Regression logistique pour diff´ erents types´ d’etudes...
53
R´ egression logistique pour diff ´ erents types d’´ etudes ´ epid ´ emiologiques Thierry Duchesne D´ epartement de math ´ ematiques et de statistique et Unit ´ e de recherche en sant ´ e des populations [email protected] Rencontre scientifique Unit ´ e de recherche en sant ´ e des populations 5 novembre 2007
Transcript of Regression logistique pour diff´ erents types´ d’etudes...

Regression logistique pour differents typesd’etudes epidemiologiques
Thierry Duchesne
Departement de mathematiques et de statistiqueet
Unite de recherche en sante des populations
Rencontre scientifiqueUnite de recherche en sante des populations
5 novembre 2007

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Apercu
1 IntroductionRegression logistiqueRegression logistique conditionnelle
2 Etudes prospectives3 Etudes cas-temoins
Etude cas-temoins non apparieeEtude cas-temoins appariee
4 Etudes cas en chasse-croise5 Etudes familiales6 Etudes longitudinales
Etude longitudinale prospectiveEtude longitudinale cas-temoins appariee
7 Discussion
Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique
Rappel: probabilite, cote
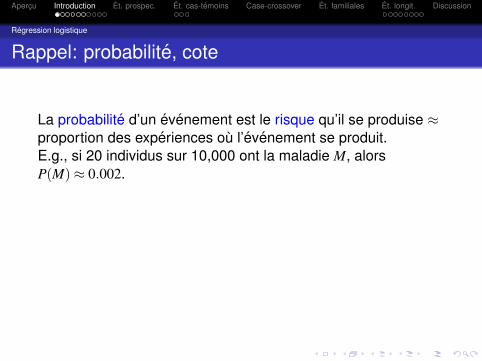
La probabilite d’un evenement est le risque qu’il se produise ≈proportion des experiences ou l’evenement se produit.E.g., si 20 individus sur 10,000 ont la maladie M, alorsP(M)≈ 0.002.
La cote d’un evenement est la rapport de la proba. qu’il seproduise sur celle qui ne se produise pas.E.g. Une cote de 3:1 (ou 3/1=3) pour un evenement A veut direque P(A)/{1−P(A)}= 3, donc que P(A) = 3/4.
Fait utile: Si P(A) est “petite” (< 10%), alors P(A)≈ cote(A).E.g. P(M) = 0.002, ⇒ cote(M) = 0.002/(1−0.002) = 0.002004.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique
Rappel: probabilite, cote
La probabilite d’un evenement est le risque qu’il se produise ≈proportion des experiences ou l’evenement se produit.E.g., si 20 individus sur 10,000 ont la maladie M, alorsP(M)≈ 0.002.
La cote d’un evenement est la rapport de la proba. qu’il seproduise sur celle qui ne se produise pas.E.g. Une cote de 3:1 (ou 3/1=3) pour un evenement A veut direque P(A)/{1−P(A)}= 3, donc que P(A) = 3/4.
Fait utile: Si P(A) est “petite” (< 10%), alors P(A)≈ cote(A).E.g. P(M) = 0.002, ⇒ cote(M) = 0.002/(1−0.002) = 0.002004.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique
Rappel: probabilite, cote
La probabilite d’un evenement est le risque qu’il se produise ≈proportion des experiences ou l’evenement se produit.E.g., si 20 individus sur 10,000 ont la maladie M, alorsP(M)≈ 0.002.
La cote d’un evenement est la rapport de la proba. qu’il seproduise sur celle qui ne se produise pas.E.g. Une cote de 3:1 (ou 3/1=3) pour un evenement A veut direque P(A)/{1−P(A)}= 3, donc que P(A) = 3/4.
Fait utile: Si P(A) est “petite” (< 10%), alors P(A)≈ cote(A).E.g. P(M) = 0.002, ⇒ cote(M) = 0.002/(1−0.002) = 0.002004.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique
Modele de regression logistique
Supposons que l’on veut estimer l’effet de certains facteurs surle risque qu’un evenement se produise ... Par exemple l’effetd’une exposition et de quelques autres variables sur le risqued’une maladie donnee.
Soit Yi = 1 si i a la maladie et Yi = 0 sinon, Ei = 1 si l’individu iest expose et Ei = 0 sinon, et xi1, . . ., xik d’autres variablespouvant avoir un effet sur le risque d’avoir la maladie.
Le modele de regression logistique suppose que
logP(Yi = 1)
1−P(Yi = 1)= α +βEEi +β1xi1 + · · ·+βkxik.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique
Interpretation des parametres
logP(Yi = 1)
1−P(Yi = 1)= α +βEEi +β1xi1 + · · ·+βkxik
α: log de la cote quand toutes les variables explicativessont a 0 (autrement dit, le “risque de base” estexp(α)/{1+ exp(α)}.βE : log du rapport de la cote de la maladie chez lesexposes sur la cote de la maladie chez les non exposesET que la valeur des autres variables demeure inchangee,i.e. si on passe de non expose a expose sans changer lesxi j, alors la cote de l’evenement est multipliee par exp(βE).β j, j = 1, . . . ,k: si xi j augmente d’une unite ET que la valeurdes autres variables demeure inchangee, alors la cote del’evenement est multipliee par exp(β j).

