valeurs de p, la figure 9.18 nous montre que le nombre de spikes des PGaugmente peu avec la taille du réseau. Si la population recrutée augmente avec la taille du
95
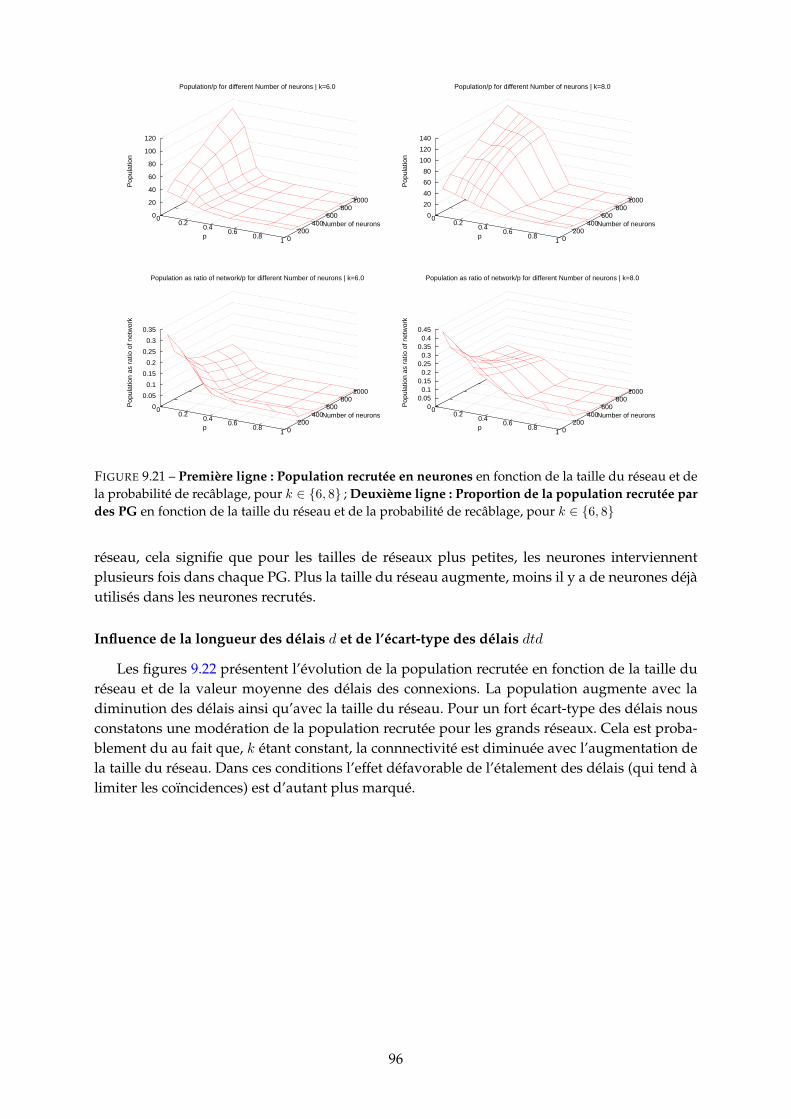
Population/p for different Number of neurons | k=6.0
0 0.2
0.4 0.6
0.8 1
p 0 200
400 600
800 1000
Number of neurons 0
20
40
60
80
100
120
Pop
ulat
ion
Population/p for different Number of neurons | k=8.0
0 0.2
0.4 0.6
0.8 1
p 0 200
400 600
800 1000
Number of neurons 0
20
40
60
80
100
120
140
Pop
ulat
ion
Population as ratio of network/p for different Number of neurons | k=6.0
0 0.2
0.4 0.6
0.8 1
p 0 200
400 600
800 1000
Number of neurons 0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
Pop
ulat
ion
as r
atio
of n
etw
ork
Population as ratio of network/p for different Number of neurons | k=8.0
0 0.2
0.4 0.6
0.8 1
p 0 200
400 600
800 1000
Number of neurons 0
0.05 0.1
0.15 0.2
0.25 0.3
0.35 0.4
0.45
Pop
ulat
ion
as r
atio
of n
etw
ork
FIGURE 9.21 – Première ligne : Population recrutée en neurones en fonction de la taille du réseau et dela probabilité de recâblage, pour k ∈ {6, 8} ; Deuxième ligne : Proportion de la population recrutée pardes PG en fonction de la taille du réseau et de la probabilité de recâblage, pour k ∈ {6, 8}
réseau, cela signifie que pour les tailles de réseaux plus petites, les neurones interviennentplusieurs fois dans chaque PG. Plus la taille du réseau augmente, moins il y a de neurones déjàutilisés dans les neurones recrutés.
Influence de la longueur des délais d et de l’écart-type des délais dtd
Les figures 9.22 présentent l’évolution de la population recrutée en fonction de la taille duréseau et de la valeur moyenne des délais des connexions. La population augmente avec ladiminution des délais ainsi qu’avec la taille du réseau. Pour un fort écart-type des délais nousconstatons une modération de la population recrutée pour les grands réseaux. Cela est proba-blement du au fait que, k étant constant, la connnectivité est diminuée avec l’augmentation dela taille du réseau. Dans ces conditions l’effet défavorable de l’étalement des délais (qui tend àlimiter les coïncidences) est d’autant plus marqué.
96

Population/d for different Number of neurons | k=8.0 and deltadelay=0
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
100
200
300
400
500
600
700
Pop
ulat
ion
Population/d for different Number of neurons | k=8.0 and deltadelay=5
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
100
200
300
400
500
600
700
Pop
ulat
ion
Population/d for different Number of neurons | k=8.0 and deltadelay=20
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
50
100
150
200
250
Pop
ulat
ion
Population/d for different Number of neurons | k=8.0 and deltadelay=50
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0 5
10 15 20 25 30 35 40 45
Pop
ulat
ion
FIGURE 9.22 – Population recrutée en neurones en fonction du délai moyen des connexions, pour unécart-type dtd ∈ {0, 5, 20, 50}, et pour k = 8
9.3.5 Proportion de PG tronqués (cycliques)
Les figures 9.23 présentent la proportion de tous les PG qui ont été tronqués, c’est-à-diredont le calcul a été interrompu avant que l’activité du PG ne se termine d’elle-même. Les PGtronqués sont probablement (mais pas nécessairement) des groupes cycliques dont l’activités’auto-entretient. Les PG cycliques sont les marqueurs d’un réseau capable de maintenir uneactivité persistante. Nous constatons que la proportion des PG tronqués est nulle pour desvaleurs de p supérieures à 0.5, mais qu’elle augmente de 0% à presque un tiers des PG pourdes valeurs de p diminuant de 0.5 à 0. En revanche cette proportion reste stable en fonction dela taille du réseau.
97

Ratio of cyclic PG/p for different Number of neurons | k=6.0
0 0.2
0.4 0.6
0.8 1
p 0 200
400 600
800 1000
Number of neurons 0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
Rat
io o
f cyc
lic P
G
Ratio of cyclic PG/p for different Number of neurons | k=8.0
0 0.2
0.4 0.6
0.8 1
p 0 200
400 600
800 1000
Number of neurons 0
0.05 0.1
0.15 0.2
0.25 0.3
0.35 0.4
0.45
Rat
io o
f cyc
lic P
G
FIGURE 9.23 – Proportion de PG tronqués (cycliques) en fonction de la taille du réseau et de la proba-bilité de recâblage, pour k ∈ {6, 8}
La figure 9.24 met en évidence le fait que des délais courts et regroupés autour du délaimoyen favorise la propagation de l’activité. En effet nous observons (à gauche) que la plusgrande proportion de PG cycliques est présente pour les valeurs de d < 50 et (à droite) pourdes valeurs de dtd ≈ 20.
Ratio of cyclic PG / d for different Number of neurons | k=8.0 and deltadelay=20
0 50
100 150
200d 0
200 400
600 800
1000
Number of neurons 0
0.1
0.2
0.3
0.4
0.5
0.6
Rat
io o
f cyc
lic P
G
Ratio of cyclic PG/dtd for different Number of neurons | k=8.0 and delay=10
0 50
100 150
200dtd 0
200 400
600 800
1000
Number of neurons 0
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
Rat
io o
f cyc
lic P
G
FIGURE 9.24 – Proportion de PG tronqués (cycliques) en fonction de la taille du réseau et à gauche : ded pour dtd = 20 ; à droite : de dtd pour d = 10, pour k ∈ {8}
Nous avons pu étudier, dans cette exploration complète des paramètres de contrôle de l’ar-chitecture du réseau, l’influence de ces différents paramètres sur les propriétés des PG. Nousavons ainsi réalisé une étude quantitative. Nous nous intéressons à présent à un aspect plusqualitatif que sont les distributions des différentes propriétés des PG.
98

10Etude des distributions des groupes
polychrones
Dans ce chapitre nous étudions l’évolution de la distribution, en nombre de groupes poly-chrones, de plusieurs mesures :• la taille des PG en nombre de spikes,• la durée des PG (timespan),• la population recrutée par chaque PG,• la fréquence neuronale moyenne des PG.
Nous étudierons l’évolution de ces distributions en fonction des différents paramètres decontrôle, à savoir :• la probabilité de recâblage p,• le délai moyen d,• l’écart-type des délais dtd.
Dans les pages suivantes nous présentons les quatre types de mesure côte à côte afin depouvoir les comparer. Ainsi à chacune des pages de distributions qui suivent correspond unvaleur de d ∈ {10, 50} et une valeur de dtd ∈ {0, 10, 20}. Une page de distribution est organi-sée en quatre colonnes (durée, nombre de spikes, population recrutée, fréquence moyenne parneurone) et neuf lignes (une par probabilité de recâblage mesurée). Rappelons que les valeursde délai d ∈ {10, 50} sont exprimées en unités de temps virtuel dont la précision est le dixièmede milliseconde, et sont donc respectivement équivalentes à d ∈ {1ms, 5ms}. Sur les figures letemps est exprimé en millisecondes. Nous ne présentons ici que ces valeurs de d et dtd, ainsipour le cas de réseaux de 600 neurones pour k = 6, que nous jugeons représentatifs de ce quel’on peut observer pour d’autres valeurs.
Le lecteur peut se référer aux distributions présentée en annexe A pour comparaison. Nousy présentons une propriété par page, avec p pour les lignes et d ou dtd pour les colonnes.
Démarche adoptée Dans les figures de distributions de ce chapitres, les échelles varient for-tement en ordonnées d’un diagramme à un autre. Notre intérêt ici est d’observer et de tenterd’expliquer l’évolution de la forme des distributions à mesure que la topologie du réseau sedéstructure de régulière (p = 0) à aléatoire (p = 1). Plus particulièrement, nous mettons envaleur (lignes encadrées sur les graphiques) la valeur de p sur laquelle une transition est vi-sible dans la forme des distributions. Nous chercherons ensuite à confirmer ces observationsen mettans en évidence des transitions de phases sur les graphiques de calcul d’entropie. Pourles distributions présentées pour d = 5ms, nous ne pouvons observer de transition claire etnous encadrerons les graphiques qui correspondent au pic d’entropie. Nous rappellerons cetteparticularité dans les explications.
99

10.1 Distributions pour d = 10 = 1ms
10.1.1 Figure 10.2 - dtd = 0
Dans un réseau régulier, p = 0 (première ligne), pour un délai moyen de 1ms (premièrecolonne), nous observons que tous les PG ont environ la même durée de 75ms. Nous voyonsqu’ils recrutent systématiquement tous les neurones du réseau (troixième colonne) et émettentexactement le même nombre de spikes qu’il y a de neurones (deuxième colonne). Cette duréede 75ms est le temps que les PG mettent à se propager à tout le réseau. En effet, du fait dela connectivité strictement locale des réseaux réguliers, les PG ne sont déclenchés que si lesneurones déclencheurs sont suffisament proches pour impacter un ou plusieurs neurones encommun. De ce point de départ, l’activité peut se propager sur l’anneau régulier, de 4 en 4neurones (figure 10.1 avec k = 2).
FIGURE 10.1 – Propagation typique de l’activité d’un groupe polychrone dans un réseau régulier, pourd = 1ms, dtd = 0 et k = 2
Par exemple, en admettant que les 3 neurones déclencheurs soient adjacents, le voisin leplus éloigné recevant 3 connexions des déclencheurs se trouve à 4 neurones de distance. Lesvoisins plus éloignés reçoivent moins de connexions. Ainsi l’activité se propage de part etd’autre du point de départ et s’arrête lorsque les deux branches se rejoignent, car les neuronesalors recrutés sont en période réfractaire. Ainsi l’activité parcourt n/2 = 300 neurones de partet d’autre des déclencheurs. Le temps de parcours est donc ((n/2) ∗ d)/4 = 300/4 = 75ms. Lavaleur de 4 se retrouve par le nombre de neurones que l’activité saute à chaque pas, c’est-à-direk − s + 1, s étant le nombre de déclencheurs. La fréquence moyenne par neurone (quatrièmecolonne) est la même pour tous les PG et, d’après l’équation 9.1, p.92, vaut :
F = [(600/600)/75] ∗ 1000 = 13.3Hz
100
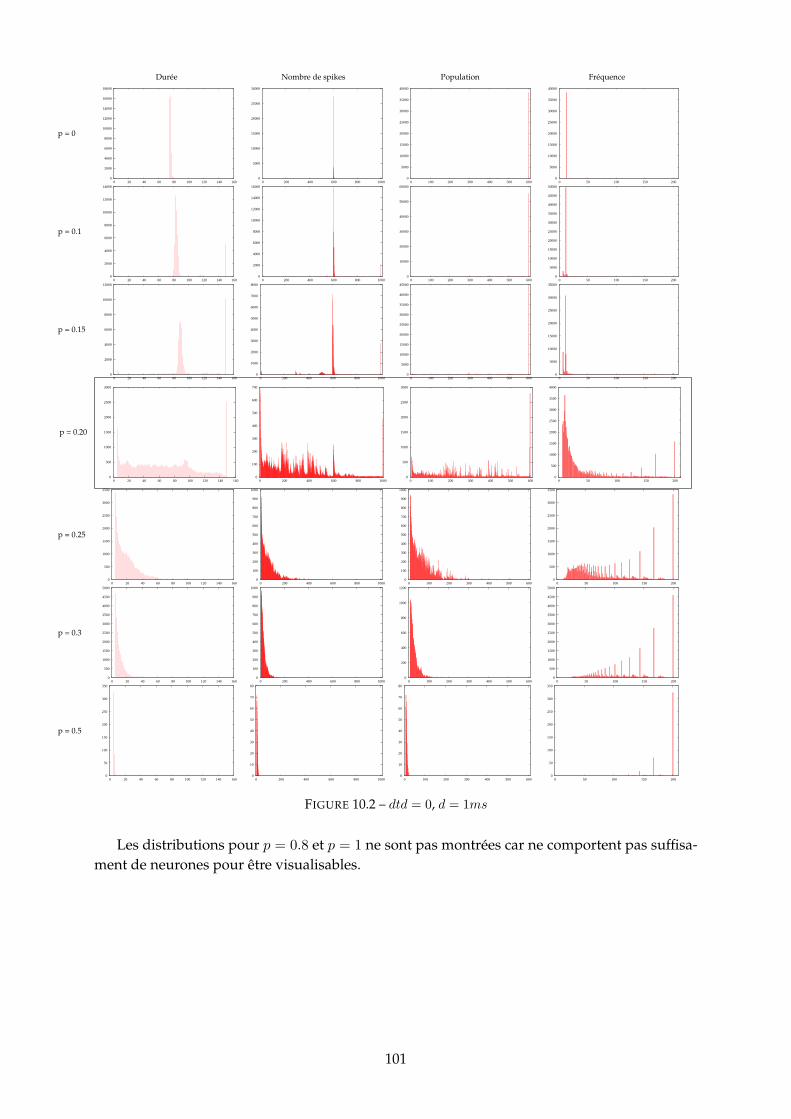
Durée Nombre de spikes Population Fréquence
p = 0
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 20 40 60 80 100 120 140 160 0
5000
10000
15000
20000
25000
30000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
30000
35000
40000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
30000
35000
40000
0 50 100 150 200
p = 0.1
0
2000
4000
6000
8000
10000
12000
14000
0 20 40 60 80 100 120 140 160 0
2000
4000
6000
8000
10000
12000
14000
16000
0 200 400 600 800 1000 0
10000
20000
30000
40000
50000
60000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
30000
35000
40000
45000
50000
0 50 100 150 200
p = 0.15
0
2000
4000
6000
8000
10000
12000
0 20 40 60 80 100 120 140 160 0
1000
2000
3000
4000
5000
6000
7000
8000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
30000
35000
40000
45000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
30000
35000
0 50 100 150 200
p = 0.20
0
500
1000
1500
2000
2500
3000
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
0 200 400 600 800 1000 0
500
1000
1500
2000
2500
3000
0 100 200 300 400 500 600 0
500
1000
1500
2000
2500
3000
3500
4000
0 50 100 150 200
p = 0.25
0
500
1000
1500
2000
2500
3000
3500
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
800
900
1000
0 200 400 600 800 1000 0
100
200
300
400
500
600
700
800
900
1000
0 100 200 300 400 500 600 0
500
1000
1500
2000
2500
3000
3500
0 50 100 150 200
p = 0.3
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
800
900
1000
0 200 400 600 800 1000 0
200
400
600
800
1000
1200
0 100 200 300 400 500 600 0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 50 100 150 200
p = 0.5
0
50
100
150
200
250
300
350
0 20 40 60 80 100 120 140 160 0
10
20
30
40
50
60
70
80
0 200 400 600 800 1000 0
10
20
30
40
50
60
70
80
0 100 200 300 400 500 600 0
50
100
150
200
250
300
350
0 50 100 150 200
FIGURE 10.2 – dtd = 0, d = 1ms
Les distributions pour p = 0.8 et p = 1 ne sont pas montrées car ne comportent pas suffisa-ment de neurones pour être visualisables.
101

