
Chapitre 2: RÉGRESSION LINÉAIRE SIMPLE … · Modèle d’analyse de la variance: variables...
45
1 chapitre 2 MTH8302 - Analyse de régression et analyse de variance Chapitre 1-Introduction Modélisation statistique Modèles statistiques Étapes d’une analyse statistique Classification des modèles Chapitre 2-Simple Modèle LINÉAIRE SIMPLE Transformations et modèles linéarisables Modèles non linéaires Modèle Logistique Chapitre 3-Multiple – partie 1 Modèle de régression MULTIPLE Régression avec STATISTICA Exemple d’utilisation et interprétation Inférence pour modèle réduit Variables standardisées Méthodes de sélection de variables (model building) Critères de sélection de modèles Chapitre 4-Multiple – partie 2 Résidus, influence, validation croisée Multicolinéarité Régression biaisée ridge Régression sur composantes principales Variables explicatives catégoriques Chapitre 5-Multiple – partie 3 Régression : variables explicatives catégoriques Régression : modèles non linéaire Régression logistique: variable réponse Y binaire Régression : variable de réponse Y Poisson Modèles lin. généralisés: variable Y non normale Data Mining CART : Classification And Regression Trees Réseau de neurones MARS : Multivariate Adaptive Regression Splines Modèles d’analyse de la variance Chapitre 1 – chapitre 2 – chapitre 3 chapitre 4 – chapitre 5 Chapitre 2: RÉGRESSION LINÉAIRE SIMPLE Copyright © Génistat Conseils Inc. Montréal, Canada, 2017
Transcript of Chapitre 2: RÉGRESSION LINÉAIRE SIMPLE … · Modèle d’analyse de la variance: variables...

1chapitre 2
MTH8302 - Analyse de régression et analyse de variance
Chapitre 1-Introduction Modélisation statistique Modèles statistiques Étapes d’une analyse statistique Classification des modèles
Chapitre 2-Simple Modèle LINÉAIRE SIMPLE Transformations et modèles linéarisables Modèles non linéaires Modèle Logistique
Chapitre 3-Multiple – partie 1 Modèle de régression MULTIPLE Régression avec STATISTICA Exemple d’utilisation et interprétation Inférence pour modèle réduit Variables standardisées Méthodes de sélection de variables
(model building) Critères de sélection de modèles
Chapitre 4-Multiple – partie 2 Résidus, influence, validation croisée Multicolinéarité Régression biaisée ridge Régression sur composantes principales Variables explicatives catégoriques
Chapitre 5-Multiple – partie 3 Régression : variables explicatives catégoriques Régression : modèles non linéaire Régression logistique: variable réponse Y binaire Régression : variable de réponse Y Poisson Modèles lin. généralisés: variable Y non normale
Data Mining CART : Classification And Regression Trees Réseau de neurones MARS : Multivariate Adaptive Regression Splines
Modèles d’analyse de la varianceChapitre 1 – chapitre 2 – chapitre 3 chapitre 4 – chapitre 5
Chapitre 2: RÉGRESSION LINÉAIRE SIMPLE
Copyright © Génistat Conseils Inc.Montréal, Canada, 2017

X 1, X2, …, Z1, Z2 ,…: facteurs, variables contrôlées en expérimentationmode actif : données expérimentales
variables observées / mesurées en observationmode passif – données observationnelles
X1 X2. . .Xk
SYSTÈME /
PROCESSUS
erreur expérimentale = sources inconnues de variabilitéε ∼ (0, σ2)
réponse - sortie mesuréeY = φ(X) + ρ(Z) + ε
Objectif de ANALYSE STATISTIQUE : comprendre / prédire / optimiser SYSTÈME / PROCESSUS
TOUTE analyse statistique repose sur un MODÈLE- relation entre input X (fixe) Z (aléatoire) et output Y- connaissance de la structure des données:
plan de collecte des données / nature variables / rôle des variablestype d’influence des variables / unités statistiques (expérimentales)
ε
Z1 Z2. . .Zh
facteursfixes
facteursaléatoires
2Copyright © Génistat Conseils Inc.Montréal, Canada, 2017

VARIABLES
RÔLEY : réponse , output
peut être: binaire (0, 1), multinomiale, continue, multidimensionnelle
X, Z : explicatives, régresseurs, input, fixes, aléatoires
NATUREX (fixes) : continues, catégoriquesZ (aléatoires) : continues, catégoriques
INFLUENCEX : affecte la centralité (moyenne) de Y : effets fixesZ : affecte la dispersion (variance) de Y : effets aléatoires
MODÈLES effets fixes aléatoires mixtes (fixes + aléatoires)
Y = f (X1, X2 , … , Xk ; β0 , β1 , β2 ,… )+ g (Z1, Z2, .., Zh ; σ12 , σ2
2, …) + ε
Objectif de ANALYSE STATISTIQUE : comprendre / prédire / optimiser SYSTÈME / PROCESSUS
3Copyright © Génistat Conseils Inc.Montréal, Canada, 2017
ε ~ N(0, σ2)

4
Linéaire simple : Y = β0 + β1X1 + ε Régression multiple : Y = β0 + β1X1 + β2X2 + • • • + βkXk + ε Effets principaux + effets d’interaction :
Y = β0 + β1X1 + β2X2 + • • • + βkXk + β12X1X2 + β13X1X3 + • • • + ε
Quadratiques (response surface avec facteurs quantitatifs ) Y = β 0 + β1X 1 + β2X2 + • • • + βkXk + β12X1X2 + β13X1X3 + • • • +
+ β11X12 + β22X2
2 + β33X32 + • • • + ε
Régression logistique : Y à valeurs catégoriques (oui / non) Régression PLS: nombre variables X > nombre d’observations (k > n) Modèle d’analyse de la variance: variables catégoriques A
codage à effets X = 0 / 1 / -1 selon les modalités de A Modèles avec 2 types de variables continues + catégoriques Mixtes: facteurs modalités fixes + facteurs modalités aléatoires Polynomial : Y = β0 + β1X + β2X2 + • • • + βkXk + ε
MODÈLES d’analyse de régression : X1, X2, …facteurs continus
chapitre 2
MTH8302
observations : Yi = φ (Xi1, Xi2 , … , Xik ; β0 , β1 , β2 , … ) + εi i = 1, 2,…, n
implicitement : une observation par unité (individu, sujet) statistiqueindépendance des Yi ?

ANALYSE STATISTIQUE : étapes
1. Spécification d’un modèle statistique
2. Estimation des paramètres du modèle
3. Décomposition de la variabilité : ANOVA
4. Tests d’hypothèses sur les paramètres
5. Analyse diagnostique des résidus
- vérification des hypothèses de base- identification d’observations influentes- transformation Y ? (si nécessaire)
6. Si nécessaire : itération des étapes 1 à 5
7. Optimisation de la réponse (s’il y a lieu)
8. Graphiques de la réponse
5chapitre 2
MTH8302 - Analyse de régression et d’analyse de variance
Copyright © Génistat Conseils Inc.Montréal, Canada, 2017
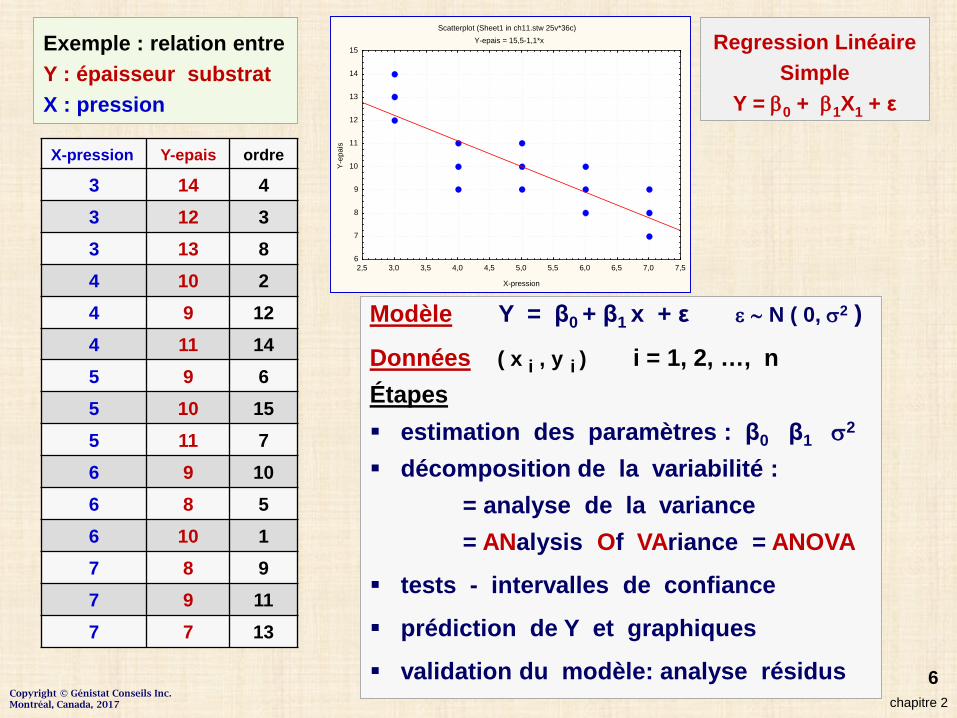
6
X-pression Y-epais ordre
3 14 43 12 33 13 84 10 24 9 124 11 145 9 65 10 155 11 76 9 106 8 56 10 17 8 97 9 117 7 13
Exemple : relation entre Y : épaisseur substratX : pression
Modèle Y = β0 + β1 x + ε ε ∼ N ( 0, σ2 )
Données ( x i , y i ) i = 1, 2, …, nÉtapes estimation des paramètres : β0 β1 σ2
décomposition de la variabilité := analyse de la variance= ANalysis Of VAriance = ANOVA
tests - intervalles de confiance
prédiction de Y et graphiques
validation du modèle: analyse résidus
Scatterplot (Sheet1 in ch11.stw 25v*36c)Y-epais = 15,5-1,1*x
2,5 3,0 3,5 4,0 4,5 5,0 5,5 6,0 6,5 7,0 7,5
X-pression
6
7
8
9
10
11
12
13
14
15
Y-ep
ais
Regression LinéaireSimple
Y = β0 + β1X1 + ε
Copyright © Génistat Conseils Inc.Montréal, Canada, 2017 chapitre 2
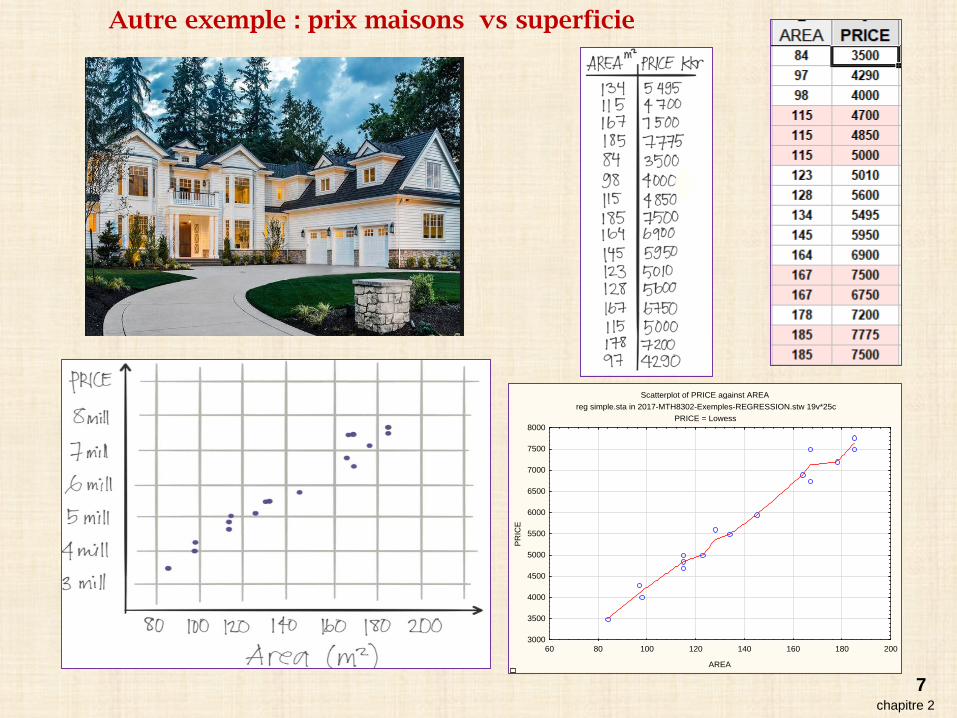
Scatterplot of PRICE against AREAreg simple.sta in 2017-MTH8302-Exemples-REGRESSION.stw 19v*25c
PRICE = Lowess
60 80 100 120 140 160 180 200
AREA
3000
3500
4000
4500
5000
5500
6000
6500
7000
7500
8000
PRIC
E
Autre exemple : prix maisons vs superficie
chapitre 27