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique
Quelques commentaires
La valeur des β s’interprete simplement seulement dans lecas des (rapports de) cotes, non pas en terme d’effets surles risques ...... sauf dans le cas ou le risque est faible (< 10%), ou alorsla cote et risque sont a toutes fins pratiques de memevaleur.Si on etudie une maladie rare par regression logistique,alors on peut interpreter les rapports de cotes commeetant aussi des risques relatifs.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique
Estimation
Les donnees
n observations independantes: (yi,Ei,xi1, . . . ,xik), i = 1, . . . ,n.
Les estimes des parametres sont les valeurs qui maximisent lafonction de vraisemblance
L =n
∏i=1
eyi(α+βE Ei+β1xi1+···+βkxik)
1+ eα+βE Ei+β1xi1+···+βkxik.
Cette maximisation s’effectue par le biais de methodesnumeriques programmees dans plusieurs logiciels (SAS, R,STATA, MINITAB, etc.)
Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique
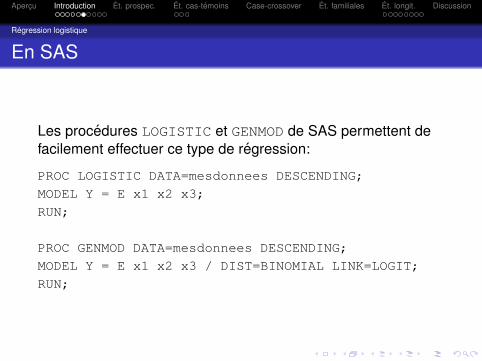
En SAS
Les procedures LOGISTIC et GENMOD de SAS permettent defacilement effectuer ce type de regression:
PROC LOGISTIC DATA=mesdonnees DESCENDING;
MODEL Y = E x1 x2 x3;
RUN;
PROC GENMOD DATA=mesdonnees DESCENDING;
MODEL Y = E x1 x2 x3 / DIST=BINOMIAL LINK=LOGIT;
RUN;

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique conditionnelle
Regression logistique conditionnelle
Parfois, les valeurs de Yi sont connues/fixees AVANT MEME deproceder a l’echantillonnage:Etudes cas-temoins appariees: Dans ce type d’etude, on
choisit un echantillon d’individus ou Yi = 1 et on lesapparie a d’autres individus pour qui Yi = 0.
Etude familiale: Dans l’etude de l’effet de la genetique sur lesmaladies rares, on echantillonne des familles chezqui on retrouve 2 cas ou plus de la maladie enquestion.
Il faut donc tenir compte de cet aspect “retrospectif” desdonnees lorsque l’on ajuste le modele ... et lorsqu’on en faitl’interpretation!

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique conditionnelle
Regression logistique conditionnelle
Parfois, les valeurs de Yi sont connues/fixees AVANT MEME deproceder a l’echantillonnage:Etudes cas-temoins appariees: Dans ce type d’etude, on
choisit un echantillon d’individus ou Yi = 1 et on lesapparie a d’autres individus pour qui Yi = 0.
Etude familiale: Dans l’etude de l’effet de la genetique sur lesmaladies rares, on echantillonne des familles chezqui on retrouve 2 cas ou plus de la maladie enquestion.
Il faut donc tenir compte de cet aspect “retrospectif” desdonnees lorsque l’on ajuste le modele ... et lorsqu’on en faitl’interpretation!

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique conditionnelle
Regression logistique conditionnelle
Parfois, les valeurs de Yi sont connues/fixees AVANT MEME deproceder a l’echantillonnage:Etudes cas-temoins appariees: Dans ce type d’etude, on
choisit un echantillon d’individus ou Yi = 1 et on lesapparie a d’autres individus pour qui Yi = 0.
Etude familiale: Dans l’etude de l’effet de la genetique sur lesmaladies rares, on echantillonne des familles chezqui on retrouve 2 cas ou plus de la maladie enquestion.
Il faut donc tenir compte de cet aspect “retrospectif” desdonnees lorsque l’on ajuste le modele ... et lorsqu’on en faitl’interpretation!