Dès lors que la probabilité de recâblage est non nulle (lignes suivantes), des raccourcis per-mettent à l’activité de se repropager à des parties du réseau n’étant plus en période réfractaire.On observe en effet un pic qui apparaît à t = 150ms, 1500 unités de temps étant la borne fixéedans notre algorithme pour limiter le temps de calcul des PG. On observe un pic équivalentà 1000 pour le nombre de spikes. Les PG ainsi tronqués à cette durée sont probablement cy-cliques, leur activité se poursuivant indéfiniment. Pour la valeur caractéristique p = 0.2 (voirencadré), il semble y avoir une transition dans les caractéristiques des PG. Concernant la du-rée, le nombre de spikes, la population recrutée, ainsi que la fréquence, nous observons que ladistribution devient plus hétérogène. Cette transition passée, la densité locale des connexionsest de plus en plus faible, la probabilité de propagation en chaîne diminue, et avec elle, lenombre de PG détectés, mais aussi la durée, la taille et la population recrutée des PG. Les fré-quences moyennes par neurone mesurées sont majoritairement faibles en p = 0.2 (beaucoupde groupes polychrones autour de 13Hz). Avec l’augmentation de p, des pics remarquables ap-paraissent aux valeurs 200, 166.66, 142.85, 125, 111.11, etc.. Ces fréquences correspondent auxgroupes dont les neurones pulsent exactement toutes les {5, 6, 7, 8, 9, ...}ms. Les pics sont doncdes artefacts du fait que toutes les connexions ont exactement la même longueur de 1ms. Nousretrouvons le même motif pour dtd = 10 (figure 10.4), mais avec des pics intermédiaires, pourles neurones qui pulsent toutes les {4.5, 4.6, 4.7, 4.8, 4.9, 5, 5.1, ...}ms.
Notons qu’avec des connexions de longueur 1ms, du fait d’une période réfractaire de 5ms,le délai est trop court pour que l’activité d’un PG puisse revenir en arrière, la propagation del’activité d’un PG se fait donc dans un seul sens le long de l’anneau. Elle ne pourra pas revenirsur ses pas, sauf si elle rencontre des connexions recâblées qui permettent de propager l’activitéà un autre point du réseau.
102

10.1.2 Figure 10.4 - dtd = 10
Pour dtd = 10 nous observons dès p = 0 une configuration différente. La majorité desgroupes durent environ 100ms. Le fait d’ajouter de la variabilité dans les délais allonge la du-rée moyenne des PG. En effet, chaque neurone ayant besoin d’un nombre d’au moins troisspikes dans un laps de temps de jitter ms, c’est l’arrivée du spike le plus tardif qui condi-tionne l’instant de déclenchement du neurone. Les PG ont majoritairement une taille de 600spikes, mais certains sont déjà cycliques.
La figure 10.3 représente la distribution des durées pour p = 0 extraites de la figure 10.4dont les quantités ont été découpées en fonction de la taille en deux courbes : une courbe pourles PG d’environ 600 spikes, une autre pour les PG d’environ 1000 spikes.
0
200
400
600
800
1000
1200
1400
0 20 40 60 80 100 120 140 160
Nom
bre
de P
G
Duree des PG
PG with nbspikes>=550 and <=650PG with nbspikes>=990 and <=1000
FIGURE 10.3 – Distribution des durées des PG de ∼ 600 et ∼ 1000 spikes pour p = 0, dtd = 10, d = 1ms
En effet, la variabilité des délais introduite par dtd = 10 permet à certains groupes de passerla zone de collision des deux branches d’activité. On observe cependant une transition similaireau cas dtd = 0, mais autour de p = 0.15 au lieu de p = 0.2. Les fréquences ont une évolution enfonction de p qui est similaire au cas précédent dtd = 0. Néanmoins, un plus grand nombre devaleurs intermédiaires sont visibles entre les pics remarqués précédemment. Il semble y avoirdeux modalités parmi ces fréquences. Il s’agit d’une part des fréquences des PG qui ont trèspeu de neurones (visibles dans les pics artefacts), et d’autre part des PG qui ont suffisamentde neurones pour que la fréquence ne tombe pas sur une valeur remarquable. Ces PG ont unefréquence moyenne qui part de 13Hz et dérive avec p vers 100Hz, soit un spike toutes les 10msen p = 0.3. Les PG de 1000 spikes peuvent durer entre 44ms et 140ms pour être dans la tranchede fréquence [11.9Hz, 37.8Hz].
103
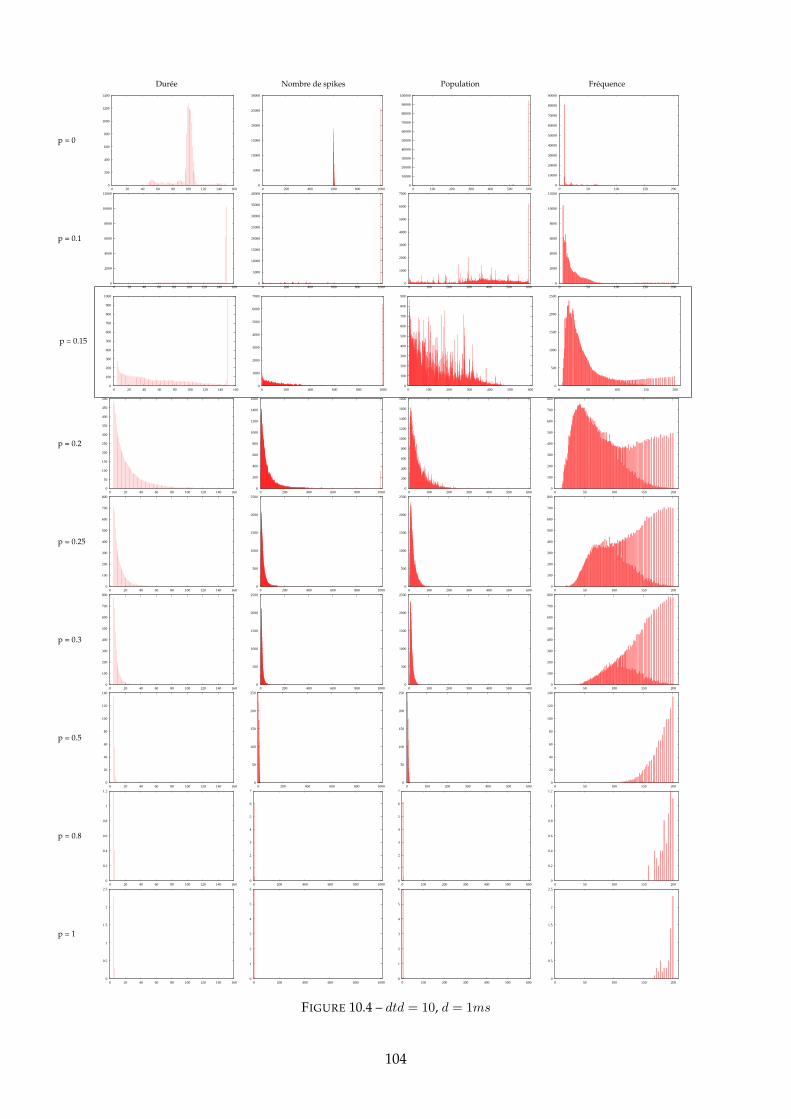
Durée Nombre de spikes Population Fréquence
p = 0
0
200
400
600
800
1000
1200
1400
0 20 40 60 80 100 120 140 160 0
5000
10000
15000
20000
25000
30000
0 200 400 600 800 1000 0
10000
20000
30000
40000
50000
60000
70000
80000
90000
100000
0 100 200 300 400 500 600 0
10000
20000
30000
40000
50000
60000
70000
80000
90000
0 50 100 150 200
p = 0.1
0
2000
4000
6000
8000
10000
12000
0 20 40 60 80 100 120 140 160 0
5000
10000
15000
20000
25000
30000
35000
40000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
7000
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
0 50 100 150 200
p = 0.15
0
100
200
300
400
500
600
700
800
900
1000
0 20 40 60 80 100 120 140 160 0
1000
2000
3000
4000
5000
6000
7000
0 200 400 600 800 1000 0
100
200
300
400
500
600
700
800
900
0 100 200 300 400 500 600 0
500
1000
1500
2000
2500
0 50 100 150 200
p = 0.2
0
50
100
150
200
250
300
350
400
450
500
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
1400
1600
0 200 400 600 800 1000 0
200
400
600
800
1000
1200
1400
1600
1800
0 100 200 300 400 500 600 0
100
200
300
400
500
600
700
800
0 50 100 150 200
p = 0.25
0
100
200
300
400
500
600
700
800
0 20 40 60 80 100 120 140 160 0
500
1000
1500
2000
2500
0 200 400 600 800 1000 0
500
1000
1500
2000
2500
0 100 200 300 400 500 600 0
100
200
300
400
500
600
700
800
0 50 100 150 200
p = 0.3
0
100
200
300
400
500
600
700
800
0 20 40 60 80 100 120 140 160 0
500
1000
1500
2000
2500
0 200 400 600 800 1000 0
500
1000
1500
2000
2500
0 100 200 300 400 500 600 0
100
200
300
400
500
600
700
800
0 50 100 150 200
p = 0.5
0
20
40
60
80
100
120
140
0 20 40 60 80 100 120 140 160 0
50
100
150
200
250
0 200 400 600 800 1000 0
50
100
150
200
250
0 100 200 300 400 500 600 0
20
40
60
80
100
120
140
0 50 100 150 200
p = 0.8
0
0.2
0.4
0.6
0.8
1
1.2
0 20 40 60 80 100 120 140 160 0
1
2
3
4
5
6
7
0 200 400 600 800 1000 0
1
2
3
4
5
6
7
0 100 200 300 400 500 600 0
0.2
0.4
0.6
0.8
1
1.2
0 50 100 150 200
p = 1
0
0.5
1
1.5
2
2.5
0 20 40 60 80 100 120 140 160 0
1
2
3
4
5
6
0 200 400 600 800 1000 0
1
2
3
4
5
6
0 100 200 300 400 500 600 0
0.5
1
1.5
2
2.5
0 50 100 150 200
FIGURE 10.4 – dtd = 10, d = 1ms
104
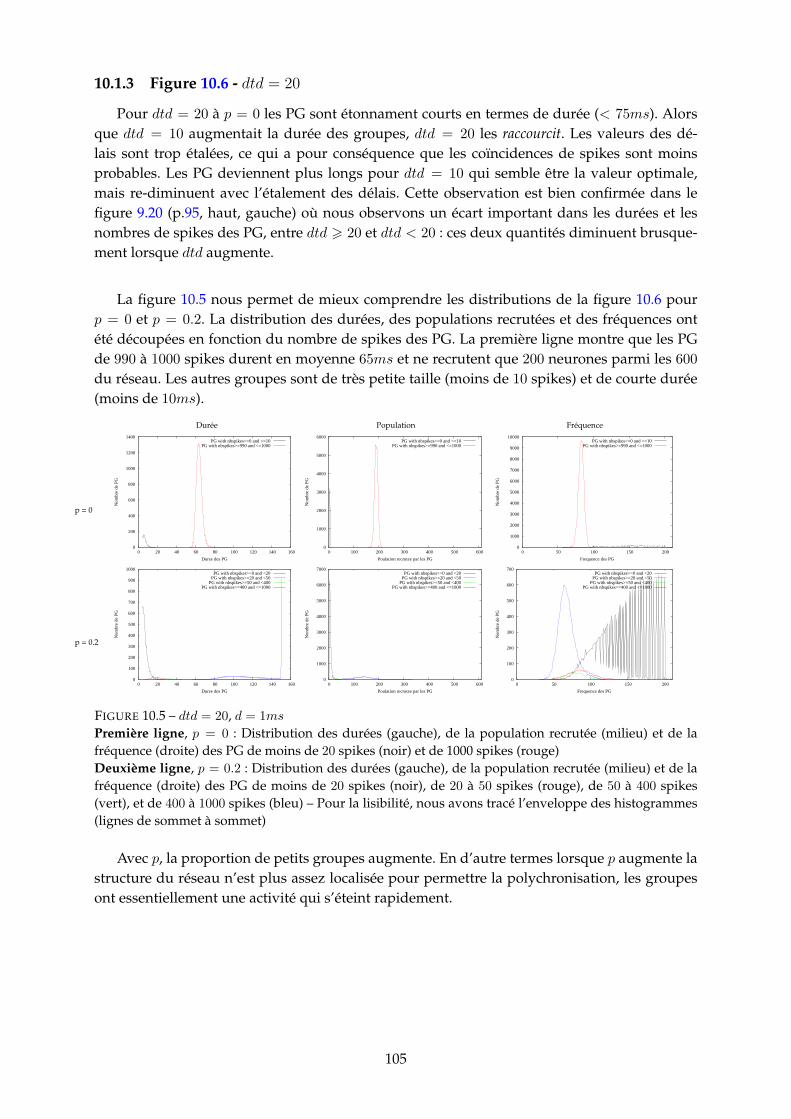
10.1.3 Figure 10.6 - dtd = 20
Pour dtd = 20 à p = 0 les PG sont étonnament courts en termes de durée (< 75ms). Alorsque dtd = 10 augmentait la durée des groupes, dtd = 20 les raccourcit. Les valeurs des dé-lais sont trop étalées, ce qui a pour conséquence que les coïncidences de spikes sont moinsprobables. Les PG deviennent plus longs pour dtd = 10 qui semble être la valeur optimale,mais re-diminuent avec l’étalement des délais. Cette observation est bien confirmée dans lefigure 9.20 (p.95, haut, gauche) où nous observons un écart important dans les durées et lesnombres de spikes des PG, entre dtd > 20 et dtd < 20 : ces deux quantités diminuent brusque-ment lorsque dtd augmente.
La figure 10.5 nous permet de mieux comprendre les distributions de la figure 10.6 pourp = 0 et p = 0.2. La distribution des durées, des populations recrutées et des fréquences ontété découpées en fonction du nombre de spikes des PG. La première ligne montre que les PGde 990 à 1000 spikes durent en moyenne 65ms et ne recrutent que 200 neurones parmi les 600du réseau. Les autres groupes sont de très petite taille (moins de 10 spikes) et de courte durée(moins de 10ms).
Durée Population Fréquence
p = 0
0
200
400
600
800
1000
1200
1400
0 20 40 60 80 100 120 140 160
Nom
bre
de P
G
Duree des PG
PG with nbspikes>=0 and <=10PG with nbspikes>=990 and <=1000
0
1000
2000
3000
4000
5000
6000
0 100 200 300 400 500 600
Nom
bre
de P
G
Poulation recrutee par les PG
PG with nbspikes>=0 and <=10PG with nbspikes>=990 and <=1000
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
0 50 100 150 200
Nom
bre
de P
G
Frequence des PG
PG with nbspikes>=0 and <=10PG with nbspikes>=990 and <=1000
p = 0.2
0
100
200
300
400
500
600
700
800
900
1000
0 20 40 60 80 100 120 140 160
Nom
bre
de P
G
Duree des PG
PG with nbspikes>=0 and <20PG with nbspikes>=20 and <50
PG with nbspikes>=50 and <400PG with nbspikes>=400 and <=1000
0
1000
2000
3000
4000
5000
6000
7000
0 100 200 300 400 500 600
Nom
bre
de P
G
Poulation recrutee par les PG
PG with nbspikes>=0 and <20PG with nbspikes>=20 and <50
PG with nbspikes>=50 and <400PG with nbspikes>=400 and <=1000
0
100
200
300
400
500
600
700
0 50 100 150 200
Nom
bre
de P
G
Frequence des PG
PG with nbspikes>=0 and <20PG with nbspikes>=20 and <50
PG with nbspikes>=50 and <400PG with nbspikes>=400 and <=1000
FIGURE 10.5 – dtd = 20, d = 1msPremière ligne, p = 0 : Distribution des durées (gauche), de la population recrutée (milieu) et de lafréquence (droite) des PG de moins de 20 spikes (noir) et de 1000 spikes (rouge)Deuxième ligne, p = 0.2 : Distribution des durées (gauche), de la population recrutée (milieu) et de lafréquence (droite) des PG de moins de 20 spikes (noir), de 20 à 50 spikes (rouge), de 50 à 400 spikes(vert), et de 400 à 1000 spikes (bleu) – Pour la lisibilité, nous avons tracé l’enveloppe des histogrammes(lignes de sommet à sommet)
Avec p, la proportion de petits groupes augmente. En d’autre termes lorsque p augmente lastructure du réseau n’est plus assez localisée pour permettre la polychronisation, les groupesont essentiellement une activité qui s’éteint rapidement.
105
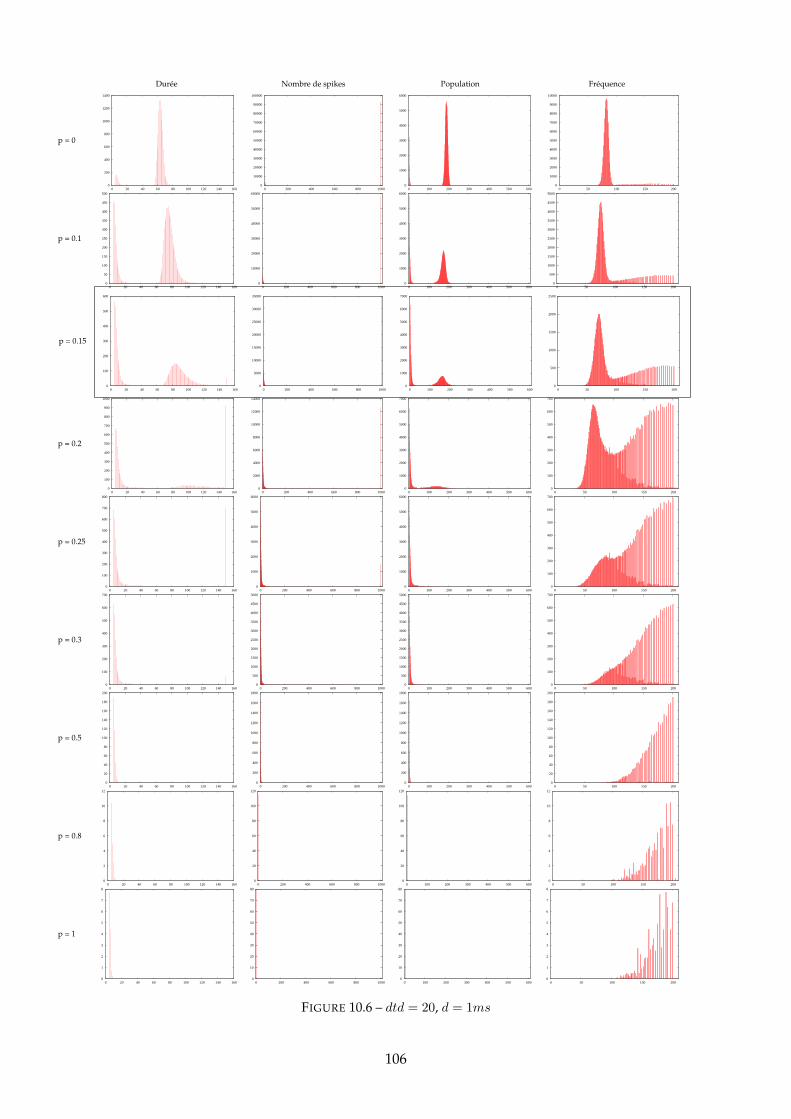
Durée Nombre de spikes Population Fréquence
p = 0
0
200
400
600
800
1000
1200
1400
0 20 40 60 80 100 120 140 160 0
10000
20000
30000
40000
50000
60000
70000
80000
90000
100000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
0 50 100 150 200
p = 0.1
0
50
100
150
200
250
300
350
400
450
500
0 20 40 60 80 100 120 140 160 0
10000
20000
30000
40000
50000
60000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
0 100 200 300 400 500 600 0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 50 100 150 200
p = 0.15
0
100
200
300
400
500
600
0 20 40 60 80 100 120 140 160 0
5000
10000
15000
20000
25000
30000
35000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
7000
0 100 200 300 400 500 600 0
500
1000
1500
2000
2500
0 50 100 150 200
p = 0.2
0
100
200
300
400
500
600
700
800
900
1000
0 20 40 60 80 100 120 140 160 0
2000
4000
6000
8000
10000
12000
14000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
7000
0 100 200 300 400 500 600 0
100
200
300
400
500
600
700
0 50 100 150 200
p = 0.25
0
100
200
300
400
500
600
700
800
0 20 40 60 80 100 120 140 160 0
1000
2000
3000
4000
5000
6000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
0 100 200 300 400 500 600 0
100
200
300
400
500
600
700
0 50 100 150 200
p = 0.3
0
100
200
300
400
500
600
700
0 20 40 60 80 100 120 140 160 0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 200 400 600 800 1000 0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 100 200 300 400 500 600 0
100
200
300
400
500
600
700
0 50 100 150 200
p = 0.5
0
20
40
60
80
100
120
140
160
180
200
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
1400
1600
1800
0 200 400 600 800 1000 0
200
400
600
800
1000
1200
1400
1600
1800
0 100 200 300 400 500 600 0
20
40
60
80
100
120
140
160
180
200
0 50 100 150 200
p = 0.8
0
2
4
6
8
10
12
0 20 40 60 80 100 120 140 160 0
20
40
60
80
100
120
0 200 400 600 800 1000 0
20
40
60
80
100
120
0 100 200 300 400 500 600 0
2
4
6
8
10
12
0 50 100 150 200
p = 1
0
1
2
3
4
5
6
7
8
0 20 40 60 80 100 120 140 160 0
10
20
30
40
50
60
70
80
0 200 400 600 800 1000 0
10
20
30
40
50
60
70
80
0 100 200 300 400 500 600 0
1
2
3
4
5
6
7
8
0 50 100 150 200
FIGURE 10.6 – dtd = 20, d = 1ms
106
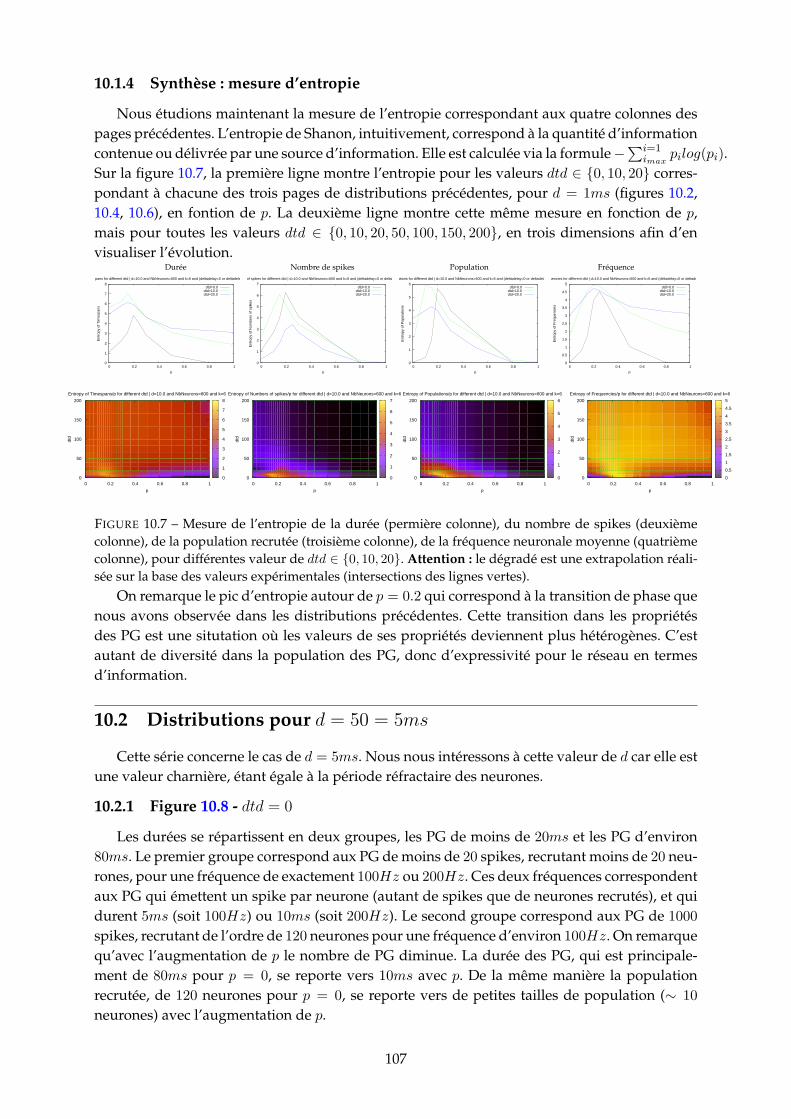
10.1.4 Synthèse : mesure d’entropie
Nous étudions maintenant la mesure de l’entropie correspondant aux quatre colonnes despages précédentes. L’entropie de Shanon, intuitivement, correspond à la quantité d’informationcontenue ou délivrée par une source d’information. Elle est calculée via la formule−
∑i=1imax
pilog(pi).Sur la figure 10.7, la première ligne montre l’entropie pour les valeurs dtd ∈ {0, 10, 20} corres-pondant à chacune des trois pages de distributions précédentes, pour d = 1ms (figures 10.2,10.4, 10.6), en fontion de p. La deuxième ligne montre cette même mesure en fonction de p,mais pour toutes les valeurs dtd ∈ {0, 10, 20, 50, 100, 150, 200}, en trois dimensions afin d’envisualiser l’évolution.
Durée Nombre de spikes Population Fréquence
0
1
2
3
4
5
6
7
8
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of T
imes
pans
p
p/Entropy of Timespans for different dtd | d=10.0 and NbNeurons=600 and k=6 and (deltadelay=0 or deltadelay=10 or deltadelay=20)
dtd=0.0dtd=10.0dtd=20.0
0
1
2
3
4
5
6
7
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of N
umbe
rs o
f spi
kes
p
p/Entropy of Numbers of spikes for different dtd | d=10.0 and NbNeurons=600 and k=6 and (deltadelay=0 or deltadelay=10 or deltadelay=20)
dtd=0.0dtd=10.0dtd=20.0
0
1
2
3
4
5
6
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of P
opul
atio
ns
p
p/Entropy of Populations for different dtd | d=10.0 and NbNeurons=600 and k=6 and (deltadelay=0 or deltadelay=10 or deltadelay=20)
dtd=0.0dtd=10.0dtd=20.0
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of F
requ
enci
es
p
p/Entropy of Frequencies for different dtd | d=10.0 and NbNeurons=600 and k=6 and (deltadelay=0 or deltadelay=10 or deltadelay=20)
dtd=0.0dtd=10.0dtd=20.0
Entropy of Timespans/p for different dtd | d=10.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
dtd
0
1
2
3
4
5
6
7
8
Entropy of Numbers of spikes/p for different dtd | d=10.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
dtd
0
1
2
3
4
5
6
7
Entropy of Populations/p for different dtd | d=10.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200dt
d
0
1
2
3
4
5
6
Entropy of Frequencies/p for different dtd | d=10.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
dtd
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
FIGURE 10.7 – Mesure de l’entropie de la durée (permière colonne), du nombre de spikes (deuxièmecolonne), de la population recrutée (troisième colonne), de la fréquence neuronale moyenne (quatrièmecolonne), pour différentes valeur de dtd ∈ {0, 10, 20}. Attention : le dégradé est une extrapolation réali-sée sur la base des valeurs expérimentales (intersections des lignes vertes).
On remarque le pic d’entropie autour de p = 0.2 qui correspond à la transition de phase quenous avons observée dans les distributions précédentes. Cette transition dans les propriétésdes PG est une situtation où les valeurs de ses propriétés deviennent plus hétérogènes. C’estautant de diversité dans la population des PG, donc d’expressivité pour le réseau en termesd’information.
10.2 Distributions pour d = 50 = 5ms
Cette série concerne le cas de d = 5ms. Nous nous intéressons à cette valeur de d car elle estune valeur charnière, étant égale à la période réfractaire des neurones.
10.2.1 Figure 10.8 - dtd = 0
Les durées se répartissent en deux groupes, les PG de moins de 20ms et les PG d’environ80ms. Le premier groupe correspond aux PG de moins de 20 spikes, recrutant moins de 20 neu-rones, pour une fréquence de exactement 100Hz ou 200Hz. Ces deux fréquences correspondentaux PG qui émettent un spike par neurone (autant de spikes que de neurones recrutés), et quidurent 5ms (soit 100Hz) ou 10ms (soit 200Hz). Le second groupe correspond aux PG de 1000spikes, recrutant de l’ordre de 120 neurones pour une fréquence d’environ 100Hz. On remarquequ’avec l’augmentation de p le nombre de PG diminue. La durée des PG, qui est principale-ment de 80ms pour p = 0, se reporte vers 10ms avec p. De la même manière la populationrecrutée, de 120 neurones pour p = 0, se reporte vers de petites tailles de population (∼ 10neurones) avec l’augmentation de p.
107