8
NOTATIONx = ∑ x i / n : moyenne de X y = ∑ y i / n : moyenne de YSPxy = ∑ (x i – x )( y i – y ) : somme des produits XYSSxx = ∑ (x i – x )2 : somme des carrés de XSSyy = ∑ (y i – y )2 = SStot = somme totale des carrés de Y
ESTIMATION principe des moindres carrés: minimiser S(β0 , β1 )
S(β 0 , β1 ) = ∑ ( y i - β 0 - β 1 x i )2 : écart par rapport à la droite
solution b1= β1 = SPxy / SSxx = ∑ ci yi où ci = (x i – x) / SSxx
b0 = β0 = y - b1 x
prédiction y = β0 + β1 x = y + b1 (x – x ) : droite de moindres carrésrésidu brut e i = y i - y isomme des carrés résiduels SSresid = ∑ e i
2 = ∑ ( y i - y i )2
carré résiduel moyen MSresid = SSresid / (n – 2 )estimation de σ2 σ2 = MSresid σ = ( MSresid )0.5
∑ci = 0 ∑ci2 = 1
chapitre 2
Regression Linéaire Simple : Y = β0 + β1X1 + εthéorie
Copyright © Génistat Conseils Inc.Montréal, Canada, 2017
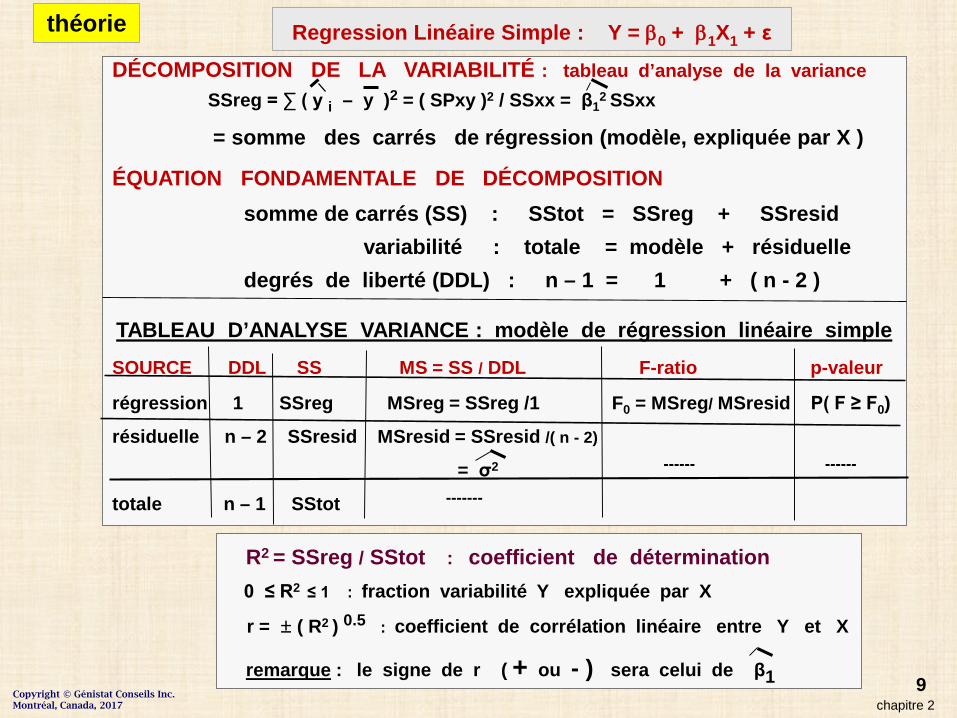
9
DÉCOMPOSITION DE LA VARIABILITÉ : tableau d’analyse de la varianceSSreg = ∑ ( y i – y )2 = ( SPxy )2 / SSxx = β1
2 SSxx
= somme des carrés de régression (modèle, expliquée par X )
ÉQUATION FONDAMENTALE DE DÉCOMPOSITIONsomme de carrés (SS) : SStot = SSreg + SSresid
variabilité : totale = modèle + résiduelledegrés de liberté (DDL) : n – 1 = 1 + ( n - 2 )
TABLEAU D’ANALYSE VARIANCE : modèle de régression linéaire simple SOURCE DDL SS MS = SS / DDL F-ratio p-valeur
régression 1 SSreg MSreg = SSreg /1 F0 = MSreg/ MSresid P( F ≥ F0)
résiduelle n – 2 SSresid MSresid = SSresid /( n - 2)
= σ2 ------ ------
totale n – 1 SStot -------
R2 = SSreg / SStot : coefficient de détermination 0 ≤ R2 ≤ 1 : fraction variabilité Y expliquée par X
r = ± ( R2 ) 0.5 : coefficient de corrélation linéaire entre Y et X
remarque : le signe de r ( + ou - ) sera celui de β1chapitre 2
Regression Linéaire Simple : Y = β0 + β1X1 + ε
Copyright © Génistat Conseils Inc.Montréal, Canada, 2017
théorie

TEST et INTERVALLE de CONFIANCE
résultat (β 1 - β 1 ) / ( σ / SSxx0.5 ) ~ T n – 2 (loi de Student)
applications
(a) test de β1 H0 : β1 = 0 vs H1 : β1 ≠ 0rejeter H0 au seuil α si │ β1 │(SSxx)0.5 / σ > t n – 2, 1-α/2
remarque : le test est équivalent au test F du tableau ANOVA
(b) intervalle de confiance de β1 : β1 ± t n – 2, 1 – α/2 σ / (SSxx)0.5
coefficient de confiance = 1 - α
(c) INTERVALLE de CONFIANCE : MOYENNE de Y à X = x*
E (Y│X = x* ) : β0 + β1 x* ± t n – 2, 1 – α/ 2 σ [ (1/n) + (( x* – x )2 /SSxx) ] 0.5
remarque : un intervalle de confiance pour β0 s’obtient avec x* = 0(d) INTERVALLE de PRÉDICTION : VALEUR de Y à X = x*
Y │ X = x* : β 0 + β1 x* ± t n – 2, 1 – α/ 2 σ [ 1 + ( 1/n) + (( x* – x )2 / SSxx)] 0.5
remarque : ne pas confondre (c) et (d)
10chapitre 2
Regression Linéaire Simple : Y = β0 + β1X1 + εthéorie

11chapitre 2
Graphics…… 2D Scatterplots
Statistics……Multiple Linear Regression
Mise en œuvre avec STATISTICA
pas d’analyse de la variancepas d’analyse de résidus
variables continues seulement
Copyright © Génistat Conseils Inc.Montréal, Canada, 2017