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique conditionnelle
Modele et interpretation
Comme ce qui nous interesse est toujours l’effet “prospectif”des variables, le modele demeure exactement le meme:
logP(Yi = 1)
1−P(Yi = 1)= α +βEEi +β1xi1 + · · ·+βkxik.
L’interpretation des estimes est tres similaire a ce qui se produitdans le cas des etudes cas-temoins avec tableau 2×2: les β
estiment les log-rapports de cotes, mais pas les risques relatifs(sauf pour maladies rares). En general, α n’est pas estimable(il disparait meme de la vraisemblance).

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique conditionnelle
Modele et interpretation
Comme ce qui nous interesse est toujours l’effet “prospectif”des variables, le modele demeure exactement le meme:
logP(Yi = 1)
1−P(Yi = 1)= α +βEEi +β1xi1 + · · ·+βkxik.
L’interpretation des estimes est tres similaire a ce qui se produitdans le cas des etudes cas-temoins avec tableau 2×2: les β
estiment les log-rapports de cotes, mais pas les risques relatifs(sauf pour maladies rares). En general, α n’est pas estimable(il disparait meme de la vraisemblance).
Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
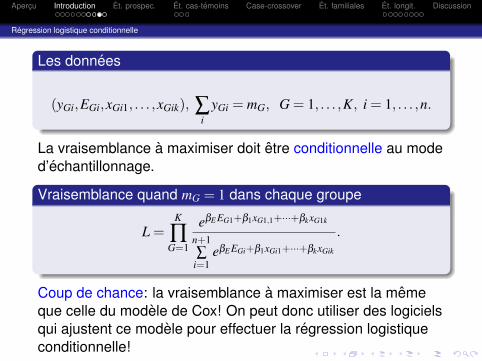
Regression logistique conditionnelle
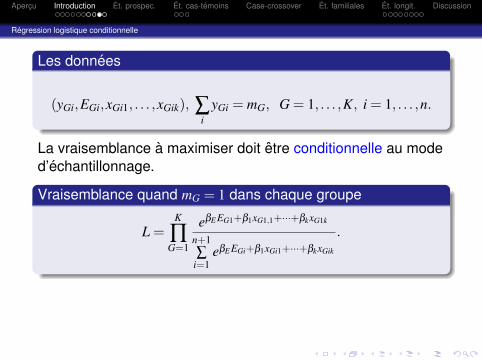
Les donnees
(yGi,EGi,xGi1, . . . ,xGik), ∑i
yGi = mG, G = 1, . . . ,K, i = 1, . . . ,n.
La vraisemblance a maximiser doit etre conditionnelle au moded’echantillonnage.
Vraisemblance quand mG = 1 dans chaque groupe
L =K
∏G=1
eβE EG1+β1xG1,1+···+βkxG1k
n+1∑
i=1eβE EGi+β1xGi1+···+βkxGik
.
Coup de chance: la vraisemblance a maximiser est la memeque celle du modele de Cox! On peut donc utiliser des logicielsqui ajustent ce modele pour effectuer la regression logistiqueconditionnelle!
Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique conditionnelle
Les donnees
(yGi,EGi,xGi1, . . . ,xGik), ∑i
yGi = mG, G = 1, . . . ,K, i = 1, . . . ,n.
La vraisemblance a maximiser doit etre conditionnelle au moded’echantillonnage.
Vraisemblance quand mG = 1 dans chaque groupe
L =K
∏G=1
eβE EG1+β1xG1,1+···+βkxG1k
n+1∑
i=1eβE EGi+β1xGi1+···+βkxGik
.
Coup de chance: la vraisemblance a maximiser est la memeque celle du modele de Cox! On peut donc utiliser des logicielsqui ajustent ce modele pour effectuer la regression logistiqueconditionnelle!
Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
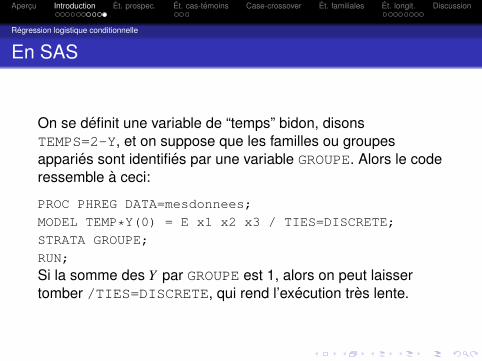
Regression logistique conditionnelle
En SAS
On se definit une variable de “temps” bidon, disonsTEMPS=2-Y, et on suppose que les familles ou groupesapparies sont identifies par une variable GROUPE. Alors le coderessemble a ceci:
PROC PHREG DATA=mesdonnees;
MODEL TEMP*Y(0) = E x1 x2 x3 / TIES=DISCRETE;
STRATA GROUPE;
RUN;
Si la somme des Y par GROUPE est 1, alors on peut laissertomber /TIES=DISCRETE, qui rend l’execution tres lente.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique et etudes prospectives
Si la reponse (Y ) n’est pas connue lors du recrutement, alorson peut utiliser la regression logistique ordinaire.L’interpretation habituelle des parametres α et β tient.
Exemples:
Etude de cohorte (prospective): Lemeshow et al. (1988),etude “ICU” (intensive care unit): cohorte d’invidus admis aune USI et on mesure le statut vital a la fin du sejour (Y = 1si mort, Y = 0 si vivant). But: predire Y a partir d’une foulede variables, incluant l’age, le sexe, la race, le service al’USI, historiques de problemes de sante specifiques, etc.Essai clinique randomise