Durée Nombre de spikes Population Fréquence
p = 0
0
5000
10000
15000
20000
25000
0 20 40 60 80 100 120 140 160 0
5000
10000
15000
20000
25000
30000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 50 100 150 200
p = 0.1
0
2000
4000
6000
8000
10000
12000
0 20 40 60 80 100 120 140 160 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 200 400 600 800 1000 0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 100 200 300 400 500 600 0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 50 100 150 200
p = 0.15
0
1000
2000
3000
4000
5000
6000
0 20 40 60 80 100 120 140 160 0
2000
4000
6000
8000
10000
12000
14000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
0 50 100 150 200
p = 0.2
0
1000
2000
3000
4000
5000
6000
7000
0 20 40 60 80 100 120 140 160 0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
7000
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
7000
0 50 100 150 200
p = 0.25
0
1000
2000
3000
4000
5000
6000
7000
0 20 40 60 80 100 120 140 160 0
1000
2000
3000
4000
5000
6000
7000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
7000
8000
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
7000
0 50 100 150 200
p = 0.3
0
1000
2000
3000
4000
5000
6000
7000
0 20 40 60 80 100 120 140 160 0
1000
2000
3000
4000
5000
6000
7000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
7000
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
7000
0 50 100 150 200
p = 0.5
0
500
1000
1500
2000
2500
3000
3500
0 20 40 60 80 100 120 140 160 0
500
1000
1500
2000
2500
3000
0 200 400 600 800 1000 0
500
1000
1500
2000
2500
3000
0 100 200 300 400 500 600 0
500
1000
1500
2000
2500
3000
3500
0 50 100 150 200
FIGURE 10.8 – dtd = 0, d = 5ms
Les distributions pour p = 0.8 et p = 1 ne sont pas montrées car ne comportent pas suffisa-ment de neurones pour être visualisables.
108

10.2.2 Figure 10.10 - dtd = 10
Pour dtd = 10, nous retrouvons un comportement similaire à dtd = 0, les valeurs des duréestrouvées étant plus diversifiées. Néanmoins nous obtenons d’une part des groupes de petitetaille et de courte durée, et d’autre part des groupes plus longs avec une centaine de neuronesrecrutés et 1000 spikes émis. Nous remarquons trois pics entre 0ms et 20ms dans la distributiondes durées pour p = 0 à 0.3. Ces trois pics s’expliquent par l’homogénéité des délais. En effet,les groupes de courte durée, qui comportent également peu de spikes, tendent à se terminerplus probablement dans un même laps de temps. Pour p = 0 nous observons également unebulle dans la distribution des durées autour de 120ms.
Nous souhaitons comprendre, dans le cas précis de p = 0, quelle est la part de chacunde ces 4 pics dans les autres distributions. La figure 10.9 reprend donc les distributions de lafigures 10.10, pour p = 0. Nous avons réalisé un découpage de la distribution du nombre despikes, de la population et des fréquences en fonction de ces 3 pics entre 0 et 20ms et de la bulleautour de 120ms.
Nombre de spikes Population Fréquence
p = O
0
5000
10000
15000
20000
25000
30000
0 200 400 600 800 1000
Nom
bre
de P
G
Nombre de spikes des PG
PG with timespan>=0 and <=9PG with timespan>9 and <=15
PG with timespan>15 and <=20PG with timespan>=100 and <=150
0
5000
10000
15000
20000
25000
30000
0 100 200 300 400 500 600
Nom
bre
de P
G
Poulation recrutee par les PG
PG with timespan>=0 and <=9PG with timespan>9 and <=15
PG with timespan>15 and <=20PG with timespan>=100 and <=150
0
500
1000
1500
2000
2500
0 50 100 150 200
Nom
bre
de P
G
Frequence des PG
PG with timespan>=0 and <=9PG with timespan>9 and <=15
PG with timespan>15 and <=20PG with timespan>=100 and <=150
FIGURE 10.9 – dtd = 10, d = 5msp = 0 : Distribution du nombre de spikes (gauche), de la population recrutée (milieu) et de la fréquence(droite) des PG durant moins de 9ms spikes (noir), de 9ms à 15ms spikes (rouge), de 15ms à 20msspikes (vert), et de 100ms à 150ms spikes (bleu) – Pour la lisibilité, nous avons tracé l’enveloppe deshistogrammes (lignes de sommet à sommet)
Nous pouvons reconnaitre trois bandes de fréquences principales qui correspondent auxtrois pics et à la bulle de durée. Les fréquences entre 120Hz et 200Hz correspondent au pre-mier pic, les PG de durée 5ms à 9ms. Les fréquences entre 80Hz et 120Hz correspondent ausecond pic, les PG de durée 10ms à 15ms. Enfin les fréquences entre 60Hz et 80Hz corres-pondent au troisième pic, les PG de durée 15ms à 20ms. Les groupes durant autour de 120mset de population 100 neurones se trouvent dans cette même bande de fréquence.
Avec l’augmentation de la probabilité de recâblage, les PG de grande taille disparaissentpour ne laisser que des PG de petite taille.
109

Durée Nombre de spikes Population Fréquence
p = 0
0
200
400
600
800
1000
1200
1400
1600
0 20 40 60 80 100 120 140 160 0
5000
10000
15000
20000
25000
30000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
30000
0 100 200 300 400 500 600 0
500
1000
1500
2000
2500
0 50 100 150 200
p = 0.1
0
200
400
600
800
1000
1200
1400
0 20 40 60 80 100 120 140 160 0
5000
10000
15000
20000
25000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
0 100 200 300 400 500 600 0
200
400
600
800
1000
1200
1400
0 50 100 150 200
p = 0.15
0
200
400
600
800
1000
1200
0 20 40 60 80 100 120 140 160 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 100 200 300 400 500 600 0
200
400
600
800
1000
1200
0 50 100 150 200
p = 0.2
0
100
200
300
400
500
600
700
800
900
0 20 40 60 80 100 120 140 160 0
2000
4000
6000
8000
10000
12000
14000
16000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
16000
0 100 200 300 400 500 600 0
100
200
300
400
500
600
700
800
900
0 50 100 150 200
p = 0.25
0
100
200
300
400
500
600
700
0 20 40 60 80 100 120 140 160 0
2000
4000
6000
8000
10000
12000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
0 100 200 300 400 500 600 0
100
200
300
400
500
600
700
0 50 100 150 200
p = 0.3
0
100
200
300
400
500
600
0 20 40 60 80 100 120 140 160 0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 100 200 300 400 500 600 0
100
200
300
400
500
600
0 50 100 150 200
p = 0.5
0
20
40
60
80
100
120
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 200 400 600 800 1000 0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 100 200 300 400 500 600 0
20
40
60
80
100
120
0 50 100 150 200
p = 0.8
0
2
4
6
8
10
12
14
0 20 40 60 80 100 120 140 160 0
20
40
60
80
100
120
140
160
180
200
0 200 400 600 800 1000 0
20
40
60
80
100
120
140
160
180
200
0 100 200 300 400 500 600 0
2
4
6
8
10
12
14
0 50 100 150 200
p = 1
0
2
4
6
8
10
12
0 20 40 60 80 100 120 140 160 0
20
40
60
80
100
120
140
160
180
0 200 400 600 800 1000 0
20
40
60
80
100
120
140
160
180
0 100 200 300 400 500 600 0
2
4
6
8
10
12
0 50 100 150 200
FIGURE 10.10 – dtd = 10, d = 5ms
110

10.2.3 Figure 10.11 - dtd = 20
Nous pouvons faire les mêmes observations pour dtd = 20 que pour le cas précédent dtd =10, à la différence que les pics présents dans le cas précédent ont été gommés par l’étalementdes délais. En effet, l’augmentation de dtd implique que la durée des groupes polychrones estdiluée sur l’ensemble des valeurs de délais présentes dans le réseau.
111

Durée Nombre de spikes Population Fréquence
p = 0
0
100
200
300
400
500
600
700
0 20 40 60 80 100 120 140 160 0
5000
10000
15000
20000
25000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
30000
0 100 200 300 400 500 600 0
200
400
600
800
1000
1200
1400
1600
0 50 100 150 200
p = 0.1
0
100
200
300
400
500
600
0 20 40 60 80 100 120 140 160 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 100 200 300 400 500 600 0
100
200
300
400
500
600
700
800
0 50 100 150 200
p = 0.15
0
50
100
150
200
250
300
350
400
450
0 20 40 60 80 100 120 140 160 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 100 200 300 400 500 600 0
100
200
300
400
500
600
0 50 100 150 200
p = 0.2
0
50
100
150
200
250
300
350
0 20 40 60 80 100 120 140 160 0
2000
4000
6000
8000
10000
12000
14000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
0 100 200 300 400 500 600 0
50
100
150
200
250
300
350
400
450
0 50 100 150 200
p = 0.25
0
50
100
150
200
250
300
0 20 40 60 80 100 120 140 160 0
2000
4000
6000
8000
10000
12000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
0 100 200 300 400 500 600 0
50
100
150
200
250
300
0 50 100 150 200
p = 0.3
0
50
100
150
200
250
0 20 40 60 80 100 120 140 160 0
1000
2000
3000
4000
5000
6000
7000
8000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
7000
8000
0 100 200 300 400 500 600 0
50
100
150
200
250
0 50 100 150 200
p = 0.5
0
10
20
30
40
50
60
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 200 400 600 800 1000 0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 100 200 300 400 500 600 0
10
20
30
40
50
60
0 50 100 150 200
p = 0.8
0
1
2
3
4
5
6
0 20 40 60 80 100 120 140 160 0
20
40
60
80
100
120
140
0 200 400 600 800 1000 0
20
40
60
80
100
120
140
0 100 200 300 400 500 600 0
1
2
3
4
5
6
0 50 100 150 200
p = 1
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
0 20 40 60 80 100 120 140 160 0
10
20
30
40
50
60
70
80
90
0 200 400 600 800 1000 0
10
20
30
40
50
60
70
80
90
0 100 200 300 400 500 600 0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
0 50 100 150 200
FIGURE 10.11 – dtd = 20, d = 5ms
112