12chapitre 2
Statistics … Advanced Linear/Nonlinear Models… General Linear Models et General Regression Models
Régression linéaire avec STATISTICA
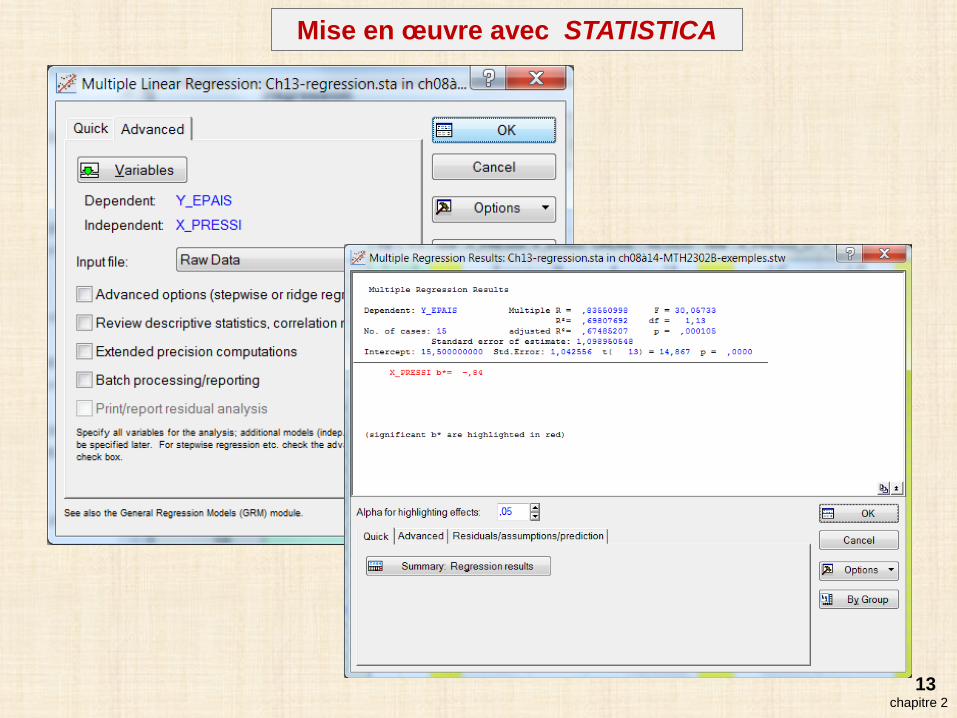
13chapitre 2
Mise en œuvre avec STATISTICA
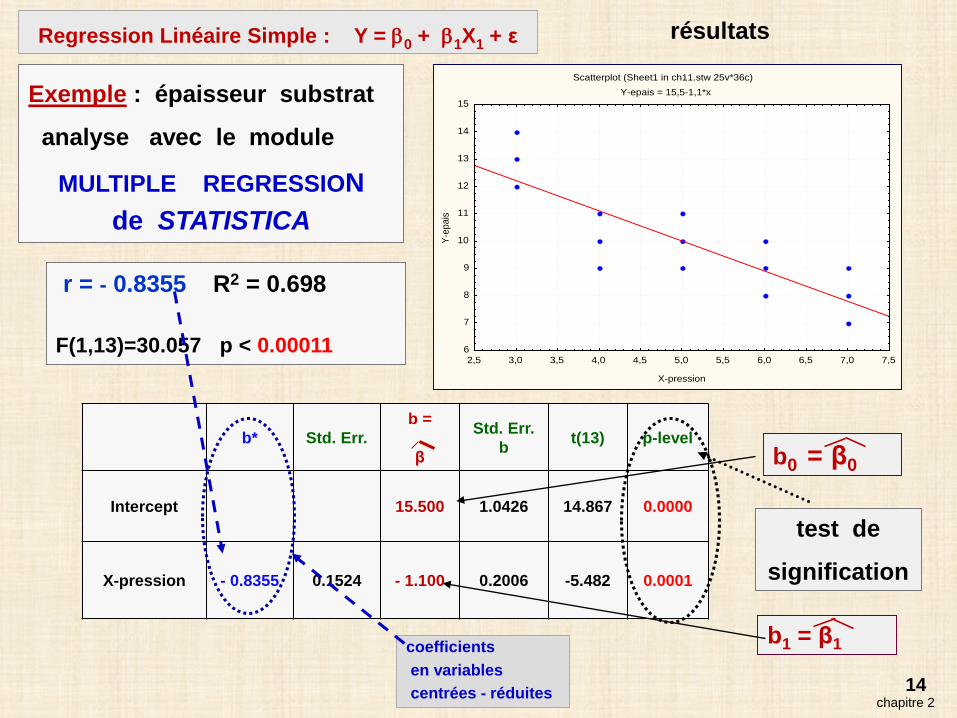
14
Scatterplot (Sheet1 in ch11.stw 25v*36c)Y-epais = 15,5-1,1*x
2,5 3,0 3,5 4,0 4,5 5,0 5,5 6,0 6,5 7,0 7,5
X-pression
6
7
8
9
10
11
12
13
14
15
Y-ep
ais
Exemple : épaisseur substrat
analyse avec le module
MULTIPLE REGRESSIONde STATISTICA
r = - 0.8355 R2 = 0.698
F(1,13)=30.057 p < 0.00011
b* Std. Err.b =
β
Std. Err.b t(13) p-level
Intercept 15.500 1.0426 14.867 0.0000
X-pression - 0.8355 0.1524 - 1.100 0.2006 -5.482 0.0001
b1 = β1
b0 = β0
coefficientsen variablescentrées - réduites
test de
signification
chapitre 2
Regression Linéaire Simple : Y = β0 + β1X1 + ε résultats
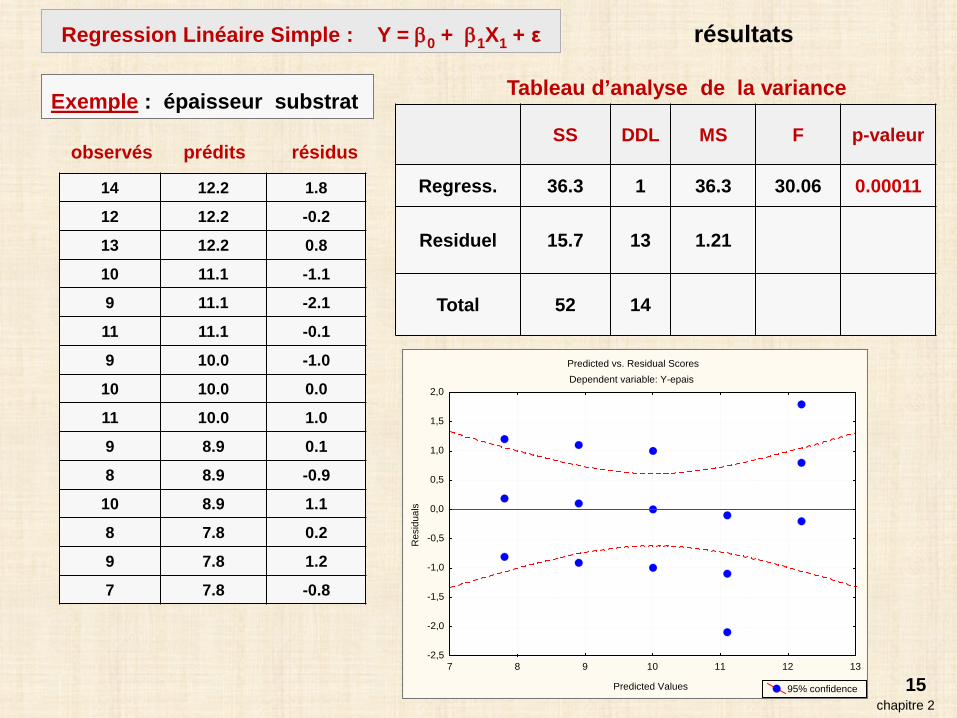
15
14 12.2 1.8
12 12.2 -0.2
13 12.2 0.8
10 11.1 -1.1
9 11.1 -2.1
11 11.1 -0.1
9 10.0 -1.0
10 10.0 0.0
11 10.0 1.0
9 8.9 0.1
8 8.9 -0.9
10 8.9 1.1
8 7.8 0.2
9 7.8 1.2
7 7.8 -0.8
SS DDL MS F p-valeur
Regress. 36.3 1 36.3 30.06 0.00011
Residuel 15.7 13 1.21
Total 52 14
Tableau d’analyse de la variance
Predicted vs. Residual ScoresDependent variable: Y-epais
7 8 9 10 11 12 13
Predicted Values
-2,5
-2,0
-1,5
-1,0
-0,5
0,0
0,5
1,0
1,5
2,0
Res
idua
ls
95% confidence
observés prédits résidus
chapitre 2
Exemple : épaisseur substrat
Regression Linéaire Simple : Y = β0 + β1X1 + ε résultats
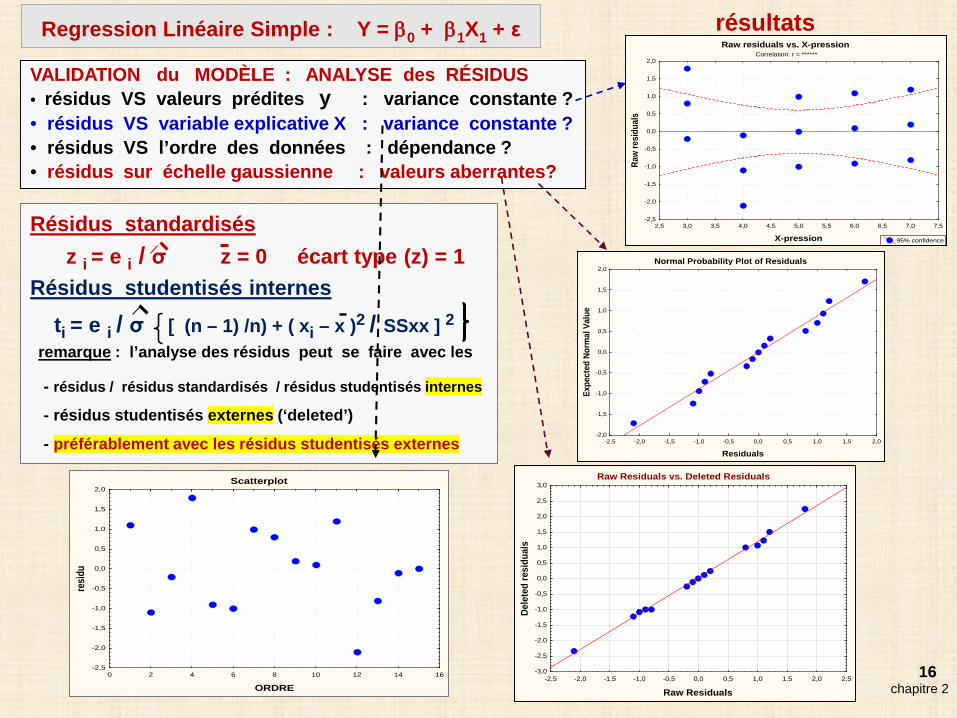
16
VALIDATION du MODÈLE : ANALYSE des RÉSIDUS• résidus VS valeurs prédites y : variance constante ?• résidus VS variable explicative X : variance constante ?• résidus VS l’ordre des données : dépendance ?• résidus sur échelle gaussienne : valeurs aberrantes?
Raw residuals vs. X-pressionCorrelation: r = ******
2,5 3,0 3,5 4,0 4,5 5,0 5,5 6,0 6,5 7,0 7,5
X-pression
-2,5
-2,0
-1,5
-1,0
-0,5
0,0
0,5
1,0
1,5
2,0
Raw
resi
dual
s
95% confidence
Scatterplot
0 2 4 6 8 10 12 14 16
ORDRE
-2,5
-2,0
-1,5
-1,0
-0,5
0,0
0,5
1,0
1,5
2,0
resid
u
Résidus standardisész i = e i / σ z = 0 écart type (z) = 1
Résidus studentisés internesti = e i / σ [ (n – 1) /n) + ( xi – x )2 / SSxx ] 2
remarque : l’analyse des résidus peut se faire avec les
- résidus / résidus standardisés / résidus studentisés internes
- résidus studentisés externes (‘deleted’)
- préférablement avec les résidus studentisés externes
chapitre 2
Regression Linéaire Simple : Y = β0 + β1X1 + ε résultats
Normal Probability Plot of Residuals
-2,5 -2,0 -1,5 -1,0 -0,5 0,0 0,5 1,0 1,5 2,0
Residuals
-2,0
-1,5
-1,0
-0,5
0,0
0,5
1,0
1,5
2,0
Expe
cted
Nor
mal
Val
ue
Raw Residuals vs. Deleted Residuals
-2,5 -2,0 -1,5 -1,0 -0,5 0,0 0,5 1,0 1,5 2,0 2,5
Raw Residuals
-3,0
-2,5
-2,0
-1,5
-1,0
-0,5
0,0
0,5
1,0
1,5
2,0
2,5
3,0
Dele
ted
resi
dual
s
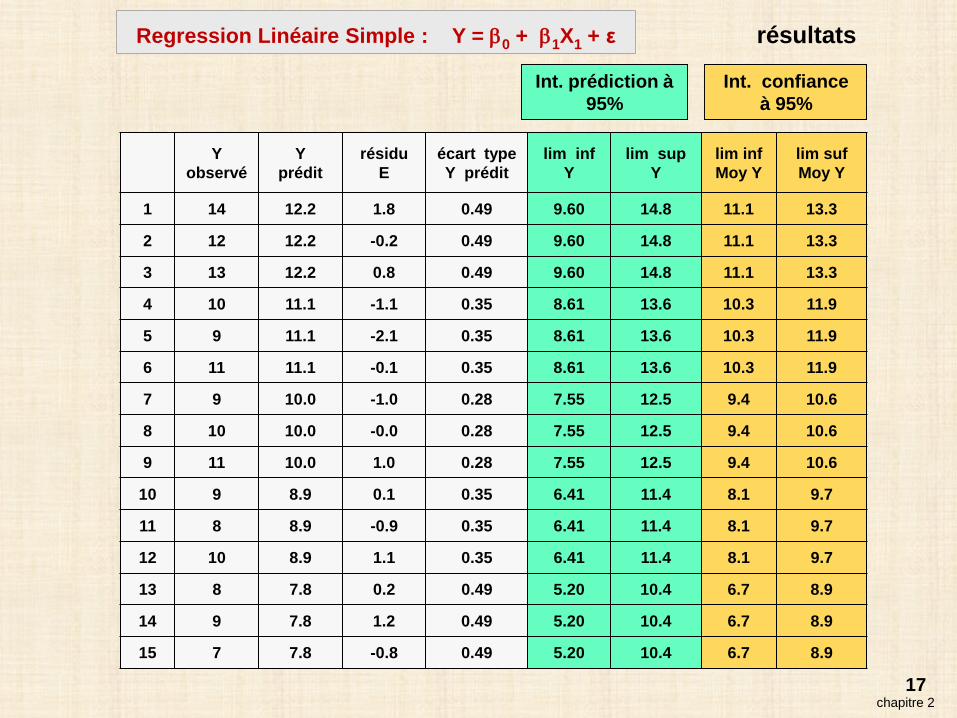
17
Yobservé
Yprédit
résiduE
écart typeY prédit
lim infY
lim supY
lim infMoy Y
lim sufMoy Y
1 14 12.2 1.8 0.49 9.60 14.8 11.1 13.3
2 12 12.2 -0.2 0.49 9.60 14.8 11.1 13.3
3 13 12.2 0.8 0.49 9.60 14.8 11.1 13.3
4 10 11.1 -1.1 0.35 8.61 13.6 10.3 11.9
5 9 11.1 -2.1 0.35 8.61 13.6 10.3 11.9
6 11 11.1 -0.1 0.35 8.61 13.6 10.3 11.9
7 9 10.0 -1.0 0.28 7.55 12.5 9.4 10.6
8 10 10.0 -0.0 0.28 7.55 12.5 9.4 10.6
9 11 10.0 1.0 0.28 7.55 12.5 9.4 10.6
10 9 8.9 0.1 0.35 6.41 11.4 8.1 9.7
11 8 8.9 -0.9 0.35 6.41 11.4 8.1 9.7
12 10 8.9 1.1 0.35 6.41 11.4 8.1 9.7
13 8 7.8 0.2 0.49 5.20 10.4 6.7 8.9
14 9 7.8 1.2 0.49 5.20 10.4 6.7 8.9
15 7 7.8 -0.8 0.49 5.20 10.4 6.7 8.9
Int. prédiction à 95%
Int. confiance à 95%
chapitre 2
Regression Linéaire Simple : Y = β0 + β1X1 + ε résultats