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique et etudes prospectives
Si la reponse (Y ) n’est pas connue lors du recrutement, alorson peut utiliser la regression logistique ordinaire.L’interpretation habituelle des parametres α et β tient.
Exemples:Etude de cohorte (prospective): Lemeshow et al. (1988),etude “ICU” (intensive care unit): cohorte d’invidus admis aune USI et on mesure le statut vital a la fin du sejour (Y = 1si mort, Y = 0 si vivant). But: predire Y a partir d’une foulede variables, incluant l’age, le sexe, la race, le service al’USI, historiques de problemes de sante specifiques, etc.
Essai clinique randomise

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Regression logistique et etudes prospectives
Si la reponse (Y ) n’est pas connue lors du recrutement, alorson peut utiliser la regression logistique ordinaire.L’interpretation habituelle des parametres α et β tient.
Exemples:Etude de cohorte (prospective): Lemeshow et al. (1988),etude “ICU” (intensive care unit): cohorte d’invidus admis aune USI et on mesure le statut vital a la fin du sejour (Y = 1si mort, Y = 0 si vivant). But: predire Y a partir d’une foulede variables, incluant l’age, le sexe, la race, le service al’USI, historiques de problemes de sante specifiques, etc.Essai clinique randomise
Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
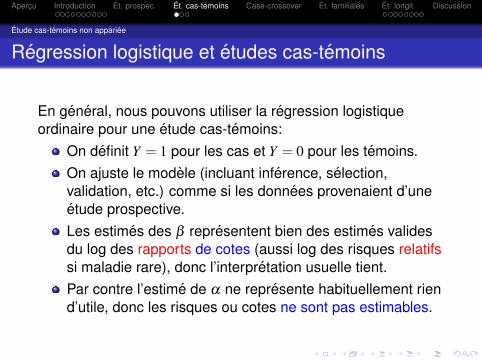
Etude cas-temoins non appariee
Regression logistique et etudes cas-temoins
En general, nous pouvons utiliser la regression logistiqueordinaire pour une etude cas-temoins:
On definit Y = 1 pour les cas et Y = 0 pour les temoins.On ajuste le modele (incluant inference, selection,validation, etc.) comme si les donnees provenaient d’uneetude prospective.Les estimes des β representent bien des estimes validesdu log des rapports de cotes (aussi log des risques relatifssi maladie rare), donc l’interpretation usuelle tient.Par contre l’estime de α ne represente habituellement riend’utile, donc les risques ou cotes ne sont pas estimables.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude cas-temoins appariee
Regression logistique et etudes cas-temoins
Dans une etude appariee, m cas et n temoins sont jumelesdans chaque strate (m = 1 et n = 1, . . . ,4 dans bien des etudesepidemiologiques).
Effectuer une regression logistique ordinaire avec la variable destratification incluse comme variable explicatrice categoriellen’est pas recommande (les inferences risquent d’etre invalides,Kleinbaum, 1994)! Il faut utiliser la regression logistiqueconditionnelle dans ce cas.
L’interpretation des β se fait comme pour une etudecas-temoins non appariee.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude cas-temoins appariee
Exemple (mastite sclerokystique, Hosmer &Lemeshow, 2000, section 7.5)
50 femmes avec diagnostic de mastite sclerokystique, chacuneappariee a trois autres du meme age. Pour i = 1, . . . ,200,
Yi = 1 pour les 50 cas, Yi = 0 pour les 150 temoins, et on mesurexi1, . . ., xi,11, des variables telles l’age, le niveau d’education, desdonnees sur les grossesses, etc. Gi prend les valeurs 1 a 50 etdenote le numero de la strate (groupe d’appariement) de lafemme i.
Ce modele peut ensuite etre ajuste grace a la procedure PHREGtel que decrit precedemment.
Un des modeles consideres par Hosmer & Lemeshow (2000)donne -1.161CHK+0.359AGMN-0.028WT+1.593NVMR, ouCHK vaut 1 pour “check ups” reguliers, 2 sinon; AGMN est l’age(en annees) a la menarche; WT est le poids (en lbs) et MVNR vaut1 si jamais marriee, 0 sinon.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude cas en chasse-croise (case-crossover)
Type d’etude introduit par Maclure (Am. J. Epi., 1991, 133:144-153)
Approprie lorsque l’on veut etudier l’association entre une“maladie” dont le declanchement est de tres courte dureeet une exposition (habituellement de courte duree) dontl’effet sur le risque est transient.Exemples: exercice phsyique intense vs infarctus,consommation d’alcool vs blessure, cellulaire au volant vsaccident de voiture, deteriotion soudaine de l’air ambiantvs problemes respiratoires aigus, ...Facon “scientifique” de repondre a la question “Le patientfaisait-il quelque chose d’inhabituel avant ledeclanchement de la maladie?”