Un constat commun aux trois cas dtd ∈ {0, 10, 20} est que la population recrutée est sys-tématiquement faible. Moins d’une dixaine de neurones sont recrutés, à l’exception des casp ≤ 0.2 pour lesquels quelques groupes recrutent jusqu’à 125 neurones.
10.2.4 Synthèse : mesure d’entropie
Nous présentons sur la figure 10.12 la mesure de l’entropie correspondant aux quatre co-lonnes des pages précédentes, pour d = 5ms (figures 10.8, 10.10, 10.11).
Durée Nombre de spikes Population Fréquence
0
1
2
3
4
5
6
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of T
imes
pans
p
p/Entropy of Timespans for different dtd | d=50.0 and NbNeurons=600 and k=6 and (deltadelay=0 or deltadelay=10 or deltadelay=20)
dtd=0.0dtd=10.0dtd=20.0
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of N
umbe
rs o
f spi
kes
p
p/Entropy of Numbers of spikes for different dtd | d=50.0 and NbNeurons=600 and k=6 and (deltadelay=0 or deltadelay=10 or deltadelay=20)
dtd=0.0dtd=10.0dtd=20.0
0
0.5
1
1.5
2
2.5
3
3.5
4
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of P
opul
atio
ns
p
p/Entropy of Populations for different dtd | d=50.0 and NbNeurons=600 and k=6 and (deltadelay=0 or deltadelay=10 or deltadelay=20)
dtd=0.0dtd=10.0dtd=20.0
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of F
requ
enci
es
p
p/Entropy of Frequencies for different dtd | d=50.0 and NbNeurons=600 and k=6 and (deltadelay=0 or deltadelay=10 or deltadelay=20)
dtd=0.0dtd=10.0dtd=20.0
Entropy of Timespans/p for different dtd | d=50.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
dtd
0
1
2
3
4
5
6
Entropy of Numbers of spikes/p for different dtd | d=50.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
dtd
0
0.5
1
1.5
2
2.5
Entropy of Populations/p for different dtd | d=50.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
dtd
0
0.5
1
1.5
2
2.5
3
3.5
4
Entropy of Frequencies/p for different dtd | d=50.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
dtd
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
FIGURE 10.12 – Entropie de la durée (permière colonne), du nombre de spikes (deuxième colonne),de la population (troisième colonne), de la fréquence (quatrième colonne) des PG, pour d = 5ms,dtd ∈ 0, 10, 20, en fontion de p. Deuxième ligne : même mesure pour toutes les valeurs dtd ∈0, 10, 20, 50, 100, 150, 200, en trois dimensions afin d’en visualiser l’évolution. Attention : le dégradé estune extrapolation réalisée sur la base des valeurs expérimentales (intersections des lignes vertes).
On observe toujours le pic d’entropie autour et en dessous de p = 0.2, qui correspond auxtransitions de phase que nous avons observées. Celles-ci sont beaucoup moins flagrantes surles figures de distributions. Nous avons encadré les lignes des figures 10.8, 10.10, 10.11 pourlesquelles l’entropie atteint son maximum. Pour le cas présent (d = 5ms) comme pour le casprécédent (d = 1ms), nous constatons un pic de l’entropie lorsque l’écart-type des délais estfaible (≤ 5) et pour des valeurs de p autour de 0.2 ou en dessous. Nous revenons sur cettevaleur dans le paragraphe suivant.
10.3 Entropie en fonction de d
Nous présentons sur les figures suivantes 10.13, 10.14, 10.15 la même mesure d’entropie queprécédemment, toujours en fonction de p, mais pour des valeurs différentes de d sur chaquefigure au lieu de dtd. De façon générale nous observons que l’entropie est plus élevée pourdes délais faibles, avec un écart-type faible, et pour p autour de 0.2. Nous pensons que cettevaleur p = 0.2 s’explique par le fait que le propriétés petit-monde ne s’expriment qu’aprèsun certain nombre de recâblages. Dans les réseaux complexes on constate une diminution dudiamètre du réseau dès les premiers recâblages. Mais dans notre cas, cette diminution n’esteffective qu’après avoir recâblé suffisament de connexions pour permettre à l’activité de sepropager à une autre portion du réseau. En effet, un neurone a besoin de recevoir plusieursspikes pour déclencher à son tour. L’ajout d’une seule connexion entrante amenant un spiken’est généralement pas suffisante.
113

Durée Nombre de spikes Population Fréquence
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of T
imes
pans
p
p/Entropy of Timespans for different dtd | d=0.0 and NbNeurons=600 and k=6 and (delay=10 or delay=50 or delay=150)
dtd=10.0dtd=50.0
dtd=150.0
0
1
2
3
4
5
6
7
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of N
umbe
rs o
f spi
kes
p
p/Entropy of Numbers of spikes for different dtd | d=0.0 and NbNeurons=600 and k=6 and (delay=10 or delay=50 or delay=150)
dtd=10.0dtd=50.0
dtd=150.0
0
1
2
3
4
5
6
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of P
opul
atio
ns
p
p/Entropy of Populations for different dtd | d=0.0 and NbNeurons=600 and k=6 and (delay=10 or delay=50 or delay=150)
dtd=10.0dtd=50.0
dtd=150.0
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of F
requ
enci
es
p
p/Entropy of Frequencies for different dtd | d=0.0 and NbNeurons=600 and k=6 and (delay=10 or delay=50 or delay=150)
dtd=10.0dtd=50.0
dtd=150.0
Entropy of Timespans/p for different d | dtd=0.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
d
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
Entropy of Numbers of spikes/p for different d | dtd=0.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
d
0
1
2
3
4
5
6
7
Entropy of Populations/p for different d | dtd=0.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
d
0
1
2
3
4
5
6
Entropy of Frequencies/p for different d | dtd=0.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
d
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
FIGURE 10.13 – Entropie de la distribution des durées en ms (permière colonne), tailles en nombre despikes (deuxième colonne), populations recrutée (troisième colonne), fréquences neuronales moyennesdes PG (quatrième colonne), pour dtd = 0. Première ligne : entropie en fonction de p pour d ={10, 50, 150} ; Deuxième ligne : entropie en fonction p et d (toutes les valeurs). Attention : le dégradé estune extrapolation réalisée sur la base des valeurs expérimentales (intersections des lignes vertes).
Durée Nombre de spikes Population Fréquence
0
1
2
3
4
5
6
7
8
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of T
imes
pans
p
p/Entropy of Timespans for different dtd | d=10.0 and NbNeurons=600 and k=6 and (delay=10 or delay=50 or delay=150)
dtd=10.0dtd=50.0
dtd=150.0
0
1
2
3
4
5
6
7
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of N
umbe
rs o
f spi
kes
p
p/Entropy of Numbers of spikes for different dtd | d=10.0 and NbNeurons=600 and k=6 and (delay=10 or delay=50 or delay=150)
dtd=10.0dtd=50.0
dtd=150.0
0
1
2
3
4
5
6
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of P
opul
atio
ns
p
p/Entropy of Populations for different dtd | d=10.0 and NbNeurons=600 and k=6 and (delay=10 or delay=50 or delay=150)
dtd=10.0dtd=50.0
dtd=150.0
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of F
requ
enci
es
p
p/Entropy of Frequencies for different dtd | d=10.0 and NbNeurons=600 and k=6 and (delay=10 or delay=50 or delay=150)
dtd=10.0dtd=50.0
dtd=150.0
Entropy of Timespans/p for different d | dtd=10.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
d
1
2
3
4
5
6
7
8
Entropy of Numbers of spikes/p for different d | dtd=10.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
d
0
1
2
3
4
5
6
7
Entropy of Populations/p for different d | dtd=10.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
d
0
1
2
3
4
5
6
Entropy of Frequencies/p for different d | dtd=10.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
d
1
1.5
2
2.5
3
3.5
4
4.5
5
FIGURE 10.14 – Même figure que 10.13 pour dtd = 10
Durée Nombre de spikes Population Fréquence
0
1
2
3
4
5
6
7
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of T
imes
pans
p
p/Entropy of Timespans for different dtd | d=20.0 and NbNeurons=600 and k=6 and (delay=10 or delay=50 or delay=150)
dtd=10.0dtd=50.0
dtd=150.0
0
0.5
1
1.5
2
2.5
3
3.5
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of N
umbe
rs o
f spi
kes
p
p/Entropy of Numbers of spikes for different dtd | d=20.0 and NbNeurons=600 and k=6 and (delay=10 or delay=50 or delay=150)
dtd=10.0dtd=50.0
dtd=150.0
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of P
opul
atio
ns
p
p/Entropy of Populations for different dtd | d=20.0 and NbNeurons=600 and k=6 and (delay=10 or delay=50 or delay=150)
dtd=10.0dtd=50.0
dtd=150.0
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
0 0.2 0.4 0.6 0.8 1
Ent
ropy
of F
requ
enci
es
p
p/Entropy of Frequencies for different dtd | d=20.0 and NbNeurons=600 and k=6 and (delay=10 or delay=50 or delay=150)
dtd=10.0dtd=50.0
dtd=150.0
Entropy of Timespans/p for different d | dtd=20.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
d
3
3.5
4
4.5
5
5.5
6
6.5
Entropy of Numbers of spikes/p for different d | dtd=20.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
d
0
0.5
1
1.5
2
2.5
3
3.5
Entropy of Populations/p for different d | dtd=20.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
d
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
Entropy of Frequencies/p for different d | dtd=20.0 and NbNeurons=600 and k=6
0 0.2 0.4 0.6 0.8 1
p
0
50
100
150
200
d
1.5
2
2.5
3
3.5
4
4.5
5
FIGURE 10.15 – Même figure que 10.13 pour dtd = 20
114

p = 0.2 est équivalent au recâblage de 0.2∗n∗ (2∗k) nœuds, soit 0.2∗600∗2∗6 = 1440 dansnotre cas, pour 7200 connexions au total. Cela signifie en moyenne 1440/600 = 2.4 connexionsmodifiées par neurones, donc en moyenne 2.4/2 = 1.2 connexions ajoutée ou supprimée. Celafait sens sachant queNbSpikesNeeded vaut 2. Les conditions petit-monde, qui sont un compro-mis entre un grand nombre de PG et un diamètre faible, pourraient donc se trouver autour dep = 0.2 et dépendre notamment deNbSpikesNeeded, c’est-à-dire de l’excitabilité des neurones.La plasticité intrinsèque qui joue sur l’excitabilité du neurone pourrait-elle être un facteur demodulation de l’effet petit-monde ?
10.4 Conclusion partielle
Nous avons étudié les propriétés des PG en fonction de celles du réseau dans lequel nousles détectons. Le critère de premier ordre qui conditionne la richesse en PG est la densité duréseau en nombre de neurones et en nombre de connexions. Plus la connectivité est élevéeplus nous trouverons de PG, plus ils sont de grande taille, voir cycliques. Par ailleurs les délaiset leur distribution affectent le nombre de groupes polychrones, ainsi que leur taille et leurdurée. Des délais courts et regroupés en gaussienne autour d’une valeur sont les conditions lesplus favorables. En effet l’étalement des délais diminue la probabilité pour deux spikes émissimultanément d’arriver en coïncidence sur un même neurone. Ensuite, nous notons un effetdestructeur de l’aléa pour le nombre de groupes polychrones. La plus grande diversité, pourtoutes les propriétés des PG, s’observe généralement pour une probabilité de recâblage prochede p = 0.2, une valeur que nous pensons liée à l’excitabilité du neurone : NbSpikesNeededdans l’algorithme de détection des PG supportés, ou le seuil de déclenchement ϑ et la fuite dupotentiel de membrane τPSP dans le modèle de neurone impulsionnel.
115

11Discussion et Perspectives
Nous avons proposé un modèle d’apprentissage à deux échelles se basant sur un modèlede neurone artificiel d’inspiration biologique dont l’intérêt est de tenir compte des instantsd’émission des spikes.
Apport pour le Reservoir Computing
Le modèle d’apprentissage que nous proposons s’inscrit dans le courant du Reservoir Com-puting (RC), mais utilise des mécanismes nouveaux que nous justifions. L’efficacité des mo-dèles de RC pour l’apprentissage artificiel a été démontrée, notamment pour l’apprentissage etla prédiction de séquences. Notre objectif était plutôt de démontrer qu’un modèle de RC pou-vait aussi être pertinent pour la classification supervisée. L’innovation de notre modèle consisted’une part en l’utilisation de la notion de délai associée à la STDP au sein du réservoir pourenrichir la dynamique, et d’autre part en l’apprentissage supervisé des délais des connexionsde sortie. Cet algorithme d’apprentissage supervisé est nouveau mais néanmoins inspiré deprincipes reconnus en apprentissage artificiel.
Vers l’optimisation du réservoir
Nos expérimentations ont montré que notre modèle est pertinent et que l’apprentissageest effectif bien que perfectible. Nous pensons que l’apport des délais peut permettre un nou-veau type d’apprentissage du point de vue du RC. C’est pourquoi nous approfondissons notreétude des dynamiques du réservoir, dans l’optique de retrouver les briques de base de la repré-sentation de l’information, support de l’apprentissage. L’observation des groupes polychrones(PG) dans la dynamique du réservoir montre à quel point la plasticité synaptique joue un rôled’adaptation aux stimulations. La sensibilité des PG aux exemples d’apprentissage justifie leurintérêt pour le RC.
Etude des Groupes Polychrones dans les réseaux complexes
Les outils des réseaux complexes ne peuvent suffire à eux seuls à saisir l’essence du stockagede l’information. Les spécificités du fonctionnement des neurons sont un aspect essentiel dontnous ne pouvons rendre compte avec le seul point de vue des réseaux complexes. Nous étu-dions donc les propriétés des PG en fonction de celles du réseau dans lequel nous les recensons.Nous avons trouvé que le nombre de neurones et le nombre de connexions du réseau sont lesdeux paramètres les plus influents, en termes de PG. Nous remarquons aussi que la distribu-tion des délais est une caractéristique essentielle pour les groupes polychrones, leur taille etleur durée. Sans être tous égaux, les délais doivent être autour d’une valeur moyenne faible. Laprobabilité de recâblage p joue fortement sur le nombre de groupes polychrones. Notamment,plus le réseau est aléatoire, moins il y a de groupes polychrones. Enfin, observation intéres-sante, la plus grande diversité dans toutes les propriétés des PG se trouve généralement pourune probabilité de recâblage proche de p = 0.2, une valeur que nous pensons liée à l’excitabilité
116

du neurone.
Sur le rôle des délais
Sans nous prononcer sur l’utilisation effective des PG in vivo, nous affirmons que ces struc-tures topologico-dynamiques attestent d’une adaptation bas niveau qui peut au moins êtremise à profit pour l’apprentissage artificiel. Or pour avoir des groupes polychrones dans unréseau de neurones artificiels, il faut des délais axonaux. Bien que nous ne sachions pas encoreclairement le rôle que jouent les délais dans le cerveau, nous savons au moins, sur la base denos expérimentations, qu’ils sont susceptibles d’être une des clés de la dynamique neuronale.Les PG sont probablement un catalyseur des oscillations comme le montre Izhikevich, et doncdes synchronisations. Leur répartition peut, plus ou moins bien, favoriser la mémorisation, laformation de la trace mnésique au sein d’une population.
Vers l’implémentation de la mémoire à traces multiples
La polychronisation dans une population c’est la reconnaissance d’une expérience déjà vé-cue. Même si les PG ne portent pas d’information dans le timing précis de leurs spikes (ce quenous ne savons pas), au moins le fait qu’ils soient capables de faciliter la naissance des oscil-lations pourrait être un argument de poids. La polychronisation ouvrirait alors la porte à lasynchronisation avec d’autre populations de neurones.
Si le timing précis des spikes des PG joue un rôle, alors la reconnaissance locale d’unestimulation, sur la base de son motif temporel, peut être l’embryon des oscillations. Si cettereconnaissance fait écho à d’autres populations alors il peut y avoir synchronisation. Ainsi,pour revenir à la théorie de la mémoire à traces multiples, la reconnaissance locale d’un motif,qui se manifeste par la polychronisation, est la réactivation d’une trace. Cette trace se seraitformée dans le passé, sous le coup des mécanismes de plasticité. Sa réactivation la renforce etpeut renforcer les liens de synchronisation qu’elle aurait avec d’autres populations.
11.1 Perspectives
Liens avec les neurosciences et la dynamique
Tout d’abord, les liens que nous venons d’évoquer avec les neurosciences restent à confir-mer et à étudier de plus près. Le rôle facilitateur des PG dans les oscillations pourrait êtreétudié en modélisation. Nous avons confirmé l’hypothèse d’Izhikevich selon laquelle le rôle dela STDP est essentiel dans ce fonctionnement. Cependant un autre aspect bio-inspiré des PGn’a pas été discuté. Il s’agit de l’influence de la balance excitation/inhibition dans le réseau. Eneffet, dans notre étude exhaustive des PG, nous n’avons utilisé que des réseaux strictement ex-citateurs, mais il a déjà été montré que l’introduction d’inhibition dans un réseau de neuronesartificiels peut complètement bouleverser les dynamiques que ce réseau peut adopter.
Propriétés locales des réseaux complexes
De nombreux aspects restent à explorer. Par exemple, certaines propriétés locales des ré-seaux complexes (au niveau du nœud ou du lien) pourraient être influentes. Nous pensons
117

notamment à la centralité des liens et des neurones, ou au degré. Ainsi, les liens entre les neu-rones et les PG dans lesquels ils interviennent pourraient aussi dépendre de ces propriétés lo-cales. Cela pourrait nous permettre de comprendre en quoi l’architecture du réseau influe surles PG. Sur cette idée de lien entre PG et architecture, nous pourrions établir des communautésde PG sur la base des neurones qu’il ont en commun, à l’aide des algorithmes de recherche demodules. Nous n’avons également pas cherché les PG dans les réseaux invariants d’échelle, orc’est aussi une piste à suivre pour explorer la richesse d’un réseau en PG.
Liens entre PG et dynamique
Dans les chapitres 9 et 10, nous n’avons parlé que des PG supportés. L’observation des PGadaptés (i.e. en tenant compte des adaptations qui ont pu avoir lieu dans le réseau au fil desstimulations), et des PG activés (i.e. apparaissant effectivement dans l’activité du réseau sousl’effet d’un stimulus), ainsi que l’évolution des propriétés des PG avec l’apprentissage, est untravail conséquent qui reste à faire.
11.2 Conclusion
Le modèle d’apprentissage artificiel que nous avons proposé s’appuie sur des principes àla fois d’apprentissage artificiels et bio-inspirés. Il apparaît que l’étude des mécanismes biolo-giques, comme dans de nombreux exemples par le passé, nous permet d’apporter une richessesupplémentaire au modèle. Cette richesse demeure à explorer ainsi qu’à mieux comprendre,tant du point vue des aspects biologiques dont elle s’inspire, que du point de vue computa-tionnel pour l’optimisation des performances des réseaux de neurones impulsionnels.
La compréhension des mécanismes les plus profonds de la mémoire et leur modélisationdemanderont encore de nombreux travaux pour en avoir enfin une vision exacte, si cela estmême possible. Nous sommes convaincu du fait que, à terme, les découvertes que ces travauxont apportées et continueront à apporter nous permettrons de développer des méthodes d’ap-prentissage artificiel performantes et que nous saurons maîtriser.
118