18
Scatterplot (CH11-v5.sta 25v*36c)Y_EPAIS = 15,5-1,1*x; 0,95 Conf.Int.
2,5 3,0 3,5 4,0 4,5 5,0 5,5 6,0 6,5 7,0 7,5
X_PRESSI
6
7
8
9
10
11
12
13
14
15
Y_EP
AIS
X_PRESSI:Y_EPAIS: y = 15,5 - 1,1*x; r = -0,8355; p = 0,0001;r2 = 0,6981
Scatterplot (CH11-v5.sta 25v*36c)Y_EPAIS = 15,5-1,1*x; 0,95 Pred.Int.
2,5 3,0 3,5 4,0 4,5 5,0 5,5 6,0 6,5 7,0 7,5
X_PRESSI
6
7
8
9
10
11
12
13
14
15
Y_EP
AIS
X_PRESSI:Y_EPAIS: y = 15,5 - 1,1*x; r = -0,8355; p = 0,0001;r2 = 0,6981
intervalle de confiance :
moyenne de Y
intervalle de prédiction de Y
chapitre 2
Regression Linéaire Simple : Y = β0 + β1X1 + ε résultats
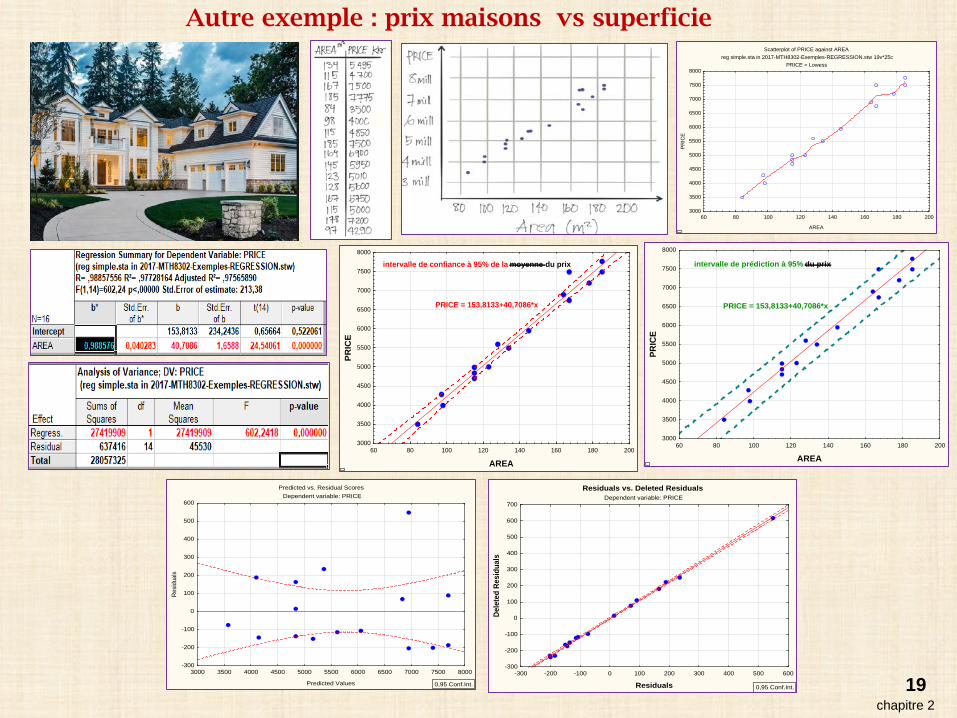
Scatterplot of PRICE against AREAreg simple.sta in 2017-MTH8302-Exemples-REGRESSION.stw 19v*25c
PRICE = Lowess
60 80 100 120 140 160 180 200
AREA
3000
3500
4000
4500
5000
5500
6000
6500
7000
7500
8000
PRIC
E
60 80 100 120 140 160 180 200
AREA
3000
3500
4000
4500
5000
5500
6000
6500
7000
7500
8000
PRIC
E
intervalle de confiance à 95% de la moyenne du prix
PRICE = 153,8133+40,7086*x
60 80 100 120 140 160 180 200
AREA
3000
3500
4000
4500
5000
5500
6000
6500
7000
7500
8000
PRIC
E
PRICE = 153,8133+40,7086*x
intervalle de prédiction à 95% du prix
Predicted vs. Residual ScoresDependent variable: PRICE
3000 3500 4000 4500 5000 5500 6000 6500 7000 7500 8000
Predicted Values
-300
-200
-100
0
100
200
300
400
500
600
Resid
uals
0,95 Conf.Int.
Residuals vs. Deleted ResidualsDependent variable: PRICE
-300 -200 -100 0 100 200 300 400 500 600
Residuals
-300
-200
-100
0
100
200
300
400
500
600
700De
lete
d Re
sidu
als
0,95 Conf.Int.
Autre exemple : prix maisons vs superficie
chapitre 219

20
JUSTESSE du MODÈLE: avec observations répétées de Y à des valeurs de X
Estimation de σ2 : - calculée avec le modèle ajusté (Droite de Moindres Carrés)- dépend du modèle postulé
question : peut – on estimer σ2 indépendamment du modèle postulé (y = β 0 + β 1 x + ε ) ?réponse : oui, si on a au moins 2 observations de Y à au moins 3 valeurs distinctes de Xutilisation : tester le manque d’ajustement (maj) du modèle postulé
X
Y Données somme carrés ddlx 1 y 11 y 12 …. y 1 n1 ( n1 - 1 ) s 1
2 n1 – 1
x 2 y 21 y 22 …. y 2 n2 ( n2 – 1 ) s 22 n2 - 1
….. …. ….. ..... ….. …………. ……….
x k y k1 y k2 …. y k nk ( nk - 1 ) s k2 nk - 1
SSE = ∑ (n j - 1) s j2 n - k
Nouvelle décomposition de la somme totale de carrés totale
avant : SStot (totale) = SSreg (modèle ) + SSresid (résiduelle)
maintenant : SStot = SSreg + SSerpu (erreur pure ) + SSmaj (manque d’ajustement)deg. liberté : n – 1 = 1 + ( n – k ) + ( k – 2 )
remarque : SSmaj est calculée par différence SSmaj = SSresid – SSerpu
Y = β0 + β1 x
chapitre 2
RÉGRESSION LINÉAIRE SIMPLE : observations répétées Théorie
Copyright © Génistat Conseils Inc.Montréal, Canada, 2017