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Cas et temoin a la fois!
Pour savoir si quelqu’un etait dans une situation “inhabituelle”avant la maladie, il faut savoir quelle est sa situation“habituelle”.
On compare donc le comportement immediatement avant ledeclanchement de la maladie au comportement dans uneperiode de temps comparable mais un peu plus distante de lamaladie chez la meme personne.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Cas et temoin a la fois!

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
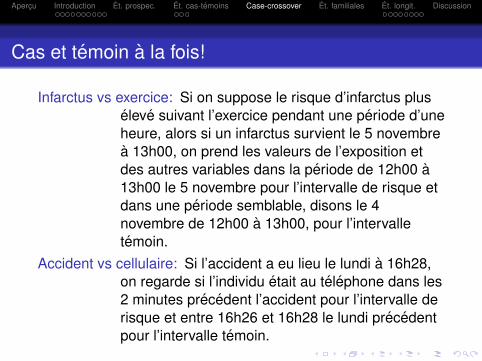
Cas et temoin a la fois!
Infarctus vs exercice: Si on suppose le risque d’infarctus pluseleve suivant l’exercice pendant une periode d’uneheure, alors si un infarctus survient le 5 novembrea 13h00, on prend les valeurs de l’exposition etdes autres variables dans la periode de 12h00 a13h00 le 5 novembre pour l’intervalle de risque etdans une periode semblable, disons le 4novembre de 12h00 a 13h00, pour l’intervalletemoin.
Accident vs cellulaire: Si l’accident a eu lieu le lundi a 16h28,on regarde si l’individu etait au telephone dans les2 minutes precedent l’accident pour l’intervalle derisque et entre 16h26 et 16h28 le lundi precedentpour l’intervalle temoin.
Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Cas et temoin a la fois!
Infarctus vs exercice: Si on suppose le risque d’infarctus pluseleve suivant l’exercice pendant une periode d’uneheure, alors si un infarctus survient le 5 novembrea 13h00, on prend les valeurs de l’exposition etdes autres variables dans la periode de 12h00 a13h00 le 5 novembre pour l’intervalle de risque etdans une periode semblable, disons le 4novembre de 12h00 a 13h00, pour l’intervalletemoin.
Accident vs cellulaire: Si l’accident a eu lieu le lundi a 16h28,on regarde si l’individu etait au telephone dans les2 minutes precedent l’accident pour l’intervalle derisque et entre 16h26 et 16h28 le lundi precedentpour l’intervalle temoin.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Remarques
L’expostion doit etre breve.Le delai entre l’expostion et le declanchement doit etrecourt.L’effet de l’exposition sur le risque ne doit pas etrecumulatif.Possibilite de biais de rappel.Effet confondant de tout ce qui peut changer avec le tempschez un meme individu.Seuls les individus qui ont un “chasse-croise” (expose etnon-expose ou non-expose et expose) apportent unecontribution a l’analyse statistique.
Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Analyse des resultats
Chaque individu est apparie a lui-meme. ⇒ On utilise donc laregression logistique conditionnelle pour analyser les resultatsd’une telle analyse.
Chaque individu forme une strate/groupe d’appariement avecdeux observations: celle prise lors de l’intervalle de risquecorrespond a Y = 1 et celle prise lors de l’intervalle temoincorrespond a Y = 0.
Les resultats s’interpretent de la meme facon qu’en regressionlogistique conditionnelle.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Analyse des resultats
Chaque individu est apparie a lui-meme. ⇒ On utilise donc laregression logistique conditionnelle pour analyser les resultatsd’une telle analyse.
Chaque individu forme une strate/groupe d’appariement avecdeux observations: celle prise lors de l’intervalle de risquecorrespond a Y = 1 et celle prise lors de l’intervalle temoincorrespond a Y = 0.
Les resultats s’interpretent de la meme facon qu’en regressionlogistique conditionnelle.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Analyse des resultats