Troisième partie
Annexes
119

ADistributions des PG
A.1 Distributions pour dtd = 10
Sur les quatre pages suivantes nous présentons les distributions vues précédemment, pourchaque propriété séparément, pour dtd = 10. Sur chaque page nous montrons l’évolution dela distribution en fonction de p (verticalement) et en fonction de d (horizontalement). Nousretrouvons l’effet destructeur de p lorsque l’aléa augmente. Idem pour d dont l’augmentationdiminue les chances de coïncidence de spikes, donc de propagation des spikes.
120
d = 10 d = 50 d = 100 d = 150
p = 0
0
200
400
600
800
1000
1200
1400
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
1400
1600
0 20 40 60 80 100 120 140 160 0
500
1000
1500
2000
2500
3000
0 20 40 60 80 100 120 140 160 0
500
1000
1500
2000
2500
3000
3500
0 20 40 60 80 100 120 140 160
p = 0.1
0
200
400
600
800
1000
1200
1400
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
1400
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
1400
1600
1800
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 20 40 60 80 100 120 140 160
p = 0.15
0
100
200
300
400
500
600
700
800
900
1000
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
1400
1600
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
1400
1600
0 20 40 60 80 100 120 140 160
p = 0.2
0
50
100
150
200
250
300
350
400
450
500
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
800
900
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
0 20 40 60 80 100 120 140 160
p = 0.25
0
100
200
300
400
500
600
700
800
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
800
900
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
800
900
0 20 40 60 80 100 120 140 160
p = 0.3
0
100
200
300
400
500
600
700
800
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
0 20 40 60 80 100 120 140 160
p = 0.5
0
20
40
60
80
100
120
140
0 20 40 60 80 100 120 140 160 0
20
40
60
80
100
120
0 20 40 60 80 100 120 140 160 0
20
40
60
80
100
120
0 20 40 60 80 100 120 140 160 0
20
40
60
80
100
120
0 20 40 60 80 100 120 140 160
p = 0.8
0
0.2
0.4
0.6
0.8
1
1.2
0 20 40 60 80 100 120 140 160 0
2
4
6
8
10
12
14
0 20 40 60 80 100 120 140 160 0
2
4
6
8
10
12
14
0 20 40 60 80 100 120 140 160 0
2
4
6
8
10
12
14
0 20 40 60 80 100 120 140 160
p = 1
0
0.5
1
1.5
2
2.5
0 20 40 60 80 100 120 140 160 0
2
4
6
8
10
12
0 20 40 60 80 100 120 140 160 0
2
4
6
8
10
12
0 20 40 60 80 100 120 140 160 0
2
4
6
8
10
12
0 20 40 60 80 100 120 140 160
FIGURE A.1 – Durées pour dtd = 10
121
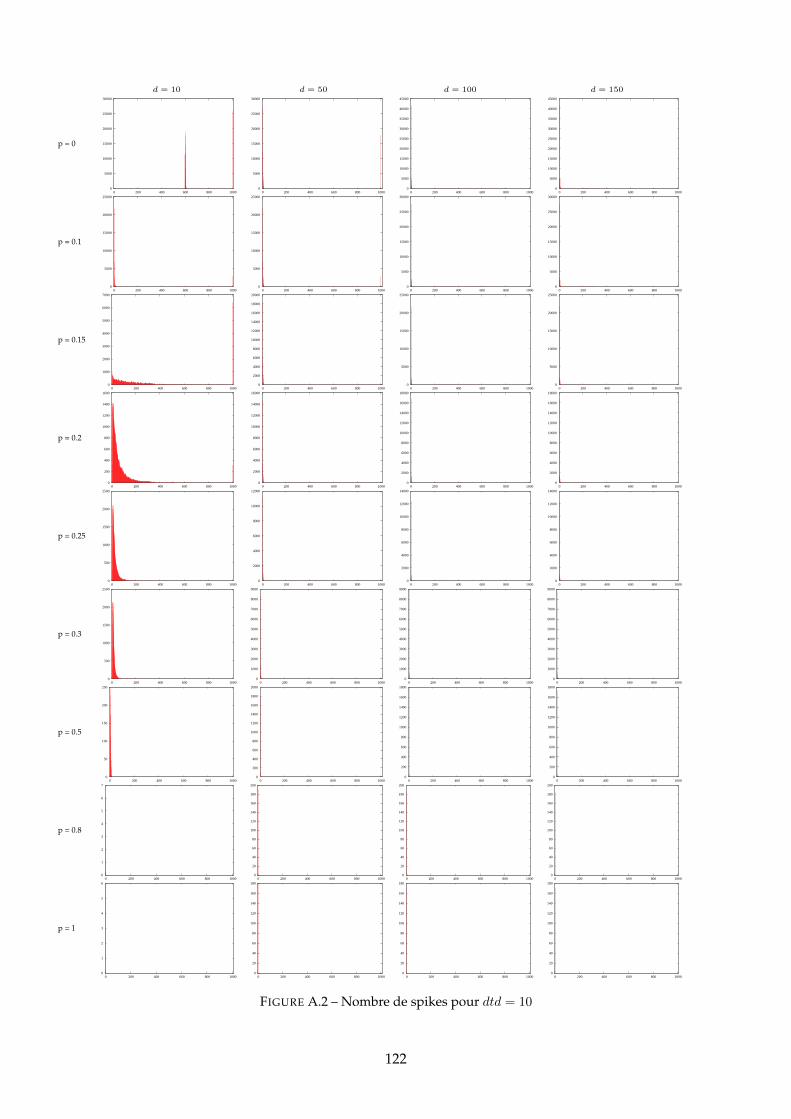
d = 10 d = 50 d = 100 d = 150
p = 0
0
5000
10000
15000
20000
25000
30000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
30000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
30000
35000
40000
45000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
30000
35000
40000
45000
0 200 400 600 800 1000
p = 0.1
0
5000
10000
15000
20000
25000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
30000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
30000
0 200 400 600 800 1000
p = 0.15
0
1000
2000
3000
4000
5000
6000
7000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
0 200 400 600 800 1000
p = 0.2
0
200
400
600
800
1000
1200
1400
1600
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
16000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 200 400 600 800 1000
p = 0.25
0
500
1000
1500
2000
2500
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
0 200 400 600 800 1000
p = 0.3
0
500
1000
1500
2000
2500
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 200 400 600 800 1000
p = 0.5
0
50
100
150
200
250
0 200 400 600 800 1000 0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 200 400 600 800 1000 0
200
400
600
800
1000
1200
1400
1600
1800
0 200 400 600 800 1000 0
200
400
600
800
1000
1200
1400
1600
1800
0 200 400 600 800 1000
p = 0.8
0
1
2
3
4
5
6
7
0 200 400 600 800 1000 0
20
40
60
80
100
120
140
160
180
200
0 200 400 600 800 1000 0
20
40
60
80
100
120
140
160
180
200
0 200 400 600 800 1000 0
20
40
60
80
100
120
140
160
180
200
0 200 400 600 800 1000
p = 1
0
1
2
3
4
5
6
0 200 400 600 800 1000 0
20
40
60
80
100
120
140
160
180
0 200 400 600 800 1000 0
20
40
60
80
100
120
140
160
180
0 200 400 600 800 1000 0
20
40
60
80
100
120
140
160
180
0 200 400 600 800 1000
FIGURE A.2 – Nombre de spikes pour dtd = 10
122

d = 10 d = 50 d = 100 d = 150
p = 0
0
10000
20000
30000
40000
50000
60000
70000
80000
90000
100000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
30000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
30000
35000
40000
45000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
30000
35000
40000
45000
0 100 200 300 400 500 600
p = 0.1
0
5000
10000
15000
20000
25000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
30000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
30000
0 100 200 300 400 500 600
p = 0.15
0
100
200
300
400
500
600
700
800
900
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
0 100 200 300 400 500 600
p = 0.2
0
200
400
600
800
1000
1200
1400
1600
1800
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
14000
16000
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 100 200 300 400 500 600
p = 0.25
0
500
1000
1500
2000
2500
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
14000
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
14000
0 100 200 300 400 500 600
p = 0.3
0
500
1000
1500
2000
2500
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 100 200 300 400 500 600
p = 0.5
0
50
100
150
200
250
0 100 200 300 400 500 600 0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 100 200 300 400 500 600 0
200
400
600
800
1000
1200
1400
1600
1800
0 100 200 300 400 500 600 0
200
400
600
800
1000
1200
1400
1600
1800
0 100 200 300 400 500 600
p = 0.8
0
1
2
3
4
5
6
7
0 100 200 300 400 500 600 0
20
40
60
80
100
120
140
160
180
200
0 100 200 300 400 500 600 0
20
40
60
80
100
120
140
160
180
200
0 100 200 300 400 500 600 0
20
40
60
80
100
120
140
160
180
200
0 100 200 300 400 500 600
p = 1
0
1
2
3
4
5
6
0 100 200 300 400 500 600 0
20
40
60
80
100
120
140
160
180
0 100 200 300 400 500 600 0
20
40
60
80
100
120
140
160
180
0 100 200 300 400 500 600 0
20
40
60
80
100
120
140
160
180
0 100 200 300 400 500 600
FIGURE A.3 – Population recrutée pour dtd = 10
123

d = 10 d = 50 d = 100 d = 150
p = 0
0
10000
20000
30000
40000
50000
60000
70000
80000
90000
0 50 100 150 200 0
500
1000
1500
2000
2500
0 50 100 150 200 0
1000
2000
3000
4000
5000
6000
0 50 100 150 200 0
1000
2000
3000
4000
5000
6000
7000
8000
0 50 100 150 200
p = 0.1
0
200
400
600
800
1000
1200
1400
0 50 100 150 200 0
200
400
600
800
1000
1200
1400
0 50 100 150 200 0
500
1000
1500
2000
2500
3000
3500
0 50 100 150 200 0
1000
2000
3000
4000
5000
6000
0 50 100 150 200
p = 0.15
0
500
1000
1500
2000
2500
0 50 100 150 200 0
200
400
600
800
1000
1200
0 50 100 150 200 0
500
1000
1500
2000
2500
3000
0 50 100 150 200 0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 50 100 150 200
p = 0.2
0
100
200
300
400
500
600
700
800
0 50 100 150 200 0
100
200
300
400
500
600
700
800
900
0 50 100 150 200 0
500
1000
1500
2000
2500
0 50 100 150 200 0
500
1000
1500
2000
2500
3000
3500
0 50 100 150 200
p = 0.25
0
100
200
300
400
500
600
700
800
0 50 100 150 200 0
100
200
300
400
500
600
700
0 50 100 150 200 0
200
400
600
800
1000
1200
1400
1600
1800
0 50 100 150 200 0
500
1000
1500
2000
2500
0 50 100 150 200
p = 0.3
0
100
200
300
400
500
600
700
800
0 50 100 150 200 0
100
200
300
400
500
600
0 50 100 150 200 0
200
400
600
800
1000
1200
0 50 100 150 200 0
200
400
600
800
1000
1200
1400
1600
1800
0 50 100 150 200
p = 0.5
0
20
40
60
80
100
120
140
0 50 100 150 200 0
20
40
60
80
100
120
0 50 100 150 200 0
50
100
150
200
250
0 50 100 150 200 0
50
100
150
200
250
300
350
0 50 100 150 200
p = 0.8
0
0.2
0.4
0.6
0.8
1
1.2
0 50 100 150 200 0
2
4
6
8
10
12
14
0 50 100 150 200 0
5
10
15
20
25
0 50 100 150 200 0
5
10
15
20
25
30
35
0 50 100 150 200
p = 1
0
0.5
1
1.5
2
2.5
0 50 100 150 200 0
2
4
6
8
10
12
0 50 100 150 200 0
5
10
15
20
25
0 50 100 150 200 0
5
10
15
20
25
30
0 50 100 150 200
FIGURE A.4 – Fréquences pour dtd = 10
124

A.2 Distributions pour d = 10
Sur les quatre pages suivantes nous présentons les distributions vues précédemment, pourchaque propriété séparément, pour d = 10. Sur chaque page nous montrons l’évolution dela distribution en fonction de p (verticalement) et en fonction de dtd (horizontalement). Nousretrouvons l’effet destructeur de p lorsque l’aléa augmente. Idem pour dtd dont l’augmentationdiminue les chances de coïncidence de spikes, donc de propagation des spikes.
125

dtd = 0 dtd = 5 dtd = 10 dtd = 20
p = 0
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 20 40 60 80 100 120 140 160 0
1000
2000
3000
4000
5000
6000
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
1400
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
1400
0 20 40 60 80 100 120 140 160
p = 0.1
0
2000
4000
6000
8000
10000
12000
14000
0 20 40 60 80 100 120 140 160 0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 20 40 60 80 100 120 140 160 0
2000
4000
6000
8000
10000
12000
0 20 40 60 80 100 120 140 160 0
50
100
150
200
250
300
350
400
450
500
0 20 40 60 80 100 120 140 160
p = 0.15
0
2000
4000
6000
8000
10000
12000
0 20 40 60 80 100 120 140 160 0
2000
4000
6000
8000
10000
12000
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
800
900
1000
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
0 20 40 60 80 100 120 140 160
p = 0.2
0
500
1000
1500
2000
2500
3000
0 20 40 60 80 100 120 140 160 0
50
100
150
200
250
300
0 20 40 60 80 100 120 140 160 0
50
100
150
200
250
300
350
400
450
500
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
800
900
1000
0 20 40 60 80 100 120 140 160
p = 0.25
0
500
1000
1500
2000
2500
3000
3500
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
800
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
800
0 20 40 60 80 100 120 140 160
p = 0.3
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
800
900
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
800
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
0 20 40 60 80 100 120 140 160
p = 0.5
0
50
100
150
200
250
300
350
0 20 40 60 80 100 120 140 160 0
10
20
30
40
50
60
70
80
90
100
0 20 40 60 80 100 120 140 160 0
20
40
60
80
100
120
140
0 20 40 60 80 100 120 140 160 0
20
40
60
80
100
120
140
160
180
200
0 20 40 60 80 100 120 140 160
p = 0.8
0
0.2
0.4
0.6
0.8
1
1.2
0 20 40 60 80 100 120 140 160 0
2
4
6
8
10
12
0 20 40 60 80 100 120 140 160
p = 1
0
0.5
1
1.5
2
2.5
0 20 40 60 80 100 120 140 160 0
1
2
3
4
5
6
7
8
0 20 40 60 80 100 120 140 160
FIGURE A.5 – Durées pour d = 10
126
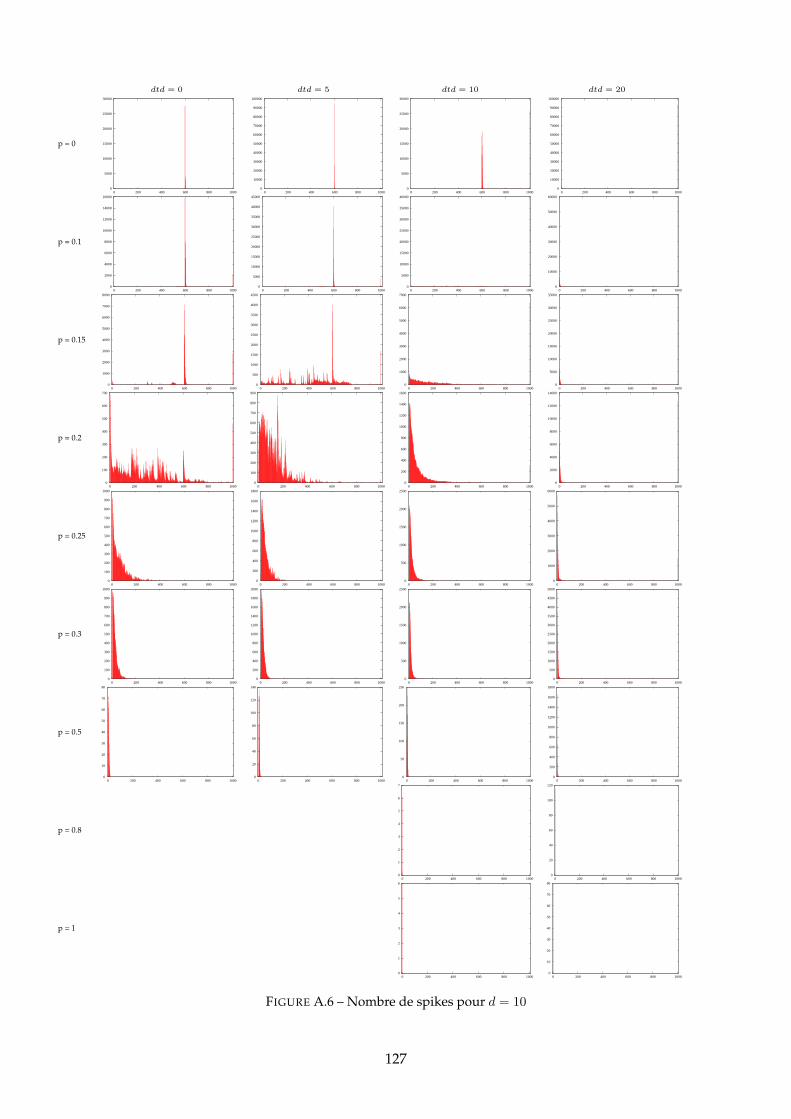
dtd = 0 dtd = 5 dtd = 10 dtd = 20
p = 0
0
5000
10000
15000
20000
25000
30000
0 200 400 600 800 1000 0
10000
20000
30000
40000
50000
60000
70000
80000
90000
100000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
30000
0 200 400 600 800 1000 0
10000
20000
30000
40000
50000
60000
70000
80000
90000
100000
0 200 400 600 800 1000
p = 0.1
0
2000
4000
6000
8000
10000
12000
14000
16000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
30000
35000
40000
45000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
30000
35000
40000
0 200 400 600 800 1000 0
10000
20000
30000
40000
50000
60000
0 200 400 600 800 1000
p = 0.15
0
1000
2000
3000
4000
5000
6000
7000
8000
0 200 400 600 800 1000 0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
7000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
30000
35000
0 200 400 600 800 1000
p = 0.2
0
100
200
300
400
500
600
700
0 200 400 600 800 1000 0
100
200
300
400
500
600
700
800
900
0 200 400 600 800 1000 0
200
400
600
800
1000
1200
1400
1600
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
0 200 400 600 800 1000
p = 0.25
0
100
200
300
400
500
600
700
800
900
1000
0 200 400 600 800 1000 0
200
400
600
800
1000
1200
1400
1600
1800
0 200 400 600 800 1000 0
500
1000
1500
2000
2500
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
0 200 400 600 800 1000
p = 0.3
0
100
200
300
400
500
600
700
800
900
1000
0 200 400 600 800 1000 0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 200 400 600 800 1000 0
500
1000
1500
2000
2500
0 200 400 600 800 1000 0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 200 400 600 800 1000
p = 0.5
0
10
20
30
40
50
60
70
80
0 200 400 600 800 1000 0
20
40
60
80
100
120
140
0 200 400 600 800 1000 0
50
100
150
200
250
0 200 400 600 800 1000 0
200
400
600
800
1000
1200
1400
1600
1800
0 200 400 600 800 1000
p = 0.8
0
1
2
3
4
5
6
7
0 200 400 600 800 1000 0
20
40
60
80
100
120
0 200 400 600 800 1000
p = 1
0
1
2
3
4
5
6
0 200 400 600 800 1000 0
10
20
30
40
50
60
70
80
0 200 400 600 800 1000
FIGURE A.6 – Nombre de spikes pour d = 10
127