21
tableau d’analyse de la variance modifié SOURCE DDL SS MS = SS / DDL F-ratio p-valeurmodèle 1 SSreg MSreg = SSreg/1 F1 = MSreg / MSresid p1= P( F ≥ F1 )
résiduelle n – 2 SSresid MSresid = SSresid/(n-2) ---------- ----------
LOF k – 2 SSmaj MSmaj = SSmaj/(k -2) F2 = MSmaj / MSerpu p2= P( F ≥ F2 )
pure n – k SSerpu MSerpu = Sserpu / (n – k) = σ2 ----------- -----------
Totale n – 1 SStot -----------
test du manque d’ajustement du modèle linéaireH0M : E(Y│x) = β 0 + β 1 x versus H1 : non H0M
test : rejeter H0 au seuil α si F2 > F n – k , k – 2 , 1 – α
remarques
- on rejette H0M si p2 < α (seuil)- si on rejette H0M , il faut postulé une autre équation ( modèle ) que la droite
- si on ne rejette pas H0M , on conserve le tableau d’analyse de la variance (p 6)
chapitre 2
RÉGRESSION LINÉAIRE SIMPLE : observations répétées Théorie
Copyright © Génistat Conseils Inc.Montréal, Canada, 2017

22
Scatterplot (Ch11-v5.sta 26v*36c)Y_STRENT = -26,32+0,498*x
95 100 105 110 115 120 125 130 135 140 145
X_DEG
15
20
25
30
35
40
45
50
Y_ST
RENT
Exemple : expérience avec un facteur X contrôlé X = température (degrés F) Y = résistance matériau
données: X = 100 : Y = 20 – 25 - 23 – 27 – 19 X = 110 : Y = 25 – 29 – 31 – 30 – 27
X = 120 : Y = 36 – 37 – 29 – 40 – 33 X = 130 : Y = 35 – 39 – 31 – 42 – 44
X = 140 : Y = 43 – 40 – 36 – 48 – 47
R = 0.879 R2 = 0.773 F(1,23)=78.323 p < 0.000
b* Std.Error b Std
Errorr t(23) p-level
Interct -26.320 6.799 -3.87 0.0007
X_DEG 0.879 0.099 0.498 0.056 8.85 0.0000
ANOVA SS DF MS F p-level
Regress. 1240.02 1 1240.02 78.323 0.0000
Residual 364.14 23 15.832
Total 1604.16 24
chapitre 2
RÉGRESSION LINÉAIRE SIMPLE : observations répétées

23
3.35 22.82.41 28.44.18 35.05.26 38.24.97 42.8
x s y100
110
120
130
140
SSerpu = 4 (3,352 + 2,412 + … + 4,972)
= 347,6 avec 4*5 = 20 ddl
SSmaj = SSresid – SSerpu = 364,14 – 347,60= 16,54 avec 23-20 = 3 ddl
MSmaj = 16,54 / 3 = 5,51
MSerpu = SSerpu / 20 = 17,38
F2 = 5,51 / 17,38 = 0,32
modèle linéaire OK : pas rejeté
chapitre 2
RÉGRESSION LINÉAIRE SIMPLE : observations répétées
Exemple: expérience avec un facteur X contrôlé X = température (degrés F) Y = résistance matériau
données: X = 100 : Y = 20 – 25 - 23 – 27 – 19 X = 110 : Y = 25 – 29 – 31 – 30 – 27
X = 120 : Y = 36 – 37 – 29 – 40 – 33 X = 130 : Y = 35 – 39 – 31 – 42 – 44
X = 140 : Y = 43 – 40 – 36 – 48 – 47

24
TRANSFORMATIONS pour stabiliser la variance : Y’ = h( Y )
Cas lien σ2 = var(Y) et μ = moy(Y) transformation Y’
Y ~ Poisson σ2 α μ Y’ = Y0.5
Y ~ Binomiale σ2 α μ ( 1 - μ ) Y’ = arcsin(Y0.5)
plusieurs ordres de σ2 α μ2 Y’ = log( Y )grandeurs pour Yautres cas: transformation Box-Cox Y’ = Y λ - 2 ≤ λ ≤ 2
λ = ?
chapitre 2
RÉGRESSION LINÉAIRE SIMPLE : analyse résidus
DÉFICIENCES DÉTECTÉES à l’analyse de résiduscorrectifs et transformations
- rendre la variance plus constante (stabilisation de la variance)
- obtenir une distribution gaussienne pour le terme d’erreur
- transformer certains modèles non linéaires en modèles linéaires
Copyright © Génistat Conseils Inc.Montréal, Canada, 2017
25
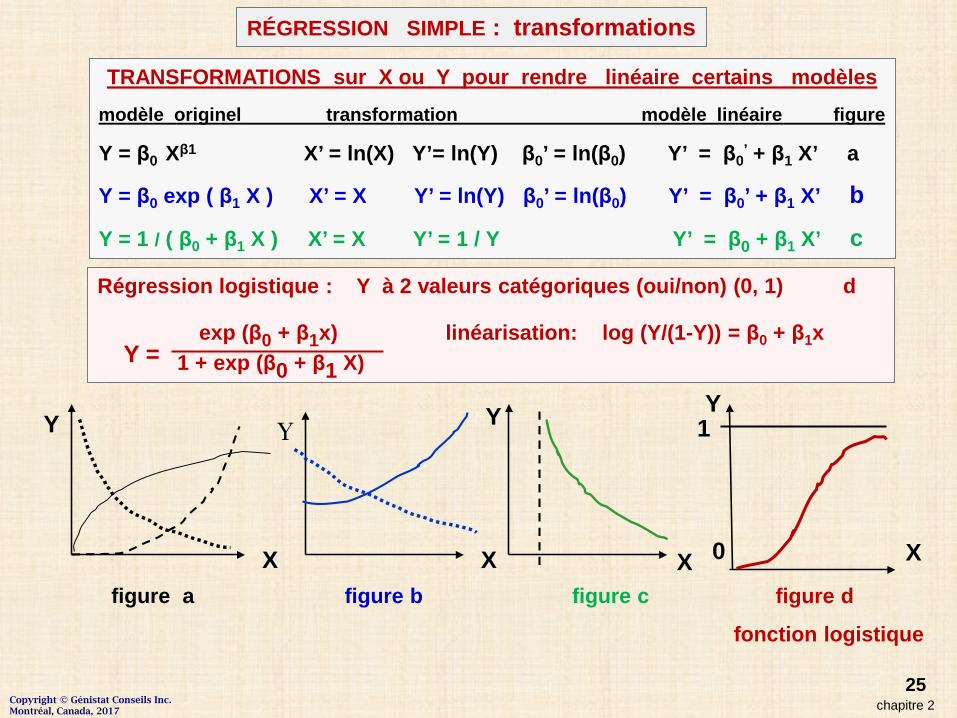
Régression logistique : Y à 2 valeurs catégoriques (oui/non) (0, 1) d
exp (β0 + β1x) linéarisation: log (Y/(1-Y)) = β0 + β1x 1 + exp (β0 + β1 X)
figure a figure b figure c figure d
fonction logistique
X X X X
1Y YY
chapitre 2
RÉGRESSION SIMPLE : transformations
Y =
TRANSFORMATIONS sur X ou Y pour rendre linéaire certains modèlesmodèle originel transformation modèle linéaire figure
Y = β0 Xβ1 X’ = ln(X) Y’= ln(Y) β0’ = ln(β0) Y’ = β0’ + β1 X’ a
Y = β0 exp ( β1 X ) X’ = X Y’ = ln(Y) β0’ = ln(β0) Y’ = β0’ + β1 X’ b
Y = 1 / ( β0 + β1 X ) X’ = X Y’ = 1 / Y Y’ = β0 + β1 X’ c
0
Y
Copyright © Génistat Conseils Inc.Montréal, Canada, 2017
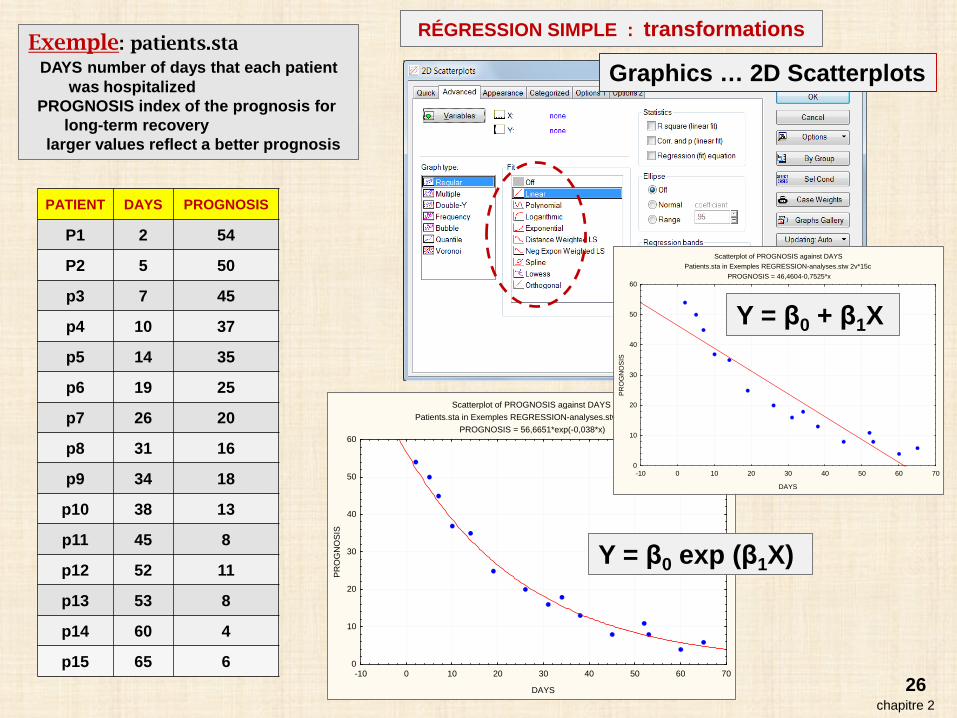
26chapitre 2
PATIENT DAYS PROGNOSIS
P1 2 54
P2 5 50
p3 7 45
p4 10 37
p5 14 35
p6 19 25
p7 26 20
p8 31 16
p9 34 18
p10 38 13
p11 45 8
p12 52 11
p13 53 8
p14 60 4
p15 65 6
Scatterplot of PROGNOSIS against DAYSPatients.sta in Exemples REGRESSION-analyses.stw 2v*15c
PROGNOSIS = 56,6651*exp(-0,038*x)
-10 0 10 20 30 40 50 60 70
DAYS
0
10
20
30
40
50
60
PRO
GN
OSI
S
Y = β0 exp (β1X)
Scatterplot of PROGNOSIS against DAYSPatients.sta in Exemples REGRESSION-analyses.stw 2v*15c
PROGNOSIS = 46,4604-0,7525*x
-10 0 10 20 30 40 50 60 70
DAYS
0
10
20
30
40
50
60
PRO
GN
OSI
S
Graphics … 2D Scatterplots
RÉGRESSION SIMPLE : transformations
Y = β0 + β1X
Exemple: patients.staDAYS number of days that each patient
was hospitalizedPROGNOSIS index of the prognosis for
long-term recoverylarger values reflect a better prognosis