Chaque individu est apparie a lui-meme. ⇒ On utilise donc laregression logistique conditionnelle pour analyser les resultatsd’une telle analyse.
Chaque individu forme une strate/groupe d’appariement avecdeux observations: celle prise lors de l’intervalle de risquecorrespond a Y = 1 et celle prise lors de l’intervalle temoincorrespond a Y = 0.
Les resultats s’interpretent de la meme facon qu’en regressionlogistique conditionnelle.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude familiale ou familiale cas-temoins
Pfeiffer et al. (2001) et Neuhaus et al. (2006) desirent etudierl’effet de variables environnementales (e.g., fumeur, age, sexe,historique de cancer, historique d’epilepsie, etc.) sur certainstypes de cancer rares, tout en tenant compte de l’impact de lastructure familiale des individus.
Leurs donnees proviennent d’etudes familiales: onechantillonne des familles avec un nombre minimal de cas dela maladie d’interet (familiale) de meme que des familles avecaucun cas de la maladie (familiale cas-temoins).
Chaque famille forme donc une strate dans laquelle le nombrede cas (Y = 1) et le nombre de temoins (Y = 0) sont fixes. Onmesure ensuite la valeur des variables explicatrices d’interetchez tous les individus.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude familiale ou familiale cas-temoins
Pfeiffer et al. (2001) et Neuhaus et al. (2006) desirent etudierl’effet de variables environnementales (e.g., fumeur, age, sexe,historique de cancer, historique d’epilepsie, etc.) sur certainstypes de cancer rares, tout en tenant compte de l’impact de lastructure familiale des individus.
Leurs donnees proviennent d’etudes familiales: onechantillonne des familles avec un nombre minimal de cas dela maladie d’interet (familiale) de meme que des familles avecaucun cas de la maladie (familiale cas-temoins).
Chaque famille forme donc une strate dans laquelle le nombrede cas (Y = 1) et le nombre de temoins (Y = 0) sont fixes. Onmesure ensuite la valeur des variables explicatrices d’interetchez tous les individus.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude familiale ou familiale cas-temoins
Pfeiffer et al. (2001) et Neuhaus et al. (2006) desirent etudierl’effet de variables environnementales (e.g., fumeur, age, sexe,historique de cancer, historique d’epilepsie, etc.) sur certainstypes de cancer rares, tout en tenant compte de l’impact de lastructure familiale des individus.
Leurs donnees proviennent d’etudes familiales: onechantillonne des familles avec un nombre minimal de cas dela maladie d’interet (familiale) de meme que des familles avecaucun cas de la maladie (familiale cas-temoins).
Chaque famille forme donc une strate dans laquelle le nombrede cas (Y = 1) et le nombre de temoins (Y = 0) sont fixes. Onmesure ensuite la valeur des variables explicatrices d’interetchez tous les individus.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Le modele
On estime l’effet des variables environnementales a l’aide d’unmodele de regression logistique auquel on ajoute des effetsaleatoires. Ces effets aleatoires servent a induire la correlationdue au fait que des observations proviennent de la memefamille.
Modele familial
logP(Yi j = 1)
1−P(Yi j = 1)= α +Fi +Gi j +βEEi j +β1xi j1 + · · ·+βkxi jk,
ou Fi est un effet aleatoire familial et Gi j est l’effet aleatoiregenetique du jeme membre de la ieme famille. Les Gi j d’unememe famille sont correles entre eux et la structure decorrelation est dictee par la structure familiale (Pfeiffer et al,2001).