dtd = 0 dtd = 5 dtd = 10 dtd = 20
p = 0
0
5000
10000
15000
20000
25000
30000
35000
40000
0 100 200 300 400 500 600 0
20000
40000
60000
80000
100000
120000
140000
0 100 200 300 400 500 600 0
10000
20000
30000
40000
50000
60000
70000
80000
90000
100000
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
0 100 200 300 400 500 600
p = 0.1
0
10000
20000
30000
40000
50000
60000
0 100 200 300 400 500 600 0
20000
40000
60000
80000
100000
120000
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
7000
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
0 100 200 300 400 500 600
p = 0.15
0
5000
10000
15000
20000
25000
30000
35000
40000
45000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
30000
35000
0 100 200 300 400 500 600 0
100
200
300
400
500
600
700
800
900
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
7000
0 100 200 300 400 500 600
p = 0.2
0
500
1000
1500
2000
2500
3000
0 100 200 300 400 500 600 0
200
400
600
800
1000
1200
1400
1600
0 100 200 300 400 500 600 0
200
400
600
800
1000
1200
1400
1600
1800
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
7000
0 100 200 300 400 500 600
p = 0.25
0
100
200
300
400
500
600
700
800
900
1000
0 100 200 300 400 500 600 0
200
400
600
800
1000
1200
1400
1600
1800
0 100 200 300 400 500 600 0
500
1000
1500
2000
2500
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
0 100 200 300 400 500 600
p = 0.3
0
200
400
600
800
1000
1200
0 100 200 300 400 500 600 0
500
1000
1500
2000
2500
0 100 200 300 400 500 600 0
500
1000
1500
2000
2500
0 100 200 300 400 500 600 0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 100 200 300 400 500 600
p = 0.5
0
10
20
30
40
50
60
70
80
0 100 200 300 400 500 600 0
20
40
60
80
100
120
140
0 100 200 300 400 500 600 0
50
100
150
200
250
0 100 200 300 400 500 600 0
200
400
600
800
1000
1200
1400
1600
1800
0 100 200 300 400 500 600
p = 0.8
0
1
2
3
4
5
6
7
0 100 200 300 400 500 600 0
20
40
60
80
100
120
0 100 200 300 400 500 600
p = 1
0
1
2
3
4
5
6
0 100 200 300 400 500 600 0
10
20
30
40
50
60
70
80
0 100 200 300 400 500 600
FIGURE A.7 – Population recrutée pour d = 10
128
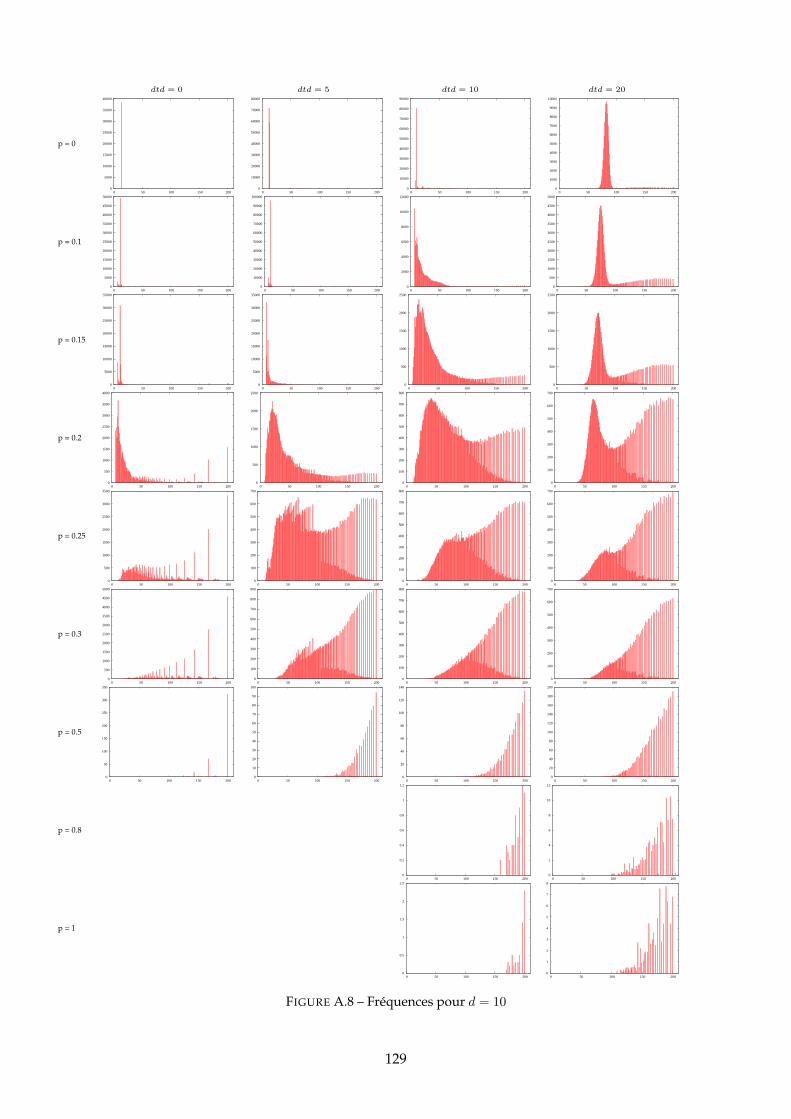
dtd = 0 dtd = 5 dtd = 10 dtd = 20
p = 0
0
5000
10000
15000
20000
25000
30000
35000
40000
0 50 100 150 200 0
10000
20000
30000
40000
50000
60000
70000
80000
0 50 100 150 200 0
10000
20000
30000
40000
50000
60000
70000
80000
90000
0 50 100 150 200 0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
0 50 100 150 200
p = 0.1
0
5000
10000
15000
20000
25000
30000
35000
40000
45000
50000
0 50 100 150 200 0
10000
20000
30000
40000
50000
60000
70000
80000
90000
100000
0 50 100 150 200 0
2000
4000
6000
8000
10000
12000
0 50 100 150 200 0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 50 100 150 200
p = 0.15
0
5000
10000
15000
20000
25000
30000
35000
0 50 100 150 200 0
5000
10000
15000
20000
25000
30000
35000
0 50 100 150 200 0
500
1000
1500
2000
2500
0 50 100 150 200 0
500
1000
1500
2000
2500
0 50 100 150 200
p = 0.2
0
500
1000
1500
2000
2500
3000
3500
4000
0 50 100 150 200 0
500
1000
1500
2000
2500
0 50 100 150 200 0
100
200
300
400
500
600
700
800
0 50 100 150 200 0
100
200
300
400
500
600
700
0 50 100 150 200
p = 0.25
0
500
1000
1500
2000
2500
3000
3500
0 50 100 150 200 0
100
200
300
400
500
600
700
0 50 100 150 200 0
100
200
300
400
500
600
700
800
0 50 100 150 200 0
100
200
300
400
500
600
700
0 50 100 150 200
p = 0.3
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 50 100 150 200 0
100
200
300
400
500
600
700
800
900
0 50 100 150 200 0
100
200
300
400
500
600
700
800
0 50 100 150 200 0
100
200
300
400
500
600
700
0 50 100 150 200
p = 0.5
0
50
100
150
200
250
300
350
0 50 100 150 200 0
10
20
30
40
50
60
70
80
90
100
0 50 100 150 200 0
20
40
60
80
100
120
140
0 50 100 150 200 0
20
40
60
80
100
120
140
160
180
200
0 50 100 150 200
p = 0.8
0
0.2
0.4
0.6
0.8
1
1.2
0 50 100 150 200 0
2
4
6
8
10
12
0 50 100 150 200
p = 1
0
0.5
1
1.5
2
2.5
0 50 100 150 200 0
1
2
3
4
5
6
7
8
0 50 100 150 200
FIGURE A.8 – Fréquences pour d = 10
129

A.3 Distributions pour d = 50
Sur les quatre pages suivantes nous présentons les distributions vues précédemment, pourchaque propriété séparément, pour d = 50. Sur chaque page nous montrons l’évolution de ladistribution en fonction de p (verticalement) et en fonction de dtd (horizontalement).
130

dtd = 0 dtd = 5 dtd = 10 dtd = 20
p = 0
0
5000
10000
15000
20000
25000
0 20 40 60 80 100 120 140 160 0
500
1000
1500
2000
2500
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
1400
1600
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
0 20 40 60 80 100 120 140 160
p = 0.1
0
2000
4000
6000
8000
10000
12000
0 20 40 60 80 100 120 140 160 0
500
1000
1500
2000
2500
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
1400
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
0 20 40 60 80 100 120 140 160
p = 0.15
0
1000
2000
3000
4000
5000
6000
0 20 40 60 80 100 120 140 160 0
500
1000
1500
2000
2500
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
0 20 40 60 80 100 120 140 160 0
50
100
150
200
250
300
350
400
450
0 20 40 60 80 100 120 140 160
p = 0.2
0
1000
2000
3000
4000
5000
6000
7000
0 20 40 60 80 100 120 140 160 0
500
1000
1500
2000
2500
3000
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
800
900
0 20 40 60 80 100 120 140 160 0
50
100
150
200
250
300
350
0 20 40 60 80 100 120 140 160
p = 0.25
0
1000
2000
3000
4000
5000
6000
7000
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
700
0 20 40 60 80 100 120 140 160 0
50
100
150
200
250
300
0 20 40 60 80 100 120 140 160
p = 0.3
0
1000
2000
3000
4000
5000
6000
7000
0 20 40 60 80 100 120 140 160 0
200
400
600
800
1000
1200
1400
1600
0 20 40 60 80 100 120 140 160 0
100
200
300
400
500
600
0 20 40 60 80 100 120 140 160 0
50
100
150
200
250
0 20 40 60 80 100 120 140 160
p = 0.5
0
500
1000
1500
2000
2500
3000
3500
0 20 40 60 80 100 120 140 160 0
50
100
150
200
250
300
350
400
450
0 20 40 60 80 100 120 140 160 0
20
40
60
80
100
120
0 20 40 60 80 100 120 140 160 0
10
20
30
40
50
60
0 20 40 60 80 100 120 140 160
p = 0.8
0
2
4
6
8
10
12
14
0 20 40 60 80 100 120 140 160 0
1
2
3
4
5
6
0 20 40 60 80 100 120 140 160
p = 1
0
2
4
6
8
10
12
0 20 40 60 80 100 120 140 160 0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
0 20 40 60 80 100 120 140 160
FIGURE A.9 – Durées pour d = 50
131

dtd = 0 dtd = 5 dtd = 10 dtd = 20
p = 0
0
5000
10000
15000
20000
25000
30000
0 200 400 600 800 1000 0
10000
20000
30000
40000
50000
60000
70000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
30000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
0 200 400 600 800 1000
p = 0.1
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
30000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 200 400 600 800 1000
p = 0.15
0
2000
4000
6000
8000
10000
12000
14000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 200 400 600 800 1000
p = 0.2
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 200 400 600 800 1000 0
5000
10000
15000
20000
25000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
16000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
0 200 400 600 800 1000
p = 0.25
0
1000
2000
3000
4000
5000
6000
7000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
0 200 400 600 800 1000
p = 0.3
0
1000
2000
3000
4000
5000
6000
7000
0 200 400 600 800 1000 0
2000
4000
6000
8000
10000
12000
14000
16000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 200 400 600 800 1000 0
1000
2000
3000
4000
5000
6000
7000
8000
0 200 400 600 800 1000
p = 0.5
0
500
1000
1500
2000
2500
3000
0 200 400 600 800 1000 0
500
1000
1500
2000
2500
3000
3500
4000
0 200 400 600 800 1000 0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 200 400 600 800 1000 0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 200 400 600 800 1000
p = 0.8
0
20
40
60
80
100
120
140
160
180
200
0 200 400 600 800 1000 0
20
40
60
80
100
120
140
0 200 400 600 800 1000
p = 1
0
20
40
60
80
100
120
140
160
180
0 200 400 600 800 1000 0
10
20
30
40
50
60
70
80
90
0 200 400 600 800 1000
FIGURE A.10 – Nombre de spikes pour d = 50
132

dtd = 0 dtd = 5 dtd = 10 dtd = 20
p = 0
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
30000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
30000
0 100 200 300 400 500 600
p = 0.1
0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
30000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 100 200 300 400 500 600
p = 0.15
0
1000
2000
3000
4000
5000
6000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 100 200 300 400 500 600
p = 0.2
0
1000
2000
3000
4000
5000
6000
7000
0 100 200 300 400 500 600 0
5000
10000
15000
20000
25000
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
14000
16000
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
14000
0 100 200 300 400 500 600
p = 0.25
0
1000
2000
3000
4000
5000
6000
7000
8000
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
0 100 200 300 400 500 600
p = 0.3
0
1000
2000
3000
4000
5000
6000
7000
0 100 200 300 400 500 600 0
2000
4000
6000
8000
10000
12000
14000
16000
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 100 200 300 400 500 600 0
1000
2000
3000
4000
5000
6000
7000
8000
0 100 200 300 400 500 600
p = 0.5
0
500
1000
1500
2000
2500
3000
0 100 200 300 400 500 600 0
500
1000
1500
2000
2500
3000
3500
4000
0 100 200 300 400 500 600 0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 100 200 300 400 500 600 0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 100 200 300 400 500 600
p = 0.8
0
20
40
60
80
100
120
140
160
180
200
0 100 200 300 400 500 600 0
20
40
60
80
100
120
140
0 100 200 300 400 500 600
p = 1
0
20
40
60
80
100
120
140
160
180
0 100 200 300 400 500 600 0
10
20
30
40
50
60
70
80
90
0 100 200 300 400 500 600
FIGURE A.11 – Population recrutée pour d = 50
133
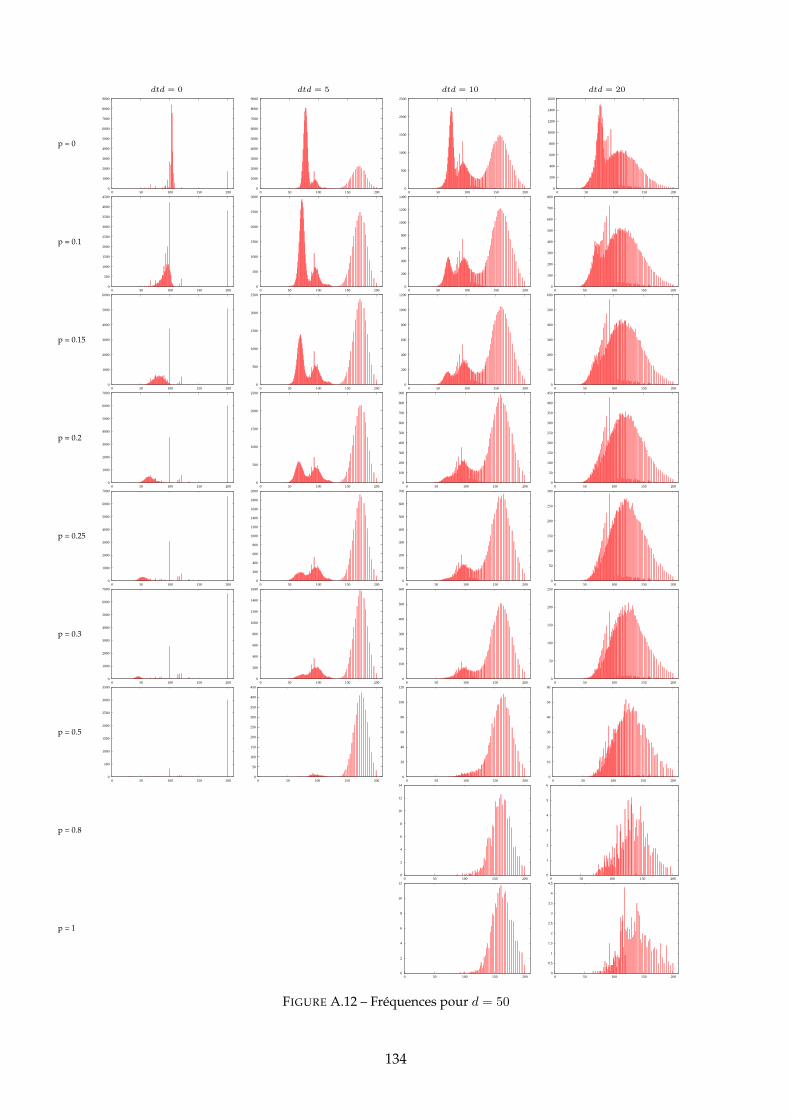
dtd = 0 dtd = 5 dtd = 10 dtd = 20
p = 0
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 50 100 150 200 0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 50 100 150 200 0
500
1000
1500
2000
2500
0 50 100 150 200 0
200
400
600
800
1000
1200
1400
1600
0 50 100 150 200
p = 0.1
0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 50 100 150 200 0
500
1000
1500
2000
2500
3000
0 50 100 150 200 0
200
400
600
800
1000
1200
1400
0 50 100 150 200 0
100
200
300
400
500
600
700
800
0 50 100 150 200
p = 0.15
0
1000
2000
3000
4000
5000
6000
0 50 100 150 200 0
500
1000
1500
2000
2500
0 50 100 150 200 0
200
400
600
800
1000
1200
0 50 100 150 200 0
100
200
300
400
500
600
0 50 100 150 200
p = 0.2
0
1000
2000
3000
4000
5000
6000
7000
0 50 100 150 200 0
500
1000
1500
2000
2500
0 50 100 150 200 0
100
200
300
400
500
600
700
800
900
0 50 100 150 200 0
50
100
150
200
250
300
350
400
450
0 50 100 150 200
p = 0.25
0
1000
2000
3000
4000
5000
6000
7000
0 50 100 150 200 0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 50 100 150 200 0
100
200
300
400
500
600
700
0 50 100 150 200 0
50
100
150
200
250
300
0 50 100 150 200
p = 0.3
0
1000
2000
3000
4000
5000
6000
7000
0 50 100 150 200 0
200
400
600
800
1000
1200
1400
1600
0 50 100 150 200 0
100
200
300
400
500
600
0 50 100 150 200 0
50
100
150
200
250
0 50 100 150 200
p = 0.5
0
500
1000
1500
2000
2500
3000
3500
0 50 100 150 200 0
50
100
150
200
250
300
350
400
450
0 50 100 150 200 0
20
40
60
80
100
120
0 50 100 150 200 0
10
20
30
40
50
60
0 50 100 150 200
p = 0.8
0
2
4
6
8
10
12
14
0 50 100 150 200 0
1
2
3
4
5
6
0 50 100 150 200
p = 1
0
2
4
6
8
10
12
0 50 100 150 200 0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
0 50 100 150 200
FIGURE A.12 – Fréquences pour d = 50
134