chapitre 2
Nonlinear Estimation
Fixed Nonlinear Regression:transformations programmées
RÉGRESSION non linéaire avec Statistica
27
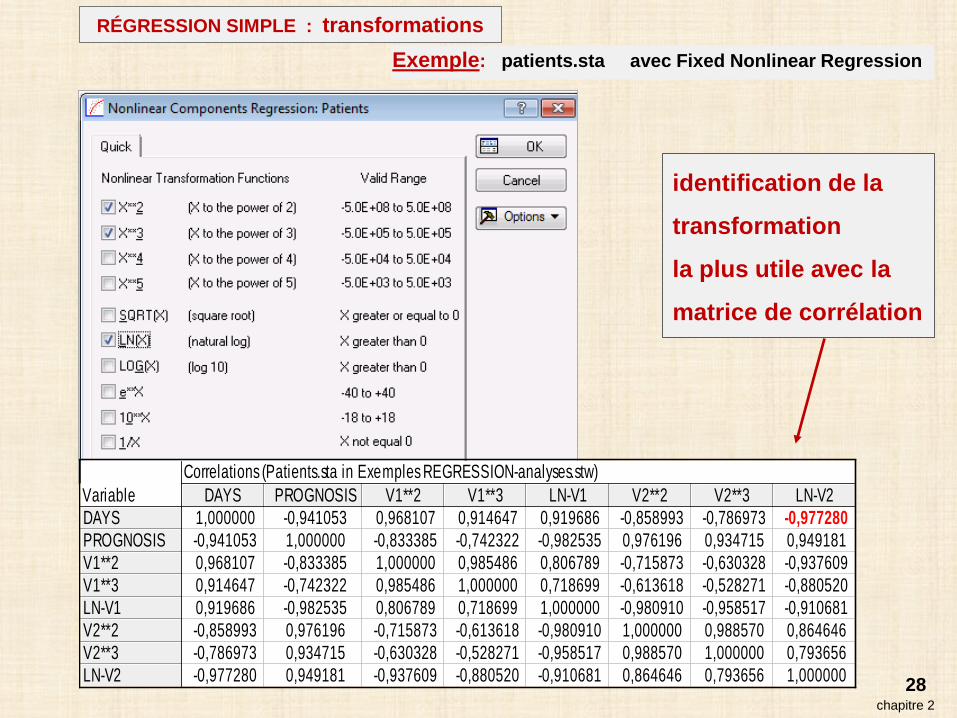
28chapitre 2
Exemple: patients.sta avec Fixed Nonlinear Regression
Correlations (Patients.sta in Exemples REGRESSION-analyses.stw)Variable DAYS PROGNOSIS V1**2 V1**3 LN-V1 V2**2 V2**3 LN-V2DAYSPROGNOSISV1**2V1**3LN-V1V2**2V2**3LN-V2
1,000000 -0,941053 0,968107 0,914647 0,919686 -0,858993 -0,786973 -0,977280-0,941053 1,000000 -0,833385 -0,742322 -0,982535 0,976196 0,934715 0,9491810,968107 -0,833385 1,000000 0,985486 0,806789 -0,715873 -0,630328 -0,9376090,914647 -0,742322 0,985486 1,000000 0,718699 -0,613618 -0,528271 -0,8805200,919686 -0,982535 0,806789 0,718699 1,000000 -0,980910 -0,958517 -0,910681-0,858993 0,976196 -0,715873 -0,613618 -0,980910 1,000000 0,988570 0,864646-0,786973 0,934715 -0,630328 -0,528271 -0,958517 0,988570 1,000000 0,793656-0,977280 0,949181 -0,937609 -0,880520 -0,910681 0,864646 0,793656 1,000000
identification de la
transformation
la plus utile avec la
matrice de corrélation
RÉGRESSION SIMPLE : transformations
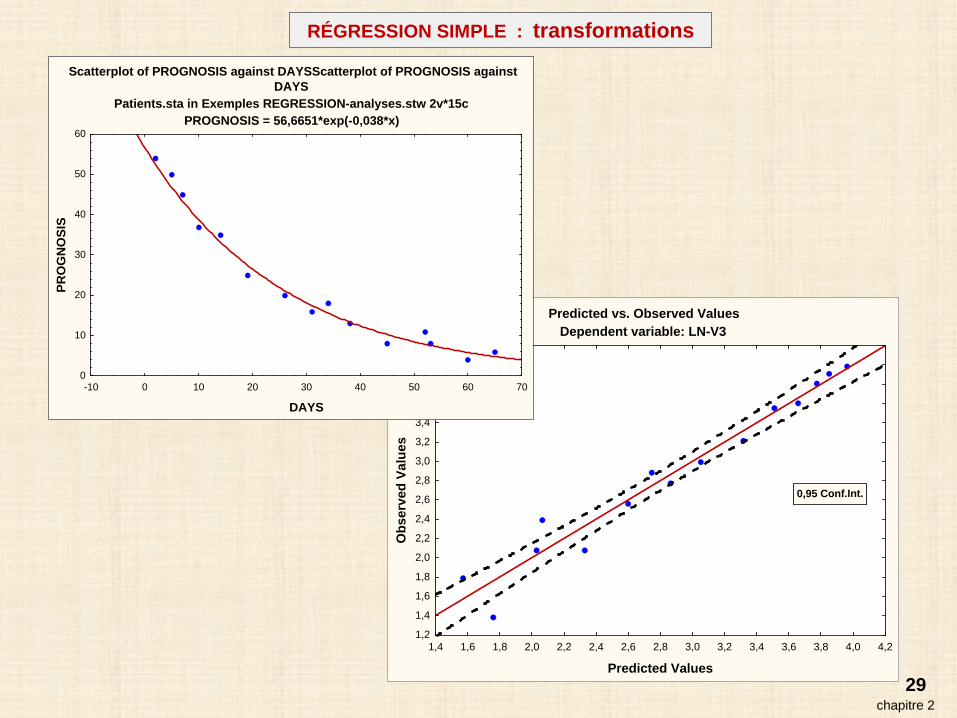
29chapitre 2
Predicted vs. Observed ValuesDependent variable: LN-V3
1,4 1,6 1,8 2,0 2,2 2,4 2,6 2,8 3,0 3,2 3,4 3,6 3,8 4,0 4,2
Predicted Values
1,2
1,4
1,6
1,8
2,0
2,2
2,4
2,6
2,8
3,0
3,2
3,4
3,6
3,8
4,0
4,2
Obs
erve
d Va
lues
0,95 Conf.Int.
Scatterplot of PROGNOSIS against DAYSScatterplot of PROGNOSIS againstDAYS
Patients.sta in Exemples REGRESSION-analyses.stw 2v*15cPROGNOSIS = 56,6651*exp(-0,038*x)
-10 0 10 20 30 40 50 60 70
DAYS
0
10
20
30
40
50
60
PRO
GN
OSI
S
RÉGRESSION SIMPLE : transformations
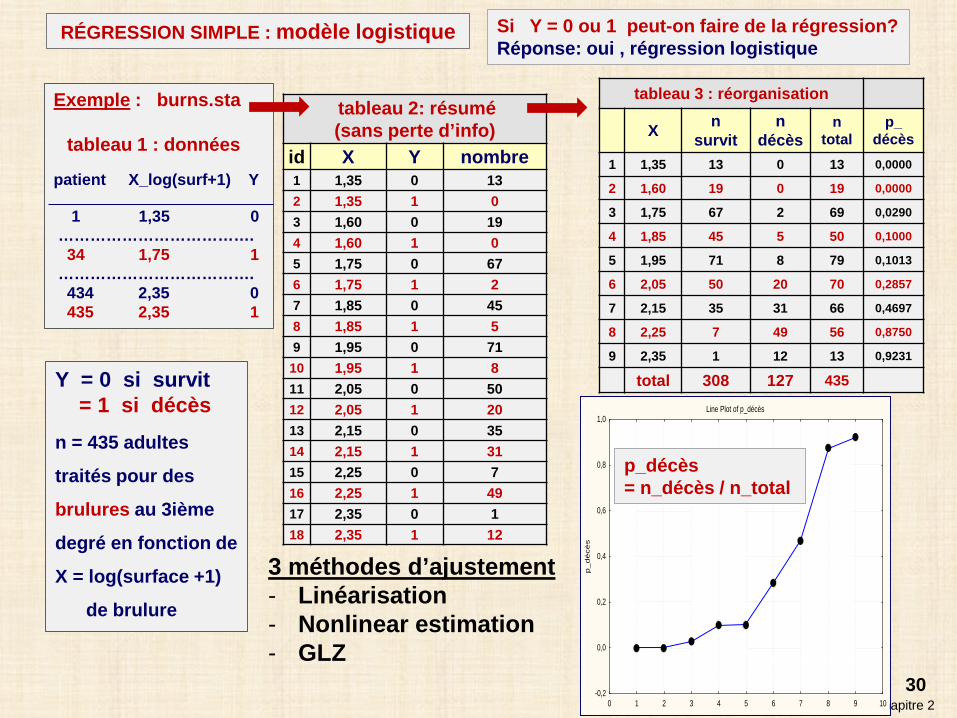
30chapitre 2
Si Y = 0 ou 1 peut-on faire de la régression?Réponse: oui , régression logistique
tableau 3 : réorganisation
X nsurvit
ndécès
ntotal
p_décès
1 1,35 13 0 13 0,0000
2 1,60 19 0 19 0,0000
3 1,75 67 2 69 0,0290
4 1,85 45 5 50 0,1000
5 1,95 71 8 79 0,1013
6 2,05 50 20 70 0,2857
7 2,15 35 31 66 0,4697
8 2,25 7 49 56 0,8750
9 2,35 1 12 13 0,9231
total 308 127 435
Exemple : burns.sta
tableau 1 : données
patient X_log(surf+1) Y
1 1,35 0……………………………….
34 1,75 1……………………………….
434 2,35 0435 2,35 1
Y = 0 si survit= 1 si décès
n = 435 adultes
traités pour des
brulures au 3ième
degré en fonction de
X = log(surface +1)
de brulure
Line Plot of p_décès
0 1 2 3 4 5 6 7 8 9 10-0,2
0,0
0,2
0,4
0,6
0,8
1,0
p_décès
tableau 2: résumé(sans perte d’info)
id X Y nombre1 1,35 0 132 1,35 1 03 1,60 0 194 1,60 1 05 1,75 0 676 1,75 1 27 1,85 0 458 1,85 1 59 1,95 0 7110 1,95 1 811 2,05 0 5012 2,05 1 2013 2,15 0 3514 2,15 1 3115 2,25 0 716 2,25 1 4917 2,35 0 118 2,35 1 12
p_décès= n_décès / n_total
RÉGRESSION SIMPLE : modèle logistique
3 méthodes d’ajustement- Linéarisation- Nonlinear estimation- GLZ