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude longitudinale prospective
Regression logistique longitudinale
Mesures repetees (e.g., on mesure Y , E et les x de chaqueindividu a plusieurs reprises): alors on peut toujours ajuster unmodele de regression logistique ordinaire a ces donnees enutilisant deux classes de methodes:
L’approche “GEE”: On n’a qu’a donner un “guess” pour le typede correlation entre les observations d’un meme individu et lesinferences sont valides.
Les β dans ce cas s’interpretent comme des effets moyens surla population, et on parle donc d’approche marginale (ou“population-averaged”).
Facile a implanter en SAS grace a la ligne REPEATED de laprocedure GENMOD.
Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude longitudinale prospective
Regression logistique longitudinale
Mesures repetees (e.g., on mesure Y , E et les x de chaqueindividu a plusieurs reprises): alors on peut toujours ajuster unmodele de regression logistique ordinaire a ces donnees enutilisant deux classes de methodes:
L’approche “GEE”: On n’a qu’a donner un “guess” pour le typede correlation entre les observations d’un meme individu et lesinferences sont valides.
Les β dans ce cas s’interpretent comme des effets moyens surla population, et on parle donc d’approche marginale (ou“population-averaged”).
Facile a implanter en SAS grace a la ligne REPEATED de laprocedure GENMOD.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude longitudinale prospective
Regression logistique longitudinale
Modele de regression mixte: La correlation est induite enajoutant des effets aleatoires dans le modele de regressionlogistique. Par exemple
logP(Yi j = 1)
1−P(Yi j = 1)= α +Ai +βEEi j +β1xi j1 + · · ·+βkxi jk.
On estime les parametres (α,β ,Var(Ai)) par maximum devraisemblance.
Les β dans ce cas s’interpretent comme des effets surl’individu moyen, et on parle donc d’approche conditionnelle (ou“subject-specific”).
S’implante en SAS avec les procedures NLMIXED et GLIMMIX.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude longitudinale cas-temoins appariee
Mesures repetees sur des strates
Et si plusieurs strates sont correlees (e.g., mesures repeteessur chaque strate, correlation spatiale ou temporelle de strates,etc)?
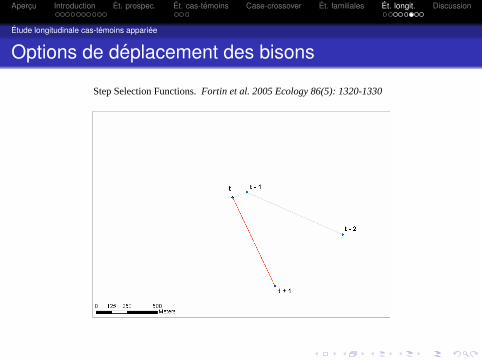
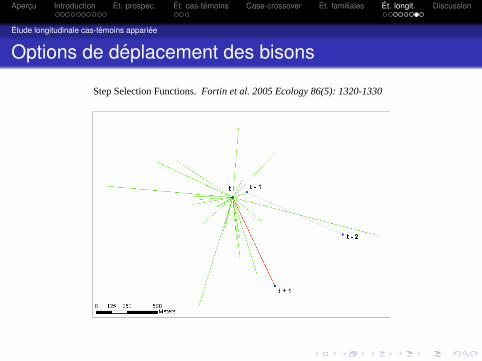
Par exemple Craiu, Duchesne & Fortin (2007) veulent identifierles facteurs qui influencent les deplacements des Bisons dansle Parc national Prince-Albert, Saskatchewan.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude longitudinale cas-temoins appariee
Mesures repetees sur des strates
Et si plusieurs strates sont correlees (e.g., mesures repeteessur chaque strate, correlation spatiale ou temporelle de strates,etc)?
Par exemple Craiu, Duchesne & Fortin (2007) veulent identifierles facteurs qui influencent les deplacements des Bisons dansle Parc national Prince-Albert, Saskatchewan.
Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude longitudinale cas-temoins appariee
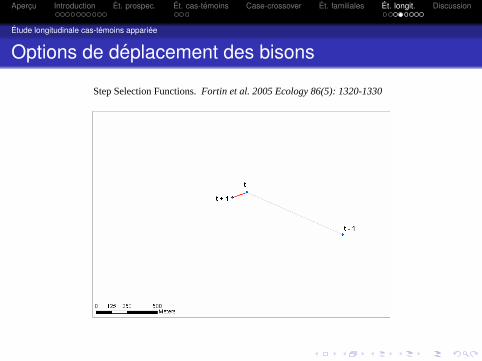
Options de deplacement des bisons
Step Selection Functions. Fortin et al. 2005 Ecology 86(5): 1320-1330
Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude longitudinale cas-temoins appariee
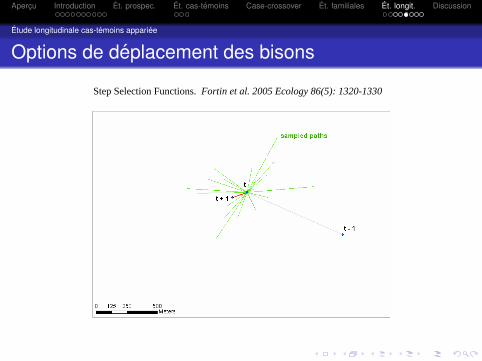
Options de deplacement des bisons
Step Selection Functions. Fortin et al. 2005 Ecology 86(5): 1320-1330
Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude longitudinale cas-temoins appariee
Options de deplacement des bisons
Step Selection Functions. Fortin et al. 2005 Ecology 86(5): 1320-1330
Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude longitudinale cas-temoins appariee
Options de deplacement des bisons
Step Selection Functions. Fortin et al. 2005 Ecology 86(5): 1320-1330