Bibliographie
Abeles, M. (1982). Role of cortical neuron : Integrator or coincidence detector ? Israel Journal ofMedical Sciences, 18(1), 83–92. 3.1, 3.2.1
Abeles, M. (1991). Corticonics : Neural circuits of the cerebral cortex. New York : CambridgeUniversity Press. 3.2.3
Ackley, D. H., Hinton, G. E., & Sejnowski, T. J. (1985). A learning algorithm for boltzmann ma-chines. Cognitive Science, 9(1), 147 – 169.URL http://www.sciencedirect.com/science/article/B6W48-4DXC45K-R/2/
9dd70cd8af63b2156a22866fb1172803 2.2
Albert, R., & Barabasi, A.-L. (2002). Statistical mechanics of complex networks. Reviews ofModern Physics, 74, 47–97. 5.2, 9.1.2
Albert, R., Jeong, H., & Barabasi, A.-L. (2000). Error and attack tolerance of complex networks.Nature, 406, 378.URL http://www.citebase.org/abstract?id=oai:arXiv.org:cond-mat/
0008064 5.4.1
Amaral, L. A. N., & Ottino, J. M. (2004). Complex networks. The European Physical Journal B, 38,147–162. 5.1, 5.1.1, 5.2, 5.3.3, 5.3.4, 5.4.1
Amaral, L. A. N., Scala, A., Barthélémy, M., & Stanley, H. E. (2000). Classes of small-worldnetworks. PNAS - Proc. Natl. Acad. Sci. U. S. A., 97, 11149–11152. 5.5
Atiya, A. F., & Parlos, A. G. (2000). New results on recurrent network training : Unifying the al-gorithms and accelerating convergence. IEEE Transactions on Neural Networks, 11(3), 697–709.URL http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.21.3096
4.3.2
Barabasi, A.-L., & Albert, R. (1999). Emergence of scaling in random networks. Science, 286,509–512. 5.3.4, 5.3.4, 5.5
Barahona, M., & Pecora, L. M. (2002). Synchronization in small-world systems. Phys. Rev. Lett.,89(5), 054101. 3.2.1, 5.4.1
Barber, M. J. (2008). Modularity and community detection in bipartite networks. Physical ReviewE, 76, 6102.URL http://link.aps.org/doi/10.1103/PhysRevE.76.066102 5.2.5, 9.1.2
Bi, G.-Q., & Poo, M.-M. (1998). Synaptic modifications in cultured hippocampal neurons : De-pendence on spike timing, synaptic strength, and postsynaptic cell type. Journal of Neuros-cience, 12(24), 10464–10472. 3.2.1
Bower, J. M., & Beeman, D. (1998). The book of GENESIS - exploring realistic neural models with theGEneral NEural SImulation System (2. ed.). 6.5.1
135

Brette, R., Rudolph, M., Carnevale, T., Hines, M., Beeman, D., Bower, J., Diesmann, M., Mor-rison, A., Goodman, P., Harris, F., Zirpe, M., Natschläger, T., Pecevski, D., Ermentrout, B.,Djurfeldt, M., Lansner, A., Rochel, O., Vieville, T., Muller, E., Davison, A., Boustani, S. E., &Destexhe, A. (2007). Simulation of networks of spiking neurons : A review of tools and stra-tegies. Journal of Computational Neuroscience, 23, 349–398. 10.1007/s10827-007-0038-6.URL http://dx.doi.org/10.1007/s10827-007-0038-6 6.5.1
Brunel, N. (2000). Dynamics of sparsely connected networks of excitatory and inhibitory spi-king neurons. Journal of Computational Neuroscience, 8(3), 183–208. 3.2.1
Brunel, N., & van Rossum, M. C. W. (2007). Quantitative investigations of electrical nerveexcitation treated as polarization : Louis lapicque - translated. Biological Cybernetics, 97(5),341–349. 2
Bullmore, E., Barnes, A., Bassett, D. S., Fornito, A., Kitzbichler, M., Meunier, D., & Suckling, J.(2009). Generic aspects of complexity in brain imaging data and other biological systems.NeuroImage, 47(3), 1125 – 1134. Brain Body Medicine.URL http://www.sciencedirect.com/science/article/B6WNP-4WB3NBY-1/2/
b8aea31df293c062c1625eb8d132e31c 5.5
Cessac, B., Paugam-Moisy, H., & Viéville, T. (2009). Overview of facts and issues about neuralcoding by spikes. Journal of Physiology. 3.1.2
Clauset, A., Newman, M. E. J., & Moore, C. (2004). Finding community structure in very largenetworks. Physical Review E, 70, 066111.URL http://arxiv.org/abs/cond-mat/0408187v2 5.2.5
Crook, S. M., Ermentrout, G. B., & Bower, J. M. (1998). Spike frequency adaptation affects thesynchronization properties of networks of cortical oscillators. Neural Computation, 10, 837–854. 3.1.2
Danon, L., Diaz-Guilera, A., Duch, J., & Arenas, A. (2005). Comparing community structureidentification. Journal of Statistical Mechanics : Theory and Experiment, 9, P09008. 5.2.5
de Solla Price, D. (1976). A general theory of bibliometric and other cumulative advantageprocesses. Journal of the American Society for Information Science, 27, 292. 5.3.4, 5.3.4
de Solla Price, D. J. (1965). Networks of scientific papers. Science, 149(3683), 510–515. 5.3.4
Delorme, A., Gautrais, J., Rullen, R. V., & Thorpe, S. (1999). Spikenet : a simulator for modelinglarge networks of integrate and fire neurons. Neurocomputing, 26, 26–27. 6.5.1
Diesmann, M., & oliver Gewaltig, M. (2002). Nest : An environment for neural systems simula-tions. In In T. Plesser and V. Macho (Eds.), Forschung und wisschenschaftliches Rechnen, Beitragezum Heinz-Billing-Preis 2001, Volume 58 of GWDG-Bericht, (pp. 43–70). 6.5.1
Edelman, G. M. (1987). Neural Darwinism : the theory of neuronal group selection. Basic Books.URL http://books.google.com/books?id=G6j3tgAACAAJ 1
Eguiluz, V. M., Chialvo, D. R., Cecchi, G. A., Baliki, M., & Apkarian, A. V. (2005). Scale-freebrain functional networks. Physical Review Letters, 94, 018102. 5.5
Elman, J. L. (1990). Finding structure in time. Cognitive Science, 14(2), 179–211. 2.1, 2.2
136

Erdos, P., & Rényi, A. (1959). On random graphs, i. Publicationes Mathematicae, 6, 290–297. 5.3.2
Ermentrout, G. B., & Kopell, N. (1986). Parabolic bursting in an excitable system coupled witha slow oscillation. SIAM Journal on Applied Mathematics, 46, 233–253. 2
Eurich, C. W., Pawelzik, K., Ernst, U., Cowan, J. D., & Milton, J. G. (1999). Dynamics of self-organized delay adaptation. Physical Review Letters, 82(7), 1594–1597. 3.2.2
Eurich, C. W., Pawelzik, K., Ernst, U., Thiel, A., Cowan, J. D., & Milton, J. G. (2000). Delayadaptation in the nervous system. Neurocomputing. 3.2.2, 3.4
Fernando, C., & Sojakka, S. (2003). Pattern recognition in a bucket. In Proceedings of the 7thEuropean Conference on Artificial Life, (p. 588–597). 4.4
Fourcaud-Trocmé, N., Hansel, D., van Vreeswijk, C., & Brunel, N. (2003). How spike generationmechanisms determine the neuronal response to fluctuating inputs. Journal of Neuroscience,23, 11628–11640. 2
Freeman, L. C. (1977). A set of measures of centrality based upon betweeness. Sociometry, 40,35–41. 5.2.4
Fuji, H., Ito, H., Aihara, K., Ichinose, N., & Tsukada, M. (1996). Dynamical cell assembly hypo-thesis – theoretical possibility of spatio-temporal coding in the cortex. Neural Networks, 9(8),1303–1350. 1, 3.2
Fukushima, K. (1975). Cognitron : A self-organizing multilayered neural network. BiologicalCybernetics, 20(3), 121–136.URL http://www.springerlink.com/content/l1325772l46801n2 2.2
Gerstner, W., Kempter, R., van Hemmen, J. L., & Wagner, H. (1997). A developmental learningrule for coincidence tuning in the barn owl auditory system. Computational Neuroscience :Trends in Research, (pp. 665–669). 3.2.1, 3.2.2
Gerstner, W., & Kistler, W. (2002). Spiking Neuron Models : Single Neurons, Populations, Plasticity.Cambridge University Press. 2.1, 3, 2.3.2
Girvan, M., & Newman, M. E. J. (2002). Community structure in social and biological networks.PNAS - Proc. Natl. Acad. Sci. USA, 99, 7821.URL doi:10.1073/pnas.122653799 5.2.4, 5.2.5
Goodman, D. F. M., & Brette, R. (2008). Brian : a simulator for spiking neural networks inpython. Frontiers in Neuroinformatics, 2(0).URL http://www.frontiersin.org/Journal/Abstract.aspx?s=752&name=
neuroinformatics&ART_DOI=10.3389/neuro.11.005.2008 6.5.1
Grossberg, S. (1976a). Adaptive pattern classification and universal recoding : I. parallel deve-lopment and coding of neural feature detectors. Biological Cybernetics, 23(3), 121–134.URL http://www.springerlink.com/content/k721320t46k2145q 2.2, 2.2
Grossberg, S. (1976b). Adaptive pattern classification and universal recoding : Ii. feedback,expectation, olfaction, illusions. Biological Cybernetics, 23(4), 187–202.URL http://www.springerlink.com/content/p170v5l48556127r 2.2
137

Guimerà, R., & Amaral, L. A. N. (2005a). Cartography of complex networks : modules anduniversal roles. Journal of Statistical Mechanics : Theory and Experiment, 2005(02), P02001.URL http://stacks.iop.org/1742-5468/2005/P02001 5.2.5
Guimerà, R., & Amaral, L. A. N. (2005b). Functional cartography of complex metabolic net-works. Nature, 433, 895–900. 5.2.5, 5.5
Guimerà, R., Sales-Pardo, M., & Amaral, L. A. N. (2004). Modularity from fluctuations in ran-dom graphs and complex networks. Physical Review E, 70(2), 025101. 5.2.5
Guimerà, R., Sales-Pardo, M., & Amaral, L. A. N. (2007). Module identification in bipartite anddirected networks. Physical Review E, 76(3), 036102.URL http://link.aps.org/doi/10.1103/PhysRevE.76.036102 5.2.5, 9.1.2
Gábor Csárdi, T. N. (2006). The igraph software package for complex network research. Inter-Journal, Complex Systems, 1695. 6.5.2
Harary, F., & Gupta, G. (1997). Dynamic graph models. Mathematical and Computer Modelling,25(7), 79 – 87.URL http://www.sciencedirect.com/science/article/B6V0V-3SNV0CS-K/2/
5a961c4fe00e064638eb21567c0d3689 5.4
Hastie, T., Tibshirani, R., & Friedman, J. (2001). The elements of statistical learning. Springer-Verlag. 7.4
Haykin, S. (1999). Neural Networks : A Comprehensive Foundation, 2nd Edition. Prentice-Hall.ISBN : 0-13-273350-1. 2.1
Hines, M. L., & Carnevale, N. T. (2001). Neuron : A tool for neuroscientists. Neuroscientist, 7,123–135. 6.5.1
Hintzman, D. L. (1986). "schema abstraction" in a multiple-trace memory model. PsychologicalReview, 93(4), 411–428.URL http://doi.apa.org/getdoi.cfm?doi=10.1037/0033-295X.93.4.411 1, 3
Hodgkin, A., & Huxley, A. (1952a). Currents carried by sodium and potassium. Journal ofPhysiology, 116, 449–472. 1
Hodgkin, A., & Huxley, A. (1952b). Ions through the membrane of the giant axon of loligo.Journal of Physiology, 116, 473–496. 1
Hopfield, J. J. (1982). Neural networks and physical systems with emergent collective compu-tational abilities. Proceedings of the National Academy of Sciences of the United States of America,79(8), 2554–2558.URL http://www.pnas.org/content/79/8/2554.abstract 2.1, 2.2, 2.2
Hopfield, J. J., Brody, C., & Roweis, S. (1998). Computing with action potentials. In M. Jor-dans, M. Kearns, & S. Solla (Eds.) Advances in Neural Information Processing Systems - NIPS’97,,vol. 10, (pp. 166–172). MIT Press. 2.4
Hüning, H., Glünder, H., & Palm, G. (1998). Synaptic delay learning in pulse-coupled neurons.Neural Computation, 10, 555–565. 3.2.2
Izhikevich, E. M. (2003). Simple model of spiking neurons. IEEE Transactions on Neural Networks,10, 1569– 1572. 4, 6.1
138

Izhikevich, E. M. (2004). Which model to use for cortical spiking neurons ? IEEE Transactionson Neural Networks, 15, 1063–1070. Special issue on temporal coding. 3
Izhikevich, E. M. (2006). Polychronization : Computation with spikes. Neural Computation,18(2), 245–282. 3.2.3, 7.1.1, 7.3, 7.3, 7.4, 8.1.1, 8.1.1, 8.3.3
Izhikevich, E. M., Gally, J. A., & Edelman, G. M. (2004). Spike-timing dynamics of neuronalgroups. Cerebral Cortex, 14, 933–944. 1
Jaeger, H. (2001a). The "echo state" approach to analysing and training recurrent neural net-works - with an erratum note. GMD Report, 148. There is an Erratum Note for this techreport :http ://www.faculty.jacobs-university.de/hjaeger/pubs/EchoStatesTechRepErratum.pdf.URL http://www.faculty.jacobs-university.de/hjaeger/pubs/
EchoStatesTechRep.pdf 4.2.1, 4.3.1, 4.3.3, 7.3.3
Jaeger, H. (2001b). Short term memory in echo state networks.URL ftp://borneo.gmd.de/pub/indy/publications_herbert/
STMEchoStatesTechRep.pdf 4.4
Jaeger, H. (2007). Echo state network. Scholarpedia, 2(9), 2330.URL http://www.scholarpedia.org/article/Echo_state_network 4.2.1
Jiang, F., Berry, H., & Schoenauer, M. (2008). Supervised and unsupervised evolutionary lear-ning of echo state networks. In G. R. et al. (Ed.) Parallel Problem Solving from Nature (PPSN’08),no. 5199 in LNCS, (pp. 215–224). Springer Verlag. To appear. 4.3.1, 4.3.1, 4.3.2
Jordan, M. I. (1986). Attractor dynamics and parallelism in a connectionist sequential machine.In Proceedings of the Eighth Annual Conference of the Cognitive Science Society, (pp. 531–546).Hillsdale, NJ : Erlbaum. 2.1, 2.2
Joshi, P., & Triesch, J. (2009). Rules for information maximization in spiking neurons usingintrinsic plasticity. Neural Networks, IEEE - INNS - ENNS International Joint Conference on, 0,1456–1461. 3.2.1
Kato, H., Ikeguchi, T., & Aihara, K. (2009). Structural analysis on stdp neural networks usingcomplex network theory. In C. Alippi, M. Polycarpou, C. Panayiotou, & G. Ellinas (Eds.)ICANN’2009, vol. 5768 of Lecture Notes in Computer Science, (pp. 306–314). Springer. 3.2.1
Kempter, R., Gerstner, W., & van Hemmen, J. (1998). How the threshold of a neuron determinesits capacity for coincidence detection. Biosystems, 48(1-3), 105–112.URL http://www.sciencedirect.com/science/article/B6T2K-3V5V00M-F/2/
432bb1a2dfe8f0993699a88a470bcfda 3.1.1, 3.2.1
Kempter, R., Gerstner, W., van Hemmen, J. L., & Wagner, H. (1996). Temporal coding in sub-millisecond range : Model of barn owl pathway. In M. E. H. D. S Touretsky, M. C. Mozer (Ed.)Advances in Neural Information Processing Systems, vol. 8, (pp. 124–130). Cambridge, MA, MITPress. 2.4
Keysers, D., Paredes, R., Ney, H., & Vidal, E. (2002). Combination of tangent vectors and localrepresentations for handwritten digit recognition. In SPR 2002, International Workshop onStatistical Pattern Recognition, (pp. 538–547). Windsor, Ontario, Canada. 7.4
Kirkpatrick, S., Gelatt, C. D., & Vecchi, M. P. (1983). Optimization by simulated annealing.Science, 220, 671–680. 5.2.5
139

Kohonen, T. (1982). Self-organized formation of topologically correct feature maps. BiologicalCybernetics, 43, 59–69. 2.1, 2.2
Kosko, B. (1988). Bidirectional associative memories. IEEE Transactions on Systems, Man, ansCybernetics, 18. 2.2
König, P., Engel, A. K., & Singer, W. (1996). Integrator or coincidence detector ? the role of thecortical neuron revisited. Trends in Neurosciences, 19(4), 130–137.URL http://www.sciencedirect.com/science/article/B6T0V-441FS4S-4/2/
8ded04cd47393791d79f15d0d5f95f37 3.1.1
Lago-Fernández, L. F., Huerta, R., Corbacho, F., & Sigüenza, J. A. (2000). Fast response andtemporal coherent oscillations in small-world networks. Physical Review Letters, 84(12), 2758–2761. 3.2.1, 5.4.1
Lapicque, L. (1907). Recherches quantitatives sur l’excitation électrique des nerfs traité commeune polarization. Journal of Physiology Pathol. Gen., 9, 620–635. Cited by Abbott, L.F., in BrainRes. Bull. 50(5/6) :303–304. 2
Latora, V., & Marchiori, M. (2001). Efficient behavior of small-world networks. Physical ReviewLetter, 87(19), 198701–1 – 198701–4. 5.2.3
Lazar, A., Pipa, G., & Triesch, J. (2006). The combination of stdp and intrinsic plasticity yieldscomplex dynamics in recurrent spiking networks. In ESANN, (pp. 647–652). 7.3.3
Lazar, A., Pipa, G., & Triesch, J. (2007). Fading memory and time series prediction in recurrentnetworks with different forms of plasticity. Neural Networks, 20(3), 312–322. 7.3.3
Legenstein, R., & Maass, W. (2007). Edge of chaos and prediction of computational performancefor neural circuit models. Neural Networks, 20(3), 323 – 334. Echo State Networks and LiquidState Machines.URL http://www.sciencedirect.com/science/article/B6T08-4NMWR88-B/2/
cdb56c1e59a2806428f4992b02d06cf6 4.3.1
Leicht, E. A., & Newman, M. E. J. (2008). Community structure in directed networks. PhysicalReview Letters, 100, 118703.URL doi:10.1103/PhysRevLett.100.118703 5.2.5
Levenberg, K. (1944). A method for the solution of certain nonlinear problems in least squares.Q. Appl. Math, 2, 164–168. 9.3.1
Liebald, B. (2004). Exploration of effects of different network topologies on the esn signal cross-correlation matrix spectrum. Bachelor of Science Thesis. 4.3.1
Lukosevicius, M., & Jaeger, H. (2009). Reservoir computing approaches to recurrent neuralnetwork training. Computer Science Review, 3(3), 127–149.URL http://www.faculty.jacobs-university.de/hjaeger/pubs/2261_
LukoseviciusJaeger09.pdf 1, 4.1
Ma, S., & Ji, C. (1998). Fast training of recurrent networks based on the em algorithm. IEEETransactions on Neural Networks, 9(1), 11–26. 4.3.2
Maass, W. (1997a). Fast sigmoidal networks via spiking neurons. Neural Computation, 10, 1659–1671. 2.1
140