31chapitre 2
fonction logistique
π(x) = exp(α + βx)/(1 + exp(α + βx))
- courbe en forme sigmoïdale- 0 ≤ π(x) ≤ 1 …. probabilités- si x tends vers - ∞ π(x) tend vers 0- si x tends vers ∞ π(x) tend vers 1- si x = - α/β alors π(x) = 0,5
et la pente de f(x) vaut β/4
graphiques de la fonction logistique
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41-0,2
0,0
0,2
0,4
0,6
0,8
1,0
1,2
f1 f2 f3 f4
f(x) =exp(a + bx) / ( 1 + exp(a + bx))
f1: a = -4 b = 0,4f2: a = -8 b = 0,4f3: a = -12 b = 0,6f4: a = -20 b = 1,0
Prob(Y = 1 si X = x) = π(x) = exp(α + βx)/(1 + exp(α + βx))
Prob(Y = 0 si X = x) = 1 – π(x) = 1/(1 + exp(α + βx))
log[π(x) /(1- π(x))] = α + βx
log[π(x) /(1- π(x))] = logit (π(x))
π(x) / (1 - π(x)): rapport des cotes(odd ratio)
RÉGRESSION SIMPLE : modèle logistique
Copyright © Génistat Conseils Inc.Montréal, Canada, 2017

32chapitre 2
Interprétation du paramètre β
logit(π(x)) = log[π(x) /(1- π(x))] = α + βx
logit(π(x+1)) = log[π(x+1) /(1- π(x+1))] = α + β(x+1) = α + βx + β
β = logit(π(x+1)) - logit(π(x))
= log {[π(x+1) /(1- π(x+1))] / π(x) /(1- π(x))]}
= log { odds (x +1) / odds(x) }
eβ = odds (x +1) / odds(x) = odds ratio (ratio des cotes)
accroissement de la probabilité que Y = 1
si x augmente de 1
RÉGRESSION SIMPLE : modèle logistique
Copyright © Génistat Conseils Inc.Montréal, Canada, 2017

33chapitre 2
2 possibilités pour le calcul des prédictionsajustement par linéarisationéquations linéaires – cas traité ici
ajustement par estimation non linéaireéquations non linéaires – page suivante
i X pdécès
logit(p)(obs)
logit(p)(pred)
p décès(pred)
1 1,35 0 indéfini -7,816 0,00042 1,60 0 Indéfini -5,248 0,00533 1,75 0,0290 -3,540 -3,708 0,02354 1,85 0,1000 -2,197 -2,670 0,06215 1,95 0,1013 -2,183 -1,640 0,15386 2,05 0,2857 -0,916 -0,621 0,33297 2,15 0,4697 -0,092 0,406 0,57818 2,25 0,8750 2,10 1,434 0,79009 2,35 0,9231 2,485 2,461 0,9117
logit(p) = ln[ p/(1-p) ]
logit(0) n‘est pas défini
régression de logit(p)(obs) sur Xcas logit(p)(obs) défini i = 3, 4,.., 7logit(p)(pred) = -21,68 + 10,27*X = u
utilisation de l’équation obtenuepour tous les cas i = 1, 2,…,7
p_pred = exp (u) / (1 + exp(u))
RÉGRESSION SIMPLE : modèle logistiqueTableau
Line Plot of multiple variablesSpreadsheet17 10v*9c
1,35 1,60 1,75 1,85 1,95 2,05 2,15 2,25 2,35-0,2
0,0
0,2
0,4
0,6
0,8
1,0
p_obs
p_pred
Copyright © Génistat Conseils Inc.Montréal, Canada, 2017
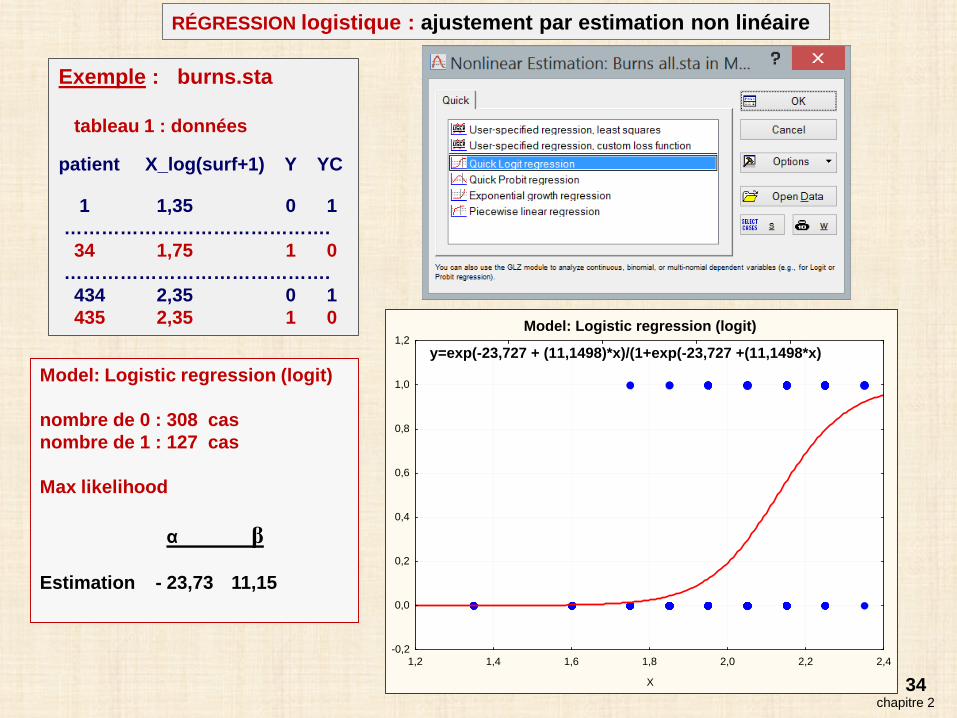
34chapitre 2
RÉGRESSION logistique : ajustement par estimation non linéaire
Exemple : burns.sta
tableau 1 : données
patient X_log(surf+1) Y YC
1 1,35 0 1…………………………………….
34 1,75 1 0…………………………………….
434 2,35 0 1435 2,35 1 0
Model: Logistic regression (logit)
nombre de 0 : 308 casnombre de 1 : 127 cas
Max likelihood
α β
Estimation - 23,73 11,15
Model: Logistic regression (logit)
1,2 1,4 1,6 1,8 2,0 2,2 2,4
X
-0,2
0,0
0,2
0,4
0,6
0,8
1,0
1,2y=exp(-23,727 + (11,1498)*x)/(1+exp(-23,727 +(11,1498*x)
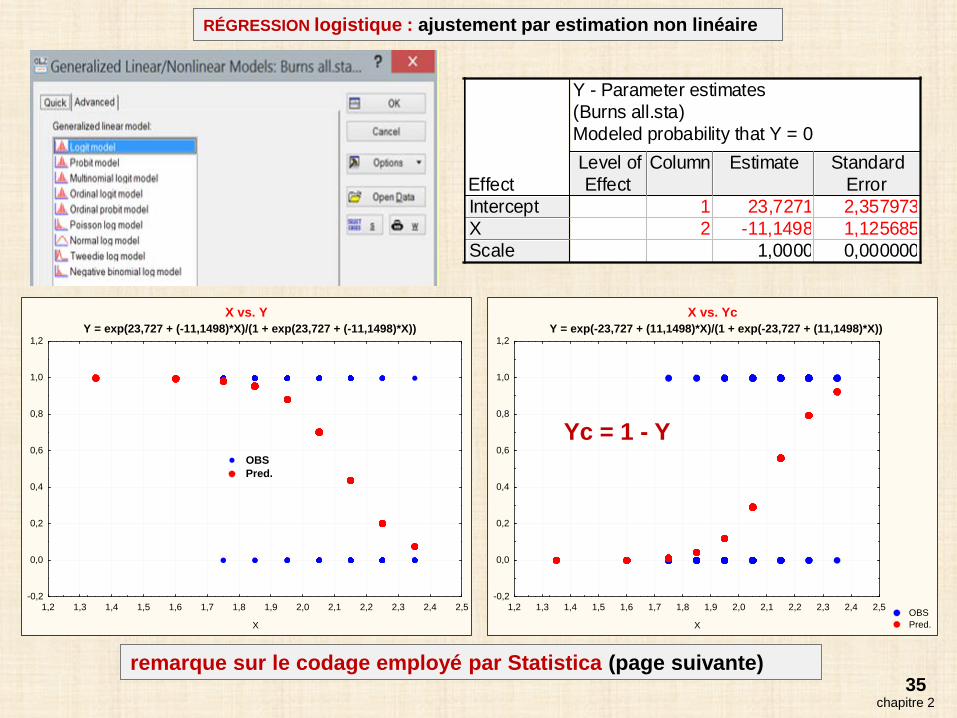
35chapitre 2
RÉGRESSION logistique : ajustement par estimation non linéaire
Y - Parameter estimates (Burns all.sta)Modeled probability that Y = 0
EffectLevel ofEffect
Column Estimate StandardError
InterceptXScale
1 23,7271 2,3579732 -11,1498 1,125685
1,0000 0,000000
X vs. YY = exp(23,727 + (-11,1498)*X)/(1 + exp(23,727 + (-11,1498)*X))
1,2 1,3 1,4 1,5 1,6 1,7 1,8 1,9 2,0 2,1 2,2 2,3 2,4 2,5
X
-0,2
0,0
0,2
0,4
0,6
0,8
1,0
1,2
OBS Pred.
X vs. YcY = exp(-23,727 + (11,1498)*X)/(1 + exp(-23,727 + (11,1498)*X))
OBS Pred.
1,2 1,3 1,4 1,5 1,6 1,7 1,8 1,9 2,0 2,1 2,2 2,3 2,4 2,5
X
-0,2
0,0
0,2
0,4
0,6
0,8
1,0
1,2
Yc = 1 - Y
remarque sur le codage employé par Statistica (page suivante)

chapitre 2Copyright © Génistat Conseils Inc.Montréal, Canada, 2014
Modèle logistique : remarque sur le codage employé par Statistica
RESPONSE CODES FOR 0 / 1 response variables (source : Help de Statistica)
When selecting (or specifying via syntax) response codes for binomial response variables (e.g., for logit models), the two selected values (numeric codes or text values) are recoded for the analysis, so that the first code that is specified will be recoded to 1, and the second value will be recoded to 0.For example, if you specified two text values No and Yes, then the first value (No) will be recoded for the analysis to 1, and the parameter estimates can be interpreted with respect to the probability of responding with No; so, if in such an analysis a positive parameter estimate is found for a particular predictor variable x¸ then it means that the more of x the greater is the likelihood of obtaining the response No.
Note that the default coding for binomial response variables in the Nonlinear Estimation module may not be the same as that performed in GLZ. One way to verify the particular coding that was performed is to review the spreadsheet of the predicted responses on the Resid 1 tab of the results dialog; that spreadsheet will report in the first column the recoded values (0 or 1) of the response variable.Codes for dep. var. Logit and probit regression models, in a sense, predict probabilities underlying the dichotomous dependent variable, and these methods will produce predicted (expected) values in the range between 0 and 1(for details, see Common Nonlinear Regression Models).
If the dependent variable is not coded in this way, that is, as 0 and 1, then you must specify the respective codes in the Codes for dep. var. boxes. To do this, double-click on this field (or press the F2 button on your keyboard) to display the variable dialog box or simply type in the two codes.As the data are read, the dependent variable will then be transformed so that all values that match the first code become 0 (zero), and all values that match the second code become 1.
36