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude longitudinale cas-temoins appariee
Possibilites pour l’inference
Craiu, Duchesne & Fortin (Biometrical Journal, 2007)proposent une approche de type “GEE” pour ajuster le modelede regression logistique conditionnelle quand les strates sontcorrelees. Dans le cas d’un cas par strate, il est possibled’utiliser PHREG pour implanter leur methode.
Ils travaillent presentement sur l’elaboration d’un modele deregression logistique conditionnel mixte. Les modeles utilisesdans les etudes familiales sont une excellente sourced’inspiration!

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Etude longitudinale cas-temoins appariee
Possibilites pour l’inference
Craiu, Duchesne & Fortin (Biometrical Journal, 2007)proposent une approche de type “GEE” pour ajuster le modelede regression logistique conditionnelle quand les strates sontcorrelees. Dans le cas d’un cas par strate, il est possibled’utiliser PHREG pour implanter leur methode.
Ils travaillent presentement sur l’elaboration d’un modele deregression logistique conditionnel mixte. Les modeles utilisesdans les etudes familiales sont une excellente sourced’inspiration!
Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Quelques remarques
Il est possible d’ajuster un modele de regression logistique a desdonnees provenant de toutes sortes de types d’etudesepidemiologiques.
Il ne faut pas oublier d’utiliser la regression logistiqueconditionnelle lorsque les donnees proviennent d’une etudeappariee.
Dans le cas d’etudes longitudinales non appariees, l’inferencemarginale a ete perfectionnee dans les annees 80-90 etl’inference conditionnelle dans les annees 90-00.
Dans le cas d’etudes longitudinales appariees, on commence avoir des methodes pour l’inference marginale (Kim & Park, 2004,Craiu et al., 2007) et l’inference conditionnelle est en cours dedeveloppement.
Pour la plupart des etudes mentionnees dans cet expose, deslogiciels effectuant le calcul de taille d’echantillon sontdisponibles sur Internet.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Quelques remarques
Il est possible d’ajuster un modele de regression logistique a desdonnees provenant de toutes sortes de types d’etudesepidemiologiques.
Il ne faut pas oublier d’utiliser la regression logistiqueconditionnelle lorsque les donnees proviennent d’une etudeappariee.
Dans le cas d’etudes longitudinales non appariees, l’inferencemarginale a ete perfectionnee dans les annees 80-90 etl’inference conditionnelle dans les annees 90-00.
Dans le cas d’etudes longitudinales appariees, on commence avoir des methodes pour l’inference marginale (Kim & Park, 2004,Craiu et al., 2007) et l’inference conditionnelle est en cours dedeveloppement.
Pour la plupart des etudes mentionnees dans cet expose, deslogiciels effectuant le calcul de taille d’echantillon sontdisponibles sur Internet.
Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Quelques remarques
Il est possible d’ajuster un modele de regression logistique a desdonnees provenant de toutes sortes de types d’etudesepidemiologiques.
Il ne faut pas oublier d’utiliser la regression logistiqueconditionnelle lorsque les donnees proviennent d’une etudeappariee.
Dans le cas d’etudes longitudinales non appariees, l’inferencemarginale a ete perfectionnee dans les annees 80-90 etl’inference conditionnelle dans les annees 90-00.
Dans le cas d’etudes longitudinales appariees, on commence avoir des methodes pour l’inference marginale (Kim & Park, 2004,Craiu et al., 2007) et l’inference conditionnelle est en cours dedeveloppement.
Pour la plupart des etudes mentionnees dans cet expose, deslogiciels effectuant le calcul de taille d’echantillon sontdisponibles sur Internet.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Quelques remarques
Il est possible d’ajuster un modele de regression logistique a desdonnees provenant de toutes sortes de types d’etudesepidemiologiques.
Il ne faut pas oublier d’utiliser la regression logistiqueconditionnelle lorsque les donnees proviennent d’une etudeappariee.
Dans le cas d’etudes longitudinales non appariees, l’inferencemarginale a ete perfectionnee dans les annees 80-90 etl’inference conditionnelle dans les annees 90-00.
Dans le cas d’etudes longitudinales appariees, on commence avoir des methodes pour l’inference marginale (Kim & Park, 2004,Craiu et al., 2007) et l’inference conditionnelle est en cours dedeveloppement.
Pour la plupart des etudes mentionnees dans cet expose, deslogiciels effectuant le calcul de taille d’echantillon sontdisponibles sur Internet.

Apercu Introduction Et. prospec. Et. cas-temoins Case-crossover Et. familiales Et. longit. Discussion
Quelques remarques
Il est possible d’ajuster un modele de regression logistique a desdonnees provenant de toutes sortes de types d’etudesepidemiologiques.
Il ne faut pas oublier d’utiliser la regression logistiqueconditionnelle lorsque les donnees proviennent d’une etudeappariee.
Dans le cas d’etudes longitudinales non appariees, l’inferencemarginale a ete perfectionnee dans les annees 80-90 etl’inference conditionnelle dans les annees 90-00.
Dans le cas d’etudes longitudinales appariees, on commence avoir des methodes pour l’inference marginale (Kim & Park, 2004,Craiu et al., 2007) et l’inference conditionnelle est en cours dedeveloppement.
Pour la plupart des etudes mentionnees dans cet expose, deslogiciels effectuant le calcul de taille d’echantillon sontdisponibles sur Internet.