Maass, W. (1997b). Networks of spiking neurons : The third generation of neural networkmodels. Neural Networks, 10, 1659–1671. 2.1
Maass, W. (2007). Liquid computing. In Computability in Europe 2007 - CiE’07. Springer (Berlin),Springer (Berlin). Invited paper in press. 4.2.2
Maass, W., & Natschläger, T. (1997). Networks of spiking neurons can emulate arbitrary hop-field nets in temporal coding. Network : Computation in Neural Systems, 8(4), 355–372. 2.1
Maass, W., Natschläger, T., & Markram, H. (2002). Real-time computing without stable states : Anew framework for neural computation based on perturbations. Neural Computation, 14(11),2531–2560. 4.2.2
Maass, W., Natschläger, T., & Markram, H. (2004). Fading memory and kernel properties ofgeneric cortical microcircuit models. Journal of Physiology, 98(4-6), 315–330. Paris. 4.4
Maass, W., & Schmitt, M. (1997). On the complexity of learning for a spiking neuron. InCOLT’97, Conf. on Computational Learning Theory, (pp. 54–61). ACM Press. 1, 3.2.1
Maier, W. L., & Miller, B. N. (2008). A minimal model for the study of polychronous groups.URL http://arxiv.org/abs/0806.1070 8.1.1, 9.2.1
Mainen, Z. F., & Sejnowski, T. J. (1995). Reliability of spike timing in neocortical neurons.Science, 268, 1503–1506.URL http://www.jstor.org/stable/2887763 3.1.2
Markram, H., Lübke, J., Frotscher, M., & Sakmann, B. (1997). Regulation of synaptic efficacy bycoincidence of postsynaptic APs and EPSPs. Science, 275, 213–215. 3.2.1
Marquardt, D. W. (1963). An Algorithm for Least-Squares Estimation of Nonlinear Parameters.SIAM Journal on Applied Mathematics, 11(2), 431–441.URL http://scitation.aip.org/getabs/servlet/GetabsServlet?prog=
normal\&id=SMJMAP000011000002000431000001\&idtype=cvips\&gifs=yes
9.3.1
Martinez, R. (2005). Parallélisme et Codage Temporel dans un Modèle de Mémoire Associative Multi-modale. Master’s thesis, Université Lumière Lyon 2. 7.1
Martinez, R. (2006). Apprentissage Dynamique dans les Réseaux de Neurones Temporels. Master’sthesis, Université Claude Bernard Lyon 1. 7.3
Martinez, R., & Paugam-Moisy, H. (2008a). Des groupes polychrones pour modéliser les tracesmnésiques. In ARCo’08 - Connaissances : Genèse, Nature et Fonction.URL http://liris.cnrs.fr/publis/?id=3613 8
Martinez, R., & Paugam-Moisy, H. (2008b). Les groupes polychrones pour capturer l’aspectspatio-temporel de la mémorisation. In E. D. L. U. Perrinet (Ed.) NeuroComp’08 - SecondFrench Conference on Computational Neuroscience, (pp. 265–268).URL http://liris.cnrs.fr/publis/?id=3612 8
Martinez, R., & Paugam-Moisy, H. (2009). Algorithms for structural and dynamical polychro-nous groups detection. In Proc. of Int. Conf. on Artificial Neural Networks ICANN’09, LectureNotes in Computer Science, volume 5769, (pp. 75–84). Springer. Lecture Notes in ComputerScience, volume 5769.URL http://liris.cnrs.fr/publis/?id=4304 8
141

McCulloch, W., & Pitts, W. (1943). A logical calculus of the ideas immanent in nervous activity.Bulletin of Mathematical Biophysics, 5, 115–133. 2.1
Meunier, D. (2007). Modelisation Evolutioniste du Liage Temporel. Ph.D. thesis, Université de Lyon- Université Lyon 2. 3.2.1, 5.5
Meunier, D., Achard, S., Morcom, A., & Bullmore, E. T. (2009a). Age-related changes in modularorganization of human brain functional networks. NeuroImage, 44(3), 715–723.URL http://www.ncbi.nlm.nih.gov/pubmed/19027073 5.5
Meunier, D., Lambiotte, R., Fornito, A., Ersche, K. D., & Bullmore, E. T. (2009b). Hierarchicalmodularity in human brain functional networks. Frontiers in NeuroInformatics, 3. 5.5
Meunier, D., Martinez, R., & Paugam-Moisy, H. (2006). Assemblées temporelles dans les ré-seaux de neurones impulsionels. In Actes de la conférence française NeuroComp 2006, (pp. 187–190). Pont-à-Mousson. 7
Meunier, D., & Paugam-Moisy, H. (2005). Evolutionary supervision of a dynamical neuralnetwork allows to learn with on-going weights. In Proc. of IJCNN’05, (pp. 1493–1498). IEEE,INNS. 3.3
Meunier, D., & Paugam-Moisy, H. (2008). Neural networks for computational neuroscience. InProc. of European Symp. On Artificial Neural Networks - ESANN’2008, Advances in Computa-tional Intelligence and Learning, (pp. 367–378).URL http://liris.cnrs.fr/publis/?id=3400 5.2.5
Milgram, S. (1967). The small world problem. Psychology Today, 1(1), 61–67.URL http://www.jstor.org/stable/2786545 5.3.3
Minsky, M. L., & Papert, S. A. (1969). Perceptrons. Cambridge, MA : MIT Press. 2.1
Mouraud, A., & Puzenat, D. (2009). Simulation of large spiking neural networks on distributedarchitectures, the "damned" simulator. In Proc. Int. Conf. on Engineering Applications of NeuralNetworks, EANN’09, (pp. 359–370). Springer.URL http://liris.cnrs.fr/publis/?id=4293 6.5.1
Naudé, J., Genet, S., Berry, H., Mahon, S., Paz, J., & Delord, B. (2008). A formalization of thecomputational impact of intrinsic plasticity. In Deuxième conférence française de NeurosciencesComputationnelles, "Neurocomp08". Marseille, France. ISBN : 978-2-9532965-0-1.URL http://hal.archives-ouvertes.fr/hal-00331558/en/ 3.2.1
Newman, M. E. J. (2001). The structure of scientific collaboration networks. PNAS - Proc. Natl.Acad. Sci. USA, 98, 404–409. 5.5
Newman, M. E. J. (2003). The structure and function of complex networks. SIAM Review, 45,167–256. 5.2, 5.2, 5.5
Newman, M. E. J. (2004). Fast algorithm for detecting community structure in networks. Phy-sical Review E, 69(6), 066133.URL http://link.aps.org/doi/10.1103/PhysRevE.69.066133 5.2.5
Newman, M. E. J., & Girvan, M. (2004). Finding and evaluating community structure in net-works. Physical Review E, 69, 6113.URL http://arxiv.org/abs/cond-mat/0308217v1 5.2.4, 5.2.5
142

Pastor-Satorras, R., & Vespignani, A. (2002). Epidemic dynamics in finite size scale-free net-works. Physical Review E, 65, 035108. 5.4.1
Pastor-Satorras, R., & Vespignani, A. (2003). Internet - Structure et évolution. Belin. 5.5
Paugam-Moisy, H. (2006). Spiking neuron networks : A survey. Idiap-RR Idiap-RR-11-2006,IDIAP. 3.1
Paugam-Moisy, H., & Bothe, S. M. (2010). Computing with spiking neuron networks. In TheHandbook of Natural Computing. Springer Verlag. 4.2
Paugam-Moisy, H., & Bothe, S. M. (2011). Computing with spiking neuron networks. In TheHandbook of Natural Computing. Springer Verlag. To appear. 2.1, 4.1
Paugam-Moisy, H., Martinez, R., & Bengio, S. (2007). A supervised learning approach based onstdp and polychronization in spiking neuron networks. In M. Verleysen (Ed.) ESANN’2007,Advances in Computational Intelligence and Learning, (pp. 427–432). ISBN 2-930307-07-2.URL http://liris.cnrs.fr/publis/?id=2718 7
Paugam-Moisy, H., Martinez, R., & Bengio, S. (2008). Delay learning and polychronization forreservoir computing. Neurocomputing, 71(7-9), 1143–1158.URL http://liris.cnrs.fr/publis/?id=3399 7
Pennock, D. M., Flake, G. W., , Lawrence, S., Glover, E. J., & Giles, C. L. (2002). Winners don’ttake all : Characterizing the competition for links on the web. PNAS - Proc. Natl. Acad. Sci.,99(8), 5207–5211. 5.3.4
Ponten, S., Bartolomei, F., & Stam, C. (2007). Small-world networks and epilepsy : graph theo-retical analysis of intracerebrally recorded mesial temporal lobe seizures. Clinical neurophy-siology, 118(918-927), 918–927. 5.4.1
Puskorius, G. V., & Feldkamp, L. A. (1994). Neurocontrol of nonlinear dynamical systems withkalman filter trained recurrent networks. IEEE Transactions on Neural Networks, 5(2), 279–297.URL http://ieeexplore.ieee.org/iel4/72/6922/00279191.pdf?arnumber=
279191http://cat.inist.fr/?aModele=afficheN&cpsidt=4123406 4.3.2
Rosenblatt, F. (1958). The perceptron : A probabilistic model for information storage and orga-nization in the brain. Psychological Review, 65(6), 386–408. Cornell Aeronautical Laboratory.2.1, 2.2
Rubin, J., Lee, D., & Sompolinsky, H. (2001). Equilibrium properties of temporally assymmetricHebbian plasticity. Physical Review Letters, 89(2), 364–367. 3.2.1
Rudolph, M., & Destexhe, A. (2006). Integrate-and-fire neurons with high-conductance statedynamics for event-driven simulation strategies. Neural Computation, 18, 2146–2210. 2
Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning internal representations byerror propagation. (pp. 318–362). 2.1, 2.2
Rumelhart, D. E., & Zipser, D. (1985). Feature discovery by competitive learning. CognitiveScience, 9(1), 75 – 112.URL http://www.sciencedirect.com/science/article/B6W48-4DXC45K-N/2/
6147ddbf806b6b930ff08b20fa694ec8 2.2
143

Saramäki, J., Kivelä, M., Onnela, J.-P., Kaski, K., & Kertész, J. (2007). Generalizations of theclustering coefficient to weighted complex networks. Phys. Rev. E, 75(2), 027105. 5.2.2
Schmitt, M. (1999). On the implications of delay adaptability for learning in pulsed neuralnetworks. In Proceedings of the Workshop on Biologically-Inspired Machine Learning. 1, 3.2.1
Schrauwen, B., Verstraeten, D., & Van Campenhout, J. (2007). An overview of reservoir compu-ting : theory, applications and implementations. In Proceedings of the 15th European Symposiumon Artificial Neural Networks, (pp. 471–482). 1, 4.1, 4.4
Schrauwen, B., Wardermann, M., Verstraeten, D., Steil, J. J., & Stroobandt, D. (2008). Improvingreservoirs using intrinsic plasticity. Neurocomputing, 71(7-9), 1159 – 1171. Progress in Mode-ling, Theory, and Application of Computational Intelligenc - 15th European Symposium onArtificial Neural Networks 2007, 15th European Symposium on Artificial Neural Networks2007.URL http://www.sciencedirect.com/science/article/B6V10-4RP0MJ8-2/2/
c8a5771b194e73f7c85664eb5b93343e 4.3.2
Senn, W., Schneider, M., & Ruf, B. (2002). Activity-dependent development of axonal and den-dritic delays, or, why synaptic transmission should be unreliable. Neural Computation, 14,583–619. 3.2.2
Seth, A. K., Izhikevich, E. I., Reeke, G. N., & Edelman, G. M. (2006). Theories and measures ofconsciousness : An extended framework. Proceedings of the National Academy of Sciences of theUSA, 103(28), 10799–10804. 5.4.2
Shadlen, M. N., & Newsome, W. T. (1994). Noise, neural codes and cortical organization. Cur-rent Opinion in Neurobiology, 4(4), 569–579.URL http://www.sciencedirect.com/science/article/B6VS3-49NRCHS-H/2/
8cb64a1e5ded4ecaa59a98bdff8f698f 3.1.1
Shanahan, M. (2008). Dynamical complexity in small-world networks of spiking neurons. Phy-sical Review E, 78(4). 041924.1-041924.7.URL http://link.aps.org/doi/10.1103/PhysRevE.78.041924 5.4.2
Singer, W., & Gray, C. M. (1995). Visual feature integration and the temporal correlation hypo-thesis. Annual Review of Neuroscience, 18, 555–586. 3, 3.2.3
Softky, W. R., & Koch, C. (1993). The highly irregular firing of cortical cells is inconsistent withtemporal integration of random epsps. Journal of Neuroscience, 13(1), 334–350.URL http://www.jneurosci.org/cgi/content/abstract/13/1/334 3.1.1
Sporns, O. (2006). Small-world connectivity, motif composition, and complexity of fractalneuronal connections. Biosystems, 85(1), 55–64. Dedicated to the Memory of Ray Paton.URL http://www.sciencedirect.com/science/article/pii/
S0303264706000396 5.5
Steil, J. J. (2004). Backpropagation-decorrelation : online recurrent learning with o(n) com-plexity. In Proceedings of International Joint Conference on Neural Network - IJCNN, vol. 1, (pp.843–848). 4.3.2
Steil, J. J. (2006). Online stability of backpropagation-decorrelation recurrent learning. Neuro-computing, 69(7-9), 642–650.URL http://dx.doi.org/10.1016/j.neucom.2005.12.012 4.3.2
144

Steil, J. J. (2007). Online reservoir adaptation by intrinsic plasticity for backpropagation-decorrelation and echo state learning. Neural Networks, 20(3), 353 – 364. 4.3.2, 7.3.3
Suzuki, T., & Ikeguchi, T. (2008). Self-organizing small-world structure of neural networks.Tech. Rep. 4, The Science and Engineering Review of Doshisha University. 3.2.1
Swadlow, H. A. (1985). Physiological properties of individual cerebral axons studied in vivofor as long as one year. Journal of Neurophysiology, 54, 1346–1362. 1, 3.2.1, 7.1.1
Triesch, J. (2005a). A gradient rule for the plasticity of a neuron’s intrinsic excitability. InProceedings of International Conference on Artificial Neural Networks - ICANN 2005, vol. 3696,(pp. 65–70). 3.2.1, 4.3.2
Triesch, J. (2005b). Synergies between intrinsic and synaptic plasticity in individual modelneurons. In L. K. Saul, Y. Weiss, & L. Bottou (Eds.) Advances in Neural Information ProcessingSystems 17, (pp. 1417–1424). Cambridge, MA : MIT Press. 4.3.2
van Vreeswijk, C., & Sompolinsky, H. (1996). Chaos in neuronal networks with balancedexcitatory and inhibitory activity. Science, 274(5293), 1724–1726.URL http://www.sciencemag.org/cgi/content/abstract/274/5293/1724
3.2.1, 3.2.3
Vapnik, V. (1998). Statistical learning theory. Wiley. 8.5.3
Vapnik, V. N. (1995). The nature of statistical learning theory. Springer. 7.2, 1
Versace, R., Labeye, E., Badard, G., & Rose, M. (2009). The contents of long-term memory andthe emergence of knowledge. The European Journal of Cognitive psychology, 21(4), 522–560. 3
Verstraeten, D., Schrauwen, B., D’Haene, M., & Stroobandt, D. (2007). An experimental unifica-tion of reservoir computing methods. Neural Networks, 20(3), 391 – 403. Echo State Networksand Liquid State Machines.URL http://www.sciencedirect.com/science/article/B6T08-4NKYNTD-3/2/
200495219ef0a4d03b64694797f421f0 4.4, 7.3.3
Verstraeten, D., Schrauwen, B., Stroobandt, D., & Campenhout, J. V. (2005). Isolated word re-cognition with the liquid state machine : a case study. Information Processing Letters, 95(6), 521– 528. Applications of Spiking Neural Networks.URL http://www.sciencedirect.com/science/article/B6V0F-4GMGWJ0-1/2/
113e3bff5aafcfefc115eff15aa87c9d 4.4
Vibert, J.-F., Alvarez, F., & Pham, J. (1998). Effects of transmission delays and noise in recurrentexcitatory neural networks. BioSystems, 48, 255–262. 3.2.1
Victor, J., & Purpura, K. (1996). Nature and precision of temporal coding in visual cortex : Ametric-space analysis. J. of Neurophysiology, 76, 1310–1326. 8.5.3
Wasserman, S., & Faust, K. (1994). Social Network Analysis : Methods and Applications. CambridgeUniversity Press. 5.5
Watanabe, M., & Aihara, K. (1997). Chaos in neural networks composed of coincidencedetector neurons. Neural Networks, 10(8), 1353–1359.URL http://www.sciencedirect.com/science/article/pii/
S0893608097000373 3.1.1, 3.2.3
145

Watts, D. J., & Strogatz, S. H. (1998). Collective dynamics of ’small-world’ networks. Nature,393, 440–442. 5.2.2, 5.2.3, 5.3.3, 5.5, 5.5, 5.5, 9.2
Watts, L. (1994). Event-driven simulation of networks of spiking neurons. In J. D. Cowan,G. Tesauro, & J. Alspector (Eds.) NIPS*1993, Advances in Neural Information Processing System,vol. 6, (pp. 927–934). MIT Press. 2.1
Werbos, P. J. (1990). Backpropagation through time : What it does and how to do it. In Procee-dings of IEEE, vol. 78, (pp. 1550–1560). 4.3.2
Zhang, W., & Linden, D. J. (2003). The other side of the engram : experience-driven changes inneuronal intrinsic excitability. Nature Reviews Neuroscience, 4, 885–900. 3.2.1
146


