RÉGRESSION SIMPLE : estimation non linéaire
Modèledose X - response Y (en %)
response = β0 (1 - 1 / [1+(dose / β2)**β1]non linéarisableβ0 valeur à saturationβ2 concentration quand Y = 50%β1 pente function
XDOSE
YRESPONSE
1 0,52 2,33 3,44 24,05 54,76 82,17 94,88 96,29 96,4
Pharmacologie.sta : estimation réponse à une dose de médicament
Model: Response = b0 - b0/(1+(Dose/b2)**b1)y=(99,54) - (99,54) / (1+(x / (4,799)) ** (6,76)
8))
0 1 2 3 4 5 6 7 8 9 10
DOSE
-20
0
20
40
60
80
100
120
chapitre 237

Model: Response = b0 - b0/(1+(Dose/b2)**b1)y=(99,54)-(99,54)/(1+(x/(4,799))**(6,76)
8))
0 1 2 3 4 5 6 7 8 9 10
DOSE
-20
0
20
40
60
80
100
120
38chapitre 2
RÉGRESSION SIMPLE : estimation non linéaire
Model is: Response = b0 - b0/(1+(Dose/b2)**b1)
r Observ ed Predicted Residuals123456789
0,500 0,0025 0,49752,300 0,2669 2,03313,400 3,9845 -0,584524,000 22,4756 1,524454,700 56,6077 -1,907782,100 81,5184 0,581694,800 92,3411 2,458996,200 96,4906 -0,290696,400 98,1416 -1,7416
Response = b0 - b0/(1+(Dose/b2)**b1)Loss: (OBS-PRED)**2Final loss: 20,1880R= 0,99932Variance explained: 99,865%
N=9 b0 b2 b1
EstimateStd.Err.
t(6)-95%CL
+95%CL
p-v alue
99,54 4,80 6,761,57 0,05 0,4363,33 95,13 15,8095,69 4,68 5,71
103,39 4,92 7,81
0,00 0,00 0,00
modélisation non linéaire :
généralement desétudes statistiques confirmatoirescar on a un modèle de départ

chapitre 239
logiciel JMP

chapitre 2
Courbes sigmoid: Logistic, Gompertz
Croissance/décroissance exponentielle: Exponentiel, Bi-exponentiel, mechanique
Modèles sommet: Gauss, Lorentz
Modèles pharmacocinétiques: 1-compartiment dose oralel, dose Bolus 2-compartimentBi-exponentielle 4P
Michaelis Menten: cinétique biochimique
40
Modèles non linéaires

chapitre 241
Courbes sigmoid: Logistic, Gompertz
Croissance/décroissance exponentielle: Exponentiel, Bi-exponentiel, mechanique
Modèles sommet: Gauss, Lorentz
Modèles pharmacocinétiques: 1-compartiment dose oralel, dose Bolus 2-compartimentBi-exponentielle 4P
Michaelis Menten: cinétique biochimique
Modèles non linéaires

chapitre 242
logiciel JMP

chapitre 243
Copyright © Génistat Conseils Inc.Montréal, Canada, 2017
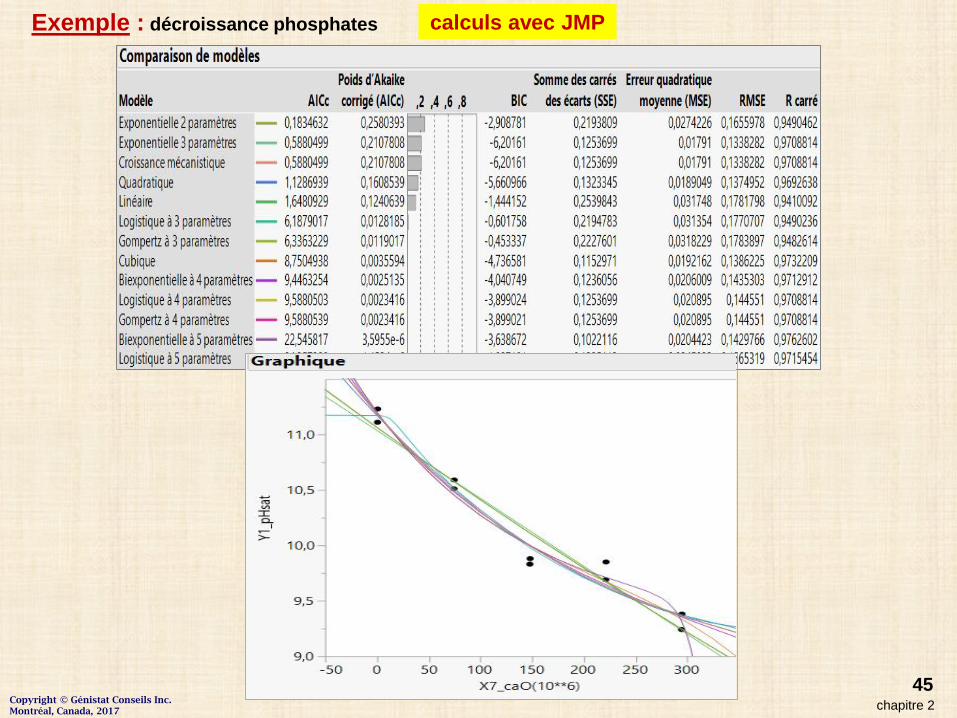
Critères pour la comparaison de modèles
AIC : critère d’information Akaike AIC = - 2 log(L) + 2kL : vraisemblance maximisée k : nombre de paramètres du modèleLa déviance du modèle (- 2 log(L)) est pénalisée par 2 fois le nombre de paramètres kL’AIC compromis entre le biais (qui diminue avec k ) et la parcimonie
(décrire les données avec le plus petit nombre de paramètres)
AICc : Akaike Information Criterion corrigé AICc = AIC + [ 2 k(k - 1) / (n - k + 1) ]modification du critère Akaide pour des petits échantillons (n < 40k). On doit avoir n ≥= k + 2. AICc est préférable à AIC pour de petits échantillons AICc permet de comparer 2 modèles ou plus.bon modèle : AICc petit
AICc WeightNormalisation des valeurs AICc pour avoir une somme de 1probabilité que le modèle est le meilleur parmi les modèles ajustés.modèle ayant AICc Weight la plus près de 1 est le modèle ayant le meilleur ajustement.
BIC : Bayesian Information Criterion BIC = -2 * LL + k * log(n)mesure de comparaison entre modèles bon modèle : BIC petit
SE : Sum of Square of Errors = différences entre les valeurs observées et les valeurs prédites.MSE : Mean Square Error valeur moyenne de SSE.RMSE : Root Mean Square Error racine carrée de MSE.R-Square proportion de la variation de la variable de réponse expliquée par le modèle.
bon modèle : R-Square près de 1
Remarque critère AIC ou AICc est préférable à R-square car il tient en compte le nombre de paramètres
chapitre 244
Copyright © Génistat Conseils Inc.Montréal, Canada, 2017
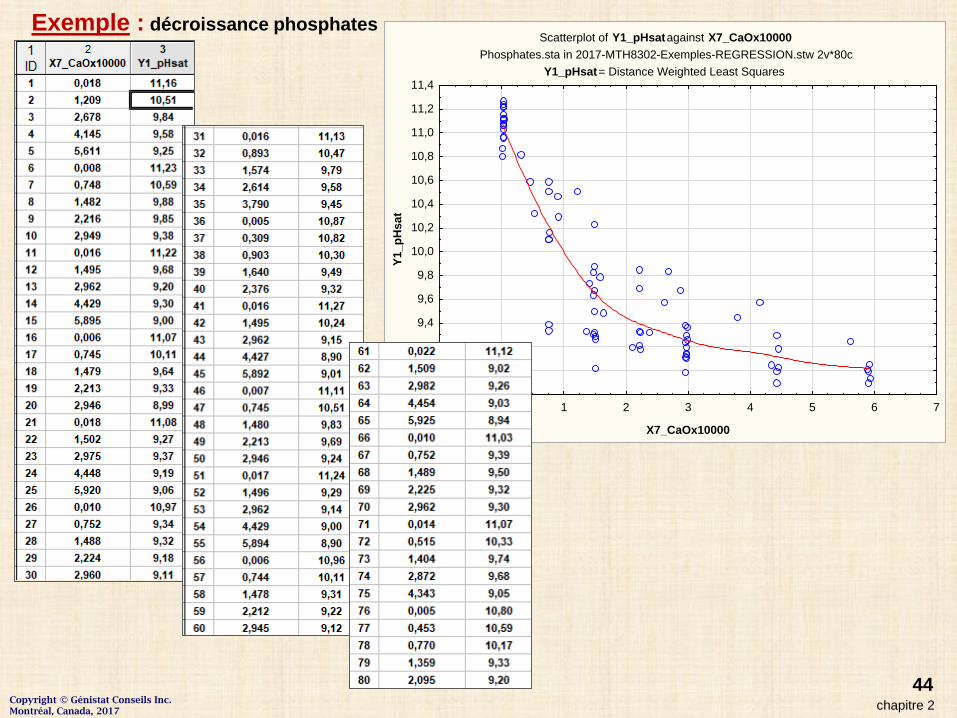
Exemple : décroissance phosphates Scatterplot of Y1_pHsat against X7_CaOx10000
Phosphates.sta in 2017-MTH8302-Exemples-REGRESSION.stw 2v*80cY1_pHsat = Distance Weighted Least Squares
-1 0 1 2 3 4 5 6 7
X7_CaOx10000
8,8
9,0
9,2
9,4
9,6
9,8
10,0
10,2
10,4
10,6
10,8
11,0
11,2
11,4
Y1_p
Hsa
t
chapitre 245
Copyright © Génistat Conseils Inc.Montréal, Canada, 2017
Exemple : décroissance phosphates calculs avec JMP


















